KR20200027475A - 음성 대 음성 변환을 위한 시스템 및 방법 - Google Patents
음성 대 음성 변환을 위한 시스템 및 방법 Download PDFInfo
- Publication number
- KR20200027475A KR20200027475A KR1020197038068A KR20197038068A KR20200027475A KR 20200027475 A KR20200027475 A KR 20200027475A KR 1020197038068 A KR1020197038068 A KR 1020197038068A KR 20197038068 A KR20197038068 A KR 20197038068A KR 20200027475 A KR20200027475 A KR 20200027475A
- Authority
- KR
- South Korea
- Prior art keywords
- speech
- voice
- tone
- target
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images

















Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/003—Changing voice quality, e.g. pitch or formants
- G10L21/007—Changing voice quality, e.g. pitch or formants characterised by the process used
- G10L21/013—Adapting to target pitch
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/02—Methods for producing synthetic speech; Speech synthesisers
- G10L13/033—Voice editing, e.g. manipulating the voice of the synthesiser
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/063—Training
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/018—Audio watermarking, i.e. embedding inaudible data in the audio signal
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
- G10L2015/025—Phonemes, fenemes or fenones being the recognition units
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/003—Changing voice quality, e.g. pitch or formants
- G10L21/007—Changing voice quality, e.g. pitch or formants characterised by the process used
- G10L21/013—Adapting to target pitch
- G10L2021/0135—Voice conversion or morphing
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/27—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the analysis technique
- G10L25/30—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the analysis technique using neural networks
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Multimedia (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Computational Linguistics (AREA)
- Acoustics & Sound (AREA)
- Signal Processing (AREA)
- Quality & Reliability (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Computation (AREA)
- Telephonic Communication Services (AREA)
- Machine Translation (AREA)
Abstract
Description
도 1은 본 발명의 예시적인 실시예들에 따른 음성 대 음성 변환 시스템의 단순화된 버전을 개략적으로 도시한다.
도 2는 본 발명의 예시적인 실시예들을 구현하는 시스템의 상세들을 개략적으로 도시한다.
도 3은 본 발명의 예시적인 실시예들에 따른, 인코딩된 음성 데이터를 나타내는 다차원 공간을 구축하기 위한 프로세스를 도시한다.
도 4는 본 발명의 예시적인 실시예들에 따른 스피치 샘플을 필터링하는 시간 수용 필터를 개략적으로 도시한다.
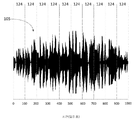
도 5a-5c는 본 발명의 예시적인 실시예들에 따른, 도 4의 동일한 스피치 세그먼트로부터의 상이한 분석적 오디오 세그먼트들의 추출된 주파수 분포들을 갖는 스펙트로그램들(spectrograms)을 도시한다.
도 5a는 "Call"이라는 단어 내의 "a"라는 단음에 대한 스펙트로그램을 도시한다.
도 5b는 "Stella" 내의 "a"라는 단음에 대한 스펙트로그램을 도시한다.
도 5c는 "Please" 내의 "ea"라는 단음에 대한 스펙트로그램을 도시한다.
도 6a-6d는 본 발명의 예시적인 실시예들에 따른 벡터 공간의 슬라이스들(slices)을 개략적으로 도시한다.
도 6a는 도 5b에 도시된 단음에 대한 타겟 음성만을 매핑하는 벡터 공간의 슬라이스를 개략적으로 도시한다.
도 6b는 타겟 음성 및 제2 음성을 매핑하는 도 6a의 벡터 공간의 슬라이스를 개략적으로 도시한다.
도 6c는 타겟 음성, 제2 음성 및 제3 음성을 매핑하는 도 6a의 벡터 공간의 슬라이스를 개략적으로 도시한다.
도 6d는 복수의 음성을 매핑하는 도 6a의 벡터 공간의 슬라이스를 개략적으로 도시한다.
도 7a는 제2 음성의 음색 내의 "Call"이라는 단어 내의 "a"라는 단음에 대한 스펙트로그램을 도시한다.
도 7b는 제3 음성의 음색 내의 "Call"이라는 단어 내의 "a"라는 단음에 대한 스펙트로그램을 도시한다.
도 8a는 본 발명의 예시적인 실시예들에 따른 합성 음성 프로파일을 포함하는 벡터 공간의 슬라이스를 개략적으로 도시한다.
도 8b는 본 발명의 예시적인 실시예들에 따른, 생성적 적대적 신경망이 합성 음성 프로파일을 세밀화(refine)한 후에 "DOG" 내의 "D"라는 단음에 대응하는 벡터 공간의 슬라이스를 개략적으로 도시한다.
도 8c는 제2 음성 및 제4 음성의 추가를 갖는 도 8b의 벡터 공간의 슬라이스를 개략적으로 도시한다.
도 9는 본 발명의 예시적인 실시예들에 따른 증강된 음성 프로파일을 세밀화하기 위해 생성적 적대적 망을 사용하는 시스템의 블록도를 도시한다.
도 10은 본 발명의 예시적인 실시예들에 따른 스피치 대 스피치(speech-to-speech) 변환 프로세스를 도시한다.
도 11은 본 발명의 예시적인 실시예들에 따른 음성을 사용하여 아이덴티티를 검증하는 프로세스를 도시한다.
Claims (78)
- 타겟 음성으로부터의 타겟 음성 정보, 및 소스 음성의 스피치 세그먼트를 나타내는 스피치 데이터를 사용하여 스피치 변환 시스템을 구축하는 방법으로서,
소스 음성의 제1 스피치 세그먼트를 나타내는 소스 스피치 데이터를 수신하는 단계;
상기 타겟 음성에 관한 타겟 음색 데이터를 수신하는 단계로서, 상기 타겟 음색 데이터는 음색 공간 내에 있는, 단계;
생성적 기계 학습 시스템을 사용하여, 상기 소스 스피치 데이터 및 상기 타겟 음색 데이터의 함수로서 제1 후보 음성 내의 제1 후보 스피치 세그먼트를 나타내는 제1 후보 스피치 데이터를 생성하는 단계;
판별적 기계 학습 시스템을 사용하여, 복수의 상이한 음성의 음색 데이터를 참조하여 상기 제1 후보 음색 데이터를 상기 타겟 음색 데이터와 비교하는 단계로서,
상기 판별적 기계 학습 시스템을 사용하는 것은 상기 복수의 상이한 음성의 상기 음색 데이터를 참조하여 상기 제1 후보 스피치 데이터와 상기 타겟 음색 데이터 사이의 적어도 하나의 불일치를 결정하는 것을 포함하며, 상기 판별적 기계 학습 시스템은 상기 제1 후보 스피치 데이터와 상기 타겟 음색 데이터 사이의 상기 불일치에 관한 정보를 갖는 불일치 메시지를 생성하는, 단계;
상기 불일치 메시지를 상기 생성적 기계 학습 시스템에 피드백하는 단계;
상기 생성적 기계 학습 시스템을 사용하여, 상기 불일치 메시지의 함수로서 제2 후보 음성 내의 제2 후보 스피치 세그먼트를 나타내는 제2 후보 스피치 데이터를 생성하는 단계; 및
상기 피드백의 결과로서 상기 생성적 기계 학습 시스템 및/또는 판별적 기계 학습 시스템에 의해 생성된 정보를 사용하여 상기 음색 공간에서 상기 타겟 음색 데이터를 세밀화하는 단계
를 포함하는, 방법. - 제1항에 있어서, 상기 소스 스피치 데이터는 상기 소스 음성의 오디오 입력으로부터 유래되는, 방법.
- 제1항에 있어서, 상기 제2 후보 스피치 세그먼트는 상기 제1 후보 스피치 세그먼트보다 높은 상기 타겟 음성으로부터 유래될 확률을 제공하는, 방법.
- 제1항에 있어서, 상기 소스 스피치 데이터를 상기 타겟 음색으로 변환하는 단계를 더 포함하는, 방법.
- 제1항에 있어서, 상기 타겟 음색 데이터는 상기 타겟 음성 내의 오디오 입력으로부터 획득되는, 방법.
- 제1항에 있어서, 상기 기계 학습 시스템은 신경망인, 방법.
- 제1항에 있어서,
벡터 공간에서 상기 복수의 음성 및 상기 제1 후보 음성의 표현을 각각의 음성에 의해 제공되는 상기 스피치 세그먼트 내의 주파수 분포의 함수로서 매핑하는 단계를 더 포함하는, 방법. - 제7항에 있어서,
상기 불일치 메시지의 함수로서 상기 제2 후보 음성을 반영하기 위해 상기 벡터 공간에서 상기 복수의 음성의 표현들에 대해 상기 제1 후보 음성의 표현을 조정하는 단계를 더 포함하는, 방법. - 제1항에 있어서, 상기 불일치 메시지는 상기 판별적 신경망이 상기 제1 후보 음성이 상기 타겟 음성이라는 95 퍼센트 미만의 신뢰 구간을 가질 때 생성되는, 방법.
- 제1항에 있어서,
상기 후보 음성을 상기 복수의 음성과 비교함으로써 상기 후보 음성에 아이덴티티를 할당하는 단계를 더 포함하는, 방법. - 제1항에 있어서, 상기 복수의 음성은 벡터 공간 내에 있는, 방법.
- 제1항에 있어서, 상기 타겟 음색 데이터는 시간 수용 필드에 의해 필터링되는, 방법.
- 제1항에 있어서, 상기 생성적 기계 학습 시스템을 사용하여, 널 불일치 메시지의 함수로서 최종 후보 음성에서 최종 후보 스피치 세그먼트를 생성하는 단계를 더 포함하며,
상기 최종 후보 스피치 세그먼트는 상기 타겟 음색 내의 상기 제1 스피치 세그먼트를 모방하는, 방법. - 제13항에 있어서, 상기 시간 수용 필드는 약 10 밀리초 내지 약 1000 밀리초사이인, 방법.
- 제1항에 있어서, 타겟 스피치 세그먼트로부터 상기 타겟 음색 데이터를 추출하기 위한 수단을 더 포함하는, 방법.
- 스피치 변환 시스템을 트레이닝하기 위한 시스템으로서,
소스 음성의 제1 스피치 세그먼트를 나타내는 소스 스피치 데이터;
타겟 음성에 관한 타겟 음색 데이터;
상기 소스 스피치 데이터 및 상기 타겟 음색 데이터의 함수로서 제1 후보 음성 내의 제1 후보 스피치 세그먼트를 나타내는 제1 후보 스피치 데이터를 생성하도록 구성된 생성적 기계 학습 시스템;
판별적 기계 학습 시스템
을 포함하고, 상기 판별적 기계 학습 시스템은:
복수의 상이한 음성의 음색 데이터를 참조하여 상기 제1 후보 스피치 데이터를 상기 타겟 음색 데이터와 비교하고,
상기 복수의 상이한 음성의 상기 음색 데이터를 참조하여 상기 제1 후보 스피치 데이터와 상기 타겟 음색 데이터 사이에 적어도 하나의 불일치가 존재하는지를 결정하고, 상기 적어도 하나의 불일치가 존재할 때:
상기 제1 후보 스피치 데이터와 상기 타겟 음색 데이터 사이의 상기 불일치에 관한 정보를 갖는 불일치 메시지를 생성하며,
상기 불일치 메시지를 다시 상기 생성적 기계 학습 시스템에 제공하도록 구성되는, 시스템. - 제16항에 있어서, 상기 생성적 기계 학습 시스템은 상기 불일치 메시지의 함수로서 제2 후보 스피치 세그먼트를 생성하도록 구성되는, 시스템.
- 제16항에 있어서, 상기 기계 학습 시스템은 신경망인, 시스템.
- 제16항에 있어서,
상기 후보 음성을 포함하는 상기 복수의 음성의 표현을 각각의 음성에 의해 제공되는 상기 스피치 세그먼트 내의 주파수 분포의 함수로서 매핑하도록 구성되는 벡터 공간을 더 포함하는, 시스템. - 제19항에 있어서, 음성 특징 추출기가 상기 벡터 공간에서 상기 복수의 음성의 표현들에 대해 상기 후보 음성의 표현을 조정하여, 상기 불일치 메시지의 함수로서 제2 후보 음성을 업데이트 및 반영하도록 구성되는, 시스템.
- 제16항에 있어서, 상기 후보 음성은 상기 판별적 신경망이 95 퍼센트 미만의 신뢰 구간을 가질 때 상기 타겟 음성으로부터 구별되는, 시스템.
- 제16항에 있어서, 상기 판별적 기계 학습 시스템은 상기 제1 또는 제2 후보 음성을 상기 복수의 음성과 비교함으로써 상기 후보 음성의 화자의 아이덴티티를 결정하도록 구성되는, 시스템.
- 제16항에 있어서, 복수의 음성을 포함하도록 구성되는 벡터 공간을 더 포함하는, 시스템.
- 제16항에 있어서, 상기 생성적 기계 학습 시스템은 널 불일치 메시지의 함수로서 최종 후보 음성에서 최종 후보 스피치 세그먼트를 생성하도록 구성되며,
상기 최종 후보 스피치 세그먼트는 상기 제1 스피치 세그먼트를 상기 타겟 음성으로서 모방하는, 시스템. - 제16항에 있어서, 상기 타겟 음색 데이터는 시간 수용 필드에 의해 필터링되는, 시스템.
- 제25항에 있어서, 상기 시간 수용 필드는 약 10 밀리초 내지 약 2000 밀리초사이인, 시스템.
- 제16항에 있어서, 상기 소스 스피치 데이터는 소스 오디오 입력으로부터 유래되는, 시스템.
- 타겟 음성 음색을 갖는 출력 음성으로 변환하기 위한 소스 음성으로부터의 스피치 세그먼트를 나타내는 소스 스피치 데이터를 사용하여 스피치 변환 시스템을 트레이닝하기 위해 컴퓨터 시스템 상에서 사용하기 위한 컴퓨터 프로그램 제품으로서, 상기 컴퓨터 프로그램 제품은 컴퓨터 판독가능 프로그램 코드를 갖는 유형적인 비일시적 컴퓨터 사용가능 매체를 포함하고, 상기 컴퓨터 판독가능 프로그램 코드는:
생성적 기계 학습 시스템으로 하여금 상기 소스 스피치 데이터 및 타겟 음색 데이터의 함수로서 제1 후보 음성 내의 제1 후보 스피치 세그먼트를 나타내는 제1 후보 스피치 데이터를 생성하게 하는 프로그램 코드;
판별적 기계 학습 시스템으로 하여금 복수의 상이한 음성의 음색 데이터를 참조하여 상기 제1 후보 스피치 데이터를 상기 타겟 음색 데이터와 비교하게 하는 프로그램 코드;
상기 판별적 기계 학습 시스템으로 하여금 상기 복수의 상이한 음성의 상기 음색 데이터를 참조하여 상기 제1 후보 스피치 데이터와 상기 타겟 음색 데이터 사이의 적어도 하나의 불일치를 결정하게 하는 프로그램 코드;
상기 판별적 기계 학습 시스템으로 하여금 상기 복수의 상이한 음성의 상기 음색 데이터를 참조하여 상기 제1 후보 스피치 데이터와 상기 타겟 음색 데이터 사이의 상기 불일치에 관한 정보를 갖는 불일치 메시지를 생성하게 하는 프로그램 코드;
상기 판별적 기계 학습 시스템으로 하여금 상기 불일치 메시지를 다시 상기 생성적 기계 학습 시스템에 제공하게 하는 프로그램 코드; 및
상기 생성적 기계 학습 시스템으로 하여금 상기 불일치 메시지의 함수로서 제2 후보 음성 내의 제2 후보 스피치 세그먼트를 나타내는 제2 후보 스피치 데이터를 생성하게 하는 프로그램 코드
를 포함하는, 컴퓨터 프로그램 제품. - 제28항에 있어서,
타겟 오디오 입력으로부터 상기 타겟 음색 데이터를 추출하는 프로그램 코드를 더 포함하는, 컴퓨터 프로그램 제품. - 제28항에 있어서, 상기 기계 학습 시스템은 신경망인, 컴퓨터 프로그램 제품.
- 제28항에 있어서,
벡터 공간에서 상기 복수의 음성 및 상기 후보 음성 각각의 표현을 각각의 음성으로부터의 상기 음색 데이터의 함수로서 매핑하기 위한 프로그램 코드를 더 포함하는, 컴퓨터 프로그램 제품. - 제31항에 있어서,
상기 벡터 공간에서 상기 복수의 음성의 적어도 하나의 표현에 대해 상기 후보 음성의 상기 표현을 조정하여, 상기 불일치 메시지의 함수로서 상기 제2 후보 음성을 업데이트 및 반영하기 위한 프로그램 코드를 더 포함하는, 컴퓨터 프로그램 제품. - 제28항에 있어서,
상기 후보 음성을 상기 복수의 음성과 비교함으로써 상기 후보 음성에 화자 아이덴티티를 할당하기 위한 프로그램 코드를 더 포함하는, 컴퓨터 프로그램 제품. - 제28항에 있어서,
시간 수용 필드를 사용하여, 입력된 타겟 오디오를 필터링하여 상기 음색 데이터를 생성하기 위한 프로그램 코드를 더 포함하는, 컴퓨터 프로그램 제품. - 제34항에 있어서, 상기 시간 수용 필드는 약 10 밀리초 내지 약 2000 밀리초사이인, 컴퓨터 프로그램 제품.
- 제28항에 있어서,
상기 소스 음성으로부터의 상기 스피치 세그먼트를 나타내는 상기 소스 스피치 데이터를 상기 타겟 음색 내의 변환된 스피치 세그먼트로 변환하기 위한 프로그램 코드를 더 포함하는, 컴퓨터 프로그램 제품. - 제36항에 있어서,
상기 변환된 스피치 세그먼트에 워터마크를 추가하기 위한 프로그램 코드를 더 포함하는, 컴퓨터 프로그램 제품. - 음색 벡터 공간을 구축하기 위한 음색 벡터 공간 구축 시스템으로서,
a) 제1 음성 내의 제1 음색 데이터를 포함하는 제1 스피치 세그먼트 및 b) 제2 음성 내의 제2 음색 데이터를 포함하는 제2 스피치 세그먼트를 수신하도록 구성된 입력;
상기 제1 스피치 세그먼트를 제1 복수의 더 작은 분석적 오디오 세그먼트로 변환하는 시간 수용 필드로서, 상기 제1 복수의 더 작은 분석적 오디오 세그먼트 각각은 상기 제1 음색 데이터의 상이한 부분을 나타내는 주파수 분포를 갖고, 필터는 또한 상기 시간 수용 필드를 사용하여 상기 제2 스피치 세그먼트를 제2 복수의 더 작은 분석적 오디오 세그먼트로 변환하도록 구성되고, 상기 제2 복수의 더 작은 분석적 오디오 세그먼트 각각은 상기 제2 음색 데이터의 상이한 부분을 나타내는 주파수 분포를 가지는, 시간 수용 필드;
a) 상기 제1 스피치 세그먼트로부터의 상기 제1 복수의 분석적 오디오 세그먼트 및 b) 상기 제2 스피치 세그먼트로부터의 상기 제2 복수의 분석적 오디오 세그먼트의 주파수 분포의 함수로서 상기 음색 벡터 공간에서 상기 제2 음성에 대해 상기 제1 음성을 매핑하도록 구성된 기계 학습 시스템
을 포함하는, 시스템. - 제38항에 있어서, 데이터베이스는 제3 음성 내의 제3 스피치 세그먼트를 수신하도록 구성되고,
상기 기계 학습 시스템은 시간 수용 필드를 사용하여 상기 제3 스피치 세그먼트를 복수의 더 작은 분석적 오디오 세그먼트로 필터링하고, 상기 벡터 공간에서 상기 제1 음성 및 상기 제2 음성에 대해 상기 제3 음성을 매핑하도록 구성되는, 시스템. - 제39항에 있어서, 상기 제1 음성 및 상기 제2 음성에 대해 상기 제3 음성을 매핑하는 것은 상기 벡터 공간 내의 상기 제2 음성에 대한 상기 제1 음성의 상대적 위치를 변경하는, 시스템.
- 제38항에 있어서, 상기 시스템은 적어도 하나의 음성에서 영어의 각각의 인간 음소를 매핑하도록 구성되는, 시스템.
- 제38항에 있어서, 상기 수용 필드는 상기 음성의 스피치 레이트 및/또는 액센트를 캡처하지 못하도록 충분히 작은, 시스템.
- 제38항에 있어서, 상기 시간 수용 필드는 약 10 밀리초 내지 약 2000 밀리초사이인, 시스템.
- 스피치 세그먼트들을 변환하기 위한 음색 벡터 공간을 구축하는 방법으로서,
a) 제1 음성 내의 음색 데이터를 포함하는 제1 스피치 세그먼트 및 b) 제2 음성 내의 음색 데이터를 포함하는 제2 스피치 세그먼트를 수신하는 단계;
시간 수용 필드를 사용하여, 상기 제1 스피치 세그먼트 및 상기 제2 스피치 세그먼트 각각을 복수의 더 작은 분석적 오디오 세그먼트로 필터링하는 단계로서, 각각의 분석적 오디오 세그먼트는 상기 음색 데이터를 나타내는 주파수 분포를 가지는, 단계;
기계 학습 시스템을 사용하여, 상기 제1 스피치 세그먼트 및 상기 제2 스피치 세그먼트로부터의 상기 복수의 분석적 오디오 세그먼트 중 적어도 하나에서의 상기 주파수 분포의 함수로서 벡터 공간에서 상기 제2 음성에 대해 상기 제1 음성을 매핑하는 단계
를 포함하는, 방법. - 제44항에 있어서, 상기 제1 스피치 세그먼트 및 상기 제2 스피치 세그먼트 각각을 필터링하기 위한 수단을 더 포함하는, 방법.
- 제44항에 있어서, 상기 제2 음성에 대해 상기 제1 음성을 매핑하기 위한 수단을 더 포함하는, 방법.
- 제44항에 있어서, 상기 필터링은 기계 학습 시스템에 의해 수행되는, 방법.
- 제44항에 있어서,
제3 음성 내의 제3 스피치 세그먼트를 수신하는 단계;
시간 수용 필드를 사용하여, 상기 제3 스피치 세그먼트를 복수의 더 작은 분석적 오디오 세그먼트로 필터링하는 단계; 및
상기 벡터 공간에서 상기 제1 음성 및 상기 제2 음성에 대해 상기 제3 음성을 매핑하는 단계
를 더 포함하는, 방법. - 제48항에 있어서,
상기 제3 음성의 매핑의 함수로서 상기 벡터 공간 내의 상기 제2 음성에 대한 상기 제1 음성의 상대적 위치를 조정하는 단계를 더 포함하는, 방법. - 제48항에 있어서, 상기 수용 필드는 상기 음성의 스피치 레이트 및/또는 액센트를 캡처하지 못하도록 충분히 작은, 방법.
- 제48항에 있어서,
적어도 하나의 음성에서 영어의 각각의 인간 음소를 매핑하는 단계를 더 포함하는, 방법. - 제48항에 있어서, 상기 시간 수용 필드는 약 10 밀리초 내지 약 500 밀리초사이인, 방법.
- 음성들을 저장하고 조직화하기 위해 컴퓨터 시스템 상에서 사용하기 위한 컴퓨터 프로그램 제품으로서, 상기 컴퓨터 프로그램 제품은 컴퓨터 판독가능 프로그램 코드를 갖는 유형적인 비일시적 컴퓨터 사용가능 매체를 포함하고, 상기 컴퓨터 판독가능 프로그램 코드는:
입력으로 하여금, a) 제1 음성 내의 음색 데이터를 포함하는 제1 스피치 세그먼트 및 b) 제2 음성 내의 음색 데이터를 포함하는 제2 음성을 수신하게 하는 프로그램 코드;
시간 수용 필드를 사용하여, 상기 제1 스피치 세그먼트 및 상기 제2 스피치 세그먼트 각각을 복수의 더 작은 분석적 오디오 세그먼트로 필터링하는 프로그램 코드로서, 각각의 분석적 오디오 세그먼트는 상기 음색 데이터를 나타내는 주파수 분포를 가지는, 프로그램 코드; 및
기계 학습 시스템으로 하여금, 상기 제1 스피치 세그먼트 및 상기 제2 스피치 세그먼트로부터의 상기 복수의 분석적 오디오 세그먼트 중 적어도 하나에서의 상기 주파수 분포의 함수로서 벡터 공간에서 상기 제2 음성에 대해 상기 제1 음성을 매핑하게 하는 프로그램 코드
를 포함하는, 컴퓨터 프로그램 제품. - 제53항에 있어서, 상기 제1 스피치 세그먼트 및 상기 제2 스피치 세그먼트 각각을 필터링하기 위한 수단을 더 포함하는, 컴퓨터 프로그램 제품.
- 제53항에 있어서, 상기 벡터 공간에서 상기 제2 음성에 대해 상기 제1 음성을 매핑하기 위한 수단을 더 포함하는, 컴퓨터 프로그램 제품.
- 제53항에 있어서,
입력으로 하여금, c) 제3 음성 내의 제3 스피치 세그먼트를 수신하게 하는 프로그램 코드; 및
시간 수용 필드를 사용하여, 상기 제3 스피치 세그먼트를 복수의 더 작은 분석적 오디오 세그먼트로 필터링하기 위한 프로그램 코드
를 더 포함하는, 컴퓨터 프로그램 제품. - 제56항에 있어서,
상기 벡터 공간에서 상기 제1 음성 및 상기 제2 음성에 대해 상기 제3 음성을 매핑하기 위한 프로그램 코드를 더 포함하며,
상기 제1 음성 및 상기 제2 음성에 대해 상기 제3 음성을 매핑하는 것은 상기 벡터 공간 내의 상기 제2 음성에 대한 상기 제1 음성의 상대적 위치를 변경하는, 컴퓨터 프로그램 제품. - 제53항에 있어서,
상기 음성의 스피치 레이트 및/또는 액센트를 캡처하지 못하도록 상기 시간 수용 필드를 정의하도록 구성되는 프로그램 코드를 더 포함하는, 컴퓨터 프로그램 제품. - 제58항에 있어서, 상기 시간 수용 필드는 약 10 밀리초 내지 약 500 밀리초사이인, 컴퓨터 프로그램 제품.
- 음색 벡터 공간을 구축하기 위한 음색 벡터 공간 구축 시스템으로서,
a) 제1 음성 내의 제1 음색 데이터를 포함하는 제1 스피치 세그먼트 및 b) 제2 음성 내의 제2 음색 데이터를 포함하는 제2 스피치 세그먼트를 수신하도록 구성된 입력;
a) 상기 제1 스피치 세그먼트를 상기 제1 음색 데이터의 상이한 부분을 나타내는 주파수 분포를 갖는 제1 복수의 더 작은 분석적 오디오 세그먼트로 필터링하고, b) 상기 제2 스피치 세그먼트를 제2 복수의 더 작은 분석적 오디오 세그먼트로 필터링하기 위한 수단으로서, 상기 제2 복수의 더 작은 분석적 오디오 세그먼트 각각은 상기 제 2 음색 데이터의 상이한 부분을 나타내는 주파수 분포를 가지는, 수단;
a) 상기 제1 스피치 세그먼트로부터의 상기 제1 복수의 분석적 오디오 세그먼트 및 b) 상기 제2 스피치 세그먼트로부터의 상기 제2 복수의 분석적 오디오 세그먼트의 상기 주파수 분포의 함수로서 상기 음색 벡터 공간에서 상기 제2 음성에 대해 상기 제1 음성을 매핑하기 위한 수단
을 포함하는, 음색 벡터 공간 구축 시스템. - 음색 벡터 공간을 사용하여 새로운 음색을 갖는 새로운 음성을 구축하는 방법으로서,
시간 수용 필드를 사용하여 필터링된 음색 데이터를 수신하는 단계로서, 상기 음색 데이터는 상기 음색 벡터 공간에서 매핑되고, 타겟 음색 데이터는 복수의 상이한 음성과 관련되고, 상기 복수의 상이한 음성 각각은 상기 음색 벡터 공간에서 각각의 음색 데이터를 가지는, 단계; 및
기계 학습 시스템을 사용하여, 상기 복수의 상이한 음성의 상기 타겟 음색 데이터를 사용하여 상기 새로운 음색을 구축하는 단계
를 포함하는, 방법. - 제61항에 있어서, 상기 타겟 음색 데이터를 필터링하기 위한 수단을 더 포함하는, 방법.
- 제61항에 있어서,
소스 스피치를 제공하는 단계; 및
소스 케이던스 및 소스 액센트를 유지하면서 상기 소스 스피치를 상기 새로운 음색으로 변환하는 단계
를 더 포함하는, 방법. - 제61항에 있어서,
새로운 음성으로부터 새로운 스피치 세그먼트를 수신하는 단계;
신경망을 사용하여 상기 새로운 스피치 세그먼트를 새로운 분석적 오디오 세그먼트로 필터링하는 단계;
복수의 매핑된 음성에 대해 상기 벡터 공간에서 상기 새로운 음성을 매핑하는 단계; 및
상기 복수의 매핑된 음성에 대한 상기 새로운 음성의 관계에 기초하여 상기 새로운 음성의 특성들 중 적어도 하나를 결정하는 단계
를 더 포함하는, 방법. - 제61항에 있어서,
생성적 신경망을 사용하여, 제1 음성과 제2 음성 사이의 수학적 연산의 함수로서, 후보 음성에서 제1 후보 스피치 세그먼트를 생성하는 단계를 더 포함하는, 방법. - 제61항에 있어서, 상기 벡터 공간 내의 음성 표현들의 클러스터는 특정 액센트를 나타내는, 방법.
- 제61항에 있어서, 상기 복수의 음성 각각으로부터의 스피치 세그먼트는 상이한 스피치 세그먼트인, 방법.
- 음색 벡터 공간을 사용하여 새로운 타겟 음성을 생성하는 시스템으로서,
시간 수용 필드를 사용하여 통합된 음색 데이터를 저장하도록 구성된 음색 벡터 공간;
시간 수용 필드를 사용하여 필터링된 음색 데이터로서, 상기 음색 데이터는 복수의 상이한 음성과 관련된, 음색 데이터; 및
상기 음색 데이터를 사용하여 상기 음색 데이터를 상기 새로운 타겟 음성으로 변환하도록 구성된 기계 학습 시스템
을 포함하는, 시스템. - 제68항에 있어서, 상기 기계 학습 시스템은 신경망인, 시스템.
- 제68항에 있어서, 상기 기계 학습 시스템은:
새로운 음성으로부터 새로운 스피치 세그먼트를 수신하고,
상기 새로운 스피치 세그먼트를 새로운 음색 데이터로 필터링하고,
복수의 음색 데이터에 대해 상기 벡터 공간에서 상기 새로운 음색 데이터를 매핑하고,
상기 복수의 음색 데이터에 대한 상기 새로운 음색 데이터의 관계에 기초하여 상기 새로운 음성의 적어도 하나의 음성 특성을 결정하도록 구성되는, 시스템. - 제68항에 있어서, 상기 음색 데이터를 상기 새로운 타겟 음성으로 변환하는 것은 상기 음색 데이터의 적어도 하나의 음성 특성을 변수로서 사용하여 수학적 연산을 수행함으로써 개시되는, 시스템.
- 제68항에 있어서, 상기 벡터 공간 내의 음성 표현들의 클러스터는 특정 액센트를 나타내는, 시스템.
- 음색 벡터 공간을 사용하여 새로운 타겟 음성을 생성하기 위해 컴퓨터 시스템에서 사용하기 위한 컴퓨터 프로그램 제품으로서, 상기 컴퓨터 프로그램 제품은 컴퓨터 판독가능 프로그램 코드를 갖는 유형적인 비일시적 컴퓨터 사용가능 매체를 포함하고, 상기 컴퓨터 판독가능 프로그램 코드는:
시간 수용 필드를 사용하여 필터링된 음색 데이터를 수신하기 위한 프로그램 코드로서, 상기 음색 데이터는 상기 시간 수용 필드를 통합하는 상기 음색 벡터 공간에 저장되고, 상기 음색 데이터는 복수의 상이한 음성과 관련된, 프로그램 코드; 및
기계 학습 시스템을 사용하여, 상기 음색 데이터를 상기 음색 데이터를 사용하여 상기 새로운 타겟 음성으로 변환하는 프로그램 코드
를 포함하는, 컴퓨터 프로그램 제품. - 제73항에 있어서,
새로운 음성으로부터 새로운 스피치 세그먼트를 수신하기 위한 프로그램 코드;
상기 기계 학습 시스템으로 하여금 상기 새로운 스피치 세그먼트를 새로운 분석적 오디오 세그먼트로 필터링하게 하는 프로그램 코드;
복수의 매핑된 음성에 대해 상기 벡터 공간에서 상기 새로운 음성을 매핑하는 프로그램 코드; 및
상기 복수의 매핑된 음성에 대한 상기 새로운 음성의 관계에 기초하여 상기 새로운 음성의 특성들 중 적어도 하나를 결정하기 위한 프로그램 코드
를 더 포함하는, 프로그램 코드. - 제73항에 있어서, 상기 기계 학습 시스템은 신경망인, 프로그램 코드.
- 제73항에 있어서, 상기 음색 데이터를 상기 새로운 타겟 음성으로 변환하는 것은 상기 음색 데이터의 적어도 하나의 음성 특성을 변수로서 사용하여 수학 연산을 수행함으로써 개시되는, 프로그램 코드.
- 제73항에 있어서, 상기 벡터 공간 내의 음성 표현들의 클러스터는 특정 액센트를 나타내는, 프로그램 코드.
- 소스 음색으로부터 타겟 음색으로 스피치 세그먼트를 변환하는 방법으로서,
복수의 상이한 음성에 관련된 음색 데이터를 저장하는 단계로서, 상기 복수의 상이한 음성 각각은 음색 벡터 공간에서 각각의 음색 데이터를 갖고, 상기 음색 데이터는 시간 수용 필드를 사용하여 필터링되고 상기 음색 벡터 공간에서 매핑되는, 단계;
소스 음성으로 변환하기 위해 소스 음성 내에 소스 스피치 세그먼트를 수신하는 단계;
타겟 음성의 선택을 수신하는 단계로서, 상기 타겟 음성은 타겟 음색을 갖고, 상기 타겟 음성은 상기 복수의 상이한 음성을 참조하여 상기 음색 벡터 공간에서 매핑되는, 단계;
기계 학습 시스템을 사용하여, 상기 소스 음성의 음색으로부터의 상기 소스 스피치 세그먼트를 상기 타겟 음성의 음색으로 변환하는 단계
를 포함하는, 방법.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020237002550A KR20230018538A (ko) | 2017-05-24 | 2018-05-24 | 음성 대 음성 변환을 위한 시스템 및 방법 |
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201762510443P | 2017-05-24 | 2017-05-24 | |
| US62/510,443 | 2017-05-24 | ||
| PCT/US2018/034485 WO2018218081A1 (en) | 2017-05-24 | 2018-05-24 | System and method for voice-to-voice conversion |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237002550A Division KR20230018538A (ko) | 2017-05-24 | 2018-05-24 | 음성 대 음성 변환을 위한 시스템 및 방법 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20200027475A true KR20200027475A (ko) | 2020-03-12 |
Family
ID=64397077
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237002550A Ceased KR20230018538A (ko) | 2017-05-24 | 2018-05-24 | 음성 대 음성 변환을 위한 시스템 및 방법 |
| KR1020197038068A Ceased KR20200027475A (ko) | 2017-05-24 | 2018-05-24 | 음성 대 음성 변환을 위한 시스템 및 방법 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237002550A Ceased KR20230018538A (ko) | 2017-05-24 | 2018-05-24 | 음성 대 음성 변환을 위한 시스템 및 방법 |
Country Status (5)
| Country | Link |
|---|---|
| US (7) | US10622002B2 (ko) |
| EP (1) | EP3631791A4 (ko) |
| KR (2) | KR20230018538A (ko) |
| CN (1) | CN111201565B (ko) |
| WO (1) | WO2018218081A1 (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025164836A1 (ko) * | 2024-01-31 | 2025-08-07 | 주식회사 자이냅스 | 다중 판별부에 기반하여 학습된 인코더를 이용하여 워터마크 오디오를 생성하는 방법 및 장치 |
Families Citing this family (75)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| SG11201903130WA (en) * | 2016-10-24 | 2019-05-30 | Semantic Machines Inc | Sequence to sequence transformations for speech synthesis via recurrent neural networks |
| WO2018218081A1 (en) | 2017-05-24 | 2018-11-29 | Modulate, LLC | System and method for voice-to-voice conversion |
| US20190082255A1 (en) * | 2017-09-08 | 2019-03-14 | Olympus Corporation | Information acquiring apparatus, information acquiring method, and computer readable recording medium |
| US11398218B1 (en) * | 2018-04-26 | 2022-07-26 | United Services Automobile Association (Usaa) | Dynamic speech output configuration |
| EP3598344A1 (en) * | 2018-07-19 | 2020-01-22 | Nokia Technologies Oy | Processing sensor data |
| US10891949B2 (en) * | 2018-09-10 | 2021-01-12 | Ford Global Technologies, Llc | Vehicle language processing |
| US10964308B2 (en) * | 2018-10-29 | 2021-03-30 | Ken-ichi KAINUMA | Speech processing apparatus, and program |
| US11706499B2 (en) * | 2018-10-31 | 2023-07-18 | Sony Interactive Entertainment Inc. | Watermarking synchronized inputs for machine learning |
| CN109473091B (zh) * | 2018-12-25 | 2021-08-10 | 四川虹微技术有限公司 | 一种语音样本生成方法及装置 |
| WO2020141643A1 (ko) * | 2019-01-03 | 2020-07-09 | 엘지전자 주식회사 | 음성 합성 서버 및 단말기 |
| US12254889B2 (en) | 2019-01-03 | 2025-03-18 | Dolby International Ab | Method, apparatus and system for hybrid speech synthesis |
| JP7309155B2 (ja) * | 2019-01-10 | 2023-07-18 | グリー株式会社 | コンピュータプログラム、サーバ装置、端末装置及び音声信号処理方法 |
| CN111554316A (zh) * | 2019-01-24 | 2020-08-18 | 富士通株式会社 | 语音处理装置、方法和介质 |
| US20200335119A1 (en) * | 2019-04-16 | 2020-10-22 | Microsoft Technology Licensing, Llc | Speech extraction using attention network |
| CN112037768B (zh) * | 2019-05-14 | 2024-10-22 | 北京三星通信技术研究有限公司 | 语音翻译方法、装置、电子设备及计算机可读存储介质 |
| US11410667B2 (en) | 2019-06-28 | 2022-08-09 | Ford Global Technologies, Llc | Hierarchical encoder for speech conversion system |
| US11538485B2 (en) | 2019-08-14 | 2022-12-27 | Modulate, Inc. | Generation and detection of watermark for real-time voice conversion |
| US11158329B2 (en) * | 2019-09-11 | 2021-10-26 | Artificial Intelligence Foundation, Inc. | Identification of fake audio content |
| CN110600013B (zh) * | 2019-09-12 | 2021-11-02 | 思必驰科技股份有限公司 | 非平行语料声音转换数据增强模型训练方法及装置 |
| US11062692B2 (en) | 2019-09-23 | 2021-07-13 | Disney Enterprises, Inc. | Generation of audio including emotionally expressive synthesized content |
| KR102637341B1 (ko) * | 2019-10-15 | 2024-02-16 | 삼성전자주식회사 | 음성 생성 방법 및 장치 |
| EP3839947A1 (en) | 2019-12-20 | 2021-06-23 | SoundHound, Inc. | Training a voice morphing apparatus |
| CN111247584B (zh) * | 2019-12-24 | 2023-05-23 | 深圳市优必选科技股份有限公司 | 语音转换方法、系统、装置及存储介质 |
| DK3855340T3 (da) * | 2019-12-30 | 2023-12-04 | Tmrw Found Ip & Holding Sarl | Tværsproglig stemmekonverteringssystem og fremgangsmåde |
| CN111213205B (zh) * | 2019-12-30 | 2023-09-08 | 深圳市优必选科技股份有限公司 | 一种流式语音转换方法、装置、计算机设备及存储介质 |
| WO2021134520A1 (zh) * | 2019-12-31 | 2021-07-08 | 深圳市优必选科技股份有限公司 | 语音转换的方法及训练方法、智能装置和存储介质 |
| US11600284B2 (en) * | 2020-01-11 | 2023-03-07 | Soundhound, Inc. | Voice morphing apparatus having adjustable parameters |
| US11183168B2 (en) * | 2020-02-13 | 2021-11-23 | Tencent America LLC | Singing voice conversion |
| US11361749B2 (en) | 2020-03-11 | 2022-06-14 | Nuance Communications, Inc. | Ambient cooperative intelligence system and method |
| US20210304783A1 (en) * | 2020-03-31 | 2021-09-30 | International Business Machines Corporation | Voice conversion and verification |
| CN111640444B (zh) * | 2020-04-17 | 2023-04-28 | 宁波大学 | 基于cnn的自适应音频隐写方法和秘密信息提取方法 |
| WO2022024183A1 (ja) * | 2020-07-27 | 2022-02-03 | 日本電信電話株式会社 | 音声信号変換モデル学習装置、音声信号変換装置、音声信号変換モデル学習方法及びプログラム |
| WO2022024187A1 (ja) * | 2020-07-27 | 2022-02-03 | 日本電信電話株式会社 | 音声信号変換モデル学習装置、音声信号変換装置、音声信号変換モデル学習方法及びプログラム |
| CN111883149B (zh) * | 2020-07-30 | 2022-02-01 | 四川长虹电器股份有限公司 | 一种带情感和韵律的语音转换方法及装置 |
| US11735204B2 (en) | 2020-08-21 | 2023-08-22 | SomniQ, Inc. | Methods and systems for computer-generated visualization of speech |
| CN114203147B (zh) * | 2020-08-28 | 2026-03-06 | 微软技术许可有限责任公司 | 用于文本到语音的跨说话者样式传递以及用于训练数据生成的系统和方法 |
| CN112164387B (zh) * | 2020-09-22 | 2024-11-19 | 腾讯音乐娱乐科技(深圳)有限公司 | 音频合成方法、装置及电子设备和计算机可读存储介质 |
| WO2022076923A1 (en) * | 2020-10-08 | 2022-04-14 | Modulate, Inc. | Multi-stage adaptive system for content moderation |
| WO2022085197A1 (ja) * | 2020-10-23 | 2022-04-28 | 日本電信電話株式会社 | 音声信号変換モデル学習装置、音声信号変換装置、音声信号変換モデル学習方法及びプログラム |
| US11783804B2 (en) * | 2020-10-26 | 2023-10-10 | T-Mobile Usa, Inc. | Voice communicator with voice changer |
| US20230419977A1 (en) * | 2020-11-10 | 2023-12-28 | Nippon Telegraph And Telephone Corporation | Audio signal conversion model learning apparatus, audio signal conversion apparatus, audio signal conversion model learning method and program |
| KR20220067864A (ko) * | 2020-11-18 | 2022-05-25 | 주식회사 마인즈랩 | 음성의 보이스 특징 변환 방법 |
| JP7700801B2 (ja) * | 2020-11-25 | 2025-07-01 | 日本電信電話株式会社 | 話者認識方法、話者認識装置および話者認識プログラム |
| CN112365882B (zh) * | 2020-11-30 | 2023-09-22 | 北京百度网讯科技有限公司 | 语音合成方法及模型训练方法、装置、设备及存储介质 |
| CN112382271B (zh) * | 2020-11-30 | 2024-03-26 | 北京百度网讯科技有限公司 | 语音处理方法、装置、电子设备和存储介质 |
| TWI763207B (zh) * | 2020-12-25 | 2022-05-01 | 宏碁股份有限公司 | 聲音訊號處理評估方法及裝置 |
| WO2022190079A1 (en) * | 2021-03-09 | 2022-09-15 | Webtalk Ltd | Dynamic audio content generation |
| CN112712813B (zh) * | 2021-03-26 | 2021-07-20 | 北京达佳互联信息技术有限公司 | 语音处理方法、装置、设备及存储介质 |
| US11862179B2 (en) * | 2021-04-01 | 2024-01-02 | Capital One Services, Llc | Systems and methods for detecting manipulated vocal samples |
| US11948550B2 (en) | 2021-05-06 | 2024-04-02 | Sanas.ai Inc. | Real-time accent conversion model |
| US11996083B2 (en) | 2021-06-03 | 2024-05-28 | International Business Machines Corporation | Global prosody style transfer without text transcriptions |
| CN113823298B (zh) * | 2021-06-15 | 2024-04-16 | 腾讯科技(深圳)有限公司 | 语音数据处理方法、装置、计算机设备及存储介质 |
| JPWO2023276234A1 (ko) * | 2021-06-29 | 2023-01-05 | ||
| US12002451B1 (en) * | 2021-07-01 | 2024-06-04 | Amazon Technologies, Inc. | Automatic speech recognition |
| WO2023002694A1 (ja) * | 2021-07-20 | 2023-01-26 | ソニーグループ株式会社 | 情報処理装置および情報処理方法 |
| CN113555026B (zh) * | 2021-07-23 | 2024-04-19 | 平安科技(深圳)有限公司 | 语音转换方法、装置、电子设备及介质 |
| CN113593588B (zh) * | 2021-07-29 | 2023-09-12 | 浙江大学 | 一种基于生成对抗网络的多唱歌人歌声合成方法和系统 |
| US12033618B1 (en) * | 2021-11-09 | 2024-07-09 | Amazon Technologies, Inc. | Relevant context determination |
| CN114420083B (zh) * | 2021-12-08 | 2025-06-13 | 西安讯飞超脑信息科技有限公司 | 音频生成方法以及相关模型的训练方法和相关装置 |
| KR102691093B1 (ko) | 2022-02-22 | 2024-08-05 | 한국전자통신연구원 | 적대적 생성 신경망을 이용한 오디오 신호 생성 모델 및 훈련 방법 |
| WO2023196624A1 (en) * | 2022-04-08 | 2023-10-12 | Modulate, Inc. | Predictive audio redaction for realtime communication |
| US11848005B2 (en) * | 2022-04-28 | 2023-12-19 | Meaning.Team, Inc | Voice attribute conversion using speech to speech |
| CN114822559B (zh) * | 2022-04-29 | 2025-05-27 | 上海大学 | 一种基于深度学习的短时语音说话人识别系统和方法 |
| US20230352011A1 (en) * | 2022-04-29 | 2023-11-02 | Zoom Video Communications, Inc. | Automatic switching between languages during virtual conferences |
| CN114758663B (zh) * | 2022-05-13 | 2025-09-23 | 平安科技(深圳)有限公司 | 语音转换模型的训练及语音转换方法、装置和相关设备 |
| US12341619B2 (en) | 2022-06-01 | 2025-06-24 | Modulate, Inc. | User interface for content moderation of voice chat |
| FR3136581B1 (fr) * | 2022-06-08 | 2024-05-31 | Musiciens Artistes Interpretes Associes M A I A | Masquage de la voix d’un locuteur |
| US20240274119A1 (en) * | 2023-02-15 | 2024-08-15 | Nvidia Corporation | Audio signal generation using neural networks |
| WO2024182319A1 (en) * | 2023-02-28 | 2024-09-06 | Google Llc | Clustering and mining accented speech for inclusive and fair speech recognition |
| US12568081B2 (en) * | 2023-07-18 | 2026-03-03 | Mcafee, Llc | Methods and apparatus for voice transformation, authentication, and metadata communication |
| KR20250081243A (ko) * | 2023-11-29 | 2025-06-05 | 견두헌 | 음악사용과 nft에 특화된 오디오 워터마크 삽입 및 음원 제공 방법 |
| WO2025158057A1 (en) * | 2024-01-24 | 2025-07-31 | Zynaptiq Gmbh | Method and apparatus for efficient real-time audio style transfer using granular synthesis |
| DE102024119154A1 (de) * | 2024-07-05 | 2026-01-08 | Dr. Ing. H.C. F. Porsche Aktiengesellschaft | Verfahren zum nutzerindividuellen Anpassen einer Sprachausgabe betreffend eine Fahrzeugfunktion eines Fahrzeugs und/oder betreffend eine Funktionseinheit des Fahrzeugs, sowie elektronisches Sprachausgabesystem und Fahrzeug |
| CN119673185B (zh) * | 2024-11-15 | 2025-10-28 | 腾讯音乐娱乐科技(深圳)有限公司 | 歌声转换模型训练方法、歌曲音色转换方法及相关产品 |
| CN119600987B (zh) * | 2024-12-02 | 2025-09-12 | 天津大学 | 基于ga-imv的音素时长预测方法 |
Family Cites Families (239)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3610831A (en) * | 1969-05-26 | 1971-10-05 | Listening Inc | Speech recognition apparatus |
| WO1993018505A1 (en) * | 1992-03-02 | 1993-09-16 | The Walt Disney Company | Voice transformation system |
| US5677989A (en) | 1993-04-30 | 1997-10-14 | Lucent Technologies Inc. | Speaker verification system and process |
| DE69427083T2 (de) | 1993-07-13 | 2001-12-06 | Theodore Austin Bordeaux | Spracherkennungssystem für mehrere sprachen |
| BR9508898A (pt) * | 1994-09-07 | 1997-11-25 | Motorola Inc | Sistema para reconhecer sons falados |
| JP3536996B2 (ja) * | 1994-09-13 | 2004-06-14 | ソニー株式会社 | パラメータ変換方法及び音声合成方法 |
| US5892900A (en) | 1996-08-30 | 1999-04-06 | Intertrust Technologies Corp. | Systems and methods for secure transaction management and electronic rights protection |
| US5749066A (en) * | 1995-04-24 | 1998-05-05 | Ericsson Messaging Systems Inc. | Method and apparatus for developing a neural network for phoneme recognition |
| JPH10260692A (ja) | 1997-03-18 | 1998-09-29 | Toshiba Corp | 音声の認識合成符号化/復号化方法及び音声符号化/復号化システム |
| US6336092B1 (en) * | 1997-04-28 | 2002-01-01 | Ivl Technologies Ltd | Targeted vocal transformation |
| US5808222A (en) | 1997-07-16 | 1998-09-15 | Winbond Electronics Corporation | Method of building a database of timbre samples for wave-table music synthesizers to produce synthesized sounds with high timbre quality |
| US6266664B1 (en) | 1997-10-01 | 2001-07-24 | Rulespace, Inc. | Method for scanning, analyzing and rating digital information content |
| JP3502247B2 (ja) | 1997-10-28 | 2004-03-02 | ヤマハ株式会社 | 音声変換装置 |
| US8202094B2 (en) | 1998-02-18 | 2012-06-19 | Radmila Solutions, L.L.C. | System and method for training users with audible answers to spoken questions |
| JP3365354B2 (ja) * | 1999-06-30 | 2003-01-08 | ヤマハ株式会社 | 音声信号または楽音信号の処理装置 |
| US20020072900A1 (en) | 1999-11-23 | 2002-06-13 | Keough Steven J. | System and method of templating specific human voices |
| US20030158734A1 (en) | 1999-12-16 | 2003-08-21 | Brian Cruickshank | Text to speech conversion using word concatenation |
| JP3659149B2 (ja) * | 2000-09-12 | 2005-06-15 | ヤマハ株式会社 | 演奏情報変換方法、演奏情報変換装置、記録媒体および音源装置 |
| EP1352307A2 (en) | 2000-09-22 | 2003-10-15 | EDC Systems, Inc. | Systems and methods for preventing unauthorized use of digital content |
| KR200226168Y1 (ko) * | 2000-12-28 | 2001-06-01 | 엘지전자주식회사 | 이퀄라이저 기능을 구비한 휴대 통신 장치 |
| US6941466B2 (en) | 2001-02-22 | 2005-09-06 | International Business Machines Corporation | Method and apparatus for providing automatic e-mail filtering based on message semantics, sender's e-mail ID, and user's identity |
| GB2376554B (en) | 2001-06-12 | 2005-01-05 | Hewlett Packard Co | Artificial language generation and evaluation |
| US20030135374A1 (en) * | 2002-01-16 | 2003-07-17 | Hardwick John C. | Speech synthesizer |
| JP4263412B2 (ja) * | 2002-01-29 | 2009-05-13 | 富士通株式会社 | 音声符号変換方法 |
| US20030154080A1 (en) * | 2002-02-14 | 2003-08-14 | Godsey Sandra L. | Method and apparatus for modification of audio input to a data processing system |
| US7881944B2 (en) | 2002-05-20 | 2011-02-01 | Microsoft Corporation | Automatic feedback and player denial |
| US20040010798A1 (en) | 2002-07-11 | 2004-01-15 | International Business Machines Corporation | Apparatus and method for logging television viewing patterns for guardian review |
| FR2843479B1 (fr) | 2002-08-07 | 2004-10-22 | Smart Inf Sa | Procede de calibrage d'audio-intonation |
| US7297859B2 (en) * | 2002-09-04 | 2007-11-20 | Yamaha Corporation | Assistive apparatus, method and computer program for playing music |
| JP4178319B2 (ja) * | 2002-09-13 | 2008-11-12 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 音声処理におけるフェーズ・アライメント |
| US7634399B2 (en) * | 2003-01-30 | 2009-12-15 | Digital Voice Systems, Inc. | Voice transcoder |
| DE10334400A1 (de) | 2003-07-28 | 2005-02-24 | Siemens Ag | Verfahren zur Spracherkennung und Kommunikationsgerät |
| US7412377B2 (en) | 2003-12-19 | 2008-08-12 | International Business Machines Corporation | Voice model for speech processing based on ordered average ranks of spectral features |
| DE102004012208A1 (de) * | 2004-03-12 | 2005-09-29 | Siemens Ag | Individualisierung von Sprachausgabe durch Anpassen einer Synthesestimme an eine Zielstimme |
| US20060003305A1 (en) | 2004-07-01 | 2006-01-05 | Kelmar Cheryl M | Method for generating an on-line community for behavior modification |
| US7873911B2 (en) | 2004-08-31 | 2011-01-18 | Gopalakrishnan Kumar C | Methods for providing information services related to visual imagery |
| US7437290B2 (en) | 2004-10-28 | 2008-10-14 | Microsoft Corporation | Automatic censorship of audio data for broadcast |
| US7987244B1 (en) * | 2004-12-30 | 2011-07-26 | At&T Intellectual Property Ii, L.P. | Network repository for voice fonts |
| US7772477B2 (en) * | 2005-03-17 | 2010-08-10 | Yamaha Corporation | Electronic music apparatus with data loading assist |
| JP4890536B2 (ja) | 2005-04-14 | 2012-03-07 | トムソン ライセンシング | 音声信号からの好ましくない音声コンテンツの自動置換 |
| JP2006319598A (ja) * | 2005-05-12 | 2006-11-24 | Victor Co Of Japan Ltd | 音声通信システム |
| US8126710B2 (en) * | 2005-06-01 | 2012-02-28 | Loquendo S.P.A. | Conservative training method for adapting a neural network of an automatic speech recognition device |
| WO2007063827A1 (ja) * | 2005-12-02 | 2007-06-07 | Asahi Kasei Kabushiki Kaisha | 声質変換システム |
| JP2009520522A (ja) | 2005-12-23 | 2009-05-28 | ザ・ユニバーシティ・オブ・クイーンズランド | 患者の意識レベルの可聴化 |
| US20080082320A1 (en) * | 2006-09-29 | 2008-04-03 | Nokia Corporation | Apparatus, method and computer program product for advanced voice conversion |
| JP4878538B2 (ja) | 2006-10-24 | 2012-02-15 | 株式会社日立製作所 | 音声合成装置 |
| US7523138B2 (en) | 2007-01-11 | 2009-04-21 | International Business Machines Corporation | Content monitoring in a high volume on-line community application |
| US8156518B2 (en) | 2007-01-30 | 2012-04-10 | At&T Intellectual Property I, L.P. | System and method for filtering audio content |
| US8060565B1 (en) * | 2007-01-31 | 2011-11-15 | Avaya Inc. | Voice and text session converter |
| JP4966048B2 (ja) * | 2007-02-20 | 2012-07-04 | 株式会社東芝 | 声質変換装置及び音声合成装置 |
| KR101415534B1 (ko) * | 2007-02-23 | 2014-07-07 | 삼성전자주식회사 | 다단계 음성인식장치 및 방법 |
| US20080221882A1 (en) | 2007-03-06 | 2008-09-11 | Bundock Donald S | System for excluding unwanted data from a voice recording |
| EP1970894A1 (fr) * | 2007-03-12 | 2008-09-17 | France Télécom | Procédé et dispositif de modification d'un signal audio |
| US7848924B2 (en) * | 2007-04-17 | 2010-12-07 | Nokia Corporation | Method, apparatus and computer program product for providing voice conversion using temporal dynamic features |
| CN101681244B (zh) * | 2007-05-09 | 2012-02-29 | 松下电器产业株式会社 | 显示装置、显示方法、显示程序 |
| GB0709574D0 (en) | 2007-05-18 | 2007-06-27 | Aurix Ltd | Speech Screening |
| GB2452021B (en) | 2007-07-19 | 2012-03-14 | Vodafone Plc | identifying callers in telecommunication networks |
| CN101359473A (zh) * | 2007-07-30 | 2009-02-04 | 国际商业机器公司 | 自动进行语音转换的方法和装置 |
| WO2009026159A1 (en) | 2007-08-17 | 2009-02-26 | Avi Oron | A system and method for automatically creating a media compilation |
| CN101399044B (zh) * | 2007-09-29 | 2013-09-04 | 纽奥斯通讯有限公司 | 语音转换方法和系统 |
| US8131550B2 (en) | 2007-10-04 | 2012-03-06 | Nokia Corporation | Method, apparatus and computer program product for providing improved voice conversion |
| JP2009157050A (ja) | 2007-12-26 | 2009-07-16 | Hitachi Omron Terminal Solutions Corp | 発話検証装置及び発話検証方法 |
| US20090177473A1 (en) * | 2008-01-07 | 2009-07-09 | Aaron Andrew S | Applying vocal characteristics from a target speaker to a source speaker for synthetic speech |
| JP5038995B2 (ja) * | 2008-08-25 | 2012-10-03 | 株式会社東芝 | 声質変換装置及び方法、音声合成装置及び方法 |
| US8225348B2 (en) | 2008-09-12 | 2012-07-17 | At&T Intellectual Property I, L.P. | Moderated interactive media sessions |
| US8571849B2 (en) | 2008-09-30 | 2013-10-29 | At&T Intellectual Property I, L.P. | System and method for enriching spoken language translation with prosodic information |
| US20100215289A1 (en) * | 2009-02-24 | 2010-08-26 | Neurofocus, Inc. | Personalized media morphing |
| US8779268B2 (en) | 2009-06-01 | 2014-07-15 | Music Mastermind, Inc. | System and method for producing a more harmonious musical accompaniment |
| WO2011004579A1 (ja) * | 2009-07-06 | 2011-01-13 | パナソニック株式会社 | 声質変換装置、音高変換装置および声質変換方法 |
| US8682669B2 (en) * | 2009-08-21 | 2014-03-25 | Synchronoss Technologies, Inc. | System and method for building optimal state-dependent statistical utterance classifiers in spoken dialog systems |
| US8473281B2 (en) | 2009-10-09 | 2013-06-25 | Crisp Thinking Group Ltd. | Net moderator |
| US8175617B2 (en) | 2009-10-28 | 2012-05-08 | Digimarc Corporation | Sensor-based mobile search, related methods and systems |
| CN102117614B (zh) * | 2010-01-05 | 2013-01-02 | 索尼爱立信移动通讯有限公司 | 个性化文本语音合成和个性化语音特征提取 |
| US8296130B2 (en) | 2010-01-29 | 2012-10-23 | Ipar, Llc | Systems and methods for word offensiveness detection and processing using weighted dictionaries and normalization |
| GB2478314B (en) * | 2010-03-02 | 2012-09-12 | Toshiba Res Europ Ltd | A speech processor, a speech processing method and a method of training a speech processor |
| JP5039865B2 (ja) * | 2010-06-04 | 2012-10-03 | パナソニック株式会社 | 声質変換装置及びその方法 |
| US10204625B2 (en) * | 2010-06-07 | 2019-02-12 | Affectiva, Inc. | Audio analysis learning using video data |
| US10897650B2 (en) * | 2010-06-07 | 2021-01-19 | Affectiva, Inc. | Vehicle content recommendation using cognitive states |
| US10401860B2 (en) * | 2010-06-07 | 2019-09-03 | Affectiva, Inc. | Image analysis for two-sided data hub |
| US10627817B2 (en) * | 2010-06-07 | 2020-04-21 | Affectiva, Inc. | Vehicle manipulation using occupant image analysis |
| US10628741B2 (en) * | 2010-06-07 | 2020-04-21 | Affectiva, Inc. | Multimodal machine learning for emotion metrics |
| WO2012005953A1 (en) * | 2010-06-28 | 2012-01-12 | The Regents Of The University Of California | Adaptive set discrimination procedure |
| WO2012011475A1 (ja) * | 2010-07-20 | 2012-01-26 | 独立行政法人産業技術総合研究所 | 声色変化反映歌声合成システム及び声色変化反映歌声合成方法 |
| US8759661B2 (en) | 2010-08-31 | 2014-06-24 | Sonivox, L.P. | System and method for audio synthesizer utilizing frequency aperture arrays |
| US9800721B2 (en) | 2010-09-07 | 2017-10-24 | Securus Technologies, Inc. | Multi-party conversation analyzer and logger |
| US8892436B2 (en) * | 2010-10-19 | 2014-11-18 | Samsung Electronics Co., Ltd. | Front-end processor for speech recognition, and speech recognizing apparatus and method using the same |
| US8676574B2 (en) | 2010-11-10 | 2014-03-18 | Sony Computer Entertainment Inc. | Method for tone/intonation recognition using auditory attention cues |
| EP2485213A1 (en) * | 2011-02-03 | 2012-08-08 | Fraunhofer-Gesellschaft zur Förderung der Angewandten Forschung e.V. | Semantic audio track mixer |
| GB2489473B (en) * | 2011-03-29 | 2013-09-18 | Toshiba Res Europ Ltd | A voice conversion method and system |
| US8756061B2 (en) | 2011-04-01 | 2014-06-17 | Sony Computer Entertainment Inc. | Speech syllable/vowel/phone boundary detection using auditory attention cues |
| US9196028B2 (en) | 2011-09-23 | 2015-11-24 | Digimarc Corporation | Context-based smartphone sensor logic |
| US8850535B2 (en) | 2011-08-05 | 2014-09-30 | Safefaces LLC | Methods and systems for identity verification in a social network using ratings |
| WO2013035659A1 (ja) * | 2011-09-05 | 2013-03-14 | 株式会社エヌ・ティ・ティ・ドコモ | 情報処理装置およびプログラム |
| US8515751B2 (en) * | 2011-09-28 | 2013-08-20 | Google Inc. | Selective feedback for text recognition systems |
| US8290772B1 (en) * | 2011-10-03 | 2012-10-16 | Google Inc. | Interactive text editing |
| US9245254B2 (en) * | 2011-12-01 | 2016-01-26 | Elwha Llc | Enhanced voice conferencing with history, language translation and identification |
| US20130166274A1 (en) | 2011-12-21 | 2013-06-27 | Avaya Inc. | System and method for managing avatars |
| US20150025892A1 (en) | 2012-03-06 | 2015-01-22 | Agency For Science, Technology And Research | Method and system for template-based personalized singing synthesis |
| KR102038171B1 (ko) * | 2012-03-29 | 2019-10-29 | 스뮬, 인코포레이티드 | 타겟 운율 또는 리듬이 있는 노래, 랩 또는 다른 가청 표현으로의 스피치 자동 변환 |
| US9153235B2 (en) | 2012-04-09 | 2015-10-06 | Sony Computer Entertainment Inc. | Text dependent speaker recognition with long-term feature based on functional data analysis |
| TWI473080B (zh) | 2012-04-10 | 2015-02-11 | Nat Univ Chung Cheng | The use of phonological emotions or excitement to assist in resolving the gender or age of speech signals |
| US9044683B2 (en) | 2012-04-26 | 2015-06-02 | Steelseries Aps | Method and apparatus for presenting gamer performance at a social network |
| JP5846043B2 (ja) * | 2012-05-18 | 2016-01-20 | ヤマハ株式会社 | 音声処理装置 |
| US20140046660A1 (en) | 2012-08-10 | 2014-02-13 | Yahoo! Inc | Method and system for voice based mood analysis |
| CN104718570B (zh) * | 2012-09-13 | 2017-07-18 | Lg电子株式会社 | 帧丢失恢复方法,和音频解码方法以及使用其的设备 |
| US8744854B1 (en) * | 2012-09-24 | 2014-06-03 | Chengjun Julian Chen | System and method for voice transformation |
| US9020822B2 (en) | 2012-10-19 | 2015-04-28 | Sony Computer Entertainment Inc. | Emotion recognition using auditory attention cues extracted from users voice |
| PL401371A1 (pl) * | 2012-10-26 | 2014-04-28 | Ivona Software Spółka Z Ograniczoną Odpowiedzialnością | Opracowanie głosu dla zautomatyzowanej zamiany tekstu na mowę |
| US9085303B2 (en) * | 2012-11-15 | 2015-07-21 | Sri International | Vehicle personal assistant |
| US9798799B2 (en) * | 2012-11-15 | 2017-10-24 | Sri International | Vehicle personal assistant that interprets spoken natural language input based upon vehicle context |
| US9672811B2 (en) | 2012-11-29 | 2017-06-06 | Sony Interactive Entertainment Inc. | Combining auditory attention cues with phoneme posterior scores for phone/vowel/syllable boundary detection |
| US8886539B2 (en) * | 2012-12-03 | 2014-11-11 | Chengjun Julian Chen | Prosody generation using syllable-centered polynomial representation of pitch contours |
| US8942977B2 (en) * | 2012-12-03 | 2015-01-27 | Chengjun Julian Chen | System and method for speech recognition using pitch-synchronous spectral parameters |
| CN102982809B (zh) * | 2012-12-11 | 2014-12-10 | 中国科学技术大学 | 一种说话人声音转换方法 |
| US20150070516A1 (en) | 2012-12-14 | 2015-03-12 | Biscotti Inc. | Automatic Content Filtering |
| US9195649B2 (en) | 2012-12-21 | 2015-11-24 | The Nielsen Company (Us), Llc | Audio processing techniques for semantic audio recognition and report generation |
| US9158760B2 (en) * | 2012-12-21 | 2015-10-13 | The Nielsen Company (Us), Llc | Audio decoding with supplemental semantic audio recognition and report generation |
| US20150005661A1 (en) * | 2013-02-22 | 2015-01-01 | Max Sound Corporation | Method and process for reducing tinnitus |
| EP3848929B1 (en) | 2013-03-04 | 2023-07-12 | VoiceAge EVS LLC | Device and method for reducing quantization noise in a time-domain decoder |
| US9477753B2 (en) * | 2013-03-12 | 2016-10-25 | International Business Machines Corporation | Classifier-based system combination for spoken term detection |
| US20140274386A1 (en) | 2013-03-15 | 2014-09-18 | University Of Kansas | Peer-scored communication in online environments |
| KR101331122B1 (ko) * | 2013-03-15 | 2013-11-19 | 주식회사 에이디자인 | 모바일 기기의 수신시 통화연결 방법 |
| US9792714B2 (en) * | 2013-03-20 | 2017-10-17 | Intel Corporation | Avatar-based transfer protocols, icon generation and doll animation |
| US10463953B1 (en) | 2013-07-22 | 2019-11-05 | Niantic, Inc. | Detecting and preventing cheating in a location-based game |
| JP2015040903A (ja) * | 2013-08-20 | 2015-03-02 | ソニー株式会社 | 音声処理装置、音声処理方法、及び、プログラム |
| CA2931105C (en) * | 2013-09-05 | 2022-01-04 | George William Daly | Systems and methods for acoustic processing of recorded sounds |
| US9799347B2 (en) | 2013-10-24 | 2017-10-24 | Voyetra Turtle Beach, Inc. | Method and system for a headset with profanity filter |
| US10258887B2 (en) | 2013-10-25 | 2019-04-16 | Voyetra Turtle Beach, Inc. | Method and system for a headset with parental control |
| US9183830B2 (en) | 2013-11-01 | 2015-11-10 | Google Inc. | Method and system for non-parametric voice conversion |
| US8918326B1 (en) | 2013-12-05 | 2014-12-23 | The Telos Alliance | Feedback and simulation regarding detectability of a watermark message |
| US9483728B2 (en) * | 2013-12-06 | 2016-11-01 | International Business Machines Corporation | Systems and methods for combining stochastic average gradient and hessian-free optimization for sequence training of deep neural networks |
| WO2015100430A1 (en) | 2013-12-24 | 2015-07-02 | Digimarc Corporation | Methods and system for cue detection from audio input, low-power data processing and related arrangements |
| US9135923B1 (en) | 2014-03-17 | 2015-09-15 | Chengjun Julian Chen | Pitch synchronous speech coding based on timbre vectors |
| US9183831B2 (en) * | 2014-03-27 | 2015-11-10 | International Business Machines Corporation | Text-to-speech for digital literature |
| US10039470B2 (en) * | 2014-04-11 | 2018-08-07 | Thomas Andrew Deuel | Encephalophone |
| US10008216B2 (en) * | 2014-04-15 | 2018-06-26 | Speech Morphing Systems, Inc. | Method and apparatus for exemplary morphing computer system background |
| EP2933070A1 (en) * | 2014-04-17 | 2015-10-21 | Aldebaran Robotics | Methods and systems of handling a dialog with a robot |
| US20170048176A1 (en) | 2014-04-23 | 2017-02-16 | Actiance, Inc. | Community directory for distributed policy enforcement |
| US20150309987A1 (en) | 2014-04-29 | 2015-10-29 | Google Inc. | Classification of Offensive Words |
| US20150356967A1 (en) | 2014-06-08 | 2015-12-10 | International Business Machines Corporation | Generating Narrative Audio Works Using Differentiable Text-to-Speech Voices |
| US9613620B2 (en) * | 2014-07-03 | 2017-04-04 | Google Inc. | Methods and systems for voice conversion |
| US10518409B2 (en) | 2014-09-02 | 2019-12-31 | Mark Oleynik | Robotic manipulation methods and systems for executing a domain-specific application in an instrumented environment with electronic minimanipulation libraries |
| US9953661B2 (en) * | 2014-09-26 | 2018-04-24 | Cirrus Logic Inc. | Neural network voice activity detection employing running range normalization |
| US9305530B1 (en) | 2014-09-30 | 2016-04-05 | Amazon Technologies, Inc. | Text synchronization with audio |
| US9881631B2 (en) * | 2014-10-21 | 2018-01-30 | Mitsubishi Electric Research Laboratories, Inc. | Method for enhancing audio signal using phase information |
| US9390695B2 (en) * | 2014-10-27 | 2016-07-12 | Northwestern University | Systems, methods, and apparatus to search audio synthesizers using vocal imitation |
| US10540957B2 (en) * | 2014-12-15 | 2020-01-21 | Baidu Usa Llc | Systems and methods for speech transcription |
| JP6561499B2 (ja) * | 2015-03-05 | 2019-08-21 | ヤマハ株式会社 | 音声合成装置および音声合成方法 |
| KR101666930B1 (ko) | 2015-04-29 | 2016-10-24 | 서울대학교산학협력단 | 심화 학습 모델을 이용한 목표 화자의 적응형 목소리 변환 방법 및 이를 구현하는 음성 변환 장치 |
| US20160379641A1 (en) | 2015-06-29 | 2016-12-29 | Microsoft Technology Licensing, Llc | Auto-Generation of Notes and Tasks From Passive Recording |
| KR102410914B1 (ko) * | 2015-07-16 | 2022-06-17 | 삼성전자주식회사 | 음성 인식을 위한 모델 구축 장치 및 음성 인식 장치 및 방법 |
| US10186251B1 (en) * | 2015-08-06 | 2019-01-22 | Oben, Inc. | Voice conversion using deep neural network with intermediate voice training |
| KR101665882B1 (ko) | 2015-08-20 | 2016-10-13 | 한국과학기술원 | 음색변환과 음성dna를 이용한 음성합성 기술 및 장치 |
| US10198667B2 (en) | 2015-09-02 | 2019-02-05 | Pocketguardian, Llc | System and method of detecting offensive content sent or received on a portable electronic device |
| CN106571145A (zh) * | 2015-10-08 | 2017-04-19 | 重庆邮电大学 | 一种语音模仿方法和装置 |
| US9830903B2 (en) * | 2015-11-10 | 2017-11-28 | Paul Wendell Mason | Method and apparatus for using a vocal sample to customize text to speech applications |
| US9589574B1 (en) * | 2015-11-13 | 2017-03-07 | Doppler Labs, Inc. | Annoyance noise suppression |
| US10327095B2 (en) | 2015-11-18 | 2019-06-18 | Interactive Intelligence Group, Inc. | System and method for dynamically generated reports |
| KR102390713B1 (ko) * | 2015-11-25 | 2022-04-27 | 삼성전자 주식회사 | 전자 장치 및 전자 장치의 통화 서비스 제공 방법 |
| US12244762B2 (en) * | 2016-01-12 | 2025-03-04 | Andrew Horton | Caller identification in a secure environment using voice biometrics |
| CN108475507A (zh) | 2016-01-28 | 2018-08-31 | 索尼公司 | 信息处理设备、信息处理方法和程序 |
| US10978033B2 (en) | 2016-02-05 | 2021-04-13 | New Resonance, Llc | Mapping characteristics of music into a visual display |
| US9591427B1 (en) * | 2016-02-20 | 2017-03-07 | Philip Scott Lyren | Capturing audio impulse responses of a person with a smartphone |
| US10453476B1 (en) * | 2016-07-21 | 2019-10-22 | Oben, Inc. | Split-model architecture for DNN-based small corpus voice conversion |
| US11010687B2 (en) | 2016-07-29 | 2021-05-18 | Verizon Media Inc. | Detecting abusive language using character N-gram features |
| US10115400B2 (en) | 2016-08-05 | 2018-10-30 | Sonos, Inc. | Multiple voice services |
| US10357713B1 (en) | 2016-08-05 | 2019-07-23 | Wells Fargo Bank, N.A. | Utilizing gaming behavior to evaluate player traits |
| US9949020B1 (en) | 2016-08-12 | 2018-04-17 | Ocean Acoustical Services and Instrumentation System | System and method for including soundscapes in online mapping utilities |
| US20180053261A1 (en) * | 2016-08-16 | 2018-02-22 | Jeffrey Lee Hershey | Automated Compatibility Matching Based on Music Preferences of Individuals |
| US10291646B2 (en) | 2016-10-03 | 2019-05-14 | Telepathy Labs, Inc. | System and method for audio fingerprinting for attack detection |
| US10339960B2 (en) * | 2016-10-13 | 2019-07-02 | International Business Machines Corporation | Personal device for hearing degradation monitoring |
| US10706839B1 (en) * | 2016-10-24 | 2020-07-07 | United Services Automobile Association (Usaa) | Electronic signatures via voice for virtual assistants' interactions |
| US20180146370A1 (en) | 2016-11-22 | 2018-05-24 | Ashok Krishnaswamy | Method and apparatus for secured authentication using voice biometrics and watermarking |
| US20190378024A1 (en) | 2016-12-16 | 2019-12-12 | Second Mind Labs, Inc. | Systems to augment conversations with relevant information or automation using proactive bots |
| US10559309B2 (en) | 2016-12-22 | 2020-02-11 | Google Llc | Collaborative voice controlled devices |
| EP3576626A4 (en) * | 2017-02-01 | 2020-12-09 | Cerebian Inc. | SYSTEM AND METHOD OF MEASURING PERCEPTUAL EXPERIENCES |
| US10147415B2 (en) | 2017-02-02 | 2018-12-04 | Microsoft Technology Licensing, Llc | Artificially generated speech for a communication session |
| US20180225083A1 (en) | 2017-02-03 | 2018-08-09 | Scratchvox Inc. | Methods, systems, and computer-readable storage media for enabling flexible sound generation/modifying utilities |
| US10706867B1 (en) * | 2017-03-03 | 2020-07-07 | Oben, Inc. | Global frequency-warping transformation estimation for voice timbre approximation |
| CA2998249A1 (en) * | 2017-03-17 | 2018-09-17 | Edatanetworks Inc. | Artificial intelligence engine incenting merchant transaction with consumer affinity |
| US11183181B2 (en) * | 2017-03-27 | 2021-11-23 | Sonos, Inc. | Systems and methods of multiple voice services |
| US20180316709A1 (en) | 2017-04-28 | 2018-11-01 | NURO Secure Messaging Ltd. | System and method for detecting regulatory anomalies within electronic communication |
| US10861210B2 (en) * | 2017-05-16 | 2020-12-08 | Apple Inc. | Techniques for providing audio and video effects |
| US10867595B2 (en) * | 2017-05-19 | 2020-12-15 | Baidu Usa Llc | Cold fusing sequence-to-sequence models with language models |
| WO2018218081A1 (en) | 2017-05-24 | 2018-11-29 | Modulate, LLC | System and method for voice-to-voice conversion |
| GB2565038A (en) | 2017-06-01 | 2019-02-06 | Spirit Al Ltd | Online user monitoring |
| GB2565037A (en) | 2017-06-01 | 2019-02-06 | Spirit Al Ltd | Online user monitoring |
| GB2572525A (en) | 2017-06-01 | 2019-10-09 | Spirit Al Ltd | Online user monitoring |
| CN107293289B (zh) | 2017-06-13 | 2020-05-29 | 南京医科大学 | 一种基于深度卷积生成对抗网络的语音生成方法 |
| WO2019010250A1 (en) | 2017-07-05 | 2019-01-10 | Interactions Llc | REAL-TIME CONFIDENTIALITY FILTER |
| US20190052471A1 (en) | 2017-08-10 | 2019-02-14 | Microsoft Technology Licensing, Llc | Personalized toxicity shield for multiuser virtual environments |
| US10994209B2 (en) | 2017-11-27 | 2021-05-04 | Sony Interactive Entertainment America Llc | Shadow banning in social VR setting |
| US10453447B2 (en) | 2017-11-28 | 2019-10-22 | International Business Machines Corporation | Filtering data in an audio stream |
| US10807006B1 (en) | 2017-12-06 | 2020-10-20 | Amazon Technologies, Inc. | Behavior-aware player selection for multiplayer electronic games |
| GB2571548A (en) | 2018-03-01 | 2019-09-04 | Sony Interactive Entertainment Inc | User interaction monitoring |
| US20210019339A1 (en) | 2018-03-12 | 2021-01-21 | Factmata Limited | Machine learning classifier for content analysis |
| US10918956B2 (en) | 2018-03-30 | 2021-02-16 | Kelli Rout | System for monitoring online gaming activity |
| US20190364126A1 (en) | 2018-05-25 | 2019-11-28 | Mark Todd | Computer-implemented method, computer program product, and system for identifying and altering objectionable media content |
| US12067971B2 (en) | 2018-06-29 | 2024-08-20 | Sony Corporation | Information processing apparatus and information processing method |
| US10361673B1 (en) | 2018-07-24 | 2019-07-23 | Sony Interactive Entertainment Inc. | Ambient sound activated headphone |
| US20200125639A1 (en) | 2018-10-22 | 2020-04-23 | Ca, Inc. | Generating training data from a machine learning model to identify offensive language |
| US20200125928A1 (en) | 2018-10-22 | 2020-04-23 | Ca, Inc. | Real-time supervised machine learning by models configured to classify offensiveness of computer-generated natural-language text |
| US10922534B2 (en) | 2018-10-26 | 2021-02-16 | At&T Intellectual Property I, L.P. | Identifying and addressing offensive actions in visual communication sessions |
| US20200129864A1 (en) | 2018-10-31 | 2020-04-30 | International Business Machines Corporation | Detecting and identifying improper online game usage |
| US11698922B2 (en) | 2018-11-02 | 2023-07-11 | Valve Corporation | Classification and moderation of text |
| US11011158B2 (en) | 2019-01-08 | 2021-05-18 | International Business Machines Corporation | Analyzing data to provide alerts to conversation participants |
| US10936817B2 (en) | 2019-02-01 | 2021-03-02 | Conduent Business Services, Llc | Neural network architecture for subtle hate speech detection |
| US20200267165A1 (en) | 2019-02-18 | 2020-08-20 | Fido Voice Sp. Z O.O. | Method and apparatus for detection and classification of undesired online activity and intervention in response |
| JP2020150409A (ja) | 2019-03-13 | 2020-09-17 | 株式会社日立情報通信エンジニアリング | コールセンタシステムおよび通話監視方法 |
| US10940396B2 (en) | 2019-03-20 | 2021-03-09 | Electronic Arts Inc. | Example chat message toxicity assessment process |
| US20200335089A1 (en) | 2019-04-16 | 2020-10-22 | International Business Machines Corporation | Protecting chat with artificial intelligence |
| US11126797B2 (en) | 2019-07-02 | 2021-09-21 | Spectrum Labs, Inc. | Toxic vector mapping across languages |
| US11544744B2 (en) | 2019-08-09 | 2023-01-03 | SOCI, Inc. | Systems, devices, and methods for autonomous communication generation, distribution, and management of online communications |
| US11538485B2 (en) | 2019-08-14 | 2022-12-27 | Modulate, Inc. | Generation and detection of watermark for real-time voice conversion |
| US11714967B1 (en) * | 2019-11-01 | 2023-08-01 | Empowerly, Inc. | College admissions and career mentorship platform |
| US20210201893A1 (en) | 2019-12-31 | 2021-07-01 | Beijing Didi Infinity Technology And Development Co., Ltd. | Pattern-based adaptation model for detecting contact information requests in a vehicle |
| US20210234823A1 (en) | 2020-01-27 | 2021-07-29 | Antitoxin Technologies Inc. | Detecting and identifying toxic and offensive social interactions in digital communications |
| US11170800B2 (en) | 2020-02-27 | 2021-11-09 | Microsoft Technology Licensing, Llc | Adjusting user experience for multiuser sessions based on vocal-characteristic models |
| US11522993B2 (en) | 2020-04-17 | 2022-12-06 | Marchex, Inc. | Systems and methods for rapid analysis of call audio data using a stream-processing platform |
| US20210322887A1 (en) | 2020-04-21 | 2021-10-21 | 12traits, Inc. | Systems and methods for adapting user experience in a digital experience based on psychological attributes of individual users |
| US11458409B2 (en) | 2020-05-27 | 2022-10-04 | Nvidia Corporation | Automatic classification and reporting of inappropriate language in online applications |
| US11266912B2 (en) | 2020-05-30 | 2022-03-08 | Sony Interactive Entertainment LLC | Methods and systems for processing disruptive behavior within multi-player video game |
| US10987592B1 (en) | 2020-06-05 | 2021-04-27 | 12traits, Inc. | Systems and methods to correlate user behavior patterns within an online game with psychological attributes of users |
| US20230245650A1 (en) | 2020-06-11 | 2023-08-03 | Google Llc | Using canonical utterances for text or voice communication |
| US11400378B2 (en) | 2020-06-30 | 2022-08-02 | Sony Interactive Entertainment LLC | Automatic separation of abusive players from game interactions |
| US11395971B2 (en) | 2020-07-08 | 2022-07-26 | Sony Interactive Entertainment LLC | Auto harassment monitoring system |
| US11235248B1 (en) | 2020-07-28 | 2022-02-01 | International Business Machines Corporation | Online behavior using predictive analytics |
| US11596870B2 (en) | 2020-07-31 | 2023-03-07 | Sony Interactive Entertainment LLC | Classifying gaming activity to identify abusive behavior |
| US11090566B1 (en) | 2020-09-16 | 2021-08-17 | Sony Interactive Entertainment LLC | Method for determining player behavior |
| US11571628B2 (en) | 2020-09-28 | 2023-02-07 | Sony Interactive Entertainment LLC | Modifying game content to reduce abuser actions toward other users |
| WO2022076923A1 (en) | 2020-10-08 | 2022-04-14 | Modulate, Inc. | Multi-stage adaptive system for content moderation |
| US11458404B2 (en) | 2020-10-09 | 2022-10-04 | Sony Interactive Entertainment LLC | Systems and methods for verifying activity associated with a play of a game |
| US12097438B2 (en) | 2020-12-11 | 2024-09-24 | Guardiangamer, Inc. | Monitored online experience systems and methods |
| US20220203244A1 (en) | 2020-12-31 | 2022-06-30 | GGWP, Inc. | Methods and systems for generating multimedia content based on processed data with variable privacy concerns |
| US12205000B2 (en) | 2020-12-31 | 2025-01-21 | GGWP, Inc. | Methods and systems for cross-platform user profiling based on disparate datasets using machine learning models |
| US10997494B1 (en) | 2020-12-31 | 2021-05-04 | GGWP, Inc. | Methods and systems for detecting disparate incidents in processed data using a plurality of machine learning models |
| US20220059071A1 (en) | 2021-11-03 | 2022-02-24 | Intel Corporation | Sound modification of speech in audio signals over machine communication channels |
| WO2023196624A1 (en) | 2022-04-08 | 2023-10-12 | Modulate, Inc. | Predictive audio redaction for realtime communication |
| US12341619B2 (en) | 2022-06-01 | 2025-06-24 | Modulate, Inc. | User interface for content moderation of voice chat |
-
2018
- 2018-05-24 WO PCT/US2018/034485 patent/WO2018218081A1/en not_active Ceased
- 2018-05-24 US US15/989,072 patent/US10622002B2/en active Active
- 2018-05-24 CN CN201880034452.8A patent/CN111201565B/zh active Active
- 2018-05-24 US US15/989,062 patent/US10614826B2/en active Active
- 2018-05-24 US US15/989,065 patent/US10861476B2/en active Active
- 2018-05-24 EP EP18806567.6A patent/EP3631791A4/en not_active Ceased
- 2018-05-24 KR KR1020237002550A patent/KR20230018538A/ko not_active Ceased
- 2018-05-24 KR KR1020197038068A patent/KR20200027475A/ko not_active Ceased
-
2020
- 2020-04-13 US US16/846,460 patent/US11017788B2/en active Active
-
2021
- 2021-05-04 US US17/307,397 patent/US11854563B2/en active Active
-
2023
- 2023-12-04 US US18/528,244 patent/US12412588B2/en active Active
-
2025
- 2025-08-15 US US19/301,342 patent/US20250378841A1/en active Pending
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025164836A1 (ko) * | 2024-01-31 | 2025-08-07 | 주식회사 자이냅스 | 다중 판별부에 기반하여 학습된 인코더를 이용하여 워터마크 오디오를 생성하는 방법 및 장치 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20210256985A1 (en) | 2021-08-19 |
| CN111201565B (zh) | 2024-08-16 |
| US20180342256A1 (en) | 2018-11-29 |
| KR20230018538A (ko) | 2023-02-07 |
| US20240119954A1 (en) | 2024-04-11 |
| EP3631791A1 (en) | 2020-04-08 |
| US10622002B2 (en) | 2020-04-14 |
| US20180342257A1 (en) | 2018-11-29 |
| US10861476B2 (en) | 2020-12-08 |
| US11017788B2 (en) | 2021-05-25 |
| WO2018218081A1 (en) | 2018-11-29 |
| CN111201565A (zh) | 2020-05-26 |
| US20180342258A1 (en) | 2018-11-29 |
| EP3631791A4 (en) | 2021-02-24 |
| US12412588B2 (en) | 2025-09-09 |
| US10614826B2 (en) | 2020-04-07 |
| US20200243101A1 (en) | 2020-07-30 |
| US20250378841A1 (en) | 2025-12-11 |
| US11854563B2 (en) | 2023-12-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12412588B2 (en) | System and method for creating timbres | |
| WO2021030759A1 (en) | Generation and detection of watermark for real-time voice conversion | |
| Kamble et al. | Advances in anti-spoofing: from the perspective of ASVspoof challenges | |
| JP7839285B2 (ja) | マルチタスク音声モデルを用いた話者検証 | |
| CN111667839B (zh) | 注册方法和设备、说话者识别方法和设备 | |
| WO2019214047A1 (zh) | 建立声纹模型的方法、装置、计算机设备和存储介质 | |
| JP2021110943A (ja) | クロスリンガル音声変換システムおよび方法 | |
| US20240355346A1 (en) | Voice modification | |
| CN114067782B (zh) | 音频识别方法及其装置、介质和芯片系统 | |
| CN112863476A (zh) | 个性化语音合成模型构建、语音合成和测试方法及装置 | |
| CN119088335B (zh) | 一种基于生物识别与ai学习的燃气灶智能控制方法 | |
| Gao | Audio deepfake detection based on differences in human and machine generated speech | |
| CN112885326A (zh) | 个性化语音合成模型创建、语音合成和测试方法及装置 | |
| CN114512133A (zh) | 发声对象识别方法、装置、服务器及存储介质 | |
| Mawalim et al. | InaSAS: Benchmarking Indonesian Speech Antispoofing Systems | |
| CN119993114A (zh) | 基于多模态风格嵌入的语音合成方法、装置、设备及介质 | |
| Ustubioglu et al. | Multi Pattern Features-Based Spoofing Detection Mechanism Using One Class Learning | |
| CN115132204B (zh) | 一种语音处理方法、设备、存储介质及计算机程序产品 | |
| CN117546238A (zh) | 一种生成音频的方法、装置及存储介质 | |
| Aloufi et al. | On-Device Voice Authentication with Paralinguistic Privacy | |
| Wickramasinghe | Replay detection in voice biometrics: An investigation of adaptive and non-adaptive front-ends | |
| Dua et al. | Audio Spoof Detection from Theory to Practical Application | |
| KR20260053996A (ko) | 음성 클로닝 데이터를 이용한 딥보이스 감지 장치 및 방법 | |
| Sivaraman | FSGAN-Key: A Novel Frequency-Shifted Generative Adversarial Network Using Voice Features for Cryptographic Key | |
| Eijaz | Counter measure system for automatic speaker verification systems |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20191223 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| A201 | Request for examination | ||
| PA0201 | Request for examination |
Patent event code: PA02012R01D Patent event date: 20200305 Comment text: Request for Examination of Application |
|
| PG1501 | Laying open of application | ||
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
Comment text: Notification of reason for refusal Patent event date: 20210527 Patent event code: PE09021S01D |
|
| E601 | Decision to refuse application | ||
| PE0601 | Decision on rejection of patent |
Patent event date: 20220422 Comment text: Decision to Refuse Application Patent event code: PE06012S01D Patent event date: 20210527 Comment text: Notification of reason for refusal Patent event code: PE06011S01I |
|
| PX0901 | Re-examination |
Patent event code: PX09011S01I Patent event date: 20220422 Comment text: Decision to Refuse Application Patent event code: PX09012R01I Patent event date: 20211129 Comment text: Amendment to Specification, etc. Patent event code: PX09012R01I Patent event date: 20200305 Comment text: Amendment to Specification, etc. Patent event code: PX09012R01I Patent event date: 20200219 Comment text: Amendment to Specification, etc. |
|
| PX0601 | Decision of rejection after re-examination |
Comment text: Decision to Refuse Application Patent event code: PX06014S01D Patent event date: 20220921 Comment text: Amendment to Specification, etc. Patent event code: PX06012R01I Patent event date: 20220819 Comment text: Decision to Refuse Application Patent event code: PX06011S01I Patent event date: 20220422 Comment text: Amendment to Specification, etc. Patent event code: PX06012R01I Patent event date: 20211129 Comment text: Notification of reason for refusal Patent event code: PX06013S01I Patent event date: 20210527 Comment text: Amendment to Specification, etc. Patent event code: PX06012R01I Patent event date: 20200305 Comment text: Amendment to Specification, etc. Patent event code: PX06012R01I Patent event date: 20200219 |
|
| J201 | Request for trial against refusal decision | ||
| PJ0201 | Trial against decision of rejection |
Patent event date: 20230120 Comment text: Request for Trial against Decision on Refusal Patent event code: PJ02012R01D Patent event date: 20220921 Comment text: Decision to Refuse Application Patent event code: PJ02011S01I Patent event date: 20220422 Comment text: Decision to Refuse Application Patent event code: PJ02011S01I Appeal kind category: Appeal against decision to decline refusal Appeal identifier: 2023101000129 Request date: 20230120 |
|
| J301 | Trial decision |
Free format text: TRIAL NUMBER: 2023101000129; TRIAL DECISION FOR APPEAL AGAINST DECISION TO DECLINE REFUSAL REQUESTED 20230120 Effective date: 20230426 |
|
| PJ1301 | Trial decision |
Patent event code: PJ13011S01D Patent event date: 20230426 Comment text: Trial Decision on Objection to Decision on Refusal Appeal kind category: Appeal against decision to decline refusal Request date: 20230120 Decision date: 20230426 Appeal identifier: 2023101000129 |