WO2024260628A1 - Procédé et dispositif de codage et décodage de séquences d'images - Google Patents
Procédé et dispositif de codage et décodage de séquences d'images Download PDFInfo
- Publication number
- WO2024260628A1 WO2024260628A1 PCT/EP2024/062652 EP2024062652W WO2024260628A1 WO 2024260628 A1 WO2024260628 A1 WO 2024260628A1 EP 2024062652 W EP2024062652 W EP 2024062652W WO 2024260628 A1 WO2024260628 A1 WO 2024260628A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- current
- maps
- map
- characteristic
- image
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T9/00—Image coding
- G06T9/002—Image coding using neural networks
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/80—Details of filtering operations specially adapted for video compression, e.g. for pixel interpolation
- H04N19/82—Details of filtering operations specially adapted for video compression, e.g. for pixel interpolation involving filtering within a prediction loop
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/117—Filters, e.g. for pre-processing or post-processing
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/132—Sampling, masking or truncation of coding units, e.g. adaptive resampling, frame skipping, frame interpolation or high-frequency transform coefficient masking
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/189—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the adaptation method, adaptation tool or adaptation type used for the adaptive coding
- H04N19/192—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the adaptation method, adaptation tool or adaptation type used for the adaptive coding the adaptation method, adaptation tool or adaptation type being iterative or recursive
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/30—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using hierarchical techniques, e.g. scalability
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/90—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using coding techniques not provided for in groups H04N19/10-H04N19/85, e.g. fractals
- H04N19/91—Entropy coding, e.g. variable length coding [VLC] or arithmetic coding
Definitions
- the invention relates to the general field of coding digital image sequences. It relates more particularly to the compression of digital videos.
- Digital videos are generally subject to source encoding aimed at compressing them in order to limit the resources required for their transmission and/or storage.
- encoding standards such as the ITU/MPEG standards (H.264/AVC, H.265/HEVC, H.266/VVC, etc.) as well as their extensions (MVC, SVC, 3D-HEVC, etc.).
- Encoding an image is generally performed by dividing the image into several rectangular blocks, and encoding these blocks of pixels according to a given processing sequence.
- the processing of a block typically includes a prediction of the pixels of the block performed using previously coded and then decoded pixels present in the image being encoded, in which case we speak of “Intra prediction”, or previously coded images, in which case we speak of “Inter prediction”.
- This exploitation of spatial and/or temporal redundancies makes it possible to avoid transmitting or storing the value of the pixels of each block of pixels, by representing at least some of the blocks by a residual representing a difference between the prediction values of the pixels of the block and the actual values of the pixels of the predicted block.
- Autoencoders are learning algorithms based on artificial neural networks, which allow to construct a new representation of a data set.
- the architecture of an autoencoder is made up of two parts: the encoder and the decoder.
- the encoder is made up of a set of layers of neurons, which process the data in order to construct new representations called “encoded”, also called “latent representations”.
- the layers of neurons of the decoder receive these representations and filter them in order to try to reconstruct the initial data.
- the differences between the reconstructed data and the initial data make it possible to measure the error made by the autoencoder.
- Training consists of modifying the parameters of the autoencoder in order to reduce the reconstruction error measured on the different samples of the data set.
- the invention relates to a method for coding a plurality of images of an image sequence comprising the following steps for at least one current image to be coded: - a construction stage, comprising the following sub-stages: - construction of a set of current feature maps, representative of said at least one current image, comprising at least one current feature map; - construction of a set of reference feature maps, comprising at least one coded and then decoded reference feature map; - for at least one sample, called current sample, of said at least one current image, associated with a position in the current image: - construction of a characteristic vector from said at least one reference characteristic map and said at least one current characteristic map, as a function of said position of said current sample; - processing of said characteristic vector by an artificial neural network, called a synthetic neural network, defined by a set of parameters, to provide a vector representative of a decoded value of the current sample; - updating at least one value of said at least one current feature map and/or at least one parameter of said network, based on
- the invention also relates to a method for decoding a sequence of images of a binary stream, comprising the following steps for at least one current image to be decoded: - decoding of a set of parameters representative of a synthetic neural network; - decoding a set of current feature maps comprising at least one current feature map representative of said at least one current image; - obtaining a set of reference feature maps, comprising at least one decoded reference feature map; - for at least one sample, called current sample, of said at least one current image to be decoded, associated with a position in the image: - construction of a characteristic vector from said at least one reference characteristic map and said at least one current characteristic map, as a function of said position of said current sample, and: - processing said vector by said synthesis neural network to provide a vector representative of a decoded value of said at least one current sample.
- encoding means the operation which consists in representing a set of samples, or pixels, in a compact form carried for example by a digital bitstream.
- Decoding means the operation which consists in processing a digital bitstream to restore decoded samples.
- sequence of images is meant a plurality of ordered two-dimensional images, for example temporally in the case of a video.
- the sequence corresponds to a scene.
- the sequence corresponds to a set of predefined images, for example a fixed number, or, within the meaning of the MPEG standards, a GOP (Group Of Pictures) comprising the images located between two images of the Intra-image type, also called "intra period”.
- the images can be views of the same scene represented in multi-views.
- the images can be a plurality of temporal and multi-view images (immersive video).
- At least one current image we mean a subsequence of at least one image of the sequence.
- sample is a value taken from an image in the sequence. Sampling a signal produces a series of discrete values called samples.
- the sample is called a pixel, which can be, for example, a color pixel traditionally represented by a triplet of values, for example (R,G,B) or (Y,U,V).
- the position of the sample is identified by its abscissa (x) and ordinate (y) coordinates in the image.
- feature map is meant a part of an abstract representation of an image, comprising a plurality of variable scalar data, also called characteristic values, for example real numbers, or integers, signed or unsigned.
- the abstract representation of an image can therefore comprise several feature maps.
- the abstract representation of an image can also correspond to a single feature map comprising a set of values associated with a position.
- a current feature map concerns only the current subsequence.
- feature vector constructed from feature maps as a function of a position is meant a vector consisting of one or more elements, or data, preferably discrete, the data being constructed from the feature maps at a position determined by that of the samples being processed in the images.
- This feature vector is the one that is applied to the input of the synthesis neural network.
- a vector can be constituted for example from a plurality of values taken from each of the feature maps at the same abscissa and ordinate coordinates as the subsequence of samples to be coded (resp. to be decoded).
- neural network is meant a neural network such as a convolutional neural network, a multilayer perceptron, an LSTM (for "Long Short Term Memory”), etc.
- neural network parameter we mean one of the values that characterizes the neural network, for example a weight associated with one of the neurons (filter coefficient, weighting, bias, value affecting the operation of non-linearity, etc.)
- processing by a synthetic neural network is meant the application of a function expressed by a neural network to the input characteristic vector to produce an output vector representative of the subsequence of samples to be encoded (resp. decoded).
- This output vector may include one or more data representative of the subsequence of samples.
- performance measurement is meant a measurement between at least one value of a sample to be encoded and a decoded value of said sample.
- the measurement can evaluate, for example, a distortion, or a perceptual error. It can be carried out on a sample or a plurality of samples (for example, the current samples, or the current images, etc.).
- the measurement can also include a measurement of the flow rate, in particular associated with the coding of the neural network and/or the coding of the feature maps.
- the measurement can be a joint measurement between the flow rate and the distortion through their weighting. As is well known in the state of the art, the value of this measurement is generally minimized until a target value is reached.
- construction step is meant a step that aims to construct the representative parameters of the image, before their actual encoding.
- the construction sub-steps can be repeated as many times as necessary to obtain an acceptable performance measure.
- the steps of a coding or decoding method should not be interpreted as being linked to a notion of temporal succession. In other words, the steps may be carried out in a different order from that indicated in the independent coding or decoding claim, or even in parallel.
- the coding method constructs the coding parameters, from a sequence of input images, by training a neural network on characteristic vectors associated with a position of a sample to be coded in one of the input images of a sub-sequence of images being processed.
- the sub-sequence comprises at least one image.
- These characteristic vectors are constructed from characteristic maps of the image itself, and reference characteristic maps of the sequence, representative of the images of the sequence.
- the characteristic maps may be at the resolution of the input images, or at a lower resolution.
- the parameters of the neural network and the values of the characteristic maps are updated according to a performance measurement, for example of the rate-distortion type.
- the effective coding of the parameters of the neural network and the values of the current feature maps can be performed and stored or transmitted to the decoder.
- the reference maps are stabilized and can be encoded and stored or transmitted to the decoder.
- the training process makes it possible to refine the parameters of the synthesis neural network and/or the values of the feature maps until an adequate representation in terms of performance is obtained, for example a desired balance between the generated flow rate and the distortion undergone by the image or the subsequence of input images being encoded.
- the training of the values of the feature maps and the parameters of the synthesis neural network can be joint.
- the coding method according to the invention makes it possible to efficiently compress the signal.
- the decoding method is simple since it suffices to decode the feature maps of the current image subsequence, the reference feature maps and the synthesis neural network to reconstruct a decoded version of the current subsequence.
- the current maps dynamically capture the local characteristics of the current subsequence, since they are encoded (resp. decoded) as the sequence is processed.
- the reference maps encoded (resp. decoded) only once for the sequence, capture the global characteristics of the sequence. We can thus benefit from both types of characteristics.
- the current maps are used to generate the current image, and we can therefore design a transmission system that works image by image with low latency, each current image being decoded upon receipt of the associated current maps.
- Such a synthetic neural network can advantageously be of very simple structure with few parameters.
- decoding can be done by sequence of samples, in a progressive manner.
- the coding method comprises a step of constructing and coding a group of reference characteristic maps representative of the sequence comprising said set of reference characteristic maps.
- the decoding method further includes: - a step of decoding a group of reference characteristic maps representative of the sequence and - obtaining said set of reference feature maps from said group.
- the group of reference maps is constructed and encoded by the encoder, and decoded by the decoder for the entire sequence. Then for each sub-sequence being processed, a part of the group of reference maps is considered to constitute the reference set used for the sub-sequence. It is thus possible to simplify the decoding by keeping a limited number of reference maps.
- the set is smaller than the group. According to one embodiment, the set is equal to the group.
- the method comprises a step of transforming said set of current and/or reference feature maps to obtain a set of feature maps transformed to the resolution of the input image, the method being characterized in that said feature vector is constructed from said transformed feature maps.
- the feature maps are divided into two sets, one of which is reserved for the extraction of feature vectors and the other for coding. It is thus possible to dissociate the two processes whose purpose is different: the maps of the first group, to be coded (resp. decoded), must be compressed as efficiently as possible, while the maps of the second group, or transformed maps, must be able to facilitate the process of extracting and constructing the feature vector.
- At least one of the current and/or reference feature maps has a lower resolution than the sub-sequence to be coded (resp. decoded) and the transformation operation includes oversampling.
- the compression of the feature maps is more efficient since at least one of the current and/or reference feature maps to be coded (resp. decoded) includes fewer values than if it were at the resolution of the signal.
- one of the current and/or reference feature maps may be at 1/2 resolution, i.e. it includes twice as many values on the abscissa and ordinate as the input image has samples, i.e.
- the transformed feature map which corresponds to a transformation of this current and/or reference map, has the same resolution as the image.
- the transformation therefore includes in this case at least one oversampling operation to obtain the same number of values in this transformed map as the input image (resp. to be decoded) has samples.
- At least one of said current and/or reference feature maps has a resolution identical to that of the sub-sequence to be coded (resp. decoded).
- at least one of the feature maps at the same resolution as the input signal to be coded (resp. decoded) allows significant fidelity and compliance with the details of the initial resolution of the image signal.
- the transformation retains in this case the number of values of the transformed feature map; it can be reduced to identity (no processing is performed on the values of the current map) or include a filtering operation, quantization, a Fourier transformation, etc.
- quantization is essential for the proper functioning of the system if the feature maps include, for example, floating point or real values. It is necessary to quantize them before coding them and/or providing them as input to the synthesis and/or prediction neural network. When decoding, however, inverse quantization is not necessary, depending on the embodiments.
- the construction of the characteristic vector includes a sub-step of extracting a value from a current and/or reference characteristic map at a position identical to that of the current sample in the current image to be encoded or decoded.
- a value from a characteristic map at the same position as the sample in the image is simple to implement.
- NF NFM + NFR, where NFM represents the number of current characteristic maps, and NFR the number of reference characteristic maps), of the same resolution as the image, a simple extraction of the values of the maps at the coordinates of the current sample (at the same abscissa and the same coordinate in the characteristic map) makes it possible to directly construct the characteristic vector of J elements.
- the construction of said characteristic vector comprises the following sub-steps: - extracting a plurality of values from said current and/or reference feature maps as a function of said position of said current sample; - processing of said extracted values to obtain the characteristic vector.
- the characteristic vector is extracted from the characteristic maps, which can be arbitrary, and in particular at a resolution lower than that of the image to be coded (resp. decoded), before undergoing processing.
- processing can for example correspond to a quantification of the extracted data, or to a scaling, or to a filtering, etc.
- a quantification is essential for the proper functioning of the system if the characteristic maps include for example floating point or real values. It is necessary to quantify them before coding them and/or providing them as input to the synthesis and/or prediction neural network.
- inverse quantification is not necessary, depending on the embodiments.
- the method comprises a step of constructing a group of additional feature maps and the feature vector is further constructed from said feature maps.
- these additional maps constructed identically to the encoder and the decoder, are neither stored nor transmitted at the encoder level, nor decoded at the decoder level. They thus make it possible to benefit from additional data to improve the compression without degrading the flow rate. They may for example comprise coordinates, causal data available in other maps, data concerning other images already processed by the encoder or decoder, etc.
- - Said sets of reference and current feature maps contain the same number of feature maps; advantageously according to this mode, the sequence and the different sub-sequences of images of the sequence are associated with the same number of feature maps, which can moreover be of the same structure. For example, the sequence and the sub-sequences are associated with five feature maps having a hierarchy of decreasing resolutions. This facilitates the generation and extraction of the values of the feature maps to produce the feature vector.
- said at least one reference map is at the same resolution as said at least one current map.
- the construction of the characteristic vector is facilitated since the reference map is at the same resolution as the current map, it is very simple to perform the extraction of a value at the same position or at a position close to that of the value of the current map being encoded.
- - Said at least one reference card is indicated in the bit stream.
- a simple indicator coded in the stream allows the decoder to directly access the reference card(s) to be used for decoding the current image or subsequence, for example via an indicator of the number of the reference card in the group of reference cards.
- the characteristic card(s) to be used for decoding the image or the current subsequence are predetermined.
- the reference characteristic card is the one which has the same order number as the current card in the group of characteristic cards to which they respectively belong.
- all the characteristic cards of the reference group serve as reference cards for the current card.
- the (at least one) reference map is used not only for the construction of the characteristic vector, but also for the decoding (for example entropic) of a current map.
- At least one current map is decoded according to at least one current map.
- a current map already at least partially decoded can be used to more efficiently encode the current map being processed.
- the invention also relates to a coding device and a decoding device.
- the invention also relates to a computer program on a recording medium, this program being capable of being implemented in a computer or a coding or decoding device in accordance with the invention.
- This program comprises instructions adapted to the implementation of the corresponding method.
- This program can use any programming language, and be in the form of source code, object code, or intermediate code between source code and object code, such as in a partially compiled form, or in any other desirable form.
- the invention also relates to a computer-readable information carrier or recording medium comprising computer program instructions mentioned above.
- the information or recording media may be any entity or device capable of storing the programs.
- the media may comprise a storage means, such as a ROM, for example a CD-ROM or a microelectronic circuit ROM, or a magnetic recording means, for example a floppy disk or a hard disk, a DNA sequence, or a flash memory.
- the information or recording media may be transmissible media such as an electrical or optical signal, which may be conveyed via an electrical or optical cable, by radio link, by wireless optical link or by other means.
- the program according to the invention can in particular be downloaded from an Internet-type network.
- each information or recording medium may be an integrated circuit in which the program is incorporated, the circuit being adapted to execute or to be used in the execution of a method according to the invention.
- the ENC coding device includes an INITc initialization module, responsible in particular for constructing and coding the group of reference maps of the sequence.
- An image may represent a two-dimensional image and the sequence a plurality of two-dimensional images (video sequence, stereoscopic, multiscopic components, series of medical images, etc.).
- the sequence is any succession of images, for example a GOP.
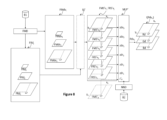
- a coding module denoted ENCv comprises a GEN module for generating current feature maps, a REF module for obtaining reference feature maps, a SE transformation module, an XTR data extraction module, an MLP synthesis module corresponding to a synthesis artificial neural network, an NNC neural network coding module capable of coding the synthesis neural network, an FMC module for coding feature maps (which can also be used by the INITc module to code the reference maps), an EVAL module for evaluating a coding performance, and an MAJ update module.
- the ENC encoding device may be implemented by means of an electronic device comprising a processor and a memory, not shown; each of the above-mentioned modules may then be realized by the cooperation of the processor and computer program instructions stored in the above-mentioned memory and designed to perform the functionalities of the module concerned, in particular as described below, when these instructions are executed by the processor.
- the ENC encoding device of the receives as input a subsequence of at least one image to be encoded, denoted I(P Vn ), comprising a plurality of samples P Vn .
- the index n indicates the pixel number in an image of N pixels.
- an image of the sequence is represented by means of at least one two-dimensional representation, such as a matrix of pixels, each pixel comprising a vector of red (R), green (G), blue (B), or, alternatively, a luminance component and at least one chrominance component.
- each pixel is defined by its abscissa and ordinate coordinates (x n and y n ) in the image.
- the sequence is a sequence of grayscale images represented by means of a two-dimensional representation, such as a pixel matrix, each pixel comprising a grayscale component, or luminance.
- the vector representing the pixel is reduced to a single component.
- a subsequence is reduced to a single image.
- the ENC encoder successively processes the current samples Pv n to be coded of the image.
- a subsequence comprises at least two successive images.
- the ENC encoder simultaneously processes the current samples Pv n to be coded of the successive images, considered as a subsequence of current samples.
- a subsequence comprises a predefined number of successive images, for example 4.
- the GEN feature map generation module is configured to generate a plurality of NFM current feature maps, denoted FMv i for the current subsequence v. These maps are called current feature maps. According to one embodiment, an optional module not shown may generate one or more additional maps, which will neither be encoded nor transmitted.
- the REF module is configured to generate a plurality of NFR reference feature maps, denoted FRv j , for the sequence v, from a group of reference feature maps, corresponding to the sequence, to the number of NFRMAX.
- NFR ⁇ NFRMAX.
- the reference feature maps considered for the current subsequence are all those of the reference group, or are selected as a subset of the reference group. In the latter case, they can be predetermined or their reference can be encoded in the stream in the form of an indicator.
- the set of current NFM maps and reference NFR maps is used by the current coding module ENCv to encode the subsequence Iv.
- the number of feature maps used is therefore NFM+NFR.
- the transformation SE module performs a transformation of the set of current and/or reference feature maps (FMv i , FRv j ) to generate a set of transformed feature maps (FMSv i , FRSv j ) at the same resolution as the input signal.
- the optional SE module can perform a quantization of the data extracted from this set of NFM+NFR feature maps, or of the feature vector formed from these data.
- the quantization of a value refers to the mapping of this value to a member of a discrete set of possible code symbols.
- the set of possible code symbols can be made up of integer values, and the quantization system performs a simple rounding of a real value to an integer value.
- the quantization consists of a multiplication by a given value and then a rounding. Then the SE module can perform a transformation of the values of at least one of the feature maps, for example an oversampling, an interpolation, a filtering, etc.
- a transformed feature map is of the same resolution as the images of the input subsequence.
- the feature maps which are coded can be of lower resolution than that of the images to be coded, while the transformed maps, which are used for the construction of the feature vectors, are at the same resolution as the sequence of images, which facilitates the extraction of the values.
- the SE module is absent, in which case the values that will be used to construct the characteristic vector are extracted from the untransformed current and reference characteristic maps.
- the XTR module performs an extraction of values in current and reference feature maps, optionally transformed, for a current sample or a subsequence of current samples Pv n to be encoded, according to its (their) coordinates in the input signal. For example, if one seeks to encode the sample or the subsequence of samples Pv n at the coordinates (x n , y n ) of an input image, the XTR module performs an extraction of values in maps at positions imposed by the coordinates (x n , y n ). In one embodiment, the extracted values constitute the feature vector Z n .
- Z n is a J-tuple, that is to say that it comprises J elements, or data z i .
- Z n comprises two sets of values: one (Zv n ) is extracted from the current feature maps of the subsequence v, and the other (Zr n ) is extracted from the reference feature maps.
- the vector Z n of index n refers to the characteristic vector of the pixel or sequence of pixels P'v n .
- J NFM + NFR.
- the XTR module performs processing of the extracted values, to generate the vector Z n .
- the XTR module can perform quantization of the data extracted from the set of feature maps.
- the processing can include other operations, such as filtering, scaling, etc.
- the SE module is not used and if the feature maps are at lower resolutions than the images of the sequence, the XTR module can take into account the coordinates of the values in the lower resolution maps.
- At least one of the SE or XTR modules must perform a quantization of the values extracted from the current feature maps of the current subsequence.
- the MLP module contains a synthesis neural network defined by K parameters W k , capable of processing the vector Z n , or J-Tuple, as input, to generate as output a vector representative of the sample or subsequence of samples Pv n to be coded of the current subsequence.
- the synthesis neural network contains according to one embodiment an MLP, or Multi Layer Perceptron, consisting of an input layer adapted to the input format (the J-tuple), optionally one or more hidden layer(s), and an output layer adapted to the output format of the output vector, generally a vector comprising NC (number of components) elements for each sample.
- NC is equal to 3 and the output vector is the triplet (R, G, B) of the pixel or pixels P'v n coded then decoded of the current subsequence.
- the MLP module contains a convolutional neural network.
- the NNC module performs the coding of the synthesis neural network of the current image or subsequence, in particular of its parameters Wv k.
- the NNC module performs a coding simulation, followed by a decoding, intended for the evaluation module. Subsequently, it performs the effective coding of the parameters of the synthesis neural network Wv k .
- the coded parameters of the current image or subsequence are denoted Wvc k .
- the coding simulation can be identical to the effective coding, or produce an approximation thereof.
- the INITc module generates and encodes the FR j maps, i.e. the values of the sequence characteristic maps.
- the reference encoded maps are denoted FRc j .
- all the (NFRMAX) maps of the sequence are constructed, then encoded and decoded so that they can be used as a reference for a subsequence to be encoded.
- the reference maps are generated dynamically as the subsequences are encoded, in the same way as the current maps.
- the encoding takes into account the neighborhood of a value to be encoded of the reference characteristic map, in the map itself and/or in another reference map.
- the FMC module When coding the subsequences, the FMC module performs the coding of the FMv i maps, i.e. the values of the feature maps of the current subsequence (excluding the transformed maps, optionally resulting from oversampling or other transformation by the SE module). During the training or construction process of the coding, i.e. as long as the performance evaluation step is not satisfactory, the FMC module performs a coding simulation, followed by decoding, intended for the evaluation module. Subsequently, it performs the actual coding of the values of the FMv i maps and according to an embodiment, as explained above, of the reference maps.
- the coded maps of the current subsequence are denoted FMcv i .
- the coding simulation can be identical to the actual coding, or produce an approximation thereof.
- the encoding module quantizes the latent representation of the card values if necessary by using a quantizer to generate an ordered collection of quantized values. Then the encoding module compresses the quantized data, for example by using an entropy encoder.
- the neighboring position is selected in the map currently being coded (for example, the neighboring value at the top left of the one currently being coded).
- this neighborhood is selected in another current map, at a neighboring position.
- the neighborhood is selected in a reference map, at a neighboring position.
- the neighborhood is selected from an encoded and decoded feature map corresponding to one or more subsequences v' of the sequence distinct from the current subsequence v, at a neighboring position, for example the previous subsequence in the sequence, or two past subsequences of the sequence, or a past and a future subsequence, to the extent that the decoding order of the sequence allows it (as is known, the decoding order may be different from the chronological order of the sequence). All these embodiments can be combined, i.e. the neighborhood can consist of values extracted from the current map, the current maps, the reference maps, and/or current maps of another subsequence.
- the FMC module may comprise for this purpose a feature map prediction neural network whose parameters may be encoded and transmitted to the decoder, which takes as input a neighborhood vector consisting of the neighborhood values and produces as output a prediction of the current value of the feature map being encoded, which may be presented, in a known manner, in the form of a prediction value or probability data.
- the EVAL module performs an evaluation and minimization of a coding performance.
- the evaluation function is for example of the rate-distortion type.
- the minimization can be carried out by a gradient descent, or any other method within the reach of a person skilled in the art.
- the MAJ module performs an update of the values of the FMv i cards to be encoded of the current subsequence, based on the results of the performance function. According to one embodiment, it also performs an update of the values of the reference cards to be encoded of the sequence, based on the results of the performance function.
- the current feature maps are stabilized, they can be encoded. In one embodiment, they are encoded using the reference maps.
- the DEC coding device comprises an initialization module INITd, responsible in particular for decoding the group of reference cards of the SV sequence, denoted FRd j .
- INITd initialization module
- all the cards (NFRMAX) of the sequence are decoded in order to be able to be used as a reference for a sub-sequence to be decoded by the DECv module.
- a current subsequence to be decoded v comprises at least one current image to be decoded denoted I(Pd Vn ), each image comprising respectively a plurality of samples.
- the decoder DECv dedicated to the subsequence receives as input the data necessary to decode the subsequence.
- the index n indicates the pixel number in an image of N pixels or a subsequence of images of N pixels.
- the decoding submodule receives as input at least: - encoded data organized into NFM feature maps FMcv i (the encoded current feature maps); - the encoded parameters Wvc k of the synthesis neural network corresponding to the current subsequence, optionally the parameters of other neural networks such as an oversampling neural network, feature map prediction, etc.;
- the DECv module obtains (for example, reads from the decoder memory) a set of reference feature maps, denoted FRdv j , from the group of reference maps FRd j.
- the decoding module DEC v comprises, for a current sub-sequence, a neural network(s) decoding module NND capable of decoding the synthesis neural network MLP', a module FMD for decoding the current feature maps (which can also be used by the module INITd to decode the reference maps), a module REF' for obtaining reference feature maps, a data extraction module XTR', a module SE' for inverse transformation, a module MLP' corresponding to a synthesis neural network, optionally a module for generating additional feature maps. According to one embodiment, it produces as an output a current decoded sub-sequence, comprising at least one image denoted I (Pdv n ), comprising a plurality of samples or sequences of decoded samples Pdv n.
- the FMD decoding module decompresses the quantized data, for example by using an entropy coder. According to one embodiment, it implements a decoding taking into account the neighborhood of a value to be decoded from the feature map. The embodiments proposed for the coder apply here by replacing the coding with a decoding of the values.
- the neighborhood can be selected from a current map (including the one currently being decoded), a reference map, or a current map of a sequence distinct from the current subsequence.
- the FMD module can comprise for this purpose a feature map prediction neural network, as described for the FMC module.
- the maps decoded by the FMD module, numbering NFM, are denoted FMdv i (cards of current image characteristics).
- the parameters of the synthetic neural network (MLP') decoded by the NND module are denoted Wdv k .
- the REF' module is identical to that of the encoder and the same examples apply.
- the reference feature maps considered for the current subsequence are all those of the reference group, or are selected as a subset of the reference group. In the latter case, they can be predetermined or their reference can be decoded in the stream in the form of an indicator.
- the set of current NFM maps and reference NFR maps is used by the current decoding module to decode the current subsequence v.
- the number of feature maps used is therefore NFM+NFR.
- the decoder can also generate one or more additional maps, identical to the additional maps generated by the encoder for the current subsequence.
- the transformation module SE' performs a transformation of the set of current and/or reference feature maps (FMdv i , FRdv j ) to generate a set of transformed feature maps (FMS'v i , FRS'v j ) at the same resolution as the input signal.
- the SE' module is identical to the SE module of the .
- the optional SE' module can perform an inverse quantization of the data extracted from this set of NFM+NFR feature maps. Then the SE' module can perform a transformation of the values of at least one of the feature maps, for example an oversampling, an interpolation, a filtering, etc.
- a transformed feature map is of the same resolution as the images of the sub-sequence to be decoded.
- the feature maps which are decoded can be of lower resolution than that of the images to be decoded, while the transformed maps, which are used for the construction of the feature vectors, are at the same resolution as the sequence of images, which facilitates the extraction of the values.
- the SE' module is absent, in which case the values which will be used to construct the characteristic vector are extracted from the untransformed current and reference characteristic maps.
- the XTR' module is identical to the XTR module of the . It performs an extraction of values in current and reference feature maps, for a current sample or a subsequence of current samples Pdv n to be decoded, according to its (their) coordinates in the input signal. For example, if one seeks to decode the sample or the subsequence of samples Pv n at the coordinates (x n , y n ) of an input image, the XTR' module performs an extraction of values in maps at positions imposed by the coordinates (x n , y n ). In one embodiment, the extracted values constitute the feature vector Zd n .
- Zd n comprises two sets of values: one (Zdv n ) is extracted from the current feature maps of the subsequence v, and the other (Zdr n ) is extracted from the reference feature maps.
- Zd n is a J-tuple, that is to say that it comprises J elements, or data zd i .
- the XTR' module performs processing of the extracted values, to generate the vector Zd n .
- the XTR' module can perform inverse quantization of the data extracted from the set of feature maps.
- the processing can include other operations, such as filtering, scaling, etc.
- the SE' module is not used and if the feature maps are at lower resolutions than the images of the sequence, the XTR' module can take into account the coordinates of the values in the lower resolution maps.
- At least one of the SE' or XTR' modules must perform an inverse quantization of the values extracted from the current feature maps of the current subsequence, if a quantization has been performed at the encoder.
- the MLP' module contains a so-called synthesis neural network, defined by K parameters Wd k , capable of processing the vector Zd n , or J-Uplet, as input, to generate as output a vector representative of the sample or subsequence of samples Pdv n to be decoded.
- the synthesis neural network contains, according to one embodiment, an MLP, or Multi Layer Perceptron, consisting of an input layer adapted to the input format (the J-uplet), optionally one or more hidden layer(s), and an output layer adapted to the output format of the output vector, generally a vector comprising NC (number of components) elements for each sample. It can also comprise a convolution neural network.
- K 3 and the output vector is the triplet (R, G, B) or (Y, U, V) of each decoded pixel Pd vn .
- the MLP' module is identical in structure to the MLP module, and its parameters are either identical if the coding of its parameters W k is lossless, or different if the coding is done with losses.
- the DEC decoding device can be implemented by means of an electronic device comprising a processor and a memory, not shown; each of the modules mentioned above can then be realized by the cooperation of the processor and computer program instructions stored in the aforementioned memory and designed to perform the functionalities of the module concerned, in particular as described below, when these instructions are executed by the processor
- the synthetic artificial neural network used for coding, MLP, and the synthetic artificial neural network used for decoding, MLP' are defined by an identical structure, comprising for example a plurality of layers of artificial neurons, and by a set of weights and activation functions associated respectively with the artificial neurons of the network concerned.
- a vector representation of a current sample (a vector Z n or Zd n from the feature maps FMv i /FMSv i and FRv j / FRSv j at the encoder or FMdv i /FMS'v i and FRdv j / FRS'v j at the decoder) is applied as input (i.e. on an input layer) of the MLP or MLP' artificial neural network.
- the input vector includes values from the current maps (Zv n ,Zdv n ) and values from the reference maps (Zr n ,Zdr n ).
- the MLP/MLP' artificial neural network produces as output a plurality of vectors P' vn or Pd vn representative of the reconstructed samples (at coding) or decoded samples (at decoding), according to one embodiment the color components (R, G, B or Y, U, V) constituting the color pixels of the sub-sequence of images.
- each subsequence of samples therefore comprises a single sample and the corresponding vector is noted P'1 n (at the encoder) or Pd 1n (at the decoder).
- P'1 n at the encoder
- Pd 1n at the decoder
- the MLP synthesis artificial neural network is trained on the image, so as to minimize the differences between the input representation of the current subsequence I (Pv n ) and its output representation I (P'v n ), while also minimizing the amount of data to be encoded.
- the EVAL module performs a performance measurement in this sense.
- the MLP/MLP' artificial neural network produces as output a plurality of vectors P' vn or Pd vn representative of the reconstructed samples (at coding) or decoded samples (at decoding), according to one embodiment the color components (R, G, B or Y, U, V) constituting the color pixels of the sub-sequence of images.
- a sample subsequence therefore comprises two samples and the two corresponding vectors (R, G, B) or (Y, U, V) are denoted P'1 n /Pd1 n .and P'2 n /Pd2 n.
- the concatenation of all these reconstructed pixels in the two images constitutes the decoded, or reconstructed, subsequence.
- 4 cards of features are presented (after having been possibly transformed by the SE/SE' module, then their characteristic vectors extracted by the XTR/XTR' module) at the input of the MLP synthesis network (resp. MLP') which synthesizes the samples of the coded (resp. decoded) images 2 and 3.
- 6 cards of features are presented (after having been possibly transformed by the SE/SE' module, then their characteristic vectors extracted by the XTR/XTR' module) at the input of the MLP synthesis network (resp. MLP') which synthesizes the samples of the coded (resp. decoded) image number 4.
- the current subsequence is a sequence of two-dimensional images, each sample subsequence to be encoded is therefore a set of pixels Pv n of coordinates (x n , y n ) in the respective images I(Pv n ) of the sequence to be encoded.
- the current subsequence comprises a single image.
- Encoding takes place in two main phases:
- a first learning is carried out at the initialization step E0 to construct, code and decode a group of reference images FRc j of the sequence SV.
- SV comprises a series of images, for example temporal images of a video sequence.
- the images are multi-view or 3D components of a multi-view or 3D image or image sequence.
- the images correspond to an Intra period or a GOP of a conventional video coder.
- These maps can be inserted into the B1 stream after coding. According to one embodiment, these maps are generated before the processing of the subsequences. According to another embodiment, they are generated during the processing of the subsequences, by optimization, in the same way as the current feature maps.
- the cost function can be of the rate-distortion, or rate, or distortion, or perceptual type.
- the coding of the W k parameters is not simulated because their influence is less significant than that of the feature maps.
- the coding of the parameters W k is also simulated and the associated flow rate (the size of the flow B2) is measured.
- the distortion D it is necessary to simulate the coding and then the decoding of at least part of the image sequence, to obtain at least one sequence of pixels P'v n resulting from a simulation of coding and then decoding of the samples of index n, then to measure the difference between this sub-sequence of images I(Pv n ) at input and a corresponding part of the sequence I(P'v n ) coded and then decoded.
- the FMv i maps and the W k parameters are encoded to produce the coded values FMcv i and Wcv k before transmission or storage. They constitute the compressed representation of the input sequence I(Pv n ).
- an input sequence I(Pv n ) to be coded comprising at least one image comprising a plurality of N samples Pv n , is provided as input to the method.
- NFM current and optionally reference feature maps are initialized. Subsequently, the parameters W k of the MLP neural network and the values of the maps must be optimized during the construction phase.
- the feature maps are initialized by predefined constant values. According to another embodiment, the feature maps are initialized by a set of random real values. The feature maps are subsequently updated, or refined, during a step E22 , by the update module MAJ of the encoder during its learning.
- NFR reference maps are obtained by the REF module, among the group of feature maps associated with the sequence.
- reference feature maps of the same size as the current feature maps can be used.
- Their reference can alternatively be encoded in the stream as an indicator.
- the set of current NFM maps and reference NFR maps constitutes a set of feature maps for the MLP synthesis network.
- the current and/or reference feature maps have the same resolution as the images of the input sequence I(Pv n ) and therefore each comprise the same number of values N as there are samples Pv n to be coded in each image.
- the current and/or reference feature maps have a resolution less than or equal to that of the images of the input sequence I(Pv n ) and therefore comprise, for at least one of them, a number N' of values to be coded less than N.
- the first current map (resp. reference map) is at the resolution of the images and each subsequent map is at a resolution half that of the previous one.
- several maps have the same resolution, less than that of the images of the input sequence I(Pv n ).
- the NFM maps of the set of current maps FMv i and/or the NFR reference maps FRv j are transformed by the module SE to generate transformed maps FMSv i / FRSv j at the resolution of the input images.
- the characteristic vectors are preferably extracted from the transformed maps, and not directly from the current maps to be coded and/or the reference maps.
- the transformed maps are neither stored nor transmitted, they are used only for the construction of the characteristic vectors.
- one or more additional cards forming an additional group of additional feature maps, are generated, and complete the set of feature maps constituted. They are used for the construction of the feature vector but are neither stored nor transmitted.
- NFM + NFR FMSv i / FRSv j maps are generated.
- each FMv i map is transformed into a FMSv i map.
- each reference FRv j map is transformed into a FRSv j map.
- At least one FMv i / FRv j map has a lower resolution than the images of the sequence to be coded and the transformation operation includes oversampling so that the transformed map includes the same number of samples as the images of the sequence.
- Oversampling consists of adding values to the FMSv i and/or FRSv j maps to achieve the resolution of the images of the input sequence. It can be simple (by replication of the nearest neighbor) or include interpolation (linear, polynomial, by filtering, etc.).
- the transformation can include an oversampling neural network.
- values are extracted by the XTR module: - current FMv i characteristic maps (or possibly transformed FMSv i , and optionally additional) . - reference characteristic maps FRv j . or possibly transformed FRSv j .
- This extraction is performed based on the coordinates (x n , y n ) of the sample subsequence Pv n currents of the current subsequence. It can also be performed according to the resolution of the map considered.
- the characteristic vector Z n results directly from this extraction.
- the characteristic vector Z n is constructed by processing the extracted values.
- the processing may include quantization of the extracted values or of the constructed vector Z n , if necessary.
- the processing may include other operations, such as filtering, scaling, applying any function, preferably monotonic, etc.
- Z n is a J-tuple constructed from values taken from the current and reference (and optionally additional) characteristic maps by applying the processing to one or more values of the maps, for example filtering values neighboring the targeted value in a map.
- a map which is at half the resolution of the input signal one can consider the values located at the coordinates (x n /2, y n /2), (x n /2-1, y n /2), (x n /2, y n /2-1) and (x n /2-1, y n /2-1) and apply a processing to these values (filtering, averaging, interpolation, etc.) to obtain the final value (z i ) of the element i of the vector Zv n or Zr n relative to this current, reference (or additional) characteristic map.
- Z n has as many values as there are input cards.
- Z n is a J-tuple with values located at coordinates (x n , y n ) of a current pixel Pv n , as will be illustrated in support of the .
- the vector Z n of index n refers to the characteristic vector of the pixel or sequence of pixels Pv n .
- J NFM + NFR.
- the vector Z n (zv 1 ... zv NFM , zr 1 ... zr NFR ) has two sets of values: one (Zv n ) is extracted from the current feature maps of subsequence v, and the other (Zr n ) is extracted from the reference feature maps.
- it can include values from the additional maps.
- Z n is a J-tuple constructed from values taken from the current and reference (and optionally additional) feature maps at coordinates that may be different across maps. For example, if the maps are at different resolutions, the coordinates are adapted (by scaling) to match the resolution of each map.
- the vector Z n is processed by the MLP neural network to generate as output the subsequence of samples Pv n to be coded, according to one embodiment the triplets (R, G, B) of the samples P'v n (the samples Pv n coded then decoded) of the images of the subsequence.
- the current FMv i maps are encoded by the FMC module of the encoder.
- this operation is an encoding simulation.
- this operation is an actual encoding and the encoded values constitute the stream B1.
- the simulation may be identical to the actual encoding but it may also be different (for example, simplified).
- any known technique for compressing the values of the maps may be used.
- the reference maps are also encoded at this step.
- the cards are encoded in order (FMv1, FMv2,..., FMv 4 ), and the variables of each card in a predefined order, for example lexicographic.
- the reference cards are also encoded in order.
- Each card undergoes entropy encoding. The entropy encoding produces a compressed stream B1 whose throughput is subsequently measured during a step E29.
- a step E28 the parameters W k of the MLP neural network are quantized and coded.
- this operation is a coding simulation.
- this operation is an actual coding and the coded values constitute the stream B2.
- the simulation can be identical to the actual coding but it can also be different (for example, simplified). Any known technique can be used for this purpose, for example the neural network coding standard proposed by the MPEG-7 part 17 standard, also called NNR (Neural Network Representation). It should be noted that in this case, the amount of degradation that the coding brings to the parameters W k must be chosen.
- the structure and the parameters W k of the neural network are initialized for example during the first iteration of this step. These parameters are subsequently updated, or refined, during the construction phase, during subsequent iterations of the method.
- the parameters of the neural network are initialized by predefined values known to give a satisfactory result (for example, following training on a corpus of image sequences).
- the parameters W k of the neural network are initialized by a set of random values.
- a performance measure is evaluated .
- the coding simulation rates associated with the feature maps (simulation of the B1 flow by coding the FMv i / FRv j maps) and optionally with the neural network parameters (simulation of the B2 flow by coding the W k parameters) are measured.
- the cost function is of type rate-distortion, denoted (D+L*R), where D for example the squared error measured between the input images and the decoded images (or the error measured on a subset of samples of the images).
- D is calculated from a perceptual function such as the SSIM (for Structural SIMilarity ), or MSSSIM (for Multi-scale Structural SIMilarity ).
- R is the simulated rate of the stream B1; according to another embodiment, R is the total rate used to encode this image, i.e. the sum of the simulated rates of B1 and B2.
- L is a parameter that adjusts the rate-distortion trade-off. Other cost functions are possible.
- the method can be interrupted after a predefined time or a predefined number of iterations, so as to control its complexity or duration. This minimization can be carried out by a mechanism known as gradient descent with parameter updates during step E22 for the values of the feature maps and E27 for the network parameters.
- an EF step if the cost function has reached its minimum, training stops. If an encoded version corresponding to the latest simulation of the neural network parameters and feature maps is available, streams B1 and B2 can be formed from it. According to another embodiment, the encoding effectively the updated neural network parameters and feature map values (FMv i ) is performed at this step to produce the encoded parameters Wc k and FMc i which constitute flows B1 and B2. According to one embodiment, the FRv cards I are encoded at the end of learning, when the entire sequence has been processed.
- Streams B1 and B2 may be concatenated to produce a final stream.
- stream B2 of encoded neural network parameters is stored or transmitted before stream B1, so that it can be decoded before stream B1.
- the decoding described relates to a subsequence of images comprising at least one image of the sequence to be decoded, it is assumed that the group of reference maps of the sequence FRc j , has been decoded by the initialization module.
- a technique for predicting a feature map value by its neighborhood is used, as has been described in support of the .
- the reference cards are decoded in order, and the values of each card in a predefined order, for example lexicographically.
- the streams B1 and B2 are extracted from the encoded stream. They contain respectively, for a current subsequence of the sequence, the coded representations of the current maps FMcv i , and of the parameters Wcv k of the neural network.
- the NFM maps FMdv i of the current subsequence are generated by decoding the values FMcv i .
- decoding entropic decoding is used for example.
- a technique for predicting a feature map value by its neighborhood is used, as described in support of the .
- the FMdv i cards are decoded in order (FMdv 1 , FMdv 2 ,... FMdv 4 ), and the values of each card in a predefined order, for example lexicographic.
- NFR reference maps are obtained by the REF' module, among the group of feature maps associated with the sequence.
- reference feature maps of the same size as the current feature maps can be used. Their reference can alternatively be encoded in the stream as an indicator.
- the set of current NFM maps and reference NFR maps constitutes a set of feature maps for the synthesis network.
- the current and/or reference feature maps have the same resolution as the sequence I (Pdv n ) to be reconstructed, i.e. they contain N values.
- the current and/or reference feature maps are at a resolution lower than or equal to that of the subsequence I (Pdv n ) to be reconstructed.
- the first current map (resp. reference map) is at the resolution of the images and each subsequent map is at a resolution half that of the previous one.
- a step E33 the NFM cards of the set of current cards FMdv i and/or the NFR reference cards FRdv j are transformed by the module SE' to generate transformed cards FMS'v i / FRS'v j at the resolution of the images to be decoded.
- This step is similar to step E24 which was described for the coder in support of the , and the embodiments apply.
- step E24 which was described for the coder in support of the , and the embodiments apply.
- NFM + NFR maps FMS'v i / FRS'v j are generated.
- each FMdv i map is transformed into a FMS'v i map.
- each FRdv j map is transformed into a FRS'v j map.
- At least one FMdv i / FRdv j map has a lower resolution than the images to be decoded and the transformation operation includes oversampling so that the transformed map includes the same number of samples as the input image.
- Oversampling consists of adding values to the FMS'v i and/or FRS'v j maps to achieve the resolution of the image to be decoded. It can be simple (by nearest neighbor replication) or include interpolation (linear, polynomial, by filtering, etc.).
- the transformation can optionally include inverse quantization of the extracted values, if necessary. However, inverse quantization is not mandatory.
- the transformation can include an oversampling neural network.
- values are extracted by the XTR' module: - current FMdv i characteristic maps (or possibly transformed FMS'v i , and optionally additional) .
- This extraction is performed based on the coordinates (x n , y n ) of the sample subsequence Pv n currents of the current subsequence. It can also be performed according to the resolution of the map considered. This step is similar to step E25 which was described for the coder in support of the , and the embodiments apply. In particular:
- Zd n has as many values as there are input cards.
- the characteristic vector Zd n is constructed by processing the extracted values.
- the processing may include quantization of the extracted values or of the constructed vector Zd n , if necessary.
- the processing may include other operations, such as filtering, scaling, application of any function, preferably monotonic, etc.
- the examples cited for the encoder apply.
- Zd n is a J-tuple with values located at coordinates (x n , y n ) of a current pixel Pdv n , as will be illustrated in support of the .
- the vector Zd n of index n refers to the characteristic vector of the pixel or sequence of pixels Pdv n .
- J NFM + NFR.
- the vector Zd n (zdv 1 ...zdv NFM , zdr 1 ...zdr NFR ), has two sets of values: one (Zdv n ) is extracted from the current feature maps of subsequence v, and the other (Zdr n ) is extracted from the reference feature maps.
- it can include values from the additional maps.
- Zd n is a J-tuple constructed from values taken from the current and reference (and optionally additional) feature maps at coordinates that may be different across maps. For example, if the maps are at different resolutions, the coordinates are adapted (by scaling) to match the resolution of each map.
- the parameters Wdv k of the MLP' synthesis neural network are generated by decoding the values Wcv k of the stream B2. Any known decoding technique corresponding to the coding technique used by the encoder can be used for this purpose.
- the MLP' synthesis neural network is similar to the MLP synthesis network, i.e. it has the same structure and includes the same parameters, except for the coding, which can be performed with or without losses.
- the characteristic vector Zd n is processed by the synthesis neural network MLP' to generate as output a vector representative of the sample or the subsequence of samples Pdv n to be decoded, according to one embodiment one or more triplets which are injected into the decoded image I (Pdv n ) at the positions (x n , y n ) of the color components (Rd, Gd, Bd).
- This step is similar to step E26 which was described for the coder in support of the .
- the B2 stream is decoded before the B1 stream (except for the reference maps), in order to have the MLP’ synthesis neural network before starting to decode the samples.
- the current decoded cards FMdv i are 3 in number. In a preferred embodiment, they are 7 in number.
- the first FMdv 1 card has the same resolution as the image I(Pdvn) to be decoded, and therefore comprises WxH variables, where W represents the width of the image in pixels, and H its height.
- the second FMdv 2 card has half the resolution (in each dimension) of the FMdv 1 card.
- Each additional card has half the resolution of the previous card.
- the FMdv 2 card is oversampled by a factor of 2 by the SE' module in each dimension, according to any oversampling method within the reach of those skilled in the art.
- the FMdv 3 card is oversampled by a factor of 4 in each dimension.
- the decoded reference maps FRd j are 3 in number. In a preferred embodiment, they are 7 in number.
- the first map FRd 1 has the same resolution as the image, and therefore comprises WxH variables, where W represents the width of the image in pixels, and H its height.
- the second map FMd 2 has half the resolution (in each dimension) of the map FMd 1 .
- Each additional map has half the resolution of the previous map. This structure makes it possible to reduce the number of variables of the characteristic maps, which facilitates decoding while minimizing the coding cost.
- the FRd 2 map is oversampled by a factor of 2 in each dimension by the SE' module, according to any oversampling method within the reach of those skilled in the art.
- the FRd 3 map is oversampled by a factor of 4 in each dimension.
- the transformed maps FMS'v i and FRS'v j are of the same resolution as the image to be decoded, and therefore have WxH values, where W represents the width of the image in pixels, and H its height.
- the vector Zd n is a 6-tuple (zv 3, zv 2, zv 1, zr 3 , zr 2 , zr 1 ) made up of the 3 values of the FMS’v cards i located at coordinates (x n , y n ) of the current pixel Pdv n .and the 3 values of the FRS’v cards I located at coordinates (x n , y n ) of the current pixel Pdv n .
- the vector Zd n is optionally dequantized then processed by the MLP’ synthesis neural network to generate as output the triplets (R, G, B) representative of the Pdv samples n to be decoded.
- the triplet (R, G, B) is inserted into each decoded image I (Pdv n ) of the subsequence v at the coordinates (x n , y n ) in the color components (Rd, Gd, Bd).
- an additional card denoted FME' 0 has been introduced.
- the vector Zd n is a 7-tuple.
- This additional map typically contains data that can assist the MLP network in the task of image reconstruction.
- the added maps can be one or more of the following list, but not limited to:
- a map containing data representing the time difference between frames of the video being encoded For example, if the first and last frames of the video are 8 frames apart, all samples in the map contain the value 8.
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
Description
- une étape de construction, comportant les sous-étapes suivantes :
- construction d’un ensemble de cartes de caractéristiques courantes, représentatives de ladite au moins une image courante, comprenant au moins une carte de caractéristiques courante ;
- construction d’un ensemble de cartes de caractéristiques de référence, comprenant au moins une carte de caractéristiques de référence codée puis décodée ;
- pour au moins un échantillon, dit échantillon courant, de ladite au moins une image courante, associé à une position dans l'image courante :
- construction d’un vecteur caractéristique à partir de ladite au moins une carte de caractéristiques de référence et de ladite au moins une carte de caractéristiques courante, en fonction de ladite position dudit échantillon courant ;
- traitement dudit vecteur caractéristique par un réseau de neurones artificiels, dit réseau de neurones de synthèse, défini par un ensemble de paramètres, pour fournir un vecteur représentatif d’une valeur décodée de l’échantillon courant ;
- mise à jour d'au moins une valeur de ladite au moins une carte de caractéristiques courante et/ou d’au moins un paramètre dudit réseau, en fonction d’une mesure de performance de codage ;
- une étape de codage dudit ensemble de cartes de caractéristiques courantes ;
- une étape de codage dudit ensemble de paramètres dudit réseau de neurones de synthèse.
- décodage d’un ensemble de paramètres représentatifs d’un réseau de neurones de synthèse ;
- décodage d’un ensemble de cartes de caractéristiques courantes comprenant au moins une carte de caractéristiques courante représentative de ladite au moins une image courante ;
- obtention d’un ensemble de cartes de caractéristiques de référence, comprenant au moins une carte de caractéristiques de référence décodée ;
- pour au moins un échantillon, dit échantillon courant, de ladite au moins une image courante à décoder, associé à une position dans l'image :
- construction d’un vecteur caractéristique à partir de ladite au moins une carte de caractéristiques de référence et de ladite au moins une carte de caractéristiques courante, en fonction de ladite position dudit échantillon courant, et :
- traitement dudit vecteur par ledit réseau de neurones de synthèse pour fournir un vecteur représentatif d’une valeur décodée dudit au moins un échantillon courant.
- une étape de décodage d’un groupe de cartes de caractéristiques de référence représentatives de la séquence et
- obtention dudit ensemble de cartes de caractéristiques de référence à partir dudit groupe.
- extraction d’une pluralité de valeurs desdites cartes de caractéristiques courantes et/ou de référence en fonction de ladite position dudit échantillon courant ;
- traitement desdites valeurs extraites pour obtenir le vecteur caractéristique.
- des données encodées organisées en NFM cartes de caractéristiques FMcvi (les cartes de caractéristiques courantes encodées) ;
- les paramètres encodés Wvck du réseau de neurones de synthèse correspondant à la sous-séquence courante , optionnellement les paramètres d'autres réseaux de neurones comme un réseau de neurones de suréchantillonnage, de prédiction de carte de caractéristiques, etc.;
- des cartes de caractéristiques courantes FMvi (ou éventuellement FMSvi transformées, et optionnellement supplémentaires).
- des cartes de caractéristiques de référence FRvj. ou éventuellement FRSvj transformées.
- des cartes de caractéristiques courantes FMdvi (ou éventuellement FMS’vi transformées, et optionnellement supplémentaires).
- des cartes de caractéristiques de référence FRdvj ou éventuellement FRS’vj transformées.
Claims (14)
- Procédé de codage d’une séquence d’images (Sv) comportant les étapes suivantes pour au moins une image courante à coder :
- une étape de construction, comportant les sous-étapes suivantes :
- construction (E21, E22) d’un ensemble de cartes de caractéristiques courantes (FMvi) représentatives de ladite au moins une image courante (v, I(Pvn)), comprenant au moins une carte de caractéristiques courante ;
- construction (E23) d’un ensemble de cartes de caractéristiques (FRvj) de référence, comprenant au moins une carte de caractéristiques de référence codée puis décodée ;
- pour au moins un échantillon, dit échantillon courant (Pvn), de ladite au moins une image courante, associé à une position (xn, yn) dans ladite au moins une image courante :
- construction (E25) d’un vecteur caractéristique (Zn) à partir de ladite au moins une carte de caractéristiques de référence (Zrn) et de ladite au moins une carte de caractéristiques courante (Zvn), en fonction de ladite position (xn, yn) dudit au moins un échantillon courant (Pvn) ;
- traitement (E26) dudit vecteur caractéristique (Zn) par un réseau de neurones artificiels (MLP), dit réseau de neurones de synthèse, défini par un ensemble de paramètres (Wvk), pour fournir un vecteur (P’vn) représentatif d’une valeur décodée dudit au moins un échantillon courant ;
- mise à jour (E22, E29) d'au moins une valeur de ladite au moins une carte de caractéristiques courante et/ou d’au moins un paramètre dudit réseau, en fonction d’une mesure de performance de codage ;
- une étape de codage (E24) dudit ensemble de cartes de caractéristiques courantes (FMvi) ;
- une étape de codage (E28) dudit ensemble de paramètres (Wvk) dudit réseau de neurones de synthèse. - Procédé de codage d’une séquence d’images selon la revendication 1, caractérisé en ce qu'il comporte en outre :
- une étape de construction (FRj) et codage (FRcj) d’un groupe de cartes de caractéristiques de référence représentatives de la séquence comprenant ledit ensemble de cartes de caractéristiques de référence (FRvj). - Procédé de décodage d’une séquence d’images (Sv) d’un flux binaire, comportant les étapes suivantes pour au moins une image courante (v) :
- décodage (E35) d’un ensemble de paramètres (Wdvk) représentatifs d’un réseau de neurones (MLP’) de synthèse ;
- décodage (E31) d’un ensemble de cartes de caractéristiques courantes (FMdvi) comprenant au moins une carte de caractéristiques courante représentative de ladite au moins une image courante;
- obtention (E32) d’un ensemble de cartes de caractéristiques (FRdvj) de référence, comprenant au moins une carte de caractéristiques de référence décodée ;
- pour au moins un échantillon, dit échantillon courant (Pdvn), de ladite au moins une image courante (v) à décoder, associé à une position (xn, yn) dans l'image :
- construction (E34) d’un vecteur caractéristique (Zdn) à partir de ladite au moins une carte de caractéristiques de référence (Zdrn) et de ladite au moins une carte de caractéristiques courante (Zdvn), en fonction de ladite position (xn, yn) dudit au moins un échantillon courant, et :
- traitement (E37) dudit vecteur (Zdn, ZRdn) par ledit réseau de neurones de synthèse (MLP’) pour fournir un vecteur représentatif d’une valeur décodée dudit au moins un échantillon courant (Pdvn). - Procédé de décodage selon la revendication 3, caractérisé en ce qu'il comporte en outre :
- une étape de décodage (E31) d’un groupe de cartes de caractéristiques (FRdj) de référence représentatives de la séquence et
- obtention (E32) dudit ensemble de cartes de caractéristiques de référence (FRdvj) à partir dudit groupe (FRdj). - Procédé de codage ou de décodage selon l'une des revendications précédentes, caractérisé en ce que l'ensemble de cartes de référence et l'ensemble de cartes courantes (FRdvj, FMdvi) contiennent le même nombre (NFM, NFR) de cartes de caractéristiques.
- Procédé de codage ou de décodage selon l'une des revendications précédentes, caractérisé en ce que ladite au moins une carte de référence est à la même résolution que ladite au moins une carte courante.
- Procédé de codage ou de décodage selon l'une des revendications précédentes, caractérisé en ce que ladite au moins une carte de référence est indiquée dans le flux binaire.
- Procédé de codage ou de décodage selon l'une des revendications précédentes, caractérisé en ce que ladite au moins une carte de référence est prédéterminée.
- Procédé de codage ou de décodage selon l'une des revendications précédentes, caractérisé en ce qu'il comporte en outre une étape de transformation dudit ensemble de cartes de caractéristiques courantes et/ou de référence pour obtenir un ensemble de cartes de caractéristiques transformées à la résolution de l'image courante, le procédé étant caractérisé en ce que ledit vecteur caractéristique est construit à partir desdites cartes de caractéristiques transformées.
- Procédé de décodage selon l’une des revendications 3 à 9, caractérisé en ce que ladite au moins une carte courante est décodée en fonction de ladite au moins une carte de référence et/ou d'un carte de caractéristique courante.
- Procédé de décodage selon la revendication 10 caractérisé en ce que le décodage est effectué par un réseau de neurones de prédiction.
- Dispositif de codage d’une séquence d’images (Sv), ledit dispositif étant configuré pour mettre en œuvre :
- une étape de construction, comportant les sous-étapes suivantes :
- construction (GEN, MAJ) d’un ensemble de cartes de caractéristiques courantes, (FMvi) représentatives de ladite au moins une image courante (v, I(Pvn)), comprenant au moins une carte de caractéristique courante ;
- construction (INITc, REF) d’un ensemble de cartes de caractéristiques (FRvj) de référence, comprenant au moins une carte de caractéristiques de référence codée puis décodée ;
- pour au moins un échantillon, dit échantillon courant (Pvn), de ladite au moins une image courante, associé à une position (xn, yn) dans ladite au moins une image courante :
- construction (XTR) d’un vecteur caractéristique (Zn) à partir de ladite carte de caractéristiques au moins une carte de caractéristiques de référence (Zrn) et de ladite au moins une carte de caractéristiques courante (Zvn), en fonction de ladite position (xn, yn) dudit au moins un échantillon courant (Pvn) ;
- traitement (MLP) dudit vecteur caractéristique (Zn) par un réseau de neurones artificiels, dit réseau de neurones de synthèse, défini par un ensemble de paramètres (Wvk), pour fournir un vecteur (P’vn) représentatif d’une valeur décodée dudit au moins un échantillon courant ;
- mise à jour (E22, E29) d'au moins une valeur de ladite au moins une carte de caractéristiques courantes et/ou d’au moins un paramètre dudit réseau, en fonction d’une mesure de performance de codage,
- une étape de codage (E24) dudit ensemble de cartes de caractéristiques courantes (FMvi) ;
- une étape de codage (E28) dudit ensemble de paramètres (Wvk) dudit réseau de neurones de synthèse. - Dispositif de décodage à partir d'un flux binaire d’une séquence d’images (SV), ledit dispositif étant configuré pour mettre en œuvre, pour au moins une image courante (v, I(Pdvn)) de la séquence :
- décodage (NND) d’un ensemble de paramètres (Wdvk) représentatifs d’un réseau de neurones (MLP’) de synthèse ;
- décodage (FMD) d’un ensemble de cartes de caractéristiques courantes comprenant au moins une carte de caractéristiques (FMdvi) courante représentative de ladite au moins une image courante;
- obtention (INITd, REF') d’un ensemble de cartes de caractéristiques (FRdvj) de référence, comprenant au moins une carte de caractéristiques de référence décodée ;
- pour au moins un échantillon, dit échantillon courant (Pdvn), de ladite au moins une image courante (v) à décoder, associé à une position (xn, yn) dans l'image :
- construction (E34) d’un vecteur caractéristique (Zdn) à partir de ladite au moins une carte de caractéristiques de référence (Zdrn) et de ladite au moins une carte de caractéristiques courante (Zdvn), en fonction de ladite position (xn, yn) dudit échantillon courant, et :
- traitement (E37) dudit vecteur (Zdn) par ledit réseau de neurones de synthèse (MLP’) pour fournir un vecteur représentatif d’une valeur décodée dudit au moins un échantillon courant (Pdvn). - Programme d’ordinateur comportant des instructions pour l’exécution des étapes d'un procédé de codage ou de décodage selon la revendication 1 ou 3 lorsque ledit programme est exécuté par un ordinateur.
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP24724527.7A EP4732241A1 (fr) | 2023-06-22 | 2024-05-07 | Procédé et dispositif de codage et décodage de séquences d'images |
| CN202480049704.XA CN121605434A (zh) | 2023-06-22 | 2024-05-07 | 用于对图像序列进行编码和解码的方法和设备 |
| KR1020267001760A KR20260025406A (ko) | 2023-06-22 | 2024-05-07 | 이미지 시퀀스를 코딩 및 디코딩하기 위한 방법 및 장치 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FR2306455A FR3150333A1 (fr) | 2023-06-22 | 2023-06-22 | Procédé et dispositif de codage et décodage de séquences d’images. |
| FRFR2306455 | 2023-06-22 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2024260628A1 true WO2024260628A1 (fr) | 2024-12-26 |
Family
ID=88689996
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/EP2024/062652 Ceased WO2024260628A1 (fr) | 2023-06-22 | 2024-05-07 | Procédé et dispositif de codage et décodage de séquences d'images |
Country Status (5)
| Country | Link |
|---|---|
| EP (1) | EP4732241A1 (fr) |
| KR (1) | KR20260025406A (fr) |
| CN (1) | CN121605434A (fr) |
| FR (1) | FR3150333A1 (fr) |
| WO (1) | WO2024260628A1 (fr) |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023280558A1 (fr) * | 2021-07-06 | 2023-01-12 | Nokia Technologies Oy | Améliorations de performance de tâches de vision artificielle par l'intermédiaire d'un filtre à base de réseau neuronal appris |
-
2023
- 2023-06-22 FR FR2306455A patent/FR3150333A1/fr not_active Withdrawn
-
2024
- 2024-05-07 CN CN202480049704.XA patent/CN121605434A/zh active Pending
- 2024-05-07 KR KR1020267001760A patent/KR20260025406A/ko active Pending
- 2024-05-07 EP EP24724527.7A patent/EP4732241A1/fr active Pending
- 2024-05-07 WO PCT/EP2024/062652 patent/WO2024260628A1/fr not_active Ceased
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023280558A1 (fr) * | 2021-07-06 | 2023-01-12 | Nokia Technologies Oy | Améliorations de performance de tâches de vision artificielle par l'intermédiaire d'un filtre à base de réseau neuronal appris |
Non-Patent Citations (5)
| Title |
|---|
| CHEN TONG ET AL: "DeepCoder: A deep neural network based video compression", 2017 IEEE VISUAL COMMUNICATIONS AND IMAGE PROCESSING (VCIP), IEEE, 10 December 2017 (2017-12-10), pages 1 - 4, XP033325713, DOI: 10.1109/VCIP.2017.8305033 * |
| ÉMILIEN DUPONT ET AL.: "COmpression with Implicit Neural représentations", ARXIV:2103.03123 |
| REZASOLTANI SHIMA ET AL: "Hyperspectral Image Compression Using Implicit Neural Representations", 2023 20TH CONFERENCE ON ROBOTS AND VISION (CRV), IEEE, 6 June 2023 (2023-06-06), pages 248 - 255, XP034412598, DOI: 10.1109/CRV60082.2023.00039 * |
| SIWEI MA ET AL: "Image and Video Compression With Neural Networks: A Review", 10 April 2019 (2019-04-10), pages 1 - 16, XP055765818, Retrieved from the Internet <URL:https://arxiv.org/pdf/1904.03567.pdf> [retrieved on 20210115] * |
| SUBIN KIM ET AL.: "Scalable Neural Video Représentations with Learnable Positional Features", NEURIPS, 2022 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN121605434A (zh) | 2026-03-03 |
| FR3150333A1 (fr) | 2024-12-27 |
| KR20260025406A (ko) | 2026-02-24 |
| EP4732241A1 (fr) | 2026-04-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| FR3143245A1 (fr) | Procédé et dispositif de codage et décodage d’images. | |
| EP3198876B1 (fr) | Génération et codage d'images intégrales résiduelles | |
| WO2024240496A1 (fr) | Procédé et dispositif de codage et décodage d'images | |
| WO2024260628A1 (fr) | Procédé et dispositif de codage et décodage de séquences d'images | |
| WO2024260629A1 (fr) | Procédé et dispositif de codage et décodage de séquences d'images | |
| FR3143247A1 (fr) | Procédé et dispositif de codage et décodage de séquences d’images. | |
| FR3143246A1 (fr) | Procédé et dispositif de codage et décodage d’images. | |
| FR3143248A1 (fr) | Procédé et dispositif de codage et décodage d’images. | |
| WO2025056651A1 (fr) | Procédé et dispositif de codage et décodage de séquences d'images | |
| WO2022175626A1 (fr) | Determination d'un mode de codage d'image | |
| WO2025056653A1 (fr) | Procédé et dispositif de codage et décodage d'images | |
| WO2024240497A1 (fr) | Procédé et dispositif de codage et décodage d'images. | |
| WO2026003293A1 (fr) | Procédé et dispositif de codage et décodage d'un signal | |
| WO2025120066A1 (fr) | Procédé et dispositif de codage et décodage contextuel de séquences d'images | |
| WO2026087142A1 (fr) | Procédé et dispositif de codage et décodage d'images | |
| WO2025180860A1 (fr) | Procédé et dispositif de codage et décodage d'images avec mécanisme de correction | |
| WO2025180859A1 (fr) | Procédé et dispositif de codage et décodage d'images avec mécanisme de correction | |
| WO2026003294A1 (fr) | Procédé et dispositif de codage et décodage d'un signal | |
| FR3164089A1 (fr) | Procédé et dispositif de codage et décodage d’images | |
| WO2026003351A1 (fr) | Procédé et dispositif de codage et décodage d'un signal | |
| WO2025056649A1 (fr) | Procédé et dispositif de codage et décodage d'images avec mécanisme d'attention. |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 24724527 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 1020267001760 Country of ref document: KR Free format text: ST27 STATUS EVENT CODE: A-0-1-A10-A15-NAP-PA0105 (AS PROVIDED BY THE NATIONAL OFFICE) |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 1020267001760 Country of ref document: KR |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2024724527 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2024724527 Country of ref document: EP Effective date: 20260122 |
|
| ENP | Entry into the national phase |
Ref document number: 2024724527 Country of ref document: EP Effective date: 20260122 |
|
| ENP | Entry into the national phase |
Ref document number: 2024724527 Country of ref document: EP Effective date: 20260122 |
|
| WWP | Wipo information: published in national office |
Ref document number: 1020267001760 Country of ref document: KR |