WO2020121616A1 - 処理システム、処理方法及びプログラム - Google Patents
処理システム、処理方法及びプログラム Download PDFInfo
- Publication number
- WO2020121616A1 WO2020121616A1 PCT/JP2019/036062 JP2019036062W WO2020121616A1 WO 2020121616 A1 WO2020121616 A1 WO 2020121616A1 JP 2019036062 W JP2019036062 W JP 2019036062W WO 2020121616 A1 WO2020121616 A1 WO 2020121616A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- call
- estimation
- target
- voice
- language
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images










Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/005—Language recognition
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04M—TELEPHONIC COMMUNICATION
- H04M3/00—Automatic or semi-automatic exchanges
- H04M3/42—Systems providing special services or facilities to subscribers
- H04M3/56—Arrangements for connecting several subscribers to a common circuit, i.e. affording conference facilities
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/063—Training
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04M—TELEPHONIC COMMUNICATION
- H04M3/00—Automatic or semi-automatic exchanges
- H04M3/42—Systems providing special services or facilities to subscribers
- H04M3/428—Arrangements for placing incoming calls on hold
- H04M3/4285—Notifying, informing or entertaining a held party while on hold, e.g. Music On Hold
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04M—TELEPHONIC COMMUNICATION
- H04M3/00—Automatic or semi-automatic exchanges
- H04M3/42—Systems providing special services or facilities to subscribers
- H04M3/487—Arrangements for providing information services, e.g. recorded voice services or time announcements
- H04M3/493—Interactive information services, e.g. directory enquiries ; Arrangements therefor, e.g. interactive voice response [IVR] systems or voice portals
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04M—TELEPHONIC COMMUNICATION
- H04M3/00—Automatic or semi-automatic exchanges
- H04M3/42—Systems providing special services or facilities to subscribers
- H04M3/50—Centralised arrangements for answering calls; Centralised arrangements for recording messages for absent or busy subscribers ; Centralised arrangements for recording messages
- H04M3/51—Centralised call answering arrangements requiring operator intervention, e.g. call or contact centers for telemarketing
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04M—TELEPHONIC COMMUNICATION
- H04M2242/00—Special services or facilities
- H04M2242/12—Language recognition, selection or translation arrangements
Definitions
- the present invention relates to a processing system, a processing method and a program.
- Patent Document 1 discloses a device that estimates a language of utterance from utterance data by using an estimation model generated by machine learning.
- Patent Document 2 realizes a three-party call including a foreigner who is a call partner, a correspondent who handles a call from the foreigner, and a support team that supports communication between the foreigner and the correspondent.
- a multilingual operating system is disclosed. Specifically, the multilingual operating system receives a designation of a language from a foreigner or a correspondent, and then connects a support team corresponding to the designated language to start a three-way call. That is, the language of the foreigner is specified based on the contents specified by the parties.
- JP 2012-103554 A JP, 2003-32373, A
- An object of the present invention is to improve estimation accuracy in a technique of estimating a language using an estimation model generated by machine learning.
- Target voice data in which a target voice that is a voice of a language estimation target is recorded, or an acquisition unit that acquires a target feature amount indicating a feature of the target voice
- An estimation model that estimates the language of the voice from voice data in which voice is recorded or a voice feature amount that indicates the feature of the voice, and an estimation that estimates the language of the target voice based on the target voice data or the target feature amount.
- Means and Result output means for outputting the estimation result by the estimation means, Determination means for determining whether the estimation result is true or false, Learning data output means for outputting the estimation result determined to be correct by the determination means, the target voice data or the target feature amount, as learning data for generating the estimation model,
- a processing system having:
- Computer Target voice data in which a target voice that is a voice of a language estimation target is recorded, or an acquisition step of acquiring a target feature amount indicating a feature of the target voice,
- An estimation model that estimates the language of the voice from voice data in which voice is recorded or a voice feature amount that indicates the feature of the voice, and an estimation that estimates the language of the target voice based on the target voice data or the target feature amount.
- a result output step of outputting the estimation result in the estimation step A determination step of determining whether the estimation result is true or false, The estimation result that is determined to be correct in the determination step, the target voice data or the target feature amount, a learning data output step of outputting as learning data for generating the estimation model, A processing method for performing is provided.
- Target voice data in which a target voice that is a voice of a language estimation target is recorded, or an acquisition unit that acquires a target feature amount indicating the feature of the target voice
- An estimation model that estimates the language of the voice from voice data in which voice is recorded or a voice feature amount that indicates the feature of the voice
- an estimation that estimates the language of the target voice based on the target voice data or the target feature amount.
- Result output means for outputting the estimation result by the estimation means
- Determination means for determining whether the estimation result is true or false
- Learning data output means for outputting the estimation result determined to be correct by the determination means and the target voice data or the target feature amount as learning data for generating the estimation model
- a program to function as is provided.
- the present invention it is possible to improve the estimation accuracy in the technology of estimating a language using an estimation model generated by machine learning.
- the processing system estimates the language of the speech of the language estimation target based on the estimation model generated by machine learning and the speech data in which the speech of the language estimation target is recorded or the feature amount of the speech. Next, the processing system outputs the estimation result and determines whether the estimation result is correct. Then, the estimation result that is determined to be correct, the voice data in which the voice of the language estimation target is recorded, or the feature amount of the voice is output as learning data for generating the estimation model.
- Each functional unit included in the processing system 10 includes a CPU (Central Processing Unit) of any computer, a memory, a program loaded in the memory, a storage unit such as a hard disk for storing the program (stored from a stage of shipping the device in advance). In addition to existing programs, it can also store programs such as storage media such as CDs (Compact Discs) and programs downloaded from servers on the Internet), and any combination of hardware and software centered on a network connection interface. To be done. It will be understood by those skilled in the art that there are various modified examples of the method and device for realizing the same.
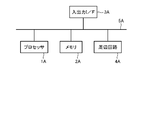
- FIG. 1 is a block diagram illustrating the hardware configuration of the processing system 10.
- the processing system 10 has a processor 1A, a memory 2A, an input/output interface 3A, a peripheral circuit 4A, and a bus 5A.
- the peripheral circuit 4A includes various modules.
- the processing system 10 may not have the peripheral circuit 4A.
- the processing system 10 may be composed of a plurality of physically and/or logically separated devices. In this case, each of the plurality of devices can have the above hardware configuration.
- the bus 5A is a data transmission path for the processor 1A, the memory 2A, the peripheral circuit 4A, and the input/output interface 3A to exchange data with each other.
- the processor 1A is an arithmetic processing unit such as a CPU or a GPU (Graphics Processing Unit).
- the memory 2A is a memory such as a RAM (Random Access Memory) or a ROM (Read Only Memory).
- the input/output interface 3A includes an interface for acquiring information from an input device, an external device, an external server, an external sensor, a camera, etc., an interface for outputting information to an output device, an external device, an external server, etc. ..
- the input device is, for example, a keyboard, a mouse, a microphone, or the like.
- the output device is, for example, a display, a speaker, a printer, a mailer, or the like.
- the processor 1A can issue a command to each module and perform a calculation based on the calculation result.
- the processing system 10 includes an acquisition unit 11, an estimation unit 12, a result output unit 13, a determination unit 14, and a learning data output unit 15.
- the processing system 10 may include the estimation model generation device 20. That is, the processing system 10 and the estimation model generation device 20 may be physically and/or logically separated, or the processing system 10 and the estimation model generation device 20 may be physically and logically integrated.
- the learning data storage unit 21 stores learning data in which voice data in which a voice is recorded or a voice feature amount indicating a feature of the voice and a language of the voice (eg, Japanese, English, Chinese, etc.) are paired. ..
- the voice feature amount is extracted from the voice data.
- the estimation model generation unit 22 generates an estimation model that estimates the language of voice from the voice data or the voice feature amount by machine learning using the learning data stored in the learning data storage unit 21.
- the machine learning technique is not particularly limited, and any technique can be adopted.
- the acquisition unit 11 acquires target voice data in which the target voice that is the voice of the language estimation target is recorded, or the target feature amount indicating the feature of the target voice.
- the target feature amount is extracted from the target voice data.
- acquisition means "the device itself is going to retrieve data stored in another device or a storage medium (actively) based on a user input or a program instruction. Acquisition)", for example, requesting or inquiring to another device to receive it, accessing another device or a storage medium for reading, etc., and based on user input or program instructions.
- Inputting data output from another device to the device itself for example, receiving data distributed (or transmitted, push notification, etc.), and received data or information Select and acquire from among the above, and "Create new data by editing data (text conversion, data rearrangement, partial data extraction, file format change, etc.) At least one of "acquiring data” is included.
- the estimation unit 12 estimates the language of the target voice based on the estimation model generated by the estimation model generation unit 22 and the target voice data or the target feature amount acquired by the acquisition unit 11.
- the result output unit 13 outputs the estimation result by the estimation unit 12.
- the result output unit 13 can output the estimation result via an output device such as a display, a speaker, a printer, a projection device, and a mailer.
- the determination unit 14 determines whether the estimation result by the estimation unit 12 is correct.
- the determination unit 14 can acquire a predetermined determination material and make a correctness determination of the estimation result based on the determination material.
- the determination material may be information (“correct” or “wrong”) that directly indicates whether the estimation result input by the user is correct or incorrect, or whether the estimation result acquired by means other than the user input is correct.
- the information may be indirectly indicated. An example in which the determination unit 14 determines whether the estimation result is correct or incorrect based on the information indirectly indicating whether the estimation result is correct or incorrect, which is obtained by means other than user input, will be described in the following embodiment.
- the learning data output unit 15 learns the estimation result determined to be correct by the determination unit 14 and the target voice data or the target feature amount from which the estimation result is derived by the estimation unit 12, to generate an estimation model. Output as. The learning data output by the learning data output unit 15 is accumulated in the learning data storage unit 21.
- the acquisition unit 11 acquires new target voice data or target feature amount (S10)
- the language of the target voice is estimated based on the feature amount (S11).
- the result output unit 13 outputs the estimation result estimated in S11 (S12).
- the determination unit 14 determines whether the estimation result estimated in S12 is correct (S13). For example, the determination unit 14 may acquire information that directly indicates whether the estimation result input by the user is correct or incorrect, and may determine whether the estimation result is correct or incorrect based on the information.
- the learning data output unit 15 determines the target voice data or the target feature amount acquired in S10 and the estimation result estimated in S11. Is output as learning data (S15).
- the learning data output by the learning data output unit 15 in S15 is accumulated in the learning data storage unit 21.
- the estimation model generation unit 22 generates an estimation model for estimating the language of the voice from the voice data or the voice feature amount by machine learning using the learning data stored in the learning data storage unit 21. ..
- the estimation model generation unit 22 may newly perform machine learning every time one new learning data is registered in the learning data storage unit 21 to generate a new estimation model. In addition, the estimation model generation unit 22 newly performs machine learning every time a new predetermined number (any number of 2 or more) of learning data is registered in the learning data storage unit 21 to generate a new estimation model. May be. In addition, the estimation model generation unit 22 may newly perform machine learning at each predetermined time to generate a new estimation model. In addition, the estimation model generation unit 22 may newly perform machine learning at the timing when there is a user input to update the estimation model and generate a new estimation model. Note that the timing of performing the machine learning illustrated here is an example, and the present invention is not limited to this.
- the processing system 10 that executes the language estimation and the generation of learning data using the estimation result in conjunction with each other, it is possible to increase the learning data while performing the processing of estimating the language. As a result, it is possible to avoid the troublesome work of only increasing the learning data.
- the processing system 10 having the above characteristics, it is possible to increase the learning data based on the estimation result obtained in practice while estimating the language using the processing system 10 in practice. According to the processing system 10 as described above, it is possible to efficiently increase the learning data suitable for the practical work, specifically, the learning data of the language having the opportunity to come into contact with the practical work. Then, the estimation model suitable for the practical work is generated. In this way, it is possible to provide the processing system 10 with performance specialized for the needs of the environment in which the processing system 10 is used.
- the processing system 10 of the present embodiment is different from that of the first embodiment in that the processing system 10 has a call means and the voice of the other party is the target voice.
- An example of the hardware configuration of the processing system 10 is the same as that of the first embodiment.
- the processing system 10 includes an acquisition unit 11, an estimation unit 12, a result output unit 13, a determination unit 14, a learning data output unit 15, a call unit 16, a call control unit 17, and an interpreter. It has a person in charge extraction section 18 and an interpreter person output section 19.
- the processing system 10 may include a learning data storage unit 21 and an estimated model generation unit 22.
- the processing system 10 is composed of the call terminal 1 shown in FIG. 5, or both the call terminal 1 and the server 2. That is, the call terminal 1 may include all the functional units included in the processing system 10. In addition, the call terminal 1 may include a part of the functional units included in the processing system 10 and the server 2 may include the remaining functional units.
- the call terminal 1 may be a device that realizes a predetermined functional unit by installing a predetermined application in a terminal device such as a personal computer, a tablet terminal, or a smartphone, or a call in which the predetermined functional unit is realized in advance. It may be a dedicated terminal.
- the call unit 16 has a function of connecting to another call terminal and realizing a call.
- the acquisition unit 11 acquires the target voice data in which the voice of the call partner is recorded, or the target feature amount indicating the feature of the voice of the call partner.
- Other configurations of the acquisition unit 11 are similar to those of the first embodiment.
- the configurations of the estimation unit 12, the result output unit 13, the determination unit 14, and the learning data output unit 15 are the same as those in the first embodiment.
- the interpreter person extraction unit 18 refers to the interpreter information in which the interpreter person and contact information for each of a plurality of languages are registered, and extracts the interpreter person in the language indicated by the estimation result.
- FIG. 6 schematically shows an example of interpreter information.
- the interpreting staff output unit 19 outputs information indicating the interpreting staff extracted by the interpreting staff extraction unit 18.
- the interpreting staff output unit 19 can output information indicating the interpreting staff extracted by the interpreting staff extraction unit 18 via an output device such as a display, a speaker, a printer, a projection device, and a mailer.
- the interpreting staff output unit 19 may output a list of extracted interpreting staff.
- the call control unit 17 puts a call on hold with the other party on the basis of user input. Then, the call control unit 17 designates one of the interpreting personnel extracted by the interpreting personnel extracting unit 18, and starts a call (eg, extension call) with the designated interpreting personnel. For example, the call control unit 17 may specify one interpreter in charge based on a user input, or may specify one interpreter in accordance with a predetermined rule.
- the predetermined rule is, for example, "a person who has made the least number of three-way calls by that time of the day" or the like, but is not limited to this.
- the call control unit 17 puts a call on hold with the call partner, starts a call with the designated interpreter, and then accepts a predetermined input. Then, the call control unit 17 includes the caller and the interpreter. Can be started.
- the first call terminal is the call terminal used by the other party.
- the call partner is a foreigner. It is assumed that the foreigner is a person who speaks a language other than the official language in the area where the processing system 10 of the present embodiment is used, or a person who speaks a language other than the language designated by the party.
- the second call terminal is a call terminal used by a corresponding operator whose business is to handle customers by telephone.
- the second call terminal may include all the functional units included in the processing system 10, or may include a part of the functional units included in the processing system 10.
- the third call terminal is a call terminal used by an interpreter who supports a predetermined language.
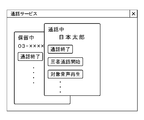
- FIG. 8 shows an example of a screen displayed on the second call terminal in the call state.
- a window including information indicating that a call is in progress, the telephone number of the other party, and a UI (user interface) button for performing various operations is displayed.
- the UI buttons include a call end button for ending the call, a hold button for putting the call on hold, a language estimation button for executing a process of estimating the language of the other party of the call, and the like.
- the corresponding operator recognizes that the other party is a foreigner, but if the other party's language cannot be recognized, after pressing the hold button to put the call on hold (S23, S24), the language estimation button push. Language estimation processing is executed in response to the depression of the language estimation button (S25).
- the acquisition unit 11 acquires the target voice data in which the voice of the call partner is recorded, or the target feature amount indicating the feature of the voice of the call partner.
- the second call terminal may be configured to record all calls regardless of the other party.
- the acquisition unit 11 may acquire a part or all of the recorded audio data as target audio data. Further, the acquisition unit 11 may extract the target feature amount from the target audio data acquired in this way.
- the estimation unit 12 estimates the language of the target voice based on the estimation model generated by the estimation model generation unit 22 and the target voice data or the target feature amount acquired by the acquisition unit 11.
- FIG. 9 shows an example of a screen displayed on the second call terminal when the result output unit 13 outputs the estimation result.
- a window showing the estimation result is displayed.
- information links indicating interpreters in the language indicated by the estimation result are linked.
- the interpreter output unit 19 acquires and outputs the information indicating the interpreter extracted by the interpreter extraction unit 18. Yes (S27).
- the interpreting staff extraction unit 18 refers to the interpreter information (see FIG. 6) in which the interpreting staff and contact information for each of a plurality of languages are registered, and extracts the interpreting staff in the language indicated by the estimation result.
- FIG. 10 shows an example of a screen displayed on the second call terminal when the interpreting staff output section 19 outputs information indicating the interpreting staff. In the figure, a window showing the person in charge of interpreting the language of the estimation result is displayed. In the window, a list of names of interpreters is displayed, and a call button for starting a call with each interpreter is displayed.
- the result output unit 13 is included in the second call terminal.
- the interpreting staff output unit 19 is included in the second call terminal.
- FIG. 11 shows an example of a screen displayed on the second call terminal in this state.
- a window including information indicating that a call is in progress, the name of the designated translator, and UI buttons for performing various operations is displayed.
- the UI buttons include a call end button for ending a call, a three-way call start button for starting a three-party call including the other party on hold, and the like.
- the call partner when the call partner is a foreigner, a three-way call including the call partner, the corresponding operator, and the interpreter corresponding to the language of the call partner is performed.
- the support operator may transfer the call to the specific language support operator corresponding to the language of the call partner.
- the specific language support operator is an operator who has the same skills as the support operator and can handle customers in a specific language.
- the language estimation processing is started according to the operation on the language estimation button.
- the language estimation button may be operated in the call state, and the language estimation process may be executed in the call state.
- the language estimation process may be started as well as being put on hold in response to an operation on the hold button. That is, the operation on the hold button may serve both as a hold state instruction and as an instruction to start the language estimation process.
- part of the processing (eg, S32, etc.) executed according to the operation of the user or the operator may be replaced with mechanical automatic processing. Also in this case, the operation and effect of this embodiment are realized.
- the processing system 10 of the present embodiment can be used in a call center or the like that handles customers by telephone. If a caller receives a call from a foreigner and he/she does not recognize the foreigner's language, it takes time to find the appropriate interpreter for that language, which causes the customer to wait. Can occur. According to the processing system 10 of the present embodiment, such inconvenience can be reduced. As a result, customer satisfaction at the call center can be increased.
- the processing system 10 of the present embodiment has the same configuration as that of the second embodiment, and is different from the first and second embodiments in that it determines whether the estimation result is correct or incorrect. Different from the embodiment.
- An example of the hardware configuration of the processing system 10 is the same as in the first and second embodiments.
- the processing system 10 includes an acquisition unit 11, an estimation unit 12, a result output unit 13, a determination unit 14, a learning data output unit 15, a call unit 16, a call control unit 17, and an interpreter. It has a person in charge extraction section 18 and an interpreter person output section 19.
- the processing system 10 may include a learning data storage unit 21 and an estimated model generation unit 22.
- the processing system 10 is composed of the call terminal 1 shown in FIG. 5, or both the call terminal 1 and the server 2. That is, the call terminal 1 may include all the functional units included in the processing system 10. In addition, the call terminal 1 may include a part of the functional units included in the processing system 10 and the server 2 may include the remaining functional units.
- the call terminal 1 may be a device that realizes a predetermined functional unit by installing a predetermined application in a terminal device such as a personal computer, a tablet terminal, or a smartphone, or a call in which the predetermined functional unit is realized in advance. It may be a dedicated terminal.
- the configuration of the acquisition unit 11, the estimation unit 12, the result output unit 13, the learning data output unit 15, the call unit 16, the call control unit 17, the interpreter person extraction unit 18, and the interpreter person output unit 19 is the first or second. It is similar to the embodiment.
- the determination unit 14 determines that the estimation result is correct when the elapsed time from the start of the three-party call including the call partner and the interpreter exceeds a predetermined time.
- the other configuration of the determination unit 14 is similar to that of the first or second embodiment.
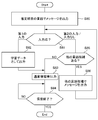
- the determination unit 14 monitors the elapsed time from the start of the three-way call. Then, as shown in the flowchart of FIG. 12, when the three-way call ends without the elapsed time exceeding the predetermined time (No in S40), the determination unit 14 determines that the estimation result in S25 is incorrect, and the processing is performed. finish.
- the determination unit 14 determines that the estimation result in S25 is correct. Then, the learning data output unit 15 outputs the target voice data or the target feature amount acquired in S25 and the estimation result estimated in S25 as learning data (S41).
- the determination unit 14 may determine that the estimation result is correct when a call is transferred to the specific language support operator and a predetermined time has elapsed.
- the processing system 10 of the present embodiment described above it is possible to achieve the same effect as that of the first or second embodiment. Further, according to the processing system 10 of the present embodiment, it is possible to determine the correctness of the estimation result based on the information indirectly indicating the correctness of the estimation result acquired by means other than the user input. Since it is possible to determine the correctness without user input, the burden on the user can be reduced.
- the processing system 10 of the present embodiment is configured such that the three-way call including the other party and the interpreter is continued, or the time the call is continued after being transferred to the specific language operator exceeds a predetermined time. If so, it is determined that the estimation result is correct. If the estimation result is wrong, the above-mentioned duration time becomes relatively short because of switching to another interpreter or re-transferring the call to another specific language operator.
- the processing system 10 of the present embodiment which determines whether the estimation result is correct or incorrect based on the above-described duration, can accurately perform the correctness determination.
- the processing system 10 of the present embodiment has the same configuration as that of the second embodiment, and is different from the first to third embodiments in that the estimation result is determined by the means different from the first to third embodiments. Different from the embodiment.
- An example of the hardware configuration of the processing system 10 is the same as that of the first to third embodiments.
- the processing system 10 includes an acquisition unit 11, an estimation unit 12, a result output unit 13, a determination unit 14, a learning data output unit 15, a call unit 16, a call control unit 17, and an interpreter. It has a person in charge extraction section 18 and an interpreter person output section 19.
- the processing system 10 may include a learning data storage unit 21 and an estimated model generation unit 22.
- the processing system 10 is composed of the call terminal 1 shown in FIG. 5, or both the call terminal 1 and the server 2. That is, the call terminal 1 may include all the functional units included in the processing system 10. In addition, the call terminal 1 may include a part of the functional units included in the processing system 10 and the server 2 may include the remaining functional units.
- the call terminal 1 may be a device that realizes a predetermined functional unit by installing a predetermined application in a terminal device such as a personal computer, a tablet terminal, or a smartphone, or a call in which the predetermined functional unit is realized in advance. It may be a dedicated terminal.
- the configuration of the acquisition unit 11, the estimation unit 12, the result output unit 13, the learning data output unit 15, the call unit 16, the interpreter person extraction unit 18, and the interpreter person output unit 19 is one of the first to third embodiments. It is similar to
- the call control unit 17 puts the call on hold with the other party, starts a call with the designated interpreter, reproduces the target audio data, and sends the reproduced sound to the interpreter's call terminal. Then, when the call control unit 17 receives a predetermined input after that, the call control unit 17 starts a three-way call including the call partner and the interpreter.
- the other configuration of the call control unit 17 is similar to that of any of the first to third embodiments.
- the determination unit 14 determines that the estimation result is correct when the three-way call is started.
- the other configuration of the determination unit 14 is similar to that of any of the first to third embodiments.
- the first call terminal, the second call terminal, and the third call terminal are as described in the second embodiment. Then, the processing of S50 to S61 is the same as the processing of S20 to S31 of FIG. 7 described in the second embodiment.
- FIG. 14 shows an example of the screen displayed on the second call terminal when the call is ready between the second call terminal and the third call terminal as shown in S61.
- a window including information indicating that a call is in progress, the name of the designated interpreter, and UI buttons for performing various operations is displayed.
- the UI button is a call end button for ending the call, a three-party call start button for initiating a three-party call including the other party on hold, and the target voice data is played back to an interpreter in charge of the target voice. Includes a target voice playback button for listening.
- the second call terminal plays back the target voice data (S62).
- the interpreter can hear the target voice.
- the interpreter determines whether or not the target voice is in the language in which the interpreter is in charge, and transmits the determination result to the corresponding operator who is talking.
- the determination result may be verbally transmitted or may be realized by a notification using the system.
- the notification using the system may be realized, for example, by transmitting and receiving a message via an application or the like running on the second call terminal and the third call terminal.
- the corresponding operator presses the three-party call start button on the screen shown in FIG. 14, for example (S63).
- the determination unit 14 determines that the estimation result estimated in S55 is correct, and the learning data output unit 15 learns the target voice data or the target feature amount acquired in S55 and the estimation result estimated in S55 as learning data. (S65).
- the call partner when the call partner is a foreigner, a three-way call including the call partner, the corresponding operator, and the interpreter corresponding to the language of the call partner was performed.
- the support operator may transfer the call to the specific language support operator corresponding to the language of the call partner.
- the specific language support operator is an operator who has the same skills as the support operator and can handle customers in a specific language.
- the determination unit 14 is estimated in S55 when the transfer for switching the call between the first call terminal and the second call terminal to the call between the first call terminal and the third call terminal is performed. The estimated result is correct. Then, the learning data output unit 15 outputs the target voice data or the target feature amount acquired in S55 and the estimation result estimated in S55 as learning data.
- a part of the processing (eg, S62, S63, etc.) executed according to the operation of the user or the operator may be replaced with mechanical automatic processing. Also in this case, the operation and effect of this embodiment are realized.
- the processing system 10 of the present embodiment described above it is possible to achieve the same operational effect as that of any of the first to third embodiments. Further, according to the processing system 10 of the present embodiment, it is possible to determine the correctness of the estimation result based on the information indirectly indicating the correctness of the estimation result acquired by means other than the user input. Since it is possible to determine the correctness without user input, the burden on the user can be reduced.
- the processing system 10 of the present embodiment can reproduce the target voice data before the three-way call or the transfer of the call, and make the target voice heard by the person in charge of interpreting or the operator for a specific language. Then, based on the judgment result of the interpreter in charge of the target voice or the operator corresponding to the specific language (the judgment result of whether or not the language of the target voice is the language in charge of itself), a three-way call or call transfer is performed. You can decide whether or not. If the estimation result of the estimation unit 12 is incorrect, a three-way call or call transfer is not performed. In other words, it can be said that the estimation result of the estimation unit 12 is correct when a three-way call or a call transfer is performed.
- the processing system 10 of the present embodiment which determines whether the estimation result is correct or incorrect based on whether or not a three-way call or a call transfer is performed after reproducing the target voice data, can accurately determine the correctness.
- the processing system 10 of the present embodiment has the same configuration as that of the second embodiment, and is different from the first to fourth embodiments in that it determines whether the estimation result is correct or incorrect by the means different from the first to fourth embodiments. Different from the embodiment.
- An example of the hardware configuration of the processing system 10 is the same as in the first to fourth embodiments.
- the processing system 10 includes an acquisition unit 11, an estimation unit 12, a result output unit 13, a determination unit 14, a learning data output unit 15, a call unit 16, a call control unit 17, and an interpreter. It has a person in charge extraction section 18 and an interpreter person output section 19.
- the processing system 10 may include a learning data storage unit 21 and an estimated model generation unit 22.
- the processing system 10 is composed of the call terminal 1 shown in FIG. 5, or both the call terminal 1 and the server 2. That is, the call terminal 1 may include all the functional units included in the processing system 10. In addition, the call terminal 1 may include a part of the functional units included in the processing system 10 and the server 2 may include the remaining functional units.
- the call terminal 1 may be a device that realizes a predetermined functional unit by installing a predetermined application in a terminal device such as a personal computer, a tablet terminal, or a smartphone, or a call in which the predetermined functional unit is realized in advance. It may be a dedicated terminal.
- the configuration of the acquisition unit 11, the estimation unit 12, the result output unit 13, the learning data output unit 15, the call unit 16, the interpreter person extraction unit 18, and the interpreter person output unit 19 is one of the first to fourth embodiments. It is similar to
- the call control unit 17 plays a hold sound that outputs a predetermined message in the language indicated by the estimation result while the call with the call partner is put on hold, and sends the played sound to the call terminal of the call partner.
- the message is "Do you want to call in the language you are reading this message? If you would like, press 1 and if you want to call in another language, please press 2.” Good.
- the judgment unit 14 accepts a predetermined input from the other party during the reproduction of the hold tone. Then, the determination unit 14 determines that the estimation result by the estimation unit 12 is correct when the input of the call partner is the first input, and the estimation result by the estimation unit 12 when the input of the call partner is the second input. Judge that the result is not correct. Further, the determination unit 14 can determine that the estimation result is incorrect if there is no input from the other party by the predetermined deadline.
- the predetermined deadline is defined, for example, by the elapsed time from the timing when the output of the above message is completed.
- Predetermined input from the other party is to the above message. For example, if the message is "Do you want to call in the language you are reading this message? If you would like to call in 1, please press 2 to call in another language.”
- the input is an input made by pressing the button 1 or an input made by pressing the button 2. In the case of this example, the input made by pressing the button 1 becomes the first input, and the input made by pressing the button 2 becomes the second input.
- the call control unit 17 first reproduces the message in the language with the highest reliability, and when the input of the call partner is the second input, or when a predetermined time limit is reached. If there is no input from the other party before, the message in the next most reliable language may be reproduced.
- the first call terminal, the second call terminal and the third call terminal are as described in the second embodiment.
- FIG. 8 shows an example of a screen displayed on the second call terminal in the call state. Since the screen of FIG. 8 has been described in the second embodiment, it will be omitted here.
- the acquisition unit 11 acquires the target voice data in which the voice of the call partner is recorded, or the target feature amount indicating the feature of the voice of the call partner.
- the second call terminal may be configured to record all calls regardless of the other party. Then, the acquisition unit 11 may acquire a part or all of the recorded audio data as target audio data. Further, the acquisition unit 11 may extract the target feature amount from the target audio data acquired in this way.
- the estimation unit 12 estimates the language of the target voice based on the estimation model generated by the estimation model generation unit 22 and the target voice data or the target feature amount acquired by the acquisition unit 11.
- FIG. 16 shows an example of a screen displayed on the second call terminal when the result output unit 13 outputs the estimation result.
- a window showing the estimation result is displayed.
- information links indicating interpreters in the language indicated by the estimation result are linked.
- the call control unit 17 reproduces the hold sound that outputs a predetermined message in the language indicated by the estimation result estimated in S73, and transmits the reproduced sound to the first call terminal (S80).
- the call control unit 17 reproduces the hold sound that outputs a predetermined message in the most reliable language, and transmits the reproduced sound to the first call terminal.
- the second call terminal waits for user input performed via the first call terminal.
- the determination unit 14 determines that the estimation result is correct.
- the learning data output unit 15 outputs the language of the output message and the target voice data or the target feature amount acquired in S73 as learning data (S82).
- the call control unit 17 reproduces a normal hold sound (eg, music, etc.) and transmits the reproduced sound to the first call terminal until it receives an input for ending the hold state (S83).
- a normal hold sound eg, music, etc.
- the call control unit 17 determines whether there is another language candidate ( S85). For example, if the estimation result includes another language, or if the estimation result includes another language whose reliability is equal to or higher than a predetermined level, or is registered in advance as a language candidate regardless of the estimation result. When there is another language in use, the call control unit 17 can determine that there is another language candidate.
- the call control unit 17 plays a normal hold sound (eg, music) until the input for ending the hold state is accepted, and the play sound is used for the first call. It is transmitted to the terminal (S83).
- a normal hold sound eg, music
- the call control unit 17 When there is another language candidate (Yes in S85), the call control unit 17 reproduces the hold sound for outputting a predetermined message in the other language candidate and transmits the reproduced sound to the first call terminal (S86). .. Then, the process returns to S81 and the same processing is repeated.
- a part of the processing (eg, S75, S76, etc.) executed according to the operation of the user or the operator may be replaced with mechanical automatic processing. Also in this case, the operation and effect of this embodiment are realized.
- the processing system 10 of the present embodiment described above it is possible to achieve the same operational effect as that of any of the first to fourth embodiments. Further, the processing system 10 of the present embodiment can reproduce the message in the language of the estimation result and make the other party hear the message while the call is on hold. Then, the processing system 10 of the present embodiment can determine whether the estimation result is correct or incorrect based on the input of the communication partner with respect to the message. According to the processing system 10 of the present embodiment as described above, it is possible to accurately determine whether the estimation result is correct.
- Target voice data in which a target voice that is a voice of a language estimation target is recorded, or an acquisition unit that acquires a target feature amount indicating a feature of the target voice An estimation model that estimates the language of the voice from voice data in which voice is recorded or a voice feature amount that indicates the feature of the voice, and an estimation that estimates the language of the target voice based on the target voice data or the target feature amount.
- Means and Result output means for outputting the estimation result by the estimation means, Determination means for determining whether the estimation result is true or false, Learning data output means for outputting the estimation result determined to be correct by the determination means, the target voice data or the target feature amount, as learning data for generating the estimation model, A processing system having. 2.
- the acquisition unit acquires the target voice data in which the voice of the call partner is recorded, or the target feature amount indicating the feature of the voice of the call partner,
- Interpreter person extracting means for extracting the interpreter person in the language indicated by the estimation result by referring to the interpreter information in which the interpreter person and contact information of each of a plurality of languages are registered,
- An interpreter person output means for outputting information indicating the extracted interpreter person,
- Call control means for holding a call with the other party and starting a call with the interpreter designated from the extracted interpreters, A processing system having. 3.
- the call control means When the call control means receives a predetermined input after holding the call with the call partner and starting the call with the designated person in charge of interpretation, the call control means includes the person in charge of call and the person in charge of interpretation. Person call, The said determination means is a processing system which determines that the said estimation result is correct, when the elapsed time after starting the said three-way call exceeds predetermined time. 4. In the processing system described in 2, The call control means puts the call on hold with the call partner, starts a call with the designated interpreter, reproduces the target voice data, and outputs a reproduced sound to the interpreter's call terminal.
- the said determination means is a processing system which determines that the said estimation result is correct, when the said three-way call is started. 5.
- the call control means reproduces a hold sound for outputting a predetermined message in the language indicated by the estimation result while the call with the call partner is put on hold, and transmits the played sound to the call terminal of the call partner.
- the determination means accepts a predetermined input from the call partner during reproduction of the hold tone, and when the input of the call partner is the first input, determines that the estimation result is correct, and inputs the call partner.
- the processing system determines that the estimation result is incorrect. 6. In the processing system according to 5, The processing system, wherein the determination means determines that the estimation result is incorrect when there is no input from the other party by a predetermined deadline. 7. In the processing system according to 5 or 6, When the estimation result includes a plurality of languages, the call control unit reproduces the message in the language with the highest reliability, and when the input of the call partner is the second input, or until a predetermined deadline. A processing system for reproducing the message in the next most reliable language when there is no input from the other party. 8.
- Computer Target voice data in which a target voice that is a voice of a language estimation target is recorded, or an acquisition step of acquiring a target feature amount indicating a feature of the target voice,
- An estimation model that estimates the language of the voice from voice data in which voice is recorded or a voice feature amount that indicates the feature of the voice, and an estimation that estimates the language of the target voice based on the target voice data or the target feature amount.
- a result output step of outputting the estimation result in the estimation step A determination step of determining whether the estimation result is true or false, The estimation result that is determined to be correct in the determination step, the target voice data or the target feature amount, a learning data output step of outputting as learning data for generating the estimation model,
- Target voice data in which a target voice that is a voice of a language estimation target is recorded, or an acquisition unit that acquires a target feature amount indicating the feature of the target voice
- An estimation model for estimating the language of the voice from the voice data in which the voice is recorded or a voice feature amount indicating the feature of the voice, and an estimation for estimating the language of the target voice based on the target voice data or the target feature amount.
- Result output means for outputting the estimation result by the estimation means
- Determination means for determining whether the estimation result is true or false
- Learning data output means for outputting the estimation result determined to be correct by the determination means and the target voice data or the target feature amount as learning data for generating the estimation model
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Human Computer Interaction (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Artificial Intelligence (AREA)
- Business, Economics & Management (AREA)
- Marketing (AREA)
- Machine Translation (AREA)
- Telephone Function (AREA)
Abstract
本発明は、言語推定対象の音声である対象音声を記録した対象音声データ、又は、対象音声の特徴を示す対象特徴量を取得する取得部(11)と、音声を記録した音声データ又は音声の特徴を示す音声特徴量から音声の言語を推定する推定モデルと、対象音声データ又は対象特徴量とに基づき、対象音声の言語を推定する推定部(12)と、推定部(12)による推定結果を出力する結果出力部(13)と、推定結果の正誤判定を行う判定部(14)と、判定部(14)により正しいと判定された推定結果と、対象音声データ又は対象特徴量とを、推定モデルを生成するための学習データとして出力する学習データ出力部(15)と、を有する処理システム(10)を提供する。
Description
本発明は、処理システム、処理方法及びプログラムに関する。
特許文献1は、機械学習で生成した推定モデルを用いて、発話データから発話の言語を推定する装置を開示している。
特許文献2は、通話相手である外国人と、当該外国人からの電話に対応する対応者と、当該外国人と当該対応者とのコミュニケーションをサポートするサポートチームとを含む三者の通話を実現する多言語オペレートシステムを開示している。具体的には、当該多言語オペレートシステムは、外国人又は対応者から言語の指定を受付けた後、指定された言語に対応したサポートチームを接続して三者通話を開始する。すなわち、当事者が指定した内容に基づき、外国人の言語が特定される。
言語の推定精度を向上させるためには機械学習する学習データを増やす必要があるが、特許文献1及び2はいずれも、当該課題及びその解決手段を開示していない。本発明は、機械学習で生成した推定モデルを用いて言語を推定する技術において、推定精度を向上させることを課題とする。
本発明によれば、
言語推定対象の音声である対象音声を記録した対象音声データ、又は、前記対象音声の特徴を示す対象特徴量を取得する取得手段と、
音声を記録した音声データ又は前記音声の特徴を示す音声特徴量から前記音声の言語を推定する推定モデルと、前記対象音声データ又は前記対象特徴量とに基づき、前記対象音声の言語を推定する推定手段と、
前記推定手段による推定結果を出力する結果出力手段と、
前記推定結果の正誤判定を行う判定手段と、
前記判定手段により正しいと判定された前記推定結果と、前記対象音声データ又は前記対象特徴量とを、前記推定モデルを生成するための学習データとして出力する学習データ出力手段と、
を有する処理システムが提供される。
言語推定対象の音声である対象音声を記録した対象音声データ、又は、前記対象音声の特徴を示す対象特徴量を取得する取得手段と、
音声を記録した音声データ又は前記音声の特徴を示す音声特徴量から前記音声の言語を推定する推定モデルと、前記対象音声データ又は前記対象特徴量とに基づき、前記対象音声の言語を推定する推定手段と、
前記推定手段による推定結果を出力する結果出力手段と、
前記推定結果の正誤判定を行う判定手段と、
前記判定手段により正しいと判定された前記推定結果と、前記対象音声データ又は前記対象特徴量とを、前記推定モデルを生成するための学習データとして出力する学習データ出力手段と、
を有する処理システムが提供される。
また、本発明によれば、
コンピュータが、
言語推定対象の音声である対象音声を記録した対象音声データ、又は、前記対象音声の特徴を示す対象特徴量を取得する取得工程と、
音声を記録した音声データ又は前記音声の特徴を示す音声特徴量から前記音声の言語を推定する推定モデルと、前記対象音声データ又は前記対象特徴量とに基づき、前記対象音声の言語を推定する推定工程と、
前記推定工程での推定結果を出力する結果出力工程と、
前記推定結果の正誤判定を行う判定工程と、
前記判定工程で正しいと判定された前記推定結果と、前記対象音声データ又は前記対象特徴量とを、前記推定モデルを生成するための学習データとして出力する学習データ出力工程と、
を実行する処理方法が提供される。
コンピュータが、
言語推定対象の音声である対象音声を記録した対象音声データ、又は、前記対象音声の特徴を示す対象特徴量を取得する取得工程と、
音声を記録した音声データ又は前記音声の特徴を示す音声特徴量から前記音声の言語を推定する推定モデルと、前記対象音声データ又は前記対象特徴量とに基づき、前記対象音声の言語を推定する推定工程と、
前記推定工程での推定結果を出力する結果出力工程と、
前記推定結果の正誤判定を行う判定工程と、
前記判定工程で正しいと判定された前記推定結果と、前記対象音声データ又は前記対象特徴量とを、前記推定モデルを生成するための学習データとして出力する学習データ出力工程と、
を実行する処理方法が提供される。
また、本発明によれば、
コンピュータを、
言語推定対象の音声である対象音声を記録した対象音声データ、又は、前記対象音声の特徴を示す対象特徴量を取得する取得手段、
音声を記録した音声データ又は前記音声の特徴を示す音声特徴量から前記音声の言語を推定する推定モデルと、前記対象音声データ又は前記対象特徴量とに基づき、前記対象音声の言語を推定する推定手段、
前記推定手段による推定結果を出力する結果出力手段、
前記推定結果の正誤判定を行う判定手段、
前記判定手段により正しいと判定された前記推定結果と、前記対象音声データ又は前記対象特徴量とを、前記推定モデルを生成するための学習データとして出力する学習データ出力手段、
として機能させるプログラムが提供される。
コンピュータを、
言語推定対象の音声である対象音声を記録した対象音声データ、又は、前記対象音声の特徴を示す対象特徴量を取得する取得手段、
音声を記録した音声データ又は前記音声の特徴を示す音声特徴量から前記音声の言語を推定する推定モデルと、前記対象音声データ又は前記対象特徴量とに基づき、前記対象音声の言語を推定する推定手段、
前記推定手段による推定結果を出力する結果出力手段、
前記推定結果の正誤判定を行う判定手段、
前記判定手段により正しいと判定された前記推定結果と、前記対象音声データ又は前記対象特徴量とを、前記推定モデルを生成するための学習データとして出力する学習データ出力手段、
として機能させるプログラムが提供される。
本発明によれば、機械学習で生成した推定モデルを用いて言語を推定する技術において、推定精度を向上させることができる。
上述した目的、およびその他の目的、特徴および利点は、以下に述べる好適な実施の形態、およびそれに付随する以下の図面によってさらに明らかになる。
<第1の実施形態>
まず、本実施形態の処理システムの概要を説明する。処理システムは、機械学習で生成した推定モデルと、言語推定対象の音声を記録した音声データ又はその音声の特徴量とに基づき、言語推定対象の音声の言語を推定する。次いで、処理システムは、推定結果を出力するとともに、推定結果の正誤判定を行う。そして、正しいと判定された推定結果と、言語推定対象の音声を記録した音声データ又はその音声の特徴量とを、推定モデルを生成するための学習データとして出力する。
まず、本実施形態の処理システムの概要を説明する。処理システムは、機械学習で生成した推定モデルと、言語推定対象の音声を記録した音声データ又はその音声の特徴量とに基づき、言語推定対象の音声の言語を推定する。次いで、処理システムは、推定結果を出力するとともに、推定結果の正誤判定を行う。そして、正しいと判定された推定結果と、言語推定対象の音声を記録した音声データ又はその音声の特徴量とを、推定モデルを生成するための学習データとして出力する。
次に、処理システム10の構成を詳細に説明する。まず、処理システム10のハードウエア構成の一例について説明する。処理システム10が備える各機能部は、任意のコンピュータのCPU(Central Processing Unit)、メモリ、メモリにロードされるプログラム、そのプログラムを格納するハードディスク等の記憶ユニット(あらかじめ装置を出荷する段階から格納されているプログラムのほか、CD(Compact Disc)等の記憶媒体やインターネット上のサーバ等からダウンロードされたプログラムをも格納できる)、ネットワーク接続用インターフェイスを中心にハードウエアとソフトウエアの任意の組合せによって実現される。そして、その実現方法、装置にはいろいろな変形例があることは、当業者には理解されるところである。
図1は、処理システム10のハードウエア構成を例示するブロック図である。図1に示すように、処理システム10は、プロセッサ1A、メモリ2A、入出力インターフェイス3A、周辺回路4A、バス5Aを有する。周辺回路4Aには、様々なモジュールが含まれる。処理システム10は周辺回路4Aを有さなくてもよい。なお、処理システム10は物理的及び/又は論理的に分かれた複数の装置で構成されてもよい。この場合、複数の装置各々が上記ハードウエア構成を備えることができる。
バス5Aは、プロセッサ1A、メモリ2A、周辺回路4A及び入出力インターフェイス3Aが相互にデータを送受信するためのデータ伝送路である。プロセッサ1Aは、例えばCPU、GPU(Graphics Processing Unit)などの演算処理装置である。メモリ2Aは、例えばRAM(Random Access Memory)やROM(Read Only Memory)などのメモリである。入出力インターフェイス3Aは、入力装置、外部装置、外部サーバ、外部センサ、カメラ等から情報を取得するためのインターフェイスや、出力装置、外部装置、外部サーバ等に情報を出力するためのインターフェイスなどを含む。入力装置は、例えばキーボード、マウス、マイク等である。出力装置は、例えばディスプレイ、スピーカ、プリンター、メーラ等である。プロセッサ1Aは、各モジュールに指令を出し、それらの演算結果をもとに演算を行うことができる。
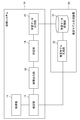
次に、処理システム10の機能構成の一例について説明する。図2の機能ブロック図に示すように、処理システム10は、取得部11と、推定部12と、結果出力部13と、判定部14と、学習データ出力部15とを有する。
なお、図では、処理システム10と推定モデル生成装置20とを分けて記載しているが、処理システム10は推定モデル生成装置20を含んでもよい。すなわち、処理システム10と推定モデル生成装置20とは物理的及び/又は論理的に分かれてもよいし、処理システム10と推定モデル生成装置20は物理的及び論理的に一体となってもよい。
学習データ記憶部21は、音声を記録した音声データ又は音声の特徴を示す音声特徴量と、その音声の言語(例:日本語、英語、中国語等)とをペアにした学習データを記憶する。音声特徴量は、音声データから抽出される。
推定モデル生成部22は、学習データ記憶部21に記憶されている学習データを用いた機械学習により、音声データ又は音声特徴量から音声の言語を推定する推定モデルを生成する。機械学習の技法は特段制限されず、あらゆる技法を採用できる。
取得部11は、言語推定対象の音声である対象音声を記録した対象音声データ、又は、対象音声の特徴を示す対象特徴量を取得する。対象特徴量は、対象音声データから抽出される。
なお、本明細書において、「取得」とは、ユーザ入力に基づき、又は、プログラムの指示に基づき、「自装置が他の装置や記憶媒体に格納されているデータを取りに行くこと(能動的な取得)」、たとえば、他の装置にリクエストまたは問い合わせして受信すること、他の装置や記憶媒体にアクセスして読み出すこと等、および、ユーザ入力に基づき、又は、プログラムの指示に基づき、「自装置に他の装置から出力されるデータを入力すること(受動的な取得)」、たとえば、配信(または、送信、プッシュ通知等)されるデータを受信すること、また、受信したデータまたは情報の中から選択して取得すること、及び、「データを編集(テキスト化、データの並び替え、一部データの抽出、ファイル形式の変更等)などして新たなデータを生成し、当該新たなデータを取得すること」の少なくともいずれか一方を含む。
推定部12は、推定モデル生成部22が生成した推定モデルと、取得部11が取得した対象音声データ又は対象特徴量とに基づき、対象音声の言語を推定する。
結果出力部13は、推定部12による推定結果を出力する。結果出力部13は、ディスプレイ、スピーカ、プリンター、投影装置、メーラ等の出力装置を介して推定結果を出力することができる。
判定部14は、推定部12による推定結果の正誤判定を行う。判定部14は、所定の判定材料を取得し、当該判定材料に基づき推定結果の正誤判定を行うことができる。判定材料は、ユーザにより入力された推定結果の正誤を直接的に示す情報(「正しい」又は「間違っている」)であってもよいし、ユーザ入力以外の手段で取得した推定結果の正誤を間接的に示す情報であってもよい。なお、判定部14が、ユーザ入力以外の手段で取得した推定結果の正誤を間接的に示す情報に基づき推定結果の正誤判定を行う例は、以下の実施形態で説明する。
学習データ出力部15は、判定部14により正しいと判定された推定結果と、推定部12によりその推定結果が導き出された対象音声データ又は対象特徴量とを、推定モデルを生成するための学習データとして出力する。学習データ出力部15により出力された学習データは、学習データ記憶部21に蓄積される。
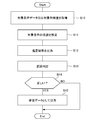
次に、図3のフローチャートを用いて、処理システム10の処理の流れの一例を説明する。
まず、取得部11が新たな対象音声データ又は対象特徴量を取得すると(S10)、推定部12は、推定モデル生成部22により生成された推定モデルと、S10で取得された対象音声データ又は対象特徴量とに基づき、対象音声の言語を推定する(S11)。次いで、結果出力部13は、S11で推定された推定結果を出力する(S12)。
その後、判定部14は、S12で推定された推定結果の正誤判定を行う(S13)。例えば、判定部14は、ユーザにより入力された推定結果の正誤を直接的に示す情報を取得し、当該情報に基づき推定結果の正誤判定を行ってもよい。
判定部14の判定結果が「正しい」でない場合(S14のNo)、処理を終了する。
一方、判定部14の判定結果が「正しい」である場合(S14のYes)、学習データ出力部15は、S10で取得された対象音声データ又は対象特徴量と、S11で推定された推定結果とを学習データとして出力する(S15)。
S15で学習データ出力部15により出力された学習データは、学習データ記憶部21に蓄積される。その後、図示しないが、推定モデル生成部22は、学習データ記憶部21に記憶されている学習データを用いた機械学習により、音声データ又は音声特徴量から音声の言語を推定する推定モデルを生成する。
推定モデル生成部22は、新たな1つの学習データが学習データ記憶部21に登録される毎に新たに機械学習を行い、新たな推定モデルを生成してもよい。その他、推定モデル生成部22は、新たな所定個数(2以上の任意の数)の学習データが学習データ記憶部21に登録される毎に新たに機械学習を行い、新たな推定モデルを生成してもよい。その他、推定モデル生成部22は、予め定められた時刻になる毎に新たに機械学習を行い、新たな推定モデルを生成してもよい。その他、推定モデル生成部22は、推定モデルを更新するユーザ入力があったタイミングで新たに機械学習を行い、新たな推定モデルを生成してもよい。なお、ここで例示した機械学習を行うタイミングは一例であり、これに限定されない。
以上、言語推定と、推定結果を用いた学習データの生成とを連動して実行する処理システム10によれば、言語を推定する処理を実行しながら、学習データを増やすことができる。結果、学習データを増やすためだけの面倒な作業を回避できる。
また、上記特徴を有する処理システム10によれば、実務において処理システム10を利用して言語を推定させながら、実務で得られた推定結果に基づき学習データを増やすことができる。このような処理システム10によれば、実務に適した学習データ、具体的には実務において接する機会がある言語の学習データを効率的に増やすことができる。そして、実務に適した推定モデルが生成されることとなる。このように、処理システム10を利用する環境のニーズに特化した性能を処理システム10に与えることができる。
<第2の実施形態>
本実施形態の処理システム10は、通話手段を有し、通話相手の音声を対象音声とする点等が第1の実施形態と異なる。
本実施形態の処理システム10は、通話手段を有し、通話相手の音声を対象音声とする点等が第1の実施形態と異なる。
処理システム10のハードウエア構成の一例は、第1の実施形態と同様である。
処理システム10の機能ブロック図の一例は、図4で示される。図示するように、処理システム10は、取得部11と、推定部12と、結果出力部13と、判定部14と、学習データ出力部15と、通話部16と、通話制御部17と、通訳担当者抽出部18と、通訳担当者出力部19とを有する。なお、図示しないが、処理システム10は、学習データ記憶部21及び推定モデル生成部22を備えてもよい。
処理システム10は、図5に示す通話端末1、又は、通話端末1とサーバ2の両方により構成される。すなわち、処理システム10が有する機能部の全てを通話端末1が備えてもよい。その他、処理システム10が有する機能部の一部を通話端末1が備え、残りの機能部をサーバ2が備えてもよい。通話端末1は、パーソナルコンピュータ、タブレット端末、スマートフォン等の端末装置に所定のアプリケーションをインストールすることで所定の機能部を実現した装置であってもよいし、所定の機能部が予め実現された通話専用の端末であってもよい。
通話部16は、他の通話端末と接続し、通話を実現する機能を有する。
取得部11は、通話相手の音声を記録した対象音声データ、又は、通話相手の音声の特徴を示す対象特徴量を取得する。取得部11のその他の構成は、第1の実施形態と同様である。
推定部12、結果出力部13、判定部14及び学習データ出力部15の構成は、第1の実施形態と同様である。
通訳担当者抽出部18は、複数の言語各々の通訳担当者及び連絡先情報を登録した通訳者情報を参照し、推定結果で示される言語の通訳担当者を抽出する。図6に、通訳者情報の一例を模式的に示す。
通訳担当者出力部19は、通訳担当者抽出部18により抽出された通訳担当者を示す情報を出力する。通訳担当者出力部19は、ディスプレイ、スピーカ、プリンター、投影装置、メーラ等の出力装置を介して、通訳担当者抽出部18により抽出された通訳担当者を示す情報を出力することができる。例えば、通訳担当者出力部19は、抽出された通訳担当者の一覧を出力してもよい。
通話制御部17は、ユーザ入力に基づき通話相手との通話を保留する。そして、通話制御部17は、通訳担当者抽出部18により抽出された通訳担当者の中から1人を指定し、指定した通訳担当者との通話(例:内線通話)を開始させる。例えば、通話制御部17は、ユーザ入力に基づき1人の通訳担当者を指定してもよいし、予め定められたルールに従い1人の通訳担当者を指定してもよい。予め定められたルールは、例えば、「当日のその時までに三者通話した回数が最も少ない人」等が例示されるが、これに限定されない。
そして、通話制御部17は、通話相手との通話を保留し、指定された通訳担当者との通話を開始させた後、所定の入力を受付けると、通話相手及び通訳担当者を含む三者通話を開始させることができる。
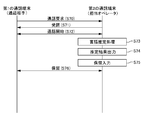
次に、図7のシーケンス図を用いて、処理システム10の処理の流れの一例を説明する。
第1の通話端末は、通話相手が利用する通話端末である。ここでは、通話相手は外国人であるものとする。なお、外国人は、本実施形態の処理システム10を利用する地域における公用語以外の言語を話す人物あるいは、当事者が指定した言語以外の言語を話す人物であることが想定される。
第2の通話端末は、電話で顧客対応を行うことを業務とする対応オペレータが利用する通話端末である。第2の通話端末は、処理システム10が有する機能部の全てを備えてもよいし、処理システム10が有する機能部の一部を備えてもよい。
第3の通話端末は、所定の言語に対応した通訳者が利用する通話端末である。
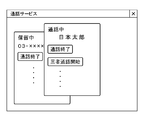
まず、第1の通話端末から第2の通話端末に通話要求が送信され(S20)、当該通話要求に対する通話受諾が第2の通話端末から第1の通話端末に送信されると(S21)、第1の通話端末と第2の通話端末との間で通話が開始され(S22)、通話が可能な状態(以下、「通話状態」)となる。通話状態において、第2の通話端末に表示される画面の一例は図8に示される。図では、通話中であることを示す情報、通話相手の電話番号、及び、各種操作を行うためのUI(user interface)ボタンを含むウインドウが表示されている。UIボタンは、通話を終了するための通話終了ボタン、通話を保留状態にするための保留ボタン、及び、通話相手の言語を推定する処理を実行するための言語推定ボタン等を含む。
対応オペレータは、通話中に、通話相手が外国人であることを認識したが、通話相手の言語を認識できない場合、保留ボタンを押して通話を保留状態にした後(S23、S24)、言語推定ボタンを押す。言語推定ボタンの押下に応じて、言語推定処理が実行される(S25)。
S25では、取得部11は、通話相手の音声を記録した対象音声データ、又は、通話相手の音声の特徴を示す対象特徴量を取得する。例えば、第2の通話端末は、通話相手に関わらず、全ての通話を録音するように構成されてもよい。そして、取得部11は、上記録音された音声データの一部又は全部を、対象音声データとして取得してもよい。また、取得部11は、このように取得した対象音声データから対象特徴量を抽出してもよい。次いで、推定部12は、推定モデル生成部22により生成された推定モデルと、取得部11により取得された対象音声データ又は対象特徴量とに基づき、対象音声の言語を推定する。
そして、結果出力部13は、推定された推定結果を出力する(S26)。図9に、結果出力部13が推定結果を出力した時に第2の通話端末に表示される画面の一例を示す。図では、推定結果を示すウインドウが表示されている。当該ウインドウでは、推定結果で示される言語の通訳担当者を示す情報のリンクがはられている。
例えば図9に示す画面において、通訳担当者を示す情報のリンクが押されると、通訳担当者出力部19は、通訳担当者抽出部18により抽出された通訳担当者を示す情報を取得し、出力する(S27)。通訳担当者抽出部18は、複数の言語各々の通訳担当者及び連絡先情報を登録した通訳者情報(図6参照)を参照し、推定結果で示される言語の通訳担当者を抽出する。図10に、通訳担当者出力部19が通訳担当者を示す情報を出力した時に第2の通話端末に表示される画面の一例を示す。図では、推定結果の言語の通訳担当者を示すウインドウが表示されている。当該ウインドウでは、通訳担当者の氏名の一覧を表示するとともに、各通訳担当者との通話を開始するための通話ボタンが表示されている。結果出力部13は、第2の通話端末が備える。通訳担当者出力部19は、第2の通話端末が備える。
例えば図10に示す画面において、1人の通訳担当者の通話ボタンが押されると(1人の通訳担当者を指定する入力(S28))、第2の通話端末は指定された通訳担当者の連絡先情報を通訳者情報(図6参照)に基づき特定し、その通訳担当者の第3の通話端末に対して通話要求を送信する(S29)。そして、当該通話要求に対する通話受諾が第3の通話端末から第2の通話端末に送信されると(S30)、第2の通話端末と第3の通話端末との間で通話が可能な状態となる(S31)。当該状態において、第2の通話端末に表示される画面の一例は図11に示される。図では、通話中であることを示す情報、指定された翻訳担当者の名称、及び、各種操作を行うためのUIボタンを含むウインドウが表示されている。UIボタンは、通話を終了するための通話終了ボタン、保留中の通話相手を含めた三者通話を開始するための三者通話開始ボタン等を含む。
当該画面において、対応オペレータが三者通話開始ボタンを押すと(S32)、第1の通話端末と、第2の通話端末と、第3の通話端末との間で三者通話が可能な状態となる。
ここで、本実施形態の変形例を説明する。図7のシーケンス図を用いて説明した例では、通話相手が外国人である場合、通話相手と、対応オペレータと、通話相手の言語に対応した通訳者とを含む三者通話を行った。変形例では、通話相手が外国人である場合、対応オペレータは、通話相手の言語に対応した特定言語用対応オペレータに通話を転送してもよい。特定言語用対応オペレータは、対応オペレータと同様のスキルを有し、特定の言語で顧客対応を行うことができるオペレータである。
変形例の場合、図7のシーケンス図を用いて行った処理の説明における「通訳担当者」を「特定言語用対応オペレータ」に読み替えればよい。そして、S31の後に第2の通話端末又は第3の通話端末において所定の入力が行われると、第1の通話端末と第2の通話端末との間の通話を、第1の通話端末と第3の通話端末との間の通話に切り替える転送が行われる。
また、図7のシーケンス図を用いて説明した例では、保留ボタンに対する操作に応じて保留状態になった後に、言語推定ボタンに対する操作に応じて言語推定処理が開始された。変形例として、通話状態のままで言語推定ボタンに対する操作が可能であり、通話状態のままで言語推定処理が実行されてもよい。その他、保留ボタンに対する操作に応じて、保留状態になるとともに、言語推定処理が開始されてもよい。すなわち、保留ボタンに対する操作は、保留状態に指示、及び、言語推定処理を開始する指示の両方を兼ねてもよい。
また、ユーザやオペレータの操作に応じて実行する処理の一部(例:S32等)を機械的な自動処理に置き換えてもよい。この場合も、本実施形態の作用効果が実現される。
以上説明した本実施形態の処理システム10によれば、第1の実施形態と同様な作用効果を実現できる。
また、本実施形態の処理システム10は、通話で顧客対応を行うコールセンター等において利用することができる。コールセンターに外国人から電話がかかってきた場合に、その外国人の言語を認識できないと、その言語に対応した適切な通訳担当者を見つけるまでに時間がかかり、顧客を待たしてしまうという不都合が発生し得る。本実施形態の処理システム10によれば、このような不都合を軽減できる。結果、コールセンターにおける顧客満足度を高めることができる。
<第3の実施形態>
本実施形態の処理システム10は、第2の実施形態と同様の構成を有し、第1及び第2の実施形態と異なる手段で推定結果の正誤判定を行う点で、第1及び第2の実施形態と異なる。
本実施形態の処理システム10は、第2の実施形態と同様の構成を有し、第1及び第2の実施形態と異なる手段で推定結果の正誤判定を行う点で、第1及び第2の実施形態と異なる。
処理システム10のハードウエア構成の一例は、第1及び第2の実施形態と同様である。
処理システム10の機能ブロック図の一例は、図4で示される。図示するように、処理システム10は、取得部11と、推定部12と、結果出力部13と、判定部14と、学習データ出力部15と、通話部16と、通話制御部17と、通訳担当者抽出部18と、通訳担当者出力部19とを有する。なお、図示しないが、処理システム10は、学習データ記憶部21及び推定モデル生成部22を備えてもよい。
処理システム10は、図5に示す通話端末1、又は、通話端末1とサーバ2の両方により構成される。すなわち、処理システム10が有する機能部の全てを通話端末1が備えてもよい。その他、処理システム10が有する機能部の一部を通話端末1が備え、残りの機能部をサーバ2が備えてもよい。通話端末1は、パーソナルコンピュータ、タブレット端末、スマートフォン等の端末装置に所定のアプリケーションをインストールすることで所定の機能部を実現した装置であってもよいし、所定の機能部が予め実現された通話専用の端末であってもよい。
取得部11、推定部12、結果出力部13、学習データ出力部15、通話部16、通話制御部17、通訳担当者抽出部18及び通訳担当者出力部19の構成は、第1又は第2の実施形態と同様である。
判定部14は、通話相手及び通訳担当者を含む三者通話が開始されてからの経過時間が所定時間を超えた場合、推定結果が正しいと判定する。判定部14のその他の構成は、第1又は第2の実施形態と同様である。
次に、処理システム10の処理の流れの一例を説明する。通話相手及び通訳担当者を含む三者通話が開始されるまでの流れは、第2の実施形態で説明した通りである(図7参照)。
三者通話が開始されると、判定部14は三者通話開始からの経過時間を監視する。そして、図12のフローチャートに示すように、経過時間が所定時間を超えずに三者通話が終了した場合(S40のNo)、判定部14はS25の推定結果は正しくないと判定し、処理を終了する。
一方、経過時間が所定時間を超えた場合(S40のYes)、判定部14はS25の推定結果は正しいと判定する。そして、学習データ出力部15は、S25で取得された対象音声データ又は対象特徴量と、S25で推定された推定結果とを学習データとして出力する(S41)。
なお、判定部14が、特定言語用対応オペレータに通話が転送され、所定時間経過すると、推定結果が正しいと判定してもよい。
以上説明した本実施形態の処理システム10によれば、第1又は第2の実施形態と同様の作用効果を実現できる。また、本実施形態の処理システム10によれば、ユーザ入力以外の手段で取得した推定結果の正誤を間接的に示す情報に基づき推定結果の正誤判定を行うことができる。ユーザ入力なしで正誤判定できるため、ユーザ負担を軽減することができる。
また、本実施形態の処理システム10は、通話相手及び通訳担当者を含む三者通話が継続した時間や、特定言語用対応オペレータに通話が転送されてから通話が継続した時間が所定時間を超えた場合、推定結果が正しいと判定する。推定結果が間違っている場合、他の通訳担当者に切り替えたり、他の特定言語用対応オペレータに通話を再転送したりするため、上述した継続時間は比較的短くなる。上述した継続時間に基づき推定結果の正誤判定を行う本実施形態の処理システム10は、精度よく正誤判定を行うことができる。
<第4の実施形態>
本実施形態の処理システム10は、第2の実施形態と同様の構成を有し、第1乃至第3の実施形態と異なる手段で推定結果の正誤判定を行う点で、第1乃至第3の実施形態と異なる。
本実施形態の処理システム10は、第2の実施形態と同様の構成を有し、第1乃至第3の実施形態と異なる手段で推定結果の正誤判定を行う点で、第1乃至第3の実施形態と異なる。
処理システム10のハードウエア構成の一例は、第1乃至第3の実施形態と同様である。
処理システム10の機能ブロック図の一例は、図4で示される。図示するように、処理システム10は、取得部11と、推定部12と、結果出力部13と、判定部14と、学習データ出力部15と、通話部16と、通話制御部17と、通訳担当者抽出部18と、通訳担当者出力部19とを有する。なお、図示しないが、処理システム10は、学習データ記憶部21及び推定モデル生成部22を備えてもよい。
処理システム10は、図5に示す通話端末1、又は、通話端末1とサーバ2の両方により構成される。すなわち、処理システム10が有する機能部の全てを通話端末1が備えてもよい。その他、処理システム10が有する機能部の一部を通話端末1が備え、残りの機能部をサーバ2が備えてもよい。通話端末1は、パーソナルコンピュータ、タブレット端末、スマートフォン等の端末装置に所定のアプリケーションをインストールすることで所定の機能部を実現した装置であってもよいし、所定の機能部が予め実現された通話専用の端末であってもよい。
取得部11、推定部12、結果出力部13、学習データ出力部15、通話部16、通訳担当者抽出部18及び通訳担当者出力部19の構成は、第1乃至第3の実施形態のいずれかと同様である。
通話制御部17は、通話相手との通話を保留し、指定された通訳担当者との通話を開始させた後、対象音声データを再生し、再生音を通訳担当者の通話端末に送信する。そして、通話制御部17は、その後に所定の入力を受付けると、通話相手及び通訳担当者を含む三者通話を開始させる。通話制御部17のその他の構成は、第1乃至第3の実施形態のいずれかと同様である。
判定部14は、三者通話が開始されると、推定結果が正しいと判定する。判定部14のその他の構成は、第1乃至第3の実施形態のいずれかと同様である。
次に、図13のシーケンス図を用いて、処理システム10の処理の流れの一例を説明する。
第1の通話端末、第2の通話端末及び第3の通話端末は、第2の実施形態で説明した通りである。そして、S50乃至S61の処理は、第2の実施形態で説明した図7のS20乃至S31の処理と同様である。
S61に示すように第2の通話端末と第3の通話端末との間で通話が可能な状態となった時に、第2の通話端末に表示される画面の一例は図14に示される。図では、通話中であることを示す情報、指定された通訳担当者の名称、及び、各種操作を行うためのUIボタンを含むウインドウが表示されている。UIボタンは、通話を終了するための通話終了ボタン、保留中の通話相手を含めた三者通話を開始するための三者通話開始ボタン、対象音声データを再生して対象音声を通訳担当者に聞かせるための対象音声再生ボタン等を含む。
当該画面において、対応オペレータが対象音声再生ボタンを押すと、第2の通話端末は対象音声データを再生する(S62)。結果、通訳担当者は、対象音声を聞くことができる。そして、通訳担当者は、対象音声が自身の担当する言語か否かを判定し、判定結果を通話中の対応オペレータに伝える。判定結果は、口頭で伝えられてもよいし、システムを利用した通知で実現されてもよい。システムを利用した通知は、例えば第2の通話端末及び第3の通話端末で実行中のアプリケーション等を介したメッセージの送受信で実現されてもよい。
対象音声が通訳担当者の担当する言語である場合、対応オペレータは、例えば図14に示す画面において、三者通話開始ボタンを押す(S63)。結果、第1の通話端末と、第2の通話端末と、第3の通話端末との間で三者通話が可能な状態となる(S64)。そして、判定部14はS55で推定された推定結果は正しいと判定し、学習データ出力部15はS55で取得された対象音声データ又は対象特徴量と、S55で推定された推定結果とを学習データとして出力する(S65)。
ここで、本実施形態の変形例を説明する。図13のシーケンス図を用いて説明した例では、通話相手が外国人である場合、通話相手と、対応オペレータと、通話相手の言語に対応した通訳者とを含む三者通話を行った。変形例では、通話相手が外国人である場合、対応オペレータは、通話相手の言語に対応した特定言語用対応オペレータに通話を転送してもよい。特定言語用対応オペレータは、対応オペレータと同様のスキルを有し、特定の言語で顧客対応を行うことができるオペレータである。
変形例の場合、図13のシーケンス図を用いて行った処理の説明における「通訳担当者」を「特定言語用対応オペレータ」に読み替えればよい。そして、S62の後に第2の通話端末又は第3の通話端末において所定の入力が行われると、第1の通話端末と第2の通話端末との間の通話を、第1の通話端末と第3の通話端末と間の通話に切り替える転送が行われる。
判定部14は、第1の通話端末と第2の通話端末との間の通話を、第1の通話端末と第3の通話端末と間の通話に切り替える転送が行われると、S55で推定された推定結果は正しいと判定する。そして、学習データ出力部15は、S55で取得された対象音声データ又は対象特徴量と、S55で推定された推定結果とを学習データとして出力する。
また、ユーザやオペレータの操作に応じて実行する処理の一部(例:S62、S63等)を機械的な自動処理に置き換えてもよい。この場合も、本実施形態の作用効果が実現される。
以上説明した本実施形態の処理システム10によれば、第1乃至第3の実施形態のいずれかと同様の作用効果を実現できる。また、本実施形態の処理システム10によれば、ユーザ入力以外の手段で取得した推定結果の正誤を間接的に示す情報に基づき推定結果の正誤判定を行うことができる。ユーザ入力なしで正誤判定できるため、ユーザ負担を軽減することができる。
また、本実施形態の処理システム10は、三者通話や通話の転送を行う前に、対象音声データを再生し、対象音声を通訳担当者や特定言語用対応オペレータに聞かせることができる。そして、対象音声を聞いた通訳担当者や特定言語用対応オペレータの判定結果(対象音声の言語が自身の担当する言語か否かの判定結果)に基づき、三者通話や通話の転送を行うか否かを決定することができる。推定部12の推定結果が間違っている場合、三者通話や通話の転送が行われることはない。換言すれば、三者通話や通話の転送が行われた場合、推定部12の推定結果が正しいということができる。
対象音声データを再生した後に三者通話や通話の転送が行われたか否かに基づき推定結果の正誤判定を行う本実施形態の処理システム10は、精度よく正誤判定を行うことができる。
<第5の実施形態>
本実施形態の処理システム10は、第2の実施形態と同様の構成を有し、第1乃至第4の実施形態と異なる手段で推定結果の正誤判定を行う点で、第1乃至第4の実施形態と異なる。
本実施形態の処理システム10は、第2の実施形態と同様の構成を有し、第1乃至第4の実施形態と異なる手段で推定結果の正誤判定を行う点で、第1乃至第4の実施形態と異なる。
処理システム10のハードウエア構成の一例は、第1乃至第4の実施形態と同様である。
処理システム10の機能ブロック図の一例は、図4で示される。図示するように、処理システム10は、取得部11と、推定部12と、結果出力部13と、判定部14と、学習データ出力部15と、通話部16と、通話制御部17と、通訳担当者抽出部18と、通訳担当者出力部19とを有する。なお、図示しないが、処理システム10は、学習データ記憶部21及び推定モデル生成部22を備えてもよい。
処理システム10は、図5に示す通話端末1、又は、通話端末1とサーバ2の両方により構成される。すなわち、処理システム10が有する機能部の全てを通話端末1が備えてもよい。その他、処理システム10が有する機能部の一部を通話端末1が備え、残りの機能部をサーバ2が備えてもよい。通話端末1は、パーソナルコンピュータ、タブレット端末、スマートフォン等の端末装置に所定のアプリケーションをインストールすることで所定の機能部を実現した装置であってもよいし、所定の機能部が予め実現された通話専用の端末であってもよい。
取得部11、推定部12、結果出力部13、学習データ出力部15、通話部16、通訳担当者抽出部18及び通訳担当者出力部19の構成は、第1乃至第4の実施形態のいずれかと同様である。
通話制御部17は、通話相手との通話を保留にしている間、推定結果で示される言語で所定のメッセージを出力する保留音を再生し、再生音を通話相手の通話端末に送信する。例えば、メッセージは、「このメッセージを読み上げている言語での通話を希望しますか?希望する場合は1を、他の言語での通話を希望する場合は2を押してください。」等であってもよい。
判定部14は、保留音を再生中に通話相手から所定の入力を受付ける。そして、判定部14は、通話相手の入力が第1の入力である場合、推定部12による推定結果が正しいと判定し、通話相手の入力が第2の入力である場合、推定部12による推定結果が正しくないと判定する。また、判定部14は、所定の期限までに通話相手の入力がない場合、推定結果が正しくないと判定することができる。所定の期限は、例えば上記メッセージを最後まで出力し終えたタイミングからの経過時間で定義される。
通話相手からの所定の入力は、上記メッセージに対して行われるものである。例えばメッセージが「このメッセージを読み上げている言語での通話を希望しますか?希望する場合は1を、他の言語での通話を希望する場合は2を押してください。」である場合、所定の入力はボタン1を押すことでなされる入力、又は、ボタン2を押すことでなされる入力である。この例の場合、ボタン1を押すことでなされる入力が第1の入力となり、ボタン2を押すことでなされる入力が第2の入力となる。
なお、通話制御部17は、推定結果が複数の言語を含む場合、信頼度が最も高い言語のメッセージを最初に再生し、通話相手の入力が第2の入力である場合、又は、所定の期限までに通話相手の入力がない場合には、次に信頼度が高い言語のメッセージを再生してもよい。
次に、図15のシーケンス図を用いて、処理システム10の処理の流れの一例を説明する。
第1の通話端末は、第2の通話端末及び第3の通話端末は、第2の実施形態で説明した通りである。
まず、第1の通話端末から第2の通話端末に通話要求が送信され(S70)、当該通話要求に対する通話受諾が第2の通話端末から第1の通話端末に送信されると(S71)、第1の通話端末と第2の通話端末との間で通話が開始され(S72)、通話が可能な状態(通話状態)となる。通話状態において、第2の通話端末に表示される画面の一例は図8に示される。図8の画面の説明は第2の実施形態で行ったので、ここでは省略する。
対応オペレータは、通話中に、通話相手が外国人であることを認識したが、通話相手の言語を認識できない場合、言語推定ボタンを押して言語推定処理を実行させる。当該入力に応じて、言語推定処理が実行される(S73)。
S73において、取得部11は、通話相手の音声を記録した対象音声データ、又は、通話相手の音声の特徴を示す対象特徴量を取得する。例えば、第2の通話端末は、通話相手に関わらず、全ての通話が録音されるように構成されてもよい。そして、取得部11は、上記録音された音声データの一部又は全部を、対象音声データとして取得してもよい。また、取得部11は、このように取得した対象音声データから対象特徴量を抽出してもよい。
次いで、推定部12は、推定モデル生成部22により生成された推定モデルと、取得部11により取得された対象音声データ又は対象特徴量とに基づき、対象音声の言語を推定する。
そして、結果出力部13は、推定された推定結果を出力する(S74)。図16に、結果出力部13が推定結果を出力した時に第2の通話端末に表示される画面の一例を示す。図では、推定結果を示すウインドウが表示されている。当該ウインドウでは、推定結果で示される言語の通訳担当者を示す情報のリンクがはられている。
例えば図16に示す画面において、通話者との通話を保留にする保留ボタンが押されると(S75)、第1の通話端末と第2の通話端末との間の通話が保留状態になる(S76)。そして、保留状態の間、第2の通話端末は図17に示す処理を実行する。
まず、通話制御部17は、S73で推定された推定結果で示される言語で所定のメッセージを出力する保留音を再生し、再生音を第1の通話端末に送信する(S80)。推定結果で示される言語が複数ある場合、通話制御部17は、最も信頼度の高い言語で所定のメッセージを出力する保留音を再生し、再生音を第1の通話端末に送信する。
その後、第2の通話端末は、第1の通話端末を介して行われるユーザ入力待ちとなる。第1の入力が行われた場合(S81の第1の入力)、判定部14は、推定結果は正しいと判定する。そして、学習データ出力部15は、出力したメッセージの言語と、S73で取得された対象音声データ又は対象特徴量とを学習データとして出力する(S82)。以降、通話制御部17は、保留状態を終了する入力を受付けるまで、通常の保留音(例:音楽等)を再生し、再生音を第1の通話端末に送信する(S83)。
一方、第2の入力が行われた場合、又は、所定の期限までに入力がない場合(S81の第2の入力/入力なし)、通話制御部17は他の言語候補があるか判断する(S85)。例えば、推定結果の中に他の言語が存在する場合、又は、推定結果の中に信頼度が所定レベル以上の他の言語が存在する場合、又は、推定結果に関係なく言語候補として予め登録されている他の言語が存在する場合などには、通話制御部17は他の言語候補があると判定することができる。
他の言語候補がない場合(S85のNo)、通話制御部17は、保留状態を終了する入力を受付けるまで、通常の保留音(例:音楽等)を再生し、再生音を第1の通話端末に送信する(S83)。
他の言語候補がある場合(S85のYes)、通話制御部17は、他の言語候補で所定のメッセージを出力する保留音を再生し、再生音を第1の通話端末に送信する(S86)。そして、S81に戻り、同様の処理を繰り返す。
なお、S76の保留状態の間、図7を用いて説明したS26乃至S32の処理や、図13を用いて説明したS56乃至S63の処理が実行されてもよい。
また、ユーザやオペレータの操作に応じて実行する処理の一部(例:S75、S76等)を機械的な自動処理に置き換えてもよい。この場合も、本実施形態の作用効果が実現される。
以上説明した本実施形態の処理システム10によれば、第1乃至第4の実施形態のいずれかと同様の作用効果を実現できる。また、本実施形態の処理システム10は、保留状態の間に、推定結果の言語でメッセージを再生し、通話相手にそのメッセージを聞かせることができる。そして、本実施形態の処理システム10は、そのメッセージに対する通話相手の入力に基づき、推定結果の正誤判定を行うことができる。このような本実施形態の処理システム10によれば、高精度に推定結果の正誤判定を行うことができる。
以下、参考形態の例を付記する。
1. 言語推定対象の音声である対象音声を記録した対象音声データ、又は、前記対象音声の特徴を示す対象特徴量を取得する取得手段と、
音声を記録した音声データ又は前記音声の特徴を示す音声特徴量から前記音声の言語を推定する推定モデルと、前記対象音声データ又は前記対象特徴量とに基づき、前記対象音声の言語を推定する推定手段と、
前記推定手段による推定結果を出力する結果出力手段と、
前記推定結果の正誤判定を行う判定手段と、
前記判定手段により正しいと判定された前記推定結果と、前記対象音声データ又は前記対象特徴量とを、前記推定モデルを生成するための学習データとして出力する学習データ出力手段と、
を有する処理システム。
2. 1に記載の処理システムにおいて、
通話手段を有し、
前記取得手段は、通話相手の音声を記録した前記対象音声データ、又は、前記通話相手の音声の特徴を示す前記対象特徴量を取得し、
複数の言語各々の通訳担当者及び連絡先情報を登録した通訳者情報を参照し、前記推定結果で示される言語の前記通訳担当者を抽出する通訳担当者抽出手段と、
抽出された前記通訳担当者を示す情報を出力する通訳担当者出力手段と、
通話相手との通話を保留し、抽出された前記通訳担当者の中から指定された前記通訳担当者との通話を開始させる通話制御手段と、
を有する処理システム。
3. 2に記載の処理システムにおいて、
前記通話制御手段は、前記通話相手との通話を保留し、指定された前記通訳担当者との通話を開始させた後、所定の入力を受付けると、前記通話相手及び前記通訳担当者を含む三者通話を開始し、
前記判定手段は、前記三者通話が開始されてからの経過時間が所定時間を超えた場合、前記推定結果が正しいと判定する処理システム。
4. 2に記載の処理システムにおいて、
前記通話制御手段は、前記通話相手との通話を保留し、指定された前記通訳担当者との通話を開始させた後、前記対象音声データを再生し、再生音を前記通訳担当者の通話端末に送信し、その後に所定の入力を受付けると、前記通話相手及び前記通訳担当者を含む三者通話を開始させ、
前記判定手段は、前記三者通話が開始されると、前記推定結果が正しいと判定する処理システム。
5. 2から4のいずれかに記載の処理システムにおいて、
前記通話制御手段は、前記通話相手との通話を保留にしている間、前記推定結果で示される言語で所定のメッセージを出力する保留音を再生し、再生音を前記通話相手の通話端末に送信し、
前記判定手段は、前記保留音を再生中に前記通話相手から所定の入力を受付け、前記通話相手の入力が第1の入力である場合、前記推定結果が正しいと判定し、前記通話相手の入力が第2の入力である場合、前記推定結果が正しくないと判定する処理システム。
6. 5に記載の処理システムにおいて、
前記判定手段は、所定の期限までに前記通話相手の入力がない場合、前記推定結果が正しくないと判定する処理システム。
7. 5又は6に記載の処理システムにおいて、
前記通話制御手段は、前記推定結果が複数の言語を含む場合、信頼度が最も高い言語の前記メッセージを再生し、前記通話相手の入力が第2の入力である場合、又は、所定の期限までに前記通話相手の入力がない場合には、次に信頼度が高い言語の前記メッセージを再生する処理システム。
8. コンピュータが、
言語推定対象の音声である対象音声を記録した対象音声データ、又は、前記対象音声の特徴を示す対象特徴量を取得する取得工程と、
音声を記録した音声データ又は前記音声の特徴を示す音声特徴量から前記音声の言語を推定する推定モデルと、前記対象音声データ又は前記対象特徴量とに基づき、前記対象音声の言語を推定する推定工程と、
前記推定工程での推定結果を出力する結果出力工程と、
前記推定結果の正誤判定を行う判定工程と、
前記判定工程で正しいと判定された前記推定結果と、前記対象音声データ又は前記対象特徴量とを、前記推定モデルを生成するための学習データとして出力する学習データ出力工程と、
を実行する処理方法。
9. コンピュータを、
言語推定対象の音声である対象音声を記録した対象音声データ、又は、前記対象音声の特徴を示す対象特徴量を取得する取得手段、
音声を記録した音声データ又は前記音声の特徴を示す音声特徴量から前記音声の言語を推定する推定モデルと、前記対象音声データ又は前記対象特徴量とに基づき、前記対象音声の言語を推定する推定手段、
前記推定手段による推定結果を出力する結果出力手段、
前記推定結果の正誤判定を行う判定手段、
前記判定手段により正しいと判定された前記推定結果と、前記対象音声データ又は前記対象特徴量とを、前記推定モデルを生成するための学習データとして出力する学習データ出力手段、
として機能させるプログラム。
1. 言語推定対象の音声である対象音声を記録した対象音声データ、又は、前記対象音声の特徴を示す対象特徴量を取得する取得手段と、
音声を記録した音声データ又は前記音声の特徴を示す音声特徴量から前記音声の言語を推定する推定モデルと、前記対象音声データ又は前記対象特徴量とに基づき、前記対象音声の言語を推定する推定手段と、
前記推定手段による推定結果を出力する結果出力手段と、
前記推定結果の正誤判定を行う判定手段と、
前記判定手段により正しいと判定された前記推定結果と、前記対象音声データ又は前記対象特徴量とを、前記推定モデルを生成するための学習データとして出力する学習データ出力手段と、
を有する処理システム。
2. 1に記載の処理システムにおいて、
通話手段を有し、
前記取得手段は、通話相手の音声を記録した前記対象音声データ、又は、前記通話相手の音声の特徴を示す前記対象特徴量を取得し、
複数の言語各々の通訳担当者及び連絡先情報を登録した通訳者情報を参照し、前記推定結果で示される言語の前記通訳担当者を抽出する通訳担当者抽出手段と、
抽出された前記通訳担当者を示す情報を出力する通訳担当者出力手段と、
通話相手との通話を保留し、抽出された前記通訳担当者の中から指定された前記通訳担当者との通話を開始させる通話制御手段と、
を有する処理システム。
3. 2に記載の処理システムにおいて、
前記通話制御手段は、前記通話相手との通話を保留し、指定された前記通訳担当者との通話を開始させた後、所定の入力を受付けると、前記通話相手及び前記通訳担当者を含む三者通話を開始し、
前記判定手段は、前記三者通話が開始されてからの経過時間が所定時間を超えた場合、前記推定結果が正しいと判定する処理システム。
4. 2に記載の処理システムにおいて、
前記通話制御手段は、前記通話相手との通話を保留し、指定された前記通訳担当者との通話を開始させた後、前記対象音声データを再生し、再生音を前記通訳担当者の通話端末に送信し、その後に所定の入力を受付けると、前記通話相手及び前記通訳担当者を含む三者通話を開始させ、
前記判定手段は、前記三者通話が開始されると、前記推定結果が正しいと判定する処理システム。
5. 2から4のいずれかに記載の処理システムにおいて、
前記通話制御手段は、前記通話相手との通話を保留にしている間、前記推定結果で示される言語で所定のメッセージを出力する保留音を再生し、再生音を前記通話相手の通話端末に送信し、
前記判定手段は、前記保留音を再生中に前記通話相手から所定の入力を受付け、前記通話相手の入力が第1の入力である場合、前記推定結果が正しいと判定し、前記通話相手の入力が第2の入力である場合、前記推定結果が正しくないと判定する処理システム。
6. 5に記載の処理システムにおいて、
前記判定手段は、所定の期限までに前記通話相手の入力がない場合、前記推定結果が正しくないと判定する処理システム。
7. 5又は6に記載の処理システムにおいて、
前記通話制御手段は、前記推定結果が複数の言語を含む場合、信頼度が最も高い言語の前記メッセージを再生し、前記通話相手の入力が第2の入力である場合、又は、所定の期限までに前記通話相手の入力がない場合には、次に信頼度が高い言語の前記メッセージを再生する処理システム。
8. コンピュータが、
言語推定対象の音声である対象音声を記録した対象音声データ、又は、前記対象音声の特徴を示す対象特徴量を取得する取得工程と、
音声を記録した音声データ又は前記音声の特徴を示す音声特徴量から前記音声の言語を推定する推定モデルと、前記対象音声データ又は前記対象特徴量とに基づき、前記対象音声の言語を推定する推定工程と、
前記推定工程での推定結果を出力する結果出力工程と、
前記推定結果の正誤判定を行う判定工程と、
前記判定工程で正しいと判定された前記推定結果と、前記対象音声データ又は前記対象特徴量とを、前記推定モデルを生成するための学習データとして出力する学習データ出力工程と、
を実行する処理方法。
9. コンピュータを、
言語推定対象の音声である対象音声を記録した対象音声データ、又は、前記対象音声の特徴を示す対象特徴量を取得する取得手段、
音声を記録した音声データ又は前記音声の特徴を示す音声特徴量から前記音声の言語を推定する推定モデルと、前記対象音声データ又は前記対象特徴量とに基づき、前記対象音声の言語を推定する推定手段、
前記推定手段による推定結果を出力する結果出力手段、
前記推定結果の正誤判定を行う判定手段、
前記判定手段により正しいと判定された前記推定結果と、前記対象音声データ又は前記対象特徴量とを、前記推定モデルを生成するための学習データとして出力する学習データ出力手段、
として機能させるプログラム。
この出願は、2018年12月11日に出願された日本出願特願2018-231461号を基礎とする優先権を主張し、その開示の全てをここに取り込む。
Claims (9)
- 言語推定対象の音声である対象音声を記録した対象音声データ、又は、前記対象音声の特徴を示す対象特徴量を取得する取得手段と、
音声を記録した音声データ又は前記音声の特徴を示す音声特徴量から前記音声の言語を推定する推定モデルと、前記対象音声データ又は前記対象特徴量とに基づき、前記対象音声の言語を推定する推定手段と、
前記推定手段による推定結果を出力する結果出力手段と、
前記推定結果の正誤判定を行う判定手段と、
前記判定手段により正しいと判定された前記推定結果と、前記対象音声データ又は前記対象特徴量とを、前記推定モデルを生成するための学習データとして出力する学習データ出力手段と、
を有する処理システム。 - 請求項1に記載の処理システムにおいて、
通話手段を有し、
前記取得手段は、通話相手の音声を記録した前記対象音声データ、又は、前記通話相手の音声の特徴を示す前記対象特徴量を取得し、
複数の言語各々の通訳担当者及び連絡先情報を登録した通訳者情報を参照し、前記推定結果で示される言語の前記通訳担当者を抽出する通訳担当者抽出手段と、
抽出された前記通訳担当者を示す情報を出力する通訳担当者出力手段と、
通話相手との通話を保留し、抽出された前記通訳担当者の中から指定された前記通訳担当者との通話を開始させる通話制御手段と、
を有する処理システム。 - 請求項2に記載の処理システムにおいて、
前記通話制御手段は、前記通話相手との通話を保留し、指定された前記通訳担当者との通話を開始させた後、所定の入力を受付けると、前記通話相手及び前記通訳担当者を含む三者通話を開始し、
前記判定手段は、前記三者通話が開始されてからの経過時間が所定時間を超えた場合、前記推定結果が正しいと判定する処理システム。 - 請求項2に記載の処理システムにおいて、
前記通話制御手段は、前記通話相手との通話を保留し、指定された前記通訳担当者との通話を開始させた後、前記対象音声データを再生し、再生音を前記通訳担当者の通話端末に送信し、その後に所定の入力を受付けると、前記通話相手及び前記通訳担当者を含む三者通話を開始させ、
前記判定手段は、前記三者通話が開始されると、前記推定結果が正しいと判定する処理システム。 - 請求項2から4のいずれか1項に記載の処理システムにおいて、
前記通話制御手段は、前記通話相手との通話を保留にしている間、前記推定結果で示される言語で所定のメッセージを出力する保留音を再生し、再生音を前記通話相手の通話端末に送信し、
前記判定手段は、前記保留音を再生中に前記通話相手から所定の入力を受付け、前記通話相手の入力が第1の入力である場合、前記推定結果が正しいと判定し、前記通話相手の入力が第2の入力である場合、前記推定結果が正しくないと判定する処理システム。 - 請求項5に記載の処理システムにおいて、
前記判定手段は、所定の期限までに前記通話相手の入力がない場合、前記推定結果が正しくないと判定する処理システム。 - 請求項5又は6に記載の処理システムにおいて、
前記通話制御手段は、前記推定結果が複数の言語を含む場合、信頼度が最も高い言語の前記メッセージを再生し、前記通話相手の入力が第2の入力である場合、又は、所定の期限までに前記通話相手の入力がない場合には、次に信頼度が高い言語の前記メッセージを再生する処理システム。 - コンピュータが、
言語推定対象の音声である対象音声を記録した対象音声データ、又は、前記対象音声の特徴を示す対象特徴量を取得する取得工程と、
音声を記録した音声データ又は前記音声の特徴を示す音声特徴量から前記音声の言語を推定する推定モデルと、前記対象音声データ又は前記対象特徴量とに基づき、前記対象音声の言語を推定する推定工程と、
前記推定工程での推定結果を出力する結果出力工程と、
前記推定結果の正誤判定を行う判定工程と、
前記判定工程で正しいと判定された前記推定結果と、前記対象音声データ又は前記対象特徴量とを、前記推定モデルを生成するための学習データとして出力する学習データ出力工程と、
を実行する処理方法。 - コンピュータを、
言語推定対象の音声である対象音声を記録した対象音声データ、又は、前記対象音声の特徴を示す対象特徴量を取得する取得手段、
音声を記録した音声データ又は前記音声の特徴を示す音声特徴量から前記音声の言語を推定する推定モデルと、前記対象音声データ又は前記対象特徴量とに基づき、前記対象音声の言語を推定する推定手段、
前記推定手段による推定結果を出力する結果出力手段、
前記推定結果の正誤判定を行う判定手段、
前記判定手段により正しいと判定された前記推定結果と、前記対象音声データ又は前記対象特徴量とを、前記推定モデルを生成するための学習データとして出力する学習データ出力手段、
として機能させるプログラム。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP19895333.3A EP3896687A4 (en) | 2018-12-11 | 2019-09-13 | TREATMENT SYSTEM, TREATMENT PROCEDURE AND PROGRAM |
| US17/312,170 US11503161B2 (en) | 2018-12-11 | 2019-09-13 | Processing system, processing method, and non-transitory storage medium |
| JP2020559735A JP7180687B2 (ja) | 2018-12-11 | 2019-09-13 | 処理システム、処理方法及びプログラム |
| US17/958,543 US11818300B2 (en) | 2018-12-11 | 2022-10-03 | Processing system, processing method, and non-transitory storage medium |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2018231461 | 2018-12-11 | ||
| JP2018-231461 | 2018-12-11 |
Related Child Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US17/312,170 A-371-Of-International US11503161B2 (en) | 2018-12-11 | 2019-09-13 | Processing system, processing method, and non-transitory storage medium |
| US17/958,543 Continuation US11818300B2 (en) | 2018-12-11 | 2022-10-03 | Processing system, processing method, and non-transitory storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2020121616A1 true WO2020121616A1 (ja) | 2020-06-18 |
Family
ID=71077181
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2019/036062 Ceased WO2020121616A1 (ja) | 2018-12-11 | 2019-09-13 | 処理システム、処理方法及びプログラム |
Country Status (4)
| Country | Link |
|---|---|
| US (2) | US11503161B2 (ja) |
| EP (1) | EP3896687A4 (ja) |
| JP (1) | JP7180687B2 (ja) |
| WO (1) | WO2020121616A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP4246962A4 (en) * | 2020-12-15 | 2024-05-01 | Huawei Cloud Computing Technologies Co., Ltd. | Simultaneous interpretation method, apparatus and system |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7476976B2 (ja) * | 2020-10-30 | 2024-05-01 | 日本電信電話株式会社 | 推論装置、推論方法、及び推論プログラム |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003032373A (ja) | 2001-07-11 | 2003-01-31 | Contents Station:Kk | 三者間通話を可能とする多言語オペレートシステム |
| JP2010021692A (ja) * | 2008-07-09 | 2010-01-28 | Metemu:Kk | 電話を使用した通訳システム |
| JP2012103554A (ja) | 2010-11-11 | 2012-05-31 | Advanced Telecommunication Research Institute International | 音声言語識別装置の学習装置、音声言語の識別装置、及びそれらのためのプログラム |
| JP2018128576A (ja) * | 2017-02-08 | 2018-08-16 | 日本電信電話株式会社 | 用件判定装置、用件判定方法およびプログラム |
| JP2018128575A (ja) * | 2017-02-08 | 2018-08-16 | 日本電信電話株式会社 | 話し終わり判定装置、話し終わり判定方法およびプログラム |
| JP2018174416A (ja) * | 2017-03-31 | 2018-11-08 | 日本電気株式会社 | 多言語振分装置、多言語振分方法、及びプログラム |
Family Cites Families (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6424989B1 (en) * | 1991-09-20 | 2002-07-23 | Venson M. Shaw | Object-oriented transaction computing system |
| US6188429B1 (en) * | 1997-09-19 | 2001-02-13 | Netergy Networks, Inc | Video TTY device and method for videocommunication |
| WO2001037528A1 (en) * | 1999-11-19 | 2001-05-25 | Intervoice Limited Partnership | Autonomously administering enhanced telephony services |
| KR100711293B1 (ko) * | 2002-09-27 | 2007-04-25 | 가부시키가이샤 깅가네트 | 전화 통역 시스템 |
| US20070206761A1 (en) * | 2004-10-12 | 2007-09-06 | Anders Joseph C | Comparative tone return time three-way call detect |
| US7792276B2 (en) * | 2005-09-13 | 2010-09-07 | Language Line Services, Inc. | Language interpretation call transferring in a telecommunications network |
| US7894596B2 (en) | 2005-09-13 | 2011-02-22 | Language Line Services, Inc. | Systems and methods for providing language interpretation |
| US8023626B2 (en) * | 2005-09-13 | 2011-09-20 | Language Line Services, Inc. | System and method for providing language interpretation |
| US20070239625A1 (en) * | 2006-04-05 | 2007-10-11 | Language Line Services, Inc. | System and method for providing access to language interpretation |
| US7773738B2 (en) * | 2006-09-22 | 2010-08-10 | Language Line Services, Inc. | Systems and methods for providing relayed language interpretation |
| US20100120404A1 (en) * | 2008-11-12 | 2010-05-13 | Bernal Andrzej | Method for providing translation services |
| US20120010886A1 (en) | 2010-07-06 | 2012-01-12 | Javad Razavilar | Language Identification |
| JP5544279B2 (ja) | 2010-11-11 | 2014-07-09 | 株式会社神戸製鋼所 | 学習支援システム、学習支援システムの学習履歴集計方法、及びコンピュータプログラム |
| US9253329B1 (en) * | 2011-06-10 | 2016-02-02 | West Corporation | Services via a conference bridge |
| US9025760B1 (en) * | 2011-06-10 | 2015-05-05 | West Corporation | Apparatus and method for connecting a translator and a customer |
| KR20150103972A (ko) * | 2014-03-04 | 2015-09-14 | 삼성전자주식회사 | 전자 장치의 촬영 기능과 통화 기능을 제어하는 방법 및 이를 구현한 전자 장치 |
| US20150347399A1 (en) * | 2014-05-27 | 2015-12-03 | Microsoft Technology Licensing, Llc | In-Call Translation |
| US9614969B2 (en) * | 2014-05-27 | 2017-04-04 | Microsoft Technology Licensing, Llc | In-call translation |
| US20160170970A1 (en) * | 2014-12-12 | 2016-06-16 | Microsoft Technology Licensing, Llc | Translation Control |
| JP2017143322A (ja) * | 2016-02-08 | 2017-08-17 | 日本Did株式会社 | 通訳システム及び通訳管理装置 |
| US20190102713A1 (en) * | 2017-10-03 | 2019-04-04 | Avaya Inc. | Split enterprise/provider workflows |
-
2019
- 2019-09-13 EP EP19895333.3A patent/EP3896687A4/en not_active Withdrawn
- 2019-09-13 US US17/312,170 patent/US11503161B2/en active Active
- 2019-09-13 JP JP2020559735A patent/JP7180687B2/ja active Active
- 2019-09-13 WO PCT/JP2019/036062 patent/WO2020121616A1/ja not_active Ceased
-
2022
- 2022-10-03 US US17/958,543 patent/US11818300B2/en active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003032373A (ja) | 2001-07-11 | 2003-01-31 | Contents Station:Kk | 三者間通話を可能とする多言語オペレートシステム |
| JP2010021692A (ja) * | 2008-07-09 | 2010-01-28 | Metemu:Kk | 電話を使用した通訳システム |
| JP2012103554A (ja) | 2010-11-11 | 2012-05-31 | Advanced Telecommunication Research Institute International | 音声言語識別装置の学習装置、音声言語の識別装置、及びそれらのためのプログラム |
| JP2018128576A (ja) * | 2017-02-08 | 2018-08-16 | 日本電信電話株式会社 | 用件判定装置、用件判定方法およびプログラム |
| JP2018128575A (ja) * | 2017-02-08 | 2018-08-16 | 日本電信電話株式会社 | 話し終わり判定装置、話し終わり判定方法およびプログラム |
| JP2018174416A (ja) * | 2017-03-31 | 2018-11-08 | 日本電気株式会社 | 多言語振分装置、多言語振分方法、及びプログラム |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP4246962A4 (en) * | 2020-12-15 | 2024-05-01 | Huawei Cloud Computing Technologies Co., Ltd. | Simultaneous interpretation method, apparatus and system |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2020121616A1 (ja) | 2021-10-14 |
| US20230027992A1 (en) | 2023-01-26 |
| EP3896687A1 (en) | 2021-10-20 |
| JP7180687B2 (ja) | 2022-11-30 |
| EP3896687A4 (en) | 2022-01-26 |
| US20220014628A1 (en) | 2022-01-13 |
| US11503161B2 (en) | 2022-11-15 |
| US11818300B2 (en) | 2023-11-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| TWI310503B (en) | Method and apparatus for use in automating access to one or more services accessible throngh a communication system, and machine readable medium recording related instructions | |
| CN108509591B (zh) | 信息问答交互方法及系统、存储介质、终端、智能知识库 | |
| JP7682950B2 (ja) | 保留を管理するための方法および装置 | |
| US11762629B2 (en) | System and method for providing a response to a user query using a visual assistant | |
| JP2016103270A (ja) | 情報処理システム、受付サーバ、情報処理方法及びプログラム | |
| WO2017175363A1 (ja) | 情報処理システム、受付サーバ、情報処理方法及びプログラム | |
| JP2012503364A (ja) | 無線機器に対する既定の応答方法及び装置 | |
| JP2019197977A (ja) | 問い合わせ処理方法、システム、端末、自動音声対話装置、表示処理方法、通話制御方法、及び、プログラム | |
| JP7180687B2 (ja) | 処理システム、処理方法及びプログラム | |
| US10178230B1 (en) | Methods and systems for communicating supplemental data to a callee via data association with a software-as-a-service application | |
| JP6627315B2 (ja) | 情報処理装置、情報処理方法、および制御プログラム | |
| JP7103681B2 (ja) | 音声認識プログラム、音声認識方法、音声認識装置および音声認識システム | |
| JP7180747B2 (ja) | 編集支援プログラム、編集支援方法、及び編集支援装置 | |
| CN109509474A (zh) | 通过语音识别选择电话客服中服务项的方法及其设备 | |
| TW200824408A (en) | Methods and systems for information retrieval during communication, and machine readable medium thereof | |
| US10419617B2 (en) | Interactive voicemail message and response tagging system for improved response quality and information retrieval | |
| CN114554017A (zh) | 语音会话方法、装置、电子设备及可读存储介质 | |
| JP2020053859A (ja) | 情報処理装置、情報処理方法およびプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19895333 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2020559735 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2019895333 Country of ref document: EP Effective date: 20210712 |