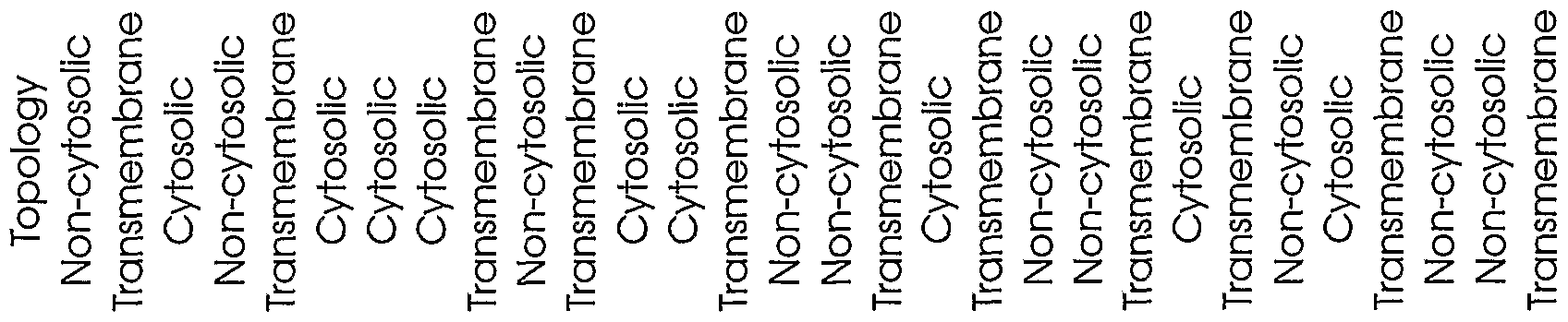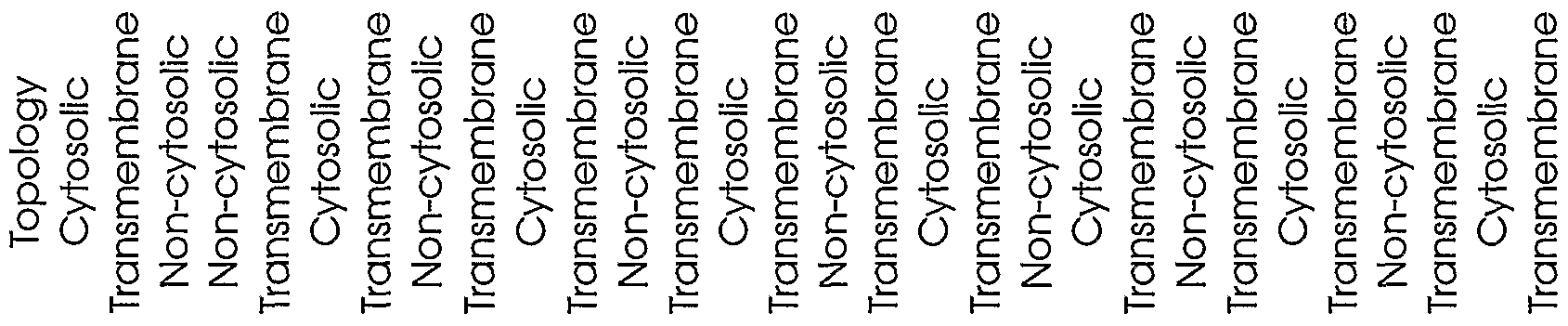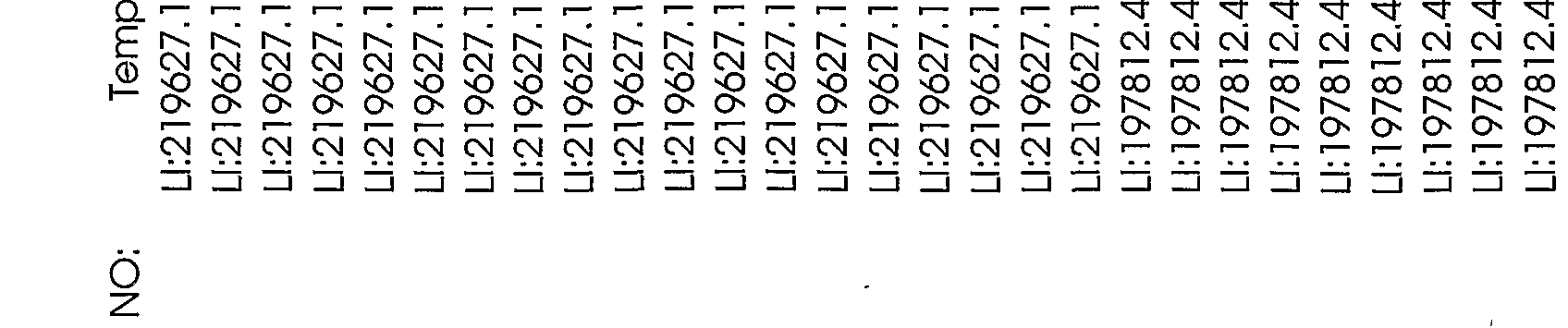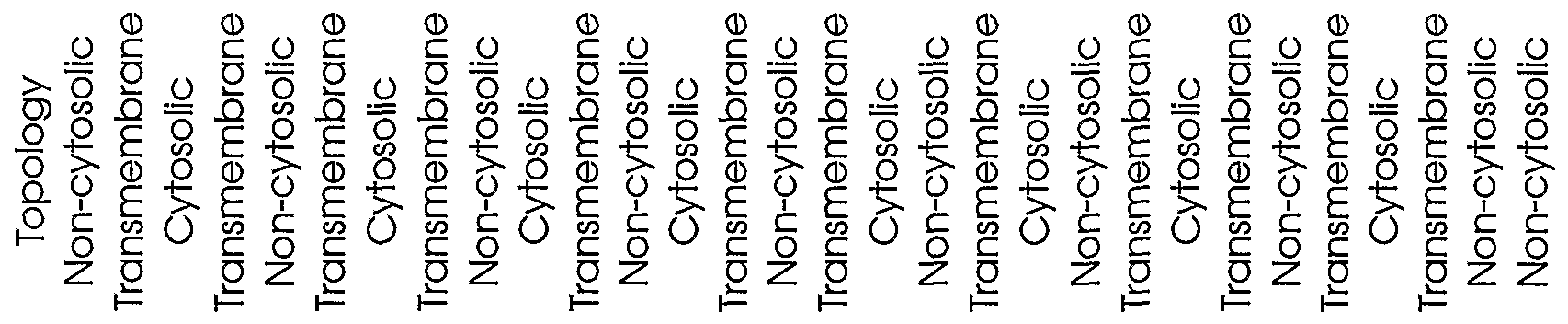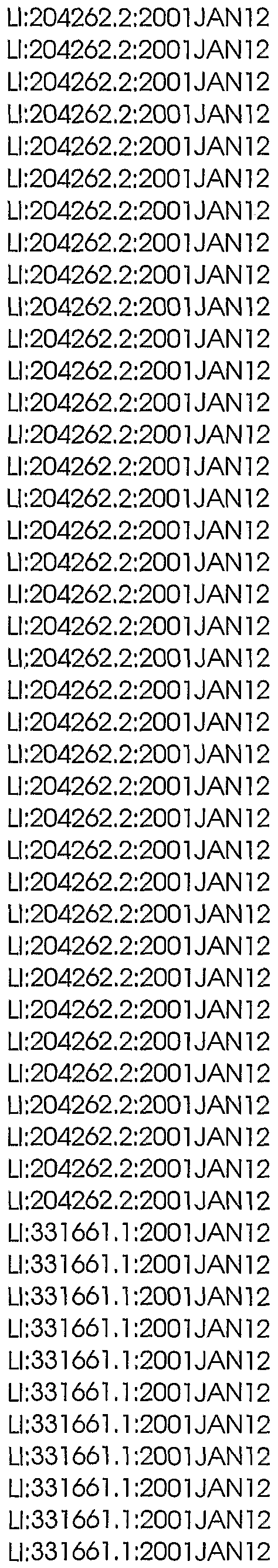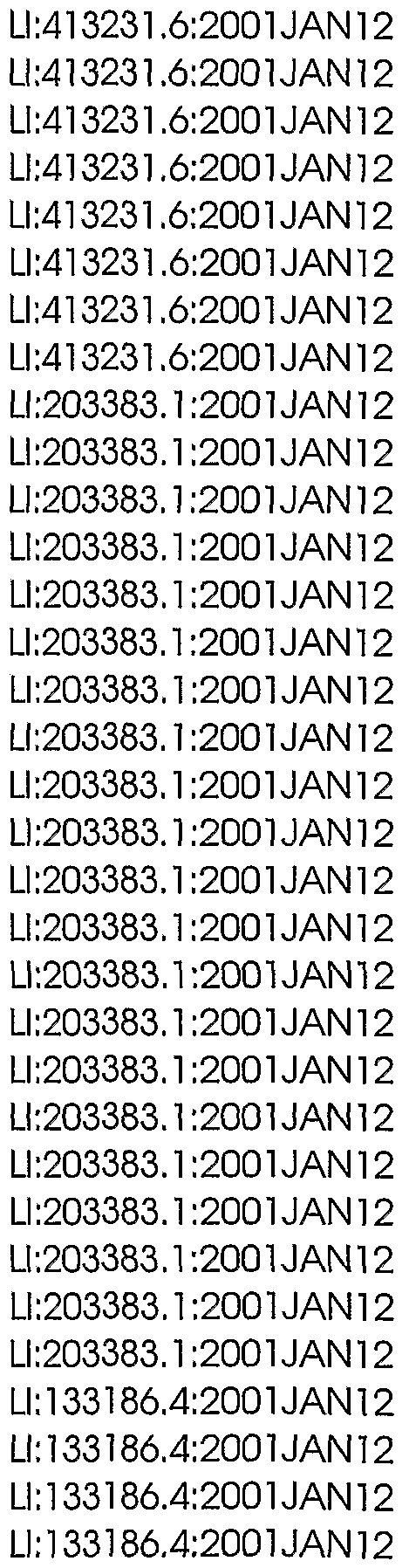SECRETORY MOLECULES
TECHNICAL FIELD The present invention relates to secretory molecules and to the use of these sequences in the diagnosis, study, prevention, and treatment of diseases associated with, as well as effects of exogenous compounds on, the expression of secretory molecules.
! BACKGROUND OF THE INVENTION Protein transport and secretion are essential for cellular function. Protein transport is mediated by a signal peptide located at the amino terminus of the protein to be transported or secreted. The signal peptide is comprised of about ten to twenty hydrophobic amino acids which target the nascent protein from the ribosome to a particular membrane bound compartment such as the endoplasmic reticulum (ER). Proteins targeted to the ER may either proceed through the secretory pathway or remain in any of the secretory organelles such as the ER, Golgi apparatus, or lysosomes. Proteins that transit through the secretory pathway are either secreted into the extracellular space or retained in the plasma membrane. Proteins that are retained in the plasma membrane contain one or more transmembrane domains, each comprised of about 20 hydrophobic amino acid residues. Proteins that are secreted from the cell are generally synthesized as inactive precursors that are activated by post-translational processing events during transit through the secretory pathway. Such events include glycosylation, proteolysis, and removal of the signal peptide by a signal peptidase. Other events that may occur during protein transport include chaperone-dependent unfolding and folding of the nascent protein and interaction of the protein with a receptor or pore complex. Examples of secretory proteins with amino terminal signal peptides are discussed below and include proteins with important roles in cell-to-cell signaling. Such proteins include transmembrane receptors and cell surface markers, extracellular matrix molecules, cytokines, hormones, growth and differentiation factors, neuropeptides, vasomediators, ion channels, transporters/pumps, and proteases. (Reviewed in Alberts, B. et al. (1994) Molecular Biology of The Cell. Garland Publishing, New York NY, pp. 557-560, 582-592.) G-protein coupled receptors (GPCRs) comprise a superfamily of integral membrane proteins which transduce extracellular signals. Not all GPCRs contain N-terminal signal peptides. GPCRs include receptors for biogenic amines such as dopamine, epinephrine, histamine, glutamate (metabotropic-type), acetylcholine (muscarinic-type), and serotonin; for lipid mediators of inflammation such as prostaglandins, platelet activating factor, and leukotrienes; for peptide hormones such as calcitonin, C5a anaphylatoxin, follicle stimulating hormone, gonadotropin
releasing hormone, neurokinin, oxytocin, and thrombin; and for sensory signal mediators such as retinal photopigments and olfactory stimulatory molecules. The structure of these highly conserved receptors consists of seven hydrophobic transmembrane regions, cysteine disulfide bridges between the second and third extracellular loops, an extracellular N-terminus, and a cytoplasmic C-terminus. The N-terminus interacts with ligands, the disulfide bridges interact with agonists and antagonists, and the large third intracellular loop interacts with G proteins to activate second messengers such as cyclic AMP, phospholipase C, inositol triphosphate, or ion channels. (Reviewed in Watson, S. and Arkinstall, S. (1994) The G-protein Linked Receptor Facts Book. Academic Press, San Diego CA, pp. 2-6; and Bolander, F.F. (1994) Molecular Endocrinology. Academic Press, San Diego CA, pp. 162- 176.)
Other types of receptors include cell surface antigens identified on leukocytic cells of the immune system. These antigens have been identified using systematic, monoclonal antibody (mAb)- based "shot gun" techniques. These techniques have resulted in the production of hundreds of mAbs directed against unknown cell surface leukocytic antigens. These antigens have been grouped into "clusters of differentiation" based on common immunocytochemical localization patterns in various differentiated and undifferentiated leukocytic cell types. Antigens in a given cluster are presumed to identify a single cell surface protein and are assigned a "cluster of differentiation" or "CD" designation. Some of the genes encoding proteins identified by CD antigens have been cloned and verified by standard molecular biology techniques. CD antigens have been characterized as both transmembrane proteins and cell surface proteins anchored to the plasma membrane via covalent attachment to fatty acid-containing glycolipids such as glycosylphosphatidylinositol (GPI). (Reviewed in Barclay, A.N. et al. (1995) The Leucocyte Antigen Facts Book. Academic Press, San Diego CA, pp. 17-20.)
Matrix proteins (MPs) are transmembrane and extracellular proteins which function in formation, growth, remodeling, and maintenance of tissues and as important mediators and regulators of the inflammatory response. The expression and balance of MPs may be perturbed by biochemical changes that result from congenital, epigenetic, or infectious diseases. In addition, MPs affect leukocyte migration, proliferation, differentiation, and activation in the immune response. MPs are frequently characterized by the presence of one or more domains which may include collagen-like domains, EGF-like domains, immunoglobulin-like domains, and fibronectin-like domains. In addition, MPs may be heavily glycosylated and may contain an Arginine-Glycine-Aspartate (RGD) tripeptide motif which may play a role in adhesive interactions. MPs include extracellular proteins such as fibronectin, collagen, galectin, vitronectin and its proteolytic derivative somatomedin B; and cell adhesion receptors such as cell adhesion molecules (CAMs), cadherins, and integrins. (Reviewed in Ayad, S. et al. (1994) The Extracellular Matrix Facts Book. Academic Press, San Diego CA, pp. 2-
16; Ruoslahti, E. (1997) Kidney Int. 51:1413-1417; Sjaastad, M.D. and Nelson, W.J. (1997) BioEssays 19:47-55.)
Cytokines are secreted by hematopoietic cells in response to injury or infection. Interleukins, neurotrophins, growth factors, interferons, and chemokines all define cytokine families that work in 5 conjunction with cellular receptors to regulate cell proliferation and differentiation. In addition, cytokines effect activities such as leukocyte migration and function, hematopoietic cell proliferation, temperature regulation, acute response to infection, tissue remodeling, and apoptosis.
Chemokines, in particular, are small chemoattractant cytokines involved in inflammation, leukocyte proliferation and migration, angiogenesis and angiostasis, regulation of hematopoiesis, HTN 0 infectivity, and stimulation of cytokine secretion. Chemokines generally contain 70-100 amino acids and are subdivided into four subfamilies based on the presence of conserved cysteine-based motifs. (Callard, R. and Gearing, A. (1994) The Cytokine Facts Book. Academic Press, New York NY, pp. 181-190, 210-213, 223-227.)
Growth and differentiation factors are secreted proteins which function in intercellular 5 communication. Some factors require oligomerization or association with MPs for activity. Complex interactions among these factors and their receptors trigger intracellular signal transduction pathways that stimulate or inhibit cell division, cell differentiation, cell signaling, and cell motility. Most growth and differentiation factors act on cells in their local environment (paracrine signaling). There are three broad classes of growth and differentiation factors. The first class includes the large o polypeptide growth factors such as epidermal growth factor, fibroblast growth factor, transforming growth factor, insulin-like growth factor, and platelet-derived growth factor. The second class includes the hematopoietic growth factors such as the colony stimulating factors (CSFs). Hematopoietic growth factors stimulate the proliferation and differentiation of blood cells such as B- lymphocytes, T-lymphocytes, erythrocytes, platelets, eosinophils, basophils, neutrophils, 5 macrophages, and their stem cell precursors. The third class includes small peptide factors such as bombesin, vasopressin, oxytocin, endothelin, transferrin, angiotensin TJ, vasoactive intestinal peptide, and bradykinin which function as hormones to regulate cellular functions other than proliferation.
Growth and differentiation factors play critical roles in neoplastic transformation of cells in vitro and in tumor progression in vivo. Inappropriate expression of growth factors by tumor cells o may contribute to vascularization and metastasis of tumors. During hematopoiesis, growth factor misregulation can result in anemias, leukemias, and lymphomas. Certain growth factors such as interferon are cytotoxic to tumor cells both in vivo and in vitro. Moreover, some growth factors and growth factor receptors are related both structurally and functionally to oncoproteins. In addition, growth factors affect transcriptional regulation of both proto-oncogenes and oncosuppressor genes. 5 (Reviewed in Pimentel, E. (1994) Handbook of Growth Factors. CRC Press, Ann Arbor MI, pp. 1-9.)
Proteolytic enzymes or proteases either activate or deactivate proteins by hydrolyzing peptide bonds. Proteases are found in the cytosol, in membrane-bound compartments, and in the extracellular space. The major families are the zinc, serine, cysteine, thiol, and carboxyl proteases.
Ion channels, ion pumps, and transport proteins mediate the transport of molecules across 5 cellular membranes. Transport can occur by a passive, concentration-dependent mechanism or can be linked to an energy source such as ATP hydrolysis. Symporters and antiporters transport ions and small molecules such as amino acids, glucose, and drugs. Symporters transport molecules and ions umdirectionally, and antiporters transport molecules and ions bidirectionally. Transporter superfamilies include facilitative transporters and active ATP-binding cassette transporters which are 0 involved in multiple-drug resistance and the targeting of antigenic peptides to MHC Class I molecules. These transporters bind to a specific ion or other molecule and undergo a conformational change in order to transfer the ion or molecule across the membrane. (Reviewed in Alberts, B. et al. (1994) Molecular Biology of The Cell. Garland Publishing, New York NY, pp. 523-546.)
Ion channels are formed by transmembrane proteins which create a lined passageway across 5 the membrane through which water and ions, such as Na+, K+, Ca2+, and Cl", enter and exit the cell. For example, chloride channels are involved in the regulation of the membrane electric potential as well as absorption and secretion of ions across the membrane. Chloride channels also regulate the internal pH of membrane-bound organelles.
Ion pumps are ATPases which actively maintain membrane gradients. Ion pumps are 0 classified as P, V, or F according to their structure and function. All have one or more binding sites for ATP in their cytosolic domains. The P-class ion pumps include Ca2+ ATPase and Na+/K+ ATPase and function in transporting H+, Na+, K+, and Ca2+ ions. P-class pumps consist of two α and two β transmembrane subunits. The V- and F-class ion pumps have similar structures but transport only H+. F class H+ pumps mediate transport across the membranes of mitochondria and chloroplasts, while V- 5 class H+ pumps regulate acidity inside lysosomes, endosomes, and plant vacuoles.
A family of structurally related intrinsic membrane proteins known as facilitative glucose transporters catalyze the movement of glucose and other selected sugars across the plasma membrane. The proteins in this family contain a highly conserved, large transmembrane domain comprised of 12 α-helices, and several weakly conserved, cytoplasmic and exoplasmic domains. (Pessin, J.E. and o Bell, G.I. (1992) Annu. Rev. Physiol. 54:911-930.)
Amino acid transport is mediated by Na+ dependent amino acid transporters. These transporters are involved in gastrointestinal and renal uptake of dietary and cellular amino acids and in neuronal reuptake of neurotransmitters. Transport of cationic amino acids is mediated by the system y+ family and the cationic amino acid transporter (CAT) family. Members of the CAT family 5 share a high degree of sequence homology, and each contains 12-14 putative transmembrane
domains. (Ito, K. and Groudine, M. (1997) J. Biol. Chem. 272:26780-26786.)
Hormones are secreted molecules that travel through the circulation and bind to specific receptors on the surface of, or within, target cells. Although they have diverse biochemical compositions and mechanisms of action, hormones can be grouped into two categories. One category includes small lipophilic hormones that diffuse through the plasma membrane of target cells, bind to cytosolic or nuclear receptors, and form a complex that alters gene expression. Examples of these molecules include retinoic acid, thyroxine, and the cholesterol-derived steroid hormones such as progesterone, estrogen, testosterone, cortisol, and aldosterone. The second category includes hydrophilic hormones that function by binding to cell surface receptors that transduce signals across the plasma membrane. Examples of such hormones include amino acid derivatives such as catecholamines and peptide hormones such as glucagon, insulin, gastrin, secretin, cholecystokinin, adrenocorticotropic hormone, follicle stimulating hormone, luteinizing hormone, thyroid stimulating hormone, and vasopressin. (See, for example, Lodish et al. (1995) Molecular Cell Biology, Scientific American Books Inc., New York NY, pp. 856-864.) Neuropeptides and vasomediators (NP/VM) comprise a large family of endogenous signaling molecules. Included in this family are neuropeptides and neuropeptide hormones such as bombesin, neuropeptide Y, neurotensin, neuromedin N, melanocortins, opioids, galanin, somatostatin, tachykinins, urotensin II and related peptides involved in smooth muscle stimulation, vasopressin, vasoactive intestinal peptide, and circulatory system-borne signaling molecules such as angiotensin, complement, calcitonin, endothelins, formyl-methionyl peptides, glucagon, cholecystokinin and gastrin. NP/VMs can transduce signals directly, modulate the activity or release of other neurotransmitters and hormones, and act as catalytic enzymes in cascades. The effects of NP/VMs range from extremely brief to long-lasting. (Reviewed in Martin, C.R. et al. (1985) Endocrine Physiology, Oxford University Press, New York, NY, pp. 57-62.) The discovery of new secretory molecules satisfies a need in the art by providing new compositions which are useful in the diagnosis, study, prevention, and treatment of diseases associated with, as well as effects of exogenous compounds on, cell signaling and the expression of secretory molecules.
SUMMARY OF THE INVENTION
The present invention relates to nucleic acid sequences comprising human polynucleotides encoding secretory polypeptides that contain signal peptides and/or transmembrane domains. These human polynucleotides (sptm) as presented in the Sequence Listing uniquely identify partial or full length genes encoding structural, functional, and regulatory polypeptides involved in cell signaling. The invention provides an isolated polynucleotide selected from the group consisting of a) a
polynucleotide comprising a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; b) a polynucleotide comprising a naturally occurring polynucleotide sequence at least 90% identical to a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; c) a polynucleotide complementary to the polynucleotide of a); d) a polynucleotide complementary to the polynucleotide of b); and e) an RNA equivalent of a) through d). In one alternative, the polynucleotide comprises a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75. In another alternative, the polynucleotide comprises at least 30 contiguous nucleotides of a polynucleotide selected from the group consisting of a) a polynucleotide comprising a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; b) a polynucleotide comprising a naturally occurring polynucleotide comprising a polynucleotide sequence at least 90% identical to a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; c) a polynucleotide complementary to the polynucleotide of a); d) a polynucleotide complementary to the polynucleotide of b); and e) an RNA equivalent of a) through d). In another alternative, the polynucleotide comprises at least 60 contiguous nucleotides of a polynucleotide selected from the group consisting of a) a polynucleotide comprising a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; b) a polynucleotide comprising a naturally occurring polynucleotide comprising a polynucleotide sequence at least 90% identical to a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; c) a polynucleotide complementary to the polynucleotide of a); d) a polynucleotide complementary to the polynucleotide of b); and e) an RNA equivalent of a) through d). The invention further provides a composition for the detection of expression of secretory polynucleotides comprising at least one isolated polynucleotide comprising a polynucleotide selected from the group consisting of a) a polynucleotide comprising a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; b) a polynucleotide comprising a naturally occurring polynucleotide sequence at least 90% identical to a polynucleotide sequence selected from the group consisting of SEQ ID NO : 1 -75 ; c) a polynucleotide complementary to the polynucleotide of a) ; d) a polynucleotide complementary to the polynucleotide of b) ; and e) an RNA equivalent of a) through d); and a detectable label.
The invention also provides a method for detecting a target polynucleotide in a sample, said target polynucleotide having a polynucleotide sequence of a polyneucleotide selected from the group consisting of a) a polynucleotide comprising a polynucleotide sequence of a polynucleotide selected from the group consisting of SEQ ID NO: 1-75; b) a polynucleotide comprising a naturally occurring polynucleotide sequence at least 90% identical to a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; c) a polynucleotide complementary to the polynucleotide of a); d) a polynucleotide complementary to the polynucleotide of b) ; and e) an RNA equivalent of a) through d). The method comprises a) amplifying said target polynucleotide or fragment thereof using
polymerase chain reaction amplification, and b) detecting the presence or absence of said amplified target polynucleotide or fragment thereof, and, optionally, if present, the amount thereof.
The invention also provides a method for detecting a target polynucleotide in a sample, said target polynucleotide having a polynucleotide sequence of a polynucleotide selected from the group 5 consisting of a) a polynucleotide comprising a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; b) a polynucleotide comprising a naturally occurring polynucleotide sequence at least 90% identical to a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; c) a polynucleotide complementary to the polynucleotide of a); d) a polynucleotide complementary to the polynucleotide of b) ; and e) an RNA equivalent of a) through 0 d). The method comprises a) hybridizing the sample with a probe comprising at least 20 contiguous nucleotides comprising a sequence complementary to said target polynucleotide in the sample, and which probe specifically hybridizes to said target polynucleotide, under conditions whereby a hybridization complex is formed between said probe and said target polynucleotide, and b) detecting the presence or absence of said hybridization complex, and, optionally, if present, the amount thereof. 5 In one alternative, the invention provides a composition comprising a target polynucleotide of the method, wherein said probe comprises at least 30 contiguous nucleotides. In one alternative, the invention provides a composition comprising a target polynucleotide of the method, wherein said probe comprises at least 60 contiguous nucleotides.
The invention further provides a recombinant polynucleotide comprising a promoter o sequence operably linked to an isolated polynucleotide selected from the group consisting of a) a polynucleotide comprising a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; b) a polynucleotide comprising a naturally occurring polynucleotide sequence at least 90% identical to a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; c) a polynucleotide complementary to the polynucleotide of a); d) a polynucleotide complementary to the 5 polynucleotide of b); and e) an RNA equivalent of a) through d). In one alternative, the invention provides a cell transformed with the recombinant polynucleotide. In another alternative, the invention provides a transgenic organism comprising the recombinant polynucleotide.
The invention also provides a method for producing a secretory polypeptide, the method comprising a) culturing a cell under conditions suitable for expression of the secretory polypeptide, o wherein said cell is transformed with a recombinant polynucleotide, said recombinant polynucleotide comprising an isolated polynucleotide selected from the group consisting of i) a polynucleotide comprising a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; ii) a polynucleotide comprising a naturally occurring polynucleotide sequence at least 90% identical to a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; iii) a polynucleotide 5 complementary to the polynucleotide of i); iv) a polynucleotide complementary to the polynucleotide
of ii); and v) an RNA equivalent of i) through iv), and b) recovering the secretory polypeptide so expressed. The invention additionally provides a method wherein the polypeptide has an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152.
The invention also provides an isolated secretory polypeptide (SPTM) encoded by at least 5 one polynucleotide comprising a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75. The invention further provides a method of screening for a test compound that specifically binds to the polypeptide having an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152. The method comprises a) combining the polypeptide having an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152 with at least one test 0 compound under suitable conditions, and b) detecting binding of the polypeptide having an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152 to the test compound, thereby identifying a compound that specifically binds to the polypeptide having an amino acid sequence selected from the group consisting of SEQ ID NO: 76- 152.
The invention further provides a microarray wherein at least one element of the microarray is 5 an isolated polynucleotide comprising at least 30 contiguous nucleotides of a polynucleotide selected from the group consisting of a) a polynucleotide comprising a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; b) a polynucleotide comprising a naturally occurring polynucleotide sequence at least 90% identical to a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; c) a polynucleotide complementary to the polynucleotide of a); d) a o polynucleotide complementary to the polynucleotide of b) ; and e) an RNA equivalent of a) through d). The invention also provides a method for generating a transcript image of a sample which contains polynucleotides. The method comprises a) labeling the polynucleotides of the sample, b) contacting the elements of the microarray with the labeled polynucleotides of the sample under conditions suitable for the formation of a hybridization complex, and c) quantifying the expression of 5 the polynucleotides in the sample.
Additionally, the invention provides a method for screening a compound for effectiveness in altering expression of a target polynucleotide, wherein said target polynucleotide comprises a polynucleotide selected from the group consisting of a) a polynucleotide comprising a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; b) a polynucleotide comprising a o naturally occurring polynucleotide sequence at least 90% identical to a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; c) a polynucleotide complementary to the polynucleotide of a); d) a polynucleotide complementary to the polynucleotide of b) ; and e) an RNA equivalent of a) through d). The method comprises a) exposing a sample comprising the target polynucleotide to a compound, b) detecting altered expression of the target polynucleotide, and c) 5 comparing the expression of the target polynucleotide in the presence of varying amounts of the
compound and in the absence of the compound.
The invention further provides a method for assessing toxicity of a test compound, said method comprising a) treating a biological sample containing nucleic acids with the test compound; b) hybridizing the nucleic acids of the treated biological sample with a probe comprising at least 20 5 contiguous nucleotides of a polynucleotide selected from the group consisting of i) a polynucleotide comprising a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; ii) a polynucleotide comprising a naturally occurring polynucleotide sequence at least 90% identical to a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; iii) a polynucleotide complementary to the polynucleotide of i); iv) a polynucleotide complementary to the polynucleotide 0 of ii); and v) an RNA equivalent of i) through iv). Hybridization occurs under conditions whereby a specific hybridization complex is formed between said probe and a target polynucleotide in the biological sample, said target polynucleotide comprising a polynucleotide sequence of a polynucleotide selected from the group consisting of i) a polynucleotide comprising a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; ii) a polynucleotide comprising a 5 naturally occurring polynucleotide sequence at least 90% identical to a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75; iii) a polynucleotide complementary to the polynucleotide of i); iv) a polynucleotide complementary to the polynucleotide of ii); and v) an RNA equivalent of i) through iv), and alternatively, the target polynucleotide comprises a polynucleotide sequence of a fragment of a polynucleotide selected from the group consisting of i-v above; c) o quantifying the amount of hybridization complex; and d) comparing the amount of hybridization complex in the treated biological sample with the amount of hybridization complex in an untreated biological sample, wherein a difference in the amount of hybridization complex in the treated biological sample is indicative of toxicity of the test compound.
The invention further provides an isolated polypeptide selected from the group consisting of 5 a) a polypeptide comprising an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152, b) a polypeptide comprising a naturally occurring amino acid sequence at least 90% identical to an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152, c) a biologically active fragment of a polypeptide having an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152, and d) an immunogenic fragment of a polypeptide having an o amino acid sequence selected from the group consisting of SEQ ID NOJ6-152. In one alternative, the invention provides an isolated polypeptide comprising an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152.
The invention further provides an isolated polynucleotide encoding a polypeptide selected from the group consisting of a) a polypeptide comprising, an amino acid sequence selected from the 5 group consisting of SEQ ID NOJ6-152, b) a polypeptide comprising a naturally occurring amino acid
sequence at least 90% identical to an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152, c) a biologically active fragment of a polypeptide having an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152, and d) an immunogenic fragment of a polypeptide having an amino acid sequence selected from the group consisting of SEQ ID NOJ6- 5 152. In one alternative, the polynucleotide encodes a polypeptide comprising an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152. In another alternative, the polynucleotide comprises a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-75. Additionally, the invention provides an isolated antibody which specifically binds to a polypeptide selected from the group consisting of a) a polypeptide comprising an amino acid 0 sequence selected from the group consisting of SEQ ID NOJ6-152, b) a polypeptide comprising a naturally occurring amino acid sequence at least 90% identical to an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152, c) a biologically active fragment of a polypeptide having an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152, and d) an immunogenic fragment of a polypeptide having an amino acid sequence selected from the group 5 consisting of SEQ ID NOJ6-152.
The invention further provides a composition comprising a polypeptide selected from the group consisting of a) a polypeptide comprising an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152, b) a polypeptide comprising a naturally occurring amino acid sequence at least 90% identical to an amino acid sequence selected from the group consisting of SEQ 0 ID NOJ6-152, c) a biologically active fragment of a polypeptide having an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152, and d) an immunogenic fragment of a polypeptide having an amino acid sequence selected from the group consisting of SEQ ID NOJ6- 152, and a pharmaceutically acceptable excipient. In one embodiment, the composition comprises a polypeptide having an amino acid sequence selected from the group consisting of SEQ ID NOJ6- 5 152. The invention additionally provides a method of treating a disease or condition associated with decreased expression of functional SPTM, comprising administering to a patient in need of such treatment the composition.
The invention also provides a method for screening a compound for effectiveness as an agonist of a polypeptide selected from the group consistmg of a) a polypeptide comprising an amino o acid sequence selected from the group consisting of SEQ ID NOJ6-152, b) a polypeptide comprising a naturally occurring amino acid sequence at least 90% identical to an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152, c) a biologically active fragment of a polypeptide having an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152, and d) an immunogenic fragment of a polypeptide having an amino acid sequence selected from the group 5 consisting of SEQ ID NOJ6-152. The method comprises a) exposing a sample comprising the
polypeptide to a compound, and b) detecting agonist activity in the sample. In one alternative, the invention provides a composition comprising an agonist compound identified by the method and a pharmaceutically acceptable excipient. In another alternative, the invention provides a method of treating a disease or condition associated with decreased expression of functional SPTM, comprising administering to a patient in need of such treatment the composition.
Additionally, the invention provides a method for screening a compound for effectiveness as an antagonist of a polypeptide selected from the group consisting of a) a polypeptide comprising an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152, b) a polypeptide comprising a naturally occurring amino acid sequence at least 90% identical to an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152, c) a biologically active fragment of a polypeptide having an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152, and d) an immunogenic fragment of a polypeptide having an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152. The method comprises a) exposing a sample comprising the polypeptide to a compound, and b) detecting antagonist activity in the sample. In one alternative, the invention provides a composition comprising an antagonist compound identified by the method and a pharmaceutically acceptable excipient. In another alternative, the invention provides a method of treating a disease or condition associated with overexpression of functional SPTM, comprising administering to a patient in need of such treatment the composition. The invention further provides a method of screening for a compound that modulates the activity of a polypeptide selected from the group consisting of a) a polypeptide comprising an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152, b) a polypeptide comprising a naturally occurring amino acid sequence at least 90% identical to an amino acid sequence selected from the group consisting of SEQ ID NO: 76- 152, c) a biologically active fragment of a polypeptide having an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152, and d) an immunogenic fragment of a polypeptide having an amino acid sequence selected from the group consisting of SEQ ID NOJ6-152. The method comprises a) combining the polypeptide with at least one test compound under conditions permissive for the activity of the polypeptide, b) assessing the activity of the polypeptide in the presence of the test compound, and c) comparing the activity of the polypeptide in the presence of the test compound with the activity of the polypeptide in the absence of the test compound, wherein a change in the activity of the polypeptide in the presence of the test compound is indicative of a compound that modulates the activity of the polypeptide.
DESCRIPTION OF THE TABLES
Table 1 shows the sequence identification numbers (SEQ ID NO:s) and template identification numbers (template IDs) corresponding to the polynucleotides of the present invention,
along with the sequence identification numbers (SEQ ID NO:s) and open reading frame identification numbers (ORF IDs) corresponding to polypeptides encoded by the template ID.
Table 2 shows the sequence identification numbers (SEQ ID NO:s) and template identification numbers (template IDs) corresponding to the polynucleotides of the present invention, along with polynucleotide segments of each template sequence as defined by the indicated "start" and "stop" nucleotide positions. The reading frames of the polynucleotide segments are shown, and the polypeptides encoded by the polynucleotide segments constitute either signal peptide (SP) or transmembrane (TM) domains, as indicated. For TM domains, the membrane topology of the encoded polypeptide sequence is indicated as being transmembrane or on the cytosolic or non- cytosolic side of the cell membrane or organelle.
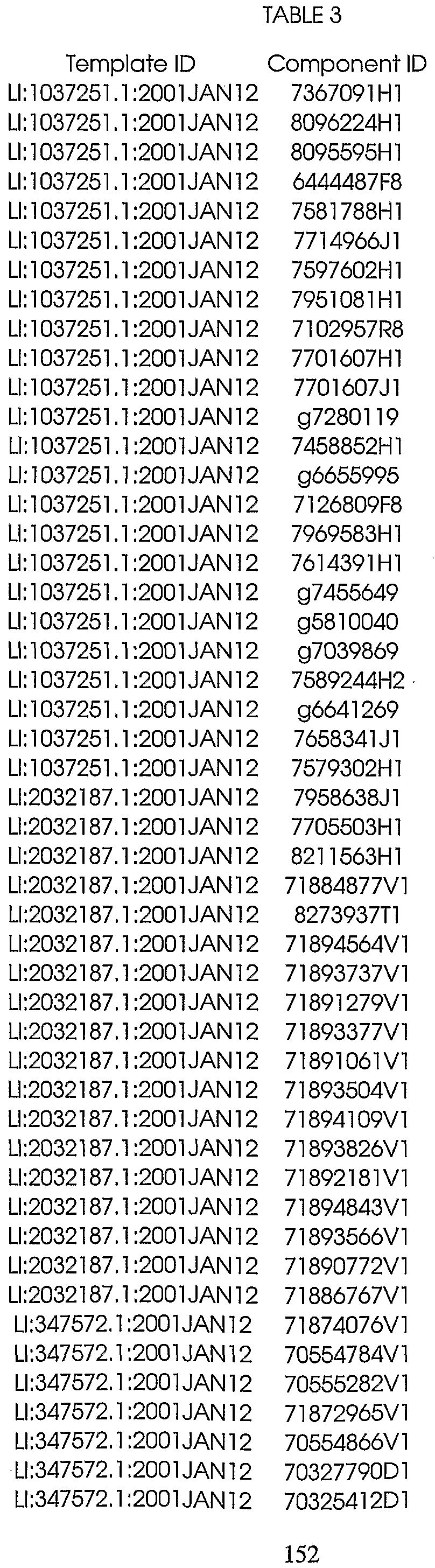
Table 3 shows the sequence identification numbers (SEQ ID NO:s) and template identification numbers (template IDs) corresponding to the polynucleotides of the present invention, along with component sequence identification numbers (component IDs) corresponding to each template. The component sequences, which were used to assemble the template sequences, are defined by the indicated "start" and "stop" nucleotide positions along each template.
Table 4 shows the tissue distribution profiles for the templates of the invention.
Table 5 shows the sequence identification numbers (SEQ ID NO:s) corresponding to the polypeptides of the present invention, along with the reading frames used to obtain the polypeptide segments, the lengths of the polypeptide segments, the "start" and "stop" nucleotide positions of the polynucleotide sequences used to define the encoded polypeptide segments, the GenBank hits (GI Numbers), probability scores, and functional annotations corresponding to the GenBank hits.
Table 6 summarizes the bioinformatics tools which are useful for analysis of the polynucleotides of the present invention. The first column of Table 6 lists analytical tools, programs, and algorithms, the second column provides brief descriptions thereof, the third column presents appropriate references, all of which are incorporated by reference herein in their entirety, and the fourth column presents, where applicable, the scores, probability values, and other parameters used to evaluate the strength of a match between two sequences (the higher the score, the greater the homology between two sequences).
DETAILED DESCRIPTION OF THE INVENTION
Before the nucleic acid sequences and methods are presented, it is to be understood that this invention is not limited to the particular machines, methods, and materials described. Although particular embodiments are described, machines, methods, and materials similar or equivalent to these embodiments may be used to practice the invention. The preferred machines, methods, and materials set forth are not intended to limit the scope of the invention which is limited only by the
appended claims.
The singular forms "a", "an", and "the" include plural reference unless the context clearly dictates otherwise. All technical and scientific terms have the meanings commonly understood by one of ordinary skill in the art. All publications are incorporated by reference for the purpose of describing and disclosing the cell lines, vectors, and methodologies which are presented and which might be used in connection with the invention. Nothing in the specification is to be construed as an admission that the invention is not entitled to antedate such disclosure by virtue of prior invention.
Definitions As used herein, the lower case "sptm" refers to a nucleic acid sequence, while the upper case
"SPTM" refers to an amino acid sequence encoded by sptm. A "full-length" sptm refers to a nucleic acid sequence containing the entire coding region of a gene endogenously expressed in human tissue. "Adjuvants" are materials such as Freund's adjuvant, mineral gels (aluminum hydroxide), and surface active substances (lysolecithin, pluronic polyols, polyanions, peptides, oil emulsions, keyhole limpet hemocyanin, and dinitrophenol) which may be administered to increase a host' s immunological response.
"Allele" refers to an alternative form of a nucleic acid sequence. Alleles result from a "mutation," a change or an alternative reading of the genetic code. Any given gene may have none, one, or many allelic forms. Mutations which give rise to alleles include deletions, additions, or substitutions of nucleotides. Each of these changes may occur alone, or in combination with the others, one or more times in a given nucleic acid sequence. The present invention encompasses allelic sptm.
An "allelic variant" is an alternative form of the gene encoding SPTM. Allelic variants may result from at least one mutation in the nucleic acid sequence and may result in altered rnRNAs or in polypeptides whose structure or function may or may not be altered. A gene may have none, one, or many allelic variants of its naturally occurring form. Common mutational changes which give rise to allelic variants are generally ascribed to natural deletions, additions, or substitutions of nucleotides. Each of these types of changes may occur alone, or in combination with the others, one or more times in a given sequence. "Altered" nucleic acid sequences encoding SPTM include those sequences with deletions, insertions, or substitutions of different nucleotides, resulting in a polypeptide the same as SPTM or a polypeptide with at least one functional characteristic of SPTM. Included within this definition are polymorphisms which may or may not be readily detectable using a particular oligonucleotide probe of the polynucleotide encoding SPTM, and improper or unexpected hybridization to allelic variants, with a locus other than the normal chromosomal locus for the polynucleotide sequence encoding
SPTM. The encoded protein may also be "altered," and may contain deletions, insertions, or substitutions of amino acid residues which produce a silent change and result in a functionally equivalent SPTM. Deliberate amino acid substitutions may be made on the basis of similarity in polarity, charge, solubility, hydrophobicity, hydrophilicity, and/or the amphipathic nature of the residues, as long as the biological or immunological activity of SPTM is retained. For example, negatively charged amino acids may include aspartic acid and glutamic acid, and positively charged amino acids may include lysine and arginine. Amino acids with uncharged polar side chains having similar hydrophilicity values may include: asparagine and glutamine; and serine and threonine. Amino acids with uncharged side chains having similar hydrophilicity values may include: leucine, isoleucine, and valine; glycine and alanine; and phenylalanine and tyrosine.
"Amino acid sequence" refers to a peptide, a polypeptide, or a protein of either natural or synthetic origin. The amino acid sequence is not limited to the complete, endogenous amino acid sequence and may be a fragment, epitope, variant, or derivative of a protein expressed by a nucleic acid sequence. "Amplification" refers to the production of additional copies of a sequence and is carried out using polymerase chain reaction (PCR) technologies well known in the art.
"Antibody" refers to intact molecules as well as to fragments thereof, such as Fab, F(ab')2, and Fv fragments, which are capable of binding the epitopic determinant. Antibodies that bind SPTM polypeptides can be prepared using intact polypeptides or using fragments containing small peptides of interest as the immunizing antigen. The polypeptide or peptide used to immunize an animal (e.g., a mouse, a rat, or a rabbit) can be derived from the translation of RNA, or synthesized chemically, and can be conjugated to a carrier protein if desired. Commonly used carriers that are chemically coupled to peptides include bovine serum albumin, thyroglobulin, and keyhole limpet hemocyanin (KLH). The coupled peptide is then used to immunize the animal. The term "aptamer" refers to a nucleic acid or oligonucleotide molecule that binds to a specific molecular target. Aptamers are derived from an in vitro evolutionary process (e.g., SELEX (Systematic Evolution of Ligands by Exponential Enrichment), described in U.S. Patent No. 5,270,163), which selects for target-specific aptamer sequences from large combinatorial libraries. Aptamer compositions may be double-stranded or single-stranded, and may include deoxyribonucleotides, ribonucleotides, nucleotide derivatives, or other nucleotide-like molecules.
The nucleotide components of an aptamer may have modified sugar groups (e.g., the 2'-OH group of a ribonucleotide may be replaced by 2'-F or 2'-NH2), which may improve a desired property, e.g., resistance to nucleases or longer lifetime in blood. Aptamers may be conjugated to other molecules, e.g., a high molecular weight carrier to slow clearance of the aptamer from the circulatory system. Aptamers may be specifically cross-linked to their cognate ligands, e.g., by photo-activation of a
cross-linker. (See, e.g., Brody, E.N. and L. Gold (2000) J. Biotechnol. 74:5-13.)
The term "intramer" refers to an aptamer which is expressed in vivo. For example, a vaccinia virus-based RNA expression system has been used to express specific RNA aptamers at high levels in the cytoplasm of leukocytes (Blind, M. et al. (1999) Proc. Natl Acad. Sci. USA 96:3606-3610). The term "spiegelmer" refers to an aptamer which includes L-DNA, L-RNA, or other left- handed nucleotide derivatives or nucleotide-like molecules. Aptamers containing left-handed nucleotides are resistant to degradation by naturally occurring enzymes, which normally act on substrates containing right-handed nucleotides.
"Antisense sequence" refers to a sequence capable of specifically hybridizing to a target sequence. The antisense sequence may include DNA, RNA, or any nucleic acid mimic or analog such as peptide nucleic acid (PNA); oligonucleotides having modified backbone linkages such as phosphorothioates, methylphosphonates, or benzylphosphonates; oligonucleotides having modified sugar groups such as 2'-methoxyethyl sugars or 2'-methoxyethoxy sugars; or oligonucleotides having modified base. "Antisense technology" refers to any technology which relies on the specific hybridization of an antisense sequence to a target sequence.
A "bin" is a portion of computer memory space used by a computer program for storage of data, and bounded in such a manner that data stored in a bin may be retrieved by the program.
"Biologically active" refers to an amino acid sequence having a structural, regulatory, or biochemical function of a naturally occurring amino acid sequence.
"Clone joining" is a process for combining gene bins based upon the bins' containing sequence information from the same clone. The sequences may assemble into a primary gene transcript as well as one or more splice variants.
"Complementary" describes the relationship between two single-stranded nucleic acid sequences that anneal by base-pairing (5 -A-G-T-3' pairs with its complement 3'-T-C-A-5').
A "component sequence" is a nucleic acid sequence selected by a computer program such as PHRED and used to assemble a consensus or template sequence from one or more component sequences.
A "consensus sequence" or "template sequence" is a nucleic acid sequence which has been assembled from overlapping sequences, using a computer program for fragment assembly such as the GELVIEW fragment assembly system (Genetics Computer Group (GCG), Madison WI) or using a relational database management system (RDMS).
"Conservative amino acid substitutions" are those substitutions that, when made, least interfere with the properties of the original protein, i.e., the structure and especially the function of the protein is conserved and not significantly changed by such substitutions. The table below shows
amino acids which may be substituted for an original amino acid in a protein and which are regarded as conservative substitutions.
Original Residue Conservative Substitution
5 Ala Gly, Ser
Arg His, Lys
Asn Asp, Gin, His
Asp Asn, Glu
Cys Ala, Ser 0 Gin Asn, Glu, His
Glu Asp, Gin, His
Gly Ala
His Asn, Arg, Gin, Glu lie Leu, Val 5 Leu lie, Val
Lys Arg, Gin, Glu
Met Leu, lie
Phe His, Met, Leu, Tip, Tyr
Ser Cys, Thr 0 Thr Ser, Val
Trp Phe, Tyr
Tyr His, Phe, Trp Val lie, Leu, Thr
5
Conservative substitutions generally maintain (a) the structure of the polypeptide backbone in the area of the substitution, for example, as a beta sheet or alpha helical conformation, (b) the charge or hydrophobicity of the molecule at the target site, or (c) the bulk of the side chain.
"Deletion" refers to a change in either a nucleic or amino acid sequence in which at least one o nucleotide or amino acid residue, respectively, is absent.
"Derivative" refers to the chemical modification of a nucleic acid sequence, such as by replacement of hydrogen by an alkyl, acyl, amino, hydroxyl, or other group.
"Differential expression" refers to increased or upregulated; or decreased, downregulated, or absent gene or protein expression, determined by comparing at least two different samples. Such 5 comparisons may be carried out between, for example, a treated and an untreated sample, or a diseased and a normal sample.
The terms "element" and "array element" refer to a polynucleotide, polypeptide, or other chemical compound having a unique and defined position on a microarray.
The term "modulate" refers to a change in the activity of SPTM. For example, modulation 0 may cause an increase or a decrease in protein activity, binding characteristics, or any other biological, functional, or immunological properties of SPTM.
"E-value" refers to the statistical probability that a match between two sequences occurred by chance.
"Exon shuffling" refers to the recombination of different coding regions (exons). Since an exon may represent a structural or functional domain of the encoded protein, new proteins may be assembled through the novel reassortment of stable substructures, thus allowing acceleration of the evolution of new protein functions.
A "fragment" is a unique portion of sptm or SPTM which is identical in sequence to but shorter in length than the parent sequence. A fragment may comprise up to the entire length of the defined sequence, minus one nucleotide/amino acid residue. For example, a fragment may comprise from 10 to 1000 contiguous amino acid residues or nucleotides. A fragment used as a probe, primer, antigen, therapeutic molecule, or for other purposes, may be at least 5, 10, 15, 16, 20, 25, 30, 40, 50, 60, 75, 100, 150, 250 or at least 500 contiguous amino acid residues or nucleotides in length. Fragments may be preferentially selected from certain regions of a molecule. For example, a polypeptide fragment may comprise a certain length of contiguous amino acids selected from the first 250 or 500 amino acids (or first 25% or 50%) of a polypeptide as shown in a certain defined sequence. Clearly these lengths are exemplary, and any length that is supported by the specification, including the Sequence Listing and the figures, may be encompassed by the present embodiments.
A fragment of sptm comprises a region of unique polynucleotide sequence that specifically identifies sptm, for example, as distinct from any other sequence in the same genome. A fragment of sptm is useful, for example, in hybridization and amplification technologies and in analogous methods that distinguish sptm from related polynucleotide sequences. The precise length of a fragment of sptm and the region of sptm to which the fragment corresponds are routinely determinable by one of ordinary skill in the art based on the intended purpose for the fragment.
A fragment of SPTM is encoded by a fragment of sptm. A fragment of SPTM comprises a region of unique amino acid sequence that specifically identifies SPTM. For example, a fragment of SPTM is useful as an immunogenic peptide for the development of antibodies that specifically recognize SPTM. The precise length of a fragment of SPTM and the region of SPTM to which the fragment corresponds are routinely determinable by one of ordinary skill in the art based on the intended purpose for the fragment. A "full length" nucleotide sequence is one containing at least a start site for translation to a protein sequence, followed by an open reading frame and a stop site, and encoding a "full length" polypeptide.
"Hit" refers to a sequence whose annotation will be used to describe a given template. Criteria for selecting the top hit are as follows: if the template has one or more exact nucleic acid matches, the top hit is the exact match with highest percent identity. If the template has no exact
matches but has significant protein hits, the top hit is the protein hit with the lowest E-value. If the template has no significant protein hits, but does have significant non-exact nucleotide hits, the top hit is the nucleotide hit with the lowest E-value.
"Homology" refers to sequence similarity either between a reference nucleic acid sequence 5 and at least a fragment of an sptm or between a reference amino acid sequence and a fragment of an SPTM.
"Hybridization" refers to the process by which a strand of nucleotides anneals with a complementary strand through base pairing. Specific hybridization is an indication that two nucleic acid sequences share a high degree of identity. Specific hybridization complexes form under defined 0 annealing conditions, and remain hybridized after the "washing" step. The defined hybridization conditions include the annealing conditions and the washing step(s), the latter of which is particularly important in determining the stringency of the hybridization process, with more stringent conditions allowing less non-specific binding, i.e., binding between pairs of nucleic acid probes that are not perfectly matched. Permissive conditions for annealing of nucleic acid sequences are routinely 5 determinable and may be consistent among hybridization experiments, whereas wash conditions may be varied among experiments to achieve the desired stringency.
Generally, stringency of hybridization is expressed with reference to the temperature under which the wash step is carried out. Generally, such wash temperatures are selected to be about 5°C to 20°C lower than the thermal melting point (Tm) for the specific sequence at a defined ionic strength 0 and pH. The Tm is the temperature (under defined ionic strength and pH) at which 50% of the target sequence hybridizes to a perfectly matched probe. An equation for calculating Tm and conditions for nucleic acid hybridization is well known and can be found in Sambrook et al., 1989, Molecular Cloning: A Laboratory Manual, 2nd ed., vol. 1-3, Cold Spring Harbor Press, Plainview NY; specifically see volume 2, chapter 9. 5 High stringency conditions for hybridization between polynucleotides of the present invention include wash conditions of 68°C in the presence of about 0.2 x SSC and about 0.1% SDS, for 1 hour. Alternatively, temperatures of about 65°C, 60°C, or 55°C may be used. SSC concentration may be varied from about 0.2 to 2 x SSC, with SDS being present at about 0.1%. Typically, blocking reagents are used to block non-specific hybridization. Such blocking reagents o include, for instance, denatured salmon sperm DNA at about 100-200 μg/ml. Useful variations on these conditions will be readily apparent to those skilled in the art. Hybridization, particularly under high stringency conditions, may be suggestive of evolutionary similarity between the nucleotides. Such similarity is strongly indicative of a similar role for the nucleotides and their resultant proteins. Other parameters, such as temperature, salt concentration, and detergent concentration may 5 be varied to achieve the desired stringency. Denaturants, such as formamide at a concentration of
about 35-50% v/v, may also be used under particular circumstances, such as RNA:DNA hybridizations. Appropriate hybridization conditions are routinely determinable by one of ordinary skill in the art.
"Immunologically active" or "immunogenic" describes the potential for a natural, recombinant, or synthetic peptide, epitope, polypeptide, or protein to induce antibody production in appropriate animals, cells, or cell lines.
"Immune response" can refer to conditions associated with inflammation, trauma, immune disorders, or infectious or genetic disease, etc. These conditions can be characterized by expression of various factors, e.g., cytokines, chemokines, and other signaling molecules, which may affect cellular and systemic defense systems.
An "immunogenic fragment" is a polypeptide or oligopeptide fragment of SPTM which is capable of eliciting an immune response when introduced into a living organism, for example, a mammal. The term "immunogenic fragment" also includes any polypeptide or oligopeptide fragment of SPTM which is useful in any of the antibody production methods disclosed herein or known in the art.
"Insertion" or "addition" refers to a change in either a nucleic or amino acid sequence in which at least one nucleotide or residue, respectively, is added to the sequence.
"Labeling" refers to the covalent or noncovalent joining of a polynucleotide, polypeptide, or antibody with a reporter molecule capable of producing a detectable or measurable signal. "Microarray" is any arrangement of nucleic acids, amino acids, antibodies, etc., on a substrate. The substrate may be a solid support such as beads, glass, paper, nitrocellulose, nylon, or an appropriate membrane.
"Linkers" are short stretches of nucleotide sequence which may be added to a vector or an sptm to create restriction endonuclease sites to facilitate cloning. "Polylinkers" are engineered to incorporate multiple restriction enzyme sites and to provide for the use of enzymes which leave 5' or 3' overhangs (e.g., BarnHI, EcoRI, and Hindlll) and those which provide blunt ends (e.g., EcoRV, SnaBI, and Stul).
"Naturally occurring" refers to an endogenous polynucleotide or polypeptide that may be isolated from viruses or prokaryotic or eukaryotic cells. "Nucleic acid sequence" refers to the specific order of nucleotides joined by phosphodiester bonds in a linear, polymeric arrangement. Depending on the number of nucleotides, the nucleic acid sequence can be considered an oligomer, oligonucleotide, or polynucleotide. The nucleic acid can be DNA, RNA, or any nucleic acid analog, such as PNA, may be of genomic or synthetic origin, may be either double-stranded or single-stranded, and can represent either the sense or antisense (complementary) strand.
"Oligomer" refers to a nucleic acid sequence of at least about 6 nucleotides and as many as about 60 nucleotides, preferably about 15 to 40 nucleotides, and most preferably between about 20 and 30 nucleotides, that may be used in hybridization or amplification technologies. Oligomers may be used as, e.g., primers for PCR, and are usually chemically synthesized. "Operably linked" refers to the situation in which a first nucleic acid sequence is placed in a functional relationship with the second nucleic acid sequence. For instance, a promoter is operably linked to a coding sequence if the promoter affects the transcription or expression of the coding sequence. Generally, operably linked DNA sequences may be in close proximity or contiguous and, where necessary to join two protein coding regions, in the same reading frame. "Peptide nucleic acid" (PNA) refers to a DNA mimic in which nucleotide bases are attached to a pseudopeptide backbone to increase stability. PNAs, also designated antigene" agents, can prevent gene expression by targeting complementary messenger RNA.
The phrases "percent identity" and "% identity", as applied to polynucleotide sequences, refer to the percentage of residue matches between at least two polynucleotide sequences aligned using a standardized algorithm. Such an algorithm may insert, in a standardized and reproducible way, gaps in the sequences being compared in order to optimize alignment between two sequences, and therefore achieve a more meaningful comparison of the two sequences.
Percent identity between polynucleotide sequences may be determined using the default parameters of the CLUSTAL V algorithm as incorporated into the MEGALIGN version 3.12e sequence alignment program. This program is part of the LASERGENE software package, a suite of molecular biological analysis programs (DNASTAR, Madison WI). CLUSTAL V is described in Higgins, D.G. and Sharp, P.M. (1989) CABIOS 5:151-153 and in Higgins, D.G. et al. (1992) CABIOS 8:189-191. For pairwise alignments of polynucleotide sequences, the default parameters are set as follows: Ktuple=2, gap penalty=5, window=4, and "diagonals saved"=4. The "weighted" residue weight table is selected as the default. Percent identity is reported by CLUSTAL V as the "percent similarity" between aligned polynucleotide sequence pairs.
Alternatively, a suite of commonly used and freely available sequence comparison algorithms is provided by the National Center for Biotechnology Information (NCBI) Basic Local Alignment Search Tool (BLAST) (Altschul, S.F. et al. (1990) J. Mol. Biol. 215:403-410), which is available from several sources, including the NCBI, Bethesda, MD, and on the Internet at http://www.ncbi.nlm.nih.gov/BLAST/. The BLAST software suite includes various sequence analysis programs including "BLASTN," that is used to determine alignment between a known polynucleotide sequence and other sequences on a variety of databases. Also available is a tool called "BLAST 2 Sequences" that is used for direct pairwise comparison of two nucleotide sequences. "BLAST 2 Sequences" can be accessed and used interactively at
http://www.ncbi.nlm.nih.gov/gorf/bl2/. The "BLAST 2 Sequences" tool can be used for both BLASTN and BLASTP (discussed below). BLAST programs are commonly used with gap and other parameters set to default settings. For example, to compare two nucleotide sequences, one may use BLASTN with the "BLAST 2 Sequences" tool Version 2.0.9 (May-07-1999) set at default 5 parameters. Such default parameters may be, for example:
Matrix: BLOSUM62
Reward for match: 1
Penalty for mismatch: -2
Open Gap: 5 and Extension Gap: 2 penalties o Gap x drop-off: 50
Expect: 10
Word Size: 11
Filter: on
Percent identity may be measured over the length of an entire defined sequence, for example, 5 as defined by a particular SEQ ID number, or may be measured over a shorter length, for example, over the length of a fragment taken from a larger, defined sequence, for instance, a fragment of at least 20, at least 30, at least 40, at least 50, at least 70, at least 100, or at least 200 contiguous nucleotides. Such lengths are exemplary only, and it is understood that any fragment length supported by the sequences shown herein, in figures or Sequence Listings, may be used to describe a o length over which percentage identity may be measured.
Nucleic acid sequences that do not show a high degree of identity may nevertheless encode similar amino acid sequences due to the degeneracy of the genetic code. It is understood that changes in nucleic acid sequence can be made using this degeneracy to produce multiple nucleic acid sequences that all encode substantially the same protein. 5 The phrases "percent identity" and "% identity", as applied to polypeptide sequences, refer to the percentage of residue matches between at least two polypeptide sequences aligned using a standardized algorithm. Methods of polypeptide sequence alignment are well-known. Some alignment methods take into account conservative amino acid substitutions. Such conservative substitutions, explained in more detail above, generally preserve the hydrophobicity and acidity of the o substituted residue, thus preserving the structure (and therefore function) of the folded polypeptide.
Percent identity between polypeptide sequences may be determined using the default parameters of the CLUSTAL V algorithm as incorporated into the MEGALIGN version 3.12e sequence alignment program (described and referenced above). For pairwise alignments of polypeptide sequences using CLUSTAL V, the default parameters are set as follows: Ktuple=l, gap 5 penalty=3, window=5, and "diagonals saved"=5. The PAM250 matrix is selected as the default
residue weight table. As with polynucleotide alignments, the percent identity is reported by CLUSTAL V as the "percent similarity" between aligned polypeptide sequence pairs.
Alternatively the NCBI BLAST software suite- may be used. For example, for a pairwise comparison of two polypeptide sequences, one may use the "BLAST 2 Sequences" tool Version 2.0.9 5 (May-07-1999) with BLASTP set at default parameters. Such default parameters may be, for example:
Matrix: BLOSUM62
Open Gap: 11 and Extension Gap: 1 penalty
Gap x drop-off: 50 0 Expect: 10
Word Size: 3
Filter: on
Percent identity may be measured over the length of an entire defined polypeptide sequence, for example, as defined by a particular SEQ ID number, or may be measured over a shorter length, for 5 example, over the length of a fragment taken from a larger, defined polypeptide sequence, for instance, a fragment of at least 15, at least 20, at least 30, at least 40, at least 50, at least 70 or at least 150 contiguous residues. Such lengths are exemplary only, and it is understood that any fragment length supported by the sequences shown herein, in figures or Sequence Listings, may be used to describe a length over which percentage identity may be measured. o "Post-translational modification" of an SPTM may involve lipidation, glycosylation, phosphorylation, acetylation, racemization, proteolytic cleavage, and other modifications known in the art. These processes may occur synthetically or biochemically. Biochemical modifications will vary by cell type depending on the enzymatic milieu and the SPTM.
"Probe" refers to sptm or fragments thereof, which are used to detect identical, allelic or 5 related nucleic acid sequences. Probes are isolated oligonucleotides or polynucleotides attached to a detectable label or reporter molecule. Typical labels include radioactive isotopes, ligands, chemiluminescent agents, and enzymes. "Primers" are short nucleic acids, usually DNA oligonucleotides, which may be annealed to a target polynucleotide by complementary base-pairing. The primer may then be extended along the target DNA strand by a DNA polymerase enzyme. o Primer pairs can be used for amplification (and identification) of a nucleic acid sequence, e.g., by the polymerase chain reaction (PCR).
Probes and primers as used in the present invention typically comprise at least 15 contiguous nucleotides of a known sequence. In order to enhance specificity, longer probes and primers may also be employed, such as probes and primers that comprise at least 20, 30, 40, 50, 60, 70, 80, 90, 100, or 5 at least 150 consecutive nucleotides of the disclosed nucleic acid sequences. Probes and primers may
be considerably longer than these examples, and it is understood that any length supported by the specification, including the figures and Sequence Listing, may be used.
Methods for preparing and using probes and primers are described in the references, for example Sambrook et al., 1989, Molecular Cloning: A Laboratory Manual, 2nd ed., vol. 1-3, Cold 5 Spring Harbor Press, Plainview NY; Ausubel et al., 1987, Current Protocols in Molecular Biology, Greene Publ. Assoc. & Wiley-Intersciences, New York NY; Innis et al., 1990, PCR Protocols, A Guide to Methods and Applications, Academic Press, San Diego CA. PCR primer pairs can be derived from a known sequence, for example, by using computer programs intended for that purpose such as Primer (Version 0.5, 1991, Whitehead Institute for Biomedical Research, Cambridge MA). 0 Oligonucleotides for use as primers are selected using software known in the art for such purpose. For example, OLIGO 4.06 software is useful for the selection of PCR primer pairs of up to 100 nucleotides each, and for the analysis of oligonucleotides and larger polynucleotides of up to 5,000 nucleotides from an input polynucleotide sequence of up to 32 kilobases. Similar primer selection programs have incorporated additional features for expanded capabilities. For example, the 5 PrimOU primer selection program (available to the public from the Genome Center at University of Texas South West Medical Center, Dallas TX) is capable of choosing specific primers from megabase sequences and is thus useful for designing primers on a genome-wide scope. The Primer3 primer selection program (available to the public from the Whitehead stitute/MIT Center for Genome Research, Cambridge MA) allows the user to input a "mispriming library," in which 0 sequences to avoid as primer binding sites are user-specified. Primer3 is useful, in particular, for the selection of oligonucleotides for microarra s. (The source code for the latter two primer selection programs may also be obtained from their respective sources and modified to meet the user's specific needs.) The PrimeGen program (available to the public from the UK Human Genome Mapping Project Resource Centre, Cambridge UK) designs primers based on multiple sequence alignments, 5 thereby allowing selection of primers that hybridize to either the most conserved or least conserved regions of aligned nucleic acid sequences. Hence, this program is useful for identification of both unique and conserved oligonucleotides and polynucleotide fragments. The oligonucleotides and polynucleotide fragments identified by any of the above selection methods are useful in hybridization technologies, for example, as PCR or sequencing primers, microarray elements, or specific probes to o identify fully or partially complementary polynucleotides in a sample of nucleic acids. Methods of oligonucleotide selection are not limited to those described above.
"Purified" refers to molecules, either polynucleotides or polypeptides that are isolated or separated from their natural environment and are at least 60% free, preferably at least 75% free, and most preferably at least 90% free from other compounds with which they are naturally associated.
A "recombinant nucleic acid" is a sequence that is not naturally occurring or has a sequence that is made by an artificial combination of two or more otherwise separated segments of sequence. This artificial combination is often accomplished by chemical synthesis or, more commonly, by the artificial manipulation of isolated segments of nucleic acids, e.g., by genetic engineering techniques such as those described in Sambrook, supra. The term recombinant includes nucleic acids that have been altered solely by addition, substitution, or deletion of a portion of the nucleic acid. Frequently, a recombinant nucleic acid may include a nucleic acid sequence operably linked to a promoter sequence. Such a recombinant nucleic acid may be part of a vector that is used, for example, to transform a cell. Alternatively, such recombinant nucleic acids may be part of a viral vector, e.g., based on a vaccinia virus, that could be use to vaccinate a mammal wherein the recombinant nucleic acid is expressed, inducing a protective immunological response in the mammal.
"Regulatory element" refers to a nucleic acid sequence fromnontranslated regions of a gene, and includes enhancers, promoters, introns, and 3' untranslated regions, which interact with host proteins to carry out or regulate transcription or translation.
"Reporter" molecules are chemical or biochemical moieties used for labeling a nucleic acid, an amino acid, or an antibody. They include radionuclides; enzymes; fluorescent, chemiluminescent, or chromogenic agents; substrates; cofactors; inhibitors; magnetic particles; and other moieties known in the art. An "RNA equivalent," in reference to a DNA sequence, is composed of the same linear sequence of nucleotides as the reference DNA sequence with the exception that all occurrences of the nitrogenous base thymine are replaced with uracil, and the sugar backbone is composed of ribose instead of deoxyribose.
"Sample" is used in its broadest sense. Samples may contain nucleic or amino acids, antibodies, or other materials, and may be derived from any source (e.g., bodily fluids including, but not limited to, saliva, blood, and urine; chromosome(s), organelles, or membranes isolated from a cell; genomic DNA, RNA, or cDNA in solution or bound to a substrate; and cleared cells or tissues or blots or imprints from such cells or tissues).
"Specific binding" or "specifically binding" refers to the interaction between a protein or peptide and its agonist, antibody, antagonist, or other binding partner. The interaction is dependent upon the presence of a particular structure of the protein, e.g., the antigenic determinant or epitope, recognized by the binding molecule. For example, if an antibody is specific for epitope "A," the presence of a polypeptide containing epitope A, or the presence of free unlabeled A, in a reaction containing free labeled A and the antibody will reduce the amount of labeled A that binds to the antibody.
"Substitution" refers to the replacement of at least one nucleotide or amino acid by a different nucleotide or amino acid.
"Substrate" refers to any suitable rigid or semi-rigid support including, e.g., membranes, filters, chips, slides, wafers, fibers, magnetic or nonmagnetic beads, gels, tubing, plates, polymers, microparticles or capillaries. The substrate can have a variety of surface forms, such as wells, trenches, pins, channels and pores, to which polynucleotides or polypeptides are bound.
A "transcript image" refers to the collective pattern of gene expression by a particular tissue or cell type under given conditions at a given time.
"Transformation" refers to a process by which exogenous DNA enters a recipient cell. Transformation may occur under natural or artificial conditions using various methods well known in the art. Transformation may rely on any known method for the insertion of foreign nucleic acid sequences into a prokaryotic or eukaryotic host cell. The method is selected based on the host cell being transformed.
"Transformants" include stably transformed cells in which the inserted DNA is capable of replication either as an autonomously replicating plasmid or as part of the host chromosome, as well as cells which transiently express inserted DNA or RNA.
A "transgenic organism," as used herein, is any organism, including but not limited to animals and plants, in which one or more of the cells of the organism contains heterologous nucleic acid introduced by way of human intervention, such as by transgenic techniques well known in the art. The nucleic acid is introduced into the cell, directly or indirectly by introduction into a precursor of the cell, by way of deliberate genetic manipulation, such as by microinjection or by infection with a recombinant virus. The term genetic manipulation does not include classical cross-breeding, or in vitro fertilization, but rather is directed to the introduction of a recombinant DNA molecule. The transgenic organisms contemplated in accordance with the present invention include bacteria, cyanobacteria, fungi, and plants and animals. The isolated DNA of the present invention can be introduced into the host by methods known in the art, for example infection, transfection, transformation or transconjugation. Techniques for transferring the DNA of the present invention into such organisms are widely known and provided in references such as Sambrook et al. (1989), supra. A "variant" of a particular nucleic acid sequence is defined as a nucleic acid sequence having at least 25% sequence identity to the particular nucleic acid sequence over a certain length of one of the nucleic acid sequences using BLASTN with the "BLAST 2 Sequences" tool Version 2.0.9 (May- 07-1999) set at default parameters. Such a pair of nucleic acids may show, for example, at least 30%, at least 50%, at least 60%, at least 70%, at least 80%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% or greater
sequence identity over a certain defined length. The variant may result in "conservative" amino acid changes which do not affect structural and/or chemical properties. A variant may be described as, for example, an "allelic" (as defined above), "splice," "species," or "polymorphic" variant. A splice variant may have significant identity to a reference molecule, but will generally have a greater or lesser number of polynucleotides due to alternate splicing of exons during mRNA processing. The corresponding polypeptide may possess additional functional domains or lack domains that are present in the reference molecule. Species variants are polynucleotide sequences that vary from one species to another. The resulting polypeptides generally will have significant amino acid identity relative to each other. A polymorphic variant is a variation in the polynucleotide sequence of a particular gene between individuals of a given species. Polymorphic variants also may encompass "single nucleotide polymorphisms" (SNPs) in which the polynucleotide sequence varies by one base. The presence of SNPs may be indicative of, for example, a certain population, a disease state, or a propensity for a disease state.
In an alternative, variants of the polynucleotides of the present invention may be generated through recombinant methods. One possible method is a DNA shuffling technique such as MOLECULARBREEDING (Maxygen Inc., Santa Clara CA; described in U.S. Patent Number 5,837,458; Chang, C.-C. et al. (1999) Nat. Biotechnol. 17:793-797; Christians, F.C. et al. (1999) Nat. Biotechnol. 17:259-264; and Crameri, A. et al. (1996) Nat. Biotechnol. 14:315-319) to alter or improve the biological properties of SPTM, such as its biological or enzymatic activity or its ability to bind to other molecules or compounds. DNA shuffling is a process by which a library of gene variants is produced using PCR-mediated recombination of gene fragments. The library is then subjected to selection or screening procedures that identify those gene variants with the desired properties. These preferred variants may then be pooled and further subjected to recursive rounds of DNA shuffling and selection/screening. Thus, genetic diversity is created through "artificial" breeding and rapid molecular evolution. For example, fragments of a single gene containing random point mutations may be recombined, screened, and then reshuffled until the desired properties are optimized. Alternatively, fragments of a given gene may be recombined with fragments of homologous genes in the same gene family, either from the same or different species, thereby maximizing the genetic diversity of multiple naturally occurring genes in a directed and controllable manner.
A "variant" of a particular polypeptide sequence is defined as a polypeptide sequence having at least 40% sequence identity to the particular polypeptide sequence over a certain length of one of the polypeptide sequences using BLASTP with the "BLAST 2 Sequences" tool Version 2.0.9 (May- 07-1999) set at default parameters. Such a pair of polypeptides may show, for example, at least 50%, at least 60%, at least 70%, at least 80%, at least 90%, at least 91%, at least 92%, at least 93%, at least
94%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% or greater sequence identity over a certain defined length of one of the polypeptides.
THE INVENTION In a particular embodiment, cDNA sequences derived from human tissues and cell lines were aligned based on nucleotide sequence identity and assembled into "consensus" or "template" sequences which are designated by the template identification numbers (template IDs) in column 2 of Table 2. The sequence identification numbers (SEQ ID NO:s) corresponding to the template IDs are shown in column 1. Segments of the template sequences are defined by the "start" and "stop" nucleotide positions listed in columns 3 and 4. These segments, when translated in the reading frames indicated in column 5, have similarity to signal peptide (SP) or transmembrane (TM) domain consensus sequences, as indicated in column 6.
The invention incorporates the nucleic acid sequences of these templates as disclosed in the Sequence Listing and the use of these sequences in the diagnosis and treatment of disease states characterized by defects in cell signaling. The invention further utilizes these sequences in hybridization and amplification technologies, and in particular, in technologies which assess gene expression patterns correlated with specific cells or tissues and their responses in vivo or in vitro to pharmaceutical agents, toxins, and other treatments. In this manner, the sequences of the present invention are used to develop a transcript image for a particular cell or tissue.
Derivation of Nucleic Acid Sequences cDNA was isolated from libraries constructed using RNA derived from normal and diseased human tissues and cell lines. The human tissues and cell lines used for cDNA library construction were selected from a broad range of sources to provide a diverse population of cDNAs representative of gene transcription throughout the human body. Descriptions of the human tissues and cell lines used for cDNA library construction are provided in the L1FESEQ database (tncyte Genomics, Inc. (Incyte), Palo Alto CA). Human tissues were broadly selected from, for example, cardiovascular, dermatologic, endocrine, gastrointestinal, hematopoietic/immune system, musculoskeletal, neural, reproductive, and urologic sources. Cell lines used for cDNA library construction were derived from, for example, leukemic cells, teratocarcinomas, neuroepitheliomas, cervical carcinoma, lung fibroblasts, and endothelial cells. Such cell lines include, for example, THP-1, Jurkat, HUVEC, hNT2, WI38, HeLa, and other cell lines commonly used and available from public depositories (American Type Culture Collection, Manassas VA). Prior to rnRNA isolation, cell lines were untreated, treated with a pharmaceutical agent such as 5'-aza-2'-deoxycytidine, treated with an activating agent such as lipopolysaccharide in
the case of leukocytic cell lines, or, in the case of endothelial cell lines, subjected to shear stress.
Sequencing of the cDNAs
Methods for DNA sequencing are well known in the art. Conventional enzymatic methods 5 employ the Klenow fragment of DNA polymerase I, SEQUENASE DNA polymerase (U.S.
Biochemical Corporation, Cleveland OH), Taq polymerase (Applied Biosystems, Foster City CA), thermostable T7 polymerase (Amersham Pharmacia Biotech, Inc. (Amersham Pharmacia Biotech), Piscataway NJ), or combinations of polymerases and proofreading exonucleases such as those found in the ELONGASE amplification system (Life Technologies Inc. (Life Technologies), Gaithersburg 0 MD), to extend the nucleic acid sequence from an oligonucleotide primer annealed to the DNA template of interest. Methods have been developed for the use of both single-stranded and double- stranded templates. Chain termination reaction products may be electrophoresed on urea- polyacrylamide gels and detected either by autoradiography (for radioisotope-labeled nucleotides) or by fluorescence (for fluorophore-labeled nucleotides). Automated methods for mechanized reaction 5 preparation, sequencing, and analysis using fluorescence detection methods have been developed. Machines used to prepare cDNAs for sequencing can include the MICROLAB 2200 liquid transfer system (Hamilton Company (Hamilton), Reno NV), Peltier thermal cycler (PTC200; MJ Research, Inc. (MJ Research), Watertown MA), and ABI CATALYST 800 thermal cycler (Applied Biosystems). Sequencing can be carried out using, for example, the ABI 373 or 377 (Applied o Biosystems) or MEGABACE 1000 (Molecular Dynamics, Inc. (Molecular Dynamics), Sunnyvale
CA) DNA sequencing systems, or other automated and manual sequencing systems well known in the art.
The nucleotide sequences of the Sequence Listing have been prepared by current, state-of- the-art, automated methods and, as such, may contain occasional sequencing errors or unidentified 5 nucleotides. Such unidentified nucleotides are designated by an N. These infrequent unidentified bases do not represent a hindrance to practicing the invention for those skilled in the art. Several methods employing standard recombinant techniques may be used to correct errors and complete the missing sequence information. (See, e.g., those described in Ausubel, F.M. et al. (1997) Short Protocols in Molecular Biology. John Wiley & Sons, New York NY; and Sambrook, J. et al. (1989) o Molecular Cloning, A Laboratory Manual, Cold Spring Harbor Press, Plainview NY.)
Assembly of cDNA Sequences
Human polynucleotide sequences may be assembled using programs or algorithms well known in the art. Sequences to be assembled are related, wholly or in part, and may be derived from 5 a single or many different transcripts. Assembly of the sequences can be performed using such
programs as PHRAP (Phils Revised Assembly Program) and the GELVIEW fragment assembly system (GCG), or other methods known in the art.
Alternatively, cDNA sequences are used as "component" sequences that are assembled into "template" or "consensus" sequences as follows. Sequence chromatograms are processed, verified, and quality scores are obtained using PHRED. Raw sequences are edited using an editing pathway known as Block 1 (See, e.g., the LIFESEQ Assembled User Guide, Incyte Genomics, Palo Alto, CA). A series of BLAST comparisons is performed and low-information segments and repetitive elements (e.g., dinucleotide repeats, Alu repeats, etc.) are replaced by "n's", or masked, to prevent spurious matches. Mitochondrial and ribosomal RNA sequences are also removed. The processed sequences are then loaded into a relational database management system (RDMS) which assigns edited sequences to existing templates, if available. When additional sequences are added into the RDMS, a process is initiated which modifies existing templates or creates new templates from works in progress (i.e., nonfinal assembled sequences) containing queued sequences or the sequences themselves. After the new sequences have been assigned to templates, the templates can be merged into bins. If multiple templates exist in one bin, the bin can be split and the templates reannotated.
Once gene bins have been generated based upon sequence alignments, bins are "clone joined" based upon clone information. Clone joining occurs when the 5' sequence of one clone is present in one bin and the 3' sequence from the same clone is present in a different bin, indicating that the two bins should be merged into a single bin. Only bins which share at least two different clones are merged.
A resultant template sequence may contain either a partial or a full length open reading frame, or all or part of a genetic regulatory element. This variation is due in part to the fact that the full length cDNAs of many genes are several hundred, and sometimes several thousand, bases in length. With current technology, cDNAs comprising the coding regions of large genes cannot be cloned because of vector limitations, incomplete reverse transcription of the mRNA, or incomplete "second strand" synthesis. Template sequences may be extended to include additional contiguous sequences derived from the parent RNA transcript using a variety of methods known to those of skill in the art. Extension may thus be used to achieve the full length coding sequence of a gene.
Analysis of the cDNA Sequences
The cDNA sequences are analyzed using a variety of programs and algorithms which are well known in the art. (See, e.g., Ausubel, 1997, supra, Chapter 7J; Meyers, R.A. (Ed.) (1995) Molecular Biology and Biotechnology, Wiley VCH, New York NY, pp. 856-853; and Table 6.) These analyses comprise both reading frame determinations, e.g., based on triplet codon periodicity for particular organisms (Fickett, J.W. (1982) Nucleic Acids Res. 10:5303-5318); analyses of potential start and
stop codons; and homology searches.
Computer programs known to those of skill in the art for performing computer-assisted searches for amino acid and nucleic acid sequence similarity, include, for example, Basic Local Alignment Search Tool (BLAST; Altschul, S.F. (1993) J. Mol. Evol. 36:290-300; Altschul, S.F. et al. (1990) J. Mol. Biol. 215:403-410). BLAST is especially useful in determining exact matches and comparing two sequence fragments of arbitrary but equal lengths, whose alignment is locally maximal and for which the alignment score meets or exceeds a threshold or cutoff score set by the user (Karlin, S. et al. (1988) Proc. Natl. Acad. Sci. USA 85:841-845). Using an appropriate search tool (e.g., BLAST or HMM), GenBank, SwissProt, BLOCKS, PFAM and other databases may be searched for sequences containing regions of homology to a query sptm or SPTM of the present invention.
Other approaches to the identification, assembly, storage, and display of nucleotide and polypeptide sequences are provided in "Relational Database for Storing Biomolecule Information," U.S.S.N. 08/947,845, filed October 9, 1997; "Project-Based Full-Length Biomolecular Sequence Database," U.S. Patent Number 5,953,727; and "Relational Database and System for Storing
Information Relating to Biomolecular Sequences," U.S.S.N. 09/034,807, filed March 4, 1998, all of which are incorporated by reference herein in their entirety.
Protein hierarchies can be assigned to the putative encoded polypeptide based on, e.g., motif, BLAST, or biological analysis. Methods for assigning these hierarchies are described, for example, in "Database System Employing Protein Function Hierarchies for Viewing Biomolecular Sequence Data," U.S. Patent Number 6,023,659, incorporated herein by reference.
Human Secretory Sequences
The sptm of the present invention may be used for a variety of diagnostic and therapeutic purposes. For example, an sptm may be used to diagnose a particular condition, disease, or disorder associated with cell signaling. Such conditions, diseases, and disorders include, but are not limited to, a cell proliferative disorder such as actinic keratosis, arteriosclerosis, atherosclerosis, bursitis, cirrhosis, hepatitis, mixed connective tissue disease (MCTD), myelofibrosis, paroxysmal nocturnal hemoglobinuria, polycythemia vera, psoriasis, primary thrombocythemia, and cancers including adenocarcinoma, leukemia, lymphoma, melanoma, myeloma, sarcoma, teratocarcinoma, and, in particular, a cancer of the adrenal gland, bladder, bone, bone marrow, brain, breast, cervix, gall bladder, ganglia, gastrointestinal tract, heart, kidney, liver, lung, muscle, ovary, pancreas, parathyroid, penis, prostate, salivary glands, skin, spleen, testis, thymus, thyroid, and uterus; an immune system disorder such as such as inflammation, actinic keratosis, acquired immunodeficiency syndrome (AIDS), Addison's disease, adult respiratory distress syndrome, allergies, ankylosing
spondylitis, amyloidosis, anemia, arteriosclerosis, asthma, atherosclerosis, autoimmune hemolytic anemia, autoimmune thyroiditis, bronchitis, bursitis, cholecystitis, cirrhosis, contact dermatitis, Crohn's disease, atopic dermatitis, dermatomyositis, diabetes mellitus, emphysema, erythroblastosis fetalis, erythema nodosum, atrophic gastritis, glomerulonephritis, Goodpasture's syndrome, gout, Graves' disease, Hashimoto's thyroiditis, paroxysmal nocturnal hemoglobinuria, hepatitis, hypereosinophilia, irritable bowel syndrome, episodic lymphopenia with lymphocytotoxins, mixed connective tissue disease (MCTD), multiple sclerosis, myasthenia gravis, myocardial or pericardial inflammation, myelofibrosis, osteoarthritis, osteoporosis, pancreatitis, polycythemia vera, polymyositis, psoriasis, Reiter's syndrome, rheumatoid arthritis, scleroderma, Sjogren's syndrome, systemic anaphylaxis, systemic lupus erythematosus, systemic sclerosis, primary thrombocythemia, thrombocytopenic purpura, ulcerative colitis, uveitis, Werner syndrome, complications of cancer, hemodialysis, and extracorporeal circulation, trauma, and hematopoietic cancer including lymphoma, leukemia, and myeloma; and a neurological disorder such as epilepsy, ischemic cerebrovascular disease, stroke, cerebral neoplasms, Alzheimer's disease, Pick's disease, Huntington's disease, dementia, Parkinson's disease and other extrapyramidal disorders, amyotrophic lateral sclerosis and other motor neuron disorders, progressive neural muscular atrophy, retinitis pigmentosa, hereditary ataxias, multiple sclerosis and other demyelinating diseases, bacterial and viral meningitis, brain abscess, subdural empyema, epidural abscess, suppurative intracranial thrombophlebitis, myelitis and radiculitis, viral central nervous system disease, prion diseases including kuru, Creutzfeldt- Jakob disease, and Gerstmann-Straussler-Scheinker syndrome, fatal familial insomnia, nutritional and metabolic diseases of the nervous system, neurofibromatosis, tuberous sclerosis, cerebelloretinal hemangioblastomatosis, encephalotrigeminal syndrome, mental retardation and other developmental disorder of the central nervous system, cerebral palsy, a neuroskeletal disorder, an autonomic nervous system disorder, a cranial nerve disorder, a spinal cord disease, muscular dystrophy and other neuromuscular disorder, a peripheral nervous system disorder, dermatomyositis and polymyositis, inherited, metabolic, endocrine, and toxic myopathy, myasthenia gravis, periodic paralysis, a mental disorder including mood, anxiety, and schizophrenic disorder, seasonal affective disorder (SAD), akathesia, amnesia, catatonia, diabetic neuropathy, tardive dyskinesia, dystonias, paranoid psychoses, postherpetic neuralgia, and Tourette's disorder. The sptm can be used to detect the presence of, or to quantify the amount of, an sptm-related polynucleotide in a sample. This information is then compared to information obtained from appropriate reference samples, and a diagnosis is established. Alternatively, a polynucleotide complementary to a given sptm can inhibit or inactivate a therapeutically relevant gene related to the sptm.
Analysis of sptm Expression Patterns
The expression of sptm may be routinely assessed by hybridization-based methods to determine, for example, the tissue-specificity, disease-specificity, or developmental stage-specificity of sptm expression. For example, the level of expression of sptm may be compared among different cell types or tissues, among diseased and normal cell types or tissues, among cell types or tissues at 5 different developmental stages, or among cell types or tissues undergoing various treatments. This type of analysis is useful, for example, to assess the relative levels of sptm expression in fully or partially differentiated cells or tissues, to determine if changes in sptm expression levels are correlated with the development or progression of specific disease states, and to assess the response of a cell or tissue to a specific therapy, for example, in pharmacological or toxicological studies. 0 Methods for the analysis of sptm expression are based on hybridization and amplification technologies and include membrane-based procedures such as northern blot analysis, high-throughput procedures that utilize, for example, microarrays, and PCR-based procedures.
Hybridization and Genetic Analysis 5 The sptm, their fragments, or complementary sequences, may be used to identify the presence of and/or to determine the degree of similarity between two (or more) nucleic acid sequences. The sptm may be hybridized to naturally occurring or recombinant nucleic acid sequences under appropriately selected temperatures and salt concentrations. Hybridization with a probe based on the nucleic acid sequence of at least one of the sptm allows for the detection of nucleic acid sequences, o including genomic sequences, which are identical or related to the sptm of the Sequence Listing.
Probes may be selected from non-conserved or unique regions of at least one of the polynucleotides of SEQ ID NO: 1-75 and tested for their ability to identify or amplify the target nucleic acid sequence using standard protocols.
Polynucleotide sequences that are capable of hybridizing, in particular, to those shown in 5 SEQ ID NO: 1-75 and fragments thereof, can be identified using various conditions of stringency.
(See, e.g., Wahl, G.M. and S.L. Berger (1987) Methods Enzymol. 152:399-407; Kimmel, A.R. (1987) Methods Enzymol. 152:507-511.) Hybridization conditions are discussed in "Definitions."
A probe for use in Southern or northern hybridization may be derived from a fragment of an sptm sequence, or its complement, that is up to several hundred nucleotides in length and is either o single-stranded or double-stranded. Such probes may be hybridized in solution to biological materials such as plasmids, bacterial, yeast, or human artificial chromosomes, cleared or sectioned tissues, or to artificial substrates containing sptm. Microarrays are particularly suitable for identifying the presence of and detecting the level of expression for multiple genes of interest by examining gene expression correlated with, e.g., various stages of development, treatment with a drug or compound, 5 or disease progression. An array analogous to a dot or slot blot may be used to arrange and link
polynucleotides to the surface of a substrate using one or more of the following: mechanical (vacuum), chemical, thermal, or UN bonding procedures. Such an array may contain any number of sptm and may be produced by hand or by using available devices, materials, and machines.
Microarrays may be prepared, used, and analyzed using methods known in the art. (See, e.g., Brennan, T.M. et al. (1995) U.S. Patent No. 5,474,796; Schena, M. et al. (1996) Proc. Natl. Acad. Sci. USA 93:10614-10619; Baldeschweiler et al. (1995) PCT application W095/251116; Shalon, D. et al. (1995) PCT application WO95/35505; Heller, R.A. et al. (1997) Proc. Natl. Acad. Sci. USA 94:2150- 2155; and Heller, MJ. et al. (1997) U.S. Patent No. 5,605,662.)
Probes may be labeled by either PCR or enzymatic techniques using a variety of commercially available reporter molecules. For example, commercial kits are available for radioactive and chemiluminescent labeling (Amersham Pharmacia Biotech) and for alkaline phosphatase labeling (Life Technologies). Alternatively, sptm may be cloned into commercially available vectors for the production of RNA probes. Such probes may be transcribed in the presence of at least one labeled nucleotide (e.g., 32P-ATP, Amersham Pharmacia Biotech). Additionally the polynucleotides of SEQ ID NO: 1-75 or suitable fragments thereof can be used to isolate full length cDNA sequences utilizing hybridization and/or amplification procedures well known in the art, e.g., cDNA library screening, PCR amplification, etc. The molecular cloning of such full length cDNA sequences may employ the method of cDNA library screening with probes using the hybridization, stringency, washing, and probing strategies described above and in Ausubel, supra. Chapters 3, 5, and 6. These procedures may also be employed with genomic libraries to isolate genomic sequences of sptm in order to analyze, e.g., regulatory elements.
Genetic Mapping
Gene identification and mapping are important in the investigation and treatment of almost all conditions, diseases, and disorders. Cancer, cardiovascular disease, Alzheimer's disease, arthritis, diabetes, and mental illnesses are of particular interest. Each of these conditions is more complex than the single gene defects of sickle cell anemia or cystic fibrosis, with select groups of genes being predictive of predisposition for a particular condition, disease, or disorder. For example, cardiovascular disease may result from malfunctioning receptor molecules that fail to clear cholesterol from the bloodstream, and diabetes may result when a particular individual' s immune system is activated by an infection and attacks the insulin-producing cells of the pancreas. In some studies, Alzheimer's disease has been linked to a gene on chromosome 21; other studies predict a different gene and location. Mapping of disease genes is a complex and reiterative process and generally proceeds from genetic linkage analysis to physical mapping. As a condition is noted among members of a family, a genetic linkage map traces parts of
chromosomes that are inherited in the same pattern as the condition. Statistics link the inheritance of particular conditions to particular regions of chromosomes, as defined by RFLP or other markers. (See, for example, Lander, E. S. and Botstein, D. (1986) Proc. Natl. Acad. Sci. USA 83:7353-7357.) Occasionally, genetic markers and their locations are known from previous studies. More often, however, the markers are simply stretches of DNA that differ among individuals. Examples of genetic linkage maps can be found in various scientific journals or at the Online Mendelian Inheritance in Man (OMIM) World Wide Web site.
In another embodiment of the invention, sptm sequences may be used to generate hybridization probes useful in chromosomal mapping of naturally occurring genomic sequences. Either coding or noncoding sequences of sptm may be used, and in some instances, noncoding sequences may be preferable over coding sequences. For example, conservation of an sptm coding sequence among members of a multi-gene family may potentially cause undesired cross hybridization during chromosomal mapping. The sequences may be mapped to a particular chromosome, to a specific region of a chromosome, or to artificial chromosome constructions, e.g., human artificial chromosomes (HACs), yeast artificial chromosomes (YACs), bacterial artificial chromosomes
(BACs), bacterial PI constructions, or single chromosome cDNA libraries. (See, e.g., Harrington, JJ. et al. (1997) Nat. Genet. 15:345-355; Price, CM. (1993) Blood Rev. 7:127-134; and Trask, B.J. (1991) Trends Genet. 7:149-154.)
Fluorescent in situ hybridization (FISH) may be correlated with other physical chromosome mapping techniques and genetic map data. (See, e.g., Meyers, supra, pp. 965-968.) Correlation between the location of sptm on a physical chromosomal map and a specific disorder, or a predisposition to a specific disorder, may help define the region of DNA associated with that disorder. The sptm sequences may also be used to detect polymorphisms that are genetically linked to the inheritance of a particular condition, disease, or disorder. In situ hybridization of chromosomal preparations and genetic mapping techniques, such as linkage analysis using established chromosomal markers, may be used for extending existing genetic maps. Often the placement of a gene on the chromosome of another mammalian species, such as mouse, may reveal associated markers even if the number or arm of the corresponding human chromosome is not known. These new marker sequences can be mapped to human chromosomes and may provide valuable information to investigators searching for disease genes using positional cloning or other gene discovery techniques. Once a disease or syndrome has been crudely correlated by genetic linkage with a particular genomic region, e.g., ataxia-telangiectasia to 1 lq22-23, any sequences mapping to that area may represent associated or regulatory genes for further investigation. (See, e.g., Gatti, R.A. et al. (1988) Nature 336:577-580.) The nucleotide sequences of the subject invention may also be used to detect differences in chromosomal architecture due to translocation,
inversion, etc., among normal, carrier, or affected individuals.
Once a disease-associated gene is mapped to a chromosomal region, the gene must be cloned in order to identify mutations or other alterations (e.g., translocations or inversions) that may be correlated with disease. This process requires a physical map of the chromosomal region containing 5 the disease-gene of interest along with associated markers. A physical map is necessary for determining the nucleotide sequence of and order of marker genes on a particular chromosomal region. Physical mapping techniques are well known in the art and require the generation of overlapping sets of cloned DNA fragments from a particular organelle, chromosome, or genome. These clones are analyzed to reconstruct and catalog their order. Once the position of a marker is 0 determined, the DNA from that region is obtained by consulting the catalog and selecting clones from that region. The gene of interest is located through positional cloning techniques using hybridization or similar methods.
Diagnostic Uses 5 The sptm of the present invention may be used to design probes useful in diagnostic assays.
Such assays, well known to those skilled in the art, may be used to detect or confirm conditions, disorders, or diseases associated with abnormal levels of sptm expression. Labeled probes developed from sptm sequences are added to a sample under hybridizing conditions of desired stringency. In some instances, sptm, or fragments or oligonucleotides derived from sptm, may be used as primers in 0 amplification steps prior to hybridization. The amount of hybridization complex formed is quantified and compared with standards for that cell or tissue. If sptm expression varies significantly from the standard, the assay indicates the presence of the condition, disorder, or disease. Qualitative or quantitative diagnostic methods may include northern, dot blot, or other membrane or dip-stick based technologies or multiple-sample format technologies such as PCR, enzyme-linked immunosorbent 5 assay (ELISA)-like, pin, or chip-based assays.
The probes described above may also be used to monitor the progress of conditions, disorders, or diseases associated with abnormal levels of sptm expression, or to evaluate the efficacy of a particular therapeutic treatment. The candidate probe may be identified from the sptm that are specific to a given human tissue and have not been observed in GenBank or other genome databases. o Such a probe may be used in animal studies, preclinical tests, clinical trials, or in monitoring the treatment of an individual patient. In a typical process, standard expression is established by methods well known in the art for use as a basis of comparison, samples from patients affected by the disorder or disease are combined with the probe to evaluate any deviation from the standard profile, and a therapeutic agent is administered and effects are monitored to generate a treatment profile. Efficacy 5 is evaluated by determining whether the expression progresses toward or returns to the standard
normal pattern. Treatment profiles may be generated over a period of several days or several months. Statistical methods well known to those skilled in the art may be use to determine the significance of such therapeutic agents.
The polynucleotides are also useful for identifying individuals from minute biological samples, for example, by matching the RFLP pattern of a sample's DNA to that of an individual's DNA. The polynucleotides of the present invention can also be used to determine the actual base-by-base DNA sequence of selected portions of an individual's genome. These sequences can be used to prepare PCR primers for amplifying and isolating such selected DNA, which can then be sequenced. Using this technique, an individual can be identified through a unique set of DNA sequences. Once a unique ID database is established for an individual, positive identification of that individual can be made from extremely small tissue samples.
In a particular aspect, oligonucleotide primers derived from the sptm of the invention may be used to detect single nucleotide polymorphisms (SNPs). SNPs are substitutions, insertions and deletions that are a frequent cause of inherited or acquired genetic disease in humans. Methods of SNP detection include, but are not limited to, single-stranded conformation polymorphism (SSCP) and fluorescent SSCP (fSSCP) methods. In SSCP, oligonucleotide primers derived from sptm are used to amplify DNA using the polymerase chain reaction (PCR). The DNA may be derived, for example, from diseased or normal tissue, biopsy samples, bodily fluids, and the like. SNPs in the DNA cause differences in the secondary and tertiary structures of PCR products in single-stranded form, and these differences are detectable using gel electrophoresis in non-denaturing gels. In fSCCP, the oligonucleotide primers are fluorescently labeled, which allows detection of the amplimers in high-throughput equipment such as DNA sequencing machines. Additionally, sequence database analysis methods, termed in silico SNP (isSNP), are capable of identifying polymorphisms by comparing the sequences of individual overlapping DNA fragments which assemble into a common consensus sequence. These computer-based methods filter out sequence variations due to laboratory preparation of DNA and sequencing errors using statistical models and automated analyses of DNA sequence chromatograms. In the alternative, SNPs may be detected and characterized by mass spectrometry using, for example, the high throughput MASSARRAY system (Sequenom, Inc., San Diego CA). DNA-based identification techniques are critical in forensic technology. DNA sequences taken from very small biological samples such as tissues, e.g., hair or skin, or body fluids, e.g., blood, saliva, semen, etc., can be amplified using, e.g., PCR, to identify individuals. (See, e.g., Erlich, H. (1992) PCR Technology. Freeman and Co., New York, NY). Similarly, polynucleotides of the present invention can be used as polymorphic markers. There is also a need for reagents capable of identifying the source of a particular tissue.
Appropriate reagents can comprise, for example, DNA probes or primers prepared from the sequences of the present invention that are specific for particular tissues. Panels of such reagents can identify tissue by species and/or by organ type. In a similar fashion, these reagents can be used to screen tissue cultures for contamination. 5 The polynucleotides of the present invention can also be used as molecular weight markers on nucleic acid gels or Southern blots, as diagnostic probes for the presence of a specific mRNA in a particular cell type, in the creation of subtracted cDNA libraries which aid in the discovery of novel polynucleotides, in selection and synthesis of oligomers for attachment to an array or other support, and as an antigen to elicit an immune response. 0
Disease Model Systems Using sptm
The polynucleotides encoding SPTM or their mammalian homologs may be "knocked out" in an animal model system using homologous recombination in embryonic stem (ES) cells. Such techniques are well known in the art and are useful for the generation of animal models of human 5 disease. (See, e.g., U.S. Patent Number 5,175,383 and U.S. Patent Number 5,767,337.) For example, mouse ES cells, such as the mouse 129/SvJ cell line, are derived from the early mouse embryo and grown in culture. The ES cells are transformed with a vector containing the gene of interest disrupted by a marker gene, e.g., the neomycin phosphotransferase gene (neo; Capecchi, M.R. (1989) Science 244: 1288-1292). The vector integrates into the corresponding region of the host genome by o homologous recombination. Alternatively, homologous recombination takes place using the Cre-loxP system to knockout a gene of interest in a tissue- or developmental stage-specific manner (Marth, J.D. (1996) Clin. Invest. 97:1999-2002; Wagner, K.U. et al. (1997) Nucleic Acids Res. 25:4323-4330). Transformed ES cells are identified and microinjected into mouse cell blastocysts such as those from the C57BL/6 mouse strain. The blastocysts are surgically transferred to pseudopregnant dams, and 5 the resulting chimeric progeny are genotyped and bred to produce heterozygous or homozygous strains. Transgenic animals thus generated may be tested with potential therapeutic or toxic agents. The polynucleotides encoding SPTM may also be manipulated in vitro in ES cells derived from human blastocysts. Human ES cells have the potential to differentiate into at least eight separate cell lineages including endoderm, mesoderm, and ectodermal cell types. These cell lineages o differentiate into, for example, neural cells, hematopoietic lineages, and cardiomyocytes (Thomson,
J.A. et al. (1998) Science 282:1145-1147).
The polynucleotides encoding SPTM of the invention can also be used to create "knockin" humanized animals (pigs) or transgenic animals (mice or rats) to model human disease. With knockin technology, a region of sptm is injected into animal ES cells, and the injected sequence integrates into 5 the animal cell genome. Transformed cells are injected into blastulae, and the blastulae are implanted
as described above. Transgenic progeny or inbred lines are studied and treated with potential pharmaceutical agents to obtain information on treatment of a human disease. Alternatively, a mammal inbred to overexpress sptm, resulting, e.g., in the secretion of SPTM in its milk, may also serve as a convenient source of that protein (Janne, J. et al. (1998) Biotechnol. Annu. Rev. 4:55-74).
Screening Assays
SPTM encoded by polynucleotides of the present invention may be used to screen for molecules that bind to or are bound by the encoded polypeptides. The binding of the polypeptide and the molecule may activate (agonist), increase, inhibit (antagonist), or decrease activity of the polypeptide or the bound molecule. Examples of such molecules include antibodies, oligonucleotides, proteins (e.g., receptors), or small molecules.
Preferably, the molecule is closely related to the natural ligand of the polypeptide, e.g., a ligand or fragment thereof, a natural substrate, or a structural or functional mimetic. (See, Coligan et al.. (1991) Current Protocols in Immunology 1(2): Chapter 5.) Similarly, the molecule can be closely related to the natural receptor to which the polypeptide binds, or to at least a fragment of the receptor, e.g., the active site. In either case, the molecule can be rationally designed using known techniques.
Preferably, the screening for these molecules involves producing appropriate cells which express the polypeptide, either as a secreted protein or on the cell membrane. Preferred cells include cells from mammals, yeast, Drosophila. or E. coli. Cells expressing the polypeptide or cell membrane fractions which contain the expressed polypeptide are then contacted with a test compound and binding, stimulation, or inhibition of activity of either the polypeptide or the molecule is analyzed.
An assay may simply test binding of a candidate compound to the polypeptide, wherein binding is detected by a fluorophore, radioisotope, enzyme conjugate, or other detectable label. Alternatively, the assay may assess binding in the presence of a labeled competitor.
Additionally, the assay can be carried out using cell-free preparations, polypeptide/molecule affixed to a solid support, chemical libraries, or natural product mixtures. The assay may also simply comprise the steps of mixing a candidate compound with a solution containing a polypeptide, measuring polypeptide/molecule activity or binding, and comparing the polypeptide/molecule activity or binding to a standard.
Preferably, an ELISA assay using, e.g., a monoclonal or polyclonal antibody, can measure polypeptide level in a sample. The antibody can measure polypeptide level by either binding, directly or indirectly, to the polypeptide or by competing with the polypeptide for a substrate.
All of the above assays can be used in a diagnostic or prognostic context. The molecules discovered using these assays can be used to treat disease or to bring about a particular result in a
patient (e.g., blood vessel growth) by activating or inhibiting the polypeptide/molecule. Moreover, the assays can discover agents which may inhibit or enhance the production of the polypeptide from suitably manipulated cells or tissues.
5 Transcript Imaging and Toxicological Testing
Another embodiment relates to the use of sptm to develop a transcript image of a tissue or cell type. A transcript image represents the global pattern of gene expression by a particular tissue or cell type. Global gene expression patterns are analyzed by quantifying the number of expressed genes and their relative abundance under given conditions and at a given time. (See Seilhamer et al., 0 "Comparative Gene Transcript Analysis," U.S. Patent Number 5,840,484, expressly incorporated by reference herein.) Thus a transcript image may be generated by hybridizing the polynucleotides of the present invention or their complements to the totality of transcripts or reverse transcripts of a particular tissue or cell type. In one embodiment, the hybridization takes place in high-throughput format, wherein the polynucleotides of the present invention or their complements comprise a subset 5 of a plurality of elements on a microarray. The resultant transcript image would provide a profile of gene activity pertaining to cell signaling.
Transcript images which profile sptm expression may be generated using transcripts isolated from tissues, cell lines, biopsies, or other biological samples. The transcript image may thus reflect sptm expression in vivo, as in the case of a tissue or biopsy sample, or in vitro, as in the case of a cell o line.
Transcript images which profile sptm expression may also be used in conjunction with m vitro model systems and preclinical evaluation of pharmaceuticals, as well as toxicological testing of industrial and naturally-occurring environmental compounds. All compounds induce characteristic gene expression patterns, frequently termed molecular fingerprints or toxicant signatures, which are 5 indicative of mechanisms of action and toxicity (Nuwaysir, E. F. et al. (1999) Mol. Carcinog. 24:153- 159; Steiner, S. and Anderson, N. L. (2000) Toxicol. Lett. 112-113:467-71, expressly incorporated by reference herein). If a test compound has a signature similar to that of a compound with known toxicity, it is likely to share those toxic properties. These fingerprints or signatures are most useful and refined when they contain expression information from a large number of genes and gene o families. Ideally, a genome-wide measurement of expression provides the highest quality signature.
Even genes whose expression is not altered by any tested compounds are important as well, as the levels of expression of these genes are used to normalize the rest of the expression data. The normalization procedure is useful for comparison of expression data after treatment with different compounds. While the assignment of gene function to elements of a toxicant signature aids in 5 interpretation of toxicity mechanisms, knowledge of gene function is not necessary for the statistical
matching of signatures which leads to prediction of toxicity. (See, for example, Press Release 00-02 from the National Institute of Environmental Health Sciences, released February 29, 2000, available at http://www.niehs.nih.gov/oc/news/toxchip.htm.) Therefore, it is important and desirable in toxicological screening using toxicant signatures to include all expressed gene sequences. 5 In one embodiment, the toxicity of a test compound is assessed by treating a biological sample containing nucleic acids with the test compound. Nucleic acids that are expressed in the treated biological sample are hybridized with one or more probes specific to the polynucleotides of the present invention, so that transcript levels corresponding to the polynucleotides of the present invention may be quantified. The transcript levels in the treated biological sample are compared with 0 levels in an untreated biological sample. Differences in the transcript levels between the two samples are indicative of a toxic response caused by the test compound in the treated sample.
Another particular embodiment relates to the use of SPTM encoded by polynucleotides of the present invention to analyze the proteome of a tissue or cell type. The term proteome refers to the global pattern of protein expression in a particular tissue or cell type. Each protein component of a 5 proteome can be subjected individually to further analysis. Proteome expression patterns, or profiles, are analyzed by quantifying the number of expressed proteins and their relative abundance under given conditions and at a given time. A profile of a cell's proteome may thus be generated by separating and analyzing the polypeptides of a particular tissue or cell type. In one embodiment, the separation is achieved using two-dimensional gel electrophoresis, in which proteins from a sample are o separated by isoelectric focusing in the first dimension, and then according to molecular weight by sodium dodecyl sulfate slab gel electrophoresis in the second dimension (Steiner and Anderson, supra). The proteins are visualized in the gel as discrete and uniquely positioned spots, typically by staining the gel with an agent such as Coomassie Blue or silver or fluorescent stains. The optical density of each protein spot is generally proportional to the level of the protein in the sample. The 5 optical densities of equivalently positioned protein spots from different samples, for example, from biological samples either treated or untreated with a test compound or therapeutic agent, are compared to identify any changes in protein spot density related to the treatment. The proteins in the spots are partially sequenced using, for example, standard methods employing chemical or enzymatic cleavage followed by mass spectrometry. The identity of the protein in a spot may be determined by o comparing its partial sequence, preferably of at least 5 contiguous amino acid residues, to the polypeptide sequences of the present invention. In some cases, further sequence data may be obtained for definitive protein identification.
A proteomic profile may also be generated using antibodies specific for SPTM to quantify the levels of SPTM expression. In one embodiment, the antibodies are used as elements on a microarray, 5 and protein expression levels are quantified by exposing the microarray to the sample and detecting
the levels of protein bound to each array element (Lueking, A. et al. (1999) Anal. Biochem. 270: 103- 11; Mendoze, L. G. et al. (1999) Biotechniques 27:778-88). Detection may be performed by a variety of methods known in the art, for example, by reacting the proteins in the sample with a thiol- or amino-reactive fluorescent compound and detecting the amount of fluorescence bound at each array 5 element.
Toxicant signatures at the proteome level are also useful for toxicological screening, and should be analyzed in parallel with toxicant signatures at the transcript level. There is a poor correlation between transcript and protein abundances for some proteins in some tissues (Anderson, N. L. and Seilhamer, J. (1997) Electrophoresis 18:533-537), so proteome toxicant signatures may be 0 useful in the analysis of compounds which do not significantly affect the transcript image, but which alter the proteomic profile. In addition, the analysis of transcripts in body fluids is difficult, due to rapid degradation of mRNA, so proteomic profiling may be more reliable and informative in such cases.
In another embodiment, the toxicity of a test compound is assessed by treating a biological 5 sample containing proteins with the test compound. Proteins that are expressed in the treated biological sample are separated so that the amount of each protein can be quantified. The amount of each protein is compared to the amount of the corresponding protein in an untreated biological sample. A difference in the amount of protein between the two samples is indicative of a toxic response to the test compound in the treated sample. Individual proteins are identified by sequencing 0 the amino acid residues of the individual proteins and comparing these partial sequences to the SPTM encoded by polynucleotides of the present invention.
In another embodiment, the toxicity of a test compound is assessed by treating a biological sample containing proteins with the test compound. Proteins from the biological sample are incubated with antibodies specific to the SPTM encoded by polynucleotides of the present invention. 5 The amount of protein recognized by the antibodies is quantified. The amount of protein in the treated biological sample is compared with the amount in an untreated biological sample. A difference in the amount of protein between the two samples is indicative of a toxic response to the test compound in the treated sample.
Transcript images may be used to profile sptm expression in distinct tissue types. This o process can be used to determine cell signaling activity in a particular tissue type relative to this activity in a different tissue type. Transcript images may be used to generate a profile of sptm expression characteristic of diseased tissue. Transcript images of tissues before and after treatment may be used for diagnostic purposes, to monitor the progression of disease, and to monitor the efficacy of drug treatments for diseases which affect cell signaling activity. 5 Transcript images of cell lines can be used to assess cell signaling activity and/or to identify
cell lines that lack or misregulate this activity. Such cell lines may then be treated with pharmaceutical agents, and a transcript image following treatment may indicate the efficacy of these agents in restoring desired levels of this activity. A similar approach may be used to assess the toxicity of pharmaceutical agents as reflected by undesirable changes in cell signaling activity. Candidate pharmaceutical agents may be evaluated by comparing their associated transcript images with those of pharmaceutical agents of known effectiveness.
Antisense Molecules
The polynucleotides of the present invention are useful in antisense technology. Antisense technology or therapy relies on the modulation of expression of a target protein through the specific binding of an antisense sequence to a target sequence encoding the target protein or directing its expression. (See, e.g., Agrawal, S., ed. (1996) Antisense Therapeutics, Humana Press Inc., Totawa NJ; Alama, A. et al. (1997) Pharmacol. Res. 36(3): 171-178; Crooke, S.T. (1997) Adv. Pharmacol. 40:1-49; Sharma, H.W. and R. Narayanan (1995) Bioessays 17(12): 1055-1063; and Lavrosky, Y. et al. (1997) Biochem. Mol. Med. 62(1): 11-22.) An antisense sequence is a polynucleotide sequence capable of specifically hybridizing to at least a portion of the target sequence. Antisense sequences bind to cellular mRNA and/or genomic DNA, affecting translation and/or transcription. Antisense sequences can be DNA, RNA, or nucleic acid mimics and analogs. (See, e.g., Rossi, J.J. et al. (1991) Antisense Res. Dev. l(3):285-288; Lee, R. et al. (1998) Biochemistry 37(3):900-1010; Pardridge, W.M. et al. (1995) Proc. Natl. Acad. Sci. USA 92(12):5592-5596; and Nielsen, P. E. and Haaima, G. (1997) Chem. Soc. Rev. 96:73-78.) Typically, the binding which results in modulation of expression occurs through hybridization or binding of complementary base pairs. Antisense sequences can also bind to DNA duplexes through specific interactions in the major groove of the double helix.
The polynucleotides of the present invention and fragments thereof can be used as antisense sequences to modify the expression of the polypeptide encoded by sptm. The antisense sequences can be produced ex vivo, such as by using any of the ABI nucleic acid synthesizer series (Applied Biosystems) or other automated systems known in the art. Antisense sequences can also be produced biologically, such as by transforming an appropriate host cell with an expression vector containing the sequence of interest. (See, e.g., Agrawal, supra.) In therapeutic use, any gene delivery system suitable for introduction of the antisense sequences into appropriate target cells can be used. Antisense sequences can be delivered intracellularly in the form of an expression plasmid which, upon transcription, produces a sequence complementary to at least a portion of the cellular sequence encoding the target protein. (See, e.g., Slater, J.E., et al. (1998) J. Allergy Clin. Immunol. 102(3):469-475; and Scanlon, K.J., et al. (1995) 9(13): 1288-1296.) Antisense sequences can also be introduced intracellularly through the use of viral
vectors, such as retrovirus and adeno-associated virus vectors. (See, e.g., Miller, A.D. (1990) Blood 76:271; Ausubel, F.M. et al. (1995) Current Protocols in Molecular Biology, John Wiley & Sons, New York NY; Uckert, W. and W. Walther (1994) Pharmacol. Ther. 63(3):323-347.) Other gene delivery mechanisms include liposome-derived systems, artificial viral envelopes, and other systems 5 known in the art. (See, e.g., Rossi, J.J. (1995) Br. Med. Bull. 51(l):217-225; Boado, RJ. et al. (1998) J. Pharm. Sci. 87(11): 1308-1315; and Morris, M.C. et al. (1997) Nucleic Acids Res. 25(14):2730- 2736.)
Expression 0 In order to express a biologically active SPTM, the nucleotide sequences encoding SPTM or fragments thereof may be inserted into an appropriate expression vector, i.e., a vector which contains the necessary elements for transcriptional and translational control of the inserted coding sequence in a suitable host. Methods which are well known to those skilled in the art may be used to construct expression vectors containing sequences encoding SPTM and appropriate transcriptional and 5 translational control elements. These methods include in vitro recombinant DNA techniques, synthetic techniques, and in vivo genetic recombination. (See, e.g., Sambrook, supra, Chapters 4, 8, 16, and 17; and Ausubel, supra. Chapters 9, 10, 13, and 16.)
A variety of expression vector/host systems may be utilized to contain and express sequences encoding SPTM. These include, but are not limited to, microorganisms such as bacteria transformed o with recombinant bacteriophage, plasmid, or cosmid DNA expression vectors; yeast transformed with yeast expression vectors; insect cell systems infected with viral expression vectors (e.g., baculovirus); plant cell systems transformed with viral expression vectors (e.g., cauliflower mosaic virus, CaMV, or tobacco mosaic virus, TMV) or with bacterial expression vectors (e.g., Ti or pBR322 plasmids); or animal (mammalian) cell systems. (See, e.g., Sambrook, supra; Ausubel, 1995, supra. Van Heeke, G. 5 and S.M. Schuster (1989) J. Biol. Chem. 264:5503-5509; Bitter, G.A. et al. (1987) Methods Enzymol. 153:516-544; Scorer, CA. et al. (1994) Bio/Technology 12:181-184; Engelhard, E.K. et al. (1994) Proc. Natl. Acad. Sci. USA 91:3224-3227; Sandig, V. et al. (1996) Hum. Gene Ther. 7:1937-1945; Takamatsu, N. (1987) EMBO J. 6:307-311; Coruzzi, G. et al. (1984) EMBO J. 3:1671-1680; Broglie, R. et al. (1984) Science 224:838-843; Winter, J. et al. (1991) Results Probl. Cell Differ. 17:85-105; o The McGraw Hill Yearbook of Science and Technology (1992) McGraw Hill, New York NY, pp.
191-196; Logan, J. and T. Shenk (1984) Proc. Natl. Acad. Sci. USA 81:3655-3659; and Harrington, J.J. et al. (1997) Nat. Genet. 15:345-355.) Expression vectors derived from retroviruses, adenoviruses, or herpes or vaccinia viruses, or from various bacterial plasmids, may be used for delivery of nucleotide sequences to the targeted organ, tissue, or cell population. (See, e.g., Di 5 Nicola, M. et al. (1998) Cancer Gen. Ther. 5(6):350-356; Yu, M. et al., (1993) Proc. Natl. Acad. Sci.
USA 90(13):6340-6344; Buller, R.M. et al. (1985) Nature 317(6040):813-815; McGregor, D.P. et al. (1994) Mol. Immunol. 31(3):219-226; and Verma, I.M. and N. Somia (1997) Nature 389:239-242.) The invention is not limited by the host cell employed.
For long term production of recombinant proteins in mammalian systems, stable expression 5 of SPTM in cell lines is preferred. For example, sequences encoding SPTM can be transformed into cell lines using expression vectors which may contain viral origins of replication and/or endogenous expression elements and a selectable marker gene on the same or on a separate vector. Any number of selection systems may be used to recover transformed cell lines. (See, e.g., Wigler, M. et al. (1977) Cell 11:223-232; Lowy, I. et al. (1980) Cell 22:817-823.; Wigler, M. et al. (1980) Proc. Natl. 0 Acad. Sci. USA 77:3567-3570; Colbere-Garapin, F. et al. (1981) J. Mol. Biol. 150:1-14; Hartman, S.C. and R.CMulligan (1988) Proc. Natl. Acad. Sci. USA 85:8047-8051; Rhodes, CA. (1995) Methods Mol. Biol. 55:121-131.)
Therapeutic Uses of sptm 5 The polynucleotides encoding SPTM of the invention may be used for somatic or germline gehe therapy. Gene therapy may be performed to (i) correct a genetic deficiency (e.g., in the cases of severe combined immunodeficiency (SCfD)-Xl disease characterized by X-linked inheritance (Cavazzana-Calvo, M. et al. (2000) Science 288:669-672), severe combined immunodeficiency syndrome associated with an inherited adenosine deaminase (ADA) deficiency (Blaese, R.M. et al. o (1995) Science 270:475-480; Bordignon, C. et al. (1995) Science 270:470-475), cystic fibrosis
(Zabner, J. et al. (1993) Cell 75:207-216; Crystal, R.G. et al. (1995) Hum. Gene Therapy 6:643-666; Crystal, R.G. et al. (1995) Hum. Gene Therapy 6:667-703), thalassemias, familial hypercholesterolemia, and hemophilia resulting from Factor Viπ or Factor IX deficiencies (Crystal, R.G. (1995) Science 270:404-410; Verma, I.M. and Somia, N. (1997) Nature 389:239-242)), (ii) 5 express a conditionally lethal gene product (e.g., in the case of cancers which result from unregulated cell proliferation), or (iii) express a protein which affords protection against intracellular parasites (e.g., against human retroviruses, such as human immunodeficiency virus (HTV) (Baltimore, D. (1988) Nature 335:395-396; Poeschla, E. et al. (1996) Proc. Natl. Acad. Sci. USA. 93:11395-11399), hepatitis B or C virus (HBV, HCV); fungal parasites, such as Candida albicans and Paracoccidioides o brasiliensis: and protozoan parasites such as Plasmodium falciparum and Trypanosoma cruzD. In the case where a genetic deficiency in sptm expression or regulation causes disease, the expression of sptm from an appropriate population of transduced cells may alleviate the clinical manifestations caused by the genetic deficiency.
In a further embodiment of the invention, diseases or disorders caused by deficiencies in sptm 5 are treated by constructing mammalian expression vectors comprising sptm and introducing these
vectors by mechanical means into sptm-deficient cells. Mechanical transfer technologies for use with cells in vivo or ex vitro include (i) direct DNA microiηjection into individual cells, (ii) ballistic gold particle delivery, (iii) liposome-mediated transfection, (iv) receptor-mediated gene transfer, and (v) the use of DNA transposons (Morgan, R.A. and Anderson, W.F. (1993) Annu. Rev. Biochem. 62:191- 5 217; Ivies, Z. (1997) Cell 91:501-510; Boulay, J-L. and Recipon, H. (1998) Curr. Opin. Biotechnol. 9:445-450).
Expression vectors that may be effective for the expression of sptm include, but are not limited to, the PCDNA 3.1, EPITAG, PRCCMV2, PREP, PVAX vectors (Invitrogen, Carlsbad CA), PCMV-SCRIPT, PCMV-TAG, PEGSH/PERV (Stratagene, La Jolla CA), and PTET-OFF, o PTET-ON, PTRE2, PTRE2-LUC, PTK-HYG (Clontech, Palo Alto CA). The sptm of the invention may be expressed using (i) a constitutively active promoter, (e.g., from cytomegalovirus (CMV), Rous sarcoma virus (RSV), SV40 virus, thymidine kinase (TK), or β-actin genes), (ii) an inducible promoter (e.g., the tetracycline-regulated promoter (Gossen, M. and Bujard, H. (1992) Proc. Natl. Acad. Sci. U.S.A. 89:5547-5551; Gossen, M. et al., (1995) Science 268:1766-1769; Rossi, F.M.V. 5 and Blau, H.M. (1998) Curr. Opin. Biotechnol. 9:451-456), commercially available in the T-REX plasmid (Invitrogen); the ecdysone-inducible promoter (available in the plasmids PVGRXR and PIND; Invitrogen); the FK506/rapamycin inducible promoter; or the RU486/mifepristone inducible promoter (Rossi, F.M.V. and Blau, H.M. supra), or (iii) a tissue-specific promoter or the native promoter of the endogenous gene encoding SPTM from a normal individual. o Commercially available liposome transformation kits (e.g., the PERFECT L D
TRANSFECTION KIT, available from Invitrogen) allow one with ordinary skill in the art to deliver polynucleotides to target cells in culture and require minimal effort to optimize experimental parameters. In the alternative, transformation is performed using the calcium phosphate method (Graham, F.L. and Eb, A.J. (1973) Virology 52:456-467), or by electroporation (Neumann, E. et al. 5 (1982) EMBO J. 1:841-845). The introduction of DNA to primary cells requires modification of these standardized mammalian transfection protocols.
In another embodiment of the invention, diseases or disorders caused by genetic defects with respect to sptm expression are treated by constructing a retrovirus vector consistmg of (i) sptm under the control of an independent promoter or the retrovirus long terminal repeat (LTR) promoter, (ii) o appropriate RNA packaging signals, and (iii) a Rev-responsive element (RRE) along with additional retrovirus czs-acting RNA sequences and coding sequences required for efficient vector propagation. Retrovirus vectors (e.g., PFB and PFBNEO) are commercially available (Stratagene) and are based on published data (Riviere, I. et al. (1995) Proc. Natl. Acad. Sci. U.S.A. 92:6733-6737), incorporated by reference herein. The vector is propagated in an appropriate vector producing cell line (VPCL) that 5 expresses an envelope gene with a tropism for receptors on the target cells or a promiscuous envelope
protein such as VSVg (Armentano, D. et al. (1987) J. Virol. 61:1647-1650; Bender, M.A. et al. (1987) J. Virol. 61:1639-1646; Adam, M.A. and Miller, A.D. (1988) J. Virol. 62:3802-3806; Dull, T. et al. (1998) J. Virol. 72:8463-8471; Zufferey, R. et al. (1998) J. Virol. 72:9873-9880). U.S. Patent Number 5,910,434 to Rigg ("Method for obtaining retrovirus packaging cell lines producing high 5 transducing efficiency retroviral supernatant") discloses a method for obtaining retrovirus packaging cell lines and is hereby incorporated by reference. Propagation of retrovirus vectors, transduction of a population of cells (e.g., CD4+ T-cells), and the return of transduced cells to a patient are procedures well known to persons skilled in the art of gene therapy and have been well documented (Ranga, U. et al. (1997) J. Virol. 71:7020-7029; Bauer, G. et al. (1997) Blood 89:2259-2267; 0 Bonyhadi, M.L. (1997) J. Virol. 71:4707-4716; Ranga, U. et al. (1998) Proc. Natl. Acad. Sci. U.S.A. 95:1201-1206; Su, L. (1997) Blood 89:2283-2290).
In the alternative, an adenovirus-based gene therapy delivery system is used to deliver sptm to cells which have one or more genetic abnormalities with respect to the expression of sptm. The construction and packaging of adenovirus-based vectors are well known to those with ordinary skill 5 in the art. Replication defective adenovirus vectors have proven to be versatile for importing genes encoding immunoregulatory proteins into intact islets in the pancreas (Csete, M.E. et al. (1995) Transplantation 27:263-268). Potentially useful adenoviral vectors are described in U.S. Patent Number 5,707,618 to Armentano ("Adenovirus vectors for gene therapy"), hereby incorporated by reference. For adenoviral vectors, see also Antinozzi, P.A. et al. (1999) Annu. Rev. Nutr. 19:511-544 o and Verma, I.M. and Somia, N. (1997) Nature 18:389:239-242, both incorporated by reference herein.
In another alternative, a herpes-based, gene therapy delivery system is used to deliver sptm to target cells which have one or more genetic abnormalities with respect to the expression of sptm. The use of herpes simplex virus (HSV)-based vectors may be especially valuable for introducing sptm to 5 cells of the central nervous system, for which HSV has a tropism. The construction and packaging of herpes-based vectors are well known to those with ordinary skill in the art. A replication-competent herpes simplex virus (HSV) type 1 -based vector has been used to deliver a reporter gene to the eyes . of primates (Liu, X. et al. (1999) Exp. Eye Res.169:385-395). The construction of aHSV-1 virus vector has also been disclosed in detail in U.S. Patent Number 5,804,413 to DeLuca ("Herpes simplex o virus strains for gene transfer"), which is hereby incorporated by reference. U.S. Patent Number
5,804,413 teaches the use of recombinant HSV d92 which consists of a genome containing at least one exogenous gene to be transferred to a cell under the control of the appropriate promoter for purposes including human gene therapy. Also taught by this patent are the construction and use of recombinant HSV strains deleted for ICP4, ICP27 and ICP22. For HSV vectors, see also Goins, W. 5 F. et al. 1999 J. Virol. 73:519-532 and Xu, H. et al., (1994) Dev. Biol. 163:152-161, hereby
incorporated by reference. The manipulation of cloned herpesvirus sequences, the generation of recombinant virus following the transfection of multiple plasmids containing different segments of the large herpesvirus genomes, the growth and propagation of herpesvirus, and the infection of cells with herpesvirus are techniques well known to those of ordinary skill in the art. 5 In another alternative, an alphavirus (positive, single-stranded RNA virus) vector is used to deliver sptm to target cells. The biology of the prototypic alphavirus, Semliki Forest Virus (SFV), has been studied extensively and gene transfer vectors have been based on the SFV genome (Garoff, H. and Li, K-J. (1998) Curr. Opin. Biotech. 9:464-469). During alphavirus RNA replication, a subgenomic RNA is generated that normally encodes the viral capsid proteins. This subgenomic 0 RNA replicates to higher levels than the full-length genomic RNA, resulting in the overproduction of capsid proteins relative to the viral proteins with enzymatic activity (e.g., protease and polymerase). Similarly, inserting sptm into the alphavirus genome in place of the capsid-coding region results in the production of a large number of sptm RNAs and the synthesis of high levels of SPTM in vector transduced cells. While alphavirus infection is typically associated with cell lysis within a few days, 5 the ability to establish a persistent infection in hamster normal kidney cells (BHK-21) with a variant of Sindbis virus (SIN) indicates that the lytic replication of alphaviruses can be altered to suit the needs of the gene therapy application (Dryga, S.A. et al. (1997) Virology 228:74-83). The wide host range of alphaviruses will allow the introduction of sptm into a variety of cell types. The specific transduction of a subset of cells in a population may require the sorting of cells prior to transduction. o The methods of manipulating infectious cDNA clones of alphaviruses, performing alphavirus cDNA and RNA transfections, and performing alphavirus infections, are well known to those with ordinary skill in the art.
Antibodies 5 Anti-SPTM antibodies may be used to analyze protein expression levels. Such antibodies include, but are not limited to, polyclonal, monoclonal, chimeric, single chain, and Fab fragments. For descriptions of and protocols of antibody technologies, see, e.g., Pound J.D. (1998) Immunochemical Protocols. Humana Press, Totowa, NJ.
The amino acid sequence encoded by the sptm of the Sequence Listing may be analyzed by o appropriate software (e.g., LASERGENE NAVIGATOR software, DNASTAR) to determine regions of high immunogenicity. The optimal sequences for immunization are selected from the C-terminus, the N-terminus, and those intervening, hydrophilic regions of the polypeptide which are likely to be exposed to the external environment when the polypeptide is in its natural conformation. Analysis used to select appropriate epitopes is also described by Ausubel (1997, supra. Chapter 11.7). 5 Peptides used for antibody induction do not need to have biological activity; however, they must be
antigenic. Peptides used to induce specific antibodies may have an amino acid sequence consisting of at least five amino acids, preferably at least 10 amino acids, and most preferably at least 15 amino acids. A peptide which mimics an antigenic fragment of the natural polypeptide may be fused with another protein such as keyhole limpet hemocyanin (KLH; Sigma, St. Louis MO) for antibody 5 production. A peptide encompassing an antigenic region may be expressed from an sptm, synthesized as described above, or purified from human cells.
Procedures well known in the art may be used for the production of antibodies. Various hosts including mice, goats, and rabbits, may be immunized by injection with a peptide. Depending on the host species, various adjuvants may be used to increase immunological response. 0 In one procedure, peptides about 15 residues in length may be synthesized using an ABI
431 A peptide synthesizer (Applied Biosystems) using fmoc-chemistry and coupled to KLH (Sigma) by reaction with M-maleimidobenzoyl-N-hydroxysuccinimide ester (Ausubel, 1995, supra). Rabbits are immunized with the peptide-KLH complex in complete Freund's adjuvant. The resulting antisera are tested for antipeptide activity by binding the peptide to plastic, blocking with 1% bovine serum 5 albumin (BSA), reacting with rabbit antisera, washing, and reacting with radioiodinated goat anti- rabbit IgG. Antisera with antipeptide activity are tested for anti-SPTM activity using protocols well known in the art, including ELISA, radioimmunoassay (RIA), and immunoblotting.
In another procedure, isolated and purified peptide may be used to immunize mice (about 100 μg of peptide) or rabbits (about 1 mg of peptide). Subsequently, the peptide is radioiodinated and o used to screen the immunized animals' B -lymphocytes for production of antipeptide antibodies.
Positive cells are then used to produce hybridomas using standard techniques. About 20 mg of peptide is sufficient for labeling and screening several thousand clones. Hybridomas of interest are detected by screening with radioiodinated peptide to identify those fusions producing peptide-specific monoclonal antibody. In a typical protocol, wells of a multi-well plate (FAST, Becton-Dickinson, 5 Palo Alto, CA) are coated with affinity-purified, specific rabbit-anti-mouse (or suitable anti-species IgG) antibodies at 10 mg/ml. The coated wells are blocked with 1% BSA and washed and exposed to supernatants from hybridomas. After incubation, the wells are exposed to radiolabeled peptide at 1 mg/ml.
Clones producing antibodies bind a quantity of labeled peptide that is detectable above o background. Such clones are expanded and subjected to 2 cycles of cloning. Cloned hybridomas are injected into pristane-treated mice to produce ascites, and monoclonal antibody is purified from the ascitic fluid by affinity chromatography on protein A (Amersham Pharmacia Biotech). Several procedures for the production of monoclonal antibodies, including in vitro production, are described in Pound (supra). Monoclonal antibodies with antipeptide activity are tested for anti-SPTM activity 5 using protocols well known in the art, including ELISA, RIA, and immunoblotting.
Antibody fragments containing specific binding sites for an epitope may also be generated. For example, such fragments include, but are not limited to, the F(ab')2 fragments produced by pepsin digestion of the antibody molecule, and the Fab fragments generated by reducing the disulfide bridges of the F(ab')2 fragments. Alternatively, construction of Fab expression libraries in filamentous bacteriophage allows rapid and easy identification of monoclonal fragments with desired specificity (Pound, supra. Chaps. 45-47). Antibodies generated against polypeptide encoded by sptm can be used to purify and characterize full-length SPTM protein and its activity, binding partners, etc.
Assays Using Antibodies Anti-SPTM antibodies may be used in assays to quantify the amount of SPTM found in a particular human cell. Such assays include methods utilizing the antibody and a label to detect expression level under normal or disease conditions. The peptides and antibodies of the invention may be used with or without modification or labeled by joining them, either covalently or noncovalently, with a reporter molecule. Protocols for detecting and measuring protein expression using either polyclonal or monoclonal antibodies are well known in the art. Examples include ELISA, RIA, and fluorescent activated cell sorting (FACS). Such immunoassays typically involve the formation of complexes between the SPTM and its specific antibody and the measurement of such complexes. These and other assays are described in Pound (supra). Without further elaboration, it is believed that one skilled in the art can, using the preceding description, utilize the present invention to its fullest extent. The following preferred specific embodiments are, therefore, to be construed as merely illustrative, and not limitative of the remainder of the disclosure in any way whatsoever.
Without further elaboration, it is believed that one skilled in the art can, using the preceding description, utilize the present invention to its fullest extent. The following preferred specific embodiments are, therefore, to be construed as merely illustrative, and not limitative of the remainder of the disclosure in any way whatsoever.
The disclosures of all patents, applications, and publications mentioned above and below, including U.S. Ser. No. 60/261,865, U.S. Ser. No. 60/262,599, U.S. Ser. No. 60/263,329, U.S. Ser. No. 60/262,209, U.S. Ser. No. 60/263,131, U.S. Ser. No. 60/262,208, U.S. Ser. No. 60/262,164, U.S.
Ser. No. 60/263,063, U.S. Ser. No. 60/261,864, U.S. Ser. No. 60 262,760, U.S. Ser. No. 60/261,981,
U.S. Ser. No. 60/263,070, U.S. Ser. No. 60/261,979, U.S. Ser. No. 60/263,066, U.S. Ser. No.
60/263,077, U.S. Ser. No. 60/263,076, U.S. Ser. No. 60/263,074, and U.S. Ser. No. 60/263,069, are hereby expressly incorporated by reference.
EXAMPLES I. Construction of cDNA Libraries
RNA was purchased from CLONTECH Laboratories, Inc. (Palo Alto CA) or isolated from various tissues. Some tissues were homogenized and lysed in guanidinium isothiocyanate, while 5 others were homogenized and lysed in phenol or in a suitable mixture of denaturants, such as
TRIZOL (Life Technologies), a monophasic solution of phenol and guanidine isothiocyanate. The resulting lysates were centrifuged over CsCl cushions or extracted with chloroform. RNA was precipitated with either isopropanol or sodium acetate and ethanol, or by other routine methods. Phenol extraction and precipitation of RNA were repeated as necessary to increase RNA 0 purity. In most cases, RNA was treated with DNase. For most libraries, poly(A+) RNA was isolated using oligo d(T)-coupled paramagnetic particles (Promega Corporation (Promega), Madison WI), OLIGOTEX latex particles (QIAGEN, Inc. (QIAGEN), Valencia CA), or an OLIGOTEX mRNA purification kit (QIAGEN). Alternatively, RNA was isolated directly from tissue lysates using other RNA isolation kits, e.g., the POLY(A)PURE mRNA purification kit (Ambion, Inc., Austin TX). 5 In some cases, Stratagene was provided with RNA and constructed the coπesponding cDNA libraries. Otherwise, cDNA was synthesized and cDNA libraries were constructed with the UNIZAP vector system (Stratagene Cloning Systems, Inc. (Stratagene), La Jolla CA) or SUPERSCRIPT plasmid system (Life Technologies), using the recommended procedures or similar methods known in the art. (See, e.g., Ausubel, 1997, supra, Chapters 5.1 through 6.6.) Reverse transcription was o initiated using oligo d(T) or random primers. Synthetic oligonucleotide adapters were ligated to double stranded cDNA, and the cDNA was digested with the appropriate restriction enzyme or enzymes. For most libraries, the cDNA was size-selected (300-1000 bp) using SEPHACRYL S1000, SEPHAROSE CL2B, or SEPHAROSE CL4B column chromatography (Amersham Pharmacia Biotech) or preparative agarose gel electrophoresis. cDNAs were ligated into compatible restriction 5 enzyme sites of the polylinker of a suitable plasmid, e.g., PBLUESCRIPT plasmid (Stratagene),
PSPORT1 plasmid (Life Technologies), PCDNA2.1 plasmid (Invitrogen, Carlsbad CA), PBK-CMV plasmid (Stratagene), PCR2-TOPOTA plasmid (Invitrogen), PCMV-ICIS plasmid (Stratagene), pIGEN (Incyte Genomics, Palo Alto CA), pRARE (Incyte Genomics), or pINCY (Incyte Genomics), or derivatives thereof. Recombinant plasmids were transformed into competent E. coli cells o including XLl-Blue, XLl-BlueMRF, or SOLR from Stratagene or DH5α, DH10B, or ElectroMAX
DH10B from Life Technologies.
II. Isolation of cDNA Clones
Plasmids were recovered from host cells by in vivo excision using the UNIZAP vector system 5 (Stratagene) or by cell lysis. Plasmids were purified using at least one of the following: the Magic or
WIZARD Minipreps DNA purification system (Promega); the AGTC Miniprep purification kit (Edge BioSystems, Gaithersburg MD); and the QIAWELL 8, QIAWELL 8 Plus, and QIAWELL 8 Ultra plasmid purification systems or the R.E.A.L. PREP 96 plasmid purification kit (QIAGEN). Following precipitation, plasmids were resuspended in 0.1 ml of distilled water and stored, with or 5 without lyophilization, at 4 ° C.
Alternatively, plasmid DNA was amplified from host cell lysates using direct link PCR in a high-throughput format. (Rao, V.B. (1994) Anal. Biochem. 216:1-14.) Host cell lysis and thermal cycling steps were carried out in a single reaction mixture. Samples were processed and stored in 384-well plates, and the concentration of amplified plasmid DNA was quantified fluorometrically 0 using PICOGREEN dye (Molecular Probes, Inc. (Molecular Probes), Eugene OR) and a FLUOROSKAN π fluorescence scanner (Labsystems Oy, Helsinki, Finland).
III. Sequencing and Analysis cDNA sequencing reactions were processed using standard methods or high-throughput 5 instrumentation such as the ABI CATALYST 800 thermal cycler (Applied Biosystems) or the PTC- 200 thermal cycler (MJ Research) in conjunction with the HYDRA microdispenser (Robbins Scientific Corp., Sunnyvale CA) or the MICROLAB 2200 liquid transfer system (Hamilton). cDNA sequencing reactions were prepared using reagents provided by Amersham Pharmacia Biotech or supplied in ABI sequencing kits such as the ABI PRISM BIGDYE Terminator cycle sequencing o ready reaction kit (Applied Biosystems). Electrophoretic separation of cDNA sequencing reactions and detection of labeled polynucleotides were carried out using the MEGABACE 1000 DNA sequencing system (Molecular Dynamics); the ABI PRISM 373 or 377 sequencing system (Applied Biosystems) in conjunction with standard ABI protocols and base calling software; or other sequence analysis systems known in the art. Reading frames within the cDNA sequences were identified using 5 standard methods (reviewed in Ausubel, 1997, supra. Chapter 7.7). Some of the cDNA sequences were selected for extension using the techniques disclosed in Example VIJJ.
IV. Assembly and Analysis of Sequences
Component sequences from chromatograms were subject to PHRED analysis and assigned a o quality score. The sequences having at least a required quality score were subject to various preprocessing editing pathways to eliminate, e.g., low quality 3' ends, vector and linker sequences, polyA tails, Alu repeats, mitochondrial and ribosomal sequences, bacterial contamination sequences, and sequences smaller than 50 base pairs. In particular, low-information sequences and repetitive elements (e.g., dinucleotide repeats, Alu repeats, etc.) were replaced by "n's", or masked, to prevent 5 spurious matches.
Processed sequences were then subject to assembly procedures in which the sequences were assigned to gene bins (bins). Each sequence could only belong to one bin. Sequences in each gene bin were assembled to produce consensus sequences (templates). Subsequent new sequences were added to existing bins using BLASTN (v.1.4 WashU) and CROSSMATCH. Candidate pairs were 5 identified as all BLAST hits having a quality score greater than or equal to 150. Alignments of at least 82% local identity were accepted into the bin. The component sequences from each bin were assembled using a version of PHRAP. Bins with several overlapping component sequences were assembled using DEEP PHRAP. The orientation (sense or antisense) of each assembled template was determined based on the number and orientation of its component sequences. Template sequences as 0 disclosed in the sequence listing correspond to sense strand sequences (the "forward" reading frames), to the best determination. The complementary (antisense) strands are inherently disclosed herein. The component sequences which were used to assemble each template consensus sequence are listed in Table 3 along with their positions along the template nucleotide sequences.
Bins were compared against each other and those having local similarity of at least 82% were 5 combined and reassembled. Reassembled bins having templates of insufficient overlap (less than 95% local identity) were re-split. Assembled templates were also subject to analysis by STITCHER/EXON MAPPER algorithms which analyze the probabilities of the presence of splice variants, alternatively spliced exons, splice junctions, differential expression of alternative spliced genes across tissue types or disease states, etc. These resulting bins were subject to several rounds of o the above assembly procedures.
Once gene bins were generated based upon sequence alignments, bins were clone joined based upon clone information. If the 5' sequence of one clone was present in one bin and the 3' sequence from the same clone was present in a different bin, it was likely that the two bins actually belonged together in a single bin. The resulting combined bins underwent assembly procedures to 5 regenerate the consensus sequences.
The final assembled templates were subsequently annotated using the following procedure. Template sequences were analyzed using BLASTN (v2.0, NCBI) versus gbpri (GenBank version 126). "Hits" were defined as an exact match having from 95% local identity over 200 base pairs through 100% local identity over 100 base pairs, or a homolog match having an E-value, i.e. a o probability score, of ≤ 1 x 10 s. The hits were subject to frameshift FASTx versus GENPEPT
(GenBank version 126). (See Table 6). In this analysis, a homolog match was defined as having an E-value of < 1 x 10 s. The assembly method used above was described in "System and Methods for Analyzing Biomolecular Sequences," U.S.S.N. 09/276,534, filed March 25, 1999, and the LIFESEQ Gold user manual (Incyte) both incorporated by reference herein. 5 Following assembly, template sequences were subjected to motif, BLAST, and functional
analyses, and categorized in protein hierarchies using methods described in, e.g., "Database System Employing Protein Function Hierarchies for Viewing Biomolecular Sequence Data," U.S. Patent Number 6,023,659; "Relational Database for Storing Biomolecule Information," U.S.S.N. 08/947,845, filed October 9, 1997; "Project-Based Full-Length Biomolecular Sequence Database," 5 U.S. Patent Number 5,953,727; and "Relational Database and System for Storing Information Relating to Biomolecular Sequences," U.S.S.N. 09/034,807, filed March 4, 1998, all of which are incorporated by reference herein.
The template sequences were further analyzed by translating each template in all three forward reading frames and searching each translation against the Pfam database of hidden Markov 0 model-based protein families and domains using the HMMER software package (available to the public from Washington University School of Medicine, St. Louis MO). (See also World Wide Web site http://pfam.wustl.edu/ for detailed descriptions of Pfam protein domains and families.)
Additionally, the template sequences were translated in all three forward reading frames, and each translation was searched against hidden Markov models for signal peptides using the HMMER 5 software package. Construction of hidden Markov models and their usage in sequence analysis has been described. (See, for example, Eddy, S.R. (1996) Curr. Opin. Str. Biol. 6:361-365.) Only those signal peptide hits with a cutoff score of 11 bits or greater are reported. A cutoff score of 11 bits or greater coπesponds to at least about 91-94% true-positives in signal peptide prediction. Template sequences were also translated in all three forward reading frames, and each translation was searched o against TMHMMER, a program that uses a hidden Markov model (HMM) to delineate transmembrane segments on protein sequences and determine orientation (Sonnhammer, E.L. et al. (1998) Proc. Sixth Intl. Conf. On Intelligent Systems for Mol. Biol., Glasgow et al., eds., The Am. Assoc. for Artificial intelligence (AAAI) Press, Menlo Park, CA, and MJT Press, Cambridge, MA, pp. 175-182.) Regions of templates which, when translated, contain similarity to signal peptide or 5 transmembrane consensus sequences are reported in Table 2.
Template sequences are further analyzed using the bioinformatics tools listed in Table 6, or using sequence analysis software known in the art such as MACDNASIS PRO software (Hitachi Software Engineering, South San Francisco CA) and LASERGENE software (DNASTAR). Template sequences may be further queried against public databases such as the GenBank rodent, o mammalian, vertebrate, prokaryote, and eukaryote databases.
The template sequences were translated to derive the corresponding longest open reading frame as presented by the polypeptide sequences as reported in Table 5. Alternatively, a polypeptide of the invention may begin at any of the methionine residues within the full length translated polypeptide. Polypeptide sequences were subsequently analyzed by querying against the GenBank 5 protein database (GENPEPT, (GenBank version 126)). Full length polynucleotide sequences are also
analyzed using MACDNASIS PRO software (Hitachi Software Engineering, South San Francisco CA) and LASERGENE software (DNASTAR). Polynucleotide and polypeptide sequence alignments are generated using default parameters specified by the CLUSTAL algorithm as incorporated into the MEGALIGN multisequence alignment program (DNASTAR), which also calculates the percent identity between aligned sequences.
Table 5 shows sequences with homology to the polypeptides of the invention as identified by BLAST analysis against the GenBank protein (GENPEPT) database. Column 1 shows the polypeptide sequence identification number (SEQ ID NO:) for the polypeptide segments of the invention. Column 2 shows the reading frame used in the translation of the polynucleotide sequences encoding the polypeptide segments. Column 3 shows the length of the translated polypeptide segments. Columns 4 and 5 show the start and stop nucleotide positions of the polynucleotide sequences encoding the polypeptide segments. Column 6 shows the GenBank identification number (GI Number) of the nearest GenBank homolog. Column 7 shows the probability score for the match between each polypeptide and its GenBank homolog. Column 8 shows the annotation of the GenBank homolog.
V. Analysis of Polynucleotide Expression
Northern analysis is a laboratory technique used to detect the presence of a transcript of a gene and involves the hybridization of a labeled nucleotide sequence to a membrane on which RNAs from a particular cell type or tissue have been bound. (See, e.g., Sambrook, supra, ch. 7; Ausubel, 1995, supra, ch. 4 and 16.)
Analogous computer techniques applying BLAST were used to search for identical or related molecules in cDNA databases such as GenBank or LIFESEQ (Incyte Genomics). This analysis is much faster than multiple membrane-based hybridizations. In addition, the sensitivity of the computer search can be modified to determine whether any particular match is categorized as exact or similar. The basis of the search is the product score, which is defined as:
BLAST Score x Percent Identity
5 x minimum {length(Seq. 1), length(Seq. 2)}
The product score takes into account both the degree of similarity between two sequences and the length of the sequence match. The product score is a normalized value between 0 and 100, and is calculated as follows: the BLAST score is multiplied by the percent nucleotide identity and the product is divided by (5 times the length of the shorter of the two sequences). The BLAST score is calculated by assigning a score of +5 for every base that matches in a high-scoring segment pair
(HSP), and -4 for every mismatch. Two sequences may share more than one HSP (separated by gaps). If there is more than one HSP, then the pair with the highest BLAST score is used to calculate the product 'score. The product score represents a balance between fractional overlap and quality in a BLAST alignment. For example, a product score of 100 is produced only for 100% identity over the 5 entire length of the shorter of the two sequences being compared. A product score of 70 is produced either by 100% identity and 70% overlap at one end, or by 88% identity and 100% overlap at the other. A product score of 50 is produced either by 100% identity and 50% overlap at one end, or 79% identity and 100% overlap.
Alternatively, polynucleotide sequences encoding SPTM are analyzed with respect to the 0 tissue sources from which they were derived. Polynucleotide sequences encoding SPTM were assembled, at least in part, with overlapping Incyte cDNA sequences. Each cDNA sequence is derived from a cDNA library constructed from a human tissue. Each human tissue is classified into one of the following organ/tissue categories: cardiovascular system; connective tissue; digestive system; embryonic structures; endocrine system; exocrine glands; genitalia, female; genitalia, male; 5 germ cells; hemic and immune system; liver; musculoskeletal system; nervous system; pancreas; respiratory system; sense organs; skin; stomatognathic system; unclassified/mixed; or urinary tract. The number of libraries in each category for each polynucleotide sequence encoding SPTM is counted and divided by the total number of libraries across all categories for each polynucleotide sequence encoding SPTM. Similarly, each human tissue is classified into one of the following 0 disease/condition categories: cancer, cell line, developmental, inflammation, neurological, trauma, cardiovascular, pooled, and other, and the number of libraries in each category for each polynucleotide sequence encoding SPTM is counted and divided by the total number of libraries across all categories for each polynucleotide sequence encoding SPTM. The resulting percentages reflect the tissue-specific and disease-specific expression of cDNA encoding SPTM. Percentage 5 . values of tissue-specific expression are reported in . cDNA sequences and cDNA library/tissue information are found in the LIFESEQ GOLD database (Incyte Genomics, Palo Alto CA).
VI. Tissue Distribution Profiling
A tissue distribution profile is determined for each template by compiling the cDNA library o tissue classifications of its component cDNA sequences. Each component sequence, is derived from a cDNA library constructed from a human tissue. Each human tissue is classified into one of the following categories: cardiovascular system; connective tissue; digestive system; embryonic structures; endocrine system; exocrine glands; genitalia, female; genitalia, male; germ cells; hemic and immune system; liver; musculoskeletal system; nervous system; pancreas; respiratory system; 5 sense organs; skin; stomatognathic system; unclassified/mixed; or urinary tract. Template sequences,
component sequences, and cDNA library/tissue information are found in the LIFESEQ GOLD database (Incyte Genomics, Palo Alto CA).
Table 4 shows the tissue distribution profile for the templates of the invention. For each template, the three most frequently observed tissue categories are shown in column 3, along with the percentage of component sequences belonging to each category. Only tissue categories with percentage values of ≥10% are shown. A tissue distribution of "widely distributed" in column 3 indicates percentage values of <10% in all tissue categories.
VII. Transcript Image Analysis Transcript images are generated as described in Seilhamer et al., "Comparative Gene
Transcript Analysis," U.S. Patent Number 5,840,484, incorporated herein by reference.
VIII. Extension of Polynucleotide Sequences and Isolation of a Full-length cDNA
Oligonucleotide primers designed using an sptm of the Sequence Listing are used to extend the nucleic acid sequence. One primer is synthesized to initiate 5' extension of the template, and the other primer, to initiate 3' extension of the template. The initial primers may be designed using OLIGO 4.06 software (National Biosciences, Inc. (National Biosciences), Plymouth MN), or another appropriate program, to be about 22 to 30 nucleotides in length, to have a GC content of about 50% or more, and to anneal to the target sequence at temperatures of about 68°C to about 72°C Any stretch of nucleotides which would result in hairpin structures and primer-primer dimerizations are avoided. Selected human cDNA libraries are used to extend the sequence. If more than one extension is necessary or desired, additional or nested sets of primers are designed.
High fidelity amplification is obtained by PCR using methods well known in the art. PCR is performed in 96-well plates using the PTC-200 thermal cycler (MJ Research). The reaction mix contains DNA template, 200 nmol of each primer, reaction buffer containing Mg2+, (NE^SO^ and β- mercaptoethanol, Taq DNA polymerase (Amersham Pharmacia Biotech), ELONGASE enzyme (Life Technologies), and Pfu DNA polymerase (Stratagene), with the following parameters for primer pair PCI A and PCI B: Step 1: 94°C, 3 min; Step 2: 94°C, 15 sec; Step 3: 60°C, 1 min; Step 4: 68°C, 2 min; Step 5: Steps 2, 3, and 4 repeated 20 times; Step 6: 68 °C, 5 min; Step 7: storage at 4°C. In the alternative, the parameters for primer pair T7 and SK+ are as follows: Step 1: 94°C, 3 min; Step 2: 94 °C, 15 sec; Step 3: 57 °C, 1 min; Step 4: 68 °C, 2 min; Step 5: Steps 2, 3, and 4 repeated 20 times; Step 6: 68 °C, 5 min; Step 7: storage at 4°C.
The concentration of DNA in each well is determined by dispensing 100 μl PICOGREEN quantitation reagent (0.25% (v/v); Molecular Probes) dissolved in IX Tris-EDTA (TE) and 0.5 μl of undiluted PCR product into each well of an opaque fluorimeter plate (Corning Incorporated
(Corning), Corning NY), allowing the DNA to bind to the reagent. The plate is scanned in a FLUOROSKAN U (Labsystems Oy) to measure the fluorescence of the sample and to quantify the concentration of DNA. A 5 μl to 10 μl aliquot of the reaction mixture is analyzed by electrophoresis on a 1 % agarose mini-gel to determine which reactions are successful in extending the sequence. The extended nucleotides are desalted and concentrated, transfeπed to 384-well plates, digested with CviJI cholera virus endonuclease (Molecular Biology Research, Madison WI), and sonicated or sheared prior to religation into pUC 18 vector (Amersham Pharmacia Biotech). For shotgun sequencing, the digested nucleotides are separated on low concentration (0.6 to 0.8%) agarose gels, fragments are excised, and agar digested with AGAR ACE (Promega). Extended clones are religated using T4 ligase (New England Biolabs, Inc., Beverly MA) into pUC 18 vector
(Amersham Pharmacia Biotech), treated with Pfu DNA polymerase (Stratagene) to fill-in restriction site overhangs, and transfected into competent E. coli cells. Transformed cells are selected on antibiotic-containing media, individual colonies are picked and cultured overnight at 37 °C in 384- well plates in LB/2x carbenicillin liquid media. The cells are lysed, and DNA is amplified by PCR using Taq DNA polymerase (Amersham
Pharmacia Biotech) and Pfu DNA polymerase (Stratagene) with the following parameters: Step 1: 94°C, 3 min; Step 2: 94°C, 15 sec; Step 3: 60°C, 1 min; Step 4: 72°C, 2 min; Step 5: steps 2, 3, and 4 repeated 29 times; Step 6: 72°C, 5 min; Step 7: storage at 4°C. DNA is quantified by PICOGREEN reagent (Molecular Probes) as described above. Samples with low DNA recoveries are reamplified using the same conditions as described above. Samples are diluted with 20% dimethysulfoxide (1:2, v/v), and sequenced using DYENAMIC energy transfer sequencing primers and the DYENAMIC DIRECT kit (Amersham Pharmacia Biotech) or the ABI PRISM BIGDYE Terminator cycle sequencing ready reaction kit (Applied Biosystems).
In like manner, the sptm is used to obtain regulatory sequences (promoters, introns, and enhancers) using the procedure above, oligonucleotides designed for such extension, and an appropriate genomic library.
IX. Labeling of Probes and Southern Hybridization Analyses
Hybridization probes derived from the sptm of the Sequence Listing are employed for screening cDNAs, mRNAs, or genomic DNA. The labeling of probe nucleotides between 100 and 1000 nucleotides in length is specifically described, but essentially the same procedure may be used with larger cDNA fragments. Probe sequences are labeled at room temperature for 30 minutes using a T4 polynucleotide kinase, γ32P-ATP, and 0.5X One-Phor-All Plus (Amersham Pharmacia Biotech) buffer and purified using a ProbeQuant G-50 Microcolumn (Amersham Pharmacia Biotech). The probe mixture is diluted to 107 dpm/μg/ml hybridization buffer and used in a typical membrane-based
hybridization analysis.
The DNA is digested with a restriction endonuclease such as Eco RV and is electrophoresed through a 0.7% agarose gel. The DNA fragments are transfeπed from the agarose to nylon membrane (NYTRAN Plus, Schleicher & Schuell, Inc., Keene NH) using procedures specified by the manufacturer of the membrane. Prehybridization is carried out for three or more hours at 68 °C, and hybridization is carried out overnight at 68 °C To remove non-specific signals, blots are sequentially washed at room temperature under increasingly stringent conditions, up to O.lx saline sodium citrate (SSC) and 0.5% sodium dodecyl sulfate. After the blots are placed in a PHOSPHOPJMAGER cassette (Molecular Dynamics) or are exposed to autoradiography film, hybridization patterns of standard and experimental lanes are compared. Essentially the same procedure is employed when screening RNA.
X. Chromosome Mapping of sptm
The cDNA sequences which were used to assemble SEQ ID NO: 1-75 are compared with sequences from the Incyte LIFESEQ database and public domain databases using BLAST and other implementations of the Smith-Waterman algorithm. Sequences from these databases that match SEQ ID NO: 1-75 are assembled into clusters of contiguous and overlapping sequences using assembly algorithms such as PHRAP (Table 6). Radiation hybrid and genetic mapping data available from public resources such as the Stanford Human Genome Center (SHGC), Whitehead Institute for Genome Research (WIGR), and Genethon are used to determine if any of the clustered sequences have been previously mapped. Inclusion of a mapped sequence in a cluster will result in the assignment of all sequences of that cluster, including its particular SEQ ID NO:, to that map location. The genetic map locations of SEQ ID NO: 1-75 are described as ranges, or intervals, of human chromosomes. The map position of an interval, in centiMorgans, is measured relative to the terminus of the chromosome' s p-arm. (The centiMorgan (cM) is a unit of measurement based on recombination frequencies between chromosomal markers. On average, 1 cM is roughly equivalent to 1 megabase (Mb) of DNA in humans, although this can vary widely due to hot and cold spots of recombination.) The cM distances are based on genetic markers mapped by Genethon which provide boundaries for radiation hybrid markers whose sequences were included in each of the clusters.
XI. Microarray Analysis
Probe Preparation from Tissue or Cell Samples
Total RNA is isolated from tissue samples using the guanidinium thiocyanate method and polyA+ RNA is purified using the oligo (dT) cellulose method. Each polyA+ RNA sample is reverse transcribed using MMLV reverse-transcriptase, 0.05 pg/μl oligo-dT primer (21mer), IX first strand
buffer, 0.03 units/μl RNase inhibitor, 500 μM dATP, 500 μM dGTP, 500 μM dTTP, 40 μM dCTP, 40 μM dCTP-Cy3 (BDS) or dCTP-Cy5 (Amersham Pharmacia Biotech). The reverse transcription reaction is performed in a 25 ml volume containing 200 ng polyA+ RNA with GEMBRIGHT kits (Incyte). Specific control polyA+ RNAs are synthesized by in vitro transcription from non-coding yeast genomic DNA (W. Lei, unpublished). As quantitative controls, the control mRNAs at 0.002 ng, 0.02 ng, 0.2 ng, and 2 ng are diluted into reverse transcription reaction at ratios of 1: 100,000, 1:10,000, 1:1000, 1:100 (w/w) to sample mRNA respectively. The control mRNAs are diluted into reverse transcription reaction at ratios of 1:3, 3:1, 1:10, 10:1, 1:25, 25:1 (w/w) to sample mRNA differential expression patterns. After incubation at 37° C for 2 hr, each reaction sample (one with Cy3 and another with Cy5 labeling) is treated with 2.5 ml of 0.5M sodium hydroxide and incubated for 20 minutes at 85° C to the stop the reaction and degrade the RNA. Probes are purified using two successive CHROMA SPIN 30 gel filtration spin columns (CLONTECH Laboratories, Inc. (CLONTECH), Palo Alto CA) and after combining, both reaction samples are ethanol precipitated using 1 ml of glycogen (1 mg/ml), 60 ml sodium acetate, and 300 ml of 100% ethanol. The probe is then dried to completion using a SpeedVAC (Savant Instruments Inc., Holbrook NY) and resuspended in 14 μl 5X SSC/0.2% SDS.
Microarray Preparation
Sequences of the present invention are used to generate array elements. Each array element is amplified from bacterial cells containing vectors with cloned cDNA inserts. PCR amplification uses primers complementary to the vector sequences flanking the cDNA insert. Array elements are amplified in thirty cycles of PCR from an initial quantity of 1-2 ng to a final quantity greater than 5 μg. Amplified array elements are then purified using SEPHACRYL-400 (Amersham Pharmacia Biotech). Purified aπay elements are immobilized on polymer-coated glass slides. Glass microscope slides (Coming) are cleaned by ultrasound in 0.1% SDS and acetone, with extensive distilled water washes between and after treatments. Glass slides are etched in 4% hydrofluoric acid (VWR Scientific Products Corporation (VWR), West Chester, PA), washed extensively in distilled water, and coated with 0.05% aminopropyl silane (Sigma) in 95% ethanol. Coated slides are cured in a 110°C oven.
Array elements are applied to the coated glass substrate using a procedure described in US Patent No. 5,807,522, incorporated herein by reference. 1 μl of the array element DNA, at an average concentration of 100 ng/μl, is loaded into the open capillary printing element by a high-speed robotic apparatus. The apparatus then deposits about 5 nl of aπay element sample per slide. Microarrays are UV-crosslinked using a STRATALINKER UV-crosslinker (Stratagene).
Microarrays are washed at room temperature once in 0.2% SDS and three times in distilled water. Non-specific binding sites are blocked by incubation of microaπays in 0.2% casein in phosphate buffered saline (PBS) (Tropix, Inc., Bedford, MA) for 30 minutes at 60° C followed by washes in 0.2% SDS and distilled water as before.
5
Hybridization
Hybridization reactions contain 9 μl of probe mixture consisting of 0.2 μg each of Cy3 and Cy5 labeled cDNA synthesis products in 5X SSC, 0.2% SDS hybridization buffer. The probe mixture is heated to 65° C for 5 minutes and is aliquoted onto the microaπay surface and covered with 0 an 1.8 cm2 coverslip. The arrays are transfeπed to a waterproof chamber having a cavity just slightly larger than a microscope slide. The chamber is kept at 100% humidity internally by the addition of 140 μl of 5x SSC in a corner of the chamber. The chamber containing the aπays is incubated for about 6.5 hours at 60° C. The aπays are washed for 10 min at 45° C in a first wash buffer (IX SSC, 0.1 % SDS), three times for 10 minutes each at 45° C in a second wash buffer (0. IX SSC), and dried. 5
Detection
Reporter-labeled hybridization complexes are detected with a microscope equipped with an Innova 70 mixed gas 10 W laser (Coherent, Inc., Santa Clara CA) capable of generating spectral lines at 488 nm for excitation of Cy3 and at 632 nm for excitation of Cy5. The excitation laser light is 0 focused on the aπay using a 20X microscope objective (Nikon, Inc., Melville NY). The slide containing the aπay is placed on a computer-controlled X-Y stage on the microscope and raster- scanned past the objective. The 1.8 cm x 1.8 cm aπay used in the present example is scanned with a resolution of 20 micrometers.
In two separate scans, a mixed gas multiline laser excites the two fluorophores sequentially. 5 Emitted light is split, based on wavelength, into two photomultiplier tube detectors (PMT R1477,
Hamamatsu Photonics Systems, Bridgewater NJ) coπesponding to the two fluorophores. Appropriate filters positioned between the aπay and the photomultiplier tubes are used to filter the signals. The emission maxima of the fluorophores used are 565 nm for Cy3 and 650 nm for Cy5. Each aπay is typically scanned twice, one scan per fluorophore using the appropriate filters at the laser source, o although the apparatus is capable of recording the spectra from both fluorophores simultaneously. The sensitivity of the scans is typically calibrated using the signal intensity generated by a cDNA control species added to the probe mix at a known concentration. A specific location on the aπay contains a complementary DNA sequence, allowing the intensity of the signal at that location to be coπelated with a weight ratio of hybridizing species of 1:100,000. When two probes from 5 different sources (e.g., representing test and control cells), each labeled with a different fluorophore,
are hybridized to a single aπay for the purpose of identifying genes that are differentially expressed, the calibration is done by labeling samples of the calibrating cDNA with the two fluorophores and adding identical amounts of each to the hybridization mixture.
The output of the photomultiplier tube is digitized using a 12-bit RTI-835H analog-to-digital 5 (A/D) conversion board (Analog Devices, Inc., Norwood, MA) installed in an IBM-compatible PC computer. The digitized data are displayed as an image where the signal intensity is mapped using a linear 20-color transformation to a pseudocolor scale ranging from blue (low signal) to red (high signal). The data is also analyzed quantitatively. Where two different fluorophores are excited and measured simultaneously, the data are first coπected for optical crosstalk (due to overlapping 0 emission spectra) between the fluorophores using each fluorophore 's emission spectrum.
A grid is superimposed over the fluorescence signal image such that the signal from each spot is centered in each element of the grid. The fluorescence signal within each element is then integrated to obtain a numerical value coπesponding to the average intensity of the signal. The software used for signal analysis is the GEMTOOLS gene expression analysis program (Incyte). 5
XII. Complementary Nucleic Acids
Sequences complementary to the sptm are used to detect, decrease, or inhibit expression of the naturally occurring nucleotide. The use of oligonucleotides comprising from about 15 to 30 base pairs is typical in the art. However, smaller or larger sequence fragments can also be used. o Appropriate oligonucleotides are designed from the sptm using OLIGO 4.06 software (National
Biosciences) or other appropriate programs and are synthesized using methods standard in the art or ordered from a commercial supplier. To inhibit transcription, a complementary oligonucleotide is designed from the most unique 5' sequence and used to prevent transcription factor binding to the promoter sequence. To inhibit translation, a complementary oligonucleotide is designed to prevent 5 ribosomal binding and processing of the transcript.
XIII. Expression of SPTM
Expression and purification of SPTM is accomplished using bacterial or virus-based expression systems. For expression of SPTM in bacteria, DNA encoding SPTM is subcloned into an 0 appropriate vector containing an antibiotic resistance gene and an inducible promoter that directs high levels of cDNA transcription. Examples of such promoters include, but are not limited to, the trp-lac (tac) hybrid promoter and the T5 or T7 bacteriophage promoter in conjunction with the lac operator regulatory element. Recombinant vectors are transformed into suitable bacterial hosts, e.g., BL21(DE3). Antibiotic resistant bacteria express SPTM upon induction with isopropyl beta-D- 5 thiogalactopyranoside (IPTG). Expression of SPTM in eukaryotic cells is achieved by infecting
insect or mammalian cell lines with recombinant Autographica californica nuclear polyhedrosis virus (AcMNPV), commonly known as baculovirus. The nonessential polyhedrin gene of baculovirus is replaced with cDNA encoding SPTM by either homologous recombination or bacterial-mediated transposition involving transfer plasmid intermediates. Viral infectivity is maintained and the strong polyhedrin promoter drives high levels of cDNA transcription. Recombinant baculovirus is used to infect Spodoptera frugiperda (Sf9) insect cells in most cases, or human hepatocytes, in some cases. Infection of the latter requires additional genetic modifications to baculovirus. (See e.g., Engelhard, supra: and Sandig, supra.)
In most expression systems, SPTM is synthesized as a fusion protein with, e.g., glutathione S- transferase (GST) or a peptide epitope tag, such as FLAG or 6-His, permitting rapid, single-step, affinity-based purification of recombinant fusion protein from crude cell lysates. GST, a 26- kilodalton enzyme from Schistosoma japonicum. enables the purification of fusion proteins on immobilized glutathione under conditions that maintain protein activity and antigenicity (Amersham Pharmacia Biotech). Following purification, the GST moiety can be proteolytically cleaved from SPTM at specifically engineered sites. FLAG, an 8-amino acid peptide, enables immunoaffinity purification using commercially available monoclonal and polyclonal anti-FLAG antibodies (Eastman Kodak Company, Rochester NY). 6-His, a stretch of six consecutive histidine residues, enables purification on metal-chelate resins (QIAGEN). Methods for protein expression and purification are discussed in Ausubel (1995, supra. Chapters 10 and 16). Purified SPTM obtained by these methods can be used directly in the following activity assay.
XIV. Demonstration of SPTM Activity
An assay for SPTM activity measures the expression of SPTM on the cell surface. cDNA encoding SPTM is subcloned into an appropriate mammalian expression vector suitable for high levels of cDNA expression. The resulting construct is ttansfected into a nonhuman cell line such as NIH3T3. Cell surface proteins are labeled with biotin using methods known in the art. hnmunoprecipitations are performed using SPTM-specific antibodies, and immunoprecipitated samples are analyzed using SDS-PAGE and immunoblotting techniques. The ratio of labeled immunoprecipitant to unlabeled immunoprecipitant is proportional to the amount of SPTM expressed on the cell surface.
Alternatively, an assay for SPTM activity measures the amount of SPTM in secretory, membrane-bound organelles. Transfected cells as described above are harvested and lysed. The lysate is fractionated using methods known to those of skill in the art, for example, sucrose gradient ultracentrifugation. Such methods allow the isolation of subcellular components such as the Golgi apparatus, ER, small membrane-bound vesicles, and other secretory organelles.
Immunoprecipitations from fractionated and total cell lysates are performed using SPTM-specific antibodies, and immunoprecipitated samples are analyzed using SDS-PAGE and immunoblotting techniques. The concentration of SPTM in secretory organelles relative to SPTM in total cell lysate is proportional to the amount of SPTM in transit through the secretory pathway.
XV. Functional Assays
SPTM function is assessed by expressing sptm at physiologically elevated levels in mammalian cell culture systems. cDNA is subcloned into a mammalian expression vector containing a strong promoter that drives high levels of cDNA expression. Vectors of choice include pCMV SPORT (Life Technologies) and pCR3.1 (Invitrogen Corporation, Carlsbad CA), both of which contain the cytomegalovirus promoter. 5-10 μg of recombinant vector are transiently ttansfected into a human cell line, preferably of endothelial or hematopoietic origin, using either liposome formulations or electtoporation. 1-2 μg of an additional plasmid containing sequences encoding a marker protein are co-ttansfected. Expression of a marker protein provides a means to distinguish ttansfected cells from nonttansfected cells and is a reliable predictor of cDNA expression from the recombinant vector. Marker proteins of choice include, e.g., Green Fluorescent Protein (GFP; CLONTECH), CD64, or a CD64-GFP fusion protein. Flow cytometry (FCM), an' automated laser optics-based technique, is used to identify ttansfected cells expressing GFP or CD64-GFP and to evaluate the apoptotic state of the cells and other cellular properties.
FCM detects and quantifies the uptake of fluorescent molecules that diagnose events preceding or coincident with cell death. These events include changes in nuclear DNA content as measured by staining of DNA with propidium iodide; changes in cell size and granularity as measured by forward light scatter and 90 degree side light scatter; down-regulation of DNA synthesis as measured by decrease in bromodeoxyuridine uptake; alterations in expression of cell surface and inttacellular proteins as measured by reactivity with specific antibodies; and alterations in plasma membrane composition as measured by the binding of fluorescein-conjugated Annexin V protein to the cell surface. Methods in flow cytometry are discussed in Ormerod, M. G. (1994) Flow Cytometry. Oxford, New York NY. The influence of SPTM on gene expression can be assessed using highly purified populations of cells ttansfected with sequences encoding SPTM and either CD64 or CD64-GFP. CD64 and CD64-GFP are expressed on the surface of ttansfected cells and bind to conserved regions of human immunoglobulin G (IgG). Transfected cells are efficiently separated from nonttansfected cells using magnetic beads coated with either human IgG or antibody against CD64 (DYNAL, Inc., Lake Success NY). mRNA can be purified from the cells using methods well known by those of skill in the art.
Expression of mRNA encoding SPTM and other genes of interest can be analyzed by northern analysis or microaπay techniques.
XVI. Production of Antibodies
5 SPTM substantially purified using polyacrylamide gel electrophoresis (PAGE; see, e.g.,
Harrington, M.G. (1990) Methods Enzymol. 182:488-495), or other purification techniques, is used to immunize rabbits and to produce antibodies using standard protocols.
Alternatively, the SPTM amino acid sequence is analyzed using LASERGENE software (DNASTAR) to determine regions of high immunogenicity, and a coπesponding peptide is o synthesized and used to raise antibodies by means known to those of skill in the art. Methods for selection of appropriate epitopes, such as those near the C-terminus or in hydrophilic regions are well described in the art. (See, e.g., Ausubel, 1995, supra, Chapter 11.)
Typically, peptides 15 residues in length are synthesized using an ABI 431 A peptide synthesizer (Applied Biosystems) using fmoc-chemistry and coupled to KLH (Sigma) by reaction 5 with N-maleimidobenzoyl-N-hydroxysuccinimide ester (MBS) to increase immunogenicity. (See, e.g., Ausubel, supra.) Rabbits are immunized with the peptide-KLH complex in complete Freund's adjuvant. Resulting antisera are tested for antipeptide activity by, for example, binding the peptide to plastic, blocking with 1% BSA, reacting with rabbit antisera, washing, and reacting with radioiodinated goat anti-rabbit IgG. Antisera with antipeptide activity are tested for anti-SPTM activity o using protocols well known in the art, including ELISA, RIA, and immunoblotting.
XVII. Purification of Naturally Occurring SPTM Using Specific Antibodies
Naturally occuπing or recombinant SPTM is substantially purified by immunoaffinity chromatography using antibodies specific for SPTM. An immunoaffinity column is constructed by 5 covalently coupling anti-SPTM antibody to an activated chromatographic resin, such as
CNBr-activated SEPHAROSE (Amersham Pharmacia Biotech). After the coupling, the resin is blocked and washed according to the manufacturer's instructions.
Media containing SPTM are passed over the immunoaffinity column, and the column is washed under conditions that allow the preferential absorbance of SPTM (e.g., high ionic strength o buffers in the presence of detergent). The column is eluted under conditions that disrupt antibody/SPTM binding (e.g., a buffer of pH 2 to pH 3, or a high concentration of a chaotrope, such as urea or thiocyanate ion), and SPTM is collected.
XVIII. Identification of Molecules Which Interact with SPTM 5 SPTM, or biologically active fragments thereof, are labeled with 125I Bolton-Hunter reagent.
(See, e.g., Bolton, A.E. and W.M. Hunter (1973) Biochem. J. 133:529-539.) Candidate molecules previously aπayed in the wells of a multi-well plate are incubated with the labeled SPTM, washed, and any wells with labeled SPTM complex are assayed. Data obtained using different concentrations of SPTM are used to calculate values for the number, affinity, and association of SPTM with the candidate molecules.
Alternatively, molecules interacting with SPTM are analyzed using the yeast two-hybrid system as described in Fields, S. and O. Song (1989) Nature 340:245-246, or using commercially available kits based on the two-hybrid system, such as the MATCHMAKER system (CLONTECH).
SPTM may also be used in the PATHCALLING process (CuraGen Corp., New Haven CT) which employs the yeast two-hybrid system in a high-throughput manner to determine all interactions between the proteins encoded by two large libraries of genes (Nandabalan, K. et al. (2000) U.S. Patent No. 6,057,101).
All publications and patents mentioned in the above specification are herein incorporated by reference. Various modifications and variations of the described method and system of the invention will be apparent to those skilled in the art without departing from the scope and spirit of the invention. Although the invention has been described in connection with specific prefeπed embodiments, it should be understood that the invention as claimed should not be unduly limited to such specific embodiments. Indeed, various modifications of the above-described modes for carrying out the invention which are obvious to those skilled in the field of molecular biology or related fields are intended to be within the scope of the following claims.
TABLE 1
SEQ ID NO: Template ID SEQ ID NO: O F ID 1 U:418914.1 :2001 JAN 12 76 U:418914.1.orfl :2001JAN12 2 U:246108J:2001JAN12 77 LI:246108J.orf3:2001JAN12 3 LI:204262.2:200UAN12 78 Ll:204262.2.orf 1 :2001 JAN 12 4 LI:331661.1 :200UAN12 79 U:331661.1.orfl :2001JAN12 5 U:335074.1 :2001 JAN 12 80 U:335074.1.orfl :2001JAN12 6 U:154608.1 :2001JAN12 81 Ll:154608.1.orf2:2001 JAN12 7 U.462889.1 :2001 JAN 12 82 U.462889.1.orf2:2001 JAN12 8 LI:236680.2:2001JAN12 83 Ll:236680.2.orf2:2001 JAN12 9 11:228186.1 :2001JAN12 84 Ll:228186.1 ,orf2:2001 JAN12 10 U:721233.1 :2001JAN12 85 U:721233.1 -orfl :2001JAN12 1 1 U:291759.2:2001 JAN 12 86 LI:291759.2.orf2:2001JAN12 12 LI:292613.17:2001JAN12 87 U:292613.17.orfl :2001JAN12 13 U:412959.15:2001JAN12 88 LI:412959.15.orf3:2001JAN12 14 U.482512.3:2001 JAN 12 89 Ll:482512.3.orf 1 :2001 JAN12 14 U:482512,3:2001 JAN 12 90 Ll:482512.3.orf2:2001 JAN 12 15 U:413231.6:2001JAN12 91 Ll:413231. ό.orf 1 :2001 JAN 12 lό LI:203383.1 :2001JAN12 92 U:203383.1.orfl :2001JAN12 17 LI: 133186.4:2001 JAN 12 93 U:133186.4.orf3:2001JAN12 18 LI:238576.2:2001JAN12 94 LI:238576.2.orfl :2001JA 12 19 Ll:903914.3:2001 JAN 12 95 LI:903914.3.orf2:2001JAN12 20 U:150817.1 :2001JAN12 96 U:150817,l .orf2:2001JAN12 21 LI:219627.1 :2001JAN12 97 U:219627.1.orf3:2001JAN12 22 LI:197812.4:2001JAN12 98 LI:197812,4.orf3:2001JAN12 23 LI: 101525.1 :2001 JAN 12 99 U:101525.1.orf2:2001JAN12 24 U:891 123.1 :2001JAN12 100 LI:891 123.1.orf3:2001JAN12 25 LI:813500.1 :2001JAN12 101 LI:813500.1.orfl :2001JAN12 26 U:1037251.1 :2001JAN12 102 U:1037251.1.orfl :2001JAN12 27 U:2032187.1 :2001JAN12 103 11:2032187.1.orf2:2001 JAN 12 28 LI :347572.1 :2001 JAN 12 104 Ll:347572.1.orf3:2001 JAN12 29 U:007788.1 :2001 JAN 12 105 LI:007788.1.orfl :2001JAN12 30 LL336872.1 :2001 JAN 12 106 Ll:336872.1.orf2:2001 JAN12 30 U:336872.1 :2001JAN12 107 LI:336872.1.orf3:2001JAN12 31 Ll:l 143291.1 :2001 JAN12 108 U:l 143291.1.orf2:2001 JAN 12 32 U:093477.1 :2001JAN12 109 U:093477.1.orf 1 :2001 JAN 12 33 U:222105.1 :2001JAN12 1 10 U:222105.1.orf2:2001JAN12 34 U:816737.2:2001JAN12 1 1 1 LI:816737.2.orf3:2001JAN12 35 U:475524.1 :2001JAN12 112 Ll:475524.1.orf2:2001 JAN 12 36 LI:383639.1 :2001JAN12 1 13 U:383639.1.orf 1 :2001 JAN 12 37 U:814346.1 :2001JAN12 1 14 LI:814346.1 ,orf2:2001 JAN 12 38 LI :898195.6:2001 JAN 12 115 U:898195.6.orf2:2001JAN12 39 LI :210497.2:2001 JAN 12 1 16 LI:210497.2.orf3:2001JAN12 40 LI: 1 10297.4:2001 JAN 12 1 17 Ll:l 10297,4.orf2:2001 JAN 12 41 LI:2051312.1 :2001JAN12 1 18 LI:2051312.1.orfl :2001JAN12 42 LI:350272.2:2001JAN12 1 19 Ll:350272.2.orf3:2001 JAN 12 43 U:1085472.4:2001JAN12 120 LI: 1085472.4.orf 1.-2001JAN 12 44 LI: 1 190272.1 :2001 JAN 12 121 U:l 190272.1.orf2:2001 JAN 12 45 LI:1086797.1 :2001JAN12 122 LI: 1086797. l .orf 1 :2001 JAN 12 46 U:1 144466.1 :2001JAN12 123 U:l 144466.1. orf 1 :2001 JAN 12 47 Ll:l 147914.1 :2001JAN12 124 Ll:l 147914.1. orf3:2001JAN12 48 LI:758086.1 :2001JAN12 125 LIJ58086.1.orf2:2001 JAN12
TABLE 1
SEQ ID NO: Template ID SEQ ID NO: ORF ID
49 LI:765245.5:2001JAN12 126 U:765245.5.orf3:2001JAN12
50 U:335608.2:2001JAN12 127 U:335608.2.orf3:2001JAN12
51 LI :405795.1 :2001 JAN 12 128 U:405795.1.orf3:2001JAN12
52 Ll:014872.1:2001 JAN12 129 LI:014872.1.orf3:2001JAN12
53 U:239245.3:2001JAN12 130 LI:239245.3.orf3:2001JAN12
54 LI: 142384.5:2001 JAN 12 131 LI:142384.5.orf3:2001JAN12
55 Ll:2068768.1 :2001 JAN 12 132 U:2068768.1.orf3:2001JAN12
56 U:21 18074.1 :2001JAN12 133 U:2118074.1. orf3:2001 JAN 12
57 LI: 1189068.4:2001 JAN 12 134 U:l 189068.4.orf2:2001JAN12
58 U:2118704.1 :2001 JAN 12 135 LI:2118704.1.orfl :2001JAN12
59 LI:031700.2:2001JAN12 136 U:031700.2.orf3:2001 JAN 12
60 U:2120122.1 :2001JAN12 137 U:2120122.1.orfl :2001JAN12
61 LI;816174.1 :2001JAN12 138 U:816174.1.orfl :2001JAN12
62 LI: 1189569.11 :2001 JAN 12 139 U:l 189569.1 l .orf2:2001 JAN 12
63 U:413584.1 :2001JAN12 140 U:413584.1.orfl :2001JAN12
64 U:791042.1 :2001JAN12 141 LI:791042.1.orf2:2001JAN12
65 U:l 167140.1 :2001JAN12 142 U:1 167140.1.orf3:2001JAN12
66 U:054831.1 :2001JAN12 143 U:054831.1.orf2:2001JAN12
67 U:1175083.1 :2001JAN12 144 LI:1175083.1.orf2:2001JAN12
68 U:2122897.2:2001JAN12 145 U:2122897.2.orf2:2001JAN12
69 U:2053195.3:2001 JAN 12 146 LI:2053195.3.orf3:2001JAN12
70 U:439397.6:2001JAN12 147 U:439397.6.orf2:2001JAN12
71 U:816379.6:2001JAN12 148 LI:816379.6.orf2:2001JAN12
72 U:2123452.4:2001 JAN 12 149 U:2123452.4.orf3:2001JAN12
73 U:474559.8:2001JAN12 150 LI:474559.8.orf3:2001JAN12
74 U:1089871.1 :2001JAN12 151 U:1089871.1.orf3:2001JAN12
75 U:289608.1 :2001JAN12 152 U:289608.1.orf3:2001 JAN12
Φ
.9 ->
O "- -> -> -> -> Έ ≥ -> -> - ->
E o
Q
.— .— .— .— r— ■— ■— i— ■— .— .— .— .— .— CM φ E
D bbbbbbbbbbbbbbbbbbbbbbbb bbbbbb oooooooooooooooooooooooo oooooo
CM
LU Q- O C CM LO OO IO OO CM -O CM IO O M CO O O (M O O lO CO
^ O C ^ ob ό ό r- cO ^, • CM "sT SO CO CO O o » o co ^ o r^~ o o <S5 - - ^ O O -- - co o co co co ^r CM CM CM
t --. ^f -o -O O cO O CO O O CO O t^ '— " T rsi -i n "* o t> i- "? ^ o r^ o -— co i— r- r- r- r- ^ CM N
Q CM CM CM CM CM CM CM CM CM CM CM CM G LU O
α Φ
C3 • — I — I — 1 — ' — 1 — I — i — 1 — 1 — I — I — I — I — < — i — I — I — I — I — I — 1 — 1 — 1 — I — I — • — I — 1 — f —
E o
Q
CM CM CM CM CM CM CM CM CM CM CM CM CO CO CO CO CO CO CO '— ■— >— ■— t— CM CN CM CM ( CM Φ O p p O O O O O O O O O p O O O O O 'O c o δ o b o o b o o α δ σ b δ o b o b b o δ b δ δ D o b b o
"" O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O
CN CN CN CN CN CN CN CN CN CN CN CN CN C CN CN CN CN CN CN CN CN CN CN CN CN CN CN CN CN zzzzzzzzzzzzzzzzzzzzzzzz∑zzzz -J -J —J --} --? —3 —3 —3 -3 —3 —3 -^ —3 —3 —3 —3 —3 —3 —3 —3 —3 —3 —3 —3 —3 -3 -^ —3 —3 —3 -£o0o0δ0o0δ0o0δ0o0o0δ0o0δ0o0δ0δ0δ0o0δ00δ0δo0δ0o0o0o0o0δ0o0o0δ0
O CN CN CN CN CN CN CN CN CN CN CN CN CN C CN CN CN CN CN CN CN CN CN CN CN CN CN CN CN CN t^ I^ t^ I^ l^ r^ t^ I^ l^ l^ t^ l^ I^ t^ t^" l^ r^ r^ l^' cM CM CM CM C^
E co' oό c co co c oό cd co od c od co ∞ cό cd od cd cM^ o-- -o- or- ol_ or- o1_ or. o-- ro- ro- ro- or. op_ o-- or- or- ro- o1_ o-. Co\1 oN o| oN Ool| oN No o| No (o oCM
^• "sT 'Nr ^r 'r 'sr 'r ^j- 'g- 'ϊ 'vr ^ T ^r r 'ϊ ^f 'sr 'r o o o o o o o o o o o
CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM
O z
Q cM l CM CM IN CM CM W CM CM N N CM CM N CM CM C CM m c O t c tO n n cO
Q UJ CO
φ c Έ Έ Έ Έ Έ Έ Έ
"o o
CM CM CN i- CM CM C CM CM t CCI tO r- r- ^- r- r- CM CM CM CM CM CO CO CO p p p p p O O O O TJ O O 'D 'O O 'D Ό Ό b b b P b α o σ o D o α o o o p σ o p o o Ό O o o o D O
£ ,p p p o p p o o o o o p o p p o p p p £ o o o o o p o
s- LO CO CO LO CO _ → 1
O -O i— C >— lO N r- ^^ o gj o o .r, co co co -_ o c j P; r_ o co LO "•' cN 's. o ^ r^ co jrϊ O CM CO CO LO LO - _ ^ s M ,= c ^.
CM CM CM CM CM CM CM ( CM CM CM CN CM ( CN CM CM CM CM ( CN CN CM CM CM CM CM CN CN CM
ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ —3 —3 —3 —3 ~3 —3 —3 ~3 —3 —3 —3 —3 —3 —3 —3 —3 —3 —3 —3 —3 —3 —3 -3 —3 —3 —3 -3 —3 —3 —3 -φδ0δ0δ0δδδδδ δ δδδδδδδδ
P CM CM CM0CM0CM0CN0CM0δδ CM0CM0δ CM0δδ CM 0CN0CM0δ CM0δδ CN 0CM0δδδδδ CM0CM0CM 0CM0CM0CM0CM0CM0CM0CM0CM0CM0CN 0CN CL CM CM CM ^ ^ ^ r^ -^ ^ r^ -' ^ r^ ^ r^ CN CM CM CN CM CN CM CM CN CM CM CM CN ^ ^
F N oi M i^ ^ ^ od cd co c c σ o^ d d d d d d d d d
S -0 0 0 >O O O O O O O O CO O CO OO CO CO ID CO (O C CD CO OO CO tO CO CO tO I_±I CN CN CM O ^0 O O O O O O O 00 C0 C0 N0 O O VO 3 O O O O - O O -O ^- '—
"^ ' T ^ ^ 1— 1— ■— LO 'vT 'vr 'r 'r 'sr cN CM CM o o o o -o o o o o o o o o co co o o o n n c t io io io w w O 'O 'O n n n r co n c n ro o c t N N
CN CN CN CO CO OO cO r- .— r- ,— r- ^ ^ ^ CN CN CN CN CN CN CN CN CN CN CN CN CN CN CN
O
Q c co ^ ^ ^ ^ iO ^ O ^ ^ ^ N i^ l^ CO O O CO CO CO O CO CO CO CO CO CO O^ O- α LU to
ABLE 2 i T Styneop M 84
-5 -5
"> i- — — t— ? 1— ? 1— ? h— ? 1— l— -> - t—> - 1—> -— - 1—> - I—> - 1—> - - o 1—> 1—> - I—> -—> - 1—> 1— — h— 1— ? I— ? 1— ? 1— ? ? ε o
Q
CM CM CM CM CM CM CN CM CM CN CN CN CN CM CM CN CN CO CO CO CO CO CO CO CO
Φ TJ TJ TJ T5 TJ TJ TJ TJ TJ TJ TJ TJ TJ TJ TJ TJ TJ T! TJ T! TJ T TJ TJ TJ TJ TJ TJ T TJ ε π o O π o π π π π π π π o π 0 π π π π π π π π π π o π O O
35 w 33 Es •5 35 35 5 35 .5 5
£ o o O s o O — o >» o— o O o O o o n o o o o o o o o o o n o o O o
o o LO o o O o o LO CO o LO 5 o
L ■5- o CM 5 LO 00 o 00 o
"g oO L g ^ O O CM LO ∞ ^ ∞ ∞ ^ g ^ ^ cO -O ? ^ „ CN CN O O LO C^O, CM LO ■— CO O O g c ∞ g ^ CN ^ LO I^ ∞ ^ ^ ^ ^ O ^ cN CN O ^. CM 'ϊ iO N Oo - '- CM CM
1260
CM CN CN CN CN CM CM CM CM CM C CN CN CM CM CM CM CN CN CN CN CM CN CN CN CM CN CM CM 1283CM
Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z
<< << < < << < << <
Q "3 — 3 — 3 — 3 — 3 — 3 - — 3 — 3 — 3 — 3 <— 3 <— 3<-3 <— 3 <— 3 <— 3 <— 3 <— 3 <— 3 <— 3 <— 3 <~ 3<— 3 — 3<— 3<— 3<— 3 <— <— 3
O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O
+ Φ- O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O o CM CM CM CN CN CM CM CM CN CM CM CN CN CM CM CM CM CN CM ( CN CM CN CN CN CM CN CN CM CM
Ω. ε 0 0 0 0 0 0 0 0 0 0 0 <3 0 0 0 0 3 0 0 0 0 0 0 0 «0 0 D O 3 0 Φ CO CO CO OO CO OO CO CO OO OO CO CO OO CO CO OO CO CO OO CO OO CO CO OO CO CO OO CO CO CO
1— co co co ∞ co co co co co oo co oo oo oo oo oo oo co co co co co co co co co oo co co co
CM CN CM ( CN CN CM CM CN CN CM CM (>1 CM CM CN CM ( CN ( CM CN CN CM CM CN CM CM CM CN CM CM CM CM CN CN CN CN CN CN CN CM CN (N CN CN CM CN CN < CM CN CM CN CM CM CM CN CM CN
o z
Q o o o o o~ c c c c> c> c> c> c c c c> c> c c> c> c> c> c> c> c c> c c c> c>
Q LU O
ZL
co rπ o ω ω ω ω ω ω ω co ω ω o ω ω M M M M Ni i M o o o ° σ
O
Ji. 4-- 4-- 4-- 4^ lO tO N> N> NO I ro
- ^> *o ) •<) O o ro to ro K. t NJ v| VI v VjI rroo
N> N. IV) IY> NJ ro IV> M NT N. N1 ro •o o o o o o ro ro NT ro
■ cn ^ cn) <) -O ) c> c^ o- cn cn oi cn oi cn oi oi ϋi cn cn cn ( (> C> vl I I v| VJ VI NT NT ro o o o o ^o -o o -o -o j o o -o CO Co Co CO CO CO ω cn cn n n cn cn ( O Cύ 00 φ o o o o J "O CO Co o o 33 cn n n cn n n n cn a- cn n n n VI Vl VI --J Vl VI ro ro ro ro ro ro J3 fό to fό fό Fό Fό ro fό iό fό Fό Fό Fό ro ro ro ro r κ> ro iό ro ro ro N3 ro NT ro NT N) o o o o o o o o o o o o o o o o o o o o o c > c I r> ( 1 o
7f o o o o o o o o o o o o o o o o o o o o o o o o o o
D
> > >z>z>zz> >z>z>z>z>z>z>z>z>z > > > > > > >
Z Z z z z z z ≤ z > z > z > z z > > z > z > z > z o ro ro ro ro io ro ro ro io ro ro ro r ro ro ro ro ro ro ro ro ro r ro ro ro ro ro ro
O vι cn vj cn C —■ s- ro -^ .&» — ■ — ro — ■ — . ~ £-?
03 cn c> co -^ ω ^ 0 -sJ CO cn cn r Wo Oro Cro) ) c Ϊ2 Co 4^ ro — ' o ro co — — ■ -o M 3 o P co c r c o o vi oo cn Q-Q f^j ro
O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O ... Q Q Q Q Q Q Q D Q Q Q Q Q Q Q Q Q Q Q Q Q Q Q Q Q Q Q Q Q Q d d d α α δ Q α Q α d α d Q -i d Q. Q. d (!i ro ro ro ro — ■ -' — ■ — —. —. —. —. — . co ro ro ro — • — ■ — ' ro ro ro — ■ — ■ — ro ro ro co
D O
3
— I — I — I — I — I — I — I — I — I — ! — I — i — I — I — 1 — i — I — I — I — I — I — I — I — I — 1 — I — I — I — I — I Q
TJ φ
cn m
0 vl ^j vl ^j vl O O O O O O O O O Cn cn cn θι θι 4- J-. 4-. ω ω cι ω c c. c c D
Z
O
φ ~- ~~ τ 3_
Q ?
0 «-
*0-» 3
ro ooooooooooooogooooooooogoooooo-..
Ω Ω Ω Q Ω Ω Ω Ω Ω Ω Ω Ω Q Q Ω Ω Ω Ω Q Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω g a 3- 3- a a a a a a a 3. a a a a Q- a a a 3. a φ —A —A —A —X — ' Co co co ro to ) — ■ — ■ — . — . — • — i — i — ' l ro ro co co c io ro ro M
D O
3
S-SSSSS-SSS SSSSSSS2S2SSSS2S Q
3 J φ
o o/zosfi/i3d toε/.so/zo OΛV
PL
) ) ) ) ) 0 ) ) 0 3 ) 3 ) ) ) ) C3 CX3 C» vI vl
o
o o O O O 0 0 o O O o 0 0 0 0 -O NO NO NO
( ) O CO CO O O CO CO CO CO CO O (ύ CO CO CO
<ύ Cύ CO <o <o (O <o ( CO O <o O (O (ύ ( O O C)0 <)0 JO CO O O CO CO O O (ύ ύ o o -o ><> ) <) • -c> ) <> ><) O • ) •o -o n cn n — » — > " vj VI v| 00 X) oo <X3 (V) <X3 oo 00 00
45* 45- 45- 45- 45- 45- 45- 45- 45- 45- 45- 4* 45- 45* 45- o o o o o o o o o o o o o 3
CO C Co CO CO Co Co Co co Co CO Co Co C C CO Co NO NO ro 4. 45- 45- 45- 45- 45- 45- 45- 45- 45- J
NO NT O NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO ro NO NO NO NO NO NO NO NO NO NO Ω
(1 < ) ( ) O CO c , o
O C_) U O O O <_) O C_> O CJ CJ o o o o CJ o o o o ^ o O O Φ
>z>z>z>z>zz>>z>z>z>zz>>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z rO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO rO NO NO NO NO
c^ c 1_i_,oooo o cn45- o o o o NO NO _, O 0 o _, ft -■ oo cn 0
CO Sv-1 45* — ' CO O - l "S* c_o. c0n0 cNnO rOo ONO ovl 4455*- — • 00 — ■ 00 — - oo en ro ^ 5- ro o o
C o 00 Ω
ro j- O o o
O 5- CO ^P^^∞OS^N ^ CΛ > ro vi oo cn cn NO — ■ O 45- N ^0 45- —■ CO •^
•o ro -~ — ^ ^ K cj O 45* NO o co P CD
"- 4 - l — ■ Oo -O O CO O O vj O 0 O vl ■ ÷ roj NNO-s ^o vi. vl O v -Og j^
NO
O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O
Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω aaaaaaaaaa a a a a a aaaaaaaaaaaaaaa φ ro to ro ro -' —■ —< —. —. —. —. —. —. — * — ' GO CO CO NO NO NO — ■ —. —. — •
D
O
3
— 1 — 1 — 1 — 1 — 1 — 1 — i → — i Ω
<L <I <: S 2 S <: s s 5
TJ φ
o o/zosfi/i3d t0£LS0/Z0 OΛV
Φ a o ΈΈ ΈΈΈΈ o
Q
CM CM CM M CM CM CM CM CN CM CM CM CM CM CM CM CN O O O CO O O CO CO CO
Φ TJ TJ TJ TJ TJ Tϊ J TJ TJ J TJ TJ TJ TJ T! T TJ TJ TJ TJ TJ TJ TJ TJ TJ TJ T! TJ TJ TJ b o π o o o π o O π π o π π o o π π o o π o α o π o o O υ o o
O j5 35 35 ^ 3> 5 35 •5 35 35 35 35 j5 35 35 ψ 35 ^ ^ _ _ o o o o o o o o o o o o n o o o o o o o o o o o o o o C) o o
L- rv oo o^ oo oo coo i- CN LO oo oo o co Srv o o co oo o o r^v rov o o orv coN O^ oO ^fc j&y '- -^) ^N w^ «S lg oS nS wfy .— rv o o
Jj c ^ ^ - ^ - i O O O N CO CO 0 0 ^I ^ ^ ^ ^ ^ π- r-^
CM CM CM CM CN CN CM CN CM CN CN CN CN CN CM zzzzzzzzzzzzzzz —3 —3 —3 —3 —3 —3 —3 —3 —3 -3 —3 —3 —3 —3 —3 δOδOδOδOoOδOδOoOδOδOδOδOδOδOoO — ■ — O O O O O O O O O O O CO CO CO OO CO CO CO CO CO CO CO CO CO CO CO O O O O O O O O O O O O O O O UO LO LO UO O O O O O O O O O O O ' — ■ — ■ — > —
o z
Q OO O OOOO OOO O O O OO O O OOOO O O O O O O O O O
.— .— .— .— CN CN CN CN
LU O
9L
CO m 0
NO NO NO NO NO NO rO rO NO NO NO NO NO ro ro ro ro No ro ro ro ro ro ro ro ro No ro ro ro
— ■ — ' — ' O O O O O O O O O O O O O O Q Z
O
NO NO NO NO NO NO rO NO NO NO NO NO NO NO NO NO — « — ■ — ■ — • — ■ — ■ — . —. —. _. _ . _. _ _.
—■ —■ —' —> —■ —■ —■ —' —■ —' — ' -J — ' —■ —■ — ' Cn cn cn cji cjo cn cn cn cn cn cn cn cn cn O O NO O O NO NO SO 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 _, O O O O O O O O O O O O O O O O OO OO OO OO OO OO OO OO OO OO OO OO OD OO ^ rO NO rO tO NO NO NO NO NO NO rO NO NO NO rO NO — ' — ■ — ■ — ■ — ■ — ■ — ■ — ■ — ■ — ■ — ■ — ■ — • -A w
NNMMMNMMNMNNNMNNNNNMNNMNNMMMMMJ '-A '-A '-, -A ^ '-A ^ ■-, '-A L-A ^ '-A --^ '-A '-A '-A '-A ^ ^ '-A -Q o ro foό foόoooroofόofόoFό Fό fό Fό fό fό rό Fό fό rό ro fό fό Fό Fό rό i^ oooooooooogooooooooooooooooooooooooooooooooooooooooo→Φ-
C_ C_ C_ <-_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ <-_ C_ <-_ C_ C_ C_ C_ C_
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ rO NO NO NO NO NO NO NO NO NO NO ro rO NO NO NO NO NO NO NO NO NO NO NO rO NO NO NO NO NO
vi o cn cn cn cn 45- 45* 45* 45- — ■ l 4_* NO — ■ 4 NO Cn NO NO O 45* 4 ■45-** N l CO Co — o
O v \OJ _, 1 O 0 v j O 0 u ki \ n r,ι _ ■, , 0 W0J c o- CO O N M J. 45. — ' NO O O O — ■ 00 00 o n N5 w
vi o o n cn vi cn n 45* 45* 45* o — . — ■ VI co CO C > — ■ o vl 4.5. N ._O — ■ 45- NO cn NO — ■ 0 45* — ■ 45* — ■ 45* o 0 PS O Co 45- CD NO ^ o n co 00
VI O vl VI ∞ P 0 0 0 o co o co o — ■ 00 -O 0 O vl NO -O vl 5*
— ■ VI 45* 00 o o --J 45. TJ m ro c — h
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 o 0 0 0 0 5"
Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω a a a 3.3. a a 3. a a. a 3. a 3. 3.3. a 3.3. 3.3. a a Φ 3
NO NO to ro ro CO CO CO CO CO CO C C CO CO CO — '
D O
3 Q
3
o o/zosfi/i3d fOZLSO/ZO OΛV
LL
oo m
NO NO NO rO NO NO rO rO rO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO o CO CO NO rO NO NO rO NO NO NO NO -^ — . —■ —. — ■ —. —. —i —i —. -- — ■ —- —• — i — i — _ . _ ■ o
—• —' —' —■ O O O O
— ■ — ' M M
Cn Cn OO OO NO NO — ' — • Ol Cli rO rO l-. --- 4_i i--
Fό fό Fό fό
OoOoOoOo (L_ c_ c_ c_
>>>>
ZZZZ
NO NO — ■ — ■ CΛ vi cn vi cn Co — ■ vi o o o cn cn cn cn ro NO NO o vl 45* cn cn — ■ O OO O Cn CO Co — < vl Oi 45* NO 45* — ■ cn NO NO O C .45* —' O C NO O O CO O O VI 45- O VI O VI 1 Ω
3-
f ιNyO —— ■ ■ — — ■
■ t-. ..- -» _2> C° O
!° —O' M C -' S K n NO O O
c o o oW cTfS o o o TJ m
NO ? c ? ^ n cT ? 3* c? c? c? cT c? c ? cT — o h 3 ? c? c? 31 3" C? cT cT ? c? 3^ cT
5 ^ ? £ ^ ^ wξ ~ ξ ~ <? §? ^ ^ j? gf ^ ^ <? ϋ? ^ ^ ^ J <? ^ ^ g? ^ ^ M o o o o Ω
0 o o u Ω o o o o Ω Ω o O. Ω Ω o o u Ω Ω o o Ω ϋ u u a a a a a a a a a a a a a a a a a a a a a a a a a a a a a ayp in φ Te
NO NO 00 Co Co NO NO NO co CO O C CO CO O C CO co co CO Co Co co O CO co CO
Ό
O
3
—1 — 1 -H — 1 — 1 — 1 — 1 -H — 1 — 1 — 1 — 1 -i Ω
- SSSSSSSSS ≤. <L <: <: <: <: <: <: <: <: <: <:
O O/zOSfl/I3d fOZLSO/ZO OΛV
φ a
-> - α i— i— i— o
CN CM CN CN CM CN CM CM CM O CO OO r- i— r— r— r— ,— r— .— CO CO CO CO CO CO OO CO CO '— φpppppppp ppppppppppppp ppppppppp D D O D o b o b b α oob bo b bb b b b o bb obb b p p p p p p p o o p p p p o p p o o £ P .P 2 .P .P 4o— 4o— P ,P .P .o
CM y Q-rv o o co rv o — o o O CM O r-.ι u LO^ "v. O CO ■— ■— rv o ^r rv r- 'r rv O '— m P lO CO O i- CM l -O N N O O O R* r- CN CM co CN CN cO CO cO CO CO CO rv CN CN Iv < .— i- σ o ^ co co ^r o <— r- r- CM CM CM LO L 0 LO
t c OO i- i- O CO r- CM O O CO -o O LO CO O CN CO -— LO CO CN UO CO r— cO -O CO O i- CM UO O cO '- '- cO i- S '- M 'vf r- cO - irj co co o cM " n -o r- CN CN CN cO cO CO cO cO cO CN CM ^ •— ■— ,— CO " i- r- r- CM CM CM U lO
CN CM CM CM CN CN CM CM C < C ( CM CN CN CN CM CM CN CM CN CN CM CM CM CN CN CM CM ^_-
ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ —3 ~3 ~3 ~3 ~3 —3 —3 —3 ~3 ~3 —3 — —3 —3 ~3 ~3 —3 ~ —3 —3 ~3 —3 ~3 —3 —3 ~3 -3 —3 —3 -_-
•φδO OδδδδδδOδδδδδδδδδδδδδδδδδδδδδδ O CN C OCM OCM OCN CO OCN CM OCM OCN OC OCN OC OCM OC OCN OCN OC OCN OCN CON OCM OCM OCN OI OCN CO OCM OCN fVj.
P -O LO LO LO LO UO I IO LO O UO UO CO CO CO CO CO O O O O O O O O O O O O m CM CN CM CM CN CM CM CM CN CM CN CN CM CM CM CN CM O O O O O O O O O O O O fy
1^ in iO iO U) iO iO U lO lO iO lO '- '- '- '- ^- io io io iO iO iO in iC) iO iO iO io £-
O O O O O O O O O O O O O O O O O .— -- ■— r- r- r- ,— ,— ,— ,— .- ,— £!-> j _j j j j j j j -] j j j _j _j j j -] _] _j -] j j j j _j j ^
O z
Q CO CO CO C CO CO CO CO O CO CO ^ ^ ^ ^ ^ LO LO LO LO LO LO L U LO UO L
CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM σ LU O
φ .> a- c -> -> -> 2 -> 2
'D o
Q
CM CN CM CN CN CN CM CN CN CN CN CN CN CO CO CO CO CO CO CO φ ε
CM u ,— " CO O CO ^ rv co ■— o co rv o Lo LO M LO CN rrx ( CN LO CO ^_ CM T O OO CM LO . ■— co uo rv O CN ^ C
O CO i— CO L CM O 00 CM LO LO
^J5 ∞ CN C - O r— o O CM O M • C -N CN ^ 0 0 CM CM CM CN T lO lO O -O O ^ i- C - ■ M - - ^ — ■N' ■ ^o
t r-, c cM L "r r o cN co co CM CM '— N' ω ι- -0 >O W lO c -0 o. CN cO -O O CN
£ y S CM T O CO C lO i- ^ rv O O CM 0 O CM r 0 CO '— CO ^- Γ CN O ∞ CN L CM CM CM (M * NL '0 O r- i- C CM CM CM - - ^ lO U O -O cr- __ ^ ^ --- _--
CO V IU
CM CM CN CN CM CN CN CM CN CN CM z z z z z z z z < —3< .....< —3< —3< —3 < —>< —3< —3 < —3< —3< —3 o o o o o o o C3 o o <r>
( > ( ) ( )
CN CM CN CN CM CN CM CM CN CN CM
ICO LO LO LO LO CO CO LO LO uo LO
CM CN CM CM CM CN CN CM CM CM CN
IV rv rv rv rv rv rv rv IV rv IV
CO CO CO CO CO CO CO CO C) CO CO o o o o o o J o o o o
o n O O -O -O O O O O O O O O O O O O fl O O O O O O 0 O -O O O O - CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CM CN CM CN CM CM a LU O
08
co m
C-O CO θ3 CO CO O3 CO CO CO C0 N0 rθ N0 ro rθ N0 N0 N0 N0 N0 N0 N0 N0 N0 N0 N0 N0 N0 N0 N0 ro ro — • —> —> — I -Ό O O O O O O O O O O CO CO CO OJ OO CO M M M SI M O o
o o 00 CO CO o o o o o o o D C Coo CCO CCOO CCo CoOo CO NO NO NO NO NO
O NO CO CO CO * 45* 45* 45* C ) C ) C ) C ) 4 455** 4455** 4455** 4455-- JJi-** 45. O O O o o
45* 45 VII VVII VVII jJ J 00 C CO Co Co g g S S S S S o o vj vl VI VI VI vi vi vi vi VVII V vl vi VI vj vi VI VI vi Cnn nn nn Cnn nn n NO NO NO NO NO — 1 vl VI vl vl vi 00 oo c» 00 CX3 uo 00 00 00 VI VI v| VI VI vi vl VI NO ro ro oo oo 00 00 00 00 00 00 00 NO ro ro ro ro ro 00 00 00 00 00
VI VI vl VI vl 3
TJ
N^ όfό ό ^ ^ NO NO NO NO NO NO NO NO NO NO NO NO NO NO o o Fό Fό NO NO NO NO NO o o o o o o o o o o o o O ro o o o o O O O o CJ O CJ O o O O o o o o o o o o O O O o o CD' c_ c_ (.. C c_ c_ c , c_ c_ c C_ c_ r , c_ c_ C_ C_ C_ o
>> >>>>>> > >> > > > > > > > > > > > > > > ?? Z ZZZ Z5 ? 3? Z -.. Z Z Z Z Z Z < Z Z Z > z > z > z > z > z
M 3 ι ro ro ro ro K) l hO M O N) I ) ' r N:) f K> M r K) , ro ro ro ιo
— ■ o o cn n 45* 45* Co 00 O CO oo co O O -O 0 -o — ■ 5* ro vi cn CO o — ' O 45* - -• 45* - -• 45* - ■■ M O -OO O O 00 C — ■ n J-* 4-. oo cn O vl O CO oo n VI VI O O vl 45. — ■ oo vi cn
3-
O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O ^ Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω 3 a a aaaaaaaaa aaaaaaaaaaaaaaaaaaa® -- —. —. —. —. ro ro ro ω C CO N0 N0 N0 — ■ — ' — ' CO CO Oo rO NO NO CO OO Co CO CO
0 3
— i — i — i — i — i — i — r —1 —1 — l -H — 1 —1 — l -H — l -H — i — 1 — 1 — i — i — 1 — 1 — l Ω
S 22 2 SSSSSSSSSS
TJ Φ
o o/zosfi/i3d fOZLSO/ZO OΛV
18
co m
Θ ω ω ω ω ω ω ω ω ω ω ω ω ω ω ω ω ω co ω ω ω ω co ω co ω ω ω CO CO pj ^ 4i J-, ^ i 4i ^ ω ω ω ω u ω ω ω ω ω ω c~ ω u ω u cJo ^o NO NO σ z O
C3D OO OO OO OO OO OO OO OO NO NO N NO NO NO N NO NO N N NO N N NO NO N NO O O O _. —. —. —< —. -- —■ —. — ■ NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO O O O O O O O O O O O rO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO CO OO CO . v vj vj vj vj v4 v vj -_J _-J __J -_, -__ _J _^ __J _. --J _-J _-_ ___ _-J _-J __J __J _j 4-i . j , ^ CO C O Cθ Co CO OO CO OO O O O O O O O O O O O O O O O O O O vI vJ vj _D
M M M M N M M M M W Ol Ol Ol Cn Cn Ol Ol Cri Ol Ol Cn Ol Ol Ol Cn Ol Cri M M M j ro Fo Fo Fo io fo Fo ro fo ^-' "— ■ '—• '—< "—A '—. '—. '—■ '— ■ —' • '—• '—■ '—A '—• '— '—• '—. '—. ~— A ~— < '—■'θ_ ro 'rό ro ro fo Fό fό Fό io iό Fό rό fό fό fύ fό Fό Fύ Fό fό fό fό fό ro M o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o →-
OO OOOO OO O OOO O O O O OOOOOOO OOO O OOO ®
C_ C_ C_ C_ C_ C_ C_ C_ C_ <-_ C__ C_ C_ C_ C_ <-_ C_ C_ C_ C_ C_ C_ (-_ <-_ C_
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ rO rO ro io r NO NO M NO NO NO NO NO NO NO NO NO NO M NO NO NO NO NO NO
O O O O OO vl vl v O d CO 00 CD 00 O O O O OO OO OO OO vj v NO NO NO -5
O 45* CO O N0 O vI Cn — ' N0 O 00 O 45. ro — ' VJ 45* N0000045* NO OO O cn ro o vι o vι vj 45* oo cn 45* — ■ — ■ o — ■ 00 <o o co o — ■ o co o O 4. S -f - 00. Ω q.
Ό O Ό CD N N M O O O OO M CD OO O O O O O OJ OO OO OO N M cn NO NO _2> o 45* NO O o vi cn 00 NO O 00 o 4-* N ∞ v ι N O o n ooθ oαi oNoo cno 4o5* cron oNoθ cno o co 4 .5* 3" pa n 45* •O O O O O CO — ' vl 45* C oj 4v5. O O ωTJ Fπ ro
O O O O 3" ό o o 5" 0 0 0 0 0 0 0 0 cT cT cT3 o o ^ ^ -rf~ O O O o o
<? 5
Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω - 5: v Ω
Ω Ω Ω 0 0 ? 0 i 0 Ω Ω Ω Ω Ω Ω Ω Ω g
3.3.3.3.3.3.3.3-3.3.3.3.3-3.3.3. a 3- a a a a a a 3. a 3. 3.3.3. a
—. —. —. —. —. —. —■ — ■ — ' NO NO NO NO NO NO NO
o o/zosιι/i3d toε/.so/zo OΛV
φ φ Φ Φ Φ Φ Φ Φ Φ Φ Φ Φ Φ Φ c c () r c o c o c o c c o c c o c c o c 2 o 2 o g f)
CO ! = Ω «) 2Ω :5 » J23 =o o <£> -2Ω =ϋ .2Ω :o " 2Ω =o j2α :o _2Ω ==o =o -2Ω :5 « -2Ω =ϋ 2Ω :δ « -2Q =o
£ ε 8 ε J
F υ C 1r c Oco 4- cC Oco ^ c Oco C -i- C Oco Oco fc Pi- ct_ Oco C P"t- £- Oco
O φ O φ J» ϋ Φ CJ Φ ?" φ O - φ O Φ ?- φ O φ ?~ φ O O φ - φ O φ - φ O α c c F >- E ^ E^ E5. E ^ E^ E ^ E ^ E ^ E^ E ^ E^ r- c <v c o C υ ^ § ^o g ^υ g § gυ ^ § goo ^ § ^o g § ^υ
2 2 z o σ z α z σ o z o o z σ σ z σ o z α
1— 1^ = H= = 1— 1^= H1 1 1^ = 1^
Φ TS J Ό Ό Ό ■O -O O J O O O -a TJ -D i i J -a O o o o o α o o o o o o o o o o o D o o o σ
"
" 4O— 4O— 4O— 4O— O-
O-
O— 4O— 4O— 4O— 4O— 4O— 4O— 4O— 4O— 4O— 4O— 4O— 4O— 4O—
4O5i
CM
t O O OO r— -O O OO r— LO O f i in rv rv O CO O - O CO π '- C θ N N' O O O CM r_ H S N N" CO O O O Ol co O LO co rv rv co o ii O O O O - r- r- r- W ^ g g O O O '- i- W N O CN O O O CO O OO co co co co o o iv rv
CN CN CN CM CM CN CM CN CM CN CN CN CN CN CN CN CN CN CN CM CN CM CM CN CN CN CN CM CN CN z z z z z z z z < < < < < < < < o o o o o o o o o o o o o o o o
CM CM CM CN CM CN CM CM
CM CM CM CM CM CM CM CM
IV rv rv IV IV rv rv IV CO CO CO CO CO CO CO CO IV rv rv rv rv rv rv iv 0 o o o o o o o OO OO OO CO CO CO CO oo
o z o ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ -vj
'vt '
vr ^ '
vr ^
'vi-
'vr '
vr
— CO CO CO CO CO CO CO CO C CO CO CO CO CO CO CO CO CO CO CO CO CO CO CO CO CO CO CO CO CO
Q LU co
£8
CO rπ ω c ω ω ω ω ω w ω ω ω ω ω ω ω ω ω ω ω ωQ ω ϋj ω ω ω ω ω vj vj v v ( o^ O O O O O O O O CJl COO CJo 45* 45* J5* 45* 45* 45* 45* 45> 45* 45* 45* Ό o
c» cι c» c» ω ω u w ω u ω ω ω cΛj ω ^ 4* ii » ca c» cn B CD co co c» θ3 θo c»
— ' — ' — ■ — i (X) 00 C» 00 00 O3 <» 00 O3 00 CX> V| vl Vl —J — ' —• —■ —< — ■ —■ —■ —■ —■ --- — ■
4 o-* 45o* 4c5o* 4ω5* θ3 co-o ωo co coo coo coo coo coo coo ooo ccnn cc-nn ccjno ovj ovj ov-j ov-j ovj ov-j o-j ovj o-j ov-j oj ov-j _T-,i
4- i_ j-, i- ω ω ω w ω ω ω o u ω ω M ιθ N3 ω uω ω ω ω ω u ω ω ω ω s
O O O O O O O O O O O O O O - ii ii N M N N N N M M M N N N j
^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ f f 'M M M M f r f i MO Fό fό rό Fό rό fό fό fό rό rό fό fό Fό fό fό fό fό fό fό fό fύ fό fό fό fό rό fό ro rό Fό Ω o o o o o o o o o o o o o o o o o o o o o o o o o σ o o o o →- o o o o o o o o o o o o o o o o o o o o o o o o o σ o o o o Φ
C_ C_ <-_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C__ C_ C_ C_ C_ C_ C_ C_ C_
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO
C CO CJ Cn Cn 45* 5* NO NO NO NO —■ —■ CO CO co 45. 00 —■ —■ NO O 0 O 45* Co O 0 vi —' O 4^ ro i i - o o g g & 'g O 5 ro o O OO Cn 45* —■ O vl 45=. —■ o VI co CO CO O Ω o o ro o cn cn c-> ^1 NO CO O →-
oo co co co o cn
VI 45* CO —
A VI NO —■ 00 vl 45* —i CO
o o o" o o o — h — o o h — h
3 Oo O Oo o o o o o o o O O O O O O O O O O O O -..
^ ig? ^ <? ϊ? 5 ~\ ^ g? g? ^ ^ g. ϊ? ^ ^
Ω Ω Ω Ω Ω Ω Ω 0 Ω Ω Ω Ω Ω Ω Ω Ω Q Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω d a a a a d a a a a a d a a a a α addaaadaaa da®
M M w ro ω ω c- ω ω ω ω ω u ω ω ω w u ω ω ω ω ω ω u ω ω ω ω ω
O
3
— 1 —1 — 1 -H — 1 — 1 — 1 -H — 1 —1 — 1 — 1 — 1 —1 — 1 — 1 -H — 1 — 1 — 1 — 1 —1 — 1 — 1 — 1 —1 — 1 — 1 — 1 —1 o
<: -2 -S S 2 S _S 2 -C 22 S -S -2 -2.22 S S S _≤ ≤ <* ≤. 2 ≤ <: <* <: 3
≤ φ
O O/zOSfl/I3d toε/.so/zo OΛV
n
oo rπ
O ω ω ω ω ω ω ω u ω ω ω tΛ u ω ω ω ω ω ω w ω ω ω u u ω ω ω ω u
CO CD CB CO C. OO CO OO N M N N M N M N sl M N 'vl N M N M N N N N N M Ό
O
C» CX3 -o o
O —O■ O—O' ) NO Λ Oi
O O fό iό
O O O O
C_ C_
>>
ZZ
CO CO CO NO NO —■■ —' Cn cn cn 45* co co co co OO OO OO OO vl vj C O Cn 45- 45- 4-. C --f. 00 00 — • 00 O 45* —■ Cn N0 O 00 θ vl O 45* — ' vi cn 45>. — ' O O Co o o oo vi cn vi Q cn o NO 45* —■ — • oo O M M J-, J5. -' Oι r vi 45* ro o — ' Oo ro o vi 4* oo oo NO .
45* CO Co Co O ro ~ . o cn cn cn 45* co co co oo o oo oo oo oo vi vi o O Cn 45* 45* 45* -5 ? O 00 00 — ■ 00 o rv _. ro 45- NO O 00 O 45- NO vi e 45* <0 O Co 45* 45* 00 00 CO O O vl 00 O O O CO CO —■ 45. 00 —< 00 O v| —. O00 OO CCDO NVI Ovl —Oj ?f-
NO
O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O
Ω
Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω aaa aαa a aa a aa aa aaaaa aaaaaaaaaaao —i — ■ —■ —■ —■ —■ —■ — ■ co co co co co co co oo co ro ro NO NO NO NO NO NO NO NO NO NO NO
O o 3
Ω
3 J φ
0 0/z0Sfl/I3d toε/.so/zo OΛV
£8
CΛ m
D ω ω ω ω ω ω ω ω ω ω ω co ω ω cj ω ω ω w ω ω ω ω ω ω ω co ω u ω s c» ∞ oo θ3 θo αι ∞ ∞ c» ∞ c» oo ω ω c» c» CD θo oo ω ∞ ω c» c» CB ∞ co oo (B C» D
O
3 j
Ω C?
45* 45. 00 NO NO Z, -A Z_ O O o !£- 'F' I →?
0000 O vl n 45* O K — vi — - oo cn cn o co £ ! N I _O O V - oo cn £ 45* 45. CO NO NO — ■ — - O O o o o NO — 00 00 O 45* — ' OO O VI O --
45* — ' M O M t- N O O M OO O NO O ^ C3 Ω_
— • — ■ — ■ co >
4_ 45* 4-* co ro ro — ■ — • — ■ — • 45* 4- 00 NO NO — ■ — ' O O o o
0 O0 —O ■ —O ' OvOl OvO, Ov_ αvιl ONvi 045.3 rθo 45* — ' NO O O
^ g-g^ coo-i 00 00 O ω^ O NO O o 00 O Co — ■ 00 o o NO o oo cn O 45. — ' O j- - oo — < oo T m
NO
-O^ O■^O-^ -Or -Or -O^Or -O^O-^ -Or -O^ -O^O-^ O-^ -O^ -O^O-^ -O O-r -O^ -O^ -O^ -O^ rO O- -Or& O3χOr$*O-rt> -Or&
Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω 3 a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a Φ
Co Co CO CO co co 00 CO 00 co CO Co NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO
D υ 3
— 1 — 1 — 1 — 1 — 1 — 1 — 1 — 1 — 1 — 1 — 1 — 1 — 1 — 1 — 1 — — 1 — 1 — 1 —1 — 1 — 1 -H —1 — 1 —1 — 1 — 1 — 1 o s s s s .. s §: s s s -_ s <_ _: s -s: s s <: -s s -_ 2 _: s s -_ s s _: 3 v?
Ό φ
o o/zosfi/i3d toε/.so/zo OΛV
98
o o o o o o o o o o o o o o C3 C3 o o C3 CO o o o o o o o 00
NO NO NO N) NO NO NO NO NO N) NO NO NO N) N) N) N) NO NO NO NO N) NO NO N) N) NO N) 45* — .
O O O O •<) O O O O O <) O O O o O O ) O O O O O o φ' vl vl VI vl VI vl vl VI VI VI vl vl VI vl VI VI VI VI vl vl VI VI VI VI VI vl VI vl vl cn 3
45* 45* 45. 45* 45* 45* 45* 45* 45* 45. 45. 45. 45. 45* 45. 45* 45* 45* 45. 45. 45* 45* 45* 45* 45* 45. 45* 45. NO o TJ
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO
CO O O C 3 o
O O O O J o O O O O O O J O O o o ;τDf c_ r r c . c c_ C_ c_ c_ c c . c c_ c c c r , C c_ f C_ c_ c_ c_ c_. c c c_ c_ π
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > >
Z z Z Z Z Z Z Z Z z z Z Z Z Z Z -_ Z Z Z
No ro ro ro No ro NO No ro ro ro No ro to NO NO No ro to No ro to ro NO No ro ro ro to to
— ' — ' m o, Ni ^ oo oo vl vj -vj o- o- o o — . -— —. — . cβ CW vl vl vi vi vl —. ,-- — > r1 SQ> W M m M Λ ^ N0 N0 O 00 O 45. N0 N0 O vl Cn 45. N0 N0 — ' O OO O NO O p P 0O0 ro o °1 ) <, cn — ■ 00 45* oo n o o vι o cn cn No co o 45. o c OJ 00 o vi TJ r m—
NO o o o ooo o o o o g oo o g o o o o o o o o o o o o g oo -_
Ω Ω Ω Ω ΩΩ Ω Ω Ω Ω Ω ΩΩ Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω ΩΩΩ Ω g daaaaaddaaaaadaaaaaaadaaddaaaa®
OO CO Co OO Co Co rO NO NO NO NO NO NO NO NO NO NO NO NO — . _• —■ —■ —■ —• —■ —■ —■ CO CO
D O
Ω ss<:s-_s2ss2 -:2<:- - <: 3'
OϊZlO/ZOSΛ/lDd fOZLSO/ZO OΛV
φ
C '
O i o Q
CO CO CO CO CO CO CO CO CO CO CO CO CO CO CO CO CO CO
£ £ _ J TJ _ _ _ ppppppppp o o o o b b p b b b b o b b o b p p p p p p p p p p p p p £ p p p p p o p p p p p p p p p p
CM
»-M a_ o o co o rv o CN CM CO — • O CO "vT p o CN ' T CO O CO CO LO UO 00 O — ■ CM o o
< o CM CO CO CO CO CO O O iv rv iv rv rv co co "v. o
^ co CM L rv O 'r iv cO r— cO cO O CM "— 'vT P LO O — • CN LO O CO O CO CO IO LO CO O — • _. rv o IV O CO — ■ "v. rv <r rv o r— CO r— CO O fo ■— CM cO cO CO cO CO O O Iv lv iv rv lv co "^ <r rv CO O CO — ■
^r so CO CO rv iv o
z o
O O Q <vT vj vj O Q O O O O O o o o o ■— ■— ■— CN CM CN CO CO CO CO CO CO
"vT "vt vj ^r 'vt 'v "vr "vf vj 'vT "v. <vT
<vT " f "v. "vf Vf vj -vj v vj vj vj ^cr vj
<T a LU CO
φ a i c O i ΈΈΈΈΈΈΈ ε o
Q
— CM CN CM CM CN — r— r— CM CM CM CO CO CO CO CO CO CO CM CM pppppppppOTJpp p p O P ΌΌΌΌU Ό TJ p Ό T3 p obbbbbbbbbbb b o o αooooσσαoσ 0 o 0 o 0
.P .P £ p p p p p p p p p p £ .P .P .P .P .P p p p p p p p p p
C C CN C CN C CN CM CN CN CN CN CM CN CM CN C C CN CN C CN CN CN CN CN CM CM CM CM
ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ
<— 3<-3<- <— 3<— 3<— 3<— 3<— 3 —< 3<— 3 —< 3 ~<3<— 3<— 3<— 3<— 3 —< 3<— 3 —< 3<— 3<-3<— 3<— 3<— 3 —< 3<— 3 -<3<— 3<— 3<— 3
" O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O ^ CM C CN CM CM C C CN CN C CN CN CN C C>4 CN CM CN CN CN C C C ( CN C C CN CN CM r C C N C W θi (N N C θi N CNi r N N rv N N N - -d <J <J <J c rv rv rv rv iv rv rv rv rv rv rv iv o o o o o o o o o o o o o o o o o o φ 'vf ' ^ N' ' ^ N N I N C N N N N N N N N N N N N N N 'ϊ ^ 'Ϊ " '?
1— LO LO UO LO W lO O O O O O O O O O O O O O O O O O O O f ' t 'vt +
CO CO CO CO OO OO O O O O O O OO OO CO OO OO OO OO αO OO OO OO CO OO J vt vJ ' T
O O O O O O ^- ^- r— r— r— r— O O O O O O O O O O O O O r- r— r- r— r—
o
Q 35 v? CO CO CO vj LO LO LO O O O O O
"v. vj -t vj 55555 LO LO IO LO LO IO LO LO UO LO
^ j ^ v j ^ j ^ ^j- ^f ^f vj 'vj- 'vr 'vr 'vj- a LU CO
a φ
■≥- c -> - -> -> O ε o
Q
CM CM CN CM r— r— r— r— .— r— ■— ^ r— c J CO cO CO CO r— ■— ■— CO CO CO CO CO CM CN CN CN
S Ό -O Ό Ό Ό Ό TJ TJ TJ TJ TJ TJ TJ TJ TJ Ό TJ TJ TJ TJ Ό Ό TJ Ό TJ TJ Ό TJ TJ α D α o o σ α o σ o α o α α α o o α o α o α D O D O o α Ω α
O O Ω Ω Ω Ω Ω Ω Ω Ω Ω O O Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω O O O O Ω
CM m Ω-co ■— "vT vj O O O CM "v. CM LO rv rv co r— <ϊ O N Wt rv LO
CQ P CN co o iv O o rv rv rv o 00 O CM O O CO O co L o L rv uo rv co o vj CM CO CO CO " j vj co co rv co cO CO o "vT o rv 2- Sf LO
<c vT CO j T CM o CM
r— 'vf r-i m rv O CO cO CO O CO CO CN U0 CO CO LO CO -' ^^ ' ^ O CO CM r IV Ov- LO uj r cu u N n o- t co <Ϊ ^ \f o co co co co CN j
CO ^ CM
^ ^ ^ ^ C CN C CM CN CM CM C C CN CM CM C CN CM CN CN CN CN CM C CM CN CN CM CM
5 <5<5<5<Z<Z<Z<<ZZ<Z<Z<Z<Z<Z<Z<Z<Z<Z<Z<Z<Z<Z<Z<Z<Z<Z<Z<Z<Z<Z<
^ -^ - - -3 —3 - —3 —3 —3 —3 —3 —3 —3 ~3 —3 ~3 —3 —3 —3 —3 —3 —3 —3 —3 —3 —3 —3 —3 ~3
Φ R r RcNRcNRcMδoδoδc:,δoδ>δc3δ0δ0δ0δ0δ0δ0δ0δ0δ0δ0δ0δ0δ0δ0δ0δ0δ0δ0δ0δ0
P ^ ^ ^ ^ C\I CN CNI OI C C N C CN N N C N CNI W C CN I C C\ (N W CN C I CN| a ε
.φ r r r 0 c3 O O 0 0 0 0 O 0 0 O 0 O CN CM CM CM CM CN CM CN 0 O O O
S g C |i ∞ ∞ 00 CO <θ 00 00 o cθ cO 00 O ∞ cθ ~ Ω cO U) U cθ U) ιfl lO L0 Cθ iO 2 2 r^ 2 LO LO ' i4θ LO ιO LO iO Lθ LO LO LO L O O O O O O O cθ cθ O cθ
^ ^ |l I. N N N N N N N N |s I\ |s |N v, N N rN N |s θ r n θ
-; ^ 3 ^ _j _j _J lJ -] - 3 j -j 3 J _J _i -J j -j -3 j -j -J -J _ -J - - -J
1—. c π ? :>
I— H-
F
Ω
LJ
C CM CM CO CO CO CO CO CO CO CO CO CO CO I— ■— r— .— ■— r— .— r— ,— CN CN CN CM CN CN CN φpppppppppppppppppppppppppppppp gbb bbbbbb bbbbbbbbbbbbbbb bobob b
^ Ω O O O O O O O O O Ω O O Ω Ω Ω Ω Ω O O Ω Ω Ω O O Ω Ω Ω Ω Ω
CM
^ C L θ 2 vϊ L ^ ^ 3 0^ -- C vJ ) 0 -0 ) c-, 1_ r_ CM O CM O O 00 ■— o
<vf j CO O r— CO ■— vj o g n o o ^ ^ ^ N CM CN n n ^ ^ o N N IV v. r— r— CO CO "v. "v. o
t o O O n cO + tv- cM O CM CM j rv rv o O CO CO O O CO O co rv o o CM ■vT O O "— CM J r— 'vT r- "V. ,— Vj
§ CM CO CO C ^r u-' r^ CM CM CN cO CO CO CO O co co o rv iv rv .— <— CO CO 'v. -t
O
O O O O O O O O O O O O O O r— ■— r— r—
r— r— r- r— r— r—
r— r- r— r— r— r— LO LO LO LO I LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO
φ .> a- c ' Σ 2 -> 5
O Q
C CM cO CO C C CO C C π- ^ r— 1— ^ r— r— ■— r— ^ — r- CM CM CN c cO CO CN CM CM φpppppppppppppppppppppppppppppp gbbbbbbbbαbbbbbαbbbbbbbbbbb bbb
^ O O Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω O O O O O Ω Ω Ω Ω Ω Ω O O Ω Ω Ω Ω Ω
CM
LO >— 5- O O L --r --t. |- O c rv, f--. 'v]- |v rv 0 rv 0 co iv O CO j rv LO
CM cM ^j θ - 'vr ^: ^ g; cN Lθ c2 2 ^f! o HJ c cou r- Vj l- -— O IV ■— CO IV O CM < CO r "vf -vt o iv rv 0o0o 0o0o 0o0o 0co0 ccoo 0co0 oo oo oo co LO rv
o r- >— r— r— r— r— r— r— r— C C C CN CM cO CO cO CO cO OO cO cO cO cO CO cO CO j v vj
Φ
C) fr
-≡ ?
D i- ? .5
I— 1— 1— ? 1— t— Έ Έ Έ Έ Έ Έ Έ Έ Έ
F
Ω
C C CM C CTM CN CN C CM CO CO CO CO CO CO CO CO CO CO CO CO CO CO CO gt=-b'b"2b"2b^b"2bb-b-2b'2bb"b"b"2b'2bbb^b"b"2b"b^b"2b^b-b"b-b-2b"2b-b
U~ Ω Ω Ω Ω Ω O O Ω Ω P P O P P O P P Ω ,p P P O P p O P O P P
CN
LM J. CO CM L L LO ∞ O C O LO CO CO CM LO "vT o rv O O CM
* P ^ W N t n n ^ ) <) |fl N ■v. ffl co θ N' ^ N -o cό ιύ ^co O^ «O ^co O CM n n <) « : oo ^
O z O 'vT 'r j v vt j L LO LO O o o o o o rv rv rv co co co co co o o o o o o
— LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO LO
G LU CO
£6
n m
© o o o o o o o cn cjo cjo cjo coo cn cn oi c-π cjo cn cn oi cn cjo cjo coo c^ o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o O
O
O O Ω Ω O O O Ω Ω O O Ω Ω Ω Ω O O Ω Ω Ω O O Ω Ω Ω Ω Ω Ω Ω Ω ^ Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω 3 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa φ
—. —. —. —. —. — ' -^ CO C-O Co ω CO CO CO CjO Co rO NO NO NO NO NO NO NO ro rO NO NO NO — ' o Ό
3
Ω
3
0 0/z0Sfl/I3d toε/.so/zo OΛV
a Φ c Έ ΈΈ ΈΈ Έ ΈΈ Έ Έ ΈΈ ΈΈ o
Q
- i— r— r— r— r— ■— CM CM C CN CM CN CM CO CO CO CO CO CO CO CO CO CO CO CO CO CO CO φ O O O O O O O O O O O O O -α -O O O O O O O O O -O O -O O -O ε o O D O D D D O O Oσ D O D O D D O O O DO OD α O D O O O "" Ω Ω Ω Ω Ω Ω Ω Ω ΩΩΩ Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω O OO O Ω Ω O
CN y Q-cO cO O O cO LO oo O CN CN oo rv LO co rv mP S -O ^ C ∞ OI ^ ^ N O ^ OSO C^O C LO L ^ LO; rv CM vj o Co o LO LO rv o r— 00 rv f )
< co CO J -vJ- 'v. -v. LO LO LO "— ■— " T vj LO CM vj o CO CM } "t 'vt " . "T LO O CM CO
•t r- <s. vj rv ■— "f o o C vOj C vOj O c-r> CN C vOj O v_. --*- r- (-v ..-* L x±O C wO O v-i O-n CO _ rv o _ 00 £ LO IV j o CM ^ 2 2 r^ v? ° '- CN ! vϊ 8 c§ ^ ^ ^ ? Cv .3- - IV
CO CO CO vj -vT rv o o j vj LO LO ■ T vj "vf LO CM
Oznpooooooooooooooooooooooooooor-^
== 0000000000000000 0000000000000 0
96
CΛ m © o o o o o o o o o o o o o o o O O O O O O O O O O O O cn cn cn cn cn cn cn cn cn cn cn cn cn 45. 45. 45. 45. CO CO OO CO CO NO NO NO NO NO NO — ■ Ό
0 r— r— r— r— r— r— != r— r— r— r— r~ ι— vj vj vj vj 4v. v. . v, 4v. _. _. _. _. -_. _-. no o o o o O o o o o o o O O O O O — ■ — ■ — ' — ■ — ' 00 00 00 00 00 00 — ■ vj vl VJ vi vj VI vl VI VI vj vj VJ vl — ■ — ■ — ■ — ■ — ■ 00 00 C0 00 C0 O O O O O O O _, o 4. ov. o4v. o. o^ o∞i OTcn c∞n o∞i oooi oθi cOn oi cn oOi Oϋi -v'l i_u1
45. 45. 45. 45. 45. 45. 4*. 45. 4v. 45. 45. 45.
C-J O O O o O O O r N0 N0 ro rO ^ ^ 5.45.45. O O _ O 45.3
NO NO NO NO NO NO NO NO NO NO NO NO NO r Oo Oro fOό Oro rOo NOJ Oro Oro NOO ON rrOτ rNO' rNτO, ^NO rNJO .-N7O' Oκ ΩH-
O o O r>
O o O o CJ O o O O O O O O O O O O O O O O O O O O O ® — . — . — i _ _. _. _> _. — ■ —' O O O O O O —' — c_ c . c_ C f C C— r . f C c c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ — . — i — . _. _ i : c_ π
> > > > > > > > > > > > >
Z Z Z z Z Z Z Z Z Z zzzzzzzzzz>>>>>>z
NO NO NO NO NO NO rO rO NO NO NO NO NO ro ro io io ro ro ro ro io ro — ■ — < —• — —• — - ro
NO NO NO N3 NO NO
45. 45. 45. 45. CO CO —• o K 45. ^ 45. CO ^ _ ro —« co <£ vj cn 45. ro oo o n co —■ o —■ ao? vj NO
45. —' VI 45. 00 00 oo cn —• 45- —' o _. co oo n oo cn O oo co cn n —■ o o oo n o co — o Q
— H-
4-. 45. 4i. 45. 45. Co CO Cn 45. 4 Cn 45. 45. 45> 45. 45. 4^ 00 M NO j g g ^ g oo - ^ oo vj cn 45. to oo o — " O S — ' O 45. oo cn co — ' O rύ έn ro -. ^ g ° g g ro ^ θ f-
Ol Co O O C. M vI O M i- -O M 4i. vI M 4-. Ol ' "
NO
O O O O O O o O O O O O O O o o O O O O O O Ω O O O O O Ω M
Ω a =ϊ ϊ:
Ω Ω Ω i? Ω Ω Ω Ω Ω Ω Ω Ω Ω U O o o O - o a a. a a a Ω Ω a 3. a a a a 3. a a a 3. a a a a a ayp 3 Φ in Te
CO OO CO CO CO CO CO NO ro ro rO NO NO NO NO NO NO NO NO NO NO N NOO N NOO — ' 00
Ό o
3
— 1 — 1 -H — 1 —1 → Ω
≤ ≤ <L <: <:
θ θ/ZOSfl/I3d fOZLSO/ZO OΛV
CO m Θ
M M M M VI M M M vl M M 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 == —• —■ O O O O O O OO OO OO OO OO OO M M M O O O O O Cn Cn z o
O NO NO —
■ — ' 45. 45. CO CO — ' M n Co — ■ CO O _. NO — •
45. n NO 45. o —
■ 00 0 0
O O NO NO - — — ■ -■ 45. 45. 45. C 45. 45- i. Co Co Co O n cn <Q≥ cn co 00 — . v n 45. NO cn co o o o o O O N . -O O cn 4^ " NO o - _! !_£ co co co 45. — ■ co o M O CO O M -A o 45. -■ M O "l NO O O C — • o o £5 00 ∞ Ό m
NO
5" Ω Ω O O O Ω Ω O Ω Ω Ω Ω Ω Ω Ω O O O Ω Ω Ω O O O O Ω Ω Ω Ω
Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Q Q Q Ω
3.3-3.2.3.3.3.3. 3.3.3.3.3.3.3.3.3.3.3.
CO OO CO OO CO CO CO CO CO NO NO NO aCO C 3O. a a CO NO NO NO NO NO CO OO
o o/zosfi/i3d toε/.so/zo OΛV
6379 L6
6379
M M M M M M M M M M vl M M M M M M M M M M v| vl M M M M M
i — i — r— r~ r— r- r— ι— r— i — ι— r— r— r— r— r~ r— ■ r— r- 1 — r— r— r— J— ι— ■ r— ι— i — r—
00 00 00 00 00 00 oo 00 00 00 00 00 oo 00 oo 00 00 00 00 00 00 00 oo 00 oo 00 oo 00 00 00
O O O o o O o O O O O o O O O o o o o O o o O o oo CO CO 00 CO co CO Co o CO CO Co CO C C 00 00 00 00 00 Co 00 o O co 00 C 00 CO M M M M M VI M M M M M M M M M M M M M M M vl M M M M M o O O O O O O O O O O O O O O O O O O O O O O O O o o o o O O O O O O O O O o O O O O o O O O O O o O
NO NO ro NO NO NO NO NO NO NO NO ro NO ro NO NO NO NO NO NO NO ro NO ro NO NO NO NO NO NO Ω O O O O O O O O O O O o O o O O O O O O O o O o O O O O O O H- O O O O O O O O O O O o O o O O O O O O O o O o O O o O O O Φ
C_ C_ C_ C_ C_ <-_ C_ <_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ CL_ C_ C_
Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO rO ro rO NO NO NO NO NO NO NO
45. 45. 4-. CO N0 — ' — ' o- rv 45. 4> 4 45. 45. CO C N NO N — ' CO l O O CD Ol C R S - ' vi K K - ■ — ' O O O 00 o o -5 45. O 00 O CO o
M CO o cn NO O 00 CO o —■ oo NO o n n oo o oo co oo n co — -• 00 oo o cn Q Oi- .
3 3" 3 3 3 3 3 5 3 3 3 3 3" 3" 3* 3* 3" 3" 3- 3 3* 3" 3 3 3 3* c? 3 3" ξ? ^ ^ J i g? ^ ^ ^ ~ ^ § <ϊ ^ ^ ϋ? ^ ^ <2 ^ 71 LI3679 <? - —π \ o Ω Ω £ g? ^ g? a Ω a Ω O o Ω a O o Ω Ω ϋ o w ^ ^ a a Ω
Ω Ω Ω Ω Ω Ω Ω o Ω o Ω a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a SEO:Q ID Nern T φ
CO CO CO CO Co CO Co Oo Co Co rO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO — ' — ' — ■ σ
Ω
3
Ω
2222 3
Ό φ
o o/zosfi/i3d fOZLSO/ZO OΛV
86
O m
M M M M VI M M M M M M M M M M M M M M M M M M M M M M M M M o== 4-. 45. 45.45.45.45.45.45. C0 Co Co θ3 ω ω ω ro rθ N0 N0 N0 N0 N0 N0 N0 N0 N0 N0 — ' — ' — ' O
Z
O
5. 45. 45. 45v. -O NO NO o o o o o o o o 4 w o oo oo
00 00 00 00 00 00 00 00 M M M M NO NO NO o o o o o o o o 45. 45. 45. 5. 45. 45. NO
Cύ CO CO o o ,
00 00 00 00 00 00 00 00 n cn cn cn 4 cn cn cn CO
45. 45. 45. o O CO M M M M M M M M cOn con n cn cn cn cn 45. o o o o O On cn cn cn M vl M φ'
NO NO NO NO o O 3 oo oo oo oo 00 OD o 45. 45. 45. 45. o o o Ό ro ro ro ro ro ro No ro roo roo NO NO NO NO fo O O C ) r> o fό NO NO ro o NO NO O o o o o o o o o o o O O O o o O o o C 3 ( ) o o o o o o o o O O O o o O D cΞ_ c_ c--c_c_c_ c_ c_ >>>> > > >z > zzzz>z>z>z>z z >z >z > > > > > z z z z
NO N0 N0 N0 N0 N0 N0 N0
I N) D K) D r ro rO rO
N0
r ND 45. 45. Co CO NO NO NO Cύ O 00 O 00 45. — ■ M — ' CO 00 Ol NO _. II 00 00 — ■ — ' O CO NO O O O 45. NO _, 00 ^ o o. a O c M. -^ 8 Co.8 oS &og,
45.45.45. CO C N0 N0 N0 IO N0 — ■ — ' NO — ' — ' O O CΛ > O CO O OO O O045. — ' — ' — ' O M — ' CO — ' ,n oo o cn rθ cr, __, oo M θ cn oo ( v ^: N NO- CD
O M O O cn ro — ' oo cn cn oo cn cn co o E oT B Cn -' ffl S o' ^ o si oo o O O. 45. ff NO ' Ox TJ
NO
O Ω Ω Ω O O O O Ω Ω .Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω O O Ω Ω Ω Ω Ω Ω Ω Ω
*z ^ —*
Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω a a a a a a a a a a a a a a a 3.3. a a 3. a 3. a a 3. a 3. a 3 9. a 93 Φ
NO NO NO NO NO NO NO NO 00 NO NO NO NO NO NO NO NO — ' _ _- —> — . _. — ' CO CO CO
O
Ω
3
Ω
3
Ό φ
OϊZlO/ZOSΛ/lDd fOZLSO/ZO OΛV
66
CΛ rπ Θ
M M M M M M M M M M M M M cn cn cn cn cn cn cn cn 45. 45. 45. 45. 45. D
O
NO — ' NO — ' — ' — ' 45. 4-> NO NO NO NO O O 45.
O 00 - -■ O 00 M 45. - -' O OO O M 45. NO - -■ Co — < oo cn 45. — ' NO O — ' 00 O NO Ol O oo n — ■ Ω
H-
NO NO — ■ NO NO — • — ■ — ' - 4- r r o r o O C > — ' O 00 NO σ OO M 45. O O CO OO M 45. NO O CD O M 45. O 00 O — ' OO O O M O — ' 45- — ' O M 45. l 3 r—
X 3π
NO
Ω Ω Ω Ω O O Ω 3 Ω Ω Ω Ω Ω Ω 3
Ω
Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω Ω aaaaa-aaaa aa aa aa 3cD
CO CO CO NO NO NO NO NO OO CO CO CO CO CO CO NO NO NO
D O
Ω
3
-α Φ
O O/zOSfl/I3d toε/.so/zo OΛV
oo m D , co ω ω ω ω ω ω cΛ ω ω ω ω ω u ω c~ ω ω ω CΛ C~ ω M M ) M r M K) Ό z
O
NO N NO NO M N M IO M NO M N M M NO N ro ro r NO N N NO M r M ro ro r0 45. 45. 45. 45. 45. 45. 45. 45. 4^
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 45. 4v. 45. 45. 4i. 4-. 4-. — I —J — . —* —. —■ —. —* —■ —■ —■ —■ —. —• —■ —■ — ' —• —■ — ■ 4-. 45. 4-. 45. 45. 45. 45. 45. 45. 4^ 45. 45. 45. 4^ 45> 45. 45. 45^ 45. 4^ 45. 45. O O O O O C00 C00 00 03 C0 C» ∞
NO NO NO NO NO rO IO NO NO NO NO rO ro rO NO NO NO rO NO NO NO rO — . —. —. —. —. —. — ' O O O O O O O O O O O O O O O O O O O O ^ O O O O O O O O O O O O O O O O O O O O O O O O O O O O O — « — ■ — ' — ■ — ■ — ■ — ' — ■ — ■ — ' — • — ■ — • — ■ — ■ — ■ —■ —■ — ■ — • sυ
No ro ro ιo ro ro Nθ io No ro Nθ o ro N Nθ !o ro ιo ro ro No ro ∞ c» oo ∞ c» ∞ ∞ 4^ ro r fo ro r r r r r ro r Ka ro r Kj M
N O NOO NO NOO NOO NOb ON MO ON NOb ONO NO ON ON NOO NO ON NO NO^ O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O H-
O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O Φ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ <-_ c_ c_ c_ <-_ c_ c_
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
Ε Ε ^ Ε z z Ε Ε: Ει Ε ζ Ε ζ Ε Ει ?: Ε ζ Ε ?ι ΕA ζ ΕA Ε ?, Ε ?: Ει ?; Ε Ε Ε Ε Ε ?: Ε Ε Εi Ε Ε, Ε Ε Ε: Ε Ε Ε
M NO NO NO NO rO ro rO NO NO NO ro rO NO NO rO NO NO NO NO rO NO M NO NO NO NO NO NO NO NO M ro rO NO NO NO W NO o o
ro — ■ — ■ — ■ 00 00 00 00 00 00 00 00 00 00 00 — ' — ' -A 45. 45. . , NO 00 00 00 o
O O M O NO — ■ — ' — ■ 00 oo cn oo M θ cn cn 45. 45. 45. co co ro — ■ — - 45. 4. o co cn N —■ o CO —■ —■ 45. Co CO NO — O CO CO CO Co NO NO CΛ o O M M cn 45. 00 CO 45. ro cn o o o cn to o ro o No cπ o oo 5» M NO —' oo Co O O 45. 45. —■ O oo O O 00 M CO oo con ron oco Ooo ooo _^
3 M 45^ 45. tO N C M C0 03 - ^ ^ ^ ^ I^ _- Z; -^ --- --- 0 . 0 M M M —' C ϋl ϋO M ^ n ^ ^ ^ f r' ^ M Ol M Ol Ol -?
O OO NO O CO O — ' O M I-_ S Z^ :^ C-) C^ -_. S _, ___ ^ OO I — ■ -. M -.4i CJι ∞ r fc g g N ^ K 5 ft S ≤ )l n -' Oι r Oι O IO CO M O Cn -' 0 -' CX ^ ^ ^ g 3j C3 ^ Zi g cθo N <30 M C» C 45. C» ∞ M ^ θ 2 o^ S
TABLE 3
SEQ ID NO: Template ID CΩmpΩnent ID Start StΩp
3 LI:2042ό2.2:2001JAN12 5697164H1 208 392
3 LI:204262,2:2001JAN12 gl933501 302 392
3 LI:204262.2:2001JAN12 3085446H1 317 591
3 U:204262.2:2001JAN12 4370458H1 379 483
3 U:2042ό2.2:2001JAN12 2429647H1 398 626
3 LI:204262.2:2001JAN12 gl301433 397 758
3 U:204262.2:2001JAN12 1907484H1 399 658
3 LI:204262,2:2001JAN12 4407466H1 399 654
3 LI:204262.2:2001JAN12 1891084H1 399 662
3 LI:204262.2:2001JAN12 1907484F6 399 721
3 -.1:204262,2:2001 JAN 12 5905191 HI 409 558
3 U:2042ό2.2:2001JAN12 2905068H1 409 609
3 LI:204262.2:2001JAN12 8180656H1 409 840
3 U:204262.2:2001JAN12 3669938H1 410 707
3 LI:204262.2:2001JAN12 3168274H1 415 695
3 Ll:2042ό2.2:2001JAN12 4370372H1 415 647
3 U;204262.2:2001JAN12 1704319H1 414 623
3 LI:204262.2:2001JAN12 2113619H1 415 640
3 LI;204262.2:2001JAN12 663536H1 415 645
3 LI:204262.2:2001JAN12 3334434H1 409 540
3 U:204262.2:2001JAN12 1955142H1 415 609
3 U:204262.2:2001JAN12 2114652H1 419 688
3 U:204262.2:2001JAN12 7077958H1 1 378
3 Li:204262.2:2001JA 12 2906317F6 1 373
3 1.1:204262.2:2001 JAN 12 2906317H1 1 306
3 LI:204262.2:2001JAN12 2905586H1 3 269
3 LI:204262.2:2001JAN12 g7317508 4 384
3 -.1:204262.2:2001 JAN12 6450961 HI 5 586
3 LI:204262,2:2001JAN12 2733223H1 483 763
3 LI:204262.2:2001JAN12 5490990H1 483 770
3 U:204262.2:2001JAN12 4367028H1 493 738
3 LI:204262.2:2001JAN12 4368445H1 493 772
3 LI:204262.2:2001JAN12 4376291 HI 499 755
3 LI:204262.2:2001JAN12 3427865H1 530 791
3 U:204262,2:2001JAN12 6206254H1 530 1098
3 LI:204262.2:2001JAN12 g2054234 543 866
3 U:204262.2;2001JAN12 5789606H1 546 837
3 LI:204262.2:2001JAN12 5795364H1 546 828
3 U:204262.2:2001JAN12 g4533121 547 1019
3 LI:204262.2:2001JAN12 g847490 562 832
3 LI:204262.2:2001JAN12 g921174 563 873
3 -.1:204262.2:2001 JAN 12 g921384 563 869
3 LI:204262.2:2001JAN12 6517347H1 577 1072
3 LI:204262.2:2001JAN12 1907484T6 591 981
3 LI:2042ό2.2:2001JAN12 6713444H1 595 1006
3 -.1:204262.2:2001 JAN 12 1569057H1 595 804
3 LI:204262.2:2001JAN12 6715344F8 609 1017
3 U:204262.2:2001JAN12 g7278310 610 1017
3 1-1:204262.2:2001 JAN 12 2905921 HI 614 893
TABLE 3
SEQ ID NO: Template ID CΩmpΩnent ID Start Stap 3 LI:204262.2:2001JAN12 g5370364 617 1027 3 U:204262.2:2001JAN12 6715344F6 616 1006 3 LI:204262.2:2001JAN12 g5740750 617 1022 * 3 LI:204262.2:2001JAN12 g5510928 618 1017 3 U:204262.2:2001JAN12 g3744370 626 1022 3 LI:204262.2:2001JAN12 1400614H1 627 860 3 LI:204262.2:2001JAN12 1396990H1 627 866 3 LI:204262.2:2001JAN12 1397508H1 627 870 3 LI:204262.2;2001JAN12 7710231J1 637 1123 3 LI:204262.2:2001JAN12 g4291140 644 1114 3 LI:204262.2:2001JAN12 g5425821 647 1113 3 U:204262.2:2001JAN12 g5235945 661 1117 3 U:204262.2:2001JAN12 g4533235 663 1118 3 LI:204262.2:2001JAN12 1333591 HI 663 904 3 U:204262.2:2001JAN12 g4524193 665 1116 3 LI:204262.2:2001JAN12 g8361553 665 1114 3 LI:204262.2:2001JAN12 g6835880 666 1117 3 LI:204262.2:2001JAN12 g4524592 667 1022 3 LI:204262.2:2001 AN12 g5675646 673 1129 3 U:204262.2:2001JAN12 g5396644 679 1114 3 U:204262.2:2001JAN12 2905087H1 419 689 3 LI:204262.2:2001JAN12 901294H1 419 717 3 U:204262.2:2001JAN12 901294R1 419 909 3 LI:204262.2:2001JAN12 3986655H1 421 690 3 LI:204262.2:2001JAN12 gl955172 424 751 3 LI:204262.2:2001JAN12 2908149H1 421 713 3 LI:204262.2:2001JAN12 2904727H1 432 731 3 LI:204262.2:2001JA 12 3762093T6 436 1046 3 LI:204262.2:2001JAN12 3590473H1 452 751 3 LI:204262.2:2001JAN12 gl301395 469 692 3 LI:204262.2:2001JAN12 5101734H1 479 720 3 U:204262,2:2001JAN12 g5744485 881 1114 3 LI:204262.2:2001JAN12 3513391HI 884 1104 3 U:204262.2:2001JAN12 625181H1 892 1114 3 LI:204262.2:2001JAN12 g1264641 910 1115 3 U:204262.2:2001JAN12 g6946728 917 1022 3 LI:204262.2:2001JAN12 5595731HI 1020 1112 3 U:204262.2:2001JAN12 g2753547 742 932 ' 3 LI:204262.2:2001JAN12 g2902957 742 888 3 LI:204262.2:2001JAN12 g1489513 745 1114 3 LI:204262.2:2001JAN12 g2834856 745 1114 3 LI:204262.2:2001JAN12 g3754537 754 1119 3 U:204262.2:2001JAN12 gό041209 759 1114 3 LI:204262.2;2001JAN12 g2265306 759 1115 3 LI:204262.2:2001JAN12 g3037803 759 1110 3 LI:204262.2:2001JA 12 g7454306 764 1114 3 U:204262.2:2001JAN12 g6086744 770 1115 3 U:204262.2:2001JA 12 g3840509 770 1116 3 LI:204262,2:2001JAN12 2936147H1 771 985
CΛ m o
45. 45. 45. 45. 45. 45. 45. 45. 45» 45. 45. C3 CO OO CO G3 CO CO C C C*> CO C3 CO G3 C O CO W α z o
it! 3 H- Φ
co co co NO o ro — ■ — ■ 00 Co CO M .- _ M^ M M M M M M M M M O O M O O O O O O O O O O O O O O OO Oo OO OO M M vl M vI M ro — ■ — ■ o co 45. n 45. -_ __ _^ — ■ — ' — ' O O O O O O O O O O O O O O O OO OO OO OO OO OO — ' — ■ — ' O CO 00 00 00 00 Ω NO NO o o n o o Co v Mi 4 r5v.. c COi vj < (j- 4-. W N0 O M O N0 M M 00 M M O O Cn O O O O Cn Cn C — ' N0 O O 45. 4-. C0 C0 O O M
M M Cn M M M O O O vJ M o -> -■ —> — ■ O M NO O CO M O — ' CO 00 ro o — « NO — ■ _, _, oo o co o o o co cn —
■ — ' Cn O O — ' 45. 45. 45.
TABLE 3
SEQ ID NO: Template ID Component ID Start Stop
4 Ll:331661.1 2001 JAN 12 1939356R6 1331 1769
4 U:331661.1 2001 JAN 12 1939356H1 1331 1571
4 U.331661.1 2001 JAN 12 1939356T6 1332 1729
4 U.331661.1 2001 JAN 12 g766482 868 1 196
4 U.331661.1 2001 JAN 12 261732H1 837 1 132
4 U.331661.1 2001 JAN 12 6120824H1 867 972
4 Ll.331661.1 2001 JAN 12 6197894H1 748 1245
4 U.331661.1 2001 JAN 12 6859071 HI 798 1 183
4 U:331661.1 2001 JAN 12 7581096H1 569 1 136
4 U.331661.1 2001 JAN 12 5924705H1 589 876
4 U.331661.1 2001 JAN 12 4716510H1 591 832
4 U.331661.1 2001 JAN 12 6856463H1 601 1076
4 U:331661.1 2001 JAN 12 1428450H1 624 862
4 U:331661.1 2001 JAN 12 1428450F6 633 1095
4 Ll:331661.1 2001 JAN 12 1229221 HI 699 923
4 U:331661.1 2001 JAN 12 7588474H1 727 1346
4 LI :331661.1 2001 JAN 12 7236708H1 728 1287
4 Ll.331661.1 2001 JAN 12 6746047H1 1 522
4 U:331661.1 2001 JAN 12 7583035H1 33 489
4 U:331661.1 2001 JAN 12 1597748H1 78 196
4 Ll:331661.1 2001 JAN 12 1594986H1 78 289
4 U:331661.1 2001 JAN 12 1597748F6 78 558
4 U:331661.1 2001 JAN 12 8000502H1 99 616
4 U:331661.1 2001 JAN 12 7280607H1 107 182
4 U:331661.1 2001 JAN 12 6448061 HI 450 861
4 U.331661.1 2001 JAN 12 4936496H1 499 776
4 U:331661.1 2001 JAN 12 5843854H1 502 758
4 Ll:331661.1 2001 JAN 12 3678519H1 1 152
4 Ll:331661.1 2001 JAN 12 14151 13H1 908 1 157
4 U.331661.1 2001 JAN 12 1413270H1 908 1 153
4 Ll:331661.1 2001 JAN 12 6338233H1 872 1400
4 U:331661.1 2001 JAN 12 gl 195372 880 1001
4 U:331661.1 2001 JAN 12 5897575H1 889 1 175
4 Ll:331661.1 2001 JAN 12 5614128H1 889 1 140
4 U.331661.1 2001 JAN 12 5900984H1 889 1 150
4 U:331661.1 2001 JAN 12 6860421 HI 924 1359
4 LI.-331661.1 2001 JAN 12 1616667F6 802 1317
4 U:331661.1 2001 JAN 12 5681028H1 822 1075
4 U.331661.1 2001 JAN 12 1616624H1 802 1000
4 U:331661.1 2001 JAN 12 1616667H1 804 939
4 Ll:331661.1 2001 JAN 12 g2017728 1 132 1405
4 U:331661.1 2001 JAN 12 2283942T6 1 120 1728
4 U.331661.1 2001 JAN 12 7950056J1 1 131 1701
4 U:331661.1 2001 JAN 12 6560062H1 948 1468
4 Ll:331661.1 2001 JAN 12 6560643H1 948 1471
4 U:331661.1 2001 JAN 12 3825378H1 993 1288
4 U.331661.1 2001 JAN 12 6199688H1 1078 1646
4 U:331661.1 2001 JAN 12 2283942R6 1079 1516
4 U:331661.1 2001 JAN 12 2283942H1 1079 1294
TABLE 3
SEQ ID NO: Template ID CampΩnent ID Start Step 4 U.331661.1.2001JAN12 7449843T2 1084 1698 4 U:331661.1 :2001JAN12 6715064H1 1419 1769 4 U.331661.1 :2001 JAN12 2040660H1 1420 1691 4 U:331661.1 :2001JAN12 gl 192246 1469 1768 4 U.331661.1.2001JAN12 g823120 1529 1781 4 U.331661.1 :2001 JAN12 g561300 1585 1769 4 U.331661.1.2001JAN12 265807H1 1592 1721 4 U:331661.1 :2001JAN12 g3179666 1616 1772 5 Ll:335074.1 :2001 JAN 12 6836554H1 1 188 5 LI:335074.1 :2001JAN12 2692045H1 30 172 5 U:335074.1 :2001JAN12 2692045F6 30 520 5 Ll:335074.1 :2001 JAN 12 g718636 97 172 5 Ll:335074.1 :2001 JAN 12 2692045T6 448 659 5 U.335074.1.2001JAN12 g4509645 452 606 5 Ll:335074.1 :2001 JAN 12 2950136H1 471 528 5 Ll:335074.1 :2001 JAN 12 g718536 489 814 5 U:335074.1 :2001 JAN 12 2734584H1 521 659 5 U:335074.1 :2001JAN12 2734584F6 521 892 5 LI :335074.1 :2001 JAN 12 503404H1 561 663 5 U:335074.1 :2001JAN12 2756506H1 594 659 6 LI: 154608.1 :2001 JAN 12 2279720H1 1 256 6 U:154608.1 :2001JAN12 2279720R6 1 463 6 U:164608.1 :2001JAN12 532191 HI 1 240 6 U:154608.1 :2001JAN12 g4850584 53 341 6 U:154608.1 :2001JAN12 g1444656 83 374 6 U:154608.1 :2001JAN12 1832633H1 228 384 6 U:154608.1 :2001JAN12 1832633R6 228 754 6 U: 154608.1 :2001JAN12 g1224646 299 730 6 LI: 154608.1 :2001 JAN 12 677523H1 535 758 7 LI:462889.1 :2001JAN12 6012788F6 1 140 7 LI :462889.1 :2001 JAN 12 6012788F8 1 140 7 U.462889.1 :2001 JAN 12 6012788H1 1 140 7 U:462889.1 :2001JAN12 6012788T8 1 67 7 LI :462889.1 :2001 JAN 12 6915723H1 20 570 7 U:462889.1 :2001 JAN 12 7111920H2 101 719 7 U.462889.1 :2001 JAN 12 7262741 HI 241 767 8 U:236680.2:2001JAN12 3075331 HI 2023 2312 8 LI:236680,2:2001JAN12 5532056H1 2026 2253 8 U:236680.2:2001JAN12 g2913620 2029 2322 8 U:236680.2:2001JAN12 481091R1 2037 2316 8 U:236680.2:2001JAN12 481091 HI 2037 2268 8 U:236680.2:2001JAN12 481091 FI 2037 2316 8 U:236680.2:2001JAN12 642676H1 2042 2289 8 U:236680.2:2001JAN12 645714H1 2042 2169 8 U:236680.2:2001JAN12 4370936H1 2047 2322 8 U:236680.2:2001JAN12 g3178618 2052 2327 8 U:236680.2:2001JAN12 g1951323 2052 2322 8 U:236680.2:2001JAN12 4369438H1 2060 2330 8 U:236680.2:2001JAN12 g2752073 2066 2323
TABLE 3
ID NO: Template ID CampΩnent ID Start Stap
8 U:236680.2:2001JAN12 g2557232 2074 2321
8 U:236680.2:2001JAN12 2108868H1 2088 2322
8 U:236680,2:2001JAN12 g3280026 2001 2327
8 U:236680.2:2001JAN12 g 1885612 2004 2322
8 U:236680.2:2001JAN12 6891 191 Jl 1218 1684
8 U.236680.2.2001JA 12 616670H1 1222 1382
8 LI:236680.2:2001JAN12 2599521 HI 1225 1536
8 U:236680.2:2001JAN12 1564553H1 1227 1441
8 U:236680.2:2001JAN12 1718424H1 1247 1452
8 LI:236680,2:2001JAN12 5734658H1 625 832
8 U:236680.2:2001JAN12 3141286H1 626 920
8 U:236680.2:2001JAN12 31 18707H1 646 930
8 U:236680.2:2001JAN12 428922H1 646 717
8 U:236680.2:2001JAN12 7693331J2 658 1282
8 U:236680.2:2001JAN12 202067H1 671 1013
8 U:236680.2:2001JAN12 203102H1 669 1039
8 LI:236680.2:2001JAN12 202742H1 671 1096
8 U:236680.2:2001JAN12 4656004H1 682 914
8 U:236680.2:2001JAN12 354907H1 682 877
8 LI:236680.2:2001JAN12 4357096H1 689 802
8 U:236680.2:2001JAN12 7065493H1 700 1264
8 LI:236680.2:2001JAN12 6443867H1 71 1 1272
8 U:236680.2:2001JAN12 7748008H1 733 1315
8 U:236680.2:2001JAN12 4696835H2 733 998
8 LI:236680.2:2001JAN12 2669248H1 734 974
8 U:236680.2:2001JAN12 7666743H1 737 1307
8 U:236680.2:2001JAN12 5138583H1 759 1043
8 U:236680.2:2001JAN12 6344271 HI 773 1064
8 U:236680.2:2001JAN12 4780947H1 782 1025
8 LI;236680.2:2001JAN12 4442960H1 785 932
8 U:236680.2:2001JAN12 2019004F6 792 1251
8 U:236680.2:2001JAN12 2019004H1 792 1018
8 U:236680.2:2001JAN12 7410429H1 808 1291
8 U:236680.2:2001JAN12 5653870H1 809 1315
8 LI:236680.2:2001JAN12 4973318H1 823 1 1 13
8 LI:236680.2:2001JAN12 3372215H1 828 1 107
8 U:236680.2:2001JAN12 g2824800 836 1 152
8 LI:236680.2:2001JAN12 1834495H1 836 1073
8 LI:236680.2:2001JAN12 4891822H1 843 1099
8 U:236680.2:2001JAN12 3737008H1 875 1053
8 LI:236680.2:2001JAN12 2222730H1 874 1 133
8 LI:236680.2:2001JAN12 3056404H1 872 1 187
8 U:236680.2:2001JAN12 1528744H1 877 1089
8 U:236680.2:2001JAN12 5832993H1 882 1 120
8 LI:236680.2:2001JAN12 g 1615059 887 1324
8 U:236680.2:2001JAN12 5568088H1 893 1 138
8 U:236680.2:2001JAN12 4722031 HI 894 1 151
8 LI:236680.2:2001JAN12 g5657452 895 1316
8 LI:236680.2:2001JAN12 g4984832 899 1316
TABLE 3
SEQ ID NO: Template ID CΩmpΩnent ID Start Stap
8 Ll:23όό80.2:2001JAN12 2322090H1 938 1198
8 U:236680.2:2001JAN12 1743450R6 940 1477
8 LI:236680.2:2001JAN12 1743450H1 940 1209
8 U:236680.2:2001JAN12 6881552J1 946 1565
8 U:236680.2:2001JAN12 1492715H1 947 1 175
8 LI:236680.2:2001JAN12 g 1439952 949 1265
8 LI:236680,2:2001JAN12 g 1745436 987 1320
8 U:236680.2:2001JAN12 5283518H1 989 1 101
8 LI:236680.2:2001JAN12 g4983084 999 1402
8 LI:236680.2:2001JAN12 5196591 HI 1006 1219
8 LI:236680.2:2001JAN12 g 1980081 1014 1300
8 LI:236680.2:2001JA 12 4585166H1 1029 1287
8 LI:236680.2:2001JAN12 3765524H1 1030 1329
8 LI:236680.2:2001JAN12 1322839H1 1030 1310
8 U:236680.2:2001JAN12 5153956H1 1032 1278
8 LI:236680.2:2001JAN12 5657480H1 1033 1305
8 U:236680.2:2001JAN12 g3933002 1040 1316
8 L1:236680.2:2001JAN12 3839495H1 1049 1321
8 U:236680.2:2001JAN12 1807156H1 1052 1330
8 U:236680.2:2001JAN12 2958652H1 1053 1317
8 LI:236680.2:2001JAN12 550594H1 1061 1215
8 U:236680.2:2001JAN12 6130516H1 1065 1223
8 LI:236680.2:2001JAN12 g2437088 1066 1265
8 L1:236680.2:2001JAN12 2937202H1 1088 1317
8 U:236680.2:2001JAN12 4531 176H1 1095 1317
8 LI:236680.2:2001JAN12 5350661 HI 1 1 1 1 1317
8 LI:236680.2:2001JAN12 6756226J1 1 136 1906
8 U:236680.2:2001JAN12 4069427H1 1 141 1419
8 LI:236680.2:2001JAN12 4441238H1 1 145 1230
8 U:236680.2:2001JAN12 2538184H1 1 146 1317
8 LI:236680.2:2001JAN12 4440839H1 1 146 1317
8 LI:236680.2:2001JAN12 2323415H1 1 149 1310
8 LI:236680.2:2001JAN12 2323415R6 1149 1300
8 LI:236680.2:2001JAN12 4091523H1 1 160 1451
8 LI:236680.2:2001JAN12 8180480H1 1 168 1804
8 LI:236680.2:2001JAN12 g 1275598 1 173 1632
8 U:236680.2:2001JAN12 4300822H1 1 174 1453
8 LI:236680.2:2001JAN12 6072812H1 1178 1505
8 LI:236680.2:2001JAN12 4769465H1 1 190 1454
8 LI:236680.2:2001JAN12 1785637H1 1 190 1443
8 U:236680.2:2001JAN12 4247606H1 1 195 1451
8 LI:236680.2:2001JAN12 7355562H1 1205 1818
8 U:236680.2:2001JAN12 6588333H1 1 514
8 LI:236680.2:2001JAN12 6928483H1 121 456
8 LI:236680.2:2001JAN12 g6701284 220 854
8 LI:236680.2:2001JAN12 4251648H1 243 519
8 LI:236680.2:2001JAN12 1310590T6 255 816
8 U:236680.2:2001JAN12 7107227H1 292 544
8 LI:236680.2:2001JAN12 7933938H1 314 951
TABLE 3
SEQ ID NO: Template ID CompΩnent ID Start Stap
8 U:236680.2:2001JAN12 3728470H1 413 724
8 LI:236680.2:2001JAN12 g!615058 408 496
8 LI:236680.2:2001JAN12 6191223H1 413 716
8 LI:236680.2:2001JAN12 693661 1 HI 419 958
8 U:236680.2:2001JAN12 5000044H2 440 702
8 LI:236680.2:2001JAN12 341967R6 445 887
8 LI:236680.2:2001JAN12 341967H1 445 552
8 LI:236680.2:2001JA 12 g4762563 444 852
8 LI:236680.2:2001JAN12 6336333H1 453 1006
8 U:236680.2:2001JAN12 3780470H1 455 782
8 LI:236680,2:2001JAN12 3315977H1 464 744
8 LI:236680.2:2001JAN12 4320212H1 485 767
8 LI:236680.2:2001JAN12 2790779H1 496 782
8 U:236680.2:2001JAN12 5497625H1 493 706
8 LI:236680.2:2001JAN12 g3918889 505 798
8 LI:236680.2:2001JAN12 5499074H1 497 687
8 LI:236680.2:2001JAN12 3405846H1 499 766
8 U:236680.2:2001JAN12 2260358H1 527 791
8 LI:236680,2:2001JAN12 351557H1 527 763
8 LI:236680.2:2001JAN12 5906465H1 573 833
8 U:236680.2:2001JAN12 g 1885791 602 851
8 L1:236680.2:2001JAN12 1992305F6 621 1092
8 U:236680.2:2001JAN12 880170H1 1809 2018
8 U:236680.2:2001JAN12 20V4995H1 1808 2063
8 U:236680.2:2001JAN12 880170R1 1812 2321
8 U:236680.2:2001JAN12 g2740731 1815 2322
8 LI:236680.2:2001JAN12 1722629H1 1817 2031
8 U:236680.2:2001JAN12 1414184H1 1820 2081
8 U:236680.2:2001JAN12 g5425815 1826 2320
8 LI:236680.2:2001JAN12 3470172H1 1837 21 17
8 LI:236680.2:2001JAN12 5067002H1 1839 2062
8 U:236680.2:2001JAN12 g4764199 1849 2325
8 LI:236680.2:2001JAN12 g5675041 1854 2325
8 LI:236680.2:2001JAN12 g 1289941 1854 2333
8 U;236680.2:2001JAN12 g3594344 1855 2327
8 LI:236680.2:2001JAN12 g 1886363 1854 2284
8 LI:236680.2:2001JAN12 gl071482 1859 2169
8 LI:236680.2:2001JAN12 2614306T6 1868 2285
8 U:23ό680.2:2001JAN12 6123995H1 1874 2220
8 LI:23όό80.2:2001JAN12 6124095H1 1874 2319
8 LI:236680.2:2001JAN12 g43081 15 1878 2322
8 U:23ό680.2:2001JAN12 4120305H1 1884 2157
8 LI:236680.2:2001JAN12 2285547H1 1889 2158
8 U:236680.2:2001JAN12 g2903185 1891 2322
8 U:236680.2:2001JAN12 2717291 HI 1899 2156
8 Ll:23ό680.2:2001JAN12 151 1984T6 1902 2283
8 LI:236680.2:2001JAN12 g2902705 1903 2319
8 U:236680.2:2001JAN12 2121490H1 1903 2190
8 U:236680.2:2001JAN12 6891 191 HI 1906 2273
TABLE 3
SEQ ID NO: Template ID ' CampΩnent ID Start Stap
8 U:236680.2:2001JAN12 1531659H1 1907 2125
8 U:236680.2:2001JAN12 g2901559 1916 2317
8 U:236680.2:2001JAN12 g 1927650 1922 2327
8 U:236680.2:2001JAN12 g 1779557 1920 2322
8 U:236680.2:2001JAN12 764247H1 1923 2225
8 U:236680.2:2001JAN12 4909776H1 1922 221 1
8 U:236680.2:2001JAN12 g3246364 1924 2328
8 U:236680.2:2001JAN12 g6034682 1924 2322
8 U:236680.2:2001JAN12 g3400920 1928 2322
8 U:236680,2:2001JAN12 g3921 126 1931 2323
8 U:236680.2:2001JAN12 g2184277 1931 2322
8 LI:236680.2:2001JAN12 g2789087 1931 2322
8 U:236680.2:2001JAN12 5266178H1 1942 2100
8 U:236680.2:2001JAN12 5268752H1 1943 2238
8 LI:236680.2:2001JAN12 g6034690 1950 2322
8 LI:236680.2:2001JAN12 gl071376 I 960 2318
8 U:236680.2:2001JAN12 gl 190233 1962 2318
8 LI:236680.2:2001JAN12 g3134236 1962 2317
8 U:236680.2:2001JAN12 gl921221 1962 2313
8 U:236680.2:2001JAN12 4024449H1 1964 2154
8 LI:236680.2:2001JAN12 6449287H1 1970 2317
8 U:236680.2:2001JAN12 4029205H1 1975 2241
8 U:236680.2:2001JAN12 6446287H1 1974 2317
8 LI:236680.2:2001 AN12 1384614H1 1985 2247
8 LI:236680.2:2001JAN12 g2154287 1988 2314
8 U:236680.2:2001JAN12 gl312625 1444 1937
8 U:236680.2:2001JAN12 4400655H1 1445 1724
8 U:236680.2:2001JAN12 g5109483 1451 1887
8 LI:236680.2:2001JAN12 5714792H1 1457 1769
8 U:236680.2:2001JAN12 6706664H1 1469 1957
8 U:236680.2:2001JAN12 5429194H1 1469 1757
8 U:236680.2:2001JAN12 g2229268 1490 1902
8 U:236680.2:2001JAN12 415958H1 1491 1737
8 U:236680.2:2001JAN12 6756226H1 1501 2209
8 LI:236680.2:2001JAN12 200080H1 1512 1827
8 LI:236680.2:2001JAN12 200081 HI 1512 1828
8 U:236680.2:2001JAN12 561 1292H1 1518 1799
8 U:236680.2:2001JAN12 gl 191362 1524 1680
8 U:236680.2:2001JAN12 7336684H1 1563 1916
8 LI:23ό680.2:2001JAN12 231451 1 HI 1585 1833
8 LI:236680.2:2001JAN12 g6702138 1580 1892
8 U:236680.2:2001JAN12 g3202284 1583 1896
8 U:236680.2:2001JAN12 724515R1 1585 2156
8 U:236680.2:2001JAN12 724515H1 1585 1825
8 LI:236680.2:2001JAN12 g6992823 1589 1892
8 U:236680.2:2001JAN12 2886039H1 1613 ' 1884
8 LI:236680.2:2001JAN12 2874078H1 1618 1916
8 LI:236680.2:2001JAN12 3702979H1 1619 1916
8 LI:236680.2:2001 AN12 2665478H1 1621 1887
m o
O
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO O O O Cύ Cύ O O Cύ CO O CO CO Cύ O O Cύ O Cύ CO O O O O CO CO O O co O O CO CO Cύ CO CO CO CO CO CO CO CO C CO CO OO CO CO ch Ch Ch c> o o O c o o o c o o o o c> C C h Ch c> Ch Ch h Ch Ch Ch (h h Ch Ch Ch Ch (h o Ch Ch Ch Ch o Ch Ch Ch h
<h o o c> o o Ch Ch < - <h o o o o o o o O C Ch Ch h Ch Ch Ch Ch h Ch h Ch h Ch Ch h Ch Ch c Ch Ch Ch Ch Ch Ch h Ch Ch Ch Ch
OO CX3 cx> OO OO c» CX3 00 00 CX3 CX3 OO 00 00 CX3 oo 00 00 c» OO OO C» 00 oo CX3 cx> c» c» 00 00 CX3 CX3 c» 00 CX> oo 00 00 00 00 CX3 00 00 JO CO 00 00 00 OO Φ o o o o o o o o o o o o o o o CD o o o o C-J o o o o o o o CD CD CJ o J SD CD CD O C-J (D D 3
NO NO NO NO NO NO NO NO NO NO NO ro NO NO NO NO NO NO NO NO ro NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO O
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO Ω
< ) ( ) < ) ( ) ( ) ( ) < ) C ) CO
O o o o o O o o o o o o o o o O O o o o O O O J o o O O O O o CD CD O (D J J D CD CJ CD D c_ c f f f c C r c__ c c c f r f . c C C f c_ c c f c_ c. c. c C c.„ c c c__ c. c C c_ c_ c. c c_ c_ ( π
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > >
Z z Z. z. z z z z Z Z Z Z Z Z. Z z. Z. ro ro NJ io io ro ro ro w M io ro ^ No ro iO M No ro io io ro M ro ro N ro ro No ro ro ro i No ro ro ro N^
-' -' -' -' -' -' -J -' -' -' -' -' -' -' -' -' -' -' -' -' -' -' -' M r I M M I M I -' -' -' -' -' -' -' -' -' -' -' -' -' -' -' -' -J -' Cn ω ω ω ω ω <_ ω ω 4-> ω c3 θ3 Cjo cjJ Co c- ω
— ■ — ' Cn cn cn cn cn cn o o oo M M M M O O O Cn cn 45. ro — ' θ cjo M θ 4-^ ω o o o o o o α3 Cn cn 4-.45. oo Nθ Nθ θ 4-. oo Nθ Nθ N Ω
NO NO — ' — ' — ■ —■ —> — ' O M O COO M W O O OS CJo ω — ' O C» M 4-^ CJ0 C00 O O O O Cn O O O — ' O ∞ C00 00 Co α3 Cn 4^ M Cj0 ∞
-J -' -' -J -' -' -' -' -' -' -' -' -' --' -' -' -' -' -' -' -' -' -' N3 M r N) r W M M -' M N3 r M -' -' M --' -' M -' -' --' --' -' --' -' Cn M O CJl C00 CJ0 CJ0 O O O O C00 Cn C00 O Cn CJ0 C^ O 45. O O O CO C0 C0 00 N0 C C N0 O O — ' NO Co O O O O O — ' OO OO CO O OO O Oo H- O M N0 45. Cn O — ' CO Cn NO O M O Cn CO OO Co rO — ' 00 O O O NO NO — ' NO 00 NO NO 00 — ' M 00 C0 O O O 00 Cn O O 4-. C0 00 _0
N045. O — ' Oo o oo No cn o oi M O — ' Cn o cn — ■ ω o - ' ∞ co ιo θ M Nθ cn oo o M θ oo o cn 45. o o cn oo o — < M — ■ o M co — ■ cn 3
TABLE 3
SEQ ID NO: Template ID CampΩnent ID Start Stap
8 U:236680.2:2001JAN12 g3048130 1313 1599
8 U:236680.2:2001JAN12 1390588H1 1312 1436
8 U:236680.2:2001JAN12 g! 885716 1307 1722
8 U:236680.2:2001JAN12 2075665H1 1308 1597
8 U;236680.2:2001JAN12 2293582H1 1308 1585
8 U:236680.2:2001JAN12 4707390H1 1310 - 1585
8 U:236680.2:2001JAN12 4342282H1 1314 1517
8 LI:236680.2:2001JAN12 201 004T6 1336 1860
8 U:236680.2:2001JAN12 6076309H1 1336 1598
8 U:236680.2:2001JAN12 6034056H1 1338 2016
8 U:236680.2:2001JAN12 gl313848 1346 1841
8 U:236680.2:2001JAN12 5805420H1 1339 1667
8 U:236680.2:2001JAN12 2222252H1 1341 1624
8 U:236680.2:2001JAN12 6040024H1 1346 1986
8 U:236680.2:2001JAN12 g!921327 1350 1669
8 U;236680.2:2001 AN12 5854844H1 1346 1644
8 U:236680.2:2001JAN12 6267478H1 1351 1892
8 U:236680.2:2001JAN12 4082468H1 1248 1545
8 LI:236680.2:2001 AN12 1743450T6 1249 1861
8 U:236680.2:2001JAN12 2101426H1 1253 1534
8 U:236680.2:2001JAN12 1700062H1 1264 1489
8 U:236680.2:2001JAN12 1698445H1 1264 1317
8 U:236680.2:2001JAN12 2955049H1 1265 1515
8 LI:236680.2:2001 AN12 341967T6 1267 1861
8 U:236680.2:2001JAN12 g2107080 1271 1661
8 U:236680.2:2001JAN12 881668H1 1282 1553
8 U:236680.2:2001 AN12 g2237266 2000 2323
8 U:236680.2:2001JAN12 4081922H1 1247 1559
' 8 U:236680.2:2001JAN12 3442789H1 2187 2322
8 U:236680.2:2001JAN12 g2881308 2217 2317
8 U:236680.2:2001JAN12 4907175H2 2233 2307
8 U:236680.2:2001JAN12 gl 238176 2242 2343
9 Ll:228186.1 :2001 JAN 12 2578858F6 3757 4250
9 U:228186.1 :2001JAN12 2578858H1 3757 4017
9 U:228186.1 :2001JAN12 g2183340 3767 4181
9 U:228186.1 :2001JAN12 g6716882 3769 4179
9 Ll:228186.1 :2001 JAN 12 g2783648 3788 4185
9 U:228186.1 :2001JAN12 g3674771 3791 4186
9 LI:228186.1 :2001JAN12 1466016H1 3790 3973
9 U:228186.1 :2001JAN12 g3418449 3819 4179
9 Ll:228186.1 :2001 JAN 12 g4988753 3819 4180
9 Ll:228186.1 :2001 JAN 12 55037512H1 3841 4180
9 LI:228186.1 :2001JAN12 g5234992 3842 4180
9 U:228186.1 :2001JAN12 g824803 3848 4273
9 U:228186.1 :2001JAN12 g5635255 3863 4128
9 LI :228186.1 :2001 JAN 12 21 17539H1 3866 4102
9 U:228186.1 :2001JAN12 50671 1 OH 1 3881 4160
9 U:228186.1 :2001JAN12 g4152912 3903 4180
9 LI :228186.1 :2001 JAN 12 1572173T6 3915 4137
CΛ m
©
OOOO O OO OO OO OOO OOOO O OO O O O O O O OO O OOOOOO OOO OO OO O O OOOO Q z O
N0 N0 N0 N O N ro t N0 N0 0 N IO r M ^ r M rO N0 N rO M N0 W N N0 K3 N0 ro ro ro M ro NO NO io M ro ro r io No ro ro ro ro ro ro ro ro ro ro ro ro ro ro No ro ro No ro c» c» c» coo coo oo co oo oo co co co oo cχ3 cx3 θo co oo oo oo oo oo oo co c» oo oo oo oo ∞
C0O C0O C0D C00 O0 C00 C00 O0 C» C» O0 CO C» O0 O3 C» C00 O0 00 CO C)D 0O O0 C»
00000000000000000000000000000000000000000000000003^
-J -J -J ^ -J LJ --J ^ ^ LJ -J _J L-' ^ --- --- --- --- ^ --- ^ --- --J --- --J --- ^ -J --J --- --
"t OO NOO NO iOvb SOό rOό rOo NOO "rOo NOo rOo rOo NOθ wO O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O H- oooooσoooooooooooooooooooooooooooooooooooooooooogΦ
C_ C_ C_ C_ C_ C_ C_ C_ C__ (-_ C_ C_ C_ C__ C_ C_ C_ C_ C_ C_- C_ C_ C_ C_ C^
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > >
ZZZ2ZZZZ2ZZZZ22ZZZZZ2Z2ZZZZZZZZZZZ2ZZZ2ZZZZZZZZZZ
M M M M M M M M M M W M W M M M M M M I M M M M I M M M I M W W M W M M M
c0 45. . 5. 4. 45. 4i. . 4i. 4i. 4. v. 4. 45. 45. 45. 45. 45. 45. 45. 45. s. 4i. 4i. 4i. 4i. 4i. 4i. 45. 45. 4s. 45. 45. 45. 4i. 45. 4i. 4i. 45. 4i. 4i. 4i. 45. 45. 45. co CO co CO Λ
4-. M M M O O O O O O O O O O o o cn cn cn en cn Cn Cn Cn Ol 4i. C CO OO O Co rO NO NO N NO — ■ O O O O O O O 0 0 0 O NO — ' — ' O M O O Cn 4-. 45. Co rO NO NO O o co 00 o O NO ro oo oo o NO NO oo M O Cn — ' O O O — ' O O O O 00 NO NO CO Cn O O O — ' O O O OO N0 00 45. 0 CO M cn n 45. 45. 5, —■ o o o cn cn M M M O o o cn o M o ro ro o M o o o O vl CO 3H"-
4i. 4-. cjo cjo cn 45. cn cn cn 45. cn 45. coo 45. o cjo cn cji cn cjo 45. c_π 45- 4^
O O O O O O O O M O 00 θ 00 O O O O O O O O 00 O O O O M O Cπ vl Cπ vl 00 Cn 4i. — ' — ' — . —. —. —. —■ —. —. —. —. — • → 00 M O — ' — ' O — ' — ■ — ' 4-. — ' O — ' M O — • — i — ■ — ■ — . O O — ' — ' Cn O — ' — ' CO O CO CX3 Cj N0 0 4i. M M θ M M CX> M OO OO C M Oθ M θ O NO — ' NO — ■ 0 —' 4i. M O —' 0 —' 0 —' — ' —■ —■ — ' NO OO O O O NO O —' Cj O M —' —' —' 4i> O Cn M O — < — ' O NO NO O O O — ' T3
TABLE 3
SEQ ID NO: Template ID CampΩnent ID Start Stap
9 U:228186.1 2001 JAN 12 2285278R6 3496 3883
9 Ll:228186.1 : 2001 JAN 12 2285278H1 3496 3739
. 9 U.228186.1 : 2001 JAN 12 5947052H1 3499 3659
9 U .228186.1 : 2001 JAN 12 667861 T6 3514 4136
9 U.228186.1 : 2001 JAN 12 2501382H1 3538 3766
9 U.228186.1 2001 JAN 12 952741 Rl 3554 4080
9 U.228186.1 : 2001 JAN 12 952741 HI 3554 3817
9 U.228186.1 2001 JAN 12 3055946H1 3566 3837
9 U '.228186.1 2001 JAN 12 2937765T6 3579 4165
9 LI :228186.1 2001 JAN 12 3525403H1 3583 3833
9 U.228186.1 2001 JAN 12 700438R6 3605 3998
9 LI :228186.1 2001 JAN 12 700438H1 3605 3860
9 LI :228186.1 2001 JAN 12 699637H1 3605 3805
9 Ll:228186.1 2001 JAN 12 700438T6 3605 4140
9 Ll:228186.1 2001 JAN 12 1572292T6 3617 4139
9 U:228186.1 2001 JAN 12 1572444T6 3617 4140
9 LI :228186.1 2001 JAN 12 57231 13H1 3667 4223
9 U:228186.1 2001 JAN 12 5723215H1 3667 4096
9 U:228186.1 2001 JAN 12 3779008H1 3675 3979
9 LI :228186.1 2001 JAN 12 5649315H1 3699 3959
9 U:22818ό.l 2001 JAN 12 g4390668 3708 • 4182
9 LI :228186.1 2001 JAN 12 g5231487 3715 4179
9 U.228186.1 2001 JAN 12 g6709352 3720 4180
9 I :228186.1 2001 JAN 12 g5526660 3724 4183
9 Ll:228186.1 2001JAN12 g4175746 3739 4183
9 U:228186.1 2001 JAN 12 727019H1 3740 4045
9 LI :228186.1 2001 JAN 12 go 132296 3745 4181
9 LI :228186.1 2001 JAN 12 568776H1 - 3749 4015
9 Ll:228186.1 2001 JAN 12 g5444612 3750 4179
9 LI :228186.1 2001 JAN 12 g6028408- 3750 4179
9 LI :228186.1 2001 JAN 12 70012310D1 2982 3368
9 U:22818ό.l 2001 JAN 12 70004276D1 2982 3380
9 LI :228186.1 2001 JAN 12 70006106D1 2981 3222
9 U.228186.1 2001 JAN 12 2937765H1 3008 3296
9 LI :228186.1 2001 JAN 12 2937765F6 3008 3503
9 U:228186.1 2001 JAN 12 2863195H1 31 1 1 3383
9 U:228186.1 2001 JAN 12 8179891 HI 31 19 3612
9 Ll:228186, 1 2001 JAN 12 70001338D1 3123 3221
9 LI :228186.1 2001 JAN 12 70008533D1 3132 3221
9 Ll:228186.1 2001 JAN 12 5867485H1 3134 3403
9 Ll:228186.1 2001 JAN 12 781214H1 1607 1791
9 Ll:228186.1 2001 JAN 12 g3900472 1677 1791
9 Ll:228186.1 2001 JAN 12 667861 R6 1716 2283
9 LI :228186.1 2001 JAN 12 667861 HI 1716 1791
9 U:228186.1 2001 JAN 12 66691 OH 1 1716 1791
9 U:228186.1 2001 JAN 12 3347266H1 2070 2332
9 LI :228186.1 2001 JAN 12 7733338J2 2100 2404
9 U.228186.1 :2001JAN12 1387055H1 2100 2221
9 LI :228186.1 :2001JAN12 4434739H1 2100 2194
CΛ rn
©
O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O
O
NO NO NO M NO NO M NO rO NO NO NO NO NO NO NO NO rO NO NJ NO NO M NO NO NO rO NO NO NO NO NO NO NO NO NO M NO NO NO NO M NO N^
M M M M M M M N) M M M rO M N3 M M W N) r W M M M M M M M fO M rO M M M M M
CW CO Cn OO CO CO ∞ CO CO OO CO COO ∞ ∞ OO OO Cβ CD ∞ OO OO OO OO OO OO OO αo oo cσ
COO OO OO OO CO OO CO CD CO CX3 03 0O OO CO CO CO OO CO CD CD CO OO CD CO CO OO CO OO CO CO OO OO OO OO ∞ O o o o o o o o o o o o o o o o o o o o o O o o o o.o 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3
N Oo kOb iOv Orό rOo rOo Oό rOo MO rOo rOo Oro rOό fOό rOo rOo Oό O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O H- O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O Φ
C_ <-_ C_ <-_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ _ C^
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
Z Z^ Z^ ^ Z^ Z^ Z^ Z^ Z^ Z^ Z^ Z^ Z^ Z^ Z^ Z^ Z^ Z^ Z^ Z^ Z^ Z^ Z^ Z^ Z Z l W M M M i W M W M M M M M M M M t M r M M M M M M
M M M M M M M M M M M M M M M M M M W M W M M M M M r M M M r M M rO M M o o o o o o o o o o <jo coo cn cn cn en o en c-n cjo cjo cjo cn en cjo cjo cn cn cn 4i. 45. 45. θ3 ω
00 00 00 M M M O 45. O — ' M M M M M O Ol Cn 45. ro — ' — • —• —A —• —• — — ■ — ' O — ' — ' CO CO — ' M M O O Cπ — ' O OO M Cn Cπ O O O Ω rO O N0 O O O M C-0 03 45» M M M M M 45. — ' — ' O O M O O O O O O O O 00 O 45. 00 — ' NO OO OO O O M M O O O CO O O O O H^
W Co M Co CO 00 CO Co CO CO N0 N0 C 00 C N0 N0 CO N0 O3 IO N0 N0 C CO 00 CO 00 N0 N0 O3 CO N0 rθ N0 N0 r^
O O O — ' — ' NO CO NO — ' — ' O O O — ' — ' M OO — < O O 00 00 O — ' O O — ' O O M O O Cn O O C_π Co 4-. 4i. 45. 00 M 4-. 4i. 4-. NO NO rθ ;-f- O M M O O — ' 00 N0 4-. M C0 M M O N0 Cn O N0 00 00 N0 M 00 θ O N0 Cn M — ■ Cn Cn Co CO CO O O M CO M O — ' O 45. — ' — ' — ' Cn o O C — ■ — ' O O OO — ' 0 45. 00 — ' Co CO Oo oo O en O O Co Oo O Oo OO O CO O O — ' NO NO O OO M NO O O rO O — ' O 4S. C0 O M M T3
TABLE 3
SEQ ID NO: Template ID Component ID Start Stop
9 LI :228186.1 2001 JAN 12 2889309H1 2682 2983
9 U.228186.1 2001 JAN 12 70006774D1 2712 3121
9 LI :228186.1 2001 JAN 12 70003888D1 2712 3320
9 U.228186.1 2001 JAN 12 70006280D1 2712 3330
9 U:228186.1 2001 JAN 12 70006292D1 2712 3222
9 U:228186.1 2001 JAN 12 70001797D1 2712 3221
9 U.228186.1 2001 JAN 12 70008495D1 2712 3177
9 Ll:228186.1 2001 JAN 12 70001207D1 2712 3164
9 U.228186.1 2001 JAN 12 70002332D1 2713 3315
9 U.228186.1 2001 JAN 12 70007897D1 2713 3313
9 LI :228186.1 2001 JAN 12 70005965D1 2713 3221
9 U.228186.1 2001 JAN 12 70006228D1 2713 3221
9 Ll:228186.1 2001 JAN 12 70006597D1 2713 3141
9 U:22818ό.l 2001 JAN 12 70002365D1 2736 3326
. 9 LI :228186.1 2001 JAN 12 3832785H1 2760 3069
9 LI :228186.1 2001 JAN 12 70005365D1 2824 3329
9 LI :228186.1 2001 JAN 12 3038130H1 2839 3096
9 LI :228186.1 2001 JAN 12 3038185H1 2839 3072
9 U.228186.1 2001 JAN 12 2889309T6 2859 3026
9 LI :228186.1 2001 JAN 12 3493336T6 2904 3382
9 U:228186.1 2001 JAN 12 70004085D1 2981 3222
9 LI :228186.1 2001 JAN 12 70002244D1 2982 3559
9 LI :228186.1 2001 JAN 12 70006170D1 2982 3561
9 LI :228186.1 2001 JAN 12 7453509H1 1 589
9 U.228186.1 2001 JAN 12 706431 HI 104 364
9 Ll:228186.1 2001 JAN 12 552849R6 209 716
9 U:228186.1 2001 JAN 12 552849H1 209 439
9 LI :228186.1 2001 JAN 12 2729487H1 294 539
9 U:228186.1 2001 JAN 12 6913225J1 335 888
9 U.228186.1 2001 JAN 12 g2153761 479 913
9 LI :228186.1 2001 JAN 12 7339459H1 537 1030
9 U.228186.1 2001 JAN 12 1255495T6 565 1081
9 U:228186.1 2001 JAN 12 1837462F6 635 1091
9 Ll:228186.1 2001 JAN 12 1837462H1 636 890
9 U:228186.1 2001 JAN 12 g4395197 729 1123
9 U:228186.1 2001 JAN 12 3097532H1 802 1 107
9 LI :228186.1 2001 JAN 12 g915974 1030 1354
9 LI :228186.1 2001 JAN 12 g 1524460 1051 1237
9 Ll:228186.1 2001 JAN 12 g2153706 1068 1440
9 LI :228186.1 2001 JAN 12 571 1878H1 1 1 10 1383
9 U.228186.1 .2001 JAN 12 1837462T6 1129 1755
9 Ll:228186.1 :2001JAN12 1544854R6 1 167 1485
9 LI :228186.1 2001 JAN 12 1544854H1 1 167 1353
9 LI :228186.1 :2001JAN12 1544854T6 1 192 1710
9 U:228186.1 :2001JAN12 552849T6 1 198 1396
9 LI :228186.1 :2001JAN12 g5664103 1290 1756
9 U.228186.1 :2001JAN12 g6196828 1332 1754
9 LI :228186.1 :2001JAN12 gό40144ό 1354 1756
9 LI :228186.1 :2001JAN12 g!523710 1390 1753
O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO M M M NO NO NO NO NO NO NO NO NO NO ro NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO ro ro NO
O O O o o • o o o O O NO NO NO NO NO ro NO NO NO NJ NO NJ NO ro N> NJ NO NJ NJ NO NO NO NO NJ NJ NO NO NJ NJ NO ro NO
OO 00 oo CJO 00 OO 00 OO 00 00 CJO 00 CJO 00 00 CJO CJO 00 oo OO CJO JO JO JO CJO CJO CJO 00 00 .
M VI M M M M M M M M M M M M M M M NO NO ro rn cn cn cn cn cn cn cn cn rn cn Cn cn cn cn cn cn co Cύ co CX3 00 00 CJO O 00 JO 00 O 00 00 CJO 00 00 00 CJO CJO C» 00 C» CJO 00 CJO CJO 00 CX) 00 00 OO φ' o o O O o o o o o o o o o o o o CO Cύ CO o o o o o O o o o O O O o o O o o o 3 ro NO NO NO NO NO NO NO ro NO NO NO NO NO NO NO NO o O NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO O NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO ro NO o o o o O o O ro CO o o O o o O o o CJ o σ o o O o o CD O o o o CD (D o CD o o o o O o o CJ CD CJ CJ o o o πDt c_ c r c . f C f c... c c . c ., c r c , c . _ c_ c , c_ c. c_ C— c_, c_ C— c.. c_ C. c_ c_ C_ c_ c_ c_ c. c c_ C- c_ c_ c_ c_ c_ c_ c_ c_ C— n
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > >
Z Z Z z z z Z Z z Z Z Z z Z Z Z Z Z z Z
M M M M M M M W J M M M M M M M M NO M M M M M M M rO M M M W M M
o cn cn ro NO NO-NO — ' — —■ —' —' —■ —■ ω c ω ω Λ ω ω ω w ω ω ω ω (j ω ) ω ω ω ω ^ 45. 4>. 4i ti i s. . -' CΛ co o cn o M Cn ro co en cn co NO — ■ — ■ CJO — ' ^. CO CO NO NO NO — ' — . —■ —■ — . —. —i — ' 4_i C C CO Co Co C CO CO M M M M M M 4s,
NO M NO — ' M O O CO O Cn — ' Cn O OO M 45, 45. o o o o coo cn ro o cn en cn eπ 4i, 45. co co o θ M cn cn — ' O O O Co co co ro ro o S o o en cn co ro o o 4ϊ. co N N 45. — ' CJO NO — ' M O CΠ OO 45. OO NO NO — ■ cn CΠ CO H-
o o _. cn oo co cπ o o o co cn — ' 4s, cn — ■ -. - .- ω u w a ω u ω - w ω ω ω ω ω Q ω u ω ω ω ri i- j- n σi i- ri CΛ o oi f-,, O M ro cn co cn cn M M O O CO M M 4 r5v. ^ v"| Cn CJO CJO Cn 4i. Co CO Cn Jv. Co 45. 4v. CO M M O O M Cn O O O O O O O O 0 4-. r_ 0 4-. M — ' to eo co o No o en 45, 00 CO CO - cn vj 45. co oo o cn o co o o o M 45. O cn M O O —' NO O 00 —■ O cn" -g — ' Cn o o M cn co co o co cn — ' NO M 00 NO —' NO 45. —' 00 —' NO M TS
CΛ m ©
D
Z g r~ ι— ι— r— r— ι— r— r— i — i— ι— r— ι— r— r— ι— i — r— r~ ι— 1 — i — i — r— i — r— 1 — ι— I- r— i — r— |— r- 1 — I — r~ i — r~ i — r— i — ι— I- ι— i — ι— ι—
NO NO NO NO NO NO NO NO NO NO NO NO ro NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO
O o O o o -O O ■o O O O O O O O O o
M M M M M M M M M M M M M VI M M M M M M VI M M M VI M M M vi M M VI M M M VI M M M M M M VI M M M VI -vl M — 1 cn cn cn cn cπ cn cn cn cπ cn cπ cπ cn cn cn cπ cn cn cn cn cn cn cn cn rn cn Cn cn cn cn cn cn cn cπ cn cn cπ cn cn cn cn cn cn cn cn cn cn cn cn φ o o o o o o O o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o 3
NO NO NO NO NO NO NO NO NO NO NO NO ro NO NO NO NO ro NO NO NO NO NO ro NO NO NO NO NO ro NO NO NO NO NO NO NO NO ro NO NO NO NO NO NO NO NO NO NO "O
NO NO NO NO NO NO NO NO NO NO NO NO O NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO O c ; C ) r> C ) C C ) O C 3 C ) C O C 3 <~ι C ) C 3 o C ) C ) C 3 C 3 C ) C ) C 3 C ) C ) O C 3 C ) C 3 C 3 C 3 CO C 3 C 3 C 3 C ) C 3 C 3 C J C 3 C 3
CD o CD C-J o C-J o CD O CD o o CJ o o o o O o CJ CD CD CD CD CJ CD o CD O o CJ o (D CD o CD CJ CJ O O cli c_ c_ c . c_ c._ c_ r ... f - c_ c f . c_ f C . c_ c_ c c... c_ c c r_ c_ r c c_ <— r c c_ c c c_. c_ c c c_ C_ c c. , c_ c. c C c_ c c c_ π
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > >
Z Z z. Z Z Z Z Z Z Z Z Z z Z z Z z Z Z ro ro NO io ro M No ro io ro ro ^ NO No ro ro ro No ro io ro ro ro No ro No ro to ro No ro No w io ro ro NO N^
O >
I— i o Ω CD TO + fe cn,,<Ω co cn k< <Ω CΩ CΩ S M<Q .Ώ N ooO N enO t voj E CΩ <Ω CΩ CΩ'CΩ CΩ CΩ ω Ω CΩ Svj Ω N Ω CΩ CΩ CΩ NO 45. NO Ω
M — ■ O O C C <ΩΩ r—
_ NO δ M O O O — ' 3 m o 00 00 00 s. o O oo — ' — ■ en cn — ' 45. ro co 0 v~0 O ^ Co o vl M CO o 4i. M — ' 4 4i5.- N0 en vj N0 en co CO
NO CO ) o 45, — ' o O 00 OO 4 4 ■5. O — ' -σ
C JS5,, cn ∞ CO v, 4S. o _ °. S o.< _,. co o oo o M o O 00 M 45. 45. 00 - — O CO0 — ' CO ( ) co £ o ∞
VJ M M — > — ; ^ ro ∞ ςn co C — ■ o cn oo 45. M M oo O NO 00 45. co
M O en cn o
45. NO -O M oo oo NO co oo O — M 00 00 o Λ 4 -, c 'n- oo NO O CO O co co co oo oo 45. vO en M 45. 3
NO NO NO 00 00 ro c co
X co en en 00 45. 00 45. NO NO NO M co β ro O O 00
■ o NO C 3 co 45. 00 C -. O
00 45. 00 cn O 45. cn NO oo — . O — ■
-C en M cn oo o o Φ ± xz c oo __, ± x± --- 0 0 4-- 0 ± X± 00 Co X X 3 vl _■ o — ■ i o^ _. ^ _ . od O °° 00 o o O NO CO 00 o → -^ → O O 45.
_, 00 00 00 o eπ cn en en en cn eπ en en cπ en cn cn cn en cn M Cn cn cn cn cn cn cπ cn o o o o o o o o o o o o o θ --i-
Co Cn — ' Oo co oo oo oo oo oo oo oo oo oo oo oo oo oo C30 4S. C» co CO CO C0O C00 O0 00 4s, 4s. 4s. 4i. 4i. 4i, 4s, O0 CjO Co Cn 4s, Co N0 n
4s. 45, 45. — ' O0 OO O0 OO O0 M O0 O0 M M M M M M M M O M M M M M M M 4i- O 00 00 M M O O O 00 Cn N0 N0 M θ 3^
NO CO
O O O — ■ — ' NO NO NO OO O O O CO CO OO CO CO O O O CO M M OO OO OO OO OO OO OO OO OO OO OO O O M O OO O OO O O O O OO O
___ O O O Cn 00 O O Cn O O 00 00 O 45. 4i. 00 4v, ch M M 4i. 4i. 4i. O IO 00 00 00 00 45. 45. 45. 45. 0 — —• — ' O — ' O O O NO NO O OO O O 45. 00 Cn O N0 O — ' — ' 0 0 4S. O — ' CO O — ' 00 00 00 M M M M NO — ' O O Cn O O O O 00 O O 45. 0l M O — • CD -ζj
TABLE 3
SEQ ID NO: Template ID Component ID Start Stop
U:291759.2:2001 JAN12 1681732T7 14 165 U:291759.2:2001 JAN12 1681732T6 14 164 U:291759.2:2001 JAN 12 g2022753 12 197 Ll:291759.2:2001 JAN12 2413084H1 832 1002 Ll:291759.2:2001 JAN12 6883666J1 779 1172 U:291759.2:2001JAN12 1927072H1 1 54 LI:291759,2:2001JAN12 g4217544 1 54 U:291759.2:2001 JAN12 gl981790 867 1155 U:291759.2:2001JAN12 5298489H1 1 54 Ll:291759.2:2001 JAN 12 2671094F6 924 1167 LI:291759,2:2001JAN12 2671094T6 924 1438 LI :291759.2:2001 JAN 12 2671094H1 924 1165 U:291759.2:2001 JAN12 g1995827 941 1027 LI:291759.2:2001JAN12 2736026F6 941 1237 U:291759.2:2001JAN12 2736026H1 941 1070 LI:291759.2:2001JAN12 5476134H1 961 1178 U:291759.2:2001JAN12 5477477H1 961 1178 U:291759.2:2001JAN12 5479864H1 961 1229 Ll:291759.2:2001 JAN 12 5478264H1 961 1110 LI :291759.2:2001 JAN 12 4692078H1 973 1129 U:291759.2:2001JAN12 gl 186868 1013 1173 U:291759.2;2001JAN12 gl 186747 1013 1188 U:291759.2:2001JAN12 5103848H1 1029 1245 Ll:291759.2:2001 JAN 12 4772463H1 1052 1246 U:291759.2:2001 JAN12 1961123H1 1066 1246 U:291759.2:2001JAN12 1961123R6 1066 1246 Ll:291759.2:2001 JAN12 6180072H1 351 643 LI:291759.2:2001JAN12 2738251Fό 409 936 LI:291759.2:2001JAN12 2738251HI 409 674 U:291759.2:2001 JAN 12 g1860299 413 683 LI:291759.2:2001JAN12 3352689H1 421 613 LI:291759.2:2001JAN12 g3280105 448 920 Ll:291759.2:2001 JAN12 g5636736 448 915 LI:291759.2:2001JAN12 g1243075 450 672 U:291759.2:2001 JAN 12 2681533H1 433 723 U.291759.2:2001 JAN12 g4175465 440 886 LI:291759.2:2001JAN12 515771H1 531 669 LI :291759.2:2001 JAN 12 gl997928 1 269 U:291759.2:2001 JAN 12 7733027J2 16 661 LI:291759.2:2001JAN12 g835195 67 392 LI:291759.2:2001JAN12 g856172 107 392 U:291759.2:2001JAN12 2654790F6 114 520 Ll:291759.2:2001 JAN12 6883666H1 114 462 U:291759.2:2001JAN12 7597338H1 114 459 U:291759.2:2001 JAN12 8194536J1 114 412 Ll:291759.2:2001 JAN12 2328960R6 114 330 LI:291759.2:2001JAN12 2654790H1 114 291 Ll:291759.2:2001 JAN12 2328960H1 114 246 U:291759.2:2001JAN12 4996248H1 114 217
TABLE 3
SEQ ID NO: Template ID CompΩnent ID Start Stop
1 1 U:291759.2:2001JAN12 5610314H1 1 14 21 1
1 1 U.291759.2.2001JAN12 g856075 1 14 206
1 1 U:291759.2:2001 JAN12 7982183H1 1 103 1246
1 1 Ll:291759.2:2001 JAN12 3475555H1 1 1 16 1270
1 1 U:291759.2:2001JAN12 291454H1 1 128 1246
1 1 Ll:291759.2:2001 JAN12 2009374H1 1 168 1246
12 U:292613.17:2001JAN12 994833R6 1 309
12 U.292613.17.2001JAN12 994833H1 1 124
12 U:292613.17:2001JAN12 994833T6 1 363
12 U:292613.17:2001 JAN 12 4149605F6 1 355
12 U:292613.17:2001JAN12 4149665H1 1 228
12 U.292613.17.2001JAN12 1507329H1 46 170
12 U:292613.17:2001JAN12 3144082H1 62 276
12 U:292613.17:2001JAN12 3143359H1 62 224
12 U:292613.17:2001JAN12 4851779H1 249 508
13 U:412959.15:2001JAN12 2674048F6 1 330
13 LI :412959.15:2001 JAN 12 2674048H1 1 21 1
13 U:412959.15:2001 JAN 12 2330307R6 29 493
13 U:412959.15:2001 JAN 12 2330307H1 29 304
13 U:412959.15:2001JAN12 1739552H1 29 95
13 U:412959.15:2001 JAN 12 2550691 HI 49 290
13 U:412959.15:2001JAN12 5205237H2 1 13 370
13 LI :412959.15:2001 JAN 12 5205237F6 1 13 406
13 U:412959.15:2001JAN12 5799259H1 178 406
13 U:412959.15:2001JAN12 5646172H1 199 293
13 LI :412959.15:2001 JAN 12 955847H1 325 563
14 U:482512.3:2001JAN12 g873524 2221 2415
14 Ll:482512.3:2001 JAN 12 g4328019 2156 2401
14 U:482512.3:2001JAN12 5835727H1 2100 2384
14 LI:482512.3:2001JAN12 g3835121 2159 2400
14 U:482512.3:2001 JAN 12 809937R1 2105 2405
14 LI :482512.3:2001 JAN 12 809937T1 2105 2362
14 U:482512.3:2001JAN12 809937H1 2105 2397
14 U:482512.3:2001JAN12 g3736000 2108 2405
14 U.482512.3:2001 JAN 12 1753767H1 21 10 2351
14 U:482512.3:2001JAN12 1754121 HI 21 10 2351
14 Ll:482512.3:2001 JAN 12 2371576H1 1856 2086
14 U:482512.3:2001 JAN 12 1496803H1 1856 2073
14 U:482512.3:2001JAN12 4530169H1 1869 2129
14 U:482512.3:2001JAN12 g21 15734 1879 2387
14 U:482512.3:2001 JAN 12 8262183J1 1887 2385
14 U:482512.3:2001JAN12 g2556760 1904 2402
14 LI:482512.3:2001JAN12 g3245066 1905 2405
14 U:482512.3:2001 JAN 12 2457752T6 1904 2360
14 U:482512.3:2001JAN12 g2553409 1907 2401
14 U:482512.3:2001 JAN 12 gl718873 1908 2227
14 U:482512.3:2001JAN12 g 1860643 1908 2281
14 U:482512.3:2001JAN12 g4524169 1915 2400
14 U:482512.3:2001 JAN12 g2115481 1917 2410
CΛ rπ © ___
4s. .r 45. 4i> 45. 4i, 4v. 4i. 4v. 4i. 4i, 4i, 4v. 4s. 4i, 4i, 4i, 4i, 4i. 4. 4v. 4v^ σ z
O
—. —■ —. —. —. ro NO No ro ro — . —. _. — ■ — —■ ro ro io ro io ro NO No ro ro NO No ro NO —' — ' —■ —' — . —. —. —. —• —. —. —. —. —. — . _■ — _. _. CΛ
4i. jv, 4s. 45. 4s. O O O O O O O O O O O O O O O O O O O O O CO CO CO NO OO OO OO OO OO OO OO O O O O O O O O O O O O ^-
O O O CO —' O o σ o o o o o oo oo ro NO NO NO NO — ■ — . —■ —. — ' 45. ro — ' cn cn 4s. ro iO N0 — ' O O o en en en cn cn 4s. 45. N0 — ' Ω
M o o o M cn o J- M O -O O Ol tt JΛ - ' 0 45. 00 — ' O O O OO O O OO O — ' — ' Ol - ■' OO OO M M Cn Cn O O CO NO NO NO OO — - Cn CD 3-
—■ —■ —> — ' NO rrOO NNOO NNOO NNOO NNOO NNOO NNOO NNOO NNOO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO — ' NO — ' N0 NO NO NO N0 NO NO NO N N0 NO NO CΛ en o o o o CO 45. 45. 45. 45...4S. 4S. 4i. N0 4i. 4i. CO — - 4s> 4i. rθ rθ 4s. 4s, rθ 4i. 4-. 45. 4i, — > Co O O O O O rθ 45. 4i. 4i. 45. 4i. 4 i, o cπ CO 45. 45. o M O O O — ' O O O M OO — ' C CoO OoOo O O O OO O O O coO Oo Oo Oo Oo Oo Oo CoOo Ccnn OoOo MM o cπ o o o o o o5, 4o5. 4oi. 4oi. 4o 4oi. ^O- oo co ro en cπ O 00 NO NO O 45, 45. o en co en o cn cn oo o o No cn oo — ' O O O M O O M Cn -' NO NO O O
v. s. 4
5. 4
5, 4
5. 4v
5v
ι— i — i — I — i — I- r— i — i — i — i — r~ r- i— r— i — i — r~ r— r— i — r— ι— t— i — i — i — i — ι— i — ;— l- ι— r- r— r— ι-— ι— i — ι— r- i— r— 1 — i— i — i — i — i —
4s. 45. 45, 45. 45. 45. 45. 45. 4s. 4s. 45. 4S. 4s. 45, 45. 4s. 4S. 4S, 4S, 4s, 4s, 45. 45. 45. 45. 45. 45. 45. 45. 45. 4s. 4S. 45. 45. 4s. ■is, 4i- 4s. 4s> 4s, 4s, 45. 4s. 45, 45. 45. 45. 45. 45.
OO OO C» CX3 c» 00 CΛ 00 00 OO c» oo c» 00 CJO JO c» oo CO CJO oo oo CX3 CJO 00 o oo C» 00 00 CJO 00 00 00 00 oo 00 00 CJO oo 00 JO CO 00 CX3 00 CJO o 00
N) N) NO N) N) NJ N) NO NO NO NO N) N) NO NJ N) NO N) N) NJ NJ NJ NJ NJ NJ NJ N) N) NJ NJ NJ ro ro ro NO N) N» NJ N) N) NO NJ NJ NJ N) NO NJ NJ NJ cn cn Cn cn π cπ cn n n en n cn π en n Cn cn cn n cn n cn n n cπ en cn cn en Cπ cn cn cn en Cn cn cπ cn cπ Cn cπ Cπ n CJO cn n cn cn n φ
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO 3 c. ω o c. ω ω ω ω ώ ω . . ω ω ω CO CO CO 00 CO Co CO CO 00 CO CO Co 00 CO 00 CO CO CO CO Co 00 00 Co 00 00 CO CO CO CO CO CO 00 Co Co "O
NO Nό NO NO NO NO NO Nό Nό Nό Nό NO N ro fό NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO Ω O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O o o o O O o O O O O O o O O O O O O O O o O O o O O O O o O O O St
C_ <-_ C_ _ C_ <-_ C_ C- C_ C_ C_ C_ C-j z > >z>z>z>z>z > >z>z>z>zz> >z>zz> >z>z>z>zz> >z>z>z>zz> >z>z>z>z>z>z > z > z > z > z > z > z > z > > > > z z>> z> z> z> z z> ro M to NJ No ro io ro io ro io No io ro No ro ro ro ro No ro ro ro ro ro ro NO No ro NO No ro ro to r^
Ό
o o o o o o o o o NO NO — ' NO — . —. —. —. —. —. —. —. —. —. —. —. — .
,J-, -v .J- >^ J^ J^ J^ l-, 'y -' 0 — ' 4s, 4s, s. 4. 4s, s, Jv, v. , jv. jv- jv- 4;-.
O O 4i. 4v. jv. 4v. cO Co c» coo ∞ cD θo CD θo cn en cn cn cn cn cn rf-
M530 θ — SJ 9ω~ MP- n. o4iv o^ cCD ° <) CD C> C» αi (» » C)i C)i C)i CJi 4- 4- J- {- J- 45. CO CO N0 — ' — ' — . —. —. — ' —. —■ — ' M CO CO CO O O O Ω M O 0 4s> 45. cn o ro M io oo M M O NO — ' OO CO O M M M O M M O N0 00 0 0 45. — ' Cn 45. 0 ^i-
_. — . _. _i _. _. _. _, -_, _. _. N NO N-) N0 — ■ —. —. —. —. —- —. —. —■ —- —. —. —. —. —. —. —. —. — ' NO NO N0 - ' NO NO NO NO — ■ — < — i — i — . — i — A ro No co 4-. M NO NO NO No ro o 45. 45. 4s, co o o en o o en o co cn o o o o o o cn en en co o — ■ o o ro cOo —M ' c0o0 4oS. eOn
4S. Cn θo OO M M 4S. — ' M O NO O O O NO — ' 45. 0 4i. 4S, O M O CO C0 4S. O CO Cn O O M Cn — ' 45. 45. 00 eOn eOn Oeπ 0o0 Vo1
45. 45. O M M Oo M OO M O o en — ' M θo cn oo 4s. cn oo cn ro oo o — ' CΠ M O CO OO O OO O — ' O en oo oo o 45. co cn co oo oo oo co en
CΛ m
©
4s, 4i. 4i. 4i> 4i, 4i. 4i, 45, 4i> 45. 45. 4S, 45. .|i. 45. 4s, 4s, 45. .r- 4 σ z O r~ i — r- i — r- i — i — r- i — ι— i — r— r— i— i — ι— I- i — i — r- r— i — r— i — i — r— r— ι— r— r— r— r— r— r— r— 1 — i — i — r~ i — r— r— i — |— i — i — r— r— r—
4S, 45. 45. 45. 45. 45. 45, 4s, 45, 45. 45. 4i- 4s, 45. 45. 45. 4s. 45. 45. 45. 4s, 4s. 4s. 45. 45. 45. 4s. 45. 4s> 45. 4s. 45. 4s. 4i, 45. 4s. 4S. 4s. 45, 4s. 45. 4s> 45. 4s. 45. 45. 4s. 4i- 45. O c» CO O CD o o c» CD OO 00 CD O O CD D CD CD CD O CD c» CO CD 00 CD CD O OO CD CD CD CD 00 CD 00 00 OO CD CD 00 CD CD no CD CD 00 CD O
N) NJ NO NO N) NJ NO NO N) NO NO N) NO NO N) NO NO NO NO NO N1 NO NO N) NO NO NO NO NO NO NO N.) NO NO N) NO NO N) NJ NO N) N) N) NO N) NO NO NO NO en cn en cπ cn cn en cn cn cn cn cn cn cn en en cn cn en Cn cn en cn cn cn en cπ Cn en cn en cn en cπ en en n cπ n cn cn en cn cn cπ en cπ en en φ
NO NO NO NO M N NO ro rO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO ro ro ro NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO to NO NO NO NO 3 CO CO CO C CO Co CO CO CO Co CO CO CO CO Co CO CO CO CO CO C CO 00 CO CO CO Co co CO co Co co CO co 00 CO co CO CO Co CO CO CO 00 Co 00 Co Co 00 "O ro fό i rό ro i ro iv ro ro ro ro ro ro Kb NO NO ro NO NO NO ro NO ro NO ro NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO Ω o o o o o o o o o o o o o o CD CD CD CD r CoD r CoD r CoD O O O o O o O o o σ o o O O O O O O O O O O O O O O O o o o o o o o o o o o o o o CD CD CD CD CD CD CD o O o o o o o o o o o o O O O O O o o O O O O O O O O 8Φ c_ c_ c_ c_
>zz>z>z>z>z> >zz> >z > > > > >>>>>>>>>>> z > >z z > > > ZZZZZZ z >zz>>zz>>z>z>zz>zz>>z>zz>>zz>>z > > > > > ro iO NO NO rO M NO NO NO NO NO NO NO NO NO NO NO NO rO NO NO NO ro rO NO rO NO IO NO NO NO NO rO NO NO ro rO NO NO rO NO NO NO NO NO M
Oo ω Co Cθ Co CO C-θ CO Co Co Co CO Oo NO N NO NO NO NO NO N ro rθ rθ — ' —■ —■ — • —> — 00 M M O O 4S. 4S. O3 00 N0 N0 — ' O O O 00 00 O Cn 4S. 00 N0 — ' — ' O CD OO O M 4S. 4s. eo NO N NO — ■ — ' — ' O 00 M M M O O 45. 4v. 00 — ' Ω oo M M oo o — ■ — ' No o o 4s. oo 4s. co co M ro o M co o co en 4s. en o o oo o oo o o cn — ' O o o cn ro o o cn cπ — ■ —
— . — ' — . _. _. _ . _■ _-. _. _-. _. _. —■ _. -_. _, _. _. _, _■ _- -_, _. _, _. _. _. _. __. _. _ι _, _, _. _. _. _- _. -_ι _. _, _. _-, _, _, _, _, _. _, Λ o en cjo o co cn cn cn o o cjo 45. cjo eπ cjo 45. 45. 45. cjo cjo cjo cn en θ 45. 4i, o en o cjo cjo ω oo co o ω cn o o cn o o o o co 45. o o M No θ M θ oo 4-. o — ' O o eo o o 45. o en — ' N0 o o o c0 o 00 M N0 o M co 00 cn vi 4s. cn — ' NJ Ω o oo oo co oo — ■ — ' coo — ■ cn oo c» o o oo o M o oo c» M oo cD io o o en cD M cn 4i. co coo o --' θ oo o3 4i, cn cn o oo o oo — - O O 3
C m ©
45. 45. 4s, 4s> 45 45, 45. 45. 4s. 4s, 45. 4s. 4s, 4s, 45. 4v. 4-. 45. .jv. 45. 4^ α z O
c -o c- -eo -o3 N^∞ ∞^∞ ∞M ∞∞ ∞σ 2n geD Sθ θB ^θ θ S ^ ^M ^M ^O ^g ^M ^δ og ∞ ^ ^ ≥ ^ r M r ^
_- —. —. —- _. -- —. — . jvo ro ro No ro No _. _■ _- __ _ _. ..-. _, _. _, --- -_. _, -_. _. _, _. _. _, — . —. CΛ
O — ' O O — ' O — O 00 4s. 4s. 4i. 00 00 NO O — • —
■ — ' —
■ — - co — ' 45. N0 Cn o o cn en o o o o cn o o o ?r oo ro M ro N 4s. oo co M θ θ o o o —
■ 45, O — ■ I0 45. — ' 45. O 00 O 4S, — ' C0 45. 0 0 00 4S. OO CO CO OO O 2
O — ' NO O O — ' C NO NO — ' M Ol O O cn M co oo — ' 00 CO 4-. N0 O O O Cn en CD 00 O 45. O 00 00 O —
■ — 'X3
CΛ m ©
4s. 4i. 4s. 45. 45, 4s, 45. 4s, 4i, 45. 4s, 4s, 4i, 4i. 45, 45, 45, 45. 45. 45. 4i. 4s, 4i, 4s, 4s, 4s^
Z
O
45. 45. 45. 45. 45, 4S. 45, 45. 45. 45. 45, 45. 45. 45, 45, 45. 45, 45. 45. 45. 45. 4S. 4s. 45, 45, 4s. 4s, 45. 45, 4s. 45. 4S, 4S, 45, 4s. 45. 45, 4s. 4S, 4s. 45. 4S, 45. 45. 4i. 4s. 4s. 4s. 4s, 00 00 00 00 00 CD 00 CD 00 00 00 oo oo oo oo oo oo oo oo 00 00 CO CD 00 00 00 CD 00 00 CD CO 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 CD 00 NO NO NO NO NO NO NO NO NO NO NO to No ro ro No No ro ro NO NO NO NO NO NO ro NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO "
Cπ cπ en en cπ en en cπ cn n en cπ cπ cπ cπ cn cπ cn cn cπ cn en en n n n cn en π cn cn cn Cn en cn Cπ cn cn en Oo en en cn cn cn en cn cn Φ
NO NO NO NO NO NO NO NO NO NO NO ro ro NO ro NO NO ro ro NO NO NO NO NO NO ro NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO N0 NO NO NO NO 3
CO Co Co CO CO 00 Co CO co CO CO ω c-o ω ω co co co co co co CO 00 00 co Co Co 00 00 CO 00 Co Co Co CO CO CO co CO 00 00 Co CO CO CO CO CO CO eo .
NO NO NO NO NO NO ro NO NO NO NO NO ro b b Kb Kb Kb fό NO NO NO NO NO ro NO NO NO NO NO NO ro NO NO NO NO NO NO NO NO NO NO NO NO "NO ro Kb Kb Kb Ω o o O O o o O oO o o o o o o o o 0 0 O 0 O 0 0 O 0 0 0 0 0 O O O O O 0 0 O 0 O O 0 o o o o o H- o o o o o o O O o o O O O o o o o o o o o 0 0 O 0 O 0 0 O 0 0 0 0 0 O O O O O 0 0 O 0 O O 0 o o o o o Φ c_ C, c , c . «... ( ,. c._ r_ r C c_ r c r . c c. c c - <-. c c. c_ c_ c C_ f c f - c_ c c_ c c , c , c, . <-.. c._ c c_ c_ C— c c_ r c_. c_ c . c_ c_
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > >
Z Z. Z. Z Z Z z Z z Z Z Z Z Z. Z. Z z z Z. Z
NO NO NO NO M NO NO NO NJ NO NO NO NO rO NO NJ NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO M NO NO N^
S.
eπ eπ en en en eπ 4s, 4 45, 5, 45. 45. 5. 0 00 1 — > —x — —■ —> — — 1 M M M M M M M O Cn Cn 4s. 4s. Oo Co θo Co Co Oo co Co Co oo θo Cθ cHn- oo M M cn 4s, o o en en ro o o o o o — ' O o o o cn cn No 00 M
— ' M M — ' 00 00 NO 45, Cθ 4-. 00 4S, 4S. OO NO O OO OO O — ' M O O o — cn —• —. —■ -A 0 — ' NO M Co oo cn — • —. —. —. —. —- —. —■ —. _ . —. o Ω
,-. 00 O M O 00 M ^ M M O O oo cn cn o oo 45. 45. 45. M Cθ N0 N0 4 Co r 4S, Co N0 C0 Co Cθ — ' CO NO — ■ N0 N0 N0 N0 N0 C v~ C v~O 4S, — ' _.
8 M — ■ 00 , 45. 00 ?3 -' N0 O 45. M 45. — ' 00 -' oo oo oo 45. No o o oo 4S en o o o o cn cn M M 45, o co M ω ro ω ol o uo ro S w o
", — ■ — ■ M o en c -o- - 4s, 0 — ' NO NO NO CO NO O M O O O 45. O 45. C0 O — O — ' O Cπ O NO NO O OO NO O 00 — ' M C O O co J^TS
CΛ rn ©
rO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO N0 N0 N0 N0 — ' O O O O O O O O O O O O O O O M M M M M M M M M M M M O O O O O O O O O O O O O O Cn en -+ cn ro co No o o o o o o o oo M M O cn 4-. co co co OO OD M 0 45, CO CO CO CO N NO O O O OD 00 45. CO NO — ■ _■ —- — ■ O O — ' O 00 Q O M 4s. cn — ' O O oo oo cn ro o eπ co cn M — ' o eo NO O 4-. Cn O C0 C00 CX> C0 — ' CD I0 45. ro — J O M CJ0 45. O Cn O 4i. 4i. O Cn C0 C0 — ' NO ^.
rO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO — ■ — ' — ■ 45. 45. 45. 4i, 4i, 4i, 4i. 4i. 45. 45. 4s. 45. 00 45. 4s, rO 4s. 00 4s, 4s, — ' 4S. O NO O O o O O O O NO O O O NO o O f-v C O O oo O f-v O O -→: o o o o o o o o o o o o ro — ' o oo o cn o — ' o oo cπ 9° 45. Co NO vi ___ θ vo 8 CJ o-o x o (v o cNov θn v3 c —n θ - - Ω
Cn O O O Cπ O O Cn — , M O M M 4S. O O CO O O M CO — ' O ≥ S&.8.4&5. CRD> vθli O£ C N rjθs ° —' 00 CO NO ^ O 45. 00 r CJ0 (3 O C0 Tj-
CΛ m
© , .,—
OO OO OO CD OO OO OO CD M M M M O O O O O O O O O O O O O O O O O O O O O CJO (JO Cjo Cn Cn Cn CjO CJ0 4s, 4S, 4S, 4i. 45. 4i. 4i. 4S, Ό z
rO NO NO NO NO NO NO NO
CO OO CO CO CO OO OO CO OO OD OO OO OO OD OO OO OO C» OO OO OO C» OO C» cj3 θι cn con cjι cn cn cjo
M vj v v-j v-j --j --j --j O O O O O O O O r ro i r r io ro ro fό fo iό io Kb Kb Kb Kb
O O O O O O O O O O O O O O O O H- O O O O O O O O O O O O O O O O Φ
C_ C_ <__ C_ C_ C_ C_ C_
>>>>>>>> >>>>>>>>
ro ro ro ro ro ro co co _, M o o o 00 o 00 o o o o M M 00 4s. o oo o M cn 4s. 4i, —' NO CΛ
NO H- 0 0 0 0 0 01 45. 45, or — • o ra _ —, M ' O O O — ' O Ol Ol >5 CO - ' N0 rO N0 rO 4s, 4S, N0 M N0 O M O O M O — ' — ■ NO NO NO — en co 4s, — ' 45. 0 0 0 00 _ . o 5, oo 4s, s. cπ o v 4i. o o o o o o oo o o o en en en 45, M O Ω o — ' Oo ro co NO o -
cn M O O cn ∞ - ≥ S M M ^ ^ ^ ^ ^ ^ r ro No g ∞ ∞ ∞ g ^ o o o -' O NO ^ O gO OO O M NO Cn — ' NO Cθ θ en NO N NO ^ -5 cn ^ S n r3 M N^ c^ vj vj vj C Oo ω co 45. I NO NO N ci " " o o ω o o ∞ ro 4s. M θ θ o g o
IO Oo 4s, 4v, rO OO OO OO OO o co ro o 00 M NO O CO O O O O NO NO CD O M 00 "O
TABLE 3
SEQ ID NO: Template ID Component ID Start Stop
18 1-1:238576.2:2001 JAN 12 71300749V 1 280 946
18 LJ.238576.2.2001JAN12 4637090H1 296 554
18 U:238576.2:2001JAN12 605951 OH 1 307 878
18 LI.238576.2.2001JAN12 6424708H1 307 865
18 U:238576.2:2001JAN12 4943507H1 307 603
18 U:238576.2:2001JAN12 5107771 H1 308 557
18 1-1:238576.2:2001 JAN 12 6858201 HI 316 637
18 U:238576.2:2001JAN12 5574827H1 324 593
18 U:238576.2:2001JAN12 5292641 H2 332 51 1
18 U:238576.2:2001JAN12 7351314H1 334 785
18 U:238576.2:2001JAN12 3126908H1 334 622
18 U:23857ό.2:2001JAN12 2913933H1 334 609
18 U:238576.2:2001JAN12 4530958H1 338 626
18 U:238576.2:2001JAN12 595195H1 337 535
18 U:238576.2:2001JAN12 7272621 HI 338 863
18 U:238576.2:2001JAN12 2899931 HI 346 652
18 U:238576.2:2001JAN12 6120217H1 260 838
18 U:238576.2:2001JAN12 51 18272H1 259 532
18 U:238576.2:2001JAN12 3984701 HI 186 494
18 U:238576.2:2001JAN12 3642338H1 184 497
18 U:238576.2:2001JAN12 3209133H1 184 419
18 U:238576.2:2001JAN12 338451 OH 1 185 454
18 LI:238576.2:2001JAN12 2690213H1 185 444
18 U:238576.2:2001JAN12 5338826H1 185 293
18 U:238576.2:2001JAN12 7231614H1 186 732
18 U:238576.2:2001JAN12 5076156H1 189 466
18 U:238576.2:2001JAN12 5265030H1 192 453
18 U:238576.2:2001JAN12 5351009H1 190 298
18 U:238576.2:2001JAN12 4056963H1 190 509
18 LI:238576.2:2001 AN12 3128195H1 190 484
18 LI:238576.2:2001JAN12 2562930H2 190 453
18 L1:238576.2:2001JAN12 1581592H1 190 394
18 L1:238576.2:2001JAN12 100567H1 190 409
18 LI:238576.2:2001JAN12 71 152815V1 185 850
18 LI:238576.2:2001JAN12 3416969H1 192 455
18 LI:238576.2:2001JAN12 974491 HI 194 352
18 LI:238576.2:2001JAN12 6126528H1 228 544
18 LI:238576.2:2001JAN12 7027657H1 198 632
18 LI:238576.2:2001JAN12 2198232H1 199 464
18 LI:238576.2:2001JAN12 6168044H1 199 321
18 LI:238576.2:2001JAN12 4563346H1 199 453
18 LI:238576.2:2001JAN12 61 18740F8 213 832
18 1-1:238576.2:2001 JAN 12 265346H1 201 557
18 LI:238576.2:2001JAN12 3163862H1 201 493
18 LI:238576.2:2001JAN12 3199104H1 205 338
18 LI:238576.2:2001JAN12 5196915H1 205 478
18 LI:238576.2:2001JAN12 60123995D2 205 415
18 U:238576.2:2001JAN12 4790072H1 207 491
18 U:238576.2:2001JAN12 4549532H1 209 489
TABLE 3
SEQ ID NO: Template ID CompΩnent ID Start StΩp 18 LI:238576.2:2001JAN12 3316908H1 210 468 8 LI:238576.2:2001JAN12 935927H1 210 437 8 LI:238576.2:2001JAN12 3928681 HI 211 497 8 LI:238576.2:2001JAN12 2057892H1 210 469 8 LI:238576.2:2001JAN12 6161637H1 211 530 8 L1:238576.2:2001JAN12 139725H1 213 277 8 LI:238576.2:2001JAN12 139726H1 213 281 8 U:238576.2:2001JAN12 5687728H1 216 497 8 LI:238576.2:2001JAN12 4997133F6 220 713 8 LI:238576.2:2001JAN12 3217567H1 219 521 8 LI:238576.2:2001JAN12 3950545H1 219 514 8 U:238576.2:2001JAN12 3566683H1 220 475 8 LI:238576.2:2001JAN12 3900367H1 221 500 8 LI:238576.2:2001JAN12 4433278H1 222 500 8 LI:238576.2:2001JAN12 4997133H1 220 410 8 LI:238576.2:2001JAN12 1806022H1 223 498 8 U:238576.2:2001JAN12 3080532H1 223 553 8 LI:238576.2:2001JAN12 3760343H1 226 529 8 LI:238576.2;2001JAN12 4220456H1 226 521 8 LI:238576.2:2001JAN12 1712435H1 227 454 8 LI:238576.2:2001JAN12 4221963H1 226 524 8 L1:238576.2:2001JAN12 4879766H1 228 479 8 LI:238576.2:2001JAN12 1419707H1 235 504 8 LI:238576.2:2001JAN12 3454496H2 240 506 8 LI:238576.2:2001JAN12 3533335H1 243 518 8 LI:238576.2:2001JAN12 4212591 HI 243 517 8 LI:238576.2:2001JAN12 6329103H1 244 828 8 U:238576.2:2001JAN12 3632279F6 243 765 8 U:238576.2:2001JAN12 4668415H1 243 525 8 LI:238576.2:2001JAN12 3155123H1 243 531 8 LI:238576.2:2001JAN12 7286542H1 244 478 8 U:238576.2:2001JAN12 1932192H1 245 521 8 LI:238576.2:2001JAN12 878880H1 246 483 8 U:238576.2:2001JAN12 6563713H1 247 702 8 LI:238576.2:2001JAN12 6902103H1 250 869 8 LI:238576.2:2001JAN12 5810544H1 248 530 8 U:238576.2:2001JAN12 134194R1 256 729 8 LI:238576.2:2001JAN12 5812769H1 253 556 8 LI:238576.2:2001JAN12 3539319H1 256 442 8 LI:238576.2:2001JAN12 134194H1 257 420 8 LI:238576.2:2001JAN12 134194R6 257 863 8 LI:238576.2:2001JAN12 3578956H1 151 420 8 LI:238576.2:2001JAN12 3616603H1 152 364 8 U:238576.2:2001JAN12 2476111 HI 156 396 8 LI:238576.2:2001JAN12 5762340H1 159 693 8 U:238576.2:2001JAN12 3320288H1 161 435 8 LI:238576.2:2001JAN12 3320240H1 160 437 8 LI:238576.2:2001JAN12 g1981931 163 537 8 LI:238576.2:2001JAN12 3320841 HI 167 443
TABLE 3
SEQ ID NO: Template ID CampΩnent ID Start Stap
18 LI:238576.2:2001JAN12 6286430H2 170 785
18 LI:238576.2:2001JAN12 6539558H1 170 727
18 U:238576.2:2001JAN12 4069509H1 170 483
18 U:238576.2:2001JAN12 2846475H1 170 443
18 U:238576.2:2001JAN12 g5665303 171 641
18 LI:238576.2:2001JAN12 3085108H1 170 486
18 LI:238576.2:2001JAN12 2515442H1 177 519
18 LI:238576.2:2001JAN12 1406990H1 177 430
18 LI:238576.2:2001JAN12 1510768H1 176 390
18 U:238576.2:2001JAN12 1512417H1 176 350
18 LI:238576.2:2001JAN12 4354246H1 179 460
18 U:238576.2:2001JAN12 2863756H1 ' 179 509
18 LI:238576.2:2001JAN12 3402689H1 181 428
18 LI:238576.2:2001JAN12 4193675H1 184 471
18 LI:238576.2:2001JAN12 5648061 HI 182 453
18 LI:238576.2:2001JAN12 4445516H1 181 454
18 LI:238576.2:2001JAN12 5646947H1 182 422
18 U:238576.2:2001JAN12 6252033H1 857 1271
18 U:238576.2:2001JAN12 g2741 102 858 1333
18 U:238576.2:2001JAN12 6252420H1 862 1333
18 LI:238576.2:2001JAN12 3999837H1 863 1 170
18 LI:238576.2:2001JAN12 4656292H1 863 1 151
18 LI:238576.2:2001JAN12 g4533809 868 1334
18 U:238576.2:2001JAN12 2698233H1 871 1113
18 U:238576.2:2001JAN12 g4243339 872 1333
18 U:238576.2:2001JAN12 g3751052 872 1333
18 U:238576.2:2001JAN12 g4899785 872 1333
18 LI:238576.2:2001JAN12 4695842H1 869 1204
18 LI:238576.2:2001JAN12 5559592H1 825 1 1 1 1
18 U:238576.2:2001JAN12 6860869H1 836 1349
18 LI:238576.2:2001JAN12 535566H1 830 1 1 18
18 LI:238576.2:2001JAN12 g5425786 832 1337
18 LI:238576.2:2001JAN12 g2964150 829 1342
18 U:238576.2:2001JAN12 g5858287 835 1334
18 U:238576.2:2001JAN12 g3884780 866 1336
18 U:238576.2:2001JAN12 71218860V1 841 1333
18 LI:238576.2:2001JAN12 g5396715 849 1338
18 LI:238576.2:2001JAN12 5864305H1 849 1 188
18 LI:238576.2:2001JAN12 5638395H1 849 1 1 12
18 LI:238576.2:2001JAN12 1259213F1 854 1 195
18 U:238576.2:2001JAN12 1259213H1 854 1 124
18 LI:238576.2:2001 AN12 6480833H1 1 439
18 U:238576.2:2001JAN12 4753971 HI 94 355
18 LI:238576.2:2001JAN12 5780889T6 104 682
18 LI:238576.2:2001JAN12 3854966H1 127 241
18 LI:238576.2:2001JAN12 905037H1 140 292
18 LI:238576.2:2001JAN12 3673616H1 140 450
18 LI:238576.2:2001JAN12 1298467H1 140 393
18 U:238576.2:2001JAN12 8174823H1 143 802
TABLE 3
SEQ ID NO: Template ID CampΩnent ID Start Stap 18 LI:238576.2:2001JAN12 161642H1 148 248 8 LI:238576.2:2001JAN12 g5657944 919 1333 8 LI:238576.2:2001JAN12 g2017125 922 1157 8 LI:238576.2:2001JAN12 gl801517 922 1337 8 LI:238576.2:2001JAN12 70831682V1 924 1350 8 U:238576.2:2001JAN12 7332139H1 931 1340 8 LI:238576.2:2001JAN12 71151083V1 929 1343 8 LI:238576.2:2001JAN12 6219936H2 930 1297 8 LI:238576.2:2001JAN12 6847334H1 943 1326 8 LI:238576.2:2001JAN12 2314966H1 934 1238 8 LI:238576.2:2001JAN12 g2270407 935 1092 8 LI:238576.2:2001JAN12 2314982H1 948 1234 8 U:238576.2:2001JAN12 501348H1 946 1121 8 LI:238576.2:2001JAN12 501349R6 946 1344 8 LI:238576.2:2001JAN12 501349T6 946 1293 8 LI:238576.2:2001JAN12 3779876H1 947 1274 8 LI:238576.2:2001JAN12 g5665235 953 1333 8 LI:238576.2:2001JAN12 g5848253 954 1338 8 LI:238576.2:2001 AN12 406979H1 956 1213 8 LI:238576.2:2001JAN12 2684534H1 964 1221 8 U:238576.2:2001JAN12 g3151135 969 1336 8 U:238576.2:2001JAN12 g3118693 969 1340 8 LI:238576.2:2001JAN12 5030434H1 964 1217 8 LI:238576.2:2001JAN12 g4083461 970 1333 8 LI:238576.2:2001JAN12 g3677123 975 1333 8 LI:238576.2:2001JAN12 g3920030 976 1333 8 LI:238576.2:2001JAN12 g3594994 976 1336 8 LI:238576.2:2001JAN12 g3802778 976 1336 8 LI:238576.2:2001JAN12 2564348H1 984 1267 8 U:238576.2:2001JAN12 g2268169 990 1333 8 U:23857ό.2:2001JAN12 g2751136 990 1326 8 U:23857ό.2:2001JAN12 g2206610 996 1333 8 LI:238576.2:2001JAN12 g!810373 1000 1312 8 LI:238576.2:2001JAN12 6847534H1 1006 1326 8 U:238576.2:2001JAN12 g4684966 1014 1333 8 LI:238576.2:2001JAN12 627744H1 1016 1287 8 LI:238576.2:2001JAN12 1840346H1 1020 1290 8 LI:238576.2:2001JAN12 g2056756 1033 1333 8 U:238576.2:2001JAN12 gl987610 1034 1332 8 LI:238576.2:2001JAN12 g1988233 1034 1321 8 U:23857ό.2:2001JAN12 g1987797 1034 1299 8 U:238576.2:2001JAN12 g5038005 1036 1326 8 U:23857ό.2:2001JAN12 286743F1 1037 1333 8 LI:238576.2:2001JAN12 g983401 1049 1336 8 LI:238576.2:2001JAN12 6555494H1 1055 1333 8 LI:238576.2:2001JAN12 g960046 1050 1301 8 LI:238576.2:2001JAN12 g5553900 1051 1327 8 LI:238576.2:2001JAN12 g3070776 1051 1336 8 U:238576.2:2001JAN12 606654H1 1061 1335
TABLE 3
SEQ ID NO: Template ID Component ID Start Stop 18 U:238576.2:2001JAN12 g2463808 1068 1335 8 U:238576.2:2001JAN12 g3070441 1074 1336 8 U:238576.2:2001JAN12 5989860H1 1076 1330 8 U:238576.2:2001JAN12 6395065H1 1080 1328 8 U:238576,2:2001JAN12 g7701004 1085 1336 8 U:238576.2:2001JAN12 1287503F1 1085 1335 8 LI:238576.2:2001JAN12 1287454H1 1085 1266 8 LI:238576.2:2001JAN12 6345648H1 1088 1333 8 LI:238576.2:2001JAN12 4124347H1 1087 1275 8 LI:23857ό.2:2001JAN12 6353879H1 1088 1325 8 U:238576.2:2001JAN12 g5913340 1095 1333 8 U:238576.2:2001JAN12 2558418H1 1128 1333 8 U:238576.2:2001JAN12 g4150032 1133 1333 8 U:238576.2:2001JAN12 5109779H1 1142 1338 8 U:238576.2:2001JAN12 1925508R6 1143 1333 8 L1:238576.2:2001JAN12 1925508H1 1143 1333 8 LI:238576.2:2001JAN12 g5529626 1157 1333 8 LI:238576.2:2001JAN12 71175323V1 884 1088 8 LI:238576.2:2001JAN12 g5450857 874 1335 8 LI:238576.2:2001JAN12 g6046820 876 1335 8 U:238576.2:2001JAN12 g3665665 880 1333 8 U:238576.2:2001JAN12 4599219H1 875 1188 8 U:23857ό.2:2001JAN12 227744R1 884 1335 8 U:238576.2:2001JAN12 g5885583 885 1335 8 U:238576.2:2001JAN12 371585H1 882 1124 8 LI:238576.2:2001JAN12 g2325594 886 1333 8 LI:238576.2:2001JAN12 g2195406 894 1332 8 LI:238576.2:2001JAN12 g4664967 897 1333 8 LI:238576.2:2001JAN12 g2674662 905 1335 8 LI:238576.2:2001JAN12 g3086953 906 1336 8 U:238576.2:2001JAN12 g4095013 907 1333 8 U:238576.2:2001JAN12 g5113058 909 1333 8 U:238576.2:2001JAN12 70942171VI 909 1079 8 U:238576.2:2001JAN12 g3958103 910 1333 8 U:238576.2:2001JAN12 g2458743 916 1336 8 U:238576.2:2001JAN12 g1383536 918 1316 8 U:238576.2:2001JAN12 3728404H1 1165 1346 8 U:238576.2:2001JAN12 g3034058 1168 1336 8 LI:238576.2:2001JAN12 235645H1 1183 1333 8 LI:238576.2:2001JAN12 236139H1 1183 1333 8 L1:238576.2:2001JAN12 2320995H1 1190 1337 8 LI:238576.2:2001JAN12 g1068687 1197 1316 8 LI:238576.2:2001JAN12 g3091528 1212 1333 8 LI:238576.2:2001JAN12 3078023H1 1243 ' 1337 8 U:238576.2:2001JAN12 786346H1 1253 1326 8 U:238576.2:2001JAN12 6133859H1 1257 1333 8 U:238576.2:2001JAN12 2278836H1 346 642 8 L1:238576.2:2001JAN12 4382957H1 346 617 8 LI:238576.2:2001JAN12 2562762H1 346 631
TABLE 3
SEQ ID NO: Template ID Component ID Start Stop 18 LI:23857ό.2:2001JA 12 6296712H1 348 729 8 L1:238576.2:2001JAN12 280390H1 349 730 8 LI:23857ό.2:2001JAN12 g1978517 352 741 8 L1:238576.2:2001JAN12 1711236H1 355 567 8 LI:23857ό,2:2001JAN12 2208941 HI 355 564 8 LI:238576.2:2001JAN12 5330792H1 360 621 8 LI:238576.2:2001JAN12 2504585H1 366 619 8 U:238576.2:2001JAN12 gl812559 366 594 8 LI:238576.2:2001JAN12 g1383596 670 1071 8 LI:238576.2:2001JAN12 879714H1 672 936 8 U:238576.2:2001JAN12 71302655V1 678 1271 8 LI:238576.2:2001JAN12 60123995B2 681 1276 8 LI:238576.2:2001JAN12 g3886420 692 839 8 U:23857ό.2:2001JAN12 71280905V1 691 867 8 U:23857ό.2:2001JAN12 70834311VI 692 1309 8 LI:238576.2:2001JAN12 71154379V1 696 868 8 U:238576.2:2001JANΪ2 71220284V1 707 1347 8 U:23857ό.2:2001JAN12 265346T6 711 1292 8 U:238576.2:2001JAN12 70832994V1 713 1348 8 U:23857ό.2:2001JAN12 71219428V1 714 1338 8 LI:238576.2:2001JAN12 g2206609 715 1005 8 Ll:23857ό.2:2001JAN12 70834220V1 738 1367 8 U:238576.2:2001JAN12 4938140H1 734 1041 8 LI:238576.2:2001JAN12 g2717345 755 1315 8 LI:238576.2:2001JAN12 71302491VI 758 1326 8 LI:238576.2:2001JAN12 134194F1 762 1333 8 LI:238576.2:2001JAN12 134194T6 767 1134 8 LI:238576.2:2001JAN12 71301214V1 773 1326* 8 U:23857ό.2:2001JAN12 71152277V1 777 1333 8 U:23857ό.2:2001JAN12 70947307V1 786 1174 8 U:23857ό.2:2001JAN12 70834128V1 797 1349 8 U:23857ό.2:2001JAN12 70831885V1 797 980 8 U:23857ό.2:2001JAN12 71153557V1 388 995 8 U:238576.2:2001JAN12 1379534H1 388 638 8 U:23857ό.2:2001JAN12 2129696H1 403 675 8 U:23857ό.2:2001 AN12 4938547H1 409 715 8 LI:23857ό.2:2001JAN12 2510749H1 415 770 8 U:238576.2:2001JAN12 5659963H1 424 697 8 U:23857ό.2:2001JAN12 1456371 HI 421 678 8 LI:238576.2:2001 AN12 3604720H1 425 757 8 U:238576.2:2001JAN12 g1977496 426 748 8 U:238576.2:2001JAN12 71220503V1 428 921 8 LI:238576.2:2001JA 12 2748683H1 429 693 8 LI:238576.2:2001JAN12 5659664H1 432 695 8 LI:238576.2:2001JAN12 71153764V1 435 949 8 LI:238576.2:2001JAN12 3079315H1 453 784 8 LI:238576.2:2001JAN12 3257890H1 463 766 8 LI:238576.2:2001JAN12 2489834H1 464 705 8 LI:238576.2:2001JAN12 2244628H1 468 729
TABLE 3
SEQ ID NO: Template ID CompΩnent ID Start Stap 18 U.238576.2:2001JAN12 1447415H1 470 748 8 U:238576.2:2001JAN12 3769925H1 481 814 8 U .238576.2:2001 JAN 12 6848683H1 481 1137 8 U:238576.2:2001JAN12 851017H1 481 745 8 LI:238576.2:2001JAN12 3641003H1 486 718 8 LI:238576.2:2001JAN12 8262729U1 488 1214 8 U..238576.2.2001JAN12 591481 HI 489 667 8 L1:238576.2:2001JAN12 591512H1 489 730 8 LI:238576.2:2001JAN12 2316586H1 489 744 8 U:238576.2:2001JAN12 71153782V1 508 1061 8 U:238576.2:2001JAN12 5274050H1 511 666 8 U .238576.2:2001 JAN 12 608208H1 513 779 8 U:238576.2:2001JAN12 5904564H1 513 843 8 U:238576.2:2001JAN12 6061631 HI 517 1142 8 U:238576.2:2001JAN12 2866403H1 523 849 8 LI:238576.2:2001JAN12 g983400 526 895 8 LI:238576.2:2001JAN12 4952292H1 543 799 8 LI:238576'.2:2001JAN12 2181660H1 551 861 8 LI:238576.2:2001JAN12 5305886H1 559 809 8 LI:238576.2:2001JAN12 2563730H1 587 874 8 U:238576.2:2001JAN12 . 4666484H1 590 858 8 U:238576.2:2001JAN12 6438124H1 592 1137 8 U:238576.2:2001JAN12 4666384H1 590 858 8 U:238576.2:2001JAN12 70819958V1 599 1090 8 U:238576.2:2001JAN12 3246108H1 599 743 8 U:238576.2:2001JAN12 5440935H1 606 753 8 LI:238576.2:2001JAN12 70947851VI 617 973 8 U:238576.2:2001JAN12 70947904V1 617 965 8 LI:238576.2:2001JAN12 2012901 HI 615 700 8 LI:238576.2:2001JAN12 1355566H1 626 886 8 U:238576.2:2001JAN12 1237154H1 625 870 8 U:238576.2:2001JAN12 1724023H1 631 839 8 LI:238576.2:2001JAN12 71217985V1 632 819 8 LI:238576.2:2001JAN12 g2015041 637 1049 8 LI:238576.2:2001JAN12 3632279T6 640 1218 8 U:238576.2:2001JAN12 6606557H1 647 1118 8 L1:238576.2:2001JAN12 1806939H1 646 950 8 U:238576.2:2001JAN12 630175H1 645 736 8 U:238576.2:2001JAN12 6513373H1 650 1275 8 U:238576.2:2001JAN12 71151178V1 651 1252 8 U:238576.2:2001JAN12 7342506H1 653 1014 8 LI:238576.2:2001JAN12 71301883V1 660 1323 8 LI:238576.2:2001JAN12 71301830V1 661 1344 8 U:238576.2;2001JAN12 3866748H1 662 961 8 LI:238576.2:2001JAN12 3501407H1 662 995 8 U:238576.2:2001JAN12 g891119 668 951 8 L1:238576.2:2001JAN12 7062009H1 673 1090 8 U:238576.2:2001JAN12 6401339H1 369 652 8 U:238576.2:2001JA 12 3483783H1 373 645
TABLE 3
SEQ ID NO: Template ID Camponent ID Start Stop
18 U:238576.2:2001JAN12 3375342H1 370 620
18 U:238576.2:2001JAN12 5473124H1 376 544
18 U:238576.2:2001JAN12 5607966H1 375 647
18 U:238576.2:2001JAN12 5610077H1 375 621
18 U:238576.2:2001JAN12 4302082H1 378 648
18 U:238576.2:2001JAN12 516261 l 385 1026
18 U:238576.2:2001JAN12 516261 HI 385 622
18 U:238576.2:2001JAN12 g21 10639 799 1249
18 U:238576.2:2001JAN12 70832396V 1 797 979
18 LI:238576.2:2001JAN12 1653928H1 809 1077
18 U:238576.2:2001JAN12 71300941V1 814 1335
18 U:238576.2:2001JAN12 70943453V1 814 979
18 U:238576.2:2001JAN12 g2953761 815 1336
18 LI:238576.2:2001JAN12 g3933979 822 1336
18 LI:238576.2:2001JAN12 659592H1 820 1 1 13
18 LI:238576.2:2001JAN12 g3674153 826 1333
18 LI:23857ό.2:2001JAN12 g2907492 824 1333
18 LI:238576.2:2001JAN12 5559560H1 825 1 1 1 1
18 LI:238576.2:2001JAN12 g4329635 827 1333
19 U:903914.3:2001 JAN 12 gό034066 2214 2619
19 U:903914.3:2001 JAN 12 g3753899 2214 2626
19 U.903914.3:2001 JAN 12 3907692H1 6327 6446
19 Ll:903914.3:2001 JAN 12 4183814H1 5402 5595
19 LI:903914.3:2001JAN12 2657830H1 5427 5675
19 U:903914.3:2001JAN12 71060769V1 5482 6060
19 U:903914.3:2001JAN12 5786706H1 5494 5819
19 U.903914.3:200. JAN 12 5792665H1 5495 5821
19 Ll:903914.3:2001 JAN 12 5792546H1 5495 5814
19 U:903914.3:2001JAN12 5785277H1 5495 581 1
19 U:903914.3:2001JAN12 5784324H1 5495 5773
19 LI:903914.3:2001JAN12 71059036V1 5542 6072
19 U:903914.3:2001JAN12 71058059V1 5572 6060
19 LI:903914.3:2001JAN12 3795036H1 5569 5742
19 U:903914.3:2001JAN12 4291223H1 5607 5863
19 Ll:903914.3:2001 JAN 12 4289457H1 5606 5867
19 U:903914.3:2001JAN12 g889341 5634 6019
19 LI:903914.3:2001JAN12 71059190V1 5652 6060
19 U:903914.3:2001JAN12 2799687T6 5668 5925
19 Ll:903914.3:2001 JAN 12 g3052888 5671 6047
19 U:903914.3:2001 JAN 12 2799687F6 5675 5961
19 U:903914.3:2001JAN12 2799687H1 5675 5937
19 U:903914.3:2001 JAN 12 71057687V 1 5705 6060
19 U:903914.3:2001 JAN 12 4028967H1 5705 5978
19 U:903914.3:2001JAN12 2892448H1 5712 6001
19 U:903914.3:2001JAN12 71060472V 1 5733 6066
19 U:903914.3:2001JAN12 71057894V 1 5738 6060
19 U:903914.3:2001JAN12 71060780V 1 5741 6429
19 U:903914.3:2001 JAN 12 4771032H1 5750 5848
19 LI:903914.3:2001JAN12 71057806V 1 5758 6425
oooooooooooooooooooooooooooooooooooooooooooooooo
0
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
C ) C i o ro o C ) CO o o CO C ) C ) o CO ro C CJ J CO CO CO J CO CO CJ CJ CO CJ CD o CD co Cύ Cύ Cύ Cύ Cύ co co co co co co Cύ 00 CO O 00 CO CO CO CO Cύ Cύ co co co CO CO co co CO co CO CO co CO CO CO CO CO co co 00 00 CO 00 OO CO o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o φ
_4-. 5. 4i. 5. 4s. s. 4s, 4s. 4i. 45, 45. 5. 45. 45. 45. 5. 5. 45, 45. 45. 45. 45. 45. 4s. 45. 45. 4s. 45. 45, 45, 45. 45. 4s, 45. 45, 45, 45. 45, 4s. 45. 45, 45. 45. 45. 4S, 45. 45, 45, 45, 3 C CO G3 00 O3 CO CO C CO CO CO ω co o ω ώ ω co Co Co 00 CO CO Co CO 00 00 CO CO CO CO CO Co Co CO Co Co CO CO CO CO Co CO CO co CO CO CO "O
Kb Kb Kb fό Kb Kb Kb Kb Kb Kb Kb ro Kb Kb Kb Kb Kb Kb Nb NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO to Ω o o o o o o o o o o o o o o o o o o o O O O O O O O O O O O O O O O O O O O O O O O O O O O O O o o o o o o o o o o o o o o o o o o o O O O O O O O O O O O O O O O O O O O O O O O O O O O O O gφ
> > > > > >> > > > > > > >> >> > >>> > > > zzz zzzzz z z z z z >> > > >>> > > > > > > > > > >> > >> > >> > zzzzzzzzz zzzzzzzzzzzz
No ro ro ro ro ro ro io NO NO NO No ro ro ro ro ro No to ro No to No ro NO NO NO No ro No ro ro NO No ro NO NJ N^
c—jo' c—jo' c—π' c—_n' c—jo ' cOn cOπ θOι cOjo cOπ O O O O O O O O O O O O OO OO OO OO CD OO OO OO OO M M M ' vi v Mi Mi -
rii- cD CD 45. 45. cn o o c» oo cn oo No o M O Cn c-n 45. 45, 45» o oo o o cn en cn cn NO — ■ o O O M M
4S. θ ω θ 03 03 N0 4S. C0 0 4S. O C-o 4S, CJO Cπ Cn 03 M O Cn Cn 4s. 4s. CO OO OO CO — ' NO Cn O M M Q1 0I -O
cn cn en cn cn coo cn cn cn cjo cji cn cn cn cn cji cji cjo cn cn cn cn cn cjo c-n cjo cjo cn cn cn cn cjo c^ o o oo en o cn cn 4s, cn cn oo 4s, oι 4s. M CD M θ o en o cπ o cn cn — ■ 01 ro 45. o n cn - ' O 0 45. 0 0 0 0 45, — ' O o o o o co o ;-!-
O O N0 45, — ' Cπ Cn CO — ' O Co rO M — ' O 4i, C0 M 03 ∞ M M O M ro 3 C0 4-. 00 O M M M O O 00 O O O O O O O O 00 O O 00 i_;
CD θ 45. θo coo ω cn — " Cn 4i. o o o o — ' 4s, en o en M co 4s. oo — ' No o o 4s. M 0 4s, o o o o o o o o M O O M cn o co oo cj
ooooooooooooooooooooooooooooooooooooooooooooooooo
o
o o o o o o o o o O O O O O o o o o o o o o o o o O O O O O O o o O co co co eo co co co co co 00 CO CO CO 00 CO co 00 CO o o o o o o o o o O O O O O O o o o s. 4s, 4s. 4s, 4i. 4s. 4s, 45, 45. 45. 45. 45. 45. 5. 45. 45. 4s, 45, όo Co CO C CO CO CO CO Co CO CO Co CO CO CO CO CO CO ro Kb ro ro Kb fό iό Kb fό Kb Kb Kb Kb fό fό ro NO NO o o o o o o o o o o o o o o o o O O
O O O O O O O O O O O O O O O o O o
C_ C_ v_ C_ C_ C_ C_ C_ C_
>>>>>>>>> z >>z>z>z>z>z>z>z>z ro ro ro ro ro ro M ro ro No ro No ro ro No to ro ro
ro ro ro ro ro - . _■ _■ —. _■ _. — . _. _ . _. _. _. _■ _. — . _. _. _ , _. _, _. _. _. _, _- _- _< —, _, _ ' M M M M 45. M M M 45. cn cn cn cn en co
O O O O O O O O O O O O O O O O 00 CD CD 00 CD 00 00 00 00 CD CD C0 00 00 ro CD 00 ro 00 N0 N0 N0 N0 00 CO N0 N0 00 4-. 00 00 C0 C0 ^- 4S, C0 03 N NO O C» 00 ∞ N N NO ^ NO O O CD M M M M M M M M M M M M M M M M O Cn Cn 4s, eπ O O O O O M en Cθ Ω NO M CO O OO — ' O 00 — ' O O O O O O OO OO — ' Ol O Oi Cn Cn Ol Ol Ol Ol Oi CJI Ol Ui Ol - ' NO Cn Cn M CO OO Cn CO O O O CO M NO Oo CO ^!-
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO — ' O N0 N0 N0 M N0 N0 N0 N0 N0 N0 N0 N0 N0 N0 NO N0 M M M M CJ0 M M M Cn Cn C_π cJ Cn Cn CΛ cπ oo ro o co Nθ ro o Nθ 4s, — ' No cπ — - en — - o — ■ — ' 4s. 4s. o - ' 00 45, 45, 45. 45. 45, 4^ ^ 10 -^ 00 45. 45. 45. 45. 45. 45. 45. 45. 45. — ' M o co cn o ^t- — ' Cn o ro M 4-. oo — ' O0 45. — ' 0 4-. cn M — ' O M OO O 4S. OO CO NO — ■ — ' O0 00 4s. 4s. NO M — ■ — • o — - NO NO — ' cn oo Nθ Nθ 4s. co M cπ oo o θ
— ' O O M O — ' NJ O CO Cn — ' N0 M O N0 45, O 45, M 4s, — ' M 00 — ' CO CO NO NO CO Co Cn O — ' M 4s, O Co 4s, 0 — • — ' C0 C0 Cn 00 45. 00 00 θT5
ooooooooooooooooooooooooooooooooooooooooooooooooo
O f— ι— r— r— t— r— r— r— r— r- i — r— r— • r— r— r— r— r— r— r- i— r— ι— I- r- i — !~ i — r— i — r— r— i — i — r— i — i — r- i — r— r— r— I- i — i — r— r— r— I- o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
C ) o o C ) r 3 C ) o o C 3 C ) C ) C ) o C ) C ) C ) C ) C ) C ) C ) C ) o C ) C J C ) C ) C ) o C ) C ) C ) C ) o C ) C ) C ) C J o c > C ) C. J C ) C_) C ) c > CO C J C ) C ) O CO CO CO Cύ O O CO CO O CO O CO O O CO O CO O O O CO CO CO O O CO O CO CO CO O CO CO CO CΛ CO CO O CO O CO O CO CO CO O o o o o o o o o O o o o O o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o φ
45, 45. 45. 45. 45, 45. 45, 45. 45, 45, 45. 45, 45, 45. 45, 45. 45. 45. 45, 45. 45. 45, 45. 45, 45. 45. 45. 4s, 45. 45. 45. 45, 45, 45. 45. 45. 45, 45. 45, 45. 45. 45, 45- 45, 45. 45. 45. 45. 5.3
00 Co co 00 00 00 CO Co CO CO CO Co CO CO Co CO co 00 CO 00 CO CO co CO CO co CO Co co Co CO Co Co Co Co CO CO 00 00 Co Co CO CO CO CO 00 Co C Co "O ro ro ro NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO ro NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO O NO NO Ω o o o O O O O O O O O O O O O O O O O O O O o O O O O O O O O O O O O O o o o o O O O o NO NO O O o O O O O o o o NO O O O O O O O o o O O O o O O O O O O O o O o o O O O O O o O O O O O O O o o NO N O O O 8ω
D
>z>z>z>z>z>z >z>z>z>z>z>zz>>z>z >z>z>z>z>z>z>z>z >z>z>z>z>z>z>z>zz>>z>z>z>z>z>z>z>z>z>z>zz>>z>z>z>z>z ro ro ro ro ro ro ro No io ro ro ro to NO No ro ro ro ro No ro No ro ro ro ro ro ro io NO No ro ro ro ro ro N^
— ' — i — ■ — ' — ■ —■ _. _ . _i _i _. _ _. _- . _ _. _ ' NO NO NO NO NO NO NO NO NO ro rO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO CΛ C00 CD CO CO CD CD 00 C00 ∞ 00 CD 00 CD Co ro M M rθ NJ N0 -- -- —' --J -- — ' -- —' —' -- -- -- —' —' —' — ' —' —' O O O O O O O O O O O ^
45. 45, 4s. 45. 4v. CO Cθ N0 N0 N0 — ' _ _ — ' O O O — ■ O O O CO M M CJ Cn 45. 4 45. C CO Oo N --' -- — ' O O O CO OO OO OO M M 0 00 45. 45. Ω
—■ —' —' — ' J O O <) CO -' OJ M O O OO M M -' CD C)1 0 -' sl M ) (» tt S O CI) 0> 0 <) CI) ) ) W O' 'N l O> O sl Ol Cil l C ^
NO NO NO NO NO — ' N0 N0 N0 N0 — ' rO O NO NO NO W NO NO NO NO NO M NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO CΛ
— ■ — ' NJ C-o σ o o o o -- o o o Nθ θ θ 45. 45, o o o o o 45. o θ 45. θ 45. cn o o o c-o cn Nθ 4i. cn en 45, θ3 c-o cn eπ cn cn N Co oo H- ro co oo — ' 45. 0 — ' M M OO O 4 OO CO 45. CΠ NO NO NO NO NO NO NO M — ■ — ' C — I NO OO IO — ■ — ' O cn eπ co o coo o o cn co oo No oo o o o α NO M O OO OO — ' cn — O i f- K sH- ω - ' O — ' 45. cn o cn No o o o cn o NO — ■ — ' O θ cn 45, o oo o o o 4s, — ■ — ■ ro cn ro I- o oΩ
ooooooooooooooooooooooooooooooooooooooooooooooooo
O
o OOooOoOoOOooOoOoOoOOooOoOoOoOoOoOoOoOoOoOOooOoOoOoOOooOoOoOOoOooOOoOooOoOOooOoOOooOOoOooOoOoOoOoO oo oo oo c-o co co c3 Co o3 eo oo co co eo oo c-o o3 Co co co o3 co cjo oo w
O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O f^
S - J S j S S S S 4>. S S S j - - S ! 4- S S K - S - S - S ^ u ω u ϋ ω ω o ω ω o ω ω ω ω ω w ω ω ω ω w ω ω ω ^
K Ob KOb fOό fOό rOo ϊOό KOb iOό KOb KOb KOb iOό fOό KOb KOb KOb KOb fOό KOb fOό fOό KOb KOb fOό OOO OOOOO OOOOO O OOO OOO O OOO OH- oooooooooooooooooooooooooooooooooooooooooooooooooCD
C_ C_ C_ l-_ C_ C_ C_ C_ C_ C_ C_ C_ C_. C_ C_ C- (-_ C_ C_ C_ _ C_ C_ C_
>>>>>>>>>>>>>>>>>>> > > >>>>>>>>>>>>>>>>>>>>>>>>>>>>
Z Z Z^ Z^ Z^ Z^ Z^ ^ Z^ Z^ Z^ IZ^ Z^ Z^Z^ Z^ Z^ Z^ Z^ Z^ Z^ Z^ Z^ Z^Z^ Z
NO tO rO NO IO ro rO rO NO rO IO rO NO rO NO NO ro rO NO rO O NO NO IO IO rO NO IO ro rO NO M rO NO IO rO NO
10 45. 45. 45. 45, 45. 45, 45, 45. 45, .T_ 4. 4, . .rv, ^ . , 4. v, v. 4v. ^ 4v. ( v-j _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ ._, _ _ _ _ _ _ _ c ) rO CD M OO CO M M M M M M M O O O O Cj0 CJ0 45. 45, 45, 45^ 45. 00 rθ CD CX) CO C» C» 00 C00 C0 00 00 C0 00 03 C0 C» 00 00 CD Cθ ∞
O 45. co o o o en co ιo ιo 4s. — ' O CD M NO — ' M Cn θ M O Cn 4S. N0 45. M M O CJl Cn Cn 45, 4s, 4S. 45. 45, 45. 45, 4i, 45. 4S. 45, 45. 45, 45. 45. 45. Ω
M N0 M O O 45, M O 00 — ' NO O O — ' O 00 O M O 45. M — ' OO M -- — ' Cn O O O — ' NO — ' _ _ _ _. _ _ _ _ _ _ _ _ — . _ _ .
N0 Cπ 4s> Cjo Cn Cn 45. CJ0 CJι CJ0 Cπ CJo <_n C-π 4i, CJ0 45, 45. Cπ 45. 45> 45> 45. 45^
O en 00 _ 45, _ 3 O 45. O N0 O 00 N0 O O O C0 — ' O M OO C0 0 45. 4S. Cn 45, — ' O — ' — ' 45, 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 — ■ ;*■
NO — ' O O O 45. OO O1 45. — ' — ' 0 0 00 00 0 00 45, 45. 0 0 — ' O O O — ' NO 45, 00 00 _ O — ' 45. 01 0 0 — ' NO C00 4s, O O C Co CO Cn M M -2 ro o O M oo co cn oo o co en o o co oo o o o — ' O M oo 4-. No ro o co -_ oo a34s, co o co o o o M 4i, o o co o 45. oo M O M roT3
C-O θ3 0o CjO Oo CO C-O OO C0 03 CO Oo ω ω C-O C-θ rθ rθ NO N N NO N NO I N NO M N^
45. oo ω — ■ —■ -- — 1 — ■ —■ —' —■ —' —' -- — ' —- c» o o o o cn en cjo cjo 4s, 4i. 45. 4i. 45, 4 45, 45, ω co eo ω cjo ro No o o o M O Cn cn 45, 4s, co co co N No en cn 4s. 45. en co — ' O 00 M O 0 45. 4- — ■ — ' 0 0o M o en en 4s. 45, 45, 45. co ro No — ' O 00 Ω
— ' CO C0 45. -J O — ' — " O O CLn CJ0 45. 45. 4-. 03 N0 O O 45. ω M C-0 θ N0 O Cj0 C» CD G3 45. M M NJ M CJ0 ω
O3 ω CΛ CO CO Co ω CO Co O3 Co C CO O3 CO O0 0i N0 N0 N0 Nv) N0 r N0 N0 M rθ M M M ro r^
∞ M ocjoo oeno Jcn. o— ■ —cjo ' c4j5o, c4j5o. c4j5o, c45n, 4cj5o, c4-5n. c45n. e45π, c45n. c4j5o, 405.4M5, c0oo0 c0oo 0co M— ' MO NO oMo Mo Cooo θ— - oM θ— ■ —M θ θ o o cn o o en o o o 4^ ' N0 _ O O M — ■ — ' M — - NO — ' O OO O NO M — ■ — ' Ω ro co — ■ — ' NO M O O O O O O O O O O — ' Cn CO — ' — ' OO CO O O O O O OO O O Cn θ CO O OO O O OO O O O M 0 45. 00 0 0 θ 3
ooooooooooooooooooooooooooooooooooooooooooooooooo
z o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o oo o o o oo o oooo o oo oo co co ooo oω oω o oeo oco oc3 oco ow oco oθ3 oθ3 oco oc co oω oco coo oco oc-o oo oω o o o o o o o o o o o o o o o o o o o o o o o O O O O O O O O O O O O O O O O O O O O 0 O O O O O O 0 O O O O O O O O O 0 O O O 0 O O O Φ1
45. 45, 45. 5. 45. 45. 4^ 45, 45, 45, 45, 4^ 45. 45. 45. 45, 5, 45. 45. 45^ 3 co όo co co co co όo co όo co co ω eo co co ω ω co co cΛ Co co ω τs r fό f fό o .ό fo ro i%b ro ro .ό ro to
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 — Ω ¥
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 CD c_ c_. c_. c_ c_ c_ c_ (__ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_. c_ c_ c_ c_ c^ Ό > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > zzz z z zzzzzzzzz z zzzz zz z zz zzzzzzzzz z z z zzz z zzz zz zz zz ro NO to NO M ro ro No ro No ro ro ro jo No io NO NO M ro No ro io ro i ro ro ro ro ro ro io NO No ro N^
O
Ω > CD
3 r— τs rπ
D
M M M M M M M M M M M M M M M M M M M M M M M M M M M — ' 45. 45, 45. 45. 45, 45, 45. 45. 4S. 45. 45, C OO (_ CO C- CO CO CO CO O OO _ _ —■ _ _ — ' O O O O O O O O O O O M CO CO CO NO NO NO NO NO — ' O O O O O CO M M M O Cn 45. H-
0 0 Cπ cn cn cn cπ cn cπ 4s. ' θ o o o co M θ cπ cn cn en jv, M M θo co 45. — . _ _ —
M NO OO OO CO CO OO O O O O — ■ — ' M CO M O NO — ' CO OO _ OO O CO _ Cn rO O O O OO O O O O N M O O O O C0 45, 0 0 00 0 45. H-
M M M M M M M M M M M M M > 4-. Cn 45. 45. 45. 45. 45, 45. 45, 4i> 5. 45. 45, 45, Cθ 45> 45. 4s, 45, CO CO CΛ
45. W O0 45. 45, 4s, 45. 45. 45. 45, 45, 4s. 45. C 45. 4s. CO 4s. 4s. 45, 00 N0 45. 45, O0 Co — ' O O Cn Cn O 45. M 00 M Cn 4^ 4s, O Cn — ' NO NO — ' O M H- rO OO O O — ' _ — ■ CO NO — ' — ' O — ' O CO NO Co M — ' — ' — ' M O C0 tO O 4S. M CD O O 45> Cn N0 O — ' NO O O Cn — ' O O _ 00 45. O M O OO OO OO — ' O O O M 45. 45. O O N0 O O 00 — ■ — ' O O O O OO — ' OO O O — ' NO Cn M O O O CO N Cn 45, O M O — ' 4s, O — ' 00 45. M T3
oooooooooooooooooooooooooooooooooooooooooooooooooO o
o O O o O o O O O o o O o O O O O O O o O o O o O O O O O O O O O O O O O O O O O o O O O O O O O O O O O o O O O O O O o O O O O O O O O O O O O O O O O O O O O O O O O O O
00 Co CO Co o 00 o 00 CO Co o 00 o CO eo CO co CO CO Co Co Co Co co CO o 00 CO o 00 CO CO CO CO CO CO CO CO CO CO CO Co Co Co CO Co CO Co CO o Co CO CO CO CO 00 O O O O O O O O o o o o o O O O O O O o O O O o o O O O O O O O O O O O O O O O O O O O O O O O O —1 φ
45. 45. 45, 45. 45, 45. 45. 45, 45, 45, 45, 45, 45, 45, 45, 45. 45, 45, 45. 45, 45, 45, 45, 45, 45, 45. 45. 45. 45, 45, 45. 45, 45. 45. 45, 45, 45, 45, 45. 45. 45, 45. 45. 45. 4s, 45. 45, 45, 45, 3
CO CO 00 CO Co Co CO eo co co Co Co CO co 00 Co 00 00 CO 00 co CO CO CO Co CO Co 00 CO CO co CO co Co CO CO CO CO C CO C co CO CO C Co CO CO CO •σ
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO Ω O O O O O O O o O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O —1- O O O O O O O o O O O o O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O φ e-_ c_ c_ _ c_ c_ _ c_ c_ c_ c_ c_ c_ c_ c_ >z>z>z>z>z>z>z>z>z>z>z>z>z>z>z >z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>zz> >z>z>z>z>z ro ro ro ro ro No ro ro ro to ro ro No ro ro No ro ro ro ro ro No ro ro ro No ro ro ro ro ro ro No ro N^
O O M M M M M M M M M M M M M O O O O O O O O O O O O 0 0 0 0 0 O O M M M M M M M M M M M M M M CΛ O O O O O O O O O O O O O O O O O O O O O O O O O O O 0 v^ 0 v-. 0 v^ 0 v^ 0 v^ v^ O v^ O ■-, .NvO. .N.-O, .NvO. .N—O . .NvO. NO NO NO NO NO NO — ' — ' — 7? 00145.45.45, 0 0010 —' O —' — O O ^v o o o o co oo oo M M M M M M O O o en cn e ,n-. 4 r5v, o ,.o- ro io N NO . . O O O O O CO Q
O O NO NO NO O Cn O CO O — ' 0 45. 00 NO OO O M Oo O M 4i. CD Cn en N0 45. — ' O O C0 00 M C0 O 00 O en O 45. M C0 O O — ' 45. Co O -
M O M M M M M M M M M M M M M M M M M M M Vl M M M VI M M M M M M M M M M M M M M M vI v-j v-j v-j v-j v-j v-j v-j f j rθ O C0 Cθ 45. C0 45. 45. N0 N0 45. 45. 4s, Cθ 45, C0 N0 N0 45. 45, 45. 45, 45, 45, 0 45- M 4s, M N0 N0 — ' N0 CO 45^
OO O — ' NO NO — ' N0 N0 OO 45, — ' O NO O NO M Cn Cπ O NO — ' NO M NO NO O NO OO NO M Co O O CO M — ' M NO NO — ' NO NO Cn — ' NO NO O NO CO -Ω
O NO No en eo NO M No o o o ro — ' θ θ oo θ M θ θ θ co 45. co co co eo co oo en co cπ o — ' O M O C0 45. 0 0 00 — ■ 00 co ω ro co 10 O
co m
D oooooooooooooooooooooooooooooooooooooooooooooooooO z o
> CD
CO
O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O CΛ ω Cθ ω4s, ω45, ωN0 oN0 ωN0 ωN0 ωN0 ωN0 ωN0 cN-0 ωN0 o45, 4o5. oOO oOO Oo No0 o— ' oO cO» røOO oCOo røM roCn OTCn o45o. røNO OTNO røO roO cOD røO M MO vOj OM Ol -Cvnj CMn M — ' — ' OM MO Oo Oo Mo ^M Ω^ O O O M M M M M M M M M 00 — ' 00 O N0 M N0 O 00 O CO M 4s. O C0 O O O 45. 45, — ' OO M O O NO CD 45, O Cn O O O — ■ — ' O O H-
O O O O O O O O O M M M V| vv| v-j vj v vvJ M vj v| vvj Vvl M C M M Vl M M vI M VI O O O O O O O O O CΛ O Cn O 45, Ol Cn en Cn O O O M CO 45. 4S, 4S. N0 — ' N0 45. OO O _ _ N0 — ' N0 45, O O C0 45, O Co O O 45, O O O O O O 00 θ O O O O ^- OO 0 — ' 45. O M O O N0 M O O — ' I I M Ol J - ' 4S. O 00 O — ' 0 4S. 0 — ' Oi — ' OO NO M CO NO NO NO — ' CO Cn OO OO M M 0 4i. 0 45. Cn O NO M Oi M NO — ' — ' M en O 45, O O N0 O CO 00 45. N0 O O 45. O 00 M O O — ' OO M O Co Cn — ' 45. 00 0 0 C O Cn OO O O — ' 45. O0 OO N0 O
ooooooooooooooooooooooooooooooooooooooooooooooooo
O
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
O co OcoωOcOo Oco cOo Ow cOoωO OcoωO Ow QO Oω Oω Ow Oω OwOωcOo Oc cOoωO cOocOo cOocOoOcocOoOcocOocOo cOocOo ωO ωO Oω Oω uO Oω cOo Oco ωO OωO O O O O o o o o o o o o o o o o o o o o o o o o o O o o o o o o o o o o o o o o. o o o o o o o o o o o o o CT
45. 45. 45, 45, 45, 45, 45, 45, 45, 45. 5, 45, 45, 45, 45, 45, 45, 45, 45. 45. 45. 45. 3 ω ω ω ω ω ω ω ω ω co co co co co ω Ό
Kb Kb Kb Kb fό iό Kb fό Kb fό Kb fύ fό 'rό iό fό fό Kb fό fό Kb Kb iό Kb N^ Ω
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 cfj
C_ I-_ C_ <-_ C_ C_. C_ C_ C_ C_ C_ C_. C_ C_ C_. C_ C_ C_ C_ C_ _. C-_ C_ C_ (_ C_ C_ <-_ C_ 0
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > >
Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z O NO NJ NO NO NO M NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO M NO NO NO NO NO NO NO NO O NO NO NO N^
45. M M cπ CO rn cn 0 Cύ 45, rπ o O
CO .15, NO NO rπ NO o NJ 0 O 0 CO O cπ c 1 NO c 1 Cύ 0 Ch CD 45. Cύ o cπ 0 rπ 0
Ch NJ CD NJ CO — . rπ 45, 45, ro ro 4s. Ω > CD CO r
CO NJ 0 45, NO cn cn CO Ch •fc- NO 0 c 1 O C ) ro 0 O 0 45, IS CO o NO o 45, 4^ NO N) CΩ I —
O — ' — ' CD 00 o 45. co
-IS, .15, 45, Co m
CO O n l\J 45, CO 45. cn 45, Ch Ch 0 h N
C ) c» 45. CO 00 CO CD 0 cn O J M rn NO Cύ VI 00 M O is lo en M 45, O Co ro 00 00 NJ O 45, 0 co NO O 45. 00 0 0 00 NO M 00 co Ch N C
Ch 00 NO NO M n CO 00 Cύ O 45. rs cπ Ω
CJ 45, Cύ CO 45. Ch cn NO M 45. Ch O M cπ 45, 45, cn 0 CO h O NO O o — ■ rn rn M e Cπ O 45, 45, CM 00 00 o 00 00
M 45, cn Ch 45. Ch c h Ch co NO CO NO 00 co 45, M n N) cπ ( — ■ 00 CJO — • 0 O o Cn 00 C ) 00 4-. Ch CO 45. -A Φ
X X X X X X X X X X X X X X cn 0 45. NJ
X X X X X X X X X O cπ rn O
X TO X X X X X X 45. 0
< < ro X TO x X X D
0
O O O NO O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O CΛ ω ω ω co ro o o o o o o o cn en cn cn cjι coo cjι cjo en cjι c_π cjι en c-π cn en cn cji 4-. 45, 45. 4^
N0 to ro ro cn 45. — ' 00000 00000045.000 0010 — . —. —. _ ' O O O O oo M O cn cn 4-. co ro — ' O oo oo o o en o cn cn Ω
M M M M — ' Cn CO CJl Cn 45, Cn O O M — ' M M O C O O O O O0 45. 45. 45. O O O O O NO CD M O 45, — ' Ol — ' OO M M — ' 0 0 0 45, 03 ^-
O O O O NO O O O O O O O O O O O O O O O O O M O O O O O O M O O M O M O O O O O O O O O O O O O O CΛ M 00 00 45. 45. 0 00 00 0 00 0 00 00 0 M OO OO M M O M O O OO O OO M O M O M M O M O M M M Cn O O O O O O O O Oo H- NO O O NO M — ' OO M — ' 00 O 00 4S. O 45. — ' CO Cn en O CO — ' M CO O — ■' 45. Oo Cn NO O O Cn 45. CO — ' O O NO O O O O OO — ' Co Co Oi Oi. 00 — ' CO Ol - ' OO O OO NO — ' C0 45> tO O 00 00 45. O O O O 00 45. O C0 M 00 00 M O O O — J Cπ NO — ' — ' NO — ' O NO O OO — ' O — ' Cπ Oo
TABLE 3
SEQ ID NO: Template ID Component ID Start Stop 19 LI:903914.3:2001JAN12 6059834H1 5891 6060 19 LI:903914.3:2001JAN12 701473H1 2213 2489 19 LI:903914.3:2001JAN12 g2674759 2215 2697 19 LI:903914.3:2001JAN12 4979871 HI 1500 1573 19 LI:903914.3:2001JAN12 3706347H1 1509 1573 19 LI:903914.3:2001JAN12 2730331F6 1593 2015 19 LI:903914.3:2001JAN12 660904H1 1740 1921 19 LI:903914.3:2001JAN12 3044527H1 6327 6458 19 LI :903914.3:2001JAN 12 5848222H1 6327 6474 19 LI:903914.3:2001JAN12 71064557V1 5953 6377 19 LI:903914.3:2001JAN12 4569837H1 5966 6060 19 LI:903914.3:2001JAN12 2893660H1 5974 6060 19 LI:903914.3:2001JAN12 71058037V1 5997 6587 19 LI:903914.3:2001JAN12 7701709H1 6128 6790 19 LI:903914.3:2001JAN12 1839135H1 6134 6401 19 LI:903914.3:2001JAN12 2252132H1 6165 6394 19 LI:903914.3:2001JAN12 5720531 HI 6296 6812 19 LI:903914.3:2001JAN12 449352H1 6310 6553 19 LI:903914.3:2001JAN12 1386956H1 6315 6566 19 LI:903914.3:2001JAN12 g2026407 6321 6571 19 LI:903914.3:2001JAN12 5800119H1 6324 6828 19 U:903914.3:2001JAN12 5662508H1 6323 6609 19 U:903914.3:2001JAN12 6052006H1 6327 6561 19 Ll:903914.3:2001 JAN 12 6520204H1 6327 6518 19 LI:903914.3:2001JAN12 3021455H1 6327 6518 19 LI:903914.3:2001JAN12 71058395V1 5904 6592 19 U:903914.3:2001JAN12 g3427623 5902 6060 19 Ll:903914.3:2001 JAN 12 5429571 HI 5917 6060 19 U:903914.3:2001JAN12 2708592H1 5918 6060 19 LI:903914.3:2001JAN12 5868759H1 5919 6060 19 U:903914.3:2001 JAN 12 2707536H1 5919 6060 19 Ll:903914.3:2001 JAN 12 5868791 HI 5920 6060 19 LI:903914.3:2001JAN12 3126247H1 5949 6060 19 U:903914.3:2001JAN12 3982986H1 6327 6429 19 U:903914.3:2001JAN12 g4392853 7309 7419 19 LI:903914.3:2001JAN12 gl013261 2252 2619 19 LI:903914.3:2001JAN12 g2874443 2217 2708 19 U:903914.3:2001JAN12 4414572H1 2245 2503 19 U:903914.3:2001JAN12 3750656H1 2249 2507 19 LI:903914.3:2001JAN12 g2216495 2216 2622 19 U:903914.3:2001JAN12 g3742849 2214 2619 19 LI:903914.3:2001JAN12 gl 119073 2214 2619 19 U:903914.3:2001JAN12 6219841 H2 2214 2586 19 LI:903914.3:2001JAN12 1006299H1 1146 1433 19 Ll:903914.3:2001 JAN 12 068728H1 1160 1277 19 Ll:903914.3:2001 JAN 12 5687390H1 1168 1423 19 Ll:903914.3:2001 JAN 12 2547870F6 1191 1593 19 LI:903914.3:2001JAN12 8104052J1 1191 1573 19 LI:903914.3:2001JAN12 2547870H1 1191 1453
CΛ m
NO NO NO _ O O O oooooooooooooooooooooooooooooooooooooooooooooo z o
— c O O O
On i Oo o o o Oo oO Oo oO Oo oO Oo Oo Oo oO oO Oo OO O O O O O O O O O O O O O O O O 1 J 3 x Ό Kb Ω
O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O φ
C_ D
> > > > > > > > > > > > > > > > > z z zzzzzzzzzzzzzzz ro
ro No
cn _ _ _ _ _. _ _ _ _ _ _ _ _ _. _ _ _ _ _ CΛ m - f^ ω u ω m ω ' - i n ^ ^ CB Oo cD Clo σ Cϊi i C oi l K) oo S vO ^ S S h^ So ^ Js ^ π CD Ji Cπ Cn cn Oo o O O en O NO ^ 45. 45, 45. 4 45. 45. 3 C0 C Co Co Co C0 C IO rO r N0 rO ^-
45. v! -_ S ω ≥ θ ω vj cπ ^ j g ^ ^ Cn 4i, 4 , O 45, C0 _. _ _ 4i. O CO C0 00 4- 00 rθ 00 00 M 4-. N0 O O O 00 Cn 45, — A CD hi o o Nθ cπ M M θo en M θo co o cn co 45, o ro o ro =ϊ-
TABLE 3
SEQ ID NO: Template ID Component ID Start Stop 20 LI:150817.1:2001JAN12 70660502V1 330 948 20 U:160817.1:2001JAN12 70658217V1 354 811 20 LI:150817.1:2001JAN12 70657193V1 373 941 20 LI:150817.1:2001JAN12 70657139V1 485 941 20 U:150817.1:2001JAN12 70657138V1 514 969 20 LI:150817.1:2001JAN12 70659173V1 604 1148 20 LI:150817.1:2001JAN12 70660195V1 697 1306 20 LI:150817.1:2001JAN12 70658942V1 707 1217 20 U:150817.1:2001JAN12 70655575V1 718 1205 20 U:150817.1:2001JAN12 70660329V1 741 1315 20 LI:150817.1:2001JAN12 70656696V1 775 1319 20 LI:150817.1:2001JAN12 70665015V1 783 1322 20 LI:150817.1:2001JAN12 70646875V1 786 1322 20 U:150817.1:2001JAN12 70655650V1 842 1334 20 LI: 150817.1:2001 JAN 12 70660055V1 860 1319 20 U:150817.1:2001JAN12 70659977V1 881 1322 20 LI:150817.1:2001JAN12 70659456V1 931 1305 20 U:150817.1:2001JAN12 70658365V1 988 1322 20 U:150817.1:2001JAN12 1943823T6 1013 1313 20 LI:150817.1:2001JAN12 70655792V1 1025 1313 20 LI:150817.1:2001JAN12 70660911VI 1115 1313 20 LI:150817.1:2001JAN12 70657216V1 1208 1819 20 U:15081J1:2001JAN12 70659311VI 1236 1788 20 LI:150817.1:2001JAN12 70656288V1 1241 1752 20 U:150817.1:2001JAN12 70659276V1 1631 1867 20 LI:150817.1:2001JAN12 70660598V1 1643 1972 20 LI:150817.1:2001JAN12 70658469V1 1642 2192 20 LI:150817.1:2001JAN12 70660035V1 1643 1867 20 LI:150817.1:2001JAN12 70657033V1 1646 1996 20 LI:150817.1:2001JAN12 70660918V1 1646 1986 20 LI:150817.1:2001JAN12 70660689V1 1646 1899 20 LI: 150817.1:2001 JAN 12 70656049V1 1741 2055 20 LI: 150817.1:2001 JAN 12 70657104V1 1817 2445 20 U: 150817.1:2001 JAN 12 70657113V1 1925 2531 20 LI:150817.1:2001JAN12 70656974V1 1982 2142 20 LI:150817.1:2001JAN12 70660750V1 2088 2752 20 U:150817.1:2001JAN12 70655811VI 2092 2644 20 LI:150817.1:2001JAN12 70660590V1 2124 2642 20 U:150817.1:2001JAN12 70658522V1 2156 2706 20 LI: 150817.1:2001 JAN 12 70658749V1 2211 2881 20 LI:150817.1:2001JAN12 70657879V1 2216 2770 20 LI: 150817.1:2001 JAN 12 70659980V1 2216 2706 20 LI:150817.1:2001JAN12 70658750V1 2227 2706 20 LI:150817.1:2001JAN12 70660410V1 2330 2706 20 U:150817.1:2001JAN12 70657215V1 2471 3064 20 U:150817.1:2001JAN12 70658900V1 2496 2887 20 LI:150817.1:2001JAN12 70666665V1 2525 2837 20 LI:15081J1:2001JAN12 70660097V1 2529 3172 20 U:150817.1:2001JAN12 70655859V1 2635 3095
m
© D rO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO rO NO NO N NO NO NO NO NO N N NO N NO N NO NO NO N N N NO ^-i n n n n n n n n n n n n n n n r e—x e—x r~x en e-~x e— σ z o
l M M M J M NJ IO r I r M NJ I M M r I M M I I M r rO I rO -' -' -' -' -' -' -' -' -' -' -' -i --1 -' -' -' -' -' -' -' -' -'
_ _ _ _ _ _ _ _ _ _ —. —. _ _ _ _ —■ _ _ _ _ _ _ _ — ' _ _ oi cn eπ en en cπ en cn cn en en cn en cn en en en cn en eπ cn cn
0 0 0 0 O O O O O O O 0 O O O O O O O O O O 0 0 0 0 0 0 O O O O O 0 O O O O O O O O O O O O O O O _j O O O O O O O O O O O O O O O O O O O O O O O O O O O OO OO OO CO CO OO OO OO OO OO OO OO OO OO OO OO OO OO CD OO OO OO ^, r MM MMMWr I MI r M Mr M I MrO Mr r MMM-'-' -'-'-'-'^-'-' -'-'-'-^-' -'-'-' -'-'-'-' -' ϊ M1_-M---MXM_M_M_M_M_M_M:__MM_M_-M_MXM:-M:__MXMMX_M,MXM_. -M_M_.-M_M_,_MM:.._M M---M:--_MM_MMM MM MM MMM MMMMM 3
K Ob KOb KOb KObOiό KOb KObOiό KObOfό KObOfό KOb KObOiό fOό iOχb KObOKb KOb KOb KOb iOo KOb OOOOO OOOOOOO OOO OOOO O O H- OOOOO OOOOOOOOOOOOOOOOOOO OOOOOOOOOOOOOO O OOOOOOCD
C_C_C_C_C_(-_C_C_<_C_C_C_C_C_C_C_C_C_C_C_C_C_C_C_
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > >
ZZZZZZZZZZZZZZZZZ22ZZZZZ
ZZZZZZZZZZZZZZZZZZZZZ
NO NO NO NO NO NO NO NO NO M NO NJ M M NO NO NO NO NO M NO NO M NO M NO NO NJ NO M NO NO NO NO NO NO NO NO NO M NO NO NO M
C o„ c_n. M - O M M M O Oo CO CO OO Oo ω Co CO Co Co CO Co NO NO NO NO NO NO NO NO NO CΛ o ω co si ω o-o o- o_ cn o _ • Ol — ' 01 M 45. 0 4s. 45. co o en
M co oo _ oo o — o — o — co O — O —l M o cn CO O 00 M O Cn 45. 45. Co rO N0 — ' O O O O OO 00 M M M O
CO CO 45. CO CO O 00 en ro o o 45. vι eπ M cn 00 45. 00 O M — ■ 00 o o en o co O _ rOv. cn cn 45, o NO oo o vi ro o o _ . o .M. C c-o-n_ N .v o_O. O c-n-_ M c- v N o_ , c-vO, . o_ O o_ N o_vO. — o_ ' _ 0 —
■ 00 O CO 45, _ Ω= o
45, cn oo o en -3-
M M IO M M M I -' J J^ 4- ^ i- CO CO CO CO CO Q O) CO CO CO Co Cd CO CO CO CO CO W θ ω N0, M _ ro ° ° O O -' -' N0 N0 C0 C0 C0 C0 C0 — O ' 4-^-. C—J0 ' —CJ0 ' OO OM OO COX> —4^ ' 4—5. ' MrO NCJ00 —_ ' 4M5. C» MCO 4O5, 0ro0 O— ' NN0O O— ' N450, —Cπ ' j4iS,. 0OO0 CN0O O45. MN0 CCOO NO0 ? co o en ^ M en 0 O ^ M ^ NO ^ CO 00 0 O^ ^M ^00 045, O- -O^ 0M" ^—1 ' M N0 Cj0 C» M M Cj0 Ji, CJ0 en O M 45. O — ' 4-. M NO CO O Cn θ O O O O O OO OO O O
TABLE 3
SEQ ID NO: Template ID Component ID Start Stop
21 LI:219627.1:2001JAN12 70790411 VI 1068 1584
-21 U.219627.1:2001 JAN12 70788322V1 1034 1579
21 LI:219627.1:2001JAN12 70792873V1 1022 1534
21 U:219627.1:2001JAN12 g3057511 1331 1519
21 LI:219627.1:2001JAN12 g5441098 1064 1519
21 LI:219627.1:2001JAN12 70787956V1 977 1504
21 U:219627.1:2001JAN12 70790407V1 970 1475
21 U:219627.1:2001JAN12 70788313V1 909 1466
21 U:219627.1:2001JAN12 70787561 VI 884 1449
21 LI:219627.1:2001JAN12 70790141 VI 893 1392
21 U:219627.1:2001JAN12 70788429V 1 847 1383
21 U:219627.1:2001JAN12 g2158894 915 1379
21 LI:219627.1:2001JAN12 70792054V 1 802 1373
21 LI:219627.1:2001JAN12 70788620V1 1065 1655
21 LI:219627.1:2001JAN12 70788818V1 1303 1669
21 LI:219627.1:2001JAN12 70792338 V 1 1105 1669
21 LI:219627.1:2001JAN12 70790643V1 1610 1669
21 LI:219627.1:2001JAN12 70789004V1 1183 1669
21 LI:219627.1:2001JAN12 70789678V1 1440 1669
21 U:219627.1:2001JAN12 70789318V1 1516 1669
21 LI:219627.1:2001JAN12 70788994V1 1232 1669
21 LI:219627.1:2001JAN12 70793045V1 1206 1658
21 LI:219627.1:2001JAN12 70791928 V 1 1297 1670
21 LI:219627.1:2001JAN12 70790374V1 1389 1669
21 LI:219627,1:2001JAN12 70793231 VI 1344 1677
21 LI:219627.1:2001JAN12 70792560V1 1548 1669
21 LI:219627.1:2001JAN12 70790741 VI 1191 1693
21 LI:219627.1:2001JAN12 70790021 VI 1316 1677
21 LI:219627.1:2001JAN12 g2903300 188 472
21 Ll:219627.1:2001 JAN 12 g6073244 1 438
22 LI:197812.4:2001JAN12 6845095F8 1 321
22 LI: 197812.4:2001 JAN 12 6845095H1 1 338
22 LI:197812.4:2001JAN12 6845095T8 1 238
23 LI:101525.1:2001JAN12 71032233 V 1 1596 2032
23 U:101525.1:2001JAN12 70973792V1 1596 2032
23 LI:101525.1:2001JAN12 70973476V1 1650 2184
23 LI: 101525, 1:2001 JAN 12 70971931V1 1715 2243
23 LI:101525.1:2001JAN12 70974856V1 1754 2320
23 LI:101525.1:2001JAN12 70974126V1 1777 2198
23 LI:101525.1:2001JAN12 70974960V1 1883 2402
23 U:101525.1:2001JAN12 71291604V1 785 1291
23 LI:101525.1:2001JAN12 70974489V1 876 1291
23 LI: 101525.1:2001 JAN 12 70972101 VI 883 1325
23 LI:101525.1:2001JAN12 70971439V 1 902 1291
23 LI: 101525.1:2001 JAN 12 70973738V1 955 1291
23 U:101525.1:2001JAN12 g2268726 958 1221
23 U:101525.1:2001JAN12 71292025V 1 1038 1291
23 LI:101525.1:2001JAN12 71290752V1 1039 1293
23 LI:101525.1:2001JAN12 70972211 VI 1050 1291
© ro ro ro ro ro ro ro ro No tO M io io ro ro ro ro io No ro io ro r ro ro ro ro ro ro io NO NO M r^ cn cn cn cn cn cn cn cn cn co cjι cjι cjι cjι cn cn cn coι cjι cn cn cn 45. 45. j j. 45, ω ω
O
co oo oo oo oo co oo co oo oo oo cD oo oo oo oo oo oo oo oo oo oo oo oo oo oo oo 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 — ' O O O O O ω oo c-o co co oo oo oo co co co co oo cjo oo eo co co oo co co eo cn cπ eπ cn en cπ cn en en eπ eπ en en cn cn eπ eπ en cn cn cn cπ - e _n.-cπ.-e -n.-e-n.Se-n2e_n c--n.2c-n-c_n.c--n.2e _n2e_n e-_n.-c_π.c-_n.-e_n.2e_n2e_n2e_n-c_n.2c_n-cπ.
O O O O O O O O O O O O O O O O O O O O O O rO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO o o o o o o o o o o o o o o o o o o o o o o cjj (-o o cjθ θ3 Cjn cjo cπ cn cn cn coo co en cn cn cjo cjo cn cn cn cn c^
X "_ "_ X "_ _ ■_ X "_ •_, •_ "_ _ ■_ "_ X X __, X "_ _ X ■_ X ■_ X •_ X X X X X X X X X X X X X X X X X X X X X X"g_ ro Kb fo fό iό fό Kb iό Kb iό fό Kb fό iό fό iό fό fό Kb Kb fό ivb M
O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O H- O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O Φ c_ c_ C_ c_ c_
>z >z >z>z>z>z>z>z>z>z >z >z z> >z >z z >>z>z>zz>>z>zz>>z>z>zz>>zz>>z>z>z > > >z>z>z>z>z>z>z>z>z>z>z > > > > o
NO M NO NO NO NO NO NO M NO NO NO NO NO NO NO NO NO NO NO M NO O NO NO NO NO NO M NO NO NO NO M W NO NO NO NO NO O NO NO M NO NO NO N^
O NO fe δ fe ω cD S S S g g Cn cn cπ cπ cn cn cn cn cn cπ cn 45. — • NO NO N 0 CO NO NO M O M NO —' —' O O CO 0 O 45, 4 .5. 4.5. 0-0 C-o 4.5. 45. -A - 7? o o o o ro - o o ω g g g ≤ vj vj vj vj vj v vj vi vj o CH M M —■ O O Cn C
O 45. 00 M O 00 0
"0- 0—0 M O M M
o o o o o cn e rn NO NO —' —' —' NO NO NO NO NO rv n CJ — O ι-_ι O _ M ^vi 0 cυ0 0 ι-u0 O O O O O O M O 45, O
X c S -_J S o o , ,- NO NO NO NO — ' -r-i m -n -n m r.i n rv rv-i — ■ — ■ — ' NO NO — ■ — ' — ' CΛ r7ι r N f o oo ro 45, Oo vl O vl O M M
O 5 o N0 4-. 45. Co v-ι _ co r-> r-> ro -n r-> N ω -, y> -, u ∞ ιvj yτ ."
45. 00 N0 N0 Cn O O N0 00 00 O M M 45, O O — ■ 00 O O __, . _ CO C O NO O O 45, O OO O — ' M CO 00 "O
rn © to ro ro ro No ro ro io No ro ro ro ro NO NO No ro ro ro ro to r No ro ro NO NO No ro ro ro ro No ro w
CJl CJi CJi CJl CJl CJi CJi CJl CJl CJi CJi CJi CJi OO CJi CJi CJi CJi Oi CJi CJl CJi CJi C)!
O
oo oo oo oo oo co oo oo oo co co co co co co co co co ro ro cπ cπ n cn cπ cn cn cn cn cn cn cn cn cn cn cn cn cn cn cn cn cn cn cn cn cn cπ cn cn cn cπ cn cn cπ cπ cn n rπ cn cn rn cn rn cn cn cn cn cn cn o < ) r ) a ro o Φ1 o o o o o o o o o o o o o o o o o o o o o o o o o o o o o 3 "ϋ ro o o < ) o ro o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o c_ c_ c_ c_ c_ c_ c_ c_ — c_ c_ c c c c c c c r r . c__ c_ c. c... c . c c . c r r r r r r r r
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > >
Z _ _. z. z. _. z z z z _. z. z. z. z z z z z z z z z z z z z z z z ro ro ro
o
00 00 00 45, 45. 45. 45. 45. 00 00 00 45.
M M M CO Co eo O O O O — ' CO CO fe 3- £ C O cπ to co cπ o o o efjθ θfe3 Cefo θ cn cn cπ co — ' r
NO NO NO NO _ _ _ ro —■ —■ CΛ
C 00 CO O 00 O 7? ocj ocj ocj ^ c- vMj " " ccnn " θu wNθ cωo σ Cβ fc--, cu3 w^ ^-' _-' MCh C0, fflcn W j45. WNθ M K) C- c- α) ( o iv 00 _, j;ι j. ( f ω 0) α, Cύ —A O 45, NO O
45. O 00 —> M M T3
CΛ rπ © ro ro ro ro ro No to ro No ro ro ro ro ro ro ro No ro No ro ro ro ro No ro No ro NO NO No ro i o o o o o o o o c-n cn cjo cjo cπ cπ cπ cπ cn cπ cjo cji cn cn cπ coi cπ cn cn cπ cπ cn cjo cjo cjo
O
CD CO CO
O O O O O
NO M NO No i
,—, oo oo oo en o o M O NO NO NO O M OO OO CO M — ' — ' NO NO NO NO NO — ' NO NO NO — ' NO O 00 o CΛ
__] O (D CD — ' Cn CO O OO O O O 45. 4S. N0 N0 CO 45, CO 45, 45> co O O O O rn v O - CO 00 CO o
— ; O O ?? vy θ i. M CO O O O — ' O O O O O O O M O
O O -' C ^ ^. O IO O CO -' — ' O NO cn M cn cn 4-. cn No o — - en CO 45. Co O M — < 45, CO N0 _ -_ o cn M 00 o
CO NO M o o No co en o o M 00 N0 O 45. Cn θ N0 N0 Cπ θ 00 C0
CΛ m © ro M io ro io ro ro io ro ro ro No ro ro ro No ro io ro i ro ro No ro ro ro ro No ro ro ro No ro ro No ro N^
CO OO OO OO OO OO OO M M M M M M M M M M M M M M M M M M O O O O O O O O O O O O O O O O O O O O O O O O ' z
O
_ _ — . _ _ c-voj ωvj cvjo ωv-j cv-oj ω cn cn oi —■ —■ —■ —■ —■ —■ —' —■ . H NO NO NO NO NO NO NO NO NO NO NO NO NO
O O O CO OO CD O OO — ■ — ■ — ' NO Oo co cn en O M 4-. o 45. No O 00 Oi -?
NO — ' _ M M CD 00 O0 — ' — ' CO NO N0 CO 00 00 45. O 45, Co O 00 O O N _, co o eπ cn eπ cn 4-. co co co co eo oo -— — - o o o o
00 O OO OO M Cn 45. 45, OO O O CO CO O OO — ' O CO NO — • c frnx cn oo Q en o o M 4s, o o o co o O O 00 O — ' — ' N0 N0 N0 4S, 45, CO M O O O O O 00 Cn 00 O N0 N0 00 45. C0 M O — ■ Cύ * -■" 4s- o .
cn
0 -- r 45, Oo 4s 4i. c^ & 0^ ;^ P? 2 : o' ro ω ω o
NO OO O M O OO O O O NO O Cn 00 O O 45. O — ' M M Ό
CΛ m © ro ro ro O No ro ro ro w ro ro ro ro No ro No ro ro to No ro ro No ro ro ro No ro ro ro No ro No io io NO M ro ro NO
C0 O0 CO O0 O0 O0 O0 O3 O0 O0 O0 O0 0O O0 CO 00 O0 0O O0 C O3 0O OO O0 OO O0 OO O0 O0 O0 CD CD O3 00 O0 0O CD 00 C» 00
Co CO Co Oo ω co Oo CO Co Co Co CO CO Co CO CO CO Oo co Oo CO CO Oo cjJ CjO Co co ω
4i, 4s 4S 4S . 4s 45. 45. 4S 4s 45. 4s» 4s 4i. 45. 45. 4s 4s 45. 45, 4S 4s 45, 45, 4S 4i, 45. 4S 4s M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M . cjo cjo cjo co cΛ cjo cn eπ cn cn en en cn cn en en cn cπ cjo en cπ cn cjo cjo cn cjo en cjo cn en cΛ
M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M iϊ NO NO NO NO NO NO NO NO M NO NO NJ NO NO O NO M NO NO NO NO rO NO NO NO NO NO NO NO NO NO NO M NO NO NO NO NO NO NO M x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x-α
O fύOfύ fOό KOb KOb KObOKb fOό fOόOfό KOb iOό fOό KOb KObOfόOfόOfό iOό KObOiό fOό KObOfό fOόOfόO O O O O O O O O O O O O O O O O O O O O O O H- O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O Φ
C_ _ _ _ _ (__ C_ _ C_ C_ C_ C_ — _ C_ r_ _ _ _ _ C_ _ _ C_ _ _. C_ _. _ _. _
>z>z^>>z^>>z^>z>^>>z^>>z>z^>>z^>>z^>>z^>>z^>>z^>>z^>>z^>>z^>>z^>>^>>z^>>z^>>^>>z^>>^>>z^>>>z>z
M M IO IO M M IO IO M M M M IO IO M M IO IO IO M M IO IO M IO M IO IO I M IO I M NJ IO M r^
01 45. 0 M M M O M M M M cn cn eπ en oo o o en ~ o o o _ o_ o_ o_ o_ o_ o_ _ o CΛ. 0 00 0 45, 45, 45, 00 0 00 00 0 0 45, M O M M O O OO rι —■ O CO M NO NO O O O O vJ M M O O O NO — ' 45. — ■ g o o o oo o o cn en en en 45.45. 45, 45.4i. cπ cn N0 cn cn M o eπ — ■ O O O O M O O Oo Co CO Co o S Q o O 45. cn No o o 45, oo cn o cn cn 45, o ^1 H-
— ' ro ro ro _ N N N No ro NO N — _ _ _ __ _ _ _ __ _ _ _ _ _ __ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ . _ _ _ _, c
C» _ CO O O O CO I0 4s 4S CO O O NO C_O N0 4 O NO NO M M Cn CO O CjO M O O O COO NO M O OO OO OO Cπ M 4s CjO M 0 4S M O O O M 4S. O O N0 M M CO 00 N0 45, N0 N0 O N0 O O 4S O O N0 O O N0 O O C0 45. co — ' O NO O — ' O NO NO O NO OO M CO M Cn M O OO OO _ en -2 O CJ1 03 CO 45. O O O O O 45. 45. O N0 O O M N0 45. O O O O CO N0 O CO 45. CD 00 M CO O O VI — ' Cn O O O O O O N N0 4S. Oo Cn Nθ X5
TABLE 3
SEQ ID NO: Template ID CΩimpΩnent ID Start Stap
28 U.347572.1 :2001 JAN 12 71873356V1 1473 2031
28 U:347572.1 :2001JAN12 70557288V1 1482 2113
28 -1:347572.1 :2001JAN12 71874760V1 1484 1745
28 LI.347572.1 :2001 JAN 12 71874458V1 1484 1745
28 U:347572.1 :2001JAN12 71873121V1 524 1161
28 U:347572.1 :2001JAN12 72334930V1 514 1110
28 Ll:347572.1 :2001 JAN 12 71157532V1 1969 2458
28 U:347572.1 :2001JAN12 71303442V1 1951 2619
28 LI:347572.1 :2001JAN12 5542815H1 1962 2117
28 U:347572.1 :2001JAN12 71156493V1 1939 2585
28 U:347572.1 :2001JAN12 71876243V1 1971 2101
28 LI:347572.1 :2001JAN12 70555668V1 1981 2636
28 LI :347572.1 :2001 JAN 12 71872502V1 1995 2548
28 LI:347572.1 :2001JAN12 70555958V1 2020 2748
28 Ll:347572.1 :2001 JAN 12 70555146V1 2021 2672
28 LI :347572.1 :2001 JAN 12 71303538V1 2050 2571
28 U:347572.1 :2001 JAN 12 71304228V1 2049 2676
28 U:347572.1 :2001JAN12 6496937H1 2059 2615
28 Ll:347572.1 :2001 JAN 12 305090H1 2062 2404
28 LI:347572.1 :2001 JAN 12 305090R6 2063 2445
28 LI:347572.1 :2001JAN12 4598818H1 2088 2347
28 LI ;347572.1 :2001 JAN 12 71874592V1 2117 2746
28 Ll:347572.1 :2001 JAN 12 71874574V1 2118 2744
28 U:347572.1 :2001JAN12 6349213H2 2146 2481
28 Ll:347572.1 :2001 JAN 12 70554811VI 2158 2817
28 Ll:347572.1 :2001 JAN 12 4515767H1 2161 2301
28 Ll:347572.1 :2001 JAN 12 71875449V1 2192 2841
28 U:347572.1 :2001JAN12 71872419V1 2257 2821
28 Ll:347572.1 :2001 JAN 12 71303748V1 2230 2767
28 L 347572.1 :2001 JAN 12 70328165D1 2243 2860
28 Ll:347572.1 :2001 JAN 12 70326303D1 2243 2828
28 Ll:347572.1 :2001 JAN 12 70326287D1 2243 2548
28 LI :347572.1 :2001 JAN 12 71155657V1 2256 2857
28 LL347572.1 :2001 JAN 12 71875041V1 2264 2819
28 Ll:347572.1 :2001 JAN 12 71869592V1 2264 2509
28 LI :347572.1 :2001 JAN 12 1501621 F6 2284 2845
28 LI:347572.1 :200UAN12 1501621H1 2284 2481
28 Ll:347572.1 :2001 JAN 12 72335048V1 2309 2465
28 LI:347572.1 :2001JAN12 72334938V1 2310 2465
28 LL347572.1 :2001 JAN 12 71870640V1 2311 2561
28 Ll:347572.1 :2001 JAN 12 71873414V1 2370 2821
28 LI:347572.1 :2001JAN12 70557357V1 2382 3069
28 U:347572.1 :2001JAN12 71157279V1 2388 2925
28 Ll:347572.1 :2001 JAN 12 6116935H1 2389 2667
28 LI :347572.1 :2001 JAN 12 70325710D1 2432 2896
28 U:347572.1 :2001JAN12 70325612D1 2509 2911
28 Ll:347572.1 :2001 JAN 12 70328746D1 2509 2876
28 U:347572.1 :2001JAN12 70327564D1 1618 2097
28 LI:347572.1 :2001JAN12 4670450H1 1632 1842
TABLE 3
SEQ ID NO: Template ID CΩmpΩnent ID Start StΩp 28 U.347572.1 :2001 JAN 12 71873093V1 1652 2229 28 Ll:347572.1 :2001 JAN 12 g5848554 3328 3605 28 U.347572.1:2001 JAN 12 2770719T6 3367 3618 28 LI:347572.1 :2001JAN12 6416515H1 3438 3605 28 LI:347572.1:2001JAN12 70555206V1 1443 2074 28 U.347572.1 :2001 JAN 12 4438947H1 2592 2871 28 U.347572.1 :2001 JAN 12 71156387V1 2607 3038 28 U:347572.1 :2001JAN12 71303533V1 2661 3094 28 U.347572.1 :2001 JAN 12 7353820H1 2678 3042 28 U.347572.1 :2001 JAN 12 4539057H1 2712 2970 28 U.347572.1 :2001 JAN 12 2328218H1 2788 3054 28 U.347572.1 :2001 JAN 12 71989940V1 2802 3588 28 U.347572.1 :2001 JAN 12 71304436V1 2821 3373 28 Ll:347572.1 :2001 JAN 12 71157628V1 2865 3438 28 U:347572.1 :2001 JAN 12 5106567H1 2868 3116 28 LI :347572.1 :2001 JAN 12 4599088H1 2916 3176 28 Ll:347572.1 :2001 JAN 12 71991623V1 2948 3657 28 U:347572.1 :2001JAN12 71991624V1 2964 3666 28 U:347572.1 :2001JAN12 71873583V1 1437 2100 28 LI:347572.1 :2001JAN12 70555054V1 1440 2039 28 U:347572.1 :2001JAN12 72335788V1 1441 1783 28 Ll:347572.1 :2001 JAN 12 4441126H1 1442 1732 28 U.347572.1.2001JAN12 70555906V1 482 1101 28 U:347572.1 :2001JAN12 70557145V1 489 1190 28 U:347572.1 :2001JAN12 6788770H1 511 1121 28 Ll:347572.1 :2001 JAN 12 71873703V1 512 1014 28 U:347572.1 :2001JAN12 71874424V1 426 nn 28 U:347572.1 :2001 JAN 12 71873494V1 476 1157 28 LI:347572.1 :2001JAN12 71873445V1 1921 2464 28 U.347572.1 :2001 JAN 12 71872975V1 817 1348 28 U:347572.1 :2001JAN12 70557219V1 818 1487 28 Ll:347572.1 :2001 JAN 12 71873072V1 825 1546 28 LI:347572.1 :2001JAN12 71872581VI 864 1320 28 U:347572.1 :2001JAN12 71873524V1 866 1417 28 LI:347572.1 :2001JAN12 71304277V1 1917 2579 28 Ll:347572.1 :2001 JAN 12 71873836V1 1435 2140 28 U:347572.1 :2001JAN12 70556149V1 1429 2090 28 U:347572.1 :2001JAN12 71874315V1 966 1506 28 LI :347572.1 :2001 JAN 12 71874126V1 988 1550 28 U:347572.1 :2001JAN12 71874156V1 1411 1947 28 U:347572.1:2001 JAN 12 70556256V1 1426 2145 28 U:347572.1 :2001JAN12 70326508D1 1881 1957 28 U:347572.1 :2001JAN12 71156538V1 1610 2126 28 LI:347572,1 :2001JAN12 71872885V1 818 1348 28 Ll:347572.1 :2001 JAN 12 71874479V1 366 927 28 U:347572.1 :2001 JAN 12 71873206V1 420 1157 28 Ll:347572.1:2001 JAN 12 71875190V1 301 852 28 U.347572.1.2001JAN12 3696047F6 1587 2158 28 Ll:347572.1 :2001 JAN 12 3696047H1 1589 1899
TABLE 3
SEQ ID NO: Template ID Component ID Start Stop 28 U.347572.1 :2001 JAN 12 71158742V1 1604 2220 28 U.347572.1 :2001 JAN 12 71875367V1 1407 2036 28 Ll:347572.1 :2001 JAN 12 71874085V1 815 1462 28 U.347572.1 :2001 JAN 12 3699373H1 25 340 28 U:347572.1 :2001JAN12 70327386D1 26 382 28 Ll:347572.1 :2001 JAN 12 6784564H2 35 537 28 U.347572.1.2001JAN12 6786847H2 39 675 28 U:347572.1 :2001JAN12 70328701 Dl 115 604 28 U:347572.1 :2001JAN12 70554791V1 269 853 28 U:347572.1 :2001 JAN 12 70557024V1 1857 2551 28 Ll:347572.1 :2001 JAN 12 70326732D1 1881 2226 28 U:347572.1 :2001JAN12 71873228V1 1381 1941 28 U:347572.1 :2001JAN12 71875062V1 1406 2131 28 U.347572.1 :2001 JAN 12 71873547V1 1381 1941 28 Ll:347572.1 :2001 JAN 12 70554523V1 806 1599 28 U:347572.1 :2001 JAN 12 70557092V1 798 1441 28 Ll:347572.1 :2001 JAN 12 4179553H1 21 247 28 U.347572.1 :2001 JAN 12 71874109V1 24 162 28 U.347572.1 :2001 JAN 12 71875577V1 922 1476 28 U:347572.1 :2001JAN12 71874930V1 941 1663 28 U:347572.1 :2001JAN12 71872822V1 951 1671 28 U:347572.1 :2001 JAN 12 70556389V1 958 1486 28 U:347572.1 :2001 JAN 12 71872491VI 1377 2044 28 U.347572.1 :2001 JAN 12 71872623V1 1377 2043 28 U:347572.1 :2001JAN12 70555528V1 1380 2090 28 U:347572.1 :2001JAN12 70556961V1 774 1485 28 U:347572.1 :2001 JAN 12 71876167V1 790 964 28 Ll:347572.1 :2001 JAN 12 71874464V1 755 1473 28 U:347572.1 :2001JAN12 71158362V1 1823 2595 28 LI :347572.1 :2001 JAN 12 70557446V1 1826 2467 28 U:347572.1 :2001JAN12 71874757V1 1336 1709 28 U:347572.1 :2001 JAN 12 70326574D1 1340 1801 28 U:347572.1 :2001 JAN 12 7629109J1 1346 1737 28 U:347572.1 :2001JAN12 7629109H1 1346 1737 28 U:347572.1 :2001JAN12 70555309V1 1357 1983 28 U:347572.1 :2001JAN12 70555879V1 757 1373 28 U:347572.1 :2001 JAN 12 71304118V1 1821 2451 28 U:347572.1 :2001 JAN 12 3279857H1 1798 2085 28 U:347572.1 :2001JAN12 71873191V1 1322 1929 28 U:347572.1 :2001JAN12 71875680V1 1794 2027 28 Ll:347572.1 :2001 JAN 12 70556404V1 1557 2115 28 U:347572.1 :2001 JAN 12 71873172V1 1307 2068 28 LI :347572.1 :2001 JAN 12 71873872V1 1292 2038 28 U:347572.1 :2001 JAN 12 71874274V1 1559 2175 28 U:347572.1 :2001 JAN 12 6830659H1 742 1312 28 U:347572.1 :2001JAN12 71875377V1 1536 2121 28 U:347572.1:2001JAN12 70555359V1 740 1356 28 LI :347572.1 :2001 JAN 12 2925464H1 16 274 28 U:347572.1 :2001JAN12 4179553F8 21 515
TABLE 3
SEQ ID NO: Template ID Component ID Start Stop 28 LI:347572.1 :2001JAN12 71156954V1 2534 3020 28 LI:347572.1 :2001JAN12 761848H1 2549 2743 28 Ll:347572.1 :2001 JAN 12 2528759H1 2514 2772 28 U:347572.1 :2001JAN12 70555774V1 2549 3232 28 Ll:347572.1 :2001 JAN 12 4172634F6 2591 3169 28 LI:347572.1 :2001JAN12 3222459H1 2553 2920 28 LI:347572.1 :2001JAN12 4172634H1 2591 2877 28 Ll:347572.1 :2001 JAN 12 71155779V1 2554 3142 28 U:347572.1 :2001JAN12 71980069V1 2591 3456 28 Ll:347572.1 :2001 JAN 12 71988432V1 2591 3290 28 LI:347572.1 :2001JAN12 71873666V1 1526 2118 28 Ll:347572.1 :2001 JAN 12 71303881VI 1527 2128 28 U:347572.1 :2001JAN12 8124422H1 1509 2190 28 Ll:347572.1 :2001 JAN 12 70327556D1 1520 2097 28 U:347572.1 :2001JAN12 70446298V1 1281 1940 28 U:347572.1 :2001JAN12 70446257V1 1283 1937 28 U:347572.1:2001 JAN 12 71874434V1 883 1601 28 Ll:347572.1 :2001 JAN 12 71873016V1 897 1590 28 LI:347572.1 :2001 AN12 6785373H1 907 1509 28 U:347572.1 :2001JAN12 70555300V1 730 1307 28 U:347572.1 :2001JAN12 70554782V1 738 1431 28 LI :347572.1 :2001 JAN 12 1582746H1 3313 3567 28 U:347572.1 :2001JAN12 g7317002 3442 3605 28 LI:347572.1 :2001JAN12 g4739984 3524 3605 28 U:347572.1 :2001JAN12 4179741T9 2966 3534 28 Ll:347572.1 :2001 JAN 12 70556579V1 2952 3281 28 Ll:347572.1 :2001 JAN 12 71303602V1 2958 3644 28 Ll:347572.1 :2001 JAN 12 g2099950 3219 3458 28 Ll:347572.1 :2001 JAN 12 g2051100 2977 3283 28 Ll:347572.1 :2001 JAN 12 6075277H1 2981 3189 28 U:347572.1:2001JAN12 g7278026 3250 3605 28 Ll:347572.1 :2001 JAN 12 1426361 Fό 3012 3472 28 LI:347572.1 :2001JAN12 g5664324 3250 3605 28 Ll:347572.1 :2001 JAN 12 1426357H1 3012 3216 28 U:347572.1 :2001JAN12 71131546V1 3021 3329 28 Ll:347572.1 :2001 JAN 12 5536040H1 3065 3300 28 LI :347572.1 :2001 JAN 12 1501621To 3108 3622 28 U:347572.1 :2001JAN12 71158019V1 3113 3605 28 LI :347572.1 :2001 JAN 12 4050931 HI 3132 3454 28 Ll:347572.1 :2001 JAN 12 70326238D1 3143 3605 28 Ll:347572.1 :2001 JAN 12 4179553T9 3155 3518 28 LI :347572.1 :2001 JAN 12 71156430V1 3157 3605 28 U:347572.1 :2001JAN12 g4665411 3160 3605 28 LI:347572.1 :2001JAN12 g6658497 3170 3661 28 Ll:347572.1 :2001 JAN 12 4172634T6 3179 3615 28 LI:347572.1 :2001JAN12 g2099982 3184 3605 28 LI:347572.1 :2001JAN12 2770719H1 3210 3499 28 U-.347572.1 :2001 JAN 12 g5452554 3275 3664 28 L1:347572.1 :2001JAN12 2770719F6 3210 3421
TABLE 3
SEQ ID NO: Template ID CompΩnent ID Start Stap 28 LI :347572.1:2001 JAN 12 g2077519 3217 3605 28 U.347572.1:2001 JAN 12 2925464F6 16 570 28 U.347572.1:2001 JAN 12 4179240H1 17 287 28 U.347572.1:2001 JAN 12 4874914H1 4 263 28 LI :347572.1:2001 JAN 12 4179741 HI 4 294 28 LI :347572.1:2001 JAN 12 6785591 HI 12 524 28 LI :347572.1:2001 JAN 12 6830659J1 1782 2441 28 U:347572.1:2001JAN12 71874444V1 1213 1849 28 LI :347572.1:2001 JAN 12 g5850365 1212 1592 28 U.347572.1-.2001JAN12 g5865429 1217 1537 28 Ll:347572.1:2001 JAN 12 71872572V1 1247 1920 28 U:347572.1:2001 JAN 12 71874921V1 1267 1914 28 U.347572.1:2001 JAN 12 71872613V1 1199 1905 28 U.347572.1:2001 JAN 12 71157014V1 1194 1832 28 U:347572.1:2001JAN12 71158855V1 1194 1698 28 U.347572.1:2001 JAN12 70556118V1 986 1611 28 U.347572.1:2001 JAN 12 71874918V1 991 1586 28 LI:347572.1:2001JAN12 71874740V1 716 1370 28 U:347572.1:2001JAN12 71873309V1 730 1454 28 U:347572.1:2001JAN12 2868052H1 716 861 28 U:347572.1:2001JAN12 6828695H1 711 1332 28 U:347572.1:2001JAN12 71874448V1 656 1329 28 Ll:347572.1:2001 JAN 12 70326955D1 625 1033 28 Ll:347572.1:2001 JAN 12 71873533V1 638 1273 28 Ll:347572.1:2001 JAN 12 6787884H1 1 326 28 LI :347572.1:2001 JAN 12 6788638H1 13 474 28 U:347572.1:2001JAN12 6788583H1 1 583 29 Ll:007788.1:2001 JAN 12 71438538V1 1 543 29 LI :007788.1:2001 JAN 12 71434963V1 584 1151 29 U:007788.1:2001JAN12 71434939V1 585 1149 29 U.007788.1:2001 JAN 12 6968941 Ul 627 971 29 U:007788.1:2001JAN12 71442343V1 837 1286 29 U:007788.1:2001JAN12 71457233V1 630 981 29 U:007788.1:2001JAN12 71442968V1 628 1057 29 U:007788.1:2001JAN12 71432203V1 667 1225 29 U:007788.1:2001JAN12 71426610V1 375 481 29 U:007788.1:2001JAN12 71436995V1 540 1112 29 U:007788.1:2001 JAN 12 71440391V1 253 822 29 LI :007788.1:2001 JAN 12 71438372V1 282 1156 29 LI :007788.1:2001 JAN 12 71432321V1 294 791 29 U.007788.1:2001 JAN 12 71440960V1 315 961 29 U:007788.1:2001 JAN 12 71432360V1 350 888 29 U:007788.1:2001JAN12 71442282V1 366 876 29 U:007788.1:2001JAN12 71441217V1 160 681 29 U:007788.1:2001JAN12 71422030V1 251 503 29 LI :007788.1:2001 JAN 12 71454158V1 719 906 29 LI :007788.1:2001 JAN 12 71443151V1 720 1085 29 U:007788.1:2001 JAN 12 71448621V1 689 1145 29 U:007788.1:2001JAN12 71443729V1 693 1314
TABLE 3
SEQ ID NO: Template ID CampΩnent ID Start Stap
29 U.007788.1 :2001 JAN 12 71443176V1 715 1061
29 U.007788.1 :2001 JAN 12 71420002V1 1304 1568
29 U:007788.1 :2001JAN12 71423336V1 1313 1535
29 U.007788.1 :2001 JAN 12 71434893V1 1319 2016
29 U.O07788.1 :2001 JAN 12 71461970V1 141 410
29 U:007788.1 :2001JAN12 g1886530 1 272
29 LI:007788.1 :2001JAN12 71440642V1 532 1047
29 U:007788.1 :2001 JAN 12 71433158V1 407 960
29 U.O07788.1 :2001 JAN 12 71435741VI 407 1072
29 U:007788.1 :2001JAN12 71436321V1 411 1064
29 U.007788.1 :2001 JAN 12 71437008V1 422 988
29 U.007788.1 :2001 JAN 12 71432688V1 494 902
29 U:007788.1 :2001JAN12 71433925V1 400 1023
29 LI:007788.1 :2001JAN12 71436863V1 394 1305
29 U:007788.1 :2001 JAN 12 71440938V1 379 1055
29 U:007788.1 :2001JAN12 71432125V1 385 943
29 LI:007788.1 :2001JAN12 71432566V1 540 948
29 U:007788.1 :2001JAN12 71424751V1 815 1338
29 U:007788.1 :2001JAN12 71438151V1 836 1393
29 U:007788.1 :2001JAN12 71431916V1 828 1059
29 U:007788.1 :2001 JAN 12 71437201V1 830 991
29 U:007788.1 :2001JAN12 71438468V1 863 1619
29 LI :007788.1 :2001 JAN 12 71437217V1 745 1429
29 U:007788.1 :2001 JAN 12 71434111V1 787 1501
29 U:007788.1 :2001 JAN 12 71436255V1 745 1040
29 U:007788.1 :2001 JAN 12 71436709V1 735 1044
29 U:007788.1 :2001JAN12 71438643V1 733 1514
29 U:007788.1 :2001 JAN 12 2844842H1 1 270
29 U.007788.1 :2001 JAN 12 2844842F6 1 600
29 U:007788.1 :2001 JAN 12 71440088V1 61 715
29 LI:007788.1 :2001JAN12 71436911VI 141 608
29 U:007788.1 :2001 JAN 12 71433281VI 1212 1655
29 LI :007788.1 :2001 JAN 12 71429319V1 1282 1515
29 U:007788.1 :2001 JAN 12 71438954V1 1142 1718
29 U:007788.1 :2001JAN12 71440857V1 1148 1649
29 U.007788.1 :2001 JAN 12 71439354V1 1150 1655
29 U:007788.1 :2001 JAN 12 71441496V1 1150 1652
29 Ll:007788.1 :2001 JAN 12 71440905V1 1149 1632
29 LI:007788.1 :2001JAN12 2844842T6 1191 1652
29 U:007788.1 :2001JAN12 71433422V1 1208 1648
29 U:007788.1 :2001JAN12 71438640V1 1377 1541
29 U:007788.1 :2001JAN12 71441467V1 1361 1976
29 U:007788.1 :2001 JAN 12 71436418V1 1407 2043
29 U:007788.1 :2001JAN12 71440289V1 1493 2094
29 U:007788.1 :2001JAN12 71441919V1 1477 1997
29 U.007788.1 :2001JAN12 71435052V1 1496 2057
29 U:007788.1:2001JAN12 71435995V1 1497 2015
29 U:007788.1 :2001 JAN 12 6630554U1 1507 2016
29 U:007788.1 :2001JAN12 71433818V1 1573 1890
TABLE 3
SEQ ID NO: Template ID CampΩnent ID Start Stap 29 U.007788.1:2001 JAN 12 71449687V1 1822 1980 29 U:007788.1 :2001JAN12 71433309V1 1941 2085 29 U.007788.1 :2001 JAN 12 71440820V1 1 542 29 U.007788.1 :2001 JAN 12 71440319V1 887 1496 29 U.007788.1 :2001 JAM 2 71433851V1 872 1489 29 U:007788.1 :2001JAN12 71439124V1 928 1571 29 U.007788.1 :2001 JAN 12 71435518V1 915 1379 29 U.007788.1 :2001 JAN 12 71435541V1 932 1067 29 U:007788.1 :2001JAN12 71442095V1 929 1450 29 U.007788.1 :2001 JAN 12 71434718V1 992 1509 29 U.007788.1 :2001 JAN 12 71436909V1 1002 1618 29 U:007788.1 :2001JAN12 71436829V1 972 1306 29 Ll:007788.1 :2001 JAN 12 71435725V1 1094 1710 29 U:007788.1 :2001 JAN 12 71433312V1 1124 1652 29 U:007788.1 :2001JAN12 71437003V1 1136 1583 29 U.007788.1 :2001 JAN 12 71436059V1 1145 1891 30 U:336872.1 :2001 JAN 12 70986562V1 381 825 30 U:336872.1 :2001JAN12 70984072V1 399 737 30 U:336872.1 :2001 JAN 12 70985543V1 399 827 30 U:336872.1 :2001 JAN 12 71295516V1 399 823 30 U:336872.1 :2001JAN12 71295044V1 399 766 30 Ll:336872.1 :2001 JAN 12 70986344V1 399 652 30 Ll:336872.1 :2001 JAN 12 71295036V1 290 825 30 U:336872.1 :2001 JAN 12 3384358F8 322 825 30 U:336872.1 :2001JAN12 70985880V1 322 582 30 U:336872.1 :2001 JAN 12 71295290V1 322 572 30 U:336872.1 :2001JAN12 70986588V1 322 519 30 U.336872.1 :2001 JAN 12 70985351VI 322 551 30 U:336872.1 :2001JAN12 3384358H1 329 501 30 U:336872.1 :2001 JAN 12 71123582V1 329 433 30 U-.336872.1 :2001 JAN 12 6535837F8 18 699 30 U.336872.1 :2001 JAN 12 3365081 HI 1 161 30 U:336872.1 :2001 JAN 12 6535437H1 18 470 30 U:336872.1 :2001 JAN 12 71296536V1 570 1200 30 L1:336872.1 :2001JAN12 71295432V1 606 825 30 Ll:336872.1 :2001 JAN 12 70983429V1 648 1210 30 U.336872.1 :2001 JAN 12 2261815H1 656 825 30 U:336872.1 :2001 JAN 12 71294916V1 672 1295 30 U:336872.1 :2001JAN12 70985853V1 679 1328 30 U:336872.1 :2001 JAN 12 3717638F6 765 1254 30 U:336872.1:2001 JAN 12 3717638H1 765 825 30 U.336872.1 :2001 JAN 12 71269157V1 1060 1281 30 Ll:336872.1 :2001 JAN 12 70983024V1 512 1142 30 U:336872.1 :2001JAN12 71294736V1 512 825 30 LI:336872.1 :2001JAN12 70986361VI 548 1192 30 U:336872.1 :2001 JAN 12 70986118V1 547 825 30 U.336872.1 :2001 JAN 12 70984218V1 1067 1300 30 U:336872.1 :2001JAN12 71295238V1 1069 1229 30 U:336872.1 :2001JAN12 71295235V1 1070 1711
TABLE 3
SEQ ID NC : Template ID < DampΩnent ID Start Stap
30 U.336872. V. 2001 JAN 12 70985136V1 1073 1353
30 U:336872.1: 2001 JAN 12 g 1980540 1450 1632
30 U:336872.1: 2001 JAN 12 g760823 1465 1597
30 U.336872.1: 2001JAN12 71295531V1 1076 1456
30 U.336872.1: 2001JAN12 3717638T6 1083 1574
30 U.336872.1 : 2001 JAN 12 70984050V1 1224 1741
30 U:336872.1: 2001 JAN 12 70986990V1 1375 1588
30 U.336872.1: 2001 JAN 12 70983054V1 1076 1561
30 U:336872.1: 2001 JAN 12 6535837T8 1074 1504
30 U:336872.1: 2001 JAN 12 70985260V1 1076 1458
31 LI: 1143291.1 2001 JAN 12 71568568V 1 765 1287
31 LI: 1143291.1 2001 JAN 12 71569363V1 770 1002
31 LI: 1143291.1 2001 JAN 12 71571480V1 771 1002
31 LI: 1143291.1 2001 JAN 12 71572931 VI 778 1390
31 LI: 1143291.1 2001 JAN 12 71228064V 1 818 1333
31 LI: 1143291.1 2001JAN12 71570836V1 828 1492
31 LI: 1143291.1 2001 JAN 12 g 1727418 844 1086
31 LI: 1143291.1 2001 JAN 12 71227387 V 1 847 1377
31 LI: 1143291.1 2001 JAN 12 70864247V1 848 1452
31 LI: 1143291.1 2001 JAN 12 71573061 VI 894 1518
31 LI: 1143291.1 2001 JAN 12 2639294H1 895 1186
31 LI: 1143291.1 2001 JAN 12 4957555H1 897 1195
31 LI: 1143291.1 2001 JAN 12 70861696V1 903 1557
31 LI: 1143291.1 2001 JAN 12 71569143V1 936 1629
31 LI: 1143291.1 .2001 JAN 12 71573232V1 924 1536
31 LI: 1143291.1 2001 JAN 12 71556832V1 623 1034
31 LI: 1143291.1 :2001JAN12 7256767H1 632 1166
31 LI: 1143291.1 2001 JAN 12 71573169V1 693 1501
31 LI: 1143291.1 2001 JAN 12 6107631 HI 672 996
31 LI: 1143291.1 2001 JAN 12 71571503VV 682 1443
31 LI: 1143291.1 '2001 JAN 12 70864234V1 1148 1748
31 LI: 1143291.1 2001 JAN 12 4825453H1 1156 1438
31 LI: 1143291.1 2001 JAN 12 6577495H1 1184 1744
31 LI: 1143291.1 :2001JAN12 3559219H1 1118 1423
31 LI: 1143291.1 :2001 AN12 g 1959565 529 978
31 LI: 1143291.1 :2001JAN12 7693774J2 528 1062
31 LI: 1143291.1 :2001JAN12 3181072H1 541 854
31 LI: 1143291.1 :2001JAN12 g 1646925 52 386
31 U:1143291.1 -.2001 JAN 12 2919186H1 34 312
31 LI: 1143291,1 :2001JAN12 6302587H1 1071 1420
31 U:1143291.1 :2001JAN12 71567814V1 1077 1215
31 LI: 1143291,1 :2001JAN12 g6986485 1076 1602
31 LI: 1143291.1 :2001JAN12 6177745H1 14 289
31 LI: 1143291,1 :2001JAN12 3367153H1 15 303
31 LI: 1143291.1 :2001JAN12 3358072H1 17 309
31 LI: 1143291.1 :2001JAN12 7454619H2 21 172
31 LI: 1143291.1 :2001 JAN 12 7660612H1 29 584
31 LI: 1143291.1 :2001JAN12 5078943H1 29 273
31 LI: 1143291.1 :2001JAN12 3218692H1 31 309
CΛ m
D ω co ω ω co co co w co ω ω co co ω w co ω ω co ω ω co w co u co co co w co co ω ω ω ω
j_ 45. 45. 45. 45. 4s 4s 45. 4 4S 45, 4S 4S 4S 45. 4S 45. 4S Js, 45, 4s, 45, 45, 4S 45. 45. 45. 45. 4^
CO CJO CO CJJ C J CO CO CJJ CJJ OJ CJ CO CJO CO CO CJJ CJO CO CO OO W — 1
No ro ro ro ro No ro ro io NO No ro ro iO NO NJ No ro ro NO io ro ro No ro ro ro ro ro ro ro ro N^ 0 0 0 0 0 0 0 0 0 0 0 0 O 0 0 O 0 0 O 0 0 0 0 O 0 0 O O 0 O 0 0 0 0 0 0 0 0 0 0 0 0 O O 0 O 0 0 3 x xxxxxxxxxxx xxxxxx
K Kb b f Kb K ro fo Kb Kb K ro Kb Kb Kb Nb
0oo0o00o0o0oo00oo00o0oo00o0o0o0o0o0o0oo00o0o0oo00oo00oo00o0o0o0oo00o0o0oo00o0oo00oo00o0o0oo00o0o0o_(0
_ C_ _ C_ C_ C_ C_ C_ C_ C_ C_ (-_ C_ C_ <--. C_ C_ C_ C_ <_ C_ C— C_ C_ C_ C_ C_ C_ C_ _
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
Ε Ε ?; Ε Ε Ε Ε Ε Ε Ε Ε Ε Ε Ε Ε ?: Ε Ε Ε; Ε Ε Ε Ε Ε Ε; Ε ΕA Ε Ε Ε Ε Ε ΕA Ε Ε Ε ΕΪ Ε Ε ?A Ε Ε Ε Ε Ε
NO NO NO M O NO M NO NO NO NO NO NO NO M NO NO NO NO NO NO NO O NO NO NO NO NO NO M NO NO M NO NO NO NO NO NO NO NO NO NO N^
>O
Co
O C C « Cύ r m nv W O O O M -J Λ NO NO NO 00 D Ol Oι Ol Co ω ω sl s| s| s| _J r O-i 0o0 v M-i vMi m Ch Ch 0i0-i 1 o r-> r-> rn r-> v> CO oCO o O O en cn M M M M M M M O O O O O O O CO Oo o CD C 1x0 0 0 00 0 45, 0 0 0 0 0 O O 00 —■ 45. CO oo cn o o o n NO 45, —' M NO _ _ _ _ _ 0 — ' CO CO O NO O O CO o cn O M CO O CO O NO — ' — ' — • _±
M 00 00 00 O
-■ ω ω oo oι
m
SD co ω ω ω ω ω co ω ω ω ω ω co ω co ω ω ω ω co ω ω ω co ω ω ω ω oj co oo ω ω ω ω ω ω
O
S S o -5 ^v Sr5v S^ Sg g ^ n§ S§ Mg M^ ^M ^=: Mg: gM Ncn) Mo Mo oM ^C ro cθs rNo0 iNJ o- ^:=; 45, CO 45.
O 00 o S ^ N O O O O O fe en NO -■ NO C ro.-x C r.-x jO o
C unι + 45^. M vi O u- Mi 00 o O o CO 00 Q CO CO NO ^ co v^ fjv ^ NO O CO M O _
TABLE 3
SEQ ID NO: Template ID Campanent ID Start StΩp
31 LI:1143291.1 2001JAN12 3541264H1 4 181
31 LI:1143291.1 2001JAN12 3541804H1 4 112
31 LI:1143291,1 2001JAN12 8114012H1 8 658
31 LI: 1143291.1 2001JAN12 984132H1 686 1004
31 LI:1143291.1 2001JAN12 g4333939 1425 1841
31 LI:1143291.1 2001JAN12 g2751759 1431 1672
31 LI:1143291.1 2001JAN12 g8365378 1435 1844
31 LI:1143291.1 2001JAN12 g4069554 1437 1836
31 LI:1143291.1 2001JAN12 5314985H1 1455 1720
31 LI:1143291.1 2001JAN12 g4762625 1451 1832
31 LI:1143291.1 2001JAN12 g5233045 1462 1848
31 LI:1143291.1 2001JAN12 g3870514 1464 1835
31 LI:1143291.1 2001JAN12 g1646926 1466 1844
31 LI:1143291.1 2001JAN12 g7154482 1469 1838
31 LI: 1143291.1 2001JAN12 g888988 1485 1837
31 LI:1143291.1 2001JAN12 g2848889 1494 1839
31 LI:1143291.1 2001JAN12 g2336365 1499 1835
31 LI:1143291.1 2001JAN12 g4438632 1524 1832
31 LI:1143291.1 :2001JAN12 g4598155 1531 1832
31 U:l 143291.1 2001JAN12 g4281669 1533 1834
31 LI:1143291.1 :2001JAN12 g2552618 1534 1841
31 Ll:1143291.1 :2001JAN12 2156356H1 1546 1686
31 LI:1143291.1 :2001JAN12 3406628H1 1552 1815
31 LI:1143291.1 :2001JAN12 1693574F6 1561 1832
31 LI:1143291.1 :2001JAN12 1693574H1 1561 1825
31 LI:1143291.1 :2001JAN12 1693574T6 1564 1788
31 LI:1143291.1 :2001JAN12 217117H1 1581 1797
31 LI:1143291.1 :2001JAN12 g4190420 1598 1842
31 LI:1143291.1 :2001JAN12 3534712H1 1633 1721
31 LI:1143291.1 :2001JAN12 6847563H1 1634 1943
31 LI:1143291.1 :2001JAN12 g4901424 1639 1797
31 U:1143291.1 :2001JAN12 2398575H1 1646 1834
31 Ll:1143291.1 :2001JAN12 2466666H1 1677 1834
31 LI:1143291.1 :2001JAN12 g4373565 1681 1840
31 Ll:1143291.1 :2001JAN12 g890701 1691 1834
31 LI:1143291.1 :2001JAN12 6848480T8 1741 1943
31 Ll:1143291.1 :2001JAN12 6848480F8 1767 1943
31 LI:1143291.1 :2001JAN12 5137506H2 1764 1859
32 Ll:093477.1: 2001JAN12 55026983H1 1 620
32 Ll:093477.1: 2001JAN12 55026983J1 534 793
32 Ll:093477.1: 2001JAN12 4187505F8 684 1310
32 Ll:093477.1: 2001JAN12 4187505H1 684 798
32 U:093477,l: 2001JAN12 6064542T8 986 1348
32 Ll;093477.1: 2001JAN12 4187505T8 1070 1473
32 U:093477.1: 2001JAN12 g6701422 1085 1585
32 Ll:093477.1: 2001JAN12 g6992369 1085 1506
32 Ll:093477.1: 2001JAN12 4187505T9 1093 1473
32 Ll:093477.1: 2001JAN12 2721392H1 1292 1529
33 Ll:222105.1: 2001JAN12 5337431 HI 2259 2485
rn co ω oo co co co co co co c3 c-o cjo co co co c-o cjo co oo oo co co cjo eo co cjo cjj co ω _ co co co co co oo oo co co cjo c-o cjo cjo cj oo co oo cjj co co eo co oo co cj c-o eo co ω O z O
No ro NO NO NO No ro ro M ro ro ro ro ro ro ro ro NO No ro ro ro ro No ro ro ro ro ro ro ro NO M ro NO N^ rO NO NO NO NO NO NO NO NO NO NO NO NO NJ NO NO NO NO NO NO NO NO NO rO NO M NO NO NJ NO NO NO NO NO NO NO NO NO NO NJ M M NO NO NO M NO NO NO NO NO M NO NO NO r rO NO NO M NO NO NO NJ ^ NO NO NO NO NJ NO NO NO NO M NO NO NO NO NO NO NO NO M NO NO N^
O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O -S cjo cji cn cn cn eπ cn en cji co Cjo Cjo cn cji en cjo en co cn en cn cn coi cn cjo cjo cn cn cn cn c^ xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx -g_ fό Kb Kb Kb Kb K fό Kb Kb rό fύ Kb fό Kb fό fό Kb fύ Kb fύ fύ fό ro Kb
O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O VJ- O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O Φ c_ c_ c_ c_ c_ <_ c_ c_ c_ c_ c_ c_ <-_ c_ c_ c_ c_ c_ (-_ <-_ c_ c_ c_ <-_ <-_ c_
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > >
_____5____--- S____________________ S5-_55- zz- - -Ei i f___ rO M NO NO NO NO NO NO M NO NO NO NO M NO NO NO NO NO M NO M NO W NO NO NO NO NO NO NO NO NO NO NO NO NO
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO — ' — ' NO NO NO NO NO NO NO NO ro NO NO NO NO NO »<β o.oq NO NO NO NO CΛ NO NO NO NO — ■ _ _ — ' NO — ' — ' — ' NO NO NO M M O Ol O O O O O O NO 00 o O O O SSOSOK00 s 00; O 00 NO NO NO r co ro - ■ — ' M M M M o oo o cn cn 45. cn o cD 0 0 45. 45. 45. 45. 45. ro O CJ1 0 vθ f^ ∞ ∞ ∞ O CJ 45. 0 Pn: C" , rE -_ NO O O M cn Cn
45. M CO O O 4S. 45. C0 45, en CO N0 M O O C0 O M O O 00 00 4S, — ' O O O 00 M oo M cπ ro o cπ o o cπ w -, c-π 00 Co CO O O O T^.
rO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO — ' lO IO NO NO NO rO NO NO NO NO NO NO — ' NO NO NO NO NO NO NO NO — ' — . _ _ — ' — < NO NO NO NO NO CΛ 4-. 45, 45, 4s, 45, C0 45. 45, 45, 45, 45. 45. 45. M M O O C0 C0 CD O CD O O O O 45. O — ' O O C0 O O C0 M O 45. 45. O 45. 45. O O 45. 45. 00 4S. ^- Cπ en θ O 45. N0 45. Cn 00 O C0 O N0 — ■ Cn M C» 45, O O O -J N0 ω θ M C0 N0 O C0 O M N0 N0 C» M N0 O O C0 θ 45, I NJ M C0 M M -y
M o co co — ' ro cn No eπ co eo o co eπ o co — ' O 0 45. — < o co oo — ■ cπ — ■ 00 ro — ■ — ' Co co oo cπ oo αo o ro N θ co oo oo o co oo o 0
CΛ m
©
C CO 00 C 03 00 CO CO CO CO 00 00 CO CO 00 CO CJ0 CJ0 C0 C CJ0 CJJ CJ0 CJ0 CJJ CJ0 CO 0J W Oo oo ω ω co Oo CO Co CO Co CO Oo Co c-o Co ω Co Oo OJ Oo c-o Co cjJ CO CO Oo Oo co w _
Z
O
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO ro NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO
NO NO N) NO NO NO NO NO NO NO NJ NO NO NO NO NO NO NO NO ro ro NO NO NO NO NJ NO NO NJ NO NO NO NO NO NO N) NO NO NJ NO NO NO NO NO NJ NO NO NO N)
NO NJ NJ NO NJ NO NO NJ NO NJ NJ NO NJ NO NJ NO NO NJ NO NO NO NJ NO NO NJ NJ NJ NJ NJ NO NJ NO NO NO NJ NJ NO NJ NJ NO NJ NO NO NO NJ NO NO NO NJ
CD D O O CD O O O o O O CD O CD O O O O O O C3 Φ cπ cn cn cπ en cn cπ en cπ cn cn cn cπ Ol cn Cn CJI cn Cn cn cn cn CJO cπ cn cn cn cn cn cn cn Cn cπ cn cn cn cπ en cn cπ cn cn cn cn cπ cn cn cn cn 3 Ό
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO Ω
CJ eo C J C ) C J o C J CO O D CO o C J C ) C ) CJ J CJ CO CJ CO CO C ) O CO C ) C J J O CD C ) C ) CO
CJ CJ CD CD CJ CJ O CJ o CJ o CJ CD o CD CD o CD CJ CD O D o CJ o o CD o O CD o o CD o CJ o o CD o CD CD CJ CJ CJ c_ c_ <_ <_ c_ c_ c. <_ c_ <_ c_ C_ c c_ c_ c_. c_ o. C c, , f_ c_ c_ <_ c_ c_ c_ c r c _ c_ c , c_ f _ c_ c C . c_ c_ c c. r_ π
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > z Z Z z Z Z z Z z Z Z z z Z z Z z _ z Z z z Z z Z. Z Z Z Z Z Z
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO ro NO NO NO NO NO NO NO ro
ro N ro No ro ro io ro i ro NO ej jv rv ,.. — . _ _ — . ro tO jv — ■ — • n —• — , -j — ■ — ■ isO M ro r i rn ro ro No ro io i NO No rv, r- r>- n NJ co
Oι a n n θι sι ι si i s| sj K ^ K sι sι i s| s| ι ^ ι sι S j sj vj si sι rjι θι cjι rjι (jι ϊ sι sj sι s| j (i oi CB vi -' ω ω -' -' K ^ ^ ϊ -' ^ o -J CΛ ω S ω S oo ci a cji Ji ffl sj si si h R
CO 00 00 O 00 45. 45. N0 — I o J. J ϋi O - ^ O O CO O CO O NO N ^ OO M O O — ■ Cn O O O I M C0 C0 _ O O — ' O ^ ^ ^ ^ M ^l.
rO N NO N N NO NO NO N N NO ^- o- -, -. _ N0 — ' — ' NO NO — ' _ NO - . NO — ' — ' NO — ' NO NO NO NO NO fv- NO NO NO NO NO NO NO NO M M g -5 M O O CO OO O O O O Oo O fe ^ ^ iFv O NO OO O O OO O O O X O O O O O O OO O O O S o O O O O O O O ro ω j M No r cΛ Co ω S N S f^ M — - w _ - V -I hi co ή o ro cπ o — ' Cn oo oo o — ■ M M ^ ^ ^ h c^ --j 0- --j -J _ jv > 0- (-) cj vo ro J — ' Oo — ' OO OO M O ∞O O∞O Oθ ObO C∞O OCDO OCOO MM Cn Ul Cn v0 0'O
CΛ m ©
Oo co C Oo CO CO Oo Co c-o CO CO CjO CjJ C-o Oo CO Oo co Co C CO CO CO Oo Oo ω c oo co oo cjo oo cjo ω c-o cjo co co cjo co ω cjo oo co c co co cjo oo ω
O
lO NO NO NO NO NO NO NO NJ NO NO NO NO ^ NO NO NO NO M NO NO NO NO h NO NO NO NO NO NJ NO NO NJ NO NO NJ IO rO O NO NO NO NO NO M NO N^
N ro N M rO M M M M M M ro rO M M M I M IO N M M M IO M IO I M W M M M M rO M M M N M rO NO NO IO NO NO NO rO NJ NO rO NO NO NO lo rO NO NO rO NO rO NO M NO rO NO NO NO rO NO NO NO NO NO NO ro rO NO IO NO NJ M c On cOo cOn cOnOcnOen cOjoOen cOn eOnOcn cOn cOnOcn eOn eOnOcπOcji Cjo en cn cjo en cn cn cjo cji en cji CΛ xxxx x x x xxxxxxxxx xxx xxxxxxxxxxxxxxxxxxxxx-D
N Ob KOb KOb fOo iOo KOb KOb KOb KOb KOb KOb KOb fOό fOό fOό fOό KOb KOKOb fOύ fOύ KOb i Kb fό o o o o o o o o o o o o o o o o o σ o o o o oOόOoOo oOoOoOoOoOoOoOoOoOoOoOoOoOoOoOoOoOoOoOoOoOoOoO oOC→D
(-_ C_ _ C_ C_ <-_ _ C_ _ C_ C_ C_ C_ C_ C_ C_ C_ C_ _ C_ C_ C_ C_ C_ C_ C_ C_ _ C^ D
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
Z^ Z ^ Z^ Z Z^ Z Z^ Z^ Z Z^ Z Z Z^ Z Z^ ^ Z Z^ Z^ Z^ Z^ ^ Z^ Z^ Z^ Z^ Z Z Z Z rO NO NJ NO NJ NO NO NO NO NO NO NO NO NO M NO NO r NO NO NO NO NO O NO NO NO
ON
-J
_ — — — . . - _ . — NO NO NO NO NO NO NO NO NO rO NO NO NO NO rO NO NO NO rO rO rO CΛ cπ cπ cπ 45. 45> 45, 45, 4s. 45. 4-. CO Oo P^ N o O O O M M M M M M M M CO — — ' — ' — ' NO NO NO NO cn oo cn en — ' —■ —■ — - o o o o NO O O O O O O O O O — ■ _ _ — ' O O O O — ' O O O o o o o o coo oo en NO NO co cn o x^ l 00 M M Ol NO NO O O O NO Ol — ' — ' Oo Cn en en N0 45, 45, 45, Ω c Co NNOO cCoO nOoO NNOO COJO rCo0 0θ o0 i4s5,, vMj κNo cCoO M 0 O 4455,. - O0 0 O — ' — ' — ' CO OO CD vJ vj cπ en 4s, en o ro o o o M oo M M 4s, σ oo oo co
— ' NO — NO — ■ _ _ — ■ — ■ — ■ NO NO O — ' — ' NO NO NO NO NO NO NO NO ,- — ' NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO CΛ o o oo — ' M CΠ CΠ M M M O NO — ■ 45. v 4-5 — ' N .,i O — ' OO O OO CO O O O O OO O -^ OO NO NO NO Co NO — ' 45, 4s. 45. 0O CO N0 CO Co OO C Co 4S, CO N0 ^f- 4s. en cn 45. cn o o o NO O 45, 45, 00 ^ — ' N0 O 45. C0 00 N0 N0 00 C0 00 M ≤ M 45, O — ' O M NO — ' M O Oi O O N0 N0 N0 M CO 4i. M -2 o co o o en o 4s, oo 00 — ■ O O oo oo O CO O O NO OO OO O OO M CO O — ' M N _ CO Oo en M I O M CO M O NO M O OO N M T3
m Θ oo co co eo co co oo cjo oo co oo eo co oo oo co co co co oo oo co cjo co co co cjo oo cj c-o ω co ω ω co co u co ω ω ω co ω co co ω co u co ω co ω co co co o ω ω co co ω co ω cj ω ω
0
NO M NJ NO NO O NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NJ NO M NJ NO O NO NO NO NO NO NO M NO M NO W M NJ NO M rO rO NO NO NO NO NO M NO M M NO M NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO rO NO M NO NO M NO NO NO NO NO NO NO W NO NO NO NO M NO NO rO NO W rO M NO NO r NO NO NO NO rO NO NO NO NO NO NO o cjoocjoocπoeπ con eonoenocnocnocn eonocnσcnocn co-nocjoocnocnocπocoocjoocnocnocoocjooenocnocnocnocnocjiowooooooooooooooooo-5 xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx-σ
Kob Kob Kob foό Kob Kob Kob Kob Kob Kob Kob Kob Kob Kob Kob Kob Kob Kob Kob Kob Kob Kob Kob foό ϊoo Kob Kob Kob foo Kobofό Kob Koboi foό K oooooooooooogoooogoogooooooob oofό i ooo Kob fό Kb Kb Kb ooooooooo ooooooogooooooooogoooΦ→- c_ c_ c_ c- c_ _ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c- _ <-_ c_
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > >
ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ
M N M M M M M M r M I M N3 W M M M M M M rθ rθ r M I M N3 M I M I I M IO M M SJ M
>co mi— co
O
NO NO NO NO NO NO NO — ' - - -■ — ' — ' — ' NO NO NO NO NO NO NO NO NO NO NO — . _ _ _ — - NO NO _ —' _ C
Cπ ϋi αi Oi Oi CJi Oi o S n NO -N -O NO NO — ' — ' _ O O O O M M M vl O O O O C0 C0 00 00 00 Cn Cn NO —■ Λ en _, on cn cn 7?
45, 45, 4s, 45. 45. 45, 4s, N0 ?y r^ M 4s, 45. O M M oo o o o o o o o o o o o o o cn O M O Oo cn cn o
00 00 00 03 03 00 03 0 NO M M M NO O M O Cn M Cn — ' — ' CO OO M M O en O CO M OO M o cn o en NO
O M cn =4-
NO NO NO NO NO NO NO — _ _ _ _ _ _ _ A — . _ _ _ ' tO NO NO NO NO NO NO NO NO NO NO — ' NO _ r .o _ I .O . NO NO ,_. , -
M O O O O O O O 45. O Cn O 00 4s. 00 O O O O O O O O 00 O O O O O O Cπ — _ ' 0 C 4455., M M O o g ω co o co - co rO vi
— ' rθ OO N NO CO C0 00 45, C0 0 0 0 45. — ' Cn 4s, 4i. 45. rO NO O N NO O CO NO N NO NO O OO NO O Cn Cn — • ex-x f.-x 01 45, 45, 00 00 — ' C
O O0 45. M OO — ■ — ' O — ■ CO Co ro Oo N0 0 45. _ _ _ CD O O CD OO M — ' OO OO OO CO Oo rO M OO O O en Cn co 00 45, CO O CO 45. 5
CO m
<D
00 Cj3 Co co CO CjJ 00 CJ Co O3 C 00 C0 Co 00 00 00 00 CO CO (-o CO CO Cj0 CJ0 W J>. 4i> 4i, 45, 4s 4s 45. 45. 45. 4i. 45> 45. 4i> 45. 45- 4s 45, 45. 4s 4s 45» 45> 45, 45, 45> 45, ω co co ω ω
O
CO IO NO NO NO NO NO NO NO NO NJ NO NO NO NO NO NO NO o NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO
M
CO o o o o o o o o o o o o o o O O O Φ
M cn cn cπ cn cπ en en cn cn cn en en cn cπ cn en en
NO X x χp_
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO Kb Kb Kb Ω
C ) O O o O O O O O O O O O O O O o o o O O o o o o o O O O O O O O o o o Φ
C_
> >>>>>>>>>>>>>>>>>
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ ' W Co cjo rO — ' CO OO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO CΛ oo oo oo oo oo oo M M M M O O O Cn cn cπ o o o NO — ■ — ' CJo o ro No o o cjo 4s c-o co c3 NO NO NJ cn en cn cn cn cn cjo cjo cn cn cn en cn ?<-
O O ∞ — ' O O O M M rθ 45. C C M — ^ O IO NO Cn O O O — ' Cn 45. 0 0 0 CJ O OO O O OO OO M 45. 45, 45, 45. 45, 4S. 45, 45. 45. Cn Cn 45, 45. Ω O M M 00 C0 O O O 4S, 4S. Cn O 00 O C0 Cπ — • Ch — ' sl J 4- 0> J- - ' M 45> 45. C0 00 O Cπ θ O M CD M M O 45> 45, N0 O O 45, 45. 00 00 -Jr
ro ro ro IO NO IO ro rO rO IO — ■ _ _ — ' NJ NO NJ IO IO ω CO CO NO NO ω Cjo ro rO NO NO NJ NO NO NO NO NJ NO NO NO NO NO NO NO NO NO NO NO NO rO CΛ CO CO — ' O O Cθ 45. C0 4S C0 θ O C0 00 O O C0 C-0 N0 45. M 45, M Cj0 45, 45. O O ∞ C0 45, en 45. 45. Cn 45. O O O O O O M O M M O O vJ ?+ — ' N0 45, O M 45, Oo 45. — ' N0 M N0 en O 45. Cn N0 N0 O C0 O Cn O 45, O N0 — ' Co — ' M M — ' O ro rO M CO Co NO M Co NO O J— Cn M NO NO — ' OO M M 00 45. M OO OO M 45. M OO O — ' 45. N0 M M 00 O O — ' 00 O 00 O 4S. O O O C0 — - M O O O OO Cn — ' CO N0 45, Co 4S. OO O M T3
CΛ m D
CJ0 CO CJ0 CO 00 CO CJ0 00 CJ0 CJJ CO O3 C0 00 CJ0 0U CO CO CO CJ0 CO 00 O3 00 O3 CJJ 00 00 C^
45. 45. 45, 45. 45. 45, 45. 45, 45. 4^ 45. 45- 45, 45- 45. 45. 45, 45, 45, 45, 45, 45. 4^ 4^ 45, 45. 45- 45^ o o
45. 45. CO CO CO NO NO — NO -A NO NO NO NO NO OO Oo Oo eo OO OO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO CO 00 O 00 NO M O NO M NO — ' O O CO NO 0 0 0 0 0 0 0 _ 0 _ 0_ 0_ 0_3 0.3 0 _0 0 -0 4.5, 45. 00 4.5, Co cn — — f 00 00 M O NO —' O O CO O — ' — ' M M M 00 CO NO cn oo M O o cn o o o S
O — ' O cn 45, cn ro o NO O CO CO 00 0 0 0 0 00 00 45. 45. 45, 45, 45, ro o o o cn NO O O rO OO M O NO O CO O O Cπ M O C0 4s. NO — ■ — ' 45. 00 45, 0 0 0 0 00 03 ^!-
M 00 O 00 O M M M CO C-O CO CO Cjo CjJ Oo CO OO CO CO CO NO NO NO NO NO NO NO OO CO CΛ
4 Jv l n^ CO c«π NO rO NO NO NO CO M rroO cjO eCjo3 ir rNoO rNoO NNo iNoO cCnO NNOO MM cCnn oO M MM CCjJJ Ceoo cCoO oWo en o NO NO co cn — • — — '' CCO0 OO MM MM MM MM 0O 0O 4455.. N0 ;-+ j^5:, vJ v^ ^ r ^ v- r N ^ n rii n l ii lO j ! - ' O M M CJl O O Cn O CO Cπ O O Cn O M O Oo O O — ' O O O — ' 0 0 0 4S- 0 03 0 0 Cπ Co Cn Ω 5- JS 5. CJ CO CJ JV. — ' Q n — ' O — ' CJI J5, - ' CO NO O — ■ — ■ — ' O O O M C0 45- ω C0 45, 00 45. 00 C0 M 45. N0 N0 45, 03 N0 45, 45. 45, — ' — ' 3
CO Co ω CO CO CΛ CO CO CO CO CO CO CO CO CO CO GO CΛ CO CO CO CO CO CO CO CJ C-O Cjo CO CO OO C0 03 00 00 CO CO OO CO CO Co Co OO CO Cjo C-o CO
45, 45, 45. 45. 45. 45. 45. 45, 45. 45, 45. 45. 45, 45, 45, 45. 45, 45, 45, 45, 45. 45. 45. 45, V. V. 4V. V. JV. 4V. V. JV. V. . V. JV. 4V. 4V. J^ 4V. J , 4V. V, JV. JV. V, 4V, gδ z
O
COO COO COO COO ∞ CO OO OO CO OO CD OO OO OO CD CO CO OO OO OO OO CD CO OO OO OO OO OO OO CD CO CO CO CO CO ∞
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M ω co ω ω ω o ω u ω ω ω ω ω u ω ω ω co ω ω w u w ω ω w o ω ω ω ω co ω Φ1
M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M 3
Ko Ko fo fo fo Ko fo fo Ko io Ko Ko Ko fo Ko Ko Ko Ko Ko Ko fo Ko fo fo fo fo fo Ko Ko fo Ko fo Ko XJ
Kb Kb Kb ro fό fό ro Kb Kb Kb fύ fό fύ fύ fό fύ Kb Kb Kb fύ fό Kb fό fύ ^ Q
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Φ
C_ <-_ (L_ C_ C_ C_ C_ C_ C_ C_ _ C_ C_ C_ <__ _ <-_ C_ _ C_ C_ _ C_ <-_ σ
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > >
Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z
NJ M W M rO M M M M IO W M IO rO M IO M M M M M W W M IO I M M M M M I M M r tO M M
M
NO NO NO NO NO NO — ' — ' — ' NO NO cπ . O M NO NO — ■ — ' — ' NO — ' — ' -' ro 45, 4s> co ro ro r v, r o-i v o . CO M — ' O O M O — " CO O O 00 Ol O - N icO-i CrOx 4 r5 M-ι v M-ι r enn
45, —
■ -' 45, O O CO O O NO CO 45, O 00 O M
o M en o rso r-h r ivi NO NO NO NO ro O — NJ O O I rv r-iv 0. rv. rv. NO N ■ — ■ ro 10 to ro 10 _ _ _ _ M 45, cn o 45. NO CO Co 45, O NO Ol 45. o o o o o o o en cn o 45. 45. en oo ro N0 4s. No O O O NO NO O 00 ro O0 M M OO ~^ ! i ^+ — ■ co o 45, NJ O — ■ M Cύ co o o cn en 00 co — ' en en o co cn — ' No oo oi o en o — • M cπ oi en — < n CB θ3 >o ro - ω _- o
M cn 00 M 45. cn —■ o NO NO o CO M o 45. NO — ' O — ' O O CO O M O 00 M — • 00 M M O NO g M oo co O oo en o -D
TABLE 3
SEQ ID NO: Template ID CΩmpΩnent ID Start StΩp
34 LI 816737.2:2001 JAN 12 7703677J1 162 587
34 LI 816737.2:2001JAN12 7703677H1 162 634
34 LI 816737,2:2001JAN12 8042881 HI 173 618
34 LI 816737.2: 2001 JAN 12 2745193H1 180 326
34 LI 816737.2:2001 JAN 12 6779803J1 185 631
34 LI 816737.2:2001JAN12 g 1966591 197 793
34 LI 816737.2:2001JAN12 2910860H1 2518 2641
34 LI 816737.2:2001JAN12 g5746758 2538 2700
34 LI 816737,2:2001JAN12 2101769H1 2547 2803
34 LI 816737.2:2001JAN12 7586935H1 2563 3144
34 LI 816737.2;2001JAN12 2909278H1 2569 2700
34 LI 816737.2:2001 JAN 12 641371 1 HI 2594 2864
34 LI 816737.2:2001JAN12 g551 1963 2601 3024
34 LI 816737.2:2001 JAN 12 g5514266 2629 3062
34 LI 816737.2:2001 JAN 12 291 1782H1 2643 2932
34 LI 816737.2:2001JAN12 414951 OH 1 2699 3014
34 LI 816737.2:2001 JAN 12 6410684H1 2718 3076
34 LI 816737.2:2001 JAN 12 5308802H1 2754 2875
34 LI 816737.2:2001 JAN 12 g4685773 2768 3027
34 LI 816737.2:2001 JAN 12 2910551 HI 2786 3077
34 LI 816737.2:2001JAN12 5308802F8 2800 3031
34 LI 816737.2:2001JAN12 6407061 HI 2821 3285
34 LI 816737.2:2001 JAN 12 g 1988622 2082 2298
34 LI 816737.2:2001 JAN 12 641 1 180H1 1991 2314
34 LI 816737.2:2001 JAN 12 760599R1 21 14 2616
34 LI 816737.2:2001 JAN 12 2561638H1 2001 2283
34 LI 816737.2:2001 JAN 12 6414151 H1 2001 2188
34 LI 816737.2:2001 JAN 12 7742741 Jl 2019 2550
34 LI 816737.2:2001 JAN 12 760599H1 21 15 2281
34 LI 816737.2:2001JAN12 g6704512 2024 2277
34 LI 816737.2:2001 JAN 12 g4690363 2046 2327
34 LI 816737.2:2001 JAN 12 g 1988942 1954 2189
34 LI 816737.2:2001 JAN 12 g 1989158 1954 2239
34 LI 816737.2:2001 JAN12 7364250H1 1974 2566
34 LI 816737,2:2001JAN12 6410621 HI 1221 1417
34 LI 816737.2:2001 JAN12 2476181 HI 1238 1463
34 LI 816737.2:2001JAN12 6412149H1 1234 1452
34 LI 816737.2:2001 JAN 12 2912945H1 1235 1502
34 LI 816737.2:2001 JAN 12 8214171 H1 1324 1744
34 LI 816737.2:2001JAN12 6405193H1 3262 3572
34 LI 816737.2:2001 JAN 12 291 1786H1 3292 3586
34 LI 816737.2:2001JAN12 8036618J1 3310 3922
34 LI 816737.2:2001 JAN 12 5734088H1 3318 3566
34 LI 816737.2:2001JAN12 5308802T8 3345 3901
34 LI 816737.2:2001JAN12 7742741 HI 3405 4001
34 LI 816737.2:2001JAN12 761851 1J1 3428 4004
34 LI 816737.2:2001 JAN 12 8048034H1 3436 3883
34 LI 816737.2:2001JAN12 2909546H1 3448 3761
34 LI 816737.2:2001JAN12 g2215564 3454 3876
g2559715 g4365747 CΛ m g406780 Θ co co co co oo co c-o oo co cjo cjo co ω co co oo oo oo eo co co oo co co c-o cjo cjo co co CO OO OO CO OO CO OO CO CO CO CO CO CJO OO CO CO CO CO CO CO
45, 45. 45, 45. 45- 4s, 45, 45, 4i, 45, 45, 45, 4s, 45> 4s 45, 4s, 4i, 45, 4i. 45, 45, 4s, 45, 45, 4i, 45, 4s 4^ 5. 45. 45, 45, 45. 4. 45. 45. 45, 45, 45, 45, 4, 45, 45, 45, 5, 5. 45, 45, O z n
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M — 1 ω ω oo ω eo cjo cjo cjo cj ω co ω c cj jo cjo co cjj co oo co co co co ω φ
M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M 3
Ko Ko Ko Ko fo Ko fo fo fo fo fo Ko iso Ko Ko fo fo Ko Ko ro Ko k) Ko Ko fo Ko fo Ko fo M τs
Kb Kb Kb K Kb fύ Kb Kb isb fό Kb iό fό Kb Kb b fό fό Kb fό fό Kb fό Kb Ω
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 φ c_ c_ c_ _ _ c_ _ _ c_ c_ c_ <-_ c_ _ c_ c_ c_ c_ c_ <-_ c_ <-_ c_ c_ c_ c^ D > z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z
M M M M M M M NJ IO M I M M iO M M I IO NJ M M W IO M rO M M ro rO M M M IO M M
1 — ' O >
NO 0 O vj 0 O O
CO CΩ CΩ CΩ O CΩ CΩ CΩ CΩ CΩ CΩ CΩ CΩ CΩ CΩ CΩ CΩ CΩ <Q CΩ CΩ CΩ CΩ CQ CΩ CΩ CΩ CΩ CΩ CΩ CΩ CΩ CΩ CΩ CΩ CΩ CD CΩ CΩ |S rv, -n _CΩ § r—
Cύ 0 cn en cn M M 45. Co Cπ M 45- cn 45- M M 45. O M cπ 0 M Cn M 45, 45. cn M 4s, cn o oι 0 0 45. en cn 0 45, en 0 r3 ro 5 ro J ΓΠ
0 — • cn cn cn ro cπ oo o ro oo o cπ — ' NO O M NO O M — ' 4s, — ' OO O M — ' O OO — ' 00 0 45, 0 M cn — « — ■ 00 ύ 45, o co en cn co o eo _ M co co 45. — ■ C cπ r [vn, rπ ro rπ CO
0 45, 0 0 rπ eo o o ro M o co _ cn M 00 — ■ M en — ■ cπ 45- (3 0 ω -
0 00 M NO 45. NO M O M — ' CO CO 45. — « 00 45, M 00 O M NO O O CO O O — ' O O NO Co 45. 0 0 cn 45, — « NO 0 NO g cn Ω §
00 — ■ O NO -' O 45. O O N0 O O 45- M 45. O CO NO O —■ N0 0 0 45. 45. OO OO M 45. 4, en 0 co 0 0 en 00 v| 0 NO 0 cn M 45, O 00 rn co o co 4s. M o en ro Ol O NO 45. NO NO O CO O Ol J- O O - ' CO M — 45, co 45. 0 — • M cn NO 0 __j a 0 Φ
45, M O CO CO 00 Cπ O O C0 4S. M O N0 M en 0 cn 0 NO 0 ro No o cn co en o — ' O CO NO 00 NO 0 NO — ■ CO O NO X X X X 00 H γ.
Ό
Cj cj3 CJ θo co oo oo cjo c-o o co ω co Cj3 Cjθ oo oo c-o co oo c-o eo co ω o o o o o o o o o o o coo cjo co cn cn cn cn cn cn cn c-π eπ cjo cjo co c-n cjo cn cn cn cjo cπ eπ cji cn 4i. co co eo ro N0 N0 — ■ — ■ — ' θ θ θ θ θ oo oo oo oo oo M M M M M θ θ θ θ θ cn en en en
45, O M OO OO Co en NO M O Cn O M O CJJ rO O C0345, 03 — ' C03 N0 — ' —
' O M M 45.45. —
' O O O M
45, 4s. 45, 4i. 4s. 4s, 45. 4S 4S 4S 45. 45. 45. 45, 45. 4s. 4s 4S 45. 45, 45, 45. 45, 45. 45, 45. 45, 4S 45. 4S 4^
O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O OO OO M OO M OO ^÷- O O O O NO — J NO O O — ' O O CO tO — ' — ' — ' O O O — ' O O — ' O — ' O — ' O O O O O — ' — ' O O O O O O O O CO Cn OO — ' M M " < 0 O _ 45. O C3 45. 45. M 00 45. 45, O O O — ' C0 45. 45- M O M O 45, O 4S. CΠ CΠ C00 M 45, O N0 — CJ0 M O O CJ0 O 45. C 00 O CO M N0 O
m © co co oo co co co oo oo co co co cjo co co co cjo co oo co co co co co cjj ω ω cn cπ cjo cjo cn co cji cπ cn cn Co cjo co en cn cn cn cn co cn en cn cn cn cn cn cn c-^ o
45, Jv v. v. jvi 4v. v. 4v. 4v. v, jv, . v. v. ^ 4. . 4v. 4v, jVi 4v> ^ jvi ^ 4v. ^ ^ ^ ^ M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M — ' — ' — ' _ _ —< _ _ _ _ _ — < cn en cn cn cn en c-n cn ci cn cn cn c-π cn en cn cn cn coo co eπ cn cjo co en eπ en cn c-n co en c^ cjo cn coo cji cn cn cn cjo cji cn cn cn cn cjo cjo cn cji cjo cjo cn ^
M NO NO NO NO NO NO NO NO NO NO iNO NO NO NO NO NJ M NO rO NO M NO rO NO rO rO NO NO M NO NO M NO NO M Co CO Co ω
_ 4i. 4s. 45. 4s. 4s, 4S 45, 4S 45. 4S 4i, 4s, 4i, 4i, 45, 4S 45. 45, 45. 4i, 4S, 45, 4s, 45. 45. 45. 45, 4^ X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X Ko Ko fo Ko NO NO No fo Ko Ko Ko fo O. ro ro iό Kb Kb Kb Kb Kb b Kb Nb Kb Nb Nb fό rsb fό Kb N Kb Kb K^
OoOoOooOoO OooO OoOoOoOooO OoOoOσoO OoOoOoOoOσOoOooO OooO OooO OooO OoOooO OoOooOoO OooOoO OooO OoOoOooOoO OoOoC.DJ-
C_ _ C_ C_ C_ c_ C_ C_ (-_. c_ C_ C_ C_ <-_ C_ <-_ c_ C_ C_ C_ C_ C_ C_ C_ _ C^
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > >
Z Z^ Z Z^ Z^ Z^ Z^ Z^ Z Z^ Z^Z^Z^ Z^ Z^ Z^Z^ Z^ Z^Z^ Z^ Z^ Z^ Z^Z Z Z ro ro ro to ro ro ro ro No to NO NO No ro ro M to NO NO NO N^
-fs.
VI CΛ
_ _ _ _ _ _ _ _ _ _ _ _ . _
45, O O Cn 0 0 0 0 45, Cn 45, — ■ oo o ro cn 4 M M vι cπ cn _ _ 4s, J--, 4s, 45, 45, 4s 45. 45. 45. Co 45, 45, CΛ NO M O CO M — ' M NO O NO O OO O CO M — ' j5 M 0 5. cn —■o — cn—'45,45,ro—' OO M M 45, — ' 00 Co 45. N0 00 N0r4o5.reonrMoC4Os,oM—O'o— 'o— 'o— ' OooOoO —o 'oOo— 'oOOoO —o ' joΩ o o o o eπ oo cn o co o cπ o O O — ' — ' CO NO Cn O rθ C0 Js. 00 N0 en N0 00 CO M 00 Cn N0 45, O O N0 O 45, 00 M Cn eπ M 45. N0 T3
TABLE 3
SEQ ID NO: Template ID CΩmpΩnent ID Start StΩp 35 U :475524.1 :2001 JAN 12 71912464V1 721 1074 35 LI .475524.1 :2001 JAN 12 70331 Oil D1 772 1113 35 Ll:475524.1 :2001 JAN 12 70331364D1 788 1239 35 11:475524.1 :2001 JAN 12 70330374D1 788 1113 35 LI:475524.1 :2001JA 12 71909029V1 815 1319 35 U:475524.1 :2001JAN12 71908983V1 817 1449 35 Ll:475524.1 :2001 JAN 12 71904215V1 825 1132 35 LI :475524.1 :2001 JAN 12 6854940H1 842 1500 35 LI:475524.V.2001JAN12 8042027J1 852 1436 35 Ll:475524.1 :2001 JAN 12 8042027H1 852 1419 35 U:475524.1 :2001JAN12 71908988V1 867 1405 35 LI:475524,1 :2001JAN12 70332528D1 873 1524 35 LI :475524.1:2001 JAN 12 70332239D1 873 1148 35 LI :475524.1 :2001 JAN 12 71835907V1 886 1197 35 LI ;475524.1 :2001 JAN 12 70287711VI 169 375 35 LI :475524.1 :2001 JAN 12 70287644V1 169 375 35 LI:475524.1 :2001JAN12 70285965V1 610 830 35 LI .475524.1 :2001 JAN 12 71839758V1 621 837 35 LI:475524,1 :2001JAN12 71836321V1 634 1287 35 LI .475524, 1 :2001 JAN 12 70286051VI 641 1269 35 Ll:475524.1 :2001 JAN 12 2777396H1 170 429 35 Ll:475524, 1 :2001 JAN 12 2417676H1 171 423 35 LI:475524,1 :2001JAN12 4400939H1 173 453 35 Ll:475524.1 :2001 JAN 12 4400939F8 173 741 35 LI :475524, 1 :2001 JAN 12 2078647H1 174 437 35 Ll:475524.1 :2001 JAN 12 2782041 HI 178 446 35 Ll:475524.1 :2001 JAN 12 71914042V1 197 953 35 Ll:475524.1 :2001 JAN 12 3639112H1 213 492 35 LI:475524.1:2001JAN12 3639112F8 213 717 35 U:475524.1 :2001JAN12 71916583V1 265 491 35 LI :475524.1 :2001 JAN 12 71839839V1 291 432 35 LI:475524.1:2001JAN12 71911695V1 301 1088 35 LI:475524.1 :2001JAN12 71912757V1 324 972 35 Ll:475524.1:2001 JAN 12 70283980V1 324 946 35 Ll:475524.1 :2001 JAN 12 70286638V1 348 423 35 Ll:475524.1 :2001 JAN 12 70331871 Dl 411 749 35 U:475524.1 :2001JAN12 71908544V1 441 1043 35 Ll:475524.1 :2001 JAN 12 70286471VI 446 1095 35 LI :475524.1 :2001 JAN 12 71911546V1 470 1066 35 LI :475524.1 :2001 JAN 12 70330636D1 472 878 35 U:475524.1 :2001JAN12 70286641VI 495 1091 35 LI:475524.1 :2001JAN12 71911879V1 503 1019 35 LI :475524.1 :2001 JAN 12 71835513V1 514 1394 35 Ll:475524.1 :2001 JAN 12 71911201V1 513 1018 35 LI :475524.1 :2001 JAN 12 70330801 Dl ' 510 852 35 Ll:475524.1 :2001 JAN 12 70289695V1 531 902 35 LI :475524.1:2001 JAN 12 71909715V1 565 1185 35 LI :475524.1 :2001 JAN 12 70287021VI 598 1231 35 Ll:475524.1 :2001 JAN 12 71908567V1 602 1307
TABLE 3
SEQ ID NO: Template ID CΩmpΩnent ID Start Stap 35 LI:475524.1 :2001JAN12 71909690V1 603 1378 35 LI :475524.1 :2001 JAN 12 4402107F8 608 1215 35 LI :475524.1 :2001 JAN 12 4402107H1 608 858 35 LI:475524.1:2001JAN12 3639112T9 1045 1346 35 Ll:475524.1 :2001 JAN 12 70329744D1 1149 1542 35 Ll:475524.1 :2001 JAN12 70284959V1 1048 1551 35 LI :475524.1 :2001 JAN 12 2825995T6 1075 1614 35 LI:475524.1 :2001JAN12 70331759D1 1149 1542 35 LI:475524.1 :2001JAN12 70284193V1 1092 1509 35 LI .475524, 1 :2001 JAN 12 1234684H1 1101 1407 35 LI:475524.1 :2001JAN12 70286063V1 1116 1597 35 LI :475524.1 :2001 JAN 12 4763439H1 1124 1406 35 LI:475524.1 :2001JAN12 2417287F6 1151 1515 35 LI:475524.1 :2001JAN12 70284906V1 1127 1698 35 LI:475524.V.2001JAN12 71835516V1 1141 1556 35 LI:475524.1 :2001JAN12 5951943H1 1198 1514 35 Ll:475524.1 :2001 JAN 12 4000924H1 1199 1464 35 U:475524.1 :2001JAN12 70329942D1 1220 1542 35 LI:475524.1 :2001JAN12 g5855014 1236 1666 35 U:475524.1 :2001JAN12 2417287T6 1242 1617 35 LI:475524.1 :2001JAN12 70287141V1 1278 1664 35 Ll:475524.1 :2001 JAN 12 70278422V1 1304 1649 35 LI:475524.1 :2001JAN12 71902622V1 1494 1653 35 LI :475524.1 :2001 JAN 12 70282132V1 1354 1665 35 LI :475524.1 :2001 JAN 12 70279417V1 1365 1514 35 LI:475524.1 :2001JAN12 2890678T6 1383 1620 35 U:475524.1 :2001JAN12 70285679V1 1395 1658 35 LI :475524, 1 :2001 JAN 12 70277527V1 1431 1801 36 LI:383639.1 :2001JAN12 70682346V1 405 1011 36 LI:383639.1 :2001JAN12 70683125V1 406 1003 36 LI:383639.1 :2001JAN12 7645332J1 2066 2531 36 LI:383639.1 :2001JAN12 70683372V1 757 1419 36 LI;383639.1 :2001JAN12 70680065V1 758 1438 36 U:383639.1 :2001JAN12 70683712V1 582 1095 36 Ll:383639.1 :2001 JAN 12 70684737V1 188 769 36 LI:383639.1 :2001JAN12 70679850V1 189 769 36 LI:383639.1 :2001JAN12 70682393V1 226 831 36 Ll:383639.1 :2001 JAN 12 70684930V1 309 820 36 U'.383639.1:2001JAN12 70684160V1 358 1014 36 LI:383639,1 :2001JAN12 70684175V1 377 1056 36 Ll:383639.1 :2001 JAN 12 70679797V1 388 1025 36 LI:383639.1 :2001JAN12 70684023V1 403 1022 36 Ll:383639.1 :2001 JAN 12 70683486V1 2027 2504 36 LI:383639.1 :2001JAN12 2733058T6 1926 2476 36 LI:383639.1 :2001JAN12 70683736V1 1972 2241 36 LI:383639.1 :2001JAN12 6558258T8 1988 2409 36 Ll:383639.1:2001 JAN 12 7741041Jl 1988 2358 36 Ll:383639.1 :2001 JAN 12 70683390V1 2021 2654 36 LI ;383639, 1 :2001 JAN 12 70683348V1 2025 2504
TABLE 3
SEQ ID NO: Template ID CΩmpΩnent ID Start StΩp 36 LI :383639.1 :2001 JAN 12 70682373V1 486 1109 36 LI;383639.1 :2001JAN12 7202070F8 490 1153 36 Ll:383639, 1 :2001 JAN 12 70708649V1 540 721 36 Ll:383639, 1 :2001 JAN 12 70679719V1 188 784 36 Ll:383639.1 :2001 JAN 12 70681944V1 1855 2327 36 LI:383639.1 :2001JAN12 7741041 HI 85 688 36 Ll:383639, 1 :2001 JAN 12 5751880H1 4 384 36 LI:383639,1 :2001JAN12 70682456V1 1430 1802 36 Ll:383639, 1 :2001 JAN 12 70682994V1 1461 1795 36 Ll:383639, 1:2001 JAN 12 70684676V1 1619 2122 36 U:383639.1 :2001JAN12 70681954V1 1699 2326 36 Ll;383639.1 :2001 JAN 12 70684297V1 423 989 36 LI:383639.1 :2001JAN12 70682426V1 1277 1737 36 Ll:383639, 1 :2001 JAN 12 70682307V1 1296 1816 36 U:383639.1 :2001JAN12 70681033V1 1322 1817 36 LI:383639.1 :2001JAN12 7202070R8 1 675 36 Ll:383639.1 :2001 JAN 12 70683142V1 1910 2521 36 U:383639.1 :2001JAN12 70685074V1 411 989 36 U:383639.1 :2001JAN12 70684926V1 1214 1361 36 Ll:383639.1 :2001 JAN 12 70681749V1 1228 1810 36 Ll:383639.1 :2001 JAN 12 70681557V1 1210 1810 ,36 LI:383639.1 :2001JAN12 6558258F6 802 1441 36 Ll:383639, 1 :2001 JAN 12 6558258F8 802 1454 36 U:383639,1 :2001JAN12 6558258H1 802 1209 36 U:383639.1 :2001JAN12 70684285V1 836 1356 36 U:383639, 1 :2001 JAN 12 70684179V1 837 1473 36 U:383639.1 :2001JAN12 70680668V1 841 1367 36 LI;383639.1 :2001JAN12 70682051VI 852 1513 36 LI:383639,1 :2001JAN12 70681684V1 900 1137 36 Ll:383639.1 :2001 JAN 12 2836771 HI 938 1198 36 U:383639.1 :2001JAN12 70684622V1 1008 1641 36 LI:383639.1 :2001JAN12 70683326V1 1018 1503 36 U:383639.1 :2001JAN12 70684440V1 1046 1480 36 Ll:383639.1 :2001 JAN 12 70683925V1 1091 1613 36 LI:383639.1 :2001JAN12 70684469V1 1099 1743 36 LI:383639.1 :2001JAN12 70681264V1 1122 1764 36 LI:383639.1 :2001JAN12 70681504V1 1197 1525 36 LI:383639,1 :2001JAN12 70708848V1 540 742 36 LI:383639.1 :2001JAN12 70680123V1 545 1195 36 LI:383639.1 :2001JAN12 70682376V1 548 1134 36 LI:383639.1 :2001JAN12 70683701VI 582 1095 36 U:383639.1 :2001JAN12 70679509V1 625 1272 36 Ll:383639.1 :2001 JAN 12 70684244V1 674 1321 36 LI:383639.1 :2001JAN12 70682159V1 698 1342 36 U:383639,1 :2001JAN12 7202070H1 699 1153 36 Ll:383639.1 :2001 JAN 12 70682801VI 740 1264 36 LI:383639.1:2001JAN12 70685242V1 753 1169 36 Ll:383639.1 :2001 JAN 12 6740467H1 2124 2628 36 LI:383639.1 :2001JAN12 6740467F6 2151 2549
CΛ m
(D
W Cjθ Oo CO CO Co θo Co oo θo Cθ Co Cθ C Cθ θo Cθ Cθ Co co Cθ 03 C Oo Co co co Co Cθ ω M M M M M M M M M M M M M M M M M M M M M M M M M M M M M O O O J o
D -D Φ_
M oo
__, _ NO NO NO CΛ P ^ o ro r -j - r > α » ffl θ θ θ θ o o α c> n cn S cSoI COo O SoI CO C OO _ o _ ^
S j K) - __ _ -. -. -- -. fi ∞ ∞wr Tj- W CO _, ^ j. g, W O sl OJ Ol ϋ 22 ^ S ^ 8i S § ≤ ≤ ∞ 2 S fe S S vi ^ a ^ o ^ - -
M M O cπ ro o M O oo en oo o 45, o NO O Cn — ■ O =}-
TABLE 3
SEQ ID NO: Template ID CΩmpΩnent ID Start Stap 37 LI:814346.1 :2001JAN12 71524467V1 942 1456 37 LI:814346.1 :2001JAN12 4246423F8 1013 1250 37 U:814346,1 :2001JAN12 4695902H1 1088 1341 37 LI:814346.1 :2001JAN12 5699360H1 1082 1355 37 LI:814346.1 :2001JAN12 71672312V1 828 1472 37 LI :814346.1 :2001 JAN 12 8117248H1 1523 2010 37 LI:814346.1 :2001JAN12 8031941Jl 1532 1787 37 U:814346.1 :2001JAN12 g7237197 1545 1994 37 LI:814346.1 :2001JAN12 gό660424 1550 1994 37 LI:814346,1 :2001JAN12 4093018H1 1101 1395 37 Ll:814346, 1 :2001 JAN 12 2637113H1 1096 1379 37 LI:814346.1 :2001JAN12 3503076H1 1098 1405 37 U:814346,1 :2001JAN12 3908373H1 1099 1391 37 LI:814346,1 :2001JAN12 4133423H2 1099 1387 37 LI:814346.1 :2001JAN12 3908259H1 1099 1378 37 Ll:814346.1 :2001 JAN 12 3908287H1 1099 1372 37 LI:814346.1 :2001JAN12 2112888H1 1100 1341 37 Ll:814346.1 :2001 JAN! 2 7753585H1 1498 1991 37 U:814346.1 :2001JAN12 5000729H1 1171 1380 37 Ll:814346.1 :2001 JAN 12 2836649H1 2478 2750 37 Ll:814346.1 :2001 JAN 12 513685H1 1128 1349 37 LI:814346.1 :2001JAN12 1719914H1 1130 1340 37 Ll:814346.1 :2001 JAN 12 2633807H1 1136 1273 37 LI:814346.1 :2001JAN12 4729726H1 1156 1459 37 U:814346.1 :2001JAN12 71523539V1 868 1484 37 Ll:814346, 1 :2001 JAN 12 71672563V1 924 1494 37 LI:814346.1 :2001JAN12 384798H1 889 1168 37 LI:814346.1 :2001JAN12 71520792V1 884 1568 37 U:814346.1 :2001JAN12 5433152T9 943 1238 37 U:814346.1 :2001JAN12 7408170H1 55 716 37 LI:814346.1 :2001JAN12 7639063H1 67 626 37 LI:814346.1 :2001JAN12 6199976H1 2141 2560 37 LI:814346.1 :2001JAN12 3941047H1 2141 2421 37 LI:814346.1 :2001JAN12 2395818H1 2226 2464 37 Ll:814346.1 :2001 JAN 12 g7703774 1646 1994 37 Ll:814346.1 :2001 JAN 12 g7155032 1656 1994 37 LI:814346.1 :2001JAN12 7380647H1 1699 1964 37 Ll:814346, 1 :2001 JAN 12 g7043267 1725 1994 37 Ll:814346.1 :2001 JAN 12 g7700997 1742 1994 37 U:814346.1 :2001JAN12 2395626H1 2228 2464 37 LI:81434ό.1 :2001JAN12 2448338T6 1748 1945 37 U:814346.1 :2001 JAN 12 3950758T9 1765 1866 37 Ll:814346.1 :2001 JAN 12 2836649T6 1786 1943 37 LI:814346.1 :2001JAN12 g2057262 2233 2643 37 Ll:814346.1 :2001 JAN 12 6542484H1 1857 2191 37 Ll:814346.1 :2001 JAN 12 2930772H2 1871 2151 37 L1:814346.1 :2001JAN12 4931846H1 1900 1994 37 LI:814346.1 :2001JAN12 2395818F6 1995 2464 37 Ll:814346.1 :2001 JAN 12 g4312220 1488 1937
CΛ m
CO OJ CJO CO C-O CO CJO OO CO OO CJO CJO CJO CO CJO CJO OO CJJ CO CJO CO CO CO CO CO CJO CO W CO CO OO OO OO M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M Ό
>
00 CD o co
00 CO 4S, — ■ — . _ _ — .
Co rO — < 00 00 O O O - _r- -_n ._- _rO1 N0 N0 N0 N0 N0 _i _J Co _ _ *» ro 45, o o o o o en en cn eπ cn cn cn 45. 45. o o o oo oo oo !-?
_ e , O 45, O 45. O 45. Γ NJ 0 4S, CO CO N O O O M NO NO N0 0 45, O OO O O M CO Q
O oCθ 45n. 45. oNO oCn oC o O5 Oo 45.) 00? ^ NO ^ O 45. 4 ro O ^ ∞ ∞ ∞ O O 45. O1 O N0 — ' NO NO — ' N0 O O O Cn 00 00 O M M O 45, .
co w j-, ro o - - ■ _ _ _ _ _ _ _ _ _ co cn oo NO O o eo co oo oo M M Oo M Oo o M M o en cn o cn o cn O f- o o o rv ,-,, 45, CO _ _ _ NO ro o ro oo No o 4s. 4-. pt eπ cn en co 45, 45. oo o — ■ 0 O —0 ' —NO ' OMo cOo — c o O ■ 0CO0O oM 0O0 COπ 0O0 —OO ' θCO Cθn θCO> OJ- 9g jo-o θO θCo sn gg ftNJ CO M 00 CO M — ' M Cn en M NO M M α
45. O C0 O C0 O 00 — ■ cn cπ NO o o g _ o O 2 O M O 0 0 00 N0 45. O
CΛ m
Cj C3 Cθ Co Co 03 Co Oo θo Co Oo co Co Co Co ω θo co C3 Co C Cθ CO Co c-o co Co Co Cjo ω CjO C03 CX> QO C» αo Oθ C O0 CD C» OO O0 OO O0 OO O0 CD C O O3 θO Cα O0 CD O0 αo OO OO O0 CD CD Cj0 CD o
00 00 00 CO co 00 00 00 00 00 CO CO 00 CO co oo CO CO CD co co co CD 00 00 00 C CO 00 00 00 00 00 CO 00 00 CD 00 oo 00 00 CO 00 00 co co 00 00 00 o o o o o o o o o o
CO o o o o o o
03 03 o o
03 03 00 CO oo co CO 00 00 00 co o CO o 03 o 00 o o 00 o 00 00 o o
00 CO CO o CD o 00 00 0 o0 o 00 o CO 0 o0 o o
00 co o o
00 00 oo o 00 o co o o
00 o oo o
00 0 o o o 0 00 o 00 00 00 co o 00 o o
00 ∞ -1 o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o cn cn cπ en cn cn o o o
Cπ cn cn Cn cn cn en en o
Cn cn cn o o n cn cn cn en cn cn cn e Cπ o o o o n cn en Cn Cn cn en en cn cn Cπ n cn cn cn en ■cn cn cn cn cπ cn cn 3 o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o O o O "Ω
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO ro ro NO ro NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO ro NO NO NO Ω o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o O o O O o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o O SΩ c_ r - r c_ r r c r e ,. c c_ r c r c c c . r , c. c_ r . c_ r_ r c_ c c , c . c . c_ c_ c_ c c r c c . r c C— c_ c r r C c c_ c_ c_
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > >
Z Z z Z Z Z z Z Z Z Z Z z Z Z Z
No ro ro ro ro io No ro ro Nj No ro ro ro io ro ro NO io ro ro ro io ro No ro ro NO No i NO NO No to M
oo co co _ _ _ oo Nθ No ro ro co oo oo co _ — ' Cj3 Cjθ Oo oo θo Oo 45, 45. 45. — ' N0 N0 N0 M CO — ' N0 N0 eo Cθ 45, 45, 45, 45, 4-. — ' — . _ _ — . _ OO CΛ o O O eo eo M — ' O Ch o o — • — • — ' O oo W _ rO N0 — ' O O O 4S, 00 00 00 00 00 N0 →-
O M Cπ 0l 45. O C0 C0 O O M 45. C0 00 O O M 4S. O Cπ CD O O — ' 4S, CO M OO O NO M OO M M M OO Cπ 45. M en Cn NO O C OO CO Co Oθ Ω co ro oo o cn ro o oo oo oo — ' 0 0 0 45, — ■ CJ0 O 45, — ■ — ' Co coo cn oo o o cn en co cn M 45, —
45. 45, 45. ro co to ro co co oo co co 45. NO — ' CO OO CO CO C0 00 4S, 45. 45. NO OO OO |O CO CO NO CO CO O _O. C —O 45. 45. 4s. 45, 4s, ro ro ro ro No ro oo cΛ
CO CO NJ O O C 'o- Cn M tO O Oo Co 4s, 45, O O Co cn cn M cπ oi oo co io — ' N NOO —— '■ CoOo NNOO ccnn ccoo —— ' 0 O 44 -_55,. 0O V- NO NO NO NO NO — ' O Oi CO ω o co →- oo oo en 4s. co 4s. M CO NO O 00 O - O - o - o o en eo cn eo — ■ co en cn o cn eo co NO o o o — > _ en ro o o o J^ oo oo o cn.α
O — — ' M O M M 00 M O 45. NO o oo en co 4s, N0 45. o cn en o cn oo oo en o co o o o en M 45, 4s. — ro o — ' Co No co NO NO oo eo _ o"0
CΛ m ©
Oo CO Co co Co Co CO CO Co Co Oo oo OO Co Co CO CO Co cjo Co CO Co cjo CO Oo Oo CO CO CO Co Co Oo Co ω CO CD 00 00 CO O3 CO O3 CD CD O0 O0 O3 O3 O3 O3 O0 θ0 CD CO 00 CO CD 00 CD CD C» CD CD CD 00 O0 CD O3 O3 O3 C» 00 ∞
O
_ _ _ |s0 N0 IO —' —' — ' —' —' — ■ N0 rθ lθ rθ —' N0 N0 C0 _ _ — ' —■ —■ — . _ _ _ ' NO rO NJ NO CO NJ NO CO NO OO Oo CO NO Co OO CO CO CO Co NO CΛ co co oo o cjo cjo cn o o cn c cπ o o cπ o oo o o oo M vj v vj v vj v-j ch o o o o o co o o o o oo o o o o o — ■ — • D o o τ- 5. 00 00 00 0 01 0 0 00 0 00 — ' 0 0 45. CO — ' O O cjn cn en cn en 4s, cjj M 4-. NO NO N ^ o cjo o o o o co — ' Cjo cn — ' W o vj cn cπ -J oo o — ' to o — ' O oi o o o o — ' 45. 45. ro — ' Co co o o oo — ' C0 O O O N0 CO 00 00 45. — ' Cn co M 45, cn ro oo M ro o o o M θ cn ^-
— ' — ' — ' NO NO NO NO NO NO NO NO — ' C NO O OO NO CO C0 45, NO NO NO ) 10 I NO — ' I M Co rO C0 4- Co W C W 4i 4 jS. rO C Co Co C C J-, I CO
O o oOO Oo 4M-. oO cOnO o— ' rcon — co " rfto c -» - oM 4—-. ■ Mo oo ωcO oM rOo cOn NMθ rOo oM Ncoθ Wco _co 4c5D, -e^o ∞— ' ωCo ∞o oo oo Ncn oMo _M _O con reon cMo rcon rcoo Mcjo tcoo r4o5. coo oo r4o5. roo oo ;C=Jf'
O ft — ' O O — ' O O 00 M — ' — ' — ' O Cπ 45. M Co Oo en 45.4s, en — ' N0 O M CJ0 C03 _ N0 O O 00 Cn 45. C0 O M 00 O O N0 Cn M Co r θ 3
θ3 Co ω co c co oo oo co cθ co oo cjo oo c3 Cjo cjo eo co cjJ Co oJ θo co cjj c» coo oo co co oo cD Co C oo θ3 Cθ co cD θo oo cD Co cD Co co oo o3 θo oo
00 00 00 00 00 CO 00 CO 00 co 00 00 00 CO CO 00 00 00 00 00 00 00 00 CO oo oo co co CO 00 00 00 CD 00 00 co 00 CO 00 oo 00 co oo co 00 CD 00 00 CD o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o O O O O
00 03 03 CD 00 o
CO 00 00 Co 00 00 00 CO 00 Oo 00 00 00 CO 00 CO 00 o o
00 CD 00 00 00 CO CD CD 00 00 o o o
00 00 00 00 00 00 00 00 00 00 00 00 00 00 CO CO 00 o o o o o o o o o o o o o o O O O o o o o o O o o o o o o o o o o o o o o o o o o o o o o o o o o CD
Ol cπ Ol Oi cn cn cn cn en cn cn cn cn en cπ i cπ cn cπ cn cπ cn cn cn cn cn cn cn cn cn cn cn cn en en cn cn Oi Oi Cn cn en cπ cn cn en en cn 3 o o o o o o o o o o o o o o o o o O o o o o o o o O o o o o o o o o o o o o o O o o o o o o o o o p. ro NO NO NO NO NO NO NO NO NO NO NO NO NO Kb iό Kb Kb Kb Kb fό Kb NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO Ω o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o O O O O o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o O O O O z > >zz> >z>z>z>z>z>z>z>z>z>z > > > >z z>>z>z>z>z>z >z>z>z>z>z>z>z>z>z >z>z>z>z>z>z >z>z>z>z>z>z>z>z>z>z>z ro M No ro ro No ro No ro ro ro ro ro No ro ro NO NO NO O M NO No ro ro NO io No ro i ro No to r^
NO fγ, fγ, fγ, NO NO C CO CO ,v fγ, n
_z o o o NO NO NO NO — ' NO o o o o ffl " ^
_ VI O NO Cn 45, NO O 45, 45, NO 45. O — ■ c cp Sc « -^ _* ωco θo M i δ M M « ω ω M M Mcπ Mcπ «_ fflo Oo Coθ Ωϊ
VI π cn CD 45, Ol 00 M ω w M 03 ω o α- v-, CD O VI o C 45. en NS ^ 5 _ S O' S O M o ω □ _ co co - oo — ' o ro O CjO N0 0 45, M O Cn OO - -
C° m m — ■ rO 4-» ft ft m — ■ „, — ' NO NO — — • —■ NO NO —• NO C CΛ ° rn no — ' ft M NO — ' — ' P? N0 )5 θ O O O 00 O O O C 00 cn co M r. n CSO 0 00 O M Cn cn 45. co 4s, O Z, CO l oo ___ _ _ _ si i. P9 n, sj -j - i, ? fj n N0 0 —0 —' C -O O- O - C-O O M IO ft Oo en oo O
_ . - M o ONθ Oθo Mcn O4s. —eo' Oen 4050, —oo • 7Ω?
O NO O M 00 45. O CO 45.
00 en co -■ ft NO
M — ' NO o O NJ OO O ft O rO M O — < NO ft 00 00 M ^g^∞o∞S oo,^n cD No — ' o o o o o coO
TABLE 3
SEQ ID NO: Template ID Cempanent ID Start StΩp
38 U:898195.ό:2001JAN12 2298219H1 2815 3073
38 LI:898195,6:2001JAN12 g3593805 2523 3001
38 LI:898195.6:2001JAN12 g2207851 2554 2995
38 U:898195.ό:2001JAN12 g3593268 2571 3003
38 LI :898195.6:2001 JAN 12 71491946V1 2077 2828
38 LI:898195.6:2001JAN12 g2007104 578 942
38 LI:898195.6:2001JAN12 g4650843 578 2996
38 LI:898195,6:2001JAN12 7255387H1 561 1147
38 LI:898195.6:2001JAN12 g7022682 562 2996
38 LI:898195.6:2001JAN12 1987775H1 563 762
38 LI:898195.ό:2001JAN12 8125276H1 522 1147
38 U:898195.6:2001JAN12 7997854H1 525 1114
38 LI:898195.ό:2001JAN12 4179939H1 539 774
38 Ll:898195,6:2001 JAN 12 8003770H1 541 1146
38 U:898195.6:2001JAN12 799421OH1 503 1088
38 LI :898195.6:2001 JAN 12 7267059H2 502 1062
38 LI:898195.6:2001JAN12 8116748H1 512 1121
38 LI:898195.ό:2001JAN12 8133184H1 511 1160
38 U:898195,6:2001JAN12 6349561 H2 518 868
38 U:898195,6:2001JAN12 71491559V1 473 868
38 LI:898195.ό:2001JAN12 3983539F6 474 856
38 LI:898195.6:2001JAN12 3983539H1 474 691
38 LI:898195.6:2001JAN12 71513785V1 474 672
38 LI:898195.6:2001JAN12 71493903V1 474 1000
38 Ll:898195.6:2001 JAN 12 71495030V1 474 988
38 LI:898195.6:2001JAN12 5649669H1 3713 3947
38 U:898195.6:2001JAN12 7451851Tl 3750 4266
38 LI:898195.6:2001JAN12 g5394901 3758 4241
38 U:898195.6:2001JAN12 2405018H1 3784 4019
38 Ll:898195.6:2001 JAN 12 g7038644 2800 3250
38 Ll:898195.6:2001 JAN 12 2088126H1 2516 2778
38 LI :898195.6:2001 JAN 12 71489807V1 2053 2766
38 LI:898195.6:2001JAN12 71491508V1 1536 2373
38 LI:898195,ό:2001JAN12 3786850H1 3692 3931
38 Ll:898195.6:2001 JAN 12 3116845H1 2788 3096
38 LI :898195.6:2001 JAN 12 4760765H1 2790 3108
38 LI:898195.6:2001JAN12 3112816T6 2774 3210
38 LI:898195.6:2001JAN12 71491496V1 2043 2815
38 Ll:898195.6:2001 JAN12 5544139H1 1467 1627
38 Ll:898195.6:2001 JAN 12 6531363H1 1513 1891
38 LI:898195.6:2001JAN12 71494444V1 1500 2116
38 Ll:898195.6:2001 JAN12 71493302V1 474 1120
38 LI :898195.6:2001 JAN 12 6377935H1 2765 3054
38 LI:898195.6:2001JAN12 70538653V1 1993 2494
38 LI:898195.6:2001JAN12 71494757V1 1992 2782
38 LI:898195.6:2001JAN12 7162193H1 2011 2614
38 LI:898195.6:2001JAN12 g1993262 2012 2449
38 LI :898195.6:2001 JAN 12 71489883V1 2016 2645
38 LI :898195.6:2001 JAN 12 71493184V1 2045 2673
CΛ rn
D
C eo cjo co o ω ω c co eo co eo co co co ω co oo cjo co co co ω oo cjo ω
CD CD 00 00 C0 00 00 00 00 00 00 00 Cj3 00 C» O3 03 O3 O3 00 CD Cθ CD CO 00 00 CD O0 00 0O CD C CO CO CD 00 00 CO ∞ ∞ C oΛo F O; z o
co co co oo co _ _ _ _ N0 N0 N0 N0 N0 N0 CO C — ' —■ _ _ _ _ —■ — ' _ —• —■ _ _ _ - NO NO NO NO NO Cύ Cύ _-! CΛ ft co oo co co _ . ft ft ft ft eo oo co ft ft M cn o oo oo oo oo o o o o o co o co oo oo oo oo cn ft ft eπ M Ch o
O M ft ft CO o ft vO — r- ft ft ro NO NO NO ft O ft Cn oo eπ M Co ft ft No — - NO — ' O O O oo M O Cn ft o o o — ' O c> ft o
Co Co M cn Ch CO Ω ft M cn ro co M coo cD oo cn o co o M Oo o o o ω ft ft O ft o ro — ' O O o o ro ft ft o co No co eπ CD en o cn ft -4-
CO CO C CO CO ft NO — ' NO NO NO NO NO NO NO NO NO ft OO NO NO NO NO ISO NO NJ NO NO NO NO IO NO NO NO IO CO OO NO NJ CO
M M O M cn 00 _ O O M Cπ 00 O M — ' o ft en — ■ — ' ro M co M o eπ o oo _ oo cn —
CO CO M ft M o o O — ' — ■ — ' CO O O 00 CO co ft o o — ' Cn — ' Cn o o oo oo o en en o o o o o o cn
O ft — ' 00 00 00 M o o eπ ft M M o o o M ro O ft O O OO O O NO O OO NO O — ' O O ft — ' O CO ft O O
3690 4 47
CΛ m 0 ft ft ft ft ft ft ft ft ω ω cjo cjo co cjo cj oo ω ω co co co oo eo co c co ω
O O O O O O O O O O CO OO OO CD OO CD CD CO OO CD CD CO OO CD CD CD CD CD CD CO CD Cσ CD CO COO CD CD ∞ CO OO GO OO OO CD OO CD OO ∞
Z
O
ft M M M M M M M M M M o >
-^ ft M M M M M M co co ft NO NO cπ ,_ M NO cπ Ω CD Ω NO o o o o o o ft CΩ M o CΩ
M ft ft ft ft ft f ft CΩ
— ' M M tCΩ O O o C ) M ft M M ftO co oo f 00 j-. ro ro f ft o M t f ft NO o 00 t O CΩ X __ o o o o po M o ≥ r
NO cπ Ch N) CO N) 3
00 cn o o o Co _ t oo o NO o o o ft co Ch "O
NO CO o o CO NO NO o o o ~ « ro ft
— ' 00 if] M M f M ft CO ft O ft
NO — ■ o o o o CO o O M ft NO o NO o o ooo co co cn tO o ft M Ch Ω O cn D
NO O ft NJ o CO o CO o NO o C -O - ft M o O NO
M co ft cπ — ' Ch NJ CJ 00 — " o — ■ en co NO co en o o oo NO
O ft —1 O oo cn CO co co Ol 0 O — ' — ' Φ o < < < < CD O <<<<<<<±<<<< < < O 1 _ 7 o2 < ?5 _ o Ξ δ! "° X X X X X X ZS
O
— - rO NO — '
∞ — CJ ' — — ' O o eπI — ' ' IV
co m
0 ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o D
Z o
CD o o o CD o O o O o o o o o o o o o o o o o o o O CD o O o O O o O o O O
NO NO N) NO NO NO NO NO NO NO N) N) NO N) N) NO NO NJ N) N) N) N) NJ NO NJ NJ NO N) NJ NO N) NJ N) NJ NJ NJ NJ NJ NO NJ NJ NO NJ NJ NJ NJ NJ NJ NJ
O vCJ O vO vO vO O vO O <> O o O O vCJ O O • o O O O O O O sCJ o O O O O O O CD
M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M 3 ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft 'Ω
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO Ω
O D C ) O CO C ) C ) O C ) C ) O C J C J C ) C ) CJ C ) C ) C ) C J C J ) CO CJ CO C ) CD CO C J C J CJ O CO CJ C ) CD CJ C J C J CJ CO CJ C_J CJ CJ — r-
O CD CJ O CD o o CD o CJ CD o O CD O O O O CD O O CJ O o O CD o CD CJ CJ CJ o CD CD CJ CD r c_ c_ r r r r r c_ r . c C r ( C r C._ c_ r r c_. r c c_, r . c , c. c_ c_ c f C . c C . c , c , C C— c c_ c_ < C c_ f c c_ c. c_ π
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > >z>z>z> zzzzzzzzz Z Z z Z Z Z Z zzzzzzz> z>z>z>z> zzzzzzzzz z> zz z ro ro io ro No ro ro No io ro w ro No ro ro NO o ro M ro o ro No ro ro ro ro M NO No ro w No ro NJ w ro ro w
_ _ _ _ _ _ _ _ _ _ N3 _ _ _ — ' — ' — ' lO NO rO IO NO NO NO _ oo M O ft co en o o ro en ft M oo ft cπ ro cn ft o o ro ro ro cn M o" c woi c Luo o uo u — ' ^ — ' rfen M mra rSt. vvji p n ffl Cii co sj oo ffl Co rji oo ft O O O OO OO CO M — ' M NO O O ft co o oo ro oo oo — ■ — ' — ■ o _ co e ft C o o o S lx Vvv ? ^ o cπ o o ft ft o -^ ro Ω o o o o cn cn M o o — ' ro o oi ro oo M O O o o ft cn oi o ro M OO O NO CO O OO NO oo ft o o cn o co co cπ co o — ' Co O M OoO
o o o CD o o o o o o o o o o o o o o o o o o o o o o o o o o o o CD o o o o o o o C3 o
N) NO ro N) N) NO NO N) N) N) NJ NO N) N) N> NO N) N) N) NJ N» N) N) N) N) NO N) N) N) N) N) N) NO N) N) N) N) N) N» N) N) N) N) N) NO N) N) N) N)
O o O ι vCJ O O O O O O O vO O O O o vCJ O O O O O O φ
M M VI M vi vj M vl M M M M M M M M vl M M M M M M M vl M M vl vl M M vl M 3
45. ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft"D
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO Ω
O Cl r 3 CO C O C O e ) r o CO
CJ O CD CJ CJ CJ o CJ CD O o CJ CJ CJ o CJ CD CD CD CO CJ o CD o CD CJ CD CD CD CD J CD CJ CD CJ o CD CD CD CJ CD CD c_ c c_ r r r r c_ c r r r c r c c... r < . ( r c c r ( ( c t c. r c, r c r r f r e r r . r n
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > z z Z Z Z Z Z z Z Z Z z. Z Z Z Z Z Z. Z Z z Z. ro NO No ro M No ro ro ro to ro ro o to o ro NO No ro ro to ro ro io r ro ro to ro ro NO No ro ro No ro ro ro N^
M M M M NJ rv MM N3 MM M MM MM M MM M M M I -' -' -' -' -',n f- ,- r. -ι -' -' -J -' -' -' -' -ι co ro ro ro NO NO NO NO NO — ■ — ■ _ _ _ _ _ — . o o o o o o o o o o o o ^ S S r^ i co cji o cjJ oo en cn cn cjo coo oS^o ft ft ft ft ft M M O O Cn ft NO — ' OO OO O ft — ' O O O O O OO M O Cn O O O CO M Co S S r S ^ ft ft CjO ft ft COO OO M M O rS oo M OO O . Ω, o c CjO M O ft oo o cn oi ft o co o ro NO N -^ o co oo No oo o cn cn co o ft o o o - v. v-j j o M o o o co C0
ro ro ro ro ro ro ro ro ro ro ft ft ft ft ft ft ft ft ft ft ro N ft ft rvo io ft rv r ft rov r jo ftv r ft io r ro oo N o ft jso. ro ft rv, r ro co r o ro co r o t JoV, r ro f rs r o-> Mo ro N — ■ _ — ' m . j r _ _ ro ro — _ _ _ ft ft ro ft roo r isoo r ios- _ ∞ ∞ ω c — oo . o roo - _ _ _ _ _ ft M OO OO O OO OO CO O ft Cn M O OO
M O O NJ O — ' M O NO M M O O M O M Cn M O CO O ft CO ft O Co ft ft — ' ft ft — ' O — ' O O O ft O ft 00 M M 00 M NO o o en cn ft en ft oo ro cn NO O NO ft en ° cn cn o o ft o M o o cn o o o o ro cπ oo cn o o _c
CΛ m ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft _
—' —' O O O o o o o o o o o o o o σ z o
ro ro ro ro ro ro o o o o o o o o o o o o o o o o o o o en en en cn cn en cn en en en Cn Oi cn en en en en Oi cn en cn en en en en cπ cn cπ en cn en cn Oi o o o o CD o CD o o o o o o o
CO CO co CO co CO CO CO CO CO co CO co 00 CO CO co CO co co CO CO CO co eo Co eo C co CO 00 CO CO CO co NO NO N) NO NO NO NO NJ NO NJ NJ NJ NJ NO vO o o O sC) vO vO ) O vO O ) Φ ro M M
NO NO NO NO NO NO NO ro M M M M M M M M M M M M O NO ro NO ro ro NO NO ro NO NO NO NO ro NO ro NO NO NO NO NO NO ro NO NO ro 3 ft ft ft ft ft ft ft ft ft ft ft ft ft ft"α ro ro ro ro ro ro NO NO NO NO NO NO NO NO NO NO NO NO NO NO o o o o o o o o o o o o o o o o o o o o o o o CO CO CO CO o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o CD O CD O CJ CD CD CJ O CD c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ c_ <-_ c_ c... c_ c. c_ c. c_ c_ C. C— C— c_ c_ r π
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > >
Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z z z Z Z Z Z Z z Z Z Z Z
M No ro w ro ro io ro ro ro to io r i Nj ro No ro ro O NO io ro ro M ro ro ro No ro No ro ro No ro ^ o o o o M VI M M M
Ch NO M M M M M M M M M M Ol M M M M M M M M M M M o cn M M M o O O NO M n NO M M M r o o o > o cn CJ h Ch O O ϋι
CO o cn o O ft C ft 00 O O O O O O O O O O ft Ch O Ch O O Ch O O ft vj O CO CO CO CO o o M O j ft M v ro o cn CO Cύ C 00 CO 00 NJ CD o M M o O CD co o o O CO CO CO CO CO OO CO OO CO CO OO CO o C o CO CO ft T3 o o M M M cn ft ft cn co o N) O o NJ CO
Ol o o o o o cn CO M cπ co n ft ft oo cn cD 03 M 03 en o t O cn cπ c ft M O OO M O NO O — ' 00 o Ch
CO N O cn O N) CD cn NO O o M cπ O en h en Ch cn cn Go cn o f o oo cπ co ) M N) N) o o CO CD cn o — '
— ' cn o cn o oo ro o — - o ro ft co ro o o NO o CO O M ft ft M O CO t ft cn ft M io ft — ' c > NO NO CO N) < ) o M o cn ft cπ t o o ft — ' o f
< X X X rn ro M Cn o O M
X s
00 < < < < < < < < < < < < < < < < < < < X o f
O < D X cn X h CO cπ M oo < < < < < << < X < < D < X σ
j- ft cn ft o o cD co co is
j —
■ Cj3 _ ft en co _ θ3 — ' N0 ft rNo0 —_ ' ——
■' oθ o _ o oo o o oo o co co cn co
^ '<) 3 K0 N0 ^ Vl M M M M M M M M M O M M M M M M M M M M N NKO Nl tvO NKO _7? Iv. C3 O i ^ 3 ra C Nv M -4 ^ ^ K ro -^ CD OO OO OO OO O OO OO OS OO CD CO OO OO O M M OO OO OO OO ∞ OO OO OO OO OO Co rx ft X oo M ft cπ ft9D r co- -- ιo o -- o co _ _ _ _ _ _ _ _ No o o o o - -- - o --' - - -- o ^ g; ^ 0 g c g Q g
99H140286 g8929040
CO m ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft 0 ft v=r
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO — ' — '
O O O O O O O O ^ ^ ^ -^ CJI W ^ ^ ^ ^ ^ ^ ^ JI I iM iMo rMo rMo rMo rMo NM fC~J fCOo ^W CO W C 3 θ ω CJ CO W ω ω ω θ
r-, ρ-' rJ rJ r-' r ^
co oo co _1 _, oo oo _I O ft ft ft ft ft ft ft o^ P. _ ro o f p o ft g oi CO M O M CΛ
NO C NO _ N NOO N NO ft N f NO — ' O NO o eSo S co 00 ft Co ro M o NO en ft o CO c On o C M o o
NO
O 00 CO g gO ft o en 00 00 O M Cn t
Co CO M O OO NO — ' Cn OO O O Cn M ft M cn ft ft oo
— ■ M o- ft ≤ CO O M O cn o — ' — ■ M o en Ω
TABLE 3
SEQ ID NO: Template ID CempΩnent ID Start StΩp 42 L1:350272.2:2001JAN12 2538770H1 320 536 42 LI:350272.2:2001JAN12 5020696T1 319 780 42 LI:350272.2:2001JAN12 g4074869 1113 1556 42 U:350272.2:2001JAN12 6606673H1 1076 1551 42 LI:350272.2:2001JAN12 g4970896 1077 1555 42 L1:350272.2:2001JAN12 g4125734 1079 1539 42 U:350272.2:2001JAN12 g3741618 1094 1559 42 LI:350272.2:2001JAN12 g6038705 1110 1550 42 LI:350272.2:2001JAN12 2697244H1 565 854 42 LI:350272.2:2001JAN12 4665428H1 570 845 42 U:350272.2:2001JAN12 708387H1 587 865 42 LI:350272.2:2001JAN12 g3213833 597 826 42 LI:350272.2:2001JAN12 2715220H1 603 850 42 LI:350272.2:2001JAN12 6486886H1 617 1161 42 LI:350272.2:2001 AN12 g2577306 1301 1550 42 LI:350272.2:2001JAN12 644238T6 1287 1516 42 LI:350272.2:2001JAN12 6326064H1 1288 1553 42 LI:350272.2:2001JAN12 6552652H1 762 1293 42 LI:350272.2:2001JAN12 4138187H1 785 892 42 LI:350272.2:2001JAN12 6552052H1 762 1227 42 LI:350272.2:2001JAN12 g5812197 1335 1536 42 LI:350272.2:2001JAN12 1684883H1 1344 1550 42 LI:350272.2:2001JAN12 3932451 HI 1363 1550 42 LI:350272.2:2001JAN12 211293H1 1365 1557 42 LI:350272.2:2001JAN12 211696H1 1365 1550 42 LI:350272.2:2001JAN12 633648H1 1372 1563 42 U:350272.2:2001JAN12 3565543H1 1384 1508 42 LI:350272.2:2001JAN12 g2359505 1463 1550 42 L1:350272.2:2001JAN12 g4649884 1466 1544 42 LI:350272.2:2001JAN12 6615126H1 1488 1550 42 LI:350272.2:2001JAN12 7322258H1 232 865 42 -.1:350272.2:2001 JAN 12 2127622H1 260 527 42 LI:350272.2:2001JAN12 1684883T6 1061 1515 42 LI:350272.2:2001JAN12 1684883F6 1061 1550 42 LI:350272.2:2001JAN12 3621890H1 1050 1132 42 LI:350272.2:2001JAN12 211114H1 1051 1101 42 U:350272.2:2001JAN12 581813T6 1052 1512 42 LI:350272.2:2001JAN12 g2820887 1053 1553 42 LI:350272.2:2001JAN12 5766360H1 665 1183 42 LI:350272.2:2001JAN12 3016843H1 692 892 42 LI:350272.2:2001JAN12 g5755074 1271 1556 42 -.1:350272.2:2001 JAN 12 6843381 HI 1271 1382 42 LI:350272.2:2001JAN12 g2669985 1217 1446 42 LI:350272.2:2001JAN12 2561156H1 1226 1522 42 L1:350272.2:2001JAN12 g5364704 1229 1551 42 LI:350272.2:2001JAN12 1637245H1 1207 1419 42 LI:350272.2:2001JAN12 g4267877 1205 1544 42 LI:350272.2:2001JAN12 g4267523 1203 1544 42 LI:350272.2:2001JAN12 g4267458 1203 1544
CΛ rπ D ft tf coftcoftooftooftooftoo ftcoftco tf ft 45. 45. 45, 45. 45, 45. 45, 45, 45. 45, 45, 45. 45. 45. 45. 45, 45.
Co coft CoftooftooftOoftOoftCOftCo COftCOftOo ftCoftooftCO ftCoftCo rftoftrO tf 45 NOftrO ftNOft . NJ NO NO NO NO NO IO NO NO NO NO NO NO NO NO NO NO IO IO
O
r cOπNftO CoO CoO OoO CoO CoO CoOoOO OoO NO NO NOoNO NO NO NO NO NO NO NO NO NO NO NO Λ u O^oOoOoOjvoOj oOhoOjvoOjv oOj Oιo-j Ooj oc o O g-j c o C_nι ι o -j t ft ft cn ft-j ι o ft- o ft —O ■ — vn rr _ f Co g ∞Ωrx ±θ^x rr∞»rx vv. r rr-κ cr cvn. c rrnnn e mrnτι e_n ι C(-O" O,~ ' — — — -n ■ o rn o C ro S o o o M O O cn ft — - ooo Mo o cπ M OO O — ' OO M Cn eo o co No ro ft
rO NO Co Co CO CO Co Oo ω Oo Oo CO Oo NO I NO NO NJ NO rO NO C-O Co Oo Oo O OO ft NO OO NO OO NO NO ft NO Cn NO O O O M M M OO O — ' O O O — ' NO NO NO cn oi ft ft _ CO M CO O 00 CD CO en o co NO OO OO NO Ol O — ' O O O CO O NO Cn Cn OO O NO NO O ft ft O O — ' ft o" "No ~ ro o ft cπ ft ^ NO v NjO M _ ft c cn Ol ft O OO O Ol O O M — ' M M O — ' Ol M ft NO Ol O NO M — ' ft ft en o M O ^ c^ o o -o o- M - O ft - o cπ cn cn o — cSn c^o e^n e^n cn Co rO O c ft cn-5 Ω
TABLE 3
SEQ ID NO: Template ID CΩmpΩnent ID Start StΩp
43 LI: 1085472.4:2001 JAN 12 71372045V1 •2601 2727
43 LI: 1085472.4:2001 JAN 12 3386621 HI 2845 3004
43 LI: 1085472.4:2001 JAN 12 7630053Jl 2857 3498
43 LI:1085472.4:2001JAN12 4933617H1 2863 3095
43 LI: 1085472.4:2001 JAN 12 1823282H1 2878 3114
43 U:1085472.4:2001JAN12 6407353H1 2884 3206
43 LI: 1085472.4:2001 JAN 12 6407395H1 2885 3278
43 U:1085472.4:2001JAN12 5511808H1 2907 3155
43 LI:1085472.4:2001JAN12 7766094H1 2933 3510
43 LI: 1085472.4:2001 JAN 12 3781871H1 2601 2794
43 LI: 1085472.4:2001 JAN 12 3781867H1 2601 2783
43 LI: 1085472.4:2001 JAN 12 1802440F6 2601 2792
43 LI: 1085472.4:2001 JAN 12 4327538H1 2601 2686
43 LI; 1085472.4:2001 JAN 12 2763622H1 2624 2874
43 LI;1085472.4:2001JAN12 4202242H1 2627 2780
43 LI: 1085472.4:2001 JAN 12 7426017H1 2630 3252
43 LI: 1085472.4:2001 JAN 12 6599647H1 2651 3221
43 LI: 1085472.4:2001 JAN 12 7766094J1 2657 3061
43 LI: 1085472.4:2001 JAN 12 70014159D1 2670 3093 43 ' LI: 1085472.4:2001 JAN 12 70015318D1 2670 3177
43 LI: 1085472.4:2001 JAN 12 6937773R8 2679 3358
43 LI: 1085472.4:2001 JAN 12 4820435H1 2701 2985
43 LI: 1085472.4:2001 JAN 12 4932948H1 2772 3047
43 LI: 1085472.4:2001 JAN 12 4970490H1 2773 3070
43 LI: 1085472.4:2001 JAN 12 2509043F6 2824 3248
43 LI: 1085472.4:2001 JAN 12 2509043H1 2824 3085
43 U:1085472.4:2001JAN12 2778212F6 2827 3334
43 LI: 1085472.4:2001 JAN 12 2778212H1 2827 3081
43 LI: 1085472.4:2001 JAN 12 2872122H1 2830 3134
43 U:1085472.4:2001JAN12 6298454H1 2601 2818
43 LI: 1085472.4:2001 JAN 12 4934841 F6 1207 1762
43 U:1085472.4:2001JAN12 7383285H1 1261 1609
43 LI:1085472.4:2001JAN12 3082109H1 1310 1630
43 LI: 1085472.4:2001 JAN 12 649924H1 1328 1608
43 LI: 1085472.4:2001 JAN 12 7765508H1 1396 2037
43 LI:1085472.4:2001JAN12 7762086H1 1489 1998
43 LI: 1085472.4:2001 JAN 12 5032294H1 1590 1762
43 LI: 1085472.4:2001 JAN 12 7667194H1 1600 2184
43 LI: 1085472.4:2001 JAN 12 g6986315 1740 2181
43 LI:1085472.4:2001JAN12 g4735856 1784 2188
43 LI:1085472.4:2001JAN12 7987343H1 1791 2321
43 LI:1085472.4:2001JAN12 7762086J1 1823 2309
43 LI: 1085472.4:2001 JAN 12 7618406J1 1833 2304
43 LI: 1085472.4:2001 JAN 12 3040429H1 1851 2132
43 LI:1085472.4:2001JAN12 7979208H1 1950 2304
43 LI: 1085472.4:2001 JAN 12 6765078H1 1976 2304
43 LI:1085472.4:2001JAN12 7179252H1 1999 2304
43 LI:1085472.4:2001JAN12 8099682H1 2137 2750
43 LI: 1085472.4:2001 JAN 12 6937773H1 2145 2304
ft ft ft ft ft 4 ft5, ft ft ft ft ft ft tf ft 45, ft 45, ft ft ft ft ft tf ft ft ft ft ft ft t ft ft ft ft ft ft ft ft ft ft p-r ft f 4t5, ft ft ft f ft ft ft ft ft ft ft ft ft ft ft 45, ft ω co co co co co co co co ω co co co cΛ Co co co oo co co co co co co O
O
cn oo o o o cn en o ft o — ■ - CJl CJl Oi CΛ ^ M ^ M Og M^ ^ M ^ M M^ vJ ft CO NO —'
NO Cn — ■ — ' O O M CO OO ft Oo ^ o - - o g g g g o ∞ g g ft NO IO CΛ 4s. o o oo ft n — ■ NO C rOo rCoO rCoO enO oO ft J Ol (-, CO NO o 00 c M NO cn 00 ft o cn o o ft ft o o o ro o o o u- u e o - o u _. u , o_> u ft t _ enι i NϊO rv o ft f M OO ft OO CO ft OO O ft 00 j- oι o M rj §
m ft ft ft ft ft ft ft ft ft ft ft ft ft 45, ft ft ft ft ft ft ft ft ft ft ft ft ft 0 cn oi en en ft ft ft ft ft ft ft ft ft tf ft f t ft" ft ft ft ft ft tf ft ft t ft ft ft ft ft ft ft ft tf ft f ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft f ftt f ftt π Ό z
O
co oo co , v NO — ■ — ■ K Ch en cn ft CO CO ft ft — ■ — ' CO Co Co Cύ Co oo Co Oo Co NO ft oo co jv. vi cn — ' CO CO M CO M M M O _, f_. . o cn oo oo cD Oo co M M j o o NO n co o g _, O M Cn en ft ft N0 co o v- — ' CO CO CO CO CO Co Oo co CO Oo Oo — ■ M M M M NoO £Q5 o o CO ■^ o O cn o o M ft cn c ro ft OO Ol M O — ' O O O O O O O O O M o cn cn o .
Co CO CO cn ft ft O —' Ϊ3 O M ft O O 0 _0 O _ o ft ft ft Cπ cπ oi o o oo o o o co -. .-. O ft o cπ oi cπ cπ cπ o cπ o ,- , t oo — ' OO O M — ' Cπ co ft No ro oo o o r° .
CJ CO o _ _ CΛ
M NO O «C o co —■ cn —■ o—o c"o eo f O o co O Co O NO - ■ O O 7t
O ft o w *> § M o oo o —' ro CO C COJ r §-i ftv v, oo o M co o cn ft o — ' M CO M Oo io cn o o M M 0 _0 "" * - c -o c - 00 O
00 o o M ft co o — ■ oo o __ co o — o O ft NO C o O
CΛ m
Θ ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft p; cjo co cn cjo cπ cjn cjn cπ cπ cn cjo cn cjn cjn cjo cn cjo cn cπ cjn cjo cji cj
→ o Φ- c_ c_ c_ c_ o
NO NO NO —' fv, -A — • NO NO NO — ' NO NO OO OO NO NO CO CO CO CO NO NO ft C CO W OO CO Co oo CO Cjo Co CO CO Oo Oo Oo Oo CΛ NO O O O 2 NO NO O v3 X O 0000 0CO0 C0O0 NO ft 00 — ' — ■ CO O O O O M 00 O CO co en eπ o en o o o co cn eπ — ' lo en o o ft — O O C M0, t" v .O - -O M M M O O M O c _n. en ft o NO NO _ ft M V, N,VOJ , NVOJ V OJl. N ivOj No cn oo cn cn o cn o — ' oo cn oo o o . NvOj - oo co co eo NO NO f ft NO r Ov. o N is ^ O — r
M . M . O
M O M OO OO O M OO M O -1 ft — ' o M O — ' NO O M O — ' — ' ft NO ft ft O O OO O O M NO O CO Ol J
TABLE 3
SEQ ID NO: Template ID Cempanent ID Start StΩp
45 LI: 1086797.1: 2001JAN12 4153824H1 1673 1906
45 LI:1086797.1 2001JAN12 3766035H1 1791 2058
45 LI:1086797.1 2001JAN12 7436283H1 1934 2320
45 LI:1086797.1 2001JAN12 8038923J1 1219 1606
45 LI:1086797.1 2001JAN12 7453632H1 1252 1845
45 LI:1086797.1 2001JAN12 3605176H1 1453 1641
45 LI:1086797.1 2001JAN12 4180723H1 1129 1246
45 LI:1086797.1 2001JAN12 6476576H1 1141 1674
45 LI:1086797.1 2001JAN12 4180723F6 1129 1349
45 LI:1086797.1 2001JAN12 7360841 HI 1078 1498
45 LI:1086797.1 2001JAN12 7163357H1 1031 1557
45 LI:1086797.1 2001JAN12 7204577F8 1039 1677
45 LI:1086797.1 2001JAN12 7163357F8 1031 1703
45 *U:1086797.1 2001JAN12 6935088F8 1 301
45 LI:1086797.1 2001JAN12 6935088F7 1 405
45 LI:1086797.1 2001JAN12 6935088H1 1 582
45 LI:1086797.1 2001JAN12 g766318 3246 3608
46 LI;1144466.1 2001JAN12 5872651 HI 1487 1610
46 U:1144466.1 2001JAN12 570945T6 2062 2114
46 LI:1144466.1 2001JAN12 6417564H1 2046 2148
46 LI:1144466.1 2001JAN12 70956541VI 549 995
46 LI:1144466.1 2001JAN12 570945H1 549 837
46 LI:1144466.1 2001JAN12 70938706V1 534 1247
46 LI:1144466.1 2001JAN12 70936971VI 535 1194
46 LI:1144466.1 2001JAN12 70947577V1 539 1181
46 LI:1144466.1 2001JAN12 5487221 HI 593 856
46 LI:1144466.1 2001JAN12 70947867V1 599 1121
46 LI: 1144466.1 2001JAN12 4411993H1 1438 1590
46 LI:1144466.1 2001JAN12 71285162V1 1145 1623
46 LI:1144466.1 2001JAN12 70954107V1 1153 1610
46 LI:1144466.1 2001JAN12 1369364R1 1158 1635
46 LI:1144466.1 2001JAN12 70950159V1 550 1200
46 LI:1144466.1 2001JAN12 70947667V1 549 1113
46 LI;1144466.1 2001JAN12 70954424V1 549 1079
46 LI:1144466.1 2001JAN12 70948040V1 549 1069
46 LI:1144466.1 2001JAN12 570945R6 549 851
46 LI:1144466.1 2001JAN12 70953419V1 549 1225
46 LI:1144466.1 2001JAN12 gl012139 553 907
46 LI:1144466.1 2001JAN12 70948638V1 557 1285
46 LI:1144466.1 2001JAN12 70938482V1 582 1186
46 LI;1144466.1 2001JAN12 g3647741 1636 2040
46 LI: 1144466.1 2001JAN12 647356H1 1051 1321
46 LI:1144466.1 :2001JAN12 6201236H1 652 1294
46 LI:1144466.1 :2001JAN12 70953487V1 706 1363
46 LI:1144466.1 :2001 AN12 70947711VI 754 1435
46 LI:1144466.1 :2001JAN12 70947562V1 783 1456
46 LI:1144466.1 :2001JAN12 70947510V1 790 1454
46 LI:1144466.1 :2001JAN12 526973H1 860 1088
46 LI:1144466.1 :2001JAN12 70936936V1 880 1506
CO rn
Θ ftoftoftoftoftoftoftotfoftotfoftotfoftoftoftoftoftoftoftoftoftooft ftoftoftotfoftoftoftoftoftoftofto ft ft ft ft ft ft ft ft ft ft ft ft ft ft
O O O O O o o o o o o o o o
ft ft ft ft £ ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft it ft ft ft ft ft ft ft ft t ft ft ft ft ft t ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft fc ft ft ft £ f f ft ft ft ft ft ft ft ft ft ft
Ch Ch h r Ch Ch Ch o Ch Ch Ch Ch h Ch Ch Ch Ch Ch Ch Ch Ch Ch Ch Ch Ch h Ch Ch Ch h Ch Ch Ch Ch Ch o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO
C ) C ) C ) ro C O C 0 C 3 r o C ) C ) ro C 0 C ) C ) C 0 C 3 C > C J C ) C ) c > C J C ) C ) C ) C ) C ) C ) C ) C ) C i C ) C ) C ) o o o O O o CD O O CD CD O o CD O o CD o CJ o O o CJ CD O o O c_ c. c_ r C c . c „ f r r c . c c C , c . c_ r c . c... c_ r c .. c_ c c , c„. c_ r c c. c_ < C c._ c_
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z Z
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO
CO CO 00 NO Js r ro Cθ Co C -
n -
n -
n -
rι Cn θ O O --i. NO NO NO M O O O CO
oo cn oo o o o o —
■ o o O O CO M
_ N0 — ' NO NO — ' — ' NO — ■ — < — ' NO NO — ' NO — ' — ' — ■ O NO — ■ _ _ — ' CΛ
M O M Cn cπ en fv ^ cn -^ ^ t o — - o ft — ■ — ' O o — ' Cπ ft co 00 CO 00 NO — ' — ' vi v-i m ro rO N M Cn o o co oo : j- o — ' O — ' O f 00 CO o _ oo oo S v n -1 - ' — ' co Nenj pOt-
— ^ Oi sl ft O co NO NO Oi M Co ft M — ' Cπ o ro oo ft No ro ft ro co o NO — ' — ' g ^ H en M O — ' -O' COn
OO O ft M O Ol O ft O ft OO O M OO Co Cπ OO — ' 45. N0 M NO CO cn o o 4^ 1^ 3 — ■ o en cn ft ft Cn coO
TABLE 3
SEQ ID NO: Template ID ( -jΩmpΩnent ID Start Stap
46 LI:1144466.1 2001JAN12 70937195V1 329 921
46 LI:1144466.1 2001JAN12 70936226V1 329 917
46 LI:1144466.1 2001JAN12 70948348V1 1244 1610
46 LI:1144466.1 2001JAN12 70950190V1 1253 1610
46 LI:1144466.1 2001JAN12 70948028V1 1264 1610
46 LI:1144466.1 2001JAN12 6110340H1 373 651
46 LI: 1144466.1 2001JAN12 70938761VI 485 1218
46 LI:1144466.1 2001JAN12 70949010V1 616 1175
46 LI:1144466.1 2001JAN12 70938744V1 604 1150
46 LI:1144466.1 2001JAN12 70948930V1 625 1189
46 LI:1144466.1 2001JAN12 4411993F6 1436 1988
46 LI:1144466.1 2001JAN12 7937564H1 1919 2148
46 LI:1144466.1 :2001JAN12 70937317V1 484 1003
46 LI;1144466.1 •2001JAN12 70935643V1 488 1013
46 LI:1144466.1 2001JAN12 3028285T6 1904 2129
46 LI:1144466.1 :2001JAN12 gόl98550 1906 2141
46 LI:1144466.1 ;2001JAN12 70948340V1 1222 1624
46 LI: 1144466.1 ;2001JAN12 g787168 934 1239
46 LI:1144466.1 :2001JAN12 g795021 934 1243
46 LI:1144466.1 :2001JAN12 6554107H1 973 1506
46 LI:1144466.1 2001JAN12 70935145V1 964 1524
46 U:1144466.1 :2001JAN12 70937449V1 965 1523
46 LI:1144466.1 :2001JAN12 70948648V1 971 1656
46 LI; 1144466.1 :2001JAN12 70949088V1 1022 1465
46 LI:1144466.1 :2001JAN12 70941525V1 1388 1523
46 LI;1144466.1 :2001JAN12 71897328V1 166 317
47 LI:1147914.1 ;2001JAN12 5099781 HI 509 735
47 LI:1147914.1 :2001JAN12 g993188 546 877
47 Ll:1147914.1 :2001JAN12 2502317H1 684 917
47 Ll:l 147914.1 :2001JAN12 5271374T9 714 1260
47 LI:1147914.1 ;2001JAN12 2183876H1 1192 1394
47 LI:1147914.1 :2001JAN12 3254347H1 1 91
47 Ll:1147914.1 :2001JAN12 3254347R6 1 586
47 Ll:l 147914.1 :2001JAN12 5668261 HI 224 452
48 Ll:75808ό.l: 2001JAN12 708062lόVl 763 1301
48 LI:758086.1: 2001JAN12 70808642V1 763 1210
48 Ll;758086.1: 2001JAN12 70805710V1 830 1298
48 Ll:758086.1: 2001JAN12 2100630H1 865 1055
48 LI:758086.1: 2001JAN12 292419T6 874 1001
48 LIJ58086.1 : 2001JAN12 1801910T6 1256 1392
48 Ll:758086.1: 2001JAN12 70810483V1 1260 1392
48 LI:758086.1: 2001JAN12 1801910F6 1263 1392
48 LI:758086.1: 2001JAN12 70807456V1 1261 1392
48 LIJ58086.1 2001JAN12 1801910H1 1263 1376
48 LIJ58086.1 : 2001JAN12 2135293T6 1293 1392
48 Ll:758086.1: 2001JAN12 70810557V1 763 1293
48 LI:758086.1 2001JAN12 70809681VI 763 1271
48 Ll:758086.1 2001JAN12 70809244V1 978 1392
48 Ll:758086.1: 2001JAN12 70809996V1 1005 1392
CΛ m
0 ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft .lv.
O O O O O O O O O O O O O O O O O O O O O O O O O O O O O OO CO CO CO CD CD OS CO CO CO CO OO OO OO OO CO CD OO OO OO o
MMMMMM MM MM MMM MMMMM M MM o o o o o o o o o o o o o o o o o o o o o coo co co eπ cjo cjo co eπ en cjo cjo cjo cjo cjo cjo cn cn cn co oo oi
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft cn cn cjo cn oo oi cn cjo co co co oo oo oi oo pi cjo cn cn cn cn 'cjo en cπ cπ cπ cn eπ cn cn cπ cπ cn cπ cn cn cjo cjo co jo cjo cjo
O r Or OroOroOi OroOroOroOroOroOro rOoOroOtόOr OroOroOMOOO OO OO OO O OOO OO OOO OOOOO O
C_ C_ C_ C_ C_ C_ C_ C_ _ C_ C_ C_ C_ C_ C_ C_ <L_ C_ C_ C_ C-
> > > > > > > > > > > > > > > > > > > > >
Ξ________- -3- Ξ-:- ?-?S_-
J5 ro isJ NO NO NO NO NO NO NO NO NO NO NO NO NO NO NJ NJ NO NO
NO NO NO NO NO NO NO NO NO NO NO — ' — ' NO NO —■ NO NO NO O O O O O O O O O O O OO M O O O O O O O cn cn oi M M M M M M O CO OO M — ' — ■ _ _ _ — ' CΛ
O O O O O O O O O O O NO OO M O O O ft ft O O O co ro c On ft M ft M M CO O O O ft ft ft ft ft O CO Co O O O o o o
NO NO NO No ro No o o No ro ro ft oo _ oo ro ro o ft io No io ft NO O O O oo co oo ft ft ft ft ft o co co co o ft cn o o ft Ω ft M O 00 3-
NO NO NO NO NJ NO rO NO NO NJ NO NO NO NJ — ' NO NO — ■ — • NO tO NO — ' NO NO NO NO NO NO — ' N0 N0 N0 N0 N0 N0 N0 O0 N0 N0 OO OO _ N0 N0 O3 cn cn CO Co 00 Cn O M O M O CO ft Cn Cn O O O NO NO NO O O NO O O ft O O oo oo -S ^ g NO NO - O O fg ∞ O O ft o ft ft O Co
^ S & ω g θ' O Ni θ O θ O
O M O No o oo O M ft ft co o oo NO O O co en o ft o oo en en oo oo ft ^ N. g ∞ S isj1 ^ Q- o ch ζv- O O ^Q rj NO NO NO O
TABLE 3
SEQ ID NO: Template ID CampΩnent ID Start Stap 49 U:765245.5:2001JAN12 2624265H1 2092 2159 49 LI:765245.5:2001JAN12 2510561 HI 2092 2215 49 LI:765245.5:2001JAN12 6292645H1 1122 1359 49 U:765245.5:2001JAN12 1668002H1 1747 1826 49 LI:765245.5:2001JAN12 1670091 HI 1747 1805 49 LI:765245.5:2001JAN12 4144443H1 1748 1826 49 LI:765245.5:2001JAN12 5585830H1 1747 1819 49 LI:765245.5:2001JAN12 2266319H1 1749 1826 49 LI:765245.5:2001JAN12 4143570H1 1748 1826 49 U:765245.5:2001JAN12 961991 HI 1711 1826 49 U:765245.5:2001JAN12 3292837H1 1720 1820 49 LI:765245.5:2001JA 12 341699H1 1722 1826 49 LI:765245.5:2001JAN12 1596869H1 1724 1821 49 LI:765245.5:2001JAN12 147603H1 1724 1805 49 LI:765245.5:2001JAN12 582805H1 1736 1805 49 U:765245.5:2001JAN12 7969039H1 1742 2292 49 LI:765245.5:2001JAN12 5597415H1 1746 1805 49 LI:765245.5:2001JAN12 4120492H1 1747 1826 49 LI:765245.5:2001JAN12 2081409H1 1747 1826 49 LI:765245.5:2001JAN12 7270879H1 1142 1782 49 U:765245.5:2001JAN12 7966934H1 1142 1522 49 LI:765245.5:2001JAN12 6374269H1 2092 2222 49 LI:765245.5:2001JAN12 2058225H1 2092 2221 49 LI:765245.5:2001JAN12 5446511HI 1547 1835 49 LI:765245.5:2001JAN12 6109284H1 1547 1805 49 U:765245.5:2001JAN12 4763556T9 1584 2187 49 LI:765245.5:2001JAN12 7966125H1 1123 1512 49 LI:765245.5:2001JAN12 55037612H1 1124 1746 49 LI:765245.5:2001JAN12 7702707H2 340 1041 49 U:765245.5:2001JAN12 7645206J1 351 1020 49 LI:765245.5:2001JAN12 7712422J1 416 1115 49 LI: 765245.5:2001 JAN 12 7754632H1 444 745 49 LI;765245.5:2001JAN12 7754632J1 444 745 49 U:765245.5:2001JAN12 2186758H1 1666 1820 49 U:765245.5:2001JAN12 898077H1 1667 1805 49 LI:765245.5:2001JAN12 70456554V1 1668 1805 49 LI:765245.5:2001JAN12 6476182H1 1675 2284 49 LI:765245.5:2001JAN12 6317527H1 1687 1805 49 L1:765245.5:2001JAN12 4816937H1 1699 1820 49 L1:765245.5:2001JAN12 7659960J1 1707 2185 49 LI:765245.5:2001JAN12 5597850H1 1708 1821 49 U:765245.5:2001JAN12 6459553H2 1521 1596 49 LI:765245.5:2001JAN12 2441116H1 1526 1794 49 LI:765245.5:2001JAN12 3105957H1 1547 1805 49 LI:765245.5:2001JAN12 70287187V1 1036 1166 49 LI:765245.5:2001JAN12 6805548H1 1060 1643 49 LI:765245.5:2001JAN12 1353540F1 1441 1820 49 LI:765245.5:2001JAN12 604743H1 1445 1731 49 U:765245.5:2001JAN12 6841152H1 1421 1842
TABLE 3
SEQ ID NO: Template ID CΩmpΩnent ID Start Stap 49 LI; 765245.5:2001 JAN 12 4321955H1 1429 1715 49 U:765245.5:2001JAN12 6835075H1 1589 1805 49 LI:765245.5:2001JAN12 1443061T6 1592 2250 49 LI:765245.5:2001JAN12 6421357T8 1598 2158 49 LI:765245.5:2001JAN12 1988920R6 1598 1821 49 LI:765245.5:2001JAN12 1988920H1 1608 1821 49 LI:765245.5:2001JAN12 6605564H1 1612 1674 49 U:765245.5:2001JAN12 3188545H1 2092 2238 49 LI:765245.5:2001JAN12 70452963V1 1088 1631 49 LI;765245.5:2001JAN12 55001225H1 1087 1513 49 U:765245.5:2001JAN12 70453631VI 1097 1633 49 LI:765245.5:2001JAN12 55001225J2 1101 1514 49 LI:765245.5:2001JAN12 7935916H1 1099 1543 49 LI:765245.5:2001JAN12 8042949H1 1113 1371 49 LI:765245.5:2001JAN12 55037612J1 1123 1729 49 U;765245.5:2001JAN12 7632103J1 1401 1805 49 LI:765245.5:2001JAN12 825687H1 1620 1805 49 U:7ό5245.5:2001JAN12 60219512D1 1628 1826 49 U:765245.5:2001JAN12 4327019H1 1629 1821 49 LI:765245.5:2001JAN12 2666912H1 1629 1805 49 LI:765245.5:2001JAN12 705567H1 1634 1805 49 U;765245.5:2001JAN12 6293475H1 1123 1324 49 LI:765245.5:2001JAN12 8042604J1 1144 1645 49 LI.Jό5245.5:2001JAN12 7422489T1 1148 1356 49 LI:765245.5:200UAN12 8044802H1 1152 1662 49 U:765245.5:200UAN12 55137358J1 1167 1805 49 LI:765245.5:200UAN12 55137366H1 1170 1915 49 LI:765245.5:200UAN12 g5633859 2092 2245 49 LI:765245.5:200UAN12 7730530J1 1325 1820 49 U:7ό5245.5:200UAN12 g5744117 1354 1472 49 U:765245.5:200UAN12 g6030957 1358 1480 49 U:765245.5:200UAN12 1217969H1 2092 2227 49 LI:765245.5:200UAN12 3933362H1 1753 1805 49 LI:765245.5:200UAN12 008630H1 1756 1826 49 LI:765245.5:200UAN12 890616H1 1753 1826 49 LI:765245.5:200UAN12 889257H1 1753 1826 49 LI:765245.5:200UAN12 70457257V1 1661 1805 49 U:765245.5:200UAN12 146717H1 1489 1729 49 LI:765245.5:200UAN12 7651088H1 1 111 49 U:765245.5:200UAN12 8042949J1 8 736 49 LI.J65245.5:200UAN12 7703528J1 45 697 49 LI:765245.5:200UAN12 7711494H2 59 616 49 L1:765245.5:200UAN12 7403504H1 77 729 49 LI:765245.5:200UAN12 7606736J1 86 591 49 LI:7ό5245.5:200UAN12 70279400V1 88 556 49 U:765245.5:200UAN12 8040796H1 90 783 49 LI:765245.5:200UAN12 8039196J1 170 923 49 LI:765245.5:200UAN12 7469804H1 194 737 49 U:765245.5:200UAN12 7702707J2 246 895
TABLE 3
SEQ ID NO; Template ID CampΩnent ID Start Stap 49 LI:765245.5:2001JAN12 7721162H2 268 933 49 U:765245.5:2001JAN12 8113950H1 294 986 49 U:765245.5:2001JAN12 7761684J1 313 933 49 LI:765245.5:2001JAN12 7712422H1 334 948 49 LI:765245.5:2001JAN12 967345H1 1451 1744 49 U:765245.5:2001JAN12 70456979V1 872 1522 49 LI:765245.5:2001JAN12 55037478J1 930 1537 49 LI:765245.5:2001JAN12 55037632J1 948 1537 49 LI:765245.5:2001JAN12 70287234V1 923 1090 49 LI:765245.5:2001JAN12 7022025H1 948 1287 49 LI:765245.5:2001JAN12 6163469H1 987 1209 49 LI:765245.5:2001JAN12 70454085V1 997 1310 49 LI:765245.5:2001JAN12 70280465V1 991 1528 49 LI:765245.5:2001JAN12 70279487V1 1033 1686 49 LI:765245.5:2001JAN12 3897531 HI 554 845 49 LI;765245.5:2001JAN12 2785983H1 565 839 49 LI:765245.5:2001JAN12 6281260H1 593 870 49 LI:765245.5:2001JAN12 2435437H1 604 861 49 LI:765245.5:2001JAN12 7963211 HI 612 1252 49 LI:765245.5:2001JAN12 7632103H1 633 1173 49 LI:765245.5:2001JAN12 4586093H1 668 929 49 LI:765245.5:2001JAN12 7711494J1 682 1363 49 LI:765245.5:2001JAN12 6348710F8 755 1038 49 LI:765245.5:2001JAN12 7704049H1 791 1308 49 LI:765245.5:2001JAN12 3377733H1 807 1112 49 LI:765245.5:2001JAN12 2262464H1 817 1088 49 Li:765245.5:2001JAN12 2477911HI 824 1091 49 U:765245.5:2001JAN12 2817737H1 830 1129 49 LI:765245.5:2001JAN12 70277721VI 827 1504 49 LI:765245.5:2001JAN12 8054791Jl 822 1465 49 LI:765245.5:2001JAN12 6574846H1 835 1305 49 U:765245.5:2001 AN12 7703528H1 836 1308 49 U:765245.5:2001JAN12 70453248V1 837 1497 49 LI:765245.5:2001JAN12 5175472H1 875 1107 49 LI:765245.5:2001JAN12 8215421 HI 878 1511 49 U:765245.5;2001JAN12 55037828J1 922 1537 49 LI:765245.5:2001JAN12 4542788H1 1579 1805 49 LI:765245.5:2001JAN12 4543188H1 1579 1805 49 LI: 765245.5:2001 JAN 12 g1962859 1613 1826 49 LI:765245.5:2001JAN12 7163644H1 1613 1826 49 LI:765245.5:2001JAN12 6605464H1 1613 1826 49 LI: 765245.5:2001 JAN 12 825687R1 1620 2248 49 LI: 765245.5:2001 JAN 12 5724371 HI 1565 1826 49 LI:765245.5:2001JAN12 2418292T6 1582 2213 49 LI:765245.5:2001JAN12 1437680F1 1573 1826 49 LI:765245.5:2001JAN12 1437680H1 1573 1812 49 LI: 765245.5:2001 JAN 12 3751512H1 1653 1821 49 LI:765245.5:2001JAN12 5180475H1 1653 1805 49 LI:765245.5:2001JAN12 782083R6 1655 1826
cn cn cπ oi cn cn cπ cn cn cπ oi cn oi oi cn cπ oi oi coo cjo
O O O O O O O O O O O O O O O O O O o o
o
co co eo eo co co co co eo co co co co eo co O O O o O o o O o O o O O o O o o o cn cπ cn cn cπ cn cn en cn cn cn cn cn cn cn cn cn cπ cn cn cn cn cn en cn en en cπ cn cn en cn cn en cn cn cn cn en en o o o o o o o o o o o o o o ro ro ro ro ro ro1 cn cn en en cn o o o o o o o o o ro ro ro ro 9] -H rr7 o o o o O o o o o O o o o o o o o o o o o o o ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft co co co co co co co co co co en cn cn cn en cn cn cn cn cn en cn cn cn cn cn en cn cn cn en cn en cn cn 3
NO ro NO ro NO fo to ro fo Ko fo NO Ko fo fo fo fo fo Ko en n en cn n cn cn Cn cn en en n en en n Cn cn Cn cn Cn "n en Cn en p
Kb ro ro fo fό Kb b Kb b Kb Kb Kb Kb Kb b Kb fό Kb Kb b Kb Kb Kb b Kb Kb Kb Kb Kb Kb b Kb Kb Kb Kb Kb Kb Kb Kb Kb Kb Kb Kb Kb Kb Kb Kb Ω o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o O o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o S Φ
C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ C_ (-_ C_ C_ C_ <-_ C_ C_ C_ C_ C_ _ C_ C_ C_ C_
> z> z> z> z> z z> >z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z ro ro ro ro NO o ro NO M ro No ro ro r ro ro ro iO NO No rα NO NO NO NO NO NJ NO NO No ro ro ro ro t O o cn t ft ft co co ft t M f rπ rπ M ft π CΩ CΩ CO o 0O o ft en o ft Ω CΩ CΩ M cvCΩ f O O no rπ rn O M α > CD cn O rn r cn cn cn o o cn vJ ~ — ' < ) ft o o ft M cπ On cπ rn cn m t o ft 3 i — m ro o rs M 00 ft o °° — ' cπ & cn ro cn cn cn f f ro cn O 3 co O co oo M ro coo O o o —, cn - " o ft cπ < cn ) t M Ol o NO en Ω O M NO — t o ro — ' ft £* ft o
NO en fo f is 00 M 00 O ■ S tf ft M ft ro CO ft D
X X X o Φ
X X X o o X lo cπ co X o X X X D o _ _ NO _ _ _ oo — « x — > *-, ft -r cn
M x ft X X X X X X N) o _ ' — ' — ' °: < < t ._
N3 X O <
M CO CO CO CO CO OO NO NO NO — ' — ' — ' m ro r« ro ro ro ro ro ro — _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ . co en M co co oo _ o 4s, ft o oo o ft oo M — ' _ ro N rO — ' — ■ _ _ — ' Cπ cn o — ' -' CO CO OO Co rO NO NO NO NO NO NO NO — ' O S-
O O NJ NO — ' NO O — ' O O O NO OO O ^ CJ K ft O M — ' -' O ft ft Ol M M CO — ' O O CD Ol ft NO NO — ' — ' — ' O Ol
"C ^vJ CO O NO O ft — ' O O O Ol M Ol CO M M — ' O O 00 00 00 M O ft Cn =}-
(-. ft ft OO ft ft ft ft ft ft ft ft ft ■ NO NO NO NO NO NO
/ o oι _ cn oι oι o o oo oo co o o ft — NO
M C .D-. - o. o--. C-D- . NNoO NO NMO CcOo NrO NoO CwO OcoO OoOo ft ft co v5 NO O ft O O O O OO O OO _ 0 cπ ^ r^ r N0 en.. N S ^ S 3 rri r3 _ ^ O O O N0 O O N0 00 O O 00 N0 N0 O C0 00 _ O C0 CO M ft O — ■ NO .° ft cπ o o cn o — ' θ r-j oo oo ft co co o co cn M Nθ _ _ rn Nθ _ O- -N-0 M M - O - ft - O _ .N0 - O _ "0
TABLE 3
SEQ ID NO: Template ID Companent ID Start Stop 50 LI:335608.2:2001JAN12 gό642002 756 990 50 LI:335608.2:2001JAN12 gό642060 756 926 50 Ll:335608.2:2001JAN12 3342492F6 768 1086 50 LI:335608.2:2001JAN12 3342492T6 768 1042 50 LI:335608.2:2001JAN12 4151552T8 768 934 50 LI:335608.2:2001JAN12 3342492H1 769 932 50 LI:335608.2:2001JAN12 6365047H1 772 967 50 LI:335608.2:2001JAN12 g6834827 787 1090 50 LI:335608.2:2001JAN12 g3424953 809 1098 51 LI :405795.1 :2001 JAN 12 6471275H1 1809 2314 51 LI :405795.1 :2001 JAN 12 71225976V1 1720 2226 51 LI:405795.1 :2001JAN12 71226158V1 1751 2226 51 Ll:405795.1 :2001 JAN 12 71225291VI 1888 2234 51 LI:405795.1 :2001JAN12 70857387V1 1688 2226 51 LI:405795.1 :2001JAN12 71226017V1 1687 2226 51 Ll:405795.1 :2001 JAN 12 70856325V1 1988 2226 51 U:405795.1 :2001JAN12 70856015V1 1733 2226 51 LI :405795.1 :2001 JAN 12 7318328H2 1733 2234 51 LI :405795.1 :2001 JAN 12 7318236H2 1733 2233 51 LI :405795.1 :2001 JAN 12 6466069H1 1734 2234 51 LI:405795.1 :2001JAN12 7318235H2 1733 2234 51 Ll:405795.1 :2001 JAN 12 g1193060 1934 2234 51 U:405795.1 :2001JAN12 70856142V1 1724 2226 51 LI:405795.1 :2001JAN12 2907964T6 1672 2195 51 Ll:405795.1 :2001 JAN 12 3650667T6 1819 2186 51 LI:405795.1 :2001JAN12 7730231 HI 1691 2170 51 LI:405795.1 :2001JAN12 . 4289041 HI 1864 2132 51 LI :405795.1 :2001 JAN 12 4289041 F6 1828 2132 51 Ll:405795.1 :2001 JAN 12 6022601 HI 1966 2123 51 LI:405795.1 :2001JAN12 70855063V1 1682 2117 51 Ll:405795.1 :2001 JAN 12 70854890V1 1687 2091 51 Ll:405795.1 :2001 JAN 12 g5741411 1078 1356 51 Ll:405795.1 :2001 JAN 12 592559H1 1071 1357 51 Ll:405795.1 :2001 JAN 12 70855772V1 1010 1356 51 LI:405795.1 :2001JAN12 70855730V1 1232 1356 51 LI:405795.1 :2001JAN12 70858382V1 1118 1356 51 LI:405795.1 :2001JAN12 70856638V1 907 1279 51 Ll:405795.1 :2001 JAN 12 g2270788 1292 1356 51 Ll:405795.1 :2001 JAN 12 70855642V1 836 1277 51 LI.405795.1 :2001 JAN 12 70856522V1 836 1244 51 Ll:405795.1 :2001 JAN 12 g856577 951 1242 51 U:405795.1 :2001JAN12 71225457V1 836 1145 51 LI:405795.1 :2001JAN12 71225773V1 360 942 51 Ll:405795.1 :2001 JAN 12 70857273V1 360 929 51 Ll:405795.1 :2001 JAN 12 70857586V1 360 511 51 Ll:405795.1 :2001 JAN 12 70855893V1 360 511 51 LI :405795.1 :2001 JAN 12 3650667F6 360 506 51 Ll:405795.1 :2001 JAN 12 6937646F8 136 505 51 LI :405795.1 :2001 JAN 12 7730231Jl 118 505
TABLE 3
SEQ ID NO: Template ID CompΩnent ID Start Stop
51 U.405795.1 2001 JAN 12 55021 12F8 1 498
51 U .405795.1 2001 JAN 12 55021 12H1 415 498
51 U.405795.1 2001 JAN 12 3650667H1 360 496
51 U.405795.1 2001 JAN 12 6937646H1 140 388
51 U.405795.1 2001 JAN 12 70858395V1 1 153 1770
51 Ll:405795.1 2001 JAN 12 71225751 VI 1205 1770
51 Ll:405795.1 2001 JAN 12 70858126V1 1 120 1764
51 Ll:405795.1 2001 JAN 12 70796610V1 1420 1757
51 U.405795.1 2001 JAN 12 71225768 V 1 1263 1367
51 U.405795.1 2001 JAN 12 71225648 V 1 1 1 13 1356
51 Ll:405795.1 2001 JAN 12 70856177V 1 1293 1790
51 Ll:405795.1 2001 JAN 12 g7317479 1030 1356
51 U:405795.1 2001 JAN 12 71225417V1 1093 1356
51 U:405795.1 2001 JAN 12 g6568042 1039 1356
51 Ll:405795.1 2001 JAN 12 70858515V1 1287 1885
51 U:405795.1 2001 JAN 12 71225808V1 1281 1867
51 U.405795.1 2001 JAN 12 70857056V1 1682 2037
51 U:405795.1 2001 JAN 12 70858566V1 1682 2004
51 Ll;405795.1 2001 JAN 12 70857338V1 1682 1980
51 Ll:405795.1 2001 JAN 12 71225089V1 1682 1952
51 Ll:405795.1 2001 JAN 12 2907964F6 1682 1852
51 Ll:405795.1 2001 JAN 12 70855009V1 1682 1830
51 U:405795.1 2001 JAN 12 70856566V1 1233 1805
51 U:405795.1 2001 JAN 12 70857847V1 1687 2051
51 Ll:405795.1 2001 JAN 12 3386941 HI 1682 1784
51 U:405795.1 2001 JAN 12 71225301 VI 1247 1775
51 U.405795.1 2001 JAN 12 70858661 VI 1 104 1774
51 U:405795.1 2001 JAN 12 2907964H1 1682 1763
51 Ll:405795.1 2001 JAN 12 71225987V1 1227 1861
51 U:405795.1 2001 JAN 12 2904539H1 1286 1393
51 U:405795.1 2001 JAN 12 2904539F6 1005 1392
52 U:014872.1 2001 JAN 12 70965142V1 301 814
52 U:014872.1 2001 JAN 12 71032124V1 301 790
52 U:014872.1 2001 JAN 12 71289921 VI 301 828
52 LI :014872.1 2001 JAN 12 3942368F6 301 730
52 Ll:014872.1 2001 JAN 12 3946947F8 428 795
52 U:014872.1 2001 JAN 12 3946947H1 429 526
52 Ll:014872.1 2001 JAN 12 71290683V1 600 1272
52 Ll:014872.1 2001 JAN 12 70965695V1 619 1243
52 Ll;014872.1 2001 JAN 12 71289423V1 686 1295
52 U:014872.1 2001 JAN 12 70967975V 1 735 1338
52 U:014872.1 2001 JAN 12 70966212V1 1064 1302
52 Ll:014872.1 2001 JAN 12 70966121V1 1069 1302
52 U.014872.1 2001 JAN 12 3942368T6 1069 1302
52 Ll:014872.1 2001 JAN 12 6713143H1 1069 1302
52 U:014872.1 2001 JAN 12 70966473V1 1071 1371
52 Ll:014872.1 2001 JAN 12 71289069V1 1071 1217
52 LI :014872.1 2001 JAN 12 3946947T9 1071 1335
52 LI :014872.1 2001 JAN 12 71289123V1 1071 1338
CO m D cjo co cjo co cjo cn cn cn cn o cπ <jo cn co θι θι θι θι θι cπ cn oι θι θι θι θι cn cn cπ cjo co oj u ω ω ω ω ω ω ω ω co ω ω co ω ω ω w w w co co ω ω ω ω ω ω co ω
O
— ' NO NO — . _ _ — ι _ _ _ N0 N0 N0 _ _ _ _ _ _ _ N0 N0 N0 — ' _ _ _ _ _ _ _ _ N0 N0 N0 co _ _ en cn o30o co co oo NO NO NO — ■ — ' — ' CO C CO CO - ■ — ■ — ' OO CO OO OO CO OO OO OO OO O O O CO CO CO CO CO CO CO ro o ftoo ooo coπ cftπ o—i ' ftOo coo oeπo rOo oM O M o eπ en cn en ro co co M O O O O O o en o M M O o o o o o o o __ CD CD CD CD CD CD 7t
CD CO CD CD SI SI U o ooo o o o o M M ft M cn — ■ — ' O en ft ft — ' Co — ' o o oo — - co Ol Ol Ol JI to -■ 4
— ' NO NO — ' NO NO NO NO NO NO NO NO NO — . _ _ _ _ _ — - isj NO NO — ' — ' — ' _ _ — ' NO — ' -' N NO NO rv v-i vi m v-i v-ι - , _ _ _ _ _ _ oo en ft M — . _ — • o — ■ o en w cjo co ft ft θ ft CD co c cn o ft cn θ ft M θ θ M Cn cn cjn fe ^ ^ c5 ls -3 S C — " ftO COO cnO ft NO o CO M ft 0 ft — o0 c NnO 7t
O Cn MNO NNOO OM O ft ' OO eOo OCn OOO ftO _NO ONO O OO OCO —Cn ' M M OO OOO CCOO COO —O ' MC NO ft NCOO OO COO OO CNJOO Co PCh C°5n —-. ' rN Scn o3 ?en2 o cn NO cn ro o 3
TABLE 3
SEQ ID NO: Template ID CampΩnent ID Start Stap 53 U:239245.3:2001JAN12 7735339J1 1324 2017 53 U;239245.3:2001JAN12 1557828H1 1339 1468 53 LI:239245.3:2001JAN12 7318489H1 863 1174 53 LI:239245.3:2001JAN12 7735339H1 863 1030 53 U:239245.3:2001JAN12 g587200 2248 2568 53 U:239245.3:2001JAN12 8093814H1 863 1262 53 U;239245.3:2001JAN12 1662458F6 863 1175 53 U:239245.3:2001JAN12 7737983H1 119 532 53 U:239245.3:2001JAN12 2519285F6 123 377 53 U:239245.3:2001JAN12 2519285H1 123 374 53 U:239245.3:2001JAN12 3818136H1 134 428 53 U:239245.3:2001JAN12 1910802F6 1749 2280 53 LI:239245.3:2001JAN12 1910802H1 1749 2023 53 LI:239245.3:2001JAN12 2845086H1 1760 2046 53 LI:239245.3:2001JAN12 2842537H1 1757 1878 53 U:239245.3:2001JAN12 7754262J1 116 532 53 U:239245.3:2001JAN12 g5865529 2164 2569 53 U:239245.3:2001JAN12 5216370H1 2165 2416 53 LI:239245.3:2001JAN12 g4452054 2166 2575 53 LI:239245.3:2001JAN12 g5879020 2166 2573 53 U:239245.3:2001JAN12 826886H1 1530 1847 53 U:239245.3:2001JAN12 g3736018 2271 2568 53 LI:239245.3:2001JAN12 g2328909 2269 2570 53 LI:239245.3:2001JAN12 go116973 2290 2556 53 U:239245.3:2001JAN12 70876454V1 1314 1824 53 U:239245.3:2001JAN12 5703843H1 1903 2186 53 LI:239245.3:2001JAN12 70876377V1 1903 2355 53 LI:239245.3:2001JAN12 4361570H1 1907 2196 53 U:239245.3:2001JAN12 7754262H1 862 1205 53 U:239245.3:2001JAN12 4543041 F8 1716 2330 53 U:239245.3:2001JAN12 4543041 HI 1716 1794 53 LI:239245.3:2001JAN12 2527887H1 1720 2070 53 LI:239245.3:2001JAN12 3550484H1 1721 1929 53 U:239245.3:2001JAN12 70874265V1 1726 2272 53 U:239245.3:2001JAN12 2737867H1 854 1030 53 LI:239245.3:2001JAN12 4884036F6 471 532 53 LI:239245.3:2001JAN12 7731661Jl 810 1430 53 U;239245.3:2001JAN12 7317594H1 820 1473 53 U:239245.3:2001JAN12 2657291 HI 839 1075 53 LI:239245.3:2001JAN12 4545275H1 847 1030 53 LI:239245.3:2001JAN12 961661 Rl 853 1381 53 U:239245.3:2001JAN12 961661 HI 853 1102 53 U:239245.3:2001JAN12 2736351 HI 854 1030 53 LI:239245.3:2001JAN12 70875758V1 1831 2165 53 LI:239245.3:2001JAN12 7093989H1 88 397 53 LI:239245.3:2001JAN12 7095177H1 88 397 53 U:239245.3:2001JAN12 555356H1 92 320 53 U:239245.3:2001 AN12 70873807V1 1512 1806 53 U:239245.3:2001JAN12 1298202H1 1512 1726
TABLE 3
SEQ ID NO: Template ID CampΩnent ID Start Stap 53 LI:239245.3:2001JAN12 857713R1 1525 2145 53 U:239245.3:2001JAN12 857713H1 1525 1756 53 LI:239245.3:2001JAN12 2794287H1 1653 1978 53 LI:239245.3:2001JAN12 3885390H2 1655 1957 53 U:239245.3:2001JAN12 624335H1 1677 1908 53 LI:239245.3:2001JAN12 7748039H1 1694 2261 53 LI:239245.3:2001JAN12 7748046H1 1694 2262 53 LI:239245.3:2001JAN12 70875390V1 1696 2187 53 LI:239245.3:2001JAN12 71077335V1 1699 1932 53 LI:239245.3:2001JAN12 684887H1 1510 1813 53 U:239245.3:2001JAN12 1256326H1 1510 1679 53 U:239245.3:2001JAN12 7054670H1 1512 2096 53 LI:239245.3:2001JAN12 1298202F1 1512 1942 53 LI:239245.3:2001JAN12 6310557H1 1767 2439 53 LI:239245.3:2001JAN12 3600715H1 1765 2057 53 LI:239245.3:2001JAN12 2592814H1 1773 2023 53 U:239245.3:2001JAN12 385678H1 1778 2076 53 LI:239245.3:2001JAN12 4852963H1 1787 2080 53 LI:239245.3:2001JAN12 213146H1 1802 2039 53 U:239245.3:2001JAN12 207370H1 1802 2028 53 U:239245.3:2001JAN12 7924721 HI 1811 2428 53 U:239245.3:2001JAN12 g1378507 1829 2118 53 U:239245.3:2001JAN12 027545H1 1761 1940 53 LI:239245.3:2001JAN12 6310542H1 1767 2382 53 U:239245.3:2001 A 12 2521749H1 1153 1402 53 LI:239245.3:2001JAN12 g1970688 1169 1477 53 LI:239245.3:2001JAN12 71075977V1 1652 1829 53 LI:239245.3:2001JAN12 71078829V1 1641 1830 53 LI:239245.3:2001JAN12 70874334V1 1661 2081 53 LI:239245,3:2001JA 12 3808662H1 1254 1468 53 LI:239245.3:2001JAN12 7596425H1 1280 1747 53 U:239245.3:2001JAN12 7596517H1 1287 1487 53 LI:239245.3:2001JAN12 70874514V1 1292 1977 53 U:239245.3:2001JAN12 7737983J1 1298 1966 53 LI:239245.3:2001JAN12 5641551HI 1219 1460 53 U:239245.3:2001JAN12 3372035H1 1225 1488 53 LI:239245.3:2001JAN12 2208403F6 1239 1713 53 U:239245.3:2001JAN12 2208403H1 1239 1468 53 L1:239245.3:2001JAN12 1232232F1 1243 1882 53 U:239245.3:2001JAN12 1232232H1 1243 1468 53 L1:239245.3:2001JAN12 2097186H1 1254 1350 53 LI:239245.3:2001JAN12 1616965H1 1984 2082 53 L1;239245.3:2001JAN12 4274892H1 1990 2266 53 U:239245.3:2001JAN12 3217425H1 1998 2285 53 LI:239245.3:2001JAN12 379451OH1 1999 2310 53 LI :239245.3:2001 JAN 12 71231645V1 2012 2538 53 LI:239245.3:2001JAN12 2917810H1 2018 2191 53 LI:239245.3:2001JAN12 1662812T6 2023 2532 53 LI:239245.3;2001JAN12 g3959977 2025 2208
CΛ rπ 0 cn cjo cjo cn cn co co co cjo cn cjo cn cjo cπ cn Cπ cn Cn cn cn co cπ en co co co cjo cΛ ω oo oo oo cjo ω oo c o co co oo co co oo co oo oo co oo co co ω oo os oo oo co oo cjo ω
O
NO NO NO IO NO NO NO ro NO NO NO NO ro ro NO NO NO NO ro NO NO ro NO NO NO NO ro NO NO NO ro NO NO NO NO NO NO ro NO NO NO ro NO NO NO NO NO NO NO
CO co co CO 00 CO 00 CO CO CO CO CO 00 CO co Co CO 00 00 co co CO CO co CO CO 00 CO CO CO co CO co CO Co CO CO 00 co CO CO co Co eo CO CO co CO co
O o o o O o o o o o O o o o o O o o o o o o o o o o o O o o o o O o O O o O o O o o o o o o o o
NO ro NO ro NO NO NO NO NO NO NO NO ro ro NO NO NO NO NO NO NO ro NO NO NO NO ro NO NO NO ro NO NO NO NO NO NO NO NO O NO NO NO ro NO NO NO NO ft ft ft ft ft tf ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft f 1 N t ft ft ft ft ft ft ft ft ft Φ1
Oi en cn cπ cn cn cπ cn cn en Oi cn cn en cn cn cn en cn en cn cn cn en on cn cn en en cπ cn Cn en cn cn Cπ cn cn cn en cn cn en cn en cn cπ cn cn 3 co co CO co CO CO "co co co co 00 co Co co Co όo co CO co CO co CO CO co CO co CO co CO Co co co CO C co CO co CO co Cύ "co co CO co Co co Ό
Kb Kb Kb Kb Kb fό Kb Kb Kb Kb Kb Kb Kb Kb Kb Kb Kb Kb Kb Kb Kb b Kb Kb Kb Kb b Kb Kb Kb iό Kb Kb fό fό Kb Kb Kb Kb Kb Kb iό Kb Kb Kb Kb Kb Kb Kb Ω o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o O o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o O o o o o o o o o o o o o o o φ
C— C_ C_ c_ c_ Ό
>z>z>z>z>z>z>zz>>zz>>z>z>z >z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z>z > z> z> z> z> z> z > > > z > z > z > z > z ro ro ro ro ro ro ro ro ro No ro ro ro ro ro M to ro NJ i ro ro ro ro ro ro NO O NO NO M ro ro NO No i^
00 00 00 00 ^ - _ _ _ co ro NO CΛ eπ cn cn cπ cn cn o o o en o o o o o o o o o o o !_ __J _, -1 -__ ) O ft ft ft c oo rorx ro fo O 00 — ' O o "O 0 00 M M O O O O O O CO CO Co _ 00 M M M ft M cn NO ft °. o Q
O O NO O M Ol _ _ _ _ . CO ft 00 ft 00 CD
NO O OO O O — ' O ft en M O O - NO 00 O g g _{
o o — ' — ' N0 N0 N0 N0 N0 — ' — ' — — ' NO NO — ' NO — . _ _ _ _ _ _ _ — . _ > r .o_ . - . _ . _ . .o- . r ro — o o cn eπ cn oi oi M M M O o o o o o oo θ 4s, cπ oo No ro co _ rNci — ιNsθ"ι — N re N θt< rθni rcnno r ro eπn N c rooO N c rooo. rr r_ eπrx o cnn ro
Onl ι ( s.o,- — f o - M ,■ , NO- • — ft .' cτiι — o f—■ , r cjτi, r cjri, . w
NO- , NO- _ rt ft Ol ft O M Oo en CO M M — ' CO ft O CO O M CO NO ft O M O O M O O M M o c cn co co
CO o CD — ' CO OO M M O M Ol o o co ro No o ft o o oo ft oo o co NO — ' O cn o No o — ' O ft ro cπ co o o o cn ro co oo oo ft Ol ft o _π_ o M ro NO ft NO O M £ X3
TABLE 3
SEQ ID NO: Template ID Component ID Start Stop 53 U:239245.3:2001JAN12 923998H1 863 956 53 U:239245.3:2001JAN12 5066463H1 863 956 53 U:239245.3;2001JAN12 2820190F6 866 1322 53 LI:239245.3:2001JAN12 2820190H1 866 1084 53 LI:239245.3:2001JAN12 2527015H1 866 1044 53 LI:239245.3:2001JAN12 1662845H1 866 1026 53 LI:239245.3:2001JAN12 1602695H1 866 970 53 U:239245.3:2001JAN12 908279H1 884 1018 53 LI:239245.3:2001JAN12 gό54291 894 1139 53 LI:239245.3:2001JAN12 3190503H1 921 1229 53 LI:239245.3:2001JAN12 3190494H1 921 1159 53 LI:239245.3:2001JAN12 3338674H1 922 1171 53 LI:239245.3:2001JAN12 4916345H1 945 1244 53 LI:239245.3:2001JAN12 1255777H1 950 1194 53 LI:239245.3:2001JAN12 1442744H1 340 532 53 LI:239245,3:2001JAN12 g3277690 2125 2575 53 LI;239245.3:2001JAN12 5648193H1 1975 2413 53 U:239245.3:2001JAN12 1616909H1 1984 2229 53 U:239245.3:2001JAN12 210406H1 1958 2142 53 U:239245.3:2001JAN12 1966577T6 1962 2538 53 U:239245.3:2001JAN12 5050857H1 1963 2218 53 U:239245.3:2001JAN12 5873551 HI 1913 2211 53 U:239245.3:2001JAN12 2820190T6 1949 2525 53 U:239245.3:2001JAN12 978588H1 1951 2252 53 U:239245.3:2001JAN12 978588R1 1953 2308 53 U:239245.3:2001JAN12 4202459H1 1889 2166 53 LI:239245.3:2001JAN12 5701154H1 1903 2184 53 U:239245.3:2001JAN12 7653736J1 235 431 53 LI:239245.3:2001JAN12 1621168H1 206 437 53 LI:239245.3:2001JAN12 7731661H1 155 532 53 U:239245.3:2001JAN12 4140667H1 182 473 53 LI:239245.3:2001JAN12 7726218H1 191 447 53 LI:239245.3:2001JAN12 7726218J1 192 447 53 LI:239245.3:2001JAN12 7255960H2 144 532 53 U:239245.3:2001JAN12 g3539348 1 374 53 U:239245.3:2001JAN12 g3931954 1 369 53 U:239245.3:2001JAN12 776737H1 68 120 53 U:239245.3:2001JAN12 1985067H1 76 345 53 U;239245.3:2001JAN12 70876515V1 1550 2105 53 U:239245.3:2001JAN12 70874022V1 1571 2180 53 U:239245.3:2001JAN12 3864706H1 1563 1941 53 U:239245.3:2001JAN12 70875501VI 1580 1915 53 LI:239245.3:2001JAN12 2102912H1 1590 1864 53 LI:239245.3:2001JAN12 71076168V1 1593 1860 53 LI:239245.3:2001JAN12 71078401VI 1600 2023 53 U:239245.3:2001JAN12 1300869H1 1601 1870 53 LI:239245.3:2001JAN12 g1685978 1606 1939 53 LI:239245.3:2001JAN12 g2026868 1611 1979 53 LI:239245.3:2001JAN12 6162750H1 1623 2183
CΛ m
Θ cn en cn cjo cjo c^ co co oi ϋi cπ oi oi oi oo oi oi oi oi cπ cn co oi oi c oi cn cn co ft ft ft ft co oo oo co co oo co co oo co co oo cjo co co oo co co oo oo co co oo oo co co oo co oo co ω σ z o
, , , , NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO ro NO NO NO NO NO ro ro NO NO NO NO NO ft ft ft ft ύ Cύ Cύ Cύ CO Cύ Cύ CO Cύ Cύ CO CO CO Cύ O CO CO CO CO CO O O CO Cύ Cύ CO O CO CO CO CO CO CO CO CO CO 00 CO CO 00 CO CO ro
N) NO NO NO o ι o o o o sCO o O vO o O o s(J o sCJ O o sO vO sO o o vC) o O
N) NO NO <> vC) o sO o o vO sO sO v) vO sO .
Cύ Cύ Cύ Cύ NO NO NO NO NO NO NO NO NO NO NO NO N) NO NO N) N) N) NO N) N) NO NO NO NO NO NO N) N) N) NO N) N) N) NO ft ro N) N) NJ N) N) NO
CO O OO 00 ft ft ft ft ft cn c ftn c ftn ft en c ft f n ftJO c ftn c ftn ft cn ft en ft cn c ftn C ftJI ft cn ft cn t cn ft cn ft cπ ft cn ft cn ft cn ft cn ft cn ft f cn ft cn ft cπ ft cn tf cn ft cn ft cn t C fJI t c fn ft Oi c ftn ft cn cn ft cn ft cn ft cn ft φ cn t cn ft cn ft Ol ft cn ft en 3 cn cn cn cn CO CO Co Co co 00 co Co CO CO C co CO co 00 oo co co oo 00 00 CO 00 co co CO 00 co Co co co co 00 00 co co CO 00 CO co 00 00 CO 00 Co Tj*
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO O NO NO NO NO NO NO NO NO NO O ro NO NO NO NO NO NO
< ) C O CO ro NO NO NO NO N
< ) o -+
CJ CD o CJ CD o o CD CD o o o o o O o o o o CD CJ CJ C-J o o o CD o o CJ CD o CJ o o o CJ o o CD o CD o CD CJ o φ c_ r r c . ( r r < ( c c r r c_ e r r r e r r f r r r c r < e r r c_ c , ( e c r r r e e r 13
> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > >
Z Z Z Z z z Z Z Z z z z z r ro i ro i ro ro ro ro No ro ro No ro ro ro ro ro No ro i ro No ro ro ro No ro Nj ro ro ro NJ i NO N^
rO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO _ _ _ _ _ _ _ _ rO N0 N0 N0 N0 N0 N0 N0 _ — ' — ' _ — ' _ CΛ o o o o ft ft ft ft co oo co ft co oo co co ro ro ro ro ro ro ro CO ft CO OO CO ft ft ft ft O O O O O O O O O O O O O O ^i-
Cύ <-• ~ o O O O M O 00 O — ' M O O OO OO OO CO Oo ro rO NO NJ NO — ' Ω
OO O NO NO M M CO O M Cn ft cn M cn co o o en ro o o en 03 o oo ft ft O OO ft O M ft OO M NO ft ft ft NO — ' Ol CJI Ol CJI CJ 00
OO OO CO CO NO NO NO NJ NO NO NO NO NO NO NO NO NO NJ NO NO NO NO IO NO ' NO NO — ' — ' NO NO NO — ' — ' NO NO NO NO NO NO NO NO NO NO NO NO NO — ' CΛ o o o o cn cjo cj cn cn o cn cn en cn cn eπ cn cπ cn cn en cn oi oi cfπ — j M O O O M O O — ' M O OO Oo Cn CO ft Cn Ol Ol — ' O NO — • CD O cn oi oo o o o o oo o co o oo eo M O o eπ o o o M Co eo o ^ K-, — ' ft CO ft CO O — ' O NO Cn O N O NO M NJ O M O O O O OO NO -2 cn en o o co o o co o oo co co oo cn ro o M O co o NO — ' No cn IXJ 00 O 00 — ' O ft l _ O M — ' — ' O O — ' O M O ft O OO NO CO NO O
CΛ m
D cn cn cn oo oi cn coo cn cn co cΛ Cjo cn cjo cjo cn co cn cjo cji cn oi oo oi cn cπ cn cn c^ ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft 45, ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft Ό z O
ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft
NJ NO NJ NO NJ NJ N) NJ N3 N> ro N) NJ NO N) NO N) NO NO N) NO NJ NJ NO NJ NJ NJ ro N) NJ N) N) NO N) NJ NO N> NO NO N) N) ro N) N) NO N) NO NO ro ,
CO CO CO CO CO CO Cύ co CO Cύ CO Cύ O ύ co Cύ Cύ O Cύ O Cύ CO CO CO CO CO co O CO Cύ CO Cύ Cύ Cύ Cύ CO Cύ O CO CO Cύ CO Cύ Cύ CO Cύ
00 CO CO CΛ CD CD 00 O CO 00 CO 00 O 00 00 O CO 00 CO 00 CO CO CO O CO O CO O 00 CO 00 ro O ro CO CO ro oo CO CD OO CD 00 oo CO 00 coo CO ω 00 - rnIO ft ft ft 45. ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft 3 cπ cπ Ol Ol en cn cn cn Ol Ol cn Ol cn cn cn cπ Ol cn en Cn en en cn cn cn Cn en en en cn cn en cn cn cn cn cn cn en cn Cπ cn en cn Cn cn Oi cn cn T3
NO NO NO NO NO NO NO ro NO NO ro NO NO NO NO NO NO NO NO NO NO NO NJ NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO Ω O o o C O c > o o CD C O o C C O o o →- o o o o o CJ D C-J o O o CD CD o CD o o o o CJ o o o o o CJ o o o o o o o o o o O CJ o o o CD o o CD o O Φ
> > > > z > > > > > > z z z z z>z>z>z>z>z>z> >z>zzzz>z>z>z>z >z >z >z >z >z >z >z >z >z > > > > > > >z >z >z z z >z >z >z >z > > >z >z
NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO NO N roO NO NO NO NO NO NO NO NO NO ro ro ro NO
oi oi n en co NO — ' cn oi ft oi oi r cnn
N0 _ — ' NO — ' —■ —■ — ' _ _ —■ _ _ _ ro oo oo co NO O O — ' O M OO O M M M O Cπ — ■ CO ft O O ft o CO COD COn oNO eMn oN cfto oOo oC eNnθ cω-n cftn cCn —O ■ IOi Ns3i --3, ft .v. rN .c^- _ -7> _ r . - _ O O NO CO ft O 00 O O ft NO M 3J CO rτ' I r' O CD CD CD 7t O Co O O O O rO M O N ft O Co O — ' NO ft NO O CO Cn O Oo O
00 — ' ft — ' ft oo o o o oo cn o o o — ■ ft ft ft O O O ft O CO NO M ft ft M NO o ft ft 00 _ O O Cn O O M OO CO Ol M O T3
CO m © cjn cn oι θι oι θo θι θι co co cjo oι θι cn cπ cn co cjo cn cn cn o cjo co cn co θι oι oι θι θo o^
M M M M M M M M M M M M M M M M M M M M M M M M M M O O O O O O O O O O O O Cn ft ft ft ft ft ft ft ft ft ft
0
0 —3 ' C0 ' O00 NO NO NO ro NO NO ro ro co φ ft ' ft ft ft ft -.
Ω
to NO CO CO — ■ — ' ft ft CO Co OO Oo ft Cn
ri r M Ol tf ft NO O Cn Cn ft ft O ft NO NO ft — ' H
i S co O cn oi ft CO CO O — ' — ' M Ol OO CO Cn O f O≤i rcnn OO Oo
^ .^ O Ol CO O M M O Ol M Ol M jv- co eo co cπ en cn ft cn cn en en θι cπ — ■ o- rO NO NO NO NO NO NJ NO CΛ ft io c^o cπ co o ft o co ro ro o oo co o o :£_ — ■ ft r ft rΛ ,n n vθ r S NO ft NO C y- s Mι rOoO Jft5, —— i' NO NOO NOO — — ■ j=-*- X ^ 'CO '^' n o ft M oo ft co o cπ — ■ o o cπ o c -n.η oo _ c _π. r _§ __ o ocj -3 r0o- -0-' NϋO- O0o0 o0o0 ^ 0- o on oωo ft0, O^ C0o- cf_. eo ft o eo co NO M No O
NO O O 00 CO CO M CO OO O O O CO ft M NO Cn O CO O O J
CΛ m
U con cn cn cn ci co cn cn cn cn cn cn cn cn cn cn cn cn cn cjo cji cjo oi oi cn Oi cn oi Oi oi oi O^
O O OO OO OO OO OO OO OO CO OO OO CD CO CO CO CO OO OO CO CO CO OO M M M M M M M M M M M M M M M M M M M M M M M M M M vj1
O
o o rO N0 N0 N0 N0 N0 N0 N0 N0 NJ N0 N0 N0 N0 N0 N0 N0 N0 N0 N0 N0 — > _ _ — . _ _ _ _ . _ _ _ 4 _ _ _ _ _ _ _ _ _ _ _ _ _ . _ _ _
__ __- — ' — ■ _ — ' — ■ _■ —- —■ — . —. -— _ i —i — .. _ _ _ . _ _ _ - . - . OO OO OO OO OO OO CO OO CO OO CO CO OO OO OO CO CO OO OO CO OO O O O O O O O O O O O O O O O O O O O O O O O O O O — 1 rv >! M M M M M M M M M M M M M M M M M M M M M O O O O O O O O O O O O O O O O O O O O O O O O O O Φ H r3 O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O _5 H J ft 4S. ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft 03 00 00 C0 03 CD CO OO CD CO CO CD C0 03 CD CO OO CD CO OO OO OO OO ∞ i i^ ^ ^ ^ ^ i^ -. x x x x x x x x jv. jv. jv- jv. jv. jv. jv. j^ K ^ Kb Kb Kb Kb fo ro Kb Nb K K b Kb Kb Nb Kb Kb Kb Kb Kb Kb
H ■.χrooOoOoOoOoOoOoOoOoOoOoOoO OooOgOoOoOoOoOoOoOoOoOoOoOoOoOoOoOoOoOoOoOoOoOoOoO OooOoOoOoOoOoOoOoOoO_rrj C_ v_ C_ C_ C_ C_ «-_ C_ ll_ C_ C_ C_ C_ C_ c_ <__ C_ c_ C_ C_ c_
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
^^- S5-ES- - S__-35______________- S- __-3_5______- _____-E
M M rO N0 N0 N0 N0 N0 N0 O N0 rO N0 N0 N0 0 N0 N0 N0 r N0 N0 N0 N0 N0 N0 N0 N0 N0 r N0 N0 N0 N0 N0 r N0 N0 NJ N0 r N^
> KO -- NJ OO ft .fv JN N NO -r-i M NO NO NO NO M Cn rn — ' NO NO NO Cn OO vj NO rrs CO NO CO Co rr en N0 m N0 m Ch O O ft Λ~, O No S CD
N ^ K ft oo Ω δ cn Nθ Q- c> co3 cjo cn co3 M fr fS c> S ω n oi s.9, oo (Q o 3 rj _ o cn o o ^ χ g rθ r ι o M θ io o c> NJ NJ — ' No o co n ^ ^ ^ ^ cn ft
^ ^ NJ ft ^ M CO N0 °v > 03 θ CO co -J N C0 O ft ft CD 4^ n CO ^ _ O CO co CO
S j2 S w03 ftN3 θ C^D ^vj cNo3 Crøo feO ^m _ O_ O'_ oι OCoo _go _∞ _ O O Cjθ ch Nθ ft rS θ v^ x S oo Oi O ^ eO NO CO ^ O v-j O ∞ O Co S co ft v. s, _ _ ft o M ^1 — ■ _ — ι θ — i — i — « — ι θ — ■ — ■ — ' O O — ' θo o o v^ _I _, _1 _1 en cn r ^ r - ' ^ - - o ° co o -+
ft ft Cn c> cπ c> cjo o o sι O M O M CO Ol Ol Ol O fv rv CO O CO O Co OO OO O OO Cύ Cn M M O O CO O -
h C 56 r »rx
■ f O3 mOO —— ι' κNOι rOs Ov nO. πO. — ι r o-χ rooo rcrox sMi ros rcnn reπn
co m
0 cn cn cn cjo cjo cn cn cn Co cn oi oi cjo eπ en oi oi oo en en cn eπ cn cπ en eπ cn cπ cn oi oo oo oi oi oi oi oi oi cn cπ en cn cn en cn oi oi oo cn o o o o o o o o o o o o o o o o o o o o o o o o o o o o O O O O O O O O O O O O O o o o o o o o o
O
C?
3 "O
Ω
Cn Ol Ol O O M O O M M M M ~^ — ' — ' rv. m m m n O Cn CD O aj CO C. sj r; O O O — ' ft ft ft O N0 M Cn en ft M M "S ro - ^ - r§s Prn= ff°j SM ■ft» o) o cn cn -. p sι ∞ M CO O NO ≥ 33 c $ & & o ;° Ol .O,Oi O- jco: n o — ' O ro — ' Co oo No en o o — ' ^ 03 NO r u> uι ui —, -j sι ^ (-r; ;-. Cj —' vi vi ug — ir. u> u. x rf
≥ rsj ft > ∞ ft ft cn o o ω co3 ∞ g ∞ ro .ft θo -θ sθ vι .ft . ^
ro — ' ro ro ro ro ro ro ro ro io ro ,,, --, - . r-, — ■ ro NO ro — ■ — . _ _ — . _ — cj ■ —ft ■ —ft ' NftJ rft _co _No _ω -2n _ r rn _ n -n _ 0
O OO O O — ft ft O _ - NCΛ0 N4v0i N4v3- N03 NjvJ- →CΛ- M O M M — ' ' OM ftM OM O OM M Nj rnn rcnπ rKθi rCv O0, v-j ftv. ftc C^Ji C_n Ojv- O O O as 0 -o 0 -M. N4v 0 CΛi- ft o ro ft ro ft co ft ft ft o o OD t ft ft o M ft CD _ o o co Oi ft Cjn O M O M ft ^ O fS ^ O X rn o S o ft M M o O o r o o o w ω ω o w ω co w ω ft M θ cn ft — ■ 3
CΛ rn
O O' O O O O O O O O O O O O O O O O O O O O O O O O O CO CjO CJi Oi CJi Cn cn cn CO CΛ CJO CJl ϋl ϋl COo CJo CjO 0 oooooσoooooooooooooσooooooooooooooooooooooooooooo σ
Z
O
Co C CO oCOαCo CoOoCOoCO oCo O
NO p.
NJ
M M M M M NO ft Oi rO C O O O OO ft O co co ft ft ft ro ft oo
o o iT^ cn cπ co coo o o cjo ft M M ro cn j-. _ _ _ _ _ N0 _ N3 — ro o co c M Cjo cjo O C -- rC Oήi ^|^ sMi O ftft cO oO O NO N0 N0 CΛ nn C o oO cC0o3 oC0o cCo3 oC0o3 -On cCo0 cCji QC»o ^o cChh —— i ■ w rn « to oβo r)n^l oo SSJ M ofBi Λcn Λo, Ao ono — ' OO N—O ■ eOn ' — fto ' N N N M —O Oo ' — OCn ' NoO r Cn OoO N—O ' N MOO — Ocn ' —o ' M ftO .?O*- e r O^ cn M -J en o — en ro — ' O oo ft o oo α cn ro o co o co o — ■ — ' ∞ ft ch ft o NO M ft ft ft ft M CO O M NO ft O O CO O TJ
CΛ rn oooooooooooooooooooo — 'oo o _ 'o — ■ _o_o_o_o_o_ _ _oo_o_o_o — 'oOoOoOoOoOoOoOoOoOoOoOoOoOoO Ό z o
O M co cn oo M oo oo ,-, oo eo co ft o co cn ft ft oo M M M -5 cn o — ■ — ■ ro oo cn ft y NO o — ■ o M cn v eo ___l _ _ _ _ __ ft _ _ — ■ cn en o i & o cjj' cn oi co No ro ro ro -' o o _ o _ NO co CO O O j δ ft ^ 7^ C o> ^o Oo M C ft C3 C θp O O Ω oo — ■ — ■ o o o co o __ o oo — ■ cπ en o o o cn oi M 00 CO O Ol ft o o o ft ft Oi 3.
ω c ∞ « ω w CO CO CO CO CO _ o_ o o o o M Cπ o oo o cn cn o o cD — ' Cn — ' Oo ft oi co _ co — ' ro ro s- o o o o o o o 00 o N0 N0 N0 _ O O N0 Cn sI — ' NO O O sl sI O CO o
CO 0 s*0o > 00 CoO O O si en M M cn f ft co ft ft ft ft ft M ft M O OO NO Ol NO — ' O OO OO O — ■ — ' O O — ' M NO CO si o cn o co oo o o oo ro cn oii-' ft t Ol ft NO NO en —■ co o ft NO M oo cn M o ro M NO — 'O
CΛ m
© o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o co co oo co co co co co co co cjo oo oo co co co θ3 Cθ θo cjo cjj C3 Co co co cj3 Co cjo co oo ω o
c —o i —co i cn vtf —co f
_ _ i O _ i nt. — ' NO ft — ' O
00 00 00 CO 00 M M 03
—■ NO co cπ oo ft ft 00 c Xo o NO CO CO OO OO NO NO CO CO CO CO NO O O O O O O O — ■ — ' O OO o o cjn cn S S ft R S ^ M O n On rκoι orno M C. r l N) fO O C ω C. rt NO M NO Cn M M o o o o o o oo o o o O ft ft ft ft ft ft ft _ O ft ft o g o cn ft g g ^ ∞ en ^ cn co o o - No o ft ft ft ft M M ft ft ft Tj
0000000000000000000000000000000000000000000000000 ;=, ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ω co ω co co ω cjo co co ω oo co co co oo co ω oo co ω
O
M M M M M M VI M M VJ M M SI SI M M M M M M M M M M M O O O O O O O O O O O O O O O O O O O O O O O O O ftft ftft ftft ft ftftft ftftft ftftftftft ft ft ft ft ft
CO OO OO CJO CJO OO CO CO OO CO CO CO OO CO CO CO CO OO CO OO CO OO CO CO o o o o o o o o o o o o o o o o o o o o o o o o o ϋi cn oi en eπ cn cn eπ cn cn cn en cn oi oi oi oi oi cπ cn oi oi oi oi ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft 0 00 NO NO N0 NO NO NO NO NO NO N0 NO N3 NO NO NO NO N0 N0 NJ N0 NO N0 NO NJ N0 ft 00ft00ft00ft00ft00 0ft ft00ft00 0ft0ftft00 00f00ft00ft00ft00ft00ft00ft00ft00ft00ft00ft03ft00 Φ ft t p. o ιsjoKb KoboKboKboKb Kob Kb Kb Kb Kb Kb KboKb Kb K Kb Kb Kb Kb Kb Kb Kb Kb K^ ooooooooooooooooooooooob ooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo→Φ- c_ c_ σ
>z >z >z >z >z >z >z >z >z > > > > > > > > > > > > > > > > >>>>> z>z>z>z>z>z>z>z>z>z>z>z>z > >
ZZZZZZZZZZZZZ zzzzz>z>z>z>z> ro ro NO No iO No ro No i ro ro ro ro ro No ro ro ro ro i ro ro ro ro to ro w ro to ro No ro NO NO
. O O M M M O en Cn Ol rs O ft ft CO OO CO OO CD ft O O O OO OO OO OO M M M M M ft CO CΛ o o o o o o o — ' O rv- Ol O O O Ol O CO O OO Co ii -o NO M CO jv, r t " c "o o " O " UJ jv, f coo orh ftjv- r f-c en co M o oo o oo oo oo oo o o o Q ft t co cmn cnoo onoo cπ s Mi - Or> v On o ~ f O -' O ft O O Q — Co ft ft Cn — ' O O 00 00 _ _ O ^.
ft — ' ft ft Oo rO ft ft OO NO NO OO O — ■ — ' ft O NO 00 NO O ft O O OO O ft O — ' NO NO ft NO
CΛ m © o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o cπ oi oi oo cn co oi oo oi cπ cπ co cπ co cjo cn en cn oi oi oi co cπ co ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft ft
O
ft _, O CO NO .f M CO M O CO M M OO CO J, U ,J . U ,J - . M NO cn cn cn O jNj — ■ — ■ sθ r _ _ ^+
— ' ft rv O r.o-x O rnl — .. N ft rv ft rv C rO.i O r.o-x y Cύ^ - r f —v ' ^ CD ft rv M
O ml O
NO Q- ft M en ft M M O O O -' M O CO jg j^j g -j ^. O ft NO o!8 cn oi oo oi ft co N O oOo OoOo Ooo Oco ofto _— ' Oo Ofto Oθ ftft NcnO Oft CcJo-l rV ii f cvo- — ' r (--'x Ω q_
CΛ m
© ooooooooooooooooooooooooooooooooooooooooooooooooooo 0000000000000000000000 == o o o o o o o o o o o o o o o o o o o o cπ eπ c o
ofti ofti ofti ofti ofti ofti ofti ofto ofti ofti ofti ft ft ft CD O3 CO CD CD OT
OoOo KJ
O O O NO NO — ' O O M O O O Cn ft ft CO NO NO NO — ' O CO _, O O M ft ft Oo Co -j CΛ M ft ft CO O M oo ft cn co No o ft o co No cn cn M O oo oo M ft — • CD Oo 4c5o. rrs-i 00 CO - o o CJ S3 Co ft
00 ft M ft CO Cn cn O 00 o ;V Q O CO CO O M O Co O Cn O ft O O ft Cπ CO 1 _ ^ _ ∞ M NO O O cπ — ■ 0000 o o M --L
TABLE 3
SEQ ID NO; Templote ID CΩmpΩnent ID StΩrt StΩp
66 LI:054831.1:2001JAN12 70941694V1 720 1245
66 U.054831.1.2001JAN12 70942457V1 322 929
66 LI:054831.1:2001JAN12 70944789V1 8 561
66 LI:054831.1:2001JAN12 70944150V1 783 1300
66 Ll:054831.1:2001JAN12 70942614V1 679 1072
66 U.054831.1:2001JAN12 70941169V1 949 1300
66 U.054831.1:2001JAN12 70942531VI 1033 1300
66 U.054831.1.2001JAN12 70943671VI 949 1300
66 U.054831.1:2001JAN12 70944285V1 1148 1756
66 LI:054831.1:2001JAN12 70942701VI 8 564
67 U:l 175083.1 :2001JAN12 70229576V1 * 221 721
67 Ll:l 175083.1 :2001JAN12 70230292V1 1 434
67 U:l 175083.1 :2001JAN12 70234276V1 1 197
67 LI: 1175083.1:2001JAN12 70229269V1 588 803
67 Ll:l 175083.1 :2001JAN12 70229037V1 339 792
67 U:l 175083.1 :2001JAN12 70230681VI 1 432
67 LI:1175083.1:2001JAN12 g4682831 379 843
67 LI:1175083.1:2001JAN12 70228423V1 412 864
67 LI:1175083.1:2001JAN12 g4684685 433 843
67 U:l 175083.1 :2001JAN12 g1202200 447 846
67 LI:1175083.1:2001JAN12 g6568818 455 843
67 U:1175083.1:2001JAN12 70232638V1 559 1065
67 U:l 175083.1 :2001JAN12 2393170H1 51 291
67 LI:1175083.1:2001JAN12 70230756V1 359 833
67 LI:1175083.1:2001JAN12 g2717002 365 731
67 U:l 175083.1 :2001JAN12 70232336V1 54 572
67 LI:1175083.1:2001JAN12 3932513H1 71 328
67 LI:1175083.1:2001JAN12 3696540H1 73 353
67 LI:1175083.1:2001JAN12 70232432V1 133 616
67 U:1175083.1:2001JAN12 3085961 HI 138 421
67 U:1175083.1:2001JAN12 2190988H1 143 360
67 LI:1175083.1:2001JAN12 70232918V1 180 693
67 LI:1175083.1:2001JAN12 g2322443 276 559
67 U:1175083.1:2001JAM2 70230724V1 359 837
67 Ll:1175083.1 :2001JAN12 g1240377 372 708
67 U:l 175083.1 :2001JAN12 70233141VI 1 440
67 U:l 175083.1 :2001JAN12 70228483V1 1 463
67 LI:1175083.1:2001JAN12 3274714F6 1 459
67 U:l 175083.1 :2001JAN12 5863352H1 28 288
67 LI:1175083.1:2001JAN12 70228662V1 1 444
67 Ll:1175083.1 :2001JAN12 70224321VI 308 593
68 LI:2122897.2:2001JAN12 6597429H1 1027 1379
68 LI:2122897.2:2001JAN12 4062815T6 1027 1365
68 U:2122897.2:2001JAN12 71745662V1 999 1377
68 U:2122897.2:2001JAN12 2867016F6 1027 1361
68 LI:2122897.2:2001JAN12 3468525H1 1051 1305
68 U:2122897,2:2001JAN12 4438637T8 1067 1287
68 U:2122897.2:2001JAN12 5153965T9 962 1292
68 Ll:2122897.2:2001JAN12 70926842V1 1133 1320
0000000000000000000000000000000000000000000000000
C» O0 O3 CD O3 O3 CO O3 00 O3 00 O0 O3 O3 O3 00 O3 CD O3 00 CD O3 00 O3 00 O3 00 O3 O3 CO CO 00 O0 O3 O3 00 CO CO O3 CO ∞
0000000000000000000000000000000000000000000000000
C03 C00 C00 00 CD CD O0 CD CD 00 CD CD CD CD 00 CD CO O0 CO 00 CD CD CO C» C CD O3 O0 O0 O3 CD O3 CD CO OT
O
NO NO NJ NO NO NO O NO NO N^
3.
< ) ( ) c »
o o o o o cn cn M M o o cn o O O O O O NO O O O 45, O — ■ O O M NO NO NO ft NO NO O o No cn r_: ; oo ; __ ! _? ft NO NO M 00 o o — ■ o rO O ? v3 N0 N0 M N0 N0 — ' N O — ' M NO O r
— > M M ft 00 00 CO O NO NO O M O M ft Ol NO 00 CO O CO CO
M O O M M M O M M M M M M O N M O O NO M NO ft — ' O O O ft 00 O _- ' gft cOO°sl °sJ ft— NjMS_f
ω ω ω ω ω ω M^ ^ M M M M i M ro i M M M i i i cΛ -' ^ Λ ω t ω ω
C —jn ' ftO t0j0 ft0 ft0 M0 ≥ ≥ O ft Moo ^o fto coooo coπo fto cn Wcn ∞cn cn — ' No o o o en co co o o No Ch 'o ft π K 0 - CO CO U .0 .0 -o _ _τj
CΛ rπ © vl M M M M sl sl M sI M sl sI M M M M SI sl M SI M M M M M M M M SI M M M M M SI M M M M M O O O O O O O O — ' — ' — O O O O O O O O 0 0 0 00 00 00 03 00 D
O
M vj sj sj o cn cn en en co ro No ro ro ro ro to ro o o O
Cn ft NO OO NJ Cn O ft NO co oo M — ' Oo ro oo No oo ro NO —■ en NO co o
_ _ _ _ _ _ _ _ N0 N0 —' NO —' —" NO —' _ _ _ _ _ _ _ _ _ _ _ —. _ ft O O ft ft ft ft ft O NJ O — ' M M — ' M CD W OO CO OO CO CO CO CO CO CO CO CO co oo co co o & ro NO O O — ' — ' — ' O — ' Cn O Ol Ol OO O IO OO O O O O O O O M O O O O M o o
NJ co oo M No o cn o oo ft oo ft o o ro oo oo o o o o o o en o NJ O O ft o o o o co E
TABLE 3
SEQ ID NO: Template ID CΩmpΩnent ID Start StΩp 71 U:81ό379.ό:2001JAN12 3034616H1 1188 1396 71 LI;81ό379.ό:2001JAN12 g4175581 1188 1612 71 Ll:816379.ό:2001JAN12 4596909F6 1189 1375 71 U:816379.ό:2001JAN12 g2874255 1044 1393 71 U:816379.6:2001JAN12 386476H1 1053 1330 71 Ll:816379.6:2001 JAN 12 6514626H1 1074 1396 71 LI:816379.6:2001JAN12 70433255D1 1088 1396 71 U:816379.6:2001JAN12 71275888V1 1120 1397 71 Ll:816379,6:2001 JAN12 71862635V1 950 1396 71 U:816379.6:2001JAN12 70516131D1 958 1396 71 Ll:816379.6:2001 JAN 12 71862788V1 961 1359 71 LI:816379.6:2001JAN12 2858353H1 1768 2033 71 LI:81ό379.ό:2001JAN12 2961864H1 1772 2047 71 Ll:816379.6:2001 JAN 12 5341535H1 1826 1934 71 LI:816379.6:2001JAN12 g1046751 729 1025 71 U:816379.6:2001JAN12 71276608V1 771 1165 71 L1:816379.6:2001JAN12 71276635V1 777 1102 71 LI:816379.6:2001JAN12 70924007V1 789 1396 71 U:816379.6:2001JAN12 71275891V1 794 1259 71 U:816379.6:2001JAN12 70924234V1 794 1368 71 Ll:816379.6:2001 JAN 12 71276231VI 802 1297 71 LI:816379.6:2001JAN12 5825651 HI 817 1394 71 LI:816379.6:2001JAN12 70925679V1 828 1361 71 LI:81ό379.ό:2001JAN12 70924744V1 840 lβ9ό 71 U:816379.6:2001JAN12 70925722V1 843 1359 71 Ll:816379.6:2001 JAN 12 70923524V1 852 1290 71 LI:816379.6:2001JAN12 70924039V1 866 1396 71 U:816379.6:2001JAN12 7729811J1 879 1375 71 LI:816379.6:2001JAN12 71863033V1 875 1396 71 U;816379.6:2001 JAN 12 71862558V1 886 1396 71 Ll:816379.6:2001 JAN 12 71862587V1 922 1396 71 LI:816379.6:2001JAN12 70513587D1 930 1396 71 LI:816379.6:2001JAN12 70516118D1 936 1394 71 U:816379.6:2001JAN12 8052754J1 1 624 71 Ll:816379.6:2001 JAN 12 7764417J1 118 654 71 LI:816379.6:2001JAN12 7401916H1 190 685 71 LI:816379.6:2001JAN12 70923844V1 346 799 71 Ll:816379.6:2001 JAN 12 70924180V1 346 933 71 U:816379.6:2001JAN12 70924465V1 346 862 71 LI :816379.6:2001 JAN 12 70924539V1 346 895 71 LI:816379.6:2001JAN12 71276579V! 346 940 71 Ll:816379.6:2001 JAN 12 70923858V1 346 896 71 Ll:816379.6:2001 JAN 12 1260150F6 346 654 71 LI:816379.6:2001JAN12 1260150H1 346 590 71 LI:816379.6:2001JAN12 70923076V1 491 1036 71 U:816379.6:2001JAN12 g712423 588 836 71 Ll:816379.6:2001 JAN12 g703559 588 849 71 Ll:816379.6:2001 JAN 12 71276111V1 595 1199 71 U:816379.6:2001JAN12 70924950V1 667 1097
TABLE 3
SEQ ID NO: Template ID ( -.ΩimpΩnent ID Start Stap
71 LI:816379.6:2001JAN12 70925379V1 666 1226
71 Ll:816379.6:2001 JAN 12 7964383H1 690 1267
71 LI:816379.6:2001JAN12 356585R6 724 1 104
71 LI:816379.6:2001JAN12 2024316H1 1 122 1406
71 Ll:816379.6:2001 JAN 12 g3416935 1144 1396
71 U:816379.6:2001JAN12 4157360H1 1 147 1384
71 LI:816379.ό:2001JAN12 4597309H1 1 189 1435
71 U:81ό379.ό:2001JAN12 g 1046650 1 190 1396
71 LI:816379.6:2001JAN12 1493337H1 1 192 1421
72 LI 2123452.4:2001 JAN 12 1456029T6 6 472
72 LI 2123452.4:2001 JAN 12 g5546101 191 470
72 LI 2123452.4:2001 JAN 12 1448389T6 58 469
72 LI 2123452.4:2001 JAN 12 g 1067509 339 447
72 LI 2123452,4:2001JAN12 2928882H1 157 427
72 LI 2123452.4:2001 JAN 12 1456029F6 6 288
72 LI 2123452.4:2001JAN12 3448555H1 1 194
72 LI 2123452.4:2001 JAN 12 1456029H1 6 1 12
73 LI:474559.8:2001JAN12 71 120072V1 647
74 LI: 1089871.1 2001 JAN 12 70762020V1 125
74 LI: 1089871.1 2001 JAN 12 70759980V 1 704
74 LI: 1089871.1 2001 JAN 12 70757962V1 481
74 Ll:1089871.1 2001 JAN 12 2959305F6 471
74 LI: 1089871.1 2001 JAN 12 70762245V1 554
74 LI; 1089871.1 2001 JAN 12 g 1972285 4 165
74 Ll:1089871.1 2001 JAN 12 3887422H1 30 300
74 Ll:1089871.1 2001 JAN 12 70761421 VI 121 461
74 LI: 1089871.1 2001 JAN 12 70758433V1 31 1 843
74 LI: 1089871.1 2001 JAN 12 70757906V 1 320 724
74 Ll:1089871.1 2001 JAN 12 70763177V1 371 840
74 Ll:1089871.1 2001 JAN 12 70762620V1 490 872
74 LI: 1089871.1 2001 JAN 12 70761079V1 531 851
74 LI: 1089871 ,1 2001 JAN 12 70762764V 1 531 851
74 Ll:1089871.1 2001 JAN 12 70759582V1 1236 1481
74 Ll:1089871.1 2001 JAN 12 70759021 VI 1285 1928
74 LI: 1089871.1 2001 JAN 12 70758815V1 1294 1468
74 Ll:1089871.1 2001 JAN 12 70757721 VI 1302 1481
74 Ll:1089871.1 2001 JAN 12 70767224V1 1310 1481
74 LI: 1089871.1 2001 JAN 12 70761857V1 1314 1481
74 LI: 1089871.1 2001 JAN 12 70764826V1 1381 1912
74 Ll:1089871.1 2001 JAN 12 70758307V1 1409 1976
74 LI: 1089871.1 2001 JAN 12 70760140V1 1774 2154
74 LI: 1089871.1 2001 JAN 12 70761329V1 1779 2007
74 U:1089871 ,l 2001 JAN 12 2959305T6 1821 2277
74 Ll:1089871.1 2001 JAN 12 70760716V1 1843 2265
74 LI: 1089871.1 2001 JAN 12 70762468V1 537 851
74 LI: 1089871.1 2001 JAN 12 70758821 VI 542 843
74 Ll:1089871.1 2001 JAN 12 70761878V1 551 843
74 Ll:1089871.1 2001 JAN 12 70762741 VI 616 851
74 LI : 1089871.1 2001 JAN 12 70757636V1 681 1265
TABLE 3
SEQ ID NO: Template ID CampΩnent ID Start Stap 74 U.1089871.1.2001JAN12 70758209V1 685 851 74 L..1089871.1.2001JAN12 70761553V1 685 851 74 U:1089871.1 :2001JAN12 70759811VI 685 1251 74 LI: 1089871.1:2001 JAN 12 70761311VI 717 1320 74 LI:1089871.1 :2001JAN12 70760042V1 759 1286 74 -1:1089871.1.2001JAN12 70760336V1 781 1320 74 LI: 1089871.1 :2001 JAN 12 70760101VI 1132 1481 74 U.1089871.1 :2001 JAN12 70760117V1 1158 1484 74 LI:1089871.1 :2001JAN12 70760813V1 1158 1315 74 U:1089871.1 ;2001JAN12 70757952V1 1158 1374 74 U.1089871.1 :2001 JAN12 70759158V1 1158 1394 74 U:1089871.1 :2001JAN12 70760818V1 1158 1394 74 LI:1089871 ,1;2001JAN12 70757680V1 1158 1467 74 LI: 1089871.1:2001 JAN 12 70761293V1 1158 1458 74 U:1089871.1:2001JAN12 70759646V1 1158 1609 74 LI:1089871.1 :2001JAN12 70761118V1 1158 1458 74 LI:1089871.1 :2001JAN12 70762739V1 1158 1481 74 LI:1089871.1 :2001JAN12 70761840V1 1161 1477 74 LI:1089871.1 :2001JAN12 70762279V1 1164 1481 74 LI: 1089871.1:2001 JAN 12 70762802V1 1195 1481 75 LI.289608.1 :2001 JAN 12 4786611 HI 1 252 75 LI:289608.1 :2001JAN12 5388881 F8 111 661 75 U:289608.1 :2001 JAN 12 5388881 HI 111 191 75 LI :289608.1:2001 JAN 12 5388881T8 113 630 75 Ll:289608.1 :2001 JAN 12 4786611 F6 1 452
TABLE 4
SEQ ID NO: Template ID Tissue Distributicn
1 LI:418914.1 :2001JAN12 Sense Organs - 56%, Respiratory System - 24%
2 LI:246108J:2001JAN12 Nervous System - 54%, Male Genitalia - 23%, Digestive System - 23%
3 LI:204262.2:200UAN12 Unclassified/Mixed - 16%, Urinary Tract - 13%, Sense Organs - 12%
4 U.331661.1 :200UAN12 Nervaus System - 43%, Endocrine System - 29%, Hemic and Immune System - 21%
5 Ll:335074.1 :2001 JAN 12 Exocrine Glands - 86%
6 LI: 154608.1 :2001 JAN 12 Urinary Tract - 31 %, Nervous System - 31 %, Male Genitalia - 23%
7 LI:462889.1:2001JAN12 Embryonic Structures - 75%, Musculoskeletal System - 12%
8 LI:236680.2:2001JAN12 Unclassified/Mixed - 11%, CardiovascuIarSystem - 11%
9 LI.228186.1:2001 JAN 12 Sense Organs - 14%, Unclassified/Mixed - 11%
10 LI:721233.1 :2001JAN12 Nervous System - 100%
11 LI :291759.2:2001 JAN 12 Digestive System - 17%, Urinary Tract - 13%, Connective Tissue - 12%
12 LI:292613.17:2001JAN12 Urinary Tract - 29%, Nervous System - 29%, Digestive System - 21 %, Male Genitalia - 21 %
13 LI:412959.15:2001JAN12 Embryonic Structures - 73%, Urinary Tract - 13%
14 LI:482512.3:2001JAN12 Sense Organs - 32%, Endocrine System - 10%
15 Ll:413231.6:2001 JAN12 Digestive System - 38%, Respiratcry System - 23%, Nerveus System - 23% lό Ll:203383.1 :2001 JAN 12 Musculoskeletal System - 36%, Germ Cells - 25%, Connective Tissue - 18%
17 U:13318ό.4:2001JAN12 Urinary Tract - 50%, Male Genitalia - 38%, Nervous System - 13%
18 LI:238576.2:2001JAN12 Urinary Tract - 12%, Respiratcry System - 12%
19 LI:903914.3:2001JAN12 Unclassified/Mixed - 13%, Skin - 11%, Nervcus System - 10%
20 LI:150817.1:2001JAN12 Nerveus System - 100%
21 U:219627.1 :2001JAN12 Unclassified/Mixed - 62%, Urinary Tract - 15%, Male Genitalia - 12%
22 LI:197812.4:2001JAN12 Urinary Tract - 100%
23 LI;101525.1 :2001JAN12 Cardiovascular System - 91 %
24 Ll:891123.1 :2001 JAN 12 Musculoskeletal System - 73%, Male Genitalia - 27%
25 LI :813500.1:2001 JAN 12 Male Genitalia - 46%, Digestive System - 21%, Female Genitalia - 13%, Nervous System - 13%
26 LI: 1037251.1 :2001 JAN 12 Sense Organs - 42%, Hemic and Immune System - 13%, Endocrine System - 11%
27 U:2032187.1 :2001JAN12 Hemic and Immune System - 54%, Connective Tissue - 42%
28 LI:347572.1 :2001JAN12 CardiovascuIarSystem - 32%, Digestive System - 28%, Cardiovascular System - 12%
29 U:007788.1 :2001 JAN 12 Hemic and Immune System - 67%, Nervous System - 33%
30 LI:336872.1 :2001JAN12 Embryenic Structures - 40%, Female Genitalia - 27%, Male Genitalia - 17%
31 Ll:l 143291.1 :2001 JAN12 Skin - 19%, Urinary Tract - 14%, Stcmatognathic System - 12%
32 LI.O93477.1:2001 JAN12 Unclassified/Mixed - 93%
TABLE 4
SEQ ID NO: Template ID Tissue Distributian
33 Ll:222105.1 :2001 JAN12 CardiovascuIarSystem - 12%
34 U.816737.2.2001JAN12 Female Genitalia - 29%, Hemic and Immune System - 15%, Urinary Tract - 13%
35 U:475524.1 :2001JAN12 Germ Cells - 47%, Liver - 17%
36 LI .383639.1 :2001 JAN 12 Hemic and Immune System - 75%, Respiratory System - 10%
37 LI:814346.1 :2001JAN12 Urinary Tract - 31%, Cardiovascular System - 12%, Hemic and Immune System - 11%
38 U.898195.6:2001 JANl 2 Respiratory System - 18%, Embryonic Structures - 14%, Liver - 13%
39 U:210497.2:2001JAN12 Hemic and Immune System - 100%
40 LI: . 10297.4:2001 JAN12 Endocrine System - 20%, Unclassified/Mixed - 12%
41 U:2051312.1 :2001JAN12 Nervous System - 39%, Respiratory System - 18%, Cardiovascular System - 15%, Female Genitalia ■
15%
42 LI:350272.2:2001JAN12 Exocrine Glands - 19%, Cardiovascular System - 12%, Musculoskeletal System - 11%
43 U:1085472.4:2001JAN12 Urinary Tract - 28%, Stomatognathic System - 20%, Female Genitalia - 14%
44 LI: 1 190272.1 :2001 JAN 12 Skin - 50%, Nervous System - 1 1 %
45 LI: 1086797.1 :2001 JAN 12 Embryonic Structures - 27%, Stomatagnathic System - 19%, Digestive System - 16% o too 46 LI: 1 144466.1 :2001 JAN 12 Embrycnic Structures - 25%, Ccnnective Tissue - 18%, Nervcus System - 15%
47 U:l 147914.1 :2001JAN12 Cennective Tissue - 30%, Musculcskeletal System - 27%, Female Genitalia - 17%
48 LIJ58086.1 :2001 JAN 12 Nerveus System - 27%, Cardiavascular System - 24%, Female Genitalia - 14%, Hemic and
Immune System - 14%, Exccrine Glands - 14%
49 LI:765245.5:2001JAN12 Pancreas - 18%, Exocrine Glands - 15%, Connective Tissue - 14%
50 LI:335608.2:2001JAN12 Stomatagnathic System - 48%, Digestive System - 15%
51 Ll:405795.1 :2001 JAN 12 Embryonic Structures - 58%, Female Genitalia - 19%
52 LI.O14872.1 :2001 JAN12 Connective Tissue - 80%
53 U:239245.3:2001JAN12 Skin - 13%, Sense Organs - 13%, Respiratory System - 13%
54 LI: 142384.5:2001 JAN 12 Stomatagnathic System - 21%, Skin - 18%, Musculoskeletal System - 16%
55 U:2068768.1 :2001JAN12 Unclassified/Mixed - 100%
56 Ll:21 18074.1 :2001 JAN 12 Endocrine System - 52%, Female Genitalia - 37%
57 LI: 1 189068.4:2001 JANl 2 Connective Tissue - 29%, Sense Organs - 26%
58 LI:21 18704.1 :2001JAN12 Sense Organs - 60%, Nervous System - 13%
59 LI:031700.2:2001JAN12 Female Genitalia - 64%, Urinary Tract - 27%
60 LI.2120122.1.2001JAN12 Unclassified/Mixed - 34%, Sense Organs - 23%, Germ Cells - 11%
61 LI:816174.1 :2001JAN12 Digestive System - 22%, Male Genitalia - 22%, Exocrine Glands - 22%
62 U: 1 189569.1 1 :2001 JAN 12 Sense Organs - 92%
TABLE 4
SEQ ID NO: Template ID Tissue Distribution
63 U:413584.1 :2001JAN12 Unclassified/Mixed - 54%, Embryonic Structures - 11%
64 LI:791042.1 :2001JAN12 Digestive System - 25%, Urinary Tract - 22%, Embryonic Structures - 20%
65 U:1167140.1 :2001JAN12 Embryonic Structures - 23%, Exocrine Glands - 19%, Nervous System - 12%, Respiratory System •
12%
66 U:054831.1 :2001JAN12 Digestive System - 60%, Hemic and Immune System - 40%
67 LI: 1 175083.1 :2001 JANl 2 Germ Cells - 67%, Male Genitalia - 10%
68 U:2122897.2:2001 JAN 12 CardiovascuIarSystem - 28%, Exocrine Glands - 18%, CardiovascuIarSystem - 14%
69 U:2053195.3:2001JAN12 Digestive System - 38%, Respiratory System - 38%, Hemic and Immune System - 25%
70 U:439397.6:2001JAN12 Endocrine System - 33%, Exocrine Glands - 28%, Urinary Tract- 22%
71 LI:816379.6:2001JAN12 Hemic and Immune System - 29%, Urinary Tract - 17%, Endocrine System - 16%
72 LI:2123452.4:2001JAN12 Sense Organs - 71%, Embryonic Structures - 16%
74 LI:1089871.1:2001JAN12 Endocrine System - 55%, Female Genitalia - 27%, Hemic and Immune System - 18%
75 LI:289608.1 :2001JAN12 Nervous System - 100%
TABLE 5
SEQ ID NO: Frame Length Start Stop Gl Number Probability Scare Annctatian
76 1 177 460 990 gl6551610 l.OOE-11 (AK056259) unnamed protein product
76 1 177 460 990 g9837385 4.00E-07 retinitis pigmentcsa GTPase regulatar-like protein
76 1 177 460 990 g16553150 1.OOE-06 (AK057442) unnamed protein product
81 2 70 383 592 g12698182 2.00E-15 hypothetical protein
81 2 70 383 592 g7021164 8.00E-14 unnamed protein product
81 2 70 383 592 g16876883 l.OOE-10 (BC016722) Unknown (protein for IMAGE:4075924)
82 2 239 2 718 gl0437745 1.00E-120 unnamed protein product
82 2 239 2 718 g8926320 1.00E-115 corneal wound healing related protein
82 2 239 2 718 g!2861811 1.OOE-111 putative
83 2 114 362 703 g16751522 2.00E-35 (AB064543) dioxin inducible factar 3
83 2 114 362 703 g12002226 2.00E-32 C3HC4-type zinc finger protein
83 2 114 362 703 g10437296 2.00E-32 unnamed protein product
85 1 151 43 495 gl5128221 1.00E-57 contains ESTs AU100786(C50379),C26898(C50379)~simiIarto Arabidapsis thaliana chromΩSome 1, F28N24J~unknown protein 85 1 151 43 495 g9502415 6.00E-46 Unknown protein 85 1 151 43 495 g15529270 6.00E-46 Atlg29250/F28N24_8
86 2 104 569 880 g7770147 6.00E-16 PRO! 847
86 2 104 569 880 gl0437752 2.00E-14 unnamed protein product
86 2 104 569 880 g6650810 3.00E-14 PRO 1902
89 85 1486 1740 gl2006213 5.00E-32 DC46
92 125 196 570 g!3938315 8.00E-42 Unknown (protein for MGC: 15634)
94 114 472 813 g12859423 2.00E-23 putative
94 114 472 813 g15919915 5.00E-23 putative
94 114 472 813 gl 841551 5.00E-21 G16
95 2 110 1592 1921 g10438620 2.00E-24 unnamed protein product
95 2 110 1592 1921 g10437485 2.00E-23 unnamed protein product
95 2 no 1592 1921 g7020625 5.00E-23 unnamed protein product
96 2 100 1241 1540 g12698192 4.00E-19 hypothetical protein
96 2 100 1241 1540 g6690223 5.00E-13 PRO0470
96 2 100 1241 1540 g1389766 6.00E-11 unknown
99 2 60 1295 1474 g16303798 2.00E-09 (AF416714) unknown
99 2 60 1295 1474 gl 1493419 2.00E-09 PR01367
TABLE 5
I ID NO: Frame Length Start Stop Gl Number Probability Score Annotatian
99 2 60 1295 1474 gό690223 2.00E-08 PRO0470
103 2 135 71 475 g 14250579 5.00E-07 hypΩthetica! prctein PP1628
103 2 135 71 475 g!0441903 5.00E-07 unknewn
108 2 197 125 715 g434779 l .OOE-20 K.AA01 12
108 2 197 125 715 g 15278392 l .OOE-20 homolog of yeast ribosome biogenesis regulatory protein RRS1
108 2 197 125 715 g 12804751 l .OOE-20 Similar to regulator for ribosΩme resistance homolog (S. cerevisi ae)
1 10 2 257 1 13 883 gl4017947 1.00E-27 KIAA1865 protein no 2 257 1 13 883 g 10636484 1.00E-27 polyglutamine-ccntaining protein
1 13 1 129 1 387 g2589160 2.00E-60 DCRA
1 13 1 129 1 387 g2588993 3.00E-55 Dcra
113 1 129 1 387 g 13277666 3.00E-55 Down syndrome critical region gene a
1 16 3 59 240 416 g 14598201 4.00E-24 human CLASP-5
116 3 59 240 416 g 16550121 3.00E-15 (AK055401) unnamed protein product
1 16 3 59 240 416 g 14597912 3.00E-15 human CLASP-3 to 1 18 1 172 1 105 1620 g4678717 4.00E-60 hypothetical protein ft 1 18 1 172 1 105 1620 g3947678 4.00E-60 dJ206D15.3
1 18 1 172 1 105 1620 g 12853820 3.00E-17 putative
1 19 3 214 3 644 g 12845866 5.00E-10 putative
121 2 204 1 16 727 g6841564 9.00E-16 HSPC172
121 2 204 1 16 727 g6650543 9.00E-16 unknown
121 2 204 1 16 727 g5531839 9.00E-16 PTD009
122 1 284 1375 2226 g 14388466 3.00E-96 hypothetical protein
122 1 284 1375 2226 g 14133251 3.00E-96 KIAA1479 protein
122 1 284 1375 2226 g 10434456 3.00E-96 unnamed protein product
124 3 81 549 791 g5726235 2.00E-13 unknown protein U5/2
125 2 129 425 81 1 g 14189960 2.00E-28 PRO0764
125 2 129 425 81 1 g 1 1493463 2.00E-22 PR02852
125 - 2 129 425 81 1 g9280152 6.00E-22 unnamed portein product
126 3 142 3 428 g 1526432 3.00E-09 neutral calpcnin
126 3 142 3 428 g4432964 4.00E-09 h2-calpanin
126 3 142 3 428 g51144 5.00E-09 h2-calpanin
131 3 206 3 620 gl 6198439 1.00E-17 hypothetical protein FLJ 13855
TABLE 5 ϊ ID NO: Frame Length Start Stop Gl Number Probability Score Annotation
131 3 206 3 620 g 15929470 1.00E-17 hypothetical protein FLJ 13855
131 3 206 3 620 g 10436290 1.00E-17 unnamed protein product
133 3 171 24 536 g 14424725 8.00E-70 hypcthetical protein FU 13055
133 3 171 24 536 g 10434892 8.00E-70 unnamed protein product
133 3 171 24 536 g 12852801 9.00E-29 putative
135 1 186 460 1017 g 13397124 7.00E-17 unnamed protein product
136 3 95 3 287 g5410527 3.00E-15 paracellin-l
138 73 55 273 g 16549456 1.00E-07 (AK054840) unnamed protein product
138 73 55 273 g9437519 5.00E-07 MOST-1
138 73 55 273 g6690229 1. OOE-06 PRO0483
140 103 148 456 g4809026 9.00E-37 suppressor of G2 allele of skpl homolog
140 103 148 456 g 15216168 9.00E-37 putative 40-6-3 protein
140 103 148 456 gl 2654187 9.00E-37 suppressor of G2 allele of SKPl, S. cerevisiae, homolog of
144 2 247 29 769 g 14026730 8.00E-14 homΩserine kinase t υo 144 2 247 29 769 g7298468 5.00E-10 CGI 5164 gene product
CΛ 144 2 247 29 769 g 15075719 7.00E-09 PUTATIVE AMINOTRANSFERASE PROTEIN
145 2 79 1040 1276 gl91 1548 2.00E-27 cytcchrome c-like pclypeptide
147 2 208 155 778 gδl 06956 4.00E-97 FH1/FH2 domain-containing protein FHOS
147 2 208 155 778 g 12697935 4.00E-61 KIAA1695 protein
147 2 208 155 778 g 10438624 4.00E-61 unnamed protein product
149 3 73 246 464 g 14189976 6.00E-27 PR02972
149 3 73 246 464 g3415134 1.00E-14 Phybl
149 3 73 246 464 g 12857019 1.00E-14 putative
151 3 158 3 476 g7243081 6.00E-90 KIAA1350 protein
152 3 84 315 566 g288145 1.00E-05 put. ORF
152 3 84 315 566 g6690248 6.00E-05 PRO0657
TABLE 6
Program Description Reference Parameter Threshold ABI FACTURA A program that removes vector sequences and masks Applied Biosystems, Foster City, CA. ambiguous bases in nucleic acid sequences.
ABI/PARACEL EDF A Fast Data Finder useful in comparing and annotating Applied Biosystems, Foster City, CA; Paracel Mismatch <50%
--rnino acid or nucleic acid sequences. Inc., Pasadena, CA.
ABI AutoAssembler A program that assembles nucleic acid sequences. Applied Biosystems, Foster City, CA. BLAST A Basic Local Alignment Search Tool useful in sequence Altschul, S.F. et al. (1990) J. Mol. Biol. 215:403 ESTs: Probability value= l.OE-8 or less; similarity search for amino acid and nucleic acid 410; Altschul, S.F. et al. (1997) Nucleic Acids Full Length sequences: Probability value sequences. BLAST includes five functions: blastp, Res. 25:3389-3402. 1.0E-10 or less blastn, blastx, tblastn, and tblastx.
, FASTA A Pearson and Lipman algorithm that searches for Pearson, W.R. and D J. Lipman (1988) Proc. ESTs: fasta E value=1.06E-6; Assemble similarity between a query sequence and a group of Natl. Acad Sci. USA 85:2444-2448; Pearson, ESTs: fasta Identity= 95% or greater an sequences of the same type. FASTA comprises as least W.R. (1990) Methods Enzymol. 183:63-98; and Match length=200 bases or greater; fastx five functions: fasta, tfasta, fastx, tfastx, and ssearch. Smith, T.F. and M.S. Waterman (1981) Adv. value=1.0E-8 or less; Full Length
Appl. Math. 2:482-489. sequences: fastx score=100 or greater w σs BLIMPS A BLocks IMProved Searcher that matches a sequence Henikoff, S. and J.G. Henikoff (1991) Nucleic Probability value= 1.0E-3 or less against those in BLOCKS, PRINTS, DOMO, PRODOM, Acids Res. 19:6565-6572; Henikoff, J.G. and S. and PFAM databases to search for gene families, Henikoff (1996) Methods Enzymol. 266:88-105; sequence homology, and structural fingerprint regions. and Attwood, T.K. et al. (1997) J. Chem. Inf.
Comput. Sci. 37:417-424.
HMMER An algorithm for searching a query sequence against Krogh, A. et al. (1994) J. Mol. Biol. 235:1501- PFAM hits: Probability value= 1.0E-3 o hidden Markov model (HMM)-based databases of 1531; Sonimammer, E.L.L. et al. (1988) Nucleic less; protein family consensus sequences, such as PFAM. Acids Res. 26:320-322; Durbin, R. et al. (1998) Signal peptide hits: Score= 0 or greater
Our World View, in a Nutshell, Cambridge
Univ. Press, pp. 1-350.
ProfileScan An algorithm that searches for structural and sequence Gribskov, M. et al. (1988) CABIOS 4:61-66; Normalized quality score≥GCG-specifϊe motifs in protein sequences that match sequence patterns Gribskov, M. et al. (1989) Methods Enzymol. "HIGH" value for that particular Prosite defined in Prosite. 183:146-159; Bairoch, A. et al. (1997) Nucleic motif. Generally, score=l .4-2.1.
Acids Res. 25:217-221.
Phred A base-calling algorithm that examines automated Ewing, B. et al. (1998) Genome Res. 8:175-185; sequencer traces with high sensitivity and probability. Ewing, B. and P. Green (1998) Genome Res.
8:186-194.
TABLE 6
Program Description Reference Parameter Threshold Phrap A Phils Revised Assembly Program including SWAT Smith, T.F. and M.S. Waterman (1981) Adv. Score= 120 or greater; and CrossMatch, programs based on efficient Appl. Math. 2:482-489; Smith, TJ3. and M.S. Match length= 56 or greater implementation of the Smith- Waterman algorithm, Waterman (1981) J. Mol. Biol. 147:195-197; useful in searching sequence homology and assembling and Green, P., University of Washington, DNA sequences. Seattle, WA.
Consed A graphical tool for viewing and editing Phrap Gordon, D. et al. (1998) Genome Res. 8:195- assemblies. 202. SPScan A weight matrix analysis program that scans protein Nielson, H. et al. (1997) Protein Engineering Score=3.5 or greater sequences for the presence of secretory signal peptides. 10:1-6; Claverie, J.M. and S. Audic (1997)
CABIOS 12:431-439.
TMAP A program that uses weight matrices to delineate Persson, B. and P. Argos (1994) J. Mol. Biol. transmembrane segments on protein sequences and 237:182-192; Persson, B. and P. Argos (1996) determine orientation. Protein Sci. 5:363-371.
TMHMMER A program that uses a hidden Markov model (HMM) to Sonnhammer, E.L. et al. (1998) Proc. Sixth Intl. tS3 o delineate transmembrane segments on protein sequences Conf. On Intelligent Systems for Mol. Biol., s. and determine orientation. Glasgow et al., eds., The Am. Assoc. for
Artificial Intelligence (AAAI) Press, Menlo
Park, CA, and MIT Press, Cambridge, MA, pp.
175-182.
Motifs A program that searches amino acid sequences for Bairoch, A. et al. (1997) Nucleic Acids Res. patterns that matched those defined in Prosite. 25:217-221; Wisconsin Package Program Manual, version 9, page M51-59, Genetics Computer Group, Madison, WI.