KR20170125021A - 다수 사용자 간에 스테레오 사운드를 공유하기 위한 기술 - Google Patents
다수 사용자 간에 스테레오 사운드를 공유하기 위한 기술 Download PDFInfo
- Publication number
- KR20170125021A KR20170125021A KR1020177022897A KR20177022897A KR20170125021A KR 20170125021 A KR20170125021 A KR 20170125021A KR 1020177022897 A KR1020177022897 A KR 1020177022897A KR 20177022897 A KR20177022897 A KR 20177022897A KR 20170125021 A KR20170125021 A KR 20170125021A
- Authority
- KR
- South Korea
- Prior art keywords
- signal
- audio
- user
- output
- audio source
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images







Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R3/00—Circuits for transducers
- H04R3/005—Circuits for transducers for combining the signals of two or more microphones
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03G—CONTROL OF AMPLIFICATION
- H03G3/00—Gain control in amplifiers or frequency changers
- H03G3/20—Automatic control
- H03G3/30—Automatic control in amplifiers having semiconductor devices
- H03G3/32—Automatic control in amplifiers having semiconductor devices the control being dependent upon ambient noise level or sound level
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03G—CONTROL OF AMPLIFICATION
- H03G7/00—Volume compression or expansion in amplifiers
- H03G7/002—Volume compression or expansion in amplifiers in untuned or low-frequency amplifiers, e.g. audio amplifiers
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R27/00—Public address systems
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R3/00—Circuits for transducers
- H04R3/02—Circuits for transducers for preventing acoustic reaction, i.e. acoustic oscillatory feedback
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R5/00—Stereophonic arrangements
- H04R5/02—Spatial or constructional arrangements of loudspeakers
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R5/00—Stereophonic arrangements
- H04R5/033—Headphones for stereophonic communication
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L2021/02082—Noise filtering the noise being echo, reverberation of the speech
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R2420/00—Details of connection covered by H04R, not provided for in its groups
- H04R2420/03—Connection circuits to selectively connect loudspeakers or headphones to amplifiers
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R2420/00—Details of connection covered by H04R, not provided for in its groups
- H04R2420/07—Applications of wireless loudspeakers or wireless microphones
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Multimedia (AREA)
- Otolaryngology (AREA)
- General Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Quality & Reliability (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Circuit For Audible Band Transducer (AREA)
- Headphones And Earphones (AREA)
- Stereophonic System (AREA)
Abstract
Description
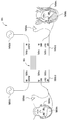
도 1은 다양한 실시예에 따라, 사용자들 간에 오디오 및 스피치 신호를 공유하도록 구성된 시스템을 도시한다;
도 2는 다양한 실시예에 따라, 도 1의 디지털 신호 프로세서(DSP)가 스피치 신호에 응답하여 오디오 신호를 더크(duck)하도록 구성되는 구현을 도시한다;
도 3은 다양한 실시예에 따라, 도 1의 DSP가 마이크로폰 피드백에 의해 야기되는 에코를 소거하도록 구성되는 또 다른 구현을 도시한다;
도 4는 다양한 실시예에 따라, 사용자들 간에 오디오 및 스피치 신호를 공유하는 방법 단계의 흐름도이다;
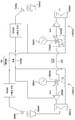
도 5는 다양한 실시예에 따라, 사용자들 간에 다수의 오디오 소스 및 스피치 신호를 선택적으로 공유하도록 구성된 도 1의 시스템을 도시한다;
도 6은 다양한 실시예에 따라, 도 5의 DSP가 상이한 오디오 소스들 간에 선택하도록 구성된 구현을 도시한다;
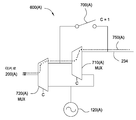
도 7a 및 도 7b는 다양한 실시예에 따라, 상이한 소스로부터 오디오를 라우팅하도록 구성된 도 6의 라우팅 회로 중 하나를 도시한다;
도 8은 다양한 실시예에 따라, 도 5의 DSP가 사용자 간에 오디오 및 스피치 신호를 공유할 때 다양한 신호 처리 동작을 수행하도록 구성되는 또 다른 구현을 도시한다; 및
도 9는 다양한 실시예들에 따라, 상이한 사용자들에 관련된 오디오 소스들 간에 선택하기 위한 방법 단계들의 흐름도이다.
Claims (26)
- 오디오 신호를 발생시키기 위한 컴퓨터 구현 방법에 있어서, 상기 방법은:
제1 오디오 소스로부터 제1 신호를 수신하고;
출력을 위해 상기 제1 사용자와 관련된 출력 요소에 상기 제1 신호를 전송하고;
제2 사용자와 관련된 입력 요소로부터 제2 신호를 수신하고;
상기 제1 신호를 상기 제2 신호와 조합하여 조합된 신호(combined signal)를 생성하고,
출력을 위해 상기 제1 사용자와 관련된 상기 출력 요소에 상기 조합된 신호를 전송하는 것을 포함하는, 컴퓨터 구현 방법. - 청구항 1에 있어서, 상기 제1 신호를 상기 제2 신호와 조합하는 것은,
상기 제2 신호에 응답하여 상기 제1 신호를 더크(duck)하여 더크된 제1 신호를 발생시키고,
상기 제2 신호에 상기 더크된 제1 신호를 추가하는 것을 포함하는, 컴퓨터 구현 방법. - 청구항 2에 있어서, 상기 제1 신호를 더크하는 것은 상기 제2 신호와 관련되고 제2 주파수 범위에 해당하는 진폭에 기초하여, 상기 제1 신호와 관련되고 제1 주파수 범위에 해당하는 진폭을 조정하는 것을 포함하는, 컴퓨터 구현 방법.
- 청구항 3에 있어서, 상기 제1 주파수 범위는 상기 제2 주파수 범위와 실질적으로 동일한, 컴퓨터 구현 방법.
- 청구항 1에 있어서, 상기 제2 사용자와 관련된 출력 요소에 의해 상기 제2 사용자와 관련된 상기 입력 요소에 입력되는 제3 신호의 적어도 일부를 필터링하도록 상기 제2 신호를 전처리하는 것을 더 포함하는, 컴퓨터 구현 방법.
- 청구항 1에 있어서, 상기 제1 사용자와 관련된 입력 요소에 입력되는 제4 신호의 적어도 일부를 필터링하기 위해 상기 제2 신호를 전처리하는 것을 더 포함하는, 컴퓨터 구현 방법.
- 청구항 1에 있어서, 상기 제1 오디오 소스는 상기 제1 사용자와 관련되고, 상기 제1 사용자가 상기 제1 오디오 소스를 선택하는 것에 응답하여 상기 제1 사용자와 관련된 상기 출력 요소가 상기 제1 신호를 상기 제1 사용자에게 출력하게 하는 것을 더 포함하는, 컴퓨터 구현 방법.
- 청구항 1에 있어서, 상기 제1 오디오 소스는 상기 제2 사용자와 관련되고, 상기 제1 사용자가 상기 제1 오디오 소스를 선택하는 것에 응답하여 상기 제1 사용자에 관련된 상기 출력 요소가 상기 제1 신호를 상기 제1 사용자에게 출력하게 하는 것을 더 포함하는, 컴퓨터 구현 방법.
- 청구항 1에 있어서, 상기 제1 오디오 소스는 상기 제1 사용자 또는 상기 제2 사용자와 관련되고, 제2 오디오 소스가 현재 비활성이라는 결정에 응답하여 상기 제1 사용자에 관련된 상기 출력 요소가 상기 제1 사용자에게 상기 제1 신호를 출력하게 하는 것을 더 포함하는, 컴퓨터 구현 방법.
- 오디오 신호를 발생시키는 시스템에 있어서,
제1 사용자와 관련되고 오디오 신호들을 생성하도록 구성된 제1 출력 요소;
상기 제1 사용자와 관련되고 오디오 신호들을 수신하도록 구성된 제1 입력 요소;
오디오 신호들을 발생시키도록 구성된 제1 오디오 소스;
제1 회로 요소로서, 상기 제1 출력 요소, 상기 제1 입력 요소, 및 상기 제1 오디오 소스에 결합되고, 그리고:
상기 제1 오디오 소스로부터 제1 신호를 수신하고;
출력을 위해 상기 제1 신호를 상기 제1 출력 요소에 전송하고;
제2 사용자와 관련된 제2 입력 요소로부터 제2 신호를 수신하고;
상기 제1 신호를 상기 제2 신호와 조합하여 조합된 신호를 생성하고; 및
출력을 위해 상기 조합된 신호를 상기 제1 출력 요소에 전송하도록 구성된, 상기 제1 회로 요소를 포함하는, 시스템. - 청구항 10에 있어서, 상기 제1 회로 요소는, 상기 제1 입력 요소에 결합되고 상기 제1 입력 요소에 의해 수신된 상기 오디오 신호들에 기초하여 상기 제1 신호를 더크하도록 구성된 더커(ducker)를 포함하는, 시스템.
- 청구항 10에 있어서, 상기 제1 회로 요소는, 상기 제1 입력 요소 및 상기 제1 오디오 소스에 결합되고 상기 제2 신호에 기초하여 상기 제1 신호를 더크하여 더크된 제1 신호를 발생시키도록 구성된 더커를 포함하고, 상기 제1 신호를 더크하는 것은 상기 제2 신호와 관련되고 제2 주파수 범위에 해당하는 진폭에 기초하여, 상기 제1 신호와 관련되고 제1 주파수 범위에 해당하는 진폭을 조정하는 것을 포함하는, 시스템.
- 청구항 12에 있어서, 상기 제1 회로 요소는, 상기 제2 입력 요소에 결합되고 오디오 신호들을 조합하도록 구성된 합산 유닛(sum unit)을 더 포함하고, 상기 합산 유닛은 상기 조합된 신호를 발생시키기 위해 상기 제2 신호에 상기 더크된 제1 신호를 추가하는, 시스템.
- 청구항 12에 있어서, 상기 제1 회로 요소는 상기 제1 입력 요소에 결합된 필터를 포함하고, 상기 필터는 상기 제1 입력 요소에 의해 수신된 제3 신호로부터 상기 제1 신호 또는 상기 더크된 제1 신호의 적어도 일부를 필터링하여 제4 신호를 발생시키도록 구성되고, 상기 필터는 적응형 필터(adaptive filter) 또는 스펙트럼 감산기(spectral subtractor)를 포함하는, 시스템.
- 청구항 14에 있어서, 상기 제1 회로 요소는 상기 제2 사용자에 관련된 제2 프로세싱 유닛 내의 제2 적응형 소거 유닛(cancellation unit)에 결합되도록 구성된 제1 적응형 에코 소거 유닛을 더 포함하는, 시스템.
- 청구항 15에 있어서, 상기 제1 적응형 에코 소거 유닛과 관련된 출력은 상기 제2 적응형 에코 소거 유닛에 관련된 입력에 결합되고, 상기 제2 적응형 에코 소거 유닛에 관련된 출력은 제1 적응형 에코 소거 유닛과 관련된 입력에 결합된, 시스템.
- 청구항 16에 있어서, 상기 제1 적응형 에코 소거 유닛은 상기 제2 적응형 에코 소거 유닛에 의해 출력된 제5 신호에 기초하여 상기 제4 신호를 필터링하여 상기 제4 신호와 관련된 에코를 감소시키도록 구성되고, 상기 제5 신호는 상기 제2 입력 요소에 의해 수신되는, 시스템.
- 청구항 10에 있어서, 상기 제1 회로 요소는,
제1 구성에서 동작할 때 상기 제1 오디오 소스를 상기 제1 출력 요소 및 제2 출력 요소에 결합하고; 및
제2 구성에서 동작할 때 제2 오디오 소스를 상기 제1 출력 요소에 결합하도록 구성된 라우팅 회로를 더 포함하는, 시스템. - 청구항 18에 있어서, 제어 회로를 더 포함하고,
상기 제어 회로는 상기 라우팅 회로에 결합되고, 그리고:
상기 제1 오디오 소스가 활성이고 상기 제2 오디오 소스가 활성이 아닐 때 상기 라우팅 회로가 상기 제1 구성에서 동작하게 하고; 및
상기 제1 오디오 소스가 활성이 아니고 상기 제2 오디오 소스가 활성일 때, 상기 라우팅 회로가 상기 제2 구성에서 동작하도록 구성된, 시스템. - 청구항 18에 있어서, 상기 라우팅 회로는 상기 라우팅 회로 내의 스위치의 상태에 기초하여 상기 제1 구성 또는 상기 제2 구성에서 동작하도록 더 구성되는, 시스템.
- 프로그램 명령들을 저장하는 비-일시적 컴퓨터 판독가능 매체에 있어서, 상기 프로그램 명령들은 프로세싱 유닛에 의해 실행될 때, 상기 프로세싱 유닛이,
제1 오디오 소스로부터 제1 신호를 수신하는 단계;
출력을 위해 상기 제1 사용자와 관련된 출력 요소에 상기 제1 신호를 전송하는 단계;
제2 사용자와 관련된 입력 요소로부터 제2 신호를 수신하는 단계;
상기 제1 신호를 상기 제2 신호와 조합하여 조합된 신호를 생성하는 단계; 및
출력을 위해 상기 제1 사용자와 관련된 상기 출력 요소에 상기 조합된 신호를 전송하는 단계를 수행함으로써, 오디오 신호를 발생시키게 하는, 비-일시적 컴퓨터 판독가능 매체. - 청구항 19에 있어서, 상기 제1 신호를 상기 제2 신호와 조합하는 단계는,
상기 제2 신호와 관련되고 제2 주파수 범위에 해당하는 진폭에 기초하여, 상기 제1 신호와 관련되고 제1 주파수 범위에 해당하는 진폭을 조정하여 더크된 제1 신호를 발생시키는 단계; 및
상기 더크된 제1 신호를 상기 제2 신호와 합산하는 단계를 포함하는, 비-일시적 컴퓨터 판독가능 매체. - 2개의 상이한 오디오 소스들로부터 오디오 신호들에 액세스하기 위한 시스템에 있어서, 상기 시스템은:
제1 오디오 소스에 결합된 제1 라우팅 회로; 및
상기 제1 라우팅 회로에 결합된 제1 출력 요소를 포함하고,
제1 상태에서, 상기 제1 라우팅 회로는 출력을 위해 오디오 신호를 상기 제1 오디오 소스로부터 제1 출력 요소에 라우팅하도록 구성되고, 및
제2 상태에서, 상기 제1 라우팅 회로는 출력을 위해 오디오 신호를 제2 오디오 소스로부터 상기 제1 출력 요소에 라우팅하도록 구성된, 시스템. - 청구항 23에 있어서, 상기 제1 라우팅 회로는 제1 멀티플렉서를 포함하고, 상기 제1 상태에서, 상기 제1 멀티플렉서는 상기 제1 오디오 소스로부터 상기 제1 출력 요소에 상기 오디오 신호를 전달하는 상기 제1 상태로 구성되고, 시스템.
- 청구항 24에 있어서, 상기 제1 라우팅 회로는 제2 멀티플렉서를 더 포함하고, 상기 제2 상태에서, 상기 제2 멀티플렉서는 상기 오디오 신호를 상기 제2 오디오 소스로부터 상기 제1 멀티플렉서에 전달하도록 구성되고, 상기 제2 상태에서, 상기 제1 멀티플렉서는 상기 오디오 신호를 상기 제2 오디오 소스로부터 상기 제1 출력 요소에 전달하고 상기 오디오 신호를 상기 제1 오디오 소스로부터 상기 제1 출력 요소에 전달하지 않도록 구성되는, 시스템.
- 청구항 25에 있어서, 상기 제1 라우팅 회로는 상기 제1 오디오 소스로부터의 상기 오디오 신호 및 상기 제2 오디오 소스로부터의 상기 오디오 신호가 상기 제1 라우팅 회로를 통해 어떻게 라우팅할지 뿐만 아니라, 상기 제1 멀티플렉서 및 상기 제2 멀티플렉서의 구성들을 제어하는 스위치를 더 포함하는, 시스템.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US14/634,687 US11418874B2 (en) | 2015-02-27 | 2015-02-27 | Techniques for sharing stereo sound between multiple users |
| US14/634,687 | 2015-02-27 | ||
| PCT/US2016/015460 WO2016137652A1 (en) | 2015-02-27 | 2016-01-28 | Techniques for sharing stereo sound between multiple users |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20170125021A true KR20170125021A (ko) | 2017-11-13 |
| KR102524590B1 KR102524590B1 (ko) | 2023-04-21 |
Family
ID=56789802
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020177022897A Active KR102524590B1 (ko) | 2015-02-27 | 2016-01-28 | 다수 사용자 간에 스테레오 사운드를 공유하기 위한 기술 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US11418874B2 (ko) |
| EP (1) | EP3262851B1 (ko) |
| JP (1) | JP2018512754A (ko) |
| KR (1) | KR102524590B1 (ko) |
| CN (1) | CN107278376A (ko) |
| WO (1) | WO2016137652A1 (ko) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108366360B (zh) * | 2018-01-05 | 2020-07-24 | 广东小天才科技有限公司 | 基于麦克风的歌唱互动方法、装置、系统及存储介质 |
| EP3895448B1 (en) * | 2018-12-13 | 2025-10-22 | Google LLC | Mixing microphones for wireless headsets |
| JP7847586B2 (ja) * | 2020-12-28 | 2026-04-17 | 深▲セン▼市韶音科技有限公司 | エコーの抑制のためのオーディオ信号処理方法及びシステム |
| KR20240056177A (ko) * | 2022-10-21 | 2024-04-30 | 삼성전자주식회사 | 오디오 재생장치의 음향 출력 제어 방법 및 그러한 방법을 수행하는 전자 장치 |
| CN117707467B (zh) * | 2024-02-04 | 2024-05-03 | 湖北芯擎科技有限公司 | 音频通路多主机控制方法、系统、装置及存储介质 |
| CN119993179A (zh) * | 2025-01-16 | 2025-05-13 | 广东保伦电子股份有限公司 | 回声消除方法以及电子设备 |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003249996A (ja) * | 2002-02-25 | 2003-09-05 | Kobe Steel Ltd | 音声信号入出力装置 |
| JP2003263872A (ja) * | 2002-03-11 | 2003-09-19 | Alpine Electronics Inc | オーディオ出力装置 |
| US20050032500A1 (en) * | 2003-08-08 | 2005-02-10 | Visteon Global Technologies, Inc. | Wireless/IR headphones with integrated rear seat audio control for automotive entertainment system |
| US20050160270A1 (en) * | 2002-05-06 | 2005-07-21 | David Goldberg | Localized audio networks and associated digital accessories |
| US20110216913A1 (en) * | 2010-03-02 | 2011-09-08 | GM Global Technology Operations LLC | Communication improvement in vehicles |
| WO2014161091A1 (en) * | 2013-04-04 | 2014-10-09 | Rand James S | Unified communications system and method |
Family Cites Families (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4677674A (en) * | 1985-04-03 | 1987-06-30 | Seth Snyder | Apparatus and method for reestablishing previously established settings on the controls of an audio mixer |
| US5228093A (en) | 1991-10-24 | 1993-07-13 | Agnello Anthony M | Method for mixing source audio signals and an audio signal mixing system |
| CA2125220C (en) * | 1993-06-08 | 2000-08-15 | Joji Kane | Noise suppressing apparatus capable of preventing deterioration in high frequency signal characteristic after noise suppression and in balanced signal transmitting system |
| US6493450B1 (en) | 1998-12-08 | 2002-12-10 | Ps Engineering, Inc. | Intercom system including improved automatic squelch control for use in small aircraft and other high noise environments |
| US7260231B1 (en) | 1999-05-26 | 2007-08-21 | Donald Scott Wedge | Multi-channel audio panel |
| US7215765B2 (en) * | 2002-06-24 | 2007-05-08 | Freescale Semiconductor, Inc. | Method and apparatus for pure delay estimation in a communication system |
| JP4804014B2 (ja) | 2005-02-23 | 2011-10-26 | 沖電気工業株式会社 | 音声会議装置 |
| US20080170740A1 (en) | 2007-01-05 | 2008-07-17 | Sync1 | Self-contained dual earbud or earphone system and uses thereof |
| US8295500B2 (en) * | 2008-12-03 | 2012-10-23 | Electronics And Telecommunications Research Institute | Method and apparatus for controlling directional sound sources based on listening area |
| US20110026745A1 (en) | 2009-07-31 | 2011-02-03 | Amir Said | Distributed signal processing of immersive three-dimensional sound for audio conferences |
| JP5356160B2 (ja) * | 2009-09-04 | 2013-12-04 | アルプス電気株式会社 | ハンズフリー通信システム及び近距離無線通信装置 |
| US9609141B2 (en) | 2012-10-26 | 2017-03-28 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Loudspeaker localization with a microphone array |
| US20140161274A1 (en) | 2012-12-10 | 2014-06-12 | Silverplus, Inc. | Dual-Mode Wire/Wireless Headphone with Wireless Audio Gateway Functionalities to Support Multiple Wireless Headphones |
| US20140363008A1 (en) | 2013-06-05 | 2014-12-11 | DSP Group | Use of vibration sensor in acoustic echo cancellation |
| US9288570B2 (en) * | 2013-08-27 | 2016-03-15 | Bose Corporation | Assisting conversation while listening to audio |
-
2015
- 2015-02-27 US US14/634,687 patent/US11418874B2/en active Active
-
2016
- 2016-01-28 CN CN201680011668.3A patent/CN107278376A/zh active Pending
- 2016-01-28 JP JP2017542869A patent/JP2018512754A/ja active Pending
- 2016-01-28 EP EP16756032.5A patent/EP3262851B1/en active Active
- 2016-01-28 KR KR1020177022897A patent/KR102524590B1/ko active Active
- 2016-01-28 WO PCT/US2016/015460 patent/WO2016137652A1/en not_active Ceased
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003249996A (ja) * | 2002-02-25 | 2003-09-05 | Kobe Steel Ltd | 音声信号入出力装置 |
| JP2003263872A (ja) * | 2002-03-11 | 2003-09-19 | Alpine Electronics Inc | オーディオ出力装置 |
| US20050160270A1 (en) * | 2002-05-06 | 2005-07-21 | David Goldberg | Localized audio networks and associated digital accessories |
| US20050032500A1 (en) * | 2003-08-08 | 2005-02-10 | Visteon Global Technologies, Inc. | Wireless/IR headphones with integrated rear seat audio control for automotive entertainment system |
| US20110216913A1 (en) * | 2010-03-02 | 2011-09-08 | GM Global Technology Operations LLC | Communication improvement in vehicles |
| WO2014161091A1 (en) * | 2013-04-04 | 2014-10-09 | Rand James S | Unified communications system and method |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3262851A1 (en) | 2018-01-03 |
| JP2018512754A (ja) | 2018-05-17 |
| EP3262851A4 (en) | 2019-02-20 |
| KR102524590B1 (ko) | 2023-04-21 |
| CN107278376A (zh) | 2017-10-20 |
| US11418874B2 (en) | 2022-08-16 |
| US20160255436A1 (en) | 2016-09-01 |
| WO2016137652A1 (en) | 2016-09-01 |
| EP3262851B1 (en) | 2024-04-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102524590B1 (ko) | 다수 사용자 간에 스테레오 사운드를 공유하기 위한 기술 | |
| EP2973540B1 (en) | Low-latency multi-driver adaptive noise canceling (anc) system for a personal audio device | |
| KR101699067B1 (ko) | 노이즈 제거 기능이 구비된 이어폰 장치 및 노이즈 제거 방법 | |
| KR102045600B1 (ko) | 이어폰 능동 노이즈 제어 | |
| JP6069829B2 (ja) | 耳孔装着型収音装置、信号処理装置、収音方法 | |
| US12407993B2 (en) | Adaptive binaural filtering for listening system using remote signal sources and on-ear microphones | |
| JP2015204627A (ja) | 電気的ヒスを低減するanc能動雑音制御オーディオヘッドセット | |
| CN102271299B (zh) | 声音信号处理装置和声音信号处理方法 | |
| CN105637892B (zh) | 用于在收听音频的同时辅助对话的系统和耳机 | |
| CN104754436B (zh) | 一种主动降噪方法以及降噪耳机 | |
| JP2016534648A (ja) | 会話の支援 | |
| US9516431B2 (en) | Spatial enhancement mode for hearing aids | |
| JP2009530950A (ja) | ウェアラブル装置のためのデータ処理 | |
| US10827253B2 (en) | Earphone having separate microphones for binaural recordings and for telephoning | |
| CN112399301A (zh) | 耳机及降噪方法 | |
| KR102577901B1 (ko) | 오디오 신호 처리 장치 및 방법 | |
| JP6197930B2 (ja) | 耳孔装着型収音装置、信号処理装置、収音方法 | |
| EP4184507A1 (en) | Headset apparatus, teleconference system, user device and teleconferencing method | |
| JP2018107577A (ja) | 音響装置 | |
| JP2007097006A (ja) | 複数人用イヤフォン並びにヘッドフォン | |
| Shen et al. | Networked acoustics around human ears | |
| CN114501210B (zh) | 具有方向通透性的主动降噪电路、方法、设备及存储介质 | |
| Ouaknine-Beaulieu et al. | Enabling personalized communication with advanced hearing protection devices: Integrating and evaluating concepts of a radio acoustical virtual environment | |
| US10264116B2 (en) | Virtual duplex operation | |
| JP2015220482A (ja) | 送受話端末、エコー消去システム、エコー消去方法、プログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
St.27 status event code: A-0-1-A10-A15-nap-PA0105 |
|
| PG1501 | Laying open of application |
St.27 status event code: A-1-1-Q10-Q12-nap-PG1501 |
|
| R17-X000 | Change to representative recorded |
St.27 status event code: A-3-3-R10-R17-oth-X000 |
|
| PA0201 | Request for examination |
St.27 status event code: A-1-2-D10-D11-exm-PA0201 |
|
| D13-X000 | Search requested |
St.27 status event code: A-1-2-D10-D13-srh-X000 |
|
| D14-X000 | Search report completed |
St.27 status event code: A-1-2-D10-D14-srh-X000 |
|
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
St.27 status event code: A-1-2-D10-D21-exm-PE0902 |
|
| P11-X000 | Amendment of application requested |
St.27 status event code: A-2-2-P10-P11-nap-X000 |
|
| P13-X000 | Application amended |
St.27 status event code: A-2-2-P10-P13-nap-X000 |
|
| E90F | Notification of reason for final refusal | ||
| PE0902 | Notice of grounds for rejection |
St.27 status event code: A-1-2-D10-D21-exm-PE0902 |
|
| E13-X000 | Pre-grant limitation requested |
St.27 status event code: A-2-3-E10-E13-lim-X000 |
|
| P11-X000 | Amendment of application requested |
St.27 status event code: A-2-2-P10-P11-nap-X000 |
|
| P13-X000 | Application amended |
St.27 status event code: A-2-2-P10-P13-nap-X000 |
|
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration |
St.27 status event code: A-1-2-D10-D22-exm-PE0701 |
|
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment |
St.27 status event code: A-2-4-F10-F11-exm-PR0701 |
|
| PR1002 | Payment of registration fee |
St.27 status event code: A-2-2-U10-U12-oth-PR1002 Fee payment year number: 1 |
|
| PG1601 | Publication of registration |
St.27 status event code: A-4-4-Q10-Q13-nap-PG1601 |
|
| R18-X000 | Changes to party contact information recorded |
St.27 status event code: A-5-5-R10-R18-oth-X000 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 4 |
|
| U11 | Full renewal or maintenance fee paid |
Free format text: ST27 STATUS EVENT CODE: A-4-4-U10-U11-OTH-PR1001 (AS PROVIDED BY THE NATIONAL OFFICE) Year of fee payment: 4 |