WO2018024058A1 - 一种混响时间估计方法及装置 - Google Patents
一种混响时间估计方法及装置 Download PDFInfo
- Publication number
- WO2018024058A1 WO2018024058A1 PCT/CN2017/090887 CN2017090887W WO2018024058A1 WO 2018024058 A1 WO2018024058 A1 WO 2018024058A1 CN 2017090887 W CN2017090887 W CN 2017090887W WO 2018024058 A1 WO2018024058 A1 WO 2018024058A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- reverberation
- autocorrelation function
- speech signal
- parameter
- reverberation time
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images




Classifications
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01H—MEASUREMENT OF MECHANICAL VIBRATIONS OR ULTRASONIC, SONIC OR INFRASONIC WAVES
- G01H7/00—Measuring reverberation time ; room acoustic measurements
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10K—SOUND-PRODUCING DEVICES; METHODS OR DEVICES FOR PROTECTING AGAINST, OR FOR DAMPING, NOISE OR OTHER ACOUSTIC WAVES IN GENERAL; ACOUSTICS NOT OTHERWISE PROVIDED FOR
- G10K15/00—Acoustics not otherwise provided for
- G10K15/08—Arrangements for producing a reverberation or echo sound
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/08—Determination or coding of the excitation function; Determination or coding of the long-term prediction parameters
- G10L19/09—Long term prediction, i.e. removing periodical redundancies, e.g. by using adaptive codebook or pitch predictor
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/26—Pre-filtering or post-filtering
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/04—Time compression or expansion
- G10L21/057—Time compression or expansion for improving intelligibility
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S7/00—Indicating arrangements; Control arrangements, e.g. balance control
- H04S7/30—Control circuits for electronic adaptation of the sound field
- H04S7/305—Electronic adaptation of stereophonic audio signals to reverberation of the listening space
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L2019/0001—Codebooks
- G10L2019/0011—Long term prediction filters, i.e. pitch estimation
Definitions
- the present invention relates to the field of audio signal processing technologies, and in particular, to a reverberation time estimation method and apparatus.
- the reverberation time (expressed as RT 60 ) is defined as: the residual acoustic energy is attenuated to -60 dB after multiple reflections in the specific house space from the time when the sound excitation stops (equivalent to the average acoustic energy density reduced to 10 - 6 ) The time required.
- Reverberation time is an important indicator to measure the spatial reverberation characteristics of a particular house, and is closely related to the calculation of the late-reverberation power in the reverberation algorithm.
- the traditional reverberation time estimation method adopts the sound excitation method.
- the main idea is to measure the time that the acoustic energy is attenuated to 60 dB below the energy of the initial observation after the sound excitation signal is stopped.
- This method requires an impulse test signal of the impulse characteristic so that the test of the acoustic energy after the sound is stopped is not affected by the smearing component. Obviously, this method cannot meet the requirements of real-time processing applications.
- the related researchers have proposed a more robust (Robust) reverberation time estimation method based on speech model (hereinafter referred to as the estimation method based on speech model).
- a linear prediction method is used to process the received speech signal, and obtain a residual signal corresponding to the speech signal, and then substitute the autocorrelation function of the residual signal into a maximum likelihood estimator of the reverberation time (Maximum-Likelihood Estimator, MLE) to obtain a corresponding reverberation time estimate for the speech signal.
- MLE Maximum-Likelihood Estimator
- Equation 1 Obtain a speech signal in a reverberant environment, assuming that there is no noise interference in the speech signal, expressed as Equation 1:
- s[n] the source speech signal
- h[n] the Room Impulse Response (RIR)
- * the linear convolution operator
- f s represents the sampling frequency and w[n] represents the zero mean white Gaussian noise.
- Equation 1 Equation 5:
- a residual signal By performing linear prediction (LP) analysis on x[n], a residual signal can be obtained, which can be regarded as an approximation of the excitation signal in the speech generation model.
- the channel filter can be represented as a time-varying all-pole filter, and the RIR is generally considered to be an all-zero filter, it can be considered that v[n] and h[n] are independent of each other, so
- the x[n] performs the LP analysis, and the effect of the channel filter can be approximately removed from the reverberant speech data, thereby obtaining the residual signal as shown in Equation 6:
- Equation 7 The autocorrelation function of the N point of the residual signal can be expressed as Equation 7:
- C e [n] is the autocorrelation function of e[n] and C h [n] is the autocorrelation function of h[n]. Since the autocorrelation function C e [n] decays faster than C h [n], it can be considered as:
- Equation 10 The best parameters a and k correspond to the natural logarithmic maxima of Equation 10, for which:
- Equation 13 N is the number of samples included in a frame of speech frames:
- the speech model-based reverberation time estimation method does not need to detect the time slot of the speech and uses all the voice data for estimation, the practical application finds that the method generally has an RT 60 for the reverberation speech whose reverberation time is less than the preset threshold. Produced an estimate.
- the embodiment of the invention provides a reverberation time estimation method and device, which is used to solve the reverberation time estimation method of the existing speech model based reverberation time, and the reverberation time of the reverberation speech whose reverberation time is less than the preset threshold is generated. Estimated problem.
- an embodiment of the present invention provides a reverberation time estimation method, including:
- the method before determining the autocorrelation function based on the historical reverberation speech signal and the current reverberation speech signal, the method further includes:
- Downsampling processing is performed on the historical reverberation speech signal and the current reverberation speech signal.
- the autocorrelation function is determined based on the historical reverberation speech signal and the current reverberant speech signal, including:
- determining a reverberation time of the current reverberant speech signal according to the autocorrelation function and a preset maximum likelihood estimation model including:
- an average autocorrelation function is determined according to the consecutive L autocorrelation functions, according to Determining a reverberation time of the current reverberant speech signal by the average autocorrelation function and the preset maximum likelihood estimation model;
- the average autocorrelation function is determined according to the consecutive L autocorrelation functions, including:
- the auto-correlation function determined this time is smoothed, including:
- determining, according to the average autocorrelation function and the preset maximum likelihood estimation model, a reverberation time of the current reverberation speech signal including:
- N represents the number of sample points participating in the autocorrelation function calculation in a reverberation speech frame
- a represents the first parameter
- k represents the second parameter
- Representing the average autocorrelation function Determining a partial derivative of the first parameter
- Determining a partial derivative of the second parameter Representing the average autocorrelation function
- the first parameter and the likelihood function of the second parameter are expressed as
- RT 60 represents an estimate of the reverberation time of the current reverberant speech signal
- f s represents the sampling rate of the reverberant speech frame used to determine the reverberation time.
- determining the reverberation time of the current reverberation speech signal including:
- N represents the number of sample points participating in the autocorrelation function calculation in a reverberation speech frame
- a represents the first parameter
- k represents the second parameter
- Indicates the autocorrelation function after smoothing Determining a partial derivative of the first parameter
- Determining a partial derivative of the second parameter Representing the smoothed autocorrelation function
- the first parameter and the likelihood function of the second parameter are expressed as
- RT 60 represents an estimate of the reverberation time of the current reverberant speech signal
- f s represents the sampling rate of the reverberant speech frame used to determine the reverberation time.
- the method further includes:
- an embodiment of the present invention provides a reverberation time estimating apparatus, including:
- a first processing module configured to obtain a current reverberation voice signal in a reverberant environment
- a second processing module configured to determine an autocorrelation function based on the historical reverberation speech signal and the current reverberation speech signal
- a third processing module configured to determine a reverberation time of the current reverberant speech signal according to the autocorrelation function and a preset maximum likelihood estimation model.
- the second processing module is further configured to:
- the second processing module is specifically configured to:
- the third processing module is specifically configured to:
- an average autocorrelation function is determined according to the consecutive L autocorrelation functions, according to Determining a reverberation time of the current reverberant speech signal by the average autocorrelation function and the preset maximum likelihood estimation model;
- the third processing module is specifically configured to:
- the third processing module is specifically configured to:
- the third processing module is specifically configured to:
- N represents the number of sample points participating in the autocorrelation function calculation in a reverberation speech frame
- a represents the first parameter
- k represents the second parameter
- Representing the average autocorrelation function Determining a partial derivative of the first parameter
- Determining a partial derivative of the second parameter Representing the average autocorrelation function
- the first parameter and the likelihood function of the second parameter are expressed as
- RT 60 represents an estimate of the reverberation time of the current reverberant speech signal
- f s represents the sampling rate of the reverberant speech frame used to determine the reverberation time.
- the third processing module is specifically configured to:
- N represents the number of sample points participating in the autocorrelation function calculation in a reverberation speech frame
- a represents the first parameter
- k represents the second parameter
- Indicates the autocorrelation function after smoothing Determining a partial derivative of the first parameter
- Determining a partial derivative of the second parameter Representing the smoothed autocorrelation function
- the first parameter and the likelihood function of the second parameter are expressed as
- RT 60 represents an estimate of the reverberation time of the current reverberant speech signal
- f s represents the sampling rate of the reverberant speech frame used to determine the reverberation time.
- the third processing module is specifically configured to:
- an embodiment of the present invention provides a device, which mainly includes a processor and a memory, wherein a preset program is stored in the memory, and the processor is configured to read a program in the memory, and execute the following process according to the program. :
- the processor is further configured to:
- the historical reverberation speech signal and the current reverberation speech signal are subjected to downsampling processing before the autocorrelation function is determined based on the historical reverberation speech signal and the current reverberation speech signal.
- the autocorrelation function is determined based on the historical reverberation speech signal and the current reverberant speech signal, including:
- the processor when determining, by the processor according to the autocorrelation function and the preset maximum likelihood estimation model, the reverberation time of the current reverberation speech signal, the processor is specifically configured to:
- an average autocorrelation function is determined according to the consecutive L autocorrelation functions, according to Average self a correlation function and the preset maximum likelihood estimation model, determining a reverberation time of the current reverberation speech signal;
- the processor when the processor determines the average autocorrelation function according to the consecutive L autocorrelation functions, the processor is specifically configured to:
- the processor when the processor performs smoothing on the auto-correlation function determined this time, it is specifically used to:
- the processor determines, according to the average autocorrelation function and the preset maximum likelihood estimation model, when the reverberation time of the current reverberation speech signal is determined, specifically:
- N represents the number of sample points participating in the autocorrelation function calculation in a reverberation speech frame
- a represents the first parameter
- k represents the second parameter
- Representing the average autocorrelation function Determining a partial derivative of the first parameter
- Determining a partial derivative of the second parameter Representing the average autocorrelation function
- the first parameter and the likelihood function of the second parameter are expressed as
- RT 60 represents an estimate of the reverberation time of the current reverberant speech signal
- f s represents the sampling rate of the reverberant speech frame used to determine the reverberation time.
- the processor determines, according to the smoothed autocorrelation function and the preset maximum likelihood estimation model, when the reverberation time of the current reverberation speech signal is determined, specifically:
- N represents the number of sample points participating in the autocorrelation function calculation in a reverberation speech frame
- a represents the first parameter
- k represents the second parameter
- Indicates the autocorrelation function after smoothing Determining a partial derivative for the first parameter
- Determining a partial derivative of the second parameter Representing the smoothed autocorrelation function
- the first parameter and the likelihood function of the second parameter are expressed as
- RT 60 represents an estimate of the reverberation time of the current reverberant speech signal
- f s represents the sampling rate of the reverberant speech frame used to determine the reverberation time.
- the processor is further configured to:
- the autocorrelation function is determined based on the historical speech signal and the current reverberation speech signal, and the reverberation of the reverberation speech signal is determined according to the autocorrelation function and the preset maximum likelihood estimation model.
- Time can further improve the estimation accuracy of the reverberation time, and solve the problem that the existing reverberation time estimation method based on the speech model has an overestimation of the reverberation time of the reverberation speech whose reverberation time is less than the preset threshold.
- FIG. 1 is a schematic flow chart of a method for performing reverberation time estimation according to an embodiment of the present invention
- FIG. 2 is a schematic diagram of a reverberation time estimation process based on a voice model according to an embodiment of the present invention
- FIG. 3 is a schematic structural diagram of a reverberation time estimating apparatus according to an embodiment of the present invention.
- FIG. 4 is a schematic structural diagram of a device according to an embodiment of the present invention.
- the existing speech-based model is used in the embodiment of the present invention.
- the reverberation time estimation method has been improved.
- the reverberation voice whose reverberation time is less than the preset threshold is made into a small reverberation voice.
- a reverberation voice having a reverberation time of less than 400 milliseconds is referred to as a small reverberation voice.
- FIG. 1 the method for performing reverberation time estimation is shown in FIG. 1 , and the details are as follows:
- Step 101 Obtain a current reverberation speech signal in a reverberant environment.
- Step 102 Determine an autocorrelation function based on the historical reverberation speech signal and the current reverberation speech signal.
- Equation 13 the calculation of the unbiased autocorrelation function has a local window effect, in order to improve and improve the calculation accuracy of the autocorrelation function, the embodiment of the present invention.
- the unbiased autocorrelation function with historical data is defined as follows:
- the process of determining the autocorrelation function based on the historical reverberation speech signal and the current reverberation speech signal is as follows:
- Representing the autocorrelation function where N represents the number of sample points participating in the autocorrelation function calculation in a reverberation speech frame.
- the coefficient is obtained by linearly predicting and filtering the reverberation speech frame based on the linear prediction coefficient, and M is a positive integer greater than 1.
- n is less than or equal to one-half of N.
- the obtained RT 60 is more accurate than the existing speech model-based estimation method, and in particular, can solve the problem of overestimation of small reverberation speech.
- Step 103 Determine a reverberation time of the current reverberation speech signal according to the autocorrelation function and a preset maximum likelihood estimation model.
- a reverberation speech frame has a duration of 20 milliseconds
- the application to the demixing response will directly affect the de-reverberation performance of the first 4.8 seconds.
- reverberation time estimation methods before the start of the reverberation time estimation of 4.8 seconds, and after the start of the reverberation time estimation of 4.8, different reverberation time estimation methods are employed. Specifically, a second processing manner of determining the reverberation time is employed before the start of the reverberation time estimation by 4.8 seconds, and a first processing manner of determining the reverberation time is employed after the start of the reverberation time estimation of 4.8.
- determining, according to the autocorrelation function and the preset maximum likelihood estimation model, the reverberation time of the current reverberation speech signal which may be specifically divided into the following two processing modes:
- the first processing mode if it is determined that the total number of extracted reverberation speech frames in the reverberation time estimation process exceeds L times of M, after each successive L autocorrelation functions are obtained, an average is determined according to the consecutive L autocorrelation functions An autocorrelation function determines a reverberation time of the current reverberant speech signal based on the average autocorrelation function and the preset maximum likelihood estimation model.
- the average autocorrelation function is determined according to the consecutive L autocorrelation functions, specifically: determining an average autocorrelation function according to formula 19,
- N represents the number of sample points participating in the autocorrelation function calculation in a reverberation speech frame
- a represents the first parameter
- k represents the second parameter
- Representing the average autocorrelation function Determining a partial derivative of the first parameter
- Determining a partial derivative of the second parameter Representing the average autocorrelation function
- the first parameter and the likelihood function of the second parameter are expressed as:
- RT 60 represents an estimate of the reverberation time of the current reverberant speech signal and f s represents a sampling rate of the reverberant speech frame used to determine the reverberation time.
- the average autocorrelation function is calculated after successively obtaining L autocorrelation functions, and the estimated value of the reverberation time is determined based on the average autocorrelation function, without affecting the accuracy of the reverberation time estimation. Further reduce the amount of calculation.
- the second processing mode if it is determined that the total number of extracted reverberation speech frames in the reverberation time estimation process does not exceed L times of M, after the smoothing processing of the autocorrelation function determined this time, according to the autocorrelation function after smoothing processing And the preset maximum likelihood estimation model determining a reverberation time of the current reverberation speech signal.
- an autocorrelation function is obtained every 240 milliseconds to determine the reverberation time.
- the autocorrelation is performed by means of recursive smoothing. The function performs smoothing.
- the autocorrelation function determined this time is smoothed, specifically: smoothing the autocorrelation function of the reverberation speech frame according to formula 23,
- the reverberation time of the current reverberation speech signal is determined according to the smoothed autocorrelation function and the preset maximum likelihood estimation model, specifically: according to the smoothing process Determining a first parameter and a second parameter according to the autocorrelation function and the first constraint defined in the preset maximum likelihood estimation model; according to the first parameter and the preset maximum likelihood estimate a second constraint defined in the model, determining an estimate of the reverberation time of the current reverberant speech signal; wherein the first constraint is expressed as:
- N represents the number of sample points participating in the autocorrelation function calculation in a reverberation speech frame
- a represents the first parameter
- k represents the second parameter
- Indicates the autocorrelation function after smoothing Determining a partial derivative of the first parameter
- Determining a partial derivative of the second parameter Representing the smoothed autocorrelation function
- the first parameter and the likelihood function of the second parameter are expressed as:
- RT 60 represents an estimate of the reverberation time of the current reverberant speech signal and f s represents a sampling rate of the reverberant speech frame used to determine the reverberation time.
- the autocorrelation function is determined based on the historical reverberation speech signal and the current reverberation speech signal
- the historical reverberation speech signal and the current reverberation speech are downsampled, based on the downmixed history mix
- the speech signal and the downsampled current reverberation speech signal determine the autocorrelation function.
- the number of sampling points included in one frame of speech frame is N
- the number of frames for calculating autocorrelation is M
- N ⁇ M needs to be large enough to enable the speech model to be established.
- the amount of calculation can be effectively reduced.
- the sampling frequency of the input speech signal is 16 kHz.
- the sampling frequency is reduced to 4 kHz, the calculation operation amount of the autocorrelation function will become 1/16 of the original, that is,
- the computational complexity of the maximum likelihood estimation process will be reduced to 1/16.
- the first or second processing mode is employed.
- the mapping relationship between the estimated value of the reverberation time determined by the downsampled reverberation speech signal frame and the effective value of the reverberation time is determined, An effective value of the reverberation time corresponding to the estimated value of the reverberation time of the reverberation speech signal is determined.
- the autocorrelation function is substituted into the maximum likelihood estimation model to obtain an estimate of the reverberation time. value.
- the autocorrelation function calculated by using the historical speech signal without downsampling and the current reverberation speech signal is substituted into the maximum likelihood estimation model to obtain the effective value of the reverberation time.
- There is a mapping relationship between the estimated value of the reverberation time and the effective value of the reverberation time can be expressed by a mathematical mapping function ⁇ ( ⁇ ):
- the second processing mode in order to reduce the volatility of the estimated effective value of the aliasing time, after determining the effective value of the reverberation time corresponding to the estimated value of the reverberation time of the reverberation speech signal, according to the formula 25 pairs of places Smoothing the effective value of the reverberation time,
- ⁇ represents the first smoothing factor
- ⁇ represents the second smoothing factor
- ⁇ is smaller than ⁇
- ⁇ is greater than zero and less than 1
- ⁇ is greater than zero and less than 1.
- the basic idea of smoothing the effective value of the reverberation time in the second processing mode is based on the criterion of “fast rising slow down”, that is, when the effective value of the instantaneous reverberation time is greater than the confusion time after the last smoothing process. Use a smaller smoothing factor ⁇ , otherwise use a larger smoothing factor ⁇ .
- the MLE is updated every 4.8 seconds according to the first processing mode to update the estimated value of the reverberation time, thereby further reducing the amount of calculation because the same space
- the reverberation time is relatively fixed.
- the speech model-based reverberation time estimation method provided by the embodiment of the present invention is fully described below through a specific embodiment.
- FIG. 2 is a schematic diagram of a reverberation time estimation process based on a speech model in the specific embodiment, and the specific process is as follows:
- Step 203 Perform downsampling processing on the reverberation speech frame.
- Step 204 Perform LPC analysis and LP filtering on the sampled reverberation speech frame.
- Step 205 Determine whether m>M is satisfied. If yes, go to step 206. Otherwise, go to step 202.
- Step 207 Determine whether Cnt>M ⁇ L is satisfied. If not, go to step 208, otherwise go to step 209;
- Step 208 After smoothing the autocorrelation function according to Formula 20, step 211 is performed.
- Step 209 After calculating the average autocorrelation function of successive L autocorrelation functions according to Formula 16, step 210 is performed.
- Step 210 Determine whether h>L is satisfied. If not, go to step 202, otherwise, go to step 211.
- Step 211 Calculate the reverberation time, specifically: according to the autocorrelation function after smoothing or the average autocorrelation function
- the Newton-Raphson method is used to solve the formula 21, and the parameters a and k are obtained.
- the estimated value of the reverberation time is obtained.
- Step 212 Determine whether the reverberation speech signal is still being received, and if yes, go to step 202, otherwise, end.
- a reverberation time estimating device is provided in the embodiment of the present invention.
- the device is mainly include:
- a first processing module 301 configured to obtain a current reverberation voice signal in a reverberation environment
- the second processing module 302 is configured to determine an autocorrelation function based on the historical reverberation speech signal and the current reverberation speech signal;
- the third processing module 303 is configured to determine a reverberation time of the current reverberation speech signal according to the autocorrelation function and a preset maximum likelihood estimation model.
- the second processing module is further configured to:
- the second processing module is specifically configured to:
- the third processing module is specifically configured to:
- an average autocorrelation function is determined according to the consecutive L autocorrelation functions, according to Determining a reverberation time of the current reverberant speech signal by the average autocorrelation function and the preset maximum likelihood estimation model;
- the third processing module is specifically configured to:
- the third processing module is specifically configured to:
- the third processing module is specifically configured to:
- N represents the number of sample points participating in the autocorrelation function calculation in a reverberation speech frame
- a represents the first parameter
- k represents the second parameter
- Representing the average autocorrelation function Determining a partial derivative of the first parameter
- Determining a partial derivative of the second parameter Representing the average autocorrelation function
- the first parameter and the likelihood function of the second parameter are expressed as
- RT 60 represents an estimate of the reverberation time of the current reverberant speech signal
- f s represents the sampling rate of the reverberant speech frame used to determine the reverberation time.
- the third processing module is specifically configured to:
- N represents the number of sample points participating in the autocorrelation function calculation in a reverberation speech frame
- a represents the first parameter
- k represents the second parameter
- Indicates the autocorrelation function after smoothing Determining a partial derivative of the first parameter
- Determining a partial derivative of the second parameter Representing the smoothed autocorrelation function
- the first parameter and the likelihood function of the second parameter are expressed as
- RT 60 represents an estimate of the reverberation time of the current reverberant speech signal
- f s represents the sampling rate of the reverberant speech frame used to determine the reverberation time.
- the third processing module is specifically configured to:
- an embodiment of the present invention further provides a device.
- the device mainly includes a processor 401 and a memory 402.
- the preset program is stored in 402, and the processor 401 is configured to read a program in the memory 402, and execute the following process according to the program:
- the processor 401 is further configured to: before determining the autocorrelation function based on the historical reverberation speech signal and the current reverberation speech signal, performing the historical reverberation speech signal and the current reverberation speech signal Downsampling processing.
- the method is: extracting consecutive M reverberation speeches from the current reverberation speech signal. a frame, the autocorrelation function is determined based on the historical reverberation speech signal and the M reverberation speech frames: among them, Representing the autocorrelation function, where N represents the number of sample points participating in the autocorrelation function calculation in a reverberation speech frame.
- n represents a shift distance
- a residual signal corresponding to the reverberation speech frame is a linear prediction of the reverberation speech frame to obtain a linear prediction coefficient and based on the linear prediction
- the coefficient is obtained by linear predictive filtering on the reverberation speech frame, and M is a positive integer greater than 1.
- the processor 401 determines, according to the autocorrelation function and the preset maximum likelihood estimation model, the reverberation time of the current reverberation speech signal, specifically: if the reverberation time estimation is determined Process extraction The total number of speech speech frames exceeds L times M, and after each successive L autocorrelation functions are obtained, an average autocorrelation function is determined according to the consecutive L autocorrelation functions, according to the average autocorrelation function and the pre- a maximum likelihood estimation model for determining a reverberation time of the current reverberant speech signal;
- the average autocorrelation function according to the consecutive L autocorrelation functions specifically: using: Determine the average autocorrelation function, where Representing the lth autocorrelation function in the autocorrelation function determined continuously for L times, Represents the average autocorrelation function.
- the method is specifically configured to:
- the processor 401 determines, according to the average autocorrelation function and the preset maximum likelihood estimation model, when the reverberation time of the current reverberation speech signal is determined, specifically:
- N represents the number of sample points participating in the autocorrelation function calculation in a reverberation speech frame
- a represents the first parameter
- k represents the second parameter
- Representing the average autocorrelation function Determining a partial derivative of the first parameter
- Determining a partial derivative of the second parameter Representing the average autocorrelation function
- the first parameter and the likelihood function of the second parameter are expressed as
- RT 60 represents an estimate of the reverberation time of the current reverberant speech signal
- f s represents the sampling rate of the reverberant speech frame used to determine the reverberation time.
- the processor 401 determines, according to the smoothed autocorrelation function and the preset maximum likelihood estimation model, when the reverberation time of the current reverberation speech signal is determined, specifically:
- N represents the number of sample points participating in the autocorrelation function calculation in a reverberation speech frame
- a represents the first parameter
- k represents the second parameter
- Indicates the autocorrelation function after smoothing Determining a partial derivative of the first parameter
- Determining a partial derivative of the second parameter Representing the smoothed autocorrelation function
- the first parameter and the likelihood function of the second parameter are expressed as
- RT 60 represents an estimate of the reverberation time of the current reverberant speech signal
- f s represents the sampling rate of the reverberant speech frame used to determine the reverberation time.
- the processor 401 is further configured to:
- the processor and the memory are connected by a bus
- the bus architecture may include any number of interconnected buses and bridges, specifically linked by one or more processors represented by the processor and various circuits of the memory represented by the memory.
- the bus architecture can also link various other circuits such as peripherals, voltage regulators, and power management circuits, which are well known in the art and, therefore, will not be further described herein.
- the bus interface provides an interface.
- the processor is responsible for managing the bus architecture and the usual processing, and the memory can store the data that the processor uses when performing operations.
- the autocorrelation function is determined based on the historical speech signal and the current reverberation speech signal, and the reverberation of the reverberation speech signal is determined according to the autocorrelation function and the preset maximum likelihood estimation model.
- Time which can further improve the estimation accuracy of reverberation time, and solve the existing estimation model of reverberation time based on speech model.
- the problem of overestimation of the reverberation time of the reverberation speech whose reverberation time is less than the preset threshold is generated.
- the downsampling process is performed on the historical speech signal and the current reverberation speech signal, and the autocorrelation function is calculated based on the downsampled historical speech signal and the downsampled current reverberation speech signal, which can be further reduced. Calculate the complexity and improve the real-time performance of the reverberation time estimate.
- the reverberation time is determined according to the autocorrelation function, so that the existing speech model based solution can be solved.
- the problem of waiting for the reverberation time is prolonged for the first time, which shortens the waiting time for the first reverberation time in the engineering implementation, making it more suitable for practical applications.
- embodiments of the present invention can be provided as a method, system, or computer program product. Accordingly, the present invention may take the form of an entirely hardware embodiment, an entirely software embodiment, or a combination of software and hardware. Moreover, the invention can take the form of a computer program product embodied on one or more computer-usable storage media (including but not limited to disk storage and optical storage, etc.) including computer usable program code.
- the computer program instructions can also be stored in a computer readable memory that can direct a computer or other programmable data processing device to operate in a particular manner, such that the instructions stored in the computer readable memory produce an article of manufacture comprising the instruction device.
- the apparatus implements the functions specified in one or more blocks of a flow or a flow and/or block diagram of the flowchart.
- These computer program instructions can also be loaded onto a computer or other programmable data processing device such that a series of operational steps are performed on a computer or other programmable device to produce computer-implemented processing for execution on a computer or other programmable device.
- the instructions provide steps for implementing the functions specified in one or more of the flow or in a block or blocks of a flow diagram.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Multimedia (AREA)
- Acoustics & Sound (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Human Computer Interaction (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- Quality & Reliability (AREA)
- General Physics & Mathematics (AREA)
- Reverberation, Karaoke And Other Acoustics (AREA)
- Cable Transmission Systems, Equalization Of Radio And Reduction Of Echo (AREA)
Abstract
一种混响时间估计方法及装置,用以解决现有的基于语音模型的混响时间估计方法中,对混响时间小于预设门限的混响语音的混响时间产生过估计的问题。该混响时间估计方法为:在混响环境下获得当前混响语音信号(101);基于历史混响语音信号和当前混响语音信号确定自相关函数(102);根据自相关函数以及预设的极大似然估计模型,确定该当前混响语音信号的混响时间(103)。
Description
本申请要求在2016年8月02日提交中国专利局、申请号为201610626191.1、发明名称为一种混响时间估计方法及装置的中国专利申请的优先权,其全部内容通过引用结合在本申请中。
本发明涉及音频信号处理技术领域,尤其涉及一种混响时间估计方法及装置。
混响时间(表示为RT60)定义为:在特定房屋空间中从声音激励停止时起算,其残余声能经过多次反射后衰减至-60dB(相当于平均声能密度降为原来的10-6)所需要的时间。混响时间是衡量特定房屋空间混响特性的一个重要指标,并且与解混响算法中后期混响(Late-Reverberation)功率的计算估计密切相关。
传统混响时间的估计方法是采用声音激励方法,主要思想为:在声音激励信号停止后测量声能衰减至低于起始观测时能量的60dB所经历的时间。该方法需要冲激特性的语音测试信号,以便在声音停止激励后对声能的测试不受语音拖尾成分的影响。显然,该方法不能满足实时处理应用的要求。
为此,人们探讨并提出用所接收的语音信号进行混响时间盲估计的方法,然而这种方法仅能在已检测出的语音间隙期间来应用,而且还需假设语音的结束时刻没有拖尾且语音中的间隙要足够长,因而也无法在实际中有效应用。
为改进和克服混响时间盲估计的缺陷,相关学者又提出了一种基于语音模型的更为鲁棒(Robust)的混响时间估计方法(以下简称基于语音模型的估计方法),该方法应用线性预测方法来处理所接收的语音信号,并获得该语音信号相应的残差信号,然后用该残差信号的自相关函数代入到混响时间的极大似然估计器(Maximum-Likelihood Estimator,MLE),从而获得该语音信号相应的混响时间估值。工作原理具体如下:
在混响环境下获得语音信号,假设该语音信号不存在噪声干扰,表示为公式1:
x[n]=s[n]*h[n] (公式1)
其中,x[n]表示接收语音信号,s[n]表示源语音信号,h[n]表示房屋冲激响应(Room Impulse Response,RIR),“*”表示线性卷积算子。根据统计声学理论,RIR可以用Polack模型表示为如公式2所示的非平稳随机过程:
h[n]=w[n]an,n>0 (公式2)
其中,公式2中:
a=e-δ (公式3)

其中,fs表示采样频率,w[n]表示零均值的高斯白噪声。
由于s[n]可以看作是激励信号e[n]与声道滤波器v[n]卷积的结果,因此公式1可以表示为公式5所示:
x[n]=e[n]*v[n]*h[n] (公式5)
通过对x[n]进行线性预测(Linear Prediction,LP)分析,获得残差信号,该残差信号可以看作是语音生成模型中激励信号的一种近似。考虑到声道滤波器可以表示成一个时变的全极点滤波器,而RIR通常被认为是全零点滤波器,故可以认为v[n]与h[n]彼此间互不相关,因此通过对x[n]进行LP分析,可以近似地将声道滤波器的效应从混响语音数据中移去,从而获得如公式6所示的残差信号:
残差信号的N点的自相关函数可以表示为公式7所示:

其中,Ce[n]是e[n]的自相关函数,Ch[n]是h[n]的自相关函数。鉴于自相关函数Ce[n]衰减速度比Ch[n]快,可以认为:
其中,k表示Ce[n]的均值。由上式可知残差信号的自相关与RIR的自相关有相同的统计特性,因此可以用残差信号的自相关代入MLE中。在工程实现中我们用时间平均代替统计平均,首先计算每一帧的自相关函数 然后每隔L帧计算一次平均自相关函数
然后每隔L帧计算一次平均自相关函数 得到的平均自相关函数作为MLE估计器的输入。
得到的平均自相关函数作为MLE估计器的输入。
计算L帧的自相关函数 的均值,表示为公式9所示:
的均值,表示为公式9所示:

基于参数a和k的自相关函数 的似然函数可表示为公式10:
的似然函数可表示为公式10:

最佳的参数a和k对应于公式10的自然对数极大值点,为此:


其中, 表示对参数a求偏导数,
表示对参数a求偏导数, 表示对参数k求偏导数。应用Newton-Raphson方法求解公式11和公式12组成的联立方程式计算出参数a和k,然后根据公式3和公式4得到混响时间的估计值。
表示对参数k求偏导数。应用Newton-Raphson方法求解公式11和公式12组成的联立方程式计算出参数a和k,然后根据公式3和公式4得到混响时间的估计值。
基于语音模型的混响时间估计方法的作者们曾建议:在实际应用中, 对于语音数据采用无偏自相关的计算方法,即表示为公式13所示,其中N为一帧语音帧包含的样点数:
对于语音数据采用无偏自相关的计算方法,即表示为公式13所示,其中N为一帧语音帧包含的样点数:
尽管基于语音模型的混响时间估计方法不需要检测语音的时隙,并且利用全部的语音数据进行估计,但实际应用发现,该方法通常对混响时间小于预设门限的混响语音的RT60产生过估计。
发明内容
本发明实施例提供一种混响时间估计方法及装置,用以解决现有的基于语音模型的混响时间估计方法中,对混响时间小于预设门限的混响语音的混响时间产生过估计的问题。
本发明实施例提供的具体技术方案如下:
第一方面,本发明实施例提供了一种混响时间估计方法,包括:
在混响环境下获得当前混响语音信号;
基于历史混响语音信号和所述当前混响语音信号确定自相关函数;
根据所述自相关函数以及预设的极大似然估计模型,确定所述当前混响语音信号的混响时间。
可能的实施方式中,基于历史混响语音信号和所述当前混响语音信号确定自相关函数之前,所述方法还包括:
对所述历史混响语音信号和所述当前混响语音信号进行降采样处理。
可能的实施方式中,基于历史混响语音信号和所述当前混响语音信号确定自相关函数,包括:
从所述当前混响语音信号中提取连续的M个混响语音帧,基于历史混响语音信号和所述M个混响语音帧确定自相关函数为: 其中,
其中, 表示所述自相关函数,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,
表示所述自相关函数,N表示一个混响语音帧中参与自相关函数计算的采样点的个数, 表示所述混响语音帧的残差信号,n表示移位距离,所述混响语音帧对应的残差信号为对所述混响语音帧进行线性预测得到线性预测系数并基于所述线性预测系数对所述混响语音帧进行线性预测滤波后得到,M为大于1的正整数。
表示所述混响语音帧的残差信号,n表示移位距离,所述混响语音帧对应的残差信号为对所述混响语音帧进行线性预测得到线性预测系数并基于所述线性预测系数对所述混响语音帧进行线性预测滤波后得到,M为大于1的正整数。
可能的实施方式中,根据所述自相关函数以及预设的极大似然估计模型,确定所述当前混响语音信号的混响时间,包括:
若确定混响时间估计过程中提取混响语音帧的总数超过M的L倍,在每获得连续的L个自相关函数后,根据所述连续的L个自相关函数确定平均自相关函数,根据所述平均自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间;
若确定混响时间估计过程中提取混响语音帧的总数未超过M的L倍,对本次确定的所述自相关函数进行平滑处理后,根据平滑处理后的自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间。
可能的实施方式中,根据所述连续的L个自相关函数确定平均自相关函数,包括:
按照公式 确定平均自相关函数,其中,
确定平均自相关函数,其中, 表示连续L次确定的自相关函数中的第l个自相关该函数,
表示连续L次确定的自相关函数中的第l个自相关该函数, 表示平均自相关函数。
表示平均自相关函数。
可能的实施方式中,对本次确定的所述自相关函数进行平滑处理,包括:
按照公式 对所述混响语音帧的自相关函数进行平滑处理,其中,
对所述混响语音帧的自相关函数进行平滑处理,其中, 表示本次确定的所述自相关函数,
表示本次确定的所述自相关函数, 表示第l次平滑处理后的自
相关函数,
表示第l次平滑处理后的自
相关函数, 表示第l-1次平滑处理后的自相关函数,β表示预设的平滑系数,0<β<1。
表示第l-1次平滑处理后的自相关函数,β表示预设的平滑系数,0<β<1。
可能的实施方式中,根据所述平均自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间,包括:
根据所述平均自相关函数以及所述预设的极大似然估计模型中定义的第一约束条件,确定第一参数和第二参数;
根据所述第一参数以及所述预设的极大似然估计模型中定义的第二约束条件,确定所述当前混响语音信号的混响时间的估计值;
根据预设的采用降采样后的混响语音信号帧确定的混响时间的估计值与混响时间的有效值之间的映射关系,确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值;
其中,所述第一约束条件表示为:

其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数, 表示所述平均自相关函数,
表示所述平均自相关函数, 表示对所述第一参数求偏导数,
表示对所述第一参数求偏导数, 表示对所述第二参数求偏导数,
表示对所述第二参数求偏导数, 表示所述平均自相关函数
表示所述平均自相关函数 所述第一参数以及所述第二参数的似然函数,表示为
所述第一参数以及所述第二参数的似然函数,表示为
其中,所述第二约束条件为: RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
可能的实施方式中,根据平滑处理后的自相关函数以及所述预设的极大似然估计模
型,确定所述当前混响语音信号的混响时间,包括:
根据所述平滑处理后的自相关函数以及所述预设的极大似然估计模型中定义的第一约束条件,确定第一参数和第二参数;
根据所述第一参数以及所述预设的极大似然估计模型中定义的第二约束条件,确定所述当前混响语音信号的混响时间的估计值;
根据预设的采用降采样后的混响语音信号帧确定的混响时间的估计值与混响时间的有效值之间的映射关系,确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值;
其中,所述第一约束条件表示为:

其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数, 表示平滑处理后的自相关函数,
表示平滑处理后的自相关函数, 表示对所述第一参数求偏导数,
表示对所述第一参数求偏导数, 表示对所述第二参数求偏导数,
表示对所述第二参数求偏导数, 表示所述平滑处理后的自相关函数
表示所述平滑处理后的自相关函数 所述第一参数以及所述第二参数的似然函数,表示为
所述第一参数以及所述第二参数的似然函数,表示为
其中,所述第二约束条件为: RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
可能的实施方式中,确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值之后,所述方法还包括:
按照公式 对所述混响时间
的有效值进行平滑处理,其中,
对所述混响时间
的有效值进行平滑处理,其中, 表示所述混响时间的有效值,
表示所述混响时间的有效值, 表示本次平滑处理后的混响时间,
表示本次平滑处理后的混响时间, 表示上一次平滑处理后的混响时间,α表示第一平滑因子,β表示第二平滑因子,α小于β,α大于零且小于1,β大于零且小于1。
表示上一次平滑处理后的混响时间,α表示第一平滑因子,β表示第二平滑因子,α小于β,α大于零且小于1,β大于零且小于1。
第二方面,本发明实施例提供了一种混响时间估计装置,包括:
第一处理模块,用于在混响环境下获得当前混响语音信号;
第二处理模块,用于基于历史混响语音信号和所述当前混响语音信号确定自相关函数;
第三处理模块,用于根据所述自相关函数以及预设的极大似然估计模型,确定所述当前混响语音信号的混响时间。
可能的实施方式中,所述第二处理模块还用于:
基于历史混响语音信号和所述当前混响语音信号确定自相关函数之前,对所述历史混响语音信号和所述当前混响语音信号进行降采样处理。
可能的实施方式中,所述第二处理模块具体用于:
从所述当前混响语音信号中提取连续的M个混响语音帧,基于历史混响语音信号和所述M个混响语音帧确定自相关函数为: 其中,
其中, 表示所述自相关函数,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,
表示所述自相关函数,N表示一个混响语音帧中参与自相关函数计算的采样点的个数, 表示所述混响语音帧的残差信号,n表示移位距离,所述混响语音帧对应的残差信号为对所述混响语音帧进行线性预测得到线性预测系数并基于所述线性预测系数对所述混响语音帧进行线性预测滤波后得到,M为大于1的正整数。
表示所述混响语音帧的残差信号,n表示移位距离,所述混响语音帧对应的残差信号为对所述混响语音帧进行线性预测得到线性预测系数并基于所述线性预测系数对所述混响语音帧进行线性预测滤波后得到,M为大于1的正整数。
可能的实施方式中,所述第三处理模块具体用于:
若确定混响时间估计过程中提取混响语音帧的总数超过M的L倍,在每获得连续的L个自相关函数后,根据所述连续的L个自相关函数确定平均自相关函数,根据所述平均自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间;
若确定混响时间估计过程中提取混响语音帧的总数未超过M的L倍,对本次确定的所述自相关函数进行平滑处理后,根据平滑处理后的自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间。
可能的实施方式中,所述第三处理模块具体用于:
按照公式 确定平均自相关函数,其中,
确定平均自相关函数,其中, 表示连续L次
确定的自相关函数中的第l个自相关该函数,
表示连续L次
确定的自相关函数中的第l个自相关该函数, 表示平均自相关函数。
表示平均自相关函数。
可能的实施方式中,所述第三处理模块具体用于:
按照公式 对所述混响语音帧的自相关函数进行平滑处理,其中,
对所述混响语音帧的自相关函数进行平滑处理,其中, 表示本次确定的所述自相关函数,
表示本次确定的所述自相关函数, 表示第l次平滑处理后的自相关函数,
表示第l次平滑处理后的自相关函数, 表示第l-1次平滑处理后的自相关函数,β表示预设的平滑系数,0<β<1。
表示第l-1次平滑处理后的自相关函数,β表示预设的平滑系数,0<β<1。
可能的实施方式中,所述第三处理模块具体用于:
根据所述平均自相关函数以及所述预设的极大似然估计模型中定义的第一约束条件,确定第一参数和第二参数;
根据所述第一参数以及所述预设的极大似然估计模型中定义的第二约束条件,确定所述当前混响语音信号的混响时间的估计值;
根据预设的采用降采样后的混响语音信号帧确定的混响时间的估计值与混响时间的有效值之间的映射关系,确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值;
其中,所述第一约束条件表示为:

其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数, 表示所述平均自相关函数,
表示所述平均自相关函数, 表示对所述第一参数求偏导数,
表示对所述第一参数求偏导数, 表示对所述第二参数求偏导数,
表示对所述第二参数求偏导数, 表示所述平均自相关函数
表示所述平均自相关函数 所述第一参数以及所述第二参数的似然函数,表示为
所述第一参数以及所述第二参数的似然函数,表示为
其中,所述第二约束条件为: RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
可能的实施方式中,所述第三处理模块具体用于:
根据所述平滑处理后的自相关函数以及所述预设的极大似然估计模型中定义的第一约束条件,确定第一参数和第二参数;
根据所述第一参数以及所述预设的极大似然估计模型中定义的第二约束条件,确定所述当前混响语音信号的混响时间的估计值;
根据预设的采用降采样后的混响语音信号帧确定的混响时间的估计值与混响时间的有效值之间的映射关系,确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值;
其中,所述第一约束条件表示为:

其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数, 表示平滑处理后的自相关函数,
表示平滑处理后的自相关函数, 表示对所述第一参数求偏导数,
表示对所述第一参数求偏导数, 表示对所述第二参数求偏导数,
表示对所述第二参数求偏导数, 表示所述平滑处理后的自相关函数
表示所述平滑处理后的自相关函数 所述第一参数以及所述第二参数的似然函数,表示为
所述第一参数以及所述第二参数的似然函数,表示为
其中,所述第二约束条件为: RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
可能的实施方式中,所述第三处理模块具体用于:
确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值之后,按照公式 对所述混响时间的有效值进行平滑处理,其中,
对所述混响时间的有效值进行平滑处理,其中, 表示所述混响时间的有效值,
表示所述混响时间的有效值, 表示本次平滑处理后的混响时间,
表示本次平滑处理后的混响时间, 表示上一次平滑处理后的混响时间,α表示第一平滑因子,β表示第二平滑因子,α小于β,α大于零且小于1,β大于零且小于1。
表示上一次平滑处理后的混响时间,α表示第一平滑因子,β表示第二平滑因子,α小于β,α大于零且小于1,β大于零且小于1。
第三方面,本发明实施例提供了一种设备,该设备主要包括处理器和存储器,其中,存储器中保存有预设的程序,处理器用于读取存储器中的程序,按照该程序执行以下过程:
在混响环境下获得当前混响语音信号;
基于历史混响语音信号和所述当前混响语音信号确定自相关函数;
根据所述自相关函数以及预设的极大似然估计模型,确定所述当前混响语音信号的混响时间。
可能的实施方式中,处理器还用于:
在基于历史混响语音信号和所述当前混响语音信号确定自相关函数之前,对所述历史混响语音信号和所述当前混响语音信号进行降采样处理。
可能的实施方式中,基于历史混响语音信号和所述当前混响语音信号确定自相关函数,包括:
从所述当前混响语音信号中提取连续的M个混响语音帧,基于历史混响语音信号和所述M个混响语音帧确定自相关函数为: 其中,
其中, 表示所述自相关函数,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,
表示所述自相关函数,N表示一个混响语音帧中参与自相关函数计算的采样点的个数, 表示所述混响语音帧的残差信号,n表示移位距离,所述混响语音帧对应的残差信号为对所述混响语音帧进行线性预测得到线性预测系数并基于所述线性预测系数对所述混响语音帧进行线性预测滤波后得到,M为大于1的正整数。
表示所述混响语音帧的残差信号,n表示移位距离,所述混响语音帧对应的残差信号为对所述混响语音帧进行线性预测得到线性预测系数并基于所述线性预测系数对所述混响语音帧进行线性预测滤波后得到,M为大于1的正整数。
可能的实施方式中,处理器在根据所述自相关函数以及预设的极大似然估计模型,确定所述当前混响语音信号的混响时间时,具体用于:
若确定混响时间估计过程中提取混响语音帧的总数超过M的L倍,在每获得连续的L个自相关函数后,根据所述连续的L个自相关函数确定平均自相关函数,根据所述平均自
相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间;
若确定混响时间估计过程中提取混响语音帧的总数未超过M的L倍,对本次确定的所述自相关函数进行平滑处理后,根据平滑处理后的自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间。
可能的实施方式中,处理器在根据所述连续的L个自相关函数确定平均自相关函数时,具体用于:
按照公式 确定平均自相关函数,其中,
确定平均自相关函数,其中, 表示连续L次确定的自相关函数中的第l个自相关该函数,
表示连续L次确定的自相关函数中的第l个自相关该函数, 表示平均自相关函数。
表示平均自相关函数。
可能的实施方式中,处理器对本次确定的所述自相关函数进行平滑处理时,具体用于:
按照公式 对所述混响语音帧的自相关函数进行平滑处理,其中,
对所述混响语音帧的自相关函数进行平滑处理,其中, 表示本次确定的所述自相关函数,
表示本次确定的所述自相关函数, 表示第l次平滑处理后的自相关函数,
表示第l次平滑处理后的自相关函数, 表示第l-1次平滑处理后的自相关函数,β表示预设的平滑系数,0<β<1。
表示第l-1次平滑处理后的自相关函数,β表示预设的平滑系数,0<β<1。
可能的实施方式中,处理器根据所述平均自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间时,具体用于:
根据所述平均自相关函数以及所述预设的极大似然估计模型中定义的第一约束条件,确定第一参数和第二参数;
根据所述第一参数以及所述预设的极大似然估计模型中定义的第二约束条件,确定所述当前混响语音信号的混响时间的估计值;
根据预设的采用降采样后的混响语音信号帧确定的混响时间的估计值与混响时间的有效值之间的映射关系,确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值;
其中,所述第一约束条件表示为:

其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数, 表示所述平均自相关函数,
表示所述平均自相关函数, 表示对所述第一参数求偏导数,
表示对所述第一参数求偏导数, 表示对所述第二参数求偏导数,
表示对所述第二参数求偏导数, 表示所述平均自相关函数
表示所述平均自相关函数 所述第一参数以及所述第二参数的似然函数,表示为
所述第一参数以及所述第二参数的似然函数,表示为
其中,所述第二约束条件为: RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
可能的实施方式中,处理器根据平滑处理后的自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间时,具体用于:
根据所述平滑处理后的自相关函数以及所述预设的极大似然估计模型中定义的第一约束条件,确定第一参数和第二参数;
根据所述第一参数以及所述预设的极大似然估计模型中定义的第二约束条件,确定所述当前混响语音信号的混响时间的估计值;
根据预设的采用降采样后的混响语音信号帧确定的混响时间的估计值与混响时间的有效值之间的映射关系,确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值;
其中,所述第一约束条件表示为:

其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数, 表示平滑处理后的自相关函数,
表示平滑处理后的自相关函数, 表示对所述第
一参数求偏导数,
表示对所述第
一参数求偏导数, 表示对所述第二参数求偏导数,
表示对所述第二参数求偏导数, 表示所述平滑处理后的自相关函数
表示所述平滑处理后的自相关函数 所述第一参数以及所述第二参数的似然函数,表示为
所述第一参数以及所述第二参数的似然函数,表示为
其中,所述第二约束条件为: RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
可能的实施方式中,处理器还用于:
在确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值之后,按照公式 对所述混响时间的有效值进行平滑处理,其中,
对所述混响时间的有效值进行平滑处理,其中, 表示所述混响时间的有效值,
表示所述混响时间的有效值, 表示本次平滑处理后的混响时间,
表示本次平滑处理后的混响时间, 表示上一次平滑处理后的混响时间,α表示第一平滑因子,β表示第二平滑因子,α小于β,α大于零且小于1,β大于零且小于1。
表示上一次平滑处理后的混响时间,α表示第一平滑因子,β表示第二平滑因子,α小于β,α大于零且小于1,β大于零且小于1。
基于以上技术方案,本发明实施例中,基于历史语音信号和当前混响语音信号确定自相关函数,根据该自相关函数以及预设的极大似然估计模型,确定混响语音信号的混响时间,可以进一步提高混响时间的估计精度,解决了现有的基于语音模型的混响时间估计方法中,对混响时间小于预设门限的混响语音的混响时间产生过估计的问题。
图1为本发明实施例中进行混响时间估计的方法流程示意图;
图2为本发明实施例中基于语音模型的混响时间估计过程示意图;
图3为本发明实施例中混响时间估计装置结构示意图;
图4为本发明实施例中设备结构示意图。
为了使本发明实施例的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施例作进一步地详细描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全
部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
为了解决现有的基于语音模型的混响时间估计方法中,对混响时间小于预设门限的混响语音的混响时间产生过估计的问题,本发明实施例中对现有的基于语音模型的混响时间估计方法进行了改进。
本发明实施例中,将混响时间小于预设门限的混响语音成为小混响语音,例如,将混响时间小于400毫秒的混响语音称为小混响语音。
本发明实施例中,对现有的基于语音模型的混响时间估计方法进行改进后,进行混响时间估计的方法流程如图1所示,具体如下:
步骤101:在混响环境下获得当前混响语音信号。
步骤102:基于历史混响语音信号和所述当前混响语音信号确定自相关函数。
发明人发现,现有的基于语音模型的混响时间估计过程中,在公式13中,计算无偏自相关函数具有局部的窗口效应,为改善和提高自相关函数的计算精度,本发明实施例中提出了基于历史混响语音信号和当前混响时间信号确定自相关函数的方法。
相对公式13提出的无偏的自相关函数的定义,带历史数据的无偏自相关函数定义如下:
首先在帧长为N的数据前填充M长的历史数据,然后根据公式14求取:
具体地,基于历史混响语音信号和所述当前混响语音信号确定自相关函数的过程具体如下:
从所述当前混响语音信号中提取连续的M个混响语音帧,基于历史混响语音信号和所述M个混响语音帧确定自相关函数为:

其中, 表示所述自相关函数,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,
表示所述自相关函数,N表示一个混响语音帧中参与自相关函数计算的采样点的个数, 表示所述混响语音帧的残差信号,n表示移位距离(以样点为单位),所述混响语音帧对应的残差信号为对所述混响语音帧进行线性预测得到线性预测系数并基于所述线性预测系数对所述混响语音帧进行线性预测滤波后得到,M为大于1的正整数。
表示所述混响语音帧的残差信号,n表示移位距离(以样点为单位),所述混响语音帧对应的残差信号为对所述混响语音帧进行线性预测得到线性预测系数并基于所述线性预测系数对所述混响语音帧进行线性预测滤波后得到,M为大于1的正整数。
较佳地,n小于或等于N的二分之一。
根据实际应用中测试的结果可知,采用 代替
代替 代入到公式11、公式12、公式3和公式4中,得到的RT60比现有的基于语音模型的估计方法更为准确,尤其是可以解决对小混响语音的过估计的问题。
代入到公式11、公式12、公式3和公式4中,得到的RT60比现有的基于语音模型的估计方法更为准确,尤其是可以解决对小混响语音的过估计的问题。
步骤103:根据所述自相关函数以及预设的极大似然估计模型,确定所述当前混响语音信号的混响时间。
本发明实施例中,鉴于现有的基于语音模型的混响时间估计方法中,需要对连续多次获得自相关函数进行平均,这就为混响时间的估计造成较大的等待时延,尤其是导致第一次计算得到混响时间的时间延迟太长。
例如,假设一个混响语音帧的时长为20毫秒,一个混响语音帧包含的采样点数为N=320,即混响语音信号的采样频率为16KHz,假设用于计算自相关函数的帧数M=12,用于计算平均自相关函数所需的自相关函数的个数L=20,则计算得到第一个混响时间估计值需要的延迟为:20毫秒×12×20=4.8秒。以应用于去混响应用为例,将直接影响前4.8秒的去混响性能。
为此,本发明实施例中在开始混响时间估计的4.8秒之前,与在开始混响时间估计的4.8之后,采用不同的混响时间估计方式。具体地,在开始混响时间估计的4.8秒之前采用确定混响时间的第二处理方式,在开始混响时间估计的4.8之后采用确定混响时间的第一处理方式。
具体地,根据所述自相关函数以及预设的极大似然估计模型,确定所述当前混响语音信号的混响时间,具体可以分为以下两种处理方式:
第一处理方式,若确定混响时间估计过程中提取混响语音帧的总数超过M的L倍,在每获得连续的L个自相关函数后,根据所述连续的L个自相关函数确定平均自相关函数,根据所述平均自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间。
第一处理方式中,根据所述连续的L个自相关函数确定平均自相关函数,具体为:按照公式19确定平均自相关函数,

其中, 表示连续L次确定的自相关函数中的第l个自相关该函数,
表示连续L次确定的自相关函数中的第l个自相关该函数, 表示平均自相关函数。
表示平均自相关函数。
该第一处理方式中,根据所述平均自相关函数以及所述预设的极大似然估计模型,
确定所述当前混响语音信号的混响时间,具体过程如下:根据所述平均自相关函数以及所述预设的极大似然估计模型中定义的第一约束条件,确定第一参数和第二参数;根据所述第一参数以及所述预设的极大似然估计模型中定义的第二约束条件,确定所述当前混响语音信号的混响时间的估计值;其中,所述第一约束条件表示为:

其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数, 表示所述平均自相关函数,
表示所述平均自相关函数, 表示对所述第一参数求偏导数,
表示对所述第一参数求偏导数, 表示对所述第二参数求偏导数,
表示对所述第二参数求偏导数, 表示所述平均自相关函数
表示所述平均自相关函数 所述第一参数以及所述第二参数的似然函数,表示为:
所述第一参数以及所述第二参数的似然函数,表示为:

其中,所述第二约束条件为:

其中,RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
该第一处理方式中,每连续获得L个自相关函数后计算平均自相关函数,基于平均自相关函数确定混响时间的估计值,可以在不影响混响时间估计的准确性的情况下,进一步降低运算量。
第二处理方式,若确定混响时间估计过程中提取混响语音帧的总数未超过M的L倍,对本次确定的所述自相关函数进行平滑处理后,根据平滑处理后的自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间。
例如,在混响时间估计开始后的4.8秒之前,每240毫秒得到一个自相关函数后就确定一次混响时间,为了避免减少由于自相关函数的波动,采用递归平滑的方式对自相关
函数进行平滑处理。
具体地,该第二处理方式中,对本次确定的所述自相关函数进行平滑处理,具体为:按照公式23对所述混响语音帧的自相关函数进行平滑处理,
其中, 表示本次确定的所述自相关函数,
表示本次确定的所述自相关函数, 表示第l次平滑处理后的自相关函数,
表示第l次平滑处理后的自相关函数, 表示第l-1次平滑处理后的自相关函数,β表示预设的平滑系数,0<β<1。
表示第l-1次平滑处理后的自相关函数,β表示预设的平滑系数,0<β<1。
该第二处理方式中,根据平滑处理后的自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间,具体为:根据所述平滑处理后的自相关函数以及所述预设的极大似然估计模型中定义的第一约束条件,确定第一参数和第二参数;根据所述第一参数以及所述预设的极大似然估计模型中定义的第二约束条件,确定所述当前混响语音信号的混响时间的估计值;其中,所述第一约束条件表示为:

其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数, 表示平滑处理后的自相关函数,
表示平滑处理后的自相关函数, 表示对所述第一参数求偏导数,
表示对所述第一参数求偏导数, 表示对所述第二参数求偏导数,
表示对所述第二参数求偏导数, 表示所述平滑处理后的自相关函数
表示所述平滑处理后的自相关函数 所述第一参数以及所述第二参数的似然函数,表示为:
所述第一参数以及所述第二参数的似然函数,表示为:

其中,所述第二约束条件为:

其中,RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
优选地,基于历史混响语音信号和所述当前混响语音信号确定自相关函数之前,对所述历史混响语音信号和所述当前混响语音进行降采样处理,基于降采样后的历史混响语音信号和降采样后的当前混响语音信号确定自相关函数。
鉴于现有的基于语音模型的混响时间估计方法中,假设一帧语音帧包含的采样点数为N,计算自相关的帧数为M,且N×M需要足够大才能够使得语音模型成立,计算自相关的运算量很大。例如,假设N×M=3840,即对应240毫秒内以16KHz的采样速率进行采样获得数据个数,如果只计算N×M/2=1920个自相关值,则计算复杂度为:乘法次数为N×M×N×M/2=7372800,加法次数为(N×M-1)×N×M/2=7370800。
通过降采样可以有效降低计算量,具体地,假设输入的语音信号的采样频率为16KHz,假设将采样频率降为4KHz,则自相关函数的计算运算量将变为原来的1/16,即降采样后的计算复杂度为:乘法次数为7372800/16=460800,加法次数为7370800/16=460680。同时极大似然估计过程的计算复杂度也会降为原来的1/16。
优选地,如果采用降采样后的历史语音信号和降采样后的当前混响语音信号计算自相关函数以及计算混响语音信号的混响时间的估计值,则在采用第一或第二处理方式确定当前混响语音信号的混响时间的估计值之后,根据预设的采用降采样后的混响语音信号帧确定的混响时间的估计值与混响时间的有效值之间的映射关系,确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值。
具体地,采用降采样后的历史语音信号和降采样后的当前混响语音信号计算得到的自相关函数后,将该自相关函数代入极大似然估计模型中得到的为混响时间的估计值。采用未进行降采样处理的历史语音信号和当前混响语音信号计算得到的自相关函数,将该自相关函数代入极大似然估计模型中得到的为混响时间的有效值。混响时间的估计值与混响时间的有效值之间存在映射关系,该映射关系可采用数学映射函数Γ(·)表示为:
其中, 表示混响时间的估计值,
表示混响时间的估计值, 表示混响时间的有效值。
表示混响时间的有效值。
优选地,对于第二处理方式,为了减小估计出的混淆时间的有效值的波动性,确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值之后,按照公式25对所
述混响时间的有效值进行平滑处理,

其中, 表示所述混响时间的有效值,
表示所述混响时间的有效值, 表示本次平滑处理后的混响时间,
表示本次平滑处理后的混响时间, 表示上一次平滑处理后的混响时间,α表示第一平滑因子,β表示第二平滑因子,α小于β,α大于零且小于1,β大于零且小于1。
表示上一次平滑处理后的混响时间,α表示第一平滑因子,β表示第二平滑因子,α小于β,α大于零且小于1,β大于零且小于1。
该第二处理方式中对混响时间的有效值进行平滑处理的基本思想是以“快上升慢下降”为准则的,即当瞬时的混响时间的有效值大于上一次平滑处理后的混淆时间时,使用较小的平滑因子α,否则,使用较大的平滑因子β。
具体应用中,在混响时间估计开始后的第一个4.8秒之后,按照第一处理方式,每4.8秒进行一次MLE来更新混响时间的估计值,从而进一步降低运算量,因为同一空间内混响时间是相对固定的。
以下通过一个具体实施例对本发明实施例所提供的基于语音模型的混响时间估计方法进行完整说明。
如图2所示为该具体实施例中基于语音模型的混响时间估计过程示意图,具体过程如下:
步骤201:在初始化过程中配置以下参数:一个语音帧中包含的样点数为N;配置M、L、平滑因子α和β,设置帧计数器Cnt=0,设置计数器m=0,以及设置计数器h=0。
步骤202:读取一个混响语音帧,更新Cnt=Cnt+1以及更新m=m+1。
步骤203:对混响语音帧进行降采样处理。
步骤204:对将采样处理后的混响语音帧进行LPC分析以及LP滤波。
步骤205:判断是否满足m>M,若是,执行步骤206,否则,执行步骤202。
步骤206:按照公式15计算M个混响语音帧的残差信号的自相关函数,并更新m=0,以及更新h=h+1。
步骤207:判断是否满足Cnt>M×L,若不满足,执行步骤208,否则执行步骤209;
步骤208:按照公式20对自相关函数进行平滑处理后,执行步骤211。
步骤209:按照公式16计算连续L个自相关函数的平均自相关函数后,执行步骤210。
步骤210:判断是否满足h>L,若不满足,转去执行步骤202,否则,执行步骤211。
步骤211:计算混响时间,具体为:根据平滑处理后的自相关函数或者平均自相关函
数,采用Newton-Raphson方法求解公式21,得到参数a和k,根据公式23得到混响时间的估计值,根据公式24得到该混响时间的估计值对应的混响时间的有效值,更新h=0。
步骤212:判断是否仍在接收混响语音信号,若是,转去执行步骤202,否则,结束。
基于同一发明构思,本发明实施例中提供了一种混响时间估计装置,该装置的具体实施可参见方法实施例部分的描述,重复之处不再赘述,如图3所示,该装置主要包括:
第一处理模块301,用于在混响环境下获得当前混响语音信号;
第二处理模块302,用于基于历史混响语音信号和所述当前混响语音信号确定自相关函数;
第三处理模块303,用于根据所述自相关函数以及预设的极大似然估计模型,确定所述当前混响语音信号的混响时间。
可能的实施方式中,所述第二处理模块还用于:
基于历史混响语音信号和所述当前混响语音信号确定自相关函数之前,对所述历史混响语音信号和所述当前混响语音信号进行降采样处理。
可能的实施方式中,所述第二处理模块具体用于:
从所述当前混响语音信号中提取连续的M个混响语音帧,基于历史混响语音信号和所述M个混响语音帧确定自相关函数为: 其中,
其中, 表示所述自相关函数,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,
表示所述自相关函数,N表示一个混响语音帧中参与自相关函数计算的采样点的个数, 表示所述混响语音帧的残差信号,n表示移位距离,所述混响语音帧对应的残差信号为对所述混响语音帧进行线性预测得到线性预测系数并基于所述线性预测系数对所述混响语音帧进行线性预测滤波后得到,M为大于1的正整数。
表示所述混响语音帧的残差信号,n表示移位距离,所述混响语音帧对应的残差信号为对所述混响语音帧进行线性预测得到线性预测系数并基于所述线性预测系数对所述混响语音帧进行线性预测滤波后得到,M为大于1的正整数。
可能的实施方式中,所述第三处理模块具体用于:
若确定混响时间估计过程中提取混响语音帧的总数超过M的L倍,在每获得连续的L个自相关函数后,根据所述连续的L个自相关函数确定平均自相关函数,根据所述平均自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间;
若确定混响时间估计过程中提取混响语音帧的总数未超过M的L倍,对本次确定的所述自相关函数进行平滑处理后,根据平滑处理后的自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间。
可能的实施方式中,所述第三处理模块具体用于:
按照公式 确定平均自相关函数,其中,
确定平均自相关函数,其中, 表示连续L次
确定的自相关函数中的第l个自相关该函数,
表示连续L次
确定的自相关函数中的第l个自相关该函数, 表示平均自相关函数。
表示平均自相关函数。
可能的实施方式中,所述第三处理模块具体用于:
按照公式 对所述混响语音帧的自相关函数进行平滑处理,其中,
对所述混响语音帧的自相关函数进行平滑处理,其中, 表示本次确定的所述自相关函数,
表示本次确定的所述自相关函数, 表示第l次平滑处理后的自相关函数,
表示第l次平滑处理后的自相关函数, 表示第l-1次平滑处理后的自相关函数,β表示预设的平滑系数,0<β<1。
表示第l-1次平滑处理后的自相关函数,β表示预设的平滑系数,0<β<1。
可能的实施方式中,所述第三处理模块具体用于:
根据所述平均自相关函数以及所述预设的极大似然估计模型中定义的第一约束条件,确定第一参数和第二参数;
根据所述第一参数以及所述预设的极大似然估计模型中定义的第二约束条件,确定所述当前混响语音信号的混响时间的估计值;
根据预设的采用降采样后的混响语音信号帧确定的混响时间的估计值与混响时间的有效值之间的映射关系,确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值;
其中,所述第一约束条件表示为:

其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数, 表示所述平均自相关函数,
表示所述平均自相关函数, 表示对所述第一参数求偏导数,
表示对所述第一参数求偏导数,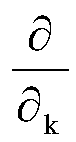 表示对所述第二参数求偏导数,
表示对所述第二参数求偏导数, 表示所述平均自相关函数
表示所述平均自相关函数 所述第一参数以及所述第二参数的似然函数,表示为
所述第一参数以及所述第二参数的似然函数,表示为
其中,所述第二约束条件为: RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
可能的实施方式中,所述第三处理模块具体用于:
根据所述平滑处理后的自相关函数以及所述预设的极大似然估计模型中定义的第一约束条件,确定第一参数和第二参数;
根据所述第一参数以及所述预设的极大似然估计模型中定义的第二约束条件,确定所述当前混响语音信号的混响时间的估计值;
根据预设的采用降采样后的混响语音信号帧确定的混响时间的估计值与混响时间的有效值之间的映射关系,确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值;
其中,所述第一约束条件表示为:

其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数, 表示平滑处理后的自相关函数,
表示平滑处理后的自相关函数, 表示对所述第一参数求偏导数,
表示对所述第一参数求偏导数, 表示对所述第二参数求偏导数,
表示对所述第二参数求偏导数, 表示所述平滑处理后的自相关函数
表示所述平滑处理后的自相关函数 所述第一参数以及所述第二参数的似然函数,表示为
所述第一参数以及所述第二参数的似然函数,表示为
其中,所述第二约束条件为: RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
可能的实施方式中,所述第三处理模块具体用于:
确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值之后,按照公式 对所述混响时间的有效值进行平滑处理,其中,
对所述混响时间的有效值进行平滑处理,其中, 表示所述混响时间的有效值,
表示所述混响时间的有效值, 表示本次平滑处理后的混响时间,
表示本次平滑处理后的混响时间, 表示上一次平滑处理后的混响时间,α表示第一平滑因子,β表示第二平滑因子,α小于β,α大于零且小于1,β大于零且小于1。
表示上一次平滑处理后的混响时间,α表示第一平滑因子,β表示第二平滑因子,α小于β,α大于零且小于1,β大于零且小于1。
基于同一发明构思,本发明实施例还提供了一种设备,该设备的具体实施可参见方法实施例的相关描述,如图4所示,该设备主要包括处理器401和存储器402,其中,存储器402中保存有预设的程序,处理器401用于读取存储器402中的程序,按照该程序执行以下过程:
在混响环境下获得当前混响语音信号;
基于历史混响语音信号和所述当前混响语音信号确定自相关函数;
根据所述自相关函数以及预设的极大似然估计模型,确定所述当前混响语音信号的混响时间。
可能的实施方式中,处理器401还用于:基于历史混响语音信号和所述当前混响语音信号确定自相关函数之前,对所述历史混响语音信号和所述当前混响语音信号进行降采样处理。
可能的实施方式中,处理器401基于历史混响语音信号和所述当前混响语音信号确定自相关函数时,具体用于:从所述当前混响语音信号中提取连续的M个混响语音帧,基于历史混响语音信号和所述M个混响语音帧确定自相关函数为: 其中,
其中, 表示所述自相关函数,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,
表示所述自相关函数,N表示一个混响语音帧中参与自相关函数计算的采样点的个数, 表示所述混响语音帧的残差信号,n表示移位距离,所述混响语音帧对应的残差信号为对所述混响语音帧进行线性预测得到线性预测系数并基于所述线性预测系数对所述混响语音帧进行线性预测滤波后得到,M为大于1的正整数。
表示所述混响语音帧的残差信号,n表示移位距离,所述混响语音帧对应的残差信号为对所述混响语音帧进行线性预测得到线性预测系数并基于所述线性预测系数对所述混响语音帧进行线性预测滤波后得到,M为大于1的正整数。
可能的实施方式中,处理器401根据所述自相关函数以及预设的极大似然估计模型,确定所述当前混响语音信号的混响时间时,具体用于:若确定混响时间估计过程中提取混
响语音帧的总数超过M的L倍,在每获得连续的L个自相关函数后,根据所述连续的L个自相关函数确定平均自相关函数,根据所述平均自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间;
若确定混响时间估计过程中提取混响语音帧的总数未超过M的L倍,对本次确定的所述自相关函数进行平滑处理后,根据平滑处理后的自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间。
可能的实施方式中,处理器401根据所述连续的L个自相关函数确定平均自相关函数时,具体用于:按照公式 确定平均自相关函数,其中,
确定平均自相关函数,其中, 表示连续L次确定的自相关函数中的第l个自相关该函数,
表示连续L次确定的自相关函数中的第l个自相关该函数, 表示平均自相关函数。
表示平均自相关函数。
可能的实施方式中,处理器401对本次确定的所述自相关函数进行平滑处理时,具体用于:
按照公式 对所述混响语音帧的自相关函数进行平滑处理,其中,
对所述混响语音帧的自相关函数进行平滑处理,其中, 表示本次确定的所述自相关函数,
表示本次确定的所述自相关函数, 表示第l次平滑处理后的自相关函数,
表示第l次平滑处理后的自相关函数, 表示第l-1次平滑处理后的自相关函数,β表示预设的平滑系数,0<β<1。
表示第l-1次平滑处理后的自相关函数,β表示预设的平滑系数,0<β<1。
可能的实施方式中,处理器401根据所述平均自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间时,具体用于:
根据所述平均自相关函数以及所述预设的极大似然估计模型中定义的第一约束条件,确定第一参数和第二参数;
根据所述第一参数以及所述预设的极大似然估计模型中定义的第二约束条件,确定所述当前混响语音信号的混响时间的估计值;
根据预设的采用降采样后的混响语音信号帧确定的混响时间的估计值与混响时间的有效值之间的映射关系,确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值;
其中,所述第一约束条件表示为:

其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数, 表示所述平均自相关函数,
表示所述平均自相关函数, 表示对所述第一参数求偏导数,
表示对所述第一参数求偏导数, 表示对所述第二参数求偏导数,
表示对所述第二参数求偏导数, 表示所述平均自相关函数
表示所述平均自相关函数 所述第一参数以及所述第二参数的似然函数,表示为
所述第一参数以及所述第二参数的似然函数,表示为
其中,所述第二约束条件为: RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
可能的实施方式中,处理器401根据平滑处理后的自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间时,具体用于:
根据所述平滑处理后的自相关函数以及所述预设的极大似然估计模型中定义的第一约束条件,确定第一参数和第二参数;
根据所述第一参数以及所述预设的极大似然估计模型中定义的第二约束条件,确定所述当前混响语音信号的混响时间的估计值;
根据预设的采用降采样后的混响语音信号帧确定的混响时间的估计值与混响时间的有效值之间的映射关系,确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值;
其中,所述第一约束条件表示为:

其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数, 表示平滑处理后的自相关函数,
表示平滑处理后的自相关函数, 表示对所述第一参数求偏导数,
表示对所述第一参数求偏导数, 表示对所述第二参数求偏导数,
表示对所述第二参数求偏导数, 表示所述平滑处理后的自相关函数
表示所述平滑处理后的自相关函数 所述第一参数以及所述第二参数的似然函数,表示为
所述第一参数以及所述第二参数的似然函数,表示为
其中,所述第二约束条件为: RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
可能的实施方式中,处理器401还用于:
在确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值之后,按照公式 对所述混响时间的有效值进行平滑处理,其中,
对所述混响时间的有效值进行平滑处理,其中, 表示所述混响时间的有效值,
表示所述混响时间的有效值, 表示本次平滑处理后的混响时间,
表示本次平滑处理后的混响时间, 表示上一次平滑处理后的混响时间,α表示第一平滑因子,β表示第二平滑因子,α小于β,α大于零且小于1,β大于零且小于1。
表示上一次平滑处理后的混响时间,α表示第一平滑因子,β表示第二平滑因子,α小于β,α大于零且小于1,β大于零且小于1。
其中,处理器和存储器之间通过总线连接,总线架构可以包括任意数量的互联的总线和桥,具体由处理器代表的一个或多个处理器和存储器代表的存储器的各种电路链接在一起。总线架构还可以将诸如外围设备、稳压器和功率管理电路等之类的各种其他电路链接在一起,这些都是本领域所公知的,因此,本文不再对其进行进一步描述。总线接口提供接口。处理器负责管理总线架构和通常的处理,存储器可以存储处理器在执行操作时所使用的数据。
基于以上技术方案,本发明实施例中,基于历史语音信号和当前混响语音信号确定自相关函数,根据该自相关函数以及预设的极大似然估计模型,确定混响语音信号的混响时间,可以进一步提高混响时间的估计精度,解决了现有的基于语音模型的混响时间估计方
法中,对混响时间小于预设门限的混响语音的混响时间产生过估计的问题。
并且,本发明实施例中,在对历史语音信号以及当前混响语音信号进行降采样处理,基于降采样后的历史语音信号以及降采样后的当前混响语音信号计算自相关函数,可以进一步降低计算复杂度,提高混响时间估计的实时性。
另外,本发明实施例中,在混响时间估计开始的设定时长内,在每次计算得到自相关函数后,根据该自相关函数确定混响时间,从而可以解决现有的基于语音模型的混响时间估计过程中,首次获得混响时间的等待时延长的问题,缩短了工程实现中首次获得混响时间的等待时长,使得更适合实际应用。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
Claims (27)
- 一种混响时间估计方法,其特征在于,包括:在混响环境下获得当前混响语音信号;基于历史混响语音信号和所述当前混响语音信号确定自相关函数;根据所述自相关函数以及预设的极大似然估计模型,确定所述当前混响语音信号的混响时间。
- 如权利要求1所述的方法,其特征在于,基于历史混响语音信号和所述当前混响语音信号确定自相关函数之前,所述方法还包括:对所述历史混响语音信号和所述当前混响语音信号进行降采样处理。
- 如权利要求2所述的方法,其特征在于,基于历史混响语音信号和所述当前混响语音信号确定自相关函数,包括:从所述当前混响语音信号中提取连续的M个混响语音帧,基于历史混响语音信号和所述M个混响语音帧确定自相关函数为:其中,
 表示所述自相关函数,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,
表示所述自相关函数,N表示一个混响语音帧中参与自相关函数计算的采样点的个数, 表示所述混响语音帧的残差信号,n表示移位距离,所述混响语音帧对应的残差信号为对所述混响语音帧进行线性预测得到线性预测系数并基于所述线性预测系数对所述混响语音帧进行线性预测滤波后得到,M为大于1的正整数。
表示所述混响语音帧的残差信号,n表示移位距离,所述混响语音帧对应的残差信号为对所述混响语音帧进行线性预测得到线性预测系数并基于所述线性预测系数对所述混响语音帧进行线性预测滤波后得到,M为大于1的正整数。
- 如权利要求2所述的方法,其特征在于,根据所述自相关函数以及预设的极大似然估计模型,确定所述当前混响语音信号的混响时间,包括:若确定混响时间估计过程中提取混响语音帧的总数超过M的L倍,在每获得连续的L个自相关函数后,根据所述连续的L个自相关函数确定平均自相关函数,根据所述平均自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间;若确定混响时间估计过程中提取混响语音帧的总数未超过M的L倍,对本次确定的所述自相关函数进行平滑处理后,根据平滑处理后的自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间。
- 如权利要求4所述的方法,其特征在于,根据所述连续的L个自相关函数确定平均自相关函数,包括:按照公式确定平均自相关函数,其中,
 表示连续L次 确定的自相关函数中的第l个自相关该函数,
表示连续L次 确定的自相关函数中的第l个自相关该函数, 表示平均自相关函数。
表示平均自相关函数。
- 如权利要求4所述的方法,其特征在于,对本次确定的所述自相关函数进行平滑处理,包括:按照公式对所述混响语音帧的自相关函数进行平滑处理,其中,
 表示本次确定的所述自相关函数,
表示本次确定的所述自相关函数, 表示第l次平滑处理后的自相关函数,
表示第l次平滑处理后的自相关函数, 表示第l-1次平滑处理后的自相关函数,β表示预设的平滑系数,0<β<1。
表示第l-1次平滑处理后的自相关函数,β表示预设的平滑系数,0<β<1。
- 如权利要求5所述的方法,其特征在于,根据所述平均自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间,包括:根据所述平均自相关函数以及所述预设的极大似然估计模型中定义的第一约束条件,确定第一参数和第二参数;根据所述第一参数以及所述预设的极大似然估计模型中定义的第二约束条件,确定所述当前混响语音信号的混响时间的估计值;根据预设的采用降采样后的混响语音信号帧确定的混响时间的估计值与混响时间的有效值之间的映射关系,确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值;其中,所述第一约束条件表示为:
 其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数,表示所述平均自相关函数,
其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数,表示所述平均自相关函数, 表示对所述第一参数求偏导数,
表示对所述第一参数求偏导数, 表示对所述第二参数求偏导数,
表示对所述第二参数求偏导数, 表示所述平均自相关函数
表示所述平均自相关函数 所述第一参数以及所述第二参数的似然函数,表示为
所述第一参数以及所述第二参数的似然函数,表示为
 其中,所述第二约束条件为:RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
其中,所述第二约束条件为:RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
- 如权利要求6所述的方法,其特征在于,根据平滑处理后的自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间,包括:根据所述平滑处理后的自相关函数以及所述预设的极大似然估计模型中定义的第一约束条件,确定第一参数和第二参数;根据所述第一参数以及所述预设的极大似然估计模型中定义的第二约束条件,确定所述当前混响语音信号的混响时间的估计值;根据预设的采用降采样后的混响语音信号帧确定的混响时间的估计值与混响时间的有效值之间的映射关系,确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值;其中,所述第一约束条件表示为:
 其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数,表示平滑处理后的自相关函数,
其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数,表示平滑处理后的自相关函数, 表示对所述第一参数求偏导数,
表示对所述第一参数求偏导数, 表示对所述第二参数求偏导数,
表示对所述第二参数求偏导数, 表示所述平滑处理后的自相关函数
表示所述平滑处理后的自相关函数 所述第一参数以及所述第二参数的似然函数,表示为
所述第一参数以及所述第二参数的似然函数,表示为
 其中,所述第二约束条件为:RT60表示所述当前混响语音信号 的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
其中,所述第二约束条件为:RT60表示所述当前混响语音信号 的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
- 如权利要求8所述的方法,其特征在于,确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值之后,所述方法还包括:按照公式对所述混响时间的有效值进行平滑处理,其中,
 表示所述混响时间的有效值,表示本次平滑处理后的混响时间,
表示所述混响时间的有效值,表示本次平滑处理后的混响时间, 表示上一次平滑处理后的混响时间,α表示第一平滑因子,β表示第二平滑因子,α小于β,α大于零且小于1,β大于零且小于1。
表示上一次平滑处理后的混响时间,α表示第一平滑因子,β表示第二平滑因子,α小于β,α大于零且小于1,β大于零且小于1。
- 一种混响时间估计装置,其特征在于,包括:第一处理模块,用于在混响环境下获得当前混响语音信号;第二处理模块,用于基于历史混响语音信号和所述当前混响语音信号确定自相关函数;第三处理模块,用于根据所述自相关函数以及预设的极大似然估计模型,确定所述当前混响语音信号的混响时间。
- 如权利要求10所述的装置,其特征在于,所述第二处理模块还用于:基于历史混响语音信号和所述当前混响语音信号确定自相关函数之前,对所述历史混响语音信号和所述当前混响语音信号进行降采样处理。
- 如权利要求11所述的装置,其特征在于,所述第二处理模块具体用于:从所述当前混响语音信号中提取连续的M个混响语音帧,基于历史混响语音信号和所述M个混响语音帧确定自相关函数为:其中,
 表示所述自相关函数,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,
表示所述自相关函数,N表示一个混响语音帧中参与自相关函数计算的采样点的个数, 表示所述混响语音帧的残差信号,n表示移位距离,所述混响语音帧对应的残差信号为对所述混响语音帧进行线性预测得到线性预测系数并基于所述线性预测系数对所述混响语音帧进行线性预测滤波后得到,M为大于1的正整数。
表示所述混响语音帧的残差信号,n表示移位距离,所述混响语音帧对应的残差信号为对所述混响语音帧进行线性预测得到线性预测系数并基于所述线性预测系数对所述混响语音帧进行线性预测滤波后得到,M为大于1的正整数。
- 如权利要求11所述的装置,其特征在于,所述第三处理模块具体用于:若确定混响时间估计过程中提取混响语音帧的总数超过M的L倍,在每获得连续的L个自相关函数后,根据所述连续的L个自相关函数确定平均自相关函数,根据所述平均自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间;若确定混响时间估计过程中提取混响语音帧的总数未超过M的L倍,对本次确定的所述自相关函数进行平滑处理后,根据平滑处理后的自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间。
- 如权利要求13所述的装置,其特征在于,所述第三处理模块具体用于:按照公式确定平均自相关函数,其中,
 表示连续L次确定的自相关函数中的第l个自相关该函数,
表示连续L次确定的自相关函数中的第l个自相关该函数, 表示平均自相关函数。
表示平均自相关函数。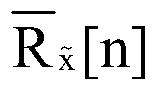
- 如权利要求13所述的装置,其特征在于,所述第三处理模块具体用于:按照公式对所述混响语音帧的自相关函数进行平滑处理,其中,
 表示本次确定的所述自相关函数,
表示本次确定的所述自相关函数, 表示第l次平滑处理后的自相关函数,
表示第l次平滑处理后的自相关函数, 表示第l-1次平滑处理后的自相关函数,β表示预设的平滑系数,0<β<1。
表示第l-1次平滑处理后的自相关函数,β表示预设的平滑系数,0<β<1。
- 如权利要求14所述的装置,其特征在于,所述第三处理模块具体用于:根据所述平均自相关函数以及所述预设的极大似然估计模型中定义的第一约束条件,确定第一参数和第二参数;根据所述第一参数以及所述预设的极大似然估计模型中定义的第二约束条件,确定所述当前混响语音信号的混响时间的估计值;根据预设的采用降采样后的混响语音信号帧确定的混响时间的估计值与混响时间的有效值之间的映射关系,确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值;其中,所述第一约束条件表示为:
 其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数,表示所述平均自相关函数,
其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数,表示所述平均自相关函数, 表示对所述第一参数求偏导数,
表示对所述第一参数求偏导数, 表示对所述第二参数求偏导数,
表示对所述第二参数求偏导数, 表示所述平均自相关函数
表示所述平均自相关函数 所述第一参数以及所述第二参数的似然函数,表示为
所述第一参数以及所述第二参数的似然函数,表示为
 其中,所述第二约束条件为:RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
其中,所述第二约束条件为:RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
- 如权利要求15所述的装置,其特征在于,所述第三处理模块具体用于:根据所述平滑处理后的自相关函数以及所述预设的极大似然估计模型中定义的第一约束条件,确定第一参数和第二参数;根据所述第一参数以及所述预设的极大似然估计模型中定义的第二约束条件,确定所述当前混响语音信号的混响时间的估计值;根据预设的采用降采样后的混响语音信号帧确定的混响时间的估计值与混响时间的有效值之间的映射关系,确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值;其中,所述第一约束条件表示为:
 其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数,表示平滑处理后的自相关函数,
其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数,表示平滑处理后的自相关函数, 表示对所述第一参数求偏导数,
表示对所述第一参数求偏导数, 表示对所述第二参数求偏导数,
表示对所述第二参数求偏导数, 表示所述平滑处理后的自相关函数
表示所述平滑处理后的自相关函数 所述第一参数以及所述第二参数的似然函数,表示为
所述第一参数以及所述第二参数的似然函数,表示为
 其中,所述第二约束条件为:RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
其中,所述第二约束条件为:RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
- 如权利要求17所述的装置,其特征在于,所述第三处理模块具体用于:确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值之后,按照公式对所述混响时间的有效值进行平滑处理,其中,
 表示所述混响时间的有效值,
表示所述混响时间的有效值, 表示本次平滑处理后的混响时间,
表示本次平滑处理后的混响时间, 表示上一次平滑处理后的混响时间,α表示第一平滑因子,β表示第二平滑因子,α小于β,α大于零且小于1,β大于零且小于1。
表示上一次平滑处理后的混响时间,α表示第一平滑因子,β表示第二平滑因子,α小于β,α大于零且小于1,β大于零且小于1。
- 一种设备,其特征在于,该设备包括处理器和存储器,其中,所述存储器用于存储计算机可读程序,所述处理器用于读取所述存储器中的程序,按照该程序执行以下过程:在混响环境下获得当前混响语音信号;基于历史混响语音信号和所述当前混响语音信号确定自相关函数;根据所述自相关函数以及预设的极大似然估计模型,确定所述当前混响语音信号的混响时间。
- 如权利要求19所述的设备,其特征在于,所述处理器还用于:在基于历史混响语音信号和所述当前混响语音信号确定自相关函数之前,对所述历史混响语音信号和所述当前混响语音信号进行降采样处理。
- 如权利要求20所述的设备,其特征在于,所述处理器基于历史混响语音信号和所述当前混响语音信号确定自相关函数时,具体用于:从所述当前混响语音信号中提取连续的M个混响语音帧,基于历史混响语音信号和所述M个混响语音帧确定自相关函数为:其中,
 表示所述自相关函数,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,
表示所述自相关函数,N表示一个混响语音帧中参与自相关函数计算的采样点的个数, 表示所述混响语音帧的残差信号,n表示移位距离,所述混响语音帧对应的残差信号为对所述混响语音帧进行线性预测得到线性预测系数并基于所述线性预测系数对所述混响语 音帧进行线性预测滤波后得到,M为大于1的正整数。
表示所述混响语音帧的残差信号,n表示移位距离,所述混响语音帧对应的残差信号为对所述混响语音帧进行线性预测得到线性预测系数并基于所述线性预测系数对所述混响语 音帧进行线性预测滤波后得到,M为大于1的正整数。
- 如权利要求20所述的设备,其特征在于,所述处理器根据所述自相关函数以及预设的极大似然估计模型,确定所述当前混响语音信号的混响时间时,具体用于:若确定混响时间估计过程中提取混响语音帧的总数超过M的L倍,在每获得连续的L个自相关函数后,根据所述连续的L个自相关函数确定平均自相关函数,根据所述平均自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间;若确定混响时间估计过程中提取混响语音帧的总数未超过M的L倍,对本次确定的所述自相关函数进行平滑处理后,根据平滑处理后的自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间。
- 如权利要求22所述的设备,其特征在于,所述处理器根据所述连续的L个自相关函数确定平均自相关函数时,具体用于:按照公式确定平均自相关函数,其中,
 表示连续L次确定的自相关函数中的第l个自相关该函数,
表示连续L次确定的自相关函数中的第l个自相关该函数, 表示平均自相关函数。
表示平均自相关函数。
- 如权利要求22所述的设备,其特征在于,所述处理器对本次确定的所述自相关函数进行平滑处理时,具体用于:按照公式对所述混响语音帧的自相关函数进行平滑处理,其中,
 表示本次确定的所述自相关函数,
表示本次确定的所述自相关函数, 表示第l次平滑处理后的自相关函数,
表示第l次平滑处理后的自相关函数, 表示第l-1次平滑处理后的自相关函数,β表示预设的平滑系数,0<β<1。
表示第l-1次平滑处理后的自相关函数,β表示预设的平滑系数,0<β<1。
- 如权利要求23所述的设备,其特征在于,所述处理器根据所述平均自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间时,具体用于:根据所述平均自相关函数以及所述预设的极大似然估计模型中定义的第一约束条件,确定第一参数和第二参数;根据所述第一参数以及所述预设的极大似然估计模型中定义的第二约束条件,确定所述当前混响语音信号的混响时间的估计值;根据预设的采用降采样后的混响语音信号帧确定的混响时间的估计值与混响时间的有效值之间的映射关系,确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值;其中,所述第一约束条件表示为:
 其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数,表示所述平均自相关函数,
其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数,表示所述平均自相关函数, 表示对所述第一参数求偏导数,
表示对所述第一参数求偏导数, 表示对所述第二参数求偏导数,
表示对所述第二参数求偏导数, 表示所述平均自相关函数
表示所述平均自相关函数 所述第一参数以及所述第二参数的似然函数,表示为
所述第一参数以及所述第二参数的似然函数,表示为
 其中,所述第二约束条件为:RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
其中,所述第二约束条件为:RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
- 如权利要求24所述的设备,其特征在于,所述处理器根据平滑处理后的自相关函数以及所述预设的极大似然估计模型,确定所述当前混响语音信号的混响时间时,具体用于:根据所述平滑处理后的自相关函数以及所述预设的极大似然估计模型中定义的第一约束条件,确定第一参数和第二参数;根据所述第一参数以及所述预设的极大似然估计模型中定义的第二约束条件,确定所述当前混响语音信号的混响时间的估计值;根据预设的采用降采样后的混响语音信号帧确定的混响时间的估计值与混响时间的有效值之间的映射关系,确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值;其中,所述第一约束条件表示为:
 其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数,表示平滑处理后的自相关函数,
其中,N表示一个混响语音帧中参与自相关函数计算的采样点的个数,a表示所述第一参数,k表示所述第二参数,表示平滑处理后的自相关函数, 表示对所述第一参数求偏导数,
表示对所述第一参数求偏导数, 表示对所述第二参数求偏导数,
表示对所述第二参数求偏导数, 表示所述平滑处理后的自相关函数
表示所述平滑处理后的自相关函数 所述第一参数以及所述第二参数的似然函数,表示为
所述第一参数以及所述第二参数的似然函数,表示为
 其中,所述第二约束条件为:RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
其中,所述第二约束条件为:RT60表示所述当前混响语音信号的混响时间的估计值,fs表示确定所述混响时间采用的混响语音帧的采样率。
- 如权利要求26所述的设备,其特征在于,所述处理器还用于:在确定所述混响语音信号的混响时间的估计值对应的混响时间的有效值之后,按照公式对所述混响时间的有效值进行平滑处理,其中,
 表示所述混响时间的有效值,
表示所述混响时间的有效值, 表示本次平滑处理后的混响时间,
表示本次平滑处理后的混响时间, 表示上一次平滑处理后的混响时间,α表示第一平滑因子,β表示第二平滑因子,α小于β,α大于零且小于1,β大于零且小于1。
表示上一次平滑处理后的混响时间,α表示第一平滑因子,β表示第二平滑因子,α小于β,α大于零且小于1,β大于零且小于1。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201610626191.1 | 2016-08-02 | ||
| CN201610626191.1A CN107680603B (zh) | 2016-08-02 | 2016-08-02 | 一种混响时间估计方法及装置 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2018024058A1 true WO2018024058A1 (zh) | 2018-02-08 |
Family
ID=61073423
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2017/090887 Ceased WO2018024058A1 (zh) | 2016-08-02 | 2017-06-29 | 一种混响时间估计方法及装置 |
Country Status (2)
| Country | Link |
|---|---|
| CN (1) | CN107680603B (zh) |
| WO (1) | WO2018024058A1 (zh) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115855227A (zh) * | 2022-12-08 | 2023-03-28 | 广州声博士声学技术有限公司 | 一种混响时间测量方法、系统、设备及介质 |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109151702B (zh) * | 2018-09-21 | 2021-10-08 | 歌尔科技有限公司 | 音频设备的音效调节方法、音频设备及可读存储介质 |
| CN109686380B (zh) * | 2019-02-18 | 2021-06-18 | 广州视源电子科技股份有限公司 | 语音信号的处理方法、装置及电子设备 |
| CN111785292B (zh) * | 2020-05-19 | 2023-03-31 | 厦门快商通科技股份有限公司 | 一种基于图像识别的语音混响强度估计方法、装置及存储介质 |
| CN113077804B (zh) | 2021-03-17 | 2024-02-20 | 维沃移动通信有限公司 | 回声消除方法、装置、设备及存储介质 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2009211021A (ja) * | 2008-03-04 | 2009-09-17 | Japan Advanced Institute Of Science & Technology Hokuriku | 残響時間推定装置及び残響時間推定方法 |
| CN105628170A (zh) * | 2014-11-06 | 2016-06-01 | 广州汽车集团股份有限公司 | 一种车内混响时间的测量和计算方法 |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| FR2729024A1 (fr) * | 1994-12-30 | 1996-07-05 | Matra Communication | Annuleur d'echo acoustique avec filtrage en sous-bandes |
| US20040213415A1 (en) * | 2003-04-28 | 2004-10-28 | Ratnam Rama | Determining reverberation time |
| CN1212609C (zh) * | 2003-11-12 | 2005-07-27 | 中国科学院声学研究所 | 基于人耳听觉特性的语音信号时间延迟估计方法 |
| CN103440869B (zh) * | 2013-09-03 | 2017-01-18 | 大连理工大学 | 一种音频混响的抑制装置及其抑制方法 |
-
2016
- 2016-08-02 CN CN201610626191.1A patent/CN107680603B/zh active Active
-
2017
- 2017-06-29 WO PCT/CN2017/090887 patent/WO2018024058A1/zh not_active Ceased
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2009211021A (ja) * | 2008-03-04 | 2009-09-17 | Japan Advanced Institute Of Science & Technology Hokuriku | 残響時間推定装置及び残響時間推定方法 |
| CN105628170A (zh) * | 2014-11-06 | 2016-06-01 | 广州汽车集团股份有限公司 | 一种车内混响时间的测量和计算方法 |
Non-Patent Citations (4)
| Title |
|---|
| JAYASHREE, R. ET AL.: "Accurate Estimation of Reverberation Time and Drr Using Maximum Likelihood Estimator", INTERNATIONAL JOURNAL OF EMERGING TECHNOLOGY AND ADVANCED ENGINEERING, vol. 3, no. 1, 30 January 2013 (2013-01-30), pages 14, XP055461333, ISSN: 2250-2459 * |
| KESHAVARZ, A. ET AL.: "Speech-Model Based Accurate Blind Reverberation Time Estimation Using an LPC Filter[J", IEEE TRANSACTIONS ON AUDIO SPEECH AND LANGUAGE PROCESSING, vol. 20, no. 6, 30 August 2012 (2012-08-30), pages 1884 - 1893, XP011442834 * |
| MEI, TIEMIN ET AL.: "New Method of Reverberation Time Estimation", JOURNAL OF SHENYANG LIGONG UNIVERSITY, vol. 31, no. 6, 30 December 2012 (2012-12-30), pages 66 - 69, ISSN: 1003-1251 * |
| WU, LIFU ET AL.: "An Improved Algorithm for Blind Estimation of Reverberation Time Based on Maximum Likelihood", JOURNAL OF APPLIED ACOUSTICS, vol. 35, no. 4, 30 July 2016 (2016-07-30), pages 288 - 293, XP055072696, ISSN: 1000-310X * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115855227A (zh) * | 2022-12-08 | 2023-03-28 | 广州声博士声学技术有限公司 | 一种混响时间测量方法、系统、设备及介质 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN107680603B (zh) | 2021-08-31 |
| CN107680603A (zh) | 2018-02-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN114298443B (zh) | 基于健康状态指数的工业设备预测性维护方法、装置和电子设备 | |
| JP7177167B2 (ja) | 混合音声の特定方法、装置及びコンピュータプログラム | |
| WO2018024058A1 (zh) | 一种混响时间估计方法及装置 | |
| RU2650617C2 (ru) | Автоматическая обработка ультразвуковых данных | |
| RU2685391C1 (ru) | Способ, устройство и система для подавления шума | |
| EP2788980B1 (en) | Harmonicity-based single-channel speech quality estimation | |
| US11074925B2 (en) | Generating synthetic acoustic impulse responses from an acoustic impulse response | |
| CN113470674B (zh) | 语音降噪方法、装置、存储介质及计算机设备 | |
| CN109643552A (zh) | 用于可变噪声状况中语音增强的鲁棒噪声估计 | |
| CN109801646B (zh) | 一种基于融合特征的语音端点检测方法和装置 | |
| EP3526792B1 (en) | Voice activity detection method and apparatus | |
| Aarts et al. | Efficient tracking of the cross-correlation coefficient | |
| CN113571076A (zh) | 信号处理方法、装置、电子设备和存储介质 | |
| CN106703797B (zh) | 一种获取气藏的动态储量及水体大小的方法及装置 | |
| CN106703796B (zh) | 一种获取油藏的动态储量及水体大小的方法及装置 | |
| EP3665895A1 (en) | Data processing device, data analyzing device, data processing system and method for processing data | |
| CN104363554A (zh) | 一种扬声器异常音检测方法 | |
| CN116086596B (zh) | 一种噪声智能检测方法、装置、计算机设备及存储介质 | |
| Blacodon et al. | Reverberation cancellation in a closed test section of a wind tunnel using a multi-microphone cesptral method | |
| CN115631762A (zh) | 噪声估计方法和相关装置 | |
| JP4965891B2 (ja) | 信号処理装置およびその方法 | |
| JP2010044150A (ja) | 残響除去装置、残響除去方法、そのプログラムおよび記録媒体 | |
| CN116137154A (zh) | 语音信号的信号增强方法、装置、设备及存储介质 | |
| CN116959495A (zh) | 一种语音信号信噪比估计方法、系统 | |
| US8150062B2 (en) | Determination of the adequate measurement window for sound source localization in echoic environments |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 17836240 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 17836240 Country of ref document: EP Kind code of ref document: A1 |