KR20200057082A - 적응적 동일하지 않은 가중 평면 예측 - Google Patents
적응적 동일하지 않은 가중 평면 예측 Download PDFInfo
- Publication number
- KR20200057082A KR20200057082A KR1020207012624A KR20207012624A KR20200057082A KR 20200057082 A KR20200057082 A KR 20200057082A KR 1020207012624 A KR1020207012624 A KR 1020207012624A KR 20207012624 A KR20207012624 A KR 20207012624A KR 20200057082 A KR20200057082 A KR 20200057082A
- Authority
- KR
- South Korea
- Prior art keywords
- coding
- prediction
- jvet
- reference pixel
- video
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images














Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/103—Selection of coding mode or of prediction mode
- H04N19/11—Selection of coding mode or of prediction mode among a plurality of spatial predictive coding modes
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/103—Selection of coding mode or of prediction mode
- H04N19/105—Selection of the reference unit for prediction within a chosen coding or prediction mode, e.g. adaptive choice of position and number of pixels used for prediction
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/119—Adaptive subdivision aspects, e.g. subdivision of a picture into rectangular or non-rectangular coding blocks
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/13—Adaptive entropy coding, e.g. adaptive variable length coding [AVLC] or context adaptive binary arithmetic coding [CABAC]
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/157—Assigned coding mode, i.e. the coding mode being predefined or preselected to be further used for selection of another element or parameter
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/176—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a block, e.g. a macroblock
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/182—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being a pixel
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/593—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving spatial prediction techniques
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/90—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using coding techniques not provided for in groups H04N19/10-H04N19/85, e.g. fractals
- H04N19/91—Entropy coding, e.g. variable length coding [VLC] or arithmetic coding
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/90—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using coding techniques not provided for in groups H04N19/10-H04N19/85, e.g. fractals
- H04N19/96—Tree coding, e.g. quad-tree coding
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/167—Position within a video image, e.g. region of interest [ROI]
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
Description
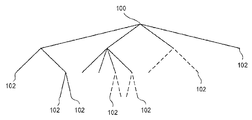
도 1은 복수의 CTU들(Coding Tree Units)로의 프레임의 분할을 묘사한다.
도 2는 쿼드트리 파티셔닝 및 대칭 바이너리 파티셔닝을 사용하는 CU들(Coding Units)로의 CTU의 예시적인 파티셔닝을 묘사한다.
도 3은 도 2의 파티셔닝의 QTBT(quadtree plus binary tree) 표현을 묘사한다.
도 4는 2개의 더 작은 CU들로의 CU의 비대칭 바이너리 파티셔닝의 4개의 가능한 타입들을 묘사한다.
도 5는 쿼드트리 파티셔닝, 대칭 바이너리 파티셔닝, 및 비대칭 바이너리 파티셔닝을 사용하는 CU들로의 CTU의 예시적인 파티셔닝을 묘사한다.
도 6은 도 5의 파티셔닝의 QTBT 표현을 묘사한다.
도 7a 및 도 7b는 JVET 인코더에서의 CU 코딩을 위한 간략화된 블록도를 묘사한다.
도 8은 JVET에서의 루마 성분들에 대한 67개의 가능한 인트라 예측 모드들을 묘사한다.
도 9는 JVET 인코더에서의 CU 디코딩을 위한 간략화된 블록도를 묘사한다.
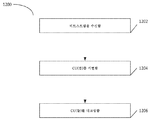
도 10은 JVET 인코더에서의 CU 코딩의 방법의 실시예를 묘사한다.
도 11은 JVET 인코더에서의 CU 코딩을 위한 간략화된 블록도를 묘사한다.
도 12는 JVET 디코더에서의 CU 디코딩을 위한 간략화된 블록도를 묘사한다.
도 13은 증가된 효율 코딩 시스템 및 방법의 간략화된 블록도를 묘사한다.
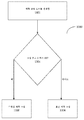
도 14는 JVET 인코더에서의 증가된 효율이 있는 CU 코딩을 위한 간략화된 블록도를 묘사한다.
도 15는 JVET 디코더에서의 증가된 효율이 있는 CU 디코딩을 위한 간략화된 블록도를 묘사한다.
도 16은 CU 코딩의 방법을 처리하도록 적응되는 및/또는 구성되는 컴퓨터 시스템의 실시예를 묘사한다.
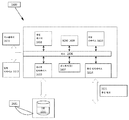
도 17은 JVET 인코더/디코더에서의 CU 코딩/디코딩을 위한 코더/디코더 시스템의 실시예를 묘사한다.
Claims (16)
- JVET 비디오를 코딩하는 방법으로서,
CU x 및 CU y 좌표들을 갖는 CU(coding unit)를 비디오 프레임의 코딩 영역 내에서 정의하는 단계;
상기 메인 참조와 연관된 메인 x 및 메인 y 좌표들을 갖는 메인 참조 픽셀을 상기 코딩 영역 내에서 정의하는 단계;
상기 사이드 참조와 연관된 사이드 x 및 사이드 y 좌표들을 갖는 사이드 참조 픽셀을 상기 코딩 영역 내에서 정의하는 단계;
예측 모드들의 세트를 정의하는 단계;
상기 예측 모드들의 세트 내에서 2개의 이산 예측 모드들을 식별하는 단계;
상기 예측 모드들의 세트로부터 예측 모드를 선택하는 단계; 및
상기 메인 참조 픽셀과 상기 사이드 참조 픽셀의 조합에 적어도 부분적으로 기초하여 상기 코딩 유닛에 대한 예측 CU를 생성하는 단계를 포함하고;
상기 코딩 유닛에 대한 상기 예측 CU는 상기 2개의 이산 예측 모드들 각각에 대해 동일한 방식으로 코딩되고; 및
상기 2개의 이산 예측 모드들 각각은 예측 방향에 적어도 부분적으로 기초하여 구별되는 JVET 비디오를 코딩하는 방법. - 제1항에 있어서, 상기 예측 방향은 상기 코딩 유닛의 하나 이상의 특성에 기초하는 JVET 비디오를 코딩하는 방법.
- 제2항에 있어서, 상기 예측 CU는 엔트로피 코딩되는 JVET 비디오를 코딩하는 방법.
- 제2항에 있어서, 상기 예측 방향은 상기 코딩 유닛의 폭에 적어도 부분적으로 기초하는 JVET 비디오를 코딩하는 방법.
- 제4항에 있어서, 상기 예측 방향은 상기 코딩 유닛의 높이에 적어도 부분적으로 기초하는 JVET 비디오를 코딩하는 방법.
- 제2항에 있어서, 상기 예측 방향은 상기 코딩 유닛의 높이에 적어도 부분적으로 기초하는 JVET 비디오를 코딩하는 방법.
- 제6항에 있어서, 상기 예측 방향은 상기 코딩 유닛의 폭에 적어도 부분적으로 기초하는 JVET 비디오를 코딩하는 방법.
- 제1항에 있어서, 상기 예측 모드들은 0과 66 사이의 정수 값들의 모드들을 포함하는 JVET 비디오를 코딩하는 방법.
- 제1항에 있어서, 상기 2개의 이산 예측 모드들은 모드 2 및 모드 66인 JVET 비디오를 코딩하는 방법.
- 제9항에 있어서, 예측 모드 2와 연관된 코딩은,
상기 메인 참조 픽셀과 연관된 메인 가중 값을 결정하는 단계;
상기 사이드 참조 픽셀과 연관된 사이드 가중 값을 결정하는 단계; 및
상기 메인 가중 값과 조합되는 상기 메인 참조 픽셀 및 상기 사이드 가중 값과 조합되는 상기 사이드 참조 픽셀의 조합에 적어도 부분적으로 기초하여 상기 코딩 유닛에 대한 예측 CU를 생성하는 단계를 포함하는 JVET 비디오를 코딩하는 방법. - 제10항에 있어서, 상기 메인 가중 값은 상기 코딩 영역과 상기 메인 참조 픽셀 사이의 거리에 적어도 부분적으로 기초하고, 상기 사이드 가중값은 상기 코딩 영역과 상기 사이드 참조 픽셀 사이의 거리에 적어도 부분적으로 기초하는 JVET 비디오를 코딩하는 방법.
- 제11항에 있어서, 상기 메인 참조 픽셀은 상기 코딩 영역 위에 위치되는 JVET 비디오를 코딩하는 방법.
- 제12항에 있어서, 상기 예측 CU는 엔트로피 코딩되는 JVET 비디오를 코딩하는 방법.
- 제9항에 있어서, 예측 모드 66과 연관된 코딩은,
상기 메인 참조 픽셀과 연관된 메인 가중 값을 결정하는 단계;
상기 사이드 참조 픽셀과 연관된 사이드 가중 값을 결정하는 단계; 및
상기 메인 가중 값과 조합되는 상기 메인 참조 픽셀 및 상기 사이드 가중 값과 조합되는 상기 사이드 참조 픽셀의 조합에 적어도 부분적으로 기초하여 상기 코딩 유닛에 대한 예측 CU를 생성하는 단계를 포함하는 JVET 비디오를 코딩하는 방법. - 제14항에 있어서, 상기 메인 가중 값은 상기 코딩 영역과 상기 메인 참조 픽셀 사이의 거리에 적어도 부분적으로 기초하고, 상기 사이드 가중 값은 상기 코딩 영역과 상기 사이드 참조 픽셀 사이의 거리에 적어도 부분적으로 기초하는 JVET 비디오를 코딩하는 방법.
- 제15항에 있어서, 상기 메인 참조 픽셀은 상기 코딩 영역의 좌측에 위치되는 JVET 비디오를 코딩하는 방법.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020257006164A KR20250030971A (ko) | 2017-10-09 | 2018-10-09 | 적응적 동일하지 않은 가중 평면 예측 |
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201762569868P | 2017-10-09 | 2017-10-09 | |
| US62/569,868 | 2017-10-09 | ||
| PCT/US2018/055099 WO2019074985A1 (en) | 2017-10-09 | 2018-10-09 | PLANAR PLANAR WEATHER ADAPTIVE PREDICTION |
| US16/155,858 | 2018-10-09 | ||
| US16/155,858 US10575023B2 (en) | 2017-10-09 | 2018-10-09 | Adaptive unequal weight planar prediction |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020257006164A Division KR20250030971A (ko) | 2017-10-09 | 2018-10-09 | 적응적 동일하지 않은 가중 평면 예측 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20200057082A true KR20200057082A (ko) | 2020-05-25 |
| KR102774763B1 KR102774763B1 (ko) | 2025-03-04 |
Family
ID=65993590
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020257006164A Pending KR20250030971A (ko) | 2017-10-09 | 2018-10-09 | 적응적 동일하지 않은 가중 평면 예측 |
| KR1020207012624A Active KR102774763B1 (ko) | 2017-10-09 | 2018-10-09 | 적응적 동일하지 않은 가중 평면 예측 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020257006164A Pending KR20250030971A (ko) | 2017-10-09 | 2018-10-09 | 적응적 동일하지 않은 가중 평면 예측 |
Country Status (8)
| Country | Link |
|---|---|
| US (4) | US10575023B2 (ko) |
| EP (1) | EP3682637A1 (ko) |
| JP (1) | JP7522036B2 (ko) |
| KR (2) | KR20250030971A (ko) |
| CN (1) | CN111345042A (ko) |
| CA (1) | CA3078804A1 (ko) |
| MX (6) | MX2020003722A (ko) |
| WO (1) | WO2019074985A1 (ko) |
Families Citing this family (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3682637A1 (en) | 2017-10-09 | 2020-07-22 | ARRIS Enterprises LLC | Adaptive unequal weight planar prediction |
| US10715810B2 (en) * | 2018-02-20 | 2020-07-14 | Qualcomm Incorporated | Simplified local illumination compensation |
| CN116320411A (zh) * | 2018-03-29 | 2023-06-23 | 日本放送协会 | 图像编码装置、图像解码装置以及程序 |
| US11611757B2 (en) * | 2018-04-02 | 2023-03-21 | Qualcomm Incorproated | Position dependent intra prediction combination extended with angular modes |
| WO2020094057A1 (en) | 2018-11-06 | 2020-05-14 | Beijing Bytedance Network Technology Co., Ltd. | Position based intra prediction |
| CN113170122B (zh) | 2018-12-01 | 2023-06-27 | 北京字节跳动网络技术有限公司 | 帧内预测的参数推导 |
| PH12021551289A1 (en) | 2018-12-07 | 2022-03-21 | Beijing Bytedance Network Tech Co Ltd | Context-based intra prediction |
| MY207950A (en) * | 2019-02-22 | 2025-03-31 | Beijing Bytedance Network Tech Co Ltd | Neighboring sample selection for intra prediction |
| CN113491121B (zh) | 2019-02-24 | 2022-12-06 | 北京字节跳动网络技术有限公司 | 对视频数据进行编解码的方法、设备及计算机可读介质 |
| CN113767631B (zh) | 2019-03-24 | 2023-12-15 | 北京字节跳动网络技术有限公司 | 用于帧内预测的参数推导中的条件 |
| CN113906737B (zh) * | 2019-08-23 | 2024-05-14 | 寰发股份有限公司 | 具有分割限制条件的小尺寸编码单元分割方法和装置 |
| KR20230111254A (ko) | 2020-12-03 | 2023-07-25 | 광동 오포 모바일 텔레커뮤니케이션즈 코포레이션 리미티드 | 인트라 예측 방법, 인코더, 디코더 및 저장 매체 |
| WO2024058430A1 (ko) * | 2022-09-15 | 2024-03-21 | 현대자동차주식회사 | 하나의 블록에 싱글 트리와 듀얼 트리를 적응적으로 이용하는 비디오 코딩을 위한 방법 및 장치 |
Family Cites Families (23)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2008084817A1 (ja) * | 2007-01-09 | 2008-07-17 | Kabushiki Kaisha Toshiba | 画像符号化と復号化の方法及び装置 |
| KR101408698B1 (ko) * | 2007-07-31 | 2014-06-18 | 삼성전자주식회사 | 가중치 예측을 이용한 영상 부호화, 복호화 방법 및 장치 |
| US20100098156A1 (en) * | 2008-10-16 | 2010-04-22 | Qualcomm Incorporated | Weighted prediction based on vectorized entropy coding |
| WO2012035640A1 (ja) | 2010-09-16 | 2012-03-22 | 株式会社 東芝 | 動画像符号化方法及び動画像復号化方法 |
| EP2635030A4 (en) * | 2010-10-26 | 2016-07-13 | Humax Co Ltd | CODING AND DECODING METHOD WITH ADAPTIVE INTRAPREDICTION |
| CN102685505B (zh) * | 2011-03-10 | 2014-11-05 | 华为技术有限公司 | 帧内预测的方法和预测装置 |
| KR101650532B1 (ko) | 2012-09-28 | 2016-08-23 | 니폰 덴신 덴와 가부시끼가이샤 | 인트라 예측 부호화 방법, 인트라 예측 복호 방법, 인트라 예측 부호화 장치, 인트라 예측 복호 장치, 이들의 프로그램 및 프로그램을 기록한 기록매체 |
| KR20170131473A (ko) * | 2015-03-29 | 2017-11-29 | 엘지전자 주식회사 | 비디오 신호의 인코딩/디코딩 방법 및 장치 |
| US20170150176A1 (en) * | 2015-11-25 | 2017-05-25 | Qualcomm Incorporated | Linear-model prediction with non-square prediction units in video coding |
| WO2017138393A1 (en) * | 2016-02-08 | 2017-08-17 | Sharp Kabushiki Kaisha | Systems and methods for intra prediction coding |
| GB2547052B (en) * | 2016-02-08 | 2020-09-16 | Canon Kk | Methods, devices and computer programs for encoding and/or decoding images in video bit-streams using weighted predictions |
| US11032550B2 (en) * | 2016-02-25 | 2021-06-08 | Mediatek Inc. | Method and apparatus of video coding |
| CA3025488A1 (en) | 2016-05-25 | 2017-11-30 | Arris Enterprises Llc | Weighted angular prediction for intra coding |
| WO2017205703A1 (en) | 2016-05-25 | 2017-11-30 | Arris Enterprises Llc | Improved weighted angular prediction coding for intra coding |
| US10986358B2 (en) * | 2016-07-05 | 2021-04-20 | Kt Corporation | Method and apparatus for processing video signal |
| US20180041778A1 (en) * | 2016-08-02 | 2018-02-08 | Qualcomm Incorporated | Geometry transformation-based adaptive loop filtering |
| US10368107B2 (en) * | 2016-08-15 | 2019-07-30 | Qualcomm Incorporated | Intra video coding using a decoupled tree structure |
| US10631002B2 (en) | 2016-09-30 | 2020-04-21 | Qualcomm Incorporated | Frame rate up-conversion coding mode |
| US10506228B2 (en) * | 2016-10-04 | 2019-12-10 | Qualcomm Incorporated | Variable number of intra modes for video coding |
| US10701366B2 (en) | 2017-02-21 | 2020-06-30 | Qualcomm Incorporated | Deriving motion vector information at a video decoder |
| US10764587B2 (en) * | 2017-06-30 | 2020-09-01 | Qualcomm Incorporated | Intra prediction in video coding |
| CN117528070A (zh) * | 2017-08-21 | 2024-02-06 | 韩国电子通信研究院 | 编码/解码视频的方法和设备以及存储比特流的记录介质 |
| EP3682637A1 (en) | 2017-10-09 | 2020-07-22 | ARRIS Enterprises LLC | Adaptive unequal weight planar prediction |
-
2018
- 2018-10-09 EP EP18793149.8A patent/EP3682637A1/en not_active Withdrawn
- 2018-10-09 US US16/155,858 patent/US10575023B2/en active Active
- 2018-10-09 CN CN201880073161.XA patent/CN111345042A/zh active Pending
- 2018-10-09 KR KR1020257006164A patent/KR20250030971A/ko active Pending
- 2018-10-09 US US16/753,296 patent/US11159828B2/en not_active Expired - Fee Related
- 2018-10-09 CA CA3078804A patent/CA3078804A1/en active Pending
- 2018-10-09 WO PCT/US2018/055099 patent/WO2019074985A1/en not_active Ceased
- 2018-10-09 MX MX2020003722A patent/MX2020003722A/es unknown
- 2018-10-09 JP JP2020540699A patent/JP7522036B2/ja active Active
- 2018-10-09 KR KR1020207012624A patent/KR102774763B1/ko active Active
-
2020
- 2020-07-13 MX MX2024010752A patent/MX2024010752A/es unknown
- 2020-07-13 MX MX2024010748A patent/MX2024010748A/es unknown
- 2020-07-13 MX MX2024010745A patent/MX2024010745A/es unknown
- 2020-07-13 MX MX2024010746A patent/MX2024010746A/es unknown
- 2020-07-13 MX MX2024010753A patent/MX2024010753A/es unknown
-
2021
- 2021-09-13 US US17/473,807 patent/US20220021907A1/en not_active Abandoned
-
2023
- 2023-08-22 US US18/236,869 patent/US20240129553A1/en not_active Abandoned
Non-Patent Citations (1)
| Title |
|---|
| V. Seregin, et. al, "Block shape dependent intra mode coding", (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11 7th Meeting: Torino, IT, 13-21 July 2017, JVET-G0159.* * |
Also Published As
| Publication number | Publication date |
|---|---|
| US20240129553A1 (en) | 2024-04-18 |
| WO2019074985A1 (en) | 2019-04-18 |
| MX2024010746A (es) | 2024-09-10 |
| KR20250030971A (ko) | 2025-03-05 |
| CA3078804A1 (en) | 2019-04-18 |
| JP2020537461A (ja) | 2020-12-17 |
| MX2024010745A (es) | 2024-09-10 |
| US10575023B2 (en) | 2020-02-25 |
| US20200336734A1 (en) | 2020-10-22 |
| US20220021907A1 (en) | 2022-01-20 |
| MX2024010753A (es) | 2024-09-10 |
| MX2024010748A (es) | 2024-09-10 |
| US20190110083A1 (en) | 2019-04-11 |
| CN111345042A (zh) | 2020-06-26 |
| EP3682637A1 (en) | 2020-07-22 |
| MX2024010752A (es) | 2024-09-10 |
| MX2020003722A (es) | 2020-09-18 |
| KR102774763B1 (ko) | 2025-03-04 |
| US11159828B2 (en) | 2021-10-26 |
| JP7522036B2 (ja) | 2024-07-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11902519B2 (en) | Post-filtering for weighted angular prediction | |
| US11533510B2 (en) | JVET coding block structure with asymmetrical partitioning | |
| US20240129553A1 (en) | Adaptive unequal weight planar prediction | |
| US20190028701A1 (en) | Intra mode jvet coding | |
| WO2018119167A1 (en) | Constrained position dependent intra prediction combination (pdpc) | |
| WO2018125972A1 (en) | Adaptive unequal weight planar prediction | |
| WO2019126163A1 (en) | System and method for constructing a plane for planar prediction | |
| EP3446481B1 (en) | Jvet coding block structure with asymmetrical partitioning |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20200429 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| PG1501 | Laying open of application | ||
| A201 | Request for examination | ||
| PA0201 | Request for examination |
Patent event code: PA02012R01D Patent event date: 20211007 Comment text: Request for Examination of Application |
|
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
Comment text: Notification of reason for refusal Patent event date: 20240523 Patent event code: PE09021S01D |
|
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration |
Patent event code: PE07011S01D Comment text: Decision to Grant Registration Patent event date: 20241204 |
|
| A107 | Divisional application of patent | ||
| GRNT | Written decision to grant | ||
| PA0104 | Divisional application for international application |
Comment text: Divisional Application for International Patent Patent event code: PA01041R01D Patent event date: 20250225 |
|
| PR0701 | Registration of establishment |
Comment text: Registration of Establishment Patent event date: 20250225 Patent event code: PR07011E01D |
|
| PR1002 | Payment of registration fee |
Payment date: 20250226 End annual number: 3 Start annual number: 1 |
|
| PG1601 | Publication of registration |