WO2018034169A1 - 対話制御装置および方法 - Google Patents
対話制御装置および方法 Download PDFInfo
- Publication number
- WO2018034169A1 WO2018034169A1 PCT/JP2017/028292 JP2017028292W WO2018034169A1 WO 2018034169 A1 WO2018034169 A1 WO 2018034169A1 JP 2017028292 W JP2017028292 W JP 2017028292W WO 2018034169 A1 WO2018034169 A1 WO 2018034169A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- understanding
- utterance
- behavior
- user
- dialogue
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images







Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/08—Text analysis or generation of parameters for speech synthesis out of text, e.g. grapheme to phoneme translation, prosody generation or stress or intonation determination
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/18—Speech classification or search using natural language modelling
- G10L15/1815—Semantic context, e.g. disambiguation of the recognition hypotheses based on word meaning
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/18—Speech classification or search using natural language modelling
- G10L15/1822—Parsing for meaning understanding
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/16—Sound input; Sound output
- G06F3/167—Audio in a user interface, e.g. using voice commands for navigating, audio feedback
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/451—Execution arrangements for user interfaces
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/08—Text analysis or generation of parameters for speech synthesis out of text, e.g. grapheme to phoneme translation, prosody generation or stress or intonation determination
- G10L13/10—Prosody rules derived from text; Stress or intonation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G10L2015/223—Execution procedure of a spoken command
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04M—TELEPHONIC COMMUNICATION
- H04M3/00—Automatic or semi-automatic exchanges
- H04M3/42—Systems providing special services or facilities to subscribers
- H04M3/487—Arrangements for providing information services, e.g. recorded voice services or time announcements
- H04M3/493—Interactive information services, e.g. directory enquiries ; Arrangements therefor, e.g. interactive voice response [IVR] systems or voice portals
- H04M3/4936—Speech interaction details
Definitions
- the present technology relates to a dialog control apparatus and method, and more particularly, to a dialog control apparatus and method capable of performing more appropriate dialog control.
- Patent Document 2 a technique for detecting a user's conflicting action or requesting a user's conflict when interacting with the user has been proposed (see, for example, Patent Document 2).
- a message that prompts voice input according to the user's level of understanding is output.
- the optimal granularity is required. That is, the user's understanding cannot be measured at the optimal timing.
- Synthetic speech in TTS has constant speed and inflection, and when the amount of information is large and the length of the spoken sentence becomes long, the user understands the utterance content and is slow despite listening intensively
- dialogue control is performed that does not match the user's situation, such as speaking at a speed or frequently prompting voice input. In such a case, not only is it difficult for the user to understand the utterance content, but it is also difficult to memorize the utterance content.
- the frequency of requesting an understanding action with more detailed clauses or meaning breaks than the sentence is controlled according to the user's concentration level or the degree of understanding, and the user is requested to have an understanding action with low load on the user at an optimal granularity. I could not.
- This technology has been made in view of such a situation, and makes it possible to perform more appropriate dialogue control.
- the dialogue control device causes an utterance that induces an understanding behavior of a user at the understanding behavior request position based on an utterance text divided at one or more understanding behavior request positions, and the understanding behavior And a dialog progress control unit for controlling the next utterance based on the detected result and the utterance text.
- the dialogue progress control unit can utter the next word that has not yet been uttered in the utterance text.
- the dialog progress control unit can be made to perform the utterance performed immediately before when the understanding behavior by the user is a negative behavior.
- the dialog progress control unit can control the utterance based on the utterance text so that the number of times the understanding action is induced decreases as the response time of the positive understanding action by the user is shorter.
- the dialogue progress control unit can control the utterance based on the utterance text so that the utterance speed becomes faster as the response time of the positive understanding action by the user is shorter.
- the dialogue progress control unit can control the utterance based on the utterance text so that the utterance tone becomes higher as the response time of the positive understanding action by the user is shorter.
- the dialogue progress control unit is made to perform the utterance performed immediately before or to perform the utterance requesting the understanding behavior. can do.
- the dialog progress control unit can control the output of notification information including the utterance text when the utterance based on the utterance text is stopped halfway.
- the dialogue control device may further include an understanding action request position detection unit that detects an incomplete position as a sentence in the sentence of the utterance text as the understanding action request position.
- the understanding action request position detection unit can detect a position based on a dependency with a predicate clause of the sentence of the utterance text as the understanding action request position.
- the understanding action request position detection unit can detect a position between each of a plurality of target clauses or phrases related to the same predicate clause in the sentence of the utterance text as the understanding action request position.
- the understanding action request position detection unit can detect the position of the first clause or phrase related to the predicate clause in the sentence of the utterance text as the understanding action request position.
- the understanding action request position detection unit can detect the position of a phrase or phrase that is a time case, a place case, a target case, or a causal case in the sentence of the utterance text as the understanding action request position.
- the dialogue control method causes an utterance that induces an understanding action of a user at the understanding action request position based on an utterance text divided at one or more understanding action request positions, and the understanding action And controlling the next utterance based on the detected result and the utterance text.
- an utterance that induces an understanding behavior of a user at the understanding behavior request position is performed based on an utterance text divided by one or a plurality of understanding behavior request positions, and the detection result of the understanding behavior And the utterance text, the next utterance is controlled.
- more appropriate dialogue control can be performed.
- this technology has the following two technical features.
- points for seeking understanding behavior by user interaction and whispering are extracted from the utterance sentence by natural language analysis on the utterance text that is a sentence uttered by speech. Then, when speech is uttered, the user's understanding behavior is induced by adding a non-completion word or intonation (intonation) in the middle of the utterance text or inserting a long time.
- the understanding behavior by the user refers to behavior such as whispering and reconciliation indicating whether or not the user understands the utterance content.
- the point, that is, the position where the user is asked for understanding behavior is, for example, the position of the break in the enumeration information transmitted to the user, the branching position of the dependency, or the like.
- the understanding behavior of the user can be induced with an appropriate granularity for each utterance text. Thereby, appropriate dialogue control can be realized.
- the point (position) for asking the user for an understanding action is also referred to as an understanding action request position.
- the type of understanding behavior of the user such as “conflict” or “whit”, that is, whether the understanding behavior of the user is a positive behavior or a negative behavior.
- the determination and the measurement of the response time until the user's understanding behavior are performed. Based on these determination results and measurement results, the user's level of understanding and the level of consciousness of voice utterances are estimated and determined, and in accordance with the level of understanding and the level of concentration, appropriately inducing understanding behavior
- the utterance progress is controlled dynamically.
- control C1 to control C4 are performed.
- Dialogue control is performed so that the speech is temporarily stopped at the understanding action request position in the utterance text, and until the user has a positive understanding action (acknowledgement), the utterance is not advanced after the utterance.
- Control C2 If there is no understanding behavior by the user even after a certain period of time has elapsed after the understanding behavior has been triggered, repeat the previous utterance, insert a word prompting the understanding behavior, or both Interactive control is performed.
- Control C4 If the response time of the user's understanding behavior is measured and the response time is short, it is determined that the user's understanding level and concentration level are high. When it is determined that the tone is increased and the user's understanding level and concentration level are low, dialogue control is performed such that the number of triggers is increased and the speech speed and tone of the uttered voice are decreased.
- FIG. 1 is a diagram illustrating a configuration example of an embodiment of a voice interaction system to which the present technology is applied.
- the server 11 and the client device 12 including a terminal device such as a smart phone are directly connected by wire or wireless or indirectly through a communication network.
- the server 11 functions as a dialog control device, generates voice data of voice utterance from feedback of understanding behavior from the user and utterance text which is text data indicating the utterance content, and outputs the voice data to the client device 12.
- the client device 12 outputs a speech voice to the user based on the voice data supplied from the server 11, receives feedback from the user as appropriate, and supplies the feedback to the server 11.
- the server 11 includes a natural language analysis unit 21, an understanding action request position detection unit 22, a speech output dialogue progress control unit 23, a speech synthesis engine 24, a speech recognition engine 25, an action recognition engine 26, and an understanding action determination unit 27.
- the client device 12 includes an audio playback device 31, an audio input device 32, and a sensor 33.
- the speech synthesis engine 24 may be provided in the client device 12.
- the utterance text which is the entire sentence of the information content presented to the user by voice utterance, is input to the natural language analysis unit 21 of the server 11.
- the natural language analysis unit 21 performs natural language analysis on the input utterance text and supplies the analysis result and the utterance text to the understanding action request position detection unit 22.
- the understanding behavior request position detection unit 22 Based on the analysis result and the utterance text supplied from the natural language analysis unit 21, the understanding behavior request position detection unit 22 detects an understanding action request position that requests an understanding behavior to the user in the sentence indicated by the utterance text. To do.
- This understanding action request position is a position that is a candidate position for uttering that induces the user's understanding action when speaking based on the utterance text.
- the understanding action request position detection unit 22 detects the understanding action request position from the sentence of the utterance text, the utterance text divided by one or more understanding action request positions is obtained.
- the understanding action request position detection unit 22 supplies the detection result of the understanding action request position and the utterance text to the voice output dialogue progress control unit 23.
- the voice output dialogue progress control unit 23 uses the detection result and utterance text of the understanding behavior request position supplied from the understanding behavior request position detection unit 22 and the determination result of the understanding behavior of the user supplied from the understanding behavior determination unit 27. Based on this, the speech utterance based on the utterance text is controlled.
- the voice output dialogue progress control unit 23 performs dialogue control with the user by outputting text data indicating the utterance wording based on the utterance text to the voice synthesis engine 24 at an appropriate timing. At this time, the voice output dialogue progress control unit 23 outputs an uncompleted word for inducing the user's understanding behavior to the utterance word indicated by the utterance text as necessary, or outputs the voice synthesizer. The engine 24 is instructed to add inflection, and the utterance interval is opened by controlling the output timing of the utterance wording.
- the non-completion word added to the utterance word for inducing the user's understanding action is also referred to as an understanding action induction word.
- an explanation will be given of an example in which an understanding action induction word is appropriately added to an utterance sentence indicated by an utterance text to induce an understanding action for a user.
- the understanding behavior induction function may be turned on or off.
- the setting result of whether to turn on or off the understanding behavior induction function may be recorded in the voice output dialogue progress control unit 23.
- the speech output dialogue progress control unit 23 does not add the understanding behavior inducing wording in particular, and the speech text is directly sent to the speech synthesis engine 24. Is output.
- the voice synthesis engine 24 generates voice data for reproducing the utterance word by voice by text-to-speech synthesis (TTS) based on the utterance word supplied from the voice output dialogue progress control unit 23, and sends the voice data to the voice reproduction device 31. Is output. That is, in the speech synthesis engine 24, text data indicating an utterance word is converted into voice data of the utterance word.
- TTS text-to-speech synthesis
- the voice playback device 31 has a voice output unit including a speaker, for example, and plays back the voice of the utterance wording based on the voice data supplied from the voice synthesis engine 24.
- the user listens to the reproduced sound and performs an understanding action such as summoning or whispering according to the situation.
- an understanding action such as summoning or whispering according to the situation.
- the user performs the understanding behavior such as competing and whispering.
- the voice input device 32 is composed of, for example, a microphone, and picks up the voice of the user as an understanding behavior, and supplies the voice pickup data obtained as a result to the voice recognition engine 25.
- the voice recognition engine 25 performs voice recognition on the voice pickup data supplied from the voice input device 32, and supplies the voice recognition result to the understanding behavior determination unit 27.
- the consonant voice based on the voice collection data is converted into text by voice recognition, and the obtained text data is output to the understanding behavior determination unit 27 as a result of the voice recognition.
- the sensor 33 includes, for example, a gyro sensor attached to the user's head, a sensor that detects the movement of the user's head, and an image sensor that captures an image of the user's head. Then, whispering as the user's understanding behavior, that is, the movement of the user's head is detected, and the detection result is supplied to the behavior recognition engine 26.
- the behavior recognition engine 26 recognizes (determines) the type of the user's whisper by performing behavior recognition based on the detection result of the user's whisper supplied from the sensor 33, and sends the recognition result to the understanding behavior determination unit 27. Supply.
- the understanding behavior determination unit 27 Based on at least one of the speech recognition result from the speech recognition engine 25 and the recognition result of the whispering type from the behavior recognition engine 26, the understanding behavior determination unit 27 understands that the user's understanding behavior is positive. It is determined whether the action is an action or a negative understanding action, and the determination result is supplied to the voice output dialogue progress control unit 23.
- the judgment result of the understanding behavior obtained in this way is used for controlling the utterance next to the utterance in which the understanding behavior is induced in the voice output dialogue progress control unit 23.
- At least one of the speech recognition result from the speech recognition engine 25 and the recognition result of the whispering type from the behavior recognition engine 26 is used in the understanding behavior determination process in the understanding behavior determination unit 27. You can do it.
- the understanding behavior determination unit 27 determines whether the user's comprehension voice as the understanding behavior is a positive or negative response based on the voice recognition result. It is determined whether they are in conflict.
- the understanding behavior determination unit 27 determines that the user's understanding behavior is a positive understanding behavior. It is determined that there is, that is, the summoned voice is a positive one.
- the understanding behavior determination unit 27 determines the understanding behavior of the user. Is a negative understanding behavior, that is, it is determined that the conflicting speech is a negative conflicting behavior.
- the understanding behavior determination unit 27 understands by the user when there is some voice utterance reaction from the user, for example, during voice segment detection. Assume that an action has been taken, and a determination result of an understanding action may be output.
- the voice recognition engine 25 determines whether the action is a positive understanding action (a positive comprehension voice).
- the understanding behavior determination unit 27 determines that the user's whispering as the understanding behavior is positive based on the recognition result. Or a negative whisper.
- the behavior recognition engine 26 uses the head 33 (The type of whispering is recognized, such as whether the user has made a movement that shakes the neck) vertically or whether the user has made a movement that shakes the head (neck) horizontally.
- the understanding behavior determination unit 27 determines that the understanding behavior of the user is a positive understanding when the recognition result that the user has shaken the head in the vertical direction is obtained. It is determined to be an action. On the other hand, the understanding behavior determination unit 27 determines that the understanding behavior of the user is a negative understanding behavior when the recognition result that the user shakes the head in the horizontal direction is obtained.
- the behavior recognition engine 26 performs image recognition on the image obtained by the sensor 33, and the user's vertical direction. Or the horizontal direction, that is, the type of the whisper.
- the recognition of the determination engine that is, the speech recognition engine 25 and the behavior recognition engine 26 is recognized.
- the recognition behavior may be determined by prioritizing the recognition results according to the reliability (recognition accuracy).
- the understanding behavior determination unit 27 performs a process of determining the understanding behavior based on the speech recognition result by the speech recognition engine 25.
- the understanding behavior determination unit 27 performs processing for determining the understanding behavior based on the recognition result of the whispering type by the behavior recognition engine 26. .
- the understanding behavior determination unit 27 suppresses the user's conflicting speech.
- the understanding behavior may be determined using the user's movement, the user's gaze direction, the user's gaze movement, and the like. In this case, what kind of speech recognition result is regarded as an ambiguous recognition result may be determined in advance by registering a word regarded as an ambiguous recognition result.
- the understanding behavior determination unit 27 determines the understanding behavior of the user based on the recognition result of the whispering type by the behavior recognition engine 26.
- the user utters a companion voice and inputs whether the companion voice is positive or negative. Then, in the voice interaction system, a dictionary is generated from the input result, the recognition result of the conflicting voice obtained by voice recognition, and the detected movement of the user's whisper or the like, or voice suppression.
- the understanding behavior determination unit 27 is an ambiguous conflicting speech at the time of actual speech utterance is obtained, the speech behavior obtained from the speech collection data collected by the speech input device 32 is suppressed.
- the user's understanding behavior is determined based on the user's movement obtained by the sensor 33 or the like and a dictionary recorded in advance.
- the example in which the voice input device 32 and the sensor 33 are provided in the client device 12 has been described as a configuration for detecting the understanding behavior of the user. An action may be detected.
- a specific button or touch panel may be provided on the client device 12, and the user may press the button or touch the touch panel. That is, a user operation on a button, a touch panel, or the like may be performed as an understanding behavior, and feedback to the user's voice interaction system may be performed.
- the client device 12 may be provided with a line-of-sight detection sensor, and the user's understanding behavior may be determined based on the output of the line-of-sight detection sensor. In such a case, for example, when it is detected that the user turns his / her line of sight in a specific direction such as the target device, it is determined that the user's understanding behavior is a positive understanding behavior.
- the audio input device 32 and the sensor 33 may be provided integrally with the audio reproduction device 31, or provided separately from the apparatus provided with the audio reproduction device 31. It may be.
- the audio playback device 31 may be provided in a smartphone, and the audio input device 32 and the sensor 33 may be connected to the smartphone.
- the smart phone acquires the voice collection data and the detection result of the user's movement from the voice input device 32 or the sensor 33, and transmits it to the voice recognition engine 25 or the behavior recognition engine 26. May be.
- the natural language analysis unit 21 performs, for example, morphological analysis as natural language analysis on the utterance text, an analysis result indicated by an arrow A12 is obtained.
- the sentence of the input utterance text is divided into phrase units, and linguistic case information of each phrase and information indicating the dependency structure of each phrase are obtained as analysis results.
- each square represents one clause, and in the rectangle, the words divided into the phrases of the utterance text, that is, the words constituting the clause are written. Moreover, the line segment which connects the quadrangle
- the end point of the line segment extending from the square representing the phrase is the phrase that is related to the phrase. Therefore, for example, in the figure, it can be seen that the uppermost phrase “Today” is related to the phrase “Go out”.
- the linguistic case of the clause is written on the right side of the square figure representing each clause.
- the linguistic case of the uppermost phrase “today” is a combination modification clause.
- the natural language analysis unit 21 obtains information on the linguistic case of the phrase and information indicating the dependency structure of each phrase as indicated by an arrow A12 as a result of the natural language analysis.
- the understanding action request position detection unit 22 obtains a position for requesting the understanding action from the user, that is, an understanding action induction wording for inducing the understanding action. A process of detecting the position for understanding action request to be inserted (added) is performed.
- the understanding action request position detection unit 22 detects whether a plurality of target clauses related to the same predicate clause are present in one sentence.
- the first sentence of the utterance text is a sentence (item) that the user should take when going out, that is, a sentence indicating a belonging list when going out, and the belongings ( Item) clause is related to the clause of the same predicate clause. That is, it is a sentence in which belongings are listed.
- a plurality of target clauses related to the same predicate clause clause in one sentence is a plurality of list information presented to the user such as the belonging list at the time of going out shown in this example. It means that.
- the structure of a sentence having a plurality of target clauses in the same predicate clause means that a plurality of list information is presented to the user.
- the understanding action request position detection unit 22 detects each target related to the clause of the same predicate clause.
- the position between the clauses of the case, that is, the position between the clauses of each enumeration information is set as the understanding action request position.
- the position indicated by the arrows W11 to W14 of the first sentence of the utterance text is the understanding action request position detected by the understanding action request position detection unit 22.
- the understanding action request position indicated by the arrow W11 is a position immediately after the phrase “with wallet”.
- the understanding action request position detection unit 22 does not determine the position between the sentence and the sentence as the understanding action request position. That is, in the second and subsequent sentences, the end position of the sentence immediately before the sentence is not the understanding action request position, and the sentence is continuously uttered. This is because it is difficult to induce comprehension behavior because the sentence is in a complete position as a sentence. For example, when the user's understanding behavior is requested at a place that is completed as a sentence, the user may receive that the utterance by the voice interactive system has ended.
- the understanding action request position detection unit 22 detects a phrase in which the first dependency on the clause of the predicate clause of the sentence occurs in the second and subsequent sentences.
- the position immediately after the phrase is the understanding action request position.
- the understanding action request position detection unit 22 detects (determines) the understanding action request position based on the phrase position related to the clause of the predicate clause in the sentence of the utterance text. That is, the position based on the dependency with the predicate clause is detected as the understanding action request position.
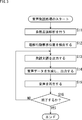
- the voice dialogue system when an utterance text is provided to a voice dialogue system, the voice dialogue system performs voice understanding processing based on voice utterance processing in which voice utterance is performed and dialogue with the user, and feedback from the user with respect to the voice utterance of the voice dialogue system. An understanding behavior determination process is performed. These voice utterance processing and understanding behavior determination processing are performed simultaneously.
- step S 11 the natural language analysis unit 21 performs natural language analysis on the supplied utterance text, and supplies the analysis result and the utterance text to the understanding action request position detection unit 22.
- step S11 morphological analysis is performed as described with reference to FIG.
- step S ⁇ b> 12 the understanding action request position detection unit 22 detects the understanding action request position based on the analysis result and the utterance text supplied from the natural language analysis unit 21, and the audio output dialogue progress control is performed on the detection result and the utterance text. To the unit 23.
- step S12 the position between the clauses of the target case, which is the enumeration information, and immediately after the clause in which the first dependency on the predicate clause in the second and subsequent sentences occurs.
- a position or the like is detected as an understanding action request position.
- step S ⁇ b> 13 the voice output dialogue progress control unit 23 detects the understanding behavior request position detection result and the utterance text supplied from the understanding behavior request position detection unit 22, and the understanding behavior of the user supplied from the understanding behavior determination unit 27. Based on the determination result, text data of an utterance word to be uttered next is output to the speech synthesis engine 24. At this time, the voice output dialogue progress control unit 23 instructs the voice synthesis engine 24 to add an inflection at the understanding action-inducing wording part as necessary. Further, the voice output dialogue progress control unit 23 appropriately controls the output timing of the text data of the utterance wording to make a gap between utterances.
- step S13 the determination result of the understanding behavior used in step S13 is obtained by the understanding behavior determination processing described later with reference to FIG.
- the voice output dialogue progress control unit 23 determines the utterance word to be uttered next for each understanding action request position, and outputs the text data of the decided utterance wording to control the progress of the voice dialogue with the user. In addition, when the speech output dialogue progress control unit 23 outputs the text data of the utterance word to which the understanding action inducing word is added, it is a predetermined length of time until the text data of the next utterance word is output. Trigger understanding behavior at intervals.
- step S ⁇ b> 14 the speech synthesis engine 24 generates speech data for reproducing the speech statement by speech based on the text speech synthesis based on the text data of the speech statement supplied from the speech output dialogue progress control unit 23. Output to the playback device 31.
- step S15 the voice playback device 31 plays back the voice of the spoken word based on the voice data supplied from the voice synthesis engine 24.
- the user appropriately performs feedback on the speech uttered in this way through understanding behavior, and performs a voice dialogue with the voice dialogue system.
- understanding behavior determination processing described later with reference to FIG. 4 is performed on the understanding behavior performed by the user, that is, feedback.
- step S16 the voice output dialogue progress control unit 23 determines whether or not to end the voice dialogue with the user. For example, when all the contents of the input utterance text are uttered, it is determined that the voice dialogue is to be ended.
- step S16 If it is determined in step S16 that the voice conversation is not terminated, the content that has not yet been spoken remains, so the process returns to step S13, and the above-described processes are repeated. That is, the next word is uttered.
- step S16 if it is determined in step S16 that the voice dialogue is to be terminated, the voice utterance process is terminated.
- the spoken dialogue system detects the understanding action request position based on the result of the natural language analysis on the utterance text, and utters the next wording based on the detection result and the determination result of the understanding action. By doing in this way, it is possible to induce a comprehension behavior with a low load such as competing and whispering to the user at an appropriate timing and to advance the dialogue. That is, more appropriate dialogue control can be performed.
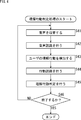
- the user When a speech utterance that induces an understanding behavior is performed by the speech dialogue system in step S15 in FIG. 3, the user performs an understanding behavior on the speech utterance. For example, as the understanding behavior, the user performs a negative or positive behavior of hitting or scolding.
- step S41 the voice input device 32 picks up the user's voice as an understanding behavior, and supplies the voice pickup data obtained as a result to the voice recognition engine 25.
- step S42 the voice recognition engine 25 performs voice recognition on the voice pickup data supplied from the voice input device 32, and supplies the voice recognition result to the understanding behavior determination unit 27.
- step S43 the sensor 33 detects the movement of the user's head, that is, the whisper as the understanding behavior of the user, and supplies the detection result to the behavior recognition engine 26.
- step S44 the behavior recognition engine 26 recognizes (determines) the type of the user's whisper by performing behavior recognition based on the detection result of the user's understanding behavior supplied from the sensor 33, and understands the recognition result. It supplies to the action determination part 27.
- step S41 and step S42 and the processing of step S43 and step S44 are performed in parallel. Further, only one of the processes in steps S41 and S42 and the processes in steps S43 and S44 may be performed.
- step S45 the understanding behavior determination unit 27 performs an understanding behavior determination based on at least one of the speech recognition result from the speech recognition engine 25 and the recognition result of the sowing type from the behavior recognition engine 26, The determination result is supplied to the voice output dialogue progress control unit 23.
- the understanding behavior determination it is determined whether the user's understanding behavior is a positive understanding behavior or a negative understanding behavior, and the determination result is used in the next process of step S13 in FIG. .
- positive or negative understanding behavior by the user is detected by the understanding behavior determination.
- the understanding behavior determination when the user's comprehension speech “Yes” or “Yes” is detected as a result of speech recognition by the speech recognition engine 25, it is determined that the user's understanding behavior is a positive understanding behavior. And a determination result indicating that the action is a positive understanding action is output.
- the recognition result that the user has swung the head in the vertical direction is obtained as the recognition result of the type of whispering in the action recognition engine 26, the understanding action of the user is a positive understanding action. And a determination result indicating that the action is a positive understanding action is output.
- the understanding behavior determination may be performed using only one of the speech recognition result from the speech recognition engine 25 and the recognition result of the sowing type from the behavior recognition engine 26, or Both may be used to make an understanding behavior determination.
- step S46 the understanding behavior determination unit 27 determines whether or not to finish the understanding behavior determination. For example, in the voice utterance process described with reference to FIG. 3, when it is determined that the voice dialogue is to be ended, it is determined that the understanding behavior determination is to be ended.
- step S46 If it is determined in step S46 that the understanding behavior determination is not terminated, the process returns to step S41, and the above-described process is repeated. That is, understanding behavior determination is performed for the next understanding behavior by the user.
- step S46 if it is determined in step S46 that the understanding behavior determination is to be ended, the understanding behavior determination processing ends.
- the voice dialogue system is a positive understanding behavior or a negative understanding behavior with respect to the understanding behavior of the user at the time of the dialogue.
- the understanding behavior is determined.
- step S13 of the voice utterance process described with reference to FIG. 3 the voice output dialogue progress control unit 23 determines the utterance word to be uttered next for each understanding action request position, and the voice utterance, that is, voice dialogue
- the dialog progress control process which is a process for controlling the progress of the above. That is, the dialogue progress control process performed by the voice output dialogue progress control unit 23 will be described below with reference to the flowchart of FIG.
- This dialogue progress control process is performed for each understanding action request position in the sentence of the utterance text in step S13 of FIG. That is, the dialogue progress control process is performed at the timing of voice uttering the phrase immediately before the understanding action request position of the sentence of the utterance text.
- the phrase in the phrase immediately before the understanding action request position in the sentence of the utterance text that is, the phrase that will be uttered from now on, is also referred to as the processing target sentence.
- step S71 the voice output dialogue progress control unit 23 determines whether or not the held understanding / concentration level is equal to or higher than a predetermined threshold th1.
- the degree of understanding / concentration is a parameter indicating how much the user concentrates on the voice utterance by the voice dialogue system and understands the utterance content.
- the initial value is assumed.
- the initial value of the degree of understanding / concentration is determined to be a value less than the threshold th1, for example.
- the value of comprehension / concentration is updated cumulatively in the process of voice conversation with the user, such as the timing immediately after the wording is issued at the understanding action request position. The value is used at the next understanding action request position.
- step S71 If it is determined in step S71 that the degree of understanding / concentration is greater than or equal to the threshold th1, that is, if it is determined that the user's concentration and degree of understanding are sufficiently high, the process proceeds to step S72.
- step S72 the voice output dialogue progress control unit 23 sets an utterance speed at the time of utterance.
- the utterance speed is determined so that the processing target word is uttered at a somewhat high speed. Specifically, for example, the utterance speed is determined so that the utterance speed becomes a speed determined with respect to the current understanding / concentration value. In this case, the greater the value of understanding / concentration, the faster the speech rate. Further, for example, the speech rate may be determined so that the speech rate is increased by a predetermined value from the previous value.
- step S73 the speech output dialogue progress control unit 23 outputs the text data of the processing target word to the speech synthesis engine 24, and the processing target word is generated at the utterance speed determined in step S72 without inducing the understanding behavior.
- the voice of the processing target word is uttered so as to be uttered.
- the voice synthesis engine 24 generates voice data in which the supplied processing target word is played at a designated utterance speed under the control of the voice output dialogue progress control unit 23, and supplies the voice data to the voice playback device 31.
- the voice reproduction device 31 reproduces the voice of the processing target wording based on the voice data from the voice synthesis engine 24.
- the process of generating and reproducing the speech data of the processing target word in this way corresponds to the processes of Step S14 and Step S15 in FIG.
- the voice of the processing target word is uttered at a relatively high speed in a state where the understanding action inducing word is not added to the processing target word.
- the user's concentration level is achieved by performing speech utterance at a relatively high speed without inducing the understanding behavior even at the position where the understanding action is requested. It is possible to realize an appropriate voice conversation according to the degree of understanding or the user's situation.
- the degree of understanding / concentration is greater than or equal to the threshold th1, that is, the case where the utterance speed is changed (determined) according to the degree of understanding / concentration. May be changed (determined).
- the tone of the processing target wording can be determined such that the higher the level of understanding / concentration and the higher the user's concentration and understanding level, the higher the tone of the uttered voice.
- step S74 the voice output dialogue progress control unit 23 lowers the held understanding / concentration value by a predetermined minute value, and then sets the processing target word in the utterance text after the utterance has ended.
- the dialogue progress control process ends as the wording of the next phrase, that is, the wording of the next clause.
- step S74 the understanding / concentration level is lowered (decreased) by a minute value in order to prevent the understanding behavior from being induced once in the subsequent dialogue. In this way, even when the user's level of concentration and understanding are sufficiently high, the user's concentration is maintained by updating the understanding / concentration level so that understanding behavior is triggered appropriately, and more appropriate dialogue control Can be realized.
- step S71 If it is determined in step S71 that the understanding / concentration level is not equal to or higher than the threshold th1, that is, if the user's concentration level and understanding level are not sufficiently high, the process proceeds to step S75.
- step S75 the speech output dialogue progress control unit 23 adds the understanding action-inducing wording to the processing target wording, and the part of the understanding action-inducing wording, that is, the wording (utterance) to which the understanding action-inducing wording is added. Add inflection so that the inflection at the end of the word rises.
- step S76 the voice output dialogue progress control unit 23 sets an utterance speed at the time of utterance.
- step S76 the speech rate is set in the same manner as in step S72.
- the user's concentration level and understanding level are not sufficiently high.
- the utterance speed is lowered so that the processing target word is uttered at a relatively slow speed. That is, for example, the utterance speed is changed to a value determined for the current understanding / concentration level.
- the value of the current speech rate may be lowered by a predetermined value.
- step S76 not only the utterance speed but also the utterance tone may be changed.
- the tone at the time of utterance is determined so that the tone of the uttered voice is lowered. That is, the tone height at the time of utterance is determined based on the degree of understanding / concentration.
- step S77 the speech output dialogue progress control unit 23 outputs the text data of the processing target word to which the understanding action inducing word is added to the speech synthesis engine 24, and the understanding action inducing wording is performed so that the understanding action is induced.
- the speech of the processing target word to which is added is uttered. That is, the voice output dialogue progress control unit 23 causes an utterance to induce the user's understanding behavior at the understanding behavior request position.
- the speech output dialogue progress control unit 23 instructs the speech synthesis engine 24 to utter the processing target word to which the understanding behavior inducing word is added at the utterance speed determined in step S76, and to the ending. Also instruct the addition of inflection. Further, the speech output dialogue progress control unit 23 allows the utterance to be spaced, and causes the understanding behavior of the user to be induced by the understanding behavior inducing wording, the inflection of the utterance of the utterance, and the utterance.
- the speech synthesis engine 24 generates speech data for reproducing the supplied wording, that is, the processing object wording and the understanding behavior induction wording with the specified utterance speed and intonation according to the control of the voice output dialogue progress control unit 23.
- the voice playback device 31 plays back the voice of the processing target word and the understanding action induction word added thereto based on the voice data from the voice synthesis engine 24.
- the process of generating and reproducing the sound data such as the processing target wording in this way corresponds to the processes of steps S14 and S15 in FIG.
- the voice of the processing target word is uttered at a relatively slow speed so that the understanding action-inducing wording is added to the processing target word and the inflection of the ending is increased by the reproduction of the voice.
- the user's concentration level and understanding level are induced by appropriately inducing the understanding behavior to the user and uttering speech at a relatively slow speed. It is possible to realize a suitable voice dialogue.
- the speech output dialogue progress control unit 23 controls the utterance to allow the user to understand the behavior.
- the speech output dialogue progress control unit 23 starts measuring the response time at the timing when the speech utterance is output to the speech synthesis engine 24, that is, when the speech utterance is instructed.
- the response time is a time from when a voice utterance is instructed until a user performs some understanding behavior with respect to the voice utterance, that is, a user response time.
- the sentence of the utterance by the spoken dialogue system is not complete, and the inflection added to the understanding action inducing word and the ending.
- the understanding behavior by the user is induced between the time and the utterance.
- the user performs understanding behaviors such as reconciliation and whispering on the spoken voice, and feeds back his / her understanding state.
- step S77 When voice is uttered in step S77, if the client device 12 can turn on an LED (Light Emitting Diode) or other visual presentation, voice dialogue can be performed by turning on the LED or presenting an icon or the like. You may make it show to a user that a system is not a halt condition. In addition, presentation to the user that it is not in a stopped state may be performed by, for example, periodically reproducing sound effects. Further, the user may be presented (notified) visually or audibly that an understanding action is required.
- LED Light Emitting Diode
- voice dialogue can be performed by turning on the LED or presenting an icon or the like. You may make it show to a user that a system is not a halt condition. In addition, presentation to the user that it is not in a stopped state may be performed by, for example, periodically reproducing sound effects. Further, the user may be presented (notified) visually or audibly that an understanding action is required.
- step S78 the voice output dialogue progress control unit 23 determines whether or not the user has understood the behavior within the specified time after starting the response time measurement. Determine. That is, it is determined whether the user's understanding behavior is detected within the specified time.
- step S78 when the understanding behavior determination unit 27 supplies the understanding behavior determination result within the specified time after starting the response time measurement, it is determined that the understanding behavior has occurred within the specified time.
- the specified time here may be a predetermined fixed time, or may be a time that is dynamically determined according to the degree of understanding and concentration. For example, when the specified time is determined by the understanding / concentration level, an appropriate time according to the user's concentration level and the understanding level can be determined by shortening the specified time as the understanding / concentration level increases.
- step S78 If it is determined in step S78 that there is no understanding behavior within the specified time, the user has not performed any understanding behavior for a while after the voice utterance is made. Lowers the level of understanding and concentration held.
- step S79 for example, the understanding / concentration level is updated so that the value of the understanding / concentration level is lowered more greatly than the understanding / concentration level is lowered in the process of step S74. This is because the fact that the user did not perform the understanding behavior is a situation in which the user has not heard the voice utterance or has not fully understood the utterance content.
- step S80 the voice output dialogue progress control unit 23 determines whether or not the degree of understanding / concentration after the update in step S79 is equal to or greater than a predetermined threshold th2.
- the value of the threshold th2 is a predetermined value that is smaller than the value of the threshold th1 described above, for example.
- step S81 the voice output dialogue progress control unit 23 assumes that the user has not heard any voice utterance by the voice dialogue system and Is finished (stopped), and the dialogue progress control process is finished. In this case, it is determined in step S16 of the subsequent voice utterance process of FIG.
- the voice output dialogue progress control unit 23 records the utterance text and the like, assuming that the utterance text is in an unspoken state, and waits for a while and then again.
- the voice utterance of the content of the utterance text may be performed.
- the timing of the voice utterance is understood by the user when, for example, the presence of the user is recognized again by the sensor 33 or the like after a certain time has elapsed, or when the voice utterance of another utterance text ends. ⁇ This can be done when the degree of concentration is high.
- the speech utterance may be performed from the beginning of the sentence of the utterance text.
- the voice output dialogue progress control unit 23 includes, for example, a message indicating that the voice conversation is terminated and the utterance text. Notification information may be generated and output of the notification information may be controlled. Thereby, the content of the utterance text can be notified to the user by a method other than the voice dialogue.
- the voice output dialogue progress control unit 23 transmits notification information to a terminal device such as a smart phone as the client device 12 by a communication unit (not shown) provided in the server 11 and is indicated by the notification information.
- the content of the utterance text is displayed on the client device 12.
- the notification information transmission method that is, the notification method may be any method such as e-mail or a notification function of an application program installed in the client device 12.
- the notification function can be used to display that the notification information has been received on the status bar of the client device 12, or the notification information can be popped up on the display screen of the client device 12. .
- the user can be notified of the contents of the utterance text.
- notification information including the content of the utterance text
- notification information including only a message for prompting confirmation of the content of the utterance text may be transmitted.
- step S80 determines whether the degree of understanding / concentration is greater than or equal to the threshold th2 or the degree of understanding are low. If it is determined in step S80 that the degree of understanding / concentration is greater than or equal to the threshold th2, the user is still listening to a voice utterance although the degree of concentration and understanding are low, and the process proceeds to step S82.
- step S82 the voice output dialogue progress control unit 23 causes the user to utter a voice requesting an understanding action.
- the voice output dialogue progress control unit 23 synthesizes text data of an understanding action request wording which is a word for directly prompting (requesting) an understanding action from the user, such as “Is it OK?”. Output to the engine 24 to instruct voice utterance.
- the voice synthesis engine 24 generates voice data of the understanding action request wording from the supplied text data of the understanding action request wording according to the instruction of the voice output dialogue progress control unit 23, and supplies it to the voice reproduction device 31. .
- the voice playback device 31 plays back the voice of the understanding action request wording based on the voice data from the voice synthesis engine 24. Thereby, the utterance requesting the understanding behavior from the user is performed. Thus, by reproducing the voice of the understanding action request wording, it is possible to prompt the user to understand the action.
- understanding action request word is not limited to “Is it OK?” But may be any other word.
- a sentence such as “Are you listening?” May be uttered as an understanding action request sentence.
- step S82 instead of causing the understanding action request word to be uttered, the current processing target word and the understanding action inducing word added to the processing target word may be uttered again. That is, the immediately preceding utterance may be repeated by performing the speech utterance that induces the understanding behavior in the process of step S77 again.
- step S82 the understanding action request word may be uttered, and the current processing target word and the understanding action inducing word added to the processing target word may be uttered again.
- the immediately preceding processing target word and understanding action inducing word may be repeatedly uttered.
- step S82 When the understanding action request word is uttered in step S82, the process returns to step S78, and the above-described process is repeated.
- step S78 when it is determined in step S78 that the understanding behavior has occurred within the specified time, that is, when the determination result of the understanding behavior is supplied from the understanding behavior determination unit 27 to the voice output dialogue progress control unit 23 within the specified time, The voice output dialogue progress control unit 23 stops measuring the response time, and the process proceeds to step S83.
- the response time which is the time from when the speech utterance of the processing target word is instructed until the judgment result of the understanding behavior is supplied. It can be said that this response time indicates a response time from when the voice utterance is performed until the user performs an understanding behavior for the voice utterance.
- the voice output dialogue progress control unit 23 detects the understanding behavior of the user and the utterance. Controls the next utterance based on the text.
- step S83 the speech output dialogue progress control unit 23 determines whether or not the determination result of the understanding behavior supplied from the understanding behavior determination unit 27 indicates a positive understanding behavior.
- step S83 If it is determined in step S83 that the action does not indicate a positive understanding action, that is, the action indicates a negative understanding action, the user does not understand the utterance content and the understanding level is low.
- the voice output dialogue progress control unit 23 lowers the value of the degree of understanding / concentration held.
- step S84 for example, the value of the understanding / concentration level is lowered by the same value as when the understanding / concentration level is lowered in the process of step S79, or by a smaller value than when the understanding / concentration level is lowered in the process of step S79.
- the degree of understanding / concentration is updated.
- step S84 the degree of understanding / concentration is updated so that the value of the degree of understanding / concentration decreases more than the degree of understanding / concentration decreases in the process of step S74.
- step S84 When the understanding / concentration level is updated in step S84, the process returns to step S76, and the above-described process is repeated.
- the voice output dialogue progress control unit 23 causes the utterance performed immediately before to be performed again.
- step S84 When the process of step S84 is performed, the user's understanding level and concentration level are reduced, so that the user can easily understand the utterance content by repeating the immediately preceding utterance at a slower utterance speed. In addition, in this case, since the dialogue does not proceed until the user understands the utterance content, the user does not give up understanding on the way or cannot understand the utterance content.
- step S85 the voice output dialogue progress control unit 23 determines the degree of understanding / concentration based on the obtained response time. Update.
- the voice output dialogue progress control unit 23 updates the understanding / concentration level so that the value of the understanding / concentration level increases as the response time becomes shorter.
- the response time of positive understanding behavior by the user is short, and when the user's concentration or understanding level is high, the understanding / concentration level increases cumulatively, so the utterance speed gradually increases as the speech utterance progresses. This also reduces the number of times that understanding behavior is triggered.
- the utterance tone is changed according to the degree of understanding / concentration, the utterance tone gradually increases as the voice utterance text advances.
- step S85 the dialogue progress control process ends. Thereafter, the phrase of the subsequent phrase is appropriately uttered, and the phrase immediately before the next understanding action request position is set as a new process target sentence, and the next dialog progress control process is performed.
- the voice output dialogue progress control unit 23 causes the next sentence that has not yet been uttered in the utterance text to be uttered, so that the utterance sentence advances to the next sentence. It will be.
- the voice output dialogue progress control unit 23 appropriately sets the speech rate, induces the understanding behavior, or requests the understanding behavior according to the degree of understanding / concentration and the understanding behavior of the user.
- the voice dialogue with the utterance content shown in the utterance text is advanced. By doing in this way, more appropriate dialogue control can be performed according to a user's concentration degree and comprehension degree.
- the voice output dialogue progress control unit 23 constantly monitors the understanding behavior by the user at a timing (time) other than the understanding behavior request position, and understands / understands according to the determination result of the understanding behavior.
- the concentration value may be updated.
- the update when there is a positive understanding behavior, the update is performed so as to increase the value of understanding / concentration, and thereafter, the induction of understanding behavior is suppressed from being performed more than necessary. Conversely, when there is a negative understanding behavior, the update is performed so as to lower the value of the understanding / concentration level, and the opportunity for inducing the understanding behavior is increased so that the user can easily understand the utterance content.
- a dialogue as shown in FIG. 6 is performed by the dialogue progress control process as described above.
- This example is an example of a dialogue sequence in which a voice utterance for presenting a shopping list is performed by a voice dialogue system.
- dialogue control starts from a state where the level of understanding and concentration is low to some extent.
- an understanding action-inducing word “Ne” is added to the processing target word by the voice dialogue system, and the word “Today's shopping is a carrot” is a slow utterance speed. Spoken at.
- the understanding action-inducing wording “Ne” indicates that there is a continuation.
- an upward arrow indicates that the inflection is raised.
- the voice dialogue system detects a positive conflict based on the utterance “Yes”, and the user performs positive understanding behavior. The next voice utterance is started.
- the spoken dialogue system utters the word “three onions” with the understanding action-inducing word added to the word to be processed as indicated by the arrow Q13. At this time, the inflection of the ending is raised, and the speech is performed at a low speech rate as in the case of the arrow Q11.
- the word “Jaigamotone” in which the understanding action-inducing wording is added to the next word to be processed is uttered with a low utterance speed and an inflection of the ending.
- the spoken dialogue system displays the understanding behavior induction wording as the next processing target wording as indicated by the arrow Q20. Speaks the word “Beef 300g Tone” with the ending of the inflection at a low speech rate.
- the word “salt tone” in which the understanding action inducing word is added to the next word to be processed is a medium speed utterance. Spoken with increased ending inflection at speed. That is, as the user's understanding / concentration level increases, the utterance is performed at a higher utterance speed than before.
- the user's level of understanding / concentration is further increased, and as shown by the arrow Q24, the word “huo tone” in which the understanding action inducing word is added to the next word to be processed is medium speed.
- the utterance is uttered with the inflection of the ending.
- the user uttered the word “Yun” indicating a positive understanding behavior with a shorter response time than the case indicated by the arrow Q23. Then, in the voice dialogue system, the user's understanding / concentration level is further increased, and as shown by an arrow Q26, the next word to be processed “soy sauce and beer” is uttered at a high utterance speed, and the dialogue sequence is finish.
- the understanding / concentration level is sufficiently high due to the understanding behavior indicated by the arrow Q25, so there is an understanding behavior-inducing wording between the word “soy sauce” and the next word “beer.”
- the speech is not added, that is, the understanding behavior is not triggered.
- the level of understanding and concentration is sufficiently high here, the speaking speed is also the fastest speaking speed.
- speech utterance is performed at an utterance speed according to the user's concentration level and comprehension level. It is possible to improve the user's understanding and ease of storage of the utterance content desired to be transmitted to the user.
- the speech utterance performance of general text-to-speech synthesis that is, the content of sentences that are difficult to understand due to constant inflection and utterance speed
- the speech utterance performance of general text-to-speech synthesis is supplemented by interaction using understanding behavior in the spoken dialogue system to which this technology is applied. be able to.
- understanding behavior in the spoken dialogue system to which this technology is applied.
- the user's concentration and understanding level is high, that is, when the user is concentrating and listening to the dialogue voice, not only is the speech speed increased, but the number of times of understanding action induction is reduced and the user's understanding behavior is reduced. As a result, the user can interact in a shorter time and with less load.
- the understanding action request position detection unit 22 immediately after the phrase “for meetings” as the causative case, immediately after the phrase “10 o'clock” as the time case, and the phrase “at Shinagawa Station” as the place case. "And the position immediately after the phrase” Mr. Yamada ", which is the target case, are detected as the understanding action request positions.
- a word dictionary in which the importance of words is registered in advance may be used.
- a word dictionary in which words and word importance are associated with each other is recorded in advance in the understanding action request position detection unit 22.
- the understanding action request position detection unit 22 refers to the word dictionary, specifies the importance level of each word included in the sentence of the utterance text, and determines the position immediately after the phrase including the word having the high importance level as the understanding action request position. Detect as. At this time, for example, immediately after a phrase including a word whose importance is equal to or higher than a predetermined threshold may be set as the understanding action request position, or the importance is selected from words included in the sentence of the utterance text. A predetermined number of words may be selected in descending order, and the immediately following phrase including the selected words may be set as the understanding action request position.
- the utterance text is an English sentence.
- the position immediately after the subject + predicate (verb) is the understanding action request position. Even in this case, understanding behaviors such as competing and whispering are appropriately induced in a state where the sentence is incomplete.
- each square represents one section in which a sentence is divided, that is, a phrase, as in the case of FIG. Has been. Moreover, the line segment which connects the squares which represent each phrase represents the dependency between phrases. The notation of these dependencies is the same as in FIG.
- the linguistic case and part of speech of the phrases are written on the right side of the square diagram representing each phrase.
- the linguistic case of the uppermost phrase “Please buy” is a predicate clause and the part of speech is a verb.
- the understanding action request position detection unit 22 detects a plurality of target cases (objective cases) related to the same predicate clause (verb) from the result of natural language analysis, and the detected phrases of the plurality of target cases. The position between is assumed as the understanding action request position.
- the position immediately after “and” included in the phrase that is, the position between the word “and” and the target word immediately after that is the understanding action request position. Is done.
- the first sentence of the utterance text is what the user should buy (item), that is, a sentence indicating a shopping list, and the predicate with the same target phrase including the article (item) to be bought is the same. It is related to the clause phrase. That is, it is a sentence that lists what should be bought.
- the position indicated by the arrows W41 to W44 of the first sentence of the utterance text is the understanding action request position detected by the understanding action request position detection unit 22.
- the understanding action request position indicated by the arrow W41 is a position between the phrases “carrots,” and “onions,”.
- the understanding action request position indicated by the arrow W44 is a position between the word “and” in the phrase “and ⁇ salt. ”And the target word“ salt ”.
- the understanding action request position detection unit 22 does not determine the position between the sentence and the sentence as the understanding action request position.
- the understanding action request position detection unit 22 detects the first predicate clause of the sentence in the second and subsequent sentences, and immediately after the phrase of the first predicate clause.
- the position is the understanding action request position.
- the position indicated by the arrow W45 in the second sentence is the understanding action request position.
- the position indicated by the arrow W45 is the position immediately before the first phrase related to the phrase of the predicate clause.
- the voice output dialogue progress control unit 23 performs dialogue control by performing processing similar to the dialogue progression control processing described with reference to FIG. 5 based on the understanding action request position detected as described above. Do.
- the speech output dialogue progress control unit 23 for example, the phrase immediately before the understanding action request position for inducing the understanding action is the target case (object), and the word “and” is included in the phrase following the phrase. If not, the word “and” is added after the last word (object) of the phrase immediately before the understanding action request position, and voice utterance is performed. In this case, if there is a “,” (comma) immediately before the added word “and”, the “,” is deleted. In this way, the word “and” added to the phrase of the utterance wording functions as an understanding action-inducing wording.
- a certain amount of time is provided at the understanding action request position for inducing the understanding action, that is, the voice is uttered after a certain period of time.
- voice utterance is performed, for example, as shown by an arrow A43.
- the first word “Pleasebuy carrots and” is spoken to induce understanding behavior, and then the word “onions and” is spoken to induce understanding behavior.
- the induction of the understanding behavior is performed, for example, by opening a utterance, adding a word “and”, or adding an inflection to the ending of the utterance.
- ⁇ Other detection example 3 of the understanding action request position> Furthermore, when the utterance text is an English sentence, when expressing the place, time, and cause by the preposition in so-called 5W1H, the position immediately after the preposition is taken as the understanding action request position, Comprehension behavior such as competing and whispering may be triggered. Even in this case, understanding behaviors such as competing and whispering are appropriately induced in a state where the sentence is incomplete.
- each square represents one section in which a sentence is divided, that is, a phrase, and the words divided into phrases of the utterance text are written in the square. Has been. Moreover, the line segment which connects the squares which represent each phrase represents the dependency between phrases. The notation of these dependencies is the same as in FIG.
- the linguistic case of the phrases is written on the right side of the square diagram representing each phrase.
- parts of speech are written along with the case as necessary.
- the linguistic case of the uppermost phrase “You” is the main case.
- the understanding action request position detection unit 22 detects a phrase of cause case, time case, and place case from the result of natural language analysis, and a position immediately after the preposition in the detected phrase (in the phrase). Is the understanding action request position.
- the position immediately after the preposition “for” in the phrase of the causal case of the utterance text that is, the position indicated by the arrow W71
- the position indicated by the arrow W72 and the position immediately after the preposition “at” in the phrase of the place case that is, the position indicated by the arrow W73 are detected by the understanding action request position detection unit 22.
- the positions indicated by the arrows W71 to W73 are the understanding action request positions.
- the voice output dialogue progress control unit 23 performs dialogue control by performing processing similar to the dialogue progression control processing described with reference to FIG. 5 based on the understanding action request position detected as described above. Do. At this time, at the understanding action request position where the understanding action is induced, a certain amount of time is provided and the speech is uttered.
- the induction of the understanding behavior is performed by, for example, opening an utterance or adding an inflection to the ending of the utterance.
- the utterance text is a sentence in a language other than Japanese
- the location case, the target case, and the position of the phrase (clause) of the cause case It is possible to detect the requested position.
- the above-described series of processing can be executed by hardware or can be executed by software.
- a program constituting the software is installed in the computer.
- the computer includes, for example, a general-purpose personal computer capable of executing various functions by installing a computer incorporated in dedicated hardware and various programs.
- FIG. 9 is a block diagram showing an example of the hardware configuration of a computer that executes the above-described series of processing by a program.
- a CPU Central Processing Unit
- ROM Read Only Memory
- RAM Random Access Memory
- An input / output interface 505 is further connected to the bus 504.
- An input unit 506, an output unit 507, a recording unit 508, a communication unit 509, and a drive 510 are connected to the input / output interface 505.
- the input unit 506 includes a keyboard, a mouse, a microphone, an image sensor, and the like.
- the output unit 507 includes a display, a speaker, and the like.
- the recording unit 508 includes a hard disk, a nonvolatile memory, and the like.
- the communication unit 509 includes a network interface or the like.
- the drive 510 drives a removable recording medium 511 such as a magnetic disk, an optical disk, a magneto-optical disk, or a semiconductor memory.
- the CPU 501 loads the program recorded in the recording unit 508 to the RAM 503 via the input / output interface 505 and the bus 504 and executes the program, for example. Is performed.
- the program executed by the computer (CPU 501) can be provided by being recorded in a removable recording medium 511 as a package medium, for example.
- the program can be provided via a wired or wireless transmission medium such as a local area network, the Internet, or digital satellite broadcasting.
- the program can be installed in the recording unit 508 via the input / output interface 505 by attaching the removable recording medium 511 to the drive 510. Further, the program can be received by the communication unit 509 via a wired or wireless transmission medium and installed in the recording unit 508. In addition, the program can be installed in the ROM 502 or the recording unit 508 in advance.
- the program executed by the computer may be a program that is processed in time series in the order described in this specification, or in parallel or at a necessary timing such as when a call is made. It may be a program for processing.
- the present technology can take a cloud computing configuration in which one function is shared by a plurality of devices via a network and is jointly processed.
- each step described in the above flowchart can be executed by one device or can be shared by a plurality of devices.
- the plurality of processes included in the one step can be executed by being shared by a plurality of apparatuses in addition to being executed by one apparatus.
- the present technology can be configured as follows.
- a dialog control device comprising a dialog progress control unit for controlling the next utterance.
- the dialogue control device according to (1) wherein the dialogue progress control unit utters the next word that has not yet been uttered in the utterance text when the understanding behavior by the user is a positive behavior.
- the dialogue progress control unit controls utterances based on the utterance text so that the number of times the understanding behavior is induced decreases as the response time of the positive understanding behavior by the user decreases.
- (1) to (3) The dialogue control device according to any one of the above.
- the dialogue progress control unit controls the utterance based on the utterance text so that the utterance speed becomes faster as the response time of the positive understanding behavior by the user is shorter.
- (1) to (4) The dialog control device according to item.
- the dialog progress control unit controls the utterance based on the utterance text so that the utterance tone becomes higher as the response time of the positive understanding behavior by the user is shorter.
- (1) to (5) The dialogue control device according to one item.
- the dialogue progress control unit causes the utterance performed immediately before to be performed again or the utterance requesting the understanding behavior is performed (1).
- the dialogue control device according to any one of (6) to (6).
- (8) The dialogue control unit according to any one of (1) to (7), wherein the dialogue progress control unit controls output of notification information including the utterance text when the utterance based on the utterance text is stopped halfway. apparatus.
- (9) The dialogue control unit according to any one of (1) to (8), wherein the dialogue progress control unit causes the utterance to induce the understanding behavior by adding a non-completion word to the word based on the utterance text. apparatus.
- the understanding action request position detection unit detects, as the understanding action request position, a position between each of a plurality of target sentence clauses or phrases related to the same predicate clause in the sentence of the utterance text. Dialog control device.
- the understanding action request position detecting unit detects a position of a phrase or phrase that is a time case, a place case, an object case, or a causal case in the sentence of the utterance text as the understanding action request position. Control device.
- utterance that induces the user's understanding action is performed at the understanding action request position, and based on the detection result of the understanding action and the utterance text.
- the dialog control method including the step of controlling the next utterance.
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Artificial Intelligence (AREA)
- Machine Translation (AREA)
- User Interface Of Digital Computer (AREA)
Abstract
本技術は、より適切な対話制御を行うことができるようにする対話制御装置および方法に関する。 対話制御装置は、1または複数の理解行動要求位置で区切られた発話テキストに基づいて、理解行動要求位置においてユーザの理解行動を誘発する発話を行わせ、理解行動の検出結果と発話テキストとに基づいて、次の発話を制御する対話進行制御部を備える。本技術は音声対話システムに適用することができる。
Description
本技術は対話制御装置および方法に関し、特に、より適切な対話制御を行うことができるようにした対話制御装置および方法に関する。
従来、ユーザとの音声対話を制御する技術が知られている。
例えばそのような技術として、ユーザに対して音声発話を要求するとともに、ユーザにより発話されたキーワードに基づいてユーザの理解度を判定し、その判定結果に応じて対話を進めていくものがある(例えば、特許文献1参照)。
また、例えばユーザとの対話をするにあたり、ユーザの相槌行為を検出したり、ユーザに相槌を要求したりする技術も提案されている(例えば、特許文献2参照)。
ところが、上述した技術ではユーザとの音声対話を適切に制御することは困難であった。
例えばキーワードに基づいてユーザの理解度を判定する技術では、ユーザの理解度に応じて音声入力を促すメッセージが出力される。しかし、ユーザへの伝達項目のリストが長かったり、伝達内容が長文であったりする場合など、システムが音声により提示する、ユーザに対して伝えたい情報の量が多い場合には、最適な粒度で、つまり最適なタイミングでユーザの理解度を測ることができない。
TTS(Text To Speech)での合成音声は速度や抑揚が一定であり、情報量が多く音声発話する文章が長くなると、ユーザが発話内容を理解し、集中して聞いているにも関わらず遅い速度で発話が行われたり、頻繁に音声入力を促されたりするなど、ユーザの状況に合わない対話制御が行われてしまうことがある。このような場合、ユーザが発話内容を理解しにくいだけでなく、発話内容も記憶しにくくなってしまう。
また、上述した技術では、音声対話中に、すなわち発話音声の文の途中で相槌や頷きなど、ユーザに対して負荷の低い理解行動自体を誘発することができない。
そのため、例えば文よりもさらに細かい文節や意味の区切りで理解行動を要求する頻度をユーザの集中度や理解度に応じて制御するなど、最適な粒度でユーザに負荷の低い理解行動を要求することができなかった。
本技術は、このような状況に鑑みてなされたものであり、より適切な対話制御を行うことができるようにするものである。
本技術の一側面の対話制御装置は、1または複数の理解行動要求位置で区切られた発話テキストに基づいて、前記理解行動要求位置においてユーザの理解行動を誘発する発話を行わせ、前記理解行動の検出結果と前記発話テキストとに基づいて、次の発話を制御する対話進行制御部を備える。
前記対話進行制御部には、前記ユーザによる前記理解行動が肯定的な行動であった場合、前記発話テキストのまだ発話がされていない次の文言を発話させるようにすることができる。
前記対話進行制御部には、前記ユーザによる前記理解行動が否定的な行動であった場合、直前に行われた発話を再度行わせるようにすることができる。
前記対話進行制御部には、前記ユーザによる肯定的な前記理解行動のレスポンス時間が短いほど前記理解行動の誘発回数が少なくなるように、前記発話テキストに基づく発話を制御させることができる。
前記対話進行制御部には、前記ユーザによる肯定的な前記理解行動のレスポンス時間が短いほど発話速度が速くなるように、前記発話テキストに基づく発話を制御させることができる。
前記対話進行制御部には、前記ユーザによる肯定的な前記理解行動のレスポンス時間が短いほど発話のトーンが高くなるように、前記発話テキストに基づく発話を制御させることができる。
前記対話進行制御部には、所定時間内に前記ユーザによる前記理解行動が検出されなかった場合、直前に行われた発話を再度行わせるか、または前記理解行動を要求する発話を行わせるようにすることができる。
前記対話進行制御部には、前記発話テキストに基づく発話を途中で停止させた場合、前記発話テキストを含む通知情報の出力を制御させることができる。
前記対話進行制御部には、前記発話テキストに基づく文言に非完了文言を付加することで、前記理解行動を誘発する発話を行わせるようにすることができる。
前記対話進行制御部には、発話の語尾に抑揚を付加することで、前記理解行動を誘発する発話を行わせるようにすることができる。
前記対話進行制御部には、前記理解行動要求位置において間をあけることで前記理解行動を誘発する発話を行わせるようにすることができる。
対話制御装置には、前記発話テキストの文章における文として非完結な位置を前記理解行動要求位置として検出する理解行動要求位置検出部をさらに設けることができる。
前記理解行動要求位置検出部には、前記発話テキストの文章の述語節との係り受けに基づく位置を前記理解行動要求位置として検出させることができる。
前記理解行動要求位置検出部には、前記発話テキストの文章における同一の述語節に係る複数の対象格の文節または句のそれぞれの間の位置を前記理解行動要求位置として検出させることができる。
前記理解行動要求位置検出部には、前記発話テキストの文章における述語節に最初に係る文節または句の位置を前記理解行動要求位置として検出させることができる。
前記理解行動要求位置検出部には、前記発話テキストの文章における時間格、場所格、対象格、または原因格である文節または句の位置を前記理解行動要求位置として検出させることができる。
本技術の一側面の対話制御方法は、1または複数の理解行動要求位置で区切られた発話テキストに基づいて、前記理解行動要求位置においてユーザの理解行動を誘発する発話を行わせ、前記理解行動の検出結果と前記発話テキストとに基づいて、次の発話を制御するステップを含む。
本技術の一側面においては、1または複数の理解行動要求位置で区切られた発話テキストに基づいて、前記理解行動要求位置においてユーザの理解行動を誘発する発話が行われ、前記理解行動の検出結果と前記発話テキストとに基づいて、次の発話が制御される。
本技術の一側面によれば、より適切な対話制御を行うことができる。
なお、ここに記載された効果は必ずしも限定されるものではなく、本開示中に記載された何れかの効果であってもよい。
以下、図面を参照して、本技術を適用した実施の形態について説明する。
〈第1の実施の形態〉
〈音声対話システムの構成例〉
本技術は、発話テキストを、ユーザに対して理解行動を要求する区間ごとに区切り、その区切りの位置でユーザに理解行動を求めるとともに、ユーザの理解行動と発話テキストとに基づいて次の発話音声を生成することで、適切な対話制御を行うことができるようにするものである。
〈音声対話システムの構成例〉
本技術は、発話テキストを、ユーザに対して理解行動を要求する区間ごとに区切り、その区切りの位置でユーザに理解行動を求めるとともに、ユーザの理解行動と発話テキストとに基づいて次の発話音声を生成することで、適切な対話制御を行うことができるようにするものである。
特に、本技術は以下の2つの技術的な特徴を有している。
まず、第1の特徴として、本技術では音声発話する文章である発話テキストに対する自然言語解析によりユーザの相槌や頷きによる理解行動を求めるポイントが発話文章から抽出される。そして、音声発話時に発話テキストの途中に非完了文言や抑揚(イントネーション)を付加したり、長い間の時間を挿入したりすることによりユーザの理解行動を誘発するようになされる。
ここで、ユーザによる理解行動とは、ユーザが発話内容を理解しているか否かを示す頷きや相槌などの行動をいう。また、ユーザに理解行動を求めるポイント、つまり位置は、例えばユーザに対して伝達する羅列情報の切れ目の位置や、係り受けの分岐位置などとされる。このように、自然言語解析の結果に基づいてユーザに理解行動を求める位置を抽出することで、発話テキストごとに適切な粒度で、ユーザの理解行動を誘発することができる。これにより、適切な対話制御を実現することができる。
なお、以下では、ユーザに対して理解行動を求めるポイント(位置)を、特に理解行動要求位置とも称することとする。
また、第2の特徴として、本技術ではユーザの「相槌」や「頷き」などの理解行動の種別、すなわちユーザの理解行動が肯定的な行動であるか、または否定的な行動であるかの判定と、ユーザの理解行動までのレスポンス時間の測定とが行われる。そして、それらの判定結果と測定結果とに基づいて、ユーザの理解度や音声発話に対する意識の集中度が推定、判定され、その理解度や集中度に応じて、適宜、理解行動誘発を行いながらの発話進行が動的に制御される。
具体的には、例えば以下の制御C1乃至制御C4が行われる。
(制御C1)
発話テキストにおける理解行動要求位置で発話音声を一旦停止させ、ユーザによる肯定的な理解行動(了解)があるまでは発話の間をあけて発話を先に進めないように対話制御が行われる。
発話テキストにおける理解行動要求位置で発話音声を一旦停止させ、ユーザによる肯定的な理解行動(了解)があるまでは発話の間をあけて発話を先に進めないように対話制御が行われる。
(制御C2)
理解行動の誘発後、一定時間が経過してもユーザによる理解行動がない場合には、直前の発話内容を繰り返したり、理解行動を催促する文言を挿入したり、それらの両方を行ったりするように対話制御が行われる。
理解行動の誘発後、一定時間が経過してもユーザによる理解行動がない場合には、直前の発話内容を繰り返したり、理解行動を催促する文言を挿入したり、それらの両方を行ったりするように対話制御が行われる。
(制御C3)
ユーザによる理解行動の種別が否定的であった場合、直前の発話内容を繰り返すように対話制御が行われる。
ユーザによる理解行動の種別が否定的であった場合、直前の発話内容を繰り返すように対話制御が行われる。
(制御C4)
ユーザの理解行動のレスポンス時間を測定し、そのレスポンス時間が短い場合にはユーザの理解度や集中度が高いと判定して、ユーザへの理解行動の誘発回数を減らし、発話音声の話速やトーンを上げていき、ユーザの理解度や集中度が低いと判定されたときには、誘発回数を増やし、発話音声の話速やトーンを下げていくような対話制御が行われる。
ユーザの理解行動のレスポンス時間を測定し、そのレスポンス時間が短い場合にはユーザの理解度や集中度が高いと判定して、ユーザへの理解行動の誘発回数を減らし、発話音声の話速やトーンを上げていき、ユーザの理解度や集中度が低いと判定されたときには、誘発回数を増やし、発話音声の話速やトーンを下げていくような対話制御が行われる。
本技術では、以上のような対話制御を行うことで、ユーザの理解度や集中度に応じて適切なタイミングで理解行動を促し、自然な音声対話を実現することができる。
続いて、本技術を適用した具体的な実施の形態について説明する。
図1は、本技術を適用した音声対話システムの一実施の形態の構成例を示す図である。
図1に示す音声対話システムは、サーバ11およびクライアントデバイス12からなり、ユーザとの音声対話を行うシステムである。この例では、サーバ11と、スマートホンなどの端末装置からなるクライアントデバイス12とが有線や無線などにより直接的に、または通信網を介して間接的に接続されている。
サーバ11は対話制御装置として機能し、ユーザからの理解行動というフィードバックと、発話内容を示すテキストデータである発話テキストとから音声発話の音声データを生成し、クライアントデバイス12に出力する。
クライアントデバイス12は、サーバ11から供給された音声データに基づいてユーザに対して発話音声を出力するとともに、適宜、ユーザからのフィードバックを受けて、そのフィードバックをサーバ11に供給する。
サーバ11は、自然言語解析部21、理解行動要求位置検出部22、音声出力対話進行制御部23、音声合成エンジン24、音声認識エンジン25、行動認識エンジン26、および理解行動判定部27を有している。また、クライアントデバイス12は、音声再生デバイス31、音声入力デバイス32、およびセンサ33を有している。
なお、ここでは音声合成エンジン24がサーバ11に設けられる例について説明するが、音声合成エンジン24はクライアントデバイス12に設けられるようにしてもよい。
サーバ11の自然言語解析部21には、音声発話によってユーザに対して提示する情報内容の全文章である発話テキストが入力される。自然言語解析部21は、入力された発話テキストに対して自然言語解析を行って、その解析結果と発話テキストを理解行動要求位置検出部22に供給する。
理解行動要求位置検出部22は、自然言語解析部21から供給された解析結果と発話テキストに基づいて、発話テキストにより示される文章内における、ユーザへの理解行動を要求する理解行動要求位置を検出する。
この理解行動要求位置は、発話テキストに基づく発話時にユーザの理解行動を誘発する発話を行う位置の候補となる位置である。理解行動要求位置検出部22が発話テキストの文章から理解行動要求位置を検出すると、1または複数の理解行動要求位置で区切られた発話テキストが得られたことになる。
理解行動要求位置検出部22は、理解行動要求位置の検出結果と発話テキストを音声出力対話進行制御部23に供給する。
音声出力対話進行制御部23は、理解行動要求位置検出部22から供給された理解行動要求位置の検出結果および発話テキストと、理解行動判定部27から供給されたユーザの理解行動の判定結果とに基づいて、発話テキストに基づく音声発話を制御する。
すなわち、音声出力対話進行制御部23は、発話テキストに基づく発話文言を示すテキストデータを適切なタイミングで音声合成エンジン24に出力することで、ユーザとの対話制御を行う。このとき、音声出力対話進行制御部23は、必要に応じて、発話テキストにより示される発話文言に対して、ユーザの理解行動を誘発するための非完了文言を付加して出力したり、音声合成エンジン24に対して抑揚の付加を指示したり、発話文言の出力タイミングを制御することで発話の間をあけたりする。
なお、以下、発話文言に対して付加される、ユーザの理解行動を誘発するための非完了文言を理解行動誘発文言とも称することとする。
また、ここでは発話テキストにより示される発話文言に対して、適宜、理解行動要求位置において理解行動誘発文言が付加され、ユーザに対して理解行動を誘発する例について説明するが、ユーザ等による設定により、理解行動の誘発機能をオンまたはオフできるようにしてもよい。また、理解行動の誘発機能をオンするか、またはオフするかの設定結果が音声出力対話進行制御部23に記録できるようにしてもよい。
この場合、例えば理解行動の誘発機能がオフに設定されている場合には、音声出力対話進行制御部23は、特に理解行動誘発文言の付加等を行わず、発話テキストをそのまま音声合成エンジン24へと出力する。
音声合成エンジン24は、音声出力対話進行制御部23から供給された発話文言に基づいて、テキスト音声合成(TTS)により発話文言を音声で再生するための音声データを生成し、音声再生デバイス31へと出力する。すなわち、音声合成エンジン24では、発話文言を示すテキストデータが、その発話文言の音声データへと変換される。
音声再生デバイス31は、例えばスピーカなどからなる音声出力部を有しており、音声合成エンジン24から供給された音声データに基づいて発話文言の音声を再生する。
発話文言の音声が再生されると、ユーザはその再生音を聞き、状況に応じて相槌や頷きなどの理解行動を行う。換言すれば、理解行動の誘発に対するフィードバックとして、相槌や頷きなどの理解行動がユーザにより行われる。
音声入力デバイス32は、例えばマイクロホンなどからなり、理解行動としてのユーザの相槌の音声を収音し、その結果得られた音声収音データを音声認識エンジン25に供給する。音声認識エンジン25は、音声入力デバイス32から供給された音声収音データに対して音声認識を行い、その音声認識の結果を理解行動判定部27に供給する。例えば音声認識によって音声収音データに基づく相槌音声がテキスト化され、得られたテキストデータが音声認識の結果として理解行動判定部27に出力される。
センサ33は、例えばユーザの頭部などに取り付けられたジャイロセンサや、ユーザ近傍に配置された、ユーザの頭部の動きを検出するセンサ、ユーザの頭部の画像を撮像するイメージセンサなどからなり、ユーザの理解行動としての頷き、すなわちユーザの頭部の動きを検出し、その検出結果を行動認識エンジン26に供給する。
行動認識エンジン26は、センサ33から供給されたユーザの頷きの検出結果に基づいて行動認識を行うことで、ユーザの頷きの種別を認識(判定)し、その認識結果を理解行動判定部27に供給する。
理解行動判定部27は、音声認識エンジン25からの音声認識結果、および行動認識エンジン26からの頷きの種別の認識結果のうちの少なくとも何れか一方に基づいて、ユーザの理解行動が肯定的な理解行動であるか、または否定的な理解行動であるかを判定し、その判定結果を音声出力対話進行制御部23に供給する。
このようにして得られた理解行動の判定結果は、音声出力対話進行制御部23において、理解行動の誘発を行った発話の次の発話の制御に用いられる。
なお、理解行動判定部27での理解行動の判定処理では、音声認識エンジン25からの音声認識結果、および行動認識エンジン26からの頷きの種別の認識結果のうちの少なくとも何れか一方が用いられるようにすればよい。
例えば音声認識結果に基づいて理解行動の判定が行われる場合、理解行動判定部27では、音声認識結果に基づいて理解行動としてのユーザの相槌音声が肯定的な相槌であるか、または否定的な相槌であるかが判定される。
具体的には、例えば相槌音声として「うん」や「はい」などを示すテキストデータが音声認識の結果として得られた場合、理解行動判定部27は、ユーザの理解行動は肯定的な理解行動である、つまり相槌音声は肯定的な相槌であると判定する。
これに対して、例えば相槌音声として「え」や「なに」、「もう1回」などを示すテキストデータが音声認識の結果として得られた場合、理解行動判定部27は、ユーザの理解行動は否定的な理解行動である、つまり相槌音声は否定的な相槌であると判定する。
なお、音声認識エンジン25において、相槌音声を認識することができなかった場合には、例えば音声区間検出などで、ユーザから何らかの音声発話反応があったときに理解行動判定部27が、ユーザによる理解行動がなされたとし、理解行動の判定結果を出力するようにしてもよい。
そのような場合、例えば設計段階において音声認識エンジン25の性能、すなわち性能信頼度に応じて、相槌音声を認識することができなかったがユーザから何らかの音声発話反応があったときに、ユーザの理解行動を肯定的なものとするか、または否定的なものとするかを定めておけばよい。
例えば音声認識エンジン25の性能信頼度が低い場合には、ユーザから何らかの音声発話反応があったときに、そのユーザの理解行動を否定的なものとすると、音声発話(対話)が先に進まなくなってしまうので、肯定的な理解行動(肯定的な相槌音声)であると判定されるようにすればよい。
これに対して、音声認識エンジン25の性能信頼度が高い場合には、ユーザの再度の相槌を正しく認識できる可能性が高いので、ユーザから何らかの音声発話反応があったときには、その理解行動が否定的な理解行動(否定的な相槌音声)であると判定されるようにすればよい。
また、例えばユーザの頷きの種別の認識結果に基づいて理解行動の判定が行われる場合、理解行動判定部27では、その認識結果に基づいて、理解行動としてのユーザの頷きが、肯定的な頷きであるか、または否定的な頷きであるかが判定される。
例えばセンサ33がユーザの頭部などに取り付けられたジャイロセンサや、ユーザの頭部の動きを検出するセンサである場合、行動認識エンジン26はセンサ33からの出力に基づいて、ユーザが頭部(首)を縦方向に振る動きをしたか、またはユーザが頭部(首)を横方向に振る動きをしたかといった頷きの種別を認識する。
そして、理解行動判定部27は、その頷きの種別の認識結果に基づいて、ユーザが頭部を縦方向に振ったとの認識結果が得られた場合には、ユーザの理解行動は肯定的な理解行動であると判定する。これに対して、理解行動判定部27は、ユーザが頭部を横方向に振ったとの認識結果が得られた場合には、ユーザの理解行動は否定的な理解行動であると判定する。
また、例えばセンサ33がユーザの頭部の画像を撮像するイメージセンサなどからなる場合には、行動認識エンジン26において、センサ33で得られた画像に対して画像認識が行われ、ユーザの縦方向や横方向への頷き、つまり頷きの種別が認識される。
さらに、例えば音声認識エンジン25による音声認識結果と、行動認識エンジン26による頷きの種別の認識結果との両方が得られた場合には、判定エンジン、つまり音声認識エンジン25や行動認識エンジン26の認識の信頼度(認識精度)に応じて認識結果に優先順位をつけて理解行動の判定を行うようにしてもよい。
そのような場合、例えば行動認識エンジン26よりも音声認識エンジン25の信頼度が高いときには、理解行動判定部27は音声認識エンジン25による音声認識結果に基づいて理解行動の判定の処理を行う。また、理解行動判定部27は、音声認識エンジン25において音声認識が正しく行うことができなかった場合には、行動認識エンジン26による頷きの種別の認識結果に基づいて理解行動の判定の処理を行う。
さらに、例えば音声認識の結果として「うーん」などの曖昧な認識結果、すなわち肯定的とも否定的とも判定できる認識結果が得られた場合には、理解行動判定部27がユーザの相槌音声の抑揚やユーザの動き、ユーザの視線方向、ユーザの視線の動きなども用いて理解行動の判定を行うようにしてもよい。この場合、どのような音声認識結果が曖昧な認識結果とされるかは、予め曖昧な認識結果とされる単語を登録するなどして定めておけばよい。
例えば曖昧な音声認識結果が得られた場合、理解行動判定部27は行動認識エンジン26による頷きの種別の認識結果に基づいて、ユーザの理解行動を判定する。
また、例えば音声対話システムにおいて「うーん」などの曖昧な相槌音声について、その相槌音声を発しているときのユーザの頷きや視線方向、視線の動きなどのユーザの動き、またはユーザの音声の抑揚をフィードバック付き学習し、その学習結果を示す辞書を生成するようにしてもよい。
そのような場合、フィードバック付き学習時にはユーザは相槌音声を発するとともに、その相槌音声が肯定的なものであるか、または否定的なものであるかの入力を行う。そして、音声対話システムでは、その入力結果と、音声認識により得られた相槌音声の認識結果と、検出されたユーザの頷き等の動きまたは音声の抑揚とから辞書が生成される。
理解行動判定部27は、実際の音声の発話時に曖昧な相槌音声であるとの音声認識結果が得られたときには、音声入力デバイス32で収音された音声収音データから得られた音声の抑揚や、センサ33等で得られたユーザの動きなどと、予め記録している辞書とに基づいてユーザの理解行動を判定する。
なお、以上においては、ユーザの理解行動を検出するための構成として、クライアントデバイス12に音声入力デバイス32およびセンサ33が設けられている例について説明したが、その他、どのような方法によりユーザの理解行動が検出されるようにしてもよい。
例えばクライアントデバイス12に特定のボタンやタッチパネルを設け、ユーザがそのボタンを押下したり、タッチパネルをタッチしたりするようにしてもよい。すなわち、ユーザによるボタンやタッチパネル等に対する操作が理解行動として行われ、ユーザの音声対話システムに対するフィードバックが行われるようにしてもよい。
また、クライアントデバイス12に視線検出センサを設け、その視線検出センサの出力に基づいて、ユーザの理解行動の判定が行われてもよい。そのような場合、例えばユーザが対象機器などの特定の方向に視線を向けたことが検出されたときに、ユーザの理解行動が肯定的な理解行動であると判定される。
さらに、クライアントデバイス12においては、音声入力デバイス32やセンサ33は、音声再生デバイス31と一体的に設けられているようにしてもよいし、音声再生デバイス31が設けられた装置とは別に設けられていてもよい。
具体的には、例えば音声再生デバイス31がスマートホンに設けられており、音声入力デバイス32やセンサ33がそのスマートホンに接続されているようにしてもよい。そのような場合には、例えばスマートホンが音声入力デバイス32やセンサ33から、音声収音データやユーザの動きの検出結果を取得して、音声認識エンジン25や行動認識エンジン26に送信するようにしてもよい。
〈自然言語解析と理解行動要求位置について〉
続いて、理解行動要求位置検出部22による理解行動要求位置の検出方法の具体的な例について説明する。
続いて、理解行動要求位置検出部22による理解行動要求位置の検出方法の具体的な例について説明する。
例えば発話テキストとして、図2の矢印A11に示すように「今日のお出かけは、財布と携帯電話と鍵と弁当と時計を持って行ってください。夕方から雨が降るかもしれないので傘を持って行ってください。」というテキストデータが自然言語解析部21に入力されたとする。
このような場合に、自然言語解析部21において発話テキストに対する自然言語解析として例えば形態素解析が行われると、矢印A12に示す解析結果が得られる。形態素解析では、入力された発話テキストの文章が文節単位に区切られ、各文節の言語的な格の情報と、各文節の係り受けの構造を示す情報とが解析結果として得られる。
矢印A12に示す部分では各四角形が1つの文節を表しており、その四角形内には発話テキストの文節に区切られた文言、つまり文節を構成する文言が記されている。また、各文節を表す四角形同士を結ぶ線分は、文節同士の係り受けを表している。
すなわち、文節を表す四角形から延びる線分の終点は、その文節の係り先の文節となっている。したがって、例えば図中、一番上側の文節「今日の」は、文節「お出かけは」に係っていることが分かる。
また、矢印A12に示す部分では、各文節を表す四角形の図中、右側には、それらの文節の言語的な格が記されている。例えば図中、一番上側の文節「今日の」の言語的な格は連体修飾節であることが記されている。
このように自然言語解析部21では、自然言語解析の結果として、矢印A12に示すように文節の言語的な格の情報と、各文節の係り受けの構造を示す情報とが得られる。
理解行動要求位置検出部22は、自然言語解析部21から供給されたそれらの情報に基づいて、ユーザに対して理解行動を要求する位置、つまり、理解行動を誘発するための理解行動誘発文言を挿入(付加)する理解行動要求位置を検出する処理を行う。
具体的には、理解行動要求位置検出部22は、1つの文の中で同一の述語節の文節に係る複数の対象格の文節が存在するかを検出する。
例えば矢印A12に示した発話テキストの1文目の例では、複数の文節「財布と」、「携帯電話と」、「鍵と」、「弁当と」、および「時計を」がそれぞれ対象格となっており、それらの文節が、述語節である同一の文節「持って行ってください。」に係っている。
この例では、発話テキストの1文目は、お出かけの際にユーザが持っていくべきもの(アイテム)、つまりお出かけの際の持ち物リストを示す文章となっており、その持ち物リストにより示される持ち物(アイテム)の文節が同一の述語節の文節に係っている。すなわち、持ち物が羅列されている文章となっている。
このように、1つの文の中で同一の述語節の文節に係る複数の対象格の文節は、この例で示したお出かけ時の持ち物リストのようなユーザに対して提示される複数の羅列情報であることを意味している。換言すれば、同一の述語節の文節に複数の対象格の文節が係る文の構造は、ユーザに対して複数の羅列情報を提示していることを意味している。
そこで、このような同一の述語節の文節に係る複数の対象格の文節、すなわち羅列情報が検出された場合、理解行動要求位置検出部22は、それらの同一の述語節の文節に係る各対象格の文節の間の位置、つまり各羅列情報の文節の間の位置を理解行動要求位置とする。
これは、各羅列情報の文節の間の位置は文として完結していない非完結な位置であり、まだ続きがあることをユーザに連想させるため、これらの文節の間の位置では理解行動が誘発されやすく、かつ各アイテム(持ち物)に対する了解をユーザから得ることができるので、理解行動を求める位置として有効であるからである。
図2の例では、発話テキストの1文目の矢印W11乃至矢印W14に示される位置が理解行動要求位置検出部22により検出された理解行動要求位置となっている。具体的には、例えば矢印W11により示される理解行動要求位置は、文節「財布と」の直後の位置となっている。
また、理解行動要求位置検出部22は、発話テキストに複数の文が含まれる場合は、文と文の区切りの位置を理解行動要求位置とは判定しない。すなわち、2つ目以降の文では、その文の直前にある文の終了位置は、理解行動要求位置とはされず、文が続けて発話される。これは、文と文の間は、文として完結した位置であるから理解行動を誘発することが困難であるからである。例えば、文として完結している箇所でユーザの理解行動を求めた場合、ユーザは音声対話システムによる発話が終了したと受け取ってしまうことがある。
さらに、理解行動要求位置検出部22は、発話テキストに複数の文が含まれる場合、2つ目以降の文において、文の述語節の文節に対する最初の係り受けが発生する文節を検出し、その文節の直後の位置を理解行動要求位置とする。
これは、文の述語節に対する最初の係り受けが発生する文節の位置は、前述した例と同様に文として非完結の状態であり、さらに2つ目以降の文でも音声対話システムによる発話に対するユーザの集中度が持続しているかを確認するのに有効な位置(タイミング)となるからである。
図2の例では、2つ目の文において述語節である文節「持って行ってください。」に係る最初の文節「降るかもしれないので」の直後の位置、すなわち矢印W15に示す位置が理解行動要求位置とされている。ここでは、矢印W15に示すように連用修飾節の直後の位置が理解行動要求位置とされるので、文として完結しない位置でユーザに対して理解行動が要求されることになる。
なお、2つ目以降の文においても、羅列情報が検出された場合、つまり同一の述語節の文節に係る複数の対象格の文節が検出された場合、それらの対象格の文節の間の位置が理解行動要求位置とされるようにしてもよい。
以上の例では、理解行動要求位置検出部22は、発話テキストの文章内の述語節の文節に係る文節位置に基づいて、理解行動要求位置を検出(決定)している。すなわち、述語節との係り受けに基づく位置が理解行動要求位置として検出される。
〈音声発話処理および理解行動判定処理の説明〉
次に、図1に示した音声対話システムの動作について説明する。
次に、図1に示した音声対話システムの動作について説明する。
例えば音声対話システムに発話テキストが供されると、音声対話システムは、音声発話を行ってユーザとの対話を行う音声発話処理と、音声対話システムの音声発話に対するユーザからのフィードバックに基づいて理解行動を判定する理解行動判定処理を行う。これらの音声発話処理と理解行動判定処理は同時に行われる。
まず、図3のフローチャートを参照して、音声対話システムによる音声発話処理について説明する。
ステップS11において、自然言語解析部21は、供給された発話テキストに対して自然言語解析を行い、その解析結果と発話テキストを理解行動要求位置検出部22に供給する。例えばステップS11では、図2を参照して説明したように形態素解析が行われる。
ステップS12において、理解行動要求位置検出部22は、自然言語解析部21から供給された解析結果と発話テキストに基づいて理解行動要求位置を検出し、その検出結果と発話テキストを音声出力対話進行制御部23に供給する。
例えばステップS12では、図2を参照して説明したように羅列情報である対象格の文節の間の位置や、2つ目以降の文における述語節に対する最初の係り受けが発生する文節の直後の位置などが理解行動要求位置として検出される。
ステップS13において、音声出力対話進行制御部23は、理解行動要求位置検出部22から供給された理解行動要求位置の検出結果および発話テキストと、理解行動判定部27から供給されたユーザの理解行動の判定結果とに基づいて、次に発話させる発話文言のテキストデータを音声合成エンジン24に出力する。このとき、音声出力対話進行制御部23は、音声合成エンジン24に対して、必要に応じて理解行動誘発文言部分での抑揚の付加も指示する。また、音声出力対話進行制御部23は、適宜、発話文言のテキストデータの出力タイミングを制御することで発話の間をあける。
ここで、ステップS13において用いられる理解行動の判定結果は、図4を参照して後述する理解行動判定処理により得られたものとされる。
音声出力対話進行制御部23は、理解行動要求位置ごとに次に発話させる発話文言を決定し、決定した発話文言のテキストデータを出力することで、ユーザとの音声対話の進行を制御する。また、音声出力対話進行制御部23は、理解行動誘発文言が付加された発話文言のテキストデータを出力したときには、次の発話文言のテキストデータの出力までに、予め定めた長さの時間である間を設けて理解行動の誘発を行う。
なお、より詳細には、次に発話させる発話文言を決定するにあたっては、理解行動の判定結果だけでなく、ユーザの理解度および集中度を示す理解・集中度も用いられる。この理解・集中度は、ユーザが音声対話システムによる音声発話に対して、どれだけ意識を集中させ、発話内容を理解できているかを示すパラメータである。
ステップS14において、音声合成エンジン24は、音声出力対話進行制御部23から供給された発話文言のテキストデータに基づいて、テキスト音声合成により発話文言を音声で再生するための音声データを生成し、音声再生デバイス31へと出力する。
ステップS15において、音声再生デバイス31は、音声合成エンジン24から供給された音声データに基づいて発話文言の音声を再生する。
ユーザは、このようにして発話された音声に対して、適宜、理解行動によりフィードバックを行い、音声対話システムとの音声対話を行う。このときユーザにより行われた理解行動、つまりフィードバックに対して、図4を参照して後述する理解行動判定処理が行われる。
ステップS16において、音声出力対話進行制御部23は、ユーザとの音声対話を終了するか否かを判定する。例えば入力された発話テキストの内容が全て発話された場合、音声対話を終了すると判定される。
ステップS16において、音声対話を終了しないと判定された場合、まだ発話していない内容が残っているので、処理はステップS13に戻り、上述した処理が繰り返し行われる。すなわち、次の文言の発話が行われる。
これに対して、ステップS16において音声対話を終了すると判定された場合、音声発話処理は終了する。
以上のようにして音声対話システムは、発話テキストに対する自然言語解析の結果に基づいて理解行動要求位置を検出し、その検出結果と理解行動の判定結果とに基づいて次の文言を発話する。このようにすることで、適切なタイミングでユーザに対して相槌や頷きなどの負荷の低い理解行動を誘発し、対話を進めることができる。すなわち、より適切な対話制御を行うことができる。
続いて、図4のフローチャートを参照して、図3を参照して説明した音声発話処理と同時に行われる、音声対話システムによる理解行動判定処理について説明する。
図3のステップS15で音声対話システムにより理解行動を誘発する音声発話が行われると、ユーザはその音声発話に対して理解行動を行う。例えばユーザは理解行動として、相槌を打ったり頷いたりするという否定的または肯定的な行動を行う。
すると、ステップS41において、音声入力デバイス32は、理解行動としてのユーザの相槌の音声を収音し、その結果得られた音声収音データを音声認識エンジン25に供給する。
ステップS42において、音声認識エンジン25は、音声入力デバイス32から供給された音声収音データに対して音声認識を行い、その音声認識の結果を理解行動判定部27に供給する。
また、ステップS43において、センサ33は、ユーザの頭部の動き、つまり頷きをユーザの理解行動として検出し、その検出結果を行動認識エンジン26に供給する。
ステップS44において、行動認識エンジン26は、センサ33から供給されたユーザの理解行動の検出結果に基づいて行動認識を行うことで、ユーザの頷きの種別を認識(判定)し、その認識結果を理解行動判定部27に供給する。
なお、より詳細には、ステップS41およびステップS42の処理と、ステップS43およびステップS44の処理とは並行して行われる。また、ステップS41およびステップS42の処理と、ステップS43およびステップS44の処理とのうちの何れか一方のみが行われるようにしてもよい。
ステップS45において、理解行動判定部27は、音声認識エンジン25からの音声認識結果、および行動認識エンジン26からの頷きの種別の認識結果のうちの少なくとも何れか一方に基づいて理解行動判定を行い、その判定結果を音声出力対話進行制御部23に供給する。
理解行動判定では、ユーザの理解行動が肯定的な理解行動であるか、または否定的な理解行動であるかが判定され、その判定結果が次に行われる図3のステップS13の処理で用いられる。換言すれば、理解行動判定によって、ユーザによる肯定的または否定的な理解行動が検出されることになる。
例えば理解行動判定では、音声認識エンジン25での音声認識の結果として、ユーザの相槌音声「うん」や「はい」などが検出された場合、ユーザの理解行動は肯定的な理解行動であると判定され、肯定的な理解行動である旨の判定結果が出力される。
また、例えば行動認識エンジン26での頷きの種別の認識結果として、ユーザが頭部を縦方向に振ったとの認識結果が得られた場合には、ユーザの理解行動は肯定的な理解行動であると判定され、肯定的な理解行動である旨の判定結果が出力される。
なお、上述したように音声認識エンジン25からの音声認識結果、および行動認識エンジン26からの頷きの種別の認識結果の何れか一方のみが用いられて理解行動判定が行われてもよいし、それらの両方が用いられて理解行動判定が行われてもよい。
ステップS46において、理解行動判定部27は、理解行動判定を終了するか否かを判定する。例えば図3を参照して説明した音声発話処理において、音声対話を終了するとされた場合、理解行動判定を終了すると判定される。
ステップS46において理解行動判定を終了しないと判定された場合、処理はステップS41に戻り、上述した処理が繰り返し行われる。すなわち、ユーザによる次の理解行動について理解行動判定が行われる。
これに対して、ステップS46において理解行動判定を終了すると判定された場合、理解行動判定処理は終了する。
以上のようにして音声対話システムは、ユーザとの音声対話が開始されると、その対話時におけるユーザの理解行動に対して、肯定的な理解行動であるか、または否定的な理解行動であるかの理解行動判定を行う。このようにして理解行動判定を行うことで、その判定結果を用いて、より適切な対話制御を行うことができるようになる。
〈対話進行制御処理の説明〉
続いて、図3を参照して説明した音声発話処理のステップS13において、音声出力対話進行制御部23が理解行動要求位置ごとに、次に発話させる発話文言を決定して音声発話、つまり音声対話の進行を制御する処理である対話進行制御処理の具体例について説明する。すなわち、以下、図5のフローチャートを参照して、音声出力対話進行制御部23により行われる対話進行制御処理について説明する。
続いて、図3を参照して説明した音声発話処理のステップS13において、音声出力対話進行制御部23が理解行動要求位置ごとに、次に発話させる発話文言を決定して音声発話、つまり音声対話の進行を制御する処理である対話進行制御処理の具体例について説明する。すなわち、以下、図5のフローチャートを参照して、音声出力対話進行制御部23により行われる対話進行制御処理について説明する。
この対話進行制御処理は、図3のステップS13において、発話テキストの文章における理解行動要求位置ごとに行われる。すなわち、発話テキストの文章の理解行動要求位置の直前の文節を音声発話するタイミングで対話進行制御処理が行われる。
以下では、特に発話テキストの文章における理解行動要求位置の直前の文節の文言、つまりこれから発話される文言を特に処理対象文言とも称することとする。
ステップS71において、音声出力対話進行制御部23は、保持している理解・集中度が予め定められた所定の閾値th1以上であるか否かを判定する。
ここで、理解・集中度は、ユーザが音声対話システムによる音声発話に対して、どれだけ意識を集中させ、発話内容を理解できているかを示すパラメータであり、例えば音声対話開始時には、予め定められた初期値とされる。このとき、理解・集中度の初期値は、例えば閾値th1未満の値となるように定められる。
理解・集中度の値は、例えば理解行動要求位置で文言を発した直後のタイミングなど、ユーザとの音声対話を行っていく過程で累積的に更新されていき、更新された理解・集中度の値は次の理解行動要求位置等で使用される。
さらに、ここでは理解・集中度の値が大きいほどユーザが意識を集中させ、高い理解度で対話を行っているものとする。すなわち、理解・集中度の値が大きいほど、音声対話に対するユーザの集中度および理解度が高いものとする。
ステップS71において理解・集中度が閾値th1以上であると判定された場合、つまりユーザの集中度および理解度が十分に高い状態であると判定された場合、処理はステップS72へと進む。
ステップS72において、音声出力対話進行制御部23は発話時における発話速度の設定を行う。
例えばステップS72が行われる状態では、ユーザが十分集中および理解している状態であるので、ある程度速い速度で処理対象文言が発話されるように発話速度が定められる。具体的には、例えば発話速度が現在の理解・集中度の値に対して定められた速度となるように発話速度が決定される。この場合、理解・集中度の値が大きいほど、発話速度が速くなるようになされる。また、例えば発話速度がこれまでの値から所定値だけ上がるように発話速度が決定されるようにしてもよい。
ステップS73において、音声出力対話進行制御部23は、処理対象文言のテキストデータを音声合成エンジン24に出力し、理解行動の誘発をせずに、ステップS72で定められた発話速度で処理対象文言が発話されるように処理対象文言の音声を発話させる。
この場合、音声合成エンジン24は、音声出力対話進行制御部23の制御に従って、供給された処理対象文言が指定された発話速度で再生される音声データを生成し、音声再生デバイス31に供給する。このとき、理解行動の誘発は行われないので、処理対象文言には、理解行動誘発文言は付加されない。また、音声再生デバイス31は音声合成エンジン24からの音声データに基づいて、処理対象文言の音声を再生する。このようにして処理対象文言の音声データを生成し、再生する処理は、図3のステップS14およびステップS15の処理に対応する。
このような場合、処理対象文言に理解行動誘発文言が付加されない状態で、かつ比較的速い速度で処理対象文言の音声が発話される。このように、ユーザの集中度や理解度が高い状態では、理解行動要求位置であっても特に理解行動の誘発をせずに、比較的速い速度で音声発話を行うことで、ユーザの集中度や理解度、つまりユーザの状況に応じた適切な音声対話を実現することができる。
なお、ここでは理解・集中度が閾値th1以上であるか否か、つまり理解・集中度に応じて発話速度が変更(決定)される場合について説明するが、発話速度だけでなく発話音声のトーンも変更(決定)されるようにしてもよい。この場合、例えば理解・集中度の値が大きく、ユーザの集中度および理解度が高いほど、発話音声のトーンが高くなるように、処理対象文言のトーンが決定されるようにすることができる。
ステップS74において、音声出力対話進行制御部23は、保持している理解・集中度の値を予め定められた微小値だけ下げた後、処理対象文言を発話テキストにおける、発話が終了した文言の次の文言、つまり次の文節の文言として対話進行制御処理は終了する。
ステップS74において、理解・集中度が微小値だけ下げられる(減少させる)のは、その後の対話において、理解行動誘発が1度も行われなくなってしまうことを防止するためである。このようにユーザの集中度や理解度が十分に高い場合でも、適宜、理解行動が誘発されるように理解・集中度の更新を行うことで、ユーザの集中を維持させ、より適切な対話制御を実現することができる。
また、ステップS71において、理解・集中度が閾値th1以上でないと判定された場合、すなわちユーザの集中度や理解度が十分に高いとはいえない場合、処理はステップS75へと進む。
ステップS75において、音声出力対話進行制御部23は、処理対象文言に対して理解行動誘発文言を付加するとともに、その理解行動誘発文言の部分、つまり理解行動誘発文言が付加された文言(発話)の語尾の抑揚が上がるように抑揚の付加を行う。
例えば理解行動誘発文言として「ね」や「ですね」などが付加されて、その語尾の抑揚が上げられる。具体的には、例えば処理対象文言が「財布と」である場合、理解行動誘発文言として「ね」が付加されて発話文言が「財布とね」とされるとともに、その語尾部分の「とね」の抑揚が上がるようになされる。
ステップS76において、音声出力対話進行制御部23は、発話時における発話速度の設定を行う。
ステップS76ではステップS72と同様にして発話速度の設定が行われるが、例えばステップS76の処理が行われる場合には、ユーザの集中度や理解度が十分に高いとはいえない状態であるので、処理対象文言が比較的遅い速度で発話されるように、発話速度が下げられる。すなわち、例えば発話速度が現時点での理解・集中度に対して定められた値となるように変更される。その他、例えば現時点での発話速度の値が予め定められた所定値だけ下げられるようにしてもよい。
また、ステップS76においても、発話速度だけでなく発話のトーンも変更されるようにしてもよい。そのような場合、例えばユーザの集中度や理解度が低い時には、発話音声のトーンが低くなるように発話時のトーンが定められる。すなわち、理解・集中度に基づいて発話時のトーンの高さが定められる。
ステップS77において、音声出力対話進行制御部23は、理解行動誘発文言が付加された処理対象文言のテキストデータを音声合成エンジン24に出力し、理解行動の誘発が行われるように、理解行動誘発文言が付加された処理対象文言の音声を発話させる。すなわち、音声出力対話進行制御部23は、理解行動要求位置においてユーザの理解行動を誘発する発話を行わせる。
この場合、音声出力対話進行制御部23は、音声合成エンジン24に対して理解行動誘発文言の付加された処理対象文言がステップS76で定めた発話速度で発話されるように指示するとともに、語尾への抑揚の付加も指示する。また、音声出力対話進行制御部23は発話に間があけられるようにし、理解行動誘発文言と、発話の語尾の抑揚と、発話の間によって、ユーザの理解行動が誘発されるようにする。
音声合成エンジン24は、音声出力対話進行制御部23の制御に従って、供給された文言、つまり処理対象文言と理解行動誘発文言を、指定された発話速度および抑揚で再生するための音声データを生成し、音声再生デバイス31に供給する。また、音声再生デバイス31は音声合成エンジン24からの音声データに基づいて、処理対象文言とそれに付加された理解行動誘発文言の音声を再生する。このようにして処理対象文言等の音声データを生成し、再生する処理は図3のステップS14およびステップS15の処理に対応する。
音声の再生により、処理対象文言に理解行動誘発文言が付加され、語尾の抑揚が上がるように、かつ比較的遅い速度で処理対象文言の音声が発話される。このように、ユーザの集中度や理解度が十分でない状態では、ユーザに対して適宜、理解行動の誘発を行い、比較的遅い速度で音声発話を行うことで、ユーザの集中度や理解度に合わせた適切な音声対話を実現することができる。
また、音声発話が行われると、ユーザによる理解行動の待ち状態となる。すなわち、音声出力対話進行制御部23による発話制御によって、ユーザの理解行動誘発のために間があけられる。
この場合、音声出力対話進行制御部23は、音声合成エンジン24に音声発話の文言を出力したタイミング、つまり音声発話を指示したタイミングでレスポンス時間の計測を開始する。
ここで、レスポンス時間とは、音声発話を指示してから、その音声発話に対してユーザが何らかの理解行動を行うまでの時間、すなわちユーザの応答時間である。
処理対象文言と理解行動誘発文言が発話された後の理解行動の待ち状態では、音声対話システムによる発話の文は完結していない状態であることと、理解行動誘発文言と語尾に付加された抑揚と発話の間とから、ユーザによる理解行動が誘発されることになる。ユーザは、発話された音声に対して、相槌や頷きなどの理解行動を行って、自身の理解の状態をフィードバックする。
なお、ステップS77での音声発話時には、クライアントデバイス12においてLED(Light Emitting Diode)の点灯や他の視覚的な提示が可能である場合には、LEDの点灯やアイコン等の提示などにより、音声対話システムが停止状態でないことをユーザに提示するようにしてもよい。また、停止状態でないことのユーザへの提示は、その他、例えば定期的な効果音の再生などにより行われてもよい。さらに、ユーザに対して理解行動が要求されている旨を視覚的または聴覚的に提示(通知)するようにしてもよい。
以上のようにしてユーザの理解行動の待ち状態となると、ステップS78において、音声出力対話進行制御部23は、レスポンス時間の計測を開始してから規定時間内に、ユーザによる理解行動があったか否かを判定する。すなわち、規定時間内にユーザの理解行動が検出されたかが判定される。
例えばステップS78では、レスポンス時間の計測を開始してから規定時間内に、理解行動判定部27から理解行動の判定結果が供給された場合に、規定時間内に理解行動があったと判定される。
なお、ここでの規定時間は予め定められた固定の時間とされてもよいし、理解・集中度などに応じて動的に定められる時間とされるようにしてもよい。例えば理解・集中度により規定時間が定められるときには、理解・集中度が高いほど規定時間を短くするなどとすることで、ユーザの集中度および理解度に応じた適切な時間を定めることができる。
ステップS78において、規定時間内に理解行動がなかったと判定された場合、音声発話がなされた後、しばらくしてもユーザは理解行動をしなかったので、ステップS79において、音声出力対話進行制御部23は保持している理解・集中度の値を下げる。
ステップS79では、例えばステップS74の処理で理解・集中度が下げられるよりも、より大きく理解・集中度の値が下がるように、理解・集中度が更新される。これは、ユーザが理解行動をしなかったということは、ユーザが音声発話を聞いていなかったり、発話内容を十分に理解していなかったりしている状況であるからである。
ステップS80において、音声出力対話進行制御部23は、ステップS79での更新後の理解・集中度が予め定められた所定の閾値th2以上であるか否かを判定する。
ここで、閾値th2の値は、例えば上述した閾値th1の値よりも小さい、予め定められた値とされる。
ステップS80において、理解・集中度が閾値th2以上でないと判定された場合、ステップS81において、音声出力対話進行制御部23は、ユーザは音声対話システムによる音声発話を全く聞いていないものとして、ユーザとの音声対話を終了(停止)させ、対話進行制御処理は終了する。この場合、その後の図3の音声発話処理のステップS16では音声対話を終了すると判定されることになる。
なお、ステップS81で音声対話を終了させる場合、音声出力対話進行制御部23は、発話テキストを未発話状態であるとして、その発話テキスト等を記録しておき、しばらく時間が経過してから、再度、発話テキストの内容の音声発話を行うようにしてもよい。この場合、音声発話が行われるタイミングは、例えば一定時間が経過した後、再度、センサ33等によりユーザの存在が認識されたときや、他の発話テキストの音声発話の終了時など、ユーザの理解・集中度が高い状態のときなどとすることができる。
未発話状態の発話テキストの音声発話を行う際には、発話テキストの文章の最初から音声発話を行うようにすればよい。
また、ステップS81で音声対話を終了させる場合、すなわち音声対話を途中で停止させた場合、音声出力対話進行制御部23は、例えば音声対話を終了させた旨のメッセージと、発話テキストとが含まれる通知情報を生成し、通知情報の出力を制御してもよい。これにより、音声対話以外の方法でユーザに対して発話テキストの内容を通知することができる。
そのような場合、例えば音声出力対話進行制御部23は、通知情報をサーバ11に設けられた図示せぬ通信部によりクライアントデバイス12としてのスマートホン等の端末装置に送信し、通知情報により示される発話テキストの内容等をクライアントデバイス12に表示させる。例えば通知情報の送信方法、つまり通知方法は、電子メールや、クライアントデバイス12にインストールされたアプリケーションプログラムの通知機能など、どのような方法であってもよい。
これにより、例えばノーティフィケーション機能を利用して、クライアントデバイス12のステータスバーに通知情報を受信した旨等を表示させたり、通知情報をクライアントデバイス12の表示画面にポップアップ表示させたりすることができる。その結果、ユーザに発話テキストの内容を通知することができる。
また、発話テキストの内容を含む通知情報を送信するのではなく、発話テキストの内容の確認を促すメッセージのみが含まれる通知情報を送信するようにしてもよい。
一方、ステップS80において、理解・集中度が閾値th2以上であると判定された場合、ユーザは集中度および理解度は低いが、まだ音声発話を聞いているとし、処理はステップS82へと進む。
ステップS82において、音声出力対話進行制御部23は、ユーザに対して理解行動要求を行う音声を発話させる。
すなわち、音声出力対話進行制御部23は、例えば「いいですか?」など、ユーザに対して理解行動を直接的に促す(要求する)旨の文言である理解行動要求文言のテキストデータを音声合成エンジン24に出力し、音声発話を指示する。
すると、音声合成エンジン24は、音声出力対話進行制御部23の指示に従って、供給された理解行動要求文言のテキストデータから、その理解行動要求文言の音声データを生成し、音声再生デバイス31に供給する。また、音声再生デバイス31は音声合成エンジン24からの音声データに基づいて、理解行動要求文言の音声を再生する。これにより、ユーザに対して理解行動を要求する発話が行われる。このようにして理解行動要求文言の音声を再生することで、ユーザに理解行動を促すことができる。
なお、理解行動要求文言は「いいですか?」に限らず、他のどのような文言であってもよい。例えばユーザの理解・集中度が著しく低い場合には、理解行動要求文言として「聞いてる?」などの文言を発話するようにしてもよい。
また、ステップS82において、理解行動要求文言を発話させるのではなく、現在の処理対象文言と、その処理対象文言に付加された理解行動誘発文言とが再度、発話されるようにしてもよい。すなわち、ステップS77の処理での理解行動を誘発する音声発話を再度行うことで、直前の発話が繰り返されるようにしてもよい。
さらに、ステップS82において、理解行動要求文言を発話させるとともに、現在の処理対象文言とその処理対象文言に付加された理解行動誘発文言とを再度、発話させるようにしてもよい。その他、ステップS78で規定時間内に理解行動がなかったと判定された場合に、直前に行った処理対象文言と理解行動誘発文言の発話が繰り返し行われるようにしてもよい。
ステップS82において理解行動要求文言の発話が行われると、その後、処理はステップS78に戻り、上述した処理が繰り返し行われる。
また、ステップS78において規定時間内に理解行動があったと判定された場合、つまり、規定時間内に理解行動判定部27から音声出力対話進行制御部23に理解行動の判定結果が供給された場合、音声出力対話進行制御部23はレスポンス時間の計測を停止し、処理はステップS83へと進む。
このようにしてレスポンス時間の計測を停止させることで、処理対象文言の音声発話が指示されてから、理解行動の判定結果が供給されるまでの時間であるレスポンス時間が得られる。このレスポンス時間は、音声発話が行われてから、ユーザがその音声発話に対する理解行動を行うまでの応答時間を示しているということができる。
また、規定時間内に理解行動があったと判定された場合、つまり規定時間内にユーザの理解行動が検出された場合、音声出力対話進行制御部23は、そのユーザの理解行動の検出結果と発話テキストに基づいて、次の発話を制御する。
すなわち、ステップS83において、音声出力対話進行制御部23は、理解行動判定部27から供給された理解行動の判定結果が肯定的な理解行動を示すものであるか否かを判定する。
ステップS83において、肯定的な理解行動を示すものでない、つまり否定的な理解行動を示すものであると判定された場合、ユーザは発話内容を理解しておらず理解度が低いので、ステップS84において、音声出力対話進行制御部23は保持している理解・集中度の値を下げる。
ステップS84では、例えばステップS79の処理で理解・集中度が下げられるときと同じだけ、またはステップS79の処理で理解・集中度が下げられるときよりも小さい値だけ、理解・集中度の値が下がるように理解・集中度が更新される。なお、ステップS84においても、ステップS74の処理で理解・集中度が下げられるよりも、より大きく理解・集中度の値が下がるように、理解・集中度が更新される。
ステップS84で理解・集中度が更新されると、その後、処理はステップS76へと戻り、上述した処理が繰り返し行われる。
この場合、音声発話時の発話速度が再度設定されて、より遅い発話速度で直前の発話内容が繰り返し発話されることになる。すなわち、ユーザが否定的な理解行動を行った場合、音声出力対話進行制御部23は、直前に行われた発話を再度行わせる。
ステップS84の処理が行われたときには、ユーザの理解度および集中度が低下しているので、より遅い発話速度で直前の発話を繰り返すことで、ユーザが発話内容を理解しやすくすることができる。しかも、この場合、ユーザが発話内容を理解するまで対話が次に進まないので、ユーザが途中で理解を諦めたり、発話内容を理解できなくなったりしてしまうようなこともない。
このようにユーザの集中度および理解度が低い場合には、理解・集中度の値が下がるように更新が行われるので、理解行動の誘発回数が増加していくとともに音声発話の発話速度やトーンも徐々に下がっていくことになる。
これに対して、ステップS83において肯定的な理解行動を示すものであると判定された場合、ステップS85において、音声出力対話進行制御部23は、得られたレスポンス時間に基づいて理解・集中度を更新する。
具体的には、例えば音声出力対話進行制御部23は、レスポンス時間が短いほど理解・集中度の値が大きくなるように、理解・集中度の更新を行う。
これにより、ユーザによる肯定的な理解行動のレスポンス時間が短く、ユーザの集中度や理解度が高いときには累積的に理解・集中度が上がるため、音声発話の文章が進むにつれて次第に発話速度が速くなり、理解行動の誘発回数も減少することになる。また、理解・集中度に応じて発話のトーンも変更する場合には、音声発話の文章が進むにつれて次第に発話のトーンが高くなっていくことになる。
このように、レスポンス時間が短いほど理解行動の誘発回数がより少なくなるとともに、発話速度が速くなり、発話のトーンが高くなるように発話を制御することで、ユーザの集中度および理解度に合わせた、より適切な対話制御を実現することができる。
ステップS85において理解・集中度が更新されると対話進行制御処理は終了する。そして、その後、適宜、それ以降の文節の文言の発話が行われ、次の理解行動要求位置の直前の文節が新たな処理対象文言とされて、次の対話進行制御処理が行われる。
すなわち、ユーザが肯定的な理解行動を行ったときには、音声出力対話進行制御部23は、発話テキストのまだ発話がされていない次の文言を発話させることで、発話文言が次の文言へと進むことになる。
以上のようにして音声出力対話進行制御部23は、理解・集中度およびユーザの理解行動に応じて、適宜、発話速度を設定したり、理解行動を誘発したり、理解行動を要求したりしながら発話テキストに示される発話内容での音声対話を進めていく。このようにすることで、ユーザの集中度および理解度に応じて、より適切な対話制御を行うことができる。
なお、ここでは理解行動要求位置において、適宜、ユーザの理解行動を誘発し、ユーザの理解行動に応じて対話を進める例について説明した。
しかし、これに限らず、例えば理解行動要求位置以外のタイミング(時間)においても音声出力対話進行制御部23がユーザによる理解行動を常時監視しておき、その理解行動の判定結果に応じて理解・集中度の値を更新するようにしてもよい。
そのような場合、肯定的な理解行動があったときには、理解・集中度の値を上げるように更新が行われ、その後において理解行動の誘発が必要以上に多く行われることが抑制される。逆に、否定的な理解行動があったときには、理解・集中度の値を下げるように更新が行われ、理解行動の誘発の機会が増やされてユーザが発話内容を理解しやすくされる。
また、以上のような対話進行制御処理により、例えば図6に示すような対話が行われることになる。この例は、音声対話システムにより買い物リストを提示する音声発話が行われる対話シーケンス例となっている。
対話シーケンスの開始時には、理解・集中度がある程度低い状態から対話制御が開始される。矢印Q11に示すように、まず音声対話システムにより処理対象文言に理解行動誘発文言「ね」が付加され、語尾の抑揚が上げられた文言「今日の買い物はニンジンとね」が、低速の発話速度で発話される。ここでは、理解行動誘発文言「ね」を付加することで、発話文言は続きがあることを示す言い方となっている。なお、図中、上向きの矢印は抑揚が上げられていることを表している。
文言「今日の買い物はニンジンとね」が発話されると理解行動の待ち状態となり、最初は長めの間が設けられ、相槌(理解行動)が促される。
これに対して、ユーザが矢印Q12に示すように発話「うん」を行うと、音声対話システムは、その発話「うん」に基づいて肯定的な相槌を検出して、ユーザが肯定的な理解行動を行ったと判定し、次の音声発話を開始する。
すなわち、音声対話システムは、矢印Q13に示すように処理対象文言に理解行動誘発文言が付加された文言「玉ねぎ3個とね」を発話する。このとき、語尾の抑揚が上げられて矢印Q11における場合と同様に低速の発話速度での発話が行われる。
この発話に対してユーザが規定時間以上、理解行動を行わなかったので理解・集中度が下げられ、音声対話システムは、矢印Q14に示すように理解行動要求文言「いいですか?」を低速の発話速度で発話する。
ここでは、文言「玉ねぎ3個とね」の発話後、ユーザの理解行動がなかったことから、ユーザの対話への意識、つまり集中度が下がったものとされて理解・集中度が下げられ、理解行動要求文言「いいですか?」の発話が行われている。
すると、ユーザにより矢印Q15に示すように否定的な相槌の発話「え?」が行われたので、音声対話システムでは、この発話、つまり理解行動の判定が行われ、否定的な理解行動であるとの判定結果が得られる。
このように否定的な理解行動がなされるとさらに理解・集中度が下げられ、音声対話システムは、矢印Q16に示すように直前の処理対象文言とそれに付加された理解行動誘発文言である文言「玉ねぎ3個とね」を再度、発話する。このとき、語尾の抑揚が上げられるように発話が行われる。すなわち、矢印Q13に示した発話と同様の発話が繰り返される。このような状態では、ユーザの理解・集中度が低いので低速の発話速度で発話が行われる。
矢印Q16に示す文言「玉ねぎ3個とね」の発話後、矢印Q17に示すように規定時間内にユーザが理解行動としての発話「うん」を行うと、音声対話システムでは、この理解行動は肯定的な理解行動であるとの判定がなされる。
そして、矢印Q18に示すように、音声対話システムによって、次の処理対象文言に理解行動誘発文言が付加された文言「じゃがいもとね」が低速の発話速度で、語尾の抑揚が上げられて発話される。
これに対して、矢印Q19に示すように規定時間内にユーザが理解行動としての発話「うん」を行うと、音声対話システムは、矢印Q20に示すように次の処理対象文言に理解行動誘発文言が付加された文言「牛肉300gとね」を低速の発話速度で、語尾の抑揚を上げて発話する。
次に、これに対してユーザにより矢印Q21に示すようにこれまでよりも短いレスポンス時間で、肯定的な理解行動を示す相槌の文言「うん」が発話された。
すると、音声対話システムでは、ユーザの理解・集中度が上げられて、矢印Q22に示すように、次の処理対象文言に理解行動誘発文言が付加された文言「塩とね」が中速の発話速度で、語尾の抑揚が上げられて発話される。つまり、ユーザの理解・集中度が高まったことに伴い、これまでよりも速い発話速度で発話が行われる。
そして、これに対してユーザにより矢印Q23に示すように、矢印Q21に示した場合よりもさらに短いレスポンス時間で、肯定的な理解行動を示す相槌の文言「うん」が発話された。
その結果、音声対話システムでは、ユーザの理解・集中度がさらに上げられて、矢印Q24に示すように、次の処理対象文言に理解行動誘発文言が付加された文言「胡椒とね」が中速の発話速度で、語尾の抑揚が上げられて発話される。
さらに、これに対してユーザにより矢印Q25に示すように、矢印Q23に示した場合よりもさらに短いレスポンス時間で、肯定的な理解行動を示す相槌の文言「うん」が発話された。そうすると、音声対話システムでは、ユーザの理解・集中度がさらに上げられて、矢印Q26に示すように、次の処理対象文言「醤油とビールです。」が高速の発話速度で発話され、対話シーケンスが終了する。
この場合、矢印Q25に示した理解行動によって理解・集中度が十分高い値となったので、文言「醤油と」と、その次の文言「ビールです。」との間には理解行動誘発文言が付加されず、つまり理解行動の誘発が行われずに発話が行われている。また、ここでは理解・集中度が十分高い値となったので、発話速度も最も速い発話速度となっている。
このように、図6に示した例では、矢印Q16に示した発話以降において、理解行動の誘発に対するユーザのレスポンス時間が短くなっていき、それに伴ってユーザの理解・集中度が徐々に大きくなっている様子が示されている。
この例では、理解・集中度が大きくなるのに伴って音声対話システムによる音声発話の発話速度も速くなっていくとともに、理解行動の誘発回数も減少している。このようにユーザの集中度および理解度に応じて理解行動を誘発したり、発話速度を変化させたりすることで、適切な対話制御を実現することができる。
以上のように、本技術を適用した音声対話システムによれば、より適切な対話制御を行うことができる。
特にテキスト音声合成が苦手とする長い文章や羅列情報を含む文章の音声発話において、ユーザの集中度および理解度に応じた発話速度で音声発話が行われるため、音声対話システムがユーザに対して確実に伝達したい発話内容について、ユーザの理解や記憶のしやすさを向上させることができる。
また、一般的なテキスト音声合成の音声発話性能により、すなわち抑揚と発話速度が一定であることにより理解しにくい文章の内容を、本技術を適用した音声対話システムでは理解行動を利用したインタラクションにより補うことができる。すなわち、理解行動の判定結果やレスポンス時間に応じて発話速度を変化させたり、抑揚を変化させたりすることで、ユーザが発話内容を理解しやすいように、また発話内容を記憶しやすいように対話を行うことができる。
さらに、ユーザの集中度および理解度が高い場合、つまりユーザが集中して対話音声を聞いている場合には、発話速度が上げられるだけでなく、理解行動誘発回数が減らされてユーザの理解行動への負荷が下がるので、ユーザはより短い時間かつ少ない負荷で対話を行うことができる。
〈理解行動要求位置の他の検出例1〉
なお、以上においては、例えば図2を参照して説明したように、発話テキストの文章内の述語節の文節に係る文節位置に基づいて、理解行動要求位置を検出する例について説明した。しかし、理解行動を誘発したいアイテム等の文言が含まれる文節位置を検出することができれば、どのような方法により理解行動要求位置を検出するようにしてもよい。
なお、以上においては、例えば図2を参照して説明したように、発話テキストの文章内の述語節の文節に係る文節位置に基づいて、理解行動要求位置を検出する例について説明した。しかし、理解行動を誘発したいアイテム等の文言が含まれる文節位置を検出することができれば、どのような方法により理解行動要求位置を検出するようにしてもよい。
例えば理解行動要求位置の他の検出方法の例として、いつ(When)、どこで(Where)、誰が(Who)、何を(What)、なぜ(Why)、どのように(How)という6つの要素、すなわち文節の格としていわゆる5W1Hを示す時間格、場所格、対象格、原因格が検出されたときに、それらの格の文節の直後の位置を理解行動要求位置と判定してもよい。
このような場合においても、文として非完結な状態の位置が理解行動要求位置とされることに加えて、5W1Hの各情報粒度でユーザの理解を確認することができる。この例は、5W1Hの各情報粒度で理解確認を行いたいときに特に有効である。
具体的には、例えば発話テキストとして、「今日の予定として、打ち合わせのため10時に品川駅で山田さんと待ち合わせがあります。」が入力されたとする。
そのような場合、理解行動要求位置検出部22では、原因格である文節「打ち合わせのため」の直後と、時間格である文節「10時に」の直後と、場所格である文節「品川駅で」の直後と、対象格である文節「山田さんと」の直後のそれぞれの位置が、理解行動要求位置として検出されることになる。
以上のように発話テキストの文章内の時間格や、場所格、対象格、原因格の文節の位置に基づいて、理解行動要求位置を検出するようにすることもできる。
また、理解行動要求位置の他の検出方法の例として、予め単語の重要度が登録された単語辞書を用いるようにしてもよい。そのような場合、単語と、単語の重要度とが対応付けられた単語辞書が予め理解行動要求位置検出部22に記録されている。
理解行動要求位置検出部22は、単語辞書を参照して、発話テキストの文章に含まれる各単語の重要度を特定し、重要度が高い単語を含む文節の直後の位置を、理解行動要求位置として検出する。このとき、例えば重要度が所定の閾値以上である単語を含む文節の直後が全て理解行動要求位置とされるようにしてもよいし、発話テキストの文章に含まれる単語の中から、重要度が高い順に所定個数の単語を選択し、選択したそれらの単語が含まれる文節の直後が理解行動要求位置とされるようにしてもよい。
〈理解行動要求位置の他の検出例2〉
さらに、以上においては発話テキストが日本語の文章である場合について説明したが、これに限らず、発話テキストが英語など、日本語以外の他の言語である場合においても本技術は適用可能である。すなわち、以上において説明した例と同様に理解行動要求位置を検出することができる。
さらに、以上においては発話テキストが日本語の文章である場合について説明したが、これに限らず、発話テキストが英語など、日本語以外の他の言語である場合においても本技術は適用可能である。すなわち、以上において説明した例と同様に理解行動要求位置を検出することができる。
例えば発話テキストが英語の文章である場合について考える。
英語では、文頭に主語+述語(動詞)が現れるが、その述語(動詞)の後から述語に係る目的語(対象格)が複数あった場合にそれらの目的語が羅列情報であるとされる。そして、日本語と同様に非完結の状態である羅列情報の間の位置、つまり「,」(カンマ)の直後の位置や「and」の直後の位置が理解行動要求位置とされ、その理解行動要求位置で、適宜、相槌や頷きなどの理解行動が誘発される。
また、2つ目以降の文では主語+述語(動詞)の直後の位置が理解行動要求位置とされる。この場合においても文章が非完結な状態で、適宜、相槌や頷きなどの理解行動が誘発されることになる。
具体例として、例えば図7の矢印A41に示すように英語の文章「Please buy carrots, onions, potatoes, beef, and salt. Please don’t forget to post the letter.」というテキストデータが自然言語解析部21に入力されたとする。
このような場合に、自然言語解析部21において発話テキストに対する自然言語解析が行われると、矢印A42に示す解析結果が得られる。
矢印A42に示す部分では、図2における場合と同様に、各四角形が文の区切られた1つの区間、つまり句を表しており、その四角形内には発話テキストの句に区切られた文言が記されている。また、各句を表す四角形同士を結ぶ線分は、句同士の係り受けを表している。これらの係り受けの表記方法は図2における場合と同様である。
さらに、矢印A42に示す部分では、各句を表す四角形の図中、右側には、それらの句の言語的な格と品詞が記されている。例えば図中、一番上側の句「Please buy」の言語的な格は述語節で品詞は動詞であることが記されている。
このような場合、理解行動要求位置検出部22は、自然言語解析の結果から同一の述語節(動詞)に係る複数の対象格(目的格)を検出し、検出された複数の対象格の句の間の位置を理解行動要求位置とする。
但し、最も後ろに位置する対象格の句については、その句に含まれる「and」の直後の位置、すなわち単語「and」と、その直後の対象語との間の位置が理解行動要求位置とされる。
この例では、発話テキストの1文目は、ユーザが買ってくるべきもの(アイテム)、つまり買い物リストを示す文章となっており、買うべき物(アイテム)を含む対象格の句が同一の述語節の句に係っている。すなわち、買うべきものが羅列されている文章となっている。
図7に示す例では、発話テキストの1文目の矢印W41乃至矢印W44に示される位置が理解行動要求位置検出部22により検出された理解行動要求位置となっている。具体的には、例えば矢印W41により示される理解行動要求位置は、句「carrots,」と「onions,」の間の位置となっている。また、例えば矢印W44により示される理解行動要求位置は、句「and salt.」における単語「and」と、対象語「salt」との間の位置となっている。
また、理解行動要求位置検出部22は、発話テキストに複数の文が含まれる場合は、文と文の区切りの位置を理解行動要求位置とは判定しない。
さらに、理解行動要求位置検出部22は、発話テキストに複数の文が含まれる場合、2つ目以降の文において、文の最初の述語節を検出し、その最初の述語節の句の直後の位置を理解行動要求位置とする。
この例では、2つ目の文における矢印W45に示される位置が理解行動要求位置とされている。ここでは、矢印W45に示される位置は、述語節の句に係る最初の句の直前の位置となっている。
音声出力対話進行制御部23は、以上のようにして検出された理解行動要求位置に基づいて、例えば図5を参照して説明した対話進行制御処理と同様の処理を行うことで、対話制御を行う。
このとき、音声出力対話進行制御部23は、例えば理解行動の誘発を行う理解行動要求位置の直前の句が対象格(目的語)であり、その句の次の句に単語「and」が含まれていないときには、理解行動要求位置の直前の句の最後の単語(目的語)の次に単語「and」を付加して音声発話を行わせる。また、この場合、付加した単語「and」の直前に「,」(カンマ)があるときには、その「,」が削除される。このように発話文言の句に付加される単語「and」は、理解行動誘発文言として機能する。
さらに、音声発話時には、理解行動の誘発を行う理解行動要求位置においては、ある程度の間が設けられて、つまりある程度長い時間があけられて音声の発話が行われる。
したがって、矢印W41乃至矢印W45のそれぞれの理解行動要求位置において理解行動の誘発が行われる場合には、例えば矢印A43に示すように音声発話が行われる。
すなわち、まず最初の文言「Please buy carrots and」が発話されて理解行動の誘発が行われ、続いて文言「onions and」が発話されて理解行動の誘発が行われる。ここで、理解行動の誘発は例えば発話の間をあけたり、単語「and」を付加したり、発話の語尾に抑揚を付加したりすることにより行われる。
さらに文言「potatoes and」が発話されて理解行動の誘発が行われてから、文言「beef and」が発話されて理解行動の誘発が行われ、文言「salt. Please don’t forget」が発話されて理解行動の誘発が行われる。そして、最後に文言「to post the letter.」が発話されて音声対話が終了する。
以上のように発話テキストが日本語以外の言語の文章であるときでも、発話テキストの文章内の述語節に係る句(文節)の位置に基づいて、理解行動要求位置を検出することが可能である。
〈理解行動要求位置の他の検出例3〉
さらに、発話テキストが英語の文章である場合、いわゆる5W1Hで前置詞により場所や時間、原因を表すときには、その前置詞の直後の位置が理解行動要求位置とされて、その理解行動要求位置で、適宜、相槌や頷きなどの理解行動が誘発されるようにしてもよい。この場合においても文章が非完結な状態で、適宜、相槌や頷きなどの理解行動が誘発されることになる。
さらに、発話テキストが英語の文章である場合、いわゆる5W1Hで前置詞により場所や時間、原因を表すときには、その前置詞の直後の位置が理解行動要求位置とされて、その理解行動要求位置で、適宜、相槌や頷きなどの理解行動が誘発されるようにしてもよい。この場合においても文章が非完結な状態で、適宜、相槌や頷きなどの理解行動が誘発されることになる。
具体的には、例えば図8の矢印A71に示すように英語の文章「You have an appointment for the meeting at 3pm at Shinagawa office.」というテキストデータが自然言語解析部21に入力されたとする。
このような場合に、自然言語解析部21において発話テキストに対する自然言語解析が行われると、矢印A72に示す解析結果が得られる。
矢印A72に示す部分では、図2における場合と同様に、各四角形が文の区切られた1つの区間、つまり句を表しており、その四角形内には発話テキストの句に区切られた文言が記されている。また、各句を表す四角形同士を結ぶ線分は、句同士の係り受けを表している。これらの係り受けの表記方法は図2における場合と同様である。
さらに、矢印A72に示す部分では、各句を表す四角形の図中、右側には、それらの句の言語的な格が記されている。また、必要に応じて格とともに品詞も記されている。例えば図中、一番上側の句「You」の言語的な格は主格であることが記されている。
このような場合、理解行動要求位置検出部22は、自然言語解析の結果から原因格、時間格、および場所格の句を検出し、検出された句内(句中)の前置詞の直後の位置を理解行動要求位置とする。
したがって、図8に示す例では、発話テキストの原因格の句の中の前置詞「for」の直後の位置、すなわち矢印W71により示される位置と、時間格の句の中の前置詞「at」の直後の位置、すなわち矢印W72により示される位置と、場所格の句の中の前置詞「at」の直後の位置、すなわち矢印W73により示される位置とが理解行動要求位置検出部22により検出される。そして、それらの矢印W71乃至矢印W73のそれぞれにより示される位置が理解行動要求位置とされている。
音声出力対話進行制御部23は、以上のようにして検出された理解行動要求位置に基づいて、例えば図5を参照して説明した対話進行制御処理と同様の処理を行うことで、対話制御を行う。このとき、理解行動の誘発を行う理解行動要求位置においては、ある程度の間が設けられて音声の発話が行われる。
したがって、矢印W71乃至矢印W73のそれぞれの理解行動要求位置において理解行動の誘発が行われる場合には、例えば矢印A73に示すように音声発話が行われる。
すなわち、まず最初の文言「You have an appointment for」が発話されて理解行動の誘発が行われ、続いて文言「the meeting at」が発話されて理解行動の誘発が行われる。ここで、理解行動の誘発は、例えば発話の間をあけたり、発話の語尾に抑揚を付加したりすることにより行われる。
さらに文言「3pm at」が発話されて理解行動の誘発が行われてから、最後に文言「Shinagawa office.」が発話されて音声対話が終了する。
以上のように発話テキストが日本語以外の言語の文章であるときでも、発話テキストの文章内の時間格や、場所格、対象格、原因格の句(文節)の位置に基づいて、理解行動要求位置を検出することが可能である。
〈コンピュータの構成例〉
ところで、上述した一連の処理は、ハードウェアにより実行することもできるし、ソフトウェアにより実行することもできる。一連の処理をソフトウェアにより実行する場合には、そのソフトウェアを構成するプログラムが、コンピュータにインストールされる。ここで、コンピュータには、専用のハードウェアに組み込まれているコンピュータや、各種のプログラムをインストールすることで、各種の機能を実行することが可能な、例えば汎用のパーソナルコンピュータなどが含まれる。
ところで、上述した一連の処理は、ハードウェアにより実行することもできるし、ソフトウェアにより実行することもできる。一連の処理をソフトウェアにより実行する場合には、そのソフトウェアを構成するプログラムが、コンピュータにインストールされる。ここで、コンピュータには、専用のハードウェアに組み込まれているコンピュータや、各種のプログラムをインストールすることで、各種の機能を実行することが可能な、例えば汎用のパーソナルコンピュータなどが含まれる。
図9は、上述した一連の処理をプログラムにより実行するコンピュータのハードウェアの構成例を示すブロック図である。
コンピュータにおいて、CPU(Central Processing Unit)501,ROM(Read Only Memory)502,RAM(Random Access Memory)503は、バス504により相互に接続されている。
バス504には、さらに、入出力インターフェース505が接続されている。入出力インターフェース505には、入力部506、出力部507、記録部508、通信部509、及びドライブ510が接続されている。
入力部506は、キーボード、マウス、マイクロホン、撮像素子などよりなる。出力部507は、ディスプレイ、スピーカなどよりなる。記録部508は、ハードディスクや不揮発性のメモリなどよりなる。通信部509は、ネットワークインターフェースなどよりなる。ドライブ510は、磁気ディスク、光ディスク、光磁気ディスク、又は半導体メモリなどのリムーバブル記録媒体511を駆動する。
以上のように構成されるコンピュータでは、CPU501が、例えば、記録部508に記録されているプログラムを、入出力インターフェース505及びバス504を介して、RAM503にロードして実行することにより、上述した一連の処理が行われる。
コンピュータ(CPU501)が実行するプログラムは、例えば、パッケージメディア等としてのリムーバブル記録媒体511に記録して提供することができる。また、プログラムは、ローカルエリアネットワーク、インターネット、デジタル衛星放送といった、有線または無線の伝送媒体を介して提供することができる。
コンピュータでは、プログラムは、リムーバブル記録媒体511をドライブ510に装着することにより、入出力インターフェース505を介して、記録部508にインストールすることができる。また、プログラムは、有線または無線の伝送媒体を介して、通信部509で受信し、記録部508にインストールすることができる。その他、プログラムは、ROM502や記録部508に、あらかじめインストールしておくことができる。
なお、コンピュータが実行するプログラムは、本明細書で説明する順序に沿って時系列に処理が行われるプログラムであっても良いし、並列に、あるいは呼び出しが行われたとき等の必要なタイミングで処理が行われるプログラムであっても良い。
また、本技術の実施の形態は、上述した実施の形態に限定されるものではなく、本技術の要旨を逸脱しない範囲において種々の変更が可能である。
例えば、本技術は、1つの機能をネットワークを介して複数の装置で分担、共同して処理するクラウドコンピューティングの構成をとることができる。
また、上述のフローチャートで説明した各ステップは、1つの装置で実行する他、複数の装置で分担して実行することができる。
さらに、1つのステップに複数の処理が含まれる場合には、その1つのステップに含まれる複数の処理は、1つの装置で実行する他、複数の装置で分担して実行することができる。
さらに、本技術は、以下の構成とすることも可能である。
(1)
1または複数の理解行動要求位置で区切られた発話テキストに基づいて、前記理解行動要求位置においてユーザの理解行動を誘発する発話を行わせ、前記理解行動の検出結果と前記発話テキストとに基づいて、次の発話を制御する対話進行制御部を備える
対話制御装置。
(2)
前記対話進行制御部は、前記ユーザによる前記理解行動が肯定的な行動であった場合、前記発話テキストのまだ発話がされていない次の文言を発話させる
(1)に記載の対話制御装置。
(3)
前記対話進行制御部は、前記ユーザによる前記理解行動が否定的な行動であった場合、直前に行われた発話を再度行わせる
(1)または(2)に記載の対話制御装置。
(4)
前記対話進行制御部は、前記ユーザによる肯定的な前記理解行動のレスポンス時間が短いほど前記理解行動の誘発回数が少なくなるように、前記発話テキストに基づく発話を制御する
(1)乃至(3)の何れか一項に記載の対話制御装置。
(5)
前記対話進行制御部は、前記ユーザによる肯定的な前記理解行動のレスポンス時間が短いほど発話速度が速くなるように、前記発話テキストに基づく発話を制御する
(1)乃至(4)の何れか一項に記載の対話制御装置。
(6)
前記対話進行制御部は、前記ユーザによる肯定的な前記理解行動のレスポンス時間が短いほど発話のトーンが高くなるように、前記発話テキストに基づく発話を制御する
(1)乃至(5)の何れか一項に記載の対話制御装置。
(7)
前記対話進行制御部は、所定時間内に前記ユーザによる前記理解行動が検出されなかった場合、直前に行われた発話を再度行わせるか、または前記理解行動を要求する発話を行わせる
(1)乃至(6)の何れか一項に記載の対話制御装置。
(8)
前記対話進行制御部は、前記発話テキストに基づく発話を途中で停止させた場合、前記発話テキストを含む通知情報の出力を制御する
(1)乃至(7)の何れか一項に記載の対話制御装置。
(9)
前記対話進行制御部は、前記発話テキストに基づく文言に非完了文言を付加することで、前記理解行動を誘発する発話を行わせる
(1)乃至(8)の何れか一項に記載の対話制御装置。
(10)
前記対話進行制御部は、発話の語尾に抑揚を付加することで、前記理解行動を誘発する発話を行わせる
(9)に記載の対話制御装置。
(11)
前記対話進行制御部は、前記理解行動要求位置において間をあけることで前記理解行動を誘発する発話を行わせる
(1)乃至(10)の何れか一項に記載の対話制御装置。
(12)
前記発話テキストの文章における文として非完結な位置を前記理解行動要求位置として検出する理解行動要求位置検出部をさらに備える
(1)乃至(11)の何れか一項に記載の対話制御装置。
(13)
前記理解行動要求位置検出部は、前記発話テキストの文章の述語節との係り受けに基づく位置を前記理解行動要求位置として検出する
(12)に記載の対話制御装置。
(14)
前記理解行動要求位置検出部は、前記発話テキストの文章における同一の述語節に係る複数の対象格の文節または句のそれぞれの間の位置を前記理解行動要求位置として検出する
(13)に記載の対話制御装置。
(15)
前記理解行動要求位置検出部は、前記発話テキストの文章における述語節に最初に係る文節または句の位置を前記理解行動要求位置として検出する
(13)に記載の対話制御装置。
(16)
前記理解行動要求位置検出部は、前記発話テキストの文章における時間格、場所格、対象格、または原因格である文節または句の位置を前記理解行動要求位置として検出する
(12)に記載の対話制御装置。
(17)
1または複数の理解行動要求位置で区切られた発話テキストに基づいて、前記理解行動要求位置においてユーザの理解行動を誘発する発話を行わせ、前記理解行動の検出結果と前記発話テキストとに基づいて、次の発話を制御する
ステップを含む対話制御方法。
1または複数の理解行動要求位置で区切られた発話テキストに基づいて、前記理解行動要求位置においてユーザの理解行動を誘発する発話を行わせ、前記理解行動の検出結果と前記発話テキストとに基づいて、次の発話を制御する対話進行制御部を備える
対話制御装置。
(2)
前記対話進行制御部は、前記ユーザによる前記理解行動が肯定的な行動であった場合、前記発話テキストのまだ発話がされていない次の文言を発話させる
(1)に記載の対話制御装置。
(3)
前記対話進行制御部は、前記ユーザによる前記理解行動が否定的な行動であった場合、直前に行われた発話を再度行わせる
(1)または(2)に記載の対話制御装置。
(4)
前記対話進行制御部は、前記ユーザによる肯定的な前記理解行動のレスポンス時間が短いほど前記理解行動の誘発回数が少なくなるように、前記発話テキストに基づく発話を制御する
(1)乃至(3)の何れか一項に記載の対話制御装置。
(5)
前記対話進行制御部は、前記ユーザによる肯定的な前記理解行動のレスポンス時間が短いほど発話速度が速くなるように、前記発話テキストに基づく発話を制御する
(1)乃至(4)の何れか一項に記載の対話制御装置。
(6)
前記対話進行制御部は、前記ユーザによる肯定的な前記理解行動のレスポンス時間が短いほど発話のトーンが高くなるように、前記発話テキストに基づく発話を制御する
(1)乃至(5)の何れか一項に記載の対話制御装置。
(7)
前記対話進行制御部は、所定時間内に前記ユーザによる前記理解行動が検出されなかった場合、直前に行われた発話を再度行わせるか、または前記理解行動を要求する発話を行わせる
(1)乃至(6)の何れか一項に記載の対話制御装置。
(8)
前記対話進行制御部は、前記発話テキストに基づく発話を途中で停止させた場合、前記発話テキストを含む通知情報の出力を制御する
(1)乃至(7)の何れか一項に記載の対話制御装置。
(9)
前記対話進行制御部は、前記発話テキストに基づく文言に非完了文言を付加することで、前記理解行動を誘発する発話を行わせる
(1)乃至(8)の何れか一項に記載の対話制御装置。
(10)
前記対話進行制御部は、発話の語尾に抑揚を付加することで、前記理解行動を誘発する発話を行わせる
(9)に記載の対話制御装置。
(11)
前記対話進行制御部は、前記理解行動要求位置において間をあけることで前記理解行動を誘発する発話を行わせる
(1)乃至(10)の何れか一項に記載の対話制御装置。
(12)
前記発話テキストの文章における文として非完結な位置を前記理解行動要求位置として検出する理解行動要求位置検出部をさらに備える
(1)乃至(11)の何れか一項に記載の対話制御装置。
(13)
前記理解行動要求位置検出部は、前記発話テキストの文章の述語節との係り受けに基づく位置を前記理解行動要求位置として検出する
(12)に記載の対話制御装置。
(14)
前記理解行動要求位置検出部は、前記発話テキストの文章における同一の述語節に係る複数の対象格の文節または句のそれぞれの間の位置を前記理解行動要求位置として検出する
(13)に記載の対話制御装置。
(15)
前記理解行動要求位置検出部は、前記発話テキストの文章における述語節に最初に係る文節または句の位置を前記理解行動要求位置として検出する
(13)に記載の対話制御装置。
(16)
前記理解行動要求位置検出部は、前記発話テキストの文章における時間格、場所格、対象格、または原因格である文節または句の位置を前記理解行動要求位置として検出する
(12)に記載の対話制御装置。
(17)
1または複数の理解行動要求位置で区切られた発話テキストに基づいて、前記理解行動要求位置においてユーザの理解行動を誘発する発話を行わせ、前記理解行動の検出結果と前記発話テキストとに基づいて、次の発話を制御する
ステップを含む対話制御方法。
11 サーバ, 12 クライアントデバイス, 21 自然言語解析部, 22 理解行動要求位置検出部, 23 音声出力対話進行制御部, 24 音声合成エンジン, 27 理解行動判定部
Claims (17)
- 1または複数の理解行動要求位置で区切られた発話テキストに基づいて、前記理解行動要求位置においてユーザの理解行動を誘発する発話を行わせ、前記理解行動の検出結果と前記発話テキストとに基づいて、次の発話を制御する対話進行制御部を備える
対話制御装置。 - 前記対話進行制御部は、前記ユーザによる前記理解行動が肯定的な行動であった場合、前記発話テキストのまだ発話がされていない次の文言を発話させる
請求項1に記載の対話制御装置。 - 前記対話進行制御部は、前記ユーザによる前記理解行動が否定的な行動であった場合、直前に行われた発話を再度行わせる
請求項1に記載の対話制御装置。 - 前記対話進行制御部は、前記ユーザによる肯定的な前記理解行動のレスポンス時間が短いほど前記理解行動の誘発回数が少なくなるように、前記発話テキストに基づく発話を制御する
請求項1に記載の対話制御装置。 - 前記対話進行制御部は、前記ユーザによる肯定的な前記理解行動のレスポンス時間が短いほど発話速度が速くなるように、前記発話テキストに基づく発話を制御する
請求項1に記載の対話制御装置。 - 前記対話進行制御部は、前記ユーザによる肯定的な前記理解行動のレスポンス時間が短いほど発話のトーンが高くなるように、前記発話テキストに基づく発話を制御する
請求項1に記載の対話制御装置。 - 前記対話進行制御部は、所定時間内に前記ユーザによる前記理解行動が検出されなかった場合、直前に行われた発話を再度行わせるか、または前記理解行動を要求する発話を行わせる
請求項1に記載の対話制御装置。 - 前記対話進行制御部は、前記発話テキストに基づく発話を途中で停止させた場合、前記発話テキストを含む通知情報の出力を制御する
請求項1に記載の対話制御装置。 - 前記対話進行制御部は、前記発話テキストに基づく文言に非完了文言を付加することで、前記理解行動を誘発する発話を行わせる
請求項1に記載の対話制御装置。 - 前記対話進行制御部は、発話の語尾に抑揚を付加することで、前記理解行動を誘発する発話を行わせる
請求項9に記載の対話制御装置。 - 前記対話進行制御部は、前記理解行動要求位置において間をあけることで前記理解行動を誘発する発話を行わせる
請求項1に記載の対話制御装置。 - 前記発話テキストの文章における文として非完結な位置を前記理解行動要求位置として検出する理解行動要求位置検出部をさらに備える
請求項1に記載の対話制御装置。 - 前記理解行動要求位置検出部は、前記発話テキストの文章の述語節との係り受けに基づく位置を前記理解行動要求位置として検出する
請求項12に記載の対話制御装置。 - 前記理解行動要求位置検出部は、前記発話テキストの文章における同一の述語節に係る複数の対象格の文節または句のそれぞれの間の位置を前記理解行動要求位置として検出する
請求項13に記載の対話制御装置。 - 前記理解行動要求位置検出部は、前記発話テキストの文章における述語節に最初に係る文節または句の位置を前記理解行動要求位置として検出する
請求項13に記載の対話制御装置。 - 前記理解行動要求位置検出部は、前記発話テキストの文章における時間格、場所格、対象格、または原因格である文節または句の位置を前記理解行動要求位置として検出する
請求項12に記載の対話制御装置。 - 1または複数の理解行動要求位置で区切られた発話テキストに基づいて、前記理解行動要求位置においてユーザの理解行動を誘発する発話を行わせ、前記理解行動の検出結果と前記発話テキストとに基づいて、次の発話を制御する
ステップを含む対話制御方法。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP17841394.4A EP3503091A4 (en) | 2016-08-17 | 2017-08-03 | DIALOGUE CONTROL DEVICE AND METHOD |
| CN201780049114.7A CN109564757A (zh) | 2016-08-17 | 2017-08-03 | 对话控制装置和方法 |
| US16/321,328 US11183170B2 (en) | 2016-08-17 | 2017-08-03 | Interaction control apparatus and method |
| JP2018534342A JP7036015B2 (ja) | 2016-08-17 | 2017-08-03 | 対話制御装置および方法 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2016159864 | 2016-08-17 | ||
| JP2016-159864 | 2016-08-17 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2018034169A1 true WO2018034169A1 (ja) | 2018-02-22 |
Family
ID=61197234
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2017/028292 Ceased WO2018034169A1 (ja) | 2016-08-17 | 2017-08-03 | 対話制御装置および方法 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US11183170B2 (ja) |
| EP (1) | EP3503091A4 (ja) |
| JP (1) | JP7036015B2 (ja) |
| CN (1) | CN109564757A (ja) |
| WO (1) | WO2018034169A1 (ja) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019204015A (ja) * | 2018-05-24 | 2019-11-28 | トヨタ自動車株式会社 | 情報処理装置、プログラム、及び制御方法 |
| CN113330512A (zh) * | 2018-12-28 | 2021-08-31 | 谷歌有限责任公司 | 根据选择的建议向自动化助理补充语音输入 |
| JP2024060391A (ja) * | 2022-10-19 | 2024-05-02 | 株式会社日立製作所 | 問診装置、問診システム及び問診方法 |
| JP2024107317A (ja) * | 2018-05-16 | 2024-08-08 | 株式会社野村総合研究所 | サーバ |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019106054A (ja) * | 2017-12-13 | 2019-06-27 | 株式会社東芝 | 対話システム |
| CN110136464B (zh) * | 2019-04-18 | 2021-05-11 | 深圳市宏电技术股份有限公司 | 一种辅助驾驶的方法、装置及设备 |
| US11551665B2 (en) * | 2019-09-12 | 2023-01-10 | Oracle International Corporation | Dynamic contextual dialog session extension |
| US12243524B2 (en) * | 2020-04-24 | 2025-03-04 | Easy Dialog G.K. | Assistance device, conversation control device, and program |
| WO2022249221A1 (ja) * | 2021-05-24 | 2022-12-01 | 日本電信電話株式会社 | 対話装置、対話方法、およびプログラム |
| US20250328727A1 (en) * | 2024-04-19 | 2025-10-23 | Augmented Reality Concepts, Inc. | Dialogue state tracking logic control layers |
Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS60247697A (ja) * | 1984-05-24 | 1985-12-07 | 株式会社東芝 | 音声対話装置 |
| JPH06342297A (ja) * | 1993-06-02 | 1994-12-13 | Sony Corp | 音声合成装置 |
| JPH1083196A (ja) * | 1996-09-06 | 1998-03-31 | Ricoh Co Ltd | 音声合成装置および方法、情報記憶媒体 |
| JPH10116177A (ja) * | 1996-10-09 | 1998-05-06 | Nippon Telegr & Teleph Corp <Ntt> | 出力制御可能型言語生成方法及び装置 |
| JP2005202076A (ja) * | 2004-01-14 | 2005-07-28 | Sony Corp | 発話制御装置及び方並びにロボット装置 |
| WO2008001549A1 (fr) * | 2006-06-26 | 2008-01-03 | Murata Kikai Kabushiki Kaisha | Dispositif audio interactif, procédé audio interactif, et programme correspondant |
| JP2010008854A (ja) * | 2008-06-30 | 2010-01-14 | Toshiba Corp | 音声認識装置及びその方法 |
| JP2010157081A (ja) * | 2008-12-26 | 2010-07-15 | Toyota Central R&D Labs Inc | 応答生成装置及びプログラム |
Family Cites Families (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH09218770A (ja) * | 1996-02-14 | 1997-08-19 | Toshiba Corp | 対話処理装置および対話処理方法 |
| JPH10116117A (ja) | 1996-10-14 | 1998-05-06 | Toshiba Eng Co Ltd | 無人搬送車並びに無人搬送車の停止制御方法 |
| CN1234109C (zh) * | 2001-08-22 | 2005-12-28 | 国际商业机器公司 | 语调生成方法、语音合成装置、语音合成方法及语音服务器 |
| US7228278B2 (en) * | 2004-07-06 | 2007-06-05 | Voxify, Inc. | Multi-slot dialog systems and methods |
| JP4760149B2 (ja) | 2005-06-10 | 2011-08-31 | 日本電気株式会社 | 再成形可能かつ2段階に優れた形状回復能を持つ形状記憶性樹脂および該樹脂の架橋物からなる成形体 |
| US20100327419A1 (en) * | 2009-06-26 | 2010-12-30 | Sriram Muthukumar | Stacked-chip packages in package-on-package apparatus, methods of assembling same, and systems containing same |
| JP2013247697A (ja) | 2012-05-23 | 2013-12-09 | Jtekt Corp | ロータ及びこれを備えた回転電機 |
| JP2015184563A (ja) * | 2014-03-25 | 2015-10-22 | シャープ株式会社 | 対話型家電システム、サーバ装置、対話型家電機器、家電システムが対話を行なうための方法、当該方法をコンピュータに実現させるためのプログラム |
| US10238333B2 (en) * | 2016-08-12 | 2019-03-26 | International Business Machines Corporation | Daily cognitive monitoring of early signs of hearing loss |
| US10467509B2 (en) * | 2017-02-14 | 2019-11-05 | Microsoft Technology Licensing, Llc | Computationally-efficient human-identifying smart assistant computer |
-
2017
- 2017-08-03 WO PCT/JP2017/028292 patent/WO2018034169A1/ja not_active Ceased
- 2017-08-03 JP JP2018534342A patent/JP7036015B2/ja not_active Expired - Fee Related
- 2017-08-03 US US16/321,328 patent/US11183170B2/en not_active Expired - Fee Related
- 2017-08-03 CN CN201780049114.7A patent/CN109564757A/zh not_active Withdrawn
- 2017-08-03 EP EP17841394.4A patent/EP3503091A4/en not_active Withdrawn
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS60247697A (ja) * | 1984-05-24 | 1985-12-07 | 株式会社東芝 | 音声対話装置 |
| JPH06342297A (ja) * | 1993-06-02 | 1994-12-13 | Sony Corp | 音声合成装置 |
| JPH1083196A (ja) * | 1996-09-06 | 1998-03-31 | Ricoh Co Ltd | 音声合成装置および方法、情報記憶媒体 |
| JPH10116177A (ja) * | 1996-10-09 | 1998-05-06 | Nippon Telegr & Teleph Corp <Ntt> | 出力制御可能型言語生成方法及び装置 |
| JP2005202076A (ja) * | 2004-01-14 | 2005-07-28 | Sony Corp | 発話制御装置及び方並びにロボット装置 |
| WO2008001549A1 (fr) * | 2006-06-26 | 2008-01-03 | Murata Kikai Kabushiki Kaisha | Dispositif audio interactif, procédé audio interactif, et programme correspondant |
| JP2010008854A (ja) * | 2008-06-30 | 2010-01-14 | Toshiba Corp | 音声認識装置及びその方法 |
| JP2010157081A (ja) * | 2008-12-26 | 2010-07-15 | Toyota Central R&D Labs Inc | 応答生成装置及びプログラム |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP3503091A4 * |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2024107317A (ja) * | 2018-05-16 | 2024-08-08 | 株式会社野村総合研究所 | サーバ |
| JP2019204015A (ja) * | 2018-05-24 | 2019-11-28 | トヨタ自動車株式会社 | 情報処理装置、プログラム、及び制御方法 |
| CN110534103A (zh) * | 2018-05-24 | 2019-12-03 | 丰田自动车株式会社 | 信息处理装置、保存程序的非暂时性计算机可读介质及控制方法 |
| US11282517B2 (en) | 2018-05-24 | 2022-03-22 | Toyota Jidosha Kabushiki Kaisha | In-vehicle device, non-transitory computer-readable medium storing program, and control method for the control of a dialogue system based on vehicle acceleration |
| JP7294775B2 (ja) | 2018-05-24 | 2023-06-20 | トヨタ自動車株式会社 | 情報処理装置、プログラム、及び制御方法 |
| CN113330512A (zh) * | 2018-12-28 | 2021-08-31 | 谷歌有限责任公司 | 根据选择的建议向自动化助理补充语音输入 |
| US12073832B2 (en) | 2018-12-28 | 2024-08-27 | Google Llc | Supplementing voice inputs to an automated assistant according to selected suggestions |
| JP2024060391A (ja) * | 2022-10-19 | 2024-05-02 | 株式会社日立製作所 | 問診装置、問診システム及び問診方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3503091A4 (en) | 2019-08-07 |
| EP3503091A1 (en) | 2019-06-26 |
| CN109564757A (zh) | 2019-04-02 |
| JPWO2018034169A1 (ja) | 2019-06-13 |
| US11183170B2 (en) | 2021-11-23 |
| US20200184950A1 (en) | 2020-06-11 |
| JP7036015B2 (ja) | 2022-03-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7036015B2 (ja) | 対話制御装置および方法 | |
| US11727914B2 (en) | Intent recognition and emotional text-to-speech learning | |
| US12087299B2 (en) | Multiple virtual assistants | |
| US11887580B2 (en) | Dynamic system response configuration | |
| US11790891B2 (en) | Wake word selection assistance architectures and methods | |
| JP4729902B2 (ja) | 音声対話システム | |
| US20020123894A1 (en) | Processing speech recognition errors in an embedded speech recognition system | |
| KR20210103002A (ko) | 감정 정보 기반의 음성 합성 방법 및 장치 | |
| US11579841B1 (en) | Task resumption in a natural understanding system | |
| US12499883B2 (en) | Interactive content output | |
| CN115088033A (zh) | 代表对话中的人参与者生成的合成语音音频数据 | |
| US11670285B1 (en) | Speech processing techniques | |
| US12001260B1 (en) | Preventing inadvertent wake in a speech-controlled device | |
| KR102948992B1 (ko) | 자동화된 어시스턴트 응답 제시의 핫워드 프리 선점 | |
| US20240274123A1 (en) | Systems and methods for phoneme recognition | |
| US11176943B2 (en) | Voice recognition device, voice recognition method, and computer program product | |
| US20250201230A1 (en) | Sending media comments using a natural language interface | |
| US12175976B2 (en) | Multi-assistant device control | |
| US12094463B1 (en) | Default assistant fallback in multi-assistant devices | |
| US12499777B1 (en) | Speech recognition for language learning systems |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| ENP | Entry into the national phase |
Ref document number: 2018534342 Country of ref document: JP Kind code of ref document: A |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 17841394 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2017841394 Country of ref document: EP Effective date: 20190318 |