이하, 본 발명의 다양한 실시 예가 첨부된 도면을 참조하여 기재된다. 그러나, 이는 본 발명을 특정한 실시 형태에 대해 한정하려는 것이 아니며, 본 발명의 실시 예의 다양한 변경(modification), 균등물(equivalent), 및/또는 대체물(alternative)을 포함하는 것으로 이해되어야 한다.
도 1은, 다양한 실시 예들에 따른, 네트워크 환경(100) 내의 전자 장치(101)의 블록도이다. 도 1을 참조하면, 네트워크 환경(100)에서 전자 장치(101)는 제1 네트워크(198)(예: 근거리 무선 통신 네트워크)를 통하여 전자 장치(102)와 통신하거나, 또는 제2 네트워크(199)(예: 원거리 무선 통신 네트워크)를 통하여 전자 장치(104) 또는 서버(108)와 통신할 수 있다. 일 실시 예에 따르면, 전자 장치(101)는 서버(108)를 통하여 전자 장치(104)와 통신할 수 있다. 일 실시 예에 따르면, 전자 장치(101)는 프로세서(120), 메모리(130), 입력 장치(150), 음향 출력 장치(155), 표시 장치(160), 오디오 모듈(170), 센서 모듈(176), 인터페이스(177), 햅틱 모듈(179), 카메라 모듈(180), 전력 관리 모듈(188), 배터리(189), 통신 모듈(190), 가입자 식별 모듈(196), 또는 안테나 모듈(197)을 포함할 수 있다. 어떤 실시 예에서는, 전자 장치(101)에는, 이 구성요소들 중 적어도 하나(예: 표시 장치(160) 또는 카메라 모듈(180))가 생략되거나, 하나 이상의 다른 구성 요소가 추가될 수 있다. 어떤 실시 예에서는, 이 구성요소들 중 일부들은 하나의 통합된 회로로 구현될 수 있다. 예를 들면, 센서 모듈(176)(예: 지문 센서, 홍채 센서, 또는 조도 센서)은 표시 장치(160)(예: 디스플레이)에 임베디드(embedded) 된 채 구현될 수 있다
프로세서(120)는, 예를 들면, 소프트웨어(예: 프로그램(140))를 실행하여 프로세서(120)에 연결된 전자 장치(101)의 적어도 하나의 다른 구성요소(예: 하드웨어 또는 소프트웨어 구성요소)을 제어할 수 있고, 다양한 데이터 처리 또는 연산을 수행할 수 있다. 일 실시 예에 따르면, 데이터 처리 또는 연산의 적어도 일부로서, 프로세서(1020)는 다른 구성요소(예: 센서 모듈(176) 또는 통신 모듈(190))로부터 수신된 명령 또는 데이터를 휘발성 메모리(132)에 로드하고, 휘발성 메모리(132)에 저장된 명령 또는 데이터를 처리하고, 결과 데이터를 비 휘발성 메모리(134)에 저장할 수 있다. 일 실시 예에 따르면, 프로세서(120)는 메인 프로세서(121)(예: 중앙 처리 장치 또는 어플리케이션 프로세서), 및 이와는 독립적으로 또는 함께 운영 가능한 보조 프로세서(123)(예: 그래픽 처리 장치, 이미지 시그널 프로세서, 센서 허브 프로세서, 또는 커뮤니케이션 프로세서)를 포함할 수 있다. 추가적으로 또는 대체적으로, 보조 프로세서(123)는 메인 프로세서(121)보다 저전력을 사용하거나, 또는 지정된 기능에 특화되도록 설정될 수 있다. 보조 프로세서(123)는 메인 프로세서(121)와 별개로, 또는 그 일부로서 구현될 수 있다.
보조 프로세서(123)는, 예를 들면, 메인 프로세서(121)가 비활성(inactive)(예: 슬립) 상태에 있는 동안 메인 프로세서(121)를 대신하여, 또는 메인 프로세서(121)가 액티브(예: 어플리케이션 실행) 상태에 있는 동안 메인 프로세서(121)와 함께, 전자 장치(101)의 구성요소들 중 적어도 하나의 구성요소(예: 표시 장치(160), 센서 모듈(176), 또는 통신 모듈(190))와 관련된 기능 또는 상태들의 적어도 일부를 제어할 수 있다. 일 실시 예에 따르면, 보조 프로세서(123)(예: 이미지 시그널 프로세서 또는 커뮤니케이션 프로세서)는 기능적으로 관련 있는 다른 구성 요소(예: 카메라 모듈(180) 또는 통신 모듈(190))의 일부로서 구현될 수 있다.
메모리(130)는, 전자 장치(101)의 적어도 하나의 구성요소(예: 프로세서(120) 또는 센서모듈(176))에 의해 사용되는 다양한 데이터를 저장할 수 있다. 데이터는, 예를 들어, 소프트웨어(예: 프로그램(140)) 및, 이와 관련된 명령에 대한 입력 데이터 또는 출력 데이터를 포함할 수 있다. 메모리(130)는, 휘발성 메모리(132) 또는 비 휘발성 메모리(134)를 포함할 수 있다.
프로그램(140)은 메모리(130)에 소프트웨어로서 저장될 수 있으며, 예를 들면, 운영 체제(142), 미들 웨어(144) 또는 어플리케이션(146)을 포함할 수 있다.
입력 장치(150)는, 전자 장치(101)의 구성요소(예: 프로세서(120))에 사용될 명령 또는 데이터를 전자 장치(101)의 외부(예: 사용자)로부터 수신할 수 있다. 입력 장치(150)는, 예를 들면, 마이크, 마우스, 또는 키보드를 포함할 수 있다.
음향 출력 장치(155)는 음향 신호를 전자 장치(101)의 외부로 출력할 수 있다. 음향 출력 장치(155)는, 예를 들면, 스피커 또는 리시버를 포함할 수 있다. 스피커는 멀티미디어 재생 또는 녹음 재생과 같이 일반적인 용도로 사용될 수 있고, 리시버는 착신 전화를 수신하기 위해 사용될 수 있다. 일 실시 예에 따르면, 리시버는 스피커와 별개로, 또는 그 일부로서 구현될 수 있다.
표시 장치(160)는 전자 장치(101)의 외부(예: 사용자)로 정보를 시각적으로 제공할 수 있다. 표시 장치(160)는, 예를 들면, 디스플레이, 홀로그램 장치, 또는 프로젝터(projector) 및 해당 장치를 제어하기 위한 제어 회로를 포함할 수 있다. 일 실시 예에 따르면, 표시 장치(160)는 터치를 감지하도록 설정된 터치 회로(touch circuitry), 또는 상기 터치에 의해 발생되는 힘의 세기를 측정하도록 설정된 센서 회로(예: 압력 센서)를 포함할 수 있다.
오디오 모듈(170)은 소리를 전기 신호로 변환시키거나, 반대로 전기 신호를 소리로 변환시킬 수 있다. 일 실시 예에 따르면, 오디오 모듈(170)은, 입력 장치(150)를 통해 소리를 획득하거나, 음향 출력 장치(155), 또는 전자 장치(101)와 직접 또는 무선으로 연결된 외부 전자 장치(예: 전자 장치(102)) (예: 스피커 또는 헤드폰))를 통해 소리를 출력할 수 있다.
센서 모듈(176)은 전자 장치(101)의 작동 상태(예: 전력 또는 온도), 또는 외부의 환경 상태(예: 사용자 상태)를 감지하고, 감지된 상태에 대응하는 전기 신호 또는 데이터 값을 생성할 수 있다. 일 실시 예에 따르면, 센서 모듈(176)은, 예를 들면, 제스처 센서, 자이로 센서, 기압 센서, 마그네틱 센서, 가속도 센서, 그립 센서, 근접 센서, 컬러 센서, IR(infrared) 센서, 생체 센서, 온도 센서, 습도 센서, 또는 조도 센서를 포함할 수 있다.
인터페이스(177)는 전자 장치(101)가 외부 전자 장치(예: 전자 장치(102))와 직접 또는 무선으로 연결되기 위해 사용될 수 있는 하나 이상의 지정된 프로토콜들을 지원할 수 있다. 일 실시 예에 따르면, 인터페이스(177)는, 예를 들면, HDMI(high definition multimedia interface), USB(universal serial bus) 인터페이스, SD카드 인터페이스, 또는 오디오 인터페이스를 포함할 수 있다.
연결 단자(178)는, 그를 통해서 전자 장치(101)가 외부 전자 장치(예: 전자 장치(102))와 물리적으로 연결될 수 있는 커넥터를 포함할 수 있다. 일 실시 예에 따르면, 연결 단자(178)는, 예를 들면, HDMI 커넥터, USB 커넥터, SD 카드 커넥터, 또는 오디오 커넥터(예: 헤드폰 커넥터)를 포함할 수 있다.
햅틱 모듈(179)은 전기적 신호를 사용자가 촉각 또는 운동 감각을 통해서 인지할 수 있는 기계적인 자극(예: 진동 또는 움직임) 또는 전기적인 자극으로 변환할 수 있다. 일 실시 예에 따르면, 햅틱 모듈(179)은, 예를 들면, 모터, 압전 소자, 또는 전기 자극 장치를 포함할 수 있다.
카메라 모듈(180)은 정지 영상 및 동영상을 촬영할 수 있다. 일 실시 예에 따르면, 카메라 모듈(180)은 하나 이상의 렌즈들, 이미지 센서들, 이미지 시그널 프로세서들, 또는 플래시들을 포함할 수 있다.
전력 관리 모듈(188)은 전자 장치(101)에 공급되는 전력을 관리할 수 있다. 일 실시 예에 따르면, 전력 관리 모듈(188)은, 예를 들면, PMIC(power management integrated circuit)의 적어도 일부로서 구현될 수 있다.
배터리(189)는 전자 장치(101)의 적어도 하나의 구성 요소에 전력을 공급할 수 있다. 일 실시 예에 따르면, 배터리(189)는, 예를 들면, 재충전 불가능한 1차 전지, 재충전 가능한 2차 전지 또는 연료 전지를 포함할 수 있다.
통신 모듈(190)은 전자 장치(101)와 외부 전자 장치(예: 전자 장치(102), 전자 장치(104), 또는 서버(108))간의 직접(예: 유선) 통신 채널 또는 무선 통신 채널의 수립, 및 수립된 통신 채널을 통한 통신 수행을 지원할 수 있다. 통신 모듈(190)은 프로세서(120)(예: 어플리케이션 프로세서)와 독립적으로 운영되고, 직접(예: 유선) 통신 또는 무선 통신을 지원하는 하나 이상의 커뮤니케이션 프로세서를 포함할 수 있다. 일 실시 예에 따르면, 통신 모듈(190)은 무선 통신 모듈(192)(예: 셀룰러 통신 모듈, 근거리 무선 통신 모듈, 또는 GNSS(global navigation satellite system) 통신 모듈) 또는 유선 통신 모듈(194)(예: LAN(local area network) 통신 모듈, 또는 전력선 통신 모듈)을 포함할 수 있다. 이들 통신 모듈 중 해당하는 통신 모듈은 제1 네트워크(1098)(예: 블루투스, WiFi direct 또는 IrDA(infrared data association) 같은 근거리 통신 네트워크) 또는 제2 네트워크(1099)(예: 셀룰러 네트워크, 인터넷, 또는 컴퓨터 네트워크(예: LAN 또는 WAN)와 같은 원거리 통신 네트워크)를 통하여 외부 전자 장치와 통신할 수 있다. 이런 여러 종류의 통신 모듈들은 하나의 구성 요소(예: 단일 칩)으로 통합되거나, 또는 서로 별도의 복수의 구성 요소들(예: 복수 칩들)로 구현될 수 있다. 무선 통신 모듈(192)은 가입자 식별 모듈(196)에 저장된 가입자 정보(예: 국제 모바일 가입자 식별자(IMSI))를 이용하여 제1 네트워크(198) 또는 제2 네트워크(199)와 같은 통신 네트워크 내에서 전자 장치(101)를 확인 및 인증할 수 있다.
안테나 모듈(197)은 신호 또는 전력을 외부(예: 외부 전자 장치)로 송신하거나 외부로부터 수신할 수 있다. 일 실시 예에 따르면, 안테나 모듈(197)은 하나 이상의 안테나들을 포함할 수 있고, 이로부터, 제1 네트워크(198) 또는 제2 네트워크(199)와 같은 통신 네트워크에서 사용되는 통신 방식에 적합한 적어도 하나의 안테나가, 예를 들면, 통신 모듈(190)에 의하여 선택될 수 있다. 신호 또는 전력은 상기 선택된 적어도 하나의 안테나를 통하여 통신 모듈(190)과 외부 전자 장치 간에 송신되거나 수신될 수 있다.
상기 구성요소들 중 적어도 일부는 주변 기기들간 통신 방식(예: 버스, GPIO(general purpose input and output), SPI(serial peripheral interface), 또는 MIPI(mobile industry processor interface))를 통해 서로 연결되고 신호(예: 명령 또는 데이터)를 상호간에 교환할 수 있다.
일 실시 예에 따르면, 명령 또는 데이터는 제2 네트워크(199)에 연결된 서버(108)를 통해서 전자 장치(101)와 외부의 전자 장치(104) 간에 송신 또는 수신될 수 있다. 전자 장치(102, 104) 각각은 전자 장치(101)와 동일한 또는 다른 종류의 장치일 수 있다. 일 실시 예에 따르면, 전자 장치(101)에서 실행되는 동작들의 전부 또는 일부는 외부 전자 장치들(102, 104, or 108) 중 하나 이상의 외부 장치들에서 실행될 수 있다. 예를 들면, 전자 장치(101)가 어떤 기능이나 서비스를 자동으로, 또는 사용자 또는 다른 장치로부터의 요청에 반응하여 수행해야 할 경우에, 전자 장치(101)는 기능 또는 서비스를 자체적으로 실행시키는 대신에 또는 추가적으로, 하나 이상의 외부 전자 장치들에게 그 기능 또는 그 서비스의 적어도 일부를 수행하라고 요청할 수 있다. 상기 요청을 수신한 하나 이상의 외부 전자 장치들은 요청된 기능 또는 서비스의 적어도 일부, 또는 상기 요청과 관련된 추가 기능 또는 서비스를 실행하고, 그 실행의 결과를 전자 장치(101)로 전달할 수 있다. 전자 장치(101)는 상기 결과를, 그대로 또는 추가적으로 처리하여, 상기 요청에 대한 응답의 적어도 일부로서 제공할 수 있다. 이를 위하여, 예를 들면, 클라우드 컴퓨팅, 분산 컴퓨팅, 또는 클라이언트-서버 컴퓨팅 기술이 이용될 수 있다.
도 2a는 일 실시 예에 따른 전자 장치(101)를 나타낸 블록도이다. 도 2b는 다른 실시 예에 따른 전자 장치(101)를 나타낸 블록도이다.
일 실시 예에 따른 전자 장치(101)는 입력 장치(150), 디스플레이(160), 통신 회로(190), 프로세서(120), 및 EM 센싱 회로(200)를 포함할 수 있다.
입력 장치(150)는 사용자가 수행하는 다양한 종류의 입력을 획득할 수 있다. 입력 장치(150)는 전자 장치(101)에 입력될 명령 또는 데이터를 전자 장치(101)의 외부로부터 수신할 수 있다. 사용자의 입력에는 터치 입력, 드래그 입력, 또는 음성 입력이 포함될 수 있다. 일 실시 예에 따른 입력 장치(150)는 마이크(111)를 포함할 수 있다. 마이크(111)는 사용자의 음성 입력을 획득할 수 있다.
디스플레이(160)는 입력 장치(150)로부터 획득한 사용자의 입력에 대한 정보를 영상 또는 텍스트로 표시할 수 있다. 예컨대, 디스플레이(160)는 획득한 음성 입력의 내용을 텍스트로 표시할 수 있다. 전자 장치(101)가 획득한 사용자의 입력에 대응하는 동작을 수행하는 경우, 디스플레이(160)는 전자 장치(101)의 수행 동작을 나타내는 영상을 표시할 수 있다.
통신 회로(190)는 네트워크(199)를 통해 전자 장치(101)가 갖고 있는 정보를 서버(예: EM 서버(205) 또는 지능형(intelligence) 서버(206))로 전송할 수 있다. 통신 회로(190)는 전자 장치(101)의 고유 정보를 서버로 전송할 수 있다. 예컨대, 통신 회로(190)는 전자 장치(101)의 사용자 계정에 관한 정보를 서버로 전송할 수 있다. 또한, 통신 회로(190)는 전자 장치(101)가 생성한 정보를 서버로 전송할 수 있다. 예컨대, 통신 회로(190)는 사용자가 모바일 게임(mobile game) 어플리케이션(application)을 실행하고 이용한 경우, 이용 후 최종적으로 저장된 정보를 서버로 전송할 수 있다. 또한, 통신 회로(190)는 전자 장치(101)가 수행하고자 하는 동작을 실현하기 위한 정보를 서버로부터 수신할 수 있다. 예컨대, 통신 회로(190)는 사용자가 모바일 게임 어플리케이션을 다시 실행할 때, 마지막으로 실행한 부분까지 저장된 정보를 서버로부터 수신할 수 있다.
프로세서(120)는 디스플레이(160)와 작동적으로 연결될(operationally connected) 수 있다. 프로세서(120)는 디스플레이(160)가 영상을 표시할 수 있도록 영상 데이터를 제공할 수 있다. 프로세서(120)는 입력 장치(150)와 작동적으로 연결될 수 있다. 프로세서(120)는 입력 장치(150)에서 획득한 사용자의 입력을 분석하고, 입력의 내용에 따른 동작을 구현하기 위하여 준비 작업을 수행할 수 있다. 프로세서(120)는 통신 회로(190)와 작동적으로 연결될 수 있다. 프로세서(120)는 통신 회로(190)가 송수신하는 정보의 종류 및 내용을 설정할 수 있다.
EM 센싱 회로(200)는 적어도 하나의 외부 전자 장치(201, 202)의 EM(electromagnetic) 신호를 수신할 수 있다. 일 실시 예에 따르면, EM 센싱 회로(200)는 EM 신호에 기반한 제1 정보를 생성할 수 있다. 예를 들어, 제1 정보는 EM 신호의 파형에 관한 정보 및 EM 신호를 방출한 적어도 하나의 외부 전자 장치(201, 202)의 종류에 대한 정보를 포함할 수 있다. EM 센싱 회로(200)는 제1 외부 전자 장치(201)로부터 제1 EM 신호(EM1)를 수신하고, 제1 EM 신호(EM1)의 파형의 진폭 및 위상을 이용하여 제1 EM 신호(EM1)에 관한 제1 정보를 생성할 수 있다. 일 실시 예에 따르면, EM 센싱 회로(200)는 프로세서(120)로 제1 EM 신호(EM1)에 관한 제1 정보를 제공할 수 있다. EM 센싱 회로(200)는 제2 외부 전자 장치(202)로부터 제2 EM 신호(EM2)를 수신하고, 제2 EM 신호(EM2)의 파형의 진폭 및 위상을 이용하여 제2 EM 신호(EM2)에 관한 제1 정보를 생성할 수 있다. EM 센싱 회로(200)는 프로세서(120)로 제2 EM 신호(EM2)에 관한 제1 정보를 제공할 수 있다.
EM 센싱 회로(200)는 프로세서(120)와 작동적으로 연결될 수 있다. EM 센싱 회로(200)는 프로세서(120)의 제어에 따라 센싱한 복수의 EM 신호들(EM1, EM2)에 관한 제1 정보를 생성할 수 있다.
일 실시 예에 따르면, 도 2a와 같이 전자 장치(101)는 외부 전자 장치(201, 202)에 관련된 정보를 EM 센싱 회로(200) 또는 메모리(130)에 저장할 수 있다. 전자 장치(101)는 외부 전자 장치(201, 202)에 관련된 정보에 기반하여 제1 정보를 분석할 수 있다. 전자 장치(101)의 프로세서(120)는 제1 정보를 분석하는 분석부(121)를 포함할 수 있다.
다른 실시 예에 따르면, 도 2b와 같이 전자 장치(101)는 EM 센싱 회로(200)가 생성한 제1 정보를 외부 전자 장치(201, 202)에 관련된 정보를 갖고 있는 EM 서버(205)로 전송할 수 있다. 전자 장치(100)는 EM 서버(205)로 제1 정보의 적어도 일부를 보낼 수 있다. EM 서버(205)는 제1 정보를 수신할 수 있다. EM 서버(205)는 외부 전자 장치(201, 202)에 관련된 정보에 기반하여 제1 정보를 분석할 수 있다. EM 서버(205)는 제1 정보를 분석한 결과를 전자 장치(101)로 전송할 수 있다. 전자 장치(101)는 통신 회로(190)를 통해 EM 서버(205)로부터 제1 정보를 분석한 결과를 수신할 수 있다.
일 실시 예에 따르면, 도 2a와 같이 전자 장치(101)는 제1 정보를 분석하여 제1 정보가 포함하고 있는 외부 전자 장치(201, 202)에 관련된 정보를 알 수 있다. 다른 실시 예에 따르면, 도 2b와 같이 전자 장치(101)는 EM 서버(205)로부터 제1 정보가 포함하고 있는 외부 전자 장치(201, 202)에 관련된 정보를 수신할 수 있다. 예를 들어, 제1 정보는 외부 전자 장치(201, 202)의 종류 및 모델명에 관한 정보를 포함할 수 있다. 전자 장치(101)는 제1 정보에 포함된 종류 및 모델명에 관한 정보를 EM 서버(205)로 보내 분석한 후, 전자 장치(101)가 EM 서버(205)로부터 분석된 정보를 수신함으로써 확인할 수 있다. 또 다른 예를 들어, 제1 정보는 외부 전자 장치(201, 202)의 동작 상태 및 명령 수행 가능 여부에 관한 정보를 포함할 수 있다.
프로세서(120)는 EM 센싱 회로(200)가 수신한 EM 신호에 기반하여 생성한 제1 정보를 통신 회로(190)를 통해 EM 서버(205)로 전송하도록 제어할 수 있다.
일 실시 예에 따르면, EM 서버(205)는 복수의 EM 신호들에 대한 정보를 포함할 수 있다. EM 서버(205)는 제1 정보에 포함된 EM 신호에 관한 정보를 미리 저장된 복수의 EM 신호들에 대한 정보와 비교할 수 있다. EM 서버(205)는 제1 정보에 포함된 EM 신호가 어느 외부 전자 장치로부터 출력되었는지 분석할 수 있다. 본 문서의 다양한 실시 예에서 EM 서버(205)는 제1 서버로 참조될 수 있다.
일 실시 예에 따르면, EM 서버(205)는 제1 정보에 포함된 EM 신호를 이용하여 EM 신호를 방출한 외부 장치를 특정(specify)할 수 있다. EM 서버(205)가 EM 신호를 이용하여 특정한 외부 장치를 대상 장치(target device)로 정의할 수 있다. 대상 장치는 외부 전자 장치(201, 202) 중 사용자의 음성 입력을 수행하는 대상이 되는 장치일 수 있다. 대상 장치는 전자 장치(101)가 사용자의 음성 입력에 따라 동작하는 경우, 전자 장치(101)의 동작에 대응하는 동작을 수행하거나, 전자 장치(101)의 동작에 응답할 수 있다. 대상 장치로 제1 외부 전자 장치(201)를 특정하는 경우, EM 서버(205)는 제1 외부 전자 장치(201)를 제1 외부 장치로 특정할 수 있다. 또는, 대상 장치로 제2 외부 전자 장치(202)를 특정하는 경우, EM 서버(205)는 제2 외부 전자 장치(202)를 제1 외부 장치로 특정할 수 있다. EM 서버(205)는 제1 외부 장치를 특정하는 정보를 포함하는 제2 정보를 생성할 수 있다.
일 실시 예에 따르면, EM 서버(205)는 제1 정보의 전송에 응답하여 제2 정보를 생성할 수 있다. EM 서버(205)는 제2 정보를 전자 장치(101)로 전송할 수 있다. 프로세서(120)는 통신 회로(190)를 통해 EM 서버(205)로부터 제2 정보를 수신할 수 있다. 프로세서(120)는 제2 정보를 이용하여 사용자의 음성 입력을 수행하도록 제어할 제1 외부 장치를 특정할 수 있다.
일 실시 예에 따르면, 프로세서(120)는 제1 외부 장치가 사용자가 전자 장치(101)의 마이크(111)에 발화한 음성 입력의 내용에 따라 동작하도록 제어할 수 있다. 이에 따라, 프로세서(120)는 통신 회로(190)를 통해 음성 입력 및 제2 정보를 지능형 서버(206)로 전송할 수 있다.
지능형 서버(206)는 텍스트 형태의 자연어를 기계어로 변환하는 자연어 처리(natural language processing)를 수행할 수 있다. 지능형 서버(206)는 수신된 음성 입력을 텍스트 데이터로 변환할 수 있다. 지능형 서버(206)는 텍스트 데이터를 문법적(syntactic) 또는 의미적(semantic)으로 분석하여 사용자의 의도를 파악할 수 있다. 지능형 서버(206)는 사용자의 의도를 지정된 패스 룰 셋(path rule set)에 매핑시켜 동작 경로를 생성할 수 있다. 지능형 서버(206)는 대상 장치 및/또는 전자 장치(101)가 음성 입력의 내용에 기반하여 동작하도록, 즉 복수의 상태들의 시퀀스(a sequence of states)에 따라 동작할 수 있도록 제어할 수 있다. 본 문서의 다양한 실시 예에서 지능형 서버(206)는 제2 서버로 참조될 수 있다.
일 실시 예에 따르면, 지능형 서버(206)는 제2 정보와 음성 입력에 포함된 정보를 이용하여 대상 장치를 직접 제어할 수 있다. 예컨대, 제2 정보에서 스피커를 특정하고, 음성 입력에서 턴-온(turn-on) 명령이 포함된 경우, 지능형 서버(206)는 음성 입력과 제2 정보를 이용하여 스피커를 켜라는 명령을 수행하기 위해 스피커를 직접 켜도록 턴-온 신호를 전송할 수 있다.
일 실시 예에 따르면, 지능형 서버(206)는 전자 장치(101)가 대상 장치의 동작을 제어할 수 있는 정보를 제공할 수 있다. 예컨대, 제2 정보에서 노트북 컴퓨터(notebook computer)를 특정하고, 음성 입력에 사진을 전송하라는 명령이 포함된 경우, 지능형 서버(206)는 음성 입력과 제2 정보를 이용하여 전자 장치(101)에 저장된 사진을 노트북 컴퓨터로 전송하도록 전자 장치(101)에 제어 신호를 전송할 수 있다.
일 실시 예에 따른 전자 장치(101)와 대상 장치는 지능형 서버(206)에 동일한 사용자 계정으로 등록되어 있을 수 있다. 전자 장치(101)의 사용자 계정은 사용자가 전자 장치(101)를 사용하기 시작할 때 지능형 서버(206)에 등록될 수 있다. 일 예로, 전자 장치(101)를 처음 사용하기 시작할 때, 미리 설정된 시스템 프로그램(system program)에 따라 이메일 또는 등록 아이디(identification)를 이용하여 전자 장치(101)의 사용자 계정을 생성할 수 있다. 이후, 전자 장치(101)를 사용하면서 사용자는 대상 장치를 지능형 서버(206)에 등록된 사용자 계정과 동일한 사용자 계정으로 등록할 수 있다. 또는, 대상 장치를 사용하기 시작할 때, 사용자는 전자 장치(101)의 사용자 계정과 동일한 사용자 계정을 이용할 수 있다.
예컨대, 전자 장치(101)의 사용을 시작하는 경우, 전자 장치(101)는 블루투스(Bluetooth), NFC(near field communication)와 같은 근거리 통신 방식을 이용하여 주변의 TV, 노트북 컴퓨터, 전등, 난방 장치 또는 냉장고와 같은 가전 기기(예: 근거리 통신을 지원하는 전자 장치)들을 검색할 수 있다. 전자 장치(101)는 검색된 가전 기기들을 등록 외부 장치 군에 포함시킬 수 있다. 등록 외부 장치 군은 전자 장치(101)가 센싱한 주변의 가전 기기 중 대상 장치로 설정될 수 있는 가전 기기를 등록한 그룹으로 정의할 수 있다. 등록 외부 장치 군에 포함된 가전 기기는 전자 장치(101)가 대상 장치로 신속하게 특정할 수 있도록 전자 장치(101)에 소정의 정보를 제공할 수 있다. 전자 장치(101)는 등록 외부 장치 군에 포함된 가전 기기를 전자 장치(101)의 사용자 계정에 추가시킬 수 있다. 전자 장치(101)는 등록 외부 장치 군에 포함된 가전 기기 중에서 대상 장치를 특정한 경우, 대상 장치를 사용하기 위해 사용자 계정을 설정할 때 전자 장치(101)에 등록된 사용자 계정과 동일한 사용자 계정을 이용하도록 전자 장치(101)의 사용자 계정을 대상 장치로 제공할 수 있다.
전자 장치(101)와 대상 장치가 지능형 서버(1200)에 동일한 사용자 계정으로 등록되어 있는 경우, 전자 장치(101)는 대상 장치의 EM 신호에 관한 정보를 EM 서버(205)로부터 수신할 수 있다. 전자 장치(101)는 대상 장치의 EM 신호에 관한 정보를 내부의 메모리(130)에 저장할 수 있다. 이후, 전자 장치(101)는 EM 센싱 회로(200)에서 센싱한 EM 신호가 미리 저장된 EM 신호와 동일한 경우, 저장된 EM 신호에 관한 정보를 이용하여 대상 장치를 특정할 수 있다. 전자 장치(101)는 EM 센싱 회로(200)에서 대상 장치의 EM 신호를 센싱하는 즉시, 음성 입력의 내용에 대응하도록 대상 장치가 동작하도록 제어할 수 있다. 이에 따라, 전자 장치(101)가 EM 서버(205)에 EM 신호를 전달하여 EM 서버(205)에서 EM 신호를 분석하는 과정을 거치지 않아도 대상 장치가 음성 입력의 내용에 따라 동작할 수 있어, 사용자의 음성 입력에 보다 신속하고 정확하게 대상 장치가 동작할 수 있다.
도 3a는 일 실시 예에 따른 EM 신호를 이용하여 외부 전자 장치들(201, 202, 203, 204)을 식별하는 개념도이다. 도 3b는 일 실시 예에 따른 머신 러닝(310)의 예시 블록도이다.
도 3a를 참고하면, 전자 장치(101)의 주변에는 복수의 외부 전자 장치들(201, 202, 203, 204)이 배치될 수 있다. 예컨대, 전자 장치(101)의 주변에는 TV(201), 냉장고(202), 블루투스 스피커(203), 및 프린터(204)가 배치될 수 있다. 일 실시 예에 따르면, 복수의 외부 전자 장치들(201, 202, 203, 204)은 내부에 다양한 전자 부품들(electronic components)을 포함할 수 있다. 복수의 외부 전자 장치들(201, 202, 203, 204)은 내부의 전자 부품들로부터 발생되는 전자기 간섭(electromagnetic interference, EMI)에 의해 다양한 EM(electromagnetic) 신호들을 방출할 수 있다. EM 신호들은 설정된 주파수 범위 내에서 복수의 고유 신호들(f1, f2, f3, f4)을 포함할 수 있다. 전자 장치(101)는 EM 신호들 중 특정 주파수 대역의 EM 신호들을 획득할 수 있다. 예를 들어, 1MHz 이하의 주파수 대역에서 특정한 주파수를 갖는 EM 신호들을 EM 센싱 회로(200)를 통해 획득할 수 있다
일 실시 예에 따르면, 전자 장치(101)가 복수의 외부 전자 장치들(201, 202, 203, 204) 중 어느 하나의 외부 전자 장치에 근접할 경우, 전자 장치(100)는 센싱 모듈(sensing module)(예: 도 2의 EM 센싱 회로(200)) 및 수신 모듈(예: 도 4의 안테나(410))을 통해 상술한 전자기 간섭에 따른 고유 신호를 검출할 수 있다. 하나의 예를 들어, 전자 장치(101)는 EM 센싱 회로(200)에서 수신한 EM 신호를 머신 러닝(310)(machine learning, ML)을 수행하여 대상 장치를 확인 및 특정(320)할 수 있다. 다른 예를 들어, 전자 장치(101)는 EM 서버(205)에 EM 신호에 기반한 제1 정보를 전송할 수 있다. EM 서버(205)는 머신 러닝(310) 과정을 통해 대상 장치를 확인 및 특정(320)할 수 있다.
보다 구체적으로, 전자 장치(101)는 EM 센싱과 연관된 기능이 활성화 된 이후, 사용자가 복수의 외부 전자 장치들(201, 202, 203, 204) 중 어느 하나의 외부 전자 장치에 전자 장치(101)를 근접시키는 경우 외부 전자 장치로부터 발생된 EM 신호를 획득할 수 있다. 획득된 EM 신호는 전자 장치(101)에 저장된 분류기(classifier)에 의해 분석 되거나 또는 EM 신호 분석 동작을 수행하는 서버(예: EM 서버(205))로 전송될 수 있다.
일 실시 예에 따르면, 상기 분류기는 외부 전자 장치의 모델명을 판별하는 기능을 수행할 수 있다. 외부 전자 장치의 모델명을 판별하는 기능은 별도의 서버(예: 지능형 서버(206))에서 학습데이터를 이용해 학습되어 전자 장치(101)에 저장될 수 있다. 또한 분류기는 인식 정확성 개선이나 대상 디바이스의 추가를 위해 지속적으로 학습되어 갱신될 수 있다. 상기 학습 알고리즘으로는 딥러닝(deep learning), GMM(Gaussian mixture model), SVM(support vector machine), random forest 중 적어도 하나를 포함하는 기계학습 알고리즘이 될 수 있다.
예를 들어, GMM방식을 적용하는 경우 도 3b와 같이 동작을 할 수 있다. EM 신호를 입력받은 전자 장치(101) 또는 EM 서버(205)는 머신 러닝(310)을 적용할 수 있는 복수의 외부 전자 장치에 관한 각각의 판별모델들을 갖고 있다. 각각의 판별모델들에 EM 신호를 적용하는 경우, 각각의 외부 전자 장치에 해당하는 적합도를 산출할 수 있다. 전자 장치(101) 또는 EM 서버(205)는 적합도를 이용하여 외부 전자 장치의 모델명을 판별할 수 있다. 전자 장치(101) 또는 EM 서버(205)는 다양한 기계학습 알고리즘을 적용하면서 다양한 판별모델이 적용된 주파수 테이블을 가질 수 있다.
일 실시 예에 따르면, 전자 장치(101)는 EM 서버(205)로부터 대상 장치를 특정(320)한 정보를 포함하는 제2 정보를 수신할 수 있다. 전자 장치(101)는 머신 러닝(310) 과정을 통해 산출된 제2 정보를 바탕으로 제1 외부 장치를 특정(320)(specify)하여 출력할 수 있다. 일 실시 예에 따르면, 대상 장치에 대한 정보는 전자 장치(101)의 디스플레이(예: 도 2의 디스플레이(160))를 통하여 표시될 수 있다. 그러나 이에 국한되지 않으며, 대상 장치에 대한 정보는 청각적으로 출력될 수도 있다.
일 실시 예에 따르면, 전자 장치(101)는 복수의 외부 전자 장치들(201, 202, 203, 204)에 대응하는 복수의 고유 신호들을 포함하는 파형 테이블이 저장된 메모리(예: 도 1의 메모리(130))를 포함할 수 있다. 그러나 이에 국한되지 않으며, 파형 테이블은 전자 장치(101)와 네트워크를 통해 통신 가능한 EM 서버(205)에 저장될 수 있다. 전자 장치(101)는 EM 서버(205)와의 통신을 통해 센싱된 EM 신호와 파형 테이블에 저장된 복수의 고유 신호들을 대비하는 동작을 수행할 수 있다. 전자 장치(101)는 검출된 EM 신호를 포함하는 제1 정보를 EM 서버(205)로 전송한 후, EM 서버(205)로부터 제1 정보에 포함된 EM 신호와 일치하는 파형을 갖는 대상 장치에 관한 식별 정보를 수신할 수 있다.
일 실시 예에 따르면, 전자 장치(101)는 대상 장치의 식별 정보를 기반으로 특정 어플리케이션을 실행할 수 있다. 예를 들어, 대상 장치가 TV로 식별될 경우, 전자 장치(101)는 리모컨에 관련된 어플리케이션을 자동으로 실행함과 동시에 TV와 연결을 자동으로 수행할 수 있다. 전자 장치(101)를 대상 장치에 근접시키는 동작만으로 대상 장치를 제어할 수 있는 상태로 스탠바이(stand-by) 시킴으로써 사용자의 편의성을 증가시킬 수 있다.
도 4는 일 실시 예에 따른 전자 장치(100)의 EM 센싱을 수행하는 구성 요소들을 나타낸 블록도이다.
전자 장치(101)는 복수의 외부 전자 장치(예: 도 2의 외부 전자 장치(201, 202)에서 방출되는 EM 신호를 검출하기 위한 안테나(410) 및 검출한 EM 신호를 분석하기 위한 EM 센싱 회로(200)를 포함할 수 있다. 일 실시 예에 따르면, 전자 장치(101)의 프로세서(120)는 EM 센싱 회로(200)로부터 제공받은 검출 정보를 이용하여 대상 장치를 식별할 수 있다.
일 실시 예에 따르면, EM 센싱 회로(200)는 트랜스임피던스 증폭기(210)(trans-impedance amplifier, TIA), 대역 통과 필터(220)(band pass filter, BPF), 가변 이득 증폭기(230)(variable gain amplifier, VGA), 아날로그-디지털 변환기(240)(analog digital converter, ADC), 및 MCU(micro controller unit)(250)를 포함할 수 있다.
안테나(410)는 EM 신호를 수신할 수 있는 수신 대역폭을 가질 수 있다. 트랜스임피던스 증폭기(210)는 안테나(410)로부터 수신된 1MHz 이하의 주파수를 증폭시킬 수 있다. 대역 통과 필터(220)는 트랜스임피던스 증폭기(210)로부터 증폭 수신된 신호 중 특성 패턴을 정의하는 주파수 성분을 통과시키고, 특성 패턴과 관계 없는 주파수 성분인 노이즈(noise)를 필터링(filtering)할 수 있다. 일 실시 예에 따르면, 대역 통과 필터(220)는 EM 신호에서 1MHz 이하의 주파수 성분을 통과시키고, 1MHz를 초과하는 주파수 성분을 차단시킬 수 있다. 일 실시 예에 따르면, 가변 이득 증폭기(230)는 필터링된 신호의 잡음 특성과 외부 간섭 신호 제거 특성을 향상시키기 위하여, 미리 설정된 이득 범위에 걸쳐서 신호를 일정한 레벨로 출력할 수 있다. 일 실시 예에 따르면, 아날로그-디지털 변환기(240)는 가변 이득 증폭기(230)로부터 제공된 아날로그 신호를 디지털 신호로 변환한 후 MCU(250)로 제공할 수 있다.
일 실시 예에 따르면, MCU(250)는 디지털 신호로 변환된 EM 신호를 전자 장치(101)에 저장된 파형 테이블과 대비하여 외부 전자 장치를 식별할 수 있다. 예컨대, MCU(250)는 EM 신호의 최대 진폭 및 EM 신호의 파형 형태를 파형 테이블에 저장된 복수의 파형들과 대비할 수 있다. MCU(250)는 식별된 정보를 전자 장치(101)의 프로세서(120)로 제공할 수 있다. 그러나 이에 국한되지 않으며, MCU(250)는 제공받은 식별된 정보를 전자 장치(101)의 프로세서(120)에 직접 제공할 수도 있다. 이러한 경우, 파형 비교에 의한 대상 장치의 식별 동작은 전자 장치(101)의 프로세서(120)에서 수행될 수도 있다.
일 실시 예에 따르면, 전자 장치(101)는 최적의 입력 신호 파형을 검출하기 위해 전자 장치(101)에서 자체적으로 발생되는 노이즈를 최소화할 필요가 있다. 일 실시 예에 따르면, EM 센싱 회로(200)에 전자 장치(101)에서 생성된 신호가 인가될 수 있어 이에 대한 보상을 수행할 필요가 있다. 일 실시 예에 따르면, 전자 장치(101)는 입력 오류를 최소화 하기 위해 터치 스크린 입력에 의한 내부 노이즈를 인지한 후, 보상 알고리즘을 적용하고, 복수의 안테나(410) 구성 시 파지 유형에 따른 왜곡 파형을 검출할 수 있다. 사용자에 의한 터치 입력 및 전자 장치(101)를 파지한 상태와 같이 전자 장치(101)의 다양한 조건에 따라, 전자 장치(101)가 센싱한 EM 신호는 대상 장치가 생성한 EM 신호와 차이를 보일 수 있다. 일 실시 예에 따르면, 전자 장치(101)는 측정한 EM 신호와 대상 장치의 고유 전자기 간섭 검출 정보를 비교하여 지속적으로 수집할 수 있다. 일 실시 예에 따르면, 수집된 정보는 빅데이터 분석을 통해 전자기 간섭 검출 정보에 대한 상관 관계를 발견하여 이후 전자기 간섭 검출 보정에 활용할 수 있다. 상술한 빅데이터 분석은 회귀분석, 클러스터링 또는 연관성 분석의 기법을 포함할 수 있다.
일 실시 예에 따르면, 프로세서(120)는 안테나(410)를 통해 수신한 EM 신호를 전달받을 수 있다. 일 예에 따른 프로세서(120)는 하나의 대상 장치에서 발생한 EM 신호를 전달받을 수 있다. 프로세서(120)는 EM 센싱 회로(200)를 통해 분석된 EM 신호로부터 대상 장치의 종류 및 모델명을 확인할 수 있다. 프로세서(120)는 대상 장치에서 발생한 EM 신호를 EM 서버(205)로 전송하여 분석할 수 있다.
다른 실시 예에 따르면, 프로세서(120)는 외부 전자 장치(201, 202, 203, 204)에서 발생하는 EM 신호들 중 수신 강도가 가장 강한 EM 신호만을 프로세서(120)로 제공하도록 제어할 수 있다. 또 다른 예에 따른 프로세서(120)는 EM 센싱 회로(200)에서 선택적으로 EM 신호를 검출하기 위해 외부 전자 장치(201, 202, 203, 204)에서 발생하는 EM 신호들 중 설정된 기준에 부합하는 EM 신호들만을 프로세서(120)로 제공하도록 제어할 수 있다.
일 예에 따르면, 프로세서(120)는 EM 센싱 회로(200)가 센싱한 EM 신호들 중 전자 장치(101)로부터 일정 거리 이내에 위치한 외부 전자 장치들(201, 202, 203, 204)로부터 발생한 EM 신호들만을 프로세서(120)로 제공하도록 제어할 수 있다. 일정 거리 이내에서 발생한 EM 신호들만을 선택적으로 센싱하는 경우, 전자 장치(101)로부터 물리적으로 일정한 범위 내에 있는 외부 전자 장치(201, 202, 203, 204)만을 센싱하도록 할 수 있다. 전자 장치(101)는 BLE, WiFi, 또는 NAN와 같은 근거리 통신을 이용하여 외부 전자 장치(201, 202, 203, 204)가 전자 장치(101)의 주변에 있는 장치인지 확인하는 동작을 수행할 수 있다.
다른 예에 따르면, 프로세서(120)는 EM 센싱 회로(200)가 센싱한 정보에 기반하여 외부 전자 장치들(201, 202, 203, 204)로부터 발생한 EM 신호들 중 동작을 수행할 대상 장치에서 발생한 EM 신호만을 프로세서(120)로 제공하도록 제어할 수 있다. 예를 들어, 프로세서(120)는 EM 신호들 중 가장 신호의 세기가 강한 EM 신호를 EM 센싱 회로(200)에서 센싱하도록 설정될 수 있다. 다른 예를 들어, 프로세서(120)는 외부 전자 장치들(201, 202, 203, 204)의 위치 정보에 기반하여 전자 장치(101)에서 가장 근접한 장치에서 발생한 EM 신호를 EM 센싱 회로(200)에서 센싱하도록 설정될 수 있다. 전자 장치(101)는 근거리 통신을 이용하여 외부 전자 장치(201, 202, 203, 204)의 위치 정보를 확인하는 동작을 수행할 수 있다.
예컨대, 전자 장치(101)가 거실에 있는 외부 전자 장치들(201, 202, 203, 204) 중 가장 근접한 TV를 대상 장치로 설정하고 센싱하고자 할 때, 전자 장치(101)는 TV에서 생성된 EM 신호의 세기가 가장 강한 것을 감지하여 TV에서 생성된 EM 신호만을 센싱할 수 있다. 또 다른 예를 들어, 전자 장치(101)는 거실에 있는 TV의 위치 정보를 확인함으로써 방에 있는 TV는 센싱되지 않도록 할 수 있다. 이에 따라, 센싱 및 분석이 불필요한 EM 신호까지 입력되는 것을 방지하여 센싱 및 분석 효율을 향상시킬 수 있다. 또한, 전자 장치(101)가 외부 전자 장치들(201, 202, 203, 204) 중 대상 장치를 센싱하는 정확도를 향상시킬 수 있다.
일 실시예에 따르면, 전자 장치(100)는 EM 센싱 회로(200)가 센싱한 EM 신호들로 감지한 외부 전자 장치들(201, 202, 203, 204) 중 사용자의 음성 입력의 내용을 수행할 수 있는 외부 전자 장치(201, 202, 203, 204)로부터 발생한 EM 신호들만을 프로세서(120)로 제공하도록 제어할 수 있다. EM 센싱 회로(200)는 외부 전자 장치(201, 202, 203, 204)로부터 발생한 EM 신호들을 센싱할 수 있다. 프로세서(120)는 센싱한 EM 신호들의 내용을 이용하여, 사용자의 음성 입력의 내용을 수행할 수 있는 외부 전자 장치로부터 발생한 EM 신호를 선택할 수 있다. 프로세서(120)는 실질적으로 사용자의 음성 입력의 내용과 관련 있는 외부 전자 장치(201, 202, 203, 204)로 대상 장치가 될 수 있는 후보군을 지정할 수 있다. 예컨대, 프로세서(120)는 "사진을 전송하라"는 음성 입력에 대해, 스마트 가전 기기들 중 사진을 전송 받을 수 있는 TV와 노트북 컴퓨터로부터의 EM 신호를 선택하거나, TV와 노트북 컴퓨터를 후보군으로 지정할 수 있다. 프로세서(120)는 "사진을 전송하라"는 명령을 수행할 때 TV와 노트북 컴퓨터로부터 발생한 EM 신호를 EM 센싱 회로(200)에서 제공받고, 스피커로부터 발생한 EM 신호는 EM 센싱 회로(200)에서 제공받지 않을 수 있다. 이에 따라, 전자 장치(101)는 센싱 및 분석이 불필요한 EM 신호까지 프로세서(120)로 입력되는 것을 방지하여 프로세서(120)의 센싱 및 분석 효율을 향상시킬 수 있다. 또한, 전자 장치(101)가 외부 전자 장치들(201, 202, 203, 204) 중 대상 장치를 센싱하는 정확도를 향상시킬 수 있다.
도 5는 일 실시 예에 따른 전자 장치(101)의 안테나를 나타낸 평면도이다. 전자 장치(101)는 EM 신호를 왜곡 없이 센싱하기 위해 안테나를 전자 장치(101)의 테두리에 대응하도록 배치할 수 있다. 전자 장치(101)는 EM 신호의 센싱 효율을 향상시키기 위해 전자 장치의 외곽을 정의하는 하우징(housing)의 적어도 일부를 안테나로 활용할 수 있다.
도 5를 참고하면, 전자 장치(예: 도 2a의 전자 장치(101))의 안테나로 활용되는 하우징의 적어도 일부는 도전성 부재로 형성될 수 있다. 한 실시 예에 따르면, 하우징은 도전성 부재와 비 도전성 부재가 이중 사출되는 방식으로 형성될 수 있다. 일 실시 예에 따르면, 하우징의 적어도 일부는 전자 장치의 테두리를 따라 노출되도록 배치될 수 있다.
일 실시 예에 따르면, 금속 부재로 형성된 하우징은 제1 길이를 갖는 제1 측면(511), 제1 측면(511)과 수직한 방향으로 연장되며 제2 길이를 갖는 제2 측면(512), 제2 측면(512)에서 제1 측면(511)과 평행하게 제1 길이를 갖도록 연장되는 제3 측면(513) 및 제3 측면(513)에서 제2 측면(512)과 평행하게 제2 길이를 갖도록 연장되는 제4 측면(514)을 포함할 수 있다. 일 실시 예에 따르면, 제1 측면(511), 제2측면(512), 제3 측면(513) 및 제4 측면(514)은 일체로 형성될 수 있다. 일 실시 예에 따르면, 제1 길이는 제2 길이보다 길게 형성될 수 있다.
일 실시 예에 따르면, 제2 측면(512)은 일정 간격으로 이격된 한 쌍의 비 도전성 부분(5121, 5122)에 의해 전기적으로 분리되는 단위 도전성 부분이 형성될 수 있다. 또한, 제4 측면(514) 역시 일정 간격으로 이격된 한 쌍의 비 도전성 부분(5141, 5142)에 의해 전기적으로 분리되는 단위 도전성 부분이 형성될 수 있다. 일 실시 예에 따르면, 비 도전성 부분들(5121, 5122, 5141, 5142)에 의해 전기적으로 분리된 복수의 도전성 부분들 중 적어도 하나는 PCB(530)에 배치되는 무선 통신 회로(미도시)와 전기적으로 연결된 급전부들(521, 522, 523, 524)과 전기적으로 연결됨으로써 적어도 하나의 공진 주파수 대역에서 동작하는 적어도 하나의 안테나로 활용될 수 있다. 제1 측면(511) 내지 제4 측면(514) 상에 안테나를 형성할 수 있다. 예를 들어, 제2 측면(512)은 low band에서 동작하는 제2 안테나부(A2)로 구성되고, 제4 측면(514)은 mid band 및 high band에서 동작하는 제4 안테나부(A4)로 구성될 수 있다. 그러나 이에 한정되지 않으며, 제1 측면(511)은 제1 안테나부(A1)로 구성될 수 있으며, 제3 측면(513)은 제3 안테나부(A3)로 구성될 수 있다.
다양한 실시 예에 따르면, EM 센싱 회로(200)는 제1, 제2, 제3, 제4 안테나부(A1, A2, A3, A4) 중 어느 하나의 안테나부로 사용되는 도전성 부재에 전기적으로 연결될 수 있다. 한 실시 예에 따르면, EM 센싱 회로(200)는 사용자의 파지 상태의 영향을 받지 않으며, 외부 전자 장치와 접촉 또는 근접하기 가장 유리한 제4 측면(514)과 전기적으로 연결될 수 있다. 일 실시 예에 따르면, EM 센싱 회로(200)는 통신 회로(524)와 도전성 라인(5241)으로 연결되어 제4 측면(514)에 전기적으로 연결될 수 있다. 일 실시 예에 따르면, 제4 측면(514)은 통신용 안테나 방사체 및 전자기 간섭 검출용 안테나 방사체로 공용으로 사용될 수 있다. 이 경우, EM 센싱 회로(200)는 제4 측면(514)을 이용하여 외부 전자 장치의 EM 신호를 검출할 수 있고, 검출된 신호에 관련된 정보를 전자 장치(101)의 프로세서(120)로 제공할 수 있다.
도 6은 일 실시 예에 따른 전자 장치(101)의 제어 방법을 나타낸 시퀀스 다이어그램이다. 도 6에서는 제1 외부 전자 장치(201)로부터 EM 신호를 수신하는 경우를 가정하였다.
동작 601에서, 전자 장치(101)는 EM 센싱 회로(200)를 턴-온 시켜 EM 기능을 활성화시킬 수 있다. EM 센싱 기능을 활성화시키는 경우 전자 장치(101)는 외부 전자 장치(예: 도 2a의 제1 외부 전자 장치(201))로부터 생성된 EM 신호를 감지할 수 있다.
동작 602에서, 제1 외부 전자 장치(201)는 EM 신호를 발생시킬 수 있다. 제1 외부 전자 장치(201)는 전원이 인가된 경우, 제1 외부 전자 장치(201)에 실장 된 전자 부품 및 동작 상태에 기반한 고유한 파형 및 주파수 특성을 갖는 EM 신호가 발생할 수 있다. 또한, 제1 외부 전자 장치(201)가 활발하게 동작하는 상태인 경우와 대기 상태인 경우에 서로 다른 세기 및 형태를 갖는 EM 신호가 발생할 수 있다.
동작 603에서, 전자 장치(101)의 EM 센싱 회로(200)는 제1 외부 전자 장치(201)로부터 방출된 EM 신호를 획득할 수 있다. EM 센싱 회로(200)는 획득한 EM 신호를 프로세서(120)로 제공할 수 있다. 프로세서(120)는 EM 신호를 포함하는 제1 정보를 생성할 수 있다.
동작 605에서, 전자 장치(101)의 프로세서(120)는 제1 정보를 통신 회로(190)를 통해 EM 서버(205)로 전송할 수 있다. EM 서버(205)로 전송되는 제1 정보는 EM 신호, EM 신호 정보를 포함한 데이터, 또는 EM 신호에 기반하여 생성된 정보를 포함할 수 있다. 이에 따라, 프로세서(120)는 EM 서버(205)로 EM 신호, EM 신호 정보를 포함한 데이터, 또는 EM 신호에 기반하여 생성된 정보를 전송할 수 있다.
동작 606에서, EM 서버(205)는 전자 장치(101)로부터 수신한 EM 신호를 분석할 수 있다. EM 서버(205)는 EM 신호를 포함하는 제1 정보를 분석하여 제1 외부 전자 장치(201)를 대상 장치(target device)로 특정하는 제2 정보를 생성할 수 있다.
동작 607에서, EM 서버(205)는 전자 장치(101)로 대상 장치 정보를 전송할 수 있다. 전자 장치(101)는 통신 회로(190)를 통해 EM 서버(205)로부터 수신한 제2 정보를 프로세서(120)로 전송할 수 있다. EM 서버(205)가 전자 장치(101)로 전송하는 제2 정보는 대상 장치를 특정하는 대상 장치 정보를 포함하므로, EM 서버(205)는 대상 장치 정보를 전자 장치(101)로 전송할 수 있다.
동작 608에서, 전자 장치(101)는 마이크(111)를 통해 사용자의 음성을 획득할 수 있다. 일 실시 예에 따르면, 전자 장치(101)가 획득한 사용자의 음성 입력은 대상 장치를 특정하지 않고, 대상 장치가 수행하여야 하는 동작에 관한 정보만을 포함할 수 있다. 예컨대, 전자 장치(101)는 "사진 전송", "턴-온", "볼륨 증가(volume up)"와 같이 목적어가 결여된 음성 입력을 획득할 수 있다. 전자 장치(101)가 동작 608을 수행하는 시점은 한정되지 않으며 상황에 따라 다양하게 변화할 수 있다. 일 예에서, 전자 장치(101)가 사용자의 음성을 획득하는 시점은 EM 신호를 획득한 이후일 수 있다. 다른 예에서, 전자 장치(101)는 EM 신호를 획득하는 시점과 동시에 사용자의 음성을 획득할 수 있다. 또 다른 예에서, 전자 장치(101)는 사용자의 음성을 입력 받은 후, 설정된 시간 내에 EM 신호를 획득할 수 있다.
동작 609에서, 프로세서(120)는 획득한 음성 입력에 기반한 음성 데이터 및 대상 장치 정보를 포함하는 제2 정보를 통신 회로(190)를 통해 지능형 서버(206)로 전송할 수 있다.
동작 610에서, 지능형 서버(206)는 획득한 음성 데이터를 분석할 수 있다. 지능형 서버(206)는 음성 데이터를 자동 음성 인식(automatic speech recognition, ASR) 및 자연어 이해(natural language understanding, NLU)를 통해 대상 장치(예: 제1 외부 전자 장치(201))가 인식할 수 있는 형태로 변환할 수 있다. 음성 데이터는 자동 음성 인식 및 자연어 이해 과정을 거치면서 제1 외부 전자 장치(201)를 동작시킬 수 있는 기계적인 데이터를 생성할 수 있는 상태의 정보로 변환될 수 있다.
동작 611에서, 지능형 서버(206)는 복수의 시퀀스의 상태(states of plurality of sequence)인 패스 룰(path rule)을 생성할 수 있다. 지능형 서버(206)는 제1 외부 전자 장치(201)가 수행하여야 하는 동작들의 순서 및 순서 내에서의 구동 상태를 결정하는 규칙을 설정할 수 있다.
동작 612에서, 지능형 서버(206)는 자연어 생성(natural language generation, NLG) 모듈을 통해 자연어를 생성할 수 있다. 자연어 생성 모듈은 지정된 정보를 텍스트 형태로 변경할 수 있다. 상기 텍스트 형태로 변경된 정보는 자연어 발화의 형태일 수 있다. 상기 지정된 정보는, 예를 들어, 추가 입력에 대한 정보, 사용자 입력에 대응되는 동작의 완료를 안내하는 정보 또는 사용자의 추가 입력을 안내하는 정보(예: 사용자 입력에 대한 피드백 정보)일 수 있다.
동작 613에서, 지능형 서버(206)는 음성 입력 및 제2 정보에 기반하여 특정한 대상 장치(예: 제1 외부 전자 장치(201))에 관한 정보를 포함하는 음성 정보, 패스 룰, 또는 도메인(domain) 정보 중 적어도 일부를 전자 장치(101)로 전달할 수 있다. 전자 장치(101)는 통신 회로(190)를 통해 지능형 서버(206)로부터 수신한 음성 정보, 패스 룰, 및 도메인 정보 중 적어도 일부를 프로세서(120)로 전달할 수 있다. 전자 장치(101)는 복수의 상태들의 시퀀스에 적어도 일부 기초하여, 통신 회로(190)를 통해 전자 장치(101)와 제1 외부 전자 장치(201) 사이의 통신 연결을 수립할 수 있다.
동작 614에서, 전자 장치(101)의 프로세서(120)가 음성 정보, 패스 룰, 및 도메인 정보 중 적어도 일부를 획득한 경우, 전자 장치(101)는 음성 정보, 패스 룰, 및 도메인 정보에 대응하는 동작을 수행할 수 있다.
동작 615에서, 전자 장치(101)는 제1 외부 전자 장치(201)로 제1 외부 전자 장치(201)가 동작을 수행하기 위해 필요한 정보 또는 제1 외부 전자 장치(201)의 동작과 연관된 정보를 전달할 수 있다. 일 실시 예에 따르면 전자 장치(101)는 복수의 상태들의 시퀀스 중 일부를 제1 외부 전자 장치(201)로 전송할 수 있다.
일 실시 예에 따르면, 음성 분석 서버(206)는 제1 외부 전자 장치(201)로 음성 정보, 패스 룰, 및 도메인(domain) 정보 중 적어도 일부를 직접 전달할 수 있다.
동작 616에서, 제1 외부 전자 장치(201)는 전자 장치(101)로부터 수신한 음성 정보, 패스 룰 및 도메인(domain) 정보 중 적어도 일부에 기반하여 사용자가 음성으로 지시한 동작을 수행할 수 있다. 예를 들어, 제1 외부 전자 장치(201)는 사용자 음성과 연관된 복수의 상태들의 시퀀스에 기반하여 동작을 수행할 수 있다.
도 7a 및 7b는 일 실시 예에 따른 전자 장치(101)의 제어 방법을 나타낸 흐름도들이다.
도 7a는 일 실시 예에 따른 전자 장치(101)가 EM 신호에 대한 제1 정보를 EM 서버(205)로 전송하고, EM 서버(205)에서 제1 정보를 분석하여 대상 장치를 특정하는 경우를 나타내었다.
동작 701에서, 전자 장치(101)는 마이크(111)를 통해 사용자의 음성 입력을 획득할 수 있다. 마이크(111)를 통해 획득된 사용자의 음성 입력은 프로세서(120)로 제공될 수 있다. 사용자의 음성 입력은 동작을 수행할 대상 장치를 특정하지 않고 지시 내용만을 포함할 수 있다. 음성 입력의 내용은 전자 장치(101)의 프로세서(120)에 입력될 수 있다. 음성 입력은 프로세서(120)에서 자연어로 변환될 수 있다.
동작 703에서, 전자 장치(101)는 EM 센싱 회로(200)를 통해 적어도 하나의 외부 전자 장치의 EM(electromagnetic) 신호를 수신할 수 있다. 상술한 바와 같이, 사용자의 음성 입력 중에는 발화문의 지시 내용만이 포함되고, 지시 대상이 포함되지 않을 수 있다. 예를 들어, "사진 전송해"와 같이 지시 대상이 포함되지 않아 대상 장치를 특정할 수 없는 경우, 전자 장치(101)는 EM 센싱 회로(200)를 활성화(activate)시켜 적어도 하나의 외부 전자 장치로부터 방출된 EM 신호를 센싱할 준비를 할 수 있다. 전자 장치(101)는 사용자의 음성 입력을 수신함과 동시에 발화문에 지시 대상이 포함되어 있는지 여부를 판단할 수 있다. 다른 예를 들어, 전자 장치(101)는 사용자의 음성이 입력되는 시점과 동시에 적어도 하나의 외부 전자 장치의 EM 신호를 수신하도록 설정될 수 있다. 전자 장치(101)는 음성 입력의 내용과 관계 없이 음성이 입력되기 시작하는 시점에 EM 센싱 회로(200)를 활성화시킬 수 있다.
일 예에 따른 전자 장치(101)의 프로세서(120)는 지능형 음성 인식 유저 인터페이스(user interface, UI)인 빅스비(bixby) 버튼이 눌려지는 경우 EM 센싱을 위한 기능을 활성화하도록 EM 센싱 회로(200)를 제어할 수 있다. 전자 장치(101)는 EM 센싱 회로(200)를 활성화하여 외부 전자 장치가 생성한 EM 신호를 획득할 수 있다. 전자 장치(101)는 EM 신호에 관한 제1 정보를 EM 서버(205)로 전달할 수 있다.
일 실시 예에 따른 EM 센싱 회로(200)는 사용자의 음성 입력에 지시 대상이 포함되지 않아 대상 장치를 특정할 수 없는 경우 활성화될 수 있다. 전자 장치(101)는 사용자의 음성 입력에 지시 대상이 포함되지 않은 것을 인지하고, 대상 장치의 특정을 사용자에게 요청할 수 있다. 전자 장치(101)는 EM 센싱 회로(200)에서 EM 신호를 수신하고, 수신한 EM 신호를 EM 서버(205)로 전송하여 대상 장치를 특정할 수 있다. 전자 장치(101)는 음성 가이드 또는 디스플레이(160) 상의 시각 가이드를 통해 대상 지정을 요청할 수 있다. 전자 장치(101)는 사용자가 대상 장치를 특정하려 할 때 사용자의 추가 음성을 입력받는 대신, 대상 장치의 EM 신호를 센싱할 수 있다. EM 센싱 회로(200)는 전자 장치(101)가 대상 지정을 요청하는 시점에 활성화되어, 사용자가 근접시키거나 태깅(tagging)한 대상 장치의 EM 신호를 센싱할 수 있다. 전자 장치(101)는 EM 센싱 회로(200)를 대상 장치를 특정할 수 없는 경우에만 선택적으로 활성화하여, EM 센싱 회로(200)의 불필요한 활성화를 방지하여 소비 전력을 저감할 수 있다.
동작 705에서, 전자 장치(101)는 통신 회로(190)를 통해, EM 신호에 대한 제1 정보를 EM 서버(205)로 전송할 수 있다. 일 실시 예에 따르면, EM 센싱 회로(200)가 생성한 제1 정보는 외부 전자 장치(201, 202)에 관련된 정보를 갖고 있는 EM 서버(205)를 통해 분석할 수 있다. 전자 장치(100)는 EM 서버(205)로 제1 정보를 보낼 수 있다. EM 서버(205)는 제1 정보를 수신할 수 있다. EM 서버(205)는 외부 전자 장치(201, 202)에 관련된 정보에 기반하여 제1 정보를 분석할 수 있다.
일 실시 예에서, 제1 정보는 EM 신호의 파형의 형태, EM 신호의 파형의 평균 진폭, 또는 EM 신호를 구성하는 주된 주파수 성분인 메인 주파수에 관한 수치 정보 중 적어도 일부를 포함할 수 있다. 프로세서(120)는 통신 회로(190)를 제어하여 EM 신호에 관한 정보를 포함하는 제1 정보를 복수의 EM 신호들에 대한 정보를 포함하는 EM 서버(205)로 전송할 수 있다.
동작 707에서, 전자 장치(101)는 제1 정보의 전송에 응답하여, EM 서버(205)로부터 통신 회로(190)를 통해 적어도 하나의 외부 전자 장치(201, 202) 중 사용자의 음성 입력에 기반하여 동작을 수행할 대상 장치를 특정하는 제2 정보를 수신할 수 있다.
EM 서버(205)는 전자 장치(101)로부터 제1 정보의 수신에 응답하여 제2 정보를 생성할 수 있다. EM 서버(205)는 제1 정보에 포함된 EM 신호에 관한 EM 신호의 파형의 형태, EM 신호의 파형의 평균 진폭, 또는 EM 신호를 구성하는 주된 주파수 성분인 메인 주파수에 관한 수치를 미리 저장된 복수의 EM 신호들과 대비할 수 있다. 미리 저장된 복수의 EM 신호들 각각은 대응하는 전자 장치의 종류, 동작 상태, 또는 모델 명에 관한 정보를 포함할 수 있다. EM 서버(205)는 제1 정보에 포함된 EM 신호를 분석하여 미리 저장된 복수의 EM 신호들 중 어느 EM 신호와 대응하는지 확인할 수 있다.
예컨대, 삼각파와 정현파가 1:1로 혼합된 파형 형태, 0.1nm의 평균 진폭, 1MHz의 주된 주파수 성분을 갖는 EM 신호가 턴-온 후 아이들(idle) 상태를 유지하는 노트북 컴퓨터에서 방출될 수 있다. 이 때, 이와 대응하는 EM 신호에 관한 제1 정보가 입력되는 경우, EM 서버(205)는 제1 정보가 노트북 컴퓨터로부터 발생한 EM 신호에 대한 정보임을 확인할 수 있다.
EM 서버(205)는 EM 신호에 대한 정보를 분석하여 미리 저장된 복수의 EM 신호들 중 어느 EM 신호와 대응하는지 확인하여 EM 신호를 방출한 대상 장치를 특정할 수 있다. EM 서버(205)는 대상 장치를 특정하는 제2 정보를 생성할 수 있다. 프로세서(120)는 통신 회로(190)를 통해 EM 서버(205)로부터 제2 정보를 수신할 수 있다.
동작 709에서, 전자 장치(101)는 대상 장치가 음성 입력에 기반하여 동작하도록, 통신 회로(190)를 통해 음성 입력에 따른 음성 데이터 및 제2 정보를 지능형 서버(206)로 전송할 수 있다.
예를 들어, 전자 장치(101)는 대상 장치를 동작시키기 위해 대상 장치를 어떻게 동작시킬지 지시하는 내용을 포함하는 음성 데이터와 대상 장치를 특정하는 제2 정보를 지능형 서버(206)로 전송할 수 있다. 지능형 서버(206)는 음성 데이터와 제2 정보를 결합하여 대상 장치를 동작시킬 수 있는 정보를 생성할 수 있다. 지능형 서버(206)는 생성한 정보를 이용하여 대상 장치의 동작 시퀀스를 설정하는 패스 룰을 생성할 수 있다.
동작 711에서, 전자 장치(101)는 지능형 서버(206)로부터 패스 룰을 수신할 수 있다. 전자 장치(101)는 수신한 패스 룰에 기반하여 대상 장치가 동작할 수 있도록 대상 장치를 제어할 수 있다. 전자 장치(101)는 대상 장치가 패스 룰에 지정된 동작을 수행하기 위해 필요한 정보를 대상 장치로 전송할 수 있다.
도 7b는 일 실시 예에 따른 전자 장치(101)가 EM 신호에 대한 제1 정보를 생성하고, 전자 장치(101)에서 제1 정보를 분석하여 대상 장치를 특정하는 경우를 나타내었다. 도 7b의 동작 701, 동작 703, 동작 709, 및 동작 711은 도 7a의 동작 701, 동작 703, 동작 709, 및 동작 711과 실질적으로 동일하므로, 이들에 대한 설명은 생략하기로 한다.
동작 704에서, 일 예에 따른 전자 장치(101)의 프로세서(120)는 EM 센싱 회로(200)에서 수신한 EM 신호를 이용하여 제1 정보를 생성할 수 있다. 전자 장치(101)는 외부 전자 장치(201, 202)에 관련된 정보를 EM 센싱 회로(200) 또는 메모리(130)에 저장할 수 있다.
동작 706에서, 전자 장치(101)는 외부 전자 장치(201, 202)에 관련된 정보에 기반하여 제1 정보를 분석할 수 있다. 전자 장치(101)는 제1 정보를 분석하여 사용자의 음성 입력에 기반하여 동작을 수행할 대상 장치를 특정할 수 있다. 전자 장치(101)는 외부 전자 장치(201, 202)에 관련된 정보를 이용하여 EM 신호를 방출한 대상 장치를 감지할 수 있다.
도 8a 및 도 8b는 일 실시 예에 따른 전자 장치(101)가 EM 신호를 수신한 후 사용자의 음성 입력을 획득하는 경우를 나타낸 흐름도들이다.
동작 801에서, 전자 장치(101)는 EM 센싱 회로(200)를 통해 적어도 하나의 외부 전자 장치의 EM 신호를 수신할 수 있다. 전자 장치(101)는 EM 센싱 회로(200)를 활성화시켜 외부 전자 장치로부터 방출된 EM 신호를 센싱할 준비를 할 수 있다. 일 실시 예에 따른 EM 센싱 회로(200)는 전자 장치(101)가 턴 온(turn on) 된 동안 활성화 상태를 지속적으로 유지할 수 있다.
일 실시 예에 따른 EM 센싱 회로(200)는 디스플레이(160)의 턴-온 시점에 활성화될 수 있다. 전자 장치(101)는 디스플레이(160)가 턴-온 되어 있는 동안 활성화된 상태를 유지할 수 있다. 이 경우, EM 센싱 회로(200)는 사용자의 음성 입력을 획득하기 전에 음성 입력을 수행할 대상 장치인 제1 외부 장치를 미리 특정할 수 있다. 사용자의 음성 입력을 획득하기 전 우선적으로 EM 신호를 센싱하여 음성 입력에 기반하여 동작을 수행할 대상 장치를 특정하는 경우, 사용자의 음성 입력에 지시 대상이 없는 경우에도 제1 외부 장치가 음성 입력의 내용에 따라 동작하도록 즉시 제어할 수 있다. 이에 따라, 제1 외부 장치를 대상 장치로 특정하기까지 소요되는 시간을 단축할 수 있다.
동작 803에서, 전자 장치(101)는 통신 회로(190)를 통해 EM 신호에 대한 제1 정보를 EM 서버(205)로 전송할 수 있다. 일 실시 예에 따르면, EM 센싱 회로(200)가 생성한 제1 정보는 외부 전자 장치(201, 202)에 관련된 정보를 갖고 있는 EM 서버(205)를 통해 분석할 수 있다. 전자 장치(100)는 EM 서버(205)로 제1 정보를 보낼 수 있다. EM 서버(205)는 제1 정보를 수신할 수 있다. EM 서버(205)는 외부 전자 장치(201, 202)에 관련된 정보에 기반하여 제1 정보를 분석할 수 있다.
일 실시 예에서, 제1 정보는 EM 신호의 파형의 형태, EM 신호의 파형의 평균 진폭, 또는 EM 신호를 구성하는 주된 주파수 성분인 메인 주파수에 관한 수치 정보 중 적어도 일부를 포함할 수 있다. 프로세서(120)는 통신 회로(190)를 제어하여 EM 신호에 관한 정보를 포함하는 제1 정보를 복수의 EM 신호들에 대한 정보를 포함하는 EM 서버(205)로 전송할 수 있다.
동작 805에서, 전자 장치(101)는 제1 정보의 전송에 응답하여, EM 서버(205)로부터 통신 회로(190)를 통해 적어도 하나의 외부 전자 장치(201, 202) 중 제1 외부 전자 장치(201)를 사용자의 음성 입력에 기반하여 동작을 수행할 대상 장치로 특정하는 제2 정보를 수신할 수 있다.
동작 807에서, 전자 장치(101)는 마이크(111)를 통해 사용자의 음성 입력을 획득할 수 있다. 마이크(111)는 획득한 사용자의 음성 입력을 프로세서(120)로 제공할 수 있다. 사용자의 음성 입력은 동작을 수행할 대상 장치(예: 제1 외부 전자 장치(201))를 특정하지 않고 지시 내용만을 포함할 수 있다. 음성 입력의 내용은 전자 장치(101)의 프로세서(120)에 입력될 수 있다. 음성 입력은 프로세서(120)에서 자연어로 변환될 수 있다.
일 실시 예에서, 전자 장치(101)는 EM 신호를 센싱하는 기능을 활성화한 상태에서 사용자의 발화를 수신할 수 있다. 획득한 사용자의 발화인 음성 입력에는 지시 내용만 포함되어 있고, 지시 대상이 없을 수 있다. 사용자의 발화에서 대상 장치를 특정하지 않은 경우, 전자 장치(101)는 EM 신호를 이용하여 대상 장치를 특정할 수 있다.
일 실시 예에서, 사용자의 발화를 수신하기 전 대상 장치를 특정할 수 있는 상태를 유지하기 위해, EM 센싱 회로(200)는 사용자의 발화 전 활성화될 수 있다. 이에 따라, 동작 807은 동작 803 또는 동작 805보다 후에 수행될 수 있다. 그러나 이에 한정되지 않으며, 동작 807은 동작 803 또는 동작 805와 동시에 수행될 수 있다.
동작 809에서, 전자 장치(101)는 대상 장치가 음성 입력에 기반하여 동작하도록, 통신 회로(190)를 통해 음성 입력에 따른 음성 데이터 및 제2 정보를 지능형 서버(206)로 전송할 수 있다. 일 실시 예에 따른 전자 장치(101)는 획득한 음성 입력에 대응하는 디지털 데이터인 음성 데이터의 적어도 일부와 대상 장치에 관한 정보인 제2 정보를 지능형 서버(206)로 전송할 수 있다.
전자 장치(101)는 EM 서버(205)로부터 수신한 제2 정보와 음성 데이터를 지능형 서버(206)로 전송할 수 있다. 지능형 서버(206)는 제2 정보에 따라 대상 장치를 지시 대상으로 특정할 수 있다. 예컨대, 지능형 서버(206)는 대상 장치에 관한 정보인 제2 정보를 음성 입력에 보충 텍스트 데이터로 결합하여 지시 대상이 없는 음성 데이터에 지시 대상을 보충할 수 있다.
예를 들어, 사용자는 전자 장치(101)에 "여기로 사진 전송해"라고 대상 장치가 특정되지 않은 발화를 할 수 있다. 종래의 전자 장치(101)는 사용자에게 "여기"가 어떤 장치를 의미하는지 대상 장치를 확인하여야 한다. 반면, 일 실시 예에 따른 전자 장치(101)는 "여기로 사진 전송해"라는 음성 입력을 획득하는 경우, 전자 장치(101)가 EM 신호를 센싱하여 특정한 대상 장치가 "여기"를 대체할 수 있다. 전자 장치(101)는 EM 신호를 센싱하여 대상 장치에 관한 정보를 획득하고, 대상 장치로 사진을 전송하는 동작을 수행할 수 있다.
일 실시 예에 따른 전자 장치(101)는 EM 센싱 기능을 먼저 활성화한 후 음성 입력을 획득할 수 있다. 다른 실시 예에 따른 전자 장치(101)는 음성 입력을 획득한 후 EM 센싱을 활성화할 수 있다. 또 다른 실시 예에 따른 전자 장치(101)는 음성 입력을 획득한 후 대상 장치에 관한 추가 정보를 획득하기 위해 EM 센싱을 가이드하여 추가 정보를 획득할 수 있다. 예를 들어, 전자 장치(101)는 "여기로 사진 전송해"라고 사용자가 발화하는 경우, "여기에 해당하는 장치를 스캔하세요"라고 가이드하는 음성 메시지 또는 영상을 표시할 수 있다. EM 센싱과 연관된 기능이 활성화되어 있지 않은 경우, 전자 장치(101)는 EM 센싱을 가이드함과 동시에 EM 센싱 회로(200)를 활성화하는 동작을 수행할 수 있다.
일 실시 예에 따른 전자 장치(101)는 지능형 서버(206)로부터 전달된 음성을 이용해 생성된 동작 정보를 수신할 수 있다. 예를 들어, 전자 장치(101)는 수신된 동작 정보의 일부를 대상 장치로 전송할 수 있다. 다른 예를 들어, 전자 장치(101)는 수신된 동작 정보에 기반하여 대상 장치를 제어할 수 있다. 다른 예를 들어, 전자 장치(101)는 대상 장치가 지능형 서버(206)로부터 동작 정보를 직접 제공받도록 제어할 수 있다.
일 실시 예에 따른 전자 장치(101)는 지능형 서버(206)로 전달된 장치의 정보 및 사용자의 입력과 연관된 정보를 전달하고, 전달된 정보에 기반하여 생성된 복수의 상태들의 시퀀스, 복수의 상태들의 시퀀스와 연관된 음성, 복수의 상태들의 시퀀스와 연관된 도메인 정보를 수신할 수 있다. 도메인 정보는 지시 대상인 대상 장치에 대한 정보일 수 있다. 예를 들어, 대상 장치가 TV로 확인되고, 사용자가 "켜줘"라고 발화한 경우, 도메인 정보는 TV가 될 수 있다.
일 실시 예에 따르면, 지능형 서버(206) 또는 지능형 서버는 자연어 이해 분석을 통해 어떤 패스 플래너(path planner)에 어떤 복수의 상태들의 시퀀스가 적용되어야 할지 결정하는 패스 룰을 생성할 수 있다. 예를 들어, 사물 인터넷(internet of things, IoT)의 환경을 구축하거나 제어하기 위한 음성 입력을 획득한 경우, 지능형 서버(206)는 사물 인터넷 구현이 지정된 어플리케이션(예: 삼성 커넥트(Samsung connect) 또는 SmartThings)로 가능하다고 판단하고, 전자 장치(101)로 지정된 어플리케이션과 관련된 패스 룰을 전송할 수 있다. 전자 장치(101) 또는 대상 장치가 지능형 서버(206)로부터 패스 룰 또는 음성을 수신하는 경우, 대상 장치는 수신한 패스 룰과 대응하는 동작을 실행할 수 있다.
일 실시 예에 따르면, 전자 장치(101)는 지능형 서버(206)로 전달된 패스 룰과 관련된 음성 정보를 수신할 수 있다. 패스 룰과 관련된 음성 정보는 사용자의 요청의 대상이 되는 대상 장치의 동작과 관련된 패스 룰이 진행 중이고, 현재 실행 중인 동작과 연관된 경우, 현재 실행 중인 동작을 제어하기 위한 음성일 수 있다. 예컨대, 사물 인터넷 제어를 위한 패스 룰과 관련된 동작이 진행 중인 경우, 지능형 서버(206)는 "TV에서 최신 영화를 검색합니다." 또는 "부엌 전등을 턴-오프 합니다."와 같이 사물 인터넷 제어 내용을 음성이나 그래픽으로 표현할 수 있는 데이터 정보를 전자 장치(101)로 전송할 수 있다.
동작 811에서, 전자 장치(101)는 지능형 서버(206)로부터 패스 룰을 수신할 수 있다. 전자 장치(101)는 수신한 패스 룰에 기반하여 대상 장치가 동작할 수 있도록 대상 장치를 제어할 수 있다. 전자 장치(101)는 대상 장치가 패스 룰에 지정된 동작을 수행하기 위해 필요한 정보를 대상 장치로 전송할 수 있다.
도 8b는 일 실시 예에 따른 전자 장치(101)가 EM 신호에 대한 제1 정보를 생성하고, 전자 장치(101)에서 제1 정보를 분석하여 대상 장치를 특정하는 경우를 나타내었다. 도 8b의 동작 801, 동작 807, 동작 809, 및 동작 811은 도 8a의 동작 801, 동작 807, 동작 809, 및 동작 811과 실질적으로 동일하므로, 이들에 대한 설명은 생략하기로 한다.
동작 804에서, 일 예에 따른 전자 장치(101)의 프로세서(120)는 EM 센싱 회로(200)에서 수신한 EM 신호를 이용하여 제1 정보를 생성할 수 있다. 전자 장치(101)는 외부 전자 장치(201, 202)에 관련된 정보를 EM 센싱 회로(200) 또는 메모리(130)에 저장할 수 있다.
동작 806에서, 전자 장치(101)는 외부 전자 장치(201, 202)에 관련된 정보에 기반하여 제1 정보를 분석할 수 있다. 전자 장치(101)는 제1 정보를 분석하여 사용자의 음성 입력에 기반하여 동작을 수행할 대상 장치를 특정할 수 있다. 전자 장치(101)는 외부 전자 장치(201, 202)에 관련된 정보를 이용하여 EM 신호를 방출한 대상 장치를 판단할 수 있다.
도 9는 다른 실시 예에 따른 전자 장치의 제어 방법을 나타낸 시퀀스 다이어그램이다. 도 9에 나타낸 동작 601 내지 동작 612는 도 6에서 설명한 동작 601 내지 동작 612와 실질적으로 동일하므로, 도 6과 결부하여 설명한 동작 601 내지 동작 612의 내용을 참조하기로 한다.
동작 901에서, 전자 장치(101)는 지능형 서버(206)로부터 복수의 상태들의 시퀀스를 수신할 수 있다. 예를 들어, 전자 장치(101)는 지능형 서버(206)로부터 음성 입력을 바탕으로 생성한 자연어, 패스 룰, 및 대상 장치(예: 제1 외부 전자 장치(201))를 특정하는 제2 정보를 수신할 수 있다. 전자 장치(101)는 통신 회로(190)를 통해 음성 분석 서버(206)로부터 수신한 음성 정보, 패스 룰, 및 도메인(domain) 정보 중 적어도 일부를 프로세서(120)로 전달할 수 있다. 패스 룰은 대상 장치의 동작 순서를 결정하는 복수의 상태들의 시퀀스일 수 있다.
동작 902에서, 전자 장치(101)는 복수의 상태들의 시퀀스에 적어도 일부 기초하여, 통신 회로(190)를 통해 전자 장치(101)와 대상 장치(예: 제1 외부 전자 장치(201)) 사이의 통신 연결을 수립할 수 있다. 예컨대, 전자 장치(101)와 지정된 어플리케이션(예: Samsung Connect 또는 SmartThings)에 등록되어 있는 스피커를 연결하기 위해 전자 장치(101)를 스피커에 태깅(tagging)하며 "연결"이라는 발화를 하게 되는 경우, 전자 장치(101)는 해당 스피커와 연결될 수 있다.
일 실시 예에 따른 전자 장치(101)는 대상 장치를 특정함과 동시에, 대상 장치의 동작을 위해 다른 동작을 더 수행할 수 있다. 예를 들어, 전자 장치(101)는 대상 장치가 지정된 어플리케이션(예: Samsung Connect 또는 SmartThings)에 등록되어 있는 기기인지 확인하는 동작을 수행할 수 있다. EM 서버(205)는 대상 장치가 지정된 어플리케이션(예: Samsung Connect)에 등록되어 있는 기기인지 확인하기 위해 지정된 어플리케이션을 관리하는 서버(예: Samsung Connect 서버)에 확인을 요청할 수 있다. 또는, 전자 장치(101)는 대상 장치가 지정된 어플리케이션에 등록되어 있는 기기인지 확인하기 위해 EM 서버(205)로부터 수신한 제2 정보를 이용하여 직접 확인할 수 있다.
동작 903에서, 전자 장치(101)는 복수의 상태들의 시퀀스 중 일부를 대상 장치(예: 제1 외부 전자 장치(201))로 전송할 수 있다. 전자 장치(101)는 제1 외부 전자 장치(201)로 복수의 상태들의 시퀀스 중 제1 외부 전자 장치(201)가 동작을 수행하기 위해 필요한 정보 또는 제1 외부 전자 장치(201)의 동작과 연관된 정보를 전달할 수 있다. 예를 들어, "노트북 컴퓨터로 사진을 전송해"라는 복수의 전자 장치(101)는 복수의 상태들의 시퀀스 중 제1 외부 전자 장치(201)가 사진 파일을 전송받기 위한 프로그램을 실행하는 시퀀스 정보를 제1 외부 전자 장치(201)로 전송할 수 있다.
동작 904에서, 제1 외부 전자 장치(201)는 전자 장치(101)로부터 복수의 상태들의 시퀀스 중 일부를 전달받고 이에 대응하는 동작을 수행할 수 있다. 제1 외부 전자 장치(201)는 전자 장치(101)로부터 제1 외부 전자 장치(201)의 동작과 연관된 정보인 복수의 상태들의 시퀀스 중 일부를 전달받을 수 있다. 제1 외부 전자 장치(201)는 수신한 정보들에 대응하여 사용자가 음성으로 지시한 동작을 수행할 수 있다.
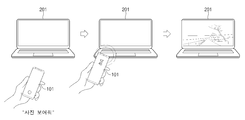
도 10a는 일 예에 따른 전자 장치(101)가 제1 외부 전자 장치(201)를 특정하여 사진을 전송하는 개념도이다. 도 10a는 다른 예에 따른 전자 장치(101)가 제1 외부 전자 장치(201)를 특정하여 사진을 전송하는 개념도이다. 도 10a 및 도 10b에서는 전자 장치(101)가 EM 신호를 센싱할 수 있는 휴대용 단말기이고 제1 외부 전자 장치(201)가 노트북 컴퓨터인 경우를 예를 들어 설명하였다.
도 10a의 경우, 사용자는 전자 장치(101)를 제1 외부 전자 장치(201)에 근접시키면서 태깅(tagging)하는 동작을 수행할 수 있다. 전자 장치(101)는 제1 외부 전자 장치(201)에서 방출된 EM 신호를 획득할 수 있다. 전자 장치(101)는 획득한 EM 신호를 분석하여 제1 외부 전자 장치(201)가 사용자가 이용하는 노트북 컴퓨터임을 확인할 수 있다. 사용자는 전자 장치(101)가 제1 외부 전자 장치(201)는 노트북 컴퓨터라는 것을 확인한 후 전자 장치(101)를 제1 외부 전자 장치(201)와 이격 시킬 수 있다. 이후, 사용자는 대상 장치를 특정하지 않고 “사진 보여줘”라는 발화를 할 수 있다. 전자 장치(101)는 “사진 보여줘”라는 음성 입력을 수신하고, EM 신호를 분석하여 확인한 노트북 컴퓨터를 대상 장치를 지정할 수 있다. 전자 장치(101)는 음성 입력과 EM 신호 분석을 통한 특정 결과를 결합하여 “노트북 컴퓨터에서 내 휴대용 단말기의 사진 보여줘”라는 음성 입력을 수신한 경우와 동일한 동작을 수행할 수 있다.
도 10b의 경우, 사용자는 먼저 대상 장치를 특정하지 않고 “사진 보여줘”라는 발화를 할 수 있다. 이후, 사용자는 전자 장치(101)를 제1 외부 전자 장치(201)에 근접시키면서 태깅(tagging)하는 동작을 수행할 수 있다. 이 경우에도 전자 장치(101)는 는 “사진 보여줘”라는 음성 입력을 수신하고, EM 신호를 분석하여 확인한 노트북 컴퓨터를 대상 장치를 지정할 수 있다. 전자 장치(101)는 음성 입력과 EM 신호 분석을 통한 특정 결과를 결합하여 “노트북 컴퓨터에서 내 휴대용 단말기의 사진 보여줘”라는 음성 입력을 수신한 경우와 동일한 동작을 수행할 수 있다.
이하에서는 본 발명의 일 실시 예가 적용될 수 있는 통합 지능화 시스템에 대해 설명한다.
도 11은 다양한 실시 예에 따른 통합 지능화 시스템을 나타낸 도면이다.
도 11을 참조하면, 통합 지능화 시스템(10)은 사용자 단말(1100), 지능형 서버(1200), 개인화 정보 서버(1300) 또는 제안 서버(1400)를 포함할 수 있다.
사용자 단말(1100)(예: 전자 장치(101))은 사용자 단말(1100) 내부에 저장된 앱(app)(또는, 어플리케이션 프로그램(application program))(예: 알람 앱, 메시지 앱, 또는 사진(갤러리) 앱)을 통해 사용자에게 필요한 서비스를 제공할 수 있다. 예를 들어, 사용자 단말(1100)은 사용자 단말(1100) 내부에 저장된 지능형 앱(또는, 음성 인식 앱)을 통해 다른 앱을 실행하고 동작시킬 수 있다. 사용자 단말(1100)은 상기 지능형 앱을 통해 상기 다른 앱을 실행하고 동작을 실행시키기 위한 사용자 입력을 수신할 수 있다. 상기 사용자 입력은, 예를 들어, 물리적 버튼, 터치 패드, 음성 입력, 또는 원격 입력을 통해 수신될 수 있다. 일 실시 예에 따르면, 사용자 단말(1100)은 휴대폰, 스마트폰, PDA(personal digital assistant) 또는 노트북 컴퓨터과 같이 인터넷에 연결 가능한 각종 단말 장치(또는, 전자 장치)가 이에 해당될 수 있다.
일 실시 예에 따르면, 사용자 단말(1100)은 사용자의 발화를 사용자 입력으로 수신할 수 있다. 사용자 단말(1100)은 사용자의 발화를 수신하고, 상기 사용자의 발화에 기초하여 앱을 동작시키는 명령을 생성할 수 있다. 이에 따라, 사용자 단말(1100)은 상기 명령을 이용하여 상기 앱을 동작시킬 수 있다.
지능형 서버(1200)(예: 지능형 서버(206))는 통신망을 통해 사용자 단말(1100)로부터 사용자 음성 입력(voice input)을 수신하여 텍스트 데이터(text data)로 변경할 수 있다. 다른 실시 예에서는, 지능형 서버(1200)는 상기 텍스트 데이터에 기초하여 패스 룰(path rule)을 생성(또는, 선택)할 수 있다. 상기 패스 룰은 앱의 기능을 수행하기 위한 동작(action)(또는, 오퍼레이션(operation))에 대한 정보 또는 상기 동작을 실행하기 위해 필요한 파라미터에 대한 정보를 포함할 수 있다. 또한, 상기 패스 룰은 상기 앱의 상기 동작의 순서를 포함할 수 있다. 사용자 단말(1100)은 상기 패스 룰을 수신하고, 상기 패스 룰에 따라 앱을 선택하고, 상기 선택된 앱에서 상기 패스 룰에 포함된 동작을 실행시킬 수 있다.
본 문서의 “패스 룰(path rule)” 이라는 용어는 일반적으로, 전자 장치가 사용자에 의해 요청된 태스크를 수행하기 위한 상태들의 시퀀스를 의미할 수 있지만, 이에 제한되지 않는다. 다시 말해, 패스 룰은 상태들의 시퀀스에 대한 정보를 포함할 수 있다. 상기 태스크는, 예를 들어, 지능형 앱이 제공할 수 있는 어떠한 동작(action)일 수 있다. 상기 태스크는 일정을 생성하거나, 원하는 상대방에게 사진을 전송하거나, 날씨 정보를 제공하는 것을 포함 할 수 있다. 사용자 단말(1100)은 적어도 하나 이상의 상태(예: 사용자 단말(1100)의 동작 상태)를 순차적으로 가짐으로써, 상기 태스크를 수행할 수 있다.
일 실시 예에 따르면, 패스 룰은 인공 지능(artificial intelligent)(AI) 시스템에 의해 제공되거나, 생성될 수 있다. 인공지능 시스템은 룰 베이스 시스템(rule-based system) 일 수도 있고, 신경망 베이스 시스템(neural network-based system)(예: 피드포워드 신경망(feedforward neural network(FNN)), 순환 신경망(recurrent neural network(RNN))) 일 수도 있다. 또는 전술한 것의 조합 또는 이와 다른 인공지능 시스템일 수도 있다. 일 실시 예에 따르면, 패스 룰은 미리 정의된 패스 룰들의 집합에서 선택될 수 있거나, 사용자 요청에 응답하여 실시간으로 생성될 수 있다. 예를 들어, 인공지능 시스템은 미리 정의 된 복수의 패스 룰 중 적어도 패스 룰을 선택하거나, 동적(또는, 실시간)으로 패스 룰을 생성할 수 있다. 또한, 사용자 단말(1100)은 패스 룰을 제공하기 위해 하이브리드 시스템을 사용할 수 있다.
일 실시 예에 따르면, 사용자 단말(1100)은 상기 동작을 실행하고, 동작을 실행한 사용자 단말(1100)의 상태에 대응되는 화면을 디스플레이에 표시할 수 있다. 다른 예를 들어, 사용자 단말(1100)은 상기 동작을 실행하고, 동작을 수행한 결과를 디스플레이에 표시하지 않을 수 있다. 사용자 단말(1100)은, 예를 들어, 복수의 동작을 실행하고, 상기 복수의 동작의 일부 결과 만을 디스플레이에 표시할 수 있다. 사용자 단말(1100)은, 예를 들어, 마지막 순서의 동작을 실행한 결과만을 디스플레이에 표시할 수 있다. 또 다른 예를 들어, 사용자 단말(1100)은 사용자의 입력을 수신하여 상기 동작을 실행한 결과를 디스플레이에 표시할 수 있다.
개인화 정보 서버(1300)는 사용자 정보가 저장된 데이터베이스를 포함할 수 있다. 예를 들어, 개인화 정보 서버(1300)는 사용자 단말(1100)로부터 사용자 정보(예: 컨텍스트 정보, 또는 앱 실행)를 수신하여 상기 데이터베이스에 저장할 수 있다. 지능형 서버(1200)는 통신망을 통해 개인화 정보 서버(1300)로부터 상기 사용자 정보를 수신하여 사용자 입력에 대한 패스 룰을 생성하는 경우에 이용할 수 있다. 일 실시 예에 따르면, 사용자 단말(1100)은 통신망을 통해 개인화 정보 서버(1300)로부터 사용자 정보를 수신하여 데이터베이스를 관리하기 위한 정보로 이용할 수 있다.
제안 서버(1400)는 단말 내에 기능 혹은 어플리케이션의 소개 또는 제공될 기능에 대한 정보가 저장된 데이터베이스를 포함할 수 있다. 예를 들어, 제안 서버(1400)는 개인화 정보 서버(1300)로부터 사용자 단말(1100)의 사용자 정보를 수신하여 사용자가 사용 할 수 있는 기능에 대한 데이터베이스를 포함 할 수 있다. 사용자 단말(1100)은 통신망을 통해 제안 서버(1400)로부터 상기 제공될 기능에 대한 정보를 수신하여 사용자에게 정보를 제공할 수 있다.
도 12는 일 실시 예에 따른 통합 지능화 시스템(10)의 사용자 단말(1100)을 나타낸 블록도이다.
도 12를 참조하면, 사용자 단말(1100)은 입력 모듈(1110)(예: 입력 장치(150)), 디스플레이(1120)(예: 표시 장치(160)), 스피커(1130)(예: 오디오 모듈(170)), 메모리(1140)(예: 메모리(130)) 또는 프로세서(1150)(예: 프로세서(120))를 포함할 수 있다. 사용자 단말(1100)은 하우징을 더 포함할 수 있고, 상기 사용자 단말(1100)의 구성들은 상기 하우징의 내부에 안착되거나 하우징 상에(on the housing) 위치할 수 있다. 사용자 단말(1100)은 상기 하우징의 내부에 위치한 통신 회로를 더 포함할 수 있다. 사용자 단말(1100)은 상기 통신 회로를 통해 외부 서버(예: 지능형 서버(1200))와 데이터(또는, 정보)를 송수신할 수 있다.
일 실시 예에 따른, 입력 모듈(1110)은 사용자로부터 사용자 입력을 수신할 수 있다. 예를 들어, 입력 모듈(1110)은 연결된 외부 장치(예: 키보드, 헤드셋)로부터 사용자 입력을 수신할 수 있다. 다른 예를 들어, 입력 모듈(1110)은 디스플레이(1120)와 결합된 터치 스크린(예: 터치 스크린 디스플레이)을 포함할 수 있다. 또 다른 예를 들어, 입력 모듈(1110)은 사용자 단말(1100)(또는, 사용자 단말(1100)의 하우징)에 위치한 하드웨어 키(또는, 물리적 키)를 포함할 수 있다.
일 실시 예에 따르면, 입력 모듈(1110)은 사용자의 발화를 음성 신호로 수신할 수 있는 마이크를 포함할 수 있다. 예를 들어, 입력 모듈(1110)은 발화 입력 시스템(speech input system)을 포함하고, 상기 발화 입력 시스템을 통해 사용자의 발화를 음성 신호로 수신할 수 있다. 상기 마이크는, 예를 들어, 하우징의 일부분(예: 제1 부분)을 통해 노출될 수 있다.
일 실시 예에 따른, 디스플레이(1120)는 이미지나 비디오, 및/또는 어플리케이션의 실행 화면을 표시할 수 있다. 예를 들어, 디스플레이(1120)는 앱의 그래픽 사용자 인터페이스(graphic user interface)(GUI)를 표시할 수 있다. 일 실시 예에 따르면, 디스플레이(1120)는 하우징의 일부분(예: 제2 부분)을 통해 노출될 수 있다.
일 실시 예에 따르면, 스피커(1130)는 음성 신호를 출력할 수 있다. 예를 들어, 스피커(1130)는 사용자 단말(1100) 내부에서 생성된 음성 신호를 외부로 출력할 수 있다. 일 실시 예에 따르면, 스피커(1130)는 하우징의 일부분(예: 제3 부분)을 통해 노출될 수 있다.
일 실시 예에 따르면, 메모리(1140)는 복수의 앱(또는, 어플리케이션 프로그램 application program))(1141, 1143)을 저장할 수 있다. 복수의 앱(1141, 1143)은, 예를 들어, 사용자 입력에 대응되는 기능을 수행하기 위한 프로그램(program)일 수 있다. 일 실시 예에 따르면, 메모리(1140)는 지능형 에이전트(1145), 실행 매니저 모듈(1147) 또는 지능형 서비스 모듈(1149)을 저장할 수 있다. 지능형 에이전트(1145), 실행 매니저 모듈(1147) 및 지능형 서비스 모듈(1149)은, 예를 들어, 수신된 사용자 입력(예: 사용자 발화)을 처리하기 위한 프레임워크(framework)(또는, 어플리케이션 프레임워크(application framework))일 수 있다.
일 실시 예에 따르면, 메모리(1140)는 사용자 입력을 인식하는데 필요한 정보를 저장할 수 있는 데이터베이스를 포함할 수 있다. 예를 들어, 메모리(1140)는 로그(log) 정보를 저장할 수 있는 로그 데이터베이스를 포함할 수 있다. 다른 예를 들어, 메모리(1140)는 사용자 정보를 저장할 수 있는 페르소나 데이터베이스를 포함할 수 있다.
일 실시 예에 따르면, 메모리(1140)는 복수의 앱(1141, 1143)을 저장하고, 복수의 앱(1141, 1143)은 로드되어 동작할 수 있다. 예를 들어, 메모리(1140)에 저장된 복수의 앱(1141,1143)은 실행 매니저 모듈(1147)에 의해 로드되어 동작할 수 있다. 복수의 앱(1141, 1143)은 기능을 수행하는 실행 서비스 모듈(1141a, 1143a)을 포함할 수 있다. 일 실시 예에서, 복수의 앱(1141, 1143)은 기능을 수행하기 위해서 실행 서비스 모듈(1141a, 1413a)를 통해 복수의 동작(예: 상태 들의 시퀀스)(1141b, 1143b)을 실행할 수 있다. 다시 말해, 실행 서비스 모듈(1141a, 1143a)는 실행 매니저 모듈(1147)에 의해 활성화되고, 복수의 동작(1141b, 1143b)을 실행할 수 있다.
일 실시 예에 따르면, 복수의 앱(1141, 1143)의 동작(1141b, 1143b)이 실행되었을 때, 동작(1141b, 1143b)의 실행에 따른 실행 상태 화면은 디스플레이(1120)에 표시될 수 있다. 상기 실행 상태 화면은, 예를 들어, 동작(1141b, 1143b)이 완료된 상태의 화면일 수 있다. 상기 실행 상태 화면은, 다른 예를 들어, 동작(1141b, 1143b)의 실행이 정지된 상태(partial landing)(예: 동작(1141b, 1143b)에 필요한 파라미터가 입력되지 않은 경우)의 화면일 수 있다.
일 실시 예에 따른, 실행 서비스 모듈(1141a, 1143a)은 패스 룰에 따라 동작(1141b, 1143b)을 실행할 수 있다. 예를 들어, 실행 서비스 모듈(1141a, 1143a)은 실행 매니저 모듈(1147)에 의해 활성화되고, 실행 매니저 모듈(1147)로부터 상기 패스 룰에 따라 실행 요청을 전달 받고, 상기 실행 요청에 따라 동작(1141b, 1143b)을 함으로써, 복수의 앱(1141, 1143)의 기능을 실행할 수 있다. 실행 서비스 모듈(1141a, 1143a)는 상기 동작(1141b, 1143b)의 수행이 완료되면 완료 정보를 실행 매니저 모듈(1147)로 전달할 수 있다.
일 실시 예에 따르면, 복수의 앱(1141, 1143)에서 복수의 동작(1141b, 1143b)이 실행되는 경우, 복수의 동작(1141b, 1143b)은 순차적으로 실행될 수 있다. 실행 서비스 모듈(1141a, 1143a)은 하나의 동작(예: 제1 앱(1141)의 동작 1, 제2 앱(1143)의 동작 1)의 실행이 완료되면 다음 동작(예: 제1 앱(1141)의 동작 2, 제2 앱(1143)의 동작 2)을 오픈하고 완료 정보를 실행 매니저 모듈(1147)로 송신할 수 있다. 여기서 임의의 동작을 오픈한다는 것은, 임의의 동작을 실행 가능한 상태로 천이시키거나, 임의의 동작의 실행을 준비하는 것으로 이해될 수 있다. 다시 말해서, 임의의 동작이 오픈되지 않으면, 해당 동작은 실행될 수 없다. 실행 매니저 모듈(147)은 상기 완료 정보가 수신되면 다음 동작(예: 제1 앱(1141)의 동작 2, 제2 앱(1143)의 동작 2)에 대한 실행 요청을 실행 서비스 모듈로 전달할 수 있다. 일 실시 예에 따르면, 복수의 앱(1141, 1143)이 실행되는 경우, 복수의 앱(1141, 1143)은 순차적으로 실행될 수 있다. 예를 들어, 제1 앱(1141)의 마지막 동작(예: 제1 앱(1141)의 동작 3)의 실행이 완료되어 완료 정보를 수신하면, 실행 매니저 모듈(1147)은 제2 앱(1143)의 첫번째 동작(예: 제2 앱(1143)의 동작 1)의 실행 요청을 실행 서비스(1143a)로 송신할 수 있다.
일 실시 예에 따르면, 앱(1141, 1143)에서 복수의 동작(1141b, 1143b)이 실행된 경우, 상기 실행된 복수의 동작(1141b, 1143b) 각각의 실행에 따른 결과 화면은 디스플레이(1120)에 표시될 수 있다. 일 실시 예에 따르면, 상기 실행된 복수의 동작(1141b, 1143b)의 실행에 따른 복수의 결과 화면 중 일부만 디스플레이(1120)에 표시될 수 있다.
일 실시 예에 따르면, 메모리(1140)는 지능형 에이전트(1145)와 연동된 지능형 앱(예: 음성 인식 앱)을 저장할 수 있다. 지능형 에이전트(1145)와 연동된 앱은 사용자의 발화를 음성 신호로 수신하여 처리할 수 있다. 일 실시 예에 따르면, 지능형 에이전트(1145)와 연동된 앱은 입력 모듈(1110)을 통해 입력되는 특정 입력(예: 하드웨어 키를 통한 입력, 터치 스크린을 통한 입력, 특정 음성 입력)에 의해 동작될 수 있다.
일 실시 예에 따르면, 메모리(1140)에 저장된 지능형 에이전트(1145), 실행 매니저 모듈(1147) 또는 지능형 서비스 모듈(1149)이 프로세서(1150)에 의해 실행될 수 있다. 지능형 에이전트(1145), 실행 매니저 모듈(1147) 또는 지능형 서비스 모듈(1149)의 기능은 프로세서(1150)에 의해 구현될 수 있다. 상기 지능형 에이전트(1145), 실행 매니저 모듈(1147) 및 지능형 서비스 모듈(1149)의 기능에 대해 프로세서(1150)의 동작으로 설명하겠다. 일 실시 예에 따르면, 메모리(1140)에 저장된 지능형 에이전트(1145), 실행 매니저 모듈(1147) 또는 지능형 서비스 모듈(1149)은 소프트웨어뿐만 아니라 하드웨어로 구현될 수 있다.
일 실시 예에 따르면, 프로세서(1150)는 사용자 단말(1100)의 전반적인 동작을 제어할 수 있다. 예를 들어, 프로세서(1150)는 입력 모듈(1110)을 제어하여 사용자 입력을 수신할 수 있다. 프로세서(1150)는 디스플레이(1120)를 제어하여 이미지를 표시할 수 있다. 프로세서(1150)는 스피커(1130)를 제어하여 음성 신호를 출력할 수 있다. 프로세서(1150)는 메모리(1140)를 제어하여 프로그램을 실행시키고, 필요한 정보를 불러오거나 저장할 수 있다.
일 실시 예에 따르면, 프로세서(1150)는 메모리(1140)에 저장된 지능형 에이전트(1145), 실행 매니저 모듈(1147) 또는 지능형 서비스 모듈(1149)을 실행시킬 수 있다. 이에 따라, 프로세서(1150)는 지능형 에이전트(1145), 실행 매니저 모듈(1147) 또는 지능형 서비스 모듈(1149)의 기능을 구현할 수 있다.
일 실시 예에 따른, 프로세서(1150)는 지능형 에이전트(1145)를 실행하여 사용자 입력으로 수신된 음성 신호에 기초하여 앱을 동작시키는 명령을 생성할 수 있다. 일 실시 예에 따른, 프로세서(1150)는 실행 매니저 모듈(1147)을 실행하여 상기 생성된 명령에 따라 메모리(1140)에 저장된 복수의 앱(1141, 1143)을 실행시킬 수 있다. 일 실시 예에 따르면, 프로세서(1150)는 지능형 서비스 모듈(1149)을 실행하여 사용자의 정보를 관리하고, 상기 사용자의 정보를 이용하여 사용자 입력을 처리할 수 있다.
프로세서(1150)는 지능형 에이전트(1145)를 실행하여 입력 모듈(1110)을 통해 수신된 사용자 입력을 지능형 서버(1200)로 송신하고, 지능형 서버(1200)를 통해 상기 사용자 입력을 처리할 수 있다.
일 실시 예에 따르면, 프로세서(1150)는 지능형 에이전트(1145)를 실행하여 상기 사용자 입력을 지능형 서버(1200)로 송신하기 전에 상기 사용자 입력을 전처리할 수 있다. 일 실시 예에 따르면, 지능형 에이전트(1145)는 상기 사용자 입력을 전처리하기 위하여, 적응 반향 제거(adaptive echo canceller)(AEC) 모듈, 노이즈 억제(noise suppression)(NS) 모듈, 종점 검출(end-point detection)(EPD) 모듈 또는 자동 이득 제어(automatic gain control)(AGC) 모듈을 포함할 수 있다. 상기 적응 반향 제거부는 상기 사용자 입력에 포함된 에코(echo)를 제거할 수 있다. 상기 노이즈 억제 모듈은 상기 사용자 입력에 포함된 배경 잡음을 억제할 수 있다. 상기 종점 검출 모듈은 상기 사용자 입력에 포함된 사용자 음성의 종점을 검출하고, 상기 검출된 종점을 이용하여 사용자의 음성이 존재하는 부분을 찾을 수 있다. 상기 자동 이득 제어 모듈은 상기 사용자 입력을 인식하고, 상기 인식된 사용자 입력을 처리하기 적합하도록 상기 사용자 입력의 음량을 조절할 수 있다. 일 실시 예에 따르면, 프로세서(1150)는 성능을 위하여 상기 전처리 구성을 전부 실행시킬 수 있지만, 다른 실시 예에서 프로세서(1150)는 저전력으로 동작하기 위해 상기 전처리 구성 중 일부를 실행시킬 수 있다.
일 실시 예에 따르면, 지능형 에이전트(1145)는 사용자의 호출을 인식하기 위해 메모리(1140)에 저장된 웨이크 업(wake up) 인식 모듈을 실행시킬 수 있다. 이에 따라, 프로세서(1150)는 상기 웨이크 업 인식 모듈을 통해 사용자의 웨이크 업 명령을 인식할 수 있고, 상기 웨이크 업 명령을 수신한 경우 사용자 입력을 수신하기 위한 지능형 에이전트(145)를 실행시킬 수 있다. 상기 웨이크 업 인식 모듈은 저전력 프로세서(예: 오디오 코덱에 포함된 프로세서)로 구현될 수 있다. 일 실시 예에 따르면, 프로세서(1150)는 하드웨어 키를 통한 사용자 입력을 수신하였을 때 지능형 에이전트(1145)를 실행시킬 수 있다. 지능형 에이전트(1145)가 실행된 경우, 지능형 에이전트(1145)와 연동된 지능형 앱(예: 음성 인식 앱)이 실행될 수 있다.
일 실시 예에 따르면, 지능형 에이전트(1145)는 사용자 입력을 실행하기 위한 음성 인식 모듈을 포함할 수 있다. 프로세서(1150)는 상기 음성 인식 모듈을 통해 앱에서 동작을 실행하도록 하기 위한 사용자 입력을 인식할 수 있다. 예를 들어, 프로세서(1150)는 상기 음성 인식 모듈을 통해 복수의 앱(1141, 1143)에서 상기 웨이크 업 명령과 같은 동작을 실행하는 제한된 사용자 (음성) 입력(예: 카메라 앱이 실행 중일 때 촬영 동작을 실행시키는 “찰칵”과 같은 발화)을 인식할 수 있다. 프로세서(1150)는 상기 지능형 서버(1200)를 보조하여 상기 음성 인식 모듈을 통해 사용자 단말(1100) 내에서 처리할 수 있는 사용자 명령을 인식하여 빠르게 처리할 수 있다. 일 실시 예에 따르면, 사용자 입력을 실행하기 위한 지능형 에이전트(1145)의 음성 인식 모듈은 앱 프로세서에서 구현될 수 있다.
일 실시 예에 따르면, 지능형 에이전트(1145)의 음성 인식 모듈(웨이크 업 모듈의 음성 인식 모듈을 포함)은 음성을 인식하기 위한 알고리즘을 이용하여 사용자 입력을 인식할 수 있다. 상기 음성을 인식하기 위해 사용되는 알고리즘은, 예를 들어, HMM(hidden markov model) 알고리즘, ANN(artificial neural network) 알고리즘 또는 DTW(dynamic time warping) 알고리즘 중 적어도 하나일 수 있다.
일 실시 예에 따르면, 프로세서(1150)는 지능형 에이전트(1145)를 실행하여 사용자의 음성 입력을 텍스트 데이터로 변환할 수 있다. 예를 들어, 프로세서(1150)는 지능형 에이전트(1145)를 통해 사용자의 음성을 지능형 서버(1200)로 송신하고, 지능형 서버(1200)로부터 사용자의 음성에 대응되는 텍스트 데이터를 수신할 수 있다. 이에 따라, 프로세서(1150) 는 상기 변환된 텍스트 데이터를 디스플레이(1120)에 표시할 수 있다.
일 실시 예에 따르면, 프로세서(1150)는 지능형 에이전트(1145)를 실행하여 지능형 서버(1200)로부터 패스 룰을 수신할 수 있다. 일 실시 예에 따르면, 프로세서(1150)는 지능형 에이전트(1145)를 통해 상기 패스 룰을 실행 매니저 모듈(1147)로 전달할 수 있다.
일 실시 예에 따르면, 프로세서(1150)는 지능형 에이전트(1145)를 실행하여 지능형 서버(1200)로부터 수신된 패스 룰에 따른 실행 결과 로그(log)를 지능형 서비스 모듈(1149)로 전달하고, 상기 전달된 실행 결과 로그는 페르소나 모듈(persona manager)(1149b)의 사용자의 선호(preference) 정보에 누적되어 관리될 수 있다.
일 실시 예에 따른, 프로세서(1150)는 실행 매니저 모듈(1147)을 실행하여 지능형 에이전트(1145)로부터 패스 룰을 전달받아 복수의 앱(1141, 1143)을 실행시키고, 복수의 앱(1141, 1143)이 상기 패스 룰에 포함된 동작(1141b, 1143b)을 실행하도록 할 수 있다. 예를 들어, 프로세서(1150)는 실행 매니저 모듈(1147)을 통해 앱(1141, 1143)으로 동작(1141b, 1143b)을 실행하기 위한 명령 정보(예: 패스 룰 정보)를 송신할 수 있고, 상기 복수의 앱(1141, 1143)로부터 동작(1141b, 1143b)의 완료 정보를 전달 받을 수 있다.
일 실시 예에 따르면, 프로세서(1150)는 실행 매니저 모듈(1147)을 실행하여 지능형 에이전트(1145)와 복수의 앱(1141, 1143)의 사이에서 복수의 앱(1141, 1143)의 동작(1141b, 1143b)을 실행하기 위한 명령 정보(예: 패스 룰 정보)를 전달할 수 있다. 프로세서(1150)는 실행 매니저 모듈(1147)을 통해 상기 패스 룰에 따라 실행할 복수의 앱(1141, 1143)을 바인딩(binding)하고, 상기 패스 룰에 포함된 동작(1141b, 1143b)의 명령 정보(예: 패스 룰 정보)를 복수의 앱(1141, 1143)으로 전달할 수 있다. 예를 들어, 프로세서(1150)는 실행 매니저 모듈(1147)을 통해 상기 패스 룰에 포함된 동작(1141b, 1143b)을 순차적으로 복수의 앱(1141, 1143)으로 전달하여, 복수의 앱(1141, 1143)의 동작(1141b, 1143b)을 상기 패스 룰에 따라 순차적으로 실행시킬 수 있다.
일 실시 예에 따르면, 프로세서(1150)는 실행 매니저 모듈(1147)을 실행하여 복수의 앱(1141, 1143)의 동작(1141b, 1143b)의 실행 상태를 관리할 수 있다. 예를 들어, 프로세서(1150)는 실행 매니저 모듈(1147)을 통해 복수의 앱(1141, 1143)으로부터 상기 동작(1141b, 1143b)의 실행 상태에 대한 정보를 전달 받을 수 있다. 상기 동작(1141b, 1143b)의 실행 상태가, 예를 들어, 정지된 상태(partial landing)인 경우(예: 동작(1141b, 1143b)에 필요한 파라미터가 입력되지 않은 경우), 프로세서(1150)는 실행 매니저 모듈(1147)을 통해 상기 정지된 상태에 대한 정보를 지능형 에이전트(1145)로 전달할 수 있다. 프로세서(1150)는 지능형 에이전트(1145)를 통해 상기 전달 받은 정보를 이용하여, 사용자에게 필요한 정보(예: 파라미터 정보)의 입력을 요청할 수 있다. 상기 동작(1141b, 1143b)의 실행 상태가, 다른 예를 들어, 동작 상태인 경우, 프로세서(1150)는 지능형 에이전트(1145)를 통해 사용자로부터 발화를 수신할 수 있다. 프로세서(1150)는 실행 매니저 모듈(1147)를 통해 상기 실행되고 있는 복수의 앱(1141, 1143) 및 복수의 앱(1141, 1143)의 실행 상태에 대한 정보를 지능형 에이전트(1145)로 전달할 수 있다. 프로세서(1150)는 지능형 에이전트(1145)를 통해 상기 사용자 발화를 지능형 서버(1200)로 송신할 수 있다. 프로세서(1150)는 지능형 에이전트(1145)를 통해 지능형 서버(1200)로부터 상기 사용자의 발화의 파라미터 정보를 수신할 수 있다. 프로세서(1150)는 지능형 에이전트(1145)를 통해 상기 수신된 파라미터 정보를 실행 매니저 모듈(1147)로 전달할 수 있다. 실행 매니저 모듈(1147)은 상기 수신한 파라미터 정보를 이용하여 동작(1141b, 1143b)의 파라미터를 새로운 파라미터로 변경할 수 있다.
일 실시 예에 따르면, 프로세서(1150)는 실행 매니저 모듈(1147)을 실행하여 패스 룰에 포함된 파라미터 정보를 복수의 앱(1141, 1143)으로 전달할 수 있다. 상기 패스 룰에 따라 복수의 앱(1141, 1143)이 순차적으로 실행되는 경우, 실행 매니저 모듈(1147)은 하나의 앱에서 다른 앱으로 패스 룰에 포함된 파라미터 정보를 전달할 수 있다.
일 실시 예에 따르면, 프로세서(1150)는 실행 매니저 모듈(1147)을 실행하여 복수의 패스 룰을 수신할 수 있다. 프로세서(1150)는 실행 매니저 모듈(1147)을 통해 사용자의 발화에 기초하여 복수의 패스 룰이 선택될 수 있다. 예를 들어, 프로세서(1150)는 실행 매니저 모듈(1147)을 통해 사용자의 발화가 일부 동작(1141a)을 실행할 일부 앱(1141)을 특정하였지만, 나머지 동작(1143b)을 실행할 다른 앱(1143)을 특정하지 않은 경우, 일부 동작(1141a)를 실행할 동일한 앱(1141)(예: 갤러리 앱)이 실행되고 나머지 동작(1143b)를 실행할 수 있는 서로 다른 앱(1143)(예: 메시지 앱, 텔레그램 앱)이 각각 실행되는 서로 다른 복수의 패스 룰을 수신할 수 있다. 프로세서(1150)는, 예를 들어, 실행 매니저 모듈(1147)을 통해 상기 복수의 패스 룰의 동일한 동작(1141b, 1143b)(예: 연속된 동일한 동작(1141b, 1143b))을 실행할 수 있다. 프로세서(1150)는 상기 동일한 동작까지 실행한 경우, 실행 매니저 모듈(1147)을 통해 상기 복수의 패스 룰에 각각 포함된 서로 다른 복수의 앱(1141, 1143)을 선택할 수 있는 상태 화면을 디스플레이(1120)에 표시할 수 있다.
일 실시 예에 따르면, 지능형 서비스 모듈(1149)은 컨텍스트 모듈(1149a), 페르소나 모듈(1149b) 또는 제안 모듈(1149c)을 포함할 수 있다.
프로세서(1150)는 컨텍스트 모듈(1149a)을 실행하여 복수의 앱(1141, 1143)으로부터 복수의 앱(1141, 1143)의 현재 상태를 수집할 수 있다. 예를 들어, 프로세서(1150)는 컨텍스트 모듈(1149a)을 실행하여 복수의 앱(1141, 1143)의 현재 상태를 나타내는 컨텍스트 정보를 수신하고, 상기 수신된 컨텍스트 정보를 통해 앱(1141, 1143)의 현재 상태를 수집할 수 있다.
프로세서(1150)는 페르소나 모듈(1149b)을 실행하여 사용자 단말(1100)을 사용하는 사용자의 개인 정보를 관리할 수 있다. 예를 들어, 프로세서(1150)는 페르소나 모듈(1149b)을 실행하여 사용자 단말(1100)의 사용 정보 및 수행 결과를 수집하고, 상기 수집된 사용자 단말(1100)의 사용 정보 및 수행 결과를 이용하여 사용자의 개인 정보를 관리할 수 있다.
프로세서(1150)는 제안 모듈(1149c)을 실행하여 사용자의 의도를 예측하고, 상기 사용자의 의도에 기초하여 사용자에게 명령을 추천해줄 수 있다. 예를 들어, 프로세서(1150)는 제안 모듈(1149c)을 실행하여 사용자의 현재 상태(예: 시간, 장소, 상황, 앱)에 따라 사용자에게 명령을 추천해줄 수 있다.
도 13은 일 실시 예에 따른 사용자 단말의 지능형 앱을 실행시키는 것을 나타낸 도면이다.
도 13을 참조하면, 사용자 단말(1100)이 사용자 입력을 수신하여 지능형 에이전트(1145)와 연동된 지능형 앱(예: 음성 인식 앱)을 실행시키는 것을 나타낸 것이다.
일 실시 예에 따르면, 사용자 단말(1100)은 하드웨어 키(1112)를 통해 음성을 인식하기 위한 지능형 앱을 실행시킬 수 있다. 예를 들어, 사용자 단말(1100)은 하드웨어 키(1112)를 통해 사용자 입력을 수신한 경우 디스플레이(1120)에 지능형 앱의 UI(user interface)(1121)를 표시할 수 있다. 사용자는, 예를 들어, 지능형 앱의 UI(1121)가 디스플레이(1120)에 표시된 상태에서 음성을 입력(1120b)하기 위해 지능형 앱의 UI(1121)에 음성인식 버튼(1121a)를 터치할 수 있다. 사용자는, 다른 예를 들어, 음성을 입력(1120b)하기 위해 상기 하드웨어 키(1112)를 지속적으로 눌러서 음성을 입력(1120b)을 할 수 있다.
일 실시 예에 따르면, 사용자 단말(1100)은 마이크(1111)를 통해 음성을 인식하기 위한 지능형 앱을 실행시킬 수 있다. 예를 들어, 사용자 단말(1100)은 마이크(1111)를 통해 지정된 음성(예: 일어나!(wake up!))이 입력(1120a)된 경우 디스플레이(1120)에 지능형 앱의 UI(1121)를 표시할 수 있다.
도 14는 일 실시 예에 따른 지능형 서비스 모듈의 컨텍스트 모듈이 현재 상태를 수집하는 것을 나타낸 도면이다.
도 14를 참조하면, 프로세서(1150)는 지능형 에이전트(1145)로부터 컨텍스트 요청을 수신(①)하면, 컨텍스트 모듈(1149a)을 통해 복수의 앱(1141, 1143)의 현재 상태를 나타내는 컨텍스트 정보를 요청(②)할 수 있다. 일 실시 예에 따르면, 프로세서(1150)는 컨텍스트 모듈(1149a)을 통해 복수의 앱(1141, 1143)으로부터 상기 컨텍스트 정보를 수신(③)하여 지능형 에이전트(1145)로 송신(④)할 수 있다.
일 실시 예에 따르면, 프로세서(1150)는 컨텍스트 모듈(1149a)을 통해 복수의 앱(1141, 1143)으로부터 복수의 컨텍스트 정보를 전달 받을 수 있다. 상기 컨텍스트 정보는, 예를 들어, 가장 최근 실행된 앱에 대한 정보일 수 있다. 상기 컨텍스트 정보는, 다른 예를 들어, 복수의 앱(1141, 1143) 내의 현재 상태에 대한 정보(예: 갤러리에서 사진을 보고 있는 경우, 해당 사진에 대한 정보)일 수 있다.
일 실시 예에 따르면, 프로세서(1150)는 컨텍스트 모듈(1149a)을 통해 복수의 앱(1141, 1143)뿐만 아니라, 디바이스 플랫폼(device platform)으로부터 사용자 단말(1100)의 현재 상태를 나타내는 컨텍스트 정보를 수신할 수 있다. 상기 컨텍스트 정보는 일반적 컨텍스트 정보, 사용자 컨텍스트 정보 또는 장치 컨텍스트 정보를 포함할 수 있다.
상기 일반적 컨텍스트 정보는 사용자 단말(1100)의 일반적인 정보를 포함할 수 있다. 상기 일반적 컨텍스트 정보는 디바이스 플랫폼의 센서 허브를 통해 데이터를 전달 받아서 내부 알고리즘을 통해 확인될 수 있다. 예를 들어, 상기 일반적 컨텍스트 정보는 현재 시공간에 대한 정보를 포함할 수 있다. 상기 현재 시공간에 대한 정보는, 예를 들어, 현재 시간 또는 사용자 단말(1100)의 현재 위치에 대한 정보를 포함할 수 있다. 상기 현재 시간은 사용자 단말(1100) 상에서의 시간을 통해 확인될 수 있고, 상기 현재 위치에 대한 정보는 GPS(global positioning system)를 통해 확인될 수 있다. 다른 예를 들어, 상기 일반적 컨텍스트 정보는 물리적 움직임에 대한 정보를 포함할 수 있다. 상기 물리적 움직임에 대한 정보는, 예를 들어, 걷기, 뛰기, 또는 운전 중에 대한 정보를 포함할 수 있다. 상기 물리적 움직임 정보는 모션 센서(motion sensor)를 통해 확인될 수 있다. 상기 운전 중에 대한 정보는 상기 모션 센서를 통해 운행을 확인할 수 있을 뿐만 아니라, 차량 내의 블루투스 연결을 감지하여 탑승 및 주차를 확인할 수 있다. 또 다른 예를 들어, 상기 일반적 컨텍스트 정보는 사용자 활동 정보를 포함할 수 있다. 상기 사용자 활동 정보는, 예를 들어, 출퇴근, 쇼핑, 또는 여행에 대한 정보를 포함할 수 있다. 상기 사용자 활동 정보는 사용자 또는 앱이 데이터베이스에 등록한 장소에 대한 정보를 이용하여 확인될 수 있다.
상기 사용자 컨텍스트 정보는 사용자에 대한 정보를 포함할 수 있다. 예를 들어, 상기 사용자 컨텍스트 정보는 사용자의 감정적 상태에 대한 정보를 포함할 수 있다. 상기 감정적 상태에 대한 정보는, 예를 들어, 사용자의 행복, 슬픔, 또는 화남에 대한 정보를 포함할 수 있다. 다른 예를 들어, 상기 사용자 컨텍스트 정보는 사용자의 현재 상태에 대한 정보를 포함할 수 있다. 상기 현재 상태에 대한 정보는, 예를 들어, 관심, 의도(예: 쇼핑)에 대한 정보를 포함할 수 있다.
상기 장치 컨텍스트 정보는 사용자 단말(1100)의 상태에 대한 정보를 포함할 수 있다. 예를 들어, 상기 장치 컨텍스트 정보는 실행 매니저 모듈(1147)이 실행한 패스 룰에 대한 정보를 포함할 수 있다. 다른 예를 들어, 상기 디바이스 정보는 배터리에 대한 정보를 포함할 수 있다. 상기 배터리에 대한 정보는, 예를 들어, 상기 배터리의 충전 및 방전 상태를 통해 확인될 수 있다. 또 다른 예를 들어, 상기 디바이스 정보는 연결된 장치 및 네트워크에 대한 정보를 포함할 수 있다. 상기 연결된 장치에 대한 정보는, 예를 들어, 상기 장치가 연결된 통신 인터페이스를 통해 확인될 수 있다.
도 15는 본 발명의 일 실시 예에 따른 지능형 서비스 모듈의 제안 모듈을 나타낸 블록도이다.
도 15를 참조하면, 제안 모듈(1149c)은 힌트 제공 모듈(1149c_1), 컨텍스트 힌트 생성 모듈(1149c_2), 조건 체킹 모듈(1149c_3), 조건 모델 모듈(1149c_4), 재사용 힌트 생성 모듈(1149c_5) 또는 소개 힌트 생성 모듈(1149c_6)을 포함할 수 있다.
일 실시 예에 따르면, 프로세서(1150)는 힌트 제공 모듈(1149c_1)을 실행하여 사용자에게 힌트(hint)를 제공할 수 있다. 예를 들어, 프로세서(1150)는 힌트 제공 모듈(1149c_1)을 통해 컨텍스트 힌트 생성 모듈(1149c_2), 재사용 힌트 생성 모듈(1149c_5) 또는 소개 힌트 생성 모듈(1149c_6)로부터 생성된 힌트를 전달 받아 사용자에게 힌트를 제공할 수 있다.
일 실시 예에 따르면, 프로세서(1150)는 조건 체킹 모듈(1149c_3) 또는 조건 모델 모듈(1149c_4)을 실행하여 현재 상태에 따라 추천될 수 있는 힌트를 생성할 수 있다. 프로세서(1150)는 조건 체킹 모듈(1149c_3)을 실행하여 현재 상태에 대응되는 정보를 전달 받을 수 있고, 조건 모델 모듈(1149c_4)을 실행하여 상기 전달 받은 정보를 이용하여 조건 모델(condition model)을 설정할 수 있다. 예를 들어, 프로세서(1150)는 조건 모델 모듈은(1149c_4)을 실행하여 사용자에게 힌트를 제공하는 시점의 시간, 위치, 또는 상황 사용중인 앱을 파악하여 해당 조건에서 사용할 가능성이 높은 힌트를 우선 순위가 높은 순으로 사용자에게 제공할 수 있다.
일 실시 예에 따르면, 프로세서(1150)는 재사용 힌트 생성 모듈(1149c_5)을 실행하여 사용 빈도에 따라 추천될 수 있는 힌트를 생성할 수 있다. 예를 들어, 프로세서(1150)는 재사용 힌트 생성 모듈(1149c_5)을 실행하여 사용자의 사용 패턴에 기초한 힌트를 생성할 수 있다.
일 실시 예에 따르면, 소개 힌트 생성 모듈(1149c_6)은 사용자에게 신규 기능 또는 다른 사용자가 많이 쓰는 기능을 소개하는 힌트를 생성할 수 있다. 예를 들어, 상기 신규 기능을 소개하는 힌트에는 지능형 에이전트(1145)에 대한 소개(예: 작동 방법)를 포함할 수 있다.
다른 실시 예에 따르면, 제안 모듈(1149c)의 컨텍스트 힌트 생성 모듈(1149c_2), 조건 체킹 모듈(1149c_3), 조건 모델 모듈(1149c_4), 재사용 힌트 생성 모듈(1149c_5) 또는 소개 힌트 생성 모듈(1149c_6)은 개인화 정보 서버(1300)에 포함될 수 있다. 예를 들어, 프로세서(1150)는 제안 모듈(1149c)의 힌트 제공 모듈(1149c_1)을 통해 사용자 개인화 정보 서버(1300)의 컨텍스트 힌트 생성 모듈(1149c_2), 재사용 힌트 생성 모듈(1149c_5) 또는 소개 힌트 생성 모듈(1149c_6)로부터 힌트를 수신하여 사용자에게 상기 수신된 힌트를 제공할 수 있다.
일 실시 예에 따르면, 사용자 단말(1100)은 다음의 일련의 프로세스에 따라 힌트를 제공할 수 있다. 예를 들어, 프로세서(1150)는 지능형 에이전트(1145)로부터 힌트 제공 요청을 수신하면, 힌트 제공 모듈(1149c_1)을 통해 컨텍스트 힌트 생성 모듈(1149c_2)로 힌트 생성 요청을 전달할 수 있다. 프로세서(1150)는 상기 힌트 생성 요청을 전달 받으면, 조건 체킹 모듈(1149c_3)을 통해 컨텍스트 모듈(1149a) 및 페르소나 모듈(1149b)로부터 현재 상태에 대응되는 정보를 전달 받을 수 있다. 프로세서(1150)는 조건 체킹 모듈(1149c_3)을 통해 상기 전달 받은 정보를 조건 모델 모듈(1149c_4)로 전달하고, 조건 모델 모듈(1149c_4)을 통해 상기 정보를 이용하여 사용자에게 제공되는 힌트 중 상기 조건에 사용 가능성이 높은 순서로 힌트에 대해 우선순위를 부여 할 수 있다. 프로세서(1150)는 컨텍스트 힌트 생성 모듈(1149c_2)을 통해 상기 조건을 확인하고, 상기 현재 상태에 대응되는 힌트를 생성할 수 있다. 프로세서(1150)는 컨텍스트 힌트 생성 모듈(1149c_2)을 통해 상기 생성된 힌트를 힌트 제공 모듈(1149c_1)로 전달할 수 있다. 프로세서(1150)는 힌트 제공 모듈(1149c_1)을 통해 지정된 규칙에 따라 상기 힌트를 정렬하고, 상기 힌트를 지능형 에이전트(1145)로 전달할 수 있다.
일 실시 예에 따르면, 프로세서(1150)는 힌트 제공 모듈(1149c_1)을 통해 복수의 컨텍스트 힌트를 생성할 수 있고, 지정된 규칙에 따라 복수의 컨텍스트 힌트에 우선 순위를 지정할 수 있다. 일 실시 예에 따르면, 프로세서(1150)는 힌트 제공 모듈(1149c_1)을 통해 상기 복수의 컨텍스트 힌트 중에서 우선 순위가 높은 것을 사용자에게 먼저 제공할 수 있다.
일 실시 예에 따르면, 사용자 단말(1100)은 사용 빈도에 따른 힌트를 제안할 수 있다. 예를 들어, 프로세서(1150)는 지능형 에이전트(1145)로부터 힌트 제공 요청을 전달 받으면, 힌트 제공 모듈(1149c_1)을 통해 재사용 힌트 생성 모듈(1149c_5)로 힌트 생성 요청을 전달할 수 있다. 프로세서(1150)는 상기 힌트 생성 요청을 전달 받으면, 재사용 힌트 생성 모듈(1149c_5)를 통해 페르소나 모듈(1149b)로부터 사용자 정보를 전달 받을 수 있다. 예를 들어, 프로세서(1150)는 재사용 힌트 생성 모듈(1149c_5)을 통해 페르소나 모듈(1149b)의 사용자의 프리퍼런스 정보에 포함된 패스 룰, 패스 룰에 포함된 파라미터, 앱의 실행 빈도, 앱이 사용된 시공간 정보를 전달 받을 수 있다. 프로세서(1150)는 재사용 힌트 생성 모듈(1149c_5)을 통해 상기 전달 받은 사용자 정보에 대응되는 힌트를 생성할 수 있다. 프로세서(1150)는 재사용 힌트 생성 모듈(1149c_5)을 통해 상기 생성된 힌트를 힌트 제공 모듈(1149c_1)로 전달할 수 있다. 프로세서(1150)는 힌트 제공 모듈(1149c_1)을 통해 상기 힌트를 정렬하고, 상기 힌트를 지능형 에이전트(1145)로 전달할 수 있다.
일 실시 예에 따르면, 사용자 단말(1100)은 새로운 기능에 대한 힌트를 제안할 수 있다. 예를 들어, 프로세서(1150)는 지능형 에이전트(1145)로부터 힌트 제공 요청을 전달 받으면, 힌트 제공 모듈(1149c_1)을 통해 소개 힌트 생성 모듈(1149c_6)로 힌트 생성 요청을 전달할 수 있다. 프로세서(1150)는 소개 힌트 생성 모듈(1149c_6)을 통해 제안 서버(1400)로부터 소개 힌트 제공 요청을 전달하여 제안 서버(1400)로부터 소개될 기능에 대한 정보를 수신할 수 있다. 제안 서버(1400)는, 예를 들어, 소개될 기능에 대한 정보를 저장할 수 있고, 상기 소개될 기능에 대한 힌트 리스트(hint list)는 서비스 운영자에 의해 업데이트될 수 있다. 프로세서(1150)는 소개 힌트 생성 모듈(1149c_6)을 통해 상기 생성된 힌트를 힌트 제공 모듈(1149c_1)로 전달할 수 있다. 프로세서(1150)는 힌트 제공 모듈(1149c_1)을 통해 상기 힌트를 정렬하고, 상기 힌트를 지능형 에이전트(1145)로 전송할 수 있다.
이에 따라, 프로세서(1150)는 제안 모듈(1149c)을 통해 컨텍스트 힌트 생성 모듈(1149c_2), 재사용 힌트 생성 모듈(1149c_5) 또는 소개 힌트 생성 모듈(1149c_6)에서 생성된 힌트를 사용자에게 제공할 수 있다. 예를 들어, 프로세서(1150)는 제안 모듈(1149c)을 통해 상기 생성된 힌트를 지능형 에이전트(1145)을 동작시키는 앱에 표시할 수 있고, 상기 앱을 통해 사용자로부터 상기 힌트를 선택하는 입력을 수신할 수 있다.
도 16은 본 발명의 일 실시 예에 따른 통합 지능화 시스템의 지능형 서버를 나타낸 블록도이다.
도 16을 참조하면, 지능형 서버(1200)는 자동 음성 인식(automatic speech recognition)(ASR) 모듈(1210), 자연어 이해(natural language understanding)(NLU) 모듈(1220), 패스 플래너(path planner) 모듈(1230), 대화 매니저(dialogue manager)(DM) 모듈(1240), 자연어 생성(natural language generator)(NLG) 모듈(1250) 또는 텍스트 음성 변환(text to speech)(TTS) 모듈(1260)을 포함할 수 있다. 일 실시 예에 따르면, 지능형 서버(1200)는 통신 회로, 메모리 및 프로세서를 포함할 수 있다. 상기 프로세서는 상기 메모리에 저장된 명령어를 실행하여 자동 음성 인식 모듈(1210), 자연어 이해 모듈(1220), 패스 플래너 모듈(1230), 대화 매니저 모듈(1240), 자연어 생성 모듈(1250) 및 텍스트 음성 변환 모듈(1260)을 구동시킬 수 있다. 지능형 서버(1200)는 상기 통신 회로를 통해 외부 전자 장치(예: 사용자 단말(1100))와 데이터(또는, 정보)를 송수신할 수 있다.
지능형 서버(1200)의 자연어 이해 모듈(1220) 또는 패스 플래너 모듈(1230)은 패스 룰(path rule)을 생성할 수 있다.
일 실시 예에 따르면, 자동 음성 인식(automatic speech recognition)(ASR) 모듈(1210)은 사용자 단말(1100)로부터 수신된 사용자 입력을 텍스트 데이터로 변환할 수 있다.
일 실시 예에 따르면, 자동 음성 인식 모듈(1210)은 사용자 단말(1100)로부터 수신된 사용자 입력을 텍스트 데이터로 변환할 수 있다. 예를 들어, 자동 음성 인식 모듈(1210)은 발화 인식 모듈을 포함할 수 있다. 상기 발화 인식 모듈은 음향(acoustic) 모델 및 언어(language) 모델을 포함할 수 있다. 예를 들어, 상기 음향 모델은 발성에 관련된 정보를 포함할 수 있고, 상기 언어 모델은 단위 음소 정보 및 단위 음소 정보의 조합에 대한 정보를 포함할 수 있다. 상기 발화 인식 모듈은 발성에 관련된 정보 및 단위 음소 정보에 대한 정보를 이용하여 사용자 발화를 텍스트 데이터로 변환할 수 있다. 상기 음향 모델 및 언어 모델에 대한 정보는, 예를 들어, 자동 음성 인식 데이터베이스(automatic speech recognition database)(ASR DB)(1211)에 저장될 수 있다.
일 실시 예에 따르면, 자연어 이해 모듈(1220)은 문법적 분석(syntactic analyze) 또는 의미적 분석(semantic analyze)을 수행하여 사용자 의도를 파악할 수 있다. 상기 문법적 분석은 사용자 입력을 문법적 단위(예: 단어, 구, 또는 형태소)로 나누고, 상기 나누어진 단위가 어떤 문법적인 요소를 갖는지 파악할 수 있다. 상기 의미적 분석은 의미(semantic) 매칭, 룰(rule) 매칭, 또는 포뮬러(formula) 매칭을 이용하여 수행할 수 있다. 이에 따라, 자연어 이해 모듈(1220)은 사용자 입력이 어느 도메인(domain), 의도(intent) 또는 상기 의도를 표현하는데 필요한 파라미터(parameter)(또는, 슬롯(slot))를 얻을 수 있다.
일 실시 예에 따르면, 자연어 이해 모듈(1220)은 도메인(domain), 의도(intend) 및 상기 의도를 파악하는데 필요한 파라미터(parameter)(또는, 슬롯(slot))로 나누어진 매칭 규칙을 이용하여 사용자의 의도 및 파라미터를 결정할 수 있다. 예를 들어, 상기 하나의 도메인(예: 알람)은 복수의 의도(예: 알람 설정, 또는 알람 해제)를 포함할 수 있고, 하나의 의도는 복수의 파라미터(예: 시간, 반복 횟수, 또는 알람음)을 포함할 수 있다. 복수의 룰은, 예를 들어, 하나 이상의 필수 요소 파라미터를 포함할 수 있다. 상기 매칭 규칙은 자연어 인식 데이터베이스(natural language understanding database)(NLU DB)(1221)에 저장될 수 있다.
일 실시 예에 따르면, 자연어 이해 모듈(1220)은 형태소, 구와 같은 언어적 특징(예: 문법적 요소)을 이용하여 사용자 입력으로부터 추출된 단어의 의미를 파악하고, 상기 파악된 단어의 의미를 도메인 및 의도에 매칭시켜 사용자의 의도를 결정할 수 있다. 예를 들어, 자연어 이해 모듈(1220)은 각각의 도메인 및 의도에 사용자 입력에서 추출된 단어가 얼마나 포함되어 있는 지를 계산하여 사용자 의도를 결정할 수 있다. 일 실시 예에 따르면, 자연어 이해 모듈(1220)은 상기 의도를 파악하는데 기초가 된 단어를 이용하여 사용자 입력의 파라미터를 결정할 수 있다. 일 실시 예에 따르면, 자연어 이해 모듈(1220)은 사용자 입력의 의도를 파악하기 위한 언어적 특징이 저장된 자연어 인식 데이터베이스(1221)를 이용하여 사용자의 의도를 결정할 수 있다. 다른 실시 예에 따르면, 자연어 이해 모듈(1220)은 개인화 언어 모델(personal language model)(PLM)을 이용하여 사용자의 의도를 결정할 수 있다. 예를 들어, 자연어 이해 모듈(1220)은 개인화된 정보(예: 연락처 리스트, 음악 리스트)를 이용하여 사용자의 의도를 결정할 수 있다. 상기 개인화 언어 모델은, 예를 들어, 자연어 인식 데이터베이스(1221)에 저장될 수 있다. 일 실시 예에 따르면, 자연어 이해 모듈(1220)뿐만 아니라 자동 음성 인식 모듈(1210)도 자연어 인식 데이터베이스(1221)에 저장된 개인화 언어 모델을 참고하여 사용자의 음성을 인식할 수 있다.
일 실시 예에 따르면, 자연어 이해 모듈(1220)은 사용자 입력의 의도 및 파라미터에 기초하여 패스 룰을 생성할 수 있다. 예를 들어, 자연어 이해 모듈(1220)은 사용자 입력의 의도에 기초하여 실행될 앱을 선택하고, 상기 선택된 앱에서 수행될 동작을 결정할 수 있다. 상기 자연어 이해 모듈(1220)은 상기 결정된 동작에 대응되는 파라미터를 결정하여 패스 룰을 생성할 수 있다. 일 실시 예에 따르면, 자연어 이해 모듈(1220)에 의해 생성된 패스 룰은 실행될 앱, 상기 앱에서 실행될 동작(예: 적어도 하나 이상의 상태(state)) 및 상기 동작을 실행하는데 필요한 파라미터에 대한 정보를 포함할 수 있다.
일 실시 예에 따르면, 자연어 이해 모듈(1220)은 사용자 입력의 의도 및 파라미터를 기반으로 하나의 패스 룰, 또는 복수의 패스 룰을 생성할 수 있다. 예를 들어, 자연어 이해 모듈(1220)은 패스 플래너 모듈(1230)로부터 사용자 단말(1100)에 대응되는 패스 룰 셋을 수신하고, 사용자 입력의 의도 및 파라미터를 상기 수신된 패스 룰 셋에 매핑하여 패스 룰을 결정할 수 있다.
다른 실시 예에 따르면, 자연어 이해 모듈(1220)은 사용자 입력의 의도 및 파라미터에 기초하여 실행될 앱, 상기 앱에서 실행될 동작 및 상기 동작을 실행하는데 필요한 파라미터를 결정하여 하나의 패스 룰, 또는 복수의 패스 룰을 생성할 수 있다. 예를 들어, 자연어 이해 모듈(1220)은 사용자 단말(1100)의 정보를 이용하여 상기 실행될 앱 및 상기 앱에서 실행될 동작을 사용자 입력의 의도에 따라 온톨로지(ontology) 또는 그래프 모델(graph model) 형태로 배열하여 패스 룰을 생성할 수 있다. 상기 생성된 패스 룰은, 예를 들어, 패스 플래너 모듈(1230)를 통해 패스 룰 데이터베이스(path rule database)(PR DB)(1231)에 저장될 수 있다. 상기 생성된 패스 룰은 데이터베이스(1231)의 패스 룰 셋에 추가될 수 있다.
일 실시 예에 따르면, 자연어 이해 모듈(1220)은 생성된 복수의 패스 룰 중 적어도 하나의 패스 룰을 선택할 수 있다. 예를 들어, 자연어 이해 모듈(1220)은 상기 복수의 패스 룰 최적의 패스 룰을 선택할 수 있다. 다른 예를 들어, 자연어 이해 모듈(1220)은 사용자 발화에 기초하여 일부 동작만이 특정된 경우 복수의 패스 룰을 선택할 수 있다. 자연어 이해 모듈(1220)은 사용자의 추가 입력에 의해 상기 복수의 패스 룰 중 하나의 패스 룰을 결정할 수 있다.
일 실시 예에 따르면, 자연어 이해 모듈(1220)은 사용자 입력에 대한 요청으로 패스 룰을 사용자 단말(1100)로 송신할 수 있다. 예를 들어, 자연어 이해 모듈(1220)은 사용자 입력에 대응되는 하나의 패스 룰을 사용자 단말(1100)로 송신할 수 있다. 다른 예를 들어, 자연어 이해 모듈(1220)은 사용자 입력에 대응되는 복수의 패스 룰을 사용자 단말(1100)로 송신할 수 있다. 상기 복수의 패스 룰은, 예를 들어, 사용자 발화에 기초하여 일부 동작만이 특정된 경우 자연어 이해 모듈(1220)에 의해 생성될 수 있다.
일 실시 예에 따르면, 패스 플래너 모듈(1230)은 복수의 패스 룰 중 적어도 하나의 패스 룰을 선택할 수 있다.
일 실시 예에 따르면, 패스 플래너 모듈(1230)은 자연어 이해 모듈(1220)로 복수의 패스 룰을 포함하는 패스 룰 셋을 전달할 수 있다. 상기 패스 룰 셋의 복수의 패스 룰은 패스 플래너 모듈(1230)에 연결된 패스 룰 데이터베이스(1231)에 테이블 형태로 저장될 수 있다. 예를 들어, 패스 플래너 모듈(1230)은 지능형 에이전트(1145)로부터 수신된 사용자 단말(1100)의 정보(예: OS 정보, 앱 정보)에 대응되는 패스 룰 셋을 자연어 이해 모듈(1220)로 전달할 수 있다. 상기 패스 룰 데이터베이스(1231)에 저장된 테이블은, 예를 들어, 도메인 또는 도메인의 버전 별로 저장될 수 있다.
일 실시 예에 따르면, 패스 플래너 모듈(1230)은 패스 룰 셋에서 하나의 패스 룰, 또는 복수의 패스 룰을 선택하여 자연어 이해 모듈(1220)로 전달할 수 있다. 예를 들어, 패스 플래너 모듈(1230)은 사용자의 의도 및 파라미터를 사용자 단말(1100) 에 대응되는 패스 룰 셋에 매칭하여 하나의 패스 룰, 또는 복수의 패스 룰을 선택하여 자연어 이해 모듈(1220)로 전달할 수 있다.
일 실시 예에 따르면, 패스 플래너 모듈(1230)은 사용자 의도 및 파라미터를 이용하여 하나의 패스 룰, 또는 복수의 패스 룰을 생성할 수 있다. 예를 들어, 패스 플래너 모듈(1230)은 사용자 의도 및 파라미터에 기초하여 실행될 앱 및 상기 앱에서 실행될 동작을 결정하여 하나의 패스 룰, 또는 복수의 패스 룰을 생성할 수 있다. 일 실시 예에 따르면, 패스 플래너 모듈(1230)은 상기 생성된 패스 룰을 패스 룰 데이터베이스(1231)에 저장할 수 있다.
일 실시 예에 따르면, 패스 플래너 모듈(1230)은 자연어 이해 모듈(1220)에서 생성된 패스 룰을 패스 룰 데이터베이스(1231)에 저장할 수 있다. 상기 생성된 패스 룰은 패스 룰 데이터베이스(1231)에 저장된 패스 룰 셋에 추가될 수 있다.
일 실시 예에 따르면, 패스 룰 데이터베이스(1231)에 저장된 테이블에는 복수의 패스 룰 또는 복수의 패스 룰 셋을 포함할 수 있다. 복수의 패스 룰 또는 복수의 패스 룰 셋은 각 패스 룰을 수행하는 장치의 종류, 버전, 타입, 또는 특성을 반영할 수 있다.
일 실시 예에 따르면, 대화 매니저 모듈(1240)은 자연어 이해 모듈(1220)에 의해 파악된 사용자의 의도가 명확한지 여부를 판단할 수 있다. 예를 들어, 대화 매니저 모듈(1240)은 파라미터의 정보가 충분하지 여부에 기초하여 사용자의 의도가 명확한지 여부를 판단할 수 있다. 대화 매니저 모듈(1240)은 자연어 이해 모듈(1220)에서 파악된 파라미터가 태스크를 수행하는데 충분한지 여부를 판단할 수 있다. 일 실시 예에 따르면, 대화 매니저 모듈(1240)은 사용자의 의도가 명확하지 않은 경우 사용자에게 필요한 정보를 요청하는 피드백을 수행할 수 있다. 예를 들어, 대화 매니저 모듈(1240)은 사용자의 의도를 파악하기 위한 파라미터에 대한 정보를 요청하는 피드백을 수행할 수 있다.
일 실시 예에 따르면, 대화 매니저 모듈(1240)은 컨텐츠 제공(content provider) 모듈을 포함할 수 있다. 상기 컨텐츠 제공 모듈은 자연어 이해 모듈(1220)에서 파악된 의도 및 파라미터에 기초하여 동작을 수행할 수 있는 경우, 사용자 입력에 대응되는 태스크를 수행한 결과를 생성할 수 있다. 일 실시 예에 따르면, 대화 매니저 모듈(1240)은 사용자 입력에 대한 응답으로 상기 컨텐츠 제공 모듈에서 생성된 상기 결과를 사용자 단말(1100)로 송신할 수 있다.
일 실시 예에 따르면, 자연어 생성 모듈(NLG)(1250)은 지정된 정보를 텍스트 형태로 변경할 수 있다. 상기 텍스트 형태로 변경된 정보는 자연어 발화의 형태일 수 있다. 상기 지정된 정보는, 예를 들어, 추가 입력에 대한 정보, 사용자 입력에 대응되는 동작의 완료를 안내하는 정보 또는 사용자의 추가 입력을 안내하는 정보(예: 사용자 입력에 대한 피드백 정보)일 수 있다. 상기 텍스트 형태로 변경된 정보는 사용자 단말(1100)로 송신되어 디스플레이(1120)에 표시되거나, 텍스트 음성 변환 모듈(1260)로 송신되어 음성 형태로 변경될 수 있다.
일 실시 예에 따르면, 텍스트 음성 변환 모듈(1260)은 텍스트 형태의 정보를 음성 형태의 정보로 변경할 수 있다. 텍스트 음성 변환 모듈(1260)은 자연어 생성 모듈(1250)로부터 텍스트 형태의 정보를 수신하고, 상기 텍스트 형태의 정보를 음성 형태의 정보로 변경하여 사용자 단말(1100)로 송신할 수 있다. 사용자 단말(1100)은 상기 음성 형태의 정보를 스피커(1130)로 출력할 수 있다.
일 실시 예에 따르면, 자연어 이해 모듈(1220), 패스 플래너 모듈(1230) 및 대화 매니저 모듈(1240)은 하나의 모듈로 구현될 수 있다. 예를 들어, 자연어 이해 모듈(1220), 패스 플래너 모듈(1230) 및 대화 매니저 모듈(1240)은 하나의 모듈로 구현되어 사용자의 의도 및 파라미터를 결정하고, 상기 결정된 사용자의 의도 및 파라미터에 대응되는 응답(예: 패스 룰)을 생성할 수 있다. 이에 따라, 생성된 응답은 사용자 단말(1100)로 송신될 수 있다.
도 17은 본 발명의 일 실시 예에 따른 패스 플래너 모듈(path planner module)의 패스 룰(path rule)을 생성하는 방법을 나타낸 도면이다.
도 17을 참조하면, 일 실시 예에 따른, 자연어 이해 모듈(1220)은 앱의 기능을 어느 하나 동작(예: 상태 A 내지 상태 F)으로 구분하여 패스 룰 데이터베이스(1231)에 저장할 수 있다. 예를 들어, 자연어 이해 모듈(1220)은 어느 하나의 동작(예: 상태)으로 구분된 복수의 패스 룰(A-B1-C1, A-B1-C2, A-B1-C3-D-F, A-B1-C3-D-E-F)을 포함하는 패스 룰 셋을 패스 룰 데이터베이스(1231)에 저장할 수 있다.
일 실시 예에 따르면, 패스 플래너 모듈(1230)의 패스 룰 데이터베이스(1231)는 앱의 기능을 수행하기 위한 패스 룰 셋을 저장할 수 있다. 상기 패스 룰 셋은 복수의 동작(예: 상태들의 시퀀스)을 포함하는 복수의 패스 룰을 포함할 수 있다. 상기 복수의 패스 룰은 복수의 동작 각각에 입력되는 파라미터에 따라 실행되는 동작이 순차적으로 배열될 수 있다. 일 실시 예에 따르면, 상기 복수의 패스 룰은 온톨로지(ontology) 또는 그래프 모델(graph model) 형태로 구성되어 패스 룰 데이터베이스(1231)에 저장될 수 있다.
일 실시 예에 따르면, 자연어 이해 모듈(1220)은 사용자 입력의 의도 및 파라미터에 대응되는 상기 복수의 패스 룰(A-B1-C1, A-B1-C2, A-B1-C3-D-F, A-B1-C3-D-E-F) 중에 최적의 패스 룰(A-B1-C3-D-F)을 선택할 수 있다.
일 실시 예에 따르면, 자연어 이해 모듈(1220)은 사용자 입력에 완벽히 매칭되는 패스 룰이 없는 경우 사용자 단말(1100)에 복수의 룰을 전달할 수 있다. 예를 들어, 자연어 이해 모듈(1220)은 사용자 입력에 부분적으로 대응된 패스 룰(예: A-B1)을 선택할 수 있다. 자연어 이해 모듈(1220)은 사용자 입력에 부분적으로 대응된 패스 룰(예: A-B1)을 포함하는 하나 이상의 패스 룰(예: A-B1-C1, A-B1-C2, A-B1-C3-D-F, A-B1-C3-D-E-F)을 선택하여 사용자 단말(1100)에 전달할 수 있다.
일 실시 예에 따르면, 자연어 이해 모듈(1220)은 사용자 단말(1100)의 추가 입력에 기초하여 복수의 패스 룰 중 하나를 선택하고, 상기 선택된 하나의 패스 룰을 사용자 단말(1100)에 전달 할 수 있다. 예를 들어, 자연어 이해 모듈(1220)은 사용자 단말(1100)에서 추가로 입력된 사용자 입력(예: C3를 선택하는 입력)에 따라 복수의 패스 룰(예: A-B1-C1, A-B1-C2, A-B1-C3-D-F, A-B1-C3-D-E-F) 중 하나의 패스 룰(예: A-B1-C3-D-F)을 선택하여 사용자 단말(1100)에 송신할 수 있다.
또 다른 실시 예에 따르면, 자연어 이해 모듈(1220)은 자연어 이해 모듈(1220)을 통해 사용자 단말(1100)에 추가로 입력된 사용자 입력(예: C3를 선택하는 입력)에 대응되는 사용자의 의도 및 파라미터를 결정할 수 있고, 상기 결정된 사용자의 의도 또는 파라미터를 사용자 단말(1100)로 송신할 수 있다. 사용자 단말(1100)은 상기 송신된 의도 또는 상기 파라미터에 기초하여, 복수의 패스 룰(예: A-B1-C1, A-B1-C2, A-B1-C3-D-F, A-B1-C3-D-E-F) 중 하나의 패스 룰(예: A-B1-C3-D-F)을 선택할 수 있다.
이에 따라, 사용자 단말(1100)은 상기 선택된 하나의 패스 룰에 의해 복수의 앱(1141, 1143)의 동작을 완료시킬 수 있다.
일 실시 예에 따르면, 자연어 이해 모듈(1220)은 정보가 부족한 사용자 입력이 지능형 서버(1200)에 수신된 경우, 상기 수신한 사용자 입력에 부분적으로 대응되는 패스 룰을 생성할 수 있다. 예를 들어, 자연어 이해 모듈(1220)은 상기 부분적으로 대응된 패스 룰을 지능형 에이전트(1145)로 송신할 수 있다. 프로세서(1150)는 지능형 에이전트(1145)를 실행하여 상기 패스 룰을 수신하고, 실행 매니저 모듈(1147)로 상기 부분적으로 대응된 패스 룰을 전달할 수 있다. 프로세서(1150)는 실행 매니저 모듈(1147)를 통해 상기 패스 룰에 따라 제1 앱(1141)을 실행시킬 수 있다. 프로세서(1150)는 실행 매니저 모듈(1147)을 통해 제1 앱(1141)을 실행하면서 부족한 파라미터에 대한 정보를 지능형 에이전트(1145)로 송신할 수 있다. 프로세서(1150)는 지능형 에이전트(1145)를 통해 상기 부족한 파라미터에 대한 정보를 이용하여 사용자에게 추가 입력을 요청할 수 있다. 프로세서(1150)는 지능형 에이전트(1145)를 통해 사용자에 의해 추가 입력이 수신되면 사용자 입력을 지능형 서버(1200)로 송신하여 처리할 수 있다. 자연어 이해 모듈(1220)은 상기 추가로 입력된 사용자 입력의 의도 및 파라미터 정보에 기초하여 추가된 패스 룰을 생성하여 지능형 에이전트(1145)로 송신할 수 있다. 프로세서(1150)는 지능형 에이전트(1145)를 통해 실행 매니저 모듈(1147)로 상기 패스 룰을 송신하여 제2 앱(1143)을 실행할 수 있다.
일 실시 예에 따르면, 자연어 이해 모듈(1220)은 일부 정보가 누락된 사용자 입력이 지능형 서버(1200)에 수신된 경우, 개인화 정보 서버(1300)로 사용자 정보 요청을 송신할 수 있다. 개인화 정보 서버(1300)는 페르소나 데이터베이스에 저장된 사용자 입력을 입력한 사용자의 정보를 자연어 이해 모듈(1220)로 송신할 수 있다. 자연어 이해 모듈(1220)은 상기 사용자 정보를 이용하여 일부 동작이 누락된 사용자 입력에 대응되는 패스 룰을 선택할 수 있다. 이에 따라, 자연어 이해 모듈(1220)은 일부 정보가 누락된 사용자 입력이 지능형 서버(1200)에 수신되더라도, 누락된 정보를 요청하여 추가 입력을 받거나 사용자 정보를 이용하여 상기 사용자 입력에 대응되는 패스 룰을 결정할 수 있다.
하기에 첨부된 표 1은 일 실시 예에 따른 사용자가 요청한 태스크와 관련한 패스 룰의 예시적 형태를 나타낼 수 있다.
| Path rule ID |
State |
parameter |
| Gallery_101 |
pictureView(25) |
NULL |
| searchView(26) |
NULL |
| searchViewResult(27) |
Location,time |
| SearchEmptySelectedView(28) |
NULL |
| SearchSelectedView(29) |
ContentType,selectall |
| CrossShare(30) |
anaphora |
표 1을 참조하면, 사용자 발화(예: “사진 공유해줘”)에 따라 지능형 서버(도 11의 지능형 서버(1200))에서 생성 또는 선택되는 패스 룰은 적어도 하나의 상태(state)(25, 26, 27, 28, 29 또는 30)를 포함할 수 있다. 예를 들어, 상기 적어도 하나의 상태 (예: 단말의 어느 한 동작 상태)는 사진 어플리케이션 실행(PicturesView)(25), 사진 검색 기능 실행(SearchView)(26), 검색 결과 표시 화면 출력(SearchViewResult)(27), 사진이 미(non)선택된 검색 결과 표시 화면 출력(SearchEmptySelectedView)(28), 적어도 하나의 사진이 선택된 검색 결과 표시 화면 출력(SearchSelectedView)(29) 또는 공유 어플리케이션 선택 화면 출력(CrossShare)(30) 중 적어도 하나에 해당될 수 있다.
일 실시 예에서, 상기 패스 룰의 파라미터 정보는 적어도 하나의 상태(state)에 대응될 수 있다. 예를 들어, 상기 적어도 하나의 사진이 선택된 검색 결과 표시 화면 출력(29) 상태에 포함될 수 있다.
상기 상태(25, 26, 27, 28, 29)들의 시퀀스를 포함한 패스 룰의 수행 결과 사용자가 요청한 태스크 (예: “사진 공유해줘!”)가 수행될 수 있다.
도 18은 본 발명의 일 실시 예에 따른 지능형 서비스 모듈의 페르소나 모듈(persona module)이 사용자의 정보를 관리하는 것을 나타낸 도면이다.
도 18을 참조하면, 프로세서(1150)는 페르소나 모듈(1149b)을 통해 복수의 앱(1141, 1143), 실행 매니저 모듈(1147) 또는 컨텍스트 모듈(1149a)로부터 사용자 단말(1100)의 정보를 전달 받을 수 있다. 프로세서(1150)는 복수의 앱(1141, 1143) 및 실행 매니저 모듈(1147)을 통해 앱의 동작(1141b, 1143b)을 실행한 결과 정보를 동작 로그 데이터베이스에 저장할 수 있다. 프로세서(1150)는 컨텍스트 모듈(1149a)을 통해 사용자 단말(1100)의 현재 상태에 대한 정보를 컨텍스트 데이터베이스에 저장할 수 있다. 프로세서(1150)는 페르소나 모듈(1149b)을 통해 상기 동작 로그 데이터베이스 또는 상기 컨텍스트 데이터베이스로부터 상기 저장된 정보를 전달 받을 수 있다. 상기 동작 로그 데이터베이스 및 상기 컨텍스트 데이터베이스에 저장된 데이터는, 예를 들어, 분석 엔진(analysis engine)에 의해 분석되어 페르소나 모듈(1149b)로 전달될 수 있다.
일 실시 예에 따르면, 프로세서(1150)는 페르소나 모듈(1149b)을 통해 복수의 앱(1141, 1143), 실행 매니저 모듈(1147) 또는 컨텍스트 모듈(1149a)로부터 수신한 정보를 제안 모듈(1149c)로 송신할 수 있다. 예를 들어, 프로세서(1150)는 페르소나 모듈(1149b)을 통해 상기 동작 로그 데이터베이스 또는 상기 컨텍스트 데이터베이스에 저장된 데이터를 제안 모듈(1149c)로 전달할 수 있다.
일 실시 예에 따르면, 프로세서(1150)는 페르소나 모듈(1149b)을 통해 복수의 앱(1141, 1143), 실행 매니저 모듈(1147) 또는 컨텍스트 모듈(1149a)로부터 전달 받은 정보를 개인화 정보 서버(1300)로 송신할 수 있다. 예를 들어, 프로세서(1150)는 페르소나 모듈(1149b)을 통해 상기 동작 로그 데이터베이스 또는 상기 컨텍스트 데이터베이스에 누적되어 저장된 데이터를 주기적으로 개인화 정보 서버(1300)에 송신할 수 있다.
일 실시 예에 따르면, 프로세서(1150)는 페르소나 모듈(1149b)을 통해 상기 동작 로그 데이터베이스 또는 상기 컨텍스트 데이터베이스에 저장된 데이터를 제안 모듈(1149c)로 전달할 수 있다. 페르소나 모듈(1149b)통해 생성된 사용자 정보는 페르소나 데이터베이스에 저장될 수 있다. 페르소나 모듈(1149b)는 상기 페르소나 데이터베이스에 저장된 사용자 정보를 주기적으로 개인화 정보 서버(1300)로 송신할 수 있다. 일 실시 예에 따르면, 페르소나 모듈(1149b)을 통해 개인화 정보 서버(1300)로 송신된 정보는 페르소나 데이터베이스에 저장될 수 있다. 개인화 정보 서버(1300)는 상기 페르소나 데이터베이스에 저장된 정보를 이용하여 지능형 서버(1200)의 패스 룰 생성에 필요한 사용자 정보를 추론할 수 있다.
일 실시 예에 따르면, 페르소나 모듈(1149b)을 통해 송신된 정보를 이용하여 추론된 사용자 정보는 프로파일(profile) 정보 또는 프리퍼런스(preference) 정보를 포함할 수 있다. 상기 프로파일 정보 또는 프리퍼런스 정보는 사용자의 계정(account) 및 누적된 정보를 통해 추론될 수 있다.
상기 프로파일 정보는 사용자의 신상 정보를 포함할 수 있다. 예를 들어, 상기 프로파일 정보는 사용자의 인구 통계 정보를 포함할 수 있다. 상기 인구 통계 정보는, 예를 들어, 사용자의 성(gender), 또는 나이를 포함할 수 있다. 다른 예를 들어, 상기 프로파일 정보는 라이프 이벤트(life event) 정보를 포함할 수 있다. 상기 라이프 이벤트 정보는, 예를 들어, 로그 정보를 라이프 이벤트 모델(life event model)과 비교하여 추론되고, 행동 패턴(behavior patter)을 분석하여 보강될 수 있다. 또 다른 예를 들어, 상기 프로파일 정보는 관심(interest) 정보를 포함할 수 있다. 상기 관심 정보는, 예를 들어, 관심 쇼핑 물품, 또는 관심 분야(예: 스포츠, 또는 정치)를 포함할 수 있다. 또 다른 예를 들어, 상기 프로파일 정보는 활동 지역 정보를 포함할 수 있다. 상기 활동 지역 정보는, 예를 들어, 집, 또는 일하는 곳에 대한 정보를 포함할 수 있다. 상기 활동 지역에 대한 정보는 장소의 위치에 대한 정보뿐만 아니라 누적 체류 시간 및 방문 횟수를 기준으로 우선 순위가 기록된 지역에 대한 정보를 포함할 수 있다. 또 다른 예를 들어, 상기 프로파일 정보는 활동 시간 정보를 포함할 수 있다. 상기 활동 시간 정보는, 예를 들어, 기상 시간, 출퇴근 시간, 또는 수면 시간에 대한 정보를 포함할 수 있다. 상기 출퇴근 시간에 대한 정보는 상기 활동 지역 정보(예: 집 및 일하는 곳에 대한 정보)를 이용하여 추론될 수 있다. 상기 수면 시간에 대한 정보는 사용자 단말(1100)의 미사용 시간을 통해 추론될 수 있다.
상기 프리퍼런스 정보는 사용자의 선호도 정보를 포함할 수 있다. 예를 들어, 상기 프리퍼런스 정보는 앱 선호도에 대한 정보를 포함할 수 있다. 상기 앱 선호도는, 예를 들어, 앱의 사용 기록(예: 시간별, 장소별 사용 기록)을 통해 추론될 수 있다. 상기 앱의 선호도는 사용자의 현재 상태(예: 시간, 장소)에 따라 실행될 앱을 결정하기 위해 이용될 수 있다. 다른 예를 들어, 상기 프리퍼런스 정보는 연락처 선호도에 대한 정보를 포함할 수 있다. 상기 연락처 선호도는, 예를 들어, 연락처의 연락 빈도(예: 시간별, 장소별 연락하는 빈도) 정보를 분석하여 추론될 수 있다. 상기 연락처 선호도는 사용자의 현재 상태(예: 중복된 이름에 대한 연락)에 따라 연락할 연락처를 결정하기 위해 이용될 수 있다. 또 다른 예를 들어, 상기 프리퍼런스 정보는 세팅(setting) 정보를 포함할 수 있다. 상기 세팅 정보는, 예를 들어, 특정 세팅 값의 설정 빈도(예: 시간별, 장소별 세팅 값으로 설정하는 빈도) 정보를 분석하여 추론될 수 있다. 상기 세팅 정보는 사용자의 현재 상태(예: 시간, 장소, 상황)에 따라 특정 세팅 값을 설정하기 위해 이용될 수 있다. 또 다른 예를 들어, 상기 프리퍼런스 정보는 장소 선호도를 포함할 수 있다. 상기 장소 선호도는, 예를 들어, 특정 장소의 방문 기록(예: 시간별 방문 기록)을 통해 추론될 수 있다. 상기 장소 선호도는 사용자의 현재 상태(예: 시간)에 따라 방문하고 있는 장소를 결정하기 위하여 이용될 수 있다. 또 다른 예를 들어, 상기 프리퍼런스 정보는 명령 선호도를 포함할 수 있다. 상기 명령 선호도는, 예를 들어, 명령 사용 빈도(예: 시간별, 장소별 사용 빈도)를 통해 추론될 수 있다. 상기 명령 선호도는 사용자의 현재 상태(예: 시간, 장소)에 따라 사용될 명령어 패턴을 결정하기 위해 이용될 수 있다. 특히, 상기 명령 선호도는 로그 정보를 분석하여 실행되고 있는 앱의 현재 상태에서 사용자가 가장 많이 선택한 메뉴에 대한 정보를 포함할 수 있다.
일 실시 예에 따른 전자 장치(101)는 디스플레이(160), 마이크(111)를 포함하는 입력 장치(150), 통신 회로(190), 적어도 하나의 외부 전자 장치(201, 202)의 EM(electromagnetic) 신호(EM1, EM2)를 수신하는 EM 센싱 회로(200), 및 상기 디스플레이(160), 상기 입력 장치(150), 상기 통신 회로(190), 및 상기 EM 센싱 회로(200)와 작동적으로 연결된 프로세서(120)를 포함하고, 상기 프로세서(120)는, 상기 마이크(111)를 통해 사용자의 음성 입력을 획득하고, 상기 통신 회로(190)를 통해 상기 EM 센싱 회로(200)에 의해 수신된 상기 EM 신호에 대한 제1 정보를 제1 서버(예: 도 2의 EM 서버(205))로 전송하고, 상기 제1 정보의 전송에 응답하여, 상기 제1 서버로부터 상기 통신 회로(190)를 통해 상기 적어도 하나의 외부 전자 장치(201, 202) 중 대상 장치(예: 도 2의 제1 외부 전자 장치(201))를 특정하는 제2 정보를 수신하고, 상기 대상 장치가 상기 음성 입력에 의해 동작하도록, 상기 통신 회로(190)를 통해 상기 음성 입력에 따른 음성 데이터 및 상기 제2 정보를 제2 서버(예: 도 2의 지능형 서버(206))로 전송하도록 설정되고, 상기 전자 장치(101)와 상기 대상 장치는 상기 제2 서버에 동일한 사용자 계정으로 등록되어 있고, 상기 전자 장치(101)는 상기 제2 서버로부터 패스 룰을 수신하고, 상기 패스 룰에 기반하여 상기 대상 장치가 동작할 수 있도록 상기 대상 장치를 제어할 수 있다.
일 실시 예에 따른 전자 장치(101)는 상기 음성 데이터 및 상기 제2 정보를 상기 제2 서버로 전송하는 것에 응답하여, 상기 제2 서버로부터 상기 통신 회로(190)를 통해 상기 음성 데이터 및 상기 제2 정보에 기초하여 생성된 복수의 상태들의 시퀀스(a sequence of states)를 수신(예: 도 9의 동작 901)하고, 상기 복수의 상태들의 시퀀스에 적어도 일부 기초하여, 상기 통신 회로(190)를 통해 상기 전자 장치(101)와 상기 대상 장치(예: 도 9의 제1 외부 전자 장치(201)) 사이의 통신 연결을 수립(예: 도 9의 동작 902)하고, 상기 복수의 상태들의 시퀀스 중 일부를 상기 대상 장치로 전송(예: 도 9의 동작 903)할 수 있다.
일 실시 예에 따른 전자 장치(101)의 상기 복수의 상태들의 시퀀스는 상기 대상 장치의 동작 순서를 결정할 수 있다.
일 실시 예에 따른 전자 장치(101)의 상기 복수의 상태들의 시퀀스는, 상기 전자 장치(101)의 지능형 앱(예: 도 12의 지능형 에이전트(1145)와 연동된 지능형 앱)이 제공할 수 있는 미리 정해진 동작(action)이고, 상기 사용자의 음성 입력을 준비하는 제1 상태가 되기 위한 규칙 및 상기 제1 상태와 다른 제2 상태로 진행하기 위한 규칙을 포함할 수 있다.
일 실시 예에 따른 상기 전자 장치(101)는 상기 제1 정보를 상기 제1 서버로 전달하거나, 상기 전자 장치에 저장된 복수의 EM 신호들과 비교하여 상기 EM 신호를 방출한 외부 전자 장치의 종류 및 모델명을 식별할 수 있다.
일 실시 예에 따른 상기 EM 센싱 회로(200)는, 상기 EM 신호에서 기준 주파수(예: 1MHz) 이하의 EM 신호를 통과시키는 대역 통과 필터(220) 및 상기 EM 신호의 최대 진폭 및 상기 EM 신호의 파형 형태를 파형 테이블에 저장된 복수의 파형들과 대비하는 MCU(250)를 포함할 수 있다.
일 실시 예에 따른 상기 EM 센싱 회로(200)는, 상기 수신한 EM 신호를 상기 프로세서(120)로 공급하고, 상기 EM 신호를 미리 저장된 복수의 EM 신호들과 대비하여 상기 대상 장치를 특정할 수 있다.
일 실시 예에 따른 상기 EM 센싱 회로(200)는 상기 음성 입력에서 상기 적어도 하나의 외부 전자 장치(201, 202)를 특정하지 않은 경우 센싱 기능을 활성화시킬 수 있다.
일 실시 예에 따른 상기 전자 장치(101)는 상기 대상 장치에 근접하도록 태깅(tagging)하는 경우, 상기 대상 장치가 상기 음성 입력에 기초하여 동작하도록 할 수 있다.
일 실시 예에 따른 전자 장치(101)는 근거리 통신(예: 블루투스, WiFi direct, IrDA, NFC, BLE, WiFi, 또는 NAN)을 이용하여 상기 적어도 하나의 외부 전자 장치가 일정 거리 이내에 배치된 경우 상기 대상 장치로 특정할 수 있다.
일 실시 예에 따른 전자 장치(101)는 통신 회로(190), 메모리(130), 상기 통신 회로(190) 및 상기 메모리(130)와 작동적으로 연결된 프로세서(120), 및 적어도 하나의 외부 전자 장치(201, 202)의 EM 신호(EM1, EM2)를 수신하는 EM 센싱 회로(200)를 포함하고, 상기 메모리(130)가 실행되는 경우, 상기 프로세서(120)는, 자동 음성 인식(automatic speech recognition(ASR)) 모듈(1210) 및 서로 독립적으로 작동하는 복수의 자연어 이해(natural language understanding(NLU)) 모듈(1220)과 연결되고, 상기 통신 회로(190)를 통해 사용자의 발화(utterance)를 포함하는 음성 입력을 수신하고, 상기 음성 입력을 상기 자동 음성 인식 모듈(1210)로 제공하고, 상기 복수의 자연어 이해 모듈(1220) 중 어느 하나의 자연어 이해 모듈을 이용하여 상기 음성 입력의 내용에 대응하는 응답을 수신하고, 상기 프로세서(120)는, 상기 통신 회로(190)를 통해 상기 EM 센싱 회로(200)에 의해 수신된 상기 EM 신호를 이용하여 상기 적어도 하나의 외부 전자 장치 중 대상 장치(target device)(예: 제1 외부 전자 장치(201))를 특정하는 정보를 적어도 하나의 서버(예: EM 서버(205))로 전송하고, 상기 통신 회로(190)를 통해 상기 적어도 하나의 서버와 다른 서버(예: 지능형 서버(206))로 상기 대상 장치가 상기 음성 입력에 기초하여 동작하도록 하는 정보를 전송하도록 설정되고, 상기 전자 장치(101)와 상기 대상 장치는 상기 적어도 하나의 서버에 동일한 사용자 계정으로 등록되어 있고, 상기 전자 장치(101)는 상기 다른 서버로부터 패스 룰을 수신하고, 상기 패스 룰에 기반하여 상기 대상 장치가 동작할 수 있도록 상기 대상 장치를 제어할 수 있다.
일 실시 예에 따른 상기 프로세서(120)는 상기 통신 회로(190)를 통해 상기 EM 센싱 회로(200)에 의해 수신된 상기 EM 신호에 대한 제1 정보를 제1 서버(예: EM 서버(205))로 전송하고, 상기 제1 정보의 전송에 응답하여, 상기 제1 서버로부터 상기 통신 회로(190)를 통해 상기 대상 장치를 특정하는 제2 정보를 수신하고, 상기 대상 장치가 상기 음성 입력에 의해 동작하도록, 상기 통신 회로(190)를 통해 상기 음성 입력에 따른 음성 데이터 및 상기 제2 정보의 적어도 일부를 제2 서버(예: 음성 분석 서버(206))로 전송하도록 설정될 수 있다.
일 실시 예에 따른 전자 장치(101)는 상기 음성 데이터 및 상기 제2 정보를 상기 제2 서버로 전송하는 것에 응답하여, 상기 제2 서버로부터 상기 통신 회로(190)를 통해 상기 음성 데이터 및 상기 제2 정보에 기초하여 생성된 복수의 상태들의 시퀀스(a sequence of states)를 수신(예: 도 9의 동작 901)하고, 상기 복수의 상태들의 시퀀스에 적어도 일부 기초하여, 상기 통신 회로를 통해 상기 전자 장치와 상기 대상 장치 사이의 통신 연결을 수립(예: 도 9의 동작 902)하고, 상기 복수의 상태들의 시퀀스 중 일부를 상기 대상 장치로 전송(예: 도 9의 동작 903)할 수 있다.
일 실시 예에 따른 상기 프로세서(120)는 상기 제1 정보를 이용하여 상기 적어도 하나의 외부 전자 장치의 종류 및 모델 정보를 포함하는 보충 텍스트 데이터(예: 노트북 컴퓨터)를 생성하고, 상기 텍스트 데이터(예: 여기로 사진 전송해)에 상기 보충 텍스트 데이터를 결합(예: 노트북 컴퓨터로 사진 전송해)할 수 있다.
일 실시 예에 따른 상기 EM 센싱 회로(200)는 상기 프로세서(120)가 상기 자동 음성 인식 모듈(1210) 및 상기 복수의 자연어 이해 모듈(1220)과 연결되는 경우 센싱 기능을 활성화시킬 수 있다.
일 실시 예에 따른 전자 장치(101)의 외부 전자 장치(예: 제1 외부 전자 장치(201)) 제어 방법은 마이크(111)를 통해 사용자의 음성 입력을 획득하는 동작(예: 도 7의 동작 701), EM 센싱 회로(200)를 통해 적어도 하나의 외부 전자 장치의 EM(electromagnetic) 신호를 수신하는 동작(예: 도 7의 동작 703), 통신 회로(190)를 통해 상기 EM 신호에 대한 제1 정보를 제1 서버(예: EM 서버(205))로 전송하는 동작(예: 도 7의 동작 705), 상기 제1 정보의 전송에 응답하여, 상기 제1 서버로부터 상기 통신 회로(190)를 통해 상기 적어도 하나의 외부 전자 장치 중 대상 장치(예: 제1 외부 전자 장치(201))를 특정하는 제2 정보를 수신하는 동작(예: 도 7의 동작 707), 상기 대상 장치가 상기 음성 입력에 의해 동작하도록, 상기 통신 회로(190)를 통해 상기 음성 입력에 따른 음성 데이터 및 상기 제2 정보의 적어도 일부를 제2 서버(예: 지능형 서버(206))로 전송하는 동작(예: 도 7의 동작 709)을 포함하고, 상기 전자 장치(101)와 상기 대상 장치는 상기 제2 서버에 동일한 사용자 계정으로 등록되어 있고, 상기 전자 장치(101)는 상기 제2 서버로부터 패스 룰을 수신하고, 상기 패스 룰에 기반하여 상기 대상 장치가 동작할 수 있도록 상기 대상 장치를 제어할 수 있다.
일 실시 예에 따른 전자 장치(101)의 상기 EM 신호를 수신하는 동작(예: 도 7의 동작 703)은 상기 음성 입력에서 상기 대상 장치를 특정하지 않은 경우(예: 여기로 사진 전송해) 수행될 수 있다.
일 실시 예에 따른 전자 장치(101)의 외부 전자 장치 제어 방법은 상기 음성 데이터 및 상기 제2 정보를 상기 제2 서버로 전송하는 것에 응답하여, 상기 제2 서버로부터 상기 통신 회로(190)를 통해 상기 음성 데이터 및 상기 제2 정보에 기초하여 생성된 복수의 상태들의 시퀀스(a sequence of states)를 수신하는 동작(예: 도 9의 동작 901), 상기 복수의 상태들의 시퀀스에 적어도 일부 기초하여, 상기 통신 회로(190)를 통해 상기 전자 장치(101)와 상기 대상 장치 사이의 통신 연결을 수립하는 동작(예: 도 9의 동작 902), 및 상기 복수의 상태들의 시퀀스 중 일부를 상기 대상 장치로 전송하는 동작(예: 도 9의 동작 903)을 더 포함할 수 있다.
일 실시 예에 따른 상기 제1 서버는 상기 적어도 하나의 외부 전자 장치의 EM 신호와 관련된 정보를 이용하여 상기 제1 정보를 분석(예: 도 2a의 분석부(121))함으로써 상기 제2 정보를 생성할 수 있다.
일 실시 예에 따른 전자 장치(101)의 외부 전자 장치 제어 방법은 상기 적어도 하나의 외부 전자 장치 중 상기 음성 입력의 내용을 수행할 수 있는 외부 전자 장치들을 감지(예: 사진을 전송 받을 수 있는 장치를 감지)하는 동작을 더 포함할 수 있다.
본 문서에 개시된 다양한 실시 예들에 따른 전자 장치는 다양한 형태의 장치가 될 수 있다. 전자 장치는, 예를 들면, 휴대용 통신 장치 (예: 스마트폰), 컴퓨터 장치, 휴대용 멀티미디어 장치, 휴대용 의료 기기, 카메라, 웨어러블 장치, 또는 가전 장치를 포함할 수 있다. 본 문서의 실시 예에 따른 전자 장치는 전술한 기기들에 한정되지 않는다.
본 문서의 다양한 실시 예들 및 이에 사용된 용어들은 본 문서에 기재된 기술적 특징들을 특정한 실시 예들로 한정하려는 것이 아니며, 해당 실시 예의 다양한 변경, 균등물, 또는 대체물을 포함하는 것으로 이해되어야 한다. 도면의 설명과 관련하여, 유사한 또는 관련된 구성요소에 대해서는 유사한 참조 부호가 사용될 수 있다. 아이템에 대응하는 명사의 단수 형은 관련된 문맥상 명백하게 다르게 지시하지 않는 한, 상기 아이템 한 개 또는 복수 개를 포함할 수 있다. 본 문서에서, "A 또는 B", "A 및 B 중 적어도 하나", “A 또는 B 중 적어도 하나,”"A, B 또는 C," "A, B 및 C 중 적어도 하나,”및 “A, B, 또는 C 중 적어도 하나"와 같은 문구들 각각은 그 문구들 중 해당하는 문구에 함께 나열된 항목들의 모든 가능한 조합을 포함할 수 있다. "제 1", "제 2", 또는 "첫째" 또는 "둘째"와 같은 용어들은 단순히 해당 구성요소를 다른 해당 구성요소와 구분하기 위해 사용될 수 있으며, 해당 구성요소들을 다른 측면(예: 중요성 또는 순서)에서 한정하지 않는다. 어떤(예: 제 1) 구성요소가 다른(예: 제 2) 구성요소에, “기능적으로” 또는 “통신적으로”라는 용어와 함께 또는 이런 용어 없이, “커플드” 또는 “커넥티드”라고 언급된 경우, 그것은 상기 어떤 구성요소가 상기 다른 구성요소에 직접적으로(예: 유선으로), 무선으로, 또는 제 3 구성요소를 통하여 연결될 수 있다는 것을 의미한다.
본 문서에서 사용된 용어 "모듈"은 하드웨어, 소프트웨어 또는 펌웨어로 구현된 유닛을 포함할 수 있으며, 예를 들면, 로직, 논리 블록, 부품, 또는 회로의 용어와 상호 호환적으로 사용될 수 있다. 모듈은, 일체로 구성된 부품 또는 하나 또는 그 이상의 기능을 수행하는, 상기 부품의 최소 단위 또는 그 일부가 될 수 있다. 예를 들면, 일 실시 예에 따르면, 모듈은 ASIC(application-specific integrated circuit)의 형태로 구현될 수 있다.
본 문서의 다양한 실시 예들은 기기(machine)(예: 전자 장치(101)) 의해 읽을 수 있는 저장 매체(storage medium)(예: 내장 메모리(136) 또는 외장 메모리(138))에 저장된 하나 이상의 명령어들을 포함하는 소프트웨어(예: 프로그램(140))로서 구현될 수 있다. 예를 들면, 기기(예: 전자 장치(101))의 프로세서(예: 프로세서(120))는, 저장 매체로부터 저장된 하나 이상의 명령어들 중 적어도 하나의 명령을 호출하고, 그것을 실행할 수 있다. 이것은 기기가 상기 호출된 적어도 하나의 명령어에 따라 적어도 하나의 기능을 수행하도록 운영되는 것을 가능하게 한다. 상기 하나 이상의 명령어들은 컴파일러에 의해 생성된 코드 또는 인터프리터에 의해 실행될 수 있는 코드를 포함할 수 있다. 기기로 읽을 수 있는 저장매체 는, 비일시적(non-transitory) 저장매체의 형태로 제공될 수 있다. 여기서, ‘비일시적’은 저장매체가 실재(tangible)하는 장치이고, 신호(signal)(예: 전자기파)를 포함하지 않는다는 것을 의미할 뿐이며, 이 용어는 데이터가 저장매체에 반영구적으로 저장되는 경우와 임시적으로 저장되는 경우를 구분하지 않는다.
일 실시 예에 따르면, 본 문서에 개시된 다양한 실시 예들에 따른 방법은 컴퓨터 프로그램 제품(computer program product)에 포함되어 제공될 수 있다. 컴퓨터 프로그램 제품은 상품으로서 판매자 및 구매자 간에 거래될 수 있다. 컴퓨터 프로그램 제품은 기기로 읽을 수 있는 저장 매체(예: compact disc read only memory (CD-ROM))의 형태로 배포되거나, 또는 어플리케이션 스토어(예: 플레이 스토어TM)를 통해 또는 두 개의 사용자 장치들(예: 스마트 폰들) 간에 직접, 온라인으로 배포(예: 다운로드 또는 업로드)될 수 있다. 온라인 배포의 경우에, 컴퓨터 프로그램 제품의 적어도 일부는 제조사의 서버, 어플리케이션 스토어의 서버, 또는 중계 서버의 메모리와 같은 기기로 읽을 수 있는 저장 매체에 적어도 일시 저장되거나, 임시적으로 생성될 수 있다.
다양한 실시 예들에 따르면, 상기 기술한 구성요소들의 각각의 구성요소(예: 모듈 또는 프로그램)는 단수 또는 복수의 개체를 포함할 수 있다. 다양한 실시 예들에 따르면, 전술한 해당 구성요소들 중 하나 이상의 구성요소들 또는 동작들이 생략되거나, 또는 하나 이상의 다른 구성요소들 또는 동작들이 추가될 수 있다. 대체적으로 또는 추가적으로, 복수의 구성요소들(예: 모듈 또는 프로그램)은 하나의 구성요소로 통합될 수 있다. 이런 경우, 통합된 구성요소는 상기 복수의 구성요소들 각각의 구성요소의 하나 이상의 기능들을 상기 통합 이전에 상기 복수의 구성요소들 중 해당 구성요소에 의해 수행되는 것과 동일 또는 유사하게 수행할 수 있다. 다양한 실시 예들에 따르면, 모듈, 프로그램 또는 다른 구성요소에 의해 수행되는 동작들은 순차적으로, 병렬적으로, 반복적으로, 또는 휴리스틱하게 실행되거나, 상기 동작들 중 하나 이상이 다른 순서로 실행되거나, 생략되거나, 또는 하나 이상의 다른 동작들이 추가될 수 있다.