발명의 개요
복잡한 거대분자 분석 프로세스 동안 직면하는 주요 문제는 비제한적으로, 생물학적 샘플 유형을 포함하는 많은 샘플 유형이 이들의 성분 분석물의 현저한 변동성을 갖는다는 점이다. 검출 및 측정 시스템은 분석물이 검출될 수 있는 규정된 동적 범위를 가지나, 분석물 양 또는 농도는 종종 이러한 동적 범위 밖에 속한다. 이러한 경우, 사용자가 주어진 샘플을 재실행하기로 결정하여, 입력 샘플의 질량 또는 부피 또는 희석을 조절할 수 있다. 재실행은 관심 분석물이 동적 범위내에 속하게 할 수 있거나, 추가의 재실행이 필요할 수 있다. 다수의 실행의 추가 시간 및 비용이 필요한 것 이외에, 샘플이 제한적이고, 재실행에 사용될 수 없는 경우가 있다. 관심 분석물이 동적 범위 밖에 속하는 경우 또 다른 접근 방법은 분석물이 시스템의 동적 범위 내에 속하도록 사용자가 기기 또는 소프트웨어를 조정하는 것이다. 이는 매우 간단한 시스템(예시적으로, 표본을 시각화할 수 있도록 현미경의 조동 나사 조정을 수동으로 변경)에서 효과적일 수 있으나, 이러한 유형의 조절은 복잡한 시스템에서 훨씬 더욱 어렵다. 시간 및 비용이 필요하다는 것 이외에, 이러한 접근 방법은 수준 높은 운영자를 필요로 한다 - 생물학적 분석 프로세스에서, 이러한 운영자는 전형적으로 실험실을 기반으로 한다.
추가로, 현재 범의학 분석가에 의한 DNA ID의 해석은 전문가 시스템에 대한 사용 유무와 관계없이 매우 주관적이다. 개개인, 개인별 차이 및 실험실별 차이에 의한 해석에 있어서 그날 그날의 차이는 모두 주어진 DNA ID에 대한 결과, 및 데이터의 주관적으로 (및 때로는 잠재의식적으로) 규정된 면의 끝에 속하는 특징을 갖는 샘플의 반복된 실행에 대한 결과의 변동성을 초래할 수 있다.
따라서, 본 발명자들은 가변 샘플에 대해 적절하게 적응하고, 효과적으로 확장된 동적 범위 내에 속하는 분석물에 대한 데이터를 처리하고, 이러한 샘플을 조작하기 위한 알고리즘을 명확하게 정의하는 자동화된 전문가 시스템을 만들어 이러한 문제를 해결하였다. 본 발명의 교시는 실험실 내부 또는 외부에서 전문적 검토자 또는 검토를 필요로 하지 않는 전문적 또는 비전문적 운영자에 의한 샘플 분석을 가속화하고, 샘플 요건을 제한하고, 재실행을 줄이고, DNA 정량화 단계를 옵션으로 만들고, 샘플 당 더욱 유용한 데이터를 제공하고, 복잡한 분석이 수행되게 하는 "적응형 전문가 시스템(AES)"을 생산한다. 본 발명의 AES는 시스템의 통상적인 동적 범위 밖에 속하거나 그러한 동적 범위내에 속하는 샘플 데이터에 적용가능하며, 단일 소스, 혼합물, 임상, 환경, 수의학, 야생동물 및 다양한 다른 샘플의 분석을 가능하게 한다. 이러한 해결책은 샘플 분석 데이터의 특정 패턴 및 특징을 식별하고, 컴퓨터 및 전문가 시스템 소프트웨어가 일반적으로 수행하는 것으로부터의 데이터 처리 및 분석 작업을 변경함으로써 달성되었다. 이러한 실질적인 분석 개선은 광범위한 환경 및 어플리케이션에 적용가능하다.
본원에 기재된 발명은 각각 그 전체가 본원에 참조로서 포함된 하기 미세유체 전기영동 특허 및 특허 출원, 및 샘플 처리 특허 및 특허 출원을 포함하는, 광범위한 기기, 시스템 및 방법으로 광범위한 샘플 유형에 대해 실시될 수 있다: 미국 특허 번호 8,018,593; 8,173,417; 8,206,974; 8,425,861; 8,720,036; 8,858,770; 8,961,765; 9,012,208; 9,174,210; 9,310,304; 9,314,795; 9,354,199; 9,366,631; 9,494,519; 9,523,656; 9,550,985; 9,606,083; 9,797,841; 9,889,449 및 9.994,895, 미국 특허 출원 일련 번호 15/894,630.
범의학적 샘플은 매우 다양하며, 그 가치가 최대화되어야 한다. 예를 들어, 형사법 집행에서, 범죄 현장 샘플로부터의 DNA 증거는 수사 단서를 만들고, 용의자를 식별하고 무고한 사람의 무죄를 입증해줄 수 있는 가능성을 갖는다. 군사 활동에서, 민감한 장소 탐방 활동 동안 수집된 샘플로부터 생성된 DNA 데이터는 민간인과 전투원을 보호할 수 있으며, 이러한 샘플로부터 얻은 데이터의 가치는 이를 확보하기 위한 희생에 상응해야 한다. 신속 DNA 식별은 범죄 현장 평가 및 SSE 미션에서 얻은 지능 리드(intelligence leads)를 확장할 가능성을 가지며, 이러한 리드를 추적할 수 있는 적시성을 단축하여 범죄자와 테러리스트의 익명성, 이들의 이동 자유 및 탐지되지 않은 운영 능력을 저해한다. 요컨대, 법의학 샘플로부터의 DNA 증거는 범죄자와 테러리스트를 식별하고 무고한 사람의 무죄를 밝혀줌으로써 사회 안전을 현격하게 개선시킬 가능성을 갖는다.
신속 DNA 식별은 DNA ID의 완전 자동 생성 및 해석이며, 바람직하게는, 2시간 미만에서 이루어지는 것이 좋다. 신속 DNA 기술의 영향은 국방부, FBI(Federal Bureau of Investigation) 및 국토 안보부가 신속 DNA 식별 시스템에 대한 일련의 요구사항을 개발하기 위해 협력했다는 점으로부터 입증된다[Ben Riley (2012) U.S. Department of Defense Biometric and Forensic Technology Forum. Center for Strategic and International Studies. https://www.csis.org/events/us-department-defense-biometric-and-forensic-technology-forum].
또한, 신속 DNA 지수 시스템(RDIS)의 FBI 구축 [Callaghan, T. (2013) Rapid DNA instrument update & enhancement plans for codis. http://docplayer.net/4802515-Rapid-dna-instrument-update-enhancement-plans-for-codis.html], 및 2017년 미국 하원의원 및 미국 연방의 신속 DNA 법의 만장일치 통과[https://www.govtrack.us/congress/bills/115/hr510/text]는 실험실 밖의 DNA ID 생성이 관례적인 것이 될 것임을 시사한다.
ANDE 6C 신속 DNA 시스템[Eugene Tan, Rosemary S Turingan, Catherine Hogan, Sameer Vasantgadkar, Luke Palombo, James W Schumm, Richard F. Selden. Fully integrated, fully automated generation of short tandem repeat profiles, Investigative Genetics (2013), 4:16; Rosemary S. Turingan, Sameer Vasantgadkar, Luke Palombo, Catherine Hogan, Hua Jiang, Eugene Tan and Richard F. Selden. Rapid DNA analysis for automated processing and interpretation of low DNA content samples. Investigative Genetics (2016) 7:2; Angelo Della Manna, Jeffrey V. Nye, Christopher Carney, Jennifer S. Hammons, Michael Mann, Farida Al Shamali, PhD, Peter M. Vallone, PhD, Erica L. Romsos, PhD, Beth Ann Marne, Eugene Tan, PhD, Rosemary S. Turingan, PhD, Catherine Hogan, Richard F. Selden, MD PhD, Julie L. French. Developmental validation of the DNAscan Rapid DNA Analysis instrument and expert system for reference sample processing. Forensic Science International: Genetics 25 (2016) 145-156; Richard F. Selden, MD, PhD, James H. Davis. Rapid DNA Identification: Changing The Paradigm. FBI National Academy Associates Magazine, Jan./Feb. 2018]은 최소한의 교육 후 비전문 운영자가 현장 진행 작업을 할 수 있는 완전히 통합된 견고한 시스템이다. 시스템은 DNA ID를 생성하기 위해 시약-함유 단일의 일회용 미세유체 칩 및 완전히 일체화된 기기를 사용한다. 여러 실시예에 제시된 바와 같은 시스템은 FlexPlex 검정을 사용한다[Ranjana Grover, Hua Jiang , Rosemary S. Turingan, Julie L. French, Eugene Tan, and Richard F. Selden, FlexPlex27―highly multiplexed rapid DNA identification for law enforcement, kinship, and military applications, Int . J. Legal Med . (2017), 131:1489-1501]. FlexPlex는 27개 유전자좌를 통합시키는 멀티플렉스 검정이다. 이러한 검정은 23개 상염색체 유전자좌(D1S1656, D2S1338, D2S441, D3S1358, D5S81, D6S1043, D7S820, D8S1179, D10S1248, D12S391, D13S317, D16S539, D18S51, D19S433, D21S11, D22S1045, FGA, CSF1PO, Penta E, TH01, vWA, TPOX, 및 SE33), 3개의 Y-크로모좀 유전자좌(DYS391, DYS576, 및 DYS570), 및 아멜로게닌을 함유한다. FBI의 확장된 CODIS 코어 유전자좌의 STR 유전자좌 이외에, FlexPlex27은 호주 국립 범죄 수사 DNA 데이터베이스, 캐나다 국립 DNA 데이터 뱅크, 중국 국립 DNA 데이터베이스, 독일 DNA-Analyze-Datei, 뉴질랜드 국립 DNA 프로파일 데이터뱅크, 및 영국 국립 DNA 데이터베이스를 포함하는 광범위한 국립 DNA 데이터베이스 및 ENFSI/EDNAP 확장된 유럽 표준 세트와 호환가능한 데이터를 생성한다. 본 발명의 교시내용은 싱글플렉스이든 또는 멀티플렉스이든 모든 STR 검정에 적용될 수 있음을 주지하라. 다수의 상업용 STR 검정이 이용가능하다.
샘플을 칩에 삽입하고, 칩을 기기에 삽인한 후, 시스템은 DNA 추출 및 정제, PCR 증폭, 전기영동 분리, 형광 검출 및 온-보드 전문가 시스템에 의한 데이터 분석을 포함하는 각 샘플에 대한 DNA ID 생성에 필요한 모든 프로세스를 수행한다[Grover et al., ibid.]. 2018년 5월에, ANDE 6C 신속 DNA 시스템은 CODIS 20 표준하에 FBI 국립 DNA 색인 시스템 승인을 받은 최초의 것이 되었다[FBI Rapid DNA General Information, https://www.fbi.gov/services/laboratory/biometric-analysis/codis/rapid-dna]. ANDE 시스템은 하기를 포함하는 계층화된 사용자 그룹에 대한 권한을 통합시킨다: 운영자(전형적으로, 아직 DNA DI에 접근할 수 없는 비전문 사용자에게 프로세스 결과를 알려주고 다음 단계를 제안할 수 있다); 관리자(전형적으로, 해당 법의학 분석가는 DNA ID 데이터에 접근한다); 및 최고관리자(전형적으로, 해당 상급자는 관할 정책을 반영하도록 사용자-구성가능한 설정을 조정할 수 있는 권한이 부여된다). 관할 요구 사항에 기초하여 다른 계층이 부가된다(또는 제거된다).
본원에 기술된 시스템은 예를 들어, 전형적으로 높은 DNA 함량을 갖는 것(예를 들어, 구강 면봉, 근육, 간, 혈액 및 뼈와 같은 신선한 인간 조직)에서부터 낮은 DNA 함량을 갖는 샘플(예를 들어, 조작된 물체(상피 접촉), 매우 소량의 인간 조직, 뼈, 치아 또는 혈액으로부터 수집된 샘플, 및 분해된 샘플)에 이르는 범위의 임의의 생물학적 또는 법의학적 샘플을 본질적으로 분석할 수 있다. 명백하게는, 임의의 샘플 유형은 DNA 함량이 높거나 낮을 수 있다 - 수집된 샘플의 양 및 샘플이 저장되는 조건은 샘플의 DNA의 양에 직접적인 영향을 미친다. 이와 같이, 본 발명은 비제한적으로, 어떤 표면에 실질적으로 증착된 액체 혈액 또는 혈액 얼룩, 액체 타액 또는 타액 얼룩, 및 액체 정액 또는 건조된 정액 얼룩(정관절제된 남성으로부터의 것을 포함); 면봉 또는 거즈 또는 흡입물로서 수집된 생식기/질/자궁 샘플; 직장/항문 면봉; 음경 면봉; 조직/피부 조각; 손톱; 뽑고 빠진 모발(예를 들어, 머리, 음모, 몸); 식음 용기 상의 피부 세포, 식음 용기(예를 들어, 컵, 병, 빨대, 유리컵, 캔) 상의 구강 상피 세포, 의류(예를 들어, 목 칼라, 허리띠, 모자 안감); 조직, 정액, 소변 및 소변 얼룩을 함유하는 슬라이드, 협측 면봉, 모발, 뼈, 치아, 손톱, 내부 장기 조직(뇌, 심장, 폐, 신장, 방광, 근육, 간 및 피부 포함), 뼈, 질 면봉, 자궁경부 면봉, 신체 면봉, 항문 면봉, 생식기 면봉, 생물학적 유체가 침착될 수 있는 의류(예를 들어, 여성 팬티 사타구니 또는 혈액-, 타액, 또는 정액-염색된 아이템) 및 피부 세포가 문질러질 수 있는 신체와 밀접하게 접촉되는 다른 의류(예를 들어, 칼라, 허리띠, 모자), 침구(질/정액 얼룩을 갖거나 피부 세포가 문지러짐), 자른 손톱, 담배 꽁초, 칫솔, 면도기 및 머리빗의 모발, 코 분비물을 갖는 버린 안면 티슈 또는 행커칩, 콘돔, 검, 여성용 제품, 병리학적 파라핀 블록 또는 이전 수술 또는 부검으로부터의 슬라이드를 포함하는 본질적으로 임의의 법의학적 샘플의 분석에 적합하다. 시스템은 또한 혼합 샘플에 직접 적용가능하다.
또한, 본 발명은 인간 및 인간외 샘플 유형에 적용가능하다. 시스템은 예를 들어, 바이러스, 박테리아 및 진균류를 함유하는 샘플의 평가에 이용될 수 있다. 이들은 인간 DNA 존재하의 임상 샘플, 수의학 샘플(숙주 동물 DNA의 존재), 식품 샘플, 환경 샘플, 연료 샘플 또는 다른 샘플 유형에서 발견될 수 있다. 본 발명은 또한, STR에 적용가능하며, 다른 유전자 특징은 포유동물(예를 들어, 말, 소, 염소, 양, 돼지, 고양이, 개, 마우스, 사자, 코끼리, 코뿔소, 얼룩말), 조류, 어류, 양서류, 파충류, 식물(예를 들어, 옥수수, 콩, 커피, 밀, 쌀, 대마초)이다.
본 발명의 적용성 전문가 시스템(AES)은 법의학적 샘플로부터 추출된 대립유전자 정보를 최대화시키기 위해 DNA의 물리적 조작 후 검출되는 샘플 데이터(샘플 데이터 및 샘플 분석물 데이터는 미가공 데이터, 광학 데이터, 일렉트로페로그램 데이터 또는 다른 유형의 데이터로서 규정됨)의 특징을 기반으로 호출 파라미터를 자동으로 및 지능적으로 적용시키는 향상된 전문가 시스템을 사용하여 DNA ID가 처리되게 한다. AES 출력값은 DNA ID 호출을 최적화하여 최대 수의 올바른 대립유전자 호출을 생성하면서 각 샘플에 대한 대립유전자 드롭인 또는 드롭아웃으로 인한 잘못된 호출을 최소화시키거나 제거한다.
DNA ID에서, 대립유전자는 크로모좀 유전자좌에서 특이적 스폿에 존재하는 DNA 단편의 하나의 복사체이다. 해당 유전자좌는 이형접합체(상이한 크기의 2개의 대립유전자), 동형접합체(동일한 크기의 두 대립유전자), 또는 반접합체(단일의 대립유전자이며, 유전자좌의 단지 하나의 복사체가 존재하기 때문이다 - 예컨대, 남성의 X 또는 Y 염색체)일 수 있다. 삼-대립유전자는 가끔 존재하며(유전자좌에서 3개의 대립유전자), 1, 2, 3, 4 또는 더 많은 대립유전자가 혼합물로부터 생성된 DNA ID로부터의 유전자좌에 존재할 수 있다(하나 초과의 기여자로부터의 DNA를 함유하는 샘플). 대립유전자 드롭인은 인공적인 DNA ID에서 관찰되는 대립유전자이며, 대립유전자 드롭아웃은 존재하지 않거나 소스 게놈에 실제로 존재하는 DNA ID에서 진정한 대립유전자이다. 드롭인 및 드롭아웃 둘 모두는, 완화된 DNA 데이터베이스 검색 기준(예를 들어, 검색 동안 하나 이상의 미스매치를 허용함)을 사용하여 이러한 이벤트를 정기적으로 보상할 수 있지만 부정확한 DNA ID를 초래할 수 있다.
STR-기반 DNA ID의 값을 최대화시키는 것 이외에, 본 발명의 적응형 전문가 시스템은 또한, 다른 분석물의 분석에 적용될 수 있다. 예를 들어, 분석물은 단백질, 펩티드, 메신저 RNA, 안티센스 RNA, 트랜스퍼 RNA, 리보솜 RNA, 기타 RNA, 핵산, 올리고뉴클레오티드, 단일 뉴클레오티드 다형체를 함유하는 DNA 또는 RNA 단편, 지질, 탄수화물, 대사산물, 스테로이드, 합성 폴리머, 기타 거대분자, 무기 또는 기타 유기 화학물질, 또는 이러한 분석물의 조합물일 수 있다. 본 발명은 분석 동안 전문가 시스템이 파라미터를 수정하게 하여 샘플로부터 가능한 많은 유용한 정보를 수확함으로써 이들 분석물을 함유하는 샘플의 분석이 현재 가능한 것보다 훨씬 더 효율적이게 한다.
이해할 수 있는 바와 같이, 전문가 시스템은 전형적으로 최소 2개 구성요소, 지식 베이스(예를 들어, 데이터베이스에 저장된 사실 및 규칙을 포함하는 데이터 요소 세트) 및 추론 엔진(예를 들어, 데이터베이스에 연결된 컴퓨팅 장치의 프로세서에서 실행되는 프로그램 명령)을 포함한다. 추론 엔진은 데이터베이스로부터 사실을 검색하고, 규칙을 사용하여 사실을 분석하여 예를 들어, 결론을 내리고/거나 추가 사실을 유추한다. 예를 들어, 사실은 미가공 데이터, 또는 광학 데이터, 또는 일렉트로페로그램 데이터, 또는 임의의 기타 데이터 입력값, 및 전문가 시스템에 의해 이러한 입력값으로부터 추론된 임의의 것을 포함할 수 있다. 예를 들어, 추론된 사실 또는 특징은 하기를 포함할 수 있다:
ㆍ각 염료 채널의 신호 대 잡음 비
ㆍ피크 위치
ㆍ피크 염기 할당
ㆍ피크 단편 크기
ㆍ피크 색상
ㆍ피크 유전자좌
ㆍ피크 대립유전자 #
ㆍ피크 높이
ㆍ피크 폭
ㆍ피크 형상
ㆍ피크 형태
ㆍ피크 비대칭
ㆍ피크 폭 편차
ㆍ피크 형상 편차
ㆍ염기 신뢰도
ㆍ이형접합체 피크 높이
ㆍ이형접합체 피크 높이 비율
ㆍ색상별 평균 이형접합체 피크 높이
ㆍ동형접합체 피크 높이
ㆍ색상별 평균 동형접합체 피크 높이
ㆍ유전자좌 내의 대립유전자의 상대적 신호 강도
ㆍ대립유전자 크기(예를 들어, 염기) 대비 대립유전자의 상대적 신호 강도
ㆍiNTA 피크 높이
ㆍiNTA 피크 높이 비율
ㆍ스터터 피크 높이
ㆍ스터터 비율
ㆍILS 성공
ㆍ유전자좌에서 피크의 수
ㆍ호출된 대립유전자의 수
ㆍ적색 경고 박스로 표지된 대립유전자의 수
ㆍ표지되지 않은 대립유전자의 수
ㆍPH 임계값 미만의 PH의 대립유전자를 갖는 유전자좌의 수
ㆍPH 임계값보다 큰 PH의 대립유전자를 갖는 유전자좌의 수
ㆍPHR 임계값 미만의 PHR을 갖는 유전자좌의 수
ㆍPHR 임계값 초과의 PHR을 갖는 유전자좌의 수
ㆍ넓은 피크를 갖는 유전자좌의 수
ㆍiNTA 임계값 초과의 iNTA을 갖는 유전자좌의 수
ㆍ적색 경고 박스로 표지된 3개 이상의 피크를 갖는 유전자좌의 수
ㆍ적색 경고 박스로 표지된 4개 이상의 피크를 갖는 유전자좌의 수
ㆍ적색 경고 박스로 표지된 이형접합체 유전자좌의 수
ㆍ적색 경고 박스로 표지된 동형접합체 유전자좌의 수
ㆍ블리드-스루 피크의 수
ㆍ호출된 CODIS20 유전자좌의 수
ㆍ호출된 CODIS 18 유전자좌의 수
ㆍ호출된 상염색체 유전자좌의 수
ㆍ호출된 플렉스 플렉스 유전자좌(flex plex loci)의 수
ㆍDNA ID 성공
ㆍ염기 할당
ㆍ염료 스펙트럼
ㆍ처리된 염료 흔적
본원에 기술된 바와 같이, AES는 전문가 시스템의 통합 모듈 또는 독립형 모듈로서 사용될 수 있다. 또한, AES는 신속 DNA 시스템, 수정된 신속 DNA 시스템, 또는 통상적인 STR 분석 시스템의 일부로서 또는 여기에 통합되어 사용될 수 있다. 본원에 기재된 원리는 또한, SNP, 상염색체 STR, Y-STR, X-STR, 억제 및 분해를 갖는 샘플(예를 들어, 여기에서 억제 또는 분해는 DNA ID에 영향을 미치며, AES는 이를 수정함), 오염물을 갖는 샘플(예를 들어, 여기에서 오염물 피크는 전문가 시스템에 의해 검출되고 의도적으로 무시됨), 혼합물을 갖는 샘플, 또는 샘플 중의 핵산(DNA 또는 RNA) 양에 의해 영향을 받은 게놈의 본질적으로 임의의 다른 측정에 적용될 수 있다.
법의학적 샘플은 이들의 DNA 함량 및 DNA 상태가 매우 다양하며, AES는 주어진 샘플로부터 유래될 수 있는 정보를 최대화시키기 위해 DNA 함량 및 상태에 적응하도록 구성된다. 다시 말해, 소량의 다소 분해된 DNA가 높은 가치의 증거 조각(예를 들어, 급조폭발물로부터의 와이어 트위스트)으로부터 생성되는 경우, AES는 구금자의 협측 면봉에서 생성된 데이터를 평가하는데 사용되는 동일한 전문가 시스템 파라미터 세트를 기반으로 하여 미가공 데이터(또는 광학 데이터, 색상-교정된 일렉트로페로그램 데이터, 또는 기타 데이터)를 평가하는 것으로 제한되어서는 안된다. 이유는 간단하고 실용적이다 - 또 다른 샘플을 수집하기 위해 수용자에게 돌아가는 것은 상대적으로 용이지만, IED에서 또 다른 샘플을 얻는 것은 어렵거나 불가능할 수 있다. 게다가, 대량의 또는 용이하게 수득가능한 양의 이용가능한 샘플을 사용하더라도, 샘플 내의 또는 샘플 상의 DNA의 양 또는 상태는 이상적인 DNA ID의 생성이 불가능할 수 있는 양이거나 상태일 수 있다. 예를 들어, 낮은 DNA 함량 샘플에 적합한 AES 파라미터 세트를 사용하여 폭발한 IED(급조폭발물)의 와이어 트위스트로부터의 DNA ID는 27개의 가능한 STR 유전자좌 중 10개만을 함유하는 출력값 DNA ID를 생성할 수 있다(이는 "부분적 DNA ID"임(검정에 존재하는 STR 유전자좌의 서브셋트만을 함유하는 것); 완전한 DNA ID는 검정에 존재하는 STR 유전자좌 모두 또는 거의 모두를 함유하는 것임). 그럼에도 불구하고, 이러한 부분적 DNA ID는 유의한 운영 가치를 가질 것이며, 미국 국방부(DoD) 데이터베이스에 대해 효과적으로 매치되게 할 것이다(무작위 매치 확률은 대략 수억 중의 1일 것이다). 뺨 면봉으로부터 유래된 증폭된 STR로부터 예측되는 특징을 필요로 하는 파라미터 세트를 단독으로 사용하여 이러한 샘플을 평가하는 것은 의미가 없다.
샘플의 운영 가치는 수집 에이전시 또는 사용자에 의해 설정되며, 에이전시 또는 사용자는 샘플 데이터가 표준 전문가 시스템 파라미터, AES 파라미터, 또는 이 둘 모두를 사용하여 자동으로 처리될 것인지의 여부를 결정할 것이다. 호출 공격성 정도가 증가함에 따라 하나 이상의 AES 파라미터 옵션이 제공될 수 있으며, 샘플의 운영 가치에 기초하여 선택될 수 있다. 가장 높은 운영 가치를 갖는 샘플, 아마도 입수하기 어렵거나 불가능하거나, 그렇지 않으면 제한된 샘플은 공격적인 파라미터 세트(예를 들어, 드롭인 또는 드롭아웃 가능성을 수용하면서 샘플로부터 가능한 많은 정보를 도출하도록 설계됨) 및 보존적 파라미터 세트(예를 들어, 주어진 샘플로부터 감소된 정보의 잠재적 비용으로 대립유전자 드롭인 및 드롭아웃을 최소화하도록 설계됨)로 처리될 수 있다. 용이하게 입수가능한 샘플 및 대량의 샘플은 더욱 보존적인 파라미터 세트로 처리될 수 있다. 그러나, 이들은 일반화된 지침일 뿐이다 - 궁극적으로, 일련의 파라미터 세트가 활용될 수 있으며, 해당 결과가 사용자에게 제시된다. 이러한 프리젠테이션은 컴퓨터-생성 파일을 통해 또는 그래픽 사용자 인터페이스(GUI)를 사용하여 이루어질 수 있다. 예를 들어, GUI는 파라미터 세트의 유형(아마도 공격성에 기초하여 번호가 매겨짐) 및 호출된 대립유전자의 수를 제시할 수 있다. 각 쌍을 이룬 데이터 세트를 클릭함으로써, 사용자는 일렉트로페로그램 또는 대립유전자 표 그 자체를 가시화시킬 수 있다.
DNA ID는 AES에 의해 호출되는 유전자좌의 수에 기초하여 통과 또는 실패로 규정될 수 있다. 이러한 규정은 전형적으로, DNA 데이터베이스를 검색하거나, 친족 관계, 혼합물 또는 기타 분석을 수행하는데 필요한 호출된 최소 유전자좌 수를 기반으로 한다. 유전자좌의 수는 에이전시 또는 사용자(바람직하게는, GUI-기반 형태 스크린을 사용함)에 의해 규정되며, 이러한 값은 AES로 전달된다. XML 파일은 샘플, 유전자좌 및 대립유전자 데이터에 대한 메타데이터를 함유하며, 데이터베이스의 검색과 양립가능한 포맷으로 출력된다(예를 들어, CODIS 소프트웨어, 및 US 국립 DNA 색인 시스템, 신속 DNA 색인 시스템, 주 DNA 색인 시스템, 지방 DNA 색인 시스템, 및 국제 DNA 색인 시스템을 포함하는 데이터베이스). XML 파일은 모든 샘플에 대해 생성되며, 그러나, AES는 샘플이 통과 또는 실패하는지의 여부에 기초하여 사용자에게 .XML 파일의 전송을 허용하거나 허용하지 않도록 구성될 수 있다.
일반적으로, 5가지 주요 클래스의 법의학적 샘플 및 상응하는 DNA ID가 존재한다:
ㆍ신속 DNA 또는 통상적인 실험실 DNA 식별 시스템의 전형적인 동적 범위 대비 적은 양의 DNA를 갖는 단일-소스 샘플(즉, 단일 기여자로부터의 게놈 DNA 함유)
ㆍ신속 DNA 또는 통상적인 실험실 DNA 식별 시스템의 전형적인 동적 범위 대비 많은 양의 DNA를 갖는 단일-소스 샘플
ㆍ신속 DNA 또는 통상적인 실험실 DNA 식별 시스템의 전형적인 동적 범위 내의 양의 DNA를 갖는 단일-소스 샘플
ㆍ2개 이상의 개체로부터의 DNA로 구성된 혼합물 샘플; 각 개체 제공자는 처음 3개 카테고리 중 하나에 속하는 DNA를 가짐. 이들 샘플에서, 각 도너로부터의 피크는 각 도너로부터의 상대적 양의 DNA에 상응하는 상대적 신호 강도로 DNA ID에 존재할 것이다. 혼합물 샘플은 증거 중의 다중 도너 게놈의 존재로 인한 것일 수 있거나 샘플 수집자, 샘플을 조작하는 개체로부터의 게놈에 의한 오염 또는 샘플을 처리하는데 사용된 시약 및 재료의 제조업체에 의한 오염으로 인한 것일 수 있다. 또한, 오염은 원래의 샘플에 존재하거나 부주의하게 샘플에 부가된 인간외 게놈의 존재로 인해 초래될 수 있다(예를 들어, 특정 박테리아 종은 특정 증폭 조건 하에 피크를 생성시킬 것이다).
ㆍ불균형 특징을 갖는 억제된/분해된 샘플. 예를 들어, 피크 높이는 피크 분자량 증가에 따라 고에서 저로(기울기), 피크 분자 중량 증가에 따라 저에서 고로(역기울기), 또는 구역적 기울기로 기울어질 수 있거나, 대립유전자-특이적 효과일 수 있다. 이러한 부류는 이전의 임의의 4개 부류와 중복될 수 있다.
다른 부류의 DNA ID는 샘플 유형, 처리 방식, 기기, 시약 및 소모품을 포함하는 광범위한 요인에 따라 가능하다. 예를 들어, (아마도 최적이 아닌 색상 수정 매트릭스로 인한 높은 신호의 부재하에서도) 과도한 블리드스루 피크를 갖는 DNA ID는 특정 광학 시스템이 사용되는 경우의 부류일 수 있다. "전형적인 동적 범위"는 본 발명의 AES의 부재하에 시스템의 동적 범위를 나타낸다. 예를 들어, 통상적인 DNA 식별 시스템의 전형적인 동적 범위는 PCR 반응으로 도입되는 0.1 ng 내지 3 ng의 정제된 DNA에 속할 수 있다.
심지어 동일한 소스 물질로부터의 샘플 중에서 대부분의 샘플 유형의 DNA 함량은 매우 변동성일 수 있다. 컵 또는 병의 면봉, 혈액얼룩, 조직 샘플(예를 들어, 근육, 뇌, 간, 신장, 방광), 성폭행 키트(SAK)로부터의 질 면봉, 담배 꽁초, 휴대폰, 키보드, 와이어 트위스트, 문 손잡이, 또는 뼈 단편에 상관없이, 샘플간 변동이 일반적이다. 변이의 소스는 조직 유형 자체(예를 들어, 더 높거나 낮은 세포 밀도를 갖는 조직 영역 - 및 오염물 DNA 함량); 셰딩 프로세스(shedding process)(예를 들어, 촉촉한 입을 갖는 사람은 건조한 입을 갖는 사람보다 담배 꽁초에 세포를 더 많이 남길 수 있음); 수집 프로세스(예를 들어, 휴대폰 배터리에서 지문의 완전한 수집은 덜 완전한 수집보다 더 많은 DNA를 생성할 수 있음); DNA와 함께 존재하는 억제제(예를 들어, 헴 및 데님은 특정 환경하에 증폭 과정을 억제하는 것으로 공지된 2개의 주요 화학물질임); 및 DNA 자체의 상태(불 또는 폭발에 노출된 DNA는 덜 까다로운 환경 조건하에 보관된 샘플로부터의 DNA보다 더욱 분해될 수 있음)일 수 있다. 전형적으로, 분해되고 억제된 샘플의 DNA ID는 증가되는 단편 크기에 따라 신호 강도 감소를 보인다. 이들 경우에, 큰 단편의 신호 강도는 표준 파라미터의 호출 요건보다 낮을 수 있다. 이러한 변동성을 수용하기 위해, 본원에 기술된 AES는 낮거나 높은 DNA 함량 또는 분해된 DNA 또는 억제된 DNA 또는 이들의 조합을 갖는 DNA ID를 인식하고, 이에 따라 호출 및 해석 규칙 및 파라미터 세트를 자동으로 적응시키도록 설계되고 프로그래밍되었다.
이러한 AES는 비전문 현장 운영자가 DNA 함량 또는 상태에 대해 전혀 알 필요없이 본질적으로 임의의 샘플 유형을 실행할 수 있게 한다는 점에서 특히 유용하다-실험실에서 법의학 과학자의 판단 및 실험 능력을 효과적으로 대체함. 실제로, AES는 오늘날 실험실에 걸쳐 발생하는 인간 대 인간의 변동성과 대조적으로 표준화된 방식으로 전문가 시스템 파라미터 세트 및 규직을 자동으로 조정한다는 점에서 실험실 과학자보다 우수하다.
일 양태에서, 본 발명은 프로그램 명령을 저장하는 메모리 및 프로그램 명령을 실행하는 프로세서를 갖는 컴퓨팅 장치를 포함하는 적응형 전문가 시스템을 특징으로 한다. 적응형 전문가 시스템은 DNA 분석 장치로부터의 미가공 데이터, 광학 데이터, 또는 일렉트로페로그램 데이터 중 적어도 하나를 포함하는 샘플 데이터를 수신하며, 상기 데이터는 DNA를 함유하는 샘플로부터 생성된다. 적응형 전문가 시스템은 상기 샘플 데이터로부터 베이스라인 DNA ID를 생성한다. 적응형 전문가 시스템은 베이스라인 DNA ID의 적어도 하나의 특징을 결정한다. 적응형 전문가 시스템은 베이스라인 DNA ID를 분류하고, 소정의 파라미터 세트를 상기 샘플 데이터에 적용하여 출력값을 생성시키는 적어도 하나의 특징을 활용한다.
상기 양태는 하기 특징 중 하나 이상을 포함할 수 있다. 일부 구체예에서, 출력값은 하기 중 하나 이상을 포함한다: .xml 파일, .fsa 파일, .bmp 파일, 또는 대립유전자 표. 일부 구체예에서, 적어도 하나의 특징은 신호 강도이다. 일부 구체예에서, 적어도 하나의 특징은 하기 중 하나 이상이다: 각 염료 채널의 신호 대 잡음 비, 피크 위치, 피크 염기 할당, 피크 단편 크기, 피크 색상, 피크 유전자좌, 피크 대립유전자 #, 피크 높이, 피크 폭, 피크 형상, 피크 형태, 피크 비대칭, 피크 폭 편차, 피크 형상 편차, 염기 신뢰, 이형접합체 피크 높이, 이형접합체 피크 높이 비율, 색상별 평균 이형접합체 피크 높이, 동형접합체 피크 높이, 색상별 평균 동형접합체 피크 높이, 유전자좌 내의 대립유전자의 상대적 신호 강도, 대립유전자 크기(예를 들어, 염기) 대비 대립유전자의 상대적 신호 강도, iNTA 피크 높이, iNTA 피크 높이 비율, 스터터(stutter) 피크 높이, 스터터 비율, ILS 성공, 유전자좌에서 피크의 수, 호출된 대립유전자의 수, 적색 경고 박스로 표지된 대립유전자의 수, 비표지된 대립유전자의 수, PH 임계값 미만의 PH의 대립유전자를 갖는 유전자좌의 수, PH 임계값보다 큰 PH의 대립유전자를 갖는 유전자좌의 수, PHR 임계값 미만의 PHR을 갖는 유전자좌의 수, PHR 임계값 초과의 PHR을 갖는 유전자좌의 수, 넓은 피크를 갖는 유전자좌의 수, iNTA 임계값 초과의 iNTA를 갖는 유전자좌의 수, 적색 경고 박스로 표지된 3개 이상의 피크를 갖는 유전자좌의 수, 적색 경고 박스로 표지된 4개 이상의 피크를 갖는 유전자좌의 수, 적색 경고 박스로 표지된 이형접합체 유전자좌의 수, 적색 경고 박스로 표지된 동형접합체 유전자좌의 수, 블리드-스루(bleed-through) 피크의 수, 호출된 CODIS20 유전자좌의 수, 호출된 CODIS 18 유전자좌의 수, 호출된 상염색체 유전자좌의 수, 호출된 플렉스 플렉스(flex plex) 유전자좌의 수, DNA ID 성공, 염기 할당, 염료 스펙트럼, 또는 처리된 염료 흔적.
일부 구체예에서, 출력값은 DNA ID의 데이터베이스를 검색하는데 사용된다. 일부 구체예에서, 출력값은 친족관계를 평가하기 위해 2개 이상의 DNA ID를 비교하는데 사용된다.
일부 구체예에서, 특징이 샘플 데이터를 높은 DNA 함량을 갖는 것으로 분류하는 경우, 적용된 소정의 파라미터 세트는 하기 중 적어도 하나를 수정한다: 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 동형접합체 피크 높이 임계값, 2nd 피크에 대한 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 비율 임계값, 반접합체 피크 높이 최소 임계값, 구역 1에서 대립유전자 PH/PA 임계값, 구역 2에서 대립유전자 PH/PA 임계값, 구역 3에서 대립유전자 PH/PA 임계값, 구역 4에서 대립유전자 PH/PA 임계값, 최대 드롭인(dropin) 수, 최대 드롭아웃(dropout) 수, 각 염료 채널의 신호 대 잡음 비율 임계값, 피크 염기 할당 한도, 피크 단편 크기 임계값, 피크 높이 임계값, 피크 폭 임계값, 피크 형상 임계값, 피크 형태 임계값, 피크 비대칭 임계값, 피크 폭 편차 한도, 피크 형상 편차 한도, 염기 신뢰 임계값, 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 색상별 평균 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 임계값, 색상별 평균 동형접합체 피크 높이 임계값, 유전자좌 내의 대립유전자의 상대적 신호 강도 임계값, 대립유전자 크기 대비 대립유전자의 상대적 신호 강도 임계값, iNTA 피크 높이 임계값, iNTA 피크 높이 비율 임계값, 스터터 피크 높이 임계값, 스터터 비율 임계값, 트리알레이트(triallate) 피크 높이 임계값, 삼대립유전자(triallele) 피크 높이 비율 임계값, 혼합물 피크 높이 임계값, ILS 성공 한도, 높은 iNTA 규칙 상태, 혼합물 샘플 보호 규칙 상태, 낮은 신호 보호 규칙 상태, 유전자좌에서 최대 피크 수, 최대 호출된 대립유전자 수, 적색 경고 박스로 표지된 최대 대립유전자 수 임계값, 비표지된 최대 대립유전자 수 임계값, PH 임계값 미만의 PH의 대립유전자를 갖는 최대 유전자좌 수, PH 임계값 초과의 PH의 대립유전자를 갖는 최대 유전자좌 수, PHR 임계값 미만의 PHR을 갖는 최대 유전자좌 수, PHR 임계값 초과의 PHR을 갖는 최대 유전자좌 수, 넓은 피크를 갖는 최대 유전자좌 수, iNTA 임계값 초과의 iNTA를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 3개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 4개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 최대 이형접합체 유전자좌 수, 적색 경고 박스로 표지된 최대 동형접합체 유전자좌 수, 최대 블리드-스루 피크 수, 호출된 최소 CODIS20 유전자좌 수, 호출된 최소 CODIS 18 유전자좌 수, 호출된 최소 상염색체 유전자좌 수, 호출된 최소 플렉스 플렉스 유전자좌 수, CMF 파일을 생성하기 위해 호출된 최소 유전자좌 수, DNA ID의 질(Quality) 임계값, 또는 검색 및 매치(match)의 질 임계값.
일부 구체예에서, 특징이 광학 데이터를 낮은 DNA 함량을 갖는 것으로 분류하는 경우, 적용된 소정의 파라미터 세트는 하기 중 적어도 하나를 수정한다: 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 동형접합체 피크 높이 임계값, 2nd 피크에 대한 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 비율 임계값, 반접합체 피크 높이 최소 임계값, 구역 1에서 대립유전자 PH/PA 임계값, 구역 2에서 대립유전자 PH/PA 임계값, 구역 3에서 대립유전자 PH/PA 임계값, 구역 4에서 대립유전자 PH/PA 임계값, 최대 드롭인 수, 최대 드롭아웃 수, 각 염료 채널의 신호 대 잡음 비율 임계값, 피크 염기 할당 한도, 피크 단편 크기 임계값, 피크 높이 임계값, 피크 폭 임계값, 피크 형상 임계값, 피크 형태 임계값, 피크 비대칭 임계값, 피크 폭 편차 한도, 피크 형상 편차 한도, 염기 신뢰 임계값, 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 색상별 평균 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 임계값, 색상별 평균 동형접합체 피크 높이 임계값, 유전자좌 내의 대립유전자의 상대적 신호 강도 임계값, 대립유전자 크기 대비 대립유전자의 상대적 신호 강도 임계값, iNTA 피크 높이 임계값, iNTA 피크 높이 비율 임계값, 스터터 피크 높이 임계값, 스터터 비율 임계값, 트리알레이트 피크 높이 임계값, 삼대립유전자 피크 높이 비율 임계값, 혼합물 피크 높이 임계값, ILS 성공 한도, 높은 iNTA 규칙 상태, 혼합물 샘플 보호 규칙 상태, 낮은 신호 보호 규칙 상태, 유전자좌에서 최대 피크 수, 최대 호출된 대립유전자 수, 적색 경고 박스로 표지된 최대 대립유전자 수 임계값, 비표지된 최대 대립유전자 수 임계값, PH 임계값 미만의 PH의 대립유전자를 갖는 최대 유전자좌 수, PH 임계값 초과의 PH의 대립유전자를 갖는 최대 유전자좌 수, PHR 임계값 미만의 PHR을 갖는 최대 유전자좌 수, PHR 임계값 초과의 PHR을 갖는 최대 유전자좌 수, 넓은 피크를 갖는 최대 유전자좌 수, iNTA 임계값 초과의 iNTA를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 3개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 4개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 최대 이형접합체 유전자좌 수, 적색 경고 박스로 표지된 최대 동형접합체 유전자좌 수, 최대 블리드-스루 피크 수, 호출된 최소 CODIS20 유전자좌 수, 호출된 최소 CODIS 18 유전자좌 수, 호출된 최소 상염색체 유전자좌 수, 호출된 최소 플렉스 플렉스 유전자좌 수, CMF 파일을 생성하기 위해 호출된 최소 유전자좌 수, DNA ID의 질 임계값, 또는 검색 및 매치의 질 임계값.
일부 구체예에서, 특징이 샘플 데이터를 혼합물로서 분류하는 경우, 적용된 소정의 파라미터 세트는 하기 중 적어도 하나를 수정한다: 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 동형접합체 피크 높이 임계값, 2nd 피크에 대한 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 비율 임계값, 반접합체 피크 높이 최소 임계값, 구역 1에서 대립유전자 PH/PA 임계값, 구역 2에서 대립유전자 PH/PA 임계값, 구역 3에서 대립유전자 PH/PA 임계값, 구역 4에서 대립유전자 PH/PA 임계값, 최대 드롭인 수, 최대 드롭아웃 수, 각 염료 채널의 신호 대 잡음 비율 임계값, 피크 염기 할당 한도, 피크 단편 크기 임계값, 피크 높이 임계값, 피크 폭 임계값, 피크 형상 임계값, 피크 형태 임계값, 피크 비대칭 임계값, 피크 폭 편차 한도, 피크 형상 편차 한도, 염기 신뢰 임계값, 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 색상별 평균 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 임계값, 색상별 평균 동형접합체 피크 높이 임계값, 유전자좌 내의 대립유전자의 상대적 신호 강도 임계값, 대립유전자 크기 대비 대립유전자의 상대적 신호 강도 임계값, iNTA 피크 높이 임계값, iNTA 피크 높이 비율 임계값, 스터터 피크 높이 임계값, 스터터 비율 임계값, 트리알레이트 피크 높이 임계값, 삼대립유전자 피크 높이 비율 임계값, 혼합물 피크 높이 임계값, ILS 성공 한도, 높은 iNTA 규칙 상태, 혼합물 샘플 보호 규칙 상태, 낮은 신호 보호 규칙 상태, 유전자좌에서 최대 피크 수, 최대 호출된 대립유전자 수, 적색 경고 박스로 표지된 최대 대립유전자 수 임계값, 비표지된 최대 대립유전자 수 임계값, PH 임계값 미만의 PH의 대립유전자를 갖는 최대 유전자좌 수, PH 임계값 초과의 PH의 대립유전자를 갖는 최대 유전자좌 수, PHR 임계값 미만의 PHR을 갖는 최대 유전자좌 수, PHR 임계값 초과의 PHR을 갖는 최대 유전자좌 수, 넓은 피크를 갖는 최대 유전자좌 수, iNTA 임계값 초과의 iNTA를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 3개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 4개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 최대 이형접합체 유전자좌 수, 적색 경고 박스로 표지된 최대 동형접합체 유전자좌 수, 최대 블리드-스루 피크 수, 호출된 최소 CODIS20 유전자좌 수, 호출된 최소 CODIS 18 유전자좌 수, 호출된 최소 상염색체 유전자좌 수, 호출된 최소 플렉스 플렉스 유전자좌 수, CMF 파일을 생성하기 위해 호출된 최소 유전자좌 수, DNA ID의 질 임계값, 또는 검색 및 매치의 질 임계값. 일부 구체예에서, 적용된 소정의 파라미터 세트는 호출된 대립유전자 제1 세트를 생성하며, 상기 호출된 대립유전자는 샘플 데이터로부터 추출되어 수정된 샘플 데이터를 생성하며, 적응형 전문가 시스템은 적어도 하나의 특징을 이용하여 수정된 샘플 데이터를 분류하고, 소정의 파라미터 세트를 상기 수정된 샘플 데이터에 적용하여 호출된 대립유전자 제2 세트를 생성한다.
일부 구체예에서, 특징이 샘플 데이터를 억제되고/거나 분해된 것으로서 분류하는 경우, 적용된 소정의 파라미터 세트는 하기 중 적어도 하나를 수정한다: 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 동형접합체 피크 높이 임계값, 2nd 피크에 대한 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 비율 임계값, 반접합체 피크 높이 최소 임계값, 구역 1에서 대립유전자 PH/PA 임계값, 구역 2에서 대립유전자 PH/PA 임계값, 구역 3에서 대립유전자 PH/PA 임계값, 구역 4에서 대립유전자 PH/PA 임계값, 최대 드롭인 수, 최대 드롭아웃 수, 각 염료 채널의 신호 대 잡음 비율 임계값, 피크 염기 할당 한도, 피크 단편 크기 임계값, 피크 높이 임계값, 피크 폭 임계값, 피크 형상 임계값, 피크 형태 임계값, 피크 비대칭 임계값, 피크 폭 편차 한도, 피크 형상 편차 한도, 염기 신뢰 임계값, 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 색상별 평균 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 임계값, 색상별 평균 동형접합체 피크 높이 임계값, 유전자좌 내의 대립유전자의 상대적 신호 강도 임계값, 대립유전자 크기 대비 대립유전자의 상대적 신호 강도 임계값, iNTA 피크 높이 임계값, iNTA 피크 높이 비율 임계값, 스터터 피크 높이 임계값, 스터터 비율 임계값, 트리알레이트 피크 높이 임계값, 삼대립유전자 피크 높이 비율 임계값, 혼합물 피크 높이 임계값, ILS 성공 한도, 높은 iNTA 규칙 상태, 혼합물 샘플 보호 규칙 상태, 낮은 신호 보호 규칙 상태, 유전자좌에서 최대 피크 수, 최대 호출된 대립유전자 수, 적색 경고 박스로 표지된 최대 대립유전자 수 임계값, 비표지된 최대 대립유전자 수 임계값, PH 임계값 미만의 PH의 대립유전자를 갖는 최대 유전자좌 수, PH 임계값 초과의 PH의 대립유전자를 갖는 최대 유전자좌 수, PHR 임계값 미만의 PHR을 갖는 최대 유전자좌 수, PHR 임계값 초과의 PHR을 갖는 최대 유전자좌 수, 넓은 피크를 갖는 최대 유전자좌 수, iNTA 임계값 초과의 iNTA를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 3개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 4개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 최대 이형접합체 유전자좌 수, 적색 경고 박스로 표지된 최대 동형접합체 유전자좌 수, 최대 블리드-스루 피크 수, 호출된 최소 CODIS20 유전자좌 수, 호출된 최소 CODIS 18 유전자좌 수, 호출된 최소 상염색체 유전자좌 수, 호출된 최소 플렉스 플렉스 유전자좌 수, CMF 파일을 생성하기 위해 호출된 최소 유전자좌 수, DNA ID의 질 임계값, 또는 검색 및 매치의 질 임계값.
일부 구체예에서, 베이스라인 DNA ID 분류 및 소정의 파라미터 세트 적용에 기초하여, 컴퓨팅 장치는 DNA ID를 분류하고 소정의 파라미터 세트를 적용하는데 이용되는 하나 이상의 특징의 값을 수정한다. 일부 구체예에서, 베이스라인 DNA ID 분류 및 소정의 파라미터 세트 적용에 기초하여, 컴퓨팅 장치는 DNA ID에 적용할 경우 출력값을 생성하는데 이용되는 하나 이상의 소정의 파라미터 세트를 수정한다. 일부 구체예에서, 컴퓨팅 장치는 디스플레이 장치에의 제시를 위한 출력값의 가시화를 생성한다. 일부 구체예에서, 가시화는 하나 이상의 파라미터 세트 각각에 대해 호출된 대립유전자의 수를 포함한다.
또 다른 양태에서, 본 발명은 프로그램 명령을 저장하는 메모리 및 프로그램 명령을 실행하는 프로세서를 갖는 컴퓨팅 장치를 포함하는 적응형 전문가 시스템을 특징으로 한다. 적응형 전문가 시스템은 DNA 분석 장치로부터의 미가공 데이터, 광학 데이터, 및 일렉트로페로그램 데이터 중 적어도 하나를 포함하는 샘플 데이터를 수신하며, 상기 데이터는 DNA를 함유하는 샘플로부터 생성된다. 적응형 전문가 시스템은 샘플 데이터의 적어도 하나의 특징을 결정한다. 적응형 전문가 시스템은 적어도 하나의 특징을 이용하여 샘플 데이터를 분류하고, 소정의 파라미터 세트를 상기 샘플 데이터에 적용하여 출력값을 생성한다.
상기 양태는 하기 특징 중 하나 이상을 포함할 수 있다. 일부 구체예에서, 출력값은 하기 중 하나 이상을 포함한다: .xml 파일, .fsa 파일, .bmp 파일, 또는 대립유전자 표. 일부 구체예에서, 적어도 하나의 특징은 신호 강도이다. 일부 구체예에서, 적어도 하나의 특징은 하기 중 하나 이상이다: 각 염료 채널의 신호 대 잡음 비, 피크 위치, 피크 염기 할당, 피크 단편 크기, 피크 색상, 피크 유전자좌, 피크 대립유전자 #, 피크 높이, 피크 폭, 피크 형상, 피크 형태, 피크 비대칭, 피크 폭 편차, 피크 형상 편차, 염기 신뢰, 이형접합체 피크 높이, 이형접합체 피크 높이 비율, 색상별 평균 이형접합체 피크 높이, 동형접합체 피크 높이, 색상별 평균 동형접합체 피크 높이, 유전자좌 내의 대립유전자의 상대적 신호 강도, 대립유전자 크기(예를 들어, 염기) 대비 대립유전자의 상대적 신호 강도, iNTA 피크 높이, iNTA 피크 높이 비율, 스터터 피크 높이, 스터터 비율, ILS 성공, 유전자좌에서 피크의 수, 호출된 대립유전자의 수, 적색 경고 박스로 표지된 대립유전자의 수, 비표지된 대립유전자의 수, PH 임계값 미만의 PH의 대립유전자를 갖는 유전자좌의 수, PH 임계값보다 큰 PH의 대립유전자를 갖는 유전자좌의 수, PHR 임계값 미만의 PHR을 갖는 유전자좌의 수, PHR 임계값 초과의 PHR을 갖는 유전자좌의 수, 넓은 피크를 갖는 유전자좌의 수, iNTA 임계값 초과의 iNTA를 갖는 유전자좌의 수, 적색 경고 박스로 표지된 3개 이상의 피크를 갖는 유전자좌의 수, 적색 경고 박스로 표지된 4개 이상의 피크를 갖는 유전자좌의 수, 적색 경고 박스로 표지된 이형접합체 유전자좌의 수, 적색 경고 박스로 표지된 동형접합체 유전자좌의 수, 블리드-스루 피크의 수, 호출된 CODIS20 유전자좌의 수, 호출된 CODIS 18 유전자좌의 수, 호출된 상염색체 유전자좌의 수, 호출된 플렉스 플렉스 유전자좌의 수, DNA ID 성공, 염기 할당, 염료 스펙트럼, 또는 처리된 염료.
일부 구체예에서, 출력값은 DNA ID의 데이터베이스를 검색하는데 이용된다. 일부 구체예에서, 출력값은 친족관계를 평가하기 위해 2개 이상의 DNA ID를 비교하는데 이용된다.
일부 구체예에서, 특징이 샘플 데이터를 높은 DNA 함량을 갖는 것으로 분류하는 경우, 적용된 소정의 파라미터 세트는 하기 중 적어도 하나를 수정한다: 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 동형접합체 피크 높이 임계값, 2nd 피크에 대한 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 비율 임계값, 반접합체 피크 높이 최소 임계값, 구역 1에서 대립유전자 PH/PA 임계값, 구역 2에서 대립유전자 PH/PA 임계값, 구역 3에서 대립유전자 PH/PA 임계값, 구역 4에서 대립유전자 PH/PA 임계값, 최대 드롭인 수, 최대 드롭아웃 수, 각 염료 채널의 신호 대 잡음 비율 임계값, 피크 염기 할당 한도, 피크 단편 크기 임계값, 피크 높이 임계값, 피크 폭 임계값, 피크 형상 임계값, 피크 형태 임계값, 피크 비대칭 임계값, 피크 폭 편차 한도, 피크 형상 편차 한도, 염기 신뢰 임계값, 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 색상별 평균 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 임계값, 색상별 평균 동형접합체 피크 높이 임계값, 유전자좌 내의 대립유전자의 상대적 신호 강도 임계값, 대립유전자 크기 대비 대립유전자의 상대적 신호 강도 임계값, iNTA 피크 높이 임계값, iNTA 피크 높이 비율 임계값, 스터터 피크 높이 임계값, 스터터 비율 임계값, 트리알레이트 피크 높이 임계값, 삼대립유전자 피크 높이 비율 임계값, 혼합물 피크 높이 임계값, ILS 성공 한도, 높은 iNTA 규칙 상태, 혼합물 샘플 보호 규칙 상태, 낮은 신호 보호 규칙 상태, 유전자좌에서 최대 피크 수, 최대 호출된 대립유전자 수, 적색 경고 박스로 표지된 최대 대립유전자 수 임계값, 비표지된 최대 대립유전자 수 임계값, PH 임계값 미만의 PH의 대립유전자를 갖는 최대 유전자좌 수, PH 임계값 초과의 PH의 대립유전자를 갖는 최대 유전자좌 수, PHR 임계값 미만의 PHR을 갖는 최대 유전자좌 수, PHR 임계값 초과의 PHR을 갖는 최대 유전자좌 수, 넓은 피크를 갖는 최대 유전자좌 수, iNTA 임계값 초과의 iNTA를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 3개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 4개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 최대 이형접합체 유전자좌 수, 적색 경고 박스로 표지된 최대 동형접합체 유전자좌 수, 최대 블리드-스루 피크 수, 호출된 최소 CODIS20 유전자좌 수, 호출된 최소 CODIS 18 유전자좌 수, 호출된 최소 상염색체 유전자좌 수, 호출된 최소 플렉스 플렉스 유전자좌 수, CMF 파일을 생성하기 위해 호출된 최소 유전자좌 수, DNA ID의 질 임계값, 또는 검색 및 매치의 질 임계값.
일부 구체예에서, 특징이 샘플 데이터를 낮은 DNA 함량을 갖는 것으로 분류하는 경우, 적용된 소정의 파라미터 세트는 하기 중 적어도 하나를 수정한다: 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 동형접합체 피크 높이 임계값, 2nd 피크에 대한 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 비율 임계값, 반접합체 피크 높이 최소 임계값, 구역 1에서 대립유전자 PH/PA 임계값, 구역 2에서 대립유전자 PH/PA 임계값, 구역 3에서 대립유전자 PH/PA 임계값, 구역 4에서 대립유전자 PH/PA 임계값, 최대 드롭인 수, 최대 드롭아웃 수, 각 염료 채널의 신호 대 잡음 비율 임계값, 피크 염기 할당 한도, 피크 단편 크기 임계값, 피크 높이 임계값, 피크 폭 임계값, 피크 형상 임계값, 피크 형태 임계값, 피크 비대칭 임계값, 피크 폭 편차 한도, 피크 형상 편차 한도, 염기 신뢰 임계값, 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 색상별 평균 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 임계값, 색상별 평균 동형접합체 피크 높이 임계값, 유전자좌 내의 대립유전자의 상대적 신호 강도 임계값, 대립유전자 크기 대비 대립유전자의 상대적 신호 강도 임계값, iNTA 피크 높이 임계값, iNTA 피크 높이 비율 임계값, 스터터 피크 높이 임계값, 스터터 비율 임계값, 트리알레이트 피크 높이 임계값, 삼대립유전자 피크 높이 비율 임계값, 혼합물 피크 높이 임계값, ILS 성공 한도, 높은 iNTA 규칙 상태, 혼합물 샘플 보호 규칙 상태, 낮은 신호 보호 규칙 상태, 유전자좌에서 최대 피크 수, 최대 호출된 대립유전자 수, 적색 경고 박스로 표지된 최대 대립유전자 수 임계값, 비표지된 최대 대립유전자 수 임계값, PH 임계값 미만의 PH의 대립유전자를 갖는 최대 유전자좌 수, PH 임계값 초과의 PH의 대립유전자를 갖는 최대 유전자좌 수, PHR 임계값 미만의 PHR을 갖는 최대 유전자좌 수, PHR 임계값 초과의 PHR을 갖는 최대 유전자좌 수, 넓은 피크를 갖는 최대 유전자좌 수, iNTA 임계값 초과의 iNTA를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 3개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 4개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 최대 이형접합체 유전자좌 수, 적색 경고 박스로 표지된 최대 동형접합체 유전자좌 수, 최대 블리드-스루 피크 수, 호출된 최소 CODIS20 유전자좌 수, 호출된 최소 CODIS 18 유전자좌 수, 호출된 최소 상염색체 유전자좌 수, 호출된 최소 플렉스 플렉스 유전자좌 수, CMF 파일을 생성하기 위해 호출된 최소 유전자좌 수, DNA ID의 질 임계값, 또는 검색 및 매치의 질 임계값.
일부 구체예에서, 특징이 샘플 데이터를 혼합물로서 분류하는 경우, 적용된 소정의 파라미터 세트는 하기 중 적어도 하나를 수정한다: 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 동형접합체 피크 높이 임계값, 2nd 피크에 대한 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 비율 임계값, 반접합체 피크 높이 최소 임계값, 구역 1에서 대립유전자 PH/PA 임계값, 구역 2에서 대립유전자 PH/PA 임계값, 구역 3에서 대립유전자 PH/PA 임계값, 구역 4에서 대립유전자 PH/PA 임계값, 최대 드롭인 수, 최대 드롭아웃 수, 각 염료 채널의 신호 대 잡음 비율 임계값, 피크 염기 할당 한도, 피크 단편 크기 임계값, 피크 높이 임계값, 피크 폭 임계값, 피크 형상 임계값, 피크 형태 임계값, 피크 비대칭 임계값, 피크 폭 편차 한도, 피크 형상 편차 한도, 염기 신뢰 임계값, 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 색상별 평균 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 임계값, 색상별 평균 동형접합체 피크 높이 임계값, 유전자좌 내의 대립유전자의 상대적 신호 강도 임계값, 대립유전자 크기 대비 대립유전자의 상대적 신호 강도 임계값, iNTA 피크 높이 임계값, iNTA 피크 높이 비율 임계값, 스터터 피크 높이 임계값, 스터터 비율 임계값, 트리알레이트 피크 높이 임계값, 삼대립유전자 피크 높이 비율 임계값, 혼합물 피크 높이 임계값, ILS 성공 한도, 높은 iNTA 규칙 상태, 혼합물 샘플 보호 규칙 상태, 낮은 신호 보호 규칙 상태, 유전자좌에서 최대 피크 수, 최대 호출된 대립유전자 수, 적색 경고 박스로 표지된 최대 대립유전자 수 임계값, 비표지된 최대 대립유전자 수 임계값, PH 임계값 미만의 PH의 대립유전자를 갖는 최대 유전자좌 수, PH 임계값 초과의 PH의 대립유전자를 갖는 최대 유전자좌 수, PHR 임계값 미만의 PHR을 갖는 최대 유전자좌 수, PHR 임계값 초과의 PHR을 갖는 최대 유전자좌 수, 넓은 피크를 갖는 최대 유전자좌 수, iNTA 임계값 초과의 iNTA를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 3개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 4개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 최대 이형접합체 유전자좌 수, 적색 경고 박스로 표지된 최대 동형접합체 유전자좌 수, 최대 블리드-스루 피크 수, 호출된 최소 CODIS20 유전자좌 수, 호출된 최소 CODIS 18 유전자좌 수, 호출된 최소 상염색체 유전자좌 수, 호출된 최소 플렉스 플렉스 유전자좌 수, CMF 파일을 생성하기 위해 호출된 최소 유전자좌 수, DNA ID의 질 임계값, 또는 검색 및 매치의 질 임계값. 일부 구체예에서, 적용된 소정의 파라미터 세트는 호출된 대립유전자 제1 세트를 생성하며, 상기 호출된 대립유전자는 샘플 데이터로부터 추출되어 수정된 샘플 데이터를 생성하며, 적응형 전문가 시스템은 적어도 하나의 특징을 이용하여 수정된 샘플 데이터를 분류하고, 소정의 파라미터 세트를 상기 수정된 샘플 데이터에 적용하여 호출된 대립유전자 제2 세트를 생성한다.
일부 구체예에서, 특징이 샘플 데이터를 억제되고/거나 분해된 것으로서 분류하는 경우, 적용된 소정의 파라미터 세트는 하기 중 적어도 하나를 수정한다: 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 동형접합체 피크 높이 임계값, 2nd 피크에 대한 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 비율 임계값, 반접합체 피크 높이 최소 임계값, 구역 1에서 대립유전자 PH/PA 임계값, 구역 2에서 대립유전자 PH/PA 임계값, 구역 3에서 대립유전자 PH/PA 임계값, 구역 4에서 대립유전자 PH/PA 임계값, 최대 드롭인 수, 최대 드롭아웃 수, 각 염료 채널의 신호 대 잡음 비율 임계값, 피크 염기 할당 한도, 피크 단편 크기 임계값, 피크 높이 임계값, 피크 폭 임계값, 피크 형상 임계값, 피크 형태 임계값, 피크 비대칭 임계값, 피크 폭 편차 한도, 피크 형상 편차 한도, 염기 신뢰 임계값, 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 색상별 평균 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 임계값, 색상별 평균 동형접합체 피크 높이 임계값, 유전자좌 내의 대립유전자의 상대적 신호 강도 임계값, 대립유전자 크기 대비 대립유전자의 상대적 신호 강도 임계값, iNTA 피크 높이 임계값, iNTA 피크 높이 비율 임계값, 스터터 피크 높이 임계값, 스터터 비율 임계값, 트리알레이트 피크 높이 임계값, 삼대립유전자 피크 높이 비율 임계값, 혼합물 피크 높이 임계값, ILS 성공 한도, 높은 iNTA 규칙 상태, 혼합물 샘플 보호 규칙 상태, 낮은 신호 보호 규칙 상태, 유전자좌에서 최대 피크 수, 최대 호출된 대립유전자 수, 적색 경고 박스로 표지된 최대 대립유전자 수 임계값, 비표지된 최대 대립유전자 수 임계값, PH 임계값 미만의 PH의 대립유전자를 갖는 최대 유전자좌 수, PH 임계값 초과의 PH의 대립유전자를 갖는 최대 유전자좌 수, PHR 임계값 미만의 PHR을 갖는 최대 유전자좌 수, PHR 임계값 초과의 PHR을 갖는 최대 유전자좌 수, 넓은 피크를 갖는 최대 유전자좌 수, iNTA 임계값 초과의 iNTA를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 3개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 4개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 최대 이형접합체 유전자좌 수, 적색 경고 박스로 표지된 최대 동형접합체 유전자좌 수, 최대 블리드-스루 피크 수, 호출된 최소 CODIS20 유전자좌 수, 호출된 최소 CODIS 18 유전자좌 수, 호출된 최소 상염색체 유전자좌 수, 호출된 최소 플렉스 플렉스 유전자좌 수, CMF 파일을 생성하기 위해 호출된 최소 유전자좌 수, DNA ID의 질 임계값, 또는 검색 및 매치의 질 임계값.
일부 구체예에서, 샘플 데이터 분류 및 소정의 파라미터 세트 적용에 기초하여, 컴퓨팅 장치는 샘플 데이터를 분류하고 소정의 파라미터 세트를 적용하는데 이용되는 하나 이상의 특징의 값을 수정한다. 일부 구체예에서, 샘플 데이터 분류 및 소정의 파라미터 세트 적용에 기초하여, 컴퓨팅 장치는 DNA ID에 적용할 경우 출력값을 생성하는데 이용되는 하나 이상의 소정의 파라미터 세트를 수정한다. 일부 구체예에서, 컴퓨팅 장치는 디스플레이 장치에의 제시를 위한 출력값의 가시화를 생성한다. 일부 구체예에서, 가시화는 하나 이상의 파라미터 세트 각각에 대해 호출된 대립유전자의 수를 포함한다.
또 다른 양태에서, 본 발명은 프로그램 명령을 저장하는 메모리 및 프로그램 명령을 실행하는 프로세서를 갖는 컴퓨팅 장치를 포함하는 적응형 전문가 시스템을 특징으로 한다. 적응형 전문가 시스템은 분석 장치로부터의 데이터를 수신하며, 상기 데이터는 분석물을 함유하는 샘플로부터 생성된다. 적응형 전문가 시스템은 데이터를 이용하여 분석물의 적어도 하나의 특징을 결정한다. 적응형 전문가 시스템은 적어도 하나의 특징을 이용하여 데이터를 분류하고, 소정의 파라미터 세트를 데이터에 적용하여 출력값을 생성한다.
상기 양태는 하기 특징 중 하나 이상을 포함할 수 있다. 일부 구체예에서, 분석물은 하기 중 하나 이상이다: 단백질, 펩티드, 메신저 RNA, 안티센스 RNA, 트랜스퍼 RNA, 리보솜 RNA, 기타 RNA, 핵산, 올리고뉴클레오티드, 단일 뉴클레오티드 다형체를 함유하는 DNA 또는 RNA 단편, 지질, 탄수화물, 대사산물, 스테로이드, 합성 폴리머, 기타 거대분자, 무기 또는 기타 유기 화학물질, 또는 이러한 분석물의 조합물.
또 다른 양태에서, 본 발명은 프로그램 명령을 저장하는 메모리 및 프로그램 명령을 실행하는 프로세서를 갖는 컴퓨팅 장치를 포함하는 적응형 전문가 시스템을 특징으로 한다. 적응형 전문가 시스템은 DNA 분석 장치로부터 데이터를 수신하며, 상기 데이터는 적어도 하나의 주류 기여자 및 적어도 하나의 비주류 기여자로부터의 복수의 게놈 DNA를 함유하는 샘플로부터 생성된다. 적응형 전문가 시스템은 데이터를 이용하여, 주류 기여자에 상응하는 제1 DNA ID의 적어도 하나의 특징을 결정한다. 적응형 전문가 시스템은 특징을 이용하여 제1 DNA ID를 분류하고, 소정의 파라미터 세트를 데이터에 적용한다. 적응형 전문가 시스템은 제1 DNA ID로부터 하나 이상의 특징을 감하여 비주류 기여자에 상응하는 제2 DNA ID의 적어도 하나의 특징을 결정한다.
또 다른 양태에서, 본 발명은 의사 결정 노드 세트를 갖는 컴퓨팅 장치를 포함하는 적응형 전문가 시스템을 특징으로 하며, 상기 노드는 알려된 출력값을 갖는 샘플 데이터 세트가 제시되는 경우 자체-학습할 수 있으며, 상기 컴퓨팅 장치는 프로그램 명령을 저장하는 메모리 및 프로그램 명령을 수행하는 프로세서를 갖는다. 적응형 전문가 시스템은 DNA 분석 장치로부터 미가공 데이터, 광학 데이터, 및 일렉트로페로그램 데이터 중 적어도 하나를 포함하는 샘플 데이터를 수신하며, 상기 데이터는 DNA를 함유하는 샘플로부터 생성된다. 적응형 전문가 시스템은 샘플 데이터의 적어도 하나의 특징을 결정한다. 적응형 전문가 시스템은 상기 의사 결정 노드 세트를 적용하여 샘플 데이터로부터의 주어진 특징 세트에 대한 최적 세트의 전문가 시스템 파라미터를 생성하며; 최적의 전문가 시스템 파라미터 세트를 상기 샘플 데이터에 적용하여 출력값을 생성한다.
상기 양태는 하기 특징 중 하나 이상을 포함할 수 있다. 일부 구체예에서, 출력값은 하기 중 하나 이상을 포함한다: .xml 파일, .fsa 파일, .bmp 파일, 또는 대립유전자 표. 일부 구체예에서, 적어도 하나의 특징은 신호 강도이다. 일부 구체예에서, 적어도 하나의 특징은 하기 중 하나 이상이다: 각 염료 채널의 신호 대 잡음 비, 피크 위치, 피크 염기 할당, 피크 단편 크기, 피크 색상, 피크 유전자좌, 피크 대립유전자 #, 피크 높이, 피크 폭, 피크 형상, 피크 형태, 피크 비대칭, 피크 폭 편차, 피크 형상 편차, 염기 신뢰, 이형접합체 피크 높이, 이형접합체 피크 높이 비율, 색상별 평균 이형접합체 피크 높이, 동형접합체 피크 높이, 색상별 평균 동형접합체 피크 높이, 유전자좌 내의 대립유전자의 상대적 신호 강도, 대립유전자 크기(예를 들어, 염기) 대비 대립유전자의 상대적 신호 강도, iNTA 피크 높이, iNTA 피크 높이 비율, 스터터 피크 높이, 스터터 비율, ILS 성공, 유전자좌에서 피크의 수, 호출된 대립유전자의 수, 적색 경고 박스로 표지된 대립유전자의 수, 비표지된 대립유전자의 수, PH 임계값 미만의 PH의 대립유전자를 갖는 유전자좌의 수, PH 임계값보다 큰 PH의 대립유전자를 갖는 유전자좌의 수, PHR 임계값 미만의 PHR을 갖는 유전자좌의 수, PHR 임계값 초과의 PHR을 갖는 유전자좌의 수, 넓은 피크를 갖는 유전자좌의 수, iNTA 임계값 초과의 iNTA를 갖는 유전자좌의 수, 적색 경고 박스로 표지된 3개 이상의 피크를 갖는 유전자좌의 수, 적색 경고 박스로 표지된 4개 이상의 피크를 갖는 유전자좌의 수, 적색 경고 박스로 표지된 이형접합체 유전자좌의 수, 적색 경고 박스로 표지된 동형접합체 유전자좌의 수, 블리드-스루 피크의 수, 호출된 CODIS20 유전자좌의 수, 호출된 CODIS 18 유전자좌의 수, 호출된 상염색체 유전자좌의 수, 호출된 플렉스 플렉스 유전자좌의 수, DNA ID 성공, 염기 할당, 염료 스펙트럼, 또는 처리된 염료 흔적.
일부 구체예에서, 출력값은 DNA ID의 데이터베이스를 검색하는데 이용된다. 일부 구체예에서, 출력값은 친족관계를 평가하기 위해 2개 이상의 DNA ID를 비교하는데 이용된다.
일부 구체예에서, 특징이 샘플 데이터를 높은 DNA 함량을 갖는 것으로 분류하는 경우, 적용된 소정의 파라미터 세트는 하기 중 적어도 하나를 수정한다: 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 동형접합체 피크 높이 임계값, 2nd 피크에 대한 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 비율 임계값, 반접합체 피크 높이 최소 임계값, 구역 1에서 대립유전자 PH/PA 임계값, 구역 2에서 대립유전자 PH/PA 임계값, 구역 3에서 대립유전자 PH/PA 임계값, 구역 4에서 대립유전자 PH/PA 임계값, 최대 드롭인 수, 최대 드롭아웃 수, 각 염료 채널의 신호 대 잡음 비율 임계값, 피크 염기 할당 한도, 피크 단편 크기 임계값, 피크 높이 임계값, 피크 폭 임계값, 피크 형상 임계값, 피크 형태 임계값, 피크 비대칭 임계값, 피크 폭 편차 한도, 피크 형상 편차 한도, 염기 신뢰 임계값, 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 색상별 평균 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 임계값, 색상별 평균 동형접합체 피크 높이 임계값, 유전자좌 내의 대립유전자의 상대적 신호 강도 임계값, 대립유전자 크기 대비 대립유전자의 상대적 신호 강도 임계값, iNTA 피크 높이 임계값, iNTA 피크 높이 비율 임계값, 스터터 피크 높이 임계값, 스터터 비율 임계값, 트리알레이트 피크 높이 임계값, 삼대립유전자 피크 높이 비율 임계값, 혼합물 피크 높이 임계값, ILS 성공 한도, 높은 iNTA 규칙 상태, 혼합물 샘플 보호 규칙 상태, 낮은 신호 보호 규칙 상태, 유전자좌에서 최대 피크 수, 최대 호출된 대립유전자 수, 적색 경고 박스로 표지된 최대 대립유전자 수 임계값, 비표지된 최대 대립유전자 수 임계값, PH 임계값 미만의 PH의 대립유전자를 갖는 최대 유전자좌 수, PH 임계값 초과의 PH의 대립유전자를 갖는 최대 유전자좌 수, PHR 임계값 미만의 PHR을 갖는 최대 유전자좌 수, PHR 임계값 초과의 PHR을 갖는 최대 유전자좌 수, 넓은 피크를 갖는 최대 유전자좌 수, iNTA 임계값 초과의 iNTA를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 3개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 4개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 최대 이형접합체 유전자좌 수, 적색 경고 박스로 표지된 최대 동형접합체 유전자좌 수, 최대 블리드-스루 피크 수, 호출된 최소 CODIS20 유전자좌 수, 호출된 최소 CODIS 18 유전자좌 수, 호출된 최소 상염색체 유전자좌 수, 호출된 최소 플렉스 플렉스 유전자좌 수, CMF 파일을 생성하기 위해 호출된 최소 유전자좌 수, DNA ID의 질 임계값, 또는 검색 및 매치의 질 임계값.
일부 구체예에서, 특징이 샘플 데이터를 낮은 DNA 함량을 갖는 것으로 분류하는 경우, 적용된 소정의 파라미터 세트는 하기 중 적어도 하나를 수정한다: 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 동형접합체 피크 높이 임계값, 2nd 피크에 대한 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 비율 임계값, 반접합체 피크 높이 최소 임계값, 구역 1에서 대립유전자 PH/PA 임계값, 구역 2에서 대립유전자 PH/PA 임계값, 구역 3에서 대립유전자 PH/PA 임계값, 구역 4에서 대립유전자 PH/PA 임계값, 최대 드롭인 수, 최대 드롭아웃 수, 각 염료 채널의 신호 대 잡음 비율 임계값, 피크 염기 할당 한도, 피크 단편 크기 임계값, 피크 높이 임계값, 피크 폭 임계값, 피크 형상 임계값, 피크 형태 임계값, 피크 비대칭 임계값, 피크 폭 편차 한도, 피크 형상 편차 한도, 염기 신뢰 임계값, 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 색상별 평균 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 임계값, 색상별 평균 동형접합체 피크 높이 임계값, 유전자좌 내의 대립유전자의 상대적 신호 강도 임계값, 대립유전자 크기 대비 대립유전자의 상대적 신호 강도 임계값, iNTA 피크 높이 임계값, iNTA 피크 높이 비율 임계값, 스터터 피크 높이 임계값, 스터터 비율 임계값, 트리알레이트 피크 높이 임계값, 삼대립유전자 피크 높이 비율 임계값, 혼합물 피크 높이 임계값, ILS 성공 한도, 높은 iNTA 규칙 상태, 혼합물 샘플 보호 규칙 상태, 낮은 신호 보호 규칙 상태, 유전자좌에서 최대 피크 수, 최대 호출된 대립유전자 수, 적색 경고 박스로 표지된 최대 대립유전자 수 임계값, 비표지된 최대 대립유전자 수 임계값, PH 임계값 미만의 PH의 대립유전자를 갖는 최대 유전자좌 수, PH 임계값 초과의 PH의 대립유전자를 갖는 최대 유전자좌 수, PHR 임계값 미만의 PHR을 갖는 최대 유전자좌 수, PHR 임계값 초과의 PHR을 갖는 최대 유전자좌 수, 넓은 피크를 갖는 최대 유전자좌 수, iNTA 임계값 초과의 iNTA를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 3개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 4개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 최대 이형접합체 유전자좌 수, 적색 경고 박스로 표지된 최대 동형접합체 유전자좌 수, 최대 블리드-스루 피크 수, 호출된 최소 CODIS20 유전자좌 수, 호출된 최소 CODIS 18 유전자좌 수, 호출된 최소 상염색체 유전자좌 수, 호출된 최소 플렉스 플렉스 유전자좌 수, CMF 파일을 생성하기 위해 호출된 최소 유전자좌 수, DNA ID의 질 임계값, 또는 검색 및 매치의 질 임계값.
일부 구체예에서, 특징이 샘플 데이터를 혼합물로서 분류하는 경우, 적용된 소정의 파라미터 세트는 하기 중 적어도 하나를 수정한다: 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 동형접합체 피크 높이 임계값, 2nd 피크에 대한 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 비율 임계값, 반접합체 피크 높이 최소 임계값, 구역 1에서 대립유전자 PH/PA 임계값, 구역 2에서 대립유전자 PH/PA 임계값, 구역 3에서 대립유전자 PH/PA 임계값, 구역 4에서 대립유전자 PH/PA 임계값, 최대 드롭인 수, 최대 드롭아웃 수, 각 염료 채널의 신호 대 잡음 비율 임계값, 피크 염기 할당 한도, 피크 단편 크기 임계값, 피크 높이 임계값, 피크 폭 임계값, 피크 형상 임계값, 피크 형태 임계값, 피크 비대칭 임계값, 피크 폭 편차 한도, 피크 형상 편차 한도, 염기 신뢰 임계값, 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 색상별 평균 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 임계값, 색상별 평균 동형접합체 피크 높이 임계값, 유전자좌 내의 대립유전자의 상대적 신호 강도 임계값, 대립유전자 크기 대비 대립유전자의 상대적 신호 강도 임계값, iNTA 피크 높이 임계값, iNTA 피크 높이 비율 임계값, 스터터 피크 높이 임계값, 스터터 비율 임계값, 트리알레이트 피크 높이 임계값, 삼대립유전자 피크 높이 비율 임계값, 혼합물 피크 높이 임계값, ILS 성공 한도, 높은 iNTA 규칙 상태, 혼합물 샘플 보호 규칙 상태, 낮은 신호 보호 규칙 상태, 유전자좌에서 최대 피크 수, 최대 호출된 대립유전자 수, 적색 경고 박스로 표지된 최대 대립유전자 수 임계값, 비표지된 최대 대립유전자 수 임계값, PH 임계값 미만의 PH의 대립유전자를 갖는 최대 유전자좌 수, PH 임계값 초과의 PH의 대립유전자를 갖는 최대 유전자좌 수, PHR 임계값 미만의 PHR을 갖는 최대 유전자좌 수, PHR 임계값 초과의 PHR을 갖는 최대 유전자좌 수, 넓은 피크를 갖는 최대 유전자좌 수, iNTA 임계값 초과의 iNTA를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 3개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 4개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 최대 이형접합체 유전자좌 수, 적색 경고 박스로 표지된 최대 동형접합체 유전자좌 수, 최대 블리드-스루 피크 수, 호출된 최소 CODIS20 유전자좌 수, 호출된 최소 CODIS 18 유전자좌 수, 호출된 최소 상염색체 유전자좌 수, 호출된 최소 플렉스 플렉스 유전자좌 수, CMF 파일을 생성하기 위해 호출된 최소 유전자좌 수, DNA ID의 질 임계값, 또는 검색 및 매치의 질 임계값. 일부 구체예에서, 적용된 소정의 파라미터 세트는 호출된 대립유전자 제1 세트를 생성하며, 상기 호출된 대립유전자는 샘플 데이터로부터 추출되어 수정된 샘플 데이터를 생성하며, 적응형 전문가 시스템은 적어도 하나의 특징을 이용하여 수정된 샘플 데이터를 분류하고, 소정의 파라미터 세트를 상기 수정된 샘플 데이터에 적용하여 호출된 대립유전자 제2 세트를 생성한다.
일부 구체예에서, 특징이 샘플 데이터를 억제된 및/또는 분해된 것으로 분류하는 경우, 적용된 소정의 파라미터 세트는 하기 중 적어도 하나를 수정한다: 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 동형접합체 피크 높이 임계값, 2nd 피크에 대한 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 비율 임계값, 반접합체 피크 높이 최소 임계값, 구역 1에서 대립유전자 PH/PA 임계값, 구역 2에서 대립유전자 PH/PA 임계값, 구역 3에서 대립유전자 PH/PA 임계값, 구역 4에서 대립유전자 PH/PA 임계값, 최대 드롭인 수, 최대 드롭아웃 수, 각 염료 채널의 신호 대 잡음 비율 임계값, 피크 염기 할당 한도, 피크 단편 크기 임계값, 피크 높이 임계값, 피크 폭 임계값, 피크 형상 임계값, 피크 형태 임계값, 피크 비대칭 임계값, 피크 폭 편차 한도, 피크 형상 편차 한도, 염기 신뢰 임계값, 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 색상별 평균 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 임계값, 색상별 평균 동형접합체 피크 높이 임계값, 유전자좌 내의 대립유전자의 상대적 신호 강도 임계값, 대립유전자 크기 대비 대립유전자의 상대적 신호 강도 임계값, iNTA 피크 높이 임계값, iNTA 피크 높이 비율 임계값, 스터터 피크 높이 임계값, 스터터 비율 임계값, 트리알레이트 피크 높이 임계값, 삼대립유전자 피크 높이 비율 임계값, 혼합물 피크 높이 임계값, ILS 성공 한도, 높은 iNTA 규칙 상태, 혼합물 샘플 보호 규칙 상태, 낮은 신호 보호 규칙 상태, 유전자좌에서 최대 피크 수, 최대 호출된 대립유전자 수, 적색 경고 박스로 표지된 최대 대립유전자 수 임계값, 비표지된 최대 대립유전자 수 임계값, PH 임계값 미만의 PH의 대립유전자를 갖는 최대 유전자좌 수, PH 임계값 초과의 PH의 대립유전자를 갖는 최대 유전자좌 수, PHR 임계값 미만의 PHR을 갖는 최대 유전자좌 수, PHR 임계값 초과의 PHR을 갖는 최대 유전자좌 수, 넓은 피크를 갖는 최대 유전자좌 수, iNTA 임계값 초과의 iNTA를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 3개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 4개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 최대 이형접합체 유전자좌 수, 적색 경고 박스로 표지된 최대 동형접합체 유전자좌 수, 최대 블리드-스루 피크 수, 호출된 최소 CODIS20 유전자좌 수, 호출된 최소 CODIS 18 유전자좌 수, 호출된 최소 상염색체 유전자좌 수, 호출된 최소 플렉스 플렉스 유전자좌 수, CMF 파일을 생성하기 위해 호출된 최소 유전자좌 수, DNA ID의 질 임계값, 또는 검색 및 매치의 질 임계값.
일부 구체예에서, 샘플 데이터 분류 및 소정의 파라미터 세트 적용에 기초하여, 컴퓨팅 장치는 샘플 데이터를 분류하고 소정의 파라미터 세트를 적용하는데 이용되는 하나 이상의 특징의 값을 수정한다. 일부 구체예에서, 샘플 데이터 분류 및 소정의 파라미터 세트 적용에 기초하여, 컴퓨팅 장치는 DNA ID에 적용할 경우 출력값을 생성하는데 이용되는 하나 이상의 소정의 파라미터 세트를 수정한다. 일부 구체예에서, 컴퓨팅 장치는 디스플레이 장치에의 제시를 위한 출력값의 가시화를 생성한다. 일부 구체예에서, 가시화는 하나 이상의 파라미터 세트 각각에 대해 호출된 대립유전자의 수를 포함한다.
또 다른 양태에서, 본 발명은 프로그램 명령을 저장하는 메모리 및 프로그램 명령을 실행하는 프로세서를 갖는 컴퓨팅 장치를 포함하는 적응형 전문가 시스템을 특징으로 한다. 적응형 전문가 시스템은 적어도 2개의 검출기 또는 검출기 요소를 포함하는 광학 검출 시스템으로부터의 샘플 데이터를 수신하며, 상기 검출기 또는 검출기 요소는 염료-표지된 DNA로부터 형광을 수집하여 광 신호를 생성하도록 구성된다. 적응형 전문가 시스템은 광 신호의 베이스라인을 감한다. 데이터의 적어도 하나의 피크에 있어서, 적응형 전문가 시스템은 검출기 또는 검출기 요소 중 적어도 하나의 광 신호를 포화시키고, 적응형 전문가 시스템은 검출기 또는 검출기 요소 중 적어도 하나의 광 신호를 포화시키지 않는다. 적응형 전문가 시스템은 검출기 또는 검출기 요소 둘 모두가 포화되지 않은 피크의 일부에서 불포화된 검출기 또는 검출기 요소 각각에 대한 포화된 검출기 또는 검출기 요소 각각의 검출기 또는 검출기 요소 광 신호의 신호 강도 비율을 계산한다. 적응형 전문가 시스템은 불포화된 검출기 또는 검출기 요소의 신호 강도를 상응하는 신호 강도 비율과 곱하여 포화된 피크 부분에서 포화된 검출기 또는 검출기 요소의 신호 강도를 계산한다.
상기 양태는 하기 특징 중 하나 이상을 포함할 수 있다. 일부 구체예에서, 광학 검출 시스템은 적어도 4개의 검출기 또는 검출기 요소를 포함한다. 일부 구체예에서, 광학 검출 시스템은 적어도 5개의 검출기 또는 검출기 요소를 포함한다. 일부 구체예에서, 광학 검출 시스템은 적어도 6개의 검출기 또는 검출기 요소를 포함한다. 일부 구체예에서, 광학 검출 시스템은 적어도 8개의 검출기 또는 검출기 요소를 포함한다. 일부 구체예에서, 광학 검출 시스템은 적어도 12개의 검출기 또는 검출기 요소를 포함한다. 일부 구체예에서, 광학 검출 시스템은 적어도 16개의 검출기 또는 검출기 요소를 포함한다. 일부 구체예에서, 광학 검출 시스템은 적어도 32개의 검출기 또는 검출기 요소를 포함한다. 일부 구체예에서, 광학 검출 시스템은 적어도 64개의 검출기 또는 검출기 요소를 포함한다. 일부 구체예에서, 광학 검출 시스템은 적어도 128개의 검출기 또는 검출기 요소를 포함한다. 일부 구체예에서, 광학 검출 시스템은 적어도 256개의 검출기 또는 검출기 요소를 포함한다.
또 다른 양태에서, 본 발명은 프로그램 명령을 저장하는 메모리 및 프로그램 명령을 실행하는 프로세서를 갖는 컴퓨팅 장치를 포함하는 적응형 전문가 시스템을 특징으로 한다. 적응형 전문가 시스템은 미가공 데이터, 광학 데이터, 및 일렉트로페로그램 데이터 중 적어도 하나를 포함하는 샘플 데이터를 DNA 분석 장치로부터 수신하며, 상기 데이터는 DNA를 함유하는 샘플로부터 생성된다. 적응형 전문가 시스템은 반복 결과를 최대화하기 위한 적어도 하나의 기준을 결정한다. 적응형 전문가 시스템은 기준을 최대화시키기 위해 파라미터 값을 반복적으로 변경하여 적어도 하나의 파라미터를 수정하고, 출력값을 생성한다.
상기 양태는 하기 특징 중 하나 이상을 포함할 수 있다. 일부 구체예에서, 적용된 파라미터 세트는 하기 중 적어도 하나를 수정한다: 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 동형접합체 피크 높이 임계값, 2nd 피크에 대한 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 비율 임계값, 반접합체 피크 높이 최소 임계값, 구역 1에서 대립유전자 PH/PA 임계값, 구역 2에서 대립유전자 PH/PA 임계값, 구역 3에서 대립유전자 PH/PA 임계값, 구역 4에서 대립유전자 PH/PA 임계값, 최대 드롭인 수, 최대 드롭아웃 수, 각 염료 채널의 신호 대 잡음 비율 임계값, 피크 염기 할당 한도, 피크 단편 크기 임계값, 피크 높이 임계값, 피크 폭 임계값, 피크 형상 임계값, 피크 형태 임계값, 피크 비대칭 임계값, 피크 폭 편차 한도, 피크 형상 편차 한도, 염기 신뢰 임계값, 이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율 임계값, 색상별 평균 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 임계값, 색상별 평균 동형접합체 피크 높이 임계값, 유전자좌 내의 대립유전자의 상대적 신호 강도 임계값, 대립유전자 크기 대비 대립유전자의 상대적 신호 강도 임계값, iNTA 피크 높이 임계값, iNTA 피크 높이 비율 임계값, 스터터 피크 높이 임계값, 스터터 비율 임계값, 트리알레이트 피크 높이 임계값, 삼대립유전자 피크 높이 비율 임계값, 혼합물 피크 높이 임계값, ILS 성공 한도, 높은 iNTA 규칙 상태, 혼합물 샘플 보호 규칙 상태, 낮은 신호 보호 규칙 상태, 유전자좌에서 최대 피크 수, 최대 호출된 대립유전자 수, 적색 경고 박스로 표지된 최대 대립유전자 수 임계값, 비표지된 최대 대립유전자 수 임계값, PH 임계값 미만의 PH의 대립유전자를 갖는 최대 유전자좌 수, PH 임계값 초과의 PH의 대립유전자를 갖는 최대 유전자좌 수, PHR 임계값 미만의 PHR을 갖는 최대 유전자좌 수, PHR 임계값 초과의 PHR을 갖는 최대 유전자좌 수, 넓은 피크를 갖는 최대 유전자좌 수, iNTA 임계값 초과의 iNTA를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 3개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 4개 이상의 피크를 갖는 최대 유전자좌 수, 적색 경고 박스로 표지된 최대 이형접합체 유전자좌 수, 적색 경고 박스로 표지된 최대 동형접합체 유전자좌 수, 최대 블리드-스루 피크 수, 호출된 최소 CODIS20 유전자좌 수, 호출된 최소 CODIS 18 유전자좌 수, 호출된 최소 상염색체 유전자좌 수, 호출된 최소 플렉스 플렉스 유전자좌 수, CMF 파일을 생성하기 위해 호출된 최소 유전자좌 수, DNA ID의 질 임계값, 또는 검색 및 매치의 질 임계값 또는 검색 엄격성.
일부 구체예에서, 반복 기준은 하기 중 적어도 하나에 의해 규정된다: 호출된 CODIS20 유전자좌의 수, 호출된 CODIS 18 유전자좌의 수, 호출된 플렉스플렉스 유전자좌의 수, 동형접합체로부터 이형접합체로 변화되는 유전자좌의 수, 드롭인의 수, 드롭아웃의 수, 적색 경고 박스로 표지된 대립유전자의 수, DNA ID의 질 임계값, 또는 검색 및 매치의 질 임계값. 일부 구체예에서, 반복 단계는 고정되어 있지 않으면, 기준 변화율에 따라 달라질 수 있다.
본 발명의 기타 양태 및 이점은 단지 예로서 본 발명의 원리를 예시하는 첨부된 도면과 함께 하기 상세한 설명으로부터 자명해질 것이다.
상세한 설명
DNA ID를 생성하는 여러 접근 방식이 존재한다:
ㆍDNA 정량화 단계를 이용한 실험실-기반의 통상적인 프로세싱(전형적으로, DNA 추출/정제, PCR 증폭, 및 전기영동 분리 및 검출을 위한 별도의 장치를 이용). 실험실-기반 통상적 프로세싱은 또한 자동화된 장비 및 로봇 공학을 이용하여 개별 프로세싱 단계를 수행할 수 있다.
ㆍDNA 정량화 단계를 사용하지 않는 실험실-기반의 통상적인 프로세싱.
ㆍ단일 칩 및 프로세싱 프로토콜을 사용하는 신속 DNA 프로세싱(샘플 중 DNA 양과 무관).
ㆍ샘플 중 추정된 DNA 양을 기반으로 단일 칩 및 다중 프로세싱 프로토콜을 사용하는 신속 DNA 프로세싱. 샘플 중 낮은 DNA 함량이 추정되는 경우, 프로세싱 프로토콜은 예를 들어, 비드 또는 또 다른 기재에의 DNA 결합을 발생시키기 위한 더 오랜 시간, PCR 증폭의 추가 사이클 사용, 전기영동 주입 조건의 수정, 또는 이러한 및 다른 수정의 조합을 포함할 수 있다.
ㆍ프로세싱 동안 DNA 함량을 정량화하는 칩을 사용한 신속 DNA 프로세싱.
ㆍ신속 DNA 칩 및 기기에서 삽입 및 프로세싱 전에 정제되고 DNA-정량화되는 세포 추출물의 신속 DNA 프로세싱.
ㆍ하나 이상의 선택 칩을 사용하는 신속 DNA 프로세싱으로서, 상기 칩은 주어진 샘플의 예상 DNA 항량을 기반으로 하여 사용된다. 예를 들어, 본 발명에서, 2개 유형의 칩이 사용된다: 1) 높은 DNA 함량을 함유하는 것으로 추정되는 샘플(예를 들어, 협측 면봉, 전형적인 혈액 얼룩 또는 신선한 조직 조각)에 최적인 HDC, HDC FP, HDC PP16, 또는 A-칩으로 불리는 칩; 2) 소량의 DNA를 함유하는 것으로 추정되는 샘플(예를 들어, 컵, 캔 또는 병의 면봉, 작은 혈액 얼룩, 인간 모발, 쉘 케이싱 건 핸들 또는 IED 구성요소 상의 지문, 또는 캡 챙 또는 셔츠 칼라와 같은 의류)에 최적인 LDC, LDC FP, LDC PP16, 또는 I-칩으로 불리는 칩.
ㆍ상기 기술된 다양한 유형의 프로세싱으로 단일 칩보다 많이 (예를 들어, 실행당 여러 카트리지) 사용하는 신속 DNA 프로세싱.
ㆍ수정된 신속 DNA 프로세싱 [https://www.fbi.gov/services/laboratory/biometric-analysis/codis/rapid-dna]으로서, DNA 프로세싱 단계 중 일부 또는 전부가 신속 DNA 장치를 사용하여 발생하나, 생성된 데이터는 인간의 검토 또는 조작으로 처리되어야 한다.
이러한 접근 방식에서, DNA ID는 DNA를 분리하고 검출하기 위한 기기에 의해 생성된다. 샘플 데이터를 생성할 수 있는 기기의 예는 실시예 1에 기술되어 있다. 이러한 경우, 기기내의 검출 시스템은 프로세서와 통신한다. 검출 시스템은 프로세서에 광학 데이터를 제공하여 DNA ID를 생성하기 위한 입력값으로서 사용한다.
이러한 접근 방식을 이용하여, 표준 전문가 시스템 파라미터 세트의 사용에 기초하여 적용되는 검출 시스템의 동적 범위 내에 속하는 피크를 갖는 DNA ID를 생성시키는 것이 종종 가능하다. 그러나, 각각의 상기 경우(DNA 함량이 정량화되는 경우에도, 통상적인 또는 신속 DNA), - PCR 증폭, 전기영동 분리 및 검출 (증폭에 사용되는 각 프라이머 쌍의 적어도 하나의 프라이머에 염료의 공유 부착을 기반으로 하는 레이저-유도된 형광에 의해 항상은 아니지만 종종) 후 - 생성된 STR 피크에 의해 생성되는 샘플 데이터(신호 강도 포함)는 전체적인 시스템의 동적 범위를 벗어나는 것이 가능하다. 결과적으로 몇 가지 기본 부류의 DNA ID가 생성될 수 있다.
A. 주어진 칩 유형 또는 시스템의 동적 범위 미만의 DNA 함량을 갖는 샘플
먼저, 비교적 낮은 DNA 함량(즉, 사용된 DNA 분석 시스템에 비해 낮은), 분해된 DNA, 억제제, 또는 최적이 아닌 핵산 정제, 증폭, 분리 또는 검출의 일부 법의학적 샘플은 비교적 낮은 신호를 갖는 DNA ID를 발생시킬 것이다. 예를 들어, 제한된 타액 또는 단일의 통상적인 지문을 갖는 담배 꽁초와 같은 샘플은 I-칩에 대해서도 낮은 DNA 함량을 가질 수 있다. 유사하게는, 간, 큰 혈액 얼룩, 또는 뼈와 같은 샘플은 샘플당 다량의 DNA를 함유할 것으로 예상될 수 있지만, A-칩을 사용하여 낮은 신호를 생성할 수 있다. 이들의 기원에 관계없이, 낮은 신호 DNA ID는 하기 특징 중 하나 이상을 나타낸다:
ㆍ검출 시스템에서 규정된 양 미만의 평균 이형접합체 피크 높이(RFU). 예를 들어, 3,000 RFU는 ANDE 시스템을 이용하는 특정 애플리케이션에 대해 선택될 수 있는 값이다.
ㆍ표지되지 않은 표준(협측) 전문가 시스템 호출 임계값 미만의 피크 높이를 갖는 유전자좌.
ㆍ너무 낮으며, 문제를 나타내기 위해 적색 경고 박스로 표지된 이형접합체 피크 높이 비율을 갖는 유전자좌. ANDE 시스템에서, 일렉트로페로그램(종종 사진으로서 제시되며, .bmp, 또는 .png, 또는 .pdf 포맷으로서 저장됨) 상의 적색 경고 박스는 특정 STR 대립유전자의 위치 및 크기를 표시하나, 이러한 대립유전자의 어떤 면이 문제가 된다는 것을 나타냄을 주목하라. ANDE 시스템에서, 적색 경고 박스로 표지된 대립유전자는 전형적으로, 최종 .XML 파일 또는 대립유전자 표에 포함되지 않는다. 이에 반해, "호출된 대립유전자"는 회색 박스로 표지되며, 최종 .XML 파일 및 대립유전자 표에 포함된다.
ㆍ적색 경고 박스로 표지된 동형접합체 유전자좌.
ㆍ적색 경고 박스로 표지된 다중 동형접합체 유전자좌.
ㆍ표준 수준 내에 있는 iNTA 수준을 갖는 대립유전자. 예를 들어, iNTA 피크는 명목상 ANDE 시스템에서 일차 피크의 0.2이다. 표준 AES 파라미터 세트는 일차 피크보다 1 염기 작고, 일차 피크의 높이의 0.2X 미만인 피크를 iNTA 피크로서 간주한다. iNTA 피크는 전문가 시스템에 의해 표지되지 않을 것이다.
ㆍ표준 수준 내에 있는 피크 폭을 갖는 대립유전자.
ㆍ적색 경고 박스로 표지된 샘플 중의 모든 피크.
신호 강도, 피크 높이 비율 및 피크 폭과 같은 특징이 DNA 분석 시스템 (또는 개별적으로 명목상 동일한 기기에서의 다른 설정)의 유형에 기반하여 반드시 달라질 것이지만, 개념은 일반적으로 임의의 이러한 시스템에 적용가능하다. 또한, 추가적인 특징이 샘플 데이터를 추가로 분류하기 위해 DNA(미가공 데이터, 광학적 데이터, 일렉트로페로그램 데이터, 또는 다른 유형의 데이터)의 물리적 조작 후 검출되는 샘플 데이터로부터 도출될 수 있다. 또한, 샘플 데이터가 낮은 DNA 함량으로서 광범위하게 분류되지만, 이러한 분류 내의 샘플 데이터는 또한 추가로 하위카테고리로 기술될 수 있다. 본원에 제시된 작업은 A-칩 및 I-칩을 사용하는 ANDE 신속 DNA 시스템에 중점을 둔다.
법의학 과학자 (또는 DNA ID의 해석에 전문 지식을 가진 또 다른 개인)에 대한 필요성을 제거하는 것 이외에, AES는 사용자의 입력을 요구하지 않는다. AES는 사람 상호작용, 분석 또는 검토의 필요 없이 DNA ID를 자동으로 처리한다.
도 1은 표준 전문가 시스템 파라미터 세트(이 경우, A-칩을 사용하는 협측 면봉을 위해 개발됨)를 사용하여 신속 DNA 시스템의 동적 범위 아래의 DNA 함량을 갖는 샘플로부터의 대표적인 DNA ID를 보여주며, 상기 언급된 특징 중 여러 특징을 갖는다. 이러한 샘플에서 관찰된 특정 특징은 다음과 같다:
ㆍ3000 RFU 미만의 평균 이형접합체 피크 높이(RFU).
ㆍ표지되지 않은 표준(협측) 전문가 시스템 호출 임계값 미만의 피크 높이를 갖는 유전자좌. D6S1043 참조.
ㆍ적색 경고 박스로 표지된 다중 동형접합체 유전자좌. Am, D13S317, D18S51, CSF1PO, D7S820 참조.
ㆍ모든 iNTA 피크는 표준 수준 내에 있으며, 전문가 시스템에 의해 표지되지 않은 수준에 있다.
ㆍ모든 대립유전자는 표준 수준 내에 있는 피크 폭을 갖는다.
적색으로 표지된 유전자좌는 유용한 데이터를 함유함을 나타냄이 중요하다 - 표준 "협측" 전문가 시스템 규칙은 낮은 DNA 함량(뼈, 근육, 치아, 케이스워크, 및 SSE 샘플에서 빈번하게 발생하는 바와 같이)을 갖는 샘플에 있어서 너무 보존적이다. 실제로, 이러한 27플렉스 DNA ID는 1 섹스틸리온(sextillion) 중 1 미만의 무작위 매치 확률로 동일성을 확립할 수 있는 충분한 정보를 함유한다(1023, 거의 트릴리온 트릴리온)! 본 발명의 AES는 본질적으로 모든 이러한 유용한 데이터를 추출할 수 있다.
도 1에서, 낮은 DNA 함량 샘플로부터의 샘플 데이터는 (예를 들어, 협측) 전문가 시스템 호출 파라미터의 표준 세트로 분석되었다. 매우 낮은 DNA 함량을 갖는 샘플의 이러한 예에서, D6 유전자좌는 하나의 대립유전자가 피크 높이 호출 임계값 미만에 속하기 때문에 호출되지 않았다. 결과적으로, 표준 전문가 시스템은 적색 경보 박스에서 6000 rfu 미만의 피크를 갖는 동형접합체 유전자좌를 표지함으로써 드롭아웃에 대해 보호하였다. 결과적으로 적어도 7개의 유전자좌가 적색 경고 박스로 표지되는 경우, 사용된 표준 전문가 시스템은 전체 DNA ID를 적색 경고 박스로 표지한다(이러한 DNA ID의 경우가 아님). 이러한 규칙은 협측 샘플에는 적합하나, SSE, 케이스워크, DVI 또는 다른 샘플에 대해 너무 보존적임을 주목하라. 적색 경보 박스 모두는 정확한 피크를 지정하고 있다는 점에 주목하라. 협측 샘플에 있어서, 일부 에이전시는 전체 DNA ID를 얻기 위해 새로운 샘플에 대해 실행을 반복하도록 (또는 정량화된 DNA로 시작하고, 새로운 증폭 반응을 실행하도록) 선택될 것이다. "완벽한" DNA ID에 대한 요구는 표준 전문가 시스템 설정의 보존적 파라미터의 사용을 유도한다.
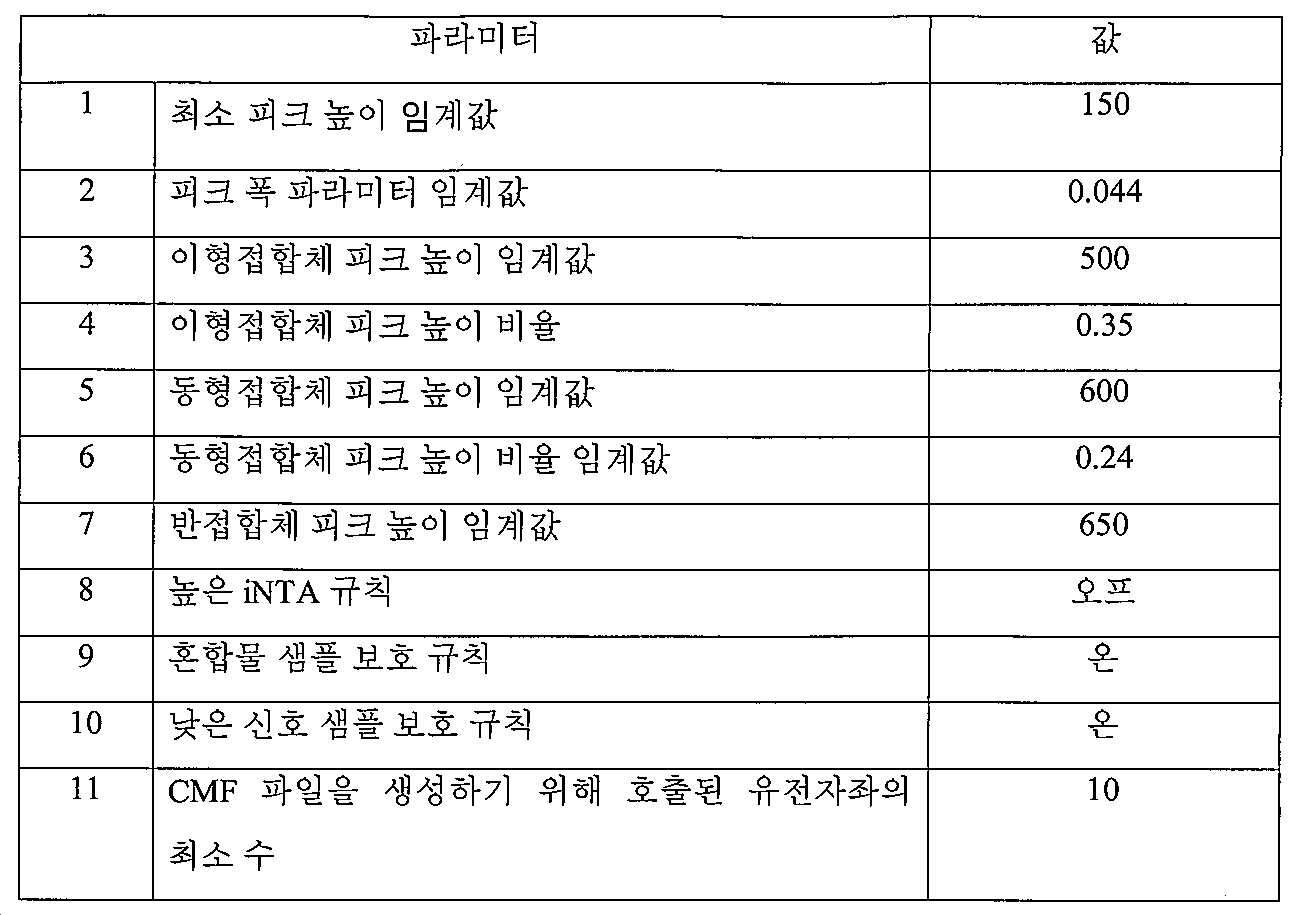
낮은 DNA 함량 샘플이 AES 소프트웨어에 의해 식별되는 경우, 호출 파라미터 세트가 호출되는 유전자좌의 수를 증가시키도록 수정된다. 파라미터 변경은 하기를 포함한다:
ㆍ호출된 유전자좌의 이형접합체 신호 강도에 기반하여 피크 높이 임계값을 설정한다. 이는 표준 전문가 시스템 파라미터 세트의 피크 높이 임계값을 효과적으로 감소시킬 것이다. 이러한 감소된 피크 높이 임계값은 일반적으로 모든 유전자좌(예를 들어, 모든 유전자좌에 대한 임계값은 동일한 값으로 설정될 것임) 또는 독립적으로 일부 특이적 또는 모든 유전자좌(예를 들어, Th01 유전자좌 내의 피크 높이 임계값은 TPOX 유전자좌 내의 값과 상이함) 또는 특정 대립유전자(예를 들어, Th01 8 대립유전자 피크 높이 임계값은 Th01 10 대립유전자 및 vWA 11 대립유전자의 것과 상이함)에 적용될 수 있다.
ㆍ피크 높이 비율(PHR) 임계값을 낮춘다. PHR 감소는 일반적으로 모든 유전자좌(예를 들어, 모든 유전자좌에 대해 감소된 PHR 임계값은 동일한 값으로 설정될 것임) 또는 독립적으로 일부 특이적 또는 모든 유전자좌(예를 들어, Th01 유전자좌 내의 PHR 임계값의 감소는 TPOX 유전자좌 내의 값과 상이함) 또는 특이적 대립유전자(예를 들어, PHR은 주어진 유전자좌에서 각 STR 대립유전자에 대해 특이적으로 확립됨)에 적용될 수 있다.
ㆍ낮은 신호 보호 규칙을 비활성화시킨다. 표준 전문가 시스템에서, 낮은 신호 보호 규칙이 적용될 수 있으며, 동형접합체 유전자좌는 이들이 보호 피크 높이 임계값보다 낮은 피크 높이를 갖는 경우 적색 경고 박스로 표지된다. AES 낮은 DNA 함량 파라미터 세트에서, 이 규칙은 비활성화되어, 이러한 낮은 신호 동형접합체 피크를 호출할 수 있게 한다.
ㆍ샘플을 통과시켜 XML 파일, 대립유전자 표 및 BMF 파일을 생성시키는데 필요한 호출된 유전자좌의 수를 감소시킨다.
도 2는 도 1과 동일한 DNA ID를 보여주는데, ANDE 6C 미가공 데이터는 상기 언급된 바와 같이 수정된 파라미터를 갖는 AES를 사용하여 처리된다. ANDE 전문가 시스템은 광학 데이터(광학 시스템의 검출기의 출력값 - .csv 포맷) 및 미가공 일렉트로페로그램 데이터(데이터 프로세싱에 의해 색상이 보정된 광학 데이터 -- .csv, .dat, ANDE 고유 포맷 . nbo, .FSA 및 .HID 포맷 포함)의 입력으로서 취해지고, .PNG 포맷, XML 포맷 및 .FSA 포맷의 DNA ID로 구성된 출력값을 생성시킬 수 있다.
도 2는 적응형 전문가 시스템으로 재호출된 도 1의 낮은 DNA 입력 샘플 데이터를 보여준다. D6 유전자좌는 이제 더 낮은 피크 높이 임계값을 기반으로 호출된다. 결과적으로, AES는 드롭아웃에 대하여 샘플을 보호하기 위해 낮은 신호 보호 규칙을 적용하지 않는다. 특히, 상대적으로 낮은 신호 강도를 갖는 동형접합체 유전자좌는 표준 전문가 시스템 파라미터를 사용하여 적색 경고 박스로 표지되었다 - 이러한 접근 방식은 드롭아웃으로부터 이들 유전자좌를 보호한다. 그러나, 적응형 전문가 시스템은 낮은 DNA 함량 샘플 패턴을 인식하고, 적색 경고 박스 없이 모든 유전자좌가 호출된다.
B. 주어진 칩 유형의 동적 범위 초과의 DNA 함량을 갖는 샘플
제공된 칩 유형의 동적 범위를 초과하는 DNA 신호를 갖는 샘플은 특정 SSE 샘플 예컨대, 담배 꽁초, 츄잉 검, 혈액얼룩 또는 음료수 잔을 포함할 수 있다. 많은 이러한 샘플은 I-칩에서 완전 DNA ID를 생성시킬 것이나, 일부는 비교적 높은 신호를 갖는 DNA ID를 생성시킬 것이다. 유사하게는, 샘플 예컨대, 근육, 간, 혈액 또는 뼈는 A-칩을 사용하더라도 높은 신호를 생성시킬 수 있다.
제공된 칩 유형의 동적 범위를 초과하는 DNA 함량을 갖는 샘플은 하기 중 하나 이상을 특징으로 하는 DNA ID를 생성시킨다:
ㆍ10,000 RFU 초과의 평균 이형접합체 피크 높이(RFU).
ㆍ포화되고 상단이 사각형인 피크.
ㆍ허용가능한 폭 임계값을 초과하는 간헐적인 넓은 피크. 이들 피크는 표지되지 않는다.
ㆍ표준 수준을 초과하고, 때때로 진정한 대립유전자로서 표지되는, 피크 높이 및 피크 높이 비율을 갖는 iNTA 피크. 특히, 아멜로게닌 유전자좌의 iNTA 피크 높이 비율은 표준 수준을 초과한다.
ㆍ3개의 표지된 대립유전자를 갖는 다중의 유전자좌를 갖는 샘플로서, 이러한 샘플 중의 모든 대립유전자는 적색으로 표지됨.
ㆍ4개의 표지된 대립유전자를 갖는 적어도 하나의 유전자좌를 갖는 샘플로서, 이러한 샘플 중의 모든 대립유전자는 적색으로 표지됨.
도 3은 칩 유형의 동적 범위 위의 DNA 함량을 갖는 샘플의 대표적인 DNA ID로서, 상기 언급된 여러 특징을 갖는 DNA ID를 보여준다. 이 도면에서 제시된 특정 특징은 다음과 같다:
ㆍ10,000 RFU 초과의 평균 이형접합체 피크 높이(RFU).
ㆍ허용가능한 폭 임계값을 초과하는 간헐적인 넓은 피크. 이들 피크는 표지되지 않는다. D13S317, Penta E, D2S1338, CSF1PO, DYS391, SE33 DYS376 참조.
ㆍ표준 수준을 초과하는, 피크 높이 및 피크 높이 비율을 갖는 iNTA 피크. Am, D16S539, D18S51, Th01 참조.
ㆍ3개의 표시된 대립유전자를 갖는 다중의 유전자좌를 갖는 샘플로서, 이러한 샘플 중의 모든 대립유전자는 적색으로 표시됨. D16S539, D18S51 참조.
ㆍ4개의 표지된 대립유전자를 갖는 적어도 하나의 유전자좌를 갖는 샘플로서, 이러한 샘플 중의 모든 대립유전자는 적색으로 표지됨. Th01 참조.
적색으로 표지된 유전자좌가 유용한 데이터를 함유한다는 것을 주지함이 중요하다 - 표준 "협측" 전문가 시스템 규칙은 조직 샘플 예컨대, 뼈, 근육, 간 및 치아를 포함하는 많은 샘플 유형에 있어서 너무 보존적이다. 실제로, 적절한 AES 파라미터 세트로 호출되는 경우, 이러한 27플렉스 DNA ID는 1 섹스틸리온 중 1 미만의 무작위 매치 확률로 동일성을 확립할 수 있는 충분한 정보를 함유한다(1023, 거의 트릴리온 트릴리온)! 본 발명의 AES는 본질적으로 모든 이러한 유용한 데이터를 추출할 수 있다. 그러나, 표준 전문가 시스템은 샘플에 대해 완전히 실패하였다. 따라서, 본 발명의 주요 특징 중 하나는 샘플 데이터를 평가하여 케이스워크, DVI 및 다른 샘플이 협측 면봉의 샘플과는 상이하게 처리되게 하는 적응형 전문가 시스템의 능력이다.
도 3은 표준 전문가 시스템으로 분석된 높은 DNA 입력 샘플을 보여준다. 높은 DNA 함량을 갖는 샘플의 이러한 예에서, 대립유전자 피크는 상승된 신호를 갖는다. AM, D16S539, D18S1, Th01, vWA 및 D22S1045의 iNTA 피크는 DNA 함량 동적 범위 내의 샘플에 대한 것보다 불균형하게 더 높다. 이러한 현상은 비례적으로 더 높고 iNTA 임계값을 초과하는 것으로 보이는 iNTA 피크를 초래한다. 표준 전문가 시스템은 더이상 이를 iNTA 피크로서 분류하지 않는다(iNTA 피크는 표지되지 않아야 한다). 일부 경우(이 예에서 관찰되지 않음), 주요 대립유전자 피크는 포화되며, iNTA(-1) 피크는 훨씬 낮으며, 포화되지 않는다. 이러한 현상으로 인해 iNTA 피크는 인위적으로 비례하여 원래보다 더 높게 나타나며, 표준 전문가 시스템은 이를 더 이상 iNTA 피크로서 분류하지 않는다(iNTA 피크는 표지되지 않아야 한다).
대신, 표준 전문가 시스템은 iNTA 피크를 대립유전자로서 표지한다. 예를 들어, D16 유전자좌에서, 12개 대립유전자가 표지되나, iNTA 피크가 또한 표지된다 - 11.3 대립유전자로서. 게다가, 여기에 사용된 표준 전문가 시스템에서, 각 3개의 대립유전자를 갖는 2개의 유전자좌의 존재는 표준 전문가 시스템이 샘플을 혼합물로 간주하여, DNA ID의 모든 대립유전자를 적색 경고 박스로 표지하게 한다(이러한 표준 전문가 시스템은 사용자에게 혼합물의 존재를 알리기 위해 설계되었다). 도 3은 또한, 높은 DNA 함량을 갖는 샘플에 있어서, D13, D2 Penta E, DYS391, SE33 및 DYS576의 대립유전자 피크는 피크 폭 임계값을 초과하는 더 넓은 피크를 가짐을 보여준다. 결과적으로, 표준 전문가 시스템 피크 폭 파라미터는 피크에 실패하며, 이들 피크는 표지되지 않는다. 표준 전문가 시스템 파라미터 세트 및 규칙은 대부분의 협측 샘플에 적절하며(대부분의 협측 샘플은 시스템의 동적 범위 내의 DNA 함량을 가짐), 그러나, 케이스워크, SSE, DVI 또는 높은 DNA 함량을 갖는 많은 다른 샘플에 대해 매우 보존적임을 주목하라. 이러한 점은 모든 적색 경고 박스가 정확한 피크를 지정하고 있는 도 3에 의해 가장 잘 설명된다.
높은 DNA 샘플이 표준 전문가 시스템을 사용하여 기록될 때, 전문가 시스템은 호출되는 유전자좌의 수를 증가하도록 수정될 수 있다:
ㆍ각 유전자좌 내에서 피크의 이종접합체 신호 강도에 기초하여 피크 높이 호출 임계값을 확립한다. 이는 표준 전문가 시스템 파라미터 세트의 것과 비교하여 피크 높이 임계값을 효과적으로 증가시킬 것이다. 이러한 증가된 피크 높이 임계값은 일반적으로 모든 유전자좌(예를 들어, 모든 유전자좌에 대한 임계값은 동일한 값으로 설정될 것임) 또는 독립적으로 일부 특이적 또는 모든 유전자좌(예를 들어, Th01 유전자좌 내의 피크 높이 임계값은 TPOX 유전자좌 내의 값과 상이함) 또는 특정 대립유전자(예를 들어, Th01 8 대립유전자 피크 높이 임계값은 Th01 10 대립유전자 및 vWA 11 대립유전자의 것과 상이함)에 적용될 수 있다.
ㆍ피크 폭 임계값을 증가시킨다. 전형적으로 피크 폭은 샘플 중 DNA 양이 증가하기 때문에 증가할 것이다. 피크 폭의 이러한 증가는 더 큰 단편 크기를 갖는 피크의 경우 더욱 악화된다. 피크 폭이 표준 파라미터를 초과하는 경우, ES는 대립유전자로서의 피크를 무시하며, 피크를 표지하지 않거나 후속 계산에 피크를 고려한다.
ㆍ더 높은 수준의 iNTA 및 스터터를 수용한다. DNA 함량이 증가함에 따라, iNTA 피크의 피크 높이는 일차 대립유전자 피크에 대해 불균형적으로 증가하는 경향이 있다. iNTA 피크의 피크 높이 임계값이 표준 파라미터를 초과하는 경우, ES는 iNTA 피크를 대립유전자로 간주한다. AES는 먼저 샘플을 높은 iNTA에 대한 높은 잠재력을 갖는 것으로서 식별함으로써 더 높은 iNTA를 수용한다. 이러한 경우, AM에 대한 iNTA PHR 비율은 높은 iNTA에 대한 표시인자로서 사용되었다. 다른 유전자좌 내의 iNTA 및/또는 다른 특징(예를 들어, 피크 형태)의 존재를 포함한 다른 측정치를 이용하여 잠재적으로 높은 iNTA 샘플을 식별할 수 있음을 주목하라. 잠재적으로 높은 iNTA 샘플이 확인되면, iNTA 호출 규칙이 적용된다. iNTA 규칙은 "높은 iNTA 모듈" 섹션에 자세히 설명되어 있다.
ㆍ유전자좌 내의 대립유전자 수에 기초하여 유전자좌 특이적 iNTA 호출 규칙을 적용한다. "높은 iNTA 모듈" 섹션에 자세히 설명되어 있는 iNTA 규칙 참조.
ㆍ샘플을 통과시키는데 필요한 호출된 유전자좌의 수를 감소시킨다. 전문가 시스템은 호출된 유전자좌의 수에 기초하여 샘플을 샐패시킬 것이며, 이러한 임계값 감소는 호출된 대립유전자를 갖는 더 많은 샘플이 통과하게 할 것이다.
도 4는 도 3과 동일한 DNA ID를 보여주는데, ANDE 6C 샘플 데이터는 적응형 전문가 시스템을 사용하여 재호출되는데, 조절된 iNTA 규칙으로 수정된 파라미터 세트로, iNTA 피크는 호출되지 않으며, 조절된 피크 폭 파라미터로, 넓은 피크가 호출된다. 따라서, 적색 경고 박스가 없는 완전한 DNA ID가 그 결과치이다. 상기 논의된 바와 같이, 적응형 전문가 시스템은 비전문적 현장 운영자가 DNA 함량 또는 상태에 대해 아무것도 알 필요 없이 임의의 샘플 유형을 본질적으로 실행하게 한다. 또한, 표준 전문가 시스템에 의해 적색으로 표지된 유전자좌가 유용한 데이터를 함유한다는 것을 주지함이 중요하다 - 표준 "협측" 전문가 시스템 파라미터 세트 및 규칙은 높은 DNA 함량을 갖는 조직 샘플에 대해 너무 보존적이다. 따라서, 본 발명의 주요 특징 중 하나는 케이스워크, SSE, DVI 및 다른 샘플을 협측 면봉과는 상이하게 처리하는 적응형 전문가 시스템의 능력이다.
C. 혼합물 샘플
다수의 도너로부터 기원하는 DNA를 갖는 샘플은 문 손잡이 또는 운전대(예를 들어, 2명 이상의 사람에 의해 조작되는)의 면봉 또는 성폭행 샘플(예를 들어, 여성 및 남성 둘 모두로부터의 DNA를 함유하는 질 또는 자궁경부 면봉)과 같은 특정 SSE 샘플을 포함할 수 있다. 표준 파라미터를 사용하는 ANDE 전문가 시스템은 아마도 이러한 혼합물 샘플의 DNA ID에 실패할 것이다. 이는 표준 파라미터가 전형적으로 단일 소스 샘플을 평가하는데 사용되기 때문이다.
2명 (또는 그 초과)의 도너로부터의 오염물을 갖는 샘플은 적어도 3개의 하위부류 중 하나로 하위분류될 수 있다:
A- 낮은 DNA 함량을 갖는 오염물을 갖는 샘플은 하기 중 하나 이상을 특징으로 한다:
ㆍ3000 RFU 미만의 평균 이형접합체 피크 높이(RFU).
ㆍ표지되지 않은 표준(협측) 전문가 시스템 호출 임계값 미만의 피크 높이를 갖는 유전자좌. D6S1043 참조.
ㆍ적색 경고 박스로 표지된 다중 동형접합체 유전자좌. Am, D13S317, D18S51, CSF1PO, D7S820 참조.
ㆍ모든 iNTA 피크는 표준 수준 내에 있으며, 전문가 시스템에 의해 표지되지 않은 수준에 있다.
ㆍ모든 대립유전자는 표준 수준 내에 있는 피크 폭을 갖는다.
ㆍ적색 경고 박스로 표지된 3개 이상의 피크를 갖는 2개 이상의 유전자좌.
ㆍ적색 경고 박스로 표지된 4개 이상의 피크를 갖는 하나 이상의 유전자좌.
ㆍ샘플 중 모든 대립유전자는 적색으로 표지된다.
ㆍ대립유전자의 평균 이형접합체 피크 높이(RFU)는 샘플을 낮은 DNA 함량(3,000 RFU 미만), 중간 DNA 함량(3,000 내지 10,000 RFU) 및 높은 DNA 함량(10,000 RFU 초과)으로서 분류하는데 사용된다.
B- 중간 DNA 함량을 갖는 오염물을 갖는 샘플은 하기 중 하나 이상을 특징으로 한다:
ㆍ대립유전자의 평균 이형접합체 피크 높이(RFU)는 3,000 내지 10,000 RFU이다.
ㆍ모든 iNTA 피크는 표준 수준 내에 있는 수준으로 존재하며, 전문가 시스템에 의해 표지되지 않는다.
ㆍ모든 대립유전자는 표준 수준 내에 있는 피크 폭을 갖는다.
ㆍ적색 경고 박스로 표지된 3개 이상의 피크를 갖는 2개 이상의 유전자좌.
ㆍ적색 경고 박스로 표지된 4개 이상의 피크를 갖는 하나 이상의 유전자좌.
ㆍ샘플 중 모든 대립유전자는 적색으로 표지된다.
ㆍ혼합물 샘플은 또한 낮은 DNA 함량 혼합물 샘플 및 높은 DNA 함량 혼합물 샘플로서 하위분류될 수 있음을 주목하라.
C- 높은 DNA 함량을 갖는 오염물을 갖는 샘플은 하기 중 하나 이상을 특징으로 한다:
ㆍ10,000 RFU 초과의 평균 이형접합체 피크 높이(RFU).
ㆍ포화되고 상단이 사각형인 피크.
ㆍ허용가능한 폭 임계값을 초과하는 간헐적인 넓은 피크. 이들 피크는 표지되지 않는다.
ㆍ표준 수준을 초과하고, 때때로 진정한 대립유전자로서 표지되는, 피크 높이 및 피크 높이 비율을 갖는 iNTA 피크. 특히, 아멜로게닌 유전자좌의 iNTA 피크 높이 비율은 표준 수준을 초과한다.
ㆍ3개의 표지된 대립유전자를 갖는 다중의 유전자좌를 갖는 샘플로서, 이러한 샘플 중의 모든 대립유전자는 적색으로 표지된다.
ㆍ4개의 표지된 대립유전자를 갖는 적어도 하나의 유전자좌를 갖는 샘플로서, 이러한 샘플 중의 모든 대립유전자는 적색으로 표지된다.
ㆍ적색 경고 박스로 표지된 3개 이상의 피크 및 추가의 피크를 갖는 2개 이상의 유전자좌는 인접 대립유전자로부터 1b 초과에 존재한다(예를 들어, iNTA 피크는 아님).
ㆍ적색 경고 박스로 표지된 4개 이상의 피크 및 추가의 피크를 갖는 하나 이상의 유전자좌는 인접 대립유전자로부터 1b 초과에 존재한다(예를 들어, iNTA 피크는 아님).
ㆍ샘플 중 모든 대립유전자는 적색으로 표지된다.
도 5는 동적 범위를 초과하는 중간체 DNA 함량을 갖는 오염된 샘플(2개의 도너로 구성됨)의 대표적인 DNA ID를 보여준다. 이 도면에 제시된 특정 특징은 다음과 같다:
ㆍ3,000 내지 10,000 RFU인 평균 이형접합체 피크 높이(RFU).
ㆍ모든 iNTA 피크는 표준 수준 내의 수준으로 존재하며, 전문가 시스템에 의해 표지되지 않는다.
ㆍ모든 대립유전자는 표준 수준 내에 있는 피크 폭을 갖는다.
ㆍ적색 경고 박스로 표지된 3개 이상의 피크를 갖는 2개 이상의 유전자좌. 유전자좌 D3S1358, Th01, vWA, 및 D7S820 참조.
ㆍ적색 경고 박스로 표지된 4개 이상의 피크를 갖는 하나 이상의 유전자좌.
ㆍ샘플 중 모든 대립유전자는 적색으로 표지된다.
도 6 및 7은 샘플 데이터가 적응형 전문가 시스템으로 처리되는 경우, 각각 일차 도너 및 이차 도너의 생성된 DNA ID를 보여준다. 이러한 과정의 상세한 논의는 실시예 13에서 논의된다. 적응형 전문가 시스템은 유전자좌 특이적 파라미터 조절을 적용하여 일차 도너의 DNA ID를 생성하였다. 일차 성분으로부터의 DNA ID를 샘플 데이터로부터 빼고, 이러한 데이터를 AES에 의해 재처리하였다. AES는 변형된 샘플 데이터를 낮은 DNA 함량의 데이터로 분류하고, 이 샘플 데이터를 낮은 DNA 함량 ES 파라미터 세트로 처리하여 2차 성분으로부터 DNA ID를 생성시켰다. 혼합물 DNA ID가 낮은, 중간 및 높은 DNA 함량의 특징들을 갖는 경우, 이러한 접근 방식 및 이러한 접근 방식에 대한 변형을 이용한다. 일반적으로, 일단 AES가 혼합물의 존재를 결정하면, 이는 (전형적으로 주류 기여자로부터의) 가장 높은 피크의 호출을 최적화시키도록 설계된 파라미터 세트를 사용하여 샘플을 평가하고, 이들 피크를 빼고, 중간 DNA 함량 호출을 최적화시키도록 설계된 파라미터 세트를 사용하여 평가하고, 중간 피크를 빼고, (전형적으로 비주류 기여자로부터의) 가장 낮은 신호 피크의 호출을 최적화시키도록 설계된 파라미터 세트를 사용하여 평가할 것이다. 빈번하게는, 주어진 피크는 2개 이상의 근본적인 STR 특징으로부터 유래될 수 있다. 예를 들어, 주어진 STR 대립유전자로부터 유래된 스터터 피크는 제2 대립유전자로부터의 피크와 동일한 위치에 속할 수 있다. AES는 이러한 피크의 상대적인 부분을 할당하기 위해 혼합물 디콘볼루션 알고리즘을 적용하도록 구성될 수 있으며, 대부분은 이진법 또는 확률론적이다. 혼합물 디콘볼루션 알고리즘은 넓게 말해, 각 기여자에 대한 모든 유전자좌에 걸친 상대적 피크 높이에 의해 그 기여자를 식별하는 것을 기초로 한다(예를 들어, 두 사람 혼합물에서 유전자좌에 걸쳐 가장 높은 피크는 주류 기여자로부터 유래되며, 더 낮은 피크는 비주류 기여자로부터 유래되는 것으로 보인다). [Gill P., Sparkes R.L., Pinchin R., Clayton T., Whitaker J.P., and Buckleton J.S.: Interpreting simple STR mixtures using allelic peak areas. Forensic Sci. Int. 1998; 91: pp. 41-53; D.A. Taylor, J.-A. Bright, J. S. Buckleton, The interpretation of single source and mixed DNA profiles, Forensic Science International: Genetics. 7(5) (2013) 516-528; J.-A. Bright, I.W. Evett, D.A. Taylor, J.M. Curran and J.S. Buckleton, A series of recommended tests when validating probabilistic DNA profile interpretation software. Forensic Science International: Genetics, 2015. 14: 125-131; T.W. Bille, S.M. Weitz, M.D. Coble, J.S. Buckleton and J.-A. Bright, Comparison of the performance of different models for the interpretation of low level mixed DNA profiles. Electrophoresis, 2014. 35:3125-33; S.J. Cooper, C.E. McGovern, J.-A. Bright, D.A. Taylor and J.S. Buckleton, Investigating a common approach to DNA profile interpretation using probabilistic software. Forensic Science International: Genetics, 2015. 16:121-131; T.R. Moretti, R.S. Just, S.C. Kehl, L.E. Willis, J.S. Buckleton, J.-A. Bright, D.A. Taylor, Internal validation of STRmixTM for the interpretation of single source and mixed DNA profiles. Forensic Science International: Genetics, 2017. 29:126-144.]
D. 분해되고/거나 억제된 샘플
DNA 억제된 샘플은 헴(혈액으로부터), 휴믹산(토양 샘플로부터), 타닌 및 인디고 염료(의류로부터) 및 EDTA(시약으로부터)와 같은 PCR 억제 물질을 함유하는 기재로부터 수집된 특정 SSE 샘플을 포함할 수 있다. 또한, 분해는 환경 인자(예를 들어, 열, 빛, 습도 및 염수)에 대한 노출로부터 발생할 수 있다. 이러한 샘플이 처리되는 경우, 하나 이상의 유전자좌의 신호 강도는 샘플의 평균 신호 강도 대비 신호 강도의 불균형을 나타낼 것이다. 표준 전문가 시스템 파라미터는 호출되는 것이 억제되며, 따라서, 정보가 손실되는 유전자좌를 초래한다.
억제제/분해가 있는 샘플은 먼저 위의 특성에 따라 낮은, 중간 또는 높은 신호 DNA 함량을 갖는 샘플로서 분류된다.
이러한 분류 후, 샘플은 유전자좌의 평균 신호 강도 대비 하나 이상의 유전자좌의 상대적 신호 강도가 범위를 벗어난 경우, 억제되는 것으로 추가로 분류된다. 억제되는/분해되는 특이적 유전자좌는 AES에 의해 식별된다. 억제/분해의 일부 경우에, 큰 단편의 신호 강도는 더 작은 단편의 강도보다 현저하게 낮다. 다른 경우, 특이적 유전자좌는 억제될 수 있으며, 훨씬 더 낮거나 훨신 더 높은 신호 강도를 입증한다. 도 8에서, 샘플은 하기 특징을 갖는다:
ㆍ3000 RFU 미만의 평균 이형접합체 피크 높이(RFU).
ㆍ표지되지 않은 표준(협측) 전문가 시스템 호출 임계값 미만의 피크 높이를 갖는 유전자좌. D6S1043 참조.
ㆍ적색 경고 박스로 표지된 다중 동형접합체 유전자좌. Am, D13S317, D18S51, CSF1PO, D7S820 참조.
ㆍ모든 iNTA 피크는 표준 수준 내에 있는 수준으로 존재하며, 전문가 시스템에 의해 표지되지 않는다.
ㆍ모든 대립유전자는 표준 수준 내에 있는 피크 폭을 갖는다.
ㆍ하나(또는 그 초과)의 유전자좌의 상대적 신호 강도는 색상에서 유전자좌의 평균 신호 강도보다 현저하게 낮거나 높다. 도 8에서, Th01은 현저하게 낮다.
도 9는 적응형 전문가 시스템으로 처리되는 경우, 도 8의 샘플 데이터의 생성된 DNA ID를 보여준다. 낮은 DNA 함량 파라미터 세트가 샘플 데이터에 적용되고, 이어서 Th01 유전자좌에 대한 유전자좌 특이적 조절이 수행된다. 억제된 유전자좌에 대한 피크 높이 임계값 및 피크 높이 비율은, 최소 수의 드롭아웃 및 드롭인을 갖는 최대 수의 대립유전자가 호출되어 완전한 DNA ID를 생산하도록 선택되었다.
실시예
1.
AES
분석 워크플로우
도 10 및 11은 어떻게 AES가 작용하는지를 보여주는 흐름도이다:
1. ANDE 실행으로부터의 샘플 데이터(.csv(콤마 구분됨) 포맷, 또는 .dat, (탭 구분됨) 또는 다른 유사한 포맷으로 저장된 검출기로부터의 광 신호) 또는 미가공 일렉트로페로그램 데이터(색상 교정되고 .nbo, 또는 .FSA, 또는 .HID 포맷으로 저장된 광학 데이터)는 ANDE 데이터베이스 관리 시스템(ADMS) 또는 ANDE FAIRS 애플리케이션으로 가져온다. 예를 들어, 광학 데이터 또는 일렉트로페로그램 데이터는 (예를 들어, 통신 네트워크 예컨대, 인터넷, 또는 이더넷을 통해 또는 이동식 디스크 또는 USB 드라이브를 통해) 컴퓨팅 장치로 전송되어 저장된다.
ANDE ADMS 및 ANDE FAIRS는 컴퓨팅 장치(예를 들어, 노트북, 또는 데스크탑, 또는 서버)에서 실행되는 독립형 애플리케이션이다. 이러한 애플리케이션은 ANDE에서 생성된 데이터를 가져오고, 내보내고, 저장하고 처리할 수 있도록 한다. 이들 애플리케이션은 ANDE 전문가 시스템 및 AES의 인스턴스(instance)를 가지며, 광학 데이터 또는 일렉트로페로그램 데이터를 포함하는 샘플 데이터를 처리할 수 있다. 또한, 이러한 애플리케이션은 샘플 데이터(광학 데이터 및 일렉트로페로그램 데이터 포함), 샘플 메타데이터, 샘플 대립유전자 데이터 및 DNA ID 특징을 저장하기 위한 데이터베이스(예를 들어, 관련 및 비관련)를 갖는다. 이들은 또한, DNA ID 데이터베이스 생성, 가져오기, 내보내기 및 편집을 허용한다(DNA ID는 ANDE, 다른 신속 DNA 또는 통상적인 lab 시스템으로부터 생성될 수 있다). 이러한 애플리케이션은 친족 분석 및 이민 및 재난 피해자 식별을 위한 가족 검색 및 청구관계 테스트를 위한 모듈을 갖는다. 또한, ADMS 및 FAIRS 소프트웨어는 포함 및 제외 분석을 포함하는 혼합물 분석 및 혼합물 디콘볼루션을 위한 모듈을 갖는다. 이들은 또한, DNA ID 검색 및 매치를 위한 모듈을 갖는다.
대안적으로, ANDE 실행으로부터의 광학 데이터는 사용자에게 제시하기 전에 전문가 시스템 또는 적응형 전문가 시스템에 의해 탑재된 기기에서 직접적으로 처리될 수 있다. 이러한 구성은 ANDE ES 및 AES를 기기와 일체화시킨다.
본원의 실시예는 DNA ID를 생성시키는데 사용되는 이러한 경우에 분석물이 DNA인 경우 광학 데이터에 초점을 맞추고 있으나, 이에 제한되지 않는다. 본 발명을 사용하여 분석될 수 있는 다른 분석물로는 단백질, 펩티드, 메신저 RNA, 복사체 DNA, 메틸화된 또는 다르게 변형된 형태의 DNA, 단일 뉴클레오티드 다형체, 서열화된 DNA, 다른 생체분자 및 무기 화학물질 중 하나 이상을 포함한다. 검출된 데이터의 형태는 광학, 전기, 열, 화학, 자기, 생리화학, 기계적 형태 등을 포함한다. 이들 경우에, 전문가 시스템 파라미터 세트는 샘플 데이터의 특정 특징을 기반으로 하여 자동으로 적용될 수 있다.
DNA 데이터의 소스는 하기로부터 일 수 있다:
ㆍ신속 DNA 기기,
ㆍ수정된 신속 DNA 기기,
ㆍ모세관 전기영동 기기,
ㆍ마이크로칩 전기영동 기기,
ㆍ질량 분광분석기,
ㆍDNA 시퀀싱 기구,
ㆍ실시간 PCR(RT-PCR, qPCR) 기기,
ㆍ미세유체 기기,
ㆍDNA의 양태를 검출하는 다른 기기.
AES는 다음에서 작동할 수 있다:
ㆍANDE 신속 DNA 기기,
ㆍ또 다른 신속 DNA 기기,
ㆍ수정된 신속 DNA 기기,
ㆍ마이크로칩 전기영동 기기,
ㆍ질량 분광분석기,
ㆍDNA 시퀀싱 기기,
ㆍ실시간 PCR(RT-PCR, qPCR) 기기,
ㆍ미세유체 기기,
ㆍANDE 신속 DNA 기기와 분리된 컴퓨팅 장치,
ㆍ신속 DNA 기기와 분리된 컴퓨팅 장치,
ㆍ수정된 신속 DNA 기기와 분리된 컴퓨팅 장치,
ㆍ모세관 전기영동 기기와 분리된 컴퓨팅 장치,
ㆍ마이크로칩 전기영동 기기와 분리된 컴퓨팅 장치,
ㆍ질량 분광분석기와 분리된 컴퓨팅 장치,
ㆍDNA 시퀀싱 기기와 분리된 컴퓨팅 장치,
ㆍ실시간 PCR(RT-PCR, qPCR) 기기와 분리된 컴퓨팅 장치,
ㆍ미세유체 기기와 분리된 컴퓨팅 장치.
ㆍ마이크로칩 전기영동 기기와 분리된 컴퓨팅 장치,
ㆍDNA의 양상을 검출하는 다른 기기와 분리된 컴퓨팅 장치.
본 실시예에서, A-칩에 있어서는 5개 이하의 샘플로부터의 샘플 데이터를 가져오고, I-칩에 있어서는 4개 이하의 샘플로부터의 샘플 데이터를 가져온다. 하기 단계는 단일 샘플로부터의 샘플 데이터의 ANDE AES 처리를 따른다.
2. 표준 전문가 시스템 파라미터를 사용하여 샘플 데이터를 처리한다. 파라미터는 이형접합체 피크 높이 비율, 이형접합체 피크 높이 임계값, 신호 대 잡음 비율, iNTA 후보 피크 높이 비율, 스터터 후보 피크 높이 비율, 삼대립유전자 피크 높이, 삼대립유전자 피크 높이 비율, 혼합물 피크 높이 임계값, 동형접합체 피크 높이 비율, 동형접합체 피크 높이 임계값, 반접합체 피크 높이 비율, 반접합체 피크 높이 임계값, 피크 폭 임계값, 및 피크 형상을 포함한다. 이러한 파라미터 세트의 애플리케이션은 DNA ID를 생성한다. DNA ID에 대한 하기 특징이 또한 정량화되고, 후속 처리에 사용가능하다: 각 대립유전자의 신호 강도, 각 유전자좌에 대한 iNTA 피크 높이 및 피크 높이 비율, 이형접합체 피크의 피크 높이 비율, 각 유전자좌에서 피크의 수, 각 대립유전자 피크의 폭 및 형상, 각 염료 채널의 신호 대 잡음 비율, 각 대립유전자의 스터터 비율.
표준 (또는 베이스라인) 전문가 시스템 파라미터로의 DNA ID의 처리는 선택사항임을 주목하라. 이러한 처리가 요망되지 않은 경우, 샘플 데이터를 이용하여 비제한적으로 하기를 포함하는 하나 이상의 특징을 직접적으로 생성할 수 있다: 각 대립유전자의 신호 강도, 각 유전자좌에 대한 iNTA 피크 높이 및 피크 높이 비율, 이형접합체 피크의 피크 높이 비율, 각 유전자좌에서 피크의 수, 각 대립유전자 피크의 폭 및 형상, 각 염료 채널의 신호 대 잡음 비율, 각 대립유전자의 스터터 비율. 그 후, 이러한 데이터는, 하나 또는 복수의 AES 파라미터 세트를 사용하여 DNA ID를 직접적으로 생성시키는데 사용될 수 있다. 더욱이, 본 발명의 AES는 샘플에 대한 메타-정보 및 칩 유형에 기초한 다양한 베이스라인 파라미터 세트를 이용할 수 있다.
3. 샘플 데이터 또는 DNA ID(비제한적으로, 각 대립유전자의 신호 강도, 대립유전자의 총 수, 유전자좌 당 대립유전자의 수, 유전자좌 내의 대립유전자의 상대적 신호 강도, 대립유전자 크기(예를 들어, 염기) 대비 대립유전자의 상대적 신호 강도, 각 유전자좌에 대한 iNTA 피크 높이 및 피크 높이 비율, 이형접합체 피크의 피크 높이 비율, 각 유전자좌에서 피크의 수, 각 대립유전자 피크의 폭 및 형상, 각 염료 채널의 신호 대 잡음 비율, 각 대립유전자의 스터터 비율을 포함)의 하나 또는 복수의 특징을 기반으로 하여, 샘플을 전형적인 범위내, 높은, 낮은, 혼합물, 분해된, 억제된 또는 기타의 샘플로서 분류한다. 분류에 사용되는 특징의 수는 1, 2, 3, 4, 5, 5 초과, 10 초과, 25 초과, 50 초과, 100 초과, 200 초과, 500 초과, 또는 1000개 초과일 수 있으며, 카테고리는 샘플 유형, 샘플 데이터 및 샘플의 작업 값을 기반으로 하여 이용될 수 있다.
4A. 표준 카테고리 DNA ID에 있어서, 데이터베이스 검색, 친족 분석 또는 다른 평가를 위한 .xml 파일을 준비한다.
도 12는 .xml 파일의 일부를 보여준다. .xml 파일은 CODIS CMF 파일 포맷을 따르며, 샘플, 유전자좌 및 대립유전자 호출에 대한 메타데이터를 함유한다. 파일은 NDIS, SDIS, LDIS 및 많은 국제 DNA 데이터베이스를 포함하는 데이터베이스의 검색을 허용하도록 포맷된다. ANDE 전문가 시스템 및 적응형 전문가 시스템은 XML 파일의 모든 호출된 대립유전자를 나열한다. ANDE 시스템에서, 기준(호출된 유전자좌의 수로 구성되고, 에어전시에 의해 규정된)을 통과하는 샘플에 대한 .XML 파일은 사용자에게의 내보내기에 이용가능하다. 이러한 실시는 ANDE에 특이적이다. 다른 시스템은 XML 파일이 에이전시 기준을 통과하거나 실패한 샘플에 대해 생성되게 할 수 있다(ANDE 시스템이 동일하게 수행하기 위해 구성될 수 있다).
4B. 높은 DNA 함량 카테고리 DNA ID에 있어서, 높은 신호 전문가 시스템 파라미터를 적용하고, 독립적으로 (및 선택적으로) 표준 전문가 시스템 파라미터를 적용한다. 데이터베이스 검색 (또는 다른 사용)을 위한 두 .xml 파일을 준비한다. 본 실시예에서, 프로세스 워크플로우는 높은 신호 전문가 시스템 파라미터 및 선택적으로, 표준 전문가 시스템 파라미터를 사용하여 호출을 생성하도록 설계된다. 대안적으로, 단지 높은 신호 전문가 시스템 파라미터 세트로만의 DNA ID의 생성을 단지 포함하는 워크플로우가 또한 적용될 수 있다. 또한, 높은 전문가 시스템 파라미터의 다중 세트가 병렬로 적용될 수 있다.
4C. 낮은 DNA 함량 카테고리 DNA ID에 있어서, 낮은 신호 전문가 시스템 파라미터를 적용하고, 독립적으로 (및 선택적으로) 표준 전문가 시스템 파라미터를 적용한다. 데이터베이스 검색 (또는 다른 용도)을 위한 두 .xml 파일을 준비한다. 본 실시예에서, 프로세스 워크플로우는 표준 전문가 시스템 파라미터 및 선택적으로, 낮은 신호 전문가 시스템 파라미터를 사용하여 호출을 생성하도록 설계된다. 대안적으로, 단지 낮은 신호 전문가 시스템 파라미터 세트로만의 DNA ID의 생성을 단지 포함하는 워크플로우가 또한 적용될 수 있다. 또한, 낮은 전문가 시스템 파라미터의 다중 세트가 병렬로 적용될 수 있다. 또한, AES가 기기와 일체화되는 경우, 에이전시 또는 개별 최고관리 사용자는 사용자를 위한 단지 하나의 .XML 출력값만 생성하기를 원할 수 있다. 이러한 XML 출력값은 AES 파라미터에 의해 생성된다.
5. 동시에, 모든 생성된 .xml 파일을 검색하고 매치한다(표준 신호인 경우, 2개, 낮은 또는 높은 신호인 경우, 4개). 수행될 수 있는 검색은 DNA ID 데이터베이스 및 검색 기능 또는 ANDE 데이터 관리 시스템 데이터베이스 및 검색 기능을 사용하여 이루어질 수 있다. 각 .xml 파일은 2회 검색되며, 한 번은 높은 엄격성의 검색 기준으로, 다른 하나는 낮은 엄격성의 검색 기준으로 검색된다.
ANDE 전문가 시스템 또는 ANDE AES에 의해 생성된 XML 파일은 단순 검색 및 매칭, 가족 검색 및 매칭, 및 ANDE ADMS 및 ANDE FAIRS 애플리케이션에 대한 혼합물 검색 및 매치에 사용될 수 있다. 데이터베이스에 대한 DNA ID를 검색할 경우, 검색은 먼저 중복되는 유전자좌를 식별함으로써 수행될 수 있다. 중복 유전자좌는 검색 중인 DNA ID 및 데이터베이스의 DNA ID 둘 모두에 존재하는 유전자좌로서 규정되며, 적어도 하나의 동일한 대립유전자 호출이 그 유전자좌에 존재한다. 각각의 중복 유전자좌에 있어서, 하기가 결정된다:
ㆍ비교되는 샘플의 유전자좌 내의 대립유전자의 수,
ㆍ비교되는 샘플의 유전자좌 내의 매치되는 대립유전자의 수,
ㆍ비교되는 샘플의 유전자좌 내의 매치되지 않는 대립유전자의 수.
모든 대립유전자가 매치되는 비교 중인 샘플의 유전자좌는 완벽한 매치로서 분류되고, 대립유전자 중 하나가 매치되는 (적어도 하나의 대립유전자는 매치되지 않는) 유전자좌는 부분 매치로서 분류되며, 대립유전자가 전혀 매치되지 않는 유전자좌는 미스매치로서 분류된다. 이러한 분석은 검색되는 샘플 및 데이터베이스의 각 개별 DNA ID에 의해 공유되는 모든 유전자좌에서 수행되며, 스프트웨어는 중복 유전자좌의 수, 완벽한 매치의 유전자좌의 수, 부분 매치의 유전자좌의 수, 및 미스매치된 유전자좌의 수를 결정한다. 이러한 데이터를 기반으로 하여, 다양한 엄격성을 갖는 광범위한 검색 기준이 적용될 수 있다:
플렉스플렉스 시스템에 있어서 낮은 엄격성의 검색 기준의 예는 27개 유전자좌의 경우 다음과 같다:
ㆍ최소 중복 유전자좌의 수는 8이며,
ㆍ최소 매칭 유전자좌의 수는 8이다.
높은 엄격성 검색 기준의 예는 다음과 같다:
ㆍ최소 중복 유전자좌의 수는 20개 CODIS 유전자좌이며,
ㆍ최소 매칭 유전자좌의 수는 19개 CODIS 유전자좌이며,
ㆍ최대 미스매치 유전자좌의 수는 1개 CODIS 유전자좌이다.
가족 검색 기준의 예는 다음과 같다:
ㆍ최소 중복 유전자좌의 수는 8이며,
ㆍ최소 부분 매칭 유전자좌의 수는 8이다.
혼합물 검색 기준의 예는 다음과 같다:
ㆍ최소 중복 유전자좌의 수는 8이며,
ㆍ최소 부분 매칭 유전자좌의 수는 8이다.
도 10은 표준/베이스라인 파라미터가 먼저 수행된 후, 샘플 특징을 평가하고, 추가로 AES 처리한, AES 프로세싱을 보여준다. 도 11은 표준/베이스라인 파라미터 세트의 초기 적용의 부재하에 AES 프로세싱을 보여준다. 추가로, 도 11에서, 표준 DNA ID는 선택적으로 생성된다. 흐름도는 ANDE 적응형 전문가 시스템 이후 데이터베이스 검색의 단계를 보여준다. 표준 신호(중앙 경로)를 갖는 DNA ID의 경우, 2개의 검색 출력값이 생성되며, 하나는 높은 엄격성의 검색을 기반으로 하며, 다른 하나는 낮은 엄격성의 검색을 기반으로 한다. 높은 또는 낮은 신호(왼쪽 또는 오른쪽 경로)를 갖는 DNA ID의 경우, 총 4개의 데이터베이스 검색 출력값이 생성된다. DNA ID 데이터베이스 검색, 친족 평가(가족 검색 및 청구된 관계 평가 포함), DVI 검색, 혼합물 검색, 확률적 유전자형 분석 및 다양한 형태의 혼합물 디콘볼루션이 AES로부터 생성된 DNA ID로 수행될 수 있다. 간략화를 위해, DNA 데이터베이스 검색이 본원에 예시된다.
본 실시예에서, 프로세스 워크플로우는 표준 전문가 시스템 파라미터 및 적응형 전문가 시스템 파라미터를 사용하여 호출을 생성하도록 설계된다. 대안적으로, 단지 낮은 신호 전문가 시스템 파라미터만으로의 DNA ID의 생성을 단지 포함하는 워크플로우가 또한 적용될 수 있다.
본 실시예에서, AES의 인스턴스는 노트북 컴퓨터 또는 데스크톱 컴퓨터 또는 서버에서 실행되는 독립실행형 ANDE AMDS 또는 ANDE FAIRS 애플리케이션에 있다. 대안적으로, AES는 ANDE 시스템과 통합되고, 기기와 일체화될 수 있다.
본 실시예에서, 프로세스 워크플로우는 표준 파라미터로 생성된 DNA ID에 있어서 낮은 엄격성의 검색 및 높은 엄격성의 검색을 생성하도록 설계된다. 또한, 낮은 엄격성의 검색 및 높은 엄격성의 검색은 또한, AES 파라미터로 생성된 DNA ID에 대해 수행된다. 대안적으로, 단지 낮은 또는 높은 엄격성의 검색을 이용한 검색을 포함하는 워크 플로우가 적용될 수 있다. 대안적으로, 가족 검색 기준(낮은 또는 높은 엄격성) 또는 혼합물 검색 기준(낮은 또는 높은 엄격성을 가짐)을 이용한 검색을 포함하는 워크 플로우가 또한 적용될 수 있다. 풍부한 지식의 당업자(예컨대, 시스템 관리자)는 바람직하게는, GUI-기반 사용자 구성 화면을 이용하여 프로세싱 파라미터 및 검색 유형과 검색 엄격성을 재구성할 수 있을 것이다.
검색 엔진은 AES 애플리케이션 내에 또는 별도로 함유될 수 있다. 두 경우에, AES 호출 기능 및 검색 엔진은 소통 방식으로 사용될 수 있다. 예를 들어, AES는 일련의 계속해서 덜 엄격성인 파라미터 세트를 사용할 수 있다. DNA ID (및 XML 출력값)가 파라미터 세트로부터 생성될 때 마다, 해당 DNA ID는 데이터베이스를 검색하는데 사용될 수 있다. 또한, 이러한 검색은 일련의 점진적으로 덜 보존적인 매치 기준을 사용하여 매치의 수를 생성시키고 스코어링할 수 있다(매치 스코어는 무작위 매치 확률, 또는 매칭되는 대립유전자 및 유전자좌의 총계, 또는 에이전시에 의해 규정된 바와 같은 다른 방법으로 규정될 수 있음). 매치 스코어가 요망되는 수준에 도달하지 않는 경우, 다음 파라미터 세트가 적용되며, 일련의 검색 기준을 사용하여 데이터베이스에 대해 다시 검색된다. 이러한 프로세스는 요망되는 매치 스코어가 달성될 때까지 자동으로 계속될 수 있다(또는 동일한 목적으로 수동으로 수행될 수 있다). 이러한 배열된 검색 접근 방식은 요망되는 경우 해당 AES 내에서 수행되며, 단순 GUI 스크린으로 구성될 수 있다. AES 보고서, AES/검색 보고서 및 배열된 검색 보고서는 내보내기를 위해 생성될 수 있으며(예를 들어, pdf 파일로서), 기기 또는 컴퓨터 스크린에 표시될 수 있다.
실시예
2.
AES
분석을 위한 샘플 데이터 생성.
DNA의 분리 및 검출이 본원에 참조로 통합된 하기 미국 특허에서 칩 및 기기에서 수행될 수 있다: 8,018,593; 8,173,417; 8,206; 974; 9,523,656; 9,606,083; "Ruggedized apparatus for analysis of nucleic acid and proteins," 9,366,631 "Integrated systems for the multiplexed amplification and detection of six and greater dye labeled fragments," 8,858,770; 8,961,765; 9,994,895 "Plastic microfluidic separation and detection platforms."
분리 및 검출 기기는 DNA 샘플에 대한 정보를 얻기 위한 여기 및 검출 하위시스템을 포함한다. DNA 샘플이 실시예에 설명되어 있지만, 샘플은 비제한적으로, 하나 이상의 형광 염료로 표지되는 DNA, RNA 및 단백질을 포함하는 하나 이상의 생물학적 분자를 포함할 수 있다.
여기 서브시스템은 여기/검출 윈도우에서 여기 소스를 컨디셔닝하고 초점을 맞추기 위해 렌즈 핀홀, 거울 및 대물렌즈를 포함하는 광학 요소를 갖는 여기 빔 경로 및 여기 소스 또는 소스들을 포함한다. 샘플의 광학적 여기는 400 내지 650 nm의 가시 영역의 방출 파장으로 일련의 레이저 유형에 의해 달성될 수 있다.
검출 하위 시스템은 여기/검출 윈도우에 존재하는 형광-표지된 DNA 단편으로부터 방출된 형광을 수집하기 위해 하나 이상의 광학 검출기, 파장 분산 장치(파장 분리를 수행함), 및 비제한적으로, 렌즈, 핀홀, 거울 및 대물렌즈를 포함하는 광학 요소 세트를 포함한다. 방출된 형광은 단일 염료 또는 염료의 조합물로부터 비롯될 수 있다. 신호를 구별하여 방출 염료 파장으로부터 신호의 기여도를 결정하기 위해, 형광 파장을 분리하고 후속하여 광학 검출기에 의해 검출한다. 형광 여기 및 검출은 각각의 마이크로채널의 일부를 통해 에너지원(예를 들어, 레이저 빔)을 스캐닝하면서, 염료로부터 유도된 형광을 수집하고 하나 이상의 광 검출기로 전송함으로써 DNA 샘플의 전기영동에 의해 분리된 구성요소를 여기시킨다.
제1 구체예에서, 파장 구성요소는 다이크로익 미러 및 밴드패스 필터의 사용에 의해 분리되며, 이러한 파장 구성요소는 포토멀티플러 튜브(Photomultiplier tube)(PMT) 검출기(H7732-10, Hammamatsu)로 검출된다. 다이크로익 미러 및 밴드패스 구성요소는, 각 PMT 상의 입사광이 1 내지 50 nm의 파장 범위의 밴드 패스를 갖는 형광 방사 피크에 대해 농축될 방사 파장에 상응하는 좁은 파장 밴드를 구성하도록 선택될 수 있다. 시스템은 8개 색상 검출이 가능하며, 방사된 형광을 각 별개의 색상으로 구분하도록 최대 8개 PMT 및 상응하는 다이크로익 미러 및 필터 세트로 설계될 수 있다. 8개 초과의 염료는 추가 다이크로익 미러 및 PMT 검출기를 적용함으로써 검출될 수 있다.
제2 구체예에서, 스펙트로그래프는 여기된 형광으로부터 파장 성분을 분리하기 위해 다이크로익 및 밴드패스 필터 대신 사용된다. 수집된 형광은 핀홀 상에 이미지화되고, 반사되고, 분산되고, 오목한 홀로그래프 격자에 의해 분광기의 출력 포트에 장착된 선형 어레이 PMT 검출기 상에 이미지화된다. 광학 검출 시스템은 적어도 2, 4, 5, 6, 16, 32, 64, 128, 또는 256개 검출기 요소를 갖는 선형 어레이 PMT 검출기를 포함한다.
제3 구체예에서, 시스템은 CCD 카메라를 사용하여 다중 레인 및 다중 염료 색상의 동시 검출을 허용한다. 이 구체예에서, 모세관 또는 미세유체 칩의 모든 레인은 동시에 조명되며, 형광으로부터 방출된 광은 파장 분산 요소(예를 들어, 프리즘)을 통해 CCD 상으로 통과된다.
상기 기술된 처음 2개의 구체예는 ANDE에서 개발되어 사용되는 광학 분리 및 검출 시스템을 사용한다. 이러한 시스템에서, 광학 검출은 광학 데이터를 제공하기 위해 프로세서와 통신하는 광검출기(PMT 검출기)에 의해 수행된다. 단일 염료 내지 많은 수의 염료에 대한 것일 수 있는 광학 데이터는 AES에 대한 입력값으로서 프로세서에 의해 사용된다.
사실, AES에 대한 입력값은 광학 데이터, 미가공 일렉트로페로그램 데이터(교정된 색상) 또는 DNA ID이다. 이러한 형태의 데이터는 시중에서 입수가능한 것 예컨대, ABI 프리즘 3100 유전자 분석기, ABI 프리즘 3130XL 유전자 분석기, Thermo Fisher Scientific 3500 유전자 분석기 및 프로메가 스펙트럼 CE 시스템을 포함하는 ANDE에 의해 제작된 것 이외의 기기로부터 획득될 수 있다. 사실, 분석을 위한 데이터는 여기서 예를 생성하는데 사용되는 모세관 또는 마이크로칩 전기영동 시스템으로부터의 데이터로 제한되지 않는다.
실시예
3. DNA ID 특징 규명 및
워킹
AES
데이터세트 생성
AES 빌딩에서, 초기 단계는 알려진 DNA ID(사실)를 갖는 광범위한 샘플 유형으로부터의 실제 DNA ID가 생성될 수 있으며, DNA ID의 특정 특성이 정량화될 수 있는 데이터세트를 확립하는 것이다. 더욱이, 이들 데이터세트로부터, 정량적 AES 규칙이 도출되어 역테스트될 수 있다. 즉, 어떤 DNA 프로세싱 시스템 및 데이터 수집 시스템이 적용되더라도, 이형접합체 신호 강도 및 피크 높이 비율, 동형접합체 피크 높이, 각 대립유전자에 대한 iNTA 피크 높이 및 피크 높이 비율, 각 유전자좌에서 피크의 수, 각 대립유전자 피크의 폭 및 형상, 각 염료 채널에서 신호 대 잡음 비율, 광범위한 샘플 중 각 대립유전자의 스터터 비율과 같은 특징을 정량화하는 것이 중요하다. 예를 들어, DNA ID의 상기 정량화된 특징은 AES 파라미터가 확립되게 하고, 궁극적으로 샘플 데이터 및 DNA ID가 분류되게 한다. 게다가, 이들 데이터세트(크고, 광범위할 수 있음)는 AES가 배우게 함으로써 인공 지능을 이용한 AES 구현의 기초를 형성한다.
유사하게는, 샘플의 대규모 데이터세트를 개발하는 것이 유용한데, 강력한 AES 규칙 세트를 보장하기 위한 광범위한 DNA ID 생성이 개발된다. 신호 강도가 DNA ID를 특징 규명하기 위한 하나의 중요한 파라미터이지만, 모든 샘플 데이터 및 애플리케이션에 대한 유일한 또는 최선의 특징은 아닐 수 있다. 즉각적인 AES 데이터세트를 생성하기 위해, 협측, 조직 및 터치 샘플 DNA ID를 ANDE 기기에서 처리하여 광범위한 신호 강도를 생성하였다.
500개 초과의 낮은 신호 샘플, 1000개 표준 샘플, 500개 높은 신호 샘플을 처리하였다.
계산된 특징은 하기를 포함하였다: 평균 이형접합체 신호 강도, PHR, iNTA, 스터터, 피크 폭, 호출된 대립유전자의 수, ILS 성공, 호출된 대립유전자의 수, 표준 ES 피크 높이 임계값 미만의 대립유전자의 수, 및 PHR 임계값 미만의 유전자좌의 수. ANDE AES에 있어서 선택된 파라미터가 관심 대상이며; ANDE를 기반으로 하지 않는 다른 AES에 있어서, 이들 또는 다른 파라미터가 관심 대상일 수 있다. 예를 들어, 주어진 데이터 프로세싱/전문가 시스템이 하나 이상의 색상에서 실질적인 블리드-스루를 특징으로 하는 경우, 증가하는 신호 강도에 기반하여 블리드스루가 증가함에 따라, 블리드스루 피크는 상기 기술된 파라미터 세트에 통합될 수 있다.
초기 데이터세트는 2,000 DNA ID로 구성되었다. 해당 데이터세트에서 DNA ID의 수는 해당 샘플 유형의 변동성 및 요망되는 카테고리의 수를 포함하는 인자에 의존적이며, 2개 만큼 적을 수 있으며, 바람직하게는, 2개 초과, 5개 초과, 10개 초과, 25개 초과, 50개 초과, 100개 초과, 250개 초과, 500개 초과, 1,000개 초과, 2,000개 초과, 5,000개 초과, 10,000개 초과, 25,000개 초과, 50,000개 초과, 100,000개 초과, 250,000개 초과, 500,000개 초과, 1,000,000개 초과, 5,000,000개 초과, 10,000,000개 초과, 및 100,000,000개 초과일 수 있다.
실시예
4. DNA ID 카테고리 (또는 표현형)의 확립
실시예 2에 기술된 바와 같이 DNA ID 데이터세트의 고찰 후, DNA ID 분류의 일련의 하위그룹을 확립하는 것이 가능하며; 이들은 AES의 기본을 형성할 것이다. 하위그룹의 수는 고정될 필요가 없으나, 대신 DNA 처리 시스템, 데이터 분석 시스템, 샘플 유형 및 샘플의 수에 의해 영향을 받는다. 본 실시예에서, 데이터세트 내의 플렉스플렉스 DNA ID는 6개의 별개의 DNA ID 분류화가 생성되게 한다:
1) 중간 신호 강도 DNA ID - 호출된 20개 CODIS 20 코어 유전자좌 및 통과 ILS를 갖는 샘플. 이들은 ANDE의 표준 ES 파라미터 세트를 사용하는 성공적인 샘플이며, 추가의 AES 처리를 필요로 하지 않는다. 또한, "성공적" DNA ID에 대해 사용되는 호출된 유전자좌 또는 특정 유전자좌의 수는 에이전시 또는 사용자에 의해 확립된다. 7개 특징의 세트가 샘플 데이터를 카테고리화하는데 사용되더라도, 이러한 특징 목록은 수정될 수 있음(예를 들어, 더욱 추가되거나 일부가 제거될 수 있음)을 주목하라. 예를 들어, 본원에 기술된 "호출된 CODIS20 유전자좌의 수"의 특징은 "호출된 CODIS 18 유전자좌의 수" 또는 "호출된 상염색체 유전자좌의 수" 또는 "호출된 플렉스 플렉스 유전자좌의 수"로 변경될 수 있다.
도 13 내지 16은 A-칩으로부터의 중간 신호 강도를 갖는 샘플의 DNA ID를 보여준다. 도 13은 A-칩으로 생성된 중간 신호 강도 샘플을 보여준다. 이러한 샘플은 호출된 모든 플렉스플렉스 27 유전자좌 및 모든 CODIS 20 유전자좌를 갖는다(이러한 DNA 샘플이 여성으로부터 유래되기 때문에, 유전자좌중 3개는 대립유전자를 갖지 않는다). 도 14는 A-칩으로 생성된 중간 신호 강도 샘플을 보여준다. 이러한 샘플은 호출된 모든 플렉스플렉스 27 유전자좌 및 모든 CODIS 20 유전자좌를 갖는다. 도 15는 A-칩으로 생성된 중간 신호 강도 샘플을 보여준다. 이러한 샘플은 호출된 모든 플렉스플렉스 27 유전자좌 및 모든 CODIS 20 유전자좌를 갖는다(이러한 DNA 샘플이 여성으로부터 유래되기 때문에, 유전자좌중 3개는 대립유전자를 갖지 않는다). 도 16은 A-칩으로 생성된 중간 신호 강도 샘플을 보여준다. 이러한 샘플은 호출된 모든 플렉스플렉스 27 유전자좌 및 모든 CODIS 20 유전자좌를 갖는다. 도 17a는 대립유전자의 신호 강도의 분포를 보여주며, 도 17b는 유전자좌에 있어서 이형접합체 피크 높이 비율을 보여준다.
도 18 내지 21은 I-칩으로부터의 중간 신호 강도를 갖는 샘플의 DNA ID를 보여준다. 도 18은 I-칩으로 생성된 중간 신호 강도 샘플을 보여준다. 이러한 샘플은 호출된 모든 플렉스플렉스 27 유전자좌 및 모든 CODIS 20 유전자좌를 갖는다. 도 19는 I-칩으로 생성된 중간 신호 강도 샘플을 보여준다. 이러한 샘플은 호출된 모든 플렉스플렉스 27 유전자좌 및 모든 CODIS 20 유전자좌를 갖는다. 도 20은 I-칩으로 생성된 중간 신호 강도 샘플을 보여준다. 이러한 샘플은 호출된 모든 플렉스플렉스 27 유전자좌 및 모든 CODIS 20 유전자좌를 갖는다. 도 21은 I-칩으로 생성된 중간 신호 강도 샘플을 보여준다. 이러한 샘플은 호출된 모든 플렉스플렉스 27 유전자좌 및 모든 CODIS 20 유전자좌를 갖는다. 도 22a는 대립유전자의 신호 강도의 분포를 보여주며, 도 22b는 유전자좌에 있어서 이형접합체 피크 높이 비율을 보여준다.
데이터세트의 모든 중간 신호 강도 샘플에 있어서 A-칩 및 I-칩 둘 모두로부터의 중앙 이형접합체 피크 높이는 1580 rfu 내지 49220 rfu의 범위이며, 8180 rfu의 중앙값을 갖는다. 8180 rfu의 중앙 신호 강도는 낮은 신호 강도 및 높은 신호 강도 샘플을 분리하는데 사용된다. 또한, 이들 값은 ANDE 신속 DNA 시스템의 특징이며; 다른 신속 DNA 시스템 또는 통상적인 STR 처리 시스템( 또는 실제로, STR 분석과 매우 별개인 다른 분석 시스템)은 "성공적" 결과에 대한 특징 값을 가질 것이다.
데이터세트의 모든 중간체 신호 강도 샘플에 있어서 A-칩 및 I-칩 둘 모두로부터의 중앙 이형접합체 피크 높이 비율은 0.614 내지 0.931의 범위이며, 0.840의 중앙값을 갖는다.
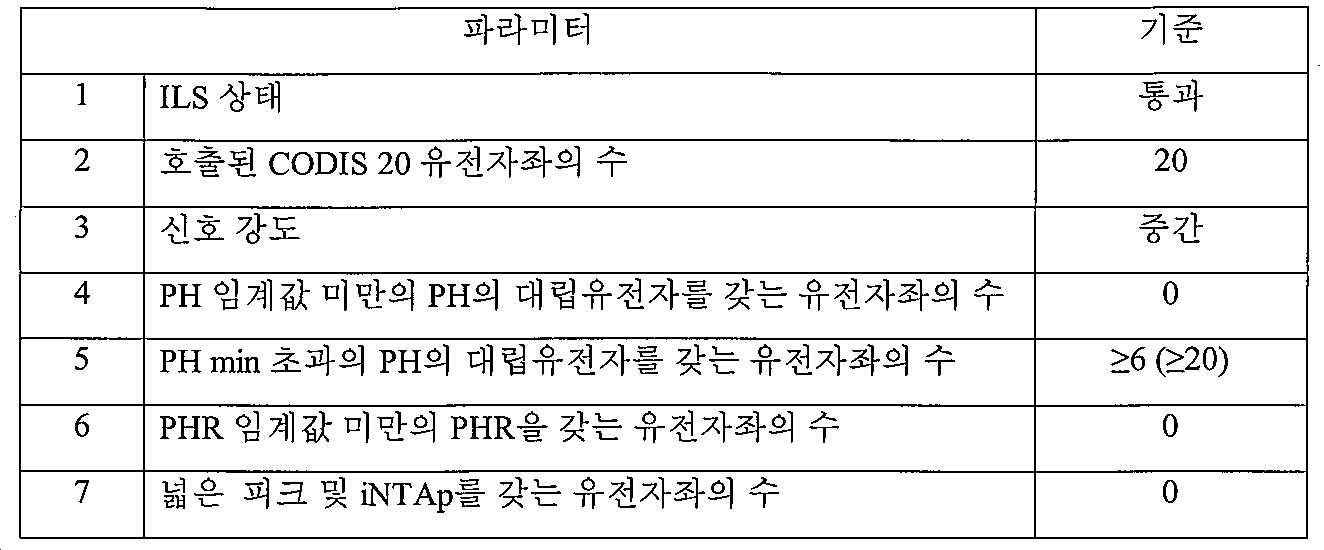
중간 신호 강도 DNA ID를 규정하는 기준은 하기 표 1에 열거된다:
표 1
2) 높은 신호 강도 DNA ID - 이들은 ILS를 통과하나, 20개 미만의 호출된 CODIS 20 코어 유전자좌를 갖는 샘플이다. 유전자좌는 하기 이유로 적색 경고 박스로 표지되거나 표지되지 않는다:
ㆍ대립유전자가 너무 넓으며, ES의 피크 형태 기준을 실패하면, 비표지된다;
ㆍiNTA 피크가 너무 높은 피크 높이 및 피크 높이 비율을 가져, 유전자좌를 혼합물로서 식별하면, 적색 경고 박스로 표지된다.
상기 언급된 바와 같이, 대립유전자 치수, 피크 형태, iNTA 피크 높이 및 형태, 혼합물 기준, 및 본질적으로 모든 다른 DNA ID 특징은 DNA 처리 시스템, 데이터 분석 시스템, 샘플 유형 및 샘플 수의 특징이다. 샘플의 유형은 또한 특징적 시그니처를 가질 수 있다. 예를 들어, 악성-관련 중복 또는 결실에 의해 특성 결정되는 임상 샘플은 샘플 유형의 특히 높은, 낮은 또는 다른 특징인 해당 피크 또는 피크들을 가질 수 있다. 본 실시예에서, 모든 치수 및 형태는 ANDE 시스템의 특징이다.
도 23 내지 26은 이러한 분류로 샘플의 DNA ID를 보여준다. 도 23은 적색으로 표지되거나 비표지된 모든 대립유전자를 갖는 높은 신호 강도 샘플을 보여준다. 도 24는 적색으로 표지된 모든 대립유전자를 갖는 높은 신호 강도 샘플을 보여준다. 도 25는 적색으로 표지된 모든 대립유전자를 갖는 높은 신호 강도 샘플을 보여준다. 도 26은 적색으로 표지되거나 비표지된 모든 대립유전자를 갖는 높은 신호 강도 샘플을 보여준다. 도 27a 및 27b는 유전자좌에 있어서 대립유전자의 신호 강도 및 이형접합체 피크 높이 비율의 분포를 보여준다. 넓은 피크 및 iNTA를 갖는 유전자좌의 수로서 규정된 파라미터는 이러한 분류를 고유하게 기술하기 위해 규정된다. 도 28은 도 23 내지 26의 샘플에서 넓은 피크 또는 iNTAp를 갖는 유전자좌의 수를 보여준다.
이러한 분류를 갖는 DNA ID를 규정하는 기준은 하기 표 2에 열거된다:
표 2
3) 중간 신호 강도 DNA ID, PHR - 이들은 ILS를 통과한 샘플이며, 20개 미만의 CODIS 20 코어 유전자좌가 호출된다. 유전자좌는 하기 이유로 적색 경고 박스로 표지된다:
ㆍ유전자좌 내의 대립유전자는 피크 높이 비율 임계값 미만인 피크 높이 비율을 갖는다. 임계값 미만의 피크 높이 비율을 갖는 유전자좌의 수는 0 초과이다.
ㆍ유전자좌 내의 대립유전자는 피크 높이 호출 임계값 미만인 피크 높이를 갖지 않는다.
ILS 통과는 성공적인 ANDE 실행에 대한 대리임을 주지하라(기기 및 칩이 설계된 바와 같이 기능함을 의미함). 많은 다른 기준이 ANDE, 다른 신속 DNA 시스템 또는 통상적인 처리에 사용될 수 있다.
도 29 및 30은 적색으로 표시된 여러 대립유전자 및 중간 신호 강도를 갖는 샘플의 이러한 분류를 보여준다. 도 31a 및 31b는 대립유전자의 신호 강도의 분포를 보여주며, 도 29 및 30의 DNA ID에 대한 유전자좌에 있어서 이형접합체 피크 높이 비율을 보여준다.
이러한 분류를 갖는 DNA ID를 규정하는 기준은 하기 표 3에 열거된다:
표 3
4) 낮은 피크 높이를 갖는 낮은 신호 강도 DNA ID - 이들은 ILS를 통과하나, 20개 미만의 호출된 CODIS 20 코어 유전자좌를 갖는 샘플이다. 유전자좌는 하기 이유로 적색 경고 박스로 표지되거나 표지되지 않는다:
ㆍ피크 높이 호출 임계값 미만인 피크 높이를 갖는 유전자좌 내의 대립유전자는 비표지된다;
ㆍ피크 높이 비율 임계값 미만인 피크 높이 비율을 갖는 유전자좌 내의 대립유전자는 적색으로 표지된다.
도 32 내지 34는 적색으로 표지된 여러 대립유전자 및 비표지된 대립유전자를 갖는 낮은 신호 강도의 샘플의 DNA ID를 보여준다. 도 35a 및 35b는 대립유전자의 신호 강도의 분포를 보여주며, 도 32 내지 34의 DNA ID에 대한 유전자좌에 있어서 이형접합체 피크 높이 비율을 보여준다.
이러한 분류로의 DNA ID를 규정하는 기준은 하기 표 4에 열거된다:
표 4
5) 매우 낮은 신호 DNA ID - 이들은 ILS를 통과하나, 20개 미만의 호출된 CODIS 20 코어 유전자좌를 갖는 샘플이다. 매우 적은 유전자좌가 적색 경고 박스로 표지되며, 많은 유전자좌는 하기 이유로 비표지된다:
ㆍ유전자좌 내의 대립유전자는 피크 높이 호출 임계값 미만인 피크 높이를 갖는다,
ㆍ유전자좌 내의 대립유전자는 피크 높이 비율 임계값 미만인 피크 높이 비율을 갖는다,
ㆍ6개 미만의 유전자좌는 최소 피크 높이 호출 임계값 초과의 피크 높이를 갖는 대립유전자를 갖는다. 이러한 임계값은 표준 전문가 시스템의 PH 임계값에서 낮아진 AES의 최소 피크 높이 임계값으로 규정된다.
모든 DNA ID 유형과 마찬가지로, 이들 기준은 달라질 수 있다; 예를 들어, 최소 피크 높이 초과의 피크 높이의 대립유전자를 갖는 유전자좌의 수는 증가되거나 감소될 수 있다.
이러한 분류로의 DNA ID를 규정하는 기준은 하기 표 5에 열거된다:
표 5
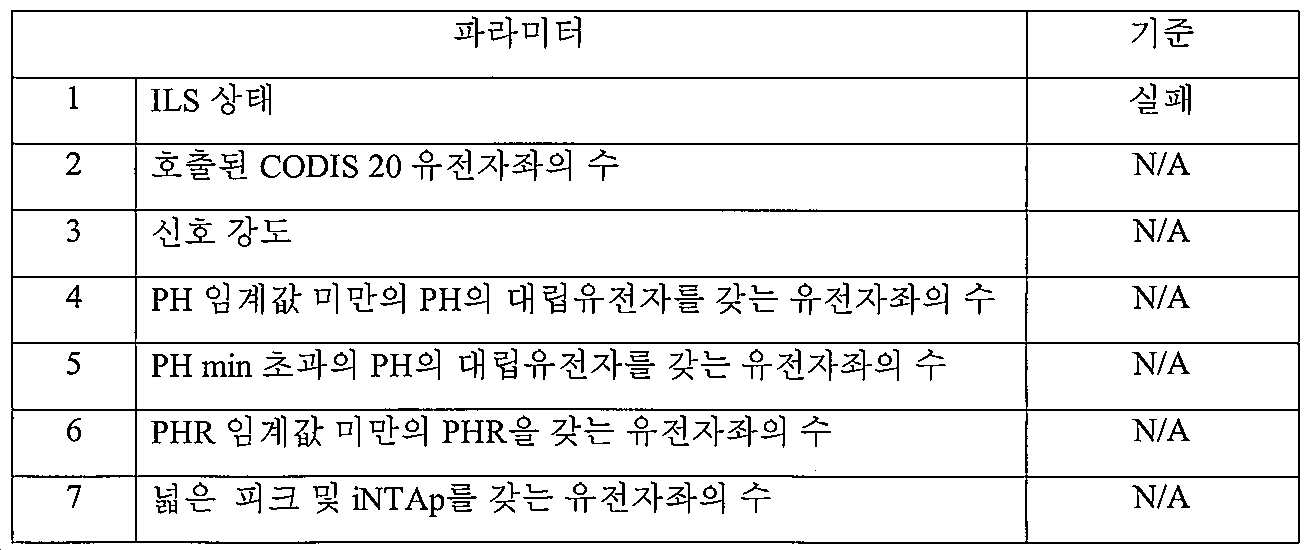
6) 실패한 DNA ID - 이들 샘플에서, ILS는 적응형 전문가 시스템에 의해 실패하였으며, 피크는 호출되지 않았다. 이들 샘플은 더 이상 처리되지 않는다. 샘플은 하기를 포함하는 다양한 이유로 실패할 수 있다:
ㆍ분리 채널의 버블. ANDE 전문가 시스템이 ILS 크기를 조정할 수 없어 샘플에 대해 실패하였다.
ㆍ샘플은 분리 및 검출 동안 주입되지 않았다. ANDE 전문가 시스템은 ILS를 검출할 수 없어 샘플에 대해 실패하였다.
ㆍ미세유체 채널이 차단되어 DNA 프로세싱을 방지하였다.
ㆍDNA 결합 필터를 찢어 DNA 정제를 방지하였다.
ㆍ이러한 실패 모드는 연구 하의 DNA 프로세싱 시스템의 특징이다.
도 36 및 37은 이러한 분류의 실패한 샘플의 예시적인 DNA ID를 보여준다.
이러한 분류로의 DNA ID를 규정하는 기준은 하기 표 6에 열거된다:
표 6
요약하면, ANDE에 의해 생성된 DNA ID는 6가지 분류로 카테고리화되었으며, 각 분류에 대한 기준이 규정되었다. 상기 표현형 DNA ID 카테고리의 규정은 AES 파라미터가 각각에 대해 사용되게 한다. 이들 파라미터는 호출된 대립유전자 및 드롭아웃/드롭인 외형을 측정함으로써 생성되고 평가된 데이터세트를 기반으로 확립되었다. 선택된 최종 파라미터 세트는 드롭인 및 드롭아웃을 최소화시키면서 호출된 가장 큰 대립유전자의 수를 생성시킨다. 이는 본 발명의 주요 이점인 DNA ID 데이터의 활용성을 최대화시킨다.
DNA ID 분류의 요약 표는 도 38에 도시된다.
ANDE 전문가 시스템은 샘플 데이터를 특징화하여 샘플을 분류한다. 사용자에게 피드백을 제공하는데 있어서 이들 샘플 분류는 도움이 될 수 있다. 많은 경우에, 사용자는 기술적 배경 또는 일렉트로페로그램을 해석하는 능력을 갖지 않으며, AES 분석을 기반으로 하여 피드백을 이러한 사용자에게 제공하는 것은 바람직할 수 있다. 이러한 피드백은 처리가 성공적으로 완료됨을 알리거나, 억류/방출 또는 매치/비매치 결과에 관한 것이거나, 결과에 문제가 있음을 사용자에게 알리는데 포커스를 맞추는 것 만큼이나 단순할 수 있으며, 또 다른 실행을 위한 샘플의 재수집에 대한 지시를 포함할 수 있다. 이들 분류는 실행이 완료된 후 사용자에게 디스플레이될 수 있다. 스크린은 샘플 ID, 또 다른 샘플 식별인자, 및/또는 칩 레인 번호 및 샘플 분류를 나타내는 아이콘 또는 메시지를 포함하는, 처리되는 샘플이 열거된다. 여러 아이콘 및 각 설명은 하기와 같다:
녹색 체크마크 아이콘/설명 - 이 아이콘은 통과 샘플이 성공적으로 처리되었음을 나타낸다. 성공에 대한 조건은 에이전시 또는 사용자가 규정한 호출된 유전자좌의 수이다. 샘플이 이러한 임계값을 충족하거나 초과하는 경우, 샘플은 통과인 것으로 간주된다. 통과 샘플의 DNA ID는 도 39에 도시된다. DNA ID 질의 측정은 이러한 또는 임의의 다른 아이콘/설명의 피드백에 통합될 수 있다. 예를 들어, 호출된 유전자좌의 수, 희귀 대립유전자의 존재 또는 삼-대립유전자의 존재를 나타낼 수 있다. 관할 정책 및 샘플의 운영 값에 기초하여, 이러한 피드백은 샘플의 반복 실행, 다른 샘플의 수집 또는 다른 작업으로 이어질 수 있다.
흐름 실패 아이콘/설명 - 때때로, 마이크로유체 칩 또는 레인 실패로 인해 샘플이 실패할 것이다. ES는 우수한 ILS 피크 세트의 부재에 의해 이러한 부류의 샘플 데이터를 식별한다. 이러한 피드백은 가능한 경우, 이러한 샘플을 재수집하고 재처리하기 위해 사용자에게 안내된다. 유체 실패를 겪는 샘플의 DNA ID는 도 40에 도시된다.
낮은 샘플 아이콘 - 낮은 신호 샘플은 낮은 신호 강도, 낮은 피크 높이 비율, 및 적색 경고 박스로 표지된 모든 대립유전자를 갖는 것으로 분류된다. 이러한 피드백은 사용자에게 샘플을 재수집하고(이상적으로는 더 많은 부피를 수득), 시스템에 재처리하도록 지시한다. 낮은 DNA 함량 샘플의 DNA ID는 도 41에 도시된다.
높은 샘플 아이콘/설명 - 높은 신호 샘플은 10,000 RFU 초과의 신호 강도, 넓은 피크를 갖는 대립유전자, iNTA 및 적색 경고 박스로 표지된 모든 대립유전자를 갖는 것으로 분류된다. 이러한 피드백은 사용자에게 샘플을 재수집하고(바람직하게는, 더 적은 부피를 수득), 시스템에 재처리하도록 지시한다. 높은 DNA 함량 샘플의 DNA ID는 도 42에 도시된다.
혼합물 아이콘/설명 - 혼합물은 유전자좌에서 3개 초과의 대립유전자를 갖는 2개 초과의 유전자좌 또는 유전자좌에서 4개의 대립유전자를 갖는 하나 초과의 유전자좌를 가짐에 의해 분류된다. 이러한 피드백은 사용자에게 샘플을 재수집하고(바람직하게는, 혼합물을 생성시킬 가능성을 낮추기 위해 전보다 더 작은 영역으로부터 이를 수득함), 시스템에 재처리하도록 지시한다. 혼합물 샘플의 DNA ID는 도 43에 도시된다.
샘플 분류화를 사용자에게 디스플레이하는 것은 처리된 샘플에 대한 유용한 지시 및 피드백을 제공한다. 이러한 피드백의 주요 이점(바람직하게는, GUI 스크린상에)은 DNA ID를 해석할 수 없는 비기술적 사용자에게 처리 방법에 대한 분명한 지시를 제공한다는 것이다. 샘플 분류의 수는 상기 도시된 것에 제한되지 않는다. 추가적인 샘플 분류는 규정될 수 있으며, 새로운 아이콘은 이들 분류 각각과 관련될 수 있다. 예로서, 청구된 관계 애플리케이션 또는 DNA ID 매치 애플리케이션에 있어서, 사용자에게 디스플레이될 수 있는 부류를 포함한다:
ㆍ동류 - 샘플 도너의 청구된 관계가 에이전시-규정된 제한에 기초하여 확인되었음을 나타내기 위해,
ㆍ매치 - 샘플이 데이터베이스 중의 또 다른 샘플과 매치됨을 나타내기 위해,
ㆍ비매치 - 샘플이 데이터베이스의 또 다른 샘플과 매치되지 않음을 나타내기 위해.
실시예
5.
AES
파라미터 세트 확립
AES를 적절하게 설계하기 위해, ANDE 표준 전문가 시스템 규칙을 고려하는 것이 중요하였다. ANDE 전문가 시스템은 기기와 일체화되며, 분리 및 검출 동안 생성되는 미가공 데이터를 자동으로 처리한다. ANDE에서, 광학 데이터는 온보드 전문가 시스템 소프트웨어(이는 온보드 ANDE CPU 내에 하우징되며; 전문가 시스템 소프트웨어가 내장될 필요는 없음을 주목)에 자동으로 전송된다. 샘플 통과에 있어서, 표준 전문가 시스템은 일렉트로페로그램, .xml 파일, 대립유전자 표, 및 .FSA 파일을 생성할 것이다. 샘플 실패에 있어서, 표준 전문가 시스템은 단지 일렉트로페로그램 및 .FSA 파일을 생성할 것이다. ANDE 전문가 시스템이 일련의 모듈을 통해 미가공 데이터를 단계식으로 처리하여 DNA ID를 생성시킨다(도 44):
1) 단편 평가 규칙 - 이러한 모듈은 최소 처리 요건을 충족시키는 일렉트로페로그램의 피크를 식별한다.
ㆍ피크는 최소 피크 높이(PHmin)보다 큰 높이를 가져야 한다.
ㆍ피크는 임계값보다 높은 신호 대 잡음 비율을 가져야 한다.
ㆍ피크는 2 포인트 초과의 폭을 가져야 한다.
ㆍ최소 요건을 충족시키는 피크는 3개의 후보 부류로 나누어진다: ILS, 대립유전자 사다리, 및 색상에 기초한 대립유전자.
2) ILS 평가 - 이 모듈은 ILS 피크를 식별하고 평가한다. 최소 요건을 통과한 ILS는 Local Southern 방법으로 도너 피크의 크기를 결정하는데 사용된다. 실패한 ILS 피크를 갖는 샘플은 거부되고, 추가 분석으로 처리되지 않는다.
3) 대립유전자 사다리 평가 - 이 모듈은 대립유전자 사다리 피크를 식별하고 평가한다. 최소 요건을 충족시킨 대립유전자 사다리 실행은 도너 대립유전자를 설계하기 위한 호출 빈(bin)을 규정하는데 사용된다. 기기 특수 사전-설치된 사다리는 대립유전자 사다리 실행이 실패하는 경우 호출 빈을 규정하는데 사용된다.
4) 대립유전자 정렬 - 이러한 모듈은 피크를 유전자좌 및 대립유전자에 할당한다.
5) 유전자좌 평가 규칙 - 이러한 모듈은 반접합체, 동형접합체 또는 동형접합체 요건을 위한 유전자좌를 평가한다. 이러한 요건을 충족하는 유전자좌를 호출한다. 3개 이상의 대립유전자를 갖는 유전자좌를 포함하는 실패한 유전자좌는 적색 경고 박스로 표지한다. 도 45는 하기와 같은 유전자좌 평가 모듈 프로세스를 보여준다:
ㆍ평가 피크는 형태에 대한 요건을 충족시킨다. 통과한 피크는 추가 분석으로 처리한다. 실패한 피크는 표지되지 않는다.
ㆍ피크를 단편 크기 및 피크 높이 비율을 이용하여 iNTA 및 스터터 피크로서 식별하고 분류한다. 스터터 및 iNTA 피크는 표지되지 않거나 추가로 처리되지 않는다.
ㆍ피크 높이가 호출 임계값을 초과하는 하나의 피크를 갖는 DYS 유전자좌로서 반접합 유전자좌를 식별하고 분류한다. 이들 유전자좌에서, 피크를 호출하고, 회색 박스로 표지한다.
ㆍ피크 높이가 호출 임계값을 초과하는 주요 피크, 및 피크 높이 비율이 임계값 미만인 유전자좌 내의 모든 나머지 피크를 갖는 유전자좌로서의 동형접합체 유전자좌를 식별하고 분류한다.
ㆍ피크 높이가 호출 임계값보다 크며, 피크 높이 비율이 임계값을 초과하는 2개 피크를 갖는 유전자좌로서의 이형접합체 유전자좌.
ㆍ반접합체, 동형접합체 및 이형접합체 규칙을 통과하지 않은 모든 유전자좌는 적색으로 표지된다.
6) 샘플 평가 규칙 - 이 모듈은 혼합물, 낮은 신호 및 최소 CODIS 유전자좌 수에 대해 샘플을 평가한다. 샘플 보호 규칙은 단일 소스 협측 샘플을 보존적으로 호출하도록 개발되었으며, 하기와 같이 적용된다(도 46):
ㆍ낮은 신호 보호 규칙은 HDC BioChipSet로의 샘플 실행에 적용된다. 이들 샘플에 있어서, 동형접합체 유전자좌는 보호 피크 높이 임계값 미만의 피크 높이인 경우 적색 경고 박스로 표지된다.
ㆍ혼합물 보호 규칙은 3개의 대립유전자를 갖는 적어도 2개의 유전자좌 또는 하나의 대립유전자를 갖는 적어도 하나의 유전자좌를 갖는 것이 식별될 때 혼합물을 식별한다. 혼합물로서 식별된 샘플은 적색 경고 박스로 표지된 모든 유전자좌를 가질 것이다.
ㆍCODIS 유전자좌의 수가 요구되는 최소치보다 작은 경우, 최소 CODIS 유전자좌 수 규칙은 샘플에 대해 실패하고, 모든 유전자좌를 적색 경고 박스로 표지할 것이다.
시스템의 동적 범위를 초과하는 DNA 함량을 갖는 샘플이 처리되는 경우, 대립유전자에 대한 iNTA 피크는 임계값 초과의 iNTA 피크 높이 비율을 가질 수 있다. 표준 전문가 시스템은 하기와 같이 이들 케이스를 처리한다:
ㆍ동형접합체 유전자좌 - 높은 iNTA는 대립유전자로서 식별되는 것으로서 1개 염기에 의해 분리되는 2개 피크를 발생시킨다. 대립유전자는 적색 경고 박스로 표지되며 유전자좌는 실패한다. (도 47a 참조).
ㆍ2개의 대립유전자가 1개 초과의 염기에 의해 서로 분리되는 이형접합체 유전자좌에 있어서 - 높은 iNTA는 대립유전자로서 확인되는 4개 피크를 발생시킨다. 대립유전자는 적색 경고 박스로 표지되며 유전자좌는 실패한다. (도 47b 참조).
ㆍ2개의 대립 유전자가 1개 염기로 분리되는 이형접합체 유전자좌에 있어서 - 높은 iNTA는 대립유전자로서 확인되는 3개 피크를 발생시킨다. 대립유전자는 적색 경고 박스로 표지되며 유전자좌는 실패한다. (도 47c 참조).
높은 DNA 함량 샘플은 또한, "피크 정량화 모듈"로 선택적으로 처리된다. 이러한 시나리오에서, 피크에 대한 일차 검출기 신호는 포화되며, 평편한 상단이 관찰된다. 이러한 모듈은 피크의 포화된 부분에서 일차 검출기의 신호를 발생시키기 위해 피크의 불포화된 광학 데이터(이차 검출기로부터)를 사용한다. 이러한 모듈은 하기 알고리즘에 따라 작업한다:
ㆍ일차 검출기에 있어서 광학 검출기 신호의 포화 및 불포화 부분의 신호 강도 및 위치를 검출하고 저장한다(광 신호는 신호가 되돌아오는 경우 포화되며, 값은 검출기에 대한 최대치이다(ANDE 시스템에서, 이 값은 262,144임).
ㆍ피크에 대한 이차 검출기 신호의 신호 강도 및 위치를 검출하고 저장한다. 이러한 피크에 대한 이차 검출기는 상이한 형광 파장에서의 검출에 대해 최대화되며, 포화되지 않는다.
ㆍ전체 피크에 걸쳐 이차 피크 대비 일차 피크의 비율로서 규정된 "일차/이차 검출기 신호 강도 비율"을 계산하고, 일차 검출기가 포화되지 않는 피크의 부분에서 이 값을 저장한다.
ㆍ피크가 포화되는 영역에서, 일차의 신호 강도를 계산하기 위해 계산된 "일차/이차 검출기 신호 강도 비율"을 사용한다. 이는 이차 피크의 단일 강도를 "일차/이차 검출기 신호 강도 비율"로 나눔으로써 수행된다.
이러한 모듈의 사용은 더 이상 포화되지 않으며, 일차 검출기의 광 신호가 포화되지 않은 것 같은 신호 수준에서 정량화되는 일차 검출기의 광 신호를 발생시킬 것이다. 이러한 접근 방식은 2개 이상, 4개 이상, 5개 이상, 6개 이상, 8개 이상, 12개 이상, 16개 이상, 32개 이상, 64개 이상, 128개 이상, 또는 256개 이상의 검출기로 이용될 수 있다. 2개 이상, 4개 이상, 5개 이상, 6개 이상, 8개 이상, 12개 이상, 16개 이상, 32개 이상, 64개 이상, 128개 이상, 또는 256개 이상의 검출기 요소로 구성된 선형 어레이 검출기가 분리된 검출기 대신 사용될 수 있다.
"높은 iNTA 모듈"은 샘플의 DNA 함량이 시스템의 동적 범위를 초과하고, 임계값을 초과하는 iNTA 수준이 관찰되는 경우 케이스를 수용하도록 개발되었다. 높은 iNTA 샘플의 존재를 식별하기 위한 한 접근 방식은 AM에서 iNTA 피크 높이 비율의 사용이다. 생성된 광범위한 데이터세트로 인해 본 발명자들은 AM의 iNTA 비율이 잠재적으로 높은 iNTA를 갖는 샘플에 대한 강하고 신뢰할 만한 지시인자임을 관찰할 수 있었다. AM이 사용되지만, 다른 유전자좌 및 대안적 조건이 또한 잠재적으로 높은 iNTA 샘플을 식별하는데 적용될 수 있다.
이러한 모듈을 키고, 잠재적으로 높은 iNTA를 갖는 샘플이 식별되는 경우(예를 들어, AM의 iNTA PHR 사용), 유전자좌에서 관찰되는 iNTA는 하기와 같이 처리된다(도 48a 내지 48d):
ㆍ호출 임계값보다 큰 피크 높이를 갖는 1개 염기로 이격된 2개 피크가 관찰되고, 제2 피크가 iNTA 임계값 초과의 PHR을 갖는 경우, 제2 피크는 표지하지 않는다(도 48a 참조).
ㆍ2개 피크 시나리오(상기)의 대안적 및 더욱 보존적 처리는 하기와 같이 적용된다: 호출 임계값보다 큰 피크 높이를 갖는 1개 염기로 이격된 2개 피크가 관찰되고, 제2 피크가 iNTA 임계값보다 큰 PHR을 갖는 경우, 두 피크 둘 모두는 적색 경고 박스로 표지한다. 이러한 처리는 1개 염기에 의해 분리되는 2개의 대립유전자의 작은 단편 크기의 드롭아웃을 예방하기 위해 적용된다(도 48b 참조).
ㆍ호출 임계값보다 큰 피크 높이를 갖는 1개 염기로 이격된 3개의 피크 및 1개 염기에 의해 분리되는 피크가 관찰되고, 제3 피크가 iNTA 임계값 초과의 PHR을 갖는 경우, 제3 피크는 표지하지 않는다(도 48c 참조).
ㆍ호출 임계값보다 높은 피크 높이를 갖는 1개 염기로 이격된 4개 피크가 관찰되고, 제2 및 제4 피크가 iNTA 임계값보다 큰 PHR을 갖는 경우, 제2 및 제 4 피크는 표지하지 않는다. (도 48d 참조).
iNTA 모듈에 대한 이러한 흐름도는 도 49에 도시되어 있다.
다양한 부류의 샘플 데이터에
AES
파라미터 세트 적용.
여러 AES 파라미터 세트는 상기 열거된 DNA ID 부류 각각에 대해 개발되었다. 이들 파라미터 세트는 호출된 대립유전자의 수 및 관찰된 드롭-아웃 및 드롭-인의 수에 대한 각 변화의 효과를 평가함으로써 개발되었다. 최적의 파라미터 세트는 호출된 대립유전자의 수가 최대화되고, 드롭-아웃 및 드롭-인이 최소화되는 경우, 확립된다. 드롭-아웃은 두 개의 대립유전자 중 단지 하나만이 호출되고, 나머지 하나는 비표지되는 이형접합체 유전자좌이다. 드롭-인은 단일-소스 도너에 속하지 않은 대립유전자가 호출되는 유전자좌이다. DNA ID 분류 각각에 대한 AES 파라미터는 하기와 같다:
중간 신호 강도 샘플 - 이들 샘플은 호출된 20개 CODIS 20 코어 유전자좌 및 통과 ILS를 갖는다. 이들은 표준 전문가 시스템 파라미터 세트를 사용하는 성공적인 샘플이며, AES로 추가 처리될 필요가 없다. 하기 제시된 ES 파라미터는 표준 A-칩 및 I-칩 처리를 위한 것이다. 10 및 11열은 표준 I-칩 파라미터 세트(표 8)와 비교한 표준 A-칩 ES 파라미터 세트(표 7) 사이의 차이를 보여준다:
표 7 - 표준 A-칩 호출 파라미터 세트.
표 8 - 표준 I-칩 호출 파라미터 세트.
넓은 피크 및 iNTA를 갖는 높은 신호 강도 샘플 - 이들 샘플은 통과 ILS를 가지나, 20개 미만의 호출된 CODIS 20 코어 유전자좌를 갖는다. 대립유전자는 피크 형태에 대해 실패하기 때문에 대립유전자는 비표지되거나, 높은 iNTA 피크가 대립유전자로서 호출되기 때문에 적색으로 표지된다. 이들 샘플이 하기 표 9에 제시된 AES 파라미터 세트로 처리되는 경우, 추가적인 대립유전자가 호출될 것이다.
표준 A-칩 및 AES 파라미터 세트로 호출된 높은 신호 강도를 갖는 샘플에 대한 DNA ID는 도 50 및 51에 도시된다. AES 파라미터는 높은 iNTA를 갖는, Th01의 대립유전자가 적절하게 호출되게 한다. 전체 DNA ID가 생성된다. 동일한 미가공 데이터가 사용됨을 주목하라 - 적절한 파라미터 세트의 적용은 데이터로부터 훨씬 더 많은 데이터를 추출하는데, 이는 본 발명의 주요 이점이다.
표준 A-칩 및 AES 파라미터 세트로 호출된 높은 신호 강도를 갖는 또 다른 샘플에 대한 DNA ID는 도 52 및 53에 도시된다. AES 파라미터 세트(표 9)는 높은 iNTA를 갖는, D18 및 Th01의 대립유전자가 적절하게 호출되게 한다. 전체 DNA ID가 생성된다.
표 9 - 높은 신호 강도 샘플 호출 파라미터 세트.
낮은 피크 높이 비율을 갖는 중간 신호 강도 샘플 - 이들 샘플은 통과 ILS를 가지나, 20개 미만의 호출된 CODIS 20 코어 유전자좌를 갖는다. 하나 이상의 유전자좌는 불량한 피크 높이 비율로 인해 적색으로 표지된다. 이들 샘플이 AES 파라미터로 처리되는 경우 추가의 대립유전자가 호출된다(하기 표에 제시됨).
표준 A-칩 및 AES 파라미터 세트로 호출된 낮은 피크 높이 비율을 갖는 샘플에 대한 DNA ID는 도 54 및 55에 도시된다. AES 파라미터 세트(표 10)는 높은 iNTA를 갖는, Th01 및 D7의 대립유전자가 적절하게 호출되게 한다. 전체 DNA ID가 생성된다.
표 10 - 낮은
PHR을
갖는 중간 신호 강도 샘플.
낮은 피크 높이 및 낮은 피크 높이 비율을 갖는 낮은 신호 강도 샘플 - 이들 샘플은 통과 ILS를 가지나, 20개 미만의 호출된 CODIS 20 코어 유전자좌를 갖는다. 유전자좌는 낮은 피크 높이 및 낮은 피크 높이 비율로 인해 적색으로 표지된다. 이들 샘플이 AES 파라미터로 처리되는 경우 추가의 대립유전자가 호출될 것이다(표 11). 도 56은 표준 I-칩 ES 파라미터 세트를 갖는 낮은 신호 샘플을 보여주며, 도 57은 AES 파라미터 세트로 처리된 낮은 신호 강도의 샘플을 보여준다.
표 11 - 낮은 신호 강도 샘플 호출 파라미터 세트.
매우 낮은 신호 함량 샘플 - 이들 샘플은 통과 ILS를 가지나, 20개 미만의 호출된 CODIS 20 코어 유전자좌를 갖는다. 매우 낮은 피크 높이를 갖는 피크가 관찰된다. 매우 적은 유전자좌는 적색 경고 박스로 표지되며, 기타는 비표지된다. 이들 샘플은 매우 낮은 신호 샘플로서 식별되나, 추가로 처리되지 않는다. 대안적으로, 파라미터 세트는 이러한 매우 낮은 신호 샘플 데이터로부터 대립유전자 호출을 생성하기 위해 개발될 수 있다.
실패 샘플 - 이들 샘플에서, ILS는 전문가 시스템에 의해 실패하였으며, 피크는 호출되지 않았다. 이들 샘플은 더 이상 처리되지 않는다.
요약하면, 2,000개 초과의 샘플 데이터세트가 생성되었으며, 정량적 파라미터가 DNA ID를 6개 분류로 카테고리화하기 위해 규정되었으며, DNA ID 분류의 재호출을 위한 AES 파라미터가 개발되었다.
실시예
6. 독립형 소프트웨어로의
AES
실행을 위한 데이터 흐름(도 58):
도 58은 ANDE 실행에 대한 데이터 흐름을 보여준다.
ㆍANDE 시스템은 광학 데이터를 생성시키고 일체형-온보드 전문가 시스템으로 자동으로 처리한다. 온보드 전문가 시스템은 표준 전문가 시스템 파라미터를 이용하여 데이터를 처리하도록 구성된다. 전문가 시스템으로부터의 출력값(실행 데이터)은 암호화되고 ANDE 데이터베이스에 저장된다.
ㆍ사용자는 암호화된 실행 데이터를 ADMS 또는 FAIRS와의 USB 스틱 또는 이더넷 연결을 이용하여 내보내고, 이러한 데이터를 ADMS 또는 FAIR로 가져온다.
ㆍADMS 또는 FAIRS는 사용자 생성 인증을 이용하여 암호화된 실행 데이터를 가져오고, ADMS 또는 FAIRS 컴퓨터의 폴더에 해독된 실행 데이터를 저장한다. 해독된 실행 데이터는 샘플 각각에 대해 .fsa, .png, 및 .xml 파일로 구성된다.
적응형 전문가 시스템은 또 다른 전문가 시스템인 ADMS 또는 FAIRS에 통합될 수 있거나, 독립형 애플리케이션으로서 작동할 수 있다. ADMS 또는 FAIRS로 통합된 적응형 전문가 시스템으로의 데이터 흐름 및 ANDE 및 AES로의 실행을 위한 데이터 흐름은 도 59에 도시된다.
ㆍANDE는 미가공 데이터를 생성시키고 일체형-온보드 전문가 시스템으로 자동으로 처리한다. 온보드 전문가 시스템은 표준 전문가 시스템 파라미터를 이용하여 데이터를 처리하도록 구성된다. 전문가 시스템으로부터의 출력값(실행 데이터)은 암호화되고 ANDE 데이터베이스에 저장된다.
ㆍ사용자는 암호화된 실행 데이터를 ADMS와의 USB 스틱 또는 이더넷 연결을 이용하여 내보내고, 이러한 데이터를 ADMS로 가져온다.
ㆍADMS는 암호화된 실행 데이터를 사용자 생성 인증서를 사용하여 가져오고, 실행 데이터를 해독한다.
ㆍ표준 파라미터로 해독된 실행 데이터는 ADMS 컴퓨터의 데이터베이스에 저장된다.
ㆍ해독된 실행 데이터는 또한, AES에 의해 처리된다. AES는 DNA ID를 분류하고, DNA ID 분류에 기반하여 최적의 AES 파라미터를 적용한다. AES 파라미터로 해독된 실행 데이터는 ADMS 컴퓨터의 데이터베이스에 저장된다.
ㆍ표준 파라미터 및 AES 파라미터로 해독된 실행 데이터는 그래픽 사용자 인터페이스(GUI)를 통해 사용자에게 디스플레이된다. 표준 파라미터 및 AES 파라미터로 해독된 실행 데이터는 사용자에게 디스플레이된다. GUI는 많은 형태를 취할 수 있다:
o 연구 하의 샘플의 성공 또는 실패만을 보고하는 단순한 인터페이스,
o 호출된 STR 대립유전자의 수(예를 들어, 어느 것이든 더 많은 호출된 대립유전자, 표준 또는 AES를 제공하는 것을 기반으로 함)를 제공하는 단순한 인터페이스,
o 예를 들어, 하나 또는 둘 모두의 전문가 시스템에 호출된 유전자좌 및 대립유전자의 수를 나타내고, 하나 또는 둘 모두의 DNA ID를 제공하는 더욱 복잡한 인터페이스,
o 이러한 및 많은 다른 구성은 하드-코딩되거나 사용자 구성가능할 수 있다.
실시예
7. 기기와 일체화된 소프트웨어로의
AES
실행을 위한 데이터 흐름.
ANDE 시스템은 광학 데이터를 생성하고 일체형-온보드 전문가 시스템으로 자동으로 처리한다. 온보드 전문가 시스템은 표준 전문가 시스템 파라미터를 이용하여 데이터를 처리하도록 구성된다. AES는 ANDE 기기에 소프트웨어를 설치하고, 이것이 상기 기기로부터 샘플 데이터를 직접 수신하게 함으로써 ANDE 기기와 일체화될 수 있다. 이러한 구성에서, 표준 전문가 시스템 및 AES로부터의 실행 데이터의 출력값 둘 모두는 기기에서 데이터베이스로 저장된다. 기기 시스템 소프트웨어는 ADMS 또는 FAIRS와의 USB 스틱 또는 이더넷 연결을 이용하여 사용자가 암호화된 표준 실행 데이터 또는 AES 실행 데이터를 가져오고, 이러한 데이터를 ADMS 또는 FAIRS에 내보내기 하도록 구성된된다. 내보낸 데이터는 표준 전문가 시스템에 의해 또는 AES에 의해 또는 둘 모두에 의해 생성되는 암호화된 실행 데이터로 구성된다. 요망되는 실행 데이터를 내보내는 옵션은 에이전시/지방 정책에 기반하여 구성될 수 있으며, 단순 GUI 스크린을 사용하여 선택된 옵션을 구성화함으로서 구현된다.
실시예
8: 매우 낮은 DNA 내지 매우 높은 DNA 함량 샘플에 대한 별도의 입력 파라미터 세트로의
AES
. 알고리즘은 샘플을 호출하는데 사용되는 최적의 것을 도출하기 위해 입력 파라미터 세트를 반복하는데 이용된다.
실시예 4는 6개의 DNA ID 분류 및 이들의 특징으로 샘플을 분리한다. 실시예 5는 높은 신호 강도 샘플(표 4), 낮은 PHR을 갖는 중간 신호 강도 샘플(표 5) 및 낮은 신호 강도 샘플(표 6)에 대한 적응형 전문가 시스템 파라미터의 세트를 규정한다. 본 실시예에서, 낮은 신호 강도 샘플에 대한 19개 파라미터 세트는 표 6의 파라미터 세트를 기반으로 생성되며, 3개 파라미터 세트는 표 4의 파라미터 세트를 기반으로 하여 높은 신호 강도 샘플에 대해 생성된다. 추가로, 높은 iNTA를 갖는 샘플에 대한 규칙이 규정되었다. 이러한 파라미터 세트는 중간 파라미터 값을 갖는 파라미터 세트를 규정함으로써 생성되었다.
낮은 신호 조건(L01 내지 L19)에 대한 19개 파라미터 세트는 규정된 범위에 걸쳐 하기 파라미터를 변경함으로써 생성되었다:
ㆍ이형접합체 피크 높이 임계값 - 250 내지 100 RFU,
ㆍ이형접합체 피크 높이 비율 - 0.35 내지 0.15,
ㆍ동형접합체 피크 높이 임계값 - 300 내지 120 RFU,
ㆍ2nd 피크에 있어서 이형접합체 피크 높이 임계값 - 100 내지 50,
ㆍ동형접합체 피크 높이 비율 - 0.15 내지 0.10,
ㆍ최소 반접합체 피크 높이 - 200 내지 80 RFU.
이들 파라미터 세트 L01 내지 L19는 호출 임계값을 감소시켜 점점 더 많은 피크가 호출되게 함으로써 설계되었다. L01은 가장 보존적 파라미터 세트이며, L19는 가장 공격적인 파라미터 세트이다.
높은 신호 조건(H01 내지 H03)에 대한 3개 파라미터 세트는 규정된 범위에 걸쳐 하기 파라미터를 변경함으로써 생성되었다:
ㆍ구역 1에서 대립유전자 PH/PA - 0.08 내지 0.07,
ㆍ구역 2에서 대립유전자 PH/PA - 0.079 내지 0.049,
ㆍ구역 3에서 대립유전자 PH/PA - 0.044 내지 0.030,
ㆍ구역 4에서 대립유전자 PH/PA - 0.03 내지 0.025.
이들 파라미터 세트 H01 내지 H03은 점점 더 넓은 폭을 갖는 피크를 허용하고, 점점 더 많은 피크가 호출되게 하도록 설계되었다. H01은 가장 보존적 파라미터 세트이며, H03은 가장 공격적인 파라미터 세트이다.
높은 수준의 iNTA를 갖는 샘플이 관찰되는 경우, 아멜로게닌 유전자좌에서 iNTA 비율은 0.4를 초과한다. 결과적으로, X 및 Y 대립유전자 중 어느 하나의 iNTA 비율이 0.4 초과인 경우, iNTA 규칙이 적용될 것이다. 이 규칙에서, 2, 3 및 4개 대립유전자를 갖는 유전자좌의 iNTA 피크는 호출되지 않는다.
최적의 파라미터 세트는 하기 알고리즘에 의해 결정된다:
1) 소위 I-칩 또는 A-칩 기준을 이용하여 각 샘플에 대한 호출된 유전자좌의 수, 및 동형접합체의 수 및 이형접합체 유전자좌의 수를 계산한다.
2) CODIS20 유전자좌 모두가 호출되는 경우, 소위 파라미터 세트는 허용가능하며, 재호출은 수행되지 않는다. 소위 파라미터 세트는 최적의 파라미터 세트이다.
3) 19개 낮은 신호 파라미터 세트(L01 내지 L19)를 반복한다. 사용된 파라미터 세트 각각에 있어서, 호출된 유전자좌의 수, 및 동형접합체의 수 및 이형접합체 유전자좌의 수를 계산한다.
4) 하기 기준을 충족시키는 파라미터 세트로서 가장 우수한 낮은 신호 파라미터 세트를 결정한다:
a. 대부분의 수의 호출된 유전자좌 CODIS20.
b. 동형접합체 내지 이형접합체로부터의 임의의 호출된 유전자좌에서의 변화 없음.
5) 3개 높은 신호 파라미터 세트(H01 내지 H03)를 반복한다. 사용된 파라미터 세트 각각에 있어서, 호출된 유전자좌의 수, 및 동형접합체의 수 및 이형접합체 유전자좌의 수를 계산한다.
6) 하기 기준을 충족시키는 파라미터 세트로서 가장 우수한 높은 신호 파라미터 세트를 결정한다:
a. 대부분의 수의 호출된 유전자좌 CODIS20.
b. 동형접합체 내지 이형접합체로부터의 임의의 호출된 유전자좌에서의 변화 없음.
7) 가장 우수한 낮은 신호 파라미터 세트 내지 가장 우수한 높은 신호 파라미터 세트 간의 호출된 유전자좌의 수를 비교한다. 가장 우수한 낮은 또는 높은 신호 파라미터 세트를 선택한다.
8) 아멜로게닌 대립유전자에 대한 iNTA의 비율을 계산한다. 이 값이 0.40 이상인 경우, iNTA 규칙을 적용한다.
상기 알고리즘은 하기 기준을 갖는 최적의 파라미터 세트의 결정을 허용한다:
ㆍ샘플 중 호출된 CODIS20 유전자좌의 수를 최대화시킨다 - 샘플로부터 이용가능한 가장 많은 정보량을 생성하기 위해.
ㆍ가장 낮은 공격성의 파라미터 세트를 적용한다 - 공격성 파라미터 세트를 사용하는 불필요한 위험을 회피하면서 가장 많은 정보량을 수득하기 위해.
ㆍ드롭-인을 회피한다 - 호출 임계값이 감소하는 경우, 대립유전자로서 호출되는 잡음 피크의 가능성은 증가한다. 잡음 피크가 대립유전자로서 잘못 호출되는 경우, 이러한 대립유전자는 미스호출을 가지며, 이러한 상태는 드롭-인으로 불린다. 드롭-인 유전자좌는 이형접합체로의 동형접합체 변화로서 초기에 호출되는 유전자좌를 발생시키는 파라미터 세트를 식별함으로써 회피될 수 있다.
도 60의 DNA ID는 0.5 ㎕의 혈액으로부터 생성되었다. 이러한 DNA ID는 중간 내지 낮은 신호 강도이며, 여기에서 4개 유전자좌는 적색 경고 박스에 표지되는 피크를 갖는다(Penta E, D2S1338, Th01, 및 FGA). L02의 파라미터 세트를 갖는 AES로의 미가공 데이터 처리는 도 61의 DNA ID를 발생시킨다. 상기 알고리즘은 L02의 파라미터 세트가 이러한 DNA ID를 재호출하는데 최적이었음을 결정하였다.
도 62의 DNA ID는 0.1 ㎕의 혈액으로부터 생성되었다. 이러한 DNA ID는 낮은 신호 강도이며, 여기에서 2개의 유전자좌는 적색 경고 박스로 표지된 피크를 가지며(D2S441 및 D21S11), 3개의 유전자좌는 표지된 피크를 갖지 않는다(D1S1656, D10S1248, 및 Th01). 파라미터 세트 L16을 이용한 AES로의 미가공 데이터 처리는 도 63의 DNA ID를 발생시킨다. 상기 알고리즘은 L16의 파라미터 세트가 이러한 DNA ID를 재호출하는데 최적이었음을 결정하였다. L16은 이전 도면의 L02와 비교하여 상대적으로 공격적인 파라미터 세트이다.
본 실시예는 낮은 신호 파라미터 세트에 대한 6개의 ES 파라미터(이형접합체 피크 높이 임계값, 이형접합체 피크 높이 비율, 동형접합체 피크 높이 임계값, 2nd 피크에 대한 이형접합체 피크 높이 임계값, 동형접합체 피크 높이 비율 임계값, 및 최소 이형접합체 피크 높이), 높은 신호 파라미터 세트에 대한 4개 파라미터, 및 iNTA에 대한 1개 테스트에 대한 값을 변경시키며; 전문가 시스템의 임의의 파라미터가 최적화를 위해 포함될 수 있다. 적응형 전문가 시스템은 334개 초과의 파라미터를 가지며, 임의의 또는 모든 이러한 파라미터는 최적화된 AES DNA ID를 생성시키기 위해 변경될 수 있다. 적어도 하나, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 50, 100, 200, 300, 500, 또는 1,000개 초과의 파라미터가 해당 파라미터 세트에 사용될 수 있다.
본 실시예는 19개의 낮은 신호 파라미터 및 3개의 높은 신호 파라미터를 사용하지만, 파라미터 세트의 수는 (1) 파라미터 세트 간의 단계 크기를 감소시켜 더욱 최적화된 파라미터를 증가시킴으로써, (2) 상위 및 하위 범위를 연장시켜 더 넓은 범위의 샘플이 처리될 수 있게 함으로써 등을 포함하는 많은 방식으로 증가될 수 있다. 사전 프로그래밍된 수의 분리된 파라미터 세트를 사용하는 대신에, 연속 파라미터 세트가 자동으로 생성되고 루프를 사용함으로써 적용될 수 있다. 이는 각 샘플에 대한 더 좋은 단계 및 더욱 최적인 파라미터 세트를 달성하는 능력을 발생시킬 것이다.
본 실시예는 최적 파라미터 세트를 결정하는데 있어서 3개의 기준(호출된 CODIS20 유전자좌의 수를 최대화시키고, 최소로 공격성인 파라미터 세트를 적용하여 가장 많은 정보량을 생성시키고, 드롭-인 및 드롭-아웃을 회피하기)을 사용하지만, 추가적인 기준이 결과를 추가로 최적화시키기 위해 추가될 수 있다.
이러한 실시예는 모든 파라미터 세트의 재계산을 보여주지만, 더욱 효율적인 수치적 최적화 기법이 최적의 파라미터 세트를 결정하는데 적용될 수 있다. 이러한 기법을 사용함으로써, 재호출의 수는 최소화되며, 결과는 더욱 신속하게 달성될 수 있다.
파라미터 세트의 총 수 및 따라서, 최적 결과를 생성하는데 요구되는 재호출의 총 수는 파라미터 세트의 수 및 따라서, 더욱 최적의 결과와 결과를 획득하는데 필요한 총 처리 시간 간의 트레이드오프에 의해 결정될 수 있다. 이러한 수는 계산력이 증가함에 따라 증가될 것이며, 솔루션 찾기를 위한 더욱 효율적인 수치적 방법이 적용된다.
AES는 혼합물 디콘볼루션 소프트웨어 및 데이터베이스 검색 및 매치 소프트웨어에 통합될 수 있다.
실시예
9: 매우 낮은 DNA 내지 매우 높은 DNA 함량
샘플에 대한 연속 입력
파라미터 세트로의
AES
. 알고리즘은 샘플을 호출하는데 사용되는 최적의 것을 도출하기 위해 입력 파라미터 세트를 반복하는데 이용된다.
실시예 8에서, 낮은 신호 강도 샘플에 대한 19개 파라미터 세트는 표 6의 파라미터 세트를 기반으로 생성되며, 3개 파라미터 세트는 표 4의 파라미터 세트를 기반으로 하여 높은 신호 강도 샘플에 대해 생성되었다. 추가로, 높은 iNTA를 갖는 샘플에 대한 규칙이 규정되었다. 본 실시예에서, 낮은 신호 강도 및 높은 신호 강도 샘플에 대한 별개의 파라미터 세트를 규정하는 대신에, 조절되는 각 파라미터에는 최소 및 최대 값 및 단계가 지정된다. 낮은 신호 조건 파라미터는 하기와 같이 리팩토어(refactore)된다:
ㆍ이형접합체 피크 높이 임계값 - 최대 값 250, 최소 값 100, 단계 10 RFU,
ㆍ이형접합체 피크 높이 비율 - 최대 값 0.35, 최소 값 0.15, 단계 0.5,
ㆍ동형접합체 피크 높이 임계값 - 최대 값 300, 최소 값 120, 단계 10 RFU,
ㆍ2nd 피크에 대한 이형접합체 피크 높이 임계값 - 최대 값 100, 최소 값 50, 단계 10 RFU,
ㆍ동형접합체 피크 높이 비율 - 최대 값 0.15, 최소 값 0.10, 단계 0.05,
ㆍ반접합체 피크 높이 최소 - 최대 값 200, 최소 값 80, 단계 10 RFU,
이러한 접근 방식에서, 각 파라미터는 규정된 단계에서 최대 값에서 출발하여 최소 값으로 반복된다. 최대 값으로부터 최소 값의 반복은 가장 보존적인 파라미터 값(예를 들어, 상대적으로 덜 호출된 대립유전자 발생)으로부터 가장 공격적인 파라미터 값(예를 들어, 상대적으로 더 많이 호출된 대립유전자 발생)으로의 흐름을 대표한다.
높은 신호 조건에 대한 파라미터는 하기와 같이 리팩토어된다.
ㆍ구역 1에서 대립유전자 PH/PA - 최대 값 0.08, 최소 값 0.07, 단계 0.01,
ㆍ구역 2에서 대립유전자 PH/PA - 최대 값 0.079, 최소 값 0.049, 단계 0.001,
ㆍ구역 3에서 대립유전자 PH/PA - 최대 값 0.044, 최소 값 0.030, 단계 0.001,
ㆍ구역 4에서 대립유전자 PH/PA - 최대 값 0.03, 최소 값 0.025, 단계 0.001,
이러한 접근 방식에서, 각 파라미터는 규정된 단계에서 최대 값에서 출발하여 최소 값으로 반복된다. 최대 값으로부터 최소 값으로의 반복은 가장 보존적인 파라미터 값으로부터 가장 공격적인 파라미터 값으로의 흐름을 나타낸다.
높은 수준의 iNTA를 갖는 샘플이 관찰되는 경우, 아멜로게닌 유전자좌에서 iNTA 비율은 0.4를 초과한다. 결과적으로, X 및 Y 대립유전자 중 어느 하나의 iNTA 비율이 0.4 초과인 경우, iNTA 규칙이 적용될 것이다. 이 규칙에서, 2, 3 및 4개 대립유전자를 갖는 유전자좌의 iNTA 피크는 호출되지 않는다.
최적의 파라미터 세트는 하기와 같이 결정된다:
1) 소위 I-칩 또는 A-칩 기준을 이용하여 각 샘플에 대한 호출된 유전자좌의 수, 및 동형접합체 유전자좌의 수 및 이형접합체 유전자좌의 수를 계산한다.
2) CODIS20 유전자좌 모두가 호출되는 경우, 소위 파라미터 세트는 허용가능하며, 재호출은 수행되지 않는다. 소위 파라미터 세트는 최적의 파라미터 세트이다.
3) 최대 값에서 최소 값으로 출발하여 주어진 단계 값에서 스텝핑하는 낮은 신호 파라미터를 반복한다. 사용된 파라미터 값 각각에 있어서, 호출된 유전자좌의 수, 및 동형접합체 유전자좌의 수 및 이형접합체 유전자좌의 수를 계산한다.
4) 하기 기준을 충족시키는 파라미터 세트로서 가장 우수한 낮은 신호 파라미터 세트를 결정한다:
a. 대부분의 수의 호출된 유전자좌 CODIS20.
b. 동형접합체 내지 이형접합체로부터의 임의의 호출된 유전자좌에서의 변화 없음.
5) 최대 값에서 최소 값으로 출발하여 주어진 단계 값에서 스텝핑하는 높은 신호 파라미터를 반복한다. 사용된 파라미터 세트 각각에 있어서, 호출된 유전자좌의 수, 및 동형접합체 유전자좌의 수 및 이형접합체 유전자좌의 수를 계산한다.
6) 하기 기준을 충족시키는 파라미터 세트로서 가장 우수한 높은 신호 파라미터 세트를 결정한다:
a. 대부분의 수의 호출된 유전자좌 CODIS20.
b. 동형접합체 내지 이형접합체로부터의 임의의 호출된 유전자좌에서의 변화 없음.
7) 가장 우수한 낮은 신호 파라미터 세트 내지 가장 우수한 높은 신호 파라미터 세트 간의 호출된 유전자좌의 수를 비교한다. 가장 우수한 낮은 또는 높은 신호 파라미터 세트를 선택한다.
8) 아멜로게닌 대립유전자에 대한 iNTA의 비율을 계산한다. 이 값이 0.40 이상인 경우, iNTA 규칙을 적용한다.
상기 알고리즘은 하기 기준을 갖는 최적의 파라미터 세트 결정을 허용한다:
ㆍ샘플 중 호출된 CODIS20 유전자좌의 수를 최대화시킨다 - 샘플로부터 이용가능한 가장 많은 정보량을 수득하기 위해.
ㆍ가장 낮은 공격성의 파라미터 세트를 적용한다 - 공격성 파라미터 세트를 사용하는 불필요한 위험을 회피하면서 가장 많은 정보량을 수득하기 위해.
ㆍ드롭-인을 회피한다 - 호출 임계값이 감소하는 경우, 대립유전자로서 호출되는 잡음 피크의 가능성은 증가한다. 잡음 피크가 대립유전자로서 잘못 호출되는 경우, 이러한 대립유전자는 미스호출을 가지며, 이러한 상태는 드롭-인으로 불린다. 드롭-인 유전자좌는 이형접합체로의 동형접합체 변화로서 초기에 호출되는 유전자좌를 발생시키는 파라미터 세트를 식별함으로써 회피될 수 있다.
이러한 알고리즘의 사용은 실시예 8의 분리된 파라미터 세트와 비교하여 파라미터 값의 더욱 분리된 스텝핑 및 AES에 대한 더욱 최적의 파라미터 세트의 달성을 허용한다.
상기 접근 방식에 대한 하기 적응이 가능하였다:
1) 소프트웨어가 제공된 초기 한계를 벗어나 반복할 수 있게 한다. 이러한 적응은 AES 파라미터 값의 범위를 초기 설정된 초기 한계를 벗어나서 효과적으로 비제한될 수 있게 한다. 이러한 적응은 추가 데이터 세트가 시험에 대해 생성되는 경우 특히 효과적이다. 초기에 설정된 한계는 전형적으로 관찰된 범위를 나타내며, 그러나, 추가 시험으로, 한계를 초과하는 샘플 데이터가 발생할 수 있다. 알고리즘이 초기 한계를 벗어나 반복될 수 있는 능력으로 인해 초기 입력 파라미터를 재조정할 필요 없이 새로운 데이터 세트가 처리되게 할 것이다.
2) 단계 크기 변경을 허용한다. 고정된 단계 크기를 선택하여 다양한 파라미터 값을 반복하는 것은 비효율적이다. 작업 속도를 최대화시키기 위해, 가변적인 단계 크기가 채택될 수 있다. 단계 크기는 단계 크기에 따른 출력값의 변화율에 의해 결정될 수 있다. 변화율이 높은 경우, 더 작은 단계 크기가 최적의 값을 놓치지 않게 보장할 것이다. 변화율이 작으면, 더 큰 단계 크기로도 최적의 값으로의 효율적인 반복을 보장할 것이다.
3) 최적의 솔루션에 대한 반복의 목적으로서 검색 및 매치 결과를 포함시킨다. 상기 예에서, 최적화된 파라미터 세트로부터 발생한 생성된 DNA ID는 데이터베이스에서 DNA ID에 대해 검색 및 매치하는데 사용될 것이다. 매치의 질은 일어나는 각 매치에 대해 발생한다. 매치의 질은 중복 유전자좌의 수, 매치되는 유전자좌의 수, 부분적으로 매치되는 유전자좌의 수, 및 매치되지 않는 유전자좌의 수, 데이터베이스에 대한 매치의 수를 포함한다. 검색의 질은 최적 파라미터 세트를 생성시키기 위한 최적의 기준에 포함될 수 있다. AES 파라미터 세트는 보다 보존적인 것에서 덜 보존적인 것으로 변경될 수 있으며, 각 파라미터 세트 검색 파라미터로부터 생성된 각 DNA ID는 데이터베이스를 검색하는데 (또는 다른 분석을 수행하는데) 사용될 수 있다. 검색/매치 기준은 또한 더 엄격성을 띠는 것에서 덜 엄격성을 띠는 것으로 변경될 수 있다. 따라서, 각 파라미터 세트는 이러한 엄격성을 기반으로 하여 범위 또는 검색 결과를 제공할 것이며, 이러한 검색 결과는 스코어링될 수 있다. 그 후, DNA ID의 어레이 vs 검색/매치 기준은 가장 높은 스코어 또는 스코어들에 대해 평가될 수 있으며, 이러한 정보는 파라미터 세트 및 가장 효과적인 이의 동반되는 검색 엄격성을 규정하는데 사용될 수 있다(이는 가장 높은 질의 매치는 물론 데이터베이스에서 매치되는 DNA ID의 상대적 수를 포함할 수 있음).
실시예
10: 인공 지능 및 기계 학습이
AES에
통합된다. 대규모 데이터세트와 함께
AES가
자체-학습 및 실행하게 한다.
실시예 5에서 생성되는 데이터세트 및 실시예 6, 7 및 8에 기술된 알고리즘은 기계 학습 및 인공 지능에 적합하다. 샘플 데이터(광학 데이터, 일렉트로페로그램, DNA ID)의 특징은 기계에 대한 입력값이며, 비제한적으로, 각 대립유전자의 각 대립유전자 신호 강도, 각 유전자좌에 대한 iNTA 피크 높이 및 피크 높이 비율, 이형접합체 피크의 피크 높이 비율, 각 유전자좌에서 피크의 수, 각 대립유전자 피크의 폭 및 형상, 각 염료 채널의 신호 대 잡음 비율, 각 대립유전자의 스터터 비율의 설계를 포함한다. 각 DNA ID의 알려진 진실은 원하는 결과로서 제공된다. 의사 결정 노드 세트는 자체-학습에 통합되며, 샘플 데이터로부터 계산된 주어진 특징 세트에 대한 최적의 ES 파라미터 세트를 생성한다. 전문가 시스템 파라미터 세트는 AES에 의해 규정 가능하며, 자체-학습을 통해 결정된다. 시간이 지남에 따라, DNA ID의 추가적인 입력값 또는 특징은 지식베이스를 추가로 증가시키기 위해 추가된다.
실시예
11: 표준 또는 베이스라인 DNA ID를 생성하지 않으면서 데이터를 분류하기 위한
AES
실행용
데이터흐름
.
본 명세서의 실시예 중 일부는 AES에 대한 입력값으로서 샘플 데이터(광학 데이터, 일렉트로페로그램 데이터, 및 DNA ID)를 사용하였다. 이들 실시예에서, 샘플 데이터는 ES 파라미터의 표준 (또는 베이스라인) 세트를 사용하여 처리되어 표준 (또는 베이스라인) DNA ID를 생성한다. 샘플 데이터의 특징은 표준 DNA ID로부터 계산되어 샘플 데이터를 분류한다. 본 실시예는 표준 (또는 베이스라인) DNA ID의 생성은 선택 사항이며, AES 처리를 위한 필수 단계가 아님을 보여줄 것이다. 샘플 데이터의 특징은 표준 DNA ID를 생성하지 않으면서 광학 데이터로부터 직접 계산될 수 있다. 샘플 유형은 특징에 기초하여 분류되며, 적절한 AES 파라미터 세트가 샘플 데이터 처리를 위해 선택될 수 있다.
도 64a-64c는 ANDE 기기에 의해 샘플에 대해 발생되는 광학 데이터의 분절을 보여준다. 광학 데이터는 쉼표로 구분되는 ASCII 파일 형태로 존재하며(.CSV)파일), 줄은 검출기 샘플링 포인트를 나타내며, 행은 6개 검출기 각각에서의 신호를 나타낸다. 광학 데이터는 일렉트로페로그램 데이터를 생성하기 위해 베이스라인 감산 및 색 보정을 포함하는 일련의 단계 후 처리된다. 일렉트로페로그램의 피크 각각의 특징은 하기 6개 특징에 대해 계산되며, 각 피크에 대해 결정된다:
ㆍ피크 색상
ㆍ피크 위치
ㆍ피크 색상
ㆍ피크 유전자좌
ㆍ피크 대립유전자 #
ㆍ피크 높이
ㆍ피크 폭
ㆍ피크 비대칭
ㆍ피크 폭 편차
ㆍ피크 형상 편차
도 65a 내지 65c에는 샘플 데이터에서 모든 피크에 대한 피크 특징의 스냅숏이 도시된다. 피크 특징 표는 광학 데이터를 등급으로 분류하는데 사용되었다. 본 실시예에서, 단지 피크 높이 및 폭은 샘플 데이터를 분류하는데 사용되었다. 구체적으로, 데이터의 평균 피크 높이는 모든 유전자좌에 걸쳐 가장 높은 2개 피크의 피크 높이를 평균화함으로써 결정하였다. 피크 높이가 8,000 RFU를 초과하는 경우, 높은 신호 파라미터가 적용되었다. 등급 및 높은 신호 강도 파라미터 세트는 이러한 미가공 데이터에 적용되었다. 도 66에는 선택된 파라미터 세트를 이용한 이러한 데이터 세트의 생성된 출력값이 도시되어 있다. 이러한 경우, 높은 신호 샘플은, 광학 데이터를 특징화하여 샘플 데이터를 높은 신호 샘플로서 분류하고, 높은 신호 AES 파라미터 세트를 적용함으로써 처리되었다.
비교로서, 도 67은 표준 파라미터 세트를 이용하여 호출된 동일한 데이터를 보여준다. 표준 DNA ID를 사용하여 처리된 경우 호출을 보이는 DNA ID는 광학 데이터를 분류하는데 필요하지 않았음을 주목하라. 도 67의 이러한 생성된 DNA ID는 도 66의 표준 DNA ID 대비 개선되었다.
도 68은 대립유전자의 피크 높이가 3000 내지 8000 RFU이기 때문에 이와 같이 분류되는 표준 신호 강도 샘플을 보여준다. 표준 파라미터를 적용하여 출력값을 생성하였다.
비교로서, 도 69는 낮은 DNA 파라미터 세트를 이용하여 호출되는 낮은 DNA 샘플의 샘플 데이터를 보여준다. 이러한 경우, 낮은 신호 샘플은, 광학 데이터를 특징화하여 샘플 데이터를 낮은 신호 샘플로서 분류하고, 낮은 신호 AES 파라미터 세트를 적용함으로써 처리하였다. 샘플 데이터는 낮은 DNA 샘플 유형으로서 분류되었은데, 이의 신호 강도는 3,000 RFU 미만이었기 때문이다. 표준 DNA ID를 사용하여 처리되는 경우 호출을 보이는 DNA ID는 광학 데이터를 분류하는데 필요하지 않았음을 주목하라. 도 69의 이러한 생성된 DNA ID는 도 70의 표준 DNA ID에 대비 개선되었다.
풍부한 지식의 당업자는 더 적은 분류(예를 들어, 단지 하나의 분류가 이용될 수 있음) 또는 더 많은 분류(예를 들어, 유전자좌의 수를 추가함으로써 또는 새로운 또는 중복되는 일련의 특징을 사용함으로써)를 사용할 수 있지만, 각 피크에 대한 6개 특징이 전형적으로 계산되었다. 게다가, 풍부한 지식의 당업자는 또한 측정을 위한 다른 특징을 규정할 수 있다. 각 분류는 다중 수준으로 나눠질 수 있다. 요컨대, 광학 데이터로부터 계산될 수 있는 특징의 수는 유동적이다. 각 특징은 많은 수준으로 나눠질 수 있다. 이들 특징 및 수준은 차례로 적용되어 샘플 데이터를 분류하고, 호출을 위해 AES 파라미터 세트를 할당할 수 있다.
실시예
12: 샘플을 분류하고 입력 파라미터를 적용하여 데이터를 호출하는데 단지 하나의 특징만을 사용하는
AES
.
실시예 4에서,
ㆍILS 상태
ㆍ호출된 CODIS 20 유전자좌의 수
ㆍ신호 강도
ㆍPH 임계값 미만의 PH의 대립유전자를 갖는 유전자좌의 수
ㆍPH min 초과의 PH의 대립유전자를 갖는 유전자좌의 수
ㆍPHR 임계값 미만의 PHR을 갖는 유전자좌의 수
ㆍ넓은 피크 및 iNTAp를 갖는 유전자좌의 수를 포함하는 샘플 데이터의 7개 특징은 샘플 데이터를 하기로 분류하는데 사용하였다:
ㆍ중간 신호 강도 샘플
ㆍ넓은 피크 및 iNTA를 갖는 높은 신호 강도 샘플
ㆍ낮은 피크 높이 비율을 갖는 중간 신호 강도 샘플
ㆍ낮은 피크 높이 및 낮은 피크 높이 비율을 갖는 낮은 신호 강도 샘플
ㆍ매우 낮은 신호 함량 샘플
ㆍ실패한 샘플
AES 파라미터 세트는 각각의 분류(분류들)와 연관되며 데이터에 적용되었다.
샘플 데이터 또는 DNA ID(분류) 각각을 분류하는데 단지 하나의 특징만이 필요하다. 하기 표 12는 하나의 특징에 대한 DNA ID 분류를 보여준다. 본 실시예에서, 신호 강도는 분류를 위한 특징으로서 선택된다:
표 12
3개의 분리된 AES 파라미터 세트는 샘플 데이터에 기초한 분류에 각각 적용되도록 규정되었다.
높은 신호 강도 샘플 - 도 71의 데이터 세트는 대립유전자의 이의 특징적인 평균 신호 강도가 10,000 RFU를 초과하기 때문에 높은 신호 샘플로서 분류된다. 데이터세트에 적용될 경우 높은 신호 강도 샘플에 대한 AES 파라미터 세트는 도 71의 생성된 DNA ID를 생성한다. 샘플 데이터를 분류하는데 하나의 특징은 사용은 표준 파라미터 세트와 비교하여 호출 결과를 개선시키기 위해 적절한 AES 파라미터 세트를 선택하는데 효과적이다.
표준 신호 강도 샘플 - 도 72의 데이터 세트는 대립유전자의 이의 특징적인 평균 신호 강도가 3,000 내지 10,000 RFU이기 때문에 표준 샘플로서 분류된다. 데이터세트에 적용되는 경우 표준 신호 강도 샘플에 대한 AES 파라미터 세트는 도 72의 생성된 DNA ID를 생성한다.
낮은 신호 강도 샘플 - 도 73의 데이터 세트는 대립유전자의 이의 특징적인 평균 신호 강도가 3,000 RFU 미만이기 때문에 낮은 신호 샘플로서 분류된다. 데이터세트에 적용되는 경우 표준 신호 강도 샘플에 대한 AES 파라미터 세트는 도 73의 생성된 DNA ID를 생성한다. 샘플 데이터를 분류하는데 하나의 특징의 사용은 표준 파라미터 세트와 비교하여 호출 결과를 개선시키기 위해 적절한 AES 파라미터 세트를 선택하는데 효과적이다.
이러한 예는 하나의 특징이 샘플 데이터를 호출하는데 있어서 샘플 데이터를 분류하고, AES 파라미터 세트를 선택하는데 효과적이다. 본 실시예에서, 3개의 분류는 하나의 특징을 사용하여 규정되었다. 각 특징에 대해 규정될 수 있는 분류의 수는 값의 범위를 더 작은 단계로 나눔으로써 증가될 수 있다.
실시예
13: 2개
도너를
갖는 혼합물 샘플을 호출하기 위한
AES
.
본 실시예에서, 2개 도너 샘플에 대한 샘플 데이터는 적응형 전문가 시스템에 의해 처리된다. 도 74는 표준 ES 파라미터를 이용하여 ES로 처리된 샘플 데이터의 DNA ID를 보여준다. 이러한 DNA ID는 표준 ES의 사용 효과를 예시하기 위해 제시된 것이며, AES 처리에 필수적인 것은 아니다. 본 도면은 샘플이 적색 경고 박스로 표지된 다중의 유전자좌 3개 대립유전자를 가짐을 보여준다(예를 들어, D3S1358, Th01, vWA, D7S820). 또한, 3개 이상의 표지되고 비표지된 피크를 갖는 많은 유전자좌가 관찰되었다. 이는 혼합물 샘플의 전형적인 특징이다. 또한, 도면에서 주류 기여자 DNA ID 및 비주류 기여자 DNA ID가 관찰된다. 비주류 기여자는 주류 기여자의 신호 강도의 0.1 내지 0.6배인 신호 강도를 갖는 대립유전자를 갖는다. 표준 ES는 DNA ID에 대해 실패하였으며, 모든 피크를 적색 경고 박스로 표지하였다.
AES는 하기 알고리즘에 따라 샘플 데이터를 처리하였다:
1) 샘플 데이터를 특징화하고 샘플을 분류한다.
적응형 전문가 시스템은 하기 샘플 데이터를 우선적으로 특징화함으로써 샘플 데이터를 처리한다:
ㆍ대립유전자의 평균 이형접합체 피크 높이는 200 내지 10,000 RFU이다.
ㆍ넓은 피크를 갖는 대립유전자는 관찰되지 않는다.
ㆍ높은 수준의 iNTA를 갖는 대립유전자는 관찰되지 않는다.
ㆍ낮은 신호 강도를 갖는 일부 대립유전자는 비표지된다.
ㆍ3개 이상의 피크를 갖는 많은 유전자좌.
이들 특징은 낮은 DNA 함량 내지 표준 DNA 함량을 갖는 혼합물로서 샘플 데이터를 분류한다.
2) ES 파라미터 세트를 결정하여 일차 기여자의 DNA ID를 생성한다.
피크 높이 임계값(특이적 유전자좌)은 각각의 유전자좌에 대해 조절되어 하기 3개 조건 중 하나를 달성한다:
ㆍ이형접합체 유전자좌 - 이러한 조건은, 피크 높이 임계값을 초과하는 피크 높이를 갖는 단지 2개의 피크가 존재하며, 피크에 대한 피크 높이 비율이 표준 DNA 함량 샘플에 대한 피크 높이 임계값보다 큰 경우 충족된다. 이러한 경우, 0.70이다.
ㆍ동형접합체 유전자좌 - 이러한 조건은, 피크 높이 임계값(특정 유전자좌)을 초과하는 피크 높이를 갖는 단지 하나의 피크가 존재하며, 유전자좌의 모든 다른 피크는 0.70 미만의 피크 높이 비율을 갖는 경우 충족된다.
ㆍ실패한 유전자좌 - 이 조건은, 유전자좌의 피크가 상기 이형접합체 또는 동형접합체 조건을 충족하지 않는 경우 충족된다. Penta E, D6S1043 및 D7S820 참조.
높은 신호 iNTA 규칙 및 높은 신호 샘플 피크 폭 조절은 이러한 샘플 데이터에 적용되지 않았는데, 이는 높은 DNA 함량 샘플로서 분류되지 않았기 때문이다.
일차 기여자의 DNA ID는 AES에 의해 생성된다(도 75의 DNA ID의 회색 박스 참조).
3) 샘플 데이터로부터 일차 기여자의 DNA ID를 감한다.
단계 2에서 확인된 일차 기여자에 대한 DNA ID에서의 대립유전자. 이들 대립유전자는, 이차 기여자의 DNA ID를 생성하기 위해 샘플 데이터가 두 번 처리될 때 AES에 의해 무시되도록 설정된다.
4) 이차 기여자에 대한 샘플 데이터를 특징 규명한다.
적응형 전문가 시스템은 샘플 데이터를 하기로서 특징 규명한다(일차 기여자의 DNA ID 피크가 무시된 후):
ㆍ대립유전자의 평균 이형접합체 피크 높이는 200 내지 3,000 RFU이다.
ㆍ넓은 피크를 갖는 대립유전자는 관찰되지 않는다.
ㆍ높은 수준의 iNTA를 갖는 대립유전자는 관찰되지 않는다.
ㆍ낮은 신호 강도를 갖는 일부 대립유전자는 비표지된다.
이들 특징은 샘플 데이터를 낮은 DNA 함량 샘플로서 분류한다.
5) 이차 기여자의 DNA ID를 생성하기 위해 ES 파라미터 세트를 결정한다.
피크 높이 임계값 및 피크 높이 비율은 최소 수의 드롭아웃 및 드롭인을 갖는 최대 수의 대립유전자가 호출되도록 선택되었다. 생성된 DNA ID는 도 76에 도시되어 있다.
AES는 일차 및 이차 기여자의 개별 DNA ID를 생성시킬 수 있다. 이러한 혼합물 디콘볼루션 방법으로, 일차 기여자간의 중복되는 이차 기여자의 임의의 대립유전자가 감해지고, 호출되지 않을 것이며, 이러한 유전자좌는 드롭아웃을 가질 것이다. 상기 알고리즘은 샘플 데이터로부터 일차 공여자를 뺄 때, 3 단계에서 신호 강도를 적용함으로써 이차 기여자와 일차 기여자간에 중첩되는 대립유전자를 추출하도록 적응될 수 있다.
본 실시예는 AES가 단지 단일 소스 샘플에 대한 것이 아니며, 다중 게놈 성분을 갖는 샘플로부터 성분을 생성시킬 수 있음을 보여준다. 이러한 실시예는 인간 법의학적 확인을 위한 비-단일 소스 샘플의 다중 성분 분석을 위한 AES의 용도를 보여주지만, 이러한 동일한 알고리즘은 또한 하나 초과의 감염원으로부터 샘플을 식별하기 위해 임상 환경에서 샘플 데이터에 적용될 수 있다. 이는 특히 이중 미생물 감염에서 중요하다.
개요:
제시된 실시예에서, 본 발명자들은 샘플 데이터를 생성하고, 샘플 데이터를 사용하여 DNA ID를 분류하고, 규칙 및 파라미터를 확립하는데 사용될 수 있는 다른 DNA ID 특징을 식별하는 방법에 대한 접근 방식을 교시하고 예시하였다. 따라서, 본 발명자가 DNA ID의 특정 특징 및 규칙에 대해 쓰지 않더라도, 독자가 실시예에 기술된 단계를 수행하여 AES에 대한 추가적인 분류, 규칙 및 파라미터를 생성시키는 것이 용이하다.
상기 기술된 방법 단계는 입력 데이터를 작동시키고/거나 출력 데이터를 생성시킴으로써 본 발명의 기능을 수행하기 위해 컴퓨터 프로그램을 실행하는 하나 이상의 특수 목적의 프로세서에 의해 수행될 수 있다. 방법 단계는 또한, 특수-목적 논리 회로, 예를 들어, FPGA(필드 프로그램가능 게이트 어레이), FPAA(필드-프로그램가능 아날로그 어레이), CPLD(컴플렉스 프로그램가능 논리 장치), PSoC(프로그램가능 시스템-온-칩), ASIP(애플리케이션-특수 명령-세트 프로세서), 또는 ASIC(애플리케이션-특수 집적 회로), 등에 의해 수행될 수 있으며, 장치는 특수-목적 논리 회로, 예를 들어, FPGA(필드 프로그램가능 게이트 어레이), FPAA(필드-프로그램가능 아날로그 어레이), CPLD(컴플렉스 프로그램가능 논리 장치), PSoC(프로그램가능 시스템-온-칩), ASIP(애플리케이션-특수 명령-세트 프로세서), 또는 ASIC(애플리케이션-특수 집적 회로), 등으로서 구현될 수 있다. 서브루틴은 저장된 컴퓨터 프로그램 및/또는 프로세서, 및/또는 하나 이상의 기능을 구현하는 특수 회로의 일부를 참조할 수 있다.
컴퓨터 프로그램의 실행에 적합한 프로세서는 예를 들어, 특수-목적 마이크로프로세서를 포함한다. 일반적으로, 프로세서는 읽기 전용 메모리 또는 랜덤 액세스 메모리 또는 둘 모두로부터 명령 및 데이터를 수신한다. 컴퓨터의 필수 요소는 명령을 실행하기 위한 특수화된 프로세서 및 명령 및/또는 데이터를 저장하기 위한 하나 이상의 특별히 할당된 메모리 장치이다. 메모리 장치, 예컨대, 캐시는 데이터를 임시적으로 저장하는데 사용될 수 있다. 메모리 장치는 또한 장기 데이터 저장에 사용될 수 있다. 일반적으로, 컴퓨터는 또한, 데이터를 저장하기 위한 하나 이상의 대용량 저장 장치 예를 들어, 자기, 자기-광 디스크, 또는 광 디스크를 포함하거나, 이들로부터 데이터를 수신하기 위해, 이들에 데이터를 전송하기 위해, 또는 이 둘 모두를 위해 작동적으로 연결된다. 컴퓨터는 또한, 네트워크로부터 명령 및/또는 데이터를 수신하고/거나 네트워크에 명령 및/또는 데이터를 전송하기 위해 통신 네트워크에 작동적으로 연결될 수 있다. 컴퓨터 프로그램 명령 및 데이터를 구현하기에 적합한 컴퓨터-판독 저장 매체는 예를 들어, 반도체 메모리 장치, 예를 들어, DRAM, SRAM, EPROM, EEPROM, 및 플래시 메모리 장치; 자기 디스크, 예를 들어, 내부 하드 디스크 또는 이동식 디스크; 자기-광 디스크; 및 광학 디스크 예를 들어, CD, DVD, HD-DVD 및 블루-레이 디스크를 포함하는 모든 형태의 휘발성 및 비-휘발성 메모리를 포함한다. 프로세서 및 메모리는 특수 목적 논리 회로에 의해 보완되고/거나 통합될 수 있다.
사용자와의 상호작용을 제공하기 위해, 상기 기술된 기법은 사용자에게 정보를 디스플레이하기 위한 디스플레이 장치 예를 들어, CRT(캐소드 레이 관), 플라즈마, 또는 LCD(액정 디스플레이) 모니터, 모바일 장치 디스플레이 또는 스크린, 홀로그래프 장치 및/또는 프로젝터, 및 사용자가 컴퓨터(예를 들어, 사용자 인터페이스 요소와 상호작용)에 입력값을 제공할 수 있는 키보드 및 포인팅 장치 예를 들어, 마우스, 트랙볼, 터치패드 또는 작동 센서와 통신하는 컴퓨팅 장치에서 구현될 수 있다. 다른 종류의 장치는 또한 사용자와의 상호작용을 제공하기 위해 사용될 수 있다; 예를 들어, 사용자에게 제공된 피드백은 임의의 형태의 감지 피드백, 예를 들어, 시각적 피드백, 청각적 피드백 또는 촉각적 피드백일 수 있으며, 사용자로부터의 입력값은 음향, 음성 및/또는 촉각 입력을 포함하는 임의의 형태로 수신될 수 있다.
상기 기술된 기법은 백-엔드(back-end) 구성요소를 포함하는 분산 컴퓨팅 시스템에서 구현될 수 있다. 백-엔드 구성요소는 예를 들어, 데이터 서버, 미들웨어 구성요소 및/또는 애플리케이션 서버일 수 있다. 상기 기술된 기법은 프론트-엔드(front-end) 구성요소를 포함하는 분산 컴퓨팅 시스템으로 구현될 수 있다. 프론트-엔드 구성요소는 예를 들어, 그래픽 사용자 인터페이스, 사용자가 예시 구현과 상호작용할 수 있는 웹 브라우저, 및/또는 전송 장치를 위한 다른 그래픽 사용자 인터페이스를 갖는 클라이언트 컴퓨터일 수 있다. 상기 기술된 기법은 이러한 백-엔드, 미들웨어, 또는 프론트-엔드 구성요소의 임의의 조합을 포함하는 분산 컴퓨팅 시스템으로 구현될 수 있다.
컴퓨팅 시스템의 구성요소는 디지털 또는 아날로그 데이터 통신의 임의의 형태 또는 매체(예를 들어, 통신 네트워크)를 포함할 수 있는 전송 매채에 의해 상호연결될 수 있다. 전송 매체는 임의의 형태의 하나 이상의 패킷-기반 네트워크 및/또는 하나 이상의 회로-기반 네트워크를 포함할 수 있다. 패킷-기반 네트워크는 예를 들어, 인터넷, 캐리어 인터넷 프로토콜(IP) 네트워크(예를 들어, 근거리 네트워크(LAN), 광역 네트워크(WAN), 캠퍼스 지역 네트워크(CAN), 도시권 네트워크(MAN), 홈 지역 네트워크(HAN)), 프라이빗 IP 네트워크, IP 사설교환기(IPBX), 무선 네트워크(예를 들어, 무선 접속 네트워크(RAN), 블루투스, 근접거리 통신(NFC) 네트워크, Wi-Fi, WiMAX 일반 패킷 무선 서비스(GPRS) 네트워크, HiperLAN), 및/또는 다른 패킷-기반 네트워크를 포함할 수 있다. 회선-기반 네트워크는 예를 들어, 공중 교환 전화 네트워크(PSTN), 레거시 사설 분기 교환(PBX), 무선 네트워크(예를 들어, RAN, 코드-분할 다중 액세스(CDMA) 네트워크, 시분할 다중 액세스(TDMA) 네트워크, 글로벌 이동 통신(GSM) 네트워크 시스템) 및/또는 다른 회로-기반 네트워크를 포함할 수 있다.
네트워크 링크는 전형적으로 다른 데이터 장치로의 하나 이상의 네트워크를 통한 데이터 통신을 제공한다. 예를 들어, 네트워크 링크는 인터넷 서비스 프로바이더 또는 사설 네트워크 서비스 프로바이더("ISP")에 의해 작동된 호스트 컴퓨터 또는 데이터 장치에의 로컬 네트워크를 통한 연결을 제공할 수 있다. ISP는 차례로 "인터넷" 또는 개인 네트워크로 일반적으로 불리는 전세계 네트워크와 같은 패킷 데이터 통신 네트워크를 통해 데이터 통신 서비스를 제공한다. 사설 네트워크의 예는 법 집행 기관을 연결하는 보안 데이터 네트워크이며, DNA 및/또는 비-DNA 정보의 전송에 사용된다. 로컬 네트워크 및 인터넷 둘 모두sms 디지털 데이터 스트림을 전달하는 전기, 전자기 또는 광 신호를 사용한다.
전송 매체를 통한 정보 전송은 하나 이상의 통신 프로토콜을 기반으로 할 수 있다. 통신 프로토콜은 예를 들어, 이더넷 프로토콜, 인터넷 프로토콜(IP), 보이스 오버 IP(VoIP), 피어-투-피어(P2P) 프로토콜, 하이퍼텍스트 트랜스퍼 프로토콜(HTTP), 세션 개시 프로토콜(SIP), H.323, 미디어 게이트웨이 제어 프로토콜(MGCP), 시그널링 시스템 #7(SS7), 글로벌 이동 통신 시스템(GSM) 프로토콜, 푸쉬-투-토크(PTT) 프로토콜, PTT 오버 셀룰라(POC) 프로토콜, 범용 이동 통신 시스템(UMTS), 3GPP 롱 텀 에볼루션(LTE) 및/또는 기타 통신 프로토콜을 포함할 수 있다.
컴퓨팅 시스템 장치는 예를 들어, 컴퓨터, 브라우저 장치를 갖는 컴퓨터, 텔레폰, IP 폰, 이동 장치(예를 들어, 핸드폰, 개인용 디지털 보조장치(PDA), 스마트폰, 태블릿, 노트북 컴퓨터, 전자 메일 장치), 및/또는 다른 통신 장치를 포함할 수 있다. 브라우저는 예를 들어, 월드 와이드 웹 브라우저(예를 들어, Google, Inc.의 ChromeTM Microsoft Corporation으로부터 입수가능한 Microsoft®Internet Explorer® 및/또는 Mozilla Corporation로부터 입수가능한 Mozilla®Firefox)를 갖는 컴퓨터(예를 들어, 데스크톱 컴퓨터 및/또는 노트북 컴퓨터)를 포함한다. 이동 컴퓨팅 장치는 예를 들어, Research in Motion로부터의 Blackberry®, Apple Corporation으로부터의 iPhone® 및/또는 AndroidTM-기재 장치를 포함한다. IP 폰은 예를 들어, Cisco Systems, Inc.로부터 입수가능한 Cisco®Unified IP Phone 7985G 및/또는 Cisco®Unified Wireless Phone 7920을 포함한다.
본원에 기술된 컴퓨터 시스템은 본 발명의 방법을 이용하여, 네트워크에 연결할 수 있는 클라이언트 컴퓨터를 갖는 법의학 요원에게 네트워크를 통해 서비스를 제공하도록 구성될 수 있다. 이들 서비스는 또한, 네트워크, 네트워크 링크 또는 컴퓨터 시스템에 대한 통신 인터페이스에 의해 연결된 상기 기술된 컴퓨터 시스템 또는 별도의 컴퓨터 시스템에 위치한 다른 소프트웨어에 제공될 수 있다. 서비스는 데이터가 손상되거나 공개되지 않도록 하고 데이터에 대한 모든 액세스를 추적하기 위해 컴퓨터 과학 및 컴퓨터 보안 분야에서 공지된 인증 및/또는 암호화 방법을 이용하여 보호될 수 있다. 컴퓨터 시스템 및 기타 관련 정보 저장 및 통신 구성요소는 방화벽, 물리적 액세스 제어, 전력 조절 장비 및 백업 또는 중복 전원과 같은 컴퓨터 과학 및 컴퓨터 보안 분야에서 알려진 장치 및 방법을 이용하여 보호될 수 있다. 컴퓨터 시스템 및 컴퓨터-판독 매체에 의해 저장되는 정보는 백업 또는 중복 정보 저장 시스템 예컨대, 당업계에 널리 공지된 것들을 사용하여 추가로 보호될 수 있다. 예로는 테이프 저장 시스템 및 RAID 저장 어레이를 포함한다.
각각의 구성, 포함 및/또는 복수 형태는 개방형이며, 나열된 부분을 포함하며, 나열되지 않은 추가 부분을 포함할 수 있다. 및/또는은 개방형이며, 나열된 부분 중 하나 이상 및 나열된 부분의 조합을 포함한다.
당업자는 본 발명의 사상 또는 본질적인 특성을 벗어나지 않으면서 주제가 다른 특정 형태로 구현될 수 있음을 이해할 것이다. 따라서, 상기 구체예는 모든 면에서 본원에 기술된 주제를 제한하기보다는 예시하는 것으로 간주되어야 한다.