KR20200074690A - 전자 장치 및 이의 제어 방법 - Google Patents
전자 장치 및 이의 제어 방법 Download PDFInfo
- Publication number
- KR20200074690A KR20200074690A KR1020180163377A KR20180163377A KR20200074690A KR 20200074690 A KR20200074690 A KR 20200074690A KR 1020180163377 A KR1020180163377 A KR 1020180163377A KR 20180163377 A KR20180163377 A KR 20180163377A KR 20200074690 A KR20200074690 A KR 20200074690A
- Authority
- KR
- South Korea
- Prior art keywords
- electronic device
- user
- information
- voice
- voice data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images








Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/28—Constructional details of speech recognition systems
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/011—Arrangements for interaction with the human body, e.g. for user immersion in virtual reality
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/16—Sound input; Sound output
- G06F3/167—Audio in a user interface, e.g. using voice commands for navigating, audio feedback
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/28—Constructional details of speech recognition systems
- G10L15/30—Distributed recognition, e.g. in client-server systems, for mobile phones or network applications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G10L2015/223—Execution procedure of a spoken command
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G10L2015/225—Feedback of the input speech
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G10L2015/226—Procedures used during a speech recognition process, e.g. man-machine dialogue using non-speech characteristics
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Human Computer Interaction (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Health & Medical Sciences (AREA)
- Multimedia (AREA)
- Computational Linguistics (AREA)
- Acoustics & Sound (AREA)
- Theoretical Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- User Interface Of Digital Computer (AREA)
- Telephonic Communication Services (AREA)
Abstract
Description
도 2 및 도 3은 본 개시의 일 실시예에 따른, 전자 장치의 구성을 나타내는 블럭도를 도시한 도면,
도 4 및 도 5는 본 개시의 다양한 실시예에 따른, 복수의 전자 장치 중 허브 장치를 결정하여 대화형 서비스를 제공하기 위한 방법을 설명하기 위한 시퀀스도들,
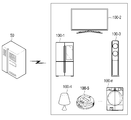
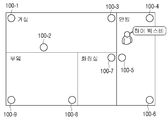
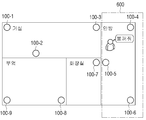
도 6a 내지 도 6d는 본 개시의 일 실시예에 따른, 복수의 전자 장치 중 허브 장치를 결정하여 대화형 서비스를 제공하는 실시예를 설명하기 위한 도면들,
도 7은 본 개시의 일 실시예에 따른, 전자 장치의 제어 방법을 설명하기 위한 흐름도,
도 8은 본 개시의 일 실시예에 따른, 인공지능 에이전트 시스템의 대화 시스템을 도시한 블록도이다.
130: 메모리 140: 프로세서
150: 디스플레이 160: 스피커
170: 입력부 180: 센서
Claims (20)
- 전자 장치에 있어서,
마이크;
통신 인터페이스;
적어도 하나의 명령을 저장하는 메모리; 및
상기 적어도 하나의 명령을 실행하는 프로세서;를 포함하고,
상기 프로세서는,
상기 마이크를 통해 수신된 사용자의 음성을 바탕으로 상기 전자 장치 주위에 사용자가 존재하는지 여부를 판단하고,
상기 사용자가 상기 전자 장치 주위에 존재하면, 상기 전자 장치와 상기 전자 장치 주변에 존재하는 적어도 하나의 타 전자 장치를 포함하는 디바이스 그룹을 결정하며,
상기 적어도 하나의 타 전자 장치 각각으로부터 수신한 상기 타 전자 장치에 대한 정보를 바탕으로 상기 디바이스 그룹 중 하나의 장치를 음성 인식을 수행하기 위한 허브 장치로 결정하고,
상기 전자 장치가 허브 장치로 결정되면, 상기 통신 인터페이스를 통해 상기 적어도 하나의 타 전자 장치 각각으로부터 상기 사용자의 음성 데이터를 수신하여 음성 인식을 수행하는 전자 장치. - 제1항에 있어서,
상기 프로세서는,
상기 사용자의 음성, 상기 전자 장치의 사용 정보, 상기 전자 장치의 사용 통계 정보, 상기 사용자의 움직임 정보 중 적어도 하나를 이용하여 상기 전자 장치 주위에 사용자가 존재하는지 여부를 판단하는 전자 장치. - 제1항에 있어서,
상기 프로세서는,
상기 사용자가 상기 전자 장치 주위에 존재하면, 상기 통신 인터페이스를 통해 복수의 타 전자 장치로부터 상기 사용자의 음성에 대한 정보를 수신하고,
상기 복수의 타 전자 장치 중 임계값 이상의 크기를 가지는 상기 사용자의 음성을 감지한 상기 적어도 하나의 타 전자 장치를 결정하고,
상기 결정된 적어도 하나의 타 전자 장치를 포함하는 디바이스 그룹을 결정하는 전자 장치. - 제1항에 있어서,
상기 프로세서는,
상기 사용자가 상기 전자 장치 주위에 존재하면, 상기 전자 장치의 위치를 바탕으로 상기 적어도 하나의 타 전자 장치를 결정하고,
상기 결정된 적어도 하나의 타 전자 장치를 포함하는 디바이스 그룹을 결정하는 전자 장치. - 제1항에 있어서,
상기 타 전자 장치에 대한 정보는,
상기 타 전자 장치의 인터넷 연결 상태에 대한 정보, 상기 타 전자 장치의 전원 상태에 대한 정보, 상기 타 전자 장치의 메모리에 대한 정보, 상기 타 전자 장치와 사용자와의 거리에 대한 정보, 상기 타 전자 장치의 음성 인식 기능에 대한 정보 중 적어도 하나를 포함하는 전자 장치. - 제1항에 있어서,
상기 프로세서는,
상기 적어도 하나의 타 전자 장치 각각으로부터 수신된 상기 사용자의 음성 데이터를 외부 서버에 전송하도록 상기 통신 인터페이스를 제어하고,
상기 통신 인터페이스를 통해 상기 외부 서버로부터 상기 사용자의 음성 데이터에 대한 응답 및 상기 사용자의 음성 데이터에 대응되는 제어 명령 중 적어도 하나를 수신하는 전자 장치. - 제6항에 있어서,
상기 프로세서는,
상기 사용자의 위치를 바탕으로 상기 디바이스 그룹에 포함된 장치들 중 상기 사용자의 음성 데이터에 대한 응답을 출력할 장치를 결정하고,
상기 결정된 장치로 상기 사용자의 음성 데이터에 대한 응답을 전송하는 전자 장치. - 제1항에 있어서,
상기 프로세서는,
상기 적어도 하나의 타 전자 장치 각각으로부터 수신된 상기 사용자의 음성 데이터를 바탕으로 상기 사용자의 음성 데이터에 대한 응답 및 상기 사용자의 음성 데이터에 대응되는 제어 명령 중 적어도 하나를 결정하는 전자 장치. - 제1항에 있어서,
상기 프로세서는,
상기 적어도 하나의 타 전자 장치 중 하나가 허브 장치로 결정되면, 허브 장치로 결정된 타 전자 장치로 상기 마이크를 통해 수신된 사용자의 음성 데이터를 전송하도록 상기 통신 인터페이스를 제어하는 전자 장치. - 제1항에 있어서,
상기 프로세서는,
상기 전자 장치 주위에 사용자가 감지되지 않으면, 상기 음성 인식을 종료하는 전자 장치. - 전자 장치의 제어 방법에 있어서,
마이크를 통해 수신된 사용자의 음성을 바탕으로 상기 전자 장치 주위에 사용자가 존재하는지 여부를 판단하는 단계;
상기 사용자가 상기 전자 장치 주위에 존재하면, 상기 전자 장치와 상기 전자 장치 주변에 존재하는 적어도 하나의 타 전자 장치를 포함하는 디바이스 그룹을 결정하는 단계;
상기 적어도 하나의 타 전자 장치 각각으로부터 수신한 상기 타 전자 장치에 대한 정보를 바탕으로 상기 디바이스 그룹 중 하나의 장치를 음성 인식을 수행하기 위한 허브 장치로 결정하는 단계;
상기 전자 장치가 허브 장치로 결정되면, 상기 적어도 하나의 타 전자 장치 각각으로부터 상기 사용자의 음성 데이터를 수신하여 음성 인식을 수행하는 단계;를 포함하는 제어 방법. - 제11항에 있어서,
상기 판단하는 단계는,
상기 사용자의 음성, 상기 전자 장치의 사용 정보, 상기 전자 장치의 사용 통계 정보, 상기 사용자의 움직임 정보 중 적어도 하나를 이용하여 상기 전자 장치 주위에 사용자가 존재하는지 여부를 판단하는 제어 방법. - 제11항에 있어서,
상기 디바이스 그룹을 결정하는 단계는,
상기 사용자가 상기 전자 장치 주위에 존재하면, 복수의 타 전자 장치로부터 상기 사용자의 음성에 대한 정보를 수신하는 단계;
상기 복수의 타 전자 장치 중 임계값 이상의 크기를 가지는 상기 사용자의 음성을 감지한 상기 적어도 하나의 타 전자 장치를 결정하는 단계; 및
상기 결정된 적어도 하나의 타 전자 장치를 포함하는 디바이스 그룹을 생성하는 단계;를 포함하는 제어 방법. - 제11항에 있어서,
상기 디바이스 그룹을 결정하는 단계는,
상기 사용자가 상기 전자 장치 주위에 존재하면, 상기 전자 장치의 위치를 바탕으로 상기 적어도 하나의 타 전자 장치를 결정하는 단계; 및
상기 결정된 적어도 하나의 타 전자 장치를 포함하는 디바이스 그룹을 결정하는 단계;를 포함하는 제어 방법. - 제11항에 있어서,
상기 타 전자 장치에 대한 정보는,
상기 타 전자 장치의 인터넷 연결 상태에 대한 정보, 상기 타 전자 장치의 전원 상태에 대한 정보, 상기 타 전자 장치의 메모리에 대한 정보, 상기 타 전자 장치와 사용자와의 거리에 대한 정보, 상기 타 전자 장치의 음성 인식 기능에 대한 정보 중 적어도 하나를 포함하는 제어 방법. - 제11항에 있어서,
상기 수행하는 단계는,
상기 적어도 하나의 타 전자 장치 각각으로부터 수신된 상기 사용자의 음성 데이터를 외부 서버에 전송하는 단계; 및
상기 외부 서버로부터 상기 사용자의 음성 데이터에 대한 응답 및 상기 사용자의 음성 데이터에 대응되는 제어 명령 중 적어도 하나를 수신하는 단계;를 포함하는 제어 방법. - 제16항에 있어서,
상기 사용자의 위치를 바탕으로 상기 디바이스 그룹에 포함된 장치들 중 상기 사용자의 음성 데이터에 대한 응답을 출력할 장치를 결정하는 단계; 및
상기 결정된 장치로 상기 사용자의 음성 데이터에 대한 응답을 전송하는 단계;를 포함하는 제어 방법. - 제11항에 있어서,
상기 적어도 하나의 타 전자 장치 각각으로부터 수신된 상기 사용자의 음성 데이터를 바탕으로 상기 사용자의 음성 데이터에 대한 응답 및 상기 사용자의 음성 데이터에 대응되는 제어 명령 중 적어도 하나를 결정하는 단계;를 포함하는 제어 방법. - 제11항에 있어서,
상기 적어도 하나의 타 전자 장치 중 하나가 허브 장치로 결정되면, 허브 장치로 결정된 타 전자 장치로 상기 마이크를 통해 수신된 사용자의 음성 데이터를 전송하는 단계를 포함하는 제어 방법. - 제11항에 있어서,
상기 전자 장치 주위에 사용자가 감지되지 않으면, 상기 음성 인식을 종료하는 단계;를 포함하는 제어 방법.
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020180163377A KR20200074690A (ko) | 2018-12-17 | 2018-12-17 | 전자 장치 및 이의 제어 방법 |
| PCT/KR2019/017832 WO2020130549A1 (en) | 2018-12-17 | 2019-12-16 | Electronic device and method for controlling electronic device |
| US16/715,903 US11367443B2 (en) | 2018-12-17 | 2019-12-16 | Electronic device and method for controlling electronic device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020180163377A KR20200074690A (ko) | 2018-12-17 | 2018-12-17 | 전자 장치 및 이의 제어 방법 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20200074690A true KR20200074690A (ko) | 2020-06-25 |
Family
ID=71072854
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020180163377A Pending KR20200074690A (ko) | 2018-12-17 | 2018-12-17 | 전자 장치 및 이의 제어 방법 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US11367443B2 (ko) |
| KR (1) | KR20200074690A (ko) |
| WO (1) | WO2020130549A1 (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025005553A1 (ko) * | 2023-06-27 | 2025-01-02 | 삼성전자주식회사 | 음성 신호 처리 방법 및 상기 방법을 수행하는 전자 장치 |
Families Citing this family (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20200074690A (ko) * | 2018-12-17 | 2020-06-25 | 삼성전자주식회사 | 전자 장치 및 이의 제어 방법 |
| EP3980992B1 (en) * | 2019-11-01 | 2025-06-25 | Samsung Electronics Co., Ltd. | Hub device, multi-device system including the hub device and plurality of devices, and operating method of the hub device and multi-device system |
| JP7584942B2 (ja) * | 2020-08-07 | 2024-11-18 | 株式会社東芝 | 入力支援システム、入力支援方法およびプログラム |
| US11751035B2 (en) * | 2020-11-25 | 2023-09-05 | Continental Automotive Systems, Inc. | Exterior speech recognition calling for emergency services |
| KR102888858B1 (ko) | 2020-12-23 | 2025-11-21 | 삼성전자주식회사 | 전자 장치 및 전자 장치에서 외부 장치들을 공간별로 그룹핑 하는 방법 |
| KR102917737B1 (ko) | 2021-01-07 | 2026-01-26 | 삼성전자주식회사 | 전자 장치 및 전자 장치에서 사용자 발화 처리 방법 |
| CN115079810B (zh) * | 2021-03-10 | 2025-01-28 | Oppo广东移动通信有限公司 | 信息处理方法与装置、主控设备和受控设备 |
| US12406671B2 (en) | 2021-10-27 | 2025-09-02 | Samsung Electronics Co., Ltd. | Method of identifying target device based on reception of utterance and electronic device therefor |
| CN117666370A (zh) * | 2022-08-29 | 2024-03-08 | 华为技术有限公司 | 一种智能设备控制方法及电子设备 |
| CN116665665A (zh) * | 2023-04-25 | 2023-08-29 | 中国第一汽车股份有限公司 | 车辆语音控制方法、装置、电子设备、存储介质及车辆 |
Family Cites Families (29)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20150309316A1 (en) * | 2011-04-06 | 2015-10-29 | Microsoft Technology Licensing, Llc | Ar glasses with predictive control of external device based on event input |
| US20170206064A1 (en) * | 2013-03-15 | 2017-07-20 | JIBO, Inc. | Persistent companion device configuration and deployment platform |
| US9396727B2 (en) * | 2013-07-10 | 2016-07-19 | GM Global Technology Operations LLC | Systems and methods for spoken dialog service arbitration |
| KR102146462B1 (ko) * | 2014-03-31 | 2020-08-20 | 삼성전자주식회사 | 음성 인식 시스템 및 방법 |
| US20150358777A1 (en) * | 2014-06-04 | 2015-12-10 | Qualcomm Incorporated | Generating a location profile of an internet of things device based on augmented location information associated with one or more nearby internet of things devices |
| US9812128B2 (en) * | 2014-10-09 | 2017-11-07 | Google Inc. | Device leadership negotiation among voice interface devices |
| US9318107B1 (en) * | 2014-10-09 | 2016-04-19 | Google Inc. | Hotword detection on multiple devices |
| US10420151B2 (en) | 2015-03-30 | 2019-09-17 | Afero, Inc. | Apparatus and method for intermediary device data collection |
| US9974015B2 (en) * | 2015-07-03 | 2018-05-15 | Afero, Inc. | Embedded internet of things (IOT) hub for integration with an appliance and associated systems and methods |
| US9948349B2 (en) * | 2015-07-17 | 2018-04-17 | Corning Optical Communications Wireless Ltd | IOT automation and data collection system |
| US10419877B2 (en) * | 2015-10-07 | 2019-09-17 | Samsung Electronics Co., Ltd. | Electronic apparatus and IoT device controlling method thereof |
| US20170127622A1 (en) * | 2015-11-10 | 2017-05-11 | Xu Hong | Smart control/iot system for agriculture environment control |
| US9729821B1 (en) * | 2016-03-31 | 2017-08-08 | Amazon Technologies, Inc. | Sensor fusion for location based device grouping |
| US9749583B1 (en) * | 2016-03-31 | 2017-08-29 | Amazon Technologies, Inc. | Location based device grouping with voice control |
| JP2017192091A (ja) | 2016-04-15 | 2017-10-19 | 泰安 盧 | 音声制御機能付きiotシステム及びその情報処理方法 |
| JP2019518985A (ja) * | 2016-05-13 | 2019-07-04 | ボーズ・コーポレーションBose Corporation | 分散したマイクロホンからの音声の処理 |
| US10237137B2 (en) * | 2016-09-12 | 2019-03-19 | Edward Linn Helvey | Remotely assigned, bandwidth-limiting internet access apparatus and method |
| US10304463B2 (en) * | 2016-10-03 | 2019-05-28 | Google Llc | Multi-user personalization at a voice interface device |
| US10283138B2 (en) * | 2016-10-03 | 2019-05-07 | Google Llc | Noise mitigation for a voice interface device |
| US10783883B2 (en) * | 2016-11-03 | 2020-09-22 | Google Llc | Focus session at a voice interface device |
| US10679608B2 (en) * | 2016-12-30 | 2020-06-09 | Google Llc | Conversation-aware proactive notifications for a voice interface device |
| US10290302B2 (en) * | 2016-12-30 | 2019-05-14 | Google Llc | Compact home assistant with combined acoustic waveguide and heat sink |
| US10672387B2 (en) * | 2017-01-11 | 2020-06-02 | Google Llc | Systems and methods for recognizing user speech |
| KR102880884B1 (ko) | 2017-01-13 | 2025-11-05 | 삼성전자주식회사 | 전자 장치 및 그의 동작 방법 |
| US10380852B2 (en) * | 2017-05-12 | 2019-08-13 | Google Llc | Systems, methods, and devices for activity monitoring via a home assistant |
| US10528228B2 (en) * | 2017-06-21 | 2020-01-07 | Microsoft Technology Licensing, Llc | Interaction with notifications across devices with a digital assistant |
| US11314215B2 (en) * | 2017-09-15 | 2022-04-26 | Kohler Co. | Apparatus controlling bathroom appliance lighting based on user identity |
| US10887125B2 (en) * | 2017-09-15 | 2021-01-05 | Kohler Co. | Bathroom speaker |
| KR20200074690A (ko) * | 2018-12-17 | 2020-06-25 | 삼성전자주식회사 | 전자 장치 및 이의 제어 방법 |
-
2018
- 2018-12-17 KR KR1020180163377A patent/KR20200074690A/ko active Pending
-
2019
- 2019-12-16 WO PCT/KR2019/017832 patent/WO2020130549A1/en not_active Ceased
- 2019-12-16 US US16/715,903 patent/US11367443B2/en active Active
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025005553A1 (ko) * | 2023-06-27 | 2025-01-02 | 삼성전자주식회사 | 음성 신호 처리 방법 및 상기 방법을 수행하는 전자 장치 |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2020130549A1 (en) | 2020-06-25 |
| US20200193994A1 (en) | 2020-06-18 |
| US11367443B2 (en) | 2022-06-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20200074690A (ko) | 전자 장치 및 이의 제어 방법 | |
| US11508378B2 (en) | Electronic device and method for controlling the same | |
| KR102688685B1 (ko) | 음성 인식 방법 및 음성 인식 장치 | |
| KR102718120B1 (ko) | 인공지능을 이용한 음성 대화 분석 방법 및 장치 | |
| US10839806B2 (en) | Voice processing method and electronic device supporting the same | |
| KR102371313B1 (ko) | 사용자 발화를 처리하는 전자 장치 및 그 전자 장치의 제어 방법 | |
| US10521723B2 (en) | Electronic apparatus, method of providing guide and non-transitory computer readable recording medium | |
| US11830502B2 (en) | Electronic device and method for controlling the same | |
| JP2019164345A (ja) | サウンドデータを処理するシステム、ユーザ端末及びシステムの制御方法 | |
| EP3707605B1 (en) | Electronic device and server for processing data received from electronic device | |
| US20190019509A1 (en) | Voice data processing method and electronic device for supporting the same | |
| KR102490916B1 (ko) | 전자 장치, 이의 제어 방법 및 비일시적인 컴퓨터 판독가능 기록매체 | |
| KR102925108B1 (ko) | 전자 장치 및 이의 제어 방법 | |
| KR20190096308A (ko) | 전자기기 | |
| US12008988B2 (en) | Electronic apparatus and controlling method thereof | |
| CN112384974B (zh) | 电子装置和用于提供或获得用于训练电子装置的数据的方法 | |
| KR102369309B1 (ko) | 파셜 랜딩 후 사용자 입력에 따른 동작을 수행하는 전자 장치 | |
| CN112567718A (zh) | 响应用户语音执行包括呼叫的任务的电子装置及操作方法 | |
| KR20200115695A (ko) | 전자 장치 및 이의 제어 방법 | |
| KR20210098250A (ko) | 전자 장치 및 이의 제어 방법 | |
| EP4131130A1 (en) | Method and device for providing interpretation situation information | |
| EP3839719B1 (en) | Computing device and method of operating the same | |
| KR20200057501A (ko) | 전자 장치 및 그의 와이파이 연결 방법 | |
| KR102402224B1 (ko) | 사용자 발화에 대응하는 태스크를 수행하는 전자 장치 | |
| KR20230018833A (ko) | 전자 장치 및 무선 오디오 장치의 연결 전환을 제공하는 방법 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application |
St.27 status event code: A-0-1-A10-A12-nap-PA0109 |
|
| PG1501 | Laying open of application |
St.27 status event code: A-1-1-Q10-Q12-nap-PG1501 |
|
| A201 | Request for examination | ||
| PA0201 | Request for examination |
St.27 status event code: A-1-2-D10-D11-exm-PA0201 |
|
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
St.27 status event code: A-1-2-D10-D21-exm-PE0902 |
|
| E13-X000 | Pre-grant limitation requested |
St.27 status event code: A-2-3-E10-E13-lim-X000 |
|
| P11-X000 | Amendment of application requested |
St.27 status event code: A-2-2-P10-P11-nap-X000 |
|
| E90F | Notification of reason for final refusal | ||
| PE0902 | Notice of grounds for rejection |
St.27 status event code: A-1-2-D10-D21-exm-PE0902 |
|
| P11 | Amendment of application requested |
Free format text: ST27 STATUS EVENT CODE: A-2-2-P10-P11-NAP-X000 (AS PROVIDED BY THE NATIONAL OFFICE) |
|
| P11-X000 | Amendment of application requested |
St.27 status event code: A-2-2-P10-P11-nap-X000 |
|
| D22 | Grant of ip right intended |
Free format text: ST27 STATUS EVENT CODE: A-1-2-D10-D22-EXM-PE0701 (AS PROVIDED BY THE NATIONAL OFFICE) |
|
| PE0701 | Decision of registration |
St.27 status event code: A-1-2-D10-D22-exm-PE0701 |