KR20200043985A - 적응적 실시간 검출 및 검사 네트워크(arden) - Google Patents
적응적 실시간 검출 및 검사 네트워크(arden) Download PDFInfo
- Publication number
- KR20200043985A KR20200043985A KR1020207004307A KR20207004307A KR20200043985A KR 20200043985 A KR20200043985 A KR 20200043985A KR 1020207004307 A KR1020207004307 A KR 1020207004307A KR 20207004307 A KR20207004307 A KR 20207004307A KR 20200043985 A KR20200043985 A KR 20200043985A
- Authority
- KR
- South Korea
- Prior art keywords
- image
- cnn
- rnn
- providing
- image frame
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images




Classifications
-
- G06K9/00664—
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
- G06V10/44—Local feature extraction by analysis of parts of the pattern, e.g. by detecting edges, contours, loops, corners, strokes or intersections; Connectivity analysis, e.g. of connected components
- G06V10/443—Local feature extraction by analysis of parts of the pattern, e.g. by detecting edges, contours, loops, corners, strokes or intersections; Connectivity analysis, e.g. of connected components by matching or filtering
- G06V10/449—Biologically inspired filters, e.g. difference of Gaussians [DoG] or Gabor filters
- G06V10/451—Biologically inspired filters, e.g. difference of Gaussians [DoG] or Gabor filters with interaction between the filter responses, e.g. cortical complex cells
- G06V10/454—Integrating the filters into a hierarchical structure, e.g. convolutional neural networks [CNN]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/40—Scenes; Scene-specific elements in video content
- G06V20/41—Higher-level, semantic clustering, classification or understanding of video scenes, e.g. detection, labelling or Markovian modelling of sport events or news items
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2413—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on distances to training or reference patterns
- G06F18/24133—Distances to prototypes
- G06F18/24143—Distances to neighbourhood prototypes, e.g. restricted Coulomb energy networks [RCEN]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2415—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on parametric or probabilistic models, e.g. based on likelihood ratio or false acceptance rate versus a false rejection rate
-
- G06K9/00718—
-
- G06K9/4628—
-
- G06K9/6274—
-
- G06K9/6277—
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
- G06N3/0442—Recurrent networks, e.g. Hopfield networks characterised by memory or gating, e.g. long short-term memory [LSTM] or gated recurrent units [GRU]
-
- G06N3/0445—
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G06N3/0454—
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/09—Supervised learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/098—Distributed learning, e.g. federated learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T11/00—Two-dimensional [2D] image generation
- G06T11/60—Creating or editing images; Combining images with text
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/20—Analysis of motion
- G06T7/246—Analysis of motion using feature-based methods, e.g. the tracking of corners or segments
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/70—Determining position or orientation of objects or cameras
- G06T7/73—Determining position or orientation of objects or cameras using feature-based methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/764—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using classification, e.g. of video objects
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/10—Terrestrial scenes
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/10—Image acquisition modality
- G06T2207/10016—Video; Image sequence
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20076—Probabilistic image processing
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20081—Training; Learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20084—Artificial neural networks [ANN]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/30—Subject of image; Context of image processing
- G06T2207/30236—Traffic on road, railway or crossing
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Multimedia (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Software Systems (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Computing Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- Data Mining & Analysis (AREA)
- Computational Linguistics (AREA)
- Molecular Biology (AREA)
- Biomedical Technology (AREA)
- General Engineering & Computer Science (AREA)
- Mathematical Physics (AREA)
- Biophysics (AREA)
- Medical Informatics (AREA)
- Databases & Information Systems (AREA)
- Biodiversity & Conservation Biology (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Probability & Statistics with Applications (AREA)
- Image Analysis (AREA)
Abstract
Description
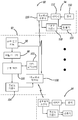
도 2는 도 1에 도시된 이미지에서 객체를 검출하고 분류하기 위한 시스템의 개략적인 블록도이다;
도 3은 입력층, 은닉층 및 출력층을 포함하는 신경망에 대한 도면이다;
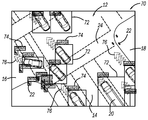
도 4는 도 2에 도시된 시스템에 의해 처리되고 이미지에서 분류된 객체 주위의 경계 상자 및 라벨과 이동하는 각각의 객체와 연관된 셰브론(chevron)을 포함하는 도 1에 도시된 이미지의 도면이고, 셰브론의 개수는 객체의 상대 속도를 나타낸다;
도 5는 도 2에 도시된 시스템에 의해 처리되고 이미지에서 분류된 객체 주위의 경계 상자 및 라벨과 이동하는 각각의 객체와 연관된 화살표를 포함하는 도 1에 도시된 이미지의 도면이고, 화살표의 길이는 객체의 상대 속도를 나타낸다; 그리고
도 6은 기계 학습 및 훈련을 도 2에 도시된 시스템의 일부인 신경망에 제공하는 시스템의 개략적인 블록도이다.
Claims (20)
- 이미지 소스로부터의 비디오 스트림에서 객체(object)의 상대 속도를 식별하고, 분류하고 나타내는 방법에 있어서,
상기 비디오 스트림으로부터의 픽셀 단위의(pixilated) 이미지 프레임의 시퀀스를 입력층과 출력층을 포함하는 컨볼루션 신경망(convolutional neural network(CNN))에 제공하는 단계;
상기 CNN을 이용하여 상기 이미지 프레임 내의 객체를 식별하여 분류하고, 상기 출력층에 객체 분류 데이터를 제공하는 단계;
상기 이미지 소스로부터 메타데이터(metadata)를 제공하는 단계;
상기 출력층에서의 상기 객체 분류 데이터와 상기 메타데이터를 순환 신경망(recurrent neural network(RNN))에 제공하는 단계;
상기 RNN을 이용하여 상기 이미지 프레임 내의 분류된 상기 객체의 모션과 상대 속도를 식별하고, 상기 RNN으로부터 객체 모션 데이터를 제공하는 단계;
상기 CNN으로부터의 상기 객체 분류 데이터와 상기 RNN으로부터의 상기 객체 모션 데이터를 조합하는 단계;
조합된 상기 객체 분류 데이터와 상기 객체 모션 데이터를 상기 이미지 프레임과 상관시켜, 각각의 분류된 객체 주위의 경계 상자와 상기 분류된 객체의 상대 속도 및 이동 방향의 인디케이터(indicator)를 포함하는 상관된 이미지를 제공하는 단계; 및
상기 상관된 이미지를 디스플레이 장치 상에 디스플레이하는 단계
를 포함하는, 방법. - 제1항에 있어서,
상기 이미지 프레임을 CNN에 제공하는 단계는, 상기 이미지 프레임을 다층 피드포워드(multi-layer feed-forward) CNN에 제공하는 단계를 포함하는, 방법. - 제2항에 있어서,
상기 이미지 프레임을 CNN에 제공하는 단계는, 상기 이미지 프레임을 구체적으로 완전 연결층(fully connected layer)을 가지지 않는 CNN에 제공하는 단계를 포함하는, 방법. - 제1항에 있어서,
상기 이미지 프레임을 CNN에 제공하는 단계는, 상기 이미지 프레임을 상기 CNN의 상기 입력층에 제공하는 단계를 포함하는, 방법. - 제4항에 있어서,
상기 메타데이터를 제공하는 단계는, 상기 CNN에서의 상기 입력층에 제공된 데이터와 동일한 데이터를 포함하는 메타데이터를 제공하는 단계를 포함하는, 방법. - 제1항에 있어서,
상기 객체 분류 데이터 및 상기 메타데이터를 RNN에 제공하는 단계는, 상기 객체 분류 데이터 및 상기 메타데이터를 LSTM(long short-term memory)을 포함하는 RNN에 제공하는 단계를 포함하는, 방법. - 제1항에 있어서,
상기 분류된 객체의 모션 및 상대 속도를 식별하는 단계는, 방향 전환하는(turning) 객체의 장래 위치를 예측하는 단계를 포함하는, 방법. - 제1항에 있어서,
상기 상관된 이미지 내의 상대 속도의 인디케이터는 이동하는 객체와 연관된 적어도 하나의 셰브론(chevron)이며, 상기 셰브론의 방향은 상기 객체의 이동 방향을 나타내고, 상기 셰브론의 개수는 상기 객체의 상대 속도를 나타내는, 방법. - 제1항에 있어서,
상기 상관된 이미지 내의 상대 속도의 인디케이터는 화살표이고, 상기 화살표의 방향은 상기 객체의 이동 방향을 식별하고, 상기 화살표의 길이는 상기 객체의 상대 속도를 식별하는, 방법. - 제1항에 있어서,
상기 비디오 소스로부터의 상기 이미지 프레임을 훈련 설비로 전송하는 단계를 더 포함하고, 상기 이미지 프레임은 상기 훈련 설비에서 훈련하는 CNN 및 훈련하는 RNN 내의 신경망 노드에서의 가중치를 훈련시키는데 사용되는, 방법. - 제10항에 있어서,
이미지 소스로부터의 비디오 스트림에서 객체의 상대 속도를 식별하고, 분류하고 나타내는 상기 방법은, 하나의 객체 검출 및 분류 시스템에서 수행되고, 상기 방법은, 훈련된 상기 신경망 가중치를 상기 훈련 설비로부터 다른 이미지 소스로부터의 다른 비디오 스트림에서 객체의 상대 속도를 식별하고, 분류하고, 나타내는 하나 이상의 다른 객체 검출 및 분류 시스템에 전송하는 단계를 더 포함하는, 방법. - 제11항에 있어서,
상기 다른 객체 검출 및 분류 시스템은 상기 훈련하는 CNN 및 RNN을 위하여 상기 신경망 노드에서의 상기 가중치를 더 훈련시키기 위하여 자신의 이미지 프레임을 상기 훈련 설비에 전송하는, 방법. - 제1항에 있어서,
상기 이미지 소스는, 카메라, 전자 광학 적외선 센서, LIDAR 센서, X-선 장치, 자기 공명 촬영(magnetic resonance imaging(MRI)) 장치 및 합성 개구 레이더(synthetic aperture radar(SAR)) 장치로 이루어진 그룹으로부터 선택되는, 방법. - 제1항에 있어서,
상기 디스플레이 장치는, 모니터, 헤드업 디스플레이(head-up display(HUD)) 장치, 고글, 프로젝터, 스마트폰 및 컴퓨터로 이루어진 그룹으로부터 선택되는, 방법. - 이미지 소스로부터의 비디오 스트림에서 객체(object)의 상대 속도를 식별하고, 분류하고 나타내는 방법에 있어서,
상기 비디오 스트림으로부터의 픽셀 단위의(pixilated) 이미지 프레임의 시퀀스를 구체적으로 완전 연결층(fully connected layer)을 가지지 않으며 입력층과 출력층을 포함하는 컨볼루션 다층 피드포워드 신경망(convolutional multi-layer feed-forward neural network(CNN))에 제공하는 단계로서, 상기 CNN의 상기 입력층에 상기 이미지 프레임을 제공하는 단계를 포함하는 단계;
상기 CNN을 이용하여 상기 이미지 프레임 내의 객체를 식별하여 분류하고, 상기 출력층에 객체 분류 데이터를 제공하는 단계;
상기 이미지 소스로부터 메타데이터(metadata)를 제공하는 단계;
상기 출력층에서의 상기 객체 분류 데이터와 상기 메타데이터를 순환 신경망(recurrent neural network(RNN))에 제공하는 단계;
상기 RNN을 이용하여 상기 이미지 프레임 내의 분류된 상기 객체의 모션과 상대 속도를 식별하고, 상기 RNN으로부터 객체 모션 데이터를 제공하는 단계로서, 방향 전환하는(turning) 객체의 장래 위치를 예측하는 단계를 포함하는 단계;
상기 CNN으로부터의 상기 객체 분류 데이터와 상기 RNN으로부터의 상기 객체 모션 데이터를 조합하는 단계;
조합된 상기 객체 분류 데이터와 상기 객체 모션 데이터를 상기 이미지 프레임과 상관시켜, 각각의 분류된 객체 주위의 경계 상자와 상기 분류된 객체의 상대 속도 및 이동 방향의 인디케이터(indicator)를 포함하는 상관된 이미지를 제공하는 단계; 및
상기 상관된 이미지를 디스플레이 장치 상에 디스플레이하는 단계
를 포함하는, 방법. - 제15항에 있어서,
상기 메타데이터를 제공하는 단계는, 상기 CNN에서의 상기 입력층에 제공된 데이터와 동일한 데이터를 포함하는 메타데이터를 제공하는 단계를 포함하는, 방법. - 제15항에 있어서,
상기 객체 분류 데이터 및 상기 메타데이터를 RNN에 제공하는 단계는, 상기 객체 분류 데이터 및 상기 메타데이터를 LSTM(long short-term memory)를 포함하는 RNN에 제공하는 단계를 포함하는, 방법. - 이미지에서 객체(object)의 상대 속도를 식별하고, 분류하고 나타내기 위한 객체 검출 및 분류 시스템에 있어서,
픽셀 단위의(pixilated) 이미지 프레임의 스트림 및 메타데이터(metadata)를 제공하는 비디오 소스;
입력층과 출력층을 포함하고, 상기 입력층에서 상기 이미지 프레임에 응답하고, 상기 이미지 프레임 내의 객체를 식별 및 분류하여 상기 출력층에서 객체 분류 데이터를 제공하는 다층 피드포워드 컨볼루션 신경망(multi-layer feed-forward convolutional neural network(CNN))을 포함하는 분류 엔진;
순환 신경망(recurrent neural network(RNN)을 포함하는 예측 엔진 - 상기 RNN은 상기 출력층에서의 상기 객체 분류 데이터 및 상기 메타데이터에 응답하고, 상기 RNN은 상기 이미지 프레임 내의 분류된 상기 객체의 모션과 상대 속도를 식별하여 객체 모션 데이터를 제공하고, 상기 예측 엔진은 상기 CNN으로부터의 상기 객체 분류 데이터와 상기 RNN으로부터의 상기 객체 모션 데이터를 조합하는 객체 분류 및 모션 벡터 프로세서를 더 포함함 -;
상기 이미지 프레임과 상기 예측 엔진으로부터의 조합된 상기 객체 분류 데이터 및 상기 객체 모션 데이터에 응답하고, 조합된 상기 객체 분류 데이터 및 상기 객체 모션 데이터를 상기 이미지 프레임과 상관시켜 각각의 분류된 객체 주위의 경계 상자와 상기 분류된 객체의 상대 속도 및 이동 방향의 인디케이터를 포함하는 상관된 이미지를 제공하는 시각화 엔진; 및
상기 상관된 이미지를 디스플레이하는 디스플레이 장치
를 포함하는, 객체 검출 및 분류 시스템. - 제18항에 있어서,
상기 RNN은 방향 전환하는(turning) 객체의 위치를 예측하는, 객체 검출 및 분류 시스템. - 제18항에 있어서,
상기 RNN은 LSTM(long short-term memory)을 포함하는, 객체 검출 및 분류 시스템.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US15/683,483 US10275691B2 (en) | 2017-08-22 | 2017-08-22 | Adaptive real-time detection and examination network (ARDEN) |
| US15/683,483 | 2017-08-22 | ||
| PCT/US2018/043128 WO2019040213A1 (en) | 2017-08-22 | 2018-07-20 | ADAPTIVE REAL TIME DETECTION AND EXAMINATION NETWORK (ARDEN) |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20200043985A true KR20200043985A (ko) | 2020-04-28 |
| KR102599212B1 KR102599212B1 (ko) | 2023-11-08 |
Family
ID=63294422
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020207004307A Active KR102599212B1 (ko) | 2017-08-22 | 2018-07-20 | 적응적 실시간 검출 및 검사 네트워크(arden) |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US10275691B2 (ko) |
| EP (1) | EP3673411B1 (ko) |
| KR (1) | KR102599212B1 (ko) |
| WO (1) | WO2019040213A1 (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11853350B2 (en) | 2021-08-24 | 2023-12-26 | Korea Institute Of Science And Technology | Method for updating query information for tracing target object from multi-camera and multi-camera system performing the same |
Families Citing this family (26)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10878592B2 (en) * | 2018-05-23 | 2020-12-29 | Apical Limited | Video data processing |
| JP6988698B2 (ja) * | 2018-05-31 | 2022-01-05 | トヨタ自動車株式会社 | 物体認識装置 |
| KR102727289B1 (ko) * | 2018-06-27 | 2024-11-07 | 삼성전자주식회사 | 모션 인식 모델을 이용한 자체 운동 추정 장치 및 방법, 모션 인식 모델 트레이닝 장치 및 방법 |
| US11423284B2 (en) * | 2018-09-07 | 2022-08-23 | Black Sesame Technologies, Inc | Subgraph tile fusion in a convolutional neural network |
| JP7402606B2 (ja) * | 2018-10-31 | 2023-12-21 | ソニーセミコンダクタソリューションズ株式会社 | 固体撮像装置及び電子機器 |
| EP3776262A1 (en) * | 2018-12-18 | 2021-02-17 | Google LLC | Systems and methods for geolocation prediction |
| CN109919087B (zh) * | 2019-03-06 | 2022-03-08 | 腾讯科技(深圳)有限公司 | 一种视频分类的方法、模型训练的方法及装置 |
| CN109829451B (zh) * | 2019-03-22 | 2021-08-24 | 京东方科技集团股份有限公司 | 生物体动作识别方法、装置、服务器及存储介质 |
| CN110020693B (zh) * | 2019-04-15 | 2021-06-08 | 西安电子科技大学 | 基于特征注意和特征改善网络的极化sar图像分类方法 |
| US20200356812A1 (en) * | 2019-05-10 | 2020-11-12 | Moley Services Uk Limited | Systems and methods for automated training of deep-learning-based object detection |
| CN110472483B (zh) * | 2019-07-02 | 2022-11-15 | 五邑大学 | 一种面向sar图像的小样本语义特征增强的方法及装置 |
| CN110415297B (zh) * | 2019-07-12 | 2021-11-05 | 北京三快在线科技有限公司 | 定位方法、装置及无人驾驶设备 |
| EP4000006B1 (en) | 2019-07-17 | 2025-10-08 | Telefonaktiebolaget LM Ericsson (publ) | A computer software module arrangement, a circuitry arrangement, an arrangement and a method for improved object detection |
| US11447063B2 (en) * | 2019-07-18 | 2022-09-20 | GM Global Technology Operations LLC | Steerable scanning and perception system with active illumination |
| CN110414414B (zh) * | 2019-07-25 | 2022-02-18 | 合肥工业大学 | 基于多层级特征深度融合的sar图像舰船目标鉴别方法 |
| US10970602B1 (en) * | 2019-10-08 | 2021-04-06 | Mythical, Inc. | Systems and methods for converting video information into electronic output files |
| CN110728695B (zh) * | 2019-10-22 | 2022-03-04 | 西安电子科技大学 | 基于图像区域积累的视频sar运动目标检测方法 |
| US11113584B2 (en) * | 2020-02-04 | 2021-09-07 | Nio Usa, Inc. | Single frame 4D detection using deep fusion of camera image, imaging RADAR and LiDAR point cloud |
| US11270170B2 (en) * | 2020-03-18 | 2022-03-08 | GM Global Technology Operations LLC | Object detection using low level camera radar fusion |
| CN113466877B (zh) * | 2020-03-30 | 2024-03-01 | 北京轻舟智航智能技术有限公司 | 一种实时物体检测的方法、装置及电子设备 |
| CN112419413B (zh) * | 2020-12-07 | 2024-01-05 | 萱闱(北京)生物科技有限公司 | 终端设备的运动方向监测方法、介质、装置和计算设备 |
| CN114937221A (zh) * | 2021-02-05 | 2022-08-23 | Tcl科技集团股份有限公司 | 一种视频分类方法、装置、终端设备和存储介质 |
| CN112926448B (zh) * | 2021-02-24 | 2022-06-14 | 重庆交通大学 | 一种相干斑模式起伏稳健的sar图像分类方法 |
| CN113111909B (zh) * | 2021-03-04 | 2024-03-12 | 西北工业大学 | 一种面向训练目标视角不完备的sar目标识别的自学习方法 |
| KR102511315B1 (ko) * | 2022-09-07 | 2023-03-17 | 주식회사 스마트인사이드에이아이 | 환경 변수 데이터 학습에 기초한 영상 기반 객체 인식 방법 및 시스템 |
| US12546881B2 (en) * | 2022-10-11 | 2026-02-10 | Gm Cruise Holdings Llc | Curvelet-based low level fusion of camera and radar sensor information |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20150104149A1 (en) * | 2013-10-15 | 2015-04-16 | Electronics And Telecommunications Research Institute | Video summary apparatus and method |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5012718B2 (ja) * | 2008-08-01 | 2012-08-29 | トヨタ自動車株式会社 | 画像処理装置 |
| US10949059B2 (en) * | 2016-05-23 | 2021-03-16 | King.Com Ltd. | Controlling movement of an entity displayed on a user interface |
| CN105628951B (zh) * | 2015-12-31 | 2019-11-19 | 北京迈格威科技有限公司 | 用于测量对象的速度的方法和装置 |
-
2017
- 2017-08-22 US US15/683,483 patent/US10275691B2/en active Active
-
2018
- 2018-07-20 WO PCT/US2018/043128 patent/WO2019040213A1/en not_active Ceased
- 2018-07-20 KR KR1020207004307A patent/KR102599212B1/ko active Active
- 2018-07-20 EP EP18758768.8A patent/EP3673411B1/en active Active
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20150104149A1 (en) * | 2013-10-15 | 2015-04-16 | Electronics And Telecommunications Research Institute | Video summary apparatus and method |
Non-Patent Citations (1)
| Title |
|---|
| M. Ghaemmaghami, ‘Tracking of Humans in Video Stream Using LSTM Recurrent Neural Network,’2017 (URN:urn:nbn:se:kth:diva-217495) 1부.* * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11853350B2 (en) | 2021-08-24 | 2023-12-26 | Korea Institute Of Science And Technology | Method for updating query information for tracing target object from multi-camera and multi-camera system performing the same |
Also Published As
| Publication number | Publication date |
|---|---|
| US20190065910A1 (en) | 2019-02-28 |
| EP3673411A1 (en) | 2020-07-01 |
| EP3673411B1 (en) | 2025-06-25 |
| KR102599212B1 (ko) | 2023-11-08 |
| US10275691B2 (en) | 2019-04-30 |
| WO2019040213A1 (en) | 2019-02-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102599212B1 (ko) | 적응적 실시간 검출 및 검사 네트워크(arden) | |
| EP3673417B1 (en) | System and method for distributive training and weight distribution in a neural network | |
| Kyrkou et al. | EmergencyNet: Efficient aerial image classification for drone-based emergency monitoring using atrous convolutional feature fusion | |
| US20230367809A1 (en) | Systems and Methods for Geolocation Prediction | |
| Khow et al. | Improved YOLOv8 model for a comprehensive approach to object detection and distance estimation | |
| US11164003B2 (en) | System and method for detecting objects in video sequences | |
| Abu-Khadrah et al. | Drone-assisted adaptive object detection and privacy-preserving surveillance in smart cities using whale-optimized deep reinforcement learning techniques | |
| CN111931720B (zh) | 跟踪图像特征点的方法、装置、计算机设备和存储介质 | |
| Praneeth et al. | Scaling object detection to the edge with yolov4, tensorflow lite | |
| JP2020170252A (ja) | 画像処理装置、情報処理方法及びプログラム | |
| An et al. | DCE-YOLOv8: Lightweight and Accurate Object Detection for Drone Vision | |
| Wang et al. | Gated image-adaptive network for driving-scene object detection under nighttime conditions | |
| US20230260259A1 (en) | Method and device for training a neural network | |
| Sathyamoorthy et al. | Ensemble deep learning approach for traffic video analytics in edge computing | |
| Kulkarni et al. | Key-track: A lightweight scalable lstm-based pedestrian tracker for surveillance systems | |
| WO2019228654A1 (en) | Method for training a prediction system and system for sequence prediction | |
| Arivazhagan et al. | FPGA implementation of GMM algorithm for background subtractions in video sequences | |
| Wu | Data-Efficient Object Detection Combining YOLO with Few-Shot Learning Techniques | |
| Kondratiuk et al. | Using the Temporal Data and Three-dimensional Convolutions for Sign Language Alphabet Recognition. | |
| Alahdal et al. | YOLO meets FedAVG: A privacy-preserving approach to autonomous vehicles object detection | |
| US20240169762A1 (en) | Methods for featureless gaze tracking in ecologically valid conditions | |
| KR102456083B1 (ko) | 영상기반 주행 속도 및 방향 추론 장치 및 이를 이용한 영상기반 주행 속도 및 방향 추론 방법 | |
| Jebadurai et al. | Efficient traffic signal detection with tiny YOLOv4: enhancing road safety through computer vision | |
| Gosika et al. | Hybrid YOLOv5-CNN Framework with Grey Wolf Optimization for Enhanced Accident Prevention in Traffic and Industrial Environments. | |
| Cordeiro | Out of Distribution Detection in Camera Perception for Autonomous Driving |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20200213 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| PG1501 | Laying open of application | ||
| A201 | Request for examination | ||
| PA0201 | Request for examination |
Patent event code: PA02012R01D Patent event date: 20210525 Comment text: Request for Examination of Application |
|
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
Comment text: Notification of reason for refusal Patent event date: 20221125 Patent event code: PE09021S01D |
|
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
Comment text: Notification of reason for refusal Patent event date: 20230527 Patent event code: PE09021S01D |
|
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration |
Patent event code: PE07011S01D Comment text: Decision to Grant Registration Patent event date: 20231019 |
|
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment |
Comment text: Registration of Establishment Patent event date: 20231102 Patent event code: PR07011E01D |
|
| PR1002 | Payment of registration fee |
Payment date: 20231103 End annual number: 3 Start annual number: 1 |
|
| PG1601 | Publication of registration |