KR20240077363A - 전자 장치 및 그 제어 방법 - Google Patents
전자 장치 및 그 제어 방법 Download PDFInfo
- Publication number
- KR20240077363A KR20240077363A KR1020230005910A KR20230005910A KR20240077363A KR 20240077363 A KR20240077363 A KR 20240077363A KR 1020230005910 A KR1020230005910 A KR 1020230005910A KR 20230005910 A KR20230005910 A KR 20230005910A KR 20240077363 A KR20240077363 A KR 20240077363A
- Authority
- KR
- South Korea
- Prior art keywords
- artificial intelligence
- intelligence model
- resolution image
- loss
- electronic device
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T3/00—Geometric image transformations in the plane of the image
- G06T3/40—Scaling of whole images or parts thereof, e.g. expanding or contracting
- G06T3/4053—Scaling of whole images or parts thereof, e.g. expanding or contracting based on super-resolution, i.e. the output image resolution being higher than the sensor resolution
- G06T3/4076—Scaling of whole images or parts thereof, e.g. expanding or contracting based on super-resolution, i.e. the output image resolution being higher than the sensor resolution using the original low-resolution images to iteratively correct the high-resolution images
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T3/00—Geometric image transformations in the plane of the image
- G06T3/40—Scaling of whole images or parts thereof, e.g. expanding or contracting
- G06T3/4046—Scaling of whole images or parts thereof, e.g. expanding or contracting using neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/10—Segmentation; Edge detection
- G06T7/11—Region-based segmentation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20081—Training; Learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20084—Artificial neural networks [ANN]
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- General Health & Medical Sciences (AREA)
- General Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Computational Linguistics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Image Analysis (AREA)
Abstract
전자 장치가 개시된다. 전자 장치는, 디스플레이, 메모리 및 하나 이상의 프로세서를 포함한다. 하나 이상의 프로세서는, 제1 인공 지능 모델을 이용하여 임계 해상도 미만의 저해상도 이미지로부터 임계 해상도 이상의 고해상도 이미지를 획득하고 획득된 고해상도 이미지를 출력하도록 디스플레이를 제어한다. 제1 인공 지능 모델은, 상이한 타입의 복수의 손실(loss) 값의 가중 합으로 정의되며 연속적으로 변경되는 오브젝티브(objective) 데이터를 학습하도록 구현되며, 제2 인공 지능 모델은, 저해상도 이미지에 기초하여 복수의 손실 값에 대응되는 가중치 조건을 식별하여 제1 인공 지능 모델로 제공하도록 구현된다.
Description
본 개시는 전자 장치 및 그 제어 방법에 관한 것으로, 더욱 상세하게는 초해상화 처리를 수행하는 전자 장치 및 그 제어 방법에 관한 것이다.
전자 기술의 발달에 힘입어 다양한 유형의 전자 기기가 개발 및 보급되고 있다. 특히, 가정, 사무실, 공공 장소 등 다양한 장소에서 이용되는 디스플레이 장치는 최근 수년 간 지속적으로 발전하고 있다.
최근에는 고해상도 영상 서비스에 대한 요구가 크게 증가하고 있다. 이러한 요구로 인해 super resolution, style transfer 등 deep learning 기반 기술이 영상 처리에 이용되고 있다.
Super Resolution은 저해상도의 입력 영상을 일련의 미디어 처리를 통해 고해상도의 영상으로 복원하는 기술이다. 예를 들어, deep learning 기반의 복수의 레이어를 포함하는 CNN 모델을 이용하여 저해상도의 입력 영상을 가로/세로 방향으로 스케일링하여 고해상도의 영상으로 복원할 수 있다.
일 실시 예에 따른 전자 장치는, 디스플레이, 제1 인공 지능 모델 및 제2 인공 지능 모델에 대한 정보가 저장된 메모리 및, 상기 디스플레이 및 상기 메모리와 연결되어 상기 전자 장치를 제어하는 하나 이상의 프로세서를 포함한다. 상기 하나 이상의 프로세서는,상기 제1 인공 지능 모델을 이용하여 임계 해상도 미만의 저해상도 이미지로부터 상기 임계 해상도 이상의 고해상도 이미지를 획득하고 상기 획득된 고해상도 이미지를 출력하도록 상기 디스플레이를 제어한다. 상기 제1 인공 지능 모델은, 상이한 타입의 복수의 손실(loss) 값의 가중 합으로 정의되며 연속적으로 변경되는 오브젝티브(objective) 데이터를 학습하도록 구현되며, 상기 제2 인공 지능 모델은, 상기 저해상도 이미지에 기초하여 상기 복수의 손실 값에 대응되는 가중치 조건을 식별하여 상기 제1 인공 지능 모델로 제공하도록 구현된다.
일 예에 따르면, 상기 제2 인공 지능 모델은, 상기 제2 인공 지능 모델의 출력 가중치 조건 및 타겟 가중치 조건을 포함하는 제1 정보 및, 상기 제1 인공 지능 모델의 출력 이미지 및 상기 오브젝티브 데이터를 포함하는 제2 정보에 기초하여 학습될 수 있다.
일 예에 따르면, 상기 제1 정보는, 트레이닝 샘플의 영역 데이터에 대응되는 상이한 타입의 복수의 손실 값 각각의 출력 가중치 조건 및 타겟 가중치 조건 간 차이 값을 포함하며, 상기 제2 정보는, 트레이닝 샘플의 영역 데이터 및 연속적으로 변경되는 오브젝티브 데이터 간 상이한 타입의 복수의 손실 값을 포함할 수 있다.
일 예에 따르면, 상기 제2 정보는, 상기 제1 인공 지능 모델의 출력 이미지 및 타겟 고해상도 이미지 간 차이를 나타내는 픽셀 단위 오브젝티브 맵 손실, 재구성 손실 및 인지 손실을 포함할 수 있다.
일 예에 따르면, 상기 제2 인공 지능 모델은, 상기 저해상도 이미지에 대응되는 크기의 가중치 조건 맵을 예측하여 상기 제1 인공 지능 모델로 제공하며, 상기 제1 인공 지능 모델은, 복수의 SFT(spatial feature transform) 레이어를 포함하는 SR(Super Resolution) Branch 및 상기 가중치 조건 맵에 기초하여 상기 복수의 SFT 레이어에 대응되는 조건을 제공하는 Condition Branch로 구현될 수 있다.
일 예에 따르면, 상기 제1 인공 지능 모델은, 상기 저해상도 이미지에 포함된 복수의 영역 각각에 대한 오브젝티브(objective) 데이터의 최적 조합에 기초하여 상기 고해상도 이미지를 획득하며, 임의로 변경되는 조건 t에 기초하여 획득되는 임의의 가중치 조건 맵에 기초하여 획득되는 복수의 오브젝티브(objective) 데이터를 학습하도록 구현될 수 있다.
일 예에 따르면, 상기 하나 이상의 프로세서는, 상기 제2 인공 지능 모델을 이용하여 상기 저해상도 이미지에 포함된 상기 복수의 영역 각각에 대응되는 복수의 손실 값에 대한 가중치 조건 맵을 획득하고, 상기 제1 인공 지능 모델을 이용하여 상기 획득된 가중치 조건 맵에 대응되는 복수의 손실 값의 가중 합에 기초하여 상기 고해상도 이미지를 획득할 수 있다.
일 예에 따르면, 상기 하나 이상의 프로세서는, 상기 제2 인공 지능 모델을 이용하여 상기 조건 t를 제1 값에서 제2 값으로 단계적으로 변경하면서 각 픽셀에 대해 LPIPS(Learned Perceptual Image Patch Similarity)가 가장 낮은 t를 선택하여 타겟 가중치 조건 맵을 획득하며, 상기 제2 인공 지능 모델은, 상기 임의의 가중치 조건 맵 및 상기 타겟 가중치 조건 맵의 차이 값에 기초하여 학습될 수 있다.
일 예에 따르면, 상기 상이한 타입의 복수의 손실 값은, 재구성 손실(reconstruction loss), 적대 손실(adversarial loss), 인지 손실(perceptual loss) 또는 왜곡 손실(distortion loss) 중 적어도 하나에 따른 손실 값을 포함할 수 있다.
일 실시 예에 따른 전자 장치의 제어 방법은, 제1 인공 지능 모델을 이용하여 임계 해상도 미만의 저해상도 이미지로부터 상기 임계 해상도 이상의 고해상도 이미지를 획득하는 단계 및 상기 획득된 고해상도 이미지를 출력하는 단계를 포함한다. 상기 제1 인공 지능 모델은, 상이한 타입의 복수의 손실(loss) 값의 가중 합으로 정의되며 연속적으로 변경되는 오브젝티브(objective) 데이터를 학습하도록 구현되며, 상기 제2 인공 지능 모델은, 상기 저해상도 이미지에 기초하여 상기 복수의 손실 값에 대응되는 가중치 조건을 식별하여 상기 제1 인공 지능 모델로 제공하도록 구현된다.
일 실시 예에 따른 전자 장치의 프로세서에 의해 실행되는 경우 상기 전자 장치가 동작을 수행하도록 하는 컴퓨터 명령을 저장하는 비일시적 컴퓨터 판독 가능 매체에 있어서, 상기 동작은, 제1 인공 지능 모델을 이용하여 임계 해상도 미만의 저해상도 이미지로부터 상기 임계 해상도 이상의 고해상도 이미지를 획득하는 단계 및 상기 획득된 고해상도 이미지를 출력하는 단계를 포함한다. 상기 제1 인공 지능 모델은, 상이한 타입의 복수의 손실(loss) 값의 가중 합으로 정의되며 연속적으로 변경되는 오브젝티브(objective) 데이터를 학습하도록 구현되며, 상기 제2 인공 지능 모델은, 상기 저해상도 이미지에 기초하여 상기 복수의 손실 값에 대응되는 가중치 조건을 식별하여 상기 제1 인공 지능 모델로 제공하도록 구현된다.
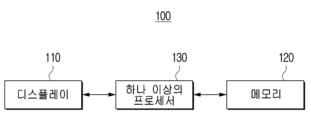
도 1은 본 개시의 일 실시 예에 따른 전자 장치의 구현 예를 설명하기 위한 도면이다.
도 2a는 일 실시 예에 따른 전자 장치의 구성을 나타내는 블럭도이다.
도 2b는 일 실시 예에 따른 디스플레이 장치의 구성을 구체적으로 나타내는 블럭도이다.
도 3은 일 실시 예에 따른 SISR Framework의 개요를 나타내는 도면이다.
도 4a 내지 도 4c는 일 실시 예에 따른 제1 인공 지능 모델의 구현 예를 설명하기 위한 도면들이다.
도 5a 내지 도 5c는 일 실시 예에 따른 제1 인공 지능 모델 및 제2 인공 지능 모델의 구현 예를 설명하기 위한 도면들이다.
도 6a 및 도 6b는 일 실시 예에 따른 오브젝티브 셋트 식별 방법을 설명하기 위한 도면들이다.
도 7은 일 실시 예에 따른 최적 오브젝티브 선택 방법을 설명하기 위한 도면이다.
도 8a 내지 도 8d, 도 9, 도 10a 및 도 10b, 도 11은 일 실시 예에 따른 objective trajectory를 설명하기 위한 도면들이다.
도 12는 일 실시 예에 따른 효과를 설명하기 위한 도면이다.
도 2a는 일 실시 예에 따른 전자 장치의 구성을 나타내는 블럭도이다.
도 2b는 일 실시 예에 따른 디스플레이 장치의 구성을 구체적으로 나타내는 블럭도이다.
도 3은 일 실시 예에 따른 SISR Framework의 개요를 나타내는 도면이다.
도 4a 내지 도 4c는 일 실시 예에 따른 제1 인공 지능 모델의 구현 예를 설명하기 위한 도면들이다.
도 5a 내지 도 5c는 일 실시 예에 따른 제1 인공 지능 모델 및 제2 인공 지능 모델의 구현 예를 설명하기 위한 도면들이다.
도 6a 및 도 6b는 일 실시 예에 따른 오브젝티브 셋트 식별 방법을 설명하기 위한 도면들이다.
도 7은 일 실시 예에 따른 최적 오브젝티브 선택 방법을 설명하기 위한 도면이다.
도 8a 내지 도 8d, 도 9, 도 10a 및 도 10b, 도 11은 일 실시 예에 따른 objective trajectory를 설명하기 위한 도면들이다.
도 12는 일 실시 예에 따른 효과를 설명하기 위한 도면이다.
본 명세서에서 사용되는 용어에 대해 간략히 설명하고, 본 개시에 대해 구체적으로 설명하기로 한다.
본 개시의 실시 예에서 사용되는 용어는 본 개시에서의 기능을 고려하면서 가능한 현재 널리 사용되는 일반적인 용어들을 선택하였으나, 이는 당 분야에 종사하는 기술자의 의도 또는 판례, 새로운 기술의 출현 등에 따라 달라질 수 있다. 또한, 특정한 경우는 출원인이 임의로 선정한 용어도 있으며, 이 경우 해당되는 개시의 설명 부분에서 상세히 그 의미를 기재할 것이다. 따라서 본 개시에서 사용되는 용어는 단순한 용어의 명칭이 아닌, 그 용어가 가지는 의미와 본 개시의 전반에 걸친 내용을 토대로 정의되어야 한다.
본 명세서에서, "가진다," "가질 수 있다," "포함한다," 또는 "포함할 수 있다" 등의 표현은 해당 특징(예: 수치, 기능, 동작, 또는 부품 등의 구성요소)의 존재를 가리키며, 추가적인 특징의 존재를 배제하지 않는다.
본 개시에서, "A 또는 B," "A 또는/및 B 중 적어도 하나," 또는 "A 또는/및 B 중 하나 또는 그 이상"등의 표현은 함께 나열된 항목들의 모든 가능한 조합을 포함할 수 있다. 예를 들면, "A 또는 B," "A 및 B 중 적어도 하나," 또는 "A 또는 B 중 적어도 하나"는, (1) 적어도 하나의 A를 포함, (2) 적어도 하나의 B를 포함, 또는 (3) 적어도 하나의 A 및 적어도 하나의 B 모두를 포함하는 경우를 모두 지칭할 수 있다.
본 명세서에서 사용된 "제1," "제2," "첫째," 또는 "둘째,"등의 표현들은 다양한 구성요소들을, 순서 및/또는 중요도에 상관없이 수식할 수 있고, 한 구성요소를 다른 구성요소와 구분하기 위해 사용될 뿐 해당 구성요소들을 한정하지 않는다.
어떤 구성요소(예: 제1 구성요소)가 다른 구성요소(예: 제2 구성요소)에 "(기능적으로 또는 통신적으로) 연결되어(operatively or communicatively) coupled with/to)" 있다거나 "접속되어(connected to)" 있다고 언급된 때에는, 어떤 구성요소가 다른 구성요소에 직접적으로 연결되거나, 다른 구성요소(예: 제3 구성요소)를 통하여 연결될 수 있다고 이해되어야 할 것이다.
본 개시에서 사용된 표현 "~하도록 구성된(또는 설정된)(configured to)"은 상황에 따라, 예를 들면, "~에 적합한(suitable for)," "~하는 능력을 가지는(having the capacity to)," "~하도록 설계된(designed to)," "~하도록 변경된(adapted to)," "~하도록 만들어진(made to)," 또는 "~를 할 수 있는(capable of)"과 바꾸어 사용될 수 있다. 용어 "~하도록 구성된(또는 설정된)"은 하드웨어적으로 "특별히 설계된(specifically designed to)" 것만을 반드시 의미하지 않을 수 있다.
어떤 상황에서는, "~하도록 구성된 장치"라는 표현은, 그 장치가 다른 장치 또는 부품들과 함께 "~할 수 있는" 것을 의미할 수 있다. 예를 들면, 문구 "A, B, 및 C를 수행하도록 구성된(또는 설정된) 프로세서"는 해당 동작을 수행하기 위한 전용 프로세서(예: 임베디드 프로세서), 또는 메모리 장치에 저장된 하나 이상의 소프트웨어 프로그램들을 실행함으로써, 해당 동작들을 수행할 수 있는 범용 프로세서(generic-purpose processor)(예: CPU 또는 application processor)를 의미할 수 있다.
단수의 표현은 문맥상 명백하게 다르게 뜻하지 않는 한, 복수의 표현을 포함한다. 본 출원에서, "포함하다" 또는 "구성되다" 등의 용어는 명세서상에 기재된 특징, 숫자, 단계, 동작, 구성요소, 부품 또는 이들을 조합한 것이 존재함을 지정하려는 것이지, 하나 또는 그 이상의 다른 특징들이나 숫자, 단계, 동작, 구성요소, 부품 또는 이들을 조합한 것들의 존재 또는 부가 가능성을 미리 배제하지 않는 것으로 이해되어야 한다.
실시 예에 있어서 "모듈" 혹은 "부"는 적어도 하나의 기능이나 동작을 수행하며, 하드웨어 또는 소프트웨어로 구현되거나 하드웨어와 소프트웨어의 결합으로 구현될 수 있다. 또한, 복수의 "모듈" 혹은 복수의 "부"는 특정한 하드웨어로 구현될 필요가 있는 "모듈" 혹은 "부"를 제외하고는 적어도 하나의 모듈로 일체화되어 적어도 하나의 프로세서(미도시)로 구현될 수 있다.
한편, 도면에서의 다양한 요소와 영역은 개략적으로 그려진 것이다. 따라서, 본 발명의 기술적 사상은 첨부한 도면에 그려진 상대적인 크기나 간격에 의해 제한되지 않는다.
이하 첨부된 도면들을 참조하여 본 개시의 일 실시 예를 보다 상세하게 설명한다.
도 1은 본 개시의 일 실시 예에 따른 전자 장치의 구현 예를 설명하기 위한 도면이다.
전자 장치(100)는 도 1에 도시된 바와 같이 TV 또는 set-top box 로 구현될 수 있으나, 이에 한정되는 것은 아니며 스마트 폰, 태블릿 PC, 노트북 PC, HMD(Head mounted Display), NED(Near Eye Display), LFD(large format display), Digital Signage(디지털 간판), DID(Digital Information Display), 비디오 월(video wall), 프로젝터 디스플레이, 카메라, 캠코더, 프린터 등과 같이 영상 처리 및/또는 디스플레이 기능을 갖춘 장치라면 한정되지 않고 적용 가능하다.
전자 장치(100)는 다양한 압축 영상 또는 다양한 해상도의 영상을 수신할 수 있다. 예를 들어, 전자 장치(100)는 MPEG(Moving Picture Experts Group)(예를 들어, MP2, MP4, MP7 등), JPEG(joint photographic coding experts group), AVC(Advanced Video Coding), H.264, H.265, HEVC(High Efficiency Video Codec) 등으로 압축된 형태로 영상을 수신할 수 있다. 또는 전자 장치(100)는 SD(Standard Definition), HD(High Definition), Full HD, Ultra HD 영상 중 어느 하나의 영상을 수신할 수 있다.
일 실시 예에 따라 전자 장치(100)가 UHD 이상의 해상도 영상을 표시할 수 있는 TV로 구현되더라도, UHD 이상의 해상도 컨텐츠 자체가 부족하기 때문에 SD(Standard Definition), HD(High Definition), Full HD 등의 영상(이하 저해상도 영상이라 함)이 입력되는 경우가 많다. 이 경우, 전자 장치(100)는 입력된 저해상도 영상을 SR(Super Resolution) 처리를 통해 UHD 이상의 해상도 영상(이하 고해상도 영상이라 함)으로 변환하여 제공할 수 있다. 여기서, SR 처리란 해상도가 낮은 저해상도(Low Resolution) 영상을 일련의 미디어 처리를 통해 고해상도(High Resolution)의 영상으로 변환하는 처리를 의미한다.
일 예에 따라 SR 처리는 크게 하나의 이미지를 이용하는지, 여러 이미지를 이용하는지에 따라 Single Image Super Resolution(이하, SISR), Multi Image Super Resolution(이하, MISR)로 구분될 수 있다.
Super Resolution, 예를 들어 SISR은 저해상도 이미지를 고해상도로 복원을 해야 하는데, 복원해야 하는 타겟인 고해상도의 이미지가 정답이 여러 개 존재할 수 있다. 정확히 말하면 유일한 정답이 존재하지 않는, 정의할 수 없는 문제를 의미하며, 이러한 경우를 Regular Inverse Problem 혹은 Ill-Posed Problem이라 한다.
이러한 어려움을 타개하기 위해 고해상도의 타겟 이미지를 Ground Truth(GT)로 정의하고, 이를 Low Resolution image로 만들기 위해 blurring, down sampling, noise 주입 등을 거쳐 저해상도 이미지로 만들 수 있다. 이 후 모종의 방법을 통해 저해상도 이미지를 GT로 복원시키도록 모델을 학습시킬 수 있다.
픽셀 단위 왜곡 지향 손실(L1 및 L2)은 초기 연구에서 널리 사용되어 높은 PSNR(신호 대 잡음비)을 얻는 데 도움이 되었지만, 이러한 손실은 모델이 가능한 HR 솔루션의 평균을 생성하도록 하며 일반적으로 흐릿하고 시각적으로 좋지 않은 문제가 있다.
이후 이러한 문제를 극복하기 위해 인지 손실, 생성적 적대 손실과 같은 지각 지향 손실을 도입하여 미세한 디테일의 사실적인 이미지를 생성하였지만, 이러한 인지 지향적 손실은 다양한 SR 방법에 사용되지만 부자연스러운 세부 사항 및 구조적 왜곡과 같은 바람직하지 않은 부작용도 가져올 수 있다.
이에 따라 이하에서는, 부작용을 완화하고 재구성의 인지 정확도를 향상시키기 위해 특별히 설계된 손실을 사용하고 손실에 대응되는 가중치 조건을 학습하여 최적의 손실 조합을 통해 SR 처리를 수행하는 다양한 실시 예에 대해 설명하도록 한다.
도 2a는 일 실시 예에 따른 전자 장치의 구성을 나타내는 블럭도이다.
도 2a에 따르면 전자 장치(100)은 디스플레이(110), 메모리(120) 및 하나 이상의 프로세서(130)를 포함한다.
디스플레이(110)는 자발광 소자를 포함하는 디스플레이 또는, 비자발광 소자 및 백라이트를 포함하는 디스플레이로 구현될 수 있다. 예를 들어, LCD(Liquid Crystal Display), OLED(Organic Light Emitting Diodes) 디스플레이, LED(Light Emitting Diodes), 마이크로 LED(micro LED), Mini LED, PDP(Plasma Display Panel), QD(Quantum dot) 디스플레이, QLED(Quantum dot light-emitting diodes) 등과 같은 다양한 형태의 디스플레이로 구현될 수 있다. 디스플레이(110) 내에는 a-si TFT, LTPS(low temperature poly silicon) TFT, OTFT(organic TFT) 등과 같은 형태로 구현될 수 있는 구동 회로, 백라이트 유닛 등도 함께 포함될 수 있다. 일 예에 따라 디스플레이(110)는 평면(flat) 디스플레이, 커브드(curved) 디스플레이, 폴딩(folding) 또는/및 롤링(rolling) 가능한 플렉서블 디스플레이 등으로 구현될 수 있다.
메모리(120)는 다양한 실시 예를 위해 필요한 데이터를 저장할 수 있다. 메모리(120)는 데이터 저장 용도에 따라 전자 장치(100')에 임베디드된 메모리 형태로 구현되거나, 전자 장치(100)에 탈부착이 가능한 메모리 형태로 구현될 수도 있다. 예를 들어,전자 장치(100)의 구동을 위한 데이터의 경우 전자 장치(100')에 임베디드된 메모리에 저장되고, 전자 장치(100)의 확장 기능을 위한 데이터의 경우 전자 장치(100)에 탈부착이 가능한 메모리에 저장될 수 있다. 한편, 전자 장치(100)에 임베디드된 메모리의 경우 휘발성 메모리(예: DRAM(dynamic RAM), SRAM(static RAM), 또는 SDRAM(synchronous dynamic RAM) 등), 비휘발성 메모리(non-volatile Memory)(예: OTPROM(one time programmable ROM), PROM(programmable ROM), EPROM(erasable and programmable ROM), EEPROM(electrically erasable and programmable ROM), mask ROM, flash ROM, 플래시 메모리(예: NAND flash 또는 NOR flash 등), 하드 드라이브, 또는 솔리드 스테이트 드라이브(solid state drive(SSD)) 중 적어도 하나로 구현될 수 있다. 또한, 전자 장치(100')에 탈부착이 가능한 메모리의 경우 메모리 카드(예를 들어, CF(compact flash), SD(secure digital), Micro-SD(micro secure digital), Mini-SD(mini secure digital), xD(extreme digital), MMC(multi-media card) 등), USB 포트에 연결가능한 외부 메모리(예를 들어, USB 메모리) 등과 같은 형태로 구현될 수 있다.
하나 이상의 프로세서(130)는 전자 장치(100)의 동작을 전반적으로 제어한다. 구체적으로, 하나 이상의 프로세서(130)는 전자 장치(100)의 각 구성과 연결되어 전자 장치(100)의 동작을 전반적으로 제어할 수 있다. 예를 들어, 하나 이상의 프로세서(130)는 디스플레이(110) 및 메모리(120)와 전기적으로 연결되어 전자 장치(100)의 전반적인 동작을 제어할 수 있다. 하나 이상의 프로세서(130)는 하나 또는 복수의 프로세서로 구성될 수 있다.
하나 이상의 프로세서(130)는 메모리(120)에 저장된 적어도 하나의 인스트럭션(instruction)을 실행함으로써, 다양한 실시 예에 따른 전자 장치(100)의 동작을 수행할 수 있다.
본 개시에 따른 인공지능과 관련된 기능은 전자 장치의 프로세서와 메모리를 통해 동작된다.
하나 이상의 프로세서(130)는 하나 또는 복수의 프로세서로 구성될 수 있다. 이때, 하나 또는 복수의 프로세서는 CPU(Central Processing Unit), GPU(Graphic Processing Unit), NPU(Neural Processing Unit) 중 적어도 하나를 포함할 수 있으나 전술한 프로세서의 예시에 한정되지 않는다.
CPU는 일반 연산뿐만 아니라 인공지능 연산을 수행할 수 있는 범용 프로세서로서, 다계층 캐시(Cache) 구조를 통해 복잡한 프로그램을 효율적으로 실행할 수 있다. CPU는 순차적인 계산을 통해 이전 계산 결과와 다음 계산 결과의 유기적인 연계가 가능하도록 하는 직렬 처리 방식에 유리하다. 범용 프로세서는 전술한 CPU로 명시한 경우를 제외하고 전술한 예에 한정되지 않는다.
GPU는 그래픽 처리에 이용되는 부동 소수점 연산 등과 같은 대량 연산을 위한 프로세서로서, 코어를 대량으로 집적하여 대규모 연산을 병렬로 수행할 수 있다. 특히, GPU는 CPU에 비해 컨볼루션(Convolution) 연산 등과 같은 병렬 처리 방식에 유리할 수 있다. 또한, GPU는 CPU의 기능을 보완하기 위한 보조 프로세서(co-processor)로 이용될 수 있다. 대량 연산을 위한 프로세서는 전술한 GPU로 명시한 경우를 제외하고 전술한 예에 한정되지 않는다.
NPU는 인공 신경망을 이용한 인공지능 연산에 특화된 프로세서로서, 인공 신경망을 구성하는 각 레이어를 하드웨어(예로, 실리콘)로 구현할 수 있다. 이때, NPU는 업체의 요구 사양에 따라 특화되어 설계되므로, CPU나 GPU에 비해 자유도가 낮으나, 업체가 요구하기 위한 인공지능 연산을 효율적으로 처리할 수 있다. 한편, 인공지능 연산에 특화된 프로세서로, NPU는 TPU(Tensor Processing Unit), IPU(Intelligence Processing Unit), VPU(Vision processing unit) 등과 같은 다양한 형태로 구현 될 수 있다. 인공 지능 프로세서는 전술한 NPU로 명시한 경우를 제외하고 전술한 예에 한정되지 않는다.
또한, 하나 이상의 프로세서(130)는 SoC(System on Chip)으로 구현될 수 있다. 이때, SoC에는 하나 이상의 프로세서(130)는 이외에 메모리(120), 및 프로세서(130)와 메모리(120) 사이의 데이터 통신을 위한 버스(Bus)등과 같은 네트워크 인터페이스를 더 포함할 수 있다.
전자 장치(100)에 포함된 SoC(System on Chip)에 복수의 프로세서가 포함된 경우, 전자 장치(100)는 복수의 프로세서 중 일부 프로세서를 이용하여 인공지능과 관련된 연산(예를 들어, 인공 지능 모델의 학습(learning)이나 추론(inference)에 관련된 연산)을 수행할 수 있다. 예를 들어, 전자 장치는 복수의 프로세서 중 컨볼루션 연산, 행렬 곱 연산 등과 같은 인공지능 연산에 특화된 GPU, NPU, VPU, TPU, 하드웨어 가속기 중 적어도 하나를 이용하여 인공지능과 관련된 연산을 수행할 수 있다. 다만, 이는 일 실시예에 불과할 뿐, CPU 등과 범용 프로세서를 이용하여 인공지능과 관련된 연산을 처리할 수 있음은 물론이다.
또한, 전자 장치(100)는 하나의 프로세서에 포함된 멀티 코어(예를 들어, 듀얼 코어, 쿼드 코어 등)를 이용하여 인공지능과 관련된 기능에 대한 연산을 수행할 수 있다. 특히, 전자 장치는 프로세서에 포함된 멀티 코어를 이용하여 병렬적으로 컨볼루션 연산, 행렬 곱 연산 등과 같은 인공 지능 연산을 수행할 수 있다.
하나 이상의 프로세서(130)는, 메모리(120)에 저장된 기정의된 동작 규칙 또는 인공 지능 모델에 따라, 입력 데이터를 처리하도록 제어한다. 기정의된 동작 규칙 또는 인공 지능 모델은 학습을 통해 만들어진 것을 특징으로 한다.
여기서, 학습을 통해 만들어진다는 것은, 다수의 학습 데이터들에 학습 알고리즘을 적용함으로써, 원하는 특성의 기정의된 동작 규칙 또는 인공 지능 모델이 만들어짐을 의미한다. 이러한 학습은 본 개시에 따른 인공지능이 수행되는 기기 자체에서 이루어질 수도 있고, 별도의 서버/시스템을 통해 이루어 질 수도 있다.
인공 지능 모델은, 복수의 신경망 레이어들로 구성될 수 있다. 적어도 하나의 레이어는 적어도 하나의 가중치(weight values)을 갖고 있으며, 이전(previous) 레이어의 연산 결과와 적어도 하나의 정의된 연산을 통해 레이어의 연산을 수행한다. 신경망의 예로는, CNN(Convolutional Neural Network), RNN(Recurrent Neural Network), DNN(Deep Neural Network), RBM(Restricted Boltzmann Machine), DBN(Deep Belief Network), BRDNN(Bidirectional Recurrent Deep Neural Network) 및 심층 Q-네트워크(Deep Q-Networks), Transformer가 있으며, 본 개시에서의 신경망은 명시한 경우를 제외하고 전술한 예에 한정되지 않는다.
학습 알고리즘은, 다수의 학습 데이터들을 이용하여 소정의 대상 기기(예컨대, 로봇)을 훈련시켜 소정의 대상 기기 스스로 결정을 내리거나 예측을 할 수 있도록 하는 방법이다. 학습 알고리즘의 예로는, 지도형 학습(supervised learning), 비지도형 학습(unsupervised learning), 준지도형 학습(semi-supervised learning) 또는 강화 학습(reinforcement learning)이 있으며, 본 개시에서의 학습 알고리즘은 명시한 경우를 제외하고 전술한 예에 한정되지 않는다. 이하에서는 설명의 편의를 위하여 하나 이상의 프로세서(130)를 프로세서(130)로 명명하도록 한다.
도 2b는 일 실시 예에 따른 디스플레이 장치의 구성을 구체적으로 나타내는 블럭도이다.
도 2b에 따르면, 전자 장치(100')은 디스플레이(110), 메모리(120), 하나 이상의 프로세서(130), 통신 인터페이스(140), 사용자 인터페이스(150), 스피커(160) 및 카메라(170)를 포함할 수 있다. 도 2b에 도시된 구성 중 도 2a에 도시된 구성과 중복되는 구성에 대해서는 자세한 설명을 생략하도록 한다.
통신 인터페이스(140)는 전자 장치(100')의 구현 예에 따라 다양한 통신 방식을 지원할 수 있다. 예를 들어 통신 인터페이스(140)는 블루투스(Bluetooth), AP 기반의 Wi-Fi(와이파이, Wireless LAN 네트워크), 지그비(Zigbee), 유/무선 LAN(Local Area Network), WAN(Wide Area Network), 이더넷(Ethernet), IEEE 1394, HDMI(High-Definition Multimedia Interface), USB(Universal Serial Bus), MHL(Mobile High-Definition Link), AES/EBU(Audio Engineering Society/ European Broadcasting Union), 옵티컬(Optical), 코액셜(Coaxial) 등과 같은 통신 방식을 통해 외부 장치, 외부 저장 매체(예를 들어, USB 메모리), 외부 서버(예를 들어 클라우드 서버) 등과 통신을 수행할 수 있다.
사용자 인터페이스(150)는 버튼, 터치 패드, 마우스 및 키보드와 같은 장치로 구현되거나, 상술한 디스플레이 기능 및 조작 입력 기능도 함께 수행 가능한 터치 스크린으로 구현될 수 있다. 일 실시 예에 따라 사용자 인터페이스(150)는 리모콘 송수신부로 구현되어 원격 제어 신호를 수신할 수 있다. 리모콘 송수신부는 적외선 통신, 블루투스 통신 또는 와이파이 통신 중 적어도 하나의 통신 방식을 통해 외부 원격 제어 장치로부터 리모콘 신호를 수신하거나, 리모콘 신호를 송신할 수 있다.
스피커(160)는 음향 신호를 출력한다. 예를 들어, 스피커(160)는 프로세서(130)에서 처리된 디지털 음향 신호를 아날로그 음향 신호로 변환하고 증폭하여 출력할 수 있다. 예를 들어, 스피커(190)는 적어도 하나의 채널을 출력할 수 있는, 적어도 하나의 스피커 유닛, D/A 컨버터, 오디오 앰프(audio amplifier) 등을 포함할 수 있다. 일 예에 따라 스피커(160)는 다양한 멀티 채널 음향 신호를 출력하도록 구현될 수 있다. 이 경우, 프로세서(130)는 입력 영상의 인핸스 처리에 대응되도록 입력된 음향 신호를 인핸스 처리하여 출력하도록 스피커(160)를 제어할 수 있다.
카메라(170)는 기 설정된 이벤트에 따라 턴 온 되어 촬영을 수행할 수 있다. 카메라(170)는 촬상된 영상을 전기적인 신호로 변환하고 변환된 신호에 기초하여 영상 데이터를 생성할 수 있다. 예를 들어, 피사체는 반도체 광학소자(CCD; Charge Coupled Device)를 통해 전기적인 영상 신호로 변환되고, 이와 같이 변환된 영상 신호는 증폭 및 디지털 신호로 변환된 후 신호 처리될 수 있다.
그 밖에 전자 장치(100')는 구현 예에 따라 마이크(미도시), 센서(미도시), 튜너(미도시) 및 복조부(미도시) 등을 포함할 수 있다.
마이크(미도시)는 사용자 음성이나 기타 소리를 입력받아 오디오 데이터로 변환하기 위한 구성이다. 다만, 다른 실시 예에 따라 전자 장치(100')는 외부 장치를 통해 입력된 사용자 음성을 통신 인터페이스(140)를 통해 수신할 수 있다.
센서(미도시)는 터치 센서, 근접 센서, 가속도 센서, 지자기 센서, 자이로 센서, 압력 센서, 위치 센서, 조도 센서 등과 같은 다양한 유형의 센서를 포함할 수 있다.
튜너(미도시)는 안테나를 통해 수신되는 RF(Radio Frequency) 방송 신호 중 사용자에 의해 선택된 채널 또는 기 저장된 모든 채널을 튜닝하여 RF 방송 신호를 수신할 수 있다.
복조부(미도시)는 튜너에서 변환된 디지털 IF 신호(DIF)를 수신하여 복조하고, 채널 복호화 등을 수행할 수도 있다.
일 실시 예에 따르면, 프로세서(130)는 제1 인공 지능 모델을 이용하여 임계 해상도 미만의 저해상도 이미지로부터 임계 해상도 이상의 고해상도 이미지를 획득할 수 있다. 여기서, 제1 인공 지능 모델은 메모리(120)에 기 저장되어 있을 수 있으나, 반드시 이에 한정되는 것은 아니며 제1 인공 지능 모델과 관련된 적어도 일부의 구성은 외부 장치(예를 들어, 외부 서버)에 저장될 수도 있다. 이 후, 프로세서(130)는 획득된 고해상도 이미지를 출력하도록 디스플레이(110)를 제어할 수 있다. 다만, 다른 예에 따라 전자 장치(100)는 디스플레이를 구비하지 않을 수 있으며, 이 경우 고해상도 이미지를 디스플레이를 구비하는 외부 장치로 전송할 수 있다.
일 예에 따라 제1 인공 지능 모델은, 상이한 타입의 복수의 손실(loss) 값의 가중 합으로 정의되며 연속적으로 변경되는 오브젝티브(objective) 데이터를 학습하도록 구현될 수 있다. 이 경우, 제1 인공 지능 모델은, 저해상도 이미지(이하, 저해상도 이미지)에 기초하여 식별된 복수의 손실 값 각각에 대응되는 가중치 조건에 기초하여 고해상도 출력 이미지(이하, 고해상도 이미지)를 획득할 수 있다. 여기서, 상이한 타입의 복수의 손실 값은, 재구성 손실(reconstruction loss), 적대 손실(adversarial loss), 인지 손실(perceptual loss) 또는 왜곡 손실(distortion loss) 중 적어도 하나에 따른 손실 값을 포함할 수 있다.
일 예에 따라 제1 인공 지능 모델로 제공되는 가중치 조건은 제2 인공 지능 모델로부터 제1 인공 지능 모델로 제공될 수 있다. 이 경우, 제2 인공 지능 모델은, 저해상도 이미지에 기초하여 복수의 손실 값 각각에 대응되는 가중치 조건을 식별하여 제1 인공 지능 모델로 제공하도록 구현될 수 있다. 예를 들어, 제2 인공 지능 모델은, 제2 인공 지능 모델의 출력 가중치 조건 및 타겟 가중치 조건을 포함하는 제1 정보 및, 제1 인공 지능 모델의 출력 이미지 및 오브젝티브 데이터를 포함하는 제2 정보에 기초하여 학습될 수 있다. 여기서, 제1 정보는, 트레이닝 샘플의 영역 데이터에 대응되는 상이한 타입의 복수의 손실 값 각각의 출력 가중치 조건 및 타겟 가중치 조건 간 차이 값을 포함할 수 있다. 또한, 제2 정보는, 트레이닝 샘플의 영역 데이터 및 연속적으로 변경되는 오브젝티브 데이터 간 상이한 타입의 복수의 손실 값을 포함할 수 있다. 이하에서는 설명의 편의를 위하여 저해상도 이미지를 LR 이미지, 고해상도 이미지를 HR 이미지로 명명하도록 한다.
도 3은 일 실시 예에 따른 SISR Framework의 개요를 나타내는 도면이다.
도 3에 따르면, SISR Framework는 제1 인공 지능 모델(300) 및 제2 인공 지능 모델(400)을 포함할 수 있다. 일 예에 따라 제1 인공 지능 모델(300)은 Generative model(Gθ)로 구현되며, 제2 인공 지능 모델(400)은 Predictive model(Cψ)로 구현될 수 있다. 제2 인공 지능 모델(400)은 입력 LR 이미지에 대해 LR 크기의 최적 오브젝티브 맵(또는 가중치 조건 맵) 를 예측하여 제1 인공 지능 모델(300)로 제공할 수 있다. 이 경우, 제1 인공 지능 모델(300)은 최적 오브젝티브 맵 에 기초하여 HR counterpart y와 가능한 한 유사한 해당 SR 이미지를 출력할 수 있다.
예를 들어, 제1 인공 지능 모델(300)은 하기 수학식 1에 따라 최적 오브젝티브 맵을 획득할 수 있다. 또한, 제2 인공 지능 모델(400)은 하기 수학식 2에 따라 SR 이미지를 획득할 수 있다.
도 4a 내지 도 4c는 일 실시 예에 따른 제1 인공 지능 모델의 구현 예를 설명하기 위한 도면들이다.
도 4a는 제1 인공 지능 모델(300)의 일 구현 예를 도시한 것으로 generative model(Gθ)로 구현될 수 있다.
도 4a에 도시된 바와 같이 제1 인공 지능 모델(300)은 복수의 신경망 레이어를 포함하고 복수의 신경망 레이어들 각각은 복수의 파라미터를 포함할 수 있다. 이 경우, 제1 인공 지능 모델(300)은 이전 레이어의 연산 결과와 복수의 파라미터들 간의 연산을 통해 신경망 연산을 수행할 수 있다.
일 예에 따라, 임의의 레이어에서 컨벌루션 필터 적용 후 활성화 함수, 예를 들어 ReLU(Rectified Linear Unit) 연산을 통해 출력되는 연산 데이터가 출력될 수 있다. 이 경우, 레이어에서 출력되는 연산 데이터는 다채널 데이터로서, 예를 들어, 64 개의 피쳐 맵(또는 액티베이션 맵) 데이터가 출력되어 다음 레이어로 제공될 수 있다. 다만, 일 예에 따라 피쳐 맵 데이터가 메모리(내부 버퍼, 또는 외부 메모리)에 저장된 후 다음 레이어로 제공될 수 있으나, 도 4a에서는 해당 구성은 생략하였다. 이 경우, 제1 인공 지능 모델(300)은 Identity Function, Logistic Sigmoid Function, Hyperbolic Tangent(tanh) Function, ReLU Function, Leaky ReLU Function 등 다양한 유형의 활성화 함수(Activation function)를 이용하여 연산을 수행할 수 있다.
일 예에 따르면, 제1 인공 지능 모델(300)은 SR(Super Resolution) Branch 및 Condition Branch로 구현될 수 있다. 일 예에 따라 SR Branch는 복수의 Basic block을 이용하여 SR 처리를 수행하도록 구현될 수 있다. 예를 들어 복수의 Basic block 각각은 도 3b에 도시된 바와 같이 복수의 Dense block 및 연산 소자를 포함하도록 구현될 수 있다. 또한, 복수의 Dense block 각각은 도 4b에 도시된 바와 같이 컨벌루션(Convolution) 레이어, 활성화 함수(예를 들어, ReLU 함수), SFT 레이어를 포함할 수 있다. SFT(Spatial Feature Transform) 레이어는 공간 단위 feature 변조를 위한 아핀 변환(affine transform)을 생성하며, loss function을 통한 end-to-end 학습이 가능할 수 있다.
일 예에 따르면, 제1 인공 지능 모델(300)은 저해상도 이미지에 포함된 복수의 영역 각각에 대한 오브젝티브(objective) 데이터의 최적 조합에 기초하여 고해상도 이미지를 획득할 수 있다. 이 경우, 제1 인공 지능 모델(300)은 임의로 변경되는 조건 t에 기초하여 획득되는 임의의 가중치 조건 맵 Tt에 기초하여 획득되는 복수의 오브젝티브(objective) 데이터를 학습하도록 구현될 수 있다. 여기서, 조건 t는 복수의 SFT 레이어에 대응되는 가중치일 수 있으며, 기 설정된 범위 내에서 연속적으로 변경될 수 있다.
도 4c는 제1 인공 지능 모델(300)의 학습 방법을 설명하기 위한 도면으로 이에 대해서는 후술하는 수학식들에 기초하여 자세히 설명하도록 한다.
도 5a 내지 도 5c는 일 실시 예에 따른 제1 인공 지능 모델 및 제2 인공 지능 모델의 구현 예를 설명하기 위한 도면들이다.
일 예에 따르면, 제2 인공 지능 모델(400)은 제1 인공 지능 모델(300)로 제1 인공 지능 모델(300)에 포함된 복수의 SFT 레이어에 대응되는 가중치 조건을 제공할 수 있다. 일 예에 따라 가중치 조건은 가중치 조건 맵 의 형태로 제공될 수 있다. 여기서, 가중치 조건 맵은 저해상도 이미지에 대응되는 크기일 수 있다. 예를 들어 제2 인공 지능 모델(400)은 저해상도 이미지에 포함된 복수의 영역 각각에 대응되는 복수의 손실 값에 대한 가중치 조건 맵을 획득하여 제1 인공 지능 모델(300)로 제공할 수 있다. 이 경우, 제1 인공 지능 모델(300)은 제2 인공 지능 모델(400)로부터 제공된 가중치 조건 맵에 대응되는 복수의 손실 값의 가중 합에 기초하여 고해상도 이미지를 획득할 수 있다.
한편, 제2 인공 지능 모델(400)은 조건 t를 제1 값에서 제2 값으로 단계적으로 변경하면서 각 픽셀에 대해 LPIPS(Learned Perceptual Image Patch Similarity)가 가장 낮은 t를 선택하여 타겟 가중치 조건 맵 Ts *를 획득하고, 타겟 가중치 조건 맵 Ts에 기초하여 학습될 수 있다. 또한, 제2 인공 지능 모델(400)은 제1 인공 지능 모델(400)의 출력 이미지 및 타겟 고해상도 이미지 간 차이를 측정하는 복수의 손실 값에 기초하여 학습될 수 있다. 예를 들어, 제2 인공 지능 모델(400)은 3개의 손실 값(픽셀 단위 오브젝티브 맵 손실, 재구성 손실, 인지 손실에 의해 학습되어 최적화될 수 있다.
일 예에 따르면, 제2 인공 지능 모델(400)은 도 5a에 도시된 바와 같이 복수의 개별 하위 네트워크로 구성될 수 있다. 예를 들어, 개별 하위 네트워크는 피처 추출기(feature extractor:F.E.) 및 예측기(predictor)를 포함할 수 있다. 도 5b는 예측기(predictor)를 구성하는 복수의 블럭의 구조의 일 예시를 나타낼 수 있다.
도 5c는 제2 인공 지능 모델(400)의 학습 방법을 설명하기 위한 도면으로 이에 대해서는 후술하는 수학식들에 기초하여 자세히 설명하도록 한다.
이하에서는 수학식을 참조하여 제1 인공 지능 모델(300) 및 제2 인공 지능 모델(400)의 동작 방법 및 학습 방법에 대해 좀더 자세히 설명하도록 한다.
일 예에 따라 제1 인공 지능 모델(300)은 국부적으로(locally) 상이한 오브젝티브를 고려할 수 있는 SR 모델로 구현될 수 있다. 예를 들어, 제1 인공 지능 모델(300)은 상이한 타입의 복수의 손실(loss) 값의 가중 합으로 정의되며 연속적으로 변경되는 오브젝티브(objective) 데이터를 학습하도록 구현될 수 있다. 이 경우, 정확한 SR 처리를 위해 오브젝티브를 효과적으로 설정하는 것이 중요하다. 예를 들어, Perceptionoriented SR의 경우 픽셀 단위 재구성 손실(reconstruction loss)(Lrec), 적대 손실(adversarial loss)(Ladv) 및 인지 손실(perceptual loss)(Lper)의 가중 합에 대응되는 오브젝티브 데이터를 학습할 수 있다.

여기서 λrec, λadv 및 λperl은 대응되는 손실에 대한 가중 파라미터이고, φperi(ㆍ)는 VGG 네트워크의 레이어 peri에서 추출된 입력의 피쳐(feature) 맵을 나타낼 수 있다. 예를 들어, VGG 네트워크는 19 레이어로 구현될 수 있으나 이에 한정되는 것은 아니다. 예를 들어, 5 개의 레이어가 수학식 5로 나타내어질 수 있다. 일 예에 따라 receptive field는 VGG network 에서 깊이 진행될수록 커지므로 V12 및 V22와 같은 얕은 레이어(shallow layer) 및 V34, V44 및 V54와 같은 깊은 레이어(deeper layer)의 피쳐들이 각각 상대적으로 로우 레벨 및 하이 레벨에 대응될 수 있다.
일 예에 따라 효과적인 오브젝티브 셋트를 식별하기 위하여 SR 오브젝티브 공간을 정의할 수 있다. 예를 들어, SR을 위한 오브젝티브는 수학식 3에서와 같이 7개의 손실 항(loss term)의 가중 합(weighted sum)이기 때문에, 오브젝티브 공간(objective space)은 이러한 기본 손실 항(basis loss terms)에 의해 확장될 수 있고, 임의의 오브젝티브는 가중 파라미터의 7차원 벡터(seven-dimensional vector) 로, 하기 수학식 6과 같이 나타내어질 수 있다.
여기서, λper∈ 는 인지 손실의 가중 벡터일 수 있다.
도 6a 및 도 6b는 일 실시 예에 따른 오브젝티브 셋트 식별 방법을 설명하기 위한 도면들이다.
도 6a는 도 6b와 같이 정의된 두 개의 오브젝티브 셋트 A(좌측) 및 B(우측)을 비교한 테이블이다. 예를 들어, ESRGAN(Enhanced Super-Resolution Generative Adversarial Network)을 기본 모델로 이용하였기 때문에 테이블의 모든 오브젝티브에 대해 λ0을 제외하고 λrec와 λadv는 각각 1×10-2, 5×10-3로 설정될 수 있다. λper가 변하는 경우를 제외하고 ESRGAN에 대한 값들은 동일할 수 있다(∥λper∥1 = 1). 특히, λper 항에서 셋트 A의 각 오브젝티브는 5개의 VGG 피쳐 공간(feature space) 중 하나에 대해서만 가중치를 갖는 반면, 셋트 B의 각 오브젝티브는 타겟 비젼 레벨보다 낮은 피쳐 공간의 각 손실에 대해 동일한 가중치를 가질 수 있다. 한편, λ0는 distortion-oriented RRDB model에 대응하기 때문에, λrec와 λadv는 각각 1×10-2, 0일 수 있다. λ0는 셋트 A 및 B에 모두 포함될 수 있다.
일 예에 따르면 도 6a의 테이블은 5개의 데이터 셋트(BSD100, General100, Urban100, Manga109, and DIV2K)에 대한 수학식 4로부터 averaged λperi 의 정규화된 버전(normalized versions)(예를 들어, min-max feature scaling)을 포함한다. 타겟팅된 V12 및 V22를 포함하는 모든 피쳐 공간들에 대해, 셋트 B에서의 λ1-2는 셋트 A에서의 λ1 및 λ2보다 L1 에러가 더 작을 수 있다. 또한, λ1-4는 λ4 및 λ5보다 더 작은 에러를 나타낼 수 있다. 또한, λ1-3이 λ3보다 V34 피쳐 공간에서 약간 더 많은 에러를 가지지만, V12 및 V22 피쳐 공간에서 에러가 더 작기 때문에 λ1-3는 V34 피쳐 공간으로 오버핏된(overfitted) λ3보다 상대적으로 왜곡이 작을 수 있다. 이는 λ1-3 를 포함하는 셋트 B에서 오브젝티브 대부분이 셋트 A보다 더 나은 PSNR(Peak Signal-to-Noise Ratio) 및 LPIPS(Learned Perceptual Image Patch Similarity)를 갖는다는 사실에 의해 뒷받침될 수 있다.
셋트 A를 이용하여 국부적으로 적합한 오브젝티브를 적용한 SR 결과를 검토하기 위하여, 각 픽셀 위치에 대해 LPIPS가 가장 낮은 SR 결과를 선택하여, ESRGAN-λa(여기서, λa ∈ A)의 6 개의 SR 결과를 믹싱할 수 있다.

여기서, 는 ESRGAN-a의 SR 결과이고, LPIPS 함수는 각 픽셀 위치에 대한 두 이미지 패치 사이의 인지 거리를 산출하여 입력 이미지 사이즈의 LPIPS 맵을 생성할 수 있다. 도 6a의 테이블에서 LPIPS 메트릭은 이러한 맵의 평균일 수 있다. T* A는 OOS(Optimal Objective Selection)이므로 믹싱을 위한 T* A 및 SR 모델은 각각 OOSA 및 ESRGAN-OOSA로 표기하도록 한다.
도 7은 일 실시 예에 따른 최적 오브젝티브 선택 방법을 설명하기 위한 도면이다.
도 7의 상측 부분은 셋트 A 및 셋트 B를 기반으로 한 OOSA와 OOSB의 예를 나타낸다. ESRGAN-OOSA와 ESRGAN-OOSB의 PSNR과 LPIPS는 도 3a의 테이블과 같으며, 여기서 ESRGAN-OOSB는 어떤 단일 오브잭티브 모델보다 우수하며, 국부적으로 적합한 오브젝티브 애플리케이션의 성능 향상 가능성을 보여준다.
도 7의 하측 부분은 도 6b에 도시된 바와 같이 셋트 B보다 오브젝티브 간 더 낮은 유사성을 가지는 셋트 A에 대한 SR 결과를 믹싱하여 발생하는 부작용을 보여준다. 도 7에서 ESRGAN-OOSB는 ESRGAN-OOSA보다 더 낮은 아티팩트(artifact) 및 더 우수한 PSNR을 가지기 때문에 셋트 B가 국부적으로 적합한 오브젝트를 적용하는데 더 적합할 수 있다.
한편, 수학식 6에서 단일 오브젝트가 아닌 궤적(trajectory)에 대한 일련의 오브젝티브의 셋트에 대해 제1 인공 지능 모델(300)을 학습시킬 수 있다. objective trajectory는 선택된 오브젝티브, 예를 들어 셋트 B의 5개 오브젝티브를 연결하여 형성될 수 있다. 로우 비전 레벨의 오브젝티브부터 시작하여 하이 레벨의 오브젝트들까지(예를 들어, λ0에서 λ1-4까지의 오브젝트들)까지 연결될 수 있다. 단일 변수 t에 의해, λ(t) = <λrec(t);λadv(t); λper(t)>는 하기 수학식으로 정의될 수 있다.
여기서, fλper(t) ∈ , fλrec(t), fλadv(t)는 가중치 함수이고, α 및 β는 스케일링 및 오프셋 벡터이다. fλ: 이기 때문에, 이러한 벡터 함수는 고차원 가중치 벡터 매니퓰레이션(high-dimensional weight-vector manipulation)을 1차원 트랙킹(onedimensional tracking)으로 대체하여 학습 프로세스를 단순화할 수 있다.
도 8a 내지 도 8d, 도 9는 일 실시 예에 따른 objective trajectory를 설명하기 위한 도면들이다.
일 예에 따른 trajectory design는, λ0을 이용하는 왜곡 지향 RRDB 모델(distortion-oriented RRDB model)이 V12 및 V22와 같은 로우 레벨의 피쳐 공간에 대해 모든 ESRGAN 모델보다 L1 오류가 더 작은 반면, ESRGAN 모델이 V34, V44 및 V54와 같은 상위 레벨 피처 공간에 대해 더 작은 L1 에러를 가진다는 도 5a의 테이블을 기반으로 할 수 있다. 이에 따라 도 8a에 도시된 바와 같이 t가 0으로 접근할 때 fλrec은 증가하고, {fλadv , Σperifλperi}는 λ0로 감소하고, 반대로 t 가 1로 증가하여 λ1-4가 되도록 가중치 함수 fλper, fλrec, fλadv를 설계할 수 있다.
Σperifλperi의 변경과 관련하여, 도 8b에 도시된 바와 같은 셋트 B에의 λ0 부터 λ1-4로의 objective trajectory를 획득하기 위하여, 도 8c에 도시된 바와 같이 fλper(t)의 5개의 컴포넌트 함수 fλperi(t)를 설계할 수 있다. 다만, 3차원 시각화의 한계 때문에 5개 컴포넌트 함수 중 3개 만 도시하였다. t를 0에서 1로 증가시키는 궤적을 통해 오브젝티브를 위한 가중치 파라미터는 왜곡 지향 오브젝티브 λ0로 시작하여 더 높은 비전 레벨 피처 공간 손실 및 적대 손실이 점진적으로 추가되고 λ1-4를 향하는 오브젝티브로 전환될 수 있다. 도 8d는 인지적으로 정확한 복원의 성능을 제한하는, V22 피처 공간만 이용하는 FxSR에 사용된 objective trajectory을 나타낼 수 있다.
일 실시 예에 따른 objective trajectory은 SR 결과의 정확성과 일관성을 효율적으로 향상시킬 수 있다. 우선, 로우 레벨의 비전에서 하이 레벨의 비전에 이르는 연속적인 궤적 상에서의 오브젝트를 이용하여 각 영역에 보다 정확한 오브젝티브를 적용할 수 있다. 또한, 일 실시 예에 따른 objective trajectory에 따르면, 하이 레벨 오브젝티브는 로우 레벨 손실 및 하이 레벨 손실을 모두 포함하므로 하위 레벨 오브젝티브에 대한 설명을 제공할 수 있다. 이러한 가중 방법은 trajectory 상에서 모든 SR 결과 간에 로우 레벨 비전 오브젝티브에 의해 주로 재구성된 구조적 구성 요소를 공유할 수 있다. 마지막으로 단일 SR 모델을 한 번만 트레이닝하면 다양한 HR 출력을 생성하는데 필요한 모델 수가 감소될 수 있다.
도 9는 t가 0에서 1로 변화함에 따라 도 8b의 OT(objective trajectory)에 대해 트레이닝된 SROT(SROT)의 SR 결과의 변화를 나타내는 도면이다.
도 10a 및 도 10b는 t의 변화에 따른 지각-왜곡 평면에서 trade-off 커브 나타낸다. t는 0.0에서 1.0까지 0.05 씩 증가하며 21개의 샘플 포인트를 가질 수 있다. 커브 상에서 각 SR 결과는 하기 수학식 12와 같이 제1 인공 지능 모델(300)의 condition branch 에 Tt = 1×t와 같이, 이미지 전체에서 동일한 t를 갖는 T를 입력하여 획득할 수 있다.
도 9의 가로 점선 라인 및 세로 점선 라인은 각각 모델의 가장 낮은 LPIPS 값과 대응되는 PSNR 값을 나타낸다. 각 시점에서 t 값은 수직 라인 옆에 기록될 수 있다. 하지만, 전체 이미지에 특정 t를 적용하는 것은 여전히 SR 성능을 제한하고, 추론 시점에서 이미지에 따른 최적 t를 알 수 없다는 문제가 있다. 이에 따라 국부적으로 최적의 오브젝티브를 예측하고 적용하는 방법에 대해 제시한다.
일 예에 따르면, 제1 인공 지능 모델(300)은 2개의 스트림 즉, 3 basic blocks을 가지는 SR branch 및 condition branch를 포함할 수 있다.
예를 들어, condition branch는 LR 사이즈의 타겟 오브젝티브 맵 T에 기초하여 SR branch의 모든 SFT 레이어로 전송될 수 있는 공유 중간 조건(shared intermediate conditions)을 생성할 수 있다. SFT 레이어는 아핀 변환을 적용하여 피처 맵을 변조하므로 T를 기반으로 변조(modulation) 파라미터를 출력하는 매핑 함수를 학습할 수 있다. 구체적으로 미리 정의된 범위에서 t가 임의로 변경되는 Tt는 condition branch로 제공될 수 있다. 이 변조 레이어을 통해 SR branch는 t에 의해 변경되는 오브젝티브를 최적화할 수 있다. 결과적으로 제1 인공 지능 모델(300)은 trajectory 상의 모든 오브젝티브를 학습하고 추론 시점에 맵에 따라 공간적으로 다른 오브젝티브를 이용하여 SR 결과를 생성할 수 있다. 예를 들어, 제1 인공 지능 모델(300)은 하기 수학식 13 및 14와 같이 distribution PZ(PZ 분포)를 사용하여 트레이닝 샘플 Z = (x; y)에서 최적화될 수 있다.


제2 인공 지능 모델(400)은 각 영역에 대한 오브젝티브의 최적 조합을 예측하도록 학습될 수 있다. 제2 인공 지능 모델(400)은 LR 이미지에 대해 예측된 최적의 오브젝티브 맵을 생성하고, 제1 인공 지능 모델(300)로 제공할 수 있다. 제1 인공 지능 모델(300)의 학습을 위한 ground truth map을 획득하기 어렵기 때문에 최대한 가능한 값의 범위를 좁히기 위해 simple exhaustive searching을 통해 approximation T* S를 획득할 수 있다. 구체적으로, 하기 수학식 15 및 16과 같이 t를 0에서 1까지 0.05씩 변경하여 N개 예를 들어, 21개의 SR 결과 셋트를 획득하고, 각 픽셀에 대해 LPIPS가 가장 낮은 t를 선택하여 최적 오브젝티브 맵을 생성할 수 있다.

여기서, Tt = 1×t, t ∈ S { 0.0. 0.05. 0.10. ..... 1.0 }이다.
도 11은 optimal objective selection(OOS) T* S 및 T* S를 이용한 SR 결과(SROOS)가 하기 수학식 17과 같이 제1 인공 지능 모델(300)의 성능의 upperbound approximation가 될 수 있음을 도시한다.
T* S 가 제2 인공 지능 모델(400)의 학습에 유용하긴 하지만, 제1 인공 지능 모델(300)의 컨벌루션에 의해 야기되는 간섭을 고려하지 않은 픽셀 단위 오브젝티브 선택은 정확한 ground truth를 가 아닐 수 있다. 이에 따라 제2 인공 지능 모델(400)은 제1 인공 지능 모델(300)의 재구성된 이미지 및 HR 이미지 간 차이를 측정하는 손실 값, 예를 들어, 3개의 손실 값(픽셀 단위 오브젝티브 맵 손실, 재구성 손실, 인지 손실)에 의해 최적화될 수 있다.
여기서, LT는 T* S 및 간 L1 손실, Lrec는 y 및 간 L1 손실을 의미한다. 한편, ZT = (x, y, T* S )는 트레이닝 데이터셋을 의미하고, λT,λrec OOE, 및 λR은 손실 항 각각에 대한 가중치를 의미한다. 제2 인공 지능 모델(400)이 학습되는 동안, 제2 인공 지능 모델(400)은 학습된 제1 인공 지능 모델(300)과 결합되고, 제1 인공 지능 모델(300)의 파라미터는 고정될 수 있다. 이에 따라 LPIPS를 포함하는 제2 인공 지능 모델(400) 학습에서의 손실은 제1 인공 지능 모델(300)의 파라미터에 영향을 주거나 변경하지 않고 최적의 로컬 오브젝티브 맵을 예측하는데만 관여될 수 있다.
일 예에 따라 제2 인공 지능 모델(400)은 두 개의 개별 하위 네트워크로 구성될 수 있다. 하나는 VGG-19를 이용하는 피처 추출기(feature extractor:F.E.)이고 다른 하나는 도 5a에 도시된 바와 같이 UNet 아키텍처의 예측기(predictor)일 수 있다. 더 나은 성능을 위해 피처 추출기는 로우 레벨 피처에서 하이 레벨 피처를 획득하며, 획득된 피처를 예측을 수행하는 Unet에 전달할 수 있다. UNet의 구조는 수용 영역이 더 넓기 때문에 컨텍스트에 맞는 오브젝티브를 예측하는 데 유리할 수 있다.
도 12는 일 실시 예에 따른 효과를 설명하기 위한 도면이다.
도 12에 따르면, 본 개시의 일 실시 예에 따른 초해상화 처리 방법(SROOE)이 LPIPS, DISTS, PSNR 및 SSIM 메트릭에서 기존의 다른 방법들보다 우수한 결과를 제공함을 확인할 수 있다. 예를 들어 일 실시 예에 따른 초해상화 처리 방법(SROOE)이 에지 구조와 디테일의 보다 정확한 재구성을 생성하는 것을 확인할 수 있다. 특히, 과 를 사용한 SROOE 결과 사이의 구조적 성분의 변화가 거의 없고, 필요에 따라 영역의 구조적 성분에 날카로운 에지와 생성된 디테일이 추가되는 것을 확인할 수 있다.
상술한 다양한 실시 예들에 따르면, 초해상화 처리에 있어 에지 구조 및 디테일을 보다 정확히 재구성하여 생성할 수 있게 된다.
한편, 상술한 본 개시의 다양한 실시 예들에 따른 방법들은, 기존 전자 장치에 대한 소프트웨어 업그레이드, 또는 하드웨어 업그레이드 만으로도 구현될 수 있다.
또한, 상술한 본 개시의 다양한 실시 예들은 전자 장치에 구비된 임베디드 서버, 또는 전자 장치의 외부 서버를 통해 수행되는 것도 가능하다.
한편, 본 개시의 일시 예에 따르면, 이상에서 설명된 다양한 실시 예들은 기기(machine)(예: 컴퓨터)로 읽을 수 있는 저장 매체(machine-readable storage media)에 저장된 명령어를 포함하는 소프트웨어로 구현될 수 있다. 기기는, 저장 매체로부터 저장된 명령어를 호출하고, 호출된 명령어에 따라 동작이 가능한 장치로서, 개시된 실시 예들에 따른 전자 장치(예: 전자 장치(A))를 포함할 수 있다. 명령이 프로세서에 의해 실행될 경우, 프로세서가 직접, 또는 프로세서의 제어 하에 다른 구성요소들을 이용하여 명령에 해당하는 기능을 수행할 수 있다. 명령은 컴파일러 또는 인터프리터에 의해 생성 또는 실행되는 코드를 포함할 수 있다. 기기로 읽을 수 있는 저장 매체는, 비일시적(non-transitory) 저장매체의 형태로 제공될 수 있다. 여기서, '비일시적'은 저장매체가 신호(signal)를 포함하지 않으며 실재(tangible)한다는 것을 의미할 뿐 데이터가 저장매체에 반영구적 또는 임시적으로 저장됨을 구분하지 않는다.
또한, 본 개시의 일 실시 예에 따르면, 이상에서 설명된 다양한 실시 예들에 따른 방법은 컴퓨터 프로그램 제품(computer program product)에 포함되어 제공될 수 있다. 컴퓨터 프로그램 제품은 상품으로서 판매자 및 구매자 간에 거래될 수 있다. 컴퓨터 프로그램 제품은 기기로 읽을 수 있는 저장 매체(예: compact disc read only memory (CD-ROM))의 형태로, 또는 어플리케이션 스토어(예: 플레이 스토어TM)를 통해 온라인으로 배포될 수 있다. 온라인 배포의 경우에, 컴퓨터 프로그램 제품의 적어도 일부는 제조사의 서버, 어플리케이션 스토어의 서버, 또는 중계 서버의 메모리와 같은 저장 매체에 적어도 일시 저장되거나, 임시적으로 생성될 수 있다.
또한, 상술한 다양한 실시 예들에 따른 구성 요소(예: 모듈 또는 프로그램) 각각은 단수 또는 복수의 개체로 구성될 수 있으며, 전술한 해당 서브 구성 요소들 중 일부 서브 구성 요소가 생략되거나, 또는 다른 서브 구성 요소가 다양한 실시 예에 더 포함될 수 있다. 대체적으로 또는 추가적으로, 일부 구성 요소들(예: 모듈 또는 프로그램)은 하나의 개체로 통합되어, 통합되기 이전의 각각의 해당 구성 요소에 의해 수행되는 기능을 동일 또는 유사하게 수행할 수 있다. 다양한 실시 예들에 따른, 모듈, 프로그램 또는 다른 구성 요소에 의해 수행되는 동작들은 순차적, 병렬적, 반복적 또는 휴리스틱하게 실행되거나, 적어도 일부 동작이 다른 순서로 실행되거나, 생략되거나, 또는 다른 동작이 추가될 수 있다.
이상에서는 본 개시의 바람직한 실시 예에 대하여 도시하고 설명하였지만, 본 개시는 상술한 특정의 실시 예에 한정되지 아니하며, 청구범위에서 청구하는 본 개시의 요지를 벗어남이 없이 당해 개시에 속하는 기술분야에서 통상의 지식을 가진 자에 의해 다양한 변형실시가 가능한 것은 물론이고, 이러한 변형실시들은 본 개시의 기술적 사상이나 전망으로부터 개별적으로 이해되어서는 안될 것이다.
100: 전자 장치 110: 디스플레이
120: 메모리 130: 하나 이상의 프로세서
120: 메모리 130: 하나 이상의 프로세서
Claims (19)
- 전자 장치에 있어서,
디스플레이;
제1 인공 지능 모델 및 제2 인공 지능 모델에 대한 정보가 저장된 메모리; 및
상기 디스플레이 및 상기 메모리와 연결되어 상기 전자 장치를 제어하는 하나 이상의 프로세서;를 포함하며,
상기 하나 이상의 프로세서는,
상기 제1 인공 지능 모델을 이용하여 임계 해상도 미만의 저해상도 이미지로부터 상기 임계 해상도 이상의 고해상도 이미지를 획득하고 상기 획득된 고해상도 이미지를 출력하도록 상기 디스플레이를 제어하며,
상기 제1 인공 지능 모델은,
상이한 타입의 복수의 손실(loss) 값의 가중 합으로 정의되며 연속적으로 변경되는 오브젝티브(objective) 데이터를 학습하도록 구현되며,
상기 제2 인공 지능 모델은,
상기 저해상도 이미지에 기초하여 상기 복수의 손실 값에 대응되는 가중치 조건을 식별하여 상기 제1 인공 지능 모델로 제공하도록 구현되는, 전자 장치. - 제1항에 있어서,
상기 제2 인공 지능 모델은,
상기 제2 인공 지능 모델의 출력 가중치 조건 및 타겟 가중치 조건을 포함하는 제1 정보 및, 상기 제1 인공 지능 모델의 출력 이미지 및 상기 오브젝티브 데이터를 포함하는 제2 정보에 기초하여 학습되는, 전자 장치. - 제2항에 있어서,
상기 제1 정보는,
트레이닝 샘플의 영역 데이터에 대응되는 상이한 타입의 복수의 손실 값 각각의 출력 가중치 조건 및 타겟 가중치 조건 간 차이 값을 포함하며,
상기 제2 정보는,
트레이닝 샘플의 영역 데이터 및 연속적으로 변경되는 오브젝티브 데이터 간 상이한 타입의 복수의 손실 값을 포함하는, 전자 장치. - 제3항에 있어서,
상기 제2 정보는,
상기 제1 인공 지능 모델의 출력 이미지 및 타겟 고해상도 이미지 간 차이를 나타내는 픽셀 단위 오브젝티브 맵 손실, 재구성 손실 및 인지 손실을 포함하는, 전자 장치. - 제2항에 있어서,
상기 제2 인공 지능 모델은,
상기 저해상도 이미지에 대응되는 크기의 가중치 조건 맵을 예측하여 상기 제1 인공 지능 모델로 제공하며,
상기 제1 인공 지능 모델은,
복수의 SFT(spatial feature transform) 레이어를 포함하는 SR(Super Resolution) Branch 및 상기 가중치 조건 맵에 기초하여 상기 복수의 SFT 레이어에 대응되는 조건을 제공하는 Condition Branch로 구현되는, 전자 장치. - 제1항에 있어서,
상기 제1 인공 지능 모델은,
상기 저해상도 이미지에 포함된 복수의 영역 각각에 대한 오브젝티브(objective) 데이터의 최적 조합에 기초하여 상기 고해상도 이미지를 획득하며,
임의로 변경되는 조건 t에 기초하여 획득되는 임의의 가중치 조건 맵에 기초하여 획득되는 복수의 오브젝티브(objective) 데이터를 학습하도록 구현되는, 전자 장치. - 제6항에 있어서,
상기 하나 이상의 프로세서는,
상기 제2 인공 지능 모델을 이용하여 상기 저해상도 이미지에 포함된 상기 복수의 영역 각각에 대응되는 복수의 손실 값에 대한 가중치 조건 맵을 획득하고,
상기 제1 인공 지능 모델을 이용하여 상기 획득된 가중치 조건 맵에 대응되는 복수의 손실 값의 가중 합에 기초하여 상기 고해상도 이미지를 획득하는, 전자 장치. - 제6항에 있어서,
상기 하나 이상의 프로세서는,
상기 제2 인공 지능 모델을 이용하여 상기 조건 t를 제1 값에서 제2 값으로 단계적으로 변경하면서 각 픽셀에 대해 LPIPS(Learned Perceptual Image Patch Similarity)가 가장 낮은 t를 선택하여 타겟 가중치 조건 맵을 획득하며,
상기 제2 인공 지능 모델은,
상기 임의의 가중치 조건 맵 및 상기 타겟 가중치 조건 맵의 차이 값에 기초하여 학습되는, 전자 장치. - 제1항에 있어서,
상기 상이한 타입의 복수의 손실 값은,
재구성 손실(reconstruction loss), 적대 손실(adversarial loss), 인지 손실(perceptual loss) 또는 왜곡 손실(distortion loss) 중 적어도 하나에 따른 손실 값을 포함하는, 전자 장치. - 전자 장치의 제어 방법에 있어서,
제1 인공 지능 모델을 이용하여 임계 해상도 미만의 저해상도 이미지로부터 상기 임계 해상도 이상의 고해상도 이미지를 획득하는 단계; 및
상기 획득된 고해상도 이미지를 출력하는 단계;를 포함하며,
상기 제1 인공 지능 모델은,
상이한 타입의 복수의 손실(loss) 값의 가중 합으로 정의되며 연속적으로 변경되는 오브젝티브(objective) 데이터를 학습하도록 구현되며,
상기 제2 인공 지능 모델은,
상기 저해상도 이미지에 기초하여 상기 복수의 손실 값에 대응되는 가중치 조건을 식별하여 상기 제1 인공 지능 모델로 제공하도록 구현되는, 제어 방법. - 제10항에 있어서,
상기 제2 인공 지능 모델은,
상기 제2 인공 지능 모델의 출력 가중치 조건 및 타겟 가중치 조건을 포함하는 제1 정보 및, 상기 제1 인공 지능 모델의 출력 이미지 및 상기 오브젝티브 데이터를 포함하는 제2 정보에 기초하여 학습되는, 제어 방법. - 제11항에 있어서,
상기 제1 정보는,
트레이닝 샘플의 영역 데이터에 대응되는 상이한 타입의 복수의 손실 값 각각의 출력 가중치 조건 및 타겟 가중치 조건 간 차이 값을 포함하며,
상기 제2 정보는,
트레이닝 샘플의 영역 데이터 및 연속적으로 변경되는 오브젝티브 데이터 간 상이한 타입의 복수의 손실 값을 포함하는, 제어 방법. - 제12항에 있어서,
상기 제2 정보는,
상기 제1 인공 지능 모델의 출력 이미지 및 타겟 고해상도 이미지 간 차이를 나타내는 픽셀 단위 오브젝티브 맵 손실, 재구성 손실 및 인지 손실을 포함하는, 제어 방법. - 제11항에 있어서,
상기 제2 인공 지능 모델은,
상기 저해상도 이미지에 대응되는 크기의 가중치 조건 맵을 예측하여 상기 제1 인공 지능 모델로 제공하며,
상기 제1 인공 지능 모델은,
복수의 SFT(spatial feature transform) 레이어를 포함하는 SR(Super Resolution) Branch 및 상기 가중치 조건 맵에 기초하여 상기 복수의 SFT 레이어에 대응되는 조건을 제공하는 Condition Branch로 구현되는, 제어 방법. - 제10항에 있어서,
상기 제1 인공 지능 모델은,
상기 저해상도 이미지에 포함된 복수의 영역 각각에 대한 오브젝티브(objective) 데이터의 최적 조합에 기초하여 상기 고해상도 이미지를 획득하며,
임의로 변경되는 조건 t에 기초하여 획득되는 임의의 가중치 조건 맵에 기초하여 획득되는 복수의 오브젝티브(objective) 데이터를 학습하도록 구현되는, 제어 방법. - 제15항에 있어서,
상기 고해상도 이미지를 획득하는 단계는,
상기 제2 인공 지능 모델을 이용하여 상기 저해상도 이미지에 포함된 상기 복수의 영역 각각에 대응되는 복수의 손실 값에 대한 가중치 조건 맵을 획득하는 단계; 및
상기 제1 인공 지능 모델을 이용하여 상기 획득된 가중치 조건 맵에 대응되는 복수의 손실 값의 가중 합에 기초하여 상기 고해상도 이미지를 획득하는 단계;를 포함하는, 제어 방법. - 제15항에 있어서,
상기 고해상도 이미지를 획득하는 단계는,
상기 제2 인공 지능 모델을 이용하여 상기 조건 t를 제1 값에서 제2 값으로 단계적으로 변경하면서 각 픽셀에 대해 LPIPS(Learned Perceptual Image Patch Similarity)가 가장 낮은 t를 선택하여 타겟 가중치 조건 맵을 획득하는 단계;를 더 포함하며,
상기 제2 인공 지능 모델은,
상기 임의의 가중치 조건 맵 및 상기 타겟 가중치 조건 맵의 차이 값에 기초하여 학습되는, 제어 방법. - 제10항에 있어서,
상기 상이한 타입의 복수의 손실 값은,
재구성 손실(reconstruction loss), 적대 손실(adversarial loss), 인지 손실(perceptual loss) 또는 왜곡 손실(distortion loss) 중 적어도 하나에 따른 손실 값을 포함하는, 제어 방법. - 전자 장치의 프로세서에 의해 실행되는 경우 상기 전자 장치가 동작을 수행하도록 하는 컴퓨터 명령을 저장하는 비일시적 컴퓨터 판독 가능 매체에 있어서,
상기 동작은,
제1 인공 지능 모델을 이용하여 임계 해상도 미만의 저해상도 이미지로부터 상기 임계 해상도 이상의 고해상도 이미지를 획득하는 단계; 및
상기 획득된 고해상도 이미지를 출력하는 단계;를 포함하며,
상기 제1 인공 지능 모델은,
상이한 타입의 복수의 손실(loss) 값의 가중 합으로 정의되며 연속적으로 변경되는 오브젝티브(objective) 데이터를 학습하도록 구현되며,
상기 제2 인공 지능 모델은,
상기 저해상도 이미지에 기초하여 상기 복수의 손실 값에 대응되는 가중치 조건을 식별하여 상기 제1 인공 지능 모델로 제공하도록 구현되는, 비일시적 컴퓨터 판독 가능 매체.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/IB2023/060785 WO2024110799A1 (ko) | 2022-11-24 | 2023-10-26 | 전자 장치 및 그 제어 방법 |
| US19/169,581 US20250232405A1 (en) | 2022-11-24 | 2025-04-03 | Electronic device and control method therefor |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020220159109 | 2022-11-24 | ||
| KR20220159109 | 2022-11-24 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20240077363A true KR20240077363A (ko) | 2024-05-31 |
Family
ID=91330591
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020230005910A Pending KR20240077363A (ko) | 2022-11-24 | 2023-01-16 | 전자 장치 및 그 제어 방법 |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR20240077363A (ko) |
-
2023
- 2023-01-16 KR KR1020230005910A patent/KR20240077363A/ko active Pending
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12412242B2 (en) | Electronic device, control method thereof, and system | |
| US11861809B2 (en) | Electronic apparatus and image processing method thereof | |
| CN113034358B (zh) | 一种超分辨率图像处理方法以及相关装置 | |
| JP6978542B2 (ja) | 電子装置及びその制御方法 | |
| US11836890B2 (en) | Image processing apparatus and image processing method thereof | |
| KR102246954B1 (ko) | 영상 처리 장치 및 그 영상 처리 방법 | |
| US11790564B2 (en) | Encoders for improved image dithering | |
| KR20240077363A (ko) | 전자 장치 및 그 제어 방법 | |
| US20230386057A1 (en) | Electronic apparatus and image processing method thereof | |
| US20250232405A1 (en) | Electronic device and control method therefor | |
| US11436442B2 (en) | Electronic apparatus and control method thereof | |
| KR20210108027A (ko) | 전자 장치 및 그 제어 방법 | |
| US20250363592A1 (en) | Electronic device and image processing method therefor | |
| US20250285235A1 (en) | Electronic device and operating method of the same | |
| US20250308007A1 (en) | Electronic device and image processing method thereof | |
| EP4734057A1 (en) | Electronic device and control method therefor | |
| KR20250024473A (ko) | 전자 장치 및 그 제어 방법 | |
| KR20240115657A (ko) | 전자 장치 및 이의 제어 방법 | |
| CN120318069A (zh) | 用于生成超分辨率图像的方法、设备和计算机程序产品 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application |
Patent event code: PA01091R01D Comment text: Patent Application Patent event date: 20230116 |
|
| PG1501 | Laying open of application |