KR20200065076A - 볼류메트릭 비디오 포맷을 위한 방법, 장치 및 스트림 - Google Patents
볼류메트릭 비디오 포맷을 위한 방법, 장치 및 스트림 Download PDFInfo
- Publication number
- KR20200065076A KR20200065076A KR1020207014179A KR20207014179A KR20200065076A KR 20200065076 A KR20200065076 A KR 20200065076A KR 1020207014179 A KR1020207014179 A KR 1020207014179A KR 20207014179 A KR20207014179 A KR 20207014179A KR 20200065076 A KR20200065076 A KR 20200065076A
- Authority
- KR
- South Korea
- Prior art keywords
- data
- scene
- video track
- container
- texture
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images


















Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N13/00—Stereoscopic video systems; Multi-view video systems; Details thereof
- H04N13/10—Processing, recording or transmission of stereoscopic or multi-view image signals
- H04N13/106—Processing image signals
- H04N13/161—Encoding, multiplexing or demultiplexing different image signal components
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/011—Arrangements for interaction with the human body, e.g. for user immersion in virtual reality
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N13/00—Stereoscopic video systems; Multi-view video systems; Details thereof
- H04N13/10—Processing, recording or transmission of stereoscopic or multi-view image signals
- H04N13/106—Processing image signals
- H04N13/172—Processing image signals image signals comprising non-image signal components, e.g. headers or format information
- H04N13/178—Metadata, e.g. disparity information
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/597—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding specially adapted for multi-view video sequence encoding
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/70—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by syntax aspects related to video coding, e.g. related to compression standards
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/20—Servers specifically adapted for the distribution of content, e.g. VOD servers; Operations thereof
- H04N21/21—Server components or server architectures
- H04N21/218—Source of audio or video content, e.g. local disk arrays
- H04N21/21805—Source of audio or video content, e.g. local disk arrays enabling multiple viewpoints, e.g. using a plurality of cameras
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/20—Servers specifically adapted for the distribution of content, e.g. VOD servers; Operations thereof
- H04N21/23—Processing of content or additional data; Elementary server operations; Server middleware
- H04N21/234—Processing of video elementary streams, e.g. splicing of video streams or manipulating encoded video stream scene graphs
- H04N21/2343—Processing of video elementary streams, e.g. splicing of video streams or manipulating encoded video stream scene graphs involving reformatting operations of video signals for distribution or compliance with end-user requests or end-user device requirements
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/20—Servers specifically adapted for the distribution of content, e.g. VOD servers; Operations thereof
- H04N21/23—Processing of content or additional data; Elementary server operations; Server middleware
- H04N21/235—Processing of additional data, e.g. scrambling of additional data or processing content descriptors
- H04N21/2353—Processing of additional data, e.g. scrambling of additional data or processing content descriptors specifically adapted to content descriptors, e.g. coding, compressing or processing of metadata
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/80—Generation or processing of content or additional data by content creator independently of the distribution process; Content per se
- H04N21/81—Monomedia components thereof
- H04N21/816—Monomedia components thereof involving special video data, e.g 3D video
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/80—Generation or processing of content or additional data by content creator independently of the distribution process; Content per se
- H04N21/85—Assembly of content; Generation of multimedia applications
- H04N21/854—Content authoring
- H04N21/85406—Content authoring involving a specific file format, e.g. MP4 format
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N13/00—Stereoscopic video systems; Multi-view video systems; Details thereof
- H04N13/30—Image reproducers
- H04N13/349—Multi-view displays for displaying three or more geometrical viewpoints without viewer tracking
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N13/00—Stereoscopic video systems; Multi-view video systems; Details thereof
- H04N13/30—Image reproducers
- H04N13/388—Volumetric displays, i.e. systems where the image is built up from picture elements distributed through a volume
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Library & Information Science (AREA)
- Computer Security & Cryptography (AREA)
- Databases & Information Systems (AREA)
- General Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Testing, Inspecting, Measuring Of Stereoscopic Televisions And Televisions (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
3D 장면을 나타내는 데이터를 컨테이너로 인코딩하기 위한 방법 및 디바이스 및 인코딩된 데이터를 디코딩하기 위한 대응하는 방법 및 디바이스가 개시된다.
Description
본 개시내용은 볼류메트릭 비디오 콘텐츠(volumetric video content)의 분야에 관한 것이다. 본 개시내용은, 예를 들어 모바일 디바이스들 또는 머리-장착 디스플레이들과 같은 최종 사용자 디바이스들 상에서 렌더링을 위한, 볼류메트릭 콘텐츠를 나타내는 데이터의 인코딩 및/또는 포맷팅의 맥락에서 또한 이해된다.
이 단원은 아래에서 설명 및/또는 청구되는 본 개시내용의 다양한 양태와 관련될 수 있는 기술의 다양한 양태를 독자에게 소개하고자 한다. 이러한 토론은 본 발명의 다양한 양태의 보다 나은 이해를 촉진하도록 독자에게 배경 정보를 제공하는데 도움이 될 것으로 생각된다. 따라서, 이러한 설명들은 이러한 관점에서 읽혀져야 하고, 선행 기술을 참작하는 것이 아니라는 것을 이해하여야 한다.
최근에 이용 가능한 넓은 시야각(large field-of-view) 콘텐츠(최대 360°)가 성장하고 있다. 이러한 콘텐츠는 머리 장착 디스플레이들, 스마트 안경들, PC 스크린들, 태블릿들, 스마트폰들 등과 같은 몰입형 디스플레이 디바이스(immersive display device)들 상의 콘텐츠를 시청하고 있는 사용자에게 완전하게 보이지 않을 가능성이 있다. 즉, 주어진 순간에 사용자는 콘텐츠의 일부만 보고 있을 수 있다는 것을 의미한다. 그러나, 사용자는 일반적으로 머리 움직임, 마우스 움직임, 터치 스크린, 음성 등과 같은 다양한 수단에 의해 콘텐츠 내에서 탐색할 수 있다. 일반적으로 이러한 콘텐츠를 인코딩하고 디코딩하는 것이 바람직하다.
360° 플랫 비디오(flat video)라고도 하는 몰입형 비디오는 사용자가 그의 머리를 정지(still) 뷰 포인트(point of view)를 중심으로 회전하여 자신을 사방으로 볼 수 있게 한다. 회전들은 3 자유도(3 Degrees of Freedom)(3DoF) 경험만 가능하게 한다. 예를 들어 머리-장착 디스플레이 디바이스(Head-Mounted Display)(HMD)를 사용하여 제1 전방향 비디오 경험을 하는데는 3DoF 비디오가 충분할지라도, 예를 들어 시차를 경험함으로써 더 많은 자유를 기대하는 시청자는 3DoF 비디오에 금방 좌절할 수 있다. 또한, 3DoF는 사용자가 그의 머리를 회전할 뿐만 아니라 그의 머리를 세 방향으로 평행이동시키기 때문에 현기증을 또한 유발할 수 있고, 그 평행이동들은 3DoF 비디오 경험에서 재현되지 않는다.
큰 시야각 콘텐츠는, 다른 것들 중에서도, 3 차원 컴퓨터 그래픽 이미지 장면(three-dimension computer graphic imagery scene)(3D CGI scene), 포인트 클라우드(point cloud) 또는 몰입형 비디오일 수 있다. 이러한 몰입형 비디오들을 디자인하는데는 다음과 같은 많은 용어: 예를 들어, 가상 현실(Virtual Reality)(VR), 360, 파노라마, 4π 입체각(steradian)들, 몰입형, 전방향(omnidirectional) 또는 넓은 시야각이 사용될 수 있다.
(6 자유도(6 Degrees of Freedom)(6DoF) 비디오라고도 알려진) 볼류메트릭 비디오는 3DoF 비디오의 대안이다. 6DoF 비디오를 시청하고 있을 때, 사용자는 회전 외에도 시청된 콘텐츠 내에서 그의 머리와 심지어 그의 몸을 또한 평행이동시킬 수 있고, 시차와 심지어 볼륨들을 경험할 수 있다. 이러한 비디오들은 몰입감 및 장면 깊이의 인식을 상당히 높여주며, 머리의 평행이동들 중에 일관적인 시각적 피드백을 제공함으로써 현기증을 또한 방지한다. 콘텐츠는 전용 센서들에 의해 생성되어 관심 장면의 컬러와 깊이의 동시적인 기록을 가능하게 한다. 사진 측량 기술들과 결합된 컬러 카메라들의 리그를 사용하는 것이 그러한 기록을 수행하는 일반적인 방법이다.
3DoF 비디오들은 텍스처 이미지들(예를 들어, 위도/경도 투영 매핑(latitude/longitude projection mapping) 또는 정방형 투영 매핑(equirectangular projection mapping)에 따라 인코딩된 구형 이미지(spherical image)들)의 매핑 해제로 생긴 이미지들의 시퀀스를 포함하지만, 6DoF 비디오 프레임들에는 여러 뷰 포인트로부터의 정보가 삽입된다. 이들은 3 차원 캡처로부터 발생한 일시적인 포인트 클라우드(point cloud)들의 시리즈로 보일 수도 있다. 시청 조건들에 따라 두 종류의 볼류메트릭 비디오가 고려될 수 있다. 첫 번째 것(즉, 완전한 6DoF)은 비디오 콘텐츠 내에서 완전 자유 항해(complete free navigation)를 가능하게 하는 반면, 두 번째 것(일명 3DoF+)은 사용자 시청 공간을 제한된 볼륨으로 제한하여, 머리의 회전 및 시차 경험이 제한되게 한다. 이러한 두 번째 맥락은 자유 항해와 좌석에 앉은 청중 구성원의 수동적 시청 조건 사이의 중요한 트레이드오프이다.
3DoF 비디오들은 선택된 투영 매핑(예를 들어, 입방체 투영 매핑(cubical projection mapping), 피라미드 투영 매핑(pyramid projection mapping) 또는 정방형 투영 매핑(equirectangular projection mapping))에 따라 생성된 직사각형 컬러 이미지들의 시퀀스로서 스트림으로 인코딩될 수 있다. 이러한 인코딩은 표준 이미지 및 비디오 처리 표준들을 이용하는 장점이 있다. 3DoF+ 및 6Dof 비디오들은 포인트 클라우드들의 컬러 포인트들의 깊이를 인코딩할 추가 데이터를 필요로 한다. 볼류메트릭 장면에 대한 렌더링의 종류(즉, 3DoF 또는 볼류메트릭 렌더링)는 장면을 스트림으로 인코딩할 때 선험적으로 알고 있지 않다. 현재까지 스트림들은 한 종류의 렌더링 또는 다른 렌더링으로 인코딩된다. 한 번에 인코딩되고 3DoF 비디오로서 또는 볼류메트릭 비디오(3DoF+ 또는 6DoF)로서 디코딩될 수 있는 볼류메트릭 장면을 나타내는 데이터를 반송할 수 있는 스트림 및, 연관된 방법들과 디바이스들은 없다.
본 명세서에서 "일 실시예", "실시예", "예시적 실시예", "특정 실시예"라는 언급들은 설명된 실시예가 특정 특징, 구조 또는 특성을 포함할 수 있지만, 모든 실시예가 반드시 특정 특징, 구조 또는 특성을 포함하지 않을 수 있다는 것을 시사한다. 더욱이, 그러한 문구들이 반드시 동일한 실시예를 언급하는 것은 아니다. 또한, 특정 특징, 구조 또는 특성이 실시예와 관련하여 설명될 때, 명시적으로 설명되든지에 관계없이 다른 실시예들과 관련하여 그러한 특징, 구조 또는 특성에 영향을 미치는 것은 관련 기술분야의 통상의 기술자의 지식 범위 내에 있다고 생각된다.
본 개시내용은 3D 장면을 나타내는 데이터를 컨테이너(container)로 인코딩하는 방법에 관한 것으로, 방법은,
- 제1 뷰 포인트에 따라 보이는 3D 장면의 텍스처를 나타내는 제1 데이터를 컨테이너의 제1 비디오 트랙으로 인코딩하는 단계;
- 제1 뷰 포인트를 포함하는 한 세트의 뷰 포인트들에 따라 보이는 3D 장면의 지오메트리를 나타내는 제2 데이터를 컨테이너의 적어도 제2 비디오 트랙으로 인코딩하는 단계;
- 제1 뷰 포인트를 제외한 세트의 뷰 포인트들로부터만 보이는 3D 장면의 텍스처를 나타내는 제3 데이터를 컨테이너의 제3 비디오 트랙으로 인코딩하는 단계; 및
- 메타데이터를 컨테이너의 제4 트랙으로 인코딩하는 단계를 포함하고, 메타데이터는 제1 비디오 트랙의 제1 데이터, 적어도 제2 비디오 트랙의 제2 데이터 및 제3 비디오 트랙의 제3 데이터와 연관되고, 메타데이터는 제2 및 제3 데이터를 획득하기 위해 사용된 적어도 투영을 나타내는 정보를 포함한다.
본 개시내용은 3D 장면을 나타내는 데이터를 컨테이너로 인코딩하도록 구성된 디바이스에 관한 것으로, 디바이스는 적어도 하나의 프로세서와 연관된 메모리를 포함하고, 적어도 하나의 프로세서는,
- 제1 뷰 포인트에 따라 보이는 3D 장면의 텍스처를 나타내는 제1 데이터를 컨테이너의 제1 비디오 트랙으로 인코딩하고;
- 제1 뷰 포인트를 포함하는 한 세트의 뷰 포인트들에 따라 보이는 3D 장면의 지오메트리를 나타내는 제2 데이터를 컨테이너의 적어도 제2 비디오 트랙으로 인코딩하고;
- 제1 뷰 포인트를 제외한 세트의 뷰 포인트들로부터만 보이는 3D 장면의 텍스처를 나타내는 제3 데이터를 컨테이너의 제3 비디오 트랙으로 인코딩하고;
- 메타데이터를 컨테이너의 제4 트랙으로 인코딩하도록 구성되고, 메타데이터는 제1 비디오 트랙의 제1 데이터, 적어도 제2 비디오 트랙의 제2 데이터 및 제3 비디오 트랙의 제3 데이터와 연관되고, 메타데이터는 제2 및 제3 데이터를 획득하기 위해 사용된 적어도 투영을 나타내는 정보를 포함한다.
본 개시내용은 3D 장면을 나타내는 데이터를 컨테이너로 인코딩하도록 구성된 디바이스에 관한 것으로, 디바이스는,
- 제1 뷰포인트에 따라 보이는 3D 장면의 텍스처를 나타내는 제1 데이터를 컨테이너의 제1 비디오 트랙으로 인코딩하도록 구성된 인코더;
- 제1 뷰 포인트를 포함하는 한 세트의 뷰 포인트들에 따라 보이는 3D 장면의 지오메트리를 나타내는 제2 데이터를 컨테이너의 적어도 제2 비디오 트랙으로 인코딩하도록 구성된 인코더;
- 제1 뷰 포인트를 제외한 세트의 뷰 포인트들로부터만 보이는 3D 장면의 텍스처를 나타내는 제3 데이터를 컨테이너의 제3 비디오 트랙으로 인코딩하도록 구성된 인코더;
- 메타데이터를 컨테이너의 제4 트랙으로 인코딩하도록 구성된 인코더를 포함하고, 메타데이터는 제1 비디오 트랙의 제1 데이터, 적어도 제2 비디오 트랙의 제2 데이터 및 제3 비디오 트랙의 제3 데이터와 연관되고, 메타데이터는 제2 및 제3 데이터를 획득하기 위해 사용된 적어도 투영을 나타내는 정보를 포함한다.
본 개시내용은 3D 장면을 나타내는 데이터를 컨테이너로 인코딩하도록 구성된 디바이스에 관한 것으로, 디바이스는,
- 제1 뷰 포인트에 따라 보이는 3D 장면의 텍스처를 나타내는 제1 데이터를 컨테이너의 제1 비디오 트랙으로 인코딩하기 위한 수단;
- 제1 뷰 포인트를 포함하는 한 세트의 뷰 포인트들에 따라 보이는 3D 장면의 지오메트리를 나타내는 제2 데이터를 컨테이너의 적어도 제2 비디오 트랙으로 인코딩하기 위한 수단;
- 제1 뷰 포인트를 제외한 세트의 뷰 포인트들로부터만 보이는 3D 장면의 텍스처를 나타내는 제3 데이터를 컨테이너의 제3 비디오 트랙으로 인코딩하기 위한 수단; 및
- 메타데이터를 컨테이너의 제4 트랙으로 인코딩하기 위한 수단을 포함하고, 메타데이터는 제1 비디오 트랙의 제1 데이터, 적어도 제2 비디오 트랙의 제2 데이터 및 제3 비디오 트랙의 제3 데이터와 연관되고, 메타데이터는 제2 및 제3 데이터를 획득하기 위해 사용된 적어도 투영을 나타내는 정보를 포함한다.
본 개시내용은 컨테이너로부터 3D 장면을 나타내는 데이터를 디코딩하는 방법에 관한 것으로, 방법은,
- 컨테이너의 제1 비디오 트랙으로부터, 제1 뷰 포인트에 따라 보이는 3D 장면의 텍스처를 나타내는 제1 데이터를 디코딩하는 단계;
- 컨테이너의 적어도 제2 비디오 트랙으로부터, 제1 뷰 포인트를 포함하는 한 세트의 뷰 포인트들에 따라 보이는 3D 장면의 지오메트리를 나타내는 제2 데이터를 디코딩하는 단계;
- 컨테이너의 제3 비디오 트랙으로부터, 제1 뷰 포인트를 제외한 세트의 뷰 포인트들로부터만 보이는 3D 장면의 텍스처를 나타내는 제3 데이터를 디코딩하는 단계; 및
- 컨테이너의 제4 트랙으로부터 메타데이터를 디코딩하는 단계를 포함하고, 상기 메타데이터는 제1 비디오 트랙의 제1 데이터, 적어도 제2 비디오 트랙의 제2 데이터 및 제3 비디오 트랙의 제3 데이터와 연관되고, 상기 메타데이터는 제2 및 제3 데이터를 획득하기 위해 사용된 적어도 투영을 나타내는 정보를 포함한다.
본 개시내용은 컨테이너로부터 3D 장면을 나타내는 데이터를 디코딩하도록 구성된 디바이스에 관한 것으로, 디바이스는 적어도 하나의 프로세서와 연관된 메모리를 포함하고, 적어도 하나의 프로세서는,
- 컨테이너의 제1 비디오 트랙으로부터, 제1 뷰 포인트에 따라 보이는 3D 장면의 텍스처를 나타내는 제1 데이터를 디코딩하고;
- 컨테이너의 적어도 제2 비디오 트랙으로부터, 제1 뷰 포인트를 포함하는 한 세트의 뷰 포인트들에 따라 보이는 3D 장면의 지오메트리를 나타내는 제2 데이터를 디코딩하고;
- 컨테이너의 제3 비디오 트랙으로부터, 제1 뷰 포인트를 제외한 세트의 뷰 포인트들로부터만 보이는 3D 장면의 텍스처를 나타내는 제3 데이터를 디코딩하고;
- 컨테이너의 제4 트랙으로부터 메타데이터를 디코딩하도록 구성되고, 상기 메타데이터는 제1 비디오 트랙의 제1 데이터, 적어도 제2 비디오 트랙의 제2 데이터 및 제3 비디오 트랙의 제3 데이터와 연관되고, 상기 메타데이터는 제2 및 제3 데이터를 획득하기 위해 사용된 적어도 투영을 나타내는 정보를 포함한다.
본 개시내용은 컨테이너로부터 3D 장면을 나타내는 데이터를 디코딩하도록 구성된 디바이스에 관한 것으로, 디바이스는,
- 컨테이너의 제1 비디오 트랙으로부터, 제1 뷰 포인트에 따라 보이는 3D 장면의 텍스처를 나타내는 제1 데이터를 디코딩하도록 구성된 디코더;
- 컨테이너의 적어도 제2 비디오 트랙으로부터, 제1 뷰 포인트를 포함하는 한 세트의 뷰 포인트들에 따라 보이는 3D 장면의 지오메트리를 나타내는 제2 데이터를 디코딩하도록 구성된 디코더;
- 컨테이너의 제3 비디오 트랙으로부터, 제1 뷰 포인트를 제외한 세트의 뷰 포인트들로부터만 보이는 3D 장면의 텍스처를 나타내는 제3 데이터를 디코딩하도록 구성된 디코더; 및
- 컨테이너의 제4 트랙으로부터 메타데이터를 디코딩하도록 구성된 디코더를 포함하고, 상기 메타데이터는 제1 비디오 트랙의 제1 데이터, 적어도 제2 비디오 트랙의 제2 데이터 및 제3 비디오 트랙의 제3 데이터와 연관되고, 상기 메타데이터는 제2 및 제3 데이터를 획득하기 위해 사용된 적어도 투영을 나타내는 정보를 포함한다.
본 개시내용은 컨테이너로부터 3D 장면을 나타내는 데이터를 디코딩하도록 구성된 디바이스에 관한 것으로, 디바이스는,
- 컨테이너의 제1 비디오 트랙으로부터, 제1 뷰 포인트에 따라 보이는 3D 장면의 텍스처를 나타내는 제1 데이터를 디코딩하기 위한 수단;
- 컨테이너의 적어도 제2 비디오 트랙으로부터, 제1 뷰 포인트를 포함하는 한 세트의 뷰 포인트들에 따라 보이는 3D 장면의 지오메트리를 나타내는 제2 데이터를 디코딩하기 위한 수단;
- 컨테이너의 제3 비디오 트랙으로부터, 제1 뷰 포인트를 제외한 세트의 뷰 포인트들로부터만 보이는 3D 장면의 텍스처를 나타내는 제3 데이터를 디코딩하기 위한 수단; 및
- 컨테이너의 제4 트랙으로부터 메타데이터를 디코딩하기 위한 수단을 포함하고, 상기 메타데이터는 제1 비디오 트랙의 제1 데이터, 적어도 제2 비디오 트랙의 제2 데이터 및 제3 비디오 트랙의 제3 데이터와 연관되고, 상기 메타데이터는 제2 및 제3 데이터를 획득하기 위해 사용된 적어도 투영을 나타내는 정보를 포함한다.
특정 특성에 따르면, 제1 비디오 트랙은 비트스트림의 제1 신택스 요소를 참조하고, 적어도 제2 비디오 트랙은 비트스트림의 적어도 제2 신택스 요소를 참조하고, 제3 비디오 트랙은 비트스트림의 제3 신택스 요소를 참조한다.
특정 특성에 따르면, 제2 데이터는 지오메트리를 획득하기 위해 사용된 투영의 포맷, 투영의 파라미터들 및 투영 파라미터들 중 적어도 일부가 동적으로 업데이트되는지를 표시하는 플래그를 나타내는 제1 정보를 포함한다.
다른 특성에 따르면, 제3 데이터는 텍스처를 획득하기 위해 사용된 투영의 포맷, 투영의 파라미터들 및 투영 파라미터들 중 적어도 일부가 동적으로 업데이트되는지를 표시하는 플래그를 나타내는 제2 정보를 포함한다.
다른 특성에 따르면, 제1 정보 및 제2 정보가 동일할 때 제1 비디오 트랙 및 적어도 제2 비디오 트랙은 동일한 트랙 그룹으로 그룹화된다.
특정 특성에 따르면, 메타데이터는 다음과 같은 정보,
- 지오메트리 및 텍스처를 획득하기 위해 사용되는 적어도 하나의 투영과 연관된 적어도 하나의 뷰 포인트를 나타내는 정보;
- 지오메트리의 직사각형 2D 패치들의 패킹을 나타내는 정보 - 지오메트리의 각각의 패치는 3D 장면의 한 부분의 투영과 연관됨 -;- 텍스처의 직사각형 2D 패치들의 패킹을 나타내는 정보 -텍스처의 각각의 패치는 3D 장면의 한 부분의 투영과 연관됨 -;
- 다수의 3D 패치들을 나타내는 정보 - 각각의 3D 패치는 3D 장면의 한 부분과 연관되고 제2 트랙 및 제1 비디오 트랙 내 또는 제3 비디오 트랙 내의 식별자와 연관됨 - 중 적어도 하나를 포함한다.
본 개시내용은 또한 3D 장면을 나타내는 데이터를 반송하는 비트스트림에 관한 것으로, 데이터는, 컨테이너의 제1 비디오 트랙 내의, 제1 뷰 포인트에 따라 보이는 3D 장면의 텍스처를 나타내는 제1 데이터; 컨테이너의 적어도 제2 비디오 트랙 내의, 제1 뷰 포인트를 포함하는 한 세트의 뷰 포인트들에 따라 보이는 3D 장면의 지오메트리를 나타내는 제2 데이터; 컨테이너의 제3 비디오 트랙 내의, 제1 뷰 포인트를 제외한 세트의 뷰 포인트들로부터만 보이는 3D 장면의 텍스처를 나타내는 제3 데이터; 및 컨테이너의 제4 트랙 내의 메타데이터를 포함하고, 메타데이터는 제1 비디오 트랙의 제1 데이터, 적어도 제2 비디오 트랙의 제2 데이터 및 제3 비디오 트랙의 제3 데이터와 연관되고, 메타데이터는 제2 및 제3 데이터를 획득하기 위해 사용된 적어도 투영을 나타내는 정보를 포함한다.
본 개시내용은 또한 이러한 프로그램이 컴퓨터 상에서 실행될 때, 3D 장면을 나타내는 데이터를 인코딩 또는 디코딩하는 방법의 단계들을 실행하는 프로그램 코드 명령어들을 포함하는 컴퓨터 프로그램 제품에 관한 것이다.
본 개시내용은 또한 프로세서로 하여금 3D 장면을 나타내는 데이터를 인코딩 또는 디코딩하는 적어도 위에서 언급한 방법을 수행하게 하는 명령어들이 저장된 (비일시적) 프로세서 판독 가능 매체에 관한 것이다.
본 개시내용은 더 잘 이해될 것이고, 첨부 도면을 참조하여 다음의 설명을 읽을 때 다른 특정 특징 및 장점이 나타날 것이며, 설명은 첨부 도면들을 참조하여 설명된다.
- 도 1은 본 원리들의 비제한적 실시예에 따라, 물체의 3 차원(three-dimension)(3D) 모델 및 3D 모델에 대응하는 포인트 클라우드의 포인트들을 도시한다.
- 도 2는 본 원리들의 비제한적 실시예에 따라, 여러 물체의 표면 표현을 포함하는 3 차원 장면을 나타내는 이미지를 도시한다.
- 도 3은 본 원리들의 비제한적 실시예에 따라, 도 2의 장면상의 뷰 포인트들의 예시적인 배열 및 이러한 배열의 상이한 뷰 포인트들로부터 이러한 장면의 가시 포인트들을 도시한다.
- 도 4는 본 원리들의 비제한적 실시예에 따라, 도 3의 뷰 포인트에 따라 도 2의 장면의 상이한 뷰들을 보여줌으로써 시차 경험을 도시한다.
- 도 5는 본 원리들의 비제한적 실시예에 따라, 정방형 투영 매핑에 따라 도 3의 뷰 포인트로부터 보이는 도 2의 장면의 포인트들의 텍스처 이미지를 도시한다.
- 도 6은 본 원리들의 비제한적 실시예에 따라, 입방체 투영 매핑에 따라 인코딩된 도 5에서와 같은 장면의 동일한 포인트들의 이미지를 도시한다.
- 도 7은 본 원리들의 비제한적 실시예에 따라, 도 3의 뷰 포인트에 따라 도 2의 3D 장면의 깊이 이미지(깊이 맵이라고도 함)를 도시한다.
- 도 8a 및 도 8b는 본 원리들의 비제한적 실시예에 따라, 도 5의 텍스처 맵 상에 투영된 장면의 포인트들에 대한 깊이 패치 아틀라스의 한 부분을 도시한다.
- 도 9는 본 원리들의 비제한적 실시예에 따라, 도 5 또는 도 6의 이미지의 인코딩 후에 패치들로서 잔차 포인트(residual point)들의 인코딩을 도시한다.
- 도 10은 본 원리들의 비제한적 실시예에 따라, 동시에 3DoF 렌더링 호환 가능하고 3DoF+ 렌더링 호환 가능한 포맷으로 3D 장면의 시퀀스를 인코딩, 송신 및 디코딩하는 예를 도시한다.
- 도 11은 본 원리들의 비제한적 실시예에 따라, 도 2의 3D 장면을 나타내는 데이터를 획득, 인코딩 및/또는 포맷팅하는 프로세스를 도시한다.
- 도 12는 본 원리들의 비제한적 실시예에 따라, 도 2의 3D 장면을 디코딩하고 렌더링하는 프로세스를 도시한다.
- 도 13은 본 원리들의 비제한적 실시예에 따라, 도 2의 3D 장면을 나타내는 정보를 포함하는 컨테이너의 예를 도시한다.
- 도 14는 본 원리들의 비제한적 실시예에 따라, 도 2의 3D 장면을 나타내는 정보 및 데이터를 반송하는 비트스트림의 신택스의 예를 도시한다.
- 도 15는 본 원리들의 비제한적 실시예에 따라, 도 11, 도 12, 도 16 및/또는 도 17과 관련하여 설명되는 방법을 구현하도록 구성될 수 있는 디바이스의 예시적인 아키텍처를 도시한다.
- 도 16은 본 원리들의 비제한적 실시예에 따라, 예를 들어 도 15의 디바이스에서 구현된, 도 2의 3D 장면을 나타내는 데이터를 인코딩하기 위한 방법을 도시한다.
- 도 17은 본 원리들의 비제한적 실시예에 따라, 예를 들어 도 15의 디바이스에서 구현된, 도 2의 3D 장면을 나타내는 데이터를 디코딩하기 위한 방법을 도시한다.
- 도 1은 본 원리들의 비제한적 실시예에 따라, 물체의 3 차원(three-dimension)(3D) 모델 및 3D 모델에 대응하는 포인트 클라우드의 포인트들을 도시한다.
- 도 2는 본 원리들의 비제한적 실시예에 따라, 여러 물체의 표면 표현을 포함하는 3 차원 장면을 나타내는 이미지를 도시한다.
- 도 3은 본 원리들의 비제한적 실시예에 따라, 도 2의 장면상의 뷰 포인트들의 예시적인 배열 및 이러한 배열의 상이한 뷰 포인트들로부터 이러한 장면의 가시 포인트들을 도시한다.
- 도 4는 본 원리들의 비제한적 실시예에 따라, 도 3의 뷰 포인트에 따라 도 2의 장면의 상이한 뷰들을 보여줌으로써 시차 경험을 도시한다.
- 도 5는 본 원리들의 비제한적 실시예에 따라, 정방형 투영 매핑에 따라 도 3의 뷰 포인트로부터 보이는 도 2의 장면의 포인트들의 텍스처 이미지를 도시한다.
- 도 6은 본 원리들의 비제한적 실시예에 따라, 입방체 투영 매핑에 따라 인코딩된 도 5에서와 같은 장면의 동일한 포인트들의 이미지를 도시한다.
- 도 7은 본 원리들의 비제한적 실시예에 따라, 도 3의 뷰 포인트에 따라 도 2의 3D 장면의 깊이 이미지(깊이 맵이라고도 함)를 도시한다.
- 도 8a 및 도 8b는 본 원리들의 비제한적 실시예에 따라, 도 5의 텍스처 맵 상에 투영된 장면의 포인트들에 대한 깊이 패치 아틀라스의 한 부분을 도시한다.
- 도 9는 본 원리들의 비제한적 실시예에 따라, 도 5 또는 도 6의 이미지의 인코딩 후에 패치들로서 잔차 포인트(residual point)들의 인코딩을 도시한다.
- 도 10은 본 원리들의 비제한적 실시예에 따라, 동시에 3DoF 렌더링 호환 가능하고 3DoF+ 렌더링 호환 가능한 포맷으로 3D 장면의 시퀀스를 인코딩, 송신 및 디코딩하는 예를 도시한다.
- 도 11은 본 원리들의 비제한적 실시예에 따라, 도 2의 3D 장면을 나타내는 데이터를 획득, 인코딩 및/또는 포맷팅하는 프로세스를 도시한다.
- 도 12는 본 원리들의 비제한적 실시예에 따라, 도 2의 3D 장면을 디코딩하고 렌더링하는 프로세스를 도시한다.
- 도 13은 본 원리들의 비제한적 실시예에 따라, 도 2의 3D 장면을 나타내는 정보를 포함하는 컨테이너의 예를 도시한다.
- 도 14는 본 원리들의 비제한적 실시예에 따라, 도 2의 3D 장면을 나타내는 정보 및 데이터를 반송하는 비트스트림의 신택스의 예를 도시한다.
- 도 15는 본 원리들의 비제한적 실시예에 따라, 도 11, 도 12, 도 16 및/또는 도 17과 관련하여 설명되는 방법을 구현하도록 구성될 수 있는 디바이스의 예시적인 아키텍처를 도시한다.
- 도 16은 본 원리들의 비제한적 실시예에 따라, 예를 들어 도 15의 디바이스에서 구현된, 도 2의 3D 장면을 나타내는 데이터를 인코딩하기 위한 방법을 도시한다.
- 도 17은 본 원리들의 비제한적 실시예에 따라, 예를 들어 도 15의 디바이스에서 구현된, 도 2의 3D 장면을 나타내는 데이터를 디코딩하기 위한 방법을 도시한다.
이제 본 주제가 도면을 참조하여 설명되며, 도면에서 유사한 참조 부호들은 전체에 걸쳐 유사한 요소들을 지칭하는데 사용된다. 다음의 설명에서, 설명 목적을 위해, 본 주제의 철저한 이해를 제공하기 위해 많은 특정 세부 사항이 제시된다. 그러나, 본 주제 실시예들은 이러한 특정 세부 사항들 없이 실시될 수 있음이 명백할 수 있다.
본 설명은 본 개시내용의 원리들을 예시한다. 따라서, 본 명세서에서 명시적으로 설명되거나 도시되지 않았지만, 관련 기술분야의 통상의 기술자가 본 개시내용의 원리들을 구현하고 그 범위 내에 포함되는 다양한 배열을 고안할 수 있다는 것이 인식될 것이다.
본 개시내용의 비제한적 실시예에 따르면, 컨테이너 및/또는 비트스트림 내의 볼류메트릭 비디오(3DoF+ 또는 6DoF 비디오라고도 함)의 이미지들을 인코딩하는 방법들 및 디바이스들이 개시된다. 스트림으로부터 볼류메트릭 비디오의 이미지들을 디코딩하는 방법들 및 디바이스들이 또한 개시된다. 볼류메트릭 비디오의 하나 이상의 이미지의 인코딩을 위한 비트스트림의 신택스의 예들이 또한 개시된다.
제1 양태에 따르면, 본 원리들은 (몰입형 비디오라고도 불리는 전방향성 콘텐츠로 표현된) 3D 장면을 나타내는 데이터를 컨테이너 및/또는 비트스트림으로 인코딩하는 방법 (및 인코딩하기 위해 구성된 디바이스)의 제1 특정 실시예를 참조하여 설명될 것이다. 그 목표에 도달하기 위해, 제1 뷰 포인트에 따라 보이는 3D 장면의 텍스처(예를 들어, 3D 장면의 요소들, 예를 들어 포인트들과 연관된 컬러 정보)를 나타내는 제1 데이터가 컨테이너의 제1 비디오 트랙에 인코딩된다. 뷰 포인트들의 세트 또는 범위에 따라 보이는 3D 장면의 지오메트리를 나타내는 제2 데이터는 컨테이너의 제2 비디오 트랙으로 인코딩되고, 뷰 포인트들의 세트는 제1 뷰 포인트를 포함한다(예를 들어 제1 뷰 포인트가 중심이 된다). 3D 장면의 텍스처를 나타내는 제3 데이터는 또한 컨테이너의 제3 비디오 트랙에 인코딩된다. 제3 데이터는 예를 들어 동일한 정보를 두 번(즉, 제1 비디오 트랙으로 한 번 및 제3 비디오 트랙으로 한 번) 인코딩하지 않도록 하기 위해 제1 뷰 포인트에 따라 보이는 장면의 부분을 제외하고, 뷰 포인트들의 세트의 뷰 포인트들로부터 보이는 3D 장면의 부분들과 연관된 텍스처 정보에 대응한다. 메타데이터는 컨테이너의 제4 트랙으로 인코딩되며, 메타데이터는 제2 데이터 및 제3 데이터를 획득하는데 사용된 하나 이상의 투영을 나타내는 정보(예를 들어, 파라미터들)를 포함한다.
3D 장면을 나타내는 데이터를 디코딩하는 대응하는 방법(및 디코딩을 위해 구성된 디바이스)이 또한 본 원리들의 제1 양태와 관련하여 설명된다.
도 1은 물체의 3 차원(3D) 모델(10) 및 3D 모델(10)에 대응하는 포인트 클라우드의 포인트들(11)을 도시한다. 모델(10)은 3D 메시 표현일 수 있고 포인트 클라우드의 포인트들(11)은 메시의 정점들일 수 있다. 포인트들(11)은 또한 메시의 면들의 표면상에 펼쳐진 포인트들일 수 있다. 모델(10)은 또한 클라우드의 포인트(11)를 뿌린 버전으로 표현될 수 있으며; 모델(10)의 표면은 클라우드 포인트(11)의 포인트를 뿌려서 생성된다. 모델(10)은 복셀(voxel)들 또는 스플라인(spline)들과 같은 많은 표현으로 나타낼 수 있다. 도 1은 3D 물체의 표면 표현으로부터 포인트 클라우드를 정의하는 것이 항상 가능하고 클라우드의 포인트로부터 3D 물체의 표면 표현을 반복적으로 생성하는 것이 항상 가능하다는 사실을 보여준다. 본 명세서에 사용되는 바와 같이, (3D 장면의 확장 포인트들에 의해) 3D 물체의 포인트들을 이미지로 투영하는 것은 이러한 3D 물체의 임의의 표현을 물체에 투영하는 것과 동등하다.
포인트 클라우드는 벡터 기반 구조로 보일 수 있으며, 여기서 각각의 포인트는 그의 좌표들(예를 들어, 3 차원 좌표들(XYZ) 또는 주어진 뷰 포인트로부터의 깊이/거리) 및 컴포넌트라고도 하는 하나 이상의 속성을 갖는다. 컴포넌트의 예는 상이한 컬러 공간들, 예를 들어 RGB(적색(Red), 녹색(Green) 및 청색(Blue)) 또는 YUV(Y는 루마 컴포넌트이고 UV는 두 개의 색차 컴포넌트임)로 나타낼 수 있는 컬러 컴포넌트이다. 포인트 클라우드는 주어진 뷰 포인트 또는 뷰 포인트들의 범위로부터 보이는 것과 같은 물체의 표현이다. 포인트 클라우드는 상이한 방법들로, 예를 들면,
● 깊이 활성 감지 디바이스(depth active sensing device)에 의해 임의로 보완되는 카메라들의 리그(rig)에 의해 촬영된 실제 물체의 캡처로부터;
● 모델링 툴에서 가상 카메라들의 리그에 의해 촬영된 가상/합성 물체의 캡처로부터;
● 실제 물체와 가상 물체 둘 모두의 혼합으로부터 획득될 수 있다.
도 2는 여러 물체의 표면 표현을 포함하는 3 차원 장면을 나타내는 이미지(20)를 도시한다. 장면은 임의의 적합한 기술을 사용하여 캡처되었을 수 있다. 예를 들어, 이것은 컴퓨터 그래픽 인터페이스(computer graphics interface)(CGI) 도구들을 사용하여 생성되었을 수 있다. 이것은 컬러 이미지 및 깊이 이미지 획득 디바이스들에 의해 캡처되었을 수 있다. 그러한 경우, 획득 디바이스들(예를 들어 카메라들)로부터 보이지 않는 물체들의 일부가 도 3, 도 8a 및 도 8b와 관련하여 설명되는 바와 같이 장면에서 표현되지 않을 수 있다. 도 2에 도시된 예시적인 장면은 주택들, 두 개의 캐릭터 및 우물을 포함한다. 도 2의 큐브(33)는 사용자가 3D 장면을 관찰할 가능성 있는 뷰 공간(space of view)을 예시한다.
도 3은 장면, 예를 들어 도 2의 3D 장면(20) 상의 뷰 포인트들의 예시적인 배열을 도시한다. 도 3은 또한 이러한 배열의 상이한 뷰 포인트들로부터/상이한 뷰 포인트들에 따라 보이는 이러한 3D 장면(20)의 포인트들을 도시한다. 몰입형 렌더링 디바이스(예를 들어, 케이브(cave) 또는 머리-장착 디스플레이 디바이스(HMD))에 의해 렌더링되고 디스플레이되기 위해, 3D 장면은 제1 뷰 포인트, 예를 들어 제1 뷰 포인트(30)로부터 고려된다. 제1 뷰 포인트(30)와 장면 포인트(31) 사이에 아무런 불투명한 물체가 놓여 있지 않기 때문에, 제1 캐릭터의 오른쪽 팔꿈치에 대응하는 장면의 포인트(31)는 제1 뷰 포인트(30)에서 보인다. 반대로, 예를 들어 제2 캐릭터의 왼쪽 팔꿈치에 대응하는 3D 장면(20)의 포인트(32)는 제1 캐릭터의 포인트들에 의해 가려 있으므로 제1 뷰 포인트(30)로부터 보이지 않는다. 3DoF 렌더링을 위해, 하나의 뷰 포인트, 예를 들어 제1 뷰 포인트(30)만 고려된다. 사용자는 3D 장면의 상이한 부분들을 시청하기 위해 그의 머리를 제1 뷰 포인트를 중심으로 3 자유도로 회전시킬 수 있지만, 사용자는 제1 뷰 포인트를 이동시킬 수는 없다. 스트림으로 인코딩될 장면의 포인트들은 이러한 제1 뷰 포인트로부터 보이는 포인트들이다. 이러한 제1 뷰 포인트로부터 보이지 않는 장면의 포인트들을 인코딩할 필요가 없는데, 왜냐하면 사용자가 제1 뷰 포인트를 이동시켜 이들 포인트에 액세스할 수 없기 때문이다.
6DoF 렌더링과 관련하여, 사용자는 장면의 어느 곳이든 뷰 포인트를 이동시킬 수 있다. 이 경우, 자신의 뷰 포인트를 이동시킬 수 있는 사용자에 의해 모든 포인트가 잠재적으로 액세스 가능하므로 콘텐츠 스트림 내 장면의 모든 포인트를 인코딩한다는 것이 값진 것이다. 인코딩 단계에서, 사용자가 어느 뷰 포인트에서 3D 장면(20)을 관찰할 것인지를 선험적으로 알게 하는 수단이 없다.
3DoF+ 렌더링과 관련하여, 사용자는 뷰 포인트를 중심으로, 예를 들어 제1 뷰 포인트(30)를 중심으로 제한된 공간 내에서 뷰 포인트를 이동시킬 수 있다. 예를 들어, 사용자는 제1 뷰 포인트(30)에 중심을 둔 큐브(33) 내에서 자신의 뷰 포인트를 이동시킬 수 있다. 이것은 도 4와 관련하여 예시된 바와 같은 시차를 경험할 수 있게 한다. 뷰 공간의 임의의 포인트, 예를 들어 큐브(33)로부터 보이는 장면의 부분을 나타내는 데이터는, 제1 뷰 포인트(30)에 따라 보이는 3D 장면을 나타내는 데이터를 포함하는, 스트림으로 인코딩되어야 한다. 뷰 공간의 크기 및 형상은 예를 들어 인코딩 단계에서 판단 및 결정되고 스트림으로 인코딩될 수 있다. 디코더는 이들 정보를 스트림으로부터 획득하고 렌더러는 뷰 공간을 획득된 정보에 의해 결정된 공간으로 제한한다. 다른 예에 따르면, 렌더러는 예를 들어 사용자의 움직임들을 검출하는 센서(들)의 능력들과 관련하여 하드웨어 제약들에 따라 뷰 공간을 결정한다. 그러한 경우에, 인코딩 단계에서, 렌더러의 뷰 공간 내의 포인트로부터 보이는 포인트가 데이터 스트림으로 인코딩되지 않았다면, 이 포인트는 렌더링되지 않을 것이다. 추가 예에 따르면, 3D 장면의 모든 포인트를 나타내는 데이터(예를 들면, 텍스처 및/또는 지오메트리)는 뷰 공간을 렌더링하는 것을 고려하지 않고 스트림으로 인코딩된다. 스트림의 크기를 최적화하기 위해, 장면의 포인트들의 서브세트만이, 예를 들면 뷰 공간을 렌더링함에 따라 보일 수 있는 포인트들의 서브세트만이 인코딩될 수 있다.
도 4는 볼류메트릭(즉, 3DoF+ 및 6DoF) 렌더링에 의해 가능해진 시차 경험을 도시한다. 도 4b는 사용자가 도 3의 제1 뷰 포인트(30)에서 볼 수 있는 장면의 일부를 도시한다. 이러한 제1 뷰 포인트로부터, 두 캐릭터는 주어진 공간 구성 내에 있는데, 예를 들어, (흰 셔츠와 함께) 제2 캐릭터의 왼쪽 팔꿈치는 그의 머리가 보이는 동안 제1 캐릭터의 몸에 가려져 있다. 사용자가 제1 뷰 포인트(30)를 중심으로 자신의 머리를 3 자유도로 회전시킬 때, 이 구성은 변하지 않는다. 뷰 포인트가 고정되면, 제2 캐릭터의 왼쪽 팔꿈치는 보이지 않는다. 도 4a는 도 3의 뷰 공간(33)의 좌측 편에서 뷰 포인트로부터 보이는 장면의 동일한 부분을 도시한다. 그러한 뷰 포인트로부터, 시차 효과로 인해 도 3의 포인트(32)가 보인다. 그러므로 볼류메트릭 렌더링을 위해, 포인트(32)는 스트림으로 인코딩되어야 한다. 인코딩되지 않으면, 이러한 포인트(32)는 렌더링되지 않을 것이다. 도 4c는 도 3의 뷰 공간(33)의 우측 편에 위치된 뷰 포인트에서 관찰된 장면의 동일한 부분을 도시한다. 이러한 뷰 포인트로부터, 제2 캐릭터는 제1 캐릭터에 의해 거의 전체가 가려진다.
3D 장면 내에서 뷰 포인트들 이동시킴으로써, 사용자는 시차 효과를 경험할 수 있다.
도 5는 도 3의 제1 뷰 포인트(30)로부터 보이는 3D 장면(20)의 포인트들의 텍스처 정보(예를 들어, RGB 데이터 또는 YUV 데이터)를 포함하는 텍스처 이미지(컬러 이미지라고도 함)를 도시하며, 이러한 텍스처 정보는 정방형 투영 매핑에 따라 획득된다. 정방형 투영 매핑은 구형 투영 매핑의 한 예이다.
도 6은 입방체 투영 매핑에 따라 획득된 또는 인코딩된 장면의 동일한 포인트들의 이미지를 도시한다. 상이한 입방체 투영 매핑이 있다. 예를 들어, 큐브의 면들은 도 6의 이미지에서 상이하게 배열될 수 있고 및/또는 면들은 상이하게 지향될 수 있다.
결정된 뷰 포인트로부터 보이는 장면의 포인트들을 획득하기 위해/인코딩하기 위해 사용되는 투영 매핑은 예를 들어 압축 기준에 따라 또는 예를 들어 표준 옵션에 따라 선택된다. 관련 기술분야의 통상의 기술자는 투영 매핑에 따라 포인트 클라우드의 투영에 의해 획득된 이미지를 상이한 투영 매핑에 따라 동일한 포인트 클라우드의 동등한 이미지로 변환하는 것이 항상 가능하다는 것을 알고 있다. 그럼에도 불구하고 그러한 변환은 투영의 해상도의 일부 손실을 의미할 수 있다.
도 5 및 도 6은 회색의 색조들로 도시된다. 이들 도면은 예를 들어, RGB 또는 YUV의 장면의 포인트들의 텍스처(컬러)를 인코딩하는 텍스처(컬러) 이미지들의 예들이라는 것이 당연히 이해된다. 도 5 및 도 6은 3D 장면의 3DoF 렌더링에 필요한 데이터를 포함한다. 신택스의 제1 요소에서, 이미지를 도 5 및 도 6의 예시적인 이미지로서 포함하는 비트스트림 또는 데이터 스트림을 수신하는 디코더는 이미지의 인코딩에 사용된 방법과 상관된 방법을 사용하여 이미지를 디코딩한다. 스트림은 표준 이미지 및 비디오 압축 방법들 및 이미지 및 비디오 전송을 위한 표준 포맷, 예를 들어 MPEG2, H.264 또는 HEVC에 따라 인코딩될 수 있다. 디코더는 디코딩된 이미지(또는 이미지들의 시퀀스)를 3DoF 렌더러 또는 예를 들면 재 포맷을 위한 모듈로 송신할 수 있다. 3DoF 렌더러는 인코딩에서 사용된 투영 매핑(예를 들어, 도 5의 이미지에 대한 구체, 도 6의 이미지에 대한 큐브)에 대응하는 표면상에 이미지를 투영한다. 변형예에서, 렌더러는 이미지를 투영하기 전에 상이한 투영 매핑에 따라 이미지를 변환한다.
이미지가 투영 매핑에 따라 3D 장면의 포인트들을 인코딩할 때 이미지는 3DoF 렌더링과 호환 가능하다. 장면은 360°에 있는 포인트들을 포함할 수 있다. 예를 들어 3DoF 렌더링과 호환 가능한 이미지들을 인코딩하는데 일반적으로 사용되는 투영 매핑들은, 구형 매핑들 중에서도 정방형 투영 또는 경도/위도 투영, 또는 상이한 레이아웃들의 입방체 투영 매핑들 또는 피라미드 투영 매핑들이다.
도 7은 제1 뷰 포인트(30)에 따른 3D 장면(20)의 깊이 이미지(깊이 맵이라고도 함)를 도시한다. 볼류메트릭 렌더링에는 깊이 정보가 필요하다. 도 7의 이미지의 예시적인 인코딩에서, 픽셀이 더 어두울수록, 포인트는 뷰 포인트로부터 이러한 픽셀에 더 가깝게 투영된다. 예를 들어, 깊이는 12 비트로 인코딩될 수 있는데, 즉 깊이는 0과 212-1=4095 사이의 정수로 표현된다. 예를 들어, 가장 가까운 포인트가 결정된 뷰 포인트로부터 1 미터에 위치되고, 가장 먼 포인트가 25 미터에 위치되면, 깊이의 선형 인코딩은 0,586 센티미터(=(2500-100)/4096)의 단계들로 수행될 것이다. 뷰 포인트로부터 먼 포인트의 깊이 값 부정확도가 뷰 포인트에 가까운 포인트에 대한 깊이 값 부정확도보다 덜 중요하므로 깊이는 또한 로그 스케일(logarithmic scale)에 따라 인코딩될 수 있다. 도 7의 예시적인 실시예에서, 뷰 포인트로부터 보이는 장면의 포인트들의 깊이는 도 5의 컬러 맵을 인코딩하는데 사용된 투영 매핑과 동일한 투영 매핑에 따라 깊이 맵으로 인코딩된다. 다른 실시예에서, 깊이는 상이한 투영 매핑에 따라 인코딩될 수 있다. 렌더러는 이러한 데이터로 인코딩된 장면의 포인트들을 역 투영하기 위해 깊이 맵 및/또는 컬러 이미지를 변환한다. 이러한 실시예는 깊이 부정확도를 증가시킬 수 있다.
다른 실시예에 따르면, 결정된 뷰 포인트, 예를 들어 도 3의 뷰 포인트(30)로부터 보이는 포인트들의 깊이는 패치 아틀라스로서 인코딩될 수 있다. 도 8a는 도 5의 컬러 맵(80)에 투영된 장면의 포인트들에 대한 깊이 패치 아틀라스(83)의 일부를 도시한다. 패치는 투영된 포인트들을 군집함으로써 획득된 픽처이다. 패치는 투영 맵에서 인접한 픽셀들의 영역을 정의하고 깊이 일관적인(depth consistent) 투영된 포인트들의 일부에 대응한다. 그 일부는 대응하는 투영된 포인트들이 뷰 포인트로부터 공간에서 차지하는 각도 범위로 정의된다. 패치들은 그들의 연결성 및 깊이에 따라 투영 맵에 군집된다. 영역(P)은 투영이 발생한 그리고 깊이 일관적인 투영 맵의 인접한 픽셀들의 세트가 점유한다. 깊이 일관성 검사는 뷰 포인트와 P에 의해 점유된 각각의 투영된 포인트 사이의 거리(Z)를 고려하고, 이러한 픽셀들의 거리 범위가 문턱치(T)보다 깊지 않음을 보장하는 것으로 귀결된다. 이러한 문턱치는 Zmax(관찰 포인트와 P에 의해 점유된 투영된 픽셀들 사이의 최대 거리), 추가 생성 동작에 의해 생성된 픽처에 저장된 깊이의 역학(D) 및 지각 특성들에 종속할 수 있다. 예를 들어, 전형적인 인간 시력은 호(arc)의 약 3 분(minute)이다. 이들 기준에 따라 문턱치(T)를 결정하는 것은 몇 가지 장점이 있다. 한편으로, 추가 생성 동작에서 생성된 픽처의 이미지 패치는 생성된 픽처의 픽셀들의 깊이 해상도(예를 들어, 10 비트 또는 12 비트)와 일관적인 깊이 범위를 점유할 것이고, 따라서 압축 아티팩트들에 강인하다. 다른 한편, 깊이 범위는 3DoF+ 맥락에 의해 지각적으로 주도된다. 실제로, 인간의 시력은 가까운 또는 먼 포인트들의 거리를 동등하게 인식하지 못한다. 예로서, 문턱치는 다음의 수학식 [수학식 1]에 따라 정의된다.
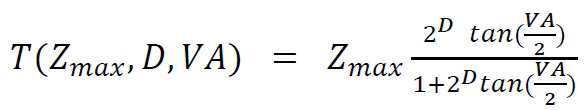
여기서 VA는 시력의 값이다.
예를 들어, 패치(81)는 제1 캐릭터의 왼쪽 팔에 대해 획득된다. 역학 범위의 2D 값들은 몇 데시미터의 짧은 거리를 인코딩하는데 사용되므로 장면의 투영된 포인트들의 부분의 깊이를 인코딩하는 것은 중요한 가치가 있어, 깊이 인코딩의 정밀도를 높이고 압축 아티팩트들에 대한 강인성을 높일 수 있다. 패치(82)는 한 쌍의 주택에 대해 획득된다. 인코딩할 깊이 범위는 더 크지만, 주택들은 뷰 포인트에서 멀리 있으므로 인코딩의 부정확도는 시각적 아티팩트들을 눈에 덜 띠게 한다. 그러나 장면의 이 부분에 대한 깊이 인코딩 정확도는 도 7의 깊이 맵과 비교하여 증가된다.
패치의 포인트들의 투영이 패치 아틀라스에서 차지할 크기에 따라, 패치들은 패치 아틀라스(83)라고 불리는 픽처(83) 내에서 주어진 각도 해상도(예를 들어, 픽셀 당 3 초 또는 픽셀 당 5 초)로 배열된다. 배열은 패치와 연관된 포인트들을 투영 (깊이 및 컬러)하기 위한 패치 아틀라스 내의 영역을 예약하는데 있다. 예약된 영역의 크기는 픽처 각도 해상도 및 패치의 각도 범위에 종속한다. 프레임에서 영역들의 위치는 겹치지 않고 픽처의 프레임을 점유하도록 최적화된다. 패치 데이터 아이템은 깊이 패치 아틀라스 내에 패킹된 깊이 패치를 컬러 이미지 내의 대응하는 컬러 픽셀 영역과 매핑하는 데이터를 포함한다. 예를 들어, 패치 데이터 아이템은 패치 아틀라스 내 패치의 좌측 위 코너의 좌표들, 패치 아틀라스 내 패치의 폭 및 높이, 컬러 이미지 내 대응하는 컬러 픽셀들의 좌측 위 코너, 대응하는 컬러 픽셀들의 컬러 이미지의 영역의 폭 및 높이를 포함한다. 변형예에서, 패치 데이터 아이템의 정보는, 예를 들어 구형 투영 매핑에 따라 인코딩된 컬러 이미지에서 국부화(localisation)를 용이하게 하기 위해 각도 범위 데이터로 표현된다.
주어진 (또는 결정된) 뷰 포인트로부터 보이는 포인트들은 3D 장면의 포인트들 중 일부이다. 3D 장면을 완전히 인코딩하기 위해, 잔차 포인트들(즉, 3DoF 호환 가능 컬러 이미지로 인코딩되지 않은 포인트 및 대응하는 깊이 데이터)이 스트림으로 인코딩된다. 도 9는 이러한 잔차 포인트들을 패치들로서 인코딩하는 것을 도시한다.
도 8b는 본 원리들의 다른 비제한적 예에 따른, 패치 아틀라스(patch atlas)(801) 상에 패킹된 3D 장면의 한 부분(예를 들어, 3D 장면(20)의 캐릭터 중 하나)의 패치들을 획득하는 것을 도시한다. 3D 물체(8)를 나타내는 포인트 클라우드는 복수의 3D 부분, 예를 들어 50, 100, 1000개 또는 그 이상의 3D 부분으로 분할되고, 그들 중 3개, 즉 3D 부분들(802, 803 및 804)이 도 8b에 도시되고, 3D 부분(804)은 사람의 머리 부분을 나타내는 포인트 클라우드의 포인트들을 포함하고, 3D 부분(802)은 사람의 겨드랑이를 나타내는 포인트 클라우드의 포인트들을 포함하며, 3D 부분(803)은 사람의 손을 나타내는 포인트 클라우드의 포인트들을 포함한다. 각각의 3D 부분 또는 3D 부분들 중 한 부분의 하나 이상의 패치는 각각의 3D 부분을 2개의 차원으로, 즉 2D 파라미터화(parametrization)에 따라, 나타내기 위해 생성된다. 예를 들어, 2D 파라미터화(8001)가 3D 부분(804)을 위해 획득되고, 2D 파라미터화(8002)가 3D 부분(802)을 위해 획득되며, 2개의 상이한 2D 파라미터화(8003 및 8004)가 3D 부분(803)을 위해 획득된다. 2D 파라미터화는 3D 부분마다 서로 다를 수 있다. 예를 들어, 3D 부분(801)과 연관된 2D 파라미터화(8001)는 선형 투시 투영(linear perspective projection)인 반면에, 3D 부분(802)과 연관된 2D 파라미터화(8002)는 LLE이고, 3D 부분(803)과 연관된 2D 파라미터화들(8003, 8004) 둘 모두는 상이한 뷰 포인트들에 따른 직교 투영(orthographic projection)들이다. 변형예에 따르면, 모든 3D 부분들과 연관된 모든 2D 파라미터화들은 동일한 유형, 예를 들어 선형 투시 투영 또는 직교 투영을 갖는다. 변형예에 따르면, 동일한 3D 부분에 대해 상이한 2D 파라미터화들이 사용될 수 있다.
포인트 클라우드의 하나의 주어진 3D 부분과 연관된 2D 파라미터화는 포인트 클라우드의 주어진 3D 부분을 2개의 차원으로 훑어 주어진 3D 부분을 샘플링할 수 있게 하는 것, 즉 (제1 이미지의 픽셀들에 대응할 수 있는) 복수의 샘플들 - 그 수는 적용되는 샘플링 단계에 따라 다름 - 을 포함하는 이러한 주어진 3D 부분의 콘텐츠(즉, 포인트(들))의 2D 표현에 대응할 수 있다. 2D 파라미터화는 다양한 방식으로, 예를 들어 다음의 방법들 중 어느 하나를 구현함으로써 획득될 수 있다:
- 포인트 클라우드의 3D 부분의 포인트들을 뷰 포인트와 연관된 평면상에 선형 투시 투영하는 방법 - 선형 투시 투영을 나타내는 파라미터들은 가상 카메라의 위치, 공간 샘플링 단계 및 2개 차원의 시야각을 포함함 -;
- 포인트 클라우드의 3D 부분의 포인트들을 표면 상에 직교 투영하는 방법 - 직교 투영을 나타내는 파라미터들은 투영 표면의 지오메트리(형상, 크기 및 방향) 및 공간 샘플링 단계를 포함함 -;
- 3D에서 2D로의 전환/변환에 여기서 적용되는 차원 축소(dimension reduction)의 수학 연산에 대응하는 LLE(Locally-Linear Embedding) - LLE를 나타내는 파라미터들은 변환 계수들을 포함함.
각각의 패치는 패치 아틀라스(801)에 대한 패킹 프로세스를 용이하게 하기 위해 유리하게 직사각형 형상을 갖는다. 패치 아틀라스(801)는 지오메트리 패치 아틀라스, 즉 (예를 들어, 픽셀들의 어레이로 보일 수 있는) 상이한 패치들(8011, 8012, 8014)을 포함하는 픽셀들의 픽처일 수 있으며, 연관된 3D 부분의 포인트들의 투영/2D 파라미터화에 의해 획득된 지오메트리 정보는 각각의 픽셀과 연관된다. 지오메트리 정보는 깊이 정보 또는 메시 요소의 정점들의 위치에 관한 정보에 대응할 수 있다. 3D 부분들과 연관된 텍스처 정보를 포함하는 대응하는 텍스처 패치 아틀라스는 동일한 방식으로 획득될 수 있다.
2D 파라미터화를 지오메트리 패치 아틀라스 내 및 텍스처 패치 아틀라스 내의 그의 연관된 패치와 각각 링크시키는 매핑 정보가 생성될 수 있다. 매핑 정보는 2D 파라미터화와 지오메트리 패치 아틀라스 및 텍스처 패치 아틀라스 내의 각각의 연관된 지오메트리 패치 및 텍스처 패치 사이의 연결을 유지하기 위해 생성될 수 있다. 매핑 정보는 예를 들어 다음의 형태를 가질 수 있다:
{2D 파라미터화의 파라미터들; 지오메트리 패치 ID; 텍스처 패치 ID}
여기서, 지오메트리 패치 ID는 지오메트리 패치가 지오메트리 패치 아틀라스의 패치들의 매트릭스에 속하는 컬럼 인덱스(column index)(U) 및 로우 인덱스(row index)(V)를 포함하는 정수 값 또는 한 쌍의 값들일 수 있고; 텍스처 패치 ID는 텍스처 패치가 텍스처 패치 아틀라스의 패치들의 매트릭스에 속하는 컬럼 인덱스(U') 및 로우 인덱스(V')를 포함하는 정수 값 또는 한 쌍의 값들일 수 있다.
지오메트리 패치들 및 텍스처 패치들이 지오메트리 패치 아틀라스 및 텍스처 패치 아틀라스에서 동일한 배열에 따라 배열될 때, 지오메트리 패치 ID와 텍스처 패치 ID는 동일하며 매핑 정보는 예를 들어 다음의 형태를 가질 수 있다:
{2D 파라미터화의 파라미터들; 지오메트리 및 텍스처 패치 ID}
여기서 '지오메트리 및 텍스처 패치 ID'는 지오메트리 패치 아틀라스 내의 지오메트리 패치 및 텍스처 패치 아틀라스 내의 텍스처 패치 둘 모두를, 지오메트리 패치 및 텍스처 패치 둘 모두와 연관된 동일한 정수 값을 통해서 또는 지오메트리 패치 및 텍스처 패치들이 각각 지오메트리 패치 아틀라스 및 텍스처 패치 아틀라스에 속하는 컬럼 인덱스(U) 및 로우 인덱스(V) 한 쌍의 값들을 통해서, 식별한다.
각각의 2D 파라미터화 및 연관된 지오메트리 패치 및 텍스처 패치에 대해 동일한 매핑 정보가 생성된다. 이러한 매핑 정보는 2D 파라미터화와 대응하는 지오메트리 패치 및 텍스처 패치와의 연관성을 확립함으로써 3D 장면의 대응하는 부분들을 재구성할 수 있게 한다. 2D 파라미터화가 투영이면, 3D 장면의 대응하는 부분은 연관된 지오메트리 패치에 포함된 지오메트리 정보 및 연관된 텍스처 패치 내의 텍스처 정보를 역투영(de-projecting)(반전 투영(inverse projection)을 수행)함으로써 재구성될 수 있다. 다음으로 매핑 정보는 다음의 매핑 정보의 리스트에 대응한다:
{2D 파라미터화의 파라미터들; 지오메트리 및 텍스처 패치 ID},
i = 1 내지 n인 경우, n은 2D 파라미터화들의 수이다.
도 10은 동시에 3DoF 렌더링 호환 가능하고 볼류메트릭 렌더링 호환 가능한 포맷으로 3D 장면의 시퀀스를 인코딩, 송신 및 디코딩하는 예를 도시한다. 3 차원 장면(100)(또는 3D 장면들의 시퀀스)은 인코더(101)에 의해 스트림(102)으로 인코딩된다. 스트림(102)은 3DoF 렌더링을 위한 3D 장면을 나타내는 데이터를 반송하는 신택스의 제1 요소 및 3DoF+ 렌더링을 위한 3D 장면을 나타내는 데이터를 반송하는 신택스의 적어도 제2 요소를 포함한다. 디코더(103)는 소스로부터 스트림(102)을 획득한다. 예를 들어, 소스는 다음과 같은 것을 포함하는 집합에 속한다:
- 로컬 메모리, 예를 들어, 비디오 메모리 또는 RAM(또는 랜덤 액세스 메모리(Random Access Memory)), 플래시 메모리, ROM(또는 판독 전용 메모리(Read Only Memory)), 하드 디스크;
- 저장 인터페이스, 예를 들어, 대용량 저장소, RAM, 플래시 메모리, ROM, 광학 디스크 또는 자기 지원(magnetic support)과의 인터페이스;
- 통신 인터페이스, 예를 들어, 유선 인터페이스(예를 들어, 버스 인터페이스, 광역 네트워크 인터페이스, 로컬 영역 네트워크 인터페이스) 또는 무선 인터페이스(예컨대, IEEE 802.11 인터페이스 또는 Bluetooth®인터페이스); 및
- 사용자가 데이터를 입력할 수 있게 하는 그래픽 사용자 인터페이스와 같은 사용자 인터페이스.
디코더(103)는 3DoF 렌더링(104)을 위해 스트림(102)의 신택스의 제1 요소를 디코딩한다. 3DoF+ 렌더링(105)을 위해, 디코더는 스트림(102)의 신택스의 제1 요소 및 신택스의 제2 요소를 둘 다 디코딩한다.
도 11은 본 원리들의 비제한적 실시예에 따른, 3D 장면(20)을 나타내는 데이터를 획득하고, 인코딩하고, 포맷하고 및/또는 캡슐화하는 프로세스를 도시한다.
동작(111)에서, 3D 장면의 요소들(예를 들어, 포인트들)과 연관된 데이터가 획득되며, 데이터는 장면의 요소들과 연관된 속성들, 즉 텍스처(컬러) 속성들 및/또는 지오메트리 속성들에 대응한다. 예를 들어, 시간적으로 연속적인 이미지들의 시퀀스가 획득될 수 있다. 텍스처 속성들은 하나 이상의 포토센서로 획득될 수 있고, 지오메트리 속성들은 예를 들어 하나 이상의 깊이 센서로 획득될 수 있다. 변형예에 따르면, 3D 장면은 컴퓨터 생성 이미지(Computer-generated imagery)(CGI)기술로 획득된다. 3D 장면의 적어도 한 부분은 복수의 뷰 포인트에 따라, 예를 들어 제1 중심 뷰 포인트를 포함하는 뷰 포인트들의 범위에 따라 보인다. 변형예에 따르면, 3D 장면은 CGI를 통해 획득되거나 생성되지 않고 클라우드, 전방향 콘텐츠의 라이브러리 또는 임의의 저장 유닛 또는 장치로부터 검색된다. 3D 장면과 연관된 오디오 트랙 또한 임의적으로 획득될 수 있다.
동작(112)에서, 3D 장면이 처리된다. 3D 장면의 이미지들은 예를 들어 복수의 카메라로 획득되면 스티칭(stitch)될 수 있다. 동작(112) 동안, 어느 포맷 하에서, 예를 들어 H.264 표준 또는 HEVC 표준에 따라, 3D 장면의 표현이 인코딩될 수 있는지 비디오 인코더로 시그널링된다. 동작(112) 동안, 그것은 3D 장면을 표현하기 위해 3D에서 2D로의 어떤 변환이 사용될지가 추가로 시그널링된다. 3D에서 2D로의 변환은 예를 들어 2D 파라미터화 예들 중 하나 또는 앞에서 설명한 투영들 중 하나에 의한 변환일 수 있다.
동작(113)에서, 임의의 사운드가 획득되었을 때, 제1 비디오와 함께 획득된 사운드 정보는 결정된 포맷에 따라, 예를 들면 고급 오디오 코딩(Advanced Audio Coding)(AAC) 표준, 윈도우즈 미디어 오디오(Windows Media Audio)(WMA), MPEG-1/2 오디오 레이어 3(MPEG-1/2 Audio Layer 3)에 따라 오디오 트랙으로 인코딩된다.
동작(114)에서, 3D 장면의 데이터(즉, 요소들(메시 요소들 또는 포인트들)과 연관된 속성들)는 결정된 포맷에 따라, 예를 들면 문헌(H.264/MPEG-4 AVC: "Advanced video coding for generic audiovisual Services", SERIES H: AUDIOVISUAL AND MULTIMEDIA SYSTEMS, Recommendation ITU-T H.264, Telecommunication Standardization Sector of ITU, February 2014)에 따라 또는 문헌(HEVC/H265: "ITU-T H.265 TELECOMMUNICATION STANDARDIZATION SECTOR OF ITU(10/2014), SERIES H: AUDIOVISUAL AND MULTIMEDIA SYSTEMS, Infrastructure of audiovisual services - Coding of moving video, High efficiency video coding, Recommendation ITU-T H.265")에 따라 비트스트림의 신택스 요소들 또는 비디오 트랙들로 인코딩된다. 예를 들어, 제1 중심 뷰 포인트(30)에 따라 보이는 3D 장면의 부분의 텍스처 정보는 제1 신택스 요소로 (또는 비디오 트랙으로) 인코딩된다. 뷰 포인트들의 세트(33)로부터 보이는 3D 장면의 부분들의 지오메트리 정보(예를 들어, 깊이 이미지들 또는 깊이 패치 아틀라스)는 제2 신택스 요소로(또는 추가 비디오 트랙으로) 인코딩된다. 제1 뷰 포인트(30)를 제외한 뷰 포인트들의 세트(33)의 뷰 포인트들로부터 보이는 3D 장면의 부분들의 텍스처 정보(즉, 제1 신택스 요소로 인코딩되지 않았던 텍스처 정보)는 제3 신택스 요소로(또는 추가 비디오 트랙으로) 인코딩된다.
변형예에 따르면, 지오메트리 정보 및 텍스처 정보는 동일한 신택스 요소로 인코딩되며, 즉, 제2 및 제3 신택스 요소는 비트스트림의 동일한 신택스 요소를 형성한다.
동작(115)에서, 3D 장면을 2개 차원으로 표현하기 위해 사용된 3D에서 2D로의 변환(들)과 연관된 시그널링 정보 및 메타데이터는 컨테이너, 예를 들어 도 13과 관련하여 보다 상세히 설명될 컨테이너(13)로 인코딩/포맷된다. 변형예에 따르면, 동작(114) 동안 인코딩된 3D 장면의 속성들을 포함하는 제1, 제2 및 제3 신택스 요소들은 시그널링 정보 및 메타데이터와 함께 컨테이너(13)에 캡슐화된다.
동작(114 및 115)에서 획득된 비트스트림(들)은 메모리 디바이스에 저장되고 및/또는 디코딩되고 처리하기 위해, 예를 들어 도 12와 관련하여 보다 상세히 설명되는 바와 같이, 그러한 비트스트림(들)에 포함된 3D 장면을 나타내는 데이터를 렌더링하기 위해 송신된다. 비트스트림은 예를 들어 컨테이너로 인코딩된/포맷된 데이터를 포함할 수 있으며, 인코딩된 데이터는 동작(114) 동안 생성된 제1, 제2 및 제3 신택스 요소를 포함할 수 있다.
도 12는 본 원리들의 특정 실시예에 따른, 도 11의 프로세스로부터 획득된 하나 이상의 비트스트림으로부터 3D 장면(20)을 나타내는 데이터를 획득하고, 역캡슐화하고, 디코딩하고 및/또는 해석하는 프로세스를 도시한다.
동작(121)에서, 동작(115)에서 획득된 컨테이너(그 예는 도 13에 도시됨)가 해석되고 이 컨테이너에 수용된 데이터가 역캡슐화되고 및/또는 디코딩된 다음에 동작(122 및 123)에서 제1, 제2 및 제3 신택스 요소들로 및/또는 오디오 트랙들로 인코딩된 데이터를 디코딩한다.
동작(124)에서, 3D 장면의 3DoF 표현 또는 3D 장면의 3DoF+ 표현은 컨테이너의 디코딩된 데이터 및 (3DoF 표현을 위한) 제1 신택스 요소의 디코딩된 데이터 또는 (3DoF+ 표현을 위한) 제1, 제2 및 제3 신택스 요소들의 디코딩된 데이터를 사용하여 합성되고 임의로 렌더링된다.
임의적인 추가 동작에서, 렌더링된 3D 장면은 HMD와 같은 디스플레이 디바이스 상에 디스플레이되거나, 또는 메모리 디바이스에 저장될 수 있다.
임의적인 추가 동작에서, 오디오 정보는 메모리 디바이스에 저장하기 위해 또는 라우드스피커(들)를 사용하여 렌더링하기 위해 디코딩된 오디오 트랙들로부터 렌더링된다.
도 13은 컨테이너(13)의 신택스의 비제한적 예를 보여준다. 컨테이너(13)는 예를 들어 다음의 요소들을 포함하는 ISOBMFF(ISO Base Media File Format, ISO/IEC 14496-12-MPEG-4 Part 12) 파일에 대응한다:
- 동작(114)에서 제1 신택스 요소로 인코딩된 텍스처 데이터로부터 3D 장면의 3D 포인트들을 생성하기 위한 메타데이터를 갖는 시그널링 정보를 포함하는 제1 비디오 트랙(131). 제1 비디오 트랙은 예를 들어, 제1 신택스 요소로 인코딩된 텍스처 데이터의 부분들을 서술하는 메타데이터를 각각 포함하는 프레임 샘플들의 시퀀스(1311)를 포함할 수 있다. 타임 스탬프가 각각의 프레임 샘플과 연관될 수 있으며, 프레임 샘플은 예를 들어 시간(t)에서 3D 장면의 픽처와 또는 픽처들의 그룹(group of pictures)(GOP)과 연관된다. 제1 비디오 트랙(131)에 포함된 메타데이터 및 시그널링 정보는 제1 신택스 요소로 인코딩된 텍스처 데이터와 조합하여 장면의 3D 표현을 획득할 수 있게 하며, 장면의 3DoF 렌더링을 위해, 3D 장면이 단일 제1 뷰 포인트에 따라 재구성된다;
- 동작(114)에서 제2 신택스 요소로 인코딩된 지오메트리 데이터로부터 3D 장면의 지오메트리를 재구성할 수 있게 하는 메타데이터를 갖는 시그널링 정보를 포함하는 제2 비디오 트랙(132). 제2 비디오 트랙(132)은 예를 들어 제2 신택스 요소로 인코딩된 지오메트리 데이터의 부분들을 서술하는 메타데이터를 각각 포함하는 프레임 샘플들의 시퀀스(1321)를 포함할 수 있다. 타임 스탬프가 각각의 프레임 샘플과 연관될 수 있으며, 프레임 샘플은 예를 들어 시간(t)에서 3D 장면의 픽처와 또는 픽처들의 그룹(GOP)과 연관된다.
- 제1 뷰 포인트와 상이한 뷰 포인트들의 범위의 뷰 포인트들에 대해, 동작(114)에서 제3 신택스 요소로 인코딩된 텍스처 데이터로부터 3D 장면의 텍스처를 재구성할 수 있게 하는 메타데이터를 갖는 시그널링 정보를 포함하는 제3 비디오 트랙(133). 제3 비디오 트랙(133)은 예를 들어 제3 신택스 요소로 인코딩된 텍스처 데이터의 부분을 서술하는 메타데이터를 각각 포함하는 프레임 샘플들의 시퀀스(1331)를 포함할 수 있다. 타임 스탬프가 각각의 프레임 샘플과 연관될 수 있으며, 프레임 샘플은 예를 들어 시간(t)에서 3D 장면의 픽처와 또는 픽처들의 그룹(GOP)과 연관된다; 및
- 제1 비디오 트랙(131), 제2 비디오 트랙(132) 및 제3 비디오 트랙(133)에 포함된 데이터와 관련하여 사용될 수 있는 시한 메타데이터(timed metadata)(예를 들어 투영 해제 파라미터(un-projection parameter)들)를 포함하는 제4 트랙(134).
(즉, 시차가 있는) 3D 장면의 3DoF+ 렌더링은 네 개의 트랙(131 내지 134)을 사용하지만 장면의 간단한 3DoF 렌더링은 3DoF+(또는 6DoF) 렌더링과 부합하지 않는 디코더 및 렌더러를 인에이블하는 제1 트랙(131)만을 사용하여, 3D 장면을 나타내는 데이터를 해석하고, 디코딩하며 렌더링한다. 위에서 설명된 포맷에 따른 데이터의 포맷팅은 디코더/렌더러의 능력들에 따라, 동일한 파일/컨테이너로부터 3DoF 또는 3DoF+에 따른 3D 장면의 디코딩/렌더링을 가능하게 한다. 이러한 파일 포맷/컨테이너는 3DoF+ 콘텐츠의 3DoF 수신기와의 하위 호환성을 가능하게 한다.
요구되는 3D 지오메트리 및 텍스처 데이터를 반송하는 제2 및 제3 비디오 트랙들(132, 133)은 3DoF+ 프리젠테이션을 가능하게 한다: 3DoF+ 지오메트리 트랙은 투영된 지오메트리 맵을 반송하고, 투영된 3DoF+ 텍스처 트랙은 투영된 텍스처 맵을 반송한다. 직사각형 비디오 프레임들의 픽셀들을 3D 포인트 클라우드 데이터 상에 매핑하기 위해 투영 해제 메커니즘이 명시된다. 소위 특정 다중 시프트된 정방형 투영(Multiple Shifted Equi-Rectangular Projection)(MS-ERP)는 디폴트 3D 대 2D 투영으로서 정의될 수 있지만, 다른 대안적인 투영 메커니즘들이 구현될 수 있다. MS-ERP는 중심 뷰포인트(즉, 제1 뷰 포인트(30))로부터 상이한 방향들로 시프트된 구체(sphere)들 상으로의 한 세트의 정방형 투영들을 결합한다.
변형예에 따르면, 추가의 제2 비디오 트랙은, 특히 지오메트리 패치들 및 텍스처 패치들이 각각 지오메트리 패치 아틀라스 및 텍스처 패치 아틀라스에서 동일한 방식으로 배열될 때, 패치 아틀라스(지오메트리 및 텍스처)의 패치들과 대응하는 2D 파라미터화 및 연관된 3D 장면의 3D 부분 사이의 매핑 정보를 전달하는데 사용될 수 있다.
변형예에 따르면, 제4 트랙(134)에 포함된 메타데이터는 컨테이너(13) 내에 캡슐화되지 않는다. 이러한 변형예에 따르면, 제4 트랙(134)의 메타데이터는 동일한 구조를 가진 채로 대역 내(in-band) 전송된다. 대역 내 전송은 예를 들어 (동작(114)에서 획득된) 제1, 제2 및 제3 신택스 요소들의 인코딩된 데이터를 갖는 비트스트림 내에서의 전송에 대응한다. 메타데이터는 예를 들어 보충 강화 정보(Supplemental Enhancement Information)(SEI) 메시지들 내에서 전송될 수 있다.
제2 비디오 트랙
본 개시내용에서 정의된 제2 비디오 트랙(132)은 3DoF+ 요소들과 관련된 지오메트리 정보를 수용한다. 이러한 지오메트리 정보의 가능한 실시예는 이 영역 각각이 깊이 맵, 마스크 및 뷰포인트 정보를 수용하는 서브영역들로 구성된 비디오를 사용하는 것이다. 일부 콘텐츠의 경우, (뷰포인트 정보와 같은) 지오메트리 정보의 부분들은 콘텐츠 전체에서 정적으로 유지되고, 본 발명은 정적 ISOBMFF 박스들 내에서 이러한 정적 정보를 시그널링할 수 있게 하지만, 언젠가 콘텐츠에서 그것이 동적으로 변경되면 그러한 정보를 시한 메타데이터 트랙 내에서 전송할 수 있게 한다.
제1 비디오 트랙(131)에 대해 수행된 것과 유사하게, 다음과 같은 정보를 반송하는 단일의 새로운 박스 (여기서 예를 들면, Projected3DoFplusGeometryBox)를 수용하는 제2 비디오 트랙(132)에 대해 제한된 비디오 스킴(restricted video scheme)(여기서 예를 들면, 투영된 3DoF+ 지오메트리의 경우, 'p3pg' 스킴 타입)이 정의된다.
● 투영된 지오메트리 맵의 투영 포맷;
● 투영 포맷에 대한 정적 투영 해제 파라미터;
● 시간적으로 동적인 다른 투영 해제 파라미터가 있는지를 표시하는 플래그.
제한된 시각적 샘플 엔트리 타입(restricted visual sample entry type)에 대해 투영된 3DoF+ 지오메트리 비디오 스킴 'resv'을 사용하는 것은 디코딩된 픽처들이 투영된 지오메트리 맵 픽처들이라는 것을 표시한다. 투영된 3DoF+ 지오메트리 스킴의 사용은 SchemeTypeBox 내에서 'p3pg'와 같은 scheme_type에 의해 표시된다. 투영된 지오메트리 맵 픽처들의 포맷은 SchemeInformationBox 내에 수용된 Projected3DoFplusGeometryBox로 표시된다.
이러한 요소들에 대한 예시적인 ISOBMFF 신택스는 다음과 같다:
투영된
3DoF
+
지오메트리
박스
박스 타입: 'p3pg'
컨테이너: 스킴 정보 박스(Scheme Information box)('schi')
필수:
scheme_type이 'p3pd'와 같을 때는 예
수량: 0 또는 1

다음과 같은 시맨틱이 있음:
projection_type (OMAF ProjectionFormatBox(Study of ISO/IEC DIS 23000-20 Omnidirectional Media Format, ISO/IEC JTC1/SC29/WG11 N16950, July 2017, Torino, Italia)에서 정의됨, 이것의 신택스는 박스 확장 메커니즘(box extension mechanism)을 통해 재사용됨)은 3D 좌표 시스템으로 직사각형 디코더 픽처 출력 샘플들의 특정 매핑을 표시하고; projection_type이 0이면 다중 시프트된 정방형 투영(multiple shifted equirectangular projection)(MS-ERP)을 표시한다.
static_flag는 0과 같으면 투영 파라미터들이 시간에 따라 동적으로 업데이트된다는 것을 표시한다. 이 경우, 현재 비디오 트랙을 참조하는 시한 메타데이터 트랙은 투영 해제의 동적 파라미터들을 서술하는데 필수적이다. projection_type이 0과 같을 때, static_flag는 0과 같아야 한다.
ShiftedViewpointsGeometry는 MS-ERP 투영에 의해 사용된 모든 뷰포인트들 및 중심 뷰잉 포인트(즉, 글로벌 좌표계의 원점)에 대해 이들의 상대적 위치들을 명시한다.
num _viewpoints는 MS-ERP 투영에 의해 사용되는 중심 뷰잉 포인트와 구별되는 뷰포인트들의 수를 표시하고; num_viewpoints 값들은 0 내지 7을 범위로 한다.
radius는 글로벌 좌표계의 원점으로부터의 거리를 명시하는 고정 포인트 16.16 값이다.
static_viewpoints_geometry_flag는 0과 같으면 MS-ERP 투영에 사용되는 추가 뷰포인트들의 수 및 지오메트리가 시간에 따라 동적으로 업데이트된다는 것을 표시한다. 이 경우 현재 비디오 트랙을 참조하는 시한 메타데이터 트랙의 ShiftedViewpointsGeometry 인스턴스가 스킴 정보 박스에서 정의된 정적 인스턴스들보다 우세하다.
제3 비디오 트랙
본 개시내용에서 정의된 제3 비디오 트랙(133)은 3DoF+ 요소들과 관련된 텍스처 정보를 수용한다.
제1 비디오 트랙(131)에 대해 수행된 것과 유사하게, 본 발명은 여기서 다음과 같은 정보를 반송하는 단일의 새로운 박스(여기서 예를 들면, Projected3DoFplusTextureBox)를 수용하는 투영된 3DoF+ 텍스처 비디오에 대해 제한된 비디오 스킴(여기서 예를 들면 'p3pt' 스킴 타입)을 정의한다.
● 투영된 텍스처 맵의 투영 포맷;
● 투영 포맷에 대한 정적 투영 해제 파라미터;
● 시간적으로 동적인 다른 투영 해제 파라미터가 있는지를 표시하는 플래그.
제한된 시각적 샘플 엔트리 타입에 대해 투영된 3DoF+ 텍스처 비디오 스킴 'resv'을 사용하는 것은 디코딩된 픽처들이 중심 뷰포인트로부터는 보이지 않지만 3DoF+ 경험에서 드러나지 않은 장면 부분들의 텍스처 콘텐츠를 수용하고 있는 투영된 픽처들이라는 것을 표시한다. 투영된 3DoF+ 텍스처 스킴을 사용하는 것은 SchemeTypeBox 내에서 'p3pt'와 같은 scheme_type에 의해 표시된다. 투영된 텍스처 맵 픽처들의 포맷은 SchemeInformationBox 내에 수용된 Projected3DoFplusTextureBox로 표시된다.
이러한 요소들에 대한 제안된 ISOBMFF 신택스는 다음과 같다:
투영된
3DoF
+
텍스처
박스
박스 타입: 'p3pt'
컨테이너: 스킴 정보 박스(Scheme Information box)('schi')
필수: scheme_type이 'p3pt'와 같을 때는 예
수량: 0 또는 1

여기서 Projected3DoFplusTextureBox는 3DoF+ 지오메트리 비디오 트랙에서와 동일한 박스이다.
제2 및 제3 비디오 트랙들의
그룹핑
(135)
제1 비디오 트랙(131)(3DoF), 3DoF+ 지오메트리 비디오 트랙 및 3DoF+ 텍스처 비디오 트랙은, 이들이 스탠드얼론 트랙들이 아니므로, 제1 비디오 트랙(131)을 저장하려면, 함께 연관되어야 한다. 제2 및 제3 비디오 트랙들은 동일한 ISOBMFF 트랙 그룹에 수용될 수 있다. 예를 들어, '3dfp'와 동일한 track_group_type을 갖는 TrackGroupTypeBox는 이것이 3DoF+ 시각적 경험에 적합한 픽처들을 획득하기 위해 처리될 수 있는 트랙들의 그룹이라는 것을 표시한다. 이러한 그룹핑에 매핑된 트랙들 (즉, '3dfp'와 동일한 track_group_type을 갖는 TrackGroupTypeBox 내의 동일한 값의 track_group_id를 갖는 트랙들)은 투영된 전방향 비디오(3DoF) 트랙과 결합될 때, 제시될 수 있는 3DoF+ 시각적 콘텐츠를 총괄적으로 나타낸다.
이러한 그룹핑에 매핑된 트랙들에는 다음의 제약들 중 하나 이상이 적용될 수 있다:
● 이러한 그룹핑은 샘플 엔트리 타입이 'resv'와 동일한 적어도 2개의 비디오 트랙으로 구성되어야 한다: 적어도 하나는 3DoF+ 지오메트리 비디오 트랙을 식별하는 scheme_type(여기서 예를 들면, 'p3pd')를 갖고 하나는 3DoF+ 텍스처 비디오 트랙을 식별하는 scheme_type(여기서 예를 들면, 'p3pt')를 갖는다;
● 3DoF+ 지오메트리 맵('p3pg') 및 텍스처 맵('p3pt') 비디오 트랙들의 샘플 엔트리들에 포함된 ProjectionFormat3DoFplusBox 의 인스턴스들의 콘텐츠는 동일해야 한다;
● ProjectionFormat3DoFplusBox 내의 static_flag가 0일 때, 동적 투영 해제 파라미터들을 서술하는 시한 메타데이터 트랙('dupp')은 'moov' 컨테이너 박스(13)에 존재하여야 하고 ('cdtg' '트랙을 참조하는) 3DoF+ 트랙 그룹(135)에 링크되어야 한다.
제4 트랙
투영 해제 파라미터들 중 일부는 정적이고 3DoF+ 지오메트리 및 텍스처 트랙들(즉, 제2 및 제3 비디오 트랙들(132, 133))에서 서술될 수 있지만, 3DoF+ 콘텐츠에 대한 투영 해제 파라미터들 중 일부는 동적이다. 이러한 동적 투영 해제 파라미터들은 제1, 제2 및 제3 비디오 트랙들(131, 132, 133)과 연관된 시한 메타데이터 트랙, 즉 제4 트랙(134)에서 송신될 수 있다.
비제한적 실시예에 따르면, 투영 해제 파라미터들에 대한 (동적 투영 해제 파라미터들의 경우) 타입 'dupp'의 메타데이터 샘플 엔트리는 아래에서 설명되는 바와 같이 정의될 수 있다:
샘플 엔트리 타입: 'dupp'
컨테이너: 샘플 서술 박스('stsd')
필수:
아니오
수량: 0 또는 1

각각의 메타데이터 샘플은 전방향(3DoF) 비디오, 투영된 3DoF+ 지오메트리 비디오 및 투영된 3DoF+ 텍스처 비디오, 즉 제1, 제2 및 제3 비디오 트랙들(131, 132 및 133)로부터 볼류메트릭 비디오의 모든 부분들(3D 패치들)의 투영 해제를 수행하는데 필요한 요구된 정보를 수용한다.
3D 패치들의 데이터를 그들의 연관된 투영 표면 상에 투영하면 불규칙한 모양의 2D 영역들의 모음이 생성되고, 2D 영역들의 직사각형 경계 박스들은 그 위치들, 방향들 및 크기들을 표시함으로써 패킹된 픽처 상에 추가로 매핑된다. 텍스처 및 지오메트리 데이터는 별도의 픽처들 내에 패킹된다. 텍스처 패킹된 픽처들 및 지오메트리 패킹된 픽처들의 시퀀스는 투영된 3DoF+ 텍스처 아틀라스 맵 및 투영된 3DoF+ 지오메트리 아틀라스 맵을 각각 구성한다.
문헌(OMAF(Study of ISO/IEC DIS 23000-20 Omnidirectional Media Format, ISO/IEC JTC1/SC29/WG11 N16950, July 2017, Torino, Italia))에서 정의된 영역별 패킹 구조로부터 영감을 얻었으나 유용한 파라미터들(영역들의 수 및 모든 영역들에 대한: 보호 대역(guard-band) 정보, 임의적 변환, 위치 및 크기)만을 보유하는 패킹 구조가 생성될 수 있다. OMAF 영역별 패킹 구조와 비교하여, 아틀라스들이 256 개를 초과하는 영역들을 사용할 것으로 예상되므로 영역들의 수가 또한 확장되어야 한다.
각각의 샘플은 3D 패치들의 리스트를 명시한다. 각각의 3D 패치는 3D 장면 볼륨(구체 범위)의 일부를 서술하고 이 패치에 대한 투영된 텍스처 및 지오메트리 데이터의 저장 구조에 링크한다. 이것은 다음을 포함한다:
● 3D 패치들이 보이는 모든 뷰포인트들에 관한 정보. 이 정보가 정적이면(그리고 이에 따라 3DoF+ 지오메트리 및 텍스처 트랙에서 시그널링되면), 시한 메타데이터에는 이것을 표시하는 플래그가 또한 있어야 한다.
● 지오메트리 비디오 내 모든 2D 직사각형 패치들의 구성/패킹에 관한 정보. 이것은 본 발명에서 3DoF+ 지오메트리 아틀라스 맵으로 지칭된다.
● 텍스처 비디오 내 모든 2D 직사각형 패치들의 구성/패킹에 관한 정보. 이것은 본 발명에서 3DoF+ 텍스처 아틀라스 맵으로 지칭된다.
● 3D 패치들의 수에 관한 정보 및 각 3D 패치 정보마다 다음과 같은 것에 관한 정보:
○ 요(yaw), 피치(pitch) 및 롤(roll) 각도들에 대한 최소 값 및 최대 값으로 식별되는 3D 패치에 의해 서술된 3D 볼륨,
○ 어떤 뷰포인트(그리고 아마도 상이한 방향의 뷰포인트)가 그것에 사용되는지,
○ 3DoF+ 지오메트리 맵 내 패치의 식별
○ 3DoF+ 텍스처 맵(즉, 제3 비디오 트랙(133)) 내 또는 제1 비디오 트랙(131) 내 패치의 식별.
메타데이터 샘플 포맷에 대한 ISOBMFF의 가능한 실시예는 다음과 같다:



여기서:
static_viewpoints_geometry_flag는 MS-ERP 투영에 의해 사용된 시프트된 뷰포인트들의 수 및 위치들이 정적이고 ProjectionFormat3DoFplusBox에서 찾을 수 있다는 것을 표시한다.
num _ 3Dpatches는 3D 패치들의 수를 명시한다.
sphericalRange는 패치에 의해 서술되는 3D 볼륨을 (구체 좌표들로) 명시한다:
● yaw_min 및 yaw_max는 최소 및 최대 요 각도들을 투영 구체 좌표축들에 대해 180*2-16 도(degree)들의 단위로 명시하고; 이것들은 -216 내지 216-1를 포함하여 -216 내지 216-1의 범위(즉 ±180°)에 있어야 한다는 것을 명시한다;
● pitch_min 및 pitch_max는 최소 및 최대 피치 각도들을 투영 구체 좌표축들에 대해 180*2-16 도들의 단위로 명시하며; 이것들은 -215 내지 215를 포함하여 -215 내지 215의 범위(즉, ±90°)에 있어야 한다는 것을 명시한다;
● rho_min 및 rho_max는 투영 구체 좌표축들에 대해 (미터 단위의) 최소 및 최대 반경들을 명시하는 고정 포인트 16.16 값들이다.
omnidirectional _compatible_flag는 패치 텍스처 콘텐츠가 제1 비디오 트랙에서 발견된다는 것을 표시하고;
sphere_id 값은 0 내지 7을 범위로 한다는 것을 표시한다:
● sphere_id가 0이면 (장면 좌표계의 원점에 중심을 둔) 제1 비디오 트랙에 사용된 투영 구체가 사용된다는 것을 표시하고; omnidirectional_compatible_flag가 1이면 sphere_id는 0과 같아야 하고; omnidirectional_compatible_flag가 0이면 sphere_id는 0이 아니어야 한다는 것을 표시한다.
● 1 내지 num_viewpoints를 범위로 하는 sphere_id 값들은 추가 MS-ERP 투영 구체들이 사용되는 num_viewpoints 중 어느 하나를 표시하고; 패치 텍스처 콘텐츠는 투영된 3DoF+ 텍스처 비디오 트랙에서 찾을 수 있다는 것을 표시한다.
orientation_id는 현재 MS-ERP 투영 구체의 좌표축들의 방향을 명시한다:
● 1 내지 3을 범위로 하는 orientation_id 값들은 3 가지 상이한 방향에 대응한다;
● orientation_id는 sphere_id가 0일 때 0과 같아야 한다.
PatchAtlasPackingStruct는 이러한 직사각형 영역들의 레이아웃을 명시한다. UnprojectionParametersSample 내 PatchAtlasPackingStruct의 제1 인스턴스는 텍스처 패치들의 패킹 배열을 명시하고 제2 인스턴스는 지오메트리 패치들의 패킹 배열을 서술한다.
texture_atlas_region_id는 패킹된 텍스처 픽처(텍스처 패치 아틀라스) 내 직사각형 영역의 인덱스를 명시한다.
geometry_atlas_region_id는 패킹된 지오메트리 픽처(지오메트리 패치 아틀라스) 내 직사각형 영역의 인덱스를 명시한다.
도 14는 데이터가 패킷 기반 전송 프로토콜을 통해 송신될 때 스트림의 신택스의 실시예의 예를 도시한다. 도 14는 볼류메트릭 비디오 스트림의 예시적인 구조(14)를 도시한다. 구조는 스트림을 신택스의 독립적 요소들로 구성하는 컨테이너로 구성된다. 구조는 스트림의 모든 신택스 요소들에 공통적인 한 세트의 데이터인 헤더 부분(141)을 포함할 수 있다. 예를 들어, 헤더 부분은 신택스 요소들 각각의 특성 및 역할을 서술하는 신택스 요소들에 관한 메타데이터를 포함한다. 헤더 부분은 3DoF 렌더링을 위한 제1 컬러 이미지를 인코딩하는데 사용되는 뷰 포인트의 좌표들 및 픽처들의 크기 및 해상도에 대한 정보를 또한 포함할 수 있다. 구조는 신택스의 제1 요소(142) 및 신택스의 적어도 하나의 제2 요소(143)를 포함하는 페이로드를 포함한다. 제1 신택스 요소(142)는 동작(114)에서 획득된 제1 신택스 요소에 인코딩된 텍스처 데이터와 연관된 제1 비디오 트랙에 대응하는, 3DoF 렌더링을 위해 준비된 제1 컬러 이미지를 나타내는 데이터를 포함한다.
하나 이상의 제2 신택스 요소(143)는 제2 및 제3 비디오 트랙들과 연관된 지오메트리 정보 및 텍스처 정보 및 동작(114)에서 획득된 인코딩된 데이터의 각각의 제2 및 제3 신택스 요소들을 포함한다.
예시 목적을 위해, ISOBMFF 파일 포맷 표준의 맥락에서, 텍스처 맵, 지오메트리 맵 및 메타데이터는 전형적으로 타입 moov의 박스 내 ISOBMFF 트랙들에서 참조될 것이며, 이때 텍스처 데이터 및 지오메트리 데이터 자체는 타입 mdat의 메타-데이터 박스에 삽입된다.
도 15는 도 11, 도 12, 도 16 및/또는 도 17과 관련하여 설명되는 방법을 구현하도록 구성될 수 있는 디바이스(15)의 예시적인 아키텍처를 도시한다. 디바이스(15)는 도 10의 인코더(101) 또는 디코더(103)로 구성될 수 있다.
디바이스(15)는 데이터 및 어드레스 버스(151)에 의해 함께 링크되는 다음의 요소들을 포함한다:
- 예를 들어, DSP(또는 디지털 신호 프로세서(Digital Signal Processor))인 마이크로프로세서(152)(또는 CPU);
- ROM(또는 판독 전용 메모리(Read Only Memory))(153);
- RAM(또는 랜덤 액세스 메모리(Random Access Memory))(154);
- 저장 인터페이스(155);
- 애플리케이션으로부터 송신할 데이터를 수신하기 위한 I/O 인터페이스(156); 및
- 전력 공급 디바이스, 예를 들어 배터리.
예에 따르면, 전력 공급 디바이스는 디바이스의 외부에 있다. 언급된 각각의 메모리에서, 본 명세서에서 사용된 ≪레지스터≫라는 단어는 작은 용량(몇 비트)의 영역에 대응하거나 또는 매우 큰 영역(예를 들어, 전체 프로그램 또는 수신되거나 디코딩된 대량의 데이터)에 대응할 수 있다. ROM(153)은 적어도 프로그램 및 파라미터들을 포함한다. ROM(153)은 본 원리들에 따라 기술들을 수행할 알고리즘들 및 명령어들을 저장할 수 있다. 스위치 온될 때, CPU(152)는 RAM에 프로그램을 업로드하고 대응하는 명령어들을 실행한다.
RAM(154)은 CPU(152)에 의해 실행되고 디바이스(150)의 스위치 온 후에 업로드되는 레지스터 내의 프로그램, 레지스터 내의 입력 데이터, 레지스터 내의 방법의 상이한 상태들의 중간 데이터, 및 레지스터 내의 방법을 실행하는데 사용된 다른 변수들을 포함한다.
본 명세서에서 설명된 구현예들은, 예를 들어, 방법 또는 프로세스, 장치, 컴퓨터 프로그램 제품, 데이터 스트림 또는 신호로 구현될 수 있다. 단일 형태의 구현예의 맥락에서만 논의될지라도 (예를 들어, 방법 또는 디바이스로서만 논의될지라도), 논의된 특징들의 구현예는 다른 형태들(예를 들어, 프로그램)로도 또한 구현될 수 있다. 장치는 예를 들어, 적절한 하드웨어, 소프트웨어 및 펌웨어로 구현될 수 있다. 방법들은, 예를 들어, 컴퓨터, 마이크로프로세서, 집적 회로 또는 프로그램 가능 로직 디바이스를 비롯한, 예를 들어, 일반적으로 처리 디바이스들을 지칭하는 프로세서와 같은 장치에서 구현될 수 있다. 프로세서는 예를 들어, 컴퓨터들, 셀 폰들, 휴대용/개인 휴대 정보 단말기(personal digital assistant)("PDA")들 및 최종 사용자들 사이에서 정보의 통신을 용이하게 하는 다른 디바이스들과 같은 통신 디바이스를 또한 포함한다.
도 10의 인코딩 또는 인코더(101)의 예에 따르면, 3 차원 장면(20)은 소스로부터 획득된다. 예를 들어, 소스는 다음과 같은 것을 포함하는 집합에 속한다:
- 로컬 메모리(153 또는 154), 예를 들어, 비디오 메모리 또는 RAM(또는 랜덤 액세스 메모리), 플래시 메모리, ROM(또는 판독 전용 메모리), 하드 디스크;
- 저장 인터페이스(155), 예를 들어, 대용량 저장소, RAM, 플래시 메모리, ROM, 광학 디스크 또는 자기 지원과의 인터페이스;
- 통신 인터페이스(156), 예를 들어, 유선 인터페이스(예를 들어, 버스 인터페이스, 광역 네트워크 인터페이스, 로컬 영역 네트워크 인터페이스) 또는 무선 인터페이스(예컨대, IEEE 802.11 인터페이스 또는 Bluetooth®인터페이스); 및
- 사용자가 데이터를 입력할 수 있게 하는 그래픽 사용자 인터페이스와 같은 사용자 인터페이스.
도 10의 디코딩 또는 디코더(들)(103)의 예들에 따르면, 스트림은 목적지로 전송된다; 구체적으로는, 목적지는 다음과 같은 것을 포함하는 집합에 속한다:
- 로컬 메모리(153 또는 154), 예를 들어, 비디오 메모리 또는 RAM, 플래시 메모리, 하드 디스크;
- 저장 인터페이스(155), 예를 들어, 대용량 저장소, RAM, 플래시 메모리, ROM, 광학 디스크 또는 자기 지원과의 인터페이스; 및
- 통신 인터페이스(156), 예를 들어, 유선 인터페이스(예를 들어, 버스 인터페이스(예를 들어, USB(또는 범용 직렬 버스(Universal Serial Bus)), 광역 네트워크 인터페이스, 로컬 영역 네트워크 인터페이스, HDMI(고화질 멀티미디어 인터페이스(High Definition Multimedia Interface) 인터페이스) 또는 무선 인터페이스(예컨대, IEEE 802.11 인터페이스, WiFi®또는 Bluetooth®인터페이스).
인코딩 또는 인코더의 예들에 따르면, 볼류메트릭 장면을 나타내는 데이터를 포함하는 비트스트림은 목적지로 전송된다. 예로서, 비트스트림은 로컬 또는 원격 메모리, 예를 들어, 비디오 메모리 또는 RAM, 하드 디스크에 저장된다. 변형예에서, 비트스트림은 저장 인터페이스, 예를 들어, 대용량 저장소, 플래시 메모리, ROM, 광학 디스크 또는 자기 지원과의 인터페이스에 전송되고 및/또는 통신 인터페이스, 예를 들어, 포인트 투 포인트 링크, 통신 버스, 포인트 투 멀티포인트 링크 또는 브로드캐스트 네트워크와의 인터페이스를 통해 송신된다.
도 10의 디코딩 또는 디코더 또는 렌더러(103)의 예들에 따르면, 비트스트림은 소스로부터 획득된다. 예시적으로, 비트스트림은 로컬 메모리, 예를 들어, 비디오 메모리, RAM, ROM, 플래시 메모리 또는 하드 디스크로부터 판독된다. 변형예에서, 비트스트림은 저장 인터페이스, 예를 들어, 대용량 저장소, RAM, ROM, 플래시 메모리, 광학 디스크 또는 자기 지원과의 인터페이스로부터 수신되고 및/또는 통신 인터페이스, 예를 들어, 포인트 투 포인트 링크, 버스, 포인트 투 멀티포인트 링크 또는 브로드캐스트 네트워크와의 인터페이스로부터 수신된다.
예들에 따르면, 디바이스(15)는 도 11, 도 12, 도 16 및/또는 도 17과 관련하여 설명된 방법을 구현하도록 구성되고 다음과 같은 것을 포함하는 집합에 속한다:
- 모바일 디바이스;
- 통신 디바이스;
- 게임 디바이스;
- 태블릿(또는 태블릿 컴퓨터);
- 랩톱;
- 스틸 픽처 카메라;
- 비디오 카메라;
- 인코딩 칩;
- 서버(예를 들어, 브로드캐스트 서버, 주문형 비디오 서버 또는 웹 서버).
도 16은 본 원리들의 비제한적 실시예에 따른, 3D 장면, 예를 들어 3D 장면(20)을 나타내는 데이터를 인코딩하기 위한 방법을 도시한다. 방법은 예를 들어 인코더(101) 및/또는 디바이스(15)에서 구현될 수 있다. 디바이스(15)의 상이한 파라미터들은 업데이트될 수 있다. 3D 장면은 예를 들어 소스로부터 획득될 수 있고, 하나 이상의 뷰 포인트가 3D 장면의 공간에서 결정될 수 있고, 투영 매핑(들)과 연관된 파라미터들이 초기화될 수 있다.
제1 동작(161)에서, 3D 장면의 텍스처를 나타내는 제1 데이터는 컨테이너 또는 파일의 제1 비디오 트랙으로 인코딩되거나 포맷된다. 제1 데이터는 단일의 제1 뷰 포인트에 따라 보이는 3D 장면의 부분들(예를 들어, 포인트들 또는 메시 요소들)을 참조한다. 제1 데이터는 예를 들어 3D-2D 변환(예를 들어, 패치들 또는 이미지들 상에 3D 장면의 정방형 투영, 각 패치 또는 이미지는 3D 장면의 한 부분과 연관됨)에 의해 획득된 3D 장면의 패치들 또는 이미지들의 픽셀들로 인코딩된 텍스처 정보를 포함하는 비트스트림의 제1 신택스 요소를 가리키는 시그널링 정보 및 메타데이터를 포함한다. 제1 비디오 트랙으로 인코딩된 메타데이터는 예를 들어 3D-2D 변환의 파라미터들 또는 역변환(2D-3D)의 파라미터들을 포함한다. 제1 데이터는, 일단 디코딩되거나 해석되면, 제1 뷰 포인트, 즉 시차 없는 표현에 따른 3D 장면의 3DoF 표현을 획득할 수 있게 한다.
제2 동작(162)에서, 3D 장면의 지오메트리를 나타내는 제2 데이터는 컨테이너 또는 파일의 제2 비디오 트랙으로 인코딩되거나 포맷된다. 제2 데이터는 제1 뷰 포인트를 포함하는 뷰 포인트들의 세트(또는 범위)에 따라 보이는 3D 장면의 부분들(예를 들어, 포인트들 또는 메시 요소들)을 참조한다. 제2 데이터는 예를 들어 3D-2D 변환(예를 들어, 패치들 또는 이미지들 상에 3D 장면의 정방형 투영, 각 패치 또는 이미지는 3D 장면의 한 부분과 연관됨)에 의해 획득된, 3D 장면의 패치들 또는 이미지들의 픽셀들로 인코딩된 지오메트리 정보를 포함하는 비트스트림의 제2 신택스 요소를 가리키는 시그널링 정보 및 메타데이터를 포함한다. 제2 비디오 트랙으로 인코딩된 메타데이터는 예를 들어 3D-2D 변환의 파라미터들 또는 역변환(2D-3D)의 파라미터들을 포함한다.
제3 동작(163)에서, 3D 장면의 적어도 한 부분의 텍스처를 나타내는 제3 데이터는 컨테이너 또는 파일의 제3 비디오 트랙으로 인코딩되거나 포맷된다. 제3 데이터는 제1 뷰 포인트에 따라 보이는 장면의 부분이 없는 세트의 뷰 포인트들에 따라 보이는 3D 장면의 부분들(예를 들어, 포인트들 또는 메시 요소들)을 참조한다. 제3 데이터는 예를 들어 제1 뷰포인트를 제외하고 세트의 뷰 포인트들로부터 보이는 3D 장면의 상기 부분들의 패치들 또는 이미지들의 픽셀들로 인코딩된 텍스처 정보를 포함하는 비트스트림의 제3 신택스 요소를 가리키는 시그널링 정보 및 메타데이터를 포함하며, 패치들(이미지들)은 3D-2D로 변환(예를 들어, 패치들 또는 이미지들 상에 3D 장면의 정방형 투영, 각 패치 또는 이미지는 3D 장면의 한 부분과 연관됨))에 의해 획득된다. 제3 비디오 트랙으로 인코딩된 메타데이터는 예를 들어 3D-2D 변환의 파라미터들 또는 역변환(2D-3D)의 파라미터들을 포함한다.
제4 동작(164)에서, 메타데이터는 제4 트랙으로 인코딩된다. 메타데이터는 제2 데이터 및 제3 데이터와 연관되고, 제1, 제2 및 제3 비디오 트랙들(및 비트스트림의 제1, 제2 및 제3 신택스 요소들로 인코딩된 연관된 데이터)과 함께 3D 장면의 3DoF+ 표현을 가능하게 한다. 메타데이터는 예를 들어, 하나의 뷰 포인트로부터 다른 뷰 포인트로, 제2 및 제3 데이터를 획득하는데 사용되는 하나 이상의 투영을 나타내는 정보를 포함한다.
메타데이터는 다음의 정보 중 적어도 하나(또는 다음의 정보의 임의의 조합)를 포함한다:
- 지오메트리 및 텍스처를 획득하기 위해 사용되는 적어도 하나의 투영과 연관된 적어도 하나의 뷰 포인트를 나타내는 정보;
- 지오메트리의 패치들의 패킹을 나타내는 정보 - 지오메트리의 각각의 패치는 3D 장면의 한 부분의 투영과 연관됨 -;
- 텍스처의 패치들의 패킹을 나타내는 정보 - 텍스처의 각각의 패치는 3D 장면의 한 부분의 투영과 연관됨 -;
- 다수의 패치들을 나타내는 정보 - 각각의 패치는 3D 장면의 한 부분과 연관되고 제2 트랙 및 제1 비디오 트랙 내 또는 제3 비디오 트랙 내의 식별자와 연관됨 -.
변형예에 따르면, 제1, 제2 및 제3 비디오 트랙들이 각각 참조하는 제1, 제2 및 제3 신택스 요소들은 제1, 제2 및 제3 비디오 트랙들과 동일한 컨테이너에 캡슐화된다. 변형예에 따르면, 제1, 제2 및 제3 신택스 요소들의 데이터는 제1, 제2, 제3 및 제4 트랙들의 데이터 또는 메타데이터를 포함하는 파일(또는 컨테이너)과 상이한 파일에 캡슐화되며, 모든 데이터는 단일 비트스트림에서 전송된다.
제2 데이터는 지오메트리를 획득하기 위해 사용된 투영의 포맷, 투영의 파라미터들 및 투영 파라미터들 중 적어도 일부가 동적으로 업데이트되는지를 표시하는 플래그를 나타내는 제1 정보를 포함한다. 플래그가 파라미터들이 동적으로 업데이트된다는 것을 표시할 때, 파서(parser)는 업데이트된 파라미터를 제4 트랙으로부터 검색할 수 있다.
제3 데이터는 지오메트리를 획득하기 위해 사용된 투영의 포맷, 투영의 파라미터들 및 투영 파라미터들 중 적어도 일부가 동적으로 업데이트되는지를 표시하는 플래그를 나타내는 제2 정보를 포함한다. 플래그가 파라미터들이 동적으로 업데이트된다는 것을 표시할 때, 파서는 업데이트된 파라미터를 제4 트랙으로부터 검색할 수 있다.
다른 변형예에 따르면, 제1 정보 및 제2 정보가 동일할 때 제1 비디오 트랙 및 적어도 제2 비디오 트랙은 동일한 트랙 그룹으로 그룹화된다.
도 17은 본 원리들의 비제한적 실시예에 따른, 3D 장면, 예를 들어 3D 장면(20)을 나타내는 데이터를 디코딩하기 위한 방법을 도시한다. 방법은 예를 들어 인코더(101) 및/또는 디바이스(15)에서 구현될 수 있다.
제1 동작(171)에서, 제1 뷰 포인트에 따라 보이는 3D 장면의 부분의 텍스처를 나타내는 제1 데이터가 수신된 컨테이너의 제1 비디오 트랙으로부터 디코딩되거나 해석되며, 컨테이너는 예를 들어 비트스트림에 포함되어 있다.
제2 동작(172)에서, 제1 뷰 포인트를 포함하는 뷰 포인트들의 세트에 따라 보이는 3D 장면의 지오메트리를 나타내는 제2 데이터가 수신된 컨테이너의 제2 비디오 트랙으로부터 디코딩되거나 해석된다.
제3 동작(173)에서, 제1 뷰 포인트를 제외하고 세트의 뷰 포인트들로부터 보이는 3D 장면의 부분(들)의 텍스처를 나타내는 제3 데이터가 컨테이너의 제3 비디오 트랙으로부터 디코딩되거나 해석된다.
제4 동작(174)에서, 메타데이터가 컨테이너의 제4 트랙으로부터 디코딩되거나 해석된다. 메타데이터는 제2 데이터 및 제3 데이터와 연관되고, 제1, 제2 및 제3 비디오 트랙들(및 비트스트림의 제1, 제2 및 제3 신택스 요소들로 인코딩된 연관된 데이터)과 함께 3D 장면의 3DoF+ 표현을 가능하게 한다. 메타데이터는 제2 및 제3 데이터를 획득하기 위해 사용된 하나 이상의 투영을 나타내는 정보를 포함한다.
당연히, 본 개시내용은 앞서 설명된 실시예로 제한되지 않는다.
특히, 본 개시내용은 3D 장면을 나타내는 데이터를 인코딩/디코딩하기 위한 방법 및 디바이스로 제한되지 않고, 인코딩된 데이터를 포함하는 비트스트림을 생성하기 위한 방법 및 이러한 방법을 구현하는 임의의 디바이스 및 특히 적어도 하나의 CPU 및/또는 적어도 하나의 GPU를 포함하는 임의의 디바이스들까지도 확장된다.
본 개시내용은 또한 비트스트림의 디코딩된 데이터로부터 렌더링된 이미지들을 디스플레이하기 위한 방법 (및 구성된 디바이스)에 관한 것이다.
본 개시내용은 또한 비트스트림을 송신 및/또는 수신하기 위한 방법 (및 구성된 디바이스)에 관한 것이다.
본 명세서에서 설명된 구현예들은, 예를 들어, 방법 또는 프로세스, 장치, 컴퓨터 프로그램 제품, 데이터 스트림 또는 신호로 구현될 수 있다. 단일 형태의 구현예의 맥락에서만 논의될지라도(예를 들어, 방법 또는 디바이스로서만 논의될지라도), 논의된 특징들의 구현예는 다른 형태들(예를 들어, 프로그램)로도 또한 구현될 수 있다. 장치는 예를 들어, 적절한 하드웨어, 소프트웨어 및 펌웨어로 구현될 수 있다. 방법들은, 예를 들어, 컴퓨터, 마이크로프로세서, 집적 회로 또는 프로그램 가능 로직 디바이스를 비롯한, 예를 들어, 일반적으로 처리 디바이스들을 지칭하는 프로세서와 같은 장치에서 구현될 수 있다. 프로세서들은, 예를 들어 스마트폰들, 태블릿들, 컴퓨터들, 모바일 폰들, 휴대용/개인 휴대 정보 단말기("PDA")들 및 최종 사용자들 사이에서 정보의 통신을 용이하게 하는 다른 디바이스들과 같은 통신 디바이스를 또한 포함한다.
본 명세서에서 설명된 다양한 프로세스들 및 특징들의 구현예들은 다양한 상이한 장비 또는 애플리케이션들, 특히, 예를 들면, 데이터 인코딩, 데이터 디코딩, 뷰 생성, 텍스처 처리, 및 이미지들 및 관련된 텍스처 정보 및/또는 깊이 정보의 다른 처리와 연관된 장비 또는 애플리케이션들에서 구현될 수 있다. 그러한 장비의 예들은 인코더, 디코더, 디코더로부터의 출력을 처리하는 후처리 프로세서, 인코더에 입력을 제공하는 전처리 프로세서, 비디오 코더, 비디오 디코더, 비디오 코덱, 웹 서버, 셋톱 박스, 랩톱, 퍼스널 컴퓨터, 셀 폰, PDA 및 다른 통신 디바이스들을 포함한다. 분명히 해야 하는 것으로서, 장비는 이동식일 수도 있고 심지어 이동 차량에 설치될 수도 있다.
또한, 방법들은 프로세서에 의해 수행되는 명령어들에 의해 구현될 수 있고, 그러한 명령어들 (및/또는 구현에 의해 생성된 데이터 값들)은, 예를 들어, 집적 회로, 예를 들면 하드 디스크, 콤팩트 디스켓(compact diskette)("CD"), (예를 들어, 종종 디지털 다용도 디스크 또는 디지털 비디오 디스크라고 지칭되는 DVD와 같은) 광학 디스크와 같은 소프트웨어 캐리어 또는 다른 저장 디바이스, 랜덤 액세스 메모리(random access memory)("RAM") 또는 판독 전용 메모리(read only memory)("ROM")와 같은 프로세서 판독 가능 매체에 저장될 수 있다. 명령어들은 프로세서 판독 가능 매체상에 유형으로 구현된 애플리케이션 프로그램을 형성할 수 있다. 명령어들은 예를 들어, 하드웨어, 펌웨어, 소프트웨어 또는 조합일 수 있다. 명령어들은 예를 들어, 운영 체제, 별개의 애플리케이션 또는 이 둘의 조합에서 발견될 수 있다. 그러므로 프로세서는 예를 들어, 프로세스를 수행하도록 구성된 디바이스 및 프로세스를 수행하기 위한 명령어들을 갖는 (저장 디바이스와 같은) 프로세서 판독 가능 매체를 포함하는 디바이스 둘 모두로서 특징지어질 수 있다. 또한, 프로세서 판독 가능 매체는 명령어들에 추가하여 또는 명령어들 대신에, 구현에 의해 생성된 데이터 값들을 저장할 수 있다.
관련 기술분야에서 통상의 기술자에게 명백해지는 바와 같이, 구현예들은 예를 들어, 저장되거나 송신될 수 있는 정보를 반송하도록 포맷된 다양한 신호를 생성할 수 있다. 정보는 예를 들어, 방법을 수행하기 위한 명령어들, 또는 설명된 구현예들 중 하나에 의해 생성된 데이터를 포함할 수 있다. 예를 들어, 신호는 설명된 실시예의 신택스를 기입하거나 판독하기 위한 규칙들을 데이터로서 반송하도록 포맷되거나, 또는 설명된 실시예에 의해 기입된 실제 신택스 값들을 데이터로서 반송하도록 포맷될 수 있다. 이러한 신호는, 예를 들어, (예를 들면, 스펙트럼의 무선 주파수 부분을 사용하는) 전자기파로서 또는 베이스밴드 신호로서 포맷될 수 있다. 포맷팅은 예를 들어, 데이터 스트림을 인코딩하는 것 및 캐리어를 인코딩된 데이터 스트림으로 변조하는 것을 포함할 수 있다. 신호가 반송하는 정보는 예를 들어, 아날로그 또는 디지털 정보일 수 있다. 신호는 알려진 바와 같이 다양한 서로 상이한 유선 또는 무선 링크들을 통해 송신될 수 있다. 신호는 프로세서 판독 가능 매체에 저장될 수 있다.
다수의 구현예가 설명되었다. 그럼에도 불구하고, 다양한 변형예들이 만들어질 수 있다는 것이 이해될 것이다. 예를 들어, 상이한 구현예들의 요소들이 조합되거나, 보충되거나, 변형되거나 또는 제거되어 다른 구현예들을 만들어 낼 수 있다. 또한, 관련 기술분야에서 통상의 기술자라면 다른 구조들 및 프로세스들이 개시된 것들에 대체될 수 있고 결과적인 구현예들이 적어도 실질적으로 동일한 기능(들)을, 적어도 실질적으로 동일한 방식(들)으로 수행하여, 개시된 구현예들과 적어도 실질적으로 동일한 결과(들)을 달성할 것이라는 점을 이해할 것이다. 따라서, 이러한 구현예들 및 다른 구현예들이 본 출원에 의해 예상된다.
Claims (15)
- 3D 장면을 나타내는 데이터를 컨테이너로 인코딩하는 방법으로서,
- 제1 뷰 포인트에 따라 보이는 상기 3D 장면의 텍스처를 나타내는 제1 데이터를 상기 컨테이너의 제1 비디오 트랙으로 인코딩하는 단계;
- 상기 제1 뷰 포인트를 포함하는 한 세트의 뷰 포인트들에 따라 보이는 상기 3D 장면의 지오메트리를 나타내는 제2 데이터를 상기 컨테이너의 적어도 제2 비디오 트랙으로 인코딩하는 단계;
- 상기 제1 뷰 포인트를 제외한 상기 세트의 뷰 포인트들로부터만 보이는 상기 3D 장면의 텍스처를 나타내는 제3 데이터를 상기 컨테이너의 제3 비디오 트랙으로 인코딩하는 단계; 및
- 메타데이터를 상기 컨테이너로 인코딩하는 단계
를 포함하고,
상기 메타데이터는 상기 제1 비디오 트랙의 상기 제1 데이터, 상기 적어도 제2 비디오 트랙의 상기 제2 데이터 및 상기 제3 비디오 트랙의 상기 제3 데이터와 연관되고, 상기 메타데이터는 상기 제2 및 제3 데이터를 획득하기 위해 사용된 적어도 투영을 나타내는 정보를 포함하는, 방법. - 3D 장면을 나타내는 데이터를 컨테이너로 인코딩하도록 구성된 디바이스로서,
상기 디바이스는 적어도 하나의 프로세서와 연관된 메모리를 포함하고, 상기 적어도 하나의 프로세서는,
- 제1 뷰 포인트에 따라 보이는 상기 3D 장면의 텍스처를 나타내는 제1 데이터를 상기 컨테이너의 제1 비디오 트랙으로 인코딩하고;
- 상기 제1 뷰 포인트를 포함하는 한 세트의 뷰 포인트들에 따라 보이는 상기 3D 장면의 지오메트리를 나타내는 제2 데이터를 상기 컨테이너의 적어도 제2 비디오 트랙으로 인코딩하고;
- 상기 제1 뷰 포인트를 제외한 상기 세트의 뷰 포인트들로부터만 보이는 상기 3D 장면의 텍스처를 나타내는 제3 데이터를 상기 컨테이너의 제3 비디오 트랙으로 인코딩하고;
- 메타데이터를 상기 컨테이너로 인코딩하도록
구성되고,
상기 메타데이터는 상기 제1 비디오 트랙의 상기 제1 데이터, 상기 적어도 제2 비디오 트랙의 상기 제2 데이터 및 상기 제3 비디오 트랙의 상기 제3 데이터와 연관되고, 상기 메타데이터는 상기 제2 및 제3 데이터를 획득하기 위해 사용된 적어도 투영을 나타내는 정보를 포함하는, 디바이스. - 제1항의 방법 또는 제2항의 디바이스에 있어서,
상기 제1 비디오 트랙은 비트스트림의 제1 신택스 요소를 참조하고, 상기 적어도 제2 비디오 트랙은 상기 비트스트림의 적어도 제2 신택스 요소를 참조하고, 상기 제3 비디오 트랙은 상기 비트스트림의 제3 신택스 요소를 참조하는, 방법 또는 디바이스. - 제1항 또는 제3항의 방법 또는 제2항 또는 제3항의 디바이스에 있어서,
상기 제2 데이터는 상기 지오메트리를 획득하기 위해 사용된 투영의 포맷, 상기 투영의 파라미터들 및 상기 투영 파라미터들 중 적어도 일부가 동적으로 업데이트되는지를 표시하는 플래그를 나타내는 제1 정보를 포함하는, 방법 또는 디바이스. - 제1항, 제3항 또는 제4항의 방법 또는 제2항 내지 제4항 중 어느 한 항의 디바이스에 있어서,
상기 제3 데이터는 상기 텍스처를 획득하기 위해 사용된 투영의 포맷, 상기 투영의 파라미터들 및 상기 투영 파라미터들 중 적어도 일부가 동적으로 업데이트되는지를 표시하는 플래그를 나타내는 제2 정보를 포함하는, 방법 또는 디바이스. - 제4항 또는 제5항의 방법 또는 제4항 또는 제5항의 디바이스에 있어서,
상기 제1 정보 및 제2 정보가 동일할 때 상기 제1 비디오 트랙 및 상기 적어도 제2 비디오 트랙은 동일한 트랙 그룹으로 그룹화되는, 방법 또는 디바이스. - 제1항 및 제3항 내지 제6항 중 어느 한 항의 방법 또는 제2항 내지 제6항 중 어느 한 항의 디바이스에 있어서,
상기 메타데이터는 다음의 정보:
- 상기 지오메트리 및 텍스처를 획득하기 위해 사용된 적어도 하나의 투영과 연관된 적어도 하나의 뷰 포인트를 나타내는 정보;
- 지오메트리의 직사각형 2D 패치들의 패킹을 나타내는 정보 - 지오메트리의 각각의 패치는 상기 3D 장면의 한 부분의 상기 투영과 연관됨 -;
- 텍스처의 직사각형 2D 패치들의 패킹을 나타내는 정보 - 텍스처의 각각의 패치는 상기 3D 장면의 한 부분의 투영과 연관됨 -;
- 다수의 3D 패치들을 나타내는 정보 - 각각의 3D 패치는 상기 3D 장면의 한 부분과 연관되고 상기 제2 트랙 및 상기 제1 비디오 트랙 내 또는 상기 제3 비디오 트랙 내 식별자와 연관됨 - 중 적어도 하나
를 포함하는, 방법 또는 디바이스. - 컨테이너로부터 3D 장면을 나타내는 데이터를 디코딩하는 방법으로서,
- 상기 컨테이너의 제1 비디오 트랙으로부터, 제1 뷰 포인트에 따라 보이는 상기 3D 장면의 텍스처를 나타내는 제1 데이터를 디코딩하는 단계;
- 상기 컨테이너의 적어도 제2 비디오 트랙으로부터, 상기 제1 뷰 포인트를 포함하는 한 세트의 뷰 포인트들에 따라 보이는 상기 3D 장면의 지오메트리를 나타내는 제2 데이터를 디코딩하는 단계;
- 상기 컨테이너의 제3 비디오 트랙으로부터, 상기 제1 뷰 포인트를 제외한 상기 세트의 뷰 포인트들로부터만 보이는 상기 3D 장면의 텍스처를 나타내는 제3 데이터를 디코딩하는 단계; 및
- 상기 컨테이너로부터 메타데이터를 디코딩하는 단계
를 포함하고,
상기 메타데이터는 상기 제1 비디오 트랙의 상기 제1 데이터, 상기 적어도 제2 비디오 트랙의 상기 제2 데이터 및 상기 제3 비디오 트랙의 상기 제3 데이터와 연관되고, 상기 메타데이터는 상기 제2 및 제3 데이터를 획득하기 위해 사용된 적어도 투영을 나타내는 정보를 포함하는, 방법. - 컨테이너로부터 3D 장면을 나타내는 데이터를 디코딩하기 위해 구성된 디바이스로서,
상기 디바이스는 적어도 하나의 프로세서와 연관된 메모리를 포함하고, 상기 적어도 하나의 프로세서는,
- 상기 컨테이너의 제1 비디오 트랙으로부터, 제1 뷰 포인트에 따라 보이는 상기 3D 장면의 텍스처를 나타내는 제1 데이터를 디코딩하고;
- 상기 컨테이너의 적어도 제2 비디오 트랙으로부터, 상기 제1 뷰 포인트를 포함하는 한 세트의 뷰 포인트들에 따라 보이는 상기 3D 장면의 지오메트리를 나타내는 제2 데이터를 디코딩하고;
- 상기 컨테이너의 제3 비디오 트랙으로부터, 상기 제1 뷰 포인트를 제외한 상기 세트의 뷰 포인트들로부터만 보이는 상기 3D 장면의 텍스처를 나타내는 제3 데이터를 디코딩하고;
- 상기 컨테이너로부터 메타데이터를 디코딩하도록
구성되고,
상기 메타데이터는 상기 제1 비디오 트랙의 상기 제1 데이터, 상기 적어도 제2 비디오 트랙의 상기 제2 데이터 및 상기 제3 비디오 트랙의 상기 제3 데이터와 연관되고, 상기 메타데이터는 상기 제2 및 제3 데이터를 획득하기 위해 사용된 적어도 투영을 나타내는 정보를 포함하는, 디바이스. - 제8항의 방법 또는 제9항의 디바이스에 있어서,
상기 제1 비디오 트랙은 비트스트림의 제1 신택스 요소를 참조하고, 상기 적어도 제2 비디오 트랙은 상기 비트스트림의 적어도 제2 신택스 요소를 참조하고, 상기 제3 비디오 트랙은 상기 비트스트림의 제3 신택스 요소를 참조하는, 방법 또는 디바이스. - 제8항 또는 제10항의 방법 또는 제9항 또는 제10항의 디바이스에 있어서,
상기 제2 데이터는 상기 지오메트리를 획득하기 위해 사용된 투영의 포맷, 상기 투영의 파라미터들 및 상기 투영 파라미터들 중 적어도 일부가 동적으로 업데이트되는지를 표시하는 플래그를 나타내는 제1 정보를 포함하는, 방법 또는 디바이스. - 제 8항, 제10항 또는 제11항의 방법 또는 제9항 내지 제11항 중 어느 한 항의 디바이스에 있어서,
상기 제3 데이터는 상기 지오메트리를 획득하기 위해 사용된 투영의 포맷, 상기 투영의 파라미터들 및 상기 투영 파라미터들 중 적어도 일부가 동적으로 업데이트되는지를 표시하는 플래그를 나타내는 제2 정보를 포함하는, 방법 또는 디바이스. - 제11항 또는 제12항의 방법 또는 제11항 또는 제12항의 디바이스에 있어서,
상기 제1 정보 및 제2 정보가 동일할 때 상기 제1 비디오 트랙 및 상기 적어도 제2 비디오 트랙은 동일한 트랙 그룹으로 그룹화되는, 방법 또는 디바이스. - 제8항 및 제10항 내지 제13항 중 어느 한 항의 방법 또는 제9항 내지 제13항 중 어느 한 항의 디바이스에 있어서,
상기 메타데이터는 다음의 정보:
- 상기 지오메트리 및 텍스처를 획득하기 위해 사용된 적어도 하나의 투영과 연관된 적어도 하나의 뷰 포인트를 나타내는 정보;
- 지오메트리의 패치들의 패킹을 나타내는 정보 - 지오메트리의 각각의 패치는 상기 3D 장면의 한 부분의 상기 투영과 연관됨 -;
- 텍스처의 패치들의 패킹을 나타내는 정보 - 텍스처의 각각의 패치는 상기 3D 장면의 한 부분의 상기 투영과 연관됨 -;
- 다수의 3D 패치들을 나타내는 정보 - 각각의 패치는 상기 3D 장면의 한 부분과 연관되고 상기 제2 트랙 및 상기 제1 비디오 트랙 내 또는 상기 제3 비디오 트랙 내 식별자와 연관됨 - 중 적어도 하나
를 포함하는, 방법 또는 디바이스. - 3D 장면을 나타내는 데이터를 반송하는 비트스트림으로서,
상기 데이터는,
컨테이너의 제1 비디오 트랙 내의, 제1 뷰 포인트에 따라 보이는 상기 3D 장면의 텍스처를 나타내는 제1 데이터; 상기 컨테이너의 적어도 제2 비디오 트랙 내의, 상기 제1 뷰 포인트를 포함하는 뷰 포인트들의 세트에 따라 보이는 상기 3D 장면의 지오메트리를 나타내는 제2 데이터; 상기 컨테이너의 제3 비디오 트랙 내의, 상기 제1 뷰 포인트를 제외한 상기 세트의 뷰 포인트들로부터만 보이는 상기 3D 장면의 텍스처를 나타내는 제3 데이터; 및 컨테이너 내 메타데이터를 포함하고,
상기 메타데이터는 상기 제1 비디오 트랙의 상기 제1 데이터, 상기 적어도 제2 비디오 트랙의 상기 제2 데이터 및 상기 제3 비디오 트랙의 상기 제3 데이터와 연관되고, 상기 메타데이터는 상기 제2 및 제3 데이터를 획득하기 위해 사용된 적어도 투영을 나타내는 정보를 포함하는, 비트스트림.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP17306443.7 | 2017-10-20 | ||
| EP17306443.7A EP3474562A1 (en) | 2017-10-20 | 2017-10-20 | Method, apparatus and stream for volumetric video format |
| PCT/US2018/054110 WO2019079032A1 (en) | 2017-10-20 | 2018-10-03 | METHOD, APPARATUS AND FLOW FOR VOLUMETRIC VIDEO FORMAT |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20200065076A true KR20200065076A (ko) | 2020-06-08 |
Family
ID=60245017
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020207014179A Withdrawn KR20200065076A (ko) | 2017-10-20 | 2018-10-03 | 볼류메트릭 비디오 포맷을 위한 방법, 장치 및 스트림 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US20210195162A1 (ko) |
| EP (2) | EP3474562A1 (ko) |
| KR (1) | KR20200065076A (ko) |
| CN (1) | CN111434121A (ko) |
| BR (1) | BR112020007727A2 (ko) |
| WO (1) | WO2019079032A1 (ko) |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021256909A1 (ko) * | 2020-06-19 | 2021-12-23 | 엘지전자 주식회사 | 포인트 클라우드 데이터 송신 장치, 포인트 클라우드 데이터 송신 방법, 포인트 클라우드 데이터 수신 장치 및 포인트 클라우드 데이터 수신 방법 |
| WO2021261865A1 (ko) * | 2020-06-21 | 2021-12-30 | 엘지전자 주식회사 | 포인트 클라우드 데이터 송신 장치, 포인트 클라우드 데이터 송신 방법, 포인트 클라우드 데이터 수신 장치 및 포인트 클라우드 데이터 수신 방법 |
| WO2021261897A1 (ko) * | 2020-06-23 | 2021-12-30 | 엘지전자 주식회사 | 포인트 클라우드 데이터 송신 장치, 포인트 클라우드 데이터 송신 방법, 포인트 클라우드 데이터 수신 장치 및 포인트 클라우드 데이터 수신 방법 |
| WO2022019713A1 (ko) * | 2020-07-23 | 2022-01-27 | 엘지전자 주식회사 | 포인트 클라우드 데이터 송신 장치, 포인트 클라우드 데이터 송신 방법, 포인트 클라우드 데이터 수신 장치 및 포인트 클라우드 데이터 수신 방법 |
| WO2022035250A1 (ko) * | 2020-08-12 | 2022-02-17 | 엘지전자 주식회사 | 포인트 클라우드 데이터 송신 장치, 포인트 클라우드 데이터 송신 방법, 포인트 클라우드 데이터 수신 장치 및 포인트 클라우드 데이터 수신 방법 |
| WO2022050612A1 (ko) * | 2020-09-07 | 2022-03-10 | 엘지전자 주식회사 | 포인트 클라우드 데이터 전송장치, 포인트 클라우드 데이터 전송방법, 포인트 클라우드 데이터 수신장치 및 포인트 클라우드 데이터 수신방법 |
| WO2022055165A1 (ko) * | 2020-09-11 | 2022-03-17 | 엘지전자 주식회사 | 포인트 클라우드 데이터 송신 장치, 포인트 클라우드 데이터 송신 방법, 포인트 클라우드 데이터 수신 장치 및 포인트 클라우드 데이터 수신 방법 |
Families Citing this family (70)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11818401B2 (en) | 2017-09-14 | 2023-11-14 | Apple Inc. | Point cloud geometry compression using octrees and binary arithmetic encoding with adaptive look-up tables |
| US10897269B2 (en) | 2017-09-14 | 2021-01-19 | Apple Inc. | Hierarchical point cloud compression |
| US11113845B2 (en) | 2017-09-18 | 2021-09-07 | Apple Inc. | Point cloud compression using non-cubic projections and masks |
| US10909725B2 (en) | 2017-09-18 | 2021-02-02 | Apple Inc. | Point cloud compression |
| US10607373B2 (en) | 2017-11-22 | 2020-03-31 | Apple Inc. | Point cloud compression with closed-loop color conversion |
| CN118921537A (zh) * | 2018-04-06 | 2024-11-08 | 华为技术有限公司 | 将文件格式对象和基于超文本传输协议的动态自适应流媒体(dash)对象进行关联 |
| US10939129B2 (en) | 2018-04-10 | 2021-03-02 | Apple Inc. | Point cloud compression |
| US11010928B2 (en) | 2018-04-10 | 2021-05-18 | Apple Inc. | Adaptive distance based point cloud compression |
| US10909727B2 (en) | 2018-04-10 | 2021-02-02 | Apple Inc. | Hierarchical point cloud compression with smoothing |
| US10909726B2 (en) | 2018-04-10 | 2021-02-02 | Apple Inc. | Point cloud compression |
| US11017566B1 (en) | 2018-07-02 | 2021-05-25 | Apple Inc. | Point cloud compression with adaptive filtering |
| US11202098B2 (en) | 2018-07-05 | 2021-12-14 | Apple Inc. | Point cloud compression with multi-resolution video encoding |
| US11012713B2 (en) | 2018-07-12 | 2021-05-18 | Apple Inc. | Bit stream structure for compressed point cloud data |
| US11558597B2 (en) * | 2018-08-13 | 2023-01-17 | Lg Electronics Inc. | Method for transmitting video, apparatus for transmitting video, method for receiving video, and apparatus for receiving video |
| US11367224B2 (en) | 2018-10-02 | 2022-06-21 | Apple Inc. | Occupancy map block-to-patch information compression |
| US11430155B2 (en) | 2018-10-05 | 2022-08-30 | Apple Inc. | Quantized depths for projection point cloud compression |
| US11823421B2 (en) * | 2019-03-14 | 2023-11-21 | Nokia Technologies Oy | Signalling of metadata for volumetric video |
| US11457231B2 (en) * | 2019-03-15 | 2022-09-27 | Mediatek Singapore Pte. Ltd. | Methods and apparatus for signaling spatial relationships for point cloud multimedia data tracks |
| US11245926B2 (en) | 2019-03-19 | 2022-02-08 | Mediatek Singapore Pte. Ltd. | Methods and apparatus for track derivation for immersive media data tracks |
| US11057564B2 (en) | 2019-03-28 | 2021-07-06 | Apple Inc. | Multiple layer flexure for supporting a moving image sensor |
| EP3973713A1 (en) | 2019-05-23 | 2022-03-30 | VID SCALE, Inc. | Video-based point cloud streams |
| US11388437B2 (en) | 2019-06-28 | 2022-07-12 | Tencent America LLC | View-position and angle dependent processing of point cloud data |
| CN115514972B (zh) * | 2019-06-28 | 2025-07-15 | 腾讯美国有限责任公司 | 视频编解码的方法、装置、电子设备及存储介质 |
| CN114009054B (zh) * | 2019-06-28 | 2024-08-09 | 索尼集团公司 | 信息处理装置和方法、再现处理装置和方法 |
| US11711544B2 (en) | 2019-07-02 | 2023-07-25 | Apple Inc. | Point cloud compression with supplemental information messages |
| US11122102B2 (en) | 2019-07-03 | 2021-09-14 | Lg Electronics Inc. | Point cloud data transmission apparatus, point cloud data transmission method, point cloud data reception apparatus and point cloud data reception method |
| EP3793199A1 (en) * | 2019-09-10 | 2021-03-17 | InterDigital VC Holdings, Inc. | A method and apparatus for delivering a volumetric video content |
| WO2021052799A1 (en) * | 2019-09-19 | 2021-03-25 | Interdigital Ce Patent Holdings | Devices and methods for generating and rendering immersive video |
| US11627314B2 (en) | 2019-09-27 | 2023-04-11 | Apple Inc. | Video-based point cloud compression with non-normative smoothing |
| BR112022005789A2 (pt) | 2019-09-27 | 2022-06-21 | Vid Scale Inc | Dispositivo de decodificação e codificação de vídeo, e, método para decodificação de vídeo |
| US11562507B2 (en) | 2019-09-27 | 2023-01-24 | Apple Inc. | Point cloud compression using video encoding with time consistent patches |
| US10977855B1 (en) * | 2019-09-30 | 2021-04-13 | Verizon Patent And Licensing Inc. | Systems and methods for processing volumetric data using a modular network architecture |
| EP4013042A1 (en) * | 2019-09-30 | 2022-06-15 | Sony Group Corporation | Information processing device, reproduction processing device, and information processing method |
| US11902540B2 (en) | 2019-10-01 | 2024-02-13 | Intel Corporation | Immersive video coding using object metadata |
| WO2021063887A1 (en) * | 2019-10-02 | 2021-04-08 | Interdigital Vc Holdings France, Sas | A method and apparatus for encoding, transmitting and decoding volumetric video |
| US11538196B2 (en) | 2019-10-02 | 2022-12-27 | Apple Inc. | Predictive coding for point cloud compression |
| US11895307B2 (en) | 2019-10-04 | 2024-02-06 | Apple Inc. | Block-based predictive coding for point cloud compression |
| EP3829166A1 (en) * | 2019-11-29 | 2021-06-02 | InterDigital CE Patent Holdings | A method and apparatus for decoding a 3d video |
| WO2021110940A1 (en) * | 2019-12-06 | 2021-06-10 | Koninklijke Kpn N.V. | Encoding and decoding views on volumetric image data |
| US12101507B2 (en) | 2019-12-19 | 2024-09-24 | Interdigital Ce Patent Holdings, Sas | Volumetric video with auxiliary patches |
| US11798196B2 (en) | 2020-01-08 | 2023-10-24 | Apple Inc. | Video-based point cloud compression with predicted patches |
| JP7477617B2 (ja) * | 2020-01-08 | 2024-05-01 | エルジー エレクトロニクス インコーポレイティド | ポイントクラウドデータ送信装置、ポイントクラウドデータ送信方法、ポイントクラウドデータ受信装置及びポイントクラウドデータ受信方法 |
| US11475605B2 (en) | 2020-01-09 | 2022-10-18 | Apple Inc. | Geometry encoding of duplicate points |
| KR102373833B1 (ko) * | 2020-01-09 | 2022-03-14 | 엘지전자 주식회사 | 포인트 클라우드 데이터 송신 장치, 포인트 클라우드 데이터 송신 방법, 포인트 클라우드 데이터 수신 장치 및 포인트 클라우드 데이터 수신 방법 |
| CN114930863B (zh) * | 2020-01-09 | 2023-08-08 | Lg电子株式会社 | 点云数据发送装置、点云数据发送方法、点云数据接收装置和点云数据接收方法 |
| EP4088480A4 (en) * | 2020-01-10 | 2023-12-06 | Nokia Technologies Oy | Storage of multiple atlases from one v-pcc elementary stream in isobmff |
| EP4090013A4 (en) * | 2020-01-10 | 2024-01-17 | LG Electronics Inc. | Point cloud data transmission device, point cloud data transmission method, point cloud data reception device, and point cloud data reception method |
| WO2021176133A1 (en) * | 2020-03-04 | 2021-09-10 | Nokia Technologies Oy | An apparatus, a method and a computer program for volumetric video |
| KR102406846B1 (ko) * | 2020-03-18 | 2022-06-10 | 엘지전자 주식회사 | 포인트 클라우드 데이터 송신 장치, 포인트 클라우드 데이터 송신 방법, 포인트 클라우드 데이터 수신 장치 및 포인트 클라우드 데이터 수신 방법 |
| WO2021201386A1 (ko) * | 2020-03-30 | 2021-10-07 | 엘지전자 주식회사 | 포인트 클라우드 데이터 송신 장치, 포인트 클라우드 데이터 송신 방법, 포인트 클라우드 데이터 수신 장치 및 포인트 클라우드 데이터 수신 방법 |
| EP4128747A4 (en) * | 2020-03-31 | 2024-03-13 | INTEL Corporation | METHODS AND APPARATUS FOR REPORTING ATLAS-ENABLED VIEWS IN IMMERSIVE VIDEO |
| EP4135321A4 (en) * | 2020-04-11 | 2024-03-27 | LG Electronics, Inc. | Point cloud data transmission device, point cloud data transmission method, point cloud data reception device and point cloud data reception method |
| CN115380528B (zh) * | 2020-04-11 | 2024-03-29 | Lg电子株式会社 | 点云数据发送设备、点云数据发送方法、点云数据接收设备和点云数据接收方法 |
| CN115443652B (zh) * | 2020-04-11 | 2024-02-20 | Lg电子株式会社 | 点云数据发送设备、点云数据发送方法、点云数据接收设备和点云数据接收方法 |
| WO2021210867A1 (ko) * | 2020-04-12 | 2021-10-21 | 엘지전자 주식회사 | 포인트 클라우드 데이터 송신 장치, 포인트 클라우드 데이터 송신 방법, 포인트 클라우드 데이터 수신 장치 및 포인트 클라우드 데이터 수신 방법 |
| WO2021210860A1 (ko) * | 2020-04-12 | 2021-10-21 | 엘지전자 주식회사 | 포인트 클라우드 데이터 송신 장치, 포인트 클라우드 데이터 송신 방법, 포인트 클라우드 데이터 수신 장치 및 포인트 클라우드 데이터 수신 방법 |
| US11615557B2 (en) | 2020-06-24 | 2023-03-28 | Apple Inc. | Point cloud compression using octrees with slicing |
| US11695957B2 (en) * | 2020-06-24 | 2023-07-04 | Samsung Electronics Co., Ltd. | Tiling for video based point cloud compression |
| US11620768B2 (en) | 2020-06-24 | 2023-04-04 | Apple Inc. | Point cloud geometry compression using octrees with multiple scan orders |
| CN114078191B (zh) * | 2020-08-18 | 2025-04-29 | 腾讯科技(深圳)有限公司 | 一种点云媒体的数据处理方法、装置、设备及介质 |
| CN111986335B (zh) * | 2020-09-01 | 2021-10-22 | 贝壳找房(北京)科技有限公司 | 纹理贴图方法和装置、计算机可读存储介质、电子设备 |
| KR102715954B1 (ko) | 2021-01-15 | 2024-10-11 | 지티이 코포레이션 | 다중-트랙 기반 몰입형 미디어 플레이아웃 |
| US11948338B1 (en) | 2021-03-29 | 2024-04-02 | Apple Inc. | 3D volumetric content encoding using 2D videos and simplified 3D meshes |
| JP7809720B2 (ja) * | 2021-04-07 | 2026-02-02 | インターディジタル・シーイー・パテント・ホールディングス・ソシエテ・パ・アクシオンス・シンプリフィエ | 光効果をサポートする容積ビデオ |
| US12149738B2 (en) * | 2021-04-13 | 2024-11-19 | Samsung Electronics Co., Ltd. | MPEG media transport (MMT) signaling of visual volumetric video-based coding (V3C) content |
| US11956409B2 (en) * | 2021-08-23 | 2024-04-09 | Tencent America LLC | Immersive media interoperability |
| CN115883871B (zh) * | 2021-08-23 | 2024-08-09 | 腾讯科技(深圳)有限公司 | 媒体文件封装与解封装方法、装置、设备及存储介质 |
| US12137336B2 (en) * | 2021-08-23 | 2024-11-05 | Tencent America LLC | Immersive media compatibility |
| US12597170B2 (en) * | 2022-04-15 | 2026-04-07 | Research & Business Foundation Sungkyunkwan University | Method and apparatus for immersive video encoding and decoding, and method for transmitting a bitstream generated by the immersive video encoding method |
| CN115914718B (zh) * | 2022-11-08 | 2024-09-13 | 天津萨图芯科技有限公司 | 截取引擎渲染内容的虚拟制片视频重映方法及系统 |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5877779A (en) * | 1995-07-06 | 1999-03-02 | Sun Microsystems, Inc. | Method and apparatus for efficient rendering of three-dimensional scenes |
| WO2012132267A1 (ja) * | 2011-03-31 | 2012-10-04 | パナソニック株式会社 | 全方向ステレオ画像出力装置 |
| KR101649207B1 (ko) * | 2011-08-31 | 2016-08-19 | 노키아 테크놀로지스 오와이 | 멀티뷰 비디오 코딩 및 디코딩을 위한 방법, 장치 및 컴퓨터 프로그램 |
| WO2013162259A1 (ko) * | 2012-04-23 | 2013-10-31 | 삼성전자 주식회사 | 다시점 비디오 부호화 방법 및 장치, 다시점 비디오 복호화 방법 및 장치 |
| BR112015026131A2 (pt) * | 2013-05-10 | 2017-07-25 | Koninklijke Philips Nv | método de codificação de um sinal de dados de vídeo para uso em um dispositivo de renderização de múltiplas vistas, sinal de dados de vídeo para uso em um dispositivo de renderização de múltiplas vistas, portadora de dados, método de decodificação de um sinal de dados de vídeo, decodificador para decodificar um sinal de dados de vídeo, produto de programa de computador, e, codificador de um sinal de dados de vídeo para uso em um dispositivo de renderização de múltiplas vistas |
| EP3419295A4 (en) * | 2016-02-17 | 2019-08-28 | LG Electronics Inc. | 360 VIDEO TRANSMISSION METHOD, 360 VIDEO RECEIVING METHOD, 360 VIDEO TRANSMISSION APPARATUS, AND 360 VIDEO RECEIVING DEVICE |
| WO2017145757A1 (ja) * | 2016-02-22 | 2017-08-31 | ソニー株式会社 | ファイル生成装置およびファイル生成方法、並びに、再生装置および再生方法 |
-
2017
- 2017-10-20 EP EP17306443.7A patent/EP3474562A1/en not_active Withdrawn
-
2018
- 2018-10-03 US US16/757,391 patent/US20210195162A1/en not_active Abandoned
- 2018-10-03 BR BR112020007727-5A patent/BR112020007727A2/pt not_active Application Discontinuation
- 2018-10-03 KR KR1020207014179A patent/KR20200065076A/ko not_active Withdrawn
- 2018-10-03 CN CN201880078058.4A patent/CN111434121A/zh active Pending
- 2018-10-03 EP EP18789554.5A patent/EP3698551A1/en not_active Withdrawn
- 2018-10-03 WO PCT/US2018/054110 patent/WO2019079032A1/en not_active Ceased
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021256909A1 (ko) * | 2020-06-19 | 2021-12-23 | 엘지전자 주식회사 | 포인트 클라우드 데이터 송신 장치, 포인트 클라우드 데이터 송신 방법, 포인트 클라우드 데이터 수신 장치 및 포인트 클라우드 데이터 수신 방법 |
| WO2021261865A1 (ko) * | 2020-06-21 | 2021-12-30 | 엘지전자 주식회사 | 포인트 클라우드 데이터 송신 장치, 포인트 클라우드 데이터 송신 방법, 포인트 클라우드 데이터 수신 장치 및 포인트 클라우드 데이터 수신 방법 |
| US11601634B2 (en) | 2020-06-21 | 2023-03-07 | Lg Electronics Inc. | Point cloud data transmission device, point cloud data transmission method, point cloud data reception device, and point cloud data reception method |
| WO2021261897A1 (ko) * | 2020-06-23 | 2021-12-30 | 엘지전자 주식회사 | 포인트 클라우드 데이터 송신 장치, 포인트 클라우드 데이터 송신 방법, 포인트 클라우드 데이터 수신 장치 및 포인트 클라우드 데이터 수신 방법 |
| US11908168B2 (en) | 2020-06-23 | 2024-02-20 | Lg Electronics Inc. | Point cloud data transmission device, point cloud data transmission method, point cloud data reception device, and point cloud data reception method |
| WO2022019713A1 (ko) * | 2020-07-23 | 2022-01-27 | 엘지전자 주식회사 | 포인트 클라우드 데이터 송신 장치, 포인트 클라우드 데이터 송신 방법, 포인트 클라우드 데이터 수신 장치 및 포인트 클라우드 데이터 수신 방법 |
| WO2022035250A1 (ko) * | 2020-08-12 | 2022-02-17 | 엘지전자 주식회사 | 포인트 클라우드 데이터 송신 장치, 포인트 클라우드 데이터 송신 방법, 포인트 클라우드 데이터 수신 장치 및 포인트 클라우드 데이터 수신 방법 |
| WO2022050612A1 (ko) * | 2020-09-07 | 2022-03-10 | 엘지전자 주식회사 | 포인트 클라우드 데이터 전송장치, 포인트 클라우드 데이터 전송방법, 포인트 클라우드 데이터 수신장치 및 포인트 클라우드 데이터 수신방법 |
| US12354310B2 (en) | 2020-09-07 | 2025-07-08 | Lg Electronics Inc. | Point cloud data transmission device, point cloud data transmission method, point cloud data reception device, and point cloud data reception method |
| WO2022055165A1 (ko) * | 2020-09-11 | 2022-03-17 | 엘지전자 주식회사 | 포인트 클라우드 데이터 송신 장치, 포인트 클라우드 데이터 송신 방법, 포인트 클라우드 데이터 수신 장치 및 포인트 클라우드 데이터 수신 방법 |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2019079032A1 (en) | 2019-04-25 |
| EP3698551A1 (en) | 2020-08-26 |
| BR112020007727A2 (pt) | 2020-10-13 |
| CN111434121A (zh) | 2020-07-17 |
| EP3474562A1 (en) | 2019-04-24 |
| US20210195162A1 (en) | 2021-06-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20200065076A (ko) | 볼류메트릭 비디오 포맷을 위한 방법, 장치 및 스트림 | |
| US11647177B2 (en) | Method, apparatus and stream for volumetric video format | |
| KR102600011B1 (ko) | 3 자유도 및 볼류메트릭 호환 가능한 비디오 스트림을 인코딩 및 디코딩하기 위한 방법들 및 디바이스들 | |
| EP3562159A1 (en) | Method, apparatus and stream for volumetric video format | |
| JP7785676B2 (ja) | 補助パッチを有する容積ビデオ | |
| JP7809720B2 (ja) | 光効果をサポートする容積ビデオ | |
| EP3547703A1 (en) | Method, apparatus and stream for volumetric video format | |
| US12212784B2 (en) | Different atlas packings for volumetric video | |
| US20250317542A1 (en) | Method and apparatus for encoding and decoding volumetric content in and from a data stream | |
| KR102607709B1 (ko) | 3 자유도 및 볼류메트릭 호환 가능한 비디오 스트림을 인코딩 및 디코딩하기 위한 방법들 및 디바이스들 | |
| EP3709659A1 (en) | A method and apparatus for encoding and decoding volumetric video | |
| RU2807582C2 (ru) | Способ, устройство и поток для формата объемного видео |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20200518 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| PG1501 | Laying open of application | ||
| PC1202 | Submission of document of withdrawal before decision of registration |
Comment text: [Withdrawal of Procedure relating to Patent, etc.] Withdrawal (Abandonment) Patent event code: PC12021R01D Patent event date: 20210712 |
|
| WITB | Written withdrawal of application |