KR20170119152A - 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델 및 이를 이용한 음성인식 방법 - Google Patents
잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델 및 이를 이용한 음성인식 방법 Download PDFInfo
- Publication number
- KR20170119152A KR20170119152A KR1020160046952A KR20160046952A KR20170119152A KR 20170119152 A KR20170119152 A KR 20170119152A KR 1020160046952 A KR1020160046952 A KR 1020160046952A KR 20160046952 A KR20160046952 A KR 20160046952A KR 20170119152 A KR20170119152 A KR 20170119152A
- Authority
- KR
- South Korea
- Prior art keywords
- neural network
- reverberation
- ensemble
- speech recognition
- acoustic model
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images





Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/16—Speech classification or search using artificial neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
- G10L17/04—Training, enrolment or model building
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/032—Quantisation or dequantisation of spectral components
- G10L19/035—Scalar quantisation
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Theoretical Computer Science (AREA)
- Biophysics (AREA)
- Mathematical Physics (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Software Systems (AREA)
- Biomedical Technology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Life Sciences & Earth Sciences (AREA)
- Signal Processing (AREA)
- User Interface Of Digital Computer (AREA)
- Cable Transmission Systems, Equalization Of Radio And Reduction Of Echo (AREA)
Abstract
Description
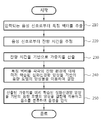
도 2는 일 실시예에 따른 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법을 나타내는 흐름도이다.
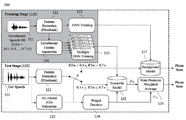
도 3은 다른 실시예에 따른 결합 학습 구조의 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템을 개략적으로 나타내는 블록도이다.
도 4는 다른 실시예에 따른 특징 맵핑 심화신경망의 입력과 출력을 설명하기 위한 도면이다.
도 5는 일 실시예에 따른 잔향 시뮬레이션 환경을 나타내는 도면이다.
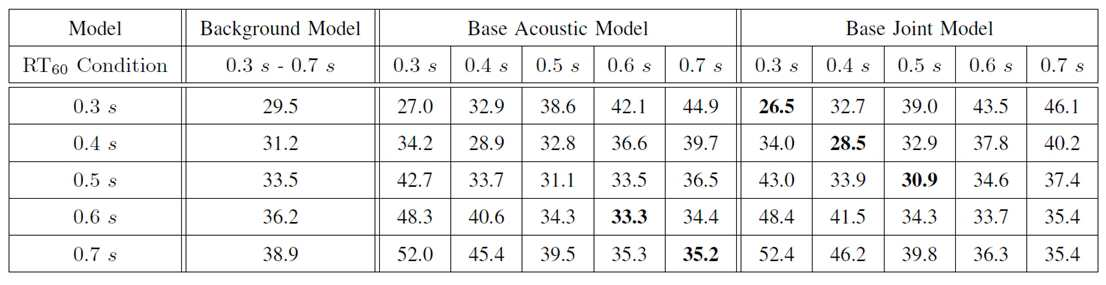
도 6은 일 실시예에 따른 다양한 잔향 환경에서 종래의 배경 모델과 제안된 앙상블 모델의 단어 오인지율의 비교를 나타내는 그래프이다.
도 7은 일 실시예에 따른 잔향 환경에서의 음성에 대해 추정된 잔향 시간에 대한 최대 우도비 그래프를 나타낸다.
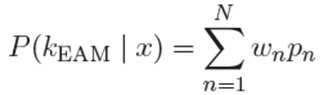
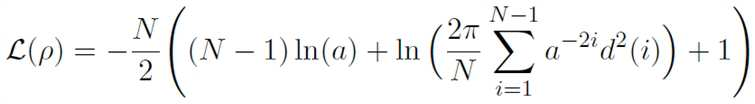





Claims (15)
- 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법에 있어서,
입력되는 음성 신호로부터 특징 벡터를 추출하는 단계;
상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 심화신경망 앙상블 기반의 음향 모델의 앙상블을 이용하여 결합하는 단계; 및
음소를 분류하여 음성을 인식하는 단계
를 포함하고,
상기 미리 학습된 심화신경망 앙상블 기반의 음향 모델은,
다수의 잔향 환경에서 각각의 잔향 환경에 대해 음소 확률을 추정하는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법. - 제1항에 있어서,
상기 음성 신호로부터 잔향 시간을 추정하는 단계; 및
상기 잔향 시간을 기반으로 가중치를 산출하는 단계
를 더 포함하고,
상기 음소를 분류하여 음성을 인식하는 단계는,
산출된 상기 가중치를 미리 학습된 상기 심화신경망 앙상블 기반의 음향 모델의 앙상블 결합에 적용하는 단계
를 포함하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법. - 제2항에 있어서,
상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 심화신경망 앙상블 기반의 음향 모델의 앙상블을 이용하여 결합하는 단계는,
상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 상기 심화신경망 앙상블 기반의 음향 모델에 기반한 앙상블 모델을 통과시켜 음소 확률을 추정하는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법. - 제3항에 있어서,
상기 음소를 분류하여 음성을 인식하는 단계는,
상기 음소 확률과 상기 가중치를 이용하여 상기 심화신경망 앙상블 기반의 음향 모델의 사후 확률(posterior probability)을 산출하여 상기 음소를 분류하는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법. - 제2항에 있어서,
상기 음성 신호로부터 잔향 시간을 추정하는 단계는,
상기 심화신경망 앙상블 기반의 음향 모델 중 우도비가 가장 큰 두 개의 음향 모델을 선택하여 최대 우도법(maximum likelihood)을 통한 상기 잔향 시간을 추정하는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법. - 제1항에 있어서,
상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 단계
를 더 포함하고,
상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 단계는,
학습 단계에서, 다수의 잔향 환경에서의 음성 신호를 입력 받아 특징 벡터를 추출하는 단계;
추출된 상기 특징 벡터의 잔향 환경의 특징을 분리하는 단계; 및
추출된 상기 특징 벡터를 심화신경망을 통하여 각각의 상기 잔향 환경에 대해 학습시키는 단계
를 포함하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법. - 제1항에 있어서,
상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 단계
를 더 포함하고,
상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 단계는,
학습 단계에서, 다수의 잔향 환경에서의 음성 신호를 입력 받아 특징 벡터를 추출하는 단계;
추출된 상기 특징 벡터의 잔향 환경의 특징을 분리하는 단계;
추출된 상기 특징 벡터를 잔향이 없는 음성 특징으로 맵핑(mapping)시키는 상기 특징 맵핑 심화신경망을 통과시키는 단계;
상기 특징 맵핑 심화신경망의 출력을 이용하여 상기 음향 모델링 심화신경망을 학습시키는 단계; 및
상기 음향 모델링 심화신경망은 상기 특징 맵핑 심화신경망 위에 바로 쌓이고, 결합된 상기 심화신경망 앙상블 기반의 음향 모델은 연결되어 재학습되는 단계
를 포함하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법. - 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템에 있어서,
입력되는 음성 신호로부터 특징 벡터를 추출하는 특징 벡터 추출부;
상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 심화신경망 앙상블 기반의 음향 모델의 앙상블을 이용하여 결합하는 앙상블 모델; 및
음소를 분류하여 음성을 인식하는 음소 분류부
를 포함하고,
상기 미리 학습된 심화신경망 앙상블 기반의 음향 모델은,
다수의 잔향 환경에서 각각의 잔향 환경에 대해 음소 확률을 추정하는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템. - 제8항에 있어서,
상기 음성 신호로부터 잔향 시간을 추정하는 잔향 시간 예측부; 및
상기 잔향 시간을 기반으로 가중치를 산출하는 가중치 결정부
를 더 포함하고,
상기 음소 분류부는,
산출된 상기 가중치를 미리 학습된 상기 심화신경망 앙상블 기반의 음향 모델의 앙상블 결합에 적용하는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템. - 제9항에 있어서,
상기 앙상블 모델은,
상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 상기 심화신경망 앙상블 기반의 음향 모델에 기반한 앙상블 모델을 통과시켜 음소 확률을 추정하는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템. - 제10항에 있어서,
상기 음소 분류부는,
상기 음소 확률과 상기 가중치를 이용하여 상기 심화신경망 앙상블 기반의 음향 모델의 사후 확률(posterior probability)을 산출하여 상기 음소를 분류하는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템. - 제9항에 있어서,
상기 잔향 시간 예측부는,
상기 심화신경망 앙상블 기반의 음향 모델 중 우도비가 가장 큰 두 개의 음향 모델을 선택하여 최대 우도법(maximum likelihood)을 통한 상기 잔향 시간을 추정하는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템. - 제8항에 있어서,
상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 학습부
를 더 포함하고,
상기 학습부는,
학습 단계에서, 다수의 잔향 환경에서의 음성 신호를 입력 받아 특징 벡터를 추출하는 특징 벡터 추출부;
추출된 상기 특징 벡터의 잔향 환경의 특징을 분리하는 잔향 특징 분류부; 및
추출된 상기 특징 벡터를 심화신경망을 통하여 각각의 상기 잔향 환경에 대해 학습시키는 다중 심화신경망 학습부
를 포함하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템. - 제8항에 있어서,
상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 학습부
를 더 포함하고,
상기 학습부는,
잔향이 없는 음성 특징으로 맵핑(mapping)시키는 특징 맵핑 심화신경망과 음향 모델링 심화신경망을 결합하는 구조를 이용하여, 서로 다른 잔향 환경에 대해 학습된 음향 모델을 구성하는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템. - 제14항에 있어서,
상기 학습부는,
학습 단계에서, 다수의 잔향 환경에서의 음성 신호를 입력 받아 특징 벡터를 추출하는 특징 벡터 추출부;
추출된 상기 특징 벡터의 잔향 환경의 특징을 분리하는 잔향 특징 분류부;
추출된 상기 특징 벡터를 잔향이 없는 음성 특징으로 맵핑(mapping)시키는 상기 특징 맵핑 심화신경망; 및
상기 특징 맵핑 심화신경망의 출력을 이용하여 학습시키는 상기 음향 모델링 심화신경망
을 포함하고,
상기 음향 모델링 심화신경망은 상기 특징 맵핑 심화신경망 위에 바로 쌓이고, 결합된 상기 심화신경망 앙상블 기반의 음향 모델은 연결되어 재학습되는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020160046952A KR101807948B1 (ko) | 2016-04-18 | 2016-04-18 | 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델 및 이를 이용한 음성인식 방법 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020160046952A KR101807948B1 (ko) | 2016-04-18 | 2016-04-18 | 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델 및 이를 이용한 음성인식 방법 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20170119152A true KR20170119152A (ko) | 2017-10-26 |
| KR101807948B1 KR101807948B1 (ko) | 2017-12-11 |
Family
ID=60300764
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020160046952A Expired - Fee Related KR101807948B1 (ko) | 2016-04-18 | 2016-04-18 | 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델 및 이를 이용한 음성인식 방법 |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR101807948B1 (ko) |
Cited By (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20190060028A (ko) * | 2017-11-23 | 2019-06-03 | 삼성전자주식회사 | 화자 인식을 위한 뉴럴 네트워크 장치, 및 그 동작 방법 |
| KR20190108711A (ko) * | 2018-03-15 | 2019-09-25 | 한양대학교 산학협력단 | 잔향 환경에 강인한 음원 방향 추정을 위한 심화 신경망 기반의 앙상블 음원 방향 추정 방법 및 장치 |
| WO2020130687A1 (en) * | 2018-12-19 | 2020-06-25 | Samsung Electronics Co., Ltd. | System and method for automated execution of user-specified commands |
| WO2020204525A1 (ko) * | 2019-04-01 | 2020-10-08 | 한양대학교 산학협력단 | 잡음 환경에 강인한 화자 인식을 위한 심화 신경망 기반의 특징 강화 및 변형된 손실 함수를 이용한 결합 학습 방법 및 장치 |
| KR102201198B1 (ko) * | 2020-05-22 | 2021-01-11 | 서울시립대학교 산학협력단 | 기계학습 및 앙상블 기법을 이용하여 데이터를 분류하는 장치 및 방법 |
| US10930268B2 (en) | 2018-05-31 | 2021-02-23 | Samsung Electronics Co., Ltd. | Speech recognition method and apparatus |
| WO2020256257A3 (ko) * | 2019-06-21 | 2021-03-11 | 한양대학교 산학협력단 | 잡음 환경에 강인한 화자 인식을 위한 심화신경망 기반의 특징 강화 및 변형된 손실 함수를 이용한 결합 학습 방법 및 장치 |
| KR20210123554A (ko) * | 2020-04-03 | 2021-10-14 | 서울시립대학교 산학협력단 | 선택적으로 원거리 발화를 보상하는 심층 신경망 기반 화자 특징 강화를 위한 장치 및 이를 위한 방법 |
| CN113593560A (zh) * | 2021-07-29 | 2021-11-02 | 普强时代(珠海横琴)信息技术有限公司 | 可定制的低延时命令词识别方法及装置 |
| WO2021251627A1 (ko) * | 2020-06-11 | 2021-12-16 | 한양대학교 산학협력단 | 다채널 음향 신호를 이용한 심화 신경망 기반의 잔향 제거, 빔포밍 및 음향 인지 모델의 결합 학습 방법 및 장치 |
| WO2023068552A1 (ko) * | 2021-10-21 | 2023-04-27 | 삼성전자주식회사 | 음성 인식을 위한 전자 장치 및 그 제어 방법 |
| US12205576B2 (en) | 2021-10-21 | 2025-01-21 | Samsung Electronics Co., Ltd. | Electronic apparatus for speech recognition, and controlling method thereof |
| US12417780B2 (en) | 2021-11-15 | 2025-09-16 | Electronics And Telecommunications Research Institute | Methods of training acoustic scene classification model and classifying acoustic scene and electronic device for performing the methods |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102550598B1 (ko) * | 2018-03-21 | 2023-07-04 | 현대모비스 주식회사 | 음성 화자 인식 장치 및 그 방법 |
-
2016
- 2016-04-18 KR KR1020160046952A patent/KR101807948B1/ko not_active Expired - Fee Related
Cited By (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20190060028A (ko) * | 2017-11-23 | 2019-06-03 | 삼성전자주식회사 | 화자 인식을 위한 뉴럴 네트워크 장치, 및 그 동작 방법 |
| KR20190108711A (ko) * | 2018-03-15 | 2019-09-25 | 한양대학교 산학협력단 | 잔향 환경에 강인한 음원 방향 추정을 위한 심화 신경망 기반의 앙상블 음원 방향 추정 방법 및 장치 |
| US10930268B2 (en) | 2018-05-31 | 2021-02-23 | Samsung Electronics Co., Ltd. | Speech recognition method and apparatus |
| WO2020130687A1 (en) * | 2018-12-19 | 2020-06-25 | Samsung Electronics Co., Ltd. | System and method for automated execution of user-specified commands |
| WO2020204525A1 (ko) * | 2019-04-01 | 2020-10-08 | 한양대학교 산학협력단 | 잡음 환경에 강인한 화자 인식을 위한 심화 신경망 기반의 특징 강화 및 변형된 손실 함수를 이용한 결합 학습 방법 및 장치 |
| KR20200116225A (ko) * | 2019-04-01 | 2020-10-12 | 한양대학교 산학협력단 | 잡음 환경에 강인한 화자 인식을 위한 심화 신경망 기반의 특징 강화 및 변형된 손실 함수를 이용한 결합 학습 방법 및 장치 |
| US12067989B2 (en) | 2019-04-01 | 2024-08-20 | Iucf-Hyu (Industry-University Cooperation Foundation Hanyang University) | Combined learning method and apparatus using deepening neural network based feature enhancement and modified loss function for speaker recognition robust to noisy environments |
| US11854554B2 (en) | 2019-06-21 | 2023-12-26 | Iucf-Hyu (Industry-University Cooperation Foundation Hanyang University) | Method and apparatus for combined learning using feature enhancement based on deep neural network and modified loss function for speaker recognition robust to noisy environments |
| WO2020256257A3 (ko) * | 2019-06-21 | 2021-03-11 | 한양대학교 산학협력단 | 잡음 환경에 강인한 화자 인식을 위한 심화신경망 기반의 특징 강화 및 변형된 손실 함수를 이용한 결합 학습 방법 및 장치 |
| KR20210123554A (ko) * | 2020-04-03 | 2021-10-14 | 서울시립대학교 산학협력단 | 선택적으로 원거리 발화를 보상하는 심층 신경망 기반 화자 특징 강화를 위한 장치 및 이를 위한 방법 |
| KR102201198B1 (ko) * | 2020-05-22 | 2021-01-11 | 서울시립대학교 산학협력단 | 기계학습 및 앙상블 기법을 이용하여 데이터를 분류하는 장치 및 방법 |
| WO2021251627A1 (ko) * | 2020-06-11 | 2021-12-16 | 한양대학교 산학협력단 | 다채널 음향 신호를 이용한 심화 신경망 기반의 잔향 제거, 빔포밍 및 음향 인지 모델의 결합 학습 방법 및 장치 |
| CN113593560A (zh) * | 2021-07-29 | 2021-11-02 | 普强时代(珠海横琴)信息技术有限公司 | 可定制的低延时命令词识别方法及装置 |
| CN113593560B (zh) * | 2021-07-29 | 2024-04-16 | 普强时代(珠海横琴)信息技术有限公司 | 可定制的低延时命令词识别方法及装置 |
| WO2023068552A1 (ko) * | 2021-10-21 | 2023-04-27 | 삼성전자주식회사 | 음성 인식을 위한 전자 장치 및 그 제어 방법 |
| US12205576B2 (en) | 2021-10-21 | 2025-01-21 | Samsung Electronics Co., Ltd. | Electronic apparatus for speech recognition, and controlling method thereof |
| US12417780B2 (en) | 2021-11-15 | 2025-09-16 | Electronics And Telecommunications Research Institute | Methods of training acoustic scene classification model and classifying acoustic scene and electronic device for performing the methods |
Also Published As
| Publication number | Publication date |
|---|---|
| KR101807948B1 (ko) | 2017-12-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101807948B1 (ko) | 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델 및 이를 이용한 음성인식 방법 | |
| EP4028953B1 (en) | Convolutional neural network with phonetic attention for speaker verification | |
| KR102294638B1 (ko) | 잡음 환경에 강인한 화자 인식을 위한 심화 신경망 기반의 특징 강화 및 변형된 손실 함수를 이용한 결합 학습 방법 및 장치 | |
| KR102167719B1 (ko) | 언어 모델 학습 방법 및 장치, 음성 인식 방법 및 장치 | |
| JP4548646B2 (ja) | 音声モデルの雑音適応化システム、雑音適応化方法、及び、音声認識雑音適応化プログラム | |
| CN104036774B (zh) | 藏语方言识别方法及系统 | |
| JP5423670B2 (ja) | 音響モデル学習装置および音声認識装置 | |
| US8428950B2 (en) | Recognizer weight learning apparatus, speech recognition apparatus, and system | |
| KR101704926B1 (ko) | 음향 환경 분류를 이용한 심화신경망의 앙상블이 구성된 통계모델 기반의 음성 검출 장치 및 음성 검출 방법 | |
| CN108364651A (zh) | 语音识别方法和设备 | |
| CN113674733B (zh) | 用于说话时间估计的方法和设备 | |
| JP7176627B2 (ja) | 信号抽出システム、信号抽出学習方法および信号抽出学習プログラム | |
| KR101618512B1 (ko) | 가우시안 혼합모델을 이용한 화자 인식 시스템 및 추가 학습 발화 선택 방법 | |
| KR102406512B1 (ko) | 음성인식 방법 및 그 장치 | |
| Ismail et al. | Mfcc-vq approach for qalqalahtajweed rule checking | |
| KR20040088368A (ko) | 스위칭 상태 공간 모델들을 갖는 변분 추론을 사용하는음성 인식 방법 | |
| JP2020042257A (ja) | 音声認識方法及び装置 | |
| KR20210009593A (ko) | 강인한 음성인식을 위한 음향 및 언어모델링 정보를 이용한 음성 끝점 검출 방법 및 장치 | |
| Hwang et al. | End-to-end speech endpoint detection utilizing acoustic and language modeling knowledge for online low-latency speech recognition | |
| CN102237082B (zh) | 语音识别系统的自适应方法 | |
| KR20200120595A (ko) | 언어 모델 학습 방법 및 장치, 음성 인식 방법 및 장치 | |
| JP4233831B2 (ja) | 音声モデルの雑音適応化システム、雑音適応化方法、及び、音声認識雑音適応化プログラム | |
| Nahar et al. | Effect of data augmentation on dnn-based vad for automatic speech recognition in noisy environment | |
| Moons et al. | Resource aware design of a deep convolutional-recurrent neural network for speech recognition through audio-visual sensor fusion | |
| Avdelidis et al. | Adaptive phoneme alignment based on rough set theory |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| PA0109 | Patent application |
St.27 status event code: A-0-1-A10-A12-nap-PA0109 |
|
| PA0201 | Request for examination |
St.27 status event code: A-1-2-D10-D11-exm-PA0201 |
|
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
St.27 status event code: A-1-2-D10-D21-exm-PE0902 |
|
| E13-X000 | Pre-grant limitation requested |
St.27 status event code: A-2-3-E10-E13-lim-X000 |
|
| P11-X000 | Amendment of application requested |
St.27 status event code: A-2-2-P10-P11-nap-X000 |
|
| P13-X000 | Application amended |
St.27 status event code: A-2-2-P10-P13-nap-X000 |
|
| PG1501 | Laying open of application |
St.27 status event code: A-1-1-Q10-Q12-nap-PG1501 |
|
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration |
St.27 status event code: A-1-2-D10-D22-exm-PE0701 |
|
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment |
St.27 status event code: A-2-4-F10-F11-exm-PR0701 |
|
| PR1002 | Payment of registration fee |
St.27 status event code: A-2-2-U10-U11-oth-PR1002 Fee payment year number: 1 |
|
| PG1601 | Publication of registration |
St.27 status event code: A-4-4-Q10-Q13-nap-PG1601 |
|
| R18-X000 | Changes to party contact information recorded |
St.27 status event code: A-5-5-R10-R18-oth-X000 |
|
| R18-X000 | Changes to party contact information recorded |
St.27 status event code: A-5-5-R10-R18-oth-X000 |
|
| FPAY | Annual fee payment |
Payment date: 20201026 Year of fee payment: 4 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 4 |
|
| PC1903 | Unpaid annual fee |
St.27 status event code: A-4-4-U10-U13-oth-PC1903 Not in force date: 20211206 Payment event data comment text: Termination Category : DEFAULT_OF_REGISTRATION_FEE |
|
| PC1903 | Unpaid annual fee |
St.27 status event code: N-4-6-H10-H13-oth-PC1903 Ip right cessation event data comment text: Termination Category : DEFAULT_OF_REGISTRATION_FEE Not in force date: 20211206 |