WO2009142257A1 - 食道ガン判定用組成物及び方法 - Google Patents
食道ガン判定用組成物及び方法 Download PDFInfo
- Publication number
- WO2009142257A1 WO2009142257A1 PCT/JP2009/059323 JP2009059323W WO2009142257A1 WO 2009142257 A1 WO2009142257 A1 WO 2009142257A1 JP 2009059323 W JP2009059323 W JP 2009059323W WO 2009142257 A1 WO2009142257 A1 WO 2009142257A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- seq
- gene
- esophageal cancer
- polynucleotide
- nos
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images





Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6883—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material
- C12Q1/6886—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material for cancer
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/575—Immunoassay; Biospecific binding assay; Materials therefor for cancer
- G01N33/5753—Immunoassay; Biospecific binding assay; Materials therefor for cancer of the stomach or small intestine
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/158—Expression markers
Definitions
- the present invention relates to a diagnostic (determination or detection) composition useful for determination or detection of esophageal cancer, an esophageal cancer detection or determination method using the composition, and an esophageal cancer diagnosis or detection kit using the composition. .
- the esophagus is a luminal organ that connects the pharynx and stomach, mostly in the thoracic cavity and partly in the neck and abdominal cavity.
- the upper part of the thoracic cavity is between the trachea and the spine, and the lower part is surrounded by the heart, aorta and lungs.
- the esophagus serves to send food from the mouth to the stomach.
- Japanese death rate from cancer in 2001 is 238.8 out of 100,000.
- the proportion of esophageal cancer among death causes is increasing year by year. In 2001, 5.0% of all cancer deaths were in men and 1.4% in women.
- the peak age of onset of esophageal cancer is in the 60s to 70s, and men often have onset.
- environmental factors such as smoking, drinking, and hot foods are closely related to the occurrence.
- the esophageal wall and its surroundings are rich in blood vessels and lymphatic vessels, it is known that there are many metastasis of cancer that has occurred.
- Treatment for esophageal cancer is determined in consideration of the degree of progression (Japanese Esophageal Disease Research Group, Clinical / Pathology, esophageal cancer handling regulations 1999), metastasis, and general condition. Standard treatment methods for esophageal cancer are described in “esophageal cancer treatment guidelines” (2002) edited by the Japan Esophageal Disease Research Group.
- the most common therapy at present is surgical treatment, and the esophagus including cancer and surrounding tissues including lymph nodes are removed (lymphadenectomy), and then the esophagus is reconstructed using other organs such as the stomach.
- surgical therapy especially wide-area lymph node dissection, places a heavy burden on patients and requires consideration for lowering QOL after surgery.
- Endoscopic mucosal resection may be possible for early cancers that remain in the mucosa.
- Radiation may be performed from both radical treatment and symptomatic treatment.
- chemotherapy is performed in combination with surgery and radiation therapy.
- the combination therapy of 5-fluorouracil and cisplatin is considered to be the most effective for chemotherapy.
- Oesophageal cancer is often found in patients who have had subjective symptoms such as discomfort during swallowing, difficulty swallowing, pain in the sternum and discomfort in the chest. However, these symptoms appear as a result of cancer growing in the esophagus, and cancers discovered at the time of consultation by self-examination often have an extra-esophageal wall progression or metastasis and often have a poor prognosis.
- Esophageal cancer is diagnosed by esophageal angiography, endoscopy, and biopsy tissue examination. Biopsy specimens are collected at the time of endoscopy or surgery, and pathological specimens are prepared and diagnosed by histopathological classification. At this time, development of a quick and simple diagnostic method that can predict the presence or absence of esophageal cancer from the properties of cells obtained by endoscopy is required.
- Patent Document 6 provides 20 types of genes that determine the presence or absence of esophageal cancer cells by detecting combinations, but that esophageal cancer cells are included and esophageal cancer cells are not included.
- Patent Document 7 Non-Patent Documents 9 and 10 shown in SPRR3 gene (Small proline-rich protein 3), Non-Patent Document 11 fgf3 gene, Patent Document 7, CSTB genes (cystatin B, liver thiol proteinase inhibitor) shown in Non-Patent Literature 12, UCP2 genes (mitochondrial uncoupling protein 2) and COL3A1 (3 'region-formal patent, patent 3) UPK1A gene (uroplatink1A) shown in Reference 7 and HSPA1B gene (Heat) shown in Non-Patent Reference 13 "Shock 70 kDa Protein 1)" has been reported. Further, as an epithelial malignant tumor marker, RRM1 gene
- the present invention relates to a disease determination composition useful for diagnosis and treatment of esophageal cancer, an esophageal cancer determination (or detection) method using the composition, and esophageal cancer determination (or detection or detection) using the composition.
- the aim is to provide a diagnostic kit.
- a method of marker search among esophageal cancer cells, a method of comparing the amount of gene expression or protein expression in a patient-derived esophageal cancer cell and a patient-derived non-cancer cell at the time of surgery, or a metabolite of the cell by some means And methods for measuring the amount of genes, proteins, metabolites, etc. contained in body fluids of esophageal cancer patients and non-cancer patients.
- probes using base sequences corresponding to hundreds to tens of thousands of genes are fixed to the DNA array.
- the gene in the sample binds to the probe, and the amount of gene expression in the test sample can be known by measuring the amount of binding by some means.
- the gene corresponding to the probe to be immobilized on the DNA array can be freely selected, and the amount of gene expressed in the sample using esophageal cancer cells and non-cancer cells derived from esophageal cancer patients during surgery or endoscopy It is possible to estimate a gene group that can serve as an esophageal cancer marker.
- the present inventors analyzed the gene expression of esophageal cancer cells and non-cancer cells derived from esophageal cancer patients at the time of surgery using a DNA chip, and found genes that can be used as detection markers for esophageal cancer. Further, the present inventors have found that the expression levels of these genes are decreased, reduced, increased or increased in esophageal cancer cells compared to non-cancer cells.
- the present invention provides a diagnostic composition for esophageal cancer comprising three or more polynucleotides selected from the group consisting of the polynucleotides shown in the following (a) to (e), variants or fragments thereof: It is a thing.
- A a polynucleotide comprising the nucleotide sequence represented by SEQ ID NOs: 1 to 38, a variant thereof, or a fragment thereof comprising 15 or more consecutive bases
- polynucleotide a polynucleotide comprising a base sequence complementary to the base sequence represented by SEQ ID NOs: 1 to 38, a variant thereof, or a fragment thereof containing 15 or more consecutive bases
- SEQ ID NOs: 1 to 38 E
- E a polynucleotide that hybridizes under stringent conditions with any of the polynucleotides (a) to (d) above, or a sequence of 15 or more sequences Fragment containing the base.
- composition wherein the fragment is a polynucleotide comprising 60 or more consecutive bases.
- the fragment includes a base sequence represented by any of SEQ ID NOs: 63 to 100 in the base sequence represented by any of SEQ ID NOs: 1 to 38, and 60 or more consecutive sequences.
- the above-mentioned composition which is a polynucleotide containing a selected base or a polynucleotide containing a base sequence complementary to the sequence of the polynucleotide.
- composition wherein the fragment is a polynucleotide comprising the base sequence represented by any of SEQ ID NOs: 63 to 100 or a base sequence complementary thereto.
- composition wherein the fragment is a polynucleotide comprising 60 or more consecutive bases.
- the fragment contains the base sequence represented by any of SEQ ID NOs: 101 to 124 in the base sequence represented by SEQ ID NOs: 39 to 62, and contains 60 or more consecutive bases.
- the above-mentioned composition which is a polynucleotide containing or a polynucleotide containing a base sequence complementary to the sequence of the polynucleotide.
- composition wherein the fragment is a polynucleotide comprising the base sequence represented by any of SEQ ID NOs: 101 to 124 or a base sequence complementary thereto.
- an esophageal cancer diagnostic kit comprising three or more of the polynucleotides, variants and / or fragments thereof described in any one of the above (a) to (e).
- kit according to any one of the above, further comprising two or more of the polynucleotides shown in (f) to (j), variants thereof and / or fragments thereof.
- the polynucleotide is a polynucleotide consisting of the base sequence represented by any one of SEQ ID NOs: 1 to 62, a polynucleotide consisting of the complementary sequence, and stringent conditions with these polynucleotides.
- the kit as described above which is a hybridizing polynucleotide or a fragment containing 15 or more consecutive bases thereof.
- the above-mentioned kit wherein the fragment is a polynucleotide comprising 60 or more consecutive bases.
- the fragment includes a base sequence represented by any of SEQ ID NOs: 63 to 124 in the base sequence represented by any of SEQ ID NOs: 1 to 62, and 60 or more consecutive sequences.
- kit which is a polynucleotide containing the base sequence complementary to the sequence
- the above-mentioned kit wherein the fragment is a polynucleotide comprising the base sequence represented by any of SEQ ID NOs: 63 to 124 or a base sequence complementary thereto.
- the above-mentioned kit wherein the fragment is a polynucleotide comprising a base sequence represented by any of SEQ ID NOs: 63 to 124.
- the kit includes 5 or more to all of a polynucleotide comprising the nucleotide sequence represented by SEQ ID NOs: 63 to 124 or a complementary sequence thereof.
- polynucleotide according to any one of the above, wherein the polynucleotides are packaged separately or in any combination in different containers.
- the present invention provides a DNA chip for esophageal cancer diagnosis, comprising three or more of the polynucleotides, mutants and / or fragments thereof described in any one of the above (a) to (e).
- the above DNA chip further comprising two or more of the polynucleotides, variants thereof and / or fragments thereof described in any one of the above (f) to (j).
- the above DNA chip comprising 5 or more to all of the polynucleotide comprising the nucleotide sequence represented by SEQ ID NOs: 63 to 124 or a complementary sequence thereof.
- a composition according to any of the above a kit according to any of the above, a DNA chip according to any of the above, or a combination thereof, a target in a biological sample derived from a subject
- the tissue includes esophageal cancer cells using the composition according to any of the above, the kit according to any of the above, the DNA chip according to any of the above, or a combination thereof.
- a first step of measuring the expression level of a target nucleic acid in a plurality of biological samples known in vitro, and a discriminant using the measured value of the expression level of the target nucleic acid obtained in the first step as a teacher A second step of creating a (support vector machine), a third step of measuring the expression level of the target nucleic acid in a specimen sample derived from the subject's esophagus in vitro as in the first step, the second step Substituting the measured value of the expression level of the target nucleic acid obtained in the third step into the discriminant obtained in the step, and based on the result obtained from the discriminant, esophageal cancer cells are included in the sample sample 4th to determine Including the extent, which is a method of determining the esophageal cancer.
- the kit described in any of the above, or the DNA chip described in any of the above for predicting the presence or absence of esophageal cancer in vitro in the composition described in any of the above, the kit described in any of the above, or the DNA chip described in any of the above. Is use.
- the esophageal cancer cell derived from a subject or the polypeptide in blood This is a method for predicting in vitro the presence or absence of esophageal cancer in a subject, comprising measuring the level of peptide in vitro.
- the method according to the above wherein the level of the polypeptide is measured by further using two or more antibodies or fragments thereof against the polypeptide encoded by the nucleotide sequence represented by SEQ ID NOs: 39 to 62 It is.
- polypeptide has the amino acid sequence represented by SEQ ID NOs: 125 to 186.
- any one of the above, wherein the polypeptide expression level is determined to be esophageal cancer if it is altered in a subject suffering from esophageal cancer compared to a healthy subject. It is a method.
- the “polynucleotide” is used as a nucleic acid including both RNA and DNA.
- the DNA includes any of cDNA, genomic DNA, and synthetic DNA.
- the RNA includes any of total RNA, mRNA, rRNA, and synthetic RNA.
- the polynucleotide is used interchangeably with the nucleic acid.
- cDNA includes a full-length DNA strand of a sequence complementary to RNA generated by gene expression and a DNA fragment composed of a partial sequence thereof.
- cDNA can be synthesized by RT-PCR (reverse transcription-polymerase chain reaction) using RNA as a template and poly-T primers.
- the term “gene” includes not only double-stranded DNA but also each single-stranded DNA such as a positive strand (or sense strand) or a complementary strand (or antisense strand) constituting the same. Used intentionally. The length is not particularly limited.
- “gene” refers to double-stranded DNA containing human genomic DNA, single-stranded DNA containing cDNA (positive strand), and single-stranded DNA having a sequence complementary to the positive strand. DNA (complementary strand) and any of these fragments are included.
- the “gene” is not limited to a “gene” represented by a specific base sequence (or SEQ ID NO), but is a protein having a biological function equivalent to a protein encoded by these, for example, a homolog (ie, homolog).
- Variants such as splice variants, and “genes” encoding derivatives are included.
- the “gene” encoding such homologue, variant or derivative is complementary to any one of the specific base sequences represented by SEQ ID NOs: 1 to 62 under the stringent conditions described later.
- a “gene” having a base sequence that hybridizes with the sequence can be mentioned.
- a homologue of a human-derived protein that is, a homolog
- a protein or gene of another species corresponding to the protein or a human gene encoding the protein can be exemplified, and these proteins or genes Homologs can be identified by HomoLoGene (http://www.ncbi.nlm.nih.gov/homoloGene/).
- HomoLoGene http://www.ncbi.nlm.nih.gov/homoloGene/
- a specific human amino acid or base sequence can be obtained by using the BLAST program (Karlin, S. et al., Processedings of the National Academic Sciences USA, 1993, Vol. 90, p.
- BLAST programs include BLASTN (gene) and BLASTX (protein).
- UniGeneClusterID number indicated by Hs. Obtained by inputting the registration number from the BLAST search into UniGene (http://www.ncbi.nlm.nih.gov/UniGene/). Enter in HomoloGene.
- a gene of another species as a gene homolog corresponding to the human gene indicated by a specific base sequence from the list showing the correlation of the gene homologue between the other species gene and the human gene obtained as a result. it can.
- a FASTA program http://www.ddbj.nig.ac.jp/search/fasta-e.html
- BLASTA program http://www.ddbj.nig.ac.jp/search/fasta-e.html
- the “gene” does not ask whether the functional region is different, and can include, for example, an expression control region, a coding region, an exon, or an intron.
- transcript refers to messenger RNA (mRNA) synthesized using a DNA sequence of a gene as a template.
- mRNA messenger RNA
- Messenger RNA is synthesized in such a manner that RNA polymerase binds to a site called a promoter located upstream of the gene and ribonucleotides are bound to the 3 ′ end so as to be complementary to the DNA base sequence.
- This messenger RNA includes not only the gene itself, but also the entire sequence from the transcription start point to the end of the poly A sequence, including the expression control region, coding region, exon or intron.
- the “translation product” refers to a protein synthesized based on the messenger RNA synthesized by transcription regardless of whether or not the RNA is subjected to modification such as splicing.
- ribosome and messenger RNA are first bound, and then amino acids are linked according to the base sequence of messenger RNA, and a protein is synthesized.
- the “probe” includes a polynucleotide used for specifically detecting RNA produced by gene expression or a polynucleotide derived therefrom and / or a polynucleotide complementary thereto.
- the “primer” includes a continuous polynucleotide and / or a complementary polynucleotide that specifically recognizes and amplifies RNA generated by gene expression or a polynucleotide derived therefrom.
- a complementary polynucleotide is a full-length sequence of a polynucleotide consisting of a base sequence defined by a sequence number, or a partial sequence thereof (here, for convenience, this is referred to as a normal strand).
- a polynucleotide having a base-complementary relationship based on a base pair relationship such as A: T (U) and G: C.
- a complementary strand is not limited to the case where it forms a completely complementary sequence with the target positive strand base sequence, but has a complementary relationship that allows hybridization with the target normal strand under stringent conditions. There may be.
- stringent conditions refers to conditions under which a probe hybridizes to its target sequence to a detectably greater extent (eg, at least twice background) than to other sequences. Say. Stringent conditions are sequence-dependent and depend on the environment in which hybridization is performed. By controlling the stringency of the hybridization and / or wash conditions, target sequences that are 100% complementary to the probe can be identified.
- variant refers to a natural variant caused by polymorphism, mutation, alternative splicing during transcription, or a variant based on the degeneracy of the genetic code, or a sequence.
- a variant comprising one or more, preferably one or several, base deletions, substitutions, additions or insertions in the base sequence represented by numbers 1 to 62 or a partial sequence thereof, or the base sequence or a partial sequence thereof About 80% or more, about 85% or more, about 90% or more, about 95% or more, about 97% or more, about 98% or more, a variant showing% identity of about 99% or more, or the base sequence or a part thereof Means a nucleic acid that hybridizes with a polynucleotide or oligonucleotide containing the sequence under the stringent conditions defined above, whereas in the case of a protein or peptide, A variant comprising one or more, preferably one or several amino acid deletions, substitutions, additions or insertions, or
- “several” means an integer of about 10, 9, 8, 7, 6, 5, 4, 3 or 2.
- % identity can be determined using the above-mentioned BLAST or FASTA protein or gene search system with or without introducing a gap (Karlin, S .; 1993, Proceedings of the National Academic Sciences, USA, Vol. 90, p. 5873-5877; Altschul, SF, et al., 1990, Journal of Molecular Biology, Vol. 215, p. 403-410; Pearson, WR et al., 1988, Proceedingsingof the National Academic Sciences USA, Vol. 85, pp. 2444-2448).
- the term “derivative” means, in the case of a nucleic acid, a labeled derivative such as a fluorophore, a modified nucleotide (for example, a nucleotide or a base containing a group such as halogen, alkyl such as methyl, alkoxy such as methoxy, thio, or carboxymethyl)
- a modified nucleotide for example, a nucleotide or a base containing a group such as halogen, alkyl such as methyl, alkoxy such as methoxy, thio, or carboxymethyl
- acetylation, acylation, alkylation, phosphorylation etc. It means chemically modified derivatives such as oxidation, sulfation, glycosylation, biotinylation and the like.
- diagnosis (or detection or determination) composition refers to the presence or absence of esophageal cancer, the degree of morbidity, the presence or absence of improvement, and the degree of improvement, and prevention and improvement of esophageal cancer. Or what is used directly or indirectly in order to screen the candidate substance useful for a treatment.
- nucleotides, oligonucleotides and polynucleotides are used as probes for detecting the gene expressed in vivo, in tissues or cells based on the above properties, and for amplifying the gene expressed in vivo. It can be effectively used as a primer.
- the “biological tissue” to be detected and diagnosed refers to a tissue in which the gene of the present invention changes in expression with the occurrence of esophageal cancer. Specifically, it refers to esophageal tissue and surrounding lymph nodes, and other organs suspected of metastasis.
- EYA2 gene or “EYA2” are the eyes absolute homolog2 gene (DNA) indicated by the specific base sequence (SEQ ID NO: 1), HTG, PRKCBP1, RPS2 unless otherwise specified by SEQ ID NO: And genes (DNA) encoding homologues, mutants and derivatives thereof.
- EYA2 gene GenBank Accession No. AL049540
- the EYA2 gene was obtained from Zimmerman J. et al. E. Et al., 1997, Genome Res. It can be obtained by the method described in Volume 7, pages 128-141.
- SERF1A gene refers to the Small EDRK-rich factor1 gene (DNA), 4F5, H4F5, which is represented by a specific base sequence (SEQ ID NO: 2), unless otherwise specified by a SEQ ID NO. , SMA modifier1, its homologues, mutants and derivatives, etc. (DNA) are included.
- SERF1A gene GenBank Accession No. AF073519 described in SEQ ID NO: 2 and other species homologues are included.
- the SERF1A gene was obtained from Scharf J. M.M. Et al., 1998, Nat. Genet. , Vol. 20, pages 83-86.
- IGHG1 gene refers to an immunoglobulin heavy gamma 1 gene (DNA), G1m marker, a specific base sequence (SEQ ID NO: 3), unless otherwise specified by a SEQ ID NO. It includes genes (DNA) encoding FLJ3998, FLJ40036, FLJ40253, FLJ40587, FLJ40789, FLJ40834, MGC45809, DKFZp686H11213, homologues, variants and derivatives thereof. Specifically, the IGHG1 gene (GenBank Accession No. NC — 000014) described in SEQ ID NO: 3 and other species homologues are included. The IGHG1 gene can be found in Hood L. Et al., 1968, Nature, 220, p.764-767.
- ITSN2 gene or “ITSN2” means the INTERSECTIN2 gene (DNA) represented by a specific base sequence (SEQ ID NO: 4), SH3domain-containing protein 1B, SH3P18, unless otherwise specified by a SEQ ID NO. And a gene (DNA) encoding SH3P18-like WASP ⁇ ⁇ associated protein, its homologues, mutants and derivatives.
- ITSN2 gene GenBank Accession No. NM — 019595
- the ITSN2 gene is Pucharcos C. Et al., FEBS Lett. 478, pp. 43-51.
- RAB11FIP5 gene refers to the Homo sapiens RAB11 family interacting protein 5 (class I) gene (DNA) indicated by a specific base sequence (SEQ ID NO: 5), unless otherwise specified by a SEQ ID NO. ), KIAA0853, RIP11, pp75, GAF1, DKFZP434H018, homologues, mutants and derivatives thereof, and the like (DNA).
- RAB11FIP5 gene GenBank Accession No. BC035013 described in SEQ ID NO: 5 and other species homologues are included.
- the RAB11FIP5 gene is Ito T. Et al., 1999, J. Am. Clin. Invest. 104, p.1265-1275.
- HSPA1A gene refers to the Heat shock 70 kDa protein 1A gene (DNA), HAPA1 (DNA) indicated by the specific base sequence (SEQ ID NO: 6), unless otherwise specified by the SEQ ID NO. ), HSP70.1 (DNA), HSP70-1 / HSP70-2 (DNA), HSPA1B (DNA), HSP72 (DNA), homologues, variants and derivatives thereof, etc.
- HSPA1A gene described in SEQ ID NO: 6 GenBank Accession No. NM_005345 and other species homologues, etc. are included.
- HSPA1A gene is Ito T. et al., 1998, J. Biochem. (Tokyo), No. 124, pages 347-353.
- NMU gene refers to a neuromedin U precursor gene (DNA), neuromedin-U-25 represented by a specific base sequence (SEQ ID NO: 7), unless otherwise specified by a SEQ ID NO. , NmU-25, its homologues, mutants and derivatives, etc. (DNA).
- SEQ ID NO: 7 a neuromedin U precursor gene
- SEQ ID NO: 7 a specific base sequence
- NMU gene GeneBank Accession No. NM_006688
- the NMU gene is Austin. Et al., 1995; Mol. D Endocrinol. 14, Vol. 14, pp. 157-169.
- E2F3 gene or “E2F3” means the E2F transcription factor 3 gene (DNA), E2F-3, which is represented by a specific base sequence (SEQ ID NO: 8), unless otherwise specified by a SEQ ID NO.
- the gene (DNA) which codes the homologue, a variant, a derivative, etc. is included.
- the E2F3 gene (GenBank Accession No. NM_001949) described in SEQ ID NO: 8 and other species homologues are included.
- the E2F3 gene is found in Lees J. A. Et al., 1993, Mol. Cell. Biol. , Vol. 13, p7813-7825.
- ESR2 gene As used herein, the terms “ESR2 gene” or “ESR2”, unless specified by a SEQ ID NO., Are the Estrogen receptor beta gene (DNA), ER-BETA, Erb shown by the specific base sequence (SEQ ID NO: 9). , NR3A2, its homologues, mutants and derivatives, etc. (DNA). Specifically, the ESR2 gene (GenBank Accession No. NM_001437) described in SEQ ID NO: 9 and other species homologues are included. The ESR2 gene was obtained from Dotzlaw H. Et al., 1997; Clin. D Endocrinol. Metab. 82, p. It can be obtained by the method described in 2371-2374.
- CFDP1 gene means, unless specified by a SEQ ID NO., A Craniofacial development protein 1 gene (DNA), Bucentaur, BCNT, represented by a specific base sequence (SEQ ID NO: 10), It includes genes (DNA) encoding CP27, p97, SWC5, Yeti, homologues, mutants and derivatives thereof. Specifically, the CFDP1 gene (GenBank Accession No. NM_006324) described in SEQ ID NO: 10 and other species homologues are included. The CFDP1 gene is found in Diekwish T. G. 1999, Gene, Vol. 235, p. It can be obtained by the method described in 19-30.
- HSPC190 gene or “HSPC190” means the Proapototic casease adapter protein gene (DNA), case-2 binding shown by the specific base sequence (SEQ ID NO: 11), unless otherwise specified by the SEQ ID NO. and a gene (DNA) encoding protein, MGC29506, its homologues, mutants and derivatives.
- the HSPC190 gene (GenBank Accession No. NM — 016459) described in SEQ ID NO: 11 and other species homologues are included.
- the HSPC190 gene was obtained from Katoh M. Et al., 2003, Int. J. NOncol. 23, p. 235-241.
- the term “COL1A2 gene” or “COL1A2” refers to a Collagen alpha-2 (I) chain precursor gene (DNA) represented by a specific base sequence (SEQ ID NO: 12), unless otherwise specified by a SEQ ID NO. , Alpha-2 type I collagen, homologues, mutants and derivatives thereof (DNA).
- SEQ ID NO: 12 specific base sequence
- COL1A2 gene GeneBank Accession No. Z74616
- the COL1A2 gene was obtained from Mottes M. Et al., 1998, Hum. Mutat. Vol. 12, p. It can be obtained by the method described in 71-72.
- GCS1 gene means the Mannosyl-oligosaccharide glucosidase gene (DNA), Processing A-glucosidease represented by the specific base sequence (SEQ ID NO: 13), unless otherwise specified by the SEQ ID NO. Including genes (DNA) encoding I, homologues, mutants and derivatives thereof.
- GCS1 gene GenBank Accession No. NM_006302 described in SEQ ID NO: 13 and other species homologues are included.
- the GCS1 gene is Kalz-FullerFB. Et al., 1995, Eur. J. Biochem. 231, p. 344-351.
- PARL gene refers to a Presennlins associated protein-like protein protein (DNA) represented by a specific nucleotide sequence (SEQ ID NO: 14), unless specified by the SEQ ID NO: Gene (DNA) encoding the body, mutant and derivative.
- SEQ ID NO: 14 a specific nucleotide sequence
- PARL gene Gene (GenBank Accession No. NM — 018622) described in SEQ ID NO: 14 and other species homologues are included.
- the PARL gene was obtained from Pellegrini L. Et al., 2001, J. Am. Alzheimers Dis. , Volume 3, p. 181-190.
- CELSR2 gene or “CELSR2” means the Cadherin EGF LAG seven-pass G-type receptor 2 precursor gene represented by the specific base sequence (SEQ ID NO: 15) unless otherwise specified by the SEQ ID NO. (DNA), epidermal growth factor-like 2, multiple epidermal growth factor-like domain 3, Flamingo 1, homologues, mutants and derivatives thereof (DNA).
- SEQ ID NO: 15 SEQ ID NO. 15
- CELSR2 gene described in SEQ ID NO: 15 GenBank Accession
- NM_001408 and other species homologues are included.
- the CELSR2 gene has been identified by Nakayama M. Et al., 1998, Genomics, 51, p. 27-34.
- NDRG1 gene refers to the N-myc downstream regulated gene 1 gene (DNA), GC4, which is represented by a specific base sequence (SEQ ID NO: 16), unless otherwise specified by a SEQ ID NO. , RTP, NDR1, NMSL, TDD5, CAP43, CMT4D, HMSNL, RIT42, TARG1, PROXY1, homologues, mutants and derivatives thereof (DNA).
- SEQ ID NO. 16 specific base sequence
- RTP RTP
- NDR1, NMSL TDD5
- CAP43 CAP43
- CMT4D HMSNL
- RIT42 TARG1, PROXY1 gene
- NDRG1 gene GeneBank Accession No. NM_006096
- the NDRG1 gene is derived from Kokame K. Et al., 1996, J. Am. Biol. Chem. 271, p. It can be obtained by the method described in 29659-29665.
- SLC25A44 gene or “SLC25A44” means a solid carrier family 25, member 44 gene (DNA) indicated by a specific base sequence (SEQ ID NO: 17), FLJ90431, unless otherwise specified by a SEQ ID NO. , KIAA0446, RP11-54H19.3, homologues, variants and derivatives thereof, etc. (DNA).
- SLC25A44 gene GenBank Accession17No. NM_014655
- the SLC25A44 gene is the protein of Haitina T. Et al., 2006, Genomics, 88, p. 779-790.
- TUSC2 gene refers to a tumor suppressor candidate 2 gene (DNA), PAP, FUS1, or a specific base sequence (SEQ ID NO: 18), unless otherwise specified by a SEQ ID NO. It includes genes (DNA) encoding PDAP2, C3orf11, homologues, mutants and derivatives thereof. Specifically, the TUSC2 gene (GenBank Accession No. NM_007275) described in SEQ ID NO: 18 and other species homologues are included. The TUSC2 gene was obtained from Lerman M. I. Et al., 2000, Cancer Res. 60, p. 6116-6133.
- SLC4A1 gene or “SLC4A1” means a single carrier family 4, anion exchanger, member 1 gene (DNA) indicated by a specific base sequence (SEQ ID NO: 19), unless otherwise specified by a SEQ ID NO. ), DI, FR, SW, WD, WR, AE1, WD1, BND3, EPB3, CD233, EMPB3, RTA1A, MGC116753, MGC126619, MGC126623, their homologues, mutants and derivatives, etc. To do. Specifically, the SLC4A1 gene (GenBank Accession No. NM_000342) described in SEQ ID NO: 19 and other species homologues are included. The SLC4A1 gene is available from Lux S. E. Et al., 1189, Proc. Natl. Acad. Sci. USA. 86, p. It can be obtained by the method described in 9089-9093.
- MS4A7 gene refers to a membrane-spanning 4-domains, sanfamily A, member 7 gene represented by a specific base sequence (SEQ ID NO: 20), unless otherwise specified by a SEQ ID NO. (DNA), CFFM4, MS4A8, 4SPAN2, CD20L4, MGC22368, homologues, mutants and derivatives thereof (DNA) are included.
- MS4A7 gene (GenBank Accession No. NM_206938) described in SEQ ID NO: 20 and other species homologues are included.
- the MS4A7 gene is IshibashiK. Et al., 2001, Gene, 264, p. 87-93.
- thymosin beta-4 gene refers to the thymosin beta-4 gene (DNA), FX indicated by the specific base sequence (SEQ ID NO: 21), unless otherwise specified by the SEQ ID NO. , TB4X, PTMB4, TMSB4, thymosin beta-4, X-linked, homologues, mutants and derivatives thereof (DNA).
- TMSB4X gene GenBank Accession No. NM_021109 described in SEQ ID NO: 21 and other species homologues are included.
- the TMSB4X gene is available from Gondo H. Et al., 1987; Immunol. 139, p. 3840-3848.
- PRC1 gene means a protein regulator of cytokinesis 1 gene (DNA) or protein regulation cytokines indicated by a specific base sequence (SEQ ID NO: 22), unless otherwise specified by a SEQ ID NO. 1, ASE1, MGC1671, MGC3669, homologues, mutants and derivatives thereof, etc. (DNA) are included.
- SEQ ID NO: 22 protein regulator of cytokinesis 1 gene
- SEQ ID NO: 22 protein regulation cytokines indicated by a specific base sequence
- PRC1 gene GeneBank Accession No. NM_003981
- the PRC1 gene is described in Jiang W. Et al., 1998, Mol. Cell. , Volume 2, p. 877-885.
- VCP gene refers to a Valosin-containing protein protein (DNA), p97, TERA, represented by a specific base sequence (SEQ ID NO: 23), unless otherwise specified by a SEQ ID NO. It includes genes (DNA) encoding IBMFFD, MGC8560, MGC131997, MGC148092, homologues, variants and derivatives thereof. Specifically, the VCP gene (GenBank Accession No. NM_007126) described in SEQ ID NO: 23 and other species homologues are included. The VCP gene is available from Druck T. Et al., 1995, Genomics, Volume 30, p. 94-97.
- RBM9 gene refers to an RNA binding protein protein 9 gene (DNA), RTA, fxh represented by a specific base sequence (SEQ ID NO: 24), unless otherwise specified by a SEQ ID NO. , Fox-2, HNRBP2, HRNBP2, dj106I20.3, homologues, mutants and derivatives thereof (DNA).
- RBM9 gene GenBank Accession No. NM_014309) described in SEQ ID NO: 24, other species homologues, and the like are included.
- the RBM9 gene is Norris J. D. Et al., 2002, Mol. D Endocrinol. 16, p. 459-468.
- GPR126 gene refers to the G protein-coupled receptor 126 gene (DNA), FLJ14937, indicated by a specific base sequence (SEQ ID NO: 25), unless otherwise specified by a SEQ ID NO. It includes a gene (DNA) encoding DKFZp564D0462, VIGR, DREG, PS1TP2, homologues, mutants and derivatives thereof. Specifically, the GPR126 gene (GenBank Accession No. BC075798) described in SEQ ID NO: 25 and other species homologues are included. The GPR126 gene was obtained from Stehlik C. Et al., FEBS IV Lett. 569, p. 149-155.
- HOXA10 gene or “HOXA10” means a homeobox A10 gene (DNA) represented by a specific base sequence (SEQ ID NO: 26), HOX1.8, MGC12859, unless specified by a SEQ ID NO.
- the gene (DNA) which codes the homologue, a variant, a derivative, etc. is included.
- the HOXA10 gene (GenBank Accession No. BC013971) described in SEQ ID NO: 26 and other species homologues are included.
- the HOXA10 gene is LowneyLP. Et al., 1991, Nucleic Acid Res. 19, p. 3443-3449.
- PPP1R1A gene or “PPP1R1A” is a protein phosphate 1, regulatory (inhibitor) subunit 1A gene (DNA) represented by a specific base sequence (SEQ ID NO: 27), unless otherwise specified by a SEQ ID NO. ), Homologues, mutants and derivatives thereof (DNA).
- SEQ ID NO: 27 specific base sequence
- PPP1R1A gene GeneBank Accession No. NM_006741
- protein phosphatease inhibitor 1, IPP-1, I-1, and other species homologs are included.
- the PPP1R1A gene is found in Endo S. Et al., 1996, Biochemistry, 35, p. It can be obtained by the method described in 5220-5228.
- MYO9B gene indicates a myosine IXB gene (DNA), MYR5, CELIAC4, or a homologue thereof, represented by a specific nucleotide sequence (SEQ ID NO: 28), unless otherwise specified by a SEQ ID NO. Gene (DNA) encoding the body, mutant and derivative.
- SEQ ID NO: 28 specific nucleotide sequence
- MYO9B gene GenBank Accession No. NM_004145
- the MYO9B gene was obtained from the Whith J. A. Et al., 1996, J. Am. Cell. Sci. 109, p. 653-661.
- SLCO4C1 gene or “SLCO4C1” means a solid carrier organic transporter family, member4C1 gene (DNA) represented by a specific base sequence (SEQ ID NO: 29), unless otherwise specified by a SEQ ID NO.
- the gene (DNA) which codes the homologue, a variant, a derivative, etc. is included.
- the SLCO4C1 gene (GenBank Accession No. NM_180991) described in SEQ ID NO: 29 and other species homologues are included.
- the SLCO4C1 gene is a product of Mikaichi T. et al. Et al., 2004, Proc. Natl. Acad. Sci. USA. 101, p. 3569-3574.
- SERPINB13 gene or “SERPINB13” means the HURPIN gene (DNA) represented by the specific base sequence (SEQ ID NO: 30), HACAT UV-REPRESABLE SERPIN, PROTEASE, unless otherwise specified by the SEQ ID NO. It includes genes (DNA) encoding INHIBITOR 13, HEADPIN, SERPIN B13, homologues, mutants and derivatives thereof. Specifically, the SERPINB13 gene (GenBank Accession No. NM — 012397) described in SEQ ID NO: 30 and other species homologues are included. The SERPINB13 gene is found in Spring P. et al. Et al., 1999, Biochem. Biophys. Res. Commun.
- SDC2 gene means the Syndecan2 gene (DNA) represented by a specific base sequence (SEQ ID NO: 31), heparan sulfate protease 1, cell-, unless otherwise specified by SEQ ID NO: It includes genes (DNA) encoding associated, fibroglycan, human heparan sulfate protein (HSPG) core protein 3'end, homologues, mutants and derivatives thereof.
- SDC2 gene GenBank Accession No. J04621 described in SEQ ID NO: 31 and other species homologues are included.
- the SDC2 gene is de Boeck H. et al. Et al., 1987, Biochem.
- TOR1A gene means a torsin family, member A gene (DNA), dystonia1, DYT1 represented by a specific base sequence (SEQ ID NO: 32), unless otherwise specified by a SEQ ID NO. , DQ2, torsin A, its homologues, mutants and derivatives, etc. (DNA).
- SEQ ID NO: 32 a specific base sequence
- DQ2 torsin A
- TOR1A gene GenBank Accession No. NM — 000113
- the TOR1A gene is derived from Ozelius L. et al. J. et al. Et al., 1997, Nat. Genet.
- RPL18A gene or “RPL18A” means a ribosomal protein L18a gene (DNA) represented by a specific base sequence (SEQ ID NO: 33), its homologue, and mutation, unless otherwise specified by SEQ ID NO: The gene (DNA) which codes a body, derivatives, etc. is included. Specifically, the RPL18A gene (GenBank Accession No. NM_000980) described in SEQ ID NO: 33 and other species homologues are included. The RPL18A gene is a product of Adams M. et al. D. 1992, Nature, 355, p. 632-634.
- GAS7 gene or “GAS7” means the Growth-arrest-specific protein7 gene (DNA), GAS-, which is represented by a specific base sequence (SEQ ID NO: 34), unless otherwise specified by a SEQ ID NO. 7, gene (DNA) encoding MGC1348, its homologues, mutants and derivatives, and the like.
- SEQ ID NO: 34 specific base sequence
- SEQ ID NO. 7 gene encoding MGC1348, its homologues, mutants and derivatives, and the like.
- GAS7 gene GenBank Accession No. NM — 201432
- the GAS7 gene is disclosed in Ju Y. et al. T.A. Et al., 1998, Proc. Natl. Acad. Sci. USA. 95, p.
- WISP1 gene means the WNT1 inducible signaling pathway 1 gene (DNA), CCN4, which is represented by a specific base sequence (SEQ ID NO: 35), unless otherwise specified by a SEQ ID NO. It includes genes (DNA) encoding WISP1c, WISP1i, WISP1tc, homologues, mutants and derivatives thereof. Specifically, the WISP1 gene (GenBank Accession No. NM_003882) described in SEQ ID NO: 35 and other species homologues are included. The WISP1 gene is derived from Pennica D. et al. Et al., 1998, Proc. Natl. Acad.
- CACNG4 gene refers to a voltage-dependent calcium channel gamma-4 subunit gene (DNA) represented by a specific base sequence (SEQ ID NO: 36), unless otherwise specified by a SEQ ID NO. , Neuronal voltage-gate calcium channel gamma-4 subunit, MGC11138, MGC24983, homologues, mutants and derivatives thereof, and the like (DNA).
- SEQ ID NO: 36 specific base sequence
- CACNG4 gene Gene (GenBank Accession No. NM — 014405) described in SEQ ID NO: 36 and other species homologues are included.
- the CACNG4 gene is described in Burgess D. et al. L. Et al., 1999, Genome Res. Vol. 9, p. It can be obtained by the method described in 1204-1213.
- the term “S100P gene” or “S100P” refers to the S-100P protein gene (DNA) represented by the specific base sequence (SEQ ID NO: 37), S100 calcium binding protein, unless otherwise specified by the SEQ ID NO. It includes genes (DNA) encoding P, MIG9, homologues, mutants and derivatives thereof. Specifically, the S100P gene (GenBank Accession No. NM — 005980) described in SEQ ID NO: 37 and other species homologues are included.
- the S100P gene is a Becker T. et al. Et al., 1992, Eur. J. et al. Biochem. 207, p. 541-547.
- the term “UCHL5 gene” or “UCHL5” means the ubiquitin carboxy-terminal hydrolase L5 gene (DNA) represented by the specific base sequence (SEQ ID NO: 38), UCH37, It includes a gene (DNA) encoding CGI-70, its homologues, mutants and derivatives.
- the UCHL5 gene (GenBank Accession No. NM — 015984) described in SEQ ID NO: 38 and other species homologues are included.
- the UCHL5 gene is described in Wicks S. et al. J. et al. Et al., 2005, Oncogene, Vol. 24, p. It can be obtained by the method described in 8080-8084.
- APQ3 gene refers to the Aquaporin 3 gene (DNA) represented by a specific base sequence (SEQ ID NO: 39), its homologues, and variants, unless otherwise specified by SEQ ID NO: And a gene (DNA) encoding a derivative and the like.
- SEQ ID NO: 39 specific base sequence
- APQ3 gene GeneBank Accession No. NM_004925
- SEQ ID NO: 39 other species homologues, and the like are included.
- the APQ3 gene was found in KuriyamayH. Et al., 1997, Biochem. Biophys. Res. Commun. 241, p. It can be obtained by the method described in 53-58.
- NSUN5 gene refers to the NOL1 / NOP2 / Sun domain family, member 5 gene (DNA) represented by a specific base sequence (SEQ ID NO: 40), unless otherwise specified by a SEQ ID NO. ), P120, NOL1R, NOL1, MGC986, NSUN5A, WBSCR20, FLJ10267, WBSCR20A, WBSCR20A, p120 (NOL1), homologues, mutants and derivatives thereof (DNA).
- SEQ ID NO: 40 GenBank Accession No. NM_018804
- the NSUN5 gene is the Doll A. Et al., 2001, Cytogenet. Cell Genet. 95, p. It can be obtained by the method described in 20-27.
- B4GALT2 gene or “B4GALT2” means the UDP-Gal: betaGlcNAc beta 1,4-galactosyltransferase, polypeptide represented by a specific base sequence (SEQ ID NO: 41), unless otherwise specified by a SEQ ID NO. 2 genes (DNA), their homologues, mutants and derivatives, etc. (DNA) are included.
- SEQ ID NO: 41 specific base sequence
- B4GALT2 gene GeneBank Accession No. BC096821
- the B4GALT2 gene is Lo N. W. 1998, Glycobiology, Vol. 8, p. It can be obtained by the method described in 517-526.
- CD48 gene refers to the CD48 molecule gene (DNA) represented by a specific base sequence (SEQ ID NO: 42), BCM1, BLAST, hCD48, unless otherwise specified by SEQ ID NO: It includes genes (DNA) encoding mCD48, BLAST1, SLAMF2, MEM-102, homologues, variants and derivatives thereof. Specifically, the CD48 gene described in SEQ ID NO: 42 (GenBank_Accession) No. NM_001778) and other species homologues are included. The CD48 gene is a Wong Y. W. Et al., 1990, J. Am. Exp. Med. 171, p. 2115-2130.
- DAB2 gene refers to Disabled homomolog 2, mitogen-responsible phosphoprotein gene (DNA) represented by a specific base sequence (SEQ ID NO: 43), It includes genes (DNA) encoding DOC2, DOC-2, FLJ26626, homologues, mutants and derivatives thereof.
- SEQ ID NO: 43 GenBank Accession No. NM_001343 and other species homologues, etc. are included.
- the DAB2 gene is Albertsen HM et al., 1996, Genomics, Vol. 33, p. It can be obtained by the method described in 207-213.
- EBI3 gene or “EBI3” means an Epstein-barr virus induced gene 3 gene (DNA) represented by a specific base sequence (SEQ ID NO: 44), unless otherwise specified by a SEQ ID NO: It includes genes (DNA) encoding homologues, mutants and derivatives. Specifically, the EBI3 gene (GenBank Accession No. NM_005755) described in SEQ ID NO: 44 and other species homologues are included. The EBI3 gene was developed by Devergne O. Et al., 1996, J. Am. Virol. 70, p. 1143-1153.
- MAP3K12 gene refers to a specific base sequence (SEQ ID NO: 45), unless otherwise specified by a SEQ ID NO: mitogen-activated protein kinase kinase 12 gene (DNA), It includes genes (DNA) encoding DLK, MUK, ZPK, ZPKP1, homologues, mutants and derivatives thereof. Specifically, the MAPK12 gene (GenBank Accession No. NM_006301) described in SEQ ID NO: 45 and other species homologues are included. The MAP3K12 gene is Ready U. R. And Pleasure D. 1994, Biochem. Biophys. Res. Commun. 202, p. 613-620.
- SPEN gene refers to a spin homolog, transcriptional regulator gene (DNA), MINT, SHARP represented by a specific base sequence (SEQ ID NO: 46), unless otherwise specified by a SEQ ID NO. , KIAA0929, RP1-134O19.1, homologues, mutants and derivatives thereof, etc. (DNA).
- SPEN gene GenBank Accession No. NM — 0100001
- SPEN gene is Shi T. Et al., 2001, Genes Dev. Vol. 15, p. It can be obtained by the method described in 1140-1151.
- ARHGEF3 gene refers to a Rho guanine nucleotide exchange factor (GEF) 3 gene (DNA) represented by a specific nucleotide sequence (SEQ ID NO: 47), unless otherwise specified by a SEQ ID NO. , GEF, STA3, XPLN, MGC118905, DKFZP434F2429, homologues, variants and derivatives thereof, and the like (DNA).
- GEF Rho guanine nucleotide exchange factor
- DNA specific nucleotide sequence
- SEQ ID NO: 47 specific nucleotide sequence
- the ARHGEF3 gene (GenBank Accession No. NM — 019555) described in SEQ ID NO: 47 and other species homologues are included.
- the ARGGEF3 gene is derived from Thiesen S. et al.
- the term “COL3A1 gene” or “COL3A1” means a 3 ′ region for pro-alpha (III) collagen gene (SEQ ID NO: 48) represented by a specific base sequence (SEQ ID NO: 48), unless otherwise specified by a SEQ ID NO: DNA), its homologues, mutants and derivatives, etc. (DNA) are included.
- the COL3A1 gene (GenBank Accession No. X06700) described in SEQ ID NO: 48 and other species homologues are included.
- the COL3A1 gene is a product of Loidl H. et al. R.
- CSTB gene or “CSTB” means the Cystatin-B gene (DNA), Stefin-B, Liver represented by the specific base sequence (SEQ ID NO: 49), unless otherwise specified by the SEQ ID NO. It includes a gene (DNA) encoding thiol proteinase inhibitor, CPI-B, its homologues, mutants and derivatives.
- the CSTB gene (GenBank Accession No. NM — 000100) described in SEQ ID NO: 49 and other species homologues are included.
- the CSTB gene is described in Jerala, R .; Et al., 1988, FEBS Lett. 239, p. 41-44.
- SPRR3 gene or “SPRR3” means the Small proline-rich protein 3 gene (DNA), Cornifine, Esophagin represented by the specific base sequence (SEQ ID NO: 50), unless otherwise specified by the SEQ ID NO. And genes (DNA) encoding homologues, mutants and derivatives thereof. Specifically, the SPRR3 gene described in SEQ ID NO: 50 (GenBank Accession No. NM_005416) and other species homologues are included. The SPRR3 gene was obtained from AbrahamhJ. M.M. Et al., 1996, Cell Growth Differ. 7, p. 855-860.
- SLIT2 gene means the Slit homolog2 protein gene (DNA), Slit-2, its specific nucleotide sequence (SEQ ID NO: 51), unless otherwise specified by SEQ ID NO: It includes genes (DNA) encoding homologues, mutants and derivatives. Specifically, the SLIT2 gene (GenBank Accession No. NM_004787) described in SEQ ID NO: 51 and other species homologues are included. The SLIT2 gene is Holmes G. P. Et al., 1998, Mech. Dev. 79, p. 57-72.
- CAMK2B gene refers to a Calcium / calmodulin-dependent protein type beta chain gene represented by a specific base sequence (SEQ ID NO: 52) unless specified by a SEQ ID NO ( DNA), CaM-kinase II beta chain, CaM kinase II subunit beta, CaMK-II subunit beta, homologues, mutants and derivatives thereof (DNA).
- SEQ ID NO: 52 DNA
- CaM-kinase II beta chain CaM kinase II subunit beta
- CaMK-II subunit beta homologues, mutants and derivatives thereof
- CAMK2B3 gene GeneBank Accession No. NM_001220
- the CAMK2B gene is derived from Tombes® R. M.M. Et al., 1997, Biochem. Biophys. Acta. 1355, p.281-292.
- SLC2A14 gene or “SLC2A14” is used unless otherwise specified by a SEQ ID NO .: Solute carrier family 2 gene (DNA) represented by a specific base sequence (SEQ ID NO: 53), facile glucose transporter member 14. Genes (DNA) encoding glucose transporter type 14, GLUT 14, homologues, mutants and derivatives thereof. Specifically, the SLC2A14 gene (GenBank Accession No. NM_153449) described in SEQ ID NO: 53 and other species homologues are included. The SLC2A14 gene can be obtained by the method described in Wu X et al., 2002, Genomics, 80, p.553-557.
- the term “SATB2 gene” or “SATB2” refers to a DNA-binding protein protein protein SATB2 gene (DNA), Special AT-, which is represented by a specific base sequence (SEQ ID NO: 54), unless otherwise specified by a SEQ ID NO. It includes genes (DNA) encoding rich sequence-binding protein 2, FLJ21474, KIAA1034, homologues, mutants and derivatives thereof. Specifically, the SATB2 gene (GenBank Accession54No. NM_015265) described in SEQ ID NO: 54 and other species homologues are included. The SATB2 gene is FitzPatrickrD. R. Et al., 2003, Hum. Mol. Genet. , Vol. 12, pp. 2491-2501.
- SEPT6 gene means the Septin-6 gene (DNA) represented by a specific base sequence (SEQ ID NO: 55), KIAA0128, MGC16619, MGC20339, unless otherwise specified by a SEQ ID NO. , SEP2, SEPT2, its homologues, mutants and derivatives, etc. (DNA) are included.
- SEPT6 gene GenBank Accession No. NM_015129 described in SEQ ID NO: 55 and other species homologues are included.
- the SEPT6 gene is derived from Sui L. Et al., 2003, Biochem. Biophys. Res. Commun. 304, p. 393-398.
- GALNS gene refers to a Galactosamine (N-acetyl) -6-sulfate sulfate gene represented by a specific base sequence (SEQ ID NO: 56) unless otherwise specified by a SEQ ID NO: DNA), a gene (DNA) encoding Morquio syndrome, mucopolysaccharidosis type IVA, its homologues, mutants and derivatives, and the like.
- GALNS gene GenBank Accession No. NM_000512
- the GALNS gene was obtained from Nakashima Y. Et al., 1994, Genomics, Volume 20, p. 99-104.
- TROAP gene means that unless specified by a SEQ ID NO, a Trophinin associated protein gene (DNA), tastin, or a homologue thereof represented by a specific base sequence (SEQ ID NO: 57) And genes (DNA) encoding mutants and derivatives.
- TROAP gene GenBank Accession No. NM_005480
- SEQ ID NO: 57 a specific base sequence
- TROAP gene Genes Dev. Vol. 9, p. 1199-1210.
- XRCC3 gene or “XRCC3” means an X-rayrarepair complementing defective in Chinese hamster cells 3 gene represented by a specific base sequence (SEQ ID NO: 58), unless otherwise specified by a SEQ ID NO. Gene (DNA) encoding (DNA), its homologues, mutants and derivatives.
- SEQ ID NO: 58 SEQ ID NO. Gene (DNA) encoding (DNA), its homologues, mutants and derivatives.
- the XRCC3 gene (GenBank Accession No. NM_005432) described in SEQ ID NO: 58 and other species homologues are included.
- the XRCC3 gene is a Tebbs R. S. Et al., Proc. Natl. Acad. Sci. USA, Vol. 92, p. It can be obtained by the method described in 6354-6358.
- FGF3 gene refers to the Fibroblast growthfactor 3 gene (DNA), murine mammary tumor virus represented by a specific base sequence (SEQ ID NO: 59), unless otherwise specified by a SEQ ID NO. It includes a gene (DNA) encoding an integration site (v-int-2) oncogene homolog, INT-2, HBGF-3, homologues, mutants and derivatives thereof. Specifically, the FGF3 gene (GenBank Accession No.GNM_005247) described in SEQ ID NO: 59 and other species homologues are included. The FGF3 gene is derived from Brookes S. et al. Et al., 1989, Oncogene, Volume 4, p. 429-436.
- EIF4EBP2 gene refers to the eukaryotic translation initiation factor 2 gene (DNA), 4EBP2 indicated by a specific base sequence (SEQ ID NO: 60), unless otherwise specified by a SEQ ID NO. And genes (DNA) encoding homologues, mutants and derivatives thereof.
- EIF4EBP2 gene (GenBank Accession No. NM_004096) described in SEQ ID NO: 60 and other species homologues are included.
- the EIF4EBP2 gene is Pause A. Et al., 1994, Nature. 371, p. 762-767. It is shown in Kawama H. et al., 2003, Cancer Science, Vol. 94, p. 699-706 that the EIF4EBP2 gene is expressed in a metastatic sub-line of esophageal cancer cell lines.
- RRM1 gene is a ribonucleotide reductase M1 polypeptide gene (DNA), R1, RR1, It includes a gene (DNA) encoding RIR1, its homologues, mutants and derivatives. Specifically, the RRM1 gene described in SEQ ID NO: 61 (GenBank Accession No. NM_001033) and other species homologues are included. The RRM1 gene is Parker N. J. et al. Et al., 1994, Genomics, Vol. 19, p. 91-96.
- M6PR gene refers to a mannose-6-phosphate receptor (cation dependent) gene (DNA) represented by a specific base sequence (SEQ ID NO: 62), unless otherwise specified by a SEQ ID NO. ), Homologues, mutants and derivatives thereof (DNA).
- SEQ ID NO: 62 specific base sequence
- M6PR gene GenBank Accession No. NM — 002355
- the M6PR gene is a product of Pohlmann R.I. Et al., 1987, Proc. Natl. Acad. Sci. USA, Vol. 84, p. It can be obtained by the method described in 5575-5579.
- the present invention provides a composition for determining a disease useful for diagnosis and treatment of esophageal cancer and a method for determining (or detecting) esophageal cancer using the composition. It has a special effect of providing a determination method that is both simple and high in prediction rate and quick and simple.
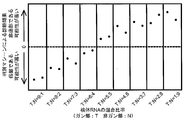
- the detection rate of the presence of esophageal cancer cells when the polynucleotides of SEQ ID NOs: 63 to 124 corresponding to the genes listed in Table 1 are used in combination is shown.
- the vertical axis represents the probability that the presence of esophageal cancer tissue in the specimen can be detected, and the horizontal axis represents the total number of genes necessary for esophageal cancer detection, which are sequentially increased in the SEQ ID NOs shown in Table 1.
- the detection rate of the presence of esophageal cancer cells when the polynucleotides of SEQ ID NOs: 63 to 124 corresponding to the genes listed in Table 1 are used in combination is shown.
- the vertical axis represents the probability of the presence of esophageal cancer tissue in the specimen
- the horizontal axis represents the ratio of total RNA obtained from esophageal cancer tissue and tissue RNA obtained from tissue not containing esophageal cancer in order from the left: 9: 1
- Data obtained from cocktails of RNA mixed to 8: 2, 7: 3, 6: 4, 5: 5, 4: 6, 3: 7, 2: 8, 1: 9 are shown respectively.
- the presence detection rate of esophageal cancer cells derived from biopsy tissues when the polynucleotides of SEQ ID NOs: 63 to 124 corresponding to the genes shown in Table 1 are used in combination is shown.
- the vertical axis is the probability of the presence of esophageal cancer tissue during biopsy
- the horizontal axis is the data obtained from the biopsy tissue without esophageal cancer of the esophageal cancer patient collected by the endoscope on the left frame
- Each frame shows data obtained from a biopsy tissue including esophageal cancer of an esophageal cancer patient collected by an endoscope.
- the presence detection rate of an esophageal cancer cell at the time of using combining the polynucleotide corresponding to the composition for esophageal cancer diagnosis of international publication 2006/118308 is shown.
- the discrimination machine created a discrimination machine for cancer discrimination to determine the presence rate of esophageal cancer tissue during biopsy.
- the vertical axis is the probability of the presence of esophageal cancer tissue during biopsy
- the horizontal axis is the data obtained from the biopsy tissue without esophageal cancer of the esophageal cancer patient collected by the endoscope on the left frame
- Each frame shows data obtained from a biopsy tissue including esophageal cancer of an esophageal cancer patient collected by an endoscope.
- the presence detection rate of an esophageal cancer cell at the time of using combining the polynucleotide corresponding to the composition for esophageal cancer diagnosis of international publication 2006/118308 is shown.
- the discrimination machine created a non-cancer discrimination machine to determine the presence rate of esophageal cancer tissue during biopsy.
- the vertical axis is the probability of the presence of esophageal cancer tissue during biopsy
- the horizontal axis is the data obtained from the biopsy tissue without esophageal cancer of the esophageal cancer patient collected by the endoscope on the left frame
- Each frame shows data obtained from a biopsy tissue including esophageal cancer of an esophageal cancer patient collected by an endoscope.
- the presence detection rate of an esophageal cancer cell at the time of using combining the polynucleotide corresponding to the composition for esophageal cancer diagnosis of international publication 2006/118308 is shown.
- a discrimination machine was created using the method described herein to determine the prevalence of esophageal cancer tissue during biopsy.
- the vertical axis is the probability of the presence of esophageal cancer tissue during biopsy
- the horizontal axis is the data obtained from the biopsy tissue without esophageal cancer of the esophageal cancer patient collected by the endoscope on the left frame
- Each frame shows data obtained from a biopsy tissue including esophageal cancer of an esophageal cancer patient collected by an endoscope.
- Target nucleic acid for esophageal cancer Target nucleic acid as an esophageal cancer marker for determining the presence and / or absence of esophageal cancer or esophageal cancer cells using the composition and kit for esophageal cancer diagnosis as defined above of the present invention
- human genes comprising the base sequences represented by SEQ ID NOs: 1 to 62 (ie, EYA2, SERF1A, IGHG1, ITSN2, RAB11FIP5, HSPA1A, NMU, E2F3, ESR2, CFDP1, HSPC190, COL1A2, GCS1, and PARL, respectively) , CELSR2, NDRG1, SLC25A44, TUSC2, SLC4A1, MS4A7, TMSB4X, PRC1, VCP, RBM9, GPR126, HOXA10, PPP1R1A, MYO9B, SLCO4C1, SERPINB13, SDC2, TOR1A, PL18
- a preferred target nucleic acid is a human gene containing the nucleotide sequence represented by SEQ ID NOs: 1 to 62, a transcription product or cDNA thereof, and more preferably the transcription product or cDNA.
- any of the above genes that are targets for esophageal cancer has an increased / decreased expression level in subjects suffering from esophageal cancer compared to healthy subjects (see Table 1 in Examples below). .
- the first target nucleic acid is an EYA2 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there is no known report that increased expression of the EYA2 gene or its transcription product can be a marker for esophageal cancer.
- the second target nucleic acid is the SERF1A gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there is no known report that increased expression of the SERF1A gene or a transcription product thereof can be a marker for esophageal cancer.
- the third target nucleic acid is an IGHG1 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there has been no report that an increase in the expression of the IGHG1 gene or a transcription product thereof can be a marker for esophageal cancer.
- the fourth target nucleic acid is the ITSN2 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there is no known report that increased expression of the ITSN2 gene or its transcription product can be a marker for esophageal cancer.
- the fifth target nucleic acid is the RAB11FIP5 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there has been no report that increased expression of the RAB11FIP5 gene and its transcription product can be a marker for esophageal cancer.
- the sixth target nucleic acid is the HSPA1A gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there has been no report that increased expression of the HSPA1A gene and its transcript can serve as a marker for esophageal cancer.
- the seventh target nucleic acid is an NMU gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there is no known report that increased expression of the NMU gene and its transcript can be a marker for esophageal cancer.
- the eighth target nucleic acid is the E2F3 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there has been no report that increased expression of the E2F3 gene and its transcript can be a marker for esophageal cancer.
- the ninth target nucleic acid is an ESR2 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there has been no report that increased expression of the ESR2 gene and its transcript can be a marker for esophageal cancer.
- the tenth target nucleic acid is a CFDP1 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there is no report that an increase in the expression of the CFDP1 gene and its transcription product can be a marker for esophageal cancer.
- the eleventh target nucleic acid is the HSPC190 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there has been no report that increased expression of the HSPC190 gene and its transcript can be a marker for esophageal cancer.
- the twelfth target nucleic acid is a COL1A2 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there is no known report that increased expression of the COL1A2 gene and its transcription product can be a marker for esophageal cancer.
- the thirteenth target nucleic acid is a GCS1 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there is no known report that increased expression of the GCS1 gene and its transcript can be a marker for esophageal cancer.
- the 14th target nucleic acid is a PARL gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there is no report that a decrease in the expression of the PRL gene and its transcript can be a marker for esophageal cancer.
- the fifteenth target nucleic acid is the CELSR2 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there is no known report that increased expression of the CELSR2 gene and its transcript can be a marker for esophageal cancer.
- the sixteenth target nucleic acid is an NDRG1 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there has been no report that increased expression of the NDRG1 gene and its transcription product can serve as a marker for esophageal cancer.
- the 17th target nucleic acid is the SLC25A44 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there is no report that an increase in the expression of the SLC25A44 gene and its transcript can be a marker for esophageal cancer.
- the 18th target nucleic acid is a TUSC2 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there is no known report that increased expression of the TUSC2 gene and its transcription product can serve as a marker for esophageal cancer.
- the nineteenth target nucleic acid is the SLC4A1 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there is no known report that increased expression of the SLC4A1 gene and its transcript can be a marker for esophageal cancer.
- the 20th target nucleic acid is the MS4A7 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there has been no report that a decrease in the expression of the MS4A7 gene and its transcript can be a marker for esophageal cancer.
- the 21st target nucleic acid is a TMSB4X gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there is no known report that increased expression of the TMSB4X gene and its transcript can serve as a marker for esophageal cancer.
- the 22nd target nucleic acid is a PRC1 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- the 23rd target nucleic acid is a VCP gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. To date, there has been no report that increased expression of the VCP gene and its transcript can be a marker for esophageal cancer.
- the 24th target nucleic acid is an RBM9 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there is no known report that increased expression of the RBM9 gene and its transcript can be a marker for esophageal cancer.
- the 25th target nucleic acid is GPR126 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there has been no report that increased expression of the GPR126 gene and its transcript can be a marker for esophageal cancer.
- the twenty-sixth target nucleic acid is the HOXA10 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there has been no report that increased expression of the HOXA10 gene and its transcript can be a marker for esophageal cancer.
- the 27th target nucleic acid is a PPP1R1A gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there has been no report that increased expression of the PPP1R1A gene and its transcription product can be a marker for esophageal cancer.
- the 28th target nucleic acid is a MYO9B gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, there is no known report that increased expression of the MYO9B gene and its transcript can serve as a marker for esophageal cancer.
- the 29th target nucleic acid is a SLCO4C1 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- SLCO4C1 gene and its transcript can be a marker for esophageal cancer.
- the 30th target nucleic acid is a SERPINB13 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- SERPINB13 gene a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- increased expression of the SERPINB13 gene and its transcript can be a marker for esophageal cancer.
- the thirty-first target nucleic acid is an SDC2 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- SDC2 gene and its transcript can be a marker for esophageal cancer.
- the thirty-second target nucleic acid is a TOR1A gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- TOR1A gene a gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- increased expression of the TOR1A gene and its transcript can be a marker for esophageal cancer.
- the 33rd target nucleic acid is an RPL18A gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- RPL18A gene and its transcript can be a marker for esophageal cancer.
- the 34th target nucleic acid is a GAS7 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. There is no known report that increased expression of the GAS7 gene and its transcript can be a marker for esophageal cancer.
- the 35th target nucleic acid is a WISP1 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- WISP1 gene a gene that has decreased expression of the WISP1 gene and its transcript can be a marker for esophageal cancer.
- the thirty-sixth target nucleic acid is a CACNG4 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- CACNG4 gene and its transcript can be a marker for esophageal cancer.
- the 37th target nucleic acid is an S100P gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. There is no known report that decreased expression of the S100P gene and its transcript can be a marker for esophageal cancer.
- the thirty-eighth target nucleic acid is a UCHL5 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- a UCHL5 gene a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- decreased expression of the UCHL5 gene and its transcript can be a marker for esophageal cancer.
- the 39th target nucleic acid is an AQP3 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. It has been known so far that expression of the AQP3 gene and its transcription product serves as a marker for esophageal cancer (WO06118308).
- the 40th target nucleic acid is NSUN5 gene, homologues thereof, transcription product or cDNA thereof, or variant or derivative thereof. It has been known so far that the expression of NSUN5 gene and its transcription product is a marker for esophageal cancer (WO06118308).
- the 41st target nucleic acid is a B4GALT2 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. It has been known so far that the expression of the B4GALT2 gene and its transcription product serves as a marker for esophageal cancer (WO06118308).
- the forty-second target nucleic acid is a CD48 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. It has been known so far that expression of the CD48 gene and its transcription product is a marker for esophageal cancer (WO06118308).
- the 43rd target nucleic acid is a DAB2 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. It has been known so far that expression of the DAB2 gene and its transcription product serves as a marker for esophageal cancer (WO06118308).
- the 44th target nucleic acid is an EBI3 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. It has been known so far that expression of the EBI3 gene and its transcription product is a marker for esophageal cancer (WO06118308).
- the 45th target nucleic acid is a MAP3K12 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. It has been known so far that expression of the MAP3K12 gene and its transcription product serves as a marker for esophageal cancer (WO06118308).
- the 46th target nucleic acid is a SPEN gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. It is known that the expression of the SPEN gene and its transcription product serve as a marker for esophageal cancer (WO06118308).
- the 47th target nucleic acid is an ARGGEF3 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. It is known that expression of the ARGGEF3 gene and its transcription product is a marker for esophageal cancer (WO06118308).
- the 48th target nucleic acid is a COL3A1 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. It is known that expression of the COL3A1 gene and its transcript can be a marker for esophageal cancer (Su, H. et al., 2003, Cancer Research, 63, p. 3872-3876).
- the 49th target nucleic acid is a CSTB gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. It has been known so far that expression of a CSTB gene or a transcription product thereof can be a marker of esophageal cancer (WO0302661, Shirai, T. et al., 1998, InternationalInJournal of Cancer, Vol. 79, p. 175). -178).
- the 50th target nucleic acid is an SPRR3 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- the SPRR3 gene is known to be a marker for esophageal cancer (WO06118308, International Publication No. 2003/042661 pamphlet, Chem, BS, et al., 2000, Carcinogenesis, p21247-2150, Abraham, J. et al. M. et al., 1996, Cell Growth & Differentiation, Volume 7, p 855-860).
- the 51st target nucleic acid is a SLIT2 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof. So far, it has been known that the SLIT2 gene is a marker for esophageal cancer (WO06118308).
- the 52nd target nucleic acid is a CAMK2B gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- the CAMK2B gene is known to be a marker for esophageal cancer (WO06118308).
- the 53rd target nucleic acid is the SLC2A14 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- the SLC2A14 gene is known to be a marker for esophageal cancer (WO06118308).
- the 54th target nucleic acid is a SATB2 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- the SATB2 gene is known to serve as a marker for esophageal cancer (WO06118308).
- the 55th target nucleic acid is a SEPT6 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- the 56th target nucleic acid is a GALNS gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- the GALNS gene is known to serve as a marker for esophageal cancer (WO06118308).
- the 57th target nucleic acid is a TROAP gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- the TROAP gene is known to be a marker for esophageal cancer (WO06118308).
- the 58th target nucleic acid is the XRCC3 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- the XRCC3 gene is known to serve as a marker for esophageal cancer (WO06118308).
- the 59th target nucleic acid is the FGF3 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- the FGF3 gene is known to serve as a marker for esophageal cancer (WO06118308).
- the 60th target nucleic acid is the EIF4EBP2 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- the EIF4EBP2 gene is known to be a marker for esophageal cancer (WO06118308).
- the 61st target nucleic acid is an RRM1 gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- the RRM1 gene is known to serve as a marker for epithelial malignant tumors (WO06119464A1).
- the 62nd target nucleic acid is an M6PR gene, a homologue thereof, a transcription product or cDNA thereof, or a variant or derivative thereof.
- the M6PR gene is known to be a marker for esophageal cancer (WO06118308).
- Target polypeptide for esophageal cancer Target polypeptide as an esophageal cancer marker for determining the presence and / or absence of esophageal cancer or esophageal cancer cells using the composition and kit for esophageal cancer diagnosis as defined above of the present invention
- human genes comprising the nucleotide sequences represented by SEQ ID NOs: 1 to 62 (ie, EYA2, SERF1A, IGHG1, ITSN2, RAB11FIP5, HSPA1A, NMU, E2F3, ESR2, CFDP1, HSPC190, COL1A2, GCS1 respectively) , PARL, CELSR2, NDRG1, SLC25A44, TUSC2, SLC4A1, MS4A7, TMSB4X, PRC1, VCP, RBM9, GPR126, HOXA10, PPP1R1A, MYO9B, SLCO4C1, SERPINB13, SDC , TOR1A
- the level of the polypeptide in is characterized by an increase / decrease in subjects suffering from esophageal cancer compared to healthy subjects.
- Esophageal cancer diagnostic composition 3.1 nucleic acid
- a nucleic acid composition that can be used to determine esophageal cancer or to diagnose esophageal cancer is human-derived EYA2 as a target nucleic acid for esophageal cancer.
- the expression level of the above target nucleic acid is increased or decreased (“increase / decrease”) in subjects suffering from esophageal cancer compared to healthy subjects. Therefore, the composition of the present invention can be effectively used for measuring the expression level of a target nucleic acid in esophageal cancer tissue and normal esophageal tissue and comparing them.
- composition that can be used in the present invention comprises a polynucleotide group comprising the nucleotide sequence represented by SEQ ID NOs: 1 to 62 and a complementary polynucleotide group thereof in a living tissue of a patient suffering from esophageal cancer, complementary to the nucleotide sequence 15 or more, preferably 20 or more, and more preferably 25 or more in the base sequence of the polynucleotide group and its complementary polynucleotide group that hybridize with DNA comprising a simple base sequence under stringent conditions, and the polynucleotide sequences thereof.
- composition of the present invention can include one or more (preferably 3 or more, more preferably 5 or more) of the following polynucleotides or fragments thereof.
- a polynucleotide group consisting of the base sequences represented by SEQ ID NOs: 1 to 62, variants thereof, or fragments containing 15 or more consecutive bases.
- a polynucleotide group comprising the base sequence represented by SEQ ID NOs: 1 to 62.
- a polynucleotide group consisting of the base sequences represented by SEQ ID NOs: 1 to 62, variants thereof, or fragments containing 15 or more consecutive bases.
- a polynucleotide group comprising the base sequences represented by SEQ ID NOs: 1 to 38.
- a polynucleotide group consisting of a base sequence complementary to the base sequence represented by SEQ ID NOs: 1 to 38, a variant thereof, or a fragment thereof containing 15 or more consecutive bases.
- a polynucleotide group comprising a base sequence complementary to the base sequences represented by SEQ ID NOs: 1 to 38.
- a polynucleotide group that hybridizes under stringent conditions with DNA comprising a base sequence complementary to each of the base sequences represented by SEQ ID NOs: 1 to 38, or a fragment thereof containing 15 or more consecutive bases .
- a polynucleotide group consisting of the base sequences represented by SEQ ID NOs: 39 to 62, a variant thereof, or a fragment thereof containing 15 or more consecutive bases.
- a polynucleotide group comprising the base sequence represented by SEQ ID NOs: 39 to 62.
- a polynucleotide group consisting of a base sequence complementary to the base sequence represented by SEQ ID NOs: 39 to 62, a variant thereof, or a fragment thereof containing 15 or more consecutive bases.
- a polynucleotide group comprising a base sequence complementary to the base sequence represented by SEQ ID NOs: 39 to 62.
- a polynucleotide group that hybridizes under stringent conditions with DNA comprising each of the base sequences represented by SEQ ID NOs: 39 to 62, or a fragment thereof containing 15 or more consecutive bases.
- each of the polynucleotide fragments comprising the nucleotide sequences represented by SEQ ID NOs: 1 to 62 is the nucleotide sequence represented by SEQ ID NOs: 63 to 124 or a complementary sequence thereof, or a contiguous 15 thereof. It preferably includes a partial sequence of bases or more.
- polynucleotides are included in the composition of the present invention.
- a polynucleotide comprising 15 or more consecutive bases in each of the base sequences represented by SEQ ID NOs: 1 to 38 or its complementary sequence.
- a polynucleotide comprising 60 or more consecutive bases in each of the base sequence represented by SEQ ID NOs: 1 to 38 or its complementary sequence.
- a polynucleotide comprising 15 or more consecutive bases in each of the base sequence represented by SEQ ID NOs: 39 to 62 or a complementary sequence thereof.
- a polynucleotide comprising 60 or more consecutive bases in each of the base sequence represented by SEQ ID NOs: 39 to 62 or a complementary sequence thereof.
- a polynucleotide comprising the base sequence represented by SEQ ID NO: 63 to 100 in the base sequence represented by SEQ ID NO: 1-38, and comprising 60 or more consecutive bases.
- the sequence complementary to the base sequence represented by SEQ ID NO: 1 to 38 includes a sequence complementary to the base sequence represented by SEQ ID NO: 63 to 100, respectively, and includes 60 or more consecutive bases Polynucleotide.
- a polynucleotide comprising the base sequence represented by SEQ ID NO: 101 to 124 in the base sequence represented by SEQ ID NO: 39 to 62 and comprising 60 or more consecutive bases.
- the sequence complementary to the base sequence represented by SEQ ID NO: 39 to 62 includes a sequence complementary to the base sequence represented by SEQ ID NO: 101 to 124, respectively, and includes 60 or more consecutive bases Polynucleotide.
- Any of the above polynucleotides or fragments thereof used in the present invention may be DNA or RNA.
- the polynucleotide as the composition of the present invention can be prepared using a general technique such as a DNA recombination technique, a PCR method, a method using a DNA / RNA automatic synthesizer.
- DNA recombination techniques and PCR methods include, for example, Ausubel et al., Current Protocols in Molecular Biology, John Willy & Sons, US (1993); Sambrook et al., Molecular Cloning A Laboratory A Laboratory. The techniques described can be used.
- the polynucleotide constituting the composition of the present invention can be chemically synthesized using an automatic DNA synthesizer.
- an automatic DNA synthesizer In general, the phosphoramidite method is used for this synthesis, and single-stranded DNA of up to about 100 bases can be automatically synthesized by this method.
- Automatic DNA synthesizers are commercially available from, for example, Polygen, ABI, Applied BioSystems, and the like.
- the polynucleotide of the present invention can also be prepared by a cDNA cloning method.
- a cDNA library is prepared by RT-PCR from poly A (+) RNA obtained by treating total RNA extracted from a living tissue such as an esophageal tissue in which the above target gene is expressed with an oligo dT cellulose column.
- the target cDNA clone can be obtained from this library by screening such as hybridization screening, expression screening, and antibody screening. If necessary, cDNA clones can be amplified by PCR.
- the probe or primer can be selected from among the contiguous sequences of 15 to 100 bases based on the base sequences shown in SEQ ID NOs: 1 to 62 and synthesized.
- the present invention further includes an esophageal cancer diagnostic kit comprising one or more (preferably three or more) antibodies, fragments thereof, or chemically modified derivatives thereof against the polypeptide having the amino acid sequence represented by SEQ ID NOs: 125 to 162. I will provide a.
- the kit of the present invention may further comprise one or more (preferably two or more) antibodies, fragments thereof or chemically modified derivatives thereof against the polypeptide having the amino acid sequence represented by SEQ ID NOs: 163 to 186.
- the combined use of these antibodies can increase the accuracy for prognosis prediction.
- polypeptides can be obtained by DNA recombination techniques.
- the cDNA clone obtained as described above can be obtained from the cell or culture supernatant by incorporating the cDNA clone obtained in the expression vector and culturing a prokaryotic or eukaryotic host cell transformed or transfected with the vector.
- Vectors and expression systems are available from Novagen, Takara Shuzo, Daiichi Chemicals, Qiagen, Stratagene, Promega, Roche Diagnostics, Invitrogen, Genetics Institute, Amersham Bioscience, and the like.
- prokaryotic cells such as bacteria (eg, Escherichia coli, Bacillus subtilis), yeast (eg, Saccharomyces cerevisiae), insect cells (eg, Sf cells), mammalian cells (eg, COS, CHO, BHK) and the like can be used. it can.
- the vector can contain regulatory elements such as promoters, enhancers, polyadenylation signals, ribosome binding sites, replication origins, terminators, selectable markers, and the like.
- a fusion polypeptide in which a labeled peptide is attached to the C-terminal or N-terminal of the polypeptide may be used.
- Typical labeled peptides include histidine repeats of 6 to 10 residues, FLAG, myc peptide, GFP polypeptide, etc., but the labeled peptide is not limited to these.
- DNA recombination technology Sambrook, J. J. et al. & Russel, D. (Above).
- examples of the purification method include a method by ion exchange chromatography. In addition to this, a method of combining gel filtration, hydrophobic chromatography, isoelectric point chromatography and the like may be used.
- a labeled peptide such as histidine repeat, FLAG, myc, or GFP
- An expression vector that facilitates isolation and purification may be constructed. In particular, if an expression vector is constructed so that it is expressed in the form of a fusion polypeptide of a polypeptide and a labeled peptide, and the polypeptide is genetically engineered, isolation and purification are easy.
- the antibody that recognizes the polypeptide thus obtained can specifically bind to the polypeptide via the antigen-binding site of the antibody.
- a polypeptide having an amino acid sequence of SEQ ID NOs: 125 to 186 or a fragment thereof, a mutant polypeptide or a fusion polypeptide thereof is used as an immunogen for producing antibodies that are immunoreactive with each other. Is possible.
- polypeptides, fragments, variants, fusion polypeptides, etc. contain antigenic determinants or epitopes that elicit antibody formation, but these antigenic determinants or epitopes may be linear or higher order. It may be a structure (intermittent).
- the antigenic determinant or epitope can be identified by any method known in the art.
- the antibody of all aspects is induced by the polypeptide of the present invention. If all or part of the polypeptide or epitope is isolated, both polyclonal and monoclonal antibodies can be prepared using conventional techniques. Methods include, for example, Kennet et al. (Supervised), Monoclonal Antibodies, Hybridomas: A A NewA Dimension in Biological Analyzes, Pleumnum Press, New York, 1980.
- the antibody of the present invention is not particularly limited as long as it specifically binds to the target polypeptide of the present invention or a fragment thereof, and either a monoclonal antibody or a polyclonal antibody can be used, but a monoclonal antibody is used. Is preferred.
- the globulin type of the antibody of the present invention is not particularly limited as long as it has the above characteristics, and may be any of IgG, IgM, IgA, IgE, and IgD.
- ⁇ Preparation of monoclonal antibody> Collection of immunity and antibody-producing cells An immunogen comprising a target polypeptide is administered to a mammal such as a rat, a mouse (for example, Balb / c of an inbred mouse), a rabbit or the like. A single dose of the immunogen is appropriately determined according to the type of animal to be immunized, the route of administration, etc., and is about 50 to 200 ⁇ g per animal. Immunization is performed mainly by injecting an immunogen subcutaneously or intraperitoneally.
- the immunization interval is not particularly limited, and after the initial immunization, booster immunization is performed 2 to 10 times, preferably 3 to 4 times at intervals of several days to several weeks, preferably at intervals of 1 to 4 weeks.
- the antibody titer in the serum of the immunized animal is repeatedly measured by ELISA (Enzyme-Linked Immuno Sorbent Assay) method. When the antibody titer reaches a plateau, the immunogen is injected intravenously or intraperitoneally. Inject and give final immunization. Then, antibody-producing cells are collected 2 to 5 days, preferably 3 days after the last immunization. Examples of antibody-producing cells include spleen cells, lymph node cells, peripheral blood cells, etc., but spleen cells or local lymph node cells are preferred.
- hybridoma cell line producing a monoclonal antibody specific for each target polypeptide is prepared. Such hybridomas can be produced and identified by conventional techniques.
- One method for producing such a hybridoma cell line is to immunize an animal with the protein of the invention, collect spleen cells from the immunized animal, and fuse the spleen cells to a myeloma cell line, thereby producing a hybridoma. Identifying a hybridoma cell line that produces cells and produces a monoclonal antibody that binds to the enzyme.
- a myeloma cell line to be fused with an antibody-producing cell a generally available cell line of an animal such as a mouse can be used.
- the cell line used has drug selectivity and cannot survive in a HAT selection medium (including hypoxanthine, aminopterin, and thymidine) in an unfused state, but can survive only in a state fused with antibody-producing cells. Those having the following are preferred.
- the cell line is preferably derived from an animal of the same species as the immunized animal. Specific examples of myeloma cell lines include BALB / c mouse-derived hypoxanthine / guanine / phosphoribosyl transferase (HGPRT) -deficient cell line P3X63-Ag. 8 strains (ATCC TIB9).
- cell fusion is performed between the myeloma cell line and antibody-producing cells.
- antibody-producing cells and myeloma cell lines are mixed at a ratio of about 1: 1 to 20: 1 in animal cell culture media such as serum-free DMEM and RPMI-1640 media, and cell fusion is performed.
- the fusion reaction is performed in the presence of an accelerator.
- an accelerator As a cell fusion promoter, polyethylene glycol having an average molecular weight of 1500 to 4000 daltons can be used at a concentration of about 10 to 80%.
- an auxiliary agent such as dimethyl sulfoxide may be used in combination in order to increase the fusion efficiency.
- antibody-producing cells and myeloma cell lines can be fused using a commercially available cell fusion device utilizing electrical stimulation (for example, electroporation).
- the target hybridoma is selected from the cells after cell fusion treatment.
- the cell suspension is appropriately diluted with, for example, fetal bovine serum-containing RPMI-1640 medium, and then plated on a microtiter plate at about 2 million cells / well, and a selective medium is added to each well. Cultivate by changing the selective medium.
- the culture temperature is 20 to 40 ° C., preferably about 37 ° C.
- the myeloma cells are of HGPRT-deficient strain or thymidine kinase-deficient strain, cells having the ability to produce antibodies and myeloma cell lines by using a hypoxanthine / aminopterin / thymidine-containing selective medium (HAT medium) Only those hybridomas can be selectively cultured and propagated. As a result, cells that grow from about 14 days after the start of culture in the selective medium can be obtained as hybridomas.
- HAT medium hypoxanthine / aminopterin / thymidine-containing selective medium
- Hybridoma screening is not particularly limited, and may be carried out according to ordinary methods. For example, a part of the culture supernatant contained in a well grown as a hybridoma is collected and performed by enzyme immunoassay (EIA: Enzyme Immuno Assay and ELISA), radioimmunoassay (RIA: Radio Immuno Assay), etc. Can do. Cloning of the fused cells is performed by limiting dilution or the like, and finally a hybridoma that is a monoclonal antibody-producing cell is established. As described later, the hybridoma of the present invention is stable in culture in a basic medium such as RPMI-1640 and DMEM, and produces and secretes a monoclonal antibody that reacts specifically with the target polypeptide.
- a basic medium such as RPMI-1640 and DMEM
- Monoclonal antibodies can be recovered by conventional techniques. That is, as a method for collecting a monoclonal antibody from the established hybridoma, a normal cell culture method or ascites formation method can be employed. In the cell culture method, the hybridoma is cultured in an animal cell culture medium such as RPMI-1640 medium containing 10% fetal bovine serum, MEM medium, or serum-free medium under normal culture conditions (eg, 37 ° C., 5% CO 2 concentration). Cultivate for 2-10 days and obtain antibody from the culture supernatant.
- an animal cell culture medium such as RPMI-1640 medium containing 10% fetal bovine serum, MEM medium, or serum-free medium under normal culture conditions (eg, 37 ° C., 5% CO 2 concentration).
- hybridomas In the case of the ascites formation method, about 10 million hybridomas are administered into the abdominal cavity of a myeloma cell-derived mammal and the same type of animal, and the hybridomas are proliferated in large quantities. Ascites fluid or serum is collected after 1 to 2 weeks.
- a known method such as ammonium sulfate salting-out method, ion exchange chromatography, affinity chromatography, gel chromatography or the like is appropriately selected or these are used. By combining, a purified monoclonal antibody can be obtained.
- ⁇ Preparation of polyclonal antibody> an animal such as a rabbit is immunized as described above, and 6 to 60 days after the last immunization, enzyme immunoassay (EIA and ELISA), radioimmunoassay (RIA), etc. The antibody titer is measured, and blood is collected on the day when the maximum antibody titer is shown to obtain antiserum. Thereafter, the reactivity of the polyclonal antibody in the antiserum is measured by an ELISA method or the like.
- EIA and ELISA enzyme immunoassay
- RIA radioimmunoassay
- a sample sample of a subject comprising measuring in vitro the level of the polypeptide in a biological sample such as an esophageal cancer cell or blood derived from a subject using the antibody of the present invention.
- a method for determining in vitro that an esophageal cancer cell is not contained therein or / or that an esophageal cancer cell is contained therein is provided.
- immunological measurement methods include enzyme immunoassay (ELISA, EIA), fluorescence immunoassay, radioimmunoassay (RIA), luminescence immunoassay, immunoturbidimetric method, latex agglutination, latex turbidimetric method, Examples include hemagglutination, particle agglutination, and Western blotting.
- ELISA enzyme immunoassay
- EIA fluorescence immunoassay
- RIA radioimmunoassay
- luminescence immunoassay immunoturbidimetric method
- latex agglutination latex agglutination
- latex turbidimetric method examples include hemagglutination, particle agglutination, and Western blotting.
- the antibody of the present invention is immobilized, or the components in the sample are immobilized and their immunological reaction is performed. Can do.
- beads made of materials such as polystyrene, polycarbonate, polyvinyl toluene, polypropylene, polyethylene, polyvinyl chloride, nylon, polymethacrylate, latex, gelatin, agarose, cellulose, sepharose, glass, metal, ceramics, or magnetic materials
- Insoluble carriers in the form of microplates, test tubes, sticks or test pieces can be used.
- the solid phase can be formed by binding the solid phase carrier and the antibody or sample component of the present invention according to a known method such as a physical adsorption method, a chemical binding method, or a combination thereof.
- the reaction of the present invention in order to easily detect the reaction between the antibody of the present invention and a target polypeptide in a sample, the reaction of the present invention is directly detected by labeling the antibody of the present invention or labeled. Detection is indirectly by using a secondary antibody. In the detection method of the present invention, it is preferable to use the latter indirect detection (eg, sandwich method) from the viewpoint of sensitivity.
- labeling substance in the case of enzyme immunoassay, peroxidase (POD), alkaline phosphatase, ⁇ -galactosidase, urease, catalase, glucose oxidase, lactate dehydrogenase, amidase or biotin- avidin complex, etc.
- POD peroxidase
- alkaline phosphatase alkaline phosphatase
- ⁇ -galactosidase urease
- catalase glucose oxidase
- lactate dehydrogenase lactate dehydrogenase
- amidase or biotin- avidin complex etc.
- fluorescein isothiocyanate fluorescein isothiocyanate, tetramethylrhodamine isothiocyanate, substituted rhodamine isothiocyanate, dichlorotriazine isothiocyanate, Alexa or AlexaFluoro, etc.
- a radioimmunoassay tritium, iodine 125 or iodine 131, etc.
- NADH-, FMNH2-, luciferase system, luminol-hydrogen peroxide-POD system, acridinium ester system, dioxetane compound system, etc. can be used for the luminescence immunoassay.
- the binding method between the labeling substance and the antibody is a known method such as glutaraldehyde method, maleimide method, pyridyl disulfide method or periodate method in the case of enzyme immunoassay, and chloramine T in the case of radioimmunoassay.
- a known method such as the Bolton Hunter method can be used.
- the operation method of measurement can be performed by a known method (Current protocol in Protein Sciences, 1995, John Wiley & Sons Inc., Current protocol in Immunology, 2001, JohnIns.).
- the components in the sample are immobilized and contacted with the labeled antibody of the present invention to form a complex of the marker polypeptide and the antibody of the present invention. Unbound labeled antibody can be washed and separated, and the amount of target polypeptide in the sample can be measured from the amount of bound labeled antibody or the amount of unbound labeled antibody.
- the antibody of the present invention and the sample are reacted (primary reaction), and further the labeled secondary antibody is reacted (secondary reaction).
- the primary reaction and the secondary reaction may be performed in the reverse order, may be performed simultaneously, or may be performed at different times.
- the substrate is reacted with the labeled enzyme under the optimum conditions, and the amount of the reaction product is measured by an optical method or the like.
- fluorescent immunoassay the fluorescence intensity by the fluorescent substance label is measured, and in the case of radioimmunoassay, the amount of radioactivity by the radioactive substance label is measured.
- the luminescence immunoassay the amount of luminescence by the luminescence reaction system is measured.
- the formation of immune complex aggregates such as immunoturbidimetric method, latex agglutination reaction, latex turbidimetric method, erythrocyte agglutination reaction or particle agglutination reaction, and the transmitted light and scattered light are measured by an optical method.
- a phosphate buffer, glycine buffer, Tris buffer, Good buffer, or the like can be used as a solvent, and further, a reaction accelerator such as polyethylene glycol or the like can be used.
- a specific reaction inhibitor may be included in the reaction system.
- kits of the present invention may exist individually or in the form of a mixture, or may be bound to a solid support or in a free form.
- the kit of the present invention contains a labeled secondary antibody, a carrier, a washing buffer, a sample diluent, an enzyme substrate, a reaction stop solution, a purified marker (target) polypeptide as a standard substance, instructions for use, etc. Can do.
- Esophageal cancer diagnostic kit (nucleic acid)
- the present invention also provides an esophageal cancer diagnosis comprising one or more (preferably 3 or more, more preferably 5 or more) of the same polynucleotides, variants and / or fragments thereof as included in the composition of the present invention ( Detection) kit is provided.
- the kit of the present invention preferably contains one or a plurality of polynucleotides selected from the polynucleotides described in 3.1 above or fragments thereof.
- the kit of the present invention comprises a polynucleotide comprising the nucleotide sequence represented by SEQ ID NOs: 1 to 38, a polynucleotide comprising the complementary sequence thereof, a polynucleotide that hybridizes with these polynucleotides under stringent conditions, or a Three or more fragments of the polynucleotide can be included.
- the kit of the present invention further comprises a polynucleotide comprising the nucleotide sequence represented by SEQ ID NOs: 39 to 62, a polynucleotide comprising the complementary sequence thereof, a polynucleotide that hybridizes with these polynucleotides under stringent conditions, or these Two or more fragments of the polynucleotide can be included.
- the polynucleotide fragment that can be included in the kit of the present invention is, for example, 5 or more DNAs selected from the group consisting of the following (1) to (5): (1) A DNA comprising 15 or more consecutive bases in the base sequence represented by SEQ ID NOs: 1 to 62 or a complementary sequence thereof.
- the base sequence represented by SEQ ID NO: 1 to 62 or its complementary sequence includes the base sequence represented by SEQ ID NO: 63 to 124 or its complementary sequence, respectively, and includes 60 or more consecutive bases DNA.
- DNA comprising a base sequence complementary to the base sequence represented by SEQ ID NOs: 63 to 124.
- the polynucleotide is a polynucleotide comprising the base sequence represented by any of SEQ ID NOs: 1 to 38, a polynucleotide comprising the complementary sequence thereof, and hybridizing with these polynucleotides under stringent conditions. Or a fragment thereof containing 15 or more, preferably 20 or more, more preferably 25 or more consecutive bases.
- the kit of the present invention comprises, in addition to the above-mentioned polynucleotide, a polynucleotide comprising the base sequence represented by SEQ ID NO: 47, a polynucleotide comprising the complementary sequence thereof, those polynucleotides and strings. It may further comprise a polynucleotide that hybridizes under gentle conditions, or a fragment comprising 15 or more consecutive bases thereof.
- the fragment may be a polynucleotide comprising 15 or more, preferably 20 or more, more preferably 25 or more, and even more preferably 60 or more consecutive bases.
- the fragment comprises the base sequence represented by any of SEQ ID NOs: 63 to 124 in the base sequence represented by any of SEQ ID NOs: 1 to 62, and 60 or more contiguous sequences Or a polynucleotide containing a base sequence complementary to the sequence of the polynucleotide.
- the fragment is a polynucleotide comprising the base sequence represented by any of SEQ ID NOs: 63 to 124.
- the fragment is a polynucleotide comprising a base sequence complementary to the base sequence represented by any of SEQ ID NOs: 63 to 124.
- the fragment is a polynucleotide comprising a base sequence represented by any of SEQ ID NOs: 63 to 124.
- Examples of the above combinations include polynucleotides containing the nucleotide sequences shown in SEQ ID NOs: 1 to 62 or their complementary sequences, polynucleotides that hybridize with these polynucleotides under stringent conditions, and / or fragments thereof (for example, sequences Nos. 63 to 124) are to combine genes in descending order of gene priority (from the first to the 62nd) shown in Table 1 described later.
- the probability is, for example, SPRR3 (SEQ ID NO: 50).
- the preferred minimal combination is that of SPRR3 (SEQ ID NO: 50), CSTB (SEQ ID NO: 49), EYA2 (SEQ ID NO: 1), SERF1A (SEQ ID NO: 2) and IGHG1 (SEQ ID NO: 3).
- Each of the polynucleotides or fragments constituting the combination is a polynucleotide comprising the nucleotide sequence shown in SEQ ID NO: 50, 49, 1, 2, or 3 or a complementary sequence thereof, under stringent conditions with those polynucleotides. Selected from hybridizing polynucleotides and / or fragments thereof.
- the other genes shown in Table 1 can be added to the above five genes, thereby increasing the probability to, for example, 89% or more, 91% or more, 92% or more, or 96% or more. .
- the kit of the present invention comprises 3 or more (preferably 5 or more) to all of the polynucleotide comprising the nucleotide sequence represented by SEQ ID NO: 63 to 124 or a complementary sequence thereof. Can do.
- the size of the fragment of the polynucleotide is, for example, the total number of bases of 15 to 15 sequences, 15 to 5000 bases, 15 to 4500 bases, 15 to 4000 bases, 15 to 3500 in the base sequence of each polynucleotide.
- Base 15-3000 base, 15-2500 base, 15-2000 base, 15-1500 base, 15-1000 base, 15-900 base, 15-800 base, 15-700 base, 15-600 base, 15-500 Base, 15-400 base, 15-300 base, 15-250 base, 15-200 base, 15-150 base, 15-140 base, 15-130 base, 15-120 base, 15-110 base, 15-100 Base, 15-90 base, 15-80 base, 15-70 base, 15-60 base, 15-50 base, 15-4 Base, 15-30 bases or 15-25 bases; 25-total number of bases in the sequence, 25-1000 bases, 25-900 bases, 25-800 bases, 25-700 bases, 25-600 bases, 25-500 bases, 25-400 bases, 25-300 bases, 25-250 bases, 25-200 bases, 25-150 bases, 25-140 bases, 25-130 bases, 25-120 bases, 25-110 bases, 25-100 bases, 25-90 bases, 25-80 bases, 25-70 bases, 25-60 bases, 25-50 bases or 25-40 bases; 50-
- the kit of the present invention can include a known or future-found polynucleotide that enables detection of esophageal cancer, in addition to the above-described polynucleotide, variant or fragment thereof of the present invention.
- polynucleotides, variants or fragments thereof contained in the kit of the present invention are packaged individually or in any combination in different containers.
- DNA chip The present invention further includes the same polynucleotide as that contained in the composition and / or kit of the present invention (or the polynucleotide described in the above-mentioned composition in Section 3.1 and / or the kit in Section 4).
- An esophageal cancer diagnostic DNA chip comprising a mutant, a fragment, and a combination thereof is provided.
- the substrate of the DNA chip is not particularly limited as long as DNA can be solid-phased, and examples thereof include a slide glass, a silicon chip, a polymer chip, and a nylon membrane. Further, these substrates may be subjected to a surface treatment such as poly L lysine coating, introduction of functional groups such as amino groups and carboxyl groups.
- the solid phase immobilization method is not particularly limited as long as it is a commonly used method, such as a method of spotting DNA using a high-density dispenser called a spotter or an arrayer, a fine droplet from a nozzle, a piezoelectric element, etc.
- a high-density dispenser called a spotter or an arrayer
- Examples include a method of spraying DNA onto a substrate using an apparatus (inkjet) ejected by the above, or a method of sequentially synthesizing nucleotides on a substrate.
- a high-density dispenser for example, put different gene solutions in each well of a plate with a large number of wells, pick up this solution with a pin (needle), and spot it on the substrate in order. by.
- genes are ejected from a nozzle, and the genes are arranged and arranged at high speed on a substrate.
- the base bonded to the substrate is protected with a functional group that can be removed by light or heat, and the functional group is removed by applying light or heat only to the base at a specific site by using a mask. Let Thereafter, the step of adding a base to the reaction solution and coupling with the base on the substrate is repeated.
- the polynucleotide to be immobilized is all the polynucleotides of the present invention described above.
- such a polynucleotide can include one or more (preferably 5 or more) of the following polynucleotides or fragments thereof.
- a polynucleotide group consisting of the base sequences represented by SEQ ID NOs: 1 to 62, variants thereof, or fragments containing 15 or more consecutive bases.
- a polynucleotide group comprising the base sequence represented by SEQ ID NOs: 1 to 62.
- a polynucleotide group consisting of the base sequences represented by SEQ ID NOs: 1 to 38, variants thereof, or fragments containing 15 or more consecutive bases.
- a polynucleotide group comprising the nucleotide sequence represented by SEQ ID NOs: 1 to 38, a variant thereof, or a fragment thereof comprising 15 or more consecutive bases.
- a polynucleotide group consisting of a base sequence complementary to the base sequence represented by SEQ ID NOs: 1 to 38, a variant thereof, or a fragment thereof containing 15 or more consecutive bases.
- a polynucleotide group comprising a base sequence complementary to the base sequences represented by SEQ ID NOs: 1 to 38.
- a polynucleotide group that hybridizes under stringent conditions with DNA comprising a base sequence complementary to each of the base sequences represented by SEQ ID NOs: 1 to 38, or a fragment thereof containing 15 or more consecutive bases .
- a polynucleotide group consisting of the base sequences represented by SEQ ID NOs: 39 to 62, a variant thereof, or a fragment thereof containing 15 or more consecutive bases.
- a polynucleotide group comprising the nucleotide sequence represented by SEQ ID NOs: 39 to 62, a variant thereof, or a fragment thereof comprising 15 or more consecutive bases.
- a polynucleotide group consisting of a base sequence complementary to the base sequence represented by SEQ ID NOs: 39 to 62, a variant thereof, or a fragment thereof containing 15 or more consecutive bases.
- a polynucleotide group comprising a base sequence complementary to the base sequence represented by SEQ ID NOs: 39 to 62.
- a polynucleotide group that hybridizes under stringent conditions with DNA comprising each of the base sequences represented by SEQ ID NOs: 39 to 62, or a fragment thereof containing 15 or more consecutive bases.
- a polynucleotide comprising 15 or more consecutive bases in each of the base sequences represented by SEQ ID NOs: 1 to 38 or a complementary sequence thereof.
- a polynucleotide comprising 60 or more consecutive bases in each of the base sequences represented by SEQ ID NOs: 1 to 38 or a complementary sequence thereof.
- a polynucleotide comprising 15 or more consecutive bases in each of the base sequence represented by SEQ ID NOs: 39 to 62 or a complementary sequence thereof.
- a polynucleotide comprising 60 or more consecutive bases in each of the base sequence represented by SEQ ID NOs: 39 to 62 or a complementary sequence thereof.
- a polynucleotide comprising the base sequence represented by SEQ ID NO: 63 to 100 in the base sequence represented by SEQ ID NO: 1-38, and comprising 60 or more consecutive bases.
- the sequence complementary to the base sequence represented by SEQ ID NO: 1 to 38 includes a sequence complementary to the base sequence represented by SEQ ID NO: 63 to 100, respectively, and includes 60 or more consecutive bases Polynucleotide.
- a polynucleotide comprising the base sequences represented by SEQ ID NOs: 39 to 62 in the base sequences represented by SEQ ID NOs: 39 to 62, and comprising 60 or more consecutive bases.
- the sequence complementary to the base sequence represented by SEQ ID NO: 39 to 62 includes a sequence complementary to the base sequence represented by SEQ ID NO: 39 to 62, respectively, and includes 60 or more consecutive bases Polynucleotide.
- the DNA chip of the present invention can comprise 5 or more to all of the polynucleotide comprising the base sequence represented by SEQ ID NOs: 63 to 124 or a complementary sequence thereof.
- the polynucleotide to be immobilized may be any of genomic DNA, cDNA, RNA, synthetic DNA, and synthetic RNA, or may be single-stranded or double-stranded.
- a method of immobilizing a previously prepared probe on a solid surface can be used.
- a polynucleotide having a functional group introduced therein is synthesized, and an oligonucleotide or polynucleotide is spotted on the surface of the surface-treated solid support and covalently bonded (for example, J. B. Lamture et al., Nucleic. Acids. Research, 1994, Vol. 22, p. 2121-2125, Z. Guo et al., Nucleic. Acids. Research, 1994, Vol. 22, p. 5465).
- a polynucleotide is covalently bound to a surface-treated solid support via a spacer or a crosslinker.
- a method is also known in which polyacrylamide gel fragments are aligned on a glass surface, and a synthetic polynucleotide is covalently bound thereto (G. Yershov et al., Processedings of the National Sciences Sciences USA, 1996, 94, p. 4913).
- an array of microelectrodes was prepared on a silica microarray, an agarose permeation layer containing streptavidin was provided on the electrode as a reaction site, and this site was positively charged to immobilize the biotinylated polynucleotide.
- a method is also known that enables high-speed and precise hybridization by controlling the charge of the site (RG Sonoski et al., Proceedings of the National AcademicmSciences USA, 1997, No. 1). 94, pp. 1119-1123).
- the present invention is a method for determining in vitro whether or not esophageal cancer cells are contained in a sample using the composition, kit, DNA chip, or combination thereof of the present invention. Compare the amount of expressed genes in the sample using esophageal cancer cells derived from esophageal cancer patients and non-cancer cells at the time of surgery or endoscopy, and increase the expression level of the target nucleic acid of the cells in the sample Determining that esophageal cancer cells are present in the specimen sample, wherein the target nucleic acid is contained in the composition, kit or DNA chip, variant thereof or the Methods are provided that are detectable by fragments.
- the present invention also provides the use of the composition, kit or DNA chip of the present invention for in vivo detection of esophageal cancer in a specimen sample derived from a subject.
- compositions, a kit or a DNA chip which contains the polynucleotide of the present invention, a variant thereof or a fragment thereof, as described above, alone or in any possible combination.
- the polynucleotide, its variant or fragment contained in the composition, kit or DNA chip of the present invention can be used as a primer or a probe.
- a primer those having a base length of usually 15 to 50 bases, preferably 15 to 30 bases, more preferably 18 to 25 bases can be exemplified.
- detection probe for example, those having a base length of 15 bases to the entire sequence, preferably 25 to 1000 bases, more preferably 25 to 100 bases can be exemplified, but the invention is not limited to this range.
- the polynucleotide, variant or fragment thereof contained in the composition or kit of the present invention is a specific gene such as Northern blot method, Southern blot method, RT-PCR method, in situ hybridization method, Southern hybridization method, etc.
- a known method for specifically detecting it can be used as a primer or a probe according to a conventional method.
- the measurement target sample may be a living body obtained by collecting a part or all of a subject's esophageal tissue or a biological tissue suspected of having esophageal cancer cells with a biopsy or by surgery. Collect from tissue.
- total RNA prepared from the RNA according to a conventional method may be used, and various polynucleotides including cDNA and poly A (+) RNA prepared based on the RNA may be used.
- the expression level of a nucleic acid such as the gene, RNA, and cDNA of the present invention in living tissue can be detected or quantified using a DNA chip (including a DNA macroarray).
- a DNA chip including a DNA macroarray
- the composition or kit of the present invention can be used as a probe for a DNA chip (for example, Affymetrix Human Genome U133 Plus 2.0 Array uses a 25-base long polynucleotide probe).
- a DNA chip is hybridized with labeled DNA or RNA prepared based on RNA collected from a biological tissue, and a complex of the probe and labeled DNA or RNA formed by the hybridization is labeled with the labeled DNA or RNA.
- RNA labeling By detecting RNA labeling as an index, the presence or absence or expression level (expression level) of the esophageal cancer-related gene of the present invention in living tissue can be evaluated.
- a DNA chip can be preferably used, which can evaluate the presence / absence or expression level of a plurality of genes for one biological sample at the same time.
- the composition, kit or DNA chip of the present invention is useful for diagnosis, determination or detection of esophageal cancer (diagnosis of presence or absence of disease and degree of disease).
- diagnosis of esophageal cancer using the composition, kit or DNA chip is carried out by using esophageal cancer cells derived from esophageal cancer patients and non-cancer cells at the time of surgery or endoscopy.
- Comparison of gene dosage, or comparison of esophageal cancer cells from esophageal cancer patients with living tissues equivalent to non-cancer cells at the time of surgery or endoscopy, and the level of gene expression detected by the diagnostic composition This can be done by determining the difference.
- the difference in gene expression level is not only the presence or absence of expression, but also when the expression level between the esophageal cancer patient-derived esophageal cancer cells and non-cancerous cell vesicles is expressed.
- EYA2 gene since the expression of EYA2 gene is induced / decreased in esophageal cancer, it is expressed / decreased in the esophageal cancer tissue of the subject, and if there is a difference between the expression level and the expression level of normal esophageal tissue, It can be determined that no cancer cells are included or / or esophageal cancer cells are included.
- a method for detecting that esophageal cancer cells are not contained in a specimen sample using the composition, kit or DNA chip of the present invention and / or that esophageal cancer cells are contained is obtained by biopsying a part or all of a living tissue of a subject. Or the like, or collected from a living tissue extracted by surgery, and the gene contained therein is used by using one or a plurality of polynucleotides selected from the polynucleotide group of the present invention, variants thereof or fragments thereof. This includes diagnosing the presence or degree of esophageal cancer by detecting and measuring the gene expression level.
- the method for detecting esophageal cancer of the present invention can also detect, determine or diagnose whether or not the disease has been improved or not when the therapeutic agent is administered to improve the disease in an esophageal cancer patient, for example. .
- the method of the present invention includes, for example, the following steps (a), (b) and (c): (A) contacting a specimen sample derived from a subject with the polynucleotide of the composition, kit or DNA chip of the present invention; (B) measuring the expression level of the target nucleic acid in the biological sample using the polynucleotide as a probe; (C) determining the presence or absence of esophageal cancer (cells) in the sample based on the result of (b), Can be included.
- Specimen samples used in the method of the present invention can include samples prepared from a subject's biological tissue, such as esophageal tissue and its surrounding tissues, tissue suspected of esophageal cancer, and the like.
- a subject's biological tissue such as esophageal tissue and its surrounding tissues, tissue suspected of esophageal cancer, and the like.
- an RNA-containing sample prepared from the tissue or a sample containing a polynucleotide further prepared therefrom is a living body obtained by collecting a part or the whole of a subject's biological tissue with a biopsy or the like, or removed by surgery. It can be recovered from the tissue and prepared from it according to conventional methods.
- subject refers to mammals such as, but not limited to, humans, monkeys, mice, rats, etc., and preferably humans.
- the method of the present invention can change the process according to the type of biological sample used as a measurement target.
- RNA When RNA is used as a measurement object, detection of esophageal cancer (cells) is performed, for example, by the following steps (a), (b) and (c): (A) a step of binding RNA prepared from a biological sample of a subject or a complementary polynucleotide (cDNA) transcribed therefrom with the polynucleotide of the composition, kit or DNA chip of the present invention; (B) a step of measuring RNA derived from a biological sample bound to the polynucleotide or a complementary polynucleotide transcribed from the RNA using the polynucleotide as a probe; (C) A step of determining the presence or absence of esophageal cancer (cells) based on the measurement result of (b) above, Can be included.
- steps (a), (b) and (c) A) a step of binding RNA prepared from a biological sample of a subject or a complementary polynucleotide (cDNA
- hybridization methods for example, Northern blot method, Southern blot method, RT-PCR method, DNA chip analysis method, in situ hybridization method, Southern hybridization method and the like can be used.
- the presence or absence of each gene expression and its expression level in RNA can be detected and measured by using the diagnostic composition of the present invention as a probe.
- the diagnostic composition of the present invention (complementary strand) labeled with a radioactive isotope (such as 32 P, 33 P, 35 S ) or a fluorescent substance, transfers etc.
- the diagnostic composition (DNA) and RNA duplex formed are labeled with the diagnostic composition (radioisotope or fluorescent substance)
- a method of detecting and measuring a signal derived from a radiation detector such as BAS-1800II, Fuji Photo Film Co., Ltd.
- a fluorescence detector such as STORM860, Amersham Bioscience, etc.
- the presence or absence of gene expression in RNA and its expression level can be detected and measured by using the diagnostic composition of the present invention as a primer.
- the diagnostic composition of the present invention so that cDNA can be prepared from RNA derived from the biological tissue of the subject according to a conventional method, and the region of each target gene can be amplified using this as a template.
- a method of detecting the resulting double-stranded DNA by hybridizing the pair of primers (consisting of a positive strand and a reverse strand that binds to the cDNA) to cDNA, performing PCR by a conventional method, and it can.
- the above PCR is performed using a primer previously labeled with a radioisotope or a fluorescent substance, the PCR product is electrophoresed on an agarose gel, and then is detected with ethidium bromide or the like.
- a method of detecting by staining a double-stranded DNA a method of detecting by detecting a diagnostic composition labeled by transferring the produced double-stranded DNA to a nylon membrane or the like according to a conventional method, and hybridizing with this as a probe be able to.
- a DNA chip in which the above-described diagnostic composition of the present invention is attached to a substrate as a DNA probe is used.
- Those obtained by immobilizing a gene group on a substrate generally have names of DNA chip and DNA array, and the DNA array includes a DNA macroarray and a DNA microarray. DNA array is included.
- Hybridization conditions are not limited. For example, hybridization is performed at 30 to 50 ° C. in 3 to 4 ⁇ SSC, 0.1 to 0.5% SDS for 1 to 24 hours, more preferably 40 to 45 ° C. At 1-24 hours in 3 ⁇ SSC, 0.3% SDS, followed by washing.
- washing conditions for example, a solution containing 3 ⁇ SSC and 0.1% SDS at 30 ° C., a solution containing 0.3 ⁇ SSC 0.1% SDS at 42 ° C., and a 0.1 ⁇ SSC solution at 30 ° C.
- the conditions such as continuous washing with can be mentioned.
- 1 ⁇ SSC is an aqueous solution (pH 7.2) containing 150 mM sodium chloride and 15 mM sodium citrate.
- the complementary strand maintain a hybridized state with the target positive strand even when washed under such conditions.
- a complementary strand composed of a base sequence that is completely complementary to the base sequence of the target positive strand, and a strand composed of a base sequence having at least 80% homology with the strand can be illustrated.
- Examples of stringent hybridization conditions when PCR is performed using the polynucleotide fragment of the composition or kit of the present invention as a primer include, for example, 10 mM Tris-HCl (pH 8.3), 50 mM KCl, 1-2 mM MgCl 2 and the like.
- Tm 10 mM Tris-HCl (pH 8.3), 50 mM KCl, 1-2 mM MgCl 2 and the like.
- Tm 2 ⁇ (number of adenine residues + number of thymine residues) + 4 ⁇ (number of guanine residues + number of cytosine residues).
- the present invention also measures the expression level of a target nucleic acid or gene in a specimen sample derived from a subject using the composition, kit, DNA chip, or a combination thereof of the present invention, and generates genes for esophageal cancer tissue and normal tissue.
- SVM support vector machine
- the present invention further uses the composition, kit, DNA chip, or combination thereof of the present invention to determine whether or not esophageal cancer cells are contained in a sample sample.
- a second step of creating a (support vector machine) a third step of measuring the expression level of the target nucleic acid in a specimen sample derived from the subject's esophagus in vitro as in the first step, the second step Substitute the measured value of the expression level of the target acetic acid obtained in the third step into the discriminant obtained in the step, and based on the result obtained from the discriminant, esophageal cancer cells are included in the sample sample Inability to escape / or esophagus Including a fourth step of determining that a cell is contained, wherein the target nucleic
- the method of the present invention includes, for example, the following steps (a), (b) and (c):
- B A step of creating a discriminant called SVM by substituting the measured value of the expression level measured in (a) into the following equations 1 to 5.
- (C) The expression level of the target gene in the specimen sample derived from the subject is measured using the diagnostic (detection) composition, kit or DNA chip according to the present invention, and these are expressed in the discriminant created in (b). Substituting and determining whether esophageal cancer cells are contained in the specimen sample based on the obtained results; Can be included.
- SVM was created in 1995 to solve the two-class classification problem. It is a learning machine proposed in the framework of statistical learning theory by Vapnik (The Nature of Statistical Leaning Theory, Springer, 1995). The SVM is a linear discriminator, but can handle nonlinear problems by combining kernels described later. For a different class of training samples, among the many hyperplanes that identify them, the hyperplane that minimizes the minimum distance between the hyperplane and the training sample is used as the discriminating surface. Can be most accurately identified as belonging to a class.
- SVM can handle only linear problems, but as a method for dealing with inherently nonlinear problems, a method is known in which feature vectors are nonlinearly transformed into a higher dimension and linear identification is performed in that space. . This is equivalent to using a nonlinear model in the original space.
- mapping to higher dimensions requires a huge amount of computation and reduces the generalization ability.
- the discriminant function is dependent only on the inner product of the input pattern. If the inner product can be calculated, an optimum discriminant function can be constructed.
- An expression in which the inner product of two elements in a non-linearly mapped space is expressed only by the input in the original space is called the kernel, and it is actually mapped while mapping in high dimensions.
- the training sample x i belongs to either a tissue group including esophageal cancer cells or a normal tissue group classified by (+1, ⁇ 1).
- the discriminant function is for example:
- the discriminant function can be uniquely obtained.
- x for the specimen sample (expressed gene amount of unknown tissue whether or not it contains esophageal cancer cells) newly given to this function, f (x) is classified (ie, +1 or ⁇ 1) To identify which class (ie, a group of tissues containing esophageal cancer cells or a group of tissues not containing esophageal cancer cells) the specimen sample belongs to.
- this training sample is an expression gene (gene x 1 , x 2 ,... X i ,... X n ) obtained from a tissue containing esophageal cancer cells of esophageal cancer patients. set that corresponds to the patient, and "expressed gene obtained from tissue that does not contain esophageal cancer cells of esophageal cancer patients (gene x 1, x 2, .. x i, ... x n) " corresponding to each patient Two groups.
- the number of expressed genes (n) measured for each of these sets varies depending on the design of the experiment. However, for each gene, there is a large difference between the two groups in any experiment and the difference between the two groups. A small or no difference is observed. In order to improve the accuracy of the discriminant expression by SVM, it is a condition that there is a clear difference between the two groups as training samples, so only genes that have a difference in expression level between the two groups from the gene set are selected. It is necessary to extract and use.
- the genes belonging to the gene set used in the discriminant formula by SVM is a nonparametric analysis. Using a Mann-Whitney U test or the like, the expression level difference between the two groups of each gene is determined. Next, genes are incorporated into the set in the order in which the difference in expression level between the two groups determined here is large, and the determination rate (probability) is calculated each time. Incorporation of genes into this gene set is repeated until the calculated determination rate reaches a maximum, and the set of genes at the time when the maximum determination rate is obtained is adopted.
- An esophageal cancer tissue derived from an esophageal cancer patient and an esophagus derived from an esophageal cancer patient using any combination of one or a plurality of (preferably 5 or more) polynucleotides, and the expression levels of the 62 target genes are all By measuring the expression level of these 62 genes by using as an index that the expression is increased / decreased in an esophageal cancer tissue derived from an esophageal cancer patient, which differs between tissues not containing cancer (normal tissue), It is possible to identify esophageal cancer with a probability of 80% or more, 85% or more, preferably 90% or more, more preferably 92% or more, and still more preferably 95% or more. (Fig.
- the present invention further includes polypeptides encoded by the above 62 genes (eg, corresponding to SEQ ID NOs: 1 to 62) or fragments thereof (eg, corresponding to SEQ ID NOs: 63 to 124), such as SEQ ID NOs: 125 to 186.
- An esophageal cancer patient-derived esophageal cancer tissue and an esophageal cancer patient-derived esophageal cancer tissue using one or more (preferably 5 or more) antibodies or fragments thereof against the polypeptide comprising the amino acid sequence represented by The present invention provides a method for detecting esophageal cancer, comprising measuring in vitro the expression level of the polypeptide or the level (or abundance) of the polypeptide in blood.
- Such antibodies or fragments include polyclonal antibodies, monoclonal antibodies, synthetic antibodies, recombinant antibodies, multispecific antibodies (including bispecific antibodies), single chain antibodies, Fab fragments, F (ab ′) 2 fragments, and the like.
- Polyclonal antibodies can be prepared as specific antibodies by the so-called absorption method, which involves binding a purified polypeptide to a bound affinity column.
- the measurement can include a step of bringing an antibody or fragment labeled with a conventional enzyme or fluorophore into contact with a tissue section or a homogenized tissue, and a step of qualitatively or quantitatively measuring an antigen-antibody complex. .
- the detection is performed by, for example, a method for measuring the presence and level of the target polypeptide by immunoelectron microscopy, a method for measuring the level of the target polypeptide by a conventional method such as ELISA or fluorescent antibody method, and the like.
- the expression level of the target polypeptide is increased / decreased in the esophageal cancer tissue derived from an esophageal cancer patient compared to the tissue and the tissue not containing esophageal cancer derived from the patient, or the level of the polypeptide in the blood is If an esophageal cancer tissue derived from an esophageal cancer patient is compared with a tissue not containing esophageal cancer derived from an esophageal cancer patient and the esophageal cancer tissue derived from an esophageal cancer patient is increased / decreased, it is determined that there is esophageal cancer.
- the increase / decrease may include a statistically significant difference (p ⁇ 0.05).
- RNA Extraction and cDNA Preparation As samples, esophageal cancer lesion tissue and non-lesion tissue in esophageal cancer patients were used. Total RNA was prepared from each tissue using TRIzol Reagent (Invitrogen) according to the recommended protocol.
- RNA ⁇ obtained by the above method, using oligo (dT) primer and random nonamer together, reverse transcription reaction with Cyscribe C First-Strand cDNA Labeling Kit (GE Healthcare) using the protocol recommended by the manufacturer went.
- Cy3-dUTP GE Healthcare
- Cy5-dUTP GE Healthcare
- Human Universal Reference RNA GE Healthcare
- CDNA was labeled during the copying reaction.
- the labeled cDNA was purified by QIAquick PCR purification Kit (Qiagen) and used for hybridization.
- the extracted 1119 genes were synthesized by selecting and synthesizing 60-70 residues of sequences with high sequence specificity so as not to cause sequence duplication, and using Toray's 1296-pillar 3D-Gene substrate. Created a custom chip.
- Hybridization Each 1 ⁇ g of labeled cDNA was collected, dissolved in a hybridization buffer (Toray Industries, Japan), and hybridized at 42 ° C. for 16 hours. After completion of hybridization, the DNA chip was subjected to a solution containing 3 ⁇ SSC and 0.1% SDS at 30 ° C., a solution containing 0.3 ⁇ SSC and 0.1% SDS at 42 ° C., and a 0.1% solution at 30 ° C. X Washed under continuous conditions with SSC solution.
- a discrimination machine is created in 56 cases except for one of the set of 57 esophageal cancer lesioned tissue and esophageal cancer non-lesioned tissue, and the remaining one of the discrimination machine
- the accuracy was evaluated by the method of calculating.
- the tissue of the esophageal cancer lesion part and the tissue of the esophageal cancer non-lesion part are respectively represented by SEQ ID NOs: 63 to 65.
- RNA obtained from esophageal cancer tissue and obtained from tissues that do not contain esophageal cancer The RNA cocktail was mixed so that the ratio of total RNA was 9: 1, 8: 2, 7: 3, 6: 4, 5: 5, 4: 6, 3: 7, 2: 8, 1: 9.
- CDNA was prepared, hybridization, and gene expression level measurement were performed to obtain data.
- the discrimination machine discriminates the data as a cancer part. (FIG. 2).
- biopsy tissues of the esophagus were obtained at the time of esophageal biopsy from 55 esophageal cancer patients who also obtained informed consent.
- Total RNA extraction, cDNA preparation, hybridization, and gene expression level measurement were performed to obtain data.
- an esophageal cancer tissue derived from an esophageal cancer patient and an esophageal cancer derived from an esophageal cancer patient had an accuracy of 85.5%.
- the probability of discriminating a tissue not containing esophageal cancer derived from an esophageal cancer patient at this time was 100% (FIG. 3).
- the discrimination machine for the discrimination discriminates the esophageal cancer tissue derived from the esophageal cancer patient and the tissue not containing the esophageal cancer patient from the esophageal cancer patient with a probability of 61.8% (FIG. 4).
- An esophageal cancer tissue derived from an esophageal cancer patient and a tissue not containing an esophageal cancer derived from an esophageal cancer patient were discriminated with a probability of 47.3% (FIG. 5).
- a composition for esophageal cancer determination excellent in specificity and sensitivity can be provided. Therefore, at least the proportion of esophageal cancer tissue contained in tissues collected from esophageal cancer patients at the time of surgery or endoscopy Very useful for discriminating.
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Immunology (AREA)
- Engineering & Computer Science (AREA)
- Organic Chemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Analytical Chemistry (AREA)
- Pathology (AREA)
- Molecular Biology (AREA)
- Genetics & Genomics (AREA)
- Wood Science & Technology (AREA)
- Zoology (AREA)
- Biochemistry (AREA)
- Biotechnology (AREA)
- Physics & Mathematics (AREA)
- Microbiology (AREA)
- General Health & Medical Sciences (AREA)
- Hematology (AREA)
- Urology & Nephrology (AREA)
- Biomedical Technology (AREA)
- Oncology (AREA)
- Biophysics (AREA)
- Hospice & Palliative Care (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- Food Science & Technology (AREA)
- General Physics & Mathematics (AREA)
- Cell Biology (AREA)
- Medicinal Chemistry (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Apparatus Associated With Microorganisms And Enzymes (AREA)
Abstract
Description
本発明は、以下の特徴を有する。
(b)配列番号1~38で表される塩基配列を含むポリヌクレオチド
(c)配列番号1~38で表される塩基配列に相補的な塩基配列からなるポリヌクレオチド、その変異体、又は15以上の連続した塩基を含むその断片
(d)配列番号1~38で表される塩基配列に相補的な塩基配列を含むポリヌクレオチド
(e)前記(a)~(d)のいずれかのポリヌクレオチドとストリンジェントな条件でハイブリダイズするポリヌクレオチド、又は15以上の連続した塩基を含むその断片。
(g)配列番号39~62で表される塩基配列を含むポリヌクレオチド
(h)配列番号39~62で表される塩基配列に相補的な塩基配列からなるポリヌクレオチド、その変異体、又は15以上の連続した塩基を含むその断片
(i)配列番号39~62で表される塩基配列に相補的な塩基配列を含むポリヌクレオチド
(j)前記(f)~(i)のいずれかのポリヌクレオチドとストリンジェントな条件でハイブリダイズするポリヌクレオチド、又は15以上の連続した塩基を含むその断片。
本明細書中で使用する用語は、以下の定義を有する。
本明細書で使用される「SDC2遺伝子」又は「SDC2」という用語は、配列番号で指定しない限り、特定塩基配列(配列番号31)で示されるSyndecan2遺伝子(DNA)、heparan sulfate proteoglycan 1,cell-associated,fibroglycan、Human heparan sulfate proteoglycan(HSPG)core protein 3‘end、その同族体、変異体及び誘導体などをコードする遺伝子(DNA)を包含する。具体的には、配列番号31に記載のSDC2遺伝子(GenBank Accession No.J04621)やその他生物種ホモログなどが包含される。SDC2遺伝子はde Boeck H.ら、1987年、Biochem. J.、第247巻、p.765-771に記載される方法によって得ることができる。
本明細書で使用される「TOR1A遺伝子」又は「TOR1A」という用語は、配列番号で指定しない限り、特定塩基配列(配列番号32)で示されるtorsin family,member A遺伝子(DNA)、Dystonia1、DYT1、DQ2、torsin A、その同族体、変異体及び誘導体などをコードする遺伝子(DNA)を包含する。具体的には、配列番号32に記載のTOR1A遺伝子(GenBank Accession No.NM_000113)やその他生物種ホモログなどが包含される。TOR1A遺伝子はOzelius L.J.ら、1997年、Nat. Genet.、第17巻、p.40-48に記載される方法によって得ることができる。
本明細書で使用される「RPL18A遺伝子」又は「RPL18A」という用語は、配列番号で指定しない限り、特定塩基配列(配列番号33)で示されるribosomal protein L18a遺伝子(DNA)、その同族体、変異体及び誘導体などをコードする遺伝子(DNA)を包含する。具体的には、配列番号33に記載のRPL18A遺伝子(GenBank Accession No.NM_000980)やその他生物種ホモログなどが包含される。RPL18A遺伝子はAdams M.D.ら、1992年、Nature、第355巻、p.632-634に記載される方法によって得ることができる。
本明細書で使用される「GAS7遺伝子」又は「GAS7」という用語は、配列番号で指定しない限り、特定塩基配列(配列番号34)で示されるGrowth-arrest-specific protein7遺伝子(DNA)、GAS-7、MGC1348、その同族体、変異体及び誘導体などをコードする遺伝子(DNA)を包含する。具体的には、配列番号34に記載のGAS7遺伝子(GenBank Accession No.NM_201432)やその他生物種ホモログなどが包含される。GAS7遺伝子はJu Y.T.ら、1998年、Proc. Natl. Acad. Sci. USA.、第95巻、p.11423-11428に記載される方法によって得ることができる。
本明細書で使用される「WISP1遺伝子」又は「WISP1」という用語は、配列番号で指定しない限り、特定塩基配列(配列番号35)で示されるWNT1 inducible signaling pathway protein 1遺伝子(DNA)、CCN4、WISP1c、WISP1i、WISP1tc、その同族体、変異体及び誘導体などをコードする遺伝子(DNA)を包含する。具体的には、配列番号35に記載のWISP1遺伝子(GenBank Accession No.NM_003882)やその他生物種ホモログなどが包含される。WISP1遺伝子はPennica D.ら、1998年、Proc. Natl. Acad. Sci. USA.、第95巻、p.14717-14722に記載される方法によって得ることができる。
本明細書で使用される「CACNG4遺伝子」又は「CACNG4」という用語は、配列番号で指定しない限り、特定塩基配列(配列番号36)で示されるVoltage-dependent calcium channel gamma-4 subunit遺伝子(DNA)、Neuronal voltage-gated calcium channel gamma-4 subunit、MGC11138、MGC24983、その同族体、変異体及び誘導体などをコードする遺伝子(DNA)を包含する。具体的には、配列番号36に記載のCACNG4遺伝子(GenBank Accession No.NM_014405)やその他生物種ホモログなどが包含される。CACNG4遺伝子はBurgess D.L.ら、1999年、Genome Res.、第9巻、p.1204-1213に記載される方法によって得ることができる。
本明細書で使用される「S100P遺伝子」又は「S100P」という用語は、配列番号で指定しない限り、特定塩基配列(配列番号37)で示されるS-100P protein遺伝子(DNA)、S100 calcium binding protein P、MIG9、その同族体、変異体及び誘導体などをコードする遺伝子(DNA)を包含する。具体的には、配列番号37記載のS100P遺伝子(GenBank Accession No.NM_005980)やその他生物種ホモログなどが包含される。S100P遺伝子はBecker T.ら、1992年、Eur. J. Biochem.、第207巻、p.541-547に記載される方法によって得ることができる。
本明細書で使用される「UCHL5遺伝子」又は「UCHL5」という用語は、配列番号で指定しない限り、特定塩基配列(配列番号38)で示されるubiquitin carboxyl-terminal hydrolase L5遺伝子(DNA)、UCH37、CGI-70、その同族体、変異体及び誘導体などをコードする遺伝子(DNA)を包含する。具体的には、配列番号38に記載のUCHL5遺伝子(GenBank Accession No.NM_015984)やその他生物種ホモログなどが包含される。UCHL5遺伝子はWicks S.J.ら、2005年、Oncogene、第24巻、p.8080-8084に記載される方法によって得ることができる。
本明細書で使用される「ARHGEF3遺伝子」又は「ARHGEF3」という用語は、配列番号で指定しない限り、特定塩基配列(配列番号47)で示されるRho guanine nucleotide exchange factor(GEF)3遺伝子(DNA)、GEF、STA3、XPLN、MGC118905、DKFZP434F2429、その同族体、変異体及び誘導体などをコードする遺伝子(DNA)を包含する。具体的には、配列番号47に記載のARHGEF3遺伝子(GenBank Accession No.NM_019555)やその他生物種ホモログなどが包含される。ARHGEF3遺伝子はThiesen S.ら、2000年、Biochem. Biophys. Res. Commun.、第273巻、p.364-369に記載される方法によって得ることができる。
本明細書で使用される「COL3A1遺伝子」又は「COL3A1」という用語は、配列番号で指定しない限り、特定塩基配列(配列番号48)で示される3‘ region for pro-alpha(III) collagen遺伝子(DNA)、その同族体、変異体及び誘導体などをコードする遺伝子(DNA)を包含する。具体的には、配列番号48に記載のCOL3A1遺伝子(GenBank Accession No.X06700)やその他生物種ホモログなどが包含される。COL3A1遺伝子はLoidl H.R.ら、1984年、Nucleic Acids Res.、第16巻、p.9383-9394に記載される方法によって得ることができる。
本明細書で使用される「CSTB遺伝子」又は「CSTB」という用語は、配列番号で指定しない限り、特定塩基配列(配列番号49)で示されるCystatin-B遺伝子(DNA)、Stefin-B、Liver thiol proteinase inhibitor、CPI-B、その同族体、変異体及び誘導体などをコードする遺伝子(DNA)を包含する。具体的には、配列番号49に記載のCSTB遺伝子(GenBank Accession No.NM_000100)やその他生物種ホモログなどが包含される。CSTB遺伝子は、Jerala, R.ら、1988年、FEBS Lett.、第239巻、p.41-44に記載される方法によって得ることができる。
本発明の上記定義の食道ガン診断用組成物及びキットを使用して食道ガン又は食道ガン細胞の存在及び/又は不存在を判定するための食道ガンマーカーとしての標的核酸には、例えば、配列番号1~62で表される塩基配列を含むヒト遺伝子(すなわち、それぞれ、EYA2、SERF1A、IGHG1、ITSN2、RAB11FIP5、HSPA1A、NMU、E2F3、ESR2、CFDP1、HSPC190、COL1A2、GCS1、PARL、CELSR2、NDRG1、SLC25A44、TUSC2、SLC4A1、MS4A7、TMSB4X、PRC1、VCP、RBM9、GPR126、HOXA10、PPP1R1A、MYO9B、SLCO4C1、SERPINB13、SDC2、TOR1A、RPL18A、GAS7、WISP1、CACNG4、S100P、UCHL5、AQP3、NSUN5、B4GALT2、CD48、DAB2、EBI3、MAP3K12、SPEN、ARHGEF3、COL3A1、CSTB、SPRR3、SLIT2、CAMK2B、SLC2A14、SATB2、SEPT6、GALNS、TROAP、XRCC3、FGF3、EIF4EBP2、RRM1、及びM6PR)、それらの同族体、それらの転写産物又はcDNA、あるいはそれらの変異体又は誘導体が含まれる。ここで、遺伝子、同族体、転写産物、cDNA、変異体及び誘導体は、上記定義のとおりである。好ましい標的核酸は、配列番号1~62で表される塩基配列を含むヒト遺伝子、それらの転写産物又はcDNA、より好ましくは該転写産物又はcDNAである。
本発明の上記定義の食道ガン診断用組成物及びキットを使用して食道ガン又は食道ガン細胞の存在及び/又は不存在を判定するための食道ガンマーカーとしての標的ポリペプチドには、例えば、配列番号1~62で表される塩基配列を含むヒト遺伝子(すなわち、それぞれ、EYA2、SERF1A、IGHG1、ITSN2、RAB11FIP5、HSPA1A、NMU、E2F3、ESR2、CFDP1、HSPC190、COL1A2、GCS1、PARL、CELSR2、NDRG1、SLC25A44、TUSC2、SLC4A1、MS4A7、TMSB4X、PRC1、VCP、RBM9、GPR126、HOXA10、PPP1R1A、MYO9B、SLCO4C1、SERPINB13、SDC2、TOR1A、RPL18A、GAS7、WISP1、CACNG4、S100P、UCHL5、AQP3、NSUN5、B4GALT2、CD48、DAB2、EBI3、MAP3K12、SPEN、ARHGEF3、COL3A1、CSTB、SPRR3、SLIT2、CAMK2B、SLC2A14、SATB2、SEPT6、GALNS、TROAP、XRCC3、FGF3、EIF4EBP2、RRM1、及びM6PR)によってコードされるポリペプチド、例えば、配列番号125~186で表されるアミノ酸配列を含むヒトポリペプチド、それらの同族体、あるいはそれらの変異体又は誘導体が含まれる。ここで、ポリペプチド、同族体、変異体及び誘導体は、上記定義のとおりである。好ましい標的ポリペプチドは、配列番号125~186で表されるアミノ酸配列を含むヒトポリペプチドである。
3.1核酸
本発明において、食道ガンを判定するための、あるいは食道ガンを診断するために使用可能な核酸組成物は、食道ガンの標的核酸としての、ヒト由来のEYA2、SERF1A、IGHG1、ITSN2、RAB11FIP5、HSPA1A、NMU、E2F3、ESR2、CFDP1、HSPC190、COL1A2、GCS1、PARL、CELSR2、NDRG1、SLC25A44、TUSC2、SLC4A1、MS4A7、TMSB4X、PRC1、VCP、RBM9、GPR126、HOXA10、PPP1R1A、MYO9B、SLCO4C1、SERPINB13、SDC2、TOR1A、RPL18A、GAS7、WISP1、CACNG4、S100P、UCHL5、AQP3、NSUN5、B4GALT2、CD48、DAB2、EBI3、MAP3K12、SPEN、ARHGEF3、COL3A1、CSTB、SPRR3、SLIT2、CAMK2B、SLC2A14、SATB2、SEPT6、GALNS、TROAP、XRCC3、FGF3、EIF4EBP2、RRM1、及びM6PR遺伝子、それらの同族体、それらの転写産物又はcDNA、あるいはそれらの変異体又は誘導体の存在、発現レベル又は存在量を定性的及び/又は定量的に測定することを可能にする。
本発明はさらに、配列番号125~162で表されるアミノ酸配列を有するポリペプチドに対する1又は複数(好ましくは3以上)の抗体、その断片、又はそれらの化学修飾誘導体を含む、食道ガン診断用キットを提供する。
(1)免疫及び抗体産生細胞の採取
標的ポリペプチドからなる免疫原を、哺乳動物、例えばラット、マウス(例えば近交系マウスのBalb/c)、ウサギなどに投与する。免疫原の1回の投与量は、免疫動物の種類、投与経路などにより適宜決定されるものであるが、動物1匹当たり約50~200μgとされる。免疫は主として皮下、腹腔内に免疫原を注入することにより行われる。また、免疫の間隔は特に限定されず、初回免疫後、数日から数週間間隔で、好ましくは1~4週間間隔で、2~10回、好ましくは3~4回追加免疫を行う。初回免疫の後、免疫動物の血清中の抗体価の測定をELISA(Enzyme-Linked Immuno Sorbent Assay)法などにより繰り返し行い、抗体価がプラトーに達したときは、免疫原を静脈内又は腹腔内に注射し、最終免疫とする。そして、最終免疫の日から2~5日後、好ましくは3日後に、抗体産生細胞を採取する。抗体産生細胞としては、脾臓細胞、リンパ節細胞、末梢血細胞等が挙げられるが、脾臓細胞又は局所リンパ節細胞が好ましい。
各標的ポリペプチドに特異的なモノクローナル抗体を産生するハイブリドーマ細胞株を作製する。こうしたハイブリドーマは、慣用的技術によって産生し、そして同定することが可能である。こうしたハイブリドーマ細胞株を産生するための1つの方法は、動物を本発明のタンパク質で免疫し、免疫された動物から脾臓細胞を採取し、該脾臓細胞を骨髄腫細胞株に融合させ、それによりハイブリドーマ細胞を生成し、そして該酵素に結合するモノクローナル抗体を産生するハイブリドーマ細胞株を同定することを含む。抗体産生細胞と融合させる骨髄腫細胞株としては、マウスなどの動物の一般に入手可能な株化細胞を使用することができる。使用する細胞株としては、薬剤選択性を有し、未融合の状態ではHAT選択培地(ヒポキサンチン、アミノプテリン、チミジンを含む)で生存できず、抗体産生細胞と融合した状態でのみ生存できる性質を有するものが好ましい。また株化細胞は、免疫動物と同種系の動物に由来するものが好ましい。骨髄腫細胞株の具体例としては、BALB/cマウス由来のヒポキサンチン・グアニン・ホスホリボシル・トランスフェラーゼ(HGPRT)欠損細胞株であるP3X63-Ag.8株(ATCC TIB9)などが挙げられる。
細胞融合処理後の細胞から目的とするハイブリドーマを選別する。その方法として、細胞懸濁液を、例えばウシ胎児血清含有RPMI-1640培地などで適当に希釈後、マイクロタイタープレート上に200万個/ウエル程度まき、各ウエルに選択培地を加え、以後適当に選択培地を交換して培養を行う。培養温度は、20~40℃ 、好ましくは約37℃である。ミエローマ細胞がHGPRT欠損株又はチミジンキナーゼ欠損株のものである場合には、ヒポキサンチン・アミノプテリン・チミジンを含む選択培地(HAT培地)を用いることにより、抗体産生能を有する細胞と骨髄腫細胞株のハイブリドーマのみを選択的に培養し、増殖させることができる。その結果、選択培地で培養開始後、約14日前後から生育してくる細胞をハイブリドーマとして得ることができる。
モノクローナル抗体は、慣用的技術によって回収可能である。すなわち樹立したハイブリドーマからモノクローナル抗体を採取する方法として、通常の細胞培養法又は腹水形成法等を採用することができる。細胞培養法においては、ハイブリドーマを10% ウシ胎児血清含有RPMI-1640培地、MEM培地又は無血清培地等の動物細胞培養培地中で、通常の培養条件(例えば37℃、5%CO2濃度)で2~10日間培養し、その培養上清から抗体を取得する。腹水形成法の場合は、ミエローマ細胞由来の哺乳動物と同種系動物の腹腔内にハイブリドーマを約1000万個投与し、ハイブリドーマを大量に増殖させる。そして、1~2週間後に腹水又は血清を採取する。
ポリクローナル抗体を作製する場合は、前記と同様にウサギ等の動物を免疫し、最終の免疫日から6~60日後に、酵素免疫測定法(EIA及びELISA)、放射免疫測定法(RIA)等で抗体価を測定し、最大の抗体価を示した日に採血し、抗血清を得る。その後は、抗血清中のポリクローナル抗体の反応性をELISA法などで測定する。
本発明によれば、本発明の上記抗体を用いて、被検者由来の食道ガン細胞、血液等の生体試料中の該ポリペプチドのレベルをin vitroで測定することを含む、被験者の検体試料中に食道ガン細胞が含まれないこと/又は食道ガン細胞が含まれることをin vitroで判定する方法が提供される。
本発明はまた、本発明の組成物に含まれるものと同じポリヌクレオチド、その変異体及び/又はその断片の1つ又は複数(好ましくは3以上、より好ましくは5以上)を含む食道ガン診断(検出)用キットを提供する。
(1)配列番号1~62で表される塩基配列又はその相補的配列において、15以上の連続した塩基を含むDNA。
本発明はさらに、本発明の組成物及び/又はキットに含まれるものと同じポリヌクレオチド(或いは、上記の3.1節の組成物及び/又は4節のキットに記載されたポリヌクレオチド)、変異体、断片及びそれらの組み合わせを含む食道ガン診断用DNAチップを提供する。
本発明は、本発明の組成物、キット、DNAチップ、又はそれらの組み合わせを用いて、検体試料中に食道ガン細胞が含まれるかどうかをin vitroで判定する方法であって、手術時又は内視鏡検査時に食道ガン患者由来の食道ガン細胞と非ガン細胞を用いて、試料中の発現遺伝子量を比較して、該検体試料中の細胞の標的核酸の発現量が増加/低下している場合、該検体試料中に食道ガン細胞が存在すると判定することを含み、ここで、該標的核酸が該組成物、キット又はDNAチップに含まれるポリヌクレオチド、その変異体又はその断片によって検出可能なものである、方法を提供する。
(a)被験者由来の検体試料を、本発明の組成物、キット又はDNAチップのポリヌクレオチドと接触させる工程、
(b)生体試料中の標的核酸の発現レベルを、上記ポリヌクレオチドをプローブとして用いて測定する工程、
(c)(b)の結果をもとに、該検体試料中の食道ガン(細胞)の存在又は不存在を判定する工程、
を含むことができる。
(a)被験者の生体試料から調製されたRNA又はそれから転写された相補的ポリヌクレオチド(cDNA)を、本発明の組成物、キット又はDNAチップのポリヌクレオチドと結合させる工程、
(b) 該ポリヌクレオチドに結合した生体試料由来のRNA又は該RNAから転写された相補的ポリヌクレオチドを、上記ポリヌクレオチドをプローブとして用いて測定する工程、
(c) 上記(b)の測定結果に基づいて、食道ガン(細胞)の存在又は不存在を判定する工程、
を含むことができる。
(a)食道ガン患者由来の食道ガン細胞を含む組織及び/又は食道ガン患者由来の食道ガン細胞を含まない組織であることが既知の生体試料中の標的遺伝子の発現量を、本発明による診断(検出)用組成物、キット又はDNAチップを用いて測定する工程、
(b)(a)で測定された発現量の測定値を、下記の数1~数5の式に代入して、SVMと呼ばれる判別式を作成する工程、
(c)被験者由来の検体試料中の該標的遺伝子の発現量を、本発明による診断(検出)用組成物、キット又はDNAチップを用いて測定し、(b)で作成した判別式にそれらを代入して、得られた結果に基づいて該検体試料中に食道ガン細胞が含まれるかどうかを判定する工程、
を含むことができる。
ただし、この関数には制約条件:

があるため、Lagurangeの未定乗数法を用いることによりLagurange乗数αを用いた以下の最適化問題に帰着する。
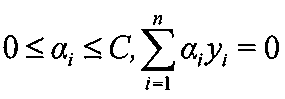
この問題を解くと最終的に、
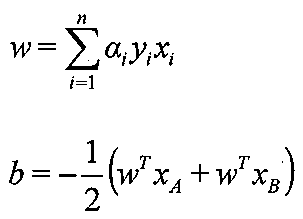
インフォームドコンセントを得た57名の食道ガン患者から、食道ガン摘出手術時又は食道生検実施時に食道の摘出組織を得た。摘出された組織片について肉眼的及び/又は病理組織学的に食道ガン組織を判断し、食道ガン病変部と正常組織部を分けてただちに凍結し、液体窒素中で保存した。
試料として食道ガン患者の食道組織における食道ガン病変部の組織及び非病変部の組織を用いた。おのおのの組織から、TRIzol Reagent(Invitrogen社)を用いて、同社推奨のプロトコールによりtotal RNAを調製した。
DNAチップとしては東レ株式会社3D-Geneヒト全遺伝子型DNAチップを用いて遺伝子の絞込みを行った。3D-Geneヒト全遺伝子型DNAチップの操作については、同社の定める手順に基づいて実施した。3D-Geneヒト全遺伝子型DNAチップを用いた解析の結果、食道ガンによって発現変動が起こる可能性がある遺伝子を重複なく計1119種抽出した。
標識したcDNAをそれぞれ1μgずつ分取し、ハイブリダイゼーションバッファー(東レ株式会社、日本)に溶解し、42℃で16時間ハイブリダイズを行った。ハイブリダイズ終了後、DNAチップを30℃の3×SSCと0.1%SDSを含む溶液、及び42℃の0.3×SSCと0.1%SDSを含む溶液、及び30℃の0.1×SSC溶液による連続した条件で洗浄した。
上述の方法によりハイブリダイゼーションを行ったDNAチップをDNAアレイスキャナー(ScanArrayLite、パーキンエルマージャパン)を用いてスキャンし、画像を取得してGenePix Pro5.0(MolecularDevice)にて蛍光強度を数値化した。統計学的処理はSpeed T.著「Statistical analysis of gene expression microarray data」Chapman & Hall/CRC,及びCauston H.C.ら著「A beginner’s guide Microarray gene expression data analysis」Blackwell publishingを参考にして行った。すなわちハイブリダイズ後の画像解析から得られたデータについて、それぞれの対数値をとり、global normalizationにてノーマライゼーション補正を行った。その結果、食道ガン病変部の組織における発現量が、食道ガン非病変部の組織よりも減少、低減もしくは増加、増大している遺伝子を見出すことができた。これらの遺伝子を食道ガン検出用遺伝子として利用することができると考えられる。
57例の患者から得た検体を教師として、Genomic Profiler(三井情報開発、日本)に搭載したSVMを用いる判別式を作成した。この判別式によって、ノーマライゼーションを行った全57例のデータについて、データの予測を行った。なおカーネルは、linear kernelを用いた。また遺伝子は二群間(食道ガン病変部の組織と食道ガン非病変部の組織)での群内発現量の中央値の差が大きい順に決定した。(表1:食道ガン患者由来の食道ガン組織と食道ガン患者由来の食道ガンを含まない組織(正常組織)での遺伝子転写産物の発現量比較)。

本発明の食道ガン診断用組成物と特許文献6(国際公開第2006/118308号)に記載の食道ガン診断用組成物のより一般的な精度を比較するために、同じくインフォームドコンセントを得た55名の食道ガン患者から、食道生検実施時に食道の生検組織を入手し、本明細書に記載の方法でtotal RNA抽出とcDNAの調製、ハイブリダイゼーション及び遺伝子発現量の測定を実施し、データを得た。これらのデータを55例の患者から得た検体のデータを、特許文献6に記載の食道ガン診断用組成物を特許文献6に記載の方法を用いて判別マシーンを用いて予測したところ、ガン判別用判別マシーンはAccuracyが61.8%の確率で食道ガン患者由来の食道ガン組織と食道ガン患者由来の食道ガンを含まない組織を判別し(図4)、非ガン判別用判別マシーンはAccuracyが47.3%の確率で食道ガン患者由来の食道ガン組織と食道ガン患者由来の食道ガンを含まない組織を判別した(図5)。この結果は本発明の食道ガン診断用組成物と本発明の方法を用いて作成した判別マシーンを用いた食道ガン患者由来の食道ガンを含まない組織を判別する確率よりも低く、特許文献6に記載の食道ガン診断用組成物及び特許文献6に記載の手法は手術検体に対しては高い精度を有するが、生検検体に対しては十分ではなく、本発明の食道ガン診断用組成物と本発明の方法が優位であることがわかった。
特許文献6(国際公開第2006/118308号)に記載の食道ガン診断用組成物を本発明の方法を用いて判別マシーンを用いて予測したところ、Accuracyが74.5%の確率で食道ガン患者由来の食道ガン組織と食道ガン患者由来の食道ガンを含まない組織を判別した(図6)。これらは本発明の食道ガン診断用組成物から作成した判別マシーンの精度よりも低くなっており、特許文献6に記載の食道ガン診断用組成物及び特許文献6に記載の手法は手術検体に対しては高い精度を有するが、生検検体に対しては十分ではなく、本発明の食道ガン診断用組成物と本発明の方法が優位であることがわかった。
Claims (28)
- 下記の(a)~(e)に示すポリヌクレオチド、その変異体又はその断片からなる群から選択される3以上のポリヌクレオチドを含む、食道ガン診断用組成物:
(a)配列番号1~38で表される塩基配列からなるポリヌクレオチド、その変異体、又は15以上の連続した塩基を含むその断片
(b)配列番号1~38で表される塩基配列を含むポリヌクレオチド
(c)配列番号1~38で表される塩基配列に相補的な塩基配列からなるポリヌクレオチド、その変異体、又は15以上の連続した塩基を含むその断片
(d)配列番号1~38で表される塩基配列に相補的な塩基配列を含むポリヌクレオチド
(e)前記(a)~(d)のいずれかのポリヌクレオチドとストリンジェントな条件でハイブリダイズするポリヌクレオチド、又は15以上の連続した塩基を含むその断片。 - 前記断片が、60以上の連続した塩基を含むポリヌクレオチドである、請求項1に記載の組成物。
- 前記断片が、配列番号1~38のいずれかで表される塩基配列において、それぞれ配列番号63~100のいずれかで表される塩基配列を含むポリヌクレオチド、又は該ポリヌクレオチドの配列に相補的な塩基配列を含むポリヌクレオチドである、請求項2に記載の組成物。
- 前記断片が、配列番号63~100のいずれかで表される塩基配列、又はこれらに相補的な塩基配列を含むポリヌクレオチドである、請求項2に記載の組成物。
- 下記の(f)~(j)に示すポリヌクレオチド、その変異体又はその断片からなる群から選択される2以上のポリヌクレオチドをさらに含む、請求項1~4のいずれか1項に記載の組成物:
(f)配列番号39~62で表される塩基配列からなるポリヌクレオチド、その変異体、又は15以上の連続した塩基を含むその断片
(g)配列番号39~62で表される塩基配列を含むポリヌクレオチド
(h)配列番号39~62で表される塩基配列に相補的な塩基配列からなるポリヌクレオチド、その変異体、又は15以上の連続した塩基を含むその断片
(i)配列番号39~62で表される塩基配列に相補的な塩基配列を含むポリヌクレオチド
(j)前記(f)~(i)のいずれかのポリヌクレオチドとストリンジェントな条件でハイブリダイズするポリヌクレオチド、又は15以上の連続した塩基を含むその断片。 - 前記断片が、60以上の連続した塩基を含むポリヌクレオチドである、請求項5に記載の組成物。
- 前記断片が、配列番号39~62で表される塩基配列において、配列番号101~124で表される塩基配列を含むポリヌクレオチド、又は該ポリヌクレオチドの配列に相補的な塩基配列を含むポリヌクレオチドである、請求項6に記載の組成物。
- 前記断片が、配列番号101~124で表される塩基配列、又はこれに相補的な塩基配列を含むポリヌクレオチドである、請求項6に記載の組成物。
- 請求項1~4のいずれかに記載の(a)~(e)に示すポリヌクレオチド、その変異体及び/又はその断片の3以上を含む、食道ガン診断用キット。
- 請求項5~8のいずれかに記載の(f)~(j)に示すポリヌクレオチド、その変異体及び/又はその断片の2以上をさらに含む、請求項9に記載のキット。
- 前記ポリヌクレオチドが、配列番号1~62のいずれかで表される塩基配列からなるポリヌクレオチド、その相補的配列からなるポリヌクレオチド、それらのポリヌクレオチドとストリンジェントな条件でハイブリダイズするポリヌクレオチド、又はそれらの15以上の連続した塩基を含む断片である、請求項9又は10に記載のキット。
- 前記断片が、60以上の連続した塩基を含むポリヌクレオチドである、請求項11に記載のキット。
- 前記断片が、配列番号1~62のいずれかで表される塩基配列において、それぞれ配列番号63~124のいずれかで表される塩基配列を含むポリヌクレオチド、又は該ポリヌクレオチドの配列に相補的な塩基配列を含むポリヌクレオチドである、請求項12に記載のキット。
- 前記断片が、配列番号63~124のいずれかで表される塩基配列、又はこれらに相補的な塩基配列を含むポリヌクレオチドである、請求項12に記載のキット。
- 前記断片が、配列番号63~124のいずれかで表される塩基配列からなるポリヌクレオチドである、請求項14に記載のキット。
- 配列番号63~124で表される塩基配列又はその相補的配列を含むポリヌクレオチドの5以上から全部を含む、請求項9に記載のキット。
- 前記ポリヌクレオチドが、別個に又は任意に組み合わせて異なる容器に包装されている、請求項9~16のいずれか1項に記載のキット。
- 請求項1~4のいずれかに記載の(a)~(e)に示すポリヌクレオチド、その変異体及び/又はその断片の3以上を含む、食道ガン診断用DNAチップ。
- 請求項5~8のいずれかに記載の(f)~(j)に示すポリヌクレオチド、その変異体及び/又はその断片の2以上をさらに含む、請求項18に記載のDNAチップ。
- 配列番号63~124で表される塩基配列又はその相補的配列を含むポリヌクレオチドの5以上~全部を含む、請求項18又は19に記載のDNAチップ。
- 請求項1~8のいずれかに記載の組成物、請求項9~17のいずれかに記載のキット、請求項18~20のいずれかに記載のDNAチップ、又はそれらの組み合わせを用いて、被験者由来の生体試料における標的核酸の発現レベルを測定することによって、被験者由来の検体試料中に食道ガン細胞が含まれないこと、又は食道ガン細胞が含まれることをin vitroで判定する方法。
- DNAチップを用いる、請求項21に記載の方法。
- 請求項1~8のいずれかに記載の組成物、請求項9~17のいずれかに記載のキット、請求項18~20のいずれかに記載のDNAチップ、又はそれらの組み合わせを用いて、食道ガン細胞を含む組織又は正常組織であることが既知の複数の生体試料中の標的核酸の発現量をin vitroで測定する第1の工程、前記第1の工程で得られた該標的核酸の発現量の測定値を教師とした判別式(サポートベクターマシーン)を作成する第2の工程、被験者の食道由来の検体試料中の該標的核酸の発現量を第1の工程と同様にin vitroで測定する第3の工程、前記第2の工程で得られた判別式に第3の工程で得られた該標的核酸の発現量の測定値を代入し、該判別式から得られた結果に基づいて、被験者由来の検体試料中に食道ガン細胞が含まれないこと、又は食道ガン細胞が含まれることを判定する第4の工程を含む、食道ガンを判定する方法。
- 請求項1~8のいずれかに記載の組成物、請求項9~17のいずれかに記載のキット、又は請求項18~20のいずれかに記載のDNAチップの、被験者由来の検体試料中に食道ガン細胞が含まれないこと、又は食道ガン細胞が含まれることをin vitroで判定するための使用。
- 配列番号1~38で表される塩基配列によってコードされるポリペプチドに対する3以上の抗体又はその断片を用いて、被検者由来の食道ガン細胞或いは血液中の該ポリペプチドのレベルをin vitroで測定することを含む、被験者由来の検体試料中に食道ガン細胞が含まれないこと、又は食道ガン細胞が含まれることをin vitroで判定する方法。
- 配列番号39~62で表される塩基配列によってコードされるポリペプチドに対する2以上の抗体又はその断片をさらに使用して、該ポリペプチドのレベルを測定する、請求項25に記載の方法。
- 前記ポリペプチドが、配列番号125~186で表されるアミノ酸配列を有する、請求項25又は26に記載の方法。
- 前記ポリペプチドの発現レベルが、健常な被験者と比べて食道ガンに罹患した被験者において変化している場合、食道ガンであると決定する、請求項25~27のいずれか1項に記載の方法。
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CA2726736A CA2726736A1 (en) | 2008-05-21 | 2009-05-21 | Composition and method for determining esophageal cancer |
| EP09750619A EP2295564A4 (en) | 2008-05-21 | 2009-05-21 | COMPOSITION AND METHOD FOR DETERMINING CREAM CANCER |
| CN2009801269313A CN102089428B (zh) | 2008-05-21 | 2009-05-21 | 食道癌确定用组合物及方法 |
| JP2010513052A JPWO2009142257A1 (ja) | 2008-05-21 | 2009-05-21 | 食道ガン判定用組成物及び方法 |
| US12/993,792 US8945849B2 (en) | 2008-05-21 | 2009-05-21 | Method for diagnosing esophageal cancer |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008-133491 | 2008-05-21 | ||
| JP2008133491 | 2008-05-21 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2009142257A1 true WO2009142257A1 (ja) | 2009-11-26 |
Family
ID=41340184
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2009/059323 Ceased WO2009142257A1 (ja) | 2008-05-21 | 2009-05-21 | 食道ガン判定用組成物及び方法 |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US8945849B2 (ja) |
| EP (1) | EP2295564A4 (ja) |
| JP (1) | JPWO2009142257A1 (ja) |
| KR (1) | KR20110034602A (ja) |
| CN (2) | CN102089428B (ja) |
| CA (1) | CA2726736A1 (ja) |
| WO (1) | WO2009142257A1 (ja) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2012147800A1 (ja) * | 2011-04-25 | 2012-11-01 | 東レ株式会社 | 乳ガン患者のトラスツズマブに対する治療感受性予測用組成物及び方法 |
| WO2017138627A1 (ja) * | 2016-02-10 | 2017-08-17 | 公立大学法人福島県立医科大学 | 食道類基底細胞癌罹患鑑別方法 |
| KR20180013213A (ko) * | 2016-07-29 | 2018-02-07 | 충남대학교산학협력단 | 알비폭스 2 단백질 항체를 유효성분으로 함유하는 소화기계 암 진단용 조성물 및 키트 |
Families Citing this family (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2014525584A (ja) * | 2011-08-31 | 2014-09-29 | オンコサイト コーポレーション | 癌の治療および診断のための方法および組成物 |
| CN103901196B (zh) * | 2013-05-07 | 2016-04-27 | 上海良润生物医药科技有限公司 | Cystatin S和CYFRA21-1在制备诊断和预示食管癌标志物中的应用 |
| CN106460068B (zh) * | 2014-06-16 | 2024-08-23 | 东丽株式会社 | 胃癌的检测试剂盒或装置以及检测方法 |
| CN105331686B (zh) * | 2015-10-21 | 2018-09-21 | 中国科学院生物物理研究所 | Myosin9b蛋白特异性抗体的制备及Myosin9b基因家族变化在肿瘤诊断及预后中的应用 |
| JP7356727B2 (ja) * | 2017-10-12 | 2023-10-05 | 慶應義塾 | アクアポリン3(aqp3)の細胞外ドメインに特異的に結合する抗aqp3モノクローナル抗体、及びその使用 |
| US12270033B2 (en) | 2019-02-15 | 2025-04-08 | Exhaura, Ltd. | Dual leucine zipper kinase inhibitors for gene therapy |
| KR102238594B1 (ko) * | 2019-06-07 | 2021-04-08 | 한양대학교 산학협력단 | Heres 발현 억제제를 포함하는 편평상피세포암 예방 또는 치료용 약학적 조성물 |
| CN110938130B (zh) * | 2019-11-08 | 2021-07-09 | 上海交通大学 | 一种生物活性多肽rvfqplphenkpltl及其制备方法和应用 |
| CN113307861A (zh) * | 2020-12-09 | 2021-08-27 | 重庆医科大学 | 细胞因子il-27作为nec与fpies鉴别诊断标志物及应用 |
| CN113151288B (zh) * | 2021-02-26 | 2022-07-22 | 广州市妇女儿童医疗中心 | 突变的HoxA10基因及应用 |
| CN117624343B (zh) * | 2023-12-06 | 2024-05-10 | 广西福莱明生物制药有限公司 | 一种重组i型人源化胶原蛋白、创伤修复组合物及其应用 |
| CN117756925B (zh) * | 2023-12-26 | 2024-09-13 | 广东普言生物科技有限公司 | 一种重组弹性蛋白Pro.ELP及其制备方法和应用 |
| CN118652982B (zh) * | 2024-07-11 | 2025-06-24 | 承德医学院附属医院 | Troap在诊断及治疗结直肠癌中的应用 |
| CN119257972B (zh) * | 2024-11-22 | 2025-10-10 | 广东丸美生物技术股份有限公司 | 重组胶原蛋白在制备增加皮肤成纤维细胞增殖相关基因表达量的制剂中的应用 |
Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2000511536A (ja) | 1996-05-30 | 2000-09-05 | プロテオム サイエンシズ ピーエルシー | 食道癌用のタンパク質マーカー |
| JP2001017200A (ja) | 1999-07-12 | 2001-01-23 | Sumitomo Electric Ind Ltd | 染色体異常の検出による食道癌のリンパ節転移の診断方法 |
| JP2002272497A (ja) | 2001-03-15 | 2002-09-24 | Venture Link Co Ltd | 癌の診断方法、およびその診断用ベクター |
| WO2003042661A2 (en) | 2001-11-13 | 2003-05-22 | Protein Design Labs, Inc. | Methods of diagnosis of cancer, compositions and methods of screening for modulators of cancer |
| JP2003259872A (ja) | 2002-03-07 | 2003-09-16 | Japan Science & Technology Corp | ヒト食道癌抗原ペプチドと食道癌診断方法 |
| WO2003076594A2 (en) | 2002-03-07 | 2003-09-18 | The Johns Hopkins University | Genomic screen for epigenetically silenced tumor suppressor genes |
| JP2004505612A (ja) | 2000-03-31 | 2004-02-26 | ユニバーシティ・オブ・サザン・カリフォルニア | 食道腺ガンに関する後成的配列 |
| WO2006119464A1 (en) | 2005-05-04 | 2006-11-09 | University Of South Florida | Predicting treatment response in cancer subjects |
| WO2006118308A1 (ja) | 2005-05-02 | 2006-11-09 | Toray Industries, Inc. | 食道ガン及び食道ガン転移診断のための組成物及び方法 |
| US20070026424A1 (en) * | 2005-04-15 | 2007-02-01 | Powell Charles A | Gene profiles correlating with histology and prognosis |
| US20070218512A1 (en) * | 2006-02-28 | 2007-09-20 | Alex Strongin | Methods related to mmp26 status as a diagnostic and prognostic tool in cancer management |
| JP2008133491A (ja) | 2006-11-27 | 2008-06-12 | Japan Atomic Energy Agency | 亜硫酸電解用電極およびこれを用いた亜硫酸電解水素製造装置 |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5990299A (en) * | 1995-08-14 | 1999-11-23 | Icn Pharmaceuticals, Inc. | Control of CD44 gene expression for therapeutic use |
| CN1223677C (zh) * | 1999-08-10 | 2005-10-19 | 中国医学科学院肿瘤医院肿瘤研究所 | 一种食管癌相关基因 |
| CA2405431A1 (en) | 2000-03-31 | 2001-10-11 | Gene Logic, Inc. | Gene expression profiles in esophageal tissue |
| CN1618985A (zh) * | 2003-11-21 | 2005-05-25 | 中国医学科学院肿瘤医院肿瘤研究所 | 一个新的食管癌标志基因rpl14及其用途 |
| US7537894B2 (en) * | 2005-03-02 | 2009-05-26 | The University Of Chicago | Methods and kits for monitoring Barrett's metaplasia |
| US20110038791A1 (en) * | 2008-02-25 | 2011-02-17 | Ford Heide L | Methods for inhibiting six1 and eya proteins |
-
2009
- 2009-05-21 CN CN2009801269313A patent/CN102089428B/zh not_active Expired - Fee Related
- 2009-05-21 US US12/993,792 patent/US8945849B2/en not_active Expired - Fee Related
- 2009-05-21 EP EP09750619A patent/EP2295564A4/en not_active Withdrawn
- 2009-05-21 KR KR1020107028629A patent/KR20110034602A/ko not_active Ceased
- 2009-05-21 WO PCT/JP2009/059323 patent/WO2009142257A1/ja not_active Ceased
- 2009-05-21 CN CN201310407690.8A patent/CN103540657A/zh active Pending
- 2009-05-21 CA CA2726736A patent/CA2726736A1/en not_active Abandoned
- 2009-05-21 JP JP2010513052A patent/JPWO2009142257A1/ja active Pending
Patent Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2000511536A (ja) | 1996-05-30 | 2000-09-05 | プロテオム サイエンシズ ピーエルシー | 食道癌用のタンパク質マーカー |
| JP2001017200A (ja) | 1999-07-12 | 2001-01-23 | Sumitomo Electric Ind Ltd | 染色体異常の検出による食道癌のリンパ節転移の診断方法 |
| JP2004505612A (ja) | 2000-03-31 | 2004-02-26 | ユニバーシティ・オブ・サザン・カリフォルニア | 食道腺ガンに関する後成的配列 |
| JP2002272497A (ja) | 2001-03-15 | 2002-09-24 | Venture Link Co Ltd | 癌の診断方法、およびその診断用ベクター |
| WO2003042661A2 (en) | 2001-11-13 | 2003-05-22 | Protein Design Labs, Inc. | Methods of diagnosis of cancer, compositions and methods of screening for modulators of cancer |
| JP2003259872A (ja) | 2002-03-07 | 2003-09-16 | Japan Science & Technology Corp | ヒト食道癌抗原ペプチドと食道癌診断方法 |
| WO2003076594A2 (en) | 2002-03-07 | 2003-09-18 | The Johns Hopkins University | Genomic screen for epigenetically silenced tumor suppressor genes |
| US20070026424A1 (en) * | 2005-04-15 | 2007-02-01 | Powell Charles A | Gene profiles correlating with histology and prognosis |
| WO2006118308A1 (ja) | 2005-05-02 | 2006-11-09 | Toray Industries, Inc. | 食道ガン及び食道ガン転移診断のための組成物及び方法 |
| WO2006119464A1 (en) | 2005-05-04 | 2006-11-09 | University Of South Florida | Predicting treatment response in cancer subjects |
| US20070218512A1 (en) * | 2006-02-28 | 2007-09-20 | Alex Strongin | Methods related to mmp26 status as a diagnostic and prognostic tool in cancer management |
| JP2008133491A (ja) | 2006-11-27 | 2008-06-12 | Japan Atomic Energy Agency | 亜硫酸電解用電極およびこれを用いた亜硫酸電解水素製造装置 |
Non-Patent Citations (103)
| Title |
|---|
| "Current protocols in Immunology", 2001, JOHN WILEY & SONS INC. |
| "Current protocols in Protein Sciences", 1995, JOHN WILEY & SONS INC. |
| ABRAHAM J. M. ET AL., CELL GROWTH DIFFER., vol. 7, 1996, pages 855 - 860 |
| ABRAHAM, J. M. ET AL., CELL GROWTH & DIFFERENTIATION, vol. 7, 1996, pages 855 - 860 |
| ABRAHAM, J.M. ET AL., CELL GROWTH & DIFFERENTIATION, vol. 7, 1996, pages 855 - 860 |
| ADAMS M. D. ET AL., NATURE, vol. 355, 1992, pages 632 - 634 |
| ALBERTSEN H.M. ET AL., GENOMICS, vol. 33, 1996, pages 207 - 213 |
| ALTSCHUL, S. F. ET AL., JOURNAL OF MOLECULAR BIOLOGY, vol. 215, 1990, pages 403 - 410 |
| AUSTIN U. ET AL., J. MOL. ENDOCRINOL., vol. 14, 1995, pages 157 - 169 |
| AUSUBEL. ET AL.: "Current Protocols in Molecular Biology", 1993, JOHN WILLEY & SONS |
| BECKER T. ET AL., EUR. J. BIOCHEM., vol. 207, 1992, pages 541 - 547 |
| BROOKES S. ET AL., ONCOGENE, vol. 4, 1989, pages 429 - 436 |
| BURGESS D. L. ET AL., GENOME RES., vol. 9, 1999, pages 1204 - 1213 |
| CHAPMAN; HALL/CRC; CAUSTON, H. C. ET AL.: "A Beginner's Guide: Microarray Gene Expression Data Analysis", BLACKWELL PUBLISHING |
| CHEM, B. S. ET AL., CARCINOGENESIS, vol. 21, 2000, pages 2147 - 2150 |
| CHEN Z. ET AL.: "Immunoglobulin G expression in carcinomas and cancer cell lines", FASEB JOURNAL, vol. 21, 2007, pages 2931 - 2938, XP008139026 * |
| CHEN, B.S. ET AL., CARCINOGENESIS, vol. 21, 2000, pages 2147 - 2150 |
| DE BOECK H. ET AL., BIOCHEM. J., vol. 247, 1987, pages 765 - 771 |
| DEVERGNE O. ET AL., J. VIROL., vol. 70, 1996, pages 1143 - 1153 |
| DIEKWISCH T.G. ET AL., GENE, vol. 235, 1999, pages 19 - 30 |
| DOLL A. ET AL., CYTOGENET. CELL GENET., vol. 95, 2001, pages 20 - 27 |
| DOTZLAW H. ET AL., J. CLIN. ENDOCRINOL. METAB., vol. 82, 1997, pages 2371 - 2374 |
| DRUCK T. ET AL., GENOMICS, vol. 30, 1995, pages 94 - 97 |
| EBIHARA Y. ET AL.: "DARPP-32 expression arises after a phase of dysplasia in oesophageal squamous cell carcinoma.", BR.J.CANCER, vol. 91, no. 1, 2004, pages 119 - 123, XP003007107 * |
| ENDO S. ET AL., BIOCHEMISTRY, vol. 35, 1996, pages 5220 - 5228 |
| FITZPATRICK D. R. ET AL., HUM. MOL. GENET., vol. 12, 2003, pages 2491 - 2501 |
| FUKUDA M.N. ET AL., GENES DEV., vol. 9, 1995, pages 1199 - 1210 |
| G. YERSHOV ET AL., PROCEEDINGS OF THE NATIONAL ACADEMIC SCIENCES, U.S.A., vol. 94, 1996, pages 4913 |
| GONDO H. ET AL., J. IMMUNOL., vol. 139, 1987, pages 3840 - 3848 |
| GOZO TSUJIMOTO: "Shokudo Gan Seiken Hyohon no Idenshi Hatsugen Profile Kaiseki ni yoru Hoshasen Kagaku Ryoho Kanjusei Yosoku no Rinsho Donyu o Mezashita Kibanteki Kenkyu", SHOKUDO GAN SEIKEN HYOHON NO IDENSHI HATSUGEN PROFILE KAISEKI NI YORU HOSHASEN KAGAKU RYOHO KANJUSEI YOSOKU NO RINSHO DONYU O MEZASHITA KIBANTEKI KENKYU HEISEI 18 NENDO SOKATSU ., 2007, pages 10 - 12, XP008139093 * |
| HAITINA T. ET AL., GENOMICS, vol. 88, 2006, pages 779 - 790 |
| HIDEO AKIYAMA: "Hito DNA Chip no Kaihatsu -Ko Kandoka ni yoru Shin Hakken eno Kitai", BIO.IND., vol. 25, no. 5, 12 May 2008 (2008-05-12), pages 78 - 84, XP008139090 * |
| HOLMES G.P. ET AL., MECH. DEV., vol. 79, 1998, pages 57 - 72 |
| HOOD L. ET AL., NATURE, vol. 220, 1968, pages 764 - 767 |
| ISHIBASHI K. ET AL., GENE, vol. 264, 2001, pages 87 - 93 |
| ITO T. ET AL., J. BIOCHEM.(TOKYO), vol. 124, 1998, pages 347 - 353 |
| ITO T. ET AL., J. CLIN. INVEST., vol. 104, 1999, pages 1265 - 1275 |
| J. B. LAMTURE ET AL., NUCLEIC. ACIDS. RESEARCH, vol. 22, 1994, pages 2121 - 2125 |
| JERALA, R. ET AL., FEBS LETT., vol. 239, 1988, pages 41 - 44 |
| JIANG W. ET AL., MOL. CELL., vol. 2, 1998, pages 877 - 885 |
| JU Y. T. ET AL., PROC. NATL. ACAD. SCI. U.S.A., vol. 95, 1998, pages 11423 - 11428 |
| KALZ-FULLER B. ET AL., EUR. J. BIOCHEM., vol. 231, 1995, pages 344 - 351 |
| KARLIN, S ET AL., PROCEEDINGS OF THE NATIONAL ACADEMIC SCIENCES, U.S.A., vol. 90, 1993, pages 5873 - 5877, Retrieved from the Internet <URL:http://www.ncbi.nlm.nih.gov/BLAST> |
| KARLIN, S. ET AL., PROCEEDINGS OF THE NATIONAL ACADEMIC SCIENCES, U.S.A., vol. 90, 1993, pages 5873 - 5877 |
| KATOH M. ET AL., INT. J. ONCOL., vol. 23, 2003, pages 235 - 241 |
| KAWAGUCHI, H., CANCER, vol. 89, 2000, pages 1413 - 1417 |
| KAWAMATA H. ET AL.: "Identification of genes differentially expressed in a newly isolated human metastasizing esophageal cancer cell line, T.Tn-AT1, by cDNA microarray", CANCER SCI., vol. 94, no. 8, 2003, pages 699 - 706, XP008139024 * |
| KAWAMATA, H. ET AL., CANCER SCIENCE, vol. 94, 2003, pages 699 - 706 |
| KAWANISHI, K. ET AL., CANCER, vol. 85, 1999, pages 1649 - 1657 |
| KAZEMI-NOUREINI,S. ET AL., WORLD JOURNAL OF GASTROENTEROLOGY, vol. 10, 2004, pages 1716 - 1721 |
| KENNET ET AL.: "Monoclonal Antibodies, Hybridomas: A New Dimension in Biological Analyses", 1980, PLENUM PRESS |
| KITAGAWA, Y. ET AL., CANCER RESEARCH, vol. 51, 1991, pages 1504 - 1508 |
| KOKAME K. ET AL., J. BIOL. CHEM., vol. 271, 1996, pages 29659 - 29665 |
| KURIYAMA H. ET AL., BIOCHEM. BIOPHYS. RES. COMMUN., vol. 241, 1997, pages 53 - 58 |
| LEES J.A. ET AL., MOL. CELL. BIOL., vol. 13, 1993, pages 7813 - 7825 |
| LERMAN M. I. ET AL., CANCER RES., vol. 60, 2000, pages 6116 - 6133 |
| LO N.W. ET AL., GLYCOBIOLOGY, vol. 8, 1998, pages 517 - 526 |
| LOIDL H. R. ET AL., NUCLEIC ACIDS RES., vol. 16, 1984, pages 9383 - 9394 |
| LOWNEY P. ET AL., NUCLEIC ACID RES., vol. 19, 1991, pages 3443 - 3449 |
| LU, J. ET AL., INTERNATIONAL JOURNAL OF CANCER, vol. 91, 2001, pages 288 - 294 |
| LUO A. ET AL.: "Discovery of Ca2+-relevant and differentiation-associated genes downregulated in esophageal squamous cell carcinoma using cDNA microarray", ONCOGENE, vol. 23, no. 6, 2004, pages 1291 - 1299, XP002432856 * |
| LUO, A. ET AL., ONCOGENE, vol. 23, 2004, pages 1291 - 1299 |
| LUX S. E. ET AL., PROC. NATL. ACAD. SCI. U.S.A., vol. 86, November 1989 (1989-11-01), pages 9089 - 9093 |
| MIKKAICHI T. ET AL., PROC. NATL. ACAD. SCI. U.S.A., vol. 101, 2004, pages 3569 - 3574 |
| MOTTES M. ET AL., HUM. MUTAT., vol. 12, 1998, pages 71 - 72 |
| NAKAMURA, T. ET AL., DISEASES OF THE ESOPHAGUS, vol. 11, 1998, pages 35 - 39 |
| NAKASHIMA Y. ET AL., GENOMICS, vol. 20, 1994, pages 99 - 104 |
| NAKAYAMA M. ET AL., GENOMICS, vol. 51, 1998, pages 27 - 34 |
| NORRIS J. D. ET AL., MOL. ENDOCRINOL., vol. 16, 2002, pages 459 - 468 |
| OZELIUS L.J. ET AL., NAT. GENET., vol. 17, 1997, pages 40 - 48 |
| PARKER N.J. ET AL., GENOMICS, vol. 19, 1994, pages 91 - 96 |
| PAUSE A. ET AL., NATURE, vol. 371, 1994, pages 762 - 767 |
| PEARSON, W. R. ET AL., PROCEEDINGS OF THE NATIONAL ACADEMIC SCIENCES, U.S.A., vol. 85, 1988, pages 2444 - 2448 |
| PELLEGRINI L. ET AL., J. ALZHEIMERS DIS., vol. 3, 2001, pages 181 - 190 |
| PENNICA D. ET AL., PROC. NATL. ACAD. SCI. U.S.A., vol. 95, 1998, pages 14717 - 14722 |
| POHLMANN R. ET AL., PROC. NATL. ACAD. SCI. U.S.A., vol. 84, 1987, pages 5575 - 5579 |
| PUCHARCOS C. ET AL., FEBS LETT., vol. 478, 2000, pages 43 - 51 |
| R. G. SOSNOWSKI ET AL., PROCEEDINGS OF THE NATIONAL ACADEMIC SCIENCES, U.S.A., vol. 94, 1997, pages 1119 - 1123 |
| READY U. R.; PLEASURE D., BIOCHEM. BIOPHYS. RES. COMMUN., vol. 202, 1994, pages 613 - 620 |
| SAMBROOK ET AL.: "Molecular Cloning: A Laboratory Manual", 1989, COLD SPRING HARBOR LABORATORY PRESS |
| SAMBROOK, J.; RUSSEL, D.: "Molecular Cloning, A LABORATORY MANUAL", vol. 1, 2, 15 January 2001, COLD SPRING HARBOR LABORATORY PRESS, pages: 7.42 - 7,45,8.9 |
| SAMBROOK, J.; RUSSEL, D.: "Molecular Cloning, A LABORATORY MANUAL", vol. 1, 2, 15 January 2001, COLD SPRING HARBOR LABORATORY PRESS, pages: 7.42 - 7.45,8.9 |
| SCHARF J. M. ET AL., NAT. GENET., vol. 20, 1998, pages 83 - 86 |
| SHI T. ET AL., GENES DEV., vol. 15, 2001, pages 1140 - 1151 |
| SHIRAISHI, T. ET AL., INTERNATIONAL JOURNAL OF CANCER, vol. 79, 1998, pages 175 - 178 |
| SHIRAISHI,T. ET AL., INTERNATIONAL JOURNAL OF CANCER, vol. 79, 1998, pages 175 - 178 |
| SPRING P. ET AL., BIOCHEM. BIOPHYS. RES. COMMUN., vol. 264, 1999, pages 299 - 304 |
| STEHLIK C. ET AL., FEBS LETT., vol. 569, 2004, pages 149 - 155 |
| SU, H. ET AL., CANCER RESEARCH, vol. 63, 2003, pages 3872 - 3876 |
| SUI L. ET AL., BIOCHEM. BIOPHYS. RES. COMMUN., vol. 304, 2003, pages 393 - 398 |
| TEBBS R.S. ET AL., PROC. NATL. ACAD. SCI. U.S.A., vol. 92, 1995, pages 6354 - 6358 |
| THIESEN S. ET AL., BIOCHEM. BIOPHYS. RES. COMMUN., vol. 273, 2000, pages 364 - 369 |
| TOMBES R.M. ET AL., BIOCHEM. BIOPHYS. ACTA., vol. 1355, 1997, pages 281 - 292 |
| WICKS S. J ET AL., ONCOGENE, vol. 24, 2005, pages 8080 - 8084 |
| WIRTH J.A. ET AL., J. CELL. SCI., vol. 109, 1996, pages 653 - 661 |
| WONG Y. W. ET AL., J. EXP. MED., vol. 171, 1990, pages 2115 - 2130 |
| WU X. ET AL., GENOMICS, vol. 80, 2002, pages 553 - 557 |
| XU, S.H. ET AL., WORLD JOURNAL OF GASTROENTEROLOGY, vol. 9, 2003, pages 417 - 422 |
| Z. GUO ET AL., NUCLEIC. ACIDS. RESEARCH, vol. 22, 1994, pages 5456 - 5465 |
| ZHANG L. ET AL.: "Transcriptional Coactivator Drosophila Eyes Absent Homologue 2 Is Up- Regulated in Epithelial Ovarian Cancer and Promotes Tumor Growth", CANCER RESEARCH, vol. 65, 2005, pages 925 - 932, XP008139078 * |
| ZHI H. ET AL.: "The deregulation of arachidonic acid metabolism-related genes in human esophageal squamous cell carcinoma", INT J CANCER., vol. 106, no. 3, 2003, pages 327 - 333, XP008139085 * |
| ZHI, H. ET AL., INTERNATIONAL JOURNAL OF CANCER, vol. 106, 2003, pages 327 - 333 |
| ZIMMERMAN J. E. ET AL., GENOME RES., vol. 7, 1997, pages 128 - 141 |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2012147800A1 (ja) * | 2011-04-25 | 2012-11-01 | 東レ株式会社 | 乳ガン患者のトラスツズマブに対する治療感受性予測用組成物及び方法 |
| JP6026408B2 (ja) * | 2011-04-25 | 2016-11-16 | 東レ株式会社 | 乳ガン患者のトラスツズマブに対する治療感受性予測用組成物及び方法 |
| WO2017138627A1 (ja) * | 2016-02-10 | 2017-08-17 | 公立大学法人福島県立医科大学 | 食道類基底細胞癌罹患鑑別方法 |
| KR20180013213A (ko) * | 2016-07-29 | 2018-02-07 | 충남대학교산학협력단 | 알비폭스 2 단백질 항체를 유효성분으로 함유하는 소화기계 암 진단용 조성물 및 키트 |
| KR101889764B1 (ko) * | 2016-07-29 | 2018-08-20 | 충남대학교 산학협력단 | 알비폭스 2 단백질 항체를 유효성분으로 함유하는 소화기계 암 진단용 조성물 및 키트 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP2295564A1 (en) | 2011-03-16 |
| KR20110034602A (ko) | 2011-04-05 |
| US8945849B2 (en) | 2015-02-03 |
| CN102089428B (zh) | 2013-11-13 |
| CN103540657A (zh) | 2014-01-29 |
| CA2726736A1 (en) | 2009-11-26 |
| JPWO2009142257A1 (ja) | 2011-09-29 |
| US20110098185A1 (en) | 2011-04-28 |
| EP2295564A4 (en) | 2011-08-10 |
| CN102089428A (zh) | 2011-06-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN102089428B (zh) | 食道癌确定用组合物及方法 | |
| US8198025B2 (en) | Method for diagnosing esophageal cancer | |
| JP5435529B2 (ja) | 腎ガン診断、腎ガン患者予後予測のための組成物および方法 | |
| CA2762082C (en) | Markers for detection of gastric cancer | |
| KR101566368B1 (ko) | 암 검출을 위한 소변 유전자 발현 비율 | |
| CN112345755A (zh) | 乳腺癌的生物标志物及其应用 | |
| CA2621060A1 (en) | Kit and method for detection of urothelial cancer | |
| JP2009065969A (ja) | 胃ガン腹腔内転移判定用組成物及び方法 | |
| JP2009065969A5 (ja) | ||
| JP2010000041A (ja) | 食道ガン転移判定用組成物及び方法 | |
| NZ577012A (en) | Human zymogen granule protein 16 as a marker for detection of gastric cancer |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 200980126931.3 Country of ref document: CN |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 09750619 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2010513052 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 12993792 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2726736 Country of ref document: CA |
|
| REEP | Request for entry into the european phase |
Ref document number: 2009750619 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2009750619 Country of ref document: EP |
|
| ENP | Entry into the national phase |
Ref document number: 20107028629 Country of ref document: KR Kind code of ref document: A |