WO2024257843A1 - ジンクフィンガータンパク質、ジンクフィンガーヌクレアーゼ、ベクター並びにこれらを用いたゲノム編集方法 - Google Patents
ジンクフィンガータンパク質、ジンクフィンガーヌクレアーゼ、ベクター並びにこれらを用いたゲノム編集方法 Download PDFInfo
- Publication number
- WO2024257843A1 WO2024257843A1 PCT/JP2024/021599 JP2024021599W WO2024257843A1 WO 2024257843 A1 WO2024257843 A1 WO 2024257843A1 JP 2024021599 W JP2024021599 W JP 2024021599W WO 2024257843 A1 WO2024257843 A1 WO 2024257843A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- nls
- zinc finger
- seq
- acid sequence
- zfp
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images

Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
- C12N9/22—Ribonucleases [RNase]; Deoxyribonucleases [DNase]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/09—Fusion polypeptide containing a localisation/targetting motif containing a nuclear localisation signal
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/80—Fusion polypeptide containing a DNA binding domain, e.g. Lacl or Tet-repressor
- C07K2319/81—Fusion polypeptide containing a DNA binding domain, e.g. Lacl or Tet-repressor containing a Zn-finger domain for DNA binding
Definitions
- the present disclosure relates to zinc finger proteins, zinc finger nucleases, vectors, and genome editing methods using these. More specifically, the disclosure relates to zinc finger proteins having three or more nuclear localization signals added to the N-terminus.
- Zinc finger nuclease consists of FokI-ND, a nucleic acid cleavage domain, zinc finger protein (ZFP), a nucleic acid binding domain, and a linker connecting them.
- Patent Document 1 discloses ZFN that contains nucleic acid cleavage domains called nuclease domain 1 (ND1) and nuclease domain 2 (ND2) instead of FokI-ND.
- ND1 is said to be a nuclease domain derived from Bacillus SGD-V-76
- ND2 is said to be a nuclease domain derived from Clostridium botulinum.
- ND1 and ND2 are said to be superior to the conventional FokI-ND in terms of functionality such as cleavage activity, specificity, and target sequence selectivity.
- Non-Patent Document 1 reports that genome editing efficiency is improved in cultured cells (dividing cells) by adding multiple nuclear localization signals (NLS) to ZF-FokI-ND.
- Non-Patent Document 2 reports that adding one NLS each to the N-terminus and C-terminus of Cas nuclease enables efficient implementation of the HITI (Homology-independent Targeted Integration) method in non-dividing cells.
- HITI Homology-independent Targeted Integration
- the primary objective of this disclosure is to provide technology that can be used to improve the efficiency of genome editing using ZFNs, particularly in non-dividing cells.
- the present disclosure provides the following [1] to [13].
- ZFP Zinc finger protein
- NLS nuclear localization signals
- a zinc finger nuclease comprising any one of the ZFPs [1] to [4] and a nucleic acid cleavage domain.
- the ZFN of [6] wherein the nucleic acid cleavage domain is ND1.
- the nucleic acid cleavage domain comprises: The amino acid sequence of positions 391 to 585 of SEQ ID NO:9; The amino acid sequence of SEQ ID NO: 14, or The amino acid sequence of SEQ ID NO: 15, The ZFN of [7], comprising:
- a genome editing method comprising the step of introducing the vector of [9] into a cell.
- the genome editing method of [10] which is an in vitro method.
- the genome editing method of [10] or [11], wherein the cell is a non-dividing cell.
- the method according to [12], wherein the non-dividing cells are photoreceptor cells.
- the present disclosure provides techniques that can be used to improve the efficiency of genome editing using ZFNs, particularly in non-dividing cells.
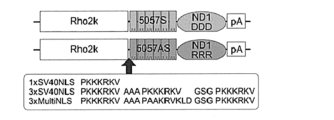
- the upstream sequence of the start codon of exon 1 of the mouse Rho gene and the recognition sequence of ZFP (ZF-5057S, ZF5057AS) contained in ZF-ND1 expressed by the ZF-ND1 expression vector are shown.
- the structure of the ZF-ND1 expression vector (pRho2k-ZF-ND1DDD, pRho2k-ZF-ND1RRR) is shown.
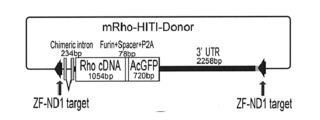
- the configuration of the donor gene vector (mRho-ZF-HITI-Donor) is shown.
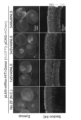
- the top panel shows a fluorescent image of retinal tissue (eyecup) harvested on P21 after a fluorescent protein (AcGFP) gene was introduced into the rhodopsin locus of rod photoreceptors in a mouse retina immediately after birth (P0-2).
- the bottom panel shows a fluorescent stained image of the retinal tissue using an anti-GFP antibody. Green indicates AcGFP fluorescence, and red indicates the fluorescence of the positive control mCherry.
- the ZFP according to the present disclosure comprises a nucleic acid binding domain and has three or more nuclear localization signals (NLS) at the N-terminus of the nucleic acid binding domain.
- the ZFP according to the present disclosure has three or more NLSs at the N-terminus, and can be combined with an effector domain to show improved genome editing efficiency.
- the improved genome editing efficiency can be achieved particularly in non-dividing cells.
- the nucleic acid binding domain of the ZFP disclosed herein comprises a zinc finger array that recognizes a specific nucleic acid sequence.
- the zinc finger array is composed of multiple zinc fingers (ZFs) that recognize a three-base sequence.
- the zinc finger array may include two or more ZFs, for example, 3-9, preferably 4-8, more preferably 5-7, typically 6 ZFs.
- the nucleic acid sequence recognized by the zinc finger array can be appropriately set depending on the nucleic acid sequence of the target nucleic acid strand to be subjected to genome editing and the nucleic acid sequence of the editing target site in the target nucleic acid strand.
- the relationship between the amino acid sequence of the ZF and the three-base sequence recognized by the ZF is publicly known, and the amino acid sequence of the ZF can be, for example, the amino acid sequence described in Supplementary Table 1 of Non-Patent Document 1 depending on the three-base sequence to be recognized. Since there are multiple amino acid sequences of ZFs that recognize the same three-base sequence, these ZFs that recognize the same three-base sequence can be used interchangeably.
- a ZFP of the present disclosure may have three or more NLSs, preferably 3-5, and particularly 3 or 5 NLSs.
- the NLS possessed by the ZFP of the present disclosure can be any conventionally known NLS, such as the SV40 T antigen NLS (PKKKRKV: SEQ ID NO: 6), c-myc NLS (PAAKRVKLD: SEQ ID NO: 7), Nucleoplasmin NLS (KRXXXXXXXXXXKKKLD: SEQ ID NO: 8, where X represents any amino acid), and NLSs having amino acid sequences derived from these sequences, without any particular limitation.
- the NLS is preferably the SV40 T antigen NLS or the c-myc NLS, more preferably the SV40 T antigen NLS and the c-myc NLS.
- the NLSs are the SV40 T antigen NLS and the c-myc NLS, they may be arranged alternately, and in particular, the three NLSs may be arranged in the order of "SV40 T antigen NLS, c-myc NLS, SV40 T antigen NLS.”
- Each NLS may be directly linked or linked by a peptide linker.
- the amino acid sequence of the peptide linker is arbitrary, but can be, for example, AAA and GSG.
- the effector domain to which the ZFP of the present disclosure is bound may be, but is not limited to, a nucleic acid cleavage domain.
- Other effector domains include cytosine base editors (UGI, APOBEC), adenine base editors (TadA), transcriptional activators (VP16)/repressors (SID), epigenomic editors (DNMT3A, TET1), imaging proteins (Dye, fluorescent proteins), transposases (PiggyBac), recombinases (Flippase), and the like.
- the effector domain may be one that functions alone (monomeric type) or one that functions as a polymer (split type).
- the ZFP and the effector domain may be linked directly or via a linker.
- the linker may, for example, consist of two or more amino acid residues and may be, for example, 2 to 20 amino acids long, for example, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 16, 17, 18, 19, or 20 amino acids long, although the length is not particularly limited.
- the type of linker is also not particularly limited, but an example of the linker is TGGS (SEQ ID NO: 13). The presence or absence of a linker and the length and type of the linker are appropriately selected by those skilled in the art, taking into consideration the type of effector domain, etc.
- the ZFP of the present disclosure is preferably combined with a nucleic acid cleavage domain to form a zinc finger nuclease (ZFN).
- ZFN of the present disclosure recognizes and binds to a specific nucleic acid sequence with a zinc finger array, resulting in a DNA double-strand break (DSB) by the nucleic acid cleavage domain.
- DSB DNA double-strand break
- the nucleic acid cleavage domain is not particularly limited, and may be FokI-ND, ND1 and ND2 described in Patent Document 2, or modified versions thereof.
- the amino acid sequence of a full-length protein (derived from Bacillus SGD-V-76) containing ND1 is shown in SEQ ID NO: 9, and its nucleotide sequence is shown in SEQ ID NO: 10.
- the amino acid sequence of a full-length protein (derived from Clostridium botulinum) containing ND2 is shown in SEQ ID NO: 11, and its nucleotide sequence is shown in SEQ ID NO: 12.
- ND1 is typically a partial peptide corresponding to positions 391 to 585 of SEQ ID NO: 9
- ND2 is typically a partial peptide corresponding to positions 389 to 579 of SEQ ID NO: 11.
- the nucleic acid cleavage domain is preferably ND1.
- the ND1 and ND2 variants may be polypeptides comprising an amino acid sequence in which one or several amino acid residues have been substituted, deleted, inserted or added in the amino acid sequence shown in positions 391 to 585 of SEQ ID NO: 9 or positions 389 to 579 of SEQ ID NO: 11, and having nuclease activity.
- “one or several” means, for example, 1 to 10, preferably 1 to 6, e.g., 1, 2, 3, 4 or 5.
- the ND1 and ND2 variants may be polypeptides that contain an amino acid sequence that has at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, or at least 98% sequence identity to the amino acid sequence shown at positions 391 to 585 of SEQ ID NO:9 or positions 389 to 579 of SEQ ID NO:11, and have nuclease activity.
- sequence identity of an amino acid sequence is determined by comparing two sequences aligned in a state in which the sequence match is maximized. Methods for determining the numerical value (%) of sequence identity are known to those skilled in the art.
- any algorithm known to those skilled in the art e.g., BLAST algorithm, FASTA algorithm, etc.
- the sequence identity of an amino acid sequence is determined, for example, using sequence analysis software such as BLASTP and FASTA.
- ND1 and ND2 variants include variants (DDD type variants) containing aspartic acid (D483, D487, and D496) at positions corresponding to positions 483, 487, and 496 in the amino acid sequence of FokI, and variants (RRR type variants) containing arginine (R483, R487, and R537) at positions corresponding to positions 483, 487, and 537 in the amino acid sequence of FokI.
- DDD type variant of ND1 (ND1DDD) has an amino acid sequence in which the 103rd and 113th amino acids in the partial peptide corresponding to positions 391 to 585 of SEQ ID NO: 9 are replaced with aspartic acid (SEQ ID NO: 14).
- the RRR type variant of ND1 (ND1RRR) has an amino acid sequence in which the 100th and 154th amino acids in the partial peptide corresponding to positions 391 to 585 of SEQ ID NO: 9 are replaced with arginine (SEQ ID NO: 15).
- the nucleic acid cleavage domain of the ZFN of the present disclosure may be a polypeptide that includes modified amino acids and/or unnatural amino acids.
- Modified amino acids include, but are not limited to, methylation, esterification, amidation, acetylation, alkylation, halogenation, and the like.
- the modified amino acids and unnatural amino acids can be introduced by known methods.
- the ZFPs and ZFNs disclosed herein can be produced in vitro or in vivo by methods known in the art. Examples include artificial synthesis based on amino acid sequence information, and artificial synthesis of nucleic acid encoding ZFN, insertion into an appropriate expression vector, and then introduction into an appropriate host cell to express ZFN in the cell.
- Vectors comprising a nucleic acid sequence encoding the ZFPs or ZFNs described above.
- the vector may contain elements of a conventional gene expression vector, such as a promoter (e.g., CMV promoter or human Elongation Factor alpha-1 (EF1a) promoter) and a polyA addition sequence (e.g., SV40 pA, HGH pA, rabbit globin pA).
- a promoter e.g., CMV promoter or human Elongation Factor alpha-1 (EF1a) promoter
- a polyA addition sequence e.g., SV40 pA, HGH pA, rabbit globin pA.
- the vector is not particularly limited and may be selected from vectors used in the field.
- vectors include phage vectors, plasmid vectors, viral vectors, retroviral vectors, chromosomal vectors, episomal vectors, virus-derived vectors (bacterial plasmids, bacteriophages, yeast episomes, etc.), yeast chromosomal elements, viruses (baculoviruses, papovaviruses, vaccinia viruses, adenoviruses, adeno-associated viruses, avian poxviruses, pseudorabies viruses, herpes viruses, lentiviruses, retroviruses, etc.), and vectors derived from combinations of these (cosmids, phagemids, etc.).
- plasmid vectors are preferred from the viewpoint of their versatility.
- viral vectors are preferred, and adeno-associated virus vectors (AAV vectors) are more preferred.
- AAV vectors adeno-associated virus vectors
- Genome Editing Method The present disclosure also provides a genome editing method comprising the step of introducing the above-mentioned vector into a cell in vivo or in vitro, preferably in vitro.
- Introduction of a vector into a cell can be carried out by a conventionally known method.
- the introduction method include, but are not limited to, electroporation, particle gun, microinjection, lipofection, protein transduction, etc.
- donor DNA may be introduced into the cell together with the vector.
- the donor DNA may be, for example, donor DNA encoding a normal gene.
- the donor DNA may be configured to be capable of introducing a normal gene into a gene locus by utilizing a repair mechanism such as nonhomologous end joining (NHEJ) or homologous recombination (HR) at the site of DNA double-strand break caused by ZFN.
- NHEJ nonhomologous end joining
- HR homologous recombination
- the break site is primarily repaired by NHEJ. Because NHEJ is error-prone, deletion, insertion, or substitution of at least one nucleotide, or a combination thereof, may occur during repair of the break. In this way, the locus of interest is modified at the break site.
- the cells may be from humans or non-human animals.
- Non-human animals include ungulates (e.g., cattle, wild boars, pigs, sheep, goats), perissodactyls (e.g., horses), rodents (e.g., mice, rats, hamsters, squirrels), lagomorphs (e.g., rabbits), and carnivores (e.g., dogs, cats, ferrets).
- the cells may be dividing or non-dividing cells, but in the present disclosure, non-dividing cells may be particularly preferably selected.
- non-dividing cells include photoreceptors, lymphocytes, monocytes, neutrophils, eosinophils, basophils, endothelial cells, epithelial cells, hepatocytes, bone cells, platelets, adipocytes, cardiac muscle cells, neurons, retinal cells, smooth muscle cells, skeletal muscle cells, spermatocytes, oocytes, and pancreatic ⁇ cells.
- Example 1 Verification of the effect of NLS in the insertion of foreign genes into non-dividing cells by HITI method using ZF-ND1
- the Homology-independent Targeted Integration (HITI) method is a technique for inserting a foreign gene (donor gene) into the genome of non-dividing cells with high efficiency and in a precise direction.
- HITI Homology-independent Targeted Integration
- mice rod photoreceptors non-dividing cells
- ZF-ND1 expression vector ND1 used for genomic DNA cleavage shows cleavage activity as a dimer, so two ZFPs (a pair of ZFPs) corresponding to the sense strand and antisense strand of the cleavage target sequence were designed. Specifically, a ZFP pair was designed that recognizes an 18-base sequence located upstream of the start codon of exon 1 of the mouse Rho gene. The sequence upstream of the start codon of exon 1 of the mouse Rho gene and the recognition sequence of the ZFP pair are shown in Figure 1.
- a sense strand ZFP (ZF-5057 S) having a zinc finger array that recognizes and binds to the sense strand sequence CTACGAAGAGCCCGTGGG (SEQ ID NO: 1) was linked to a DDD-type mutant of ND1 (ND1DDD, SEQ ID NO: 14) to give ZF-5057S-ND1DDD.
- the amino acid sequence of ZF-5057S-ND1DDD is shown in SEQ ID NO: 16 .
- An antisense strand ZFP (ZF-5057AS) having a zinc finger array that recognizes and binds to the antisense strand sequence ACCAAGGCTGCTTGGCGA (SEQ ID NO: 2) was linked to an RRR type mutant of ND1 (ND1RRR, SEQ ID NO: 15) to obtain ZF-5057AS-ND1RRR.
- the amino acid sequence of ZF-5057AS-ND1RRR is shown in SEQ ID NO: 17.
- a peptide linker (sequence Thr-Gly-Gly-Ser: SEQ ID NO: 13) was used to link ND1 and ZFP.
- the nucleic acid sequences encoding ZF-5057AS-ND1RRR and ZF-5057S-ND1DDD were each inserted into a plasmid vector to prepare expression vectors pRho2k-ZF-ND1DDD and pRho2k-ZF-ND1RRR.
- the promoter used was the bovine Rho promoter (2174 bp), and the polyA addition sequence was rabbit beta-globin polyA.
- the structure of the expression vector is shown in Figure 2.
- Each expression vector had one of the following three nuclear localization signal sequences inserted at the N-terminus of ZF.
- SV40 NLS 1 sequence (1xSV40NLS): PKKKRKV (SEQ ID NO:3)
- B) SV40 NLS 3 sequence (3xSV40NLS): PKKKRKV AAA PKKKRKV GSG PKKKRKV (SEQ ID NO: 4)
- the donor gene was prepared by adding a nucleic acid sequence encoding the fluorescent protein GFP to the cDNA of mouse Rho gene.
- a construct in which a chimeric intron sequence, mouse rhodopsin cDNA (Rho cDNA), an autolytic peptide sequence (Furin+Spacer+P2A), AcGFP, and a 3'UTR sequence derived from the mouse Rho locus were linked in that order was introduced into the pLeaklessIII plasmid, and a sequence in which the ZF recognition sequence was reversed (ZF-ND1 target) was inserted into both ends of this construct.
- the resulting gene cassette was named mRho-ZF-HITI-Donor (see Figure 3).
- 0.3-0.4 ⁇ L of vector solution adjusted to a concentration of 5-7ug/ ⁇ L was injected subretinally into mice immediately after birth (P0-2).
- the head was clamped with tweezers (Nepagene CUY650-7) with the retina side as the anode, and an electric pulse was applied to transfer the gene.
- the mixing ratio of the vector solution was as follows in percentage. pRho2k-ZF-ND1DDD 15% pRho2k-ZF-ND1RRR 15% mRho-ZF-HITI-Donor 60% pCAG-mCherry 10%
- Rho promoters of pRho2k-ZF-ND1DDD and pRho2k-ZF-ND1RRR are activated from P7 to P10 onwards after rod photoreceptor differentiation, so ZF-ND1DDD and ZF-ND1RRR begin to be expressed in rod photoreceptors after differentiation (i.e., after cell division stops).
- Eyeballs were harvested on P21, when retinal cell differentiation was almost complete.
- the outer sclera was peeled off and removed, and the remaining tissue (eyecup) was fixed in 4% paraformaldehyde solution (Nacalai), and fluorescent images of GFP and mCherry were photographed under a fluorescent stereo microscope. Tissue sections were also prepared and subjected to fluorescent immunostaining with anti-GFP antibodies.
- the upper panel of Figure 4 shows fluorescent images of the eyecup when pRho2k-ZF-ND1DDD and pRho2k-ZF-ND1RRR, into which three types of nuclear localization signal sequences (1xSV40NLS, 3xSV40NLS, and 3xMultiNLS) were inserted, respectively (green indicates AcGFP fluorescence, and red indicates mCherry fluorescence).
- the construct with one NLS sequence introduced (1xSV40NLS) barely showed any green fluorescence, and it was at the same level as the negative control group (No ZF) without the ZF-ND1 vector introduced.
- the constructs with three NLS sequences introduced showed an increase in green fluorescence in the order 3xSV40NLS, 3xMulti40NLS.
- the lower panel of Figure 4 shows fluorescent staining images using an anti-GFP antibody when pRho2k-ZF-ND1DDD and pRho2k-ZF-ND1RRR, into which three types of nuclear localization signal sequences (1xSV40NLS, 3xSV40NLS, and 3xMultiNLS) were inserted, were used.
- AcGFP-positive cells were found only in the outer nuclear layer (ONL) where photoreceptors are located, and mCherry-positive cells were found in the inner nuclear layer (INL) where horizontal cells, bipolar cells, and amacrine cells are located, confirming that the knock-in of the mRho-ZF-HITI-Donor cassette occurred exclusively in photoreceptors.
- the number of AcGFP-positive photoreceptors increased in the following order: 1xSV40NLS, 3xSV40NLS, 3xMulti40NLS.
- SEQ ID NO: 1 Recognition sequence of ZF-5057S
- SEQ ID NO: 2 Recognition sequence of ZF-5057AS
- SEQ ID NO: 3 Amino acid sequence of SV40 NLS 1 sequence (1xSV40NLS)
- SEQ ID NO: 4 Amino acid sequence of SV40 NLS 3 sequence (3xSV40NLS)
- SEQ ID NO: 5 Amino acid sequence of sequence (3xMultiNLS) in which SV40 NLS, c-Myc NLS, and SV40 NLS are arranged in this order
- SEQ ID NO: 6 Amino acid sequence of SV40 T antigen NLS
- SEQ ID NO: 7 Amino acid sequence of c-myc NLS
- SEQ ID NO: 8 Nucleoplasmin
- SEQ ID NO:9 Amino acid sequence of full-length protein containing ND1 (derived from Bacillus SGD-V-76)
- SEQ ID NO:10 Nucleotide sequence of full-length protein containing ND1 (derived from
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Wood Science & Technology (AREA)
- Molecular Biology (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Organic Chemistry (AREA)
- Zoology (AREA)
- Genetics & Genomics (AREA)
- Medicinal Chemistry (AREA)
- Microbiology (AREA)
- Biotechnology (AREA)
- Biochemistry (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Peptides Or Proteins (AREA)
Abstract
Description
[1] N末端に3以上の核移行シグナル(NLS)を有する、ジンクフィンガータンパク質(ZFP)。
[2] NLSがSV40 T抗原NLS及び/又はc-myc NLSである、[1]のZFP。
[3] 交互に配列した、SV40 T抗原NLS及びc-myc NLSを有する[2]のZFP。
[4] SV40 T抗原NLSを2つ、c-myc NLSを1つ有する、[3]のZFP。
[7] 核酸切断ドメインが、ND1である、[6]のZFN。
[8] 核酸切断ドメインが、
配列番号9の391~585位のアミノ酸配列、
配列番号14のアミノ酸配列、又は、
配列番号15のアミノ酸配列、
を含んでなる、[7]のZFN。
[11] in vitro方法である、[10]のゲノム編集方法。
[12] 前記細胞が、非分裂細胞である、[10]又は[11]のゲノム編集方法。
[13] 前記非分裂細胞が、視細胞である、[12]の方法。
本開示に係るZFPは、核酸結合ドメインを含んでなり、核酸結合ドメインのN末端に3以上の核移行シグナル(NLS)を有することを特徴とする。本開示に係るZFPは、N末端に3以上のNLSを有することにより、エフェクタードメインと結合されて向上されたゲノム編集効率を示し得る。ゲノム編集効率の向上は、特に非分裂細胞において奏され得る。
本開示に係るZFPが有するNLSには、SV40 T抗原NLS(PKKKRKV:配列番号6)、c-myc NLS(PAAKRVKLD:配列番号7)、Nucleoplasmin NLS(KRXXXXXXXXXXKKKLD:配列番号8。Xは任意のアミノ酸を示す)及びこれらの配列から誘導されるアミノ酸配列を有するNLS等の従来公知のNLSを特に限定されずに用いることができる。
NLSは、SV40 T抗原NLS又はc-myc NLSであることが好ましく、SV40 T抗原NLS及びc-myc NLSであることがより好ましい。
NLSがSV40 T抗原NLS及びc-myc NLSである場合、それらは交互に配列していてよく、特には「SV40 T抗原NLS、c-myc NLS、SV40 T抗原NLS」の順に3つのNLSが配列していてよい。
本開示に係るZFPが結合されるエフェクタードメインは、特に限定されないが、例えば、核酸切断ドメインであってよい。他のエフェクタードメインとしては、Cytosine base editor (UGI, APOBEC), Adenine base editor (TadA), transcriptional activator (VP16)/repressor (SID), epigenomic editor (DNMT3A, TET1), imaging protein (Dye, fluorescent protein)、transposase (PiggyBac)、recombinase (Flippase)等が挙げられる。
エフェクタードメインは、単独で機能するもの(モノマー型)であっても、多量体により機能するもの(スプリット型)であってもよい。
る。核酸切断ドメインは、ND1とされることが好ましい。
、1個、2個、3個、4個または5個である。
本開示は、上述のZFP又はZFNをコードする核酸配列を含むベクターをも提供する。
ベクターは、ZFP又はZFNをコードする核酸配列に加えて、従来の遺伝子発現ベクターが備える要素を含んでいてもよい。このような要素として、例えばプロモーター(CMVプロモーターやヒトEF1a(Elongation Factor alpha-1)プロモーター等)、polyA付加配列(SV40 pA, HGH pA、ウサギグロビン pA等)が挙げられる。
本開示は、上述のベクターをin vivo又はin vitroで、好ましくはin vitroで、細胞に導入する手順を含むゲノム編集方法をも提供する。
HITI(Homology-independent Targeted Integration)法は、非分裂細胞において、外来遺伝子(ドナー遺伝子)を高効率にかつ正確な方向でゲノムに挿入する技術である。本実施例ではゲノム編集因子にZF-ND1を用いたHITI法におけるNLSの有効性を検討した。
ゲノムDNA切断に用いるND1は2量体で切断活性を示すため、切断標的となる配列に対してセンス鎖とアンチセンス鎖に対応する2つのZFP(ペアのZFP)を設計した。具体的には、マウスRho遺伝子のエキソン1開始コドンより上流に位置する18塩基の配列をそれぞれ認識するZFPペアを設計した。マウスRho遺伝子のエキソン1開始コドン上流の配列と、ZFPペアの認識配列を図1に示す。ND1のDDD型変異体(ND1DDD、配列番号14)に、センス鎖の配列CTACGAAGAGCCCGTGGG(配列番号1)を認識して結合するジンクフィンガーアレイを有するセンス鎖ZFP(ZF-5057 S)を連結し、ZF-5057S-ND1DDDとした。ZF-5057S-ND1DDDのアミノ酸配列を配列番号16に示す。ND1のRRR型変異体(ND1RRR、配列番号15)に、アンチセンス鎖の配列ACCAAGGCT GCTTGGCGA(配列番号2)を認識して結合するジンクフィンガーアレイを有するアンチセ ンス鎖ZFP(ZF-5057AS)を連結し、ZF-5057AS-ND1RRRとした。ZF-5057AS-ND1RRRのアミノ酸配列を配列番号17に示す。ND1とZFPとの間の連結にはペプチドリンカー(配列Thr-Gl y-Gly-Ser:配列番号13)を用いた。
プロモーターにはウシ由来のRhoプロモーター(2174bp)を用い、polyA付加配列にはウサギbeta-globin polyAを用いた。発現ベクターの構成を図2に示す。各発現ベクターには、ZFのN末端に以下の3種類のいずれかの核移行シグナル配列を挿入した。
A)SV40 NLS 1配列(1xSV40NLS):PKKKRKV(配列番号3)
B)SV40 NLS 3配列(3xSV40NLS):PKKKRKV AAA PKKKRKV GSG PKKKRKV(配列番号4)
C)SV40 NLS, c-Myc NLS, SV40 NLSの順に並べた配列(3xMultiNLS):PKKKRKV AAA PAA KRVKLD GSG PKKKRKV(配列番号5)
(下線アミノ酸配列がNLS配列、AAA及びGSGはリンカー配列を示す)
ドナー遺伝子には、マウスRho遺伝子のcDNAに蛍光タンパク質GFPをコードする核酸配列を付加したものとした。キメライントロン配列、マウスロドプシンcDNA(Rho cDNA)、自己消化ペプチド配列(Furin+Spacer+P2A)、AcGFP、及びマウスRho遺伝子座由来の3'UTR 配列を順に連結したコンストラクトをpLeaklessIIIプラスミドに導入し、さらにこのコンストラクトの両端にZFの認識配列を逆転させた配列(ZF-ND1 target)を挿入した。得られた遺伝子カセットをmRho-ZF-HITI-Donorと命名した(図3参照)。
CAGプロモーターの制御下でmCherry赤色蛍光蛋白質を発現させるプラスミドを作製した。
pRho2k-ZF-ND1DDD 15%
pRho2k-ZF-ND1RRR 15%
mRho-ZF-HITI-Donor 60%
pCAG-mCherry 10%
のP7~10以降から活性化するため、ZF-ND1DDD, ZF-ND1RRRは分化後(すなわち細胞分裂停止後)の杆体視細胞で発現が開始される。網膜の細胞分化が概ね完了したP21に眼球を回収した。外側の強膜部分を剥がして除去し、残存組織(eyecup)を4%パラホルムアルデヒ ド溶液(Nacalai)で固定し、蛍光実態顕微鏡でGFPとmCherryの蛍光像を撮影した。また、組織切片を作製して、抗GFP抗体で蛍光免疫染色を行った。
NLSを1配列導入したコンストラクト(1xSV40NLS)では緑色蛍光をほとんど認めず、ZF-ND1ベクターを導入しないネガティブコントロール群(No ZF)と同程度であった。NLSを3配列導入したコンストラクトでは、3xSV40NLS、3xMulti40NLSの順で緑色蛍光の増加を認めた。
AcGFP陽性細胞は視細胞が局在する網膜外顆粒層(ONL)のみに認められ、mCherry陽性細胞は水平細胞、双極細胞及びアマクリン細胞が局在する網膜内顆粒層(INL)にも認められることから、mRho-ZF-HITI-Donorカセットのノックインは視細胞限定的に起きていることが確認できる。AcGFP陽性視細胞は、1xSV40NLS, 3xSV40NLS, 3xMulti40NLSの順で増加を認めた。
配列番号2:ZF-5057ASの認識配列
配列番号3:SV40 NLS 1配列(1xSV40NLS)のアミノ酸配列
配列番号4:SV40 NLS 3配列(3xSV40NLS)のアミノ酸配列
配列番号5:SV40 NLS, c-Myc NLS, SV40 NLSの順に並べた配列(3xMultiNLS)のアミノ酸配列
配列番号6:SV40 T抗原NLSのアミノ酸配列
配列番号7:c-myc NLSのアミノ酸配列
配列番号8:Nucleoplasmin NLSのアミノ酸配列
配列番号9:ND1を含む全長タンパク質(バチルス属SGD-V-76由来)のアミノ酸配列
配列番号10:ND1を含む全長タンパク質(バチルス属SGD-V-76由来)のヌクレオチド配列
配列番号11:ND2を含む全長タンパク質(ボツリヌス菌由来)のアミノ酸配列
配列番号12:ND2を含む全長タンパク質(ボツリヌス菌由来)のアミノ酸配列のヌクレオチド配列
配列番号13:ペプチドリンカーのアミノ酸配列
配列番号14:ND1DDDのアミノ酸配列
配列番号15:ND1RRRのアミノ酸配列
配列番号16:ZF-5057S-ND1DDDのアミノ酸配列
配列番号17:ZF-5057AS-ND1RRRのアミノ酸配列
Claims (11)
- N末端に3以上の核移行シグナル(NLS)を有する、ジンクフィンガータンパク質(ZFP)。
- NLSがSV40 T抗原NLS及び/又はc-myc NLSである、請求項1に記載のZFP。
- 交互に配列した、SV40 T抗原NLS及びc-myc NLSを有する、請求項2に記載のZFP。
- SV40 T抗原NLSを2つ、c-myc NLSを1つ有する、請求項3に記載のZFP。
- 請求項1-4のいずれか一項に記載のZFPをコードする核酸配列を含むベクター。
- 請求項1-4のいずれか一項に記載のZFPと核酸切断ドメインとからなるジンクフィンガーヌクレアーゼ(ZFN)。
- 核酸切断ドメインが、ND1である、請求項6に記載のZFN。
- 請求項6に記載のZFNをコードする核酸配列を含むベクター。
- 請求項8に記載のベクターを細胞に導入する手順を含む、ゲノム編集方法。
- 前記細胞が、非分裂細胞である、請求項9に記載の方法。
- 前記非分裂細胞が、視細胞である、請求項10に記載の方法。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2025527997A JPWO2024257843A1 (ja) | 2023-06-16 | 2024-06-14 | |
| EP24823456.9A EP4729547A1 (en) | 2023-06-16 | 2024-06-14 | Zinc finger protein, zinc finger nuclease, vector, and genome editing method using said substances |
| CN202480032441.1A CN121127501A (zh) | 2023-06-16 | 2024-06-14 | 锌指蛋白、锌指核酸酶、载体和应用它们的基因组编辑方法 |
| AU2024302819A AU2024302819A1 (en) | 2023-06-16 | 2024-06-14 | Zinc finger protein, zinc finger nuclease, vector, and genome editing method using said substances |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023098848 | 2023-06-16 | ||
| JP2023-098848 | 2023-06-16 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2024257843A1 true WO2024257843A1 (ja) | 2024-12-19 |
Family
ID=93852226
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2024/021599 Ceased WO2024257843A1 (ja) | 2023-06-16 | 2024-06-14 | ジンクフィンガータンパク質、ジンクフィンガーヌクレアーゼ、ベクター並びにこれらを用いたゲノム編集方法 |
Country Status (5)
| Country | Link |
|---|---|
| EP (1) | EP4729547A1 (ja) |
| JP (1) | JPWO2024257843A1 (ja) |
| CN (1) | CN121127501A (ja) |
| AU (1) | AU2024302819A1 (ja) |
| WO (1) | WO2024257843A1 (ja) |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2020045281A1 (ja) | 2018-08-27 | 2020-03-05 | 国立大学法人広島大学 | 新規ヌクレアーゼドメインおよびその利用 |
| US20200224194A1 (en) * | 2017-09-20 | 2020-07-16 | Helix Nanotechnologies, Inc. | Expression systems that facilitate nucleic acid delivery and methods of use |
| JP2022534809A (ja) * | 2019-06-07 | 2022-08-03 | スクライブ・セラピューティクス・インコーポレイテッド | 操作されたcasxシステム |
| CN115716880A (zh) * | 2022-12-07 | 2023-02-28 | 云舟生物科技(广州)股份有限公司 | 一种核定位荧光蛋白及其应用 |
| WO2023049872A2 (en) * | 2021-09-23 | 2023-03-30 | Scribe Therapeutics Inc. | Self-inactivating vectors for gene editing |
-
2024
- 2024-06-14 JP JP2025527997A patent/JPWO2024257843A1/ja active Pending
- 2024-06-14 EP EP24823456.9A patent/EP4729547A1/en active Pending
- 2024-06-14 CN CN202480032441.1A patent/CN121127501A/zh active Pending
- 2024-06-14 WO PCT/JP2024/021599 patent/WO2024257843A1/ja not_active Ceased
- 2024-06-14 AU AU2024302819A patent/AU2024302819A1/en active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20200224194A1 (en) * | 2017-09-20 | 2020-07-16 | Helix Nanotechnologies, Inc. | Expression systems that facilitate nucleic acid delivery and methods of use |
| WO2020045281A1 (ja) | 2018-08-27 | 2020-03-05 | 国立大学法人広島大学 | 新規ヌクレアーゼドメインおよびその利用 |
| JP2022534809A (ja) * | 2019-06-07 | 2022-08-03 | スクライブ・セラピューティクス・インコーポレイテッド | 操作されたcasxシステム |
| WO2023049872A2 (en) * | 2021-09-23 | 2023-03-30 | Scribe Therapeutics Inc. | Self-inactivating vectors for gene editing |
| CN115716880A (zh) * | 2022-12-07 | 2023-02-28 | 云舟生物科技(广州)股份有限公司 | 一种核定位荧光蛋白及其应用 |
Non-Patent Citations (4)
| Title |
|---|
| JIA LIU ET AL.: "Improved Cell-Penetrating Zinc-Finger Nuclease Proteins forPrecision Genome Engineering Molecular Therapy", NUCLEIC ACIDS, vol. 4, 2015, pages e232 |
| KEIICHIRO SUZUKI ET AL.: "In vivo genome editing via CRISPR/Cas9 mediated homology-independent targeted integration", NATURE, vol. 540, 2016, pages 144 - 149 |
| LID, JIA ET AL.: "Improved Cell -Penetrating Zinc-Finger Nuclease Proteins for Precision Genome Engineering", MOLECULAR THERAPY-NUCLEIC ACIDS, vol. 4, 2015, pages e232, XP055894163, DOI: 10.1038/mtna.2015.6 * |
| WRIGHT ET AL.: "Standardized reagents and protocols for engineering zinc-finger nucleases by modular assembly", NATURE PROTOCOLS, vol. 1, no. 3, 2006, pages 1637 - 52 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN121127501A (zh) | 2025-12-12 |
| EP4729547A1 (en) | 2026-04-22 |
| AU2024302819A1 (en) | 2026-01-22 |
| JPWO2024257843A1 (ja) | 2024-12-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12612625B2 (en) | Compositions for genome editing | |
| US20250235556A1 (en) | Gene therapy for autosomal dominant diseases | |
| JP6788082B2 (ja) | ヌクレアーゼ媒介性標的化組み込みのための方法および組成物 | |
| CN113151215B (zh) | 工程化的Cas12i核酸酶及其效应蛋白以及用途 | |
| US11274288B2 (en) | Compositions and methods for promoting homology directed repair mediated gene editing | |
| KR102636351B1 (ko) | 고활성 조절 요소 | |
| US20200340012A1 (en) | Crispr-cas genome engineering via a modular aav delivery system | |
| KR20200132849A (ko) | CRISPR/Cas 시스템을 사용한 동물에서의 전사 조절 | |
| CA3106738A1 (en) | Method for modulating rna splicing by inducing base mutation at splice site or base substitution in polypyrimidine region | |
| KR20090031938A (ko) | 방향성 진화로 촉매 작용을 최적화시킨 키메라 징크 핑거 리컴비나제 | |
| CN112543808A (zh) | 增强的hAT家族转座子介导的基因转移及相关组合物、系统和方法 | |
| JP2022523166A (ja) | 挿入部位選択特性が向上したトランスポザーゼ | |
| JP2025501473A (ja) | エンジニアリングされたCas12bエフェクタータンパク質及びその使用方法 | |
| CN113874510A (zh) | 包括具有β滑移突变的人源化TTR基因座的非人动物和使用方法 | |
| WO2020187268A1 (zh) | 一种增强基因编辑的融合蛋白及其应用 | |
| WO2024240138A1 (zh) | 基于perv逆转录酶的先导编辑系统 | |
| EP3749754A1 (en) | Methods for screening variant of target gene | |
| CN119256086A (zh) | 工程化基因效应因子、组合物及其使用方法 | |
| WO2023138617A1 (zh) | 工程化的CasX核酸酶、效应蛋白及其用途 | |
| WO2024257843A1 (ja) | ジンクフィンガータンパク質、ジンクフィンガーヌクレアーゼ、ベクター並びにこれらを用いたゲノム編集方法 | |
| CN114144203A (zh) | 源于显性变异基因的疾患的治疗剂 | |
| WO2021061946A2 (en) | A promoter specific for non-pigmented ciliary epithelial cells | |
| RU2833486C1 (ru) | Стратегии crispr и aav для терапии х-сцепленного ювенильного ретиношизиса | |
| WO2024257844A1 (ja) | ジンクフィンガーヌクレアーゼ、ベクター並びにこれらを用いたゲノム編集方法及び視細胞製造方法 | |
| RU2784927C1 (ru) | Отличные от человека животные, включающие в себя гуманизированный ttr локус, и способы применения |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 24823456 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2025527997 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2025527997 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: AU2024302819 Country of ref document: AU |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2024823456 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2024302819 Country of ref document: AU Date of ref document: 20240614 Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 2024823456 Country of ref document: EP Effective date: 20260116 |
|
| ENP | Entry into the national phase |
Ref document number: 2024823456 Country of ref document: EP Effective date: 20260116 |
|
| ENP | Entry into the national phase |
Ref document number: 2024823456 Country of ref document: EP Effective date: 20260116 |
|
| WWP | Wipo information: published in national office |
Ref document number: 2024823456 Country of ref document: EP |