WO2009095981A1 - Procédé et dispositif permettant la construction de données arborescentes à partir d'une table - Google Patents
Procédé et dispositif permettant la construction de données arborescentes à partir d'une table Download PDFInfo
- Publication number
- WO2009095981A1 WO2009095981A1 PCT/JP2008/051185 JP2008051185W WO2009095981A1 WO 2009095981 A1 WO2009095981 A1 WO 2009095981A1 JP 2008051185 W JP2008051185 W JP 2008051185W WO 2009095981 A1 WO2009095981 A1 WO 2009095981A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- record
- node
- array
- parent
- value
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images






























Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/28—Databases characterised by their database models, e.g. relational or object models
- G06F16/284—Relational databases
Definitions
- the present invention relates to a method and apparatus for constructing tree structure data from tabular data, and in particular, tree structure data composed of a plurality of nodes, each node being represented by an attribute name and attribute value, each record being an array of records.
- the present invention relates to a method and apparatus constructed on a storage device as an array of virtual records identified by record sequence numbers representing the order.
- the present invention provides a device that includes a memory that stores original data having a table structure, converts the original data into tree structure data including a plurality of nodes each represented by an attribute name and an attribute value, and stores the converted data in the memory. Also related.
- the present invention relates to a program for causing a computer to execute the above method, a program product, and a recording medium on which the program is recorded.
- the present invention provides a virtual record in which tree structure data composed of a plurality of nodes each represented by an attribute name and attribute value is identified by the record sequence number in which each record represents the order of the records.
- the recording medium recorded as an array of
- DBMS database management system
- RDB relational database
- Patent Document 1 A technique for expressing the data structure in a format has been proposed (Patent Document 1).
- XML data is stored in each table in order from the root element, and appearance order information is given to the stored data.
- a downgrip column including appearance order information and an upgrip column assigned with appearance order information of the downgrip column of the parent data having a parent-child relationship with the stored data are created.
- a level column for storing a level value representing the depth of the hierarchy from the root element is created in each table.
- one table is created for each element as a data unit based on the schema information of XML data, and data according to the schema information is stored in the table.
- Patent Document 1 or Patent Document 2 The tabular data handled in Patent Document 1 or Patent Document 2 is data intended to be converted into tree structure data.
- a down grip column and an up grip column are present in a table.
- BOM Bact of Materials
- BOM expansion When comprehending or understanding data, it is necessary to expand the BOM into a tree data structure (BOM expansion).
- BOM expansion For example, in the structure type parts table, a pair of a parent part drawing number and a child part drawing number is stored as one data.
- the data expression format describing the tree structure data can cope with dynamic changes in the data structure and has a high degree of freedom in editing.
- Tree structure data reduces the number of comparison operations to interpret itself, reduces memory usage to store itself, reduces the amount of data to be rewritten when updating the tree structure, It is preferable to make the definition unnecessary.
- tree structure data consisting of a plurality of nodes each represented by an attribute name and attribute value is identified by a record sequence number in which each record represents the sequence of records.
- a device constructed on a storage device as an array of records Means for matching a plurality of tables having a hierarchical structure with a matching key for each hierarchy, and creating a row number correspondence table between row numbers having a parent-child relationship between the parent side table and the child side table; Means for searching the row number in the parent table and the row number in the child table having a parent-child relationship from the row number correspondence table;
- a record sequence number assigned to a row in the child table is determined in the order found by the searching means, and a parent-child relationship is determined at the position identified by the record sequence number in the virtual record array.
- An apparatus comprising:
- one record may correspond to one node.
- a plurality of tables having a hierarchical structure is original data of a table structure to be expanded into tree structure data.
- the matching key may be a join key.
- Matching using a join key, i.e., join generates a join table, i.e., intermediate data, from the original data.
- the join table is a table that represents the original data itself in the parent-child relationship and the connection relationship between the original data in the parent-child relationship.
- the apparatus uniquely identifies the attribute names in the order of the record order numbers from an array in which the attribute name field values of the nodes are stored in the order of the record order numbers.
- An attribute name number array storing attribute name numbers
- an attribute name array storing the attribute names uniquely specified by the attribute name numbers in the order of the elements of the attribute name number array
- the record sequence number An attribute value number array storing attribute value numbers that uniquely identify the attribute values in order, and the attribute values uniquely specified by the attribute value numbers are stored in the order of the elements of the attribute value number array.
- the plurality of tables is a structure-type parts table that expresses a parent-child relationship of parts
- the means for creating the row number correspondence table includes the tree structure as a top-level table. The part corresponding to the root node of the data is selected, and the same structure type parts table is used as the data of the other hierarchy.
- the means for creating the row number correspondence table includes, as the matching key, a sequence number assigned in the order of appearance of data in the parent table, and data in the child table. The pair with the sequence number assigned to the parent data corresponding to is used.
- a memory for storing a plurality of tables having a hierarchical structure is provided, and the plurality of tables are converted into tree structure data composed of a plurality of nodes each represented by an attribute name and an attribute value.
- a device for converting and storing in the memory A matching unit for matching the plurality of tables with a matching key for each hierarchy; A correspondence table creation unit that creates a row number correspondence table between row numbers having a parent-child relationship between a parent table and a child table that are matched for each hierarchy of the plurality of tables; A search unit for searching for a row number in the parent table and a row number in the child table having a parent-child relationship from the row number correspondence table; A record sequence number assigned to a row in the child table is determined in the order found by the search unit, and a parent-child relationship field is located at a position identified by the record sequence number in the virtual record array.
- the record order number of the parent node of the node corresponding to the row in the child table is stored as a value
- the item name belonging to the row in the child table is stored as the attribute name field value of the node
- a record generation unit for storing an item value belonging to the original data belonging to a row in the child table as an attribute value field value of the node;
- the apparatus uniquely identifies the attribute names in the order of the record order numbers from an array in which the attribute name field values of the nodes are stored in the order of the record order numbers.
- An attribute name number array storing attribute name numbers
- an attribute name array storing the attribute names uniquely specified by the attribute name numbers in the order of the elements of the attribute name number array
- the record sequence number An attribute value number array storing attribute value numbers that uniquely identify the attribute values in order, and the attribute values uniquely specified by the attribute value numbers are stored in the order of the elements of the attribute value number array.
- a value separator for creating the attribute value array.
- the plurality of tables is a structure-type parts table that expresses a parent-child relationship of parts
- the correspondence table creation unit uses the tree structure as intermediate data of the table structure of the highest hierarchy. A part corresponding to the root node of the data is selected, and the same structure type parts table is used as intermediate data of other table structures.
- the correspondence table creating unit uses the sequence number assigned in the order of appearance of data in the parent table as the matching key and the parent corresponding to the data in the child table. Use the pair with the sequence number assigned to the side data.
- tree structure data consisting of a plurality of nodes each represented by an attribute name and attribute value is identified by a record sequence number in which each record represents the sequence of records.
- a method of constructing an array of records on a storage device A step of matching a plurality of tables having a hierarchical structure with a matching key for each hierarchy, and creating a row number correspondence table between row numbers having a parent-child relationship between the parent side table and the child side table; The row number in the parent table and the row number in the child table that have a parent-child relationship are searched from the row number correspondence table and assigned to the rows in the child table in the order found by the search.
- a step of storing A method comprising:
- the method uniquely identifies the attribute names in the order of the record order numbers from an array in which the attribute name field values of the nodes are stored in the order of the record order numbers.
- An attribute name number array storing attribute name numbers
- an attribute name array storing the attribute names uniquely specified by the attribute name numbers in the order of the elements of the attribute name number array
- the record sequence number An attribute value number array storing attribute value numbers that uniquely identify the attribute values in order, and the attribute values uniquely specified by the attribute value numbers are stored in the order of the elements of the attribute value number array.
- the method further includes the step of creating an attribute value array.
- the plurality of tables is a structure-type parts table that expresses a parent-child relationship of parts, and in the step of creating the row number correspondence table, the tree structure is used as a top-level table. The part corresponding to the root node of the data is selected, and the same structure type parts table is used as the table of the other hierarchy.
- the sequence number assigned in the order of appearance of the data in the parent table and the data in the child table is used.
- a memory for storing a plurality of tables having a hierarchical structure is provided, and the plurality of tables are converted into tree structure data composed of a plurality of nodes each represented by an attribute name and an attribute value.
- a function of matching the plurality of tables with a matching key for each hierarchy A function for creating a row number correspondence table between row numbers having a parent-child relationship between the matched parent table and child table for each of the plurality of table hierarchies; A function for searching for a row number in the parent table and a row number in the child table having a parent-child relationship from the row number correspondence table;
- the tree structure data is constructed in the memory as a virtual record array, wherein each record is identified by the record sequence number representing the order of the records.
- the record sequence number of the parent node of the node corresponding to the row in the child side table is stored as the parent-child relationship field value, and the child side attribute name field value is stored in the child side as the attribute name field value.
- the program uniquely identifies the attribute names in the order of the record order numbers from an array in which the attribute name field values of the nodes are stored in the order of the record order numbers.
- An attribute name number array storing attribute name numbers
- an attribute name array storing the attribute names uniquely specified by the attribute name numbers in the order of the elements of the attribute name number array
- the record sequence number An attribute value number array storing attribute value numbers that uniquely identify the attribute values in order, and the attribute values uniquely specified by the attribute value numbers are stored in the order of the elements of the attribute value number array.
- the plurality of tables is a structure-type parts table that represents a parent-child relationship of parts
- the program corresponds to a root node of the tree structure data as a top-level table.
- a function of selecting a part and using the same structure-type parts table as a table of another hierarchy is further realized in the computer.
- the program uses, as the matching key, a sequence number assigned in the order of appearance of data in the parent table and parent data corresponding to the data in the child table.
- the computer is further realized with a function of using a pair with the sequence number assigned to the computer.
- a computer-readable recording medium recording the above program is provided.
- a memory for storing a plurality of tables having a hierarchical structure is provided, and the plurality of tables are converted into tree structure data composed of a plurality of nodes each represented by an attribute name and an attribute value.
- a function of matching the plurality of tables with a matching key for each hierarchy A function for creating a row number correspondence table between row numbers having a parent-child relationship between the matched parent table and child table for each of the plurality of table hierarchies; A function for searching for a row number in the parent table and a row number in the child table having a parent-child relationship from the row number correspondence table;
- the tree structure data is constructed in the memory as a virtual record array, wherein each record is identified by the record sequence number representing the order of the records.
- the record sequence number of the parent node of the node corresponding to the row in the child side table is stored as the parent-child relationship field value, and the child side attribute name field value is stored in the child side as the attribute name field value.
- a program product for realizing the above is provided.
- a computer-readable recording medium on which tree structure data including a plurality of nodes each represented by an attribute name and an attribute value is recorded.
- the tree structure data is represented by a virtual array of records, each record being identified by a record sequence number representing the order of the records.
- the record includes a parent-child relationship field that stores a record sequence number of a parent node of a node corresponding to the record, an attribute name field that stores an attribute name number that specifies an attribute name that belongs to the node, and an attribute value that belongs to the node
- An attribute value field for storing an attribute value number for specifying The parent node of the node is identified by the record sequence number stored in the parent-child relationship field included in the record corresponding to the node, The attribute name belonging to the node is specified by the attribute name number included in the record corresponding to the node and the attribute name array in which the attribute name is stored in the order of the attribute name number, The attribute value belonging to the node is specified by the attribute value number included in the record corresponding to the node and the attribute value array in which the attribute value is stored in the order of the attribute name number;
- a computer readable recording medium is provided.
- the record sequence number is assigned to the record corresponding to each node of the plurality of nodes in the order of depth-first search or width-first search.
- the comparison operation for interpreting the tree structure data is reduced, the memory usage is reduced, the amount of data to be rewritten when the tree structure is updated is reduced, and the prior data structure is reduced. It is possible to construct tree structure data that eliminates the need to define
- FIG. 1 is a block diagram showing a hardware configuration of a computer system that processes tree structure data according to an embodiment of the present invention.
- FIG. 2 is a diagram illustrating the hierarchical relationship of nodes in an example of tree structure data.
- FIG. 3A is an explanatory diagram of a data representation format with depth priority describing tree structure data according to an embodiment of the present invention.
- FIG. 3B is an explanatory diagram of a data representation format with breadth priority describing tree structure data according to an embodiment of the present invention.
- FIG. 4A is an explanatory diagram of a data representation format in which values describing tree structure data according to an embodiment of the present invention are separated.
- FIG. 4B is an explanatory diagram of an information block type data representation format describing tree structure data according to an embodiment of the present invention.
- FIG. 5 is a diagram illustrating an example of tabular data for explaining a data management mechanism based on information blocks.
- FIG. 6 is an explanatory diagram of an information block type data representation format.
- FIG. 7 is an explanatory diagram of an example of a structure-type parts table.
- FIG. 8 is a diagram showing the hierarchical relationship embedded in the structure-type parts table.
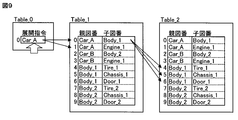
- FIG. 9 is a diagram showing the correspondence between the intermediate data created from the structure-type parts table and the records between the intermediate data.
- FIG. 10A is an explanatory diagram of an example of tree structure data in a depth-first format generated from a structure-type parts table.
- FIG. 10B is an explanatory diagram of an example of tree structure data in a width-first format generated from the structure-type parts table.
- FIG. 10A is an explanatory diagram of an example of tree structure data in a depth-first format generated from a structure-type parts table.
- FIG. 10B is an explanatory diagram of an example of tree structure data in
- FIG. 11A is an explanatory diagram of an example of tree structure data (information block type) in a depth-first format generated from a structure-type parts table.
- FIG. 11B is an explanatory diagram of an example of tree structure data (information block type) in a width-first format generated from a structure-type parts table.
- FIG. 12A is an explanatory diagram of an example of a plurality of tables describing tree structure data.
- FIG. 12B is a diagram illustrating a hierarchical relationship of tree structure data described in a plurality of tables.
- FIG. 13A is an explanatory diagram of record number correspondence table creation processing according to an embodiment of the present invention.
- FIG. 13B is an explanatory diagram of record number correspondence table creation processing according to an embodiment of the present invention.
- FIG. 14A is an explanatory diagram of tree structure data generation processing based on the depth priority method according to an embodiment of the present invention.
- FIG. 14B is an explanatory diagram of tree structure data generation processing based on the depth priority scheme according to an embodiment of the present invention.
- FIG. 14C is an explanatory diagram of tree structure data generation processing based on the depth priority scheme according to an embodiment of the present invention.
- FIG. 15A is an explanatory diagram of tree structure data generation processing based on the depth priority method according to an embodiment of the present invention.
- FIG. 15B is an explanatory diagram of tree structure data generation processing based on the depth priority scheme according to an embodiment of the present invention.
- FIG. 15C is an explanatory diagram of tree structure data generation processing based on the depth priority scheme according to an embodiment of the present invention.
- FIG. 15A is an explanatory diagram of tree structure data generation processing based on the depth priority method according to an embodiment of the present invention.
- FIG. 15B is an explanatory diagram of tree structure data generation processing
- FIG. 16A is an explanatory diagram of tree structure data generation processing based on the depth priority method according to an embodiment of the present invention.
- FIG. 16B is an explanatory diagram of tree structure data generation processing based on the depth priority scheme according to an embodiment of the present invention.
- FIG. 16C is an explanatory diagram of a tree structure data generation process based on the depth priority method according to an embodiment of the present invention.
- FIG. 17A is an explanatory diagram of tree structure data generation processing based on the depth priority scheme according to an embodiment of the present invention.
- FIG. 17B is an explanatory diagram of tree structure data generation processing based on the depth priority scheme according to an embodiment of the present invention.
- FIG. 17C is an explanatory diagram of a tree structure data generation process based on the depth priority method according to an embodiment of the present invention.
- FIG. 18A is an explanatory diagram of tree structure data generation processing based on the depth priority scheme according to an embodiment of the present invention.
- FIG. 18B is an explanatory diagram of tree structure data generation processing based on the depth priority method according to an embodiment of the present invention.
- FIG. 18C is an explanatory diagram of a tree structure data generation process based on the depth priority method according to an embodiment of the present invention.
- FIG. 19A is an explanatory diagram of tree structure data generation processing based on the depth priority method according to an embodiment of the present invention.
- FIG. 19B is an explanatory diagram of tree structure data generation processing based on the depth priority method according to an embodiment of the present invention.
- FIG. 19C is an explanatory diagram of tree structure data generation processing based on the depth priority method according to an embodiment of the present invention.
- FIG. 20A is an explanatory diagram of tree structure data generation processing based on the depth priority method according to an embodiment of the present invention.
- FIG. 20B is an explanatory diagram of tree structure data generation processing based on the depth priority method according to an embodiment of the present invention.
- FIG. 20C is an explanatory diagram of tree structure data generation processing based on the depth priority scheme according to an embodiment of the present invention.
- FIG. 21A is a diagram showing integrated tree structure data.
- FIG. 21A is a diagram showing integrated tree structure data.
- FIG. 21B is a diagram showing tree structure data from which a value list is separated.
- FIG. 21C is a diagram showing information block type tree structure data.
- FIG. 22 is an explanatory diagram of a conversion process to a data format based on an information block according to an embodiment of the present invention.
- FIG. 23 is an explanatory diagram of a value list sharing process according to an embodiment of the present invention.
- FIG. 24 is an explanatory diagram of a process for separating a list of item values into a value number and a value list according to an embodiment of the present invention.
- FIG. 25A is an explanatory diagram of a process of creating a record number correspondence table using a join according to an embodiment of the present invention.
- FIG. 25B is an explanatory diagram of a process of creating a record number correspondence table using a join according to an embodiment of the present invention.
- FIG. 26A is an explanatory diagram of processing for creating a record number correspondence table using a join according to an embodiment of the present invention.
- FIG. 26B is an explanatory diagram of a process for creating a record number correspondence table using a join according to an embodiment of the present invention.
- FIG. 27 is an explanatory diagram of the result of applying the tree structure data generation processing according to an embodiment of the present invention.
- FIG. 28 is an explanatory diagram of the result of applying the tree structure data generation processing according to another embodiment of the present invention.
- FIG. 29 is an explanatory diagram of a tree structure data generation process of the width priority method according to an embodiment of the present invention.
- FIG. 30 is an explanatory diagram of the tree structure data generation processing of the width priority method according to an embodiment of the present invention.
- FIG. 31 is an explanatory diagram of a tree structure data generation process of the width priority method according to an embodiment of the present invention.
- FIG. 32 is an explanatory diagram of a tree structure data generation process of the width priority method according to an embodiment of the present invention.
- FIG. 33 is an explanatory diagram of a tree structure data generation process of the width priority method according to an embodiment of the present invention.
- FIG. 34 is an explanatory diagram of a tree structure data generation process of the width priority method according to an embodiment of the present invention.
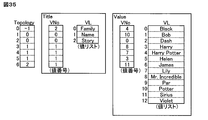
- FIG. 35 is an explanatory diagram of information block type tree structure data generated using the tree structure data generation process of the breadth-first method according to an embodiment of the present invention.
- FIG. 36 is an explanatory diagram of a result of applying the tree structure data generation processing according to the embodiment of the present invention.
- FIG. 37 is an explanatory diagram of the result of applying the tree
- Computer system 12 CPU 14 RAM 16 ROM 18 Hard disk 19 CD-ROM 20 CD-ROM driver 22 Interface 24 Input device 26 Display device 28 Bus
- FIG. 1 is a block diagram showing a hardware configuration of a computer system that processes tree structure data according to an embodiment of the present invention.
- a computer system 10 has a configuration similar to that of a normal computer system, and a CPU 12 that controls the entire system and individual components by executing a program, and a RAM that stores work data and the like.
- ROM Read Only Memory
- a fixed storage device 18 such as a hard disk
- CD-ROM driver 20 for driving a CD-ROM 19
- CD-ROM driver 20 and an interface (I / F) 22 provided between an external terminal connected to an external network (not shown)
- an input device 24 including a keyboard and a mouse
- a display device 26 The CPU 12, RAM 14, ROM 16, external storage device 18, I / F 22, input device 24, and display device 26 are connected to each other via a bus 28.
- a program for processing tree structure data may be stored in the CD-ROM 19 and read by the CD-ROM driver 20 or may be stored in the ROM 16 in advance. Further, what is once read from the CD-ROM 19 may be stored in a predetermined area of the external storage device 18. Alternatively, the program may be supplied from the outside via a network (not shown), an external terminal, and the I / F 22.
- the information processing apparatus is realized by causing the computer system 10 to execute a program for processing tree structure data.
- various embodiments of the present invention are implemented in the environment of a computer system, and the main operation is a processor such as a CPU that executes software such as program instructions, and dedicated hardware. Or firmware or a combination thereof.
- FIG. 2 is a diagram showing the hierarchical relationship of nodes in this tree structure data example.
- the root node is a child node having an attribute Family: Potter, and Family: Black. It can be seen that there are child nodes having attributes.
- the node Family: Potter there are a child node Name: James, a child node Name: Lily, and a child node Name: Harry.
- the node is designated by the notation of node attribute name: attribute value.
- FIG. 3 is an explanatory diagram of a data representation format that describes tree structure data according to an embodiment of the present invention.
- FIG. 3A shows a data representation format with depth priority in the example of the tree structure data shown in FIG. 2, and
- FIG. 3B shows a data representation format with width priority.
- the depth priority method and the width priority method will be briefly described. For example, consider a case where the nodes of the tree structure data in FIG. 2 are searched in a depth-first order from the root node, and node identifiers are assigned to the nodes in the order found.
- an array element A can be expressed as A [i], where i is a subscript.
- an array element A [i] is within a region surrounded by a solid line.
- the boundary between the element A [i] and the element A [i + 1] is indicated by a dotted line.
- the subscript i of element A [i] is shown on the left side of element A [i]. Further, the subscript i of the array is represented by an integer starting from 0.
- the tree structure data is represented by an array of records where one record corresponds to one node and each record is identified by a record sequence number representing the order of the records. ing. Since the node and the record have a one-to-one correspondence, the record sequence number matches the node identifier described above.
- the record includes a parent-child relationship field Topology that stores the record order number of the parent node of the node corresponding to the record, an attribute name field Title that specifies an attribute name that belongs to the node, and an attribute value that specifies an attribute value that belongs to the node Field Value.
- Topology that stores the record order number of the parent node of the node corresponding to the record
- attribute name field Title that specifies an attribute name that belongs to the node
- an attribute value that specifies an attribute value that belongs to the node Field Value.
- the data representation format for describing the tree structure data according to the embodiment of the present invention is integrated into one table, so that it is very easy to operate and flexible for adding a new tree or deleting a tree. Corresponding, the freedom of data editing is high.
- the array of records describing the tree structure data shown in FIGS. 3A and 3B is stored in the same format on the storage device such as a memory, that is, as an array Topology, an array Title, and an array Value. There is no need, and any representation can be used as long as the array of records can be substantially represented. Data that can equivalently represent an array of records in this way is sometimes referred to as a “virtual” record array in this document.
- a record belongs to a parent-child relationship field that stores the record order number of the parent node of the node corresponding to the record, an attribute name field that stores an attribute name number that specifies an attribute name that belongs to the node, and the node It can be defined by an attribute value field that stores an attribute value number that specifies an attribute value.
- the parent node of the node is identified by the record sequence number stored in the parent-child relationship field included in the record corresponding to the node, and the attribute name belonging to the node is included in the record corresponding to the node Number and attribute name are stored in the attribute name array stored in the order of attribute name number, and the attribute value number and attribute value included in the record corresponding to the node are attribute value numbers belonging to the node. It can be configured to be specified by the attribute value array stored in order.
- FIG. 4A and 4B are explanatory diagrams of a data representation format of tree structure data constructed on a storage device by introducing the concept of this information block according to an embodiment of the present invention.
- the example in the figure follows the depth priority method.
- FIG. 4A is an explanatory diagram of a data expression format in which an attribute name Title is separated into an attribute name number array Title_VNo and an attribute name array Title_VL, and an attribute value Value is separated into an attribute value number array Value_VNo and an attribute value array Value_VL.
- 4B is an explanatory diagram of an information block type data representation format derived based on the representation format of FIG. 4A.
- the value of the parent-child relationship field is specified by Topology [i]
- the attribute name is specified by Title_VL [Title_VNo [i]]
- the attribute value is Value_VL [Value_VNo [i]. ] Will be understood.
- FIG. 5 is a diagram showing an example of tabular data for explaining a data management mechanism based on information blocks.
- the tabular data is stored in a memory (for example, RAM 14) as a data structure as shown in FIG. 6 in the computer by using the data management mechanism proposed in Patent Document 4 described above.
- This data structure has been proposed to realize retrieval, sorting, aggregation, etc. of large-scale tabular data using hardware resources of commercially available computers, for example, personal computers, in particular, processors and memories. It should be noted that the data structure of tabular data placed on the computer memory.
- Every record has a source record position number associated with it.
- This primitive record position number is virtual information used for specifying individual records including item values corresponding to data items.
- records are not always arranged in the order of the original record position numbers. For example, when the original tabular data is sorted in ascending order with respect to the item value of a certain item, the order of the records of the tabular data obtained is different from the order of the records of the original tabular data.
- the records in the original tabular data may be arranged in the order of the source record position numbers. In this case, the source record position number and the record sequence number are initially matched. Yes.
- the order number (record order number) of each record of the tabular data and the original record position number are abbreviated as a record order designation array 601 (hereinafter, this array is abbreviated as “OrdSet”). .).
- the record order specification array 601 stores source record position numbers in the order of record order numbers. In the example of FIG. 6, the records are arranged in the order of the original record position numbers.
- the actual gender value for the record whose source record position number is “0”, ie, “male” or “female” is a value list in which the actual values are sorted according to a predetermined order (eg, ascending or descending order).
- An item value number array 602 (hereinafter, an item value number array, that is, a pointer array) that is a pointer array to a certain item value array 603 (hereinafter, an item value array, that is, a value list is abbreviated as “VL”). Is abbreviated as “VNo.”).
- the pointer array 602 stores pointers that point to elements in the actual value list 603 according to the order of the source record position numbers stored in the array OrdSet 601.
- Item values can be obtained for other records as well as for age and height.
- the tabular data is expressed by a combination of the value list VL and the pointer array VNo to the value list, and this combination is particularly referred to as an “information block”.
- information blocks relating to gender, age and height are shown as information blocks 608, 609 and 610, respectively.
- a single computer has a single memory (physically multiple, but a single memory in the sense that it is located and accessed in a single address space) May store the ordered set array OrdSet, the value list VL constituting each information block, and the pointer array VNo in the memory.
- the manipulation of tabular data can be performed in parallel by a plurality of arithmetic units.
- FIG. 7 is an explanatory diagram of an example of a structure-type parts table relating to the configuration of the vehicle.
- pairs of figure numbers that is, parent figure numbers
- figure numbers that is, child figure numbers
- the numbers from 0 to 9 at the left end represent the record numbers of the parts table.
- a pair of a parent figure number and a child figure number in the BOM that is, a record is identified by this record number.
- the parts table in FIG. 7 is also called a structure-type parts table because the hierarchical relationship of the parts is embedded.
- FIG. 8 is a diagram showing the hierarchical relationship of the vehicle configuration described in the parts table of FIG.
- One embodiment of the present invention provides a method for converting (expanding) the parts table (original data) shown in FIG. 7 into the tree structure data shown in FIG.
- This method is performed by the computer system 10 shown in FIG. 1 in one embodiment of the invention. That is, the processing steps described below are executed by the computer system 10, particularly the CPU 12 in the computer system 10. Further, data, tables, and arrays generated in the processing steps are each stored in a memory (for example, RAM 14).
- the converted tree structure data is described in the data representation format of the tree structure data described with reference to FIGS. 3A and 3B or FIGS. 4A and 4B.
- Step 1 Designation of Data to be Expanded
- the parts table itself describes a parent-child relationship, but it is not always arranged in, for example, depth priority order or width priority order. Therefore, in order to convert the parts table into tree structure data, first, the data to be expanded (the root node of the tree structure data) is designated.
- Data to be expanded is stored in advance in the hard disk 18 and the input device 24 of the computer system 10 shown in FIG. 1, or supplied from the CD-ROM 19 via the CD-ROM driver 20, or the I / F 22 It is given in various forms such as being supplied from an external terminal via
- the CPU 12 of the computer system 10 designates data given in any form as data to be developed. In this example, consider the case where Car_A is converted into tree structure data.
- Step 2 Creation of a table of data to be expanded
- a table of data to be expanded is created as intermediate data of the first hierarchy.
- the record order number is sometimes referred to as a record number for simplicity.
- the item name and the item value may be collectively referred to as an item.
- Step 3 Create record number correspondence table (first time) A parts table that is original data is prepared as intermediate data of the second hierarchy.
- the key item for sharing ie, matching key
- the intermediate data of the first hierarchy ie, the parent table
- the intermediate data of the second hierarchy ie, the child table
- Matching is executed, and a record number correspondence table is created between the two hierarchies. For example, if a certain record (for example, record a) in the intermediate data of the first hierarchy and a certain record (for example, record b) in the intermediate data of the second hierarchy have the same item value for the key item
- the combination of the record a in the intermediate data of the first hierarchy and the record b in the intermediate data of the second hierarchy is registered in the record number correspondence table.
- a record included in original data or intermediate data may be referred to as a “row” in order to distinguish it from a record in a virtual record array.
- the record number may be referred to as a “line number”
- the record number correspondence table may be referred to as a “line number correspondence table”.
- An example of such matching can be realized by join.
- an equivalent item that is, a join key
- This is a technique for comparing value lists included in an information block relating to an item, and sharing a value list referenced by both tabular data.
- a method of creating a record number correspondence table using a join will be described later.
- the record number correspondence table is created.
- Step 4 Create record number correspondence table (second time) The record number correspondence table is continued until there is no record having the same item value for the key item for sharing. More specifically, it is checked whether or not there is further data having a parent-child relationship with respect to the record 0 and the record 1 of the intermediate data in the second hierarchy appearing in the record number correspondence table created in step 3.
- a parts table that is original data is further prepared as intermediate data in the third hierarchy.
- original data is repeatedly used as intermediate data. This is because the structure type parts table has a hierarchical relationship embedded in one table.
- the item value of the record 4 of the intermediate data in the third layer Tire_1
- the item value of the record 5 Chassis_1
- FIG. 9 is a diagram showing the correspondence between the intermediate data created from the structure-type parts table and the records between the intermediate data by the processing from step 1 to step 5 described above.
- the arrows between the intermediate data Table_0 and the intermediate data Table_1 and the arrows between the intermediate data Table_1 and the intermediate data Table_2 are respectively a record number correspondence table between the first hierarchy and the second hierarchy, and This is equivalent to the record number correspondence table between the second layer and the third layer.
- Step 6 Generation of tree structure data from record number correspondence table
- tree structure data is generated from the acquired record number correspondence table.
- the record number correspondence table between Table_0 and Table_1 is 0 ⁇ 0, 1
- the record number correspondence table between Table_1 and Table_2 is 0 ⁇ 4, 5, 6 1 ⁇
- FIG. 10A and 10B show the generated tree structure data.
- FIG. 10A is an explanatory diagram of an example of tree structure data in a depth priority format generated from a structure type BOM
- FIG. 10B is an explanatory diagram of an example of tree structure data in a width priority format generated from the same structure type BOM. It is.
- the step of generating tree structure data from the record number correspondence table is either depth-first or width-priority, and the record number in the intermediate data on the parent side having a parent-child relationship from the record number correspondence table and the intermediate on the child side
- a step 6-1 for searching for a record number in the data and a step 6-2 for generating a record in the virtual record array of the tree structure data are included.
- step 6-1 if depth-first search is executed, tree structure data in the depth-first format is generated, and if width-first search is executed, tree structure data in the width-first format is generated. Whether to select depth priority or width priority may be set in advance, may be specified every time by the user, or may be automatically selected according to the application.
- Step 6-2 is executed every time one parent-child relationship is acquired in Step 6-1.
- a record sequence number 0 is assigned to a record to be newly created in the virtual record array, and the record sequence number 0 is set.
- the assigned record Record [0] corresponds to the record sequence number Topology [0] of the parent node of the node corresponding to this record, the item name Title [0] of the original data corresponding to this record, and this record
- the item value Value [0] of the original data to be stored is stored.
- step 6-2 when a new record is generated, the process returns to step 6-1 to search for the next parent-child relationship.
- step 6-2 the process proceeds again to step 6-2 to generate a new record.
- Step 6-1 and Step 6-2 by the depth priority method, an array of virtual records representing tree structure data as shown in FIG. 10A is generated.
- the virtual record array representing the tree structure data as shown in FIG. 10B can be obtained by repeatedly executing Step 6-1 and Step 6-2 as in the depth priority method. Generated.
- Step 7 Separation of values
- item Topology is described by an array of integers, there is no need to convert it to an information block type.
- 11A and 11B are diagrams showing tree structure data generated by converting the tree structure data shown in FIGS. 10A and 10B into an information block type.
- 11A corresponds to the depth-priority tree structure data in FIG. 10A
- FIG. 11B corresponds to the width-priority tree structure data in FIG. 10B.
- Tree structure data integrated from a structure-type parts table.
- Tree structure data can be generated in either depth-first or width-first format as required.
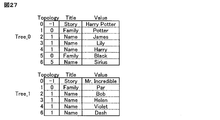
- FIG. 12A and 12B are explanatory diagrams of an example of tree structure data described in a plurality of tables.
- FIG. 12A illustrates a plurality of tables describing tree structure data
- FIG. 12B illustrates a plurality of tables. The hierarchical relationship of the tree structure data described by is shown.
- the first table Table_0 has an item story and an item DGrip.
- the item Story is substantive information belonging to the data
- the item DGrip is information used to express the parent-child relationship between the elements of the table.
- the second table Table_1 has an item UGrip, an item Family, and an item DGrip.
- the item Family is substantive information
- the item UGrip and the item DGrip are information used to express a parent-child relationship.
- the third table Table_2 holds an item UGrip which is information for expressing a parent-child relationship and an item Name which is substantial information.
- the down grip represented as DGrip is a sequence number assigned in the order of appearance of data.
- the up grip indicated as UGrip is the value of the down grip assigned to the parent element. Therefore, generally, if the value of UGrip of a record i in a certain table is m and the value of DGrip of record j in the immediately preceding table is m, the parent element of record i in a certain table is Record j in the table.
- Each record corresponds to one node in the tree structure data, and an item name and an item value, which are substantive information of each record, represent an attribute name and an attribute value belonging to the node corresponding to the record. Yes.
- the tree structure data is described in a plurality of tables by combining the up grip and the down grip.
- the plurality of tables in FIG. 12A include a tree having Harry Potter as a root node, Mr. It can be seen that it represents tree structure data including two trees of which the Incredible is a root node.
- Such multiple tables are known to know what data structure exists in advance by scanning data or defining the data structure, creating a storage destination table accordingly, and storing the data Since it is constructed according to the procedure, it is unsuitable in terms of performance for an application such as an editor in which various data structures are generated at any time.
- Step 1 Creation of Record Number Correspondence Table
- a record number correspondence table is created between the first layer table Table_0 and the second layer table Table_1.
- FIG. 13A shows a record number correspondence table between Table_0 and Table_1
- FIG. 13B A record number correspondence table between Table_1 and Table_2 is shown.
- Step 2 Generation of tree structure data from record number correspondence table
- tree structure data is generated from the acquired record number correspondence table. Specifically, the value of the Topology field, the value of the Title field, and the value of the Value field are stored in each record of the virtual record array.
- Step 2-1 Generation of record 0
- Step 2-1 Initialization The area of the stack array ParentNodeNo for storing the array Topology, array Title, array Value, and the record identification number of the parent node is secured in the memory. ⁇ 1 is set to the beginning of the array, that is, ParentNodeNo [0]. Further, the value ⁇ 1 stored in the stack array ParentNodeNo is copied to Topology [0].
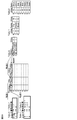
- 14A to 14C are explanatory diagrams of tree structure data generation processing based on the depth priority method according to an embodiment of the present invention, and FIG. 14A shows the processing of step 2-1-1.
- Step 2-1-2 Value Storage FIG. 14B shows a process for generating record 0 corresponding to the root node (node 0). Since the current position in the record number correspondence table indicated by the upward arrow in the drawing is the record 0 of Table_0, the item name and item value of the record 0 of Table_0 are acquired, and Title [0] and Value [ 0] respectively.
- Step 2-1-3 Move to Child Node
- FIG. 14C shows a move process to the child node.
- the current position is moved to the child node according to the record number correspondence table.
- the pointers to the array Topology, array Title, and array Value indicated by the horizontal arrows in the same figure indicate the record positions where the values have been stored, the pointer is incremented (go forward one step). ).
- FIGS. 15A to 15C show processing for generating record 1 corresponding to node 1.
- FIG. 15A the value stored in the stack array ParentNodeNo is copied to the array Topology [1].
- FIG. 15B since the current position in the record number correspondence table is the record 1 of Table_1, the item name and item value of the record 1 of Table_1 are acquired, and Title [1] And Value [1].
- FIG. 15C the current position is moved to the child node according to the record number correspondence table.
- the pointer is incremented (go forward one step). ).
- FIGS. 16A to 16C show processing for generating record 2 corresponding to node 2.
- FIG. 16A the value stored in the stack array ParentNodeNo is copied to the array Topology [2].
- FIG. 16B since the current position in the record number correspondence table is the record 1 of Table_2, the item name and the item value of the record 1 of Table_2 are acquired, and Title [2] And Value [2].
- FIG. 16C it is checked whether there is a child node according to the record number correspondence table. If there is no child node, it is checked whether there is a younger brother node.
- the current position in the record number correspondence table is moved to the younger brother node. Since this is a depth-first method, the child node is examined in preference to the brother node. When the current position is moved to the younger brother node, the stack array ParentNodeNo is not operated. Further, since the pointers to the array Topology, array Title, and array Value indicated by the horizontal arrows in FIG. 16C point to the record positions where the values have been stored, the pointers are incremented (go forward one step). ).
- Step 2-4 Generation of Record 3 As shown in FIGS. 17A-C, record 3 is generated in the same manner as in Step 2-3 shown in FIGS. 16A-C.
- FIGS. 18A to 18C show processing for generating record 4 corresponding to node 4.
- the value stored in the stack array ParentNodeNo is copied to the array Topology [4].
- the item name and the item value of the record 3 of Table_2 are acquired, and Title [4] And Value [4].
- FIG. 18C it is checked whether there is a child node according to the record number correspondence table. If there is no child node, it is checked whether there is a brother node.
- the current position in the record number correspondence table is moved (returned) to the parent node.
- the record sequence number stored from the stack array ParentNodeNo is popped.
- the parent node corresponds to the record 1 of Table_1.
- the current position in the record number correspondence table is moved to the younger brother node of the record 1 of Table_1, that is, the record 2 of Table_1.
- the pointers to the array Topology, array Title, and array Value indicated by the horizontal arrows in FIG. 18C point to the record positions where the values have been stored, the pointers are incremented (go forward one step). ).
- FIGS. 19A to 19C show processing for generating record 5 corresponding to node 5.
- the value stored in the stack array ParentNodeNo is copied to the array Topology [5].
- the current position in the record number correspondence table is the record 2 of Table_1, the item name and the item value of the record 2 of Table_1 are acquired, and Title [5] And Value [5].
- the current position is moved to the child node according to the record number correspondence table.
- the pointers to the array Topology, array Title, and array Value indicated by the horizontal arrows in FIG. 19C point to the record positions where the values have been stored, the pointers are incremented (go forward one step). ).
- FIGS. 20A to 20C show processing for generating record 6 corresponding to node 6.
- the value stored in the stack array ParentNodeNo is copied to the array Topology [6].
- the item name and the item value of the record 0 of Table_2 are acquired, and Title [6] And Value [6], respectively.
- FIG. 20C it is checked whether there is a child node according to the record number correspondence table. Since there is no child node, it is checked whether a brother node exists.
- the current position in the record number correspondence table is moved (returned) to the parent node.
- the record sequence number stored from the stack array ParentNodeNo is popped.
- the parent node corresponds to the record 2 of Table_1.
- the current position in the record number correspondence table is moved to the parent node of the record 2 of Table_1, that is, the record 0 of Table_0.
- the record sequence number stored from the stack array ParentNodeNo is popped.
- the pointers to the array Topology, array Title, and array Value indicated by the horizontal arrows in FIG. 20C point to the record positions where the values have been stored, the pointers are incremented (go forward one step). ).
- the integrated tree structure data of the depth-first method regarding Incredible is also generated by the same processing.
- the process of the record 1 of Table_0 may be sequentially executed by one processor after the process related to the record 0 of Table_0. For example, the process related to the record 0 of Table_0 using a plurality of processors, Processing regarding the record 1 of Table_0 may be executed in parallel.
- Step 3 Generation of Tree Structure Data with Separated Value List
- the tree structure data generated in Step 2 can be converted into tree structure data with a separated value list.
- the tree structure data from which the value list is separated is equivalent to the information block type tree structure data.
- a method is provided for converting consolidated tree structure data into tree structure data with separated value lists.
- FIGS. 21A to 21C are explanatory diagrams of tree structure data generated from the original data of FIG. FIG. 21A shows the integrated tree structure data.
- values appearing in the array Title are separated into a value number and a unique and ascending (or descending) value list, and values appearing in the array Value are also unique and ascending (or descending) values. Separated into a list.
- FIG. 21B shows tree structure data in which values are separated into value numbers and value lists in this way.
- FIG. 21C shows information block type tree structure data in which a set of a value number and a value list is separated with respect to an item Title and an item Value.
- the separation of the value list eliminates the holding of duplicate values, thereby reducing the data size. Furthermore, the separation of the value list eliminates the need to repeatedly check whether the search condition is satisfied for the same value at the time of search, thus facilitating the search. In addition, the separation of the value list facilitates tabulation because the list of dimension values can be used immediately at the time of tabulation. In addition, by separating the value list, counting can be used for sorting, so that sorting becomes easy.
- the values in the tree structure data are separated into value numbers and value lists after the integrated tree structure data is created.
- tree structure data described in a plurality of tables that is, integrated tree structure data is generated after separating original data into an ordered set and an information block.
- a method is provided. The processing steps described below are also executed by the computer system 10, particularly the CPU 12 in the computer system 10. Further, data, tables, and arrays generated in the processing steps are each stored in a memory (for example, RAM 14).
- Step 1 Conversion of Data Format
- the original data shown in FIG. 12A that is, Table_0, Table_1, and Table_2 are converted into a data format composed of an ordered set array OrdSet and an information block.
- This data format is as described in [Data management mechanism based on information block].
- FIG. 22 is an explanatory diagram of the conversion from the original data shown in FIG. 12A to the data format based on the information block.
- Step 2 Common Value List for Item Value
- common value lists for Item Story, Item Family, and Item Name are made common. Therefore, the value list of the item story and the value list of the item family are first made common, and then the value list made common first and the value list of the item name are made common.
- the sharing of the value list is a process necessary for creating the information block of the item value of the final information block type tree structure data.
- FIG. 23 is an explanatory diagram of a value list sharing process. When the value list of the item story and the value list of the item family are made common, elements from the respective value lists are stored in the common value list in alphabetical order without duplication.
- the value number of the element of the value number array of each item is rewritten so as to specify the corresponding value in the common value list. If a value list of a plurality of items is shared, a plurality of items can be handled as one information block.
- Step 3 Separation of Item Title Value Number and Value List
- the Title list is separated into a value number array VNo and a value list VL.
- FIG. 24 is an explanatory diagram of processing for separating a value array into a value number and a value list.
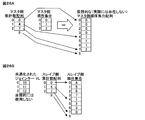
- FIGS. 25A and 25B are explanatory diagrams of processing for creating a record number correspondence table using a join according to an embodiment of the present invention.
- FIG. 25A shows join processing between Table_0 and Table_1
- FIG. 25B shows join processing between Table_1 and Table_2.
- the master side represents a table in which the order of the ordered set of the original table is stored.
- the upper layer table corresponds to the master side, and conversely, the slave side.
- the lower layer table corresponds to the slave side.
- the key items are DGrip of Table_1 on the master side and UGrip of Table_2 on the slave side.
- the join table generated by the join includes the record m in the master side table. Appears repeatedly n times.
- there are four records that is, a record 4, a record 5, a record 6, and a record 7, corresponding to the record 0 on the slave side corresponding to the record 0 on the table 1 on the master side.
- the record 1 on the slave side corresponds to the record 1
- the record 2 on the slave side corresponds to the record 2 on the master side.
- the combination of the master side cumulative number array and the master side ordered set array expresses a virtual ordered set array as shown in FIG. 26A in a compact manner.
- the master side cumulative number array [i] represents the start position where the element specified by the corresponding master side ordered set array [i] appears in the virtual ordered set array.
- the slave side ordered set is sorted by join key, in this example, the value of UGrip.
- the slave side cumulative number array [i] also indicates the start position at which the element corresponding to the shared join key VL [i] appears in the slave side ordered set array. Yes.
- the value lists are compared to make both value lists equivalent.
- the pointer array is converted along with the addition of the item value to generate a new pointer array.
- a slave side existence number array that stores the existence number indicating the number of records related to the slave table format data corresponding to the item value is generated, and the item value is referred to by referring to the existence number in the slave side existence number array.
- a slave side cumulative number array storing the cumulative number of corresponding existence numbers is generated.
- the pointer value in the pointer array indicated by the record number on the master side is taken out, the element in the slave side existence number array corresponding to the item value indicated by the pointer value is specified, and the master side is associated with the record number on the master side.
- a record corresponding to the record number on the master side, stored in the record number indicating array indicating the number of records of the slave tabular data corresponding to each record of the tabular data, and referring to the number of records in the record number indicating array Generate a master-side cumulative number array that stores the cumulative number of numbers.
- a new record number for determining the total number of the total number of records and identifying a new record related to the combined tabular data that can accommodate the number of elements of the total number By comparing a new record number in the array and an element in the master side cumulative number array, a master side ordered set array that accommodates the record numbers in the master tabular data in consideration of duplication is obtained.
- the element in the pointer array related to the slave table format data specified by the record number in the master table format data which is an element in the master side ordered set array is specified, and the element in the pointer array related to the slave table format data is Identify the element in the slave side cumulative number array to point to, temporarily hold this as the start address on the slave side, record number in the new record number array, and master cumulative number array specified by the record number
- a slave side ordered set array containing record numbers in the slave table format data considering duplication is obtained from the elements inside and the start address on the slave side.
- 1 ⁇ 1, 2, 3 in the second row of the record number correspondence table Can be obtained.
- Step 5 Generation of tree structure data
- values are stored in order from the record 0 in the Topology array, Title_VNo array, and Value_VNo array of the tree structure data.
- Tree structure data with separated values is generated.
- a value number and a value list related to the item Value in which the item Story, the item Family and the item Name are made common, and a value number related to the item Title as shown in FIG. And a list of values is used.
- Step 5-1 Generation of record 0
- Step 5-1 Initialization
- the array Topology, the array Title, the array Value, and the area of the stack array ParentNodeNo for storing the record identification number of the parent node are secured in the memory, and the stack ⁇ 1 is set to the beginning of the array, that is, ParentNodeNo [0]. Further, the value ⁇ 1 stored in the stack array ParentNodeNo is copied to Topology [0]. This process is similar to the process described with reference to FIG. 14A.
- Step 5-1-3 Move to Child Node This process is similar to the move process to the child node described with reference to FIG. 14C.
- the current position is moved to the child node according to the record number correspondence table.
- the pointers to the array Topology, array Title, and array Value indicated by the horizontal arrows in the same figure indicate the record positions where the values have been stored, the pointer is incremented (go forward one step). ).
- Step 5-2 Generation of Record 1
- This process is similar to the process of generating record 1 corresponding to node 1 described with reference to FIGS. 15A-C.
- the value stored in the stack array ParentNodeNo is copied to the array Topology [1].
- the current position is moved to the child node according to the record number correspondence table.
- the pointers to the array Topology, array Title, and array Value indicated by the horizontal arrows in FIG. 15C indicate the record positions where the values have been stored, the pointers are incremented (go forward one step). ).
- tree structure data with separated value lists is generated as shown in FIG. 21B.
- the process of converting the tree structure data from which the value list is separated into the information block type tree structure data as shown in FIG. 21C is as described above.
- the tree structure data of the depth priority method related to Incredible is also generated by the same processing.
- the process of the record 1 of Table_0 may be sequentially executed by one processor after the process related to the record 0 of Table_0.
- the process related to the record 0 of Table_0 using a plurality of processors, Processing regarding the record 1 of Table_0 may be executed in parallel.
- FIG. 27 shows a result of applying the tree structure data generation processing according to the embodiment of the present invention to both the record 0 and the record 1 of Table_0.
- the record 0 of Table_0 corresponds to one root node
- the record 1 of Table_1 corresponds to the other root node.
- FIG. 28 shows a result of applying the tree structure data generation processing according to another embodiment of the present invention in which the record 0 and the record 1 of Table_0 are handled as sibling nodes.
- Step 1 Creation of Record Number Correspondence Table
- the record number correspondence table creation processing in the depth priority method described with reference to FIGS. 13A and 13B is also applied to the width priority method in exactly the same manner.
- Step 2 Generation of tree structure data from record number correspondence table
- tree structure data is generated from the acquired record number correspondence table. Specifically, because of the breadth-first method, the storage position in the virtual record array is determined in order from the highest layer, and the value of the Topology field, the value of the Title field, And the value of the Value field is stored.
- Step 3 Generation of Record 0
- the highest node is Record 0 of Table_0. Since the parent node does not exist in the highest node, ⁇ 1 is stored in Topology [0] (Transfer 1).
- the item name and the item value of the record 0 of Table_0 are acquired and stored in Title [0] and Value [0], respectively (Transfer 2).
- the confirmed record sequence number (that is, the node number, 0 in this example) is added to the record number correspondence table (Transfer 3). Since there is no younger brother node in node 0, the next node is the first node existing in the next hierarchy (depth).
- FIG. 29 is an explanatory diagram of such a breadth-first tree structure data generation process according to an embodiment of the present invention.
- Step 4 Generation of Record 1
- the current node is record 1 of Table_1. Since the record order number of the parent node is 0, 0 is stored in Topology [1] (Transfer 1). The item name and item value of the record 1 of Table_1 are acquired and stored in Title [1] and Value [1], respectively (Transfer 2). The confirmed node number (1 in this example) is added to the record number correspondence table (transfer 3). Since node 1 has a younger brother node, the next node is a younger brother node.
- Step 5 Generation of Record 2
- the current node is the record 2 of Table_1. Since the record order number of the parent node is 0, 0 is stored in Topology [2] (Transfer 1). The item name and item value of the record 2 of Table_1 are acquired and stored in Title [2] and Value [2], respectively (Transfer 2). The confirmed node number (2 in this example) is added to the record number correspondence table (transfer 3). Since there is no younger brother node in node 2 and there is no undetermined node in the same generation, the next node is the first node existing in the next hierarchy (depth).
- Step 6 Generation of Record 3
- the current node is record 1 of Table_2. Since the record order number of the parent node is 1, 1 is stored in Topology [3] (Transfer 1). The item name and item value of the record 1 of Table_2 are acquired and stored in Title [3] and Value [3], respectively (Transfer 2). The confirmed node number (3 in this example) is added to the record number correspondence table (transfer 3). Since the younger brother node exists in the node 3, the next node is the younger brother node.
- Step 7 Generation of Record 4 Next, generation processing of the record 4 of the tree structure data will be described.
- the current node is record 2 of Table_2. Since the record order number of the parent node is 1, 1 is stored in Topology [4] (Transfer 1). The item name and item value of the record 2 of Table_2 are acquired and stored in Title [4] and Value [4], respectively (Transfer 2). The confirmed node number (4 in this example) is added to the record number correspondence table (transfer 3). Since node 4 has a brother node, the next node is a brother node.
- Step 8 Generation of Record 5
- the current node is record 3 of Table_2. Since the record order number of the parent node is 1, 1 is stored in Topology [5] (Transfer 1). The item name and item value of the record 3 of Table_2 are acquired and stored in Title [5] and Value [5], respectively (Transfer 2). The confirmed node number (5 in this example) is added to the record number correspondence table (transfer 3). Although there is no younger brother node in node 5, there is an indeterminate node of the same generation, so the next node is the next data of the same generation.
- Step 9 Generation of Record 6
- the current node is record 0 of Table_2. Since the record order number of the parent node is 2, 2 is stored in Topology [6] (Transfer 1). The item name and item value of record 0 of Table_2 are acquired and stored in Title [6] and Value [6], respectively (Transfer 2). The confirmed node number (6 in this example) is added to the record number correspondence table (transfer 3). Since the node 6 has neither a younger brother node nor a next generation node, the generation process of the tree structure data is completed.
- FIG. 35 is an explanatory diagram of information block type tree structure data generated using the tree structure data generation process of the breadth-first method according to an embodiment of the present invention.
- the breadth-first tree structure data related to Incredible is also generated by the same processing.
- the process of the record 1 of Table_0 may be sequentially executed by one processor after the process related to the record 0 of Table_0.
- the process related to the record 0 of Table_0 using a plurality of processors, Processing regarding the record 1 of Table_0 may be executed in parallel.
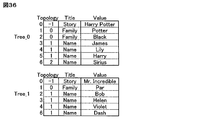
- FIG. 36 shows the result of applying the tree structure data generation processing according to the embodiment of the present invention to both the record 0 and the record 1 of Table_0.
- the record 0 of Table_0 corresponds to one root node
- the record 1 of Table_1 corresponds to the other root node.
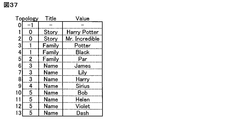
- FIG. 37 shows a result of applying tree structure data generation processing according to another embodiment of the present invention in which the records 0 and 1 of Table_0 are handled as sibling nodes.
Landscapes
- Engineering & Computer Science (AREA)
- Databases & Information Systems (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
La présente invention concerne de données arborescentes formées par une pluralité de nœuds dont chacun est exprimé par un nom d'attribut et une valeur d'attribut est exprimée par un agencement de fiche virtuelle dans lequel une fiche correspond à un nœud et chaque fiche est identifiée par un numéro de séquence de fiches exprimant un ordre d'agencement de fiches. Chaque fiche comprend un champ de relation parentale pour le stockage d'un numéro de séquence de fiche d'un nœud parent du nœud correspondant à la fiche, un champ de nom d'attribut pour le stockage d'un numéro de nom d'attribut qui spécifie un nom d'attribut appartenant au nœud, et un champ de valeur d'attribut pour le stockage d'un numéro de valeur d'attribut qui spécifie la valeur d'attribut appartenant au nœud.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009551334A JP5241738B2 (ja) | 2008-01-28 | 2008-01-28 | 表からツリー構造データを構築する方法及び装置 |
| PCT/JP2008/051185 WO2009095981A1 (fr) | 2008-01-28 | 2008-01-28 | Procédé et dispositif permettant la construction de données arborescentes à partir d'une table |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2008/051185 WO2009095981A1 (fr) | 2008-01-28 | 2008-01-28 | Procédé et dispositif permettant la construction de données arborescentes à partir d'une table |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2009095981A1 true WO2009095981A1 (fr) | 2009-08-06 |
Family
ID=40912352
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2008/051185 Ceased WO2009095981A1 (fr) | 2008-01-28 | 2008-01-28 | Procédé et dispositif permettant la construction de données arborescentes à partir d'une table |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP5241738B2 (fr) |
| WO (1) | WO2009095981A1 (fr) |
Cited By (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2011014643A1 (fr) | 2009-07-30 | 2011-02-03 | The Procter & Gamble Company | Composition de conditionnement dentretien de textile sous la forme dun article |
| JP2011150546A (ja) * | 2010-01-21 | 2011-08-04 | Toshiba Corp | 認識装置 |
| JP2014064056A (ja) * | 2012-09-19 | 2014-04-10 | Hitachi Solutions Ltd | 端末管理装置、端末管理システム |
| JP2016502699A (ja) * | 2012-10-22 | 2016-01-28 | アビニシオ テクノロジー エルエルシー | 位置情報を用いたデータのプロファイリング |
| US9971798B2 (en) | 2014-03-07 | 2018-05-15 | Ab Initio Technology Llc | Managing data profiling operations related to data type |
| WO2018096998A1 (fr) * | 2016-11-28 | 2018-05-31 | 株式会社ターボデータラボラトリー | Compresseur de données, programme informatique et procédé de compression de données |
| CN109213775A (zh) * | 2018-09-18 | 2019-01-15 | 深圳壹账通智能科技有限公司 | 搜索方法、装置、计算机设备和存储介质 |
| WO2019163610A1 (fr) * | 2018-02-21 | 2019-08-29 | 株式会社ターボデータラボラトリー | Système de traitement d'informations et procédé de traitement d'informations |
| CN110727687A (zh) * | 2019-10-23 | 2020-01-24 | 京东方科技集团股份有限公司 | 一种物料清单转换方法及其系统 |
| US11068540B2 (en) | 2018-01-25 | 2021-07-20 | Ab Initio Technology Llc | Techniques for integrating validation results in data profiling and related systems and methods |
| CN114185894A (zh) * | 2021-12-14 | 2022-03-15 | 武昌船舶重工集团有限公司 | 一种产品结构树的生成方法和装置 |
| CN114510913A (zh) * | 2022-01-10 | 2022-05-17 | 厦门海迈科技股份有限公司 | 一种树形表格生成优化的方法、服务器及存储介质 |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2000267906A (ja) * | 1999-03-19 | 2000-09-29 | Mitsubishi Electric Corp | データベースモデル変換方法 |
| JP2003067403A (ja) * | 2001-08-24 | 2003-03-07 | Fuji Xerox Co Ltd | 構造化文書管理装置及び構造化文書管理方法、検索装置、検索方法 |
| JP2004310249A (ja) * | 2003-04-03 | 2004-11-04 | Systems Engineering Constructions Co Ltd | Xmlデータの検索方法及び検索装置、並びにプログラムおよびプログラムを記録した記録媒体 |
| JP2006114045A (ja) * | 2004-10-15 | 2006-04-27 | Microsoft Corp | スキーマデータ(schemadata)からデータ構造へのマッピング |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3861044B2 (ja) * | 2002-10-24 | 2006-12-20 | 株式会社ターボデータラボラトリー | 連鎖したジョインテーブルのツリー構造への変換方法、および、変換プログラム |
-
2008
- 2008-01-28 WO PCT/JP2008/051185 patent/WO2009095981A1/fr not_active Ceased
- 2008-01-28 JP JP2009551334A patent/JP5241738B2/ja not_active Expired - Fee Related
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2000267906A (ja) * | 1999-03-19 | 2000-09-29 | Mitsubishi Electric Corp | データベースモデル変換方法 |
| JP2003067403A (ja) * | 2001-08-24 | 2003-03-07 | Fuji Xerox Co Ltd | 構造化文書管理装置及び構造化文書管理方法、検索装置、検索方法 |
| JP2004310249A (ja) * | 2003-04-03 | 2004-11-04 | Systems Engineering Constructions Co Ltd | Xmlデータの検索方法及び検索装置、並びにプログラムおよびプログラムを記録した記録媒体 |
| JP2006114045A (ja) * | 2004-10-15 | 2006-04-27 | Microsoft Corp | スキーマデータ(schemadata)からデータ構造へのマッピング |
Non-Patent Citations (1)
| Title |
|---|
| YOSHIFUMI MASUNAGA: "Relational Database Nyumon -Data Model ·SQL · Kanri System", 25 January 1991, SAIENSU-SHA CO., LTD., pages: 145 - 148 * |
Cited By (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2011014643A1 (fr) | 2009-07-30 | 2011-02-03 | The Procter & Gamble Company | Composition de conditionnement dentretien de textile sous la forme dun article |
| JP2011150546A (ja) * | 2010-01-21 | 2011-08-04 | Toshiba Corp | 認識装置 |
| JP2014064056A (ja) * | 2012-09-19 | 2014-04-10 | Hitachi Solutions Ltd | 端末管理装置、端末管理システム |
| JP2016502699A (ja) * | 2012-10-22 | 2016-01-28 | アビニシオ テクノロジー エルエルシー | 位置情報を用いたデータのプロファイリング |
| US9990362B2 (en) | 2012-10-22 | 2018-06-05 | Ab Initio Technology Llc | Profiling data with location information |
| US10719511B2 (en) | 2012-10-22 | 2020-07-21 | Ab Initio Technology Llc | Profiling data with source tracking |
| US9971798B2 (en) | 2014-03-07 | 2018-05-15 | Ab Initio Technology Llc | Managing data profiling operations related to data type |
| JPWO2018096998A1 (ja) * | 2016-11-28 | 2019-10-17 | 株式会社ターボデータラボラトリー | データ圧縮装置、コンピュータプログラム及びデータ圧縮方法 |
| WO2018096998A1 (fr) * | 2016-11-28 | 2018-05-31 | 株式会社ターボデータラボラトリー | Compresseur de données, programme informatique et procédé de compression de données |
| US11068540B2 (en) | 2018-01-25 | 2021-07-20 | Ab Initio Technology Llc | Techniques for integrating validation results in data profiling and related systems and methods |
| WO2019163610A1 (fr) * | 2018-02-21 | 2019-08-29 | 株式会社ターボデータラボラトリー | Système de traitement d'informations et procédé de traitement d'informations |
| CN109213775A (zh) * | 2018-09-18 | 2019-01-15 | 深圳壹账通智能科技有限公司 | 搜索方法、装置、计算机设备和存储介质 |
| CN110727687A (zh) * | 2019-10-23 | 2020-01-24 | 京东方科技集团股份有限公司 | 一种物料清单转换方法及其系统 |
| CN110727687B (zh) * | 2019-10-23 | 2023-06-27 | 京东方科技集团股份有限公司 | 一种物料清单转换方法及其系统 |
| US12198099B2 (en) | 2019-10-23 | 2025-01-14 | Boe Technology Group Co., Ltd. | Bill of material conversion method, electronic apparatus and non-transitory computer-readable storage medium |
| CN114185894A (zh) * | 2021-12-14 | 2022-03-15 | 武昌船舶重工集团有限公司 | 一种产品结构树的生成方法和装置 |
| CN114510913A (zh) * | 2022-01-10 | 2022-05-17 | 厦门海迈科技股份有限公司 | 一种树形表格生成优化的方法、服务器及存储介质 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2009095981A1 (ja) | 2011-05-26 |
| JP5241738B2 (ja) | 2013-07-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5241738B2 (ja) | 表からツリー構造データを構築する方法及び装置 | |
| JP4886693B2 (ja) | 情報処理方法、情報処理装置および情報処理プログラム | |
| CN107491561B (zh) | 一种基于本体的城市交通异构数据集成系统及方法 | |
| US7752192B2 (en) | Method and system for indexing and serializing data | |
| US9753960B1 (en) | System, method, and computer program for dynamically generating a visual representation of a subset of a graph for display, based on search criteria | |
| KR101572299B1 (ko) | 시스템의 모델을 변환하는 방법, 컴퓨터 프로그램 및 시스템 모델 변환 장치 | |
| JP4681544B2 (ja) | 配列の生成方法、情報処理装置、及び、プログラム | |
| JP2005521954A (ja) | リレーショナルデータベースをクエリーする方法および装置 | |
| US20080270435A1 (en) | Method for Handling Tree-Type Data Structure, Information Processing Device, and Program | |
| WO2015010509A1 (fr) | Procédé basé sur un espace linéaire unidimensionnel et permettant d'implémenter une recherche dans un dictionnaire par arbre préfixe | |
| CN113590894B (zh) | 一种动态高效的遥感影像元数据入库检索方法 | |
| CN108681603B (zh) | 数据库中快速搜索树形结构数据的方法、存储介质 | |
| KR101244466B1 (ko) | NoSQL 기반 데이터 모델링 방법 | |
| JP5090481B2 (ja) | データモデリング方法及び装置及びプログラム | |
| JP4712718B2 (ja) | 配列の生成方法、及び、配列生成プログラム | |
| JP2005521953A (ja) | リレーショナルデータベースをクエリーする方法および装置 | |
| CN102662948A (zh) | 一种快速发现效用模式的数据挖掘方法 | |
| JP2007087216A (ja) | 階層型辞書作成装置、プログラムおよび階層型辞書作成方法 | |
| JP2005250820A (ja) | ストレージシステムにおけるxml文書分類方法 | |
| CN100565508C (zh) | 结构化文档管理设备、搜索设备、存储和搜索方法 | |
| JP4681555B2 (ja) | ノード挿入方法、情報処理装置、および、ノード挿入プログラム | |
| KR100345277B1 (ko) | Xml 문서의 논리적인 구조정보 추출기 | |
| CN112328543B (zh) | 一种基于标签属性图结构的ifc数据高效存储方法 | |
| JP5374456B2 (ja) | 文書検索装置の動作方法およびこれをコンピュータに実行させるためのコンピュータプログラム | |
| JPH07262018A (ja) | 構造化型知識データベース作成方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 08703994 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2009551334 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 08703994 Country of ref document: EP Kind code of ref document: A1 |