KR20190105745A - 전자 장치 및 그 제어 방법 - Google Patents
전자 장치 및 그 제어 방법 Download PDFInfo
- Publication number
- KR20190105745A KR20190105745A KR1020180026209A KR20180026209A KR20190105745A KR 20190105745 A KR20190105745 A KR 20190105745A KR 1020180026209 A KR1020180026209 A KR 1020180026209A KR 20180026209 A KR20180026209 A KR 20180026209A KR 20190105745 A KR20190105745 A KR 20190105745A
- Authority
- KR
- South Korea
- Prior art keywords
- image block
- image blocks
- noise
- compression rate
- frame
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images




Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/85—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using pre-processing or post-processing specially adapted for video compression
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/176—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a block, e.g. a macroblock
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2413—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on distances to training or reference patterns
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0495—Quantised networks; Sparse networks; Compressed networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/09—Supervised learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/20—Image preprocessing
- G06V10/30—Noise filtering
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
- G06V10/44—Local feature extraction by analysis of parts of the pattern, e.g. by detecting edges, contours, loops, corners, strokes or intersections; Connectivity analysis, e.g. of connected components
- G06V10/443—Local feature extraction by analysis of parts of the pattern, e.g. by detecting edges, contours, loops, corners, strokes or intersections; Connectivity analysis, e.g. of connected components by matching or filtering
- G06V10/449—Biologically inspired filters, e.g. difference of Gaussians [DoG] or Gabor filters
- G06V10/451—Biologically inspired filters, e.g. difference of Gaussians [DoG] or Gabor filters with interaction between the filter responses, e.g. cortical complex cells
- G06V10/454—Integrating the filters into a hierarchical structure, e.g. convolutional neural networks [CNN]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/764—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using classification, e.g. of video objects
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/117—Filters, e.g. for pre-processing or post-processing
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/119—Adaptive subdivision aspects, e.g. subdivision of a picture into rectangular or non-rectangular coding blocks
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/136—Incoming video signal characteristics or properties
- H04N19/137—Motion inside a coding unit, e.g. average field, frame or block difference
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/136—Incoming video signal characteristics or properties
- H04N19/14—Coding unit complexity, e.g. amount of activity or edge presence estimation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/146—Data rate or code amount at the encoder output
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/164—Feedback from the receiver or from the transmission channel
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/182—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being a pixel
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/186—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being a colour or a chrominance component
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/85—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using pre-processing or post-processing specially adapted for video compression
- H04N19/86—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using pre-processing or post-processing specially adapted for video compression involving reduction of coding artifacts, e.g. of blockiness
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Multimedia (AREA)
- General Physics & Mathematics (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Software Systems (AREA)
- Computing Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- Data Mining & Analysis (AREA)
- Molecular Biology (AREA)
- Biomedical Technology (AREA)
- General Engineering & Computer Science (AREA)
- Mathematical Physics (AREA)
- Computational Linguistics (AREA)
- Biophysics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Medical Informatics (AREA)
- Databases & Information Systems (AREA)
- Biodiversity & Conservation Biology (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
Description
도 1b는 전자 장치의 세부 구성의 일 예를 나타내는 블럭도이다.
도 2는 본 개시의 일 실시 예에 따른 프로세서의 동작을 개략적으로 설명하기 위한 도면이다.
도 3은 본 개시의 일 실시 예에 따른 압축률을 획득하는 방법을 설명하기 위한 도면이다.
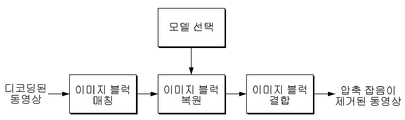
도 4a 및 도 4b는 본 개시의 다양한 실시 예에 따른 압축 잡음 제거 방법을 설명하기 위한 도면들이다.
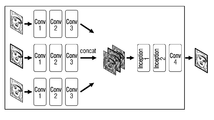
도 5a 및 도 5b는 본 개시의 일 실시 예에 따른 압축 잡음 제거 네트워크 모델을 설명하기 위한 도면들이다.
도 6은 본 개시의 일 실시 예에 따른 전자 장치의 제어 방법을 설명하기 위한 흐름도이다.
120 : 프로세서 130 : 통신부
140 : 디스플레이 150 : 사용자 인터페이스부
160 : 오디오 처리부 170 : 비디오 처리부
Claims (20)
- 복수의 압축률 중 이미지 블럭에 적용된 압축률을 판단하기 위한 압축률 네트워크 모델 및 상기 복수의 압축률 별로 압축 잡음을 제거하기 위한 복수의 압축 잡음 제거 네트워크 모델이 저장된 스토리지; 및
상기 압축률 네트워크 모델에 기초하여 디코딩된 동영상의 프레임에 포함된 복수의 이미지 블럭 각각의 압축률을 획득하고, 상기 획득된 복수의 압축률에 기초하여 상기 프레임의 압축률을 획득하며, 상기 복수의 압축 잡음 제거 네트워크 모델 중 상기 프레임의 압축률에 대응되는 압축 잡음 제거 네트워크 모델에 기초하여 상기 프레임의 압축 잡음을 제거하는 프로세서;를 포함하며,
상기 압축률 네트워크 모델은, 상기 복수의 압축률에 각각 대응되는 복수의 복원 이미지 블럭의 이미지 특성을 제1 인공지능 알고리즘을 통해 학습하여 획득되고,
상기 복수의 복원 이미지 블럭은, 복수의 원본 이미지 블럭을 인코딩하고, 상기 인코딩된 복수의 원본 이미지 블럭을 디코딩하여 생성되며,
상기 복수의 압축 잡음 제거 네트워크 모델은, 상기 복수의 원본 이미지 블럭 및 상기 복수의 복원 이미지 블럭의 관계를 제2 인공지능 알고리즘을 통해 학습하여 획득된, 전자 장치. - 제1항에 있어서,
상기 프로세서는,
상기 프레임의 전후로 기설정된 개수의 복수의 프레임 각각을 복수의 추가 이미지 블럭으로 구분하고, 상기 압축률 네트워크 모델에 기초하여 상기 복수의 추가 이미지 블럭 각각의 추가 압축률을 획득하며, 상기 복수의 압축률 및 상기 복수의 추가 압축률에 기초하여 상기 프레임의 압축률을 획득하는, 전자 장치. - 제1항에 있어서,
상기 프로세서는,
상기 복수의 이미지 블럭 각각의 픽셀 값에 대한 분산을 산출하고, 상기 산출된 분산에 기초하여 상기 복수의 이미지 블럭 중 기설정된 개수의 이미지 블럭을 획득하며, 상기 압축률 네트워크 모델에 기초하여 상기 획득된 기설정된 개수의 이미지 블럭 각각의 압축률을 획득하고, 상기 획득된 복수의 압축률에 기초하여 상기 프레임의 압축률을 획득하는, 전자 장치. - 제1항에 있어서,
상기 프로세서는,
상기 프레임을 상기 복수의 이미지 블럭으로 구분하고, 상기 압축 잡음 제거 네트워크 모델에 기초하여 상기 복수의 이미지 블럭 각각의 압축 잡음을 제거하며, 상기 압축 잡음이 제거된 복수의 이미지 블럭을 결합하여 압축 잡음이 제거된 프레임을 획득하는, 전자 장치. - 제4항에 있어서,
상기 프로세서는,
상기 프레임의 전후 프레임에서 상기 복수의 이미지 블럭 중 하나인 제1 이미지 블럭에 대응되는 제2 이미지 블럭 및 제3 이미지 블럭을 획득하고, 상기 제2 이미지 블럭 및 상기 제3 이미지 블럭을 이용하여 상기 제1 이미지 블럭의 압축 잡음을 제거하는, 전자 장치. - 제5항에 있어서,
상기 프로세서는,
상기 압축 잡음 제거 네트워크 모델에 기초하여 상기 제1 이미지 블럭, 상기 제2 이미지 블럭 및 상기 제3 이미지 블럭 각각에 대해 적어도 한 번의 컨볼루션 연산을 수행하고, 상기 컨볼루션 연산이 수행된 제1 이미지 블럭, 제2 이미지 블럭 및 제3 이미지 블럭을 결합하며, 상기 결합된 이미지 블럭에 대해 적어도 한 번의 컨볼루션 연산을 수행하여 상기 제1 이미지 블럭의 압축 잡음을 제거하는, 전자 장치. - 제5항에 있어서,
상기 프로세서는,
상기 제1 이미지 블럭 및 상기 제2 이미지 블럭의 제1 최대 신호 대 잡음비(Peak Signal-to-noise ratio, PSNR) 및 상기 제1 이미지 블럭 및 상기 제3 이미지 블럭의 제2 최대 신호 대 잡음비를 산출하며, 상기 제1 최대 신호 대 잡음비 및 상기 제2 최대 신호 대 잡음비 중 적어도 하나가 기설정된 값보다 작은 경우, 상기 제2 이미지 블럭 및 상기 제3 이미지 블럭 중 상기 기설정된 값보다 작은 최대 신호 대 잡음비에 대응되는 이미지 블럭을 대신하여 상기 제1 이미지 블럭을 상기 압축 잡음 제거 네트워크 모델에 입력하는, 전자 장치. - 제4항에 있어서,
상기 프로세서는,
경계로부터의 거리에 따른 가중치에 기초하여 상기 압축 잡음이 제거된 복수의 이미지 블럭을 오버랩하여 결합하는, 전자 장치. - 제1항에 있어서,
상기 프로세서는,
상기 프레임을 색차 성분과 휘도 성분으로 구분하고, 상기 압축 잡음 제거 네트워크 모델에 기초하여 상기 휘도 성분의 압축 잡음을 제거하며, 상기 색차 성분과 상기 압축 잡음이 제거된 휘도 성분을 결합하여 상기 프레임의 압축 잡음을 제거하며,
상기 복수의 압축 잡음 제거 네트워크 모델은, 상기 복수의 원본 이미지 블럭의 휘도 성분 및 상기 복수의 복원 이미지 블럭의 휘도 성분의 관계를 제2 인공지능 알고리즘을 통해 학습하여 획득된, 전자 장치. - 제1항에 있어서,
상기 압축률 네트워크 모델 및 상기 복수의 압축 잡음 제거 네트워크 모델은, 딥러닝(Deep Learning) 네트워크 구조인, 전자 장치. - 전자 장치의 제어 방법에 있어서,
복수의 압축률 중 이미지 블럭에 적용된 압축률을 판단하기 위한 압축률 네트워크 모델에 기초하여 디코딩된 동영상의 프레임에 포함된 복수의 이미지 블럭 각각의 압축률을 획득하는 단계;
상기 획득된 복수의 압축률에 기초하여 상기 프레임의 압축률을 획득하는 단계; 및
상기 복수의 압축률 별로 압축 잡음을 제거하기 위한 복수의 압축 잡음 제거 네트워크 모델 중 상기 프레임의 압축률에 대응되는 압축 잡음 제거 네트워크 모델에 기초하여 상기 프레임의 압축 잡음을 제거하는 단계;를 포함하며,
상기 압축률 네트워크 모델은, 상기 복수의 압축률에 각각 대응되는 복수의 복원 이미지 블럭의 이미지 특성을 제1 인공지능 알고리즘을 통해 학습하여 획득되고,
상기 복수의 복원 이미지 블럭은, 복수의 원본 이미지 블럭을 인코딩하고, 상기 인코딩된 복수의 원본 이미지 블럭을 디코딩하여 생성되며,
상기 복수의 압축 잡음 제거 네트워크 모델은, 상기 복수의 원본 이미지 블럭 및 상기 복수의 복원 이미지 블럭의 관계를 제2 인공지능 알고리즘을 통해 학습하여 획득된, 제어 방법. - 제11항에 있어서,
상기 프레임의 압축률을 획득하는 단계는,
상기 프레임의 전후로 기설정된 개수의 복수의 프레임 각각을 복수의 추가 이미지 블럭으로 구분하는 단계;
상기 압축률 네트워크 모델에 기초하여 상기 복수의 추가 이미지 블럭 각각의 추가 압축률을 획득하는 단계; 및
상기 복수의 압축률 및 상기 복수의 추가 압축률에 기초하여 상기 프레임의 압축률을 획득하는 단계;를 더 포함하는, 제어 방법. - 제11항에 있어서,
상기 복수의 이미지 블럭 각각의 압축률을 획득하는 단계는,
상기 복수의 이미지 블럭 각각의 픽셀 값에 대한 분산을 산출하는 단계;
상기 산출된 분산에 기초하여 상기 복수의 이미지 블럭 중 기설정된 개수의 이미지 블럭을 획득하는 단계; 및
상기 압축률 네트워크 모델에 기초하여 상기 획득된 기설정된 개수의 이미지 블럭 각각의 압축률을 획득하는 단계;를 포함하고,
상기 프레임의 압축률을 획득하는 단계는,
상기 획득된 기설정된 개수의 이미지 블럭 각각의 압축률에 기초하여 상기 프레임의 압축률을 획득하는 단계;를 더 포함하는, 제어 방법. - 제11항에 있어서,
상기 압축 잡음을 제거하는 단계는,
상기 프레임을 상기 복수의 이미지 블럭으로 구분하는 단계;
상기 압축 잡음 제거 네트워크 모델에 기초하여 상기 복수의 이미지 블럭 각각의 압축 잡음을 제거하는 단계; 및
상기 압축 잡음이 제거된 복수의 이미지 블럭을 결합하여 압축 잡음이 제거된 프레임을 획득하는 단계;를 포함하는, 제어 방법. - 제14항에 있어서,
상기 압축 잡음을 제거하는 단계는,
상기 프레임의 전후 프레임에서 상기 복수의 이미지 블럭 중 하나인 제1 이미지 블럭에 대응되는 제2 이미지 블럭 및 제3 이미지 블럭을 획득하는 단계; 및
상기 제2 이미지 블럭 및 상기 제3 이미지 블럭을 이용하여 상기 제1 이미지 블럭의 압축 잡음을 제거하는 단계;를 더 포함하는, 제어 방법. - 제15항에 있어서,
상기 제1 이미지 블럭의 압축 잡음을 제거하는 단계는,
상기 압축 잡음 제거 네트워크 모델에 기초하여 상기 제1 이미지 블럭, 상기 제2 이미지 블럭 및 상기 제3 이미지 블럭 각각에 대해 적어도 한 번의 컨볼루션 연산을 수행하는 단계;
상기 컨볼루션 연산이 수행된 제1 이미지 블럭, 제2 이미지 블럭 및 제3 이미지 블럭을 결합하는 단계; 및
상기 결합된 이미지 블럭에 대해 적어도 한 번의 컨볼루션 연산을 수행하여 상기 제1 이미지 블럭의 압축 잡음을 제거하는 단계;를 포함하는 제어 방법. - 제15항에 있어서,
상기 압축 잡음을 제거하는 단계는,
상기 제1 이미지 블럭 및 상기 제2 이미지 블럭의 제1 최대 신호 대 잡음비(Peak Signal-to-noise ratio, PSNR) 및 상기 제1 이미지 블럭 및 상기 제3 이미지 블럭의 제2 최대 신호 대 잡음비를 산출하는 단계; 및
상기 제1 최대 신호 대 잡음비 및 상기 제2 최대 신호 대 잡음비 중 적어도 하나가 기설정된 값보다 작은 경우, 상기 제2 이미지 블럭 및 상기 제3 이미지 블럭 중 상기 기설정된 값보다 작은 최대 신호 대 잡음비에 대응되는 이미지 블럭을 대신하여 상기 제1 이미지 블럭을 상기 압축 잡음 제거 네트워크 모델에 입력하는 단계;를 더 포함하는, 제어 방법. - 제14항에 있어서,
경계로부터의 거리에 따른 가중치에 기초하여 상기 압축 잡음이 제거된 복수의 이미지 블럭을 오버랩하여 결합하는 단계;를 더 포함하는, 제어 방법. - 제11항에 있어서,
상기 압축 잡음을 제거하는 단계는,
상기 프레임을 색차 성분과 휘도 성분으로 구분하는 단계;
상기 압축 잡음 제거 네트워크 모델에 기초하여 상기 휘도 성분의 압축 잡음을 제거하는 단계; 및
상기 색차 성분과 상기 압축 잡음이 제거된 휘도 성분을 결합하여 상기 프레임의 압축 잡음을 제거하는 단계;를 포함하며,
상기 복수의 압축 잡음 제거 네트워크 모델은, 상기 복수의 원본 이미지 블럭의 휘도 성분 및 상기 복수의 복원 이미지 블럭의 휘도 성분의 관계를 제2 인공지능 알고리즘을 통해 학습하여 획득된, 제어 방법. - 제11항에 있어서,
상기 압축률 네트워크 모델 및 상기 복수의 압축 잡음 제거 네트워크 모델은, 딥러닝(Deep Learning) 네트워크 구조인, 제어 방법.
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020180026209A KR102606200B1 (ko) | 2018-03-06 | 2018-03-06 | 전자 장치 및 그 제어 방법 |
| CN201980017219.3A CN111869220B (zh) | 2018-03-06 | 2019-02-14 | 电子装置及其控制方法 |
| PCT/KR2019/001801 WO2019172546A1 (en) | 2018-03-06 | 2019-02-14 | Electronic apparatus and control method thereof |
| EP19763926.3A EP3707906B1 (en) | 2018-03-06 | 2019-02-14 | Electronic apparatus and control method thereof |
| US16/292,655 US11153575B2 (en) | 2018-03-06 | 2019-03-05 | Electronic apparatus and control method thereof |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020180026209A KR102606200B1 (ko) | 2018-03-06 | 2018-03-06 | 전자 장치 및 그 제어 방법 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20190105745A true KR20190105745A (ko) | 2019-09-18 |
| KR102606200B1 KR102606200B1 (ko) | 2023-11-24 |
Family
ID=67843667
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020180026209A Active KR102606200B1 (ko) | 2018-03-06 | 2018-03-06 | 전자 장치 및 그 제어 방법 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US11153575B2 (ko) |
| EP (1) | EP3707906B1 (ko) |
| KR (1) | KR102606200B1 (ko) |
| CN (1) | CN111869220B (ko) |
| WO (1) | WO2019172546A1 (ko) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20220085212A (ko) * | 2020-12-15 | 2022-06-22 | 세종대학교산학협력단 | 딥러닝 기반 이미지 복구 기술을 이용한 패션 이미지 검색 방법 및 장치 |
| WO2023055112A1 (ko) * | 2021-09-30 | 2023-04-06 | 삼성전자 주식회사 | 전자 장치에서 이미지의 압축 품질 예측 방법 및 장치 |
| KR20230078649A (ko) * | 2020-09-23 | 2023-06-02 | 소니 인터랙티브 엔터테인먼트 엘엘씨 | 저해상도 압축 데이터 구조로부터 텍스처를 나타내는 고해상도 압축 데이터 구조를 생성하고 이를 위한 훈련을 위한 머신 러닝 기술 |
| US12462356B2 (en) | 2021-09-30 | 2025-11-04 | Samsung Electronics Co., Ltd. | Apparatus and method for predicting compression quality of image in electronic device |
Families Citing this family (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11750811B2 (en) * | 2018-04-06 | 2023-09-05 | Comcast Cable Communications, Llc | Systems, methods, and apparatuses for processing video |
| KR102825472B1 (ko) * | 2018-08-30 | 2025-06-30 | 삼성전자주식회사 | 전자 장치 및 그 제어 방법 |
| US10705170B1 (en) * | 2019-02-15 | 2020-07-07 | GE Precision Healthcare LLC | Methods and systems for removing spike noise in magnetic resonance imaging |
| EP3767536B1 (en) * | 2019-07-17 | 2025-02-19 | Naver Corporation | Latent code for unsupervised domain adaptation |
| WO2021061748A1 (en) * | 2019-09-23 | 2021-04-01 | Apple Inc. | Video compression with in-loop sub-image level controllable noise generation |
| CN112995673B (zh) * | 2019-12-13 | 2023-04-07 | 北京金山云网络技术有限公司 | 一种样本图像处理方法、装置、电子设备以及介质 |
| CN111105375B (zh) * | 2019-12-17 | 2023-08-22 | 北京金山云网络技术有限公司 | 图像生成方法及其模型训练方法、装置及电子设备 |
| CN111738952B (zh) * | 2020-06-22 | 2023-10-10 | 京东方科技集团股份有限公司 | 一种图像修复的方法、装置及电子设备 |
| CN111726554B (zh) * | 2020-06-30 | 2022-10-14 | 阿波罗智能技术(北京)有限公司 | 图像处理方法、装置、设备和存储介质 |
| US11538136B2 (en) * | 2020-10-28 | 2022-12-27 | Qualcomm Incorporated | System and method to process images of a video stream |
| KR20220124528A (ko) * | 2021-03-03 | 2022-09-14 | 삼성전자주식회사 | 전자 장치에서 이미지의 압축 품질에 기반한 이미지 보정 방법 및 장치 |
| CN115409719A (zh) * | 2021-05-28 | 2022-11-29 | 武汉Tcl集团工业研究院有限公司 | 数据处理方法、装置、终端设备及计算机可读存储介质 |
Family Cites Families (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7346208B2 (en) * | 2003-10-25 | 2008-03-18 | Hewlett-Packard Development Company, L.P. | Image artifact reduction using a neural network |
| US20060140268A1 (en) | 2004-12-29 | 2006-06-29 | Samsung Electronics Co., Ltd. | Method and apparatus for reduction of compression noise in compressed video images |
| JP5597968B2 (ja) * | 2009-07-01 | 2014-10-01 | ソニー株式会社 | 画像処理装置および方法、プログラム、並びに記録媒体 |
| US9565439B2 (en) * | 2009-10-15 | 2017-02-07 | Nbcuniversal Media, Llc | System and method for enhancing data compression using dynamic learning and control |
| JP6083162B2 (ja) | 2012-09-10 | 2017-02-22 | 株式会社ニコン | 画像処理装置、撮像装置及び画像処理プログラム |
| US9147374B2 (en) * | 2013-05-21 | 2015-09-29 | International Business Machines Corporation | Controlling real-time compression detection |
| KR20150054554A (ko) * | 2013-11-12 | 2015-05-20 | 삼성전자주식회사 | 영상 처리장치 및 방법 |
| KR102288280B1 (ko) | 2014-11-05 | 2021-08-10 | 삼성전자주식회사 | 영상 학습 모델을 이용한 영상 생성 방법 및 장치 |
| US11221990B2 (en) * | 2015-04-03 | 2022-01-11 | The Mitre Corporation | Ultra-high compression of images based on deep learning |
| US20160321523A1 (en) | 2015-04-30 | 2016-11-03 | The Regents Of The University Of California | Using machine learning to filter monte carlo noise from images |
| KR20170077621A (ko) | 2015-12-28 | 2017-07-06 | 연세대학교 산학협력단 | 영상 압축에서의 플리커링 현상 제거 방법 및 그 장치 |
| US9881208B2 (en) * | 2016-06-20 | 2018-01-30 | Machine Learning Works, LLC | Neural network based recognition of mathematical expressions |
| CN106295682A (zh) | 2016-08-02 | 2017-01-04 | 厦门美图之家科技有限公司 | 一种判断图片质量因子的方法、装置和计算设备 |
| CN106331741B (zh) * | 2016-08-31 | 2019-03-08 | 徐州视达坦诚文化发展有限公司 | 一种电视广播媒体音视频数据的压缩方法 |
| US10083499B1 (en) * | 2016-10-11 | 2018-09-25 | Google Llc | Methods and apparatus to reduce compression artifacts in images |
| JP6581068B2 (ja) * | 2016-11-11 | 2019-09-25 | 株式会社東芝 | 画像処理装置、画像処理方法、プログラム、運転制御システム、および、車両 |
| CN107743235B (zh) * | 2017-10-27 | 2019-09-27 | 厦门美图之家科技有限公司 | 图像处理方法、装置及电子设备 |
-
2018
- 2018-03-06 KR KR1020180026209A patent/KR102606200B1/ko active Active
-
2019
- 2019-02-14 CN CN201980017219.3A patent/CN111869220B/zh active Active
- 2019-02-14 EP EP19763926.3A patent/EP3707906B1/en active Active
- 2019-02-14 WO PCT/KR2019/001801 patent/WO2019172546A1/en not_active Ceased
- 2019-03-05 US US16/292,655 patent/US11153575B2/en active Active
Non-Patent Citations (2)
| Title |
|---|
| Pavel Svoboda 등, Compression Artifacts Removal Using Convolutional Neural Networks, arXiv, 2016. 5. 2.* * |
| Sebastian Bosse 등, A DEEP NEURAL NETWORK FOR IMAGE QUALITY ASSESSMENT, ICIP 2016, IEEE, 2016. 8. 19.* * |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20230078649A (ko) * | 2020-09-23 | 2023-06-02 | 소니 인터랙티브 엔터테인먼트 엘엘씨 | 저해상도 압축 데이터 구조로부터 텍스처를 나타내는 고해상도 압축 데이터 구조를 생성하고 이를 위한 훈련을 위한 머신 러닝 기술 |
| KR20220085212A (ko) * | 2020-12-15 | 2022-06-22 | 세종대학교산학협력단 | 딥러닝 기반 이미지 복구 기술을 이용한 패션 이미지 검색 방법 및 장치 |
| WO2023055112A1 (ko) * | 2021-09-30 | 2023-04-06 | 삼성전자 주식회사 | 전자 장치에서 이미지의 압축 품질 예측 방법 및 장치 |
| US12462356B2 (en) | 2021-09-30 | 2025-11-04 | Samsung Electronics Co., Ltd. | Apparatus and method for predicting compression quality of image in electronic device |
Also Published As
| Publication number | Publication date |
|---|---|
| US20190281310A1 (en) | 2019-09-12 |
| WO2019172546A1 (en) | 2019-09-12 |
| EP3707906A1 (en) | 2020-09-16 |
| CN111869220B (zh) | 2022-11-22 |
| EP3707906B1 (en) | 2023-08-16 |
| US11153575B2 (en) | 2021-10-19 |
| KR102606200B1 (ko) | 2023-11-24 |
| CN111869220A (zh) | 2020-10-30 |
| EP3707906A4 (en) | 2020-12-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102606200B1 (ko) | 전자 장치 및 그 제어 방법 | |
| US12356035B2 (en) | Apparatus and method with artificial intelligence for scaling image data | |
| US12175632B2 (en) | Image processing method and apparatus, device, and video processing method | |
| CN111771226B (zh) | 电子设备、其图像处理方法及计算机可读记录介质 | |
| CN114418069B (zh) | 一种编码器的训练方法、装置及存储介质 | |
| KR101882704B1 (ko) | 전자 장치 및 그 제어 방법 | |
| EP3910507B1 (en) | Method and apparatus for waking up screen | |
| CN113128368B (zh) | 一种人物交互关系的检测方法、装置及系统 | |
| KR102488338B1 (ko) | 언어 모델을 압축하기 위한 전자 장치, 추천 워드를 제공하기 위한 전자 장치 및 그 동작 방법들 | |
| CN116309173B (zh) | 视频质量增强方法、装置、设备及存储介质 | |
| KR20200027080A (ko) | 전자 장치 및 그 제어 방법 | |
| CN109547803B (zh) | 一种时空域显著性检测及融合方法 | |
| US10997947B2 (en) | Electronic device and control method thereof | |
| US20260100017A1 (en) | Image Processing Method, Model Training Method, and Related Apparatus | |
| Du et al. | Adaptive visual interaction based multi-target future state prediction for autonomous driving vehicles | |
| EP3738305B1 (en) | Electronic device and control method thereof | |
| CN113780252B (zh) | 视频处理模型的训练方法、视频处理方法和装置 | |
| CN119478760A (zh) | 图像处理模型训练方法、图像处理方法及相关设备 | |
| KR20200027085A (ko) | 전자 장치 및 그 제어 방법 | |
| CN121685672A (zh) | 图像压缩方法、装置、电子设备和可读介质 | |
| EP4732233A1 (en) | Generative photo uncropping and recomposition | |
| CN118823619A (zh) | 一种数据处理方法及相关设备 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application |
St.27 status event code: A-0-1-A10-A12-nap-PA0109 |
|
| P11-X000 | Amendment of application requested |
St.27 status event code: A-2-2-P10-P11-nap-X000 |
|
| P13-X000 | Application amended |
St.27 status event code: A-2-2-P10-P13-nap-X000 |
|
| P22-X000 | Classification modified |
St.27 status event code: A-2-2-P10-P22-nap-X000 |
|
| P22-X000 | Classification modified |
St.27 status event code: A-2-2-P10-P22-nap-X000 |
|
| R18-X000 | Changes to party contact information recorded |
St.27 status event code: A-3-3-R10-R18-oth-X000 |
|
| R18-X000 | Changes to party contact information recorded |
St.27 status event code: A-3-3-R10-R18-oth-X000 |
|
| P22-X000 | Classification modified |
St.27 status event code: A-2-2-P10-P22-nap-X000 |
|
| PN2301 | Change of applicant |
St.27 status event code: A-3-3-R10-R13-asn-PN2301 St.27 status event code: A-3-3-R10-R11-asn-PN2301 |
|
| PG1501 | Laying open of application |
St.27 status event code: A-1-1-Q10-Q12-nap-PG1501 |
|
| PN2301 | Change of applicant |
St.27 status event code: A-3-3-R10-R13-asn-PN2301 St.27 status event code: A-3-3-R10-R11-asn-PN2301 |
|
| A201 | Request for examination | ||
| PA0201 | Request for examination |
St.27 status event code: A-1-2-D10-D11-exm-PA0201 |
|
| R18-X000 | Changes to party contact information recorded |
St.27 status event code: A-3-3-R10-R18-oth-X000 |
|
| R18-X000 | Changes to party contact information recorded |
St.27 status event code: A-3-3-R10-R18-oth-X000 |
|
| D13-X000 | Search requested |
St.27 status event code: A-1-2-D10-D13-srh-X000 |
|
| D14-X000 | Search report completed |
St.27 status event code: A-1-2-D10-D14-srh-X000 |
|
| R18-X000 | Changes to party contact information recorded |
St.27 status event code: A-3-3-R10-R18-oth-X000 |
|
| R18-X000 | Changes to party contact information recorded |
St.27 status event code: A-3-3-R10-R18-oth-X000 |
|
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
St.27 status event code: A-1-2-D10-D21-exm-PE0902 |
|
| E13-X000 | Pre-grant limitation requested |
St.27 status event code: A-2-3-E10-E13-lim-X000 |
|
| P11-X000 | Amendment of application requested |
St.27 status event code: A-2-2-P10-P11-nap-X000 |
|
| P13-X000 | Application amended |
St.27 status event code: A-2-2-P10-P13-nap-X000 |
|
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration |
St.27 status event code: A-1-2-D10-D22-exm-PE0701 |
|
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment |
St.27 status event code: A-2-4-F10-F11-exm-PR0701 |
|
| PR1002 | Payment of registration fee |
St.27 status event code: A-2-2-U10-U11-oth-PR1002 Fee payment year number: 1 |
|
| PG1601 | Publication of registration |
St.27 status event code: A-4-4-Q10-Q13-nap-PG1601 |
|
| R18-X000 | Changes to party contact information recorded |
St.27 status event code: A-5-5-R10-R18-oth-X000 |
|
| P22-X000 | Classification modified |
St.27 status event code: A-4-4-P10-P22-nap-X000 |
|
| R18-X000 | Changes to party contact information recorded |
St.27 status event code: A-5-5-R10-R18-oth-X000 |
|
| R18 | Changes to party contact information recorded |
Free format text: ST27 STATUS EVENT CODE: A-5-5-R10-R18-OTH-X000 (AS PROVIDED BY THE NATIONAL OFFICE) |
|
| R18-X000 | Changes to party contact information recorded |
St.27 status event code: A-5-5-R10-R18-oth-X000 |