정의
"포함하는" 또는 "포함된" 일반적인 실시형태들은 "로 구성되는" 보다 구체적인 실시형태들을 포함한다. 또한, 단수 및 복수 형태는 제한적 방식으로 사용되는 것은 아니다. 본원에서 사용되는 바와 같이, 단수 형태 "한(a)", "하나(an)" 및 "상기(the)"는 단수만을 표기하는 것으로 명확히 언급되지 않는 한, 단수 및 복수 둘 다를 나타낸다.
본원에서 사용되는 용어 "리보핵산", "RNA" 또는 "RNA 올리고뉴클레오타이드"는 뉴클레오타이드의 서열로 이루어진 분자를 기술하고, 이는 뉴클레오염기, 리보스 당, 및 포스페이트 그룹으로 이루어진다. RNA는 일반적으로 단일 가닥의 분자이고 각종 기능을 발휘할 수 있다. 용어 리보핵산은 구체적으로 전령 RNA(mRNA: messenger RNA), 전이 RNA(tRNA: transfer RNA), 리보솜 RNA(rRNA: ribosomal RNA), 짧은 간섭 RNA(siRNA), 소형 헤어핀 RNA(shRNA: small hairpin RNA) 및 마이크로 RNA(miRNA: micro RNA)를 포함하고, 이의 각각은 생물학적 세포에서 특정한 역할을 한다. 이는 소형 비-암호화 RNA, 예를 들면 마이크로 RNA(miRNA), 짧은 간섭 RNA(siRNA), 소형 헤어핀 RNA(shRNA), 및 Piwi-상호작용 RNA(piRNA)를 포함한다. 용어 "비-암호화(non-coding)"는 RNA 분자가 아미노산 서열로 번역되지 않음을 의미한다.
용어 "RNA 간섭"(RNAi)은 단백질 합성의 일반화된 억제 부재 하의 유전자 발현(단백질 합성)의 서열-특이적 또는 유전자-특이적 억제를 말한다. RNAi는 전사된 mRNA의 번역을 방지하는 RNA-유도된 침묵 복합체(RISC: RNA-induced silencing complex)에 의한 전령 RNA(mRNA)의 분해를 포함할 수 있다. RNAi에 의해 야기된 유전자 발현의 억제는 일시적일 수 있거나, 보다 안정할 수 있거나, 심지어 영구적일 수 있다. RNAi는 siRNA 또는 shRNA에 의해 매개될 수 있다. 바람직하게, 본 발명에 따른 RNAi는 유전자-특이적이다(하나의 유전자만을 표적으로 한다). RNAi는 RNA 올리고뉴클레오타이드가 표적 유전자와의 완전한 서열 상보성(즉, 소형 간섭 RNA의 RNA 듀플렉스(duplex)의 안티센스 가닥과 표적 mRNA 사이의 완벽한 염기 짝짓기(pairing))을 갖는 서열을 포함하는 경우 유전자-특이적 또는 이의 표적 유전자에 대해 특이적인 것으로 간주된다. 유전자-특이적 RNAi는 siRNA 또는 shRNA에 의해 매개될 수 있다. 한 바람직한 실시형태에서, RNAi는 siRNA 또는 shRNA에 의해 매개된다. 다른 바람직한 실시형태에서, RNAi는 miRA에 의해 매개되지 않는다.
용어 "마이크로RNA" 또는 "miRNA"는 본원에서 상호교환적으로 사용된다. 마이크로RNA는 작은 약 22 뉴클레오타이드-길이(전형적으로는 19 내지 25개 뉴클레오타이드 길이)의 비-암호화 단일 가닥의 RNA이다. miRNA는 전형적으로 1개 초과의 유전자를 표적으로 한다. 마이크로RNA는 진핵생물 세포의 게놈 내에 암호화되어 있고 전형적으로 RNA 폴리머라제 III에 의해 긴 1차 전사물로서 전사되고, 이는 이어서 우선 몇몇의 단계에서 약 70nt-길이 헤어핀-루프 구조로 그리고 후속적으로는 약 22nt RNA 듀플렉스로 프로세싱된다. 이어서, 표적 단백질의 번역 또는 이들의 각각의 mRNA의 분해를 차단하기 위해 활성의 성숙 가닥을 RNA-유도된 침묵 복합체(RISC)에 부하한다. miRNA를 이용한 표적화는 미스매치(mismatch)를 가능하게 하고 mRNA 번역 억압(repression)은 불완전한 상보성(즉, 작은 간섭 RNA의 RNA 듀플렉스의 안티센스 가닥과 표적 mRNA 사이의 완벽하지 않은 염기 짝짓기)에 의해 매개되고, 한편 siRNA 및 shRNA는 완전한 서열 상보성(즉, 소형 간섭 RNA의 RNA 듀플렉스의 안티센스 가닥과 표적 mRNA 사이의 완벽한 염기 짝짓기)으로 인하여 이들의 표적에 대해 특이적이다. 전형적으로, miRNA는 3'비번역 영역(3'UTR: 3'untranslated region)에 결합하고, 유전자-특이적이지 않지만, 다중 mRNA를 표적으로 한다. 본원에서 사용되는 용어 "마이크로RNA"는 사람 miRNA와 같은 내인성(endogenous) 게놈 포유동물 miRNA에 관한 것이다. 접두사 "hsa"는 예를 들면, 마이크로RNA의 사람 기원을 나타낸다. 이들은 포유동물 숙주 세포에서의 miRNA의 일시적 또는 안정한 발현을 위한 게놈 마이크로RNA 서열(들)을 포함하는 발현 벡터를 이용하여 포유동물 숙주 세포에 도입될 수 있다. 게놈 마이크로RNA를 발현 벡터로 클로닝하기 위한 수단은 당해 분야에 공지되어 있다. 이들로는 프로모터에 작동가능하게 링크된(operably linked) pBIP-1과 같은 포유동물 발현 벡터에 대략 300bp의 플랭킹(flanking) 영역을 갖는 게놈 miRNA 서열을 클로닝하는 것이 포함된다. 대안으로, 하나 이상의 마이크로RNA는 포유동물 발현 벡터 내로 조작된 pre-miRNA 서열(즉, 짧은 헤어핀)을 암호화하는 폴리뉴클레오타이드로서 클로닝될 수 있다. 예를 들면, 성숙 miRNA 서열은 뮤린 miRNA mir-155로부터 유도된 것과 같은 3' 및 5' 플랭킹 영역 및 최적화된 헤어핀 루프 서열을 암호화하는 주어진 서열 내로 클로닝될 수 있다(Lagos-Quintana et al., 2002. Curr Biol. 30;12(9):735-9). 상기 miRNA 서열, 상기 언급된 루프 및 2개의 뉴클레오타이드가 고갈된 각각의 성숙한 miRNA의 안티센스 서열을 암호화하여 헤어핀 줄기에 내부 루프를 생성하는 DNA 올리고뉴클레오타이드가 고안된다. 또한, 양쪽 말단에 클로닝하기 위해 오버행(overhang)을 부가하여 3' 및 5' 플랭킹 영역에 DNA 올리고뉴클레오타이드를 융합시킨다. 본원에서 사용되는 miRNA는 비-정규(non-canonical) miRNA를 추가로 포함한다. 이들 RNA는 리보솜 RNA(rRNA) 또는 전이 RNA(tRNA)를 포함하는 '하우스킵핑' 비-암호화 RNA(ncRNA)로부터 유도될 수 있고, miRNA-유사 방식으로 기능한다. 이들 RNA는 또한 포유동물 미토콘드리아 ncRNA로부터 기원할 수 있고, 미토콘드리아 게놈-암호화된 소형 RNA(mitosRNA)라고 명명한다.
본원에서 사용되는 용어 "소형 간섭" 또는 "짧은 간섭 RNA" 또는 "siRNA"는 원하는 유전자를 표적으로 하고 이와 상동성을 공유하는 유전자의 발현을 저해할 수 있는 뉴클레오타이드의 RNA 듀플렉스를 나타낸다. 이는 긴 이중 가닥의 RNA(dsRNA) 또는 shRNA로부터 형성된다. RNA 듀플렉스는 전형적으로 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 또는 27개 염기 쌍을 형성하는 19, 20, 21, 22, 23, 24, 25, 26, 27, 28 또는 29개 뉴클레오타이드의 2개의 상보성 단일-가닥의 RNA를 포함하고 2개의 뉴클레오타이드의 3' 오버행을 갖고, 바람직하게는 상기 RNA 듀플렉스는 17 내지 25개 염기 쌍을 형성하는 19 내지 27개 뉴클레오타이드의 2개의 상보성 단일 가닥의 RNA를 포함하고 2개의 뉴클레오타이드의 3' 오버행을 갖는다. siRNA는 siRNA의 듀플렉스 부분의 뉴클레오타이드 서열이 표적으로 하는 유전자의 mRNA의 뉴클레오타이드 서열과 상보성인 유전자를 "표적으로 한다". 상기 siRNA 또는 이의 전구체는 항상 상기 세포 내로 예를 들면, 직접 또는 상기 siRNA를 암호화하는 서열을 갖는 벡터의 형질감염에 의해 외인성으로 도입되고, 내인성 miRNA 경로는 siRNA의 정확한 프로세싱 및 표적 mRNA의 절단(cleavage) 또는 분해를 위해 이용된다. 듀플렉스 RNA는 단일 작제물로부터 세포에서 발현될 수 있다.
본원에서 사용되는 용어 "shRNA"(소형 헤어핀 RNA)는 상기 siRNA의 일부가 헤어핀 구조의 부분(shRNA)인 RNA 듀플렉스를 말한다. 상기 shRNA는 기능성 siRNA에 세포내 프로세싱될 수 있다. 듀플렉스 부분에 추가하여, 상기 헤어핀 구조는 듀플렉스를 형성하는 2개의 서열들 사이에 위치된 루프 부분을 함유할 수 있다. 상기 루프의 길이는 다를 수 있다. 몇몇의 실시형태들에서, 상기 루프는 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 또는 14개 뉴클레오타이드 길이이다. 상기 헤어핀 구조는 또한 3' 또는 5' 오버행 부분을 함유할 수 있다. 몇몇의 양상들에서, 상기 오버행은 0, 1, 2, 3, 4 또는 5개의 뉴클레오타이드 길이의 3' 또는 5' 오버행이다. 본 발명의 한 양상에서, 벡터 내에 포함된 뉴클레오타이드 서열은 센스 영역, 루프 영역 및 안티센스 영역을 포함하는 소형 헤어핀 RNA의 발현을 위한 주형(template)으로서 작용한다. 발현 후 상기 센스 및 안티센스 영역은 듀플렉스를 형성한다. shRNA는 항상 예를 들면, 상기 shRNA를 암호화하는 서열을 갖는 벡터의 형질감염에 의해 외인성으로 도입되고, 내인성 miRNA 경로는 siRNA의 정확한 프로세싱 및 표적 mRNA의 절단 또는 분해를 위해 이용된다. shRNA를 암호화하는 서열을 갖는 벡터의 사용은 표적 유전자의 억제가 전형적으로 장기간이고 안정하다는 점에서 화학적으로 합성된 siRNA의 사용에 비해 이점을 갖는다.
전형적으로, siRNA 및 shRNA는 완전한 서열 상보성(즉, 소형 간섭 RNA의 RNA 듀플렉스의 안티센스 가닥과 표적 mRNA 사이의 완벽한 염기 짝짓기)에 의해 mRNA 억압을 매개하므로, 이들의 표적에 대해 특이적이다. RNA 듀플렉스의 안티센스 가닥은 또한 RNA 듀플렉스의 활성 가닥으로서 나타낼 수 있다. 본원에 사용된 바와 같은 완벽한 염기 짝짓기의 완전한 서열 상보성은 소형 간섭 RNA의 RNA 듀플렉스의 안티센스 가닥이 적어도 15개의 연속 뉴클레오타이드, 적어도 16개의 연속 뉴클레오타이드, 적어도 17개의 연속 뉴클레오타이드, 적어도 18개의 연속 뉴클레오타이드 및 바람직하게는 적어도 19개의 연속 뉴클레오타이드에 대해 표적 mRNA와 적어도 89%의 서열 동일성을 갖거나, 또는 바람직하게는 적어도 15개의 연속 뉴클레오타이드, 적어도 16개의 연속 뉴클레오타이드, 적어도 17개의 연속 뉴클레오타이드, 적어도 18개의 연속 뉴클레오타이드 및 바람직하게는 적어도 19개의 연속 뉴클레오타이드에 대해 표적 mRNA와 적어도 93%의 서열 동일성을 갖는다. 보다 바람직하게, 소형 간섭 RNA의 RNA 듀플렉스의 안티센스 가닥은 적어도 15개의 연속 뉴클레오타이드, 적어도 16개의 연속 뉴클레오타이드, 적어도 17개의 연속 뉴클레오타이드, 적어도 18개의 연속 뉴클레오타이드 및 바람직하게는 적어도 19개의 연속 뉴클레오타이드에 대해 표적 mRNA와 100%의 서열 동일성을 갖는다.
본원에서 사용되는 용어 "ATF6B"는 단백질 활성화 전사 인자 6 베타를 말한다. 이는 또한 CREBL1, CAMP 반응 요소-결합 단백질-관련된 단백질, CAMP 반응성 요소 결합 단백질-유사 1, CAMP-의존적 전사 인자 ATF-6 베타, CAMP-반응성 dth-결합 단백질-유사 1, 단백질 G13 CREB-RP, G13, 환형 AMP-의존적 전사 인자 ATF-6 베타, Creb-관련된 단백질, ATF6-베타로서도 공지되어 있다. Atf6b에 대한 외부 Id는 HGNC: 2349; Entrez Gene: 1388, Ensembl: ENSG00000213676; OMIM: 600984; UniProtKB: Q99941이다(http://www.genecards.org/cgi in/carddisp.pl?gene=ATF6B&keywords=ATF6B). 이는 서열번호 6의 아미노산 서열 또는 서열번호 6과 적어도 80%의 서열 동일성을 갖는 아미노산 서열을 갖는 단백질을 포함한다.
본원에서 사용되는 용어 "CERS2"는 단백질 세라마이드 신타제 2를 말한다. 이는 또한 LASS2, Longevity Assurance(LAG1, 에스. 세레비지애(S. Cerevisiae)) 동족체(Homolog) 2, 종양 전이-억제제 유전자 1 단백질, LAG1 동족체, 세라마이드 신타제 2, SP260, TMSG1, LAG1 장수 보장 동족체(Longevity Assurance Homolog) 2(에스. 세레비지애), LAG1 장수 보장 동족체 2, LAG1 장수 보장 2, L3으로서 공지되어 있다. CerS2에 대한 외부 Id는 HGNC: 14076; Entrez Gene: 29956; Ensembl: ENSG00000143418; OMIM: 606920; UniProtKB: Q96G23이다(http://www.genecards.org/cgi-bin/carddisp.pl?gene=CERS2). 이는 서열번호 5의 아미노산 서열 또는 서열번호 5와 적어도 80%의 서열 동일성을 갖는 아미노산 서열을 갖는 단백질을 포함한다.
본원에서 사용되는 용어 "TBC1D20"은 TBC1 도메인 패밀리 구성원 20을 말한다. 이는 또한 C20orf140, WARBM4 및 염색체 20 개방 판독 프레임(Open Reading Frame) 140으로서도 공지되어 있다. Tbc1d20에 대한 외부 Id는 HGNC: 16133; Entrez Gene: 128637; Ensembl: ENSG00000125875; OMIM: 611663; UniProtKB: Q96BZ9이다(http://www.genecards.org/cgi-bin/carddisp.pl?gene=TBC1D20). 이는 서열번호 4의 아미노산 서열 또는 서열번호 4와 적어도 80%의 서열 동일성을 갖는 아미노산 서열을 갖는 단백질을 포함한다.
본원에서 사용되는 바와 같이, RNAi에 의해 TBC1D20, CERS2 또는 ATF6B의 발현을 저해하는 RNA 올리고뉴클레오타이드는 구체적으로 각각 TBC1D20, CERS2 또는 ATF6B를 암호화하는 RNA를 표적으로 한다. 한 바람직한 실시형태에서, 상기 RNA 뉴클레오타이드로는 miRNA가 제외된다.
용어 "녹다운" 또는 "녹다운 기술"은 표적 유전자 또는 목적하는 유전자의 발현이 RNA-간섭에 의해, 예를 들면 siRNA 또는 shRNA를 이용함에 의해 표적 유전자의 발현을 저해하는 RNA 올리고뉴클레오타이드의 도입 이전의 유전자 발현과 비교하여 감소되는 유전자 침묵 기술을 말하고, 이는 표적 유전자 생성물의 생산 저해를 유도할 수 있다. "이중 녹다운"은 2개의 유전자의 녹다운이다.
유전자는 또한 "녹아웃" 기술을 이용하여 유전자를 결실시킴으로써 변형될 수 있다. 용어 "녹아웃"은 숙주 세포 단백질 AFT6B 또는 숙주 세포 단백질 TBC1D20 및 CERS2의 조합의 발현이 저해되어 각각의 숙주 세포 단백질이 생산되지 않도록(100%까지 감소됨) 유전적으로 변형된 세포를 말한다. 이는 CRISPR-Cas9 또는 아연 핑거(Zinc finger) 뉴클레아제 기술을 포함하는 당해 분야에 공지되어 있는 각종 기술을 이용하여 달성할 수 있다.
대안으로, 상기 유전자는 상기 유전자 내의 돌연변이 도입에 의해 이의 단백질의 발현을 저해하도록 변경될 수 있다. 상기 유전자 돌연변이는 상기 유전자의 암호화 영역 내의 또는 프로모터 또는 조절 영역 내의 결실, 부가 또는 치환일 수 있다. 이러한 유전자 돌연변이는 유전자의 하나 또는 양쪽 대립유전자(allele) 중 어느 하나에 존재할 수 있다.
본원에서 사용되는 용어 "감소", "감소된" 또는 "감소시키다"는 일반적으로 참조 수준과 비교하여 적어도 10% 만큼의 감소, 예를 들면 대조군 포유동물 세포와 비교하여 적어도 약 20% 또는 적어도 약 30%, 또는 적어도 약 40%, 또는 적어도 약 50%, 또는 적어도 약 60%, 또는 적어도 약 70%, 또는 적어도 약 75%, 또는 적어도 약 80%, 또는 적어도 약 90% 만큼의 감소 또는 100% 이하의 감소 또는 10 내지 100% 사이의 임의의 정수의 감소를 의미한다. 숙주 세포 단백질 TBC1D20 및 CERS2의 또는 숙주 세포 단백질 ATF6B의 발현은 대조군 포유동물 세포와 비교하여 적어도 30%, 적어도 40%, 적어도 50%, 적어도 75% 또는 100%만큼 감소되는 것이 바람직하다.
본원에 사용되는 용어 "향상", "향상된", "향상되는", "증가" 또는 "증가된"은 일반적으로 대조군 세포와 비교하여 적어도 10% 만큼의 증가, 예를 들면 대조군 세포와 비교하여 적어도 약 20%, 또는 적어도 약 30%, 또는 적어도 약 40%, 또는 적어도 약 50%, 또는 적어도 약 75%, 또는 적어도 약 80%, 또는 적어도 약 90%, 또는 적어도 약 100%, 또는 적어도 약 200%, 또는 적어도 약 300% 또는 10 내지 300% 사이의 임의의 정수의 감소를 의미한다.
본원에서 사용되는 "대조군 세포" 또는 "대조군 포유동물 세포"는 숙주 세포 단백질 TBC1D20 및 CERS2 또는 ATF6B의 발현이 감소되지 않았음을 제외하고는 이와 비교되는 세포와 동일한 세포이다. 상기 대조군 포유동물 세포는 본 발명의 방법에 의해 생산될 수 있지만, 숙주 세포 단백질 TBC1D20 및 CERS2의 또는 숙주 세포 단백질 ATF6B의 발현을 감소시키는 단계는 생략할 수 있다. 특히, 대조군 포유동물 세포에는 TBC1D20 및 CERS2 또는 ATF6B의 발현을 저해하는 임의의 유전적 변형이 결여되어 있고 RNA-간섭에 의해 유전자 Tbc1d20 및 Cers2 또는 Atf6b를 저해하는 임의의 형질감염된 RNA 올리고뉴클레오타이드가 결여되어 있다.
본 발명에서 사용되는 용어 "유도체" 또는 "동족체"는 본래 서열 또는 이의 상보성 서열과 서열에 있어서 적어도 70% 동일한 폴리펩타이드 분자 또는 핵산 분자를 의미한다. 바람직하게는, 폴리펩타이드 분자 또는 핵산 분자는 본래 서열 또는 이의 상보성 서열과 서열에 있어서 적어도 80% 동일하다. 보다 바람직하게, 폴리펩타이드 분자 또는 핵산 분자는 본래 서열 또는 이의 상보성 서열과 서열에 있어서 적어도 90% 동일하다. 보다 더 바람직하게, 폴리펩타이드 분자 또는 핵산 분자는 본래 서열 또는 이의 상보성 서열과 서열에 있어서 적어도 95% 동일하다. 가장 바람직하게는, 폴리펩타이드 분자 또는 핵산 분자는 본래 서열 또는 이의 상보성 서열과 서열에 있어서 적어도 98% 동일하다. 동종 단백질은 본래 서열과 동일하거나 유사한 단백질 활성을 추가로 나타낸다.
서열 차이는 상이한 유기체로부터의 상동 서열의 차이에 기초할 수 있거나 자연 발생 대립유전자 변이일 수 있다. 이들은 또한 하나 이상의 뉴클레오타이드 또는 아미노산, 바람직하게는 1, 2, 3, 4, 5, 6, 7, 8, 9 또는 10개의 치환, 삽입 또는 결실에 의한 서열의 표적화된 변형에 기초할 수 있다. 결실, 삽입 또는 치환 돌연변이체는 부위-특이적 돌연변이 유발(mutagenesis) 및/또는 PCR-기반 돌연변이 유발 기술을 이용하여 생성될 수 있다.
본원에서 사용되는 용어 "숙주 세포"는 분비형 재조합 치료학적 단백질의 생산에 적합한 포유동물 세포주이고, 따라서 "포유동물 세포"로서도 나타내어질 수 있다. 본 발명에 따른 바람직한 포유동물 세포는 설치류 세포, 예를 들면 햄스터 세포이다. 상기 포유동물 세포는 단리된 세포 또는 세포주이다. 상기 포유동물 세포는 형질전환되고/되거나 불멸화된 세포주인 것이 바람직하다. 이들은 세포 배양에서 일련의 계대에 적응하고 1차 비-형질전환된 세포 또는 기관 구조의 일부인 세포를 포함하지 않는다. 바람직한 포유동물 세포는 BHK21, BHK TK-, CHO, CHO-K1(예를 들면, CHO-DUKX, CHO-DUKX B1) 및 CHO-DG44 세포 또는 이러한 세포주 중 어느 것의 유도체/자손이다. 특히 바람직한 것은 CHO-DG44, CHO-K1 및 BHK21이고, 더욱 더 바람직한 것은 CHO-DG44 및 CHO-K1 세포이다. 가장 바람직한 것은 CHO-DG44 세포이다. 상기 포유동물 세포의, 특히 CHO-DG44 및 CHO-K1 세포의 글루타민 신테타제(GS)-결핍 유도체도 포함된다. 상기 포유동물 세포는 재조합 분비형 치료학적 단백질을 암호화하는 하나 이상의 발현 카세트(들)를 추가로 포함할 수 있다. 상기 숙주 세포는 또한 뮤린 세포, 예를 들면 뮤린 골수종 세포, 예를 들면, NS0 및 Sp2/0 세포 또는 이러한 세포주 중 어느 것의 유도체/자손일 수 있다. 본 발명의 의미에서 사용될 수 있는 포유동물 세포의 비-제한적 예는 또한 표 1에 요약된다. 그러나, 이들 세포의 유도체/자손, 사람, 마우스, 래트, 원숭이 및 설치류 세포주를 포함하지만 이들에 한정되는 것은 아닌 다른 포유동물 세포 또한 본 발명에서, 특히 생물약제학적 단백질의 생산을 위해 사용될 수 있다.
숙주 세포는 무혈청 조건 하에 그리고 임의로 동물 기원의 임의의 단백질/펩타이드를 포함하지 않는 배지에서 확립되고, 적응되고, 완전하게 배양되는 경우에 가장 바람직하다. 상업적으로 입수가능한 배지, 예를 들면 Ham's F12(Sigma, Deisenhofen, Germany), RPMI-1640(Sigma), 둘베코 변형 이글 배지(Dulbecco's Modified Eagle's Medium)(DMEM; Sigma), 최소 필수 배지(Minimal Essential Medium)(MEM; Sigma), 이스코브 변형 둘베코 배지(Iscove's Modified Dulbecco's Medium)(IMDM; Sigma), CD-CHO(Invitrogen, Carlsbad, CA), CHO-S(Invitrogen), 무혈청 CHO 배지(Sigma), 및 무-단백질 CHO 배지(Sigma)가 예시의 적절한 영양분 용액이다. 상기 배지 중 임의의 것은 필요에 따라 각종 화합물이 보충될 수 있고, 이의 비-제한적 예로는 호르몬 및/또는 다른 성장 인자(예를 들면, 인슐린, 트랜스페린, 표피 성장 인자, 인슐린 유사 성장 인자), 염(예를 들면, 나트륨 클로라이드, 칼슘, 마그네슘, 포스페이트), 완충제(예를 들면 HEPES), 뉴클레오사이드(예를 들면, 아데노신, 티미딘), 글루타민, 글루코스 또는 다른 등가의 에너지 공급원, 항생제 및 미량 원소가 있다. 임의의 다른 필요한 보충제는 또한 당해 분야 숙련가들에게 공지되어 있을 적절한 농도로 포함될 수 있다. 본 발명에서, 무혈청 배지의 사용이 바람직하지만, 적합한 양의 혈청이 보충된 배지도 숙주 세포의 배양에 사용될 수 있다. 선택성 유전자를 발현하는 유전적으로 변형된 세포의 성장 및 선택을 위해 적합한 선택제(selection agent)를 배양 배지에 부가한다.
용어 "단백질"은 "아미노산 잔기 서열" 또는 "폴리펩타이드"와 상호교환적으로 사용되고 임의의 길이의 아미노산들의 중합체를 말한다. 이들 용어는 또한 당화, 아세틸화, 인산화 또는 단백질 프로세싱을 포함하지만 이들에 한정되는 것은 아닌 반응을 통해 번역-후 변형된 단백질을 포함한다. 변형 및 변화, 예를 들면 다른 단백질에의 융합, 아미노산 서열 치환, 결실 또는 삽입은 폴리펩타이드의 구조에서 이루어질 수 있고, 한편 상기 분자는 이의 생물학적 기능 활성을 유지한다. 예를 들면, 소정 아미노산 서열 치환은 폴리펩타이드 또는 이의 근본적인 핵산 암호화 서열에서 이루어질 수 있고, 동일한 특성을 갖는 단백질이 수득될 수 있다.
용어 "폴리펩타이드"는 10개 초과의 아미노산을 갖는 서열을 의미하고 용어 "펩타이드"는 10개 이하의 아미노산 길이를 갖는 서열을 의미한다. 그러나, 상기 용어들은 상호교환적으로 사용될 수 있다.
본 발명은 생물약제학적 또는 진단학적 폴리펩타이드/단백질의 생산을 위한 숙주 세포를 생성시키는데 적합하다. 본 발명은 특히 향상된 세포 생산성을 보여주는 세포에 의한 목적하는 다수의 상이한 유전자들의 고-수율 발현에 적합하다.
"재조합 분비형 치료학적 단백질"은 진단학적 또는 치료학적 용도에, 바람직하게는 치료학적 용도에 적합한, 숙주 세포에 도입된 임의의 길이의 폴리뉴클레오타이드 서열에 의해 암호화되는 목적하는 분비형 단백질을 말한다. 상기 단백질을 암호화하는 선택된 서열은 전장 또는 절단된(truncated) 유전자, 융합 또는 태그된(tagged) 유전자일 수 있고, cDNA, 게놈 DNA 또는 DNA 단편, 바람직하게는 cDNA일 수 있다. 이는 본래 서열, 즉 천연 발생 형태(들)일 수 있거나, 또는 원하는 대로 돌연변이되거나 그렇지 않으면 변형될 수 있다. 이들 변형으로는 선택된 숙주 세포에서의 코돈 사용을 최적화하기 위한 코돈 최적화, 사람화, 융합 또는 태깅(tagging)이 포함된다. "재조합" 단백질은 이종(heterologous) 서열로부터 발현된 단백질이다.
용어 "숙주 세포 단백질"은 일반적으로 숙주 세포에 대해 내생적인 모든 단백질에 관한 것이지만, 본원에서는 구체적으로 숙주 세포 단백질 ATF6B에 또는 2개의 숙주 세포 단백질 TBC1D20 및 CERS2에 관한 것으로서 사용된다.
본원에서 사용되는 용어 "생산하는" 또는 "고도로 생산성인", "생산", "생산 및/또는 분비", "생산성" 또는 "생산 세포"는 재조합 분비형 치료학적 단백질의 생산에 관한 것이다. "증가된 생산 및/또는 분비"는 재조합 분비형 치료학적 단백질의 발현에 관한 것이고 비 생산성(specific productivity)의 증가, 증가된 역가(titer) 또는 둘 다를 의미한다. 바람직하게는, 역가 또는 비 생산성 및 역가가 증가된다. 본원에서 사용되는 증가된 역가는 동일한 용적 중의 증가된 농도, 즉 총 수율의 증가에 관한 것이다. 생산된 재조합 분비형 치료학적 단백질은 예를 들면, 항체, 바람직하게는 모노클로날 항체, 이특이적 항체 또는 이들의 단편, 또는 융합 단백질, 바람직하게는 Fc-융합 단백질일 수 있다. 본원에서 사용되는 용어 "발현 카세트"는 단백질(재조합 분비형 치료학적 단백질)을 암호화하는 하나 이상의 유전자 및 이들의 발현을 제어하는 서열을 포함하는 벡터의 부분을 말한다. 따라서, 이는 프로모터 서열, 개방 판독 프레임, 및 전형적으로 폴리아데닐화 부위를 함유하는 3' 비번역 영역을 포함한다. 바람직하게, 상기 벡터는 재조합 분비형 치료학적 단백질을 암호화하는 하나 이상의 유전자를 포함하는 발현 벡터이다. 이는 플라스미드 또는 바이러스 벡터를 포함하는 벡터, 전형적으로는 발현 벡터의 부분일 수 있다. 이는 또한 무작위 또는 표적화 통합에 의해, 예를 들면 상동성 재조합에 의해 염색체에 통합될 수 있다. 발현 카세트는 클로닝 기술을 이용하여 제조되고, 따라서 천연 발생 유전자 구조를 나타내지 않는다.
"벡터"는 벡터에 링크된 다른 핵산(또는 "작제물")을 세포 내로 도입하는데 사용될 수 있는 핵산이다. 벡터의 한 유형은 "플라스미드"이고, 이는 추가의 핵산 절편이 플라스미드 내에 라이게이션될(ligated) 수 있는 선형 또는 환형 이중 가닥의 DNA 분자를 말한다. 벡터의 다른 유형은 추가의 DNA 절편이 바이러스 게놈 내로 도입될 수 있는 바이러스 벡터(예를 들면, 복제 결함 레트로바이러스, 아데노바이러스 및 아데노-관련 바이러스)이다. 소정의 벡터(예를 들면, 세균성 복제 기원을 포함하는 세균성 벡터 및 에피솜성 포유동물 벡터)는 이들이 도입되는 숙주 세포에서 자가 복제할 수 있다. 다른 벡터들(예를 들면, 비-에피솜성 포유동물 벡터)은 숙주 세포로의 도입 및 선택적 압력 하의 배양시 숙주 세포의 게놈 내로 통합되고, 이에 의해 숙주 게놈과 함께 복제된다. 벡터는 세포에서의 선택된 폴리뉴클레오타이드의 발현을 지시하는데 사용될 수 있다.
용어 "발현 벡터"는 이에 세포에서 작동가능하게 링크되는 핵산 단편의 발현을 부여하는 능력을 갖는 핵산을 의미한다. 본원에서 사용되는 바와 같이, 발현 벡터는 예를 들면 플라스미드, 코스미드, 바이러스 하위-게놈 또는 게놈 단편, 또는 포유동물 세포에서 이종 DNA를 발현가능한 포맷으로 유지하고/하거나 복제할 수 있는 기타 핵산일 수 있다.
용어 "항체"는 면역글로불린 유전자에 의해 실질적으로 암호화된 하나 이상의 폴리펩타이드로 이루어진 단백질을 말한다. 인식된 면역글로불린 유전자로는 카파, 람다, 알파, 감마, 델타, 엡실론 및 뮤 불변 영역 유전자 및 무수한 면역글로불린 가변 영역 유전자가 포함된다. 본원에서 사용되는 바와 같이, 용어 "항체"는 폴리클로날, 모노클로날, 이-특이적, 다-특이적, 사람, 사람화된 또는 키메라 항체를 포함한다. 용어 "항체" 및 "면역글로불린"은 상호교환적으로 사용되고, 면역글로불린에 대해 상기 언급된 구조적 특성들을 갖는 당단백질을 나타내는 것으로 사용되지만 이에 한정되는 것은 아니다.
용어 "항체"는 본원에서 이의 가장 광범위한 의미로 사용되고 모노클로날 항체(전장 모노클로날 항체 포함), 폴리클로날 항체, 키메라 항체, 사람화된 항체, 사람 항체, 다특이적 항체(예를 들면, 이특이적 항체), 단일 도메인 항체, 및 항체 단편(예를 들면, Fv, Fab, Fab', F(ab)2 또는 항체의 다른 항원-결합 하위서열)을 포함한다. 용어 "항체"는 또한 항체 접합체 및 융합 항체를 포함한다. 이특이적 항체로는 BITE®(Bispecific T-cell Engager: 이특이적 T-세포 인게이저) 및 DART®(Dual-Affinity Re-Targeting: 이중-친화성 재-표적화) 항체가 포함된다. 단일 도메인 항체로는 낙타과(camelids) 항체가 포함된다. 전장 "항체" 또는 "면역글로불린"은 일반적으로 2개의 동일한 경쇄 및 2개의 동일한 중쇄로 이루어진 약 150kDa의 이종사량체성 당단백질이다. 각각의 경쇄는 1개의 공유결합적 디설파이드 결합에 의해 중쇄에 링크되어 있고, 한편 디설파이드 링크의 수는 상이한 면역글로불린 이소타입의 중쇄들간에 다양하다. 각각의 중쇄 및 경쇄는 또한 규칙적 간격의 쇄내 디설파이드 가교(bridge)를 갖는다. 각각의 중쇄는 아미노 말단 가변 도메인(VH), 이어서 3개의 카르복시 말단 불변 도메인(CH)을 갖는다. 각각의 경쇄는 가변 N-말단 도메인(VL) 및 단일 C-말단 불변 도메인(CL)을 갖는다. 용어 "항체"는 추가로 동일한 특이성(가변 도메인)을 갖고 동일한 불변 도메인을 갖는 복수의 개별 항체를 포함하는 항체의 유형을 나타낸다.
본원에서 사용되는 용어 "모노클로날 항체"(mAb)는 아미노산 서열에 기초하여 실질적으로 상동성인 항체들의 집단으로부터 수득된 항체를 말한다. 모노클로날 항체는 고도로 특이적이어서 단일 항원성 부위에 대해 지시된다. 또한, 전형적으로 상이한 결정인자들(에피토프들)에 대해 지시되는 상이한 항체들을 포함하는 종래의 (폴리클로날) 항체 조제(preparation)와 대조적으로, 각각의 mAb는 항원 상의 단일 결정인자에 대해 지시된다. 이들의 특이성에 추가하여, 상기 mAb는 이들이 다른 면역글로불린에 의해 오염되지 않은 세포 배양(하이브리도마 또는 재조합 세포 등)에 의해 합성될 수 있다는 점에서 유리하다. 본원의 mAb로는 키메라, 사람화된 및 사람 항체가 포함된다.
"키메라 항체"는 전형적으로 유전자 조작에 의해 마우스 및 사람과 같은 상이한 종들의 면역글로불린 가변 및 불변 영역으로부터 경쇄 및/또는 중쇄 유전자가 작제된 항체이다. 또는 대안으로, 이들의 중쇄 유전자는 특정 항체 클래스(class) 또는 하위 클래스(subclass)에 속하고, 한편 쇄들의 나머지는 동일한 종 또는 다른 종의 다른 항체 클래스 또는 하위 클래스 유래이다. 또한, 이러한 항체의 단편, 바람직하게는 적어도 하나의 CH2 도메인을 함유하거나 이를 함유하도록 변형된 단편도 포함된다. 예를 들면, 마우스 모노클로날 항체로부터의 유전자의 가변성 절편은 감마 1 및 감마 3과 같은 사람 불변 절편에 링크될 수 있다. 따라서, 다른 포유동물 종들도 사용될 수 있지만, 전형적인 치료학적 키메라 항체는 마우스 항체로부터의 가변 또는 항원-결합 도메인 및 사람 항체로부터의 불변 또는 이펙터(effector) 도메인으로 구성된 하이브리드 단백질이다(예를 들면 ATCC 수탁번호 CRL 9688은 항-Tac 키메라 항체를 분비한다).
본원에서 사용되는 용어 "사람화된 항체"는 특이적 키메라 항체, 면역글로불린 쇄 또는 이들의 단편(Fv, Fab, Fab', F(ab)2 또는 항체의 다른 항원-결합 하위서열)을 말하고, 이는 비-사람 면역글로불린으로부터 유도된 최소한의 서열을 함유한다. 사람화된 항체는 사람 프레임워크(framework) 영역 및 비-사람(통상적으로 마우스 또는 래트) 항체로부터의 하나 이상의 CDR을 포함한다. 바람직하게는, 이들은 N-링크된 당화 부위를 포함하는 중쇄 면역글로불린 불변 영역의 CH2 도메인의 적어도 일부를 함유하거나 이를 함유하도록 변형된다. 대부분의 경우, 사람화된 항체는 수용자(recipient)의 상보성-결정 영역(CDR)으로부터의 잔기가 원하는 특이성, 친화성 및 능력(capacity)을 갖는 마우스, 래트 또는 토끼와 같은 비-사람 종(공여자(donor) 항체)의 CDR로부터의 잔기로 대체된 사람 면역글로불린(수용자 항체)이다. 도메인의 항원 결합 특이성, 친화성 및/또는 구조를 유지하기 위해서 프레임워크 아미노산의 조정이 필요할 수도 있다. 몇몇의 경우, 사람 면역글로불린의 Fv 프레임워크 잔기는 상응하는 비-사람 잔기로 대체된다. 또한, 사람화된 항체는 수용자 항체에서도 또는 이입된(imported) CDR 또는 프레임워크 서열에서도 발견되지 않는 잔기를 포함할 수 있다. 이들 변형은 항체 성능을 추가로 개량하고 최대화하기 위해 이루어진다. 일반적으로, 사람화된 항체는 모든 또는 실질적으로 모든 CDR 영역이 비-사람 면역글로불린의 것들에 상응하고 모든 또는 실질적으로 모든 프레임워크 영역이 사람 면역글로불린 컨센서스 서열의 것들인, 적어도 하나, 그리고 전형적으로는 2개의 가변 도메인을 포함할 것이다. 바람직하게는, 사람화된 항체는 또한 면역글로불린 불변 영역의 적어도 일부, 전형적으로는 사람 면역글로불린의 적어도 일부를 포함한다.
본 발명에 따른 용어 "CH2 도메인"은 N-링크된 당화 부위를 포함하는 중쇄 면역글로불린 불변 영역의 CH2 도메인을 기술하는 것을 의미한다. 면역글로불린 CH2 도메인을 정의함에 있어서, 일반적으로 면역글로불린에 대한, 특히 Kabat, E.A.(Kabat EA, 1988. J. Immunol. 141:S25-S36; Kabat EA, et al., 1991. Sequences of Proteins of Immunological Interest. U. S. Department of Health and Human Services, Natl. Inst. of Health, Bethesda)에 의한 사람 IgG1에 적용되는 면역글로불린의 도메인 구조에 대한 참조가 이루어진다. 따라서, 면역글로불린은 일반적으로 2개의 동일한 경쇄 및 2개의 동일한 중쇄로 구성된 약 150kDa의 이종사량체성 당단백질이다. 각각의 경쇄는 하나의 공유결합적 디설파이드 결합에 의해 중쇄에 링크되어 있고, 한편 디설파이드 링크의 수는 상이한 면역글로불린 이소타입의 중쇄들간에 다양하다. 각각의 중쇄 및 경쇄는 또한 규칙적 간격의 쇄내 디설파이드 가교를 갖는다. 각각의 중쇄는 아미노 말단 가변 도메인(VH), 이어서 3개의 카르복시 말단 불변 도메인(CH)을 갖는다. 각각의 경쇄는 가변 N-말단 도메인(VL) 및 단일 C-말단 불변 도메인(CL)을 갖는다.
중쇄의 불변 도메인의 아미노산 서열에 따라, 항체는 상이한 클래스에 할당될 수 있다. IgA, IgD, IgE, IgG 및 IgM의 5개의 주요 클래스가 존재한다. 항체의 상이한 클래스에 상응하는 중쇄 불변 도메인은 각각 알파, 델타, 엡실론, 감마 및 뮤 도메인이라고 칭한다. IgM의 뮤(mu) 쇄는 5개의 도메인(VH, CHmu1, CHmu2, CHmu3 및 CHmu4)을 함유한다. IgE의 중쇄는 또한 5개의 도메인을 함유하고, 한편 IgA의 중쇄는 4개의 도메인을 갖는다. 면역글로불린 클래스는 하위 클래스(이소 타입), 예를 들면 IgG1, IgG2, IgG3, IgG4, IgA1 및 IgA2로 추가로 세분될 수 있다.
상이한 클래스의 면역글로불린의 서브유닛 구조 및 3차원 입체배치(configuration)는 익히 공지되어 있다. 이들 중에서도, IgA 및 IgM은 중합체성이고, 각각의 서브유닛은 2개의 경쇄 및 2개의 중쇄를 함유한다. IgG의 중쇄는 힌지(hinge) 영역으로서 공지되어 있는 CHgamma1 및 CHgamma2 도메인 사이에 놓이는 폴리펩티드 쇄를 함유한다. IgA의 알파 쇄는 O-링크된 당화 부위를 함유하는 힌지 영역을 갖는다. 뮤 및 엡실론 쇄는 감마 및 알파 쇄의 힌지 영역과 유사한 서열을 갖지 않지만, 이들은 다른 면역글로불린 클래스에서 다른 것들이 결여된 제4 불변 도메인을 함유한다.
완전 항체의 Fc 영역은 일반적으로 2개의 CH2 도메인 및 2개의 CH3 도메인을 포함한다. 본 발명에 따르면, 상기 CH2 도메인은 상기 명시된 5개의 면역글로불린 클래스들 중 하나의 CH2 도메인인 것이 바람직하다. 영장류 또는 뮤린 면역글로불린과 같은 포유동물 면역글로불린 CH2 도메인이 바람직하고, 영장류 그리고 특히 사람 면역글로불린 CH2 도메인이 바람직하다. 면역글로불린 CH2 도메인의 아미노산 서열이 공지되어 있거나 당해 분야 숙련가들에게 일반적으로 이용가능하다(Kabat EA, et al., 1991. Sequences of Proteins of Immunological Interest. U. S. Department of Health and Human Services, Natl. Inst. of Health, Bethesda). 본 발명의 맥락 내에서 바람직한 면역글로불린 CH2 도메인은 사람 IgG이고, 바람직하게는 IgG1, IgG2, IgG3, IgG4 유래이고, 보다 바람직하게는 사람 IgG1 및 IgG3이고, 더욱 더 바람직하게는 사람 IgG1이다. 에델만(Edelman)의 넘버링(numbering) 시스템(Edelman GM, et al., 1969. Proc. Natl. Acad. Sci. 63:78-85)을 이용하여, 면역글로불린 CH2 도메인은 바람직하게는 사람 IgG1의 글루타민 233에 상당하는 아미노산 위치에서 시작하여 라이신 340에 상당하는 아미노산을 통해 연장된다(Ellison J and Hood L, 1982. Proc. Natl. Acad. Sci. 79:1984-1988).
사람 항체 분자에 관해서는, N-링크된 올리고사카라이드가 Fc 영역의 CH2 도메인의 내면(inner face)의 베타-4 벤드(bend)의 Asn 297의 아미드 측쇄에 부착되어 있는 IgG 클래스에 대한 참조가 이루어진다. 바람직하게는, 항체 또는 Fc-융합 단백질은 적어도 CH2 도메인을 함유하거나 이를 함유하도록 변형된다. CH2 도메인은 사람 IgG CH2 도메인의 단일 N-링크된 올리고사카라이드를 갖는 면역글로불린의 CH2 도메인이다. CH2 도메인은 바람직하게는 사람 IgG1의 CH2 도메인이다.
"Fc-융합 단백질"은 적어도 단일 N-링크된 당화 부위를 포함하는 중쇄 면역글로불린 불변 영역의 CH2 도메인의 부분을 함유하거나 이를 함유하도록 변형된 단백질로서 정의된다. 카바트(Kabat) EU 명명법(Kabat EA, et al., 1991. Sequences of Proteins of Immunological Interest. U. S. Department of Health and Human Services, Natl. Inst. of Health, Bethesda)에 따르면, 이러한 N-링크된 당화 부위는 IgG1, IgG2, IgG3 또는 IgG4 항체에서의 Asn297 위치에 존재한다. 상기 융합 단백질의 다른 부분은 천연 또는 변형된 이종 단백질의 서열의 완전한 서열 또는 임의의 일부 또는 천연 또는 변형된 이종 단백질의 서열의 완전한 서열 또는 임의의 일부의 조성물일 수 있다. Fc-융합 단백질은 예를 들면 효소적으로 활성인 단백질 부분인 다른 면역글로불린 도메인, 또는 이펙터 도메인을 포함하는 다른 발현 작제물에 N-링크된 당화 부위를 포함하는 중쇄 면역글로불린 불변 영역의 CH2 도메인을 도입함으로써 유전자 조작 접근법에 의해 작제될 수 있다. 따라서, 본 발명에 따른 Fc-융합 단백질은 또한 예를 들면 N-링크된 당화 부위를 포함하는 중쇄 면역글로불린 불변 영역의 CH2 도메인에 링크된 단일 쇄 Fv 단편을 포함한다.
또한, 항체 단편으로는 예를 들면 "Fab 단편"(단편 항원-결합 = Fab)이 포함된다. Fab 단편은 인접한 불변 영역에 의해 함께 유지되는 양쪽 쇄 둘 다의 가변 영역들로 이루어진다. 이들은 예를 들면 파파인을 이용한 종래 항체로부터의 프로테아제 소화(digestion)에 의해 형성될 수 있지만, 유전자 조작에 의해서도 유사한 Fab 단편이 생산될 수 있다. 추가의 항체 단편으로는 펩신을 이용한 단백질분해성 절단에 의해 제조될 수 있는 F(ab')2 단편이 포함된다.
정의에 따르면, 숙주 세포에 도입된 임의의 서열 또는 유전자는 도입된 서열, RNA 또는 유전자가 숙주 세포의 내인성 서열, RNA 또는 유전자와 동일한 경우라도, 숙주 세포에 대한 "이종 서열", "이종 유전자", "이종성 RNA" 또는 "전이유전자(transgene)" 또는 "재조합 유전자"라고 칭한다. 따라서, "이종" 또는 "재조합" 단백질 또는 RNA는 이종 서열 또는 유전자로부터 발현된 단백질 또는 RNA이다. 한 바람직한 실시형태에서, 도입된 서열, RNA 또는 유전자는 당해 숙주 세포의 내인성 서열, RNA 또는 유전자와 동일하지는 않지만, 이가 동일한 실시형태들도 본 발명과 관련하여 고려된다.
"이종 유전자" 또는 "이종 서열"은 표적 세포(예를 들면, siRNA)에 직접 또는 "발현 벡터", 바람직하게는 포유동물 발현 벡터를 이용함으로써 도입될 수 있다. 벡터를 작제하는데 사용되는 방법은 당해 분야 숙련가들에게 익히 공지되어 있고, 다양한 출판물에 기술되어 있다. 특히, 프로모터, 인핸서, 종결 및 폴리아 데닐화 신호, 선택 마커, 복제 기원 및 스플라이싱(splicing) 신호와 같은 기능성 구성요소(component)의 기술을 포함하는, 적합한 벡터를 작제하기 위한 기술은 문헌[Sambrook J, et al., 1989. Molecular Cloning: A Laboratory Manual. Cold Spring Harbor: Cold Spring Harbor Laboratory Press] 및 이에 인용된 참조문헌들에 상당히 상세하게 검토되어 있다. 벡터로는 플라스미드 벡터, 파지미드(phagemid), 코스미드, 인공적/미니-염색체(예를 들면, ACE) 또는 배큘로바이러스, 레트로바이러스, 아데노바이러스, 아데노-관련 바이러스, 헤르페스 심플렉스 바이러스, 레트로바이러스 및 박테리오파지(bateriophage)와 같은 바이러스 벡터가 포함될 수 있지만, 이들에 한정되는 것은 아니다. 또한, 진핵생물 발현 벡터는 전형적으로 세균에서의 벡터의 증식을 촉진시키는 원핵생물 서열, 예를 들면 복제 기원 및 세균에서의 선택을 위한 항생제 내성 유전자를 함유할 것이다. 폴리뉴클레오타이드가 작동가능하게 링크될 수 있는 클로닝 부위를 함유하는 다양한 진핵생물 발현 벡터가 당해 분야에 익히 공지되어 있고, 몇몇은 Stratagene, La Jolla, CA; Invitrogen, Carlsbad, CA; Promega, Madison, WI 또는 BD Biosciences Clonetech, Palo Alto, CA와 같은 회사로부터 상업적으로 입수가능하다. 통상적으로, 발현 벡터는 또한 선택성 마커를 암호화하는 발현 카세트를 포함하고, 이는 상기 발현 마커를 지닌 숙주 세포의 선택을 가능하게 한다.
본 발명에서 상기 발현 벡터는 또한 숙주 세포에 siRNA 또는 shRNA를 암호화하는 "이종 서열" 또는 "폴리뉴클레오타이드 서열"을 도입하기 위해 사용된다. 이러한 발현 벡터는 세포에서의, 구체적으로는 포유동물 세포에서의, 보다 더 구체적으로는 CHO 세포에서의 siRNA 또는 shRNA의 일시적 또는 안정한 발현을 위한 siRNA 또는 shRNA 서열(들)을 포함할 수 있다. 바람직하게, 상기 발현 벡터는 포유동물 발현 벡터이다. 발현 벡터에 siRNA 또는 shRNA를 암호화하는 뉴클레오타이드 서열을 클로닝하기 위한 수단은 당해 분야 숙련가들에게 공지되어 있다. 이들로는 프로모터, 바람직하게는 강력한 프로모터, 예를 들면 CMV 프로모터 또는 숙주 세포에서 작동하는 것으로 공지되어 있는 임의의 다른 강력한 프로모터에 작동가능하게 링크되어 있는 포유동물 발현 벡터, 예를 들면 pcDNA6.2 또는 당해 분야에 공지되어 있는 임의의 다른 벡터에 플랭킹 영역을 포함하는 siRNA 또는 shRNA 서열을 클로닝하는 것이 포함되지만, 이들에 한정되는 것은 아니다.
본원에서 사용되는 용어 "발현"은 숙주 세포 내에서의 이종 핵산 서열의 전사 및/또는 번역을 말한다. 숙주 세포에서의 TBC1D20, CERS2 또는 ATF6B와 같은 숙주 세포 단백질의 발현 수준은 상기 세포에 존재하는 상응하는 mRNA의 양 또는 본 발명의 실시예에서와 같이 선택된 서열에 의해 암호화되는 폴리펩타이드의 양 중 어느 하나에 기초하여 결정될 수 있다. 예를 들면, 선택된 서열로부터 전사된 mRNA는 노던 블롯 하이드브리드화(Northern blot hybridization), 리보뉴클레아제 RNA 보호, 세포 RNA에 대한 동일 반응계내(in situ) 하이브리드화에 의해 또는 qPCR과 같은 PCR에 의해 정량할 수 있다. 선택된 서열에 의해 암호화된 단백질은 각종 방법들, 예를 들면 ELISA에 의해, 웨스턴 블롯팅(Western blotting)에 의해, 방사성 면역검정에 의해, 면역침전에 의해, 단백질의 생물학적 활성에 관한 검정에 의해, 단백질의 면역염색(immunostaining)에 이은 FACS 분석에 의해 또는 균질 시간-분해 형광성(HTRF: homogeneous time-resolved fluorescence) 검정에 의해 정량할 수 있다. 비-암호화 RNA, 예를 들면 miRNA의 발현 수준도 PCR, 예를 들면, qPCR에 의해 정량할 수 있다.
본원에서 사용되는 용어 "형질전환" 또는 "형질전환하다", "형질감염 또는 "형질감염시키다"는 포유동물 숙주 세포에의 유전적 물질의 임의의 도입을 의미하고, 여기서 상기 포유동물 숙주 세포는 일시적으로 형질감염되거나 안정하게 형질감염된다. 상기 유전적 물질은 목적하는 유전자(예를 들면, 재조합 분비형 치료학적 단백질) 또는 siRNA 또는 shRNA를 암호화하는 폴리뉴클레오타이드 서열을 포함하는 발현 벡터일 수 있다. 이는 또한 각각의 바이러스에 대해 본래의 하나인 방식으로의 바이러스 핵산 서열의 도입을 의미한다. 바이러스 핵산 서열은 네이키드(naked) 핵산 서열로서 존재할 필요는 없지만, 바이러스 단백질 외피(envelope) 내에 패키징될 수 있다.
유전적으로 변형된 세포 또는 유전자전이 세포를 초래하는 폴리뉴클레오타이드 또는 발현 벡터로의 진핵생물 숙주 세포의 형질감염은 당해 분야에 공지되어 있는 임의의 방법에 의해 수행할 수 있다(예를 들면, 문헌[Sambrook J, et al., 1989. Molecular Cloning: A Laboratory Manual. Cold Spring Harbor: Cold Spring Harbor Laboratory Press]을 참조한다). 형질감염 방법으로는 리포솜-매개된 형질감염, 칼슘 포스페이트 공동(co)-침전, 전기천공, 뉴클레오펙션(nucleofection), 뉴클레오포레이션(nucleoporation), 마이크로포레이션(microporation), 다중 양이온(polycation)(예를 들면 DEAE-덱스트란)-매개된 형질감염, 원형질체 융합, 바이러스 감염 및 마이크로인젝션(microinjection)이 포함되지만, 이들에 한정되는 것은 아니다. 형질전환은 숙주 세포의 일시적 또는 안정한 형질전환을 초래할 수 있다. 바람직하게, 형질감염은 안정한 형질감염이다. 특정 숙주 세포주 및 세포 유형에서 최적의 형질감염 빈도 및 이종 유전자의 발현을 제공하는 형질감염 방법이 바람직하다. 적합한 방법은 일상적 절차에 의해 결정될 수 있다. 안정한 형질전환체를 위해, 작제물은 숙주 세포의 게놈 또는 인공적 염색체/미니 염색체에 통합되거나 숙주 세포 내에서 안정하게 유지되도록 에피솜에 위치된다. 따라서, 안정하게 형질감염된 서열은 세포 및 이의 딸 세포의 게놈에 실제로 잔존한다. 전형적으로, 이는 선택성 마커 유전자 및 목적하는 유전자의 사용을 포함하거나 또는 RNA를 암호화하는 폴리 뉴클레오타이드 서열이 선택성 마커 유전자와 함께 통합된다. 몇몇의 경우, 전체 발현 벡터는 세포의 게놈에 통합되고, 다른 경우 발현 벡터의 일부만이 세포의 게놈에 통합된다. 재조합 분비형 치료학적 단백질 또는 RNA를 "안정하게 발현하는" 세포는 상기 재조합 분비형 치료학적 단백질을 암호화하는 유전자로 또는 상기 RNA를 암호화하는 폴리뉴클레오타이드 서열로 안정하게 형질감염된다. 따라서, 재조합 분비형 치료학적 단백질 또는 RNA를 암호화하는 서열은 세포 및 이의 딸 세포의 게놈에 잔존한다.
본 발명의 발현 벡터는 선택성 마커 유전자, 예를 들면 항생제 내성 유전자 또는 증폭가능한 마커 유전자를 추가로 포함할 수 있다. 증폭가능한 선택 마커 유전자는 RNA를 암호화하는 폴리뉴클레오타이드 서열에 작동가능하게 링크될 수 있다. 작동가능하게 링크하기 위해서, 상기 RNA를 암호화하는 폴리뉴클레오타이드 서열 및 증폭가능한 선택 마커 유전자는 동일한 벡터 상에 위치될 수 있다. 전형적으로, 본 발명의 발현 벡터에서 재조합 분비형 치료학적 단백질 및 RNA를 암호화하는 폴리뉴클레오타이드 서열은 프로모터 및/또는 종결인자(terminator)에 작동가능하게 링크된다. 프로모터 및/또는 종결인자에 작동가능하게 연결된 재조합 분비형 치료학적 단백질 또는 RNA를 암호화하는 폴리뉴클레오타이드 서열은 또한 발현 카세트로서도 나타낼 수 있다.
"선택성 마커 유전자" 또는 "선택 마커 유전자"는 전형적으로 배양 배지에 상응하는 "선택제"의 부가에 의해, 선택가능한 마커를 암호화하여 이러한 유전자를 함유하는 세포의 특이적 선택을 가능하게 하는 유전자이다. 예시로서, 항생제 내성 유전자가 양성 선택성 마커로서 사용될 수 있다. 이러한 유전자로 형질전환된 세포만이 상응하는 항생제의 존재시에 성장될 수 있고, 이로써 선택된다. 반면, 형질전환되지 않은 세포는 이들 선택 조건 하에서 성장하거나 생존할 수 없다. 양성, 음성 및 이기능적 선택성 마커가 존재한다. 양성 선택성 마커는 선택제에 대한 내성을 부여함으로써 또는 숙주 세포에서의 대사적 또는 이화적 결함을 보상함으로써 형질전환된 세포의 선택 그리고 이에 따른 농축을 가능하게 한다. 대조적으로, 선택성 마커에 대한 유전자를 수용한 세포는 음성 선택성 마커에 의해 선택적으로 제거될 수 있다. 이의 한 예는 헤르페스 심플렉스 바이러스의 티미딘 키나제 유전자이고, 아시클로버(acyclovir) 또는 간시클로버(gancyclovir)를 동시 부가한 세포에서의 이의 발현은 이들의 제거를 유도한다. 본 발명에서 유용한 선택성 마커 유전자로는 또한 증폭가능한 선택성 마커가 포함된다. 문헌은 이기능적 (양성/음성) 마커를 포함하는 다수의 선택성 마커 유전자를 기술한다(예를 들면 WO 92/08796 및 WO 94/28143을 참조한다). 본 발명에서 유용한 선택성 마커의 예로는 아미노글리코시드 포스포트랜스퍼라제(APH), 하이그로마이신 포스포트랜스퍼라제(HYG), 디하이드로폴레이트 리덕타제(DHFR), 티미딘 키나제(TK), 글루타민 신테타제, 아스파라긴 신테타제의 유전자 및 네오마이신(G418/제네티신(Geneticin)), 퓨로마이신, 히스티디놀 D, 블레오마이신, 플레오마이신, 블라스티시딘 및 제오신에 대한 내성을 부여하는 유전자가 포함되지만, 이들에 한정되는 것은 아니다. 선택성 마커가 이의 선택적 품질을 보유하는 한, 유전적으로 변형된 돌연변이체 및 변이체, 단편, 기능성 등가물, 유도체, 동족체 및 다른 단백질 또는 펩타이드와의 융합물도 포함된다. 이러한 유도체는 선택적인 것으로 간주되는 영역 또는 도메인의 아미노산 서열에서 상당한 상동성을 나타낸다.
또한, 재조합 세포를 선택하기 위해, 예를 들면, 세포 표면 마커, 세균 β-갈락토시다제 또는 형광성 단백질(예를 들면, 애쿼레아 빅토리아(Aequorea victoria) 및 레닐라 레니포르미스(Renilla reniformis) 또는 다른 종으로부터의 녹색 형광성 단백질(GFP) 및 이들의 변이체; 적색 형광성 단백질, 비-생물발광성(non-bioluminescent) 종(예를 들면, 디스코소마(Discosoma) 종, 아네모니아(Anemonia) 종, 클라불라리아(Clavularia) 종, 조안투스(Zoanthus) 종)으로부터의 형광성 단백질 및 이들의 변이체)을 이용하는 형광성 활성화된 세포 분류(FACS)에 의해 선택이 이루어질 수 있다.
용어 "선택제" 또는 "선택성 제제"는 선택제의 영향을 완화시키는 소정의 선택성 마커 유전자 생성물이 세포에 존재하지 않는 한, 세포의 성장 또는 생존을 간섭하는 물질을 말한다. 예를 들면, 형질감염된 세포에서의 항생제 내성 유전자 유사 APH(아미노글리코사이드 포스포트랜스퍼라제)의 존재에 대해 선택하기 위해서 항생제 제네티신(G418)을 사용한다.
용어 "변형된 네오마이신-포스포트랜스퍼라제(NPT)"는 WO2004/050884에 기술되어 있는 모든 돌연변이체, 특히 아미노산 위치 227에서의 글리신(Gly, G)에 대한 아스파르트산(Asp, D)의 치환을 특징으로 하는 돌연변이체 D227G(Asp227Gly), 특히 바람직하게는 아미노산 위치 240에서의 이소류신(Ile, I)에 대한 페닐알라닌(Phe, F)의 치환을 특징으로 하는 돌연변이체 F240I(Phe240Ile)를 포함한다.
"증폭가능한 선택성 마커 유전자"는 통상적으로 소정 배양 조건 하에 진핵생물 세포의 성장에 요구되는 효소를 암호화한다. 예를 들면, 증폭가능한 선택성 마커 유전자는 디하이드로폴레이트 리덕타제(DHFR) 또는 글루타민 신테타제(GS)를 암호화할 수 있다. 이러한 경우에, 상기 유전자는 이들로 형질감염된 숙주 세포가 각각 선택제 메토트렉세이트(MTX) 또는 메티오닌 설폭스이민(MSX)의 존재 하에 배양되는 경우에 증폭된다. 증폭가능한 선택성 마커 유전자에 링크된 서열(즉, 이에 물리적으로 근접한 서열)은 상기 증폭가능한 선택성 마커 유전자와 함께 공동-증폭된다. 상기 공동-증폭된 서열은 동일한 발현 벡터 상에 또는 별도의 벡터 상에 도입될 수 있다.
하기 표 2는 본 발명에 따라 사용될 수 있는 증폭가능한 선택성 마커 유전자 및 관련 선택제의 비-제한적 예를 제공한다. 적합한 증폭가능한 선택성 마커 유전자는 또한 카우프만(Kaufman)에 의한 개요에도 기술되어 있다(Kaufman RJ, 1990. Methods Enzymol. 185:537-566).
본 발명에 따르면, 바람직한 증폭가능한 선택성 마커 유전자는 GS 또는 DHFR의 기능을 갖는 폴리펩타이드를 암호화하는 유전자이다.
본 발명은, 숙주 세포 단백질을 암호화하는 적어도 하나의 유전자가 상기 숙주 세포 단백질의 발현을 저해하는 유전적 변형을 포함하거나 포유동물 세포가 RNA-간섭에 의해 숙주 세포 단백질을 암호화하는 유전자의 발현을 저해하는 RNA 올리고뉴클레오타이드를 포함하는, 포유동물 세포에 관한 것이고, 여기서 상기 적어도 하나의 숙주 세포 단백질은 ATF6B 또는 TBC1D20 및 CERS2이다. 본 발명은 또한 상기 포유동물 세포를 제조하는 방법에 관한 것이고, 분비형 재조합 치료학적 단백질의 생산 방법에서의 상기 세포의 용도에 관한 것이다. 본 발명에 따르면, 상기 숙주 세포 단백질의 감소된 발현은 상기 포유동물 세포에서의 상기 TBC1D20 및 CERS2의 단백질 발현 또는 상기 ATF6B의 단백질 발현이 상기 유전적 변형(들) 또는 RNA 올리고뉴클레오타이드(들)을 함유하지 않는 동일한 포유동물 세포와 비교하여 감소됨을 의미한다.
한 양상에서, 본 발명은 숙주 세포 단백질 TBC1 도메인 패밀리 구성원 20(TBC1D20) 및 세라마이드 신타제 2(CERS2)의 감소된 발현을 포함하는 재조합 치료학적 단백질의 분비가 향상된 포유동물 세포에 관한 것이고; 여기서 상기 포유동물 세포는 임의로 재조합 분비형 치료학적 단백질을 암호화하는 하나 이상의 발현 카세트(들)를 추가로 포함한다.
다른 양상에서, 본 발명은 상기 숙주 세포 단백질 활성화 전사 인자 6 베타(ATF6B)의 감소된 발현을 포함하는 재조합 치료학적 단백질의 분비가 향상된 포유동물 세포에 관한 것이고, 여기서 상기 포유동물 세포는 재조합 분비형 치료학적 단백질을 암호화하는 하나 이상의 발현 카세트(들)를 추가로 포함한다.
본 발명의 한 실시형태에서, 재조합 치료학적 단백질의 분비가 향상된 포유동물 세포는 숙주 세포 단백질 TBC1 도메인 패밀리 구성원 20(TBC1D20) 및 세라마이드 신타제 2(CERS2)의 감소된 발현; 또는 숙주 세포 단백질 활성화 전사 인자 6 베타(ATF6B)의 감소된 발현을 포함하고, 여기서 상기 포유동물 세포는 재조합 분비형 치료학적 단백질을 암호화하는 하나 이상의 발현 카세트(들)를 추가로 포함한다.
본 발명의 포유동물 세포에서의 숙주 세포 단백질의 발현을 감소시키기 위해서, 상기 숙주 세포 단백질을 암호화하는 유전자는 상기 숙주 세포 단백질의 발현을 저해하는 유전적 변형을 포함할 수 있거나, 상기 포유동물 세포는 RNA-간섭에 의해 상기 숙주 세포 단백질을 암호화하는 유전자의 발현을 저해하는 RNA 올리고뉴클레오타이드를 포함할 수 있다. 상기 숙주 세포 단백질의 감소된 발현은 상기 포유동물 세포에서의 상기 TBC1D20 및 CERS2의 단백질 발현 또는 상기 ATF6B의 단백질 발현이 상기 유전적 변형(들) 또는 RNA 올리고뉴클레오타이드(들)를 함유하지 않는 동일한 포유동물 세포와 비교하여 감소됨을 의미한다. 한 실시형태에서, RNA-간섭에 의해 상기 숙주 세포 단백질의 유전자의 발현을 저해하는 RNA 올리고뉴클레오타이드는 miRNA가 아니다.
본 발명은 또한 (a) (i) 상기 숙주 세포 단백질의 발현을 저해하는 숙주 세포 단백질을 암호화하는 유전자에의 유전자 변형, 또는 (ii) RNA-간섭에 의해 상기 숙주 세포 단백질을 암호화하는 유전자의 발현을 저해하는 포유동물 세포에의 RNA 올리고뉴클레오타이드를 도입함으로써 포유동물 세포에서의 숙주 세포 단백질 TBC1D20 및 CERS2의 또는 숙주 세포 단백질 ATF6B의 발현을 감소시키는 단계, 및 (b) 재조합 분비형 치료학적 단백질을 암호화하는 하나 이상의 유전자(들)를 도입하는 단계를 포함하는, 재조합 치료학적 단백질의 분비가 향상된 포유동물 세포를 생산하는 방법에 관한 것이다. 상기 방법은 (c) 재조합 치료학적 단백질의 분비가 향상된 세포를 선택하는 단계를 추가로 포함할 수 있다. 상기 방법은 또한 (d) 재조합 분비형 치료학적 단백질을 암호화하는 하나 이상의 유전자(들)의 발현을 가능하게 하는 조건 하에 단계 (c)에서 수득된 세포를 배양하는 단계를 추가로 포함할 수 있다. 단계(b)에서의 분비형 치료학적 단백질을 암호화하는 하나 이상의 유전자(들)의 도입은 바람직하게는 재조합 분비형 치료제를 암호화하는 하나 이상의 발현 카세트(들)를 도입하는 것을 포함한다. 본 발명의 방법의 단계 (a)는 단계 (b)의 전에 또는 단계 (b)의 후에 수행할 수 있다. 따라서, 재조합 분비형 단백질을 암호화하는 하나 이상의 유전자(들)는 상기 숙주 세포 단백질 ATF6B 또는 상기 숙주 세포 단백질 TBC1D20 및 CERS2의 감소된 발현을 초래하는 유전적 변형 또는 RNA 올리고뉴클레오타이드(또는 상기 RNA 올리고뉴클레오타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 발현 벡터)가 도입되기 전에 도입될 수 있다. 대안으로, 재조합 분비형 단백질을 암호화하는 하나 이상의 유전자(들)는 상기 숙주 세포 단백질 ATF6B 또는 상기 숙주 세포 단백질 TBC1D20 및 CERS2의 감소된 발현을 초래하는 유전적 변형 또는 RNA 올리고뉴클레오타이드(또는 상기 RNA 올리고뉴클레오타이드를 암호화하는 뉴클레오타이드 서열을 포함하는 발현 벡터)가 도입된 후에 도입될 수 있다. 본 발명은 추가로 본 발명의 방법에 의해 생산되는 포유동물 세포주에 관한 것이다.
상기 포유동물 세포 및 본 발명의 방법에 의해 생산된 포유동물 세포는 추가로 포유동물 세포에서의 재조합 분비형 치료학적 단백질의 생산 방법에서 사용될 수 있다. 상기 방법은 (a) 재조합 분비형 치료학적 단백질로 형질감염된 본 발명의 포유동물 세포를 제공하거나 본 발명의 방법에 의해 생산된 상기 포유동물 세포를 제공하는 단계; (b) 상기 재조합 분비형 치료학적 단백질의 생산을 가능하게 하는 조건에서 세포 배양 배지에서 단계 (a)의 상기 포유동물 세포를 배양하는 단계, 및 (c) 상기 재조합 분비형 치료학적 단백질을 수거하는 단계를 포함한다. 상기 방법은 (d) 상기 재조합 분비형 치료학적 단백질을 정제하는 단계를 추가로 포함할 수 있다.
본 발명의 방법에서 상기 숙주 세포 단백질의 발현을 감소시키기 위해서, 상기 숙주 세포 단백질을 암호화하는 유전자가 상기 숙주 세포 단백질의 발현을 저해하는 유전적 변형을 포함할 수 있거나, 또는 상기 포유동물 세포가 RNA-간섭에 의해 상기 숙주 세포 단백질을 암호화하는 유전자의 발현을 저해하는 RNA 올리고뉴클레오타이드를 포함할 수 있다. 상기 숙주 세포 단백질의 감소된 발현은 상기 포유동물 세포에서의 상기 TBC1D20 및 CERS2의 단백질 발현 또는 상기 ATF6B의 단백질 발현이 상기 유전적 변형(들) 또는 RNA 올리고뉴클레오타이드(들)를 함유하지 않는 동일한 포유동물 세포에 비하여 감소됨을 의미한다.
상기 포유동물 세포 및 본 발명의 방법에 의해 생산된 포유동물 세포는 추가로 재조합 분비형 치료학적 단백질의 생산을 위해 또는 상기 재조합 분비형 치료학적 단백질의 수율을 증가시키기 위해 사용될 수 있다. 따라서, 본 발명은 또한 재조합 분비형 치료학적 단백질의 수율을 증가시키기 위한 본 발명의 방법에 의해 생산되는 포유동물 세포 또는 본 발명의 포유동물 세포의 용도에 관한 것이다. 이는 추가로 재조합 분비형 치료학적 단백질의 생산을 위한 본 발명의 방법에 의해 생산된 포유동물 세포 또는 본 발명의 포유동물 세포의 용도에 관한 것이다.
본 발명의 포유동물 세포 또는 방법에 의해 생산된 재조합 분비형 치료학적 단백질은 바람직하게는 항체, 바람직하게는 모노클로날 항체, 이-특이적 항체 또는 이들의 단편, 또는 Fc-융합 단백질이다.
숙주 세포 단백질 TBC1D20, CERS2 또는 ATF6B의 감소된 발현
숙주 세포 단백질 TBC1D20, CERS2 또는 ATF6B의 발현은 본 발명에 따른 또는 본 발명의 방법에서 사용되거나 생산되는 포유동물 세포에서 감소된다. 이는 포유동물 세포에서의 TBC1D20, CERS2 또는 ATF6B의 단백질 발현이 유전자 녹다운 또는 유전자 녹아웃에 의해 상기 유전적 변형 또는 RNA 올리고뉴클레오타이드를 함유하지 않는 동일한 포유동물 세포와 비교하여 감소됨을 의미한다.
한 실시형태에서, 숙주 세포 단백질 TBC1D20 및 CERS2의 발현이 감소된다. 상기 숙주 세포 단백질 TBC1D20은 서열번호 1의 cDNA 서열에 의해 암호화되거나 서열번호 4의 아미노산 서열을 갖는 CHO 세포에서 발현되는 햄스터 TBC1D20 또는 이들의 임의의 동족체를 나타낸다. 본원에서 사용되는 이들의 동족체는 서열번호 4의 아미노산 서열과 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95% 또는 적어도 98%의 서열 동일성을 갖는 단백질을 의미한다. 상기 숙주 세포 단백질 CERS2는 서열번호 2의 cDNA의 서열에 의해 암호화되거나 서열번호 5의 아미노산 서열을 갖는 CHO 세포에서 발현되는 햄스터 CERS2 또는 이들의 임의의 동족체를 나타낸다. 본원에서 사용되는 바와 같이, 이들의 동족체는 서열번호 5의 아미노산 서열과 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95% 또는 적어도 98%의 서열 동일성을 갖는 단백질을 의미한다.
다른 실시형태에서, ATF6B의 발현은 대조군 세포와 비교하여 감소된다. 상기 숙주 세포 단백질 ATF6B는 서열번호 3의 cDNA 서열에 의해 암호화되거나 서열번호 6의 아미노산 서열을 갖는 CHO 세포에서 발현되는 햄스터 ATF6B 또는 이들의 임의의 동족체를 나타낸다. 본원에서 사용되는 바와 같이, 이들의 동족체는 서열번호 6의 아미노산 서열과 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95% 또는 적어도 98%의 서열 동일성을 갖는 단백질을 의미한다. 당해 분야 숙련가는 숙주 세포 단백질 ATF6B, TBC1D20 및 CERS2의 발현도 감소될 수 있음을 이해할 것이다.
용어 "녹다운" 또는 "녹다운 기술"은 표적 유전자 또는 목적하는 유전자의 발현이 표적 유전자 생성물의 생산의 저해를 유도할 수 있는 RNA-간섭에 의해, 예를 들면 siRNA EH는 shRNA를 이용함으로써 표적 유전자의 발현을 저해하는 RNA 올리고뉴클레오타이드의 도입 전의 유전자 발현과 비교하여 감소되는 유전자 침묵 기술을 말한다. "이중 녹다운"은 TBC1D20 및 CERS2를 암호화하는 유전자들과 같은 2개의 유전자들의 녹다운이다.
한 실시형태에서, 상기 포유동물 세포는 RNA-간섭에 의해 상기 숙주 세포 단백질을 암호화하는 유전자의 발현을 저해하는 RNA 올리고뉴클레오타이드를 포함하고, 여기서 숙주 세포 단백질은 ATF6B 또는 TBC1D20 및 CERS2를 나타낸다. 당해 분야 숙련가는 RNA 올리고뉴클레오타이드가 세포에 직접 형질감염될 수 있거나, 또는 예를 들면 발현 벡터를 이용함으로써 세포 내의 폴리뉴클레오타이드 서열에 의해 암호화될 수 있음을 인지할 것이다. 따라서, 발현 벡터는 상기 RNA 올리고뉴클레오타이드를 암호화하는 폴리뉴클레오타이드 서열을 포함한다. 발현 벡터는 또한 제2 RNA 올리고뉴클레오타이드를 암호화하는 폴리뉴클레오타이드 서열을 포함할 수 있다. 2개의 RNA 올리고뉴클레오타이드는 2개의 별도의 발현 카세트에 의해 또는 분리된 동일한 발현 카세트에 의해, 예를 들면 IRES 서열에 의해 암호화될 수 있다. ATF6B 또는 TBC1D20과 CERS2의 조합을 표적으로 하는 siRNA(들) 또는 shRNA(들)의 과발현은 포유동물 발현 시스템에서의 분비형 재조합 치료학적 단백질의 향상된 생산 및/또는 분비를 유도한다.
바람직하게는 RNA 올리고뉴클레오타이드는 완전한 서열 상보성 (즉, 억압 간섭 RNA의 RNA 이중 가닥의 안티센스 가닥과 표적 mRNA 사이의 완벽한 염기 짝짓기)에 의한 mRNA 억압을 매개하므로, 이의 표적에 특이적이다. 본원에서 사용된 완벽한 염기 짝짓기의 완벽한 상보성은 소형 간섭 RNA의 RNA 듀플렉스의 안티센스 가닥은 적어도 15개의 연속 뉴클레오타이드, 적어도 16개의 연속 뉴클레오타이드, 적어도 17개의 연속 뉴클레오타이드, 적어도 18개의 연속 뉴클레오타이드 및 적어도 19 개의 연속 뉴클레오타이드에서 표적 mRNA에 대해 적어도 89%의 서열 동일성을 갖고, 또는 적어도 15개의 연속 뉴클레오타이드, 적어도 16개의 연속 뉴클레오타이드, 적어도 17개의 연속 뉴클레오타이드, 적어도 18개의 연속 뉴클레오타이드 및 적어도 19 개의 연속 뉴클레오타이드에서 표적 mRNA에 대해 적어도 93%의 서열 동일성을 갖는다는 것을 의미한다. 바람직하게는, 소형 간섭 RNA의 RNA 듀플렉스의 안티센스 가닥은 적어도 15개의 연속 뉴클레오티드, 적어도 16개의 연속 뉴클레오타이드, 적어도 17개의 연속 뉴클레오타이드, 적어도 18개의 연속 뉴클레오타이드 및 바람직하게는 적어도 19개의 연속 뉴클레오타이드에서 표적 mRNA에 대해 100%의 서열 동일성을 갖는다. 당해 분야 숙련자는 miRNA가 완전한 서열 상보성에 의해 mRNA 억압을 매개하지 않으며 따라서 유전자 특이적이 아님을 이해할 것이다. 따라서, 한 실시형태에서, RNA 올리고뉴클레오타이드는 miRNA가 아니다.
바람직하게는, RNA-간섭은 소형 헤어핀 RNA (shRNA) 또는 짧은 간섭 RNA (siRNA)에 의해 매개된다. 포유 동물 세포는 상기 siRNA(들) 또는 shRNA(들)을 코딩하는 하나 이상의 발현 벡터(들)로 형질 감염될 수 있다. 바람직하게는, 포유 동물 세포는 상기 siRNA(들) 또는 shRNA(들)를 코딩하는 하나 이상의 발현 벡터(들)로 안정적으로 형질 감염된다. RNA 올리고뉴클레오티드는 구성적으로 발현되거나 조건적으로 발현될 수 있다. 예를 들어, RNA 올리고뉴클레오타이드의 발현은 성장 단계 동안 침묵하고 단백질 생산 단계 동안 스위치 온(switch on)될 수 있다.
TBC1D20을 녹-다운시키기 위한 예시적인 siRNA는 siTbc1D20#1 (서열번호 7)이다. CERS2를 녹-다운시키기 위한 예시적인 siRNA는 siCerS2#1 (서열번호 8)이다. 바람직하게는, 서열번호 7 또는 8의 서열을 갖는 siRNA는 CHO 세포에 사용된다. 이 siRNA는 서로 독립적으로 사용할 수 있다. 따라서, siTbc1D20#1 또는 siCERS2#1 각각을 사용하거나 또는 두 siRNA를 사용할 수 있다. TBC1D20 및 CERS2 둘 다의 발현이 본 발명의 방법 또는 포유동물 세포에 따라 감소되는 동안, 숙주 세포 단백질의 감소를 달성하기위한 수단은 서로 독립적이다. 따라서, 숙주 세포 단백질 TBC1D20의 발현은 siRNA를 이용한 유전자 녹다운에 의해 감소될 수 있고, 숙주 세포 단백질 CERS2의 발현은 shRNA를 이용한 유전자 녹다운에 의해 감소되거나 또는 그 반대로도 그렇다. 대안적으로, 숙주 세포 단백질 TBC1D20의 발현은 유전자 녹다운에 의해, 예를 들어 siRNA를 사용하여 감소될 수 있고, 숙주 세포 단백질 CERS2의 발현은 유전자 녹아웃에 의해 감소될 수 있거나, 또는 그 반대로도 그렇다.
녹-다운 TBC1D20에 대한 예시적인 shRNA는 shTbc1D20#1 (서열번호 12)를 포함하며, 녹-다운 CERS2에 대한 예시적인 shRNA는 shCerS2#1 (서열번호 13) 또는 shCerS2#2 (서열번호 14), 또는 상기 shRNA의 조합을 포함한다. 바람직하게는, 서열번호 12, 13 또는 14의 서열을 포함하는 shRNA는 CHO 세포에서 사용된다. 녹-다운 TBC1D20 (서열번호 16 및 17) 또는 CERS2 (서열번호 18 내지 21)를 위해 본 발명에 적합한 shRNA를 코딩하는 예시적인 DNA 올리고뉴클레오타이드는 하기에 나타나 있다. 바람직하게는, TBCD1D20을 표적으로하는 shRNA를 코딩하는 DNA 올리고뉴클레오타이드는 서열번호 16 (shTBC1D20#1 올리고뉴크레오타이드 순방향)의 뉴클레오타이드 6 내지 26의 서열을 포함하며, 보다 바람직하게는 서열번호 16 (shTBC1D20#1 올리고뉴클레오타이드 순방향)의 뉴클레오타이드 6 내지 26 및 46 내지 64의 서열을 포함한다. 바람직하게는, CERS2를 표적으로 하는 shRNA를 코딩하는 DNA 올리고뉴클레오티드는 서열 번호 18 또는 20 (shCERS2#1 또는 #2 올리고뉴클레오타이드 순방향)의 뉴클레오타이드 6 내지 26의 서열을 포함하고, 더욱 바람직하게는 서열 번호 18 또는 20 (shCERS2#1 또는 #2 올리고뉴클레오타이드 순방향)의 뉴클레오타이드 6 내지 26 및 46 내지 64의 서열을 포함한다.
이 shRNA는 서로 독립적으로 사용할 수 있습니다. 따라서, shTbc1D20#1, shCERS2#1 또는 shCERS2#2가 사용될 수도 있고, 또는 shTbc1D20#1 및 shCERS2#1 또는 shCERS2#2가 사용될 수도 있다. TBC1D20 및 CERS2 둘 다의 발현이 본 발명의 방법 또는 포유동물 세포에 따라 감소되는 동안, 숙주 세포 단백질의 감소를 달성하는 수단은 서로 독립적이다. 따라서, 숙주 세포 단백질 TBC1D20의 발현은 siRNA를 이용한 유전자 녹다운에 의해 감소될 수 있고, 숙주 세포 단백질 CERS2의 발현은 shRNA를 이용한 유전자 녹다운에 의해 감소되거나 또는 그 반대로도 그렇다. 대안 적으로, 숙주 세포 단백질 TBC1D20의 발현은 예를 들어 shRNA를 이용한 유전자 녹다운에 의해 감소될 수 있고, 숙주 세포 단백질 CERS2의 발현은 유전자 녹아웃에 의해 감소되거나 그 반대로도 그렇다.
ATF6B를 녹다운시키기 위한 예시적인 siRNA는 siAtf6b#1 (서열번호 9), siAtf6b#2 (서열번호 10) 또는 siAtf6b#3 (서열번호 11)이다. 바람직하게는, 본 발명에 따라 siAtf6b#1 (서열번호 9), siAtf6b#2 (서열번호 10) 및 siAtf6b#3 (서열번호 11) 중 하나 이상이 사용되며, 더욱 바람직하게는 siAtf6b#1 서열번호 9) 및 siAtf6b#2 (서열번호 10) 중 하나 이상이 사용된다. ATF6B를 녹다운시키기 위한 예시적인 shRNA는 shAtf6b#1 (서열번호 15) 또는 shAtf6b#2 (서열번호 37), 바람직하게는 shAtf6b#1 (서열번호 15)를 포함한다. 바람직하게는, 서열번호 9, 10 또는 11의 서열을 갖는 siRNA 또는 서열번호 15 또는 37의 서열을 포함하는 shRNA는 CHO 세포에서 사용된다. ATF6B을 녹다운시키기 위한 본 발명에서 적합한 shRNA를 암호화하는 예시적인 DNA 올리고뉴클레오타이드는 하기에 나타낸다 (서열번호 22, 23, 35 및 36). 바람직하게는, ATF6B를 표적화하는 각각의 shRNA를 암호화하는 DNA 올리고뉴클레오타이드는 서열번호 22 또는 35 (shATF6B#1 또는 #2 올리고뉴클레오타이드 순방향)의 뉴클레오타이드 6 내지 26의 서열을 포함하며, 보다 바람직하게는 서열번호 22 또는 35 (shATF6B#1 또는 #2 올리고뉴클레오타이드 순방향)의 뉴클레오타이드 6 내지 26 및 46 내지 64의 서열을 포함한다.
다른 실시형태에서, 숙주 세포 단백질을 암호화하는 적어도 하나의 유전자는 상기 숙주 세포 단백질의 발현을 저해하는 유전자 변형을 포함한다. 숙주 세포 단백질(들) TBC1D20, CERS2 또는 ATF6B를 암호화하는 유전자(들)의 유전자 변형은 서로 독립적으로 숙주 세포 단백질의 발현을 저해하는 유전자 결실 또는 유전자의 돌연변이일 수 있다. 돌연변이는 결실, 추가 또는 치환일 수 있다. 당해 분야 숙련자는 돌연변이가 유전자의 암호화 영역에 있으며/또는 유전자 발현이 감소되는 한 돌연변이가 프로모터 또는 유전자의 조절 영역에 존재할 수 있음을 알 것이다. 바람직하게는, 돌연변이는 유전자의 프로모터 또는 조절 영역에 있다. 돌연변이는 당 업계에 알려진 방법을 이용하여 도입될 수 있다. 당해 분야 숙련자는 단백질 활성이 감소된 우성 돌연변이 숙주 세포 단백질의 과발현을 이용하여 동일한 효과가 달성될 수 있음을 이해할 것이다. 대안적으로, 숙주 세포 단백질 유전자는 포유 동물 세포에서 결실 될 수 있으며, 약한 프로모터의 조절하에 상기 숙주 세포 단백질을 암호화하는 발현 카세트가 포유 동물 세포 내로 도입되어, 대조군 세포(즉, 상기 유전자 결실을 포함하지 않는 동일한 포유 동물 세포)와 비교하여 숙주 세포 단백질의 발현이 전체적으로 감소된다. 이 유전자 돌연변이는 유전자의 하나 또는 둘 다의 대립 유전자일 수 있다.
감소된 숙주 세포 단백질 발현은 대조 포유 동물 세포, 즉 상기 유전자 변형 또는 RNA 올리고뉴클레오타이드를 함유하지 않는 동일한 포유 동물 세포와 비교하여 포유 동물 세포에서의 TBC1D20, CERS2 또는 ATF6B의 단백질 발현을 비교함으로써 결정될 수 있다. 바람직하게는, 숙주 세포 단백질 ATF6B 또는 숙주 세포 단백질 TBC1D20, CERS2의 발현은 대조 포유 동물 세포에 비해 적어도 30 %, 적어도 40 %, 적어도 50 %, 적어도 75 % 또는 100 % 감소한다. 이것은 단백질 수준, 예를 들어 ELISA, 웨스턴 블랏팅, 방사 면역 측정법, 면역 침강법, 단백질의 생물학적 활성에 대한 분석, 단백질의 면역 염색법에 이은 FACS 분석법 또는 동일 시간-분해 형광법(HTRF), 또는 단백질을 정량하기위한 당 업계에 공지된 임의의 다른 적합한 방법에 의해 측정될 수 있다. 숙주 세포 단백질 ATF6B 또는 숙주 세포 단백질 TBC1D20, CERS2의 감소된 발현은 예를 들어 정량적 PCR 또는 mRNA를 정량하기위한 당해 분야에 공지된 임의의 다른 적합한 방법에 의해 mRNA 수준에서 또한 결정될 수 있다. 선택된 서열로부터 전사된 mRNA는 노던 블랏 하이브리드화, 리보뉴클레아제 RNA 보호, 세포 RNA에 대한 동일반응계내 하이브리드화 또는 PCR에 의해 더 정량화 될 수 있다.
생산 단계에서 숙주 세포 단백질 발현이 감소되는 것이 특히 중요하다. 따라서, 숙주 세포 단백질 발현이 생산 단계의 대부분 동안 감소되는 한, 성장 단계 이후 또는 생산 단계 초기에 숙주 세포 단백질 발현의 녹다운이 유발될 수 있다. 숙주 세포 단백질 발현은 적어도 배양 종료 3 일전, 적어도 배양 종료 5 일전, 적어도 배양 종료 7 일전 또는 적어도 배양 종료 9 일전에 감소시켜야 한다. 바람직하게는, 숙주 세포 단백질 발현은 세포 배양을 통해 감소된다.
유전자는 또한 "녹아웃 (knockout)"기술을 이용하여 유전자를 삭제함으로써 변형될 수 있다. "녹아웃"이란 용어는 숙주 세포 단백질 AFT6B의 발현 또는 숙주 세포 단백질 TBC1D20 및 CERS2의 조합이 저해되고 각 숙주 세포 단백질이 생성되지 않도록 유전적으로 조작된 세포를 말한다 (100%까지 감소). 이것은 CRISPR-Cas9 또는 아연 핑거 뉴클레아제 기술을 포함하여 당해 분야 숙련자에게 공지된 다양한 기술을 이용하여 달성할 수 있다. 대안으로, 유전자는 유전자에 돌연변이를 도입함으로써 그의 단백질의 발현을 저해하도록 변형될 수 있다. 유전자 돌연변이는 암호화 영역 또는 유전자의 프로모터 또는 조절 영역에서 뉴클레오타이드 결실, 부가 또는 치환일 수 있다. 이 유전자 돌연변이는 유전자의 하나 또는 둘 다 대립 유전자 중 하나일 수 있다.
재조합 치료 단백질의 향상된 분비
본 발명에 따른 포유 동물 세포에서 ATF6B 또는 TBC1D20 및 CERS2의 감소된 발현은 재조합 치료 단백질의 분비를 증가시킨다. 단백질 분비는 향상된 세포 밀도 또는 세포 생존력에 의해 증가될 수 있다. 그것은 또한 특정 세포 생산성 향상에 의해 증가될 수 있다. 그러나, 세포 밀도 또는 세포 생존력을 개선하는 것은 특정 세포 생산성이 실질적으로 영향을 받지 않거나 심지어 개선되지 않는 경우에 분비된 재조합 치료 단백질의 총 수율만을 증가시킨다는 것을 당업자는 이해할 것이다. 마찬가지로 특정 세포 생산성을 증가시키는 것은 세포 밀도 또는 세포 생존력이 실질적으로 영향을 받지 않거나 심지어 개선되지 않는 경우에 분비된 재조합 치료 단백질의 총 수율만을 증가시킨다. 따라서, 재조합 치료 단백질의 증강된 분비는 전형적으로 mg/ml와 같은 농도 (역가)로서 측정되는 세포 배양물 내 재조합 치료 단백질의 총 수율을 의미한다. 본 발명에 따른 재조합 치료 용 단백질의 분비는 적어도 10 %, 적어도 20 %, 적어도 30 %, 적어도 40 %, 적어도 50 %, 적어도 75 %, 적어도 100 % 또는 상기 포유류 세포 대조군, 즉 상기 유전자 변형체 또는 RNA 올리고 뉴클레오타이드를 함유하지 않는 것보다 적어도 200%이상 증가한다. 바람직한 실시형태에서, 재조합 치료 단백질의 분비의 수율은 수확시에 증가한다.
단백질 ATF6b는 폴딩되지 않은 단백질 반응 (UPR)에 관여한다. 이전에 "ATF6β도 ATF4도 아닌 ATF6α만이 ER의 확장을 유발할 수 있는 능력이 있다" (Bommiasamy et al., 2009, Journal of Cell Sciences. 122: 1626-1636) 및 ATF6a만이 ER 샤프론의 전사 유도를 담당한다 (Yamamoto et al., 2007, Cell. 13 : 365-376) 라고 기재되었다. ATF6b가 ATF6a와 비교하여 ER 스트레스 반응 (ERSR) 유전자의 매우 약한 전사 활성화제인 것으로 추가 보고되었다 (Thuerauf et al., 2007, The Journal of Biological Chemistry. 282(31): 22865-22878). 이론에 얽매이지 않고, 우리는 생산 세포주에서 ATF6b가 결실되면 ATF6a의 전사 활성을 증가시켜서 ER 샤프론의 발현을 촉발시켜 ER의 단백질 폴딩 능력을 증가시킬 수 있다고 믿는다.
다양한 사슬 길이의 세라마이드는 ER의 세라마이드 신타아제 (CERS1-6)의 6가지 다른 isoform에 의해 합성된다. CERS2는 매우 긴 사슬 세라마이드 (C20 내지 C26)의 합성을 촉매하고 마우스에서의 결실은 매우 긴 사슬 세라마이드 (>C22)를 감소시키는 것으로 나타난 반면 C16 내지 C18 세라마이드의 보상 증가를 유도하는 것으로 나타났다 (Groesch S, et al., 2012. Progress in Lipid Research. 51:50-62). CERT는 C14, C16, C18 및 C20 사슬을 갖는 세라마이드를 효율적으로 전달하지만 더 긴 아실 사슬을 전달하지는 않는다 (Kumagai D, et al., 2005. The Journal of Biological Chemistry. 280(8):6488-6495). 따라서 이론에 얽매이지 않고서 CERT 매개 세라마이드 수송의 효율은 CERS2를 결실함으로써 증가될 수 있으며, 이로 인해 플라즈마 막으로 전달되는 단백질의 양이 증가하게 된다.
작은 GTPase Rab1은 ER에서 처리된 단백질의 소포성 수송에 결정적인 역할을 한다. 골지체를 유지하기 위해서는 Gab-결합된 Rab1이 필요하다 (Haas A, et al., 2007. Journal of Cell Science. 120:2997-3010). TBC1D20은 GTPase-활성화 단백질(GAP)이다. 그것은 활성 전환, GTP-결합된 Rab1의 비활성, GDP-결합된 상태를 촉진한다. 따라서, 이론에 구애됨이 없이, TBC1D20의 결실은 소포성 단백질 수송 과정에 긍정적인 영향을 주는 Rab1의 구성적 활성 형태를 초래할 수 있다.
TBC1D20과 CERS2는 모두 골지체에서 단백질 수송에 관여한다. 따라서 TBC1D20 및 CERS2 발현의 감소는 상승 작용으로 작용하여 상기 단백질 각각의 감소에 비해 재조합 단백질 분비를 증가시키는 것으로 보인다.
분비된 재조합 치료 단백질
본 발명의 포유 동물 세포에서 생산된 분비된 재조합 치료 단백질은 Fc-융합 단백질과 같은 항체 또는 융합 단백질을 포함하지만 이에 한정되지는 않는다. 다른 분비된 재조합 치료 단백질은 예를 들어 효소, 사이토카인, 림포카인, 접착 분자, 그에 대한 수용체 및 유도체 또는 단편, 및 작용제 또는 길항제로서 작용할 수 있는 다른 폴리펩타이드 및 골격 및/또는 치료 또는 진단 용도를 가질 수 있다.
관심의 대상이 되는 다른 재조합 단백질은 예를 들어 인슐린, 인슐린 유사 성장 인자, hGH, tPA, 인터루킨(IL)과 같은 사이토카인, 예를 들어 IL-1, IL-2, IL-3, IL-4, IL-5, IL-6, IL-7, IL-8, IL-9, IL-10, IL-11, IL-12, IL-13, IL-14, IL-15, IL-16, IL-17, IL-18, 인터페론 (IFN) 알파, IFN 베타, IFN 감마, IFN 오메가 또는 IFN 타우, TNF 알파 및 TNF 베타와 같은 종양 괴사 인자 (TNF), TNF 감마, TRAIL; G-CSF, GM-CSF, M-CSF, MCP-1 및 VEGF가 포함되지만 이에 한정되지는 않는다. 또한, 에리트로포이에틴 또는 다른 호르몬 성장 인자 및 작용제 또는 길항제로서 작용할 수 있는 다른 폴리펩타이드 및/또는 치료 또는 진단 용도의 생산이 포함된다.
바람직한 재조합 분비된 치료 용 단백질은 항체 또는 단편 또는 그의 유도체이다. 따라서, 본 발명은 모노클로날 항체, 다중특이성 항체 또는 그의 단편, 바람직하게는 단클론 항체, 이중 특이성 항체 또는 그의 단편과 같은 항체의 제조에 유리하게 이용될 수 있다. 또한, 본 발명에 따른 재조합 분비된 치료용 단백질의 제조 방법은 단클론 항체, 다중 특이성 항체 또는 그의 단편, 바람직하게는 단클론 항체, 이중 특이성 항체 또는 그의 단편과 같은 항체의 제조에 유리하게 이용될 수 있다. 본 발명의 범위 내의 예시적인 항체는 항-CD2, 항-CD3, 항-CD20, 항-CD22, 항-CD30, 항-CD33, 항-CD37, 항-CD40, 항-CD44, 항-CD44v6, 항-CD49d, 항-CD52, 항-EGFR1 (HER1), 항-EGFR2 (HER2), 항-GD3, 항-IGF, 항-VEGF, 항-TNF알파, 항-IL2, 항-IL-5R 또는 항-IgE 항체를 포함하지만 그에 한정되지는 않으며, 항-CD20, 항-CD33, 항-CD37, 항-CD40, 항-CD44, 항-CD52, 항-HER2/neu (erbB2), 항-EGFR, 항-IGF, 항-VEGF, 항-TNF알파, 항-IL2 및 항-IgE 항체를 포함하는 군에서 선택되는 것이 바람직하다.
항체 단편은 예를 들어 "Fab 단편" (단편 항원-결합 = Fab)을 포함한다. Fab 단편은 인접한 불변 영역에 의해 함께 유지되는 두 사슬의 가변 영역으로 구성된다. 이들은 프로테아제 분해, 예를 들어 통상적인 항체로부터 파파인을 통해 형성될 수 있지만, 유사한 Fab 단편 또한 유전 공학에 의해 생산될 수 있다. 추가 항체 단편은 펩신으로 단백질분해성 절단에 의해 준비될 수 있는 F(ab')2 단편을 포함한다.
유전자 조작 방법을 사용하여 중쇄(VH) 및 경쇄(VL)의 가변 영역만으로 구성된 단축된 항체 단편을 생산하는 것이 가능하다. 이것들은 Fv 단편 (단편 변수 = 가변 부분의 단편)라고 한다. 이들 Fv 단편은 불변 사슬의 시스테인에 의한 2 개의 사슬의 공유 결합이 없기 때문에, Fv 단편은 종종 안정화된다. 중쇄 및 경쇄의 가변 영역을 짧은 펩타이드 단편, 예를 들어 10 내지 30 아미노산, 바람직하게는 15 아미노산으로 연결하는 것이 유리하다. 이러한 방식으로 펩티드 링커에 의해 연결된 VH 및 VL로 이루어진 단일 펩티드 가닥이 얻어진다. 이러한 종류의 항체 단백질은 단일 사슬-Fv (scFv)로 알려져 있다. scFv-항체 단백질의 예는 당해분야 숙련자에게 공지되어 있다.
최근 몇년간, scFv를 다량체성 유도체로서 제조하기위한 다양한 전략이 개발되어왔다. 이는 특히, 향상된 약물동태 및 생체 분포 특성과 더불어 증가된 결합력을 갖는 재조합 항체를 유도하기 위한 것이다. scFv의 다량화를 달성하기 위해, scFv를 다량화 도메인을 갖는 융합 단백질로서 조제하였다. 다량화 도메인은, 예를 들어 IgG의 CH3 영역 또는 류신-지퍼 도메인과 같은 코일 형 코일 구조 (나선 구조)가 될 수 있다. 그러나 scFv의 VH/VL 영역 사이의 상호 작용이 다량화 (예를 들어 이중-, 삼중- 및 오중체)에 사용되는 전략도 있습니다. 당해분야 숙련자는 이중체에 대해 2가의 단독이량체 scFv 유도체를 의미한다. scFv 분자에서 5 내지 10 개의 아미노산으로 링커를 단축하면, 사슬 간 VH/VL 중첩이 일어나는 호모다이머가 형성된다. 이중체는 디설파이드 가교의 혼입에 의해 추가로 안정화 될 수 있다. 이중체-항체 단백질의 예는 당해분야 숙련자에게 공지되어 있다.
본 발명에 따른 바람직한 분비된 재조합 치료용 항체는 이중특이성 항체이다. 이중특이성 항체는 전형적으로 표적 세포 (예를 들어, 악성 B 세포) 및 이펙터 세포 (예를 들어, T 세포, NK 세포 또는 대식세포)에 대한 항원-결합 특이성을 하나의 분자 내에 결합시킨다. 거기에 제한됨 없이 예시적인 이중 특이성 항체는 이중체, BiTE (이중-특정 T-세포 인게이저) 포맷 및 DART (이중-친화성 재표적화) 포맷이다. 이중체 형식은 두 개의 폴리펩타이드 사슬이 비공유 결합되어있는 두 개의 개별 폴리펩타이드 사슬에서 두 개의 항원 결합 특이성의 중쇄 및 경쇄의 동족 가변 도메인을 분리한다. DART 형식은 이중체 형식을 기반으로 하지만 C 말단 디설파이드 가교를 통해 추가 안정화를 제공한다.
삼중체에 대해 당해분야 숙련자는 3가 동종 삼량체 scFv 유도체를 의미한다. 상기 scFv 유도체에서, VH-VL 도메인은 링커 서열없이 직접 융합되어 삼량체의 형성을 유도한다. 당해분야 숙련자는 2가, 3가 또는 4 가의 구조를 가지며 scFv로부터 유래된 소위 미니항체를 잘 알고있을 것이다. 다중 화합은 2중, 3중 또는 4중 코일형 코일 구조에 의해 수행된다.
또한 미니바디가 본 발명과 관련하여 예상된다. 미니바디에 대해, 당해분야 숙련자는 2가의 동종이량체 scFv 유도체를 의미한다. 그것은 면역 글로불린, 바람직하게는 IgG, 가장 바람직하게는 IgG1의 CH3 영역을 Hinge 영역 (예를 들면 IgG1로부터) 및 링커 영역을 통해 scFv에 연결되는 이합체 영역으로서 함유하는 융합 단백질로 구성된다. 미니바디-항체 단백질의 예는 당해분야 숙련자에게 공지되어 있다.
또 다른 바람직한 재조합 분비된 치료 용 단백질은 Fc 융합 단백질과 같은 융합 단백질이다. 따라서, 본 발명은 Fc 융합 단백질과 같은 융합 단백질의 생산에 유리하게 사용될 수 있다. 또한, 본 발명에 따른 분비된 재조합 치료 용 단백질의 제조 방법은 Fc 융합 단백질과 같은 융합 단백질의 제조에 유리하게 사용될 수 있다.
융합 단백질의 이펙터 부분은 천연 서열 또는 변형된 이종 단백질의 서열의 완전한 서열 또는 임의의 일부 또는 완전한 서열의 조성물 또는 천연 또는 변형된 이종 단백질의 서열의 임의의 일부일수 있다. 면역 글로불린 불변 도메인 서열은 임의의 면역 글로불린 아형, 예컨대 IgG1, IgG2, IgG3, IgG4, IgA1 또는 IgA2 아형 또는 IgA, IgE, IgD 또는 IgM과 같은 부류로부터 수득 될 수 있다. 우선적으로 이들은 인간 면역 글로불린으로부터 유래되며, 보다 바람직하게는 인간 IgG로부터, 그리고 더욱더 바람직하게는 인간 IgG1 및 IgG3으로부터 유래된다. Fc-융합 단백질의 비 제한적인 예는 N- 연결된 당쇄 화 부위를 포함하는 중쇄 면역 글로불린 불변 영역의 CH2 도메인에 결합된 MCP1-Fc, ICAM-Fc, EPO-Fc 및 scFv 단편 등이다. Fc- 융합 단백질은 N- 결합된 글라이코실화 부위를 포함하는 중쇄 면역 글로불린 불변 영역의 CH2 도메인을, 예를 들어 다른 면역 글로불린 도메인, 효소 적 활성 단백질 부분 또는 작동기 도메인을 포함하는 또 다른 발현 구조물에 도입함으로써 유전 공학적 접근법에 의해 구축될 수 있다. 따라서, 본 발명에 따른 Fc-융합 단백질은 또한 예를 들어, N-링크된 당화 부위를 포함하는 중쇄 면역글로불린 불변 영역의 CH2 도메인에 연결된 단일 사슬 Fv 단편을 포함한다.
재조합 분비형 치료학적 단백질, 특히 항체, 항체 단편 또는 Fc-융합 단백질은 바람직하게는 분비형 폴리펩타이드로서 배양 배지로부터 회수/단리된다. 재조합 분비형 치료학적 단백질의 실질적으로 균질한 제제를 얻기 위해 다른 재조합 단백질 및 숙주 세포 단백질로부터 재조합 분비형 치료학적 단백질을 정제할 필요가 있다. 제1 단계로서, 세포 및/또는 미립자 세포 잔해(debris)fmf 배양 배지 또는 용해물로부터 제거한다. 또한, 예를 들어, 면역친화성 또는 이온-교환 컬럼, 에탄올 침전, 역상 HPLC, Sephadex 크로마토그래피 및 실리카 또는 DEAE와 같은 양이온 교환 수지 상에서의 크로마토그래피에 의한 오염물 용해성 단백질, 폴리펩타이드 및 핵산으로부터 재조합 분비형 치료학적 단백질을 정제한다. 숙주 세포에 의해 발현된 이종 단백질을 정제하는 방법은 당해 분야에 공지되어 있다.
한 실시형태에서, 재조합 분비형 치료학적 단백질은 상기 분비형을 암호화하는 하나 이상의 발현 카세트(들)에 의해 암호화된다.
몇몇의 실시형태들에서, 분비형 치료학적 단백질은 디하이드로폴레이트 리덕타제(DHFR), 글루타민 신테타제(GS)와 같은 증폭가능한 유전자 선택 마커의 제어 하에 놓일 수 있다. 증폭가능한 선택 마커 유전자는 분비형 치료학적 단백질 발현 카세트와 동일한 발현 벡터 상에 존재할 수 있다. 대안으로, 증폭가능한 선택 마커 유전자 및 분비형 치료학적 단백질 발현 카세는 상이한 발현 벡터들 상에 존재할 수 있지만, 숙주 세포의 게놈으로 근접하게 통합될 수 있다. 동시에 공동-형질감염된 2개 이상의 벡터는 예를 들면, 종종 숙주 세포의 게놈에 근접하게 통합된다. 이어서, 분비형 치료학적 단백질 발현 카세트를 함유하는 유전적 영역의 증폭은 배양 배지 내로 증폭제(예를 들면, DHFR에 대한 MTX 또는 GS에 대한 MSX)를 부가함으로써 매개된다.
또한, 발현 벡터 내로 분비형 치료학적 단백질 암호화-폴리뉴클레오타이드의 다중 카피를 클로닝함으로써, 숙주 세포 또는 생산자 세포에서 분비형 치료학적 단백질의 충분히 높은 안정한 수준을 달성할 수 있다. 분비형 치료학적 단백질-암호화 폴리뉴클레오타이드의 다중 카피를 발현 벡터에 클로닝하고 전술한 바와 같이 분비형 치료학적 단백질 발현 카세트를 증폭시키는 것은 추가로 조합될 수 있다.
항체 생산
재조합 항체를 제조하기 위해, 전장 경쇄 및 중쇄 또는 그의 단편을 코딩하는 DNA 분자를 발현 벡터에 삽입하여 서열이 전사 및 번역 조절 서열에 작동 가능하게 연결되도록 한다. 대안적으로, 경쇄 가변 영역 및 중쇄 가변 영역을 암호화하는 DNA 분자는 본 명세서에 제공된 서열 정보를 사용하여 화학적으로 합성될 수 있다. 합성 DNA 분자는 원하는 항체를 암호화하는 통상적인 유전자 발현 구조물을 생성하기 위해, 예를 들어, 불변 영역 암호화 서열 및 발현 조절 서열을 포함하는 다른 적절한 뉴클레오타이드 서열에 연결될 수 있다. 본 발명의 항체를 제조하기 위해, 당업자는 당해분야에 널리 공지된 다양한 발현 시스템, 예를 들어, Kipriyanow와 Le Gall (2004. Molecular Biotechnology. 26:39 - 60.)에 의해 검토된것들로부터 선택할 수 있다. 발현 벡터는 플라스미드, 레트로바이러스, 코스미드, EBV 유래 에피솜 등을 포함한다. 용어 "발현 벡터"는 외래 DNA의 발현에 적합한 임의의 벡터를 포함한다. 이러한 발현 벡터의 예로는 바이러스 벡터, 예를 들어 아데노 바이러스, 백시니아 바이러스, 바큘로바이러스 및 아데노 관련 바이러스 벡터가 있다. 이와 관련하여, "바이러스 벡터"라는 표현은 DNA 및 바이러스 입자 모두를 의미하는 것으로 이해된다. 파아지 또는 코스 미드 벡터의 예는 pWE15, M13, λEMBL3, λEMBL4, λFIXII, λDASHII, λZAPII, λgT10, λgt11, Charon4A 및 Charon21A 를 포함한다. 플라스미드 벡터의 예는 pBR, pUC, pBluescriptII, pGEM, pTZ 및 pET 군을 포함한다. 예를 들어, E. coli 및 Pseudomonas sp와 같은 다수의 숙주 미생물에서 자율적으로 복제할 수 있는 벡터와 같은 다양한 셔틀 벡터가 사용될 수 있다. 또한, 인공 염색체 벡터가 발현 벡터로 고려된다. 발현 벡터 및 발현 조절 서열은 숙주 세포와 양립할 수 있도록 선택된다. 포유 동물 발현 벡터의 예로는 Invitrogen으로부터 입수할 수 있는 pcDNA3, pcDNA3.1(+/-), pGL3, pZeoSV2(+/-), pSecTag2, pDisplay, pEF/myc/cyto, pCMV/myc/cyto, pCR3.1, pSinRepS, D H26S, D HBB, pNMT1, pNMT41, pNMT81 및 Promega, pMbac, pPbac, pBK-RSV로부터 입수할 수 있는 pCI 및 Stratagene으로부터 입수할 수 있는 pBK-CMV 및 Clontech로부터 입수 가능한 pTRES 및 그 유도체가 있다.
항체 경쇄 유전자 및 항체 중쇄 유전자는 별개의 벡터에 삽입될 수 있다. 특정 실시 양태에서, 두 DNA 서열은 동일한 발현 벡터에 삽입된다. 편리한 벡터는 기능적으로 완전한 인간 CH 또는 CL 면역 글로불린 서열을 암호화하고, 상기 서술한 바와 같이 어떤 VH 또는 VL 서열이든 용이하게 삽입되고 발현될 수 있도록 조작된 적절한 제한 효소 부위를 가지며, CH1 및/또는 상부 힌지 영역은 본 발명의 적어도 하나의 아미노산 변형을 갖는다. 불변 사슬은 일반적으로 항체 경쇄에 대해 카파 또는 람다이다. 재조합 발현 벡터는 또한 숙주 세포로부터 항체 사슬의 분비를 촉진시키는 신호 펩티드를 암호화 할 수 있다. 항체 사슬을 코딩하는 DNA는 신호 펩타이드가 성숙한 항체 사슬 DNA의 아미노 말단에 인-프레임 (in-frame)으로 연결되도록 벡터 내로 클로닝 될 수 있다. 신호 펩타이드는 면역 글로블린 신호 펩타이드 또는 비-면역 글로불린 단백질의 이종 펩타이드일 수 있다. 대안으로, 항체 사슬을 코딩하는 DNA 서열은 이미 신호 펩타이드 서열을 함유할 수 있다. 항체 사슬을 암호화하는 DNA 서열 이외에, 재조합 발현 벡터는 프로모터, 인핸서, 종결 및 폴리아데닐화 신호 및 숙주 세포에서 항체 사슬의 발현을 조절하는 다른 발현 조절 요소를 포함하는 조절 서열을 지니고 있다. CMV Simian Virus 40 (SV40) (예: SV40 프로모터 / 인핸서), 아데노 바이러스 (예 : SV40 프로모터/인핸서)와 같은 (CMV) 유래의 프로모터 및/또는 인핸서 (enhancer) 아데노 바이러스 주요 후반 프로모터 (AdMLP)), 폴리오마 및 천연 면역 글로불린 및 액틴 프로모터와 같은 강한 포유류 프로모터를 포함한다. 폴리아데닐화 신호의 예는 BGH 폴리 A, SV40 후반 또는 초기 폴리 A이며, 대안으로 면역 글로불린 유전자의 3'UTR 등이 사용될 수 있다.
재조합 발현 벡터는 또한 숙주 세포에서의 벡터의 복제 (예를 들어, 복제 기원) 및 선별 마커 유전자를 조절하는 서열을 보유할 수 있다. 본 발명의 항체의 중쇄 또는 이의 항원-결합 부분 및/또는 경쇄 또는 그의 항원-결합 부분을 암호화하는 핵산 분자, 및 이들 DNA 분자를 포함하는 벡터는 리포좀 매개 형질감염, 다중 매개 형질감염, 원형질 융합, 현미주입, 칼슘 인산염 침전, 전기 천공법 또는 바이러스성 벡터에 의한 수송을 포함하여 당해 분야에 잘 공지된 형질감염 방법에 따라 예를 들어 박테리아 세포 또는 고등 진핵 세포, 예를 들면, 포유 동물 세포에 도입될 수 있다.
단일 발현 벡터로부터 또는 2개의 별개의 발현 벡터로부터 중쇄 및 경쇄를 발현하는 것은 당업자의 통상의 지식 범위내에 있다. 바람직하게는, 중쇄 및 경쇄를 암호화하는 DNA 분자는 숙주 세포, 바람직하게는 포유 동물 세포 내로 공동 형질 감염된 2개의 벡터 상에 존재한다.
발현을 위한 숙주로서 입수 가능한 포유 동물 세포주는 당 업계에 잘 공지되어 있으며, 특히 중국 햄스터 난소 (CHO, CHO-DG44, CHO-K1) 세포, NSO, SP2/0 세포, HeLa 세포, HEK293 세포, 베이비 햄스터 신장 (BHK) 세포, 원숭이 신장 세포 (COS), 인간 암종 세포 (예 : HepG2), A549 세포, 3T3 세포 또는 임의의 그러한 세포주의 유도체/자손을 포함한다. 인간, 마우스, 래트, 원숭이 및 설치류 세포주를 비롯한 다른 포유류 세포, 또는 효모, 곤충 및 식물 세포를 포함 하나 이에 한정되지 않는 다른 진핵 세포 또는 박테리아와 같은 원핵 세포가 사용될 수있다. 본 발명의 항체 분자는 숙주 세포에서 항체 분자의 발현을 허용하기에 충분한 시간 동안 숙주 세포를 배양함으로써 생산된다. 발현에 따라, 완전한 항체 (또는 항체의 항원-결합 단편)는 예를 들어 단백질 A, 단백질 G, 글루타티온-S-트랜스퍼라제 (GST) 및 히스티딘 태그와 같은 친화성 태그와 같은 당해 분야에 널리 공지된 기술을 사용하여 수확 및 정제될 수 있다.
단백질 정제
재조합 분비된 치료용 단백질은 바람직하게 분비된 폴리 펩타이드로서 배양 배지로부터 회수된다. 재조합 단백질에 대해 사용되는 표준 단백질 정제 방법을 사용하여 재조합 분비된 치료용 단백질을 정제하는 것이 필수적이며, 이는 단백질의 실질적으로 균질한 제제가 얻어지는 방식이다. 예로서, 본 발명의 재조합 분비된 치료용 단백질을 수득하는데 유용한 최첨단 정제 방법은 제1단계로서 배양 배지 또는 용 해물로부터 세포 및/또는 미립자 세포 파편을 제거하는 단계를 포함한다. 재조합 분비된 치료 용 단백질은 예를 들어 면역 친 화성 또는 이온 교환 칼럼, 에탄올 침전, 역상 HPLC, Sephadex 크로마토 그래피, 실리카상의 크로마토 그래피 또는 양이온 교환 수지상에서의 분 해화에 의해 오염성 용해성 단백질, 폴리펩타이드 및 핵산으로부터 정제된다. 항체 또는 Fc 융합 단백질은 예를 들어 단백질 A 스핀 컬럼 (GE Healthcare)을 사용하여 표준 단백질 A 크로마토 그래피에 의해 정제될 수 있다. 단백질 순도는 SDS PAGE를 감소시킴으로써 확인 될 수있다. 재조합 분비된 치료 용 단백질 농도는 280nm에서 흡광도를 측정하고 단백질 특이적 흡광 계수를 이용하여 결정할 수 있다. 재조합 분비된 치료 용 단백질 제제를 얻는 공정의 최종 단계로서, 정제된 재조합 분비된 치료 용 단백질은 예를 들어 치료적 적용을 위해 하기에 기술된 바와 같이 동결 건조와 같이 건조될 수 있다.
약제학적 조성물
이론에서 사용하기 위해, 재조합 분비형 치료학적 단백질은 동물 또는 사람에게의 투여를 가능하게 하기에 적절한 약제학적 조성물로 제형화될 수 있다. 재조합 분비형 치료학적 단백질을 함유하는 약제학적 조성물은 용량 단위 형태(dosage unit form)로 제시될 수 있고 임의의 적합한 방법에 의해 제조될 수 있다. 재조합 분비형 치료학적 단백질의 전형적 제형은 생리학적으로 허용가능한 담체, 부형제 또는 안정화제와 혼합함으로써 동결건조된 형태 또는 건조된 제형 또는 수용액 또는 수성 또는 비-수성 현탁액으로 제조될 수 있다. 담체, 부형제, 개질제 또는 안정제는 사용된 용량과 농도에서 독성이 없다. 여기에는 인산염, 구연산염, 아세테이트 및 기타 무기산 또는 유기산과 그 염과 같은 완충제가 포함된다. 아스코르빈 산 및 메티오닌을 포함하는 항산화제; 페놀, 부틸 또는 벤질 알코올, 메틸 또는 프로필 파라벤과 같은 알킬 파라벤, 카테콜, 레조르시놀, 사이클로헥산올, 3-펜탄올 및 m-크레졸과 같은 방부제; 혈청 알부민, 젤라틴 또는 면역 글로불린과 같은 단백질; 친수성 중합체, 예컨대 폴리 비닐 피 롤리 돈 또는 폴리에틸렌 글리콜 (PEG); 글라이신, 글루타민, 아스파라긴, 히스티딘, 아르기닌 또는 라이신과 같은 아미노산; 모노사카라이드, 디사카라이드, 올리고사카라이드 또는 폴리사카라이드 및 글루코스, 만노오스, 슈크로스, 트레할로스, 덱스트린 또는 덱스트란을 포함하는 다른 탄수화물; EDTA와 같은 킬레이트제; 당 알콜, 예컨대 만니톨 또는 소르비톨; 나트륨과 같은 염-형성 반대 이온; 금속 착물(예, Zn- 단백질 착물); 및/또는 TWEENTM (폴리소르베이트), PLURONICSTM 또는 지방산 에스테르, 지방산 에테르 또는 당 에스테르와 같은 이온성 또는 비이온성 계면활성제를 함유할 수 있다. 또한 유기 용매는 에탄올 또는 이소프로판올과 같은 재조합 분비형 치료학적 단백질 제제에 함유될 수 있다. 부형제는 또한 방출-변형 또는 흡수-변형 기능을 가질 수 있다.
재조합 분비형 치료학적 단백질은 또한 건조(동결 건조, 분무 건조, 분무 동결 건조, 근사 또는 초 임계 가스에 의한 건조, 진공 건조, 공기 건조), 침전 또는 결정화되거나 캡슐화 된 마이크로 캡슐에 포획 될 수있다/ 콜로이드 성 약물 전달 시스템 (예 : 리포솜, 알부민 마이크로 스피어, 마이크로 에멀젼, 나노 입자 및 나노 캡슐)에서, 코아 세르 베이션 기술에 의해, 또는 예를 들어 하이드 록시 메틸 셀룰로즈 또는 젤라틴 및 폴리 - (메틸 메타시 레이트)를 각각 사용하는 계면 중합에 의해 또는 예를 들어 pcmc 기술 (단백질 코팅 된 미세 결정)에 의해 침전되거나 또는 담체 또는 표면 상에 고정 될 수있다. 이러한 기술은 Remington: The Science and Practice of Pharmacy, 21st edition, Hendrickson R. Ed.에 개시되어 있다.
당연히, 생체내 투여에 사용되는 제형은 무균이어야 한다; 살균은 종래 기술, 예를 들면, 멸균 여과 멤브레인을 통한 여과에 의한 것이다.
소위 고농도 액상 제제(HCLF)에 이르기 위해 항체의 농도를 증가시키는 것이 유용할 수 있다. 그러한 HCLF를 생성하는 다양한 방법이 설명되어 있다.
재조합 분비형 치료학적 단백질은 또한 서방 형 제제에 함유 될 수있다. 또한, 재조합 분비형 치료학적 단백질은 투과 증진 장치, 웨이퍼, 비강, 협측 또는 비강을 갖는 또는 갖지 않는 분산액, 현탁액 또는 리포좀, 정제, 캡슐, 분말, 스프레이, 경피 또는 피부 패치 또는 크림과 같은 다른 적용 형태로 혼입될 수 있다. 폐포 제제를 사용하거나, 이식된 세포 또는 유전자 치료 후 개인의 세포에 의해 생산될 수 있다.
재조합 분비형 치료학적 단백질은 또한 폴리에틸렌 글리콜 (PEG), 메틸 또는 에틸 그룹, 또는 탄수화물 그룹과 같은 화학 그룹으로 유도체화될 수 있다. 이들 그룹은 항체의 생물학적 특성을 개선시키는데 유용할 수 있다. 혈청 반감기를 늘리거나 조직 결합을 증가시킬 수 있다.
바람직한 적용 모드는 주입 또는 주사 (정맥 내, 근육 내, 피하, 복강 내, 피내)에 의한 비경 구이지만, 흡입, 경피, 비강 내, 협측, 구강과 같은 다른 적용 형태 또한 적용 가능할 수 있다.
질병의 예방 또는 치료를 위해, 재조합 분비형 치료학적 단백질의 적절한 투여 량은 치료 될 질병의 유형, 질병의 중증도 및 진행 경로, 재조합 분비형 치료학적 단백질이 예방 또는 치료 목적을 위해 투여되는지 여부, 이전의 치료, 환자의 임상 내력 및 재조합 분비 된 치료 단백질에 대한 반응, 그리고 주치의의 재량에 달려있다. 재조합 분비형 치료학적 단백질은 한 번에 또는 일련의 치료에 걸쳐 환자에게 적합하게 투여된다.
재료 및 방법
현탁 세포의 세포 배양물
CHO-DG44 세포를 생산하는 mAb의 현탁 배양물(Urlaub G, et al., 1986 Somatic Cell and Molecular Genetics., 12 (6): 555-566) 및 이들의 안정한 형질전환체를 화학적으로 정의된 무-혈청 배지에서 인큐베이션하였다. 씨드 스톡 배양물은 각각 2 내지 3일마다 3 Х 105 내지 2 Х 105 세포/mL의 씨딩 밀도로 계대배양하였다. 세포를 T-플라스크(Greiner)에서 성장시켰다. T-플라스크를 37℃ 및 5% CO2에서 습윤 인큐베이터(Varolab)에서 인큐베이션하였다. 세포 농도 및 생존력은 계수 챔버를 사용하여 트립판 블루 배제에 의해 측정하였다.
유가식 배양
항생제 또는 MTX가 없는 화학적으로 정의된 무-혈청 배지 30ml에 125ml 진탕 플라스크(Corning)에 세포를 3 x 105 세포/ml로 씨딩하였다. 배양물을 3일 후 2%로 감소된 미니트론 인큐베이터(Infors)에서 37℃ 및 5% CO2에서 120rpm으로 교반하였다. 3일째부터 매일 피드 용액을 부가하고, 오프라인 글루코스 분석 장치 "LaboTRACE"(추적 분석)을 사용하여 글루코스를 측정하였다. 3g/L 미만의 농도에서 글루코스(#G8769, Sigma-Aldrich)를 5g/L로 조정하였다. 세포 밀도와 생존력은 "Countess 2 FL 자동화된 세포 계수기"(Life Technologies)를 사용하여 트립판-블루 배제에 의해 측정되었다. 누적 비 생산성은 주어진 시점까지 "생존가능한 세포의 적분"(IVC: integral of viable cells)으로 나눈 주어진 시점에서의 ELISA에 의해 분석된 생성물 농도로서 계산되었다.
항체-생산성 세포의 생성
CHO-DG44 세포(Urlaub G, et al., 1983. Cell. 33 : 405-412)를 IgG1 항체 mAb1을 암호화하는 발현 플라스미드(서열번호 24에 따른 서열을 갖는 중쇄 및 서열번호 25에 따른 경쇄 서열)로 안정하게 형질감염되었고, 본원에서 CHO-mAb1이라 칭한다. 선택은 하이포크산틴 및 티미딘의 부재 하에 그리고 각각의 선택제의 존재 하에 형질감염된 세포의 배양에 의해 수행되었으며, 이 경우 저항 카세트는 발현 플라스미드에 의해 암호화된다. 약 3주의 선택 후, 안정한 세포 집단을 수득하고 2 내지 3일마다 계대배양으로의 표준 스톡 배양 체계에 따라 추가로 배양한다. 증가하는 농도의 메토트렉세이트를 단계별로 첨가하여 mAb1 유전자 발현을 증가시켰다. 다음 단계에서, 안정하게 형질감염된 세포 집단의 FACS-기반 단일 세포 클로닝을 수행하여 모노클로날 세포주를 생성시켰다.
대안으로, CHO-DG44 세포(Urlaub G, et al., 1983. Cell. 33 : 405-412)를 IgG1 항체 mAb2를 암호화하는 발현 플라스미드(서열번호 26에 따른 서열을 갖는 중쇄 및 서열번호 27에 따른 경쇄 서열)로 안정하게 형질감염시켰고, 본원에서 CHO-mAb2로서 칭한다. 선택은 하이포크산틴 및 티미딘의 부재 하에 그리고 각각의 선택제의 존재 하에 형질감염된 세포의 배양에 의해 수행되었으며, 이 경우 저항 카세트는 발현 플라스미드에 의해 암호화된다. 약 3주의 선택 후, 안정한 세포 집단을 수득하고 2 내지 3일마다 계대배양으로의 표준 스톡 배양 체계에 따라 추가로 배양한다. 증가하는 농도의 메토트렉세이트를 단계별로 첨가하여 mAb2 유전자 발현을 증가시켰다. 다음 단계에서, 안정하게 형질감염된 세포 집단의 ClonePixFL-기반 단일 세포 클로닝을 수행하여 모노클로날 세포주를 생성시켰다.
안정하게 형질감염된 CHO-mAb1 또는 CHO-mAb2 세포를 G418(Gibco, Life technologies)이 보충된 화학적으로 정의된 무혈청 배지(Boehringer-Ingelheim)에서 배양하였다. CHO-mAb1 세포 배지는 400nM MTX로 보충되었고, CHO-mAb2 세포 배지는 100nM MTX(Sigma-Aldrich, Germany)로 보충되었다. 세포는 3x105 세포/mL 또는 2 x 105 세포/mL의 씨딩 밀도로 2 또는 3일마다 계대배양하였다.
CHO 생산자 세포에서의 사람 마이크로RNA의 일시적 발현
IgG1 항체(mAb1)를 안정하게 분비하는 CHO-DG44 세포를 G418(Gibco, Life technologies) 및 400nM MTX(Sigma-Aldrich, Germany)가 보충된 화학적으로 정의 된 무혈청 배지(Boehringer-Ingelheim)에서 배양하고 3x105 세포/mL 또는 2 x 105 세포/mL의 씨딩 밀도로 2 또는 3일마다 계대배양하였다.
제조업체의 지침에 따라 Amaxa 96-웰 셔틀 장치(Lonza) 및 프로그램 96-DT-133을 사용하여 1μM miRNA를 함유하는 96 웰 뉴클레오펙터 키트 SG(Lonza)에서의 계대배양(4 x 105 세포/샘플) 1일 후 뉴클레오펙션을 통해 세포를 형질감염시켰다. 일시적 형질감염의 경우, 음성 대조군 miRNA miR-c#1(miRIDIAN microRNA 모방 음성 대조군#1, Dharmacon)을 사용하였다. 이어서, 세포를 24-웰 평저 플레이트(Greiner)에 3 x 105 세포/mL의 밀도로 씨딩하였다. 형질감염 1일 후에, 배지의 용적은 새로운 배지를 부가함으로써 배가 되었다. 형질감염 2일 후에, RNeasy Plus Mini Kit(Qiagen)를 사용하여 총 RNA를 추출하고 표적 유전자의 mRNA 수준을하기 기술된 바와 같이 qPCR에 의해 측정하였다.
차세대 서열분석
IgG1 항체(mAb1)를 안정하게 분비하는 CHO-DG44 세포는 Amaxa 96- 웰 셔틀 장치 (Lonza) 및 프로그램 96-DT-133을 사용하여 1μM miRNA(miR-c#1, miR-1287 또는 hsa-miR-1978)를 함유하는 96웰 뉴클레오펙터 키트 SG(Lonza)에서 계대배양(4x105 세포/샘플) 1일 후 뉴클레오펙션을 통해 형질감염시켰다. 형질감염 12시간 후 RNeasy Plus Mini Kit(Qiagen)을 사용하여 제조사의 지침에 따라 총 RNA를 추출하고 RNA 6000 Nano Kit를 사용하여 2100 Bioanalyzer(Agilent)로 품질과 양을 분석하였다. 후속적으로, 제조업자의 지침에 따라 TruSeq RNA Sample Prep Kit v2 (Illumina)를 이용하여 200ng RNA로 cDNA 라이브러리를 생성시켰다. 간략하게, 폴리A+RNA를 농축시켰고, 이어서 폴리-A+ RNA(100 내지 500bp)의 무작위 단편화, 가닥 특이성이 없는 ds cDNA의 합성, 샘플당 바코드-표지된 어댑터의 라이게이션 및 비대칭 라이게이션된 단편의 증폭이 이어졌다. DNA 1000 키트를 이용하는 2100 Bioanalyzer(agilent)를 이용하여 품질 및 양이 분석되었다. cDNA 라이브러리는 단일 판독 모드 및 60 사이클의 단편 서열분석 및 7 사이클의 바코드 서열분석을 갖는 HiSeq 2000 서열분석 기기(Illumina) 상의 완전 유동 셀 상에 9pmol/레인으로 부하되었다. 샘플당 서열 판독은 Cricetulus griseus(assembly "CriGri_1.0" https://www.ncbi.nlm.nih.gov/assembly/309608)로부터의 참조 게놈에 대한 TopHat 소프트웨어로 맵핑하였다. 정량은 문헌[Mortazavi et al. (Nature Methods - 5, 621 - 628 (2008)]에 따라 수행하였다. 따라서, 전사체 풍부성(transcript abundance)은 RPKM (= 백만 맵핑된 판독당 엑슨 모델의 킬로베이스당 판독)으로서 계산된다.
CHO 생산자 세포에서의 사람 siRNA의 일시적 발현
CHO-mAb1 세포 및 CHO-mAb2 세포는 각각 400nM MTX(Sigma-Aldrich, Germany) 및 100nM MTX, 및 G418(Gibco, Life technologies)이 보충된 화학적으로 정의된 무혈청 배지(Boehringer-Ingelheim)에서 배양하였다. 세포는 3x 105 세포/mL 또는 2x 105 세포/mL의 씨딩 밀도로 2 또는 3일마다 계대배양하였다.
제조업자의 지침에 따라 Amaxa 96-웰 셔틀 장치(Lonza)와 프로그램 96-DT-133을 사용하여 2μM siRNA를 함유하는 96-웰 뉴클레오펙터 키트 SG(Lonza)에서의 계대배양(4 x 105 세포/샘플) 한 후 뉴클레오펙션을 통해 세포를 형질감염시켰다. 이어서, 세포를 24-웰 평저 플레이터(Greiner)에 3 x 105 세포/mL의 밀도로 씨딩하였다. 형질감염 1일 후에, 배지의 용적은 신선한 배지를 부가함으로써 배가 되었다. 형질감염 2일 후에, RNeasy Plus Mini Kit(Qiagen)을 사용하여 총 RNA를 추출하였고 표적 유전자 ATF6B, CERS2 및 TBC1D20의 mRNA 수준을 하기 기재된 바와 같이 qPCR에 의해 측정하였다. 상청액을 형질감염 후 1 내지 4일째에 수집하였고 ELISA에 의한 항체 측정까지 -20℃에서 보관하였다. 음성 대조군 세포를 하기 서열을 갖는 siRNA(모의 대조군) 대신에 물로 또는 비-표적화 음성 대조군 풀(NT siRNA)로 형질감염시켰다: UGGUUUACAUGUCGACUAA, UGGUUUACAUGUUGUGUGA, UGGUUUACAUGUUUUCUGA 및 UGGUUUACAUGUUUUCCUA (각각 서열번호 38 내지 서열번호 41) (Dharmacon, #D-001810-10).
qPCR 분석에 의한 ATF6B, CERS2, TBC1D20, GRP78, CHOP 및 Herpud1 RNA 발현 측정
RNeasy Plus Mini Kit(Qiagen)를 이용하여 2x105 내지 2x106 세포의 총 RNA를 추출하였다. 제조사의 지침에 따라 Quantitect 역방향 전사 키트(Qiagen)를 사용하여 100ng RNA를 이용하여 cDNA가 생성되었다. qPCR은 Cfx96 장치(Biorad)를 사용하여 백색 96-웰 PCR 플레이트(Biorad)에서 DyNAmo ColorFlash SYBR Green qPCR 키트(Thermo Scientific)로 수행하였다. 베타 액틴을 참조 유전자로서 사용하였다. 계산은 단일 임계(threshold) 방법으로 수행되었으며 ΔΔCq 값이 계산되었다(Bio-rad CFX 관리자 소프트웨어 2.1).
재조합 항체 농도의 측정
형질감염된 세포에서 재조합 항체 생산을 평가하기 위해서, 주어진 시점에 세포 배양물로부터 상청액을 수집하였다. 이어서, 생성물 농도를 효소 링크된 면역흡착 검정(ELISA)에 의해 분석하였다. 우선 고 결합성 96-웰 마이크로플레이트(Greiner)를 사람 IgG Fc 단편에 대한 항체(Jackson Immuno Research Laboratories)를 이용하여 4℃에서 밤새 1:480 희석으로 코팅하였다. PBS(pH 7.4) 중의 0.15% Tween 20으로 3회 세척한 후, 상기 플레이트를 실온에서 1시간 동안 차단 완충액과 함께 인큐베이션하였고, 3회의 세척 단계가 이어졌다. 상청액을 희석 완충액(0.5% BSA, PBS 중의 0.01% Tween 80, pH 7.4)에 표준 곡선의 범위(1 내지 50ng/μl 또는 1 내지 100ng/μl)의 적절한 농도로 희석시켰다. 표준 물질로서 mAb1 항체를 0 내지 100ng/μL의 일련의 희석으로 사용하였다. 희석된 샘플 및 표준물을 실온에서 1.5시간 동안 배양하였다. 반복 세척 후, 샘플을 실온에서 1시간 동안 1:5000 희석하여 사람 카파 경쇄(Sigma)에 대한 HRP-접합된 항체와 함께 인큐베이션하였고, 3회의 세척 단계가 이어졌다. 기질 p-니트로페닐포스페이트(Sigma Aldrich)를 0.1M 글리신, 1mM ZnCl2 및 1mM MgCl2(pH 10.4)로 1mg/mL의 농도로 신선하게 조제하였고 암소에서 20분 동안 인큐베이션하였다. 반응은 3M NaOH의 부가에 의해 정지시켰고 405nm에서 및 492nm의 기준 파장에서의 흡수를 Infinite M200 Pro 다중 모드 판독기(Tecan)를 사용하여 측정하였다.
마이크로RNA miR-1287 및 miR-1978의 안정한 과발현
BLOCK-iTTM Pol II miR RNAi 발현 벡터 키트(pcDNA6.2-GW/emGFP-miRNA 발현 시스템 키트)는 miRNA를 안정적으로 발현시키기 위해 사용되었다. 특정 microRNA의 2개의 카피를 암호화하는 DNA 올리고뉴클레오타이드는 포유동물 발현 벡터 pcDNA6.2에 짧은 헤어핀으로서 클로닝되었다. 그 목적을 위해, 각 miRNA를 암호화하는 DNA 올리고뉴클레오타이드는 설명서에 기술된 바와 같이 고안되었다. 간략하게, 성숙한 miRNA 서열은 최적화된 헤어핀 루프 서열 및 뮤린 miRNA mir-155로부터 유도된 3' 및 5' 플랭킹 영역을 포함하는 주어진 서열에 간삽되었다(Lagos-Quintana et al., 2002). 플랭킹 영역은 벡터 상에 존재하였고, DNA 올리고뉴클레오타이드가 고안되었으며, 이는 miRNA 서열, 언급된 루프 및 2개의 뉴클레오타이드 고갈을 갖는 각각의 성숙한 miRNA의 안티센스 서열을 암호화하여 헤어핀 줄기에 내부 루프를 생성시켰다. 또한, 양 말단에서 클로닝을 위해 오버행이 부가되었다. 헤어핀 구조는 온라인 도구 mfold를 사용하여 분석할 수 있다(M. Zuker. Mfold web server for nucleic acid folding and hybridization prediction. Nucleic Acids Res.31 (13), 3406-3415, 2003). DNA 가닥을 어닐링시키고 제조자에 의해 기술된 바와 같이 에메랄드 GFP 리포터 단백질 유전자의 3'-UTR에 라이게이션시켰다. miRNA를 벡터 백본으로 클로닝하는데 사용된 올리고 뉴클레오타이드 서열은 다음과 같다:
hsa-miR-1287 올리고뉴클레오타이드 순방향:
TGCTGTGCTGGATCAGTGGTTCGAGTCGTTTTGGCCACTGACTGACGACTCGAACCACATCCAGCA
(서열번호 28)
hsa-miR-1287 올리고뉴클레오타이드 역방향:
CCTGTGCTGGATGTGGTTCGAGTCGTCAGTCAGTGGCCAAAACGACTCGAACCACTGATCCAGCAC
(서열번호 29)
hsa-miR-1978 올리고뉴클레오타이드 순방향:
TGCTGGGTTTGGTCCTAGCCTTTCTAGTTTTGGCCACTGACTGACTAGAAAGGCTAACCAAACC
(서열번호 30)
hsa-miR-1978 올리고뉴클레오타이드 역방향:
CCTGGGTTTGGTTAGCCTTTCTAGTCAGTCAGTGGCCAAAACTAGAAAGGCTAGGACCAAACCC
(서열번호 31)
연쇄(chaining) 기술을 적용하여 하나 이상의 miRNA를 포함하는 벡터를 생성하였다. 2개의 카피를 갖는 하나의 miRNA에 대해, 특정 마이크로RNA(예를 들면, pcDNA6.2-GW/emGFP-miR1287-miR1287 또는 pcDNA6.2-GW/emGFP-miR1978-miR1978로 표시되는 hsa-miR1287 또는 miR-1978)의 2개의 카피는 제조사가 기술한 바와 같이 포유동물 발현 벡터 pcDNA6.2-GW/emGFP-miRNA(BLOCK-iTTM PolII miR RNAi 발현 벡터 키트, life technologies의 K4936-00)에 짧은 헤어핀으로서 상기 miRNA를 암호화하는 DNA 올리고 뉴클레오타이드로서 클로닝되었다. 요약하면, miRNA 카세트를 효소 BamHI 및 XhoI로 절제하였다. 이미 하나의 miRNA가 함유된 벡터를 효소 BglII와 XhoI로 개방하였다. DNA를 오렌지색 부하 완충액과 혼합하고 TAE 완충액으로 제조된 1% 아가로스 겔에서 분리하였고, 밴드를 에티듐 브로마이드로 시각화하였고, 적절한 크기의 밴드를 겔로부터 절제하였다. 크기는 DNA 사다리(ladder)로 입증되었다. 겔 추출 키트로 DNA를 용출시켰다. DNA 삽입물을 제조사의 지시에 따라 T4 DNA 리가제를 사용하여 벡터에 라이게이션시켰다. 후속적으로, 적격한 이. 콜라이를 DNA로 형질전환시키고 스펙티노마이신(spectinomycin)을 함유한 한천 플레이트에 플레이팅하였다. 콜로니를 채취하고 DNA 정제 키트를 이용하여 DNA를 추출하고 우선 BamHI 및 BglII로의 대조군 소화에 의해 확인한 후 서열분석을 수행하였다.
안정한 세포 풀 생성을 위해, CHO-mAb1은 제조업자에 의해 기술된 바와 같이 pcDNA6.2-GW/emGFP-miR-1287-1287 또는 pcDNA6.2-GW/emGFP-mi-1978-1978의 최적화된 프로토콜을 사용하여 Lipofectamine 2000 및 Plus 시약(Invitrogen)으로 형질감염시켰고, 세포를 10μg/mL 블라스티시딘 S(Life Technologies)로 선택하였고 FACS(FACS Diva)에 의해 GFP 양성 세포를 농축시켰다. 대조군 벡터로서 GFP를 발현하는 음성 대조군 miRNA 발현 벡터(pcDNA6.2-GW/emGFP-음성 대조군 miRNA, 키트에 의해 제공됨)는 기재된 바와 같이 안정하게 형질감염시켰다. 음성 대조군 miRNA는 다음 서열을 갖는다: GAAAUGUACUGCGCGUGGAGAC (서열번호 34)
ATF6B, CERS2 및 TBC1D20의 안정한 shRNA-매개된 녹다운
shRNA를 안정적으로 발현시키기 위해 BLOCK-iTTM Pol II miR RNAi 발현 벡터 키트(pcDNA6.2-GW/emGFP-miRNA 발현 시스템 키트)를 사용하였다. 특정 shRNA를 암호화하는 DNA 올리고뉴클레오타이드를 짧은 헤어핀으로서 포유동물 발현 벡터 pcDNA6.2에 클로닝하였다. 그 목적을 위해, miRNA의 클로닝을 위해 상기 기술된 바와 같이, 각각의 shRNA를 암호화하는 DNA 올리고뉴클레오타이드를 고안하고 통합 벡터에 클로닝하였다. shRNA를 벡터 골격 내로 클로닝하는데 사용된 올리고뉴클레오타이드 서열은 하기와 같았고, 여기서 밑줄은 루프 서열과 연결된 2개의 뉴클레오타이드의 결실을 갖는 안티센스 표적 부위 및 이의 상보성 서열을 나타낸다:
shTBC1D20#1 올리고뉴클레오타이드 순방향:
TGCTGAATCCTTGCTCAACTGTCGAAGTTTTGGCCACTGACTGACTTCGACAGGAGCAAGGATT
(서열번호 16)
shTBC1D20#1 올리고뉴클레오타이드 역방향:
CCTGAATCCTTGCTCCTGTCGAAGTCAGTCAGTGGCCAAAACTTCGACAGTTGAGCAAGGATTC
(서열번호 17)
shCERS2#1 올리고뉴클레오타이드 순방향:
TGCTGTTAAGTTCACAGGCAGCCATAGTTTTGGCCACTGACTGACTATGGCTGTGTGAACTTAA
(서열번호 18)
shCERS2#1 올리고뉴클레오타이드 역방향:
CCTGTTAAGTTCACACAGCCATAGTCAGTCAGTGGCCAAAACTATGGCTGCCTGTGAACTTAAC
(서열번호 19)
shCERS2#2 올리고뉴클레오타이드 순방향:
TGCTGTGATGTAGAGGTCTGAGGCTTGTTTTGGCCACTGACTGACAAGCCTCACCTCTACATCA
(서열번호 20)
shCERS2#2 올리고뉴클레오타이드 역방향:
CCTGTGATGTAGAGGTGAGGCTTGTCAGTCAGTGGCCAAAACAAGCCTCAGACCTCTACATCAC
(서열번호 21)
shATF6B#1 올리고뉴클레오타이드 순방향:
TGCTGTCCATCTTCACACTGAGGACCGTTTTGGCCACTGACTGACGGTCCTCAGTGAAGATGGA
(서열번호 22)
shATF6B#1 올리고뉴클레오타이드 역방향:
CCTGTCCATCTTCACTGAGGACCGTCAGTCAGTGGCCAAAACGGTCCTCAGTGTGAAGATGGAC
(서열번호 23)
shATF6B#2 올리고뉴클레오타이드 순방향:
TGCTGTTCACTTCCAGAACCTCCTCTGTTTTGGCCACTGACTGACAGAGGAGGCTGGAAGTGAA
(서열번호 35)
shATF6B#2 올리고뉴클레오타이드 역방향:
CCTGTTCACTTCCAGCCTCCTCTGTCAGTCAGTGGCCAAAACAGAGGAGGTTCTGGAAGTGAAC
(서열번호 36)
대조군 벡터로서, GFP를 발현하는 벡터(pcDNA6.2-GW/emGFP-음성 대조군 miRNA, 키트에 의해 제공됨)를 발현하는 음성 대조군 miRNA(서열번호 34)를 전술한 바와 같이 안정하게 형질감염시켰다.
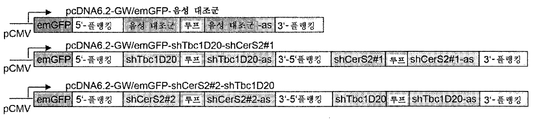
상기한 바와 같이 연쇄 기술을 적용하여 하나 이상의 shRNA(pcDNA6.2-GW/emGFP-shTbc1D20-shCerS2#1 및 pcDNA6.2-GW/emGFP-shCerS2#2-shTbc1D20)를 포함하는 벡터를 생성하였다.
안정한 세포 풀의 생성을 위해, CHO-mAb2 세포를 제조사의 지침에 따라 세포주 뉴클레오펙터 키트 V(Lonza)를 이용하는 뉴클레오펙션을 통한 계대배양 1일 후 형질감염시켰다. 간략하게, 5x106 세포/샘플을 5μg 플라스미드 DNA를 함유하는 100μL 용액 V(Lonza)에 재현탁시키고 세포주 뉴클레오펙터 장치(Lonza)와 프로그램 H14를 사용하여 큐벳에서 뉴클레오펙션시켰다. 이어서, T25-플라스크에 항생제가 없는 예열된 화학적으로 정의된 무-혈청 배지 5 mL를 세포에 씨딩하였다. 형질감염 72시간 후, 선택을 위해 배지를 1μg/mL 블라스티시딘 S(Life Technologies)를 함유하는 화학적으로 정의된 무혈청 배지로 변경하였다. 형질감염 14일 후, 세포를 FACS(BD FACS Aria III)에 의해 GFP 양성 세포에 대해 농축시켰다. ATF6B, CERS2 및 TBC1D20의 효율적인 녹다운을 전술한 바와 같이 qPCR에 의해 모니터링하였고, 배양 42일 후에 세포를 GFP 발현에 대해 유동 세포측정법(Miltenyi MacsQuant)에 의해 분석하였다.
ATF6B, CERS2 및 TBC1D20의 녹아웃
ATF6B, CERS2 또는 TBC1D20이 고갈된 녹아웃 세포를 생성하기 위해, CRISPR/Cas9 기술이 적용되었다. gRNA 고안을 위해, 제1 엑손에서 프로토스페이서 인접 모티프(PAM)의 업스트림에서 선택된 게놈 유전자좌의 표적 부위는 각각의 유전자의 모든 전사 변이체에 존재한다. 각각의 표적 유전자에 대해, 3개의 gRNA 서열을 고안하였고, CMV 프로모터 및 가이드 RNA(gRNA) 클로닝 카세트에 의해 구동되는 OF9 발현 카세트 및 Cas9 뉴클레아제를 함유하는 OFP 리포터(Life Technologies)를 갖는 GeneArt® CRISPR 뉴클레아제 벡터에 클로닝하였다. 가이드 RNA(표적 부위에 특이적인 crRNA 및 트랜스 활성화 RNA로 이루어짐) 발현은 U6 polIII 타입 프로모터에 의해 유도된다. 후속적으로, 적격한 이. 콜라이를 DNA로 형질전환시키고 암피실린을 함유하는 한천 플레이트 상에 플레이팅하였다. 콜로니를 채취하고 DNA 정제 키트로 DNA를 추출하고 플라스미드의 무결성을 서열분석에 의해 분석하였다. 안정한 세포의 생성을 위해, 전술한 바와 같이 세포주 뉴클레오펙터 키트 V(Lonza)를 이용한 뉴클레오펙션을 통한 계대배양 1일 후 CHO-mAb2 세포를 형질감염시켰다. 절단 효율은 GeneART® 게놈 절단 검출 키트(Life Technologies)를 사용하여 제조자의 지침에 따라 검출하였다. 안정한 세포 클론을 생성하기 위해, 목적의 표적 부위를 플랭킹하는 게놈 영역에 상보성인 플랭킹 영역에 간삽된, 기술된 gRNA 및 Cas9 함유 벡터 및 CMV 프로모터 구동 퓨로마이신 또는 대안으로 형광성 마커 유전자로 CHO-mAb2 세포를 형질감염시켰다. 효율적인 표적 부위 절단 후 선택 마커 유전자의 상동성 시시된 수복(HDR) 기반 통합은 각각 항생제 선택 및 FACS 분류를 가능하게 한다. 이로써 ATF6B, CERS2 또는 TBC1D20 유전자에서 녹아웃된 세포를 선택하여 화학적으로 정의된 무-혈청 배지(Boehringer Ingelheim)에서 배양하였다.
항체 정제
항체는 피펫핑 로봇에서 작동하는 MabSelect 수지(GE Healthcare)가 채워진 RoboColumns(Atoll)을 사용하여 무-세포 세포 배양 상청액으로부터 정제되었다. 용출에 사용된 낮은 pH는 항체 변성을 방지하기 위해 1M TRIS를 이용하여 pH 5.5로 중화시켰다. 아미노 그룹이 당화 분석을 간섭하므로, 완충액을 10kDa MWCO PES Vivaspin 500 필터 유닛(Sartorius)을 사용하여 한외여과하여 순수한 물로 교환하였다. 최종 단백질 농도는 NanoDrop 2000c 분광기(Thermo Scientific)를 사용하여 측정하였다.
당화 패턴의 분석
실시예 10 및 실시예 11에 기술된 shRNA 발현 CHO-mAb2 세포 풀에서 생산된 IgG의 Fc-당화의 구조 및 조성을 밝히기 위해, PNGase F를 사용한 효소적 소화에 의한 환원 후에 정제된 항체로부터 글리칸을 방출시켰다. IgG 항체의 Fc-당화는 PNGaseF 방출 및 제조사의 프로토콜에 따라 LabChip GXII 기기(PerkinElmer) 상의 ProfilerPro 글리칸 프로파일링 시스템을 사용하여 마이크로칩-기반 모세관 전기영동(CE)을 사용한 형광성 표지 후 분석하였다. 전기영동도를 LabChip GX 소프트웨어에 의해 분석하여 개별 당 구조를 확인하고 정량했다. 글리콜-형태의 백분율은 크로마토그래피 피크 면적으로부터 계산하였다. 모든 값은 샘플당 총 100%의 당 구조에 대해 표준화하였다.
실시예
실시예 1: 차세대 서열분석(NGS)에 의한 전사체 프로파일링
CHO 세포는 치료학적 단백질의 생산에 통상적으로 사용된다. 유전자 조작 접근법은 특정 cDNA를 발현시킴으로써 이들 세포의 생산성을 최적화하는 것을 시도하였다. 자연적으로 존재하는 비-암호화 RNA는 표적 단백질의 전체 세트의 발현을 조절함으로써 세포 운명을 조절하고, 이는 CHO 생산자 세포에서 과-발현될 때 가능한 한 초(super)-분비성 표현형을 초래할 수 있다. 비-암호화 RNA의 파워(power)를 활용하고 이종 치료학적 단백질의 분비에 긍정적인 영향을 미치는 RNA를 동정하기 위해 CHO-mAb1 세포를 사람 마이크로RNA의 라이브러리로 형질감염시켰다. CHO-mAb1 세포의 항체 생산성을 향상시키는 miRNA를 동정하기 위한 이러한 게놈-범위의 기능성 마이크로RNA(miRNA) 스크린에 기초하여, 항체 생산 및 비 생산성에 대한 강한 영향을 갖는 2회의 miRNA 스크린 히트가 추가의 분석을 위해 선택되었다(도 1). CHO 세포 생산성에 대한 긍정적인 영향에 관여하는 직접적 miRNA 표적 유전자를 동정하기 위해, CHO-mAb1 세포를 2개의 miRNA의 각각으로 일시적으로 형질감염시켰다. 상기 기술한 바와 같이 96-웰 뉴클레오펙터 키트(Nucleofector Kit) SG(Lonza)에서 계대배양(4x105개 세포/샘플) 1일 후에 뉴클레오펙션을 통해 세포를 형질감염시켰다. 이어서, 세포를 24-웰 플레이트(Greiner)에 3 x 105개 세포/mL의 밀도로 씨딩(seeding)하였다. 형질감염 12시간 후에, 세포는 상기 기술된 바와 같이 차세대 서열분석(NGS)을 사용하여 전사체 프로파일에 의해 분석되었다.
1을 초과하는 이들의 발현 배수 변화(형질감염되지 않은 세포에서의 2배 초과의 발현)의 |log2|로 유의하게 하향조절된 유전자는 히트(hit)로서 정의되었다. 이어서, 후보물 miRNA 표적 유전자는 관련 경로에 관한 기존 지식을 참조하여 추가의 분석을 위해 선택하였다. ATF6B는 이의 하향조절이 폴딩되지 않은 단백질 반응(UPR: unfolded protein response)을 유발한다는 가정 하에 miR-1287의 표적 유전자로서 선택되었다. CERS2 및 TBC1D20 둘 다는 각각 소포성 및 비-소포성 단백질 분비의 조절에 관여하는 miR-1978의 표적 유전자로서 선택되었다. 항체 생산 및 비 생산성에 대한 이들의 영향은 siRNA-매개된 유전자 녹다운에 의해 처음으로 평가되었다. 일시적인 접근법에서 비 생산성에 대한 긍정적인 효과를 요약하면, shRNA에 의해 표적 유전자의 장기간 고갈이 얻어졌다. siRNA 및 shRNA의 명칭 및 서열은 도 1b에 열거된다.
실시예 2: 선택된 NGS 히트는 qPCR 분석에 의해 입증된다
각각 miRNA miR-1287 및 miR-1978의 직접적 표적 유전자로서의 NGS 히트 ATF6B 및 CERS2/TBC1D20를 입증하기 위해, 이들의 발현 수준을 qPCR에 의해 분석하였다. CHO-mAb1 세포를 상기 기술된 바와 같은 2개의 마이크로RNA의 각각으로 형질감염시켰다. 형질감염 1일 후, RNA를 추출하여 qPCR 분석에 의해 ATF6B, CERS2 또는 TBCD20의 mRAN 수준(도 2a 및 도 2b)을 측정하였다. 참조 유전자 베타 액틴에 대해 표준화함으로써 상대적 발현을 계산하였다. 추가로, 목적하는 유전자의 발현 수준의 변화는 각각의 miRNA를 안정하게 과발현하는 CHO-mAb1 세포에서 qPCR에 의해 분석하였다. 이들 세포 풀은 CHO-mAb1 세포를 miR-1287 또는 miR-1978을 추가로 암호화하는 GFP-함유 발현 벡터(pcDNA6.2-GW/emGFP-miR-1287-1287 및 pcDNA6.2-GW/emGFP-miR-1978-1978)로 형질감염시킴으로써 생성되었다(도 2c 및 도 2d). miR-1287을 일시적으로 그리고 안정하게 발현하는 CHO-mAb1 세포 둘 다는 ATF6B의 감소된 발현 수준을 보여주었고, 이는 miRNA에 의한 직접적인 표적화를 나타낸다. miR-1978을 일시적으로 발현하는 CHO-mAb1 및 안정한 miR-1978 과발현을 갖는 세포 풀은 CERS2 및 TBC1D20의 감소된 mRNA 수준을 보여주었다. 따라서, 3개의 NGS 히트 전부는 각각의 miRNA의 직접적인 표적 유전자로서 입증되었다.
실시예 3: ATF6B, CERS2 및 TBC1D20의 효과적인 siRNA 매개된 녹아웃
miR-1287 및 miR-1978의 발현은 재조합 항체 발현 CHO 세포주(CHO-mAb1)의 비 생산성을 강력하게 개선시켰다. 입증된 miR-1287 표적 유전자 ATF6B 및 입증된 miR-1978 표적 CERS2 및 TBC1D20의 고갈이 또한 재조합 항체 생산성 CHO 세포의 비 생산성에 긍정적 영향을 미치는지를 조사하기 위해, CHO-mAb1 세포를 각각의 표적 mRNA에 대해 특이적인 siRNA로 형질감염시켰다. 3개의 독립적인 siRNA는 ATF6B의 하향 조절에 그리고 2개의 siRNA는 각각 CERS2 및 TBC1D20에 사용되었다. 형질감염 1일 후, RNA를 추출하였고 ATF6B, CERS2 및 TBC1D20의 mRNA 수준을 qPCR 분석에 의해 정량하였다. 참조 유전자 베타 액틴에 대해 표준화함으로써 상대적 발현을 계산하였다(도 3). ATF6B에 특이적인 siRNA로 일시적으로 형질감염된 CHO-mAb1 세포는 형질감염되지 않은 대조군 세포와 비교하여(그리고 별도의 실험에서 비-표적화 대조군 siRNA로 형질감염된 세포와 비교하여, 데이터 도시하지 않음) ATF6B mRNA의 수준을 강력하게 감소시켰다. 녹다운 효율은 3개의 독립적인 siRNA들 전부에 대해 유사하였다. CERS2에 대해 특이적인 siRNA 및 TBC1D20에 대해 특이적인 siRNA 조합으로의 CHO-mAb1 세포의 일시적 형질감염은 형질감염되지 않은 대조군 세포와 비교하여(그리고 별도의 실험에서 비-표적화 대조군 siRNA로 형질감염된 세포와 비교하여, 데이터 도시하지 않음) CERS2 및 TBC1D20의 감소된 발현을 초래하였다. 따라서, ATF6B에 대한 그리고 CERS2에 대한 그리고 TBC1D20에 대한 siRNA 전부는 각각의 표적 유전자의 효과적인 녹다운을 유도하였다.
실시예 4: ATF6B의 siRNA-매개된 녹다운은 CHO-mAb1 세포의 비 생산성을 증가시킨다
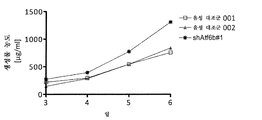
ATf6B의 녹다운이 mAb1 항체 세포를 안정하게 발현하는 CHO-mAb1 세포의 비 생산성을 향상시키는지를 조사하기 위해, ATF6B에 대해 특이적인 3개의 독립적인 siRNA(siAtf6b#1(서열번호 9), siAtf6b#2(서열번호 10) 및 siAtf6b#3(서열번호 11))로 형질 감염시켰다. 상기 세포를 삼중 샘플로 1mL의 총 용적으로(24웰 포맷(well format)) 4일 동안 배양하였다. 형질감염된 세포의 상청액 중의 항체 농도는 상기 기술된 바와 같이 ELISA에 의해 형질감염 후 3일째 및 4일째에 측정하였다. 또한, 세포 밀도 및 생존력은 상기 기술된 각각의 날에 측정하였고, 이는 비 생산성의 계산을 가능하게 한다. ATF6B의 녹다운은 형질감염되지 않은 대조군 세포와 비교하여(그리고 별도의 실험에서 비-표적화 대조군 siRNA로 형질감염된 세포와 비교하여, 데이터 도시하지 않음) 4일째에 개선된 비 생산성을 초래하였다(도 4).
실시예 5: CERS2 및 TBC1D20의 조합된 siRNa-매개된 녹다운은 CHO-mAb1 세포의 비 생산성을 1.5배까지 증가시킨다
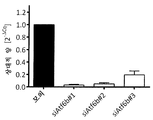
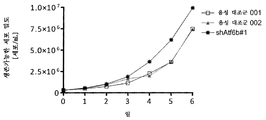
2개의 miR-1978 표적 CERS2 및 TBC1D20의 녹다운이 CHO-mAb1 세포의 비 생산성에 긍정적인 영향을 미치는지 탐구하기 위해, 이들 세포를 우선 CERS2 또는 TBC1D20에 대해 특이적인 siRNA로 형질감염시켰고, 제2 실험에서 세포를 siRNA 둘 다로 함께 형질감염시켰다. 실험은 실시예 4에 기술된 바와 같이 수행하였다. 3일째 및 4일째의 비 생산성의 측정은 CERS2 또는 TBC1D20 중 어느 하나의 단일 녹다운은 비 생산성을 약간 개선시켰고, 반면 2개의 표적 유전자의 조합된 녹다운은 비 생산성을 1.5배까지 증가시켰다(도 5).
실시예 6: ATF6B에 대한 3개의 독립적인 siRNA는 CHO-mAb2 세포의 비 생산성을 개선시킨다
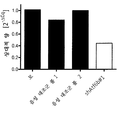
증가된 비 생산성이 mAb1- 생산성 CHO 세포에 대해 특이적이었거나 다른 IgG-생산성 CHO 세포주에서 동일하게 나타날 수 있는지를 탐구하기 위해, CHO-mAb2 세포를 ATF6B에 대해 특이적인 3개의 독립적인 siRNA들, siAtf6b#1(서열번호 9), siAtf6b#2(서열번호 10), siAtf6b#3(서열번호 11)의 각각으로 일시적으로 형질감염시켰다. 실험은 실시예 4에 기술된 바와 같이 수행하였다. 현저하게, 3개의 siRNA 전부가 형질감염 후 3일째 및 4일째에 비 생산성을 1.2 내지 1.6배 증가시켰다(도 6).
실시예 7: CERS2 및 TBC1D20의 조합된 녹다운은 CHO-mAb2 세포의 비 생산성을 개선시킨다
또한, 보 발명자들은 CERS2와 TBC1D20의 조합된 녹다운이 또한 CHO-mAb2 세포의 증가된 비 생산성을 유도하는지에 관심을 가졌다. 실험은 TBC1D20에 대해 특이적인 siRNA, siTbc1D20#1(서열번호 7) 및 CERS2에 대해 특이적인 siRNA, siCerS2#1(서열번호 8)을 이용하여 실시예 4에 기술된 바와 같이 수행하였다. mAb1 항체를 안정하게 발현하는 CHO 세포와 유사하게, 비 생산성은 모의 형질감염된 대조군 세포와 비교하여 1.5배까지 증가되었고(도 7), 이는 CERS2 및 TBC1D20의 일시적 하향조절에 의한 이러한 개선이 세포 클론, 배지 및 생산된 항체와 독립적이라는 증거를 제공한다.
또한, 사람 혈청 알부민을 안정하게 발현하는 CHO-DG44 세포에 대해서 비 특이성의 유사한 증가가 관찰되었다(도시하지 않음).
실시예 8: 유동 세포측정법에 의한 CHO-mAb2 세포에서의 shRNA 발현의 분석
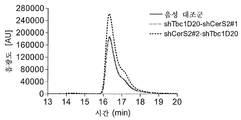
CHO-mAb2 세포를 GFP 카세트 + ATF6B를 특이적으로 표적화하는 뉴클레오타이드 서열을 포함하는 shRNA 서열(shAtf6b#1; 서열번호 15) 또는 CERS2(shCerS2#1; 서열번호 13 및 shCerS2#2; 서열번호 14) 및 TBC1D20(shTbc1D20#1; 서열번호 12)를 특이적으로 표적화하는 서열을 포함하는 2개의 개별 shRNA 서열의 조합을 암호화하는 플라스미드(pcDNA6.2-GW/emGFP-shAtf6b#1, pcDNA6.2-GW/emGFP-shTbc1D20#1-shCerS2#1 및 pcDNA6.2-GW/emGFP-shCerS2#2-shTbc1D20#1)로 안정하게 형질감염시켰다. 블라스티시딘 S로의 선택 후(블라스티시딘 내성 유전자는 pcDNA6.2-GW/emGFP 벡터에 의해 암호화된다), 세포를 이들의 GFP 형광성에 기초하여 분류하였다. 대조군 세포는 형질감염되지 않은 모 세포였다. 안정하게 형질감염된 shRNA의 발현을 입증하기 위해서, 세포는 GFP 발현에 대해 유동 세포측정법에 의해 분석하였고, 이는 shRNA 발현과 상호관련되어 있고, GFP 양성 집단이 적어도 42일 동안 검출되었다(도 8). 이는 CHO 세포가 적어도 6주 동안 shRNA를 안정하게 과발현할 수 있음을 보여준다.
실시예 9: 정량적 PCR에 의한 안정하게 형질감염된 IgG-생산성 CHO 세포에서의 shRNA 발현의 분석
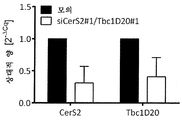
CHO-mAb2 세포는 상기 기술된 바와 같이 GFP 카세트 + ATF6B를 특이적으로 표적화하는 뉴클레오타이드 서열을 포함하는 shRNA 서열 또는 CERS2 및 TBC1D20을 특이적으로 표적화하는 서열을 포함하는 2개의 개별 shRNA 서열의 조합을 암호화하는 플라스미드(pcDNA6.2-GW/emGFP-shAtf6b#1, pcDNA6.2-GW/emGFP-shTbc1D20#1-shCerS2#1 또는 pcDNA6.2-GW/emGFP-shCerS2#2-shTbc1D20#1)로 안정하게 형질감염시켰다. 블라스티시딘 S로의 선택 후(블라스티시딘 내성 유전자는 pcDNA6.2-GW/emGFP 벡터에 의해 암호화된다), 세포를 이들의 GFP 형광성에 기초하여 분류하였다. 대조군 벡터(pcDNA6.2-GW/emGFP-음성 대조군)를 안정하게 발현하는 세포 풀 및 형질감염되지 않은 모 세포가 음성 대조군으로서 작용하였다. 안정하게 형질감염된 shRNA의 발현을 입증하기 위해서, 본 발명자들은 모든 세포로부터 RNA를 단리하였고, 상기 기술된 바와 같이 각각 ATF6B, CERS2 및 TBC1D20의 qPCR 분석을 수행하였다. 대조군 벡터 형질감염된 세포 및 모 세포와 비교하여, shRNA-암호화 플라스미드로 형질감염된 세포는 ATF6B의 mRNA 수준을 감소시키거나 CERS2 및 TBC1D20 둘 다의 mRNA 수준을 감소시켰다(도 9). 이는 플라스미드-암호화된 shRNA의 안정한 게놈 통합이 CHO 세포에서의 각각의 표적 유전자의 감소된 수준을 유도함을 입증한다.
실시예 10: ATF6B에 대해 shRNA를 안정하게 발현하는 CHO-mAb2 세포의 유가식 배양
상기 기술된 바와 같이, CHO-mAb2 세포를 ATF6B를 특이적으로 표적화하는 뉴클레오타이드 서열을 포함하는 shRNA 서열을 함유하는 발현 벡터(pcDNA6.2-GW/emGFP-shAtf6b#1)로 안정하게 형질감염시켰고 세포를 이들의 GFP 발현에 기초하여 분류하였다. ATF6B를 표적으로 하는 shRNA 서열을 발현하는 세포의 하나의 풀 및 음성 대조군 벡터로 형질감염된 세포의 2개의 독립적인 풀을 유가식 배양 동안 사용하였다. 세포 밀도, 생존력 및 생성물 형성(㎍/ml)은 상기 기술된 바와 같이 각각 트립판 블루 배제을 이용한 세포 계수 및 ELISA 분석에 의해 3 내지 6일째에 측정하였다. 비 생산성을 계산하였다. 흥미롭게도, ATF6B에 대해 특이적인 shRNA를 발현하는 세포는 음성 대조군 벡터로 형질감염된 세포와 비교하여 개선된 항체 역가, 개선된 비 생산성 및 증가도니 생존가능 세포 밀도를 보여주었다(도 10). 추가로, 세포 생존력은 변경되지 않았다(도시하지 않음). 이는 ATF6B가 고갈된 CHO 세포의 안정한 풀은 생존가능한 세포 밀도 및 생존력을 손상시키지 않으면서 유가식 배양 농안 증가된 생산 능력을 가짐을 증명한다.
실시예 11: CERS2 및 TBC1D20에 대해 특이적인 shRNA의 조합을 안정하게 발현하는 CHO-mAb2 세포의 유가식 배양
CHO-mAb2 세포를 CERS2 및 TBC1D20을 특이적으로 표적화하는 서열을 포함하는 shRNA 서열을 함유하는 발현 벡터(pcDNA6.2-GW/emGFP-shTbc1D20#1-shCerS2#1 또는 pcDNA6.2-GW/emGFP-shCerS2#2-shTbc1D20#1)로 안정하게 형질감염시켰고, 상기와 같이 세포를 이들의 GFP 발현에 기초하여 분류하였다. CERS2 및 TBC1D20 mRNA를 표적으로 하는 shRNA의 2개의 독립적인 조합 및 음성 대조군 벡터로 형질감염된 세포의 2개의 독립적인 풀을 2개의 독립적인 실험에서 유가식 배양 동안 사용하였다. 상기 기술된 바와 같이, 트립판 블루 배제를 이용한 세포 계수 및 ELISA 분석에 의해 세포 밀도, 생존력 및 생성물 형성을 각각 3 내지 11일째에 측정하였다. 비 생산성을 계산하였다. CERS2 및 TBC1D20에 대해 shRNA를 발현하는 세포 풀 둘 다는 음성 대조군 벡터로 형질감염된 세포 풀과 비교하여 개선된 항체 발현 및 비 생산성을 보여주었다(도 11). 이는 CERS2 및 TBC1D20 둘 다가 고갈된 CHO 세포의 안정한 풀은 증가된 역가 및 비 생산성 능력을 가짐을 증명한다.
실시예 12: 항체 당화 및 항체 응집체 형성의 분석
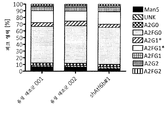
생성물 품질을 분석하기 위해, 본 발명자들은 상기 실시예 10 및 실시예 11에 기술된 shRNA 발현 CHO-mAb2 세포 풀에서 생산된 IgG의 Fc-당화의 구조 및 조성을 분석하였다. 글리칸은 PNGase F로의 효소적 소화에 의한 환원 후에 정제된 항체로부터 방출되었다. IgG 항체의 Fc-당화의 조성은 PNGaseF 방출 및 제조업자의프로토콜에 따라 LabChip GXII 기기(PerkinElmer)에서 ProfilerPro Glycan 프로파일링 시스템으로의 마이크로칩-기반 모세관 전기영동(CE)을 이용한 형광성 표지 후에 분석하였다. 전기영동도(Electropherogram)는 LabChip GX 소프트웨어에 의해 분석되어 개별 당 구조를 확인하고 정량하였다. 글리콜-형태의 백분율은 크로마토그래피 피크 면적으로부터 계산하였다. 모든 값은 샘플당 100%의 총 당 구조에 대해 표준화하였다. 도 12의 결과는 ATF6B(도 12a), CERS2 및 TBC1D20(도 12b)의 고갈은 mAb2 항체의 당화에 영향을 미치지 않는다는 것을 보여준다. shAtf6b#1을 발현하는 세포로부터 정제된 항체에 추가하여, shAtf6b#2를 발현하는 세포로부터 정제된 항체에서 항체 당화의 변화는 관찰되지 않았다(데이터 도시하지 않음).
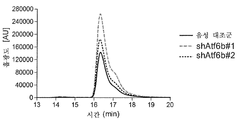
생성물 품질이 유지되었음을 추가로 증명하기 위해, 유가식 배양의 종료시 HPLC에 의해 응집체의 형성을 분석하였다. shAtf6b#1 또는 shAtf6b#2(pcDNA6.2-GW/emGFP-shAtf6b#1 또는 pcDNA6.2-GW/emGFP-shAtf6b#2) 또는 음성 대조군 서열을 안정하게 발현하는 CHO-mAb2 세포를 7일 동안 유가식 조건 하에 정제하였다. 상청액으로부터 분비형 항체를 정제하였고, HPLC에 의해 분석하였다. 도 12c는 상이한 세포(shAtf6b#1 또는 shAtf6b#2 발현 세포 및 음성 대조군)로부터의 항체 조제는 1.5% 미만의 응집체 비율로 매우 유사하였음을 보여준다.
shTbc1D20-shCerS2#1(pcDNA6.2-GW/emGFP-shTbc1D20#1-shCerS2#1) 및 shCerS#2-shTbc1D20(pcDNA6.2-GW/emGFP-shCerS2#2-shTbc1D20#1) 또는 음성 대조군 서열을 안정하게 발현하는 세포의 제2 풀을 11일 동안 유가식 조건 하에 배양하였다. 상청액으로부터 분비형 항체를 정제하였고 HPLC에 의해 분석하였다. 도 12d는 상이한 세포(shTbc1D20-shCerS2#1 또는 shCerS#2-shTbc1D20 발현 세포 및 음성 대조군)로부터의 항체 조제는 1.5% 미만의 응집체 비율로 매우 유사하였음을 보여준다.
실시예 13: 글루코스 조절된 단백질 78(GRP78/BiP), CHOP 및 ER-관련된 분해(ERAD) 구성성분 HERPUD1의 발현은 ATF6B 녹다운에서 증가된다
ATF6은 ER 스트레스 동안 전사 인자로서 작용하므로, 본 발명자들은 ATF6B 녹다운이 UPR-관련된 유전자의 임의의 변화를 초래하였는지를 탐구하였다. 3개의 진실한 UPR 마커 - 글루코스 조절된 단백질 78(GRP78), 유비퀴틴-유사 도메인 1(Herpud1)을 갖는 호모시스테인 유도가능한 ER 단백질 및 CCAAT-인핸서-결합 단백질 상동 단백질(CHOP 또는 DDIT3, NCBI 참조 서열 XM_007648092.1)의 mRNA 수준을 ER 스트레스 유도성 시약 투니카마이신(TM)으로의 치료 후에 분석하였다.
안정하게 형질감염된 세포를 실시예 8에 기술된 바와 같이 생산하였다. 간략하게, CHO-mAb2 세포를 GFP 카세트 + 서열번호 15의 서열 (UCCAUCUUCACACUGAGGACC)을 포함하는 shAtf6b#1 및 서열번호 37의 서열(UUCACUUCCAGAACCUCCUCU)을 포함하는 shAtf6b#2를 암호화하는 ATR6B를 특이적으로 표적화하는 뉴클레오타이드 서열을 포함하는 shRNA 서열(pcDNA6.2-GW/emGFP-shAtf6b#1 또는 pcDNA6.2-GW/emGFP-shAtf6b#2)을 암호화하는 플라스미드로 안정하게 형질감염시켰다. 대조군 벡터(pcDNA6.2-GW/emGFP-음성 대조군)를 안정하게 발현하는 세포 풀이 음성 대조군으로서 작용하였다. 안정하게 형질감염된 shRNA의 발현을 입증하기 위해서, 상기 기술된 바와 같이 RNA를 단리하였고 ATF6B mRNA 수준의 qPCR 분석을 수행하였다. shRNA-암호화 플라스미드로 형질감염된 세포는 음성 대조군에 비하여 ATF6B mRNA의 수준을 감소시켰다(도 13a). 이는 ATF6B를 표적으로 하는 플라스미드-암호화된 shRNA의 안정한 게놈 통합이 CHO 세포에서 각각의 표적 유전자의 감소된 발현을 유도함을 재차 입증한다.
다운스트림 UPR-관련된 유전자의 발현에 영향을 미치는지를 조사하기 위해서, 음성 대조군 서열을 발현하는 CHO-mAb2 세포 또는 ATF6B에 특이적인 shRNA를 투니카마이신(TM)의 존재 또는 부재 하에 치료하였다. 치료되지 않은 세포 및 TM 치료된 세포에서 GRP78, Herpud1 및 CHOP의 mRNA 수준을 qPCR에 의해 정량하였다(도 13b). GRP78 및 Herpud1 둘 다의 발현은 음성 대조군 작제물을 발현하는 세포 풀(흑색 막대)과 비교하여 ATF6B에 대해 특이적인 shRNA로 안정하게 형질감염된 세포에서 유의하게 향상되었고, 반면 CHOP 발현은 단지 약간 향상되었다. 이들 결과는 전사 인자 ATF6B의 녹다운이 전사 수준에서 UPR을 유발함을 나타낸다.
본 발명자들은 유가식 배양에서 다운스트림 UPR-관련 유전자의 발현에도 영향을 미치는지를 추가로 분석하였다. ATF6B-특이적 shRNA 또는 음성 대조군 작제물을 안정하게 발현하는 CHO-mAb2 세포를 매일 급식(feed)하면서 진탕 플라스크에서 배양하였다. 5일째에 UPR-관련 유전자 GRP78/BiP, CHOP 및 Herpud1의 mRNA 수준을 분석하였다. 씨드 스톡(seed stock) 배양물에서 얻어진 결과에 따라, UPR-관련 유전자 GRP78/BiP 및 Herpud1의 mRNA 수준은 대조군 세포와 비교할 때 shATF6B 발현 세포에서 상승되었다(도 13c). 추가로, shAtf6b#1 및 shAtf6b#2 형질감염된 세포는 음성 대조군과 비교하여 7일째에 증가된 생존가능한 세포 밀도(도시하지 않음) 및 상청액 중의 증가된 항체 농도(1.36배)를 보여주었고, 한편 생존력은 7일째까지 변하지 않았으며, 당화 패턴은 변경되지 않았다(도시하지 않음).
실시예 14: 재조합 CHO 세포에서 TBC1D20 녹다운은 Rab1 활성을 향상시키고 CERS2 녹다운은 세라마이드 조성을 변경시킨다.
TBC1D20은 소형 GTPase Rab1에 대한 GTPase 활성화 단백질(GAP)이다. 따라서, 본 발명자들은 CHO-mAb2 세포에서의 TBC1D20 녹다운이 GST 풀 다운 검정을 이용하여 활성 Rab1의 향상된 수준을 초래하는지를 조사하였다.
p115-GST 발현 작제물의 클로닝
p115-GST 융합 단백질을 생성하기 위해서, p115(문헌[Brandon et al. 2006; Mol. Biol. Cell., 17(7): 2996-3008]에 기술된 바와 같은 pEGFP-N2-p115로부터 유도됨)는 BamHI를 갖는 KpnI 및 NotI를 갖는 SalI를 각각 사용하여 벡터 pGex-6P-1(GE Healthcare) 내로 서브클로닝되었다. 작제물의 무결성(integrity)은 Sanger 서열분석(GATC Biotech AG)에 의해 확인되었다.
단백질 발현 및 추출
p115-GST 융합 단백질은 에스케리키아 콜라이(Escherichia coli)에서 발현되었고, 이어서 단백질 추출되었다. 간략하게, 형질전환체는 100μg/mL의 암피실린을 갖는 루리아 브로쓰(LB: Luria Broth) 배지에서 선택되었고, 배양물이 0.8 내지 1.0의 OD600에 도달하였을 때 0.3mM 이소프로필-β-D-티오갈락토피라노시드(IPTG)를 부가함으로써 발현을 자극하였다. 세균을 원심분리에 의해 수거하였고, 펠렛(pellet)을 드라이 아이스 상에서 30분 동안 동결시켰다. 상기 펠렛을 용해 완충액(pH 7.5에서 50mM Tris-HCl, 1mM EDTA, 1mM DTT 및 완전한 프로테아제 저해제(Roche))에 재현탁시켰고 0.1μg/mL 라이소자임을 부가하였다. 온화하게 진탕하면서 빙상에서 30분 동안 인큐베이션(incubation)한 후, 5mM MgCl2 및 20ng/mL DNAse를 빙상에 추가의 30분 동안 부가하였고, 이어서 3000 g에서 30분 동안 원심분리하였다. 이어서, 단백질 추출 상청액을 1mL의 50% 글루타티온 비드(GE Healthcare)(1h, 4℃)와 함께 인큐베이션하였다. 비드를 펠렛화하였고(500 g에서 5분, 4℃), 4ml 세척 완충액(용해 완충액 + 100mM NaCl)으로 3회 세척하였고, 4mL 재현탁 완충액(EDTA가 없는 세척 완충액)에 재현탁시켰고, 펠렛화하였고(500 g에서 5분, 4℃), 1회 더 세척하였고, 마지막으로 0.5mL의 재현탁 완충액에 재현탁시켜 GST-p115-비드의 50% 슬러리의 1mL를 얻었다.
GST 풀 다운 검정
CHO-IgG 세포는 뉴클레오펙션을 통해 NT 대조군 또는 siTbc1D20, siTbc1D20, siCerS2 및 siTbc1D20 조합으로 형질감염시켰다. 형질감염 72시간 후, 1 x 106 세포를 1mL 균질화 완충액(10mM HEPES pH 7.4, 150mM NaCl, 5mM MgCl2, 1% Triton-X-100, 1mM DTT, 5% 글리세롤, 포스파타제 저해제 칵테일 및 완전한 프로테아제 저해제 칵테일(Roche))에 용해시켰고, 빙상에서 10분 동안 인큐베이션하였다. 각각의 용해물을 25μL의 50% GST-p115-비드와 혼합하였고, 온화하게 진탕하면서 4℃에서 1시간 동안 인큐베이션하였다. 비드를 펠렛화하였고 균질화 완충액으로 3회 세척하였다. 비드를 10μL의 겔 부하 완충액을 갖는 20μL의 균질화 완충액에 재현탁시켰고, 95℃에서 5분 동안 인큐베이션하였고, 간단히 와류교반하였고, 펠렛화하였다. 단백질을 12% 아크릴아미드 겔 상에서 분리하였고, 니트로셀룰로스 막으로 이동시켰고, 항-Rab1 항체(antibodies-online.com)로 검출하였다. 융합 단백질은 항-GST 항체(GE Healthcare)로 검출하였다. 세포 용해물의 분획(aliquot)(투입)도 항-액틴 항체(Sigma-Aldrich)를 이용한 면역블롯팅에 의해 분석하여 동일한 단백질 양이 풀다운 검정에 실시되었음을 확인하였다.
형질감염 3일 후에 p115-GST 융합 단백질을 이용한 풀-다운 검정을 이용하여 세포 균질물로부터 활성 Rab1을 추출하였고, 이는 GST에 융합된 Rab1 이펙터 단백질 p115에 대한 결합 친화성을 이용하였다. siTbc1D20 단독으로 또는 siCerS2와 조합하여 형질감염된 CHO-mAb2 세포는 활성 Rab1의 향상된 양을 보여주었다(도 14a). Image J 소프트웨어를 이용한 정량화는 Rab1 활성이 siTbc1D20 단독으로 또는 siCerS2와 조합하여 형질감염된 세포에서 2배 증가하였음을 확인시켜 주었다(도 14b). 형질감염 후 2일째의 녹다운 제어(qPCR)는 siTbc1D20 단독으로 또는 siCerS2와 조합하여 형질감염된 세포에서 Tbc1D20 mRNA의 50% 감소를 나타내었다(도 14c). 이들 발견은 Rab1 GAP TBC1D20의 녹다운이 CHO-mAb2 세포에서 Rab1 활성을 증폭시켰다는 것을 확인시켜 준다.
본 발명자들은 siCerS2 단독으로 또는 siTbc1D20와 조합하여 형질감염된 세포에서 세라마이드 조성을 분석하였다. ER에서의 세라마이드 합성, 및 골지 복합체로의 이의 후속적 수송은 분비 경로에서 필수적인 단계이다. CERS2는 포유동물 세포에서 발현되는 6개의 세라마이드 신타제 이소형 중 하나이다. 각각의 이소형은 세라마이드 합성을 위한 기질로서 지방산 아실-CoA의 제한된 서브세트를 사용한다. CERS2는 매우 긴 쇄 세라마이드, 특히 C22 및 C24-세라마이드를 우선적으로 생성한다. 분비 경로에서 중요한 역할을 하기 때문에 ER 막의 변경된 세라마이드 조성은 카고 단백질의 분류 및 통행에 영향을 미칠 수 있다고 여겨진다.
CERS2 녹다운 세포에서 세라마이드 조성이 변경되는지를 조사하기 위해서, CHO-mAb2 세포를 siCerS2#1(서열번호 8) 단독으로, Tbc1D20#1(서열번호 7)과 조합으로 또는 대조군으로서의 비-표적화 siRNA 풀(siRNA NT-대조군, 서열번호 38 내지 서열번호 41)로 형질감염시켰고, 형광성 세라마이드 신타제 활성 검정을 이용하여 분석하였다.
형광성 세라마이드 신타제 활성 검정
뉴클레오펙션 후 3일째에, 1.5 x 106 세포를 펠렛화하였고, 1mL 용해 완충액(pH 7.4에서 20mM HEPES, 25mM KCl, 2mM MgCl2, 250mM 슈크로스 및 완전 프로테아제 저해제 칵테일(Roche))에 재현탁시켰고, 26G 니들(Terumo)을 이용하여 기계적으로 용해시켰다. 단백질 농도는 비친코닌산(BCA: bicinchoninic acid) 검정(BioRad)을 사용하여 측정하였다. 세라마이드 신타제 활성을 측정하기 위해서, Kim 등(Kim et al., 2012)에 의해 기술된 바와 같은 형광성 검정이 약간 변형되어 수행되었다. 간략하게, 50μg의 균질화물 단백질을 반응 완충액(20mM Hepes, pH 7.4, 25mM KCl, 2mM MgCl2, 0.5mM DTT, 0.1%(w/v) 지방산-불포함 BSA, 10μM NBD-스핑가닌, 50μM 지방산-CoA 및 250mM 슈크로스)에서 35℃에서 30분 동안(C16-세라마이드 정량화의 경우) 및 120분 동안(C24-세라마이드 정량화의 경우) 진탕하면서 인큐베이션하였다. 250μL의 클로로포름/메탄올(2:1)로 반응을 정지시켰고, 와류교반하였고, 원심분리하였고, 하부 상(lower phase)을 5mL 유리 튜브에 이동시켰다. 상부 수성 상을 상기한 바와 같이 재추출하였고, 유기 상 둘 다를 합하였고 질소 스트림 하에 건조시켰고, 이어서 100㎕ 메탄올에 재현탁시켰다. 2 x 2μL의 각 반응물을 알루미늄-지지된(backed) 실리카 겔(Silica Gel) 60 TLC 플레이트에 적용하였고 크로마토그래피(클로로포름/메탄올/물, 8:1:0.1 v/v/v)로 분리하였다. 생성물의 형광성은 Typhoon Trio+Scanner(GE Healthcare)를 이용하여 검출하였다. 생성물 C16-디하이드로세라마이드 및 C24-디하이드로세라마이드는 박층 크로마토그래피에 의해 분리하였고, 형광성 스캐너를 이용하여 검출하였다(도 14d). C16-디하이드로세라마이드 및 C24-디하이드로세라마이드의 밴드 강도는 Image J 소프트웨어를 이용하여 정량하였다(도 14e).
대조군과 비교하여, CERS2의 녹다운 및 CERS2 및 TBC1D20의 조합된 녹다운은 감소된 수준의 C24-세라마이드 및 증가된 양의 C16-세라마이드를 초래하였다(도 14d 및 도 14e). 정량화는 C24-세라마이드의 분획이 평균적으로 CERS2의 녹다운 후 67.6%, CERS2와 TBC1D20의 조합된 녹다운 후 68.8%로 감소되었다. C16-세라마이드는 siCerS2로 형질감염된 세포에서 73.0%, siCerS2 및 siTbc1D20으로 형질감염된 세포에서 19.1% 증가하였다. C24-세라마이드의 감소가 C16-세라마이드의 향상보다 분명히 더 강력하기 때문에, 추가로 LC 세라마이드(예를 들면 C14- 또는 C18-세라마이드)가 추가로 영향을 받을 수 있다. siRNA-매개된 녹다운의 효율은 상기 기술된 바와 같이 qPCR에 의해 확인되었다(도 14f). 따라서, CERS2의 녹다운은 C16-세라마이드 대 C24-세라마이드의 비율이 증가된 변경된 세라마이드 조성을 초래한다.
실시예 15: CERS2의 안정한 녹다운은 재조합 CHO 세포에서 세라마이드 조성을 변경시킨다
CHO-mAb2 세포를 실시예 11에 기술된 바와 같이 CERS2 및 TBC1D20을 특이적으로 표적으로 하는 서열을 포함하는 shRNA 서열을 함유하는 발현 벡터(pcDNA6.2-GW/emGFP-shTbc1D20#1-shCerS2#1 또는 pcDNA6.2-GW/emGFP-shCerS2#2-shTbc1D20#1)로 안정하게 형질감염시켰다. 계대배양 1일 후에 세포를 용해시켰고, 실시예 14에 기술된 바와 같이 형광성 세라마이드 신타제 활성 검정을 이용하여 세라마이드 조성을 분석하였다.
독립적 shRNA 조합 둘 다에 의한 CERS2 및 TBC1D20의 이중 녹다운은 대조군 세포와 비교하여 C24-세라마이드의 강력한 감소를 초래하였다(shTbc1D20#1-shCerS2#1: 51.7%, shCerS2#2-shTbc1D20#1 52.1%). 동시에, C16-세라마이드의 양은 97.7%(shTbc1D20#1-shCerS2#1) 및 74.5%(shCerS2#2-shTbc1D20#1)로 현저하게 증가하였고, 이는 일시적 실험에서 얻어진 결과를 확인시며 준다(도 14d 및 도 14e).
실시예 16: CHO-mAb2 세포에서의 ATF6B의 CRISPR/Cas9-매개된 녹아웃
현재까지, 본 발명자들은 CHO-mAb2 세포에서 ATF6B의 일시적 및 안정한 녹다운이 비-형질감염 세포 또는 음성 대조군 플라스미드로 형질감염된 세포와 비교하여 항체 분비를 향상시켰음을 보여줄 수 있었다. ATF6B 단백질의 총 고갈이 생산성을 추가로 향상시킬 수 있는지를 조사하기 위해서, ATF6B 유전자를 돌연변이시켜 전사의 조기 정지를 획득하고 이로써 ATF6B 단백질 형성을 방지함으로써 녹아웃 세포를 생성한다. CRISPR/Cas9 시스템을 적용하여, ATF6B가 안정하게 고갈된 CHO 세포 클론을 생성하기 위해 ATF6B 유전자를 표적으로하는 3개의 독립적 인 gRNA 서열을 사용한다. 표적 부위는 ATF6B 전사 변이체 둘 다에 존재하는 처음 2개의 엑손에서 프로토스페이서 인접 모티프(PAM: protospacer adjacent motif)를 확인함으로써 선택된다. PAM 부위의 업스트림의 서열에 각각 20개의 상보성 뉴클레오타이드를 갖는 3개의 가이드 RNA가 고안된다. 각각의 gRNA는 OFP Reporter(Life Technologies)를 갖는 GeneArt® CRISPR 뉴클레아제 벡터에 클로닝된다. 벡터는 카스파제 9 타입 2 뉴클레아제 및 OFP 유전자에 대한 CMV 프로모터 유도된 카세트 및 U6 polIII 타입 프로모터에 의해 유도되는 가이드 RNA용 추가의 발현 카세트를 함유한다. 상기 벡터는 적격(competent) 이. 콜라이에서 증폭되었고 이전에 기술된 바와 같이 정제되었다. CHO-mAb2 세포는 이전에 기술한 바와 같이 세포주 뉴클레오펙터 키트 V(Lonza)로의 뉴클레오펙션을 통한 계대배양 1일 후에 형질감염시켰다. 절단 효율은 GeneART® 게놈 절단 검출 키트(Life Technologies)를 사용하여 제조업자의 지시에 따라 검출한다. 안정한 세포 클론을 생성하기 위해, CHO-mAb2 세포를 기술된 gRNA 및 Cas9 함유 벡터로 형질감염시키고, 추가로 단일-가닥의 CMV 프로모터로 퓨로마이신 또는 대안으로 형광성 마커 유전자를 형질감염시킨다. 이러한 선택 마커 유전자는 목적하는 표적 부위를 플랭킹하는 게놈 영역에 상보성인 플랭킹 영역에 관심 대상 부위에 인접한 게놈 부위에 상보적인 인접 부위에 간삽되어 있다(embedded). 게놈 ATF6B 표적 부위가 Cas9 뉴클레아제에 의해 절단되고, 이어서 상동성 지시된 수복(HDR)에 의해 선택 마커 유전자가 통합된 세포만이 각각 저항성 또는 형광성 마커를 갖는다. 단일 세포 클론은 OFP 양성 세포에 대한 FACS 분류 및 배지(Boehringer Ingelheim)에서의 후속적 배양에 의해 생성된다. ATF6B 단백질의 효율적인 고갈은 예를 들면 PCR에 의해 또는 특이적 항-ATF6B 항체를 이용한 웨스턴 블롯팅에 의해 제어되고, ATF6B 유전자의 효율적인 돌연변이는 목적하는 게놈 유전자좌를 서열분석함으로써 분석된다.
실시예 17: CHO-mAb2 세포에서 조합으로의 CERS2 및 TBC1D20의 CRISPR/Cas9-매개된 녹아웃
본 발명자들은 전에 CHO-mAb2 세포에서 CERS2와 TBC1D20의 일시적이고 안정한 녹다운이 비-형질감염된 세포 또는 음성 대조군 플라스미드로 형질감염된 세포와 비교하여 항체 분비를 향상시켰음을 보여줄 수 있었다. CERS2 및 TBC1D20 단백질 총 고갈이 생산성을 추가로 향상시킬 수 있는지를 조사하기 위해, CERS2 및 TBC1D20 유전자를 돌연변이시켜 녹아웃 세포주를 생성하여 전사의 조기 정지를 획득하고, 이로써 CERS2 및 TBC1D20 단백질 형성을 방지한다. CRISPR/Cas9 기술을 적용하여, CERS2를 표적으로 하는 3개의 독립적인 gRNA와 TBC1D20을 표적으로 하는 3개의 독립적인 gRNA를 사용하여 각각의 유전자를 돌연변이시킨다. 표적 부위는 각각 6개의 CERS2 전사 변이체 또는 2개의 TBC1D20 전사 변이체에 존재하는 처음 2 개의 엑손에서 프로토스페이서 인접 모티프(PAM)를 확인함으로써 선택된다. 3개의 가이드 RNA는 PAM 부위의 업스트림의 서열에 대해 20개의 상보성 뉴클레오타이드를 갖는 각 유전자에 대해 고안된다. 각 gRNA는 상기 기술된 바와 같이 OFP Reporter(Life Technologies)를 갖는 GeneArt® CRISPR 뉴클레아제 벡터 내로 클로닝된다. CHO-mAb2 세포를 전술한 바와 같이 형질감염시키고, 절단 효율은 제조업자의 지침에 따라 GeneART® 게놈 절단 검출 키트(Life Technologies)를 사용하여 검출된다. 안정한 세포 클론을 생성하기 위해, CHO-mAb2 세포를 기술 된 gRNA 및 Cas9 함유 벡터로 트랜 스펙 션시키고, 추가로 단일 가닥 CMV 프로모터로 퓨로 마이신 또는 형광 마커 유전자를 형질 감염시킨다. 안정한 세포 클론을 생성하기 위해서, CHO-mAb2 세포를 기술된 gRNA 및 Cas9 함유 벡터, 추가로 단일-가닥의 CMV 프로모터 유도된 퓨로마이신 또는 대안으로 형광성 마커 유전자로 형질감염시켰다. 이러한 선택 마커 유전자는 목적하는 표적 부위를 플랭킹하는 게놈 영역에 상보성인 플랭킹 영역에 간삽된다. 게놈 CERS2 또는 TBC1D20 표적 부위가 Cas9 뉴클레아제에 의해 이어서 상동성 지시 수복(HDR)에 의한 선택 마커 유전자의 통합에 의해 절단된 세포만이 각각 저항성 또는 형광성 마커를 갖는다. 단일 세포 클론은 OFP 양성 세포에 대한 FACS 분류 및 배지(Boehringer Ingelheim)에서의 후속적 배양에 의해 생성된다. CERS2 또는 TBC1D20 단백질의 효율적인 고갈은 예를 들면 PCR에 의해 또는 각각 특이적 항-CERS2 항체 또는 항-TBC1D20 항체를 이용한 웨스턴 블롯팅에 의해 제어되고, 게놈 내의 효율적인 돌연변이는 목적하는 게놈 유전자좌를 서열분석함으로써 분석된다.
본 발명은 하기 항목들에 포함된다:
1. (a) 숙주 세포 단백질 TBC1 도메인 패밀리 구성원 20(TBC1D20) 및 세라마이드 신타제 2(CERS2: ceramide synthase 2)의 감소된 발현; 또는
(b) 숙주 세포 단백질 활성화 전사 인자 6 베타(ATF6B: activating transcription factor 6 beta)의 감소된 발현
을 포함하는, 재조합 치료학적 단백질의 분비가 향상된 포유동물 세포로서,
상기 포유동물 세포는 재조합 분비형 치료학적 단백질을 암호화하는 하나 이상의 발현 카세트(cassette)(들)를 추가로 포함하는, 재조합 치료학적 단백질의 분비가 향상된 포유동물 세포.
2. 항목 1에 있어서, 감소된 ATF6B 단백질 발현을 갖고 재조합 분비형 치료학적 단백질을 암호화하는 하나 이상의 발현 카세트(들)를 추가로 포함하는, 포유동물 세포.
3. 항목 1 또는 항목 2에 있어서, 상기 숙주 세포 단백질 TBC1D20 및 CERS2의 또는 상기 숙주 세포 단백질 ATF6B의 발현이 대조군 포유동물 세포와 비교하여 적어도 30%, 적어도 40%, 적어도 50%, 적어도 75% 또는 100%만큼 감소된, 포유동물 세포.
4. 항목 1 내지 항목 3 중 어느 하나에 있어서, 상기 재조합 치료학적 단백질의 분비가 대조군 포유동물 세포와 비교하여 적어도 10%, 적어도 20%, 적어도 30%, 적어도 40%, 적어도 50%, 적어도 75%, 적어도 100% 또는 적어도 200%만큼 향상된, 포유동물 세포.
5. 항목 1 내지 항목 4 중 어느 하나에 있어서:
(a) 상기 숙주 세포 단백질을 암호화하는 유전자가 상기 숙주 세포 단백질의 발현을 저해하는 유전적 변형을 포함하거나, 또는
(b) 상기 포유동물 세포가 RNA-간섭에 의해 상기 숙주 세포 단백질을 암호화하는 유전자의 발현을 저해하는 RNA 올리고뉴클레오타이드를 포함하고,
상기 포유동물 세포에서의 상기 TBC1D20 및 CERS2의 단백질 발현 또는 상기 ATF6B의 단백질 발현이 상기 유전적 변형(들) 또는 RNA 올리고뉴클레오타이드(들)를 함유하지 않는 동일한 포유동물 세포와 비교하여 감소된, 포유동물 세포.
6. 항목 5에 있어서, 상기 RNA-간섭이 소형 헤어핀 RNA(shRNA) 또는 짧은 간섭 RNA(siRNA)에 의해 매개되는, 포유동물 세포.
7. 항목 6에 있어서, 상기 포유동물 세포가 상기 siRNA(들) 또는 shRNA(들)를 암호화하는 뉴클레오타이드 서열을 포함하는 하나 이상의 발현 벡터(들)로 형질감염된, 포유동물 세포.
8. 항목 7에 있어서, 상기 포유동물 세포가 상기 siRNA(들) 또는 shRNA(들)를 암호화하는 뉴클레오타이드 서열을 포함하는 하나 이상의 발현 벡터(들)로 안정하게 형질감염된, 포유동물 세포.
9. 항목 6 내지 항목 8 중 어느 하나에 있어서, 상기 siRNA가
(a) siTbc1D20#1(서열번호 7) 또는 siCerS2#1(서열번호 8) 또는 이들의 조합; 또는
(b) siAtf6b#1(서열번호 9), siAtf6b#2(서열번호 10) 및 siAtf6b#3(서열번호 3)
인, 포유동물 세포.
10. 항목 6 내지 항목 8 중 어느 하나에 있어서, 상기 shRNA가
(a) shTbc1D20#1(서열번호 12) 또는 shCerS2#1(서열번호 13) 및 shCerS2#2(서열번호 14) 중 하나 이상, 또는 이들의 조합; 또는
(b) shAtf6b#1(서열번호 15) 및 shAtf6b#2(서열번호 37) 중 하나 이상, 바람직하게는 shAtf6b#1(서열번호 15)
을 포함하는, 포유동물 세포.
11. 항목 5에 있어서, 상기 숙주 세포 단백질(들) TBC1D20, CERS2 또는 ATF6B를 암호화하는 유전자(들)에서의 상기 유전적 변형이 독립적으로
(a) 유전자 결실; 또는
(b) 상기 숙주 세포 단백질의 발현을 저해하는 유전자 내의 돌연변이
인, 포유동물 세포.
12. 항목 11에 있어서, 상기 돌연변이가 결실, 부가 또는 치환인, 포유동물 세포.
13. 항목 12에 있어서:
(a) 상기 돌연변이가 상기 유전자의 암호화 영역 내에 존재하고/하거나;
(b) 상기 돌연변이가 상기 유전자의 프로모터 또는 조절 영역 내에 존재하는, 포유동물 세포.
14. 항목 1 내지 항목 13 중 어느 하나에 있어서:
(a) 상기 숙주 세포 단백질 TBC1D20이 서열번호 4의 아미노산 서열과 적어도 80%의 서열 동일성을 갖고 상기 숙주 세포 단백질 CERS2가 서열번호 5의 아미노산 서열과 적어도 80%의 서열 동일성을 갖거나; 또는
(b) 상기 숙주 세포 단백질 ATF6B가 서열번호 6의 아미노산 서열과 적어도 80%의 서열 동일성을 갖는, 포유동물 세포.
15. 항목 14에 있어서,
(a) 상기 숙주 세포 단백질 TBC1D20이 서열번호 4의 아미노산 서열을 갖고 상기 숙주 세포 단백질 CERS2가 서열번호 5의 아미노산 서열을 갖거나; 또는
(b) 상기 숙주 세포 단백질 ATF6B가 서열번호 6의 아미노산 서열을 갖는, 포유동물 세포.
16. 상기 숙주 세포 단백질 TBC1D20 및 CERS2의 감소된 발현을 포함하는 재조합 단백질의 분비가 향상된 포유동물 세포.
17. 항목 16에 있어서, 상기 재조합 분비형 치료학적 단백질을 암호화하는 하나 이상의 발현 카세트(들)를 추가로 포함하는, 포유동물 세포.
18. 항목 17에 있어서, 상기 재조합 치료학적 단백질의 분비가 대조군 포유동물 세포와 비교하여 적어도 10%, 적어도 20%, 적어도 30%, 적어도 40%, 적어도 50%, 적어도 75%, 적어도 100% 또는 적어도 200%만큼 향상된, 포유동물 세포.
19. 항목 16 내지 항목 18 중 어느 하나에 있어서, 상기 숙주 세포 단백질 TBC1D20 및 CERS2의 발현이 대조군 포유동물 세포와 비교하여 적어도 30%, 적어도 40%, 적어도 50%, 적어도 75% 또는 100%만큼 감소된, 포유동물 세포.
20. 항목 16 내지 항목 19 중 어느 하나에 있어서:
(a) 상기 숙주 세포 단백질을 암호화하는 유전자가 상기 숙주 세포 단백질의 발현을 저해하는 유전적 변형을 포함하거나, 또는
(b) 상기 포유동물 세포가 RNA-간섭에 의해 상기 숙주 세포 단백질을 암호화하는 유전자의 발현을 저해하는 RNA 올리고뉴클레오타이드를 포함하고,
상기 포유동물 세포에서의 TBC1D20 및 CERS2의 단백질 발현이 상기 유전적 변형 또는 RNA 올리고뉴클레오타이드를 함유하지 않는 동일한 포유동물 세포와 비교하여 감소된, 포유동물 세포.
21. 항목 20에 있어서, 상기 RNA-간섭이 소형 헤어핀 RNA(shRNA) 또는 짧은 간섭 RNA(siRNA)에 의해 매개되는, 포유동물 세포.
22. 항목 21에 있어서, 상기 포유동물 세포가 상기 siRNA(들) 또는 shRNA(들)를 암호화하는 뉴클레오타이드 서열을 포함하는 하나 이상의 발현 벡터(들)로 형질감염된, 포유동물 세포.
23. 항목 22에 있어서, 상기 포유동물 세포가 상기 siRNA(들) 또는 shRNA(들)를 암호화하는 뉴클레오타이드 서열을 포함하는 하나 이상의 발현 벡터(들)로 안정하게 형질감염된, 포유동물 세포.
24. 항목 21 내지 항목 23 중 어느 하나에 있어서, 상기 siRNA가 siTbc1D20#1(서열번호 7) 또는 siCerS2#1(서열번호 8), 또는 이들의 조합인, 포유동물 세포.
25. 항목 21 내지 항목 23 중 어느 하나에 있어서, 상기 shRNA가 shTbc1D20#1(서열번호 12) 또는 shCerS2#1(서열번호 13) 및 shCerS2#2(서열번호 14) 중 하나 이상, 또는 이들의 조합을 포함하는, 포유동물 세포.
26. 항목 20에 있어서, 상기 숙주 세포 단백질 TBC1D20 및 CERS2를 암호화하는 유전자 내의 상기 유전적 변형이 독립적으로
(a) 유전자 결실; 또는
(b) 상기 숙주 세포 단백질의 발현을 저해하는 유전자 내의 돌연변이
인, 포유동물 세포.
27. 항목 26에 있어서, 상기 돌연변이가 결실, 부가 또는 치환인, 포유동물 세포.
28. 항목 27에 있어서,
(a) 상기 돌연변이가 상기 유전자의 암호화 영역 내에 존재하고/하거나;
(b) 상기 돌연변이가 상기 유전자의 프로모터 또는 조절 영역 내에 존재하는, 포유동물 세포.
29. 항목 16 내지 항목 28 중 어느 하나에 있어서, 상기 숙주 세포 단백질 TBC1D20이 서열번호 4의 아미노산 서열과 적어도 80%의 서열 동일성을 갖고 상기 숙주 세포 단백질 CERS2가 서열번호 5의 아미노산 서열과 적어도 80%의 서열 동일성을 갖는, 포유동물 세포.
30. 항목 16 내지 항목 29 중 어느 하나에 있어서, 상기 숙주 세포 단백질 TBC1D20이 서열번호 4의 아미노산 서열을 갖고 상기 숙주세포 단백질 CERS2가 서열번호 5의 아미노산 서열을 갖는, 포유동물 세포.
31. 항목 1 내지 항목 30 중 어느 하나에 있어서, 상기 재조합 분비형 치료학적 단백질이
(a) 항체, 바람직하게는 모노클로날 항체, 이-특이적 항체 또는 이의 단편, 또는
(b) Fc-융합 단백질
인, 포유동물 세포.
32. 항목 1 내지 항목 31 중 어느 하나에 있어서, 상기 세포가 설치류 또는 사람 세포인, 포유동물 세포.
33. 항목 32에 있어서, 상기 설치류 세포가 햄스터 세포인, 포유동물 세포.
34. 항목 33에 있어서, 상기 햄스터 세포가 CHO 세포, 바람직하게는 CHO-DG44 세포, CHO-K1 세포 또는 이들의 글루타민 신테타제(GS: glutamine synthetase)-결핍 유도체인, 포유동물 세포.
35. (a) (i) 상기 숙주 세포 단백질의 발현을 저해하는 상기 숙주 세포 단백질을 암호화하는 유전자에의 유전적 변형, 또는
(ii) RNA-간섭에 의해 상기 숙주 세포 단백질을 암호화하는 유전자의 발현을 저해하는 상기 포유동물 세포에의 RNA 올리고뉴클레오타이드
를 도입함으로써 상기 포유동물 세포에서의 상기 숙주 세포 단백질 TBC1D20 및 CERS2의 발현 또는 상기 숙주 세포 단백질 ATF6B의 발현을 감소시키는 단계, 및
(b) 재조합 분비형 치료학적 단백질을 암호화하는 하나 이상의 유전자(들)를 도입하는 단계
를 포함하는, 재조합 치료학적 단백질의 분비가 향상된 포유동물 세포를 생산하는 방법.
36. 항목 35에 있어서, 하기 단계들을 추가로 포함하는, 방법:
(c) 상기 재조합 치료학적 단백질의 분비가 향상된 세포를 선택하는 단계; 및
(d) 재조합 분비형 치료학적 단백질을 암호화하는 하나 이상의 유전자(들)의 발현을 가능하게 하는 조건 하에 단계 (c)에서 수득된 상기 세포를 임의로 배양하는 단계.
37. 항목 35 또는 항목 36에 있어서, 상기 포유동물 세포에서의 상기 TBC1D20 및 CERS2의 단백질 발현 또는 상기 ATF6B의 단백질 발현이 상기 유전적 변형(들) 또는 RNA 올리고뉴클레오타이드(들)를 함유하지 않는 동일한 포유동물 세포와 비교하여 감소된, 방법.
38. 항목 35 또는 항목 37에 있어서, 상기 포유동물 세포에서의 TBC1D20 및 CERS2 단백질 발현을 감소시키는 단계를 포함하는, 방법.
39. 항목 35 또는 항목 37에 있어서, 상기 포유동물 세포에서의 ATF6B 단백질 발현을 감소시키는 단계를 포함하는, 방법.
40. 항목 35 내지 항목 39 중 어느 하나에 있어서, 상기 RNA-간섭이 소형 헤어핀 RNA(shRNA) 또는 짧은 간섭 RNA(siRNA)에 의해 매개되는, 방법.
41. 항목 40에 있어서, 상기 포유동물 세포를 상기 siRNA(들) 또는 shRNA(들)를 암호화하는 뉴클레오타이드 서열을 포함하는 하나 이상의 발현 벡터(들)로 형질감염시키는 단계를 포함하는, 방법.
42. 항목 41에 있어서, 상기 포유동물 세포가 상기 siRNA(들) 또는 shRNA(들)를 암호화하는 뉴클레오타이드 서열을 포함하는 하나 이상의 발현 벡터(들)로 안정하게 형질감염되는, 방법.
43. 항목 40 내지 항목 42 중 어느 하나에 있어서, 상기 siRNA가
(a) siTbc1D20#1(서열번호 7) 또는 siCerS2#1(서열번호 8), 또는 이들의 조합; 또는
(b) siAtf6b#1(서열번호 9), siAtf6b#2(서열번호 10), 및 siAtf6b#3(서열번호 11) 중 하나 이상
인, 방법.
44. 항목 40 내지 항목 42 중 어느 하나에 있어서, 상기 shRNA가
(a) shTbc1D20#1(서열번호 12) 또는 shCerS2#1(서열번호 13) 및 shCerS2#2(서열번호 14) 중 하나 이상, 또는 이들의 조합; 또는
(b) shAtf6b#1(서열번호 15) 및 shAtf6b#2(서열번호 37) 중 하나 이상, 바람직하게는 shAtf6b#1(서열번호 15)
을 포함하는, 방법.
45. 항목 35에 있어서, 상기 숙주 세포 단백질(들) TBC1D20 및 CERS2, 또는 ATF6B를 암호화하는 유전자(들) 내의 유전적 변형이 독립적으로
(a) 유전자 결실; 또는
(b) 상기 숙주 세포 단백질의 발현을 저해하는 유전자 내의 돌연변이
인, 방법.
46. 제45항에 있어서, 상기 돌연변이가 결실, 부가 또는 치환인, 방법.
47. 항목 46에 있어서:
(a) 상기 돌연변이가 상기 유전자의 암호화 영역 내에 존재하고/하거나;
(b) 상기 돌연변이가 상기 유전자의 프로모터 또는 조절 영역 내에 존재하는, 방법.
48. 항목 35 내지 항목 47 중 어느 하나에 있어서:
(a) 상기 숙주 세포 단백질 TBC1D20이 서열번호 4의 아미노산 서열과 적어도 80%의 서열 동일성을 갖고 상기 숙주 세포 단백질 CERS2가 서열번호 5의 아미노산 서열과 적어도 80%의 서열 동일성을 갖거나; 또는
(b) 상기 숙주 세포 단백질 ATF6B가 서열번호 6의 아미노산 서열과 적어도 80%의 서열 동일성을 갖는, 방법.
49. 항목 35 내지 항목 48 중 어느 하나에 있어서,
(a) 상기 숙주 세포 단백질 TBC1D20이 서열번호 4의 아미노산 서열을 갖고 상기 숙주 세포 단백질 CERS2가 서열번호 5의 아미노산 서열을 갖거나; 또는
(b) 상기 숙주 세포 단백질 ATF6B가 서열번호 6의 아미노산 서열을 갖는, 방법.
50. 항목 35 내지 항목 49 중 어느 하나에 있어서, 상기 재조합 분비형 치료학적 단백질이
(a) 항체, 바람직하게는 모노클로날 항체, 이-특이적 항체 또는 이들의 단편, 또는
(b) Fc-융합 단백질
인, 방법.
51. 항목 35 내지 항목 50 중 어느 하나에 있어서, 상기 세포가 설치류 또는 사람 세포인, 방법.
52. 항목 51에 있어서, 상기 설치류 세포가 햄스터 세포인, 방법.
53. 항목 52에 있어서, 상기 햄스터 세포가 CHO 세포, 바람직하게는 CHO-DG44 세포, CHO-K1 세포 또는 이들의 글루타민 신테타제(GS)-결핍 유도체인, 방법.
54. 항목 35 내지 항목 53 중 어느 하나에 있어서, 단계 (a)가 단계 (b) 전에 또는 단계 (b) 후에 수행될 수 있는, 방법.
55. 항목 35 내지 항목 54 중 어느 하나에 있어서, 단계(c)의 상기 선택 단계가 선택제(selection agent)의 존재 하에 수행되는, 방법.
56. 항목 35 내지 항목 55 중 어느 하나에 있어서, 단계 (b)에서 유도된 하나 이상의 유전자(들)를 증폭가능한 선택성 마커 유전자와 함께 증폭시키고 증폭가능한 선택성 마커 유전자의 증폭을 가능하게 하는 제제의 존재 하에 상기 포유동물 세포를 배양하는 것을 포함하는 증폭 단계 (b')를 추가로 포함하는, 방법.
57. 항목 56에 있어서, 상기 증폭가능한 선택성 마커 유전자가 증폭가능한 선택성 마커 디하이드로폴레이트 리덕타제 또는 글루타민 신테타제를 암호화하는, 방법.
58. 항목 35 내지 항목 57 중 어느 하나에 있어서, 상기 숙주 세포 단백질 TBC1D20 및 CERS2의 또는 상기 숙주 세포 단백질 ATF6B의 발현이 단계 (a)를 생략한 것 이외에는 동일한 출발 재료를 이용한 항목 35 내지 항목 56 중 어느 하나의 방법에 의해 생산된 포유동물 세포와 비교하여 적어도 30%, 적어도 40%, 적어도 50%, 적어도 75% 또는 100%만큼 감소된, 방법.
59. 항목 35 내지 항목 58 중 어느 하나에 있어서, 상기 재조합 치료학적 단백질의 분비가 단계 (a)를 생략한 것 이외에는 동일한 출발 재료를 이용한 항목 35 내지 항목 58 중 어느 하나의 방법에 의해 생산된 포유동물 세포와 비교하여 적어도 10%, 적어도 20%, 적어도 30%, 적어도 40%, 적어도 50%, 적어도 75%, 적어도 100% 또는 적어도 200%만큼 향상된, 방법.
60. (a) 항목 1 내지 항목 34 중 어느 한 항의 재조합 분비형 치료학적 단백질로 형질감염된 상기 포유동물 세포를 제공하거나 항목 35 내지 항목 59 중 어느 하나의 방법에 의해 생산된 상기 포유동물 세포를 제공하는 단계,
(b) 상기 재조합 분비형 치료학적 단백질의 생산을 가능하게 하는 조건에서 세포 배양 배지에서 단계 (a)의 상기 포유동물 세포를 배양하는 단계,
(c) 상기 재조합 분비형 치료학적 단백질을 수거하는 단계, 및 임의로
(d) 상기 재조합 분비형 치료학적 단백질을 정제하는 단계
를 포함하는, 포유동물 세포에서의 재조합 분비형 치료학적 단백질의 생산 방법.
61. 재조합 분비형 치료학적 단백질의 수율을 증가시키기 위한 항목 1 내지 항목 34 중 어느 하나의 상기 포유동물 세포 또는 항목 35 내지 항목 59 중 어느 하나의 상기 방법에 의해 생산된 포유동물 세포의 용도.
62. 항목 61에 있어서, 상기 재조합 분비형 치료학적 단백질이
(a) 항체, 바람직하게는 모노클로날 항체, 이-특이적 항체 또는 이들의 단편, 또는
(b) Fc-융합 단백질
인, 용도.
서열 표
서열번호 1: Tbc1D20 차이니즈 햄스터 cDNA
서열번호 2: CerS2 차이니즈 햄스터 cDNA
서열번호 3: Atf6b 차이니즈 햄스터 rDNA
서열번호 4: TBC1D20 차이니즈 햄스터 단백질
서열번호 5: CERS2 차이니즈 햄스터 단백질
서열번호 6: ATF6B 차이니즈 햄스터 단백질
서열번호 7: siTbc1D20#1
서열번호 8: siCerS2#1
서열번호 9: siAtf6b#1
서열번호 10: siAtf6b#2
서열번호 11: siAtf6b#3
서열번호 12: shTbc1D20#1
서열번호 13: shCerS2#1
서열번호 14: shCerS2#2
서열번호 15: shAtf6b#1
서열번호 16: shTbc1D20#1_올리고뉴클레오타이드_순방향
서열번호 17: shTbc1D20#1_올리고뉴클레오타이드_역방향
서열번호 18: shCerS2#1_올리고뉴클레오타이드_순방향
서열번호 19: shCerS2#1_올리고뉴클레오타이드_역방향
서열번호 20: shCerS2#2_올리고뉴클레오타이드_순방향
서열번호 21: shCerS2#2_올리고뉴클레오타이드_역방향
서열번호 22: shAtf6b#1_올리고뉴클레오타이드_순방향
서열번호 23: shAtf6b#1_올리고뉴클레오타이드_역방향
서열번호 24: mAb1 IgG1 중쇄
서열번호 25: mAb1 IgG1 경쇄
서열번호 26: mAb2 IgG1 중쇄
서열번호 27: mAb2 IgG1 경쇄
서열번호 28: hsa-miR-1287_올리고뉴클레오타이드_순방향
서열번호 29: hsa-miR-1287_올리고뉴클레오타이드_역방향
서열번호 30: hsa-miR-1978_올리고뉴클레오타이드_순방향
서열번호 31: hsa-miR-1978_올리고뉴클레오타이드_역방향
서열번호 32: hsa-miR-1287
서열번호 33: hsa-miR-1978
서열번호 34: 음성 대조군
서열번호 35: shAtf6b#2_올리고뉴클레오타이드_순방향
서열번호 36: shAtf6b#2_올리고뉴클레오타이드_역방향
서열번호 37: shAtf6b#2
서열번호 38: siRNA NT-대조군#1
서열번호 39: siRNA NT-대조군#2
서열번호 40: siRNA NT-대조군#3
서열번호 41: siRNA NT-대조군#4
서열번호 42: qPCR 프라이머 (Atf6b) 순방향
서열번호 43: qPCR 프라이머 (Atf6b) 역방향
서열번호 44: qPCR 프라이머 (Tbc1D20) 순방향
서열번호 45: qPCR 프라이머 (Tbc1D20) 역방향
서열번호 46: qPCR 프라이머 (CerS2) 순방향
서열번호 47: qPCR 프라이머 (CerS2) 역방향
서열번호 48: qPCR 프라이머 (CHOP) 순방향
서열번호 49: qPCR 프라이머 (CHOP) 역방향
서열번호 50: qPCR 프라이머 (GRP78) 순방향
서열번호 51: qPCR 프라이머 (GRP78) 역방향
서열번호 52: qPCR 프라이머 (Herpud1) 순방향
서열번호 53: qPCR 프라이머 (Herpud1) 역방향