KR20220129366A - 음성 인식 시스템 및 그 제어 방법 - Google Patents
음성 인식 시스템 및 그 제어 방법 Download PDFInfo
- Publication number
- KR20220129366A KR20220129366A KR1020210034171A KR20210034171A KR20220129366A KR 20220129366 A KR20220129366 A KR 20220129366A KR 1020210034171 A KR1020210034171 A KR 1020210034171A KR 20210034171 A KR20210034171 A KR 20210034171A KR 20220129366 A KR20220129366 A KR 20220129366A
- Authority
- KR
- South Korea
- Prior art keywords
- voice recognition
- recognition system
- user
- intention
- function corresponding
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images










Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/02—Methods for producing synthetic speech; Speech synthesisers
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/02—Methods for producing synthetic speech; Speech synthesisers
- G10L13/033—Voice editing, e.g. manipulating the voice of the synthesiser
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/04—Segmentation; Word boundary detection
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/18—Speech classification or search using natural language modelling
- G10L15/1815—Semantic context, e.g. disambiguation of the recognition hypotheses based on word meaning
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/26—Speech to text systems
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/28—Constructional details of speech recognition systems
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/28—Constructional details of speech recognition systems
- G10L15/32—Multiple recognisers used in sequence or in parallel; Score combination systems therefor, e.g. voting systems
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
- G10L17/22—Interactive procedures; Man-machine interfaces
- G10L17/24—Interactive procedures; Man-machine interfaces the user being prompted to utter a password or a predefined phrase
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/02—Methods for producing synthetic speech; Speech synthesisers
- G10L13/027—Concept to speech synthesisers; Generation of natural phrases from machine-based concepts
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/18—Speech classification or search using natural language modelling
- G10L15/1822—Parsing for meaning understanding
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L2015/088—Word spotting
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G10L2015/223—Execution procedure of a spoken command
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G10L2015/226—Procedures used during a speech recognition process, e.g. man-machine dialogue using non-speech characteristics
- G10L2015/228—Procedures used during a speech recognition process, e.g. man-machine dialogue using non-speech characteristics of application context
Landscapes
- Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Computational Linguistics (AREA)
- Artificial Intelligence (AREA)
- Telephonic Communication Services (AREA)
- Selective Calling Equipment (AREA)
Abstract
Description
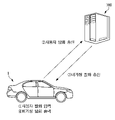
도 2는 일 실시예에 따른 음성 인식 시스템과 연결된 차량의 내부 구성을 나타낸 도면이다.
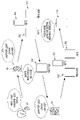
도 3은 일 실시예에 따른 음성 인식 시스템과 연결된 차량의 제어 블록도이다.
도 4는 일 실시예에 따른 음성 인식 시스템과 차량 사이에 주고 받는 신호를 간략하게 나타낸 도면이다.
도 5는 일 실시예에 따른 음성 인식 시스템에 저장되는 다른 음성 인식 시스템에 관한 정보의 예시를 나타낸 테이블이다.
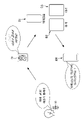
도 6 내지 도 10은 다른 음성 인식 시스템에 의해 사용자 의도에 대응되는 기능이 제공되는 과정의 예시를 나타낸 도면이다.
도 11은 일 실시예에 따른 음성 인식 시스템의 제어 방법에 관한 순서도이다.
도 12는 일 실시예에 따른 음성 인식 시스템의 제어 방법의 다른 순서도이다.
도 13은 일 실시예에 따른 음성 인식 시스템의 제어 방법에 있어서, 사용자 의도에 대응되는 기능을 대신 수행 할 다른 음성 인식 시스템을 결정하는 방법에 관한 순서도이다.
120: 음성 처리부
130: 제어부
140: 발화 생성부
100: 음성 인식 시스템
Claims (24)
- 사용자 발화에 포함된 사용자 의도를 판단하는 음성 처리부;
상기 사용자 의도에 대응되는 기능의 수행이 가능한지 여부를 판단하고, 상기 사용자 의도에 대응되는 기능의 수행이 불가능한 경우 적어도 하나의 다른 음성 인식 시스템에 상기 사용자 의도에 대응되는 기능의 수행을 요청하기 위한 발화 텍스트를 생성하는 제어부; 및
상기 발화 텍스트를 비가청 주파수 대역의 음성 신호로 변환하는 발화 생성부를 포함하는 음성 인식 시스템. - 제 1 항에 있어서,
상기 제어부는,
상기 적어도 하나의 다른 음성 인식 시스템을 미리 등록하고, 상기 사용자 의도에 대응되는 기능의 수행이 불가능한 경우 상기 등록된 적어도 하나의 다른 음성 인식 시스템에 상기 사용자 의도에 대응되는 기능의 수행을 요청하기 위한 발화 텍스트를 생성하는 음성 인식 시스템. - 제 1 항에 있어서,
상기 제어부는,
상기 사용자 의도에 대응되는 기능을 수행 할 다른 음성 인식 시스템을 결정하고, 상기 판단된 다른 음성 인식 시스템에 상기 사용자 의도에 대응되는 기능의 수행을 요청하기 위한 발화 텍스트를 생성하는 음성 인식 시스템. - 제 3 항에 있어서,
상기 제어부는,
복수의 다른 음성 인식 시스템 별로 수행 가능한 기능에 관한 정보를 미리 저장하고, 상기 저장된 정보에 기초하여 상기 사용자 의도에 대응되는 기능을 수행 할 다른 음성 인식 시스템을 판단하는 음성 인식 시스템. - 제 3 항에 있어서,
상기 제어부는,
상기 사용자 의도에 대응되는 기능을 다른 음성 인식 시스템이 수행한 이력이 있는 경우, 상기 이력을 가진 다른 음성 인식 시스템을 상기 사용자 의도에 대응되는 기능을 수행 할 다른 음성 인식 시스템으로 결정하는 음성 인식 시스템. - 제 1 항에 있어서,
상기 제어부는,
상기 음성 인식 시스템의 사용자 단말과 연결된 다른 음성 인식 시스템이 존재하는 경우, 상기 연결된 다른 음성 인식 시스템에 상기 사용자 의도에 대응되는 기능의 수행을 요청하기 위한 발화 텍스트를 생성하는 음성 인식 시스템. - 제 1 항에 있어서,
상기 제어부는,
상기 적어도 하나의 다른 음성 인식 시스템에 대응되는 웨이크업 워드를 포함하여 상기 발화 텍스트를 생성하는 음성 인식 시스템. - 제 7 항에 있어서,
상기 제어부는,
상기 사용자 발화와 상기 웨이크업 워드를 결합하여 상기 발화 텍스트를 생성하는 대화 시스템. - 제 8 항에 있어서,
상기 제어부는,
상기 적어도 하나의 다른 음성 인식 시스템에 대해 기능 별 샘플 문장을 저장하고, 상기 사용자 의도와 상기 샘플 문장에 기초하여 상기 발화 텍스트를 생성하는 음성 인식 시스템. - 제 1 항에 있어서,
사용자 단말로부터 상기 사용자 발화를 수신하고, 상기 비가청 주파수 대역의 오디오 신호를 상기 사용자 단말에 전송하는 통신부;를 더 포함하는 음성 인식 시스템. - 제 10 항에 있어서,
상기 제어부는,
상기 등록된 적어도 하나의 다른 음성 인식 시스템이 복수인 경우, 상기 복수의 다른 음성 인식 시스템에 각각 대응되는 복수의 비가청 주파수 대역의 오디오 신호를 상기 사용자 단말에 순차적으로 전송하는 음성 인식 시스템. - 제 11 항에 있어서,
상기 제어부는,
상기 사용자 단말을 통해 출력된 비가청 주파수 대역의 오디오 신호에 대한 응답이 수신되지 않은 경우, 다음 순서의 비가청 주파수 대역의 오디오 신호를 상기 사용자 단말에 전송하는 음성 인식 시스템. - 사용자 발화에 포함된 사용자 의도를 판단하고;
상기 사용자 의도에 대응되는 기능의 수행이 가능한지 여부를 판단하고;
상기 사용자 의도에 대응되는 기능의 수행이 불가능한 경우 다른 음성 인식 시스템에 상기 사용자 의도에 대응되는 기능의 수행을 요청하기 위한 발화 텍스트를 생성하고;
상기 발화 텍스트를 비가청 주파수 대역의 음성 신호로 변환하는 것;을 포함하는 음성 인식 시스템의 제어 방법. - 제 13 항에 있어서,
적어도 하나의 다른 음성 인식 시스템을 미리 등록하는 것;을 더 포함하고,
상기 발화 텍스트를 생성하는 것은,
상기 사용자 의도에 대응되는 기능의 수행이 불가능한 경우 상기 미리 등록된 적어도 하나의 다른 음성 인식 시스템에 상기 사용자 의도에 대응되는 기능의 수행을 요청하기 위한 발화 텍스트를 생성하는 것;을 포함하는 음성 인식 시스템의 제어 방법. - 제 13 항에 있어서,
상기 발화 텍스트를 생성하는 것은,
복수의 다른 음성 인식 시스템 중에서 상기 사용자 의도에 대응되는 기능을 수행 할 다른 음성 인식 시스템을 결정하고;
상기 결정된 다른 음성 인식 시스템에 상기 사용자 의도에 대응되는 기능의 수행을 요청하기 위한 발화 텍스트를 생성하는 것;을 포함하는 음성 인식 시스템의 제어 방법. - 제 15 항에 있어서,
상기 복수의 다른 음성 인식 시스템 별로 수행 가능한 기능에 관한 정보를 미리 저장하는 것;을 더 포함하고,
상기 발화 텍스트를 생성하는 것은,
상기 저장된 정보에 기초하여 상기 사용자 의도에 대응되는 기능을 수행 할 다른 음성 인식 시스템을 결정하는 것;을 포함하는 음성 인식 시스템의 제어 방법. - 제 15 항에 있어서,
상기 발화 텍스트를 생성하는 것은,
상기 사용자 의도에 대응되는 기능을 다른 음성 인식 시스템이 수행한 이력이 있는 경우, 상기 이력을 가진 다른 음성 인식 시스템을 상기 사용자 의도에 대응되는 기능을 수행 할 다른 음성 인식 시스템으로 결정하는 것;을 포함하는 음성 인식 시스템. - 제 13 항에 있어서,
상기 발화 텍스트를 생성하는 것은,
상기 음성 인식 시스템의 사용자 단말과 연결된 다른 음성 인식 시스템이 존재하는 경우, 상기 연결된 다른 음성 인식 시스템에 상기 사용자 의도에 대응되는 기능의 수행을 요청하기 위한 발화 텍스트를 생성하는 것;을 포함하는 음성 인식 시스템. - 제 13 항에 있어서,
상기 발화 텍스트를 생성하는 것은,
상기 다른 음성 인식 시스템에 대응되는 웨이크업 워드를 포함하여 상기 발화 텍스트를 생성하는 것;을 포함하는 음성 인식 시스템. - 제 19 항에 있어서,
상기 발화 텍스트를 생성하는 것은,
상기 사용자 발화와 상기 웨이크업 워드를 결합하여 상기 발화 텍스트를 생성하는 것;을 포함하는 대화 시스템. - 제 20 항에 있어서,
상기 다른 음성 인식 시스템에 대해 기능 별 샘플 문장을 저장하는 것;을 더 포함하고,
상기 발화 텍스트를 생성하는 것은,
상기 저장된 샘플 문장 중 상기 사용자 의도에 대응되는 기능에 대한 샘플 문장에 기초하여 상기 발화 텍스트를 생성하는 것;을 포함하는 음성 인식 시스템. - 제 14 항에 있어서,
사용자 단말로부터 상기 사용자 발화를 수신하고;
상기 비가청 주파수 대역의 오디오 신호를 상기 사용자 단말에 전송하는 것;을 더 포함하는 음성 인식 시스템. - 제 22 항에 있어서,
상기 사용자 단말에 전송하는 것은,
상기 등록된 적어도 하나의 다른 음성 인식 시스템이 복수인 경우, 상기 복수의 다른 음성 인식 시스템에 각각 대응되는 복수의 비가청 주파수 대역의 오디오 신호를 상기 사용자 단말에 순차적으로 전송하는 것;을 포함하는 음성 인식 시스템. - 제 23 항에 있어서,
상기 사용자 단말에 전송하는 것은,
상기 사용자 단말을 통해 출력된 비가청 주파수 대역의 오디오 신호에 대한 응답이 수신되지 않은 경우, 다음 순서의 비가청 주파수 대역의 오디오 신호를 상기 사용자 단말에 전송하는 것;을 포함하는 음성 인식 시스템.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020210034171A KR20220129366A (ko) | 2021-03-16 | 2021-03-16 | 음성 인식 시스템 및 그 제어 방법 |
| US17/539,943 US11955123B2 (en) | 2021-03-16 | 2021-12-01 | Speech recognition system and method of controlling the same |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020210034171A KR20220129366A (ko) | 2021-03-16 | 2021-03-16 | 음성 인식 시스템 및 그 제어 방법 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20220129366A true KR20220129366A (ko) | 2022-09-23 |
Family
ID=83283946
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020210034171A Pending KR20220129366A (ko) | 2021-03-16 | 2021-03-16 | 음성 인식 시스템 및 그 제어 방법 |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US11955123B2 (ko) |
| KR (1) | KR20220129366A (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024177220A1 (ko) * | 2023-02-23 | 2024-08-29 | 삼성전자주식회사 | 전자 장치 및 이의 제어 방법 |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20250048974A (ko) * | 2023-10-04 | 2025-04-11 | 현대자동차주식회사 | 차량 헤드 유닛 시스템에서 음성인식을 위한 장치 및 방법 |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20140089862A (ko) * | 2013-01-07 | 2014-07-16 | 삼성전자주식회사 | 디스플레이 장치 및 그의 제어 방법 |
| KR101560798B1 (ko) * | 2015-02-23 | 2015-10-16 | 성균관대학교산학협력단 | 비가청 주파수대역을 활용한 디바이스의 데이터 통신방법 |
| KR101755648B1 (ko) * | 2015-10-23 | 2017-07-10 | 도용남 | 비가청 주파수 대역을 이용한 데이터 송수신 시스템 및 방법 |
| KR102562227B1 (ko) * | 2018-06-12 | 2023-08-02 | 현대자동차주식회사 | 대화 시스템, 그를 가지는 차량 및 차량의 제어 방법 |
-
2021
- 2021-03-16 KR KR1020210034171A patent/KR20220129366A/ko active Pending
- 2021-12-01 US US17/539,943 patent/US11955123B2/en active Active
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024177220A1 (ko) * | 2023-02-23 | 2024-08-29 | 삼성전자주식회사 | 전자 장치 및 이의 제어 방법 |
Also Published As
| Publication number | Publication date |
|---|---|
| US11955123B2 (en) | 2024-04-09 |
| US20220301560A1 (en) | 2022-09-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20210358496A1 (en) | A voice assistant system for a vehicle cockpit system | |
| JP3479691B2 (ja) | 実時間作動での音声対話又は音声命令による1つ又は複数の機器の自動制御方法及びこの方法を実施する装置 | |
| KR20210103002A (ko) | 감정 정보 기반의 음성 합성 방법 및 장치 | |
| US12597419B2 (en) | Natural language processing apparatus and natural language processing method | |
| US11996099B2 (en) | Dialogue system, vehicle, and method of controlling dialogue system | |
| KR20230135396A (ko) | 대화 관리 방법, 사용자 단말 및 컴퓨터로 판독 가능한 기록 매체 | |
| KR20230146898A (ko) | 대화 처리 방법 및 대화 시스템 | |
| KR20220130952A (ko) | 이모지 생성 장치, 차량 및 이모지 생성 방법 | |
| KR20210098250A (ko) | 전자 장치 및 이의 제어 방법 | |
| US11955123B2 (en) | Speech recognition system and method of controlling the same | |
| US20210193142A1 (en) | Computing device and method of operating the same | |
| CN116580699A (zh) | 车辆及其控制方法 | |
| KR20240103748A (ko) | 챗봇 서비스 제공 방법 및 챗봇 서비스 제공 시스템 | |
| KR20230036843A (ko) | 발화 제안 방법 및 기록 매체 | |
| US20230238020A1 (en) | Speech recognition system and a method for providing a speech recognition service | |
| JP3846500B2 (ja) | 音声認識対話装置および音声認識対話処理方法 | |
| JP2020152298A (ja) | エージェント装置、エージェント装置の制御方法、およびプログラム | |
| KR20230142243A (ko) | 대화 처리 방법, 사용자 단말 및 대화 시스템 | |
| US12499877B2 (en) | Dialogue system and method for controlling the same | |
| US12437759B2 (en) | Dialogue management method, dialogue management system, and computer-readable recording medium | |
| KR20230153854A (ko) | 사용자 단말, 사용자 단말의 제어 방법 및 대화 관리 방법 | |
| EP4428854A1 (en) | Method for providing voice synthesis service and system therefor | |
| KR20250053414A (ko) | 동승자 프로필을 참조하여 음성 명령에 대한 응답 액션을 수행하기 위한 방법 및 장치 | |
| KR20250053418A (ko) | 차량의 음성 명령어를 권유하기 위한 방법 및 장치 | |
| KR20230131004A (ko) | 사용자 단말, 대화 관리 시스템, 사용자 단말의 제어 방법 및 대화 관리 방법 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application |
St.27 status event code: A-0-1-A10-A12-nap-PA0109 |
|
| PN2301 | Change of applicant |
St.27 status event code: A-3-3-R10-R13-asn-PN2301 St.27 status event code: A-3-3-R10-R11-asn-PN2301 |
|
| PG1501 | Laying open of application |
St.27 status event code: A-1-1-Q10-Q12-nap-PG1501 |
|
| A201 | Request for examination | ||
| PA0201 | Request for examination |
St.27 status event code: A-1-2-D10-D11-exm-PA0201 |
|
| R17-X000 | Change to representative recorded |
St.27 status event code: A-3-3-R10-R17-oth-X000 |
|
| D13 | Search requested |
Free format text: ST27 STATUS EVENT CODE: A-1-2-D10-D13-SRH-X000 (AS PROVIDED BY THE NATIONAL OFFICE) |
|
| D13-X000 | Search requested |
St.27 status event code: A-1-2-D10-D13-srh-X000 |