WO2017017748A1 - Système informatique et procédé d'échantillonnage - Google Patents
Système informatique et procédé d'échantillonnage Download PDFInfo
- Publication number
- WO2017017748A1 WO2017017748A1 PCT/JP2015/071196 JP2015071196W WO2017017748A1 WO 2017017748 A1 WO2017017748 A1 WO 2017017748A1 JP 2015071196 W JP2015071196 W JP 2015071196W WO 2017017748 A1 WO2017017748 A1 WO 2017017748A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- sampling
- data
- index
- characteristic
- computer system
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images













Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
Definitions
- the present invention generally relates to a sampling technique using a computer.
- Patent Document 1 describes a stratified extraction mechanism provided in a database system.
- the stratification extraction mechanism defines a phrase meaning a request for stratification extraction in a query.
- Data from the source table is classified into different subgroups based on the stratification conditions in the query. Sampling is performed by subgroup.
- the work accuracy (for example, analysis accuracy) may be greatly reduced as compared to the case where the entire population is the search target. This problem is not limited to cases where the population is a database.
- the computer system identifies a task associated with a sampling candidate data group that is one or more sampling candidate data.
- the computer system sets the sampling conditions according to the sampling rule corresponding to the specified business characteristics based on the management information, which is information including information indicating the relationship between the business including the data search and the business characteristics and the sampling rule. decide.
- the computer system samples data that meets the determined sampling condition from the sampling candidate data group. Sampling results are referenced during data retrieval performed in the identified business. At least one of a sampling data group that is one or more sampling data including the sampled data and a sampling index that is an index of the sampling data group is used in a data search performed in the specified job. Referenced sampling result.
- sampling condition is a condition that follows a sampling rule corresponding to the characteristics of the business for which data search is to be performed. For this reason, high accuracy is expected as the accuracy of the work including the search with the sampling result as the search target.
- summary of embodiment is shown.
- a configuration example of the entire system is shown.
- the structural example of business management information is shown.
- the structural example of characteristic management information is shown.
- the structural example of a sampling index is shown.
- the structural example of rule management information is shown.
- the structural example of relationship management information is shown.
- An example of characteristic input GUI is shown.
- An example of the flow of a data addition process is shown.
- An example of the flow of a sampling process is shown.
- An example of the flow of a sampling condition determination process is shown.
- An example of the flow of maintenance processing is shown.
- An example of the flow of a thinning process is shown.
- An example of the flow of search processing is shown.
- the structural example of the search query by which the sampling index was designated is shown.
- An example of the flow of a definition process is shown.
- a configuration example of a definition query in which a sampling index is specified is shown.
- bbb unit or bbb accelerator
- these functional units perform processing determined by being executed by the processor as a memory and a communication port (network). I / F) can be used, and therefore the description may be made with the processor as the subject.
- the processor typically includes a microprocessor (for example, CPU (Central Processing Unit)), and further includes dedicated hardware (for example, ASIC (Application Specific Integrated Circuit) or FPGA (Field-Programmable Gate Array)). Good.
- the processing disclosed with these functional units as the subject may be processing performed by a computer. In addition, some or all of these functional units may be realized by dedicated hardware.
- Various functional units may be installed in each computer by a program distribution server or a computer-readable storage medium.
- Various functional units and servers may be installed and executed on one computer, or may be installed and executed on a plurality of computers.
- the processor is an example of a control unit, and may include a hardware circuit that performs part or all of the processing.
- the program may be installed in a computer-like device from a program source.
- the program source may be, for example, a storage medium that can be read by a program distribution server or a computer.
- the program distribution server may include a processor (for example, a CPU) and a storage unit, and the storage unit may further store a distribution program and a program to be distributed.
- the processor of the program distribution server executes the distribution program, so that the processor of the program distribution server may distribute the distribution target program to other computers.
- two or more programs may be realized as one program, or one program may be realized as two or more programs.
- the “storage unit” may be one or more storage devices including a memory.
- the storage unit may be at least a main storage device of a main storage device (typically a volatile memory) and an auxiliary storage device (typically a nonvolatile storage device).
- a “population” is a data group (one or more data).
- the “additional data group” is one or more additional data.
- Additional data is data added to the population.
- “Sampling” refers to extracting data from at least one of a population and an additional data group.
- “Sampling data” is data extracted from at least one of the population and the additional data group, that is, sampled data.
- the “sampling data group” is one or more sampling data.
- FIG. 1 shows an example of an outline of the embodiment.
- Table 221 (table name “Table1”) is an example of a population.
- An additional data group that is one or more additional data 232 is repeatedly added to the table 221 (for example, regularly or irregularly).
- the number of additional data 232 constituting the additional data group may not be constant.
- the table 221 and at least the table 221 of the additional data group may be so-called big data.
- the sampling index 223 is associated.
- the sampling index 223 is an index of a part of the population (sampling data group), not the entire population.
- the sampling index 223 may be a set of a plurality of data IDs (for example, pointers) respectively indicating a plurality of sampling data constituting the sampling data group.
- the data composition ratio of the sampling index 223 is maintained to be the same as the data composition ratio of the table 221.
- the “data composition ratio” is a plurality of data ratios respectively corresponding to a plurality of value ranges, and may be a frequency distribution, for example.
- the “value range” may be a range composed of a minimum value and a maximum value, but may be a single value.
- the data ratio in the value range is the ratio of the number of target data to the total number of source data.
- the “total number of source data” is the number of data constituting the source data group (for example, the number of data IDs constituting the sampling index 223 or the number of data constituting the table 221 (eg, the number of records)).
- the “number of target data” in the value range is the number of data (or data ID of the data) including the values belonging to the value range.
- the computer performs data addition processing (S101), sampling processing (S102), maintenance processing (S103), and search processing (S104).
- the data addition process for example, the following process is performed. That is, the computer adds an additional data group to the table 221.
- a sampling process (S102) and a maintenance process (S103) are performed.
- Sampling processing includes, for example, data acquisition (S102-1), condition determination (S102-2), and data sampling (S102-3).
- the computer acquires the business ID “BID1” corresponding to the sampling index name “S-Index1” of the sampling index 223 in the addition destination table 221 from the business management information 224 indicating the relationship between the sampling index name and the business ID. . Further, the computer acquires the characteristic details “PID1 / Y” and “PID2 / N” corresponding to the business ID “BID1” from the characteristic management information 225 indicating the relationship between the business ID and the characteristic details.
- the computer acquires the sampling rules “rule F” and “rule G” corresponding to the characteristics “PID1 / Y” and “PID2 / N” from the rule management information 226 representing the relationship between the characteristics and the sampling rules. . Further, the computer obtains the inter-characteristic relationship “PID1 AND ⁇ PID2” corresponding to the business type of the business ID “BID1” from the relationship management information 227 indicating the relationship between the business type and the inter-characteristic relationship.
- the relationship between characteristics is a relationship between characteristics, for example, a combination of a characteristic ID and a logical operator.
- the computer combines the sampling rules “Rule F” and “Rule G” corresponding to the characteristics “PID1 / Y” and “PID2 / N”, respectively, according to the inter-characteristic relationship “PID1 AND ⁇ PID2”.
- the AND rule G is determined. That is, each of the plurality of characteristic IDs in the inter-characteristic relationship “PID1 AND PID2” is replaced with a sampling rule corresponding to the characteristic details including the characteristic ID, and as a result, the sampling condition “rule F AND rule G” is generated. Is done.
- the “sampling condition” is a condition of data to be sampled.
- data sampling for example, the following processing is performed. That is, the computer samples data that satisfies the sampling condition “rule F AND rule G” from the additional data group.
- the computer adds the data ID (for example, a pointer) of sampling data (data sampled from the additional data group) added to the table 221 to the sampling index 223 of the table 221. That is, the computer maintains the sampling index 223 associated with the table 221 to which the sampling data is added based on the result of the sampling process (S102).
- the data ID for example, a pointer
- sampling data data sampled from the additional data group
- the computer determines whether or not the sampling index 223 is specified by a search query from a query issuer (for example, a client computer). If there is a description (for example, “QUICK S-Index1”) that means the sampling index 223 in the search query, the determination result is affirmative. If the determination result is affirmative, the computer obtains data that matches the search condition specified by the search query from only a part (sampling data group) of the table 221 through the sampling index 223 of the table 221 specified by the search query. look for. If the determination result is negative, the computer searches the entire table 221 specified by the search query for data that matches the search condition specified by the search query.
- a query issuer for example, a client computer.
- the computer according to the present embodiment is applied to a computer of an electric power company.
- a power company computer receives power consumption data (data representing power consumption) in a first period (for example, every minute) from sensors installed on the switchboards of each household.
- the computer accumulates the received power consumption data in the DB table at a second period that is the same as or different from the first period (for example, every 5 minutes). Therefore, the table is an example of the population, and the power consumption data group stored in the table is an example of the additional data group.
- the amount of power consumption data group depends on the number of households, but is generally large. It takes a long time to calculate the latest average power consumption using all of the power consumption data group. Therefore, a sampling index corresponding to a part of the table 221 is prepared, and when the power consumption data group is added, the computer samples and samples data from the power consumption data group according to the characteristics of the analysis work described above.
- the sampling index is maintained based on the collected power consumption data. Sampling indexes are referenced in searches in analytical work. Since the sampling index is updated when the power consumption data group is added, it is expected that the sampling index to be referenced is always maintained in the latest state. Further, since the sampling index is used instead of the sampling data group, the used capacity (consumed storage capacity) can be suppressed. Since the sampling index is maintained based on the data sampled according to the characteristics of the analysis work, it is expected that the work including the search using the sampling index has high accuracy.
- the additional data group is an example of a sampling candidate data group (one or more sampling candidate data).
- a population as shown in Table 221 may be adopted instead of or in addition to the additional data group.
- the sampling index 223 is an example of the sampling result.
- a sampling data group such as a part of the table 221 may be adopted. That is, the sampling index 223 may not be provided. In that case, however, the sampling data group is stored in the storage device in addition to the table 221. As a result, the used capacity of the storage device is large. This problem is even greater when table 221 is big data. For this reason, it is preferable to employ the sampling index 223 instead of the sampling data group as the sampling result as in this embodiment.
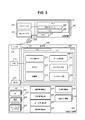
- FIG. 2 shows a configuration example of the entire system.
- the terminal device 201 and the external storage device 220 are connected to the computer 209.
- the terminal device 201 is an example of a client system.
- the terminal device 201 includes an I / F (interface device) 11, an input device 202, a display device 203, a memory 12, and a CPU 207 connected thereto.
- the I / F 11 is connected to the computer 209 via the first communication network 208.
- the input device 202 may be a keyboard and a pointing device.
- the display device 203 may be a liquid crystal display or the like.
- the input device 202 and the display device 203 may be integrated like a touch panel.
- the memory 12 stores an OS (Operating System) 206 and a business program 205.
- the CPU 207 executes these programs.
- the business program 205 issues a query such as a search query to the computer 209 for business.
- the query is described in, for example, SQL (Structured Query Language).
- the computer 209 is an example of a computer system.
- the computer 209 includes an FE-I / F (front end interface device) 210, a BE-I / F (back end interface device) 241, a memory 200, and a CPU 219 connected to them.
- the FE-I / F 210 and the BE-I / F 241 are examples of interface devices.
- the memory 200 is an example of a storage unit.
- the CPU 219 is an example of a processor.
- the terminal device 201 is connected to the FE-I / F 210 via the first communication network 208.
- An external storage device 220 is connected to the BE-I / F 241 via a second communication network (not shown). There may be no at least one of the first and second communication networks, or they may be the same communication network.
- the memory 200 stores an OS 211 and a DBMS (Database Management System) 212.
- the CPU 219 executes those programs.
- the DBMS 212 includes a query control unit 213, a search unit 214, a definition unit 215, a data addition unit 216, a sampling unit 217, and a maintenance unit 218.
- the query control unit 213 receives a query and processes the query. For query processing, the query control unit 213 can call at least one of the search unit 214, the definition unit 215, the data addition unit 216, the sampling unit 217, and the maintenance unit 218 as necessary.
- the search unit 214 can execute a search with reference to the sampling index 223.
- the definition unit 215 can execute the definition of the sampling index 223.
- the data addition unit 216 performs addition of an additional data group, specifically, the above-described data addition process (S101).
- the sampling unit 217 performs sampling of data from the additional data group, specifically, the above-described sampling process (S102).
- the maintenance unit 218 performs maintenance of the sampling index 223, specifically, the above-described maintenance process (S103).
- the external storage device 220 may be a storage system having a plurality of storage devices, for example.
- a plurality of storage devices may constitute one or more RAID (Redundant Array of Independent (or Inexpensive) Disks) groups.
- Each storage device in the RAID group is a non-volatile storage device, and may be, for example, an HDD (Hard Disk Drive) or an SSD (Solid Disk Drive).
- the external storage device 220 stores a DB 242, business management information 224, characteristic management information 225, rule management information 226, relationship management information 227, DB management information 228, and characteristic GUI (Graphical User Interface) information 230.
- At least one of the DB 242, business management information 224, characteristic management information 225, rule management information 226, relationship management information 227, DB management information 228, and characteristic GUI information 230 may be stored in the memory 200 of the computer 209. That is, for example, the computer 209 may be an in-memory database system. Further, for example, a combination of the computer 209 and at least a part of the external storage device 220 may be an example of a computer system. For example, at least a part of the external storage device 220 may be a part of the storage unit. Further, the different types of information described above may be integrated into the same information, or may be divided into further different information. For example, the characteristic management information 225 (see FIG. 4) and the relationship management information 227 (see FIG. 7) may be integrated into one.
- the DB 242 includes a table 221, a normal index 222, and a sampling index 223.
- the table 221 typically includes a plurality of columns and a plurality of records. At least a part of the record is an example of data constituting the table 221.
- One or more normal indexes 222 are associated with the table 221.
- One or more sampling indexes 223 are associated with at least one table 221. All normal indexes 222 associated with the table 221 refer to the entire table 221. All sampling indexes 223 associated with the table 221 refer to a part of the table 221.
- the normal index 222 is any index other than the sampling index 223, and is typically a general index.
- the sampling index 223 is an index having a data ID of sampled data.
- both the normal index 222 and the sampling index 223 may have a list structure or a B-tree structure (FIG. 5 shows a configuration example of the sampling index 223).
- the business management information 224, characteristic management information 225, rule management information 226, relationship management information 227, and characteristic GUI information 230 will be described later.
- Information including business management information 224, characteristic management information 225, rule management information 226, and relationship management information 227 is an example of management information.
- the characteristic GUI information 230 may be included in the management information.
- the management information may further include DB management information 228.
- the DB management information 228 includes information related to the DB 242.
- the DB management information 228 is information that represents the number of data IDs (for example, the number of pointers) that the sampling index 223 has for each sampling index 223, and information that represents the relationship between the table 221 and the indexes (the normal index 222 and the sampling index 223).
- Index management information that is:
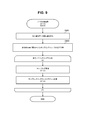
- FIG. 3 shows a configuration example of the business management information 224.
- the business management information 224 represents the relationship between the sampling index 223 and the business. Specifically, for example, the business management information 224 has entries corresponding to the sampling indexes 223, respectively. Each entry includes information such as a sampling index name 301 and a business ID 302.
- the sampling index name 301 represents the name of the sampling index 223 (may be another type of ID).
- the business ID 302 is a business ID.
- FIG. 4 shows a configuration example of the characteristic management information 225.
- the characteristic management information 225 represents the relationship between the business and the business characteristics. Specifically, for example, the characteristic management information 225 has an entry corresponding to each business. Each entry includes information such as a business ID 401, a characteristic ID 402, and an input value 403. A combination of the characteristic ID 402 and the input value 403 is characteristic details. A characteristic ID 402 is an ID of the characteristic. An input value 403 is a value input for the characteristic. The entry includes all the characteristic details belonging to the corresponding business. In other words, a business may be represented with one or more characteristic details. There are one or more characteristics per job.
- FIG. 6 shows a configuration example of the rule management information 226.
- the rule management information 226 represents the relationship between characteristics (characteristic details) and sampling rules. Specifically, for example, the rule management information 226 has an entry corresponding to each characteristic. Each entry includes information of a characteristic ID 601, an input value 602, a sampling rule 603, an external input 604, and an acquisition source 605.
- the sampling rule 603 represents a data sampling rule.
- the “data generation ID” is an ID that uniquely identifies a subject that generates data (for example, a sensor ID that uniquely identifies a sensor that generates sensor data)
- the “sampling ratio” is This is the ratio of the number of additional sampled data (number of sampled additional data 232) to the total number of additional data (number of additional data 232 constituting the additional data group).
- the external input 604 represents a value input from the outside of the sampling unit 217 (DBMS 212) when the sampling condition is determined.
- An acquisition source 605 represents an acquisition source 605 (input source) of a value represented by the external input 604.
- the characteristic details and the sampling rule 603 correspond one-to-one. According to the example of FIG. 6, for example, the following can be said.
- the sampling rule 603 corresponding to the characteristic detail “PID4 / Y” the data is sampled so that the composition ratio of the sampling index 223 is the same as that of the table 221 with which the sampling index 223 is associated. (Sampling index 223 is maintained).
- the external input 604, and the acquisition source 605 corresponding to the characteristic details “PID5 / Y” the priority of the additional data 232 is input by the user, and the higher the input priority, the higher the priority. Will be sampled.
- the “user” referred to in the present embodiment is a user of the terminal device 201, but may be an administrator of the computer 209.
- “external storage” of the acquisition source 605 means the external storage device 220.
- the characteristic details are classified into two, “Y” or “N”, for each characteristic.
- the number of characteristic details is not limited to two for at least one characteristic, and even one An integer of 3 or more may be used.
- FIG. 7 shows a configuration example of the relationship management information 227.
- the relationship management information 227 represents the relationship between the business and the relationship between characteristics. Specifically, for example, the relationship management information 227 has an entry corresponding to each business type. Each entry includes information such as a job type 701, a job ID 702, a characteristic ID 703, and a characteristic relationship 704.
- the business type 701 represents the business type 701.
- the business ID 702 is an ID of a business that belongs to the corresponding business type 701.
- a characteristic ID 703 is an ID of a characteristic belonging to the corresponding business type 701.
- the inter-characteristic relationship 704 represents a relationship between characteristics belonging to the corresponding business type 701.
- the inter-characteristic relationship 704 is that one characteristic ID.
- the inter-characteristic relationship 704 is a plurality of characteristic IDs connected in series with one or more logical operators (for example, “AND” or “OR”).
- the inter-characteristic relationship 704 is not limited to concatenation of a plurality of characteristic IDs by a logical operator, but according to such a configuration of the inter-characteristic relationship 704, elements such as a logical operator and a characteristic ID are added, deleted, or changed It is considered that the convenience is high because the relationship 704 between the characteristics is changed by simply doing.
- the DBMS 212 determines from the relationship management information 227 the inter-characteristic relationship “PID1 AND PID2 AND PID5 AND PID6 corresponding to the business type“ sensor data analysis ”to which the business ID“ BID2 ”belongs. ”Is specified. Further, it is assumed that the DBMS 212 specifies the characteristic details “PID1 / Y”, “PID2 / Y”, “PID5 / Y”, and “PID6 / Y” corresponding to the business ID “BID2” from the characteristic management information 225.
- the sampling condition is “sampling rule corresponding to PID1 / Y sampling rule corresponding to PID2 / Y sampling rule corresponding to AND PID5 / Y sampling rule corresponding to AND PID6 / Y”. That is, each characteristic ID in the inter-characteristic relationship is replaced with a sampling rule (sampling rule 603 specified from the rule management information 226) corresponding to the characteristic details including the characteristic ID. As a result, the sampling condition is a set of sampling rules that follow the relationship between characteristics.
- FIG. 8 shows an example of the characteristic input GUI.
- the characteristic input GUI 800 is a GUI generated and displayed based on the characteristic GUI information 230 corresponding to the GUI.
- the characteristic input GUI 800 is an example of a UI (user interface) that receives an input of business characteristics.
- the characteristic input GUI 800 is provided to the terminal device 201 by the DBMS 212 and displayed on the display device 203 of the terminal device 201.
- the characteristic input GUI 800 may be provided and displayed on the terminal device 201 used by the administrator of the computer 209.
- the characteristic input GUI 800 (characteristic GUI information 230), the characteristic detail sub-UI 802 is displayed.
- the sub UI 802 for at least one characteristic, a characteristic ID, a characteristic content, an input value, and supplementary items are displayed.
- the sub UI for the input value may be a plurality of radio buttons respectively corresponding to a plurality of selectable input values.
- the supplementary matter is an example of providing the necessity of input for at least one characteristic.
- the supplementary items indicate whether or not the characteristics corresponding to the supplementary items are required to be input according to the business type specified by the user.
- the supplementary matter may further include a sentence representing a specific example (for example, for the characteristic ID “PID4”, “maintaining the composition ratio of 20% male data and 80% female data”).
- the characteristic input GUI 800 may include a sub UI 801 that receives a job type from the user.
- the DBMS 212 enables input only for characteristics that are required to be input (for example, only for a characteristic ID corresponding to the input business type), and for characteristics that do not require input (for example, (For characteristic IDs that do not correspond to the entered business type), the input may be disabled (for example, “no input” may be automatically selected).
- Automatic enabling / disabling of inputs may also be an example of providing input necessity for at least one characteristic.
- FIG. 9 shows an example of the flow of data addition processing (S101).
- the data adding unit 216 adds an additional data group to the table 221 (S901).
- the data adding unit 216 refers to the index management information in the DB management information 228, and acquires all sampling index names associated with the addition destination table 221 (S902). For each acquired sampling index name (for each sampling index 223), a sampling process (S102) and a maintenance process (S103) are performed.
- sampling index 223 corresponding to one sampling index name is taken as an example.
- the sampling index 223 employed as an example is referred to as “target sampling index 223” in the description of FIGS.
- FIG. 10 shows an example of the flow of the sampling process (S102).
- the sampling process (S102) may be performed, for example, by calling the sampling unit 217 by the data adding unit 216 in the data adding process (S101).
- the sampling unit 217 refers to the business management information 224 and acquires the business ID 302 associated with the target sampling index name 301 (S1001).
- the sampling unit 217 refers to the characteristic management information 225, and acquires characteristic details (a combination of the characteristic ID 402 and the input value 403) associated with the business ID 302 acquired in S1001 (S1002).
- the sampling unit 217 executes a sampling condition determination process using the characteristic details acquired in S1002 (S1003).
- the sampling unit 217 performs the following processing for each additional data included in the additional data group. That is, the sampling unit 217 determines whether or not the additional data meets the sampling condition determined in S1003 (S1011). If the determination result in S1011 is affirmative, the sampling unit 217 samples the additional data from the additional data group (S1012). The additional data sampled in S1012 is sampling data.
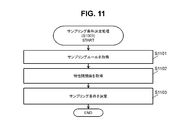
- FIG. 11 shows an example of the flow of sampling condition determination processing (S1003).
- the sampling unit 217 refers to the rule management information 226, and acquires the sampling rule 603 associated with each of the characteristic details acquired in S1002 (S1101).
- the sampling unit 217 refers to the relationship management information 227, and acquires the inter-characteristic relationship 704 associated with the job type 701 to which the job ID acquired in S1001 belongs (1102).
- the sampling unit 217 generates (determines) a sampling condition by combining the sampling rule 603 acquired in S1101 according to the inter-characteristic relationship 704 acquired in S1102 (S1103). Specifically, for example, each characteristic ID in the inter-characteristic relationship 704 acquired in S1102 is replaced with the sampling rule 603 associated with the characteristic details including the characteristic ID in the sampling rule 603 acquired in S1101. . The result is a sampling condition.
- FIG. 12 shows an example of the flow of the maintenance process (S103).
- the maintenance process (S103) may be performed, for example, by calling the maintenance unit 218 by the data adding unit 216 in the data adding process (S101).
- the maintenance unit 218 acquires a data ID (for example, a pointer) for each sampled data (S1201). The maintenance unit 218 adds the data ID acquired in S1201 to the target sampling index 223 (S1202). Then, the maintenance unit 218 performs a thinning process (S1203).
- a data ID for example, a pointer
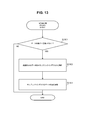
- FIG. 13 shows an example of the flow of the thinning process (S1203).
- the maintenance unit 218 determines whether the number of data IDs held by the target sampling index 223 after S1202 is greater than a certain number (S1301).
- the number of data IDs that the target sampling index 223 has may be specified from the DB management information 228, for example, or may be specified by scanning the target sampling index 223.
- the maintenance unit 218 deletes the excess number of data IDs from the target sampling index 223, thereby determining the number of data IDs of the target sampling index 223, It is made below a certain number (S1302).
- the maintenance unit 218 updates information indicating the number of data IDs of the target sampling index 223 in the DB management information 228 to the number of data IDs after S1302 (S1303).
- the deletion target candidate (data ID that can be deleted) may be any data ID in the target sampling index 223. Further, in the target sampling index 223, the data ID added in the immediately preceding S1203 (that is, the data ID of additional data (sampling data) that meets the latest sampling condition) may be excluded from the deletion target candidates.
- the deletion condition may be, for example, a data ID indicating data that does not conform to the latest sampling condition, or may be an old data ID.
- the maintenance unit 218 preferentially deletes the data ID of data that does not conform to the latest sampling condition from the target sampling index 223, and the number of data IDs of the target sampling index 223 is still a fixed number. If it exceeds, the older data ID may be deleted from the target sampling index 223 with priority. Since the data ID of data that does not conform to the latest sampling conditions is preferentially deleted, as a result, the data ID of the latest sampling data is automatically excluded from the deletion target, and the existing data that conforms to the latest sampling conditions The data ID of the data can be left preferentially.
- the “latest sampling condition” is the sampling condition determined in the sampling process (S102) of the current data addition process (S101). At least one of the inter-characteristic relationship 704 and the sampling rule 603 may be changed during the data addition process. For this reason, even if the work is the same, the determined sampling conditions are not always the same. Therefore, the “latest sampling condition” may be given priority over the past sampling condition in at least one of the deletion target candidate and the deletion condition.
- FIG. 14 shows an example of the flow of search processing.
- the query control unit 213 analyzes the query.
- the query control unit 213 calls the search unit 214, thereby starting a search process.
- the search process data that matches the search condition specified by the search query is acquired as a result set, and the search result is returned to the terminal device 201.
- the search result may be the acquired result set itself, or may be a result of the acquired result set being classified or aggregated.
- the search unit 214 determines whether or not a hint indicating that the sampling index 223 is used is specified in the search query (S1401).
- the “hint” referred to here is an example of a description meaning the use of the sampling index 223.
- FIG. 15 shows a configuration example of a search query. According to the example, there is “QUICK-S-Index1” as a hint.
- the sampling index 223 to be used may be individually specified, or only the use of the sampling index 223 may be specified. In the latter case, all the sampling indexes 223 related to the table 221 to be searched are used.
- the search query is a query generated by a query issuer such as the business program 205.
- the search unit 214 identifies the sampling index 223 from the search query (S1402), and matches the search condition specified in the search query through the specified sampling index 223. Data is acquired as a result set (S1403). Specifically, for example, for each data ID of the specified sampling index 223, the search unit 214 refers to data specified from the data ID (data in the table 221), and whether the data meets the search condition. Judge whether or not. A set of data that meets the search condition is a result set. The search unit 214 returns a result set (S1405).
- the search unit 214 uses the normal index 222 associated with the table 221 identified from the search query for data that matches the search condition specified in the search query. To obtain a result set (S1404). The search unit 214 returns a result set (S1405).
- FIG. 16 shows an example of the flow of definition processing.
- the query control unit 213 analyzes the query. If the input query is a definition query, the query control unit 213 calls the definition unit 215, thereby starting the definition process.
- the definition unit 215 adds the table 221 name, the index name, and the index type described in the definition query to the DB management information 228 (for example, index management information) (S1601).
- the definition unit 215 determines whether or not a hint indicating that the definition of the sampling index 223 is specified in the definition query (S1602). For example, according to the example of the definition query shown in FIG. 17, the hint is “ON Table1 QUICK”.
- the definition unit 215 provides (displays) the characteristic input GUI 800 to the terminal device 201 (S1603).
- the definition unit 215 receives a business characteristic (input value) via the provided characteristic input GUI 800 (S1604), and receives a business ID and characteristic details (for example, a characteristic in which an input value other than “no input” is input). Then, it is registered in the characteristic management information 225 (S1605).
- the business ID 702 may be specified by a definition query, or may be an ID automatically assigned by the definition unit 215.
- the definition unit 215 registers the business ID and the sampling index name (index name specified by the definition query) in the business management information 224 (S1606).
- the computer 209 includes a memory 200 for storing management information, which is information including information indicating the relationship between a job including data search, a property of the job, and a sampling rule, and a CPU 219 connected to the memory 200.
- the CPU 219 specifies (A) the business associated with the table 221 to which the additional data group is added, and (B) the sampling condition according to the sampling rule corresponding to the business characteristics specified in (A) based on the management information (C) and data that meet the sampling conditions determined in (B) are sampled from the additional data group.
- a sampling index 223, which is an index of sampled data, is referred to during data retrieval performed in the specified job.
- the sampling index 223 depends on the sampling conditions.
- the sampling condition is a condition that follows a sampling rule corresponding to the characteristics of the business for which data search is to be performed. For this reason, high accuracy is expected as the accuracy of the business (for example, analysis) including the search using the sampling index 223 as the search target.
- the total amount of data referred in the sampling process is typically smaller than sampling from the table 221.
- the sampling index 223 is referred to, the use capacity can be suppressed as compared with storing a copy of the sampling data group which is a part of the table 221.
- the CPU 219 executes maintenance including processing for adding data indicating the data sampled in (D) and (C) to the sampling index 223.
- the sampling index 223 can be updated in every sampling.
- the CPU 219 executes (A) to (D) when the additional data group is added to the table 221. Since sampling and maintenance are performed during the data addition process, it can be expected that the sampling index 223 is maintained in the latest state.
- Table 221 and at least the table 221 of the additional data group are big data.
- the above-described embodiment is considered to be more effective as the size of the table 221 is larger.
- the CPU 219 specifies (b1) a sampling rule corresponding to each specified business characteristic and a relationship between the specified business characteristics based on the management information, and (b2) according to the specified inter-characteristic relationship. Combine the specified sampling rules. A combination of the specified sampling loops is a sampling condition. As a result, it is possible to expect a sampling condition that is optimal for the relationship between business characteristics.
- the relationship between characteristics is a combination of characteristics and logical operators. For this reason, the configuration of the inter-characteristic relationship can be changed only by changing at least one of the characteristic and the logical operator, which is highly convenient.
- the specified sampling rule combination is a combination of a sampling rule corresponding to each characteristic included in the specified inter-characteristic relationship and a logical operator included in the inter-characteristic relationship. If a sampling rule is prepared for each characteristic, the sampling condition can be generated by a simple process of replacing the characteristic in the inter-characteristic relationship with the sampling rule corresponding to the characteristic according to the inter-characteristic relationship.
- the CPU 219 provides a characteristic input GUI 800 that receives an input of business characteristics.
- the characteristic input GUI 800 provides the necessity of input corresponding to the business type specified by the user for at least one characteristic.
- the user can immediately specify a characteristic that requires input value input, and can input the input value of the characteristic for the specified characteristic.
- At least one characteristic of the identified business is that the data composition ratio represented by the sampling index 223 is the same as the data composition ratio in the table 221. Thereby, it can be expected that the accuracy of the business including the search using the sampling index 223 is close to (for example, equivalent to) the accuracy of the business including the search referring to the entire table 221.
- the CPU 219 starts from the sampling index 223 so that the number of data IDs in the sampling index 223 is equal to or less than the certain number. Delete the data ID. Thereby, the size of the sampling index 223 can be suppressed to a certain size or less.
- the CPU 219 preferentially deletes the data ID of data that does not conform to the sampling conditions determined in (e1) and (B) from the sampling index 223, and (e2) the sampling index 223 after (e1). If the number of data IDs still exceeds a certain number, older data IDs are deleted from the sampling index 223 with higher priority. Since the data ID of data that does not conform to the latest sampling conditions is preferentially deleted, as a result, the data ID of the latest sampling data is automatically excluded from the deletion target, and the existing data that conforms to the latest sampling conditions The data ID of the data can be preferentially left in the sampling index 223.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
L'invention concerne un système informatique qui identifie le travail associé à un groupe de données candidates d'échantillonnage (un ou plusieurs éléments de données candidates d'échantillonnage). Sur la base d'informations de gestion, qui sont des information qui comprennent des informations exprimant une relation entre le travail incluant une recherche de données, les propriétés de travail et la règle d'échantillonnage, le système informatique détermine une condition d'échantillonnage en fonction d'une règle d'échantillonnage correspondant aux propriétés du travail identifié. Ensuite, le système informatique échantillonne, à partir du groupe de données candidates d'échantillonnage, des éléments de données qui satisfont à la condition d'échantillonnage déterminée. Un résultat d'échantillonnage est référencé au moment de la recherche de données effectuée au cours du travail identifié. Un groupe de données d'échantillonnage, qui représente un ou plusieurs éléments de données d'échantillonnage qui comprennent les données échantillonnées, et/ou un indice d'échantillonnage, qui est un indice du groupe de données d'échantillonnage, est le résultat d'échantillonnage qui est référencé au moment de la recherche de données effectuée au cours du travail identifié.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2015/071196 WO2017017748A1 (fr) | 2015-07-27 | 2015-07-27 | Système informatique et procédé d'échantillonnage |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2015/071196 WO2017017748A1 (fr) | 2015-07-27 | 2015-07-27 | Système informatique et procédé d'échantillonnage |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2017017748A1 true WO2017017748A1 (fr) | 2017-02-02 |
Family
ID=57884193
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2015/071196 Ceased WO2017017748A1 (fr) | 2015-07-27 | 2015-07-27 | Système informatique et procédé d'échantillonnage |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2017017748A1 (fr) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107506383A (zh) * | 2017-07-25 | 2017-12-22 | 中国建设银行股份有限公司 | 一种审计数据处理方法和计算机设备 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20020198863A1 (en) * | 1999-12-08 | 2002-12-26 | Vijayakumar Anjur | Stratified sampling of data in a database system |
| WO2010095457A1 (fr) * | 2009-02-20 | 2010-08-26 | 日本電気株式会社 | Système, procédé et programme de prétraitement d'analyse |
| JP2012194894A (ja) * | 2011-03-17 | 2012-10-11 | Fujitsu Ltd | データ解析プログラム、データ解析方法、およびデータ解析装置 |
-
2015
- 2015-07-27 WO PCT/JP2015/071196 patent/WO2017017748A1/fr not_active Ceased
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20020198863A1 (en) * | 1999-12-08 | 2002-12-26 | Vijayakumar Anjur | Stratified sampling of data in a database system |
| WO2010095457A1 (fr) * | 2009-02-20 | 2010-08-26 | 日本電気株式会社 | Système, procédé et programme de prétraitement d'analyse |
| JP2012194894A (ja) * | 2011-03-17 | 2012-10-11 | Fujitsu Ltd | データ解析プログラム、データ解析方法、およびデータ解析装置 |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107506383A (zh) * | 2017-07-25 | 2017-12-22 | 中国建设银行股份有限公司 | 一种审计数据处理方法和计算机设备 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10585915B2 (en) | Database sharding | |
| US8527556B2 (en) | Systems and methods to update a content store associated with a search index | |
| US20170206265A1 (en) | Distributed Consistent Database Implementation Within An Object Store | |
| US10552378B2 (en) | Dividing a dataset into sub-datasets having a subset of values of an attribute of the dataset | |
| US20150293958A1 (en) | Scalable data structures | |
| US20190057133A1 (en) | Systems and methods of bounded scans on multi-column keys of a database | |
| US10127272B2 (en) | Modifying a database query | |
| US10635668B2 (en) | Intelligently utilizing non-matching weighted indexes | |
| US10706022B2 (en) | Space-efficient secondary indexing on distributed data stores | |
| US9734177B2 (en) | Index merge ordering | |
| US20170046353A1 (en) | Database management system and database management method | |
| CN110807028B (zh) | 用于管理存储系统的方法、设备和计算机程序产品 | |
| CN108268614A (zh) | 一种森林资源空间数据的分布式管理方法 | |
| US9176996B2 (en) | Automated resolution of database dictionary conflicts | |
| WO2015025401A1 (fr) | Système de gestion de base de données et procédé de gestion de base de données | |
| US11494504B2 (en) | Access to data in multiple instances through a single record | |
| US12253974B2 (en) | Metadata processing method and apparatus, and a computer-readable storage medium | |
| WO2017017748A1 (fr) | Système informatique et procédé d'échantillonnage | |
| US11914612B2 (en) | Selective synchronization of linked records | |
| JP2016062522A (ja) | データベース管理システム、データベースシステム、データベース管理方法およびデータベース管理プログラム | |
| JP6193491B2 (ja) | 計算機システム | |
| US12613853B2 (en) | Fast iterators for key-value databases | |
| JP2017142672A (ja) | データベースシステム | |
| JP5810982B2 (ja) | 検索装置、検索方法、および検索プログラム | |
| US11194817B2 (en) | Enterprise object search and navigation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 15899582 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 15899582 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: JP |