KR20190140976A - 음향 심리학적 그룹화 현상을 이용한 스테레오 전개 - Google Patents
음향 심리학적 그룹화 현상을 이용한 스테레오 전개 Download PDFInfo
- Publication number
- KR20190140976A KR20190140976A KR1020197033763A KR20197033763A KR20190140976A KR 20190140976 A KR20190140976 A KR 20190140976A KR 1020197033763 A KR1020197033763 A KR 1020197033763A KR 20197033763 A KR20197033763 A KR 20197033763A KR 20190140976 A KR20190140976 A KR 20190140976A
- Authority
- KR
- South Korea
- Prior art keywords
- sound
- stereo
- feeds
- play sound
- frequency
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
- 238000011161 development Methods 0.000 title description 10
- 238000012545 processing Methods 0.000 claims abstract description 14
- 238000000034 method Methods 0.000 claims description 80
- 238000007493 shaping process Methods 0.000 claims description 20
- 230000001934 delay Effects 0.000 claims description 8
- 230000005236 sound signal Effects 0.000 claims description 6
- 239000003381 stabilizer Substances 0.000 claims description 2
- 210000004556 brain Anatomy 0.000 abstract description 32
- 238000005516 engineering process Methods 0.000 abstract description 14
- 230000003111 delayed effect Effects 0.000 abstract description 2
- 238000010586 diagram Methods 0.000 description 24
- 230000008569 process Effects 0.000 description 24
- 230000004807 localization Effects 0.000 description 16
- 230000008859 change Effects 0.000 description 7
- 210000005069 ears Anatomy 0.000 description 6
- 230000004044 response Effects 0.000 description 6
- 230000002889 sympathetic effect Effects 0.000 description 6
- 230000008447 perception Effects 0.000 description 5
- 238000007781 pre-processing Methods 0.000 description 4
- 230000008685 targeting Effects 0.000 description 4
- 230000002238 attenuated effect Effects 0.000 description 3
- 238000000605 extraction Methods 0.000 description 3
- 230000006872 improvement Effects 0.000 description 3
- 238000004091 panning Methods 0.000 description 3
- 238000001228 spectrum Methods 0.000 description 3
- 208000032041 Hearing impaired Diseases 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 235000019800 disodium phosphate Nutrition 0.000 description 2
- 230000006870 function Effects 0.000 description 2
- 230000036651 mood Effects 0.000 description 2
- 238000003672 processing method Methods 0.000 description 2
- 238000000926 separation method Methods 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- PICXIOQBANWBIZ-UHFFFAOYSA-N zinc;1-oxidopyridine-2-thione Chemical class [Zn+2].[O-]N1C=CC=CC1=S.[O-]N1C=CC=CC1=S PICXIOQBANWBIZ-UHFFFAOYSA-N 0.000 description 2
- 206010011878 Deafness Diseases 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- ZYXYTGQFPZEUFX-UHFFFAOYSA-N benzpyrimoxan Chemical compound O1C(OCCC1)C=1C(=NC=NC=1)OCC1=CC=C(C=C1)C(F)(F)F ZYXYTGQFPZEUFX-UHFFFAOYSA-N 0.000 description 1
- 239000006227 byproduct Substances 0.000 description 1
- 239000002131 composite material Substances 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 230000001627 detrimental effect Effects 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 230000004438 eyesight Effects 0.000 description 1
- 238000002868 homogeneous time resolved fluorescence Methods 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 238000007654 immersion Methods 0.000 description 1
- 239000007943 implant Substances 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 239000000047 product Substances 0.000 description 1
- 230000004800 psychological effect Effects 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
- 230000016776 visual perception Effects 0.000 description 1
Images









Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S1/00—Two-channel systems
- H04S1/007—Two-channel systems in which the audio signals are in digital form
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S3/00—Systems employing more than two channels, e.g. quadraphonic
- H04S3/002—Non-adaptive circuits, e.g. manually adjustable or static, for enhancing the sound image or the spatial distribution
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/022—Blocking, i.e. grouping of samples in time; Choice of analysis windows; Overlap factoring
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/04—Time compression or expansion
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S7/00—Indicating arrangements; Control arrangements, e.g. balance control
- H04S7/30—Control circuits for electronic adaptation of the sound field
- H04S7/307—Frequency adjustment, e.g. tone control
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2400/00—Details of stereophonic systems covered by H04S but not provided for in its groups
- H04S2400/11—Positioning of individual sound objects, e.g. moving airplane, within a sound field
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2400/00—Details of stereophonic systems covered by H04S but not provided for in its groups
- H04S2400/13—Aspects of volume control, not necessarily automatic, in stereophonic sound systems
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2400/00—Details of stereophonic systems covered by H04S but not provided for in its groups
- H04S2400/15—Aspects of sound capture and related signal processing for recording or reproduction
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S3/00—Systems employing more than two channels, e.g. quadraphonic
- H04S3/02—Systems employing more than two channels, e.g. quadraphonic of the matrix type, i.e. in which input signals are combined algebraically, e.g. after having been phase shifted with respect to each other
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Signal Processing (AREA)
- Multimedia (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Quality & Reliability (AREA)
- Stereophonic System (AREA)
Abstract
스테레오 전개 기술은 최신 DSP 기술을 사용하여 좌측(L) 및 우측(R) 스테레오 채널로부터 정보를 추출하여 처리 알고리즘들에 공급되는 여러 가지 새로운 채널들을 생성함으로써 스테레오 재생의 고유한 문제점들을 해결한다. 스테레오 전개 기술은, 일반적인 스테레오 정보를 일반적인 방식으로 청취자에게 전송하여 음장 내에서 연주자들의 인식된 위치를 매우 정확하게 설정하고 그 후 지연되고 주파수 성형된 추출된 신호를 전방뿐만 아니라 다른 방향들로 투영하여 귀와 두뇌에 음향 심리학적으로 기반한 추가적인 단서를 제공함으로써 작동된다. 추가적인 단서는 음원들의 3 차원 특성과 음원들이 수행하는 음향 환경을 설정함과 동시에 증가된 세부사항 및 투명성의 느낌을 생성한다. 스테레오 전개 기술은 연속적인 실제 음향 환경에서 사운드를 생성하는 3 차원 음원들로 채워진 실제와 같은 3 차원 사운드 스테이지를 만들어낸다.
Description
도입
오리지널 스테레오 전개 기술(original Stereo Unfold Technology)은 DSP 알고리즘들을 사용하여 정상 스테레오 레코딩으로부터 정보를 추출하고 전방뿐만 아니라 다른 방향들을 목표로 하는 스피커 드라이버들을 통해 시간에 따라 계층화된 추가 정보를 재생함으로써 일반적인 스테레오 사운드 재생을 개선했다. 스테레오 전개 기술은 연속적인 실제 음향 환경에서 사운드를 생성하는 3 차원 음원으로 채워진 실제와 같은 3 차원 사운드 스테이지를 생성하여 일반적인 스테레오 재생에 비해 현저한 개선을 이루고 있다.
스테레오 전개 기술을 계속 사용하는 동안 인간의 두뇌가 사운드를 어떻게 해석하는지에 대한 추가적인 발견이 있었고 이는 방법을 개선할 수 있게 되었다. 새로운 개선된 버전의 스테레오 전개는 이제 청취자를 향하는 전방과는 다른 방향들을 목표로 하는 추가적인 드라이버들과 함께 사용될 수 있을 뿐만 아니라 이들 드라이버 없이도 사용될 수 있다. 따라서, 새로운 개선된 버전의 스테레오 전개는 모든 타입의 기존 표준 라우드스피커들 및 헤드폰 청취에도 적용 가능하다. 전방 전용 스피커 드라이버들과 함께 사용할 경우 이 스테레오 전개는 이전 방법과 적어도 동일한 양의 개선을 간신히 제공하고, 추가적인 드라이버들을 통해 훨씬 더 개선을 제공하게 된다. 헤드폰 상에서의 스테레오 전개는 인식된 사운드 스테이지를 청취자 헤드 내에서 두 귀 사이의 끈을 통해 청취자 헤드 외부로 간신히 이동시킨다. 이는 청취자의 물리적 특성들, 즉, 귀, 헤드 및 어깨의 형상 및 크기에 대한 어떠한 사전 정보가 없이도 그렇게 수행한다.
개선된 버전의 스테레오 전개(Stereo Unfold EV)는 특히 음향 심리학적 그룹화 현상과 전개 프로세스(Unfold Process)에 미치는 영향을 더 잘 이해함으로써 개선되었다.
스테레오 전개 및 종래 기술
오디오 DSP 분야에는 사운드 재생에 존재하는 다양한 문제를 해결하기 위한 많은 종래 기술이 있다. 그 종래 기술 모두는 IIR 필터들, FIR 필터들, 지연들, 좌측-우측 추출 알고리즘들 등과 같은 동일한 기본 DSP 빌딩 블록을 사용하지만 최종 결과들은 상이하다. 종래 기술을 보면, 오디오 DSP 분야에서는 스테레오 전개 기술과 다소 관련되는 것으로 간주될 수 있는 3 개의 주요 그룹이 있음이 명백하다.
첫째, 보다 넓은 스테레오 이미지를 달성하기 위한 방법들을 개략적으로 설명하는 종래 기술이 있다. 이들 종개 기술들은 주로 좌측 및 우측 스피커들을 단일 인클로저에서조차 물리적으로 서로 가깝게 함께 배치하는 스테레오 스피커들에 초점을 두고 있다. 이것들은 모두 스테레오 이미지를 넓히고 간격이 좁게 배치된 스테레오 스피커들에서 발생하는 문제점들을 완화시키는 것을 목표로 하고 있다.
둘째, 소위 사운드 바(sound bars), 즉, 서라운드 사운드 시스템의 청취룸 내에서 사방에 퍼져 있는 다수의 서라운드 스피커들을 대체하는 전방 중앙에 위치한 하나의 박스 스피커에 관한 또다른 그룹의 특허 문헌들이 있다. 이 그룹의 목표는 청취자에게 룸(room)의 전방 및 후방에 위치한 수 개의 스피커들을 사용하여 통상적으로 생성되는 서라운드 음장 내에 존재하는 느낌을 제공하기 위한 것이다. 사운드 바는 DSP 알고리즘들과 함께 상이한 방향들을 목표로 하는 드라이버들을 사용한 다양한 기술들을 이용하여 서라운드 사운드 경험을 생성하고 있다.
상기 설명과 관련하여, 예를 들어, 미국 특허 문헌 US2015/0189439 및 US2015/0071451은 모두 이러한 제 1 그룹 및 제 2 그룹을 지칭하는 것으로 언급될 수 있다.
셋째, 기본적으로 좌측-우측 유도 콘텐츠를 전방보다는 다른 방향으로 목표함으로써 스테레오 경험을 향상시키는 것을 목표로 하는 전반적으로 다소 오래된 종래 기술 그룹이 있다. 이들 기술은 DSP 기술이 쉽게 이용 가능하고 비용 효율적으로 되기 전에 수행되었기 때문에, 사용된 처리는 매우 기본적이고 당시에 가능했던 것으로 제한된다. 사용 가능한 기술은 실현 가능한 사운드 품질을 심각하게 저하시켰으며, 결과가 대부분 실망스러웠기 때문에, 이 그룹에서의 연구는 종료된 것으로 보인다.
제 1 그룹은 간격이 좁게 배치된 두 개의 스피커를 갖는 것과 관련한 기술적인 문제점을 다루고, 넓은 간격으로 배치된 스테레오 스피커들과 비슷한 결과를 달성하려고 시도한다. 제 2 그룹은 여러 개의 스피커들 대신 하나의 스피커만 사용하여 청취룸에서 서라운드 음장을 복제하려고 시도한다. 제 3 그룹은 스테레오를 들을 때 인식되는 분위기를 개선하려고 시도하지만, 부적절한 처리로 인해 실패하고 스테레오 고유의 음향 심리학적 문제점들을 해결하지 못한다. 상기 종래 기술 그룹 중 어느 것도 스테레오의 일반적인 단점, 즉 방법으로서의 스테레오에 결함이 있는 이유 및 스테레오 기술이 어떻게 개선될 수 있는지를 다루지 않는다. 스테레오 전개 기술은 스테레오 기술 내에서 이러한 고유의 문제점들을 해결하는 것을 목표로 한다.
스테레오 전개 기술은 실제 음향 이벤트와 유사한 연속적인 공간 3D 음장을 재현한다. 일반적인 스테레오 재생은 기껏해야 사운드 스테이지를 투영할 수 있지만, 그 사운드 스테이지 내의 음원들은 어떤 개별적인 깊이의 확장이 없는 페이퍼 컷아웃의 연주자들이고 이 페이퍼 컷아웃의 연주자들은 마치 블랙룸에 매달려 있는 섬광등처럼, 음향 공간에 있지 않고 고독하게 연주하는 것처럼 보인다. 스테레오 전개 기술은 공간 3D 음장을 생성하지만 서라운드 사운드 시스템을 듣는 것과 완전히 동일한 경험은 아니다. 서라운드 사운드 시스템은 스테레오와 동일한 제한으로 스테레오를 확장하는 데 그 핵심이 있다. 이 서라운드 사운드 시스템은 룸 주위에 배치된 추가적인 스피커들을 사용하면 좌측 및 우측 스피커들 사이의 전방뿐만 아니라 룸 내의 다른 위치들로부터의 포지션 정보를 생성할 수 있다. 스테레오 전개는 특히 인간의 두뇌에서 음향 심리학적 그룹화 현상과 공간 사운드 처리에 대한 이해를 통해 달성되었기 때문에, 이는 완전히 다른 방법이며, 결과는 실제 음향 이벤트와 같은 청각적인 공간 3D 음장이 된다.
스테레오 확장 처리와는 달리, 개별 음원들의 오리지널 위치들은 스테레오 전개 프로세스에 의해서는 크게 변경되지 않는다. 스테레오 전개 처리는 사운드 스테이지 크기를 증가시키지만, 레코딩이 발생한 음향 환경으로부터의 또는 인공적으로 생성된 분위기가 레코딩에 다른 방식으로 계산적으로 추가되는 경우 그 인공적으로 생성된 분위기로부터의 누락된 주변 정보를 다시 추가함으로써 그 사운드 스테이지 크기를 증가시킨다.
또한, 일부 다른 종래 기술 문헌들이 아래에서 간략히 논의된다. US5671287에는 의사 스테레오 신호를 생성하기 위해 모노 신호 소스들을 처리하는 것을 주요 목표로 하는 방향성 확산 음원을 생성하는 방법이 개시되어 있다. US5671287에 개시된 방법은 본 발명에 따른 스테레오 전개 방법과 완전히 동일한 것은 아니며 아래에 추가로 개시되는 것은 또한 본 발명 및 US5671287의 목표가 완전히 무관하다는 것이다.
또한, EP0276159는 헤드폰에 의한 사운드 몰입을 개선하기 위해 인공적인 로컬리제이션 신호(artificial localization cues)를 생성하는 방법을 개시하고 있다. 개시된 방법은 공통 헤드 관련 전달 함수들을 사용하여 방향성 신호들을 생성하고, 조기 및 만기 반사들(early and later reflections)의 가산을 언급하고 있다. 본 발명에 따른 스테레오 전개 방법은 레코딩으로부터 주변 정보를 추출하고 그 후 그것을 음향 심리학적 그룹화를 가능하게 하는 신호 처리 방법을 사용하여 다시 추가함으로써 레코딩에서의 자연 발생 주변 대 직접 사운드 비(naturally occurring ambient to direct sound ratio)를 복원한다. 상기로부터 이해되는 바와 같이, 본 발명 및 EP0276159의 목표 및 방법은 완전히 상이하다.
또한, US20130077792는 새로운 헤드 관련 전달 함수들을 사용하여 로컬리제이션을 개선하는 방법을 개시하고 있다. 이것은 또한 본 발명에 따른 스테레오 전개 방법의 모든 영역에 속하는 것은 아니며, 그 목표와 처리 방법은 완전히 상이하다. 본 발명에 따른 스테레오 전개는 스테레오 재생 사운드 스테이지의 로컬리제이션 또는 확대의 개선을 목표로 하지 않는다. 재생된 레코딩에서의 개별 신호 소스들(연주자들)은 스테레오 전개 처리 후에, 사운드 스테이지 내에서의 로컬리제이션을 크게 변경하지 않는다. 발생하는 로컬리제이션의 비교적 작은 변화는 처리의 부산물이지만 그 목표는 아니다. 목표는 보다 자연스러운 사운드 레코딩을 달성하기 위해 직접 대 주변 사운드 비(direct to ambient sound ratio)를 재현하는 것이다. 추가된 주변 에너지는 사운드 스테이지를 확대시키지만 훨씬 더 두드러진 확대된 요소는 레코딩 장소로부터의 주변 음장이며 개별 신호 소스(연주자)의 위치의 변경은 아니다.
상기에 기초하여, US5671287, EP0276159 및 US20130077792 중 어느 것도 본 발명에 따른 스테레오 전개 방법과 관련이 없다는 것이 명백하다.
모노 및 스테레오
처음에, 사운드는 모노(mono)로 레코딩 및 재생되었다. 모노 프로세스는 기껏해야 청취자 앞에 투영된 사운드 스테이지의 일부 인식된 깊이와 높이를 제공할 수 있지만 기본적으로는 레코딩의 개별 음원들에 대해 임의의 로컬리제이션 단서들을 전달할 수는 없다. 사용 가능한 제한된 사운드 스테이지는 청취룸의 표면들로부터의 반사들에 의해 생성된다. 반사들은 단일 라우드스피커 소스 주위의 사운드 구름의 환상을 생성한다. 이는 사운드 구름이 사라지는 무반향 환경(anechoic environment)에서 모노를 들으면 쉽게 확인될 수 있다.
1931년에 Alan Blumlein은 스테레오 프로세스를 발명했다. 스테레오는 두 개의 라우드스피커를 사용하여 물리적 수평면에서 전개되는 모노의 전개 버전이었다. 이는 라우드스피커들 사이의 임의의 장소에서 수평으로 음원들의 로컬리제이션을 가능하게 했다. 스테레오가 라우드스피커들 상에서 적절히 레코딩 및 재생될 경우, 청취자 앞에서 약간의 높이와 깊이가 있는 비교적 연속적인 수평면의 사운드를 간신히 생성하게 된다. 청취자의 두뇌는 스테레오 프로세스에 의해 기만되어 모든 소리가 두 개의 스피커에서만 발산된다는 사실에도 불구하고 그 앞에 여러 개의 음원이 있다고 믿게 된다. 라우드스피커들을 통해 재생되는 스테레오는 음향 심리학을 이용하여 청취자 앞의 서로 다른 수평 위치들에서 여러 음원들로 채워진 사운드 스테이지의 환상을 생성하게 된다. 모노와 마찬가지로, 청취룸 내의 표면들에 의해 반사되는 라우드스피커들로부터의 반사된 사운드는 청취자 앞에 사운드 스테이지의 환상을 생성하게 된다. 이러한 반사들이 없다면, 사운드는 청취자의 헤드 내부로부터 나오는 것으로 인식될 것이다.
이러한 현상의 이유는 스테레오 레코딩이 좌측-우측 로컬리제이션 단서들만을 포함하고 모든 추가 공간 정보를 누락하고 있기 때문이다[5]. 스테레오 프로세스는 인간의 두뇌가 좌측-우측 로컬리제이션 이외의 다른 공간 정보를 알아낼 수 있게 하는 어떠한 음향 심리학적 단서도 제공하지 않는다. 이것은 헤드폰을 사용하여 스테레오 레코딩을 청취함으로써 쉽게 테스트되며, 사운드는 청취자의 귀 사이의 헤드 내부에 항상 위치하게 된다. 무반향 룸 내에서 한 쌍의 고 방향성 스피커들, 파라볼릭 스피커들, 또는 스피커들을 사용하면, 유사하게 사운드 스테이지가 청취자의 헤드 내에 위치하게 된다.
개별화된 HTRF들로 만들어진 레코딩의 경우, 즉 레코딩을 청취하고자 하는 모든 사람을 위한 하나의 맞춤형 더미 헤드의 경우, 각 레코딩 내에 개별화된 음향 심리학적 단서가 내장될 것이고 우리는 헤드폰을 청취할 수 있고 공간 정보를 적절히 디코딩할 수 있다. 불행히도, 이것은 명백한 이유 때문에 수행될 수 없으며, 따라서 우리에게는 적어도 인간의 두뇌에 대해 의미있는 어떠한 공간 정보도 없는 레코딩이 남겨지게 된다.
현재 대부분의 사람들은 입체 음향 재생에 꽤 익숙하고, 그 한계점에 대해 더 이상 크게 생각하지 않을 정도로 매우 친숙하다. 이것은 입체 음향 재생과 라이브 사운드 간의 차이를 들을 수 없는 것이라고 의미하는 것은 아니며, 대부분은 라이브 사운드와 스테레오 재생 사운드를 쉽게 구별할 수 있다는 것에 동의할 것이며, 유일한 것은 스테레오가 라이브 사운드처럼 들리는 것으로 우리가 기대하지 않으며, 우리의 기대를 자동으로 변경한다는 것이다.
기껏해야, 통상적으로 적절하게 설정된 라우드스피커들을 사용하게 되면, 스테레오 재생은 깊이, 너비 및 높이를 갖는 사운드 스테이지를 투영할 수 있다. 그 사운드 스테이지 내의 음원들은 불행히도 임의의 개별적인 깊이 확장이 없는 페이퍼 컷아웃의 연주자들인 것 같다. 더욱이, 페이퍼 컷아웃의 연주자는 거의 마치 블랙룸에 매달려 있는 섬광등처럼, 음향 공간에 있지 않고 고독하게 연주하여 그 사운드를 청취자를 향해 직진으로만 투영하고 있다. 스테레오 재생에는 몇 가지 분위기 정보가 존재하며, 우리는 이를 통해, 레코딩이 행해졌지만 실제 공간의 음향과 전혀 유사한 것이 아닌 음향 서라운딩을 들을 수 있게 된다. 도 1의 심포니 오케스트라 및 두 개의 스피커는 스테레오로부터의 사운드를 시각적으로 보여줄 것을 시도하고 있다. 대부분의 사운드 스테이지는, 약간의 높이와 깊이를 가지지만 사실상 음향 서라운딩이 없는 두 개의 스피커 사이에 있는 것으로 인식된다.
개선된 버전의 스테레오 전개(Stereo Unfold EV)
스테레오 전개 기술은 연속적인 실제 음향 환경에서 사운드를 생성하는 3 차원 음원으로 채워진 실제와 같은 3 차원 사운드 스테이지를 생성한다. 도 2는 스테레오 전개로부터 인식된 사운드 스테이지를 시각적으로 보여 주려고 시도하며, 일반적인 스테레오를 보여주는 도 1과 비교되어야 한다. 연주자들은 크기가 다소 확대되어 대략 동일한 장소들에 위치하며, 홀과 분위기가 추가되어 사운드에 대한 3D 품질뿐만 아니라 주된 확대를 제공하고 있다.
이름에서 알 수 있듯이, 스테레오 전개는 모노가 물리적으로 좌측/우측 스테레오로 전개된 것과 매우 유사하게 일반 스테레오 레코딩을 전개하고 있지만 이번에는 스테레오가 시간 차원에서 전개된다. 스테레오로부터 스테레오 전개로의 점프는 모노를 스테레오로 물리적으로 전개하는 것과는 실제로 음향 심리학적으로 크게 다르지 않다. 이것은 설명할 수 없을 것 같지만 스테레오와 그것이 음향 심리학적으로 어떻게 작동하는지를 자세히 살펴보면 그렇지 않다는 것이 분명해질 것이다.
스테레오 재생에서 좌측으로부터 우측으로의 음원들의 로컬리제이션은 두 가지 주요 음향 심리학적 현상을 통해 작동된다. 우리의 귀 두뇌는 청각 시간 차이와 좌측 귀와 우측 귀 사이의 인식된 레벨 차이에 기초하여 음원의 수평적 로컬리제이션을 판단한다. 우측 귀와 좌측 귀에 있는 소스로부터의 레벨을 각각 조정하여 음원을 좌측에서 우측으로 패닝(panning)할 수 있다. 이는 일반적으로 레벨 패닝으로 지칭된다. 좌측 및 우측 귀로의 도착 시간을 변경하여 로컬리제이션을 조정할 수도 있으며 이 패닝 방법은 두 가지 중 더 효과적이다. 청각 시간 차이를 통해 패닝의 효과를 쉽게 테스트할 수 있다. 청취자 앞에 스테레오 스피커 쌍을 설정하고 청취자가 스피커 사이의 중앙 위치에서 좌측 또는 우측으로 멀어지게 이동하게 한다. 인식된 사운드 스테이지는 스테레오 스피커들 중 하나를 향하여 꽤 빠르게 감쇄되는데, 그 이유는, 청각 시간 차이가 음향 심리학적으로 우리에게 보다 인접한 스피커가 소스임을 알려주기 때문이다. 이는 헤드폰을 사용하여 두 귀 중 하나로의 스테레오 신호를 어떠한 레벨의 변화도 없이 지연시키되, 전체 사운드 스테이지는 지연되지 않은 귀쪽으로 감쇄되는 것으로 예시될 수 있다. 스테레오에서 수평면에서의 로컬리케이션은 실제로 좌측 및 우측 신호들 사이의 청각 시간 차이에 의해 주로 발생하며, 즉, 스테레오는 귀들 사이의 시간 차이에 기초하여 음향 심리학적 수평 로컬리제이션 단서를 생성하기 위해 시간적으로 전개되는 모노 신호이다. Blumlein은 두 개의 스피커의 물리적 분리를 사용하여 좌측-우측 로컬리제이션의 생성을 위해 필요한 청각 시간 차이를 생성할 수 있었다.
이제, 모노가 스테레오로 전개된 것과 유사하게 스테레오 신호들을 시간적으로 전개하면, 스테레오를 음향 심리학적으로 진정한 3 차원의 사운드로 전개할 수 있을 것이다. 이것이 스테레오 전개가 수행하는 것이다.
도 3은 일반적인 디지털 스테레오 사운드 레코딩의 한 채널을 도시한다. 실시간 도메인 축 상에서 도면의 좌측으로부터 시작하여 중앙에서 끝나는 축을 따르는 사운드 샘플들이 있다. 그래프는 각 시간 인스턴스에서 사운드 신호의 절대 값을 표시하며, 높이는 레벨에 해당한다. 도면의 우측에서 중앙으로의 축을 따르는 제 2의 시간 차원이 있다. 오리지널 스테레오 레코딩에서 이 차원에서는 추가 정보가 존재하지 않는데, 그 이유는 스테레오가 오직 좌우 신호만을 포함하는 2 차원 프로세스에 불과하기 때문이다.
도 4는 도 3과 동일한 디지털 스테레오 사운드 레코딩을 도시한다. 차이점은 스테레오 전개가 처리되었다는 것이다. 그것은 시간적으로 전개되었고, 우측에서 중앙으로의 축을 따라 전개되었으며, 이제 각각의 시간 인스턴스에서의 신호가 제 2의 시간 차원으로 어떻게 전개되는지를 알 수 있다. 다이어그램에서, 신호가 제 2의 시간 축을 따라 20 개의 이산 전개 신호 피드(discrete unfold signal feeds)를 사용하는 전개 프로세스에 의해 전개된다는 것을 관찰할 수 있다. 도 4의 3D 그래프의 개념은 처음 보면 다소 이상하지만 인간의 두뇌가 사운드를 해석하는 방법과 매우 유사하다. 특정 시점에서 들리는 사운드는 제 2의 시간 축을 따라 두뇌에 의해 추적되며, 다이어그램에서 오리지널 신호의 시작부터 끝까지에 이르는 모든 정보는 두뇌에 의해 그 사운드에 대한 정보를 얻는 데 사용된다.
두뇌는 우리의 시각과 매우 동일한 방식으로 우리의 사운드 환경을 이해하려고 시도한다. 이는 객체들을 생성하고 각 객체에 대해 특정 사운드들을 할당함으로써 사운드 환경을 단순화한다[2]. 우리는 초인종을 부수적인 잔향과 함께 객체로서 듣게 되며, 사람이 룸을 가로 질러 걸을 때, 우리는 그 움직임의 모든 사운드를 그 사람 등에 할당한다. 시각적 인식과 그룹화의 예는 아마도 세부 사항을 보다 이해하기 쉽게 만든다. 녹색 잎이 달린 작은 나무와 나무 뒤에 서있는 남자를 생각해 보자. 나무와 남자를 보면서 우리는 즉시 나무의 가지와 잎을 함께 나무 객체로 그룹화하고, 나무 뒤에 남자가 보이는 부분들로부터 다른 객체가 비록 이 시점에 일부만이 보일지라도 이 부분을 공제하고, 이를 남자 그룹으로 그룹화한다. 남자 그룹에 대한 우리의 인식은 나뭇잎이 남자의 대부분을 가리기 때문에 제한적이지만 여전히 우리는 그것이 별도의 그룹이고 남자일 가능성이 높다고 합리적으로 확실하게 말할 수 있다. 시각적 예는 우리의 청각이 작동하는 방법 및 두뇌가 사운드를 디코딩하고 그룹화하는 방법과 유사하다. 두뇌가 부분적으로 제한된 정보만을 가지고 있더라도 나무 뒤에 있는 남자와 같이 사운드 객체들을 인식하고 그룹화하는 것이 여전히 가능하다. 우리가 듣는 정보가 적을수록 세부 사항과 그룹을 확실하게 분류하는 것이 어렵지만 여전히 가능하며, 두뇌는 더 열심히 작동해야만 한다. 나무에 어떠한 잎도 존재하지 않는다면, 우리는 보다 많은 세부 사항을 보고 나무 뒤에 있는 남자 그룹을 훨씬 쉽고 확실하게 인식할 수 있을 것이다.
이를 염두에 두고, 도 3 및 도 4의 차이점을 다시 살펴보자. 도 4의 전개된 버전의 신호에는 사운드에 대한 더 많은 정보가 있으며, 이는 결과적으로 두뇌가 세부 사항을 분류하고, 인식하고, 사운드를 그룹화하는 것을 보다 용이하게 한다. 이것은 일반적인 스테레오와 비교하여 스테레오 전개로 들리는 것과 정확히 일치하고, 용이성과 세부 사항에 대한 인식을 향상시켰다. 각 사운드와 관련된 음향 환경 및 감쇄는 훨씬 더 명확해지고, 사운드 스테이지는 일반적인 스테레오에는 존재하지 않는 3D 품질을 취하게 된다. 사운드 스테이지의 전체 크기도 크게 증가하게 된다.
도 4의 그래프에는 두 개의 시간 차원이 있으며, 행렬의 추가적인 제 2의 시간 차원은 처리 차원을 실제 시간 차원으로 접는 동안이다.
입체 음향 재생 및 그 한계
스테레오 문제점의 근원은 레코딩 및 재생 체인 내에 공간 정보가 부족한 데 있다. 레코딩 엔지니어는 콘서트 홀의 전형적인 청취 포지션에 레코딩 마이크로폰을 배치하지 않을 것이다. 그는 마이크로폰을 항상 연주자에 훨씬 더 가깝게 이동시킬 것이다. 마이크로폰이 청중이 일반적으로 앉는 홀의 외부에 위치했다면, 레코딩은 지나치게 잔향적이고 부자연스럽게 들릴 것이다. 이는 스테레오 레코딩이 홀의 음장으로부터 공간 정보 특성을 캡처하지 못하기 때문에 발생한다. 이는 음압 레벨만 캡처할 뿐이다. 홀 내의 인간 청취자는 모든 정보, 즉 음압 및 공간 정보를 포착할 것이고, 무대에서 공연자에게 자신의 주의를 집중시키기 위해 그리고 나중에 논의될 음향 심리학적 그룹화 프로세스에 대한 입력으로서 공간 정보를 자동으로 사용할 것이다. 주변 음장은 다른 방향들로부터 청취자에게 도달하고 있으며, 무대에서 나오는 사운드와 비교하여 두뇌에 의해 다르게 인식 가능하게 관측된다. 공간 정보가 스테레오 레코딩에서 누락되었기 때문에, 청취자는 공간 정보를 사용하여 사운드를 디코딩할 수 없으며, 따라서 레코딩이 홀 내의 청취 포지션에서 이루어지면 그것은 상당한 양의 잔향 에너지를 갖는 것으로 인식될 것이다. 인간의 두뇌는 공간 도메인과 음압 도메인을 모두 사용하여 사운드 환경을 이해하고 처리한다.
Barron은 반사 에너지와 직접 에너지의 비율을 조사하고 임의의 정상적인 상황을 포괄하도록 -25dB 내지 +5dB (D/R) 범위의 다이어그램을 생성했다[1]. 전형적인 슈박스 콘서트 홀(shoebox concert hall)에서 좌석의 적어도 절반은 D/R이 -8dB 이하이다[4]. 거의 모든 입체 음향 레코딩에서 D/R 비율은 +4dB보다 작지 않으며, 즉 콘서트 홀에서 레코딩과 사운드 간에 적어도 12dB의 차이가 있다. 이것이 필요한 이유는 레코딩에는 공간 정보가 부족하고 청취자가 레코딩의 잔향 필드를 직접 사운드와 구별할 수 없기 때문이다. 레코딩이 홀 내에 존재하는 만큼의 잔향 에너지를 포함하고 있으면 그 레코딩은 불균일하게 잔향적으로 들릴 것이다.
도 5는 두 개의 룸의 두 단면을 도시하고 있다. 보다 큰 룸은 무대 섹션이 좌측에 있고 청중 공간이 우측에 있는 전형적인 콘서트 홀이다. 무대에는 한 명의 연주자와 청중 공간에는 한 명의 청취자가 있다. 사운드는 무대 상의 연주자로부터 발산되어 도면에 예시된 상상할 수 있는 다수의 경로를 따라 이동하게 된다. 직접 사운드는 홀 내의 임의의 표면들에 반사되지 않고 연주자로부터 청취자로 직접 이동하게 된다. 알 수 있는 바와 같이, 직접 사운드의 경로는 청취자에게 도달하는 제 1 반사의 경로보다 훨씬 짧으며, 이는 현저한 도착 시간 차이를 생성한다.
도 5의 하단에 있는 보다 작은 룸은 좌측에 스피커가 있고 우측에 청취자가 있는 전형적인 청취룸이다. 다시, 음파 경로들은 직접 경로 및 반사된 경로와 함께 도면에 도시된다. 보다 작은 룸에서, 직접 사운드와 제 1 반사 사이의 경로 길이 차이는 보다 큰 홀에서의 것보다 작으며, 이는 보다 작은 도달 시간 차이로 변환된다.
홀과 룸 사이의 근본적인 차이점들 중 하나는 잔향 시간에 있다. 보다 큰 홀은 작은 룸보다 잔향 시간이 훨씬 더 길다. 보다 큰 공간에서, 동일한 시간 동안 보다 적은 음파의 반사들이 있다. 넓은 공간에서, 사운드는 음장으로부터 에너지를 흡수하는 다음 반사 표면에 도달하기 전에 더 먼 거리를 이동해야 하며, 따라서 사운드는 보다 넓은 공간에서 보다 오랜 시간 동안 유지된다.
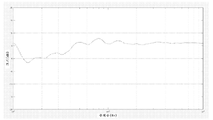
도 6은 청취자의 귀에 사운드가 도착하는 것을 5 개의 상이한 다이어그램으로 도시하고 있다. X 축을 따라 시간이 있고 Y 축 상에는 레벨이 있다. 5 개의 다이어그램은 임펄스 사운드의 잔향 감쇄 스펙트럼을 도시하고 있다. 다이어그램 1은 도 5의 콘서트 홀에서 나온 것이고, 다이어그램 2는 도 5의 청취룸에서 나온 것이고, 다이어그램 3은 다이어그램 1에 도시된 콘서트 홀에서 만들어진 스테레오 레코딩이고, 다이어그램 4는 청취룸에서 재생되는 스테레오 레코딩이고, 마지막으로 다이어그램 5는 스테레오 전개가 처리된 후에 청취룸에서 재생되는 스테레오 레코딩을 도시하고 있다.
도 1의 콘서트 홀에서 나오는 도 6의 제 1 다이어그램에서, 좌측의 제 1 피크는 연주자로부터 청취자에게 도달하는 직접 사운드이다. 다음 피크는 특정 시간 지연 후에 도달한 제 1 반사이다. 제 1 반사 후에 이어서 나중의 반사들이 후속되며, 제 1 반사는 간격이 희박하게 하나의 표면 상에서만 바운스되었고 이어서 다수 회 바운스되고 점점 더 밀집되는 반사들의 어레이가 후속된다. 이것은 많은 홀들에서 볼 수 있는 전형적인 임펄스 응답 감쇄이다.
도 2의 제 2 다이어그램은 제 1 다이어그램과 동일한 종류의 사운드 도달을 보여주지만 이제는 도 5의 전형적인 청취룸에서 보여진다. 다시 우리는 직접 사운드, 제 1 피크, 이에 후속하여 초기의 다소 간격이 이격된 반사들 및 이어지는 보다 밀집된 다수의 반사 경로들을 갖게 된다. 작은 룸의 사운드는 홀에서보다 빠르게 흡수되며 이는 도 6의 다이어그램 1과 2에서의 사운드 감쇄를 비교하여 명확하게 도시된다.
홀과 룸 사이의 가장 중요한 차이점은 직접 사운드와 관련한 제 1 반사의 타이밍에 있다. 그것은 콘서트 홀 음향에서는 홀 사운드의 선명도와 명료성을 유지하기 위해 직접 사운드 도달과 제 1 반사 사이에 약 25ms 내지 35ms이어야 한다는 것이 잘 알려져 있다. 이 시간이 감소되면, 사운드는 덜 선명해지며 피로해질 정도로 정확하지 않게 된다. 작은 룸은 이 정도의 지연 시간을 제공할 수 있을 만큼 물리적으로 충분히 크지 않아서 룸 내에 주변 에너지를 추가하면 사운드의 선명도는 항상 저하된다.
도 6의 다이어그램 3은 도 5에 도시된 홀에서 캡처한 스테레오 레코딩에서의 잔향 감쇄를 도시하고 있다. 도 6의 다이어그램 1에 도시된 레코딩과 홀 간의 차이점이 존재하는데, 그 이유는 전술한 바와 같이 레코딩 엔지니어가 스테레오 레코딩의 균형을 맞추기 위해 마이크로폰을 연주자 가까이로 이동해야 했기 때문이다. 이제 마이크로폰이 연주자에 훨씬 더 가까워지므로 홀 반사들은 직접 사운드와 관련하여 감쇠된다. 또한, 레코딩된 반사들은 더 이상 메인 홀의 주된 반사가 아니라, 무대 섹션에서 인접한 표면들의 물리적으로 보다 근접한 근접성 때문에 홀의 메인 청중 섹션에서의 희박한 간격의 반사들보다 더 우세해진다. 전체적으로 다이어그램들을 보면, 오히려 스테레오 레코딩에서 캡처된 잔향 필드 전체는 홀의 청취 포지션에서 자연적으로 발생하는 필드와 매우 유사하지 않다는 것이 분명하다.
도 6의 다이어그램 4는 도 6의 다이어그램 3에 도시된 레코딩이 도 6의 다이어그램 2에 도시된 잔향 감쇄가 있는 룸에서 스피커들에 의해 재생될 때 무엇이 발생하는지를 도시하고 있다. 여기에서 레코딩된 잔향 감쇄는 룸 잔향 감쇄에 겹쳐 져서 도 6의 다이어그램 4의 복합 잔향 감쇄를 초래하게 된다. 이것은 여전히 도 6의 다이어그램 1에서의 홀의 잔향 감쇄와는 전혀 유사해 보이지는 않지만 스테레오 레코딩의 재생시 청취룸에서 일반적으로 발견되는 감쇄가 된다.
앞에서 언급했듯이 직접 사운드와 제 1 반사 사이의 시간 간격이 부족하면 피로감을 느낄 정도로 사운드가 덜 선명하고 덜 정확해진다. 작은 룸의 사운드는 분명히 인간의 두뇌에 문제를 유발하고, 또한 콘서트 홀을 에뮬레이트하기에 충분한 잔향 감쇄 에너지가 부족하다.
스테레오 사운드에 모든 공간 정보가 없으며, 공간 음장만이 청취룸 내에서 스피커들과 청취룸 모두에 의해 생성되며, 그리고 감쇄 패턴이 약 12dB의 잔향 에너지가 없는 뮤직홀에서 자연적으로 발생하는 것과 매우 다르게 보인다는 것을 감안하면, 스테레오가 인공적으로 들리는 것은 그리 놀라운 일이 아니다.
스테레오 전개는, 인간 두뇌가 쉽게 해석할 수 있는 음향 심리학적 기반의 공간 3D 음장을 재생하고 그리고 음향 심리학적 그룹화로 지칭되는 음향 심리학적 효과를 활용함으로써 스테레오의 두 가지 근본적인 한계를 해결하고 있다.
제 1 구현예에서, 스테레오 전개는 공간 필드와 직접 사운드의 기본적인 그룹화와 더불어, 전방 이외의 다른 방향들의 추가적인 드라이버들을 사용함으로써 청취룸에서 공간 3D 음장을 생성한다.
제 2 구현예에서, 스테레오 전개는 일반적인 라우드스피커들과 함께 개시된 개선된 그룹화 방법을 사용한다. 순방향 방사 라우드스피커는 필수적으로 먼저 스테레오 정보를 재생하고, 그 후 나중에 그룹화된 공간 정보를 재생하여 전방 이외의 다른 방향들을 목표로 하는 추가적인 드라이버들을 사용하지 않고 공간 필드를 재현한다. 이는 나중에 설명되는 공감 그룹화(sympathetic grouping) 방법을 사용하는 개선된 그룹화 프로세스를 사용함으로써 가능하다.
제 3 구현예에서, 스테레오 전개는 공간 필드와 직접 사운드의 개선된 그룹화와 더불어, 전방 이외의 다른 방향들의 추가적인 드라이버들을 사용함으로써 청취룸에서 공간 3D 음장을 생성한다. 이 구현예는 최고의 환상을 재현하지만 추가적인 드라이버들을 필요로 하므로 제 2 구현예에 비해 그 적용성이 다소 제한적이다.
제 4 구현예에서, 스테레오 전개 처리는 개선된 그룹화 프로세스를 사용하여 헤드폰으로 공간적 3D 음장을 생성한다. 직접 및 주변 음장은 개선된 그룹화를 통해 연결되고, 개선된 그룹화는 사운드 경험을 청취자 헤드 내의 공통부로부터 청취자의 헤드 외부로 이동시킨다. 이는 청취자의 물리적 특성, 즉, 귀, 헤드 및 어깨의 형상 및 크기에 대한 어떠한 사전 정보가 없이도 그렇게 수행한다.
개선된 버전의 스테레오 전개의 추출 프로세스
개선된 버전의 스테레오 전개의 DSP 추출 프로세스는 스테레오 전개 처리에서 오리지널 L 및 R 채널과 함께 빌딩 블록들로서 사용되는 추가적인 기본 L+R, L-R 및 R-L 피드들(feeds)을 생성한다. 기본 피드들(Fx)에 대한 방정식은 다음과 같이 나타나며, 즉 Gx, Dx 및 Frx는 각각 게인, 지연 및 주파수 성형을 나타내며, Gfx는 개선된 버전의 스테레오 전개 처리 후 동일하게 인식된 출력 레벨을 유지하기 위해 전방 메인 출력 레벨을 조정하기 위한 게인 승수들이며, Frfx는 전방 직접 사운드의 전체적인 톤 밸런스를 유지하도록 수정될 수 있는 주파수 성형 필터들이다.
F1 = L * Gf1 * Frf1
F2 = R * Gf2 * Frf2
F3 = L * G1 * Fr1 * D1
F4 = R * G2 * Fr2 * D2
F5 = (L * G3 * Fr3 * D3) + (R * G4 * Fr4 * D4)
F6 = (L * G5 * Fr5 * D5) - (R * G6 * Fr6 * D6)
F7 = (R * G7 * Fr7 * D7) - (L * G8 * Fr8 * D8)
F8 = L * G9 * Fr9 * D9
F9 = R * G10 * Fr10 * D10
Gx 게인 승수들은 0과 무한대 사이의 임의의 수일 수 있다. 주파수 성형 Frx은 콘서트 홀에서의 전형적인 잔향 필드 에너지 및 공기에서의 자연적으로 발생하는 보다 높은 주파수의 흡수를 에뮬레이트하기 위해 주파수 범위를 50Hz 초과로 주로 제한하고 7kHz 초과의 주파수들은 롤링(roll)하게 된다. 선호되는 주파수 범위는 100Hz 내지 4kHz이다. 그것은 또한 콘서트 홀에서 자연스럽게 발생하는 것과 유사한 주변 음장의 롤(roll)을 따르도록 응답을 윤곽화한다. 지연들 D1 및 D2는 0ms 내지 3ms이며, 나머지 Dx는 최소 5ms에서 최대 50ms이며, 선호되는 범위는 10ms 내지 40ms이고, 더욱 선호되는 범위는 15ms 내지 35ms이다. 도시된 기본 피드들 F3 내지 F9는 각각 Gx, Frx 및 Dx 설정이 상이한 처리에 대한 여러 입력 피드가 될 수 있다. 이하의 텍스트 및 방정식에서, 피드들 F3 내지 F9 중 임의의 것에 대한 언급은 적어도 하나의 동일한 기본 피드를 나타내지만, 또한 각각의 인스턴스에서 상이한 Gx, Frx 및 Dx를 갖는 2 개의, 3 개의, 4 개의, 5 개의 또는 수 개 초과의 동일한 기본 피드일 수 있다.
5 개의 전개 피드(unfold feeds)를 사용하는 개선된 버전의 스테레오 전개의 기본적인 구현예에서, 다음의 신호들이 방정식에 따라 재생된다.
좌측 채널 = F1 + F3 + F6 + F8 + F5
우측 채널 = F2 + F4 + F7 + F8 + F5
매우 간단한 구현에서는 최소 3 개의 전개 피드를 사용할 수 있다. 개선된 버전은 도 4에 도시된 대로 20 개의 피드를 사용할 수 있으며, 피드의 수에 대한 상한은 없으며, 사용 가능한 DSP 처리 리소스에 의해서만 제한된다. 지각할 수 있을 정도의 중요한 콘텐츠를 가진 30 개 초과의 피드를 사용하면, 가청 경험에 제한적인 이점만 제공할 수 있어, 유해할 수 있으므로, 선호되는 범위는 3 내지 30 개의 피드가 된다. 3 개 미만의 피드는 음향 심리학적으로 유효한 그룹화 정보가 없기 때문에 작동되지 않으며, 결과는 손상된다.
3 개의 전개 피드를 사용하는 개선된 버전의 스테레오 전개의 다른 기본적인 구현예에서, 신호들은 다음의 방정식들에 따라 재생된다.
좌측 채널 = F1 + F3 + F6
우측 채널 = F2 + F4 + F7
12 개의 전개 피드를 사용하는 개선된 버전의 스테레오 전개의 보다 개선된 구현예에서, 신호들은 다음의 방정식들에 따라 재생된다. "2*"는 각 피드가 각 인스턴스에서 Gx, Frx 및 Dx에 대해 서로 다른 파라미터들과 함께 사용된 횟수를 나타낸다.
좌측 채널 = F1 + 2*F3 + 4*F6 + 2*F8 + F5
우측 채널 = F2 + 2*F4 + 4*F7 + 2*F8 + F5
물론 무한한 수의 가능한 조합이 있으며, 모두 예시할 수는 없지만 일반적인 접근 방식은 이제 분명해야 한다. 예들에서의 좌측 및 우측 채널 신호는 헤드폰들 및/또는 일반적인 라우드스피커들을 통해 재생될 수 있다.
좌측 채널 및 우측 채널 신호 외에도, 라우드스피커들을 통해 재생될 때, F1 및 F2 컴포넌트가 없는 개선된 버전의 스테레오 전개 피드는 청취자에게 직접 향하기 보다는 다른 방향들을 목표로 하는 드라이버들로 전송될 수도 있다. 추가적인 피드들은 임의의 타입의 라우드스피커 드라이버들 또는 그 어레이를 사용하여 하나의 방향 또는 모든 가능한 추가적인 방향들로, 즉 내부로, 외부로, 상방으로, 후방으로 및 하방으로 전송될 수 있다. 기본적으로 확산된 광범위한 음장을 생성하는 임의의 타입의 성좌(constellation)가 작동될 것이다. 또한, 메인 스피커들에 가깝게 위치하거나 심지어는 메인 스피커들에 부착 가능한 추가적인 피드들에 대해 별도의 추가적인 라우드스피커들이 사용될 수 있다. 서라운드 설정과 유사하거나 벽과 천장에 통합된 별도의 라우드스피커들도 룸 주위에 배치될 수 있다. 또한 위의 임의의 타입의 조합이 가능하며 작동될 것이다.
개선된 버전의 스테레오 전개의 음향 심리학적 그룹화 프로세스
음향 심리학적 그룹화 현상은 개선된 버전의 스테레오 전개 프로세스의 핵심이다. 그룹화가 없으면, 두뇌는 시간 계층 피드들을 함께 연결하지 않을 것이고, 그 시간 계층 피드들은 두뇌에 추가적인 정보를 제공하지 않고, 오히려 반대로 혼란을 제공하고 사운드를 덜 선명하게 하고 이해하기 어렵게 만든다. 그룹화는 복잡하지 않은 예에서 설명하기가 쉬우므로, 출력 방정식과 함께 위의 3 개의 전개 피드 예에서 좌측 채널 신호를 자세히 살펴보자;
좌측 채널 = F1 + F3 + F6
이 경우, F3 및 F6 피드에도 나타나는 F1 직접 피드에 사운드가 있으므로 그 피드들을 그룹화할 필요가 있다. 음향 심리학적 그룹화의 안정화가 보다 양호하고 더 안정적일수록 가청 결과가 더 좋아지고 명료도가 개선된다.
음향 심리학적 연구로부터 이해되는 것은 그룹화가 오리지널 직접 사운드 신호 및 추가된 정보의 위상 관계 및 주파수 관계에 기초하여 발생한다는 것이다. 직접 사운드와 추가된 피드 간의 주파수 형상이 다른 경우, 추가된 피드는 실제 음향 환경에 존재하는 신호로부터 인간 두뇌가 기대하는 것과 일치하는 위상 및 주파수 콘텐츠를 유지할 필요가 있다. 이것이 의미하는 바는 우리가 직접 사운드와 일정 시간 후에 도착하는 제 2 피드를 갖는다면 두뇌는 제 2 신호가 청취자에게 도달하도록 이동하는 거리 및 시간에 따라 직접 사운드보다 고주파수 콘텐츠를 덜 가질 것으로 예상한다는 것이다. 약 8.5 미터에 해당하는 25ms 동안 이동한 신호는 해당 거리에서 공기 중에 존재하는 양과 적어도 동일한 만큼의 고주파수 롤 오프(high frequency roll off)를 나타내야 한다. 만약 그것이 직접 신호와 동일한 주파수 콘텐츠를 가지고 있다면 그것은 두뇌를 혼동시킬 것이고 두뇌는 그것을 의도된 대로 직접 사운드와 함께 그룹화하지 않을 것이다. 만약 그것이 고주파수 콘텐츠를 덜 갖는다면, 그것은 보다 더 신뢰 가능하게 되는데, 그 이유는 사운드가 아마도 공기 중에서만 이동하는 것과는 별개로 적어도 하나의 객체에 반사되고 그 반사 자체가 고주파수 콘텐츠를 또한 제거하기 때문이다. 유사하게, 보다 작은 객체의 반사는 저주파 에너지의 많은 부분을 다시 바운싱하지 않을 것이며 특정 주파수 미만의 반사된 사운드는 파장과 관련된 객체의 물리적 크기에 따라 롤링(roll)될 것이다. 본질적으로, F1, F3 및 F6의 신호들을 양호하게 그룹화하려면 물리 법칙을 준수해야 하며 신호들은 설명된 대로 이동 거리 등에 따라 유사한 주파수 콘텐츠를 수정해야 한다.
또 다른 중요한 특성은 위상 관계이다. 피드 F1 및 F6의 신호들이 그 위상 관계에서 랜덤하다면 그룹화되지 않을 것이다.
지연과 조합되는 저주파 롤 오프는 그룹화를 설정하기 위해 함께 작동되며, 공감 그룹화는 상이한 조합의 지연 및 주파수 롤 오프에서 발생한다. 가령, 250Hz에서 롤오프하면 공감 그룹화를 유발하는 지연이 기본의 배수, 즉 4ms * 6 = 24ms가 된다. 지연이 기본 주파수에 비해 길지만 양호한 그룹화가 발생하도록 하기 위해서는 최저 주파수가 직접 피드와 여전히 동위상을 이루는 것이 중요하다는 것을 알게 되었다. 위의 예는 24ms의 지연을 제공한다. 이것은 정확히 24ms가 될 필요가 있거나 그룹화가 발생하지 않을 것이라는 점에서 정확한 값은 아니다. 그것은 오히려 그룹화가 발생하는 범위 내의 중간 지점이며 그룹화가 발생할 지연에 대한 안내 지점으로서 간주되어야 한다. 또한 그룹화는 6이 아닌 다른 배수에서 발생하며, 즉, 다양한 배수들을 사용하여 다양한 가청 결과를 생성할 수 있다. 보다 큰 배수는 사운드가 50ms보다 큰 지연에서 에코로 인식되기 시작하는 지점에까지 이르는 보다 넓은 사운드를 생성하는 것으로 인식될 것이다. 보다 낮은 배수는 보다 덜 넓은 사운드를 생성하며, 만약 총 지연 시간이 10ms 미만이면 사운드는 인간의 두뇌가 직접 사운드와 분리되는 것이 불분명해지기 시작하고 어려워지기 시작한다.
F3 피드는 사운드에 위상 안정화를 제공하기 위해 F1 및 F6과 함께 그룹화하는 데 요구된다. F6 피드는 본질적으로 L-R 피드이고, 따라서 상당한 양으로 추가되는 경우, 위상이 어긋난 스피커들 중 하나로 스테레오 콘텐츠를 재생할 때 발생하는 것과 유사한 정도로 사운드에 다소 불쾌한 위상화(phasiness)를 유발할 것이다. 이 현상을 상쇄시키기 위해 F3 피드는 위상을 제거하는 안정화 요소로서 제공되며, F1 및 F6 피드와 그룹화될 때 더 이상의 위상화는 존재하지 않는다.
개선된 버전의 스테레오 전개의 공감 그룹화
인간의 두뇌는 공간 정보 및 음압 정보를 모두 사용하여 음향 환경을 디코딩, 그룹화 및 일반적으로 이해한다. 스테레오 레코딩 방법에 의해 공간 정보가 제거되면 자연 그룹화 프로세스는 작동을 중단하게 된다. 일반적으로 주변 사운드 에너지는 직접 사운드 에너지보다 상당히 크며, 공간 정보가 상실될 경우, 두뇌는 공간 정보에 액세스할 때에 수행하는 것과 동일한 방식으로 주변 사운드 정보를 억제 및 처리할 수 없다. 각 그룹에 직접 및 반사된 사운드가 포함되는 경우, 자연 발생 사운드 객체들의 그룹화는 작동을 중단하게 된다. 그룹화의 결여는 스테레오 레코딩에서 친숙한 주관적인 주변 사운드 에너지의 상당한 증가를 유발하며, 주변 에너지가 감소되어야 하는 이유가 된다.
공간 정보없이 그룹화를 가능하게 하고 자연 발생 직접 대 주변 에너지 비율들을 복원할 수 있으려면 공감 그룹화가 필요하다.
자연 사운드 환경에서 직접 사운드와 반사된 사운드 간의 위상 관계는 랜덤하며 그 환경의 표면들과 관련하여 음원과 청취자의 위치에 따라 달라진다. 공간 정보의 도움으로 두뇌는 직접 사운드 및 반사된 사운드를 분류하여 그것을 인식 가능하게 상이하게 디코딩할 수 있다. 그것은 또한 사운드, 직접 사운드 및 반사된 사운드의 상이한 기여 부분들을 함께 추가하며, 그에 따라 이들은 여전히 함께 공감 그룹화된 것으로, 즉 동위상인 것으로 인식된다.
연주자들과 악기들로부터의 라이브 사운드는 청취자 포지션에서 수행된 스테레오 레코딩과 비교하여 장엄하고 풍부한 것으로 인식된다. 그 이유는 라이브 사운드를 사용하면 두뇌가 공간 정보에 액세스할 수 있고 그룹화된 사운드들을 함께 추가하며 그에 따라 그룹화된 사운드들은 동위상인 것처럼 인식 가능하게 들리기 때문이다. 공간 정보가 제거되면 두뇌는 더 이상 그렇게 할 수 없으며 사운드들의 합산은 위상을 랜덤하게 한다. 이 합산은 랜덤한 위상 관계에 있는 사운드의 단순한 에너지 합산과 동일한 방식으로 발생한다.
도 7은 룸에서 일반적으로 발생하는 것과 유사한 랜덤한 위상 관계를 갖는 다수의 소스들로부터의 음압의 복잡한 합산을 도시하고 있다. 다이어그램의 트레이스는 랜덤한 합산에 의해 유발되는 로컬 제거 딥 및 피크(local cancellation dips and peaks)를 제거하고 특정 주파수에서 전체 평균 레벨을 보여주기 위해 하나의 옥타브로 평활화된다(smoothed). 랜덤 합산은 대략 120Hz 내지 400Hz의 기본 주파수 범위에서 주파수 응답의 폭넓은 딥(dip)을 유발한다는 것이 분명하다. 그것은 또한 약 400Hz 내지 2kHz의 폭넓은 피크(peak)를 생성한다. 이것은 청취자 포지션에서 수행된 레코딩에서의 톤 밸런스의 인식과 매우 잘 일치한다. 일반적으로 이러한 레코딩은 하위 내지 고위의 중간 범위를 강조하는 기본 에너지가 부족한 타일된 매우 잔향적인 공간에서 만들어진 것처럼 들린다. 이것은 공간 정보가 없이 자연 레벨의 주변 에너지로 들리는 전형적인 사운드이다. 이것은 매우 부자연스럽게 들리므로 앞에서 언급한 대책으로서 마이크로폰을 소스에 더 가깝게 이동시키고 주변 에너지를 감쇠시키는 것이 레코딩 엔지니어에 의해 적용되어 레코딩 사운드를 보다 자연스럽고 톤이 밸런싱되게 만든다.
도 8은 랜덤 위상 합산 대신 공감 그룹화가 적용된 동일한 하나의 옥타브가 평활화된 주파수 응답을 도시하고 있다. 주파수 응답은 이제 전체 주파수 스펙트럼에 걸쳐 매우 균일하며 톤 밸런스의 변화는 거의 없다. 이 주파수 응답은 톤 밸런스를 인식 가능하게 변화시키지 않는 120Hz 내지 400Hz 범위의 아주 작은 흔들림만을 보여 주고 있다.
도 9는 공감 그룹화에서 상이한 사운드 컴포넌트들을 표시하고 있다. 트레이스 1은 직접 사운드이고 트레이스 2는 주변 사운드 피드이다. 주변 사운드 피드의 낮은 컷오프 주파수는 약 250Hz이며 그것은 이전 예에서 설명한 대로 24ms 지연된다. 주변 레벨(ambient level)은 주변 대 직접 사운드 비율을 음향 공간에서 일반적으로 발생하는 레벨로 복원하기 위해 만들어진다. 주변 사운드는 또한 일반적으로 음향 공간에서와 유사한 방식으로 보다 높은 주파수에서 감쇠된다. 직접 사운드의 주파수 밸런스인 트레이스 1은 복원된 주변 사운드 및 직접 사운드 간의 합산이 전체 주파수 스펙트럼에 걸쳐 균일해지도록 수정된다.
도 10은 트레이스 3과 함께 트레이스 1의 직접 사운드 및 트레이스 2의 주변 정보를 다시 도시하며, 트레이스 3은 이들 두 개 간의 복잡한 합산이 된다. 도 10의 트레이스 3은 위의 도 8에서 개별적으로 도시되었다.
적용 및 기술적 솔루션
개선된 버전의 스테레오 전개는 모든 스테이지에서의 사운드 레코딩에 적용될 수 있다. 그것은 기존 레코딩에 적용될 수 있거나 새로운 레코딩을 만드는 프로세스에 적용될 수 있다. 그것은 레코딩에 개선된 버전의 스테레오 전개 정보를 추가하는 전처리로서 오프라인으로 적용될 수 있거나 사운드 레코딩이 재생되는 동안 적용될 수 있다.
그것을 제품으로 구현하는 방법에는 여러 가지가 있으며, 칩 상의 집적 회로, FPGA, DSP, 프로세서 등의 하드웨어 형태일 수 있다. 설명된 처리를 가능하게 하는 임의의 타입의 하드웨어 솔루션이 사용될 수 있다. 그것은 또한 DSP, 프로세서, FPGA 등과 같은 이미 존재하는 처리 디바이스 상에서 실행되는 펌웨어 또는 소프트웨어로서 하드웨어 플랫폼 내에 구현될 수 있다. 이러한 플랫폼은 퍼스널 컴퓨터, 전화기, 패드, 전용 사운드 처리 디바이스, TV 세트 등이 될 수 있다.
개선된 버전의 스테레오 전개는 또한 상술한 바와 같이 하드웨어, 소프트웨어 또는 펌웨어로서 상상할 수 있는 임의의 타입의 전처리 또는 재생 디바이스에서 구현될 수 있다. 이러한 디바이스들의 몇 가지의 예로는 액티브 스피커들, 증폭기들, DA 컨버터들, PC 뮤직 시스템들, TV 세트, 헤드폰 증폭기들, 스마트폰들, 전화기들, 패드들, 마스터링 및 레코딩 산업용의 사운드 처리 유닛들, 전문 마스터링 및 믹싱 소프트웨어에서의 소프트웨어 플러그인, 미디어 플레이어용의 소프트웨어 플러그인, 소프트웨어 플레이어에서의 스트리밍 미디어 처리, 스트리밍 콘텐츠의 전처리를 위한 전처리 소프트웨어 모듈들 또는 하드웨어 유닛들, 또는 임의의 타입의 레코딩의 전처리를 위한 전처리 소프트웨어 모듈들 또는 하드웨어 유닛들이 있다.
다른 적용 분야
개선된 버전의 스테레오 전개를 통한 작동 동안 우리는 또한 일반 청취자가 인식하는 사운드의 선명도 개선이 청각 장애가 있는 청취자에게는 훨씬 더 중요하다는 것을 발견했다. 청각 장애가 있는 청취자들은 정기적으로 사운드의 명료성에 어려움을 겪고 있으며 어떠한 구제도 커다란 도움이 된다.
개선된 버전의 스테레오 전개에 의해 제공되는 추가된 단서는 두뇌가 디코딩할 수 있는 더 많은 정보를 제공함으로써 어려움을 감소시키며, 보다 많은 단서는 명료성을 향상시킨다. 따라서, 이 기술은 보청기, 달팽이관 임플란트, 대화 증폭기 등과 같은 청각 장애인용 디바이스들에 큰 도움이 될 가능성이 높다.
개선된 버전의 스테레오 전개는 또한 아마도 PA 사운드 분배 시스템에 적용되어, 기차역 및 공항과 같은(단, 이에 국한되지는 않음) 음향적으로 어려운 환경에 있는 모든 사람에 대한 명료성을 향상시킬 수 있다. 개선된 버전의 스테레오 전개는 사운드의 명료성에 관심을 두고 있는 모든 타입의 적용 분야에서 장점을 제공할 수 있다.
개선된 버전의 스테레오 전개는 PA 시스템에서 사운드 강화를 위해 적절하게 사용되며 일반적으로 음악 및 음성의 명료성과 음질을 향상시킨다. 그것은 스타디움, 강당, 회의장, 콘서트 홀, 교회, 영화관, 야외 콘서트 등의 모든 타입의 라이브 또는 재생 공연에 사용될 수 있다.
스테레오 소스들을 시간에 맞춰 전개하는 것 외에도 개선된 버전의 스테레오 전개는 음향 심리학적 그룹화를 통해 스테레오 소스들을 시간에 맞춰 전개하는 것과 유사하게 모노 소스들을 전개하여 명료성의 관점으로부터의 경험을 개선하거나 전반적으로 개선된 재생 성능을 제공하는 데 사용될 수 있다.
그것은 또한 재생을 위해 단 하나의 단일 모노 스피커가 있는 시스템들에서도 사용될 수 있다. 좌측 및 우측 콘텐츠가 하나의 스피커 재생을 위해 합산되기 전에 서로와 관련하여 시간적으로 서로 관련되어 있지 않으면, 스테레오 전개 처리는 두 개의 스피커를 통해 수행하는 것과 유사하게 들리고 작동한다.
개선된 버전의 스테레오 전개는 또한 스테레오 재생 시스템에 국한되지 않고 개별 서라운드 채널에서 발생하는 처리, 시간의 전개 및 그룹화와 함께 모든 서라운드 사운드 설정에 사용될 수 있다.
본 발명에 따른 다른 실시예들
본 발명의 제 1 양태에 따르면, 사운드 재생 방법이 제공되며, 상기 방법은:
-사운드 신호(들)의 처리된 알고리즘들인 다수의 전개된 피드들(Fx)을 제공하는 단계;
-적어도 하나의 전개된 피드(Fx)를 또 다른 하나 이상의 전개된 피드와 함께 음향 심리학적으로 그룹화하는 단계; 및
-전개되고 음향 심리학적으로 그룹화된 피드 사운드를 사운드 재생 유닛에서 재생하는 단계를 포함하고;
상기 전개된 피드들(Fx)의 수는 적어도 3이며, 예컨대, 3 내지 30의 범위에 있다.
상기 방법은 또한
-디지털 신호 프로세서(digital signal processing)(DSP)를 이용하여 좌측(L) 채널 및 우측(R) 채널로부터의 추출된 정보를 제공하는 단계를 포함할 수 있고, 다수의 전개된 피드들(Fx)을 제공하는 단계는 좌측(L) 채널 및 우측(R) 채널로부터의 추출된 정보에 기초한다.
위에서 이해될 수 있는 바와 같이, 본 발명의 일 실시예에 따르면, 본 발명은 스테레오 사운드 재생 방법을 제공하는 것에 관한 것으로, 좌측(L) 채널 및 우측(R) 채널이 좌측(L) 및 우측(R) 스테레오 채널임을 의미한다. 위에서 주목할 수 있는 바와 같이, 스테레오는 본 발명이 사용하는 많은 기술적인 적용들 중 가능한 하나에 불과할 뿐이다.
또 다른 특정 실시예에 따르면, 처리된 알고리즘들에서는 지연(들)(Dx) 및/또는 주파수 성형(들)(Frx)이 이용된다. 일 실시예에서, 처리된 알고리즘들에서는 지연(들)(Dx)이 이용된다. 다른 실시예에 따르면, 처리된 알고리즘들에서는 지연(들)(Dx) 및 주파수 성형(들)(Frx)이 이용된다. 또한, 또 다른 실시예에 따르면, 처리된 알고리즘들에서는 게인(들)(Gx)이 또한 이용된다.
또한, 이 방법은 또한 주파수 성형(들)(Frx)을 포함할 수도 있다. 일 실시예에 따르면, 주파수 성형(들)(Frx)이 이용되고 주파수 성형들(Frx)은 주파수 범위를 50Hz 초과로 주로 제한한다. 또 다른 실시예에 따르면, 주파수 성형(들)(Frx)이 이용되고 주파수 성형(들)(Frx)이 수행되어, 7kHz 초과의 보다 높은 주파수 콘텐츠가 롤링된다. 또 다른 실시예에 따르면, 주파수 성형(들)(Frx)이 이용되고 주파수 성형(들)(Frx)은 100 Hz 내지 4 kHz의 주파수 범위에서 수행된다.
또한 지연(들)은 관련성이 있다. 본 발명의 일 특정 실시예에 따르면, 처음 2 개의 지연 D1 및 D2는 0 내지 3ms의 범위에 있다. 또 다른 실시예에 따르면, D1 및 D2를 제외한 모든 지연은 적어도 5ms이고, 예컨대, 5 내지 50ms의 범위에 있고, 바람직하게는 10 내지 40ms의 범위에 있고, 보다 바람직하게는 15 내지 35ms의 범위에 있다.
또한, 또 다른 실시예에 따르면, 하나 이상의 피드들(Fx)은 위상 안정화기로서 제공된다. 또한, 또 다른 특정 실시예에 따르면, 피드들(Fx)은 기본(들)의 배수(들)를 사용함으로써 음향 심리학적으로 그룹화된다. 더욱이, 몇몇 피드들(Fx)은 유사한 주파수 콘텐츠를 갖도록 수정될 수 있다.
주목해야 하는 것은 위의 모든 특징들은 스테레오 사운드 재생에 사용되는 경우에도 적용된다는 것이다. 그러한 경우 이들 특징은 좌측(L) 및 우측(R) 스테레오 채널에 각각 사용될 수 있다. 위에서 이해되는 바와 같이, 본 발명은 피드들(Fx)의 그룹화에 관한 것이다. 따라서, 하나의 특정 실시예에 따르면, 피드들(Fx)은 각각 좌측(L) 및 우측(R) 스테레오 채널에서 음향 심리학적으로 그룹화된다.
본 발명은 또한 방법에 의해 사운드 재생을 제공하도록 구성된 디바이스에 관한 것이이며, 상기 방법은:
-사운드 신호(들)의 처리된 알고리즘들인 다수의 전개된 피드들(Fx)을 제공하는 단계;
-적어도 하나의 전개된 피드(Fx)를 또 다른 하나 이상의 전개된 피드와 함께 음향 심리학적으로 그룹화하는 단계; 및
-전개되고 음향 심리학적으로 그룹화된 피드 사운드를 사운드 재생 유닛에서 재생하는 단계를 포함하고;
상기 전개된 피드들(Fx)의 수는 적어도 3이다.
또한 이 경우에, 상기 디바이스는, 예컨대, 임의의 타입의 스테레오 유닛, 증폭기 등에서와 같은 임의의 타입의 사운드 레코딩 유닛일 수 있다.
하나의 특정 실시예에 따르면, 상기 디바이스는 칩 상의 집적 회로, FPGA 또는 프로세서이다. 또 다른 실시예에 따르면, 상기 디바이스는 하드웨어 플랫폼으로 구현된다. 위에서 이해되는 바와 같이, 본 발명에 따른 방법은 또한 소프트웨어 애플리케이션에서도 이용될 수 있다.
참고 문헌
[1] 바론 마이클(Barron, Michael)에 의한 “Auditorium Acoustics and Architectural Design” E&FN SPON 1993
[2] 앨버트 에스 브레그만(Albert S. Bregman)에 의한 “Auditory Scene Analysis The Perceptual Organization of Sound”, 1994, ISBN 978-0-262-52195-6
[3] 2007년 5월 5일부터 8일까지의 오스트리아 비엔나의 122회 오디오 엔지니어링 협회 협약에서 발표된 데이빗 그리에싱거(David Griesinger)에 의한 “The importance of the direct to reverberant ratio in the perception of distance, localization, clarity, and envelopment”
[4] 2007년 5월 5일부터 8일까지의 오스트리아 비엔나의 122회 오디오 엔지니어링 협회 협약에서 발표된 데이빗 그리에싱거(David Griesinger)에 의한 “Perception of Concert Hall Acoustics in seats where the reflected energy is stronger than the direct energy”
[5] 2012년 4월 26일부터 29일까지의 헝가리 부다페스트의 132회 오디오 엔지니어링 협회 협약에서 발표된 데이빗 그리에싱거(David Griesinger)에 의한 “Pitch, Timbre, Source Separation and the Myths of Loudspeaker Imaging”
Claims (20)
- 사운드 재생 방법으로서,
-사운드 신호(들)의 처리된 알고리즘들인 다수의 전개된 피드들(a number of unfolded feeds)(Fx)을 제공하는 단계;
-적어도 하나의 전개된 피드(Fx)를 또 다른 하나 이상의 전개된 피드와 함께 음향 심리학적으로 그룹화하는 단계; 및
-전개되고 음향 심리학적으로 그룹화된 피드 사운드(feed sound)를 사운드 재생 유닛에서 재생하는 단계
를 포함하고;
상기 전개된 피드들(Fx)의 수는 적어도 3인
사운드 재생 방법. - 제1항에 있어서,
상기 사운드 재생 방법은 또한
-디지털 신호 프로세서(digital signal processing)(DSP)를 이용하여 좌측(L) 채널 및 우측(R) 채널로부터의 추출된 정보를 제공하는 단계를 포함하고, 다수의 전개된 피드들(Fx)을 제공하는 단계는 좌측(L) 채널 및 우측(R) 채널로부터의 상기 추출된 정보에 기초하는
사운드 재생 방법. - 제1항 또는 제2항에 있어서,
상기 처리된 알고리즘들에서는 지연(들)(Dx) 및/또는 주파수 성형(들)(Frx)이 이용되는
사운드 재생 방법. - 제1항 내지 제3항 중 어느 한 항에 있어서,
상기 처리된 알고리즘들에서는 지연(들)(Dx)이 이용되는
사운드 재생 방법. - 제1항 내지 제4항 중 어느 한 항에 있어서,
상기 처리된 알고리즘들에서는 지연(들)(Dx) 및 주파수 성형(들)(Frx)이 이용되는
사운드 재생 방법. - 제1항 내지 제5항 중 어느 한 항에 있어서,
상기 처리된 알고리즘들에서는 게인(들)(Gx)이 또한 이용되는
사운드 재생 방법. - 제1항 내지 제6항 중 어느 한 항에 있어서,
주파수 성형(들)(Frx)이 이용되고 상기 주파수 성형(들)(Frx)은 주파수 범위를 50Hz 초과로 주로 제한하는
사운드 재생 방법. - 제1항 내지 제7항 중 어느 한 항에 있어서,
주파수 성형(들)(Frx)이 이용되고 상기 주파수 성형(들)(Frx)이 수행되어 7kHz 초과의 보다 높은 주파수 콘텐츠가 롤링되는
사운드 재생 방법. - 제1항 내지 제8항 중 어느 한 항에 있어서,
주파수 성형(들)(Frx)이 이용되고 상기 주파수 성형(들)(Frx)은 100 Hz 내지 4 kHz의 주파수 범위에서 수행되는
사운드 재생 방법. - 제1항 내지 제9항 중 어느 한 항에 있어서,
처음 2 개의 지연 D1 및 D2는 0 내지 3ms의 범위에 있는
사운드 재생 방법. - 제1항 내지 제10항 중 어느 한 항에 있어서,
D1 및 D2를 제외한 모든 지연들은 적어도 5ms인
사운드 재생 방법. - 제1항 내지 제11항 중 어느 한 항에 있어서,
D1 및 D2를 제외한 모든 지연들은 5 내지 50ms의 범위에 있는
사운드 재생 방법. - 제1항 내지 제12항 중 어느 한 항에 있어서,
상기 피드들(Fx)은 각각 좌측(L) 및 우측(R) 스테레오 채널에서 음향 심리학적으로 그룹화되는
사운드 재생 방법. - 제1항 내지 제13항 중 어느 한 항에 있어서,
하나 이상의 피드들(Fx)이 위상 안정화기로서 제공되는
사운드 재생 방법. - 제1항 내지 제14항 중 어느 한 항에 있어서,
상기 피드들(Fx)은 기본(들)의 배수(들)를 사용함으로써 음향 심리학적으로 그룹화되는
사운드 재생 방법. - 제1항 내지 제15항 중 어느 한 항에 있어서,
몇몇 피드들(Fx)은 유사한 주파수 콘텐츠를 갖도록 수정되는
사운드 재생 방법. - 제1항 내지 제16항 중 어느 한 항에 있어서,
피드들(Fx)의 수는 3 내지 30ms의 범위에 있는
사운드 재생 방법. - 방법에 의해 사운드 재생을 제공하도록 구성된 디바이스로서,
상기 방법은:
-사운드 신호(들)의 처리된 알고리즘들인 다수의 전개된 피드들(Fx)을 제공하는 단계;
-적어도 하나의 전개된 피드(Fx)를 또 다른 하나 이상의 전개된 피드와 함께 음향 심리학적으로 그룹화하는 단계; 및
-전개되고 음향 심리학적으로 그룹화된 피드 사운드를 사운드 재생 유닛에서 재생하는 단계
를 포함하고;
상기 전개된 피드들(Fx)의 수는 적어도 3인
디바이스. - 제18항에 있어서,
상기 디바이스는 칩 상의 집적 회로, FPGA 또는 프로세서인
디바이스. - 제18항에 있어서,
상기 디바이스는 하드웨어 플랫폼으로 구현되는
디바이스.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| SE1750448 | 2017-04-18 | ||
| SE1750448-1 | 2017-04-18 | ||
| PCT/SE2018/050300 WO2018194501A1 (en) | 2017-04-18 | 2018-03-23 | Stereo unfold with psychoacoustic grouping phenomenon |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20190140976A true KR20190140976A (ko) | 2019-12-20 |
Family
ID=63857120
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020197033763A Withdrawn KR20190140976A (ko) | 2017-04-18 | 2018-03-23 | 음향 심리학적 그룹화 현상을 이용한 스테레오 전개 |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US11197113B2 (ko) |
| EP (1) | EP3613222A4 (ko) |
| JP (1) | JP2020518159A (ko) |
| KR (1) | KR20190140976A (ko) |
| CN (1) | CN110495189A (ko) |
| BR (1) | BR112019021241A2 (ko) |
| WO (1) | WO2018194501A1 (ko) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| FR3114209B1 (fr) | 2020-09-11 | 2022-12-30 | Siou Jean Marc | Systeme de reproduction de sons avec virtualisation du champ reverbere |
| EP4264962A4 (en) | 2020-12-16 | 2024-11-13 | LISN Technologies Inc. | PSYCHOACOUSTIC SOUND LOCALIZATION SYSTEM FOR STEREO HEADPHONES AND METHOD FOR RECONSTRUCTING STEREO PSYCHOACOUSTIC SOUND SIGNALS USING SAME |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4817149A (en) * | 1987-01-22 | 1989-03-28 | American Natural Sound Company | Three-dimensional auditory display apparatus and method utilizing enhanced bionic emulation of human binaural sound localization |
| GB9107011D0 (en) * | 1991-04-04 | 1991-05-22 | Gerzon Michael A | Illusory sound distance control method |
| GB9211756D0 (en) * | 1992-06-03 | 1992-07-15 | Gerzon Michael A | Stereophonic directional dispersion method |
| JP2988289B2 (ja) * | 1994-11-15 | 1999-12-13 | ヤマハ株式会社 | 音像音場制御装置 |
| US6111958A (en) | 1997-03-21 | 2000-08-29 | Euphonics, Incorporated | Audio spatial enhancement apparatus and methods |
| AUPR647501A0 (en) * | 2001-07-19 | 2001-08-09 | Vast Audio Pty Ltd | Recording a three dimensional auditory scene and reproducing it for the individual listener |
| WO2007137232A2 (en) * | 2006-05-20 | 2007-11-29 | Personics Holdings Inc. | Method of modifying audio content |
| US8520873B2 (en) * | 2008-10-20 | 2013-08-27 | Jerry Mahabub | Audio spatialization and environment simulation |
| GB201109731D0 (en) * | 2011-06-10 | 2011-07-27 | System Ltd X | Method and system for analysing audio tracks |
| US8964992B2 (en) * | 2011-09-26 | 2015-02-24 | Paul Bruney | Psychoacoustic interface |
| US9286863B2 (en) | 2013-09-12 | 2016-03-15 | Nancy Diane Moon | Apparatus and method for a celeste in an electronically-orbited speaker |
| CN106104678A (zh) * | 2013-10-02 | 2016-11-09 | 斯托明瑞士有限责任公司 | 从两个或多个基本信号导出多通道信号 |
| US9374640B2 (en) | 2013-12-06 | 2016-06-21 | Bradley M. Starobin | Method and system for optimizing center channel performance in a single enclosure multi-element loudspeaker line array |
| JP6297721B2 (ja) * | 2014-05-30 | 2018-03-20 | クゥアルコム・インコーポレイテッドQualcomm Incorporated | 高次アンビソニックオーディオレンダラのための希薄情報を取得すること |
-
2018
- 2018-03-23 EP EP18788470.5A patent/EP3613222A4/en not_active Withdrawn
- 2018-03-23 US US16/605,009 patent/US11197113B2/en active Active
- 2018-03-23 KR KR1020197033763A patent/KR20190140976A/ko not_active Withdrawn
- 2018-03-23 BR BR112019021241-8A patent/BR112019021241A2/pt not_active Application Discontinuation
- 2018-03-23 JP JP2019556628A patent/JP2020518159A/ja active Pending
- 2018-03-23 CN CN201880020404.3A patent/CN110495189A/zh active Pending
- 2018-03-23 WO PCT/SE2018/050300 patent/WO2018194501A1/en not_active Ceased
Also Published As
| Publication number | Publication date |
|---|---|
| WO2018194501A1 (en) | 2018-10-25 |
| EP3613222A4 (en) | 2021-01-20 |
| CN110495189A (zh) | 2019-11-22 |
| EP3613222A1 (en) | 2020-02-26 |
| JP2020518159A (ja) | 2020-06-18 |
| US20200304929A1 (en) | 2020-09-24 |
| BR112019021241A2 (pt) | 2020-05-12 |
| US11197113B2 (en) | 2021-12-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Hacihabiboglu et al. | Perceptual spatial audio recording, simulation, and rendering: An overview of spatial-audio techniques based on psychoacoustics | |
| US20030007648A1 (en) | Virtual audio system and techniques | |
| Camras | Approach to recreating a sound field | |
| JP5956994B2 (ja) | 拡散音の空間的オーディオの符号化及び再生 | |
| AU2019204177A1 (en) | Spatial audio rendering for beamforming loudspeaker array | |
| CA2744429C (en) | Converter and method for converting an audio signal | |
| JPS62501105A (ja) | 空間残響 | |
| JP6246922B2 (ja) | 音響信号処理方法 | |
| Pierce | Hearing in time and space | |
| KR20190140976A (ko) | 음향 심리학적 그룹화 현상을 이용한 스테레오 전개 | |
| CN107925839A (zh) | 用于在反射环境中、尤其在听音室中播放声音的方法 | |
| Pulkki et al. | Spatial effects | |
| Abel et al. | Live Auralization of Cappella Romana at the Bing Concert Hall, Stanford University | |
| US20200045419A1 (en) | Stereo unfold technology | |
| Blauert | Hearing of music in three spatial dimensions | |
| Yan et al. | Visual and Objective Comparison of Two Concert Halls Using B-Format Recordings and HOA-Based Immersive Maps | |
| Brereton et al. | The Virtual Singing Studio: A loudspeaker-based room acoustics simulation for real-time musical performance | |
| Høier | Surrounded by ear candy? The use of surround sound in oscar-nominated movies 2000-2012 | |
| WO2025236211A1 (en) | Sound reproduction apparatus and sound reproduction system | |
| Schroeder | Concert halls: from magic to number theory | |
| Schlemmer | Reverb design | |
| von Schultzendorff et al. | Real-diffuse enveloping sound reproduction | |
| Atkinson | Surrounded by sound: The aesthetics of multichannel and hypersonic soundscapes and aural architectures | |
| Barbour | Spatial Audio Engineering, Exploring Height in Acous-tic Space | |
| Del Cerro et al. | Three-dimensional sound spatialization at Auditorio400 in Madrid designed by Jean Nouvel |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20191115 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| PG1501 | Laying open of application | ||
| PC1203 | Withdrawal of no request for examination |