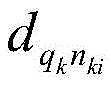Background
The visual position identification specifically refers to that the image is subjected to feature extraction, and then the geographic position of the image is identified according to the extracted image features. With the growing development of automated driving, the increasing demand for autonomous navigation mobile robots, and the increasing popularity of virtual reality and augmented reality, research in visual location identification has attracted considerable attention in the field of computer vision, the community of robots, and other related fields.
In the early stage of computer vision research, image features such as Scale Invariant Feature Transform (SIFT) feature points are extracted mainly by a manually and carefully designed method for extracting image feature points. The design of the extracted features is very dependent on experience, some expert scholars can design a good feature even after decades, the algorithm for extracting the image feature points by utilizing manual design has very poor effect under the conditions of sharp illumination change (such as day to night) and scene change (editing occurs to pedestrians and vehicles in the scene), and the performance of a visual position identification method relying on the features, such as a visual bag-of-words model (V-BOW), can also be sharply reduced. In recent years, with the rise of deep learning, and the method is widely applied to the fields of target recognition, target detection, target tracking, semantic segmentation, and the like, some visual position recognition methods based on deep learning are proposed. For example, based on the position Recognition (Convolutional Neural Network-based plant Recognition) of the Convolutional Neural Network, the method extracts the image features by using the deep Convolutional Neural Network, and the extracted image features are more robust because the deep Convolutional Neural Network can perform end-to-end training according to a specific task. For another example, the CNN architecture NetVLAD (NetVLAD: CNN architecture for weak supervised location recognition) for the location recognition gives play to the advantages of the conventional local feature aggregation (VLAD) method, effectively aggregates local features of an image to obtain a compact image expression feature vector, and makes image features extracted by using a deep neural network more robust.
Compared with the traditional visual position identification method based on the manually designed image feature points, the image features extracted by the visual position identification method based on the deep neural network are more robust, and the visual position identification is more accurate. However, the deep neural network needs to be trained before use, and due to the influence of factors such as viewing angle and illumination, the feature distribution of the image used for training often has a large difference from the feature distribution of the actual image to be recognized, and in this case, the accuracy of visual position recognition cannot be guaranteed. In general, the existing visual position recognition methods are less robust.
Disclosure of Invention
Aiming at the defects and improvement requirements of the prior art, the invention provides a model training method, a domain adaptive visual position identification method and a domain adaptive visual position identification device, and aims to improve the robustness of visual position identification.
To achieve the above object, according to a first aspect of the present invention, there is provided an image feature extraction model training method, including:
(1) establishing an image feature extraction model based on a deep neural network, and obtaining feature vectors of an image;
the image feature extraction model comprises a feature extraction network and a local feature aggregation network;
the feature extraction network comprises a plurality of cascaded first networks; the first network is formed by sequentially connecting one or more second networks and a maximum pooling layer, and the maximum pooling layer is used for carrying out feature selection on images output by the previous second networks; the second network comprises a convolution layer, a batch standardization layer and an activation function layer which are sequentially connected, wherein the convolution layer is used for carrying out feature extraction on images, the batch standardization layer is used for carrying out zero-mean standardization processing on the images output by the convolution layer, and the activation function layer is used for carrying out activation processing on the images output by the batch standardization layer;
the local feature aggregation network is used for aggregating all local features in the image output by the feature extraction network so as to obtain a feature vector of the image;
(2) in the standard data set, obtaining a positive sample and s negative samples of each target image, so as to form a training sample by one target image and the positive sample and the negative sample thereof, thereby obtaining a training set formed by all the training samples;
the positive sample of the target image is the nearest distance to the characteristic in the adjacent imageThe distance d between the target image and the adjacent image satisfies TNL≤d<TNH(ii) a The position distance between the target image and the negative sample thereof satisfies d ≥ TF;
(3) Training the image feature extraction model by using a training set so as to obtain each model parameter;
the position information of each image in the standard data set is known, and the target image is a plurality of images screened in advance in the standard data set; the characteristic distance between the images is the distance between the characteristic vectors of the images; t isNL、TNHAnd TFAre all preset threshold values, T is more than 0NL<TNH,TNH≤TF;s≥1。
According to the image feature extraction model training method, in the established image feature extraction model, after each convolution used for feature extraction, zero-mean standardization processing is carried out on the image output by the convolution layer through a Batch Normalization layer (Batch Normalization), so that the image features extracted by the image feature extraction model are distributed similarly while model training is accelerated, the problem that the model training effect is poor due to the fact that the feature distribution difference of the images in a training set is large is effectively avoided, and the problem that the robustness of visual position recognition is low when the feature distribution difference of the images is large is solved.
Further, the local feature aggregation network includes: the integrated structure comprises a dimensionality reduction convolution layer, a soft-max layer, a polymerization layer, an internal normalization layer and an integral normalization layer;
the dimension reduction convolutional layer is a convolutional layer and is used for reducing the dimension of the image to be aggregated to be equal to the number of preset clustering centers so that each channel of the image to be aggregated represents the weight of the difference between the local feature and each clustering center;
the soft-max layer is used for normalizing the weight of the difference between the local feature and each cluster center;
the aggregation layer is used for aggregating according to the local features, the clustering center and the weight after normalization to obtain VLAD (vector of localization aggregated descriptors) vectors; the VLAD vector consists of vectors of N D dimensions, wherein N is the number of the clustering centers, and D is the dimension of the clustering centers;
the internal normalization layer is used for normalizing the vector of each D dimension in the VLAD vector so as to enable the distribution of the vector of each D dimension to be in the same order of magnitude;
the integral normalization layer is used for serially connecting the D-dimension vectors processed by the internal normalization layer into a column vector, and then normalizing the column vector so as to enable each local feature of the image to be aggregated to be distributed in the same order of magnitude; therefore, the convergence speed of the neural network model and the accuracy of the network model can be improved;
wherein, the image to be aggregated is the image output by the feature extraction network.
Further, s > 1; the training precision of the model can be improved by selecting a plurality of negative samples, so that the image feature vector acquired by the image feature extraction model has higher robustness when being used for visual position identification.
Further, in the step (3), when the training set is used to train the image feature extraction model, the loss function adopted is:
wherein n is the total number of training samples, k is the serial number of the training samples, i is the serial number of the negative sample, q
k、p
kAnd n
kiRespectively representing a target image, a positive sample and an ith negative sample in a kth training sample,
representing a target image q
kWith its positive sample p
kThe characteristic distance between the two or more of them,
is a target image q
kWith its negative sample n
kiM is a predefined hyper-parameter, max represents taking the maximum value, and min represents taking the minimum value;
above mentioned damageThe loss function is based on the thought of triple loss, so that the characteristic distance between a target image and a positive sample is minimized and the characteristic distance between the target image and a negative sample is maximized through training; wherein by passing
The negative sample with the largest loss is selected, so that the negative sample which is difficult to distinguish is more noticed in the model training process based on the idea of difficult example mining, and the interference of the negative sample similar to the image to be recognized can be avoided when the visual position recognition is carried out by utilizing the image feature extraction model.
According to a second aspect of the present invention, there is also provided a domain-adaptive visual position recognition method based on the image feature extraction model training method provided in the first aspect of the present invention, including:
determining a target domain to which an image to be identified belongs, obtaining a plurality of images at different positions in the target domain, and taking the obtained image and the image to be identified as an image to be retrieved;
taking an image to be retrieved as input, and obtaining a feature vector of each image to be retrieved by using an image feature extraction model; when the image characteristic vector is obtained, for each convolution layer, counting the mean value and the standard deviation of the characteristic graph obtained after all the images to be retrieved pass through the convolution layer, and taking the mean value and the standard deviation as the parameters of a batch standard layer behind the convolution layer; the rest model parameters in the image feature extraction model are model parameters obtained by training;
acquiring a feature vector of each image in the test data set by using an image feature extraction model;
obtaining an image which is closest to the characteristic distance of the image to be recognized in the test data set according to the obtained characteristic vector, and determining the position information of the image as the position information of the image to be recognized, so as to complete the visual position recognition of the image to be recognized;
the position information of each image in the test data set is known, and the domain is a factor set influencing the characteristic distribution of the image;
according to practical application, the domain can be defined according to the influence of factors such as illumination, visual angle, season and the like on the image characteristic distribution, and the characteristic distribution of the images in the same domain is similar; for example, if only light irradiation has a large influence on the feature distribution of an image, and an image photographed in the daytime has a similar feature distribution and an image photographed in the nighttime has a similar feature distribution, two domains may be divided according to the light condition;
according to the domain self-adaptive visual position recognition method, when the image feature extraction model is used for obtaining the feature vector of the image to be recognized, the parameters of each batch of standardized layers in the model do not depend on the training set, but a plurality of images belonging to the same domain with the image to be recognized are used for obtaining corresponding parameters, and the images in the same domain have similar feature distribution, so that the domain self-adaptive visual position recognition method can realize the domain self-adaptation, and can still accurately complete the visual position recognition when the difference between the feature distribution of the image in the training set and the feature distribution of the image to be recognized is large, namely, the robustness of the visual position recognition can be improved.
Further, when the feature vector of each image in the test data set is obtained by using the image feature extraction model, the setting mode of each model parameter is as follows:
setting each model parameter by using the model parameters obtained by training;
or, for each convolution layer, counting the mean value and the standard deviation of the characteristic diagram obtained after all the images in the test data set pass through the convolution layer, and taking the mean value and the standard deviation as the parameters of a batch of normalization layers behind the convolution layer; and the rest model parameters in the image feature extraction model are model parameters obtained by training.
According to a third aspect of the present invention, there is provided an image feature extraction model training apparatus comprising: the system comprises a model establishing module, a training set constructing module and a model training module;
the model establishing module is used for establishing an image feature extraction model based on a deep neural network, and the image feature extraction model is used for acquiring a feature vector of an image;
the training set construction module is used for obtaining a positive sample and s negative samples of each target image in the standard data set so as to form a training sample by one target image and the positive sample and the negative sample thereof, thereby obtaining a training set formed by all the training samples;
the model training module is used for training the image feature extraction model by utilizing a training set so as to obtain each model parameter;
the image feature extraction model comprises a feature extraction network and a local feature aggregation network;
the feature extraction network comprises a plurality of cascaded first networks; the first network is formed by sequentially connecting one or more second networks and a maximum pooling layer, and the maximum pooling layer is used for carrying out feature selection on images output by the previous second networks; the second network comprises a convolution layer, a batch standardization layer and an activation function layer which are sequentially connected, wherein the convolution layer is used for carrying out feature extraction on images, the batch standardization layer is used for carrying out zero-mean standardization processing on the images output by the convolution layer, and the activation function layer is used for carrying out activation processing on the images output by the batch standardization layer;
the local feature aggregation network is used for aggregating all local features in the image output by the feature extraction network so as to obtain a feature vector of the image;
the positive sample of the target image is the image which is closest to the characteristic distance of the target image in the adjacent images, and the position distance d between the target image and the adjacent images meets TNL≤d<TNH(ii) a The position distance d between the target image and the negative sample thereof satisfies that d is more than or equal to TF;
The position information of each image in the standard data set is known, and the target image is a plurality of images screened in advance in the standard data set; the characteristic distance between the images is the distance between the characteristic vectors of the images; t isNL、TNHAnd TFAre all preset threshold values, T is more than 0NL<TNH,TNH≤TF;s≥1。
According to a fourth aspect of the present invention, there is further provided a domain-adaptive visual position recognition apparatus based on the image feature extraction model training method provided in the first aspect of the present invention, including: the system comprises a retrieval set acquisition module, a first feature extraction module, a second feature extraction module and an identification module;
the retrieval set acquisition module is used for determining a target domain to which the image to be identified belongs, acquiring a plurality of images at different positions in the target domain, and taking the acquired image and the image to be identified as the image to be retrieved;
the first feature extraction module is used for taking the images to be retrieved as input and obtaining feature vectors of the images to be retrieved by utilizing the image feature extraction model; when the image characteristic vector is obtained, for each convolution layer, counting the mean value and the standard deviation of the characteristic graph obtained after all the images to be retrieved pass through the convolution layer, and taking the mean value and the standard deviation as the parameters of a batch standard layer behind the convolution layer; the rest model parameters in the image feature extraction model are model parameters obtained by training;
the second feature extraction module is used for acquiring feature vectors of all images in the test data set by using the image feature extraction model;
the identification module is used for acquiring an image which is closest to the characteristic distance of the image to be identified in the test data set according to the characteristic vectors extracted by the first characteristic extraction module and the second characteristic extraction module, and determining the position information of the image as the position information of the image to be identified, so that the visual position identification of the image to be identified is completed;
the position information of each image in the test data set is known, and the domain is a factor set influencing the image characteristic distribution.
Generally, by the above technical solution conceived by the present invention, the following beneficial effects can be obtained:
(1) according to the image feature extraction model training method provided by the invention, in the established image feature extraction model, after each convolution used for feature extraction, zero-mean standardization processing is carried out on the image output by the convolution layer through one batch of standardization layers, so that the image features extracted by the image feature extraction model can be distributed similarly while the model training is accelerated, the problem that the model training effect is poor due to the fact that the feature distribution difference of the images in a training set is large is effectively avoided, and the problem that the robustness of visual position identification is low when the image feature distribution difference is large can be further improved.
(2) In the preferred scheme of the image feature extraction model training method provided by the invention, the training sample is constructed by selecting a plurality of negative samples, so that the training precision of the model can be improved, and the image feature vector acquired by the image feature extraction model has higher robustness when being used for visual position identification.
(3) In the preferred scheme of the image feature extraction model training method provided by the invention, the loss function is constructed based on the thought of triple loss and difficult example mining, so that the negative sample which is difficult to distinguish is paid more attention in the model training process, and the interference of the negative sample similar to the image to be recognized can be avoided when the image feature extraction model is used for visual position recognition.
(4) According to the domain self-adaptive visual position identification method provided by the invention, when the image feature extraction model is used for acquiring the feature vector of the image to be identified, the parameters of each batch of standardized layers in the model do not depend on the training set, but a plurality of images belonging to the same domain as the image to be identified are used for acquiring corresponding parameters, so that the domain self-adaptation is realized, and the robustness of visual position identification can be improved.
Detailed Description
In order to make the objects, technical solutions and advantages of the present invention more apparent, the present invention is described in further detail below with reference to the accompanying drawings and embodiments. It should be understood that the specific embodiments described herein are merely illustrative of the invention and are not intended to limit the invention. In addition, the technical features involved in the embodiments of the present invention described below may be combined with each other as long as they do not conflict with each other.
The invention provides an image feature extraction model training method, which comprises the following steps:
(1) establishing an image feature extraction model based on a deep neural network, and obtaining feature vectors of an image;
as shown in fig. 1, the image feature extraction model includes a feature extraction network and a local feature aggregation network;
the feature extraction network comprises a plurality of cascaded first networks; the first network is formed by sequentially connecting one or more second networks and a maximum pooling layer (Pool), and the maximum pooling layer is used for carrying out feature selection on images output by the previous second network; the second network comprises a convolution layer (Conv), a batch standardization layer (BN) and an activation function layer (Relu) which are sequentially connected, wherein the convolution layer is used for carrying out feature extraction on images, the batch standardization layer is used for carrying out zero-mean standardization processing on the images output by the convolution layer, and the activation function layer is used for carrying out activation processing on the images output by the batch standardization layer; in this embodiment, the convolution kernel size of the convolution layer in each second network is specifically 3 × 3; the number of the second networks included in each first network may be the same or different;
the local feature aggregation network is used for aggregating all local features in the image output by the feature extraction network so as to obtain a feature vector of the image;
in an alternative embodiment, as shown in fig. 1, a local feature aggregation network includes: a dimension-reducing convolutional layer (Conv), a Soft-max layer (Soft-max), a polymeric layer (VLAD), an inner-normalization layer (Intra-normalization), and an overall-normalization layer (L2-normalization);
the dimension reduction convolutional layer is a convolutional layer, the convolution sum of the dimension reduction convolutional layer is 1x1, and the dimension reduction convolutional layer is used for reducing the dimension of the image to be aggregated to be equal to the number of preset clustering centers so that each channel of the image to be aggregated represents the weight of the difference between a local feature and each clustering center; wherein, the image to be aggregated is the image output by the feature extraction network;
the soft-max layer is used for normalizing the weight of the difference between the local feature and each cluster center;
the aggregation layer is used for aggregating according to the local features, the clustering center and the weight after normalization to obtain a VLAD vector; the VLAD vector consists of vectors of N D dimensions, wherein N is the number of the clustering centers, and D is the dimension of the clustering centers;
let N cluster centers be represented by CluCenter ═ c1,c2,...cj,...cN]Wherein the dimension of each cluster center is D, cj(j ∈ {1,2, …, N }) represents the jth cluster center;
the local Features of each image output by the feature extraction network are n, and are expressed by Features, wherein the Features is f1,f2,...fi...fn]Wherein f isi(i ∈ {1,2, …, n }) represents the ith local feature;
the weight of the difference between the ith local feature and the jth cluster center is given by aijAs indicated, the vector VLADvector of the jth D dimension in the VLAD vector can be obtainedj(i.e., the jth element of the VLAD vector) is:
the internal normalization layer is used for normalizing the vector of each D dimension in the VLAD vector so as to enable the distribution of the vector of each D dimension to be in the same order of magnitude;
the integral normalization layer is used for serially connecting the D-dimension vectors processed by the internal normalization layer into a column vector, and then normalizing the column vector so as to enable each local feature of the image to be aggregated to be distributed in the same order of magnitude; therefore, the convergence speed of the neural network model and the accuracy of the network model can be improved;
in this embodiment, the internal normalization layer and the integral normalization layer both perform normalization operations by means of norm normalization with L2;
(2) in the standard data set, obtaining a positive sample and s negative samples of each target image, so as to form a training sample by one target image and the positive sample and the negative sample thereof, thereby obtaining a training set formed by all the training samples;
the position information of each image in the standard data set is known, and the target image is a plurality of images screened in advance in the standard data set;
the positive sample of the target image is the image which is closest to the characteristic distance of the target image in the adjacent images, and the position distance d between the target image and the adjacent images meets TNL≤d<TNH(ii) a The position distance between the target image and the negative sample thereof satisfies d ≥ TF(ii) a Wherein, TNL、TNHAnd TFAre all preset threshold values, T is more than 0NL<TNH,TNH≤TF(ii) a s is more than or equal to 1; the characteristic distance between the images is the distance between the characteristic vectors of the images;
in this embodiment, the standard dataset for model training is the TokyoTimeMachine google streetscape dataset; the data set includes images taken from a plurality of different locations, each location taken from 12 angular directions, for a total of about 47000 images, each with geographic coordinate information; in the data set, the target images are 10000 images randomly selected, that is, the total number of training samples is n is 10000; in other applications, other data sets can be selected as standard data sets according to actual application requirements;
threshold value TNL、TNHAnd TFCan be set according to the adopted standard data set and the actual application scene, and in general, T isNH≤25,25≤TF(ii) a In this embodiment, the threshold setting is specifically TNL=1,TNH=10,TF25; passing threshold TNLAnd TNHSetting the upper and lower limits of the distance between the target image and the positive sample thereof can ensure that the positive sample is similar to the target image but different from the target image, avoid overfitting the model and further ensure better model training effect;
in this embodiment, specifically, in each training sample, the number of negative samples is s-4; the training precision of the model can be improved by selecting a plurality of negative samples, so that the image feature vector acquired by the image feature extraction model has higher robustness when being used for visual position identification;
the training set train set constructed in this embodiment may be specifically expressed as:
wherein for any k-th training sample Sk,qk、pkAnd nki(i e belongs to {1,2,3,4}) respectively represents a target image, a positive sample and an ith negative sample in the training sample;
(3) and training the image feature extraction model by using a training set so as to obtain each model parameter.
According to the image feature extraction model training method, in the established image feature extraction model, after each convolution used for feature extraction, zero-mean standardization processing is carried out on the image output by the convolution layer through a Batch Normalization layer (Batch Normalization), so that the image features extracted by the image feature extraction model are distributed similarly while model training is accelerated, the problem that the model training effect is poor due to the fact that the feature distribution difference of the images in a training set is large is effectively avoided, and the problem that the robustness of visual position recognition is low when the feature distribution difference of the images is large is solved.
In order to further improve the robustness of visual location recognition, in step (3) of the image feature extraction model training method, when the image feature extraction model is trained by using a training set, the adopted loss function is specifically:
wherein,
representing a target image q
kWith its positive sample p
kThe characteristic distance between the two or more of them,
is a target image q
kWith its negative sample n
kiM is a predefined hyper-parameter, max represents taking the maximum value, and min represents taking the minimum value;
the loss function is based on the thought of triple loss, so that the characteristic distance between a target image and a positive sample is minimized and the characteristic distance between the target image and a negative sample is maximized through training; wherein by passing
The negative sample with the largest loss is selected, so that the negative sample which is difficult to distinguish is more noticed in the model training process based on the idea of difficult example mining, and the interference of the negative sample similar to the image to be recognized can be avoided when the visual position recognition is carried out by utilizing the image feature extraction model.
The invention also provides a domain-adaptive visual position recognition method based on the image feature extraction model training method, as shown in fig. 2, comprising the following steps:
determining a target domain to which an image to be identified belongs, obtaining a plurality of images at different positions in the target domain, and taking the obtained image and the image to be identified as an image to be retrieved;
taking an image to be retrieved as input, and obtaining a feature vector of each image to be retrieved by using an image feature extraction model; when the image characteristic vector is obtained, for each convolution layer, counting the mean value and the standard deviation of the characteristic graph obtained after all the images to be retrieved pass through the convolution layer, and taking the mean value and the standard deviation as the parameters of a batch standard layer behind the convolution layer; the rest model parameters in the image feature extraction model are model parameters obtained by training;
acquiring a feature vector of each image in the test data set by using an image feature extraction model; in the present embodiment, the test data set for visual position identification is specifically a tokyo247 data set, where each image carries geographic coordinate information;
obtaining an image which is closest to the characteristic distance of the image to be recognized in the test data set according to the obtained characteristic vector, and determining the position information of the image as the position information of the image to be recognized, so as to complete the visual position recognition of the image to be recognized;
the position information of each image in the test data set is known, and the domain is a factor set influencing the characteristic distribution of the image;
according to practical application, the domain can be defined according to the influence of factors such as illumination, visual angle, season and the like on the image characteristic distribution, and the characteristic distribution of the images in the same domain is similar; for example, if only light irradiation has a large influence on the feature distribution of an image, and an image photographed in the daytime has a similar feature distribution and an image photographed in the nighttime has a similar feature distribution, two domains may be divided according to the light condition; the domain is specifically defined according to which factors and the similarity degree of image feature distribution in the same domain can be determined according to actual application requirements, and only the accuracy of final visual position identification is ensured to meet the requirements;
according to the domain self-adaptive visual position recognition method, when the image feature extraction model is used for obtaining the feature vector of the image to be recognized, the parameters of each batch of standardized layers in the model do not depend on the training set, but a plurality of images belonging to the same domain with the image to be recognized are used for obtaining corresponding parameters, and the images in the same domain have similar feature distribution, so that the domain self-adaptive visual position recognition method can realize the domain self-adaptation, and can still accurately complete the visual position recognition when the difference between the feature distribution of the image in the training set and the feature distribution of the image to be recognized is large, namely, the robustness of the visual position recognition can be improved.
In the above method for recognizing a visual position, because the images in the test data set tokyo247 for recognizing a visual position and the standard data set tokyo timemachine for training a model have similar feature distributions, in this embodiment, when the feature vectors of the images in the test data set are obtained by using the image feature extraction model, the model parameters obtained by training the image feature extraction model training method are directly used to set the model parameters;
in other application scenarios, in order to avoid the dependence on the training set to the greatest extent, when the feature vector of each image in the test data set is obtained by using the image feature extraction model, the setting of the model parameters can be realized by adopting the following method: for each convolution layer, counting the mean value and the standard deviation of the characteristic diagram obtained after all images in the test data set pass through the convolution layer, and taking the mean value and the standard deviation as parameters of a batch of normalization layers behind the convolution layer; and the rest model parameters in the image feature extraction model are model parameters obtained by training.
Fig. 3 shows an example of using visual location recognition, where a training set image represents a standard data set for model training, a query image is an image to be retrieved, and a galery image is a test set database image.
The invention also provides an image feature extraction model training device, which is used for realizing the image feature extraction model training method and comprises the following steps: the system comprises a model establishing module, a training set constructing module and a model training module;
the model establishing module is used for establishing an image feature extraction model based on a deep neural network, and the image feature extraction model is used for acquiring a feature vector of an image;
the training set construction module is used for obtaining a positive sample and s negative samples of each target image in the standard data set so as to form a training sample by one target image and the positive sample and the negative sample thereof, thereby obtaining a training set formed by all the training samples;
the model training module is used for training the image feature extraction model by utilizing a training set so as to obtain each model parameter;
the image feature extraction model comprises a feature extraction network and a local feature aggregation network;
the feature extraction network comprises a plurality of cascaded first networks; the first network is formed by sequentially connecting one or more second networks and a maximum pooling layer, and the maximum pooling layer is used for carrying out feature selection on images output by the previous second networks; the second network comprises a convolution layer, a batch standardization layer and an activation function layer which are sequentially connected, wherein the convolution layer is used for carrying out feature extraction on images, the batch standardization layer is used for carrying out zero-mean standardization processing on the images output by the convolution layer, and the activation function layer is used for carrying out activation processing on the images output by the batch standardization layer;
the local feature aggregation network is used for aggregating all local features in the image output by the feature extraction network so as to obtain a feature vector of the image;
the positive sample of the target image is the image which is closest to the characteristic distance of the target image in the adjacent images, and the position distance d between the target image and the adjacent images meets TNL≤d<TNH(ii) a The position distance d between the target image and the negative sample thereof satisfies that d is more than or equal to TF;
The position information of each image in the standard data set is known, and the target image is a plurality of images screened in advance in the standard data set; the characteristic distance between the images is the distance between the characteristic vectors of the images; t isNL、TNHAnd TFAre all preset threshold values, T is more than 0NL<TNH,TNH≤TF;s≥1;
In this embodiment, the detailed implementation of each module may refer to the description of the method embodiment described above, and will not be repeated here.
The invention also provides a domain adaptive visual position recognition device, which is used for realizing the domain adaptive visual position recognition method and comprises the following steps: the system comprises a retrieval set acquisition module, a first feature extraction module, a second feature extraction module and an identification module;
the retrieval set acquisition module is used for determining a target domain to which the image to be identified belongs, acquiring a plurality of images at different positions in the target domain, and taking the acquired image and the image to be identified as the image to be retrieved;
the first feature extraction module is used for taking the images to be retrieved as input and obtaining feature vectors of the images to be retrieved by utilizing the image feature extraction model; when the image characteristic vector is obtained, for each convolution layer, counting the mean value and the standard deviation of the characteristic graph obtained after all the images to be retrieved pass through the convolution layer, and taking the mean value and the standard deviation as the parameters of a batch standard layer behind the convolution layer; the rest model parameters in the image feature extraction model are model parameters obtained by training;
the second feature extraction module is used for acquiring feature vectors of all images in the test data set by using the image feature extraction model;
the identification module is used for acquiring an image which is closest to the characteristic distance of the image to be identified in the test data set according to the characteristic vectors extracted by the first characteristic extraction module and the second characteristic extraction module, and determining the position information of the image as the position information of the image to be identified, so that the visual position identification of the image to be identified is completed;
the position information of each image in the test data set is known, and the domain is a factor set influencing the characteristic distribution of the image;
in this embodiment, the detailed implementation of each module may refer to the description of the method embodiment described above, and will not be repeated here.
It will be understood by those skilled in the art that the foregoing is only a preferred embodiment of the present invention, and is not intended to limit the invention, and that any modification, equivalent replacement, or improvement made within the spirit and principle of the present invention should be included in the scope of the present invention.