WO2019020054A1 - 一种基于免疫算法的密码子优化方法 - Google Patents
一种基于免疫算法的密码子优化方法 Download PDFInfo
- Publication number
- WO2019020054A1 WO2019020054A1 PCT/CN2018/097040 CN2018097040W WO2019020054A1 WO 2019020054 A1 WO2019020054 A1 WO 2019020054A1 CN 2018097040 W CN2018097040 W CN 2018097040W WO 2019020054 A1 WO2019020054 A1 WO 2019020054A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- optimization
- sequence
- proteins
- codon
- protein
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images






Classifications
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
- G16B30/10—Sequence alignment; Homology search
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
- C12N9/12—Transferases (2.) transferring phosphorus containing groups, e.g. kinases (2.7)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/43504—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from invertebrates
- C07K14/43595—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from invertebrates from coelenteratae, e.g. medusae
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/67—General methods for enhancing the expression
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y207/00—Transferases transferring phosphorus-containing groups (2.7)
- C12Y207/11—Protein-serine/threonine kinases (2.7.11)
- C12Y207/11024—Mitogen-activated protein kinase (2.7.11.24), i.e. MAPK or MAPK2 or c-Jun N-terminal kinase
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/12—Computing arrangements based on biological models using genetic models
- G06N3/126—Evolutionary algorithms, e.g. genetic algorithms or genetic programming
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
- G16B20/20—Allele or variant detection, e.g. single nucleotide polymorphism [SNP] detection
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B25/00—ICT specially adapted for hybridisation; ICT specially adapted for gene or protein expression
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B40/00—ICT specially adapted for biostatistics; ICT specially adapted for bioinformatics-related machine learning or data mining, e.g. knowledge discovery or pattern finding
- G16B40/20—Supervised data analysis
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/40—Fusion polypeptide containing a tag for immunodetection, or an epitope for immunisation
- C07K2319/43—Fusion polypeptide containing a tag for immunodetection, or an epitope for immunisation containing a FLAG-tag
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
Definitions
- the invention relates to a protein engineering technology, in particular to a codon optimization method in protein engineering, in particular to a codon optimization method based on an immune algorithm.
- Codon degeneracy refers to the phenomenon that an amino acid can be encoded by multiple different codons during protein translation. Different codons encoding the same amino acid are called synonymous codons, and a protein consisting of 200 amino acids in length. It can be encoded by more than 10 20 different DNA sequences. Synonymous codons appear differently in different species, a phenomenon known as codon preference. Codon optimization mainly uses the computer algorithm to select the DNA that can express the most efficient protein in the host expression system from a large number of DNA coding sequences without changing the amino acid sequence of the host, based on factors such as codon preference of the host expression system. sequence.
- the main factors affecting protein expression that are often considered in the current codon optimization process include host cell codon preference (the commonly used characterization parameters are codon fitness index [CAI], host cell binary codon preference [Codon Context], CBI [Codon Bias Index], ENC [Effective Number of Codon], FOP [Frequency of Optimal Codons], CPP [Codon Preference Parameter], tAI [tRNA adaptation index], Hidden Stop Codon number, GC content, rare codon content , mRNA inhibitory regulation motif number, mRNA secondary structure (mainly including hairpin structure and folding free energy), key codon and mathematical model scoring in machine learning, microRNA binding site, G4 content and protein secondary Structural codon preference (Joshua B.
- CAI codon fitness index
- CAI codon Context
- CBI Codon Bias Index
- ENC Effectivee Number of Codon
- FOP Frequency of Optimal Codons
- CPP Codon Preference Parameter
- tAI tRNA adaptation index
- immune algorithms Compared to heuristic algorithms (such as particle swarms and genetic algorithms) that have been used in codon optimization algorithms, immune algorithms have their unique advantages.
- the immune algorithm is an improved genetic algorithm based on the biological immune mechanism, which corresponds to the objective function of the actual solution to the antigen, and the solution of the problem corresponds to the antibody.
- the biological immune system automatically generates corresponding antibodies to resist the invasion and differentiation of antigens invading living organisms, and this process is called an immune response. During the immune response, some antibodies are preserved as memory cells.
- the memory cells are activated and rapidly produce a large number of antibodies, making the re-response faster and more intense than the initial response, reflecting the memory function of the immune system.
- an antibody binds to an antigen, it destroys the antigen through a series of reactions.
- the antibody and the antibody also promote and inhibit each other to maintain antibody diversity and immune balance, which is based on a concentration mechanism, that is, The higher the concentration of the antibody, the more inhibited; the lower the concentration, the more promoted, reflecting the self-regulating function of the immune system.
- the object of the present invention is to solve the problem that the existing codon optimization method has a long cycle and poor expression accuracy, and the invention can effectively complete a large-scale search for the codon optimization space in a limited time, that is, from The protein coding sequence focuses on an immune algorithm-based codon optimization method that screens the most efficiently expressed DNA sequences.
- a codon optimization method based on immune algorithm which uses the immune algorithm and the genetic algorithm to perform local multi-objective optimization and global multi-objective optimization on protein coding sequences respectively, and then fine-tunes the sequence by exhaustive method to maximize the search. To the optimal expression sequence.
- the method of the invention comprises the following three steps: the first step is local optimization, ie cutting the protein sequence into non-overlapping sequence fragments A 1 , A 2 ... A n , and then using an immune algorithm for each The sequence fragment completes codon optimization to generate approximate optimal sequence of DNA sequences B 1 , B 2 ... B n ; the second step is global optimization, that is, using genetic algorithm to initialize the full length of the protein based on B 1 , B 2 ...
- the DNA coding sequence selects the optimal DNA sequence C 1 of the protein sequence; the third step is the fine tuning optimization, which comprises exhaustive optimization of the 5' end of the DNA sequence corresponding to the N-terminal region of the encoded protein to generate a DNA sequence C 2 , And the expression inhibitory motif is eliminated, and finally the optimal expression sequence D is generated.
- the protein refers to a compound composed of twenty or more amino acids. Included in the localization are secretory proteins, membrane proteins, cytoplasmic proteins, intranuclear proteins, etc.; functionally comprising antibody proteins, regulatory proteins, structural proteins, etc.; comprising homologously expressed proteins and heterologously expressed proteins on the source; Contains natural proteins and artificially engineered proteins, intact proteins/antibodies and truncated partial proteins/antibodies, and fusion proteins formed between two or more proteins and between proteins and peptide chains.
- Antibodies as defined in the present invention include, but are not limited to, intact antibodies and Fabs, ScFVs, SdAbs, Chimeric antibodies, bispecific antibodies, Fc fusion proteins, and the like.
- the immune genetic algorithm adopts a multi-objective optimization method to locally optimize protein fragments, and the population is initialized based on a double codon table of high-expressed protein coding sequences, and each gene is directly encoded by a synonymous codon; during optimization
- the algorithm's global search ability is increased.
- the genetic algorithm adopts a multi-objective optimization method for global optimization of protein full-sequence, and the initial population is randomly generated based on the optimization of the local optimization, and each gene is directly encoded by using an optimized sequence set of each protein fragment.
- the fine tuning optimization uses the exhaustive method to calculate and sort the folding free energy MFE, Codon Context and CAI at the 5' end of the DNA sequence, and select the optimal N-terminal coding sequence of the protein sequence according to the sorting result.
- the codon optimization method is applicable to at least the following host expression systems: 1) a mammalian expression system; 2) an insect expression system; 3) a yeast expression system; 4) an E. coli expression system; 5) a Bacillus subtilis expression system; 6) Plant expression systems and 7) Cell-free expression systems.
- the codon optimization method is at least applicable to the following expression vectors: transient expression vectors and stable expression vectors, viral expression vectors and non-viral expression vectors, and induced and non-induced expression vectors.
- Immune algorithm is an improved algorithm of genetic algorithm.
- the present invention introduces immune algorithm for codon optimization for local optimization for the first time, and globally through subsequent genetic algorithm.
- Optimization, and finally fine-tuning optimization developed a new three-step hybrid optimization algorithm that combines the advantages of different algorithms; and the efficiency of codon optimization is proved by the following example test.
- the immune algorithm of the invention has the following characteristics: Firstly, it has an immune memory function, which can speed up the search speed and improve the overall search ability of the genetic algorithm; secondly, it has the diversity maintenance function of the antibody, and utilizes the function. It can improve the local search ability of the genetic algorithm; finally it has a self-regulating function, which can be used to improve the global search ability of the genetic algorithm and avoid falling into local solutions. Therefore, the immune genetic algorithm not only retains the characteristics of random global parallel search of genetic algorithm, but also avoids immature convergence to a considerable extent, ensuring rapid convergence to the global optimal solution.
- the codon optimization is carried out through a step-by-step process (individually local optimization, global optimization, fine tuning optimization), and the algorithm is proved by the example test.
- the efficiency of suboptimization is carried out through a step-by-step process (individually local optimization, global optimization, fine tuning optimization), and the algorithm is proved by the example test. The efficiency of suboptimization.
- the invention has the advantages of high speed and high efficiency.
- 1 is a schematic flow chart of an optimization algorithm of the present invention.
- FIG. 2 is a schematic flow chart of the immune algorithm of the present invention (ie, a partial optimization process).
- 3 is a genetic algorithm flow (ie, a global optimization process) of the present invention.
- Figure 4 is a 5' end optimization procedure of the DNA sequence of the present invention.
- Figure 5 is a schematic diagram showing the design of the test protein gene sequence of the present invention.
- Figure 6 is a map of the pTT expression vector of the present invention.
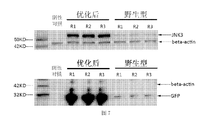
- Figure 7 is a schematic illustration of the results of Western Blotting of the present invention.
- a codon optimization method based on immune algorithm which uses localized multi-objective optimization and global multi-objective optimization of protein coding sequences (SEQ ID NO.3 and SEQ ID NO.4) using immune algorithm and genetic algorithm, respectively.
- the sequence was fine-tuned to optimize the optimal expression sequences (SEQ ID NO. 5 and SEQ ID NO. 6), as shown in Figure 1. among them:
- the number of optimized variables L in this step is 2, that is, the two features of Codon Context and CAI are optimized for each segment (described below), which belongs to multi-objective optimization.
- the immune system consists of N antibodies (ie, population size N)
- each antibody gene is M in length (equivalent to the number M of amino acid sequences of the protein sequence), and each gene is directly encoded using a synonymous codon.
- the initial antibody is generated based on the double codon frequency.
- the synonymous codons of a 1 are c 11 and c 12
- the synonymous codons of a 2 are c 21 , c 22 and c 23 .
- the codon of the first amino acid a 1 is selected based on the frequency of c 11 and c 12 in the codon frequency table.
- the two-codon corresponding to the diamino acid a 1 a 2 is c 11 c 21 , c 11 c 22 , c 11 c 23 , c 12 c 21 , c 12 c 22 and c 12 c 23 , wherein the binary synonym code There are two groups, including [c 11 c 21 , c 11 c 22 , c 11 c 23 ] and [c 12 c 21 , c 12 c 22 , c 12 c 23 ].
- the codon of amino acid a 2 is selected from c 21 , c 22 and c 23 according to the frequencies of c 11 c 21 , c 11 c 22 and c 11 c 23 .
- the codon selected by a 1 is C 12
- one of the codons c 21 , c 22 and c 23 of the amino acid a 2 is selected according to the frequencies of c 12 c 21 , c 12 c 22 and c 12 c 23 .
- the codons of other amino acids are selected in relation to the selection of the codons of its previous amino acid, and their binary synonymous passwords. The frequency of the child is determined.
- the population consists of K antibodies stored in the parental individual and the memory unit.
- the memory unit antibody records the K optimal antibodies that have appeared in the optimization history, and the antibody with low fitness is in the optimization process. It is gradually replaced by individuals with higher fitness.
- the present invention utilizes Shannon's average information entropy H(N) to measure the population similarity S.
- P ij is the probability that the synonym codon i appears on the amino acid j, namely:
- N ij is the total number of occurrences of its synonymous codon i at the j-th amino acid position of all individuals in the population.
- Hj(N) is the information entropy of the jth gene (ie, the jth amino acid of the protein sequence), defined as:
- the average information entropy of the entire population is:
- the group similarity S is defined as:
- the antibody concentration refers to the percentage of each antibody in the population with similar antibodies, namely:
- Ai refers to the number of antibodies whose degree of similarity to antibody i is greater than the similarity constant ⁇ .
- ⁇ refers to the number of identical codons in M codons when two individuals are compared.
- the polymerization fitness F' is a value obtained by correcting the antibody fitness F according to the antibody concentration, that is,
- the initialization group N is randomly generated, and the fitness calculation, the selection of the generation group, the intersection, the variation and the memory update are completed according to the flow of the genetic algorithm, and the termination algebra is stopped.
- Evolution, and output the optimal DNA coding sequence of the protein sequence the whole process belongs to multi-objective optimization.
- Fine tuning optimization involves two steps, first optimizing the 5' end of the DNA and then eliminating the expression inhibitory motif.
- the optimization process of the 5' end of DNA is shown in Figure 4. All possible DNA coding sequences of the N-terminal amino acid sequence (8-15 amino acids) of the protein are enumerated using an exhaustive method, and their codon context and CAI are calculated, and then the protein sequence is The vector sequence upstream of the start codon 50 bp (default value is 50 bp, length range 0 to 50 bp) is connected in sequence, and the fold free energy (MFE) of the ligated sequence is calculated by using mfold software. The optimal 5' end sequence is selected based on the folding free energy (the larger the value, the better), the codon context (the larger the better) and the CAI (the larger the value, the better).
- the basic data set refers to highly expressed proteins in different host expression systems and their corresponding DNA coding sequences.
- the binary codon table refers to the relative fitness of all the two codons of the basic data set (for the calculation method, see below).
- x ij represents the number of occurrences of the jth synonymous codon of the ith amino acid in the underlying data set
- x imax represents the number of synonymous codons with the highest frequency of use of the ith amino acid in the underlying data set.
- CAI Codon Adaptation Index
- L refers to the number of the target amino acid sequence (i.e., protein sequences or fragments), w k of each codon corresponding to amino acid codon usage codons base data set relative adaptiveness.
- the value of CAI is between 0 and 1. During the optimization process we try to increase the value of the CAI encoding the DNA.
- Representing the relative fitness of the kth binary codon of the target sequence Represents the relative fitness of the kth binary codon of the underlying data set.
- the value of CC is between 0 and 1.
- the multi-objective optimization process of immune algorithm and genetic algorithm can use NSGA2 and SPEA2 algorithm (NSGA2 is used by default), and cross-point two-point crossover.
- the host expression system used in the test case was a CHO cell line, and two proteins were optimized for sequencing (see Table 1 for related information).
- the JNK3 protein sequence is shown in SEQ ID NO. 1
- the GFP protein sequence is shown in SEQ ID NO. 2
- the pre-optimized JNK3 protein and GFP protein coding sequences are shown in SEQ ID NO. 3 and SEQ ID NO. 4, respectively.
- the post-JNK3 protein and GFP protein coding sequences are set forth in SEQ ID NO. 5 and SEQ ID NO. 6, respectively.
- a gene fragment encoding the test protein was synthesized and cloned into the pTT5 expression vector (purchased from NRC, the plasmid map is shown in Figure 6) by EcoR I and Hind III restriction sites, respectively.
- CHO 3E7 suspension cells in logarithmic growth phase were diluted to 5 ⁇ 10 5 cells/mL with fresh FreeStyle CHO medium, and 30 mL of cell suspension was inoculated into each 125 mL triangular shake flask.
- the cells were cultured in suspension at 37 ° C under 5% CO 2 .
- the plasmid vector cloned with the gene of interest is transfected into CHO 3E7 cells according to the amount of 1 ug/ml by PEI transfection reagent.
- the medium was centrifuged at 1500 rpm to harvest the cells. Samples can be stored in a -80 ° C refrigerator.
- the anti-Flag tag antibody was used to detect the expression level of the target protein in the cell lysate by Western Blotting.
- the beta-actin protein was used as an internal reference, and the expression of each plasmid was repeated three times.
- the results of Western Blotting are shown in Fig. 7.
- CHO cells were lysed using cell lysate to determine the protein concentration.
- bromophenol blue can reach the vicinity of the bottom end of the gel to stop electrophoresis.
- the film transfer voltage is 100V, and the low temperature film transfer time is 60 minutes.
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Chemical & Material Sciences (AREA)
- Genetics & Genomics (AREA)
- Biophysics (AREA)
- General Health & Medical Sciences (AREA)
- Biotechnology (AREA)
- Organic Chemistry (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Theoretical Computer Science (AREA)
- Molecular Biology (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- General Engineering & Computer Science (AREA)
- Medical Informatics (AREA)
- Biomedical Technology (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Biochemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Data Mining & Analysis (AREA)
- Analytical Chemistry (AREA)
- Microbiology (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Software Systems (AREA)
- Medicinal Chemistry (AREA)
- Physiology (AREA)
- Mathematical Physics (AREA)
- Computational Linguistics (AREA)
- General Physics & Mathematics (AREA)
- Computing Systems (AREA)
- Plant Pathology (AREA)
- Epidemiology (AREA)
- Public Health (AREA)
- Databases & Information Systems (AREA)
- Computer Vision & Pattern Recognition (AREA)
Abstract
一种基于免疫算法的密码子优化方法, 其特征在于先后使用免疫算法和遗传算法分别对蛋白质编码序列进行局部多目标优化和全局多目标优化,再用穷举法对序列进行微调优化,从而最大限度的搜索到最优表达序列。本发明既保留了遗传算法随机全局并行搜索的特点,又在相当大程度上避免未成熟收敛,确保快速收敛于全局最优解。本发明第一次结合利用免疫算法与遗传算法的准确度和效率的优势,通过分步流程(依次分别是局部优化、全局优化、微调优化)进行密码子优化,并通过实例测试证明该算法进行密码子优化的高效性。
Description
本发明涉及一种蛋白工程技术,尤其是一种蛋白工程中的密码子优化方法,具体地说是一种基于免疫算法的密码子优化方法。
密码子简并性是指在蛋白翻译过程中,一个氨基酸可以由多个不同密码子编码的现象,编码相同氨基酸的不同密码子称为同义密码子,一个长度为200个氨基酸组成的蛋白一般可以由超过10
20个不同DNA序列编码。在不同物种中,同义密码子出现的频率并不相同,这种现象称之为密码子的偏好性。密码子优化主要根据宿主表达系统的密码子偏好性等因素,在不改变蛋白氨基酸序列的前提下利用计算机算法从大量DNA编码序列中筛选出能在宿主表达系统中最高效表达蛋白的那条DNA序列。
目前密码子优化过程中常被考虑的影响蛋白表达的主要因素包括宿主细胞密码子偏好性(其常用表征参数有密码子适应度指数[CAI]、宿主细胞二联密码子偏好性[Codon Context]、CBI[Codon Bias Index]、ENC[Effective Number of Codon]、FOP[Frequency of Optimal Codons]、CPP[Codon Preference Parameter]、tAI[tRNA adaptation index])、Hidden Stop Codon数量、GC含量、稀有密码子含量、mRNA抑制性调控模序(motif)数量、mRNA二级结构(主要包括发夹结构和折叠自由能)、关键密码子和机器学习中数学模型打分、microRNA结合位点、G4含量以及蛋白二级结构密码子偏好性(Joshua B.Plotkin&Grzegorz Kudla,Nature Reviews Genetics,2011)。目前可用于密码子优化的软件和算法包括DNAWorks、Jcat、Synthetic gene designer、GeneDesign 2.0、OPTIMIZER、Eugene、mRNA Optimizer、COOL、D-Tailor、UpGene、GASCO、Codon Harmonization、QPSO、GeMS和ATGME(Evelina Angov,Biotechnology Journal,2011;Nathan Gould et al.,Frontiers in Bioengineering and Biotechnology,2014)。
相较于密码子优化算法中已经被使用的启发式算法(比如粒子群和遗传算法),免疫算法具有其独特优势。免疫算法是基于生物免疫机制提出的一种改进的遗传算法,它将实际求解问题的目标函数对应为抗原,而问题的解对应为抗体。由生物免疫原理可知,生物免疫系统对入侵生命体的抗原通过细胞的分裂和分化作用,自动产生相应的抗体来抵御,这一过程被称为免疫应答。在免疫应答过程中,部分抗体作为记忆细胞保存下来,当同类 抗原再次侵入时,记忆细胞被激活并迅速产生大量抗体,使再次应答比初次应答更快更强烈,体现了免疫系统的记忆功能.抗体与抗原结合后,会通过一系列的反应而破坏抗原.同时,抗体与抗体之间也相互促进和抑制,以维持抗体的多样性及免疫平衡,这种平衡是根据浓度机制进行的,即抗体的浓度越高,则越受抑制;浓度越低,则越受促进,体现了免疫系统的自我调节功能。
发明内容
本发明的目的是针对现有的密码子优化方法存在周期过长,表达准确性较差的问题,发明一种能在有限的时间内有效的完成对密码子优化空间的大规模搜索,即从蛋白编码序列集中筛选出最高效表达的DNA序列的基于免疫算法的密码子优化方法。
本发明的技术方案是:
一种基于免疫算法的密码子优化方法,先后使用免疫算法和遗传算法分别对蛋白质编码序列进行局部多目标优化和全局多目标优化,再用穷举法对序列进行微调优化,从而最大限度的搜索到最优表达序列。
具体而言,本发明的方法包括以下三个步骤:;第一步是局部优化,即将蛋白质序列切割成无重叠的序列片段A
1、A
2……A
n,然后利用免疫算法,对每个序列片段完成密码子优化,生成近似最优DNA序列集B
1、B
2……B
n;第二步是全局优化,即利用遗传算法,基于B
1、B
2……B
n初始化蛋白质全长的DNA编码序列,筛选出蛋白质序列最优DNA序列C
1;第三步是微调优化,包括对编码蛋白质N端区域所对应的DNA序列5’端进行穷举法优化,生成DNA序列C
2,并消除表达抑制性模序,最终生成最优表达序列D。
所述的蛋白质是指由二十个以上的氨基酸组成化合物。在定位上包括分泌蛋白、膜蛋白、胞质蛋白、细胞核内蛋白等;在功能上包含抗体蛋白、调节蛋白、结构蛋白等;在来源上包含同源表达蛋白和异源表达蛋白;在序列上包含天然蛋白和人工改造后的蛋白,完整的蛋白/抗体和截断的部分蛋白/抗体,以及2个或2个以上蛋白之间、蛋白与肽链之间形成的融合蛋白。本发明中所定义的抗体包括但不限于完整的抗体和Fab、ScFV、SdAb、嵌合抗体(Chimeric antibody)、双特异性抗体(bispecific antibody)、Fc融合蛋白等等。
所述的免疫遗传算法采用多目标优化方法对蛋白质片段进行局部优化,群体的初始化基于高表达蛋白编码序列的二联密码子表,直接采用同义密码子对每个基因进行编码;优化过程中通过计算免疫遗传算法的抗体信息熵、抗体群体相似度、抗体浓度和聚合适应度以及更新记忆单元来保证抗体多样性并防止群体退化现象,从而增加算法的全局搜索能力。
所述的遗传算法采用多目标优化方法用来对蛋白质全序进行全局优化,初始化群体基于局部优化的优化后片段随机生成,直接采用每个蛋白质片段的优化序列集对每个基因进行编码。
所述的微调优化利用穷举法对DNA序列5’端的折叠自由能MFE、Codon Context和CAI进行计算和排序,并根据排序结果选择最佳的蛋白序列N端编码序列。
所述的密码子优化方法至少适用于以下的宿主表达系统:1)哺乳动物表达系统;2)昆虫表达系统;3)酵母表达系统;4)大肠杆菌表达系统;5)枯草芽孢杆菌表达系统;6)植物表达系统和7)无细胞表达系统。
所述的密码子优化方法至少适用于以下表达载体:瞬时表达载体和稳定表达载体、病毒表达载体和非病毒表达载体、诱导和非诱导表达载体。
本发明的有益效果是:
免疫算法是一种遗传算法的改进型算法,鉴于免疫算法在优化中防止过早局部收敛的优势,本发明第一次引入免疫算法进行密码子优化进行局部优化,并通过随后的遗传算法进行全局优化,以及最后的微调优化,开发了一种全新的结合了不同算法优势的三步杂合优化算法;更通过下文的实例测试证明该算法进行密码子优化的高效性。
本发明的免疫算法与遗传算法相比,具有如下特点:首先它具有免疫记忆功能,该功能可以加快搜索速度,提高遗传算法的总体搜索能力;其次它具有抗体的多样性保持功能,利用该功能可以提高遗传算法的局部搜索能力;最后它具有自我调节功能,这种功能可用于提高遗传算法的全局搜索能力,避免陷入局部解。所以免疫遗传算法既保留了遗传算法随机全局并行搜索的特点,又在相当大程度上避免未成熟收敛,确保快速收敛于全局最优解。本第一次结合利用免疫算法与遗传算法的准确度和效率的优势,通过分步流程(依次分别是局部优化、全局优化、微调优化)进行密码子优化,并通过实例测试证明该算法进行密码子优化的高效性。
本发明具有速度快,效率高的优点。
图1是本发明的优化算法流程示意图。
图2是本发明的免疫算法流程示意图(即局部优化流程)。
图3是本发明的遗传算法流程(即全局优化流程)。
图4是本发明的DNA序列5’端优化流程。
图5是本发明的测试蛋白基因序列设计示意图。
图6是本发明的pTT表达载体图谱。
图7是本发明的Western Blotting结果示意图。
下面结合附图和实施例对本发明作进一步的说明。
如图1-7所示。
一种基于免疫算法的密码子优化方法,它先后使用免疫算法和遗传算法分别对蛋白质编码序列(SEQ ID NO.3和SEQ ID NO.4)进行局部多目标优化和全局多目标优化,再用穷举法对序列进行微调优化,从而最大限度的搜索到最优表达序列(SEQ ID NO.5和SEQ ID NO.6),如图1所示。其中:
一、免疫算法(即局部优化,流程见图2)。
该步骤的优化变量个数L为2,即对每个片段优化Codon Context和CAI这两个特征(具体描述见下文),属于多目标优化。假设免疫系统由N个抗体组成(即群体规模为N),每个抗体基因长度为M(等同于蛋白质序列的氨基酸个数M),直接采用同义密码子对每个基因进行编码。
(1)根据不同宿主表达系统的基础数据集(即高表达蛋白的编码序列)计算密码子频率表和二联密码子频率表,供生成序列和计算codon context和CAI使用。
(2)初次应答时,初始抗体根据二联密码子频率产生。具体以蛋白质序列a
1a
2…a
m为例,假设a
1的同义密码子是c
11和c
12,a
2的同义密码子是c
21、c
22和c
23。首个氨基酸a
1的密码子根据密码子频率表中c
11和c
12的频率选取。二联氨基酸a
1a
2对应的二联密码子为c
11c
21、c
11c
22、c
11c
23、c
12c
21、c
12c
22和c
12c
23,其中二联同义密码子有两组,包括[c
11c
21、c
11c
22、c
11c
23]和[c
12c
21、c
12c
22、c
12c
23]。假设a
1选取的密码子为C
11,则氨基酸a
2的密码子根据c
11c
21、c
11c
22和c
11c
23的频率从c
21、c
22和c
23中选择一个。如果a
1选取的密码子是C
12,则根据c
12c
21、c
12c
22和c
12c
23的频率选择氨基酸a
2的密码子c
21、c
22和c
23中的一个。简言之,除第一个氨基酸直接根据密码子频率表选取密码子以外,其他氨基酸的密码子的选取都与它的上一个氨基酸的密码子的选取有关,并由它们的二联同义密码子的频率决定。
(3)非初次应答时,群体由父代个体和记忆单元中存储的K个抗体组成,记忆单元抗体记录有优化历史中出现过的K个最佳抗体,其中适应度低的抗体在优化过程中逐步被更高适应度的个体替代。
(4)计算抗体的适应度F(包括F
[codon
Context]和F
[CAI]),根据多目标优化选择N个子代个体并对新群体完成交叉和变异操作。这里的变异是随机突变密码子。
(5)计算抗体群体相似度S
本发明利用Shannon的平均信息熵H(N)来度量群体相似度S。
首先P
ij为同义密码子i出现在氨基酸j上的概率,即:

其中N
ij为群体所有个体的第j个氨基酸位置上其同义密码子i出现的总个数。则Hj(N)为第j个基因(即蛋白序列的第j个氨基酸)的信息熵,定义为:

整个群体的平均信息熵为:

群体相似度S的定义为:

(6)随着优化的进行,群体中抗体的相似度不断提高,为了避免抗体的同质性,提高抗体的多样度,从而提高全局搜索能力,防止未成熟收敛,当群体相似度S大于阈值S
0时,模仿免疫系统细胞的新陈代谢功能,产生P个新抗体,生成过程同上述(2),使抗体总数达到P+N。如果群体相似度S小于阈值S
0则群体继续直接进入下一代进化,并更新记忆单元。
(7)当S>S
0时,对抗体群体P+N计算抗体浓度和聚合适应度。其中抗体浓度是指每个抗体在群体中与其相似抗体所占的百分比,即:

其中Ai指与抗体i相似度大于相似度常数λ的抗体个数。λ指两个个体比较时在M个密码子中相同的密码子的个数。
聚合适应度F’是依据抗体浓度对抗体适应度F进行修正后的值,即:

根据聚合适应度选取子代群体,更新记忆单元,并进入下一轮优化,由于我们同时考虑了codon context和CAI两个序列特征,所以F’
[codon
context]基于F
[codon
context]计算,F’
[CAI]基于F
[CAI]计算。如果达到终止代数则停止进化,并输出单个蛋白片段的优化序列集。
二、遗传算法(即全局优化,流程见图3)。
基于免疫算法优化生成的所有蛋白片段的优化序列集,随机生成初始化群体N,根据遗传算法的流程,完成适应度计算、子代群体的选取、交叉、变异和记忆体更新,到达终止代数则停止进化,并输出蛋白全序的最优DNA编码序列,整个流程属于多目标优化。优化过程中我们直接采用每个蛋白质片段的优化序列集对每个基因进行编码。
三、微调优化。
微调优化包括两步,首先是对DNA 5’端进行优化,然后消除表达抑制性模序。其中DNA 5’端的优化过程如图四,使用穷举法列举出蛋白N端氨基酸序列(8-15个氨基酸)所有可能的DNA编码序列,并计算它们的codon context和CAI,然后将蛋白序列起始密码子上游的载体序列50bp(默认值为50bp,长度可选范围0~50bp)与其依序连接,并利用mfold软件计算连接后的序列的折叠自由能(minimum free energy,MFE)。根据折叠自由能(值越大越好)、codon context(值越大越好)和CAI(值越大越好)对信号肽的编码序列进行排序,选择出最佳5’端序列。
四、上述流程相关细节
(1)基础数据集及二联密码子表生成
基础数据集是指不同宿主表达系统中高表达蛋白及其所对应的DNA编码序列。二联密码子表是指基础数据集的所有二联密码子相对适应度(计算方法见下文)。
(2)codon context和CAI的计算流程
a)密码子相对适应度w
ij:

其中x
ij表示基础数据集中第i种氨基酸的第j个同义密码子的出现个数,x
imax表示基础数据集中第i种氨基酸使用频率最高的同义密码子出现的个数。
b)目标序列的密码子适应指数(Codon Adaptation Index,CAI):

其中L指目标序列(即蛋白质序列或片段)的氨基酸个数,w
k为每个氨基酸密码子使用的密码子对应的基础数据集的密码子相对适应度。CAI的值介于0到1之间。优化过程中我们尽量提高编码DNA的CAI的值。
c)二联密码子相对适应度p
k:

其中二联密码子有3721种(61×61=3721,不考虑终止密码子),
 表示第k种二联密码子在蛋白序列基础数据集或目标序列(即蛋白质序列或片段)中出现的个数,
表示第k种二联密码子在蛋白序列基础数据集或目标序列(即蛋白质序列或片段)中出现的个数,
 表示表示该二联密码子对应的二联氨基酸出现的个数。
表示表示该二联密码子对应的二联氨基酸出现的个数。
d)目标序列的二联密码子适应指数(Codon Context,CC):

其中
 表示目标序列的第k种二联密码子的相对适应度,
表示目标序列的第k种二联密码子的相对适应度,
 表示基础数据集的第k种二联密码子的相对适应度。CC的值介于0到1之间。优化过程中我们尽量提高编码DNA的CC的值。
表示基础数据集的第k种二联密码子的相对适应度。CC的值介于0到1之间。优化过程中我们尽量提高编码DNA的CC的值。
(3)免疫算法和遗传算法的多目标优化过程中子代群体选择可使用NSGA2和SPEA2算法(默认使用NSGA2),交叉使用两点交叉。
以下通过一个实例进一步说明本发明的优点:
测试例使用的宿主表达系统是CHO细胞系,一共优化测序了两个蛋白质(相关信息见表一)。JNK3蛋白序列如SEQ ID NO.1所示,GFP蛋白序列如SEQ ID NO.2所示;优化前JNK3蛋白和GFP蛋白编码序列分别如SEQ ID NO.3和SEQ ID NO.4所示,优化后JNK3蛋白和GFP蛋白编码序列分别如SEQ ID NO.5和SEQ ID NO.6所示。
表一:优化测试蛋白序列信息

按照图5所示,合成编码测试蛋白的基因片段,并通过EcoR I和Hind III酶切位点将其分别克隆到pTT5表达载体(购买自NRC,质粒图谱如图6所示)。
CHO 3E7细胞瞬转表达步骤:
1、将处于对数生长期的CHO 3E7悬浮细胞用新鲜的FreeStyle CHO培养基稀释到5X10
5个细胞/mL,每个125mL三角摇瓶中接种30mL细胞悬液。
2、将细胞在37℃ 5%CO
2条件下进行悬浮培养。
3、当细胞密度达到1-1.2X10
6个/mL时,通过PEI转染试剂将克隆有目的基因的质粒载体按照1ug/ml的用量分别转染CHO 3E7细胞。
4、转染48小时后,将培养基经1500转/min离心,收获细胞。样品可于-80℃冰箱内保存。
Western Blot实验步骤:
利用抗Flag tag抗体,通过Western Blotting检测细胞裂解液中目标蛋白的表达量,beta-actin蛋白作为内参,每个质粒的表达实验重复三次,Western Blotting结果见图7。
详细步骤如下。
1、使用细胞裂解液裂解CHO细胞,对蛋白浓度进行测定。
2、向蛋白溶液中加入5X SDS-PAGE蛋白上样缓冲液,沸水浴加热10分钟。
3、用微量移液器将蛋白样品加入SDS-PAGE胶加样孔内,每孔上样20ul。
4、使用140V恒压电泳60分钟,溴酚蓝到达胶的底端处附近即可停止电泳。
5、转膜电压为100V,低温转膜时间为60分钟。
6、转膜完毕后把蛋白膜放置到预先准备好的洗涤液中,漂洗1-2分钟洗去膜上的转膜液。
7、摇床上缓慢摇动室温封闭45分钟。
8、加入稀释好的一抗,室温缓慢摇动孵育一小时。
9、加入洗涤液,在摇床上缓慢摇动洗涤5分钟,共洗涤3次。
10、加入稀释好的二抗,室温缓慢摇动孵育一小时。
11、加入洗涤液,在摇床上缓慢摇动洗涤5分钟,共洗涤3次。
12、化学发光检测。
13、使用Image J软件对Western Blotting结果图片进行定量分析。
表二:优化前后蛋白相对表达量(经Western Blotting检测)

*相对表达量:蛋白表达量除以野生型序列三次重复实验中表达量的最小值
由表二可见,JNK3和GFP蛋白经过本专利的三步杂合密码子优化后,表达量分别较野生型序列提升7.42±0.58倍和18.37±2.90倍,充分证明新算法的高效性。在公司的实际生产中,我们也比较测试了该算法与其他算法对多个蛋白的优化效果,同样证明该算法更加稳定高效。
本发明未涉及部分均与现有技术相同或可采用现有技术加以实现。
Claims (8)
- 一种基于免疫算法的密码子优化方法,其特征在于先后使用免疫算法和遗传算法分别对蛋白质编码序列进行局部多目标优化和全局多目标优化,再用穷举法对序列进行微调优化,从而最大限度的搜索到最优表达序列。
- 根据权利要求1所述的优化方法,其特征是它包括以下三个步骤:;第一步是局部优化,即将蛋白质序列切割成无重叠的序列片段A 1、A 2……A n,然后利用免疫算法,对每个序列片段完成密码子优化,生成近似最优DNA序列集B 1、B 2……B n;第二步是全局优化,即利用遗传算法,基于B 1、B 2……B n初始化蛋白质全长的DNA编码序列,筛选出蛋白质序列最优DNA序列C 1;第三步是微调优化,包括对编码蛋白质N端区域所对应的DNA序列5’端进行穷举法优化,生成DNA序列C 2,并消除表达抑制性模序,最终生成最优表达序列D。
- 根据权利要求1或2所述的优化方法,其特征是所述的蛋白质是指由二十个以上的氨基酸组成化合物。在定位上包括分泌蛋白、膜蛋白、胞质蛋白、细胞核内蛋白等;在功能上包含抗体蛋白、调节蛋白、结构蛋白等;在来源上包含同源表达蛋白和异源表达蛋白;在序列上包含天然蛋白和人工改造后的蛋白,完整的蛋白/抗体和截断的部分蛋白/抗体,以及2个或2个以上蛋白之间、蛋白与肽链之间形成的融合蛋白。本发明中所定义的抗体包括但不限于完整的抗体和Fab、ScFV、SdAb、嵌合抗体、双特异性抗体、Fc融合蛋白等等。
- 根据权利要求1或2所述的优化方法,其特征是所述的免疫遗传算法采用多目标优化方法对蛋白质片段进行局部优化,群体的初始化基于高表达蛋白编码序列的二联密码子表,直接采用同义密码子对每个基因进行编码;优化过程中通过计算免疫遗传算法的抗体信息熵、抗体群体相似度、抗体浓度和聚合适应度以及更新记忆单元来保证抗体多样性并防止群体退化现象,从而增加算法的全局搜索能力。
- 根据权利要求1或2所述的优化方法,其特征是所述的遗传算法采用多目标优化方法用来对蛋白质全序进行全局优化,初始化群体基于局部优化的优化后片段随机生成,直接采用每个蛋白质片段的优化序列集对每个基因进行编码。
- 根据权利要求1或2所述的优化方法,其特征是所述的微调优化利用穷举法对DNA序列5’端的折叠自由能MFE、Codon Context和CAI进行计算和排序,并根据排序结果选择最佳的蛋白序列N端编码序列。
- 根据权利要求1或2所述的优化方法,其特征是所述的密码子优化方法至少适用于以下的宿主表达系统:1)哺乳动物表达系统;2)昆虫表达系统;3)酵母表达系统;4)大肠杆菌表达系统;5)枯草芽孢杆菌表达系统;6)植物表达系统和7)无细胞表达系统。
- 根据权利要求1或2所述的优化方法,其特征是所述的密码子优化方法至少适用于以下表达载体:瞬时表达载体和稳定表达载体、病毒表达载体和非病毒表达载体、诱导和非诱导表达载体。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP18839139.5A EP3660852B1 (en) | 2017-07-25 | 2018-07-25 | Codon optimization method based on immune algorithm |
| JP2020503285A JP2020534794A (ja) | 2017-07-25 | 2018-07-25 | 免疫アルゴリズムに基づくコドン最適化方法 |
| US16/633,910 US20210027858A1 (en) | 2017-07-25 | 2018-07-25 | Codon optimization method based on immune algorithm |
| KR1020207005489A KR102730745B1 (ko) | 2017-07-25 | 2018-07-25 | 면역 알고리즘에 근거된 코돈 최적화 방법 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201710611752.5A CN110070913B (zh) | 2017-07-25 | 2017-07-25 | 一种基于免疫算法的密码子优化方法 |
| CN201710611752.5 | 2017-07-25 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2019020054A1 true WO2019020054A1 (zh) | 2019-01-31 |
Family
ID=65039394
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2018/097040 Ceased WO2019020054A1 (zh) | 2017-07-25 | 2018-07-25 | 一种基于免疫算法的密码子优化方法 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US20210027858A1 (zh) |
| EP (1) | EP3660852B1 (zh) |
| JP (1) | JP2020534794A (zh) |
| KR (1) | KR102730745B1 (zh) |
| CN (1) | CN110070913B (zh) |
| WO (1) | WO2019020054A1 (zh) |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109979539A (zh) * | 2019-04-10 | 2019-07-05 | 电子科技大学 | 基因序列优化方法、装置及数据处理终端 |
| CN110580390A (zh) * | 2019-09-04 | 2019-12-17 | 电子科技大学 | 基于改进遗传算法与信息熵的地质统计学随机反演方法 |
| CN111243679A (zh) * | 2020-01-15 | 2020-06-05 | 重庆邮电大学 | 微生物群落物种多样性数据的存储检索方法 |
| CN112466393A (zh) * | 2020-11-12 | 2021-03-09 | 苏州大学 | 基于自适应免疫遗传算法的代谢标志物组群识别方法 |
| CN112735525A (zh) * | 2021-01-18 | 2021-04-30 | 江苏普瑞康生物医药科技有限公司 | 一种基于分治法的mRNA序列优化的方法与装置 |
| CN116072231A (zh) * | 2022-10-17 | 2023-05-05 | 中国医学科学院病原生物学研究所 | 基于氨基酸序列的密码子优化在mRNA疫苗研发中的应用 |
| WO2024109911A1 (zh) | 2022-11-24 | 2024-05-30 | 南京金斯瑞生物科技有限公司 | 密码子优化 |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113792877B (zh) * | 2021-09-18 | 2024-02-20 | 大连大学 | 基于双策略黑蜘蛛算法的dna存储编码优化方法 |
| CN113962548A (zh) * | 2021-10-21 | 2022-01-21 | 上海欧冶物流股份有限公司 | 货物配载方案优化方法、程序产品、可读介质和电子设备 |
| CN116218881B (zh) * | 2022-10-21 | 2024-08-13 | 山东大学 | 一种治疗或者预防乙肝病毒的疫苗 |
| CN115440300B (zh) * | 2022-11-07 | 2023-01-20 | 深圳市瑞吉生物科技有限公司 | 一种密码子序列优化方法、装置、计算机设备及存储介质 |
| KR102883373B1 (ko) * | 2022-12-02 | 2025-11-10 | 성균관대학교산학협력단 | 코돈 최적화 양자어닐링 알고리즘 |
| CN117238374B (zh) * | 2023-09-13 | 2025-09-19 | 上海交通大学宁波人工智能研究院 | 一种基于CAI和AUP的mRNA序列联合优化方法 |
| CN117497092B (zh) * | 2024-01-02 | 2024-05-14 | 微观纪元(合肥)量子科技有限公司 | 基于动态规划和量子退火的rna结构预测方法及系统 |
| CN118038986B (zh) * | 2024-02-05 | 2025-09-02 | 北京百度网讯科技有限公司 | mRNA序列的确定方法、装置、设备和介质 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101490262A (zh) * | 2006-06-29 | 2009-07-22 | 帝斯曼知识产权资产管理有限公司 | 实现改进的多肽表达的方法 |
| CN106951726A (zh) * | 2017-02-20 | 2017-07-14 | 苏州金唯智生物科技有限公司 | 一种基因编码序列的优化方法及装置 |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE10260805A1 (de) * | 2002-12-23 | 2004-07-22 | Geneart Gmbh | Verfahren und Vorrichtung zum Optimieren einer Nucleotidsequenz zur Expression eines Proteins |
| GB0419424D0 (en) * | 2004-09-02 | 2004-10-06 | Viragen Scotland Ltd | Transgene optimisation |
| CN101885760B (zh) * | 2010-03-16 | 2012-12-05 | 王世霞 | 密码子优化的HIV-1gp120基因共有序列及gp120核酸疫苗 |
| US20140244228A1 (en) * | 2012-09-19 | 2014-08-28 | Agency For Science, Technology And Research | Codon optimization of a synthetic gene(s) for protein expression |
-
2017
- 2017-07-25 CN CN201710611752.5A patent/CN110070913B/zh active Active
-
2018
- 2018-07-25 KR KR1020207005489A patent/KR102730745B1/ko active Active
- 2018-07-25 EP EP18839139.5A patent/EP3660852B1/en active Active
- 2018-07-25 JP JP2020503285A patent/JP2020534794A/ja active Pending
- 2018-07-25 US US16/633,910 patent/US20210027858A1/en not_active Abandoned
- 2018-07-25 WO PCT/CN2018/097040 patent/WO2019020054A1/zh not_active Ceased
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101490262A (zh) * | 2006-06-29 | 2009-07-22 | 帝斯曼知识产权资产管理有限公司 | 实现改进的多肽表达的方法 |
| CN106951726A (zh) * | 2017-02-20 | 2017-07-14 | 苏州金唯智生物科技有限公司 | 一种基因编码序列的优化方法及装置 |
Non-Patent Citations (7)
| Title |
|---|
| EVELINA ANGOV, BIOTECHNOLOGY JOURNAL, 2011 |
| FU, PING ET AL.: "Clustering analysis of immune-genetic algorithm based on information entropy", COMPUTER ENGINEERING, vol. 34, no. 6, 31 March 2008 (2008-03-31), pages 227 - 228,232, XP009519108, ISSN: 1000-3428 * |
| JOSHUA B. PLOTKINGRZEGORZ KUDLA, NATURE REVIEWS GENETICS, 2011 |
| NATHAN GOULD ET AL., FRONTIERS IN BIOENGINEERING AND BIOTECHNOLOGY, 2014 |
| SANDHU,K.S. ET AL.: "GASCO: Genetic algorithm simulation for codon optimization", IN SILICO BIOLOGY, vol. 8, no. 2, 13 April 2008 (2008-04-13), pages 187 - 191, XP009189299, ISSN: 1386-6338 * |
| See also references of EP3660852A4 |
| ZHENG, JIANGANG ET AL.: "DNA-Immune-Genetic algorithm based on information entropy", COMPUTER SIMULATION, vol. 23, no. 6, 30 June 2006 (2006-06-30), pages 163 - 165, XP009519109 * |
Cited By (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109979539B (zh) * | 2019-04-10 | 2020-10-02 | 电子科技大学 | 基因序列优化方法、装置及数据处理终端 |
| CN109979539A (zh) * | 2019-04-10 | 2019-07-05 | 电子科技大学 | 基因序列优化方法、装置及数据处理终端 |
| CN110580390A (zh) * | 2019-09-04 | 2019-12-17 | 电子科技大学 | 基于改进遗传算法与信息熵的地质统计学随机反演方法 |
| CN111243679B (zh) * | 2020-01-15 | 2023-03-31 | 重庆邮电大学 | 微生物群落物种多样性数据的存储检索方法 |
| CN111243679A (zh) * | 2020-01-15 | 2020-06-05 | 重庆邮电大学 | 微生物群落物种多样性数据的存储检索方法 |
| CN112466393A (zh) * | 2020-11-12 | 2021-03-09 | 苏州大学 | 基于自适应免疫遗传算法的代谢标志物组群识别方法 |
| CN112466393B (zh) * | 2020-11-12 | 2024-02-20 | 苏州大学 | 基于自适应免疫遗传算法的代谢标志物组群识别方法 |
| CN112735525A (zh) * | 2021-01-18 | 2021-04-30 | 江苏普瑞康生物医药科技有限公司 | 一种基于分治法的mRNA序列优化的方法与装置 |
| CN112735525B (zh) * | 2021-01-18 | 2023-12-26 | 苏州科锐迈德生物医药科技有限公司 | 一种基于分治法的mRNA序列优化的方法与装置 |
| CN116072231A (zh) * | 2022-10-17 | 2023-05-05 | 中国医学科学院病原生物学研究所 | 基于氨基酸序列的密码子优化在mRNA疫苗研发中的应用 |
| CN116072231B (zh) * | 2022-10-17 | 2024-02-13 | 中国医学科学院病原生物学研究所 | 基于氨基酸序列的密码子优化设计mRNA疫苗的方法 |
| WO2024109911A1 (zh) | 2022-11-24 | 2024-05-30 | 南京金斯瑞生物科技有限公司 | 密码子优化 |
| EP4625419A1 (en) | 2022-11-24 | 2025-10-01 | Nanjing GenScript Biotech Co., Ltd. | Codon optimization |
Also Published As
| Publication number | Publication date |
|---|---|
| KR20200038263A (ko) | 2020-04-10 |
| EP3660852A4 (en) | 2021-05-12 |
| CN110070913B (zh) | 2023-06-27 |
| KR102730745B1 (ko) | 2024-11-15 |
| US20210027858A1 (en) | 2021-01-28 |
| EP3660852B1 (en) | 2024-05-01 |
| CN110070913A (zh) | 2019-07-30 |
| JP2020534794A (ja) | 2020-12-03 |
| EP3660852A1 (en) | 2020-06-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2019020054A1 (zh) | 一种基于免疫算法的密码子优化方法 | |
| CN111363029B (zh) | 重组人源ⅲ型胶原蛋白、表达菌株及其构建方法 | |
| CN112513989B (zh) | 密码子优化 | |
| JP2022543234A5 (zh) | ||
| JP2020534794A5 (zh) | ||
| CN111363028B (zh) | 重组人源ⅰ型胶原蛋白、表达菌株及其构建方法 | |
| CN101490262A (zh) | 实现改进的多肽表达的方法 | |
| CN108893417A (zh) | 一种用于高核酸酵母选育的高通量筛选体系及应用 | |
| CN112899252B (zh) | 一种高活性转座酶及其应用 | |
| CN106987559A (zh) | 一种重组chok1细胞株的构建方法及其应用 | |
| CN104894652A (zh) | 一种cTnI人源化单链抗体库的构建及应用 | |
| CN118077011A (zh) | 一种降低外源核酸免疫原性的密码子优化 | |
| WO2021136347A1 (zh) | 一种哺乳动物表达系统使用的高表达载体 | |
| Cregg et al. | Expression of recombinant genes in the yeast Pichia pastoris | |
| CN114774421B (zh) | 运动发酵单胞菌内源性启动子突变体 | |
| CN102344897B (zh) | 基因工程用工具菌及其应用 | |
| Cregg et al. | Expression of recombinant genes in the yeast Pichia pastoris | |
| CN109402096B (zh) | 一种aid酶突变体及其应用 | |
| CN121270671B (zh) | 一种近红外光响应的组合优化光遗传系统 | |
| WO2025108365A1 (en) | Novel tandem repeat-containing polypeptides that bind to dna | |
| CN115960934A (zh) | 大肠杆菌表达外源基因优化方法及其序列 | |
| Tan et al. | Optimization of Physical Parameters for the Enhanced Expression of Recombinant Chemokine Receptors D6 and DARC in Pichia pastoris | |
| WO2017163946A1 (ja) | 誘導型プロモーター | |
| CN118562794A (zh) | 一种高强度表达枯草芽孢杆菌基因的rbs文库及应用 | |
| CN121343792A (zh) | 一种高同源重组效率毕赤酵母工程菌及其构建方法和应用 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| ENP | Entry into the national phase |
Ref document number: 2020503285 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 20207005489 Country of ref document: KR Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 2018839139 Country of ref document: EP Effective date: 20200225 |