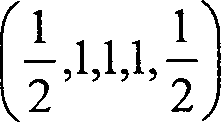-
Gebiet der Erfindung
-
Diese Erfindung bezieht sich auf
ein Verfahren und ein System zum Kombinieren der Informationen aus
mehreren Videofeldern in ein einzelnes, hochqualitatives Standbild.
-
Hintergrund
der Erfindung
-
Individuelle Felder aus Videoquellen
weisen allgemein folgende Nachteile auf:
Sensor-, Band- und Übertragungs-Rauschen;
Luminanz-Aliasing
aufgrund von nicht ausreichend dichter räumlicher Abtastung der optischen
Szene;
Chrominanz-Aliasing aufgrund von nicht ausreichend dichter
räumlicher
Abtastung bestimmter Farbkomponenten in der optischen Szene (tritt
häufig
bei einzelnen CCD-Videokameras auf, die nur eine Farbkomponente an
jeder Pixelposition erfassen können);
relativ
schlechte Auflösung.
-
Videoquellen weisen jedoch den Vorteil
auf, daß viele
Bilder derselben Szene verfügbar
sind, üblicherweise
mit relativ geringen Verschiebungen der Szenenelemente zwischen aufeinanderfolgenden
Feldern. Nach einer geeigneten Bewegungskompensation können diese
mehreren Bilder kombiniert werden, um ein Standbild mit weniger
Rauschen zu erzeugen. Vielleicht noch wichtiger jedoch ist, daß das Vorhandensein
von Bewegung ermöglicht,
daß eine
effektiv dichtere Abtastung der Szene vorliegt als von einem einzelnen
Feld verfügbar
ist. Dies eröffnet
die Möglichkeit
einer Aliasing-Entfernung
sowie einer Auflösungsverbesserung.
-
Während
analoges Video betrachtet wird, treffen viele der nachfolgenden
Beobachtungen ferner auf eine Vielzahl von digitalen Videoquellen
zu. Eine Beobachtung ist, daß die
Auflösung
der Chrominanzkomponenten bedeutend geringer ist als die der Luminanzkomponenten.
Genauer gesagt ist die horizontale Chrominanzauflösung einer
NTSC-Rundsendevideoquelle (NTSC = National Television System Standard)
ungefähr 1/7
der Luminanz. Ferner, obwohl der NTSC-Standard die vertikale Auflösung der
Chrominanzkomponenten nicht unter die der Luminanzkomponenten einschränkt, halbieren
die meisten bekannten Videokameras von Natur aus die vertikale Chrominanzauflösung aufgrund
ihres einzelnen CCD-Entwurfs. Da die Chrominanzkomponenten sehr
wenig räumliche
Informationen im Vergleich zu der Luminanzkomponente tragen, könnte sich
ein Verfahren auf Auflösungsverbesserungsversuche
für den
Luminanzkanal allein konzentrieren. Ferner kann der Rechenaufwand
des Mehrfachfeld-Verbesserungssystems reduziert werden, durch Arbeiten
mit einem groberen Satz von Chrominanzabtastwerten als jenen, die
für die
Luminanzkomponente verwendet werden.
-
Eine zweite Beobachtung, die analoges
Video betrifft ist, daß die
Luminanzkomponente häufig
in der vertikalen Richtung schwer verfälscht ist, aber dies in der
horizontalen Richtung weniger ist. Dies ist zu erwarten, da die
optische Bandbreite sowohl in der horizontalen als auch in der vertikalen
Richtung ungefähr
gleich ist, aber die vertikale Abtastdichte ist weniger als die
Hälfte
der horizontalen Abtastdichte. Ferner verwenden neuere Videokameras
CCD-Sensoren mit
einer ansteigenden Anzahl von Sensoren pro Zeile, wohingegen die Anzahl
von Sensorzeilen durch den NTSC-Standard gesetzt ist. Empirische
Untersuchungen bestätigen
die Erwartung, daß hohe
Horizontalfrequenzen ein vernachlässigbares Aliasing erfahren,
wohingegen hohe Vertikalfrequenzen einem beträchtlichen Aliasing unterliegen.
Somit ist es wahrscheinlich nicht möglich, die horizontale Auflösung des
abschließenden
Standbildes durch eine Mehrfachfeldverarbeitung zu verbessern. Es sollte
jedoch möglich
sein, Aliasingkomponenten zu „entpacken", um die vertikale
Auflösung
zu verbessern und die störenden
Aliasing-Artefakte
(„Zacken") um nicht vertikale
Kanten zu entfernen. Was benötigt
wird ist somit ein Verfahren und ein System zum Kombinieren von
Informationen aus mehreren Videofeldern in ein einzelnes Hochqualitätsstandbild.
-
Die
US
5,341,174 umfaßt
ein Verfahren und eine Vorrichtung zum Erzeugen einer Hochauflösungskopie
eines Zielvideorahmens, der aus einer Sequenz von Videorahmen ausgewählt ist.
Der Prozeß beginnt
mit dem Erzeugen eines Referenzzielrahmens aus jeder zweiten Zeile
des Zielrahmens, wobei der Verschachtelungsmodus der meisten Videokameras
berücksichtigt
wird. Ein vergrößerter Zielrahmen
wird ebenfalls erzeugt, wobei der vergrößerte Zielrahmen eine bestimmte
Auflösung
aufweist, die mit der einer Hochauflösungsdruckvorrichtung übereinstimmt.
Der vergrößerte Zielrahmen
wird durch Zuweisen von Pixeln des Zielrahmens oder Pixeln von früheren oder
späteren
Rahmen zu Pixelpositionen in dem vergrößerten Zielrahmen erzeugt.
Die Zuweisung wird durch Erzeugen von Bewegungsvektoren durchgeführt, die
die Verschiebung von Pixeln zwischen dem früheren und späteren Rahmen
und dem Referenzzielrahmen anzeigen und durch Verwenden dieser Bewegungsvektoren,
um zu bestimmen, welche Pixel des früheren und späteren Rahmens
zu einer jeweiligen Pixelposition in dem Referenzzielrahmen gehören. Dadurch
werden nicht zugewiesene Pixelpositionen des vergrößerten Zielrahmens
zu jeweiligen Pixeln in dem Zielrahmen oder dem früheren oder
späteren
Rahmen zugewiesen. Somit wird der vergrößerte Zielrahmen durch die
Zuweisung zu jeweiligen Pixeln erzeugt und nicht durch Bilden eines
gewichteten Durchschnittsbildes aus den vor-interpolierten Videorahmen. Deshalb
unterliegt der Prozeß aus
der
US 5,341,174 Artefakten
und Rauschen.
-
Es ist eine Aufgabe der vorliegenden
Erfindung, ein Verfahren und eine Vorrichtung zum Erzeugen eines
verbesserten Standbildes zu liefern, das Bilder höherer Qualität erzeugt.
-
Diese Aufgabe wird durch ein Verfahren
gemäß Anspruch
1 und eine Vorrichtung gemäß Anspruch
10 gelöst.
-
Zusammenfassung
der Erfindung
-
Diese Erfindungsoffenbarung beschreibt
ein System zum Kombinieren der Informationen aus mehreren Videofeldern
in ein einzelnes Hochqualitätsstandbild.
Eines der Felder wird ausgewählt,
um die Referenz zu sein, und die verbleibenden Felder werden als
Hilfs-Felder identifiziert. Das System reduziert das Rauschen sowie
die Luminanz- und Farb- Aliasingartefakte,
die dem Referenzfeld zugeordnet sind, während dessen Auflösung verbessert
wird, durch Verwenden von Informationen aus den Hilfsfeldern.
-
Eine Ausrichtungsabbildung wird für das Referenzfeld
aufgebaut und wird verwendet, um dieses Feld mit bis zu vier Mal
der vertikalen Feldauflösung
direktional zu interpolieren.
-
Bewegungsabbildungen sind aufgebaut,
um die lokale Verschiebung zwischen Merkmalen in dem Referenzfeld
und entsprechenden Merkmalen in jedem der Hilfsfelder zu modellieren.
Die Bewegung wird auf Ein-Viertel-Pixelgenauigkeit in der vertikalen
Richtung und Ein-Halb-Pixel-Genauigkeit in der horizontalen Richtung
berechnet, unter Verwendung des direktional interpolierten Referenzfeldes,
um die Teilpixelsuche zu erreichen. Die Bewegungsabbildungen werden
erstens verwendet, um eine Ausrichtungsabbildung für jedes der
Hilfsfelder direkt von der Ausrichtungsabbildung des Referenzfeldes
herzuleiten (es wird darauf hingewiesen, daß Ausrichtungsabbildungen für jedes
Feld separat berechnet werden könnten,
wenn der Rechenaufwand nicht als übermäßig betrachtet werden würde) und
später,
um die Einlagerung von Informationen aus den Hilfsfeldern in das
Referenzfeld zu führen.
-
Die Hilfsfelder werden dann direktional
auf dieselbe Auflösung
interpoliert wie das interpolierte Referenzfeld, unter Verwendung
ihrer hergeleiteten Ausrichtungsabbildungen.
-
Eine Misch-Maske wird für jedes
Hilfsfeld bestimmt, um Pixel auszublenden, die in dem abschließenden verbesserten
Standbild nicht verwendet werden sollten; die ausgeblendeten Pixel
entsprechen allgemein Regionen, in denen Bewe gungsabbildungen die
Beziehung zwischen dem Referenz- und den Hilfs-Feldern nicht korrekt
modellieren. Solche Regionen können
z. B. einen nicht abgedeckten Hintergrund umfassen.
-
Ein gewichteter Durchschnitt wird
aus den Referenzfeldpixeln und den bewegungskompensierten Hilfsfeldpixeln
erzeugt, die nicht ausgeblendet wurden. Die Gewichte, die dieser
gewichteten Mittelungsoperation zugeordnet sind, sind räumlich variierend
und abhängig
von den Misch-Masken und den aufgezeichneten Verschiebungen in den
Bewegungsabbildungen. Im Gegensatz zu herkömmlichen Feldmittelungstechniken zerstört dieser
Lösungsansatz
eine verfügbare
Bildauflösung
bei dem Prozeß des
Entfernens von Aliasing-Artefakten
nicht.
-
Das abschließende Standbild wird nach einer
horizontalen Interpolation durch einen zusätzlichen Faktor von 2 erhalten
(um das korrekte Aspektverhältnis
nach der oben beschriebenen vierfachen vertikalen Interpolation
zu erhalten), und nach einer optionalen Nachverarbeitungsoperation,
die das Bild schärft,
das aus dem oben beschriebenen gewichteten Mittelungsprozeß gebildet
wird. Die oben beschriebenen Schritte werden gewissermaßen für die Chrominanzkomponenten
modifiziert, um die Tatsache zu reflektieren, daß diese Komponenten viel weniger
Raumfrequenzinhalt aufweisen als die Luminanzkomponente.
-
Eine wichtige Eigenschaft dieses
Bildverbesserungssystems ist, daß dasselbe mit einer Anzahl
von Videofeldern arbeiten kann. Wenn nur ein Feld geliefert wird,
verwendet das System die oben erwähnte fortschrittliche Richtungsinterpolationstechnik.
Wenn zusätzliche
Felder verfügbar
sind, werden dieselben direktional interpoliert und in das interpolierte
Referenzfeld zusammengeführt,
um den Raumfrequenzinhalt fortschreitend zu verbessern, während Rauschen
und andere Artefakte verringert werden. In dem speziellen Fall, in
dem zwei Felder verfügbar
sind, kann das System ferner als ein „Entschachtelungs"-Werkzeug betrachtet werden.
-
Andere Vorteile dieser Erfindung
werden aus der nachfolgenden Beschreibung in der Verbindung mit den
beiliegenden Zeichnungen offensichtlich, die bestimmte Ausführungsbeispiele
dieser Erfindung darstellend und beispielhaft zeigen. Die Zeichnungen
bilden einen Teil dieser Erklärung
und umfassen exemplarische Ausführungsbeispiele,
Objekte und Merkmale der vorliegenden Erfindung.
-
Kurze Beschreibung
der Zeichnungen
-
1 zeigt
eine Blockstruktur, die für
eine Bewegungsschätzung
und eine Feldzusammenführung
verwendet wird: a) nicht-überlappende
Segmentierung des Referenzfeldes; b) überlappende Bewegungsblöcke umgeben
jeden Segmentierungsblock.
-
2 zeigt
die acht Ausrichtungsklassen und ihre Beziehung zu dem Zielluminanzpixel,
dem dieselben zugeordnet sind.
-
3 zeigt
eine Tabelle von orthogonalen Wahrscheinlichkeitswerten
für jede der gerichteten Ausrichtungsklassen,
C.
-
4 zeigt
direktionale Tiefpaßfilter,
die an die Luminanzkomponente des vorbereiteten Referenzfeldes angewendet
werden, um für
die Berechnung der Ausrichtungsklassen-Wahrscheinlichkeitswerte
vorzubereiten: a) LV, LV– und
LV+; b) D–;
c) D+; d) O–;
und e) O+.
-
5 zeigt
lineare Zwischenkombinationen, v1, v2, v3 und v4 von horizontal vorgefilterten Luminanzpixeln,
die verwendet werden, um den vertikalen Unwahrscheinlichkeitswert
UV zu bilden.
-
6 zeigt
horizontal vorgefilterte Luminanzpixel, die zum Bilden der annähernd vertikalen
Unwahrscheinlichkeitswerte verwendet werden: a) UV– und b)
UV+.
-
7 zeigt
lineare Zwischenkombinationen; d / i von diagonal vorgefilterten Luminanzpixeln,
die verwendet werden, um die diagonalen Unwahrscheinlichkeitswerte
zu bilden: a) UD– und b) UD+.
-
8 zeigt
lineare Zwischenverbindungen, o / i von annähernd vertikal vorgefilterten
Luminanzpixeln, die verwendet werden, um die schrägen Unwahrscheinlichkeitswerte
zu bilden: a) Uo– und b) Uo+.
-
9 zeigt
benachbarte Klassenwerte, die verwendet werden, um die geglättete Ausrichtungsklasse C
m,n zu
bilden, die dem Zielpixel bei Zeile m und Spalte n zugeordnet ist.
-
10 zeigt
ein Beispiel der linearen Richtungsinterpolationsstrategie, die
verwendet wird, um die drei fehlenden Luminanzabtastwerte wiederzugewinnen,
Y4m+1,n, Y4m+2,n und
Y4m+3,n aus benachbarten Originalfeldzeilen.
Bei diesem Beispiel ist die Ausrichtungsklasse Cm,n =
V+.
-
Detaillierte
Beschreibung des bevorzugten Ausführungsbeispiels
-
Es sollte darauf hingewiesen werden,
daß während bestimmte
Formen der Erfindung dargestellt sind, dieselben nicht auf die spezifischen
Formen oder Anordnungen von Teilen beschränkt sein sollen, die hierin beschrieben
und gezeigt sind. Für
Fachleute auf dem Gebiet ist es offensichtlich, daß verschiedene Änderungen
durchgeführt
werden können,
ohne von dem Schutzbereich der Erfindung abzuweichen, und daß die Erfindung
nicht als darauf beschränkt
betrachtet wird, was in den Zeichnungen und Beschreibungen gezeigt
ist.
-
Um die nachfolgende Erörterung
zu erleichtern, bezeichnen HF und WF die Anzahl von Zeilen (Höhe) und
Spalten (Breite) jedes digitalisierten Videofeldes. Viele Videodigitalisierer
erzeugen Felder mit WF = 640 Spalten und
HF = 240 Zeilen, aber dies muß nicht
der Fall sein. Das Mehrfachfeldverarbeitungssystem interpoliert
das Referenzfeld direktional auf eine Auflösung von HI =
4HF mal WI = WF (d. h. vertikale Erweiterung um einen Faktor
von 4) und verbessert dann den vertikalen Informationsgehalt durch
adaptives Zusammenfügen
der direktional interpolierten, bewegungskompensierten und angemessen
gewichteten Hilfsfelder in dieses interpolierte Referenzfeld. Dieser
adaptive Zusammenfüh rungsprozeß dient
ferner zum Entfernen von Aliasing und zum Reduzieren von Rauschen.
-
Es sollte darauf hingewiesen werden,
daß diese
Abmessungen nur die Luminanzkomponente des Videosignals beschreiben.
Die Chrominanzkomponenten werden unterschiedlich behandelt. Originalchrominanzfelder
weisen jeweils HF Zeilen auf, aber nur WF/4 Spalten. Die Videodigitalisierungs- und
Decodierungs-Operationen können
Chrominanzkomponenten mit diesen Auflösungen erzeugen oder ansonsten
kann der Prozeß die
Chrominanzkomponenten auf eine Sammlung von Videofeldern dezimieren,
die bereits codiert wurden. Auf diese Weise reduziert der Prozeß die Speicheranforderungen
und den Rechenaufwand, der der Mehrfachfeldverbesserungsoperation
zugeordnet ist, ohne ein Opfern tatsächlicher Informationen. Das
Mehrfachfeldverarbeitungssystem interpoliert die Chrominanzkomponenten
des Referenzfeldes direktional auf eine Auflösung von HI/2
= 2HF mal WI/4 =
WF/4 (d. h. eine vertikale Erweiterung um
einen Faktor von 2) und führt dann
die direktional interpolierten und bewegungskompensierten Chrominanzkomponenten
des Hilfsfeldes adaptiv zu Komponenten in dem Referenzfeld zusammen,
um das Chrominanzrauschen und Artefakte zu reduzieren. Es wird darauf
hingewiesen, daß die
Chrominanzkomponenten aus den verschiedenen Feldern durch einfaches
Mitteln zusammengeführt
werden, nachdem ungültige
Pixel aus Regionen, die dem geschätzten Zwischenfeldbewegungsmodell
nicht entsprechen, ausgeblendet wurden. Dieses temporäre Mitteln
ist in der Lage, Rausch- und Farb-Aliasingartefakte zu mitteln, ist aber
nicht in der Lage, den räumlichen
Frequenzinhalt des Bildes zu verbessern. Die Luminanzkomponenten
aus den verschiedenen Feldern werden jedoch unter Verwendung eines
räumlich
variierenden gewichteten Mittels zusammengeführt, dessen Gewichte aus der
ge schätzten
Zwischenfeldbewegung berechnet werden, um ein Aliasing zu entfernen,
während
der räumliche
Frequenzinhalt des Bildes verbessert wird.
-
Das abschließende Bild, das durch das System
erzeugt wird, weist H = H
I = 4 H
F Zeilen mal W = 2W
I =
2W
F Spalten auf. Es wird durch Verdoppeln
der horizontalen Auflösung
der Luminanzkomponente und Vervierfachen der horizontalen Auflösung und
Verdoppeln der vertikalen Auflösung
der Chrominanzkomponenten gebildet, die durch das oben beschriebene
Verfahren erzeugt werden. Diese Operationen sind erforderlich, um die
Luminanzkomponente auf das korrekte Aspektverhältnis wiederherzustellen und
um einen vollen Satz von Chrominanzabtastwerten an jeder Pixelposition
zu erhalten. Bei dem bevorzugten Ausführungsbeispiel der Erfindung
kann ein horizontales Verdoppeln der Luminanzauflösung durch
Anwenden des Interpolationsfilterkernels erreicht werden,
-
Dieses Kernel bzw. Betriebssystemkern
wurde ausgewählt,
um das horizontale Frequenzansprechverhalten des Originalvideosignals
zu bewahren, während
eine multiplikationsfreie Implementierung ermöglicht wird. Derselbe Interpolationsbetriebssystemkern
wird verwendet, um die horizontale Chromianzauflösung um einen Faktor von 2
zu erweitern, wonach die Chrominanzkomponenten um einen zusätzlichen
Faktor von 2 in beiden Richtungen erweitert werden, unter Verwendung
einer herkömmlichen
bilinearen Interpolation.
-
Abschnitt 2 unten offenbart ein Verfahren
zum Schätzen
von lokalen Ausrichtungen innerhalb des Referenzfeldes zusammen mit
einem Interpolationsverfahren, das verwendet wird, um die Referenz-
und Hilfs-Felder gemäß der geschätzten Ausrichtungsabbildung
direktional zu interpolieren. Abschnitt 1 offenbart ein Verfahren
zum Erhalten der Bewegungsabbildungen zwischen den Referenz- und
Hilfs-Feldern. Abschnitt 3 offenbart schließlich Verfahren zum Aufbauen
von Zusammenführungsmasken
und Zusammenführungsgewichtungsfaktoren
zusammen mit dem schnellen Algorithmus, der verwendet wird, um die
Referenz- und Hilfs-Felder tatsächlich
in ein verbessertes Standbild zusammenzuführen.
-
1 Bewegungsschätzung zwischen
Referenz- und Hilfs-Feldern
-
Das Referenzfeld wird zuerst in nicht überlappende
Blöcke
segmentiert, die ungefähr
15 Feldzeilen und 23 Feldspalten bei der aktuellen Implementierung
aufweisen. Diese Segmentierung ist in 1a gezeigt. Jeder
dieser Segmentierblöcke 10 ist
durch einen etwas größeren Bewegungsblock 12 umgeben,
wie in 1b gezeigt ist.
Benachbarte Bewegungsblöcke überlappen
einander um zwei Feldzeilen 14 und vier Feldspalten 16 bei
der aktuellen Implementierung. Das Bewegungsschätzungs-Teilsystem ist verantwortlich
für das Berechnen
eines einzelnen Bewegungsvektors für jeden Bewegungsblock für jedes
Hilfsfeld. Der Bewegungsvektor soll die Verschiebung von Szeneobjekten
innerhalb des Bewegungsblocks beschreiben, zwischen dem Referenz-
und dem relevanten Hilfs-Feld. Diese Bewegungsvektoren werden verwendet,
um den Prozeß zu leiten,
der in Abschnitt 3 beschrieben ist, wodurch interpolierte Referenz-
und Hilfs-Felder in ein einzelnes Bild zusammengeführt werden.
Dieser Zusammenführungsprozeß wird unabhängig von
jedem Bewegungsblock durchgeführt,
wonach die zusammengeführten
Bewegungsblöcke
zusammengeflickt werden, um das abschließende Bild zu bil den. Eine
geglättete
Gewichtungsfunktion wird verwendet, um die überlappenden Regionen aus benachbarten
Bewegungsblöcken
zu mitteln. Der Zweck dieses Abschnittes ist nur das Beschreiben des
Verfahrens, das verwendet wird, um die Bewegungsvektoren für einen
gegebenen Bewegungsblock zu schätzen.
-
Für
jedes der Hilfsfelder verarbeitet das System die Bewegungsblöcke auf
lexikographische Weise. Eine Schätzung
des Bewegungsvektors für
jeden dieser Blöcke
erfolgt in drei einzelnen Phasen. Die erste Phase versucht, den
Bewegungsvektor basierend auf den Bewegungsvektoren vorherzusagen,
die aus vorangehend verarbeiteten, benachbarten Bewegungsblöcken erhalten
wurden. Die Vorhersagestrategie ist in Abschnitt 1.1 beschrieben.
Dieser vorhergesagte Bewegungsvektor wird verwendet, um die effiziente
und robuste Grobbewegungsschätzungstechnik
vorzuspannen, die in Abschnitt 1.2 beschrieben ist, die eine Bewegung
nur mit Genauigkeit ganzer Pixel schätzt. Die abschließende Verfeinerung
auf Viertel-Pixel-Genauigkeit in der vertikalen Richtung und Halb-Pixel-Genauigkeit
in der horizontalen Richtung wird unter Verwendung einer herkömmlichen
MAD-Blockanpassungstechnik durchgeführt. Details werden nachfolgend
in Abschnitt 1.3 gegeben.
-
1.1 Bewegungsvorhersage
-
Um die Erörterung zu erleichtern, bezeichnet
den groben – d. h.
Pixelauflösungs – Bewegungsvektor
für den
(m, n)ten Bewegungsblock, d. h. den n-ten Bewegungsblock in der
m-ten Reihe der Bewegungsblöcke,
die dem Referenzfeld zugeordnet sind. Da Bewegungsvektoren in lexikographischer
Reihefolge geschätzt
werden, wurden die benach barten Grobbewegungsvektoren
bereits
-
geschätzt und können verwendet werden, um eine
anfängliche
Vorhersage für
zu bilden. Genauer gesagt
setzt das Bewegungsschätzungsteilsystem
den vorhergesagten Vektor
um der arithmetische
Mittelwert der drei am wenigsten unterschiedlichen dieser vier benachbarten
Bewegungsvektoren zu sein. Zu dem Zweck dieser Berechnung ist die
Disparität
unter einer Sammlung von drei Bewegungsvektoren
und
wie folgt definiert
das heißt, die Summe der L
1 Distanzen zwischen jedem der Vektoren und
ihrem arithmetischen Mittelwert. Ein Grund zum Bilden dieser Vorhersage
ist nicht, um die volle
Bewegungsvektorsuchzeit zu reduzieren, sondern die Entwicklung von
glatten Bewegungsabbildungen zu unterstützen. In Regionen der Szene,
die wenig Informationen enthalten, aus denen eine Bewegung geschätzt werden
kann, wird bevorzugt, die vorhergesagten Vektoren anzunehmen, wann
immer dies vernünftig
erscheint. Anderweitig können
die „willkürlichen" Bewegungsvektoren,
die üblicherweise
durch Blockbewegungsschätzungsalgorithmen
in diesen Regionen erzeugt werden, störende visuelle Artefakte verursachen,
wenn Versuche gemacht werden, die Referenz- und Hilfs-Felder in
ein einzelnes Standbild zusammenzuführen.
-
1.2 Grobe Bewegungsschätzung
-
Im allgemeinen erzeugt der Prozeß eine grobe – d. h.
Ganzpixelgenauigkeit – Schätzung der
Bewegung
zwischen dem Referenzfeld
und einem gegebenen Hilfsfeld, für
den (m, n)ten Bewegungsblock. Ferner ist es erwünscht, die Schätzung hin
zu dem vorhergesagten Vektor
vorzuspannen, immer
wenn dies konsistent mit den Merkmalen ist, die in den zwei Feldern
angetroffen werden. Das Grobbewegungsschätzungsteilsystem führt eine
umfassende Suche durch, die bei einem Ausführungsbeispiel des Systems
einen Suchbereich von
Feldspalten und
Feldzeilen umfaßt. Für jeden
Vektor v in diesem Bereich berechnet der Prozeß eine objektive Funktion,
die nachfolgend erörtert wird.
Um die Erörterung
zu erleichtern bezeichnet O
min den Minimalwert,
der durch
über den Suchbereich erlangt
wird, und V bezeichnet den Satz aller Bewegungsvektoren
derart, daß
wobei T
m eine
vordefinierte Schwelle ist. Die abschließende Grobbewegungsschätzung
wird als der Vektor
genommen, der am nächsten zu
dem vorhergesagten Vektor
ist. Hier wird die L
1-Distanzmetrik verwendet, so daß die Distanz
zwischen
und
ist.
-
Die tatsächliche objektive Funktion
die für die Grobbewegungsschätzung verwendet
wird, ist wie folgt offenbart. Anstelle des Verwendens von rechenintensiven
Maximale-Absolute-Distanz-Objektiven (MAD-Objektive) erzeugt der
Prozeß die
objektive Funktion auf einer neuen Darstellung mit 2 Bit pro Pixel
der Referenz- und Hilfs-Felder. Genauer gesagt werden die Luminanzkomponenten
der Referenz- und Hilfs-Felder erst mit einem räumlichen Bandpaßfilter
vorbereitet, wie in Unterabschnitt 1.2.1 beschrieben ist; eine 2-Bit-Darstellung
jedes Bandpaß-gefilterten
Luminanzabtastwerts wird durch eine einfache Schwellwertbildungstechnik gebildet,
die in Abschnitt 1.2.2 beschrieben ist, und dann wird die objektive
Funktion durch eine Kombination von „exklusiven Oder" (XOR) und Zähl-Operationen
bewertet, die an die 2-Bit-Pixeldarstellungen angewendet werden,
wie in Abschnitt 1.2.3 beschrieben ist.
-
1.2.1 Bandpaßfiltern
für eine
Grobbewegungsschätzung
-
Ein einfaches Bandpaßfilter
ist bei einem Ausführungsbeispiel
durch Nehmen der Differenz von zwei Bewegungsfenster-Tiefpaßfiltern
aufgebaut. Genauer gesagt sei y[i,j] der Luminanzabtastwert aus
einem gegebenen Feld bei Zeile i und Spalte j. Das Bandpaß-gefilterte
Pixel
y[i,j] wird gemäß nachfolgender
Formel berechnet:
-
Hier sind Lx und
Ly und die Breite und Höhe des „Lokalskala"-Bewegungsdurchschnittsfensters,
während
Wx und Wy die Breite
und die Höhe
des „Weitskala"-Bewegungsdurchschnittsfensters
sind. Die Skalierungsoperationen können reduziert werden, um Operationen
zu verschieben, durch Sicherstellen, daß jede diese vier Abmessungen
eine Leistung von 2 ist, wobei in diesem Fall die gesamte Bandpaßfilterungsoperation mit
vier Additionen, vier Subtraktionen und zwei Verschiebungen pro
Pixel implementiert werden kann. Bei unserer bestimmten Implementierung
hat sich herausgestellt, daß die
Abmessungen LX = Ly =
4, Wx = 32 und Wy =
16 die Robustheit des Gesamtbewegungsschätzungsschemas optimieren. Es
ist nichts wert, daß diese Bandpaßfilterungsoperation
die Bewegungsschätzer-
zu Zwischenfeld-Beleuchtungsabweichungen sowie zu Hochfrequenz-Aliasing-Artefakten
in den individuellen Feldern desensibilisiert. Gleichzeitig erzeugt
dieselbe Pixel, die einen Null- Mittelwert aufweisen – eine Schlüsselanforderung
für die
Erzeugung von nützlichen
zwei Bit pro Pixeldarstellungen gemäß dem Verfahren, das in dem
nachfolgenden Abschnitt beschrieben ist.
-
1.2.2 2-Bit-Pixeldarstellung
für Grobbewegungsschätzung
-
Nach dem Bandpaßfiltern wird jedem gefilterten
Abtastwert
y[i,j] eine 2-Bit-Darstellung
bei dem bevorzugten Ausführungs
beispiel der Erfindung zugewiesen, wobei diese Darstellung auf einem
Parameter T
b basiert. Das erste Bit wird
auf 1 gesetzt, wenn
y[i,j]>T
b und
ansonsten auf 0, während
das zweite Bit auf 1 gesetzt wird, wenn
y[i,j]<–T
b und ansonsten auf 0. Diese Zwei-Bit-Darstellung
umfaßt
eine bestimmte Redundanz, insofern, daß dieselbe
y[i,j] in nur drei unterschiedlichen Betriebsverfahren
quantisiert. Die Darstellung weist jedoch die nachfolgende wichtige
Eigenschaft auf. Wenn
die Gesamtanzahl von
einem Bit in dem Zwei-Bit-Ergebnis darstellt, das durch Nehmen des
exklusiven Oder von entsprechenden Bits in den Zwei-Bit-Darstellungen erhalten
wird, die
y
1 und
y
2 zugeordnet
sind, dann ist es einfach zu verifizieren, daß
die nachfolgende Beziehung
erfüllt.
-
Somit kann
als ein Maß für die Distanz
zwischen
y
1 und
y
2 interpretiert
werden.
-
1.2.3 Die Grobbewegungsschätzungs-Objektivfunktion
-
Unsere Objektivfunktion
ist aufgebaut durch
Nehmen der Summe der 2-Bit-Distanzmetrik,
über alle Pixel (i,j) die innerhalb
eines Grobanpassungsblocks liegen; dieser Grobanpassungsblock ist
allgemein größer als
der Bewegungsblock selbst. Hier ist
y
r[i,j] der Bandpaßgefilterte Abtastwert bei
Zeile i und Spalte j des Referenzwerts, während
y
a[i,j] der Bandpaß-gefilterte
Abtastwert bei Zeile i und Spalte j des Hilfsfeldes ist. Bei unserer
Implementierung besteht der Grobanpassungsblock aus 20 Feldzeilen
mal 32 Feldspalten, die den interessierenden Bewegungsblock umgeben.
-
1.3 Verfeinerung auf Teilpixelgenauigkeit
-
Bei einem Ausführungsbeispiel der Erfindung
wird eine herkömmliche
MAD-Suche (MAD = Mean Absolute Difference) durchgeführt, mit
einem Suchbereich von einer Feldspalte und einer halben Feldzeile
um den Vektor, zurückgesendet
durch das Grobbewegungsschätzungsteilsystem,
Suchen in Inkrementen von der Hälfte
der Feldspaltenteilung und eines Viertels der Feldzeilenteilung.
Nur das Referenzfeld muß auf
die höhere
Auflösung
interpoliert werden (viermal die vertikale und zweimal die horizontale
Auflösung),
um diese Teilpixelgenauigkeitssuche zu erreichen. Die Hilfsfelder
werden durch Anwenden eines 5-Abgriff-Vertikaltiefpaßfilters
mit Betriebssystemkern angewendet,
vor dem Durchführen der
Bewegungsverfeinerungssuche. Dieses Tiefpaßfiltern reduziert die Sensibilität gegenüber einem
vertikalen Aliasing.
-
2. Richtungsinterpolation
jedes Feldes
-
2.1 Ausrichtungsschätzung
-
Das Ziel der Ausrichtungsschätzung ist
es, die Richtung der Bildkanten in der Nachbarschaft eines gegebenen
Pixels zu identifizieren, so daß die
vertikale Zwischenfeldinterpolationsoperation, die in Abschnitt
2.2 unten beschrieben wird, sorgfältig ausgeführt werden kann, um entlang
und nicht über
eine Kante zu interpolieren. Zusätzlich
zu der korrekten Identifizierung der Kantenausrichtung ist es eine
Schlüsselanforderung
des Schätzers,
daß die
resultierende Ausrichtungsabbildung so glatt wie möglich ist.
Es wird bevorzugt, daß die Ausrichtungsabbildung
nicht wild in texturierten Regionen oder in glatten Regionen schwankt,
die nahe an tatsächlichen
Bildkanten liegen, da solche Fluktuationen sich nach der Interpolation
als visuell störende
Artefakte manifestieren könnten.
Es ist daher wichtig die numerische Komplexität der Schätzungstechnik zu steuern.
-
Das Ausrichtungsschätzungs-Teilsystem
arbeitet mit der Luminanzkomponente des Referenzfeldes. Für jedes „Ziel"-Luminanzpixel in diesem Feld wird eine
Ausrichtungsklasse ausgewählt.
Die Ausrichtungsklasse, die einer gegebenen Zielzeile und Zielspalte
zugeordnet ist, wird als die dominante Merkmalsausrichtung interpretiert,
die in einer Nachbarschaft beobachtet wird, deren Flächenschwerpunkt
zwischen der Ziel- und den nächsten
Feld-Zeilen und zwischen der Ziel- und den nächsten Feld-Spalten liegt.
Dieser Flächenschwerpunkt
ist mit einem Kreuzmuster 20 in 2 markiert. Die Figur stellt ferner den
Satz von acht Ausrichtungsklassen dar, die jedem Zielluminanzpixel
zugeordnet sein können.
Dies sind:
22 N: Keine bestimmte Ausrichtung.
24 V: Bestimmtes
Ausrichtungsmerkmal bei 90° (vertikal)
26
V–:
Bestimmtes Ausrichtungsmerkmal bei 63° (annähernd vertikal) von oben links
nach unten rechts.
28 V+: Bestimmtes
Ausrichtungsmerkmal bei 63° (annähernd vertikal)
von oben rechts nach unten links.
30 D–:
Bestimmtes Ausrichtungsmerkmal bei 45° (diagonal) von oben links nach
unten rechts.
32 D+: Bestimmtes Ausrichtungsmerkmal
bei 45° (diagonal)
von oben rechts nach unten links.
34 O–:
Bestimmtes Ausrichtungsmerkmal bei 27° (schräg) von oben links nach unten
rechts.
36 O+: Bestimmtes Ausrichtungsmerkmal
bei 27° (schräg) von oben
rechts nach unten links.
-
Die Ausrichtungsklassenzuordnungen
für jedes
Luminanzpixel in dem Referenzfeld bilden die Ausrichtungsabbildung.
-
Die Schätzungsstrategie besteht aus
einer Anzahl von Elementen, deren Details nachfolgend separat erörtert werden.
Im wesentlichen ist ein numerischer Wert, LC,
jeder der einzeln ausgerichteten Klassen C ∈ {V, V–,
V+, D–, D+,
O– ,
O–}
zugeordnet, was als Wahrscheinlichkeit interpretiert wird, daß ein lokales
Ausrichtungsmerkmal mit entsprechender Ausrichtung existiert. Die
geschätzte
Ausrichtungsklasse wird vorläufig
auf die bestimmte Ausrichtungsklasse C gesetzt, die den Maximalwert
LC aufweist. Der Wahrscheinlichkeitswert LC für
die ausgewählte
Klasse wird dann mit einem orthogonalen Wahrscheinlichkeitswert
L1/2 verglichen, der die Wahrscheinlichkeit darstellt, die der orthogonalen
Richtung zugeordnet ist. Wenn der Unterschied zwischen LC und L1/2 geringer ist als eine vorbestimmte
Schwelle, dann wird die Ausrichtungsklasse auf N gesetzt, d. h.
keine bestimmte Ausrichtung. Der orthogonale Wahrscheinlichkeitswert
wird aus der Tabelle von 3 erhalten.
Die Ausrich tungsabbildung, die auf die oben beschriebene Weise erhalten
wird, wird einer abschließenden
morphologischen Glättungsoperation
unterzogen, um die Anzahl von störenden
Artefakten zu minimieren, die während
einer Richtungsinterpolation erzeugt werden. Diese Glättungsoperation
ist in Abschnitt 2.1.3 beschrieben.
-
Um die Wahrscheinlichkeitswerte,
LC, für
jede gerichtete Ausrichtungsklasse C zu berechnen, werden die Luminanzpixel
zuerst verarbeitet, unter Verwendung eines direktionalen Tiefpaßfilters,
der in einer Richtung glättet,
die ungefähr
senkrecht zu der von C ist. LC basiert dann
auf einer Gesamtabweichungsmetrik (TV-Metrik; TV = Total Variation),
die entlang einer Bahn berechnet wird, die parallel zu der Ausrichtung
von C ist; je größer die
Abweichung, desto kleiner der Wahrscheinlichkeitswert. Die sieben
direktionalen Filterungsoperationen werden in Abschnitt 2.1.1 beschrieben,
während
die TV-Metrik in Abschnitt 2.1.2 unten beschrieben wird.
-
2.1.1 Ausgerichtetes Vorfiltern
des Luminanzfeldes
-
Die Luminanzkomponente des Referenzfeldes
wird zuerst vorbereitet durch Anwenden eines vertikalen Tiefpaßfilters
mit dem Drei-Abgriff-Kern,
-
Ein Zweck dieses Vorkonditionierungsfilters
ist es, den Einfluß von
vertikalen Aliasingartefakten zu reduzieren, die das Schätzungsteilsystem
nachteilig beeinflussen können.
-
Um das vorkonditionierte Luminanzfeld
für eine
Berechnung von vertikalen Wahrscheinlichkeitswerten, LV,
und annähernd
vertikalen Wahrscheinlichkeitswerten Lv– und Lv+ vorzubehandeln, wird das horizontale Tiefpaßfilter
angewendet, dessen fünf
Abgriffe in 4a dargestellt sind.
-
Um das vorkonditionierte Luminanzfeld
für eine
Berechnung der diagonalen Wahrscheinlichkeitswerte LD– vorzubereiten,
wird das diagonale Tiefpaßfilter
angewendet, dessen drei Abgriffe 42 in 4b dargestellt sind.
Das komplementäre
Filter, dessen drei Abgriffe 44 in 4c dargestellt
sind, wird verwendet, um für
eine Berechnung der komplementären
diagonalen Wahrscheinlichkeitswerte LC+
vorzubereiten.
-
Schließlich, um das vorkonditionierte
Luminanzfeld für
eine Berechnung der schrägen
Wahrscheinlichkeitswerte Lo– und Lo+ vorzubereiten, werden annähernd vertikale
Tiefpaßfilter 46, 48 angewendet,
die in den 4d bzw. 4e dargestellt
sind.
-
2.1.2 Die Direktionale
TV-Metrik
-
Für
jede gerichtete Ausrichtungsklasse, C, werden die Wahrscheinlichkeitswerte,
LC, durch Negieren eines Satzes von entsprechenden „Unwahrscheinlichkeits"-Werten, UC, gefunden. Die Unwahrscheinlichkeitswerte
für jede
gerichtete Ausrichtungsklasse werden durch Anwenden eines angemessenen „Gesamtabweichungs"-Maßes an die
Luminanzkomponente des Referenzfeldes berechnet, nach dem Vorkonditionieren
und dem angemessenen direktionalen Vorfiltern, wie oben in Abschnitt
2.1.1 beschrieben wurde.
-
Der vertikale Unwahrscheinlichkeitswert
wird berechnet aus
wobei
v
1, v
2, v
3 und v
4 lineare
Kombinationen von Pixeln aus dem vorkonditionierten und horizontal
vorgefilterten Luminanzfeld sind; diese lineare Kombinationen sind
in
5 gezeigt. Der Mittelwert
dieser Berechnung liegt auf halbem Weg zwischen der Ziel-
50 und
der nächsten
Feld-Zeile
52 und auf halbem Weg zwischen der Ziel-
54 und
der nächsten
Feld-Spalte
56, die
2 entspricht.
Die annähernd
vertikalen Unwahrscheinlichkeitswerte werden berechnet aus
und
wobei
der Ausdruck v / i Pixelwerte aus dem vorkonditionierten und horizontal
vorgefilterten Luminanzfeld darstellt; die relevanten Pixel sind
in
6a und
6b gezeigt.
Der Mittelwert dieser Berechnungen liegt wiederum eine halbe Feldzeile
unter und eine halbe Feldspalte rechts von der Zielfeld-Zeile
60 und
der -Spalte
62, wie für
eine Konsistenz mit der Definition der Ausrichtungsklassen erforderlich
ist.
-
Die diagonalen Unwahrscheinlichkeitswerte
werden berechnet aus
und
wobei die Ausdrücke d / i jeweils
eine lineare Kombination aus zwei Pixelwerten aus dem vorkonditionierten
und diagonal vorgefilterten Luminanzfeld darstellen. Die Ausdrücke d; werden
nach dem Anwenden des diagonalen Vorfilters gebildet, der in
4b gezeigt ist, während die Ausdrücke d; nach
dem Anwenden des diagonalen Vorfilters gebildet werden, der in
4c gezeigt ist. Die Pixel und Gewichte,
die verwendet werden, um die Ausdrücke d / i und d + / i zu bilden sind
in
7a bzw. 7b dargestellt. Es wird
darauf hingewiesen, daß der
Mittelwert dieser Berechnungen wiederum eine halbe Feldzeile unter
und eine halbe Feldspalte rechts von der Zielfeld-Zeile
70 und
der -Spalte
72 liegt, wie für eine Konsistenz mit der Definition
der Ausrichtungsklassen erforderlich ist.
-
Schließlich werden die schrägen Unwahrscheinlichkeitswerte
berechnet aus
und
wobei die Ausdrücke o / i jeweils
eine lineare Kombination aus zwei Pixelwerten aus dem vorkonditionierten
und annähernd
vertikal vorgefilterten Luminanzfeld darstellen. Die Ausdrücke o / i werden
nach dem Anwenden des annähernd
vertikalen Vorfilters gebildet, der in
4d gezeigt
ist, während
die Ausdrücke
o + / i nach dem Anwenden des annähernd
vertikalen Vorfilters gebildet werden, der in
4e gezeigt
ist. Die Pixel und Gewichte, die verwendet werden, um die Ausdrücke o / i und
o + / i zu bilden, sind in
8a bzw.
8b dargestellt. Es wird darauf hingewiesen,
daß der
Mittelwert dieser Berechnungen wiederum eine halbe Feldzeile unter
und eine halbe Feldspalte rechts von der Zielfeld-Zeile
80 und
der -Spalte
82 liegt, wie für eine Konsistenz mit der Definition der
Ausrichtungsklassen erforderlich ist.
-
2.1.3 Morphologisches
Glätten
der Ausrichtungsabbildung
-
Der Morphologisches-Glätten-Operator
nimmt als Eingabe die Anfangsklassifizierung jedes Pixels in dem
Referenzfeld in eine der Ausrichtungsklassen V, V–,
V+, D– , D+,
O– oder
O+, und erzeugt eine neue Klassifizierung,
die allgemein weniger Zwischenklassenübergänge aufweist. Um die Erörterung
zu vereinfachen sei Cm,n die Anfangsausrichtungsklassifizierung,
die der Zielfeldzeile m 90 und der Zielfeldspalte n 92 zugeordnet ist.
Der Glättungsoperator
erzeugt eine potentiell unterschiedliche Klassifizierung C
m,n,
durch Berücksichtigen von
Cm,n zusammen mit den 14 Nachbarn 94,
die in 9 dargestellt
sind. Die Glättungstaktik
ist, daß der
Wert C
m,n identisch
zu Cm,n sein sollte, außer entweder eine Mehrzahl
der sechs Nachbarn 96, die links von dem Zielpixel liegen,
und eine Mehrzahl der sechs Nachbarn 98, die rechts von
dem Zielpixel liegen, weisen dieselbe Klassifizierung C auf, oder
eine Mehrzahl der fünf
Nachbarn 100, die über
dem Zielpixel liegen, und eine Mehrzahl der fünf Nachbarn 102, die
unter dem Zielpixel liegen, weisen dieselbe Klassifizierung C auf.
In jedem dieser Fälle
ist der Wert von Cm,n auf C gesetzt.
-
2.2 Interpolation
-
Dieser Abschnitt beschreibt die direktionale
Interpolationsstrategie, die verwendet wird, um die Anzahl von Luminanzzeilen
zu vervierfachen und die Anzahl von Chrominanzzeilen zu verdoppeln.
Um die nachfolgende Erörterung
zu erleichtern sei Y4m,n in 10 das Luminanzpixel bei Feldzeile m
und Feldspalte n. Der Zweck der Luminanzinterpolation ist es, drei
neue Luminanzzeilen Y4m+1,n; Y4m+2,n und
Y4m+3,n herzuleiten, zwischen jedem Paar
von Originalluminanzzeilen Y4m,n 120 und
Y4m+4,n 122. Auf ähnliche
Weise ist es der Zweck der Chrominanzinterpolation, eine neue Chrominanzzeile,
C2m+i,k zwischen jedem Paar von Originalchrominanzzeilen,
C2m,k und C2m+2,k herzuleiten.
Nur auf eine der Chrominanzkomponenten wird ausdrücklich Bezug genommen,
mit dem Verständnis,
daß beide
Chrominanzkomponenten identisch verarbeitet werden sollten. Ferner
sollte der Index k und nicht n verwendet werden, um die Chrominanzspalten
zu bezeichnen, da die horizontale Chrominanzauflösung nur ein Viertel der horizontalen
Luminanzauflösung
ist.
-
Wie oben beschrieben ist, bezieht
sich Cm,n auf die lokale Ausrichtungsklasse,
die einer Region zugeordnet ist, deren Flächenschwerpunkt zwischen den
Feldzeilen m und m+1 liegt. Die fehlenden Luminanzabtastwerte Y4m+1,n, Y4m+2,n und
Y4m+3,n werden linear basierend auf einer
Linie 124 interpoliert, die durch die fehlende Abtastwertposition 126 mit
der Ausrichtung Cn,m gezeichnet ist. 10 stellt diesen Prozeß für eine annähernd vertikale
Ausrichtungsklasse von Cm,n = V+ dar.
Es wird darauf hingewiesen, daß die
Originalfeldzeilen Y4m,n 120 und
Y4m+4,n 122 häufig horizontal interpoliert
werden müssen,
um Abtastwerte an den Endpunkten 120 der ausgerichteten
Interpolationslinien zu finden. Bei einem Ausführungsbeispiel wird das Interpolationsfilter von
Gleichung (1) verwendet, um einen Verlust eines räumlichen
Frequenzinhalts während
dieses Interpolationsprozesses zu minimieren. Die nicht-gerichtete
Ausrichtungsklasse, N, wird auf dieselbe vertikale Interpolationsstrategie
voreingestellt wie die V-Klasse.
-
Chrominanzkomponenten werden auf ähnliche
Weise behandelt. Genauer gesagt wird der fehlende Chrominanzabtastwert,
C2m+1,k, linear basierend auf einer Linie
interpoliert, die durch die fehlende Abtastwertposition mit der
Ausrichtung, Cm,2k, gezogen ist. Die Chrominanzabtastwerte
aus den Originalfeldzeilen, C2m,k und C2m+2,k, müssen
wiederum häufig
horizontal interpoliert werden, um Abtastwerte auf den Endpunkten
der ausgerichteten Interpolationslinien zu finden.
-
3 Adaptives, nicht-stationäres Zusammenführen von
interpolierten Feldern
-
In diesem Abschnitt wird das Verfahren
beschrieben, das zum Zusammenführen
räumlich
interpolierter Pixel aus den Hilfsfeldern in das Referenzfeld verwendet
wird, um ein Hochqualitäts-Standbild
zu erzeugen. Wie in Abschnitt 1 erwähnt wurde, wird die Zusammenführungsoperation
unabhängig
an jedem der überlappenden
Bewegungsblöcke
durchgeführt,
die in 1 dargestellt
sind. Das Bild wird aus diesen überlappenden Blöcken unter
Verwendung einer Glättungsübergangsfunktion
innerhalb der überlappenden
Regionen zusammengestückelt.
Die nachfolgende Erörterung
betrachtet die Operationen, die verwendet werden, um einen einzelnen
Bewegungsblock zusammenzuführen.
Der Einfachheit halber werden diese Operationen beschrieben, als
ob dieser Bewegungsblock das gesamte Referenzfeld einnehmen würde.
-
Der Zusammenführungsprozeß wird durch einen einzelnen
Teilpixel-genauen Bewegungsvektor für jedes der Hilfsfelder geführt. Der
erste Schritt umfaßt
die Erzeugung einer Zusammenführungsmaske
für jedes Hilfsfeld,
um die Regionen zu identifizieren, in denen dieser Bewegungsvektor
berücksichtigt
werden kann, um eine Szenenbewegung zwischen dem Referenzfeld und
dem relevanten Hilfsfeld zu beschreiben. Eine Zusammenführungsmaskenerzeugung
wird in Abschnitt 3.1 unten erörtert.
Der nächste
Schritt ist es, Gewichte zu jedem räumlich interpolierten Pixel
in den Referenz- und Hilfs-Feldern
zuzuweisen, die den Beitrag identifizieren, den jedes derselben
zu dem zusammengeführten
Bild machen wird. Der Schritt wird in Abschnitt 3.2 unten erörtert. Schließlich wird
der gewichtete Mittelwert aus Pixeln aus den verschiedenen Feldern
unter Verwendung der schnellen Technik gebildet, die nachfolgend
in Abschnitt 3.3 beschrieben ist.
-
3.1 Erzeugung von Zusammenführungsmasken
-
Für
ein gegebenes Hilfsfeld ist es das allgemeine Ziel des Zusammenführungsmaskenerzeugungs-Teilsystems,
einen Binärmaskenwert
für jedes
Pixel in dem Originalreferenzfeld zu bestimmen, nicht dem interpolierten
Referenzfeld. Der Maskenwert für
ein bestimmtes Pixel identifiziert, ob der Bewegungsvektor, der
dem gegebenen Hilfsfeld zugeordnet ist, eine Szenenbewegung zwischen
den Referenz- und Hilfs-Feldern
in der Nähe
dieses Pixels richtig beschreibt oder nicht. Unser grundlegender
Lösungsansatz
zum Erzeugen dieser Masken umfaßt
ein Berechnen eines direktional empfindlichen, gewichteten Mittelwerts
von benachbarten Pixeln in dem Referenzfeld und entsprechender bewegungskompensierter
Pixel in dem Hilfsfeld und ein Vergleichen dieser Mittelwerte. Ein
Schlüssel
zu dem Erfolg dieses Verfahrens ist die direktionale Empfindlichkeit
der Lokalpixelmittelwerte.
-
Um die nachfolgende Erörterung
zu erleichtern sei y
r[i,j] der Luminanzabtastwert
bei Zeile i und Spalte j in dem Referenzfeld. Der Einfachheit halber
sei y
a[i,j] das entsprechende Pixel in dem
Hilfsfeld, nach dem Kompensieren des geschätzten Bewegungsvektors. Es
wird darauf hingewiesen, daß die
Bewegungskompensation eine Teilpixelinterpolation umfassen kann,
da die Bewegungsvektoren auf Teilpixelgenauigkeit geschätzt werden.
Wenn der Bewegungsvektor eine Bewegung in der Nähe des Pixels (i,j) korrekt
beschreibt, kann erwartet werden, daß Nachbarschaftsmittelwerte
um y
r[i,j] und y
a[i,j] ähnliche
Ergebnisse ergeben würden.
Ein Problem sind Bildkanten, wo der Erfolg von folgenden Feldzusammenführungen
bedeutend von der Bewegungsvektorgenauigkeit in der Richtung senkrecht
zu der Kantenausrichtung abhängt.
Um diesen Problempunkt zu adressieren wird die Aus richtungsabbildung
verwendet, die in Abschnitt 2.1 erörtert wurde. Nur in dem speziellen
Fall, in dem die Ausrichtungsklasse für das Pixel (i,j) N ist, d.
h. keine bestimmte Richtung, verwendet der Prozeß einen nicht-direktionalen
gewichteten Mittelwert, dessen Gewichte aus dem Tensorprodukt der
sieben horizontalen Abgriffbetriebssystemkerne,
und den fünf vertikalen
Abgriffbetriebssystemkernen,
bei einem bestimmten Ausführungsbeispiel
der Erfindung gebildet werden. In diesem Fall, wenn die gewichteten
Mittelwerte, die um y
r[i,j] und y
a[i,j] gebildet sind, um mehr als eine vorbestimmte
Schwelle abweichen, ist die Zusammenführungsmaske, m
i,j,
auf 0 gesetzt, was anzeigt, daß das
Bewegungsmodell in dieser Region nicht als gültig betrachtet werden sollte.
-
Für
alle anderen Ausrichtungsklassen werden die Referenzund Hilfs-Felder
zuerst mit den drei horizontalen Abgriff-Niedrigpaßbetriebssystemkernen,
gefiltert, und dann werden
vier eindimensionale gewichtete Mittelwerte, p[i,j], α
1[i,j], α
2[i,j]
und α
3[i,j] berechnet. Jeder dieser gewichteten
Mittelwerte wird entlang einer Li nie ausgerichtet in der Richtung
genommen, die durch die Ausrichtungsklasse für das Pixel (i,j) identifiziert
wird, unter Verwendung der Gewichte
Die ausgerichtete Linie,
die verwendet wird, um p[i,j] zu bilden, ist um das Pixel (i,j)
in dem Referenzfeld zentriert. Auf ähnliche Weise ist die Linie,
die verwendet wird, um α
2[i,j] zu bilden um das Pixel (i,j) in dem
Hilfsfeld zentriert. Die Linien für α
1[i,j]
und α
2[i,j] weisen Mittelpunkte auf, die auf jede
Seite des Pixels (i,j) in dem Hilfsfeld fallen, versetzt um ungefähr die Hälfte einer
Feldzeile oder einer Feldspalte, wie angemessen, in der orthogonalen
Richtung zu der, die durch die Ausrichtungsklasse identifiziert
ist. Somit wäre
in einer Region, deren Ausrichtungsklasse einheitlich vertikal ist,
das Ergebnis α
1[i,j] = α
2[i,j–1]
= α
3[i,j–2].
Andererseits, in einer Region deren Ausrichtungsklasse einheitlich
schräg
ist, O
–-oder O
+,
sollte der horizontale Mittelwert, α
1[i,j],
ungefähr
gleich zu dem arithmetischen Mittel von α
2[i,j]
und α
2[i,j–1]
sein. Aus diesen direktionalen Mittelwerten werden drei absolute
Differenzen gebildet,
-
Wenn δ2[i,j]
eine vorbestimmte Schwelle überschreitet,
wird gefolgert, daß der
Bewegungsvektor keine Szenenbewegung in der Nähe des Pixels (i,j) beschreibt
und mi,j wird entsprechend auf 0 gesetzt.
Anderweitig wird gefolgert, daß der
Bewegungsvektor ungefähr
genau ist, aber der Prozeß muß trotzdem
prüfen,
um zu sehen, ob er ausreichend genau für eine Feldzusammenführung ist,
um die Qualität
eines Kantenmerkmals zu verbessern. Unter der Annahme, daß ein kleiner
Bewegungsvektor allgemein verursachen würde, daß eines von δ1[i,j]
und δ2[i,j] kleiner ist als δ2[i,j]
und nicht beide, testet der Prozeß nach diesem Zustand, wobei
mi,j auf 0 gesetzt wird, immer wenn sich
dasselbe als wahr herausstellt.
-
3.2 Erzeugung von räumlichen
Gewichtungsfaktoren
-
Das Zusammenführungs-Teilsystem bildet einen
gewichteten Mittelwert zwischen den direktional interpolierten Pixeln
aus jedem Feld. Dieser Abschnitt beschreibt die Methodik, die verwendet
wird, um relevante Gewichte zu bestimmen. Die Chrominanz- und Luminanz-Komponenten
werden auf fundamental unterschiedliche Weise behandelt, da ein
Großteil
der räumlichen
Informationen nur in dem Luminanzkanal getragen wird. Allen Chrominanz-Abtastwerten
in dem Referenzfeld ist ein Gewicht von 1 zugewiesen, während den
Chrominanz-Abtastwerten
aus den Hilfsfeldern Gewichte von entweder 1 oder 0 zugewiesen sind,
ausschließlich
abhängig
von dem Wert der Zusammenführungsmaske
für das
relevante Hilfsfeld. Auf diese Weise werden die Chrominanzkomponenten
einfach über
alle Felder gemittelt, außer
in Regionen, in denen die Bewegungsvektoren die zugrundeliegende
Szenenbewegung nicht reflektieren. Dies hat den Effekt des wesentlichen
Reduzierens von Chrominanzrauschen. Ferner bedeutet die Tatsache,
daß die
meisten Szenen zumindest eine bestimmte Zwischenfeldbewegung enthalten,
daß die
Feldmittelwertbildung der Chrominanzkomponenten dazu neigt, Farbaliasingartefakte
zu löschen,
die aus dem harmonischen Takten von Szenenmerkmalen mit dem Farbmosaik
entstehen, das bei Einzel-CCD-Videokameras
verwendet wird.
-
Derselbe Lösungsansatz könnte für ein Zusammenführen der
Chrominanzkomponenten ebenfalls angenommen werden; aber es könnten Einschränkungen
im Hinblick auf das Verbessern des räumlichen Frequenzinhalts bestehen.
Trotzdem ist die direktionale räumliche
Interpolationstechnik in der Lage, den räumlichen Frequenzinhalt von
ausgerichteten Kantenmerkmalen zu verbessern, wobei texturierte
Regionen vollkommen abhängig
von den Informationen aus mehreren Feldern für eine Auflösungsverbesserung sind. In
Anbetracht der Einschränkung
daß die
Anzahl von verfügbaren
Feldern sehr groß wird,
hat ein einfaches Mittelwertbilden der interpolierten Felder den
Effekt, daß die
räumlichen
Originalfrequenzen in der Szene einem Tiefpaßfilter unterzogen werden,
dessen Impulsansprechverhalten identisch zu dem räumlichen
Interpolationsbetriebssystemkern ist. Wenn ein „idealer" Sink-Interpolierer verwendet wird,
um die fehlenden Zeilen in jedem Feld vertikal zu interpolieren,
ist das Ergebnis ein Bild, das keinen vertikalen Frequenzinhalt über die
Nyquist-Grenze aufweist, die einem einzelnen Feld zugeordnet ist.
Bei dem Beispielsausführungsbeispiel
der Erfindung wird eine linerare Interpolation verwendet, um die
fehlenden Feldzeilen vor dem Zusammenführen zu interpolieren; und
der Mittelwertbildungsprozeß neigt
dazu, Aliasingartefakte zu beseitigen. Um hohe räumliche Frequenzen zu bewahren,
während
weiterhin Aliasing entfernt und Rauschen in den Luminanzkomponenten
reduziert wird, kann eine räumlich
variierende Gewichtungsfunktion angenommen werden. Genauer gesagt
ist jedem Luminanzabtastwert in einem gegebenen Hilfswert ein Gewicht
von 2 zugeordnet, wenn derselbe einem Originalpixel aus diesem Feld
entspricht, 1 wenn derselbe innerhalb einer interpolierten Zeile
(d. h. ein Viertel einer Feldzeile) aus einem Originalpixel positioniert
ist und an sonsten 0. Wenn die relevante Zusammenführungsmaske
0 ist, dann setzt der Prozeß das
Gewicht auf 0, unabhängig
von der Distanz zwischen dem Abtastwert und einem Originalfeldabtastwert.
Die Referenzfeld-Luminanzabtastwerte werden auf dieselbe Weise gewichtet,
außer
daß allen
Abtastwerten ein Gewicht von zumindest 1 zugewiesen wird, um vorzusehen,
daß zumindest
ein Gewicht ungleich Null für
jeden Abtastwert in dem zusammengeführten Bild verfügbar ist.
Diese Gewichtungstaktik hat den Effekt, daß vertikale Frequenzen einem
bedeutend weniger starken Tiefpaßfilter unterzogen werden als
ein einfaches Mittelwertbilden mit einheitlichen Gewichten.
-
3.3 Schnelles Verfahren
zum Implementieren der gewichteten Mittelwerte
-
Dieser Abschnitt beschreibt ein effizientes
Verfahren, das verwendet wird, um das gewichtete Mittelwertbilden
von interpolierten Abtastwerten aus den Referenz- und Hilfs-Feldern zu implementieren.
Dieselbe Technik kann sowohl für
Luminanz- als auch Chrominanz-Abtastwerte verwendet werden. Um diese
Erörterung
zu erleichtern seien v
1, v
2,...,
v
F die Abtastwerte, die aus jedem der F
Felder zusammengeführt
werden sollen, um einen einzelnen Luminanz- oder Chrominanz-Abtastwert
in dem abschließenden
Bild zu bilden. Ferner seien w
1, w
2,..., w
F die entsprechenden
Gewichtungswerte, die Werte von 0, 1 oder 2 annehmen, gemäß der Erörterung
in Abschnitt 3.2. Der gewünschte
gewichtete Mittelwert kann wie folgt berechnet werden
-
Dieser Ausdruck umfaßt eine
kostenbehaftete Divisionsoperation. Um diese Schwierigkeit zu lösen, bildet
der Prozeß bei
einem Ausführungsbeispiel
der Erfindung ein einzelnes 16-Bit-Wort, v ^
f,
für jeden
Abtastwert. Die niedrigstwertigen neun Bits von v ^
f halten
den gewichteten Abtastwert, v
f·w
f; die nächsten
drei Bits sind auf 0 gesetzt; und die höchstwertigen vier Bits von v ^
f halten das Gewicht, w
f.
Der gewichtete Mittelwert wird dann implementiert durch Bilden der
Summe
und
Verwenden von v ^ als den Index für
eine Nachschlagetabelle mit 2
16 Einträgen. Diese
Technik ist so lange effektiv, wie die Anzahl von Feldern, F, 8
nicht überschreitet.
Gemäß diesem
Zustand halten die niedrigstwertigen 12 Bits von v ^ die Summe der
gewichteten Abtastwerte und die höchstwertigen vier Bits halten
die Summe der Gewichte, so daß eine
Tabellennachschlageoperation ausreichend ist, um den gewichteten
Mittelwert wiederzugewinnen.
-
4 Verhalten
-
Obwohl das Mehrfachfeld-Verbesserungssystem,
das in diesem Dokument offenbart ist, erscheinen kann, um zahlreiche
Operationen zu umfassen, sollte darauf hingewiesen werden, daß eine effiziente
Implementierung keine übermäßigen Ansprüche an das
Berechnen von Speicherressourcen eines Allzweckcomputers stellen
muß. Dies
liegt daran, daß die
zahlreichen Zwischenergebnisse, die erforderlich sind, um die verschie denen
Teilsysteme zu implementieren, die vorangehend beschrieben wurden,
inkrementell auf einer Zeile-Für-Zeile-Basis erzeugt und
verworfen werden können.
Ferner können
Zwischenergebnisse häufig
zwischen den unterschiedlichen Teilsystemen gemeinschaftlich verwendet
werden. Viele Parameter, wie z. B. Filterkoeffizienten und Abmessungen
wurden im Hinblick auf die Implementierungseffizienz ausgewählt. Als
ein Beispiel, um vier Voll-Farb-Videofelder zu verarbeiten, jedes
mit 240 Zeilen und 640 Spalten, erfordert das System eine Gesamtspeicherungskapazität von nur
1,1 MB, wobei fast die gesamte derselben (0,92 MB) verwendet wird,
um die Quellfelder selbst zu speichern. Das Verarbeiten dieser vier
Felder erfordert ungefähr
8 Sekunden CPU-Zeit z. B. an einer Arbeitsstation der HP-Serie 735,
die mit 99 MHz arbeitet. An einem PC mit einem 200 MHz Pentium Pro
Prozessor benötigt
dieselbe Operation weniger als 4 Sekunden CPU-Zeit. Empirische Beobachtungen zeigen
an, daß dieses
Mehrfachfeld-Verarbeitungssystem eine bedeutend höhere Standbildqualität erreicht
als herkömmliche
Einzelfeld-Verbesserungs- oder -Entschachtelungs-Techiken. Ferner
erscheint das System über
einen breiten Bereich von Zwischenfeldbewegung robust zu sein, von
einer einfachen Kameraerschütterung
bis hin zu einer komplexen Bewegung von Szenenobjekten.


 bereits
bereits
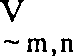 um der arithmetische Mittelwert der drei am wenigsten unterschiedlichen dieser vier benachbarten Bewegungsvektoren zu sein. Zu dem Zweck dieser Berechnung ist die Disparität unter einer Sammlung von drei Bewegungsvektoren
um der arithmetische Mittelwert der drei am wenigsten unterschiedlichen dieser vier benachbarten Bewegungsvektoren zu sein. Zu dem Zweck dieser Berechnung ist die Disparität unter einer Sammlung von drei Bewegungsvektoren und
und wie folgt definiert
wie folgt definiert das heißt, die Summe der L1 Distanzen zwischen jedem der Vektoren und ihrem arithmetischen Mittelwert. Ein Grund zum Bilden dieser Vorhersage
das heißt, die Summe der L1 Distanzen zwischen jedem der Vektoren und ihrem arithmetischen Mittelwert. Ein Grund zum Bilden dieser Vorhersage ist nicht, um die volle Bewegungsvektorsuchzeit zu reduzieren, sondern die Entwicklung von glatten Bewegungsabbildungen zu unterstützen. In Regionen der Szene, die wenig Informationen enthalten, aus denen eine Bewegung geschätzt werden kann, wird bevorzugt, die vorhergesagten Vektoren anzunehmen, wann immer dies vernünftig erscheint. Anderweitig können die „willkürlichen" Bewegungsvektoren, die üblicherweise durch Blockbewegungsschätzungsalgorithmen in diesen Regionen erzeugt werden, störende visuelle Artefakte verursachen, wenn Versuche gemacht werden, die Referenz- und Hilfs-Felder in ein einzelnes Standbild zusammenzuführen.
ist nicht, um die volle Bewegungsvektorsuchzeit zu reduzieren, sondern die Entwicklung von glatten Bewegungsabbildungen zu unterstützen. In Regionen der Szene, die wenig Informationen enthalten, aus denen eine Bewegung geschätzt werden kann, wird bevorzugt, die vorhergesagten Vektoren anzunehmen, wann immer dies vernünftig erscheint. Anderweitig können die „willkürlichen" Bewegungsvektoren, die üblicherweise durch Blockbewegungsschätzungsalgorithmen in diesen Regionen erzeugt werden, störende visuelle Artefakte verursachen, wenn Versuche gemacht werden, die Referenz- und Hilfs-Felder in ein einzelnes Standbild zusammenzuführen. vorzuspannen, immer wenn dies konsistent mit den Merkmalen ist, die in den zwei Feldern angetroffen werden. Das Grobbewegungsschätzungsteilsystem führt eine umfassende Suche durch, die bei einem Ausführungsbeispiel des Systems einen Suchbereich von
vorzuspannen, immer wenn dies konsistent mit den Merkmalen ist, die in den zwei Feldern angetroffen werden. Das Grobbewegungsschätzungsteilsystem führt eine umfassende Suche durch, die bei einem Ausführungsbeispiel des Systems einen Suchbereich von Feldspalten und
Feldspalten und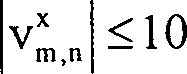 Feldzeilen umfaßt. Für jeden Vektor v in diesem Bereich berechnet der Prozeß eine objektive Funktion,
Feldzeilen umfaßt. Für jeden Vektor v in diesem Bereich berechnet der Prozeß eine objektive Funktion, die nachfolgend erörtert wird. Um die Erörterung zu erleichtern bezeichnet Omin den Minimalwert, der durch
die nachfolgend erörtert wird. Um die Erörterung zu erleichtern bezeichnet Omin den Minimalwert, der durch über den Suchbereich erlangt wird, und V bezeichnet den Satz aller Bewegungsvektoren
über den Suchbereich erlangt wird, und V bezeichnet den Satz aller Bewegungsvektoren wobei Tm eine vordefinierte Schwelle ist. Die abschließende Grobbewegungsschätzung
wobei Tm eine vordefinierte Schwelle ist. Die abschließende Grobbewegungsschätzung wird als der Vektor
wird als der Vektor genommen, der am nächsten zu dem vorhergesagten Vektor
genommen, der am nächsten zu dem vorhergesagten Vektor ist. Hier wird die L1-Distanzmetrik verwendet, so daß die Distanz zwischen
ist. Hier wird die L1-Distanzmetrik verwendet, so daß die Distanz zwischen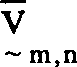 und
und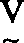
 ist.
ist.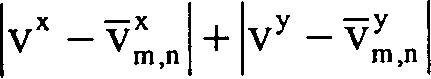
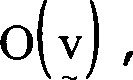





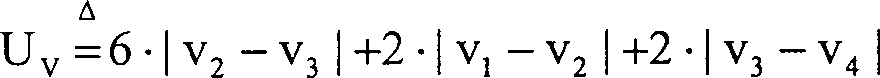




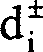



 Die ausgerichtete Linie, die verwendet wird, um p[i,j] zu bilden, ist um das Pixel (i,j) in dem Referenzfeld zentriert. Auf ähnliche Weise ist die Linie, die verwendet wird, um α2[i,j] zu bilden um das Pixel (i,j) in dem Hilfsfeld zentriert. Die Linien für α1[i,j] und α2[i,j] weisen Mittelpunkte auf, die auf jede Seite des Pixels (i,j) in dem Hilfsfeld fallen, versetzt um ungefähr die Hälfte einer Feldzeile oder einer Feldspalte, wie angemessen, in der orthogonalen Richtung zu der, die durch die Ausrichtungsklasse identifiziert ist. Somit wäre in einer Region, deren Ausrichtungsklasse einheitlich vertikal ist, das Ergebnis α1[i,j] = α2[i,j–1] = α3[i,j–2]. Andererseits, in einer Region deren Ausrichtungsklasse einheitlich schräg ist, O–-oder O+, sollte der horizontale Mittelwert, α1[i,j], ungefähr gleich zu dem arithmetischen Mittel von α2[i,j] und α2[i,j–1] sein. Aus diesen direktionalen Mittelwerten werden drei absolute Differenzen gebildet,
Die ausgerichtete Linie, die verwendet wird, um p[i,j] zu bilden, ist um das Pixel (i,j) in dem Referenzfeld zentriert. Auf ähnliche Weise ist die Linie, die verwendet wird, um α2[i,j] zu bilden um das Pixel (i,j) in dem Hilfsfeld zentriert. Die Linien für α1[i,j] und α2[i,j] weisen Mittelpunkte auf, die auf jede Seite des Pixels (i,j) in dem Hilfsfeld fallen, versetzt um ungefähr die Hälfte einer Feldzeile oder einer Feldspalte, wie angemessen, in der orthogonalen Richtung zu der, die durch die Ausrichtungsklasse identifiziert ist. Somit wäre in einer Region, deren Ausrichtungsklasse einheitlich vertikal ist, das Ergebnis α1[i,j] = α2[i,j–1] = α3[i,j–2]. Andererseits, in einer Region deren Ausrichtungsklasse einheitlich schräg ist, O–-oder O+, sollte der horizontale Mittelwert, α1[i,j], ungefähr gleich zu dem arithmetischen Mittel von α2[i,j] und α2[i,j–1] sein. Aus diesen direktionalen Mittelwerten werden drei absolute Differenzen gebildet,