CN110175615B - 模型训练方法、域自适应的视觉位置识别方法及装置 - Google Patents
模型训练方法、域自适应的视觉位置识别方法及装置 Download PDFInfo
- Publication number
- CN110175615B CN110175615B CN201910350741.5A CN201910350741A CN110175615B CN 110175615 B CN110175615 B CN 110175615B CN 201910350741 A CN201910350741 A CN 201910350741A CN 110175615 B CN110175615 B CN 110175615B
- Authority
- CN
- China
- Prior art keywords
- image
- feature
- feature extraction
- training
- layer
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2413—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on distances to training or reference patterns
- G06F18/24133—Distances to prototypes
- G06F18/24137—Distances to cluster centroïds
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
- G06V10/44—Local feature extraction by analysis of parts of the pattern, e.g. by detecting edges, contours, loops, corners, strokes or intersections; Connectivity analysis, e.g. of connected components
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Physics & Mathematics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- General Engineering & Computer Science (AREA)
- Evolutionary Computation (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Evolutionary Biology (AREA)
- Biophysics (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Biomedical Technology (AREA)
- Health & Medical Sciences (AREA)
- Multimedia (AREA)
- Image Analysis (AREA)
Abstract
本发明公开了一种模型训练方法、域自适应的视觉位置识别方法及装置,属于计算机视觉技术领域,包括:建立基于深度神经网络的图像特征提取模型;根据标准数据集构建训练集,训练集中每个训练样本包括目标图像及其正样本和s个负样本;利用训练集对图像特征提取模型进行训练;图像特征提取模型中,特征提取网络包括级联的多个第一网络;第一网络由一个或多个第二网络以及一个极大池化层依次连接而成,极大池化层用于特征选择;第二网络包括依次连接的卷积层,用于特征提取;批标准化层,用于进行零均值标准化处理;激活函数层,用于进行激活处理;局部特征聚合网络用于聚合局部特征以得到图像的特征向量。本发明能够提高视觉位置识别的鲁棒性。
Description
技术领域
本发明属于计算机视觉技术领域,更具体地,涉及一种模型训练方法、域自适应的视觉位置识别方法及装置。
背景技术
视觉位置识别,具体是指通过对图像进行特征提取,然后根据所提取的图像特征识别图像的地理位置。在现如今大力发展自动驾驶,自主导航移动机器人的需要越来越高以及虚拟现实和增强现实越来越普遍的情况下,视觉位置识别的研究在计算机视觉领域、机器人社区及其他相关领域中均引起了广泛的关注。
在早期的计算机视觉研究时期,主要利用人工精心设计的提取图像特征点的方法提取图像特征,如尺度不变特征变换(SIFT)特征点。所提取特征的设计非常依赖经验,一些专家学者甚至历时数十年才能设计出一个比较好的特征,并且这些利用手工设计的提取图像特征点的算法在急剧的光照变化(如白天到夜间)和场景变化(场景中的行人和车辆发生编发)等情况下效果非常差,依赖这些特征的视觉位置识别方法,如视觉词袋模型(V-BOW)等,其性能也会急剧下降。近年来,随着深度学习的兴起,并被广泛应用于目标识别、目标检测、目标跟踪、语义分割等领域,一些基于深度学习的视觉位置识别方法被提了出来。例如,基于卷积神经网络的位置识别(Convolutional Neural Network-based PlaceRecognition),该方法利用深度卷积神经网络提取图像特征,由于深度卷积神经网络可以根据特定的任务进行端到端的训练,提取的图像特征更具有鲁棒性。又例如,用于弱监督位置识别的CNN架构NetVLAD(NetVLAD:CNN architecture for weakly supervised placerecognition),该方法发挥了传统的局部特征聚合(VLAD)方法的优势,有效地聚合图像的局部特征,得到紧凑的图像表达特征向量,并该方法还使的利用深度神经网络提取的图像特征更具有鲁棒性。
相比于传统的基于手工设计图像特征点的视觉位置识别方法,基于深度神经网络的视觉位置识别方法所提取的图像特征更具有鲁棒性,并且视觉位置识别较为准确。但是,深度神经网络在使用前需要进行训练,而由于视角、光照等因素的影响,用于训练的图像的特征分布与实际待识别图像的特征分布往往具有较大差异,在这种情况下,视觉位置识别的准确度得不到保证。总的来说,现有视觉位置识别方法的鲁棒性较低。
发明内容
针对现有技术的缺陷和改进需求,本发明提供了一种模型训练方法、域自适应的视觉位置识别方法及装置,其目的在于,提高视觉位置识别的鲁棒性。
为实现上述目的,按照本发明的第一方面,提供了一种图像特征提取模型训练方法,包括:
(1)建立基于深度神经网络的图像特征提取模型,用于获取图像的特征向量;
图像特征提取模型包括特征提取网络和局部特征聚合网络;
特征提取网络包括级联的多个第一网络;第一网络由一个或多个第二网络以及一个极大池化层依次连接而成,极大池化层用于对其前的第二网络输出的图像进行特征选择;第二网络包括依次连接的卷积层、批标准化层以及激活函数层,卷积层用于对图像进行特征提取,批标准化层用于对卷积层输出的图像进行零均值标准化处理,激活函数层用于对批标准化层输出的图像进行激活处理;
局部特征聚合网络用于对特征提取网络输出的图像中所有的局部特征进行聚合,从而得到图像的特征向量;
(2)在标准数据集中,获得各目标图像的正样本和s个负样本,以由一张目标图像及其正样本和负样本构成一个训练样本,从而得到由所有训练样本构成的训练集;
目标图像的正样本为其临近图像中与其特征距离最近的图像,目标图像与其临近图像的位置距离d满足TNL≤d<TNH;目标图像与其负样本的位置距离满足d≥TF;
(3)利用训练集对图像特征提取模型进行训练,从而得到各模型参数;
其中,标准数据集中各图像的位置信息已知,目标图像为标准数据集中预先筛选出的多张图像;图像间的特征距离为图像的特征向量之间的距离;TNL、TNH和TF均为预设的阈值,0<TNL<TNH,TNH≤TF;s≥1。
上述图像特征提取模型训练方法,所建立的图像特征提取模型中,每个用于特征提取的卷积之后都由一个批标准化层(Batch Normalization)对该卷积层所输出的图像进行零均值标准化处理,由此能够在加速模型训练的同时,使得经该图像特征提取模型所提取的图像特征都有相似的分布,从而有效避免由于训练集中图像的特征分布差异较大而导致模型训练效果不佳,进而能够改善图像特征分布差异较大时,视觉位置识别的鲁棒性较低的问题。
进一步地,局部特征聚合网络包括:降维卷积层、soft-max层、聚合层、内部归一化层以及整体归一化层;
降维卷积层为一层卷积层,用于将待聚合图像的维度降维到与预设的聚类中心的个数相等,以使得待聚合图像的每个通道表示局部特征与每个聚类中心之差的权重;
soft-max层用于对局部特征与每个聚类中心之差的权重进行归一化;
聚合层用于根据局部特征、聚类中心以及归一化之后的权重聚合得到VLAD(vector of locally aggregated descriptors)向量;VLAD向量由N个D维度的向量组成,N为聚类中心个数,D为聚类中心的维度;
内部归一化层用于对VLAD向量中每个D维度的向量进行归一化,以使得每个D维度的向量的分布在同一数量级;
整体归一化层用于将经过内部归一化层处理后的D维度的向量串联为一个列向量后,对该列向量进行归一化,以使得待聚合图像的每个局部特征分布在同一数量级;由此可以提高神经网络模型的收敛速度和网络模型的精度;
其中,待聚合图像为特征提取网络输出的图像。
进一步地,s>1;通过选定多个负样本能够提高模型的训练精度,使得利用上述图像特征提取模型获取的图像特征向量进行视觉位置识别时,具有较高的鲁棒性。
进一步地,步骤(3)中,利用训练集对图像特征提取模型进行训练时,所采用的损失函数为:

其中,n为训练样本总数,k为训练样本序号,i为负样本序号,qk、pk和nki分别表示第k个训练样本中的目标图像、正样本和第i个负样本, 表示目标图像qk与其正样本pk之间的特征距离,
表示目标图像qk与其正样本pk之间的特征距离, 为目标图像qk与其负样本nki之间的特征距离,m为预定义的超参数,max表示取最大值,min表示取最小值;
为目标图像qk与其负样本nki之间的特征距离,m为预定义的超参数,max表示取最大值,min表示取最小值;
上述损失函数,基于三元组损失的思想,使得通过训练,目标图像与正样本的特征距离最小化,同时到负样本的特征距离最大化;其中通过 这一项选择了损失最大的负样本,由此能够基于难例挖掘的思想,使得模型训练过程中更注意比较难于辨别的负样本,进而可以在利用上述图像特征提取模型进行视觉位置识别时,避免与待识别图像相似的负样本的干扰。
这一项选择了损失最大的负样本,由此能够基于难例挖掘的思想,使得模型训练过程中更注意比较难于辨别的负样本,进而可以在利用上述图像特征提取模型进行视觉位置识别时,避免与待识别图像相似的负样本的干扰。
按照本发明的第二方面,还提供了一种基于本发明第一方面所提供的图像特征提取模型训练方法的域自适应的视觉位置识别方法,包括:
确定待识别图像所属的目标域,并获得目标域中不同位置处的多张图像,将所获取的图像与待识别图像均作为待检索图像;
以待检索图像为输入,利用图像特征提取模型获得各待检索图像的特征向量;获取图像特征向量时,对于每一个卷积层,统计所有待检索图像经过该卷积层后,所得到的特征图的均值和标准差,作为该卷积层之后的一层批标准化层的参数;图像特征提取模型中其余的模型参数为训练所得的模型参数;
利用图像特征提取模型获取测试数据集中各图像的特征向量;
根据所获取的特征向量获得测试数据集中与待识别图像的特征距离最近的图像,并将该图像的位置信息确定为待识别图像的位置信息,从而完成对待识别图像的视觉位置识别;
其中,测试数据集中各图像的位置信息已知,域为影响图像特征分布的因素集合;
根据实际应用中,会根据光照、视角、季节等因素对图像特征分布的影响情况完成域的划定,同一个域中,图像的特征分布相似;例如,如果仅光照会对图像的特征分布产生较大的影响,并且白天拍摄的图像具有相似的特征分布,夜间拍摄的图像具有相似的特征分布,则可根据光照条件划分得到两个域;
上述域自适应的视觉位置识别方法,在利用图像特征提取模型获取待识别图像的特征向量时,模型中各批标准化层的参数不依赖于训练集,而是利用多个与该待识别图像属于同一个域的图像获取相应的参数,由于同一个域中的图像具有相似的特征分布,因此,本发明能够实现域自适应,在训练集中图像与该待识别图像的特征分布差异较大时,仍然能够准确完成视觉位置识别,也即是说,本发明能够提高视觉位置识别的鲁棒性。
进一步地,利用图像特征提取模型获取测试数据集中各图像的特征向量时,各模型参数的设置方式为:
利用训练所得的模型参数设置各模型参数;
或者,对于每一个卷积层,统计测试数据集中所有图像经过该卷积层后,所得到的特征图的均值和标准差,作为该卷积层之后的一层批标准化层的参数;图像特征提取模型中其余的模型参数为训练所得的模型参数。
按照本发明的第三方面,提供了一种图像特征提取模型训练装置,包括:模型建立模块、训练集构造模块以及模型训练模块;
模型建立模块用于建立基于深度神经网络的图像特征提取模型,图像特征提取模型用于获取图像的特征向量;
训练集构造模块用于在标准数据集中,获得各目标图像的正样本和s个负样本,以由一张目标图像及其正样本和负样本构成一个训练样本,从而得到由所有训练样本构成的训练集;
模型训练模块用于利用训练集对图像特征提取模型进行训练,从而得到各模型参数;
其中,图像特征提取模型包括特征提取网络和局部特征聚合网络;
特征提取网络包括级联的多个第一网络;第一网络由一个或多个第二网络以及一个极大池化层依次连接而成,极大池化层用于对其前的第二网络输出的图像进行特征选择;第二网络包括依次连接的卷积层、批标准化层以及激活函数层,卷积层用于对图像进行特征提取,批标准化层用于对卷积层输出的图像进行零均值标准化处理,激活函数层用于对批标准化层输出的图像进行激活处理;
局部特征聚合网络用于对特征提取网络输出的图像中所有的局部特征进行聚合,从而得到图像的特征向量;
目标图像的正样本为其临近图像中与其特征距离最近的图像,目标图像与其临近图像的位置距离d满足TNL≤d<TNH;目标图像与其负样本的位置距离d满足d≥TF;
标准数据集中各图像的位置信息已知,目标图像为标准数据集中预先筛选出的多张图像;图像间的特征距离为图像的特征向量之间的距离;TNL、TNH和TF均为预设的阈值,0<TNL<TNH,TNH≤TF;s≥1。
按照本发明的第四方面,还提供了一种基于本发明第一方面所提供的图像特征提取模型训练方法的域自适应的视觉位置识别装置,包括:检索集获取模块、第一特征提取模块、第二特征提取模块以及识别模块;
检索集获取模块用于确定待识别图像所属的目标域,并获得目标域中不同位置处的多张图像,将所获取的图像与待识别图像均作为待检索图像;
第一特征提取模块用于以待检索图像为输入,利用图像特征提取模型获得各待检索图像的特征向量;获取图像特征向量时,对于每一个卷积层,统计所有待检索图像经过该卷积层后,所得到的特征图的均值和标准差,作为该卷积层之后的一层批标准化层的参数;图像特征提取模型中其余的模型参数为训练所得的模型参数;
第二特征提取模块用于利用图像特征提取模型获取测试数据集中各图像的特征向量;
识别模块用于根据第一特征提取模块和第二特征提取模块所提取的特征向量,获得测试数据集中与待识别图像的特征距离最近的图像,并将该图像的位置信息确定为待识别图像的位置信息,从而完成对待识别图像的视觉位置识别;
其中,测试数据集中各图像的位置信息已知,域为影响图像特征分布的因素集合。
总体而言,通过本发明所构思的以上技术方案,能够取得以下有益效果:
(1)本发明所提供的图像特征提取模型训练方法,所建立的图像特征提取模型中,每个用于特征提取的卷积之后都由一个批标准化层对该卷积层所输出的图像进行零均值标准化处理,由此能够在加速模型训练的同时,使得经该图像特征提取模型所提取的图像特征都有相似的分布,从而有效避免由于训练集中图像的特征分布差异较大而导致模型训练效果不佳,进而能够改善图像特征分布差异较大时,视觉位置识别的鲁棒性较低的问题。
(2)本发明所提供的图像特征提取模型训练方法,在其优选方案中,通过选定多个负样本完成训练样本的构建,能够提高模型的训练精度,使得利用上述图像特征提取模型获取的图像特征向量进行视觉位置识别时,具有较高的鲁棒性。
(3)本发明所提供的图像特征提取模型训练方法,在其优选方案中,同时基于三元组损失和难例挖掘的思想构建损失函数,使得模型训练过程中更注意比较难于辨别的负样本,进而可以在利用上述图像特征提取模型进行视觉位置识别时,避免与待识别图像相似的负样本的干扰。
(4)本发明所提供的域自适应的视觉位置识别方法,在利用图像特征提取模型获取待识别图像的特征向量时,模型中各批标准化层的参数不依赖于训练集,而是利用多个与该待识别图像属于同一个域的图像获取相应的参数,由此实现了域自适应,从而能够提高视觉位置识别的鲁棒性。
附图说明
图1为本发明实施例提供的图像特征提取模型示意图;
图2为本发明实施例提供的域自适应的视觉位置识别方法流程图;
图3为本发明实施例提供的域自适应的视觉位置识别方法示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明所提供的图像特征提取模型训练方法,包括:
(1)建立基于深度神经网络的图像特征提取模型,用于获取图像的特征向量;
如图1所示,图像特征提取模型包括特征提取网络和局部特征聚合网络;
特征提取网络包括级联的多个第一网络;第一网络由一个或多个第二网络以及一个极大池化层(Pool)依次连接而成,极大池化层用于对其前的第二网络输出的图像进行特征选择;第二网络包括依次连接的卷积层(Conv)、批标准化层(BN)以及激活函数层(Relu),卷积层用于对图像进行特征提取,批标准化层用于对卷积层输出的图像进行零均值标准化处理,激活函数层用于对批标准化层输出的图像进行激活处理;在本实施例中,各第二网络中卷积层的卷积核大小具体为3x3;各个第一网络所包含的第二网络的个数可以相同,也可以不同;
局部特征聚合网络用于对特征提取网络输出的图像中所有的局部特征进行聚合,从而得到图像的特征向量;
在一个可选的实施方式中,如图1所示,局部特征聚合网络包括:降维卷积层(Conv)、soft-max层(Soft-max)、聚合层(VLAD)、内部归一化层(Intra-normalization)以及整体归一化层(L2-normalization);
降维卷积层为一层卷积层,其卷积和大小为1x1,用于将待聚合图像的维度降维到与预设的聚类中心的个数相等,以使得待聚合图像的每个通道表示局部特征与每个聚类中心之差的权重;其中,待聚合图像为特征提取网络输出的图像;
soft-max层用于对局部特征与每个聚类中心之差的权重进行归一化;
聚合层用于根据局部特征、聚类中心以及归一化之后的权重聚合得到VLAD向量;VLAD向量由N个D维度的向量组成,N为聚类中心个数,D为聚类中心的维度;
设聚类中心有N个,用CluCenter表示,CluCenter=|c1,c2,...cj,...cN],其中,每个聚类中心的维度为D,cj(j∈{1,2,…,N})表示第j个聚类中心;
特征提取网络输出每张图像的局部特征为n个,用Features表示,Features=[f1,f2,...fi...fn],其中,fi(i∈{1,2,…,n})表示第i个局部特征;
第i个局部特征与第j个聚类中心的差的权重用aij表示,可以得到VLAD向量中第j个D维度的向量VLADvectorj(即VLAD向量的第j个元素)为:

内部归一化层用于对VLAD向量中每个D维度的向量进行归一化,以使得每个D维度的向量的分布在同一数量级;
整体归一化层用于将经过内部归一化层处理后的D维度的向量串联为一个列向量后,对该列向量进行归一化,以使得待聚合图像的每个局部特征分布在同一数量级;由此可以提高神经网络模型的收敛速度和网络模型的精度;
在本实施例中,内部归一化层和整体归一化层均通过L2范数归一化的方法完成归一化操作;
(2)在标准数据集中,获得各目标图像的正样本和s个负样本,以由一张目标图像及其正样本和负样本构成一个训练样本,从而得到由所有训练样本构成的训练集;
其中,标准数据集中各图像的位置信息已知,目标图像为标准数据集中预先筛选出的多张图像;
目标图像的正样本为其临近图像中与其特征距离最近的图像,目标图像与其临近图像的位置距离d满足TNL≤d<TNH;目标图像与其负样本的位置距离满足d≥TF;其中,TNL、TNH和TF均为预设的阈值,0<TNL<TNH,TNH≤TF;s≥1;图像间的特征距离为图像的特征向量之间的距离;
在本实施例中,用于模型训练的标准数据集为TokyoTimeMachine谷歌街景数据集;该数据集包括采集自多个不同的位置、每个位置从12个角度方向采集的图像,总共大约47000张图像,每个图像带有地理坐标信息;在该数据集中,目标图像为随机选取的10000张图像,即训练样本总数为n=10000;在其他应用中,也可根据实际应用需求选用其他的数据集作为标准数据集;
阈值TNL、TNH和TF可根据所采用的标准数据集和实际的应用场景设定,一般情况下,TNH≤25,25≤TF;在本实施例中,阈值设置具体为TNL=1,TNH=10,TF=25;通过阈值TNL和TNH设置目标图像与其正样本间位置距离的上下限,可以保证正样本与目标图像相似但又有所区别,避免模型过拟合,从而可以保证较好的模型训练效果;
在本实施例中,具体设置每个训练样本中,负样本数量为s=4;通过选定多个负样本能够提高模型的训练精度,使得利用上述图像特征提取模型获取的图像特征向量进行视觉位置识别时,具有较高的鲁棒性;
本实施例所构建的训练集trainSet具体可表示为:

其中,对于任意第k个训练样本Sk,qk、pk和nki(i∈{1,2,3,4})分别表示该训练样本中的目标图像、正样本和第i个负样本;
(3)利用训练集对图像特征提取模型进行训练,从而得到各模型参数。
上述图像特征提取模型训练方法,所建立的图像特征提取模型中,每个用于特征提取的卷积之后都由一个批标准化层(Batch Normalization)对该卷积层所输出的图像进行零均值标准化处理,由此能够在加速模型训练的同时,使得经该图像特征提取模型所提取的图像特征都有相似的分布,从而有效避免由于训练集中图像的特征分布差异较大而导致模型训练效果不佳,进而能够改善图像特征分布差异较大时,视觉位置识别的鲁棒性较低的问题。
为了进一步提高视觉位置识别的鲁棒性,上述图像特征提取模型训练方法的步骤(3)中,利用训练集对图像特征提取模型进行训练时,所采用的损失函数具体为:

其中, 表示目标图像qk与其正样本pk之间的特征距离,
表示目标图像qk与其正样本pk之间的特征距离, 为目标图像qk与其负样本nki之间的特征距离,m为预定义的超参数,max表示取最大值,min表示取最小值;
为目标图像qk与其负样本nki之间的特征距离,m为预定义的超参数,max表示取最大值,min表示取最小值;
上述损失函数,基于三元组损失的思想,使得通过训练,目标图像与正样本的特征距离最小化,同时到负样本的特征距离最大化;其中通过 这一项选择了损失最大的负样本,由此能够基于难例挖掘的思想,使得模型训练过程中更注意比较难于辨别的负样本,进而可以在利用上述图像特征提取模型进行视觉位置识别时,避免与待识别图像相似的负样本的干扰。
这一项选择了损失最大的负样本,由此能够基于难例挖掘的思想,使得模型训练过程中更注意比较难于辨别的负样本,进而可以在利用上述图像特征提取模型进行视觉位置识别时,避免与待识别图像相似的负样本的干扰。
本发明还提供了一种基于上述图像特征提取模型训练方法的域自适应的视觉位置识别方法,如图2所示,包括:
确定待识别图像所属的目标域,并获得目标域中不同位置处的多张图像,将所获取的图像与待识别图像均作为待检索图像;
以待检索图像为输入,利用图像特征提取模型获得各待检索图像的特征向量;获取图像特征向量时,对于每一个卷积层,统计所有待检索图像经过该卷积层后,所得到的特征图的均值和标准差,作为该卷积层之后的一层批标准化层的参数;图像特征提取模型中其余的模型参数为训练所得的模型参数;
利用图像特征提取模型获取测试数据集中各图像的特征向量;在本实施例中,用于视觉位置识别的测试数据集具体为tokyo247数据集,其中每张图像带有地理坐标信息;
根据所获取的特征向量获得测试数据集中与待识别图像的特征距离最近的图像,并将该图像的位置信息确定为待识别图像的位置信息,从而完成对待识别图像的视觉位置识别;
其中,测试数据集中各图像的位置信息已知,域为影响图像特征分布的因素集合;
根据实际应用中,会根据光照、视角、季节等因素对图像特征分布的影响情况完成域的划定,同一个域中,图像的特征分布相似;例如,如果仅光照会对图像的特征分布产生较大的影响,并且白天拍摄的图像具有相似的特征分布,夜间拍摄的图像具有相似的特征分布,则可根据光照条件划分得到两个域;具体根据哪些因素完成域的划定,以及同一个域中图像特征分布的相似程度,可根据实际的应用需求确定,只要保证最终视觉位置识别的精度满足要求即可;
上述域自适应的视觉位置识别方法,在利用图像特征提取模型获取待识别图像的特征向量时,模型中各批标准化层的参数不依赖于训练集,而是利用多个与该待识别图像属于同一个域的图像获取相应的参数,由于同一个域中的图像具有相似的特征分布,因此,本发明能够实现域自适应,在训练集中图像与该待识别图像的特征分布差异较大时,仍然能够准确完成视觉位置识别,也即是说,本发明能够提高视觉位置识别的鲁棒性。
在上述视觉位置识别方法中,由于用于视觉位置识别的测试数据集tokyo247与用于模型训练的标准数据集TokyoTimeMachine中图像具有相似的特征分布,因此,在本实施例中,利用图像特征提取模型获取测试数据集中各图像的特征向量时,直接利用上述图像特征提取模型训练方法训练所得的模型参数设置各模型参数;
在其他应用场景中,为了最大程度上避免对训练集的依赖,在利用图像特征提取模型获取测试数据集中各图像的特征向量时,还可以采用如下方式实现对模型参数的设置:对于每一个卷积层,统计测试数据集中所有图像经过该卷积层后,所得到的特征图的均值和标准差,作为该卷积层之后的一层批标准化层的参数;图像特征提取模型中其余的模型参数为训练所得的模型参数。
图3所示为利用进行视觉位置识别的一个示例,其中,训练集图像表示用于模型训练的标准数据集,query图像为待检索图像,gallery图像为测试集数据库图像。
本发明还提供了一种图像特征提取模型训练装置,用于实现上述图像特征提取模型训练方法,该装置包括:模型建立模块、训练集构造模块以及模型训练模块;
模型建立模块用于建立基于深度神经网络的图像特征提取模型,图像特征提取模型用于获取图像的特征向量;
训练集构造模块用于在标准数据集中,获得各目标图像的正样本和s个负样本,以由一张目标图像及其正样本和负样本构成一个训练样本,从而得到由所有训练样本构成的训练集;
模型训练模块用于利用训练集对图像特征提取模型进行训练,从而得到各模型参数;
其中,图像特征提取模型包括特征提取网络和局部特征聚合网络;
特征提取网络包括级联的多个第一网络;第一网络由一个或多个第二网络以及一个极大池化层依次连接而成,极大池化层用于对其前的第二网络输出的图像进行特征选择;第二网络包括依次连接的卷积层、批标准化层以及激活函数层,卷积层用于对图像进行特征提取,批标准化层用于对卷积层输出的图像进行零均值标准化处理,激活函数层用于对批标准化层输出的图像进行激活处理;
局部特征聚合网络用于对特征提取网络输出的图像中所有的局部特征进行聚合,从而得到图像的特征向量;
目标图像的正样本为其临近图像中与其特征距离最近的图像,目标图像与其临近图像的位置距离d满足TNL≤d<TNH;目标图像与其负样本的位置距离d满足d≥TF;
标准数据集中各图像的位置信息已知,目标图像为标准数据集中预先筛选出的多张图像;图像间的特征距离为图像的特征向量之间的距离;TNL、TNH和TF均为预设的阈值,0<TNL<TNH,TNH≤TF;s≥1;
在本实施例中,各模块的具体实施方式,可参考上述方法实施例中的描述,在此将不再复述。
本发明还提供了一种域自适应的视觉位置识别装置,用于实现上述域自适应的视觉位置识别方法,该装置包括:检索集获取模块、第一特征提取模块、第二特征提取模块以及识别模块;
检索集获取模块用于确定待识别图像所属的目标域,并获得目标域中不同位置处的多张图像,将所获取的图像与待识别图像均作为待检索图像;
第一特征提取模块用于以待检索图像为输入,利用图像特征提取模型获得各待检索图像的特征向量;获取图像特征向量时,对于每一个卷积层,统计所有待检索图像经过该卷积层后,所得到的特征图的均值和标准差,作为该卷积层之后的一层批标准化层的参数;图像特征提取模型中其余的模型参数为训练所得的模型参数;
第二特征提取模块用于利用图像特征提取模型获取测试数据集中各图像的特征向量;
识别模块用于根据第一特征提取模块和第二特征提取模块所提取的特征向量,获得测试数据集中与待识别图像的特征距离最近的图像,并将该图像的位置信息确定为待识别图像的位置信息,从而完成对待识别图像的视觉位置识别;
其中,测试数据集中各图像的位置信息已知,域为影响图像特征分布的因素集合;
在本实施例中,各模块的具体实施方式,可参考上述方法实施例中的描述,在此将不再复述。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
Claims (6)
1.一种图像特征提取模型训练方法,其特征在于,包括:
(1)建立基于深度神经网络的图像特征提取模型,用于获取图像的特征向量;
所述图像特征提取模型包括特征提取网络和局部特征聚合网络;
所述特征提取网络包括级联的多个第一网络;所述第一网络由一个或多个第二网络以及一个极大池化层依次连接而成,所述极大池化层用于对其前的第二网络输出的图像进行特征选择;所述第二网络包括依次连接的卷积层、批标准化层以及激活函数层,所述卷积层用于对图像进行特征提取,所述批标准化层用于对所述卷积层输出的图像进行零均值标准化处理,所述激活函数层用于对所述批标准化层输出的图像进行激活处理;
所述局部特征聚合网络用于对所述特征提取网络输出的图像中所有的局部特征进行聚合,从而得到图像的特征向量;
(2)在标准数据集中获得各目标图像的正样本和s个负样本,以由一张目标图像及其正样本和负样本构成一个训练样本,从而得到由所有训练样本构成的训练集;
目标图像的正样本为其临近图像中与其特征距离最近的图像,目标图像与其临近图像的位置距离d1满足TNL≤d1≤TNH;目标图像与其负样本的位置距离d2满足d2≥TF;
(3)利用所述训练集对所述图像特征提取模型进行训练,从而得到各模型参数;
其中,所述标准数据集中各图像的位置信息已知,目标图像为所述标准数据集中预先筛选出的多张图像;图像间的特征距离为图像的特征向量之间的距离;TNL、TNH和TF均为预设的阈值,0<TNL<TNH,TNH≤TF;s>1;
所述步骤(3)中,利用所述训练集对所述图像特征提取模型进行训练时,所采用的损失函数为:

其中,n为训练样本总数,k为训练样本序号,i为负样本序号,qk、pk和nki分别表示第k个训练样本中的目标图像、正样本和第i个负样本, 表示目标图像qk与其正样本pk之间的特征距离,
表示目标图像qk与其正样本pk之间的特征距离, 为目标图像qk与其负样本nki之间的特征距离,m为预定义的超参数,max表示取最大值,min表示取最小值。
为目标图像qk与其负样本nki之间的特征距离,m为预定义的超参数,max表示取最大值,min表示取最小值。
2.如权利要求1所述的图像特征提取模型训练方法,其特征在于,所述局部特征聚合网络包括:降维卷积层、soft-max层、聚合层、内部归一化层以及整体归一化层;所述降维卷积层为一层卷积层,用于将待聚合图像的维度降维到与预设的聚类中心的个数相等,以使得所述待聚合图像的每个通道表示局部特征与每个聚类中心之差的权重;
所述soft-max层用于对局部特征与每个聚类中心之差的权重进行归一化;
所述聚合层用于根据局部特征、聚类中心以及归一化之后的权重聚合得到VLAD向量;
所述VLAD向量由N个D维度的向量组成,N为聚类中心个数,D为聚类中心的维度;
所述内部归一化层用于对所述VLAD向量中每个D维度的向量进行归一化,以使得每个D维度的向量的分布在同一数量级;
所述整体归一化层用于将经过所述内部归一化层处理后的D维度的向量串联为一个列向量后,对该列向量进行归一化,以使得所述待聚合图像的每个局部特征分布在同一数量级;
其中,所述待聚合图像为所述特征提取网络输出的图像。
3.一种基于权利要求1-2任一项所述的图像特征提取模型训练方法的域自适应的视觉位置识别方法,其特征在于,包括:
确定待识别图像所属的目标域,并获得所述目标域中不同位置处的多张图像,将所获取的图像与所述待识别图像均作为待检索图像;
以所述待检索图像为输入,利用所述图像特征提取模型获得各待检索图像的特征向量;获取图像特征向量时,对于每一个卷积层,统计所有待检索图像经过该卷积层后,所得到的特征图的均值和标准差,作为该卷积层之后的一层批标准化层的参数;所述图像特征提取模型中其余的模型参数为训练所得的模型参数;
利用所述图像特征提取模型获取测试数据集中各图像的特征向量;
根据所获取的特征向量获得所述测试数据集中与所述待识别图像的特征距离最近的图像,并将该图像的位置信息确定为所述待识别图像的位置信息,从而完成对所述待识别图像的视觉位置识别;
其中,所述测试数据集中各图像的位置信息已知,域为影响图像特征分布的因素集合。
4.如权利要求3所述的域自适应的视觉位置识别方法,其特征在于,利用所述图像特征提取模型获取测试数据集中各图像的特征向量时,各模型参数的设置方式为:
利用训练所得的模型参数设置各模型参数;
或者,对于每一个卷积层,统计所述测试数据集中所有图像经过该卷积层后,所得到的特征图的均值和标准差,作为该卷积层之后的一层批标准化层的参数;所述图像特征提取模型中其余的模型参数为训练所得的模型参数。
5.一种图像特征提取模型训练装置,其特征在于,包括:模型建立模块、训练集构造模块以及模型训练模块;
所述模型建立模块用于建立基于深度神经网络的图像特征提取模型,所述图像特征提取模型用于获取图像的特征向量;
所述训练集构造模块用于在标准数据集中,获得各目标图像的正样本和s个负样本,以由一张目标图像及其正样本和负样本构成一个训练样本,从而得到由所有训练样本构成的训练集;
所述模型训练模块用于利用所述训练集对所述图像特征提取模型进行训练,从而得到各模型参数;
其中,所述图像特征提取模型包括特征提取网络和局部特征聚合网络;
所述特征提取网络包括级联的多个第一网络;所述第一网络由一个或多个第二网络以及一个极大池化层依次连接而成,所述极大池化层用于对其前的第二网络输出的图像进行特征选择;所述第二网络包括依次连接的卷积层、批标准化层以及激活函数层,所述卷积层用于对图像进行特征提取,所述批标准化层用于对所述卷积层输出的图像进行零均值标准化处理,所述激活函数层用于对所述批标准化层输出的图像进行激活处理;
所述局部特征聚合网络用于对所述特征提取网络输出的图像中所有的局部特征进行聚合,从而得到图像的特征向量;
目标图像的正样本为其临近图像中与其特征距离最近的图像,目标图像与其临近图像的位置距离d1满足TNL≤d1≤TNH;目标图像与其负样本的位置距离d2满足d2≥TF;
所述标准数据集中各图像的位置信息已知,目标图像为所述标准数据集中预先筛选出的多张图像;图像间的特征距离为图像的特征向量之间的距离;TNL、TNH和TF均为预设的阈值,0<TNL<TNH,TNH≤TF;s>1;
所述模型训练模块利用所述训练集对所述图像特征提取模型进行训练时,所采用的损失函数为:

其中,n为训练样本总数,k为训练样本序号,i为负样本序号,qk、pk和nki分别表示第k个训练样本中的目标图像、正样本和第i个负样本, 表示目标图像qk与其正样本pk之间的特征距离,
表示目标图像qk与其正样本pk之间的特征距离,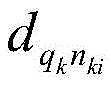 为目标图像qk与其负样本nki之间的特征距离,m为预定义的超参数,max表示取最大值,min表示取最小值。
为目标图像qk与其负样本nki之间的特征距离,m为预定义的超参数,max表示取最大值,min表示取最小值。
6.一种基于权利要求1-2任一项所述的图像特征提取模型训练方法的域自适应的视觉位置识别装置,其特征在于,包括:检索集获取模块、第一特征提取模块、第二特征提取模块以及识别模块;
所述检索集获取模块用于确定待识别图像所属的目标域,并获得所述目标域中不同位置处的多张图像,将所获取的图像与所述待识别图像均作为待检索图像;
所述第一特征提取模块用于以所述待检索图像为输入,利用所述图像特征提取模型获得各待检索图像的特征向量;获取图像特征向量时,对于每一个卷积层,统计所有待检索图像经过该卷积层后,所得到的特征图的均值和标准差,作为该卷积层之后的一层批标准化层的参数;所述图像特征提取模型中其余的模型参数为训练所得的模型参数;
所述第二特征提取模块用于利用所述图像特征提取模型获取测试数据集中各图像的特征向量;
所述识别模块用于根据所述第一特征提取模块和所述第二特征提取模块所提取的特征向量,获得所述测试数据集中与所述待识别图像的特征距离最近的图像,并将该图像的位置信息确定为所述待识别图像的位置信息,从而完成对所述待识别图像的视觉位置识别;
其中,所述测试数据集中各图像的位置信息已知,域为影响图像特征分布的因素集合。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910350741.5A CN110175615B (zh) | 2019-04-28 | 2019-04-28 | 模型训练方法、域自适应的视觉位置识别方法及装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910350741.5A CN110175615B (zh) | 2019-04-28 | 2019-04-28 | 模型训练方法、域自适应的视觉位置识别方法及装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN110175615A CN110175615A (zh) | 2019-08-27 |
| CN110175615B true CN110175615B (zh) | 2021-01-01 |
Family
ID=67690216
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201910350741.5A Expired - Fee Related CN110175615B (zh) | 2019-04-28 | 2019-04-28 | 模型训练方法、域自适应的视觉位置识别方法及装置 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN110175615B (zh) |
Families Citing this family (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112541515B (zh) * | 2019-09-23 | 2024-12-03 | 北京京东乾石科技有限公司 | 模型训练方法、驾驶数据处理方法、装置、介质和设备 |
| CN112906724B (zh) * | 2019-11-19 | 2024-09-13 | 华为技术有限公司 | 一种图像处理装置、方法、介质及系统 |
| CN110866140B (zh) * | 2019-11-26 | 2024-02-02 | 腾讯科技(深圳)有限公司 | 图像特征提取模型训练方法、图像搜索方法及计算机设备 |
| CN111627065B (zh) * | 2020-05-15 | 2023-06-20 | Oppo广东移动通信有限公司 | 一种视觉定位方法及装置、存储介质 |
| CN111914712B (zh) * | 2020-07-24 | 2024-02-13 | 合肥工业大学 | 一种铁路地面轨道场景目标检测方法及系统 |
| CN112380319B (zh) * | 2020-11-12 | 2023-10-17 | 平安科技(深圳)有限公司 | 一种模型训练的方法及相关装置 |
| CN112328891B (zh) * | 2020-11-24 | 2023-08-01 | 北京百度网讯科技有限公司 | 训练搜索模型的方法、搜索目标对象的方法及其装置 |
| CN112733701A (zh) * | 2021-01-07 | 2021-04-30 | 中国电子科技集团公司信息科学研究院 | 一种基于胶囊网络的鲁棒场景识别方法及系统 |
| CN115345930B (zh) * | 2021-05-12 | 2026-01-16 | 浙江菜鸟供应链管理有限公司 | 模型训练方法、视觉定位方法、装置和设备 |
| CN113591771B (zh) * | 2021-08-10 | 2024-03-08 | 武汉中电智慧科技有限公司 | 一种多场景配电室物体检测模型的训练方法和设备 |
| CN115761246A (zh) * | 2022-11-21 | 2023-03-07 | Oppo广东移动通信有限公司 | 特征提取模型的训练方法、信息推荐方法、装置和设备 |
| CN116468784B (zh) * | 2023-04-10 | 2025-12-16 | 哈尔滨工业大学 | 一种基于注意力压缩编码特征的视觉位置识别方法、系统及装置 |
| CN116863164A (zh) * | 2023-07-03 | 2023-10-10 | 浙江大学 | 一种视觉位置识别方法、电子设备、介质 |
| CN119359802B (zh) * | 2024-09-26 | 2025-10-03 | 浙江大学 | 一种基础视觉模型的图像位置识别方法和装置 |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107122712A (zh) * | 2017-03-27 | 2017-09-01 | 大连大学 | 基于卷积神经网络和双向局部特征聚合描述向量的掌纹图像识别方法 |
| CN107767378A (zh) * | 2017-11-13 | 2018-03-06 | 浙江中医药大学 | 基于深度神经网络的gbm多模态磁共振图像分割方法 |
| CN107967457A (zh) * | 2017-11-27 | 2018-04-27 | 全球能源互联网研究院有限公司 | 一种适应视觉特征变化的地点识别与相对定位方法及系统 |
| WO2018184195A1 (en) * | 2017-04-07 | 2018-10-11 | Intel Corporation | Joint training of neural networks using multi-scale hard example mining |
| CN108647577A (zh) * | 2018-04-10 | 2018-10-12 | 华中科技大学 | 一种自适应难例挖掘的行人重识别模型、方法与系统 |
| CN109684977A (zh) * | 2018-12-18 | 2019-04-26 | 成都三零凯天通信实业有限公司 | 一种基于端到端深度学习的视图地标检索方法 |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10025976B1 (en) * | 2016-12-28 | 2018-07-17 | Konica Minolta Laboratory U.S.A., Inc. | Data normalization for handwriting recognition |
-
2019
- 2019-04-28 CN CN201910350741.5A patent/CN110175615B/zh not_active Expired - Fee Related
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107122712A (zh) * | 2017-03-27 | 2017-09-01 | 大连大学 | 基于卷积神经网络和双向局部特征聚合描述向量的掌纹图像识别方法 |
| WO2018184195A1 (en) * | 2017-04-07 | 2018-10-11 | Intel Corporation | Joint training of neural networks using multi-scale hard example mining |
| CN107767378A (zh) * | 2017-11-13 | 2018-03-06 | 浙江中医药大学 | 基于深度神经网络的gbm多模态磁共振图像分割方法 |
| CN107967457A (zh) * | 2017-11-27 | 2018-04-27 | 全球能源互联网研究院有限公司 | 一种适应视觉特征变化的地点识别与相对定位方法及系统 |
| CN108647577A (zh) * | 2018-04-10 | 2018-10-12 | 华中科技大学 | 一种自适应难例挖掘的行人重识别模型、方法与系统 |
| CN109684977A (zh) * | 2018-12-18 | 2019-04-26 | 成都三零凯天通信实业有限公司 | 一种基于端到端深度学习的视图地标检索方法 |
Non-Patent Citations (4)
| Title |
|---|
| Adaptive Batch Normalization for practical domain adaptation;Yanghao Li等;《Pattern Recognition》;20180831;第80卷;第111-112页,图2 * |
| NetVLAD: CNN architecture for weakly supervised place recognition;Relja Arandjelovic 等;《IEEE Transactions on Pattern Analysis and Machine Intelligence》;20180131;第40卷(第6期);第5299-5302页,图2 * |
| 基于卷积神经网络的位置识别;王丽君 等;《电子科技》;20170115;第30卷(第1期);104-106,114 * |
| 基于卷积神经网络的视觉位置识别方法;仇晓松 等;《计算机工程与设计》;20190131;第40卷(第1期);223-229 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN110175615A (zh) | 2019-08-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110175615B (zh) | 模型训练方法、域自适应的视觉位置识别方法及装置 | |
| CN110209859B (zh) | 地点识别及其模型训练的方法和装置以及电子设备 | |
| Jin Kim et al. | Learned contextual feature reweighting for image geo-localization | |
| Li et al. | SAR image change detection using PCANet guided by saliency detection | |
| CN114279433B (zh) | 地图数据自动化生产方法、相关装置及计算机程序产品 | |
| CN113705596B (zh) | 图像识别方法、装置、计算机设备和存储介质 | |
| CN110188225B (zh) | 一种基于排序学习和多元损失的图像检索方法 | |
| CN111310662B (zh) | 一种基于集成深度网络的火焰检测识别方法及系统 | |
| CN107679078A (zh) | 一种基于深度学习的卡口图像车辆快速检索方法及系统 | |
| CN111582178B (zh) | 基于多方位信息和多分支神经网络车辆重识别方法及系统 | |
| CN113743251B (zh) | 一种基于弱监督场景的目标搜索方法及装置 | |
| CN112084895B (zh) | 一种基于深度学习的行人重识别方法 | |
| CN110689043A (zh) | 一种基于多重注意力机制的车辆细粒度识别方法及装置 | |
| CN114429565B (zh) | 一种基于跨场景自适应学习的高光谱图像分类方法 | |
| CN111950498A (zh) | 一种基于端到端实例分割的车道线检测方法及装置 | |
| CN114927236A (zh) | 一种面向多重目标图像的检测方法及系统 | |
| CN113283404B (zh) | 行人属性识别方法、装置、电子设备及存储介质 | |
| CN109871892A (zh) | 一种基于小样本度量学习的机器人视觉认知系统 | |
| CN108830254B (zh) | 一种基于数据均衡策略和密集注意网络的细粒度车型检测与识别方法 | |
| CN110991349A (zh) | 一种基于度量学习的轻量级车辆属性识别方法 | |
| CN114596546A (zh) | 车辆重识别方法、装置及计算机、可读存储介质 | |
| CN110188864B (zh) | 基于分布表示和分布度量的小样本学习方法 | |
| CN112668662B (zh) | 基于改进YOLOv3网络的野外山林环境目标检测方法 | |
| CN117456480A (zh) | 一种基于多源信息融合的轻量化车辆再辨识方法 | |
| CN110619280B (zh) | 一种基于深度联合判别学习的车辆重识别方法及装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20210101 |