KR20190122232A - 망막층간분리증의 비인간 동물 모델 - Google Patents
망막층간분리증의 비인간 동물 모델 Download PDFInfo
- Publication number
- KR20190122232A KR20190122232A KR1020197027972A KR20197027972A KR20190122232A KR 20190122232 A KR20190122232 A KR 20190122232A KR 1020197027972 A KR1020197027972 A KR 1020197027972A KR 20197027972 A KR20197027972 A KR 20197027972A KR 20190122232 A KR20190122232 A KR 20190122232A
- Authority
- KR
- South Korea
- Prior art keywords
- rodent
- gene
- exon
- polypeptide
- endogenous
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
- 230000002207 retinal effect Effects 0.000 title claims description 49
- 238000000926 separation method Methods 0.000 title claims description 31
- 238000010171 animal model Methods 0.000 title abstract description 19
- 241000282414 Homo sapiens Species 0.000 claims abstract description 274
- 238000000034 method Methods 0.000 claims abstract description 105
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims abstract description 47
- 201000010099 disease Diseases 0.000 claims abstract description 27
- 208000035475 disorder Diseases 0.000 claims abstract description 19
- 208000024891 symptom Diseases 0.000 claims abstract description 17
- 101000668058 Infectious salmon anemia virus (isolate Atlantic salmon/Norway/810/9/99) RNA-directed RNA polymerase catalytic subunit Proteins 0.000 claims abstract description 12
- 108090000623 proteins and genes Proteins 0.000 claims description 422
- 241000283984 Rodentia Species 0.000 claims description 201
- 229920001184 polypeptide Polymers 0.000 claims description 198
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 198
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 198
- 210000004027 cell Anatomy 0.000 claims description 160
- 238000006467 substitution reaction Methods 0.000 claims description 155
- 230000035772 mutation Effects 0.000 claims description 113
- 235000001014 amino acid Nutrition 0.000 claims description 111
- 238000012217 deletion Methods 0.000 claims description 101
- 230000037430 deletion Effects 0.000 claims description 101
- 239000003814 drug Substances 0.000 claims description 100
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 88
- 108091026890 Coding region Proteins 0.000 claims description 72
- 230000014509 gene expression Effects 0.000 claims description 71
- 108700008625 Reporter Genes Proteins 0.000 claims description 69
- 150000007523 nucleic acids Chemical group 0.000 claims description 66
- 108010091086 Recombinases Proteins 0.000 claims description 54
- 238000003780 insertion Methods 0.000 claims description 50
- 230000037431 insertion Effects 0.000 claims description 50
- 102000004169 proteins and genes Human genes 0.000 claims description 46
- 102200047033 rs61752158 Human genes 0.000 claims description 44
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 42
- 102200046985 rs62645889 Human genes 0.000 claims description 42
- 108700024394 Exon Proteins 0.000 claims description 35
- 102000039446 nucleic acids Human genes 0.000 claims description 35
- 108020004707 nucleic acids Proteins 0.000 claims description 35
- 108020004705 Codon Proteins 0.000 claims description 29
- 235000018102 proteins Nutrition 0.000 claims description 29
- 239000002773 nucleotide Substances 0.000 claims description 28
- 125000003729 nucleotide group Chemical group 0.000 claims description 28
- 101150066555 lacZ gene Proteins 0.000 claims description 27
- 238000004519 manufacturing process Methods 0.000 claims description 27
- 230000001105 regulatory effect Effects 0.000 claims description 26
- 239000011229 interlayer Substances 0.000 claims description 23
- 108010052160 Site-specific recombinase Proteins 0.000 claims description 22
- 239000003550 marker Substances 0.000 claims description 22
- 238000002679 ablation Methods 0.000 claims description 20
- 238000003556 assay Methods 0.000 claims description 20
- 210000001161 mammalian embryo Anatomy 0.000 claims description 20
- 229940124597 therapeutic agent Drugs 0.000 claims description 19
- 238000011282 treatment Methods 0.000 claims description 17
- 210000001671 embryonic stem cell Anatomy 0.000 claims description 16
- 235000018417 cysteine Nutrition 0.000 claims description 14
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 claims description 14
- 108010049959 Discoidins Proteins 0.000 claims description 13
- 108010076504 Protein Sorting Signals Proteins 0.000 claims description 13
- 108091005957 yellow fluorescent proteins Proteins 0.000 claims description 13
- 239000003795 chemical substances by application Substances 0.000 claims description 12
- 108091081024 Start codon Proteins 0.000 claims description 11
- 125000000151 cysteine group Chemical class N[C@@H](CS)C(=O)* 0.000 claims description 10
- 108091005941 EBFP Proteins 0.000 claims description 9
- 108010043121 Green Fluorescent Proteins Proteins 0.000 claims description 9
- 102000004144 Green Fluorescent Proteins Human genes 0.000 claims description 9
- 108010048367 enhanced green fluorescent protein Proteins 0.000 claims description 9
- 239000005090 green fluorescent protein Substances 0.000 claims description 9
- 108010082025 cyan fluorescent protein Proteins 0.000 claims description 8
- -1 eYFP Proteins 0.000 claims description 7
- 108060001084 Luciferase Proteins 0.000 claims description 6
- 239000005089 Luciferase Substances 0.000 claims description 6
- 210000004899 c-terminal region Anatomy 0.000 claims description 6
- 108010021843 fluorescent protein 583 Proteins 0.000 claims description 6
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 claims description 5
- 108091005948 blue fluorescent proteins Proteins 0.000 claims description 5
- 125000001165 hydrophobic group Chemical group 0.000 claims description 5
- 125000001500 prolyl group Chemical group [H]N1C([H])(C(=O)[*])C([H])([H])C([H])([H])C1([H])[H] 0.000 claims description 3
- 208000030533 eye disease Diseases 0.000 claims 1
- 238000002271 resection Methods 0.000 claims 1
- 241001465754 Metazoa Species 0.000 abstract description 80
- 206010038848 Retinal detachment Diseases 0.000 abstract description 21
- 230000004264 retinal detachment Effects 0.000 abstract description 19
- 229940124598 therapeutic candidate Drugs 0.000 abstract 1
- 230000008685 targeting Effects 0.000 description 93
- 241000699666 Mus <mouse, genus> Species 0.000 description 88
- 239000013598 vector Substances 0.000 description 88
- 108020004414 DNA Proteins 0.000 description 75
- 229940079593 drug Drugs 0.000 description 70
- 210000001525 retina Anatomy 0.000 description 56
- 241000699670 Mus sp. Species 0.000 description 55
- 241000700159 Rattus Species 0.000 description 49
- 102000040430 polynucleotide Human genes 0.000 description 35
- 108091033319 polynucleotide Proteins 0.000 description 35
- 239000002157 polynucleotide Substances 0.000 description 35
- 238000002571 electroretinography Methods 0.000 description 34
- 108700028369 Alleles Proteins 0.000 description 32
- 238000011161 development Methods 0.000 description 32
- 230000018109 developmental process Effects 0.000 description 32
- 230000000694 effects Effects 0.000 description 31
- 102000018120 Recombinases Human genes 0.000 description 29
- 210000001508 eye Anatomy 0.000 description 26
- 150000001413 amino acids Chemical class 0.000 description 25
- 239000012634 fragment Substances 0.000 description 24
- 230000001404 mediated effect Effects 0.000 description 21
- 238000012014 optical coherence tomography Methods 0.000 description 21
- 108091034117 Oligonucleotide Proteins 0.000 description 20
- 239000010410 layer Substances 0.000 description 20
- 210000004436 artificial bacterial chromosome Anatomy 0.000 description 19
- 230000006870 function Effects 0.000 description 19
- 108020004999 messenger RNA Proteins 0.000 description 19
- 238000004458 analytical method Methods 0.000 description 18
- 239000000203 mixture Substances 0.000 description 18
- 210000001519 tissue Anatomy 0.000 description 18
- 210000002257 embryonic structure Anatomy 0.000 description 15
- 238000001415 gene therapy Methods 0.000 description 15
- 238000002744 homologous recombination Methods 0.000 description 15
- 230000006801 homologous recombination Effects 0.000 description 15
- 238000001727 in vivo Methods 0.000 description 15
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 14
- 108091092195 Intron Proteins 0.000 description 14
- 210000001766 X chromosome Anatomy 0.000 description 14
- 230000002093 peripheral effect Effects 0.000 description 14
- 239000000523 sample Substances 0.000 description 14
- 229960005486 vaccine Drugs 0.000 description 14
- 108090000790 Enzymes Proteins 0.000 description 13
- PYTKULIABVRXSC-BWBBJGPYSA-N Ser-Ser-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PYTKULIABVRXSC-BWBBJGPYSA-N 0.000 description 13
- 230000006378 damage Effects 0.000 description 13
- 201000001408 X-linked juvenile retinoschisis 1 Diseases 0.000 description 12
- 208000017441 X-linked retinoschisis Diseases 0.000 description 12
- 210000004602 germ cell Anatomy 0.000 description 12
- 210000000287 oocyte Anatomy 0.000 description 12
- UBCPNBUIQNMDNH-NAKRPEOUSA-N Arg-Ile-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O UBCPNBUIQNMDNH-NAKRPEOUSA-N 0.000 description 11
- GISFCCXBVJKGEO-QEJZJMRPSA-N Asp-Glu-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O GISFCCXBVJKGEO-QEJZJMRPSA-N 0.000 description 11
- VGTDBGYFVWOQTI-RYUDHWBXSA-N Gln-Gly-Phe Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 VGTDBGYFVWOQTI-RYUDHWBXSA-N 0.000 description 11
- GTBXHETZPUURJE-KKUMJFAQSA-N Gln-Tyr-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GTBXHETZPUURJE-KKUMJFAQSA-N 0.000 description 11
- MWMJCGBSIORNCD-AVGNSLFASA-N Glu-Leu-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O MWMJCGBSIORNCD-AVGNSLFASA-N 0.000 description 11
- JSNNHGHYGYMVCK-XVKPBYJWSA-N Gly-Glu-Val Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O JSNNHGHYGYMVCK-XVKPBYJWSA-N 0.000 description 11
- UESJMAMHDLEHGM-NHCYSSNCSA-N Gly-Ile-Leu Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O UESJMAMHDLEHGM-NHCYSSNCSA-N 0.000 description 11
- UNDGQKWQNSTPPW-CYDGBPFRSA-N Ile-Arg-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCSC)C(=O)O)N UNDGQKWQNSTPPW-CYDGBPFRSA-N 0.000 description 11
- RKQAYOWLSFLJEE-SVSWQMSJSA-N Ile-Thr-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)O)N RKQAYOWLSFLJEE-SVSWQMSJSA-N 0.000 description 11
- NXRNRBOKDBIVKQ-CXTHYWKRSA-N Ile-Tyr-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N NXRNRBOKDBIVKQ-CXTHYWKRSA-N 0.000 description 11
- 108010065920 Insulin Lispro Proteins 0.000 description 11
- IBMVEYRWAWIOTN-UHFFFAOYSA-N L-Leucyl-L-Arginyl-L-Proline Natural products CC(C)CC(N)C(=O)NC(CCCN=C(N)N)C(=O)N1CCCC1C(O)=O IBMVEYRWAWIOTN-UHFFFAOYSA-N 0.000 description 11
- OGCQGUIWMSBHRZ-CIUDSAMLSA-N Leu-Asn-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O OGCQGUIWMSBHRZ-CIUDSAMLSA-N 0.000 description 11
- USTCFDAQCLDPBD-XIRDDKMYSA-N Leu-Asn-Trp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N USTCFDAQCLDPBD-XIRDDKMYSA-N 0.000 description 11
- AMSSKPUHBUQBOQ-SRVKXCTJSA-N Leu-Ser-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N AMSSKPUHBUQBOQ-SRVKXCTJSA-N 0.000 description 11
- RVOMPSJXSRPFJT-DCAQKATOSA-N Lys-Ala-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RVOMPSJXSRPFJT-DCAQKATOSA-N 0.000 description 11
- VHFFQUSNFFIZBT-CIUDSAMLSA-N Lys-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCCCN)N VHFFQUSNFFIZBT-CIUDSAMLSA-N 0.000 description 11
- HIIZIQUUHIXUJY-GUBZILKMSA-N Lys-Asp-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HIIZIQUUHIXUJY-GUBZILKMSA-N 0.000 description 11
- RDIILCRAWOSDOQ-CIUDSAMLSA-N Lys-Cys-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N RDIILCRAWOSDOQ-CIUDSAMLSA-N 0.000 description 11
- 241001529936 Murinae Species 0.000 description 11
- JWQWPTLEOFNCGX-AVGNSLFASA-N Phe-Glu-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 JWQWPTLEOFNCGX-AVGNSLFASA-N 0.000 description 11
- FXGIMYRVJJEIIM-UWVGGRQHSA-N Pro-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FXGIMYRVJJEIIM-UWVGGRQHSA-N 0.000 description 11
- CNIIKZQXBBQHCX-FXQIFTODSA-N Ser-Asp-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O CNIIKZQXBBQHCX-FXQIFTODSA-N 0.000 description 11
- FZXOPYUEQGDGMS-ACZMJKKPSA-N Ser-Ser-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O FZXOPYUEQGDGMS-ACZMJKKPSA-N 0.000 description 11
- DFTCYYILCSQGIZ-GCJQMDKQSA-N Thr-Ala-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O DFTCYYILCSQGIZ-GCJQMDKQSA-N 0.000 description 11
- UHBPFYOQQPFKQR-JHEQGTHGSA-N Thr-Gln-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O UHBPFYOQQPFKQR-JHEQGTHGSA-N 0.000 description 11
- XFTYVCHLARBHBQ-FOHZUACHSA-N Thr-Gly-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O XFTYVCHLARBHBQ-FOHZUACHSA-N 0.000 description 11
- CDHQEOXPWBDFPL-QWRGUYRKSA-N Tyr-Gly-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 CDHQEOXPWBDFPL-QWRGUYRKSA-N 0.000 description 11
- WVGKPKDWYQXWLU-BZSNNMDCSA-N Tyr-His-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CCCCN)C(=O)O)N)O WVGKPKDWYQXWLU-BZSNNMDCSA-N 0.000 description 11
- TYFLVOUZHQUBGM-IHRRRGAJSA-N Tyr-Ser-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 TYFLVOUZHQUBGM-IHRRRGAJSA-N 0.000 description 11
- OUUBKKIJQIAPRI-LAEOZQHASA-N Val-Gln-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O OUUBKKIJQIAPRI-LAEOZQHASA-N 0.000 description 11
- JVYIGCARISMLMV-HOCLYGCPSA-N Val-Gly-Trp Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N JVYIGCARISMLMV-HOCLYGCPSA-N 0.000 description 11
- OVBMCNDKCWAXMZ-NAKRPEOUSA-N Val-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](C(C)C)N OVBMCNDKCWAXMZ-NAKRPEOUSA-N 0.000 description 11
- 230000001419 dependent effect Effects 0.000 description 11
- 238000003364 immunohistochemistry Methods 0.000 description 11
- 108010051673 leucyl-glycyl-phenylalanine Proteins 0.000 description 11
- 108010056582 methionylglutamic acid Proteins 0.000 description 11
- 108700042769 prolyl-leucyl-glycine Proteins 0.000 description 11
- 230000009467 reduction Effects 0.000 description 11
- 230000004044 response Effects 0.000 description 11
- 108010051110 tyrosyl-lysine Proteins 0.000 description 11
- JTWOBPNAVBESFW-FXQIFTODSA-N Arg-Cys-Asp Chemical compound C(C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)CN=C(N)N JTWOBPNAVBESFW-FXQIFTODSA-N 0.000 description 10
- JEPNYDRDYNSFIU-QXEWZRGKSA-N Asn-Arg-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CC(N)=O)C(O)=O JEPNYDRDYNSFIU-QXEWZRGKSA-N 0.000 description 10
- WJHYGGVCWREQMO-GHCJXIJMSA-N Asp-Cys-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WJHYGGVCWREQMO-GHCJXIJMSA-N 0.000 description 10
- 108010051219 Cre recombinase Proteins 0.000 description 10
- KEBJBKIASQVRJS-WDSKDSINSA-N Cys-Gln-Gly Chemical compound C(CC(=O)N)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N KEBJBKIASQVRJS-WDSKDSINSA-N 0.000 description 10
- 102000004190 Enzymes Human genes 0.000 description 10
- FYBSCGZLICNOBA-XQXXSGGOSA-N Glu-Ala-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FYBSCGZLICNOBA-XQXXSGGOSA-N 0.000 description 10
- XXCDTYBVGMPIOA-FXQIFTODSA-N Glu-Asp-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XXCDTYBVGMPIOA-FXQIFTODSA-N 0.000 description 10
- HUFCEIHAFNVSNR-IHRRRGAJSA-N Glu-Gln-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HUFCEIHAFNVSNR-IHRRRGAJSA-N 0.000 description 10
- GVVKYKCOFMMTKZ-WHFBIAKZSA-N Gly-Cys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CS)NC(=O)CN GVVKYKCOFMMTKZ-WHFBIAKZSA-N 0.000 description 10
- WECYRWOMWSCWNX-XUXIUFHCSA-N Ile-Arg-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(C)C)C(O)=O WECYRWOMWSCWNX-XUXIUFHCSA-N 0.000 description 10
- RGSOCXHDOPQREB-ZPFDUUQYSA-N Ile-Asp-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N RGSOCXHDOPQREB-ZPFDUUQYSA-N 0.000 description 10
- IVXJIMGDOYRLQU-XUXIUFHCSA-N Ile-Pro-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O IVXJIMGDOYRLQU-XUXIUFHCSA-N 0.000 description 10
- HYIFFZAQXPUEAU-QWRGUYRKSA-N Leu-Gly-Leu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(C)C HYIFFZAQXPUEAU-QWRGUYRKSA-N 0.000 description 10
- DSFYPIUSAMSERP-IHRRRGAJSA-N Leu-Leu-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DSFYPIUSAMSERP-IHRRRGAJSA-N 0.000 description 10
- INCJJHQRZGQLFC-KBPBESRZSA-N Leu-Phe-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O INCJJHQRZGQLFC-KBPBESRZSA-N 0.000 description 10
- WBRJVRXEGQIDRK-XIRDDKMYSA-N Leu-Trp-Ser Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](CO)C(O)=O)=CNC2=C1 WBRJVRXEGQIDRK-XIRDDKMYSA-N 0.000 description 10
- IHRFZLQEQVHXFA-RHYQMDGZSA-N Met-Thr-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCCN IHRFZLQEQVHXFA-RHYQMDGZSA-N 0.000 description 10
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 10
- 229930193140 Neomycin Natural products 0.000 description 10
- LNOWDSPAYBWJOR-PEDHHIEDSA-N Pro-Ile-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LNOWDSPAYBWJOR-PEDHHIEDSA-N 0.000 description 10
- QGMLKFGTGXWAHF-IHRRRGAJSA-N Ser-Arg-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QGMLKFGTGXWAHF-IHRRRGAJSA-N 0.000 description 10
- JLPMFVAIQHCBDC-CIUDSAMLSA-N Ser-Lys-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N JLPMFVAIQHCBDC-CIUDSAMLSA-N 0.000 description 10
- YBXMGKCLOPDEKA-NUMRIWBASA-N Thr-Asp-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O YBXMGKCLOPDEKA-NUMRIWBASA-N 0.000 description 10
- YVXIAOOYAKBAAI-SZMVWBNQSA-N Trp-Leu-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 YVXIAOOYAKBAAI-SZMVWBNQSA-N 0.000 description 10
- UMSZZGTXGKHTFJ-SRVKXCTJSA-N Tyr-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 UMSZZGTXGKHTFJ-SRVKXCTJSA-N 0.000 description 10
- 108010060199 cysteinylproline Proteins 0.000 description 10
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 10
- 108010087823 glycyltyrosine Proteins 0.000 description 10
- 108010034529 leucyl-lysine Proteins 0.000 description 10
- 229960004927 neomycin Drugs 0.000 description 10
- 230000009261 transgenic effect Effects 0.000 description 10
- 201000004569 Blindness Diseases 0.000 description 9
- 241000283690 Bos taurus Species 0.000 description 9
- FKGNJUCQKXQNRA-NRPADANISA-N Glu-Cys-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CCC(O)=O FKGNJUCQKXQNRA-NRPADANISA-N 0.000 description 9
- RIUZKUJUPVFAGY-HOTGVXAUSA-N Gly-Trp-His Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CN=CN3)C(=O)O)NC(=O)CN RIUZKUJUPVFAGY-HOTGVXAUSA-N 0.000 description 9
- QBEPTBMRQALPEV-MNXVOIDGSA-N Lys-Ile-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCCCN QBEPTBMRQALPEV-MNXVOIDGSA-N 0.000 description 9
- 206010028980 Neoplasm Diseases 0.000 description 9
- QCARZLHECSFOGG-CIUDSAMLSA-N Pro-Glu-Cys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CS)C(=O)O QCARZLHECSFOGG-CIUDSAMLSA-N 0.000 description 9
- 201000011510 cancer Diseases 0.000 description 9
- 230000004048 modification Effects 0.000 description 9
- 238000012986 modification Methods 0.000 description 9
- 239000000243 solution Substances 0.000 description 9
- FIQQRCFQXGLOSZ-WDSKDSINSA-N Gly-Glu-Asp Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O FIQQRCFQXGLOSZ-WDSKDSINSA-N 0.000 description 8
- 101000814438 Homo sapiens Retinoschisin Proteins 0.000 description 8
- PWWVAXIEGOYWEE-UHFFFAOYSA-N Isophenergan Chemical compound C1=CC=C2N(CC(C)N(C)C)C3=CC=CC=C3SC2=C1 PWWVAXIEGOYWEE-UHFFFAOYSA-N 0.000 description 8
- 241001494479 Pecora Species 0.000 description 8
- NDXSOKGYKCGYKT-VEVYYDQMSA-N Thr-Pro-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O NDXSOKGYKCGYKT-VEVYYDQMSA-N 0.000 description 8
- RVMNUBQWPVOUKH-HEIBUPTGSA-N Thr-Ser-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RVMNUBQWPVOUKH-HEIBUPTGSA-N 0.000 description 8
- 108010093581 aspartyl-proline Proteins 0.000 description 8
- 230000000877 morphologic effect Effects 0.000 description 8
- 108091008695 photoreceptors Proteins 0.000 description 8
- 210000002966 serum Anatomy 0.000 description 8
- 238000001262 western blot Methods 0.000 description 8
- 238000002965 ELISA Methods 0.000 description 7
- 241000282326 Felis catus Species 0.000 description 7
- 101000687343 Mus musculus PR domain zinc finger protein 1 Proteins 0.000 description 7
- SXJGROGVINAYSH-AVGNSLFASA-N Phe-Gln-Asp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N SXJGROGVINAYSH-AVGNSLFASA-N 0.000 description 7
- 108091023045 Untranslated Region Proteins 0.000 description 7
- 241000700605 Viruses Species 0.000 description 7
- 230000000903 blocking effect Effects 0.000 description 7
- 238000001493 electron microscopy Methods 0.000 description 7
- 102000055658 human RS1 Human genes 0.000 description 7
- 108010038320 lysylphenylalanine Proteins 0.000 description 7
- 239000012528 membrane Substances 0.000 description 7
- ZVFVBBGVOILKPO-WHFBIAKZSA-N Ala-Gly-Ala Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O ZVFVBBGVOILKPO-WHFBIAKZSA-N 0.000 description 6
- ZYRXTRTUCAVNBQ-GVXVVHGQSA-N Glu-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZYRXTRTUCAVNBQ-GVXVVHGQSA-N 0.000 description 6
- BRFJMRSRMOMIMU-WHFBIAKZSA-N Gly-Ala-Asn Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O BRFJMRSRMOMIMU-WHFBIAKZSA-N 0.000 description 6
- JPVGHHQGKPQYIL-KBPBESRZSA-N Gly-Phe-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 JPVGHHQGKPQYIL-KBPBESRZSA-N 0.000 description 6
- 241000283973 Oryctolagus cuniculus Species 0.000 description 6
- 241000700157 Rattus norvegicus Species 0.000 description 6
- DKKGAAJTDKHWOD-BIIVOSGPSA-N Ser-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CO)N)C(=O)O DKKGAAJTDKHWOD-BIIVOSGPSA-N 0.000 description 6
- AHERARIZBPOMNU-KATARQTJSA-N Thr-Ser-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O AHERARIZBPOMNU-KATARQTJSA-N 0.000 description 6
- 230000004927 fusion Effects 0.000 description 6
- 239000013612 plasmid Substances 0.000 description 6
- 230000002829 reductive effect Effects 0.000 description 6
- 230000002441 reversible effect Effects 0.000 description 6
- 230000035945 sensitivity Effects 0.000 description 6
- FWBHETKCLVMNFS-UHFFFAOYSA-N 4',6-Diamino-2-phenylindol Chemical compound C1=CC(C(=N)N)=CC=C1C1=CC2=CC=C(C(N)=N)C=C2N1 FWBHETKCLVMNFS-UHFFFAOYSA-N 0.000 description 5
- 241000282472 Canis lupus familiaris Species 0.000 description 5
- 241000283707 Capra Species 0.000 description 5
- 241000283073 Equus caballus Species 0.000 description 5
- XTZDZAXYPDISRR-MNXVOIDGSA-N Glu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N XTZDZAXYPDISRR-MNXVOIDGSA-N 0.000 description 5
- 101100429083 Homo sapiens RS1 gene Proteins 0.000 description 5
- KFKWRHQBZQICHA-STQMWFEESA-N L-leucyl-L-phenylalanine Natural products CC(C)C[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KFKWRHQBZQICHA-STQMWFEESA-N 0.000 description 5
- 241000282560 Macaca mulatta Species 0.000 description 5
- 101100451662 Mus musculus Prm1 gene Proteins 0.000 description 5
- YTILBRIUASDGBL-BZSNNMDCSA-N Phe-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 YTILBRIUASDGBL-BZSNNMDCSA-N 0.000 description 5
- 241000282898 Sus scrofa Species 0.000 description 5
- PKZIWSHDJYIPRH-JBACZVJFSA-N Trp-Tyr-Gln Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O PKZIWSHDJYIPRH-JBACZVJFSA-N 0.000 description 5
- SJWLQICJOBMOGG-PMVMPFDFSA-N Trp-Tyr-His Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)N[C@@H](CC4=CN=CN4)C(=O)O)N SJWLQICJOBMOGG-PMVMPFDFSA-N 0.000 description 5
- 238000007792 addition Methods 0.000 description 5
- 230000004071 biological effect Effects 0.000 description 5
- 230000007850 degeneration Effects 0.000 description 5
- 238000013461 design Methods 0.000 description 5
- 239000000499 gel Substances 0.000 description 5
- 108010044056 leucyl-phenylalanine Proteins 0.000 description 5
- 108010017391 lysylvaline Proteins 0.000 description 5
- 230000003287 optical effect Effects 0.000 description 5
- 230000008569 process Effects 0.000 description 5
- 230000028327 secretion Effects 0.000 description 5
- 239000000126 substance Substances 0.000 description 5
- 230000004393 visual impairment Effects 0.000 description 5
- NHBKXEKEPDILRR-UHFFFAOYSA-N 2,3-bis(butanoylsulfanyl)propyl butanoate Chemical compound CCCC(=O)OCC(SC(=O)CCC)CSC(=O)CCC NHBKXEKEPDILRR-UHFFFAOYSA-N 0.000 description 4
- 101710148099 Blue fluorescence protein Proteins 0.000 description 4
- WSFSSNUMVMOOMR-UHFFFAOYSA-N Formaldehyde Chemical compound O=C WSFSSNUMVMOOMR-UHFFFAOYSA-N 0.000 description 4
- 241000124008 Mammalia Species 0.000 description 4
- PHKBGZKVOJCIMZ-SRVKXCTJSA-N Met-Pro-Arg Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PHKBGZKVOJCIMZ-SRVKXCTJSA-N 0.000 description 4
- 229930040373 Paraformaldehyde Natural products 0.000 description 4
- 101710168705 Protamine-1 Proteins 0.000 description 4
- 201000007737 Retinal degeneration Diseases 0.000 description 4
- 102100040435 Sperm protamine P1 Human genes 0.000 description 4
- NGALWFGCOMHUSN-AVGNSLFASA-N Tyr-Gln-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NGALWFGCOMHUSN-AVGNSLFASA-N 0.000 description 4
- 108010005774 beta-Galactosidase Proteins 0.000 description 4
- 239000000872 buffer Substances 0.000 description 4
- 230000008859 change Effects 0.000 description 4
- 238000006243 chemical reaction Methods 0.000 description 4
- 150000001875 compounds Chemical class 0.000 description 4
- 238000010276 construction Methods 0.000 description 4
- 238000010586 diagram Methods 0.000 description 4
- 238000009826 distribution Methods 0.000 description 4
- 230000002068 genetic effect Effects 0.000 description 4
- 210000005260 human cell Anatomy 0.000 description 4
- 238000001802 infusion Methods 0.000 description 4
- 210000000472 morula Anatomy 0.000 description 4
- 210000004940 nucleus Anatomy 0.000 description 4
- 210000000056 organ Anatomy 0.000 description 4
- 229920002866 paraformaldehyde Polymers 0.000 description 4
- 230000002265 prevention Effects 0.000 description 4
- 230000006798 recombination Effects 0.000 description 4
- 238000005215 recombination Methods 0.000 description 4
- 230000001172 regenerating effect Effects 0.000 description 4
- 230000004243 retinal function Effects 0.000 description 4
- 238000012216 screening Methods 0.000 description 4
- 238000012163 sequencing technique Methods 0.000 description 4
- 230000035939 shock Effects 0.000 description 4
- 238000010186 staining Methods 0.000 description 4
- 238000012360 testing method Methods 0.000 description 4
- 230000002103 transcriptional effect Effects 0.000 description 4
- 238000005406 washing Methods 0.000 description 4
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 4
- 241000271566 Aves Species 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- 208000003098 Ganglion Cysts Diseases 0.000 description 3
- CAEZLMGDJMEBKP-AVGNSLFASA-N Met-Pro-His Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CNC=N1 CAEZLMGDJMEBKP-AVGNSLFASA-N 0.000 description 3
- 206010027476 Metastases Diseases 0.000 description 3
- 241000699660 Mus musculus Species 0.000 description 3
- 241000288906 Primates Species 0.000 description 3
- FIDMVVBUOCMMJG-CIUDSAMLSA-N Ser-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO FIDMVVBUOCMMJG-CIUDSAMLSA-N 0.000 description 3
- 208000005400 Synovial Cyst Diseases 0.000 description 3
- DEGCBBCMYWNJNA-RHYQMDGZSA-N Thr-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O DEGCBBCMYWNJNA-RHYQMDGZSA-N 0.000 description 3
- 230000002159 abnormal effect Effects 0.000 description 3
- 230000002776 aggregation Effects 0.000 description 3
- 238000004220 aggregation Methods 0.000 description 3
- 238000013459 approach Methods 0.000 description 3
- 210000001106 artificial yeast chromosome Anatomy 0.000 description 3
- 102000005936 beta-Galactosidase Human genes 0.000 description 3
- 229960000074 biopharmaceutical Drugs 0.000 description 3
- 210000004369 blood Anatomy 0.000 description 3
- 239000008280 blood Substances 0.000 description 3
- 238000012512 characterization method Methods 0.000 description 3
- 238000010367 cloning Methods 0.000 description 3
- 230000004069 differentiation Effects 0.000 description 3
- 238000004520 electroporation Methods 0.000 description 3
- 238000011156 evaluation Methods 0.000 description 3
- 230000004438 eyesight Effects 0.000 description 3
- 238000012239 gene modification Methods 0.000 description 3
- 230000005017 genetic modification Effects 0.000 description 3
- 235000013617 genetically modified food Nutrition 0.000 description 3
- 108010013768 glutamyl-aspartyl-proline Proteins 0.000 description 3
- 230000000670 limiting effect Effects 0.000 description 3
- 208000018769 loss of vision Diseases 0.000 description 3
- 231100000864 loss of vision Toxicity 0.000 description 3
- 108091070501 miRNA Proteins 0.000 description 3
- 239000002679 microRNA Substances 0.000 description 3
- 238000012544 monitoring process Methods 0.000 description 3
- 238000002703 mutagenesis Methods 0.000 description 3
- 231100000350 mutagenesis Toxicity 0.000 description 3
- 239000012188 paraffin wax Substances 0.000 description 3
- 230000001575 pathological effect Effects 0.000 description 3
- 210000000608 photoreceptor cell Anatomy 0.000 description 3
- 230000012846 protein folding Effects 0.000 description 3
- 230000004258 retinal degeneration Effects 0.000 description 3
- 238000007423 screening assay Methods 0.000 description 3
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 3
- 230000000638 stimulation Effects 0.000 description 3
- 238000002560 therapeutic procedure Methods 0.000 description 3
- 238000011144 upstream manufacturing Methods 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- OPIFSICVWOWJMJ-AEOCFKNESA-N 5-bromo-4-chloro-3-indolyl beta-D-galactoside Chemical group O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1OC1=CNC2=CC=C(Br)C(Cl)=C12 OPIFSICVWOWJMJ-AEOCFKNESA-N 0.000 description 2
- LRFVTYWOQMYALW-UHFFFAOYSA-N 9H-xanthine Chemical compound O=C1NC(=O)NC2=C1NC=N2 LRFVTYWOQMYALW-UHFFFAOYSA-N 0.000 description 2
- 241000894006 Bacteria Species 0.000 description 2
- 241000282461 Canis lupus Species 0.000 description 2
- CURLTUGMZLYLDI-UHFFFAOYSA-N Carbon dioxide Chemical compound O=C=O CURLTUGMZLYLDI-UHFFFAOYSA-N 0.000 description 2
- 241000699800 Cricetinae Species 0.000 description 2
- 238000001712 DNA sequencing Methods 0.000 description 2
- 230000006820 DNA synthesis Effects 0.000 description 2
- 108010008532 Deoxyribonuclease I Proteins 0.000 description 2
- 102000007260 Deoxyribonuclease I Human genes 0.000 description 2
- 241000287828 Gallus gallus Species 0.000 description 2
- 102100039289 Glial fibrillary acidic protein Human genes 0.000 description 2
- 101710193519 Glial fibrillary acidic protein Proteins 0.000 description 2
- SAEBUDRWKUXLOM-ACZMJKKPSA-N Glu-Cys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CCC(O)=O SAEBUDRWKUXLOM-ACZMJKKPSA-N 0.000 description 2
- OWVURWCRZZMAOZ-XHNCKOQMSA-N Glu-Cys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CS)NC(=O)[C@H](CCC(=O)O)N)C(=O)O OWVURWCRZZMAOZ-XHNCKOQMSA-N 0.000 description 2
- FEUPVVCGQLNXNP-IRXDYDNUSA-N Gly-Phe-Phe Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 FEUPVVCGQLNXNP-IRXDYDNUSA-N 0.000 description 2
- SCJJPCQUJYPHRZ-BQBZGAKWSA-N Gly-Pro-Asn Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O SCJJPCQUJYPHRZ-BQBZGAKWSA-N 0.000 description 2
- WZUVPPKBWHMQCE-UHFFFAOYSA-N Haematoxylin Chemical compound C12=CC(O)=C(O)C=C2CC2(O)C1C1=CC=C(O)C(O)=C1OC2 WZUVPPKBWHMQCE-UHFFFAOYSA-N 0.000 description 2
- 108010025815 Kanamycin Kinase Proteins 0.000 description 2
- YQEZLKZALYSWHR-UHFFFAOYSA-N Ketamine Chemical compound C=1C=CC=C(Cl)C=1C1(NC)CCCCC1=O YQEZLKZALYSWHR-UHFFFAOYSA-N 0.000 description 2
- 208000010415 Low Vision Diseases 0.000 description 2
- XPVCDCMPKCERFT-GUBZILKMSA-N Met-Ser-Arg Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O XPVCDCMPKCERFT-GUBZILKMSA-N 0.000 description 2
- 208000022873 Ocular disease Diseases 0.000 description 2
- 108700026244 Open Reading Frames Proteins 0.000 description 2
- 238000010222 PCR analysis Methods 0.000 description 2
- 101150049281 PRM1 gene Proteins 0.000 description 2
- 229920001213 Polysorbate 20 Polymers 0.000 description 2
- 101150084777 RS1 gene Proteins 0.000 description 2
- 208000031472 Retinal fibrosis Diseases 0.000 description 2
- 208000032400 Retinal pigmentation Diseases 0.000 description 2
- TYYBJUYSTWJHGO-ZKWXMUAHSA-N Ser-Asn-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O TYYBJUYSTWJHGO-ZKWXMUAHSA-N 0.000 description 2
- HJEBZBMOTCQYDN-ACZMJKKPSA-N Ser-Glu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HJEBZBMOTCQYDN-ACZMJKKPSA-N 0.000 description 2
- 238000002105 Southern blotting Methods 0.000 description 2
- 229930006000 Sucrose Natural products 0.000 description 2
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 2
- 241000282887 Suidae Species 0.000 description 2
- 108700019146 Transgenes Proteins 0.000 description 2
- 108090000848 Ubiquitin Proteins 0.000 description 2
- 102000044159 Ubiquitin Human genes 0.000 description 2
- 108010017070 Zinc Finger Nucleases Proteins 0.000 description 2
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 2
- 125000000539 amino acid group Chemical class 0.000 description 2
- 229960000723 ampicillin Drugs 0.000 description 2
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 2
- 239000000427 antigen Substances 0.000 description 2
- 108091007433 antigens Proteins 0.000 description 2
- 102000036639 antigens Human genes 0.000 description 2
- 108010062796 arginyllysine Proteins 0.000 description 2
- 238000003766 bioinformatics method Methods 0.000 description 2
- 230000015572 biosynthetic process Effects 0.000 description 2
- 210000002459 blastocyst Anatomy 0.000 description 2
- 210000005252 bulbus oculi Anatomy 0.000 description 2
- 235000011089 carbon dioxide Nutrition 0.000 description 2
- 230000001413 cellular effect Effects 0.000 description 2
- 235000013330 chicken meat Nutrition 0.000 description 2
- 238000004590 computer program Methods 0.000 description 2
- 150000001944 cysteine derivatives Chemical class 0.000 description 2
- 230000004452 decreased vision Effects 0.000 description 2
- 230000007547 defect Effects 0.000 description 2
- 230000002950 deficient Effects 0.000 description 2
- 238000003745 diagnosis Methods 0.000 description 2
- 239000000539 dimer Substances 0.000 description 2
- 230000008030 elimination Effects 0.000 description 2
- 238000003379 elimination reaction Methods 0.000 description 2
- 210000002472 endoplasmic reticulum Anatomy 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 238000010195 expression analysis Methods 0.000 description 2
- 238000000605 extraction Methods 0.000 description 2
- 239000003889 eye drop Substances 0.000 description 2
- 229940012356 eye drops Drugs 0.000 description 2
- 230000037433 frameshift Effects 0.000 description 2
- 230000007849 functional defect Effects 0.000 description 2
- 102000054766 genetic haplotypes Human genes 0.000 description 2
- 239000011521 glass Substances 0.000 description 2
- 210000005046 glial fibrillary acidic protein Anatomy 0.000 description 2
- 108010040856 glutamyl-cysteinyl-alanine Proteins 0.000 description 2
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 2
- 239000010931 gold Substances 0.000 description 2
- 229910052737 gold Inorganic materials 0.000 description 2
- 238000009396 hybridization Methods 0.000 description 2
- 230000002209 hydrophobic effect Effects 0.000 description 2
- 230000002779 inactivation Effects 0.000 description 2
- 230000010354 integration Effects 0.000 description 2
- 238000007912 intraperitoneal administration Methods 0.000 description 2
- 238000001990 intravenous administration Methods 0.000 description 2
- 229960003299 ketamine Drugs 0.000 description 2
- 230000004303 low vision Effects 0.000 description 2
- 210000004072 lung Anatomy 0.000 description 2
- 230000009401 metastasis Effects 0.000 description 2
- 230000009456 molecular mechanism Effects 0.000 description 2
- 230000007170 pathology Effects 0.000 description 2
- 108010073101 phenylalanylleucine Proteins 0.000 description 2
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 2
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 2
- 230000002028 premature Effects 0.000 description 2
- 230000000750 progressive effect Effects 0.000 description 2
- 230000000644 propagated effect Effects 0.000 description 2
- 210000001747 pupil Anatomy 0.000 description 2
- 108010054624 red fluorescent protein Proteins 0.000 description 2
- 108091008146 restriction endonucleases Proteins 0.000 description 2
- 239000012723 sample buffer Substances 0.000 description 2
- 238000007480 sanger sequencing Methods 0.000 description 2
- 238000010374 somatic cell nuclear transfer Methods 0.000 description 2
- 238000012453 sprague-dawley rat model Methods 0.000 description 2
- 239000005720 sucrose Substances 0.000 description 2
- 230000001225 therapeutic effect Effects 0.000 description 2
- 150000003573 thiols Chemical group 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 230000014616 translation Effects 0.000 description 2
- 210000004291 uterus Anatomy 0.000 description 2
- 230000000007 visual effect Effects 0.000 description 2
- BPICBUSOMSTKRF-UHFFFAOYSA-N xylazine Chemical compound CC1=CC=CC(C)=C1NC1=NCCCS1 BPICBUSOMSTKRF-UHFFFAOYSA-N 0.000 description 2
- 229960001600 xylazine Drugs 0.000 description 2
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 1
- YMHOBZXQZVXHBM-UHFFFAOYSA-N 2,5-dimethoxy-4-bromophenethylamine Chemical compound COC1=CC(CCN)=C(OC)C=C1Br YMHOBZXQZVXHBM-UHFFFAOYSA-N 0.000 description 1
- 102220541135 3 beta-hydroxysteroid dehydrogenase/Delta 5->4-isomerase type 1_C38S_mutation Human genes 0.000 description 1
- 102100022900 Actin, cytoplasmic 1 Human genes 0.000 description 1
- 241000251468 Actinopterygii Species 0.000 description 1
- 108010085238 Actins Proteins 0.000 description 1
- 102000006822 Agouti Signaling Protein Human genes 0.000 description 1
- 108010072151 Agouti Signaling Protein Proteins 0.000 description 1
- YAXNATKKPOWVCP-ZLUOBGJFSA-N Ala-Asn-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O YAXNATKKPOWVCP-ZLUOBGJFSA-N 0.000 description 1
- MQIGTEQXYCRLGK-BQBZGAKWSA-N Ala-Gly-Pro Chemical compound C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O MQIGTEQXYCRLGK-BQBZGAKWSA-N 0.000 description 1
- NBTGEURICRTMGL-WHFBIAKZSA-N Ala-Gly-Ser Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O NBTGEURICRTMGL-WHFBIAKZSA-N 0.000 description 1
- OBVSBEYOMDWLRJ-BFHQHQDPSA-N Ala-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N OBVSBEYOMDWLRJ-BFHQHQDPSA-N 0.000 description 1
- HOVPGJUNRLMIOZ-CIUDSAMLSA-N Ala-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)N HOVPGJUNRLMIOZ-CIUDSAMLSA-N 0.000 description 1
- 102100036475 Alanine aminotransferase 1 Human genes 0.000 description 1
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 1
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 1
- 102220472239 Alpha-1B-glycoprotein_C110S_mutation Human genes 0.000 description 1
- NIELFHOLFTUZME-HJWJTTGWSA-N Arg-Phe-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O NIELFHOLFTUZME-HJWJTTGWSA-N 0.000 description 1
- FXGMURPOWCKNAZ-JYJNAYRXSA-N Arg-Val-Phe Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 FXGMURPOWCKNAZ-JYJNAYRXSA-N 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- HZZIFFOVHLWGCS-KKUMJFAQSA-N Asn-Phe-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O HZZIFFOVHLWGCS-KKUMJFAQSA-N 0.000 description 1
- UFAQGGZUXVLONR-AVGNSLFASA-N Asp-Gln-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N)O UFAQGGZUXVLONR-AVGNSLFASA-N 0.000 description 1
- DGKCOYGQLNWNCJ-ACZMJKKPSA-N Asp-Glu-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O DGKCOYGQLNWNCJ-ACZMJKKPSA-N 0.000 description 1
- CJUKAWUWBZCTDQ-SRVKXCTJSA-N Asp-Leu-Lys Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O CJUKAWUWBZCTDQ-SRVKXCTJSA-N 0.000 description 1
- PWAIZUBWHRHYKS-MELADBBJSA-N Asp-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC(=O)O)N)C(=O)O PWAIZUBWHRHYKS-MELADBBJSA-N 0.000 description 1
- 238000012935 Averaging Methods 0.000 description 1
- 235000017166 Bambusa arundinacea Nutrition 0.000 description 1
- 235000017491 Bambusa tulda Nutrition 0.000 description 1
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 1
- 238000011814 C57BL/6N mouse Methods 0.000 description 1
- 108091033409 CRISPR Proteins 0.000 description 1
- 238000010354 CRISPR gene editing Methods 0.000 description 1
- 101100006960 Caenorhabditis elegans let-2 gene Proteins 0.000 description 1
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 1
- 101100518995 Caenorhabditis elegans pax-3 gene Proteins 0.000 description 1
- 241000398949 Calomyscidae Species 0.000 description 1
- 241000700193 Calomyscus Species 0.000 description 1
- 229920002134 Carboxymethyl cellulose Polymers 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- 241000282994 Cervidae Species 0.000 description 1
- 241000579895 Chlorostilbon Species 0.000 description 1
- 241000251730 Chondrichthyes Species 0.000 description 1
- 108700010070 Codon Usage Proteins 0.000 description 1
- 241000938605 Crocodylia Species 0.000 description 1
- 241000484025 Cuniculus Species 0.000 description 1
- 108091005943 CyPet Proteins 0.000 description 1
- OJQJUQUBJGTCRY-WFBYXXMGSA-N Cys-Ala-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CS)N OJQJUQUBJGTCRY-WFBYXXMGSA-N 0.000 description 1
- WDQXKVCQXRNOSI-GHCJXIJMSA-N Cys-Asp-Ile Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WDQXKVCQXRNOSI-GHCJXIJMSA-N 0.000 description 1
- SFRQEQGPRTVDPO-NRPADANISA-N Cys-Gln-Val Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O SFRQEQGPRTVDPO-NRPADANISA-N 0.000 description 1
- ODDOYXKAHLKKQY-MMWGEVLESA-N Cys-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CS)N ODDOYXKAHLKKQY-MMWGEVLESA-N 0.000 description 1
- 108010053770 Deoxyribonucleases Proteins 0.000 description 1
- 102000016911 Deoxyribonucleases Human genes 0.000 description 1
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 1
- 241001095404 Dipodoidea Species 0.000 description 1
- 206010061818 Disease progression Diseases 0.000 description 1
- 101001091269 Escherichia coli Hygromycin-B 4-O-kinase Proteins 0.000 description 1
- 241000702191 Escherichia virus P1 Species 0.000 description 1
- 101150007884 Gata6 gene Proteins 0.000 description 1
- 206010064571 Gene mutation Diseases 0.000 description 1
- 241000699694 Gerbillinae Species 0.000 description 1
- 208000010412 Glaucoma Diseases 0.000 description 1
- 206010018341 Gliosis Diseases 0.000 description 1
- IKDOHQHEFPPGJG-FXQIFTODSA-N Gln-Asp-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O IKDOHQHEFPPGJG-FXQIFTODSA-N 0.000 description 1
- CKOFNWCLWRYUHK-XHNCKOQMSA-N Glu-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N)C(=O)O CKOFNWCLWRYUHK-XHNCKOQMSA-N 0.000 description 1
- QSDKBRMVXSWAQE-BFHQHQDPSA-N Gly-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN QSDKBRMVXSWAQE-BFHQHQDPSA-N 0.000 description 1
- FKESCSGWBPUTPN-FOHZUACHSA-N Gly-Thr-Asn Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O FKESCSGWBPUTPN-FOHZUACHSA-N 0.000 description 1
- 241001670157 Gymnura Species 0.000 description 1
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 1
- 206010018910 Haemolysis Diseases 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101000700402 Homo sapiens Regulatory solute carrier protein family 1 member 1 Proteins 0.000 description 1
- 108010091358 Hypoxanthine Phosphoribosyltransferase Proteins 0.000 description 1
- 102000018251 Hypoxanthine Phosphoribosyltransferase Human genes 0.000 description 1
- 101150002416 Igf2 gene Proteins 0.000 description 1
- PFPUFNLHBXKPHY-HTFCKZLJSA-N Ile-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(=O)O)N PFPUFNLHBXKPHY-HTFCKZLJSA-N 0.000 description 1
- 101150040658 LHX2 gene Proteins 0.000 description 1
- 208000034693 Laceration Diseases 0.000 description 1
- 241000880493 Leptailurus serval Species 0.000 description 1
- YOZCKMXHBYKOMQ-IHRRRGAJSA-N Leu-Arg-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N YOZCKMXHBYKOMQ-IHRRRGAJSA-N 0.000 description 1
- IBMVEYRWAWIOTN-RWMBFGLXSA-N Leu-Arg-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(O)=O IBMVEYRWAWIOTN-RWMBFGLXSA-N 0.000 description 1
- JRJLGNFWYFSJHB-HOCLYGCPSA-N Leu-Gly-Trp Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O JRJLGNFWYFSJHB-HOCLYGCPSA-N 0.000 description 1
- OMHLATXVNQSALM-FQUUOJAGSA-N Leu-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(C)C)N OMHLATXVNQSALM-FQUUOJAGSA-N 0.000 description 1
- QNTJIDXQHWUBKC-BZSNNMDCSA-N Leu-Lys-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QNTJIDXQHWUBKC-BZSNNMDCSA-N 0.000 description 1
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 1
- YWFZWQKWNDOWPA-XIRDDKMYSA-N Leu-Trp-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(N)=O)C(O)=O YWFZWQKWNDOWPA-XIRDDKMYSA-N 0.000 description 1
- XFBBBRDEQIPGNR-KATARQTJSA-N Lys-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCCCN)N)O XFBBBRDEQIPGNR-KATARQTJSA-N 0.000 description 1
- 206010025421 Macule Diseases 0.000 description 1
- WYEXWKAWMNJKPN-UBHSHLNASA-N Met-Ala-Phe Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CCSC)N WYEXWKAWMNJKPN-UBHSHLNASA-N 0.000 description 1
- YORIKIDJCPKBON-YUMQZZPRSA-N Met-Glu-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O YORIKIDJCPKBON-YUMQZZPRSA-N 0.000 description 1
- 241000699729 Muridae Species 0.000 description 1
- 241000711408 Murine respirovirus Species 0.000 description 1
- 241000398750 Muroidea Species 0.000 description 1
- 101100518997 Mus musculus Pax3 gene Proteins 0.000 description 1
- 101100429084 Mus musculus Rs1 gene Proteins 0.000 description 1
- 241000282339 Mustela Species 0.000 description 1
- 241000398990 Nesomyidae Species 0.000 description 1
- 239000000020 Nitrocellulose Substances 0.000 description 1
- 108020004485 Nonsense Codon Proteins 0.000 description 1
- 101710163270 Nuclease Proteins 0.000 description 1
- CTQNGGLPUBDAKN-UHFFFAOYSA-N O-Xylene Chemical compound CC1=CC=CC=C1C CTQNGGLPUBDAKN-UHFFFAOYSA-N 0.000 description 1
- 206010057249 Phagocytosis Diseases 0.000 description 1
- MSHZERMPZKCODG-ACRUOGEOSA-N Phe-Leu-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 MSHZERMPZKCODG-ACRUOGEOSA-N 0.000 description 1
- 102220524049 Phosphoribosylaminoimidazole carboxylase_C219W_mutation Human genes 0.000 description 1
- 244000082204 Phyllostachys viridis Species 0.000 description 1
- 235000015334 Phyllostachys viridis Nutrition 0.000 description 1
- 241001338313 Platacanthomyidae Species 0.000 description 1
- 239000002202 Polyethylene glycol Substances 0.000 description 1
- WPQKSRHDTMRSJM-CIUDSAMLSA-N Pro-Asp-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]1CCCN1 WPQKSRHDTMRSJM-CIUDSAMLSA-N 0.000 description 1
- 102000007327 Protamines Human genes 0.000 description 1
- 108010007568 Protamines Proteins 0.000 description 1
- 229940124158 Protease/peptidase inhibitor Drugs 0.000 description 1
- 239000012083 RIPA buffer Substances 0.000 description 1
- 108010025216 RVF peptide Proteins 0.000 description 1
- 102220490391 Regucalcin_C40S_mutation Human genes 0.000 description 1
- 102220532188 Required for meiotic nuclear division protein 1 homolog_C63S_mutation Human genes 0.000 description 1
- 208000007014 Retinitis pigmentosa Diseases 0.000 description 1
- 102100039507 Retinoschisin Human genes 0.000 description 1
- 101710111169 Retinoschisin Proteins 0.000 description 1
- 102220472708 Retinoschisin_R209C_mutation Human genes 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 241000566137 Sagittarius Species 0.000 description 1
- 206010039491 Sarcoma Diseases 0.000 description 1
- 102220508445 Scavenger receptor class F member 2_C219S_mutation Human genes 0.000 description 1
- 206010040047 Sepsis Diseases 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- NLOAIFSWUUFQFR-CIUDSAMLSA-N Ser-Leu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O NLOAIFSWUUFQFR-CIUDSAMLSA-N 0.000 description 1
- JLKWJWPDXPKKHI-FXQIFTODSA-N Ser-Pro-Asn Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CO)N)C(=O)N[C@@H](CC(=O)N)C(=O)O JLKWJWPDXPKKHI-FXQIFTODSA-N 0.000 description 1
- DKGRNFUXVTYRAS-UBHSHLNASA-N Ser-Ser-Trp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O DKGRNFUXVTYRAS-UBHSHLNASA-N 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 241000700584 Simplexvirus Species 0.000 description 1
- 241000398956 Spalacidae Species 0.000 description 1
- 101001091268 Streptomyces hygroscopicus Hygromycin-B 7''-O-kinase Proteins 0.000 description 1
- 210000001744 T-lymphocyte Anatomy 0.000 description 1
- 238000010459 TALEN Methods 0.000 description 1
- 102220537854 Teashirt homolog 1_C42S_mutation Human genes 0.000 description 1
- NJEMRSFGDNECGF-GCJQMDKQSA-N Thr-Ala-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O NJEMRSFGDNECGF-GCJQMDKQSA-N 0.000 description 1
- XKWABWFMQXMUMT-HJGDQZAQSA-N Thr-Pro-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O XKWABWFMQXMUMT-HJGDQZAQSA-N 0.000 description 1
- 102000006601 Thymidine Kinase Human genes 0.000 description 1
- 108020004440 Thymidine kinase Proteins 0.000 description 1
- 108010043645 Transcription Activator-Like Effector Nucleases Proteins 0.000 description 1
- BGDKAVGWHJFAGW-UHFFFAOYSA-N Tropicamide Chemical compound C=1C=CC=CC=1C(CO)C(=O)N(CC)CC1=CC=NC=C1 BGDKAVGWHJFAGW-UHFFFAOYSA-N 0.000 description 1
- QEJHHFFFCUDPDV-WDSOQIARSA-N Trp-His-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N QEJHHFFFCUDPDV-WDSOQIARSA-N 0.000 description 1
- VPRHDRKAPYZMHL-SZMVWBNQSA-N Trp-Leu-Glu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O)=CNC2=C1 VPRHDRKAPYZMHL-SZMVWBNQSA-N 0.000 description 1
- SGQSAIFDESQBRA-IHPCNDPISA-N Trp-Tyr-Asn Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N SGQSAIFDESQBRA-IHPCNDPISA-N 0.000 description 1
- CELJCNRXKZPTCX-XPUUQOCRSA-N Val-Gly-Ala Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O CELJCNRXKZPTCX-XPUUQOCRSA-N 0.000 description 1
- GVNLOVJNNDZUHS-RHYQMDGZSA-N Val-Thr-Lys Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O GVNLOVJNNDZUHS-RHYQMDGZSA-N 0.000 description 1
- 241001105470 Valenzuela Species 0.000 description 1
- 206010053649 Vascular rupture Diseases 0.000 description 1
- 241000545067 Venus Species 0.000 description 1
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 1
- 102100035071 Vimentin Human genes 0.000 description 1
- 108010065472 Vimentin Proteins 0.000 description 1
- 230000010530 Virus Neutralization Effects 0.000 description 1
- 108010027570 Xanthine phosphoribosyltransferase Proteins 0.000 description 1
- 210000001015 abdomen Anatomy 0.000 description 1
- 230000005856 abnormality Effects 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 230000006978 adaptation Effects 0.000 description 1
- 239000000556 agonist Substances 0.000 description 1
- 108010024078 alanyl-glycyl-serine Proteins 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 210000000411 amacrine cell Anatomy 0.000 description 1
- 210000004102 animal cell Anatomy 0.000 description 1
- 229940006133 antiglaucoma drug and miotics carbonic anhydrase inhibitors Drugs 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 108010029539 arginyl-prolyl-proline Proteins 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 108010066988 asparaginyl-alanyl-glycyl-alanine Proteins 0.000 description 1
- 238000000429 assembly Methods 0.000 description 1
- 230000000712 assembly Effects 0.000 description 1
- 210000003719 b-lymphocyte Anatomy 0.000 description 1
- 239000011425 bamboo Substances 0.000 description 1
- 239000011324 bead Substances 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 239000012620 biological material Substances 0.000 description 1
- 230000007321 biological mechanism Effects 0.000 description 1
- 238000001574 biopsy Methods 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- OWMVSZAMULFTJU-UHFFFAOYSA-N bis-tris Chemical compound OCCN(CCO)C(CO)(CO)CO OWMVSZAMULFTJU-UHFFFAOYSA-N 0.000 description 1
- 230000000740 bleeding effect Effects 0.000 description 1
- 210000001185 bone marrow Anatomy 0.000 description 1
- 229940098773 bovine serum albumin Drugs 0.000 description 1
- 210000004556 brain Anatomy 0.000 description 1
- 244000309464 bull Species 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 239000003489 carbonate dehydratase inhibitor Substances 0.000 description 1
- 235000010948 carboxy methyl cellulose Nutrition 0.000 description 1
- 239000001768 carboxy methyl cellulose Substances 0.000 description 1
- 239000008112 carboxymethyl-cellulose Substances 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 210000000845 cartilage Anatomy 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 150000001768 cations Chemical class 0.000 description 1
- 230000021164 cell adhesion Effects 0.000 description 1
- 230000030833 cell death Effects 0.000 description 1
- 230000032823 cell division Effects 0.000 description 1
- 230000007910 cell fusion Effects 0.000 description 1
- 230000017455 cell-cell adhesion Effects 0.000 description 1
- 230000005754 cellular signaling Effects 0.000 description 1
- JBTHDAVBDKKSRW-UHFFFAOYSA-N chembl1552233 Chemical compound CC1=CC(C)=CC=C1N=NC1=C(O)C=CC2=CC=CC=C12 JBTHDAVBDKKSRW-UHFFFAOYSA-N 0.000 description 1
- 210000000038 chest Anatomy 0.000 description 1
- 210000003161 choroid Anatomy 0.000 description 1
- 239000013611 chromosomal DNA Substances 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 238000003776 cleavage reaction Methods 0.000 description 1
- 230000009194 climbing Effects 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 230000021615 conjugation Effects 0.000 description 1
- 108091036078 conserved sequence Proteins 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000003412 degenerative effect Effects 0.000 description 1
- 210000004443 dendritic cell Anatomy 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000012631 diagnostic technique Methods 0.000 description 1
- 239000003989 dielectric material Substances 0.000 description 1
- 238000010790 dilution Methods 0.000 description 1
- 239000012895 dilution Substances 0.000 description 1
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 1
- 238000011037 discontinuous sequential dilution Methods 0.000 description 1
- 230000005750 disease progression Effects 0.000 description 1
- 230000036267 drug metabolism Effects 0.000 description 1
- 239000002359 drug metabolite Substances 0.000 description 1
- 230000003503 early effect Effects 0.000 description 1
- 208000033530 early-onset macular degeneration Diseases 0.000 description 1
- 239000012636 effector Substances 0.000 description 1
- 238000001962 electrophoresis Methods 0.000 description 1
- 229910052876 emerald Inorganic materials 0.000 description 1
- 239000010976 emerald Substances 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- YQGOJNYOYNNSMM-UHFFFAOYSA-N eosin Chemical compound [Na+].OC(=O)C1=CC=CC=C1C1=C2C=C(Br)C(=O)C(Br)=C2OC2=C(Br)C(O)=C(Br)C=C21 YQGOJNYOYNNSMM-UHFFFAOYSA-N 0.000 description 1
- 210000000981 epithelium Anatomy 0.000 description 1
- 210000003527 eukaryotic cell Anatomy 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 210000002950 fibroblast Anatomy 0.000 description 1
- 239000000834 fixative Substances 0.000 description 1
- 101150003286 gata4 gene Proteins 0.000 description 1
- 238000012224 gene deletion Methods 0.000 description 1
- 238000001476 gene delivery Methods 0.000 description 1
- 238000003197 gene knockdown Methods 0.000 description 1
- 230000030279 gene silencing Effects 0.000 description 1
- 238000010363 gene targeting Methods 0.000 description 1
- 230000004077 genetic alteration Effects 0.000 description 1
- 231100000118 genetic alteration Toxicity 0.000 description 1
- 230000007387 gliosis Effects 0.000 description 1
- 108010081551 glycylphenylalanine Proteins 0.000 description 1
- 210000004209 hair Anatomy 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 210000002216 heart Anatomy 0.000 description 1
- 238000007490 hematoxylin and eosin (H&E) staining Methods 0.000 description 1
- 230000008588 hemolysis Effects 0.000 description 1
- 238000010562 histological examination Methods 0.000 description 1
- 210000002287 horizontal cell Anatomy 0.000 description 1
- 230000001900 immune effect Effects 0.000 description 1
- 230000028993 immune response Effects 0.000 description 1
- 238000003125 immunofluorescent labeling Methods 0.000 description 1
- 238000012744 immunostaining Methods 0.000 description 1
- 239000007943 implant Substances 0.000 description 1
- 238000000126 in silico method Methods 0.000 description 1
- 238000007901 in situ hybridization Methods 0.000 description 1
- 238000011503 in vivo imaging Methods 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- 208000015181 infectious disease Diseases 0.000 description 1
- 230000002458 infectious effect Effects 0.000 description 1
- 230000005764 inhibitory process Effects 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 239000007924 injection Substances 0.000 description 1
- 238000002347 injection Methods 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 230000008611 intercellular interaction Effects 0.000 description 1
- 230000009878 intermolecular interaction Effects 0.000 description 1
- 210000000936 intestine Anatomy 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 238000007917 intracranial administration Methods 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 239000007928 intraperitoneal injection Substances 0.000 description 1
- 238000010253 intravenous injection Methods 0.000 description 1
- 238000007914 intraventricular administration Methods 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 229940043355 kinase inhibitor Drugs 0.000 description 1
- 210000002414 leg Anatomy 0.000 description 1
- 230000003902 lesion Effects 0.000 description 1
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 1
- 101150115794 lhx5 gene Proteins 0.000 description 1
- 230000004301 light adaptation Effects 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 210000004185 liver Anatomy 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 230000004777 loss-of-function mutation Effects 0.000 description 1
- 235000019557 luminance Nutrition 0.000 description 1
- 210000001165 lymph node Anatomy 0.000 description 1
- 210000004698 lymphocyte Anatomy 0.000 description 1
- 210000002540 macrophage Anatomy 0.000 description 1
- 208000002780 macular degeneration Diseases 0.000 description 1
- 241001515942 marmosets Species 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 230000002503 metabolic effect Effects 0.000 description 1
- 239000002207 metabolite Substances 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- 229910052751 metal Inorganic materials 0.000 description 1
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 1
- 230000002438 mitochondrial effect Effects 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 210000001616 monocyte Anatomy 0.000 description 1
- 230000001459 mortal effect Effects 0.000 description 1
- 210000003205 muscle Anatomy 0.000 description 1
- 210000005036 nerve Anatomy 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 229920001220 nitrocellulos Polymers 0.000 description 1
- 230000037434 nonsense mutation Effects 0.000 description 1
- 229920002113 octoxynol Polymers 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 210000001672 ovary Anatomy 0.000 description 1
- 210000003101 oviduct Anatomy 0.000 description 1
- 230000036542 oxidative stress Effects 0.000 description 1
- 210000000496 pancreas Anatomy 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 231100000915 pathological change Toxicity 0.000 description 1
- 230000036285 pathological change Effects 0.000 description 1
- 230000035515 penetration Effects 0.000 description 1
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 1
- 230000005043 peripheral vision Effects 0.000 description 1
- 101150079312 pgk1 gene Proteins 0.000 description 1
- 230000008782 phagocytosis Effects 0.000 description 1
- 230000003285 pharmacodynamic effect Effects 0.000 description 1
- 229960001802 phenylephrine Drugs 0.000 description 1
- SONNWYBIRXJNDC-VIFPVBQESA-N phenylephrine Chemical compound CNC[C@H](O)C1=CC=CC(O)=C1 SONNWYBIRXJNDC-VIFPVBQESA-N 0.000 description 1
- 239000008363 phosphate buffer Substances 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 239000003757 phosphotransferase inhibitor Substances 0.000 description 1
- 230000019612 pigmentation Effects 0.000 description 1
- 210000004560 pineal gland Anatomy 0.000 description 1
- 210000002381 plasma Anatomy 0.000 description 1
- 229920001223 polyethylene glycol Polymers 0.000 description 1
- 238000003752 polymerase chain reaction Methods 0.000 description 1
- 239000011148 porous material Substances 0.000 description 1
- 230000002516 postimmunization Effects 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 108010070643 prolylglutamic acid Proteins 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 230000001902 propagating effect Effects 0.000 description 1
- 238000011321 prophylaxis Methods 0.000 description 1
- 229940048914 protamine Drugs 0.000 description 1
- 238000000164 protein isolation Methods 0.000 description 1
- 230000017854 proteolysis Effects 0.000 description 1
- 108010045647 puromycin N-acetyltransferase Proteins 0.000 description 1
- 230000001373 regressive effect Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000003938 response to stress Effects 0.000 description 1
- 230000004491 retinal development Effects 0.000 description 1
- 230000004281 retinal morphology Effects 0.000 description 1
- 210000000844 retinal pigment epithelial cell Anatomy 0.000 description 1
- 210000003583 retinal pigment epithelium Anatomy 0.000 description 1
- 201000007714 retinoschisis Diseases 0.000 description 1
- 238000009420 retrofitting Methods 0.000 description 1
- 239000011435 rock Substances 0.000 description 1
- 102220010377 rs104894722 Human genes 0.000 description 1
- 102200047000 rs104894928 Human genes 0.000 description 1
- 102200046935 rs104894929 Human genes 0.000 description 1
- 102200046910 rs104894930 Human genes 0.000 description 1
- 102200047012 rs104894934 Human genes 0.000 description 1
- 102200046984 rs104894935 Human genes 0.000 description 1
- 102220231146 rs1064797048 Human genes 0.000 description 1
- 102200000811 rs121912608 Human genes 0.000 description 1
- 102200047034 rs1800001 Human genes 0.000 description 1
- 102200047011 rs281865345 Human genes 0.000 description 1
- 102200046895 rs281865351 Human genes 0.000 description 1
- 102200046933 rs281865369 Human genes 0.000 description 1
- 102200046938 rs281865369 Human genes 0.000 description 1
- 102200036702 rs529855742 Human genes 0.000 description 1
- 102200058471 rs587777041 Human genes 0.000 description 1
- 102220033211 rs61752062 Human genes 0.000 description 1
- 102200047004 rs61752063 Human genes 0.000 description 1
- 102200047008 rs61752067 Human genes 0.000 description 1
- 102200047007 rs61752068 Human genes 0.000 description 1
- 102200047010 rs61752075 Human genes 0.000 description 1
- 102200047024 rs61752149 Human genes 0.000 description 1
- 102200047029 rs61752153 Human genes 0.000 description 1
- 102200047031 rs61752159 Human genes 0.000 description 1
- 102200047045 rs61753161 Human genes 0.000 description 1
- 102220033240 rs61753170 Human genes 0.000 description 1
- 102200046888 rs61753174 Human genes 0.000 description 1
- 102220033244 rs61753174 Human genes 0.000 description 1
- 102200047001 rs62645899 Human genes 0.000 description 1
- 102200029776 rs72552282 Human genes 0.000 description 1
- 102200088234 rs786200925 Human genes 0.000 description 1
- 102200028271 rs879255236 Human genes 0.000 description 1
- 102200076351 rs886044845 Human genes 0.000 description 1
- 229910052594 sapphire Inorganic materials 0.000 description 1
- 239000010980 sapphire Substances 0.000 description 1
- 230000007017 scission Effects 0.000 description 1
- 210000003786 sclera Anatomy 0.000 description 1
- 230000001953 sensory effect Effects 0.000 description 1
- 238000013207 serial dilution Methods 0.000 description 1
- 210000003491 skin Anatomy 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 241000894007 species Species 0.000 description 1
- 230000003595 spectral effect Effects 0.000 description 1
- 210000000952 spleen Anatomy 0.000 description 1
- 229910001220 stainless steel Inorganic materials 0.000 description 1
- 239000010935 stainless steel Substances 0.000 description 1
- 210000002784 stomach Anatomy 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 238000013268 sustained release Methods 0.000 description 1
- 239000012730 sustained-release form Substances 0.000 description 1
- 210000000225 synapse Anatomy 0.000 description 1
- 230000000946 synaptic effect Effects 0.000 description 1
- 239000008399 tap water Substances 0.000 description 1
- 235000020679 tap water Nutrition 0.000 description 1
- 210000001550 testis Anatomy 0.000 description 1
- 238000011285 therapeutic regimen Methods 0.000 description 1
- 210000001541 thymus gland Anatomy 0.000 description 1
- 210000002303 tibia Anatomy 0.000 description 1
- 238000003325 tomography Methods 0.000 description 1
- 238000011200 topical administration Methods 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 239000003053 toxin Substances 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000005945 translocation Effects 0.000 description 1
- 229960004791 tropicamide Drugs 0.000 description 1
- 229940026157 tropicamide ophthalmic solution Drugs 0.000 description 1
- 108010080629 tryptophan-leucine Proteins 0.000 description 1
- 108010029384 tryptophyl-histidine Proteins 0.000 description 1
- 108010015666 tryptophyl-leucyl-glutamic acid Proteins 0.000 description 1
- 210000003932 urinary bladder Anatomy 0.000 description 1
- 108700026220 vif Genes Proteins 0.000 description 1
- 210000005048 vimentin Anatomy 0.000 description 1
- 230000004304 visual acuity Effects 0.000 description 1
- 201000010371 vitreoretinal dystrophy Diseases 0.000 description 1
- 239000011534 wash buffer Substances 0.000 description 1
- 230000003442 weekly effect Effects 0.000 description 1
- 239000012224 working solution Substances 0.000 description 1
- 229940075420 xanthine Drugs 0.000 description 1
- 239000008096 xylene Substances 0.000 description 1
- 210000004340 zona pellucida Anatomy 0.000 description 1
Images














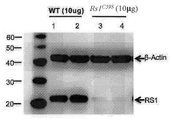



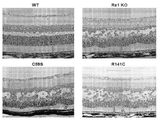



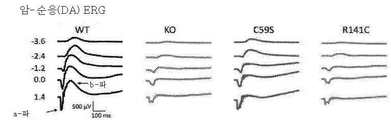











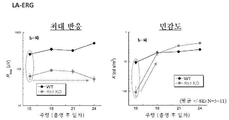



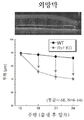

Classifications
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K67/00—Rearing or breeding animals, not otherwise provided for; New or modified breeds of animals
- A01K67/027—New or modified breeds of vertebrates
- A01K67/0275—Genetically modified vertebrates, e.g. transgenic
- A01K67/0276—Knock-out vertebrates
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K67/00—Rearing or breeding animals, not otherwise provided for; New or modified breeds of animals
- A01K67/027—New or modified breeds of vertebrates
- A01K67/0275—Genetically modified vertebrates, e.g. transgenic
- A01K67/0278—Knock-in vertebrates, e.g. humanised vertebrates
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K49/00—Preparations for testing in vivo
- A61K49/0004—Screening or testing of compounds for diagnosis of disorders, assessment of conditions, e.g. renal clearance, gastric emptying, testing for diabetes, allergy, rheuma, pancreas functions
- A61K49/0008—Screening agents using (non-human) animal models or transgenic animal models or chimeric hosts, e.g. Alzheimer disease animal model, transgenic model for heart failure
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P27/00—Drugs for disorders of the senses
- A61P27/02—Ophthalmic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- C07K14/47—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/8509—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells for producing genetically modified animals, e.g. transgenic
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/5005—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving human or animal cells
- G01N33/5008—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving human or animal cells for testing or evaluating the effect of chemical or biological compounds, e.g. drugs, cosmetics
- G01N33/5082—Supracellular entities, e.g. tissue, organisms
- G01N33/5088—Supracellular entities, e.g. tissue, organisms of vertebrates
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/68—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids
- G01N33/6893—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids related to diseases not provided for elsewhere
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2217/00—Genetically modified animals
- A01K2217/05—Animals comprising random inserted nucleic acids (transgenic)
- A01K2217/054—Animals comprising random inserted nucleic acids (transgenic) inducing loss of function
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2217/00—Genetically modified animals
- A01K2217/07—Animals genetically altered by homologous recombination
- A01K2217/072—Animals genetically altered by homologous recombination maintaining or altering function, i.e. knock in
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2217/00—Genetically modified animals
- A01K2217/07—Animals genetically altered by homologous recombination
- A01K2217/075—Animals genetically altered by homologous recombination inducing loss of function, i.e. knock out
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2217/00—Genetically modified animals
- A01K2217/15—Animals comprising multiple alterations of the genome, by transgenesis or homologous recombination, e.g. obtained by cross-breeding
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2217/00—Genetically modified animals
- A01K2217/20—Animal model comprising regulated expression system
- A01K2217/206—Animal model comprising tissue-specific expression system, e.g. tissue specific expression of transgene, of Cre recombinase
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2227/00—Animals characterised by species
- A01K2227/10—Mammal
- A01K2227/105—Murine
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2267/00—Animals characterised by purpose
- A01K2267/03—Animal model, e.g. for test or diseases
- A01K2267/0306—Animal model for genetic diseases
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2267/00—Animals characterised by purpose
- A01K2267/03—Animal model, e.g. for test or diseases
- A01K2267/0393—Animal model comprising a reporter system for screening tests
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/8509—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells for producing genetically modified animals, e.g. transgenic
- C12N2015/8527—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells for producing genetically modified animals, e.g. transgenic for producing animal models, e.g. for tests or diseases
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/8509—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells for producing genetically modified animals, e.g. transgenic
- C12N2015/8527—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells for producing genetically modified animals, e.g. transgenic for producing animal models, e.g. for tests or diseases
- C12N2015/8536—Animal models for genetic diseases
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2510/00—Genetically modified cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2800/00—Nucleic acids vectors
- C12N2800/30—Vector systems comprising sequences for excision in presence of a recombinase, e.g. loxP or FRT
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2830/00—Vector systems having a special element relevant for transcription
- C12N2830/008—Vector systems having a special element relevant for transcription cell type or tissue specific enhancer/promoter combination
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Chemical & Material Sciences (AREA)
- Biomedical Technology (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Biotechnology (AREA)
- Immunology (AREA)
- Zoology (AREA)
- Urology & Nephrology (AREA)
- Environmental Sciences (AREA)
- Organic Chemistry (AREA)
- Hematology (AREA)
- Genetics & Genomics (AREA)
- Biochemistry (AREA)
- Veterinary Medicine (AREA)
- Medicinal Chemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Cell Biology (AREA)
- Animal Behavior & Ethology (AREA)
- Microbiology (AREA)
- Physics & Mathematics (AREA)
- Toxicology (AREA)
- Pathology (AREA)
- Biodiversity & Conservation Biology (AREA)
- Animal Husbandry (AREA)
- Analytical Chemistry (AREA)
- General Physics & Mathematics (AREA)
- Food Science & Technology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biophysics (AREA)
- General Engineering & Computer Science (AREA)
- Wood Science & Technology (AREA)
- Gastroenterology & Hepatology (AREA)
- Tropical Medicine & Parasitology (AREA)
- Public Health (AREA)
- Plant Pathology (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
Abstract
망막층간분리증에 대한 동물 모델로서 사용하기에 적합한 비인간 동물이 제공된다. 일부 구현예에서, 제공된 비인간 동물은 망막층간 단백질-1 유전자좌에서의 파괴를 특징으로 한다. 일부 구현예에서, 제공된 비인간 동물은 돌연변이 망막층간 단백질-1 유전자를 특징으로 한다. 비인간 동물은, 일부 구현예에서, 망막층간분리증과 관련된 하나 이상의 증상 또는 표현형의 발생을 포함하는 표현형을 갖는 것으로 기술될 수 있다. 망막층간분리증 또는 안구 관련 질환, 장애 또는 병태를 예방하거나, 지연시키거나 치료하는 데 사용될 수 있는 치료 후보물질을 식별하는 방법이 또한 제공된다.
Description
관련 출원에 대한 교차 참조
본 출원은 2017년 2월 27일에 출원된 미국 가출원 제62/463,872호 및 2017년 10월 24일에 출원된 미국 가출원 제62/576,256호의 우선권의 이익을 주장하며, 동 문헌의 내용 전체는 참조로서 본원에 통합된다.
참조에 의한 서열 목록의 통합
2018년 2월 5일자로 생성되어, EFS-Web을 통해 미국 특허 상표청에 제출된 35518_10328WO01_SequenceListing.txt의 파일명을 가진 117 KB의 ASCII 텍스트 파일 형태의 서열 목록이 참조로써 본원에 통합된다.
세계 보건 기구(WHO)는 전 세계적으로 시각적인 장애를 가진 사람은 약 1억 8천만 명이고, 이 중 아동 실명이 원인인 사람들을 합치면 거의 6백만 명에 달할 것으로 추산하고 있다(Blindness: Vision 2020, The Global Initiative for the Elimination of Avoidable Blindness, 세계 보건 기구 백서 213호, 2000년 개정). 망막층간 단백질-1(Rs1) 유전자에서의 돌연변이에 의해 초래되는 X-염색체 관련 유아기 망막층간분리증(XLRS)은, 망막 내층이 분리되어 시력이 심각하게 상실되는 것을 특징으로 하는 남아(male children)의 조기 발병성 황반 변성이다. 현재 치료 옵션은 광학 장치(예: 돋보기), 비광학 장치(예: 작업등, 독서대 등) 및 전자 장치와 같은 저시력 보조 수단으로 제한되어 있다.
본 개시는 망막층간분리증(예: X-염색체 관련 망막층간분리증)의 치료 및/또는 예방에 사용될 수 있는 새로운 치료제 및, 일부 구현예에서는, 치료 처방을 식별하고 개발하기 위한 개선된 생체내 시스템을 제공하기 위해, 비인간 동물을 조작하는 것이 바람직하다는 인식을 포함한다. 일부 구현예에서, 본원에 기술된 생체내 시스템은 안구-관련 질환, 장애 및/또는 병태를 치료하기 위한 새로운 치료제를 식별하고 개발하는 데 사용될 수 있다. 일부 구현예에서, 제공된 생체내 시스템은 시력 상실과 연관된 질환, 장애 및/또는 병태를 치료하기 위한 새로운 치료제를 식별하고 개발하는 데에도 사용될 수 있다. 제공된 비인간 동물은, 일부 구현예에서는, 숙주 RS1 폴리펩티드가 발현되거나 생산되지 않도록 Rs1 유전자 내에 파괴를 포함하고/하거나, 달리 기능적으로 침묵화된 Rs1 유전자를 포함하며, 예를 들어, 망막의 구조 및/또는 기능을 회복 및/또는 개선하는 치료제의 식별 및 개발에 사용하기에 바람직하다. 비인간 동물로서, 변이체 또는 돌연변이체 RS1 폴리펩티드가 조작된 변이체 또는 돌연변이체 Rs1 유전자로부터 생산되도록 조작된 변이체 또는 돌연변이체 Rs1 유전자를 포함하는 비인간 동물도 제공되는데, 제공된 비인간 동물은, 예를 들어, 망막의 구조 및/또는 기능을 회복 및/또는 개선하는 치료제의 식별 및 개발에 사용하기에 바람직하다. 일부 구현예에서, 본원에 기술된 비인간 동물은 망막층간분리증에 대한 개선된 생체내 시스템(또는 모델)을 제공한다. 일부 구현예에서, 본원에 기술된 비인간 동물은 눈-관련 질환, 장애 및/또는 병태에 대한 개선된 생체내 시스템(또는 모델)을 제공한다.
일부 구현예에서, 망막층간분리증에 대한 동물 모델로서 사용하기에 바람직한 비인간 동물이 제공된다.
다양한 구현예에서, 제공된 비인간 동물은 Rs1 유전자에서의 파괴(예: 코딩 영역 전체 또는 일부의 결실) 또는 돌연변이(예: 코딩 서열에서 하나 이상의 점 돌연변이)를 특징으로 한다. 일부 구현예에서, Rs1 유전자에서의 파괴 또는 돌연변이는 파괴 또는 돌연변이를 포함하는 비인간 동물의 하나 이상의 망막에 영향을 미친다. 일부 구현예에서, 본원에 기술된 바와 같은 비인간 동물의 Rs1 유전자에서의 파괴 또는 돌연변이는 비인간 동물에서 다음의 표현형들 중 하나 이상을 형성하거나, 발생시키거나, 나타나게 한다: 망막층간분리증-유사 표현형(예를 들어, 내부 망막 층의 분리, 망막 퇴화, 및 시력 감소); 황반 또는 망막의 분리; 시력 저하; 망막 섬유증; 및 망막 착색, 그리고, 특정 구현예에서, 표현형은 야생형 비인간 동물과 비교하여 내부 망막 내 낭포 구조체의 발생, 및 ERG b- 및 a-파 반응의 감소를 포함하는데, 이는 광수용기(photoreceptor) 세포의 상실로 이어진다. 일부 구현예에서, 본원에 기술된 바와 같은 비인간 동물의 Rs1 유전자에서의 파괴 또는 돌연변이는 비인간 동물에서 망막의 기능적 및 형태학적 표현형이 조기에 (예를 들어, 출생일에 또는 출생 후 15, 18, 21, 24 또는 27일 이내에) 나타나도록 한다. 일부 구현예에서, 망막의 조기 발병성 기능적 결함은, 야생형 비인간 동물과 비교하여, (i) 암-순응(dark-adapted) 및 명-순응(light-adapted) ERG 분석에서 a-파에 대해 상대적인 b-파의 감소(부의 ERG로 나타남); (ii) ERG b-파의 최대 반응 값 및 감도 값의 감소; (iii) ERG a-파의 최대 반응 값의 감소; 또는 (iv) (i) 내지 (iii)의 조합으로 반영될 수 있다. 일부 구현예에서, 망막의 조기 발병성 형태학적 결함은 야생형 비인간 동물과 비교하여, 분리(schisis), 더 넓은 타원체 구역(ellipsoid zone, EZ), 더 얇은 외망막, 또는 이들의 조합으로 반영될 수 있다.
일부 구현예에서, 비인간 Rs1 유전자에서의 파괴(예: 결실) 또는 돌연변이는 내인성 Rs1 유전자좌에 있는 내인성 Rs1 유전자의 파괴 또는 돌연변이이다. 일부 구현예에서, 비인간 Rs1 내인성 유전자에서의 파괴(예: 결실)는 (일부 특정 구현예에서는 리포터 유전자를 포함하는) 내인성 Rs1 유전자좌에 있는 내인성 Rs1 유전자 내로 핵산 서열을 삽입하는 것에 의해 일어난다. 일부 구현예에서, 파괴(disruption)는 내인성 Rs1 유전자의 전체적 또는 부분적 결실이거나 이를 포함하며, 이는 유전자 산물(예: mRNA 또는 폴리펩티드)의 발현 또는 생산을 차단한다. 일부 구현예에서, 비인간 Rs1 유전자에서의 돌연변이(예: 점 돌연변이)는, 일부 특정 구현예에서는 합성 엑손(예: 점 돌연변이를 포함하는 합성 엑손)을 포함하는 내인성 Rs1 유전자좌에 있는 내인성 Rs1 유전자 내로 핵산 서열을 삽입하는 것에 의해 일어난다. 일부 구현예에서, 돌연변이는 Rs1 유전자에서의 하나 이상의 점 돌연변이이거나 이를 포함하는데, 이는 야생형 RS1 폴리펩티드와 비교해 기능이 감소되었거나 변경된 변이체 RS1 폴리펩티드를 발현시키며; 일부 특정 구현예에서, 비인간 동물에서의 변이체 RS1 폴리펩티드의 수준은 야생형 비인간 동물에서의 야생형 RS1 폴리펩티드의 수준보다 적다. 일부 구현예에서, 본원에 기술된 바와 같은 변이체 RS1 폴리펩티드는 야생형 RS1 폴리펩티드와 비교해 하나 이상의 아미노산 치환을 포함한다.
일부 구현예에서, 제공된 비인간 동물은 조작된 Rs1 유전자를 포함하는 게놈을 갖는다. 일부 구현예에서, 조작된 Rs1 유전자는 내인성 Rs1 유전자좌에 위치하고; 다른 구현예에서는, 조작된 Rs1 유전자가 상이한 유전자좌에 위치한다. 일부 구현예에서, 조작된 Rs1 유전자는 이종 Rs1 유전자(예: 인간 Rs1 유전자)이거나 이를 포함한다. 일부 구현예에서, 조작된 Rs1 유전자는 이종 RS1 폴리펩티드를 전체적으로 또는 부분적으로 암호화하는 유전 물질을 포함한다. 일부 구현예에서, 조작된 Rs1 유전자는 이종 폴리펩티드의 디스코이딘 도메인(discoidin domain)을 암호화하는 유전 물질을 포함하는데, 디스코이딘 도메인은 야생형 또는 부모 이종 RS1 폴리펩티드와 비교해 아미노산 치환을 함유한다. 일부 구현예에서, 조작된 Rs1 유전자는 야생형 또는 부모 Rs1 유전자(예를 들어, 내인성 또는 상동체)와 비교해 하나 이상의 돌연변이를 포함하는데, 이는 변이체 RS1 폴리펩티드를 발현시킨다. 일부 구현예에서, 조작된 Rs1 유전자는 설치류 RS1 폴리펩티드의 디스코이딘 도메인을 암호화하는 유전 물질을 포함하는데, 디스코이딘 도메인은 야생형 또는 부모 설치류 RS1 폴리펩티드와 비교해 아미노산 치환을 함유한다. 일부 구현예에서, 조작된 Rs1 유전자는 이종 RS1 폴리펩티드의 디스코이딘 도메인을 암호화하는 유전 물질을 포함하는데, 디스코이딘 도메인은 야생형 또는 부모 이종 RS1 폴리펩티드와 비교해 아미노산 치환을 함유하며; 예를 들어, 조작된 Rs1 유전자는 인간 RS1 폴리펩티드의 디스코이딘 도메인을 암호화하는 뉴클레오티드 서열을 포함하는데, 디스코이딘 도메인은 야생형 인간 RS1 폴리펩티드와 비교해 아미노산 치환을 함유한다. 일부 구현예에서, 본원에 기술된 바와 같은 조작된 Rs1 유전자에 의해 암호화된 RS1 폴리펩티드의 디스코이딘 도메인은 야생형 또는 부모 RS1 폴리펩티드와 비교해 하나 이상의 아미노산 치환을 포함한다. 따라서, 일부 구현예에서, 본원에 기술된 바와 같은 비인간 동물의 조작된 Rs1 유전자는 아미노산 치환(예: 변이체 RS1 폴리펩티드)을 포함하는 디스코이딘 도메인을 특징으로 하는 RS1 폴리펩티드를 암호화한다.
일부 구현예에서, 비인간 동물로서, 내인성 Rs1 유전자좌에 있는 내인성 Rs1 유전자의 코딩 서열 전체 또는 일부가 결실된 게놈을 포함하는 비인간 동물이 제공된다. 일부 구현예에서, 결실은 Rs1 유전자좌로부터 만들어진 기능적 RS1 폴리펩티드를 결여시킨다. 일부 구현예에서, 결실은 적어도 엑손 2~3의 결실이다. 일부 특정 구현예에서, 결실은 엑손 1 및 엑손 2~3 중 적어도 일부분의 결실이다. 일부 구현예에서, 결실은 시작(ATG) 코돈의 바로 3'에서 엑손 3의 마지막 6개의 뉴클레오티드까지 (그 중간의 것들을 포함해) 걸치는 내인성 Rs1 유전자의 뉴클레오티드의 결실이거나 이를 포함한다. 일부 구현예에서, 결실을 포함하는 Rs1 유전자좌는 리포터 유전자를 추가로 포함한다. 일부 구현예에서, 리포터 유전자는 Rs1 프로모터에 작동 가능하게 연결된다. 일부 구현예에서, Rs1 프로모터는 내인성 Rs1 프로모터(예를 들어, 결실을 포함하는 Rs1 유전자좌에 있는 내인성 Rs1 프로모터)이다. 일부 구현예에서, Rs1 프로모터는 이종 Rs1 프로모터이다.
일부 구현예에서, Rs1 유전자좌는 엑손 1 및 엑손 2~3의 일부가 결여되어 있으며(또는 이들의 결실을 포함하고), 예를 들어, 시작(ATG) 코돈의 바로 3'에서 엑손 2를 지나 엑손 3의 마지막 6개의 뉴클레오티드까지의 뉴클레오티드가 결여되어 있으며, Rs1 유전자좌의 시작(ATG) 코돈에 프레임 내(in-frame) 융합되는 리포터 유전자 코딩 서열을 포함한다. 일부 특정 구현예에서, 리포터 유전자 코딩 서열(예를 들어, lacZ 유전자의 코딩 서열)은 Rs1 유전자좌에 있는 내인성 Rs1 프로모터에 작동 가능하게 연결되거나 이에 의해 전사 조절된다.
일부 구현예에서, 리포터 유전자는 lacZ 유전자이다. 일부 구현예에서, 리포터는 루시퍼라아제, 녹색 형광 단백질(GFP), 강화된 GFP(eGFP), 시안 형광 단백질(CFP), 황색 형광 단백질(YFP), 강화된 황색 형광 단백질(eYFP), 청색 형광 단백질(BFP), 강화된 청색 형광 단백질(eBFP), DsRed 및 MmGFP로 이루어진 군으로부터 선택된다. 일부 구현예에서, 리포터 유전자의 발현 패턴은 Rs1 유전자(예를 들어, Rs1 유전자좌에 있는 야생형 Rs1 유전자)의 발현 패턴과 유사하다. 일부 구현예에서, 리포터 유전자의 발현은 야생형 또는 부모 RS1 폴리펩티드의 발현 패턴과 유사하다.
일부 구현예에서, 조작된 Rs1 유전자를 포함하는 게놈을 가진 비인간 동물이 제공되며, 조작된 Rs1 유전자는 하나 이상의 점 돌연변이를 엑손에 포함하고, 야생형 RS1 폴리펩티드와 비교해 하나 이상의 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화한다. 야생형 RS1 폴리펩티드와 비교해 하나 이상의 아미노산 치환을 갖는 RS1 폴리펩티드는 본원에서 변이체 또는 돌연변이체 RS1 폴리펩티드로도 지칭된다.
일부 구현예에서, 본원에 기술된 아미노산 치환은, 예를 들어, 본원에 기술된 비인간 동물의 소포체에서 국소화된 변이체(또는 돌연변이체) RS1 폴리펩티드의 응집을 야기할 수 있는 단백질의 미스폴딩(misfolding)으로 인해, 비인간 동물에서 기능적 RS1 폴리펩티드가 생산되는 것을 차단하거나 생산되는 수준을 유의하게 감소시키고, 이황화 결합된 서브유닛 조립체를 손상시키며, 단백질 분비 프로세스의 일부로서 ER의 막 내에 삽입될 RS1 폴리펩티드를 불능화시킨다.
일부 구현예에서, 변이체 RS1 폴리펩티드는 신호 서열에서 아미노산 치환, 예를 들어, 프롤린이나 친수성 잔기 또는 하전된 잔기와 소수성 잔기의 치환을 포함한다.
일부 구현예에서, 변이체 RS1 폴리펩티드는 디스코이딘 도메인의 측면에 위치하는 영역, 즉 RS1 영역 및 RS1 폴리펩티드의 C-말단 분절에서 아미노산 치환을 포함한다. 일부 구현예에서, 변이체 RS1 폴리펩티드는 38, 40, 59 및 223으로 이루어진 군으로부터 선택된 위치에서 시스테인의 치환을 포함한다. 일부 구현예에서, 변이체 RS1 폴리펩티드는 C59S 치환을 포함한다.
일부 구현예에서, 변이체 RS1 폴리펩티드는 디스코이딘 도메인에서 아미노산 치환을 포함한다. 일부 구현예에서, 변이체 RS1 폴리펩티드는 63, 83, 110, 142 및 219로 이루어진 군으로부터 선택된 위치에서 비-시스테인 잔기와 시스테인의 치환을 포함한다. 다른 구현예에서, 변이체 RS1 폴리펩티드는 디스코이딘 도메인에서 시스테인과 비-시스테인 잔기의 치환을 포함한다. 특정 구현예에서, 치환은 R141C 치환이다. 일부 구현예에서, 변이체 RS1 폴리펩티드는 디스코이딘 도메인에서 비-하전된 잔기와 하전된 잔기의 치환, 하전된 잔기와 비-하전된 잔기의 치환, 또는 역 하전된(reversely charged) 잔기와 하전된 잔기의 치환을 포함한다. 다른 구현예에서, 변이체 RS1 폴리펩티드는 디스코이딘 도메인에서 프롤린의 삽입 또는 제거에 의한 (즉, 프롤린 잔기를 또 다른 잔기로 치환하거나, 그 반대에 의한) 치환을 포함한다. 여전히 다른 구현예에서, 변이체 RS1 폴리펩티드는 디스코이딘 도메인에서 극성 잔기의 삽입 또는 제거에 의한 (즉, 극성 잔기를 비-극성 잔기로 치환하거나, 그 반대에 의한) 치환을 포함한다.
일부 구현예에서, 비인간 동물로서, 아미노산 치환을 포함하고, 일부 특정 구현예에서는 C59S 또는 R141C 치환을 포함하는 RS1 폴리펩티드를 발현하는 비인간 동물이 제공된다. 일부 구현예에서, 조작된 Rs1 유전자는 엑손 3에서 점 돌연변이를 포함하고, C59S 치환을 갖는 RS1 폴리펩티드를 암호화하며; 일부 특정 구현예에서는, 엑손 3에서의 점 돌연변이는 TGT에서 AGT로의 코돈 변화이거나 이를 포함한다. 일부 구현예에서, 조작된 Rs1 유전자는 엑손 5에서 점 돌연변이를 포함하고, R141C 치환을 갖는 RS1 폴리펩티드를 암호화하며; 일부 특정 구현예에서는, 엑손 5에서의 점 돌연변이는 CGC에서 TGC로의 코돈 변화이거나 이를 포함한다.
일부 구현예에서, 본원에 개시된 바와 같이 비-인간 동물은 수컷 동물이다. X 염색체 상의 내인성 Rs1 유전자좌에 있는 Rs1 유전자에서 파괴 또는 돌연변이를 포함하는 수컷 동물은 파괴 또는 돌연변이에 대해 반접합성(hemizygous)인 것으로 또한 이해된다.
일부 구현예에서, 제공된 비인간 동물은 암컷 동물이다. 일부 구현예에서, 암컷 비인간 동물은 본원에 기술된 바와 같은 내인성 Rs1 유전자좌에 있는 Rs1 유전자에서의 결실에 대해 동형접합성(homozygous)이거나 이형접합성(heterozygous)이다. 일부 구현예에서, 암컷 비인간 동물은, 일부 구현예에서는 내인성 Rs1 유전자좌에 있는, 본원에 기술된 바와 같은 조작된 (또는 돌연변이체) Rs1 유전자에 대해 동형접합성이거나 이형접합성이다.
일부 구현예에서, 조작된 Rs1 유전자는 하나 이상의 선택 마커(selection markers)를 추가로 포함한다. 일부 구현예에서, 조작된 Rs1 유전자는 하나 이상의 부위 특이적 재조합효소 인식 부위를 추가로 포함한다. 일부 구현예에서, 조작된 Rs1 유전자는 재조합효소 유전자 및 하나 이상의 부위 특이적 재조합효소 인식 부위가 측면에 위치한 선택 마커를 추가로 포함하며, 부위 특이적 재조합효소 인식 부위는 절제를 유도하도록 배향된다.
일부 구현예에서, 하나 이상의 부위 특이적 재조합효소 인식 부위는 loxP, lox511, lox2272, lox2372, lox66, lox71, loxM2, lox5171, FRT, FRT11, FRT71, attp, att, FRT, Dre, rox, 또는 이들의 조합을 포함한다. 일부 구현예에서, 재조합 효소 유전자는 Cre, Flp(예: Flpe, Flpo), 및 Dre로 이루어진 군으로부터 선택된다. 일부 특정 구현예에서, 하나 이상의 부위 특이적 재조합효소 인식 부위는 lox (예: loxP) 부위이며, 및 재조합효소 유전자는 Cre 재조합 효소를 암호화한다.
일부 구현예에서, 재조합효소 유전자는, 분화된 세포에서 재조합효소 유전자의 발현을 유도하지만 미분화 세포에서는 재조합효소 유전자의 발현을 유도하지 않는 프로모터에 작동 가능하게 연결된다. 일부 구현예에서, 재조합효소 유전자는 전사적으로 유능하고 발달 조절되는 프로모터에 작동 가능하게 연결된다.
프로모터에 작동 가능하게 연결된 재조합효소 유전자의 일부 구현예에서, 프로모터는 프로타민(Prot; 예를 들어, Prot1 또는 Prot5), Blimp1, Blimp1(1 kb 단편), Blimp1(2 kb 단편), Gata6, Gata4, Igf2, Lhx2, Lhx5 및 Pax3으로 이루어진 군으로부터 선택된다. 프로모터에 작동 가능하게 연결된 재조합효소 유전자의 일부 구현예에서, 프로모터는 서열번호 30, 서열번호 31, 또는 서열번호 32이거나 이를 포함한다. 프로모터에 작동 가능하게 연결된 재조합효소 유전자의 일부 구현예에서, 프로모터는 서열번호 30이거나 이를 포함한다.
일부 구현예에서, 선택성 마커는 네오마이신 포스포트랜스퍼라아제(neoR), 히그로마이신 B 포스포트랜스퍼라아제(hygR), 퓨로마이신-N-아세틸트랜스퍼라아제(puroR), 블라스티딘 S 디아미나아제(bsrR), 크산틴/구아닌 포스포리보실 트랜스퍼라아제(gpt), 및 단순 포진 바이러스 티미딘키나아제(HSV-tk)로 이루어진 군으로부터 선택된다. 일부 구현예에서, 선택성 마커는 UBc 프로모터, Ubi 프로모터, hCMV 프로모터, mCMV 프로모터, CAGGS 프로모터, EF1 프로모터, pgk1 프로모터, 베타-액틴 프로모터, 및 ROSA26 프로모터로 이루어진 군으로부터 선택된 프로모터에 의해 전사 조절된다. 일부 특정 구현예에서, 선택성 마커는 neoR 또는 hygR이며, Ubi 프로모터에 의해 전사 조절된다.
일부 구현예에서, 제공된 비인간 동물은 망막층간분리증의 (또는 이와 관련된) 하나 이상의 징후, 증상 및/또는 병태를 발생시킨다.
일부 구현예에서, 단리된 비인간 세포 또는 조직이 제공되며, 이들의 게놈은 (i) 내인성 Rs1 유전자좌에 있는 내인성 Rs1 유전자에서 코딩 서열의 전체 또는 일부의 결실을 포함하거나, (ii) 하나 이상의 점 돌연변이를 엑손에 포함하고, 하나 이상의 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하는 조작된 Rs1 유전자(일부 구현예에서는 조작된 Rs1 유전자가 내인성 Rs1 유전자좌에 존재함)를 포함한다. 일부 구현예에서, 세포는 림프구이다. 일부 구현예에서, 세포는 B 세포, 수지상 세포, 대식 세포, 단핵구 및 T 세포로부터 선택된다. 일부 구현예에서, 세포는 눈 또는 망막의 세포 유형으로부터 유래되거나 이와 관련된다. 일부 특정 구현예에서, 세포는 안구 신경절 세포(ganglion cell), 양극 세포(bipolar cell), 무축삭 세포(amacrine cell), 수평 세포(horizontal cell), 원뿔체 세포(cone cell), 간상 세포(rod cell) 또는 망막 색소 상피 세포(retinal pigment epithelial cell)이다. 일부 구현예에서, 조직은 지방, 방광, 뇌, 가슴, 골수, 눈, 심장, 장, 신장, 간, 폐, 림프절, 근육, 췌장, 혈장, 혈청, 피부, 비장, 위, 흉선, 고환, 난자, 및 이의 조합으로부터 선택된다. 일부 특정 구현예에서, 안구 조직은 공막(sclera), 맥락막(choroid) 또는 망막(retina)으로부터 선택된다.
일부 구현예에서, 본원에서 기술된 바와 같은 단리된 비인간 세포 또는 조직으로부터 만들어지거나, 생성되거나, 생산되거나, 수득된 불멸화 세포가 제공된다.
일부 구현예에서, 비인간 배아 줄기 세포가 제공되며, 이의 게놈은 (i) Rs1 유전자좌에 있는 내인성 Rs1 유전자에서 코딩 서열의 전체 또는 일부의 결실을 포함하거나, (ii) 하나 이상의 점 돌연변이를 엑손에 포함하고, 하나 이상의 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하는 조작된 Rs1 유전자(일부 구현예에서는 조작된 Rs1 유전자가 내인성 Rs1 유전자좌에 존재함)를 포함한다. 일부 구현예에서, 비인간 배아 줄기 세포는 설치류 배아 줄기 세포이다. 일부 구현예에서, 설치류 배아 줄기 세포는 마우스 배아 줄기 세포이고, 129 계통, C57BL 계통 또는 이의 혼합체로부터 유래한다. 일부 특정 구현예에서, 설치류 배아 줄기 세포는 마우스 배아 줄기 세포이고, 129 계통 및 C57BL 계통의 혼합체이다. 일부 특정 구현예에서, 설치류 배아 줄기 세포는 마우스 배아 줄기 세포이며, Crb1 rd8 돌연변이가 없는 게놈을 가진 (즉, 야생형 Crbs1 유전자를 포함하는 게놈을 가진) C57BL 계통으로부터 유래한다. 일부 구현예에서, 본원에 기술된 바와 같은 비인간 ES 세포는 서열번호 23, 서열번호 26, 및 서열번호 28 중 임의의 하나를 포함한다. 일부 구현예에서, 본원에 기술된 바와 같은 비인간 ES 세포는 서열번호 33, 서열번호 34, 서열번호 36, 서열번호 37, 서열번호 39 및 서열번호 40 중 임의의 하나를 포함한다.
일부 구현예에서, 비인간 동물을 만들기 위한, 본원에 기술된 바와 같은 비인간 배아 줄기 세포의 용도가 제공된다. 일부 특정 구현예에서, 비인간 ES 세포는 마우스 ES 세포이며; (i) Rs1 유전자좌에 있는 내인성 Rs1 유전자에서 코딩 서열의 전체 또는 일부의 결실을 포함하거나, (ii) 하나 이상의 점 돌연변이를 엑손에 포함하고, 본원에 기술된 바와 같이 하나 이상의 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하는 조작된 Rs1 유전자(일부 구현예에서는 조작된 Rs1 유전자가 내인성 Rs1 유전자좌에 존재함)를 포함하는 마우스를 만드는 데 사용된다. 일부 특정 구현예에서, 비인간 ES 세포는 랫트 ES 세포이며, 이는 (i) Rs1 유전자좌에 있는 내인성 Rs1 유전자에서 코딩 서열의 전체 또는 일부의 결실을 포함하거나, (ii) 하나 이상의 점 돌연변이를 엑손에 포함하고, 본원에 기술된 바와 같이 하나 이상의 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하는 조작된 Rs1 유전자(일부 구현예에서는 조작된 Rs1 유전자가 내인성 Rs1 유전자좌에 존재함)를 포함하는 랫트를 만드는 데 사용된다.
일부 구현예에서, 본원에 기술된 바와 같은 비인간 ES 세포로부터 만들어지거나, 생산되거나, 수득된 비인간 ES가 제공된다. 일부 특정 구현예에서, 비인간 배아는 설치류 배아이고; 일부 구현예에서는, 마우스 배아이며; 일부 구현예에서는, 랫트 배아이다. 일부 특정 구현예에서, 제공된 비인간 배아는 서열번호 25, 서열번호 27 또는 서열번호 29를 포함한다. 일부 특정 구현예에서, 제공된 비인간 배아는 서열번호 35, 서열번호 38 또는 서열번호 41을 포함한다.
일부 구현예에서, 비인간 동물을 만들기 위한 본원에 기술된 비인간 배아의 용도가 제공된다. 일부 특정 구현예에서, 비인간 배아는 마우스 배아이며, 이는 (i) Rs1 유전자좌에 있는 내인성 Rs1 유전자에서 코딩 서열의 전체 또는 일부의 결실을 포함하거나, (ii) 하나 이상의 점 돌연변이를 엑손에 포함하고, 본원에 기술된 바와 같이 하나 이상의 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하는 조작된 Rs1 유전자(일부 구현예에서는 조작된 Rs1 유전자가 내인성 Rs1 유전자좌에 존재함)를 포함하는 마우스를 만드는 데 사용된다. 일부 특정 구현예에서, 비인간 배아는 랫트 배아이며, 이는 (i) Rs1 유전자좌에 있는 내인성 Rs1 유전자에서 코딩 서열의 전체 또는 일부의 결실을 포함하거나, (ii) 하나 이상의 점 돌연변이를 엑손에 포함하고, 본원에 기술된 바와 같이 하나 이상의 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하는 조작된 Rs1 유전자(일부 구현예에서는 조작된 Rs1 유전자가 내인성 Rs1 유전자좌에 존재함)를 포함하는 랫트를 만드는 데 사용된다.
일부 구현예에서, 본원에 기술된 바와 같은 비인간 동물, 단리된 비인간 세포 또는 조직, 불멸화 세포, 비인간 ES 세포, 또는 비인간 배아를 포함하는 키트가 제공된다. 일부 구현예에서, 치료 또는 진단을 위한 약물(예: 항체 또는 이의 항원 결합 단편)의 제조 및/또는 개발에 사용하기 위한 본원에 기술된 바와 같은 키트가 제공된다. 일부 구현예에서, 질병, 질환 또는 병태의 치료, 예방 또는 완화를 위한 약물(예: 항체 또는 그의 항원 결합 단편)의 제조 및/또는 개발에 사용하기 위한 본원에 기술된 바와 같은 키트가 제공된다.
일부 구현예에서, 본원에 기술된 바와 같은 핵산 작제물, 또는 표적화 벡터가 제공된다. 일부 특정 구현예에서, 제공된 핵산 작제물 또는 표적화 벡터는 본원에 기술된 바와 같은 Rs1 유전자(또는 유전자좌)를 전체적으로 또는 부분적으로 포함한다. 일부 특정 구현예에서, 제공된 핵산 작제물, 또는 표적화 벡터는 본원에 기술된 바와 같은 Rs1 유전자(또는 유전자좌)를 전체적으로 또는 부분적으로 포함하는 DNA 단편을 포함한다. 일부 구현예에서, 설치류 Rs1 유전자좌에 있는 설치류 Rs1 유전자에 통합될 핵산 서열로서 설치류 Rs1 유전자좌에서의 뉴클레오티드 서열에 상동인 5' 뉴클레오티드 서열 및 3' 뉴클레오티드 서열이 측면에 위치한 핵산 서열을 포함하는 핵산 작제물이 제공되는데, 핵산 서열이 Rs1 유전자에 통합되면 (i) 설치류 Rs1 유전자의 코딩 서열 전체 또는 일부가 결실되거나, (ii) 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하는 조작된 Rs1 유전자가 생성된다. 일부 구현예에서, 통합될 핵산 서열은 리포터 유전자를 포함하며, 핵산 서열이 통합되면 엑손 1 및 엑손 2~3의 일부가 결실된다. 일부 구현예에서, 통합될 핵산 서열은, 핵산 서열이 설치류 Rs1 유전자에 통합되는 것에 의해 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하는 조작된 Rs1 유전자가 생성되도록, 돌연변이체 Rs1 엑손을 포함한다. 일부 특정 구현예에서, 제공된 핵산 작제물 또는 표적화 벡터는 서열번호 23, 서열번호 26, 및 서열 번호 28 중 임의의 하나를 포함한다. 일부 특정 구현예에서, 제공된 핵산 작제물 또는 표적화 벡터는 서열번호 33과 서열번호 35, 서열번호 36과 서열번호 37, 또는 서열번호 39와 서열번호 40을 포함한다. 일부 특정 구현예에서, 제공된 핵산 작제물 또는 표적화 벡터는 하나 이상의 선택 마커를 포함한다. 일부 특정 구현예에서, 제공된 핵산 작제물 또는 표적화 벡터는 하나 이상의 부위 특이적 재조합 부위(예: loxP, Frt, 또는 이들의 조합)를 포함한다. 일부 특정 구현예에서, 제공된 핵산 작제물 또는 표적화 벡터는 도면에 예시되어 있다.
일부 구현예에서, 비인간 ES 세포, 비인간 세포, 비인간 배아 및/또는 비인간 동물을 만들기 위한, 본원에 기술된 바와 같은 핵산 작제물 또는 표적화 벡터의 용도가 제공된다.
일부 구현예에서, 비인간 동물을 만드는 방법이 제공되며, 상기 방법은 (a) (i) Rs1 유전자좌에 있는 내인성 Rs1 유전자의 코딩 서열이 전체적으로 또는 부분적으로 결실되거나, (ii) 아미노산 치환을 포함하는 RS1 폴리펩티드를 암호화하기 위해 Rs1 유전자좌에 있는 내인성 Rs1 유전자의 엑손이 돌연변이되도록, 내인성 배아 줄기 세포의 게놈 내로 핵산 서열을 도입하는 단계(핵산 서열은 Rs1 유전자좌에서의 서열에 상동인 폴리뉴클레오티드를 포함함); (b) (a) 단계에서 유전자 변형된 비인간 배아 줄기 세포를 수득하는 단계; 및 (c) (b) 단계의 유전자 변형된 비인간 배아 줄기 세포를 사용하여 비인간 동물을 생성하는 단계를 포함한다.
비인간 동물을 만드는 방법의 일부 구현예에서, Rs1 유전자의 엑손 3은 C59S 치환을 포함하는 RS1 폴리펩티드를 암호화하도록 돌연변이된다. 비인간 동물을 만드는 방법의 일부 특정 구현예에서, Rs1 유전자의 엑손 3은 C59S 치환을 포함하는 RS1 폴리펩티드를 암호화하도록 돌연변이되며, Rs1 유전자의 인트론 2에서 25 bp의 결실이 이루어지고 Rs1 유전자의 인트론 3에서 28 bp의 결실이 이루어진다. 비인간 동물을 만드는 방법의 일부 구현예에서, Rs1 유전자의 엑손 5는 R141C 치환을 포함하는 RS1 폴리펩티드를 암호화하도록 돌연변이된다. 비인간 동물을 만드는 방법의 일부 구현예에서, Rs1 유전자의 엑손 5는 R141C 치환을 포함하는 RS1 폴리펩티드를 암호화하도록 돌연변이되며, Rs1 유전자의 인트론 4에서 10 bp의 결실이 이루어지고 Rs1 유전자의 인트론 5에서 29 bp의 결실이 이루어진다. 비인간 동물을 만드는 방법의 일부 구현예에서, Rs1 유전자좌에서의 코딩 서열의 엑손 1 및 엑손 2~3의 일부가 결실된다. 비인간 동물을 만드는 방법의 일부 특정 구현예에서, Rs1 유전자좌에 있는 Rs1 유전자의 13,716 bp가 결실된다.
비인간 동물을 만드는 방법의 일부 구현예에서, 핵산 서열은 하나 이상의 선택 마커를 추가로 포함한다. 비인간 동물을 만드는 방법의 일부 구현예에서, 핵산 서열은 하나 이상의 부위 특이적 재조합효소 인식 부위를 추가로 포함한다. 비인간 동물을 만드는 방법의 일부 구현예에서, 핵산 서열은 재조합효소 유전자, 및 하나 이상의 부위 특이적 재조합효소 인식 부위가 측면에 위치한 선택 마커를 추가로 포함하며, 부위 특이적 재조합효소 인식 부위는 절제를 유도하도록 배향된다. 비인간 동물을 만드는 방법의 일부 구현예에서, 핵산 서열은 선택 마커의 하류에 있는 리포터 유전자를 추가로 포함한다.
비인간 동물을 만드는 방법의 일부 구현예에서, 재조합효소 유전자는, 분화된 세포에서 재조합효소 유전자의 발현을 유도하지만 미분화 세포에서는 재조합효소 유전자의 발현을 유도하지 않는 프로모터에 작동 가능하게 연결된다. 비인간 동물을 만드는 방법의 일부 구현예에서, 재조합효소 유전자는 전사적으로 유능하고 발달 조절되는 프로모터에 작동 가능하게 연결된다.
비인간 동물을 만드는 방법의 일부 구현예에서, 상기 방법은 결실에 대해 동형접합체이거나, 돌연변이 Rs1 유전자에 대해 동형접합체인 비인간 동물이 생성되도록 (c) 단계에서 생성된 비인간 동물을 번식시키는 단계를 추가로 포함한다.
일부 구현예에서, 비인간 동물을 만드는 방법이 제공되며, 상기 방법은 변형된 게놈이 (i) 내인성 Rs1 유전자좌에 있는 내인성 Rs1 유전자의 코딩 서열 전체 또는 일부의 결실, 또는 (ii) 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하는 조작된 Rs1 유전자를 포함하도록 비인간 동물 게놈을 변형시키는 단계(일부 구현예에서, 조작된 Rs1 유전자는 내인성 Rs1 유전자좌에 존재함); 및 변형된 게놈을 포함하는 비인간 동물을 만드는 단계를 포함한다. 일부 구현예에서, 비인간 동물 게놈은 배아 줄기(ES) 세포를 사용하여 변형되고(즉, ES 세포의 게놈이 변형됨), 변형된 게놈을 갖는 ES 세포는 변형된 게놈을 포함하는 비인간 동물을 만드는 데 사용된다. 비인간 동물을 만드는 방법의 일부 구현예에서, 게놈은 C59S 또는 R141C 치환을 갖는 RS1 폴리펩티드를 암호화하는 조작된 Rs1 유전자를 포함하도록 변형된다. 비인간 동물을 만드는 방법의 일부 구현예에서, 게놈은 Rs1 유전자좌에서의 코딩 서열 중 엑손 1 및 엑손 2~3의 적어도 일부의 결실을 포함하도록 변형되고; 일부 특정 구현예에서는, Rs1 유전자좌에 있는 Rs1 유전자에서 13,716 bp의 결실을 포함하도록 변형된다.
일부 구현예에서, 본원에 기술된 바와 같은 방법에 의해 만들어지거나, 생성되거나, 생산되거나, 수득되거나 수득될 수 있는 비인간 동물이 제공된다.
일부 실시예에서, 비인간 동물에서 망막층간분리증(또는 안구와 관련된 질환, 장애 또는 병태)의 치료를 위한 치료제를 식별하는 방법이 제공되며, 상기 방법은 (a) (i) Rs1 유전자좌에 있는 내인성 Rs1 유전자의 코딩 서열 전체 또는 일부의 결실, 또는 (ii) 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하는 조작된 Rs1 유전자를 포함하는 게놈을 가진 비인간 동물에게 하나 이상의 제제를 투여하는 단계(조작된 Rs1 유전자는 일부 구현예에서는 내인성 Rs1 유전자좌에 있음); (b) 하나 이상의 제제가 망막층간분리증(또는 안구와 관련된 질환, 장애 또는 병태)와 관련된 하나 이상의 징후, 증상 및/또는 병태에 대해 효과를 갖는지 여부를 결정하기 위해 하나 이상의 분석을 수행하는 단계; 및 (c) 망막층간분리증(또는 안구와 관련된 질환, 장애 또는 병태)과 관련된 하나 이상의 징후, 증상 및/또는 병태에 대해 효과를 갖는 하나 이상의 제제를 치료제로서 식별하는 단계를 포함한다.
일부 구현예에서, Rs1 유전자의 시작(ATG) 코돈에 작동 가능하게 연결된 리포터 유전자를 포함하는 게놈을 가진 비인간 동물이 제공되는데, 리포터 유전자는 Rs1 유전자의 엑손 1 및 엑손 2~3의 일부를 대체하여 위치되어, Rs1 유전자 서열 중 13,716 bp를 결실시킨다.
일부 구현예에서, TGT에서 AGT로의 점 돌연변이가 엑손 3에 존재하고, 인트론 2에서 25 bp가 결실되고, 인트론 3에서 28 bp가 결실되는 것을 특징으로 하는 조작된 Rs1 유전자를 포함하는 게놈을 가진 비인간 동물이 제공되는데, 조작된 Rs1 유전자는 C59S 치환을 갖는 RS1 폴리펩티드를 암호화한다.
일부 구현예에서, CGC에서 TGC로의 점 돌연변이가 엑손 5에 존재하고, 인트론 4에서 10 bp가 결실되고, 인트론 5에서 29 bp가 결실되는 것을 특징으로 하는 조작된 Rs1 유전자를 포함하는 게놈을 가진 비인간 동물이 제공되는데, 조작된 Rs1 유전자는 R141C 치환을 갖는 RS1 폴리펩티드를 암호화한다.
일부 구현예에서, 망막층간분리증의 비인간 동물 모델이 제공되는데, 비인간 동물은 본원에 기술된 바와 같은 아미노산 치환을 갖는 RS1 폴리펩티드를 발현하거나 생산한다.
일부 구현예에서, 망막층간분리증의 비인간 동물 모델이 제공되며, 비인간 동물은 본원에 기술된 바와 같은 조작된 Rs1 유전자를 포함하는 게놈을 갖는다.
일부 구현예에서, 망막층간분리증의 비인간 동물 모델이 제공되며, 비인간 동물은 본원에 기술된 바와 같은 Rs1 유전자에서의 코딩 서열 전체 또는 일부의 결실을 포함하는 게놈을 갖는다.
일부 구현예에서, 망막층간분리증의 비인간 동물 모델이 제공되는데, 망막층간분리증의 상기 비인간 동물 모델은 (i) 본원에 기술된 바와 같은 조작된 Rs1 유전자를 포함하는 게놈을 가지거나, (ii) 본원에 기술된 바와 같은 Rs1 유전자(또는 유전자좌)에서 코딩 서열 전체 또는 일부의 결실을 포함하는 게놈을 가지거나, (iii) 본원에 기술된 바와 같은 아미노산 치환을 갖는 RS1 폴리펩티드를 발현하는 비인간 동물을 제공하여 수득된 것이다.
일부 구현예에서, 치료 또는 진단을 위한 약물의 제조 및/또는 개발에 사용하기 위해 본원에서 기술된 바와 같은 비인간 동물 또는 세포가 제공한다.
일부 구현예에서, 질병, 질환 또는 병태의 치료, 예방 또는 완화를 위한 약제(medicament)의 제조에 사용하기 위해 본원에서 기술된 바와 같은 비인간 동물 또는 세포가 제공한다.
일부 구현예에서, 의료용으로 사용하기 위한 약물 또는 백신의 제조 및/또는 개발에 있어서 본원에서 기술된 바와 같은 비인간 동물 또는 세포의 용도, 예컨대 약제로서의 용도가 제공된다.
일부 구현예에서, 망막층간분리증에 대한 유전자 치료 약물의 제조 및/또는 개발에 있어서 본원에 기술된 바와 같은 비인간 동물 또는 세포의 용도가 제공한다.
일부 구현예에서, 질환, 장애 또는 병태는 망막층간분리증이다. 일부 구현예에서, 질병, 장애 또는 병태는 안구 관련 질환, 장애 또는 병태이거나, Rs1의 기능 및/또는 활성의 결실로부터 발생한다.
다양한 구현예에서, 본원에 기술된 바와 같은 하나 이상의 표현형은 기준 또는 대조군과 비교되어 기술된다. 다양한 구현예에서, 기준 또는 대조군은 본원에 기술된 바와 같은 변형 또는 본원에 기술된 바와 상이한 변형을 가지거나 변형을 가지지 않는 비인간 동물(즉, 야생형 비인간 동물)을 포함한다.
다양한 구현예에서, 본원에서 기술된 바와 같은 비인간 동물은 설치류이고; 일부 구현예에서는, 마우스이며; 일부 구현예에서는, 랫트이다. 일부 구현예에서, 본원에서 기술된 바와 같은 마우스는 129 균주, BALB/C 균주, C57BL/6 균주, 및 혼합 129xC57BL/6 균주로 이루어지는 군으로부터 선택되고; 일부 특정 구현예에서, C57BL/6균주이다.
특허 또는 출원 파일은 컬러로 작업된 적어도 하나의 도면을 포함한다. 컬러 도면이 있는 본 특허 또는 특허 출원 공개의 사본은 요청 시 필요한 수수료를 납부하면 특허청에서 제공될 것이다.
다음의 도면들로 구성된 본원에 포함된 도면은 단지 예시를 위한 것이며 한정하기 위한 것이 아니다.
도 1 비인간(예: 마우스) 망막층간 단백질-1(Rs1) 유전자 (상단) 및 유전자 산물(하단)의 구성도를 도시한 것으로, 축척에 비례하지는 않는다. 상단: 엑손의 번호는 각 엑손의 아래에 표시되어 있고, 미번역 영역(흰 박스) 및 코딩 서열(수직 사선)도 표시되어 있다. 하단: 리더 서열(LS), Rs1 도메인(Rs1), 디스코이딘 도메인(DD) 및 C 말단 영역(CT)이 선택된 시스테인 및 질병 결합 미스센스 돌연변이의 위치와 함께 표시되어 있다(Wu, W.W.H. 등의 2003, J. Biol. Chem. 278(30):28139-146의 도 1을 수정한 것임).
도 2는 실시예 1에 기술된 바와 같이 설치류에서 Rs1 유전자의 결실을 생성하기 위한 예시적인 표적화 벡터의 도해를 도시한 것으로, 축척에 비례하지는 않는다. lacZ 리포터 유전자는 마우스 Rs1 시작 (ATG) 코돈에 작동 가능하게 연결된 상태로 엑손 1에 삽입되어 마우스 Rs1 유전자좌의 엑손 1의 나머지 부분을 포함하여 엑손 3의 마지막 6개의 뉴클레오티드까지를 결실시킨다(13,716 bp 결실). Rs1-lacZ-SDC 표적화 벡터는 자체 결실 약물 선택 카세트(예: loxP 서열이 측면에 위치한 네오마이신 내성 유전자; 본원에 참조로서 통합된 미국 특허 제8,697,851호, 제8,518,392호 및 제8,354,389호 참조)를 함유한다. 상동성 재조합 시, 표적화 벡터에 함유된 서열은 도시된 바와 같이 내인성 쥣과 Rs1 유전자좌의 엑손 1~3을 대신해 삽입된다. 약물 선택 카세트는 발달 의존 방식으로 제거되는데, 다시 말해, 전술한 바와 같은 Rs1 유전자좌에서 파괴를 함유하는 생식계열 세포를 갖는 마우스로부터 유래된 자손이 발달 도중에 분화된 세포로부터 선택성 마커를 제거하게 된다. 후속하는 엑손(수직 사선)의 번호가 각 엑손의 위에 표시되어 있으며, 미번역 영역(흰색 박스) 및 코딩 서열(검은색 사선)도 표시되어 있다. lacZ: β-갈락토시다아제(galactosidase) 유전자; Cre: Cre 재조합효소 유전자; Neo: 네오마이신 내성 유전자.
도 3은 쥣과 Rs1 유전자의 게놈 구조도로서, 실시예 1에서 기술된 바와 같이 예시적인 파괴(예: 엑손 1~3의 결실 13,716 bp)을 도시한 것이며, 축척에 비례하지는 않는다. 엑손(검은색 사선)의 번호는 각 엑손의 위에 표시되어 있고, 미번역 영역(흰 박스)도 표시되어 있다. 실시예 1에 기술된 스크리닝 분석에 사용된 프로브의 대략적인 위치(즉, Rs1KOmTU, Rs1KOmTD)는 두꺼운 수직 사선으로 표시되어 있다.
도 4는 실시예 1에서 기술된 바와 같은 예시적인 파괴된 쥣과 Rs1 유전자의 도해를 도시한 것으로서, 축척에 비례하지는 않는다. 마우스 Rs1 유전자좌의 엑손 1~3의 결실(13,716 bp 결실)은 마우스 Rs1 시작 (ATG) 코돈에 작동 가능하게 연결된 lacZ 리포터 유전자의 삽입에 기인하는 것으로 도시되어 있다. 엑손(수직 사선)의 번호는 각 엑손의 위에 표시되어 있고, 미번역 영역(흰색 박스) 및 나머지 코딩 서열(빗금 사각형)도 표시되어 있다. 선택된 뉴클레오티드 접합부 위치는 각각의 접합부 아래에 선으로 표기되어 있고, 서열번호가 표시되어 있다.
도 5는 실시예 1에 기술된 바와 같이 설치류(예: 마우스)에서 돌연변이체 Rs1 유전자를 생성하기 위한 표적화 벡터의 도해를 도시한 것으로서, 축척에 비례하지는 않는다. 보존적 엑손(수직 사선)의 번호는 각 엑손의 위 아래에 표시되어 있다. 엑손 3에서의 예시적인 점 돌연변이(C59S; TGT에서 AGT로의 돌연변이)는 상동성 재조합에 의한 합성 DNA 단편 및 카세트 요소의 삽입에 의한 것으로 엑손 3 위에 표시되어 있다. Rs1C59S-SDC 표적화 벡터는 자체 결실 약물 선택 카세트(예: loxP 서열이 측면에 위치한 히그로마이신 내성 유전자; 본원에 참조로서 통합된 미국 특허 제8,697,851호, 제8,518,392호 및 제8,354,389호 참조)를 함유한다. 상동성 재조합 시, 표적화 벡터에 함유된 합성 DNA 단편은 도시된 바와 같이 내인성 쥣과 Rs1 유전자좌의 엑손 3을 대신해 삽입된다. 약물 선택 카세트는 발달 의존 방식으로 제거되는데, 다시 말해, 전술한 바와 같은 Rs1 유전자좌에서 파괴를 함유하는 생식계열 세포를 갖는 마우스로부터 유래된 자손이 발달 도중에 분화된 세포로부터 선택성 마커를 제거하게 된다. 선택된 뉴클레오티드 접합부 위치는 각각의 접합부 아래에 선으로 표기되어 있고, 서열번호가 표시되어 있다.
도 6은 마우스 Rs1 유전자의 엑손 3의 확대도, 및 도 5에 도시된 (실시예 1도 참조함) 돌연변이체 Rs1 유전자의 설계에 대한 도해를 도시한 것으로서, 축척에 비례하지는 않는다. 표적화된 점 돌연변이(C59S)와 주변 인트론을 갖는 엑손 3(검은 직사각형)은 TAQMANβ 분석에 적합하도록 설계된 2개의 작은 결실과 함께 도시되어 있다. 상동성 재조합에 의해 표적화 벡터를 통합하면, C59S 치환을 갖고 돌연변이체 Rs1 유전자 내의 주변 인트론에서 2개의 작은 결실(25 bp 및 28 bp)을 갖는 RS1 폴리펩티드의 일부를 암호화하는 엑손 3이 생성된다. 실시예 1에 기술된 스크리닝 분석에 사용된 프로브의 대략적인 위치(즉, Rs1-C59SmTU 및 Rs1-C59SmTD)는 두꺼운 수직 사선으로 표시되어 있다.
도 7은 실시예 1에서 기술된 표적화 벡터 내에 함유된 카세트의 재조합효소 매개 절제 이후 생성된 설치류(예: 마우스)에서의 Rs1 유전자의 확대도를 도시한 것으로서, 축척에 비례하지는 않는다. Rs1 유전자 산물에서 C59S 치환을 초래하는 점 돌연변이를 갖는 엑손 3이 잔여 loxP 부위와 함께 도시되어 있다. 카세트의 재조합효소 매개 절제 후에 남은 뉴클레오티드 접합부의 위치는 접합부 아래에 선으로 표기되어 있고 서열 번호로 표시되어 있다.
도 8은 실시예 1에 기술된 바와 같이 설치류(예: 마우스)에서 돌연변이체 Rs1 유전자를 생성하기 위한 표적화 벡터의 도해를 도시한 것으로서, 축척에 비례하지는 않는다. 보존적 엑손(수직 사선)의 번호는 각 엑손의 위 아래에 표시되어 있다. 엑손 5에서의 예시적인 점 돌연변이(R141C; CGC에서 TGC로의 돌연변이)는 상동성 재조합에 의한 합성 DNA 단편 및 카세트 요소의 삽입에 의한 것으로 엑손 5 위에 표시되어 있다. Rs1R141C-SDC 표적화 벡터는 자체 결실 약물 선택 카세트(예: loxP 서열이 측면에 위치한 히그로마이신 내성 유전자; 본원에 참조로서 통합된 미국 특허 제8,697,851호, 제8,518,392호 및 제8,354,389호 참조)를 함유한다. 상동성 재조합 시, 표적화 벡터에 함유된 합성 DNA 단편은 도시된 바와 같이 내인성 쥣과 Rs1 유전자좌의 엑손 5를 대신해 삽입된다. 약물 선택 카세트는 발달 의존 방식으로 제거되는데, 다시 말해, 전술한 바와 같은 Rs1 유전자좌에서 파괴를 함유하는 생식계열 세포를 갖는 마우스로부터 유래된 자손이 발달 도중에 분화된 세포로부터 선택성 마커를 제거하게 된다. 선택된 뉴클레오티드 접합부 위치는 각각의 접합부 아래에 선으로 표기되어 있고, 서열번호가 표시되어 있다.
도 9는 마우스 Rs1 유전자의 엑손 5의 확대도, 및 도 8에 도시된 (실시예 1도 참조함) 돌연변이체 Rs1 유전자의 설계에 대한 도해를 도시한 것으로서, 축척에 비례하지는 않는다. 표적화된 점 돌연변이(R141C)와 주변 인트론을 갖는 엑손 5(검은 직사각형)는 TAQMANβ 분석에 적합하도록 설계된 2개의 작은 결실과 함께 도시되어 있다. 상동성 재조합에 의해 표적화 벡터를 통합하면, R141C 치환을 갖고 돌연변이체 Rs1 유전자 내의 주변 인트론에서 2개의 작은 결실(10 bp 및 29 bp)을 갖는 RS1 폴리펩티드의 일부를 암호화하는 엑손 5가 생성된다. 실시예 1에 기술된 스크리닝 분석에 사용된 프로브의 대략적인 위치(즉, Rs1-R141CmTU 및 Rs1-R141CmTD)는 두꺼운 수직 사선으로 표시되어 있다.
도 10은 실시예 1에서 기술된 표적화 벡터 내에 함유된 카세트의 재조합효소 매개 절제 이후 생성된 설치류(예: 마우스)에서의 Rs1 유전자의 확대도를 도시한 것으로서, 축척에 비례하지는 않는다. Rs1 유전자 산물에서 R141C 치환을 초래하는 점 돌연변이를 갖는 엑손 5가 잔여 loxP 부위와 함께 도시되어 있다. 카세트의 재조합효소 매개 절제 후에 남은 뉴클레오티드 접합부의 위치는 접합부 아래에 선으로 표기되어 있고 서열 번호로 표시되어 있다.
도 11a~11c는 Rs1 널(Rs1 KO) 및 Rs1 돌연변이체(Rs1 C59S, Rs1 R141C) 동물의 망막 내에서 Rs1 mRNA 및 단백질 발현의 분포를 lacZ 발현, RNASCOPEβ 및 면역조직화학(IHC)에 의해 도시한 것이다. A, Rs1 KO 동물의 ONL 및 광수용기에서 정의 X-gal 신호를 보여주는 lacZ 염색. B, 야생형(WT) 동물에서의 내인성 Rs1 mRNA의 발현을 보여주는, RNASCOPEβ를 통한 Rs1 mRNA의 발현. Rs1 KO 동물의 망막에서는 Rs1 mRNA가 검출되지 않았다. C, WT 동물의 모든 망막 층에서의 RS1 단백질 분포를 보여주는 IHC. RS1 단백질 발현은 Rs1 KO 동물에서 검출되지 않았고, Rs1 C59S 및 Rs1 R141C 동물의 ONL과 IS에 RS1 단백질 발현은 Rs1KO 동물에서 검출되지 않았고, Rs1C59S 및 Rs1R141C 동물의 ONL과 IS에 한정되지 않았다(GCL, ganglion cell layer: 신경절 세포층; IPL, inner plexiform layer: 내망상층; INL, inner nuclear layer: 내핵층; OPL, outer plexiform layer: 외망상층; ONL, outer nuclear layer: 외핵층; IS, inner segments: 내절; RPE, retinal pigment epithelium: 망막 세포 상피). Rs1: 적색; DAPI: 청색.
도 12a~12d는 Rs1 널(Rs1 KO) 및 Rs1 돌연변이체(Rs1 C59S, Rs1 R141C) 동물의 망막에서의 RS1 단백질 발현을 웨스턴 블롯 및 ELISA 분석에 의해 도시한 것이다. A, Rs1 KO 및 C57BL/6-유래 수컷 계통에서의 RS1 발현을 보여주는, 환원 조건 하의 SDS-PAGE 겔의 웨스턴 블롯. B, 야생형(WT) 및 Rs1 C59S 수컷 동물에서의 RS1 발현을 보여주는, 환원 조건 하의 SDS-PAGE 겔의 웨스턴 블롯. C, 야생형(WT) 및 Rs1 R141C 수컷 동물에서의 RS1 발현을 보여주는, 환원 조건 하의 SDS-PAGE 겔의 웨스턴 블롯. D, 야생형(WT), Rs1 KO, Rs1 C59S 및 Rs1 R141C 수컷 동물에서의 RS1 단백질 수준을 보여주는 ELISA 분석. 야생형 한배 새끼와 비교해 Rs1 돌연변이체 동물에서의 RS1 단백질 발현 백분율은 각각의 막대 위에 표시되어 있다. D, 웨스턴 블롯과 ELISA 분석에서, Rs1 녹아웃 암컷 동물의 망막에서의 RS1 단백질 발현. KO: 동형접합성 Rs1 녹아웃(Rs1 -/- ); HET: 이형접합성 Rs1 녹아웃(Rs1 -/+ ). RS1 HET 암컷 동물은 야생형("WT") 수컷 및 암컷 동물과 유사한 양의 RS1 단백질을 가졌다.
도 13a~13d는 Rs1 널(Rs1 KO) 및 Rs1 돌연변이체(Rs1 C59S, Rs1 R141C) 동물의 망막에서의 병리학적 변화를 조직학적, IHC 및 광간섭 단층촬영(OCT) 분석에 의해 도시한 것이다. A, 조직학적 검사로 Rs1 KO, Rs1 C59S 및 Rs1 R141C 수컷 동물에서, INL 내의 공동 및 갈라짐(적색 삼각형), INL 및 OPL의 전반적인 해체(disorganization), ONL의 박화(수직 적색 이중 화살표) 및/또는 내절/외절(수직 적색 선)의 얇아짐(thinning)을 동반하는 광수용기의 퇴행을 나타냄. B, 망막-특이적 세포 마커(GFAP, glial fibrillary acidic protein - 신경아교섬유질 산성 단백질, 및 비멘틴(vimentin))를 사용하여 IHC로 Rs1 KO 수컷 동물에서 INL(*표는 활성화된 뮐러 세포를 나타냄)의 신경아교증(gliosis)을 밝혀 냄. C, 스펙트랄리스 히델버그(Spectralis Heidelberg) 광 간섭 단층촬영(OCT)을 사용하는 생체내 영상촬영에 의해 Rs1 KO, Rs1 C59S 및 Rs1 R141C 암컷 동물에서 망막층간분리증 및 광수용기 퇴행을 관찰함. D, 이형접합성 RS1 녹아웃 암컷(Rs1 -/+) ("Het")에서는 분리(schisis)가 관찰되지 않은 반면, 동형접합성 RS1 녹아웃 암컷(Rs1 -/-) ("KO")는 반 KO 수컷과 일치하는 표현형을 가짐.
도 14a~d는 20주령의 동물에서 암-순응(DA-) 및 명-순응(LA-) 전장 망막전위도(electroretinograms, ERG)에 의한 외망막 기능에 대한 분석을 보여준다. A, 암-순응 조건 하에 야생형(WT), Rs1 KO (KO), Rs1 C59S (C59S) 및 Rs1 R141C (R141C) 수컷 동물로부터 획득한 대표적인 ERG. B, 명-순응 조건 하에 야생형(WT), Rs1 KO (KO), Rs1 C59S (C59S) 및 Rs1 R141C (R141C) 수컷 동물로부터 획득한 대표적인 ERG. C, 자극 휘도의 함수로서 도시된, 암-순응 및 명-순응 ERG의 주요 구성 요소의 대표적인 진폭. 데이터 포인트는 6마리의 암컷 동물을 대상으로 한 평균(± SD)을 나타낸다. 야생형과 비교하면, Rs1 KO, Rs1 C59S 및 Rs1 R141C (R141C) 수컷 동물의 a-파와 b-파 둘 다는 진폭이 감소되었다. 자극 휘도(A 및 B)는 가장 왼쪽 파형 그래프의 왼쪽에 표기되어 있다. D, 암-순응 및 명-순응 조건 하에 야생형(Rs1 +/+ ), 동형접합성 녹아웃(Rs1 -/-) 및 이형접합성 녹아웃(Rs1 -/+) 암컷 동물로부터 획득한 대표적인 ERG. 담체(이형접합성) 암컷의 ERG는 모든 조건 하에서 WT 대조군과 일치하였다. 비교하면, 동형접합성 녹아웃 암컷의 ERG 표현형은 부의 파형 및 감소된 진폭의 a-파를 갖는 반접합성 녹아웃 수컷의 것과 유사하였다.
도 15는 Rs1 KO 마우스에서 망막의 조기 발병성 표현형을 조사하기 위해 실시예 4에 기술된 연구에 대한 예시적인 설계를 보여준다. Rs1 (-/Y) 또는 Rs1 (+/Y) 마우스와
Rs1 (-/Y) 또는 Rs1 (+/Y) 마우스와  Rs1 (+/-) 마우스를 교배하여 Rs1 KO 마우스 (Rs1 (-/Y) 또는 Rs1 (-/-)), 및 Rs1 WT 마우스 (Rs1 (+/Y) 또는 Rs1 (+/+))를 수득하였다. ERG는 생후 15, 18, 21 및 24일차에 수행하였고, 각각의 마우스는 6일 간격으로 2회 이하의 ERG 또는 OCT를 거쳤다.
Rs1 (+/-) 마우스를 교배하여 Rs1 KO 마우스 (Rs1 (-/Y) 또는 Rs1 (-/-)), 및 Rs1 WT 마우스 (Rs1 (+/Y) 또는 Rs1 (+/+))를 수득하였다. ERG는 생후 15, 18, 21 및 24일차에 수행하였고, 각각의 마우스는 6일 간격으로 2회 이하의 ERG 또는 OCT를 거쳤다.
도 16a~16f는 Rs1 KO 마우스의 조기 발병성 표현형을 ERG 및 OCT 분석에서 도시한 것이다. 외망막 기능은 암-순응(DA-)(A 및 D) 및 명-순응(LA-)(B 및 E) 전장 ERG에 의해 평가하였는데, a-파에 비해 b-파가 감소한 것으로 나타나며, 결과적으로는 모든 시점에서 부의 ERG가 나타났다(정량 데이터는 도시되지 않음). 망막층간분리증 표현형은 관찰 시간 과정 전체에 걸쳐(P15~P24) 존재하였다(C 및 F, 황색 삼각형으로 표시됨).
도 17a~17b는 시간 경과에 따른 Rs1 KO 마우스 및 야생형(WT) 마우스의 ERG 파라미터 변화를 보여준다(Naka-Rushton 분석). WT 대조군과 비교하면, 생후 15일차(P15)의 Rs1 KO 마우스에서는 a-파 및 b-파 모두의 Rmax 값이 더 낮았으며; 생후 15일차의 Rs1 KO 마우스에서는 DA-ERG의 b-파 및 LA-ERG의 b-파의 Rmax 및 감도 값 모두가 크게 감소하였다. 시간이 지날수록 Rmax 값은 지속적으로 감소하였지만, 감도 값은 Rs1 KO 및 WT 마우스에서 비슷하였다.
도 18은 시간 경과에 따른 OCT 이미지의 변화를 보여준다. 생후 15일차에는 INL 및 OPL(별표)에서 현저한 분리 및 ELM의 증거가 관찰되지 않았는데, 이는 시점이 경과할수록 완화되는 경향을 보이는 것이었다. Rs1 KO의 망막 내 타원체 구역(EZ)은 전체 기간에 걸쳐 WT보다 더 넓었다.
도 19a~19c는 정량적 OCT 분석의 결과를 보여준다. WT 마우스에서 망막(외망막 포함)은 발생 기간(C) 동안 약간 얇아졌다. Rs1 KO 마우스에서의 망막(A 및 B)은 더 얇아졌는데, 이는 주로 분리의 완화와 관련된 것이었으며, Rs1 KO 망막 내의 외망막은 기간(C) 동안 WT보다 더 얇았다.
도 20은 마우스, 랫트 및 인간 RS1 폴리펩티드의 정렬을 보여준다. 신호 서열은 밑줄이 그어져 있다. 서열이 상이한 위치는 "*"에 의해 식별된다.
다음의 도면들로 구성된 본원에 포함된 도면은 단지 예시를 위한 것이며 한정하기 위한 것이 아니다.
도 1 비인간(예: 마우스) 망막층간 단백질-1(Rs1) 유전자 (상단) 및 유전자 산물(하단)의 구성도를 도시한 것으로, 축척에 비례하지는 않는다. 상단: 엑손의 번호는 각 엑손의 아래에 표시되어 있고, 미번역 영역(흰 박스) 및 코딩 서열(수직 사선)도 표시되어 있다. 하단: 리더 서열(LS), Rs1 도메인(Rs1), 디스코이딘 도메인(DD) 및 C 말단 영역(CT)이 선택된 시스테인 및 질병 결합 미스센스 돌연변이의 위치와 함께 표시되어 있다(Wu, W.W.H. 등의 2003, J. Biol. Chem. 278(30):28139-146의 도 1을 수정한 것임).
도 2는 실시예 1에 기술된 바와 같이 설치류에서 Rs1 유전자의 결실을 생성하기 위한 예시적인 표적화 벡터의 도해를 도시한 것으로, 축척에 비례하지는 않는다. lacZ 리포터 유전자는 마우스 Rs1 시작 (ATG) 코돈에 작동 가능하게 연결된 상태로 엑손 1에 삽입되어 마우스 Rs1 유전자좌의 엑손 1의 나머지 부분을 포함하여 엑손 3의 마지막 6개의 뉴클레오티드까지를 결실시킨다(13,716 bp 결실). Rs1-lacZ-SDC 표적화 벡터는 자체 결실 약물 선택 카세트(예: loxP 서열이 측면에 위치한 네오마이신 내성 유전자; 본원에 참조로서 통합된 미국 특허 제8,697,851호, 제8,518,392호 및 제8,354,389호 참조)를 함유한다. 상동성 재조합 시, 표적화 벡터에 함유된 서열은 도시된 바와 같이 내인성 쥣과 Rs1 유전자좌의 엑손 1~3을 대신해 삽입된다. 약물 선택 카세트는 발달 의존 방식으로 제거되는데, 다시 말해, 전술한 바와 같은 Rs1 유전자좌에서 파괴를 함유하는 생식계열 세포를 갖는 마우스로부터 유래된 자손이 발달 도중에 분화된 세포로부터 선택성 마커를 제거하게 된다. 후속하는 엑손(수직 사선)의 번호가 각 엑손의 위에 표시되어 있으며, 미번역 영역(흰색 박스) 및 코딩 서열(검은색 사선)도 표시되어 있다. lacZ: β-갈락토시다아제(galactosidase) 유전자; Cre: Cre 재조합효소 유전자; Neo: 네오마이신 내성 유전자.
도 3은 쥣과 Rs1 유전자의 게놈 구조도로서, 실시예 1에서 기술된 바와 같이 예시적인 파괴(예: 엑손 1~3의 결실 13,716 bp)을 도시한 것이며, 축척에 비례하지는 않는다. 엑손(검은색 사선)의 번호는 각 엑손의 위에 표시되어 있고, 미번역 영역(흰 박스)도 표시되어 있다. 실시예 1에 기술된 스크리닝 분석에 사용된 프로브의 대략적인 위치(즉, Rs1KOmTU, Rs1KOmTD)는 두꺼운 수직 사선으로 표시되어 있다.
도 4는 실시예 1에서 기술된 바와 같은 예시적인 파괴된 쥣과 Rs1 유전자의 도해를 도시한 것으로서, 축척에 비례하지는 않는다. 마우스 Rs1 유전자좌의 엑손 1~3의 결실(13,716 bp 결실)은 마우스 Rs1 시작 (ATG) 코돈에 작동 가능하게 연결된 lacZ 리포터 유전자의 삽입에 기인하는 것으로 도시되어 있다. 엑손(수직 사선)의 번호는 각 엑손의 위에 표시되어 있고, 미번역 영역(흰색 박스) 및 나머지 코딩 서열(빗금 사각형)도 표시되어 있다. 선택된 뉴클레오티드 접합부 위치는 각각의 접합부 아래에 선으로 표기되어 있고, 서열번호가 표시되어 있다.
도 5는 실시예 1에 기술된 바와 같이 설치류(예: 마우스)에서 돌연변이체 Rs1 유전자를 생성하기 위한 표적화 벡터의 도해를 도시한 것으로서, 축척에 비례하지는 않는다. 보존적 엑손(수직 사선)의 번호는 각 엑손의 위 아래에 표시되어 있다. 엑손 3에서의 예시적인 점 돌연변이(C59S; TGT에서 AGT로의 돌연변이)는 상동성 재조합에 의한 합성 DNA 단편 및 카세트 요소의 삽입에 의한 것으로 엑손 3 위에 표시되어 있다. Rs1C59S-SDC 표적화 벡터는 자체 결실 약물 선택 카세트(예: loxP 서열이 측면에 위치한 히그로마이신 내성 유전자; 본원에 참조로서 통합된 미국 특허 제8,697,851호, 제8,518,392호 및 제8,354,389호 참조)를 함유한다. 상동성 재조합 시, 표적화 벡터에 함유된 합성 DNA 단편은 도시된 바와 같이 내인성 쥣과 Rs1 유전자좌의 엑손 3을 대신해 삽입된다. 약물 선택 카세트는 발달 의존 방식으로 제거되는데, 다시 말해, 전술한 바와 같은 Rs1 유전자좌에서 파괴를 함유하는 생식계열 세포를 갖는 마우스로부터 유래된 자손이 발달 도중에 분화된 세포로부터 선택성 마커를 제거하게 된다. 선택된 뉴클레오티드 접합부 위치는 각각의 접합부 아래에 선으로 표기되어 있고, 서열번호가 표시되어 있다.
도 6은 마우스 Rs1 유전자의 엑손 3의 확대도, 및 도 5에 도시된 (실시예 1도 참조함) 돌연변이체 Rs1 유전자의 설계에 대한 도해를 도시한 것으로서, 축척에 비례하지는 않는다. 표적화된 점 돌연변이(C59S)와 주변 인트론을 갖는 엑손 3(검은 직사각형)은 TAQMANβ 분석에 적합하도록 설계된 2개의 작은 결실과 함께 도시되어 있다. 상동성 재조합에 의해 표적화 벡터를 통합하면, C59S 치환을 갖고 돌연변이체 Rs1 유전자 내의 주변 인트론에서 2개의 작은 결실(25 bp 및 28 bp)을 갖는 RS1 폴리펩티드의 일부를 암호화하는 엑손 3이 생성된다. 실시예 1에 기술된 스크리닝 분석에 사용된 프로브의 대략적인 위치(즉, Rs1-C59SmTU 및 Rs1-C59SmTD)는 두꺼운 수직 사선으로 표시되어 있다.
도 7은 실시예 1에서 기술된 표적화 벡터 내에 함유된 카세트의 재조합효소 매개 절제 이후 생성된 설치류(예: 마우스)에서의 Rs1 유전자의 확대도를 도시한 것으로서, 축척에 비례하지는 않는다. Rs1 유전자 산물에서 C59S 치환을 초래하는 점 돌연변이를 갖는 엑손 3이 잔여 loxP 부위와 함께 도시되어 있다. 카세트의 재조합효소 매개 절제 후에 남은 뉴클레오티드 접합부의 위치는 접합부 아래에 선으로 표기되어 있고 서열 번호로 표시되어 있다.
도 8은 실시예 1에 기술된 바와 같이 설치류(예: 마우스)에서 돌연변이체 Rs1 유전자를 생성하기 위한 표적화 벡터의 도해를 도시한 것으로서, 축척에 비례하지는 않는다. 보존적 엑손(수직 사선)의 번호는 각 엑손의 위 아래에 표시되어 있다. 엑손 5에서의 예시적인 점 돌연변이(R141C; CGC에서 TGC로의 돌연변이)는 상동성 재조합에 의한 합성 DNA 단편 및 카세트 요소의 삽입에 의한 것으로 엑손 5 위에 표시되어 있다. Rs1R141C-SDC 표적화 벡터는 자체 결실 약물 선택 카세트(예: loxP 서열이 측면에 위치한 히그로마이신 내성 유전자; 본원에 참조로서 통합된 미국 특허 제8,697,851호, 제8,518,392호 및 제8,354,389호 참조)를 함유한다. 상동성 재조합 시, 표적화 벡터에 함유된 합성 DNA 단편은 도시된 바와 같이 내인성 쥣과 Rs1 유전자좌의 엑손 5를 대신해 삽입된다. 약물 선택 카세트는 발달 의존 방식으로 제거되는데, 다시 말해, 전술한 바와 같은 Rs1 유전자좌에서 파괴를 함유하는 생식계열 세포를 갖는 마우스로부터 유래된 자손이 발달 도중에 분화된 세포로부터 선택성 마커를 제거하게 된다. 선택된 뉴클레오티드 접합부 위치는 각각의 접합부 아래에 선으로 표기되어 있고, 서열번호가 표시되어 있다.
도 9는 마우스 Rs1 유전자의 엑손 5의 확대도, 및 도 8에 도시된 (실시예 1도 참조함) 돌연변이체 Rs1 유전자의 설계에 대한 도해를 도시한 것으로서, 축척에 비례하지는 않는다. 표적화된 점 돌연변이(R141C)와 주변 인트론을 갖는 엑손 5(검은 직사각형)는 TAQMANβ 분석에 적합하도록 설계된 2개의 작은 결실과 함께 도시되어 있다. 상동성 재조합에 의해 표적화 벡터를 통합하면, R141C 치환을 갖고 돌연변이체 Rs1 유전자 내의 주변 인트론에서 2개의 작은 결실(10 bp 및 29 bp)을 갖는 RS1 폴리펩티드의 일부를 암호화하는 엑손 5가 생성된다. 실시예 1에 기술된 스크리닝 분석에 사용된 프로브의 대략적인 위치(즉, Rs1-R141CmTU 및 Rs1-R141CmTD)는 두꺼운 수직 사선으로 표시되어 있다.
도 10은 실시예 1에서 기술된 표적화 벡터 내에 함유된 카세트의 재조합효소 매개 절제 이후 생성된 설치류(예: 마우스)에서의 Rs1 유전자의 확대도를 도시한 것으로서, 축척에 비례하지는 않는다. Rs1 유전자 산물에서 R141C 치환을 초래하는 점 돌연변이를 갖는 엑손 5가 잔여 loxP 부위와 함께 도시되어 있다. 카세트의 재조합효소 매개 절제 후에 남은 뉴클레오티드 접합부의 위치는 접합부 아래에 선으로 표기되어 있고 서열 번호로 표시되어 있다.
도 11a~11c는 Rs1 널(Rs1 KO) 및 Rs1 돌연변이체(Rs1 C59S, Rs1 R141C) 동물의 망막 내에서 Rs1 mRNA 및 단백질 발현의 분포를 lacZ 발현, RNASCOPEβ 및 면역조직화학(IHC)에 의해 도시한 것이다. A, Rs1 KO 동물의 ONL 및 광수용기에서 정의 X-gal 신호를 보여주는 lacZ 염색. B, 야생형(WT) 동물에서의 내인성 Rs1 mRNA의 발현을 보여주는, RNASCOPEβ를 통한 Rs1 mRNA의 발현. Rs1 KO 동물의 망막에서는 Rs1 mRNA가 검출되지 않았다. C, WT 동물의 모든 망막 층에서의 RS1 단백질 분포를 보여주는 IHC. RS1 단백질 발현은 Rs1 KO 동물에서 검출되지 않았고, Rs1 C59S 및 Rs1 R141C 동물의 ONL과 IS에 RS1 단백질 발현은 Rs1KO 동물에서 검출되지 않았고, Rs1C59S 및 Rs1R141C 동물의 ONL과 IS에 한정되지 않았다(GCL, ganglion cell layer: 신경절 세포층; IPL, inner plexiform layer: 내망상층; INL, inner nuclear layer: 내핵층; OPL, outer plexiform layer: 외망상층; ONL, outer nuclear layer: 외핵층; IS, inner segments: 내절; RPE, retinal pigment epithelium: 망막 세포 상피). Rs1: 적색; DAPI: 청색.
도 12a~12d는 Rs1 널(Rs1 KO) 및 Rs1 돌연변이체(Rs1 C59S, Rs1 R141C) 동물의 망막에서의 RS1 단백질 발현을 웨스턴 블롯 및 ELISA 분석에 의해 도시한 것이다. A, Rs1 KO 및 C57BL/6-유래 수컷 계통에서의 RS1 발현을 보여주는, 환원 조건 하의 SDS-PAGE 겔의 웨스턴 블롯. B, 야생형(WT) 및 Rs1 C59S 수컷 동물에서의 RS1 발현을 보여주는, 환원 조건 하의 SDS-PAGE 겔의 웨스턴 블롯. C, 야생형(WT) 및 Rs1 R141C 수컷 동물에서의 RS1 발현을 보여주는, 환원 조건 하의 SDS-PAGE 겔의 웨스턴 블롯. D, 야생형(WT), Rs1 KO, Rs1 C59S 및 Rs1 R141C 수컷 동물에서의 RS1 단백질 수준을 보여주는 ELISA 분석. 야생형 한배 새끼와 비교해 Rs1 돌연변이체 동물에서의 RS1 단백질 발현 백분율은 각각의 막대 위에 표시되어 있다. D, 웨스턴 블롯과 ELISA 분석에서, Rs1 녹아웃 암컷 동물의 망막에서의 RS1 단백질 발현. KO: 동형접합성 Rs1 녹아웃(Rs1 -/- ); HET: 이형접합성 Rs1 녹아웃(Rs1 -/+ ). RS1 HET 암컷 동물은 야생형("WT") 수컷 및 암컷 동물과 유사한 양의 RS1 단백질을 가졌다.
도 13a~13d는 Rs1 널(Rs1 KO) 및 Rs1 돌연변이체(Rs1 C59S, Rs1 R141C) 동물의 망막에서의 병리학적 변화를 조직학적, IHC 및 광간섭 단층촬영(OCT) 분석에 의해 도시한 것이다. A, 조직학적 검사로 Rs1 KO, Rs1 C59S 및 Rs1 R141C 수컷 동물에서, INL 내의 공동 및 갈라짐(적색 삼각형), INL 및 OPL의 전반적인 해체(disorganization), ONL의 박화(수직 적색 이중 화살표) 및/또는 내절/외절(수직 적색 선)의 얇아짐(thinning)을 동반하는 광수용기의 퇴행을 나타냄. B, 망막-특이적 세포 마커(GFAP, glial fibrillary acidic protein - 신경아교섬유질 산성 단백질, 및 비멘틴(vimentin))를 사용하여 IHC로 Rs1 KO 수컷 동물에서 INL(*표는 활성화된 뮐러 세포를 나타냄)의 신경아교증(gliosis)을 밝혀 냄. C, 스펙트랄리스 히델버그(Spectralis Heidelberg) 광 간섭 단층촬영(OCT)을 사용하는 생체내 영상촬영에 의해 Rs1 KO, Rs1 C59S 및 Rs1 R141C 암컷 동물에서 망막층간분리증 및 광수용기 퇴행을 관찰함. D, 이형접합성 RS1 녹아웃 암컷(Rs1 -/+) ("Het")에서는 분리(schisis)가 관찰되지 않은 반면, 동형접합성 RS1 녹아웃 암컷(Rs1 -/-) ("KO")는 반 KO 수컷과 일치하는 표현형을 가짐.
도 14a~d는 20주령의 동물에서 암-순응(DA-) 및 명-순응(LA-) 전장 망막전위도(electroretinograms, ERG)에 의한 외망막 기능에 대한 분석을 보여준다. A, 암-순응 조건 하에 야생형(WT), Rs1 KO (KO), Rs1 C59S (C59S) 및 Rs1 R141C (R141C) 수컷 동물로부터 획득한 대표적인 ERG. B, 명-순응 조건 하에 야생형(WT), Rs1 KO (KO), Rs1 C59S (C59S) 및 Rs1 R141C (R141C) 수컷 동물로부터 획득한 대표적인 ERG. C, 자극 휘도의 함수로서 도시된, 암-순응 및 명-순응 ERG의 주요 구성 요소의 대표적인 진폭. 데이터 포인트는 6마리의 암컷 동물을 대상으로 한 평균(± SD)을 나타낸다. 야생형과 비교하면, Rs1 KO, Rs1 C59S 및 Rs1 R141C (R141C) 수컷 동물의 a-파와 b-파 둘 다는 진폭이 감소되었다. 자극 휘도(A 및 B)는 가장 왼쪽 파형 그래프의 왼쪽에 표기되어 있다. D, 암-순응 및 명-순응 조건 하에 야생형(Rs1 +/+ ), 동형접합성 녹아웃(Rs1 -/-) 및 이형접합성 녹아웃(Rs1 -/+) 암컷 동물로부터 획득한 대표적인 ERG. 담체(이형접합성) 암컷의 ERG는 모든 조건 하에서 WT 대조군과 일치하였다. 비교하면, 동형접합성 녹아웃 암컷의 ERG 표현형은 부의 파형 및 감소된 진폭의 a-파를 갖는 반접합성 녹아웃 수컷의 것과 유사하였다.
도 15는 Rs1 KO 마우스에서 망막의 조기 발병성 표현형을 조사하기 위해 실시예 4에 기술된 연구에 대한 예시적인 설계를 보여준다.
도 16a~16f는 Rs1 KO 마우스의 조기 발병성 표현형을 ERG 및 OCT 분석에서 도시한 것이다. 외망막 기능은 암-순응(DA-)(A 및 D) 및 명-순응(LA-)(B 및 E) 전장 ERG에 의해 평가하였는데, a-파에 비해 b-파가 감소한 것으로 나타나며, 결과적으로는 모든 시점에서 부의 ERG가 나타났다(정량 데이터는 도시되지 않음). 망막층간분리증 표현형은 관찰 시간 과정 전체에 걸쳐(P15~P24) 존재하였다(C 및 F, 황색 삼각형으로 표시됨).
도 17a~17b는 시간 경과에 따른 Rs1 KO 마우스 및 야생형(WT) 마우스의 ERG 파라미터 변화를 보여준다(Naka-Rushton 분석). WT 대조군과 비교하면, 생후 15일차(P15)의 Rs1 KO 마우스에서는 a-파 및 b-파 모두의 Rmax 값이 더 낮았으며; 생후 15일차의 Rs1 KO 마우스에서는 DA-ERG의 b-파 및 LA-ERG의 b-파의 Rmax 및 감도 값 모두가 크게 감소하였다. 시간이 지날수록 Rmax 값은 지속적으로 감소하였지만, 감도 값은 Rs1 KO 및 WT 마우스에서 비슷하였다.
도 18은 시간 경과에 따른 OCT 이미지의 변화를 보여준다. 생후 15일차에는 INL 및 OPL(별표)에서 현저한 분리 및 ELM의 증거가 관찰되지 않았는데, 이는 시점이 경과할수록 완화되는 경향을 보이는 것이었다. Rs1 KO의 망막 내 타원체 구역(EZ)은 전체 기간에 걸쳐 WT보다 더 넓었다.
도 19a~19c는 정량적 OCT 분석의 결과를 보여준다. WT 마우스에서 망막(외망막 포함)은 발생 기간(C) 동안 약간 얇아졌다. Rs1 KO 마우스에서의 망막(A 및 B)은 더 얇아졌는데, 이는 주로 분리의 완화와 관련된 것이었으며, Rs1 KO 망막 내의 외망막은 기간(C) 동안 WT보다 더 얇았다.
도 20은 마우스, 랫트 및 인간 RS1 폴리펩티드의 정렬을 보여준다. 신호 서열은 밑줄이 그어져 있다. 서열이 상이한 위치는 "*"에 의해 식별된다.
정의
파괴(disruption): 일부 구현예에서, 파괴는 DNA 서열(들)의 삽입, 결실, 치환, 대체, 과오 돌연변이 또는 틀 이동 또는 이들의 임의의 조합을 달성하거나 나타낼 수 있다. 삽입은 전체 유전자 또는 유전자의 단편, 예를 들어, 내인성 서열(예: 이종 서열) 이외의 기원일 수 있는 엑손의 삽입을 포함할 수 있다. 일부 구현예에서, 파괴는 유전자 또는 유전자 산물(예를 들어, 유전자에 의해 암호화된 단백질)의 발현 및/또는 활성을 증가시킬 수 있다. 일부 구현예에서, 파괴는 유전자 또는 유전자 산물의 발현 및/또는 활성을 감소시킬 수 있다. 일부 구현예에서, 파괴는 유전자 또는 암호화된 유전자 산물(예: 암호화된 폴리펩티드)의 서열을 바꿀 수 있다. 일부 구현예에서, 파괴는 유전자 또는 암호화된 유전자 산물(예를 들어, 암호화된 단백질)을 절단하거나 단편화할 수 있다. 일부 구현예에서, 파괴는 유전자 또는 암호화된 유전자 산물을 확장할 수 있다. 일부 이러한 구현예에서, 손상은 융합 폴리펩티드의 조립을 달성할 수 있다. 일부 구현예에서, 파괴는 유전자 또는 유전자 산물의 수준에 영향을 미칠 수 있지만 활성에는 영향을 미치지 않을 수 있다. 일부 구현예에서, 파괴는 유전자 또는 유전자 산물의 활성에는 영향을 미칠 수 있지만 수준에는 영향을 미치지 않을 수 있다. 일부 구현예에서, 파괴는 유전자 또는 유전자 산물의 수준에 유의한 효과를 가지지 않을 수 있다. 일부 구현예에서, 파괴는 유전자 또는 유전자 산물의 활성에 유의한 효과를 가지지 않을 수 있다. 일부 구현예에서, 파괴는 유전자 또는 유전자 산물의 수준 또는 활성에 유의한 효과를 가지지 않을 수 있다.
비인간 동물(non-human animal ): 본원에서 사용되는 바와 같이, 인간이 아닌 임의의 척추 동물 유기체를 지칭한다. 일부 구현예에서, 비인간 동물은 원구류, 경골어, 연골 어류(예를 들어, 상어 또는 가오리), 양서류, 파충류, 포유동물, 및 새이다. 일부 구현예에서, 비인간 동물은 포유류이다. 일부 구현예에서, 비인간 포유류는 영장류, 염소, 양, 돼지, 개, 소, 또는 설치류이다. 일부 구현예에서, 비인간 동물은 랫트 또는 마우스와 같은 설치류이다.
실질적 상동(substantial homology ): 본원에서 사용되는 바와 같이, 아미노산 또는 핵산 서열 간의 비교를 지칭한다. 당업자에 의해 이해되는 바와 같이, 2개의 서열이 상응하는 위치에 상동성 잔기를 함유하는 경우, 이들은 "실질적 상동성"인 것으로 일반적으로 간주된다. 상동성 잔기는 동일한 잔기일 수 있다. 대안적으로, 상동성 잔기는 적절하게 유사한 구조적 및/또는 기능적 특성을 갖는 동일하지 않은 잔기일 수 있다. 예를 들어, 당업자에게 공지된 바와 같이, 특정 아미노산은 일반적으로 "소수성" 또는 "친수성" 아미노산으로서, 및/또는 "극성" 또는 "비극성" 측쇄를 갖는 것으로서 분류된다. 하나의 아미노산이 동일한 유형의 다른 것으로 치환되는 것은 흔히 "상동성" 치환으로 간주될 수 있다. 일반적인 아미노산 분류가 아래에 요약되어 있다.


당업계에서 잘 알려진 바와 같이, 아미노산 또는 핵산 서열은, 뉴클레오티드 서열에 대한 BLASTN 및 아미노산 서열에 대한 BLASTP, 갭 BLAST 및 PSI-BLAST와 같이 상업적 컴퓨터 프로그램에서 사용할 수 있는 것들을 포함하여, 임의의 다양한 알고리즘을 사용하여 비교될 수 있다. 예시적인 이러한 프로그램은 Altschul, S. F. 외, 1990, J. Mol. Biol., 215(3): 403-410; Altschul, S. F. 외, 1997, Methods in Enzymology; Altschul, S. F. 외, 1997, Nucleic Acids Res., 25:3389-3402; Baxevanis, A.D., 및 B. F. F. Ouellette (eds.) Bioinformatics: A Practical Guide to the Analysis of Genes and Proteins, Wiley, 1998; 및 Misener 외 (eds.) Bioinformatics Methods and Protocols (Methods in Molecular Biology, Vol. 132), Humana Press, 1998에 기술되어 있다. 상동성 서열을 확인하는 것 외에도, 전술된 프로그램은 일반적으로 상동성의 정도에 대한 지표를 제공한다. 일부 구현예에서, 2개의 서열의 상응하는 잔기의 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상이 잔기의 관련 구간에 걸쳐 상동성인 경우 이들은 실질적으로 상동성인 것으로 간주된다. 일부 구현예에서, 관련 구간은 완전한 서열이다. 일부 구현예에서, 관련 구간은 적어도 9, 10, 11, 12, 13, 14, 15, 16, 17개 이상의 잔기이다. 일부 구현예에서, 관련 구간은 완전한 서열을 따라 인접 잔기를 포함한다. 일부 구현예에서, 관련 구간은 전체 서열을 따라 불연속 잔기, 예를 들면, 폴리펩티드 또는 이의 부분의 접힌 형태에 의해 한데 모인 인접하지 않은 잔기를 포함한다. 일부 구현예에서, 관련 구간은 적어도 10, 15, 20, 25, 30, 35, 40, 45, 50개 이상의 잔기이다.
실질적 동일성(substantial identity ): 본원에서 사용되는 바와 같이, 아미노산 서열 또는 핵산 서열 간의 비교를 지칭한다. 당업자에 의해 이해되는 바와 같이, 2개의 서열이 상응하는 위치에 동일한 잔기를 함유하는 경우, 이들은 "실질적으로 동일한" 것으로 일반적으로 간주된다. 당업계에서 공지된 바와 같이, 아미노산 또는 핵산 서열은, 뉴클레오티드 서열에 대한 BLASTN 및 아미노산 서열에 대한 BLASTP, 갭 BLAST 및 PSI-BLAST와 같이 상업적 컴퓨터 프로그램에서 사용할 수 있는 것들을 포함하여, 임의의 다양한 알고리즘을 사용하여 비교될 수 있다. 예시적인 이러한 프로그램은 Altschul, S. F. 외, 1990, J. Mol. Biol., 215(3): 403-10; Altschul S.F. 외의 1996, Meth. Enzymol. 266:460-80; Altschul, S.F. 외의 1997, Nucleic Acids Res., 25:3389-402; Baxevanis, A.D. and B.F.F. Ouellette (eds.) Bioinformatics: A Practical Guide to the Analysis of Genes and Proteins, Wiley, 1998; 및 Misener 외 (eds.) Bioinformatics Methods and Protocols, Methods in Molecular Biology, Vol. 132, Humana Press, 1998에 기술되어 있다. 동일한 서열을 확인하는 것 외에도, 전술된 프로그램은 일반적으로 동일성의 정도에 대한 지표를 제공한다. 일부 구현예에서, 2개의 서열의 상응하는 잔기의 적어도 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 이상이 잔기의 관련 구간에 걸쳐 동일한 경우 이들은 실질적으로 동일한 것으로 간주된다. 일부 구현예에서, 관련 구간은 완전한 서열이다. 일부 구현예에서, 관련 구간은 적어도 10, 15, 20, 25, 30, 35, 40, 45, 50개 이상의 잔기이다.
표적화 벡터(targeting vector ) 또는 표적화 작제물( targeting construct ): 본원에서 사용되는 바와 같이, 표적 영역을 포함하는 폴리뉴클레오티드 분자를 지칭한다. 표적 영역은 표적 세포, 조직 또는 동물에서의 서열과 동일하거나 실질적으로 동일한 서열을 포함하며, 상동성 재조합을 통해 표적화 작제물 (및/또는 이에 포함된 서열)이 세포, 조직 또는 동물의 게놈 내 위치에 통합되도록 한다. 부위 특이적 재조합효소 인식 부위(예: loxP 또는 Frt 부위)를 사용하는 재조합효소 매개 카세트 교환을 통해 세포, 조직 또는 동물의 위치를 표적으로 하는 표적 영역도 포함된다. 일부 구현예에서, 본원에 기술된 바와 같은 표적화 작제물은 특정 관심 핵산 서열이나 유전자(예: 리포터 유전자, 상동 유전자, 이종 유전자 또는 돌연변이 유전자), 선택 가능한 마커, 대조군 및/또는 조절 서열, 및 재조합 효소나 재조합유전성 폴리펩티드를 암호화하는 기타 핵산을 포함한다. 일부 구현예에서, 표적화 작제물은 관심 유전자를 전체적으로 또는 부분적으로 포함할 수 있으며, 관심 유전자는 내인성 서열에 의해 암호화된 단백질과 유사한 기능을 갖는 폴리펩티드를 전체적으로 또는 부분적으로 암호화한다. 일부 구현예에서, 표적화 작제물은 관심 돌연변이 유전자를 전체적으로 또는 부분적으로 포함할 수 있으며, 관심 돌연변이 유전자는 내인성 서열에 의해 암호화된 폴리펩티드와 유사한 기능을 갖는 변이체 폴리펩티드를 전체적으로 또는 부분적으로 암호화한다. 일부 구현예에서, 표적화 작제물은 리포터 유전자를 전체적으로 또는 부분적으로 포함할 수 있으며, 리포터 유전자는 당업계에 공지된 기술을 사용해 용이하게 식별되고/되거나 측정되는 폴리펩티드를 암호화한다.
변이체(variant ): 본원에서 사용되는 바와 같이, 기준 개체와 상당한 구조적 동일성을 나타내지만, 기준 개체와 비교하여, 하나 이상의 화학적 모이어티의 존재 또는 수준에서 기준 개체와 구조적으로 상이한 개체를 지칭한다. 일부 구현예에서, "변이체"는 기준 개체와 기능적으로도 상이하다. 예를 들어, "변이체 폴리펩티드"는 아미노산 서열에서의 하나 이상의 차이 및/또는 폴리펩티드 골격에 공유 결합된 화학적 모이어티(예를 들어, 탄수화물, 지질 등)에서의 하나 이상의 차이의 결과로서 기준 폴리펩티드와 상이할 수 있다. 일부 구현예에서, "변이체 폴리펩티드"는 기준 폴리펩티드와 적어도 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 또는 99%의 전체 서열 동일성을 보인다. 대안적으로 또는 추가적으로, 일부 구현예에서, "변이체 폴리펩티드"는 기준 폴리펩티드와 적어도 하나의 특징적인 서열 요소를 공유하지 않는다. 일부 구현예에서, 기준 폴리펩티드는 하나 이상의 생물학적 활성을 가진다. 일부 구현예에서, "변이체 폴리펩티드"는 기준 폴리펩티드의 하나 이상의 생물학적 활성을 공유한다. 일부 구현예에서, "변이체 폴리펩티드"는 기준 폴리펩티드의 하나 이상의 생물학적 활성이 결여되어 있다. 일부 구현예에서, "변이체 폴리펩티드"는 기준 폴리펩티드와 비교하여 하나 이상의 생물학적 활성의 수준의 감소를 나타낸다. 일부 구현예에서, 관심 폴리펩티드가 특정 위치에서 소수의 서열 변경을 제외하고 부모 아미노산 서열과 동일한 아미노산 서열을 갖는 경우, 관심 폴리펩티드는 부모 폴리펩티드 또는 기준 폴리펩티드의 "변이체"인 것으로 간주된다. 통상적으로, 모체와 비교해 변이체 내 잔기의 15%, 10%, 9%, 8%, 7%, 6%, 5%, 4%, 3%, 또는 2% 미만이 치환된다. 일부 구현예에서, "변이체"는 모체에 비해 10, 9, 8, 7, 6, 5, 4, 3, 2 또는 1개의 치환된 잔기(들)를 가진다. 흔히, "변이체"는 매우 적은 수(예를 들어, 5, 4, 3, 2, 또는 1 미만)의 치환된 기능적 잔기(즉, 특정 생물학적 활성에 참여하는 잔기)를 가진다. 또한, "변이체"는 모체에 비해 통상적으로 5, 4, 3, 2, 또는 1개 이하의 첨가 또는 결실을 가지며, 흔히 첨가 또는 결실을 갖지 않는다. 또한, 임의의 첨가 또는 결실은, 통상적으로 약 10, 약 9, 약 8, 약 7, 약 6개 미만, 보통은 약 5, 약 4, 약 3, 또는 약 2개 미만의 잔기이다. 일부 구현예에서, 부모 폴리펩티드 또는 기준 폴리펩티드는 자연계에서 발견되는 것이다. 당업자에 의해 이해되는 바와 같이, 특히 관심 폴리펩티드가 감염원 폴리펩티드인 경우, 관심 특정 폴리펩티드의 복수의 변이체는 자연에서 흔히 발견될 수 있다.
특정 구현예의 상세한 설명
망막층간 단백질-1(RS1) 폴리펩티드를 암호화하는 유전 물질에 파괴 또는 돌연변이(들)를 갖는 설치류(예를 들어, 마우스 또는 랫트)와 같은 비인간 동물이 제공된다. 특히, Rs1 유전자의 코딩 서열 전체 또는 일부가 결실되어 RS1 폴리펩티드를 생산하지 못하는 돌연변이체 Rs1 유전자를 갖는 비인간 동물이 제공된다. 또한, 야생형 RS1 폴리펩티드(돌연변이가 없는 Rs1 유전자에 의해 암호화되는 RS1 폴리펩티드)와 비교해 하나 이상의 아미노산 치환을 포함하는 변이체 또는 돌연변이체 RS1 폴리펩티드를 암호화하는 돌연변이체 Rs1 유전자를 생성하는 하나 이상의 돌연변이를 Rs1 유전자의 코딩 서열 내에 갖는 비인간 동물이 제공된다. 본원에 기술된 바와 같은 이러한 하나 이상의 아미노산 치환은 생산된 기능적 RS1 폴리펩티드를 제거하거나 현저하게 감소시키고, 비인간 동물에서 망막층간분리증(예: X-염색체 관련 망막층간분리증, XLRS)과 관련된 병리학적 및 기능적 특징을 형성시킨다. 따라서, 본원에 개시된 비인간 동물은 망막층간분리증의 치료 및/또는 완화를 위한 후보 치료제의 개발 및 식별에 특히 유용하다. 이러한 비인간 동물은 망막층간분리증의 치료 및/또는 완화를 위한 치료제(예를 들어, 유전자 요법)를 식별하고 개발하기 위한 세포 공급원을 제공한다. 또한, 이러한 비인간 동물은 안구 관련 질환, 장애 및 병태의 치료를 위한 치료제의 개발을 위한 유용한 동물 모델 시스템의 자원을 제공한다.
일부 구현예에서, 본원에 기술된 비인간 동물은 수컷 동물이다. 일부 구현예에서, 본원에 기술된 비인간 동물은 암컷 동물이다. 일부 구현예에서, 본원에 기술된 비인간 동물은 본원에 기술된 바와 같은 Rs1 유전자에서의 파괴 또는 돌연변이(들)에 대한 이형접합체이다. 일부 구현예에서, 본원에 기술된 비인간 동물은 본원에 기술된 바와 같은 Rs1 유전자에서의 파괴 또는 돌연변이(들)에 대한 동형접합체이다.
본 개시의 다양한 양태는 다음의 섹션에서 상세히 설명된다. 이러한 섹션의 사용은 제한하는 것으로 의도되지 않는다. 각각의 섹션은 본원에 기술된 하나 이상의 구현예에 적용될 수 있다. 본 출원에서, "또는(or)"의 사용은 달리 명시하지 않는 한 "및/또는(and/or)"을 의미한다.
망막층간 단백질-1 및 망막층간분리증
망막층간 단백질-1은, 염색체 Xp22.2 상에 위치된 6개의 엑손 및 5개의 인트론을 함유하는 약 32,4 kb 길이의 작은 유전자이며, 망막층간 단백질(Retinoschisin)로 불리는 224-아미노산 전구체 폴리펩티드로 번역되는 3,1 kb의 mRNA를 암호화한다. 망막층간 단백질은 4개의 상이한 도메인, 즉 세포 외부로 단백질의 전좌를 지시하는 N-말단 신호 서열(23개 아미노산); 고유 Rs1 도메인(39개 아미노산 길이의 긴/고도로 보존된 서열 모티프); 망막 세포 구조를 보존하고 적절한 시냅스 연결성(synaptic connectivity)을 확립하기 위해 RS1의 접착 기능에 기여하는 디스코이딘 도메인(157개 아미노산); 및 C 말단 분절(5개 아미노산)을 함유하는 모노머로서 발현된다.
망막층간 단백질은 소포체에서 조립되고 기능성 이황화-결합 호모-옥타머(Cys59-Cys223 이황화 결합에 의해 함께 연결된 8개의 서브유닛)로서 분비된다. 옥타머 내의 서브유닛은 추가로 Cys(40)-Cys(40) 이황화 결합에 의해 매개된 이량체로 구성된다. RS1은 이온력(ionic forces)에 의해 광수용기 내절 원형질막의 외소엽(outer leaflet)에 결합되고 세포-세포 상호작용 및 세포 부착에서 작용한다. RS1은 망막 내에서 발현되며, 주로 간상 내절 및 원뿔체 내절, 양극 세포, 및 송과선(pineal gland)에 의해 발현된다. 망막에서의 면역염색은 망막층간 단백질을 광수용기의 내절, 양극 세포, 및 내망상층과 외망상층으로 국한시킨다. 인간, 마우스, 랫트 및 토끼에는 높은 서열 상동성이 존재한다(마우스와 인간 사이에는 96% 동일하고 및 97.8% 유사함; 도 20도 참조).
망막층간분리증은 퇴행성, 유전적, 수축성 및 삼출성 형태로 분류된 심각한 안구 질환이다. 특히, 유전적 형태의 망막층간분리증인 X-염색체 관련 유아기 망막층간분리증(XLRS)은 시력 상실, 망막의 신경감각 층의 비정상적인 분리, 및 망막전이도(ERG)에서 b-파의 감소를 특징으로 하는 조기 발병성 황반 변성이다. XLRS는 망막층간 단백질-1(RS1) 유전자에서의 돌연변이에 의해 발생하며, 수컷에서만 질환을 유발하는 X-염색체 관련 열성 패턴으로 유전된다. RS1 유전자 산물에서의 돌연변이는 RS1 폴리펩티드를 전혀 갖지 않거나, 기능이 저하되었거나 전혀 기능을 갖지 않는 손상된 RS1 폴리펩티드를 생산한다. 200가지에 달하는 RS1 유전자의 돌연변이가 XLRS와 관련된 것으로 보고되었으며, 개체별로 매우 가변적인 표현형을 나타낸다(예: Kim, D.Y. 및 S. Mukai, 2013, Sem. Ophthalmol. 28(5-6):392-6에서 검토됨). 보고된 200가지에 달하는 돌연변이 중에서, 질환 유발 돌연변이의 약 40%는 넌센스 돌연변이 또는 프레임 시프트 돌연변이이며, 이들은 전장 폴리펩티드를 갖지 않을 것으로 예상된다. 그러나, 질환 유발 돌연변이의 약 50%(100/191)는 미스센스 돌연변이이며, 이는 전장 돌연변이 폴리펩티드가 생산될 수 있게 한다(Molday, R.S. 등의 Prog. Retin. Eye Res. 31:195-212 (2012년) 참조). 이들 돌연변이의 대부분(85/191)은 디스코이딘 도메인에서 발견되며, 기능적으로 불능화된 미스폴딩 폴리펩티드를 생성한다.
XLRS에 대한 다양한 표현형이 있다. 중심와(fovea)를 포함하는 낭포성 황반 병변은 XRLS의 특징적인 임상적 특징이다. 특히, "카트휠(cartwheel)" 또는 "스포크-휠(spoke-wheel)" 패턴을 갖는 중심와 분리(foveal schisis)는 기저부 검사(fundus exam)에서 특징적으로 발견되며(거의 100%의 사례에 존재함), 최대 50%의 환자에서 또는 망막 박리(retinal detachments)에서 주변부 분리가 발생할 수 있다. 주변부 분리(peripheral schisis)는, 지지되지 않는 교차 혈관으로부터의 잠재적 출혈을 동반하는 내엽(inner leaf)의 천공 및 열상으로 이어질 수 있다. 주변부의 추가적인 변화는 색소성 망막염(retinitis pigmentosa), 망막 섬유증(retinal fibrosis) 및 백색 비문증(white fleck)과 비슷한 착색(pigmentation), 및 유리체-망막 이영양증(vitreo-retinal dystrophy)을 포함한다. ERG는 현저한 b-파 감소를 나타내고, 일부 환자에서는 비정상적인 a-파를 나타내지만, 많은 경우, a-파는 정상이다.
XLRS의 임상 증상(clinical presentation)과 질환의 진행 과정은 가변적이며, 빠르게는 출생 시점에서 늦게는 학생기까지 가벼운 시각 증상(visual symptoms)만을 동반하는 것으로 나타난다. 이러한 가변성과 임상적 중증도는 유전자형과는 무관한 것으로 보이며, 암컷 보균자에게는 증상이 없다. 현재는, 스펙트럼 영역 광간섭 단층촬영(SD-OCT)이 이러한 질환에 대한 주요 진단 기법인 반면, 기존의 관리 옵션은 저시력 보조제로 제한되어 있다. 보고된 작은 연구들에서, 탄산 탈수효소 억제제(CAI, 국소 및 경구용, 녹내장에 사용 승인됨)는 치료된 안구의 약 50%에서 시력을 개선하는 것으로 나타났다.
돌연변이체 또는 조작된 Rs1 유전자를 갖는 비인간 동물
XLRS의 이해에서는 상당한 진전을 이루었지만, XLRS의 정확한 메커니즘의 많은 부분은 알려지지 않고 있다. 본 개시는, 현재 확립된 시스템에 존재하지 않는 고유한 유전 구조에 의존하는 XLRS용 치료제를 생성하고 개발하기 위한 개선된 생체내 시스템을 생성하는 것에 기초한다. 따라서, 본 개시는 XLRS용 치료제를 생성하고 개발하기 위한 개선된 생체내 시스템이 설치류(예: 마우스)와 같은 비인간 동물에서 내인성 Rs1 유전자좌에서의 유전자 변화(genetic alterations)를 생성하는 것에 의해 제공될 수 있다는 인식에 기초한다. 본원에서 기술된 바와 같이, 본 개시는 무엇보다도, 인간 XLRS 질환 표현형을 반복하는 Rs1-결핍 비인간 동물 및 Rs1-조작(예, 돌연변이체 Rs1) 비인간 동물(예: 마우스와 같은 설치류 동물)을 생성하는 예시적인 전략을 구체적으로 입증한다. 임의의 특정 이론에 구속되고자 함이 없이, 본원에 기술된 전략은 다른 Rs1-결핍 비인간 동물 및/또는 Rs1-조작 비인간 동물을 원하는대로 생성하는데 사용될 수 있다. 예를 들어, Rs1-조작 비인간 동물은 아래의 실시예 섹션에 기술된 것들 이외의 돌연변이, 또는 돌연변이의 조합을 함유하는 조작된 Rs1 유전자를 포함하도록 생성될 수 있다. 내인성 Rs1 유전자 내로 조작될 수 있는 예시적인 돌연변이는 X-염색체 관련 망막층간분리증 서열 변이 데이터베이스(RETINOSCHISISDB )에서 확인할 수 있다.
)에서 확인할 수 있다.
일부 구현예에서, 본원에 개시된 비인간 동물은 내인성 Rs1 유전자좌에 있는 Rs1 유전자의 코딩 서열의 전체 또는 일부의 결실을 게놈에 가지며, 이는 비인간 동물에서 생산되고 있는 기능적 RS1 폴리펩티드를 결여시킨다. 일부 구현예에서, 결실은 Rs1 유전자의 적어도 엑손 2~3을 포함한다. 엑손 2는 RS1 폴리펩티드의 아미노산 18~26을 암호화한다(아미노산 18~23은 신호 서열의 마지막 5개 아미노산임). 엑손 3은 RS1 폴리펩티드의 아미노산 27~61을 암호화한다. 일부 구현예에서, 결실은 Rs1 유전자의 엑손 1의 적어도 일부 및 엑손 2~3을 포함한다. 예를 들어, ATG 시작 코돈의 바로 3'에서 시작해 엑손 1의 3' 말단까지이면서 RS1 폴리펩티드의 아미노산 2~17을 암호화하는 엑손 1의 부분이 결실에 포함될 수 있다. 특정 구현예에서, 결실은 Rs1 유전자의 엑손 1 내의 ATG 시작 코돈 바로 다음부터 시작해서 엑손 2를 포함하고, 엑손 3의 3' 말단까지, 또는 엑손 3의 3' 말단에 있는 6개의 뉴클레오티드까지인 인접 게놈 단편의 결실이다.
Rs1 유전자좌가 Rs1 유전자의 코딩 서열의 전체 또는 일부의 결실을 갖는 구현예 중 일부에서, Rs1 유전자좌는 리포터 유전자를 포함한다. 일부 구현예에서, 리포터 유전자는 Rs1 프로모터, 예를 들어, Rs1 유전자의 코딩 서열의 전체 또는 일부의 결실을 갖는 Rs1 유전자좌에 있는 Rs1 프로모터에 작동 가능하게 연결된다. 일부 구현예에서, Rs1 유전자좌는 Rs1 유전자의 엑손 1의 ATG 시작 코돈 바로 다음부터 시작해서 엑손 3의 3' 말단까지인 (또는 엑손 3의 3' 말단에 있는 6개의 뉴클레오티드까지인) 인접 게놈 단편의 결실을 가지며, 리포터 유전자의 코딩 서열은 Rs1 유전자의 ATG 시작 코돈에 프레임 내 융합된다. 리포터 유전자가 Rs1 유전자좌에 있는 Rs1 프로모터에 작동 가능하게 연결된 결과, 리포터 유전자의 발현 패턴은 Rs1 유전자의 발현 패턴과 유사하다. 본원에서 사용하기에 적합한 리포터 유전자는, 예를 들어, lacZ, 및 루시퍼라아제, 녹색 형광 단백질(GFP), 강화된 GFP(eGFP), 시안 형광 단백질(CFP), 황색 형광 단백질(YFP), 강화된 황색 형광 단백질(eYFP), 청색 형광 단백질(BFP), 강화된 청색 형광 단백질(eBFP), DsRed 및 MmGFP와 같은 리포터 단백질을 암호화하는 유전자를 포함한다.
다른 구현예에서, 본원에 개시된 비인간 동물은 Rs1 유전자 (예를 들어, 내인성 Rs1 유전자 또는 이종 Rs1 유전자)의 코딩 서열에 하나 이상의 점 돌연변이를 가지며, 이는 (점 돌연변이가 없는 Rs1 유전자에 의해 암호화된) 야생형 RS1 폴리펩티드에 비해 하나 이상의 아미노산 치환을 포함하는 변이체 RS1 폴리펩티드, 예를 들어, 야생형 설치류 RS1 폴리펩티드에 비해 하나 이상의 아미노산 치환을 갖는 변이체 설치류(예: 마우스 또는 랫트) RS1 폴리펩티드, 또는 야생형 인간 RS1 폴리펩티드에 비해 하나 이상의 아미노산 치환을 포함하는 변이체 인간 RS1 폴리펩티드를 생성한다.
본원에 기술된 아미노산 치환은 Rs1 돌연변이체 대립유전자(결실 또는 점 돌연변이를 갖는 Rs1 유전자)로부터 생산된 기능적 RS1 폴리펩티드를 제거하거나 이의 수준을 현저하게 감소시킨다. 아미노산 치환은, 예를 들어, 폴리펩티드의 미스폴딩, 손상된 서브유닛 또는 올리고머 조립체의 결과, 생산된 기능적 RS1 폴리펩티드의 제거 또는 이의 수준의 상당한 감소를 초래할 수 있고, 폴리펩티드가 단백질 분비 프로세스의 일부로서 ER의 막 내로 삽입될 수 없게 할 수 있다.
일부 구현예에서, 아미노산 치환은 신호 서열에서의 치환이며, 이는 아미노산 치환을 갖는 변이체 RS1 폴리펩티드가 분비를 위해 ER의 막 내로 삽입될 수 없게 한다. 예를 들어, 신호 서열 내의 소수성 잔기가 프롤린으로 치환되거나 친수성/하전된 잔기로 치환되면, 신호 서열이 ER 막 내로의 삽입에 필요한 α-나선 이차 구조를 받아들이는 것을 방지할 수 있다. 특정 구현예에서, 아미노산 치환은 L13의 치환(예를 들어, L13P)이다.
일부 구현예에서, 아미노산 치환은 디스코이딘 도메인의 측면에 위치한 영역, 즉 아미노산 24~62 및 (아미노산 220~224로 이루어진) C-말단 분절로 이루어진 Rs1 영역에서의 아미노산 치환이다. 특정 구현예에서, 치환은 위치 38, 40, 42, 59 또는 223에서 시스테인이 비-시스테인 잔기, 예를 들어, Ser, Arg, Trp, Tyr 또는 Gly로 치환되는 것이다. C40은 C40-C40 이황화-결합 이량체의 형성을 담당하며, C59 및 C223은 RS1 이량체를 옥타머로 조립할 수 있도록 이황화 분자간 결합을 형성한다. 따라서, 40, 59 또는 223에서 Cys의 치환이 단백질 접힘 및 분비에 미치는 효과는 제한될 수 있지만, 여전히, 이러한 치환을 포함하는 돌연변이체 RS1 폴리펩티드가 세포 접착 단백질로서는 작용할 수 없게 한다. 일부 구현예에서, 위치 40, 59 또는 223에서의 시스테인은 Ser, Arg, Trp, Tyr 또는 Gly 로 치환된 것이다. 치환의 특정 예는 C38S, C40S, C42S, C59S, C223S, C223R 및 C223Y를 포함한다.
다른 구현예에서, 아미노산 치환은 아미노산 63~219로 구성된, RS1 폴리펩티드의 디스코이딘 도메인에서의 치환이다.
일부 구현예에서, 디스코이딘 도메인에서의 치환은 디스코이딘 도메인 내 5개의 Cys 잔기, 즉 C63, C83, C110, C142, 및 C219 중 하나가 치환되는 것이다. Cys63과 Cys219, 및 Cys110-Cys142는 단백질 접힘에 중요한 2개의 분자내 이황화 결합을 형성한다. 일부 구현예에서, 위치 63, 83, 110, 142 또는 219 중 하나에 있는 시스테인은 비-시스테인 잔기, 예를 들어, Ser, Arg, Trp, Tyr 또는 Gly로 치환된 것이다. 치환의 특정 예는 C63S, C83S, C110S, C110Y, C142S, C142R, C142W, C219S, C219R, C219W 및 C219G를 포함한다.
일부 구현예에서, 디스코이딘 도메인에서의 치환은 이황화 결합의 형성에 직접적으로 관여하지는 않지만 단백질 접힘, 디스코이딘 도메인의 형성 또는 안정성, 및/또는 인접한 서브유닛들 간의 분자간 상호작용에 중요한 아미노산 잔기의 치환이다. 이러한 잔기의 예로는, 고도로 보존된, 용매 비접근성 핵심 잔기(solvent inaccessible core residues), 예컨대 E72, G109, E146, R182, 및 P203, 뿐만 아니라 R141 및 D143를 포함한다. 일부 특정 구현예에서, 치환은 비-시스테인 잔기를 시스테인으로 대체하는 것이며, 이는 티올 교환에 영향을 미칠 수 있다(예: W92C, W96C, R141C, R182C, R200C, P203C, 및 R209C). 일부 다른 특정 구현예에서, 치환은 아미노산 잔기의 전하를 제거 또는 역전시키거나, 티올 잔기에 영향을 미치지 않으면서 비-하전된 잔기를 하전된 잔기로 대체함으로써 단백질 전하에 영향을 미치는 것이다(예: E72K, W96R, R102W, R102Q, G109E, G109R, R141H, D143V, N179D 및 R213W). 다른 구현예에서, 치환은 Pro 잔기의 삽입 또는 제거에 의해 형태 안정성에 영향을 미칠 수 있는 것이다(예: S73P, L127P, P192S, P192T, P193S 및 P203L). 또 다른 구현예에서, 치환은 극성 잔기의 삽입 또는 제거에 의해(즉, 소수성 잔기를 극성 잔기로 대체하거나, 극성 잔기를 소수성 잔기로 대체하는 것에 의해) 소수성 코어에 영향을 줄 수 있는 것이다(예: I136T 및 N163Y).
일부 구현예에서, 본원에 기술된 비인간 동물은 하나 이상의 점 돌연변이를 Rs1 유전자 내에 포함하는데, 이는 암호화된 RS1 폴리펩티드에서 시스테인[Cys, C]을 세린[Ser, S]으로 치환시키거나, 아르기닌[Arg, R]을 시스테인[Cys, C]으로 치환시킨다. 일부 특정 구현예에서, 치환은 C59S 치환이다. 일부 특정 구현예에서, 치환은 R141C 치환이다.
일부 구현예에서, Rs1 유전자 내에 파괴 또는 돌연변이를 포함하거나, 조작된 Rs1 유전자를 포함하는 본원에 기술된 바와 같은 비인간 동물은 이종 종(예: 인간) 유래의 유전 물질을 추가로 포함한다. 일부 구현예에서, 본원에 기술된 바와 같은 비인간 동물은 돌연변이체 인간 Rs1 유전자인 조작된 Rs1 유전자를 포함하되, 돌연변이체 인간 Rs1 유전자는 본원에서 전술한 치환(예: C59S 치환 또는 R141C 치환)을 포함하는 인간 RS1 폴리펩티드를 암호화한다. 일부 특정 구현예에서, 본원에 기술된 바와 같은 비인간 동물은, 본원에서 전술한 치환(예: C59S 치환 또는 R141C 치환)을 포함하는 인간 RS1 폴리펩티드가 발현되도록 비인간 동물의 게놈에 무작위 삽입되는 돌연변이체 Rs1 유전자를 포함한다.
망막층간 단백질-1 서열
예시적인 인간 및 비인간 Rs1 서열은 서열번호 1~22에 제시되어 있고 표 1에 요약되어 있다.
lacZ 리포터 유전자, 마우스 프로타민 1 프로모터에 의해 전사 조절되는 Cre 재조합효소 유전자 및 loxP 부위가 측면에 위치하고 유비퀴틴 프로모터에 의해 전사 조절되는 네오마이신 내성 유전자를 포함하는 비인간(예를 들어, 마우스) Rs1 대립유전자의 파괴에 사용되는 예시적인 자가 결실 카세트는 서열번호 23에 제시되어 있다(8,202 bp).
비인간(예를 들어, 마우스) Rs1 대립유전자의 예시적인 결실(내인성 설치류 Rs1 유전자좌로부터 결실된 엑손 1~3의 서열)은 서열번호 24에 제시되어 있다(13,716 bp).
선택 카세트의 재조합효소 매개 절제 후에 파괴된 생쥐(Mus musculus) Rs1 대립유전자의 예시적인 부분은 서열번호 25에 제시되어 있다.
자가 결실 히그로마이신 선택 카세트를 포함하는 C59S 아미노산 치환을 암호화하는 돌연변이체 비인간(예: 마우스) Rs1 대립유전자의 예시적인 부분은 서열번호 26에 제시되어 있다.
선택 카세트의 재조합효소 매개 절제 후, C59S 아미노산 치환을 암호화하는 돌연변이체 비인간(예: 마우스) Rs1 대립유전자의 예시적인 부분은 서열번호 27에 제시되어 있다.
자가 결실 히그로마이신 선택 카세트를 포함하는 R141C 아미노산 치환을 암호화하는 돌연변이체 비인간(예: 마우스) Rs1 대립유전자의 예시적인 부분은 서열번호 28에 제시되어 있다.
선택 카세트의 재조합효소 매개 절제 후, R141C 아미노산 치환을 암호화하는 돌연변이체 비인간(예: 마우스) Rs1 대립유전자의 예시적인 부분은 서열번호 29에 제시되어 있다.
| 서열 번호 | 설명 | 특징 |
|
| 1 | Mus musculus(생쥐) Rs1 mRNA (NCBI 기준 서열 NM_011302) | 길이: 5855 nt 코딩 영역: nt. 174~848 엑손 1~6: nt 1~225, 226~251, 252~357, 358~499, 500~695, 696~5840. |
|
| 2 | Mus musculus Rs1 아미노산 (NCBI 기준 서열 NP_035432) | 길이: 224 aa신호 서열: aa 1~23 | |
| 3 | Rattus norvegicus(시궁쥐) Rs1 mRNA (NCBI 기준 서열 NM_001104643) | 길이: 675 nt코딩 영역: nt 1~675 |
|
| 4 | Rattus norvegicus Rs1 아미노산 (NCBI 기준 서열 NP_001098113) | 길이: 224 aa신호 서열: aa 1~21 |
|
| 5 | Macaca mulatta(히말라야 원숭이) RS1 mRNA (NCBI 기준 서열 NM_001194911) | 길이: 994 nt코딩 영역: nt. 42~716 |
|
| 6 | Macaca mulatta RS1 아미노산 (NCBI 기준 서열 NP_001181840 | 길이: 224 aa신호 서열: aa 1~21 |
|
| 7 | Homo sapiens(사람) RS1 mRNA (NCBI 기준 서열 NM_000330) | 길이: 3039 nt코딩 영역: 36~710 엑손 1~6: 1~87, 88~113, 114~219, 220~360, 361~557, 558~3025. |
|
| 8 | Homo sapiens RS1 아미노산 (NCBI 기준 서열 NP_000321) | 길이: 224 aa신호 서열: aa 1~23 |
|
| 9 | Canis lupus familiaris(개) Rs1 mRNA (NCBI 기준 서열 XM_548882) | 길이: 2061 nt 코딩 영역: nt 89~763 |
|
| 10 | Canis lupus familiaris Rs1 아미노산 (NCBI 기준 서열 XP_548882) |
길이: 224 aa |
|
| 11 | Sus scrofa(멧돼지) Rs1 mRNA(NCBI 기준 서열 XM_013985956) | 길이: 1772 nt 코딩 영역: nt 295~969 |
|
| 12 | Sus scrofa Rs1 아미노산 (NCBI 기준 서열 XP_013841410) | 길이: 224 aa | |
| 13 | Bos taurus(소) Rs1 mRNA (NCBI 기준 서열 XM_010822174) | 길이: 899 nt 코딩 영역: nt. 45~719 |
|
| 14 | Bos taurus Rs1 아미노산 (NCBI 기준 서열 XP_010820476) | 길이: 224 aa | |
| 15 | Ovis aries(양) RS1 mRNA (NCBI 기준 서열 XM_012106316) | 길이: 1604 nt 코딩 영역: nt 702~1337 |
|
| 16 | Ovis aries(양) RS1 아미노산 (NCBI 기준 서열 XP_011961706) |
길이: 211 aa | |
| 17 | Felis catus(고양이) RS1 mRNA (NCBI 기준 서열 XM_019823621) | 길이: 4553 nt코딩 영역: nt. 59-733 | |
| 18 | Felis catus(고양이) RS1 아미노산 (NCBI 기준 서열 XP_019679180) | 길이: 224 aa | |
| 19 | Equus caballus(말) RS1 mRNA (NCBI 기준 서열 XM_001491183) | 길이: 1193 nt코딩 영역: nt. 1~675 | |
| 20 | Equus caballus RS1 아미노산(NCBI 기준 서열 XP_001491233) | 길이: 224 aa | |
| 21 | Oryctolagus cuniculus(굴토끼) RS1 mRNA (NCBI 기준 서열 NM_001109823) | 길이: 675 nt 코딩 영역: nt. 1~675 |
|
| 22 | Oryctolagus cuniculus RS1 아미노산(NCBI 기준 서열 NP_001103293) | 길이: 224 aa신호 서열: aa 1~21 | |
| 23 | lacZ 리포터 유전자, 마우스 프로타민 1 프로모터에 의해 전사 조절되는 Cre 재조합효소 유전자 및 loxP 부위가 측면에 위치하고 유비퀴틴 프로모터에 의해 전사 조절되는 네오마이신 내성 유전자를 포함하는 비인간(예를 들어, 마우스) Rs1 대립유전자의 파괴에 사용되는 예시적인 자가 결실 카세트. | 길이: 8,202 bploxP 부위: nt. 3431~3464 및 8163~8196 | |
| 24 | 마우스 Rs1 대립유전자(엑손 1의 일부 및 엑손 2~3 포함)의 예시적인 결실 | 길이: 13,716 bp | |
| 25 | 선택 카세트의 재조합효소 매개 절제 후, 파괴된 생쥐 Rs1 대립유전자의 예시적인 부분. | 길이: 3670 nt 마우스 서열: nt 1~100 및 3571~3670 lacZ 및 잔여 클로닝 부위: nt. 101~3570 loxP 서열: nt. 3531~3564 |
|
| 26 | 자가 결실 히그로마이신 선택 카세트를 포함하는 C59S 아미노산 치환을 암호화하는 돌연변이체 마우스 Rs1 대립유전자의 예시적인 부분 | 길이: 5987 nt마우스 서열: nt. 1~755 및 5788~5987 돌연변이된 코돈: nt. 572~574 엑손 3: nt. 476~581 표적화 벡터 서열: nt. 756~5787 |
|
| 27 | 선택 카세트의 재조합효소 매개 절제 후, C59S 아미노산 치환을 암호화하는 돌연변이체 마우스 Rs1 대립유전자의 예시적인 부분 | 길이: nt 1033 nt마우스 서열: nt. 1~755 및 834~1033 돌연변이된 코돈: nt. 572~574 엑손 3: nt. 476~581 표적화 벡터 서열: nt. 756~833 |
|
| 28 | 자가 결실 히그로마이신 선택 카세트를 포함하는 R141C 아미노산 치환을 암호화하는 돌연변이체 마우스 Rs1 대립유전자의 예시적인 부분 | 길이: 5629 nt마우스 서열: nt. 1~497 및 5530~5629 돌연변이된 코돈: nt. 278~280 엑손 5: nt. 184~379 표적화 벡터 서열: nt. 498~5529. |
|
| 29 | 선택 카세트의 재조합효소 매개 절제 후, R141C 아미노산 치환을 암호화하는 마우스 Rs1 대립유전자의 예시적인 부분 | 길이: 675 nt마우스 서열: nt. 1~497 돌연변이된 코돈: nt. 278~280 엑손 5: nt. 184~379 표적화 벡터 서열: nt. 498~675. |
|
| 30 | 프로타민 1(Prm1) 프로모터 | ||
| 31 | Blimp1 프로모터 1 kb | ||
| 32 | Blimp1 프로모터 2 kb | ||
| 33~41 | 실시예 1에 기술된 돌연변이체 Rs1 대립유전자에서의 접합 서열 | ||
| 42~59 | 실시예 1에 기술된 프라이머 및 프로브 서열 | ||
비인간 동물의 생산
본원에 기술된 바와 같은 Rs1 유전자에서 파괴 또는 돌연변이(들)을 갖는 비인간 동물의 생산을 위한 DNA 작제물, 표적화 벡터 및 방법이 본원에 제공된다.
녹아웃 동물(예: Rs1 KO)에 대한 표적화 벡터를 제작하는 데 DNA 서열이 사용될 수 있다. 일반적으로, 리포터 유전자 또는 돌연변이체 (또는 조작된) Rs1 유전자를 전체적으로 또는 부분적으로 암호화하는 폴리뉴클레오티드 분자(예: 삽입 핵산)가 적절한 숙주 세포에서 폴리뉴클레오티드 분자를 복제하기 위해 벡터에, 바람직하게는 DNA 벡터에 삽입된다.
폴리뉴클레오티드 분자(또는 삽입 핵산)는 표적 유전자좌 또는 유전자에 통합하고자 하는 DNA의 세그먼트를 포함한다. 일부 구현예에서, 삽입 핵산은 하나 이상의 관심 폴리뉴클레오티드를 포함한다. 일부 구현예에서, 삽입 핵산은 하나 이상의 발현 카세트를 포함한다. 일부 특정 구현예에서, 발현 카세트는 관심 뉴클레오티드, 선택 마커를 암호화하는 폴리뉴클레오티드 및/또는 리포터 유전자를, 일부 특정 구현예에서는 발현에 영향을 미치는 다양한 조절 성분(예: 프로모터, 인핸서 등)과 함께 포함한다. 사실상, 임의의 관심 폴리뉴클레오티드가 삽입 핵산 내에 함유되어 표적 게놈 유전자좌에서 통합될 수 있다. 본원에 개시된 방법은 적어도 1, 2, 3, 4, 5, 6개 또는 그 이상의 관심 폴리뉴클레오티드가 표적화된 Rs1 유전자(또는 유전자좌)에 통합될 수 있게 한다.
일부 구현예에서, 삽입 핵산에 함유된 관심 폴리뉴클레오티드는 리포터를 암호화한다. 일부 구현예에서, 삽입 핵산에 함유된 관심 폴리뉴클레오티드는 이종, 변이체 또는 이종 변이체 RS1 폴리펩티드를 암호화한다. 일부 구현예에서, 삽입 핵산에 함유된 관심 폴리뉴클레오티드는 선택성 마커 및/또는 재조합 효소를 암호화한다.
일부 구현예에서, 관심 폴리뉴클레오티드는 부위 특이적 재조합 부위(예: loxP, Frt 등)가 측면에 위치하거나 이를 포함한다. 일부 구현예에서, 부위 특이적 재조합 부위는 리포터를 암호화하는 DNA 분절, 선택성 마커를 암호화하는 DNA 분절, 재조합 효소를 암호화하는 DNA 분절, 및 이들의 조합의 측면에 위치한다. 삽입 핵산 내에 포함될 수 있는 선택 마커, 리포터 유전자 및 재조합 효소 유전자를 포함하는 예시적인 관심 폴리뉴클레오티드가 본원에 기술된다.
크기에 따라, Rs1 유전자 또는 RS1 암호화 서열은 상업적 공급자로부터 입수 가능한 cDNA 공급원으로부터 직접 클로닝되거나 GenBank로부터 이용 가능한 공개된 서열에 기초하여 가상 환경에서(in silico) 설계될 수 있다(상기 참조). 대안적으로, 박테리아 인공 염색체(BAC) 라이브러리에 의해 관심 유전자(예: 설치류 또는 이종 Rs1 유전자)로부터 Rs1 서열이 제공될 수 있다. BAC 라이브러리에는 100~150 kb의 평균 삽입체 크기가 포함되며, 300 kb 크기의 삽입체가 수용될 수 있다(Shizuya, H. 외, 1992, Proc. Natl. Acad. Sci., U.S.A. 89:8794-7; Swiatek, P.J. and T. Gridley, 1993, Genes Dev. 7:2071-84; Kim, U.J. 외, 1996, Genomics 34:213-8; 참조로서 본원에 통합됨). 예를 들어, 인간 및 마우스 유전자 BAC 라이브러리가 구축되었고 상업적으로 이용 가능하다(예: Invitrogen, 캘리포니아 칼즈배드). 또한, 게놈 BAC 라이브러리는 전사 조절 영역을 비롯하여 설치류 또는 이종 Rs1 서열의 공급원 역할을 할 수 있다.
대안적으로, 설치류 또는 이종 Rs1 서열은 효모 인공 염색체(YAC)로부터 단리되고, 클로닝되고/되거나 전달될 수 있다. 전체 설치류 또는 이종 Rs1 유전자가 하나 또는 여러 개의 YAC 내에서 클로닝되어 이에 포함될 수 있다. 다수의 YAC가 사용되고 중첩된 상동성의 영역을 포함하는 경우, 이들은 효모 숙주 계통 내에서 재조합되어 전체 유전자좌를 나타내는 단일 구조체를 생성할 수 있다. 당 업계에 공지된 방법 및/또는 본원에 설명된 방법에 의해 구조체를 배아 줄기 세포 또는 배아에 도입하는 것을 돕기 위해, 레트로피팅(retrofitting)에 의해 포유류 선택 카세트로 YAC 아암을 추가로 변형시킬 수 있다.
본원에 기술된 바와 같은 Rs1 서열을 함유하는 표적화 벡터 또는 DNA 작제물은, 일부 구현예에서, 유전자 변형 비인간 동물에서의 발현을 위해 비인간 조절 서열(예: 설치류 프로모터)에 작동 가능하게 연결된 야생형 또는 부모 설치류 RS1 폴리펩티드와 비교해 하나 이상의 아미노산 치환을 포함하는 설치류 RS1 폴리펩티드를 암호화하는 설치류 Rs1 게놈 서열을 포함한다. 일부 구현예에서, 본원에 기술된 바와 같은 Rs1 서열을 함유하는 DNA 작제물 또는 표적화 벡터는, 설치류 Rs1 프로모터에 작동 가능하게 연결된 야생형 또는 부모 설치류 RS1 폴리펩티드와 비교해 하나 이상의 아미노산 치환(예: C59S 또는 R141C)을 포함하는 변이체 설치류 RS1 폴리펩티드를 암호화하는 설치류 Rs1 게놈 서열을 포함한다. 바람직한 아미노산 치환의 예는 본원에 기술되어 있다. 본원에 기술된 DNA 작제물에 포함된 설치류 및/또는 이종 서열은 자연에서 발견되는 설치류 및/또는 이종 서열(예: 게놈 서열)과 동일하거나 실질적으로 동일할 수 있다. 대안적으로, 이러한 서열은 인공적(예: 합성)이거나 사람의 손에 의해 조작될 수 있다. 일부 구현예에서, Rs1 서열은 합성에 의한 것이며, 자연에서 발견된 설치류 또는 이종 Rs1 유전자에서 발견되는 서열 또는 서열들을 포함한다. 일부 구현예에서, Rs1 서열은 설치류 또는 이종 Rs1 유전자와 자연적으로 결합된 서열을 포함한다. 일부 구현예에서, Rs1 서열은 설치류 또는 이종 Rs1 유전자와 자연적으로 결합되지 않은 서열을 포함한다. 일부 구현예에서, Rs1 서열은 비인간 동물에서의 발현에 최적화된 서열을 포함한다. 추가 서열이 본원에 기술된 돌연변이체 (또는 변이체) Rs1 유전자의 발현을 최적화하는 데 유용한 경우, 이러한 서열은 기존의 서열을 프로브로서 사용하여 클로닝될 수 있다. 돌연변이체 Rs1 유전자 또는 RS1 암호화 서열의 발현을 최대화하는 데 필요한 추가 서열은 원하는 결과에 따라 게놈 서열이나 다른 공급원으로부터 수득될 수 있다.
DNA 작제물이나 표적화 벡터는 당업계에 공지된 방법을 사용해 제작될 수 있다. 예를 들어, DNA 구조체는 더 큰 플라스미드의 일부로서 제작될 수 있다. 이러한 제작은 당업계에 공지된 바와 같은 효율적인 방식으로 정확한 구조체의 클로닝 및 선택을 가능하게 한다. 본원에 기술된 바와 같은 서열을 함유하는 DNA 단편은, 원하는 동물로의 통합을 위해 이들이 잔여 플라스미드로부터 쉽게 단리될 수 있도록 플라스미드 상의 편리한 제한 부위(restriction sites) 사이에 위치될 수 있다. 플라스미드, DNA 작제물 및/또는 표적화 벡터의 제작 및 숙주 기관의 형질변환에 사용된 다양한 방법이 당업계에 공지되어 있다. 원핵 세포 및 진핵 세포 모두에 적합한 다른 발현 시스템 및 일반적인 재조합 절차에 관해서는, Molecular Cloning: A Laboratory Manual, 제2 판, 편집자 Sambrook, J. 외, Cold Spring Harbor Laboratory Press: 1989를 참조한다.
전술한 바와 같이, 파괴되었거나 조작된 Rs1 유전자를 함유하는 비인간 동물에 대한 표적화 벡터에 사용하기 위한 예시적인 비인간 Rs1 핵산 및 아미노산 서열은 위에 제공되어 있다. 다른 비인간 Rs1 서열 또한 GenBank 데이터베이스에서 확인할 수 있다. Rs1 표적화 벡터는, 일부 구현예에서, 유전자 이식된 비인간 동물의 게놈에 삽입하기 위한 리포터 유전자를 암호화하는 DNA 서열, 선택성 마커, 재조합 효소 유전자(또는 이들의 조합) 및 비인간 Rs1 서열(즉, 표적 영역의 인접 서열)을 포함한다. 일 실시예에서, 결실 시작 점은, 삽입 핵산이 내인성 조절 서열(예: 프로모터)에 작동 가능하게 연결될 수 있도록 시작 코돈의 바로 하류(3')로 설정될 수 있다. 도 2~4는, 시작 코돈을 제외한 쥣과 Rs1 유전자의 암호화 서열의 일부(예: 엑손 1~3)를 표적화 결실시키고, G418-내성 배아 줄기(ES) 세포 콜로니의 선택을 위해 β-갈락토시다아제(β-galactosidase)를 암호화하는 lacZ 유전자 및 네오마이신 포스포트란스퍼라아제(Neo)를 암호화하는 약물 선택 카세트 유래의 서열을 함유하는 카세트로 치환하기 위한 예시적인 방법 및 표적화 벡터를 도시한다. 또한, 표적화 벡터는 ES-세포 특이적 마이크로 RNA(miRNA) 또는 생식 세포 특이적 프로모터(예: 프로타민 1 프로모터; Prot-Cre-SV40)에 의해 조절되는 재조합 효소(예: Cre)를 암호화하는 서열을 포함한다. 네오마이신 선택 카세트 및 Cre 재조합효소 암호화 서열의 측면에는 네오마이신 선택 카세트의 Cre-매개 절제를 발달 의존 방식으로 가능하게 하는 (즉, 전술한 파괴된 Rs1 유전자를 함유하는 생식 세포를 가진 설치류 유래의 자손이 발달 도중에 선택성 마커를 제거하게 하는) loxP 재조합효소 인식 부위가 위치한다(참조: 미국 특허 제8,697,851호, 제8,518,392호, 제8,354,389호, 제8,946,505호, 및 제8,946,504호; 이들 모두는 본원에 참조로서 통합됨). 이는, 무엇보다도, 네오마이신 선택 카세트가 분화된 세포 또는 생식 세포로부터 자동적으로 절제되도록 한다. 따라서, 표현형 분석 이전에 네오마이신 선택 카세트는 쥣과 Rs1 프로모터에 작동 가능하게 연결된 lacZ 리포터 유전자(마우스 Rs1 시작 코돈에 융합됨)만을 남기고 제거된다 (도 4).
본원에 기술된 바와 같은 비인간 동물을 생성하는 방법에는 자가 결실 선택 카세트 기술이 사용된다(참조: 미국 특허 제8,697,851호, 제8,518,392호 및 제8,354,389호. 이들 모두는 본원에 참조로서 통합됨). 이러한 기술의 사용은 비인간 동물의 게놈 내에 약물 내성 클론의 선택을 용이하게 하는 선택 카세트의 존재로 인한 단점을 피할 수 있게 한다. 이러한 자가 결실 선택 카세트 기술은, 일부 구현예에서는, 재조합효소 유전자에 작동 가능하게 연결된 프로모터를 표적화 벡터 내에 포함하는 것을 특징으로 한다. 프로모터는, 미분화 세포(즉, ES 세포)에 한정된 프로모터 활성으로 인해 프로모터가 재조합효소 유전자의 발현을 발달 의존적 방식으로 조절하도록 전사적으로 유능하다(전사 유능성에 대해서는, 예를 들어, Ram, R. 및 E. Meshorer의 Genes Dev. 23:2793-98 (2009년); Xu, J. 등의 Genes Dev. 23:2824-38 (2009년)을 또한 참조한다). 결과적으로, 재조합효소 폴리펩티드는 ES 세포의 분화(발달)가 시작된 후에만 발현된다. 본원에 기술된 바와 같은 표적화 벡터가 통합된 ES 세포는 재조합효소 유전자의 발현을 조절하는 (즉, 재조합효소 유전자에 작동 가능하게 연결된) 프로모터의 비활성으로 인해 선택 카세트를 보유하지만, 일단 ES 세포가 재조합효소 발현 개시에 의해 분화하기 시작하면 선택 카세트의 절단을 촉진한다. 따라서, 설계에 의해, 게놈 내에 표적화 벡터를 함유하는 ES 세포로부터 발생하는 자손은 조기 발달 단계에서 재조합효소를 발현하며, 선택성 마커는 선택 카세트의 측면에 위치하는 부위 특이적 재조합효소 인식 부위에 대한 재조합효소 폴리펩티드의 작용에 의해 매개된 분화(발달)가 이루어지면 절단된다.
미분화 ES 세포 내에서 비활성인 적합한 프로모터가 본원에서 제공된다. 이러한 프로모터를 재조합효소 유전자에 작동 가능하게 연결하는 것은 발현을 가능하게 하는데, 구체적으로는 분화가 이루어질 때 발현이 일어나게 한다. 본원에 기술된 바와 같이, 표적화 벡터는, 발현 시에 재조합효소 폴리펩티드가 선택성 마커의 절제(즉, 결실)를 유도하도록, 부위 특이적 재조합효소 인식 부위가 선택 마커의 측면에 평행하게 배향되도록 설계된다. 부위 특이적 재조합효소 인식 부위는, 재조합효소 폴리펩티드가 발현 시 선택성 마커의 역전을 유도하도록 선택 마커의 측면에 역전된 배향으로 배치될 수도 있다. 일부 선택성 마커의 경우, 역전은 불활성화에 충분할 수 있다. 그러나, 선택성 마커가 완전히 제거되는 것이 바람직할 수도 있다. 부위 특이적 재조합효소 인식 부위가 선택 카세트의 측면에 평행한 배향으로 위치하는 경우, 분화된 세포에서 재조합효소 폴리펩티드가 발현되면 세포가 선택성 마커를 게놈으로부터 절단하게 된다. 분화된 세포가 선택된 상태로 유지되는 경우, 이들은 선택성 마커가 게놈으로부터 결실됨으로 인해 사멸하게 된다. 이러한 방식으로, 미분화 ES 세포가 숙주 배아에 대한 공여자 세포로서 추후에 사용되도록 배양물 내에서 유지되고 풍부화된다.
본원에 기술된 바와 같이, Rs1 유전자의 파괴는 Rs1 유전자 또는 이의 일부를 삽입 핵산으로 교체하는 것 또는 삽입 핵산을 이에 삽입/첨가하는 것을 포함할 수 있다. 일부 구현예에서, 삽입 핵산은 리포터 유전자를 포함한다. 일부 특정 구현예에서, 리포터 유전자는 내인성 Rs1 프로모터와 작동 가능하게 연결되어 위치된다. 이러한 변형은 내인성 Rs1 프로모터에 의해 유도되는 리포터 세포의 발현을 가능하게 한다. 대안적으로, 리포터 유전자는 내인성 Rs1 프로모터와 작동 가능하게 연결되어 배치되지 않고, 또 다른 프로모터에 작동 가능하게 연결된다.
다양한 리포터 유전자(또는 검출 가능한 모이어티)가 본원에 기술된 표적화 벡터에 사용될 수 있다. 예시적인 리포터 유전자는, 예를 들어, β-갈락토시다아제(암호화된 lacZ 유전자), 녹색 형광 단백질(Green Fluorescent Protein, GFP), 강화된 녹색 형광 단백질(eGFP), MmGFP, 청색 형광 단백질(BFP), 강화된 청색 형광 단백질(eBFP), mPlum, mCherry, tdTomato, mStrawberry, J-Red, DsRed, mOrange, mKO, mCitrine, Venus, YPet, 황색 형광 단백질(YFP), 강화된 황색 형광 단백질(eYFP), 에머랄드(Emerald), CyPet, 홍색 형광 단백질(CFP), 진청색(Cerulean), T-Sapphire, 루시퍼라제(luciferase), 알칼리 포스파타아제(alkaline phosphatase), 또는 이들의 조합을 포함한다. 본원에 기술된 방법은, β-갈락토시다아제를 암호화하는 lacZ 리포터 유전자를 사용하는 표적화 벡터의 작제를 입증하지만, 본 개시를 읽음으로써 당업자는 본원에 기술된 비인간 동물이 리포터 유전자의 부재 중에 생성되거나 당업계에 알려진 임의의 리포터 유전자를 사용해 생성될 수 있다는 것을 이해할 것이다.
Rs1 표적화 벡터는, 일부 구현예에서, 유전자 이식된 비인간 동물의 게놈에 삽입하기 위한 돌연변이체 Rs1 유전자, 선택성 마커와 재조합 효소, 및 비인간 Rs1 서열(즉, 표적 영역의 측면 서열)을 암호화하는 DNA 서열을 포함한다. 일 실시예에서, 돌연변이 Rs1 유전자 또는 RS1-암호화 서열에 의해 원하는 RS1 폴리펩티드(예: 변이체 RS1 폴리펩티드)가 암호화되도록 하나 이상의 돌연변이가 (가령, 부위 지향적 돌연변이 유발에 의해) Rs1 유전자 또는 RS1-암호화 서열(예: 엑손)에 도입될 수 있다. 이러한 돌연변이 Rs1 서열은 원하는대로 내인성 조절 서열(예: 프로모터)이나 구성 프로모터(constitutive promoter)에 작동 가능하게 연결될 수 있다. 도 5~7 및 8~10은 쥣과 Rs1 유전자의 엑손에 (예를 들어, 엑손 3 및 5의 각각에) 하나 이상의 선택된 점 돌연변이를 만들고, 돌연변이체 배아 줄기(ES) 세포 콜로니를 선택하기 위해 히그로마이신(Hyg)를 암호화하는 약물 선택 마커를 함유하는 카세트로 주변 인트론에 작은 결실을 만들기 위한 2개의 예시적인 표적화 벡터를 도시한다. 실시예 섹션에서 기술되는 바와 같이, 각각의 점 돌연변이를 위해 주변 마우스 Rs1 인트론에 도입된 작은 결실은 돌연변이체 (또는 변이체) ES 세포 콜로니의 스크리닝을 용이하게 하도록 설계되었다. 도 5 및 8에 도시된 바와 같이, 표적화 벡터는 ES-세포 특이적 miRNA 또는 생식 세포 특이적 프로모터(예: 프로타민 1 프로모터; Prot-Cre-SV40)에 의해 조절되는 재조합효소(예: Cre)를 암호화하는 서열도 각각 포함하였다. 히그로마이신 선택 카세트 및 Cre 재조합효소 암호화 서열은 히그로마이신 선택 카세트의 Cre-매개된 절제를 발달 의존 방식으로 (예를 들어, 전술한 돌연변이체 (또는 변이체) Rs1 유전자를 함유하는 생식 세포를 가진 설치류 유래의 자손이 발달 도중에 선택성 마커를 제거하게 되는 방식으로) 가능하게 하는 loxP 재조합효소 인식 부위가 측면에 위치한다(참조: 미국 특허 번호 제8,697,851호, 제8,518,392호, 제8,354,389호, 제8,946,505호, 및 제8,946,504호. 이들 모두는 본원에 참조로서 통합됨). 이는, 무엇보다도, 히그로마이신 선택 카세트가 분화된 세포 또는 생식 세포로부터 자동적으로 절제되도록 한다. 따라서, 히그로마이신 선택 카세트는 쥣과 Rs1 프로모터에 작동 가능하게 연결된 돌연변이 Rs1 엑손들만을 남기고 표현형 분석 이전에 제거된다(도 7 및 10).
Rs1 표적화 벡터는, 일부 구현예에서, 전술한 바와 같은 돌연변이체 (또는 변이체) Rs1에 상응하는 DNA 서열을 포함할 수 있는데, 상기 돌연변이체 (또는 변이체) Rs1 유전자는 이종 Rs1 유전자 또는 이종 RS1 암호화 서열을 포함한다. 적합한 이종 Rs1 서열은 본원에서 제공되며, 아래의 실시예 섹션에서 예시된 서열로 치환될 수 있다. 이러한 이종 서열은 야생형 또는 부모 이종 RS1 폴리펩티드 서열과 비교해 아미노산 치환을 암호화하는 점 돌연변이를 포함하도록 조작될 수도 있다.
경우에 따라, 리포터 폴리펩티드(및/또는 선택성 마커, 및/또는 재조합효소)를 전체적 또는 부분적으로 암호화하거나 RS1 폴리펩티드(예: 변이체 RS1 폴리펩티드)를 암호화하는 유전 물질 또는 폴리뉴클레오티드 서열(들)의 코딩 영역은 비인간 동물에서의 발현에 최적화된 코돈을 포함하도록 변형될 수 있다(예: 미국 특허 제5,670,356호 및 제5,874,304호 참조). 코돈 최적화된 서열은 합성 서열이고, 바람직하게는 코돈 최적화되지 않은 모 폴리뉴클레오티드에 의해 암호화되는 동일한 폴리펩티드(또는 전장 폴리펩티드와 실질적으로 동일한 활성을 갖는 전장 폴리펩티드의 생물학적으로 활성인 단편)를 암호화한다. 일부 구현예에서, 전체적 또는 부분적으로 리포터 폴리펩티드(예: lacZ)를 암호화하는 유전 물질의 코딩 영역은, 특정한 세포 유형(예를 들어, 설치류 세포)에 대한 코돈 사용을 최적화하기 위해 변경된 서열을 포함할 수 있다. 일부 구현예에서, 본원에 기술된 바와 같은 RS1 폴리펩티드(예: 변이체 RS1 폴리펩티드)를 전체적 또는 부분적으로 암호화하는 유전 물질의 코딩 영역은, 특정한 세포 유형(예를 들어, 설치류 세포)에 대해 코돈 사용을 최적화하도록 변경된 서열을 포함할 수 있다. 한 가지 예를 들자면, 비인간 동물(예: 설치류)의 게놈에 삽입될 리포터 또는 돌연변이 Rs1 유전자의 코돈은 비인간 동물의 세포에서의 발현에 최적화될 수 있다. 이러한 서열은 코돈 최적화 서열로서 기술될 수 있다.
본원에 기술된 바와 같은 Rs1 유전자에 파괴 또는 돌연변이를 포함하는 비인간 동물을 만들기 위한 조성물 및 방법이 제공되며, 이에는 Rs1 프로모터와 같은 Rs1 조절 서열의 조절 하에 리포터 유전자를 발현하는 비인간 동물, 및 Rs1 프로모터와 같은 Rs1 조절 서열의 조절 하에 변이체 RS1 폴리펩티드를 발현하는 비인간 동물을 만들기 위한 조성물 및 방법을 포함한다. 일부 구현예에서, 내인성 프로모터(예: 내인성 Rs1 프로모터)와 같은 내인성 조절 서열의 조절 하에 리포터 유전자 또는 변이체 RS1 폴리펩티드를 발현하는 비인간 동물을 만들기 위한 조성물 및 방법이 또한 제공된다. 상기 방법은, Rs1 유전자의 코딩 서열의 일부가 전체적으로 또는 부분적으로 결실되도록, 리포터 유전자(예: lacZ; 도 2~4 참조)를 포함하는 본원에 기술된 바와 같은 표적화 벡터를 비인간 동물의 게놈에 삽입하는 단계를 포함한다. 일부 구현예에서, 상기 방법은 Rs1 유전자의 엑손 1~3이 결실되도록 비인간 동물의 게놈에 표적화 벡터를 삽입하는 단계를 포함한다.
Rs1 프로모터(예: 내인성 Rs1 프로모터)에 작동 가능하게 연결된 리포터 유전자를 삽입하면 게놈의 변형이 상대적으로 최소한으로 사용되고, 비인간 동물에서 Rs1-특이적 방식으로 리포터 폴리펩티드가 발현된다(예를 들어, 도 11 참조). 일부 구현예에서, 본원에 기술된 바와 같은 비인간 동물 또는 세포는 본원에 기술된 바와 같은 표적화 벡터를 포함하는 Rs1 유전자를 포함하고, 일부 특정 구현예에서는 도2 또는 4에 나타나는 표적화 벡터를 포함한다.
다양한 구현예에서, 본원에 기술된 바와 같은 파괴된 Rs1 유전자는 리포터 유전자의 삽입으로 생성된 하나 이상의 (예: 제1 및 제2) 삽입 접합부를 포함한다.
다양한 구현예에서, 본원에 기술된 바와 같은 파괴된 Rs1 유전자는 서열 번호 33과 적어도 80%(예: 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상) 동일한 서열을 포함하는 제1 삽입 접합부 및 서열 번호 34와 적어도 80%(예: 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상) 동일한 서열을 포함하는 제2 삽입 접합부를 포함한다. 다양한 구현예에서, 본원에 기술된 바와 같은 파괴된 Rs1 유전자는 서열 번호 33과 동일하거나 실질적으로 동일한 서열을 포함하는 제1 삽입 접합부 및 서열 번호 34와 동일하거나 실질적으로 동일한 서열을 포함하는 제2 삽입 접합부를 포함한다.
다양한 구현예에서, 본원에 기술된 바와 같은 파괴된 Rs1 유전자는 서열 번호 33과 적어도 80%(예: 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상) 동일한 서열을 포함하는 제1 삽입 접합부 및 서열 번호 35와 적어도 80%(예: 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상) 동일한 서열을 포함하는 제2 삽입 접합부를 포함한다. 다양한 구현예에서, 본원에 기술된 바와 같은 파괴된 Rs1 유전자는 서열 번호 33과 동일하거나 실질적으로 동일한 서열을 포함하는 제1 삽입 접합부 및 서열 번호 35와 동일하거나 실질적으로 동일한 서열을 포함하는 제2 삽입 접합부를 포함한다.
다양한 구현예에서, 본원에 기술된 바와 같은 파괴된 Rs1 유전자 또는 대립 유전자는 서열번호 23 또는 서열번호 25와 적어도 80%(예: 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상) 동일한 서열을 포함한다. 다양한 구현예에서, 본원에 기술된 바와 같은 파괴된 Rs1 유전자 또는 대립 유전자는 서열번호 23 또는 서열번호 25와 동일하거나 실질적으로 동일한 서열을 포함한다.
다양한 구현예에서, 본원에 기술된 바와 같은 파괴된 Rs1 유전자 또는 대립유전자는 내인성 Rs1 유전자 또는 대립유전자의 13,716 bp의 결실을 포함한다. 다양한 구현예에서, 본원에 기술된 바와 같은 파괴된 Rs1 유전자 또는 대립 유전자는 서열번호 24와 동일하거나 실질적으로 동일한 서열이 결여된다.
상기 방법은 또한, Rs1 유전자의 코딩 서열의 일부(예: 엑손)가 변경되도록, 변이체 RS1 폴리펩티드를 암호화하는 본원에 기술된 바와 같은 표적화 벡터를 비인간 동물의 게놈에 전체적으로 또는 부분적으로 삽입하는 단계를 포함한다(도 5~7 및 8~10 참조). 일부 구현예에서, 상기 방법은 Rs1 유전자의 엑손이 변이체 RS1 폴리펩티드를 암호화하기 위해 돌연변이되도록, 비인간 동물의 게놈에 표적화 벡터를 삽입하는 단계를 포함한다.
Rs1 프로모터(예: 내인성 Rs1 프로모터)에 작동 가능하게 연결된 돌연변이체 Rs1 유전자를 삽입하면 게놈의 변형이 상대적으로 최소한으로 사용되고, 야생형 비인간 동물에서 나타나는 RS1 폴리펩티드와 기능적 및 구조적으로 상이한 변이체 RS1 폴리펩티드가 비인간 동물에서 발현된다. 일부 구현예에서, 본원에 기술된 바와 같은 비인간 동물 또는 세포는 본원에 기술된 바와 같은 표적화 벡터를 포함하는 Rs1 유전자를 포함하고, 일부 특정 구현예에서는 도5 또는 8에 나타나는 표적화 벡터를 포함한다.
다양한 구현예에서, 본원에 기술된 바와 같은 돌연변이체 Rs1 유전자는 본원에 기술된 바와 같은 표적화 벡터의 삽입으로 생성된 하나 이상의(예: 제1 및 제2) 삽입 접합부를 포함한다.
다양한 구현예에서, 본원에 기술된 바와 같은 돌연변이체 Rs1 유전자는 서열 번호 36과 적어도 80%(예: 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상) 동일한 서열을 포함하는 제1 삽입 접합부 및 서열 번호 37과 적어도 80%(예: 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상) 동일한 서열을 포함하는 제2 삽입 접합부를 포함한다. 다양한 구현예에서, 본원에 기술된 바와 같은 돌연변이체 Rs1 유전자는 서열 번호 36과 동일하거나 실질적으로 동일한 서열을 포함하는 제1 삽입 접합부 및 서열 번호 37과 동일하거나 실질적으로 동일한 서열을 포함하는 제2 삽입 접합부를 포함한다.
다양한 구현예에서, 본원에 기술된 바와 같은 돌연변이체 Rs1 유전자는 서열번호 38과 적어도 80%(예: 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상) 동일한 서열을 포함하는 삽입 접합부를 포함한다. 다양한 구현예에서, 본원에 기술된 바와 같은 돌연변이체 Rs1 유전자는 서열번호 38과 동일하거나 실질적으로 동일한 서열을 포함하는 삽입 접합부를 포함한다.
다양한 구현예에서, 돌연변이체 Rs1 유전자는, 돌연변이체 Rs1 유전자가 C59S 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하도록 점 돌연변이를 포함하는 제3 엑손을 포함한다. 다양한 구현예에서, 돌연변이체 Rs1 유전자는, 돌연변이체 Rs1 유전자가 C59S 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하도록 TGT에서 AGT로의 코돈 돌연변이를 포함하는 제3 엑손을 포함한다.
다양한 구현예에서, 본원에 기술된 바와 같은 돌연변이체 Rs1 유전자는 서열 번호 39와 적어도 80%(예: 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상) 동일한 서열을 포함하는 제1 삽입 접합부 및 서열 번호 40과 적어도 80%(예: 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상) 동일한 서열을 포함하는 제2 삽입 접합부를 포함한다. 다양한 구현예에서, 본원에 기술된 바와 같은 돌연변이체 Rs1 유전자는 서열 번호 39와 동일하거나 실질적으로 동일한 서열을 포함하는 제1 삽입 접합부 및 서열 번호 40과 동일하거나 실질적으로 동일한 서열을 포함하는 제2 삽입 접합부를 포함한다.
다양한 구현예에서, 본원에 기술된 바와 같은 돌연변이체 Rs1 유전자는 서열번호 41과 적어도 80%(예: 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상) 동일한 서열을 포함하는 삽입 접합부를 포함한다. 다양한 구현예에서, 본원에 기술된 바와 같은 돌연변이체 Rs1 유전자는 서열번호 41과 동일하거나 실질적으로 동일한 서열을 포함하는 삽입 접합부를 포함한다.
다양한 구현예에서, 본원에 기술된 바와 같은 돌연변이체 Rs1 유전자는, 돌연변이체 Rs1 유전자가 R141C 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하도록 점 돌연변이를 포함하는 제5 엑손을 포함한다. 다양한 구현예에서, 본원에 기술된 바와 같은 돌연변이체 Rs1 유전자는, 돌연변이체 Rs1 유전자가 R141C 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하도록 CGC에서 TGC로의 코돈 돌연변이를 포함하는 제5 엑손을 포함한다.
다양한 구현예에서, 본원에 기술된 바와 같은 돌연변이체 Rs1 유전자 또는 대립 유전자는 서열번호 27, 또는 서열번호 29와 적어도 80%(예: 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 그 이상) 동일한 서열을 포함한다. 다양한 구현예에서, 본원에 기술된 바와 같은 돌연변이체 Rs1 유전자 또는 대립 유전자는 서열번호 27 또는 서열번호 29와 동일하거나 실질적으로 동일한 서열을 포함한다.
대안적으로, 다른 Rs1 유전자 또는 RS1-암호화 서열이 본원에 기술된 방법에 사용되어 본원에 기술된 바와 같은 돌연변이체 Rs1 유전자를 함유하는 게놈을 가진 비인간 동물을 생성할 수 있다. 예를 들어, 이종 Rs1 유전자는 비인간 동물에 도입될 수 있으며, 상기 이종 Rs1 유전자는 본원에 기술된 바와 같은 변이체 RS1 폴리펩티드를 암호화한다(즉, 비인간 동물에서 망막층간분리증-유사 표현형을 확립하는 돌연변이를 포함함). 또 다른 예에서, 유전자 이식된 Rs1 유전자가 (예를 들어, 유전자 변형, DNA 또는 RNA 올리고뉴클레오티드와의 유전자 녹다운 등을 통해) 비인간 동물의 게놈 및 비기능적이 된 내인성 Rs1 유전자에 무작위로 삽입될 수 있다. 예시적인 대안적 Rs1 유전자 또는 RS1 암호화 서열이 본원에서 제공된다. 당업자는 본 개시를 읽음으로써 이러한 Rs1 유전자 또는 RS1-암호화 서열이 본원에 기술된 방법에 사용되어 비인간 동물을 생성시킬 수 있다는 것을 이해할 것이다.
본원에 기술된 표적화 벡터가 ES 세포에 도입되어, 본원 및 Frendewey, D., 등의 Methods Enzymol. 476:295-307(2010년)에 기술된 바와 같은 파괴된 또는 돌연변이체 Rs1 유전자를 포함하는 ES 클론에 대해 스크리닝될 수 있다. 다양한 숙주 배아가 본원에 기술된 방법 및 조성물에 사용될 수 있다. 예를 들어, 표적화된 유전자 변형을 갖는 다능성(pluripotent) 및/또는 재생성(totipotent) 세포가 상응하는 기관으로부터 전 상실배기(pre-morula stage) 배아(예: 8세포 단계 배아)에 도입될 수 있다. 참조: 예를 들어, 미국 특허 번호 제7,576,259호, 제7,659,442호, 제7,294,754호, 및 미국 특허 출원 번호 제2008-0078000 A1호 (이들 모두는 그 전체가 본원에 참조로서 통합됨). 다른 예에서, 공여자 ES 세포가 2세포 단계, 4세포 단계, 8세포 단계, 16세포 단계, 32세포 단계, 또는 64세포 단계에 숙주 배아에 이식될 수 있다. 숙주 배아는 배반포(blastocyst)일 수도 있고, 배반포 전 배아(pre-blastocyst embryo), 상실배전기 배아(pre-morula stage embryo), 상실배기 배아(morula stage embryo), 전기 상실배기 배아(uncompacted morula stage embryo), 또는 후기 상실배기 배아(compacted morula stage embryo)일 수 있다.
일부 구현예에서, 양성 ES 세포를 8세포 배아에 주입하여 lacZ 발현 프로파일링 또는 동형접합성 교배가 즉시 가능한 완전한 ES 세포 유래의 F0 세대 이형접합체 마우스를 생성하기 위해 VELOCIMOUSE® 방법(Poueymirou, W.T. 등의 Nat. Biotechnol. 25:91-99(2007년) 참조)이 적용될 수 있다. 파괴된 또는 돌연변이체 Rs1 유전자를 갖는 비인간 동물을 생성하는 예시적인 방법이 실시예 섹션에서 제공된다.
녹아웃(knockouts) 및 녹인(knock-ins)을 포함하여 유전자이식 비인간 동물을 생성하는 방법이 당업계에 잘 알려져 있다(예: Kitamura, D. 외의 1991, Nature 350:423-6; Komori, T. 외의 1993, Science 261:1171-5; Shinkai, Y. 외의 1993, Science 259:822-5; Mansour, S.L. 외의 1998, Nature 336:348-52; Gene Targeting: A Practical Approach, Joyner, ed., Oxford University Press, Inc., 2000; Valenzuela, D.M. 외의 2003, Nature Biotech. 21(6):652-9; Adams, N.C. 및 N.W. Gale, in Mammalian and Avian Transgenesis-New Approaches, ed. Lois, S.P.a.C., Springer Verlag, Berlin Heidelberg, 2006 참조). 예를 들어, 유전자이식 설치류의 생성은 내인성 설치류의 유전자좌를 손상시키고 (일부 구현예에서는, 내인성 설치류 유전자와 동일한 위치에 있는) 설치류 게놈에 리포터 유전자를 도입하거나, 내인성 설치류 유전자의 유전자좌를 변경하고 (일부 구현예에서는, 내인성 설치류 유전자와 동일한 위치에 있는) 설치류 게놈에 하나 이상의 돌연변이를 도입하여, 변이체 폴리펩티드를 발현시키는 것을 포함할 수 있다.
마우스 Rs1 유전자의 게놈 구성에 대한 개략도(축척에 비례하지는 않음)가 도 1에 제공된다. 리포터 유전자를 사용하여 마우스 Rs1 유전자의 코딩 서열의 일부를 결실시키기 위한 예시적인 표적화 벡터가 도 2에 제공된다. 도시된 바와 같이, 마우스 Rs1 유전자의 엑손 1~3을(엑손 1의 ATG 시작 코돈은 제외함) 함유하는 게놈 DNA가 결실되어, 부위 특이적 재조합효소 인식 부위가 측면에 위치한 자체 결실 약물 선택 카세트 및 리포터 유전자로 치환된다. 표적화 벡터는 재조합효소가 미분화 세포에서 발현되도록, 발달적으로 조절되는 프로모터에 작동 가능하게 연결되는 재조합효소 암호화 서열을 포함한다. 상동성 재조합 시, 내인성 마우스 Rs1 유전자의 엑손 1~3은 도시된 바와 같이 표적화 벡터에 함유된 서열에 의해 결실(또는 대체)되고, 도 4에 도시된 구조를 갖는 Rs1 유전자를 갖는 조작된 마우스는 마우스 Rs1 프로모터에 작동 가능하게 연결된 lacZ 리포터 유전자(마우스 Rs1 시작 코돈에 융합됨)를 남겨두고 발달 도중에 네오마이신 카세트를 Cre-매개 절제함으로써 생성된다.
마우스 Rs1 유전자에 돌연변이(예를 들어, 치환 돌연변이)를 생성하기 위한 예시적인 표적화 벡터는 도 5~7 및 8~10에 제공되어 있다. 도시된 바와 같이, 돌연변이체 마우스 Rs1 유전자(즉, 엑손 3 또는 5에 점 돌연변이를 갖는 돌연변이체 Rs1 유전자)는, 돌연변이 Rs1 엑손의 하류 및 Rs1 인트론 내에 위치한 부위 특이적 재조합효소 인식 부위가 측면에 위치한 자체 결실 약물 선택 카세트를 포함하는 표적화 벡터를 사용해 생성된다(도 5 또는 8도 참조할 것). 표적화 벡터는 재조합효소가 미분화 세포에서 발현되도록 발달적으로 조절되는 프로모터에 작동 가능하게 연결되는 재조합효소 암호화 서열을 포함한다. 상동성 재조합 시, 내인성 마우스 Rs1 유전자의 하나의 엑손(및 주변 인트론)은 도시된 바와 같이 표적화 벡터에 함유된 서열에 의해 대체되며, 도 7 또는 10에 도시된 구조를 갖는 돌연변이체 Rs1 유전자를 갖는 조작된 마우스는 마우스 Rs1 프로모터에 작동 가능하게 연결된 하나의 엑손에 점 돌연변이를 갖는 돌연변이체 Rs1 유전자, 및 인접 인트론(들) 내의 작은 결실들을 (고유한 loxP 부위와 함께) 남겨두고 발달 도중에 선택 카세트를 Cre 매개 절제함으로써 생성된다. 생성된 돌연변이체 Rs1 유전자는 아미노산 치환(예를 들어, C59S 또는 R141C)을 포함하는 RS1 폴리펩티드를 각각 암호화한다.
본원에 기술된 표적화 벡터에 포함될 수 있는 예시적인 프로모터는 프로타민 1 (Prm1) 프로모터(예컨대, 서열번호 30에 제시된 것), Blimp1 프로모터 1 kb(예컨대, 서열번호 31에 제시된 것), 및 Blimp1 프로모터 2 kb(서열번호 32에 제시된 것)를 포함한다. 본원에 기술된 표적화 벡터에 사용될 수 있는 적합한 추가 프로모터는 미국 특허 제8,697,851호, 제8,518,392호 및 제8,354,389호(이들 모두는 본원에 참조로서 통합됨)에 기술된 것들을 포함한다.
유전자 이식된 파운더(founder) 비인간 동물은, 그의 게놈 내 리포터 유전자의 존재 (또는 Rs1의 부재) 및/또는 비인간 동물의 조직이나 세포에서 리포터의 발현 (또는 RS1의 발현 결여), 또는 Rs1 코딩 서열(예: 엑손) 내 하나 이상의 점 돌연변이의 존재 및/또는 그의 게놈 내 비-암호화 Rs1 서열(예: 인트론)의 결실 및/또는 비인간 동물의 조직 또는 세포에서 변이체 RS1 폴리펩티드의 발현 (또는 야생형 RS1 폴리펩티드의 발현 결여)에 기초하여 식별될 수 있다. 이어서, 유전자 이식된 파운더 비인간 동물은 리포터 유전자 또는 돌연변이체 Rs1 유전자를 가진 추가 비인간 동물과 교배시켜, 본원에 기술된 바와 같은 파괴된 또는 돌연변이체 Rs1 유전자의 하나 이상의 카피를 각각 갖는 일련의 비인간 동물을 생성하는 데 사용될 수 있다.
유전자 이식된 비인간 동물은 이식 유전자 또는 폴리뉴클레오티드 분자(예를 들어, 삽입 핵산)의 발현을 조절하거나 지시할 수 있는 선택된 시스템을 함유하도록 생산될 수도 있다. 예시적인 시스템은 박테리오파지 P1의 Cre/loxP 재조합 효소 시스템(예를 들어, Lakso, M. 등의 Proc. Natl. Acad. Sci. USA 89:6232-6236 (1992년) 참조) 및 S. 세레비시아(S. cerevisiae)의 FLT/Frt 재조합효소 시스템(O'Gorman, S. 등의 Science 251:1351-1355 (1991년))을 포함한다. 이러한 동물은 "이중(double)" 유전자이식 동물을 작제를 통해, 예를 들어, 2가지의 유전자 이식 동물, 즉 선택된 폴리펩티드(예: 리포터, 또는 변이체 또는 이종 RS1 폴리펩티드)를 암호화하는 이식 유전자를 함유하는 한 가지와 재조합효소(예: Cre 재조합효소)를 암호화하는 이식 유전자를 함유하는 다른 한 가지를 교배시킴으로써 제공될 수 있다.
Rs1 유전자에서의 파괴나 돌연변이를 마우스에 사용하는 구현예들이 본원에서 집중적으로 논의되지만, 이러한 변형(또는 변경)을 Rs1 유전자좌에 포함하는 다른 비인간 동물도 제공된다. 일부 구현예에서, 이러한 비인간 동물은 내인성 Rs1 프로모터에 작동 가능하게 연결된 리포터의 삽입을 특징으로 하는 Rs1 유전자에서의 파괴(예: Rs1 코딩 서열의 일부가 결실된 마우스), 또는 내인성 Rs1 프로모터에 작동 가능하게 연결된 돌연변이체 Rs1 엑손 또는 엑손들(예: 하나 이상의 점 돌연변이를 함유하는 엑손)의 삽입을 특징으로 하는 Rs1 유전자에서의 돌연변이(예: 하나 이상의 Rs1 엑손에 하나 이상의 점 돌연변이를 갖는 마우스)를 포함한다. 이러한 비인간 동물은, 예를 들어 마우스, 랫트, 토끼, 돼지, 소(예: 젖소, 황소, 버팔로), 사슴, 양, 염소, 닭, 고양이, 개, 흰담비, 영장류(예: 마모셋, 붉은털 원숭이) 등과 같은 포유 동물을 포함하여, 본원에 개시된 바와 같은 Rs1 유전자의 코딩 서열을 파괴하거나 돌연변이시키도록 유전적으로 변형될 수 있는 임의의 것들을 포함한다. 적절한 유전자 변형이 가능한 ES 세포를 쉽게 구할 수 없는 비인간 동물의 경우, 유전자 변형을 포함하여 비인간 동물을 제조하기 위한 다른 방법이 사용된다. 이러한 방법은, 예를 들어, 비ES 세포 게놈(예를 들어, 섬유아세포 또는 유도 다능성 세포)을 변형하는 단계 및 적합한 세포, 예를 들어, 핵이 없는 난모세포에 유전자 변형된 게놈을 전달하기 위해 체세포 핵 전달(SCNT)을 채용하는 단계, 및 변형된 세포(예를 들어, 변형된 난모세포)를 배아를 형성하기에 적합한 조건 하에 비-인간 동물에 잉태시키는 단계를 포함한다.
간단히 설명하자면, 핵전사를 위한 방법은: (1) 난모 세포를 탈핵하는 단계; (2) 탈핵된 난모 세포와 결합될 공여자 세포 또는 핵을 단리하는 단계; (3) 공여자 세포 또는 핵을 탈핵된 난모 세포에 삽입하여 재구성 세포를 형성시키는 단계; (4) 재구성 세포를 동물의 자궁에 이식하여 배아를 형성시키는 단계; 및 (5) 배아를 발달시키는 단계를 포함한다. 이러한 방법에서, 난모 세포를 살아있는 동물의 난관(oviducts) 및/또는 난소(ovaries)에서 단리할 수도 있지만, 일반적으로는 죽은 동물로부터 수거한다. 탈핵에 앞서, 난모 세포는 당업자에게 공지된 다양한 배지에서 성숙될 수 있다. 난모 세포의 탈핵은 당업자에게 공지된 다양한 방식으로 수행될 수 있다. 탈핵된 난모 세포에 공여자 세포 또는 핵을 삽입하여 재구성 세포를 형성시키는 것은 융합 이전에 투명대(zona pellucida) 밑에 공여자 세포를 미세 주입함으로써 일반적으로 달성된다. 융합은, 접촉/융합면에 걸쳐 DC 전기 펄스를 적용(전기 융합)시키거나, 폴리에틸렌 글리콜과 같은 융합 촉진 화학물질에 세포를 노출시키거나, 센다이 바이러스(Sendai virus)와 같은 비활성화 바이러스를 통해 유도될 수 있다. 재구성 세포는 핵 공여자와 수여자 난모 세포의 융합 이전, 도중 및/또는 이후에 전기적 및/또는 비전기적 수단에 의해 일반적으로 활성화된다. 활성화 방법에는 전기 펄스, 화학적으로 유도된 충격, 정자에 의한 침투, 난모 세포에서 2가 양이온 레벨의 증가, 및 (키나아제 억제제를 통한) 난모 세포에서 세포 단백질의 인산화 감소가 포함된다. 활성화된 재구성 세포 또는 배아는 일반적으로 당업자에게 공지된 배지에서 배양된 후 동물의 자궁에 옮겨진다. 예시적인 참조 문헌: 미국 특허 번호 제7,612,250호; 미국 특허 출원 공개 번호 제2004-0177390 A1호 및 제2008-0092249 A1호; 및 국제 특허 출원 공개 번호 제WO 1999/005266 A2호 및 제WO 2008/017234 Al호 (이들 각각은 본원에 참조로서 통합됨).
비인간 동물 게놈(예: 돼지, 젖소, 설치류, 닭 등의 게놈)을 변형하는 방법은, 예를 들어, 징크 핑거 뉴클레아제(zinc finger nuclease, ZFN), 전사 활성인자 유사 작동자 뉴클레아제(TALEN), 또는 Cas 단백질(즉, CRISPR/Cas 시스템)을 사용하여 게놈이 본원에 기술된 바와 같은 손상된 또는 돌연변이체 Rs1 유전자를 포함하도록 변형시키는 것을 포함한다.
일부 구현예에서, 본 개시의 비인간 동물은 포유동물이다. 일부 구현예에서, 본원에 기술된 바와 같은 비인간 동물은, 예를 들어, 뛰는 쥐상과(Dipodoidea 또는 Muroidea) 아목의 작은 포유동물이다. 일부 구현예에서, 본원에서 기술된 바와 같은 비인간 동물은 설치류이다. 일부 구현예에서, 본원에 기술된 바와 같은 설치류는 마우스, 랫트 및 햄스터로부터 선택된다. 일부 구현예에서, 본원에 기술된 바와 같은 설치류는 쥐상과 아목으로부터 선택된다. 일부 구현예에서, 본원에 기술된 바와 같은 유전적으로 변형된 동물은 칼로미스쿠스과(Calomyscidae)(예를 들어, 마우스 유사 햄스터), 비단털쥐과(Cricetidae)(예: 햄스터, 미국 랫트 및 마우스, 들쥐), 쥐과(Muridae)(진짜 마우스 및 랫트, 사막쥐, 가시쥐, 갈기쥐), 네소미스과(Nesomyidae)(클라이밍 마우스, 락 마우스(rock mice), 흰꼬리 랫트, 말라가시 랫트 및 마우스), 가시겨울잠쥐과(Platacanthomyidae)(예: 가시겨울잠쥐), 및 소경쥐과(Spalacidae)(예: 두더쥐, 대나무쥐, 및 동북)로부터 선택된 과(family)로부터 유래한다. 일부 특정 구현예에서, 본원에 기술된 바와 같은 설치류는 진짜 마우스 또는 랫트(쥐상과), 사막쥐(gerbil), 가시쥐(spiny mouse), 갈기쥐(crested rat)로부터 선택된다. 일부 특정 구현예에서, 본원에 기술된 바와 같은 마우스는 쥐상과의 구성원으로부터 선택된다. 일부 구현예에서, 본원에서 기술된 바와 같은 비인간 동물은 설치류이다. 일부 특정 구현예에서, 본원에 기술된 바와 같은 설치류는 마우스와 랫트로부터 선택된다. 일부 구현예에서, 본원에서 기술된 바와 같은 비인간 동물은 마우스이다.
일부 구현예에서, 본원에서 기술된 바와 같은 비인간 동물은 C57BL/A, C57BL/An,C57BL/GrFa, C57BL/KaLwN, C57BL/6, C57BL/6J, C57BL/6ByJ, C57BL/6NJ, C57BL/10,C57BL/10ScSn, C57BL/10Cr, 및 C57BL/Ola로부터 선택된 C57BL 계통의 마우스인 설치류이다. 일부 특정 구현예에서, 본원에서 기술된 바와 같은 마우스는 129P1, 129P2, 129P3, 129X1, 129S1(예를 들어, 129S1/SV, 129S1/SvIm), 129S2, 129S4, 129S5, 129S9/SvEvH, 129/SvJae, 129S6(129/SvEvTac), 129S7, 129S8, 129T1, 129T2인 계통으로 이루어지는 군으로부터 선택된 129 계통이다(예: Festing 외, 1999, Mammalian Genome 10:836; Auerbach, W. 외, 2000, Biotechniques 29(5):1024-1028, 1030, 1032 참조). 일부 특정 구현예에서, 본원에 기술된 바와 같은 유전자 변형된 마우스는 전술한 129 계통 및 전술한 C57BL/6 계통의 혼합체이다. 일부 특정 구현예에서, 본원에 기술된 바와 같은 마우스는 전술한 129 계통의 혼합체, 또는 전술한 BL/6 계통의 혼합체이다. 일부 특정 구현예에서, 본원에 기술된 바와 같은 마우스는 Crb1 rd8 돌연변이를 함유하지 않거나 결여된 (즉, 야생형 Crb1를 포함하는) 전술한 BL/6 계통의 혼합체이거나 이로부터 유래된다. 일부 특정 구현예에서, 본원에 설명된 바와 같은 129 계통의 혼합체는 129S6(129/SvEvTac) 계통이다. 일부 구현예에서, 본원에 기술된 바와 같은 마우스는 BALB 계통, 예를 들어 BALB/c 계통이다. 일부 구현예에서, 본원에 기술된 바와 같은 마우스는 BALB 계통 및 전술한 다른 계통의 혼합체이다.
일부 구현예에서, 본원에서 기술된 바와 같은 비인간 동물은 랫트이다. 일부 특정 구현예에서, 본원에 기술된 바와 같은 랫트는 위스타 랫트(Wistar rat), LEA 계통, 스프래그 다울리(Sprague Dawley) 계통, 피셔(Fischer) 계통, F344, F6, 및 다크 아구티(Dark Agouti)로부터 선택된다. 일부 특정 구현예에서, 본원에 설명된 바와 같은 랫트 계통은 위스타, LEA, 스프래그 다울리, 피셔, F344, F6, 및 아크 아구티로 이루어지는 군으로부터 선택된 2가지 이상 계통의 혼합체이다.
랫트 다능성 및/또는 재생성 세포는, 예를 들어, ACI 랫트 계통, 검은 아구티(Dark Agouti, DA) 랫트 계통, 위스타 랫트 계통, LEA 랫트 계통, 스프래그 다울리(SD) 랫트 계통, 또는 피셔 F344나 피셔 F6과 같은 피셔 랫트 계통을 포함하는 임의의 랫트 계통으로부터 유래될 수 있다. 랫트 다능성 및/또는 재생성 세포는 위에 인용된 하나 이상의 계통의 혼합체로부터 유래된 계통으로부터 수득될 수도 있다. 예를 들어, 랫트 다능성 및/또는 재생성 세포는 DA 균주 또는 ACI 균주로부터 유래될 수 있다. ACI 랫트 균주는 흰 배와 다리 및 RT1 av1 일배체형을 가진 검은 아구티를 가지는 것을 특징으로 한다. 이러한 계통은 Harlan Laboratories를 포함하는 다양한 공급원으로부터 이용이 가능한다. ACI 랫트 유래의 랫트 ES 세포주의 예는 ACI.G1 랫트 ES 세포이다. 검은 아구티(DA) 랫트 균주는 아구티 코트(coat) 및 RT1 av1 일배체형을 가지는 것을 특징으로 한다. 이러한 랫트는 Charles River 및 Harlan Laboratories를 포함하는 다양한 공급원으로부터 이용이 가능한다. DA 랫트 유래의 랫트 ES 세포주의 실시예는 DA.2B 랫트 ES 세포주 및 DA.2C 랫트 ES 세포주이다. 일부 경우에, 랫트 다능성 및/또는 재생성 세포는 동종 번식된 랫트 균주로부터 유래된다. 예시적 참조 문헌: 미국 특허 공개 번호 제2014-0235933 A1호(본원에 참조로서 통합됨). 랫트 ES 세포 및 유전적으로 변형된 랫트를 제조하는 방법 또한 당업계에 기술되어 있다. 예를 들어, US 2014/0235933 A1, US 2014/0310828 A1, Tong 등의 (2010) Nature 467:211-215, 및 Tong 등의 (2011) Nat Protoc. 6(6): doi:10.1038/nprot.2011.338을 참조한다(이들 모두는 참조로서 본원에 통합됨).
Rs1 유전자에 파괴 또는 돌연변이를 포함하는 비인간 동물이 제공된다. 일부 구현예에서, Rs1 유전자에서의 파괴 또는 돌연변이는 기능 상실(loss-of-function)을 초래한다. 특히, 기능 상실 돌연변이는 RS1의 발현을 감소 또는 결여시키고/결여시키거나 RS1의 활성/기능을 감소시키거나 결여시키는 돌연변이를 포함한다. 일부 구현예에서, 기능 상실 돌연변이는 야생형 비인간 동물과 비교하여 하나 이상의 표현형을 초래한다. RS1의 발현은, 예를 들어, 본원에 기술된 바와 같은 비인간 동물의 세포 또는 조직에서 RS1의 수준을 분석함으로써 직접적으로 측정될 수 있다.
일반적으로, RS1의 발현 및/또는 활성 수준이 동일한 파괴(예: 결실)를 포함하지 않는 적절한 대조군 세포 또는 비인간 동물에서의 RS1 수준보다 통계적으로 낮은 경우(p≤0.05), RS1의 발현 수준 및/또는 활성이 감소한다. 일부 구현예에서, RS1의 농도 및/또는 활성은 동일한 파괴(예: 결실)가 없는 대조군 세포 또는 비인간 동물에 비해 동형접합성 암컷 또는 반접합성 수컷 동물에서 적어도 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 95%, 99% 또는 그 이상 감소한다.
다른 구현예에서, RS1의 발현 수준 및/또는 활성을 감소시키는 파괴 또는 돌연변이를 Rs1 유전자에 갖는 세포 또는 기관은, 서던 블롯 분석(Southern blot analysis), DNA 시퀀싱, PCR 분석, 또는 표현형 분석을 포함하되 이들로 한정되지 않는 방법을 사용해 선택된다. 이어서, 이러한 세포 또는 비인간 동물은 본원에 기술된 다양한 방법 및 조성물에 사용된다.
일부 구현예에서, 내인성 Rs1 유전자는 결실되지 않는다 (즉, 온전하게 유지된다). 일부 구현예에서, 내인성 Rs1 유전자는 변경, 파괴, 결실되거나 이종 서열(예: 리포터 유전자 암호화 서열)로 대체된다. 일부 구현예에서, 내인성 Rs1 유전자의 전부 또는 실질적으로 전부가 삽입 핵산으로 대체되는데; 일부 특정 구현예에서, 대체는 리포터 유전자가 Rs1 프로모터(예: 내인성 Rs1 프로모터)와 작동 가능하게 연결되도록, 내인성 Rs1 유전자의 코딩 서열 중 일부가 리포터 유전자(예: lacZ)로 대체되는 것을 포함한다. 일부 구현예에서, 리포터 유전자의 일부(예: 이의 기능적 단편)는 내인성 비인간 Rs1 유전자에 삽입된다. 일부 구현예에서, 리포터 유전자는 lacZ 유전자이다. 일부 구현예에서, 리포터 유전자는 암컷 비인간 동물에서 내인성 Rs1 유전자의 2개의 카피 중 하나에 삽입되어, 리포터 유전자에 대해 이형접합성인 비인간 암컷 동물을 생성시킨다. 일부 구현예에서, 리포터 유전자에 대해 동형접합성인 비인간 암컷 동물이 제공된다.
Rs1 유전자에 돌연변이(들)를 포함하는 비인간 동물이 제공된다. 일부 구현예에서, Rs1 유전자에서의 돌연변이는 변이체 RS1 폴리펩티드(예: 야생형 RS1 폴리펩티드와 비교하여 하나 이상의 아미노산 치환을 포함하는 RS1 폴리펩티드)를 발현시킨다. 변이체 RS1의 발현은, 예를 들어, 본원에 기술된 바와 같은 비인간 동물의 세포 또는 조직에서의 변이체 RS1의 수준을 분석함으로써 직접적으로 측정될 수 있다.
다른 구현예에서, Rs1 유전자에 돌연변이(들)를 갖는 세포 또는 기관은, 서던 블롯 분석, DNA 시퀀싱, PCR 분석, 또는 표현형 분석을 포함하되 이들로 한정되는 않는 방법을 사용해 선택된다. 이어서, 이러한 세포 또는 비인간 동물은 본원에 기술된 다양한 방법 및 조성물에 사용된다.
일부 구현예에서, 내인성 Rs1 유전자는 돌연변이 Rs1 서열(예: 돌연변이체 RS1 암호화 서열의 전체 또는 부분)로 변경되거나 이와 대체된다. 일부 구현예에서, 내인성 Rs1 유전자의 전부 또는 실질적으로 전부가 삽입 핵산으로 대체되는데; 일부 특정 구현예에서, 치환은 돌연변이체 Rs1 엑손이 Rs1 프로모터(예를 들어, 내인성 Rs1 (프로모터) 및 기타 내인성 Rs1 엑손들과 작동 가능하게 연결되도록 내인성 Rs1 엑손(예를 들어, 엑손 3 또는 5)를 돌연변이체 Rs1 엑손(예를 들어, 합성 엑손 3 또는 합성 엑손 5)와 대체하는 것을 포함한다. 일부 구현예에서, 돌연변이체 Rs1 엑손은 내인성 Rs1 유전자에 삽입되는데, 돌연변이체 Rs1 엑손은 하나 이상의 점 돌연변이를 함유하며; 일부 특정 구현예에서는 1개의 점 돌연변이를 함유한다. 일부 구현예에서, 돌연변이체 Rs1 엑손은 암컷 비인간 동물에서의 내인성 Rs1 유전자의 2개의 카피 중 1개에 삽입되어, 돌연변이체 Rs1 엑손에 대해 이형접합성인 암컷 비인간 동물을 생성시킨다. 일부 구현예에서, 돌연변이체 Rs1 엑손에 대해 동형접합성인 암컷 비인간 동물이 제공된다. 일부 구현예에서, 돌연변이체 내인성 Rs1 유전자를 포함하는 비인간 동물은 결실 및/또는 부위 특이적 재조합 효소 인식 부위(예: loxP)를 포함하는 하나 이상의 Rs1 인트론을 추가로 포함한다.
망막층간분리증의 비인간 동물 모델 및 이의 사용 방법
본원에 기술된 비인간 동물은 망막층간분리증을 위한 개선된 동물 모델을 제공한다. 특히, 본원에 기술된 바와 같은 비인간 동물은, 예를 들어 망막 퇴화로 인한 중심 시각 및 주변부 시각의 진행성 상실을 특징으로 하는, X-염색체 관련 망막층간분리증 질환 병리학에 대해 번역되는 개선된 동물 모델을 제공한다.
예를 들어, 본원에 기술된 바와 같은 Rs1 유전자에서의 파괴 또는 돌연변이는 본원에 제공된 비인간 동물에서 다양한 증상(또는 표현형)을 야기할 수 있다. 일부 구현예에서, Rs1 유전자에서의 파괴 또는 돌연변이는, 출생 시 지극히 정상이지만 수령이 늘어날 때 (예를 들어 8주 후, 9주 후, 10주 후, 11주 후, 12주 후, 13주 후, 14주 후, 15주 후, 16주 후, 17주 후, 18주 후, 19주 후, 20주 후, 21주 후, 22주 후, 23주 후, 24주 후, 25주 후, 26주 후, 27주 후, 28주 후, 29주 후, 30주 후, 31주 후, 32주 후, 33주 후, 34주 후, 35주 후, 36주 후, 37주 후, 38주 후, 39주 후, 40주 후, 41주 후, 42주 후, 43주 후, 44주 후, 45주 후, 46주 후, 47주 후, 48주 후, 49주 후, 50주 후, 51주 후, 52주 후, 53주 후, 54주 후, 55주 후, 56주 후, 57주 후, 58주 후, 59주 후, 60주 후 등) 하나 이상의 증상을 나타내는 비인간 동물을 생성한다. 일부 구현예에서, Rs1 유전자에서의 파괴 또는 돌연변이는 비인간 동물의 망막 중 하나 또는 둘 다에 대해 구조적 및/또는 기능적 이상을 초래한다. 일부 구현예에서, Rs1 유전자의 파괴는 망막층간분리증과 관련된 하나 이상의 증상(또는 표현형)을 나타내는 비인간 동물을 생성한다. 이러한 증상(또는 표현형)은, 예를 들어, 망막 중 하나 또는 둘 다가 2개의 층으로 분리되는 것, 비정상적인 망막 및/또는 황반 구조 또는 아키텍처, 중심와(황반의 중심) 내의 스포크형 스트리크(streak), 망막 중 하나 또는 둘 다가 2개의 층으로 분리되어 생성된 공간 내 블리스터(blister) 및/또는 혈관 파열의 존재, 망막 중 하나 또는 둘 다의 유리체 내로 혈액의 유출, 시력 상실 및/또는 장애, 실명, 망막 착색 및/또는 퇴화, 유리체의 퇴화 또는 망막으로부터의 분리, 및 망막 박리를 포함할 수 있다. 특정 구현예에서, 증상 또는 표현형은 내망막 내 낭포 구조의 발생, 및 야생형 비인간 동물과 비교하여 ERG b- 및 a-파 반응의 감소를 포함하며, 이는 광수용기 세포의 상실로 이어진다. 일부 구현예에서, 본원에 기술된 바와 같은 비인간 동물의 Rs1 유전자좌에서의 파괴 또는 돌연변이는 비인간 동물에서 망막의 기능적 및 형태학적 표현형이 조기에 (예를 들어, 출생일에 또는 출생 후 15, 18, 21, 24 또는 27일 이내에) 나타나도록 한다. 일부 구현예에서, 망막의 조기 발병성 기능적 결함은, 야생형 비인간 동물과 비교하여, (i) 암-순응(dark-adapted) 및 명-순응(light-adapted) ERG 분석에서 a-파에 대해 상대적인 b-파의 감소(부의 ERG로 나타남); (ii) ERG b-파의 최대 반응 값 및 감도 값의 감소; (iii) ERG a-파의 최대 반응 값의 감소; 또는 (iv) (i) 내지 (iii)의 조합으로 반영될 수 있다. 일부 구현예에서, 망막의 조기 발병성 형태학적 결함은 야생형 비인간 동물과 비교하여, 분리, 더 넓은 타원체 구역(EZ), 더 얇은 외망막, 또는 이들의 조합으로 반영될 수 있다. 일부 구현예에서, 본원에 기술된 비인간 동물은 망막층간분리증(예: X-염색체 관련 망막층간분리증)의 치료를 위한 후보 치료제의 식별 및 개발을 위한 개선된 생체 내(in vivo) 시스템을 제공한다. 따라서, 적어도 일부 구현예에서, 본원에 기술된 비인간 동물은 X-염색체 관련 망막층간분리증 및/또는 안구 질환에 대한 개선된 동물 모델을 제공하고, 안구 관련 질환, 장애 또는 병태의 치료 및/또는 예방을 위한 치료제의 개발 및/또는 식별에 사용될 수 있다.
본원에 기술된 바와 같은 비인간 동물은 RS1의 발현이 없고 다양한 분석에 유용한 변이체 RS1 폴리펩티드를 발현하는 생물학적 물질(예: 세포)의 공급원 및 개선된 생체 내 시스템을 제공한다. 다양한 구현예에서, 본원에 기술된 비인간 동물은 RS1 발현 및/또는 활성의 결핍과 관련된 하나 이상의 증상을 치료, 예방 및/또는 억제하는 치료법(예: 유전자 요법/대체)을 개발하는데 사용된다. 다양한 구현예에서, 본원에 기술된 비인간 동물은 변이체 RS1 폴리펩티드의 발현과 관련된 하나 이상의 증상을 치료, 예방 및/또는 억제하는 치료법을 개발하는데 사용된다. 변이체 RS1 폴리펩티드의 발현으로 인해, 본원에 기술된 비인간 동물은 망막의 구조 및 발달에 대한 기능적 결과를 알아내기 위한 다양한 분석법에 사용하기에 유용하다. 일부 구현예에서, 본원에 기술된 비인간 동물은 RS1 구조 및/또는 기능에 관여하는 분자를 스크리닝하기 위한 동물 모델을 제공한다.
본원에 기술된 비인간 동물은 망막 중 하나 또는 둘 다의 구조 및/또는 기능 퇴화에 기인하는 진행성 시력 상실의 치료, 예방 및/또는 억제를 위한 치료제를 식별하기 위한 생체 내 시스템도 제공한다. 일부 구현예에서, 치료제의 효과는 상기 치료제를 본원에 기술된 바와 같은 Rs1 유전자를 포함하는 게놈을 가진 비인간 동물에게 투여함으로써 생체 내에서 결정된다.
본원에 기술된 비인간 동물은 안구 관련 질환, 장애 및 병태에 대한 개선된 동물 모델도 제공한다. 특히, 본원에 기술된 바와 같은 비인간 동물은 망막 중 하나 또는 둘 다의 신경감각 층에서 세포-대-세포 부착이 파괴되는 것을 특징으로 하는 병태에 대해 번역하는 개선된 동물 모델을 제공한다.
비인간 동물에게 시험 대상 치료제가 임의의 편리한 경로로, 예를 들어 정맥내 주사, 복강내 주사, 또는 유리체내 주사로 투여될 수 있다. 이러한 동물은 면역학적 연구에 포함되어, 치료제가 투여되지 않은 적절한 대조군 비인간 동물과 비교해 비인간 동물의 시력에 대한 치료제의 효과(예: 망막의 감각 신경 기능에 미치는 효과)를 결정할 수 있다. 동물 조직(예: 안구 조직)의 생검이나 해부학적 평가가 수행될 수도 있고/있거나 혈액 샘플이 수집될 수 있다.
다양한 구현예에서, 본원에 기술된 비인간 동물은 망막 중 하나 또는 둘 다에서 광수용기 기능을 회복시키는 후보 치료제(예: 항체)를 식별하고, 스크리닝하고/하거나 개발하는 데 사용된다. 다양한 구현예에서, 본원에 기술된 비인간 동물은 광수용기에 대한 Rs1 유전자 전달의 효능을 결정하는 데 사용된다. 일부 구현예에서, 본원에 기술된 비인간 동물은 RS1 폴리펩티드를 암호화하는 하나 이상의 후보 망막 유전자 요법의 벡터 설계를 결정 및/또는 최적화하는데 사용된다.
다양한 구현예에서, 본원에 기술된 비인간 동물은 Rs1 유전자 요법 약물과 같은 후보 약물의 약동학적 프로파일을 결정하는 데 사용된다. 다양한 구현예에서, 본원에 기술된 하나 이상의 비인간 동물 및 하나 이상의 대조군 비인간 동물 또는 기준 비인간 동물은 각각 하나 이상의 후보 약물(예: Rs1 유전자 요법 약물)의 다양한 투여량(예를 들어, 0.1 mg/kg, 0.2 mg/kg, 0.3 mg/kg, 0.4 mg/kg, 0.5 mg/kg, 1 mg/kg, 2 mg/kg, 3 mg/kg, 4 mg/kg, 5 mg/mg, 7.5 mg/kg, 10 mg/kg, 15 mg/kg, 20 mg/kg, 25 mg/kg, 30 mg/kg, 40 mg/kg, 또는 50 mg/kg 이상)에 노출된다. 후보 약물(예: Rs1 유전자 요법 약물)은 본원에 기술된 비인간 동물에서의 평가를 위해 비경구 및 비경구 이외의 투여 경로를 포함하는 임의의 바람직한 투여 경로를 통해 투여될 수 있다. 비경구 경로는, 예를 들어, 정맥내, 동맥내, 문맥내, 근육내, 피하, 복강내, 척수내, 척추강내, 뇌심실내, 두개내, 흉막내 주입 경로 또는 다른 주입 경로를 포함한다. 비경구가 아닌 경로는, 예를 들어, 경구, 비강, 경피, 폐, 직장, 볼, 질내, 안내를 포함한다. 투여는 또한 연속적 주입, 국소 투여, 이식물(겔, 막 등)으로부터의 서방출, 및/또는 정맥내 주입일 수 있다. 혈액은 다양한 시점(예를 들어, 0시간차, 6시간차, 1일차, 2일차, 3일차, 4일차, 5일차, 6일차, 7일차, 8일차, 9일차, 10일차, 11일차, 또는 최대 30일차 또는 그 이상)에 비인간 동물로부터 단리된다. 본원에 기술된 비인간 동물로부터 수득한 샘플을 사용하여 투여된 약물의 약동학적 프로파일을 결정하기 위한 다양한 분석을 수행할 수 있으며, 이에는 총 IgG, 항약물 반응, 응집 반응 등을 포함되지만 이들로 한정되지는 않는다.
다양한 구현예에서, 본원에 기술된 비인간 동물은 Rs1 유전자 요법 약물과 같은 하나 이상의 후보 약물의 치료 효능을 결정하는 데 사용된다. 다양한 구현예에서, 본원에 기술된 하나 이상의 비인간 동물 및 하나 이상의 대조군 또는 기준 비인간 동물은 각각 하나 이상의 후보 약물(예: Rs1 요법 약물)의 다양한 투여량(예: 0.1 mg/mL, 0.2 mg/mL, 0.3 mg/mL, 0.4 mg/mL, 0.5 mg/mL, 0.6 mg/mL, 0.7 mg/mL, 0.8 mg/mL, 0.9 mg/mL, 1.0 mg/mL, 1.1 mg/mL, 1.2 mg/mL, 1.3 mg/mL, 1.4 mg/mL, 1.5 mg/mL, 1.6 mg/mL, 1.7 mg/mL, 1.8 mg/mL, 1.9 mg/mL, 2.0 mg/mL, 2.1 mg/mL, 2.2 mg/mL, 2.3 mg/mL, 2.4 mg/mL, 2.5 mg/mL, 2.6 mg/mL, 2.7 mg/mL, 2.8 mg/mL, 2.9 mg/mL, 3.0 mg/mL, 3.1 mg/mL, 3.2 mg/mL, 3.3 mg/mL, 3.4 mg/mL, 3.5 mg/mL, 3.6 mg/mL, 3.7 mg/mL, 3.8 mg/mL, 3.9 mg/mL, 4.0 mg/mL, 4.1 mg/mL, 4.2 mg/mL, 4.3 mg/mL, 4.4 mg/mL, 4.5 mg/mL, 4.6 mg/mL, 4.7 mg/mL, 4.8 mg/mL, 4.9 mg/mL 또는 5.0 mg/mL 이상)에 노출된다. 일부 구현예에서, 후보 약물(예: Rs1 유전자 요법 약물)은 본원에 기술된 비인간 동물의 출생 시 또는 출생 직후에 (예를 들어 출생 후 18, 15, 12, 10, 9, 8, 7, 6, 5, 4, 3, 2, 또는 1일 이내에) 동 비인간 동물에게 투여된다. 후보 약물(예: Rs1 유전자 요법 약물)은 바람직하게는 유리체내 경로(intravitreal route)를 통해 투여되지만, 비경구 및 비경구 이외의 투여 경로를 포함하는 임의의 바람직한 투여 경로(상기 참조)가 본원에 기술된 비인간 동물에서 평가될 수 있다. 다양한 구현예에서, 하나 이상의 후보 약물(예를 들어, Rs1 유전자 요법 약물)은 유리체내 경로를 통해 다양한 부피로 (예를 들어, 1mL, 2mL, 3mL, 4mL, 5mL, 6mL, 7mL, 8mL, 9mL, 10mL, 11mL, 12mL, 13mL, 14mL, 15mL, 16mL, 17mL, 18mL, 19mL, 20mL, 21mL, 22mL, 23mL, 24mL, 25mL, 26mL, 27mL, 28mL, 29mL, 30mL, 31mL, 32mL, 33mL, 34mL, 35mL, 36mL, 37mL, 38mL, 39mL, 40mL, 41mL, 42mL, 43mL, 44mL, 45mL, 46mL, 47mL, 48mL, 49mL 또는 50mL 이상) 주입된다. 주입은 연속적으로, 또는 특정 시간 과정(예를 들어, 매주, 2주마다, 매월 등)에 따라 이뤄질 수 있다. 망막 기능 및/또는 시력은 다양한 시점에 (예를 들어, 0시간차, 6시간차, 1일차, 2일차, 3일차, 4일차, 5일차, 6일차, 7일차, 8일차, 9일차, 10일차, 11일차, 15일차, 18일차, 21일차, 24일차, 또는 최대 30일차 또는 그 이상) 당업계에 알려진 분석법 및/또는 본원에 기술된 분석법을 사용해 결정된다. RS1 기능 및/또는 RS1 의존적 프로세스에 대한 효과를 결정하기 위해, 본원에 기술된 비인간 동물 및 하나 이상의 대조군 또는 기준 비인간 동물에게 하나 이상의 후보 약물(예: Rs1 유전자 요법 약물)을 투여한 후 이들로부터 수확한 망막 및/또는 안배(eyecup) 상에서 다양한 기능적 및/또는 형태학적 분석이 수행될 수 있다.
다양한 구현예에서, 본원에 기술된 바와 같은 비인간 동물은, 안구에서의 세포 변화의 결과로서, Rs1 활성을 회복하는 치료 효과 및 망막의 구조 및/또는 기능에 미치는 영향을 측정하는 데 사용된다. 다양한 구현예에서, 본원에 기술된 바와 같은 비인간 동물 또는 이로부터 단리된 세포는 후보 약물(예를 들어, Rs1 유전자 요법 약물)에 노출되고, 후속 기간 경과 후, Rs1 의존적 프로세스(또는 상호작용)에 미치는 영향에 대해 분석된다.
본원에 기술된 바와 같은 비인간 동물 유래의 세포(예: 망막 세포)는 단리되어 필요에 따라 수시로(ad hoc basis) 사용되거나, 많은 세대에 걸쳐 배양물로 유지될 수 있다. 다양한 구현예에서, 본원에 기술된 바와 같은 비인간 동물 유래의 세포는 (예컨대, 바이러스의 사용, 세포 융합 등을 통해) 불멸화되고 배양물 내에서 (예를 들어, 계대 배양물 내에서) 무기한으로 유지된다.
본원에 설명된 비-인간 동물은 약물 또는 백신의 분석 및 시험을 위한 생체 내 시스템을 제공한다. 다양한 구현예에서, 후보 약물 또는 백신이 본원에 설명된 하나 이상의 비-인간 동물에 전달된 다음, 약물 또는 백신에 대한 한 가지 이상의 면역 반응, 약물 또는 백신의 안전성 프로파일, 또는 질환 또는 병태에 대한 효과 및/또는 질환 또는 병태의 하나 이상의 증상을 알아내기 위해 비-인간 동물의 모니터링이 이어질 수 있다. 안전성 프로파일을 결정하기 위해 사용되는 예시적인 방법은 약물 또는 백신의 독성, 최적 용량 농도, 효능, 및 가능한 위험 인자의 측정을 포함한다. 이러한 약물 또는 백신은 이러한 비인간 동물에서 개선되고/되거나 개발될 수 있다.
백신 효능은 여러 가지 방식으로 결정될 수 있다. 요약하자면, 본원에 기술된 비인간 동물을 당업계에 공지된 방법을 사용하여 백신 접종한 다음 백신을 투여하거나, 이미 감염된 비인간 동물에 백신을 투여한다. 백신에 대한 비인간 동물(들)의 반응은, 비인간 동물(들) (또는 그로부터 단리된 세포)을 모니터링 하고/하거나 백신의 효능을 알아내기 위한 하나 이상의 검정을 수행함으로써 측정할 수 있다. 그리고 나서 백신에 대한 비인간 동물(들)의 반응은 당 기술분야에 공지된 및/또는 본원에 설명된 하나 이상의 방법을 사용하여 대조군 동물과 비교된다.
백신 효능은 바이러스 중화 분석에 의해 추가로 알아낼 수 있다. 요약하자면, 본원에 기술된 비인간 동물을 면역화시키고, 면역 후 다양한 일 차에 혈청을 수집한다. 혈청의 순차 희석액을 바이러스와 함께 사전 배양하는데, 그 동안 바이러스에 특이적인 혈청 내의 항체가 그것에 결합하게 된다. 그리고 나서, 바이러스/혈청 혼합물을 허용 세포에 가하여 플라크 분석 또는 미세중화 분석에 의해 감염성을 측정한다. 혈청 내의 항체가 바이러스를 중화시키는 경우, 대조군과 비교해 플라크가 더 적거나 상대 루시퍼라제 단위가 더 낮다.
본원에 기술된 비인간 동물은 약물(예: Rs1 유전자 전달 약물)의 약동학적 특성 및/또는 효능을 평가하기 위한 생체 내 시스템을 제공한다. 다양한 구현예에서, 약물이 본원에 기술된 하나 이상의 비인간 동물에게 전달되거나 투여된 후, 비인간 동물에 대한 약물의 효과를 알아내기 위해 비인간 동물(또는 이로부터 단리된 세포)에 대한 모니터링 또는 이에 대한 하나 이상의 분석 수행이 이어질 수 있다. 약동학적 특성은, 비인간 동물이 약물을 다양한 대사산물로 가공하는 방법(또는 독성 대사산물을 포함하되 이에 한정되지 않는 하나 이상의 약물 대사산물의 존재 여부의 검출), 약물 반감기, 투여 후 약물의 순환 레벨(예를 들어, 약물의 혈청 농도), 항약물 반응(예를 들어, 항약물 항체), 약물 흡수 및 분포, 투여 경로, 약물의 배출 및/또는 제거 경로를 포함하되 이들로 한정되지 않는다. 일부 구현예에서, 약물의 약동학적 및 약력학적 특성은 본원에 기술된 비인간 동물에서 또는 이의 사용을 통해 모니터링된다.
일부 구현예에서, 분석의 수행은 약물이 투여된 비인간 동물의 표현형 및/또는 유전자형에 대한 효과를 알아내는 것을 포함한다. 일부 구현예에서, 분석의 수행은 약물에 대한 로트별(lot-to-lot) 변이성(variability)을 알아내는 것을 포함한다. 일부 구현예에서, 분석의 수행은 본원에 기술된 비인간 동물과 기준 비인간 동물에 투여된 약물의 효과 간의 차이를 알아내는 것을 포함한다. 다양한 구현예에서, 기준 비인간 동물은 본원에 기술된 변형, 본원에 기술된 것과는 다른 변형을 가지거나 변형을 가지지 않을 수 있다(즉, 야생형 비인간 동물).
약물의 약동학적 특성을 평가하기 위한 비인간 동물에서 (또는 이로부터 단리된 세포에서 및/또는 이를 이용하여) 측정될 수 있는 예시적인 파라미터는 응집, 자가 소화, 세포 분열, 세포 사멸, 보체 매개 용혈, DNA 무결성, 약물 특이적 항체 역가, 약물 대사, 유전자 발현 어레이, 대사 활성, 미토콘드리아 활성, 산화적 스트레스, 식세포 작용, 단백질 생합성, 단백질 분해, 단백질 분비, 스트레스 반응, 표적 조직 약물 농도, 비 표적 조직 약물 농도, 전사 활성 등을 포함하되 이들로 한정되지 않는다. 다양한 구현예에서, 본원에 기술된 비인간 동물은 약물의 약학적으로 유효한 용량을 알아내기 위해 사용된다.
키트
본 개시는, 적어도 하나의 비인간 동물, 비인간 세포, DNA 단편, 및/또는 본원에 기술된 바와 같은 표적화 벡터가 들어있는 하나 이상의 용기를 포함하는 팩 또는 키트를 추가로 제공한다. 키트는 임의의 적용 가능한 방법(예: 연구 방법)에서 사용될 수 있다. 이러한 용기(들)에는 의약품 또는 생물학적 제제의 제조, 사용 또는 판매를 규제하는 정부 기관에 의해 규정된 양식으로 된 공지가 선택적으로 부착될 수 있으며, 공지에는 (a) 인간 투여용으로 제조, 사용 및 판매하는 것에 대한 기관의 승인 사항, (b) 사용 지침, 또는 둘 모두가 반영되거나, 둘 이상의 개체 간에 물질 및/또는 생물학적 산물(예: 본원에 기술된 바와 같은 비인간 동물 또는 비인간 동물 세포)의 이전을 규율하는 계약이 반영된다.
본 개시의 다른 특징은 예시적인 구현예에 대한 다음의 설명 과정에서 명백해질 것이며, 이들 구현예는 본 발명의 다른 특징의 예시를 위해 제공되고 이를 제한하도록 의도되지 않는다.
실시예
다음의 실시예는 당업자에게 본 개시의 방법 및 조성물을 어떻게 제조하고 사용하는지를 설명하기 위해 제공되며, 발명자가 그들의 개시로서 간주하는 것의 범위를 제한하고자 하는 것은 아니다. 달리 명시되지 않는 한, 온도는 섭씨로 표시되고, 압력은 대기압이거나 대기압에 가깝다.
실시예 1. 조작된 망막층간 단백질-1 설치류 계통의 생성
본 실시예는 설치류의 망막층간 단백질-1(Rs1) 유전자좌에서 변형을 생성하기 위한 일련의 표적화 벡터를 작제하는 것을 예시한다. 특히, 본 실시예는 Rs1 유전자좌(즉, 널 대립유전자)에서 파괴를 생성하고 Rs1 유전자좌에서의 코딩 서열의 하나 이상의 엑손 내에 하나 이상의 점 돌연변이를 도입함으로써, 부모 RS1 폴리펩티드와 비교해 하나 이상의 아미노산 치환을 갖는 변이체 RS1 폴리펩티드를 암호화하는 돌연변이체 Rs1 유전자를 생산하기 위한 표적화 벡터를 작제하는 것을 구체적으로 기술한다. 돌연변이체 대립유전자는, 점 돌연변이를 함유하는 단일 엑손을 포함하는 합성 DNA 단편을 사용하여 작제하였다(하기 참조). 후술하는 바와 같이, 마우스 상동성 박스(mouse homology boxes) 및 연결 QC(ligation QC)를 위해 시퀀싱 올리고뉴클레오티드(sequencing oligonucleotides)를 설계하였다. 히그로마이신 내성 유전자를 함유하는 자체 결실 카세트(SDC)를 클로닝하여 박테리아 인공 염색체(BAC) 클론을 표적화하기 위한 공여자(donor)를 생성하였다. 각 점 돌연변이에 특이적인 2개의 별개 공여자를 PCR 및 생어 시퀀싱(Sanger sequencing)에 의해 확인하였다. 공여자를 선형화하여 골격을 제거하고, 돌연변이체 Rs1 유전자를 생성하기 위해 설치류 Rs1 유전자를 함유하는 BAC 클론 DNA를 표적화하는 데 사용하였다. 변형된 BAC는 약물 선택, 상동성 접합부에 대한 PCR 및 생어 시퀀싱, PFG 전기영동, 및 일루미나 분석(Illumina analysis)에 의해 확인하였다.
요약하면, 널 대립유전자의 경우, 마우스 Rs1 프로모터와 작동 가능하게 연결되어 배치된(즉 엑손 1의 ATG 코돈과 프레임 내에 있는) lacZ 리포터 작제물을 사용해 마우스 Rs1 유전자의 코딩 서열의 엑손 1~3을 결실시켰다(즉, 엑손 1 내의 ATG 코돈의 3'에서 시작해서 엑손 3의 3' 말단까지 13,716 bp가 결실됨). 전술한 바와 같이 내인성 마우스 Rs1 유전자좌에 파괴를 생성하기 위한 Rs1-lacZ-SDC 표적화 벡터를 제작하였다(예: 미국 특허 제6,586,251호; Valenzuela 등의 2003, Nature Biotech. 21(6):652-659; 및 Adams, N.C. 및 N.W. Gale, in Mammalian and Avian Transgenesis-New Approaches, 편집자 Lois, S.P.a.C., Springer Verlag, Berlin Heidelberg, 2006 참조). Rs1 널 대립유전자의 생성을 위한 예시적인 표적화 벡터(또는 DNA 작제물)는 도 2에 제시되어 있다.
요약하자면, 전술한 바와 같이 마우스 박테리아 인공 염색체(BAC) 클론 RP23-213O8 (인비트로젠, Invitrogen) 및 자체 결실 네오마이신 선택 카세트(lacZ-pA-ICeuI-loxP-mPrm1-Crei-SV40pA-hUb1-em7-Neo-PGKpA-loxP)를 사용해 Rs1-lacZ-SDC 표적화 벡터를 생성하였다(참조: 미국 특허 번호 제8,697,851호, 제8,518,392호 및 제8,354,389호; 이들 모두는 본원에 참조로서 통합됨). Rs1-lacZ-SDC 표적화 벡터는 재조합 효소가 미분화 세포에서 발현되도록 발달적으로 조절되는 마우스 프로타민 1 프로모터에 작동 가능하게 연결된 Cre 재조합 효소 암호화 서열을 포함하였다. 상동성 재조합 시, 내인성 쥣과 Rs1 유전자의 엑손 1에서의 ATG 코돈의 3'에서 엑손 3의 3' 말단 이전의 마지막 6개의 뉴클레오티드까지의 뉴클레오티드를 포함하는 결실(13,716 bp)은 표적화 벡터에 함유된 서열(~8,202 bp)로 대체된다. 약물 선택 카세트는 발달 의존 방식으로 제거된다. 즉, 전술한 파괴된 Rs1 유전자를 함유하는 생식계열 세포를 가진 마우스 유래의 자손은 발달 도중에 선택성 마커를 분화된 세포로부터 제거하게 된다(참조: 미국 특허 제8,697,851호, 제8,518,392호 및 제8,354,389호; 이들 모두는 본원에 참조로서 통합됨).
제1 돌연변이체 대립유전자의 경우, C59S 아미노산 치환을 갖는 RS1 폴리펩티드가 생성된 돌연변이체 Rs1 유전자에 의해 암호화되도록, 마우스 박테리아 인공 염색체(BAC) 클론 RP23-213O8을 변형시켜 내인성 Rs1 유전자의 엑손 3에 (TGT에서 AGT로의) 점 돌연변이를 도입하였다(도 5). 양성 클론의 스크리닝을 용이하게 하기 위해 인트론 2 및 3에 추가의 결실(각각 25bp 및 28bp)을 만들었다(도 6). 점 돌연변이와 결실은 데 노보 DNA 합성(de novo DNA synthesis)에 의해 만들어진 합성 단편을 사용해 도입하였다(GenEscript, Piscataway, NJ 참조). 돌연변이체 엑손 3과 주변 인트론 서열(5' 및 3')을 포함하는 합성된 단편을 플라스미드 백본에 포함시키고 암피실린(ampicillin)으로 선택한 박테리아에서 증식시켰다. 히그로마이신 내성 유전자를 합성 단편에 연결시키고 제한 효소를 사용해 상동성 아암을 첨부하여 RP23-213O8 BAC와의 상동성 재조합을 위한 표적화 벡터를 생성하였다(도 5). 이어서, 생성된 변형된 RP23-213O8 BAC 클론을 ES 세포 내로 전기 천공하였다(하기 참조). Rs1C59S-SDC 표적화 벡터는, 재조합 효소가 미분화된 세포에서 발현되도록 발달적으로 조절되는 마우스 프로타민 1 프로모터에 작동 가능하게 연결되는 Cre 재조합효소 암호화 서열을 포함하였다(도 5; 및 미국 특허 제8,697,851호, 제8,518,392호 및 제8,354,389호 참조; 이들 모두는 본원에 참조로서 통합됨). 상동성 재조합 시, 합성 돌연변이된 Rs1 엑손 3은 내인성 쥣과 Rs1 유전자좌의 엑손 3을 대신해 삽입되며, 주변 인트론(즉, 인트론 2 및 3)에서의 작은 결실은 표적화 벡터에 포함된 서열에 의해 만들어진다. 약물 선택 카세트는 발달 의존 방식으로 제거된다. 즉, 전술한 돌연변이된 Rs1 유전자를 함유하는 생식계열 세포를 가진 마우스 유래의 자손은 발달 도중에 선택 가능한 마커를 분화된 세포로부터 제거하게 된다(도 7; 및 미국 특허 제8,697,851호, 제8,518,392호 및 제8,354,389호 참조; 이들 모두는 본원에 참조로서 통합됨). 주변 엑손, 인트론 및 미번역 영역(UTR)을 함유하는 내인성 DNA는 돌연변이 유발 및 선택 카세트에 의해 변경되지 않았다. 표적화 벡터의 서열 분석을 통해 돌연변이체 Rs1 유전자의 모든 엑손, 인트론, 스플라이싱 신호(splicing signal) 및 개방 해독틀(open reading frame)을 확인하였다.
제2 돌연변이체 대립유전자의 경우, R141C 아미노산 치환을 갖는 RS1 폴리펩티드가 생성된 돌연변이체 Rs1 유전자에 의해 암호화되도록, 마우스 박테리아 인공 염색체(BAC) 클론 RP23-213O8을 변형시켜 내인성 Rs1 유전자의 엑손 5에 (CGC에서 TGC로의) 점 돌연변이를 도입하였다(도 8). 특히, 전술한 R141C 점 돌연변이를 함유하는 합성 엑손 5는 양성 클론의 스크리닝을 용이하게 하기 위해 포함된 인트론 4 및 5에서의 추가적인 결실(각각 10 bp 및 29 bp)과 함께 야생형 엑손 5 대신에 삽입하였다(도 9). 합성 단편은 데 노보 DNA 합성에 의해 만들어진다(GenEscript, Piscataway, NJ). 돌연변이체 엑손 5와 주변 인트론 서열 (5' 및 3')이 포함된 합성된 단편을 플라스미드 백본에 포함시키고 암피실린으로 선택된 박테리아에서 증식시켰다. (loxP-mPrm1-Crei-pA-hUb1-em7-Hygro-pA-loxP, 5,032 bp를 사용해) 히그로마이신 내성 유전자를 포함한 카세트를 합성 단편에 연결시키고, 제한 효소를 사용하여 상동성 아암을 첨가하여 RP23-213O8 BAC와의 상동성 재조합을 위한 표적화 벡터를 생성하였다(도 8). 이어서, 생성된 변형된 RP23-213O8 BAC 클론을 ES 세포 내로 전기 천공하였다(하기 참조). Rs1R141C-SDC 표적화 벡터는, 재조합 효소가 미분화된 세포에서 발현되도록 발달적으로 조절되는 마우스 프로타민 1 프로모터에 작동 가능하게 연결되는 Cre 재조합 효소 암호화 서열을 포함하였다(도 8; 및 미국 특허 제8,697,851호, 제8,518,392호 및 제8,354,389호 참조; 이들 모두는 본원에 참조로서 통합됨). 상동성 재조합 시, 합성 돌연변이된 Rs1 엑손 5는 내인성 쥣과 Rs1 유전자좌의 엑손 5를 대신해 삽입되며, 주변 인트론(즉, 인트론 4 및 5)에서의 작은 결실은 표적화 벡터에 포함된 서열에 의해 만들어진다. 약물 선택 카세트는 발달 의존 방식으로 제거된다. 즉, 전술한 돌연변이된 Rs1 유전자를 함유하는 생식계열 세포를 가진 마우스 유래의 자손은 발달 도중에 선택 가능한 마커를 분화된 세포로부터 제거하게 된다(도 10; 및 미국 특허 제8,697,851호, 제8,518,392호 및 제8,354,389호 참조; 이들 모두는 본원에 참조로서 통합됨). 주변 엑손, 인트론 및 미번역 영역(UTR)을 함유하는 내인성 DNA는 돌연변이 유발 및 선택 카세트에 의해 변경되지 않았다. 표적화 벡터의 서열 분석을 통해 돌연변이체 Rs1 유전자의 모든 엑손, 인트론, 스플라이싱 신호 및 개방 해독틀을 확인하였다.
각각의 표적화 벡터의 작제는 중합효소 연쇄 반응 및 서열 분석에 의해 확인한 다음, 이를 사용해 마우스 배아 줄기(ES) 세포를 전기천공하여 널 및 돌연변이체 Rs1 유전자를 포함하는 변형된 ES 세포를 생성하였다. 전기천공에 사용된 마우스 ES 세포는 하이브리드 백그라운드로 유래의 것이다(50% 129/S6/SvEv/Tac, 50% C57BL/6NTac; Auerbach, W. 등의 (2000) Biotechniques 29(5):1024-8, 1030, 1032 참조). 전기천공 후 10일차에 약물 내성 클론을 골라내고, 내인성 Rs1 유전자 내에 적절하게 도입된 엑손 lacZ 리포터 유전자 또는 점 돌연변이를 검출한 프라이머/프로브 세트를 사용하여 전술한 바와 같이(Valenzuela 등의 전술한 문헌; Frendewey, D. 등의 2010, Methods Enzymol. 476:295-307 참조) 정확한 표적화를 위해 TAQMANβ 및 핵형분석에 의해 스크리닝하였다(표 1 및 도 3, 6 및 9). 양성 ES 세포 클론은 시퀀싱에 의해 확인하였다.
이어서, 표적화된 ES 세포를 전기 8-세포기의 Swiss Webster 배아에 주입하는 VELOCIMOUSE® 방법(예: 미국 특허 제7,294,754호; DeChiara, T.M. 등의 2010, Methods Enzymol. 476:285-94; DeChiara, T.M., 2009, Methods Mol. Biol. 530:311-24; Poueymirou 등의 2007, Nat. Biotechnol. 25:91-9 참조)을 사용해 암컷 마우스를 이식하는데 양성 ES 세포 클론을 사용하여, 돌연변이체 Rs1 유전자에 대해 이형접합성인 건강한 완전 ES 세포 유래의 F0 세대 마우스를 생산하였다. C57BL/6N 마우스 계통은 망막 퇴화의 동물 모델을 형성하는 데 이들을 사용하는 것을 복잡하게 만드는 돌연변이(Crb1 rd8 )를 함유하는 것으로 보고되었다(예를 들어, Mattapallil, M.J. 등의 2012, Immunol. Microbiol. 53(6):2921-7; Mehalow, A.K. 등의 2003, Hum. Mol. Genet. 12:2179-89 참조). 이러한 돌연변이에 기인하는 임의의 가능한 복잡성을 피하기 위해 F0 세대 이형접합성 수컷을 C57Bl6/NTac Crbs1 암컷과 교배시킴으로써 이러한 돌연변이를 보정하였다. 그런 다음, 이러한 육종으로부터의 생성된 F1 이형접합체를 이종 교배시켜 표현형 분석을 위한 F2 세대 동형접합체 및 야생형 마우스를 생산하였다.
전술한 조작된 Rs1 마우스 계통을 생성한 결과 각각의 조작된 Rs1 유전자좌에서 고유한 뉴클레오티드 접합부가 생성되었다. 널 대립유전자의 경우, 상류 접합점 양단의 뉴클레오티드 서열은 다음을 포함하였는데, 이는 내인성 마우스 Rs1 5' 서열 및 마우스 Rs1 ATG 코돈(괄호 안에 포함된 대문자이며, ATG 코돈은 대괄호로 표시됨)이 lacZ 코딩 서열(소문자)과 인접함을 나타낸다: (GCTCTCCACT TCACTTAGAT CTTGCTGTGA CCAAGGACAA GGAGAAA[ATG]) ggtaccgatt taaatgatcc agtggtcctg cagaggagag attgggagaa (서열번호 33). 하류 접합점 양단의 뉴클레오티드 서열은 다음을 포함하였는데, 이는 카세트 서열(소문자이며, NheI 부위는 대괄호로 표시됨)이 엑손 3의 마지막 6개의 뉴클레오티드 및 마우스 Rs1 유전자의 인트론 4의 시작 부위(괄호 안의 대문자)와 인접함을 나타낸다: cagcccctag ataacttcgt ataatgtatg ctatacgaag ttat[gctagc] (TTCCAGGTGA GTGGCTCAAC GCCCTAGCAT TCCTCCTTCC AACTCTTAAT) (서열 번호 34). 선택 카세트의 재조합효소 매개 절제 후 하류 접합점 양단의 뉴클레오티드 서열은 다음을 포함하였는데, 이는 나머지 lacZ 서열(소문자이며, ICeu-I, loxP 및 NheI 부위는 대괄호로 표시됨)이 마우스 Rs1 서열(괄호 안의 대문자)과 인접함을 나타낸다: atcccccggc tagagtttaa acactagaac tagtggatcc ccgggctcga [taactataac ggtcctaagg tagcga]ctcgac [ataacttcg tataatgtat gctatacgaa gttat gctagc] (TTCCAGGTGA GTGGCTCAAC GCCCTAGCAT TCCTCCTTCC AACTCTTAAT) (서열 번호 35).
C59S 대립유전자의 경우, 상류 접합점 양단의 뉴클레오티드 서열은 다음을 포함하였는데, 이는 내인성 마우스 Rs1 엑손 3 및 주변 인트론 서열(아래 괄호 안의 대문자이며, 엑손 3은 대괄호로 표시되고 돌연변이된 코돈은 굵은 글씨로 표시됨)이 삽입점에서의 카세트 서열(소문자이며, XhoI 부위는 대괄호로 표시되고 loxP 부위는 굵을 글씨로 표시됨)과 인접함을 나타낸다: (CTGGAGTGT ACCTTTGTTG ATAGAACACT TGTTTAGGAT TCGTGAAGGT AAACTGGGCA CCCATCTAGA AGCCCAGCAC TCAGAGGTGG AGACAGGAGG TCAGGAGTTC AACAAGGTCA TTCTCTGCTA CACAGTGAGT TTAAAATCGG CCTGGGATAC ACGAGAGAGA CCCTGTGTAA GAGCAGTAGC AGCAGCAAGA ACTCAAGCTG AAAAGGAACA TGCAGTGTAA GACAAAGGGC CACTGTGTGC ATAGAGCCAG CAACCTCACA CTGTAATGAA CGGGTCTGAC CTTTGCAAGT AAGCTTCTTG TGATGCTCTG GTTGAGCCTT TGACTACGAC TTTTGTGACT TGTGCTCCTC TGGATGCTTG CAG[GATGAGG GTGAGGACCC CTGGTACCAG AAAGCATGCA AGTGTGATTG CCAGGTAGGA GCCAATGCTC TGTGGTCTGC TGGAGCTACC TCCTTAGACA GTATTCCAG]G TGAGTGGCTC AACGCCCTAG CATTCCTCCT TCCAACTCTT AATCCCTCTG CTTTCTCTCA AGTTGGCTTG TGAGCTTCAC ATCTCACCGT GGCCACTGCT CCAACATTCT GTTCATTATC AAGTGCCAGG CTCTCTCCCT CCCTGGCTTG CCTGAGATGG TCAGGTAAGA CCC) [ctcgag] ataacttcg tataatgtat gctatacgaa gttatatgca tgccagtagc agcaccc (서열번호 36). 하류 접합점 양단의 뉴클레오티드 서열은 다음을 포함하였는데, 이는 카세트 서열(소문자이며, I-CeuI 및 NheI 부위 모두는 대괄호로 표시되고, loxP 부위는 굵은 글씨로 표시됨)이 삽입점의 하류에서 마우스 Rs1 인트론 3 서열(아래 괄호 안의 대문자)과 인접함을 나타낸다: ttccatcaga cctcgacctg cagcccctag ataacttcgt ataatgtatg ctatacgaag ttatgctagg [taactataac ggtcctaagg tagcga gctagc] (AGCGTGAGGG AAGTCCCTTC CTCTTAGGTA) (서열번호 37). 선택 카세트의 재조합효소 매개 절제 후 삽입점 양단의 뉴클레오티드 서열은 다음을 포함하였는데, 이는 마우스 Rs1 엑손 3 서열 및 잔여 인트론 3 서열(대문자이며, 엑손 3은 대괄호로 표시됨)이 잔여 카세트 서열(아래 괄호 안의 소문자이며, XhoI, I-CeuI 및 NheI 부위는 대괄호로 표시되고 loxP 부위는 굵은 글씨로 표시됨)과 병치됨을 나타낸다: CTGGAGTGT ACCTTTGTTG ATAGAACACT TGTTTAGGAT TCGTGAAGGT AAACTGGGCA CCCATCTAGA AGCCCAGCAC TCAGAGGTGG AGACAGGAGG TCAGGAGTTC AACAAGGTCA TTCTCTGCTA CACAGTGAGT TTAAAATCGG CCTGGGATAC ACGAGAGAGA CCCTGTGTAA GAGCAGTAGC AGCAGCAAGA ACTCAAGCTG AAAAGGAACA TGCAGTGTAA GACAAAGGGC CACTGTGTGC ATAGAGCCAG CAACCTCACA CTGTAATGAA CGGGTCTGAC CTTTGCAAGT AAGCTTCTTG TGATGCTCTG GTTGAGCCTT TGACTACGAC TTTTGTGACT TGTGCTCCTC TGGATGCTTG CAG[GATGAGG GTGAGGACCC CTGGTACCAG AAAGCATGCA AGTGTGATTG CCAGGTAGGA GCCAATGCTC TGTGGTCTGC TGGAGCTACC TCCTTAGACA GTATTCCAG]G TGAGTGGCTC AACGCCCTAG CATTCCTCCT TCCAACTCTT AATCCCTCTG CTTTCTCTCA AGTTGGCTTG TGAGCTTCAC ATCTCACCGT GGCCACTGCT CCAACATTCT GTTCATTATC AAGTGCCAGG CTCTCTCCCT CCCTGGCTTG CCTGAGATGG TCAGGTAAGA CCC ([ctcgag] ataacttcg tataatgtat gctatacgaa gttat gctagg//[taactataac ggtcctaagg tagcga gctagc] agcgtgaggg aagtcccttc ctcttaggta) (서열번호 38).
R141C 대립유전자의 경우, 상류 접합점 양단의 뉴클레오티드 서열은 다음을 포함하였는데, 이는 내인성 마우스 Rs1 엑손 5 및 주변 인트론 서열(아래 괄호 안의 대문자이며, 엑손 5는 대괄호로 표시되고 돌연변이된 코돈은 굵은 글씨로 표시됨)이 삽입점에서의 카세트 서열(소문자이며, XhoI 부위는 대괄호로 표시되고 loxP 부위는 굵을 글씨로 표시됨)과 인접함을 나타낸다: (TCTTTCCTAA GGAAAAGAAT TAAGAGTCGG GCTATGTCTG AAGGCCCAGA TACCTCTTGA TGCTAGGTAA CCCTTCAAAA CTCAGCACCT GTTGGCTTTT TACAGACATA GATAAGAGGA TGGCTCCTGG TAATTTGGTG TGTTCCTGGC AG[GTGTGCTT GGCTTTCCAA GTATCAGGAC AGCAGCCAGT GGTTACAGAT AGATTTGAAG GAGATCAAGG TGATTTCGGG GATCCTGACC CAAGGATGCT GTGACATAGA CGAGTGGGTG ACCAAGTACA GTGTGCAGTA TAGGACTGAT GAGCGCCTGA ACTGGATCTA CTATAAGGAT CAGACCGGAA ACAATCGG]GT AAGTGGGGGT CACTCCGAGT CAGCTTCAGC TCACACTGCG GAGACACACT CCATCCCTAT GTTCCTGCTG TCCGCGTCTG TCTGAGCATT GACCCCTCTA CATGCTGGGT CATCTG) [ctcgag] ataacttcg tataatgtat gctatacgaa gttatatgca tgccagtagc agcaccc (서열번호 39). 하류 접합점 양단의 뉴클레오티드 서열은 다음을 포함하였는데, 이는 카세트 서열(소문자이며, I-CeuI 및 NheI 부위 모두는 대괄호로 표시되고, loxP 부위는 굵은 글씨로 표시됨)이 삽입점의 하류에서 마우스 Rs1 인트론 5 서열(아래 괄호 안의 대문자)과 인접함을 나타낸다: ttccatcaga cctcgacctg cagcccctag ataacttcgt ataatgtatg ctatacgaag ttatgctagg [taactataac ggtcctaagg tagcga gctagc] (TTTTCCAGAT GTGATCTGGG AGACTAGCAG) (서열번호 40). 선택 카세트의 재조합효소 매개 절제 후(인트론 5에 78 bp 남음) 삽입점 양단의 뉴클레오티드 서열은 다음을 포함하였는데, 이는 마우스 Rs1 서열(인트론 4, 엑손 5 및 인트론 5는 대문자임)을 잔여 카세트 서열(loxP 및 인트론 5에 남아 있는 클로닝 부위[78 bp]는 괄호 안의 소문자이며; XhoI, I-CeuI 및 NheI 부위는 대괄호로 표시되고, loxP 부위는 굵은 글씨로 표시됨)과 함께 나타낸다: TCTTTCCTAA GGAAAAGAAT TAAGAGTCGG GCTATGTCTG AAGGCCCAGA TACCTCTTGA TGCTAGGTAA CCCTTCAAAA CTCAGCACCT GTTGGCTTTT TACAGACATA GATAAGAGGA TGGCTCCTGG TAATTTGGTG TGTTCCTGGC AGGTGTGCTT GGCTTTCCAA GTATCAGGAC AGCAGCCAGT GGTTACAGAT AGATTTGAAG GAGATCAAGG TGATTTCGGG GATCCTGACC CAAGGATGCT GTGACATAGA CGAGTGGGTG ACCAAGTACA GTGTGCAGTA TAGGACTGAT GAGCGCCTGA ACTGGATCTA CTATAAGGAT CAGACCGGAA ACAATCGGGT AAGTGGGGGT CACTCCGAGT CAGCTTCAGC TCACACTGCG GAGACACACT CCATCCCTAT GTTCCTGCTG TCCGCGTCTG TCTGAGCATT GACCCCTCTA CATGCTGGGT CATCTG ([ctcgag] ataacttcg tataatgtat gctatacgaa gttatgctagg [taactataac ggtcctaagg tagcga gctagc])TTTTCCAGAT GTGATCTGGG AGACTAGCAG (서열번호 41).
종합하면, 본 실시예는 조작된 Rs1 유전자좌를 포함하는 게놈을 가진 3가지 설치류(예: 마우스) 계통을 생성하는 것을 예시한다. 이러한 조작된 Rs1 설치류 계통은 망막층간분리증에 생물학 및 분자 메커니즘을 밝히고, 이러한 질환을 효과적으로 치료하거나 완화시키기 위한 치료제를 개발하기 위한 생체내 시스템을 제공한다.
| TAQMAN® 분석을 위한 프라이머/프로브 세트 | ||
| 명칭 | 프라이머 | 서열 (5'-3') |
| Rs1-KOmTU | 정방향 | TGGGACAAGTGTAAATGAGGAC (서열번호 42) |
| 역방향 | AGTGGTGCTTGGCCTTATGC (서열번호 43) | |
| 프로브 | TCCCAGGCAAATCAGGACAAAGGGTC (서열번호 44) | |
| Rs1-KOmTD | 정방향 | GAGCCAGCAACCTCACAC (서열번호 45) |
| 역방향 | GCATCCAGAGGAGCACAAGTC (서열번호 46) | |
| 프로브 | TGTAATGAACGGGTCTGACCTTTGCAA (서열번호 47) | |
| Rs1-C59SmTU | 정방향 | TCGTGAAGGTCTTGATTTGATCCT (서열번호 48) |
| 역방향 | ACCTCCTGTCTCCACCTCTG (서열번호 49) | |
| 프로브 | AAGCACCATGTAAACTGGGCACCC (서열번호 50) | |
| Rs1-C59SmTD | 정방향 | CCCTGGCTTGCCTGAGATG (서열번호 51) |
| 역방향 | GGACTTCCCTCACGCTGAGTT (서열번호 52) | |
| 프로브 | TCAGGTAAGACCCAATTGTCAATGCA (서열번호 53) | |
| Rs1-R141CmTU | 정방향 | GAGTCGGGCTATGTCTGAAGG (서열번호 54) |
| 역방향 | GCCAACAGGTGCTGAGTTT (서열번호 55) | |
| 프로브 | CCAGATTTGGGATGATACCTCTTGATGC (서열번호 56) | |
| Rs1-R141CmTD | 정방향 | CCTCTACATGCTGGGTCATCTG (서열번호 57) |
| 역방향 | GGACTTCCCTCACGCTGAGTT (서열번호 58) | |
| 프로브 | GACCCACATTCATTTACAAACTGC (서열번호 59) | |
실시예 2. 조작된 Rs1 설치류 계통의 특성 분석
본 실시예는 실시예 1에 따라 만들어진 조작된 Rs1 설치류 계통의 특성 분석을 기술한다. 특히, 본 실시예는 이러한 조작된 마우스의 망막 내에서 RS1 단백질의 국소화 및 분포를 보여준다. 또한, 모든 조작된 Rs1 계통에 대한 망막 구조가 기술된다.
LacZ 발현 프로파일링. 마우스에게 CO2를 흡입시켜 안락사시켰다. 안구를 적출하고, 4 에서 PBS(Electron Microscopy Sciences) 중의 4% 파라포름알데히드로 3시간 동안 고정시켰다. 1xPBS(ThermoFisher Sci.)로 3회 세척한 후, 해부 현미경 하에서 안구를 절개하였다. 앞 부분과 수정체를 제거하고; 안구의 나머지 부분(안배)은 HiStomark X-Gal 기재 세트(KPL)로 37
에서 PBS(Electron Microscopy Sciences) 중의 4% 파라포름알데히드로 3시간 동안 고정시켰다. 1xPBS(ThermoFisher Sci.)로 3회 세척한 후, 해부 현미경 하에서 안구를 절개하였다. 앞 부분과 수정체를 제거하고; 안구의 나머지 부분(안배)은 HiStomark X-Gal 기재 세트(KPL)로 37 에서 천천히 회전시키면서 2일 동안 염색하였다. 염색한 후, 1xPBS로 안구를 꼼꼼히 헹군 다음 30% 수크로오스로 옮겨서 밤새 두었다. 안배를 Tissue-Tek® O.C.T. 화합물(VWR)에 포매시키고(embedded) 드라이 아이스 상에서 냉동시켰다. Superfrost® Plus 마이크로 슬라이드 상에서 20 μ의 냉동 절편(cryostat section)을 제조하였다. 절편을 실온에서 30분 동안 건조시킨 다음, 1xPBS로 3회 세척하여 O.C.T. 화합물을 제거하고, ProLong Gold Antifade Mountant with DAPI (ThermoFisher Sci.)로 커버슬립을 덮었다. 수컷 마우스로부터의 대표적인 결과는 도 11a에 제시되어 있다.
에서 천천히 회전시키면서 2일 동안 염색하였다. 염색한 후, 1xPBS로 안구를 꼼꼼히 헹군 다음 30% 수크로오스로 옮겨서 밤새 두었다. 안배를 Tissue-Tek® O.C.T. 화합물(VWR)에 포매시키고(embedded) 드라이 아이스 상에서 냉동시켰다. Superfrost® Plus 마이크로 슬라이드 상에서 20 μ의 냉동 절편(cryostat section)을 제조하였다. 절편을 실온에서 30분 동안 건조시킨 다음, 1xPBS로 3회 세척하여 O.C.T. 화합물을 제거하고, ProLong Gold Antifade Mountant with DAPI (ThermoFisher Sci.)로 커버슬립을 덮었다. 수컷 마우스로부터의 대표적인 결과는 도 11a에 제시되어 있다.
Rs1 mRNA 발현. 실시예 1에 기술된 조작된 Rs1 마우스 계통에서의 Rs1 mRNA의 발현 패턴은 RNASCOPEβ를 제조업체의 사양(Advanced Cell Diagnostics)에 따라 사용하여 인 시튜(in situ) 혼성화(hybridization)에 의해 결정하였다. 요약하자면, 포르말린 또는 4% 파라포름알데히드(PFA)로 고정되고 파라핀 또는 O.C.T.로 포매된 마우스 안배를 5 내지 10 μm의 절편으로 절단하고 SUPERFROST® Plus 유리 슬라이드 상에 장착하였다. 절차는 10분 동안 실온에 두는 전처리 1(ACD, 320037)로 시작하였고, Oster Steamer(IHC World, LLC, 모델 5709)로 20분 동안 끓이는 전처리 2(ACD, 320043) 및 HyBeZ 오븐(ACD, 310010) 내에 30분 동안 40 로 두는 전처리 3(ACD, 320037)이 이어졌다. 추가의 DNase 처리 단계를 포함시켜, 염색체 DNA를 사용한 프로브 혼성화에 기인하는 잠재적인 백그라운드를 감소시켰다. 전처리 3 후에, 슬라이드를 물로 3회 세척하고, DNase I 용액(1x DNase I 완충액 중 50 u/ml, AM2224, Ambion)을 안구 조직에 첨가하여 40
로 두는 전처리 3(ACD, 320037)이 이어졌다. 추가의 DNase 처리 단계를 포함시켜, 염색체 DNA를 사용한 프로브 혼성화에 기인하는 잠재적인 백그라운드를 감소시켰다. 전처리 3 후에, 슬라이드를 물로 3회 세척하고, DNase I 용액(1x DNase I 완충액 중 50 u/ml, AM2224, Ambion)을 안구 조직에 첨가하여 40 에서 30분 배양하였다. 그런 다음, 슬라이드를 물로 5회 세척하고, RNASCOPEβ 프로브를 사용해 40
에서 30분 배양하였다. 그런 다음, 슬라이드를 물로 5회 세척하고, RNASCOPEβ 프로브를 사용해 40 에서 2시간 동안 혼성화하였고, 제조사의 검정 프로토콜 중 나머지(ACD, 322360)를 증폭 1(Amplified 1) 단계에서 증폭 6 단계까지 구현하였다. RNASCOPEβ 세척 완충액(ACD, 310091)으로 매 단계마다 슬라이드를 2회 (실온에서 각각 2분씩) 세척하였다. 증폭 단계(Amplified step) 후, 빛이 없는 상태에서 슬라이드를 적색 작용액(Red working solution)(적색 B와 적색 A의 비율 1:60)으로 실온에서 10분 동안 인큐베이션하고, 이어서 슬라이드를 물로 여러 차례 세척하고 현미경으로 관찰하여 신호를 검출하였다. 일부 실험에서, IHC 기술을 따랐고, 형광 신호는 오픈 필드 니콘 이클립스(open-field Nikon Eclipse) Ti-E 현미경을 사용하여 가시화시키고 캡쳐하였다. 수컷 마우스로부터의 대표적인 결과는 도 11b에 제시되어 있다.
에서 2시간 동안 혼성화하였고, 제조사의 검정 프로토콜 중 나머지(ACD, 322360)를 증폭 1(Amplified 1) 단계에서 증폭 6 단계까지 구현하였다. RNASCOPEβ 세척 완충액(ACD, 310091)으로 매 단계마다 슬라이드를 2회 (실온에서 각각 2분씩) 세척하였다. 증폭 단계(Amplified step) 후, 빛이 없는 상태에서 슬라이드를 적색 작용액(Red working solution)(적색 B와 적색 A의 비율 1:60)으로 실온에서 10분 동안 인큐베이션하고, 이어서 슬라이드를 물로 여러 차례 세척하고 현미경으로 관찰하여 신호를 검출하였다. 일부 실험에서, IHC 기술을 따랐고, 형광 신호는 오픈 필드 니콘 이클립스(open-field Nikon Eclipse) Ti-E 현미경을 사용하여 가시화시키고 캡쳐하였다. 수컷 마우스로부터의 대표적인 결과는 도 11b에 제시되어 있다.
RS1 단백질 발현. 면역조직화학(IHC), 웨스턴 블롯 및 ELISA 분석에 의해 야생형 및 조작된 Rs1 설치류 망막의 다양한 층에서 단백질 발현 수준을 결정하였다. 수컷 마우스로부터의 대표적인 결과가 도 11c 및 도 12a 내지 도 12d에 제시되어 있으며; 암컷 동형접합성 KO(Rs1 -/- ) 및 Rs1 이형접합성 KO(Rs1- /+ ) 계통으로부터의 대표적인 결과는 도 12e에 제시되어 있다.
면역조직화학(IHC). 요약하자면, 동물에게 CO2를 흡입시켜 안락사시켰다. 안구를 적출하고, 4 에서 1xPBS(Electron Microscopy Sci.) 중의 4% PFA(Electron Microscopy Sciences)로 3시간 동안 고정시켰다. 1xPBS로 3회 세척한 후, 해부 현미경 하에서 안구를 절개하였다. 앞 절편과 수정체를 제거하고, 안구의 나머지 부분(안배)은 30% 수크로오스로 4
에서 1xPBS(Electron Microscopy Sci.) 중의 4% PFA(Electron Microscopy Sciences)로 3시간 동안 고정시켰다. 1xPBS로 3회 세척한 후, 해부 현미경 하에서 안구를 절개하였다. 앞 절편과 수정체를 제거하고, 안구의 나머지 부분(안배)은 30% 수크로오스로 4 에서 밤새 배양하였다. 그런 다음, 안배를 TISSUE-TEK® O.C.T. 화합물(VWR)에 포매시키고 드라이 아이스 상에서 급속 냉동시켰다. 면역형광 염색에 사용된 SUPERFROST® Plus 마이크로 슬라이드 상에서 10 μ의 냉동 절편을 제조하였다. 슬라이드 상의 절편을 액체 차단제(Liquid Blocker)인 Super Pap Pen(Electron Microscopy Sciences)으로 둘러싼 뒤 실온에서 30분 동안 공기 건조시켰다. 1xPBS 중의 5% 정상 염소 혈청(VectorLabs), 1% 소 혈청 알부민(Sigma-Aldrich), 및 0.3% Triton-X 100(Sigma-Aldrich)으로 차단 용액(blocking solution)을 제조하였다. 1xPBS 중의 0.1% Tween 20(Amresco)으로 세척액을 제조하였다. 검정색 뚜껑이 달린 염색 용기에 슬라이드를 넣고, 1xPBS로 3회 세척하여 O.C.T 화합물을 제거하였다. 차단 용액을 슬라이드에 첨가하고 실온에서 1시간 동안 놓아두었다. 차단 용액을 제거한 후, 1차 항체를 차단 용액 중에서 희석하고 4
에서 밤새 배양하였다. 그런 다음, 안배를 TISSUE-TEK® O.C.T. 화합물(VWR)에 포매시키고 드라이 아이스 상에서 급속 냉동시켰다. 면역형광 염색에 사용된 SUPERFROST® Plus 마이크로 슬라이드 상에서 10 μ의 냉동 절편을 제조하였다. 슬라이드 상의 절편을 액체 차단제(Liquid Blocker)인 Super Pap Pen(Electron Microscopy Sciences)으로 둘러싼 뒤 실온에서 30분 동안 공기 건조시켰다. 1xPBS 중의 5% 정상 염소 혈청(VectorLabs), 1% 소 혈청 알부민(Sigma-Aldrich), 및 0.3% Triton-X 100(Sigma-Aldrich)으로 차단 용액(blocking solution)을 제조하였다. 1xPBS 중의 0.1% Tween 20(Amresco)으로 세척액을 제조하였다. 검정색 뚜껑이 달린 염색 용기에 슬라이드를 넣고, 1xPBS로 3회 세척하여 O.C.T 화합물을 제거하였다. 차단 용액을 슬라이드에 첨가하고 실온에서 1시간 동안 놓아두었다. 차단 용액을 제거한 후, 1차 항체를 차단 용액 중에서 희석하고 4 에서 밤새 절편에 도포하였다. 2일차에, 세척액으로 슬라이드를 3회 세척하였다. 형광단이 접합된(fluorophore-conjugated) 2차 항체들을 1xPBS 중에서 1:1000으로 희석하고, (광퇴색을 방지하기 위해 암소에서) 실온에서 1시간 동안 절편에 도포하였다. 슬라이드를 1xPBS로 3회 세척하고 ProLong Gold Antifade Mountant with DAPI (ThermoFisher Sci.)로 커버 슬립을 덮었다.
에서 밤새 절편에 도포하였다. 2일차에, 세척액으로 슬라이드를 3회 세척하였다. 형광단이 접합된(fluorophore-conjugated) 2차 항체들을 1xPBS 중에서 1:1000으로 희석하고, (광퇴색을 방지하기 위해 암소에서) 실온에서 1시간 동안 절편에 도포하였다. 슬라이드를 1xPBS로 3회 세척하고 ProLong Gold Antifade Mountant with DAPI (ThermoFisher Sci.)로 커버 슬립을 덮었다.
ELISA. 요약하자면, 절개 현미경 아래에서 마우스 망막을 단리하고, Omini 균질화기가 구비된 금속 비드 튜브 내에서 칵테일 프로테아제 억제제를 사용하여 망막당 100 μl의 RIPA 완충액 중에서 균질화시켰다. 단백질 농도를 BCA 키트로 결정한 다음, 사용할 때까지 -80 에서 보관하였다(ELISA, 웨스턴 블롯). ELISA 플레이트(NUNC)를 RS1 표준 단백질(Novus Biologicals, 0~40 ng/ml) 및 총 망막 단백질 샘플(PBS 중 1:2000 희석물)로 4
에서 보관하였다(ELISA, 웨스턴 블롯). ELISA 플레이트(NUNC)를 RS1 표준 단백질(Novus Biologicals, 0~40 ng/ml) 및 총 망막 단백질 샘플(PBS 중 1:2000 희석물)로 4 에서 밤새 3회 코팅하였다. T-TBS 용액(T-TBS 완충액, TBS 용액 중 0.05% Tween20)으로 플레이트를 3회 세척한 후, 차단 완충액(1% BSA, TBS 중 5% 염소 혈청)으로 실온에서 1시간 동안 차단하였다. 3회 세척한 후, 항RS1 다클론 항체(Novus Biologicals USA, 차단 완충액 중 1:4000)를 플레이트에 첨가하고, 실온에서 2시간 동안 배양한 다음, 비오틴-접합 염소 항마우스 항체(Jackson Lab, 1:5000) 및 Strepavidin-HRP(Thermo, 1:200)를 첨가하고, 빛이 없는 상태에서 기질 작용액(R&D systems)을 마지막으로 첨가하였다. 2N Hcl에 의해 반응을 중단시켰다. SpectrAmax Plus 시스템(Molecular Devices)을 사용해 광학 밀도(OD)를 기록하였다.
에서 밤새 3회 코팅하였다. T-TBS 용액(T-TBS 완충액, TBS 용액 중 0.05% Tween20)으로 플레이트를 3회 세척한 후, 차단 완충액(1% BSA, TBS 중 5% 염소 혈청)으로 실온에서 1시간 동안 차단하였다. 3회 세척한 후, 항RS1 다클론 항체(Novus Biologicals USA, 차단 완충액 중 1:4000)를 플레이트에 첨가하고, 실온에서 2시간 동안 배양한 다음, 비오틴-접합 염소 항마우스 항체(Jackson Lab, 1:5000) 및 Strepavidin-HRP(Thermo, 1:200)를 첨가하고, 빛이 없는 상태에서 기질 작용액(R&D systems)을 마지막으로 첨가하였다. 2N Hcl에 의해 반응을 중단시켰다. SpectrAmax Plus 시스템(Molecular Devices)을 사용해 광학 밀도(OD)를 기록하였다.
웨스턴 블롯. 단백질 분리를 위해 4% SDS를 함유하는 샘플 완충액(Nupage LDS 샘플 버퍼, Thermo) 중에서 4~12% 비스-트리스 겔 상에 10~20 μg의 총 망막 단백질을 첨가한 다음, 니트로셀룰로오스 막(0.45 μm 기공 크기, Invitrogen)으로 옮기고, 이어서 SuperBlock T20(TBS, Thermo)로 1시간 동안 실온에서 차단하였다. 블롯(blot)을 항RS1 항체(Novus Biologicals USA, 1:4000)와 함께 실온에서 2시간 동안, 또는 4 에서 밤새 배양하였다. 항RS1 항체와 함께 배양한 후, HRP 접합된 항마우스 다클론 항체(Cell Signaling)를 실온에서 1시간 동안 1:5000으로 첨가하였다. SuperSignal West Pico chemiluminescence(Thermo)를 사용하여 C-Dogit Blot 스캐너(Li-Cor)에 의해 단백질 밴드(protein band)를 가시화시키고 영상을 촬영하였다.
에서 밤새 배양하였다. 항RS1 항체와 함께 배양한 후, HRP 접합된 항마우스 다클론 항체(Cell Signaling)를 실온에서 1시간 동안 1:5000으로 첨가하였다. SuperSignal West Pico chemiluminescence(Thermo)를 사용하여 C-Dogit Blot 스캐너(Li-Cor)에 의해 단백질 밴드(protein band)를 가시화시키고 영상을 촬영하였다.
조직학. 요약하자면, 동물에게 CO2를 흡입시켜 안락사시켰다. 안구를 적출하여 Davidson 고정제(Electron Microscopy Sciences)로 1시간 동안 실온에서 고정시키고, Tissue Processing Embedding Cassettes(Electron Microscopy Sciences)에 옮겨서 실온에서 5분 동안 수돗물로 세척하였다. 인산 완충액(Electron Microscopy Sciences) 중의 10% 중성 완충 포르말린(Neutral Buffered Formalin)으로 카세트를 고정하였다. 포매를 위해 에탄올의 연속 희석, 3회의 크실렌 교환 및 2회의 파라핀 교환을 통해 안구를 처리하였다. 5 μ의 파라핀 절편을 SUPERFROST® Plus 마이크로 슬라이드(VWR) 상에서 제조하고, 제조업체의 사양(Hematoxylin and Eosin (H&E) Staining (Regressive) Ricca Chemical Company)에 따라 헤마톡실린 및 에오신으로 염색하였다. 수컷 마우스로부터의 대표적인 결과는 도 13a~13b에 제시되어 있다.
종합하면, 본 실시예는 X-염색체 관련 망막층간분리증과 관련된 질환 표현형의 전형적인 병리학적 특징이 실시예 1에 따라 만들어진 조작된 Rs1 설치류 계통에서 반복되었음을 입증한다. 따라서, 이러한 조작된 설치류 계통은 치료제(예: 실험적 유전자 요법)의 평가 및 개발에 유용하다.
실시예 3. 조작된 Rs1 설치류 계통의 기능적 및 형태학적 분석
본 실시예는 실시예 1에 따라 만들어진 조작된 Rs1 설치류 계통의 망막 표현형의 특성 분석을 기술한다. 특히, 실시예 1에서 만들어진 널 및 돌연변이체 Rs1 설치류 계통에서의 외망막 기능을 암-순응(DA-) 및 명-순응(LA-) 전장 망막전이도(ERG)에 의해 평가하였다. 망막 구조도 광 간섭 단층촬영(OCT)에 의해 평가하였다. 수컷 마우스로부터의 대표적인 결과가 도 13c 및 도 14a~14c에 제시되어 있으며; 암컷 동형접합성 KO(Rs1 -/- ) 및 이형접합성 KO(Rs1 -/+ ) 계통으로부터의 대표적인 결과는 도 13d 및 14d에 제시되어 있다.
광 간섭 단층촬영(OCT). 요약하자면, 생존 중 안과 검사(in-life ophthalmic examinations)를 지정된 시점에 히델베르그 스펙트랄리스 HRA + OCT 시스템(Heidelberg Engineering, 미국 매사추세츠주 프랭클린)을 사용해 수행하였다. 동물에게 케타민(120 mg/kg) 및 자일라진(5 mg/kg)을 복강내 투여하여 마취시켰다. 0.5% 트로피카마이드 안과용액(Tropicamide ophthalmic solution, Bausch & Lomb, 뉴욕 로체스터)을 사용해 동공을 확장시켰다. 중심부 및 선택된 사반부(일반적으로 비강 상측 및 관자 상측)로부터 적외선 안저 영상을 촬영한 다음, 망막 형태 평가를 위한 일련의 61개의 측방향 광학 스캔 영상을 획득하였다.
망막전이도검사(ERG). 요약하자면, 동물을 밤새 암-순응시키고 마취시킨 뒤(케타민: 80 mg/kg; 자일라진: 16 mg/kg), 점안액(1% 트로피카마이드; 2.5% 페닐레프린 HCl)을 사용해 동공을 확장시키고, 점안액(1% 프로파라카인 HCl)을 사용해 각막 표면을 마취시켰다. 바늘 전극을 기준(뺨) 및 접지(꼬리)로서 사용하였고, 1% 카르복시메틸셀룰로오스로 습윤된 스테인리스 스틸 전극을 사용하여 ERG를 기록하였다. 스트로브 플래시 자극을 암-순응 안구에 적용하고, 적어도 5분의 명 순응(light adaptation) 후에 정상 적응 필드(20 cd/m2)를 중첩시켰다. 자극 범위는 -3.6 내지 2.1 log cd s/m2이었다. 반응을 증폭시키고(0.03~1000 Hz) LKC(Gaithersburg, 메릴랜드주)의 UTAS E-3000 신호 평균화 시스템을 사용하여 저장하였다. 예비-자극 베이스라인으로부터 플래시 발생 후 8 ms에 a-파의 진폭을 측정한 반면, b-파 진폭은 a-파 저점에서 b-파 피크까지 측정하였다.
종합하자면, 본 실시예는 본원에 기술된 조작된 Rs1 설치류 계통에서 나타난 표현형이 X-염색체 관련 망막층간분리증 환자에서 관찰된 것을 복제한다는 것을 입증한다. 또한, 이러한 표현형에서의 변동성은 유전자 돌연변이의 성질과 상관된다. 본 명세서는 망막층간분리증의 비인간 동물 모델을 생성하는 것을 구체적으로 보여준다. 내망막 내 낭포 구조의 발생 및 ERG b- 및 a-파 반응의 특징적 감소 후 광수용기 세포의 상실을 포함하는 X-염색체 관련 망막층간분리증과 전형적으로 관련된 병리학적 및 기능적 특징이 본원에 기술된 3개의 조작된 Rs1 설치류 계통 모두에서 반복되었다. 이러한 조작된 계통은 망막 구조의 세포 해체의 근간이 되는 분자 메커니즘을 더 이해하는 데 유용하며, X-염색체 관련 유아기 망막층간분리증의 치료를 위한 유전자 요법의 개발에 적합한 생체 내 시스템을 제공한다.
실시예 4.
Rs1
KO 마우스에서 망막의 조기 발병성 표현형.
본 실시예는 실시예 1에 기술된 Rs1 녹아웃(KO) 마우스에서 망막의 조기 발병성 기능적 및 형태적 표현형을 조사하기 위해 수행된 실험을 기술한다.
Rs1 KO 마우스 및 야생형(WT) 한 배 새끼의 망막을 출생 후 15~24일 사이에 3일 간격으로 (P15, P18, P21 및 P24) 검사하였다(도 15). 외망막의 기능은 암-순응(DA-) 및 명-순응(LA-) 전장 ERG에 의해 평가하였다. ERG a-파 및 b-파 진폭을 Naka-Rushton 등식으로 분석하여, 최대 반응(R max ) 및 감도(K) 파라미터를 산출했다. 망막 구조도 광 간섭 단층촬영(OCT)에 의해 평가하였다.
수컷 마우스로부터의 결과는 도 16a 내지 19c에 도시되어 있다. 암-순응 및 명-순응 ERG로 평가한 외망막의 기능은 모든 시점에서 a-파에 비해 b-파가 상대적으로 감소하였음을 나타냈으며, 망막층간분리증 표현형은 관찰 시간 과정 전체에 걸쳐(P15~P24) 존재하였다. Rs1 KO 망막은 또한 광수용기의 조기 손상을 나타냈는데, 구체적으로는, a-파 진폭의 감소, EZ의 확장, 및 더 얇아진 외망막(ONL+PRL)을 나타냈다. Rs1 KO 망막에서, b-파의 변화는 진폭 및 민감도 모두에서 a-파보다 컸으며, 이는 Rs1 결실이 시냅스에 조기에 영향을 미쳤음을 나타낸다.
이러한 관찰은 망막층간 단백질이 초기 망막 발달 중에 중요한 역할을 한다는 것을 나타낸다.
SEQUENCE LISTING
<110> Regeneron Pharmaceuticals, Inc.
<120> NON-HUMAN ANIMAL MODELS OF RETINOSCHISIS
<130> 35518 (10328WO01)
<150> 62/463,872
<151> 2017-02-27
<150> 62/576,256
<151> 2017-10-24
<160> 59
<170> PatentIn version 3.5
<210> 1
<211> 5855
<212> DNA
<213> Mus musculus
<400> 1
aacaatacct ccccagactg cttgttgagg caggggacta tgtggcttaa ttggatgggg 60
gctgagtgaa agacctaaga actaaatgaa ataagatgct taagttaatc gcctgctcct 120
atgccagctc tccacttcac ttagatcttg ctgtgaccaa ggacaaggag aaaatgccac 180
acaagattga aggcttcttc ttgttacttc tctttggcta tgaagccaca ttgggattgt 240
catcgacaga ggatgagggt gaggacccct ggtaccagaa agcatgcaag tgtgattgcc 300
aggtaggagc caatgctctg tggtctgctg gagctacctc cttagactgt attccagaat 360
gcccatatca caagcccctg ggtttcgagt caggggaggt cacgccagat cagatcactt 420
gctccaaccc agagcagtat gtgggctggt attcctcatg gacagcaaac aaggcccgac 480
tcaacagtca aggttttggg tgtgcttggc tttccaagta tcaggacagc agccagtggt 540
tacagataga tttgaaggag atcaaggtga tttcggggat cctgacccaa ggacgctgtg 600
acatagacga gtgggtgacc aagtacagtg tgcagtatag gactgatgag cgcctgaact 660
ggatctacta taaggatcag accggaaaca atcgggtctt ctatggaaac tcagaccgga 720
gttctacagt tcagaactta ctcaggcccc ccatcatttc ccgcttcatc cgactgatcc 780
ctctaggctg gcatgtccga attgccatcc ggatggagct gcttgagtgt gccagcaagt 840
gtgcctgatg tctatttcag ctcagttctg tcacttgcag ggagagcttt ggggggaggg 900
caccctgaaa taccactggg atgaatgggg ctatatctta taagcacttt acaatgtaga 960
tctgggtaga gaatatttca ctttttaaaa gatagtttca aatttcaaag ggagagagag 1020
agagagagag agagagagag agagagagag agaagctttt aagcttttct tcaactcagg 1080
gccaaagaaa ataagaacaa agaaagtatc tctcaaacca attttcttac acaaacccaa 1140
atagcagggg taatttgctg ctctggctcc ccatcttttt ctctttgtct cagtgacacc 1200
gtcaaaggtg caggcccagg ggaacacaaa gcagctctga taatttgaaa attctttttg 1260
gctcttagca cattcagaag aggagcgtac tctttggcaa agcctcacat gaacacttgc 1320
atgaaatcct cactatagag gcctggtgac aagtacatag gtgtgaagaa agcagaagga 1380
agcctggcgt atggcccacg agtctggagc cagtaaccaa ccaaccaact aaccaactaa 1440
ccaaccagtc aaggcttccc cctccctgga attgcttttg cctggaaggg gtggagctcc 1500
ttgtgcagaa actccattct acagcccttt tggcaatgtg tccttctgtg attgcctgga 1560
gatgaatgca aggggcaggc tatatgtgtg tgtggatagt gaggtttccc ttaaactgag 1620
gaagcccaaa taactagaat acatcacacc ttctttatcc atggctacag tttcccagaa 1680
attgaacagg cttagaaaac agctgagata aaccatatct ctatctactg ggaagagatc 1740
atgctttggg ggaaggggtt aggactccta tcatagagga ctgtacacag atgatctgtc 1800
agtaaagggc ttgctgtaca gcataggaac ttgagattat atttctagaa tgcatgtaaa 1860
aagctaggta tggacaggta tggtggaaca tgccattagt cttagtattt ggaagacaga 1920
ggcaagcaga tctgagttca gggccagcct ggtctacata gcagttccaa gctagccaag 1980
gctacacagt aaggccctgt ttcaagaaaa aaagaccagg catggagggg cacacctgca 2040
aatccaggac taggaggcag gcagagacag gatgatgcct agagcttgtc tgccaatcag 2100
tacactccag gttcatggtc agaccctgtc tcaaaactaa agtgaagagc tattgaggaa 2160
gataccagat gtcaacctct gtccaacatg cacacataca catacactgg taggtttcaa 2220
acctggggca aatggcagag gtgcctagtt aaggttctcc cagcatctct cagcccctac 2280
caggtcctcc tagttggcat accccgcccc ctaccccgaa actcttcagc ccagggggtt 2340
gggcttcttc cctatataat ccaactattt tggtcaccct ttctctttgt acctttgggc 2400
ctcctggttg ctgcatctgg ttcctctgtt ctcccttatc tcttttcctc cctcctctcc 2460
tcacaaggcc cagcttagag tgttcatgtc tattctggac tctctcccgg atgcccctgc 2520
ctctggctat gctctcccac atatctacca taaactctct cctctaccat acctaggaca 2580
agtcatgttc ctttcctttt cctttttgtt tcccattcaa acatgtaaat aggaaaaaca 2640
aaatacaaca acaacaaaca aaaataaaac cacaaaagcc ttctctccga gcggcttcct 2700
cccgtcctgc ccacccaaac atgcttactc agacatgaca tttgaaactt ctttcggtag 2760
tcattctctg gcaggaatag ctcatttaat caggagcttt ggagcctgag agaatgacta 2820
ctggtctcta gctcatttcc atctgtagct caagctgggt ttgaggctct tctctgggag 2880
aggctgttaa ctggagtgag ggtcaaaaag gcatgcgggg agaagctgag aatgagaact 2940
gcccagagac aaggtcttgg cctcacacac acacaataca gccttggtta gtacttttct 3000
ctgagctatt ttctatttcc aggtattaaa ggagattaca tggattcaca ccaaaataac 3060
tttggatggc cagacatggt atcttccatc tttaatccta gcactgggaa aacacagaca 3120
ggtggatctc tgtgagttca aggccaggtt tgcatagcaa gctccagacc agccaaggct 3180
atgtagtgag actgtctcaa aaatcaatcc atcaatcaaa tgatcttgga tgtcacattc 3240
ttctcagtga atagaacaac attttaatag catcaaattt cctacctagt attttggagt 3300
tccacaggtg tgtgtgtatg tgtggcaatg tacaacaata ttcctggtat gactacatat 3360
gtacaaattc attttggata atattcctga cagcagacct ttatttggaa aattgagtta 3420
cctttctcac cacactgagt aattgttaga gaaaaatggc aataacttaa gaatactgat 3480
cagggagaaa aaaacccaaa tggtacaagg catgggtaaa tagtcatcaa attaaaaaat 3540
catgccataa atttgttttc taatagtttc attaacttca cataaacagt cctaattcat 3600
ttaaggtgtg taattcaata tagtatattc aaacttgaac aatcatcact acaagtaact 3660
ttagactatt cttatcaccc ccaagagaat cctctaacaa tgggccatca gccaccacag 3720
ctctagatta ctcgtcatcc attttctatt tgtgtgtgga ttttttttcc attctgggca 3780
tttctccaca caaatggaat cttagaatat atagtagttt atgacttgtt tcttgtactt 3840
atcatagtgt ttttaaagtc catgtgttgg agaagtacat cctccttttt tgttattaac 3900
attctgtgta gggtattgta ttattattta tccatgcatt tgggtggggc tagtatgaat 3960
aatgctgctt catgaaaatt tatatgtaag ttattgcgtg gacatgtttt atcttgggca 4020
tactcacact gagaatagag aattgttggg tctcttggga actatttctc caggtggctg 4080
taccatcttc tgttcccacc agcaatgtct aatgcttcca gcctctcatc tttagcaatg 4140
cttcttgtat ttcattagat ctgtcctagt atgtatgaag tagcattcga tgatgaattt 4200
gatttgcatt tctctaataa ccaatgtttt ttgagcatct tttcaagtca ccagtgacat 4260
atttttggag aaagttctat tcagaccctt gcccatataa agatttcatt tcacggattc 4320
attaagagtt ctttgggtgt tctacataca attctcttat gcaaacattt cttccatcct 4380
gtttttcttc ttgtcattgt cttggtttag ttttgcacca ggatttcact atgtagctca 4440
ggctggcctg gaacttgcaa agatccttct gtctctgcct cccaggttct gagattctgg 4500
gtatttgcca ccacacctgg cctttctctg aagcacaaca aataccaaat tttaatgaag 4560
tccaaccttc cggtttcctt ttttggtgta ttatctgaga aactactgtc aaaccatggt 4620
caagaagatt cactcttgtg ttttcttcta aatgttttga aaaaaaattt ttaaaaagtt 4680
ttaaagtttt aactcttact ttgtgaacag ttataaagta agggtgtaat ttcattcttt 4740
ggatatcaat atgcagctgt cttggtagct tgtgttgtct tcaccacagt caatggtctt 4800
tattcttcca aaaacaactg accaagaata ttagagtata tgctaggcct cataattcta 4860
ttaccacata gtcttcatta ctgtagcatt gtagtgagtt gtggaattag gacatataaa 4920
tcttccaatt ctggttatgt ttcaagactg aactaactat tctgggttcc ttaaacttct 4980
aagtaagtat atctgtaaat aagccagcca ggggtctcac aatggaaaat gttttcaatt 5040
tcaaaattaa ataaacaatg agatattaag atctgcaaga tatttatctg tagttaattt 5100
tctttcaata gttaatgaaa atgttagcat tttcttcctt ttgtgttagg atatatatat 5160
aaaagaaacc ctattattaa agtaaacctg aaaaagaatc ttcctattaa acaaaaaata 5220
tgtttgcaat attatttctt ttagggggca actaattcaa taaagattat ataatggagg 5280
aaagtcattc ctatcttaac acattttgtt tatttttacc actagacttt gggttattaa 5340
ggattttatt ttttatggtt ttgaggacat aacccaggtt tttcatacat ggtaggcaaa 5400
tactcttcaa ttgagttctc tctgcagcct gcagatcaaa acaaaacaaa acattatggt 5460
aaagcataac aatttacata cttttagtta actgtgaagc attaaataat gatattaaga 5520
aaaaaatgga agtaatcctg gtagttgatg tgggaggtta tatagtgtgg tggtttggat 5580
atgcttggcc tattaggagg tgtggctttg ttggagtagg tgtggccttg ttggaagaag 5640
tacatcattg tgggagtggg ctttgacacc ctcctcctcg ctgcccgaaa gacagtattc 5700
tggctacctt tggatcaaga tatagaactc ttggctcctt ctccagcacc atgtctgcct 5760
gcatgctgtt ggctaggatg ataattgact aaacatctga aactgtaagc cagccccaat 5820
taaatgttgt ctttctaaga aaaaaaaaaa aaaaa 5855
<210> 2
<211> 224
<212> PRT
<213> Mus musculus
<400> 2
Met Pro His Lys Ile Glu Gly Phe Phe Leu Leu Leu Leu Phe Gly Tyr
1 5 10 15
Glu Ala Thr Leu Gly Leu Ser Ser Thr Glu Asp Glu Gly Glu Asp Pro
20 25 30
Trp Tyr Gln Lys Ala Cys Lys Cys Asp Cys Gln Val Gly Ala Asn Ala
35 40 45
Leu Trp Ser Ala Gly Ala Thr Ser Leu Asp Cys Ile Pro Glu Cys Pro
50 55 60
Tyr His Lys Pro Leu Gly Phe Glu Ser Gly Glu Val Thr Pro Asp Gln
65 70 75 80
Ile Thr Cys Ser Asn Pro Glu Gln Tyr Val Gly Trp Tyr Ser Ser Trp
85 90 95
Thr Ala Asn Lys Ala Arg Leu Asn Ser Gln Gly Phe Gly Cys Ala Trp
100 105 110
Leu Ser Lys Tyr Gln Asp Ser Ser Gln Trp Leu Gln Ile Asp Leu Lys
115 120 125
Glu Ile Lys Val Ile Ser Gly Ile Leu Thr Gln Gly Arg Cys Asp Ile
130 135 140
Asp Glu Trp Val Thr Lys Tyr Ser Val Gln Tyr Arg Thr Asp Glu Arg
145 150 155 160
Leu Asn Trp Ile Tyr Tyr Lys Asp Gln Thr Gly Asn Asn Arg Val Phe
165 170 175
Tyr Gly Asn Ser Asp Arg Ser Ser Thr Val Gln Asn Leu Leu Arg Pro
180 185 190
Pro Ile Ile Ser Arg Phe Ile Arg Leu Ile Pro Leu Gly Trp His Val
195 200 205
Arg Ile Ala Ile Arg Met Glu Leu Leu Glu Cys Ala Ser Lys Cys Ala
210 215 220
<210> 3
<211> 675
<212> DNA
<213> Rattus norvegicus
<400> 3
atgccacaca agattgaagg cttcttctta ttgcttctct ttggctatga agccacattg 60
ggattgtctt cgacagagga tgagggtgag gacccttggt accagaaagc gtgcaagtgt 120
gattgccagg gaggagccaa tgctctgtgg tctgctggag ccgcctcctt agactgtatt 180
ccagaatgcc catatcacaa gcccctgggt ttcgagtcag gggaagtcac accagatcag 240
atcacttgct ccaacccaga gcagtatgtg ggctggtatt cctcatggac tgcaaacaag 300
gcccggctca acagtcaagg ttttgggtgt gcttggcttt ccaagtatca ggacagtagc 360
cagtggttac agatagattt gaaggagatc aaggtgattt cggggatcct tacccaagga 420
cgctgtgaca tagatgagtg gatgaccaag tacagtgtgc aatataggac tgatgaacgc 480
ctgaactgga tttactataa ggatcagact ggaaacaatc gggtcttcta tggaaactcc 540
gaccggagtt ctacagtcca gaacttactg aggcccccca ttatttcccg cttcatccga 600
ctgatccctc taggctggca tgtccgaatt gccatccgga tggagctgct tgagtgtgcc 660
agcaagtgtg cctga 675
<210> 4
<211> 224
<212> PRT
<213> Rattus norvegicus
<400> 4
Met Pro His Lys Ile Glu Gly Phe Phe Leu Leu Leu Leu Phe Gly Tyr
1 5 10 15
Glu Ala Thr Leu Gly Leu Ser Ser Thr Glu Asp Glu Gly Glu Asp Pro
20 25 30
Trp Tyr Gln Lys Ala Cys Lys Cys Asp Cys Gln Gly Gly Ala Asn Ala
35 40 45
Leu Trp Ser Ala Gly Ala Ala Ser Leu Asp Cys Ile Pro Glu Cys Pro
50 55 60
Tyr His Lys Pro Leu Gly Phe Glu Ser Gly Glu Val Thr Pro Asp Gln
65 70 75 80
Ile Thr Cys Ser Asn Pro Glu Gln Tyr Val Gly Trp Tyr Ser Ser Trp
85 90 95
Thr Ala Asn Lys Ala Arg Leu Asn Ser Gln Gly Phe Gly Cys Ala Trp
100 105 110
Leu Ser Lys Tyr Gln Asp Ser Ser Gln Trp Leu Gln Ile Asp Leu Lys
115 120 125
Glu Ile Lys Val Ile Ser Gly Ile Leu Thr Gln Gly Arg Cys Asp Ile
130 135 140
Asp Glu Trp Met Thr Lys Tyr Ser Val Gln Tyr Arg Thr Asp Glu Arg
145 150 155 160
Leu Asn Trp Ile Tyr Tyr Lys Asp Gln Thr Gly Asn Asn Arg Val Phe
165 170 175
Tyr Gly Asn Ser Asp Arg Ser Ser Thr Val Gln Asn Leu Leu Arg Pro
180 185 190
Pro Ile Ile Ser Arg Phe Ile Arg Leu Ile Pro Leu Gly Trp His Val
195 200 205
Arg Ile Ala Ile Arg Met Glu Leu Leu Glu Cys Ala Ser Lys Cys Ala
210 215 220
<210> 5
<211> 994
<212> DNA
<213> Macaca mulatta
<400> 5
cagttcagta aggtagagct tcggccgagg acgaggggaa gatgtcacgc aagatagaag 60
gctttttgct attacttctc tttggctatg aagccacatt gggattatcg tctaccgagg 120
atgaaggcga ggacccctgg taccaaaaag catgcaagtg tgattgccaa ggaggaccca 180
atgctctgtg gtctgcaggt gccacctcct tggactgcat accagaatgc ccatatcaca 240
agcccctggg tttcgagtca ggggaggtca caccagacca gatcacctgc tctaacccgg 300
agcagtatgt gggctggtat tcctcgtgga ctgcaaacaa ggcccggctc aacagtcaag 360
gctttgggtg cgcctggctc tccaagttcc aggacagtag ccagtggtta cagatagatc 420
tgaaggagat caaggtgatt tcagggatcc ttacccaggg gcgctgtgac atcgatgagt 480
ggatgaccaa gtacagcgtg cagtacagga ccgatgagcg cctgaactgg atttactata 540
aggaccagac tggaaataac cgggtcttct atggcaactc ggaccgcacc tccacggttc 600
agaacctgct gcggcccccc atcatctccc gcttcattcg cctcatcccg ctgggctggc 660
acgtccgcat tgccatccgg atggagctgc tggagtgcgt cagcaagtgt gcctgatgcc 720
tgcctcagct tggcgcctgc tggggggtga ccggcgcaga gcggggccgt aggggacccc 780
ctcacatacc actgggatgg acagggctat atttcgcaaa gcaaatttta actgcagtgc 840
tgggtagata cttttttttt tttttttttt aagatatagc tttctgattt caatgaaata 900
aaaatgaact tattccccac tcagggccag agaaagtcag aacaaagaaa atgtcccgaa 960
aaccaatttt cttacaaaag cctaagcagc aggg 994
<210> 6
<211> 224
<212> PRT
<213> Macaca mulatta
<400> 6
Met Ser Arg Lys Ile Glu Gly Phe Leu Leu Leu Leu Leu Phe Gly Tyr
1 5 10 15
Glu Ala Thr Leu Gly Leu Ser Ser Thr Glu Asp Glu Gly Glu Asp Pro
20 25 30
Trp Tyr Gln Lys Ala Cys Lys Cys Asp Cys Gln Gly Gly Pro Asn Ala
35 40 45
Leu Trp Ser Ala Gly Ala Thr Ser Leu Asp Cys Ile Pro Glu Cys Pro
50 55 60
Tyr His Lys Pro Leu Gly Phe Glu Ser Gly Glu Val Thr Pro Asp Gln
65 70 75 80
Ile Thr Cys Ser Asn Pro Glu Gln Tyr Val Gly Trp Tyr Ser Ser Trp
85 90 95
Thr Ala Asn Lys Ala Arg Leu Asn Ser Gln Gly Phe Gly Cys Ala Trp
100 105 110
Leu Ser Lys Phe Gln Asp Ser Ser Gln Trp Leu Gln Ile Asp Leu Lys
115 120 125
Glu Ile Lys Val Ile Ser Gly Ile Leu Thr Gln Gly Arg Cys Asp Ile
130 135 140
Asp Glu Trp Met Thr Lys Tyr Ser Val Gln Tyr Arg Thr Asp Glu Arg
145 150 155 160
Leu Asn Trp Ile Tyr Tyr Lys Asp Gln Thr Gly Asn Asn Arg Val Phe
165 170 175
Tyr Gly Asn Ser Asp Arg Thr Ser Thr Val Gln Asn Leu Leu Arg Pro
180 185 190
Pro Ile Ile Ser Arg Phe Ile Arg Leu Ile Pro Leu Gly Trp His Val
195 200 205
Arg Ile Ala Ile Arg Met Glu Leu Leu Glu Cys Val Ser Lys Cys Ala
210 215 220
<210> 7
<211> 3039
<212> DNA
<213> Homo sapiens
<400> 7
agtaaggtag agctttggcc gaggacgagg ggaagatgtc acgcaagata gaaggctttt 60
tgttattact tctctttggc tatgaagcca cattgggatt atcgtctacc gaggatgaag 120
gcgaggaccc ctggtaccaa aaagcatgca agtgcgattg ccaaggagga cccaatgctc 180
tgtggtctgc aggtgccacc tccttggact gtataccaga atgcccatat cacaagcctc 240
tgggtttcga gtcaggggag gtcacaccgg accagatcac ctgctctaac ccggagcagt 300
atgtgggctg gtattcttcg tggactgcaa acaaggcccg gctcaacagt caaggctttg 360
ggtgtgcctg gctctccaag ttccaggaca gtagccagtg gttacagata gatctgaagg 420
agatcaaagt gatttcaggg atcctcaccc aggggcgctg tgacatcgat gagtggatga 480
ccaagtacag cgtgcagtac aggaccgatg agcgcctgaa ctggatttac tacaaggacc 540
agactggaaa caaccgggtc ttctatggca actcggaccg cacctccacg gttcagaacc 600
tgctgcggcc ccccatcatc tcccgcttca tccgcctcat cccgctgggc tggcacgtcc 660
gcattgccat ccggatggag ctgctggagt gcgtcagcaa gtgtgcctga tgcctgcctc 720
agctcggcgc ctgccagggg gtgactggca cagagcgggc cgtaggggac cccctcacac 780
accaccgaga tggacagggc tatatttcgc aaagcaattg taactgcagt gctgggtaga 840
taattttttt ttttttaaga tatagctttc tgatttcaat gaaataaaaa tgaacttatt 900
ccccactcag ggccagagaa agtcagaaca aagaaaatgt ccccgaaacg aattttctta 960
caaaagccta agtagcaggg gtaattttct gctcattttt tgtctcagtg atactgtgaa 1020
aggtgcagtc tcaggggaac acaaagcagc cctgataatt tgaaaattca tttgctttac 1080
cacattcaag acagaaacat acagtttcct aaagcctggc tttgaatgca gaagggagca 1140
gctcctccta gttaagtttc cactaaatca tcgccaaaga ggacttcaga gccctgggga 1200
ggcagctgag ggtctcaagg gtgactgggt ggcagggatg agtgcggtgg gtgagaatcc 1260
cggtgccctg agaggctata cgtgacaaat gaccaaaagc ccaaggtagg ggagtttcct 1320
ctgctcacag ttcttacctt caaggcggat ctgggcttcc accctcatga acacagggat 1380
tggggaggga ccagagcgcc caatacacac agctccatta tgcaatccat tccagcaaat 1440
tccccgtgtc tgtggtcacc atttaggtga tcatacagga caggctgcac atctcagtat 1500
atgtagggac cccaaatgac cacaacacag tacaattgcc ctttacctag ggctaccatt 1560
tcctagcaaa ccaaacatag ttcgagaaca gctggcccag gagctaccac tggctactca 1620
gaggaggctc attagctggc tacatgcttc gcaggaagtg ggaaggactc acatcataaa 1680
aaggaccatg tagctttttc cctgaaagct tctcaccctc caccctctgc cttgcaatac 1740
gcaaactgcg cctgctcctg aaaagctctc tgggaaggaa tgggcctggc tttccgttcc 1800
tggaggcggc gccttagatt gggaggcctc attggccact tagagcgcag cctgagtttc 1860
caggcccctt cctgggagag gctgttaaca cgggggaggg gcaggagagg gatatggaga 1920
gcaggtggtg gaatcagagg acgaggctgc tctaaagact gttctggccc cagacacagg 1980
gtagtctttg ctagcagctc atttccgagt tacttttcat tttcaaatgc caaggcaagt 2040
gactagactc gcgctaatac agtgctggac aacacattca ccttttctgt gaacaggcag 2100
ccttctaaaa gccccaaaca tccttcttga tgctttgggg gctcaattat tttatatcca 2160
acccagcatc tttctagtcc ctatgctgta tgcttgaact cggaaaatgc ttttccccgc 2220
ccaatcttct ctcaaatata aacacatcac acagggtgtt gggggtgggg ggggggggtg 2280
gggggactta tccctggcct taggacacag gacaaatcta ttttggatag aaatgcctga 2340
acagagaccc ttatttggaa aggtgaatta actttggtca cgacatggac tgtcagacaa 2400
aatggcagta tcctaagagt taaggcacat caaacacagg agtcgagaga gtgcagttca 2460
gggaaaaagg agaggaggaa acagtgaggc agggagaaag gctttccaaa taagagttca 2520
tgttggaaac ttttgtcacg gctttattga gattaagttc acatacaatt tgtatccatt 2580
taaagtgtac aatttgatga cttttggtat attcagagtt gtgcaaccat tatcactaga 2640
tcaattttag aaagtttatc accccaaaga gaaatcctgc acccatcagc caacactccc 2700
caacccatcg gccaccccaa gccctctgca accacgaatc gactgtctct gtagattggc 2760
cttctggacg ttctacataa atgaaatcat atagtatgtg gtatttcgtg actggcttct 2820
ttcacttagc atagtgtttt aaagttcatc cacgttataa catgtgtatc actatgtcac 2880
ttgtcactcc tttttattgc tgaacatcat tgttcagtat catgtcaaga gcacattgtt 2940
atttatccat tcatccattg atggatattt gggtttccac tctttagcta ttatgaataa 3000
tgctgctatg aacatttgtg tataaaaaaa aaaaaaaaa 3039
<210> 8
<211> 224
<212> PRT
<213> Homo sapiens
<400> 8
Met Ser Arg Lys Ile Glu Gly Phe Leu Leu Leu Leu Leu Phe Gly Tyr
1 5 10 15
Glu Ala Thr Leu Gly Leu Ser Ser Thr Glu Asp Glu Gly Glu Asp Pro
20 25 30
Trp Tyr Gln Lys Ala Cys Lys Cys Asp Cys Gln Gly Gly Pro Asn Ala
35 40 45
Leu Trp Ser Ala Gly Ala Thr Ser Leu Asp Cys Ile Pro Glu Cys Pro
50 55 60
Tyr His Lys Pro Leu Gly Phe Glu Ser Gly Glu Val Thr Pro Asp Gln
65 70 75 80
Ile Thr Cys Ser Asn Pro Glu Gln Tyr Val Gly Trp Tyr Ser Ser Trp
85 90 95
Thr Ala Asn Lys Ala Arg Leu Asn Ser Gln Gly Phe Gly Cys Ala Trp
100 105 110
Leu Ser Lys Phe Gln Asp Ser Ser Gln Trp Leu Gln Ile Asp Leu Lys
115 120 125
Glu Ile Lys Val Ile Ser Gly Ile Leu Thr Gln Gly Arg Cys Asp Ile
130 135 140
Asp Glu Trp Met Thr Lys Tyr Ser Val Gln Tyr Arg Thr Asp Glu Arg
145 150 155 160
Leu Asn Trp Ile Tyr Tyr Lys Asp Gln Thr Gly Asn Asn Arg Val Phe
165 170 175
Tyr Gly Asn Ser Asp Arg Thr Ser Thr Val Gln Asn Leu Leu Arg Pro
180 185 190
Pro Ile Ile Ser Arg Phe Ile Arg Leu Ile Pro Leu Gly Trp His Val
195 200 205
Arg Ile Ala Ile Arg Met Glu Leu Leu Glu Cys Val Ser Lys Cys Ala
210 215 220
<210> 9
<211> 2061
<212> DNA
<213> Canis lupus
<400> 9
aatgaggcca gcgctcaagt taagcccctg ctcctggaga agctctccac ttggataagg 60
tagagctgcg gccaaggaca aggggagaat gccccgcaag atagaaggct tcttgttttt 120
acttctcttc ggctatgaag ccacactggg attatcgtct actgaggatg agagtgagga 180
cccctggtac cagaaagcat gcaaatgtga ctgccaaggc agtcccaatg gcctctggtc 240
ggctggtgcc acctccttag attgcatacc agaatgcccg tatcataagc ccctgggttt 300
cgagtcagga gaggttacac cagaccagat cacttgctcc aacctggatc agtatgtggg 360
ctggtattcc tcatggacag ctaacaaggc ccggctcaac agtcaaggct ttgggtgcgc 420
ctggctctcc aagtaccagg acagcagcca gtggttacag atcgatctga aggaggtcaa 480
ggtgatttca ggaatcctca cccaggggcg ctgtgacatc gacgagtgga tgaccaagta 540
cagcgtgcag tacaggacgg atgagaacct gaactggatt tactataagg accagacagg 600
aaacaatcgg gtcttctatg gaaattcaga ccgaacctcc acagtccaga accttctgcg 660
gccccccatc atttcccgct tcattcggct gatcccgctg ggctggcatg tccgcattgc 720
catccggatg gagctgctgg aatgcgtcag caagtgtgcc tgaggcctcc ttcagctcca 780
cacctgccct ggggtggggg tggggggtag ataggggtgg agggctcaga gcagcctgca 840
ggggaaccct gacagggttc caacagggtg acaaacgcag ctgtatttta caagctcttt 900
tcaatgcaga gcctggcaga aataatttct ttaaaaaaac aagtttccca tttcaatcaa 960
agagaaagga aaacgagcgt atttcccact cactgccaaa gaaaataaga acaaagaaaa 1020
cgtccctaaa actagttttc atctaaaagc ctaagtagca ggggtaattt tgctgctttt 1080
tctttttggt tttggtctga cagtgtgaaa ggtgtggtcc cagggaacac aaaagagccc 1140
agataattta aaaactcttt tgctttacca cactaaaaac aggaacatag aggtttttct 1200
tttcttttct tttcttttct tttcttttct tttcttttct tttcttttct tttcttttct 1260
tttctttccg gaacacagag tttcataaaa ccttgatttg attgcaaatg gggagcaagc 1320
ttgcggtttc tccttttaag ttttcagtga atcatggcct tttaggactt ttagagcacc 1380
cggcatgcag ggggcaaggt tttgggtgac tggttgtcag agatgagtag agcagttggg 1440
agcctgtgtc ctggtgtcct gagagctgtg cacaaccaat ccccccaggt aagagggctt 1500
cctctgctct gagctttcac ccccacgcac acaaggatag ggagggggtg gttgcagagc 1560
tctcattaca tacagatcta ttctagcaaa tttttccagc ctgtggtcac tatctgggtg 1620
aatacatggg acaggctgca catgtaagca gcagttctct atatttagga aagccaaatg 1680
accagagctc accagaattt ccccttatct agggctacca tttttcaaca agcttaacat 1740
tttaaaaaca gctggcccag gagctatcac tggctacaca gaggaagccc attagctaac 1800
tgcatgcttt gcaggaagtg gtcagaccct atgtcctaag aagggccatg tggctgtgtc 1860
tctcacgacc caactgttta acctctcccc cttgccctag aacacacaac catgcctact 1920
cctgaggctg aaatggcctt gggagggacg gggctaggaa tgggcctggc cttccgaggg 1980
gagtgcataa agcagggact tttcagggac cacagcctaa gcctcctctg tcatttatag 2040
ctcagcctga gttttcaggc t 2061
<210> 10
<211> 224
<212> PRT
<213> Canis lupus
<400> 10
Met Pro Arg Lys Ile Glu Gly Phe Leu Phe Leu Leu Leu Phe Gly Tyr
1 5 10 15
Glu Ala Thr Leu Gly Leu Ser Ser Thr Glu Asp Glu Ser Glu Asp Pro
20 25 30
Trp Tyr Gln Lys Ala Cys Lys Cys Asp Cys Gln Gly Ser Pro Asn Gly
35 40 45
Leu Trp Ser Ala Gly Ala Thr Ser Leu Asp Cys Ile Pro Glu Cys Pro
50 55 60
Tyr His Lys Pro Leu Gly Phe Glu Ser Gly Glu Val Thr Pro Asp Gln
65 70 75 80
Ile Thr Cys Ser Asn Leu Asp Gln Tyr Val Gly Trp Tyr Ser Ser Trp
85 90 95
Thr Ala Asn Lys Ala Arg Leu Asn Ser Gln Gly Phe Gly Cys Ala Trp
100 105 110
Leu Ser Lys Tyr Gln Asp Ser Ser Gln Trp Leu Gln Ile Asp Leu Lys
115 120 125
Glu Val Lys Val Ile Ser Gly Ile Leu Thr Gln Gly Arg Cys Asp Ile
130 135 140
Asp Glu Trp Met Thr Lys Tyr Ser Val Gln Tyr Arg Thr Asp Glu Asn
145 150 155 160
Leu Asn Trp Ile Tyr Tyr Lys Asp Gln Thr Gly Asn Asn Arg Val Phe
165 170 175
Tyr Gly Asn Ser Asp Arg Thr Ser Thr Val Gln Asn Leu Leu Arg Pro
180 185 190
Pro Ile Ile Ser Arg Phe Ile Arg Leu Ile Pro Leu Gly Trp His Val
195 200 205
Arg Ile Ala Ile Arg Met Glu Leu Leu Glu Cys Val Ser Lys Cys Ala
210 215 220
<210> 11
<211> 1772
<212> DNA
<213> Sus scrofa
<400> 11
ccgggtcttc tgattccagt ttctattttc ctccactgct tcccttacat ttaaagatag 60
aataaagcca gtagcttcct ttgctaaacc gacctcagtt gacatcggct tcttctcaga 120
gacttccttg ttgaggcagg taacgacgtg ggttaacttg tcggggctca gccaaagccc 180
taagagctaa atggaataag atgcttaatg aggccagtgc tcaagttaag ctcctgttcc 240
tagggaagct ctccacttcg ataaggaaga gcagcagcca aggacaaggg gagaatgcca 300
cgcaagatag aaggcttctt gtttttactt ctctttggct atgaagccac cctgggatta 360
tcgtctacgg aggatgaggg tgaggacccc tggtacaaca aagcgtgcaa gtgtgactgc 420
caaggaggcg ccaatgccct gtggtctgcg ggcaccaccc ccttagactg cataccggaa 480
tgcccgtatc ataagcccct ggggttcgag tcaggagagg ttacaccaga ccagattacc 540
tgctccaacc tggagcagta cgtgggctgg tattcctcgt ggactgccaa caaggcccgg 600
ctcaacagtc aaggctttgg gtgcgcctgg ctctccaagt tccaggacag cagccagtgg 660
ttacagatag atctgaagga ggtcaaggtg atttcaggga tcctcaccca gggccgctgt 720
gacatcgatg agtggatgac caagtacagc gtgcagtaca ggaccgatga gagcctgaac 780
tggatttact ataaggacca gactggaaac aaccgggttt tctatggaaa ctcagaccga 840
acctccacag tccagaacct gctacggccc cccatcattt cccgcttcat ccggctcatc 900
ccgctgggct ggcacgtgcg cattgccatc cggatggagt tgctggagtg cgtcagcaag 960
tgtacctgac ggggtgcccg ccagggtgcg cagggcacgg agcagccggg cgactgctga 1020
tctaccgctg tgaccaacaa ggctgtatct tacaggctct actcaatgca gagctgggca 1080
gagaagacat ctttctttct ttggttttct tcctttcttt ttttttaaat atagtttgca 1140
tttcaataaa caaaccgaat taaatcttca ctcagggcca aagaaaataa gaacaaagaa 1200
aatgtcccta aaaacaattt tcatgcaaaa gcaaagcagg agtaatttgc tgctctctgg 1260
agttttttgt tttcgctttt tttttttttt ttttttttga ttgtttgctt tttggtctca 1320
gtgacactgt gcaaggtgcc ctcccaggag aatgcaaagc agccctaata atctgaaaat 1380
tcttttgctt taccacattc aaaacaagaa cacagagttt cataaagcct cactttgaaa 1440
gcaaagaggg agcaagcttg tgggttctcc tagcttcgtt ttcattaaat catggccttt 1500
tagaacttga gagcactggg tatgcagggt aaaaggttct ggagtgacta ggagggtggg 1560
agcccatttt acggtcccct gagagccagg taggagggcc tcccctgctc agagtttcac 1620
ccccagtcag tgcaatttat cctagtctgt ggtcactact taggtgaata atggacaggc 1680
tgcacatgta tgtagccaag tctccctata tttaggaacc tcaaatgacc agaacacacc 1740
agaatttcct tttatctagg gtaaccattt aa 1772
<210> 12
<211> 224
<212> PRT
<213> Sus scrofa
<400> 12
Met Pro Arg Lys Ile Glu Gly Phe Leu Phe Leu Leu Leu Phe Gly Tyr
1 5 10 15
Glu Ala Thr Leu Gly Leu Ser Ser Thr Glu Asp Glu Gly Glu Asp Pro
20 25 30
Trp Tyr Asn Lys Ala Cys Lys Cys Asp Cys Gln Gly Gly Ala Asn Ala
35 40 45
Leu Trp Ser Ala Gly Thr Thr Pro Leu Asp Cys Ile Pro Glu Cys Pro
50 55 60
Tyr His Lys Pro Leu Gly Phe Glu Ser Gly Glu Val Thr Pro Asp Gln
65 70 75 80
Ile Thr Cys Ser Asn Leu Glu Gln Tyr Val Gly Trp Tyr Ser Ser Trp
85 90 95
Thr Ala Asn Lys Ala Arg Leu Asn Ser Gln Gly Phe Gly Cys Ala Trp
100 105 110
Leu Ser Lys Phe Gln Asp Ser Ser Gln Trp Leu Gln Ile Asp Leu Lys
115 120 125
Glu Val Lys Val Ile Ser Gly Ile Leu Thr Gln Gly Arg Cys Asp Ile
130 135 140
Asp Glu Trp Met Thr Lys Tyr Ser Val Gln Tyr Arg Thr Asp Glu Ser
145 150 155 160
Leu Asn Trp Ile Tyr Tyr Lys Asp Gln Thr Gly Asn Asn Arg Val Phe
165 170 175
Tyr Gly Asn Ser Asp Arg Thr Ser Thr Val Gln Asn Leu Leu Arg Pro
180 185 190
Pro Ile Ile Ser Arg Phe Ile Arg Leu Ile Pro Leu Gly Trp His Val
195 200 205
Arg Ile Ala Ile Arg Met Glu Leu Leu Glu Cys Val Ser Lys Cys Thr
210 215 220
<210> 13
<211> 899
<212> DNA
<213> Bos taurus
<400> 13
ctccactttg ataaggaaga gcagcagcca aggacaaggg gagaatgcca cgcaagatag 60
aaaacttctt gtttttactt ctcttcggct atgaagccac actgggatta tcatctactg 120
aggatgaggg tgaagatccc tggtaccaca aagcgtgcaa gtgcgattgc caaggaggtg 180
ccaatgccct gtggtctgca ggtcccaccc ccttggactg cataccggaa tgcccatacc 240
ataagcccct gggtttcgag tcaggagagg ttacaccaga ccagatcacc tgctccaacg 300
tggagcagta cgtgggctgg tattcttcct ggactgccaa caaggcccgg cttaacagtc 360
aaggctttgg gtgtgcctgg ctctccaagt tccaggacag cagccagtgg ttacagatag 420
atctgaagga ggtcaaggtg atttcgggga tcctcaccca ggggcgctgt gacatcgatg 480
agtggatgac caagtacagt gtgcagtaca ggaccgatga gagtctgaac tggatttact 540
ataaagacca gaccggaaac aaccgggttt tctatggaaa ttcggaccga acctccacag 600
tccagaacct gctgcggccc cccatcatct cccgcttcat ccggctcata ccgctaggct 660
ggcatgttcg cattgccatc cggatggagc tgctggagtg cgtcagcaag tgtacctgat 720
gttgcctcgg ctcatacctg cagtgggtga agggtgcaga gcggcccatg ggggaacgct 780
gacttatcac tgtgaccagc agggctggat tttacaggct cttttcagcg cagggctggg 840
cagagaatac tatctttttt gcatagtttc caatttcagt gagagaaaat gaaaatgaa 899
<210> 14
<211> 224
<212> PRT
<213> Bos taurus
<400> 14
Met Pro Arg Lys Ile Glu Asn Phe Leu Phe Leu Leu Leu Phe Gly Tyr
1 5 10 15
Glu Ala Thr Leu Gly Leu Ser Ser Thr Glu Asp Glu Gly Glu Asp Pro
20 25 30
Trp Tyr His Lys Ala Cys Lys Cys Asp Cys Gln Gly Gly Ala Asn Ala
35 40 45
Leu Trp Ser Ala Gly Pro Thr Pro Leu Asp Cys Ile Pro Glu Cys Pro
50 55 60
Tyr His Lys Pro Leu Gly Phe Glu Ser Gly Glu Val Thr Pro Asp Gln
65 70 75 80
Ile Thr Cys Ser Asn Val Glu Gln Tyr Val Gly Trp Tyr Ser Ser Trp
85 90 95
Thr Ala Asn Lys Ala Arg Leu Asn Ser Gln Gly Phe Gly Cys Ala Trp
100 105 110
Leu Ser Lys Phe Gln Asp Ser Ser Gln Trp Leu Gln Ile Asp Leu Lys
115 120 125
Glu Val Lys Val Ile Ser Gly Ile Leu Thr Gln Gly Arg Cys Asp Ile
130 135 140
Asp Glu Trp Met Thr Lys Tyr Ser Val Gln Tyr Arg Thr Asp Glu Ser
145 150 155 160
Leu Asn Trp Ile Tyr Tyr Lys Asp Gln Thr Gly Asn Asn Arg Val Phe
165 170 175
Tyr Gly Asn Ser Asp Arg Thr Ser Thr Val Gln Asn Leu Leu Arg Pro
180 185 190
Pro Ile Ile Ser Arg Phe Ile Arg Leu Ile Pro Leu Gly Trp His Val
195 200 205
Arg Ile Ala Ile Arg Met Glu Leu Leu Glu Cys Val Ser Lys Cys Thr
210 215 220
<210> 15
<211> 1604
<212> DNA
<213> Ovis aries
<400> 15
actttgactt cttccagaag gggccttgtt aactttttat gtgactatta tcactttgct 60
tttccgtgta atgagtcatt tgttgaattt ttctttcttg ttttaacttg atttttcctc 120
tcttgtcctt ttgctcagcc acactgggat tatcatctac tgaggtatgt tacagtaaga 180
aggctggaat tcatacggat actgtttttg aacattttca tagccaaaaa caatgtatag 240
gattatcact tctttaaaaa tgtattttta aacatatatt ttttctggtg gtggaaatag 300
catgttttat ctggacaaag ttcaagactg attcagataa atgagacaat gcaagtgaac 360
caggtcttat gtcagatggc agaatcttga attcagtccc ttttaaaact ggatccccag 420
aagggccctg cagatgtgag gagcctgact ggaagatcac tacaatgggg tggacacggc 480
tctctacata ggtgtgtctg tgaagttttt agctggtcat ccacagtgac aaacatttgt 540
ctatttagac tcaaagatga gtggtgactg tgtgttaaac tgggttcata agtcagttgc 600
actgctgtag agtgaaagct gccctagaca ataggaacta aatgagtgag gtttgtgaat 660
gcaagctttt ccagtagttc tgaccacagt tgcctttgac tatggctttt ctgaagttcc 720
tgccccctga tttcccgcag gatgagggtg aggatccctg gtaccacaaa gcatgcaagt 780
gtgattgcca aggaggtgcc aatgccctgt ggtctgcagg ttccaccccc ttggactgca 840
taccggaatg cccataccat aagcccctgg gtttcgagtc aggagaggtt acaccagacc 900
agatcacctg ctccaacgtg gagcagtacg tgggctggta ttcttcctgg actgccaaca 960
aggcccggct caacagtcaa ggctttgggt gcgcttggct ctccaagttc caggacagca 1020
gccagtggtt acagatagat ctgaaggagg tcaaggtgat ttcggggatc ctcacccagg 1080
ggcgctgtga catcgatgag tggatgacca agtacagtgt gcagtacagg accgatgaga 1140
gcctgaactg gatttactat aaagaccaga ctggaaacaa ccgggttttc tatggaaatt 1200
cggaccgaac ctccacagtc cagaacctgc tgcggccccc catcatctcc cgcttcatcc 1260
ggctcatccc actaggctgg catgtccgca ttgccatccg gatggagctg ctggagtgcg 1320
tcagcaagtg tacctgatgc tgcctcggct catgcctgca gtgggtgaag ggcgcagagt 1380
ggcccatggg ggaactctga cttatcactg tgaccaacag ggctggattt tacaggctct 1440
tttcagtgca gggctgggca gagaatacta tcttttttgc atagtttcca atttcagtaa 1500
gagaaaatga aaataaacgt atttcccatt cagggtcaaa gaaaataaga acaaagaaaa 1560
tgtctctaaa aacaatttcc atgcagaaag cctaagtagc agga 1604
<210> 16
<211> 211
<212> PRT
<213> Ovis aries
<400> 16
Met Ala Phe Leu Lys Phe Leu Pro Pro Asp Phe Pro Gln Asp Glu Gly
1 5 10 15
Glu Asp Pro Trp Tyr His Lys Ala Cys Lys Cys Asp Cys Gln Gly Gly
20 25 30
Ala Asn Ala Leu Trp Ser Ala Gly Ser Thr Pro Leu Asp Cys Ile Pro
35 40 45
Glu Cys Pro Tyr His Lys Pro Leu Gly Phe Glu Ser Gly Glu Val Thr
50 55 60
Pro Asp Gln Ile Thr Cys Ser Asn Val Glu Gln Tyr Val Gly Trp Tyr
65 70 75 80
Ser Ser Trp Thr Ala Asn Lys Ala Arg Leu Asn Ser Gln Gly Phe Gly
85 90 95
Cys Ala Trp Leu Ser Lys Phe Gln Asp Ser Ser Gln Trp Leu Gln Ile
100 105 110
Asp Leu Lys Glu Val Lys Val Ile Ser Gly Ile Leu Thr Gln Gly Arg
115 120 125
Cys Asp Ile Asp Glu Trp Met Thr Lys Tyr Ser Val Gln Tyr Arg Thr
130 135 140
Asp Glu Ser Leu Asn Trp Ile Tyr Tyr Lys Asp Gln Thr Gly Asn Asn
145 150 155 160
Arg Val Phe Tyr Gly Asn Ser Asp Arg Thr Ser Thr Val Gln Asn Leu
165 170 175
Leu Arg Pro Pro Ile Ile Ser Arg Phe Ile Arg Leu Ile Pro Leu Gly
180 185 190
Trp His Val Arg Ile Ala Ile Arg Met Glu Leu Leu Glu Cys Val Ser
195 200 205
Lys Cys Thr
210
<210> 17
<211> 4553
<212> DNA
<213> Felis catus
<400> 17
cttctgagga aaccctccac tcggataagg tagagctaca gccaaggaca aggggagaat 60
gccacgcaag atagaaggtt tcttgttctt acttctcttt ggctacgaag ccacactggg 120
actgtcgtct actgaggatg agggtgagga cccctggtac cacaaagcat gcaaatgcga 180
ttgccaagga ggtgccaatg ccctctggtc tgctggcgcc acctccttag actgcattcc 240
ggaatgccca tatcataagc ccctgggttt cgaatcggga gaagttacac cagaccagat 300
cacctgctcc aacctggagc agtacgtggg ctggtattcc tcgtggaccg ctaacaaggc 360
ccggctcaac agtcaaggct ttgggtgcgc ctggctgtcc aagtaccagg acagcagcca 420
gtggctagag atagatctga aggaggtcaa ggtgatttca gggatcctca cccaggggcg 480
ctgtgacatt gatgagtgga tgaccaagta cagcgtgcag tacaggaccg atgagaacct 540
gaactggatt tactataagg accagacagg aaacaaccgg gtcttctacg gcaactcaga 600
ccgaacctcc acggtccaga acctcctgcg gccccccatc atttcccgct tcatccggct 660
gatcccactg ggctggcacg tccgcattgc catccggatg gagctgttgg agtgcgtcag 720
caagtgtgcg tgacgcctcc ttcagctcgg cacctgccag gtggggtgga gggcgcagag 780
cagcctgtag gggaaaattg acgcgaccag ggcttgaaca gggtgacaaa cagggctgaa 840
ttttacaagc tcttttcaat gcagagctgg gcagaaataa tttctttttt ttaagacgta 900
gtttccaatg tcaatgagag agaaagaaaa atgaactcat tccccactca gggccaaaga 960
aaataagaac aaagaaaatg tccctaaaga caatgttcat caaaagccta agtagcaggg 1020
gtaattttct gctcttgggt ttttgtgttt ggcctgacag tgtgaaaggt gtggtctcag 1080
ggaacacaaa ggagcccaga taatttaaaa acccttttgc ttcaccaccc tgaaaacagg 1140
aacagaagtt tcataaaacc ttgatttgaa cgcaaatggg tagcaggctt gcggtctctc 1200
cggcgttttc accaaattag ggcctctcac aactttagag caccgtgtat gcagacggaa 1260
aggatttggg gtgactgggg ggccgaaagg catagtcggg agcctgtgtc ctggtctcct 1320
ggaggctggc accatcaccc caggcaggag ggcctcccct gctctgcgcc ttcaccccca 1380
cgcacacaag gactgtggag ccacaaaagc tctcatcaca tacagatcca ttctagcaaa 1440
gttttccagt ctgtggtcac tatttgggta aatacatggg acgggctgca tgtgtaagta 1500
gcaaagtttc tctgtattta ggaaccccac atgaccgaag cacaccagaa tttcccttca 1560
tctagggcta ccatttttca acaggattca cattttaaaa ccagttggca caggagctag 1620
atcactggct acacggagga ggcccatcag ctaaccacat gctttgcagg aagtgggcag 1680
accgcaagtc ctaagaaggg atgtggatac gtttcttgtg acccacggtt aaacttcacc 1740
ccttgccttg caacacacaa aacaggcctg ctcctgaggt tgaaacctcc ttgagaagga 1800
ccgggcctgg catgggcctg gccttccccc tcctggagga gctcatgaag ctgggacctt 1860
tcgggaagag tctcagtctc ctgagttttc aggcccttcc ctggggagag gctgatgaca 1920
tggggagtgg gcaggagagg tatatgaaag taggagctga gagggggtga aactggggga 1980
tgagggccct ctgacaagac tggggaatcc gagactgtcc tggccctgac acagcacagc 2040
ctctactaga ggctttctcc tgagttactt tctgttttca aatgccaagc cgagtgaaga 2100
ctcacactaa catgatcctg gacatcacat tcaccttctc tgtgaggggg aagcctccta 2160
aaaaccccaa atctcttccc tggtgttttg ggcttagaac agctctatat ttaacccacc 2220
atcctttttt tttttttttt tttttttttt aacgtttatt ttgaaagaga gaggagagag 2280
agagagggag agagcatgca tacgcacgcg agcaagcaga gaagggtcag atagagaggg 2340
agacagagga tctgaagcgg gctctgcacg gtcagcagtg agcctgatgt ggggccgaac 2400
ttgtgacctg tgagatcatg acctgagctg aagtcggacg cttaaccgac tgagccgccc 2460
aggtgcccct aacccaccat ctttttaatc ccccaactgt atacttggac ctggaaaaat 2520
gcttcccttg ctcagtattc tctcaaatac aaacatatca aattcaaggt ggggaaaaaa 2580
aaatccttct ctggactttg gacacatgaa taaatccatt tagagcaggc gcctcatcag 2640
agccccttag tgaaaagctg aatgaacttt catcatgaca cggattgtca gagaaaatgg 2700
tggtagccta agagctcagg tcctctacag tggtcacatc agacacagga ggcgagtacg 2760
gttaagagga aagaagaaaa gaatgaaact gtgaggcagt gataaaggtt ctccaactaa 2820
ttgttcatgt tagaaatgtt tgctttgtaa aggtttaatg agataaagtc acataccgta 2880
caaatttcaa ccatttcaag tgtacaattc aatgactttt agtagactca gagttgagga 2940
accattatca caattttaga aaaatttcat caccccacag agaaaccctg cacccattaa 3000
ccatcacctc ccaacctact cgtccccgca gccctaggca accactgatg gactttctgt 3060
ctcagtagat ttgcctattc tggacatttc atataaatgg gatcattttc tgcctggctt 3120
cttttgctta gcatagtgtt tttccaagtt tcattcaggt tgcagcatgc acttaattcc 3180
ttcttatagc tgaacatcat tccgttatat ggataggtca cattgtattt atccgttcat 3240
ctgttgatgg acatttgggt tgtttctaca tttttggcta tcgtgaataa tgctgctata 3300
aacacctgtg tacaagtttt tgtttggaca tatgttttta tttatcttgg gcatatacct 3360
aggagtggaa tgctggggtc atatggtaac tctacgtcta acctttttag gaactgtcag 3420
acaattttcc aaaggggcca caccattatg cattcccacc agcaacatat gagagtttca 3480
ggttctctac atttgttatt atctttttga ttagagccgt cctggtgtgt atgaagtagc 3540
atcactctgg tttttgattt gcatttccct aggactaatg atgctaagca tcttttttat 3600
gtgttcactg gccttttgaa taacttcttt ggagaaatgt cttttccgat cctttgccca 3660
tttaaaaatc aggtggcctt tttattaacg aattgtaaga gctctttaat attctagata 3720
caaccccctt aggagatacg tgacttgcaa atactttctc ctattcggta ggttatcttc 3780
ttactctctt gatggagtcc tttgaaacac atttttaaat tttgataaag tccaatttat 3840
tcttttttgt tgcatgtgtt tttggtgtca tatctgaggt accattgcca aatcccgatc 3900
atgaagattt actcctatgt ttcaagagtt ttatagtttt acttcttaca tttagacctt 3960
tgatctattt ggggttattt tgtatatggt atgaggtagg ggtccaactt cagtatctgc 4020
acgtggacat ccagttgtcc cagcaccatt tgttgaaaag actttttccc cactgaatgg 4080
tcttggcatc ctttttgaga aatcaattaa ccataaaggt gagaatttgt ttctggatcc 4140
tcaattctat tccattatag gtctatcttt ataccagtac cacacagttg tcattactgt 4200
agccttttta gtaagttttg aaattggaac aggttaactc tccaactttg ttcttcttca 4260
aggctgtctg ggctgctgag tcctttgaat gtccatatga attttagaat cactgtgtca 4320
atttctgcaa agaagccagc tgagatttca catcggaaat cgctccatac ttgagaattt 4380
aatcaacaat gagatactga gatccataat acgttaatct gtaggtaacc tgtgtataac 4440
agcatattaa ttatttactt catttaattt agaacagaaa gtataaaaac aaaactttta 4500
ttgaggggca tctgcagcct aacagaatct tgctattaaa cacatgaact gtg 4553
<210> 18
<211> 224
<212> PRT
<213> Felis catus
<400> 18
Met Pro Arg Lys Ile Glu Gly Phe Leu Phe Leu Leu Leu Phe Gly Tyr
1 5 10 15
Glu Ala Thr Leu Gly Leu Ser Ser Thr Glu Asp Glu Gly Glu Asp Pro
20 25 30
Trp Tyr His Lys Ala Cys Lys Cys Asp Cys Gln Gly Gly Ala Asn Ala
35 40 45
Leu Trp Ser Ala Gly Ala Thr Ser Leu Asp Cys Ile Pro Glu Cys Pro
50 55 60
Tyr His Lys Pro Leu Gly Phe Glu Ser Gly Glu Val Thr Pro Asp Gln
65 70 75 80
Ile Thr Cys Ser Asn Leu Glu Gln Tyr Val Gly Trp Tyr Ser Ser Trp
85 90 95
Thr Ala Asn Lys Ala Arg Leu Asn Ser Gln Gly Phe Gly Cys Ala Trp
100 105 110
Leu Ser Lys Tyr Gln Asp Ser Ser Gln Trp Leu Glu Ile Asp Leu Lys
115 120 125
Glu Val Lys Val Ile Ser Gly Ile Leu Thr Gln Gly Arg Cys Asp Ile
130 135 140
Asp Glu Trp Met Thr Lys Tyr Ser Val Gln Tyr Arg Thr Asp Glu Asn
145 150 155 160
Leu Asn Trp Ile Tyr Tyr Lys Asp Gln Thr Gly Asn Asn Arg Val Phe
165 170 175
Tyr Gly Asn Ser Asp Arg Thr Ser Thr Val Gln Asn Leu Leu Arg Pro
180 185 190
Pro Ile Ile Ser Arg Phe Ile Arg Leu Ile Pro Leu Gly Trp His Val
195 200 205
Arg Ile Ala Ile Arg Met Glu Leu Leu Glu Cys Val Ser Lys Cys Ala
210 215 220
<210> 19
<211> 1193
<212> DNA
<213> Equus caballus
<400> 19
atgccacaca aaatagaagg cttcttgttt ttacttctct ttggctatga agccacactg 60
ggattatcgt ctactgagga tgagggcgag gacccctggt accacaaagc gtgcaagtgc 120
gattgccaag gaggcaccaa caccctgtgg tctgtgggtg ccacctcctt agactgcata 180
ccggaatgcc cataccataa gcccctgggt ttcgagtcag gagaggtgac cccagagcag 240
atcacctgct ccaacccgga gcagtacgtg ggctggtact cctcgtggac cgccaacaag 300
gcccggctca acagtcaagg ctttgggtgc gcctggctct ccaaattcca ggacagcagc 360
cagtggttac agatagacct gaaggaggtc aaggtgattt cagggatcct cacccagggg 420
cgctgtgaca tcgacgagtg gatgaccaag tacagcgtgc agtacaggac tgatgagagc 480
ctgaactgga tttactataa ggaccagacc ggaaataacc gggtcttcta tggaaactca 540
gaccgaacct ccacagtcca gaacctgctg cggcccccaa ttatttcccg cttcatccgg 600
ctgatcccac tgggctggca cgtccgcatc gccatccgga tggagctgct ggagtgtgtc 660
agcaagtgtc cctgacgcct cctgcctcag cctcggccct cggggggagg gcgcagaggg 720
cctgggggac cctgatgccg cactgtgaca aacaaggccg tattttacaa gctgctctcg 780
ggtttttttt gtctccatga tgctgtgaaa ggtgcagtcc caggggaaca cgaagcagcc 840
ctgatcattc gagaattctt gtgctttacc acgttcaaaa caggaacaga gagtttcata 900
aaccctcact ttgaatgcaa agggggagca agcttgcagt ttctcctagc taggttttcg 960
ttaaatcagg gcctcttagg actttagagc accgggtagg cagagtgaaa gttttggggc 1020
tgactgggtg gcggcgttga gtatggtgga tgggagcctg tgtcctggtc tcctgagagc 1080
catacacgtc caaacgcctc acgtaggatg gcctcccctg ccccgggctc tcgtctcctg 1140
cacacagaga ttgtgcatgg gcccatgctg cagcccattt caggccaact gtc 1193
<210> 20
<211> 224
<212> PRT
<213> Equus caballus
<400> 20
Met Pro His Lys Ile Glu Gly Phe Leu Phe Leu Leu Leu Phe Gly Tyr
1 5 10 15
Glu Ala Thr Leu Gly Leu Ser Ser Thr Glu Asp Glu Gly Glu Asp Pro
20 25 30
Trp Tyr His Lys Ala Cys Lys Cys Asp Cys Gln Gly Gly Thr Asn Thr
35 40 45
Leu Trp Ser Val Gly Ala Thr Ser Leu Asp Cys Ile Pro Glu Cys Pro
50 55 60
Tyr His Lys Pro Leu Gly Phe Glu Ser Gly Glu Val Thr Pro Glu Gln
65 70 75 80
Ile Thr Cys Ser Asn Pro Glu Gln Tyr Val Gly Trp Tyr Ser Ser Trp
85 90 95
Thr Ala Asn Lys Ala Arg Leu Asn Ser Gln Gly Phe Gly Cys Ala Trp
100 105 110
Leu Ser Lys Phe Gln Asp Ser Ser Gln Trp Leu Gln Ile Asp Leu Lys
115 120 125
Glu Val Lys Val Ile Ser Gly Ile Leu Thr Gln Gly Arg Cys Asp Ile
130 135 140
Asp Glu Trp Met Thr Lys Tyr Ser Val Gln Tyr Arg Thr Asp Glu Ser
145 150 155 160
Leu Asn Trp Ile Tyr Tyr Lys Asp Gln Thr Gly Asn Asn Arg Val Phe
165 170 175
Tyr Gly Asn Ser Asp Arg Thr Ser Thr Val Gln Asn Leu Leu Arg Pro
180 185 190
Pro Ile Ile Ser Arg Phe Ile Arg Leu Ile Pro Leu Gly Trp His Val
195 200 205
Arg Ile Ala Ile Arg Met Glu Leu Leu Glu Cys Val Ser Lys Cys Pro
210 215 220
<210> 21
<211> 675
<212> DNA
<213> Oryctolagus cuniculus
<400> 21
atgctacgca agatggaagg cttcttgttc ttacttctct ttggctatga agccacactg 60
ggattatcgt ctactgagga tgagagtgag gacccgtggt accacaaagc gtgcaagtgc 120
gactgccaag gaggagccaa tgccctgtgg aatgcaggtg ccacctcctt agactgcata 180
ccagaatgcc cgtatcacaa gcccctgggt ttcgagtcag gggaagtgac agcagaccag 240
atcacctgct ccaatccgga gcagtatgtg ggctggtatt cctcgtggac cgcaaacaag 300
gcccggctca atagtcaagg ctttgggtgc gcttggctct ccaagttcca ggacagcagc 360
cagtggttac agatagacct gaaggagatc aaggtgattt cgggcatcct cacccaagga 420
cgctgtgaca tcgatgagtg gatgaccaag tacagtgtgc agtacaggac cgatgagcgc 480
ctgaactgga tttactacaa ggaccagacc ggaaacaacc gggtcttcta tggcaactcg 540
gaccgaagct ccacagtcca gaacctgctg cggccaccga tcatctcccg cttcatccgg 600
ctgatcccgc tgggctggca cgtccgcatt gccatccgga tggagctgct ggagtgtgtc 660
agcaagtgtg cctga 675
<210> 22
<211> 224
<212> PRT
<213> Oryctolagus cuniculus
<400> 22
Met Leu Arg Lys Met Glu Gly Phe Leu Phe Leu Leu Leu Phe Gly Tyr
1 5 10 15
Glu Ala Thr Leu Gly Leu Ser Ser Thr Glu Asp Glu Ser Glu Asp Pro
20 25 30
Trp Tyr His Lys Ala Cys Lys Cys Asp Cys Gln Gly Gly Ala Asn Ala
35 40 45
Leu Trp Asn Ala Gly Ala Thr Ser Leu Asp Cys Ile Pro Glu Cys Pro
50 55 60
Tyr His Lys Pro Leu Gly Phe Glu Ser Gly Glu Val Thr Ala Asp Gln
65 70 75 80
Ile Thr Cys Ser Asn Pro Glu Gln Tyr Val Gly Trp Tyr Ser Ser Trp
85 90 95
Thr Ala Asn Lys Ala Arg Leu Asn Ser Gln Gly Phe Gly Cys Ala Trp
100 105 110
Leu Ser Lys Phe Gln Asp Ser Ser Gln Trp Leu Gln Ile Asp Leu Lys
115 120 125
Glu Ile Lys Val Ile Ser Gly Ile Leu Thr Gln Gly Arg Cys Asp Ile
130 135 140
Asp Glu Trp Met Thr Lys Tyr Ser Val Gln Tyr Arg Thr Asp Glu Arg
145 150 155 160
Leu Asn Trp Ile Tyr Tyr Lys Asp Gln Thr Gly Asn Asn Arg Val Phe
165 170 175
Tyr Gly Asn Ser Asp Arg Ser Ser Thr Val Gln Asn Leu Leu Arg Pro
180 185 190
Pro Ile Ile Ser Arg Phe Ile Arg Leu Ile Pro Leu Gly Trp His Val
195 200 205
Arg Ile Ala Ile Arg Met Glu Leu Leu Glu Cys Val Ser Lys Cys Ala
210 215 220
<210> 23
<211> 8202
<212> DNA
<213> Artificial Sequence
<220>
<223> recombinant or synthetic polynucleotide
<400> 23
ggtaccgatt taaatgatcc agtggtcctg cagaggagag attgggagaa tcccggtgtg 60
acacagctga acagactagc cgcccaccct ccctttgctt cttggagaaa cagtgaggaa 120
gctaggacag acagaccaag ccagcaactc agatctttga acggggagtg gagatttgcc 180
tggtttccgg caccagaagc ggtgccggaa agctggctgg agtgcgatct tcctgaggcc 240
gatactgtcg tcgtcccctc aaactggcag atgcacggtt acgatgcgcc catctacacc 300
aacgtgacct atcccattac ggtcaatccg ccgtttgttc ccacggagaa tccgacgggt 360
tgttactcgc tcacatttaa tgttgatgaa agctggctac aggaaggcca gacgcgaatt 420
atttttgatg gcgttaactc ggcgtttcat ctgtggtgca acgggcgctg ggtcggttac 480
ggccaggaca gtcgtttgcc gtctgaattt gacctgagcg catttttacg cgccggagaa 540
aaccgcctcg cggtgatggt gctgcgctgg agtgacggca gttatctgga agatcaggat 600
atgtggcgga tgagcggcat tttccgtgac gtctcgttgc tgcataaacc gactacacaa 660
atcagcgatt tccatgttgc cactcgcttt aatgatgatt tcagccgcgc tgtactggag 720
gctgaagttc agatgtgcgg cgagttgcgt gactacctac gggtaacagt ttctttatgg 780
cagggtgaaa cgcaggtcgc cagcggcacc gcgcctttcg gcggtgaaat tatcgatgag 840
cgtggtggtt atgccgatcg cgtcacacta cgtctgaacg tcgaaaaccc gaaactgtgg 900
agcgccgaaa tcccgaatct ctatcgtgcg gtggttgaac tgcacaccgc cgacggcacg 960
ctgattgaag cagaagcctg cgatgtcggt ttccgcgagg tgcggattga aaatggtctg 1020
ctgctgctga acggcaagcc gttgctgatt cgaggcgtta accgtcacga gcatcatcct 1080
ctgcatggtc aggtcatgga tgagcagacg atggtgcagg atatcctgct gatgaagcag 1140
aacaacttta acgccgtgcg ctgttcgcat tatccgaacc atccgctgtg gtacacgctg 1200
tgcgaccgct acggcctgta tgtggtggat gaagccaata ttgaaaccca cggcatggtg 1260
ccaatgaatc gtctgaccga tgatccgcgc tggctaccgg cgatgagcga acgcgtaacg 1320
cgaatggtgc agcgcgatcg taatcacccg agtgtgatca tctggtcgct ggggaatgaa 1380
tcaggccacg gcgctaatca cgacgcgctg tatcgctgga tcaaatctgt cgatccttcc 1440
cgcccggtgc agtatgaagg cggcggagcc gacaccacgg ccaccgatat tatttgcccg 1500
atgtacgcgc gcgtggatga agaccagccc ttcccggctg tgccgaaatg gtccatcaaa 1560
aaatggcttt cgctacctgg agagacgcgc ccgctgatcc tttgcgaata cgcccacgcg 1620
atgggtaaca gtcttggcgg tttcgctaaa tactggcagg cgtttcgtca gtatccccgt 1680
ttacagggcg gcttcgtctg ggactgggtg gatcagtcgc tgattaaata tgatgaaaac 1740
ggcaacccgt ggtcggctta cggcggtgat tttggcgata cgccgaacga tcgccagttc 1800
tgtatgaacg gtctggtctt tgccgaccgc acgccgcatc cagcgctgac ggaagcaaaa 1860
caccagcagc agtttttcca gttccgttta tccgggcaaa ccatcgaagt gaccagcgaa 1920
tacctgttcc gtcatagcga taacgagctc ctgcactgga tggtggcgct ggatggtaag 1980
ccgctggcaa gcggtgaagt gcctctggat gtcgctccac aaggtaaaca gttgattgaa 2040
ctgcctgaac taccgcagcc ggagagcgcc gggcaactct ggctcacagt acgcgtagtg 2100
caaccgaacg cgaccgcatg gtcagaagcc gggcacatca gcgcctggca gcagtggcgt 2160
ctggcggaaa acctcagtgt gacgctcccc gccgcgtccc acgccatccc gcatctgacc 2220
accagcgaaa tggatttttg catcgagctg ggtaataagc gttggcaatt taaccgccag 2280
tcaggctttc tttcacagat gtggattggc gataaaaaac aactgctgac gccgctgcgc 2340
gatcagttca cccgtgcacc gctggataac gacattggcg taagtgaagc gacccgcatt 2400
gaccctaacg cctgggtcga acgctggaag gcggcgggcc attaccaggc cgaagcagcg 2460
ttgttgcagt gcacggcaga tacacttgct gatgcggtgc tgattacgac cgctcacgcg 2520
tggcagcatc aggggaaaac cttatttatc agccggaaaa cctaccggat tgatggtagt 2580
ggtcaaatgg cgattaccgt tgatgttgaa gtggcgagcg atacaccgca tccggcgcgg 2640
attggcctga actgccagct ggcgcaggta gcagagcggg taaactggct cggattaggg 2700
ccgcaagaaa actatcccga ccgccttact gccgcctgtt ttgaccgctg ggatctgcca 2760
ttgtcagaca tgtatacccc gtacgtcttc ccgagcgaaa acggtctgcg ctgcgggacg 2820
cgcgaattga attatggccc acaccagtgg cgcggcgact tccagttcaa catcagccgc 2880
tacagtcaac agcaactgat ggaaaccagc catcgccatc tgctgcacgc ggaagaaggc 2940
acatggctga atatcgacgg tttccatatg gggattggtg gcgacgactc ctggagcccg 3000
tcagtatcgg cggaattcca gctgagcgcc ggtcgctacc attaccagtt ggtctggtgt 3060
caaaaataat aataaccggg caggggggat ctaagctcta gataagtaat gatcataatc 3120
agccatatca catctgtaga ggttttactt gctttaaaaa acctcccaca cctccccctg 3180
aacctgaaac ataaaatgaa tgcaattgtt gttgttaact tgtttattgc agcttataat 3240
ggttacaaat aaagcaatag catcacaaat ttcacaaata aagcattttt ttcactgcat 3300
tctagttgtg gtttgtccaa actcatcaat gtatcttatc atgtctggat cccccggcta 3360
gagtttaaac actagaacta gtggatcccc gggctcgata actataacgg tcctaaggta 3420
gcgactcgac ataacttcgt ataatgtatg ctatacgaag ttatatgcat gccagtagca 3480
gcacccacgt ccaccttctg tctagtaatg tccaacacct ccctcagtcc aaacactgct 3540
ctgcatccat gtggctccca tttatacctg aagcacttga tggggcctca atgttttact 3600
agagcccacc cccctgcaac tctgagaccc tctggatttg tctgtcagtg cctcactggg 3660
gcgttggata atttcttaaa aggtcaagtt ccctcagcag cattctctga gcagtctgaa 3720
gatgtgtgct tttcacagtt caaatccatg tggctgtttc acccacctgc ctggccttgg 3780
gttatctatc aggacctagc ctagaagcag gtgtgtggca cttaacacct aagctgagtg 3840
actaactgaa cactcaagtg gatgccatct ttgtcacttc ttgactgtga cacaagcaac 3900
tcctgatgcc aaagccctgc ccacccctct catgcccata tttggacatg gtacaggtcc 3960
tcactggcca tggtctgtga ggtcctggtc ctctttgact tcataattcc taggggccac 4020
tagtatctat aagaggaaga gggtgctggc tcccaggcca cagcccacaa aattccacct 4080
gctcacaggt tggctggctc gacccaggtg gtgtcccctg ctctgagcca gctcccggcc 4140
aagccagcac catgggaacc cccaagaaga agaggaaggt gcgtaccgat ttaaattcca 4200
atttactgac cgtacaccaa aatttgcctg cattaccggt cgatgcaacg agtgatgagg 4260
ttcgcaagaa cctgatggac atgttcaggg atcgccaggc gttttctgag catacctgga 4320
aaatgcttct gtccgtttgc cggtcgtggg cggcatggtg caagttgaat aaccggaaat 4380
ggtttcccgc agaacctgaa gatgttcgcg attatcttct atatcttcag gcgcgcggtc 4440
tggcagtaaa aactatccag caacatttgg gccagctaaa catgcttcat cgtcggtccg 4500
ggctgccacg accaagtgac agcaatgctg tttcactggt tatgcggcgg atccgaaaag 4560
aaaacgttga tgccggtgaa cgtgcaaaac aggtaaatat aaaattttta agtgtataat 4620
gatgttaaac tactgattct aattgtttgt gtattttagg ctctagcgtt cgaacgcact 4680
gatttcgacc aggttcgttc actcatggaa aatagcgatc gctgccagga tatacgtaat 4740
ctggcatttc tggggattgc ttataacacc ctgttacgta tagccgaaat tgccaggatc 4800
agggttaaag atatctcacg tactgacggt gggagaatgt taatccatat tggcagaacg 4860
aaaacgctgg ttagcaccgc aggtgtagag aaggcactta gcctgggggt aactaaactg 4920
gtcgagcgat ggatttccgt ctctggtgta gctgatgatc cgaataacta cctgttttgc 4980
cgggtcagaa aaaatggtgt tgccgcgcca tctgccacca gccagctatc aactcgcgcc 5040
ctggaaggga tttttgaagc aactcatcga ttgatttacg gcgctaagga tgactctggt 5100
cagagatacc tggcctggtc tggacacagt gcccgtgtcg gagccgcgcg agatatggcc 5160
cgcgctggag tttcaatacc ggagatcatg caagctggtg gctggaccaa tgtaaatatt 5220
gtcatgaact atatccgtaa cctggatagt gaaacagggg caatggtgcg cctgctggaa 5280
gatggcgatt aggcggccgg ccgctaatca gccataccac atttgtagag gttttacttg 5340
ctttaaaaaa cctcccacac ctccccctga acctgaaaca taaaatgaat gcaattgttg 5400
ttgttaactt gtttattgca gcttataatg gttacaaata aagcaatagc atcacaaatt 5460
tcacaaataa agcatttttt tcactgcatt ctagttgtgg tttgtccaaa ctcatcaatg 5520
tatcttatca tgtctggatc ccccggctag agtttaaaca ctagaactag tggatccccc 5580
gggatcatgg cctccgcgcc gggttttggc gcctcccgcg ggcgcccccc tcctcacggc 5640
gagcgctgcc acgtcagacg aagggcgcag cgagcgtcct gatccttccg cccggacgct 5700
caggacagcg gcccgctgct cataagactc ggccttagaa ccccagtatc agcagaagga 5760
cattttagga cgggacttgg gtgactctag ggcactggtt ttctttccag agagcggaac 5820
aggcgaggaa aagtagtccc ttctcggcga ttctgcggag ggatctccgt ggggcggtga 5880
acgccgatga ttatataagg acgcgccggg tgtggcacag ctagttccgt cgcagccggg 5940
atttgggtcg cggttcttgt ttgtggatcg ctgtgatcgt cacttggtga gtagcgggct 6000
gctgggctgg ccggggcttt cgtggccgcc gggccgctcg gtgggacgga agcgtgtgga 6060
gagaccgcca agggctgtag tctgggtccg cgagcaaggt tgccctgaac tgggggttgg 6120
ggggagcgca gcaaaatggc ggctgttccc gagtcttgaa tggaagacgc ttgtgaggcg 6180
ggctgtgagg tcgttgaaac aaggtggggg gcatggtggg cggcaagaac ccaaggtctt 6240
gaggccttcg ctaatgcggg aaagctctta ttcgggtgag atgggctggg gcaccatctg 6300
gggaccctga cgtgaagttt gtcactgact ggagaactcg gtttgtcgtc tgttgcgggg 6360
gcggcagtta tggcggtgcc gttgggcagt gcacccgtac ctttgggagc gcgcgccctc 6420
gtcgtgtcgt gacgtcaccc gttctgttgg cttataatgc agggtggggc cacctgccgg 6480
taggtgtgcg gtaggctttt ctccgtcgca ggacgcaggg ttcgggccta gggtaggctc 6540
tcctgaatcg acaggcgccg gacctctggt gaggggaggg ataagtgagg cgtcagtttc 6600
tttggtcggt tttatgtacc tatcttctta agtagctgaa gctccggttt tgaactatgc 6660
gctcggggtt ggcgagtgtg ttttgtgaag ttttttaggc accttttgaa atgtaatcat 6720
ttgggtcaat atgtaatttt cagtgttaga ctagtaaatt gtccgctaaa ttctggccgt 6780
ttttggcttt tttgttagac gtgttgacaa ttaatcatcg gcatagtata tcggcatagt 6840
ataatacgac aaggtgagga actaaaccat gggatcggcc attgaacaag atggattgca 6900
cgcaggttct ccggccgctt gggtggagag gctattcggc tatgactggg cacaacagac 6960
aatcggctgc tctgatgccg ccgtgttccg gctgtcagcg caggggcgcc cggttctttt 7020
tgtcaagacc gacctgtccg gtgccctgaa tgaactgcag gacgaggcag cgcggctatc 7080
gtggctggcc acgacgggcg ttccttgcgc agctgtgctc gacgttgtca ctgaagcggg 7140
aagggactgg ctgctattgg gcgaagtgcc ggggcaggat ctcctgtcat ctcaccttgc 7200
tcctgccgag aaagtatcca tcatggctga tgcaatgcgg cggctgcata cgcttgatcc 7260
ggctacctgc ccattcgacc accaagcgaa acatcgcatc gagcgagcac gtactcggat 7320
ggaagccggt cttgtcgatc aggatgatct ggacgaagag catcaggggc tcgcgccagc 7380
cgaactgttc gccaggctca aggcgcgcat gcccgacggc gatgatctcg tcgtgaccca 7440
tggcgatgcc tgcttgccga atatcatggt ggaaaatggc cgcttttctg gattcatcga 7500
ctgtggccgg ctgggtgtgg cggaccgcta tcaggacata gcgttggcta cccgtgatat 7560
tgctgaagag cttggcggcg aatgggctga ccgcttcctc gtgctttacg gtatcgccgc 7620
tcccgattcg cagcgcatcg ccttctatcg ccttcttgac gagttcttct gaggggatcc 7680
gctgtaagtc tgcagaaatt gatgatctat taaacaataa agatgtccac taaaatggaa 7740
gtttttcctg tcatactttg ttaagaaggg tgagaacaga gtacctacat tttgaatgga 7800
aggattggag ctacgggggt gggggtgggg tgggattaga taaatgcctg ctctttactg 7860
aaggctcttt actattgctt tatgataatg tttcatagtt ggatatcata atttaaacaa 7920
gcaaaaccaa attaagggcc agctcattcc tcccactcat gatctataga tctatagatc 7980
tctcgtggga tcattgtttt tctcttgatt cccactttgt ggttctaagt actgtggttt 8040
ccaaatgtgt cagtttcata gcctgaagaa cgagatcagc agcctctgtt ccacatacac 8100
ttcattctca gtattgtttt gccaagttct aattccatca gacctcgacc tgcagcccct 8160
agataacttc gtataatgta tgctatacga agttatgcta gc 8202
<210> 24
<211> 13716
<212> DNA
<213> Artificial Sequence
<220>
<223> recombinant or synthetic polynucleotide
<400> 24
ccacacaaga ttgaaggctt cttcttgtta cttctctttg gctatgaagg tatgtactat 60
tctactattg gcatttatta atgtatttaa taatgtgatt taatatagaa atatatagaa 120
aatagttgat aaatagaaat gcaacctgag taataaaaat tgttggatga caacatgcca 180
attagttcac aggttattaa tttaaaaggt cactgttgtg tggctctttg tcactgtctt 240
gctcctggct tcctggtttc atgaggaacc ttctaaagtt caaatgatat tgaaactcaa 300
cagaaagaag gaagggcctc agagtttcta taaaaacaac tttaaattgc aacaattaat 360
gagaagtcat gtttcttgga aattttagga ggcaaagttg aagcaattgt agaatttaat 420
attgtaagcc ggactattac tgagggttaa ggatgaagct attaatagct ctgctgggac 480
aagtgtaaat gaggactgtc ccaggcaaat caggacaaag ggtcacccta gtttaaatat 540
ggattagcat aaggccaagc accactgcag tctaatagaa gtctaataaa ataatccaaa 600
gaaagtcaat aaaccctaaa gactcaatat attccatcac ttttaaactt ctaaatgtgg 660
ccctggcagg cataatatgc ttaaataagg acagattaaa gctaaatctc taaaatgtca 720
atcaaataaa ctttaaatct ctttccatct tagacataat actctctcat gcctctctta 780
cctctctagt gcccatcaat tcagaattcc ttttaaagtt tatactttca aatattaaaa 840
attggttgaa gggttgggga tgtggctcag tggtacagcc cctgcccagc cttcatgagt 900
ccctgagtta aattcccaga agcagtataa gacaaacaaa caaaaacctt acttcatcca 960
ttttctggca tagctacaca tacctgcaat cctagttctg gacaaattca agcaggagca 1020
ttcaatgcca acctcagcta cttaggtttg ggctatctga gaccctgtct taacattggg 1080
ggagagccta ggctaggctg agctatacag taagcctctg tctgggaagg agggaaaaag 1140
gaaggaaaga cattggttga atgacttgtg ggtgacactg tatgtttaga gtgttcaggg 1200
aaaaggaggc ctctctgctc tgcaaatgac ctgccactca gataagacga atacacacaa 1260
gagtcagaat tcctctgttt cttctatatt catgaaccag cagtcttgtg tcttttatta 1320
tctaataata tttctagtgt ctggaaagcc ttgtgaaaat aaaatctcaa ggtcatacgg 1380
caaacacaaa gaaacaggtt tttttttctt ttttttcttt tttttttttt atacatattt 1440
gttttattta tttatttatt atatgtacgt acactgtagc tgtcttcaga cactccagaa 1500
gagggcatca gatctcgtta cggatggttg tgagccacca tgtggttgct gggatttgaa 1560
cttcagacct tcggaagagc agtcgggtgc tcttacccac tgagccatct caccagcccc 1620
aggttttttt tttcttagtt gttattatta ttgttattct tttgagacag gatcccacac 1680
tgaaactcag gctagccttc aatttcctat ggatttgacc tcatagcagt cagccagttt 1740
ccaccttctg agtgctaaga tttcaagcct gagccaccac acccaattcc taagatatgt 1800
ttttaagcaa ggttattggc attacacctt aaccctttgc aatgacgtgt caggaatttg 1860
cacctttttt ttttttccag ttgtcaggcc tggcaatgga gcccagggcc ctgtgcttgc 1920
taaacgatgg ctctacccct aagttatata tacccagctt atcccaggat ctttctcaga 1980
ctttctgatg tttgctatcg atgttgcttc tctttggttc cttgctcttt tctcacaaaa 2040
agatctaagc aagaaccctt gtctggagtc agagagatag cttagtctgg aaagtgctta 2100
tagcttacac acagaaactt gagttcgatc cccagaactt ttcttgttta aaaaacaaac 2160
aaacaaacaa acaaaaacta ggcatgacag ctggagaggt ggcttcgcaa ttaacagcac 2220
ttgttaaaga ggacctcagc ttggttccca gggctctata actccagttc cagggcctca 2280
gacagcctcc tgtagcctct tcatgcatca gacatggtcc atatgcatgc aggtcaaaca 2340
ctcatacaca ttaaatgaaa aataaaagtc taaaaaaagg tcaaacatag tgatgcatgc 2400
tataatccca gtgctaggga ggcaaatgtc tggaccttgt cggtcggcca gtcagtcagc 2460
cagccagtca gtctagccta gcatagccta ctaggtgtgc tccagcccaa tgagagacct 2520
tgtctctaaa aaaaagggta gaaagaaaag acaaaatgga tgtctcctga ggaatgatac 2580
ccacggatac ccacaattgt cctctggtct ccgtgtgcaa tacaaaccca tgtctgaata 2640
tttgcaacag ggtaaacatt agagtttgat gttcagaatt agactagatt ccctcatcta 2700
gtaaagctgt gctttggccc tcccatctgt cttatttttc tactggtgtg ctaaggcacc 2760
atgaccaagg caacttagag aagaagaaac agtttattga gggtttatag ttatagaggg 2820
taaggcaagg acttggtagc aggcaggcag gcaggcatgg tactggtgta gtagctggga 2880
gcttgtatct tgagacacgg ttacaaagct gagagatagc taagtgggcc tggtgtgagc 2940
ttttgaaacc tcaaagctgt ccccagtgaa atgcctccat caacaaggcc acacctaacc 3000
cttcccaaac agttctacca actgggaacc aagcattcat atgagcctca ggggagcagt 3060
ctcattcaag taagtactca gtacactgcc ccatgggcag aagtcctcta aacggttact 3120
aatgtgtgtg tgtatatccc tcaccatact tagaaggaaa caagccatcc caaaatggat 3180
agcatgactc agaaagttcc tgtgtacttc acccagagca aatgtggata cggtgggaaa 3240
cagaggacag tgataggaca caaaggctgt gctgtctcag tttctagttc agatggagac 3300
ataaaccaac acacatagga aagatacact ccactggaca gtgggagccc atgcacaaag 3360
gttctttggc tcatttagtc tatgctgttt ctattcttcg atgacagcag tttcttatta 3420
ttgggaaata agatcagtag atgagctttg tttctgccct gggtgagagt ttatttagga 3480
acacacatgt gatcacacta agacaaccac tgatggccta gaacaaagtc agagcactgt 3540
gcgttgtgga tcttaggcca ttcatgatga ttaaagcatc catcctatta aaatgtgtta 3600
gtccattttt ggggttatgt ttactataca aaggtggaag gggttatctg gccccatctt 3660
acaggtaact gtgtcccttt tgtggatata aaaaccatca gatactgcaa ttttattttt 3720
gtaaaaagca actgtttttt tttaagactt attttatttt tgattatgtg tctgagggag 3780
cagtatgcac atctgcatgc aggtgcctgt ggaagcctgt ggagacatca gatcacctga 3840
agctggagtt tcaggcagtt ttatgccacc agacactggt gctgagaata gagtctcctg 3900
caaaagcagt atattttatt aatctgtgag ccatctctcc agccaaaagc aacctttaaa 3960
agctgtggtt tatgtgccat ttaattcatc cacttagagg gtacacttca atagtttttt 4020
ttaaaaatat gcttacagat ctgtgggcac atatgatcca attttagaac ccttttagca 4080
ctacagatat taaatactta ctccctattc tccccagccc ccagctccag tccctggcat 4140
ccacaaatcc ccttcctgcc atctatagat tcacctcttc tagactttac actgaaatgg 4200
tattacacaa catgtggtct tttgtctttt gcttgccgtg tgtctgtgag gttcatctgt 4260
gttgagcatg aaaggataac agatttaccc atgaatatgc ctgtcgccta aaatagcaac 4320
actttcacac tagaagcaat ttccttcttt cttcttccca agagggacat tattgcagcc 4380
tgctagtttt ctcctgtgtc ttttttcgtg tttctcaagt agatgaaggg actggttact 4440
tttatttttt taatcattca tacttttata cttttctccc ctgctttgtc agtttcctaa 4500
atgagtgaat actgtatttg gtgatcccca atcagaaaga ccaaaataat ttaaaataat 4560
ctcgtctcta tatcactaag gtatcctttt ccacttgggc catgcagaga aataagcatg 4620
ccttgattga ccccacccca ccccaacccc cagtggtgac aaggacctcc ccagcggctc 4680
aaccatttga ataaaaagga cacttgagcc cattttgcac aaatctaaga tgagcaagtg 4740
gcagtgtcac ctgtaaacat gtgcctggag cacggaacga cctgagtagg cagaaaaagg 4800
tggaagtaat ttatgatttt tcttttaaag gttgccattt cccccacctt tctcactttc 4860
caacaatatt atattctggt gtgatatgtt gtagacaaaa aaagctttaa gcttttattc 4920
cccagttgtt ttggtgatta aatcattttg ggggaactgc aacagtgact ctcattcact 4980
gctcccttgg tgacagtgtt ttttttctgt aaaaagcgcc tgctgttccc tctgtctctg 5040
ctcattttca taggaatctg gcaccttaga atcccaggct gcctgcagtc aaatgcttgc 5100
tagggagggg agccagtggg tgggggaacc tgcaagaaat caactccaaa tttaatagga 5160
ctaagctcct acaccatgcc tgattagcag ctaggtctca tccttacccc tccaggaata 5220
aggaaggttg cagaagtccc tgaaaggtat ttgctgagcc tcttgtgaac cgtgggttgg 5280
ctcacctgaa ctttagtaga tattctttag cgacatattt gggctttggt cctctctctt 5340
ttatctctcc acaaaagtct tggcaaactg atgtttatgc aaccagtaag gcctctgggg 5400
ctgagggggt gggaagccag tgggtggcgg aacctgcaag aaatccgccc caaatttaag 5460
gaagcatagg aataagctcc taccctatgt ctgccttgtg gctaggtcct tagttcattg 5520
tctcttaggt atcccagatt ctcttgagag tagaaggtgg aacatagtac ctcctgatta 5580
acaaatccga gaggtgctaa tctcatgaat tctcccggac tatggttata tatagctcag 5640
tgatctcatg tagcttaggc tggctggaag ctagttttga gctcactatg aagcaaagga 5700
tgaccctgaa cttcttggtt ttcctgcttt catcttccaa gtgctgcgat tacaagaatg 5760
aatgctgcca tgtctagttc atgtggtgct agggatcaac cctgaggctt tgtgcatgtt 5820
aagacaagca ctctactaac tgagctctag ctctagccct gaccctgact caaaagaata 5880
gggggggagg aaggaaggaa ggaaggaagg aagggaggga gggagggagg gagggaggga 5940
gggagggagg gaggaaggat gttgagaaca aaagccaagg ccaacaggtg agttgggatt 6000
aggaaaagtc cttttcatag caaaggggat gtggaagaag agaagttgac aggtaagtag 6060
ggaaatttga gacaaagaaa aaagaaaaaa atctgtggac cagggcatgg caagaaacgc 6120
agagagcaaa tgttcataaa gagaggtggg caggaggcag accatggtct caagactcat 6180
cagagagata aggcaatatc ctgaggagca cccatctgag gggcgttgag caagtgggtt 6240
tcatttctct gcattcacag atggaggata gatgtgtgca actatcttta gcagtgaggc 6300
atgctgggta gtgctaagag cgggcggggt ctgtggaatg gagaggagaa accactcctt 6360
attaccacgt cattttactt ttgattatct tcattgtgat ttagtgttct agtttgtgaa 6420
tttatcacta tgtatcttgc ctcttgacgg tcacacaagt acttccagtt gaagagtagg 6480
cattacaagg tctgcttcca tgaatattct agggcacatt tttattccag gaaaaaatat 6540
atgaaagcat ttctaattat gaatggaatt ggtggtttat ggggaacaca tatgctcagc 6600
cttggaataa attaccaaaa ccaaagaggc tagactccct tctaccgatc aacagaagca 6660
tataagagtt ggcactgttc tctactctac caacttgtgg ttgggtcctg tttagaataa 6720
taagaggcat ctacatgtag agctctagga agccattcaa tgcaggatct aaaccttggc 6780
tttagcaatg tctgtgcggt acttggagta agctaagctc tcaaagaaaa ccaagattta 6840
tcggaatggt ggacactgaa agtagacagg aaaggctgac aatacctagt gtgcagtgtg 6900
cagatggaag ggcagtgctg gggagaatcc attgcatttg gaaagaagaa gccctctgcg 6960
atttcttttg ctaatgcagg ccttttcact gtagtacttg cttgtggtgg tttgaatgaa 7020
aatggtcccc acaggctatt tttgaaaact tgatccccag ttggtgaaac tgtttggaaa 7080
ggattaggaa gtgtggcctt gctggatgag gtctgtcaat ggcggaaggc tttgaagttt 7140
cccagtgtgc ctctctctgt ctcctactta ttgattgaaa aatgagcttt cagctgtcat 7200
gcctttgctc tgccatccag aattctaatc acccaaaacc atatagccta attaaatact 7260
gtttttataa gttaccttgg tcatggtact ttaggatatc aatagttaag aaactaagac 7320
attggttcac ttgctcaact taaccaaaac accacagacg ggcttgcata tgacaacagt 7380
tctagaggat caaatgtccc tgatcaaatg ccctagcagg ttctgtgtct gatgagggct 7440
gctggttcat gggtggtgct ttttctcagt gtccttacag gtggaaggta tccagctttc 7500
ttggacctta tattaaagca cgcattccat tgatgtgagt agatagctta gtcagagccc 7560
caaagtgatt taagcacctc caaaaccctc cgtctccgga tgctccccca ttggtgaaca 7620
gatttcaaca tagcaattga gcaggaggaa aggaagccaa attatttgat cacagccagt 7680
actttggtga acacccaaac ccagcatgga gctgaatatc tgtaatctca gtatccagca 7740
ggtggatatt ggggaattaa gacttcaagg ccagacttgg ctacatagta agtttgatgc 7800
catcctgggc tatatgagat cctgtttcca aaacccccaa atagaaacaa taaaaaaatg 7860
gcagtccttc atgttcactg ctaccctaga aggtcagttt tgcttgtaac agatgactaa 7920
cagaggaaca aggtcccgga agagctacca gtatgctggc tgccaatgaa gctgctgaag 7980
tcttagtaga tttaggagct atggtcctga cttccatcac agccccagca ccaccatggg 8040
cactgcccag cagtctatct tcttttaggt cttcaggtgt ccctgggtag agaacaaggc 8100
ttctgcttgc atagggctga tgccccagta cagtgacagt ctcacaatga gtgcagcaat 8160
gtggccacag aacggggaaa tgtgtgttct ttaactagta gcttttataa tcatgataaa 8220
aagataagtg tctactctca agctgaaagc ttttcacagg catctgattc tcttgctaaa 8280
tgacaaagtg gttagaggag ggacctacag ctttcattgt ctacactcag gtttcttttg 8340
agaattttac agtaggtatg tattgttttc tagtcaacac agaaataaaa ggatttgttt 8400
tgttgaaaag aagtgggggt tttggtactg atgaggggaa attgatttat gttacttatt 8460
cattctcagg ttcatggctg agactcctta tgacaaatga tagattaata aaagcatgca 8520
aatgctggag ctctgctggc ggagtacctg atatgcaagg atgaagatct ctgttcaatc 8580
cccagaaatc aaataaaaaa gctgggcata gtgaggaaga ggagatggga ggattcctgt 8640
ggctggctgg acagctaacc tagcctattc atctatttcc aggccactaa gggatggtac 8700
cttaaaaaat aacaataata ataaaaaata acaataataa taaataaaaa aggtagctgg 8760
ttcctgagga gcatctaagg atatccttta actccacgtg cacatacact gtatacacag 8820
gaacacatac aagcatgcag atttacctat caagttttac caaaaaaaaa aaaaaaaaaa 8880
aaaaagaaca ctttattcac tgttggtggg tatgtaaact ggcatatgta gccactatga 8940
aaatcagcac agaggttccc ttcccactcc aacaaaacaa aacaaaacaa aacaaaacaa 9000
aacaaaacaa aacaaaacaa aaccctctag aactagaact agaactactg cacgatccag 9060
gtttaccact cctaggtatt tactcaaagg actctatacg tcaacctgtg acagaggcat 9120
catatacaag cagggagtgg tggcacctgc ctttaatccc acccctcagg aggcagagtc 9180
aggtagatct ctgtgagttc gaggccagtt tggtctacat agtgagttct agtacagcca 9240
taagaccata tagccatatg gaggggggat tgtgagcata gagtatgaat gttcttgaga 9300
gaattattaa atgaattgga attattatac actgtcttct ttcataggaa aaatgaacag 9360
aaagggagag atctttgggt ggggctaaca gcatacatga catgaaagca gaaggggatt 9420
agttattgga aggcagggag ggacccagga ggatgaaggg aagagaatgc aagggaaagg 9480
agtaaaggag gaggaggtag aggtacacac tattaattcc agcacttgtg aggaggggac 9540
agagctctgt gagttcaagg tcagccccct ctgcatagtc agttccagga tagccaatgg 9600
ctacataatg agaccctgtg tcagagaagg tggccggcga gggatattga tgcttacagt 9660
ttactttagc caccacacag ctgaatgagt taaacctgtt cctgctactt ttgcactttc 9720
aatgctccca gattacttac atggaattta tattttattg tggtttaata gctcctgtac 9780
atcatagaca aacctcaaga aaaattttca accaatagtc caggcaaaaa taacctcttt 9840
ttctttcttt ctttctttct tttttttttt ttttttttgg ttttttgaaa cagggtttct 9900
ctgtatagcc ctggctgtcc tggaactcac tttgtacacc aggctggcct cgaactcaga 9960
aatccacctg cctctgcctc ccgagtgctc ggattaaagg cgtgcaccac caccgtcccg 10020
caaaaaataa cctgtttttg ttgttttaat tatttttaag attttatgtg tatgggtgtc 10080
tgtctgtatg tatgtctgtg taccacttgt atgcttggtg cccaagaagg acagaacaga 10140
tcatagggtt tcctgggata agagttatag gagttataga tgactgtaag ccaccaagtg 10200
gacgctggga attgaacctt ggttagctgg aagagtgtcc agtattttta attccagtcc 10260
ccgttgtttg tctatgaaga ttttgcttgg tagtccagtc tggctttaag aaacagggtc 10320
tcatgcatcc ctggcttgct cagacttcca tgcagctgag gatggcttta gagtaacaac 10380
cctcctgcct tttcctcgta gagtgctgag attacagtcc tgtgccacca gcagacttct 10440
cctaacaaga atgtggcaca gggaggcaac tgggaatcaa acaggaagga ggagtaaaag 10500
gaaggggagg aaggagagga gaagtggcag gaggagaaga aaaaggaggc ggagaaaagg 10560
tggtagtggt ggaggaagag gaggaggagg aggaggagga ggagggggac ttaatcagta 10620
aaggaaaaag gctgagctca gtccttggaa cctacatggt aggagagaat gagacttctg 10680
caaagtttcc tctgatcccc acactggagc aatggtgcca tcacatcact ctcccacttc 10740
acccaactcc tcacaaaaat aaaaaacaaa aacaaaacaa cagacaaaca aatacataaa 10800
taaatgtagt ttaaaaaaga aagctgtagc cgggcgtggt ggcacacact tttaatcccg 10860
gcacttggga ggcagaggca agcggatttc tgagttcgag gccagcttgg tctacaaagt 10920
gagttccagg acagccaggg ctacacagag aaaccctgtc ttgaaaaacc aaaagaaaaa 10980
aagaaagctg tactgcaccc tgctttgcta tattaatata ttttccataa ttctataaga 11040
aaaaacaaca gtcattgcca tccttttcct ccctccagaa tgagctcctt aatctctatg 11100
gcattgtttt cattttgcct tctttccttt cttaatttca ttttttccct ctcttgttct 11160
tttgctcagc cacattggga ttgtcatcga cagaggtatg ttacagtaag aagggtggaa 11220
ttttcatcgg tgttgctttt gaagtaaaac taatatatga gtctagcact attgggggga 11280
agagtgctga gggtgaagcc aagggccttg ggcatgctag gcacgtgatt cacactgata 11340
ccctactcct gaagcctgag agcctttttc aaatgtctgt tgttttagtt gggtgttggg 11400
tgtgggcatg agtggaaagg caggtcttcc tattgttcta tccctccttg ccttaattca 11460
ggctctctca ctaaactgga agcttgcttt tgtggttagg tgggctggcc atgagttacc 11520
caaatcaccc ttctctatcc cctccccccc taaactatgg ccacatcaag cagccatgcc 11580
cagctttctg cctgggctct ggagatttga gctcaggtgc tcatatttgc acagcaaagg 11640
ctcttaccca cttagccatc tccccagccc ctttcaaatg tttttttttt taagttttac 11700
actgaactta ggcctatcac tccagcatgc agtaaactga ggcactcaag tctagttatc 11760
ctgggctaca aagtgagaca ttgactaaaa ggaaaaagag aaaaggaagg aagggaggga 11820
gggaggaaga aaggaaggaa ggaaggaagg aaggaaggaa ggaaggaagg aaggaaggaa 11880
gggagggagg gagggaggga gggagggaga aaggagagag agagaaagag gacaaagaag 11940
gagggaaaga tggatggatg gagggaggga gggagggagg gagagaaaga ggggggagtt 12000
cagtggagaa gctagggata tggctcagtt ggcagagtgc ttatctagca tacatgatag 12060
tgaatgccta taatctcaga actctagagg catcattcca aggttttact ttgactccat 12120
agagtttaag gccagcttgg gacacaagag actgtgtctc aaaacaagga aataaaaaca 12180
aaaatctaaa aaacacccac ccagacctat tttaggcacc ttttttgtcc atgctaggca 12240
agtgatttaa cacttagctg catccatagg aagcttgctg gacttctttg tttttgggac 12300
aggagttttg tatgtagccc agataccaga cccagttaca ttggcatttg ttttgctatt 12360
gttattgctt tttgatgtca ttgttgcttt tttttttttt tttttttttt tttttttggc 12420
aagttctcct gtagcccagg cttgcctgga actctggaac ttgataggta gctgatgata 12480
actttgtact cttgatcctc ctatccctat cttccaagtg ctgggattac agtcacgtac 12540
tactctagtt ttaaaattgg atgccttaga taggatcctc cagggagcat aaagagtcca 12600
atcttgtact ggaactccat ctccaagaag gtaaacatta tccttgtgta cataggtagc 12660
cctaggaata atcagttggt gcctatagtg agaagcattt ttttttttat ttagatgagc 12720
agggcatggt ggaacatgtc tttaattcta gcatttggga catagaggca ggaggatcaa 12780
aaggctcaag gccattcttg gctacacaga gagttggagg ttagccagcc tgtgctgaat 12840
gagacccagc ctgaaacaaa aagggggagg tgggagatag aaggatggct cctgtggtaa 12900
atccagagac tcataaaaaa tgctgggcat ggtggcagga gtttgtaatc ccagtgtcgg 12960
ggaggtgaag acaagagaat ccccagggca tgctggccaa ctaactagtc tagcctaatt 13020
ggtgagctcc aggacagtaa gataccctgc ttcaaagaag gcacatggga ttcctgagga 13080
tgccacccaa aggtgtcctc tagcatcctc acatgagcat gcaagaacat gtgcacctga 13140
atgtaacatg tgcgcacaca cacacacaca cacacacaca cacacacaca cacacacatt 13200
tttaaaaagt aatatagagc tggagtgtac ctttgttgat agaacacttg tttaggattc 13260
gtgaaggtct tgatttgatc ctaagcacca tgtaaactgg gcacccatct agaagcccag 13320
cactcagagg tggagacagg aggtcaggag ttcaacaagg tcattctctg ctacacagtg 13380
agtttaaaat cggcctggga tacacgagag agaccctgtg taagagcagt agcagcagca 13440
agaactcaag ctgaaaagga acatgcagtg taagacaaag ggccactgtg tgcatagagc 13500
cagcaacctc acactgtaat gaacgggtct gacctttgca agtaagcttc ttgtgatgct 13560
ctggttgagc ctttgactac gacttttgtg acttgtgctc ctctggatgc ttgcaggatg 13620
agggtgagga cccctggtac cagaaagcat gcaagtgtga ttgccaggta ggagccaatg 13680
ctctgtggtc tgctggagct acctccttag actgta 13716
<210> 25
<211> 3670
<212> DNA
<213> Artificial Sequence
<220>
<223> recombinant or synthetic polynucleotide
<400> 25
aagaactaaa tgaaataaga tgcttaagtt aatcgcctgc tcctatgcca gctctccact 60
tcacttagat cttgctgtga ccaaggacaa ggagaaaatg ggtaccgatt taaatgatcc 120
agtggtcctg cagaggagag attgggagaa tcccggtgtg acacagctga acagactagc 180
cgcccaccct ccctttgctt cttggagaaa cagtgaggaa gctaggacag acagaccaag 240
ccagcaactc agatctttga acggggagtg gagatttgcc tggtttccgg caccagaagc 300
ggtgccggaa agctggctgg agtgcgatct tcctgaggcc gatactgtcg tcgtcccctc 360
aaactggcag atgcacggtt acgatgcgcc catctacacc aacgtgacct atcccattac 420
ggtcaatccg ccgtttgttc ccacggagaa tccgacgggt tgttactcgc tcacatttaa 480
tgttgatgaa agctggctac aggaaggcca gacgcgaatt atttttgatg gcgttaactc 540
ggcgtttcat ctgtggtgca acgggcgctg ggtcggttac ggccaggaca gtcgtttgcc 600
gtctgaattt gacctgagcg catttttacg cgccggagaa aaccgcctcg cggtgatggt 660
gctgcgctgg agtgacggca gttatctgga agatcaggat atgtggcgga tgagcggcat 720
tttccgtgac gtctcgttgc tgcataaacc gactacacaa atcagcgatt tccatgttgc 780
cactcgcttt aatgatgatt tcagccgcgc tgtactggag gctgaagttc agatgtgcgg 840
cgagttgcgt gactacctac gggtaacagt ttctttatgg cagggtgaaa cgcaggtcgc 900
cagcggcacc gcgcctttcg gcggtgaaat tatcgatgag cgtggtggtt atgccgatcg 960
cgtcacacta cgtctgaacg tcgaaaaccc gaaactgtgg agcgccgaaa tcccgaatct 1020
ctatcgtgcg gtggttgaac tgcacaccgc cgacggcacg ctgattgaag cagaagcctg 1080
cgatgtcggt ttccgcgagg tgcggattga aaatggtctg ctgctgctga acggcaagcc 1140
gttgctgatt cgaggcgtta accgtcacga gcatcatcct ctgcatggtc aggtcatgga 1200
tgagcagacg atggtgcagg atatcctgct gatgaagcag aacaacttta acgccgtgcg 1260
ctgttcgcat tatccgaacc atccgctgtg gtacacgctg tgcgaccgct acggcctgta 1320
tgtggtggat gaagccaata ttgaaaccca cggcatggtg ccaatgaatc gtctgaccga 1380
tgatccgcgc tggctaccgg cgatgagcga acgcgtaacg cgaatggtgc agcgcgatcg 1440
taatcacccg agtgtgatca tctggtcgct ggggaatgaa tcaggccacg gcgctaatca 1500
cgacgcgctg tatcgctgga tcaaatctgt cgatccttcc cgcccggtgc agtatgaagg 1560
cggcggagcc gacaccacgg ccaccgatat tatttgcccg atgtacgcgc gcgtggatga 1620
agaccagccc ttcccggctg tgccgaaatg gtccatcaaa aaatggcttt cgctacctgg 1680
agagacgcgc ccgctgatcc tttgcgaata cgcccacgcg atgggtaaca gtcttggcgg 1740
tttcgctaaa tactggcagg cgtttcgtca gtatccccgt ttacagggcg gcttcgtctg 1800
ggactgggtg gatcagtcgc tgattaaata tgatgaaaac ggcaacccgt ggtcggctta 1860
cggcggtgat tttggcgata cgccgaacga tcgccagttc tgtatgaacg gtctggtctt 1920
tgccgaccgc acgccgcatc cagcgctgac ggaagcaaaa caccagcagc agtttttcca 1980
gttccgttta tccgggcaaa ccatcgaagt gaccagcgaa tacctgttcc gtcatagcga 2040
taacgagctc ctgcactgga tggtggcgct ggatggtaag ccgctggcaa gcggtgaagt 2100
gcctctggat gtcgctccac aaggtaaaca gttgattgaa ctgcctgaac taccgcagcc 2160
ggagagcgcc gggcaactct ggctcacagt acgcgtagtg caaccgaacg cgaccgcatg 2220
gtcagaagcc gggcacatca gcgcctggca gcagtggcgt ctggcggaaa acctcagtgt 2280
gacgctcccc gccgcgtccc acgccatccc gcatctgacc accagcgaaa tggatttttg 2340
catcgagctg ggtaataagc gttggcaatt taaccgccag tcaggctttc tttcacagat 2400
gtggattggc gataaaaaac aactgctgac gccgctgcgc gatcagttca cccgtgcacc 2460
gctggataac gacattggcg taagtgaagc gacccgcatt gaccctaacg cctgggtcga 2520
acgctggaag gcggcgggcc attaccaggc cgaagcagcg ttgttgcagt gcacggcaga 2580
tacacttgct gatgcggtgc tgattacgac cgctcacgcg tggcagcatc aggggaaaac 2640
cttatttatc agccggaaaa cctaccggat tgatggtagt ggtcaaatgg cgattaccgt 2700
tgatgttgaa gtggcgagcg atacaccgca tccggcgcgg attggcctga actgccagct 2760
ggcgcaggta gcagagcggg taaactggct cggattaggg ccgcaagaaa actatcccga 2820
ccgccttact gccgcctgtt ttgaccgctg ggatctgcca ttgtcagaca tgtatacccc 2880
gtacgtcttc ccgagcgaaa acggtctgcg ctgcgggacg cgcgaattga attatggccc 2940
acaccagtgg cgcggcgact tccagttcaa catcagccgc tacagtcaac agcaactgat 3000
ggaaaccagc catcgccatc tgctgcacgc ggaagaaggc acatggctga atatcgacgg 3060
tttccatatg gggattggtg gcgacgactc ctggagcccg tcagtatcgg cggaattcca 3120
gctgagcgcc ggtcgctacc attaccagtt ggtctggtgt caaaaataat aataaccggg 3180
caggggggat ctaagctcta gataagtaat gatcataatc agccatatca catctgtaga 3240
ggttttactt gctttaaaaa acctcccaca cctccccctg aacctgaaac ataaaatgaa 3300
tgcaattgtt gttgttaact tgtttattgc agcttataat ggttacaaat aaagcaatag 3360
catcacaaat ttcacaaata aagcattttt ttcactgcat tctagttgtg gtttgtccaa 3420
actcatcaat gtatcttatc atgtctggat cccccggcta gagtttaaac actagaacta 3480
gtggatcccc gggctcgata actataacgg tcctaaggta gcgactcgac ataacttcgt 3540
ataatgtatg ctatacgaag ttatgctagc ttccaggtga gtggctcaac gccctagcat 3600
tcctccttcc aactcttaat ccctctgctt tctctcaagt tggcttgtga gcttcacatc 3660
tcaccgtggc 3670
<210> 26
<211> 5987
<212> DNA
<213> Artificial Sequence
<220>
<223> recombinant or synthetic polynucleotide
<400> 26
gcatgcaaga acatgtgcac ctgaatgtaa catgtgcgca cacacacaca cacacacaca 60
cacacacaca cacacacaca catttttaaa aagtaatata gagctggagt gtacctttgt 120
tgatagaaca cttgtttagg attcgtgaag gtaaactggg cacccatcta gaagcccagc 180
actcagaggt ggagacagga ggtcaggagt tcaacaaggt cattctctgc tacacagtga 240
gtttaaaatc ggcctgggat acacgagaga gaccctgtgt aagagcagta gcagcagcaa 300
gaactcaagc tgaaaaggaa catgcagtgt aagacaaagg gccactgtgt gcatagagcc 360
agcaacctca cactgtaatg aacgggtctg acctttgcaa gtaagcttct tgtgatgctc 420
tggttgagcc tttgactacg acttttgtga cttgtgctcc tctggatgct tgcaggatga 480
gggtgaggac ccctggtacc agaaagcatg caagtgtgat tgccaggtag gagccaatgc 540
tctgtggtct gctggagcta cctccttaga cagtattcca ggtgagtggc tcaacgccct 600
agcattcctc cttccaactc ttaatccctc tgctttctct caagttggct tgtgagcttc 660
acatctcacc gtggccactg ctccaacatt ctgttcatta tcaagtgcca ggctctctcc 720
ctccctggct tgcctgagat ggtcaggtaa gacccctcga gataacttcg tataatgtat 780
gctatacgaa gttatatgca tgccagtagc agcacccacg tccaccttct gtctagtaat 840
gtccaacacc tccctcagtc caaacactgc tctgcatcca tgtggctccc atttatacct 900
gaagcacttg atggggcctc aatgttttac tagagcccac ccccctgcaa ctctgagacc 960
ctctggattt gtctgtcagt gcctcactgg ggcgttggat aatttcttaa aaggtcaagt 1020
tccctcagca gcattctctg agcagtctga agatgtgtgc ttttcacagt tcaaatccat 1080
gtggctgttt cacccacctg cctggccttg ggttatctat caggacctag cctagaagca 1140
ggtgtgtggc acttaacacc taagctgagt gactaactga acactcaagt ggatgccatc 1200
tttgtcactt cttgactgtg acacaagcaa ctcctgatgc caaagccctg cccacccctc 1260
tcatgcccat atttggacat ggtacaggtc ctcactggcc atggtctgtg aggtcctggt 1320
cctctttgac ttcataattc ctaggggcca ctagtatcta taagaggaag agggtgctgg 1380
ctcccaggcc acagcccaca aaattccacc tgctcacagg ttggctggct cgacccaggt 1440
ggtgtcccct gctctgagcc agctcccggc caagccagca ccatgggaac ccccaagaag 1500
aagaggaagg tgcgtaccga tttaaattcc aatttactga ccgtacacca aaatttgcct 1560
gcattaccgg tcgatgcaac gagtgatgag gttcgcaaga acctgatgga catgttcagg 1620
gatcgccagg cgttttctga gcatacctgg aaaatgcttc tgtccgtttg ccggtcgtgg 1680
gcggcatggt gcaagttgaa taaccggaaa tggtttcccg cagaacctga agatgttcgc 1740
gattatcttc tatatcttca ggcgcgcggt ctggcagtaa aaactatcca gcaacatttg 1800
ggccagctaa acatgcttca tcgtcggtcc gggctgccac gaccaagtga cagcaatgct 1860
gtttcactgg ttatgcggcg gatccgaaaa gaaaacgttg atgccggtga acgtgcaaaa 1920
caggtaaata taaaattttt aagtgtataa tgatgttaaa ctactgattc taattgtttg 1980
tgtattttag gctctagcgt tcgaacgcac tgatttcgac caggttcgtt cactcatgga 2040
aaatagcgat cgctgccagg atatacgtaa tctggcattt ctggggattg cttataacac 2100
cctgttacgt atagccgaaa ttgccaggat cagggttaaa gatatctcac gtactgacgg 2160
tgggagaatg ttaatccata ttggcagaac gaaaacgctg gttagcaccg caggtgtaga 2220
gaaggcactt agcctggggg taactaaact ggtcgagcga tggatttccg tctctggtgt 2280
agctgatgat ccgaataact acctgttttg ccgggtcaga aaaaatggtg ttgccgcgcc 2340
atctgccacc agccagctat caactcgcgc cctggaaggg atttttgaag caactcatcg 2400
attgatttac ggcgctaagg atgactctgg tcagagatac ctggcctggt ctggacacag 2460
tgcccgtgtc ggagccgcgc gagatatggc ccgcgctgga gtttcaatac cggagatcat 2520
gcaagctggt ggctggacca atgtaaatat tgtcatgaac tatatccgta acctggatag 2580
tgaaacaggg gcaatggtgc gcctgctgga agatggcgat taggcggccg gccgctaatc 2640
agccatacca catttgtaga ggttttactt gctttaaaaa acctcccaca cctccccctg 2700
aacctgaaac ataaaatgaa tgcaattgtt gttgttaact tgtttattgc agcttataat 2760
ggttacaaat aaagcaatag catcacaaat ttcacaaata aagcattttt ttcactgcat 2820
tctagttgtg gtttgtccaa actcatcaat gtatcttatc atgtctggat cccccggcta 2880
gagtttaaac actagaacta gtggatcccc cgggatcatg gcctccgcgc cgggttttgg 2940
cgcctcccgc gggcgccccc ctcctcacgg cgagcgctgc cacgtcagac gaagggcgca 3000
gcgagcgtcc tgatccttcc gcccggacgc tcaggacagc ggcccgctgc tcataagact 3060
cggccttaga accccagtat cagcagaagg acattttagg acgggacttg ggtgactcta 3120
gggcactggt tttctttcca gagagcggaa caggcgagga aaagtagtcc cttctcggcg 3180
attctgcgga gggatctccg tggggcggtg aacgccgatg attatataag gacgcgccgg 3240
gtgtggcaca gctagttccg tcgcagccgg gatttgggtc gcggttcttg tttgtggatc 3300
gctgtgatcg tcacttggtg agtagcgggc tgctgggctg gccggggctt tcgtggccgc 3360
cgggccgctc ggtgggacgg aagcgtgtgg agagaccgcc aagggctgta gtctgggtcc 3420
gcgagcaagg ttgccctgaa ctgggggttg gggggagcgc agcaaaatgg cggctgttcc 3480
cgagtcttga atggaagacg cttgtgaggc gggctgtgag gtcgttgaaa caaggtgggg 3540
ggcatggtgg gcggcaagaa cccaaggtct tgaggccttc gctaatgcgg gaaagctctt 3600
attcgggtga gatgggctgg ggcaccatct ggggaccctg acgtgaagtt tgtcactgac 3660
tggagaactc ggtttgtcgt ctgttgcggg ggcggcagtt atggcggtgc cgttgggcag 3720
tgcacccgta cctttgggag cgcgcgccct cgtcgtgtcg tgacgtcacc cgttctgttg 3780
gcttataatg cagggtgggg ccacctgccg gtaggtgtgc ggtaggcttt tctccgtcgc 3840
aggacgcagg gttcgggcct agggtaggct ctcctgaatc gacaggcgcc ggacctctgg 3900
tgaggggagg gataagtgag gcgtcagttt ctttggtcgg ttttatgtac ctatcttctt 3960
aagtagctga agctccggtt ttgaactatg cgctcggggt tggcgagtgt gttttgtgaa 4020
gttttttagg caccttttga aatgtaatca tttgggtcaa tatgtaattt tcagtgttag 4080
actagtaaat tgtccgctaa attctggccg tttttggctt ttttgttaga cgtgttgaca 4140
attaatcatc ggcatagtat atcggcatag tataatacga caaggtgagg aactaaacca 4200
tgaaaaagcc tgaactcacc gcgacgtctg tcgagaagtt tctgatcgaa aagttcgaca 4260
gcgtgtccga cctgatgcag ctctcggagg gcgaagaatc tcgtgctttc agcttcgatg 4320
taggagggcg tggatatgtc ctgcgggtaa atagctgcgc cgatggtttc tacaaagatc 4380
gttatgttta tcggcacttt gcatcggccg cgctcccgat tccggaagtg cttgacattg 4440
gggaattcag cgagagcctg acctattgca tctcccgccg tgcacagggt gtcacgttgc 4500
aagacctgcc tgaaaccgaa ctgcccgctg ttctgcagcc ggtcgcggag gccatggatg 4560
cgattgctgc ggccgatctt agccagacga gcgggttcgg cccattcgga ccgcaaggaa 4620
tcggtcaata cactacatgg cgtgatttca tatgcgcgat tgctgatccc catgtgtatc 4680
actggcaaac tgtgatggac gacaccgtca gtgcgtccgt cgcgcaggct ctcgatgagc 4740
tgatgctttg ggccgaggac tgccccgaag tccggcacct cgtgcacgcg gatttcggct 4800
ccaacaatgt cctgacggac aatggccgca taacagcggt cattgactgg agcgaggcga 4860
tgttcgggga ttcccaatac gaggtcgcca acatcttctt ctggaggccg tggttggctt 4920
gtatggagca gcagacgcgc tacttcgagc ggaggcatcc ggagcttgca ggatcgccgc 4980
ggctccgggc gtatatgctc cgcattggtc ttgaccaact ctatcagagc ttggttgacg 5040
gcaatttcga tgatgcagct tgggcgcagg gtcgatgcga cgcaatcgtc cgatccggag 5100
ccgggactgt cgggcgtaca caaatcgccc gcagaagcgc ggccgtctgg accgatggct 5160
gtgtagaagt actcgccgat agtggaaacc gacgccccag cactcgtccg agggcaaagg 5220
aataggggga tccgctgtaa gtctgcagaa attgatgatc tattaaacaa taaagatgtc 5280
cactaaaatg gaagtttttc ctgtcatact ttgttaagaa gggtgagaac agagtaccta 5340
cattttgaat ggaaggattg gagctacggg ggtgggggtg gggtgggatt agataaatgc 5400
ctgctcttta ctgaaggctc tttactattg ctttatgata atgtttcata gttggatatc 5460
ataatttaaa caagcaaaac caaattaagg gccagctcat tcctcccact catgatctat 5520
agatctatag atctctcgtg ggatcattgt ttttctcttg attcccactt tgtggttcta 5580
agtactgtgg tttccaaatg tgtcagtttc atagcctgaa gaacgagatc agcagcctct 5640
gttccacata cacttcattc tcagtattgt tttgccaagt tctaattcca tcagacctcg 5700
acctgcagcc cctagataac ttcgtataat gtatgctata cgaagttatg ctaggtaact 5760
ataacggtcc taaggtagcg agctagcagc gtgagggaag tcccttcctc ttaggtatca 5820
gaggaaatgt gtgtgtgtgt gtgtgtgtgt gtgtttctat atcctgtgga gtcatgctgt 5880
ctctaaatca gtaatgagga tatggagggc aagaatttag taaaacaagt cgcttctaga 5940
agctaaatta ctgtcatttc atggattggc agaaaactgg gcaccca 5987
<210> 27
<211> 1033
<212> DNA
<213> Artificial Sequence
<220>
<223> recombinant or synthetic polynucleotide
<400> 27
gcatgcaaga acatgtgcac ctgaatgtaa catgtgcgca cacacacaca cacacacaca 60
cacacacaca cacacacaca catttttaaa aagtaatata gagctggagt gtacctttgt 120
tgatagaaca cttgtttagg attcgtgaag gtaaactggg cacccatcta gaagcccagc 180
actcagaggt ggagacagga ggtcaggagt tcaacaaggt cattctctgc tacacagtga 240
gtttaaaatc ggcctgggat acacgagaga gaccctgtgt aagagcagta gcagcagcaa 300
gaactcaagc tgaaaaggaa catgcagtgt aagacaaagg gccactgtgt gcatagagcc 360
agcaacctca cactgtaatg aacgggtctg acctttgcaa gtaagcttct tgtgatgctc 420
tggttgagcc tttgactacg acttttgtga cttgtgctcc tctggatgct tgcaggatga 480
gggtgaggac ccctggtacc agaaagcatg caagtgtgat tgccaggtag gagccaatgc 540
tctgtggtct gctggagcta cctccttaga cagtattcca ggtgagtggc tcaacgccct 600
agcattcctc cttccaactc ttaatccctc tgctttctct caagttggct tgtgagcttc 660
acatctcacc gtggccactg ctccaacatt ctgttcatta tcaagtgcca ggctctctcc 720
ctccctggct tgcctgagat ggtcaggtaa gacccctcga gataacttcg tataatgtat 780
gctatacgaa gttatgctag gtaactataa cggtcctaag gtagcgagct agcagcgtga 840
gggaagtccc ttcctcttag gtatcagagg aaatgtgtgt gtgtgtgtgt gtgtgtgtgt 900
ttctatatcc tgtggagtca tgctgtctct aaatcagtaa tgaggatatg gagggcaaga 960
atttagtaaa acaagtcgct tctagaagct aaattactgt catttcatgg attggcagaa 1020
aactgggcac cca 1033
<210> 28
<211> 5629
<212> DNA
<213> Artificial Sequence
<220>
<223> recombinant or synthetic polynucleotide
<400> 28
aagagctcat ttgttaaaca tgccagggaa gtctttccta aggaaaagaa ttaagagtcg 60
ggctatgtct gaaggcccag atacctcttg atgctaggta acccttcaaa actcagcacc 120
tgttggcttt ttacagacat agataagagg atggctcctg gtaatttggt gtgttcctgg 180
caggtgtgct tggctttcca agtatcagga cagcagccag tggttacaga tagatttgaa 240
ggagatcaag gtgatttcgg ggatcctgac ccaaggatgc tgtgacatag acgagtgggt 300
gaccaagtac agtgtgcagt ataggactga tgagcgcctg aactggatct actataagga 360
tcagaccgga aacaatcggg taagtggggg tcactccgag tcagcttcag ctcacactgc 420
ggagacacac tccatcccta tgttcctgct gtccgcgtct gtctgagcat tgacccctct 480
acatgctggg tcatctgctc gagataactt cgtataatgt atgctatacg aagttatatg 540
catgccagta gcagcaccca cgtccacctt ctgtctagta atgtccaaca cctccctcag 600
tccaaacact gctctgcatc catgtggctc ccatttatac ctgaagcact tgatggggcc 660
tcaatgtttt actagagccc acccccctgc aactctgaga ccctctggat ttgtctgtca 720
gtgcctcact ggggcgttgg ataatttctt aaaaggtcaa gttccctcag cagcattctc 780
tgagcagtct gaagatgtgt gcttttcaca gttcaaatcc atgtggctgt ttcacccacc 840
tgcctggcct tgggttatct atcaggacct agcctagaag caggtgtgtg gcacttaaca 900
cctaagctga gtgactaact gaacactcaa gtggatgcca tctttgtcac ttcttgactg 960
tgacacaagc aactcctgat gccaaagccc tgcccacccc tctcatgccc atatttggac 1020
atggtacagg tcctcactgg ccatggtctg tgaggtcctg gtcctctttg acttcataat 1080
tcctaggggc cactagtatc tataagagga agagggtgct ggctcccagg ccacagccca 1140
caaaattcca cctgctcaca ggttggctgg ctcgacccag gtggtgtccc ctgctctgag 1200
ccagctcccg gccaagccag caccatggga acccccaaga agaagaggaa ggtgcgtacc 1260
gatttaaatt ccaatttact gaccgtacac caaaatttgc ctgcattacc ggtcgatgca 1320
acgagtgatg aggttcgcaa gaacctgatg gacatgttca gggatcgcca ggcgttttct 1380
gagcatacct ggaaaatgct tctgtccgtt tgccggtcgt gggcggcatg gtgcaagttg 1440
aataaccgga aatggtttcc cgcagaacct gaagatgttc gcgattatct tctatatctt 1500
caggcgcgcg gtctggcagt aaaaactatc cagcaacatt tgggccagct aaacatgctt 1560
catcgtcggt ccgggctgcc acgaccaagt gacagcaatg ctgtttcact ggttatgcgg 1620
cggatccgaa aagaaaacgt tgatgccggt gaacgtgcaa aacaggtaaa tataaaattt 1680
ttaagtgtat aatgatgtta aactactgat tctaattgtt tgtgtatttt aggctctagc 1740
gttcgaacgc actgatttcg accaggttcg ttcactcatg gaaaatagcg atcgctgcca 1800
ggatatacgt aatctggcat ttctggggat tgcttataac accctgttac gtatagccga 1860
aattgccagg atcagggtta aagatatctc acgtactgac ggtgggagaa tgttaatcca 1920
tattggcaga acgaaaacgc tggttagcac cgcaggtgta gagaaggcac ttagcctggg 1980
ggtaactaaa ctggtcgagc gatggatttc cgtctctggt gtagctgatg atccgaataa 2040
ctacctgttt tgccgggtca gaaaaaatgg tgttgccgcg ccatctgcca ccagccagct 2100
atcaactcgc gccctggaag ggatttttga agcaactcat cgattgattt acggcgctaa 2160
ggatgactct ggtcagagat acctggcctg gtctggacac agtgcccgtg tcggagccgc 2220
gcgagatatg gcccgcgctg gagtttcaat accggagatc atgcaagctg gtggctggac 2280
caatgtaaat attgtcatga actatatccg taacctggat agtgaaacag gggcaatggt 2340
gcgcctgctg gaagatggcg attaggcggc cggccgctaa tcagccatac cacatttgta 2400
gaggttttac ttgctttaaa aaacctccca cacctccccc tgaacctgaa acataaaatg 2460
aatgcaattg ttgttgttaa cttgtttatt gcagcttata atggttacaa ataaagcaat 2520
agcatcacaa atttcacaaa taaagcattt ttttcactgc attctagttg tggtttgtcc 2580
aaactcatca atgtatctta tcatgtctgg atcccccggc tagagtttaa acactagaac 2640
tagtggatcc cccgggatca tggcctccgc gccgggtttt ggcgcctccc gcgggcgccc 2700
ccctcctcac ggcgagcgct gccacgtcag acgaagggcg cagcgagcgt cctgatcctt 2760
ccgcccggac gctcaggaca gcggcccgct gctcataaga ctcggcctta gaaccccagt 2820
atcagcagaa ggacatttta ggacgggact tgggtgactc tagggcactg gttttctttc 2880
cagagagcgg aacaggcgag gaaaagtagt cccttctcgg cgattctgcg gagggatctc 2940
cgtggggcgg tgaacgccga tgattatata aggacgcgcc gggtgtggca cagctagttc 3000
cgtcgcagcc gggatttggg tcgcggttct tgtttgtgga tcgctgtgat cgtcacttgg 3060
tgagtagcgg gctgctgggc tggccggggc tttcgtggcc gccgggccgc tcggtgggac 3120
ggaagcgtgt ggagagaccg ccaagggctg tagtctgggt ccgcgagcaa ggttgccctg 3180
aactgggggt tggggggagc gcagcaaaat ggcggctgtt cccgagtctt gaatggaaga 3240
cgcttgtgag gcgggctgtg aggtcgttga aacaaggtgg ggggcatggt gggcggcaag 3300
aacccaaggt cttgaggcct tcgctaatgc gggaaagctc ttattcgggt gagatgggct 3360
ggggcaccat ctggggaccc tgacgtgaag tttgtcactg actggagaac tcggtttgtc 3420
gtctgttgcg ggggcggcag ttatggcggt gccgttgggc agtgcacccg tacctttggg 3480
agcgcgcgcc ctcgtcgtgt cgtgacgtca cccgttctgt tggcttataa tgcagggtgg 3540
ggccacctgc cggtaggtgt gcggtaggct tttctccgtc gcaggacgca gggttcgggc 3600
ctagggtagg ctctcctgaa tcgacaggcg ccggacctct ggtgagggga gggataagtg 3660
aggcgtcagt ttctttggtc ggttttatgt acctatcttc ttaagtagct gaagctccgg 3720
ttttgaacta tgcgctcggg gttggcgagt gtgttttgtg aagtttttta ggcacctttt 3780
gaaatgtaat catttgggtc aatatgtaat tttcagtgtt agactagtaa attgtccgct 3840
aaattctggc cgtttttggc ttttttgtta gacgtgttga caattaatca tcggcatagt 3900
atatcggcat agtataatac gacaaggtga ggaactaaac catgaaaaag cctgaactca 3960
ccgcgacgtc tgtcgagaag tttctgatcg aaaagttcga cagcgtgtcc gacctgatgc 4020
agctctcgga gggcgaagaa tctcgtgctt tcagcttcga tgtaggaggg cgtggatatg 4080
tcctgcgggt aaatagctgc gccgatggtt tctacaaaga tcgttatgtt tatcggcact 4140
ttgcatcggc cgcgctcccg attccggaag tgcttgacat tggggaattc agcgagagcc 4200
tgacctattg catctcccgc cgtgcacagg gtgtcacgtt gcaagacctg cctgaaaccg 4260
aactgcccgc tgttctgcag ccggtcgcgg aggccatgga tgcgattgct gcggccgatc 4320
ttagccagac gagcgggttc ggcccattcg gaccgcaagg aatcggtcaa tacactacat 4380
ggcgtgattt catatgcgcg attgctgatc cccatgtgta tcactggcaa actgtgatgg 4440
acgacaccgt cagtgcgtcc gtcgcgcagg ctctcgatga gctgatgctt tgggccgagg 4500
actgccccga agtccggcac ctcgtgcacg cggatttcgg ctccaacaat gtcctgacgg 4560
acaatggccg cataacagcg gtcattgact ggagcgaggc gatgttcggg gattcccaat 4620
acgaggtcgc caacatcttc ttctggaggc cgtggttggc ttgtatggag cagcagacgc 4680
gctacttcga gcggaggcat ccggagcttg caggatcgcc gcggctccgg gcgtatatgc 4740
tccgcattgg tcttgaccaa ctctatcaga gcttggttga cggcaatttc gatgatgcag 4800
cttgggcgca gggtcgatgc gacgcaatcg tccgatccgg agccgggact gtcgggcgta 4860
cacaaatcgc ccgcagaagc gcggccgtct ggaccgatgg ctgtgtagaa gtactcgccg 4920
atagtggaaa ccgacgcccc agcactcgtc cgagggcaaa ggaatagggg gatccgctgt 4980
aagtctgcag aaattgatga tctattaaac aataaagatg tccactaaaa tggaagtttt 5040
tcctgtcata ctttgttaag aagggtgaga acagagtacc tacattttga atggaaggat 5100
tggagctacg ggggtggggg tggggtggga ttagataaat gcctgctctt tactgaaggc 5160
tctttactat tgctttatga taatgtttca tagttggata tcataattta aacaagcaaa 5220
accaaattaa gggccagctc attcctccca ctcatgatct atagatctat agatctctcg 5280
tgggatcatt gtttttctct tgattcccac tttgtggttc taagtactgt ggtttccaaa 5340
tgtgtcagtt tcatagcctg aagaacgaga tcagcagcct ctgttccaca tacacttcat 5400
tctcagtatt gttttgccaa gttctaattc catcagacct cgacctgcag cccctagata 5460
acttcgtata atgtatgcta tacgaagtta tgctaggtaa ctataacggt cctaaggtag 5520
cgagctagct tttccagatg tgatctggga gactagcagt ttgtaaatga atgtgggtct 5580
tttttgaaaa aaaggaaaaa aaagtaattt tctagttctc actatcagc 5629
<210> 29
<211> 675
<212> DNA
<213> Artificial Sequence
<220>
<223> recombinant or synthetic polynucleotide
<400> 29
aagagctcat ttgttaaaca tgccagggaa gtctttccta aggaaaagaa ttaagagtcg 60
ggctatgtct gaaggcccag atacctcttg atgctaggta acccttcaaa actcagcacc 120
tgttggcttt ttacagacat agataagagg atggctcctg gtaatttggt gtgttcctgg 180
caggtgtgct tggctttcca agtatcagga cagcagccag tggttacaga tagatttgaa 240
ggagatcaag gtgatttcgg ggatcctgac ccaaggatgc tgtgacatag acgagtgggt 300
gaccaagtac agtgtgcagt ataggactga tgagcgcctg aactggatct actataagga 360
tcagaccgga aacaatcggg taagtggggg tcactccgag tcagcttcag ctcacactgc 420
ggagacacac tccatcccta tgttcctgct gtccgcgtct gtctgagcat tgacccctct 480
acatgctggg tcatctgctc gagataactt cgtataatgt atgctatacg aagttatgct 540
aggtaactat aacggtccta aggtagcgag ctagcttttc cagatgtgat ctgggagact 600
agcagtttgt aaatgaatgt gggtcttttt tgaaaaaaag gaaaaaaaag taattttcta 660
gttctcacta tcagc 675
<210> 30
<211> 680
<212> DNA
<213> Artificial Sequence
<220>
<223> recombinant or synthetic polynucleotide
<400> 30
ccagtagcag cacccacgtc caccttctgt ctagtaatgt ccaacacctc cctcagtcca 60
aacactgctc tgcatccatg tggctcccat ttatacctga agcacttgat ggggcctcaa 120
tgttttacta gagcccaccc ccctgcaact ctgagaccct ctggatttgt ctgtcagtgc 180
ctcactgggg cgttggataa tttcttaaaa ggtcaagttc cctcagcagc attctctgag 240
cagtctgaag atgtgtgctt ttcacagttc aaatccatgt ggctgtttca cccacctgcc 300
tggccttggg ttatctatca ggacctagcc tagaagcagg tgtgtggcac ttaacaccta 360
agctgagtga ctaactgaac actcaagtgg atgccatctt tgtcacttct tgactgtgac 420
acaagcaact cctgatgcca aagccctgcc cacccctctc atgcccatat ttggacatgg 480
tacaggtcct cactggccat ggtctgtgag gtcctggtcc tctttgactt cataattcct 540
aggggccact agtatctata agaggaagag ggtgctggct cccaggccac agcccacaaa 600
attccacctg ctcacaggtt ggctggctcg acccaggtgg tgtcccctgc tctgagccag 660
ctcccggcca agccagcacc 680
<210> 31
<211> 1052
<212> DNA
<213> Artificial Sequence
<220>
<223> recombinant or synthetic polynucleotide
<400> 31
tgccatcatc acaggatgtc cttccttctc cagaagacag actggggctg aaggaaaagc 60
cggccaggct cagaacgagc cccactaatt actgcctcca acagctttcc actcactgcc 120
cccagcccaa catccccttt ttaactggga agcattccta ctctccattg tacgcacacg 180
ctcggaagcc tggctgtggg tttgggcatg agaggcaggg acaacaaaac cagtatatat 240
gattataact ttttcctgtt tccctatttc caaatggtcg aaaggaggaa gttaggtcta 300
cctaagctga atgtattcag ttagcaggag aaatgaaatc ctatacgttt aatactagag 360
gagaaccgcc ttagaatatt tatttcattg gcaatgactc caggactaca cagcgaaatt 420
gtattgcatg tgctgccaaa atactttagc tctttccttc gaagtacgtc ggatcctgta 480
attgagacac cgagtttagg tgactagggt tttcttttga ggaggagtcc cccaccccgc 540
cccgctctgc cgcgacagga agctagcgat ccggaggact tagaatacaa tcgtagtgtg 600
ggtaaacatg gagggcaagc gcctgcaaag ggaagtaaga agattcccag tccttgttga 660
aatccatttg caaacagagg aagctgccgc gggtcgcagt cggtgggggg aagccctgaa 720
ccccacgctg cacggctggg ctggccaggt gcggccacgc ccccatcgcg gcggctggta 780
ggagtgaatc agaccgtcag tattggtaaa gaagtctgcg gcagggcagg gagggggaag 840
agtagtcagt cgctcgctca ctcgctcgct cgcacagaca ctgctgcagt gacactcggc 900
cctccagtgt cgcggagacg caagagcagc gcgcagcacc tgtccgcccg gagcgagccc 960
ggcccgcggc cgtagaaaag gagggaccgc cgaggtgcgc gtcagtactg ctcagcccgg 1020
cagggacgcg ggaggatgtg gactgggtgg ac 1052
<210> 32
<211> 2008
<212> DNA
<213> Artificial Sequence
<220>
<223> recombinant or synthetic polynucleotide
<400> 32
gtggtgctga ctcagcatcg gttaataaac cctctgcagg aggctggatt tcttttgttt 60
aattatcact tggacctttc tgagaactct taagaattgt tcattcgggt ttttttgttt 120
tgttttggtt tggttttttt gggttttttt tttttttttt tttttggttt ttggagacag 180
ggtttctctg tatatagccc tggcacaaga gcaagctaac agcctgtttc ttcttggtgc 240
tagcgccccc tctggcagaa aatgaaataa caggtggacc tacaaccccc cccccccccc 300
ccagtgtatt ctactcttgt ccccggtata aatttgattg ttccgaacta cataaattgt 360
agaaggattt tttagatgca catatcattt tctgtgatac cttccacaca cccctccccc 420
ccaaaaaaat ttttctggga aagtttcttg aaaggaaaac agaagaacaa gcctgtcttt 480
atgattgagt tgggcttttg ttttgctgtg tttcatttct tcctgtaaac aaatactcaa 540
atgtccactt cattgtatga ctaagttggt atcattaggt tgggtctggg tgtgtgaatg 600
tgggtgtgga tctggatgtg ggtgggtgtg tatgccccgt gtgtttagaa tactagaaaa 660
gataccacat cgtaaacttt tgggagagat gatttttaaa aatgggggtg ggggtgaggg 720
gaacctgcga tgaggcaagc aagataaggg gaagacttga gtttctgtga tctaaaaagt 780
cgctgtgatg ggatgctggc tataaatggg cccttagcag cattgtttct gtgaattgga 840
ggatccctgc tgaaggcaaa agaccattga aggaagtacc gcatctggtt tgttttgtaa 900
tgagaagcag gaatgcaagg tccacgctct taataataaa caaacaggac attgtatgcc 960
atcatcacag gatgtccttc cttctccaga agacagactg gggctgaagg aaaagccggc 1020
caggctcaga acgagcccca ctaattactg cctccaacag ctttccactc actgccccca 1080
gcccaacatc ccctttttaa ctgggaagca ttcctactct ccattgtacg cacacgctcg 1140
gaagcctggc tgtgggtttg ggcatgagag gcagggacaa caaaaccagt atatatgatt 1200
ataacttttt cctgtttccc tatttccaaa tggtcgaaag gaggaagtta ggtctaccta 1260
agctgaatgt attcagttag caggagaaat gaaatcctat acgtttaata ctagaggaga 1320
accgccttag aatatttatt tcattggcaa tgactccagg actacacagc gaaattgtat 1380
tgcatgtgct gccaaaatac tttagctctt tccttcgaag tacgtcggat cctgtaattg 1440
agacaccgag tttaggtgac tagggttttc ttttgaggag gagtccccca ccccgccccg 1500
ctctgccgcg acaggaagct agcgatccgg aggacttaga atacaatcgt agtgtgggta 1560
aacatggagg gcaagcgcct gcaaagggaa gtaagaagat tcccagtcct tgttgaaatc 1620
catttgcaaa cagaggaagc tgccgcgggt cgcagtcggt ggggggaagc cctgaacccc 1680
acgctgcacg gctgggctgg ccaggtgcgg ccacgccccc atcgcggcgg ctggtaggag 1740
tgaatcagac cgtcagtatt ggtaaagaag tctgcggcag ggcagggagg gggaagagta 1800
gtcagtcgct cgctcactcg ctcgctcgca cagacactgc tgcagtgaca ctcggccctc 1860
cagtgtcgcg gagacgcaag agcagcgcgc agcacctgtc cgcccggagc gagcccggcc 1920
cgcggccgta gaaaaggagg gaccgccgag gtgcgcgtca gtactgctca gcccggcagg 1980
gacgcgggag gatgtggact gggtggac 2008
<210> 33
<211> 100
<212> DNA
<213> Artificial Sequence
<220>
<223> recombinant or synthetic polynucleotide
<400> 33
gctctccact tcacttagat cttgctgtga ccaaggacaa ggagaaaatg ggtaccgatt 60
taaatgatcc agtggtcctg cagaggagag attgggagaa 100
<210> 34
<211> 100
<212> DNA
<213> Artificial Sequence
<220>
<223> recombinant or synthetic polynucleotide
<400> 34
cagcccctag ataacttcgt ataatgtatg ctatacgaag ttatgctagc ttccaggtga 60
gtggctcaac gccctagcat tcctccttcc aactcttaat 100
<210> 35
<211> 172
<212> DNA
<213> Artificial Sequence
<220>
<223> recombinant or synthetic polynucleotide
<400> 35
atcccccggc tagagtttaa acactagaac tagtggatcc ccgggctcga taactataac 60
ggtcctaagg tagcgactcg acataacttc gtataatgta tgctatacga agttatgcta 120
gcttccaggt gagtggctca acgccctagc attcctcctt ccaactctta at 172
<210> 36
<211> 714
<212> DNA
<213> Artificial Sequence
<220>
<223> recombinant or synthetic polynucleotide
<400> 36
ctggagtgta cctttgttga tagaacactt gtttaggatt cgtgaaggta aactgggcac 60
ccatctagaa gcccagcact cagaggtgga gacaggaggt caggagttca acaaggtcat 120
tctctgctac acagtgagtt taaaatcggc ctgggataca cgagagagac cctgtgtaag 180
agcagtagca gcagcaagaa ctcaagctga aaaggaacat gcagtgtaag acaaagggcc 240
actgtgtgca tagagccagc aacctcacac tgtaatgaac gggtctgacc tttgcaagta 300
agcttcttgt gatgctctgg ttgagccttt gactacgact tttgtgactt gtgctcctct 360
ggatgcttgc aggatgaggg tgaggacccc tggtaccaga aagcatgcaa gtgtgattgc 420
caggtaggag ccaatgctct gtggtctgct ggagctacct ccttagacag tattccaggt 480
gagtggctca acgccctagc attcctcctt ccaactctta atccctctgc tttctctcaa 540
gttggcttgt gagcttcaca tctcaccgtg gccactgctc caacattctg ttcattatca 600
agtgccaggc tctctccctc cctggcttgc ctgagatggt caggtaagac ccctcgagat 660
aacttcgtat aatgtatgct atacgaagtt atatgcatgc cagtagcagc accc 714
<210> 37
<211> 132
<212> DNA
<213> Artificial Sequence
<220>
<223> recombinant or synthetic polynucleotide
<400> 37
ttccatcaga cctcgacctg cagcccctag ataacttcgt ataatgtatg ctatacgaag 60
ttatgctagg taactataac ggtcctaagg tagcgagcta gcagcgtgag ggaagtccct 120
tcctcttagg ta 132
<210> 38
<211> 760
<212> DNA
<213> Artificial Sequence
<220>
<223> recombinant or synthetic polynucleotide
<400> 38
ctggagtgta cctttgttga tagaacactt gtttaggatt cgtgaaggta aactgggcac 60
ccatctagaa gcccagcact cagaggtgga gacaggaggt caggagttca acaaggtcat 120
tctctgctac acagtgagtt taaaatcggc ctgggataca cgagagagac cctgtgtaag 180
agcagtagca gcagcaagaa ctcaagctga aaaggaacat gcagtgtaag acaaagggcc 240
actgtgtgca tagagccagc aacctcacac tgtaatgaac gggtctgacc tttgcaagta 300
agcttcttgt gatgctctgg ttgagccttt gactacgact tttgtgactt gtgctcctct 360
ggatgcttgc aggatgaggg tgaggacccc tggtaccaga aagcatgcaa gtgtgattgc 420
caggtaggag ccaatgctct gtggtctgct ggagctacct ccttagacag tattccaggt 480
gagtggctca acgccctagc attcctcctt ccaactctta atccctctgc tttctctcaa 540
gttggcttgt gagcttcaca tctcaccgtg gccactgctc caacattctg ttcattatca 600
agtgccaggc tctctccctc cctggcttgc ctgagatggt caggtaagac ccctcgagat 660
aacttcgtat aatgtatgct atacgaagtt atgctaggta actataacgg tcctaaggta 720
gcgagctagc agcgtgaggg aagtcccttc ctcttaggta 760
<210> 39
<211> 528
<212> DNA
<213> Artificial Sequence
<220>
<223> recombinant or synthetic polynucleotide
<400> 39
tctttcctaa ggaaaagaat taagagtcgg gctatgtctg aaggcccaga tacctcttga 60
tgctaggtaa cccttcaaaa ctcagcacct gttggctttt tacagacata gataagagga 120
tggctcctgg taatttggtg tgttcctggc aggtgtgctt ggctttccaa gtatcaggac 180
agcagccagt ggttacagat agatttgaag gagatcaagg tgatttcggg gatcctgacc 240
caaggatgct gtgacataga cgagtgggtg accaagtaca gtgtgcagta taggactgat 300
gagcgcctga actggatcta ctataaggat cagaccggaa acaatcgggt aagtgggggt 360
cactccgagt cagcttcagc tcacactgcg gagacacact ccatccctat gttcctgctg 420
tccgcgtctg tctgagcatt gacccctcta catgctgggt catctgctcg agataacttc 480
gtataatgta tgctatacga agttatatgc atgccagtag cagcaccc 528
<210> 40
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> recombinant or synthetic polynucleotide
<400> 40
ttttccagat gtgatctggg agactagcag 30
<210> 41
<211> 574
<212> DNA
<213> Artificial Sequence
<220>
<223> recombinant or synthetic polynucleotide
<400> 41
tctttcctaa ggaaaagaat taagagtcgg gctatgtctg aaggcccaga tacctcttga 60
tgctaggtaa cccttcaaaa ctcagcacct gttggctttt tacagacata gataagagga 120
tggctcctgg taatttggtg tgttcctggc aggtgtgctt ggctttccaa gtatcaggac 180
agcagccagt ggttacagat agatttgaag gagatcaagg tgatttcggg gatcctgacc 240
caaggatgct gtgacataga cgagtgggtg accaagtaca gtgtgcagta taggactgat 300
gagcgcctga actggatcta ctataaggat cagaccggaa acaatcgggt aagtgggggt 360
cactccgagt cagcttcagc tcacactgcg gagacacact ccatccctat gttcctgctg 420
tccgcgtctg tctgagcatt gacccctcta catgctgggt catctgctcg agataacttc 480
gtataatgta tgctatacga agttatgcta ggtaactata acggtcctaa ggtagcgagc 540
tagcttttcc agatgtgatc tgggagacta gcag 574
<210> 42
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 42
tgggacaagt gtaaatgagg ac 22
<210> 43
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 43
agtggtgctt ggccttatgc 20
<210> 44
<211> 26
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 44
tcccaggcaa atcaggacaa agggtc 26
<210> 45
<211> 18
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 45
gagccagcaa cctcacac 18
<210> 46
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 46
gcatccagag gagcacaagt c 21
<210> 47
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 47
tgtaatgaac gggtctgacc tttgcaa 27
<210> 48
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 48
tcgtgaaggt cttgatttga tcct 24
<210> 49
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 49
acctcctgtc tccacctctg 20
<210> 50
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 50
aagcaccatg taaactgggc accc 24
<210> 51
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 51
ccctggcttg cctgagatg 19
<210> 52
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 52
ggacttccct cacgctgagt t 21
<210> 53
<211> 26
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 53
tcaggtaaga cccaattgtc aatgca 26
<210> 54
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 54
gagtcgggct atgtctgaag g 21
<210> 55
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 55
gccaacaggt gctgagttt 19
<210> 56
<211> 28
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 56
ccagatttgg gatgatacct cttgatgc 28
<210> 57
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 57
cctctacatg ctgggtcatc tg 22
<210> 58
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 58
ggacttccct cacgctgagt t 21
<210> 59
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic oligonucleotide
<400> 59
gacccacatt catttacaaa ctgc 24
Claims (79)
- 설치류로서, 내인성 설치류 Rs1 유전자좌에 있는 내인성 설치류 망막층간 단백질-1(Rs1) 유전자의 코딩 서열 전체 또는 일부의 결실을 그의 게놈에 포함하는, 설치류.
- 제1항에 있어서, 상기 결실은 상기 Rs1 유전자좌로부터 생산된 기능적 RS1 폴리펩티드를 결여시키는 것인, 설치류.
- 제1항 또는 제2항에 있어서, 상기 결실은 적어도 엑손 2~3의 결실인, 설치류.
- 제1항 또는 제2항에 있어서, 상기 결실은 엑손 1 및 엑손 2~3의 적어도 일부의 결실인, 설치류.
- 제1항 내지 제4항 중 어느 한 항에 있어서, 상기 Rs1 유전자좌는 리포터 유전자를 포함하는, 설치류.
- 제5항에 있어서, 상기 리포터 유전자는 Rs1 프로모터에 작동 가능하게 연결되는, 설치류.
- 제6항에 있어서, 상기 Rs1 프로모터는 내인성 프로모터인, 설치류.
- 제2항에 있어서, 상기 Rs1 유전자좌는 엑손 1의 ATG 시작 코돈의 바로 3'부터 코딩 부분이 결여되어 있고, 엑손 2~3이 결여되어 있으며, Rs1 유전자의 시작(ATG) 코돈에 프레임 내(in-frame) 융합되는 리포터 유전자 코딩 서열을 포함하는, 설치류.
- 제5항 내지 제8항 중 어느 한 항에 있어서, 상기 리포터 유전자는 lacZ이거나, 루시퍼라아제, 녹색 형광 단백질(GFP), 강화된 GFP(eGFP), 시안 형광 단백질(CFP), 황색 형광 단백질(YFP), 강화된 황색 형광 단백질(eYFP), 청색 형광 단백질(BFP), 강화된 청색 형광 단백질(eBFP), DsRed 및 MmGFP로 이루어진 군으로부터 선택된 단백질을 암호화하는 유전자인, 설치류.
- 제5항 내지 제9항 중 어느 한 항에 있어서, 상기 리포터 유전자의 발현 패턴은 야생형 비인간 동물에서의 내인성 설치류 Rs1 유전자좌에 있는 야생형 설치류 Rs1 유전자의 발현 패턴과 유사한, 설치류.
- 제1항에 있어서, 상기 설치류는 수컷 설치류인, 설치류.
- 제1항에 있어서, 상기 설치류는 암컷 설치류인, 설치류.
- 제12항에 있어서, 상기 설치류는 상기 결실에 대해 동형접합체(homozygous)인, 설치류.
- 제12항에 있어서, 상기 설치류는 상기 결실에 대해 이형접합체(heterozygous)인, 설치류.
- 조작된 Rs1 유전자를 포함하는 게놈을 가진 설치류로서, 조작된 Rs1 유전자는 하나 이상의 점 돌연변이를 엑손에 포함하고, 야생형 RS1 폴리펩티드와 비교해 적어도 하나의 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하는, 설치류.
- 제15항에 있어서, 상기 적어도 하나의 아미노산 치환은 신호 서열에서의 치환인, 설치류.
- 제16항에 있어서, 상기 적어도 하나의 아미노산 치환은 소수성 잔기가 프롤린으로 치환되거나 친수성 또는 하전된 잔기로 치환되는 것인, 설치류.
- 제15항에 있어서, 상기 적어도 하나의 아미노산 치환은 디스코이딘 도메인의 측면에 위치하는 C-말단 분절 또는 RS1 영역에서의 치환인, 설치류.
- 제18항에 있어서, 상기 적어도 하나의 아미노산 치환은 38, 40, 59 및 223으로 이루어진 군으로부터 선택된 위치에서의 시스테인의 치환인, 설치류.
- 제19항에 있어서, 상기 적어도 하나의 아미노산 치환은 C59S 치환인, 설치류.
- 제15항에 있어서, 상기 적어도 하나의 아미노산 치환은 디스코이딘 도메인에서의 치환인, 설치류.
- 제21항에 있어서, 상기 적어도 하나의 아미노산 치환은 63, 83, 110, 142 및 219로 이루어진 군으로부터 선택된 위치에서의 시스테인의 치환인, 설치류.
- 제21항에 있어서, 상기 적어도 하나의 아미노산 치환은 상기 디스코이딘 도메인에서 비-시스테인이 시스테인으로 치환되는 것인, 설치류.
- 제23항에 있어서, 상기 적어도 하나의 아미노산 치환은 R141C 치환인, 설치류.
- 제21항에 있어서, 상기 적어도 하나의 아미노산 치환은 디스코이딘 도메인에서 하전된 잔기가 비-하전된 잔기로 치환되는 것, 비-하전된 잔기가 하전된 잔기로 치환되는 것, 또는 하전된 잔기가 역 하전된 잔기로 치환되는 것인, 설치류.
- 제21항에 있어서, 상기 적어도 하나의 아미노산 치환은 디스코이딘 도메인에서 프롤린의 삽입 또는 제거에 의한 치환인, 설치류.
- 제21항에 있어서, 상기 적어도 하나의 아미노산 치환은 디스코이딘 도메인에서 극성 잔기의 삽입 또는 제거에 의한 치환인, 설치류.
- 제15항 내지 제27항 중 어느 한 항에 있어서, 상기 조작된 Rs1 유전자는 하나 이상의 선택 마커를 추가로 포함하는, 설치류.
- 제15항 내지 제27항 중 어느 한 항에 있어서, 상기 조작된 Rs1 유전자는 하나 이상의 부위 특이적 재조합효소 인식 부위를 추가로 포함하는, 설치류.
- 제29항에 있어서, 상기 조작된 Rs1 유전자는 재조합효소 유전자, 및 상기 하나 이상의 부위 특이적 재조합효소 인식 부위가 측면에 위치한 선택 마커를 추가로 포함하되, 상기 부위 특이적 재조합효소 인식 부위는 절제를 유도하도록 배향되는, 설치류.
- 제30항에 있어서, 상기 재조합효소 유전자는, 분화된 세포에서 상기 재조합효소 유전자의 발현을 유도하지만 미분화 세포에서는 상기 재조합효소 유전자의 발현을 유도하지 않는 프로모터에 작동 가능하게 연결되는, 설치류.
- 제20항 또는 제21항에 있어서, 상기 프로모터는 서열 번호 30, 서열 번호 31, 또는 서열 번호 32이거나 이를 포함하는, 설치류.
- 제15항 내지 제32항 중 어느 한 항에 있어서, 상기 조작된 Rs1 유전자는 내인성 설치류 Rs1 유전자좌에 있는, 설치류.
- 제33항에 있어서, 상기 점 돌연변이는 상기 내인성 설치류의 Rs1 유전자좌에 있는 상기 내인성 설치류 Rs1 유전자의 엑손 내에 있는, 설치류.
- 제33항 내지 제34항 중 어느 한 항에 있어서, 상기 설치류는 수컷 설치류인, 설치류.
- 제33항 내지 제34항 중 어느 한 항에 있어서, 상기 설치류는 암컷 설치류인, 설치류.
- 제36항에 있어서, 상기 설치류는 상기 조작된 Rs1 유전자에 대해 동형접합체인, 설치류.
- 제36항에 있어서, 상기 설치류는 상기 조작된 Rs1 유전자에 대해 이형접합체인, 설치류.
- C59S 또는 R141C 치환을 포함하는 RS1 폴리펩티드를 발현하는 설치류.
- 제1항 내지 제39항 중 어느 한 항에 있어서, 상기 설치류는 망막층간분리증의 하나 이상의 증상을 발생시키되, 선택적으로는 출생 후 15, 18, 21 또는 24일까지 발생시키는, 설치류.
- 제1항 내지 제40항 중 어느 한 항에 있어서, 상기 설치류는 랫트 또는 마우스인, 설치류.
- 단리된 설치류 세포 또는 조직으로서, 이의 게놈은
(i) 내인성 설치류 Rs1 유전자좌 내의 내인성 설치류 Rs1 유전자의 코딩 서열 전체 또는 일부의 결실을 포함하거나,
(ii) 하나 이상의 점 돌연변이를 엑손에 포함하며 하나 이상의 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하는 조작된 Rs1 유전자를 포함하는, 단리된 설치류 세포 또는 조직. - 제42항의 상기 단리된 설치류 세포로부터 만들어진 불멸화 세포.
- 설치류 배아 줄기(ES) 세포로서, 이의 게놈은
(i) 내인성 설치류 Rs1 유전자좌 내의 내인성 설치류 Rs1 유전자의 코딩 서열 전체 또는 일부의 결실을 포함하거나,
(ii) 하나 이상의 점 돌연변이를 엑손에 포함하며 하나 이상의 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하는 조작된 Rs1 유전자를 포함하는, 설치류 배아 줄기(ES) 세포. - 제44항의 상기 배아 줄기 세포로부터 생성된 설치류 배아.
- 제1항 내지 제41항 중 어느 한 항의 상기 설치류, 제42항의 상기 단리된 설치류 세포, 제43항의 상기 불멸화 세포, 제44항의 상기 설치류 배아 줄기 세포, 또는 제45항의 상기 설치류 배아를 포함하는 키트.
- 유전자 변형 설치류를 만드는 방법으로서, 상기 방법은
설치류 게놈을 변형시키되, 상기 변형된 게놈이
(i) 내인성 설치류 Rs1 유전자좌 내의 내인성 설치류 Rs1 유전자의 코딩 서열 전체 또는 일부의 결실을 포함하거나,
(ii) 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하는 조작된 Rs1 유전자를 포함하도록 변형시키는 단계; 및
상기 변형된 게놈을 포함하는 유전자 변형 설치류를 만드는 단계를 포함하는, 방법. - 제47항에 있어서, 상기 설치류 게놈은
(a) 핵산 서열을 설치류 ES 세포의 게놈에 도입하여, (i)의 상기 결실 또는 (ii)의 상기 조작된 Rs1 유전자를 포함하는 게놈을 가진 유전자 변형 설치류 ES 세포를 획득하는 단계; 및
(b) (a) 단계의 상기 유전자 변형 설치류 ES 세포를 사용해 설치류를 생성하는 단계를 포함하는 방법에 의해 변형되는, 방법. - 제48항에 있어서, 상기 조작된 Rs1 유전자는 내인성 설치류 Rs1 유전자좌에 있는 내인성 설치류 Rs1 유전자의 엑손에 점 돌연변이를 생성하는, 상기 설치류 ES 세포 내로의 상기 핵산 서열의 도입에 의해 생성되는, 방법.
- 제49항에 있어서, 상기 내인성 설치류 Rs1 유전자의 엑손 3은 C59S 치환을 포함하는 RS1 폴리펩티드를 암호화하도록 돌연변이되는, 방법.
- 제49항에 있어서, 상기 내인성 설치류 Rs1 유전자의 엑손 5는 R141C 치환을 포함하는 RS1 폴리펩티드를 암호화하도록 돌연변이되는, 방법.
- 제48항에 있어서, 상기 결실은 상기 Rs1 유전자좌에 있는 상기 Rs1 유전자의 코딩 서열의 엑손 1 및 엑손 2~3의 일부가 결실되는 것인, 방법.
- 제48항 내지 제52항 중 어느 한 항에 있어서, 상기 핵산 서열은 하나 이상의 선택 마커를 추가로 포함하는, 방법.
- 제48항 내지 제53항 중 어느 한 항에 있어서, 상기 핵산 서열은 하나 이상의 부위 특이적 재조합효소 인식 부위를 추가로 포함하는, 방법.
- 제54항에 있어서, 상기 핵산 서열은 재조합효소 유전자, 및 상기 하나 이상의 부위 특이적 재조합효소 인식 부위가 측면에 위치한 선택 마커를 추가로 포함하되, 상기 부위 특이적 재조합효소 인식 부위는 절제를 유도하도록 배향되는, 방법.
- 제55항에 있어서, 상기 핵산 서열은 상기 선택 마커의 하류에 있는 리포터 유전자를 추가로 포함하는, 방법.
- 제55항 또는 제56항에 있어서, 상기 재조합효소 유전자는 발달 조절되는 프로모터에 작동 가능하게 연결되는, 방법.
- 제57항에 있어서, 상기 프로모터는 서열 번호 30, 서열 번호 31, 또는 서열 번호 32이거나 이를 포함하는, 방법.
- 제52항에 있어서, 상기 결실을 포함하는 상기 Rs1 유전자좌는 리포터 유전자를 추가로 포함하는, 방법.
- 제59항에 있어서, 상기 리포터 유전자는 설치류 Rs1 프로모터에 작동 가능하게 연결되는, 방법.
- 제60항에 있어서, 상기 설치류 Rs1 프로모터는 상기 Rs1 유전자좌에 있는 상기 내인성 Rs1 프로모터인, 방법.
- 제59항 내지 제61항 중 어느 한 항에 있어서, 상기 결실은 엑손 1 내의 상기 ATG 시작 코돈 바로 다음부터 시작하여 상기 Rs1 유전자의 엑손 3의 엑손 3의 마지막 6개의 뉴클레오티드까지의 결실이며, 상기 리포터 유전자의 상기 코딩 서열은 상기 Rs1 유전자의 엑손 1 내의 상기 시작(ATG) 코돈에 프레임 내(in-frame) 융합되는, 방법.
- 제56항 또는 제59항 내지 제62항 중 어느 한 항에 있어서, 상기 리포터 유전자는 lacZ이거나 루시퍼라아제, GFP, eGFP, CFP, YFP, eYFP, BFP, eBFP, DsRed, 및 MmGFP로 이루어진 군으로부터 선택되는 단백질을 암호화하는 유전자인, 방법.
- 제56항 또는 제59항 내지 제63항 중 어느 한 항에 있어서, 상기 리포터 유전자의 발현 패턴은 내인성 설치류 Rs1 유전자좌에 있는 야생형 설치류 Rs1 유전자의 발현 패턴과 유사한, 방법.
- 제47항 내지 제64항 중 어느 한 항에 있어서, 상기 설치류는 수컷 설치류인, 방법.
- 제47항 내지 제64항 중 어느 한 항에 있어서, 상기 설치류는 암컷 설치류인, 방법.
- 제66항에 있어서, 상기 설치류는 상기 조작된 Rs1 유전자의 상기 결실에 대해 동형접합체인, 방법.
- 제47항 내지 제67항 중 어느 한 항의 방법에 의해 수득될 수 있는 설치류.
- 설치류에서 망막층간분리증의 치료를 위한 치료제를 식별하는 방법으로서, 상기 방법은
(a) 하나 이상의 제제를 설치류에게 투여하되, 상기 설치류의 게놈은
(i) 내인성 설치류 Rs1 유전자좌 내의 내인성 설치류 Rs1 유전자의 코딩 서열 전체 또는 일부의 결실을 포함하거나,
(ii) 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하는 조작된 Rs1 유전자를 포함하는 것인, 단계;
(b) 상기 하나 이상의 제제가 망막층간분리증과 관련된 하나 이상의 징후, 증상 및/또는 병태에 대해 효과가 있는지 여부를 결정하기 위한 하나 이상의 분석을 수행하는 단계; 및
(c) 망막층간분리증과 관련된 상기 하나 이상의 징후, 증상 및/또는 병태에 효과가 있는 상기 하나 이상의 제제를 치료제로서 식별하는 단계를 포함하는, 방법. - 설치류에서 안구와 연관된 질환, 장애 또는 병태의 치료를 위한 치료제를 식별하는 방법으로서, 상기 방법은
(a) 하나 이상의 제제를 설치류에게 투여하되, 상기 설치류의 게놈은
(i) 내인성 설치류 Rs1 유전자좌 내의 내인성 설치류 Rs1 유전자의 코딩 서열 전체 또는 일부의 결실을 포함하거나,
(ii) 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하는 조작된 Rs1 유전자를 포함하는 것인, 단계;
(b) 상기 하나 이상의 제제가 안구와 관련된 질환, 장애 또는 병태와 관련된 하나 이상의 징후, 증상 및/또는 병태에 대해 효과가 있는지 여부를 결정하기 위한 하나 이상의 분석을 수행하는 단계; 및
(c) 안구와 관련된 상기 하나 이상의 질환, 장애 또는 병태와 관련된 상기 하나 이상의 징후, 증상 및/또는 병태에 효과가 있는 상기 하나 이상의 제제를 치료제로서 식별하는 단계를 포함하는, 방법. - 제69항 또는 제70항에 있어서, 상기 설치류의 게놈은 C59S 치환을 갖는 RS1 폴리펩티드를 암호화하는 조작된 Rs1 유전자를 포함하는, 방법.
- 제69항 또는 제70항에 있어서, 상기 설치류의 게놈은 R141C 치환을 갖는 RS1 폴리펩티드를 암호화하는 조작된 Rs1 유전자를 포함하는, 방법.
- 제69항 또는 제70항에 있어서, 상기 설치류의 게놈은 내인성 설치류 Rs1 유전자좌 내에 있는 내인성 설치류 Rs1 유전자의 코딩 서열의 엑손 1 및 엑손 2~3의 적어도 일부의 결실을 포함하는, 방법.
- 제69항 또는 제70항에 있어서, 상기 하나 이상의 제제는 출생 시 또는 출생 직후에 상기 설치류에 투여되는, 방법.
- 제74항에 있어서, 상기 하나 이상의 분석은 출생 후 15~24일차에 수행되는, 방법.
- 제47항 내지 제75항 중 어느 한 항에 있어서, 상기 설치류는 랫트 또는 마우스인, 방법.
- 핵산 작제물로서,
설치류 Rs1 유전자좌에 있는 설치류 Rs1 유전자에 통합될 핵산 서열로서, 설치류 Rs1 유전자좌에 있는 뉴클레오티드 서열에 상동인 5' 뉴클레오티드 서열 및 3' 뉴클레오티드 서열이 측면에 위치한 핵산 서열을 포함하되, 상기 핵산 서열이 상기 설치류 Rs1 유전자에 통합되면
(i) 설치류 Rs1 유전자의 코딩 서열의 전체 또는 일부가 결실되거나,
(ii) 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하는 조작된 Rs1 유전자가 생성되는, 핵산 작제물. - 제77항에 있어서, 상기 핵산 서열은 리포터 유전자를 포함하며, 상기 핵산 서열이 통합되면 엑손 1 및 엑손 2~3의 일부가 결실되는, 핵산 작제물.
- 제77항에 있어서, 상기 핵산 서열은, 상기 핵산 서열이 상기 설치류 Rs1 유전자에 통합되는 것에 의해 아미노산 치환을 갖는 RS1 폴리펩티드를 암호화하는 조작된 Rs1 유전자가 생성되도록, 돌연변이체 Rs1 엑손을 포함하는, 핵산 작제물.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201762463872P | 2017-02-27 | 2017-02-27 | |
| US62/463,872 | 2017-02-27 | ||
| US201762576256P | 2017-10-24 | 2017-10-24 | |
| US62/576,256 | 2017-10-24 | ||
| PCT/US2018/019721 WO2018157058A1 (en) | 2017-02-27 | 2018-02-26 | Non-human animal models of retinoschisis |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20190122232A true KR20190122232A (ko) | 2019-10-29 |
Family
ID=61627173
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020197027972A Withdrawn KR20190122232A (ko) | 2017-02-27 | 2018-02-26 | 망막층간분리증의 비인간 동물 모델 |
Country Status (12)
| Country | Link |
|---|---|
| US (2) | US11064685B2 (ko) |
| EP (1) | EP3585158B1 (ko) |
| JP (1) | JP2020508073A (ko) |
| KR (1) | KR20190122232A (ko) |
| CN (1) | CN110461146A (ko) |
| AU (1) | AU2018224227A1 (ko) |
| CA (1) | CA3053386A1 (ko) |
| ES (1) | ES2953875T3 (ko) |
| IL (1) | IL268621A (ko) |
| RU (1) | RU2019125818A (ko) |
| SG (1) | SG11201907490XA (ko) |
| WO (1) | WO2018157058A1 (ko) |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU2018224227A1 (en) | 2017-02-27 | 2019-08-29 | Regeneron Pharmaceuticals, Inc. | Non-human animal models of Retinoschisis |
| CN111621502B (zh) * | 2019-02-28 | 2023-05-02 | 武汉纽福斯生物科技有限公司 | 视网膜劈裂蛋白的编码序列、其表达载体构建及其应用 |
| US20200288683A1 (en) * | 2019-03-15 | 2020-09-17 | Regeneron Pharmaceuticals, Inc. | Loss of function rodent model of solute carrier 39 member 5 |
| CN114761563B (zh) * | 2019-05-15 | 2026-01-27 | 艾迪姆丹麦公司 | 诱导型质粒自毁辅助重组 |
| CN112899311B (zh) * | 2019-11-19 | 2023-04-28 | 上海朗昇生物科技有限公司 | 一种rs1-ko小鼠模型的构建方法及其应用 |
| EP4323390A1 (en) | 2021-04-16 | 2024-02-21 | Regeneron Pharmaceuticals, Inc. | Treatment of x-linked juvenile retinoschisis |
| CN115851745B (zh) * | 2022-10-19 | 2023-10-27 | 河南省人民医院 | 调控Esrrb活性的物质在制备用于干预视网膜劈裂症的产品中的应用 |
| CN115968834A (zh) * | 2023-01-20 | 2023-04-18 | 北京因诺惟康医药科技有限公司 | 一种rs1点突变小鼠模型的制备方法及其用途 |
| CN117683779B (zh) * | 2024-01-26 | 2024-04-30 | 广州嘉检医学检测有限公司 | 视网膜劈裂症相关的基因突变体及其应用 |
Family Cites Families (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5670356A (en) | 1994-12-12 | 1997-09-23 | Promega Corporation | Modified luciferase |
| US5874304A (en) | 1996-01-18 | 1999-02-23 | University Of Florida Research Foundation, Inc. | Humanized green fluorescent protein genes and methods |
| AU8587598A (en) | 1997-07-26 | 1999-02-16 | Wisconsin Alumni Research Foundation | Trans-species nuclear transfer |
| US6586251B2 (en) | 2000-10-31 | 2003-07-01 | Regeneron Pharmaceuticals, Inc. | Methods of modifying eukaryotic cells |
| AUPR451401A0 (en) | 2001-04-20 | 2001-05-24 | Monash University | A method of nuclear transfer |
| US7612250B2 (en) | 2002-07-29 | 2009-11-03 | Trustees Of Tufts College | Nuclear transfer embryo formation method |
| US20040261141A1 (en) * | 2003-04-30 | 2004-12-23 | Weber Bernhard Heinrich Friedrich | Animal model for therapy of diseases of the eye |
| ES2463476T3 (es) | 2004-10-19 | 2014-05-28 | Regeneron Pharmaceuticals, Inc. | Método para generar un ratón homocigótico para una modificación genética |
| US20100004156A1 (en) * | 2005-07-27 | 2010-01-07 | Shalesh Kaushal | Small Compounds That Correct Protein Misfolding and Uses Thereof |
| CN101117633B (zh) | 2006-08-03 | 2011-07-20 | 上海交通大学附属儿童医院 | 一种细胞核移植方法 |
| US8518392B2 (en) | 2009-08-14 | 2013-08-27 | Regeneron Pharmaceuticals, Inc. | Promoter-regulated differentiation-dependent self-deleting cassette |
| MX377561B (es) * | 2012-11-05 | 2025-03-10 | Regeneron Pharma | Animales no humanos genéticamente modificados y métodos de uso de los mismos. |
| MX384291B (es) | 2013-02-20 | 2025-03-14 | Regeneron Pharma | Modificación genética de ratas. |
| DK3456831T3 (da) | 2013-04-16 | 2021-09-06 | Regeneron Pharma | Målrettet modifikation af rottegenom |
| CN104250656A (zh) * | 2013-06-28 | 2014-12-31 | 上海人类基因组研究中心 | Irtks基因剔除的小鼠模型及其构建方法与应用 |
| MY198884A (en) * | 2013-08-07 | 2023-10-02 | Regeneron Pharma | Lincrna-deficient non-human animals |
| MX2016009331A (es) * | 2014-01-23 | 2016-10-26 | Akebia Therapeutics Inc | Composiciones y metodos para tratar enfermedades oculares. |
| AU2018224227A1 (en) | 2017-02-27 | 2019-08-29 | Regeneron Pharmaceuticals, Inc. | Non-human animal models of Retinoschisis |
| CN107287243A (zh) * | 2017-06-20 | 2017-10-24 | 温州医科大学 | 一种人源性视网膜劈裂症转基因小鼠模型及其构建方法 |
-
2018
- 2018-02-26 AU AU2018224227A patent/AU2018224227A1/en not_active Abandoned
- 2018-02-26 RU RU2019125818A patent/RU2019125818A/ru not_active Application Discontinuation
- 2018-02-26 ES ES18710956T patent/ES2953875T3/es active Active
- 2018-02-26 US US15/905,068 patent/US11064685B2/en active Active
- 2018-02-26 CN CN201880021518.XA patent/CN110461146A/zh active Pending
- 2018-02-26 CA CA3053386A patent/CA3053386A1/en active Pending
- 2018-02-26 WO PCT/US2018/019721 patent/WO2018157058A1/en not_active Ceased
- 2018-02-26 EP EP18710956.6A patent/EP3585158B1/en active Active
- 2018-02-26 JP JP2019546349A patent/JP2020508073A/ja active Pending
- 2018-02-26 KR KR1020197027972A patent/KR20190122232A/ko not_active Withdrawn
- 2018-02-26 SG SG11201907490XA patent/SG11201907490XA/en unknown
-
2019
- 2019-08-11 IL IL26862119A patent/IL268621A/en unknown
-
2021
- 2021-06-16 US US17/348,907 patent/US12082565B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| WO2018157058A1 (en) | 2018-08-30 |
| SG11201907490XA (en) | 2019-09-27 |
| US20180255754A1 (en) | 2018-09-13 |
| EP3585158B1 (en) | 2023-07-05 |
| AU2018224227A1 (en) | 2019-08-29 |
| RU2019125818A (ru) | 2021-03-29 |
| US12082565B2 (en) | 2024-09-10 |
| US11064685B2 (en) | 2021-07-20 |
| JP2020508073A (ja) | 2020-03-19 |
| EP3585158C0 (en) | 2023-07-05 |
| IL268621A (en) | 2019-10-31 |
| ES2953875T3 (es) | 2023-11-16 |
| CN110461146A (zh) | 2019-11-15 |
| EP3585158A1 (en) | 2020-01-01 |
| US20210307304A1 (en) | 2021-10-07 |
| CA3053386A1 (en) | 2018-08-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20190122232A (ko) | 망막층간분리증의 비인간 동물 모델 | |
| JP7665609B2 (ja) | オトフェリン二重ベクター系及びそれを含む感音難聴を治療するための組成物 | |
| KR20190137126A (ko) | 조직 선택적 트랜스진 발현 | |
| EP1471926B1 (en) | Compositions and methods for the therapeutic use of an atonal-associated sequence | |
| KR20190057104A (ko) | C9orf72 유전자좌에서 헥사뉴클레오티드 반복 확장을 갖는 비인간 동물 | |
| US20190263883A1 (en) | Method for augmenting vision in persons suffering from photoreceptor cell degeneration | |
| JP7610672B2 (ja) | ヒト化trkb遺伝子座を含む非ヒト動物 | |
| AU2018262427B2 (en) | Gene therapy for ciliopathies | |
| CN115461082A (zh) | 用于治疗遗传性黄斑变性的组合物和方法 | |
| TW202307213A (zh) | 血管收縮素轉化酶ii(ace2)基因轉殖動物及其用途 | |
| KR20170127459A (ko) | 저하된 상위 및 하위 운동 뉴런 기능 및 감각 지각을 나타내는 비-인간 동물 | |
| AU2020313004A1 (en) | Therapeutic agent for disease caused by dominant mutant gene | |
| RU2800428C2 (ru) | НЕ ЯВЛЯЮЩИЕСЯ ЧЕЛОВЕКОМ ЖИВОТНЫЕ, СОДЕРЖАЩИЕ ГУМАНИЗИРОВАННЫЙ ЛОКУС TrkB | |
| EP4475671A1 (en) | Compositions and methods for defining optimal treatment timeframes in lysosomal disease | |
| HK40104014A (en) | Rats comprising a humanized trkb locus | |
| CN116139297A (zh) | Rnf20基因在制备无精子症的治疗药物中的应用及治疗药物 | |
| HK40017997A (en) | Rats comprising a humanized trkb locus | |
| HK40017997B (en) | Rats comprising a humanized trkb locus | |
| JPWO2004060055A1 (ja) | Wt1遺伝子トランスジェニック動物 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20190924 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| PG1501 | Laying open of application | ||
| PC1203 | Withdrawal of no request for examination |