KR20200038263A - 면역 알고리즘에 근거된 코돈 최적화 방법 - Google Patents
면역 알고리즘에 근거된 코돈 최적화 방법 Download PDFInfo
- Publication number
- KR20200038263A KR20200038263A KR1020207005489A KR20207005489A KR20200038263A KR 20200038263 A KR20200038263 A KR 20200038263A KR 1020207005489 A KR1020207005489 A KR 1020207005489A KR 20207005489 A KR20207005489 A KR 20207005489A KR 20200038263 A KR20200038263 A KR 20200038263A
- Authority
- KR
- South Korea
- Prior art keywords
- optimization
- sequence
- protein
- codon
- proteins
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images






Classifications
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
- G16B30/10—Sequence alignment; Homology search
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
- C12N9/12—Transferases (2.) transferring phosphorus containing groups, e.g. kinases (2.7)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/43504—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from invertebrates
- C07K14/43595—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from invertebrates from coelenteratae, e.g. medusae
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/67—General methods for enhancing the expression
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y207/00—Transferases transferring phosphorus-containing groups (2.7)
- C12Y207/11—Protein-serine/threonine kinases (2.7.11)
- C12Y207/11024—Mitogen-activated protein kinase (2.7.11.24), i.e. MAPK or MAPK2 or c-Jun N-terminal kinase
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/12—Computing arrangements based on biological models using genetic models
- G06N3/126—Evolutionary algorithms, e.g. genetic algorithms or genetic programming
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
- G16B20/20—Allele or variant detection, e.g. single nucleotide polymorphism [SNP] detection
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B25/00—ICT specially adapted for hybridisation; ICT specially adapted for gene or protein expression
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B40/00—ICT specially adapted for biostatistics; ICT specially adapted for bioinformatics-related machine learning or data mining, e.g. knowledge discovery or pattern finding
- G16B40/20—Supervised data analysis
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/40—Fusion polypeptide containing a tag for immunodetection, or an epitope for immunisation
- C07K2319/43—Fusion polypeptide containing a tag for immunodetection, or an epitope for immunisation containing a FLAG-tag
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Chemical & Material Sciences (AREA)
- Genetics & Genomics (AREA)
- Biophysics (AREA)
- General Health & Medical Sciences (AREA)
- Biotechnology (AREA)
- Organic Chemistry (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Theoretical Computer Science (AREA)
- Molecular Biology (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- General Engineering & Computer Science (AREA)
- Medical Informatics (AREA)
- Biomedical Technology (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Biochemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Data Mining & Analysis (AREA)
- Analytical Chemistry (AREA)
- Microbiology (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Software Systems (AREA)
- Medicinal Chemistry (AREA)
- Physiology (AREA)
- Mathematical Physics (AREA)
- Computational Linguistics (AREA)
- General Physics & Mathematics (AREA)
- Computing Systems (AREA)
- Plant Pathology (AREA)
- Epidemiology (AREA)
- Public Health (AREA)
- Databases & Information Systems (AREA)
- Computer Vision & Pattern Recognition (AREA)
Abstract
Description
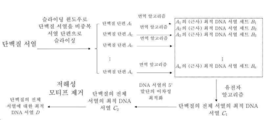
도 1은 본 발명의 최적화 알고리즘의 계통 흐름도이다.
도 2는 본 발명의 면역 알고리즘의 계통 흐름도 (다시 말하면, 국부 최적화 흐름)이다.
도 3은 본 발명의 유전자 알고리즘의 흐름 (다시 말하면, 전역 최적화 흐름)을 보여준다.
도 4는 본 발명의 DNA 서열의 5' 말단을 최적화하는 흐름을 보여준다.
도 5는 본 발명의 검사 단백질의 유전자 서열 설계의 계통도이다.
도 6은 본 발명의 pTT 발현 벡터 지도이다.
도 7은 본 발명의 웨스턴 블롯팅 결과의 계통도이다.

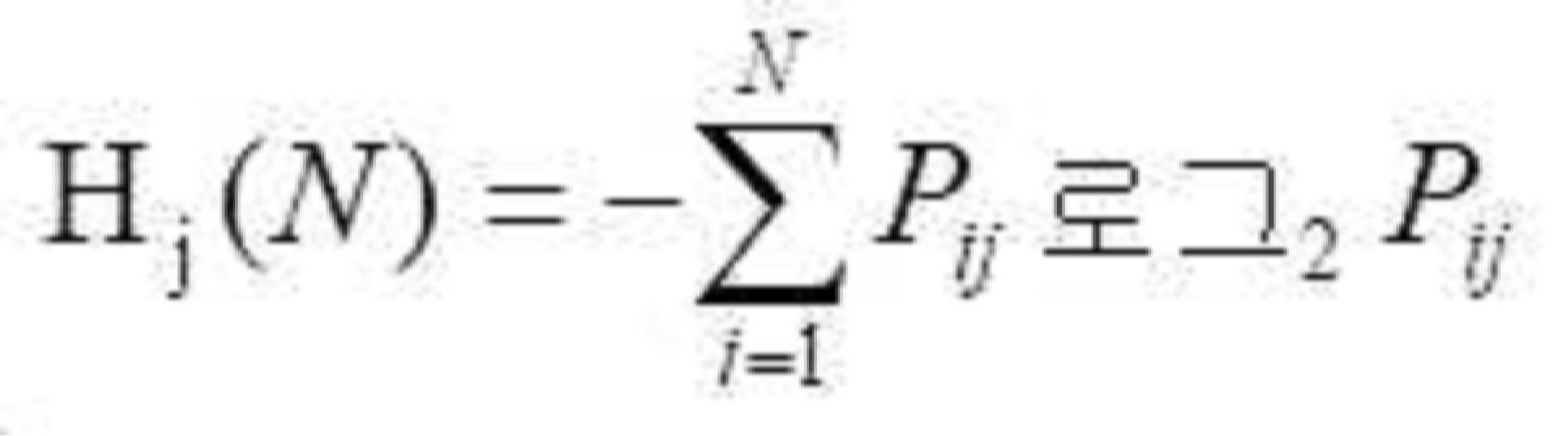



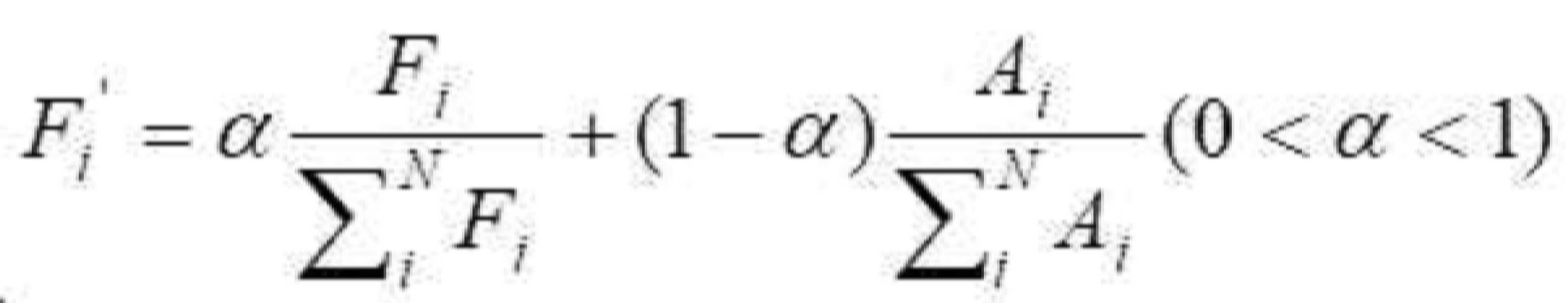


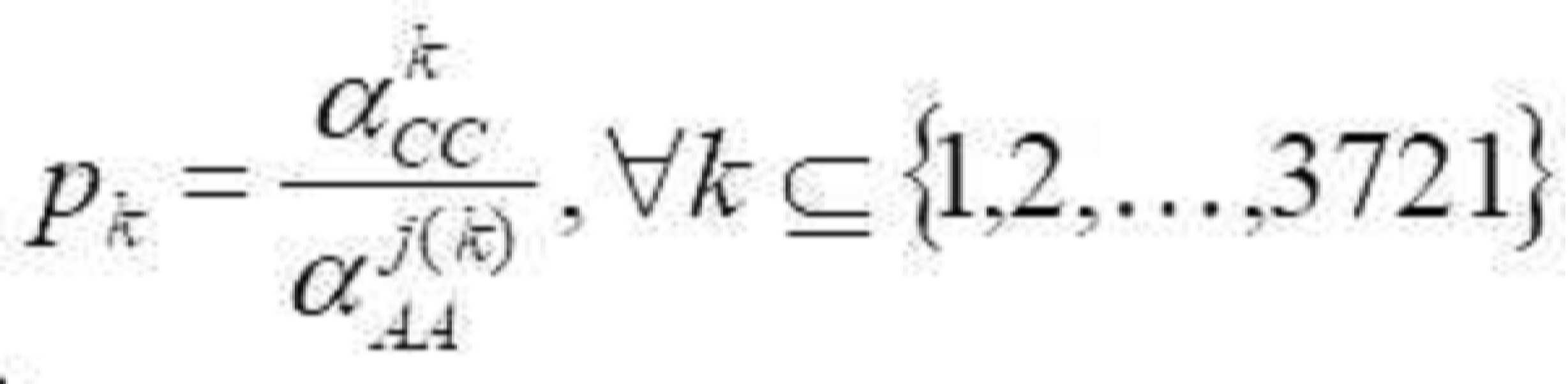
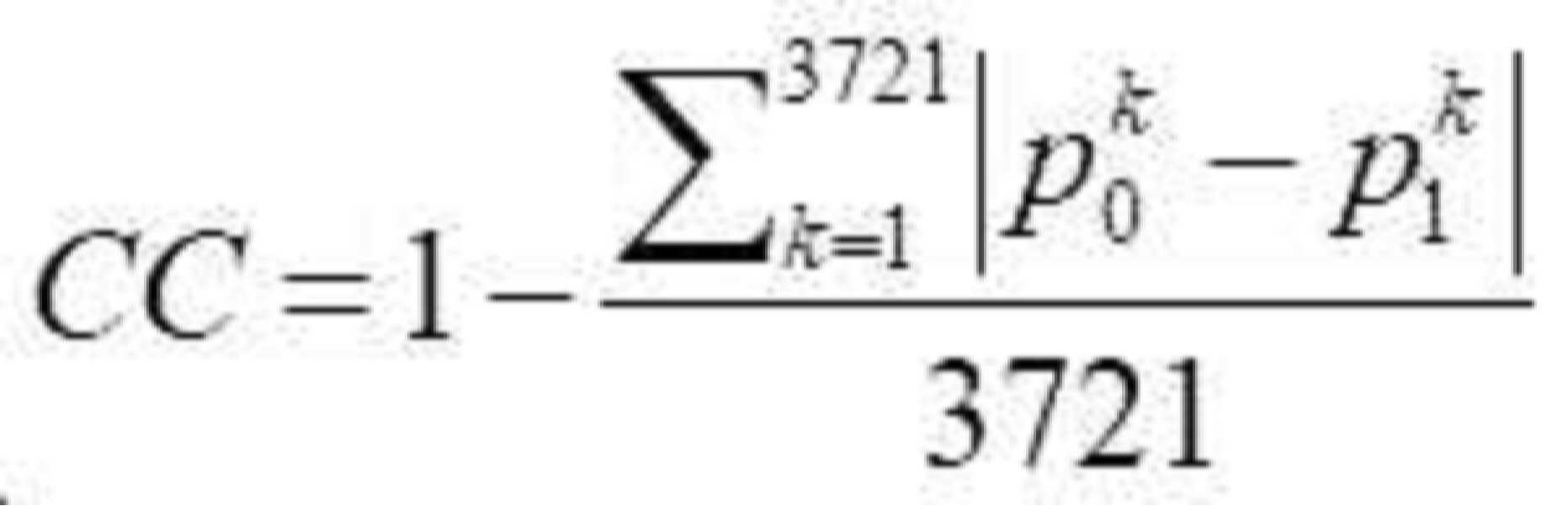
| 단백질 |
GenBank 수탁 번호
(야생형) |
태그 | 태그의 위치 |
| JNK3 | U34820.1 | Flag 태그 | C 말단 |
| GFP | AY174111.1 | Flag 태그 | C 말단 |
| GFP (상대적 발현량 ± 표준 편차) | JNK3 (상대적 발현량 ± 표준 편차) | |
| 최적화 후 | 22.06 ± 1.78 | 8.01 ± 0.21 |
| 야생형 | 1.19 ± 0.16 | 1.09 ± 0.10 |
| 비율 | 18.37 ± 2.90 | 7.42 ± 0.58 |
Claims (8)
- 면역 알고리즘에 근거된 코돈 최적화 방법에 있어서, 면역 알고리즘 및 유전자 알고리즘이 단백질 코딩 서열에서 국부 다목적 최적화 및 전역 다목적 최적화를 각각 수행하는데 연속적으로 이용되고, 그리고 이후 전면적 방법이 최적 발현 서열을 최대 정도까지 검색하기 위해, 상기 서열에서 미세 조정과 최적화를 수행하는데 이용되는 것을 특징으로 하는 최적화 방법.
- 청구항 1에 있어서, 하기의 3 단계를 포함하는 것을 특징으로 하는 최적화 방법: 국부 최적화의 첫 번째 단계, 다시 말하면, 단백질 서열을 비중복 서열 단편 A 1 , A 2 ...A n 으로 개열하고, 그리고 이후, 대략적으로 최적의 DNA 서열 세트 B 1 , B 2 ...B n 를 산출하기 위해, 면역 알고리즘을 이용하여 각 서열 단편에 대한 코돈 최적화를 완결하는 단계; 전역 최적화의 두 번째 단계, 다시 말하면, 유전자 알고리즘을 활용하여 B 1 , B 2 ...B n 에 근거된 단백질의 전장의 DNA 코딩 서열을 초기화하고, 그리고 단백질 서열의 최적 DNA 서열 C 1 을 걸러내는 단계; 그리고 미세 조정과 최적화의 세 번째 단계, 이것은 인코딩된 단백질의 N 말단 영역에 상응하는 DNA 서열의 5' 말단에서 전면적 최적화를 수행하여 DNA 서열 C 2 를 산출하고, 그리고 발현 저해성 모티프를 제거하여, 최적 발현 서열 D 를 최종적으로 산출하는 것을 포함함.
- 청구항 1 또는 2에 있어서, 단백질은 20개보다 많은 아미노산으로 구성되는 화합물을 지칭하고; 단백질은 위치의 면에서 분비 단백질, 막 단백질, 세포질 단백질, 핵 단백질 등을 포함하고; 기능의 면에서 항체 단백질, 조절 단백질, 구조 단백질 등을 포함하고; 공급원의 면에서 상동성 발현 단백질 및 이종성 발현 단백질을 포함하고; 서열의 면에서 자연 단백질 및 인위적으로-변형된 단백질, 완전한 단백질/항체, 절두된 부분적인 단백질/항체, 그리고 2개 또는 그 이상의 단백질로부터 및 단백질과 펩티드 사슬로부터 형성된 융합 단백질을 포함하고; 본 발명에서 규정된 항체는 무손상 항체, 그리고 Fab, ScFV, SdAb, 키메라 항체, 이중특이적 항체, Fc 융합 단백질, 기타 등등을 포함하지만 이들에 한정되지 않는 것을 특징으로 하는 최적화 방법.
- 청구항 1 또는 2에 있어서, 면역 유전자 알고리즘은 단백질 단편에서 국부 최적화를 수행하기 위한 다목적 최적화 방법을 채택하고, 모집단 초기화는 고도로-발현된 단백질을 인코딩하는 서열의 이중 코돈 표에 근거되고, 그리고 각 유전자는 동의 코돈에 의해 직접적으로 인코딩되고; 그리고 최적화 과정에서, 항체 다양성이 담보되고, 그리고 알고리즘의 전역 검색 능력을 증가시키기 위해, 면역 유전자 알고리즘의 항체 정보 엔트로피, 항체 모집단 유사성, 항체 농도 및 중합화 적합도를 계산하고 기억 세포를 갱신함으로써 모집단 변성의 현상이 예방되는 것을 특징으로 하는 최적화 방법.
- 청구항 1 또는 2에 있어서, 유전자 알고리즘은 단백질의 전체 서열에서 전역 최적화를 수행하기 위한 다목적 최적화 방법을 채택하고, 초기화된 모집단은 국부 최적화에 종속되는 최적화된 단편에 근거하여 무작위로 산출되고, 그리고 각 유전자는 각 단백질 단편의 최적화된 서열 세트에 의해 직접적으로 인코딩되는 것을 특징으로 하는 최적화 방법.
- 청구항 1 또는 2에 있어서, 미세 조정과 최적화는 DNA 서열의 5' 말단에서 최소 자유 에너지 MFE, 코돈 콘텍스트 및 CAI를 계산하고 분류하고, 그리고 분류 결과에 따라서 단백질 서열의 N 말단에 대한 최적 코딩 서열을 선택하기 위한 전면적 방법을 이용하는 것을 특징으로 하는 최적화 방법.
- 청구항 1 또는 2에 있어서, 코돈 최적화 방법은 하기의 숙주 발현 시스템에 최소한 적용가능한 것을 특징으로 하는 최적화 방법: 1) 포유류 발현 시스템; 2) 곤충 발현 시스템; 3) 효모 발현 시스템; 4) 대장균 (Escherichia coli) 발현 시스템; 5) 바실루스 서브틸리스 (Bacillus subtilis) 발현 시스템; 6) 식물 발현 시스템, 그리고 7) 무세포 발현 시스템.
- 청구항 1 또는 2에 있어서, 코돈 최적화 방법은 하기의 발현 벡터에 최소한 적용가능한 것을 특징으로 하는 최적화 방법: 일시적인 발현 벡터 및 안정된 발현 벡터, 바이러스 발현 벡터 및 비바이러스 발현 벡터, 유도된 및 비-유도된 발현 벡터.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201710611752.5A CN110070913B (zh) | 2017-07-25 | 2017-07-25 | 一种基于免疫算法的密码子优化方法 |
| CN201710611752.5 | 2017-07-25 | ||
| PCT/CN2018/097040 WO2019020054A1 (zh) | 2017-07-25 | 2018-07-25 | 一种基于免疫算法的密码子优化方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20200038263A true KR20200038263A (ko) | 2020-04-10 |
| KR102730745B1 KR102730745B1 (ko) | 2024-11-15 |
Family
ID=65039394
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020207005489A Active KR102730745B1 (ko) | 2017-07-25 | 2018-07-25 | 면역 알고리즘에 근거된 코돈 최적화 방법 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US20210027858A1 (ko) |
| EP (1) | EP3660852B1 (ko) |
| JP (1) | JP2020534794A (ko) |
| KR (1) | KR102730745B1 (ko) |
| CN (1) | CN110070913B (ko) |
| WO (1) | WO2019020054A1 (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20240086767A (ko) * | 2022-12-02 | 2024-06-19 | 성균관대학교산학협력단 | 코돈 최적화 양자어닐링 알고리즘 |
Families Citing this family (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109979539B (zh) * | 2019-04-10 | 2020-10-02 | 电子科技大学 | 基因序列优化方法、装置及数据处理终端 |
| CN110580390B (zh) * | 2019-09-04 | 2021-05-11 | 电子科技大学 | 基于改进遗传算法与信息熵的地质统计学随机反演方法 |
| CN111243679B (zh) * | 2020-01-15 | 2023-03-31 | 重庆邮电大学 | 微生物群落物种多样性数据的存储检索方法 |
| CN112466393B (zh) * | 2020-11-12 | 2024-02-20 | 苏州大学 | 基于自适应免疫遗传算法的代谢标志物组群识别方法 |
| CN112735525B (zh) * | 2021-01-18 | 2023-12-26 | 苏州科锐迈德生物医药科技有限公司 | 一种基于分治法的mRNA序列优化的方法与装置 |
| CN113792877B (zh) * | 2021-09-18 | 2024-02-20 | 大连大学 | 基于双策略黑蜘蛛算法的dna存储编码优化方法 |
| CN113962548A (zh) * | 2021-10-21 | 2022-01-21 | 上海欧冶物流股份有限公司 | 货物配载方案优化方法、程序产品、可读介质和电子设备 |
| CN116072231B (zh) * | 2022-10-17 | 2024-02-13 | 中国医学科学院病原生物学研究所 | 基于氨基酸序列的密码子优化设计mRNA疫苗的方法 |
| CN116218881B (zh) * | 2022-10-21 | 2024-08-13 | 山东大学 | 一种治疗或者预防乙肝病毒的疫苗 |
| CN115440300B (zh) * | 2022-11-07 | 2023-01-20 | 深圳市瑞吉生物科技有限公司 | 一种密码子序列优化方法、装置、计算机设备及存储介质 |
| CN120266212A (zh) * | 2022-11-24 | 2025-07-04 | 南京金斯瑞生物科技有限公司 | 密码子优化 |
| CN117238374B (zh) * | 2023-09-13 | 2025-09-19 | 上海交通大学宁波人工智能研究院 | 一种基于CAI和AUP的mRNA序列联合优化方法 |
| CN117497092B (zh) * | 2024-01-02 | 2024-05-14 | 微观纪元(合肥)量子科技有限公司 | 基于动态规划和量子退火的rna结构预测方法及系统 |
| CN118038986B (zh) * | 2024-02-05 | 2025-09-02 | 北京百度网讯科技有限公司 | mRNA序列的确定方法、装置、设备和介质 |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20140244228A1 (en) * | 2012-09-19 | 2014-08-28 | Agency For Science, Technology And Research | Codon optimization of a synthetic gene(s) for protein expression |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE10260805A1 (de) * | 2002-12-23 | 2004-07-22 | Geneart Gmbh | Verfahren und Vorrichtung zum Optimieren einer Nucleotidsequenz zur Expression eines Proteins |
| GB0419424D0 (en) * | 2004-09-02 | 2004-10-06 | Viragen Scotland Ltd | Transgene optimisation |
| WO2008000632A1 (en) * | 2006-06-29 | 2008-01-03 | Dsm Ip Assets B.V. | A method for achieving improved polypeptide expression |
| CN101885760B (zh) * | 2010-03-16 | 2012-12-05 | 王世霞 | 密码子优化的HIV-1gp120基因共有序列及gp120核酸疫苗 |
| CN106951726A (zh) * | 2017-02-20 | 2017-07-14 | 苏州金唯智生物科技有限公司 | 一种基因编码序列的优化方法及装置 |
-
2017
- 2017-07-25 CN CN201710611752.5A patent/CN110070913B/zh active Active
-
2018
- 2018-07-25 KR KR1020207005489A patent/KR102730745B1/ko active Active
- 2018-07-25 EP EP18839139.5A patent/EP3660852B1/en active Active
- 2018-07-25 JP JP2020503285A patent/JP2020534794A/ja active Pending
- 2018-07-25 US US16/633,910 patent/US20210027858A1/en not_active Abandoned
- 2018-07-25 WO PCT/CN2018/097040 patent/WO2019020054A1/zh not_active Ceased
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20140244228A1 (en) * | 2012-09-19 | 2014-08-28 | Agency For Science, Technology And Research | Codon optimization of a synthetic gene(s) for protein expression |
Non-Patent Citations (5)
| Title |
|---|
| B. K.-S. Chung 외, "Computational codon optimization of synthetic gene for protein expression", BMC Systems Biology, 6:132 (2012.10.20.)* * |
| J. X. Chin 외, "Codon Optimization OnLine (COOL): a web-based multi-objective optimization platform for synthetic gene design", Bioinformatics, 30(15):2210-2212 (2014.04.10.) * |
| K. C. Tan 외, "An evolutionary artificial immune system for multi-objective optimization", European Journal of Operational Research, 187(2):371-392 (2008.06.01.)* * |
| N. Gould 외, "Computational tools and algorithms for designing customized synthetic genes", Frontiers in Bioengineering and Biotechnology, 2 (2014.10.06.) * |
| W. Gao 외, "UpGene: Application of a Web-Based DNA Codon Optimization Algorithm", Applied Cellular Physiology and Metabolic Engineering, 20(2):443-448 (2008.09.05.) * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20240086767A (ko) * | 2022-12-02 | 2024-06-19 | 성균관대학교산학협력단 | 코돈 최적화 양자어닐링 알고리즘 |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2019020054A1 (zh) | 2019-01-31 |
| EP3660852A4 (en) | 2021-05-12 |
| CN110070913B (zh) | 2023-06-27 |
| KR102730745B1 (ko) | 2024-11-15 |
| US20210027858A1 (en) | 2021-01-28 |
| EP3660852B1 (en) | 2024-05-01 |
| CN110070913A (zh) | 2019-07-30 |
| JP2020534794A (ja) | 2020-12-03 |
| EP3660852A1 (en) | 2020-06-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102730745B1 (ko) | 면역 알고리즘에 근거된 코돈 최적화 방법 | |
| Hemmingsen et al. | Homologous plant and bacterial proteins chaperone oligomeric protein assembly | |
| CN105695485B (zh) | 一种用于丝状真菌Crispr-Cas系统的Cas9编码基因及其应用 | |
| CN112513989A (zh) | 密码子优化 | |
| CN101490262A (zh) | 实现改进的多肽表达的方法 | |
| CN102492692A (zh) | 增强子Hr3 | |
| Develtere et al. | Continual improvement of CRISPR‐induced multiplex mutagenesis in Arabidopsis | |
| EA200600554A1 (ru) | Способ получения рекомбинантных белков | |
| Herynek et al. | Increasing recombinant protein production in E. coli via FACS‐based selection of N‐terminal coding DNA libraries | |
| CN114350660A (zh) | 一种基于Lux群体感应元件的枯草芽孢杆菌自诱导基因表达系统 | |
| CN118077011A (zh) | 一种降低外源核酸免疫原性的密码子优化 | |
| Cregg et al. | Expression of recombinant genes in the yeast Pichia pastoris | |
| Bogdanov et al. | In silico search for functionally similar proteins involved in meiosis and recombination in evolutionarily distant organisms | |
| CN114540364B (zh) | 一种提高蚕茧中丝素蛋白含量的转基因方法及其家蚕品种 | |
| Chen et al. | Structure-guided discovery of protein functions in plants | |
| US11718857B2 (en) | Broad host range genetic tools for engineering microalgae | |
| CN114774421A (zh) | 运动发酵单胞菌内源性启动子突变体 | |
| WO2025108365A1 (en) | Novel tandem repeat-containing polypeptides that bind to dna | |
| CN106191088A (zh) | 一套将质粒表达系统经优化重组到大肠杆菌染色体的方法 | |
| CN112877309A (zh) | 一种N端延长型PTEN亚型PTENζ蛋白及其编码基因和应用 | |
| Muraguchi et al. | Identification and characterisation of structural maintenance of chromosome 1 (smc1) mutants of Coprinopsis cinerea | |
| CN119912541B (zh) | 一种稻曲病菌效应蛋白UvScd1及其应用 | |
| CN115960934A (zh) | 大肠杆菌表达外源基因优化方法及其序列 | |
| Mamun et al. | Multiple genes evolved for fungal septal pore plugging identified via large-scale localization and functional screenings | |
| John et al. | General molecular organization of genomes |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20200225 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| PG1501 | Laying open of application | ||
| A201 | Request for examination | ||
| PA0201 | Request for examination |
Patent event code: PA02012R01D Patent event date: 20210622 Comment text: Request for Examination of Application |
|
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
Comment text: Notification of reason for refusal Patent event date: 20240129 Patent event code: PE09021S01D |
|
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration |
Patent event code: PE07011S01D Comment text: Decision to Grant Registration Patent event date: 20241024 |
|
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment |
Comment text: Registration of Establishment Patent event date: 20241112 Patent event code: PR07011E01D |
|
| PR1002 | Payment of registration fee |
Payment date: 20241113 End annual number: 3 Start annual number: 1 |
|
| PG1601 | Publication of registration |