WO2014002776A1 - Système d'extraction de synonymes, procédé et support d'enregistrement - Google Patents
Système d'extraction de synonymes, procédé et support d'enregistrement Download PDFInfo
- Publication number
- WO2014002776A1 WO2014002776A1 PCT/JP2013/066286 JP2013066286W WO2014002776A1 WO 2014002776 A1 WO2014002776 A1 WO 2014002776A1 JP 2013066286 W JP2013066286 W JP 2013066286W WO 2014002776 A1 WO2014002776 A1 WO 2014002776A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- word
- similarity
- information
- context
- notation
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/237—Lexical tools
- G06F40/247—Thesauruses; Synonyms
Definitions
- the present invention relates to a synonym extraction system, method, and recording medium, and in particular, extracts synonyms from documents that have synonyms that can be established only in a document group related to a specific item, such as proposals and specifications related to information system construction.
- the present invention relates to a synonym extraction system, method, and recording medium.
- Patent Document 1 An example of prior art relating to a synonym extraction system is described in Patent Document 1 as a “word meaning relationship extraction device”.
- This word semantic relationship extraction device disclosed in Patent Document 1 refers to a means for generating feature vectors having different types of similarity as elements for a set of words extracted from text, and a known dictionary.
- the synonym expansion system disclosed in Patent Literature 2 includes at least one computer including a processor, a memory connected to the processor, and a storage device.
- the processor executes a process described below by executing a program for synonym expansion processing stored in the memory.
- the processor refers to a first database in which first context information including a word that is a destination of a word is stored, and the first context information of a first word and the first context of a second word By comparing the information, a similarity indicating the closeness of meaning between the first word and the second word is calculated. Then, the processor determines at least one or more second words having a high calculated similarity as synonym candidates for the first word, and determines the determined at least one or more synonym candidates and their similarities.
- the first information including is output.
- the processor refers to a second database in which second context information including words that appear within a predetermined number of words in a sentence from a certain word is stored, the second context information of the first word, Context matching indicating the probability that the context in which the at least one or more synonym candidates appear matches the second context information of the at least one or more synonym candidates included in the output first information Calculate the degree.
- the processor calculates a synonym expansion score of the synonym candidate based on the similarity of the at least one synonym candidate and the calculated context suitability, and the at least one or more synonym expansion scores are calculated. Second information including the synonym candidate and the synonym expansion score is output.
- the processor determines a synonym candidate having a high calculated synonym expansion score as a synonym of the first word among at least one or more synonym candidates included in the output second information. Then, the third information including the synonym of the determined first word is output.
- the dictionary registration device disclosed in Patent Document 3 is a device for registering a word not registered in the dictionary in the dictionary, a dictionary storage means for storing a dictionary holding the word, and an unknown by performing morphological analysis on the input document.
- a morpheme analysis unit that extracts words, an unknown word range expansion unit that generates an extended unknown word that combines at least one of the front and rear words of the unknown word, and a word that matches the notation of the expanded part of the unknown word
- a partial match search unit for searching for a registered word registered in the dictionary; a character attribute of a portion corresponding to the unknown word in the registered word; and a character attribute of a notation of the unknown word
- the notation similarity determination unit for determining the notation similarity, and the notation similarity case unit determines that the notation of the portion corresponding to the unknown word in the registered word is similar to the notation of the unknown word If
- the serial expansion unknown words and a dictionary registration unit to be registered in the dictionary.
- the first problem of such prior art is the extraction of synonyms from documents with synonyms that can be made only in a document group related to a specific case, such as proposals and specifications related to information system construction.
- a specific case such as proposals and specifications related to information system construction.
- synonym extraction method according to the prior art it is not possible to extract a synonym that is formed only in a document group related to a specific case.
- the reason for this is that synonyms that exist only in documents related to a specific project, such as proposals and specifications related to information system construction, are embedded unintentionally, and it is difficult to grasp their synonyms in advance. This is because it is difficult to prepare a known dictionary as correct answer information used for learning as used in the conventional method of Patent Document 1.
- the second problem of the above prior art is to extract synonyms from documents that have synonyms that only exist in a group of documents related to a specific project, such as proposals and specifications related to information system construction. If this extraction method is applied, the extraction rate of synonyms is lowered. The reason for this is that many of the documents with synonyms that consist only of documents related to a specific case, such as proposals and specifications related to information system construction, are small corpora with a limited amount of text.
- text data that is the same quality as the analysis object, such as dependency and co-occurrence words such as a second database in which information is stored
- similarity determination is performed on the assumption of a corpus of the same quality as the analysis object This is because it is difficult.
- the notation similarity determination unit in the dictionary registration apparatus disclosed in Patent Document 3 extracts a portion corresponding to an unknown word from the partial character strings included in the words searched by the partial match search unit by the morpheme analysis unit. It is only determined whether or not it is similar to the unknown word.
- the purpose of the present invention is to create a specific case from a document having a synonym that can be found only in a document group related to a specific case, such as a proposal or specification related to information system construction, without requiring correct information or a large amount of corpus. It is an object to provide a synonym extraction system, a method, and a recording medium that extract with high accuracy synonyms that are established only in a document group.
- a synonym extraction system is a synonym extraction system that analyzes a document and extracts synonyms, a document input unit that receives input of a target document or a document group; and is used for each sentence
- a word analysis unit that extracts all words that are extracted, word metric information that is a quantitative feature of the word, and word information that is a qualitative feature of the word; and is used for each sentence extracted by the word analysis unit
- For each word use the word information to create context information about the context in which each word was used, and use the context similarity calculation method to calculate the similarity between the context information of each word as the context similarity of each word combination
- a notation information on the character composition of each word for each word used in each sentence extracted by the word analysis unit, and each notation information is calculated by a notation similarity calculation method.
- a notation similarity calculation unit that calculates the similarity between the notation information of each word combination as the notation similarity of each word combination; with respect to a word combination that has been determined to be a synonym in the past, word metric information of the word combination in the document, word Context similarity information between words, notation similarity information between words, and judgment results whether or not the words are synonyms are collected and accumulated, and the context similarity information between words and the words are determined by the value of word metric information Similarity evaluation information, which is statistical information indicating how much the notation similarity information is valid for the determination of synonyms, is calculated by any similarity evaluation method, and word metric information of words in word combinations is supported
- a similarity evaluation database that responds to similarity evaluation information; and for each word combination in the target document, the similarity evaluation information corresponding to the word metric information of each word extracted by the word analysis unit is The synonymity of word combinations is determined by calculating the word similarity using a predetermined synonym determination method from the similarity evaluation information inquired and responded to the similar
- a specific case without requiring correct answer information or a large amount of corpus Can be extracted with high accuracy.
- FIG. 1 is a block diagram showing a configuration of a synonym extraction system according to an embodiment of the present invention.
- FIG. 2 is a sequence diagram showing an operation example of the synonym extraction system shown in FIG.
- FIG. 3 is a block diagram showing the configuration of the synonym extraction system according to the first embodiment of the present invention.
- FIG. 4 is an explanatory diagram showing an example of a part of the word co-occurrence table E.
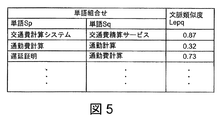
- FIG. 5 is an explanatory diagram showing an example of a part of the context similarity Lepq between words Si.
- FIG. 6 is an explanatory diagram showing a partial example of the notation similarity Lwpq between words Si.
- FIG. 7 is an explanatory diagram illustrating an example of accumulated data of the appearance number P, the context similarity Le, and the notation similarity Lw.
- FIG. 8 is an explanatory diagram showing an example of a part of the result of calculating the word similarity Lpq.
- FIG. 1 is a block diagram showing a configuration of a synonym extraction system 100 according to an embodiment of the present invention.
- a synonym extraction system 100 according to an embodiment of the present invention is basically in an electronic device or a system composed of an information communication network such as a server and an electronic device and the Internet interconnecting them. And at least a document input unit 10, a word analysis unit 20, a context similarity calculation unit 30, a notation similarity calculation unit 40, a synonym candidate estimation unit 50, a synonym candidate output unit 60, and a similarity evaluation database 110. .
- the illustrated synonym extraction system 100 is a synonym extraction system that extracts a synonym from a document having a synonym that is formed only in a document group related to a specific item, such as a proposal or a specification regarding an information system construction.
- the synonym extraction system 100 uses the number of occurrences of words and the number of words between words from a document having synonyms that are formed only in a document group related to a specific item, such as a proposal or specification for information system construction.
- the synonym extraction system 100 can be realized by a computer that operates under program control. Although not shown, this type of computer, as is well known, includes an input device for inputting data, a data processing device, an output device for outputting processing results in the data processing device, and an auxiliary memory serving as various databases. Device.
- the data processing device stores data in a read-only memory (ROM) that stores a program, a random access memory (RAM) that is used as a work area that temporarily stores data, and a program stored in the ROM. It consists of a central processing unit (CPU) that processes stored data.
- the input device functions as the document input unit 10.
- the data processing device functions as the word analysis unit 20, context similarity calculation unit 30, notation similarity calculation unit 40, and synonym candidate estimation unit 50.
- the auxiliary storage device operates as the similarity evaluation database 110.
- the output device functions as the synonym candidate output unit 60. Next, the operation of each component constituting the synonym extraction system 100 will be described.
- the document input unit 10 receives input of a target document or document group.
- the word analysis unit 20 applies morphological analysis and syntax analysis to each sentence constituting a document or a document group, thereby extracting all words used in each sentence and word metric information that is a quantitative feature of the word, Extract word information that is a qualitative feature of the word.
- the word may be limited to a self-supporting word such as a noun, a verb, or an adjective.
- the word metric information is data that can be quantified with respect to word combinations. For example, the number of characters and words in a document in which the word combinations are used, or the number of occurrences of each word and the number of occurrences on the word side with a small number of appearances.
- the above word information includes information that makes it possible to identify the character composition of the word and the source sentence, as well as paragraphs and table of contents of the source sentence, the part of speech of the word, and the dependency relationship between words as necessary. May be included.
- the context similarity calculation unit 30 uses the word information for each word used in each sentence extracted by the word analysis unit 20 to create context information regarding the context in which each word is used.
- the context information is information indicating in what context each word is used, and a character string in an arbitrary range before and after the word, or a co-occurrence relationship with an arbitrary word by an arbitrary co-occurrence determination method.
- a co-occurrence set in which the co-occurrence words considered to be and their co-occurrence numbers are summarized in one sentence unit, or a co-occurrence vector in which the co-occurrence set is aggregated for a sentence group in an arbitrary range is effective.
- conceptual context information such as a concept set or a concept vector obtained by converting each co-occurrence word of the co-occurrence set or the co-occurrence vector into a concept word based on a thesaurus is also suitable. ing.
- a range to be considered as a co-occurrence word is set according to the characteristics of the document, such as one sentence, all sentences in one paragraph, all sentences in the same item on the table of contents, or the entire document.
- the range considered as co-occurrence may be changed for each part of speech, such as a co-occurring verb in one sentence and a noun in a sentence in the same item on the table of contents.
- the word information includes a dependency relationship between words, whether the word has a dependency relationship may be used as the co-occurrence determination method.
- the number of co-occurrence may be the number of co-occurrence, but may be a frequency obtained by dividing the number of co-occurrence by the total number of co-occurrence words for each word.
- the context similarity calculation unit 30 calculates the similarity between the context information of each word as the context similarity of each word combination by an arbitrarily set context similarity calculation method.
- the context similarity calculation method is a method for calculating an index indicating similarity between context information of each word, and i) when the context information is a character string in an arbitrary range before and after the word.
- a method in which the number of matching characters in a character string or a ratio, or a function value that is in a monotonically decreasing relationship with an edit distance between character strings is used as a context similarity, ii) co-occurrence when the context information is a co-occurrence set
- a method in which the number of matching co-occurrence words in a set is used as context similarity, and iii) when the context information is a co-occurrence vector, cosine similarity between co-occurrence vectors and Euclidean distance between co-occurrence vectors Any of the methods in which the function value that is in a decreasing relationship is set as the context similarity is suitable.
- the notation similarity calculation unit 40 uses the word information for each word used in each sentence extracted by the word analysis unit 20 to create notation information regarding the character configuration of each word.
- the notation information is information indicating in what notation each word is used, and corresponds to a character string of the word.
- the compound word may be decomposed with a component word that is a partial idiom constituting the compound word, and a combination of the component words may be used as the above described notation information.
- the notation similarity calculation unit 40 calculates the similarity between the notation information of each word as the notation similarity of each word combination by an arbitrarily set notation similarity calculation method.
- the notation similarity calculation method is a method for calculating an index indicating the similarity between the notation information of each word, and i) if the notation information is a word character string, the word character string A method in which a context value is a function value that is in a monotonically decreasing relationship with the number or ratio of matching characters or an edit distance between character strings, and ii) when the above described information is a combination of constituent words Any of the methods in which the number or ratio of each constituent word matched in the above is used as the context similarity is suitable. Further, the constituent words in the compound word may be weighted by an arbitrary weighting method, and an index may be given so that the similarity between words increases as the constituent words having higher weights match.
- the similarity evaluation database 110 is not limited to the target document in the document input unit 10, and the word metric information of the word combination in the document and the context similarity information between words regarding the word combination for which a synonym has been determined in the past. , The notation similarity information between words, and the determination result of whether or not the words are synonyms are collected and accumulated, and the context similarity information between words and the notation similarity information between words are determined by the value of the word metric information.
- Similarity evaluation information which is statistical information indicating how much synonym is valid for each, is calculated by an arbitrary similarity evaluation method, and a word of an arbitrary word combination from the synonym candidate estimation unit 50 It is a database which respond
- the context similarity information may be information indicating similarity between words based on the word context information. For example, the relative rank or deviation value of the word combination based on the context similarity or the context similarity. And so on.
- the notation similarity information may be information indicating similarity between words based on word notation information. For example, the relative rank or deviation value of the word combination based on the notation similarity or the notation similarity And so on.
- the similarity evaluation method includes statistical information indicating how effective the context similarity information between words and the notation similarity information between words are for synonym determination with respect to word metric information of words. Any analysis method that can be calculated may be used. For example, in the similarity evaluation method, i) for a synonym set group consisting of word combinations determined to be synonyms, a value obtained by dividing context similarity information by notation similarity information is used as an objective variable, and each synonym set A multiple regression equation based on multiple regression analysis using some of the word metric information (for example, the number of appearances of words on the larger side and the number of appearances of words on the smaller side in the word combination) as explanatory variables is calculated as the similarity evaluation information.
- Context similarity effective centroid which is the centroid of the synonym set that was valid (for example, the coordinates of the number of occurrences of words and the ratio of the number of occurrences between words), and the synonym where the notation similarity information was more effective than the context similarity information Word set
- the title similarity effective center of gravity is a heart and a method of calculating a degree of similarity evaluation information is valid.
- the similarity evaluation method includes: iii) a conditional probability determined to be a synonym when the word metric information, context similarity information between words, and notation similarity information between words are preconditions.
- a method of calculating the similarity evaluation information may be used.
- the number of appearances in the case of assuming the “word appearance count” as the “word metric information of the word” may be the sum of the word appearance counts for each word combination, The word appearance number with the larger appearance number may be used.
- the synonym candidate estimation unit 50 inquires the similarity evaluation database 110 for the similarity evaluation information corresponding to the word metric information of each word extracted by the word analysis unit 20 for each word combination in the target document, and receives a response.
- the word similarity is calculated by a predetermined synonym determination method from the similarity evaluation information and the context similarity between each word and the notation similarity, thereby determining the synonym of the word combination, and as a synonym candidate combination Extract.
- the synonym determination method may be any method for determining candidate synonyms based on similarity that is estimated by synonym extraction and estimated from word metric information.
- each word metric information for example, the word on the larger side
- the function value that is monotonically increasing with the value of the objective variable obtained is used as the weighting factor for context similarity, and the value of the objective variable and monotonically decreasing
- the synonym determination method ii) when the similarity evaluation information is a context similarity effective centroid and a notation similarity effective centroid on the two-dimensional plane, the context similarity effective centroid and each word
- the function value that is in a monotonically decreasing relationship with the Euclidean distance of coordinates consisting of the number of occurrences and the ratio of the number of occurrences between each word is used as the context similarity coefficient, the above-mentioned notation similarity effective centroid, the number of occurrences of each word, and each word
- a method is also effective in which a word sum is used as a linear sum in which a function value that is in a monotonically decreasing relationship with the Euclidean distance between the coordinates of the number of occurrences is used as a notation similarity coefficient.
- the synonym candidate output unit 60 outputs the synonym candidates extracted by the synonym candidate estimation unit 50.
- a suitable output form is a form in which the entire document is output by clearly indicating the combination of synonym candidates in the document by color coding or bold emphasis.
- the output form may be a form such as a table from which synonym candidate combinations are extracted.
- a graph in which the relationship is linked by using a word that is a synonym candidate as a main node, a co-occurrence word as an intermediate node, and a concept as an end node is displayed. It may be in a form such as highlighting the links to be connected in the shortest color.
- quantitative synonyms are added between synonyms such as dissimilarity used when extracting synonym candidates, and only synonyms whose synonyms are larger than a set threshold are set. The display may be limited. Or as an output form, depending on the synonym degree between synonym candidates, color coding, emphasis by bold letters, or the size of character of a word of a graph may be given.
- each output form may be selected so that the display form as a base can be shifted to a table or a graph as necessary. Moreover, you may make it selectively output a verb, a noun, etc. as needed.
- the synonym candidate output unit 60 causes the analyst to select a word combination determined to be a synonym from the output synonym candidates, word metric information regarding the word combination, and context similarity and notation between the words The similarity is registered in the similarity evaluation database 110.
- the document input unit 10 receives an input of a target document or document group (step A1 in FIG. 2).
- the word analysis unit 20 applies morphological analysis and syntax analysis to each sentence constituting a document or a document group, thereby extracting all words used in each sentence and word metric information that is a quantitative feature of the word, Extract word information that is a qualitative feature of the word. (Step A2).
- the context similarity calculation unit 30 uses the word information to create context information regarding the context in which each word is used (step A3). ).
- the context similarity calculation unit 30 calculates the similarity between the context information of each word as the context similarity of each word combination by an arbitrarily set context similarity calculation method (step A4).
- the notation similarity calculation unit 40 uses the word information for each word used in each sentence extracted by the word analysis unit 20 to create notation information regarding the character configuration of each word (step A5). Further, the notation similarity calculation unit 40 calculates the similarity between the notation information of each word as the notation similarity of each word combination by an arbitrarily set notation similarity calculation method (step A6).
- the similarity evaluation database 110 is not limited to the target document in the document input unit 10, and the word metric information of the word combination in the document and the context similarity information between words regarding the word combination for which a synonym has been determined in the past.
- the notation similarity information between words, and the determination result of whether or not the words are synonyms are collected and accumulated, and the context similarity information between words and the notation similarity information between words are determined by the value of the word metric information.
- Similarity evaluation information which is statistical information indicating how much synonym is valid for each, is calculated by an arbitrary similarity evaluation method, and a word of an arbitrary word combination from the synonym candidate estimation unit 50 For the measurement information, the corresponding similarity evaluation information is returned (step A7).
- the synonym candidate estimation unit 50 inquires the similarity evaluation database 110 for the similarity evaluation information corresponding to the word metric information of each word extracted by the word analysis unit 20 for each word combination in the target document, and receives a response.
- the word similarity is calculated by a predetermined synonym determination method from the similarity evaluation information and the context similarity between each word and the notation similarity, thereby determining the synonym of the word combination, and as a synonym candidate combination Extraction (estimation) is performed (step A8).
- the synonym candidate output unit 60 outputs the synonym candidates extracted (estimated) by the synonym candidate estimation unit 50 (step A9).
- the synonym candidate output unit 60 causes an analyst to select a word combination determined to be a synonym from the output synonym candidates, word metric information of each word related to this word combination, and context similarity between the words
- the degree and the notation similarity are registered in the similarity evaluation database 110 (step A10).
- the effect of the synonym extraction system 100 according to the embodiment of the present invention will be described.
- statistical information that is easy to collect with little change due to document characteristics such as the degree of similarity extraction of data that can be measured with respect to word combinations such as the number of words appearing and the ratio of the number of words, is used.
- synonym candidates are extracted with an emphasis on a similarity index with a higher probability of extracting a word combination that was a synonym set.
- the synonym extraction system 100 can be realized as a synonym extraction method.
- the synonym extraction system 100 according to the embodiment of the present invention may be executed by a computer using a synonym extraction program.
- the synonym extraction system 100 is a synonym that is formed only in a document group related to a specific case included in a document D having a synonym that is formed only in a document group related to a specific case, such as a proposal or specification regarding an information system construction.
- Word candidate A is estimated.
- the synonym extraction system 100 supports the creation of a glossary and unification of words related to detection of typographical errors and unregistered terms by outputting an estimation result.
- the synonym extraction system 100 is composed of a document analysis system Y and an Internet server Z as shown in FIG.
- the document analysis system Y operates on the PC terminal of the analyst B, and through the input unit and the output unit, the input of sentences constituting the document group that the analyst B wants to extract synonyms and synonyms Realization of candidate A is realized.
- the Internet server Z is connected via a communication network to a PC terminal of the analysis person B who has implemented the document analysis system Y.
- the Internet server Z determines the context similarity information between the words according to the value of the word metric information. This is a device that enables retrieval of similarity evaluation information, which is statistical information indicating how much the notation similarity information between words is effective in determining synonyms.
- the document input unit 10 operates as an input unit of a PC terminal.
- the word analysis unit 20, the context similarity calculation unit 30, the notation similarity calculation unit 40, and the synonym candidate estimation unit 50 are included in the document analysis system Y.
- the synonym candidate output unit 60 operates as an output unit of the PC terminal.
- the similarity evaluation database 110 is included in the Internet server Z.
- the document analysis system Y and the Internet server Z provided with such means operate as follows.
- the document analysis system Y receives from the input unit input of a document D that constitutes a document group for which the analysis operator B wants to estimate a synonym candidate A having the same meaning but different word form from a document related to a specific case.
- the document analysis system Y applies morphological analysis and syntactic analysis to each sentence of the document constituting the document D, decomposes it into words constituting the document, and analyzes the sentence and part of speech from which each word is extracted.
- Nouns, verbs, adjectives, and adjective verbs are extracted as word W.
- the verbs the verbs belonging to the use of sa line modification are extracted in the form of so-called sa variant nouns by removing the use part.
- a word co-occurrence table E is created that is tabulated and summarized in tabular form for each co-occurrence word V for all words S.
- a data set in which the number of co-occurrence Nij of each co-occurrence word Vj with respect to the word Si in the word co-occurrence table E is referred to as a word co-occurrence vector Ni.
- the word Si of the document D includes words such as “transportation cost calculation system”, “commuting cost calculation”, “delay certificate”, “transportation cost settlement service”, and “commuting calculation”.
- the word co-occurrence table E is a table in which the word Si is arranged in each row and the co-occurrence word Vij is arranged in each column as shown in FIG. 4 corresponds to the word co-occurrence vector Ni
- the word co-occurrence vector Ni of the “transportation cost calculation system” is ⁇ 4, 2, 1, 1, 1, 0, 2, It is expressed as 0, 0,.
- the word previously selected as a word is also treated as a co-occurrence word when another word is a word, and is registered redundantly.
- the cosine similarity between Nq is calculated as the context similarity Lepq. For example, a part of the context similarity Lepq between the words Si in FIG. 4 is shown in a table as shown in FIG.
- the document analysis system Y extracts each character string of the word Sp and the word Sq as notation information, calculates an edit distance dpq between the character strings, and further, the larger one of the number of characters of the word Sp and the word Sq.
- the notation similarity Lwpq of the word Sp and the word Sq is calculated by the following formula 1.
- Lwpq 1 ⁇ dpq / (Ppqmax + k) Equation 1
- k is a constant for preventing the denominator of the fraction in the expression from being 0, and a value of 0.1 or less is appropriate.
- the Internet server Z determines the number of occurrences P of each synonym in each document in which the synonym set is used, The context similarity Le between words and the notation similarity Lw between words are collected and accumulated.
- the Internet server Z uses the similarity ratio obtained by dividing the context similarity Le by the notation similarity Lw between words for the collected synonym set group as an objective variable, and the more common word combinations in each synonym set Multiple-regression analysis using the occurrence number Pmax of the word and the occurrence number Pmin of the smaller word as explanatory variables, and the context similarity between words by the combination of the word appearance numbers Pmax and Pmin as shown in Equation 2 below
- An expression representing a statistical relationship indicating how much Le and the notation similarity Lw are effective in determining synonyms is calculated.
- the Internet server Z calculates a value of Le / Lw corresponding to the number of appearances Pmax and Pmin of the word combination to be inquired and responds.
- Le / Lw ⁇ 1 ⁇ Pmax + ⁇ 2 ⁇ Pmin + ⁇ Equation 2
- ⁇ 1 corresponds to the multiple regression coefficient of the word appearance number Pmax
- ⁇ 2 corresponds to the multiple regression coefficient of the word appearance number Pmin
- ⁇ corresponds to the intercept.
- a multiple regression equation based on synonym set data composed of accumulated data of appearance number P, context similarity Le and notation similarity Lw as shown in FIG.
- the document analysis system Y substitutes the number of appearances Ppqmax and Ppqmin based on the number of appearances of the word Sp and the word Sq in the document D into the multiple regression equation, and the obtained Le / Lw is obtained as in the following Equation 4.
- the average value based on the linear sum with the square of the value of as the weighting factor of the context similarity Lepq and the inverse of the square of the obtained Le / Lw as the weighting factor of the notation pulse similarity Lwpq is used as the similarity between words Calculated as the degree Lpq.
- Lpq ((Le / Lw) 2 ⁇ Lepq + (Lw / Le) 2 ⁇ Lwpq) / 2 ...
- the weighting coefficient is not a continuous value as in Equation 4, and if the obtained Le / Lw value is greater than 1, the weighting coefficient for the context similarity Lepq is 1, and the weighting coefficient for the notation pulse similarity Lwpq is When the obtained Le / Lw value is 1, the weighting factor of the context similarity Lepq is 1 ⁇ 2, the weighting factor of the notation pulse similarity Lwpq is 1 ⁇ 2, and the obtained Le / Lw value When is smaller than 1, a discontinuous value may be given such that the weighting coefficient of the context similarity Lepq is 0 and the weighting coefficient of the notation pulse similarity Lwpq is 1.
- the context similarity Le is a pattern that is considered to be more effective in determining synonyms than the notation similarity Lw
- Le / Lw is 1
- the synonym determination is effective in the context similarity Le and the notation similarity Lw. If Le / Lw is less than 1, the notation similarity Lw is the context. This is because the pattern is considered to be more effective for determining synonyms than the similarity Le.
- the document analysis system Y assumes that a combination of a word Sp and a word Sq having a word similarity Lpq larger than an arbitrary determination threshold T has a high semantic similarity in the word co-occurrence vector and may be a synonym.
- the document analysis system Y processes the synonym candidate Aa ⁇ Sp, Sq ⁇ , such as color coding or emphasis by bolding, for the corresponding synonym candidate Aa ⁇ Sp, Sq ⁇ in the request document D, and the requested document after processing D is output from the output unit.
- the synonym extraction system of the present invention it is possible to obtain correct information and a large amount of information from a document having a synonym that is formed only in a document group related to a specific case, such as a proposal or a specification regarding information system construction. Without requiring a corpus, it is possible to extract synonyms that consist only of a document group related to a specific case with high accuracy, leading to reduction of confusion and failure due to misunderstanding.
- the reason for this is the use of statistical information that is easy to collect with little change due to document features, such as the extraction of similarity indices for data that can be measured with respect to word combinations, such as the number of occurrences of words and the ratio of the number of words.
- the similarity index according to the synonym generation pattern This is because it is possible to calculate the similarity between words to which is applied.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Machine Translation (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2014522532A JP6187877B2 (ja) | 2012-06-25 | 2013-06-06 | 同義語抽出システム、方法および記録媒体 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012141680 | 2012-06-25 | ||
| JP2012-141680 | 2012-06-25 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2014002776A1 true WO2014002776A1 (fr) | 2014-01-03 |
Family
ID=49782938
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2013/066286 Ceased WO2014002776A1 (fr) | 2012-06-25 | 2013-06-06 | Système d'extraction de synonymes, procédé et support d'enregistrement |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP6187877B2 (fr) |
| WO (1) | WO2014002776A1 (fr) |
Cited By (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2016021136A (ja) * | 2014-07-14 | 2016-02-04 | 株式会社東芝 | 類義語辞書作成装置 |
| CN107748755A (zh) * | 2017-09-19 | 2018-03-02 | 华为技术有限公司 | 同义词挖掘方法、装置、设备和计算机可读存储介质 |
| JP2018088101A (ja) * | 2016-11-28 | 2018-06-07 | 富士通株式会社 | 同義表現抽出装置、同義表現抽出方法、及び同義表現抽出プログラム |
| WO2018220688A1 (fr) * | 2017-05-29 | 2018-12-06 | 株式会社Pfu | Générateur de dictionnaire, procédé de génération de dictionnaire, et programme |
| WO2019082362A1 (fr) * | 2017-10-26 | 2019-05-02 | 三菱電機株式会社 | Dispositif et procédé de déduction de relation sémantique entre des mots |
| CN110287337A (zh) * | 2019-06-19 | 2019-09-27 | 上海交通大学 | 基于深度学习和知识图谱获取医学同义词的系统及方法 |
| CN110348010A (zh) * | 2019-06-21 | 2019-10-18 | 北京小米智能科技有限公司 | 同义短语获取方法及装置 |
| CN110399615A (zh) * | 2019-07-29 | 2019-11-01 | 中国工商银行股份有限公司 | 交易风险监控方法及装置 |
| CN112733521A (zh) * | 2021-01-16 | 2021-04-30 | 江苏网进科技股份有限公司 | 一种用于确认法律案件相似关系的方法 |
| US11100149B2 (en) | 2017-12-21 | 2021-08-24 | Hitachi, Ltd. | Search support system, search support method, and search support program |
| CN113874854A (zh) * | 2019-05-20 | 2021-12-31 | 三菱电机株式会社 | 本体生成系统、本体生成方法和本体生成程序 |
| CN114240487A (zh) * | 2021-12-09 | 2022-03-25 | 金瓜子科技发展(北京)有限公司 | 线下服务的数据处理方法、装置以及电子设备 |
| US11520987B2 (en) * | 2015-08-28 | 2022-12-06 | Freedom Solutions Group, Llc | Automated document analysis comprising a user interface based on content types |
| EP4339829A4 (fr) * | 2021-05-12 | 2025-04-23 | Hitachi, Ltd. | Système et procédé de détermination de synonymes |
| CN120745572A (zh) * | 2025-09-08 | 2025-10-03 | 灵犀科技有限公司 | 产业诊断报告的自动化生成方法及系统 |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7457531B2 (ja) * | 2020-02-28 | 2024-03-28 | 株式会社Screenホールディングス | 類似度算出装置、類似度算出プログラム、および、類似度算出方法 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2009129323A (ja) * | 2007-11-27 | 2009-06-11 | Hitachi Ltd | 同義語抽出装置 |
| JP2010152561A (ja) * | 2008-12-24 | 2010-07-08 | Toshiba Corp | 類似表現抽出装置、サーバ装置及びプログラム |
-
2013
- 2013-06-06 WO PCT/JP2013/066286 patent/WO2014002776A1/fr not_active Ceased
- 2013-06-06 JP JP2014522532A patent/JP6187877B2/ja active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2009129323A (ja) * | 2007-11-27 | 2009-06-11 | Hitachi Ltd | 同義語抽出装置 |
| JP2010152561A (ja) * | 2008-12-24 | 2010-07-08 | Toshiba Corp | 類似表現抽出装置、サーバ装置及びプログラム |
Non-Patent Citations (2)
| Title |
|---|
| EIJI HIRAO: "Development of the detection method of synonyms in the requirements documents", THE INSTITUTE OF ELECTRONICS, INFORMATION AND COMMUNICATION ENGINEERS 2012 NEN SOGO TAIKAI KOEN RONBUNSHU, JOHO SYSTEM 1, 6 March 2012 (2012-03-06), pages 26 * |
| MINORU YOSHIDA: "Application of text mining", THE JOURNAL OF INFORMATION SCIENCE AND TECHNOLOGY ASSOCIATION, vol. 60, no. 6, 1 June 2010 (2010-06-01), pages 230 - 235 * |
Cited By (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2016021136A (ja) * | 2014-07-14 | 2016-02-04 | 株式会社東芝 | 類義語辞書作成装置 |
| US11983499B2 (en) | 2015-08-28 | 2024-05-14 | Freedom Solutions Group, Llc | Automated document analysis comprising a user interface based on content types |
| US11520987B2 (en) * | 2015-08-28 | 2022-12-06 | Freedom Solutions Group, Llc | Automated document analysis comprising a user interface based on content types |
| JP2018088101A (ja) * | 2016-11-28 | 2018-06-07 | 富士通株式会社 | 同義表現抽出装置、同義表現抽出方法、及び同義表現抽出プログラム |
| WO2018220688A1 (fr) * | 2017-05-29 | 2018-12-06 | 株式会社Pfu | Générateur de dictionnaire, procédé de génération de dictionnaire, et programme |
| CN107748755A (zh) * | 2017-09-19 | 2018-03-02 | 华为技术有限公司 | 同义词挖掘方法、装置、设备和计算机可读存储介质 |
| WO2019056781A1 (fr) * | 2017-09-19 | 2019-03-28 | 华为技术有限公司 | Procédé de découverte de synonymes, dispositif, équipement et support d'informations lisible par ordinateur |
| WO2019082362A1 (fr) * | 2017-10-26 | 2019-05-02 | 三菱電機株式会社 | Dispositif et procédé de déduction de relation sémantique entre des mots |
| JPWO2019082362A1 (ja) * | 2017-10-26 | 2020-02-27 | 三菱電機株式会社 | 単語意味関係推定装置および単語意味関係推定方法 |
| US11100149B2 (en) | 2017-12-21 | 2021-08-24 | Hitachi, Ltd. | Search support system, search support method, and search support program |
| CN113874854A (zh) * | 2019-05-20 | 2021-12-31 | 三菱电机株式会社 | 本体生成系统、本体生成方法和本体生成程序 |
| CN110287337A (zh) * | 2019-06-19 | 2019-09-27 | 上海交通大学 | 基于深度学习和知识图谱获取医学同义词的系统及方法 |
| CN110348010B (zh) * | 2019-06-21 | 2023-06-02 | 北京小米智能科技有限公司 | 同义短语获取方法及装置 |
| CN110348010A (zh) * | 2019-06-21 | 2019-10-18 | 北京小米智能科技有限公司 | 同义短语获取方法及装置 |
| CN110399615A (zh) * | 2019-07-29 | 2019-11-01 | 中国工商银行股份有限公司 | 交易风险监控方法及装置 |
| CN110399615B (zh) * | 2019-07-29 | 2023-08-18 | 中国工商银行股份有限公司 | 交易风险监控方法及装置 |
| CN112733521A (zh) * | 2021-01-16 | 2021-04-30 | 江苏网进科技股份有限公司 | 一种用于确认法律案件相似关系的方法 |
| CN112733521B (zh) * | 2021-01-16 | 2023-07-04 | 江苏网进科技股份有限公司 | 一种用于确认法律案件相似关系的方法 |
| EP4339829A4 (fr) * | 2021-05-12 | 2025-04-23 | Hitachi, Ltd. | Système et procédé de détermination de synonymes |
| CN114240487A (zh) * | 2021-12-09 | 2022-03-25 | 金瓜子科技发展(北京)有限公司 | 线下服务的数据处理方法、装置以及电子设备 |
| CN120745572A (zh) * | 2025-09-08 | 2025-10-03 | 灵犀科技有限公司 | 产业诊断报告的自动化生成方法及系统 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2014002776A1 (ja) | 2016-05-30 |
| JP6187877B2 (ja) | 2017-08-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6187877B2 (ja) | 同義語抽出システム、方法および記録媒体 | |
| CN105095204B (zh) | 同义词的获取方法及装置 | |
| JP5754018B2 (ja) | 多義語抽出システム、多義語抽出方法、およびプログラム | |
| CN106096664B (zh) | 一种基于社交网络数据的情感分析方法 | |
| US20100205198A1 (en) | Search query disambiguation | |
| JP5754019B2 (ja) | 同義語抽出システム、方法およびプログラム | |
| CN114254653A (zh) | 一种科技项目文本语义抽取与表示分析方法 | |
| CN111563384A (zh) | 面向电商产品的评价对象识别方法、装置及存储介质 | |
| CN111625621B (zh) | 一种文档检索方法、装置、电子设备及存储介质 | |
| CN112182145B (zh) | 文本相似度确定方法、装置、设备和存储介质 | |
| JP5057474B2 (ja) | オブジェクト間の競合指標計算方法およびシステム | |
| JPWO2014002775A1 (ja) | 同義語抽出システム、方法および記録媒体 | |
| JP2014120053A (ja) | 質問応答装置、方法、及びプログラム | |
| CN109783806A (zh) | 一种利用语义解析结构的文本匹配方法 | |
| JPWO2014002774A1 (ja) | 同義語抽出システム、方法および記録媒体 | |
| JP6830226B2 (ja) | 換言文識別方法、換言文識別装置及び換言文識別プログラム | |
| Tumitan et al. | Tracking Sentiment Evolution on User-Generated Content: A Case Study on the Brazilian Political Scene. | |
| CN111444713B (zh) | 新闻事件内实体关系抽取方法及装置 | |
| JP6108212B2 (ja) | 同義語抽出システム、方法およびプログラム | |
| Liu et al. | Exploring the steps of verb phrase ellipsis | |
| JP6303508B2 (ja) | 文書分析装置、文書分析システム、文書分析方法およびプログラム | |
| CN117709334A (zh) | 文本纠错方法及装置、存储介质和服务器 | |
| Alian et al. | Unsupervised learning blocking keys technique for indexing Arabic entity resolution | |
| JP2009157458A (ja) | インデックス作成装置、その方法、プログラム及び記録媒体 | |
| Phannachitta et al. | Orthophonomatch: Integrating Orthographic And Phonological Features For Enhanced Spell Correction In Tonal Language Search Engines |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 13809166 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2014522532 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 13809166 Country of ref document: EP Kind code of ref document: A1 |