WO2016152715A1 - 音制御装置、音制御方法、および音制御プログラム - Google Patents
音制御装置、音制御方法、および音制御プログラム Download PDFInfo
- Publication number
- WO2016152715A1 WO2016152715A1 PCT/JP2016/058490 JP2016058490W WO2016152715A1 WO 2016152715 A1 WO2016152715 A1 WO 2016152715A1 JP 2016058490 W JP2016058490 W JP 2016058490W WO 2016152715 A1 WO2016152715 A1 WO 2016152715A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- sound
- control
- key
- syllable
- control parameter
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images
















Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H1/00—Details of electrophonic musical instruments
- G10H1/02—Means for controlling the tone frequencies, e.g. attack or decay; Means for producing special musical effects, e.g. vibratos or glissandos
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H1/00—Details of electrophonic musical instruments
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H1/00—Details of electrophonic musical instruments
- G10H1/0008—Associated control or indicating means
- G10H1/0025—Automatic or semi-automatic music composition, e.g. producing random music, applying rules from music theory or modifying a musical piece
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/02—Methods for producing synthetic speech; Speech synthesisers
- G10L13/033—Voice editing, e.g. manipulating the voice of the synthesiser
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/08—Text analysis or generation of parameters for speech synthesis out of text, e.g. grapheme to phoneme translation, prosody generation or stress or intonation determination
- G10L13/10—Prosody rules derived from text; Stress or intonation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2210/00—Aspects or methods of musical processing having intrinsic musical character, i.e. involving musical theory or musical parameters or relying on musical knowledge, as applied in electrophonic musical tools or instruments
- G10H2210/155—Musical effects
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2210/00—Aspects or methods of musical processing having intrinsic musical character, i.e. involving musical theory or musical parameters or relying on musical knowledge, as applied in electrophonic musical tools or instruments
- G10H2210/155—Musical effects
- G10H2210/161—Note sequence effects, i.e. sensing, altering, controlling, processing or synthesising a note trigger selection or sequence, e.g. by altering trigger timing, triggered note values, adding improvisation or ornaments or also rapid repetition of the same note onset
- G10H2210/165—Humanizing effects, i.e. causing a performance to sound less machine-like, e.g. by slightly randomising pitch or tempo
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2220/00—Input/output interfacing specifically adapted for electrophonic musical tools or instruments
- G10H2220/005—Non-interactive screen display of musical or status data
- G10H2220/011—Lyrics displays, e.g. for karaoke applications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2250/00—Aspects of algorithms or signal processing methods without intrinsic musical character, yet specifically adapted for or used in electrophonic musical processing
- G10H2250/025—Envelope processing of music signals in, e.g. time domain, transform domain or cepstrum domain
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2250/00—Aspects of algorithms or signal processing methods without intrinsic musical character, yet specifically adapted for or used in electrophonic musical processing
- G10H2250/315—Sound category-dependent sound synthesis processes [Gensound] for musical use; Sound category-specific synthesis-controlling parameters or control means therefor
- G10H2250/455—Gensound singing voices, i.e. generation of human voices for musical applications, vocal singing sounds or intelligible words at a desired pitch or with desired vocal effects, e.g. by phoneme synthesis
Definitions
- the present invention relates to a sound control device, a sound control method, and a sound control program that can easily perform expressive sounds.
- This application claims priority based on Japanese Patent Application No. 2015-057946 for which it applied to Japan on March 20, 2015, and uses the content here.
- Patent Document 1 discloses a singing sound synthesizer that performs singing synthesis based on performance data input in real time.
- This singing sound synthesizer forms a singing synthesis score based on performance data received from a MIDI (musical instrument digital interface) device, and synthesizes a singing based on this score.
- the singing synthesis score includes a phonological track, a transition track, and a vibrato track. Volume control and vibrato control are performed according to the operation of the MIDI device.
- Non-Patent Document 1 discloses vocal track creation software that inputs notes and lyrics and sings the lyrics along the pitch of the notes.
- Non-Patent Document 1 describes that a large number of parameters for adjusting changes in voice expression and inflection, voice quality, and tone color are equipped, and fine nuances and intonation can be added to the singing voice.
- Non-Patent Document 1 When performing singing sound synthesis by real-time performance, there is a limit to the number of parameters that can be operated during performance. For this reason, there is a problem that it is difficult to control a large number of parameters as in the vocal track creation software described in Non-Patent Document 1 that is sung by reproducing previously input information.
- An example of an object of the present invention is to provide a sound control device, a sound control method, and a sound control program that can easily perform expressive sounds.
- a sound control device includes a reception unit that receives a start instruction indicating start of sound output, and a control parameter that determines the sound output mode in response to the reception of the start instruction. And a control unit that outputs the sound in a manner according to the read control parameter.
- the sound control method receives a start instruction indicating the start of sound output, reads a control parameter for determining the sound output mode in response to the reception of the start instruction, Outputting the sound in a manner according to the read control parameter.
- a sound control program receives a start instruction indicating start of sound output from a computer, and determines a sound output mode in response to the start instruction being received. And outputting the sound in a manner according to the read control parameter.
- sound is output in a sound generation mode according to the read control parameter in response to the start instruction. This makes it easy to perform expressive sounds.
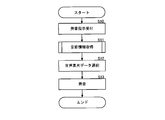
- FIG. 1 is a functional block diagram showing a hardware configuration of a sound producing device according to an embodiment of the present invention.
- a sound producing device 1 according to an embodiment of the present invention shown in FIG. 1 includes a CPU (Central Processing Unit) 10, a ROM (Read Only Memory) 11, a RAM (Random Access Memory) 12, a sound source 13, and a sound system 14.
- the sound control device may correspond to the sound generation device 1 (100, 200).
- Each of the reception unit, the reading unit, the control unit, the storage unit, and the operation element of the sound control device may correspond to at least one of these configurations of the sound generation device 1.
- the reception unit may correspond to at least one of the CPU 10 and the performance operator 16.
- the reading unit may correspond to the CPU 10.
- the control unit may correspond to at least one of the CPU 10, the sound source 13, and the sound system 14.
- the storage unit may correspond to the data memory 18.
- the operator may correspond to the performance operator 16.
- the CPU 10 is a central processing unit that controls the entire sounding device 1 according to the embodiment of the present invention.
- a ROM (Read Only Memory) 11 is a non-volatile memory in which a control program and various data are stored.
- the RAM 12 is a volatile memory used as a work area for the CPU 10 and various buffers.
- the data memory 18 stores syllable information including text data obtained by dividing lyrics into syllables, and a phonological database that stores speech segment data of singing sounds.
- the display unit 15 is a display unit including a liquid crystal display or the like on which an operation state, various setting screens, a message for the user, and the like are displayed.
- the performance operator 16 is a performance operator composed of a keyboard (see part (c) in FIG. 7) having a plurality of keys corresponding to different pitches.
- the performance operator 16 generates performance information such as key-on, key-off, pitch, and velocity.
- the performance operator may be referred to as a key.
- This performance information may be MIDI message performance information.
- the setting operator 17 is various setting operators such as operation knobs and operation buttons for setting the sounding device 1.
- the sound source 13 has a plurality of sound generation channels.
- One tone generation channel is assigned to the sound source 13 according to real-time performance using the user's performance operator 16 under the control of the CPU 10.
- the sound source 13 reads out the speech segment data corresponding to the performance from the data memory 18 in the assigned sound generation channel and generates singing sound data.
- the sound system 14 converts the singing sound data generated by the sound source 13 into an analog signal using a digital / analog converter, amplifies the singing sound converted into an analog signal, and outputs the amplified singing sound to a speaker or the like.
- the bus 19 is a bus for performing data transfer between each unit in the sound generator 1.
- FIG. 2A shows an explanatory diagram of the sound generation acceptance process in the key-on process.
- FIG. 3B shows an explanatory diagram of the syllable information acquisition process.
- FIG. 3C shows an explanatory diagram of the speech segment data selection process.
- FIG. 4 is a timing chart showing the operation of the sounding device 1 of the first embodiment.
- FIG. 5 shows a flowchart of key-off processing executed when the performance operator 16 is key-off in the sound producing device 1 of the first embodiment.
- the performance operator 16 is operated to perform the performance.
- the performance operator 16 may be a keyboard or the like.
- the CPU 10 detects that the performance operator 16 has been keyed on as the performance progresses, the key-on process shown in FIG. 2A is started.
- the CPU 10 executes the sound generation instruction acceptance process in step S10 and the syllable information acquisition process in step S11 in the key-on process.
- the sound source 13 is executed under the control of the CPU 10 in the speech segment data selection process in step S12 and the sound generation process in step S13.
- step S10 of the key-on process a sound generation instruction (an example of a start instruction) based on the key-on of the operated performance operator 16 is received.
- the CPU 10 receives performance information such as key-on timing, pitch information of the operated performance operator 16 and velocity.
- performance information such as key-on timing, pitch information of the operated performance operator 16 and velocity.
- step S11 a syllable information acquisition process for acquiring syllable information corresponding to key-on is performed.
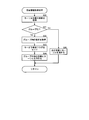
- FIG. 2B is a flowchart showing details of the syllable information acquisition process.
- the syllable information acquisition process is executed by the CPU 10.
- step S20 the CPU 10 acquires the syllable at the cursor position.
- specific lyrics are designated prior to the user's performance.
- the specific lyrics are, for example, lyrics corresponding to the score shown in FIG. 3A and stored in the data memory 18.
- a cursor is placed on the first syllable of the text data. This text data is data obtained by dividing designated lyrics into syllables.
- the text data 30 is text data corresponding to lyrics designated corresponding to the score shown in FIG. 3A.
- the text data 30 includes the syllables c1 to c42 shown in FIG. 3B, ie, “ha (ha)”, “ru (ru)”, “yo (yo)”, “ko (ko)”, “i ( i) "text data consisting of five syllables.
- “ha (ha)”, “ru (ru)”, “yo (yo)”, “ko (ko)”, and “i (i)” each indicate a Japanese hiragana character, It is an example.
- the syllables “ha (ha)”, “ru (ru)”, and “yo (yo)” of c1 to c3 are independent of each other.
- the syllables “ko (ko)” and “i (i)” of c41 and c42 are grouped.
- Information indicating whether or not grouping is performed is grouping information (an example of setting information) 31.
- the grouping information 31 is embedded in each syllable or is associated with each syllable.
- the symbol “x” represents that the group is not grouped, and the symbol “ ⁇ ” represents that the group is grouped.
- the grouping information 31 may be stored in the data memory 18. As shown in FIG.
- the CPU 10 when receiving a sound generation instruction for the first key-on n 1, the CPU 10 reads “ha (ha)” that is the first syllable c 1 of the designated lyrics from the data memory 18. At this time, the CPU 10 also reads out the grouping information 31 embedded or associated with “ha (ha)” from the data memory 18. Next, the CPU 10 determines whether or not the syllables acquired in step S21 are grouped from the acquired syllable grouping information 31. When the syllable acquired in step S20 is “ha (ha)” of c1, since the grouping information 31 is “x”, it is determined that the syllable is not grouped, and the process proceeds to step S25.
- step S25 the CPU 10 advances the cursor to the next syllable of the text data 30, and places the cursor on "ru" of the second syllable c2.
- step S25 ends, the syllable information acquisition process ends, and the process returns to step S12 of the key-on process.
- FIG. 3C is a diagram for explaining the speech segment data selection process in step S12.
- the speech segment data selection process in step S12 is a process performed by the sound source 13 under the control of the CPU 10.
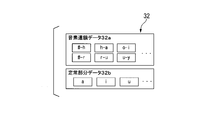
- the sound source 13 selects speech segment data for generating the acquired syllable from the phoneme database 32.
- the phoneme database 32 stores “phoneme chain data 32a” and “steady part data 32b”.
- the phoneme chain data 32a is data of phonemes when the pronunciation changes, corresponding to “silence (#) to consonant”, “consonant to vowel”, “vowel to (consonant or vowel of the next syllable)”, etc. is there.
- the stationary part data 32b is phoneme piece data when the vowel sound continues.
- the sound source 13 When the syllable acquired in response to receiving the pronunciation instruction of the first key-on n1 is “ha (ha)” of c1, the sound source 13 generates a speech unit corresponding to “silence ⁇ consonant h” from the phoneme chain data 32a. The speech unit data “ha” corresponding to the data “# -h” and “consonant h ⁇ vowel a” is selected, and the speech unit data “a” corresponding to “vowel a” from the steady part data 32b. Select. Next, in step S13, the sound source 13 performs a sound generation process based on the speech segment data selected in step S12 under the control of the CPU 10.
- the pronunciation of the speech unit data “# -h” ⁇ “ha” ⁇ “a” is sequentially generated in the sound generation process in step S13. 13.
- the pronunciation of “ha (ha)” in the syllable c1 is performed.
- the singing sound of “ha (ha)” is produced at the volume corresponding to the velocity information at the pitch of E5 received at the time of accepting the pronunciation instruction of the key-on n1.
- the key-on process also ends.
- FIG. 4 shows the operation of this key-on process.
- Part (a) of FIG. 4 shows an operation of pressing a key.
- Part (b) of FIG. 4 shows the content of pronunciation.
- Part (c) of FIG. 4 shows a speech unit.
- the CPU 10 receives a sound generation instruction for the first key-on n1 at time t1 (step S10).
- the CPU 10 acquires the first syllable c1 and determines that the syllable c1 is not grouped with another syllable (step S11).
- the sound source 13 selects speech segment data “# -h”, “ha”, and “a” that generate the syllable c1 (step S12).
- the envelope ENV1 having a volume corresponding to the velocity information of the key-on n1 is started, and the speech unit data “# -h” ⁇ “ha” ⁇ “a” is converted into the pitch of the E5 and the envelope ENV1.
- a sound is produced at a volume (step S13).
- the envelope ENV1 is a continuous sound envelope in which sustain continues until the key-on n1 is turned off.
- the speech unit data “a” is repeatedly reproduced until the key on key n1 is keyed off at time t2.
- the CPU 10 detects that the key is turned off at time t2 an example of a stop instruction
- the key-off process shown in FIG. 5 is started.
- the CPU 10 executes steps S30 and S33 of the key-off process.
- the processing of step S31 and step S32 is executed by the sound source 13 under the control of the CPU 10.
- step S30 it is determined in step S30 whether or not the key-off sound generation flag is on.
- the key-off pronunciation flag is set when the acquired syllables are grouped. In the syllable information acquisition process shown in FIG. 2A, the first syllable c1 is not grouped. Therefore, the CPU 10 determines that the key-off sound generation flag has not been set (No in step S30), and the process proceeds to step S34.
- step S34 the sound source 13 performs a mute process under the control of the CPU 10, and as a result, the pronunciation of the singing sound “ha (ha)” is stopped. That is, the singing sound “ha (ha)” is muted on the release curve of the envelope ENV1.
- step S10 When the performance operator 16 is operated as the real-time performance progresses and the second key-on n2 is detected, the above-described key-on process is restarted and the above-described key-on process is performed.
- the sound generation instruction receiving process in step S10 in the second key-on process will be described.
- the CPU 10 when receiving a sound generation instruction based on the key-on n2 of the operated performance operator 16, the CPU 10 receives velocity information corresponding to the timing of the key-on n2, the pitch information indicating the pitch of E5, and the key speed.
- the CPU 10 reads from the data memory 18 “ru” which is the second syllable c2 where the cursor of the designated lyrics is placed.
- the grouping information 31 of the acquired syllable “ru” is “ ⁇ ”. For this reason, the CPU 10 determines that it is not grouped, and advances the cursor to “yo” of c3 of the third syllable.
- the sound source 13 uses the speech unit data “# -r” corresponding to “silence ⁇ consonant r” and the speech corresponding to “consonant r ⁇ vowel u” from the phoneme chain data 32a.
- the unit data “ru” is selected, and the speech unit data “u” corresponding to the “vowel u” is selected from the steady part data 32b.
- step S13 the sound source data of ““ # ⁇ r ” ⁇ “ r ⁇ u ” ⁇ “ u ”” is sequentially generated in the sound source 13 under the control of the CPU 10. As a result, the syllable of “ru” in c2 is generated, and the key-on process ends.
- step S10 in the third key-on process will be described.
- the CPU 10 when receiving a sound generation instruction based on the key-on n3 of the operated performance operator 16, the CPU 10 receives the timing information of the key-on n3, pitch information indicating the pitch of D5, and velocity information according to the key speed.
- the CPU 10 reads from the data memory 18 “yo” which is the third syllable c3 on which the cursor of the designated lyrics is placed.
- the grouping information 31 of the acquired syllable “yo” is “x”. Therefore, the CPU 10 determines that the group is not grouped, and advances the cursor to “ko” of c41 of the fourth syllable.
- the speech segment data selection process in step S12 the sound source 13 corresponds to speech segment data “uy” and “consonant y ⁇ vowel o” corresponding to “vowel u ⁇ consonant y” from the phoneme chain data 32a.
- the speech segment data “yo” is selected, and the speech segment data “o” corresponding to “vowel o” is selected from the steady portion data 32b.
- the third key-on n3 is legato and is smoothly connected from “ru” to “yo” for sound generation.
- the sound source data ““ u ⁇ y ” ⁇ “ yo ” ⁇ “ o ”” is sequentially generated by the sound source 13 under the control of the CPU 10.
- the pronunciation of the syllable of “yo” of c3 smoothly connected from “ru” of c2 is performed, and the key-on process ends.
- FIG. 4 shows the second and third key-on processing operations.
- the CPU 10 receives a second key-on n2 sounding instruction at time t3 (step S10).
- the CPU 10 acquires the next syllable c2, and determines that the syllable c2 is not grouped with another syllable (step S11).
- the sound source 13 selects speech segment data “# -r”, “ru”, “u” that pronounces the syllable c2 (step S12).
- the sound source 13 starts the envelope ENV2 having a volume corresponding to the velocity information of the key-on n2, and converts the voice element data “# -r” ⁇ “ru” ⁇ “u” into the pitch of the E5 and the envelope ENV2.
- Step S13 Thereby, the singing sound of “ru” is generated.
- the envelope ENV2 is the same as the envelope ENV1.
- the speech unit data “u” is reproduced repeatedly.
- the third key-on n3 sounding instruction is accepted at time t4 before the key applied to key-on n2 is keyed off (step S10).
- the CPU 10 acquires the next syllable c3, and determines that the syllable c3 is not grouped with another syllable (step S11).
- step S11 since the third key-on n3 is legato, the CPU 10 starts the key-off process shown in FIG.
- step S30 of the key-off process the second syllable c2 “ru” is not grouped. Therefore, the CPU 10 determines that the key-off sound generation flag has not been set (No in step S30), and the process proceeds to step S34.
- step S34 the pronunciation of the “ru” singing sound is stopped.
- the key-off process ends. This is due to the following reason. In other words, one channel is prepared for the sound channel for singing sound, and two singing sounds cannot be generated simultaneously.
- the sound source 13 selects speech segment data “u-y”, “yo”, “o” that pronounces “yo”, which is the syllable c3 (step S12), and starts from time t4.
- ““ U ⁇ y ” ⁇ “ yo ” ⁇ “ o ”” is generated with the pitch of D5 and the sustain volume of envelope ENV2 (step S13).
- the singing sound is smoothly connected and pronounced from “ru” to “yo”.
- the key of key-on n2 is keyed off at time t5
- the processing of the singing sound based on key-on n2 has already been stopped, and no processing is performed.
- step S30 of the key-off process the CPU 10 determines that the key-off sound generation flag is not set (No in step S30), and the process proceeds to step S34.
- step S34 the sound source 13 performs a mute process, and the sound of the “yo” singing sound is stopped. That is, the singing sound of “yo” is muted by the release curve of the envelope ENV2.
- step S10 in the fourth key-on process When the performance operator 16 is operated as the real-time performance progresses and the fourth key-on n4 is detected, the above-described key-on process is restarted and the above-described key-on process is performed.
- the sound generation instruction receiving process in step S10 in the fourth key-on process will be described.
- the CPU 10 when receiving a sound generation instruction based on the fourth key-on n4 of the operated performance operator 16, the CPU 10 receives the pitch information indicating the timing of the key-on n4, the pitch of E5, and the velocity information according to the key speed. Receive.
- step S11 the CPU 10 reads from the data memory 18 "ko", which is the fourth syllable c41 on which the cursor of the designated lyrics is placed (step S20).
- the grouping information 31 of the acquired syllable “ko” is “ ⁇ ”. For this reason, the CPU 10 determines that the syllable c41 is grouped with another syllable (step S21), and proceeds to step S22.
- step S22 syllables belonging to the same group (syllables in the group) are acquired.
- the CPU 10 since “ko (ko)” and “i (i)” are grouped, the CPU 10 stores the syllable c42 “i (i)” that belongs to the same group as the syllable c41 in the data memory 18. Read from. Next, the CPU 10 sets a key-off sound generation flag in step S23, and prepares to sound the next syllable "I (i)" belonging to the same group when the key is turned off. In the next step S24, the CPU 10 moves the cursor of the text data 30 to the next syllable beyond the group to which “ko (ko)” and “i (i)” belong. However, in the illustrated example, this process is skipped because there is no next syllable. When the process of step S24 ends, the syllable information acquisition process ends, and the process returns to step S12 of the key-on process.
- the sound source 13 selects speech segment data corresponding to the syllables “ko (ko)” and “i (i)” belonging to the same group. That is, the sound source 13 uses the speech unit data “# -k” and “consonant k ⁇ corresponding to“ silence ⁇ consonant k ”from the phoneme chain data 32 a as speech unit data corresponding to the syllable“ ko ”. The speech segment data “ko” corresponding to the vowel o is selected, and the speech segment data “o” corresponding to the “vowel o” is selected from the steady portion data 32b.
- the sound source 13 selects the speech unit data “oi” corresponding to “vowel o ⁇ vowel i” from the phoneme chain data 32 a as speech unit data corresponding to the syllable “i (i)”. Then, speech unit data “i” corresponding to “vowel i” is selected from the steady part data 32b.
- the first syllable is pronounced among the syllables belonging to the same group. That is, the sound source 13 sequentially generates the speech unit data “# -k” ⁇ “ko” ⁇ “o” under the control of the CPU 10. As a result, “ko” that is the syllable c41 is pronounced.
- the singing sound of “ko” is generated at the volume corresponding to the velocity information at the pitch of E5 received at the time of receiving the sound generation instruction of key-on n4.
- the key-on process also ends.
- FIG. 4 shows the operation of this key-on process.
- the CPU 10 accepts the fourth key-on n4 sounding instruction at time t7 (step S10).
- the CPU 10 acquires the fourth syllable c41 (and grouping information 31 embedded or associated with the syllable c41). Based on the grouping information 31, the CPU 10 determines that the syllable c41 is grouped with another syllable.
- the CPU 10 acquires a syllable c42 belonging to the same group as the syllable c41 and sets a key-off sounding flag (step S11).
- the sound source 13 selects speech segment data “# -k”, “ko”, “o” and speech segment data “oi”, “i” that pronounce the syllables c41, c42 (Ste S12). Then, the sound source 13 starts the envelope ENV3 having a volume corresponding to the velocity information of the key-on n4, and converts the speech unit data “#k” ⁇ “ko” ⁇ “o” into the pitch of E5 and The sound is generated at the volume level of the envelope ENV3 (step S13). Thereby, the singing sound of “ko” is generated.
- the envelope ENV3 is the same as the envelope ENV1.
- the voice segment data “o” is repeatedly reproduced until the key applied to key-on n4 is key-off at time t8.
- the CPU 10 detects that the key-on n4 is keyed off at time t8, the CPU 10 starts the key-off process shown in FIG.
- step S30 of the key-off process the CPU 10 determines that the key-off sound generation flag is set (Yes in step S30), and the process proceeds to step S31.
- step S31 the sound generation process for the next syllable belonging to the same group as the previously pronounced syllable is performed. That is, the sound source 13 selects the sound ““ oi ” ⁇ “ i ”” selected as the speech segment data corresponding to the syllable “i (i)” in the syllable information acquisition process performed in step S12.
- the segment data is sounded with the pitch of E5 and the volume of the envelope ENV3 release curve.
- the singing sound of “i (i)” that is the syllable c42 is generated with the same pitch E5 as “ko” of c41.
- a mute process is performed in step S32, and the pronunciation of the singing sound “I (i)” is stopped. That is, the singing sound “I (i)” is muted by the release curve of the envelope ENV3.
- the pronunciation of “ko (ko)” is stopped when the pronunciation shifts to “i (i)”.
- step S33 the key-off sound generation flag is reset and the key-off process ends.
- a singing voice that is a singing sound corresponding to a user's real-time performance is generated and an operation of pressing a key once during real-time performance is performed.
- a plurality of singing voices can be pronounced by (that is, performing a single continuous operation from pressing a key to releasing it, and so on). That is, in the sounding device 1 of the first embodiment, the grouped syllables are a set of syllables that are sounded by pressing the key once. For example, the grouped syllables c41 and c42 are pronounced by pressing the key once.
- the first syllable sound is output in response to pressing the key
- the second and subsequent syllable sounds are output in response to moving away from the key.
- the grouping information is information that determines whether or not the next syllable is pronounced by key-off, it can be referred to as “key-off pronunciation information (setting information)”.
- key-on referred to as key-on n5
- key-on n5 is sounded after the key-off process for the key-on n4 is performed.
- step S31 may be omitted in the key-off process of the key-on n4 that is executed in response to the operation of the key-on n5.
- the syllable of c42 is not pronounced, and the syllable next to c42 is pronounced immediately in response to key-on n5.
- FIGS. 6A to 6C show another example of the key-off process that can sufficiently lengthen the pronunciation of the next syllable belonging to the same group.
- the attenuation start is delayed by a predetermined time td from the key-off.
- the release length of the next syllable belonging to the same group can be made sufficiently long by delaying the release curve R1 by the time td like the release curve R2 indicated by the alternate long and short dash line.
- the pronunciation length of the next syllable belonging to the same group can be made sufficiently long. That is, in the example shown in FIG. 6A, the sound source 13 outputs the sound of the syllable c41 at a constant volume in the second half of the envelope ENV3. Next, the sound source 13 starts outputting the sound of the syllable c42 continuously after the output of the sound of the syllable c41 is stopped.
- the volume of the sound of syllable c42 is the same as the volume immediately before mute of syllable c41.
- the sound source 13 starts decreasing the sound volume of the syllable c42 after maintaining the sound volume for a predetermined time td.
- the envelope ENV3 is slowly attenuated. That is, by generating the release curve R3 in which the slope of the release curve indicated by the alternate long and short dash line is relaxed, the pronunciation length of the next syllable belonging to the same group can be made sufficiently long. That is, in the example shown in FIG.
- the sound source 13 attenuates slower than the sound volume attenuation rate of the sound of the syllable c41 when the sound of the syllable c42 is not output (when the syllable c41 is not grouped with other syllables).
- the sound of the syllable c42 is output while decreasing the volume of the sound of the syllable c42 at a speed.
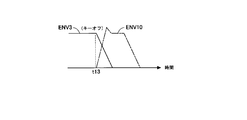
- the key-off is regarded as a new note-on instruction, and the next syllable is generated with a new note having the same pitch.
- the envelope ENV10 is started at the key-off time t13, and the next syllable belonging to the same group is pronounced.
- the pronunciation length of the next syllable belonging to the same group can be made sufficiently long. That is, in the example shown in FIG. 6C, the sound source 13 starts to output the sound of the syllable c42 at the same time as the sound volume of the syllable c41 is started to decrease. At this time, the sound source 13 outputs the sound of the syllable c42 while increasing the volume of the sound of the syllable c42.
- the lyrics are in Japanese is illustrated.
- a syllable sound of “sep” is output at the pitch of the key.
- the syllable “tem” is pronounced at the pitch of the key in response to the operation of moving away from the key.
- the lyrics are not limited to Japanese, but may be other languages.
- the sound generation device of the second embodiment generates a predetermined sound without lyrics such as a humming sound, a singing sound such as scat, chorus, or a normal instrument sound or a sound effect such as a bird singing or a telephone bell.
- the sounding device of the second embodiment is referred to as a sounding device 100.
- the configuration of the sound producing device 100 of the second embodiment is substantially the same as that of the sound producing device 1 of the first embodiment. However, the second embodiment is different from the first embodiment in the configuration of the sound source 13.
- FIG. 7 is a diagram for explaining an operation example of the sound producing device 100 according to the second embodiment.
- key-off sound generation information 40 is stored in the data memory 18 instead of the syllable information including the text data 30 and the grouping information 31.
- the sound producing device 100 according to the second embodiment causes a predetermined sound without lyrics to be produced when the user performs a real-time performance using the performance operator 16.
- key-off sounding information processing is performed in place of the syllable information acquisition processing shown in FIG. 2B in step S11 of the key-on processing shown in FIG. 2A.
- the speech segment data selection process in step S12, a sound source waveform and speech segment data for generating a predetermined sound or speech are selected. The operation will be described below.
- the CPU 10 starts the key-on process shown in FIG. 2A when detecting that the performance operator 16 has been key-on by performing a real-time performance by the user.
- a case will be described in which the user plays the musical piece of the score shown in part (a) of FIG.
- the CPU 10 receives a sound generation instruction for the first key-on n1 in step S10, and receives pitch information indicating the pitch of E5 and velocity information corresponding to the key speed.
- the CPU 10 acquires key-off sound generation information corresponding to the first key-on n1 with reference to the key-off sound generation information 40 shown in the part (b) of FIG. In this case, specific key-off pronunciation information 40 is designated prior to the user's performance.
- This specific key-off pronunciation information 40 corresponds to the score shown in part (a) of FIG. 7 and is stored in the data memory 18. Also, the first key-off pronunciation information of the designated key-off pronunciation information 40 is referred to. Since the first key-off pronunciation information is “x”, the key-off pronunciation flag is not set for key-on n1.
- the sound source 13 performs a speech segment data selection process. That is, the sound source 13 selects speech segment data for generating a predetermined speech. As a specific example, a case where the sound of “na” is pronounced will be described. In the following, “na” indicates one character of Japanese katakana.
- the sound source 13 selects the speech unit data “#n” and “na” from the phoneme chain data 32a, and selects the speech unit data “a” from the stationary partial data 32b.
- step S13 a sound generation process corresponding to the key-on n1 is performed.
- the sound source 13 uses the pitch of E5 received when the key-on n1 is detected, and ““ # ⁇ n ” ⁇ “ The speech unit data “na” ⁇ “a” ”is pronounced. As a result, the singing sound of “na” is produced. This sound generation is continued until the key-on n1 is keyed off. When the key-on is turned off, the sound is muted and stopped.
- the CPU 10 detects key-on n2 as the real-time performance progresses, the same processing as described above is performed. Since the second key-off sound generation information corresponding to key-on n2 is “x”, the key-off sound flag for key-on n2 is not set. As shown in part (c) of FIG. 7, a predetermined voice is generated with a pitch of E5, for example, a singing sound of “na”. If the key-on n3 is detected before the key-on n2 is keyed off, the same processing as described above is performed. Since the third key-off sound generation information corresponding to key-on n3 is “x”, the key-off sound flag for key-on n3 is not set. As shown in part (c) of FIG.
- a predetermined voice is generated with a pitch of D5, for example, a singing sound of “na”.
- the pronunciation corresponding to the key-on n3 is a legato smoothly connected to the pronunciation corresponding to the key-on n2.
- the sound generation corresponding to the key-on n2 is stopped simultaneously with the start of the sound generation corresponding to the key-on n3. Further, when the key of key-on n3 is keyed off, the sound corresponding to key-on n3 is muted and stopped.
- the CPU 10 detects the key-on n4 as the performance further progresses, the same processing as described above is performed. Since the fourth key-off sound generation information corresponding to key-on n4 is “ ⁇ ”, the key-off sound flag for key-on n4 is set. As shown in part (c) of FIG. 7, a predetermined voice is generated with a pitch of E5, for example, a singing sound of “na”. When the key-on n4 is keyed off, the sound corresponding to the key-on n2 is muted and stopped. However, since the key-off sound generation flag is set, the CPU 10 determines that the key-on n4 ′ shown in part (c) of FIG.
- the sound source 13 determines the sound generation corresponding to the key-on n4 ′ as the key-on n4. Perform at the same pitch. That is, a predetermined voice with a pitch of E5, for example, a singing sound of “na” is generated when the key of key-on n4 is keyed off. In this case, the pronunciation length corresponding to the key-on n4 'is a predetermined length.
- the syllable of the text data 30 is changed every time the performance operator 16 is pressed. A sound is produced at the pitch of the performance operator 16.
- the text data 30 is text data obtained by dividing designated lyrics into syllables. Thereby, the lyrics designated at the time of real-time performance are sung. By grouping the syllables of the lyrics to be sung, the first syllable and the second syllable can be generated at the pitch of the performance operator 16 by one continuous operation on the performance operator 16.
- the first syllable is generated with the pitch applied to the performance operator 16.
- the second syllable is generated at the pitch applied to the performance operator 16 in accordance with the operation of moving away from the performance operator 16.
- a predetermined sound without the above-mentioned lyrics can be generated with the pitch of the depressed key instead of the singing sound based on the lyrics. Therefore, the sound producing device 100 according to the second embodiment can be applied to a karaoke guide or the like. In this case as well, a predetermined sound without lyrics is included depending on the operation of pressing the performance operator 16 and the operation of leaving the performance operator 16 included in one continuous operation on the performance operator 16. Can be pronounced.
- the sounding device 200 according to the third embodiment of the present invention when the user performs a real-time performance using the performance operator 16 such as a keyboard, it is possible to perform a singing voice with rich expression.
- the hardware configuration of the sound producing device 200 of the third embodiment is the same as the configuration shown in FIG.
- the key-on process shown in FIG. 2A is executed as in the first embodiment.
- the contents of the syllable information acquisition process in step S11 in this key-on process are different from those in the first embodiment.
- the flowchart shown in FIG. 8 is executed as the syllable information acquisition process in step S11.
- FIG. 8 the flowchart shown in FIG. 8 is executed as the syllable information acquisition process in step S11.
- FIG. 9A is a diagram for explaining a sound generation instruction receiving process executed by the sound generation apparatus 200 of the third embodiment.
- FIG. 9B is a diagram for explaining syllable information acquisition processing executed by the sound producing device 200 of the third embodiment.
- FIG. 10 shows “value v1” to “value v3” in the lyrics information table.
- FIG. 11 shows an operation example of the sound producing device 200 of the third embodiment.
- the sounding device 200 of the third embodiment will be described with reference to these drawings.
- the performance operator 16 is operated to perform the performance.
- the performance operator 16 is a keyboard or the like.
- the key-on process shown in FIG. 2A is started.
- the CPU 10 executes the sound generation instruction reception process in step S10 and the syllable information acquisition process in step S11 of the key-on process.
- the sound source 13 is executed under the control of the CPU 10 in the speech segment data selection process in step S12 and the sound generation process in step S13.
- step S10 of the key-on process a sound generation instruction based on the key-on of the operated performance operator 16 is accepted.
- the CPU 10 receives performance information such as key-on timing, pitch information of the operated performance operator 16 and velocity.
- performance information such as key-on timing, pitch information of the operated performance operator 16 and velocity.
- the CPU 10 receives pitch information indicating the pitch of E5 and velocity information corresponding to the key speed.
- step S11 syllable information acquisition processing for acquiring syllable information corresponding to key-on n1 is performed.
- FIG. 8 shows a flowchart of this syllable information acquisition process.
- the CPU 10 acquires the syllable at the cursor position in step S40.
- the lyrics information table 50 is designated prior to the user's performance.
- the lyric information table 50 is stored in the data memory 18.
- the lyrics information table 50 includes text data in which lyrics corresponding to a score corresponding to a performance are divided into syllables.
- the lyrics are lyrics corresponding to the score shown in FIG. 9A.
- the cursor is placed on the first syllable of the text data in the designated lyrics information table 50.
- step S ⁇ b> 41 the CPU 10 acquires a pronunciation control parameter (an example of a control parameter) associated with the syllable of the acquired first text data with reference to the lyrics information table 50.
- FIG. 9B shows a lyrics information table 50 corresponding to the score shown in FIG. 9A.
- the lyrics information table 50 is a characteristic configuration. As shown in FIG. 9B, the lyrics information table 50 includes syllable information 50a, a pronunciation control parameter type 50b, and value information 50c of the pronunciation control parameter.
- the syllable information 50a includes text data in which lyrics are divided into syllables.
- the sound generation control parameter type 50b designates one of various parameter types.
- the sound generation control parameters include a sound generation control parameter type 50b and sound generation control parameter value information 50c.
- the syllable information 50a is composed of syllables obtained by dividing the lyrics of c1, c2, c3, and c41, similar to the text data 30 shown in FIG.
- the sound generation control parameter type 50b one or a plurality of parameters a, b, c, and d are set for each syllable.
- Specific examples of the pronunciation control parameter type are “Harmonics”, “Brightness”, “Resonance”, and “GenderFactor”.
- “Harmonics” is a type parameter that changes the balance of overtone components contained in the voice.
- “Brightness” is a parameter of a type that produces a tone change by producing the contrast of a voice.
- “Resonance” is a type parameter that produces the tone and strength of voiced sound.
- “GenderFactor” is a parameter of a type that changes the thickness and texture of feminine or masculine voice by changing the formant.
- the value information 50c is information for setting the value of the sound generation control parameter, and includes “value v1”, “value v2”, and “value v3”.
- “Value v1” sets how the sound generation control parameter changes over time, and can be represented by a graph shape (waveform).
- Part (a) of FIG. 10 shows an example of “value v1” expressed in a graph shape.
- Part (a) of FIG. 10 shows graph shapes w1 to w6 as “value v1”. Each of the graph shapes w1 to w6 changes over time.
- the “value v1” is not limited to the graph shapes w1 to w6. As “value v1”, it is possible to set a graph shape (value) that changes over time.
- the “value v2” is a value for setting the time on the horizontal axis of the “value v1” shown in the graph shape as shown in the part (b) of FIG. By setting “value v2”, it is possible to set the speed of change that is the time from the start of the effect to the end of the effect.
- the “value v3” is a value for setting the vertical axis amplitude of the “value v1” shown in the graph shape as shown in the part (b) of FIG. By setting “value v3”, the depth of change indicating the degree of effect can be set.
- the settable range of the value of the sound generation control parameter set by the value information 50c differs depending on the sound generation control parameter type.
- the syllable specified by the syllable information 50a may include a syllable for which the pronunciation control parameter type 50b and its value information 50c are not set.
- the pronunciation control parameter type 50b and its value information 50c are not set in the syllable c3 shown in FIG.
- the syllable information 50a, the pronunciation control parameter type 50b, and the value information 50c in the lyrics information table 50 are created and / or edited prior to the user's performance and stored in the data memory 18.
- step S41 the CPU 10 acquires the syllable of c1 in step S40. Therefore, in step S41, the CPU 10 acquires the pronunciation control parameter type and the value information 50c associated with the syllable c1 from the lyrics information table 50. That is, the CPU 10 acquires the parameters a and b set in the row next to c1 of the syllable information 50a as the pronunciation control parameter type 50b, and the “value v1” to “value” whose detailed information is not shown. v3 "is acquired as the value information 50c.
- step S41 ends, the process proceeds to step S42.
- step S42 the CPU 10 advances the cursor to the next syllable of the text data, so that the cursor is placed at c2 of the second syllable.
- the syllable information acquisition process ends, and the process returns to step S12 of the key-on process.
- the speech segment data for generating the acquired syllable c1 is selected from the phonological database 32.
- the sound source 13 sequentially generates sound of the selected speech segment data. As a result, the syllable c1 is pronounced.
- the singing sound of syllable c1 is generated at a volume corresponding to the pitch of E5 and velocity information received at the time of reception of key-on n1.
- the key-on process also ends.
- Part (c) of FIG. 11 shows a piano roll score 52.
- the sound source 13 performs sound generation of the selected speech segment data with the pitch of E5 received when key-on n1 is detected.
- the singing sound of syllable c1 is generated.
- the parameter a set with “value v1”, “value v2”, and “value v3” is different from the parameter b set with “value v1”, “value v2”, and “value v3”.
- the sound generation control of the singing sound is performed by two sound generation control parameter types, that is, two different modes. Therefore, the expression, intonation, voice quality and tone of the singing voice can be changed, and the singing voice can be given detailed nuances and intonation.
- the CPU 10 detects the key-on n2 as the real-time performance progresses, the same processing as described above is performed, and the second syllable c2 corresponding to the key-on n2 is pronounced with a pitch of E5.
- the syllable c2 is associated with the three sound generation control parameter types of parameter b, parameter c, and parameter d as the sound generation control parameter type 50b.
- the type is set by “value v1”, “value v2”, and “value v3”. For this reason, when the syllable c2 is pronounced, as shown by the piano roll score 52 in part (c) of FIG.
- the pronunciation of the singing sound is generated by three pronunciation control parameter types having different parameters b, c and d. Control is performed. Thereby, a change can be given to the expression, intonation, voice quality and tone of the singing voice.
- the CPU 10 detects the key-on n3 as the real-time performance progresses, the same processing as described above is performed, and the third syllable c3 corresponding to the key-on n3 is pronounced with a pitch of D5.
- the sound generation control parameter type 50b is not set for the syllable c3. For this reason, when the syllable c3 is sounded, as shown by the piano roll score 52 in part (c) of FIG.
- the CPU 10 detects the key-on n4 as the real-time performance progresses, the same processing as described above is performed, and the fourth syllable c41 corresponding to the key-on n4 is pronounced with a pitch of E5.
- sounding control according to the sounding control parameter type 50b (not shown) and value information 50c (not shown) associated with the syllable c41 is performed.
- the syllable of the text data designated every time the user performs a pressing operation of the performance operator 16 when the user performs a real-time performance using the performance operator 16 such as a keyboard.
- the grouped syllables can be generated at the pitch of the performance operator 16 by one continuous operation on the performance operator 16. That is, when the performance operator 16 is pressed, the first syllable is generated at the pitch of the performance operator 16. Further, the second syllable is generated at the pitch of the performance operator 16 according to the operation of moving away from the performance operator 16. At this time, sound generation control is performed using a sound generation control parameter associated with each syllable. For this reason, it is possible to change the expression, intonation, voice quality and tone of the singing voice, and to add fine nuances and intonation to the singing voice.
- the sounding device 200 of the third embodiment can sound a predetermined sound without the above-mentioned lyrics that is sounded by the sounding device 100 of the second embodiment.
- the number of key pressing operations is not determined based on the syllable information, but rather the sound generation control parameter to be acquired is determined.
- the sound generation control parameter to be acquired may be determined according to the above.
- the pitch is specified according to the operated performance operator 16 (key pressed). Alternatively, the pitch may be specified according to the order in which the performance operator 16 is operated.
- a first modification of the third embodiment will be described. In this modification, the data memory 18 stores a lyrics information table 50 shown in FIG.
- the lyrics information table 50 includes a plurality of control parameter information (an example of control parameters), that is, first to nth control parameter information.
- the first control parameter information includes a combination of parameter a and values v1 to v3, and a combination of parameter b and values v1 to v3.
- the plurality of control parameter information are associated with each other in different orders.
- the first control parameter information is associated with the first order.
- the second control parameter information is associated with the second order.
- the CPU 10 when detecting the n-th (n-th) key-on, the CPU 10 reads out the pronunciation control parameter information associated with the n-th control parameter information associated with the n-th order from the lyrics information table 50. .
- the sound source 13 outputs sound in a manner according to the read nth control parameter information.
- the data memory 18 stores a lyrics information table 50 shown in FIG.
- the lyrics information table 50 includes a plurality of control parameter information.
- the plurality of control parameter information is associated with different pitches.
- the first control parameter information is associated with the pitch A5.
- the second control parameter information is associated with the pitch B5.
- the CPU 10 When detecting the key-on of the key applied to the pitch A5, the CPU 10 reads the first parameter information associated with the pitch A5 from the data memory 18. The sound source 13 outputs sound in a mode according to the read first control parameter information and with a pitch A5. Similarly, when detecting the key-on of the key applied to the pitch B5, the CPU 10 reads out the second control parameter information associated with the pitch B5 from the data memory 18. The sound source 13 outputs sound in a mode according to the read second control parameter information and with a pitch B5.
- a third modification of the third embodiment will be described. In this modification, the data memory 18 stores text data 30 shown in FIG.
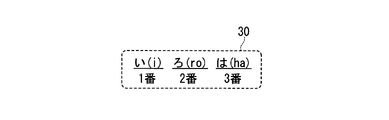
- the text data 30 includes a plurality of syllables, that is, a first syllable “i (i)”, a second syllable “ro (ro)”, and a third syllable “ha (ha)”.
- each of “i (i)”, “ro (ro)”, and “ha (ha)” represents one Japanese hiragana character and is an example of a syllable.
- the first syllable “i (i)” is associated with the first order.
- the second syllable “ro” is associated with the second order.
- the third syllable “ha (ha)” is associated with the third order.
- the data memory 18 further stores a lyrics information table 50 shown in FIG.
- the lyrics information table 50 includes a plurality of control parameter information.
- the plurality of control parameter information is associated with different syllables.
- the second control parameter information is associated with the syllable “I (i)”.
- the 26th control parameter information (not shown) is associated with the syllable “ha (ha)”.
- the 45th control parameter information is associated with “ro”.
- the CPU 10 When detecting the first (first) key-on, the CPU 10 reads “i (i)” associated with the first order from the text data 30. Further, the CPU 10 reads out the second control parameter information associated with “I (i)” from the lyrics information table 50.
- the sound source 13 outputs a singing sound indicating “i (i)” in a manner according to the read second control parameter information.
- the CPU 10 reads “ro” associated with the second order from the text data 30 when the second (second) key-on is detected. Further, the CPU 10 reads 45th control parameter information associated with “ro” from the lyrics information table 50. The sound source 13 outputs a singing sound indicating “ro” in a manner according to the 45th control parameter information.
- the key-off pronunciation information according to the embodiment of the present invention described above may be stored separately from the syllable information instead of being included in the syllable information.
- the key-off sounding information may be data describing how many times the key is pressed when the key-off sounding is executed.
- the key-off pronunciation information may be information generated by a user instruction in real time during performance. For example, key-off sounding may be executed for the note only when the user steps on the pedal while pressing the key. The key-off sounding may be executed when the time during which the key is pressed exceeds a predetermined length. Alternatively, key-off sounding may be executed when the key-pressing velocity exceeds a predetermined value.
- the sound generation device can generate a singing sound without lyrics or lyrics, and can generate predetermined sounds without lyrics such as instrument sounds and sound effects.
- the sound generation device can generate a predetermined sound including a singing sound.
- the explanation has been given by taking Japanese as an example, where the lyrics are approximately one character per syllable.
- the embodiment of the present invention is not limited to such a case.
- a performance data generating device may be prepared instead of the performance operator, and performance information may be sequentially given from the performance data generating device to the sound generating device.
- a program for realizing the functions of the singing sound generating apparatuses 1, 100, 200 according to the embodiments described above is recorded on a computer-readable recording medium, and the program recorded on the recording medium is read into a computer system.
- the processing may be performed by executing.
- the “computer system” referred to here may include hardware such as an operating system (OS) and peripheral devices.
- “Computer-readable recording medium” refers to a flexible disk, a magneto-optical disk, a ROM (Read Only Memory), a writable nonvolatile memory such as a flash memory, a portable medium such as a DVD (Digital Versatile Disk), and a computer system. Includes a storage device such as a built-in hard disk.
- the “computer-readable recording medium” is a volatile memory (for example, DRAM (Dynamic Random Access) in a computer system that serves as a server or a client when a program is transmitted via a network such as the Internet or a communication line such as a telephone line. Memory)) that holds a program for a certain period of time.
- the above program may be transmitted from a computer system storing the program in a storage device or the like to another computer system via a transmission medium or by a transmission wave in the transmission medium.
- a “transmission medium” for transmitting a program refers to a medium having a function of transmitting information, such as a network (communication network) such as the Internet or a communication line (communication line) such as a telephone line.
- the above program may be a program for realizing a part of the functions described above.
- the above program may be a so-called difference file (difference program) that can realize the above-described functions in combination with a program already recorded in the computer system.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Theoretical Computer Science (AREA)
- Electrophonic Musical Instruments (AREA)
- Reverberation, Karaoke And Other Acoustics (AREA)
Abstract
音制御装置は、音の出力の開始を示す開始指示を受け付ける受付部と、前記開始指示が受け付けられたことに応答して、前記音の出力態様を決定する制御パラメータを読み出す読出部と、前記読み出された制御パラメータに従った態様で前記音を出力させる制御部と、を備える。
Description
この発明は、簡単に、表情豊かな音の演奏を行える音制御装置、音制御方法、および音制御プログラムに関する。
本願は、2015年3月20日に日本国に出願された特願2015-057946号に基づいて優先権を主張し、その内容をここに援用する。
本願は、2015年3月20日に日本国に出願された特願2015-057946号に基づいて優先権を主張し、その内容をここに援用する。
特許文献1には、リアルタイムに入力される演奏データに基づいて、歌唱合成を行う歌唱音合成装置が開示されている。この歌唱音合成装置は、MIDI(musical instrument digital interface)機器から受信した演奏データに基づき歌唱合成スコアを形成し、このスコアに基づいて歌唱を合成する。歌唱合成スコアは、音韻トラック、遷移トラック、ビブラートトラックを含んでいる。MIDI機器の操作に応じて音量制御やビブラート制御が行われる。
非特許文献1には、ノートと歌詞を入力して、ノートの音高にそって歌詞を歌わせるボーカルトラック作成ソフトウェアが開示されている。非特許文献1には、声の表情や抑揚、声質や音色の変化を調整するためのパラメータが多数装備して、歌声に細かなニュアンスや抑揚をつけられることが記載されている。
非特許文献1には、ノートと歌詞を入力して、ノートの音高にそって歌詞を歌わせるボーカルトラック作成ソフトウェアが開示されている。非特許文献1には、声の表情や抑揚、声質や音色の変化を調整するためのパラメータが多数装備して、歌声に細かなニュアンスや抑揚をつけられることが記載されている。
VOCALOID使いこなしマニュアル「VOCALOID EDITOR活用法」[online], [平成27年 2月27日検索],インターネット<http://www.crypton.co.jp/mp/pages/download/pdf/vocaloid_master_01.pdf>
リアルタイム演奏により歌唱音合成を行う場合には、演奏中に操作できるパラメータ数に限界がある。このため、事前に入力した情報を再生することで歌わせる非特許文献1記載のボーカルトラック作成ソフトウェアのように多数のパラメータを制御するのは困難であるという問題点があった。
本発明の目的の一例は、簡単に、表情豊かな音の演奏を行える音制御装置、音制御方法、および音制御プログラムを提供することである。
本発明の実施態様にかかる音制御装置は、音の出力の開始を示す開始指示を受け付ける受付部と、前記開始指示が受け付けられたことに応答して、前記音の出力態様を決定する制御パラメータを読み出す読出部と、前記読み出された制御パラメータに従った態様で前記音を出力させる制御部と、を備える。
本発明の実施態様にかかる音制御方法は、音の出力の開始を示す開始指示を受け付け、前記開始指示が受け付けられたことに応答して、前記音の出力態様を決定する制御パラメータを読み出し、前記読み出された制御パラメータに従った態様で前記音を出力させる、ことを含む。
本発明の実施態様にかかる音制御プログラムは、コンピュータに、音の出力の開始を示す開始指示を受け付け、前記開始指示が受け付けられたことに応答して、前記音の出力態様を決定する制御パラメータを読み出し、前記読み出された制御パラメータに従った態様で前記音を出力させる、ことを実行させる。
本発明の実施態様にかかる音制御方法は、音の出力の開始を示す開始指示を受け付け、前記開始指示が受け付けられたことに応答して、前記音の出力態様を決定する制御パラメータを読み出し、前記読み出された制御パラメータに従った態様で前記音を出力させる、ことを含む。
本発明の実施態様にかかる音制御プログラムは、コンピュータに、音の出力の開始を示す開始指示を受け付け、前記開始指示が受け付けられたことに応答して、前記音の出力態様を決定する制御パラメータを読み出し、前記読み出された制御パラメータに従った態様で前記音を出力させる、ことを実行させる。
本発明の実施形態にかかる発音装置では、開始指示に応じて、読み出した制御パラメータに従った発音態様で音を出力させる。このため、簡単に、表情豊かな音の演奏を行えるようになる。
図1は、本発明の実施形態にかかる発音装置のハードウェア構成を示す機能ブロック図を示す。
図1に示す本発明の実施形態にかかる発音装置1は、CPU(Central Processing Unit)10と、ROM(Read Only Memory)11と、RAM(Random Access Memory)12と、音源13と、サウンドシステム14と、表示部(表示器)15と、演奏操作子16と、設定操作子17と、データメモリ18と、バス19とを備える。
音制御装置は、発音装置1(100、200)に相当してもよい。この音制御装置の受付部、読出部、制御部、記憶部、操作子は各々、発音装置1のこれらの構成の少なくとも一つに相当してもよい。例えば、受付部は、CPU10および演奏操作子16の少なくとも一つに相当してもよい。読出部は、CPU10に相当してもよい。制御部は、CPU10、音源13およびサウンドシステム14の少なくとも一つに相当してもよい。記憶部は、データメモリ18に相当してもよい。操作子は、演奏操作子16に相当してもよい。
CPU10は、本発明の実施形態にかかる発音装置1全体の制御を行う中央処理装置である。ROM(Read Only Memory)11は制御プログラムおよび各種のデータなどが格納されている不揮発性のメモリである。RAM12はCPU10のワーク領域および各種のバッファなどとして使用される揮発性のメモリである。データメモリ18は歌詞を音節に区切ったテキストデータを含む音節情報および歌唱音の音声素片データが格納されている音韻データベースなどが格納されている。表示部15は、動作状態および各種設定画面やユーザーに対するメッセージなどが表示される液晶表示器等からなる表示部である。演奏操作子16は、それぞれ異なる音高に対応する複数の鍵を有する鍵盤(図7の部分(c)参照)などからなる演奏操作子である。演奏操作子16は、キーオン、キーオフ、音高、ベロシティなどの演奏情報を発生する。以下において、演奏操作子を鍵と称する場合がある。この演奏情報は、MIDIメッセージの演奏情報であってもよい。設定操作子17は、発音装置1を設定する操作つまみや操作ボタンなどの各種設定操作子である。
図1に示す本発明の実施形態にかかる発音装置1は、CPU(Central Processing Unit)10と、ROM(Read Only Memory)11と、RAM(Random Access Memory)12と、音源13と、サウンドシステム14と、表示部(表示器)15と、演奏操作子16と、設定操作子17と、データメモリ18と、バス19とを備える。
音制御装置は、発音装置1(100、200)に相当してもよい。この音制御装置の受付部、読出部、制御部、記憶部、操作子は各々、発音装置1のこれらの構成の少なくとも一つに相当してもよい。例えば、受付部は、CPU10および演奏操作子16の少なくとも一つに相当してもよい。読出部は、CPU10に相当してもよい。制御部は、CPU10、音源13およびサウンドシステム14の少なくとも一つに相当してもよい。記憶部は、データメモリ18に相当してもよい。操作子は、演奏操作子16に相当してもよい。
CPU10は、本発明の実施形態にかかる発音装置1全体の制御を行う中央処理装置である。ROM(Read Only Memory)11は制御プログラムおよび各種のデータなどが格納されている不揮発性のメモリである。RAM12はCPU10のワーク領域および各種のバッファなどとして使用される揮発性のメモリである。データメモリ18は歌詞を音節に区切ったテキストデータを含む音節情報および歌唱音の音声素片データが格納されている音韻データベースなどが格納されている。表示部15は、動作状態および各種設定画面やユーザーに対するメッセージなどが表示される液晶表示器等からなる表示部である。演奏操作子16は、それぞれ異なる音高に対応する複数の鍵を有する鍵盤(図7の部分(c)参照)などからなる演奏操作子である。演奏操作子16は、キーオン、キーオフ、音高、ベロシティなどの演奏情報を発生する。以下において、演奏操作子を鍵と称する場合がある。この演奏情報は、MIDIメッセージの演奏情報であってもよい。設定操作子17は、発音装置1を設定する操作つまみや操作ボタンなどの各種設定操作子である。
音源13は、複数の発音チャンネルを有する。音源13には、CPU10の制御の基で、ユーザーの演奏操作子16を使用するリアルタイム演奏に応じて1つの発音チャンネルが割り当てられる。音源13は、割り当てられた発音チャンネルにおいて、データメモリ18から演奏に対応する音声素片データを読み出して歌唱音データを生成する。サウンドシステム14は、音源13で生成された歌唱音データをデジタル/アナログ変換器によりアナログ信号に変換して、アナログ信号とされた歌唱音を増幅してスピーカ等へ出力している。バス19は発音装置1における各部の間のデータ転送を行うためのバスである。
本発明の第1実施形態にかかる発音装置1について以下に説明する。第1実施形態の発音装置1では、演奏操作子16をキーオンした際に図2Aに示すフローチャートのキーオン処理が実行される。図2Bは、このキーオン処理における音節情報取得処理のフローチャートを示す。図3Aは、キーオン処理における発音受付処理の説明図を示す。図3Bは、音節情報取得処理の説明図を示す。図3Cは、音声素片データ選択処理の説明図を示す。図4は、第1実施形態の発音装置1の動作を示すタイミング図を示す。図5は、第1実施形態の発音装置1において、演奏操作子16をキーオフした際に実行されるキーオフ処理のフローチャートを示す。
第1実施形態の発音装置1において、ユーザーがリアルタイム演奏を行う場合は、演奏操作子16を操作して演奏を行う。演奏操作子16は鍵盤等であってもよい。演奏の進行に伴い演奏操作子16がキーオンされたことをCPU10が検出すると、図2Aに示すキーオン処理をスタートする。キーオン処理におけるステップS10の発音指示受付処理およびステップS11の音節情報取得処理はCPU10が実行する。ステップS12の音声素片データ選択処理およびステップS13の発音処理はCPU10の制御の基で音源13が実行する。
第1実施形態の発音装置1において、ユーザーがリアルタイム演奏を行う場合は、演奏操作子16を操作して演奏を行う。演奏操作子16は鍵盤等であってもよい。演奏の進行に伴い演奏操作子16がキーオンされたことをCPU10が検出すると、図2Aに示すキーオン処理をスタートする。キーオン処理におけるステップS10の発音指示受付処理およびステップS11の音節情報取得処理はCPU10が実行する。ステップS12の音声素片データ選択処理およびステップS13の発音処理はCPU10の制御の基で音源13が実行する。
キーオン処理のステップS10では、操作された演奏操作子16のキーオンに基づく発音指示(開始指示の一例)を受け付ける。この場合、CPU10はキーオンのタイミング、操作された演奏操作子16の音高情報およびベロシティなどの演奏情報を受け取るようになる。図3Aに示す楽譜の通りユーザーがリアルタイム演奏した場合は、最初のキーオンn1の発音指示を受け付けた時に、CPU10はE5の音高を示す音高情報と鍵速度に応じたベロシティ情報を受け取る。
次いで、ステップS11にて、キーオンに対応する音節情報を取得する音節情報取得処理を行う。図2Bは、音節情報取得処理の詳細を示すフローチャートである。音節情報取得処理はCPU10で実行される。CPU10は、ステップS20においてカーソル位置の音節を取得する。この場合、ユーザーの演奏に先立って、特定の歌詞が指定されている。特定の歌詞とは、例えば、図3Aに示す楽譜に対応し、データメモリ18に格納されている歌詞である。また、テキストデータの先頭の音節にカーソルが置かれている。このテキストデータは、指定された歌詞を音節毎に区切ったデータである。具体例として、テキストデータ30が、図3Aに示す楽譜に対応して指定された歌詞に対応するテキストデータである場合について説明する。この場合、テキストデータ30は、図3Bに示す音節c1~c42、すなわち、「は(ha)」、「る(ru)」、「よ(yo)」、「こ(ko)」、「い(i)」の5つの音節からなるテキストデータである。以下において、「は(ha)」、「る(ru)」、「よ(yo)」、「こ(ko)」、「い(i)」各々は、日本語のひらがなの一文字を示し、音節の一例である。この場合、c1~c3の音節「は(ha)」、「る(ru)」、「よ(yo)」はそれぞれ独立している。c41とc42との音節「こ(ko)」「い(i)」はグループ化されている。このグループ化されているか否かを示す情報がグループ化情報(設定情報の一例)31である。グループ化情報31は、各音節に埋め込まれ、または、各音節に対応付けられている。グループ化情報31において、記号「×」はグループ化されていないことを表し、記号「○」はグループ化されていることを表している。グループ化情報31は、データメモリ18に記憶されていてもよい。図3Bに示すように、最初のキーオンn1の発音指示を受け付けた際には、CPU10は、指定された歌詞の最初の音節c1である「は(ha)」をデータメモリ18から読み出す。この際、CPU10は、「は(ha)」に埋め込まれまたは対応付けられているグループ化情報31もデータメモリ18から読み出す。次いで、ステップS21にて取得した音節がグループ化されているか否かを、取得された音節のグループ化情報31からCPU10が判断する。ステップS20で取得された音節がc1の「は(ha)」の場合は、そのグループ化情報31が「×」であることからグループ化されていないと判断されて、処理がステップS25に進む。ステップS25では、CPU10がテキストデータ30の次の音節にカーソルを進められ、2番目の音節c2の「る(ru)」にカーソルが置かれる。ステップS25の処理が終了すると音節情報取得処理は終了し、キーオン処理のステップS12にリターンする。
図3Cは、ステップS12の音声素片データ選択処理を説明するための図である。このステップS12の音声素片データ選択処理は、CPU10の制御の基で音源13によって行われる処理である。音源13は、取得された音節を発音させる音声素片データを音韻データベース32から選択する。音韻データベース32には、「音素連鎖データ32a」と「定常部分データ32b」が記憶されている。音素連鎖データ32aは、「無音(#)から子音」、「子音から母音」、「母音から(次の音節の)子音または母音」などに対応する、発音が変化する際の音素片のデータである。定常部分データ32bは、母音の発音が継続する際の音素片のデータである。最初のキーオンn1の発音指示を受け付けることに応じて取得された音節がc1の「は(ha)」の場合、音源13は、音素連鎖データ32aから「無音→子音h」に対応する音声素片データ「#-h」と「子音h→母音a」に対応する音声素片データ「h-a」を選択すると共に、定常部分データ32bから「母音a」に対応する音声素片データ「a」を選択する。次いで、ステップS13にて、ステップS12で選択した音声素片データに基づく発音処理をCPU10の制御の基で音源13が行う。上記したように、音声素片データが選択された場合は、ステップS13の発音処理において、『「#-h」→「h-a」→「a」』の音声素片データの発音が順次音源13によって行われる。その結果、音節c1の「は(ha)」の発音が行われる。発音の際には、キーオンn1の発音指示の受付の際に受け取ったE5の音高で、ベロシティ情報に応じた音量で「は(ha)」の歌唱音が発音される。ステップS13の発音処理が終了するとキーオン処理も終了する。
図4は、このキーオン処理の動作を示す。図4の部分(a)は鍵を押す操作を示す。図4の部分(b)は発音内容を示す。図4の部分(c)は、音声素片を示す。CPU10は、時刻t1で最初のキーオンn1の発音指示を受け付ける(ステップS10)。次に、CPU10は、最初の音節c1を取得し、音節c1が別の音節とグループ化されていないと判断する(ステップS11)。次いで、音源13は、音節c1を発音する音声素片データ「#-h」,「h-a」,「a」を選択する(ステップS12)。次に、キーオンn1のベロシティ情報に応じた音量のエンベロープENV1が開始され、『「#-h」→「h-a」→「a」』の音声素片データをE5の音高およびエンベロープENV1の音量で発音させる(ステップS13)。これにより、「は(ha)」の歌唱音が発音される。エンベロープENV1は、キーオンn1のキーオフまでサスティンが持続する持続音のエンベロープである。時刻t2でキーオンn1の鍵がキーオフされるまで「a」の音声素片データが繰り返し再生される。そして、時刻t2でキーオフ(停止指示の一例)されたことがCPU10で検出されると、図5に示すキーオフ処理をスタートする。キーオフ処理のステップS30,ステップS33の処理はCPU10が実行する。ステップS31,ステップS32の処理はCPU10の制御の基で音源13が実行する。
キーオフ処理がスタートされると、ステップS30でキーオフ発音フラグがオンか否かが判断される。キーオフ発音フラグは、取得した音節がグループ化されている場合にセットされる。図2Aに示す音節情報取得処理において、最初の音節c1はグループ化されていない。このため、CPU10は、キーオフ発音フラグが設定されていないと判断し(ステップS30でNo)、処理がステップS34に進む。ステップS34では、CPU10の制御の基で音源13は、消音処理を行い、その結果、「は(ha)」の歌唱音の発音が停止される。すなわち、エンベロープENV1のリリースカーブで「は(ha)」の歌唱音が消音されていく。ステップS34の処理が終了すると、キーオフ処理は終了する。
リアルタイム演奏の進行に伴い演奏操作子16が操作されて、2回目のキーオンn2が検出されると上述したキーオン処理が再度スタートされて、上述したキーオン処理が行われる。2回目のキーオン処理における、ステップS10の発音指示受付処理について説明する。この処理では、操作された演奏操作子16のキーオンn2に基づく発音指示を受け付ける際に、CPU10はキーオンn2のタイミング、E5の音高を示す音高情報と鍵速度に応じたベロシティ情報を受け取る。ステップS11の音節情報取得処理では、CPU10は、指定された歌詞のカーソルが置かれた2番目の音節c2である「る(ru)」をデータメモリ18から読み出す。この取得した音節「る(ru)」のグループ化情報31が「×」である。このため、CPU10は、グループ化されていないと判断し、3番目の音節目のc3の「よ(yo)」にカーソルを進める。ステップS12の音声素片データ選択処理では、音源13は、音素連鎖データ32aから「無音→子音r」に対応する音声素片データ「#-r」と「子音r→母音u」に対応する音声素片データ「r-u」を選択すると共に、定常部分データ32bから「母音u」に対応する音声素片データ「u」を選択する。ステップS13の発音処理では、『「#-r」→「r-u」→「u」』の音声素片データの発音がCPU10の制御の基で順次音源13において行われる。その結果、c2の「る(ru)」の音節の発音が行われ、キーオン処理は終了する。
リアルタイム演奏の進行に伴い演奏操作子16が操作されて、3回目のキーオンn3が検出されると上述したキーオン処理が再度スタートされて、上述したキーオン処理が行われる。この3回目のキーオンn3は、2回目のキーオンn2がキーオフされる前にキーオンするレガートとされている。3回目のキーオン処理における、ステップS10の発音指示受付処理について説明する。この処理では、操作された演奏操作子16のキーオンn3に基づく発音指示を受け付ける際に、CPU10はキーオンn3のタイミング、D5の音高を示す音高情報と鍵速度に応じたベロシティ情報を受け取る。ステップS11の音節情報取得処理では、CPU10は、指定された歌詞のカーソルが置かれた3番目の音節c3である「よ(yo)」をデータメモリ18から読み出す。この取得した音節「よ(yo)」のグループ化情報31が「×」である。このため、CPU10は、グループ化されていないと判断し、4番目の音節目のc41の「こ(ko)」にカーソルを進める。ステップS12の音声素片データ選択処理では、音源13は、音素連鎖データ32aから「母音u→子音y」に対応する音声素片データ「u-y」と「子音y→母音o」に対応する音声素片データ「y-o」を選択すると共に、定常部分データ32bから「母音o」に対応する音声素片データ「o」を選択する。これは、3回目のキーオンn3がレガートであって「る(ru)」から「よ(yo)」へ滑らかにつなげて発音させるためである。ステップS13の発音処理では、『「u-y」→「y-o」→「o」』の音声素片データの発音がCPU10の制御の基で順次音源13よって行われる。その結果、c2の「る(ru)」から滑らかにつながるc3の「よ(yo)」の音節の発音が行われ、キーオン処理は終了する。
図4は、この2,3回目のキーオン処理の動作を示す。CPU10は、時刻t3で2回目のキーオンn2の発音指示を受け付ける(ステップS10)。CPU10は、次の音節c2を取得し、音節c2が別の音節とグループ化されていないと判断する(ステップS11)。次いで、音源13は、音節c2を発音する音声素片データ「#-r」,「r-u」,「u」を選択する(ステップS12)。音源13は、キーオンn2のベロシティ情報に応じた音量のエンベロープENV2を開始し、『「#-r」→「r-u」→「u」』の音声素片データをE5の音高およびエンベロープENV2の音量で発音させる(ステップS13)。これにより、「る(ru)」の歌唱音が発音される。エンベロープENV2は、エンベロープENV1と同様である。「u」の音声素片データが繰り返し再生される。キーオンn2にかかる鍵がキーオフされる前の時刻t4で3回目のキーオンn3の発音指示を受け付ける(ステップS10)。その発音指示に応答して、CPU10は、次の音節c3を取得し、音節c3が別の音節とグループ化されていないと判断する(ステップS11)。時刻t4では、3回目のキーオンn3がレガートであることから、図5に示すキーオフ処理をCPU10がスタートする。キーオフ処理のステップS30では、2番目の音節c2である「る(ru)」はグループ化されていない。このため、CPU10は、キーオフ発音フラグが設定されていないと判断し(ステップS30でNo)、処理がステップS34に進む。ステップS34では、「る(ru)」の歌唱音の発音が停止される。ステップS34の処理が終了すると、キーオフ処理は終了する。これは以下の理由による。すなわち、歌唱音用の発音チャンネルには1チャンネルが用意されて2つの歌唱音を同時に発音できない。ゆえに、キーオンn2の鍵がキーオフされる時刻t5より前の時刻t4で次のキーオンn3が検出された場合(すなわち、レガートの場合)は、時刻t4でキーオンn2に基づく歌唱音の発音を停止して、時刻t4からキーオンn3に基づく歌唱音の発音を開始させるためである。
このため、音源13は、音節c3である「よ(yo)」を発音する音声素片データ「u-y」,「y-o」,「o」を選択し(ステップS12)、時刻t4から、『「u-y」→「y-o」→「o」』の音声素片データをD5の音高およびエンベロープENV2のサスティンの音量で発音させる(ステップS13)。これにより、「る(ru)」から「よ(yo)」へ歌唱音が滑らかにつながって発音される。なお、時刻t5でキーオンn2の鍵がキーオフされても、既にキーオンn2に基づく歌唱音の発音は停止されているため、処理は何も行われない。
CPU10は、時刻t6でキーオンn3がキーオフされたことを検出すると、図5に示すキーオフ処理をスタートする。3番目の音節c3である「よ(yo)」はグループ化されていない。よって、キーオフ処理のステップS30では、CPU10は、キーオフ発音フラグが設定されていないと判断し(ステップS30でNo)、処理がステップS34に進む。ステップS34では、音源13は、消音処理を行い、「よ(yo)」の歌唱音の発音が停止される。すなわち、エンベロープENV2のリリースカーブで「よ(yo)」の歌唱音が消音されていく。ステップS34の処理が終了すると、キーオフ処理は終了する。
CPU10は、時刻t6でキーオンn3がキーオフされたことを検出すると、図5に示すキーオフ処理をスタートする。3番目の音節c3である「よ(yo)」はグループ化されていない。よって、キーオフ処理のステップS30では、CPU10は、キーオフ発音フラグが設定されていないと判断し(ステップS30でNo)、処理がステップS34に進む。ステップS34では、音源13は、消音処理を行い、「よ(yo)」の歌唱音の発音が停止される。すなわち、エンベロープENV2のリリースカーブで「よ(yo)」の歌唱音が消音されていく。ステップS34の処理が終了すると、キーオフ処理は終了する。
リアルタイム演奏の進行に伴い演奏操作子16が操作されて、4回目のキーオンn4が検出されると上述したキーオン処理が再度スタートされて、上述したキーオン処理が行われる。4回目のキーオン処理における、ステップS10の発音指示受付処理について説明する。この処理では、操作された演奏操作子16の4回目のキーオンn4に基づく発音指示を受け付ける際に、CPU10はキーオンn4のタイミング、E5の音高を示す音高情報と鍵速度に応じたベロシティ情報を受け取る。ステップS11の音節情報取得処理では、CPU10は、指定された歌詞のカーソルが置かれた4番目の音節c41である「こ(ko)」をデータメモリ18から読み出す(ステップS20)。この取得した音節「こ(ko)」のグループ化情報31が「○」である。このため、CPU10は、音節c41が別の音節とグループ化されていると判断し(ステップS21)、ステップS22に進む。ステップS22では、同じグループに属する音節(グループ内の音節)が取得される。この場合は「こ(ko)」と「い(i)」がグループ化されていることから、CPU10は、音節c41と同じグループに属する音節である音節c42「い(i)」をデータメモリ18から読み出す。次いで、CPU10は、ステップS23でキーオフ発音フラグをセットして、キーオフされた際に同じグループに属する次の音節「い(i)」を発音させる準備をする。次のステップS24では、CPU10は、テキストデータ30は、カーソルを、「こ(ko)」と「い(i)」が属するグループを越えて次の音節に進める。ただし、図示例の場合は次の音節がないことから、この処理はスキップされる。ステップS24の処理が終了すると音節情報取得処理は終了し、キーオン処理のステップS12にリターンする。
ステップS12の音声素片データ選択処理では、音源13は、同じグループに属する音節「こ(ko)」および「い(i)」に対応する音声素片データを選択する。すなわち、音源13は、音節「こ(ko)」に対応する音声素片データとして、音素連鎖データ32aから「無音→子音k」に対応する音声素片データ「#-k」と「子音k→母音o」に対応する音声素片データ「k-o」を選択すると共に、定常部分データ32bから「母音o」に対応する音声素片データ「o」を選択する。また、音源13は、音節「い(i)」に対応する音声素片データとして、音素連鎖データ32aから「母音o→母音i」に対応する音声素片データ「o-i」を選択すると共に、定常部分データ32bから「母音i」に対応する音声素片データ「i」を選択する。ステップS13の発音処理では、同じグループに属する音節のうち、先頭の音節の発音が行われる。すなわち、音源13は、CPU10の制御の基で、『「#-k」→「k-o」→「o」』の音声素片データを順次発音する。その結果、音節c41である「こ(ko)」が発音される。発音の際には、キーオンn4の発音指示の受け付けの際に受け取ったE5の音高で、ベロシティ情報に応じた音量で「こ(ko)」の歌唱音が発音される。ステップS13の発音処理が終了するとキーオン処理も終了する。
図4は、このキーオン処理の動作を示す。CPU10は、時刻t7で4番目のキーオンn4の発音指示を受け付ける(ステップS10)。CPU10は、4番目の音節c41(および音節c41に埋め込まれまたは対応付けられているグループ化情報31)を取得する。CPU10は、そのグループ化情報31に基づいて、音節c41が別の音節とグループ化されていると判断する。CPU10は、音節c41と同じグループに属する音節c42を取得すると共にキーオフ発音フラグをセットする(ステップS11)。次いで、音源13は、音節c41,c42を発音する音声素片データ「#-k」,「k-o」,「o」および音声素片データ「o-i」,「i」を選択する(ステップS12)。そして、音源13は、キーオンn4のベロシティ情報に応じた音量のエンベロープENV3を開始し、『「#-k」→「k-o」→「o」』の音声素片データをE5の音高およびエンベロープENV3の音量で発音させる(ステップS13)。これにより、「こ(ko)」の歌唱音が発音される。エンベロープENV3は、エンベロープENV1と同様である。時刻t8でキーオンn4にかかる鍵がキーオフされるまで「o」の音声素片データが繰り返し再生される。そして、時刻t8でキーオンn4がキーオフされたことがCPU10で検出されると、図5に示すキーオフ処理をCPU10がスタートする。
音節c41,c42である「こ(ko)」および「い(i)」がグループ化されていて、キーオフ発音フラグがセットされている。このため、キーオフ処理のステップS30では、CPU10は、キーオフ発音フラグが設定されていると判断し(ステップS30でYes)、処理がステップS31に進む。ステップS31では、先に発音された音節と同じグループに属する次の音節の発音処理が行われる。すなわち、音源13は、先に行ったステップS12の音節情報取得処理において、音節「い(i)」に対応する音声素片データとして選択された『「o-i」→「i」』の音声素片データをE5の音高およびエンベロープENV3のリリースカーブの音量で発音させる。これにより、c41の「こ(ko)」と同じ音高E5で音節c42である「い(i)」の歌唱音が発音される。次いで、ステップS32で消音処理が行われて、「い(i)」の歌唱音の発音が停止される。すなわち、エンベロープENV3のリリースカーブで「い(i)」の歌唱音が消音されていく。なお、「こ(ko)」の発音は、発音が「い(i)」に移行した時点において、停止されている。次いで、ステップS33でキーオフ発音フラグをリセットしてキーオフ処理は終了する。
以上説明したように、第1実施形態の発音装置1では、ユーザーのリアルタイム演奏に応じた歌唱音である歌声が発音されるようになると共に、リアルタイム演奏時に鍵を1回の押す操作を行うこと(すなわち、鍵を押してから離すまでの連続する1回の操作を行うこと、以下同様)により複数の歌声を発音することができる。すなわち、第1実施形態の発音装置1において、グループ化された音節は、鍵を1回押す操作で発音される音節の集合とされる。例えばグループ化されたc41とc42の音節は鍵を1回の押す操作で発音される。この場合、1音節目の音は鍵を押すことに応答して出力され、2音節目以降の音は鍵から離れることに応答して出力される。グループ化の情報は、キーオフにより次の音節を発音するか否かを決定する情報なので、「キーオフ発音情報(設定情報)」ということができる。キーオンn4にかかる鍵がキーオフされる前に、演奏操作子16の他の鍵にかかるキーオン(キーオンn5とする)が行われた場合について説明する。この場合は、キーオンn4のキーオフ処理が行われたあとにキーオンn5の発音が行われる。すなわち、キーオンn4のキーオフ処理としてc42の音節が発音された後に、キーオンn5に対応するc42の次の音節が発音されるようになる。別法として、キーオンn5に対応する音節をすぐに発音させるために、キーオンn5の操作に応答して実行されるキーオンn4のキーオフ処理においては、ステップS31の処理を省略してもよい。この場合、c42の音節は発音されず、キーオンn5に応じてすぐにc42の次の音節の発音が行われるようになる。
上記したように、先の音節c41と同じグループに属する次の音節c42の「い(i)」の発音は、キーオンn4にかかる鍵がキーオフされたタイミングで発音される。このため、キーオフで発音指示された音節の発音長が短すぎて不明瞭になるおそれがある。図6A~6Cは、同じグループに属する次の音節の発音を十分長くすることができるキーオフ処理の他の動作例を示す。
図6Aに示す例では、キーオンn4の発音指示により開始されるエンベロープENV3において、減衰開始を、キーオフから所定時間tdだけ遅らせるようにしている。すなわち、リリースカーブR1を一点鎖線で示すリリースカーブR2のように時間tdだけ遅らせることで、同じグループに属する次の音節の発音長を十分長くすることができる。サスティンペダル等の操作によって、同じグループに属する次の音節の発音長を十分長くすることもできる。すなわち、図6Aに示す例では、音源13は、エンベロープENV3の後半において、音節c41の音を一定の音量で出力させる。次に、音源13は、音節c41の音の出力の停止に連続して音節c42の音の出力を開始させる。その際、音節c42の音の音量は、音節c41の消音直前の音量と同じである。音源13は、所定時間tdだけ音量を維持した後に、音節c42の音の音量の低下を開始する。
図6Bに示す例では、エンベロープENV3において、ゆっくり減衰させるようにしている。すなわち、リリースカーブを一点鎖線で示す傾斜を緩くしたリリースカーブR3を発生することで、同じグループに属する次の音節の発音長を十分長くすることができる。すなわち、図6Bに示す例では、音源13は、音節c42の音を出力させない場合(音節c41が他の音節とグループ化されていない場合)における音節c41の音の音量の減衰速度よりも遅い減衰速度で音節c42の音の音量を低下させながら音節c42の音を出力させる。
図6Cに示す例では、キーオフを新たなノートオン指示とみなし、同じ音高の新たなノートで次の音節を発音させる。すなわち、エンベロープENV10を、キーオフの時刻t13において開始して、同じグループに属する次の音節の発音を行う。これにより、同じグループに属する次の音節の発音長を十分長くすることができる。すなわち、図6Cに示す例では、音源13は、音節c41の音の音量の低下を開始させることと同時に、音節c42の音の出力を開始させる。この際、音源13は、音節c42の音の音量を増加させながら音節c42の音を出力させる。
以上説明した本発明の第1実施形態の発音装置1では、歌詞が日本語の場合を例示している。日本語では、ほぼ1文字が1音節である。一方で、他の言語においては1文字が1音節とならない場合が多い。具体例として、英語の歌詞が「september」の場合について説明する。「september」は、「sep」、「tem」、「ber」の3音節からなる。よって、演奏操作子16をユーザーが鍵を押す毎にその3の音節が、その鍵の音高で順次発音されていくようになる。この場合、「sep」および「tem」の2音節をグループ化することにより、1回の鍵を押す操作に応じて「sep」および「tem」の2音節が発音される。すなわち、鍵を押す操作に応じてその鍵の音高で「sep」の音節の音が出力される。また、鍵から離れる操作に応じて「tem」の音節がその鍵の音高で発音される。歌詞は日本語に限らず他の言語とされていても良い。
図6Aに示す例では、キーオンn4の発音指示により開始されるエンベロープENV3において、減衰開始を、キーオフから所定時間tdだけ遅らせるようにしている。すなわち、リリースカーブR1を一点鎖線で示すリリースカーブR2のように時間tdだけ遅らせることで、同じグループに属する次の音節の発音長を十分長くすることができる。サスティンペダル等の操作によって、同じグループに属する次の音節の発音長を十分長くすることもできる。すなわち、図6Aに示す例では、音源13は、エンベロープENV3の後半において、音節c41の音を一定の音量で出力させる。次に、音源13は、音節c41の音の出力の停止に連続して音節c42の音の出力を開始させる。その際、音節c42の音の音量は、音節c41の消音直前の音量と同じである。音源13は、所定時間tdだけ音量を維持した後に、音節c42の音の音量の低下を開始する。
図6Bに示す例では、エンベロープENV3において、ゆっくり減衰させるようにしている。すなわち、リリースカーブを一点鎖線で示す傾斜を緩くしたリリースカーブR3を発生することで、同じグループに属する次の音節の発音長を十分長くすることができる。すなわち、図6Bに示す例では、音源13は、音節c42の音を出力させない場合(音節c41が他の音節とグループ化されていない場合)における音節c41の音の音量の減衰速度よりも遅い減衰速度で音節c42の音の音量を低下させながら音節c42の音を出力させる。
図6Cに示す例では、キーオフを新たなノートオン指示とみなし、同じ音高の新たなノートで次の音節を発音させる。すなわち、エンベロープENV10を、キーオフの時刻t13において開始して、同じグループに属する次の音節の発音を行う。これにより、同じグループに属する次の音節の発音長を十分長くすることができる。すなわち、図6Cに示す例では、音源13は、音節c41の音の音量の低下を開始させることと同時に、音節c42の音の出力を開始させる。この際、音源13は、音節c42の音の音量を増加させながら音節c42の音を出力させる。
以上説明した本発明の第1実施形態の発音装置1では、歌詞が日本語の場合を例示している。日本語では、ほぼ1文字が1音節である。一方で、他の言語においては1文字が1音節とならない場合が多い。具体例として、英語の歌詞が「september」の場合について説明する。「september」は、「sep」、「tem」、「ber」の3音節からなる。よって、演奏操作子16をユーザーが鍵を押す毎にその3の音節が、その鍵の音高で順次発音されていくようになる。この場合、「sep」および「tem」の2音節をグループ化することにより、1回の鍵を押す操作に応じて「sep」および「tem」の2音節が発音される。すなわち、鍵を押す操作に応じてその鍵の音高で「sep」の音節の音が出力される。また、鍵から離れる操作に応じて「tem」の音節がその鍵の音高で発音される。歌詞は日本語に限らず他の言語とされていても良い。
次に、本発明の第2実施形態にかかる発音装置を説明する。第2実施形態の発音装置は、ハミング音や、スキャット、コーラスなどの歌唱音、または、通常の楽器音あるいは鳥のさえずりや電話のベルなどの効果音などの歌詞のない所定の音を発音する。第2実施形態の発音装置を発音装置100と称する。第2実施形態の発音装置100の構成は第1実施形態の発音装置1とほぼ同様である。しかしながら、第2実施形態は、音源13の構成が第1実施形態と相違する。すなわち、第2実施形態の音源13は上記した歌詞のない所定の音の音色を備えており、指定された音色に応じて歌詞のない所定の音を発音することができる。図7は、第2実施形態の発音装置100の動作例を説明するための図である。
第2実施形態の発音装置100において、テキストデータ30とグループ化情報31からなる音節情報に替えてキーオフ発音情報40がデータメモリ18に格納されている。また、第2実施形態の発音装置100は、ユーザーが演奏操作子16を利用してリアルタイム演奏を行った際に歌詞のない所定の音を発音させる。第2実施形態の発音装置100では、図2Aに示すキーオン処理のステップS11で、図2Bに示す音節情報取得処理に替えてキーオフ発音情報処理が行われる。また、ステップS12の音声素片データ選択処理では、予め定められた音や音声を発音させる音源波形や音声素片データが選択される。以下にその動作を説明する。
第2実施形態の発音装置100において、テキストデータ30とグループ化情報31からなる音節情報に替えてキーオフ発音情報40がデータメモリ18に格納されている。また、第2実施形態の発音装置100は、ユーザーが演奏操作子16を利用してリアルタイム演奏を行った際に歌詞のない所定の音を発音させる。第2実施形態の発音装置100では、図2Aに示すキーオン処理のステップS11で、図2Bに示す音節情報取得処理に替えてキーオフ発音情報処理が行われる。また、ステップS12の音声素片データ選択処理では、予め定められた音や音声を発音させる音源波形や音声素片データが選択される。以下にその動作を説明する。
CPU10は、ユーザーがリアルタイム演奏を行うことによって演奏操作子16がキーオンされたことを検出すると、図2Aに示すキーオン処理をスタートする。図7の部分(a)に示す楽譜の楽曲の通りユーザーが演奏する場合について説明する。この場合、CPU10は、ステップS10で最初のキーオンn1の発音指示を受け付け、E5の音高を示す音高情報と鍵速度に応じたベロシティ情報を受け取る。そして、CPU10は、図7の部分(b)に示すキーオフ発音情報40を参照して最初のキーオンn1に対応するキーオフ発音情報を取得する。この場合、ユーザーの演奏に先立って、特定のキーオフ発音情報40が指定されている。この特定のキーオフ発音情報40は、図7の部分(a)に示す楽譜に対応し、データメモリ18に格納されている。また、指定されたキーオフ発音情報40の最初のキーオフ発音情報が参照される。最初のキーオフ発音情報が「×」とされていることから、キーオンn1に対してはキーオフ発音フラグはセットされない。次いで、ステップS12で音声素片データ選択処理を音源13が行う。すなわち、音源13は、予め定められた音声を発音させる音声素片データを選択する。具体例として、「ナ(na)」の音声を発音させる場合について説明する。以下において、「ナ(na)」は、日本語のカタカナの一文字を示す。音源13は、音素連鎖データ32aから「#-n」と「n-a」の音声素片データを選択すると共に、定常部分データ32bから音声素片データ「a」を選択する。そして、ステップS13でキーオンn1に対応する発音処理が行われる。この発音処理では、図7の部分(c)に示すピアノロール譜41で示すように、音源13は、キーオンn1の検出の際に受け取ったE5の音高で、『「#-n」→「n-a」→「a」』の音声素片データの発音が行われる。その結果、「ナ(na)」の歌唱音が発音される。この発音はキーオンn1がキーオフされるまで持続され、キーオフされると消音処理されて停止される。
リアルタイム演奏の進行に伴いキーオンn2をCPU10が検出すると、上記と同様の処理が行われる。キーオンn2に対応する2番目のキーオフ発音情報が「×」とされていることから、キーオンn2に対するキーオフ発音フラグはセットされない。図7の部分(c)に示すようにE5の音高で予め定められた音声、例えば「ナ(na)」の歌唱音が発音される。キーオンn2の鍵がキーオフされる前にキーオンn3が検出されると、上記と同様の処理が行われる。キーオンn3に対応する3番目のキーオフ発音情報が「×」とされていることから、キーオンn3に対するキーオフ発音フラグはセットされない。図7の部分(c)に示すようにD5の音高で予め定められた音声、例えば「ナ(na)」の歌唱音が発音される。この場合、キーオンn3に対応する発音は、キーオンn2に対応する発音に滑らかにつながるレガートとなる。また、キーオンn3に対応する発音の開始と同時にキーオンn2に対応する発音が停止される。さらに、キーオンn3の鍵がキーオフされると、キーオンn3に対応する発音は消音処理されて停止される。
さらなる演奏の進行に伴いキーオンn4をCPU10が検出すると、上記と同様の処理が行われる。キーオンn4に対応する4番目のキーオフ発音情報が「○」とされていることから、キーオンn4に対するキーオフ発音フラグがセットされる。図7の部分(c)に示すようにE5の音高で予め定められた音声、例えば「ナ(na)」の歌唱音が発音される。キーオンn4がキーオフされると、キーオンn2に対応する発音は消音処理されて停止される。しかしながら、キーオフ発音フラグがセットされていることから、CPU10が図7の部分(c)に示すキーオンn4’が新たに行われたと判断し、音源13がキーオンn4’に対応する発音をキーオンn4と同じ音高で行う。すなわち、E5の音高で予め定められた音声、例えば「ナ(na)」の歌唱音が、キーオンn4の鍵がキーオフされた時に発音される。この場合、キーオンn4’に対応する発音長は、予め決められた長さとされる。
上記した第1実施形態にかかる発音装置1では、ユーザーが鍵盤等の演奏操作子16を利用してリアルタイム演奏した際に、演奏操作子16を押す操作を行う毎にテキストデータ30の音節が、その演奏操作子16の音高で発音される。テキストデータ30は、指定された歌詞を音節に区切ったテキストデータである。これにより、リアルタイム演奏時に指定された歌詞が歌われる。歌唱される歌詞の音節をグループ化することにより、演奏操作子16に対する1回の連続する操作により、1音節目と2音節目とを演奏操作子16の音高で発音させることができる。すなわち、演奏操作子16を押すことに応じて1音節目を演奏操作子16にかかる音高で発音させる。また、演奏操作子16から離れる操作に応じて2音節目を演奏操作子16にかかる音高で発音させる。
上記した第2実施形態にかかる発音装置100では、歌詞による歌唱音に替えて上記した歌詞のない所定の音を押鍵された鍵の音高で発音することができる。よって、第2実施形態にかかる発音装置100は、カラオケのガイドなどに適用することができる。この場合も、演奏操作子16に対する1回の連続する操作に含まれる、演奏操作子16を押す操作と、演奏操作子16をから離れる操作とのにそれぞれに応じて、歌詞のない所定の音を発音させることができる。
上記した第2実施形態にかかる発音装置100では、歌詞による歌唱音に替えて上記した歌詞のない所定の音を押鍵された鍵の音高で発音することができる。よって、第2実施形態にかかる発音装置100は、カラオケのガイドなどに適用することができる。この場合も、演奏操作子16に対する1回の連続する操作に含まれる、演奏操作子16を押す操作と、演奏操作子16をから離れる操作とのにそれぞれに応じて、歌詞のない所定の音を発音させることができる。
次に、本発明にかかる第3実施形態の発音装置200について説明する。第3実施形態の発音装置200では、ユーザーが鍵盤等の演奏操作子16を利用してリアルタイム演奏した際に、表情豊かな歌声の演奏を行うことができる。第3実施形態の発音装置200のハードウェア構成は図1に示す構成と同じである。第3実施形態では、第1実施形態と同様に、図2Aに示すキーオン処理が実行される。ただし、第3実施形態では、このキーオン処理におけるステップS11の音節情報取得処理の内容が、第1実施形態とは異なる。具体的には、第3実施形態では、ステップS11の音節情報取得処理として図8に示すフローチャートが実行される。図9Aは、第3実施形態の発音装置200によって実行される発音指示受付処理を説明するための図である。図9Bは、第3実施形態の発音装置200によって実行される音節情報取得処理を説明するための図である。図10は、歌詞情報テーブルの「値v1」~「値v3」を示す。図11は、第3実施形態の発音装置200の動作例を示す。これらの図を参照しながら第3実施形態の発音装置200を説明する。
第3実施形態の発音装置200において、ユーザーがリアルタイム演奏を行う場合、演奏操作子16を操作して演奏を行う。演奏操作子16は鍵盤等である。演奏の進行に伴い演奏操作子16がキーオンされたことをCPU10が検出すると、図2Aに示すキーオン処理をスタートする。キーオン処理のステップS10の発音指示受付処理およびステップS11の音節情報取得処理はCPU10が実行する。ステップS12の音声素片データ選択処理およびステップS13の発音処理はCPU10の制御の基で音源13が実行する。
第3実施形態の発音装置200において、ユーザーがリアルタイム演奏を行う場合、演奏操作子16を操作して演奏を行う。演奏操作子16は鍵盤等である。演奏の進行に伴い演奏操作子16がキーオンされたことをCPU10が検出すると、図2Aに示すキーオン処理をスタートする。キーオン処理のステップS10の発音指示受付処理およびステップS11の音節情報取得処理はCPU10が実行する。ステップS12の音声素片データ選択処理およびステップS13の発音処理はCPU10の制御の基で音源13が実行する。
キーオン処理のステップS10では、操作された演奏操作子16のキーオンに基づく発音指示を受け付ける。この場合、CPU10はキーオンのタイミング、操作された演奏操作子16の音高情報およびベロシティなどの演奏情報を受け取る。図9Aに示す楽譜の楽曲の通りユーザーが演奏した場合は、最初のキーオンn1のタイミングを受け付ける時に、CPU10はE5の音高を示す音高情報と鍵速度に応じたベロシティ情報を受け取る。次いで、ステップS11にて、キーオンn1に対応する音節情報を取得する音節情報取得処理を行う。図8は、この音節情報取得処理のフローチャートを示す。図8に示す音節情報取得処理がスタートされると、CPU10はステップS40においてカーソル位置の音節を取得する。この場合、ユーザーの演奏に先立って、歌詞情報テーブル50が指定されている。歌詞情報テーブル50は、データメモリ18に格納されている。歌詞情報テーブル50は、演奏に対応する楽譜に対応する歌詞を音節に区切ったテキストデータを含む。この歌詞は、図9Aに示す楽譜に対応する歌詞である。また、指定された歌詞情報テーブル50のテキストデータの先頭の音節にカーソルが置かれている。次いで、CPU10は、ステップS41において、取得した先頭のテキストデータの音節に対応付けられた発音制御パラメータ(制御パラメータの一例)を歌詞情報テーブル50を参照して取得する。図9Bは、図9Aに示す楽譜に対応する歌詞情報テーブル50を示す。
第3実施形態の発音装置200においては、歌詞情報テーブル50が特徴的な構成である。図9Bに示すように歌詞情報テーブル50は、音節情報50aと、発音制御パラメータタイプ50bと、発音制御パラメータの値情報50cとから構成されている。音節情報50aは、歌詞を音節に区切ったテキストデータを含む。発音制御パラメータタイプ50bは、各種パラメータタイプのいずれかを指定する。発音制御パラメータは、発音制御パラメータタイプ50bと発音制御パラメータの値情報50cとを含む。図9Bに示す例では、音節情報50aは、図3Bに示すテキストデータ30と同様のc1,c2,c3,c41の歌詞を区切った音節からなる。発音制御パラメータタイプ50bとして、一音節ごとに、パラメータa,b,c,dの何れか一つあるいは複数が設定されている。この発音制御パラメータタイプの具体例は、「Harmonics」、「Brightness」、「Resonance」および「GenderFactor」である。「Harmonics」は、声に含まれる倍音成分のバランスを変化させるタイプのパラメータである。「Brightness」は、声の明暗を演出してトーン変化を与えるタイプのパラメータである。「Resonance」は、有声音の音色や強弱を演出するタイプのパラメータである。「GenderFactor」は、フォルマントを変化させることにより、女性的なあるいは男性的な声の太さや質感を変化させるタイプのパラメータである。値情報50cは、発音制御パラメータの値を設定するための情報であり、「値v1」と「値v2」と「値v3」と含む。「値v1」は発音制御パラメータの時間上の変化のしかたを設定し、グラフ形状(波形)で表すことができる。図10の部分(a)は、グラフ形状で表した「値v1」の例を示す。図10の部分(a)は、「値v1」として、グラフ形状w1~w6を示している。グラフ形状w1~w6は、それぞれ異なる時間上の変化をしている。「値v1」は、グラフ形状w1~w6に限られない。「値v1」として、種々の時間上の変化をするグラフ形状(値)を設定することができる。「値v2」は、図10の部分(b)に示すようにグラフ形状で示す「値v1」の横軸の時間を設定するための値である。「値v2」を設定することにより、効果のかかり始めからかかり終わりまでの時間となる変化の速度を設定できる。「値v3」は、図10の部分(b)に示すようにグラフ形状で示す「値v1」の縦軸の振幅を設定するための値である。「値v3」を設定することにより、効果のかかる度合いを示す変化の深さを設定できる。値情報50cで設定される発音制御パラメータの値の設定可能範囲は、発音制御パラメータタイプにより異なっている。ただし、音節情報50aで指定される音節は、発音制御パラメータタイプ50bおよびその値情報50cが設定されていない音節を含んでもよい。例えば、図11に示す音節c3には発音制御パラメータタイプ50bおよびその値情報50cが設定されていない。この歌詞情報テーブル50の音節情報50a、発音制御パラメータタイプ50b、値情報50cは、ユーザーの演奏に先立って作成およびまたは編集されて、データメモリ18に格納されている。
説明をステップS41に戻す。なお、最初のキーオンn1の時には、CPU10は、ステップS40でc1の音節を取得する。よって、ステップS41では、CPU10は、歌詞情報テーブル50から音節c1に対応付けられた発音制御パラメータタイプと値情報50cとを取得する。すなわち、CPU10は、音節情報50aのc1の横の段に設定されているパラメータa,パラメータbを発音制御パラメータタイプ50bとして取得し、詳細情報の図示が省略されている「値v1」~「値v3」を値情報50cとして取得する。ステップS41の処理が終了すると処理がステップS42に進む。ステップS42では、CPU10がテキストデータの次の音節にカーソルを進めることにより、2音節目のc2にカーソルが置かれる。ステップS42の処理が終了すると音節情報取得処理は終了し、キーオン処理のステップS12にリターンする。ステップS12の音節情報取得処理では、上記したように、取得された音節c1を発音させる音声素片データが音韻データベース32から選択される。次に、ステップS13の発音処理において、選択された音声素片データの発音が順次音源13によって行われる。その結果、c1の音節の発音が行われる。発音の際には、キーオンn1の受付の際に受け取ったE5の音高およびベロシティ情報に応じた音量で音節c1の歌唱音が発音される。ステップS13の発音処理が終了するとキーオン処理も終了する。
図11の部分(c)は、ピアノロール譜52を示す。このステップS13の発音処理では、ピアノロール譜52に示すように、音源13は、キーオンn1の検出の際に受け取ったE5の音高で、選択された音声素片データの発音を行う。その結果、音節c1の歌唱音が発音される。この発音の際に、「値v1」、「値v2」、「値v3」で設定されたパラメータaと、「値v1」、「値v2」、「値v3」で設定されたパラメータbの異なる2つの発音制御パラメータタイプ、すなわち、2つの異なる態様により、歌唱音の発音制御が行われる。よって、歌唱される歌声の表情や抑揚、声質や音色に変化を与えることができ、歌声に細かなニュアンスや抑揚をつけられるようになる。
そして、リアルタイム演奏の進行に伴いキーオンn2をCPU10が検出すると、上記と同様の処理が行われて、キーオンn2に対応する2番目の音節c2がE5の音高で発音される。音節c2には図9の部分(b)で示すように、発音制御パラメータタイプ50bとしてパラメータbとパラメータcとパラメータdの3つの発音制御パラメータタイプが対応付けられていると共に、それぞれの発音制御パラメータタイプはそれぞれの「値v1」、「値v2」、「値v3」で設定されている。このため、音節c2の発音の際に、図11の部分(c)にピアノロール譜52で示すように、パラメータbとパラメータcとパラメータdの異なる3つの発音制御パラメータタイプにより、歌唱音の発音制御が行われる。これにより、歌唱される歌声の表情や抑揚、声質や音色に変化を与えられる。
リアルタイム演奏の進行に伴いキーオンn3をCPU10が検出すると、上記と同様の処理が行われて、キーオンn3に対応する3番目の音節c3がD5の音高で発音される。音節c3には図9Bに示すように、発音制御パラメータタイプ50bが設定されていない。このため、音節c3の発音の際には、図11の部分(c)にピアノロール譜52で示すように、発音制御パラメータによる歌唱音の発音制御が行われない。
リアルタイム演奏の進行に伴いキーオンn3をCPU10が検出すると、上記と同様の処理が行われて、キーオンn3に対応する3番目の音節c3がD5の音高で発音される。音節c3には図9Bに示すように、発音制御パラメータタイプ50bが設定されていない。このため、音節c3の発音の際には、図11の部分(c)にピアノロール譜52で示すように、発音制御パラメータによる歌唱音の発音制御が行われない。
リアルタイム演奏の進行に伴いキーオンn4をCPU10が検出すると、上記と同様の処理が行われて、キーオンn4に対応する4番目の音節c41がE5の音高で発音される。図9Bで示すように、音節c41の発音の際には、音節c41に対応付けられている発音制御パラメータタイプ50b(図示略)および値情報50c(図示略)に応じた発音制御が行われる。
上記した第3実施形態にかかる発音装置200では、ユーザーが鍵盤等の演奏操作子16を利用してリアルタイム演奏した際に、演奏操作子16を押す操作を行う毎に指定されたテキストデータの音節が、その演奏操作子16の音高で発音される。テキストデータを歌詞とすることで歌声が発音される。この際に、音節毎に対応付けられた発音制御パラメータにより発音制御が行われる。このため、歌唱される歌声の表情や抑揚、声質や音色に変化を与えることができ、歌声に細かなニュアンスや抑揚をつけられるようになる。
第3実施形態にかかる発音装置200における歌詞情報テーブル50の音節情報50aを、図3Bに示すように歌詞を区切った音節のテキストデータ30とそのグループ化情報31とからなるようにする場合について説明する。この場合、グループ化された音節を演奏操作子16に対する1回の連続する操作により、演奏操作子16の音高で発音させることができる。すなわち、演奏操作子16を押すことに応じて1音節目を演奏操作子16の音高で発音させる。また、演奏操作子16から離れる操作に応じて2音節目を演奏操作子16の音高で発音させる。この際に、音節毎に対応付けられた発音制御パラメータにより発音制御が行われる。このため、歌唱される歌声の表情や抑揚、声質や音色に変化を与えることができ、歌声に細かなニュアンスや抑揚をつけられるようになる。
第3実施形態の発音装置200は、第2実施形態の発音装置100で発音される上記した歌詞のない所定の音を発音することができる。第3実施形態の発音装置200で上記した歌詞のない所定の音を発音する場合には、音節情報に応じて、取得する発音制御パラメータを決定するのではなく、何回目の押鍵操作であるかに応じて取得する発音制御パラメータを決定するようにすればよい。
第3実施形態において、音高は、操作された演奏操作子16(押された鍵)に応じて指定されている。別法として、音高は、演奏操作子16が操作された順番に応じて指定されてもよい。
第3実施形態の第1の変形例について説明する。この変形例では、データメモリ18が、図12に示す歌詞情報テーブル50を格納している。歌詞情報テーブル50は、複数の制御パラメータ情報(制御パラメータの一例)、すなわち、第1から第n制御パラメータ情報を含む。例えば、第1制御パラメータ情報は、パラメータaと値v1~v3の組み合わせ、および、パラメータbと値v1~v3の組み合わせを含む。複数の制御パラメータ情報はそれぞれ異なる順番に対応付けられている。例えば、第1制御パラメータ情報は、第1の順番に対応づけられている。第2制御パラメータ情報は、第2の順番に対応づけられている。CPU10は、第1番目(1回目)のキーオンを検出した場合、歌詞情報テーブル50から、第1の順番に対応付けられた第1制御パラメータ情報を読み出す。音源13は、読み出された第1制御パラメータ情報に従った態様で音を出力する。同様に、CPU10は、第n番目(n回目)のキーオンを検出した場合、歌詞情報テーブル50から、第nの順番に対応付けられた第n制御パラメータ情報に関連付けられた発音制御パラメータ情報を読み出す。音源13は、読み出された第n制御パラメータ情報に従った態様で音を出力する。
第3実施形態の第2の変形例について説明する。この変形例では、データメモリ18が、図13に示す歌詞情報テーブル50を格納している。歌詞情報テーブル50は、複数の制御パラメータ情報を含む。複数の制御パラメータ情報はそれぞれ異なる音高に対応付けられている。例えば、第1制御パラメータ情報は、音高A5に対応づけられている。第2制御パラメータ情報は、音高B5に対応づけられている。CPU10は、音高A5にかかる鍵のキーオンを検出した場合、データメモリ18から、音高A5に対応付けられた第1パラメータ情報を読み出す。音源13は、読み出された第1制御パラメータ情報に従った態様かつ音高A5で音を出力する。同様に、CPU10は、音高B5にかかる鍵のキーオンを検出した場合、データメモリ18から、音高B5に対応付けられた第2制御パラメータ情報を読み出す。音源13は、読み出された第2制御パラメータ情報に従った態様かつ音高B5で音を出力する。
第3実施形態の第3の変形例について説明する。この変形例では、データメモリ18が、図14に示すテキストデータ30を格納している。テキストデータ30は、複数の音節、すなわち、第1の音節「い(i)」、第2の音節「ろ(ro)」および第3の音節「は(ha)」を含む。以下において、「い(i)」、「ろ(ro)」および「は(ha)」各々は、日本語のひらがなの一文字を示し、音節の一例である。第1の音節である「い(i)」は、第1の順番に対応づけられている。第2の音節である「ろ(ro)」は、第2の順番に対応づけられている。第3の音節である「は(ha)」は、第3の順番に対応づけられている。データメモリ18は、さらに、図15に示す歌詞情報テーブル50を格納している。歌詞情報テーブル50は、複数の制御パラメータ情報を含む。複数の制御パラメータ情報は、それぞれ異なる音節に対応付けられている。例えば、第2制御パラメータ情報は、音節「い(i)」に対応づけられている。第26制御パラメータ情報(不図示)は、音節「は(ha)」に対応づけられている。第45制御パラメータ情報は、「ろ(ro)」に対応づけられている。CPU10は、第1番目(1回目)のキーオンを検出した場合、テキストデータ30から、第1の順番に対応付けられた「い(i)」を読み出す。また、CPU10は、歌詞情報テーブル50から、「い(i)」に対応付けられた第2制御パラメータ情報を読み出す。音源13は、読み出された第2制御パラメータ情報に従った態様で「い(i)」を示す歌唱音を出力する。同様に、CPU10は、第2番目(2回目)キーオンを検出した場合、テキストデータ30から、第2の順番に対応付けられた「ろ(ro)」を読み出す。また、CPU10は、歌詞情報テーブル50から、「ろ(ro)」に対応付けられた第45制御パラメータ情報を読み出す。音源13は、第45制御パラメータ情報に従った態様で「ろ(ro)」を示す歌唱音を出力する。
上記した第3実施形態にかかる発音装置200では、ユーザーが鍵盤等の演奏操作子16を利用してリアルタイム演奏した際に、演奏操作子16を押す操作を行う毎に指定されたテキストデータの音節が、その演奏操作子16の音高で発音される。テキストデータを歌詞とすることで歌声が発音される。この際に、音節毎に対応付けられた発音制御パラメータにより発音制御が行われる。このため、歌唱される歌声の表情や抑揚、声質や音色に変化を与えることができ、歌声に細かなニュアンスや抑揚をつけられるようになる。
第3実施形態にかかる発音装置200における歌詞情報テーブル50の音節情報50aを、図3Bに示すように歌詞を区切った音節のテキストデータ30とそのグループ化情報31とからなるようにする場合について説明する。この場合、グループ化された音節を演奏操作子16に対する1回の連続する操作により、演奏操作子16の音高で発音させることができる。すなわち、演奏操作子16を押すことに応じて1音節目を演奏操作子16の音高で発音させる。また、演奏操作子16から離れる操作に応じて2音節目を演奏操作子16の音高で発音させる。この際に、音節毎に対応付けられた発音制御パラメータにより発音制御が行われる。このため、歌唱される歌声の表情や抑揚、声質や音色に変化を与えることができ、歌声に細かなニュアンスや抑揚をつけられるようになる。
第3実施形態の発音装置200は、第2実施形態の発音装置100で発音される上記した歌詞のない所定の音を発音することができる。第3実施形態の発音装置200で上記した歌詞のない所定の音を発音する場合には、音節情報に応じて、取得する発音制御パラメータを決定するのではなく、何回目の押鍵操作であるかに応じて取得する発音制御パラメータを決定するようにすればよい。
第3実施形態において、音高は、操作された演奏操作子16(押された鍵)に応じて指定されている。別法として、音高は、演奏操作子16が操作された順番に応じて指定されてもよい。
第3実施形態の第1の変形例について説明する。この変形例では、データメモリ18が、図12に示す歌詞情報テーブル50を格納している。歌詞情報テーブル50は、複数の制御パラメータ情報(制御パラメータの一例)、すなわち、第1から第n制御パラメータ情報を含む。例えば、第1制御パラメータ情報は、パラメータaと値v1~v3の組み合わせ、および、パラメータbと値v1~v3の組み合わせを含む。複数の制御パラメータ情報はそれぞれ異なる順番に対応付けられている。例えば、第1制御パラメータ情報は、第1の順番に対応づけられている。第2制御パラメータ情報は、第2の順番に対応づけられている。CPU10は、第1番目(1回目)のキーオンを検出した場合、歌詞情報テーブル50から、第1の順番に対応付けられた第1制御パラメータ情報を読み出す。音源13は、読み出された第1制御パラメータ情報に従った態様で音を出力する。同様に、CPU10は、第n番目(n回目)のキーオンを検出した場合、歌詞情報テーブル50から、第nの順番に対応付けられた第n制御パラメータ情報に関連付けられた発音制御パラメータ情報を読み出す。音源13は、読み出された第n制御パラメータ情報に従った態様で音を出力する。
第3実施形態の第2の変形例について説明する。この変形例では、データメモリ18が、図13に示す歌詞情報テーブル50を格納している。歌詞情報テーブル50は、複数の制御パラメータ情報を含む。複数の制御パラメータ情報はそれぞれ異なる音高に対応付けられている。例えば、第1制御パラメータ情報は、音高A5に対応づけられている。第2制御パラメータ情報は、音高B5に対応づけられている。CPU10は、音高A5にかかる鍵のキーオンを検出した場合、データメモリ18から、音高A5に対応付けられた第1パラメータ情報を読み出す。音源13は、読み出された第1制御パラメータ情報に従った態様かつ音高A5で音を出力する。同様に、CPU10は、音高B5にかかる鍵のキーオンを検出した場合、データメモリ18から、音高B5に対応付けられた第2制御パラメータ情報を読み出す。音源13は、読み出された第2制御パラメータ情報に従った態様かつ音高B5で音を出力する。
第3実施形態の第3の変形例について説明する。この変形例では、データメモリ18が、図14に示すテキストデータ30を格納している。テキストデータ30は、複数の音節、すなわち、第1の音節「い(i)」、第2の音節「ろ(ro)」および第3の音節「は(ha)」を含む。以下において、「い(i)」、「ろ(ro)」および「は(ha)」各々は、日本語のひらがなの一文字を示し、音節の一例である。第1の音節である「い(i)」は、第1の順番に対応づけられている。第2の音節である「ろ(ro)」は、第2の順番に対応づけられている。第3の音節である「は(ha)」は、第3の順番に対応づけられている。データメモリ18は、さらに、図15に示す歌詞情報テーブル50を格納している。歌詞情報テーブル50は、複数の制御パラメータ情報を含む。複数の制御パラメータ情報は、それぞれ異なる音節に対応付けられている。例えば、第2制御パラメータ情報は、音節「い(i)」に対応づけられている。第26制御パラメータ情報(不図示)は、音節「は(ha)」に対応づけられている。第45制御パラメータ情報は、「ろ(ro)」に対応づけられている。CPU10は、第1番目(1回目)のキーオンを検出した場合、テキストデータ30から、第1の順番に対応付けられた「い(i)」を読み出す。また、CPU10は、歌詞情報テーブル50から、「い(i)」に対応付けられた第2制御パラメータ情報を読み出す。音源13は、読み出された第2制御パラメータ情報に従った態様で「い(i)」を示す歌唱音を出力する。同様に、CPU10は、第2番目(2回目)キーオンを検出した場合、テキストデータ30から、第2の順番に対応付けられた「ろ(ro)」を読み出す。また、CPU10は、歌詞情報テーブル50から、「ろ(ro)」に対応付けられた第45制御パラメータ情報を読み出す。音源13は、第45制御パラメータ情報に従った態様で「ろ(ro)」を示す歌唱音を出力する。
以上説明した本発明の実施形態にかかるキーオフ発音情報は、音節情報の中に含むことに替えて、音節情報とは別に記憶されていてもよい。この場合、キーオフ発音情報は、何回目に鍵が押された場合にキーオフ発音を実行するかを記述したデータであってもよい。キーオフ発音情報は、演奏時にリアルタイムでユーザーの指示により発生される情報であってもよい。例えば、ユーザーが鍵を押している間にペダルを踏んだときのみ、そのノートに対してキーオフ発音を実行してもよい。鍵が押されている時間が所定長を超えたときにキーオフ発音を実行してもよい。また、押鍵ベロシティが所定値を超えたときにキーオフ発音を実行してもよい。
以上説明した本発明の実施形態にかかる発音装置は、歌詞または歌詞のない歌唱音を発音すること、および、楽器音や効果音などの歌詞のない所定の音を発音することができる。また、本発明の実施形態にかかる発音装置は、歌唱音を含む所定の音を発音することができる。
以上説明した本発明の実施形態にかかる発音装置において歌詞を発音させる際に、歌詞をほぼ1文字1音節となる日本語を例に上げて説明した。しかしながら、本発明の実施形態はこのような場合に限定されない。1文字が1音節とならない他の言語の歌詞を音節毎に区切って、本発明の実施形態にかかる発音装置で上記したように発音させることにより、他の言語の歌詞を歌唱させるようにしても良い。
また、以上説明した本発明の実施形態にかかる発音装置において、演奏操作子に替えて、演奏データ発生装置を用意し、演奏データ発生装置から演奏情報を発音装置に順次与えるようにしても良い。
以上説明した本発明の実施形態にかかる発音装置は、歌詞または歌詞のない歌唱音を発音すること、および、楽器音や効果音などの歌詞のない所定の音を発音することができる。また、本発明の実施形態にかかる発音装置は、歌唱音を含む所定の音を発音することができる。
以上説明した本発明の実施形態にかかる発音装置において歌詞を発音させる際に、歌詞をほぼ1文字1音節となる日本語を例に上げて説明した。しかしながら、本発明の実施形態はこのような場合に限定されない。1文字が1音節とならない他の言語の歌詞を音節毎に区切って、本発明の実施形態にかかる発音装置で上記したように発音させることにより、他の言語の歌詞を歌唱させるようにしても良い。
また、以上説明した本発明の実施形態にかかる発音装置において、演奏操作子に替えて、演奏データ発生装置を用意し、演奏データ発生装置から演奏情報を発音装置に順次与えるようにしても良い。
以上に示した実施形態に係る歌唱音発音装置1、100、200の機能を実現するためのプログラムをコンピュータ読み取り可能な記録媒体に記録して、この記録媒体に記録されたプログラムをコンピュータシステムに読み込ませ、実行することにより、処理を行ってもよい。
ここでいう「コンピュータシステム」は、オペレーティング・システム(OS:Operating System)や周辺機器等のハードウェアを含んでもよい。
「コンピュータ読み取り可能な記録媒体」は、フレキシブルディスク、光磁気ディスク、ROM(Read Only Memory)、フラッシュメモリ等の書き込み可能な不揮発性メモリ、DVD(Digital Versatile Disk)等の可搬媒体、コンピュータシステムに内蔵されるハードディスク等の記憶装置を含む。
「コンピュータ読み取り可能な記録媒体」は、フレキシブルディスク、光磁気ディスク、ROM(Read Only Memory)、フラッシュメモリ等の書き込み可能な不揮発性メモリ、DVD(Digital Versatile Disk)等の可搬媒体、コンピュータシステムに内蔵されるハードディスク等の記憶装置を含む。
「コンピュータ読み取り可能な記録媒体」は、インターネット等のネットワークや電話回線等の通信回線を介してプログラムが送信された場合のサーバやクライアントとなるコンピュータシステム内部の揮発性メモリ(例えばDRAM(Dynamic Random Access Memory))のように、一定時間プログラムを保持しているものも含む。
上記のプログラムは、このプログラムを記憶装置等に格納したコンピュータシステムから、伝送媒体を介して、あるいは、伝送媒体中の伝送波により他のコンピュータシステムに伝送されてもよい。プログラムを伝送する「伝送媒体」は、インターネット等のネットワーク(通信網)や電話回線等の通信回線(通信線)のように情報を伝送する機能を有する媒体のことをいう。
上記のプログラムは、前述した機能の一部を実現するためのものであってもよい。
上記のプログラムは、前述した機能をコンピュータシステムに既に記録されているプログラムとの組み合わせで実現できるもの、いわゆる差分ファイル(差分プログラム)であってもよい。
上記のプログラムは、このプログラムを記憶装置等に格納したコンピュータシステムから、伝送媒体を介して、あるいは、伝送媒体中の伝送波により他のコンピュータシステムに伝送されてもよい。プログラムを伝送する「伝送媒体」は、インターネット等のネットワーク(通信網)や電話回線等の通信回線(通信線)のように情報を伝送する機能を有する媒体のことをいう。
上記のプログラムは、前述した機能の一部を実現するためのものであってもよい。
上記のプログラムは、前述した機能をコンピュータシステムに既に記録されているプログラムとの組み合わせで実現できるもの、いわゆる差分ファイル(差分プログラム)であってもよい。
1,100,200 発音装置
10 CPU
11 ROM
12 RAM
13 音源
14 サウンドシステム
15 表示部
16 演奏操作子
17 設定操作子
18 データメモリ
19 バス
30 テキストデータ
31 グループ化情報
32 音韻データベース
32a 音素連鎖データ
32b 定常部分データ
40 キーオフ発音情報
41 ピアノロール譜
50 歌詞情報テーブル
50a 音節情報
50b 発音制御パラメータタイプ
50c 値情報
52 ピアノロール譜
10 CPU
11 ROM
12 RAM
13 音源
14 サウンドシステム
15 表示部
16 演奏操作子
17 設定操作子
18 データメモリ
19 バス
30 テキストデータ
31 グループ化情報
32 音韻データベース
32a 音素連鎖データ
32b 定常部分データ
40 キーオフ発音情報
41 ピアノロール譜
50 歌詞情報テーブル
50a 音節情報
50b 発音制御パラメータタイプ
50c 値情報
52 ピアノロール譜
Claims (19)
- 音の出力の開始を示す開始指示を受け付ける受付部と、
前記開始指示が受け付けられたことに応答して、前記音の出力態様を決定する制御パラメータを読み出す読出部と、
前記読み出された制御パラメータに従った態様で前記音を出力させる制御部と、
を備える音制御装置。 - 音節を示す音節情報、および前記音節情報に対応付けられた前記制御パラメータを記憶する記憶部をさらに備え、
前記読出部は、前記記憶部から、前記音節情報および前記制御パラメータを読み出し、
前記制御部は、前記読み出された制御パラメータに従った態様で、前記音節を示す歌唱音を前記音として出力させる
請求項1に記載の音制御装置。 - 前記制御部は、前記制御パラメータに従った態様かつある音高で前記歌唱音を出力させる
請求項2に記載の音制御装置。 - 前記音節は、一つ以上の文字である
請求項2に記載の音制御装置。 - 前記一以上の文字は、日本語の仮名である
請求項4に記載の音制御装置。 - 互いに異なる複数の順番にそれぞれ対応付けられた複数の制御パラメータを記憶する記憶部をさらに備え、
前記受付部は、前記開始指示を含む複数の開始指示を順番に受け付け、
前記読出部は、前記記憶部から、前記制御パラメータとして、前記複数の制御パラメータのうち、前記開始指示が受け付けられた順番に対応付けられた制御パラメータを読み出す、
請求項1に記載の音制御装置。 - 互いに異なる複数の音高にそれぞれ対応付けられた複数の制御パラメータを記憶する記憶部をさらに備え、
前記開始指示は、音高を示す音高情報を含み、
前記読出部は、前記記憶部から、前記制御パラメータとして、前記複数の制御パラメータのうち、前記音高情報によって示される音高に対応付けられた制御パラメータを読み出し、
前記制御部は、前記制御パラメータに従った態様かつ前記音高で前記音を出力させる
請求項1に記載の音制御装置。 - ユーザからの操作を受け付けるとともに互いに異なる複数の音高にそれぞれ対応付けられた複数の操作子をさらに備え、
前記受付部は、前記複数の操作子のうちの任意の一つの操作子に対するユーザからの操作を受け付けた場合に、前記開始指示を受け付けたと判断し、
前記制御部は、前記読み出された制御パラメータに従った態様かつ前記一つの操作子に対応付けられている音高で前記音を出力させる
請求項1に記載の音制御装置。 - 互いに異なる複数の音にそれぞれ対応付けられた複数の制御パラメータを記憶する記憶部をさらに備え、
前記読出部は、前記記憶部から、前記制御パラメータとして、前記複数の制御パラメータのうち、前記音に対応付けられた制御パラメータを読み出す、
請求項1に記載の音制御装置。 - 互いに異なる複数の音、および前記複数の音にそれぞれ対応付けられた複数の制御パラメータを記憶する記憶部をさらに備え、
前記読出部は、前記記憶部から、前記制御パラメータとして、前記複数の制御パラメータのうち、前記音に対応付けられた制御パラメータを読み出す、
請求項1に記載の音制御装置。 - 互いに異なる複数の順番に対応付けられた複数の音、および前記複数の音にそれぞれ対応付けられた複数の制御パラメータを記憶する記憶部をさらに備え、
前記受付部は、前記開始指示を含む複数の開始指示を順番に受け付け、
前記読出部は、前記記憶部から、前記音として、前記複数の音のうち、前記開始指示が受け付けられた順番に対応付けられた音を読み出し、
前記読出部は、前記記憶部から、前記制御パラメータとして、前記複数の制御パラメータのうち、前記音に対応付けられた制御パラメータを読み出す、
請求項1に記載の音制御装置。 - 前記制御部は、前記音として、音節、文字、または日本語の仮名を示す歌唱音を出力させる
請求項9から11のいずれか一項に記載の音制御装置。 - 前記制御パラメータは、編集可能である
請求項1に記載の音制御装置。 - 前記制御パラメータは、それぞれ種類の異なる第1および第2制御パラメータを含み、
前記制御部は、前記1の制御パラメータに従った第1態様で前記音を出力させることと同時に前記2制御パラメータに従った第2態様で前記音を出力させ、
前記第1態様と前記第2態様とは互いに異なる
請求項1に記載の音制御装置。 - 前記制御パラメータは、音の変化のタイプを示す情報を含む
請求項1に記載の音制御装置。 - 前記音の変化のタイプは、
声に含まれる倍音成分のバランスを変化させるタイプと、
声の明暗を演出してトーン変化を与えるタイプと、
有声音の音色および強弱を演出するタイプと、
フォルマントを変化させることにより、女性的なあるいは男性的な声の太さおよび質感を変化させるタイプと、
のうちの一つである
請求項15に記載の音制御装置。 - 前記制御パラメータは、前記音の変化のしかたを示す値、前記音の変化の大きさを示す値、前記および音の変化の深さを示す値をさらに含む
請求項15または16に記載の音制御装置。 - 音の出力の開始を示す開始指示を受け付け、
前記開始指示が受け付けられたことに応答して、前記音の出力態様を決定する制御パラメータを読み出し、
前記読み出された制御パラメータに従った態様で前記音を出力させる、
ことを含む音制御方法。 - コンピュータに、
音の出力の開始を示す開始指示を受け付け、
前記開始指示が受け付けられたことに応答して、前記音の出力態様を決定する制御パラメータを読み出し、
前記読み出された制御パラメータに従った態様で前記音を出力させる、
ことを実行させる音制御プログラム。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201680016405.1A CN107430849B (zh) | 2015-03-20 | 2016-03-17 | 声音控制装置、声音控制方法和存储声音控制程序的计算机可读记录介质 |
| EP16768618.7A EP3273441B1 (en) | 2015-03-20 | 2016-03-17 | Sound control device, sound control method, and sound control program |
| US15/705,696 US10354629B2 (en) | 2015-03-20 | 2017-09-15 | Sound control device, sound control method, and sound control program |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015-057946 | 2015-03-20 | ||
| JP2015057946 | 2015-03-20 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US15/705,696 Continuation US10354629B2 (en) | 2015-03-20 | 2017-09-15 | Sound control device, sound control method, and sound control program |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2016152715A1 true WO2016152715A1 (ja) | 2016-09-29 |
Family
ID=56977484
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2016/058490 Ceased WO2016152715A1 (ja) | 2015-03-20 | 2016-03-17 | 音制御装置、音制御方法、および音制御プログラム |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US10354629B2 (ja) |
| EP (1) | EP3273441B1 (ja) |
| JP (1) | JP6728754B2 (ja) |
| CN (1) | CN107430849B (ja) |
| WO (1) | WO2016152715A1 (ja) |
Families Citing this family (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6728754B2 (ja) * | 2015-03-20 | 2020-07-22 | ヤマハ株式会社 | 発音装置、発音方法および発音プログラム |
| JP6828530B2 (ja) * | 2017-03-14 | 2021-02-10 | ヤマハ株式会社 | 発音装置及び発音制御方法 |
| WO2019003348A1 (ja) * | 2017-06-28 | 2019-01-03 | ヤマハ株式会社 | 歌唱音効果生成装置及び方法、プログラム |
| CN108320741A (zh) * | 2018-01-15 | 2018-07-24 | 珠海格力电器股份有限公司 | 智能设备的声音控制方法、装置、存储介质和处理器 |
| CN111656434B (zh) * | 2018-02-14 | 2023-08-04 | 雅马哈株式会社 | 音响参数调整装置、音响参数调整方法及记录介质 |
| CN110189741B (zh) * | 2018-07-05 | 2024-09-06 | 腾讯数码(天津)有限公司 | 音频合成方法、装置、存储介质和计算机设备 |
| JP7419903B2 (ja) | 2020-03-18 | 2024-01-23 | ヤマハ株式会社 | パラメータ制御装置、パラメータ制御方法およびプログラム |
| JP7036141B2 (ja) * | 2020-03-23 | 2022-03-15 | カシオ計算機株式会社 | 電子楽器、方法及びプログラム |
| US12346667B2 (en) * | 2021-09-29 | 2025-07-01 | Olga Vechtomova | Autoencoder-based lyric generation |
| CN116758882A (zh) * | 2023-07-18 | 2023-09-15 | 上海哔哩哔哩科技有限公司 | 音色生成方法及系统 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH04349497A (ja) * | 1991-05-27 | 1992-12-03 | Yamaha Corp | 電子楽器 |
| JPH0895588A (ja) * | 1994-09-27 | 1996-04-12 | Victor Co Of Japan Ltd | 音声合成装置 |
| JPH1031496A (ja) * | 1996-07-15 | 1998-02-03 | Casio Comput Co Ltd | 楽音発生装置 |
| JP2000330584A (ja) * | 1999-05-19 | 2000-11-30 | Toppan Printing Co Ltd | 音声合成装置および音声合成方法、ならびに音声通信装置 |
| JP2014098801A (ja) * | 2012-11-14 | 2014-05-29 | Yamaha Corp | 音声合成装置 |
Family Cites Families (40)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5998725A (en) * | 1996-07-23 | 1999-12-07 | Yamaha Corporation | Musical sound synthesizer and storage medium therefor |
| JP2000105595A (ja) * | 1998-09-30 | 2000-04-11 | Victor Co Of Japan Ltd | 歌唱装置及び記録媒体 |
| JP2001356784A (ja) * | 2000-06-12 | 2001-12-26 | Yamaha Corp | 端末装置 |
| JP3879402B2 (ja) * | 2000-12-28 | 2007-02-14 | ヤマハ株式会社 | 歌唱合成方法と装置及び記録媒体 |
| JP3815347B2 (ja) * | 2002-02-27 | 2006-08-30 | ヤマハ株式会社 | 歌唱合成方法と装置及び記録媒体 |
| JP4153220B2 (ja) * | 2002-02-28 | 2008-09-24 | ヤマハ株式会社 | 歌唱合成装置、歌唱合成方法及び歌唱合成用プログラム |
| JP4300764B2 (ja) * | 2002-07-26 | 2009-07-22 | ヤマハ株式会社 | 歌唱音声を合成する方法および装置 |
| JP3938015B2 (ja) * | 2002-11-19 | 2007-06-27 | ヤマハ株式会社 | 音声再生装置 |
| JP3823930B2 (ja) * | 2003-03-03 | 2006-09-20 | ヤマハ株式会社 | 歌唱合成装置、歌唱合成プログラム |
| JP2004287099A (ja) * | 2003-03-20 | 2004-10-14 | Sony Corp | 歌声合成方法、歌声合成装置、プログラム及び記録媒体並びにロボット装置 |
| JP4483188B2 (ja) * | 2003-03-20 | 2010-06-16 | ソニー株式会社 | 歌声合成方法、歌声合成装置、プログラム及び記録媒体並びにロボット装置 |
| JP3858842B2 (ja) * | 2003-03-20 | 2006-12-20 | ソニー株式会社 | 歌声合成方法及び装置 |
| JP3864918B2 (ja) * | 2003-03-20 | 2007-01-10 | ソニー株式会社 | 歌声合成方法及び装置 |
| JP2008095588A (ja) * | 2006-10-11 | 2008-04-24 | Sanden Corp | スクロール圧縮機 |
| JP4858173B2 (ja) * | 2007-01-05 | 2012-01-18 | ヤマハ株式会社 | 歌唱音合成装置およびプログラム |
| US8244546B2 (en) * | 2008-05-28 | 2012-08-14 | National Institute Of Advanced Industrial Science And Technology | Singing synthesis parameter data estimation system |
| JP2010031496A (ja) * | 2008-07-28 | 2010-02-12 | Sanwa Shutter Corp | すべり出し窓の開閉装置 |
| CN101923794A (zh) * | 2009-11-04 | 2010-12-22 | 陈学煌 | 多功能音准练习机 |
| WO2012011475A1 (ja) * | 2010-07-20 | 2012-01-26 | 独立行政法人産業技術総合研究所 | 声色変化反映歌声合成システム及び声色変化反映歌声合成方法 |
| US20120234158A1 (en) * | 2011-03-15 | 2012-09-20 | Agency For Science, Technology And Research | Auto-synchronous vocal harmonizer |
| US8653354B1 (en) * | 2011-08-02 | 2014-02-18 | Sonivoz, L.P. | Audio synthesizing systems and methods |
| JP6056437B2 (ja) * | 2011-12-09 | 2017-01-11 | ヤマハ株式会社 | 音データ処理装置及びプログラム |
| CN103207682B (zh) * | 2011-12-19 | 2016-09-14 | 国网新疆电力公司信息通信公司 | 基于音节切分的维哈柯文智能输入法 |
| JP6136202B2 (ja) * | 2011-12-21 | 2017-05-31 | ヤマハ株式会社 | 音楽データ編集装置および音楽データ編集方法 |
| JP5943618B2 (ja) | 2012-01-25 | 2016-07-05 | ヤマハ株式会社 | 音符列設定装置および音符列設定方法 |
| JP5895740B2 (ja) * | 2012-06-27 | 2016-03-30 | ヤマハ株式会社 | 歌唱合成を行うための装置およびプログラム |
| US9012756B1 (en) * | 2012-11-15 | 2015-04-21 | Gerald Goldman | Apparatus and method for producing vocal sounds for accompaniment with musical instruments |
| EP2930714B1 (en) * | 2012-12-04 | 2018-09-05 | National Institute of Advanced Industrial Science and Technology | Singing voice synthesizing system and singing voice synthesizing method |
| JP5949607B2 (ja) * | 2013-03-15 | 2016-07-13 | ヤマハ株式会社 | 音声合成装置 |
| JP5935815B2 (ja) * | 2014-01-15 | 2016-06-15 | ヤマハ株式会社 | 音声合成装置およびプログラム |
| EP3159892B1 (en) * | 2014-06-17 | 2020-02-12 | Yamaha Corporation | Controller and system for voice generation based on characters |
| US9711133B2 (en) * | 2014-07-29 | 2017-07-18 | Yamaha Corporation | Estimation of target character train |
| JP2016080827A (ja) * | 2014-10-15 | 2016-05-16 | ヤマハ株式会社 | 音韻情報合成装置および音声合成装置 |
| JP6728754B2 (ja) * | 2015-03-20 | 2020-07-22 | ヤマハ株式会社 | 発音装置、発音方法および発音プログラム |
| JP6728755B2 (ja) * | 2015-03-25 | 2020-07-22 | ヤマハ株式会社 | 歌唱音発音装置 |
| JP6620462B2 (ja) * | 2015-08-21 | 2019-12-18 | ヤマハ株式会社 | 合成音声編集装置、合成音声編集方法およびプログラム |
| JP6759545B2 (ja) * | 2015-09-15 | 2020-09-23 | ヤマハ株式会社 | 評価装置およびプログラム |
| JP6705142B2 (ja) * | 2015-09-17 | 2020-06-03 | ヤマハ株式会社 | 音質判定装置及びプログラム |
| JP6690181B2 (ja) * | 2015-10-22 | 2020-04-28 | ヤマハ株式会社 | 楽音評価装置及び評価基準生成装置 |
| US10134374B2 (en) * | 2016-11-02 | 2018-11-20 | Yamaha Corporation | Signal processing method and signal processing apparatus |
-
2016
- 2016-02-23 JP JP2016032392A patent/JP6728754B2/ja not_active Expired - Fee Related
- 2016-03-17 WO PCT/JP2016/058490 patent/WO2016152715A1/ja not_active Ceased
- 2016-03-17 EP EP16768618.7A patent/EP3273441B1/en not_active Not-in-force
- 2016-03-17 CN CN201680016405.1A patent/CN107430849B/zh not_active Expired - Fee Related
-
2017
- 2017-09-15 US US15/705,696 patent/US10354629B2/en active Active
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH04349497A (ja) * | 1991-05-27 | 1992-12-03 | Yamaha Corp | 電子楽器 |
| JPH0895588A (ja) * | 1994-09-27 | 1996-04-12 | Victor Co Of Japan Ltd | 音声合成装置 |
| JPH1031496A (ja) * | 1996-07-15 | 1998-02-03 | Casio Comput Co Ltd | 楽音発生装置 |
| JP2000330584A (ja) * | 1999-05-19 | 2000-11-30 | Toppan Printing Co Ltd | 音声合成装置および音声合成方法、ならびに音声通信装置 |
| JP2014098801A (ja) * | 2012-11-14 | 2014-05-29 | Yamaha Corp | 音声合成装置 |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP3273441A4 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN107430849A (zh) | 2017-12-01 |
| JP6728754B2 (ja) | 2020-07-22 |
| CN107430849B (zh) | 2021-02-23 |
| EP3273441A1 (en) | 2018-01-24 |
| US20180005617A1 (en) | 2018-01-04 |
| JP2016177276A (ja) | 2016-10-06 |
| EP3273441B1 (en) | 2020-08-19 |
| EP3273441A4 (en) | 2018-11-14 |
| US10354629B2 (en) | 2019-07-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10354629B2 (en) | Sound control device, sound control method, and sound control program | |
| JP6561499B2 (ja) | 音声合成装置および音声合成方法 | |
| US20210295819A1 (en) | Electronic musical instrument and control method for electronic musical instrument | |
| US9711123B2 (en) | Voice synthesis device, voice synthesis method, and recording medium having a voice synthesis program recorded thereon | |
| JP2019101094A (ja) | 音声合成方法およびプログラム | |
| WO2016152717A1 (ja) | 音制御装置、音制御方法、および音制御プログラム | |
| US20220044662A1 (en) | Audio Information Playback Method, Audio Information Playback Device, Audio Information Generation Method and Audio Information Generation Device | |
| JP6167503B2 (ja) | 音声合成装置 | |
| JP4277697B2 (ja) | 歌声生成装置、そのプログラム並びに歌声生成機能を有する携帯通信端末 | |
| WO2016152708A1 (ja) | 音制御装置、音制御方法、および音制御プログラム | |
| JP6809608B2 (ja) | 歌唱音生成装置及び方法、プログラム | |
| JP5157922B2 (ja) | 音声合成装置、およびプログラム | |
| JP5106437B2 (ja) | カラオケ装置及びその制御方法並びにその制御プログラム | |
| JP4929604B2 (ja) | 歌データ入力プログラム | |
| JP6828530B2 (ja) | 発音装置及び発音制御方法 | |
| JP2010169889A (ja) | 音声合成装置、およびプログラム | |
| JP2018151548A (ja) | 発音装置及びループ区間設定方法 | |
| JP5953743B2 (ja) | 音声合成装置及びプログラム | |
| JP5552797B2 (ja) | 音声合成装置および音声合成方法 | |
| JP7537419B2 (ja) | 子音長変更装置、電子楽器、楽器システム、方法及びプログラム | |
| JP7158331B2 (ja) | カラオケ装置 | |
| JP4432834B2 (ja) | 歌唱合成装置および歌唱合成プログラム | |
| WO2023175844A1 (ja) | 電子管楽器及び電子管楽器の制御方法 | |
| JP2015161822A (ja) | ブレス音設定装置 | |
| WO2019003348A1 (ja) | 歌唱音効果生成装置及び方法、プログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 16768618 Country of ref document: EP Kind code of ref document: A1 |
|
| DPE1 | Request for preliminary examination filed after expiration of 19th month from priority date (pct application filed from 20040101) | ||
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| REEP | Request for entry into the european phase |
Ref document number: 2016768618 Country of ref document: EP |