WO2017149722A1 - 演算装置および演算方法 - Google Patents
演算装置および演算方法 Download PDFInfo
- Publication number
- WO2017149722A1 WO2017149722A1 PCT/JP2016/056583 JP2016056583W WO2017149722A1 WO 2017149722 A1 WO2017149722 A1 WO 2017149722A1 JP 2016056583 W JP2016056583 W JP 2016056583W WO 2017149722 A1 WO2017149722 A1 WO 2017149722A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- scalar quantization
- unit
- scalar
- value
- layer
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0499—Feedforward networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0495—Quantised networks; Sparse networks; Compressed networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/09—Supervised learning
Definitions
- the present invention relates to a calculation device and a calculation method for calculating an output value of a multilayer neural network (DNN).
- DNN multilayer neural network
- DNN-HMM has been proposed in which acoustic likelihood calculation based on HMM (Hidden Markov Model) is performed by DNN.
- HMM Hidden Markov Model
- This DNN-HMM has a significantly improved performance compared to a conventional GMM-HMM that performs acoustic likelihood calculation using a GMM (Gaussian Mixture Model) (see, for example, Non-Patent Document 1).
- a filter bank feature quantity and a vector obtained by connecting a plurality of dynamic features of the filter bank feature quantity are input to the DNN input layer, and the output value of the output layer is normalized by the prior probability calculated from the number of learning data. And the acoustic likelihood is calculated.
- DNN-HMM is generally expected to have higher recognition performance as the number of hidden layer units increases.
- the calculation time is proportional to the square of the number of units in the hidden layer. Therefore, when the DNN-HMM is applied to an arithmetic device such as an embedded device that has a limited calculation resource, the number of units cannot be increased and high recognition performance cannot be obtained.
- Non-Patent Document 2 describes that singular value decomposition is applied to DNN to reduce the number of hidden layer units by low rank approximation. Since the recognition performance by DNN depends on the low rank approximation method and the relearning method after approximation, even if the number of units can be reduced by the method described in Non-Patent Document 2, it is difficult to obtain stable recognition performance. .
- the present invention has been made to solve the above-described problems, and an object thereof is to improve the recognition performance of a multi-layer neural network mounted on an arithmetic device such as an embedded device that is limited in calculation resources. .
- An arithmetic device includes a weight storage unit storing a weight matrix for each layer of a multilayer neural network, a weight matrix stored in the weight storage unit, and a vector input to an input layer of the multilayer neural network.
- a matrix multiplication unit that performs multiplication with a vector output from the previous layer, and a scalar quantization table that represents the correspondence between the quantization range for performing scalar quantization and the quantization value are stored.
- a scalar quantization table storage unit a scalar quantization unit that scalar-quantizes each dimension value of the vector output from the matrix multiplication unit with reference to the scalar quantization table, and a scalar quantization in the output layer of the multilayer neural network
- a likelihood calculator that calculates the likelihood vector using the vector output from the unit, and scalar quantization for each layer of the multilayer neural network It is intended and a scalar quantization control section for controlling whether to perform the scalar quantization by.
- scalar quantization when scalar quantization is performed in a layer of a multilayer neural network, multiplication of a scalar quantized vector and a weight matrix is performed in the next layer, so that scalar quantization is not performed.
- the amount of calculation can be reduced compared with the case of multiplying a vector and a weight matrix. Therefore, a multi-layer neural network having a large number of units can be mounted even in an arithmetic device with limited calculation resources, and recognition performance can be improved.
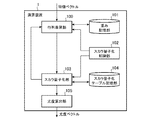
- FIG. 1 It is a block diagram which shows the structural example of the arithmetic unit which concerns on Embodiment 1 of this invention.
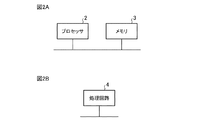
- 2A and 2B are hardware configuration diagrams of the arithmetic device according to the first embodiment.
- 3 is a flowchart showing the operation of the arithmetic device according to the first embodiment.
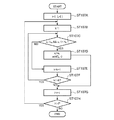
- 6 is a flowchart illustrating an operation of a scalar quantization unit in the arithmetic device according to the first embodiment.
- 4 is an example of a scalar quantization table stored in a scalar quantization table storage unit in the arithmetic device according to the first embodiment.
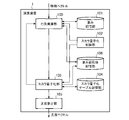
- FIG. 1 is a block diagram showing a configuration example of an arithmetic device 1 according to Embodiment 1 of the present invention.
- This computing device 1 is a device that performs likelihood computation processing on a feature vector using a multilayer neural network and outputs a likelihood vector.
- the arithmetic device 1 according to the first embodiment includes a matrix multiplication unit 100, a weight storage unit 101, a scalar quantization control unit 102, a scalar quantization unit 103, a scalar quantization table storage unit 104, and a likelihood.
- a calculation unit 105 is provided.
- FIG. 2A is a hardware configuration diagram of the arithmetic device 1 according to the first embodiment.
- the arithmetic device 1 includes a processor 2 and a memory 3.
- the functions of the matrix multiplication unit 100, the scalar quantization control unit 102, the scalar quantization unit 103, and the likelihood calculation unit 105 in the arithmetic device 1 are realized by the processor 2 executing a program stored in the memory 3.
- the processor 2 is also referred to as a CPU (Central Processing Unit), a processing device, a microprocessor, a microcomputer, or a DSP (Digital Signal Processor).
- CPU Central Processing Unit
- DSP Digital Signal Processor
- the memory 3 includes, for example, RAM (Random Access Memory), ROM (Read Only Memory), EPROM (Erasable Programmable ROM), EEPROM (Electrically Programmable EPROM), flash memory, SSD (Solid State Nonvolatile Drive). It may be a semiconductor memory, a magnetic disk such as a hard disk or a flexible disk, or an optical disk such as a CD (Compact Disc) or a DVD (Digital Versatile Disc). Further, the weight storage unit 101 and the scalar quantization table storage unit 104 in the arithmetic device 1 are the memory 3.
- RAM Random Access Memory
- ROM Read Only Memory
- EPROM Erasable Programmable ROM
- EEPROM Electrically Programmable EPROM
- flash memory SSD (Solid State Nonvolatile Drive). It may be a semiconductor memory, a magnetic disk such as a hard disk or a flexible disk, or an optical disk such as a CD (Compact Disc) or a DVD (Digital Versatile Disc).
- the functions of the matrix multiplication unit 100, the scalar quantization control unit 102, the scalar quantization unit 103, and the scalar quantization table storage unit 104 are software. , Firmware, or a combination of software and firmware. Software or firmware is described as a program and stored in the memory 3. The processor 2 implements the functions of the respective units by reading out and executing the program stored in the memory 3.
- the arithmetic unit 1 when executed by the processor 2, performs a matrix multiplication step for multiplying a weight matrix and a vector, and a scalar quantum for scalar-quantizing each dimension value of the vector output in the matrix multiplication step.
- Step, likelihood calculation step for calculating likelihood vector using vector output in scalar quantization step in output layer of multilayer neural network, and whether or not to perform scalar quantization for each layer of multilayer neural network A memory 3 for storing a program to be executed. It can also be said that this program causes a computer to execute the procedures or methods of the matrix multiplication unit 100, the scalar quantization control unit 102, the scalar quantization unit 103, and the likelihood calculation unit 105.
- the arithmetic unit 1 may be realized by a dedicated processing circuit 4.
- the processing circuit 4 includes, for example, a single circuit, a composite circuit, a programmed processor, a parallel programmed processor, (Application-Specific Integrated Circuit), FPGA (Field-Programmable Gate Array), or a combination of these. To do.
- the functions of the matrix multiplication unit 100, the scalar quantization control unit 102, the scalar quantization unit 103, and the likelihood calculation unit 105 may be realized by a plurality of processing circuits 4, or these functions are combined into one processing circuit 4 It may be realized with.
- part of the functions of the matrix multiplication unit 100, the scalar quantization control unit 102, the scalar quantization unit 103, and the likelihood calculation unit 105 are realized by the processing circuit 4, and a part is realized by software or firmware. It may be.
- FIG. 3 is a flowchart showing the operation of the arithmetic device 1 according to the first embodiment.
- the arithmetic device 1 is used for voice recognition.
- the present invention is not limited to the use of voice recognition, and is generally applicable to pattern recognition such as image recognition and object recognition from sensor information.
- step ST101 the matrix multiplication unit 100 initializes the layer number L of the multilayer neural network to 1.
- DNN-HMM a vector obtained by connecting a plurality of filter bank feature quantities and their dynamic features is generally used as a feature vector.
- the matrix multiplication unit 100 refers to the input dimension number DIN L of the hierarchy L in the weight storage unit 101 and substitutes it for I, and refers to the output dimension number DOUT L of the hierarchy L in the weight storage unit 101. Substitute for J.
- the weight storage unit 101 stores a weight matrix w ji of DOUT L ⁇ DIN L for each hierarchy. Note that the number of units in the layer L matches the output dimension number DOUT L.
- step ST103 the matrix multiplication unit 100 acquires a determination result SQDo (L-1) from the scalar quantization control unit 102 as to whether or not the scalar quantization has been performed in the layer L-1 immediately before the layer L. Then, when the determination result SQDo (L ⁇ 1) is 1 (step ST103 “YES”), that is, when scalar quantization is performed, the matrix multiplication unit 100 performs matrix multiplication with a reduced amount of computation. The process proceeds to ST105, and if not (step ST103 “NO”), the process proceeds to step ST104 to perform normal matrix multiplication.
- the matrix multiplication unit 100 acquires a weight matrix w ji necessary for the calculation of Expression (1) from the weight storage unit 101.
- Equation (2) a k is a scalar quantized x i
- I k is a set of indices i of the scalar i quantized to a k .
- the matrix multiplication unit 100 acquires a weight matrix w ji necessary for the calculation of Expression (2) from the weight storage unit 101.
- step ST106 the scalar quantization unit 103 acquires, from the scalar quantization control unit 102, a determination result SQDo (L) for determining whether or not to perform scalar quantization in the hierarchy L. If the determination result SQDo (L) is 1 (step ST106 “YES”), the scalar quantization unit 103 proceeds to step ST107 to perform the scalar quantization, and otherwise (step ST106 “NO”). It progresses to step ST110. Note that whether or not to perform scalar quantization on the layer L is determined in consideration of the trade-off between the degree of reduction in recognition performance and the effect of reducing the amount of computation by performing scalar quantization in advance. Assume that the setting is made for the unit 102. The scalar quantization control unit 102 controls the scalar quantization unit 103 according to the setting.
- step ST107 the scalar quantization unit 103 performs scalar quantization on the output u j of the matrix multiplication unit 100.
- FIG. 4 is a flowchart showing the operation of the scalar quantization unit 103 in the arithmetic device 1 according to the first embodiment.
- step ST107A the scalar quantization unit 103 inputs 1 to the dimension index i of the input vector, and clears the set I k of the scalar quantized index.
- step ST107B the scalar quantization unit 103 initializes the scalar quantization table index k to 1.
- step ST107C the scalar quantization unit 103 compares the quantization range lower limit value L k and upper limit value H k stored in the scalar quantization table storage unit 104 with x i . Then, the scalar quantization unit 103, if x i is greater than L k, and x i is equal to or less than H k (step ST107C "YES"), the process proceeds to step ST107D, otherwise (step ST107C "NO" ) Proceeds to step ST107E.
- FIG. 5 is an example of the scalar quantization table stored in the scalar quantization table storage unit 104.
- the above-described scalar quantization table index k is an index of the quantization value a k stored in the scalar quantization table of the scalar quantization table storage unit 104.
- the scalar quantization table size K is the maximum value of the index k of the quantization value stored in the scalar quantization table.
- the scalar quantization table is determined in advance for each layer in consideration of the trade-off between the degree of reduction in recognition performance and the effect of reducing the amount of calculation.
- a value after applying the activation function is stored as a quantization value of the scalar quantization table. In the example of FIG. 4, the quantized value after application of the sigmoid function is shown.
- the scalar quantization table storage unit 104 may store a single scalar quantization table that does not distinguish between hierarchies, or may store a scalar quantization table for each hierarchy.
- the quantization width and quantization range of scalar quantization affect the final recognition performance, for example, fine quantization is applied to layers that have a large impact on recognition performance due to scalar quantization. It is desirable to perform rough quantization for a layer that has a small effect on the frequency. Therefore, compared to the case of using a single scalar quantization table that does not distinguish between hierarchies, the use of a scalar quantization table prepared for each layer does not degrade the recognition performance, but the overall amount of computation. Can be reduced.
- step ST107D the scalar quantization unit 103 quantizes x i into a k using the following equations (3) and (4).
- equation (4) add (I k , i) is a function for adding i to the quantized index set I k .
- the scalar quantization unit 103 proceeds to step ST107G after step ST107D.
- x i a k (3) add (I k , i) (4)
- step ST107E the scalar quantization unit 103 increments the scalar quantization table index k.
- step ST107G the scalar quantization unit 103 increments the dimension index i of the input vector.
- step ST107H when the dimension index i of the input vector is equal to or less than the input dimension number I (step ST107H “YES”), the scalar quantization unit 103 returns to step ST107B. On the other hand, if the dimension index i of the input vector is larger than the input dimension number I (step ST107H “NO”), the scalar quantization unit 103 ends the scalar quantization process and proceeds to step ST108 in FIG.
- step ST108 the scalar quantization unit 103 determines that the scalar quantized value is a value after application of an activation function such as a sigmoid function ("YES" in step ST108), that is, the value x i of each dimension of the input vector is If converted to the quantization value ak of the scalar quantization table, the process proceeds to step ST109.
- the case where the scalar quantized value is a value after the activation function is applied is a case where the value x i of each dimension of the input vector is converted into the quantized value a k of the scalar quantization table in step ST107. Otherwise (step ST108 “NO”), the scalar quantization unit 103 proceeds to step ST110.
- step ST109 the scalar quantization unit 103 does not need to apply an activation function, and thus calculates an output z j according to the following equation (5).
- step ST110 the scalar quantization unit 103 needs to apply an activation function, and thus calculates an output z j according to the following equation (6).
- f is an activation function.
- the logistic sigmoid function of Expression (7) or the normalized linear function of Expression (8) is used in the intermediate layer, and Expression (9) of Expression (9) is used in the output layer.
- a softmax function is used.
- step ST111 the scalar quantization unit 103 determines whether or not the layer L is an output layer of the multilayer neural network. Then, the scalar quantization unit 103 proceeds to step ST113 when the layer L is the output layer of the multilayer neural network (step ST111 “YES”), and proceeds to step ST112 when it is not the output layer (step ST111 “NO”). .
- step ST112 the scalar quantization unit 103 outputs the output z j calculated in step ST109 or step ST110 to the matrix multiplication unit 100.
- the matrix multiplication unit 100 that has received the output z j increments the hierarchy number L, and outputs the output of the hierarchy L ⁇ 1 to the value xj of each dimension of the input vector for the hierarchy L after the increment using the following equation (10). Substitute values z j for each dimension of the vector. Thereafter, the matrix multiplication unit 100 returns to step ST102.
- step ST113 the scalar quantization unit 103 outputs the output z j calculated in step ST109 or step ST110 to the likelihood calculating unit 105.
- the likelihood calculating unit 105 that has received the output z j uses the following expression (11) to calculate the likelihood p (v
- j from the values z j (i 1 to J) of the output vectors of the output layer. ) Is calculated.
- p 0 (j) is the probability of prior distribution calculated from the number of learning data.
- j) z j / p 0 (j) (11)
- the arithmetic device 1 includes the weight storage unit 101 storing the weight matrix for each layer of the multilayer neural network, the weight matrix stored in the weight storage unit 101, and the multilayer neural network.
- a matrix multiplication unit 100 that performs multiplication with a vector input to the input layer of the network or a vector output from the previous layer, and a correspondence relationship between a quantization range for performing scalar quantization and its quantization value.
- a scalar quantization table storage unit 104 that stores the scalar quantization table, and a scalar quantization unit that performs scalar quantization on values of each dimension of the vector output from the matrix multiplication unit 100 with reference to the scalar quantization table 103 and a likelihood calculation for calculating a likelihood vector using the vector output from the scalar quantization unit 103 in the output layer of the multilayer neural network
- And parts 105 each layer of a multilayer neural network, a structure and a scalar quantization controller 102 for controlling whether to perform the scalar quantization by the scalar quantizer 103.
- the matrix multiplication unit 100 applies the activation function in the layer L.
- the number of multiplications caused by vector operations can be reduced to K / I. Therefore, a multi-layer neural network having a large number of units can be mounted even in the arithmetic device 1 having a limited calculation resource such as an embedded device, and recognition performance can be improved.
- the scalar quantization control unit 102 takes into account the tradeoff between the degree of reduction in recognition performance due to scalar quantization and the effect of reducing the amount of computation, controlling whether or not scalar quantization is performed for each layer of the multilayer neural network, It becomes easy to satisfy both the recognition performance and the computational resources required for the arithmetic device 1.
- the scalar quantization unit 103 performs scalar quantization to a value after applying the activation function when performing scalar quantization on each dimension value of the vector output from the matrix multiplication unit 100. It is a configuration. With this configuration, the activation function application processing itself can be reduced, and a multi-layer neural network having a large number of units can be mounted even in the arithmetic device 1 having a limited calculation resource such as an embedded device.
- the scalar quantization table storage unit 104 stores a scalar quantization table for each layer of the multilayer neural network, and the scalar quantization unit 103 is stored in the scalar quantization table storage unit 104.
- the scalar quantization table corresponding to the layer that performs the scalar quantization is referred to. With this configuration, it is possible to reduce the overall calculation amount without degrading the recognition performance as compared with the case where a single scalar quantization table is used.
- Embodiment 2 When the quantized value becomes 0 in the scalar quantization unit 103 of the first embodiment, the subsequent multiplication result by the matrix multiplying unit 100 is also 0, so that the multiplication itself is unnecessary. Therefore, in the second embodiment, considering the case where the quantized value becomes 0, the object is to reduce the number of multiplications and the number of additions compared to the first embodiment.
- FIG. 6 is a graph showing the frequency of the output vector values of each layer of the multilayer neural network counted in increments of 0.01. From this result, it can be seen that the frequency of values close to 0 is high in all layers. Therefore, as will be described below, by appropriately determining the quantization range for scalar quantization to 0, it is possible to reduce the amount of computation without degrading the recognition performance.
- the configuration of the arithmetic device 1 according to the second embodiment is the same as the configuration of the arithmetic device 1 according to the first embodiment shown in FIG.
- the difference between the second embodiment and the first embodiment is a calculation formula for matrix multiplication in which the calculation amount in the matrix multiplication unit 100 is reduced.
- the scalar quantization unit 103 is configured to store the quantization range corresponding to the quantization value 0.
- the matrix multiplication unit 100 calculates the sum of weights corresponding to the scalar-quantized dimension to a quantized value other than 0 among the dimensions of the scalar-quantized vector output from the previous layer.
- the weight matrix stored in the weight storage unit 101 is used for calculation, and the total value of the weights is multiplied by a quantization value other than zero.
- the number of multiplications of Wx matrix ⁇ vector operations occurring in each layer of the multilayer neural network can be reduced to (K ⁇ 1) / I, and the number of additions can be reduced to (I ⁇ cnt (I 0 )) / I.
- cnt ( ⁇ ) is a function for counting the number of elements. Therefore, a multi-layer neural network having a large number of units can be mounted even in the arithmetic device 1 having a limited calculation resource such as an embedded device.
- Embodiment 3 FIG.
- the first embodiment and the second embodiment are mainly intended to reduce the number of multiplications of the Wx matrix ⁇ vector operation occurring in each layer of the multilayer neural network.
- the third embodiment is different from the first embodiment in the first embodiment. The purpose is to further reduce the number of additions than 2.
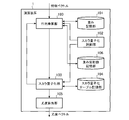
- FIG. 7 is a block diagram illustrating a configuration of the arithmetic device 1 according to the third embodiment. 7, parts that are the same as or correspond to those in FIG. 1 are given the same reference numerals, and descriptions thereof are omitted.
- the difference between the third embodiment and the first and second embodiments is that a set of indexes scalar-quantized to the same quantized value and a sum of weights corresponding to the indexes belonging to the set.
- the weight sum total value storage unit 106 is stored. This weight sum value storage unit 106 is, for example, the memory 3 shown in FIG. 2A.
- FIG. 8 is an example of a set of indexes and a total weight value stored in the total weight value storage unit 106.
- the total weight value is expressed by the following equation (14).
- a set I k ⁇ 1, 3, 5,..., 511 ⁇ of dimension indexes i in which the quantized values a k are the same frequently appears.
- the sum total value of the weights corresponding to the set I k is stored in the weight sum value storage unit 106 as s j (R n ).
- the respective weights before the sum value is obtained are shown, but the actual weight sum value storage unit 106 stores the sum value calculated from each weight.
- the arithmetic device 1 for each layer of the multi-layer neural network, weights corresponding to a set of vector dimensions scalar-quantized to the same quantized value and dimensions belonging to the set. It is the structure provided with the weight sum total value memory
- the number of additions of Wx matrix ⁇ vector operations occurring in each layer of the multilayer neural network can be reduced. Therefore, a multi-layer neural network having a large number of units can be mounted even in the arithmetic device 1 having a limited calculation resource such as an embedded device.
- Embodiment 4 FIG.
- the weight sum total storage unit 106 according to the third embodiment is configured to store in advance the sum total s j (R n ) of the weights corresponding to the frequent index set R n , but in the fourth embodiment, A configuration is adopted in which a set of indexes R n based on the result of scalar quantization calculated in the past and a total weight value s j (R n ) corresponding to the set are stored.
- FIG. 9 is a block diagram illustrating a configuration of the arithmetic device 1 according to the fourth embodiment. 9, parts that are the same as or correspond to those in FIG. 3 are given the same reference numerals, and descriptions thereof are omitted.
- the difference between the fourth embodiment and the third embodiment corresponds to the set of indexes scalar-quantized to the same quantization value by the scalar quantization unit 103 and the indexes belonging to the set.
- the weight sum value is stored in the weight sum value storage unit 106.
- R n and s j (R n ) can be stored in the weight sum total storage unit 106 as a cache.
- the arithmetic unit 1 stores R n and s j (R n ) obtained when the utterance at a certain time in the past is recognized as speech in the weight sum storage unit 106 and recognizes the subsequent utterance as speech.
- the latest R n and s j (R n ) are sequentially replaced with the least referenced R n and s j (R n ) in the weight sum total storage unit 106.
- the number of additions can be reduced by using the value stored in the weight summation value storage unit 106, so that the effect of reducing the amount of computation can be expected to increase.
- the weight sum storage unit 106 performs the weights corresponding to the sets of dimensions of vectors that have been previously quantized to the same quantized value and the dimensions belonging to the set. Is stored.
- the number of Wx matrix ⁇ vector operations added in each layer of the multilayer neural network can be reduced. Therefore, a multi-layer neural network having a large number of units can be mounted even in the arithmetic device 1 having a limited calculation resource such as an embedded device.
- Embodiments 1 to 4 are intended to reduce the number of multiplications and additions caused by Wx matrix ⁇ vector operations by scalar quantization.
- the recognition performance may be slightly reduced.
- the scalar quantization control unit 102 determines whether or not to perform scalar quantization for each layer of the multilayer neural network according to the load of the arithmetic device 1, and controls the scalar quantization unit 103. To do.
- the scalar quantization control unit 102 increases the number of layers in which the scalar quantization unit 103 performs scalar quantization when the load on the arithmetic device 1 is large. When the load on the arithmetic device 1 is small, the scalar quantization unit 103 causes the scalar quantization unit 103 to perform scalar quantization. Fewer layers to perform quantization.
- the processor 2 shown in FIG. 2A has not only the voice recognition function described in the first to fourth embodiments but also the car navigation. Functions such as the system will also be executed. For example, in a configuration in which the arithmetic device 1 is incorporated in a car navigation system, the processor 2 executes applications such as route search and music playback. When a destination is set, the processor 2 is temporarily used for route search. In some cases, the computing resources of the processor 2 are occupied and the system load increases.
- the scalar quantization control unit 102 increases the number of layers for performing the scalar quantization even if the recognition performance is sacrificed to some extent. Reduce the amount of computation of the neural network.
- the scalar quantization control unit 102 performs scalar quantization to ensure maximum recognition performance. Instead, normal matrix multiplication is performed.
- the configuration of the arithmetic device 1 according to the fifth embodiment is the same as the configuration of the arithmetic device 1 according to the first to fourth embodiments shown in FIGS. Is omitted.
- the scalar quantization control unit 102 is configured to determine whether or not to perform scalar quantization for each layer of the multilayer neural network according to the load of the arithmetic device 1.
- the load on the computing device 1 that is an embedded device is large, the amount of computation is reduced by scalar quantization, thereby enabling speech recognition even if there is a slight degradation in recognition performance.
- the degradation of recognition performance can be minimized by minimizing the number of hierarchies.
- the arithmetic device reduces the amount of calculation without degrading the recognition performance of the multilayer neural network, it is suitable for use in an embedded device in which calculation resources are limited.
- 1 arithmetic unit, 2 processor, 3 memory, 4 processing circuit, 100 matrix multiplication unit, 101 weight storage unit, 102 scalar quantization control unit, 103 scalar quantization unit, 104 scalar quantization table storage unit, 105 likelihood calculation unit 106 Total weight value storage unit.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Image Analysis (AREA)
Abstract
演算装置(1)は、多層ニューラルネットワークの層ごとの重み行列を記憶している重み記憶部(101)と、重み記憶部(101)に記憶されている重み行列と、多層ニューラルネットワークの入力層に入力されたベクトルまたは一つ前の層から出力されたベクトルとの乗算を行う行列乗算部(100)と、スカラ量子化を行う量子化範囲とその量子化値との対応関係を表したスカラ量子化テーブルを記憶しているスカラ量子化テーブル記憶部(104)と、スカラ量子化テーブルを参照して行列乗算部(100)から出力されたベクトルの各次元の値をスカラ量子化するスカラ量子化部(103)と、多層ニューラルネットワークの出力層においてスカラ量子化部(103)から出力されたベクトルを用いて尤度ベクトルを算出する尤度算出部(105)と、多層ニューラルネットワークの層ごとにスカラ量子化を実施するか否かを制御するスカラ量子化制御部(102)とを備える。
Description
この発明は、多層ニューラルネットワーク(Deep Neural Network:DNN)の出力値を演算する演算装置および演算方法に関するものである。
近年、パターン認識の分野において、DNNを使用することによる顕著な性能向上が報告されている。例えば音声認識の分野では、HMM(Hidden Markov Model)ベースの音響尤度計算をDNNで行うDNN-HMMが提案されている。このDNN-HMMは、従来のGMM(Gaussian Mixture Model)で音響尤度計算を行うGMM-HMMに比べ、性能が大幅に向上する(例えば、非特許文献1参照)。DNN-HMMでは、DNNの入力層にフィルタバンク特徴量およびその動的特徴を複数フレーム連結したベクトルが入力され、出力層の出力値に対して学習データ数から算出される事前確率による正規化が行われ、音響尤度が算出される。
DNN-HMMは、一般的に、隠れ層のユニット数が多いほど高い認識性能が期待できる。しかし、DNNの各層の活性化関数適用前の出力の計算において積和演算が生じるため、演算時間は隠れ層のユニット数の2乗に比例する。よって、組み込み機器のような計算リソースに制限がある演算装置に対してDNN-HMMを適用した場合、ユニット数を増やせず、高い認識性能を得られない。
非特許文献2には、特異値分解をDNNに適用し、低ランク近似により隠れ層のユニット数を削減することが記載されている。DNNによる認識性能は低ランク近似の方法および近似後の再学習の方法に依存するため、非特許文献2記載の方法ではユニット数を削減することができても、安定した認識性能は得られ難い。
G. Hinton, L. Deng, D. Yu, G. Dahl, A. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, T. Sainath, and B. Kingsbury, "Deep neural networks for acoustic modeling in speech recognition." Signal Processing Magazine, IEEE, 2012, Vol. 29(6), p. 82-97
J. Xue, J. Li, and Y. Gong, "Restructuring of deep neural network acoustic models with singular value decomposition." Proceedings of INTERSPEECH, Aug., 2013, p. 2365-2369
以上のように、従来は、組み込み機器のような計算リソースに制限がある演算装置に搭載された多層ニューラルネットワークでは高い認識性能を得られないという課題があった。
この発明は、上記のような課題を解決するためになされたもので、組み込み機器のような計算リソースに制限がある演算装置に搭載された多層ニューラルネットワークの認識性能を向上させることを目的とする。
この発明に係る演算装置は、多層ニューラルネットワークの層ごとの重み行列を記憶している重み記憶部と、重み記憶部に記憶されている重み行列と、多層ニューラルネットワークの入力層に入力されたベクトルまたは一つ前の層から出力されたベクトルとの乗算を行う行列乗算部と、スカラ量子化を行う量子化範囲とその量子化値との対応関係を表したスカラ量子化テーブルを記憶しているスカラ量子化テーブル記憶部と、スカラ量子化テーブルを参照して行列乗算部から出力されたベクトルの各次元の値をスカラ量子化するスカラ量子化部と、多層ニューラルネットワークの出力層においてスカラ量子化部から出力されたベクトルを用いて尤度ベクトルを算出する尤度算出部と、多層ニューラルネットワークの層ごとに、スカラ量子化部によるスカラ量子化を実施するか否かを制御するスカラ量子化制御部とを備えるものである。
この発明によれば、多層ニューラルネットワークのある層においてスカラ量子化を実施した場合、次の層ではスカラ量子化されたベクトルと重み行列との乗算を行うことになるので、スカラ量子化されていないベクトルと重み行列との乗算を行う場合に比べて演算量を削減することができる。従って、計算リソースに制限がある演算装置においてもユニット数の大きい多層ニューラルネットワークを搭載可能となり、認識性能を向上させることができる。
以下、この発明をより詳細に説明するために、この発明を実施するための形態について、添付の図面に従って説明する。
実施の形態1.
図1は、この発明の実施の形態1に係る演算装置1の構成例を示すブロック図である。この演算装置1は、多層ニューラルネットワークを用いて特徴ベクトルに対する尤度演算処理を行い、尤度ベクトルを出力する装置である。図示するように、実施の形態1に係る演算装置1は、行列乗算部100、重み記憶部101、スカラ量子化制御部102、スカラ量子化部103、スカラ量子化テーブル記憶部104、および尤度算出部105を備えている。
実施の形態1.
図1は、この発明の実施の形態1に係る演算装置1の構成例を示すブロック図である。この演算装置1は、多層ニューラルネットワークを用いて特徴ベクトルに対する尤度演算処理を行い、尤度ベクトルを出力する装置である。図示するように、実施の形態1に係る演算装置1は、行列乗算部100、重み記憶部101、スカラ量子化制御部102、スカラ量子化部103、スカラ量子化テーブル記憶部104、および尤度算出部105を備えている。
図2Aは、実施の形態1に係る演算装置1のハードウェア構成図である。演算装置1は、プロセッサ2およびメモリ3を備えている。演算装置1における行列乗算部100、スカラ量子化制御部102、スカラ量子化部103および尤度算出部105の各機能は、プロセッサ2がメモリ3に格納されているプログラムを実行することによって実現される。プロセッサ2は、CPU(Central Processing Unit)、処理装置、マイクロプロセッサ、マイクロコンピュータ、またはDSP(Digital Signal Processor)等ともいう。メモリ3は、例えば、RAM(Random Access Memory)、ROM(Read Only Memory)、EPROM(Erasable Programmable ROM)、EEPROM(Electrically EPROM)、フラッシュメモリ、SSD(Solid State Drive)等の不揮発性または揮発性の半導体メモリであってもよいし、ハードディスク、フレキシブルディスク等の磁気ディスクであってもよいし、CD(Compact Disc)、DVD(Digital Versatile Disc)等の光ディスクであってもよい。また、演算装置1における重み記憶部101およびスカラ量子化テーブル記憶部104は、メモリ3である。
図2Aに示すように、演算装置1がプロセッサ2を備える構成である場合、行列乗算部100、スカラ量子化制御部102、スカラ量子化部103およびスカラ量子化テーブル記憶部104の機能は、ソフトウェア、ファームウェア、またはソフトウェアとファームウェアとの組み合わせにより実現される。ソフトウェアまたはファームウェアはプログラムとして記述され、メモリ3に格納される。プロセッサ2は、メモリ3に格納されたプログラムを読み出して実行することにより、各部の機能を実現する。即ち、演算装置1は、プロセッサ2により実行されるときに、重み行列とベクトルとの乗算を行う行列乗算ステップと、行列乗算ステップで出力されたベクトルの各次元の値をスカラ量子化するスカラ量子化ステップと、多層ニューラルネットワークの出力層においてスカラ量子化ステップで出力されたベクトルを用いて尤度ベクトルを算出する尤度算出ステップと、多層ニューラルネットワークの層ごとにスカラ量子化を実施するか否かを制御するスカラ量子化制御ステップとが実行されることになるプログラムを格納するためのメモリ3を備える。また、このプログラムは、行列乗算部100、スカラ量子化制御部102、スカラ量子化部103および尤度算出部105の手順または方法をコンピュータに実行させるものであるともいえる。
あるいは、図2Bに示すように、演算装置1を専用の処理回路4により実現してもよい。処理回路4は、例えば、単一回路、複合回路、プログラム化したプロセッサ、並列プログラム化したプロセッサ、(Application-Specific Integrated Circuit)、FPGA(Field-Programmable Gate Array)、またはこれらを組み合わせたものが該当する。行列乗算部100、スカラ量子化制御部102、スカラ量子化部103および尤度算出部105の機能を複数の処理回路4で実現してもよいし、これらの機能をまとめて1つの処理回路4で実現してもよい。また、行列乗算部100、スカラ量子化制御部102、スカラ量子化部103および尤度算出部105の各機能について、一部を処理回路4で実現し、一部をソフトウェアまたはファームウェアで実現するようにしてもよい。
次に、図3を参照し演算装置1の具体的な処理手順を述べる。図3は、実施の形態1に係る演算装置1の動作を示すフローチャートである。
以下では演算装置1を音声認識に用いる例を説明するが、音声認識の用途に限定されるものではなく、画像認識およびセンサ情報からの物体認識など、パターン認識一般に適用可能である。
以下では演算装置1を音声認識に用いる例を説明するが、音声認識の用途に限定されるものではなく、画像認識およびセンサ情報からの物体認識など、パターン認識一般に適用可能である。
ステップST101において、行列乗算部100は、多層ニューラルネットワークの階層番号Lを1に初期化する。また、行列乗算部100は、入力層に入力される入力ベクトルの各次元の値xi(i=1~I)に、特徴ベクトルの各次元の値vi(i=1~I)を代入する。
DNN-HMMでは一般的に、特徴ベクトルとして、フィルタバンク特徴量およびその動的特徴を複数フレーム連結したベクトルが用いられる。
DNN-HMMでは一般的に、特徴ベクトルとして、フィルタバンク特徴量およびその動的特徴を複数フレーム連結したベクトルが用いられる。
ステップST102において、行列乗算部100は、重み記憶部101における階層Lの入力次元数DINLを参照してIに代入すると共に、重み記憶部101における階層Lの出力次元数DOUTLを参照してJに代入する。重み記憶部101は、階層別にDOUTL×DINLの重み行列wjiを記憶している。
なお、階層Lのユニット数は、その出力次元数DOUTLと一致する。
なお、階層Lのユニット数は、その出力次元数DOUTLと一致する。
ステップST103において、行列乗算部100は、階層Lの一つ前の階層L-1でスカラ量子化が行われたかどうかの判定結果SQDo(L-1)をスカラ量子化制御部102から取得する。そして、行列乗算部100は、判定結果SQDo(L-1)が1である場合(ステップST103“YES”)、つまりスカラ量子化が行われた場合、演算量を削減した行列乗算を行うためステップST105に進み、そうでない場合(ステップST103“NO”)は通常の行列乗算を行うためステップST104に進む。
ステップST104において、行列乗算部100は、通常の行列乗算として、以下の式(1)を用いて活性化関数適用前の出力uj(j=1~J)の計算を行う。また、行列乗算部100は、式(1)の計算に必要な重み行列wjiを、重み記憶部101から取得する。

ステップST105において、行列乗算部100は、通常の行列乗算よりも演算量を削減した行列乗算として、以下の式(2)を用いて活性化関数適用前の出力uj(j=1~J)の計算を行う。式(2)において、akは、スカラ量子化されたxiであり、Ikは、akにスカラ量子化されたxiのインデックスiの集合である。また、行列乗算部100は、式(2)の計算に必要な重み行列wjiを、重み記憶部101から取得する。


ステップST104またはステップST105で計算されたujは、行列乗算部100からスカラ量子化部103に出力される。
ステップST106において、スカラ量子化部103は、階層Lでスカラ量子化を行うかどうかの判定結果SQDo(L)をスカラ量子化制御部102から取得する。そして、スカラ量子化部103は、判定結果SQDo(L)が1である場合(ステップST106“YES”)、スカラ量子化を行うためステップST107に進み、そうでない場合(ステップST106“NO”)はステップST110に進む。
なお、当該階層Lに対してスカラ量子化を行うかどうかは、事前にスカラ量子化を行うことによる認識性能の低下度合いおよび演算量削減効果のトレードオフを考慮して決定され、スカラ量子化制御部102に対して設定されているものとする。スカラ量子化制御部102は、その設定に従ってスカラ量子化部103を制御する。
なお、当該階層Lに対してスカラ量子化を行うかどうかは、事前にスカラ量子化を行うことによる認識性能の低下度合いおよび演算量削減効果のトレードオフを考慮して決定され、スカラ量子化制御部102に対して設定されているものとする。スカラ量子化制御部102は、その設定に従ってスカラ量子化部103を制御する。
ステップST107において、スカラ量子化部103は、行列乗算部100の出力ujをスカラ量子化する。
ここで、図4を参照し、ステップST107におけるスカラ量子化の具体的な処理手順を述べる。図4は、実施の形態1に係る演算装置1におけるスカラ量子化部103の動作を示すフローチャートである。
ステップST107Aにおいて、スカラ量子化部103は、入力ベクトルの次元インデックスiに1を入力し、スカラ量子化されたインデックスの集合Ikをクリアする。
ステップST107Bにおいて、スカラ量子化部103は、スカラ量子化テーブルインデックスkを1に初期化する。
ステップST107Cにおいて、スカラ量子化部103は、スカラ量子化テーブル記憶部104に記憶されている、量子化範囲の下限値Lkと上限値Hkをxiと比較する。そして、スカラ量子化部103は、xiがLkよりも大きく、かつxiがHk以下である場合(ステップST107C“YES”)、ステップST107Dに進み、そうでない場合(ステップST107C“NO”)はステップST107Eに進む。
図5は、スカラ量子化テーブル記憶部104が記憶しているスカラ量子化テーブルの一例である。上述のスカラ量子化テーブルインデックスkは、スカラ量子化テーブル記憶部104のスカラ量子化テーブルに記憶されている量子化値akのインデックスのことである。スカラ量子化テーブルサイズKは、スカラ量子化テーブルに記憶されている量子化値のインデックスkの最大値である。
スカラ量子化テーブルは、事前に階層毎に認識性能の低下度合いおよび演算量削減効果のトレードオフを考慮して決定されたものである。また、スカラ量子化テーブルの量子化値として活性化関数適用後の値が格納されている。図4の例では、シグモイド関数適用後の量子化値が示されている。
スカラ量子化テーブルは、事前に階層毎に認識性能の低下度合いおよび演算量削減効果のトレードオフを考慮して決定されたものである。また、スカラ量子化テーブルの量子化値として活性化関数適用後の値が格納されている。図4の例では、シグモイド関数適用後の量子化値が示されている。
なお、スカラ量子化テーブル記憶部104には、階層の区別がない単一のスカラ量子化テーブルが記憶されていてもよいし、階層毎のスカラ量子化テーブルが記憶されていてもよい。ただし、スカラ量子化の量子化幅と量子化範囲は、最終的な認識性能に影響するため、例えばスカラ量子化により認識性能への影響が大きい層に対しては細かい量子化を行い、認識性能への影響が小さい層に対しては大雑把な量子化を行うことが望ましい。そのため、階層の区別がない単一のスカラ量子化テーブルを使用する場合と比較して、階層毎に用意されたスカラ量子化テーブルを使用する場合の方が認識性能を落とさずに全体の演算量を削減することが可能となる。
ステップST107Dにおいて、スカラ量子化部103は、以下の式(3)と(4)を用いてxiをakに量子化する。式(4)において、add(Ik,i)は、量子化されたインデックスの集合Ikにiを追加する関数である。スカラ量子化部103は、ステップST107Dの後、ステップST107Gに進む。
xi=ak (3)
add(Ik,i) (4)
xi=ak (3)
add(Ik,i) (4)
ステップST107Eにおいて、スカラ量子化部103は、スカラ量子化テーブルインデックスkをインクリメントする。
ステップST107Fにおいて、スカラ量子化部103は、スカラ量子化テーブルインデックスkがスカラ量子化テーブルサイズK以下である場合(ステップST107F“YES”)、ステップST107Cに戻る。一方、スカラ量子化部103は、スカラ量子化テーブルインデックスkがスカラ量子化テーブルサイズKより大きい場合(ステップST107F“NO”)、ステップST107Gに進む。このようにして、スカラ量子化部103は、xiが該当する量子化範囲をk=1からk=Kへと探索していき、xiを該当する量子化範囲の量子化値akに置換する。
ステップST107Gにおいて、スカラ量子化部103は、入力ベクトルの次元インデックスiをインクリメントする。
ステップST107Hにおいて、スカラ量子化部103は、入力ベクトルの次元インデックスiが入力次元数I以下である場合(ステップST107H“YES”)、ステップST107Bに戻る。一方、スカラ量子化部103は、入力ベクトルの次元インデックスiが入力次元数Iより大きい場合(ステップST107H“NO”)、スカラ量子化の処理を終了し、図3のステップST108に進む。
続いて図3のステップST108に戻り、スカラ量子化後の処理を説明する。
ステップST108において、スカラ量子化部103は、スカラ量子化した値がシグモイド関数などの活性化関数適用後の値である場合(ステップST108“YES”)、つまり入力ベクトルの各次元の値xiがスカラ量子化テーブルの量子化値akに変換された場合、ステップST109に進む。スカラ量子化した値が活性化関数適用後の値である場合とは、ステップST107において入力ベクトルの各次元の値xiがスカラ量子化テーブルの量子化値akに変換された場合である。そうでない場合(ステップST108“NO”)、スカラ量子化部103はステップST110に進む。
ステップST108において、スカラ量子化部103は、スカラ量子化した値がシグモイド関数などの活性化関数適用後の値である場合(ステップST108“YES”)、つまり入力ベクトルの各次元の値xiがスカラ量子化テーブルの量子化値akに変換された場合、ステップST109に進む。スカラ量子化した値が活性化関数適用後の値である場合とは、ステップST107において入力ベクトルの各次元の値xiがスカラ量子化テーブルの量子化値akに変換された場合である。そうでない場合(ステップST108“NO”)、スカラ量子化部103はステップST110に進む。
ステップST109において、スカラ量子化部103は、活性化関数を適用する必要がないため、以下の式(5)に従い出力zjを算出する。
zj=uj(j=1~J) (5)
zj=uj(j=1~J) (5)
ステップST110において、スカラ量子化部103は、活性化関数を適用する必要があるため、以下の式(6)に従い出力zjを算出する。式(6)において、fは活性化関数であり、一般的に中間層では式(7)のロジスティックシグモイド関数または式(8)の正規化線形関数が用いられ、出力層では式(9)のソフトマックス関数が用いられる。
zj=f(uj)(j=1~J) (6)
f(uj)=1/(1+exp(-uj)) (7)
f(uj)=max(0,uj) (8)
f(uj)=exp(uj)/Σk=1 Kexp(uk) (9)
zj=f(uj)(j=1~J) (6)
f(uj)=1/(1+exp(-uj)) (7)
f(uj)=max(0,uj) (8)
f(uj)=exp(uj)/Σk=1 Kexp(uk) (9)
ステップST111において、スカラ量子化部103は、階層Lが多層ニューラルネットワークの出力層であるかどうかを判定する。そして、スカラ量子化部103は、階層Lが多層ニューラルネットワークの出力層である場合(ステップST111“YES”)、ステップST113に進み、出力層でない場合(ステップST111“NO”)、ステップST112に進む。
ステップST112において、スカラ量子化部103は、ステップST109またはステップST110で計算された出力zjを行列乗算部100に出力する。出力zjを受け取った行列乗算部100は、階層番号Lをインクリメントし、以下の式(10)を用いてインクリメント後の階層Lに対する入力ベクトルの各次元の値xjに、階層L-1の出力ベクトルの各次元の値zjを代入する。その後、行列乗算部100はステップST102に戻る。
xj=zj(j=1~J) (10)
xj=zj(j=1~J) (10)
ステップST113において、スカラ量子化部103は、ステップST109またはステップST110で計算された出力zjを尤度算出部105に出力する。出力zjを受け取った尤度算出部105は、以下の式(11)を用いて、出力層の出力ベクトルの各次元の値zj(i=1~J)から尤度p(v|j)を算出する。式(11)において、p0(j)は、学習データの個数から算出される事前分布の確率である。
p(v|j)=zj/p0(j) (11)
p(v|j)=zj/p0(j) (11)
以上のように、実施の形態1に係る演算装置1は、多層ニューラルネットワークの層ごとの重み行列を記憶している重み記憶部101と、重み記憶部101に記憶されている重み行列と多層ニューラルネットワークの入力層に入力されたベクトルまたは一つ前の層から出力されたベクトルとの乗算を行う行列乗算部100と、スカラ量子化を行う量子化範囲とその量子化値との対応関係を表したスカラ量子化テーブルを記憶しているスカラ量子化テーブル記憶部104と、スカラ量子化テーブルを参照して行列乗算部100から出力されたベクトルの各次元の値をスカラ量子化するスカラ量子化部103と、多層ニューラルネットワークの出力層においてスカラ量子化部103から出力されたベクトルを用いて尤度ベクトルを算出する尤度算出部105と、多層ニューラルネットワークの層ごとに、スカラ量子化部103によるスカラ量子化を実施するか否かを制御するスカラ量子化制御部102とを備える構成である。スカラ量子化部103において階層Lの一つ前の階層L-1からの出力ベクトルの各次元の値に対してスカラ量子化を行った場合、行列乗算部100は、階層Lにおいて活性化関数適用前の出力uj(j=1~J)の計算を式(1)ではなく式(2)を用いて行うことになり、以下の式(12)の行列表現で表されるWxの行列×ベクトル演算で生じる乗算回数をK/Iに削減することができる。従って、組み込み機器のような計算リソースに制限がある演算装置1においてもユニット数の大きい多層ニューラルネットワークを搭載可能となり、認識性能を向上させることができる。

さらに、スカラ量子化制御部102により、スカラ量子化による認識性能の低下度合いおよび演算量削減効果のトレードオフを考慮して、多層ニューラルネットワークの層ごとにスカラ量子化の実施有無を制御すれば、演算装置1に要求される認識性能と計算リソースの両方を満たすことが容易となる。
また、実施の形態1のスカラ量子化部103は、行列乗算部100から出力されたベクトルの各次元の値をスカラ量子化する際に、活性化関数を適用した後の値にスカラ量子化する構成である。この構成により、活性化関数の適用処理自体を削減でき、組み込み機器のような計算リソースに制限がある演算装置1においてもユニット数の大きい多層ニューラルネットワークを搭載することができる。
また、実施の形態1のスカラ量子化テーブル記憶部104は、多層ニューラルネットワークの層ごとのスカラ量子化テーブルを記憶しており、スカラ量子化部103は、スカラ量子化テーブル記憶部104に記憶されているスカラ量子化テーブルのうち、スカラ量子化を行う層に該当するスカラ量子化テーブルを参照する構成である。この構成により、単一のスカラ量子化テーブルを使用する場合と比較して、認識性能を落とさずに全体の演算量を削減することができる。
実施の形態2.
実施の形態1のスカラ量子化部103において量子化値が0になった場合、その後の行列乗算部100による乗算結果も0になるため、乗算自体が不要である。そこで、実施の形態2では、量子化値が0になった場合を考慮して、実施の形態1より乗算回数を削減すると共に加算回数も削減することを目的とする。
実施の形態1のスカラ量子化部103において量子化値が0になった場合、その後の行列乗算部100による乗算結果も0になるため、乗算自体が不要である。そこで、実施の形態2では、量子化値が0になった場合を考慮して、実施の形態1より乗算回数を削減すると共に加算回数も削減することを目的とする。
ここで、図6は、多層ニューラルネットワークの各層の出力ベクトルの値を0.01刻みでカウントし、その頻度をグラフにしたものである。この結果より、全ての層で0に近い値の頻度が高いことが分かる。よって、以下に説明するように、0にスカラ量子化する量子化範囲を適切に決定しておくことで、認識性能を低下させずに演算量を削減することが可能となる。
実施の形態2に係る演算装置1の構成は、図1に示された実施の形態1に係る演算装置1の構成と図面上は同一であるため、図示を省略する。
実施の形態2と実施の形態1の差異は、行列乗算部100における演算量を削減した行列乗算の計算式である。実施の形態2の行列乗算部100は、図3のステップST105において、上式(2)の代わりに以下の式(13)を用いて、活性化関数適用前の出力uj(j=1~J)の計算を行う。

また、実施の形態2のスカラ量子化テーブル記憶部104は、a1=0を含むスカラ量子化テーブルを記憶している。これに対し、実施の形態2以外のスカラ量子化テーブルは、a1=0を含んでもよいし含まなくてもよい。
以上のように、実施の形態2のスカラ量子化部103は、量子化値0に対応する量子化範囲を記憶している構成である。また、行列乗算部100は、一つ前の層から出力されたスカラ量子化されたベクトルの各次元のうちの0以外の量子化値にスカラ量子化された次元に対応する重みの総和値を、重み記憶部101に記憶されている重み行列を用いて算出し、当該重みの総和値を0以外の量子化値と乗算する構成である。これにより、多層ニューラルネットワークの各層で生じるWxの行列×ベクトル演算の乗算回数を(K-1)/I、加算回数を(I-cnt(I0))/Iに削減することができる。ここで、cnt(・)は要素数をカウントする関数である。従って、組み込み機器のような計算リソースに制限がある演算装置1においてもユニット数の大きな多層ニューラルネットワークを搭載することができる。
実施の形態3.
実施の形態1および実施の形態2は、多層ニューラルネットワークの各層で生じるWxの行列×ベクトル演算の主に乗算回数を削減することを目的としているが、実施の形態3は、実施の形態1,2よりもさらに加算回数を削減することを目的としている。
実施の形態1および実施の形態2は、多層ニューラルネットワークの各層で生じるWxの行列×ベクトル演算の主に乗算回数を削減することを目的としているが、実施の形態3は、実施の形態1,2よりもさらに加算回数を削減することを目的としている。
図7は、実施の形態3に係る演算装置1の構成を示すブロック図である。図7において図1と同一または相当する部分は、同一の符号を付し説明を省略する。
実施の形態3と実施の形態1,2との差異は、図7に示すように、同一の量子化値にスカラ量子化されたインデックスの集合とその集合に属するインデックスに対応する重みの総和値とを記憶する重み総和値記憶部106を備えたことである。この重み総和値記憶部106は、例えば図2Aに示されたメモリ3である。
図8は、重み総和値記憶部106が記憶しているインデックスの集合と重みの総和値の一例である。この重み総和値記憶部106には、予め頻出するインデックスの集合Rn(n=1~N)と対応する重みの総和値sj(Rn)とが格納されている。重みの総和値は以下の式(14)で表される。
sj(Rn)=Σi∈Iwji(j=1~J) (14)
sj(Rn)=Σi∈Iwji(j=1~J) (14)
例えば、入力ベクトルの各次元の値xiをスカラ量子化したとき、量子化値akが同一になる次元インデックスiの集合Ik={1,3,5,・・・,511}が頻出することが事前に判明している場合、集合Ikに対応する各重みの総和値が、sj(Rn)として重み総和値記憶部106に格納される。なお、図8では総和値を求める前の各重みが示されているが、実際の重み総和値記憶部106には各重みから計算された総和値が格納されることになる。
実施の形態3の行列乗算部100は、図3のステップST105において、上式(2)の代わりに以下の式(15)と(16)を用いて、活性化関数適用前の出力uj(j=1~J)の計算を行う。すなわち、行列乗算部100は、量子化値が同一になる次元インデックスの集合Ikが重み総和値記憶部106に記憶されている集合Rnに一致する場合、その集合Rnに対応する重みの総和値sjを用いて式(15)により出力ujを計算する。一方、集合Ikが重み総和値記憶部106に記憶されている集合Rnに一致しない場合、行列乗算部100は重み記憶部101に記憶されている重み行列wjiを用いて式(16)により出力ujを計算する。なお、式(15)と(16)では実施の形態2と同様に量子化値a1=0を除外しているが、実施の形態1のように量子化値a1=0を含めてもよい。

以上のように、実施の形態3に係る演算装置1は、多層ニューラルネットワークの層ごとに、同一の量子化値にスカラ量子化されたベクトルの次元の集合とその集合に属する次元に対応する重みの総和値とを記憶している重み総和値記憶部106を備える構成である。また、行列乗算部100は、一つ前の層から出力されたスカラ量子化されたベクトルの各次元のうちの同一の量子化値にスカラ量子化された次元の集合が、重み総和値記憶部106に記憶されている集合に該当する場合、当該集合に対応する重みの総和を重み総和値記憶部106から取得して量子化値と乗算する構成である。これにより、多層ニューラルネットワークの各層で生じるWxの行列×ベクトル演算の加算回数を削減することができる。従って、組み込み機器のような計算リソースに制限がある演算装置1においてもユニット数の大きな多層ニューラルネットワークを搭載することができる。
実施の形態4.
実施の形態3の重み総和値記憶部106は、頻出するインデックスの集合Rnと対応する重みの総和値sj(Rn)を予め格納している構成であったが、実施の形態4では過去に算出されたスカラ量子化の結果に基づくインデックスの集合Rnと対応する重みの総和値sj(Rn)を格納する構成にする。
実施の形態3の重み総和値記憶部106は、頻出するインデックスの集合Rnと対応する重みの総和値sj(Rn)を予め格納している構成であったが、実施の形態4では過去に算出されたスカラ量子化の結果に基づくインデックスの集合Rnと対応する重みの総和値sj(Rn)を格納する構成にする。
図9は、実施の形態4に係る演算装置1の構成を示すブロック図である。図9において図3と同一または相当する部分は、同一の符号を付し説明を省略する。
実施の形態4と実施の形態3との差異は、図9に示すように、スカラ量子化部103により同一の量子化値にスカラ量子化されたインデックスの集合およびその集合に属するインデックスに対応する重みの総和値を、重み総和値記憶部106に記憶するようにした点である。

このように、実施の形態4では、Rnとsj(Rn)をキャッシュとして重み総和値記憶部106に記憶しておくことが可能である。例えば、演算装置1は、過去のある時点での発話を音声認識したときのRnとsj(Rn)を重み総和値記憶部106に記憶させておき、これ以降の発話を音声認識するときには最新のRnとsj(Rn)を重み総和値記憶部106の最も参照されないRnとsj(Rn)と逐次入れ替えていく。これにより、頻度の高い発話に関しては重み総和値記憶部106に記憶されている値を使用することで加算回数を削減できるので、演算量削減効果が高くなることが期待できる。
以上のように、実施の形態4の重み総和値記憶部106は、過去に算出された、同一の量子化値にスカラ量子化されたベクトルの次元の集合とその集合に属する次元に対応する重みの総和値とを記憶する構成である。これにより、実施の形態3と同様に、多層ニューラルネットワークの各層で生じるWxの行列×ベクトル演算の加算回数を削減することができる。従って、組み込み機器のような計算リソースに制限がある演算装置1においてもユニット数の大きな多層ニューラルネットワークを搭載することができる。
実施の形態5.
実施の形態1~4は、スカラ量子化によりWxの行列×ベクトル演算で生じる乗算回数および加算回数を削減することを目的としている。しかし、スカラ量子化により、若干ではあるが認識性能が低下する可能性がある。そのため、演算装置1の計算リソースに余裕がある場合は、認識性能の低下が懸念される層のスカラ量子化を行わず、Wxの行列×ベクトル演算を行うことが望ましい。そこで、実施の形態5のスカラ量子化制御部102は、演算装置1の負荷に応じて多層ニューラルネットワークの層ごとにスカラ量子化を実施するか否かを判定し、スカラ量子化部103を制御する。スカラ量子化制御部102は、演算装置1の負荷が大きい場合、スカラ量子化部103がスカラ量子化を実施する層を多くし、演算装置1の負荷が小さい場合、スカラ量子化部103がスカラ量子化を実施する層を少なくする。
実施の形態1~4は、スカラ量子化によりWxの行列×ベクトル演算で生じる乗算回数および加算回数を削減することを目的としている。しかし、スカラ量子化により、若干ではあるが認識性能が低下する可能性がある。そのため、演算装置1の計算リソースに余裕がある場合は、認識性能の低下が懸念される層のスカラ量子化を行わず、Wxの行列×ベクトル演算を行うことが望ましい。そこで、実施の形態5のスカラ量子化制御部102は、演算装置1の負荷に応じて多層ニューラルネットワークの層ごとにスカラ量子化を実施するか否かを判定し、スカラ量子化部103を制御する。スカラ量子化制御部102は、演算装置1の負荷が大きい場合、スカラ量子化部103がスカラ量子化を実施する層を多くし、演算装置1の負荷が小さい場合、スカラ量子化部103がスカラ量子化を実施する層を少なくする。
演算装置1がカーナビゲーションシステム、PC(Personal Computer)またはサーバなどに組み込まれている場合、図2Aに示されたプロセッサ2は、実施の形態1~4で説明した音声認識機能だけでなくカーナビゲーションシステム等の機能も実行することになる。例えば演算装置1がカーナビゲーションシステムに組み込まれている構成では、プロセッサ2は、経路探索および音楽再生などのアプリケーションを実行しており、目的地を設定した場合などには経路探索のため一時的にプロセッサ2の計算リソースが占有されシステム負荷が上がる場合がある。このとき、プロセッサ2が多層ニューラルネットワークの演算に使用できる計算リソースが少なくなるため、スカラ量子化制御部102は、ある程度認識性能を犠牲にしてもスカラ量子化を実施させる層を多くして、多層ニューラルネットワークの演算量を削減する。一方、他のアプリケーションが動作しておらず、多層ニューラルネットワークの演算に使用できる計算リソースが余っている場合、スカラ量子化制御部102は、認識性能を最大限確保するためにスカラ量子化を行わせず通常の行列乗算を行わせる。
なお、実施の形態5に係る演算装置1の構成は、図1、図7および図9に示された実施の形態1~4に係る演算装置1の構成と図面上は同一であるため、図示を省略する。
以上のように、実施の形態5のスカラ量子化制御部102は、演算装置1の負荷に応じて、多層ニューラルネットワークの層ごとにスカラ量子化を実施するか否かを判定する構成である。これにより、組み込み機器である演算装置1の負荷が大きい場合はスカラ量子化により演算量を削減することで、多少の認識性能低下があっても音声認識を可能にし、負荷が小さい場合はスカラ量子化を行う階層数を最低限とすることで認識性能の低下を最低限に抑えることができる。
なお、本発明はその発明の範囲内において、各実施の形態の自由な組み合わせ、各実施の形態の任意の構成要素の変形、または各実施の形態の任意の構成要素の省略が可能である。
この発明に係る演算装置は、多層ニューラルネットワークの認識性能を低下させずに演算量を削減するようにしたので、計算リソースが制限される組み込み機器などに用いるのに適している。
1 演算装置、2 プロセッサ、3 メモリ、4 処理回路、100 行列乗算部、101 重み記憶部、102 スカラ量子化制御部、103 スカラ量子化部、104 スカラ量子化テーブル記憶部、105 尤度算出部、106 重み総和値記憶部。
Claims (9)
- 多層ニューラルネットワークの層ごとの重み行列を記憶している重み記憶部と、
前記重み記憶部に記憶されている重み行列と、前記多層ニューラルネットワークの入力層に入力されたベクトルまたは一つ前の層から出力されたベクトルとの乗算を行う行列乗算部と、
スカラ量子化を行う量子化範囲とその量子化値との対応関係を表したスカラ量子化テーブルを記憶しているスカラ量子化テーブル記憶部と、
前記スカラ量子化テーブルを参照して前記行列乗算部から出力されたベクトルの各次元の値をスカラ量子化するスカラ量子化部と、
前記多層ニューラルネットワークの出力層において前記スカラ量子化部から出力されたベクトルを用いて尤度ベクトルを算出する尤度算出部と、
前記多層ニューラルネットワークの層ごとに、前記スカラ量子化部によるスカラ量子化を実施するか否かを制御するスカラ量子化制御部とを備える演算装置。 - 前記行列乗算部は、一つ前の層から出力されたスカラ量子化されたベクトルの各次元のうちの同一の量子化値にスカラ量子化された次元に対応する重みの総和値を、前記重み記憶部に記憶されている重み行列を用いて算出し、当該重みの総和値を前記量子化値と乗算することを特徴とする請求項1記載の演算装置。
- 前記スカラ量子化テーブル記憶部は、量子化値0に対応する量子化範囲が記憶されており、
前記行列乗算部は、一つ前の層から出力されたスカラ量子化されたベクトルの各次元のうちの0以外の量子化値にスカラ量子化された次元に対応する重みの総和値を、前記重み記憶部に記憶されている重み行列を用いて算出し、当該重みの総和値を前記0以外の量子化値と乗算することを特徴とする請求項1記載の演算装置。 - 前記スカラ量子化部は、前記行列乗算部から出力されたベクトルの各次元の値をスカラ量子化する際に、活性化関数を適用した後の値にスカラ量子化することを特徴とする請求項1記載の演算装置。
- 前記多層ニューラルネットワークの層ごとに、同一の量子化値にスカラ量子化されたベクトルの次元の集合とその集合に属する次元に対応する重みの総和値とを記憶している重み総和値記憶部を備え、
前記行列乗算部は、一つ前の層から出力されたスカラ量子化されたベクトルの各次元のうちの同一の量子化値にスカラ量子化された次元の集合が、前記重み総和値記憶部に記憶されている集合に該当する場合、当該集合に対応する重みの総和値を前記重み総和値記憶部から取得して前記量子化値と乗算することを特徴とする請求項1記載の演算装置。 - 前記重み総和値記憶部は、過去に算出された、同一の量子化値にスカラ量子化されたベクトルの次元の集合とその集合に属する次元に対応する重みの総和値とを記憶することを特徴とする請求項5記載の演算装置。
- 前記スカラ量子化制御部は、前記演算装置の負荷に応じて、前記多層ニューラルネットワークの層ごとにスカラ量子化を実施するか否かを判定することを特徴とする請求項1記載の演算装置。
- 前記スカラ量子化テーブル記憶部は、前記多層ニューラルネットワークの層ごとのスカラ量子化テーブルを記憶しており、
前記スカラ量子化部は、前記スカラ量子化テーブル記憶部に記憶されているスカラ量子化テーブルのうち、スカラ量子化を行う層に該当するスカラ量子化テーブルを参照することを特徴とする請求項1記載の演算装置。 - 行列乗算部が、多層ニューラルネットワークの層ごとの重み行列を記憶している重み記憶部から取得した重み行列と、前記多層ニューラルネットワークの入力層に入力されたベクトルまたは一つ前の層から出力されたベクトルとの乗算を行う行列乗算ステップと、
スカラ量子化部が、スカラ量子化を行う量子化範囲とその量子化値との対応関係を表したスカラ量子化テーブルを記憶しているスカラ量子化テーブル記憶を参照して、前記行列乗算ステップで出力されたベクトルの各次元の値をスカラ量子化するスカラ量子化ステップと、
尤度算出部が、前記多層ニューラルネットワークの出力層において前記スカラ量子化ステップで出力されたベクトルを用いて尤度ベクトルを算出する尤度算出ステップと、
スカラ量子化制御部が、前記多層ニューラルネットワークの層ごとに、前記スカラ量子化ステップのスカラ量子化を実施するか否かを制御するスカラ量子化制御ステップとを備える演算方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2016/056583 WO2017149722A1 (ja) | 2016-03-03 | 2016-03-03 | 演算装置および演算方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2016/056583 WO2017149722A1 (ja) | 2016-03-03 | 2016-03-03 | 演算装置および演算方法 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2017149722A1 true WO2017149722A1 (ja) | 2017-09-08 |
Family
ID=59743717
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2016/056583 Ceased WO2017149722A1 (ja) | 2016-03-03 | 2016-03-03 | 演算装置および演算方法 |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2017149722A1 (ja) |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3518152A1 (en) | 2018-01-29 | 2019-07-31 | Panasonic Intellectual Property Corporation of America | Information processing method and information processing system |
| EP3518153A1 (en) | 2018-01-29 | 2019-07-31 | Panasonic Intellectual Property Corporation of America | Information processing method and information processing system |
| CN110874626A (zh) * | 2018-09-03 | 2020-03-10 | 华为技术有限公司 | 一种量化方法及装置 |
| WO2020141587A1 (ja) | 2019-01-02 | 2020-07-09 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | 情報処理装置、情報処理方法及びプログラム |
| JP6795721B1 (ja) * | 2019-08-29 | 2020-12-02 | 楽天株式会社 | 学習システム、学習方法、及びプログラム |
| WO2021059791A1 (ja) * | 2019-09-26 | 2021-04-01 | 日立Astemo株式会社 | 内燃機関の制御装置 |
| CN113168574A (zh) * | 2018-12-12 | 2021-07-23 | 日立安斯泰莫株式会社 | 信息处理装置、车载控制装置、车辆控制系统 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0660051A (ja) * | 1991-09-18 | 1994-03-04 | Matsushita Electric Ind Co Ltd | ニューラルネットワーク回路 |
| JPH0854893A (ja) * | 1994-08-09 | 1996-02-27 | Matsushita Electric Ind Co Ltd | 帰属度算出装置およびhmm装置 |
| JPH08272759A (ja) * | 1995-03-22 | 1996-10-18 | Cselt Spa (Cent Stud E Lab Telecomun) | 相関信号処理用ニューラルネットワークの実行スピードアップの方法 |
-
2016
- 2016-03-03 WO PCT/JP2016/056583 patent/WO2017149722A1/ja not_active Ceased
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0660051A (ja) * | 1991-09-18 | 1994-03-04 | Matsushita Electric Ind Co Ltd | ニューラルネットワーク回路 |
| JPH0854893A (ja) * | 1994-08-09 | 1996-02-27 | Matsushita Electric Ind Co Ltd | 帰属度算出装置およびhmm装置 |
| JPH08272759A (ja) * | 1995-03-22 | 1996-10-18 | Cselt Spa (Cent Stud E Lab Telecomun) | 相関信号処理用ニューラルネットワークの実行スピードアップの方法 |
Cited By (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3518152A1 (en) | 2018-01-29 | 2019-07-31 | Panasonic Intellectual Property Corporation of America | Information processing method and information processing system |
| EP3518153A1 (en) | 2018-01-29 | 2019-07-31 | Panasonic Intellectual Property Corporation of America | Information processing method and information processing system |
| US11036980B2 (en) | 2018-01-29 | 2021-06-15 | Panasonic Intellectual Property Corporation Of America | Information processing method and information processing system |
| US11100321B2 (en) | 2018-01-29 | 2021-08-24 | Panasonic Intellectual Property Corporation Of America | Information processing method and information processing system |
| CN110874626A (zh) * | 2018-09-03 | 2020-03-10 | 华为技术有限公司 | 一种量化方法及装置 |
| CN110874626B (zh) * | 2018-09-03 | 2023-07-18 | 华为技术有限公司 | 一种量化方法及装置 |
| CN113168574A (zh) * | 2018-12-12 | 2021-07-23 | 日立安斯泰莫株式会社 | 信息处理装置、车载控制装置、车辆控制系统 |
| WO2020141587A1 (ja) | 2019-01-02 | 2020-07-09 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | 情報処理装置、情報処理方法及びプログラム |
| US12412084B2 (en) | 2019-01-02 | 2025-09-09 | Panasonic Intellectual Property Corporation Of America | Information processing device, information processing method, and recording medium |
| JP6795721B1 (ja) * | 2019-08-29 | 2020-12-02 | 楽天株式会社 | 学習システム、学習方法、及びプログラム |
| WO2021059791A1 (ja) * | 2019-09-26 | 2021-04-01 | 日立Astemo株式会社 | 内燃機関の制御装置 |
| US11655791B2 (en) | 2019-09-26 | 2023-05-23 | Hitachi Astemo, Ltd. | Internal combustion engine control device |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2017149722A1 (ja) | 演算装置および演算方法 | |
| Shangguan et al. | Optimizing speech recognition for the edge | |
| US11868867B1 (en) | Decompression and compression of neural network data using different compression schemes | |
| CN105719001B (zh) | 使用散列的神经网络中的大规模分类 | |
| US10152676B1 (en) | Distributed training of models using stochastic gradient descent | |
| EP3474194A1 (en) | Method and apparatus with neural network parameter quantization | |
| JP2022042467A (ja) | 人工ニューラルネットワークモデル学習方法およびシステム | |
| US20170200446A1 (en) | Data augmentation method based on stochastic feature mapping for automatic speech recognition | |
| US20200210843A1 (en) | Training and application method of a multi-layer neural network model, apparatus and storage medium | |
| CN110265002B (zh) | 语音识别方法、装置、计算机设备及计算机可读存储介质 | |
| US20210287074A1 (en) | Neural network weight encoding | |
| TW202004658A (zh) | 深度神經網絡自我調整增量模型壓縮的方法 | |
| JP2019148896A (ja) | 演算処理装置、情報処理装置、情報処理方法、およびプログラム | |
| JP2019139338A (ja) | 情報処理装置、情報処理方法、およびプログラム | |
| Lee et al. | Accelerating recurrent neural network language model based online speech recognition system | |
| WO2022046199A1 (en) | Multi-token embedding and classifier for masked language models | |
| CN112651485A (zh) | 识别图像的方法和设备以及训练神经网络的方法和设备 | |
| CN111723901A (zh) | 神经网络模型的训练方法及装置 | |
| CN117136364A (zh) | 用于经量化训练的量化范围估计 | |
| CN118369667A (zh) | 融合用于神经网络硬件加速器的算子 | |
| CN117130693B (zh) | 张量卸载方法、装置、计算机设备及存储介质 | |
| US20220147821A1 (en) | Computing device, computer system, and computing method | |
| WO2022044465A1 (ja) | 情報処理方法及び情報処理システム | |
| US20210216867A1 (en) | Information processing apparatus, neural network computation program, and neural network computation method | |
| KR102921712B1 (ko) | 음성인식 모델을 경량화하는 방법 및 시스템 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 16892562 Country of ref document: EP Kind code of ref document: A1 |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 16892562 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: JP |