KR20200045439A - 재조합 슈도모나스 푸티다 균주 및 이를 이용한 메발론산 생산 방법 - Google Patents
재조합 슈도모나스 푸티다 균주 및 이를 이용한 메발론산 생산 방법 Download PDFInfo
- Publication number
- KR20200045439A KR20200045439A KR1020190131749A KR20190131749A KR20200045439A KR 20200045439 A KR20200045439 A KR 20200045439A KR 1020190131749 A KR1020190131749 A KR 1020190131749A KR 20190131749 A KR20190131749 A KR 20190131749A KR 20200045439 A KR20200045439 A KR 20200045439A
- Authority
- KR
- South Korea
- Prior art keywords
- strain
- gene
- dna
- recombinant
- artificial sequence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images



















Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/40—Preparation of oxygen-containing organic compounds containing a carboxyl group including Peroxycarboxylic acids
- C12P7/42—Hydroxy-carboxylic acids
Landscapes
- Organic Chemistry (AREA)
- Chemical & Material Sciences (AREA)
- Engineering & Computer Science (AREA)
- Zoology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Wood Science & Technology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Microbiology (AREA)
- General Chemical & Material Sciences (AREA)
- Biotechnology (AREA)
- Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
Abstract
Description
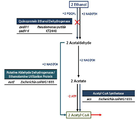
도 2a는 상부 메발론산 경로에 대한 모식도이다.
도 2b는 pSGP10 벡터 맵이다.
도 3은 pK19mobsacB 매개 Markerless 결손 방법에 대한 모식도이다.
도 4a 및 4b는 P. putida 내 에탄올 이화작용 경로 및 조절에 대한 모식도이다.
도 5는 에탄올 이화작용 조절 유전자 재조합에 대한 모식도이다.
도 6은 지방산 생합성 조절 경로 및 유전자 재조합에 대한 모식도이다.
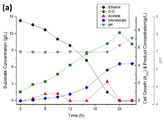
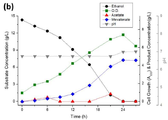
도 7a는 재조합 균주 ELPP000의 대사 프로파일에 대한 그래프이다.
도 7b는 재조합 균주 ELPP010의 대사 프로파일에 대한 그래프이다.
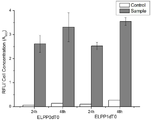
도 8은 엔도뉴클레아제(endA, endX) 결손 여부에 따른 외부 유전자 삽입 벡터의 안정성 증대 효과를 dTomato 형광 분석을 통해 확인한 결과이다.
도 9는 재조합 균주 ELPP110의 대사 프로파일에 대한 그래프이다.
도 10a는 재조합 균주 ELPP111의 대사 프로파일에 대한 그래프이다.
도 10b는 재조합 균주 ELPP211의 대사 프로파일에 대한 그래프이다.
도 10c는 재조합 균주 ELPP212의 대사 프로파일에 대한 그래프이다.
도 10d는 재조합 균주 ELPP213의 대사 프로파일에 대한 그래프이다.
도 11a는 재조합 균주 ELPP221의 대사 프로파일에 대한 그래프이다.
도 11b는 재조합 균주 ELPP311의 대사 프로파일에 대한 그래프이다.
도 12는 Nile-red 염색을 통해 재조합 균주 내 지방산을 분석한 그래프이다.
도 13a는 pH 7.0 조건에서 배양한 재조합 균주 ELPP211의 대사 프로파일에 대한 그래프이다.
도 13b는 pH 6.75 조건에서 배양한 재조합 균주 ELPP211의 대사 프로파일에 대한 그래프이다.
도 13c는 pH 6.5 조건에서 배양한 재조합 균주 ELPP211의 대사 프로파일에 대한 그래프이다.
| Strain, plasmid | Genotype or properties | 메발론산 생산량 |
| Strains | ||
| P. putida KT2440 | Wild-Type | - |
| E. coli DH10B | F-endA1recA1 galE15 galK16 nupG rpsL ΔlacX74 Φ80lacZΔM15 araD139Δ(ara,leu)7697 mcrA Δ(mrr-hsdRMS-mcrBC) λ-T1R | - |
| ELPP000(- con) | P. putida KT2440 harboring pSGP10, pAWP89-0 | - |
| ELPP010 | P. putida KT2440 harboring pSGP11, pAWP89-0 | 1.7 g/L |
| ELPP0dT0 | P. putida KT2440 harboring pSGP1dT, pAWP89-0 | - |
| ELPP1dT0 | P. putida KT2440 ΔendA ΔendX harboring pSGP1dT, pAWP89-0 | - |
| ELPP110 | P. putida KT2440 ΔendA ΔendX harboring pSGP11, pAWP89-0 | 2.43 g/L |
| ELPP111 | P. putida KT2440 ΔendA ΔendX harboring pSGP11, pAWP89-1 | 2.88 g/L |
| ELPP211 | P. putida KT2440 ΔendA ΔendX ΔqedH-I ΔqedH-II harboring pSGP11, pAWP89-1 | 4.07 g/L |
| ELPP212 | P. putida KT2440 ΔendA ΔendX ΔqedH-I ΔqedH-II harboring pSGP11, pAWP89-2 | 0.68 g/L |
| ELPP213 | P. putida KT2440 ΔendA ΔendX ΔqedH-I ΔqedH-II harboring pSGP11, pAWP89-3 | 3.94 g/L |
| ELPP221 | P. putida KT2440 ΔendA ΔendX ΔqedH-I ΔqedH-II harboring pSGP12, pAWP89-1 | 0.78 g/L |
| ELPP311 | P. putida KT2440 ΔendA ΔendX ΔqedH-I ΔqedH-II ΔphaG harboring pSGP11, pAWP89-1 | 3.88 g/L |
| Plasmids | |
| pUCP19 | E. coli-Pseudomonas Shuttle Expression Vector, P lac , Amp R |
| pUC19 | E. coli Expression Vector, lacI, P lac , Amp R |
| pTrc99A | E. coli Expression Vector, lacI, P trc , Amp R |
| pCM184 | Allelic Exchange Vector, Amp R , Tet R , loxP-Kan R -loxP |
| pAWP89 | Broad Host Range Expression Vector, P tac -dTomato, Kan R |
| pK19mobsacB | Allelic Exchange Vector, sacB, Kan R |
| pK19mobsacB (::lacI) | pK19mobsacB -lacI (derived from pTrc99A) |
| pSGP10 | E. coli-Pseudomonas Shuttle Expression Vector (pUCP19 derived), lacI + P trc derived from pTrc99A, Tet R derived from pCM184 |
| pSGP1dT | pSGP10 -dTomato (derived from pAWP89) |
| pSGP11 | pSGP10 -mvaE_opti -mvaS_opti -atoB_opti |
| pSGP12 | pSGP10 -mvaE_opti -mvaS_opti -atoB_opti -nphT7_opti |
| pAWP89-0 | Broad Host Range Expression Vector (pAWP89 derived), P lac drived from pUC19, MCS from MEV Vector |
| pAWP89-1 | pAWP89-0 -acs_opti |
| pAWP89-2 | pAWP89-0 -eutE_opti |
| pAWP89-3 | pAWP89-0 -acs_opti -eutE_opti |
| Primer | Sequence | 서열번호 |
| F-lacI (pK19mobsacB) | TGCATGCCTGCAGGTCGACTCTAGAGACACCATCGAATGGTGC | 11 |
| R-lacI (pK19mobsacB) | AAAACGACGGCCAGTGAATTCTCACTGCCCGCTTTCC | 12 |
| F-endA-upstream | CTATGACCATGATTACGCCAAGCTTTGCTGCTCTTGAAATGAACC | 13 |
| R-endA-upstream | TTTGAAACGGGGGGAAAACATATTTCAGGTTG | 14 |
| F-endA-downstream | TGTTTTCCCCCCGTTTCAAAGGCTGCG | 15 |
| R-endA-downstream | TGCACCATTCGATGGTGTCTCTAGAATGAAGAAGCGAATCGTCCT | 16 |
| F-endX-upstream | CTATGACCATGATTACGCCAAGCTTGTGCTTCCCCCTCAGGG | 17 |
| R-endX-upstream | GGCCTGAGGAGCGCAGTCAATCTTCCTTCG | 18 |
| F-endX-downstream | TTGACTGCGCTCCTCAGGCCAGCGTTTG | 19 |
| R-endX-downstream | TGCACCATTCGATGGTGTCTCTAGAACCAGTAAAAGTGGCGCCG | 20 |
| F-qedH-I-upstream | CTATGACCATGATTACGCCAAGCTTGTGGCCATGAACTGGCG | 21 |
| R-qedH-I-upstream | CCGCTGCAGGGGTTGCAGTTCCCAGTGGA | 22 |
| F-qedH-I-downstream | AACTGCAACCCCTGCAGCGGGGAGC | 23 |
| R-qedH-I-downstream | TGCACCATTCGATGGTGTCTCTAGAATGAATATCGTGTTGGTCGATGAC | 24 |
| F-qedH-II-upstream | CTATGACCATGATTACGCCAAGCTTGTGGCCATGAACTGGCG | 25 |
| R-qedH-II-upstream | TAGGCAGGCGGACGGCTACCTTTGGTTTTTTTG | 26 |
| F-qedH-II-downstream | GGTAGCCGTCCGCCTGCCTACTGCCG | 27 |
| R-qedH-II-downstream | TGCACCATTCGATGGTGTCTCTAGATTAGAAGAAGCCCAGCGGAT | 28 |
| F-phaG-upstream | CTATGACCATGATTACGCCAAGCTTGTGTCTGCAGTGAAACCCG | 29 |
| R-phaG-upstream | GCCGAGCCGCGTCATCGACTCCTGGCGC | 30 |
| F-phaG-downstream | AGTCGATGACGCGGCTCGGCGCC | 31 |
| R-phaG-downstream | TGCACCATTCGATGGTGTCTCTAGACTAACCCTGTTCGGTCACTTG | 32 |
| F-Confirm1-upstream | (Universal) CGATTCATTAATGCAGCTGGC | 33 |
| R-Confirm1-downstream | (Universal) TCCACTTTTTCCCGCGTTTTC | 34 |
| R-Confirm1-upstream | (endA) GGCACGATGTGTTCCCAC | 35 |
| F-Confirm1-downstream | (endA) AAGCCAGAGGCCAAACCAA | 36 |
| R-Confirm1-upstream | (endX) TTTACAGCCGCAATAAAACTCGG | 37 |
| F-Confirm1-downstream | (endX) AAGCCTGGGAGCGGCAA | 38 |
| R-Confirm1-upstream | (qedH-I) TGGCCGCTGTTGCCA | 39 |
| F-Confirm1-downstream | (qedH-I) CGTGGGCTACGGCGG | 40 |
| R-Confirm1-upstream | (qedH-II) GCATCGAGCATGCGCAAG | 41 |
| F-Confirm1-downstream | (qedH-II) ATCTCCAGGTCCGCCGC | 42 |
| R-Confirm1-upstream | (phaG) GCCGTGGTGGCCAGC | 43 |
| F-Confirm1-downstream | (phaG) CCCGCAATGTCATGCTGG | 44 |
| F-Confirm2-endA | TGCTGCTCTTGAAATGAACC | 45 |
| R-Confirm2-endA | ATGAAGAAGCGAATCGTCCT | 46 |
| F-Confirm2-endX | GCAACGTCACCGACACC | 47 |
| R-Confirm2-endX-R | AGCTCTGCGGTGGAGC | 48 |
| F-Confirm2-qedH-I | GCATCGAGCATGCGCAAG | 49 |
| R-Confirm2-qedH-I | ATCTCCAGGTCCGCCGC | 50 |
| F-Confirm2-qedH-II | CACCGCCTGAGGTTGCT | 51 |
| R-Confirm2-qedH-II | AGCCACGGTGCCTTCG | 52 |
| F-Confirm2-phaG | TCCGCAACACCGTACCG | 53 |
| R-Confirm2-phaG | GCCGATCAGGATCGGCC | 54 |
| F-lacI+P trc (pSGP10) | GTGCGGTATTTCACACCGCATATGGGCTTCACCTTCAACCCAACAC | 55 |
| R-lacI+P trc (pSGP10) | CGATGGTGTCGAGCGTCAGACCCCGTAG | 56 |
| F-ori+Tet R (pSGP10) | TCTGACGCTCGACACCATCGAATGGTGCA | 57 |
| R-ori+Tet R (pSGP10) | GACCTGCAGGCATGCAAGCTTCATGGTCTGTTTCCTGTGTGAA | 58 |
| F-dTomato | TGCATGCCTGCAGGTCGACTCTAGAATGGTGAGCAAGGGCGAG | 59 |
| R-dTomato | TGAATTCGAGCTCGGTACCCGGGCTACTTGTACAGCTCGTCCATG | 60 |
| F-mvaE_opti | AAGCTTGCATGCCTGCAGGTCGACTCTAGAATTTAAGGAGAACTTTATATGAAGACCGT | 61 |
| R-mvaE_opti | AAAGTGTCTAGGATTATTGCTTACGCAAATCGTTCA | 62 |
| F-mvaS_opti | GCGTAAGCAATAATCCTAGACACTTTCACCATAAGGA | 63 |
| R-mvaS_opti | TACCCAGCGGACTTTAGTTGCGATAGCTGCGC | 64 |
| F-atoB_opti | CTATCGCAACTAAAGTCCGCTGGGTAGACTAAGG | 65 |
| R-atoB_opti | GCCAGTGAATTCGAGCTCGGTACCCGGGTCAGTTCAGGCGCTCGATC | 66 |
| R-atoB_opti (pSGP12) | CTACAGAACTTAATCAGTTCAGGCGCTCGATC | 67 |
| F-nphT7_opti | GCGCCTGAACTGATTAAGTTCTGTAGGGCCGAGAC | 68 |
| R-nphT7_opti | GCCAGTGAATTCGAGCTCGGTACCCGGGTCACCACTCGATCAGCGC | 69 |
| F-acs_opti | TTTCACACAGGAAACAGCGGGCCCCTGAGAATAGCCCTCAACTACGT | 70 |
| F-acs_opti (pAWP89-3) | CATCGTGTGACTGAGAATAGCCCTCAACTACGT | 71 |
| R-acs_opti | GATAGTCTAGAAGGTACCAGAATTCTCAGCTCGGCATGGCG | 72 |
| F-eutE_opti | TTTCACACAGGAAACAGCGGGCCCAGAAAGACAAGAGATAAGGAGGT | 73 |
| R-eutE_opti | GATAGTCTAGAAGGTACCAGAATTCTCACACGATGCGGAAGGC | 74 |
| R-eutE_opti (pAWP89-3) | CTATTCTCAGTCACACGATGCGGAAGGC | 75 |
| - | M9D | M9E |
| Phosphate Buffer | K2HPO4 16.0 g/L KH2PO4 8.0 g/L |
|
| Nitrogen Source | (NH4)2SO4 4.7 g/L | |
| Carbon Substrate | Dextrose 12 g/L | Ethanol 200mM (11.7 mL/L) Dextrose 1 g/L |
| MgSO47H2O | 0.12 g/L | |
| NaCl | 0.5 g/L | |
| FeSO47H2O | 6 mg/L | |
| CaCO3 | 2.7 mg/L | |
| ZnSO4H2O | 2.0 mg/L | |
| MnSO4H2O | 1.16 mg/L | |
| CuSO45H2O | 0.33 mg/L | |
| CoSO47H2O | 0.37 mg/L | |
| H3BO3 | 0.08 mg/L | |
| HCl | 0.01 mL | |
| Media Composition | Physiological Condition |
| M9E Media Ethanol 200 mM (9.2 g/L) O.D. = 1.0 Inoculation from M9D (Dextrose 12 g/L) Culture |
Baffled Flask Working Volume : 50 mL Agitation : 230rpm Temperature : 30℃ IPTG Induction : 0.1 mM |
| HPLC 분석 조건 | |
| Instrument | LC-20A Prominence Series (Shimazu) |
| Column | Hi Plex-H Column |
| Temperature | 40℃ |
| Mobile Phase | 0.1N H2SO4 |
| Flow Rate | 0.6 mL/min |
| Analysis Time | 25 min |
Claims (7)
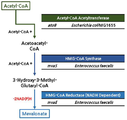
- 서열번호 1로 표시되는 아세틸 조효소 아세틸전달효소(Acetyl coenzyme A Acetyltransferase)의 핵산서열, 서열번호 2로 표시되는 HMG CoA 합성효소(3-hydroxy-3-methylglutaryl coenzyme A synthetase)의 핵산서열 및 서열번호 3으로 표시되는 HMG CoA 환원효소(3-hydroxy-3-methylglutaryl coenzyme A reductase)의 핵산서열을 포함하는 재조합 벡터로 형질전환되고, 엔도뉴클레아제 A(endonuclease A, endA) 유전자 및 엔도뉴클레아제 X(endonuclease A, endX) 유전자가 결손된 재조합 슈도모나스 푸티다(Pseudomonas putida) 균주.
- 제 1 항에 있어서, 상기 재조합 벡터는 서열번호 4로 표시되는 아세틸 조효소 합성효소(Acetyl coenzyme A synthetase)의 핵산서열을 추가적으로 포함하는 것인, 재조합 슈도모나스 푸티다(Pseudomonas putida) 균주.
- 제 1 항에 있어서, 상기 균주는 퀴노단백질 에탄올 탈수소효소 I(Quinoprotein Ethanol Dehydrogenase I) 유전자 및 퀴노단백질 에탄올 탈수소효소 II(Quinoprotein Ethanol Dehydrogenase II) 유전자가 추가로 결손된 것인, 재조합 슈도모나스 푸티다(Pseudomonas putida) 균주.
- 서열번호 1로 표시되는 아세틸 조효소 아세틸전달효소(Acetyl coenzyme A Acetyltransferase)의 핵산서열, 서열번호 2로 표시되는 HMG CoA 합성효소(3-hydroxy-3-methylglutaryl coenzyme A synthetase)의 핵산서열 및 서열번호 3으로 표시되는 HMG CoA 환원효소(3-hydroxy-3-methylglutaryl coenzyme A reductase)의 핵산서열을 포함하는 재조합 벡터로 형질전환되고, 엔도뉴클레아제 A(endonuclease A, endA) 유전자 및 엔도뉴클레아제 X(endonuclease A, endX) 유전자가 결손된 재조합 슈도모나스 푸티다(Pseudomonas putida) 균주를 포함하는 메발론산(mevalonate) 생산용 조성물.
- 제 4 항에 있어서, 상기 재조합 벡터는 서열번호 4로 표시되는 아세틸 조효소 합성효소(Acetyl coenzyme A synthetase)의 핵산서열을 추가적으로 포함하는 것인, 메발론산 생산용 조성물.
- 제 4 항에 있어서, 상기 균주는 퀴노단백질 에탄올 탈수소효소 I(Quinoprotein Ethanol Dehydrogenase I) 유전자 및 퀴노단백질 에탄올 탈수소효소 II(Quinoprotein Ethanol Dehydrogenase II) 유전자가 추가로 결손된 것인, 메발론산 생산용 조성물.
- 다음 단계를 포함하는 메발론산의 생산 방법:
상기 제 1 항 내지 제 3 항 중 어느 한 항의 재조합 슈도모나스 푸티다 균주를 배양하는 단계; 및
상기 배양 결과물로부터 메발론산을 수득하는 단계.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR20180125997 | 2018-10-22 | ||
| KR1020180125997 | 2018-10-22 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20200045439A true KR20200045439A (ko) | 2020-05-04 |
| KR102716655B1 KR102716655B1 (ko) | 2024-10-14 |
Family
ID=70732690
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020190131749A Active KR102716655B1 (ko) | 2018-10-22 | 2019-10-22 | 재조합 슈도모나스 푸티다 균주 및 이를 이용한 메발론산 생산 방법 |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR102716655B1 (ko) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023027335A1 (ko) * | 2021-08-26 | 2023-03-02 | 한국생명공학연구원 | 메발론산을 생산하는 재조합 미생물 및 이를 이용한 메발론산의 생산 방법 |
| WO2023186037A1 (zh) * | 2022-04-02 | 2023-10-05 | 元素驱动(杭州)生物科技有限公司 | 一种利用苏氨酸制备甘氨酸、乙酰辅酶a及乙酰辅酶a衍生物的方法 |
| CN120005941A (zh) * | 2025-04-18 | 2025-05-16 | 吉林农业大学 | GmHMGS基因及重组过表达载体在调控植物脂肪酸含量中的应用 |
| CN120700011A (zh) * | 2025-07-04 | 2025-09-26 | 浙江大学 | 合成单萜的基因工程菌及其构建方法与应用 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20150006097A (ko) * | 2013-07-05 | 2015-01-16 | 경상대학교산학협력단 | 메발론산의 생산에 관여하는 효소를 코딩하는 유전자를 포함하는 미생물 및 이를 이용한 메발론산의 생산 방법 |
| KR20150134512A (ko) * | 2014-05-21 | 2015-12-02 | 아주대학교산학협력단 | 메발로네이트 또는 메발로노락톤 생성능을 가지는 재조합 미생물, 및 이를 이용한 메발로네이트 또는 메발로노락톤의 제조방법 |
| KR20160002915A (ko) * | 2013-04-18 | 2016-01-08 | 리젠츠 오브 더 유니버시티 오브 미네소타 | 생합성 경로 및 생성물 |
-
2019
- 2019-10-22 KR KR1020190131749A patent/KR102716655B1/ko active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20160002915A (ko) * | 2013-04-18 | 2016-01-08 | 리젠츠 오브 더 유니버시티 오브 미네소타 | 생합성 경로 및 생성물 |
| KR20150006097A (ko) * | 2013-07-05 | 2015-01-16 | 경상대학교산학협력단 | 메발론산의 생산에 관여하는 효소를 코딩하는 유전자를 포함하는 미생물 및 이를 이용한 메발론산의 생산 방법 |
| KR20150134512A (ko) * | 2014-05-21 | 2015-12-02 | 아주대학교산학협력단 | 메발로네이트 또는 메발로노락톤 생성능을 가지는 재조합 미생물, 및 이를 이용한 메발로네이트 또는 메발로노락톤의 제조방법 |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023027335A1 (ko) * | 2021-08-26 | 2023-03-02 | 한국생명공학연구원 | 메발론산을 생산하는 재조합 미생물 및 이를 이용한 메발론산의 생산 방법 |
| WO2023186037A1 (zh) * | 2022-04-02 | 2023-10-05 | 元素驱动(杭州)生物科技有限公司 | 一种利用苏氨酸制备甘氨酸、乙酰辅酶a及乙酰辅酶a衍生物的方法 |
| EP4506462A4 (en) * | 2022-04-02 | 2025-11-19 | Mint Biotechnologies Co Ltd | PROCESS FOR PREPARING GLYCINE, ACETYL COENZYME A AND ACETYL COENZYME A USING THREONIN |
| CN120005941A (zh) * | 2025-04-18 | 2025-05-16 | 吉林农业大学 | GmHMGS基因及重组过表达载体在调控植物脂肪酸含量中的应用 |
| CN120700011A (zh) * | 2025-07-04 | 2025-09-26 | 浙江大学 | 合成单萜的基因工程菌及其构建方法与应用 |
Also Published As
| Publication number | Publication date |
|---|---|
| KR102716655B1 (ko) | 2024-10-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| AU760575C (en) | Pyruvate carboxylase overexpression for enhanced production of oxaloacetate-derived biochemicals in microbial cells | |
| KR102716655B1 (ko) | 재조합 슈도모나스 푸티다 균주 및 이를 이용한 메발론산 생산 방법 | |
| JP7759930B2 (ja) | グアニジノ酢酸の発酵産生方法 | |
| CA3158505A1 (en) | Methods for the production of psilocybin and intermediates or side products | |
| KR102761743B1 (ko) | 1,4-부탄디올을 생산하는 미생물 및 이를 이용한 1,4-부탄디올의 생산 방법 | |
| CN110546255B (zh) | 对赖氨酸脱羧酶酶类的修饰 | |
| US20190338293A1 (en) | High growth capacity auxotrophic escherichia coli and methods of use | |
| BR112021009177A2 (pt) | Produção aprimorada de riboflavina | |
| CN110904018A (zh) | 5-氨基乙酰丙酸生产菌株及其构建方法和应用 | |
| CN116606820A (zh) | Atp合酶新型变体及利用其的l-芳香族氨基酸的生产方法 | |
| CN108368477A (zh) | 修饰的膜渗透性 | |
| RU2678139C2 (ru) | Микроорганизм рода Escherichia, продуцирующий L-триптофан, и способ продуцирования L-триптофана с использованием данного микроорганизма | |
| HU220798B1 (hu) | A butiro-betain/krotono-betain-L-karnitin-anyagcsere génjeit kódoló DNS-molekulák és alkalmazásuk L-karnitin mikrobiológiai előállítására | |
| CN111406104B (zh) | 减少为了生产氨基酸或氨基酸衍生产物的亚胺/烯胺的积累 | |
| CN110997899B (zh) | 嗜热赖氨酸脱羧酶的异源表达及其用途 | |
| US20130045515A1 (en) | Heterogeneous e. coli for improving fatty acid content using fatty acid biosynthesis and preparation method thereof | |
| CN103890186A (zh) | 通过高丝氨酸生产丙烯酸酯和其它产品的微生物和方法 | |
| KR102226445B1 (ko) | Gaba 생산성이 향상된 대장균, 이의 제조방법 및 이를 이용한 gaba 생산방법 | |
| RU2837131C2 (ru) | Вариант corynebacterium glutamicum, имеющий улучшенную способность к продукции l-лизина, и способ продуцирования l-лизина посредством его применения | |
| KR102685486B1 (ko) | L-라이신 생산능이 향상된 변이 미생물 및 이를 이용한 l-라이신의 생산 방법 | |
| KR102913627B1 (ko) | 카복시도써머스 하이드로게노포먼스 유래 재조합 일산화탄소 탈수소효소의 가용성 단백질 발현 및 활성증대 방법 | |
| US20250154536A1 (en) | 1,4-butanediol producing microorganism and method for preparing butanediol using the same | |
| KR20250164010A (ko) | L-이소류신 생산능이 향상된 에스케리키아 속 미생물 및 이를 이용한 l-이소류신의 생산 방법 | |
| RU2838210C2 (ru) | Вариант corynebacterium glutamicum, имеющий улучшенную способность к продукции l-лизина, и способ продуцирования l-лизина с его применением | |
| KR102110156B1 (ko) | 젖산 생산용 미생물, 이의 제조 방법 및 이를 이용한 젖산 생산 방법 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application |
Patent event code: PA01091R01D Comment text: Patent Application Patent event date: 20191022 |
|
| PG1501 | Laying open of application | ||
| A201 | Request for examination | ||
| PA0201 | Request for examination |
Patent event code: PA02012R01D Patent event date: 20220923 Comment text: Request for Examination of Application Patent event code: PA02011R01I Patent event date: 20191022 Comment text: Patent Application |
|
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration |
Patent event code: PE07011S01D Comment text: Decision to Grant Registration Patent event date: 20240930 |
|
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment |
Comment text: Registration of Establishment Patent event date: 20241008 Patent event code: PR07011E01D |
|
| PR1002 | Payment of registration fee |
Payment date: 20241008 End annual number: 3 Start annual number: 1 |
|
| PG1601 | Publication of registration |