TW201804345A - 基於結構化網路知識的自動中文本體庫建構方法、系統及電腦可讀媒體 - Google Patents
基於結構化網路知識的自動中文本體庫建構方法、系統及電腦可讀媒體 Download PDFInfo
- Publication number
- TW201804345A TW201804345A TW106125119A TW106125119A TW201804345A TW 201804345 A TW201804345 A TW 201804345A TW 106125119 A TW106125119 A TW 106125119A TW 106125119 A TW106125119 A TW 106125119A TW 201804345 A TW201804345 A TW 201804345A
- Authority
- TW
- Taiwan
- Prior art keywords
- concept
- aforementioned
- interest
- chinese text
- text corpus
- Prior art date
Links
Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Machine Translation (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
本發明提供一種基於結構化網路知識的自動中文本體庫建構的方法、系統及電腦可讀媒體。前述方法包括步驟:從結構化知識網路抓取結構化知識,其中結構化知識包括至少一個關注概念用於前述自動中文本體庫的生成;過濾無關的鏈結;提取有關所關注概念的知識;發現前述關注概念的相關聯概念;基於餘弦相似性度量推斷前述關注概念及其相關聯概念之間的語義相關性;並且儲存推斷出的前述語義相關性數據。本發明提供更有效率的自動中文本體庫生成的系統及方法,以應對快速發展的數位世界並迎合數據用戶的需求。
Description
本發明關於自動生成本體庫的方法及系統,特別是基於結構化網路知識自動中文本體庫建構。
在訊息技術的時代,大量的數據每天被上載至網路、企業計算機網路或其他資料庫或者從此等之處被下載。數據用戶總是期待從網路、企業計算機網路或資料庫獲得他們所需要的各種訊息,但是並非每次均能獲得正確的訊息。本體表示的是不同概念之間特有的相似性及連接關係,可以用來幫助對網路、企業計算機網路或任何其他資料庫獲得的訊息或文件進行語義搜索。
傳統的本體生成通常是專家通過手動輸入概念之間的關係來完成的,因此需要耗費許多人力。當前,不同的計算機實現程式,諸如人工神經網路(ANN)可以用於發現語料庫中詞語之間的語義相關性。然而,ANN需要預先進行訓練,因此仍然需要大量人力準備具有多種輸入模式的數據。因此採用ANN可能未必能夠有效的跟上網路、企業計算機網路或任
何資料庫數據的更新速度。
本體可以從各種語言的知識中產生。無論運用何種語言,使用者必須以該種語言來處理語料庫並且提煉關鍵字段用於本體生成。某些語言諸如中文,在詞語之間沒有明確的分隔符,與英文相比在語言處理方面更加困難或復雜,使關鍵詞提取更困難。因此,中文文字語料庫的語義內容很不容易理解。自然語言處理(NLP)和潛在語義分析(LSA)在計算機科學中被用於涉及計算機和人類語言之間互動的領域。結合NLP和LSA可對中文文字語料庫進行詞法、語法、句法和語義分析。這種分析特別涉及詞語切分、詞性標註、詞例提煉、統計分析和詞例相關性的確定。然而,由於中文語言的復雜性,NLP和LSA可能未必有效且準確地提煉用於本體生成的正確關鍵詞或概念。
總之,需要一種更有效率的系統和方法,理想地需要一種電腦自動實現的方法和系統,用於中文本體庫生成,以應對快速發展的數據世界和滿足數據用戶的需求。
利用結構化網路知識可以自動中文本體庫建構。結構化網路知識是儲存在網路上的結構化訊息資料庫。例如,具有許多基於網路的中文百科全書,諸如百度百科和中文維基百科,這些是流行的由幾百萬條文章組成的公眾知識庫。每條文章包含一個主題,該主題通常由具有該主題知識的數據用戶手工編輯。如果發現錯誤或者無效的訊息,可以向基於網
路的百科全書的主辦方匯報,以糾正那些錯誤或無效的訊息。因此每個主題可以被認為是手工編輯的,並且由專家刪選的,因此可以被認為是該主題的專家意見。在用於生成本體時,每個主題可以被進一步當作一個概念。此外,數據用戶可以通過在文章中插入鏈結展示相關聯的文章。這種鏈結可以被認為是概念中的結合點,因此表示不同概念之間的語義關係。由於結構化的網路知識是基於包括眾多數量的概念以及概念之間的關係而建立的,與ANN需要預先訓練不同,使用結構化網路知識的生成本體可以自動完成,而無需大量的人力準備數據。因此,本發明不需要任何人力介入,因此在本體生成方面更有效率。
由於中文語言在詞語之間沒有明確的分隔符,生成中文本體庫中提煉的知識的準確性通常依賴於句子分割的方式以及選擇哪些詞例進行提煉。生成中文本體庫通常使用NLP和LSA進行知識提取。NLP和LSA是計算機執行的程式,這些程式進行中文文字語料庫的詞法、語法、句法和語義分析。NLP和LSA可以被認為使用計算機語言對人的語言進行理解,並且與中文母語的人對中文語料庫的理解相比,這種理解可能不夠準確有效。考慮到這一點,本發明使用結構化知識網路中的超鏈結來發現相關聯的概念,以有效地提取中文知識。由於這些超鏈結已經被專家審查過,因此可以認為它們能更準確地描述概念之間的關係。
下文描述的是一種用於基於結構化的網路知識自動中文本體庫建構的方法及電腦可讀媒體,其編碼在處理器執行時能使處理器實現
該方法的指示,包括下列步驟,從一結構化知識網路中抓取結構化知識,其中的結構化知識包括至少一個用於自動中文本體庫生成所關注的概念;過濾無關的鏈結;提取與前述所關注的概念相關的知識;發現前述所關注的概念的相關聯概念;通過餘弦相似性的度量推斷出前述所關注的概念以及其相關聯概念的語義相關性;並且儲存推斷出的前述語義相關性數據。
理想地,從結構化知識網路抓取的結構化知識的步驟包括下列步驟:通過超文本傳輸協議(“HTTP”)協議瀏覽前述的結構化知識;使用廣度優先搜索方法訪問結構化知識分類頁中的超鏈結,直到訪問完所有鏈結的中文文本語料;從前述結構化知識網路取得至少一個中文文本語料,其中前述中文文本語料的主題、摘要和內容由包含前述中文文本語料的靜態超文本標記語言(“HTML”)頁面中的HTML頭部,標題和主體標簽來確定;並且對取得的每個中文文本語料生成鏈結記錄。
進一步,從結構化知識網路抓取的結構化知識的步驟包括下列步驟:對取得的每個中文文本語料生成唯一標識符。
進一步,從結構化知識網路中抓取的結構化知識的步驟包括下列步驟:對取得的每個中文文本語料儲存網址(“URL”),標識符及/或最後修改時間。
進一步,從結構化知識網路中抓取的結構化知識的步驟包括下列步驟:以預先設定的時間間隔掃描所有取得的中文文本語料;通過檢索是否存在具有相同最後修改時間的匹配記錄來產生或更新中文文本語料記錄;並且消除所有重復的中文文本語料。
進一步,消除重復的中文文本語料的步驟包括下列步驟:對
每個中文文本語料僅保留一個識別符;並且將相同中文文本語料所有其他不同的識別符轉換為重定向識別符。
理想地,過濾無關鏈結的步驟包括下列步驟:對連接到外部網頁的無關鏈結、訪問菜單中不涉及前述所關注的概念知識的無關鏈結、以及在前述結構化知識網路中重復出現的鏈結進行噪聲過濾。
理想地,提取與前述所關注的概念相關的知識的步驟包括下列步驟:從描述所關注概念的中文文本語料中提取相關名詞術語。
理想地,發現前述所關注的概念的相關聯概念的步驟包括如下步驟:從所關注的概念的中文文本語料中提取超鏈結列表,其中每個超鏈結的中文文本語料表示與前述所關注的概念相關的概念。
理想地,通過餘弦相似性的度量推斷出前述所關注的概念以及其相關聯概念的語義相關性的步驟包括如下步驟:計算前述所關注概念的術語頻率權重向量V1;訪問前述所關注概念的中文文本語料中的超級鏈結,從而定位前述所關注的概念的相關聯概念;計算每個前述相關聯概念的術語頻率權重向量,其中每個前述相關聯概念的前述術語頻率權重向量代表每個相關聯概念的唯一語義;並計算所關注概念和每個相關聯概念的術語頻率權重向量之間的餘弦相似性。
進一步,由下列方程來計算術語頻率權重向量V1:V1=(tf(t1,c1),tf(t2,c1),....tf(tn,c1))
其中tf(t1,c1)為所關注概念c1的中文文本語料中的第一個相關術語的術語頻率;tf(t2,c1)為所關注概念c1的中文文本語料中的第二個相關術語的術語
頻率;並且tf(tn,c1)為所關注概念c1的中文文本語料中的第n個相關術語的術語頻率。
進一步,由下列方程來計算每個相關聯概念的術語頻率權重向量:V2=(tf(t1,c2),tf(t2,c2),....tf(tn,c2))
其中V2為相關聯概念c2的術語頻率權重向量;tf(t1,c2)為前述相關聯概念c2的中文文本語料中的第一個相關術語的術語頻率;tf(t2,c2)為前述相關聯概念c2的中文文本語料中的第二個相關術語的術語頻率;並且tf(tn,c2)為前述相關聯概念c2的中文文本語料中的第n個相關術語的術語頻率。
此外,由下列方程來計算所關注的概念及每個相關聯概念的術語頻率權重向量之間的餘弦相似性的步驟:

其中V1和V2分別為所關注概念c1和相關聯概念c2的術語頻率權重向量。
此外,儲存推斷出的前述語義相關性數據的步驟包括:用網路本體語言儲存語義相關性;並對前述語義相關性的訊息建立索引。
理想地,使用的網路本體語言是資源描述框架(“RDF”)。
理想地,對前述語義相關性的訊息建立索引的步驟包括建立
包括所關注概念、相關聯概念、相關聯概念的數量和RDF圖標的概念圖。
理想地,從結構化知識網路抓取結構化知識的步驟包括下列步驟:從基於網路的中文百科全書中抓取結構化知識。
理想地,從結構化知識網路抓取結構化知識的步驟包括下列步驟:從百度百科或中文維基百科抓取結構化知識。
另外關於一種基於結構化網路知識自動中文本體庫建構的系統,包括:網路爬行模組,配置為從結構化知識網路抓取結構化知識;噪聲過濾模組,配置為過濾無關鏈結;知識提取模組,配置為提取中文文本語料中與所關注的概念相關的知識;儲存從結構化網路知識中下載的中文文本語料的資料庫;以及關係發現模組,配置為提取所關注概念的相關聯概念,並且利用餘弦相似性的度量計算所關注的概念和相關聯的概念之間的語義相關性。
理想地,該無關鏈結是連接到外部網頁的無關鏈結、訪問菜單中不涉及前述所關注的概念知識的無關鏈結、以及在前述結構化知識網路中重復出現的鏈結。
此外,該系統包括一顯示概念圖的可視化界面,其中前述概念圖包括所關注的概念,相關聯概念,相關聯概念的數量和RDF圖標,其中相關聯概念的數量為涉及前述所關注概念的前述相關聯概念的總數,前述的RDF圖標允許用戶下載前述所關注概念的RDF三元組。
理想地,語義相關性由RDF所編碼。
本發明提供一種更有效率的自動中文本體庫生成的系統及方法,以應對快速發展的數位世界並迎合數據用戶的需求。
1‧‧‧靜態HTML網頁
2‧‧‧基於結構化網路知識自動中文本體庫建構的系統
21‧‧‧網路爬行模組
22‧‧‧噪聲過濾模組
23‧‧‧知識提取模組
24‧‧‧資料庫
25‧‧‧關係發現模組
26‧‧‧可視化模組
51‧‧‧關注的概念
52‧‧‧相關聯概念
【圖1】為基於結構化網路知識自動中文本體庫建構的系統的可能實施方式的方框圖。
【圖2】為展示基於結構化網路知識自動中文本體庫建構主要步驟的流程圖。
【圖3】為展示關係發現的進一步步驟的流程圖。
【圖4】為概念「三國」的概念圖。
【圖5】為以RDF格式顯示的主題和相互語義相關性。
參照附圖中所示的示例,具體描述示範性實施方式的細節,其中全文相似的附圖標記涉及相似的元素。
僅通過示意性的方式,附圖及以下描述較佳的實施方式。應該註意到的是,根據下文的討論,這裏公開的結構和方法的替代實施方式將毫無疑問地被認為是可行的替代方案,不會偏離要求保護的原則。
在此所記載之系統、方法及電腦可讀媒體的實施方式基於結構化的網路知識自動中文本體庫建構。
從圖1中可見,基於結構化網路知識自動中文本體庫建構的系統2包括網路爬行模組21,噪聲過濾模組22,知識提取模組23,資料庫24,
關係發現模組25和可視化模組26。圖2中展示基於結構化的網路知識自動中文本體庫建構的流程圖。
在步驟S21,可以通過網路爬行模組21,從網路抓取諸如基於網路的中文百科全書的結構化知識網路的靜態HTML網頁1。例如,基於網路的中文百科全書可以是著名的百度百科和中文維基百科。每個靜態HTML網頁1描述一個特定概念,並且有連到相關網頁的鏈結。為了從結構化知識網頁抓取所有的靜態HTML網頁1(包括所有鏈結的網頁),網路爬行模組21通過HTTP協議瀏覽結構化知識網路中的目錄,並使用廣度優先搜索方法訪問目錄網頁中的超鏈結,直到所有鏈結的目錄均被訪問。網路爬行模組21接著從鏈結的靜態HTML網頁1中僅取得並提取中文文本語料,其中主題、摘要和內容由被取得的靜態HTML頁面上的HTML標簽(例如頭部,標題和主體標簽)來確定。
下文描述了網路爬行模組21一種可能的實施方式。網路爬行模組21可使用正規表示法"<a(.*?)</a>"從結構化的知識網路中找到所有可能的鏈結,對每個取得的中文文本語料建立鏈結記錄、並將該鏈結記錄和取得的中文文本語料存入資料庫24中。每個從抓取的靜態HTML網頁1中取得的中文文本語料可以由該被抓取的靜態HTML網頁1的網址來識別。為了便於識別,基於代表該中文文字語料的網址(“URL”),可為該中文文字語料生成唯一的識別符。例如,如果從URL為http://baike.baidu.com/view/2347.htm抓取的靜態HTML網頁1中取得了中文文本語料A,那麽該中文文本語料A將具有的標識符為2347。如果從URL為http://baike.baidu.com/view/10088.htm抓取的的靜態HTML網頁1取得了中文
文本語料B,那麽該該中文文本語料B將具有的標識符為10088。將每個中文文本語料的URL,標識符和最後修改時間儲存在資料庫24中。
網路爬行模組21以預先設定的時間間隔掃描所有下載的中文文本,通過檢索下載的中文文本語料的最後修改時間是否與現存鏈結記錄中的最後修改時間是否相匹配,來建立或者更新儲存的鏈結記錄。網路爬行模組21還可以在兩個或多個抓取的具有不同網址的靜態HTML網頁1中掃描並找出相同的中文文本語料。例如,相同的中文文本語料可能存在於抓取的具有以下不同網址的靜態HTML網頁1的瀏覽頁和子瀏覽頁下:(瀏覽頁下)http://baike.baidu.com/view/1005619.htm(子瀏覽頁下)http://baike.baidu.com/subview/1005619/1005619.htm這種從不同網址取得的中文文本語料的複製將產生不同的識別符並使標識符不唯一。為了消除資料庫24中重復的中文文本語料,網路爬行模組21可將次瀏覽頁中的中文文本語料的標識符定為一個重定向標識符,將該中文文本語料重定向至瀏覽頁下的標識符。因此,每個中文文本語料只有一個標識符,從而保持鏈結記錄中標識符的唯一性。
總之,網路爬行模組21能掃描所有用上述正規表示法提取的鏈結記錄,通過<a>標簽中匹配的“href”屬性值從鏈結中提取標識符,將該標識符用於尋找資料庫24記錄的儲存在語料中的唯一標識符,並在鏈結記錄重定向標識符存在時對其進行更新。接著,在資料庫24中建立所有下載的中文文本語料的鏈結記錄。
在步驟S22,噪聲過濾模組22過濾所有連接到外部網頁的無關鏈結、與中文文本語料中描述的知識無關的訪問菜單中的無關鏈結,和
結構化知識網路中重復出現的鏈結。
每個取得的中文文本語料可以代表一個概念,並且這個概念經常是該中文文本語料的主題。概念是一個抽象的想法。通過審視與該概念相關的細節訊息,與這個概念相關的事件、人物、物體、地點、時間、特性和特點等等,人們能夠理解這個概念。所有上述訊息均可以認為是概念的知識。在步驟S23,知識提取模組23提取中文文本語料中的概念知識。有很多提取概念知識的方法。其中一個方法是,提取描述這個概念的中文文本語料中的相關名詞術語。可以理解的是,不偏離本發明的精神和範圍,可以採取從所有已知或今後發展的手段中衍生出的任何本質上準確的知識提取措施。
從中文文本語料中提取的知識可以用於計算前述中文文本語料的術語頻率權重向量。既然每個中文文本語料代表一個概念,中文文本語料的術語頻率權重向量也可以是一個概念的術語頻率權重向量。V1是所關注概念c1的術語頻率權重向量,並且計算如下:V1=(tf(t1,c1),tf(t2,c1),....tf(tn,c1))
其中tf(t1,c1)為所關注概念c1的中文文本語料中的第一個相關術語的術語頻率;tf(t2,c1)為所關注概念c1的中文文本語料中的第二個相關術語的術語頻率;並且tf(tn,c1)為所關注概念c1的中文文本語料中的第n個相關術語的術語頻率。
中文文本語料中具有連接到其他中文文本語料的超鏈結。這
些超鏈結中文文本語料代表與原始所關注概念相關聯的概念。在步驟S24,關係發現模組25通過計算中文文本語料(代表所關注的概念)和超鏈結文本語料(代表相關聯的概念)上得到的術語頻率權重向量,和計算中文文本語料和超鏈結中文文本語料術語頻率權重向量的餘弦相似性來發現概念之間的聯繫。
如圖3中進一步說明的,對關係發現模組25一個可能的實施方式進行如下描述。在步驟S31,執行從概念c1的已抓取的靜態HTML網頁1提取超鏈結列表的步驟。中文文本語料中的每個超鏈結代表一個相關聯的概念。在步驟S32,通過訪問所關注概念的中文文本語料中找到的超鏈結,識別相關聯的概念。還可以找到相關聯概念的相應術語頻率權重向量。例如,可以在所關注概念c1的中文文本語料中找到的相關聯概念c2和c3,而相關聯概念c2和c3的術語頻率權重向量可以進行如下計算:V2=(tf(t1,c2),tf(t2,c2),....tf(tn,c2))
V3=(tf(t1,c3),tf(t2,c3),....tf(tn,c3))其中V2是相關聯概念c2的術語頻率權重向量;V3是相關聯概念c3的術語頻率權重向量;tf(t1,c2)為相關聯概念c2的中文文本語料中的第一個相關術語的術語頻率;tf(t2,c2)為相關聯概念c2的中文文本語料中的第二個相關術語的術語頻率;並且tf(tn,c2)為相關聯概念c2的中文文本語料中的第n個相關術語的術語頻率;
tf(t1,c3)為相關聯概念c3的中文文本語料中的第一個相關術語的術語頻率;tf(t2,c3)為相關聯概念c3的中文文本語料中的第二個相關術語的術語頻率;並且tf(tn,c3)為相關聯概念c3的中文文本語料中的第n個相關術語的術語頻率;在步驟S33,每個相關聯的概念就具有代表其唯一語義的術語頻率權重向量。在步驟S34,由餘弦相似性度量來推斷相關聯概念的語義相關性。通過一個概念和其相關聯概念的餘弦相似性可以推斷這兩個概念之間的相近程度,即度量一個概念和相關聯概念的術語頻率權重向量的餘弦角:
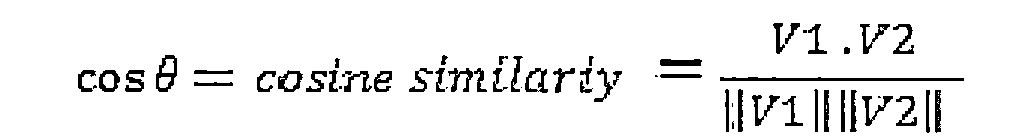
其中V1和V2分別是所關注概念c1和相關聯概念c2的術語頻率權重向量。
如果兩個概念之間的餘弦相似性接近1,那麽這兩個概念之間的內容很大程度上彼此相似。換句話說,這兩個概念很大程度上可能是語義相關的。如果兩個概念之間的餘弦相似性等於0,那麽這兩個概念具有完全不同的內容,意味著從語義角度來說可能是完全無關的。因此餘弦相似性有助於相關聯概念相似性的量化。
從資料庫24中能取得所有的中文文本語料記錄,其中每一個代表一個概念,並且計算每個中文文本語料的術語頻率權重向量。推導出每個中文文本語料記錄和所有與其通過超鏈結相連的中文文本語料記錄之
間的餘弦相似性。主要的主體可以由正式語言進行編碼,例如網路本體語言“OWL”,資源描述框架(“RDF”或“RDFS”)。也可以使用其他本體語言。在本實施方式中,如圖5所示,中文文本語料轉換為RDF三元組。所有具有術語頻率權重的相關聯概念也以RDF三元組的方式被記錄下來。例如,具有語義相關性的中文文本語料的所有相關聯的概念以RDF格式在步驟S35進行儲存,而在步驟S36為具有語義相關性訊息的RDF文件建立索引。生成的RDF三元組和儲存的RDF數據可以用於進一步的查詢和操作。
為了便於在生成中文本體庫時進行概念的檢索,可以建立標題和摘要的索引。可以通過度量概念的相關性來實現概念檢索和展示相關聯概念在概念圖中。
在一個實施方式中,以如圖4中顯示的概念圖用戶界面的形式,系統2包括可視化界面26,從而便於展開搜索。可視化界面26展示一個概念圖,其中所關注的概念51(即本實施方式中指“三國”)展示在圖中央,周邊展示所有相關聯的概念52。所關注的概念51下的一個數字代表與所關注概念51相關聯概念52的總數目。如圖4所顯示的,與“三國”相關聯的概念共有707個。該可視化界面26還可以展示RDF圖標,允許用戶下載所關注概念51的RDF三元組。不偏離本公開的範圍,所關注的概念、相關聯概念、RDF圖標數目的位置和方向可以變化。
在此提供特別參考示例性實施方式的描述和示例,但是可以理解的是在申請專利範圍的精神和範圍下的變體和修正也是有效的。上述具體實施方式展示說明書可能的範圍,但不限於該公開的範圍。
1‧‧‧靜態HTML網頁
2‧‧‧基於結構化網路知識自動中文本體庫建構的系統
21‧‧‧網路爬行模組
22‧‧‧噪聲過濾模組
23‧‧‧知識提取模組
24‧‧‧資料庫
25‧‧‧關係發現模組
26‧‧‧可視化模組
Claims (42)
- 一種用於基於結構化網路知識自動中文本體庫建構之方法,其特徵係包括下列步驟:從結構化知識網路中抓取的結構化知識,其中結構化的知識包括至少一個所關注的概念用於自動中文本體庫建構;過濾無關的鏈結;提取與前述所關注的概念相關的知識;發現前述所關注的概念的相關聯概念;通過餘弦相似性的度量推斷出前述所關注的概念以及其相關聯概念的語義相關性;並且儲存推斷出的前述語義相關性數據。
- 如申請專利範圍第1項所記載之方法,其中,從結構化知識網路中抓取的結構化知識的步驟包括下列步驟:通過前述結構化知識的超文本傳輸協議(“HTTP”)協議進行瀏覽;使用廣度優先搜索方法訪問結構化知識的分類頁,直到訪問所有鏈結的中文文本語料;從前述結構化知識網路取得至少一個中文文本語料,其中前述中文文本語料的主題、摘要及內容由包含前述中文文本語料的靜態超文本標記語言(“HTML”)頁面上展示的HTML頭部,標題及主體標簽來確定;並且對取得的每個中文文本語料生成鏈結記錄。
- 如申請專利範圍第2項所記載之方法,其中,進一步包括下列步驟:對取得的每個中文文本語料生成唯一標識符。
- 如申請專利範圍第3項所記載之方法,其中,進一步包括下列步驟:對取得的每個中文文本語料儲存網址(“URL”),標識符及/或最後修改時間。
- 如申請專利範圍第4項所記載之方法,其中,進一步包括下列步驟:以預先設定的時間間隔掃描所有取得的中文文本語料;通過檢索是否存在具有相同的最後修改時間的匹配記錄來產生或更新中文文本語料記錄;並且消除所有重復的中文文本語料。
- 如申請專利範圍第5項所記載之方法,其中,前述消除所有重復的中文文本語料的步驟包括下列步驟:對每個中文文本語料僅保留一個識別符;並且將相同中文文本語料所有其他不同的識別符轉換為重定向識別符。
- 如申請專利範圍第1項所記載之方法,其中,前述過濾無關鏈結的步驟包括下列步驟:對連接到外部網頁的無關鏈結、訪問菜單中不涉及前述所關注的概念知識的無關鏈結、以及在前述結構化知識網路中重復出現的鏈結進行噪聲過濾。
- 如申請專利範圍第1項所記載之方法,其中,前述提取與前述所關注的概念相關的知識的步驟包括下列步驟:從描述所關注概念的中文文本語料中提取相關名詞術語。
- 如申請專利範圍第1項所記載之方法,其中,發現前述所關注的概念的相關聯概念的步驟包括如下步驟:從所關注的概念的中文文本語料中提取 超鏈結列表,其中每個超鏈結的中文文本語料表示與前述所關注的概念相關的概念。
- 如申請專利範圍第1項所記載之方法,其中,前述通過餘弦相似性的度量推斷出前述所關注的概念以及其相關聯概念的語義相關性的步驟包括如下步驟:計算前述所關注概念的術語頻率權重向量V1;訪問前述所關注概念的中文文本語料中的超鏈結,從而定位前述所關注的概念的相關聯概念;計算每個前述相關聯概念的術語頻率權重向量,其中每個前述相關聯概念的前述術語頻率權重向量代表每個相關聯概念的唯一語義;並且計算所關注概念及每個相關聯概念的術語頻率權重向量之間的餘弦相似性。
- 如申請專利範圍第10項所記載之方法,其中,前述計算術語頻率權重向量V1的步驟由下列方程來實現:V1=(tf(t1,c1),tf(t2,c1),....tf(tn,c1))其中tf(t1,c1)為所關注概念c1的中文文本語料中的第一個相關術語的術語頻率;tf(t2,c1)為所關注概念c1的中文文本語料中的第二個相關術語的術語頻率;並且tf(tn,c1)為所關注概念c1的中文文本語料中的第n個相關術語的術語頻率。
- 如申請專利範圍第10項所記載之方法,其中,每個相關聯概念的術語頻 率權重向量的步驟由下列方程來實現:V2=(tf(t1,c2),tf(t2,c2),....tf(tn,c2))其中V2為相關聯概念c2的術語頻率權重向量;tf(t1,c2)為前述相關聯概念c2的中文文本語料中的第一個相關術語的術語頻率;tf(t2,c2)為前述相關聯概念c2的中文文本語料中的第二個相關術語的術語頻率;並且tf(tn,c2)為前述相關聯概念c2的中文文本語料中的第n個相關術語的術語頻率。
- 如申請專利範圍第10項所記載之方法,其中,由下列方程來計算所關注的概念及每個相關聯概念的術語頻率權重向量之間的餘弦相似性的步驟:

- 如申請專利範圍第1項所記載之方法,其中,儲存推斷出的前述語義相關性數據的步驟包括:用網路本體語言儲存語義相關性;並且對前述語義相關性的訊息建立索引。
- 如申請專利範圍第14項所記載之方法,其中,前述網路本體語言是資源描述框架(“RDF”)。
- 如申請專利範圍第14項所記載之方法,其中,前述對前述語義相關性的訊息建立索引的步驟包括:建立包括所關注概念、相關聯概念、相關聯概念的數量及RDF圖標的概念圖。
- 如申請專利範圍第1項所記載之方法,其中,前述從結構化知識網路抓取結構化知識的步驟包括下列步驟:從基於網路的中文百科全書抓取的結構化知識。
- 如申請專利範圍第1項所記載之方法,其中,前述從結構化知識網路抓取結構化知識的步驟包括下列步驟:從百度百科或中文維基百科抓取結構化知識。
- 一種基於結構化網路知識自動中文本體庫建構之系統,其特徵係包括:網路爬行模組,配置為從結構化知識網路抓取結構化知識;噪聲過濾模組,配置為過濾無關鏈結;知識提取模組,配置為提取中文文本語料中與所關注的概念相關的知識;儲存從結構化網路知識中下載的中文文本語料的資料庫;以及關係發現模組,配置為提取所關注概念的相關聯概念,並且利用餘弦相似性的度量計算所關注的概念和相關聯的概念之間的語義相關性。
- 如申請專利範圍第19項所記載之系統,其中,前述無關鏈結是連接到外部網頁的無關鏈結、訪問菜單中不涉及前述所關注的概念知識的無關鏈結、以及在前述結構化知識網路中重復出現的鏈結。
- 如申請專利範圍第19項所記載之系統,其中,進一步包括顯示概念圖的可視化界面,其中前述概念圖包括所關注的概念,相關聯概念,相關聯概念的數量和RDF圖標。
- 如申請專利範圍第21項所記載之系統,其中,前述相關聯概念的數量為涉及前述所關注概念的前述相關聯概念的總數。
- 如申請專利範圍第21項所記載之系統,其中,前述RDF圖標允許用戶下載前述所關注概念的RDF三元組。
- 如申請專利範圍第19項所記載之系統,其中,前述語義相關性由RDF所編碼。
- 一種電腦可讀媒體,其特徵係其編碼在處理器執行時能使處理器實現一方法的指示,該方法包括下列步驟:從結構化知識網路中抓取結構化知識,其中結構化的知識包括至少一個所關注的概念用於自動中文本體庫建構;過濾無關的鏈結;提取與前述所關注的概念相關的知識;發現前述所關注的概念的相關聯概念;通過餘弦相似性的度量推斷出前述所關注的概念以及其相關聯概念的語義相關性;並且儲存推斷出的前述語義相關性數據。
- 如申請專利範圍第25項所記載之電腦可讀媒體,其中,從結構化知識網路中抓取的結構化知識的步驟包括下列步驟:通過前述結構化知識的超文本傳輸協議(“HTTP”)協議進行瀏覽;使用廣度優先搜索方法訪問結構化知識的分類頁,直到訪問所有鏈結的中文文本語料;從前述結構化知識網路取得至少一個中文文本語料,其中前述中文文本語料的主題、摘要及內容由包含前述中文文本語料的靜態超文本標記語言(“HTML”)頁面上展示的HTML頭部,標題及主體標簽來確定;並且 對取得的每個中文文本語料生成鏈結記錄。
- 如申請專利範圍第26項所記載之電腦可讀媒體,其中,前述方法進一步包括下列步驟:對取得的每個中文文本語料生成唯一標識符。
- 如申請專利範圍第27項所記載之電腦可讀媒體,其中,前述方法進一步包括下列步驟:對取得的每個中文文本語料儲存網址(“URL”),標識符及/或最後修改時間。
- 如申請專利範圍第28項所記載之電腦可讀媒體,其中,前述方法進一步包括下列步驟:以預先設定的時間間隔掃描所有取得的中文文本語料;通過檢索是否存在具有相同的最後修改時間的匹配記錄來產生或更新中文文本語料記錄;並且消除所有重復的中文文本語料。
- 如申請專利範圍第29項所記載之電腦可讀媒體,其中,前述轉化中文文本語料副本的步驟包括下列步驟:對每個中文文本語料僅保留一個識別符;並且將相同中文文本語料所有其他不同的識別符轉換為重定向識別符。
- 如申請專利範圍第25項所記載之電腦可讀媒體,其中,前述過濾無關鏈結的步驟包括下列步驟:對連接到外部網頁的無關鏈結、訪問菜單中不涉及前述所關注的概念知識的無關鏈結、以及在前述結構化知識網路中重復出現的鏈結進行噪聲過 濾。
- 如申請專利範圍第25項所記載之電腦可讀媒體,其中,前述提取與前述所關注的概念相關的知識的步驟包括下列步驟:從描述所關注概念的中文文本語料中提取相關名詞術語。
- 如申請專利範圍第25項所記載之電腦可讀媒體,其中,發現前述所關注的概念的相關聯概念的步驟包括如下步驟:從所關注的概念的中文文本語料中提取超鏈結列表,其中每個超鏈結的中文文本語料表示與前述所關注的概念相關的概念。
- 如申請專利範圍第25項所記載之電腦可讀媒體,其中,前述通過餘弦相似性的度量推斷出前述所關注的概念以及其相關聯概念的語義相關性的步驟包括如下步驟:計算前述所關注概念的術語頻率權重向量V1;訪問前述所關注概念的中文文本語料中的超級鏈結,從而定位前述所關注的概念的相關聯概念;計算每個前述相關聯概念的術語頻率權重向量,其中每個前述相關聯概念的前述術語頻率權重向量代表每個相關聯概念的唯一語義;並且計算所關注概念和每個相關聯概念的術語頻率權重向量之間的餘弦相似性。
- 如申請專利範圍第34項所記載之電腦可讀媒體,其中,前述計算術語頻率權重向量V1的步驟由下列方程來實現:V1=(tf(t1,c1),tf(t2,c1),....tf(tn,c1))其中tf(t1,c1)為所關注概念c1的中文文本語料中的第一個相關術語的術 語頻率;tf(t2,c1)為所關注概念c1的中文文本語料中的第二個相關術語的術語頻率;並且tf(tn,c1)為所關注概念c1的中文文本語料中的第n個相關術語的術語頻率。
- 如申請專利範圍第34項所記載之電腦可讀媒體,其中,每個相關聯概念的術語頻率權重向量的步驟由下列方程來實現:V2=(tf(t1,c2),tf(t2,c2),....tf(tn,c2))其中V2為相關聯概念c2的術語頻率權重向量;tf(t1,c2)為前述相關聯概念c2的中文文本語料中的第一個相關術語的術語頻率;tf(t2,c2)為前述相關聯概念c2的中文文本語料中的第二個相關術語的術語頻率;並且tf(tn,c2)為前述相關聯概念c2的中文文本語料中的第n個相關術語的術語頻率。
- 如申請專利範圍第34項所記載之電腦可讀媒體,其中,由下列方程來計算所關注的概念及每個相關聯概念的術語頻率權重向量之間的餘弦相似性的步驟:

- 如申請專利範圍第25項所記載之電腦可讀媒體,其中,儲存推斷出的前述語義相關性數據的步驟包括: 用網路本體語言儲存語義相關性;並且對前述語義相關性的訊息建立索引。
- 如申請專利範圍第38項所記載之電腦可讀媒體,其中,前述網路本體語言是資源描述框架(“RDF”)。
- 如申請專利範圍第38項所記載之電腦可讀媒體,其中,前述對前述語義相關性的訊息建立索引的步驟包括:建立包括所關注概念、相關聯概念、相關聯概念的數量和RDF圖標的概念圖。
- 如申請專利範圍第25項所記載之電腦可讀媒體,其中,前述從結構化知識網路抓取結構化知識的步驟包括下列步驟:從基於網路的中文百科全書抓取的結構化知識。
- 如申請專利範圍第25項所記載之電腦可讀媒體,其中,前述從結構化知識網路抓取結構化知識的步驟包括下列步驟:從百度百科或中文維基百科抓取結構化知識。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| HK16109078.8A HK1220319A2 (zh) | 2016-07-29 | 2016-07-29 | 基於结构化网络知识的自动中文本体库建构方法、系统及计算机可读介质 |
| HK16109078.8 | 2016-07-29 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| TW201804345A true TW201804345A (zh) | 2018-02-01 |
Family
ID=58633644
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| TW106125119A TW201804345A (zh) | 2016-07-29 | 2017-07-26 | 基於結構化網路知識的自動中文本體庫建構方法、系統及電腦可讀媒體 |
Country Status (4)
| Country | Link |
|---|---|
| CN (1) | CN109643315B (zh) |
| HK (1) | HK1220319A2 (zh) |
| TW (1) | TW201804345A (zh) |
| WO (1) | WO2018019289A1 (zh) |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11550835B2 (en) * | 2017-06-16 | 2023-01-10 | Elsevier, Inc. | Systems and methods for automatically generating content summaries for topics |
| CN111859975B (zh) * | 2019-04-22 | 2024-08-16 | 广东小天才科技有限公司 | 一种扩充样本语料的语料正则式的方法和系统 |
| CN110502640A (zh) * | 2019-07-30 | 2019-11-26 | 江南大学 | 一种基于建构的概念词义发展脉络的提取方法 |
| CN110851612B (zh) * | 2019-08-29 | 2023-08-18 | 国家计算机网络与信息安全管理中心 | 基于百科知识的移动应用知识图谱复合型补全方法及装置 |
| CN111783422B (zh) * | 2020-06-24 | 2022-03-04 | 北京字节跳动网络技术有限公司 | 一种文本序列生成方法、装置、设备和介质 |
| CN113971206B (zh) * | 2021-11-05 | 2026-01-20 | 京东科技信息技术有限公司 | 语料处理方法、装置、电子设备及存储介质 |
| CN115658931B (zh) * | 2022-12-27 | 2023-04-07 | 清华大学 | 百科知识图谱动态更新方法、装置、设备及介质 |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN100568230C (zh) * | 2004-07-30 | 2009-12-09 | 国际商业机器公司 | 基于超文本的多语言网络信息搜索方法和系统 |
| CN102609512A (zh) * | 2012-02-07 | 2012-07-25 | 北京中机科海科技发展有限公司 | 异构信息知识挖掘与可视化分析系统及方法 |
| US20150019174A1 (en) * | 2013-07-09 | 2015-01-15 | Honeywell International Inc. | Ontology driven building audit system |
| US11250203B2 (en) * | 2013-08-12 | 2022-02-15 | Microsoft Technology Licensing, Llc | Browsing images via mined hyperlinked text snippets |
| US9672197B2 (en) * | 2014-10-14 | 2017-06-06 | Sugarcrm Inc. | Universal rebranding engine |
| US9582493B2 (en) * | 2014-11-10 | 2017-02-28 | Oracle International Corporation | Lemma mapping to universal ontologies in computer natural language processing |
| CN105488105B (zh) * | 2015-11-19 | 2019-11-05 | 百度在线网络技术(北京)有限公司 | 信息提取模板的建立方法、知识数据的处理方法和装置 |
| CN105843965B (zh) * | 2016-04-20 | 2019-06-04 | 广东精点数据科技股份有限公司 | 一种基于url主题分类的深层网络爬虫表单填充方法和装置 |
-
2016
- 2016-07-29 HK HK16109078.8A patent/HK1220319A2/zh not_active IP Right Cessation
-
2017
- 2017-07-26 TW TW106125119A patent/TW201804345A/zh unknown
- 2017-07-28 WO PCT/CN2017/094881 patent/WO2018019289A1/zh not_active Ceased
- 2017-07-28 CN CN201780046326.XA patent/CN109643315B/zh active Active
Also Published As
| Publication number | Publication date |
|---|---|
| HK1220319A2 (zh) | 2017-04-28 |
| WO2018019289A1 (zh) | 2018-02-01 |
| CN109643315A (zh) | 2019-04-16 |
| CN109643315B (zh) | 2024-05-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Auer et al. | Dbpedia: A nucleus for a web of open data | |
| TW201804345A (zh) | 基於結構化網路知識的自動中文本體庫建構方法、系統及電腦可讀媒體 | |
| JP5283208B2 (ja) | 情報検索システム及び方法及びプログラム並びに情報検索サービス提供方法 | |
| US20090070322A1 (en) | Browsing knowledge on the basis of semantic relations | |
| Bedi et al. | Focused crawling of tagged web resources using ontology | |
| US8180751B2 (en) | Using an encyclopedia to build user profiles | |
| US20190391976A1 (en) | Research and development auxiliary system using patent database and method thereof | |
| KR102256007B1 (ko) | 자연어 질의를 통한 문서 검색 및 응답 제공 시스템 및 방법 | |
| Grigalis | Towards web-scale structured web data extraction | |
| Belozerov et al. | Semantic web technologies: Issues and possible ways of development | |
| Yang | Developing an ontology-supported information integration and recommendation system for scholars | |
| Babekr et al. | Personalized semantic retrieval and summarization of web based documents | |
| Cheng et al. | Context-based page unit recommendation for web-based sensemaking tasks | |
| WO2009035871A1 (en) | Browsing knowledge on the basis of semantic relations | |
| Kramár et al. | Disambiguating search by leveraging a social context based on the stream of user’s activity | |
| JP2006164086A (ja) | オンライン知識検索支援装置、およびオンライン知識検索支援方法 | |
| CN102495844B (zh) | 用于构建用户模型的改进的GuTao法 | |
| Alfred et al. | A robust framework for web information extraction and retrieval | |
| Oramas et al. | Automatic creation of knowledge graphs from digital musical document libraries | |
| Jiang et al. | Personalized recommendation method of E-commerce based on fusion technology of smart ontology and big data mining | |
| Hsu et al. | Using domain ontology to implement a frequently asked questions system | |
| Alkwai et al. | Making recommendations from web archives for" lost" web pages | |
| Wasim et al. | Extracting and modeling user interests based on social media | |
| Khatavkar et al. | Use of noun phrases in identification of a website | |
| Fung et al. | Discover information and knowledge from websites using an integrated summarization and visualization framework |