메발로네이트-독립적 (MEP) 경로를 변경시키는 것에 의한 테르페노이드의 증가된 생성을 위한 대사 조작 전략이 본원에 기재된다. MEP, 또는 테르페노이드, 경로는, 상업적으로 가치있는 테르페노이드 및 다른 화합물을 생성하기 위한 다양한 하류 과정에서 사용될 수 있는 생성물인 게라닐 피로포스페이트 (GPP)를 생성한다.
또한, 네이티브 대장균 ispD 및 ispF에 의해 수행되는 반응 둘 다를 촉매할 수 있는 2작용성 효소 ispDF가 본원에 기재된다. 2작용성 효소는 다양한 시험관내 또는 생체내 이소프렌, 테르페노이드, 또는 칸나비노이드 생성 시스템에서 사용될 수 있다. 일부 구현예에서, 본원에 기재된 대사 조작 전략은, ispDF와 함께 또는 이것 없이, 이종 숙주 세포에서 이소프렌, GPP, 또는 하류 테르페노이드의 생성을 증가시키기 위해 사용될 수 있다.
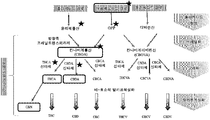
GPP는 칸나비노이드 경로의 제1 효소, 칸나비게롤산 신타제 (CBGAS), 방향족 프레닐트랜스퍼라제 효소에 대한 기질이다 (도 1). CBGAS는 기질 GPP 및 올리베톨산 (OA)을 사용하여 칸나비게롤산 (CBGA)을 생성한다. 일부 경우에, CBGA는, THCA 신타제 (THCAS)에 의해 촉매화된 반응을 통해 Δ9-테트라히드로칸나비놀산 (THCA)을, 또는 CBDA 신타제 (CBDAS)에 의해 촉매화된 반응을 통해 칸나비디올산 (CBDA)을 생성하는 것과 같은, 추가의 시험관내 또는 생체내 효소-촉매화된 반응에 대한 기질로서 사용될 수 있다. 칸나비노이드의 생성에 대한 추가의 경로는 Thakur et al., Life Sciences, 78 (2005) 454-466에 기재된 것들을 포함하나, 이에 제한되지는 않는다. Thakur 등의 문헌은 그 전체가 모든 목적상 본원에 참조로 포함되며, 이는 본원에 기재된 효소, 생성물, 효소 기질, 경로 및 그의 부분, 및 합성 체계를 포함하나, 이에 제한되지는 않는다.
일부 구현예에서, 기질 CBGA, THCA, CBDA, CBCA, THCVA, CBCVA, CBDVA, 및 이들의 조합이 관여하는 하류 효소-촉매화된 반응의 생성물은, 예를 들어 도 1에 도시된 바와 같이, 다양한 칸나비노이드를 생성하기 위한 화학적, 효소적, 또는 열적 수단을 사용하여 시험관내 또는 생체내에서 탈카르복실화될 수 있다.
정의
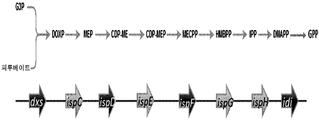
하기 약어가 본원에서 사용된다:"G3P"는 글리세르알데히드 3-포스페이트를 의미하고; "DOXP"는 1-데옥시-D-크실룰로스 5-포스페이트를 의미하고; "MEP"는 2-C-메틸에리트리톨 4-포스페이트를 의미하고; "CDP-ME"는 4-디포스포시티딜-2-C-메틸에리트리톨을 의미하고; "CDP-MEP"는 4-디포스포시티딜-2-C-메틸-D-에리트리톨 2-포스페이트를 의미하고; "MECPP"는 2-C-메틸-D-에리트리톨 2,4-시클로디포스페이트를 의미하고; "HMBPP"는 (E)-4-히드록시-3-메틸-부트-2-에닐 피로포스페이트를 의미하고; "IPP"는 이소펜테닐 디스포스페이트를 의미하고; "DMAPP"는 디메틸알릴 디포스페이트를 의미하고; "GPP"는 게라닐 피로포스페이트를 의미한다.
"DXP 경로" 및 "MEP 경로"는 메발로네이트-독립적 경로로서 또한 공지된 비-메발로네이트 경로를 지칭한다. MEP 경로의 유전자는 dxs, ispC, ispD, ispE, ispF, ispG, ispH, 및 idi이다. DXP 또는 MEP 경로 유전자 또는 유전자 생성물, 또는 이를 코딩하는 핵산과 관련하여, 유전자는, 예를 들어, 이종 핵산이 존재하는 숙주 세포의 네이티브 유전자, 그의 코돈 적합화된 버전, 상이한 유기체로부터 유래된 (예: 코돈 적합화된) 유전자, 또는 그의 오르토로그(orthologue)일 수 있다.
"dxs"는 DOXP 신타제를 지칭하고; "ispC"는 DOXP 리덕타제를 지칭하고; "ispD"는 2-C-메틸-D-에리트리톨 4-포스페이트 시티딜릴트랜스퍼라제를 지칭하고; "ispE"는 4-디포스포시티딜-2-C-메틸-D-에리트리톨 키나제를 지칭하고; "ispF"는 2-C-메틸-D-에리트리톨 2,4-시클로디포스페이트 신타제를 지칭하고; "ispG"는 HMB-PP 신타제를 지칭하고; "ispH"는 HMB-PP 리덕타제를 지칭하고; "idi"는 이소펜테닐/디메틸알릴 디포스페이트 이소머라제를 지칭하고; "ispA"는, DMAPP + IPP를 GPP로, 또한 GPP + IPP를 파르네실 피로포스페이트로 전환시킬 수 있는, "GPP 신타제"로도 공지된 파르네실 디포스페이트 신타제를 지칭한다.
용어 "ispDF"는 2개의 상이한 활성 자리를 갖고 ispD 활성 (EC 2.7.7.60) 및 ispF 활성 (EC 4.6.1.12)을 나타내는 2작용성 단일-쇄 효소를 지칭한다. 전형적으로, ispDF는 자연 발생 2작용성 효소 또는 하나 이상의 아미노산의 결실, 삽입, 또는 치환과 같은 하나 이상의 변형을 갖는 자연 발생 2작용성 효소의 유도체이다. 일부 경우에, 유전자는 식물-유래, 또는 칸나비스 유전자이다. 일부 경우에, 유전자는 대장균 유전자, 또는 그의 오르토로그이다.
"OA"는 올리베톨산을 지칭하고; "CBGA"는 칸나비게롤산을 지칭하고; "CBNA"는 칸나비네롤산을 지칭하고; ; "칸나비놀"또는 "CBN"은 6,6,9-트리메틸-3-펜틸벤조[c]크로멘-1-올을 지칭하고; "CBGVA"는 칸나비게리바린산을 지칭하고; "THCA"는 Δ9 이성질체를 포함한 테트라히드로칸나비놀산을 지칭하고; "CBDV"는 칸나비디바린을 지칭하고; "CBC"는 칸나비크로멘을 지칭하고; "CBCA"는 칸나비크로멘산을 지칭하고; "CBCV"는 칸나비크로메바린을 지칭하고; "CBG는 칸나비게롤을 지칭하고; "CBGB"는 칸나비게로바린을 지칭하고; "CBE"는 칸나비엘소인을 지칭하고; "CBL"은 칸나비시클롤을 지칭하고; "CBV"는 칸나비바린을 지칭하고; "CBT"는 칸나비트리올을 지칭하고; "THCV"는 테트라히드로칸니비바린 (THCV)을 지칭하고; "THC"는 테트라히드로칸나비놀을 지칭하고, "△9-THC"는 △9-테트라히드로칸나비놀을 지칭하고; "CBDA"는 칸나비디올산을 지칭한다.
본원에서 사용되는 바와 같이 "MEP 경로를 통한 증가된 플럭스"는 IPP 및/또는 DMAPP의 증가된 생성을 지칭한다. 전형적으로, IPP 및/또는 DMAPP의 생성은, 반응물로서 IPP 및/또는 DMAPP를 활용하는 리포터 효소의 작용에 의해 형성된 생성물을 검출함으로써 간접적으로 결정된다. 예를 들어, MEP 경로를 통한 증가된 플럭스는 리포터로서 이소프렌 신타제 (ispS)를 사용함으로써 증가된 이소프렌 생성으로서 검출될 수 있다. 또 다른 예로, MEP 경로를 통한 증가된 플럭스는 리포터로서 GPP 신타제를 사용함으로써 증가된 GPP 생성으로서 검출될 수 있다. 일부 경우에, GPP 생성은 리포터 효소를 사용하여 검출된다. 예를 들어, 증가된 GPP 생성은 GPP 신타제 효소 및 라이코펜 신타제 리포터 효소를 사용하여 증가된 라이코펜 생성을 검출함으로써 검출될 수 있고, 이로써 MEP 경로를 통한 증가된 플럭스를 검출한다. 또 다른 예로, 증가된 GPP 생성은 GPP 신타제 효소 및 모노테르펜 (예: 리모넨, 카렌, 미르센) 신타제 리포터 효소를 사용하여 증가된 모노테르펜 (예: 리모넨, 카렌, 미르센) 생성을 검출함으로써 검출될 수 있고, 이로써 MEP 경로를 통한 증가된 플럭스를 검출한다. 또 다른 예로, 증가된 GPP 생성은 GPP 신타제 효소 및 칸나비노이드 (예: CBGA) 신타제 리포터 효소를 사용하여 증가된 칸나비노이드 (예: CBGA) 생성을 검출함으로써 검출될 수 있고, 이로써 MEP 경로를 통한 증가된 플럭스를 검출한다. 전형적으로, 증가는, 시험 균주에서의 하나 이상의 이종 발현 카세트가 없는 대조 균주에 비해 적어도 10%이다. 일부 경우에, 증가는, 시험 균주에서의 하나 이상의 이종 발현 카세트가 없는 대조 균주에 비해 적어도 2배이다.
본원에서 사용되는 바와 같이, 용어 "칸나비디올", "CBD" 또는 "칸나비디올들"은 하기 화합물 중 하나 이상을 지칭하며, 특정 다른 입체이성질체 또는 입체이성질체들이 특정되지 않는 한, 화합물 "△2-칸나비디올"을 포함한다. 이들 화합물은 하기와 같다:(1) △5-칸나비디올 (2-(6-이소프로페닐-3-메틸-5-시클로헥센-1-일)-5-펜틸-1,3-벤젠디올); (2) △4-칸나비디올 (2-(6-이소프로페닐-3-메틸-4-시클로헥센-1-일)-5-펜틸-1,3-벤젠디올); (3) △3-칸나비디올 (2-(6-이소프로페닐-3-메틸-3-시클로헥센-1-일)-5-펜틸-1,3-벤젠디올); (4) △3,7-칸나비디올 (2-(6-이소프로페닐-3-메틸렌시클로헥스-1-일)-5-펜틸-1,3-벤젠디올); (5)△2-칸나비디올 (2-(6-이소프로페닐-3-메틸-2-시클로헥센-1-일)-5-펜틸-1,3-벤젠디올); (6) △1-칸나비디올 (2-(6-이소프로페닐-3-메틸-1-시클로헥센-1-일)-5-펜틸-1,3-벤젠디올); 및 (7) △6-칸나비디올 (2-(6-이소프로페닐-3-메틸-6-시클로헥센-1-일)-5-펜틸-1,3-벤젠디올).
이들 화합물은 하기에 언급되는 바와 같이 하나 이상의 키랄 중심 및 2개 이상의 입체이성질체를 갖는다:(1) (1) △5-칸나비디올은 2개의 키랄 중심 및 4개의 입체이성질체를 갖고; (2) △4-칸나비디올은 3개의 키랄 중심 및 8개의 입체이성질체를 갖고; (3) △3-칸나비디올은 2개의 키랄 중심 및 4개의 입체이성질체를 갖고; (4) △3,7-칸나비디올은 2개의 키랄 중심 및 4개의 이성질체를 갖고; (5) △2-칸나비디올은 2개의 키랄 중심 및 4개의 입체이성질체를 갖고; (6) △1-칸나비디올은 2개의 키랄 중심 및 4개의 입체이성질체를 갖고; (7) △6-칸나비디올은 1개의 키랄 중심 및 2개의 입체이성질체를 갖는다. 바람직한 구현예에서, 칸나비디올은 구체적으로 D2-칸나비디올이다. 구체적으로 언급되지 않는 한, "칸나비디올" "CBD" 또는 "칸나비디올들" 또는 상기에 언급된 구체적 칸나비디올 화합물 (1)-(7) 중 임의의 것의 언급은 언급에 의해 포함된 모든 화합물의 모든 가능한 입체이성질체를 포함한다. 하나의 구현예에서, "△2-칸나비디올"은 이종 시스템에서 부분적으로 또는 전적으로 생성된 △2-칸나비디올 입체이성질체의 혼합물일 수 있다.
용어 "이소프레노이드" 또는 "테르페노이드"는, 선형 및 시클릭 테르페노이드를 포함한, 하나 이상의 5-탄소 이소프렌 빌딩 블록을 포함하는 임의의 화합물을 지칭한다. 본원에서 사용되는 바와 같이, 용어 "테르펜"은 테르페노이드 및 이소프레노이드와 상호교환가능하다. 테르펜이 산화 또는 탄소 사슬의 재배열 등에 의해 화학적으로 변형된 경우, 생성된 화합물은 일반적으로 테르페노이드로 언급되며 또한 이소프레노이드라고도 불리운다.
테르페노이드는, 참조로서 5 및 10개의 탄소의 군을 사용하여, 존재하는 탄소 원자의 수에 따라 명명될 수 있다. 예를 들어 헤미테르페노이드 (C5)는 1개의 이소프렌 단위를 갖고 (절반-테르페노이드); 모노테르페노이드 (C10)는 2개의 이소프렌 단위를 갖고 (1개의 테르페노이드); 세스퀴테르페노이드 (C15)는 3개의 이소프렌 단위를 갖고 (1.5개의 테르페노이드); 디테르페노이드 (C20)는 4개의 이소프렌 단위를 갖는다 (또는 2개의 테르페노이드). 전형적으로, 모노테르페노이드는 C10 테르페노이드 전구체 게라닐 피로포스페이트 (GPP)로부터 자연에서 생성된다. 유사하게, "시클릭 모노테르펜"은 시클릭 또는 방향족 테르페노이드 (즉, 고리 구조를 포함함)를 지칭한다. 이는 2개의 이소프렌 빌딩 블록, 전형적으로 GPP로부터 만들어진다. 선형 모노테르펜은 게라니올, 리날로올, 오시멘, 및 미르센을 포함하나 이에 제한되지는 않는다. 시클릭 모노테르펜 (모노시클릭, 바이시클릭 및 트리시클릭)은 리모넨, 피넨, 카렌, 테르피네올, 테르피놀렌, 펠란드렌, 투젠, 트리시클렌, 보르네올, 사비넨, 및 캄펜을 포함하나, 이에 제한되지는 않는다.
"테르페노이드 신타제"는 하나의 테르페노이드 또는 테르페노이드 전구체의 또 다른 테르페노이드 또는 테르페노이드 전구체로의 전환을 촉매할 수 있는 효소를 지칭한다. 예를 들어, GPP 신타제는, 예를 들어 테르페노이드 전구체 IPP 및 DMAPP로부터의 GPP의 형성을 촉매하는 효소이다. 유사하게, FPP 신타제는, 예를 들어 GPP 및 IPP로부터의 FPP의 생성을 촉매하는 효소이다. 테르펜 신타제는 프레닐 디포스페이트 (예컨대 GPP)의 이소프레노이드 또는 이소프레노이드 전구체로의 전환을 촉매하는 효소이다. 용어는 선형 및 시클릭 테르펜 신타제 둘 다를 포함한다.
"시클릭 테르페노이드 신타제"는 고리 구조를 제공하도록 테르페노이드 또는 테르페노이드 전구체를 변형시키는 반응을 촉매할 수 있는 효소를 지칭한다. 예를 들어, 시클릭 모노테르페노이드 신타제는 기질로서 선형 모노테르펜을 사용하여 시클릭 또는 방향족 (고리-함유) 모노테르페노이드 화합물을 생성할 수 있는 효소를 지칭한다. 일례는, 이는 선형 모노테르펜 전구체 GPP로부터의 시클릭 모노테르펜 사비넨의 형성을 촉매할 수 있는 사비넨 신타제이다. 본원에서 사용되는 바와 같이, 용어 "테르펜 신타제"는 테르페노이드 신타제와 상호교환가능하다.
프레닐 트랜스퍼라제 또는 이소프레닐 트랜스퍼라제 효소 (또한 프레닐 또는 이소프레닐 신타제라 불림)는 테르페노이드 또는 이소프레노이드 화합물의 피로포스페이트 전구체의 생성을 촉매할 수 있는 효소이다. 예시적 프레닐 트랜스퍼라제 또는 이소프레닐 트랜스퍼라제 효소는, 적합한 기질의 존재 하에 게라닐 디포스페이트 (GPP) 또는 파르네실 디포스페이트 (FPP)의 형성을 촉매할 수 있는 ispA이다.
"칸나비노이드 신타제"는 하기 활성 중 하나 이상을 촉매하는 효소를 지칭한다:CBGA의 THCA, CBDA, 또는 CBCA로의 고리화; CBGVA의 THCVA, CBCVA, CBDVA로의 고리화, CBGA를 형성하는 올리베톨산의 프레닐화, 및 이들의 조합.예시적 칸나비노이드 신타제는 칸나비스 속의 식물에서 자연 발생으로 나타나는 것들, 예컨대 칸나비스 사티바의 THCA 신타제, CBDA 신타제, 및 CBCA 신타제를 포함하나, 이에 제한되지는 않는다.
예시적 이소프레노이드, 테르페노이드, 칸나비노이드, 및 MEP 경로 폴리펩티드 및 핵산은 KEGG 데이터베이스에 기재된 것들을 포함한다. KEGG 데이터베이스는 수많은 예시적 이소프레노이드, 테르페노이드, 칸나비노이드, 및 MEP 경로 폴리펩티드 및 핵산의 아미노산 및 핵산 서열을 함유한다 (예를 들어, "genome.jp/kegg/pathway/map/map00100.html"의 월드-와이드 웹 및 그 안의 서열을 참조하며, 이들 각각은, 특히 이소프레노이드, 테르페노이드, 칸나비노이드, 및 MEP 경로 폴리펩티드 및 핵산의 아미노산 및 핵산 서열과 관련하여 그 전체가 참조로 포함된다). 신호 펩티드 및 이를 코딩하는 핵산을 함유하는 본원에 기재된 폴리펩티드는, 신호 펩티드가 제거되거나 다른 방식으로 부재하는 절단된 버전을 추가로 나타내는 것으로 이해된다.
본원에서 사용되는 바와 같이, 용어 "이종"은 자연적으로 함께 나타나지 않는 임의의 두 성분을 지칭한다. 예를 들어, 작동가능하게 연결된 프로모터에 대하여 이종인 유전자를 코딩하는 핵산은, 특정 게놈에서 작동가능하게 연결된 프로모터에 의해 그의 자연 상태에서 (예를 들어, 유전적으로 변형되지 않은 세포 내에서) 제어되지 않는 발현을 갖는 핵산이다. 본원에서 제공되는 바와 같이, 비-자연 발생 프로모터에 작동가능하게 연결된 모든 유전자는 "이종"으로 고려된다. 유사하게, 숙주 세포에 대해 "이종"인 유전자는, 특정 유기체의 유전적으로 변형되지 않은 세포에서 나타나지 않는 또는 상이한 게놈 또는 비-게놈 (예: 플라스미드) 위치에서 나타나는, 또는 유전적으로 변형되지 않은 세포에서 상이한 프로모터에 작동가능하게 연결된 유전자이다. 추가로, 숙주 세포에 대해 "이종"인 프로모터는, 특정 유기체의 유전적으로 변형되지 않은 세포에서 나타나지 않는 또는 상이한 게놈 또는 비-게놈 (예: 플라스미드) 위치에서 나타나는, 또는 유전적으로 변형되지 않은 세포에서 상이한 핵산에 작동가능하게 연결된 프로모터이다.
본원에서 사용되는 바와 같이, "발현 카세트"는 적어도 하나의 표적 유전자에 작동가능하게 연결된 프로모터 폴리뉴클레오티드를 포함하는 폴리뉴클레오티드 서열을 지칭하며, 여기서 프로모터는 적어도 하나의 작동가능하게 연결된 유전자에 대해 이종이거나, 프로모터는 이것이 존재하는 숙주 세포에 대해 이종이거나, 또는 적어도 하나의 작동가능하게 연결된 유전자는 숙주 세포에 대해 이종이거나, 또는 이들의 조합이다.
"염"은 본 발명의 방법에서 사용되는 화합물의 산 또는 염기 염을 지칭한다. 제약상 허용가능한 염의 예시적 예는 무기 산 (염산, 브롬화수소산, 인산 등) 염, 유기 산 (아세트산, 프로피온산, 글루탐산, 시트르산 등) 염, 4급 암모늄 (메틸 아이오다이드, 에틸 아이오다이드 등) 염이다. 제약상 허용가능한 염은 비-독성임이 이해된다. 적합한 제약상 허용가능한 염에 대한 추가의 정보는 문헌 Remington's Pharmaceutical Sciences, 17th ed., Mack Publishing Company, Easton, Pa., 1985에서 찾아볼 수 있고, 이는 본원에 참조로 포함된다.
본원에서 사용되는 바와 같이, 용어 "용매화물"은 용매화 (용매 분자와 용질의 분자 또는 이온의 조합)에 의해 형성된 화합물, 또는 용질 이온 또는 분자, 즉, 본 발명의 화합물과 하나 이상의 용매 분자로 이루어진 응집물을 의미한다. 물이 용매인 경우, 상응하는 용매화물은 "수화물"이다. 수화물의 예는, 반수화물, 일수화물, 이수화물, 삼수화물, 육수화물, 및 다른 물-함유 종을 포함하나, 이에 제한되지는 않는다. 화합물의 제약상 허용가능한 염, 및/또는 전구약물 또한 용매화물 형태로 존재할 수 있음이 당업자에 의해 이해되어야 한다. 용매화물은 전형적으로, 본 발명의 무수 화합물에 의한 수분의 자연 흡수를 통해 또는 화합물의 제조의 부분인 수화에 의해 형성된다. 일반적으로, 모든 물리적 형태는 본 발명의 범위 내에 있는 것으로 의도된다.
따라서, 본 발명에 따른 방법에서 제조되는 또는 본 발명에 따른 조성물 중에 포함되는 비제한적으로 칸나비노이드 또는 테르페노이드와 같은 치료 활성제가 충분히 산성인, 충분히 염기성인, 또는 충분히 산성이고 충분히 염기성인 작용기를 갖는 경우, 이들 기 또는 기들은 그에 따라 임의 수의 무기 또는 유기 염기, 및 무기 및 유기 산과 반응하여 제약상 허용가능한 염을 형성할 수 있다. 예시적 제약상 허용가능한 염은, 무기 또는 유기 산 또는 무기 염기와 약리 활성 화합물의 반응에 의해 제조된 염, 예컨대 술페이트, 피로술페이트, 비술페이트, 술파이트, 비술파이트, 포스페이트, 모노히드로겐포스페이트, 디히드로겐포스페이트, 메타포스페이트, 피로포스페이트, 클로라이드, 브로마이드, 아이오다이드, 아세테이트, 프로피오네이트, 데카노에이트, 카프릴레이트, 아크릴레이트, 이소부티레이트, 카프로에이트, 헵타노에이트, 프로피올레이트, 옥살레이트, 말로네이트, 숙시네이트, 수베레이트, 세바케이트, 푸마레이트, 말레에이트, 부틴-1,4-디오에이트, 헥신-1,6-디오에이트, 벤조에이트, 클로로벤조에이트, 메틸벤조에이트, 디니트로벤조에이트, 히드록시벤조에이트, 메톡시벤조에이트, 프탈레이트, 술포네이트, 크실렌술포네이트, 페닐아세테이트, 페닐프로피오네이트, 페닐부티레이트, 시트레이트, 락테이트, β-히드록시부티레이트, 글리콜레이트, 타르트레이트, 메탄-술포네이트, 프로판술포네이트, 나프탈렌-1-술포네이트, 나프탈렌-2-술포네이트, 및 만델레이트를 포함한 염을 포함한다. 약리 활성 화합물이 하나 이상의 염기성 작용기를 갖는 경우, 요망되는 제약상 허용가능한 염은 당업계에서 이용가능한 임의의 적합한 방법, 예를 들어, 무기 산, 예컨대 염산, 브롬화수소산, 황산, 질산, 인산 등으로의, 또는 유기 산, 예컨대 아세트산, 말레산, 숙신산, 만델산, 푸마르산, 말론산, 피루브산, 옥살산, 글리콜산, 살리실산, 피라노시딜산, 예컨대 글루쿠론산 또는 갈락투론산, 알파-히드록시산, 예컨대 시트르산 또는 타르타르산, 아미노산, 예컨대 아스파르트산 또는 글루탐산, 방향족 산, 예컨대 벤조산 또는 신남산, 술폰산, 예컨대 p-톨루엔술폰산 또는 에탄술폰산 등으로의 유리 염기의 처리에 의해 제조될 수 있다. 약리 활성 화합물이 하나 이상의 산성 작용기를 갖는 경우, 요망되는 제약상 허용가능한 염은 당업계에서 이용가능한 임의의 적합한 방법, 예를 들어, 무기 또는 유기 염기, 예컨대 아민 (1급, 2급 또는 3급), 알칼리 금속 수산화물 또는 알칼리 토금속 수산화물 등으로의 유리 산의 처리에 의해 제조될 수 있다. 적합한 염의 예시적 예는, 아미노산, 예컨대 글리신 및 아르기닌, 암모니아, 1급, 2급 및 3급 아민, 및 시클릭 아민, 예컨대 피페리딘, 모르폴린 및 피페라진으로부터 유래된 유기 염, 및 나트륨, 칼슘, 칼륨, 마그네슘, 망가니즈, 철, 구리, 아연, 알루미늄 및 리튬으로부터 유래된 무기 염을 포함한다.
본원에서 사용되는 바와 같이 "조성물"은 특정된 성분을 특정된 양으로 포함하는 생성물, 뿐만 아니라 특정된 양의 특정된 성분의 조합으로부터 생성된 임의의 생성물을 포함하도록 의도된다. "제약상 허용가능한"이란, 담체, 희석제 또는 부형제가 제제의 다른 성분과 상용성이고 그의 수용자에게 유해하지 않아야 함을 의미한다.
"제약상 허용가능한 부형제"는 대상체에 대한 활성제의 투여 및 대상체에 의한 활성제의 흡수를 보조하는 물질을 지칭한다. 본 발명에서 유용한 제약 부형제는, 결합제, 충전제, 붕해제, 윤활제, 코팅, 감미제, 향미제 및 착색제를 포함하나, 이에 제한되지는 않는다. 당업자는 다른 제약 부형제가 본 발명에서 유용함을 인식할 것이다.
일부 경우에, 보호 기가 본 발명에 따른 방법에서 사용되는 화합물 중에 또는 본 발명에 따른 조성물 중에 포함될 수 있다. 이러한 보호 기의 사용은 생체내에서 일어날 수 있고 화합물을 분해할 수 있는 후속 가수분해 또는 다른 반응을 막기 위한 것이다. 보호될 수 있는 기는 알콜, 아민, 카르보닐, 카르복실산, 포스페이트, 및 3급 아민을 포함한다. 알콜 보호를 위해 유용한 보호 기는, 아세틸, 벤조일, 벤질, β-메톡시에톡시에틸 에테르, 디메톡시트리틸, 메톡시메틸 에테르, 메톡시트리틸, p-메톡시벤질 에테르, 메틸티오메틸 에테르, 피발로일, 테트라히드로피라닐, 테트라히드로푸란, 트리틸, 실릴 에테르, 메틸 에테르, 및 에톡시에틸 에테르 포함하나, 이에 제한되지는 않는다. 아민 보호를 위해 유용한 보호 기는, 카르보벤질옥시, p-메톡시벤질카르보닐, t-부틸옥시카르보닐, 9-플루오레닐메틸옥시카르보닐, 아세틸, 벤조일, 벤질, 카르바메이트, p-메톡시벤질, 3,4-디메톡시벤질, p-메톡시페닐, 토실, 트리클로로에틸 클로로포르메이트, 및 술폰아미드를 포함한다. 카르보닐 보호를 위해 유용한 보호 기는, 아세탈, 케탈, 아실랄, 및 디티안을 포함한다. 카르복실산 보호를 위해 유용한 보호 기는, 메틸 에스테르, 벤질 에스테르, t-부틸 에스테르, 2,6-이치환된 페놀의 에스테르, 실릴 에스테르, 오르토에스테르, 및 옥사졸린을 포함한다. 포스페이트 기 보호를 위해 유용한 보호 기는, 2-시아노에틸 및 메틸을 포함한다. 말단 알킬렌 보호를 위해 유용한 보호 기는, 프로파르길 알콜 및 실릴 기를 포함한다. 다른 보호 기는 당업계에 공지되어 있다.
본원에서 사용되는 바와 같이, 용어 "전구약물"은, 투여 후, 일부 화학적 또는 생리적 과정을 통해 생물학적 활성 화합물을 생체내에서 방출하는 전구체 화합물을 지칭한다 (예를 들어, 전구약물은 생리적 pH 도달시 또는 효소 작용을 통해 생물학적 활성 화합물로 전환될 수 있음). 전구약물 자체는 요망되는 생물학적 활성을 갖지 않거나 가질 수 있다. 따라서, 용어 "전구약물"은 제약상 허용가능한 생물학적 활성 화합물의 전구체를 지칭한다. 특정 경우에, 전구약물은, 전구약물이 유래된 모(parent) 화합물에 비해 개선된 물리적 및/또는 전달 특성을 갖는다. 전구약물은 종종 포유류 유기체에서 용해도, 조직 적합성, 또는 지연 방출의 이점을 제공한다. (H.Bundgard, Design of Prodrugs (Elsevier, Amsterdam, 1988), pp. 7-9, 21-24). 전구약물에 관한 논의가 T.Higuchi et al., "Pro-Drugs as Novel Delivery Systems," ACS Symposium Series, Vol. 14 및 in E.B.Roche, ed., Bioreversible Carriers in Drug Design (American Pharmaceutical Association & Pergamon Press, 1987)에서 제공된다. 전구약물의 예시적 이점은 그의 물리적 특성, 예컨대 장기간 저장 동안 향상된 약물 안정성을 포함할 수 있으나, 이에 제한되지는 않는다.
용어 "전구약물"은 또한, 전구약물이 대상체에게 투여될 때 생체내에서 활성 화합물을 방출하는 임의의 공유 결합된 담체를 포함하도록 의도된다. 본원에 기재된 바와 같은 치료 활성 화합물의 전구약물은, 본 발명에 따른 방법에서 사용되는 또는 본 발명에 따른 조성물 중에 포함된 칸나비노이드, 테르페노이드, 및 다른 치료 활성 화합물을 포함한 치료 활성 화합물 중에 존재하는 하나 이상의 작용기를, 변형이 일상적 조작 또는 생체내에서 분열되어 모 치료 활성 화합물을 생성하는 방식으로 변형시킴으로써 제조될 수 있다. 전구약물은, 활성 화합물의 전구약물이 대상체에게 투여될 때, 분열되어 각각 유리 히드록시, 유리 아미노, 또는 유리 메르캅토 기를 형성하는 임의의 기에 히드록시, 아미노, 또는 메르캅토 기가 공유 결합된 화합물을 포함한다. 전구약물의 예는, 알콜의 포르메이트 또는 벤조에이트 유도체 또는 반응을 위해 이용가능한 아민 작용기를 갖는 치료 활성제의 아세트아미드, 포름아미드 또는 벤즈아미드 유도체 등을 포함하나, 이에 제한되지는 않는다.
예를 들어, 치료 활성제 또는 치료 활성제의 제약상 허용가능한 형태는 카르복실산 작용기를 함유하는 경우, 전구약물은 카르복실산 기의 수소 원자가 C1-8 알킬, C2-12 알카노일옥시메틸, 4 내지 9개의 탄소 원자를 갖는 1-(알카노일옥시)에틸, 5 내지 10개의 탄소 원자를 갖는 1-메틸-1-(알카노일옥시)에틸, 3 내지 6개의 탄소 원자를 갖는 알콕시카르보닐옥시메틸, 4 내지 7개의 탄소 원자를 갖는 1-(알콕시카르보닐옥시)에틸, 5 내지 8개의 탄소 원자를 갖는 1-메틸-1-(알콕시카르보닐옥시)에틸, 3 내지 9개의 탄소 원자를 갖는 N-(알콕시카르보닐)아미노메틸, 4 내지 10개의 탄소 원자를 갖는 1-(N-(알콕시카르보닐)아미노)에틸, 3-프탈리딜, 4-크로토노락토닐, 감마-부티로락톤-4-일, 디-N,N(C1-C2)알킬아미노(C2-C3)알킬 (예컨대 (3-디메틸아미노에틸), 카르바모일-(C1-C2)알킬, N,N-디 (C1-C2)알킬카르바모일-(C1-C2)알킬 및 피페리디노-, 피롤리디노-, 또는 모르폴리노(C2-C3)알킬 등의 기로 치환되어 형성된 에스테르를 포함할 수 있다.
유사하게, 개시된 화합물 또는 화합물의 제약상 허용가능한 형태가 알콜 작용기를 함유하는 경우, 전구약물은 알코올 기의 수소 원자를 (C1-C6)알카노일옥시메틸, 1-((C1-C6))알카노일옥시)에틸, 1-메틸-1-((C1-C6)알카노일옥시)에틸 (C1-C6)알콕시카르보닐옥시메틸, N(C1-C6)알콕시카르보닐아미노메틸, 숙시노일, (C1-C6)알카노일, α-아미노(C1-C4)알카노일, 아릴아실 및 α-아미노아실, 또는 α-아미노아실-α-아미노아실 등의 기로 치환되어 형성될 수 있고, 여기서 각각의 α-아미노아실 기는 독립적으로 자연 발생 L-아미노산, P(O)(OH)2, P(O)(O(C1-C6)알킬)2 또는 글리코실 (탄수화물의 헤미아세탈 형태의 히드록실 기의 제거로부터 형성되는 라디칼)로부터 선택된다.
개시된 화합물 또는 상기 화합물의 제약상 허용가능한 형태가 아민 작용기를 포함하는 경우, 전구약물은 아민 기 내의 수소 원자가 R-카르보닐, RO-카르보닐, NRR'-카르보닐, C(OH)C(O)OY1 , C(OY2)Y3 ,C(Y4)Y5 등의 기로 치환되어 형성될 수 있되, R 및 R'은 각각 독립적으로 (C1-C10)알킬, (C3-C7)시클로알킬, 벤질이거나, 또는 R-카르보닐은 천연 α-아미노아실 또는 천연 α-아미노아실-천연 α-아미노아실이고, Y1은 H, (C1-C6)알킬 또는 벤질이고, Y2는 (C1-C4) 알킬이고, Y3은 (C1-C6)알킬, 카르복시(C1-C6)알킬, 아미노(C1-C4)알킬 또는 모노-N 또는 디-N,N(C1-C6)알킬아미노알킬이고, Y4는 H 또는 메틸이고 Y5는 모노-N 또는 디-N,N(C1-C6)알킬아미노, 모르폴리노, 피페리딘-1-일 또는 피롤리딘-1-일이다.
전구약물 시스템의 사용은 하기 문헌에 기재되어 있다: T.Jarvinen et al., "Design and Pharmaceutical Applications of Prodrugs" in Drug Discovery Handbook (S.C. Gad, ed., Wiley-Interscience, Hoboken, NJ, 2005), ch.17, pp. 733-796. 전구약물 구성 및 사용에 대한 다른 대안은 당업계에 공지되어 있다. 본 발명에 따른 방법 또는 제약 조성물이 칸나비노이드, 테르페노이드, 또는 다른 치료 활성제의 전구약물을 사용하거나 포함하는 경우, 화합물의 전구약물 및 대사물은 당업계에 공지된 일상적 기술을 사용하여 식별될 수 있다. 예를 들어, Bertolini et al., J. Med. Chem., 40, 2011-2016 (1997); Shan et al., J. Pharm.Sci., 86 (7), 765-767; Bagshawe, Drug Dev. Res., 34, 220-230 (1995); Bodor, Advances in Drug Res., 13, 224-331 (1984); Bundgaard, Design of Prodrugs (Elsevier Press 1985); Larsen, Design and Application of Prodrugs, Drug Design and Development (Krogsgaard-Larsen et al., eds., Harwood Academic Publishers, 1991); Dear et al., J. Chromatogr.B, 748, 281-293 (2000); Spraul et al., J. Pharmaceutical & Biomedical Analysis, 10, 601-605 (1992); and Prox et al., Xenobiol., 3, 103-112 (1992)을 참조한다.
칸나비노이드
칸나비노이드는 피부를 포함한 인간 신체 전반에 걸쳐 세포 내에서 칸나비노이드 수용체를 활성화시키는 것으로 공지된 화학물질의 군이다. 파이토칸나비노이드는 칸나비스 식물로부터 유래된 칸나비노이드이다. 이들은 식물로부터 단리되거나 합성적으로 생성될 수 있다. 엔도칸나비노이드는 인간 신체에서 나타나는 내생 칸나비노이드이다. 정통 파이토칸나비노이드는 벤조피란 모이어티를 갖는 ABC 트리시클릭 테르페노이드 화합물이다.
칸나비노이드는 세포의 표면 상에 존재하는 칸나비노이드 수용체와의 상호작용에 의해 그의 효과를 발휘한다. 지금까지, 2종의 칸나비노이드 수용체, CB1 수용체 및 CB2 수용체가 식별되었다. 이들 2종의 수용체는 약 48% 아미노산 서열 동일성을 공유하고, 상이한 조직 내에 분포하고 또한 상이한 신호전달 메커니즘을 갖는다. 이들은 또한 작동제 및 길항제에 대한 이들의 민감성에 있어 상이하다.
따라서, 칸나비노이드의 생체내 생성을 위한 유전자, 프로모터, 및 발현 카세트를 스크리닝하고 식별하기 위한 시험관내 및 생체내 방법이 본원에 기재된다.
전형적으로, 본원에 기재된 방법 및 조성물은 숙주 세포에서의 하나 이상의 테르페노이드, 예컨대 칸나비노이드의 생성, 또는 증가된 생성, 또는 숙주 세포에서의 하나 이상의 테르페노이드 또는 칸나비노이드 전구체의 생성을 위해 사용될 수 있다. 일부 경우에, 테르페노이드 또는 칸나비노이드 또는 그의 전구체는, 정제되고/거나, 유도체화되고/거나 (예를 들어 전구약물, 용매화물, 또는 염을 형성하거나, 전구체로부터 표적 테르페노이드 또는 칸나비노이드를 형성함), 제약 조성물 중에서 제제화될 수 있다.
본 발명의 방법에 따라 및/또는 본 발명의 조성물을 사용하여 생성될 수 있는 칸나비노이드는 파이토칸나비노이드를 포함하나 이에 제한되지는 않는다. 일부 경우에, 칸나비노이드는, 칸나비놀, 칸나비디올, △9-테트라히드로칸나비놀 (△9-THC), 합성 칸나비노이드 HU-210 (6aR,10aR)-9-(히드록시메틸)-6,6-디메틸-3-(2-메틸옥탄-2-일)-6H,6aH,7H,10H,10aH-벤조[c]이소크로멘-1-올), 칸나비디바린 (CBDV), 칸나비크로멘 (CBC), 칸나비크로메바린 (CBCV), 칸나비게롤 (CBG), 칸나비게로바린 (CBGV), 칸나비엘소인 (CBE),칸나비시클롤 (CBL),칸나비바린 (CBV), 및 칸나비트리올 (CBT)를 포함하나 이에 제한되지는 않는다. 또한 다른 칸나비노이드는, 예컨대 테트라히드로칸니비바린 (THCV) 및 칸나비게롤 모노메틸 에테르 (CBGM)를 포함한다. 추가의 칸나비노이드는 칸나비크로멘산 (CBCA), △9-테트라히드로칸나비놀산 (THCA); 및 칸나비디올산 (CBDA)을 포함하고; 이들 추가의 칸나비노이드는 이들의 구조 내의 카르복실산 기의 존재에 의해 특성화된다.
또한 다른 칸나비노이드는 나빌론, 리모나반트, JWH-018 (나프탈렌-1-일-(1-펜틸인돌-3-일)메타논), JWH-073 나프탈렌-1-일-(1-부틸인돌-3-일)메타논, CP-55940 (2-[(1R,2R,5R)-5-히드록시-2-(3-히드록시프로필) 시클로헥실]-5-(2-메틸옥탄-2-일)페놀), 디메틸헵틸피란, HU-331 (3-히드록시-2-[(1R)-6-이소프로페닐-3-메틸-시클로헥스-2-엔-1-일]-5-펜틸-1,4-벤조퀴논), SR144528 (5-(4-클로로-3-메틸페닐)-1-[(4-메틸페닐)메틸]-N-[(1S,2S,4R)-1,3,3-트리메틸비시클로[2.2.1]헵탄-2-일]-1H-피라졸-3-카르복사미드), WIN 55,212-2 ((11R)-2-메틸-11-[(모르폴린-4-일)메틸]-3-(나프탈렌-1-카르보닐)-9-옥사-1-아자트리시클로[6.3.1.04,12]도데카-2,4(12),5,7-테트라엔), JWH-133 ((6aR,10aR)-3-(1,1-디메틸부틸)-6a,7,10,10a-테트라히드로-6,6,9-트리메틸-6H-디벤조[b,d]피란), 레보나트라돌, 및 AM-2201 (1-[(5-플루오로펜틸)-1H-인돌-3-일]-(나프탈렌-1-일)메타논)을 포함한다. 다른 칸나비노이드는 △8-테트라히드로칸나비놀 (△8-THC), 11-히드록시-△9-테트라히드로칸나비놀, △11-테트라히드로칸나비놀, 및 11-히드록시-테트라칸나비놀을 포함한다.
또 다른 대안에서는, 칸나비노이드 전구체의 생성 및 추가의 유도체화 (예를 들어 합성 수단에 의한)에 의해 이들 칸나비노이드의 유사체 또는 유도체가 얻어질 수 있다. 합성 칸나비노이드는 미국 특허 번호 9,394,267 (Attala et al.);미국 특허 번호 9,376,367 (Herkenroth et al.);미국 특허 번호 9,284,303 (Gijsen et al.);미국 특허 번호 9,173,867 (Travis); 미국 특허 번호 9,133,128 (Fulp et al.);미국 특허 번호 8,778,950 (Jones et al.);미국 특허 번호 7,700,634 (Adam-Worrall et al.);미국 특허 번호 7,504,522 (Davidson et al.);미국 특허 번호 7,294,645 (Barth et al.);미국 특허 번호 7,109,216 (Kruse et al.);미국 특허 번호 6,825,209 (Thomas et al.); 및 미국 특허 번호 6,284,788 (Mittendorf et al.)에 기재된 것들을 포함하나, 이에 제한되지는 않는다:
또 다른 대안으로, 칸나비노이드는 엔도칸나비노이드 또는 그의 유도체 또는 유사체일 수 있다. 엔도칸나비노이드는 아난다미드, 2-아라키도노일글리세롤, 2-아라키도닐 글리세릴 에테르, N-아라키도노일 도파민, 및 비로다민을 포함하나 이에 제한되지는 않는다. 엔도칸나비노이드의 다수의 유사체가 공지되어 있고, 이는 7,10,13,16-도코사테트라에노일에탄올아미드, 올레아미드, 스테아로일에탄올아민아미드, 및 호모-γ-리놀레노일에탄올아민을 포함하며, 이것 또한 공지되어 있다.
본 발명에 따른 방법 및 조성물에서 생성된 칸나비노이드는, CB2 칸나비노이드 수용체에 대해 선택적이거나, 2개의 칸나비노이드에 대해 비-선택적이어서, CB1 칸나비노이드 수용체 또는 CB2 칸나비노이드 수용체에 결합한다. 일부 경우에, 본 발명에 따른 방법 및 조성물에서 생성된 칸나비노이드는 CB2 칸나비노이드 수용체에 대해 선택적이다. 일부 경우에, 칸나비노이드, 또는 칸나비노이드의 혼합물 중의 하나의 칸나비노이드는 CB2의 길항제 (예: 선택적 또는 비-선택적 길항제)이다. 일부 경우에, 본 발명에 따른 방법 및 조성물에서 생성된 칸나비노이드는 CB2 칸나비노이드 수용체에 대해 선택적이다. 일부 경우에, 칸나비노이드, 또는 칸나비노이드의 혼합물 중의 하나의 칸나비노이드는 CB1의 길항제 (예: 선택적 또는 비-선택적 길항제)이다.
발현 카세트
숙주 세포에서 하나 이상의 표적 유전자를 발현시키기에 적합한 발현 카세트가 본원에 기재된다. 본원에 기재된 발현 카세트는 플라스미드의 성분이거나 숙주 세포 게놈에 통합될 수 있다. 단일 플라스미드가 하나 이상의 본원에 기재된 발현 카세트를 함유할 수 있다. 본원에서 사용되는 바와 같이, 둘 이상의 발현 카세트가 기재되는 경우, 대안적으로 둘 이상의 발현 카세트 중 적어도 2개가 조합되어 발현 카세트의 수를 감소시킬 수 있음이 이해된다. 유사하게, 다수의 표적 유전자가 단일 프로모터에 작동가능하게 연결되는 것으로 기재되고, 그에 따라 단일 발현 카세트의 성분으로서 기재되는 경우, 단일 발현 카세트는 단일 기재된 발현 카세트의 오버랩핑 또는 비-오버랩핑 서브세트를 함유하는 둘 이상의 발현 카세트로 세분될 수 있음이 이해된다.
본원에 기재된 발현 카세트는 당업계에 공지된 바와 같은 적합한 프로모터를 함유할 수 있다. 일부 경우에, 프로모터는 구성성분 프로모터이다. 다른 경우에, 프로모터는 유도가능 프로모터이다. 바람직한 구현예에서, 프로모터는 T5 프로모터, T7 프로모터, Trc 프로모터, Lac 프로모터, Tac 프로모터, Trp 프로모터, 팁 프로모터, λPL 프로모터, λPR 프로모터, λPRPL 프로모터, 아라비노스 프로모터 (araBAD) 등이다. 일부 구현예에서, 프로모터는 Zaslaver et al., Nat Methods.2006 Aug;3(8):623-8에 기재된 대장균 프로모터로 이루어진 군으로부터 선택되고, 상기 문헌은 특히 본원에 기재된 관심 핵산, 표적 유전자, 숙주 세포, 및 이들의 조합의 발현에 대한, 프로모터, 발현 카세트 (플라스미드 포함)와 관련하여, 그 전체가 참조로 포함된다. 다양한 숙주 세포에서 하나 이상의 표적 유전자의 발현을 추진하기에 유용한 프로모터는 많고 당업자에게 친숙하다 (예를 들어, WO 2004/033646; U.S. 8,507,235; U.S. 8,715,962; 및 WO 2011/017798, 및 그에 인용된 참조문헌을 참조한다, 이들 각각은, 특히 본원에 기재된 관심 핵산, 표적 유전자, 숙주 세포, 및 이들의 조합의 발현에 대한, 프로모터, 플라스미드를 비롯한 발현 카세트와 관련하여, 그 전체가 본원에 참조로 포함된다.
본원에 기재된 방법 및 조성물은 적합한 숙주 세포에서 MEP 경로의 하나 이상의 유전자의 발현, 및/또는 MEP 경로의 하나 이상의 생성물의 생성에 사용될 수 있다. 일부 구현예에서, MEP 경로 플럭스는, 강한 구성성분 또는 유도가능 이종 프로모터에 대한 내생 유전자 (또는 그의 카피)의 작동가능 연결 및/또는 유전자 카피 수의 증폭에 의한 숙주 세포의 하나 이상의 내생 성분의 과발현에 의해 증가된다. 따라서, 하나의 구현예에서, MEP 경로의 하나 이상의 유전자를 코딩하는 핵산에 작동가능하게 연결된 프로모터를 포함하는 발현 카세트가 제공된다. 대장균에서, 내생 MEP 경로 유전자는 dxs, ispC, ispD, ispE, ispF, ispG, ispH, 및 idi이다.
일부 경우에, 발현 카세트의 프로모터는 MEP 경로의 둘 이상의 유전자를 코딩하는 핵산에 작동가능하게 연결된다. 일부 경우에, 발현 카세트의 프로모터는 MEP 경로의 셋 이상의 유전자를 코딩하는 핵산에 작동가능하게 연결된다. 일부 경우에, 발현 카세트의 프로모터는 MEP 경로의 4, 5, 6개 또는 모든 8개 유전자를 코딩하는 핵산에 작동가능하게 연결된다. 일부 경우에, 발현 카세트에 제공되는 MEP 경로의 유전자는 대장균 유전자이다. 다른 경우에, 발현 카세트에 제공되는 MEP 경로의 유전자 중 하나 이상은 야생형 대장균에 대해 이종이다. 일부 경우에, MEP 경로의 하나 이상의 유전자는 제1 발현 카세트에 제공되고, MEP 경로의 하나 이상의 유전자는 제2 발현 카세트에 제공된다. 바람직한 구현예에서, dxs 및 idi에 작동가능하게 연결된 프로모터를 포함하는 발현 카세트가 제공된다.
일부 경우에, MEP 경로의 하나 이상의 유전자를 코딩하고 추가로 GPP 신타제, 칸나비노이드 신타제, 또는 이소프렌 신타제를 코딩하는 핵산에 작동가능하게 연결된 프로모터를 포함하는 발현 카세트가 제공된다. 일부 경우에, MEP 경로의 하나 이상의 유전자를 코딩하고 추가로 THCA 신타제를 코딩하는 핵산에 작동가능하게 연결된 프로모터를 포함하는 발현 카세트가 제공된다. 일부 경우에, MEP 경로의 하나 이상의 유전자를 코딩하고 추가로 CBGA 신타제를 코딩하는 핵산에 작동가능하게 연결된 프로모터를 포함하는 발현 카세트가 제공된다. 일부 경우에, MEP 경로의 하나 이상의 유전자를 코딩하고 추가로 CBCA 신타제를 코딩하는 핵산에 작동가능하게 연결된 프로모터를 포함하는 발현 카세트가 제공된다. 일부 경우에, MEP 경로의 하나 이상의 유전자를 코딩하고 추가로 CBDA 신타제를 코딩하는 핵산에 작동가능하게 연결된 프로모터를 포함하는 발현 카세트가 제공된다.
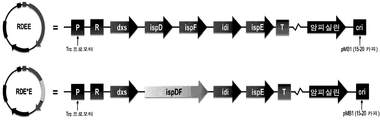
일부 구현예에서, 2작용성 ispDF 효소를 코딩하는 핵산에 작동가능하게 연결된 프로모터를 함유하는 발현 카세트가 제공된다. ispDF 유전자는 숙주 세포에서 네이티브 ispD 및/또는 ispF의 과발현에 추가로, 또는 그에 대한 대안으로서 사용될 수 있다. 일부 경우에, 핵산은 하기 아미노산 서열을 갖는 ispDF 단백질을 코딩한다 (서열 번호1):
MIALQRSLSMHVTAIIAAAGEGRRLGAPLPKQLLDIGGRSILERSVMAFARHERIDDVIVVLPPALAAAPPDWIAASGRVPAVHVVSGGERRQDSVANAFDRVPAQSDVVLVHDAARPFVTAELISRAIDGAMQHGAAIVAVPVRDTVKRVDPDGEHPVITGTIPRDTIYLAQTPQAFRRDVLGAAVALGRSGVSATDEAMLAEQAGHRVHVVEGDPANVKITTSADLDQARQRLRSAVAARIGTGYDLHRLIEGRPLIIGGVAVPCDKGALGHSDADVACHAVIDALLGAAGAGNVGQHYPDTDPRWKGASSIGLLRDALRLVQERGFTVENVDVCVVLERPKIAPFIPEIRARIAGALGIDPERVSVKGKTNEGVDAVGRGEAIAAHAVALLSES.
다른 구현예에서, ispDF 핵산은 서열 번호 1에 대하여 적어도 32%, 40%, 45%, 50%, 52%, 55%, 60%, 65%, 70%, 80%, 85%, 90%, 95%, 또는 99% 동일성을 갖는 ispDF 단백질을 코딩한다. 또한 다른 구현예에서, ispDF 핵산은 서열 번호 1의 적어도 300개 인접 아미노산에 대하여 적어도 32%, 40%, 45%, 50%, 52%, 55%, 60%, 65%, 70%, 80%, 85%, 90%, 95%, 또는 99% 동일성을 갖는 ispDF 단백질을 코딩한다.
일부 경우에, 2작용성 ispDF는 에이치. 필로리 HP1020, 에이치. 필로리 HP1020, 에이치. 필로리 J99 jhp0404, 에이치. 필로리 HPAG1 HPAG1_0427, 에이치. 헤파티쿠스 HH1582, 에이치. 아시노니키스 st.쉬바 Hac_1124, 더블유. 숙시노게네스 DSM 1740 WS1940, 에스. 데니트리피칸스 DSM 1251 수덴_1487, 씨. 제주니 아종 제주니 NCTC 11168 Cj1607, 씨. 제주니 RM1221 CJE1779, 씨. 제주니 아종 제주니 81-176 CJJ81176_1594, 및 씨. 페투스 아종 페투스 82-40 CFF8240_0409의 적어도 300개 인접 아미노산과 75% 이하 동일한 1차 아미노산 서열을 갖는다. 일부 경우에, 2작용성 ispDF는 에이치. 필로리 HP1020, 에이치. 필로리 HP1020, 에이치. 필로리 J99 jhp0404, 에이치. 필로리 HPAG1 HPAG1_0427, 에이치. 헤파티쿠스 HH1582, 에이치. 아시노니키스 st.쉬바 Hac_1124, 더블유. 숙시노게네스 DSM 1740 WS1940, 에스. 데니트리피칸스 DSM 1251 수덴_1487, 씨. 제주니 아종 제주니 NCTC 11168 Cj1607, 씨. 제주니 RM1221 CJE1779, 씨. 제주니 아종 제주니 81-176 CJJ81176_1594, 또는 씨. 페투스 아종 페투스 82-40 CFF8240_0409가 아니다.
2작용성 ispDF는 플라스미드 내의 핵산에 의해 코딩될 수 있다. 대안적으로, 2작용성 ispDF는 이종 숙주 세포의 게놈으로 통합된 핵산에 의해 코딩될 수 있다. 일부 경우에, 이종 프로모터는 2작용성 ispDF를 코딩하는 핵산에 작동가능하게 연결된다. 추가로 또는 대안적으로, 숙주 세포는 2작용성 ispDF를 코딩하는 핵산에 대해 이종일 수 있다.
2작용성 ispDF를 코딩하는 핵산은 MEP 경로 유전자를 코딩하는 핵산을 함유하는 상기 발현 카세트 중 임의의 하나와 같은 MEP 경로 발현 카세트 내에 있을 수 있다. 일부 경우에, 2작용성 ispDF를 코딩하는 핵산은 칸나비노이드 신타제를 코딩하는 핵산을 함유하는 발현 카세트 내에 있을 수 있다. 일부 경우에, 2작용성 ispDF를 코딩하는 핵산은 GPP 신타제를 코딩하는 핵산을 함유하는 발현 카세트 내에 있을 수 있다. 일부 경우에, 2작용성 ispDF를 코딩하는 핵산은 이소프렌 신타제를 코딩하는 핵산을 함유하는 발현 카세트 내에 있을 수 있다.
본원에 기재된 방법 및 조성물은 적합한 숙주 세포에서 MEP 경로에서 생성된 전구체로부터의 GPP의 생성에 사용될 수 있다. 따라서, 일부 구현예에서, GPP 신타제를 코딩하는 핵산에 작동가능하게 연결된 프로모터를 포함하는 발현 카세트가 제공된다. GPP 신타제는 MEP 경로의 유전자를 코딩하는 핵산을 또한 함유하는 발현 카세트 내에 있을 수 있다. 추가로, 또는 대안적으로, GPP 신타제는 칸나비노이드 신타제를 코딩하는 핵산을 또한 함유하는 발현 카세트 내에 있을 수 있다. 일부 경우에, GPP 신타제를 코딩하는 핵산에 작동가능하게 연결된 발현 카세트의 프로모터는 또한 칸나비노이드 신타제에 작동가능하게 연결된다. 추가로, 또는 대안적으로, GPP 신타제는 GPP 신타제를 코딩하는 핵산을 또한 함유하는 발현 카세트 내에 있을 수 있다. 추가로, 또는 대안적으로, GPP 신타제는 이소프렌 신타제를 코딩하는 핵산을 또한 함유하는 발현 카세트 내에 있을 수 있다.
본원에 기재된 방법 및 조성물은 숙주 세포에서 칸나비노이드의 생성에 사용될 수 있다. 따라서, 일부 구현예에서, 칸나비노이드 신타제를 코딩하는 핵산에 작동가능하게 연결된 프로모터를 포함하는 발현 카세트가 제공된다. 칸나비노이드 신타제는 칸나비스 속의 식물에 대해 내생적인 칸나비노이드 신타제, 또는 그의 오르토로그일 수 있다. 일부 경우에, 칸나비노이드 신타제는 칸나비스 사티바 또는 칸나비스 인디카(Cannabis indica)에 대해 내생적인 칸나비노이드 신타제, 또는 그의 오르토로그일 수 있다. 일부 경우에, 칸나비노이드 신타제는 CBGA 신타제, THCA 신타제, CBDA 신타제, 또는 CBCA 신타제 (예: 칸나비스 속의 식물에 대해 내생적인 것, 또는 그의 오르토로그)이다.
칸나비노이드 신타제는 숙주에서 발현을 위해 변형될 수 있다. 예를 들어, 하나 이상의 막횡단 또는 신호 펩티드 도메인은 절단될 수 있다. 추가로, 또는 대안적으로, 하나 이상의 글리코실화 자리가 결실 (예를 들어, 1차 아미노산 서열의 돌연변이에 의해)될 수 있다. 유사하게, 그의 네이티브 숙주에서 네이티브 단백질 내의 분자내 디술파이드 결합에서 나타나는 하나 이상의 또는 모든 시스테인이, 예를 들어, 세린으로 돌연변이될 수 있다. 유사하게, 그의 네이티브 숙주에서 네이티브 단백질 내의 분자간 디술파이드 결합에서 나타나는 하나 이상의 또는 모든 시스테인이, 예를 들어, 세린으로 돌연변이될 수 있다.
숙주 세포
상기 발현 카세트, 및 이들의 조합 중 임의의 것을, 적합한 숙주 세포 내로 도입하고, 표적 테르페노이드 또는 칸나비노이드의 생성에 사용할 수 있다. 적합한 숙주 세포는 원핵생물, 예컨대 에스케리키아, 판테오아, 코리네박테리움, 바실루스, 또는 락토콕쿠스 속의 원핵생물을 포함하나, 이에 제한되지는 않는다. 바람직한 원핵생물 숙주 세포는, 에스케리키아 콜라이 (대장균), 판테오아 시트레아, 씨. 글루타미쿰, 바실루스 서브틸리스, 및 락토콕쿠스 락티스를 포함하나, 이에 제한되지는 않는다. 일부 구현예에서, 본원에 기재된 발현 카세트는 하나 이상의 표적 유전자 (예: MEP 경로 유전자, 칸나비노이드 신타제 유전자, ispA, ispS, ispDF, 또는 GPP 신타제)를 코딩하는 핵산에 작동가능하게 연결된 프로모터 (예: 이종 프로모터)를 포함하고, 여기서 하나 이상의 표적 유전자를 코딩하는 핵산은 발현 카세트를 포함하는 숙주 세포에 대해 코돈 적합화된다.
일부 경우에, 숙주 세포는 MEP 경로의 하나 이상의 생성물, 예컨대 DMAPP 및/또는 IPP를 포함한다. 예를 들어, 본원에 기재된 바와 같은 MEP 경로 발현 카세트를 함유하는 숙주 세포는, MEP 경로 발현 카세트를 함유하지 않는 숙주 세포에 비해 증가된 양의 MEP 경로 생성물, 예컨대 DMAPP 및/또는 IPP를 포함할 수 있다.
일부 경우에, 숙주 세포는 MEP 경로의 하류인 하나 이상의 생성물을 포함할 수 있다. 예를 들어, GPP 신타제 발현 카세트를 포함하는 숙주 세포는, GPP 신타제 발현 카세트가 없는 숙주 세포에 비해 증가된 양의 GPP를 포함할 수 있다. 또 다른 예로, 이소프렌 신타제 발현 카세트를 포함하는 숙주 세포는, 이소프렌 신타제 발현 카세트가 없는 숙주 세포에 비해 증가된 양의 이소프렌을 포함할 수 있다.
또한 또 다른 예로, 칸나비노이드 신타제 발현 카세트를 포함하는 숙주 세포는, 칸나비노이드 신타제 발현 카세트가 없는 숙주 세포에 비해 증가된 양의 칸나비노이드를 포함할 수 있다. 일부 경우에, 칸나비노이드는 CBGA이다. 일부 경우에, 칸나비노이드는 CBCA이다. 일부 경우에, 칸나비노이드는 CBDA이다. 일부 경우에, 칸나비노이드는 THCA이다. 일부 경우에, 칸나비노이드는 CBN이다. 일부 경우에, 칸나비노이드는 CBD이다. 일부 경우에, 칸나비노이드는 THC이다. 일부 경우에, 칸나비노이드는 CBC이다. 일부 경우에, 칸나비노이드는 THCV이다. 일부 경우에, 칸나비노이드는 CBDV이다. 일부 경우에, 칸나비노이드는 CBCV이다.
유사하게, 숙주 세포는, 숙주 세포가 발현 카세트로부터의 발현을 유도하기에 적합한 조건 하에 배양되는 경우 비-유도 조건에 비해 발현 카세트에 의해 코딩되는 하나 이상의 효소의 생성물의 상승된 양을 포함할 수 있다. 예를 들어, 숙주 세포는 유도제의 부재 하에 (예를 들어, IPTG, 아라비노스 등의 부재 하에) 배양된 동일한 숙주 세포에 비해 유도시 증가된 DMAPP 및/또는 IPP를 나타낼 수 있다. 또 다른 예로, 숙주 세포는 유도제의 부재 하에 (예를 들어, IPTG, 아라비노스 등의 부재 하에) 배양된 동일한 숙주 세포에 비해 유도시 증가된 GPP를 나타낼 수 있다. 또 다른 예로, 숙주 세포는 유도제의 부재 하에 (예를 들어, IPTG, 아라비노스 등의 부재 하에) 배양된 동일한 숙주 세포에 비해 유도시 증가된 이소프렌을 나타낼 수 있다. 또 다른 예로, 숙주 세포는 유도제의 부재 하에 (예를 들어, IPTG, 아라비노스 등의 부재 하에) 배양된 동일한 숙주 세포에 비해 유도시 증가된 칸나비노이드를 나타낼 수 있다.
일부 구현예에서, 숙주 세포는 올리베톨산 (OA)을 포함한다. OA는, 숙주 세포를 OA를 함유하는 배지 내에서 배양함으로써 숙주 세포 내로 도입될 수 있다. 일부 구현예에서, 숙주 세포는 디바린산 (DVA)을 포함한다. DVA는, 숙주 세포를 DVA를 함유하는 배지 내에서 배양함으로써 숙주 세포 내로 도입될 수 있다.
일부 구현예에서, 숙주 세포는, MEP 경로를 통한 플럭스를 감소시키는 내생 효소를 코딩하는 하나 이상의 유전자의 발현을 제거하거나 감소시키도록 유전적으로 변형된다. 일부 구현예에서, 숙주 세포는, MEP 경로를 통한 플럭스를 감소시키는 내생 효소의 양 또는 활성을 제거하거나 감소시키도록 유전적으로 변형된다. 예를 들어, 피루베이트 및 글리세르알데히드-3 포스페이트 (G3P)는 MEP 경로dml 초기 효소 dxs의 기질이다. 피루베이트 및 G3P를 소비하는 내생 경로는, 피루베이트 및 G3P의 양을 증가시키고 그에 따라 MEP 경로를 통한 플럭스를 증가시키도록 유전적으로 변형될 수 있다. 일부 경우에, ackA-pta, poxB, ldhA, dld, adhE, pps, 및 atoDA로 이루어진 군으로부터 선택된 하나 이상의 숙주 세포 내생 유전자 또는 유전자 생성물은 피루베이트 또는 G3P 수준을 증가시키도록 변형된다.
배양 방법
본 발명은 또한, 표적 대사 생성물을 생성하는, 유도 조건 하에 적합한 배지 내에서 본 발명에 따른 숙주 세포를 배양하는 방법을 제공한다. 표적 대사 생성물은 칸나비노이드, 테르페노이드, 또는 그의 전구체일 수 있다. 방법은 대사산물을 소비된 배지 및/또는 숙주 세포에 집중시키는 것을 포함할 수 있다.
생성된 미생물을, 요망되는 유기-화학 화합물의 생성을 위해 연속적으로 (예를 들어 WO 05/021772에 기재된 바와 같이) 또는 불연속적으로 배치식 방법으로 (배치 재배) 또는 유가식(fed-batch) 또는 반복된 유가식 방법으로 배양할 수 있다. 공지된 재배 방법에 대한 일반적 성질의 요약은 하기 교본에서 이용가능하다: 키미엘(Chmiel)에 의한 교본 (BioprozeBtechnik.1 : Einfiihrung in die Bioverfahrenstechnik (Gustav Fischer Verlag, Stuttgart, 1991)) 또는 스토르하스(Storhas)에 의한 교본 (Bioreaktoren and periphere Einrichtungen (Vieweg Verlag, Braunschweig/Wiesbaden, 1994)).
사용되는 배지 또는 발효 배지는 적합한 방식으로 각각의 균주의 요구를 만족시켜야 한다. 다양한 미생물에 대한 배지의 설명은 문헌 "Manual of Methods for General Bacteriology" of the American Society for Bacteriology (Washington D.C., USA, 1981)에 제공되어 있다. 용어 배지 및 발효 배지는 상호교환가능하다.
탄소 공급원으로서, 당 및 탄수화물, 예컨대 글루코스, 수크로스, 락토스, 프룩토스, 말토스, 당밀, 사탕 무 또는 사탕 수수 가공처리로부터의 수크로스-함유 용액, 전분, 전분 가수분해물, 및 셀룰로스; 오일 및 지방, 예컨대 대두유, 해바라기유, 땅콩유 및 코코넛 지방; 지방 산, 예컨대 팔미트산, 스테아르산, 및 리놀레산; 알코올, 예컨대 글리세롤, 메탄올, 및 에탄올; 및 유기 산, 예컨대 아세트산 또는 락트산을 사용할 수 있다.
질소 공급원으로서, 유기 질소-함유 화합물, 예컨대 펩톤, 이스트 추출물, 육류 추출물, 맥아 추출물, 옥수수 침지액, 대두분, 및 우레아; 또는 무기 화합물, 예컨대 황산암모늄, 염화암모늄, 인산암모늄, 탄산암모늄, 및 질산암모늄을 사용할 수 있다. 질소 공급원은 개별적으로 또는 혼합물로서 사용될 수 있다.
인 공급원으로서, 인산, 인산이수소칼륨 또는 인산수소이칼륨 또는 상응하는 나트륨-함유 염을 사용할 수 있다.
배양 배지는, 성장을 위해 필수적인, 예를 들어, 금속, 예컨대 나트륨, 칼륨, 마그네슘, 칼슘 및 철의 클로라이드 또는 술페이트, 예컨대, 황산마그네슘 또는 황산철 형태의 염을 추가로 포함할 수 있다. 마지막으로, 필수 성장 인자, 예컨대 아미노산, 예를 들어 호모세린 및 비타민, 예를 들어 티아민, 비오틴 또는 판토텐산이, 상기 언급된 기질에 추가로 사용될 수 있다.
상기 출발 물질은 단일 배치 형태로 배양물에 첨가되거나 적합한 방식으로 재배 동안 공급될 수 있다.
배양물의 pH는 적합한 방식으로 염기성 화합물, 예컨대 수산화나트륨, 수산화칼륨, 암모니아, 또는 수성 암모니아; 또는 산성 화합물, 예컨대 인산 또는 황산을 사용함으로써 제어될 수 있다. pH는 일반적으로 6.0 내지 8.5, 바람직하게는 6.5 내지 8의 값으로 조정된다. 발포를 제어하기 위해, 예를 들어, 지방 산 폴리글리콜 에스테르와 같은 소포제를 사용할 수 있다. 플라스미드의 안정성을 유지하기 위해, 배지에, 예를 들어 항생제와 같은 적합한 선택적 물질을 첨가할 수 있다. 배양은 바람직하게는 호기적 조건 하에 수행된다. 이들 조건을 유지하기 위해, 산소 또는 산소-함유 기체 혼합물, 예컨대 공기를 배양물 중에 도입한다. 과산화수소 풍부화된 액체를 사용할 수도 있다. 배양은, 적절한 경우, 승압, 예를 들어 0.03 내지 0.2 MP a의 승압에서 수행된다. 배양물의 온도는 통상적으로 20 ℃ 내지 45 ℃, 또한 바람직하게는 25 ℃ 내지 40 ℃, 특히 바람직하게는 30 ℃ 내지 37 ℃이다. 배치식 또는 유가식 방법에서, 재배는 바람직하게는, 회수되기에 충분한 요망되는 양의 유기-화학 화합물이 형성될 때까지 계속된다. 이 목표는 통상적으로 10시간 내지 160시간 내에 달성된다. 연속적 방법에서는, 보다 긴 재배 시간이 가능하다. 미생물의 활성은 발효 배지 및/또는 상기 미생물의 세포 내의 유기-화학 화합물의 농축 (축적)을 제공한다.
적합한 배양 배지의 예는 특히 특허 US 5,770,409, US 5,990,350, US 5,275,940, WO 2007/012078, US 5,827,698, WO 2009/043803, US 5,756,345 및 US 7,138,266에서 찾아볼 수 있다.
크로마토그래피, 바람직하게는 역상 크로마토그래피에 의해 대사산물을 분리함으로써 배양 동안 1회 이상 농도를 측정하기 위한 표적 대사 생성물의 분석을 수행할 수 있다.
검출은 광도측정 (흡수, 형광)으로 수행될 수 있다.
농도 (단위 부피 당 형성된 표적 대사 생성물), 수율 (소비된 단위 탄소 공급원 당 형성된 표적 대사 생성물), 형성률 (단위 부피 및 시간 당 형성된 표적 대사 생성물) 및 비형성률(specific formation) (단위 건조 세포 물질 또는 건조 바이오매스(biomass) 및 시간 당 표적 대사 생성물 또는 단위 세포 단백질 및 시간 당 형성된 화합물) 또는 다른 공정 파라미터 및 이들의 조합의 군으로부터 선택된 파라미터 중 하나 이상에 대하여, 본 발명에 따른 하나 이상의 발현 카세트를 함유하는 숙주 세포를 사용한 배양 방법의 성능은, 본 발명에 따른 발현 카세트를 함유하지 않는 숙주 세포를 사용한 배양 방법을 기준으로 하여, 적어도 0.5%, 적어도 1%, 적어도 1.5%, 적어도 2%, 적어도 3%, 적어도 4%, 적어도 5%, 적어도 10%, 적어도 20%, 적어도 30%, 적어도 40%, 적어도 50%, 적어도 60%, 적어도 70%, 적어도 80%, 적어도 90%, 또는 적어도 100%만큼 증가될 수 있다. 이는 대규모 산업적 공정에 있어 매우 가치있는 것으로 고려된다.
이에 따라 표적 대사 생성물을 함유하는 생성물은 액체 또는 고체 형태로 제공되거나 생성되거나 회수될 수 있다.
소비된 배지는, 숙주 세포가 특정 시간 동안 특정 온도에서 배양되었던 배지를 의미한다. 배양 동안 사용되는 배지 또는 배지들은, 요망되는 표적 대사 생성물의 생성 및 전형적으로 전파 및 생존력을 보장하는 모든 물질 또는 성분을 포함한다. 배양이 완료되면, 이에 따라 생성된 소비된 배지는 하기의 것을 포함한다: a) 미생물의 바이오매스 (세포 매스)로서, 상기 미생물의 세포의 전파로 인해 생성된 것인 바이오매스; b) 배양 동안 형성된 요망되는 표적 대사 생성물; c) 배양 동안 가능하게 형성되는 유기 부산물; 및 d) 배양 동안 소비되지 않은, 예를 들어, 비타민, 예컨대 비오틴 또는 염, 예컨대 황산마그네슘과 같은, 출발 물질의 또는 사용된 배지의 구성성분.
유기 부산물은, 특정 요망되는 화합물에 추가로 배양에서 사용된 미생물에 의해 생성되고 임의로 분비되는 물질을 포함한다. 소비된 배지는 배양 용기 또는 발효 탱크로부터 제거되고, 적절한 경우 수집되고, 액체 또는 고체 형태의 표적 대사 생성물을 함유하는 생성물을 제공하기 위해 사용될 수 있다. 가장 간단한 경우에, 발효 탱크로부터 제거된 표적 대사 생성물-함유 소비된 배지 자체가 회수 생성물을 구성한다.
일부 경우에, 표적 대사 생성물 (예: 테르페노이드, 칸나비노이드, 또는 그의 전구체)의 회수는, a) 부분적 (> 0% 내지 < 80%) 내지 완전한 (100%) 또는 실질적으로 완전한 (> 80%, > 90%, > 95%, > 96%, > 97%, > 98%, 또는 > 99%) 물의 제거; b) 부분적 (> 0% 내지 < 80%) 내지 완전한 (100%) 또는 실질적으로 완전한 (> 80%, > 90%, > 95%, > 96%, > 97%, > 98%, 또는 > 99%) 바이오매스의 제거로, 후자는 임의로 제거 전에 불활성화된다; c) 부분적 (> 0% 내지 < 80%) 내지 완전한 (100%) 또는 실질적으로 완전한 (> 80%, > 90%, > 95%, > 96%, > 97%, > 98%, > 99%, > 99.3%, 또는 > 99.7%), 배양 동안 형성된 유기 부산물의 제거; 및 d) 부분적 (> 0%) 내지 완전한 (100%) 또는 실질적으로 완전한 (> 80%, > 90%, > 95%, > 96%, > 97%, > 98%, > 99%, > 99.3%, 또는 > 99.7%), 소비된 배지로부터의, 배양에서 소비되지 않은, 출발 물질의 또는 사용된 발효 배지의 구성성분의 제거로 이루어진 군으로부터 선택된 방안 중 하나 이상을 포함하나, 이에 제한되지는 않고, 이는 요망되는 표적 대사 생성물의 농도 또는 정제를 달성한다. 요망되는 함량의 상기 표적 대사 생성물을 갖는 조성물은 이러한 방식으로 단리된다.
부분적 (> 0% 내지 < 80%) 내지 완전한 (100%) 또는 실질적으로 완전한 (> 80% 내지 < 100%) 물의 제거 (방안 a))는 또한 건조로서 언급된다.
방법의 하나의 변법에서, 완전한 또는 실질적으로 완전한, 물의, 바이오매스의, 유기 부산물의, 또한 사용된 발효 배지의 소비되지 않은 구성성분의 제거는, 요망되는 표적 대사 생성물의 순수 (> 80 중량%, > 90 중량%) 또는 고순도 (> 95 중량%, > 97 중량%, 또는 > 99 중량%) 생성물을 제공한다. 방안 a), b), c) 및 d)에 대한 풍부한 기술적 지시가 선행 기술에서 이용가능하다.
요건에 따라, 바이오매스는, 예를 들어, 원심분리, 여과, 경사분리(decantation) 또는 이들의 조합과 같은 분리 방법에 의해 소비된 배지로부터 완전히 또는 부분적으로 제거되거나, 그 안에 완전히 남겨질 수 있다. 적절한 경우, 바이오매스 또는 바이오매스-함유 소비된 배지는, 예를 들어 열 처리 (가열)에 의해 또는 알칼리 또는 산의 첨가에 의해, 적합한 공정 단계 동안 불활성화된다.
하나의 절차에서, 바이오매스는, 제로 (0%) 또는 최대 30%, 최대 20%, 최대 10%, 최대 5%, 최대 1% 또는 최대 0.1% 바이오매스가 제조된 생성물 중에 남아있도록 완전히 또는 실질적으로 완전히 제거된다. 추가의 절차에서, 바이오매스는, 모든 (100%) 또는 70%, 80%, 90%, 95%, 99% 또는 99.9% 초과의 바이오매스가 제조된 생성물 중에 남아있도록 제거되지 않거나, 단지 작은 비율로 제거된다. 따라서, 본 발명에 따른 하나의 방법에서, 바이오매스는 > 0% 내지 < 100%의 비율로 제거된다. 마지막으로, 발효 후에 얻어진 발효 브로스(broth)는, 바이오매스의 완전한 또는 부분적 제거 전 또는 후에, 최종 생성물의 취급 특성을 개선시키도록, 예를 들어, 염산, 황산, 또는 인산 등의 무기 산; 또는 예를 들어, 프로피온산 등의 유기 산에 의해 산성 pH로 조정될 수 있다 (GB 1,439,728호 또는 EP 1 331220). 바이오매스의 완전한 함량으로 발효 브로스를 산성화할 수도 있다. 마지막으로, 브로스는 또한, 중아황산나트륨 (NaHC03, GB 1,439,728) 또는 또 다른 염, 예를 들어 아황산의 암모늄, 알칼리 금속, 또는 알칼리 토금속 염을 첨가함으로써 안정화될 수 있다.
바이오매스의 제거 동안, 소비된 배지 내에 존재하는 임의의 유기 또는 무기 고체는 부분적으로 또는 완전히 제거될 수 있다. 소비된 배지 중에 용해된 유기 부산물, 및 용해된 발효 배지 (출발 물질)의 소비되지 않은 구성성분은, 생성물 중에 적어도 부분적으로 (> 0%), 일부 경우에는 적어도 25%의 정도로, 일부 경우에는 적어도 50%의 정도로, 또한 일부 경우에는 적어도 75%의 정도로 남아있을 수 있다. 적절한 경우, 이들은 또한 생성물 중에 완전히 (100%) 또는 실질적으로 완전히 남아있으며, 이는 > 95% 또는 > 98% 또는 > 99%를 의미한다.
이어서, 물을 소비된 배지로부터 제거할 수 있거나, 또는 상기 소비된 배지를, 예를 들어, 회전 증발기, 박막 증발기, 강하-막 증발기의 사용과 같은 공지된 방법에 의해, 역삼투에 의해 또는 나노여과에 의해 증점 또는 농후화시킬 수 있다. 이어서, 이 농축된 소비된 배지를, 동결 건조, 분무 건조, 분무 과립화의 방법에 의해 또는 예를 들어 PCT/EP2004/006655에 따라 기재된 바와 같은, 순환 유동층에서와 같은 다른 방법에 의해 자유-유동 생성물, 특히 미세 분말 또는 바람직하게는 조대 과립까지 후처리할 수 있다.
제약 조성물
표적 대사 생성물은 제약 조성물 중으로 제제화될 수 있다. 일부 경우에 소비된 배지 또는 농축된 소비된 배지, 또는 본원에 기재된 배양 방법에서 얻어진 소비된 배지 또는 바이오매스로부터의 부분적으로 또는 완전히 정제된 표적 대사 생성물은 제약 조성물 중으로 제제화된다.
본 발명에 따른 제약 조성물은 하나 이상의 부형제를 포함할 수 있다. 피부 적용을 위해 의도된 국소 조성물에서의 사용에 적합한 이러한 부형제는, 보존제; 농후화제; 완충액; 액체 담체; 등장화제; 습윤제, 가용화제, 및 유화제; 산성화제; 항산화제; 알칼리화제; 운반제; 킬레이팅제; 착물화제; 용매; 현탁화제 또는 점도-증가제; 오일; 침투 향상제; 중합체; 경화제; 단백질; 탄수화물; 및 벌킹제를 포함하나, 이에 제한되지는 않는다.
제약 제제의 업계에서 일반적으로 공지된 바와 같이, 특정 부형제는, 부형제의 농도, 조성물 중의 다른 부형제, 조성물의 물리적 형태, 조성물 중의 활성제의 농도, 조성물의 의도된 투여 방식, 및 다른 인자에 따라, 특정 제약 조성물에서 이들 기능 중 하나 이상을 충족할 수 있다. 하기 카테고리에서의 특정 부형제의 언급은 또 다른 카테고리 또는 카테고리들에서의 부형제의 가능한 사용을 배제하도록 의도되지 않는다.
액체 담체는, 식염수, 인산염 완충 식염수, 글리세롤, 및 에탄올로 이루어진 군으로부터 선택된 액체 담체일 수 있지만, 이에 제한되지는 않는다.
농후화제는, 글리세롤 및 프로필렌 글리콜로 이루어진 군으로부터 선택된 농후화제일 수 있지만, 이에 제한되지는 않는다.
등장화제는, 만니톨 및 소르비톨; 염화나트륨; 및 염화칼륨으로 이루어진 군으로부터 선택된 폴리알콜일 수 있지만, 이에 제한되지는 않는다.
습윤제, 가용화제, 또는 유화제는 일반적으로 계면활성제이다. 전형적으로, 계면활성제는 벤즈알코늄 클로라이드, 벤제토늄 클로라이드, 세틸피리디늄 클로라이드, 도쿠세이트 나트륨, 노녹시놀 9, 노녹시놀 10, 옥톡시놀 9, 폴록사머, 폴리옥실 35 피마자유, 폴리옥실 40, 수소화된 피마자유, 폴리옥실 50 스테아레이트, 폴리옥실 10 올레일 에테르, 폴리옥실 20, 세토스테아릴 에테르, 폴리옥실 40 스테아레이트, 폴리소르베이트 20, 폴리소르베이트 40, 폴리소르베이트 60, 폴리소르베이트 80, 나트륨 라우릴 술페이트, 소르비탄 모노라우레에이트, 소르비탄 모노올레에이트, 소르비탄 모노팔미테이트, 소르비탄 모노스테아레이트, 틸록사폴, 아카시아, 콜레스테롤, 디에탄올아민, 글리세릴 모노스테아레이트, 라놀린 알콜, 레시틴, 모노- 및 디-글리세리드, 모노에탄올아민 (부가물), 올레산 (부가물), 올레일 알콜 (안정화제), 폴록사머, 폴리옥시에틸렌 50 스테아레이트, 폴리옥실 35 피마자유, 폴리옥실 40 수소화된 피마자유, 폴리옥실 10 올레일 에테르, 폴리옥실 20 세토스테아릴 에테르, 폴리옥실 40 스테아레이트, 폴리소르베이트 20, 폴리소르베이트 40, 폴리소르베이트 60, 폴리소르베이트 80, 프로필렌 글리콜 디아세테이트, 프로필렌 글리콜 모노스테아레이트, 나트륨 라우릴 술페이트, 나트륨 스테아레이트, 소르비탄 모노라우레이트, 소르비탄 모노올레에이트, 소르비탄 모노팔미테이트, 소르비탄 모노스테아레이트, 스테아르산, 트리에탄올아민, 유화 왁스, 세토마크로골, 및 세틸 알콜로 이루어진 군으로부터 선택된다.
국소 적용을 위한 제약 조성물은 연화제를 포함할 수 있다. 본원에서 사용되는 바와 같이, 용어 "연화제"는 피부 또는 다른 점막을 연화시키고, 부드럽게 하고, 그의 지질 함량을 개선시키는 소수성 작용제를 지칭한다. 사용하기에 적합한 연화제의 예는 이소스테아르산 유도체, 이소프로필 팔미테이트, 라놀린 오일, 디이소프로필 디메레이트, 디이소프로필 아디페이트, 디메틸 이소소르비드, 말레에이트 대두유, 옥틸 팔미테이트, 이소프로필 이소스테아레이트, 세틸 알콜, 세틸 락테이트, 세틸 리시놀레에이트, 토코페릴 아세테이트, 아세틸화 라놀린 알콜, 세틸 아세테이트, 페닐 트리메티콘, 글리세릴 올레에이트, 토코페릴 리놀레에이트, 밀 배아 글리세리드, 아라키딜 프로피오네이트, 미리스틸 락테이트, 데실 올레에이트, 프로필렌 글리콜 리시놀레에이트, 이소프로필 라놀레이트, 펜타에리트리틸 테트라스테아레이트, 네오펜틸글리콜 디카프릴레이트/디카프레이트, 수소화된 코코-글리세리드, 이소노닐 이소노나노에이트, 이소트리데실 이소노나노에이트, 미리스틸 미리스테이트, 트리이소세틸 시트레이트, 옥틸 도데칸올, 옥틸 히드록시스테아레이트, 포도씨유, 하나 이상의 세라미드, 시클로메티콘, 및 이들의 혼합물을 포함한다. 다른 적합한 연화제의 다른 예는 또한 Cosmetic Bench Reference, pp. 1.19-1.22 (1996)에서 찾아볼 수 있다. 당업자는 다른 연화제가 본 발명에서 유용함을 인지할 것이다.
보존제는 벤즈알코늄 클로라이드, 벤즈알코늄 클로라이드 용액, 벤제토늄 클로라이드, 벤조산, 벤질 알콜, 부틸파라벤, 세틸피리디늄 클로라이드, 클로로부탄올, 클로로크레졸, 크레졸, 데히드로아세트산, 디아졸리디닐 우레아, 에틸파라벤, 메틸파라벤, 메틸파라벤 나트륨, 페놀, 페닐에틸 알콜, 페닐머큐릭 아세테이트, 페닐머큐릭 니트레이트, 칼륨 벤조에이트, 칼륨 소르베이트, 프로필파라벤, 프로필파라벤 나트륨, 나트륨 벤조에이트, 나트륨 데히드로아세테이트, 나트륨 프로피오네이트, 소르브산, 티메로살, 및 티몰로 이루어진 군으로부터 선택될 수 있다.
조성물은 아세트산, 암모늄 카르보네이트, 암모늄 포스페이트, 붕산, 시트르산, 락트산, 인산, 칼륨 시트레이트, 칼륨 메타포스페이트, 칼륨 포스페이트 일염기성, 나트륨 아세테이트, 나트륨 시트레이트, 나트륨 락테이트 용액, 이염기성 나트륨 포스페이트, 일염기성 나트륨 포스페이트, 나트륨 비카르보네이트, 트리스 (트리스(히드록시메틸)아미노메탄), MOPS (3-(N-모르폴리노)프로판술폰산), HEPES (N-(2-히드록시에틸)피페라진-N'-(2-에탄술폰산), ACES (2-[(2-아미노-2-옥소에틸)아미노]에탄술폰산), ADA (N-(2-아세트아미도)2-이미노디아세트산), AMPSO (3-[(1,1-디메틸-2-히드록시에틸아미노]-2-프로판술폰산), BES (N,N-비스(2-히드록시에틸)-2-아미노에탄술폰산, 비신 (N,N-비스(2-히드록시에틸글리신), 비스-트리스 (비스-(2-히드록시에틸)이미노-트리스(히드록시메틸)메탄, CAPS (3-(시클로헥실아미노)-1-프로판술폰산), CAPSO (3-(시클로헥실아미노)-2-히드록시-1-프로판술폰산), CHES (2-(N-시클로헥실아미노)에탄술폰산), DIPSO (3-[N,N-비스(2-히드록시에틸아미노]-2-히드록시-프로판술폰산), HEPPS (N-(2-히드록시에틸피페라진)-N'-(3-프로판술폰산), HEPPSO (N-(2-히드록시에틸)피페라진-N'-(2-히드록시프로판술폰산), MES (2-(N-모르폴리노)에탄술폰산), 트리에탄올아민, 이미다졸, 글리신, 에탄올아민, 포스페이트, MOPSO (3-(N-모르폴리노)-2-히드록시프로판술폰산), PIPES (피페라진-N,N'-비스(2-에탄술폰산), POPSO (피페라진-N,N'-비스(2-히드록시프로판울폰산), TAPS (N-트리스[히드록시메틸)메틸-3-아미노프로판술폰산), TAPSO (3-[N-트리스(히드록시메틸)메틸아미노]-2-히드록시-프로판술폰산), TES (N-트리스(히드록시메틸)메틸-2-아미노에탄술폰산), 트리신 (N-트리스(히드록시메틸)메틸글리신), 2-아미노-2-메틸-1,3-프로판디올, 및 2-아미노-2-메틸-1-프로판올로 이루어진 군으로부터 선택된 완충액을 포함할 수 있다.
전형적으로, 산성화제는 아세트산, 시트르산, 푸마르산, 염산, 희석된 염산, 말산, 질산, 인산, 희석된 인산, 황산, 및 타르타르산으로 이루어진 군으로부터 선택된다.
전형적으로, 항산화제는 아스코르브산, 아스코르빌 팔미테이트, 부틸화 히드록시아니솔, 부틸화 히드록시톨루엔, 차아인산, 모노티오글리세롤, 프로필 갈레이트, 나트륨 아스코르베이트, 중아황산나트륨, 나트륨 포름알데히드 술폭실레이트, 나트륨 메타비술파이트, 나트륨 티오술페이트, 이산화황, 및 토코페롤로 이루어진 군으로부터 선택된다.
전형적으로, 알칼리화제는 강한 암모니아 용액, 암모늄 카르보네이트, 디에탄올아민, 디이소프로판올아민, 수산화칼륨, 나트륨 비카르보네이트, 나트륨 보레이트, 나트륨 카르보네이트, 수산화나트륨, 및 트롤아민으로 이루어진 군으로부터 선택된다.
운반제는 옥수수유, 광유, 땅콩유, 참깨유, 정균 염화나트륨 및 정균수로 이루어진 군으로부터 선택될 수 있다.
킬레이팅제는 에데테이트 이나트륨, 에틸렌디아민테트라아세트산, 시트르산, 및 살리실레이트로 이루어진 군으로부터 선택될 수 있다.
착물화제는 에틸렌디아민테트라아세트산, 에틸렌디아민테트라아세트산의 염, 젠티스산 에탄올아미드, 및 옥시퀴놀린 술페이트로 이루어진 군으로부터 선택될 수 있다.
용매는 아세톤, 에탄올, 희석된 알콜, 아밀렌 수화물, 벤질 벤조에이트, 부틸 알콜, 사염화탄소, 클로로포름, 옥수수유, 면실유, 에틸 아세테이트, 글리세롤, 헥실렌 글리콜, 이소프로필 알콜, 메틸 이소부틸 케톤, 광유, 올레산, 땅콩유, 폴리에틸렌 글리콜, 프로필렌 카르보네이트, 프로필렌 글리콜, 참깨유, 물, 멸균수, 및 정제수로 이루어진 군으로부터 선택될 수 있다.
전형적으로, 현탁화제 및/또는 점도-증가제는 아카시아, 아가, 알긴산, 알루미늄 모노스테아레이트, 벤토나이트, 정제된 벤토나이트, 마그마 벤토나이트, 카르보머, 카르보머 934p, 카르복시메틸셀룰로스 칼슘, 카르복시메틸셀룰로스 나트륨, 카르복시메티셀룰로스 나트륨 12, 카라기난, 미세결정 및 카르복시메틸셀룰로스 나트륨 셀룰로스, 덱스트린, 젤라틴, 구아 검, 히드록시에틸 셀룰로스, 히드록시프로필 셀룰로스, 히드록시프로필 메틸셀룰로스, 마그네슘 알루미늄 실리케이트, 메틸셀룰로스, 펙틴, 폴리에틸렌 옥시드, 폴리비닐 알콜, 포비돈, 프로필렌 글리콜 알기네이트, 이산화규소, 콜로이달 이산화규소, 나트륨 알기네이트, 트라가칸트, 비검, 및 크산탄 검으로 이루어진 군으로부터 선택된다.
전형적으로, 오일은 아라키스유, 광유, 올리브유, 참깨유, 면실유, 홍화유, 옥수수유, 및 대두유로 이루어진 군으로부터 선택된다.
전형적으로, 침투 향상제는 모노히드록시 또는 폴리히드록시 알콜, 일가 또는 다가 알콜, 포화 또는 불포화 지방 알콜, 포화 또는 불포화 지방 에스테르, 포화 또는 불포화 디카르복실산, 에센셜 오일, 포스파티딜 유도체, 세팔린, 테르펜, 아미드, 에테르, 케톤, 및 우레아로 이루어진 군으로부터 선택된다.
전형적으로, 중합체는 셀룰로스 아세테이트, 알킬 셀룰로스, 히드록시알킬셀룰로스, 아크릴 중합체 및 공중합체, 폴리에스테르, 폴리카르보네이트, 및 폴리무수물로 이루어진 군으로부터 선택된다.
전형적으로, 경화제는 수소화된 피마자유, 세토스테아릴 알콜, 세틸 알콜, 세틸 에스테르 왁스, 경질 지방, 파라핀, 폴리에틸렌 부형제, 스테아릴 알콜, 유화 왁스, 화이트 왁스, 및 옐로우 왁스로 이루어진 군으로부터 선택된다.
전형적으로, 단백질은 소 혈청 알부민, 인간 혈청 알부민 (HSA), 재조합 인간 알부민 (rHA), 젤라틴, 및 카세인으로 이루어진 군으로부터 선택된다.
전형적으로, 탄수화물은 프룩토스, 말토스, 갈락토스, 글루코스, D-만노스, 소르보스, 락토스, 수크로스, 트레할로스, 셀로비오스, 라피노스, 멜레지토스, 말토덱스트린, 덱스트란, 전분, 만니톨, 말티톨, 락티톨, 크실리톨, 소르비톨, 및 미오이노시톨로 이루어진 군으로부터 선택된다.
전형적으로, 벌킹제는 폴리펩티드 및 아미노산으로 이루어진 군으로부터 선택된다.
조성물은 피부용 국소 진정제, 국소 항-염증제, 국소 항-박테리아제, 국소 항-진균제, 국소 스테로이드, 및 국소 항산화제를 추가로 포함할 수 있다.
피부용 국소 진정제는 전형적으로 캐모마일 및 알로에를 포함하고; 다른 국소 진정제가 당업계에 공지되어 있고 이것이 사용될 수 있다.
국소 항-염증제는 전형적으로 디클로페낙, 케토프로펜, 이부프로펜, 피록시캄, 및 인도메타신을 포함하고; 다른 국소 항-염증제가 당업계에 공지되어 있고 이것이 사용될 수 있다.
국소 항-박테리아제는 전형적으로 바시트라신, 폴리믹신 B, 에리트로마이신, 나트륨 술파세타미드, 은 술파디아진, 레타파물린, 무피로신, 네오마이신, 및 프라목신을 포함하고; 다른 국소 항-박테리아제가 당업계에 공지되어 있고 이것이 사용될 수 있다.
국소 항-진균제는 전형적으로 벤조산, 살리실산, 운데실렌산, 케토코나졸, 니스타틴, 나프티핀, 톨나프테이트, 미코나졸, 에코나졸, 시클로피록스, 옥시코나졸, 세르타코나졸, 에피나코나졸, 테르비나핀, 타바보롤, 클로트리마졸, 술코나졸, 및 부테나핀을 포함하고; 다른 국소 항-진균제가 당업계에 공지되어 있고 이것이 사용될 수 있다.
국소 스테로이드는 전형적으로 히드로코르티손, 트리암시놀론, 플루오시놀론, 프레드니카르베이트, 데소니드, 베타메타손, 할시노니드, 디플로라손, 플루오시놀론, 클로베타솔, 데속시메타손, 모메타손, 클로코르톨론, 플루티카손, 플루오시노니드, 플루란드레놀리드, 알클로메타손, 및 할로베타솔을 포함하고; 다른 국소 스테로이드가 당업계에 공지되어 있고 이것이 사용될 수 있다.
국소 항산화제는 전형적으로 비타민 C, 비타민 E, 및 L-셀레노메티오닌을 포함하고; 다른 국소 항산화제가 당업계에 공지되어 있고 이것이 사용될 수 있다.
다른 활성제가 포함될 수 있다.
대안적으로, 다수의 이들 추가의 작용제, 예컨대 국소 항-염증제, 국소 항-박테리아제, 국소 항-진균제, 국소 스테로이드, 및 국소 항산화제는, 상기에 기재된 바와 같은 하나 이상의 부형제를 포함하는 하나 이상의 추가의 제약 조성물에서와 같이, 별도로 투여될 수 있다.
상기에 기재된 바와 같은 전구약물의 사용을 포함한 일부 대안에서, 칸나비노이드 및 테르페노이드를 포함하나 이에 제한되지는 않는 본 발명에 따른 방법 및 조성물에서 사용되는 치료 활성 화합물은, 하나 이상의 컨쥬게이션 파트너를 치료 활성 화합물에 공유 가교시킴으로써 형성된다. 많은 작용기의 조합의 가교에 적합한 시약은 당업계에 공지되어 있다.
예를 들어, 친전자성 기가, 단백질 또는 폴리펩티드 내에 존재하는 것들을 포함한, 많은 작용기와 반응할 수 있다. 반응성 아미노산 및 친전자체의 다양한 조합이 당업계에 공지되어 있고 이것이 사용될 수 있다. 예를 들어, 티올 기를 함유하는 N-말단 시스테인이 할로겐 또는 말레이미드와 반응할 수 있다. 티올 기는 많은 수의 커플링제, 예컨대 알킬 할라이드, 할로아세틸 유도체, 말레이미드, 아지리딘, 아크릴로일 유도체, 아릴화제, 예컨대 아릴 할라이드 등과의 반응성을 갖는 것으로 공지되어 있다. 이들은 G.T.Hermanson, "Bioconjugate Techniques"(Academic Press, San Diego, 1996), pp. 146-150에 기재되어 있다.
시스테인 잔기의 반응성은 이웃하는 아미노산 잔기의 적절한 선택에 의해 적합화될 수 있다. 예를 들어, 시스테인 잔기에 인접한 히스티딘 잔기는 시스테인 잔기의 반응성을 증가시킬 것이다. 반응성 아미노산 및 친전자성 시약의 다른 조합이 당업계에 공지되어 있다. 예를 들어, 말레이미드가, 특히 보다 높은 pH 범위에서, 아미노 기, 예컨대 리신의 측쇄의 e-아미노 기와 반응할 수 있다. 또한 아릴 할라이드가 이러한 아미노 기와 반응할 수 있다. 할로아세틸 유도체가 히스티딘의 이미다졸릴 측쇄 질소, 메티오닌의 측쇄의 티오에테르 기, 및 리신의 측쇄의 .엡실론.-아미노 기와 반응할 수 있다. 리신의 측쇄의 e-아미노 기와 반응하는 많은 다른 친전자성 시약이 공지되어 있고, 이는 이소티오시아네이트, 이소시아네이트, 아실 아지드, N-히드록시숙신이미드 에스테르, 술포닐 클로라이드, 에폭시드, 옥시란, 카르보네이트, 이미도에스테르, 카르보디이미드, 및 무수물을 포함하나, 이에 제한되지는 않는다. 이들은 G.T.Hermanson, "Bioconjugate Techniques"(Academic Press, San Diego, 1996), pp. 137-146에 기재되어 있다.
추가로, 아스파르테이트 및 글루타메이트의 것들과 같은 카르복실레이트 측쇄와 반응하는 친전자성 시약이 공지되어 있고, 이는 예컨대 디아조알칸 및 디아조아세틸 화합물, 카르보니딜미다졸, 및 카르보디이미드이다. 이들은 G.T.Hermanson, "Bioconjugate Techniques" (Academic Press, San Diego, 1996), pp. 152-154에 기재되어 있다. 또한, 세린 및 트레오닌의 측쇄에서의 것들과 같은 히드록실 기와 반응하는 친전자성 시약이 공지되어 있고, 이는 반응성 할로알칸 유도체를 포함한다. 이들은 G.T.Hermanson, "Bioconjugate Techniques"(Academic Press, San Diego, 1996), pp. 154-158에 기재되어 있다. 또 다른 대안적 구현예에서는, 친전자체 및 친핵체 (즉, 친전자체와 반응성인 분자)의 상대적 위치가 역전되고, 그에 따라 단백질이 친핵체와 반응성인 친전자성 기를 갖는 아미노산 잔기를 갖고, 표적화 분자는 그 안에 친핵성 기를 포함한다. 이는 상기에 기재된 바와 같은 히드록실아민 (친핵체)와 알데히드 (친전자체)의 반응을 포함하지만, 그 반응보다 더 일반적이고; 다른 기가 친전자체 및 친핵체로서 사용될 수 있다. 적합한 기는 유기 화학에서 널리 공지되어 있고, 추가로 상세히 기재될 필요는 없다.
가교를 위한 반응성 기의 추가의 조합이 당업계에 공지되어 있다. 예를 들어, 아미노 기가 이소티오시아네이트, 이소시아네이트, 아실 아지드, N-히드록시숙신이미드 (NHS) 에스테르, 술포닐 클로라이드, 알데히드, 글리옥살, 에폭시드, 옥시란, 카르보네이트, 알킬화제, 이미도에스테르, 카르보디이미드, 및 무수물과 반응할 수 있다. 티올 기가 할로아세틸 또는 알킬 할라이드 유도체, 말레이미드, 아지리딘, 아크릴로일 유도체, 아실화제, 또는 다른 티올 기와 산화 및 혼합 디술피드의 형성에 의해 반응할 수 있다. 카르복시 기가 디아조알칸, 디아조아세틸 화합물, 카르보닐디이미다졸, 카르보디이미드와 반응할 수 있다. 히드록실 기가 에폭시드, 옥시란, 카르보닐디이미다졸, N,N'-디숙신이미딜 카르보네이트, N-히드록시숙신이미딜 클로로포르메이트, 페리오데이트 (산화를 위한), 알킬 할로겐, 또는 이소시아네이트와 반응할 수 있다. 알데히드 및 케톤 기가 히드라진, 쉬프(Schiff) 염기 형성 시약, 및 다른 기와 환원성 아미노화 반응 또는 만니히(Mannich) 축합 반응에서 반응할 수 있다. 가교 반응에 적합한 또한 다른 반응이 당업계에 공지되어 있다. 이러한 가교 시약 및 반응은 G.T.Hermanson, "Bioconjugate Techniques"(Academic Press, San Diego, 1996)에 기재되어 있다.
본 발명에 따른 제약 조성물의 단위 용량 중에 포함된, 비제한적으로 상기에 기재된 바와 같은 칸나비노이드 또는 테르페노이드와 같은 주어진 치료 활성제의 양은, 특정 화합물, 질환 상태 및 그의 중증도, 치료를 필요로 하는 대상체의 정체 (예: 체중)와 같은 인자에 따라 달라질 것이지만, 그럼에도 불구하고 당업자에 의해 일상적으로 결정될 수 있다. 선택된 투여량 수준은, 특정 치료제의 활성, 투여 방식, 투여 시간, 사용되는 특정 화합물의 배설 속도, 병태의 중증도, 대상체에게 영향을 주는 다른 건강 고려사항, 및 대상체의 간 및 신장 기능의 상태를 포함한 다양한 약동학적 인자에 따라 달라진다.
이는 또한, 치료의 지속기간, 사용되는 특정 치료제와 조합되어 사용되는 다른 약물, 화합물 및/또는 물질, 뿐만 아니라 치료되는 대상체의 연령, 체중, 병태, 일반적 건강 및 이전 병력, 및 유사 인자에 따라 달라진다. 최적 투여량을 결정하는 방법은 당업계에, 예를 들어, Remington:The Science and Practice of Pharmacy, Mack Publishing Co., 20th ed., 2000에 기재되어 있다. 주어진 세트의 병태에 대한 최적 투여량은 작용제에 대한 실험 데이터를 고려하여 종래의 투여량-결정 시험을 사용하여 당업자에 의해 확인될 수 있다.
본 발명의 조성물 또는 본 발명에 따라 사용되는 조성물은, 제약 조성물의 제조에 대해 일반적으로 공지된 기술을 사용하여, 예를 들어, 종래 기술, 예컨대 혼합, 용해, 과립화, 당제(dragee)-제조, 부양(levitating), 유화, 캡슐화, 포획 또는 동결건조에 의해 제조될 수 있다. 제약 조성물은, 활성 화합물의 조제물로의 가공처리를 용이하게 하는 부형제 및 보조제로부터 선택될 수 있는, 하나 이상의 생리학상 허용가능 담체를 사용하여 종래 방식으로 제제화될 수 있다.
본 발명에 따른 제약 조성물은 통상적으로 다수회로 대상체에게 투여된다. 단일 투여량 사이의 간격은 1주마다, 1개월마다 또는 1년마다일 수 있다. 간격은 또한 당업계에 널리 공지된 치료적 반응 또는 다른 파라미터에 의해 지시되는 바와 같이 불규칙적일 수 있다. 대안적으로, 제약 조성물은 지속 방출 제제로서 투여될 수 있고, 이 경우에는 보다 덜 빈번한 투여가 요구된다. 투여량 및 빈도수는 제약 조성물 중에 포함된 약리 활성제의 대상체에서의 반감기에 따라 달라진다. 투여량 및 투여 빈도수는, 치료가 예방적인지 치료적인지에 따라 달라질 수 있다.
예방적 적용에서는, 비교적 낮은 투여량이 장기간에 걸쳐 비교적 드문 간격으로 투여된다. 일부 대상체는 이들의 남은 생애 동안 계속해서 치료를 수용할 수 있다. 치료적 적용에서는, 질환의 진행이 감소되거나 종료될 때까지, 또한 바람직하게는 대상체가 질환 증상의 부분적 또는 완전한 개선을 나타낼 때까지, 비교적 짧은 간격으로 비교적 높은 투여량이 때때로 요구된다. 그 후, 대상체는 예방적 요법을 투여받을 수 있다.
Nardella에게 허여된 미국 특허 번호 6,573,292, Nardella에게 허여된 미국 특허 번호 6,921,722, Chao et al.에게 허여된 미국 특허 번호 7,314,886, 및 Chao et al.에게 허여된 미국 특허 번호 7,446,122는, 암을 포함한 다수의 질환 및 병태 치료에서의 다양한 약리 활성제 및 제약 조성물의 사용 방법, 및 이러한 약리 활성제 및 제약 조성물의 치료적 효과를 결정하는 방법을 개시하며, 이들 모두 본원에 참조로 포함된다.
참조문헌
하기 공개문헌이 본원에 참조로 포함된다. 이들 공개문헌은 하기에 제공되는 번호로 본원에서 언급된다. 공개문헌의 이 목록 내의 임의의 공개문헌의 포함은 본원에서 언급되는 임의의 공개문헌이 선행 기술임을 인정하는 것으로 간주되어선 안된다.
JAMA.2006; 295(7):761-775
Comput Struct Biotechnol J, 2012, 3, 1-11
Biotechnol.Bioeng.2004 88, 909-915.
Science 2002, 298 (5599), 1790-3.
실시예
실시예 1
:대장균에서 MEP 경로의 조작
MEP 경로를 그의 열역학적 유리성 및 적합한 박테리아 숙주 시스템의 이용가능성에 대해 선택하였다. MEP 경로는 숙주 대장균에 대해 네이티브이다. 대장균 BL21 (DE3)을 이 실험에서 발현 숙주로서 선택하였다. MEP 경로에서 속도-제한 효소를 코딩하는 유전자를 과발현시켜 칸나비노이드 전구체의 생성을 최대화하였다.
MEP 경로의 4개 단계는 가장 느리고 낮은 플럭스를 겪는다. 이들 속도-제한 단계를 촉매하는 효소의 과발현은 MEP 경로를 통한 플럭스를 개선시키고 하류 테르페노이드 생합성을 증가시키는 것으로 보고되었다. 따라서, 칸나비노이드 (도 1)에 대한 전구체 이소펜테닐 디포스페이트 (IPP) 및 디메틸알릴 디포스페이트 (DMAPP)의 생성을 최대화하기 위해, 라이코펜, 모노테르펜, 또는 이소프렌 경로, 비-메발로네이트 경로를 조작하여 4개의 상이한 속도-제한 유전자 dxs, ispD, ispF 및 idi의 추가 카피를 도입하였다 (도:2).
이 과정을 폴리머라제 사슬 반응 (PCR) 및 제한 소화 및 결찰을 통한, T7 프로모터 및 p15A 복제 기점을 갖는 벡터 백본으로의 클로닝을 통해 단계적 방식으로 수행하여, 적절한 배향을 갖는 유전자 카세트를 구성하였다. 이어서, 전체 유전자 카세트를 Trc 프로모터 및 pBR322 복제 기점을 갖는 pTrc-trGPPS(CO)-LS 플라스미드 (도 3)로 서브-클로닝하여 유전자 발현을 제어하는 폭넓은 윈도우 및 이소프레노이드 전구체의 생성을 얻었다. 이어서, pTrc 프로모터 및 선택 마커 유전자와 함께 유전자 카세트를 유도가능 추가 카피로서 대장균 염색체로 통합하여 이소프레노이드 전구체의 과생성을 제공하였다. MEP 경로 발현 카세트의 대략적 맵을 도 3에 나타내었다. 속도 제한 효소의 과발현은 SDS 페이지 분석에 의해 확인된다 (도 4).
유사하게, GPP 신타제를, 예를 들어, 식물 공급원으로부터 클로닝하고, 대장균에서 발현시켜 GPP, 칸나비노이드 신타제 CBGA 신타제의 기질 및 모노테르펜 신타제, 예컨대 카렌, 미르센, 또는 리모넨 신타제의 기질을 생성한다. 또한, 올리베톨산, CBGA 신타제의 기질의 합성을 위한 폴리케티드 경로를 클로닝하고, 대장균에서 발현시키거나, 또는 올리베톨산을 외생 공급한다. 따라서, CBGA의 생성에 대한 경로가 원핵생물 숙주 세포에서 재현된다.
실시예 2
:대장균에서의 하류 경로 칸나비노이드 신타제 유전자의 클로닝 및 발현
도입:
칸나비게롤산 (CBGA)은 다른 칸나비노이드의 합성에 대한 모 화합물이다. CBGA는, CBGA 신타제 (방향족 프레닐트랜스퍼라제 패밀리로부터의 효소)에 의해 촉매화된 올리베톨산 (OA) 및 게라닐 피로포스페이트 (GPP)로부터의 효소적 반응에 의해 생성된다. 이 프레닐화된 생성물 (CBGA)의 고리화는 추가로 3개의 상이한 옥시도시클라제에 의해 촉매화된 3개의 상이한 칸나비노이드 생성물을 제공한다. Δ9-테트라히드로칸나비놀산 (THCA) 신타제, 칸나비디올 (CBDA) 신타제, 및 칸나비크로멘산 (CBCA) 신타제는 각각 Δ9-테트라히드로칸나비놀산 (THCA), 칸나비디올산 (CBDA) 및 칸나비크로멘산 (CBCA)의 형성을 촉매한다. 미생물 숙주 (대장균)에서의 이들 칸나비노이드 생성물의 생합성은 THCA 신타제, CBGA 신타제, CBCA 신타제, CBDA 신타제, 및 이들의 조합의 클로닝, 발현, 및 활성 결정을 포함한다. 전형적으로, 칸나비노이드 생성물은, 임의로 THCA 신타제, CBCA 신타제, 및 CBDA 신타제 중 하나 이상과 조합되어, 적어도 CBGA 신타제를 발현하는 미생물 숙주에서 생성된다.
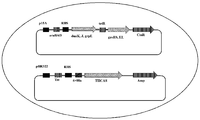
CBGA 신타제
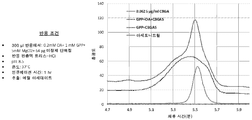
대장균에 대해 코돈 적합화된, 칸나비스 사티바로부터의 CBGA 신타제 유전자를, 강한 IPTG 유도가능 T5 프로모터에 작동가능하게 연결된 플라스미드 벡터로 성공적으로 클로닝하였다. 플라스미드는 높은 카피 pUC 복제 기점을 함유하고, 카나마이신 내성이다. CBGA 신타제에 대한 플라스미드 구성을 도 5에 나타내었다. 대장균에서의 CBGA 신타제의 발현은 SDS 페이지 분석에 의해 확인되었다 (도 6). CBGAS의 발현 확인 후, 효소 용액에 대한 기질 (OA 및 GPP)의 외생 첨가에 의해 효소의 활성을 결정하고, 내부 개발 HPLC 방법을 사용하여 생성물 프로파일링을 수행하였다. 정화된 세포 용해물을 37 ℃에서 OA 및 GPP의 혼합물에 첨가함으로써 프레닐화 반응을 수행하고, 에틸 아세테이트를 사용하여 반응 혼합물을 추출하고, HPLC 상에서 진행시켜 생성물 형성을 측정하였다. (도 7) 결과는, CBGAS가 대장균에서 발현될 수 있고, CBGA로의 기질 OA 및 GPP와의 프레닐화 반응을 촉매할 수 있음을 나타내었다.
또 다른 실험에서, CBGA 활성을 생체내에서 시험하였다. 이 실험에서는, IPTG의 첨가에 의해 로그-기 성장 (OD600 = 0.6) 도달시 CBGAS 발현 플라스미드를 함유하는 숙주 세포를 배양하고 유도하였다. 유도기 동안 세포에 GPP 및 OA를 공급하고, 밤새 성장시켰다. 이어서 세포 현탁액을 원심분리하고, 이어서 상청액을 HPLC에 주입하여 CBGA 형성을 확인하였다. 도 8은 대장균에서 생성된 (낮은 카피 플라스미드, pBAD33 사용) CBGA의 검출에 대한 HPLC 크로마토그램을 나타낸다. 생성된 CBGA의 농도는 5 mL 배양물로부터 대략 1.2 ㎍/ml로 계산되었다.
THCA 신타제 (THCAS)
강한 IPTG 유도가능 T5 프로모터의 제어 하에 THCA 신타제 유전자를 또한 높은 카피, 카나마이신 내성, 플라스미드로 클로닝하였다. 유전자 삽입은 PCR 및 유전자 시퀀싱에 의해 확인되었다. THCA 신타제 유전자에 대한 생성된 발현 카세트의 개략도를 도 9에 나타내었다. THCA 신타제의 발현을 IPTG 유도에 의해 수행하고, 세포 용해물을 SDS 페이지에 의해 분석하여 발현을 확인하였다. 그러나, THCA 신타제는 대장균으로 성공적으로 발현되지 않았다.
THCA 신타제 유전자는 8개의 글리코실화 자리 및 28개의 아미노산 신호 펩티드를 N 말단에 갖는 단백질의 플라비닐화된 옥시다제를 코딩한다. 글리코실화된 막횡단 단백질의 생성에 대한 대장균의 이들 제한은 단백질의 THCA 신타제 부류의 활성 형태를 발현시키기 어렵게 만든다. 이 제한을 극복하기 위해, 단백질 발현이 시토졸에서 나타나는 것을 보장하기 위해 신호 펩티드 없이 유전자를 발현하도록, 단백질 폴딩을 보조하고 활성 단백질의 생성을 증가시키기 위해 모듈식 샤페로닌과 함께 유전자를 공동-발현하도록 (예: 도 10), 또한 단백질 폴딩을 보조하기 위해 글리코실화 기관과 공동-발현하도록 (예: 도 11) 다중-인자 전략을 디자인하였다. CBDA 신타제 (CBDAS) 또한 동일한 부류의 단백질에 포함되고, 따라서 CBDA 신타제 발현을 위해서도 동일한 전략이 적용될 것이다. 유사하게, CBCA 신타제 (CBCAS)는 네이티브 신호 서열을 갖는 글리코실화된 단백질이고, 따라서 CBCA 신타제 발현을 위해서도 동일한 전략이 적용될 것이다. 연구의 이 부분은 진행 하에 있고, THCAS와 관련하여 다음 접근이 고려되고, 당업자는 이들 접근이 또한 CBDAS 및 CBCAS에 적용될 수 있음을 인지할 것이다.
절단된 THCAS
THCAS는 코딩된 N 말단으로부터 28개 아미노산 (유전자 서열의 5' 말단으로부터 84 bp)을 제거함으로써 절단된다.
샤페로닌 플라스미드와의 공동-발현
THCA 신타제 유전자를, 이것이 샤페로닌 시스템 및 글리코실화 시스템을 갖는 플라스미드와의 공동-발현을 위한 상이한 및 상용성인 복제 기점을 가짐을 확신하도록 pTRC 프로모터의 제어 하에, pBR322 복제 기점, 암피실린 내성을 갖는 플라스미드 상으로 클로닝하였다 (도 11). 신호 펩티드를 갖는, 또한 갖지 않는 THCAS를, 대장균에서 단백질 폴딩에서 구별되는, 그러나 협동적인 역할을 하는, 대장균에서의 2개의 주요 샤페론 경로 성분, DnaK-DnaJ-GrpE 및 GroEl-GroES와 공동-발현시킨다. 대장균은 그의 네이티브 샤페론 시스템을 갖지만, 재조합 단백질의 높은 수준의 생성은 내생 샤페로닌 시스템을 포화시킬 수 있고 비생산적 응집을 초래할 수 있다. 이들 조건 하에, 폴딩에 대해 제한적인 분자 샤페론의 세포내 농도 증가는 봉입체 형성을 감소시킬 수 있다. 일본의 다카하시 유라(Takahashi Yura) 그룹은 상이한 프로모터 하에 2개의 샤페론 경로를 갖는 pACYC184-기반 플라스미드를 구성하였다. 이 플라스미드 (pG-KJE8), 또는 그의 유도체는 숙주 세포에서 활성 THCA 신타제의 생성에 대한 조건을 식별하기 위해 사용된다.
글리코실화 시스템과의 공동-발현
글리코실화는 대장균에서 THCA 신타제의 증가된 발현, 폴딩, 프로세싱, 용해도, 및/또는 활성을 위해 요구될 수 있다. 불행히도, 대장균은 네이티브 단백질 글리코실화 시스템을 갖지 않는다. pgl 시스템이라 불리는, 캄필로박테르 제주니(Campylobacter jejuni)로부터의 N 글리코실화 시스템은, 대장균에서 성공적으로 발현되었다. 씨. 제주니 pgl 시스템 유전자를 갖는 플라스미드가 제공된다. 이 플라스미드, 또는 그의 유도체는 숙주 세포에서 활성 THCA 신타제의 생성에 대한 조건을 식별하기 위해 사용된다 (도 11).
실시예 3
:칸나비노이드 경로 유전자의 발현의 최적화
대장균에서 CBGA의 내생 생성을 최적화하기 위해, CBGA 신타제를, CBGA의 생성을 위해 요구되는, 기질 GPP 및 OA를 제공하도록 폴리케티드 경로 성분 및 또는 MEP 경로, GPP 신타제와 동시에 공동-발현시킨다.
공동-발현 후보는 하기의 것을 포함한다:
IPP 및 DMAPP를 생성하기 위한 MEP 경로와의 공동-발현
IPP 및 DMAPP로부터 내생적으로 GPP를 공급하기 위한 GPP 신타제와의 공동-발현
내생 올리베톨산 (OA) 공급을 위한 폴리케티드 경로와의 공동-발현.
대장균에서 2개의 상이한 플라스미드의 공동-발현을 위해, 낮은 또는 중간 카피 수를 갖는 플라스미드를 사용하여 세포 성장에 대한 유해 효과를 감소시켰고, 상용성 복제 기점을 사용하여 2개 이상의 플라스미드의 유지를 보장하였고, 플라스미드 각각의 엄중한 선택을 위해 독립적 항생제 선택을 사용하였다. 따라서, CBGA 신타제 유전자를 낮은 카피 플라스미드 pBAD33으로 클로닝하였다. 낮은 카피 CBGA 신타제 발현 플라스미드의 개략도를 나타내었다 (도 12). 클로닝된 CBGAS 유전자를 제한 소화 및 시퀀싱에 의해 확인하였다. GPP 신타제 및 MEP 경로를 갖는 CBGAS의 공동-발현을 위해, GPP 신타제를 pBAD33에서 CBGAS의 상류에서 클로닝하고, 이어서 pTRC_RDE와 공동-변환시켰다 (도 13). 공동-변환 후, OD600이 0.6에 도달하면 세포를 항생제 선택과 함께 성장시키고 유도하였다. 유도제 농축물의 양을 도 14에 기재하였다.
유도제 첨가 후, 세포를 밤새 성장시켰다. OD600을 측정하여 단백질 생성시 세포 생존력을 검사하였다. 상이한 배양물에 대한 OD600 비교를 도 15에 나타내었다. pBAD33_GPPS_CBGAS를 갖는 균주를 10, 15 및 20 mM의 농도로 아라비노스에 의해 유도하였다. pBAD33_GPPS_CBGAS 및 pTRC_RDE를 갖는 균주를 상이한 농도 조합의 아라비노스 및 IPTG로 유도하였다. 세포 용해 후 단백질을 추출하고, 단백질의 농도를 브래드포드(Bradford) 방법을 사용하여 측정하였다. 단백질의 유도 및 발현을 SDS 페이지에 의해 검사하였다 (도 16). 총 추출된 단백질 농도를 플롯팅하여 (도 17) SDS 페이지 상의 발현 데이터와 비교하였다. 유도제 농도 증가에 따라 총 단백질 농도는 증가하는 것으로 나타났고, 이는 세포 집단수 및 성장과 반비례한다.
리(Lee) 등은 아라비노스의 유도에 대한 IPTG의 개입을 발견하였다. 따라서 CBGAS의 발현을 상이한 조합의 아라비노스 및 IPTG 농도로 검사하였다. 세포가 10 mM 아라비노스 및 0.5 mM IPTG로 유도된 경우 총 단백질 농도는 보다 높은 것으로 나타났다. 다중 플라스미드 유지는 DNA, RNA, 및 단백질 합성으로부터의 세포에 대한 대사 부담 뿐만 아니라 세포가 생성해야 하는 항생제 내성 단백질의 총 수를 증가시키고, 요망되는 최종 생성물의 낮은 생성을 초래한다. 또한 상이한 유도제들 사이의 밸런스 유지는 또한 최종 생성물에 대한 비-재현가능 생성 수준을 제공할 것이다. 이 제한을 극복하기 위해, 전체 유전자 카세트를, MEP 경로 및 GPPS 및 CBGAS 오페론을 함께 갖는 단일 플라스미드 상에서 구성한다. 추가로 또는 대안적으로, MEP 경로, GPPS, 및/또는 CBGAS를 숙주 세포 게놈으로 통합한다.
실시예 4
:MEP 경로 상의 2작용성 ispDF 유전자의 메타게놈 스크리닝 및 클로닝
토양 박테리아로부터의 환경 메타게놈을 스크리닝하여 대안적 MEP 경로 유전자를 식별하였다. 상응하는 대장균 오르토로그에 비해 상당히 더 활성인 비-메발로네이트 경로에서의 신규한 2작용성 효소를 식별하였다. 새로운 2작용성 효소는 단일 폴리펩티드 스캐폴드 상으로 IspD 및 ispF의 활성 자리를 공동-국소화하였다. 2작용성 유전자의 활성을 칸나비노이드 합성 대신에 라이코펜 생성에 대해 평가하였다. 유전자를 ispDF라 칭하고, 동일한 강한 RBS를 사용하여 ispD 및 ispF를 ispDF로 대체하여 pTrc-RDE 오페론에서 클로닝하였다. 이 조작된 플라스미드를 pTrc-RDE*라 칭하고, 대장균에서 변환시켰다 (DE3). ispD 및 ispF의 활성 자리를 공동-국소화한 2개의 추가의 메타게노믹스 2작용성 효소를 각각 ispDF2, 및 ispDF3이라 칭하였다.
단백질 발현 연구
플라스미드 pTrc-RDE 및 pTrc-RDE*를 보유하는 균주를 IPTG로의 유도에 의해 단백질 발현에 대해 시험하였다. 세포를 37 ℃에서 LB 브로스에서 성장시켜 0.6의 OD600에 도달하였고, 배지 내로의 IPTG의 첨가에 의해 유도하였고, 이어서 배양물을 30 ℃에서 밤새 인큐베이션하였다. 배양물로부터 수확된 세포를 용해시키고, 전체 단백질을 추출하였다. 총 단백질 농도를 브래드포드 방법으로 추정하고, SDS-페이지 겔 상에서 진행시켰다. 가시화를 위해 겔을 쿠마시 브릴리언트 블루(Coomassie Brilliant Blue) G-250으로 염색하였다. 발현시 pTrc-RDE 및 pTrc-RDE* 플라스미드는 둘 다 SDS-페이지 상에서 경로 효소에 상응하는 밴드를 나타내었다. 유도된 세포 용해물의 SDS-페이지 분석에 의해 ispDF 발현이 나타났다 (도 18).
ispDF 모델링:캄필로박테르 제주니로부터의 2작용성 ispDF는 CJ-ispDF로서 보고되었다. 본 발명자들의 연구에서 보고된 IspDF (ispDF1)를 스위스 모델을 사용하여 CJ-ispDF로 모델링하였다. 이는 대략 31% 서열 유사성을 보유한다. 그의 CJ-ispDF 및, 네이티브 ispD 및 ispF와의 정렬은 상이한 아미노산을 나타낸다 (도 19). 이는 ispDF가 신규한 것이고 보고된 바 없음을 시사한다. 활성 자리 공동-국소화에 대한 보다 많은 분석이 수행되고 있다.
플랫폼 균주의 기능 분석:
조작된 대장균 균주를, C5 이소프레노이드 전구체의 라이코펜으로의 전환을 위해 하류 유전자를 함유하는 플라스미드로 변환시켰다. 라이코펜 생합성 유전자를 구성성분 프로모터의 제어 하에 클로닝하였다. 라이코펜 발현 플라스미드는 낮은 카피였고, 공동-발현에 대한 복제 기점의 상용성을 가졌다.
ispD, ispF 및 ispE 효소는 2개의 연속적 촉매 단계를 통해 채널 대사산물에 대한 다성분 복합체를 형성한다고 보고되어 있다. 이를 추가로 연구하기 위해, 본 발명자들은 두 오페론에서 게놈으로부터 증폭된 네이티브 ispE 유전자를 클로닝하였다. 변종 플라스미드를 pTrc-RDE 및 pTrc-RDE*에 대해 각각 pTrc-RDEE 및 pTrc-RDE*E라 칭하였다 (도 20). 또한 이들 변종 둘 다에서, 하기에 기재되는 바와 같은 라이코펜 생성에 대한 기능성을 시험하였다.
실시예 5
:MEP 경로의 하나 이상의 성분의 이종 발현을 통한 테르페노이드 생합성 증가
상이한 구성물을 생성하고, 증가된 테르페노이드 생합성을 위한 능력에 대해 시험하였다 (도 21).
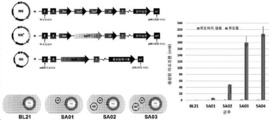
이소프렌 합성
대장균의 하기 균주를 제공하였다: 모 대조 균주 (BL21); 아라비노스 프로모터에 작동가능하게 연결된 이소프렌 신타제 (ispS)를 코딩하는 발현 카세트를 함유하는 대조 균주 SA01; Trc 프로모터에 작동가능하게 연결된 dxs, ispD, ispF, 및 idi를 코딩하는 RDE 발현 카세트 및 SA01 내의 발현 카세트를 함유하는 균주 SA02; 및 Trc 프로모터 균주에 작동가능하게 연결된 dxs, ispDF1, 및 idi를 코딩하는 RDE* 발현 카세트 및 SA01 내의 발현 카세트를 함유하는 균주 SA03 (도 22, 좌측). SA03에서, 명칭 ispDF1-는, ispDF1을 코딩하는 핵산이 이종 숙주 세포에서 증가된 발현을 위해 코돈 적합화되지 않음을 나타내며, ispDF+ (도 22에 나타내지 않음)는 효소를 코딩하는 핵산이 코돈 적합화됨을 나타낸다. 배양물을 밀봉 유리 배양 튜브에서 30 ℃에서 230 rpm으로 성장시켰다. 배양물을 OD600 0.6 도달 후에 유도하고, 20 h 동안 추가로 인큐베이션하였다. 0.05mM IPTG 및 10 mM 아라비노스를 유도제로서 사용하였다. 배양물 헤드 스페이스를 GC-MS에 의해 분석하였다. 샘플을 70 ℃로 가열한 후 주입하였다. 보정 곡선을 사용하여 이소프렌을 정량화하였다. 본원에 기재된 균주에 의한 이소프렌 생성을 도 22 우측에 나타내었다.
라이코펜 합성
플라스미드 pAC-LYC (Addgene 플라스미드 #53270)를 얻었다. 이 플라스미드는 라이코펜 합성 유전자 crtE, crtI, 및 crtB에 작동가능하게 연결된 구성성분 프로모터를 갖는 발현 카세트를 함유한다. Cunningham FX Jr, et al., Plant Cell.1994 Aug;6(8):1107-21을 참조한다. 대장균의 하기 균주를 제공하였다: 모 대조 균주 (BL21(DE3)); 상기에 기재된 RDE 발현 카세트를 함유하는 플라스미드 및 플라스미드 pAC-LYC를 함유하는 균주 RDE; 상기에 기재된 RDE* 발현 카세트를 함유하는 플라스미드 및 플라스미드 pAC-LYC를 함유하는 균주 RDE*(DF1-); 코돈 적합화된 ispDF1을 코딩하는 핵산을 갖는 RDE* 발현 카세트를 함유하는 플라스미드 및 플라스미드 pAC-LYC를 함유하는 균주 RDE*(DF1+); 코돈 적합화된 ispDF2를 코딩하는 핵산을 갖는 RDE* 발현 카세트를 함유하는 플라스미드 및 플라스미드 pAC-LYC를 함유하는 균주 RDE*(DF2+); 및 코돈 적합화된 ispDF3을 코딩하는 핵산을 갖는 RDE* 발현 카세트를 함유하는 플라스미드 및 플라스미드 pAC-LYC를 함유하는 균주 RDE*(DF3+). 생성된 추가의 균주는 pAC-LYC를 함유하는 SA01; pAC-LYC 및 pTrc-RDE를 함유하는 SA02; pAC-LYC 및 pTrc-RDEE를 함유하는 SA03; pAC-LYC 및 pTrc-RDE*를 함유하는 SA04; 및 pAC-LYC 및 pTrc-RDE*E를 함유하는 SA05를 포함한다. ispDF1, ispDF2, 및 ispDF3의 서열을 도 26에 나타내었다.
라이코펜 생성을 위해, SA01-SA05의 시드 배양물을 30 ℃에서 밤새 LB 배지 내에서 성장시켰다. 이어서, 이들 배양물을 신선한 배지로 0.2의 광학 밀도로 희석하고, IPTG에 의해 유도하였다. 생성 배양물을 250rpm으로 광 차단 진탕시키며 30 ℃에서 20h 동안 인큐베이션하였다. 4mL의 배양물을 2mL의 아세톤으로 추출함으로써 라이코펜 추출을 수행하였다. 아세톤 추출물을 HPLC 상에서 분석하였다. HPLC 방법: 컬럼-C18, 이동 상-메탄올:테트라히드로푸란:물 (66:30:4), 유속 - 1mL/min, 포토다이오드 어레이 검출기를 사용하여 472nm 파장에서 검출, 라이코펜 피크를 내부 라이코펜 표준으로 확인하였다. 도 23은 IPTG 유도가 라이코펜 생성을 증가시킴을 보여준다. 최적 유도 수준은 상이한 균주에서 상이하다.
제2 실험에서는, 배양물을 LB에서 밤새 30 ℃에서 성장시켰다. 이어서 이들 배양물을 LB로 0.2의 OD600로 희석하였다. 이들을 IPTG로 유도하고, 30 ℃에서 24 h 동안 성장시켰다. 2 mL의 배양물을 5 min 동안 8000 rpm으로 원심분리하여 세포 펠릿을 생성하였다. 세포 펠릿으로부터의 라이코펜을 55 ℃에서 15 min 동안 1 mL 아세톤으로 추출하였다. 이어서, 혼합물을 14000 rpm으로 원심분리하였다. 생성된 상청액을, 1 mL/min의 유속으로 메탄올, 테트라히드로푸란 및 물 (66:30:4)의 혼합물로 등용매 용리 방법을 사용하여 HPLC에 의해 C-18 컬럼 상에서 분석하였다. 라이코펜 피크에서 HPLC 곡선 하의 면적으로서 라이코펜 수율을 측정하였다. 피크를 내부 표준으로 확인하였다. 면적을 0 μM IPTG를 갖는 RDE 균주에 대하여 정규화하였다. 결과를 도 24에 나타내었다.
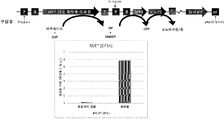
모노테르펜 합성
도 25 상단은 숙주 세포에서 모노테르펜의 생성을 위한 구성물을 나타낸다. 구성물은 T7 프로모터에 작동가능하게 연결된 dxs, 코돈 적합화된 ispDF1 (DF1+), 및 idi를 코딩하는 MEP 경로 플랫폼 오페론; 및 Trc 프로모터에 작동가능하게 연결된 GPP 신타제 및 모노테르펜 신타제를 코딩하는 모노테르펜 오페론을 포함한다. 이 실험에서, 모노테르펜 신타제는 카렌 신타제였다.
배양물을 LB + 0.5% 이스트 추출물에서 밤새 30 ℃에서 성장시켰다. 이어서, 이들 배양물을 2mM 염화마그네슘 보충된 배지로 0.2의 OD600로 희석하고, 37 ℃에서 인큐베이션하고, 이어서 0.8의 OD600에서 IPTG로 유도하였다. 배양물을 10% 도데칸으로 오버레잉하였다. 표준 곡선을 사용하여 GC-MS 상에서 모노테르펜 농도를 분석하였다. 결과를 도 25 저부에 나타내었다. 각각 리모넨 신타제, 및 미르센 신타제를 사용하여 모노테르펜 리모넨 및 미르센의 성공적인 생성이 또한 달성되었다. IspDF2+; ispDF3+; 및 dxs, ispD, ispF, 및 idi 또한 모노테르펜의 증가된 생성을 지지할 수 있었다.
예시적 서열
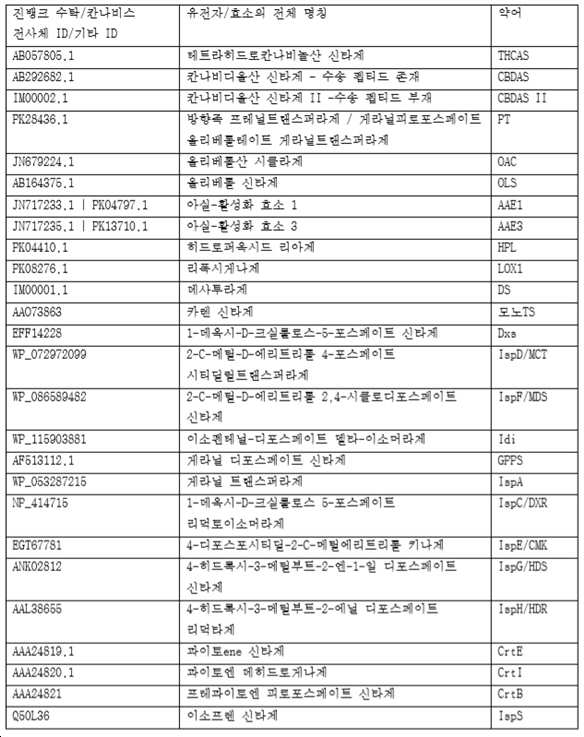
본 출원에서 언급되는 예시적 서열은 하기 표에 기재된 것들을 포함하나, 이에 제한되지는 않는다:
유전자의 일부는 진뱅크 데이터베이스로부터 유래되며, 다른 것은 칸나비스 게놈 브라우저 (genome.ccbr.utoronto.ca/cgi-bin/hgGateway )로부터 유래된다. IM00001.1은 칸나비스 mRNA 및 EST의 공공 서열로부터 생성되는 데사투라제를 나타내는 서열 ID이다.
예시적 서열을 하기에 제공한다.
>AB057805.1| 테트라히드로칸나비놀산 신타제 (THCAS)에 대한 칸나비스 사티바 mRNA, 완전한 cds
ATGAATTGCTCAGCATTTTCCTTTTGGTTTGTTTGCAAAATAAT
ATTTTTCTTTCTCTCATTCCATATCCAAATTTCAATAGCTAATCCTCGAGAAAACTTCCTTAAATGCTTC
TCAAAACATATTCCCAACAATGTAGCAAATCCAAAACTCGTATACACTCAACACGACCAATTGTATATGT
CTATCCTGAATTCGACAATACAAAATCTTAGATTCATCTCTGATACAACCCCAAAACCACTCGTTATTGT
CACTCCTTCAAATAACTCCCATATCCAAGCAACTATTTTATGCTCTAAGAAAGTTGGCTTGCAGATTCGA
ACTCGAAGCGGTGGCCATGATGCTGAGGGTATGTCCTACATATCTCAAGTCCCATTTGTTGTAGTAGACT
TGAGAAACATGCATTCGATCAAAATAGATGTTCATAGCCAAACTGCGTGGGTTGAAGCCGGAGCTACCCT
TGGAGAAGTTTATTATTGGATCAATGAGAAGAATGAGAATCTTAGTTTTCCTGGTGGGTATTGCCCTACT
GTTGGCGTAGGTGGACACTTTAGTGGAGGAGGCTATGGAGCATTGATGCGAAATTATGGCCTTGCGGCTG
ATAATATTATTGATGCACACTTAGTCAATGTTGATGGAAAAGTTCTAGATCGAAAATCCATGGGAGAAGA
TCTGTTTTGGGCTATACGTGGTGGTGGAGGAGAAAACTTTGGAATCATTGCAGCATGGAAAATCAAACTG
GTTGCTGTCCCATCAAAGTCTACTATATTCAGTGTTAAAAAGAACATGGAGATACATGGGCTTGTCAAGT
TATTTAACAAATGGCAAAATATTGCTTACAAGTATGACAAAGATTTAGTACTCATGACTCACTTCATAAC
AAAGAATATTACAGATAATCATGGGAAGAATAAGACTACAGTACATGGTTACTTCTCTTCAATTTTTCAT
GGTGGAGTGGATAGTCTAGTCGACTTGATGAACAAGAGCTTTCCTGAGTTGGGTATTAAAAAAACTGATT
GCAAAGAATTTAGCTGGATTGATACAACCATCTTCTACAGTGGTGTTGTAAATTTTAACACTGCTAATTT
TAAAAAGGAAATTTTGCTTGATAGATCAGCTGGGAAGAAGACGGCTTTCTCAATTAAGTTAGACTATGTT
AAGAAACCAATTCCAGAAACTGCAATGGTCAAAATTTTGGAAAAATTATATGAAGAAGATGTAGGAGCTG
GGATGTATGTGTTGTACCCTTACGGTGGTATAATGGAGGAGATTTCAGAATCAGCAATTCCATTCCCTCA
TCGAGCTGGAATAATGTATGAACTTTGGTACACTGCTTCCTGGGAGAAGCAAGAAGATAATGAAAAGCAT
ATAAACTGGGTTCGAAGTGTTTATAATTTTACGACTCCTTATGTGTCCCAAAATCCAAGATTGGCGTATC
TCAATTATAGGGACCTTGATTTAGGAAAAACTAATCATGCGAGTCCTAATAATTACACACAAGCACGTAT
TTGGGGTGAAAAGTATTTTGGTAAAAATTTTAACAGGTTAGTTAAGGTGAAAACTAAAGTTGATCCCAAT
AATTTTTTTAGAAACGAACAAAGTATCCCACCTCTTCCACCGCATCATCATTAA (서열 번호 4)
> AB292682.1| 수송 펩티드를 갖는 칸나비디올산 신타제 (CBDAS)에 대한 칸나비스 사티바 CBDAS mRNA
ATGAAGTGCTCAACATTCTCCTTTTGGTTTGTTTGCAAGATAATATTTTTCTTTTTCTCATTCAATATCC
AAACTTCCATTGCTAATCCTCGAGAAAACTTCCTTAAATGCTTCTCGCAATATATTCCCAATAATGCAAC
AAATCTAAAACTCGTATACACTCAAAACAACCCATTGTATATGTCTGTCCTAAATTCGACAATACACAAT
CTTAGATTCACCTCTGACACAACCCCAAAACCACTTGTTATCGTCACTCCTTCACATGTCTCTCATATCC
AAGGCACTATTCTATGCTCCAAGAAAGTTGGCTTGCAGATTCGAACTCGAAGTGGTGGTCATGATTCTGA
GGGCATGTCCTACATATCTCAAGTCCCATTTGTTATAGTAGACTTGAGAAACATGCGTTCAATCAAAATA
GATGTTCATAGCCAAACTGCATGGGTTGAAGCCGGAGCTACCCTTGGAGAAGTTTATTATTGGGTTAATG
AGAAAAATGAGAATCTTAGTTTGGCGGCTGGGTATTGCCCTACTGTTTGCGCAGGTGGACACTTTGGTGG
AGGAGGCTATGGACCATTGATGAGAAACTATGGCCTCGCGGCTGATAATATCATTGATGCACACTTAGTC
AACGTTCATGGAAAAGTGCTAGATCGAAAATCTATGGGGGAAGATCTCTTTTGGGCTTTACGTGGTGGTG
GAGCAGAAAGCTTCGGAATCATTGTAGCATGGAAAATTAGACTGGTTGCTGTCCCAAAGTCTACTATGTT
TAGTGTTAAAAAGATCATGGAGATACATGAGCTTGTCAAGTTAGTTAACAAATGGCAAAATATTGCTTAC
AAGTATGACAAAGATTTATTACTCATGACTCACTTCATAACTAGGAACATTACAGATAATCAAGGGAAGA
ATAAGACAGCAATACACACTTACTTCTCTTCAGTTTTCCTTGGTGGAGTGGATAGTCTAGTCGACTTGAT
GAACAAGAGTTTTCCTGAGTTGGGTATTAAAAAAACGGATTGCAGACAATTGAGCTGGATTGATACTATC
ATCTTCTATAGTGGTGTTGTAAATTACGACACTGATAATTTTAACAAGGAAATTTTGCTTGATAGATCCG
CTGGGCAGAACGGTGCTTTCAAGATTAAGTTAGACTACGTTAAGAAACCAATTCCAGAATCTGTATTTGT
CCAAATTTTGGAAAAATTATATGAAGAAGATATAGGAGCTGGGATGTATGCGTTGTACCCTTACGGTGGT
ATAATGGATGAGATTTCAGAATCAGCAATTCCATTCCCTCATCGAGCTGGAATCTTGTATGAGTTATGGT
ACATATGTAGTTGGGAGAAGCAAGAAGATAACGAAAAGCATCTAAACTGGATTAGAAATATTTATAACTT
CATGACTCCTTATGTGTCCAAAAATCCAAGATTGGCATATCTCAATTATAGAGACCTTGATATAGGAATA
AATGATCCCAAGAATCCAAATAATTACACACAAGCACGTATTTGGGGTGAGAAGTATTTTGGTAAAAATT
TTGACAGGCTAGTAAAAGTGAAAACCCTGGTTGATCCCAATAACTTTTTTAGAAACGAACAAAGCATCCC
ACCTCTTCCACGGCATCGTCATTAA (서열 번호 5)
>IM00002.1| 수송 펩티드가 없는 칸나비디올산 신타제 II (CBDASII)에 대한 칸나비스 사티바 CBDAS mRNA
ATGAATCCTCGAGAAAACTTCCTTAAATGCTTCTCGCAATATATTCCCAATAATGCAACAAATCTAAAAC
TCGTATACACTCAAAACAACCCATTGTATATGTCTGTCCTAAATTCGACAATACACAATCTTAGATTCAC
CTCTGACACAACCCCAAAACCACTTGTTATCGTCACTCCTTCACATGTCTCTCATATCCAAGGCACTATT
CTATGCTCCAAGAAAGTTGGCTTGCAGATTCGAACTCGAAGTGGTGGTCATGATTCTGAGGGCATGTCCT
ACATATCTCAAGTCCCATTTGTTATAGTAGACTTGAGAAACATGCGTTCAATCAAAATAGATGTTCATAG
CCAAACTGCATGGGTTGAAGCCGGAGCTACCCTTGGAGAAGTTTATTATTGGGTTAATGAGAAAAATGAG
AATCTTAGTTTGGCGGCTGGGTATTGCCCTACTGTTTGCGCAGGTGGACACTTTGGTGGAGGAGGCTATG
GACCATTGATGAGAAACTATGGCCTCGCGGCTGATAATATCATTGATGCACACTTAGTCAACGTTCATGG
AAAAGTGCTAGATCGAAAATCTATGGGGGAAGATCTCTTTTGGGCTTTACGTGGTGGTGGAGCAGAAAGC
TTCGGAATCATTGTAGCATGGAAAATTAGACTGGTTGCTGTCCCAAAGTCTACTATGTTTAGTGTTAAAA
AGATCATGGAGATACATGAGCTTGTCAAGTTAGTTAACAAATGGCAAAATATTGCTTACAAGTATGACAA
AGATTTATTACTCATGACTCACTTCATAACTAGGAACATTACAGATAATCAAGGGAAGAATAAGACAGCA
ATACACACTTACTTCTCTTCAGTTTTCCTTGGTGGAGTGGATAGTCTAGTCGACTTGATGAACAAGAGTT
TTCCTGAGTTGGGTATTAAAAAAACGGATTGCAGACAATTGAGCTGGATTGATACTATCATCTTCTATAG
TGGTGTTGTAAATTACGACACTGATAATTTTAACAAGGAAATTTTGCTTGATAGATCCGCTGGGCAGAAC
GGTGCTTTCAAGATTAAGTTAGACTACGTTAAGAAACCAATTCCAGAATCTGTATTTGTCCAAATTTTGG
AAAAATTATATGAAGAAGATATAGGAGCTGGGATGTATGCGTTGTACCCTTACGGTGGTATAATGGATGA
GATTTCAGAATCAGCAATTCCATTCCCTCATCGAGCTGGAATCTTGTATGAGTTATGGTACATATGTAGT
TGGGAGAAGCAAGAAGATAACGAAAAGCATCTAAACTGGATTAGAAATATTTATAACTTCATGACTCCTT
ATGTGTCCAAAAATCCAAGATTGGCATATCTCAATTATAGAGACCTTGATATAGGAATAAATGATCCCAA
GAATCCAAATAATTACACACAAGCACGTATTTGGGGTGAGAAGTATTTTGGTAAAAATTTTGACAGGCTA
GTAAAAGTGAAAACCCTGGTTGATCCCAATAACTTTTTTAGAAACGAACAAAGCATCCCACCTCTTCCAC
GGCATCGTCATTAA (서열 번호 6)
> PK28436.1 | 방향족 프레닐트랜스퍼라제 (PT) 또는 게라닐피로포스페이트 올리베톨레이트 게라닐트랜스퍼라제
ATGGGACTCTCATCAGTTTGTACCTTTTCATTTCAAACTAATTACCATACTTTATTAAATCCTCACAATA
ATAATCCCAAAACCTCATTATTATGTTATCGACACCCCAAAACACCAATTAAATACTCTTACAATAATTT
TCCCTCTAAACATTGCTCCACCAAGAGTTTTCATCTACAAAACAAATGCTCAGAATCATTATCAATCGCA
AAAAATTCCATTAGGGCAGCTACTACAAATCAAACTGAGCCTCCAGAATCTGATAATCATTCAGTAGCAA
CTAAAATTTTAAACTTTGGGAAGGCATGTTGGAAACTTCAAAGACCATATACAATCATAGCATTTACTTC
ATGCGCTTGTGGATTGTTTGGGAAAGAGTTGTTGCATAACACAAATTTAATAAGTTGGTCTCTGATGTTC
AAGGCATTCTTTTTTTTGGTGGCTATATTATGCATTGCTTCTTTTACAACTACCATCAATCAGATTTACG
ATCTTCACATTGACAGAATAAACAAGCCTGATCTACCACTAGCTTCAGGGGAAATATCAGTAAACACAGC
TTGGATTATGAGCATAATTGTGGCACTGTTTGGATTGATAATAACTATAAAAATGAAGGGTGGACCACTC
TATATATTTGGCTACTGTTTTGGTATTTTTGGTGGGATTGTCTATTCTGTTCCACCATTTAGATGGAAGC
AAAATCCTTCCACTGCATTTCTTCTCAATTTCCTGGCCCATATTATTACAAATTTCACATTTTATTATGC
CAGCAGAGCAGCTCTTGGCCTACCATTTGAGTTGAGGCCTTCTTTTACTTTCCTGCTAGCATTTATGAAA
TCAATGGGTTCAGCTTTGGCTTTAATCAAAGATGCTTCAGACGTTGAAGGCGACACTAAATTTGGCATAT
CAACCTTGGCAAGTAAATATGGTTCCAGAAACTTGACATTATTTTGTTCTGGAATTGTTCTCCTATCCTA
TGTGGCTGCTATACTTGCTGGGATTATCTGGCCCCAGGCTTTCAACAGTAACGTAATGTTACTTTCTCAT
GCAATCTTAGCATTTTGGTTAATCCTCCAGACTCGAGATTTTGCGTTAACAAATTACGACCCGGAAGCAG
GCAGAAGATTTTACGAGTTCATGTGGAAGCTTTATTATGCTGAATATTTAGTATATGTTTTCATATAA (서열 번호 7)
> JN679224.1| 칸나비스 사티바 올리베톨산 시클라제 (OAC) mRNA, 완전한 cds
ATGGCAGTGAAGCATTTGATTGTATTGAAGTTCAAAGATGAAATCACAGAAGCCCAAAAGGAAGAATTTT
TCAAGACGTATGTGAATCTTGTGAATATCATCCCAGCCATGAAAGATGTATACTGGGGTAAAGATGTGAC
TCAAAAGAATAAGGAAGAAGGGTACACTCACATAGTTGAGGTAACATTTGAGAGTGTGGAGACTATTCAG
GACTACATTATTCATCCTGCCCATGTTGGATTTGGAGATGTCTATCGTTCTTTCTGGGAAAAACTTCTCA
TTTTTGACTACACACCACGAAAGTAG (서열 번호 8)
> AB164375.1| 올리베톨 신타제 (OLS)에 대한 칸나비스 사티바 OLS mRNA, 완전한 cds
ATGAATCATCTTCGTGCTGAGGGTCCGGCCTCCGTTCTCGCCATTGGCACCGCCAATCCGGAGAACATTT
TATTACAAGATGAGTTTCCTGACTACTATTTTCGCGTCACCAAAAGTGAACACATGACTCAACTCAAAGA
AAAGTTTCGAAAAATATGTGACAAAAGTATGATAAGGAAACGTAACTGTTTCTTAAATGAAGAACACCTA
AAGCAAAACCCAAGATTGGTGGAGCACGAGATGCAAACTCTGGATGCACGTCAAGACATGTTGGTAGTTG
AGGTTCCAAAACTTGGGAAGGATGCTTGTGCAAAGGCCATCAAAGAATGGGGTCAACCCAAGTCTAAAAT
CACTCATTTAATCTTCACTAGCGCATCAACCACTGACATGCCCGGTGCAGACTACCATTGCGCTAAGCTT
CTCGGACTGAGTCCCTCAGTGAAGCGTGTGATGATGTATCAACTAGGCTGTTATGGTGGTGGAACCGTTC
TACGCATTGCCAAGGACATAGCAGAGAATAACAAAGGCGCACGAGTTCTCGCCGTGTGTTGTGACATAAT
GGCTTGCTTGTTTCGTGGGCCTTCAGAGTCTGACCTCGAATTACTAGTGGGACAAGCTATCTTTGGTGAT
GGGGCTGCTGCGGTGATTGTTGGAGCTGAACCCGATGAGTCAGTTGGGGAAAGGCCGATATTTGAGTTGG
TGTCAACTGGGCAAACAATCTTACCAAACTCGGAAGGAACTATTGGGGGACATATAAGGGAAGCAGGACT
GATATTTGATTTACATAAGGATGTGCCTATGTTGATCTCTAATAATATTGAGAAATGTTTGATTGAGGCA
TTTACTCCTATTGGGATTAGTGATTGGAACTCCATATTTTGGATTACACACCCAGGTGGGAAAGCTATTT
TGGACAAAGTGGAGGAGAAGTTGCATCTAAAGAGTGATAAGTTTGTGGATTCACGTCATGTGCTGAGTGA
GCATGGGAATATGTCTAGCTCAACTGTCTTGTTTGTTATGGATGAGTTGAGGAAGAGGTCGTTGGAGGAA
GGGAAGTCTACCACTGGAGATGGATTTGAGTGGGGTGTTCTTTTTGGGTTTGGACCAGGTTTGACTGTCG
AAAGAGTGGTCGTGCGTAGTGTTCCCATCAAATATTAA (서열 번호 9)
> JN717233.1 | PK04797.1 | 아실-활성화 효소 1 (AAE1)
ATGGGTAAGAATTACAAGTCCCTGGACTCTGTTGTGGCCTCTGACTTCATAGCCCTAGGTATCACCTCTG
AAGTTGCTGAGACACTCCATGGTAGACTGGCCGAGATCGTGTGTAATTATGGCGCTGCCACTCCCCAAAC
ATGGATCAATATTGCCAACCATATTCTGTCGCCTGACCTCCCCTTCTCCCTGCACCAGATGCTCTTCTAT
GGTTGCTATAAAGACTTTGGACCTGCCCCTCCTGCTTGGATACCCGACCCGGAGAAAGTAAAGTCCACCA
ATCTGGGCGCACTTTTGGAGAAGCGAGGAAAAGAGTTTTTGGGAGTCAAGTATAAGGATCCCATTTCAAG
CTTTTCTCATTTCCAAGAATTTTCTGTAAGAAACCCTGAGGTGTATTGGAGAACAGTACTAATGGATGAG
ATGAAGATAAGTTTTTCAAAGGATCCAGAATGTATATTGCGTAGAGATGATGACATTAATAATCCAGGGG
GTAGTGAATGGCTTCCAGGAGGTTATCTTAACTCAGCAAAGAATTGCTTGAATGTAAATAGTAACAAGAA
ATTGAATGATACAATGATTGTATGGCGTGATGAAGGAAATGATGATTTGCCTCTAAACAAATTGACACTT
GACCAATTGCGTAAACGTGTTTGGTTAGTTGGTTATGCACTTGAAGAAATGGGTTTGGAGAAGGGTTGTG
CAATTGCAATTGATATGCCAATGCATGTGGATGCTGTGGTTATCTATCTAGCTATTGTTCTTGCGGGATA
TGTAGTTGTTTCTATTGCTGATAGTTTTTCTGCTCCTGAAATATCAACAAGACTTCGACTATCAAAAGCA
AAAGCCATTTTTACACAGGATCATATTATTCGTGGGAAGAAGCGTATTCCCTTATACAGTAGAGTTGTGG
AAGCCAAGTCTCCCATGGCCATTGTTATTCCTTGTAGTGGCTCTAATATTGGTGCAGAATTGCGTGATGG
CGATATTTCTTGGGATTACTTTCTAGAAAGAGCAAAAGAGTTTAAAAATTGTGAATTTACTGCTAGAGAA
CAACCAGTTGATGCCTATACAAACATCCTCTTCTCATCTGGAACAACAGGGGAGCCAAAGGCAATTCCAT
GGACTCAAGCAACTCCTTTAAAAGCAGCTGCAGATGGGTGGAGCCATTTGGACATTAGGAAAGGTGATGT
CATTGTTTGGCCCACTAATCTTGGTTGGATGATGGGTCCTTGGCTGGTCTATGCTTCACTCCTTAATGGG
GCTTCTATTGCCTTGTATAATGGATCACCACTTGTTTCTGGCTTTGCCAAATTTGTGCAGGATGCTAAAG
TAACAATGCTAGGTGTGGTCCCTAGTATTGTTCGATCATGGAAAAGTACCAATTGTGTTAGTGGCTATGA
TTGGTCCACCATCCGTTGCTTTTCCTCTTCTGGTGAAGCATCTAATGTAGATGAATACCTATGGTTGATG
GGGAGAGCAAACTACAAGCCTGTTATCGAAATGTGTGGTGGCACAGAAATTGGTGGTGCATTTTCTGCTG
GCTCTTTCTTACAAGCTCAATCATTATCTTCATTTAGTTCACAATGTATGGGTTGCACTTTATACATACT
TGACAAGAATGGTTATCCAATGCCTAAAAACAAACCAGGAATTGGTGAATTAGCGCTTGGTCCAGTCATG
TTTGGAGCATCGAAGACTCTGTTGAATGGTAATCACCATGATGTTTATTTTAAGGGAATGCCTACATTGA
ATGGAGAGGTTTTAAGGAGGCATGGGGACATTTTTGAGCTTACATCTAATGGTTATTATCATGCACATGG
TCGTGCAGATGATACAATGAATATTGGAGGCATCAAGATTAGTTCCATAGAGATTGAACGAGTTTGTAAT
GAAGTTGATGACAGAGTTTTCGAGACAACTGCTATTGGAGTGCCACCTTTGGGCGGTGGACCTGAGCAAT
TAGTAATTTTCTTTGTATTAAAAGATTCAAATGATACAACTATTGACTTAAATCAATTGAGGTTATCTTT
CAACTTGGGTTTACAGAAGAAACTAAATCCTCTGTTCAAGGTCACTCGTGTTGTGCCTCTTTCATCACTT
CCGAGAACAGCAACCAACAAGATCATGAGAAGGGTTTTGCGCCAACAATTTTCTCACTTTGAATGA (서열 번호 10)
> JN717235.1 | PK13710.1| 아실-활성화 효소 3 (AAE3)
ATGGAGAAATCTGGGTATGGAAGAGACGGTATTTACAGGTCTCTGAGACCACCTCTACACCTCCCCAACA
ACAACAACCTCTCAATGGTTTCATTCCTTTTCAGAAACTCATCTTCATACCCACAAAAGCCAGCTCTCAT
TGATTCCGAAACCAACCAAATACTCTCCTTTTCCCACTTCAAATCTACGGTTATCAAGGTCTCCCATGGC
TTTCTCAATCTGGGTATCAAGAAAAACGACGTCGTTCTCATCTACGCCCCTAATTCTATCCACTTCCCTG
TTTGTTTCCTTGGAATTATAGCCTCTGGAGCCATTGCCACTACCTCAAATCCTCTCTACACAGTTTCCGA
GCTTTCCAAACAGGTCAAGGATTCCAATCCCAAACTCATTATCACCGTTCCTCAACTCTTGGAAAAAGTA
AAGGGTTTCAATCTCCCCACGATTCTAATTGGTCCTGATTCTGAACAAGAATCTTCTAGTGATAAAGTAA
TGACCTTTAACGATTTGGTCAACTTAGGTGGGTCGTCTGGCTCAGAATTTCCAATTGTTGATGATTTTAA
GCAGAGTGACACTGCTGCGCTATTGTACTCATCTGGCACAACGGGAATGAGTAAAGGTGTGGTTTTGACT
CACAAAAACTTCATTGCCTCTTCTTTAATGGTGACAATGGAGCAAGACCTAGTTGGAGAGATGGATAATG
TGTTTCTATGCTTTTTGCCAATGTTTCATGTATTTGGTTTGGCTATCATCACCTATGCTCAGTTGCAGAG
AGGAAACACTGTTATTTCAATGGCGAGATTTGACCTTGAGAAGATGTTAAAAGATGTGGAAAAGTATAAA
GTTACCCATTTGTGGGTTGTGCCTCCTGTGATACTGGCTCTGAGTAAGAACAGTTTGGTGAAGAAGTTTA
ATCTTTCTTCTATAAAGTATATTGGCTCTGGTGCAGCTCCTTTGGGCAAAGATTTAATGGAGGAGTGCTC
TAAGGTTGTTCCTTATGGTATTGTTGCTCAGGGATATGGTATGACAGAAACTTGTGGGATTGTATCCATG
GAGGATATAAGAGGAGGTAAACGAAATAGTGGTTCAGCTGGAATGCTGGCATCTGGAGTAGAAGCCCAGA
TAGTTAGTGTAGATACACTGAAGCCCTTACCTCCTAATCAATTGGGGGAGATATGGGTGAAGGGGCCTAA
TATGATGCAAGGTTACTTCAATAACCCACAGGCAACCAAGTTGACTATAGATAAGAAAGGTTGGGTACAT
ACTGGTGATCTTGGATATTTTGATGAAGATGGACATCTTTATGTTGTTGACCGTATAAAAGAGCTCATCA
AATATAAAGGATTTCAGGTTGCTCCTGCTGAGCTTGAAGGATTGCTTGTTTCTCACCCTGAAATACTCGA
TGCTGTTGTGATCCCATTTCCTGATGCTGAAGCGGGTGAAGTCCCAGTTGCTTATGTTGTGCGCTCTCCC
AACAGTTCATTAACCGAAAATGATGTGAAGAAATTTATCGCGGGCCAGGTTGCATCTTTCAAAAGATTGA
GAAAAGTAACATTTATAAACAGTGTCCCGAAATCTGCTTCGGGGAAAATCCTCAGAAGAGAACTCATTCA
GAAAGTACGCTCCAACATGTGA (서열 번호 11)
> PK04410.1 | 히드로퍼옥시드 리아제 (HPL)
ATGTCTTTTATGATGAGCATGAATCCTTCTCCCTCCTCGCCACCGCCACCGTTATCGTCGCCGTCGGAAT
CTTCCTCAACGCCGTCAACACTGCCAGTCCGTACGATCCCGGGAAGCTACGGATGGCCGTTACTGGGGCC
CATCTCGGACCGGTTAGACTACTTCTGGTTCCAAGGCCCAGATACGTTTTTCAGAAAAAGAGTAGAGAAA
TACAAGAGCACAGTGTTCCGTACCAACATACCCCCGACCTTTCCTTTCTTCAGCGTTAATCCGAACATTG
TGGCCGTGCTGGACTGTAAATCATTTTCTCATCTTTTCGACATGGAAATTGTCGAGAAAAAGAATGTTCT
TGTTGGAGATTTCATGCCCAGTGTCAATTACACTGGTGATATTAGGGTTGGAGCTTATCTCGACACTTCT
GAACCACAACACGCTAAGGTTAAGAACTTCGCAATGGATGTACTAAAACAAAGCTCGAAGATATGGGTGG
GAGAACTGACATCAAATCTGTCGACGATGTGGGACACAATAGAAAAAGACGTATCTGAGAAATCATCCTC
ATCCTACTTAGCCCCACTTCAAAAGTTCTTGTTCAACTTCCTGGTCAAGTGTCTAATTGGTGCTGACCCT
TCCAACTCCCCCAAGATTGCAGAGTCTGGCTACATCATGCTCGACCGATGGTTAGCCTTCCAGCTCCTTC
CCACTATCAAGATTGGGATCCTTCAGCCTCTTGAGGAGCTTTTCATTCACTCTTTTGCCTATCCTTTTTT
CTTGGTCAGTGGTGACTACAATAACCTCTCCAGTTTTGTAGAGGAATATGGTAAAGAAATAGTAGCGAGA
GGTGAAACCGAGTTCGGGCTGAGTAAACAAGAAGCGATTCACAACCTTCTCTTCATTTTGGGTTTCAACG
CCTTCGGGGGATTCTCTATATTTCTACCGAGCCTACTGGGCACCGTGGCGAGTGACACAACCGATCTACA
ACAAAGACTGGTCAAAGAAGTCAGACAAAATGGCGGGTCAACTCTGACGTTTGACTCGATCAAAGAAATG
CCACTCGTTCAATCGGTCGTGTACGAGACTCTCCGGCTCAATCCACCTGTTCCGCTCCAATTCGCCAGGG
CCAGGAAGGACTTCCGGCTCAGCTCGCACGACGCGGCCTTCGAGGTGAAGAAAGGCGAGCTCCTATGCGG
GTTTCAAAGCCTTGTTATGAGGGACCCAAAAATATTCTCGGAACCGGAGTCGTTCATTGGGGACCGGTTC
ATGAAAGATAAAGGTCTCTTAGATTATCTTTACTGGTCCAATGGACCTCAAACCGGTGTGCCCAGCGTCA
CCAATAAGCAATGCGCGGGAAAAGATATCGTCACGCTTACGGCTTGTTTGATCTTGGCTTACACCTTCCG
TCGTTATGACTCCATCAGCGGGAGCTCAAGTTCAATCACAGCCCTTAAAAAGGCTTAA (서열 번호 12)
> PK08276.1 | 리폭시게나제 (LOX1)
ATGTTGAAGCCTCCTCATCAAGTAGTTCAAAATTTGAAATATGAGAAAACCCTAGTTCTTTTGAACAAGC
CATTCATCCATGGCTACAACGGGGCTATTATCGGTGTCAACTCTCGGCTATTTCCAGTAAAACCTAAAAC
CAAAAGACGAGTCGCTTCATCATCATCATCATCATCTCCCGGAACCAAAAACATTATTAAAGCTTCTTTA
TTTTCTCCAATGGAGAAGAAGAATACAGCTAGGGTTTCGGTTAGTGTGGCGGTACAACGTGTGACTCCAA
AGTTTTGGAGATTTGAATTGTCTGAGAAAATCCAAGATGGACGTGATAGGCTTGAGGATCTTCTAGGGCT
AAACTCTTTAAGTATTGAGCTTGTTAGTACTCAAAAAGATCCAGTAACGGGGAAAGAGCGAACGGTTAAA
GGTTTTCCAAAAAGGCCCAACTTTAACATATTTTCATCAAGTGATGTAAAATACGAAGCGAAATTTGACA
TACCAAAAGATTTTGGAGAAGTGGGTGCTATAATCGTCGAAAATGATTTTGAAAGAGAAATATTTTTAAA
GAATATTATACTCGAAGACTTGCCCTCCGAACCAAGCACCCTTGAATTCTCTTGCAACTCGTGGGTTCAG
TCCAAACATGATGTCCCTACTGATCAACACAAGAGAGTCTTCTTCTCTAATAAGTGTTACCTACCATCAC
AAACACCAAGTGGGATAAAAGAATTGAGAAAAATTGCATTGGAAAATTTGAGAGGAGATGGAAAAGGAGA
GAGGAAGAAGAATGAAAGAGTTTATGATTATGATGTGTATAATGATCTTGGACAACCGGACAACAATGAT
GACCTAAAAAGACCTATTCTTGGCGGATCAAAAGAATTCCCTTATCCTAGGCGTTGTAGAACCGGACGGC
CTCCAACTGAAACTGATCCATTATCTGAGTCAAGGATTAGTGATTTTTATGTACCAAGAGATGAAGAATT
TGCAGAAGTGAAGCAAAGTAATTTTAGTTTGAAGACTGTATACTCAGTAATACATGCAGTGATTCCCATA
CTCAGACAAGTCTTAATTGATGAAAATTTCCCATACTTCACTGCCATTGATGTTCTCTATGATGAAGGCA
TTAAAATCCCTTCTAATGCTGAAAAGACCTTAATTCAAACCATCAAAAATGTCAATGCAAGAATATACAA
AACTGTTTCTGATGCTGATGATTTTTTACAGTTTCAGCAGCCTCCAACCATGGACAAGGACAAATTCTTC
TGGTTTAGAGATGAAGAGTTTTGTAGACAAACTATTGCCGGTCTCAACCCTTGCTGCATTGAATTGGTTA
AGGAGTGGCCTTTGAAAAGTGAACTTGACCCCACAATCTATGGCCCACCAGAGTCAAAAATCACCACAGA
ATTGGTTGAGAAATTCATCAAAGTATATGGCTACAATAATATTAATGAGGCTTTAAAAGAAAAAAAATTG
TTCATGTTGGATTACCATGATGTATTATTACCATATGTTAGCAAAGTAAGGGAACTGGAAAATAAAACCT
TGTATGGATCAAGAACACTTTTTTTCTTGACTCCTTATGGTACATTGTTGCCTTTGGCCATTGAATTGAT
TCGGCCACCGATGGATGGTAAGCCGCAATGGAAGGAAGTCTACACCCCGATGAATTGGCATTCTACCGAT
CTTTGGCTTTGGAGACTCGCAAAAGCTCATGTCCTTGCTCATGATTCCGGTGTTCATCAACTCGTTAGTC
ACTGGCTAAGAACACATTGTGCAGTTGAGCCATATATAATTGCAACAAATAGACAATTGAGTGCAATGCA
TCCTATCCATAGATTATTGAAGCCACATTTTAGATACACAATGGAGATTAATGCTCTTGCTCGAGAAAGT
TTGATCAATGCAGGTGGTATCATCGAAACAGCATTTGCACCTGGAAAATATTCTATGGAGTTAAGCTCCG
TCATGTACGACAAACAATGGCGATTCGATCTACAAGCATTGCCAGCTGACCTAATTCATAGAGGAATGGC
TGTTGAGGACAAGGATAGTGAACATGGTGTAAGAGTAATAATTGAAGATTACCCTTACGCCAACGACGGT
CTTCTCATATGGAGCTCCATCAAACAATGGGTTACTGACTACGTCAACCACTACTACCCTACCTCCAGTG
AGGTAGAGCGCGACGAAGAATTACAAGCATGGTGGACAGAGATCAGAACTGTAGGTCACGCTGACAAGAA
AGACGCACCTGGGTGGCCTGACTTAAAAACGAAACAAGATCTCATAGACATTGTCACAAACATGGCATGG
ACAGCATCAGCTCACCATGCAGCTGTCAACTTTGGACAATATGCTTACGCTGGCTATTTCCCTAACCGAC
CAACCATAACAAGAACTGTTATGCCGTCAGAAGAGAAGGAGTATAACCTAGATGCGTGGAAACACTTCAA
AAATAGTCCTGAAGACGCCCTTTTGAAGTGCTTACCTACGCAATTACAAGCAGGCCTAGTTGTGGCCGTG
TTAGACGTGTTGTCTACTCACTCGCCAGACGAAGAGTATCTTGGAGACAAGATGGAACCCTCGTGGGGCT
CGAATCTTGTTATAGCGGAAGCTTTTAATCGGTTCAATAAGAGGATGAACGAGATTGAAAGTATCATTAA
TGAAAAGAATGATAATGAGAATTTAAGGAATAGACATGGAGCTGGAATTTTGTCTTATGAACTTCTCAAG
CCCTTTTCTGAGCCTGGTGTCACTAACAAGGGTATTCCATATAGCATATCTATTTGA (서열 번호 13)
> IM00001.1 | 데사투라제 (DS) 코딩 서열
ATGGGAGCCGGTGGCAAAAATAGTAGACTTGAGCGAGCACCACACACCACACCACCATTCACACTAAGCC
AACTCAAGAAAGCCATTCCACCCCATTGCTTCAACCATTCTCTTCTTCGTTCCTTCTCTCATGTCCTTCA
AGACCTTTTTTTCTCCTTTTTGTTCTACTACATAGCAACCTCTTACTTCCATCTTCTCCCACACCCGCTC
CAATACTTAGCTTGGCCACTTTATTGGATCTTCCAAGGCAGCATTTTTGCTGGTATTTGGGTCCTTGGTC
ATGATTGTGGTCACCAAGCTTTCAGTGACCACCAATGGGTGGATGACACcGTTGGCTTTGTCCTCCACTC
CGCTCTTCTCTTCCCATACTTCTCTTTTAAGTATAGTCATCGTCGCCATCATTCAAACATCGGCTCCCTT
GAACATGATCAATTGTTTGTTCCAGTCCCCGAATCTCAAATCGCATGGCTCTACAAACgTTACTTGGACA
ATCCACTAGGAAGAGCCCTAAAGCTTTCCACTATAGTGTTCCTTGGTTtTCCTTTGTACTTAGGTTTCAA
TCTTACAGGCAAACcATATGATCGTTaTGCATGTCATTATGATCCTTACTCTCCACTCTACTCAAAAAGT
GAAAGGCTTCATATATTGATTTCAGATATCGGTGTTTTCATCACCACATTaGTGTTATACCAGCTTGGCT
CGACTAAAGGgTTGAGTTGGCTTGTGTTCATGTATGGGGTGCCATTGTTTACAGGGAATAGCATCCTTGT
GACAATCGCATACTTGAATCATACTCACCCTTCATTGCCTCATTATGACTCGTCaGAGTGGGATTGGTTG
AAAGGAGCATTGTCAACAACTGATCGAAACTATGGATCAATTCTCAATAGGGTTTTCCATCACCTTACAG
ATGCTCATATGGCACACCATTTATTCGCAACAATACCTCACTACCATGCAAATGAAGCCACCAAAGTTAT
CAAATCCATATTGGGAGAATACTACTCTTTTGATGATACTCCAATAATTAAAGCTCTTTGGAGAGAGACT
AAGGAGTGTGTCTATATTGAGCCAAATCATGAATCTTCTCCTAATAATAACAAAGGTGTTTTCTGGTACA
ACAACAAGTTCTGA (서열 번호 14)
> PK10442.1 | 게라닐 피로포스페이트 (GPP) 신타제 큰 서브유닛 | GPP 신타제 lsu
ATGAGCACTGTAAATCTCACATGGGTTCAAACCTGTTCCATGTTCAACCAAGGAGGTAGATCCAGATCCT
TATCAACTTTCAATCTCAATCTCTACCACCCTTTGAAAAAAACACCCTTTTCAATCCAAACCCCAAAACA
AAAACGACCCACTTCACCATTTTCATCAATCTCAGCTGTTCTAACCGAGCAAGAAGCCGTTAAAGAAGGC
GATGAAGAAAAATCCATCTTCAATTTCAAGTCTTACATGGTCCAAAAAGCCAACTCAGTCAACCAAGCTT
TAGACTCAGCCGTTTTGCTCAGAGATCCCATTATGATACACGAGTCCATGCGTTACTCACTCCTCGCCGG
AGGAAAACGAGTCAGACCCATGCTCTGTCTCTCAGCCTGTGAACTCGTAGGCGGAAAAGAATCCGTAGCC
ATGCCGGCTGCCTGCGCCGTCGAAATGATCCACACCATGTCTCTAATCCACGACGACCTCCCTTGTATGG
ACAACGATGACCTCCGCCGTGGAAAGCCCACAAACCACAAAGTCTTCGGAGAAGACGTGGCCGTTTTAGC
CGGCGATGCACTTTTAGCCTTTGCTTTTGAGCACATGGCGGTCTCTACCGTTGGTGTTCCGGCAGCCAAG
ATTGTCAGGGCGATTGGTGAGCTTGCTAAGTCAATTGGGTCAGAAGGATTAGTGGCTGGTCAAGTGGTTG
ATATTGATTCAGAGGGTTTGGCTAATGTTGGGCTTGAACAACTTGAGTTCATTCATCTCCATAAGACTGG
GGCTCTTCTAGAAGCTTCTGTTGTTTTGGGGGCTATTCTTGGTGGTGGTACAGATGAAGAAGTTGAAAAA
CTTAGGAGCTTTGCTAGGTGTATTGGCTTGCTTTTTCAGGTTGTTGATGACATTCTTGATGTGACTAAAT
CTTCTCAAGAATTGGGTAAAACTGCTGGGAAAGATTTGGTGGCTGATAAGGTTACTTATCCAAGGCTAAT
GGGTATTGACAAATCAAGAGAATTTGCTGAGCAATTGAACACAGAAGCCAAACAGCATCTTTCTGGTTTT
GATCCCATAAAGGCTGCTCCTTTAATTGCTTTGGCTAATTATATTGCTTATAGGCAAAATTGA (서열 번호 15)
> PK15935.1 | 게라닐 피로포스페이트 (GPP) 신타제 작은 서브유닛 | GPP 신타제 ssu
ATGGCGGTTTATAATCTATCAATTAATTGCAGTCCAAGATTTGTTCATCATGTTTACGTTCCACATTTCA
CATGTAAATCCAATAAGTCGTTAAGTCACGTACCCATGAGAATAACCATGTCCAAACAGCATCATCATTC
TTATTTTGCCTCCACAACAGCCGATGTAGATGCCCATCTCAAGCAATCCATCACTATCAAGCCACCACTC
TCAGTTCACGAGGCCATGTACAATTTCATCTTTTCCACACCTCCGAATTTAGCACCGTCATTGTGCGTGG
CGGCGTGTGAGCTTGTCGGGGGCCACCAGGACCAGGCCATGGCAGCAGCCTCCGCCTTGCGCGTCATCCA
CGCAGCCATCTTCACTCATGACCACCTCCCTTTAACGGGCAGGCCCAATCCAACAAGTCCTGAGGCAGCG
ACCCACAATTCTTACAACCCAAATATTCAGCTCCTTCTCCCGGACGCAATTGTACCTTTTGGGTTCGAAT
TGTTGGCCAATTCTGATGACCTTACCCATAATAAATCAGATCGGATTTTGCGGGTCATTGTAGAGTTCAC
ACGCACCTTTGGATCACGAGGAACTATTGATGCTCAATACCATGAGAAGCTAGCCAGTAGATTTGACGTT
GATAGTCATGAAGCCAAAACTGTCGGGTGGGGCCATTATCCCTCTTTGAAGAAGGAAGGTGCGATGCATG
CATGCGCTGCTGCATGTGGGGCCATTCTTGGAGAGGCACATGAAGAAGAGGTTGAGAAGTTGAGAACTTT
TGGTCTTTATGTGGGCATGATTCAAGGATATGCCAATAGATTTATAATGAGCAGCACAGAAGAAAAGAAA
GAAGCAGATAGAATCATCGAGGAGTTAACCAATTTGGCTCGCCAGGAACTAAAATATTTCGATGGGAGAA
ACTTAGAGCCATTTTCAACCTTTCTTTTTCGTCTATAG (서열 번호 16)
> PK17903.1 | 게라닐 피로포스페이트 (IPP) 이소머라제
ATGGGAGACTCTGCCGACGCTGGAATGGACGCTGTCCAGAGACGCCTTATGTTTGATGATGAATGCATTC
TAGTGGATGAGAATGACCGAGTTGTTGGTCATGATACAAAATATAACTGTCACTTGATGGAAAAGATTGA
AAAGGATAATTTGCTACACAGGGCTTTCAGTGTGTTCTTGTTCAACTCAAAATATGAGTTGCTTCTTCAG
CAACGTTCTGCAACAAAGGTAACATTCCCTCTTGTGTGGACAAACACCTGTTGTAGCCACCCGCTCTACC
GTGAATCTGAGCTTATCGATGAGGAGTCCCTTGGAGCAAGGAATGCAGCACAGAGAAAGCTTTTAGATGA
GCTGGGTATTCCTGCTGAAGATGTGCCAGTTGATCAATTTACCCCACTAGGCAGGATGCTGTACAAAGCT
CCTTCTGATGGCAAATGGGGCGAGCATGAACTTGATTACCTGCTCTTCATCGTCCGGGATGTTAGTGTCA
ATCCAAATCCAGATGAAGTAGCTGATATCAAGTATGTAAACCGGGACGAGTTGAAAGAGTTGTTGAGGAA
AGCAGATGCTGGGGAAGGAGGCTTGAAGCTATCCCCTTGGTTCAGACTGGTTGTGGATAATTTCTTGTTC
AAGTGGTGGGACCATGTTGAGAAAGGCACACTTAAGGAAGTTGCTGATATGAAAACCATTCACAAGTTGA
CTTAA (서열 번호 17)
> PK16122.1 | 1-데옥시크실룰로스-5-포스페이트 신타제 1 (DXS1)
ATGGCGTTTTGTGCATTATCATTTCCTGCTCATATTAGCCGGGCAACTACACCAGCACCTTCAGATCTTC
ACAAATCTAGTTCTTTCTCTTCTCGGTTTTATTGGGGAGCAGATCTGCTGAGGCCATCTCAATACAAGGT
CAGGAAAATACAAAGTGGGGTTTATGCATCACTGTCAGAAAGTGGAGAATATCACTCAAGGAGACCACCA
ACTCCTCTCTTGGACACCATAAATTATCCAATTCATATGAAAAATCTCTCTGTTAAGGAGCTTAAACAAC
TATCAGATGAACTAAGGTCTGATGTCATCTTCAACGTTTCTAACACCGGGGGTCACCTGGGCTCAAGCCT
TGGTGTTGTTGAGCTTACTGTGGCTCTTCATTTTGTCTTCAATACTCCTCAGGATAGGATACTATGGGAT
GTTGGTCATCAGTCTTACCCTCATAAAATTCTGACTGGAAGAAGAGATAAGATGCACACCATGAGGCAGA
CCAACGGGTTAGCCGGATTCACTAAGCGGTCTGAGAGTGAATATGATTGTTTTGGGACTGGTCATAGTTC
TACCACCATCTCAGCTGGCTTGGGAATGGCTGTTGGAAGGGATCTTAAAGGAAGAAAGAATAATGTTGTG
GCTGTCATAGGTGATGGTGCCATGACAGCAGGTCAAGCTTATGAAGCCATGAATAATGCCGGGTACCTTG
ATTCCGACATGATTATTATTCTTAACGACAATAAACAGGTTTCTTTACCTACTGCCTCTCTTGATGGGCC
CATACCACCTGTTGGAGCTTTGAGTAGTGCTCTCAGTAGGCTGCAATCAAACAGGCCTCTTAGAGAACTA
AGAGAAGTAGCCAAGGGAGTTACTAAACAAATAGGTGGATCAGTACATGAATTGGCTGCAAAAGTTGATG
AATATGCTCGTGGAATGATAAGTGGTTCTGGCTCAACATTGTTTGAGGAGCTTGGACTCTATTATATTGG
TCCAGTTGATGGTCACAATATAGATGATCTTGTTTCCATACTAGAGGAGGTTAAGAGCACTAAAACAACA
GGTCCAGTCTTGATCCATTGCATCACTGAGAAAGGAAGAGGATATCCATATGCAGAGAAAGCTGCTGATA
AGTATCATGGGGTGGCCAAGTTTGATCCAGCAACTGGAAAGCAATTCAAAGGCACTTCTAACACACAGTC
ATACACTACATACTTTGCTGAGGCTTTGGTTGCAGAAGCAGAGGCAGACAAAGATGTTGTGGCCATCCAT
GCTGCAATGGGTGGTGGAACAGGCTTGAATCTCTTCCTTCGCCGTTTTCCAACAAGATGTTTTGATGTTG
GGATAGCAGAACAGCATGCTGTTACTTTCGCTGCTGGTTTGGCTTGCGAGGGCCTTAAGCCGTTTTGTGC
AATTTACTCATCTTTCATGCAGCGAGCCTATGATCAGGTAGTACATGATGTTGATTTGCAGAAGTTGCCG
GTGAGATTTGCAATGGACAGAGCTGGACTTGTTGGGGCCGACGGCCCTACACATTGTGGTGCTTTTGATG
TTACTTTCATGGCATGCCTCCCAAACATGGTTGTGATGGCTCCTTCCGATGAGGCAGAGCTCTTCCACAT
GGTTGCCACCGCTGCTGCCATAGATGACAGACCAAGTTGTTTCCGTTACCCCAGAGGAAATGGAATTGGT
GTTCCATTACCTCAAGGGAATAAAGGAACTCCTCTTGAGATCGGAAAAGGCAGGGTATTGGTTGAAGGGG
AAAGAGTAGCACTTCTAGGCTATGGAACAGCAGTTCAGAGTTGTTTGGCTGCTGCAGCCTTAGTAGAACC
TCACGGTCTACGGCTAACAGTTGCTGATGCACGATTTTGCAAGCCTTTGGATCATGCCCTCATTCGCGAA
CTAGCGAAAAATCACGAGGTTTTGATTACAGTGGAAGAAGGATCTATAGGAGGTTTTGGATCTCATGTTG
CTCAGTTTATGGCCCTTGATGGCCTTCTTGATGGAAAAACAAAGTGGAGACCAATTGTTCTTCCTGACCG
ATACATCGACCACGGTTCGCCTGCTGATCAATATGTCGACGCGGGTCTCACGCCACCTCACATTGCAGCC
ACAGTTTTCAATGTACTAGGACAAACAAGAGAGGCCTTGAAGGTTATGACAACATGA (서열 번호 18)
> PK26473.1 | 1-데옥시크실룰로스-5-포스페이트 신타제 2 (DXS2)
ATGGCGGTTTCTGGTTCATTCATTGTACCAAATCATTCATTCCTTTCACAACTTAAATCTCCACAGCCAT
ATTACAGTTCCAACAAACAGTTGAGTTTAAGGGTGAGAGGATCTCTTTGTAGCTCAGATGATGGGGAAGG
AAAATTCATCAGCAAAGAAAAAGATGAATGGAAAATCAAGTATTCCAGTGAAAAACCAATCACTCCATTG
CTTGATACAGTCAATTACCCAGTTCACATGAAGAATTTATCCACACAGGATCTTGAACAGCTAGCAGCAG
AGCTTAGAGCAGATGTAGTCCATACAGTATCAAAAACAGGTGGTCATCTGAGTGCAAGCTTGGGAGTTGT
GGAGCTCACTGTAGCACTGCATCATGTTTTCAATACCCCTGATGATAAAATCATATGGGATGTTGGACAT
CAGACATACCCGCATAAGATTCTTACAGGAAGGAGGTCTCAAATGCATACCATTAGAAAGACTTCTGGTC
TAGCAGGGTTTCCCAAAAGAGATGAGAGTGTTTACGATGCTTTCGGTGCAGGTCACAGTTCTACAAGCAT
ATCAGCAGGCCTTGGCATGGCAGTTGCCAGGGATCTTCTGGGAAAGAAGAACAGTGTTGTTTCTGTGATT
GGAGATGGGGCCATGACTGCAGGAATGGCATATGAAGCCATGAATAATGCCGGCTACTTGGACGCCAACT
TGATTGTTGTATTAAACGACAATAAACAAGTTTCTTTACCAACTGCTACTCTTGATGGTCCTGCAACCCC
AGTGGGAGCTCTAAGTGGTGCTTTGACTAAGCTTCAAGCAAGCACCAAGTTCAGAAAACTTCGCGAAGCT
GCGAAAACCATCACAAAACAAATTGGAGGGCCAGCACATGAAGTTGCAGCTAAAGTAGATGAGTATGCTA
GAGGAATGATAAGTGCTTCTGGGTCAACACTCTTTGAGGAGCTTGGGTTGTATTATATTGGTCCGGTGGA
TGGACATAATGTTGGAGATTTAGTCACCATTTTTGAGAAAGTGAAATCAATGCCAGCGCCAGGACCAGTC
TTGATCCACATCGTCACAGAGAAAGGGAAAGGCTATCCCCCAGCTGAAGTAGCACCTGATAAAATGCATG
GAGTTGTAAAGTTTGACCCAACAACAGGAAAGCAATTTAAGTCCAAATCGTCGACACTTTCATATACTCA
ATACTTTGCTGAATCTCTAATAAAAGAAGCTGAAGAAGATGACAAGATTGTTGCCATACACGCAGCAATG
GGTGGTGGCACTGGTCTCAATTATTTCCAGAAGAAATTTCCTGATCGTTGCTTTGATGTGGGGATTGCTG
AGCAACATGCTGTCACGTTTGCAGCTGGATTAGCTGCAGAGGGTCTCAAACCATTCTGTGCCATATACTC
ATCATTCCTGCAACGAGGATATGATCAGGTTGCACATGATGTAGACCTTCAAAAATTACCTGTCCGTTTT
GCATTGGATAGAGCTGGCATGGTTGGCGCAGATGGGCCTACCCACTGCGGTGCATTTGATATCACCTACA
TGGCCTGCTTGCCCAACATGGTTGTCATGGCTCCATCAGATGAGGCTGAACTTATGCACATGGTGGCCAC
AGCAACAGCTATAGATGACAGACCCAGTTGCTTCAGGTTTCCAAGGGGCAATGGAATTGGAGCAAAGCTT
CCAGCTAATAATAAAGGAACTATACTTGAGATTGGAAAAGGCAGAATATTAATGGAAGGCAGCAGAGTAG
CTATTTTGGGTTATGGTTCTATTGTTCAGCAATGTGTGGAAGCTGCAAGCATATTAAAGAAACAAGACAT
TTCAGTGACAGTAGCTGATGCAAGATTTTGCAAACCATTGGATACAAATCTCATAAGACGGTTAGCCAAC
GAGCATGAAATCCTAATCACTGCCGAAGAAGGTTCTATTGGAGGCTTTGGGTCTCATGTGTCACACTTTC
TAAGCTTAAGTGGACTTCTTGATGGGTCTTTAAAGTTGAGAGCAATGGTTCTTCCTGATAGATACATTGA
CCATGGATCACCCCAAGATCAGACTGAAACAGCCGGGCTCTCCTCGAGGCATATATCTGCAACAGTCTTA
TCTCTCTTGGGGAAGCCCAAGGAAGCACTTCAGTTCATGTAA (서열 번호 19)
> PK04218.1 | 1-데옥시-D-크실룰로스 5-포스페이트 리덕토이소머라제 (XDR)
ATGGCTCTGAACTTGTTATCCCCAGCTGAAGTGAAGGCTCTATCCTTTTTGGACTCCACCAAGTCCACCC
GCTTCCCTAAGCTGTGTCCAGGTGGAATTACTTTGCATAGAAAGGATTGCAGAGTACCACTTAGAAGAAG
AGTTCATTGTTCGTTGCAGCAACCTCCTCCAGCTTGGCCAGGAAGAGCTATTCCAGAGCAAGATCTTTGT
AATTGGAATGTCCCAAAGCCTATATCTATTATTGGCTCTACTGGCTCTATAGGAACTCAGACACTGGACA
TTGTGGCAGAGAATCCAGATAAATTCAGAATAGTGGGACTTGCAGCTGGTTCGAATGTGACACTTCTTGC
AGACCAGGTGAAGAGATTCAAGCCTCAAATAGTTGCTCTTAGAAATGAATCATTAATTGGTGAACTAAAA
GAGGCCTTAGCTGATGTGGAAGAAATGCCCGAAATTATTCCTGGGGAACAAGGAGTAATTGAGGTTGCCC
GGCACCCAGATGCAGTCACAGTGGTTACAGGAATAGTAGGTTGTGCTGGATTACAGCCTACAGTTGCTGC
AATTGAGGCAGGTAAACACATAGCTTTAGCCAATAAAGAGACCCTGATTGCTGGAGGTCCATTCATCCTT
CCTCTAGCTCACAAGCATAACATAAAAATTCTTCCTGCCGATTCAGAACATTCGGCAATATTCCAGTGTA
TCCAGGGCTTGCCTGATGGTGCACTACGGCGTATCATTTTGACAGCATCTGGGGGAGCTTTCAGAGATTG
GCCGGTTGAAAAGCTAAAAGATGTTAAGGTTGCTGATGCTCTGAAACATCCAAACTGGCCGGGTATGGGA
AAGAAAGTCACTATTGATTCTGCTACCCTTTTCAACAAGGGTCTGGAAGTCATTGAAGCCCATTATCTAT
TCGGAGCAGACTATGACGATATTGACATTGTGATTCACCCAGAAGCTATTATACACTCTATGATTGAAAC
ACAGGATTCTTCTGTTCTGGCTCAGTTAGGGTGGCCTGACATGCATATACCGATTCTCTATACTATGTCA
TGGCCAGACAGAATATACTGTTCTGAAGTAACTTGGCCTCGACTTGATCTTTGCAAGCTTGGTTCGCTGA
CCTTTAGGAGTCCTGACAACCAGAAGTACCCATCCATAGATCTTGCCTATTCTGCTGGACGTGCTGGGGG
CACCATGACTGGAGTTCTCAGTGCAGCCAATGAGAAAGCTGTAGAGATGTTTATTGATGAGAAGATAAGT
TATCTTGAAATCTTCAAAGTTGTTGAGCTAACATGCGACAAGCATCGATCAGAGATGGTGACTTCACCTT
CTCTTGATGAAATTATCCACTATGACTCGTGGGCACGAGAGTATGCAACTACTAGTTTGAAGAGTTCTTC
CAGTCCAAGACCTGTTACAGCATGA (서열 번호 20)
> PK03569.1 | 4-디포스포시티딜-메틸에리트리톨 2-포스페이트 신타제 (MCT)
ATGGCGTTACTTGCAATGGACCTTACTTTCTCTTCTGCTTCTCTTTCTTCTTCTTCCTACAATGCTGCTC
CTCTACTATTTCCTTCTATTCGCCCATCCTCTCAATCCATTGTTCGATTCCCAGTCCATGAGGTGGGATT
CAGGGGGAAATGCAGAATTTCCAAGATAAGGTTCGCTCGCTGCTCTGCAAATGTTGGCCAAAAGCCTGGT
GTTGTGGAAAAGAAAAGCGTTTCGGTGGTTCTTCTGGCAGGTGGGAAGGGTAAACGGATGGGGGCCAACA
TGCCAAAGCAGTATCTTCCACTTTTAGGGCAACCAATTGCACTGTATAGCTTCTACACTTTTTCTAAAAT
GATTGAAGTGACTGAAATTGTTGTAGTTTGTGATCCCTCTTACGAGGATATCTTTGAAGATTCCAAAGTC
AAGATCCATGTTGGACTTAAATTCGCTCTGCCTGGAAAGGAAAGACAGGATTCAGTTTATAGTGGACTTC
AGGCAATTGATCCAAACTCTAAGCTTGTGTGCATTCACGATTCTGCTAGACCTTTGGTAACAACAGAAGA
AGTTAAAAAGGTCATTGAAGATGGTTGGTTGCATGGAGCAGCTGTACTTGGTGTTCCTGTCAAAGCTACA
ATCAAAGAGGCAAACAATGCATCTTTTGTAACTAAAACGTTGGAGAGGAAAAAACTTTGGGAAATGCAGA
CACCCCAGGTGATCAAACCCGAGTTGCTCAAGGAAGGATTTGAGCTTGTAAATAGGGAAAATCTGGAAGT
GACTGATGATGTGTCTATAGTGGAACACCTTGGACATCCTGTATATATAACTGAAGGTGCTTACACCAAC
ATCAAGGTTACTACTCCAGATGATTTATTGCTTGCGGAGAGAGTATTGAGTATGAACTCTGTGAAGGCTG
TTGCATAA (서열 번호 21)
> PK19074.1 | 4-디포스포시티딜-2-C-메틸-D-에리트리톨 키나제 (CMK)
ATGGCTTCCTCTCATATTCTCTGCCACAACAACGTTTTTAATCTTTCTCCCAATCCTTTTAGGAACAGGG
GTCTCTCTTCCTTAAACTCAAATGGGTTTTGTTTTTTTGGTTCGAAATCTAGAATTTCGAGGCCTTCATC
TCTCAAAATTGTGGTTTCTGAAAGAAGACAAGTTGAGATAGTTTATGATGCTGATGAAAGGATAAACAAA
TTGGCTGATGTAGTGGACAAGGAAGCGCCTCTTTCTAGGCTCACTCTTTTCTCACCTTGCAAGATTAATG
TTTTCTTGAGAATAACTAGCAAAAGGGAAGATGGGTATCATGATTTGGCATCCCTCTTTCACGTGATAAG
TCTTGGAGATGTGCTTAAGTTCTCTTTGTCTCCTTCAACAAAGAAAGATTCTTTGTCAACGAATGCCTCT
GGGGTACCACTTGATGATAGAAATTTGATTATCAAGGCCCTTAATCTTTACCGAAAGAAAACTGGTACAA
ACAAATACTTTTGGATTCATCTTGACAAGAAAGTGCCCACTGGAGCAGGGCTAGGTGGTGGGAGCAGCAA
TGCTGCAACAGCCCTATGGGCAGCAAATCAGTTCAATGGTTGTCTTGTTACTGAAAAGGAATTGCAAGAA
TGGTCAAGTGAGATTGGTTCAGATGTTCCTTTCTTTTTCTCCCAAGGGGCAGCCTATTGTACAGGTCGAG
GTGAGGTTGTTCAGGATATTCTACCACCTGTACCATTAAACATTCCCATGGTTCTCATAAAGCCCCCAGA
AGCATGTTCAACAGCCGAAGTTTATAAGCGTTTTCGGTTGGATAAAACCAGTAATAGTGATCCTTTACAA
TTGCTCCACAAGATCTCAAGTGATGGAATAAGTCAAGATGTCTGCATCAATGACTTAGAACCTCCTGCCT
TTGAAGTTCTTCCATCTCTTAAGAGATTGAAACAGCGTATAATTGCAGCTAGTCGTGGACAATATGATGC
TGTTTTTATGTCTGGGAGTGGAAGCACCATTGTCGGGGTCGGTTCCCCAGATCCACCTCAGTTTATATAT
GATGATGAGGACTACAAGGATGTGTTTTTGTCAGAGGCCAACTTTCTGACTCGAGAAGCAAATGAATGGT
ACAAAGAACCTGCTTCAGCTAGCGCTTGTAGCCCTTCAGATGATTTCTCTCGTAATTTTTCCTCCTCTGT
CGAGTAA (서열 번호 22)
> PK25433.1 | 2-C-메틸-D-에리트리톨 2:4-시클로디포스페이트 신타제 (MDS)
ATGGCGGCGGCGACGGCAACACCACTCTGTGCTTCAACTCTTCCACCACACTACTCCAATACCTCCCCCA
AATCATTCAATCACTCCCATTTCACAGTCGCAGTTCCCAGAAATCTCTTCTCATCGTCCTCAATTTCATC
TCTAAGACAATCGAAAACGACGCCGCTTTCGGCTCTGCCTTCTGTATCGGCCGCCGCGACCACCGCTTTG
AACGCTGAGCAAGCTCCGTCTGAGGTATCTGCTACTCCCTCAAAGGCTCTTCCTTTTCGGGTTGGTCATG
GGTTTGACCTTCATCGATTGGAGCCTGGGTATCCTTTGATAATTGGAGGTATTAATATACCTCATGAGAA
AGGTTGCGAAGCTCATTCTGATGGGGATGTTTTGCTTCATTGTGTAGTTGATGCTATTTTGGGTGCTTTG
GGGCTTCCTGATATTGGTCAAATTTTCCCTGATTCTGATCCCAAATGGAAAGGGGCTGCATCATCAGTTT
TCATCAAAGAAGCTGTGAGACTGATGCATGAGGCAGGTTATGAGCTTGGAAATTTAGATGCAACATTAAT
TCTTCAAAGACCAAAGTTAAGTCCACACAAGGAAGCTATCAGAGCCAACTTGTCTGAACTTCTAGGAGCT
GACCCTGCAGTTGTTAATCTGAAAGCGAAAACTCACGAAAAGGTCGATAGTCTCGGGGAAAATCGAAGCA
TCGCTGCTCACACTGTGGTTCTTCTTATGAAAAAATAG (서열 번호 23)
> PK23068.1 | 4-히드록시-3-메틸부트-2-엔-1-일 디포스페이트 신타제 (HDS)
ATGGCTTCTGGAGCTGTACCAGCATCAATTTCATGTCTGAAAAGCAGAGACTCTGGCTTGAGCTTTGCTA
AAAGTTCTGATTTTGTGAGGCTTTCTGATTTAAAGAGGGTTGGTTCATCTAGAACAAGAGTTTCAGTTAT
CCGAAATTCGAATCCTGGTTCAGATATTGCTGAACTTCAGCCTGCATCAAAAGGAAGCCCTCTATTAGTT
CCTAGACAGAAGTACTGTGAATCCTTACACAAAACTGTTAGGAGGAAAACGCGAACTGTGATGGTGGGAA
ATGTGGCTCTTGGCAGTGAGCATCCCATAAGAATTCAAACGATGACGACAAATGATACCAAGGATGTTGC
TGGAACAGTTGAAGAGGTGATGAGAATAGCTGATAAGGGAGCTGATATTGTTCGGATAACAGTTCAGGGA
AGAAAAGAAGCAGATGCTTGTTTCGAAATAAAAAATTCACTTGTGCAGAAGAATTATAATATACCTCTTG
TGGCAGATATTCATTTTGCTCCCCCAGTTGCATTAAGAGTTGCTGAATGCTTCGATAAAATTCGTGTCAA
TCCTGGAAATTTCGCTGACAGACGGGCTCAGTTTGAGACGCTCGAGTACACAGACGACGACTATCAGAAA
GAACTTGAGCATATTGAGCAGGTTTTTTCTCCATTGGTTGAGAAATGTAAGAAATATGGTAGAGCAATGC
GTATCGGGACAAACCATGGGAGTCTTTCAGATCGTATCATGAGCTACTATGGAGATTCTCCAAGGGGAAT
GGTTGAATCTGCATTTGAGTTTGCAAGGATTTGCCGGAAGTTGGATTTCCATAATTTTGTGTTTTCGATG
AAAGCAAGCAACCCAGTTGTCATGGTTCAGGCGTATCGTCTACTTGTTGCTGAAATGTATGTCCAGGGCT
GGGACTATCCACTTCACTTGGGAGTTACTGAAGCGGGAGAAGGTGAGGATGGACGAATGAAATCTGCAAT
TGGCATCGGGACCCTTCTTCAGGATGGTTTGGGTGATACTATCAGGGTTTCACTCACCGAACCGCCCGAG
GAGGAGATTGATCCCTGCAGAAGGTTGGCCAATTTGGGTACAAAAGCAGCTGATCTTCAGCAAGGAGTGG
CTCCATTTGAAGAGAAGCACAGGCATTATTTTGATTTTCAACGACGAACTGGTCAACTGCCTCTACAGAA
GGAGGGCGATGAGGTTGACTATAGAGGTGCTCTGCACCGTGATGGTTCTGTTCTCATGTCAGTGTCTCTC
AATAACTTAAAGATGCCCGAGCTCCTATACAGGTCACTAGCAGCAAAGCTTGTCGTCGGGATGCCATTTA
AGGATCTGGCAACAGTAGACTCCATCTTATTGAGACAACTTCCACCTATTGACGATGACAACGCTCGATT
AGCTCTCAAAAGATTGATAGACATAAGTATGGGGGTCATAACTCCTTTGTCGGAGCAGCTAACAAAGCCA
TTGCCAAATGCTATGGTTTTGGTAAATCTTAAGGAGTTATCATCTGGTGCACACAAGCTTTTGCCAGAAG
GCACGCGTTTGGTTGTATCCTTGCGCGGTGATGAACCTTACGAAGAACTGGAGATTCTCAAAGGGGTTGA
TGATGTTGTTATGATTCTTCATGATCTTCCGTTCGATGAACATAAAATTAGCAGAGTCCACTCAGCAAGA
AGATTATTTGAGTATCTATCAGATAATTCTCTTAACTTTCCTGTAATACACCACATTCAATTTCCAAATG
GAATCCACAGGGATGACTTAGTCATCGGTGCAGGTAGCAACGCTGGTGCCCTTTTAGTAGATGGACTCGG
GGACGGTATCCTCTTAGAAGCCCCAGATCAGGATTTCGATTTTCTTAGAAATACTTCTTTCAACCTACTT
CAAGGTTGTAGAATGCGAAATACAAAGACGGAGTATGTCTCGTGCCCATCCTGCGGTAGAACTTTGTTTG
ACCTTCAAGAAATCAGCGCAGAGATTCGAGAGAAGACATCACACCTGCCCGGTGTCTCAATTGCAATCAT
GGGTTGCATTGTTAATGGACCCGGAGAGATGGCTGATGCAGACTTCGGTTATGTCGGTGGTGCTCCCGGA
AAGATTGACCTTTATGTTGGAAAGACGGTAGTGCAGCGTGGAATCGCAATGGAACAAGCGACCGATGCAT
TGATTCAGCTAATAAAAGATCATGGCCGATGGGTTGAACCACCCTCGGACGAAGAATGA (서열 번호 24)
> PK13726.1 | 4-히드록시-3-메틸부트-2-에닐 디포스페이트 리덕타제 (HDR)
ATGTCGATCACTTTCCAGCTCTGCCGGATTCCAATCCGTACCGACCTCGCCTTGGCGGAGCCTCTCTCCG
TAACCGGAACCCTCCGCTGCCGGAAACCTTTCGTCATCCGATGCGCCGGCGAGTCATCTTCAACGGCAGC
AGATTCTGATTTCGATGCGAAAGTGTTCCGTAAGAACTTGGTCCGAAGCAAGAACTACAATCGGAAAGGT
TTTGGCCATAAGGAAGAGACCCTTCAACTCATGGACAGCGAGTACACCAGTGATATTATAAAGACTTTGA
AGGATAATGGAAATGAGTACAGGTGGGGGAACGTGACGGTAAAATTGGCCGAAGCATATGGGTTTTGCTG
GGGTGTGGAGCGAGCTGTCCAAATTGCTTACGAAGCAAGGAAACAGTTCCCCGAAGAAAAGATTTGGATT
ACAAACGAAATTATTCATAATCCGACAGTCAACAAGAGACTAGAGGAAATGAAAGTGGAAAATATTCCAA
TTGATGAAGGGAGGAAACAATTTGAGATTGTAAACAAGGGTGATGTTGTGATATTGCCTGCTTTTGGTGC
TGGAGTGGATGAGATGTTGGCTTTGAGTGATAGGAATGTTCAAATTGTTGATACCACATGCCCATGGGTT
TCCAAGGTTTGGAATACAGTCGAGAAACATAAGAAAGGTGAATACACTTCCATTATTCATGGTAAATATG
CTCATGAGGAGACTATAGCTACTGCATCTTTTGCTGGAACTTACATTATTGTAAAGAACATGAAAGAGGC
AATGTATGTCTGTGATTATATTCTTGGCGGTCAACTTGATGGATCCAGCTCAACAAGAGAGGAGTTTATG
GAGAAATTTAAGAATGCAGTTTCTAAGGGATTTGATCCTGACAAACATCTTGTGAAGGCTGGTATTGCAA
ATCAGACTACAATGCTCAAGGGGGAAACCGAAGAGATTGGGAAACTGGTTGAGAGGACTATGATGCAAAA
GTACGGAGTTGAAAACATTAATGAACACTTCCAAAGCTTTAACACAATTTGCGATGCAACCCAAGAGCGT
CAAGATGCAATGTACAAGATGGTGGAGGAACGTATTGACCTTATGTTAGTTGTTGGAGGATGGAACTCTA
GTAACACTTCTCATCTACAAGAGATTGCAGAGGAACGAGGTATTCCCTCGTATTGGATTGACAGTGAACA
GAGAATAGGTCCTGGAAACAAGATAGCCTACAAGCTAAATCATGGAGAGTTGGTTGAGAAAGAGAACTGG
TTACCAGAGGGTCCCATCACGGTCGGTGTAACATCAGGTGCTTCTACTCCAGATAAGGTTGTGGAAGATG
TTCTCATCAAGGTGTTTGACCTTAAGAGCGAAGAAGCTTTGCAAGTTGCTTAG (서열 번호 25)
> AAO73863| 카렌 신타제 모노TS
MSVISILPLASKSCLYKSLMSSTHELKALCRPIATLGMCRRGKSVMASKSTSLTTAVSDDGVQRRIGDHH
SNLWDDNFIQSLSSPYGASSYGERAERLIGEVKEIFNSLSRTDGELVSHVDDLLQHLSMVDNVERLGIDR
HFQTEIKVSLDYVYSYWSEKGIGSGRDIVCTDLNTTALGFRILRLHGYTVFPDVFEHFKDQMGRIACSDN
HTERQISSILNLFRASLIAFPGEKVMEEAEIFSATYLKEALQTIPVSSLSQEIQYVLQYRWHSNLPRLEA
RTYIDILQENTKNQMLDVNTKKVLELAKLEFNIFHSLQQNELKSVSRWWKESGFPDLNFIRHRHVEFYTL
VSGIDMEPKHCTFRLSFVKMCHLITVLDDMYDTFGTIDELRLFTAAVKRWDPSTTECLPEYMKGVYTVLY
ETVNEMAQEAQKSQGRDTLSYVRQALEAYIGAYHKEAEWISSGYLPTFDEYFENGKVSSGHRIATLQPTF
MLDIPFPHHVLQEIDFPSKFNDFACSILRLRGDTRCYQADRARGEEASCISCYMKDNPGSTQEDALNHIN
NMIEETIKKLNWELLKPDNNVPISSKKHAFDINRGLHHFYNYRDGYTVASNETKNLVIKTVLEPVPM (서열 번호 26)
>EFF14228 1-데옥시-D-크실룰로스-5-포스페이트 신타제 Dxs [에스케리키아 콜라이 B354]
1 mmsfdiakyp tlalvdstqe lrllpkeslp klcdelrryl ldsvsrssgh fasglgtvel
61 tvalhyvynt pfdqliwdvg hqayphkilt grrdkigtir qkgglhpfpw rgeseydvls
121 vghsstsisa gigiavaaek egknrrtvcv igdgaitagm afeamnhagd irpdmlvvln
181 dnemsisenv galnnhlaql lsgklysslr eggkkvfsgv ppikellkrt eehikgmvvp
241 gtlfeelgfn yigpvdghdv lglittlknm rdlkgpqflh imtkkgrgye paekdpitfh
301 avpkfdpssg clpkssgglp syskifgdwl cetaakdnkl maitpamreg sgmvefsrkf
361 pdryfdvaia eqhavtfaag laiggykpiv aiystflqra ydqvlhdvai qklpvlfaid
421 ragivgadgq thqgafdlsy lrcipemvim tpsdenecrq mlytgyhynd gpsavryprg
481 navgveltpl eklpigkgiv krrgeklail nfgtlmpeaa kvaeslnatl vdmrfvkpld
541 ealilemaas healvtveen aimggagsgv nevlmahrkp vpvlniglpd ffipqgtqee
601 mraelgldaa gmeakikawl a (서열 번호 27)
>WP_072972099 2-C-메틸-D-에리트리톨 4-포스페이트 시티딜릴트랜스퍼라제 IspD/MCT
1 matthldvca vvpaagfgrr mqtecpkqyl signqtileh svhallahpr vkrvviaisp
61 gdsrfaqlpl anhpqitvvd ggderadsvl aglkaagdaq wvlvhdaarp clhqddlarl
121 lalsetsrtg gilaapvrdt mkraepgkna iahtvdrngl whaltpqffp rellhdcltr
181 alnegatitd easaleycgf hpqlvegrad nikitrpedl alaefyltrt ihqent (서열 번호 28)
>WP_086589482 2-C-메틸-D-에리트리톨 2,4-시클로디포스페이트 신타제 IspF/MDS
1 mrighgfdvh afggegpiii ggvripyekg llahsdgdva lhaltdallg aaalgdigkl
61 fpdtdpafkg adsrellrea wrriqakgyt lgnidvtiia qapkmlphip qmrvfiaedl
121 gchmddvnvk attteklgft grgegiacea vallikatk (서열 번호 29)
>WP_115903881 이소펜테닐-디포스페이트 델타-이소머라제 Idi
1 mqtehvilln aqgvptgtle kyaahtadtr lhlafsswlf nakgqllvtr ralskkawpg
61 vwtnsvcghp qlgesnedav irrcryelgv eitppesiyp dfryratdps givenevcpv
121 faarttsalq inddevmdyq wcdladilhg idatpwafsp wmvmqatnre arkrlsaftq
181 lk (서열 번호 30)
>AF513112.1 게라닐 디포스페이트 신타제 GPPS
MAYSAMATMGYNGMAASCHTLHPTSPLKPFHGASTSLEAFNGEHMGLLRGYSKRKLSSYKNPASRSSNATVAQLLNPPQKGKKAVEFDFNKYMDSKAMTVNEALNKAIPLRYPQKIYESMRYSLLAGGKRVRPVLCIAACELVGGTEELAIPTACAIEMIHTMSLMHDDLPCIDNDDLRRGKPTNHKIFGEDTAVTAGNALHSYAFEHIAVSTSKTVGADRILRMVSELGRATGSEGVMGGQMVDIASEGDPSIDLQTLEWIHIHKTAMLLECSVVCGAIIGGASEIVIERARRYARCVGLLFQVVDDILDVTKSSDELGKTAGKDLISDKATYPKLMGLEKAKEFSDELLNRAKGELSCFDPVKAAPLLGLADYVAFRQN (서열 번호 31)
>WP_053287215 게라닐 트랜스퍼라제 IspA
1 mdfpqqleac vkqanqalsr fiaplpfqnt pvvetmqyga llggkrlrpf lvyatghmfg
61 istntldapa aavecihays lihddlpamd dddlrrglpt chvkfgeana ilagdalqtl
121 afsilsdadm pevsdrdris miselasasg iagmcggqal dldaegkhvp ldalerihrh
181 ktgaliraav rlgalsagdk grralpvldk yaesiglafq vqddildvvg dtatlgkrqg
241 adqqlgksty pallgleqar kkardlidda rqslkqlaeq sldtsaleal adyiiqrnk (서열 번호 32)
>NP_414715 1-데옥시-D-크실룰로스 5-포스페이트 리덕토이소머라제 IspC/DXR
1 mkqltilgst gsigcstldv vrhnpehfrv valvagknvt rmveqclefs pryavmddea
61 sakllktmlq qqgsrtevls gqqaacdmaa ledvdqvmaa ivgaagllpt laairagkti
121 llankeslvt cgrlfmdavk qskaqllpvd sehnaifqsl pqpiqhnlgy adleqngvvs
181 illtgsggpf retplrdlat mtpdqacrhp nwsmgrkisv dsatmmnkgl eyiearwlfn
241 asasqmevli hpqsvihsmv ryqdgsvlaq lgepdmrtpi ahtmawpnrv nsgvkpldfc
301 kl염faap dydrypclkl ameafeqgqa attalnaane itvaaflaqq irftdiaaln
361 lsvlekmdmr epqcvddvls vdanarevar kevmrlas (서열 번호 33)
>EGT67781 4-디포스포시티딜-2-C-메틸에리트리톨 키나제 IspE/CMK
1 mrtqwpspak lnlflyitgq radgyhtlqt lfqfldygdt isielrddgd irlltpvegv
61 ehednlivra arlliktaad sgrlptgsga nisidkrlpm ggglgggssn aatvlvalny
121 lwqcglsmde laemgltlga dvpvfvrgha afaegvgeil tpvdppekwy lvahpgvsip
181 tpvifkdpel prntpkrsie tllkcefsnd ceviarkrfr evdavlswll eyapsrltgt
241 gacvfaefdt esearqvleq apewlngfva kgvnlsplhr aml (서열 번호 34)
>ANK02812 4-히드록시-3-메틸부트-2-엔-1-일 디포스페이트 신타제 IspG/HDS
1 mhnqapiqrr kstriyvgnv pigdgapiav qsmtntrttd veatvnqika lervgadivr
61 vsvptmdaae afklikqqvn vplvadihfd yrialkvaey gvdclrinpg nigneerirm
121 vvdcardkni pirigvnags lekdlqekyg eptpqalles amrhvdhldr lnfdqfkvsv
181 kasdvflave syrllakqid qplhlgitea ggarsgavks aiglglllse gigdtlrvsl
241 aadpveeikv gfdilkslri rsrginfiac ptcsrqefdv igtvnaleqr lediitpmdv
301 siigcvvngp gealvstlgv tggnkksgly edgvrkdrld nndmidqlea rirakasqld
361 earridvqqv ek (서열 번호 35)
>AAL38655 4-히드록시-3-메틸부트-2-에닐 디포스페이트 리덕타제 IspH/HDR
1 mqillanprg fcagvdrais ivenalaiyg apiyvrhevv hnryvvdslr ergaifieqi
61 sevpdgaili fsahgvsqav rneaksrdlt vfdatcplvt kvhmevaras rrgeesilig
121 haghpevegt mgqysnpegg mylvespddv wkltvkneek lsfmtqttls vddtsdvida
181 lrkrfpkivg prkddicyat tnrqeavral aeqaevvlvv gsknssnsnr laelaqrmgk
241 rafliddakd iqeewvkevk cvgvtagasa pdilvqnvva rlqqlgggea iplegreeni
301 vfevpkelrv direvd (서열 번호 36)
>AAA24819.1 파이토엔 신타제 CrtE
1 mvsgskagvs phreievmrq siddhlagll petdsqdivs lamregvmap gkrirpllml
61 laardlryqg smptlldlac avelthtasl mlddmpcmdn aelrrgqptt hkkfgesvai
121 lasvgllska fgliaatgdl pgerraqavn elstavgvqg lvlgqfrdln daaldrtpda
181 ilstnhlktg ilfsamlqiv aiasasspst retlhafald fgqafqlldd lrddhpetgk
241 drnkdagkst lvnrlgadaa rqklrehids adkhltfacp qggairqfmh lwfghhladw
301 spvmkia (서열 번호 37)
>AAA24820.1 파이토엔 데히드로게나제 CrtI
1 mkktvvigag fgglalairl qaagiptvll eqrdkpggra yvwhdqgftf dagptvitdp
61 talealftla grrmedyvrl lpvkpfyrlc wesgktldya ndsaeleaqi tqfnprdveg
121 yrrflaysqa vfqegylrlg svpflsfrdm lragpqllkl qawqsvyqsv srfiedehlr
181 qafsfhsllv ggnpfttssi ytlihalere wgvwfpeggt galvngmvkl ftdlggeiel
241 narveelvva dnrvsqvrla dgrifdtdav asnadvvnty kkllghhpvg qkraaalerk
301 smsnslfvly fglnqphsql ahhticfgpr yrelideift gsaladdfsl ylhspcvtdp
361 slappgcasf yvlapvphlg napldwaqeg pklrdrifdy leerympglr sqlvtqrift
421 padfhdtlda hlgsafsiep lltqsawfrp hnrdsdianl ylvgagthpg agipgvvasa
481 kataslmied lq (서열 번호 38)
>AAA24821.1 프레파이토엔 피로포스페이트 신타제 [판토에아 아글로메란스(Pantoea agglomerans)] CrtB
MSQPPLLDHATQTMANGSKSFATAAKLFDPATRRSVLMLYTWCRHCDDVIDDQTHGFASEAAAEEEATQRLARLRTLTLAAFEGAEMQDPAFAAFQEVALTHGITPRMALDHLDGFAMDVAQTRYVTFEDTLRYCYHVAGVVGLMMARVMGVRDERVLDRACDLGLAFQLTNIARDIIDDAAIDRCYLPAEWLQDAGLTPENYAARENRAALARVAERLIDAAEPYYISSQAGLHDLPPRCAWAIATARSVYREIGIKVKAAGGSAWDRRQHTSKGEKIAMLMAAPGQVIRAKTTRVTPRPAGLWQRPV (서열 번호 39)
>sp|Q50L36.1|ISPS_POPAL RecName:전체=이소프렌 신타제, 클로로플라스틱; 짧은=PaIspS; IspS.
MATELLCLHRPISLTHKLFRNPLPKVIQATPLTLKLRCSVSTENVSFTETETEARRSANYEPNSWDYDYLLSSDTDESIEVYKDKAKKLEAEVRREINNEKAEFLTLLELIDNVQRLGLGYRFESDIRGALDRFVSSGGFDAVTKTSLHGTALSFRLLRQHGFEVSQEAFSGFKDQNGNFLENLKEDIKAILSLYEASFLALEGENILDEAKVFAISHLKELSEEKIGKELAEQVNHALELPLHRRTQRLEAVWSIEAYRKKEDANQVLLELAILDYNMIQSVYQRDLRETSRWWRRVGLATKLHFARDRLIESFYWAVGVAFEPQYSDCRNSVAKMFSFVTIIDDIYDVYGTLDELELFTDAVERWDVNAINDLPDYMKLCFLALYNTINEIAYDNLKDKGENILPYLTKAWADLCNAFLQEAKWLYNKSTPTFDDYFGNAWKSSSGPLQLVFAYFAVVQNIKKEEIENLQKYHDTISRPSHIFRLCNDLASASAEIARGETANSVSCYMRTKGISEELATESVMNLIDETWKKMNKEKLGGSLFAKPFVETAINLARQSHCTYHNGDAHTSPDELTRKRVLSVITEPILPFER (서열 번호 40)
* * *
본원에 설명적으로 기재된 발명은, 본원에 구체적으로 개시되지 않은 임의의 요소 또는 요소들, 제한 또는 제한들의 부재 하에 적합하게 실행될 수 있다. 따라서, 예를 들어, 용어 "포함하는" "포함한" "함유하는" 등은 확장적으로 제한 없이 이해된다. 추가로, 본원에서 사용된 용어 및 표현은 설명적이며 비제한적 용어로서 사용되었고, 이러한 용어 및 표현의 사용에서 차후에 나타내고 기재되는 임의의 등가물 또는 임의의 이들의 부분을 배제하려는 의도는 없으며, 청구된 발명의 범주 내에서 다양한 변형이 가능함이 인식된다.
따라서, 본 발명을 바람직한 구현예 및 임의적 특징에 의해 구체적으로 개시하였지만, 개시된 본원 발명의 변형 및 변화가 당업자에 의해 이루어질 수 있고, 이러한 변형 및 변화는 본원에 개시된 발명의 범주 내에 있는 것으로 간주됨을 이해하여야 한다. 본 발명은 본원에서 광범위하게, 또한 일반적으로 기재되었다. 일반적 개시내용의 범주 내에 포함되는 보다 좁은 종 및 하위 그룹 각각 또한 이들 발명의 부분을 형성한다. 이는, 삭제된 물질이 구체적으로 존재하는지 여부에 관계없이, 부류로부터 임의의 주제를 제거하는 단서 또는 부정적 제한을 갖는 각 발명의 일반적 설명을 포함한다.
추가로, 본 발명의 특징 또는 양태가 마쿠쉬(Markush) 그룹으로 기재되는 경우, 당업자는, 본 발명이 또한 이로써 마쿠쉬 그룹의 임의의 개별 구성원 또는 구성원들의 하위군으로 기재됨을 인식할 것이다. 또한, 상기 설명은 예시적 및 비제한적인 것으로 의도됨을 이해하여야 한다. 상기 설명을 검토함에 따라 많은 구현예가 당업자에게 명백할 것이다. 따라서, 본 발명의 범주는, 상기 설명과 관련하여 결정되지 않아야 하며, 그 대신에, 첨부된 청구범위와 함께, 이러한 청구범위가 부여되는 등가물의 전체 범주와 관련하여 결정되어야 한다. 특허 공개문헌 및 데이터베이스 (예: 진뱅크) 수탁 번호에 의해 참조되는 내용을 포함한, 모든 논문 및 참조문헌의 개시내용은, 본원에 참조로 포함된다.