WO2014132402A1 - データ処理装置および物語モデル構築方法 - Google Patents
データ処理装置および物語モデル構築方法 Download PDFInfo
- Publication number
- WO2014132402A1 WO2014132402A1 PCT/JP2013/055477 JP2013055477W WO2014132402A1 WO 2014132402 A1 WO2014132402 A1 WO 2014132402A1 JP 2013055477 W JP2013055477 W JP 2013055477W WO 2014132402 A1 WO2014132402 A1 WO 2014132402A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- case
- feature
- event slot
- series
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images



















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/237—Lexical tools
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/40—Processing or translation of natural language
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/40—Document-oriented image-based pattern recognition
- G06V30/41—Analysis of document content
- G06V30/416—Extracting the logical structure, e.g. chapters, sections or page numbers; Identifying elements of the document, e.g. authors
Definitions
- Embodiments described herein relate generally to a data processing apparatus and a story model construction method.
- Contextual analysis such as anaphora resolution, coreference resolution, and dialog processing, is an important task for correctly understanding documents in natural language processing. It is known that it is effective to use procedural knowledge such as Shank script or Fillmore frame for context analysis. Procedural knowledge is knowledge about what is a procedure that follows a series of procedures. A model that reproduces this procedural knowledge with a computer is a narrative model.
- event slots a series of predicate and case pairs (hereinafter referred to as “event slots”) that are related to each other is acquired from an arbitrary document group, case data is generated from the event slot series, and a story is learned by machine learning training. It has been proposed to build a model.
- the event slot series is an event slot that is a combination of a predicate sharing a term and a case type of the shared term as an element, and the event slots are arranged in the order of appearance. Since there are a wide variety of event slots that are elements of the event slot series, a large amount of learning data is required to construct a highly accurate story model by performing sufficient learning. However, it is very expensive to obtain a large amount of highly reliable learning data. Therefore, there is a concern that sufficient learning data is not collected and learning data is insufficient, and as a result, the accuracy of the story model to be constructed is lowered.
- the problem to be solved by the present invention is to provide a data processing apparatus and a story model construction method capable of constructing a story model with high accuracy.
- the data processing apparatus includes an extraction unit, a case generation unit, and a model construction unit.
- the extraction unit includes, as an element, a combination of a predicate having a shared term and case type information indicating a case type of the shared term from a document that has been subjected to predicate term structure analysis and coreference analysis.
- the element series arranged in the order of appearance of the previous description words in the document is extracted together with the shared term.
- the case generation unit when one of the elements constituting the element series is set as an attention element, for each of the attention elements, one of the partial series in the element series having the attention element as the last element Case data represented by a feature vector including at least one of the above feature quantities and one or more feature quantities related to the shared term series corresponding to the partial series is generated.
- the model construction unit constructs a story model for estimating the elements following the preceding context by performing machine learning based on the identification model using the case data.
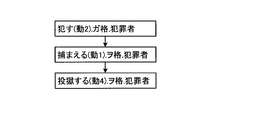
- FIG. 1 is a schematic diagram of a probability model using an event slot sequence having “criminal” as a shared term.
- FIG. 2 is a schematic diagram for explaining the method described in Non-Patent Document 3.
- FIG. 3 is a block diagram illustrating a configuration example of the data processing device according to the first embodiment.
- FIG. 4 is a diagram illustrating a specific example of a training tagged document.
- FIG. 5 is a diagram showing a specific example of training event slot series data.
- FIG. 6 is a flowchart for explaining processing performed by the event slot series extractor.
- FIG. 7 is a diagram illustrating a specific example of training example data.
- FIG. 8 is a flowchart for explaining processing performed by the machine learning case generator.
- FIG. 1 is a schematic diagram of a probability model using an event slot sequence having “criminal” as a shared term.
- FIG. 2 is a schematic diagram for explaining the method described in Non-Patent Document 3.
- FIG. 3 is a block diagram illustrating
- FIG. 9 is a flowchart for explaining processing by the event slot history feature generator.
- FIG. 10 is a flowchart for explaining processing by the shared term history feature generator.
- FIG. 11 is a diagram illustrating an example of a shared term expression group generated by the shared term expression generator.
- FIG. 12 is a flowchart for explaining processing by the shared term expression generator.
- FIG. 13 is a diagram illustrating an example of a subsequent event slot estimation model.
- FIG. 14 is a flowchart for explaining processing performed by the subsequent event slot estimation trainer.
- FIG. 15 is a flowchart for explaining the process of the machine learning case generator in the prediction process.
- FIG. 16 is a diagram illustrating an example of a subsequent event slot estimation result.
- FIG. 17 is a flowchart for explaining processing executed by the subsequent event slot predictor.
- FIG. 11 is a diagram illustrating an example of a shared term expression group generated by the shared term expression generator.
- FIG. 12 is a flowchart for explaining processing by the shared term expression
- FIG. 18 is a block diagram illustrating a configuration example of a data processing device according to the second embodiment.
- FIG. 19 is a diagram illustrating a specific example of training example data.
- FIG. 20 is a flowchart for explaining processing by the combination feature generator.
- FIG. 21 is a diagram illustrating the hardware configuration of the data processing apparatus.
- an event slot sequence group is extracted from a document group that has been subjected to predicate term structure analysis and coreference analysis, and a machine learning case data group is generated using the extracted event slot sequence group. Generate a story model by machine learning using this case data group.
- the event slot series is a series of predicate / case type pairs with shared terms.
- attempts have been made to perform context analysis using the event slot sequence probability model as procedural knowledge. This is based on the hypothesis that predicates that share terms have some relationship.
- the shared term is used to find an event slot, and the frequency is counted only for the event slot sequence excluding the shared term.
- FIG. 1 is a schematic diagram of a probability model using an event slot sequence having “criminal” as a shared term.
- 1A shows an example of Japanese
- FIG. 1B shows an example of English.
- the arrows in the figure indicate the existence of a probability model, where the source of the arrow indicates a random variable that is a condition in the conditional probability, and the end of the arrow indicates a random variable that is an evaluation target.
- the broken line in the figure indicates that there is no probability model.
- the frequency count (and the probability calculation based on the frequency count) is an event slot series excluding the shared item “criminal” (crime (movement 2). It is performed only for catching (motion 1).
- discriminal crime (movement 2).
- predicate meaning ambiguity removal processing is performed, and the meaning specification information for identifying the meaning of the predicate is specified in the predicate of each event slot constituting the event slot series (dynamic 2, dynamic 1, motion 4, etc.) are added, but it is not essential to add meaning-specific information to the predicate.
- the event slot which is an element of the event slot series, is a combination of predicate and case type, so the type is enormous with the number of predicate vocabulary times the number of case types. Therefore, in order to perform sufficient learning, a large amount of learning data corresponding to the learning is required. Collecting a lot of reliable learning data is very expensive. For this reason, sufficient learning data is not collected, learning data is insufficient, and as a result, there is a problem that the accuracy of the model to be built is lowered.
- Non-Patent Document 4 As a method for solving the zero probability, conventionally, various smoothing methods (for example, see Non-Patent Document 4) have been proposed. These smoothing methods are methods for assigning a certain low probability to an unknown sequence. However, these smoothing methods are methods for eliminating statistical unevenness, and although a zero probability can be avoided, an appropriate probability is not always assigned.
- the essential problem is that there are not enough clues to solve the problem of what event slot follows an event slot. Therefore, in the embodiment, more clues for predicting subsequent event slots are extracted from a certain amount of analyzed text for learning (a document subjected to predicate term structure analysis and coreference analysis) than in the conventional method.
- a tree structure composed of three nodes, a predicate, a plurality of cases subordinate to the predicate, and a term satisfying each case is called a predicate term structure.
- the predicate term structure is applicable to all languages such as Japanese and English. However, in the case of Japanese, the case type is clearly indicated by particles such as “GA”, “O”, and “NI”. On the other hand, in the case of English, there are cases that can be determined unless the meaning is taken into account. As described above, the method of expressing the case differs depending on the language.
- the predicate term structure of a sentence can be analyzed by a predicate term structure analyzer.
- a predicate term structure analyzer is prepared for each language, and processes a language-specific case expression method to output a predicate term structure.
- the output predicate term structure itself is the same even if the case type is different.
- This embodiment is based on the premise that an existing predicate term structure analyzer is used. For this reason, there is no need to be aware of the difference in the way the case is expressed. In other words, this embodiment is not specialized for Japanese and can be applied to any language.
- a surface case is a case classification method that treats surface phenomena such as “ga”, “to”, and “ni” as case types.
- the deep case is a method of classifying cases from a semantic point of view. The difference between the surface case and the deep case is also absorbed by the predicate term structure analyzer.
- [A] Calculation of the frequency of event slot series (statistics according to).
- [B] Calculation of frequency of shared term series (statistics according to).
- [C] Probability calculation that integrates statistics [A] and [B] in a form that includes a process of taking the sum of these.
- the machine learning method based on an identification model is a method that can derive a probability distribution under conditions of a plurality of different events from one optimization process.
- a process of calculating the statistics of [A] and [B] having different origins, and a process of integrating a plurality of statistics of [C] are performed.
- This paper proposes a method of solving with a single optimization process using machine learning technique based on the identification model.
- the story model construction method of the present embodiment includes the following procedures.
- the event slot history refers to a partial series (Ngram series) in an event slot sequence having the event slot as the last element.
- Ngram series a partial series
- Wo case” is “captured (motion 1).
- Wo case” becomes “crime (motion 2).
- Wo case includes not only the feature amount of the Ngram sequence but also the feature amount of all the partial sequences whose order is n or less.
- the feature amount related to the history of the event slot is not only the feature amount of the partial series (big series) including the event slot and the previous event slot connected to the event slot, It also includes a feature amount of a partial series (unigram series (unigram is also regarded as a series in this embodiment)) having only event slots as elements.
- bigram is 0 frequency
- the effect of smoothing complemented by unigram can be acquired.
- the shared term history refers to a sequence of shared terms corresponding to the partial sequence of event slots described above.
- the history of the shared term in the case of the bigram series, in the example of FIG. 1 (a), the history of the shared term “I jail (motion 4). Wo case” and the history of the shared term “capture (motion 1). Both become "criminals"-"criminals".
- the history of shared terms represents the number of shared terms corresponding to the number of elements included in the partial series (the number of consecutive shared terms).
- the feature quantity related to the history of the shared term is not only the feature quantity of the surface series such as “criminal”, but also the series in other expression methods that express the semantic category or specific expression type of the shared term, for example. Are also included. As a result, the frequency of the shared term sequence can be obtained with an appropriate granularity.
- Non-Patent Document 5 describes the use of an identification model as a language model construction method.
- Non-Patent Document 5 introduces an example of integration of various different statistics using an identification model, and Section 5.3 builds a language model that integrates two clues of Ngram and trigger as an example. It is described.
- the method described in Non-Patent Document 5 is applied, and a story model can be constructed using a machine learning technique based on an identification model.
- the case data represented by the case vector including the feature quantity related to the history of the event slot and the feature quantity related to the history of the shared term is generated from the event slot series, and the case data is Since the story model is constructed by performing machine learning based on the identification model, a highly accurate story model can be constructed.
- Non-Patent Document 3 describes that not only event slot sequence information but also shared term information is used in connection with the construction of a probabilistic model using an event slot sequence.
- the method described in Non-Patent Document 3 does not use information on the history of shared terms, and the information on shared terms is used to more strictly distinguish event slot sequences.
- the method described in Non-Patent Document 3 constructs a probability model in a form that is substantially close to taking the product of the probability of an event slot and the probability of a shared term, as shown in FIG. ing. For this reason, the method described in Non-Patent Document 3 does not solve the problem of insufficient learning data, but rather the problem tends to become more serious.
- case data is generated in such a manner that the feature quantity related to the history of the shared term is included in the dimension of the feature vector, and based on the identification model using this case data. Since the story model is constructed by performing machine learning, it is possible to solve the lack of learning data and construct a highly accurate story model.
- FIG. 3 is a block diagram illustrating a configuration example of the data processing apparatus 100 according to the first embodiment.
- the data processing apparatus 100 includes a text analyzer 1, an event slot sequence extractor 2 (extraction unit), a machine learning case generator 3 (example generation unit), and an event slot history feature generation. 4, a shared term history feature generator 5, a shared term expression generator 6, a subsequent event slot estimation trainer 7 (model construction unit), and a subsequent event slot estimation predictor 8 (prediction unit).
- . 3 represents the input / output data of each of the modules 1 to 8 constituting the data processing apparatus 100.
- the processing executed by the data processing apparatus 100 is roughly divided into “training processing” and “prediction processing”.
- the training process includes an event slot series extractor 2, a machine learning case generator 3, an event slot history feature generator 4, a shared term history feature generator 5, a shared term expression generator 6, and a subsequent event slot estimation trainer 7.
- This is a process of constructing a subsequent event slot estimation model D10 (story model) from the training tagged document group D1.
- the prediction processing includes a text analyzer 1, an event slot series extractor 2, a machine learning case generator 3, an event slot history feature generator 4, a shared term history feature generator 5, a shared term expression generator 6, and a subsequent event slot.
- 3 indicates a processing flow in the training process
- a solid line arrow indicates a processing flow in the prediction process
- a dashed-dotted arrow indicates a processing flow common to both the training process and the prediction process.
- the event slot series extractor 2 receives the training tagged document group D1.
- the event slot series extractor 2 receives the training-tagged document group D1, performs a process of extracting an event slot series from the training-tagged documents included in the training-tagged document group D1, and performs a training event slot.
- the series data group D2 is output.
- the machine learning case generator 3 receives the training event slot series data group D2, and cooperates with the event slot history feature generator 4, the shared term history feature generator 5, and the shared term expression generator 6, A process for generating case data from the training event slot series data included in the training event slot series data group D2 is performed, and a training case data group D3 is output.
- the subsequent event slot estimation trainer 7 receives the training case data group D3, performs machine learning training using the training case data group D3, and outputs a subsequent event slot estimation model D10.
- the subsequent event slot estimation model D10 is a story model itself, and is used to estimate the subsequent event slot of the analysis target document D5 in the prediction process described below.
- the analysis target document D5 is input to the text analyzer 1.
- the text analyzer 1 receives the analysis target document D5, performs predicate term structure analysis, co-reference analysis, etc. on the analysis target document D5, and outputs an analysis target tagged document D6.
- the event slot series extractor 2 receives the analysis target tagged document D6, performs a process of extracting the event slot series from the analysis target tagged document D6, and outputs a prediction event slot series data group D7. .
- the machine learning case generator 3 receives the prediction event slot sequence data group D7, and cooperates with the event slot history feature generator 4, the shared term history feature generator 5 and the shared term expression generator 6, A process for generating case data from the prediction event slot series data included in the prediction event slot series data group D7 is performed, and a prediction case data group D8 is output.
- the subsequent event slot estimation predictor 8 receives the prediction case data group D8 and the subsequent event slot estimation model D10 constructed by the training process, and predicts the subsequent event slot using the subsequent event slot estimation model D10.
- the subsequent event slot estimation result D9 is output.
- the subsequent event slot estimation result D9 indicates the probability for each event slot that may appear as a subsequent event slot that follows the event slot sequence extracted from the analysis target document D5.
- the application utilizing the narrative model can use the information of the subsequent event slot estimation result D9 as some judgment material for context understanding in its own processing.
- the event slot series extractor 2 In the training process, the event slot series extractor 2 inputs the training tagged document group D1 and outputs the training event slot series data group D2 as described above.
- FIG. 4 is a diagram showing a specific example of a training tagged document that is a part of the training tagged document group D1 input by the event slot series extractor 2, and FIG. FIG. 4B shows an example in English.
- the tagged document for training includes text with morpheme (word division) information, preanalyzed resolved predicate term structure analysis information in which anaphoric relations such as zero anaphora and pronoun anaphora are resolved, And co-reference information.
- the predicate term structure analysis information and the coreference information are indispensable, but the document with the training tag cannot be processed unless the format shown in FIG. 4 is used.
- the training tagged document includes predicate term structure analysis information and coreference information
- a document expressed in an arbitrary format can be used. Note that although there is a difference in the language used between the Japanese example in FIG. 4A and the English example in FIG. 4B, there is no essential difference in the data itself. Therefore, only the Japanese example will be described below.
- the text and morphological analysis (word division) information the text is divided into words, and a morpheme number is assigned to each word.
- anaphoric resolved predicate term structure information information on the predicate term structure of each predicate in a state where the terms omitted in the text are anaphorically resolved by anaphoric analysis is allocated to each predicate. Together with the ID.
- the predicate term structure of each predicate includes the morpheme number of the predicate, its meaning, the case type of each term subordinate to the predicate, and the morpheme number. In the example shown in FIG.
- the predicates with the morpheme number 12 and the predicates with the morpheme number 15 are terms solved by the anaphora analysis.
- the ID assigned to each co-reference cluster and its co-reference cluster The members of are associated with the predicate term structure.
- the training-tagged document as illustrated in FIG. 4 is obtained by analyzing, for example, an arbitrary text using a text analyzer 1 (or a module having an equivalent function) used in a prediction process described later. It may be generated by adding a tag or by manually adding a tag to any text.
- FIG. 5 is a diagram showing a specific example of training event slot series data that is part of the training event slot series data group D2 output from the event slot series extractor 2, and shows the training shown in FIG. 2 shows an example of training event slot series data extracted from a tagged document for use.
- the left slot shows an event slot series to which an element “ ⁇ / s>” is added at the end.
- Each event slot in the series shares a term, and the information on the shared term is shown in the right section.
- the element “ ⁇ / s>” at the end of the sequence is a pseudo event slot indicating the end of the sequence, and is used for learning a sequence pattern that is likely to end.
- the training event slot series data as shown in FIG. 5 is generated by the number of co-reference clusters from the training tagged document as shown in FIG. That is, the example of FIG. 5 is training event slot sequence data generated for the co-reference cluster indicated by the ID of [C01] from the training tagged document shown in FIG. From the training tagged document shown in (a), training event slot series data is similarly generated for the co-reference cluster indicated by the ID of [C02].
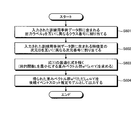
- FIG. 6 is a flowchart for explaining the processing performed by the event slot series extractor 2.
- the event slot series extractor 2 performs the following steps S101 to S104 on each of the training tagged documents (see FIG. 4) included in the input training tagged document group D1 for training.
- Event slot sequence data (see FIG. 5) is generated, and a training event slot sequence data group D2 is output.
- the process of the event slot sequence extractor 2 illustrated in FIG. 6 is an example of generating training event slot sequence data in the format illustrated in FIG. 5 from the training tagged document in the format illustrated in FIG. . If the format of the training-tagged document or the training event slot sequence data is different from the examples in FIGS. 4 and 5, the event slot sequence extractor 2 may perform processing according to the format.
- Step S101 The event slot series extractor 2 extracts one co-reference cluster from the “co-reference information” section of the training tagged document that is input data.
- Step S102 The event slot series extractor 2 lists the morpheme numbers and surface layers of each member in the co-reference cluster in the right section of the training event slot series data as output data.
- Step S103 The event slot sequence extractor 2 takes out information (event slot information) written in parentheses of each member in the co-reference cluster as a sequence, replaces the morpheme number of the predicate with the surface layer and meaning of the predicate, and After adding the element “ ⁇ / s>” at the end of the sequence, it is described in the left section of the training event slot sequence data to be output data.
- event slot information written in parentheses of each member in the co-reference cluster as a sequence, replaces the morpheme number of the predicate with the surface layer and meaning of the predicate, and After adding the element “ ⁇ / s>” at the end of the sequence, it is described in the left section of the training event slot sequence data to be output data.
- Step S104 The event slot series extractor 2 performs the above-described steps S101 to S103 for all the coreference clusters described in the “coreference information” section of the training tagged document.
- the machine learning case generator 3 will be described. First, the positioning of the machine learning case generator 3 in the data processing apparatus 100 according to the present embodiment will be described.
- the machine learning process performed by the subsequent event slot estimation trainer 7 and the subsequent event slot estimation predictor 8 is intended to predict the probability of the Ngram sequence based on the identification model. To do. That is, when y is an event slot and x is an event slot sequence history, P (y
- the machine learning case generator 3 is in charge of the process of creating the case data.
- the machine learning case generator 3 receives the training event slot series data group D2 from the event slot series extractor 2 as an input, and outputs the training case data group D3.
- FIG. 7 is a diagram showing a specific example of the training case data that is a part of the training case data group D3 output from the machine learning case generator 3. From the training event slot sequence data shown in FIG. An example of generated training case data is shown. However, the training case data in FIG. 7 is obtained when the Ngram order is 2 (big) and the training event slot sequence data shown in FIG. 5 is “imprisoned (motion 4). The case data for training related to the element of interest.
- the output label represents an event slot that is a correct answer in a prediction process for predicting a subsequent event slot.
- a feature vector corresponding to information serving as a clue for predicting the subsequent event slot is described in a section beginning with “x:”.
- the feature vector is delimited by a comma for each element (dimension), and each element is delimited by a colon.
- a dimension ID for identifying the dimension
- a value (feature amount) in that dimension is regarded as 0.
- This notation is a notation often used for compactly expressing a high-dimensional sparse vector in which most elements are zero.
- the dimension ID is represented by a character string, and is used to determine whether or not the elements are included in the feature vectors of different cases.
- each dimension ID is appropriately assigned so as to have a different vector element number (each dimension ID is assigned to which element number of the mathematical vector). Even if it is assigned, the result of optimization is the same). In the present embodiment, only 1 or 0 is used for each dimension value.
- the feature vector includes one or more feature quantities related to the event slot history and one or more feature quantities related to the shared term history.
- the value corresponding to the dimension ID starting with “[EventSlot]” is a feature amount related to the event slot history (hereinafter referred to as event slot history feature), and the dimension ID starting with “[ShareArg]”.
- a value corresponding to is a feature amount related to the history of the shared term (hereinafter referred to as shared term history feature).
- the event slot history feature and the shared term history feature are generated for Ngram sequences of all orders equal to or smaller than i, where Ngram order is i. For example, in the example shown in FIG.
- FIG. 8 is a flowchart for explaining processing performed by the machine learning case generator 3.
- the machine learning case generator 3 performs the following steps S201 to S208 for each of the training event slot sequence data (see FIG. 5) included in the input training event slot sequence data group D2.
- the training case data (see FIG. 7) is generated, and the training case data group D3 is output.
- Step S201 The machine learning case generator 3 selects an event slot (hereinafter referred to as an attention slot) as an element of interest from the event slot series described in the left section of the training event slot series data as input data. Take one in order.
- an attention slot an event slot
- Step S202 The machine learning case generator 3 extracts a partial series corresponding to the history of the slot of interest from the event slot series. For example, in the case of bigram, a partial series including up to the event slot immediately before the target slot is extracted, and in the case of trigram, a partial series including up to the event slot two times before the target slot is extracted.
- the event slot that is the element of interest is near the beginning of the event slot series and does not have a length that can satisfy the Ngran order, dummy elements such as “ ⁇ s>” are added to the beginning for the number of event slots that are insufficient. do it.
- Step S203 The machine learning case generator 3 extracts information on the shared term described in the right section of the event slot series data.
- Step S204 The machine learning case generator 3 describes the output label in the section beginning with “y:” of the training case data to be output data based on the description of the slot of interest.
- the description of the slot of interest becomes the output label as it is.
- Step S205 The machine learning case generator 3 passes the information on the slot of interest and the history of the slot of interest to the event slot history feature generator 4, and obtains an event slot history feature group from the event slot history feature generator 4.
- an event slot history feature group is acquired from the event slot history feature generator 4.
- Step S206 The machine learning case generator 3 passes the shared term information to the shared term history feature generator 5, and obtains a shared term history feature group from the shared term history feature generator 5.
- a value corresponding to a dimension ID starting with “[ShareArg]” is a shared term history feature, and the machine learning case generator 3 collects these shared term history features. Is acquired from the shared term history feature generator 5.
- Step S207 The machine learning case generator 3 uses the result of merging the event slot history feature group and the common term history feature group acquired as described above as a feature vector, and “x” of the training case data that becomes output data : Write in the section starting with “”.
- Step S208 The machine learning case generator 3 performs the above-described steps S201 to S207 for all event slots included in the event slot sequence described in the left section of the event slot sequence data.
- the event slot history feature generator 4 receives the information of the attention slot and the history of the attention slot from the machine learning case generator 3 as input, and returns the event slot history feature group described above to the machine learning case generator 3.
- FIG. 9 is a flowchart for explaining processing by the event slot history feature generator 4.
- the event slot history feature generator 4 receives the information of the attention slot and the history of the attention slot from the machine learning case generator 3, the event slot history feature generator 4 performs the processing of steps S301 to S310 in FIG. Is returned to the machine learning case generator 3.
- Step S301 The event slot history feature generator 4 prepares a variable result for a return value (feature value expression character string list), and substitutes an empty list.
- Step S302 The event slot history feature generator 4 prepares a loop variable len in the range from 1 to N when the Ngram order is N, and starts loop 1.
- Step S303 The event slot history feature generator 4 prepares the feature amount expression character string s and substitutes “[EventSlot]” + the slot of interest.
- Step S304 The event slot history feature generator 4 prepares a loop variable i ranging from 1 to len, and starts loop 2.
- Step S305 The event slot history feature generator 4 extracts the i-th event slot before the noticed slot from the notice slot history information, and adds it to the feature quantity expression character string s with an underscore.
- Step S306 The event slot history feature generator 4 performs a loop 2 branching process (determination of whether to repeat or end).
- Step S307 The event slot history feature generator 4 adds “: 1” to the feature amount expression character string s.
- Step S308 The event slot history feature generator 4 adds the feature amount expression character string s to the feature amount expression character string list result.
- Step S309 The event slot history feature generator 4 performs a loop 1 branching process (determination of whether to repeat or end).
- Step S310 The event slot history feature generator 4 returns the feature amount expression character string list result as a return value.
- the shared term history feature generator 5 receives the shared term information from the machine learning case generator 3 as an input, and returns the above-described shared term history feature group to the machine learning case generator 3.
- FIG. 10 is a flowchart for explaining processing by the shared term history feature generator 5.
- the shared term history feature generator 5 receives the shared term information from the machine learning case generator 3, the shared term history feature generator 5 performs the processing of steps S401 to S413 in FIG. Return to vessel 3.
- Step S401 The shared term history feature generator 5 prepares a variable result for a return value (feature value expression character string list), and substitutes an empty list.
- Step S402 The shared term history feature generator 5 passes the shared term information to the shared term representation generator 6 and calls it, and obtains a shared term representation group from the shared term representation generator 6.
- Step S403 The shared term history feature generator 5 extracts one by one from the shared term expression group in order and executes the following processing (loop 1).
- Step S404 When the Ngram order is N, the shared term history feature generator 5 prepares a loop variable len ranging from 1 to N, and starts loop 2.
- Step S405 The shared term history feature generator 5 prepares a feature quantity expression character string s, and substitutes “[ShareArg]” + shared term expression.
- Step S406 The shared term history feature generator 5 prepares a loop variable i ranging from 1 to len, and starts loop 3.
- Step S407 The shared term history feature generator 5 adds a shared term expression to the feature amount expression character string s with an underscore therebetween.
- Step S408 The shared term history feature generator 5 performs a loop 3 branching process (determination of whether to repeat or end).
- Step S409 The shared term history feature generator 5 adds “: 1” to the feature quantity expression character string s.
- Step S410 The shared term history feature generator 5 adds the feature quantity expression character string s to the feature quantity expression character string list result.
- Step S411 The shared term history feature generator 5 performs a branch process of loop 2 (determination of whether to repeat or end).
- Step S412 The shared term history feature generator 5 performs a loop 1 branching process (determination of whether to repeat or end).
- Step S413 The shared term history feature generator 5 returns the feature quantity expression character string list result as a return value.
- the shared term expression generator 6 receives the shared term information from the shared term history feature generator 5 as an input, and returns a shared term expression group to the shared term history feature generator 5.
- FIG. 11 is a diagram illustrating an example of a shared term expression group generated by the shared term expression generator 6, and information on shared terms included in the event slot series data illustrated in FIG. 5 is stored in the shared term expression generator 6. It is an example of the common term expression group produced
- the shared term expression group generated by the shared term expression generator 6 is an expression using the result of the specific expression recognition in addition to the surface layer of the shared term (which may be a normalized surface layer). And expressions by semantic categories. In addition to these expressions, parts of speech (common nouns, proper nouns, several names, etc.) may be added to one of the common term expressions.
- the shared term expression is a distinction of shared terms using at least one of the above-mentioned surface layer or normalized surface layer, grammatical category information, semantic category information, or specific expression type information. If it is.
- FIG. 12 is a flowchart for explaining processing by the shared term expression generator 6.
- the shared term expression generator 6 receives the shared term information from the shared term history feature generator 5, the shared term expression generator 6 performs the processing of steps S 501 to S 507 in FIG. 12 to convert the shared term expression group into the shared term history feature generator 5.
- Step S501 The shared term expression generator 6 prepares a variable result for a return value (shared term expression list) and substitutes an empty list.
- Step S502 The shared term expression generator 6 extracts the surface layers one by one from the surface layer group in order and executes the following processing (loop 1).
- Step S503 The shared term expression generator 6 adds the surface layer to the feature quantity expression character string list result.
- Step S504 The shared term expression generator 6 performs a unique expression recognition process based on the surface layer, and adds the obtained unique expression type to the feature quantity expression character string list result.
- the specific expression recognition is a process for identifying a specific expression type such as PERSON, ORGANIZATION, or LOCATION.
- Step S505 The shared term expression generator 6 identifies a semantic category using a thesaurus for the surface layer, and adds the obtained semantic category to the feature amount expression character string list result for each layer.
- Step S506 The shared term expression generator 6 performs a loop 1 branching process (determination of whether to repeat or end).
- Step S507 The shared term expression generator 6 returns the feature quantity expression character string list result as a return value.
- the subsequent event slot estimator 7 receives the training case data group D3 from the machine learning case generator 3 as an input, and outputs a subsequent event slot estimation model D10 (story model).
- FIG. 13 is a diagram illustrating an example of the subsequent event slot estimation model D10.
- each row corresponds to a feature vector of each class, and is arranged in order of class number.
- the class corresponds to the output label y described above, and the class number is a number corresponding to the output label y.
- each field in the row is an element (dimension) of the feature vector, and is arranged in the order of the dimension number.
- the dimension number is a number corresponding to the dimension ID.
- FIG. 13 shows an example with a small number of dimensions and number of classes.
- FIG. 14 is a flowchart for explaining processing performed by the subsequent event slot estimation trainer 7.
- the subsequent event slot estimation trainer 7 performs the processing of the following steps S601 to S604 using the input training case data group D3, and generates and outputs a subsequent event slot estimation model D10 that becomes a story model. .
- Step S601 The subsequent event slot estimation trainer 7 assigns output labels y included in the input training case data group D3 to different numbers (class numbers).
- Step S602 The subsequent event slot estimation trainer 7 assigns dimension IDs of feature amounts included in the input training case data group D3 to different numbers (dimension numbers).
- Step S603 The subsequent event slot estimation trainer 7 solves the logistic regression optimization formula shown by the following formula (1). That is, a weight vector group w (c) (where ⁇ Y) that minimizes the objective function L is obtained.
- ⁇ (x) is a feature vector extracted from x
- ⁇ is an arbitrary constant
- N is the number of cases
- (x (i), y (i)) is an i-th case.
- Step S604 The subsequent event slot estimation trainer 7 outputs the weight vector group w (c) (where c ⁇ Y) obtained by solving the optimization expression of the equation (1) as the subsequent event slot estimation model D10. To do.
- the text analyzer 1 will be described.
- the analysis target document D5 is input to the text analyzer 1 as described above.
- the text analyzer 1 performs, for example, morphological analysis, predicate structure analysis, and coreference analysis on the input analysis target document D5, and analyzes the same format as the training tagged document illustrated in FIG. A document D6 with a target tag is generated and output.
- the morpheme analysis, predicate structure analysis, and coreference analysis performed by the text analyzer 1 are existing technologies, and thus description thereof is omitted here.
- the event slot series extractor 2 receives the analysis target tagged document D6 output from the text analyzer 1 as an input, and outputs a prediction event slot series data group D7.
- the process performed by the event slot series extractor 2 in the prediction process is the same as the process in the training process.
- the prediction event slot series data group D7 is a collection of prediction event slot series data in the same format as the training event slot series data illustrated in FIG.
- problem settings to be predicted in the prediction process will be described.
- the problem settings to be predicted depend on the application.
- a problem setting of estimating an event slot likely to follow a given document and its probability is appropriate.
- an abbreviation of a predicate in the document in the case of pronoun anaphora analysis in English etc., a pronoun rather than an abbreviation
- the problem setting is to select the event slot series that is most easily connected.
- the most likely subsequent event slot (or the case where nothing continues) and its probability are estimated for a given event slot sequence.
- the machine learning case generator 3 receives the event slot sequence data group D7 for prediction output from the event slot sequence extractor 2 as input, and generates prediction case data from the selected event slot sequence data. Then, the prediction case data group D8 is output.
- the case data for prediction has the same format as the case data for training illustrated in FIG. 7, but differs from the case data for training only in that the output label y is indefinite.
- FIG. 15 is a flowchart for explaining the process of the machine learning case generator 3 in the prediction process.
- the machine learning case generator 3 performs the following processing in step S701 and step S702 on the prediction event slot series data selected from the input prediction event slot series data group D7, and performs prediction case data. And a prediction case data group D8 is output.
- Step S701 The machine learning case generator 3 removes the last element “ ⁇ / s>” from the event slot series described in the left section of the prediction event slot series data.
- Step S702 The machine learning case generator 3 regards the remaining event slot series as a history, performs the same processing as Step S202, Step S203, and Steps S205 to S208 in FIG. D8 is output.
- the output label y of the prediction case data is indefinite, it is left blank or a dummy value is embedded.
- the subsequent event slot estimation predictor 8 receives the prediction case data group D8 output from the machine learning case generator 3 as an input, and uses the subsequent event slot estimation model D10 constructed in the training process to predict machine learning. Processing is performed to output a subsequent event slot estimation result D9.
- FIG. 16 is a diagram showing an example of the subsequent event slot estimation result D9.
- x) (where c ⁇ Y) of each class are listed in order of class number.
- the probability of each class indicates the probability that each event slot will follow for a given event slot sequence.
- FIG. 17 is a flowchart for explaining processing executed by the subsequent event slot estimation predictor 8.
- the subsequent event slot estimation predictor 8 performs the following steps S801 to S803 on the input case data group D8 for prediction using the subsequent event slot estimation model D10, and obtains the subsequent event slot estimation result D9. Output.
- Step S801 The subsequent event slot estimation predictor 8 uses the same procedure as the subsequent event slot estimation trainer 7 (same as step S602 in FIG. 14) to determine the dimension ID of the feature amount included in the input prediction case data group D8. ) To assign different numbers (dimension numbers).
- Step S803 The subsequent event slot estimation predictor 8 outputs the probability P (c
- the event slot series extractor 2 performs the training tagged document (predicate term structure analysis and From the event slot sequence data for training (a combination of a predicate having a shared term and case type information representing the case type of the shared term) as elements, and multiple elements of the predicate in the document The element series arranged in the order of appearance and the shared term) are extracted. Then, the machine learning case generator 3 (case generation unit), from the training event slot sequence data, is a combination of the feature vector x including the event slot history feature and the shared term history feature and the output label y.
- the subsequent event slot estimation trainer 7 uses the training case data to solve the logistic regression optimization formula shown in Formula (1) (performs machine learning based on the identification model).
- the subsequent event slot estimation model D10 (story model) is constructed.
- the case data expressed by the feature vector including not only the event slot history feature but also the shared term history feature is generated, and the machine using the case data is used. Since the story model is constructed by learning, more clues for predicting subsequent event slots can be extracted than before, and a highly accurate story model can be constructed.
- the shared term history feature generator 5 and the shared term expression generator 6 are used. Shared by each shared term expression that distinguishes shared terms using at least one of the surface or normalized surface, grammatical category information, semantic category information, and proper expression type information. A term history feature is generated. Therefore, according to the data processing apparatus 100 according to the present embodiment, a shared term history feature can be generated with an appropriate granularity, and a highly accurate story model can be constructed.
- the unigram (unigram) is used as the event slot history feature and the shared term history feature. ) A feature amount is generated for each of the partial series including the series. Therefore, according to the data processing apparatus 100 according to the present embodiment, it is possible to effectively solve the zero probability that the probability of the event slot series is zero, and to construct a highly accurate story model.
- the event slot sequence extracted by the event slot sequence extractor 2 has the meaning specifying information for specifying the meaning of the predicate added to the predicate included in each event slot. Yes. Therefore, according to the data processing apparatus 100 according to the present embodiment, it is possible to remove the ambiguity of the meaning of the predicate and build a highly accurate story model.
- the wild card history is obtained by replacing some elements of the partial series in the event slot series as the event slot history with wild cards (elements that match any event slot). For example, if there is a history of “A_B_C” (A, B, and C are event slots appearing in this order), if the wild card is *, “A_B_C” (history without wild card), “A_B_ *” (C is wild) History replaced with a card), “A _ * _ C” (history replaced with a wild card), “A _ * _ *” (history replaced with a wild card of B and C), “* _B_C” (A replaced with a wild card) (History replaced with a card), “* _ * _ C” (history where A and B are replaced with wild cards), “* _ * _ *” (history where all of A, B and C are replaced with wild cards) , As a variation of wild card history.
- the shared term history used in the first embodiment is defined in such a way that the shared terms are arranged by the length of the event slot history (the number corresponding to the number of elements of the partial series that is the event slot history). For example, when the shared term is “X”, the history of the shared term corresponding to the partial sequence of length 3 is expressed as “X_X_X”.
- a combination feature obtained by ANDing a wild card history and a shared term is considered.
- the combined feature is a feature amount that is 1 only when both feature amounts are 1, and the dimension ID is represented by connecting both IDs with “&”.
- a combination feature obtained by ANDing the wild card history “A _ * _ *” and the shared term “X” is represented as “A _ * _ *”.
- the shared term history feature used in the first embodiment is included in the combination feature of the wild card history and the shared term.
- the shared term history feature relating to the length 3 history “X_X_X” of the shared term “X” is the combined feature “* _ * _ * & X of the wild card history“ * _ * _ * ”and the shared term“ X ”. It has the same meaning as “.” Because the wild card history “* _ * _ *” represents a history of length 3, and “* _ * _ * & X” represents a history of length 3. This is because it represents that the history is related to the shared term “X”.
- the combination feature of the wild card history and the shared term other than “* _ * _ *” is a feature that is slightly more restrictive than the above combination feature.
- “A _ * _ * & X” has a history of a shared term “X” having a length of 3, and the element three elements before the element of interest in the event slot history must be “X”. This indicates that when the constraint is too loose with the shared term history feature alone, it can be adjusted to give an appropriate constraint to the event slot sequence by combining with another wild card history feature.
- a wild card is used instead of the shared term history feature used in the first embodiment.
- the combination feature of the history and the shared term when the restriction is too loose with the shared term history feature, the adjustment that gives an appropriate restriction to the event slot series is realized.
- machine learning is performed by providing all the variations of the wild card history and the combined features of the shared terms in the feature vector.
- Machine learning has an adjustment mechanism that assigns large weights to features that are important for prediction and assigns small weights to features that are not important, so in a pattern that can not be predicted sufficiently with only shared term history, Large weights can be assigned to the combined features of wildcard history and shared terms with appropriate constraints. Note that no special treatment is added to the machine learning process of the second embodiment, and the same process as that of the first embodiment is used.
- the combination feature of the shared term and the one obtained by replacing all elements with the wild card has the same meaning as the shared term history feature used in the first embodiment as described above.
- the case data for training and the case data for prediction generated in the second embodiment are further focused on the feature vector x of the case data for training and the case data for prediction generated in the first embodiment.
- FIG. 18 is a block diagram illustrating a configuration example of the data processing device 200 according to the second embodiment.
- the data processing device 200 according to the second embodiment is a machine instead of the machine learning case generator 3 as compared with the data processing device 100 according to the first embodiment shown in FIG.
- the difference is that a learning case generator 3 ′ (case generation unit) is used and a combination feature generator 9 is used instead of the shared term history feature generator 5.
- Other configurations of the data processing device 200 according to the second embodiment are the same as those of the data processing device 100 according to the first embodiment. For this reason, below, the component similar to the data processing apparatus 100 which concerns on 1st Embodiment attaches
- the machine learning case generator 3 ′ receives the training event slot series data group D2 (or the prediction event slot series data group D7) as an input from the event slot series extractor 2, and receives the event slot history feature generator 4 and the combination.
- a process for generating case data is performed in cooperation with the feature generator 9 and the shared term expression generator 6 to output a training case data group D3 ′ (or a prediction case data group D8 ′).
- FIG. 19 is a diagram showing a specific example of training case data that is part of the training case data group D3 ′ output from the machine learning case generator 3 ′, and the training event slot sequence shown in FIG. An example of training case data generated from the data is shown.
- the training case data in FIG. 19 is obtained when the Ngram order is 2 (big) and the event slot sequence data for training shown in FIG. 5 is “imprisoned (motion 4).
- the shared term history corresponding to the dimension ID starting with “[ShareArg]” in the feature vector x Features are not included.
- the feature vector x includes a combination feature of a wild card history and a shared term corresponding to a dimension ID starting with “[Wild & Arg]”.
- the wildcard history “* _ *” and shared item combination features are shared item history features included in the training case data of the first embodiment illustrated in FIG. Is equivalent. Therefore, the feature vector x of the training case data illustrated in FIG. 19 is obtained by adding 18 types of feature amounts to the feature vector x of the training case data of the first embodiment illustrated in FIG. Become.
- the machine learning case generator 3 ′ applies the machine learning case of the first embodiment to each of the training event slot series data (see FIG. 5) included in the input training event slot series data group D2. Processing similar to that of the generator 3 (steps S201 to S208 in FIG. 8) is performed to generate training case data as shown in FIG. 19, and a training case data group D3 ′ is output.
- the shared term history feature generator 5 is passed to the shared term history feature generator 5 to obtain the shared term history feature group in step S206 of FIG.
- the machine learning case generator 3 ′ of the second embodiment passes the event slot history information and the shared term information to the combination feature generator 9 to obtain a combination feature group of the wild card history and the shared term.
- the machine learning case generator 3 ′ receives the event slot sequence data group D7 for prediction output from the event slot sequence extractor 2 as an input, and applies the first event slot sequence data to the selected event slot sequence data.
- the same processing (step S701 and step S702 in FIG. 15) as the machine learning case generator 3 of one embodiment is performed to generate prediction case data, and the prediction case data group D8 is output.
- the case data for prediction has the same format as the case data for training illustrated in FIG. 19, but differs from the case data for training only in that the output label y is indefinite.
- the combination feature generator 9 receives the event slot history information and the shared term information from the machine learning case generator 3 ′ as input, and generates the above-described wild card history and shared term combination feature group for machine learning case generation. Return to vessel 3 '.
- FIG. 20 is a flowchart for explaining processing by the combination feature generator 9.
- the combination feature generator 9 receives the event slot history information and the shared term information from the machine learning case generator 3 ′, the combination feature generator 9 performs the processing of steps S901 to S910 in FIG.
- the combination feature group of shared terms is returned to the machine learning case generator 3.
- Step S901 The combination feature generator 9 prepares a variable called a wild card event slot history list w and substitutes an empty list.
- Step S902 The combination feature generator 9 passes the event slot history information (the information about the slot of interest and the history of the slot of interest) to the event slot history feature generator 4, and the event slot history feature generator 4 outputs the event slot history. Get a feature group.
- Step S903 The combination feature generator 9 extracts one event slot history feature from the event slot history feature group.
- Step S904 The combination feature generator 9 acquires all the variations of the wild card history by replacing any element included in the event slot history with the wild card “*” (the length of the event slot history is N). If there is, obtain a variation of 2 to the power of N).
- Step S905 The combination feature generator 9 adds all variations of the acquired wild card history to the wild card event slot history list w.
- Step S906 The combination feature generator 9 performs the above-described steps S903 to S905 for all event slot history features of the event slot history feature group.
- Step S907 The combination feature generator 9 prepares a variable called a shared term expression list a and substitutes an empty list.
- Step S908 The combination feature generator 9 adds the shared term representation group obtained by passing the shared term information to the shared term representation generator 6 to the shared term representation list a.
- Step S909 The combination feature generator 9 forms a pair of an arbitrary element in the wildcard event slot history list w and an arbitrary element in the shared term expression list a by sandwiching both character strings with “&”. The pairing process is performed on all pairs to obtain a dimension ID group c of the combination feature of the wild card history and the shared term.
- Step S910 The combination feature generator 9 returns, as a return value, each element of the dimension ID group c of the combination feature of the wild card history and the shared term with “: 1” added at the end.
- the shared term history feature used in the case data of the first embodiment is too restrictive, the event It is possible to construct a highly accurate narrative model by making adjustments that give appropriate restrictions to the slot series.
- the data processing apparatus 100 stores a control device such as a CPU (Central Processing Unit) 101, a ROM (Read Only Memory) 102, a RAM (Random Access Memory) 103, and the like.
- a control device such as a CPU (Central Processing Unit) 101, a ROM (Read Only Memory) 102, a RAM (Random Access Memory) 103, and the like.
- a hardware configuration using a normal computer including a device, a communication I / F 104 that performs communication by connecting to a network, a bus 110 that connects each unit, and the like can be employed.
- the program executed by the data processing apparatus 100 (200) is an installable or executable file in a CD-ROM (Compact Disk Read Only Memory), flexible disk (FD), CD-R (Compact Disk Recordable). ), DVD (Digital Versatile Disc), etc., recorded on a computer-readable recording medium and provided as a computer program product.
- CD-ROM Compact Disk Read Only Memory
- FD flexible disk
- CD-R Compact Disk Recordable
- DVD Digital Versatile Disc
- the program executed by the data processing apparatus 100 (200) may be stored on a computer connected to a network such as the Internet and provided by being downloaded via the network.
- the program executed by the data processing apparatus 100 (200) may be provided or distributed via a network such as the Internet.
- a program executed by the data processing apparatus 100 (200) may be provided by being incorporated in advance in the ROM 102 or the like.
- the program executed by the data processing device 100 (200) includes each processing unit (text analyzer 1, event slot series extractor 2, machine learning case generator 3 (3 ′), data processing device 100 (200), Module configuration including event slot history feature generator 4, shared term history feature generator 5 (combination feature generator 9), shared term expression generator 6, subsequent event slot estimation training 7, and subsequent event slot estimation predictor 8)
- each processing unit described above is loaded on the main storage device, and each processing described above is performed. Are generated on the main memory.
- the data processing apparatus 100 (200) realizes part or all of the above-described processing units using dedicated hardware such as an ASIC (Application Specific Integrated Circuit) or an FPGA (Field-Programmable Gate Array). It is also possible.
- the data processing apparatus 100 (200) described above uses the training process for constructing the subsequent event slot estimation model D10 (story model) and the analysis target document D5 using the subsequent event slot estimation model D10 constructed by the training process. Both the prediction process for estimating the subsequent event slot is performed. However, the data processing apparatus 100 (200) can be configured to perform only the prediction process. In this case, for example, a training process is performed in advance using an external device or the like, and a subsequent event slot estimation model D10 is constructed. The data processing apparatus 100 (200) inputs the analysis target document D5 and also inputs the subsequent event slot estimation model D10 from an external apparatus or the like, and performs the above-described prediction process.
- the data processing apparatus 100 (200) described above is an example in which a prediction process for estimating the subsequent event slot of the analysis target document D5 is performed using the subsequent event slot estimation model D10 constructed by the training process.
- the processing apparatus 100 (200) may be configured to execute various other applications using the subsequent event slot estimation model D10 (story model) constructed in the training process. For example, when an application of anaphora analysis is executed, case data for anaphora analysis is generated using a subsequent event slot estimation model D10 (story model) constructed by training processing, and machine learning is performed using this case data.
- the anaphoric analysis can be performed by adopting the configuration for performing the above.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- General Engineering & Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Multimedia (AREA)
- Machine Translation (AREA)
Abstract
Description
ここで、本実施形態の物語モデル構築方法の概要について説明する。本実施形態の物語モデル構築方法は、後続するイベントスロットを予測するための手がかりとなるイベントスロットの連接性に関する情報として、従来の手法で用いているイベントスロット系列の頻度に加えて、共有項の系列の頻度を利用することを基本方針とする。すなわち、本実施形態では、イベントスロット系列の頻度と共有項の系列の頻度との2種類の統計量を評価値として扱い、これらの合算を含む計算処理を用いて、後続するイベントスロットの確率を求める。合算は手がかりのORを取る効果があるため、少なくともどちらかの手がかりが有効であれば、イベントスロットのつながりを予測することが可能となる。
[A]:イベントスロット系列の頻度(に準ずる統計量)の計算。
[B]:共有項の系列の頻度(に準ずる統計量)の計算。
[C]:統計量[A]と統計量[B]とを、これらの和を取る処理を含むかたちで統合する確率計算。
[1]:述語項構造解析および共参照解析が行われた文書群から共有項を持つイベントスロット系列群を抽出する。
[2]:[1]で抽出したイベントスロット系列群に対し、イベントスロット系列内のイベントスロット(注目要素)ごとに、そのイベントスロットの履歴に関する1つ以上の特徴量と、共有項の履歴に関する1つ以上の特徴量と、の少なくともいずれかの特徴量を含む特徴ベクトルxと、イベントスロット(注目要素)を識別するためのラベルyとを組み合わせた事例データ(x,y)を生成し、事例データ群を得る。
[3]:ロジスティック回帰などの確率を計算できる識別モデル手法を用い、[2]で取得した事例データ群を学習データとした多クラス分類問題を解く(機械学習を行う)ことにより、物語モデルを構築する。
次に、本実施形態に係るデータ処理装置の具体例について説明する。図3は、第1実施形態に係るデータ処理装置100の構成例を示すブロック図である。データ処理装置100は、図3に示すように、テキスト解析器1と、イベントスロット系列抽出器2(抽出部)と、機械学習用事例生成器3(事例生成部)と、イベントスロット履歴特徴生成器4と、共有項履歴特徴生成器5と、共有項表現生成器6と、後続イベントスロット推定訓練器7(モデル構築部)と、後続イベントスロット推定予測器8(予測部)と、を備える。なお、図3中の角丸四角形は、データ処理装置100を構成する上記各モジュール1~8の入出力データを表している。


次に、第2実施形態について説明する。第2実施形態では、第1実施形態で用いた共有項履歴特徴の代わりに、共有項履歴特徴を包含する機能を持つワイルドカード履歴と共有項の組み合わせ特徴を用いる。
捕まえる(動1).ヲ格_投獄する(動4).ヲ格
*_投獄する(動4).ヲ格
捕まえる(動1).ヲ格_*
*_*
一方、ワイルドカード履歴と共有項の組み合わせ特徴に用いる共有項のバリエーションは以下の6つである。
山田
犯罪者
<PERSON>
<Thing>
<Thing/Agent>
<Thing/Agent/Person>
したがって、ワイルドカード履歴と共有項の組み合わせ特徴としては、合計24(=4×6)種類の特徴が生成される。
Claims (7)
- 述語項構造解析および共参照解析が行われた文書から、共有項を持つ述語と前記共有項の格の種別を表す格種別情報との組み合わせを要素とし、複数の前記要素を前記文書における前記述語の出現順に並べた要素系列を、前記共有項とともに抽出する抽出部と、
前記要素系列を構成する前記要素の1つを注目要素としたときに、前記注目要素のそれぞれについて、前記注目要素を末尾の要素とする前記要素系列内の部分系列に関する1つ以上の特徴量と、前記部分系列に対応する前記共有項の系列に関する1つ以上の特徴量と、の少なくともいずれかの特徴量を含む特徴ベクトルで表現された事例データを生成する事例生成部と、
前記事例データを用いて識別モデルに基づく機械学習を行うことにより、先行文脈に後続する前記要素を推定するための物語モデルを構築するモデル構築部と、を備えるデータ処理装置。 - 前記事例生成部は、前記注目要素のそれぞれについて、一部の前記要素をワイルドカードで置き換えた前記部分系列と前記共有項とのAND条件による組み合わせに関する1以上の特徴量をさらに含む特徴ベクトルで表現された前記事例データを生成する、請求項1に記載のデータ処理装置。
- 前記共有項の系列に関する特徴量は、前記共有項を、表層または正規化された表層、文法的カテゴリの情報、意味的カテゴリの情報、固有表現タイプの情報、の少なくともいずれかを用いて区別した1以上の特徴量である、請求項1に記載のデータ処理装置。
- 前記部分系列は、前記注目要素のみを要素とするユニグラム系列を含む、請求項1に記載のデータ処理装置。
- 前記要素に含まれる前記述語は、該述語の語義を特定する語義特定情報が付加されている、請求項1に記載のデータ処理装置。
- 述語項構造解析および共参照解析が行われた文書から、共有項を持つ述語と前記共有項の格の種別を表す格種別情報との組み合わせを要素とし、複数の前記要素を前記文書における前記述語の出現順に並べた要素系列を、前記共有項とともに抽出する抽出部と、
前記要素系列を構成する前記要素の1つを注目要素としたときに、前記注目要素のそれぞれについて、前記注目要素を末尾の要素とする前記要素系列内の部分系列に関する1つ以上の特徴量と、前記部分系列に対応する前記共有項の系列に関する1つ以上の特徴量と、の少なくともいずれかの特徴量を含む特徴ベクトルで表現された事例データを生成する事例生成部と、
先行文脈に後続する前記要素を推定するための物語モデルを入力する入力部と、
前記事例データと前記物語モデルとを用いて、先行文脈に後続する前記要素を予測する予測部と、を備え、
前記物語モデルは、事前に訓練用の前記事例データを用いて識別モデルに基づく機械学習を行うことにより生成されている、データ処理装置。 - データ処理装置において実行される物語モデル構築方法であって、
前記データ処理装置の抽出部が、述語項構造解析および共参照解析が行われた文書から、共有項を持つ述語と前記共有項の格の種別を表す格種別情報との組み合わせを要素とし、複数の前記要素を前記文書における前記述語の出現順に並べた要素系列を、前記共有項とともに抽出する工程と、
前記データ処理装置の事例生成部が、前記要素系列を構成する前記要素の1つを注目要素としたときに、前記注目要素のそれぞれについて、前記注目要素を末尾の要素とする前記要素系列内の部分系列に関する1つ以上の特徴量と、前記部分系列に対応する前記共有項の系列に関する1つ以上の特徴量と、の少なくともいずれかの特徴量を含む特徴ベクトルで表現された事例データを生成する工程と、
前記データ処理装置のモデル構築部が、前記事例データを用いて識別モデルに基づく機械学習を行うことにより、先行文脈に後続する前記要素を推定するための物語モデルを構築する工程と、を含む物語モデル構築方法。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015502663A JP5945062B2 (ja) | 2013-02-28 | 2013-02-28 | データ処理装置および物語モデル構築方法 |
| PCT/JP2013/055477 WO2014132402A1 (ja) | 2013-02-28 | 2013-02-28 | データ処理装置および物語モデル構築方法 |
| CN201380073967.6A CN105264518B (zh) | 2013-02-28 | 2013-02-28 | 数据处理装置及故事模型构建方法 |
| US14/837,197 US9904677B2 (en) | 2013-02-28 | 2015-08-27 | Data processing device for contextual analysis and method for constructing script model |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2013/055477 WO2014132402A1 (ja) | 2013-02-28 | 2013-02-28 | データ処理装置および物語モデル構築方法 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US14/837,197 Continuation US9904677B2 (en) | 2013-02-28 | 2015-08-27 | Data processing device for contextual analysis and method for constructing script model |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2014132402A1 true WO2014132402A1 (ja) | 2014-09-04 |
Family
ID=51427703
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2013/055477 Ceased WO2014132402A1 (ja) | 2013-02-28 | 2013-02-28 | データ処理装置および物語モデル構築方法 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US9904677B2 (ja) |
| JP (1) | JP5945062B2 (ja) |
| CN (1) | CN105264518B (ja) |
| WO (1) | WO2014132402A1 (ja) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110399126A (zh) * | 2019-07-31 | 2019-11-01 | 北京百度网讯科技有限公司 | 用于生成脚本的方法和装置 |
| JP2020064630A (ja) * | 2019-10-11 | 2020-04-23 | 株式会社野村総合研究所 | 文章記号挿入装置及びその方法 |
| JP2020064370A (ja) * | 2018-10-15 | 2020-04-23 | 株式会社野村総合研究所 | 文章記号挿入装置及びその方法 |
Families Citing this family (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6074820B2 (ja) * | 2015-01-23 | 2017-02-08 | 国立研究開発法人情報通信研究機構 | アノテーション補助装置及びそのためのコンピュータプログラム |
| JP6551968B2 (ja) * | 2015-03-06 | 2019-07-31 | 国立研究開発法人情報通信研究機構 | 含意ペア拡張装置、そのためのコンピュータプログラム、及び質問応答システム |
| CN105975458B (zh) * | 2016-05-03 | 2018-10-09 | 安阳师范学院 | 一种基于细粒度依存关系的中文长句相似度计算方法 |
| CN109643397B (zh) * | 2016-09-06 | 2023-07-21 | 日本电信电话株式会社 | 时间序列数据特征量提取装置、时间序列数据特征量提取方法和时间序列数据特征量提取程序 |
| CN110520875B (zh) * | 2017-04-27 | 2023-07-11 | 日本电信电话株式会社 | 学习型信号分离方法和学习型信号分离装置 |
| US10652592B2 (en) | 2017-07-02 | 2020-05-12 | Comigo Ltd. | Named entity disambiguation for providing TV content enrichment |
| US11625533B2 (en) * | 2018-02-28 | 2023-04-11 | Charles Northrup | System and method for a thing machine to perform models |
| JP7120914B2 (ja) * | 2018-12-25 | 2022-08-17 | 株式会社日立製作所 | 生産実績データ分析装置 |
| CN111325020B (zh) * | 2020-03-20 | 2023-03-31 | 北京百度网讯科技有限公司 | 一种事件论元抽取方法、装置以及电子设备 |
| CN113536784B (zh) * | 2021-01-05 | 2024-08-09 | 腾讯科技(深圳)有限公司 | 文本处理方法、装置、计算机设备和存储介质 |
| US20220237838A1 (en) * | 2021-01-27 | 2022-07-28 | Nvidia Corporation | Image synthesis using one or more neural networks |
| US12417623B2 (en) * | 2021-05-28 | 2025-09-16 | Google Llc | Conditional object-centric learning with slot attention for video and other sequential data |
| CN113312464B (zh) * | 2021-05-28 | 2022-05-31 | 北京航空航天大学 | 一种基于对话状态追踪技术的事件抽取方法 |
| CN113792053B (zh) * | 2021-09-17 | 2023-08-01 | 浙江大学 | 一种数据故事生成方法 |
| CN114840771B (zh) * | 2022-03-04 | 2023-04-28 | 北京中科睿鉴科技有限公司 | 基于新闻环境信息建模的虚假新闻检测方法 |
| EP4318301A1 (en) * | 2022-08-05 | 2024-02-07 | Tata Consultancy Services Limited | Method and system for automated authoring of purposive models from natural language documents |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH11250085A (ja) * | 1998-03-02 | 1999-09-17 | Nippon Telegr & Teleph Corp <Ntt> | 事象推移予測方法および事象推移予測プログラムを記録した記録媒体 |
Family Cites Families (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU2001264928A1 (en) * | 2000-05-25 | 2001-12-03 | Kanisa Inc. | System and method for automatically classifying text |
| JP2002109103A (ja) * | 2000-09-29 | 2002-04-12 | Toshiba Corp | コンテンツ流通システムおよびコンテンツ流通方法 |
| US6925432B2 (en) * | 2000-10-11 | 2005-08-02 | Lucent Technologies Inc. | Method and apparatus using discriminative training in natural language call routing and document retrieval |
| US20040024585A1 (en) * | 2002-07-03 | 2004-02-05 | Amit Srivastava | Linguistic segmentation of speech |
| US8200487B2 (en) * | 2003-11-21 | 2012-06-12 | Nuance Communications Austria Gmbh | Text segmentation and label assignment with user interaction by means of topic specific language models and topic-specific label statistics |
| US7865352B2 (en) * | 2006-06-02 | 2011-01-04 | Microsoft Corporation | Generating grammatical elements in natural language sentences |
| US20080162117A1 (en) * | 2006-12-28 | 2008-07-03 | Srinivas Bangalore | Discriminative training of models for sequence classification |
| US8583416B2 (en) * | 2007-12-27 | 2013-11-12 | Fluential, Llc | Robust information extraction from utterances |
| US8122066B2 (en) * | 2008-10-14 | 2012-02-21 | Hewlett-Packard Development Company, L.P. | Database query profiler |
| JP5536518B2 (ja) | 2009-04-23 | 2014-07-02 | インターナショナル・ビジネス・マシーンズ・コーポレーション | システムの自然言語仕様から当該システム用のシステム・モデル化メタモデル言語モデルを自動的に抽出するための方法、装置及びコンピュータ・ |
| CN101968785A (zh) * | 2009-07-28 | 2011-02-09 | 万继华 | 理解人类自然语言的逻辑机器模型 |
| KR100963885B1 (ko) * | 2010-03-30 | 2010-06-17 | 한국과학기술정보연구원 | Rdf 네트워크 기반 연관검색 서비스 시스템 및 방법 |
| US8620836B2 (en) * | 2011-01-10 | 2013-12-31 | Accenture Global Services Limited | Preprocessing of text |
| JP5197774B2 (ja) * | 2011-01-18 | 2013-05-15 | 株式会社東芝 | 学習装置、判定装置、学習方法、判定方法、学習プログラム及び判定プログラム |
| CN102110304B (zh) * | 2011-03-29 | 2012-08-22 | 华南理工大学 | 一种基于素材引擎的漫画自动生成方法 |
| US8909516B2 (en) * | 2011-10-27 | 2014-12-09 | Microsoft Corporation | Functionality for normalizing linguistic items |
| US20130346066A1 (en) * | 2012-06-20 | 2013-12-26 | Microsoft Corporation | Joint Decoding of Words and Tags for Conversational Understanding |
| CN104169909B (zh) * | 2012-06-25 | 2016-10-05 | 株式会社东芝 | 上下文解析装置及上下文解析方法 |
| US8856642B1 (en) * | 2013-07-22 | 2014-10-07 | Recommind, Inc. | Information extraction and annotation systems and methods for documents |
-
2013
- 2013-02-28 WO PCT/JP2013/055477 patent/WO2014132402A1/ja not_active Ceased
- 2013-02-28 CN CN201380073967.6A patent/CN105264518B/zh not_active Expired - Fee Related
- 2013-02-28 JP JP2015502663A patent/JP5945062B2/ja not_active Expired - Fee Related
-
2015
- 2015-08-27 US US14/837,197 patent/US9904677B2/en not_active Expired - Fee Related
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH11250085A (ja) * | 1998-03-02 | 1999-09-17 | Nippon Telegr & Teleph Corp <Ntt> | 事象推移予測方法および事象推移予測プログラムを記録した記録媒体 |
Non-Patent Citations (3)
| Title |
|---|
| NATHANAEL CHAMBERS ET AL.: "Unsupervised Learning of Narrative Event Chains", PROCEEDINGS OF ACL/HLT 2008, 2008, pages 1 - 9, Retrieved from the Internet <URL:http://www.usna.edu/Users/cs/nchamber/pubs/ac108-narrative-chains.pdf> [retrieved on 20130326] * |
| NATHANAEL CHAMBERS ET AL.: "Unsupervised Learning of Narrative Schemas and their Participants", PROCEEDINGS OF ACL-IJCNLP 2009, 2009, pages 1 - 9, Retrieved from the Internet <URL:http://www.stanford.edu/~jurafsky/ac109-narrative-schema.pdf> [retrieved on 20130326] * |
| YUTA HAYASHIBE ET AL.: "Improving Japanese Inter-sentential Predicate Argument Structure Analysis with Contextual Information and Similarity between Case Structures", IPSJ SIG NOTES, vol. 2011 - N, no. 10, 15 June 2011 (2011-06-15), pages 1 - 8 * |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2020064370A (ja) * | 2018-10-15 | 2020-04-23 | 株式会社野村総合研究所 | 文章記号挿入装置及びその方法 |
| CN110399126A (zh) * | 2019-07-31 | 2019-11-01 | 北京百度网讯科技有限公司 | 用于生成脚本的方法和装置 |
| JP2020064630A (ja) * | 2019-10-11 | 2020-04-23 | 株式会社野村総合研究所 | 文章記号挿入装置及びその方法 |
| JP7229144B2 (ja) | 2019-10-11 | 2023-02-27 | 株式会社野村総合研究所 | 文章記号挿入装置及びその方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN105264518B (zh) | 2017-12-01 |
| US9904677B2 (en) | 2018-02-27 |
| US20160012040A1 (en) | 2016-01-14 |
| JP5945062B2 (ja) | 2016-07-05 |
| JPWO2014132402A1 (ja) | 2017-02-02 |
| CN105264518A (zh) | 2016-01-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5945062B2 (ja) | データ処理装置および物語モデル構築方法 | |
| Belinkov et al. | Arabic diacritization with recurrent neural networks | |
| CN109933780B (zh) | 使用深度学习技术确定文档中的上下文阅读顺序 | |
| Ghosh et al. | Fracking sarcasm using neural network | |
| Wadud et al. | Word embedding methods for word representation in deep learning for natural language processing | |
| Chandrasekaran et al. | Deep learning and TextBlob based sentiment analysis for coronavirus (COVID-19) using twitter data | |
| JP5389273B1 (ja) | 文脈解析装置および文脈解析方法 | |
| Bitvai et al. | Non-linear text regression with a deep convolutional neural network | |
| Spangher et al. | Newsedits: A news article revision dataset and a novel document-level reasoning challenge | |
| Moores et al. | A survey on automated sarcasm detection on Twitter | |
| CN116432646A (zh) | 预训练语言模型的训练方法、实体信息识别方法及装置 | |
| Kumaragurubaran et al. | Sentimental Analysis for Social Media Platform Based on Trend Analysis | |
| Gupta et al. | Multi-class railway complaints categorization using Neural Networks: RailNeural | |
| Lima et al. | A novel data and model centric artificial intelligence based approach in developing high-performance named entity recognition for bengali language | |
| CN111159405B (zh) | 基于背景知识的讽刺检测方法 | |
| Anam et al. | A deep learning approach for Named Entity Recognition in Urdu language | |
| Salsabiila et al. | Comparison of fasttext and word2vec weighting techniques for classification of multiclass emotions using the conv-LSTM method | |
| Suman et al. | Astartwice at semeval-2021 task 5: Toxic span detection using roberta-crf, domain specific pre-training and self-training | |
| CN115827884A (zh) | 文本处理方法、装置、电子设备、介质及程序产品 | |
| Oudah et al. | Person name recognition using the hybrid approach | |
| US11599580B2 (en) | Method and system to extract domain concepts to create domain dictionaries and ontologies | |
| KR102422844B1 (ko) | 인공지능에 기반하여 영상 컨텐츠의 언어 위기를 관리하는 방법 | |
| Prom et al. | A bilstm-based sentiment analysis scheme for khmer nlp in time-series data | |
| Yutika et al. | Aspect Extraction on Indonesia Beauty Product Review Using Pre-Trained Language Model | |
| CN116910237A (zh) | 文本处理方法、装置、电子设备及存储介质 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 201380073967.6 Country of ref document: CN |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 13876233 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2015502663 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 13876233 Country of ref document: EP Kind code of ref document: A1 |