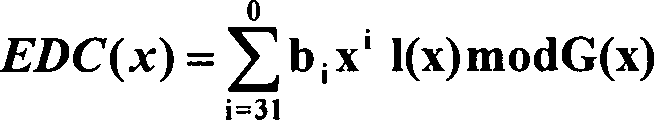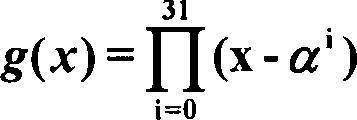-
HINTERGRUND DER ERFINDUNG
-
Die
Erfindung betrifft ein Verfahren gemäß dem Oberbegriff von Anspruch
1. Die
US-Patentschriften 4,559,625 von
Berlekamp et al. und
US 5,299,208 von
Blaum et al. offenbaren eine Decodierung von verschachtelten und
fehlergeschützten
Informationswörtern,
wobei ein Fehlermuster, das in einem ersten Wort gefunden wurde,
einen Hinweis (Clue) liefern kann, um Fehler in einem anderen Wort
derselben Gruppe von Wörtern
zu lokalisieren. In den zitierten Quellen wird ein Defektmodell
mit mehrere Symbole enthaltenden Fehlerbündeln über mehrere Wörter hinweg
verwendet. Ein Fehler in einem bestimmten Wort führt zu einer hohen Wahrscheinlichkeit
dafür,
dass ein Fehler an einer entsprechenden Symbolposition, auf die
gezeigt wird, in einem nächsten
Wort oder in nächsten
Wörtern
auftritt. Die Prozedur kann die Anzahl korrigierter Fehler erhöhen. Ein
Hinweis kommt jedoch nur dann zur Realisierung, wenn das Hinweiswort
vollständig
korrigiert worden ist. Ferner speichert das Medium Informationen
sowie Synchronisationsbitgruppen, welche eine beträchtliche Menge
an Redundanz repräsentieren,
die ebenfalls verwendet werden kann, um Fehler in den Zielwörtern zu signalisieren,
so dass in gewissem Maße
Hinweiswörter
gegen Synchronisationsbitgruppen ausgetauscht werden können. Ein
Teil der Fehler ist auf so genannte Bitslips (Bitschlupf) zurückzuführen, welche
weiter entfernt von den Synchronisationsbitgruppen häufiger sind.
Daher kann ein Verschachteln der Hinweiswörter zwischen Hinweisspalten
und ebenso ein Verschachteln der Zielwörter zwischen Zielspalten den
Fehlerschutz weiter verbessern.
-
Die
Veröffentlichung
von E. Paaske "Improved
Decoding for a Concatenated Coding System Recommended By CCSDS", IEEE Transactions
an Communications, Bd. 38, Nr. 8, August 1990, Seiten 1138–1144, XP000162505,
offenbart ein Fehlerkorrekturverfahren, bei welchem Reed-Solomon-Codewörter in
einer Spaltenrichtung angeordnet sind und welches den Schritt des
Ableitens von Hinweisen auf Fehlerbündel in der Zeilenrichtung
aus erfolgreich decodierten Codewörtern umfasst. Alle RS-Codewörter sind
RS(255, 223) mit derselben Schutzwirkung.
-
Die
Veröffentlichung
von E. Paaske "Alternative
to NASA's concatenated
coding system for the Galileo mission", IEEE Proceedings an Communications,
Bd. 141, August 1994, Seiten 229–232, XP006001668,
offenbart ein Verfahren des Fehlerschutzes, bei welchem Reed-Solomon-Codewörter mit
hoher und niedriger Schutzwirkung in einer Spaltenrichtung in einer
alternierenden Art und Weise angeordnet sind.
-
KURZDARSTELLUNG DER ERFINDUNG
-
Demzufolge
ist es unter anderem eine Aufgabe der Erfindung, ein Codierungsformat
zu schaffen, das es ermöglicht,
dass Hinweiswörter
mit Synchronisationsbitgruppen in einem systematischen Format zusammenwirken,
während
außerdem
mögliche
negative Auswirkungen von Bitslips gleichmäßiger zwischen den verschiedenen
Wörtern
ausgeglichen werden. Daher ist die Erfindung gemäß einem ihrer Aspekte gekennzeichnet,
wie in dem Kennzeichnungsteil von Anspruch 1 dargelegt. Ein Hinweis
kann auf ein Lösch-Symbol zeigen.
Zeigen kann eine Fehlerkorrektur leistungsfähiger machen. Tatsächlich werden
viele Codes höchstens t
Fehler korrigieren, wenn keine lokative (ortsbestimmende) Angabe
für den
Fehler bekannt ist. Sind die Löschstellen
gegeben, kann im Allgemeinen eine größere Anzahl e > t von Löschungen
korrigiert werden. Auch der Schutz vor einer Kombination von Bündeln und
zufälligen
Fehlern kann sich verbessern. Die Erfindung kann sowohl für die Speicherung
als auch für
die Übertragung
verwendet werden.
-
Vorteilhafterweise
weist das Verfahren die Merkmale von Anspruch 2 auf. Dies ist eine
relativ einfache Anordnung. Stattdessen kann die Anzahl von Synchronisationsspalten
auch größer als
eins sein, und die Anzahl von Hinweisspalten kann gerade sein, falls
dies bevorzugt wird.
-
Vorteilhafterweise
weist das Verfahren die Merkmale von Anspruch 3 auf. Bei einer Videoaufzeichnung beziehen
sich Benutzerdaten auf das Bild und den begleitenden Ton, die einem
Benutzer präsentiert
werden sollen, während
Systemdaten den Programmnamen, Zeit, Adressen, und verschiedene
andere Parameter, welche von Nutzen sein können, angeben können, ohne
Bezugnahme auf das eigentliche Video oder Audio. Dieses Merkmal
ermöglicht
einen schnellen Zugriff auf die Systemdaten ohne die Notwendigkeit,
die Zielwörter zu
decodieren.
-
Vorteilhafterweise
weist das Verfahren die Merkmale von Anspruch 4 auf. Falls fehlerfrei,
gibt dieses Merkmal unmittelbar einer Benutzereinrichtung an, ob
der verarbeitete Informationsrahmen korrekt ist.
-
Vorteilhafterweise
weist das Verfahren die Merkmale von Anspruch 5 auf. Dies ist eine
geradlinige Organisation. Vorteilhafterweise weist das Verfahren
die Merkmale von Anspruch 6 auf. Es hat sich erwiesen, dass dies
den ungünstigsten
Fall auf das mittlere Niveau anhebt, das für dieses Codeformat erreichbar
ist. Vorteilhafterweise weist das Verfahren die Merkmale von Anspruch
7 auf. Optische Speicher haben sich als ein günstiges Medium erwiesen.
-
Die
Erfindung betrifft außerdem
ein Verfahren zum Decodieren von so codierten Informationen, eine Codier-
und/oder Decodiereinrichtung zur Verwendung mit dem Verfahren und
einen Träger,
der so codierte Informationen enthält. Weitere vorteilhafte Aspekte
der Erfindung sind in abhängigen
Ansprüchen
dargelegt.
-
KURZBESCHREIBUNG DER ZEICHNUNG
-
Diese
und weitere Aspekte und Vorteile der Erfindung werden im Folgenden
unter Bezugnahme auf die Beschreibung bevorzugter Ausführungsform
ausführlicher
erläutert,
und insbesondere unter Bezugnahme auf die beigefügten Figuren. Es zeigen:
-
1a, 1b einen
Aufzeichnungsträger;
-
2 eine
Abspieleinrichtung;
-
3 eine
Aufzeichnungseinrichtung;
-
4 ein
System mit Codierer, Träger
und Decodierer;
-
5 ein
Codeformat-Prinzip;
-
6 eine
schematische Darstellung eines physischen Clusters auf dem Träger;
-
7 einen
Datenrahmen;
-
8 einen
Aufbau eines Datensektors aus zwei Datenrahmen;
-
9 das
Umnummerieren von Datenbytes und Bilden eines ECC-Sektors durch
Hinzufügen
von Paritäten;
-
10 einen
Aufbau eines ECC-Clusters durch Multiplexing von 16 ECC- Sektoren;
-
11 einen
umnummerierten ECC-Cluster vor dem Verschachteln;
-
12 einen
verschachtelten ECC-Cluster;
-
13 ein
Multiplexing des BIS-Clusters mit dem verschachtelten ECC- Cluster;
-
14 einen
BIS-Block, der 24 BIS-Codewörter
enthält;
-
14A die Abbildung des BIS-Blockes in den BIS-Cluster;
-
15 die
Rahmenstruktur zur Erläuterung
der Verschachtelung der Hauptdaten;
-
16 die
eigentliche Verschachtelung;
-
17 ein Beispiel der teilweisen Abbildung
der BIS-Bytes auf die ersten acht Sektoren;
-
18 ein
Beispiel der teilweisen Abbildung der BIS-Bytes auf die letzten
acht Sektoren;
-
19 eine
schematische Darstellung des Gesamtprozesses der Codierung.
-
AUSFÜHRLICHE
BESCHREIBUNG BEVORZUGTER AUSFÜHRUNGSFORMEN
-
1a zeigt
einen plattenförmigen
Aufzeichnungsträger 11 mit
einer Spur 19 und einer zentralen Bohrung 10.
Die Spur 19 ist in einem spiralförmigen Muster von Windungen
angeordnet, das im Wesentlichen parallele Spuren auf einer Informationsschicht
bildet. Der Träger
kann eine optische Platte mit einer beschreibbaren oder vorbeschriebenen
Informationsschicht sein. CD-R, CD-RW und DVD-RAM sind beschreibbar,
während
eine Audio-CD ein Beispiel einer vorbeschriebenen Platte ist. Der
vorbeschriebene Typ kann auf eine bekannte Weise hergestellt werden,
indem zuerst eine Masterplatte beschrieben wird und danach Platten
für den Verkauf
gepresst werden. Auf einem beschreibbaren Träger ist die Spur durch eine
vorgeprägte
Spurstruktur angegeben, die während
der Herstellung des Rohlings des Trägers geschaffen wird. Die Spur
kann als eine Vorspur (Pregroove) 14 strukturiert sein,
um einem Lese-Schreibkopf zu ermöglichen,
der Spur 19 während des
Abtastens zu folgen. Die Informationen sind auf der Informationsschicht
mittels optisch erkennbarer Markierungen dargestellt, z. B. Pits
(Täler)
und Lands (Erhebungen).
-
1b ist
ein Querschnitt entlang der Linie b-b des Aufzeichnungsträgers 11 vom
beschreibbaren Typ, wobei ein durchsichtiges Substrat 15 mit
einer Aufzeichnungsschicht 16 und einer Schutzschicht 17 versehen
ist. Die Vorspur 14 kann als Vertiefung oder eine Erhebung
implementiert sein, oder als eine Materialeigenschaft, die von ihrer
Umgebung abweicht.
-
Der
Aufzeichnungsträger
kann Benutzerinformationen tragen, welche im Interesse der Benutzerfreundlichkeit
in kleinere Stücke
unterteilt worden sind, welche jeweils eine Dauer von einigen Minuten
haben können,
z. B. Songs eines Albums oder Sätze einer
Sinfonie. Zugriffsinformationen zum Identifizieren der Stücke können ebenfalls
auf dem Träger
vorgesehen sein, z. B. ein so genanntes Inhaltsverzeichnis (Table
Of Contents, TOC) oder ein Dateisystem wie ISO 9660 für CD-ROM.
Die Zugriffsinformationen können
für jedes Stück Wiedergabezeit
und Startadresse beinhalten, und weitere Informationen wie einen
Songtitel. Solche Informationen können Systeminformationen darstellen.
Die Informationen werden nach Analog-Digital-(A/D-)Wandlung auf
eine digitale Weise aufgezeichnet.
-
2 zeigt
ein Abspielgerät
gemäß der Erfindung
zum Lesen eines Aufzeichnungsträgers 11,
wie in 1 dargestellt. Die Einrichtung
weist einen Antrieb 21 auf, um den Aufzeichnungsträger 11 in
Rotation zu versetzen, und einen Lesekopf 22 zum Abtasten
der Spur auf dem Aufzeichnungsträger.
Das Gerät
weist Positionierungsmittel 25 für eine grobe radiale Positionierung
des Lesekopfes 22 auf. Der Lesekopf umfasst ein optisches
System eines bekannten Typs zum Erzeugen eines Strahls 24,
welcher durch optische Elemente hindurch geführt und auf einen Lichtpunkt 23 auf
einer Spur der Informationsschicht fokussiert wird. Der Strahl 24 wird
von einer bekannten Strahlungsquelle erzeugt. Der Lesekopf weist
ferner einen Fokussierungs-Aktor (Focusing Actuator) zum Bewegen
des Fokus des Strahls 24 entlang der optischen Achse des
Strahls und einen Tracking-Aktor (Tracking Actuator) zur Feinpositionierung
des Lichtpunktes 23 in einer radialen Richtung auf der
Mitte der Spur auf. Der Tracking-Aktor kann Spulen umfassen, um
ein optisches Element radial zu bewegen, oder kann dazu vorgesehen
sein, den Winkel eines reflektierenden Elements zu verändern. Die
von der Informationsschicht reflektierte Strahlung wird von einem
Detektor eines üblichen
Typs, z. B. einer Vier-Quadranten-Diode, im Lesekopf 22 detektiert,
um ein Lesesignal und weitere Detektorsignale zu erzeugen, darunter
ein Trackingfehler- und ein Fokusfehler-Signal, die mit dem besagten
Tracking- bzw. Fokussierungs-Aktor gekoppelt sind. Das Lesesignal
wird von Lesemitteln 27 verarbeitet, um die Daten wiederzugewinnen,
wobei diese Lesemittel von einem üblichen Typ sind, der zum Beispiel
einen Kanaldecoder und einen Fehlerkorrektor umfasst. Die wiedergewonnenen
Daten werden zu einer Datenauswahleinrichtung 28 gesendet,
um gewisse Informationen aus den gelesenen Daten auszuwählen und
zu dem Puffer 29 zu senden. Die Auswahl beruht auf Datentyp-Indikatoren,
die auf dem Aufzeichnungsträger
aufgezeichnet sind, z. B. Headern in einem Rahmenformat. Die komprimierten
Informationen werden von dem Puffer 29 mittels eines Signals 30 zu
einem Dekompressor 31 gesendet. Dieses Signal kann außerdem extern
verfügbar
sein. Der Dekompressor 31 decodiert die Daten, um die ur sprünglichen
Informationen am Ausgang 32 wiederzugeben. Der Dekompressor
kann separat eingebaut sein, wie durch das Rechteck 33 in 2 angegeben
ist. Stattdessen kann der Puffer vor der Datenauswahl positioniert
sein. Die Steuereinheit 20 empfängt ferner Steuerbefehle von
einem Benutzer oder von einem Hostcomputer über Steuerleitungen 26 wie
etwa einen Systembus, der den Antrieb 21, Positionierungsmittel 25,
Lesemittel 27 und Datenauswahlmittel 28 und möglicherweise
auch den Puffer 29 zur Füllstandsregelung verbindet.
Zu diesem Zweck umfasst die Steuereinheit 20 Steuerschaltungen
wie etwa einen Mikroprozessor, einen Programmspeicher und Steuergates
oder eine Zustandsmaschine.
-
Kompression
und Dekompression sind wohlbekannt. Während der Dekompression wird
ein inverser Prozess angewendet, um das ursprüngliche Signal wiederherzustellen.
Wenn das ursprüngliche
digitalisierte Signal exakt wiederhergestellt wird, ist die (De-)Kompression
verlustfrei, während
bei einer verlustbehafteten (De-)Kompression manche Details des
ursprünglichen
Signals nicht wiedergegeben werden. Diese weggelassenen Details
sind für
das menschliche Ohr oder Auge im Wesentlichen nicht wahrnehmbar.
Die meisten bekannten Systeme, wie etwa MPEG, verwenden eine verlustbehaftete
Kompression für
Audio und Video; eine verlustfreie Kompression wird für das Speichern
von Computerdaten angewendet.
-
Die
Datenauswahl 28 ist dazu vorgesehen, Steuerinformationen
aus den gelesenen Daten wiederzugewinnen und eventuelle Fülldaten
zu verwerfen, die während
des Aufzeichnens hinzugefügt
wurden. Die Drehzahl kann unter Verwendung des durchschnittlichen
Füllstandes
des Puffers 29 eingestellt werden, z. B. indem die Drehzahl
verringert wird, wenn der Puffer im Mittel mehr als zu 50% voll
ist.
-
3 zeigt
eine Aufzeichnungseinrichtung zum Schreiben von Informationen auf
einem (wieder)beschreibbaren Aufzeichnungsträger 11. Während eines
Schreibvorgangs werden Markierungen, welche die Informationen repräsentieren,
auf dem Aufzeichnungsträger
ausgebildet. Die Markierungen können
in einer beliebigen optisch lesbaren Form vorliegen, z. B. in der
Form von Bereichen, deren Reflexionskoeffizient sich von dem ihrer
Umgebung unterscheidet, durch Aufzeichnen in Materialien wie etwa
Farbstoff, Legierung oder Phasenumwandlungsmaterial, oder in der
Form von Bereichen mit einer Magnetisierungsrichtung, die von der
ihrer Umgebung verschieden ist, wenn in einem magnetooptischen Material
aufgezeichnet wird. Das Schreiben und Lesen von Informationen zum
Aufzeichnen auf optischen Platten und die anwendbaren Regeln für das Formatieren,
die Fehlerkorrektur und die Kanalcodierung sind in der Technik wohlbekannt,
z. B. vom CD- System
her. Die Markierungen können
durch einen Lichtpunkt 23 gebildet werden, der auf der
Aufzeichnungsschicht mittels eines elektromagnetischen Strahls 24 von
einer Laserdiode erzeugt wird. Die Aufzeichnungseinrichtung umfasst ähnliche
Grundelemente wie das Gerät
zum Lesen, das oben in Verbindung mit 2 beschrieben
wurde, d. h. eine Steuereinheit 20, Antriebsmittel 21 und
Positionierungsmittel 25, doch sie weist einen Schreibkopf 39 auf.
Die Informationen werden dem Eingang von Kompressionsmitteln 35 zugeführt, welche
in einem separaten Gehäuse
angebracht sein können.
Die mit variabler Bitrate komprimierten Informationen am Ausgang
der Kompressionsmittel 35 werden zu einem Puffer 36 weitergegeben.
Vom Puffer 36 werden die Daten zu Datenkombinationsmitteln 37 gesendet,
um Fülldaten
und weitere Steuerdaten hinzuzufügen.
Der gesamte aufzuzeichnende Datenstrom wird Schreibmitteln 38 zugeführt. Der
Schreibkopf 39 ist mit den Schreibmitteln 38 gekoppelt,
welche einen Formstierer, einen Fehlercodierer und einen Kanalmodulator
umfassen. Die Daten, die dem Eingang der Schreibmittel 38 zugeführt werden,
werden entsprechend Formatierungs- und Codierungsregeln, die weiter
unten erläutert
werden, über
logische und physikalische Sektoren verteilt und in ein Schreibsignal
für den
Schreibkopf 39 umgewandelt. Die Steuereinheit 20 ist
dazu vorgesehen, den Puffer 36, die Datenkombinationsmittel 37 und
die Schreibmittel 38 über
Steuerleitungen 26 zu steuern und den Positionierungsvorgang
auszuführen,
wie oben für
das Lesegerät
beschrieben wurde. Das Aufzeichnungsgerät kann durch die Merkmale eines
Abspielgerätes
und eines kombinierten Lese-Schreibkopfes ebenfalls für ein Lesen vorgesehen
sein.
-
4 zeigt
ein umfassendes System gemäß der Erfindung,
das mit einem Codierer, einem Träger
und einem Decodierer ausgestattet ist. Die Ausführungsform wird zum Codieren,
Speichern und schließlich
zum Decodieren einer Folge von Samples oder Multibit-Symbolen verwendet,
die von einem Audio- oder Videosignal oder von Daten abgeleitet
wurde. Das Endgerät 120 empfangt
einen Strom, welcher Acht-Bit-Symbole aufweisen kann. Der Splitter 122 überträgt rekurrent
und zyklisch erste Symbole, die für die Hinweiswörter (Clue
Words) bestimmt sind, zu dem Codierer 124 und alle anderen
Symbole zu dem Codierer 126. In dem Codierer 124 werden
die Hinweiswörter
gebildet, indem die Daten zu Codewörtern eines ersten Multisymbol-Fehlerkorrekturcodes
codiert werden. Dieser Code kann ein Reed-Solomon-Code, ein Produktcode,
ein verschachtelter Code oder eine Kombination davon sein. Im Codierer 126 werden
die Zielwörter
durch Codieren zu Codewörtern
eines zweiten Multisymbol-Fehlerkorrekturcodes gebildet. In 5 haben
alle Codewörter eine
einheitliche Länge,
doch dies ist keine Einschränkung.
Die Hinweis- Wörter können einen
wesentlich höheren
Grad des Fehlerschutzes aufweisen. Dies kann durch eine größere Anzahl
von Prüfsymbolen,
durch eine kleinere Anzahl von Datensymbolen oder durch eine Kombination
davon bewirkt werden.
-
In
Block 128 werden die Codewörter zu einem oder mehreren
Ausgängen übertragen,
von welchen eine willkürliche
Anzahl dargestellt wurde, so dass die Verteilung auf einem später zu erörternden
Medium gleichmäßig wird.
Block 130 symbolisiert das einheitliche Medium, wie etwa
ein Band oder eine Platte, welches die codierten Daten empfängt. Diese
kann sich auf ein direktes Schreiben in einer Kombination von Schreibmechanismus
plus Medium beziehen. Stattdessen kann das Medium auch eine Kopie
von einem als Master codierten Medium wie etwa einem Stempel sein.
Die Speicherung kann optisch und vollständig seriell erfolgen, doch
können
auch andere Konfigurationen verwendet werden. In Block 132 werden
die verschiedenen Wörter wieder
von dem Medium gelesen. Danach werden die Hinweiswörter des
ersten Codes zu einem Decodierer 134 gesendet und decodiert,
basierend auf den ihnen innewohnenden Redundanzen. Ferner kann,
wie nachfolgend bei der Erörterung
von 5 ersichtlich wird, diese Decodierung Hinweise
auf die Stellen von Fehlern in anderen als diesen Hinweiswörtern liefern.
Außerdem
kann die Information aus Synchronisationsbitspalten in Bezug auf
darin enthaltene Interferenzen analysiert werden, um unmittelbar
zusätzliche
Hinweise für
die Zielwörter
zu erzeugen. Block 135 empfangt alle Hinweise und enthält ein Programm
zur Verwendung einer oder mehrerer unterschiedlicher Strategien,
um diese Hinweise in Löschstellen
zu übersetzen.
Die Zielwörter werden
in einem Decodierer 136 decodiert. Mit Hilfe der Löschstellen
wird der Fehlerschutz der Zielwörter
auf ein höheres
Niveau gehoben. Schließlich
werden alle decodierten Wörter
mittels eines Elements 138 zum Ausgang 140 demultiplext,
so dass sie mit dem ursprünglichen
Format konform sind. Der Kürze
halber wurden elektromechanische Schnittstellen zwischen den verschiedenen
Teilsystemen ignoriert.
-
5 zeigt
ein einfaches Codeformat. Die codierten Informationen wurden als
in einem 480 Symbole enthaltenden Block mit 15 horizontalen Reihen
und 32 vertikalen Reihen angeordnet dargestellt. Die Speicherung
auf einem Medium beginnt oben links und setzt sich entlang vertikaler
Reihen fort. Der schraffierte Bereich enthält Prüfsymbole: die horizontalen
Reihen 4, 8 und 12 weisen jeweils 8 Prüfsymbole auf und stellen Hinweiswörter dar.
Die anderen Reihen enthalten jeweils 4 Prüfsymbole und stellen Zielwörter dar.
Der gesamte Block weist 408 Informationssymbole und 72 Prüfsymbole
auf. Die Letzteren können
auf eine stärker über die
jeweiligen Wörter
verteilte Weise angeordnet sein. Zusätz lich zu Obigem enthält die obere
horizontale Reihe eine Darstellung von Synchronisationsbitgruppen.
Diese sind auf dem Medium vorhanden, um eine Leseeinrichtung mit
dem Format zu synchronisieren, enthalten jedoch im Allgemeinen weder
Systemdaten noch Benutzerdaten und haben ein vorgeschriebenes Format
mit viel Redundanz. Daher ist es oft leicht, eine Interferenz zu
detektieren, und das Auftreten einer einzelnen oder mehrerer gestörter Synchronisationsbitgruppen, welche
physisch nahe beieinander oder bei verteilten Hinweissymbolen sind,
kann verwendet werden, um das Auftreten eines Bündelfehlers zu signalisieren.
Dies erzeugt dann Hinweise auf eine ähnliche Weise wie die Hinweiswörter.
-
Der
Reed-Solomon-Code ermöglicht,
in jedem Hinweiswort bis zu vier Symbolfehler zu korrigieren. Eigentliche
Symbolfehler wurden durch Kreuze bezeichnet. Demzufolge können alle
Hinweiswörter
korrekt decodiert werden, insofern als sie nicht mehr als vier Fehler
aufweisen. Insbesondere die Wörter
2 und 3 können jedoch
nicht auf der Grundlage ihrer eigenen Redundanz allein decodiert
werden. In der Figur stellen alle Fehler außer 62, 66, 68 Fehlerstrings
(Fehlerzeichenketten) dar. Nur die Strings 52 und 58 durchqueren
mindestens drei aufeinander folgende Hinweiswörter und werden als Fehlerbündel betrachtet,
die zur Folge haben, dass mindestens alle dazwischen befindlichen
Symbolstellen ein Lösch-Flag
erhalten. Außerdem
können
Zielwörter
unmittelbar vor dem ersten Hinweiswort-Fehler des Bündels und
Zielwörter
unmittelbar nach dem letzten Hinweiswort-Fehler des Bündels ein
Lösch-Flag
an der betreffenden Stelle erhalten, in Abhängigkeit von der verfolgten
Strategie. String 54 wird nicht als ein Bündel betrachtet,
da er zu kurz ist.
-
Infolgedessen
erzeugen zwei der Fehler in Wort 4 ein Lösch-Flag in den zugehörigen vertikalen
Reihen. Dies macht die Wörter
2 und 4 korrigierbar, jeweils mit einem Fehlersymbol und zwei Löschsymbolen. Jedoch
stellen die zufälligen
Fehler 62, 68 und auch der String 54 keine
Hinweise für
die Wörter
5, 6, 7 dar, da jeder von ihnen nur ein Hinweiswort enthält. Manchmal
verursacht eine Löschung
ein Null-Fehler-Muster, da ein beliebiger Fehler in einem 8-Bit-Symbol
eine Wahrscheinlichkeit von 1/256 aufweist, wieder ein korrektes Symbol
zu verursachen. Ebenso kann ein langes Bündel, das ein bestimmtes Hinweiswort
durchquert, ein korrektes Symbol darin erzeugen. Durch eine Überbrückungsstrategie
zwischen vorhergehenden und nachfolgenden Hinweissymbolen desselben
Bündels
wird dieses korrekte Symbol dann in das Bündel integriert und auf dieselbe
Weise wie fehlerbehaftete Hinweissymbole in Löschwerte für entsprechende Zielsymbole übersetzt.
Die obigen Entscheidungen können
entsprechend der Decodierungspolitik variieren.
-
Die
Hinweise durch die Synchronisationsbitgruppen können in ähnlicher Weise verwendet werden
wie diejenigen von den Hinweiswörtern.
-
Die
Relevanz der vorliegenden Erfindung wird durch neuere Verfahren
zur digitalen optischen Speicherung bewirkt. Ein besonderes Merkmal
ist, dass im Falle eines Substrate-Incident Reading (Lesen durch ein
durchsichtiges Substrat hindurch) die obere durchlässige Schicht
nur 100 Mikrometer dünn
ist. Die Kanalbits haben eine Größe von etwa
0,14 Mikrometer, so dass ein Datenbyte bei einer Kanalrate von 2/3
dann eine Länge
von nur 1,7 Mikrometern hat. An der oberen Fläche hat der Strahl einen Durchmesser
von etwa 125 Mikrometern. Eine Plastikkassette oder Hülle für die Platte
verringert dann die Wahrscheinlichkeit großer Bündel. Nicht konforme Partikel
von weniger als 50 Mikrometern können
kurze Defekte verursachen, obwohl die Erfindung auch gegen längere Defekte
von Nutzen ist. Es wurde ein Defektmodell verwendet, bei dem Defekte von
50 Mikrometern durch Fehlerfortpflanzung zu Bündeln von 200 Mikrometern führen können, die
etwa 120 Bytes entsprechen. Ein spezielles Modell weist Bündel mit
fester Größe von 120B
auf, welche zufällig
mit einer Wahrscheinlichkeit pro Byte von 2,6·10–5 beginnen,
oder im Mittel ein Bündel
pro Block von 32 kB. Die Erfindung wurde für optische Plattenspeicher
entwickelt, jedoch würden
auch andere Konfigurationen wie etwa mehrspurige Magnetbänder und
andere Technologien wie etwa magnetische und magnetooptische von
dem verbesserten Ansatz profitieren.
-
Erörterung
eines bevorzugten Formats der Information
-
Vor
dem Aufzeichnen werden Benutzerdaten, die von einer Quelle empfangen
wurden, welche eine Anwendung oder ein Host sein kann, in einer
Anzahl von aufeinander folgenden Schritten formatiert, welche unter
Bezugnahme auf 19 eingehender erläutert werden,
nämlich:
Datenrahmen, Datensektoren, ECC-Sektoren, ein ECC-Cluster, ein BIS-Cluster,
ein physischer Cluster und Aufzeichnungsrahmen.
-
Die
Daten werden in Partitionen von 64k aufgezeichnet, die physische
Cluster genannt werden und welche jeweils 32 Datenrahmen mit 2048
Bytes von Benutzerdaten enthalten. Ein physischer Cluster wird durch
zwei Fehlerkorrekturmechanismen geschützt:
- – erstens,
einen Long-Distance-(LDS) (248,216,33) Reed-Solomon-(RS-)Fehlerkorrekturcode;
- – zweitens,
die Daten werden mit einem Burst Indicator Subcode (BIS) gemultiplext,
welcher aus (62,30,33) Reed-Solomon-(RS-)Codewörtern besteht. Die Anzahl von
Paritäts symbolen
ist für
die zwei Codekategorien gleich, was es ermöglicht, für beide Fälle dieselbe Decoder-Hardware
zu verwenden. Der BIS-Code wird verwendet, um längere Bündelfehler anzuzeigen, wodurch
der LDS-Code Löschkorrekturen
effizienter durchführen
kann. Alle Daten sind in einem Array angeordnet, wie in 6 dargestellt.
Es ist anzumerken, dass die horizontale und die vertikale Richtung
in Bezug auf 5 vertauscht worden sind. Das
Array wird entlang einer horizontalen Richtung gelesen und wird
nach dem Einfüngen
von Synchronisationsmustern und zusätzlichen d. c. Steuerbits sowie
nach Modulation auf der Platte aufgezeichnet.
-
Die
Fehlerkorrekturcodes werden in vertikaler Richtung angewendet, was
ein gutes grundlegendes Aufbrechen von Bündelfehlern auf der Platte
bewirkt. Zusätzlich
sind die LDS-Codewörter
in einer diagonalen Richtung verschachtelt worden. Zum Zwecke einer
Adressierung wird ein ganzer physischer Cluster in 16 physische
Sektoren unterteilt, die jeweils aus 32 aufeinander folgenden Reihen
bestehen.
-
Ein
Datenrahmen besteht aus 2052 Bytes: 2048 Benutzerdatenbytes, die
mit d
0 bis d
2047 nummeriert sind,
und 4 Error Detection Code (EDC, Fehlerdetektionscode) Bytes, die
mit e
2048 bis e
2851 nummeriert
sind. Die Bytes e
2048 bis e
2851 enthalten
einen Fehlerdetektionscode, der über
2048 Bytes des Datenrahmens berechnet wurde. Der Datenrahmen wird
als ein Feld von einzelnen Bits betrachtet, beginnend mit dem höchstwertigen
Bit des ersten Benutzerdatenbytes d
o und
endend mit dem niedrigstwertigen Bit des letzten EDC-Bytes e
2051. Das höchstwertige Bit ist b
16415 und das niedrigstwertige Bit ist b
0. Jedes Bit b
i des
EDC ist wie folgt dargestellt, für
i = 0 bis 31:
wobei:
-
Als
nächstes
werden zwei Datenrahmen (A, B) in einem Array von 19 Spalten mal
216 Zeilen, Datensektor genannt, angeordnet. Das Füllen des
Arrays erfolgt Spalte für
Spalte, beginnend am oberen Ende der ersten mit Byte d0,A und
endend am unteren Ende der letzten Spalte mit Byte e2051,B,
siehe 8.
-
Als
nächstes
werden in 9 die Bytes in jeder Spalte
des Datensektors wie folgt umnummeriert, beginnend am oberen Ende
der Spalte: dL,0, dL,1 ..
dL,i .. bis dL,215, wobei
L die Spaltennummer (0 .. 18) ist. Der ECC-Sektor wird vervollständigt, indem
jede Spalte um 32 Paritätsbytes
eines (248,216,33) Long-Distance-RS-Codes verlängert wird. Die Paritätsbytes
sind: PL,216, PL,217,
... PL,j ... bis PL,247.
-
Der
Long-Distance-RS-Code ist über
dem finiten Feld GF(2
8) definiert. Von null
verschiedene Elemente des finiten Feldes GF(2
8)
werden durch ein primitives Element α erzeugt, welches eine Wurzel
des primitiven Polynoms p(X) = X
8 + X
4 + X
3 + X
2 + 1 ist. Die Symbole von GF(2
8)
werden durch 8-Bit-Bytes dargestellt, unter Verwendung einer Polynombasis-Darstellung
mit (α
7, α
6, α
5,... α
2, α,
1) als Basis. Die Wurzel α wird
als α = 00000010
dargestellt. Jedes LDS-Codewort, dargestellt durch den Vektor lds
= (d
L,O .. d
L,i ..
d
L,215 P
L,216 --
P
L,j -- P
L,247),
gehört
zu einem Reed-Solomon-Code über
GF(2
8), mit 216 Informationsbytes und 32
Paritätsbytes.
Ein solches Codewort kann durch ein Polynom lds(x) vom Grad 247
dargestellt werden, welches einige Koeffizienten null haben kann,
wobei die höchsten
Grade dem Informationsteil des Vektors (d
L,0 ..
usw.) entsprechen und die niedrigsten Grade dem Paritätsteil (P
L,216 .. usw.) entsprechen. Nun ist lds(x)
ein Vielfaches des Generatorpolynoms g(x) des LDS-Codewortes. Das
Generatorpolynom ist:
-
Der
LDS-Code ist systematisch: Die 216 Informationsbytes erscheinen
unverändert
in den Positionen höchster
Ordnung jedes Codewortes. Die Paritätsprüfungsmatrix von Code lds ist
so beschaffen, dass gilt: HLDS·ldsT = 0 für
alle LDS-Codewörter
lds.
-
Die
zweite Zeile HLDS 2 der Paritätsprüfungsmatrix
HLDS ist gegeben durch HLDS
2 = (α247 α246 ... α2 α 1) und entspricht
der Nullstelle α des
Generatorpolynoms g(x), welche die Codewortpositionen definiert,
die für Fehlerstellen
zu verwenden sind.
-
Nach
dem Erzeugen der LDS-Codewörter
in den ECC-Sektoren werden 16 aufeinander folgende ECC-Sektoren
zu einem ECC-Cluster kombiniert, indem die 16·19 Spalten der Höhe 248 in
Zweiergruppen gemultiplext werden, einschließlich der Paritäten. Auf
diese Weise werden 152 neue Spalten mit einer Höhe von 496 Bytes gebildet,
wie in 10 dargestellt. Die Nummerierung
der Bytes erfolgt entsprechend dL,M,N, wobei:
- L = 0..18 die LDS-Codewort-Nummer innerhalb des ECC-Sektors
ist,
- M = 0..247 die Bytenummer innerhalb des LDS-Codewortes ist,
- N = 0..15 die ECC-Sektor-Nummer ist.
-
Um
die Fähigkeiten
zur Korrektur von Bündelfehlern
noch weiter zu verbessern, wird eine zusätzliche Verschachtelung eingeführt, indem
die Bytes in horizontaler Richtung durch alle Zeilen des ECC-Clusters
hindurch umnummeriert werden, siehe 11. Nun
werden alle Zeilen eines ECC-Clusters in Zweiergruppen um mod(k·3,152)
Bytes nach links verschoben, beginnend ab Zeile 2 aufwärts, wobei
die erste Zeile die Zeile 0; k = div(row-number, 2) ist. Die Bytes,
welche auf der linken Seite herausgeschoben werden, treten von der
rechten Seite her wieder in das Array ein, siehe 12.
Nach diesem Prozess werden die Bytes noch einmal in horizontaler
Richtung durch alle Zeilen hindurch umnummeriert, was die Nummerierung
D0 bis D75391 zum
Ergebnis hat, die in 6 angegeben ist. Die Umnummerierung
der Bytes bewirkt eine ungleichförmige
Abbildung von logischen Adressen auf physische Adressen. Die Folgen
davon werden weiter unten erörtert.
-
Nach
der Verschachtelung wird der ECC-Cluster in 4 Gruppen von jeweils
38 Spalten aufgespaltet. Zwischen die 4 Gruppen werden 3 Spalten
von jeweils einem Byte Breite eingefügt. Diese Spalten tragen die Adressinformationen,
welche die Daten betreffen, die in dem verschachtelten ECC-Cluster
enthalten sind. Sie bestehen aus (62,30,33) RS-BIS-Codewörtern mit
30 Bytes Information und 32 Bytes Parität. Aufgrund der hohen Fehlerschutz-Fähigkeiten
und eines anspruchsvollen Verschachtelungsschemas können diese
Spalten auch eine zuverlässige
Anzeige von Bündelfehlern
bieten.
-
Ein
Array von 3 mal 496 Bytes, das von den 3 BIS-Spalten aus dem physischen
Cluster gebildet wird, wird ein BIS-Cluster genannt. Der Inhalt
des BIS-Clusters wird gebildet, indem alle BIS-Codewörter eines BIS-Clusters
in den 24 Spalten eines Arrays von 24 mal 62 Bytes angeordnet werden,
siehe 14.
-
Der
BIS-RS-Code ist über
dem finiten Feld GF(28) definiert. Die von
null verschiedenen Elemente des finiten Feldes GF(28)
werden durch ein primitives Element α erzeugt, welches eine Wurzel
des primitiven Polynoms p(X) = X8 + X4 + X3 + X2 + 1 ist. Die Symbole von GF(28)
werden durch 8-Bit-Bytes dargestellt, unter Verwendung der Polynombasis-Darstellung
mit (α7, α6,... α2, α,
1) als Basis. Die Wurzel α wird
als α =
00000010 dargestellt.
-
Jedes
BIS-Codewort ist durch einen Vektor bis = (b
c,0 ..
b
c,i .. b
c,29, Pb
c,30 .. Pb
c,61) in
einem Reed-Solomon-Code über
GF(2
8), mit 32 Paritätsbytes und 30 Informationsbytes.
Ein solches Codewort kann durch ein Polynom bis(x) vom Grad 61 dargestellt
werden, welches einige Koeffizienten null haben kann, wobei die höchsten Grade
den Informationsteil des Vektors (b
c,0 ..
usw.) darstellen und die niedrigsten Grade den Paritäts teil des
Vektors (Pb
c,30 .. usw.). Jedes Codewort
ist ein Vielfaches des Generatorpolynoms g(x) des BIS-Codewortes:
-
Der
BIS-Code ist systematisch: Die 30 Informationsbytes erscheinen unverändert in
den Positionen höchster
Ordnung jedes Codewortes. Die Paritätsprüfungsmatrix von Code bis ist
so beschaffen, dass gilt: HBIS·bisT = 0 für
alle BIS-Codewörter
bis. Die zweite Zeile hBIS 2 der Paritätsprüfungsmatrix
HBIS ist gegeben durch hBIS
2 = (α61 α60 ... α2, α,
1). Sie entspricht der Nullstelle α des Generatorpolynoms g(x)
und definiert die Codewortpositionen, die für Fehlerstellen zu verwenden
sind.
-
15 zeigt
die Rahmenstruktur zur Erläuterung
der Verschachtelung der Hauptdaten. Die verschiedenen physischen
Sektoren und Spalten sind mit einer entsprechenden Nummerierung
versehen. Es gibt 304·[248,216,33]
LDS-Codewörter
und 24·[62,30,33]
BIS-Codewörter.
-
Ein
logischer Sektor von 2kB enthält
9,5 LDS-Codewörter,
in welchen 2048 Benutzerdatenbytes und 4 EDC-Bytes codiert worden
sind, und ferner 22,5 BIS-Bytes zum Speichern eines Headers, 4ID
+ 2EDC Bytes, Copyright-Daten und 6 Copyright Management Information
CPR_MAI. Ferner sind 10,5 BIS-Bytes für eine mögliche zukünftige Verwendung reserviert
worden. Ein physischer Sektor von 4 kB besteht aus 31 Zeilen, wobei
die Header-Bytes von zwei logischen Sektoren von 2 kB an physisch
vorgeschriebenen Positionen gespeichert sind. 16 zeigt
die eigentliche Verschachtelung. Hierbei enthält das i-te LDS-Codewort, mit
0 ≤ i ≤ 303, 248
Bytes d_j, wobei j von folgender Form ist: j = [(i mod 2) + 2·a]·152 +
{[(i div 2) – 3·a] mod
152} für
gewisse Werte 0 ≤ a ≤ 247. Für die Anbringung
der Paritäten
sind verschiedene Stellen möglich,
wie etwa das untere Ende, oder permutiert gemäß a + 31·i, a ≥ 22 ....
-
Als
nächstes
wird die Erzeugung eines BIS-Clusters erörtert. Nach dem Erzeugen der
BIS-Codewörter wird
der BIS-Block auf eine verschachtelte Art und Weise auf ein Array
von 496 = (16 × 31)
Zeilen·3
Spalten abgebildet. Dieses neue Array wird ein BIS-Cluster genannt,
dargestellt in 14A. Die Positionierung der Bytes
aus einem BIS-Block (14) in einem BIS-Cluster wird
zuerst durch mathematische Ausdrücke
angegeben. Zu diesem Zweck wird der BIS-Cluster entsprechend den
in 6 dargestellten physischen Sektoren unterteilt.
Die Sektoren werden mit s = 1 ...15 nummeriert, die Zeilen in einem
solchen Sektor werden mit r = 0...30 nummeriert, und die Spalten
werden mit e = 0..2 nummeriert, siehe 14A.
Nun bekommt ein Byte bN,C die folgende Position:
- Sektornummer s = mod{[div(N, 2) + 8 – div(C, 3)], 8) + 8·mod (N,
2)
- Zeilennummer r = div(N,2)
- Spaltennummer e = mod {[C + div(N, 2)], 3)
-
Die
Bytenummer m gibt die laufende Nummer Bm an,
wenn der physische Cluster auf die Platte geschrieben wird, wie
in 6 dargestellt, entsprechend m = (s·31 + r)·3 + e.
Die wesentlichen Elemente des Verschachtelungsschemas sind in den 17, 18 beispielhaft
dargestellt und betreffen Folgendes:
Jede Zeile eines BIS-Blockes
wird in 8 Gruppen von jeweils 3 Bytes aufgespaltet, wobei diese
Drei-Byte-Gruppen jeweils in einer entsprechenden Zeile des BIS-Clusters
angeordnet werden.
-
Die
geraden Zeilen des BIS-Blockes werden auf die Sektoren 0 bis 7 abgebildet,
die ungeraden Zeilen des BIS-Blockes werden auf die Sektoren 8 bis
15 abgebildet. Die acht Drei-Byte-Gruppen aus einer geraden Zeile
des BIS-Blockes werden jeweils auf dieselbe Zeile von acht aufeinander
folgenden Sektoren gesetzt, wobei die Sektoren in einer Richtung
verwendet werden, welche umgekehrt zu ihrer Nummerierung ist. Es
wurde festgestellt, dass diese Umkehrung ein besseres Zerstreuen
von Bündelfehlern
bewirkt. Der Anfangssektor für jede
Zeile des BIS-Blockes ist einen Sektor höher als für die vorhergehende Zeile.
- – Zeile
N = 0 des BIS-Blockes wird auf die Zeilen r = 0 der Sektoren 0,
7, 6, 5,..., 2, 1 gesetzt.
- – Zeile
N = 2 des BIS-Blockes wird auf die Zeilen r = 1 der Sektoren 1,
0, 7, 6,..., 3, 2 gesetzt.
- – Zeile
N = 4 des BIS-Blockes wird auf die Zeilen r = 2 der Sektoren 2,
1, 0, 7,..., 4, 3 gesetzt.
- – Diese
Prozedur wird zyklisch wiederholt bis zur Zeile N = 60, welche auf
die Zeilen r = 30 der Sektoren 6, 5, 4,..., 0, 7 gesetzt wird.
-
Nun
wird innerhalb jedes Sektors jede Zeile zyklisch um mod(r, 3) Positionen
nach rechts verschoben; so wird Zeile r = 0 überhaupt nicht verschoben,
Zeile r = 1 wird um 1 verschoben, Zeile r = 2 wird um 2 verschoben,
Zeile r = 3 wird nicht verschoben, Zeile r = 4 wird um 1 verschoben
usw. Für
die ungeraden Zeilen des BIS-Blockes wird nach einer entsprechenden
Prozedur verfahren.
-
Diesbezüglich zeigt 17 ein Beispiel der teilweisen Abbildung
von BIS-Bytes auf
die ersten acht Sektoren und 18 ein
Beispiel der teilweisen Abbildung von BIS-Bytes auf die letzten
acht Sektoren, welche nach dem Obigen unmittelbar verständlich sind.
-
19 zeigt
in Form einer Zusammenfassung eine schematische Darstellung des
Gesamtprozesses der Codierung. Die Benutzerdaten, die von einer
Quelle empfangen wurden, welche ein Host oder eine Anwendung sein
kann, werden zuerst in Datenrahmen aufgeteilt, welche jeweils aus
2048+4 Bytes bestehen; wie in Block 200 der Figur dargestellt,
werden 32 von diesen Rahmen für
den nächsten
Codierungsschritt berücksichtigt.
In Block 202 wird ein Datenblock gebildet und in 304 Spalten
mit jeweils 216 Zeilen angeordnet. In Block 204 wird ein
Long-Distance-Code-Block durch Hinzufügen von 32 Zeilen Parität gebildet.
In Block 206 wird ein ECC-Cluster entsprechend 152 Spalten
und 496 Zeilen angeordnet. Dieser wird so angeordnet, dass er die
vier mit ECC bezeichneten Sektionen in dem physischen Cluster-Block 218 füllt, welcher
die allumfassende Codeformat-Entität ist.
-
Die
Adress- und Steuerdaten, die durch das Aufzeichnungssystem hinzugefügt werden,
werden ebenfalls in aufeinander folgenden Schritten umgewandelt.
Zuerst werden die logische Adresse und die Steuerdaten in Block 208 in
32·18
Bytes angeordnet. Die logischen Adressen sind diejenigen, welche
zu Benutzerfunktionalitäten
gehören,
und können
Aspekte angeben, welche eine Dauer der Wiedergabe eines Benutzerprogramms
betreffen. Auch die physischen Adressen werden in Block 210 in
16·9
Bytes angeordnet. Die physischen Adressen betreffen physische Abstände auf
dem Träger.
Infolge der wiederholten Umnummerierung und Verschachtelung ging
der Zusammenhang zwischen physischen und logischen Adressen verloren.
Elemente, die in einem Programm nahe aufeinander folgen, können durch
einen beträchtlichen
physischen Abstand voneinander getrennt sein, und umgekehrt. Außerdem ist
die Abbildung nicht gleichmäßig fortschreitend. In
Block 212 werden die Adressen in einem Zugriffsblock von
24 Spalten mal 30 Zeilen kombiniert. In Block 214 werden
32 Zeilen Parität
hinzugefügt.
In Block 216 werden diese zu einem BIS-Cluster von 3 Spalten
und 496 Zeilen angeordnet. Diese füllen die drei BIS-Spalten in Block 218.
Außerdem
wird eine Spalte von Synchronisationsbitgruppen hinzugefügt, so dass
ein physischer Cluster von 155 Spalten mal 496 Zeilen gebildet wird.
Zusammen bilden diese 16 physische Sektoren, welche zu 496 Aufzeichnungsrahmen
gruppiert sind, wie dargestellt.
-
6
- words
- Wörter
- physical
sector
- Physischer
Sektor
- data
stream an disc
- Datenstrom
auf Platte
-
7
- User
Data
- Benutzerdaten
-
8
- 19
columns
- 19
Spalten
- 216
rows with data
- 216
Zeilen mit Daten
-
9
- 19
code words
- 19
Codewörter
- 216
rows with data
- 216
Zeilen mit Daten
- 32
rows with parity
- 32
Zeilen mit Parität
-
10
- 16
ECS Sectors = 152 columns
- 16
ECS-Sektoren = 152 Spalten
- 432
rows with data
- 432
Zeilen mit Daten
- 64
rows with parity
- 64
Zeilen mit Parität
-
11
- 16
ECC Sectors with 2 data frames each (152 columns)
- 16
ECC-Sektoren mit je 2 Datenrahmen (152 Spalten)
- 38
columns
- 38
Spalten
- 432
rows data
- 432
Zeilen Daten
- 64
rows parity
- 64
Zeilen Parität
-
12
- 152
bytes
- 152
Bytes
- shift
- Verschiebung
-
13
- BIS
column
- BIS-Spalte
- 8
BIS codewords = 496 bytes
- 8
BIS-Codewörter
= 496 Bytes
-
14
- codeword
- Codewort
- 1
BIS codeword = 62 bytes
- 1
BIS-Codewort = 62 Bytes
- 30
information
- 30
Information
- 32
parity
- 32
Parität
-
14A
- 3
columns
- 3
Spalten
- 496
rows
- 496
Zeilen
- 31
rows
- 31
Zeilen
- 16
sectors
- 16
Sektoren
-
15
- BIS
columns
- IS-Spalten
- etc.
- usw.
- Data
stream an disk
- Datenstrom
auf Platte
- physical
sector
- physischer
Sektor
-
16
- row
+ 2
- Zeile
+ 2
- column – 3 mod
152
- Spalte – 3 mod
152
- column – 3
- Spalte – 3
- LDS
code Word direction
- Richtung
der LDS-Codewörter
- Column
numbers
- Spaltennummern
-
17(1), 17(2), 18
- sector
s
- Sektor
s
- row
r
- Zeile
r
- byte
number N,C from BIS Block
- Bytenummer
N,C aus BIS-Block
- column
e
- Spalte
e
- shift
right (= mod(r,3))
- nach
rechts verschieben (= mod(r,3))
- filling
in upward direction
- Füllen in
Aufwärtsrichtung
- start
of Block row
- Beginn
von Block-Zeile
- continuation
of Block row
- Fortsetzung
von Block-Zeile
- end
of Block row
- =
Ende von Block-Zeile
-
19
- 200
- Benutzerdaten
32
Rahmen·(2048
+4) Bytes
- 202
- Datenblock
304
Spalten·216
Zeilen
- 204
- LDC-Block
304
Spalten
- 216
- Zeilen
Daten
32 Zeilen Parität
- 206
- ECC-Cluster
152
Spalten·496
Zeilen
- 208
- Logische
Adresse + Steuerdaten
32·18
Bytes
- 210
- Physische
Adresse 16·9
Bytes
- 212
- Zugriffsblock
24 Spalten·30
Zeilen
- 214
- BIS
Block
24 Spalten
30 Zeilen Daten
32 Zeilen Parität
- 216
- BIS
Cluster = BIS-Cluster
3 Spalten·496 Zeilen
- 496
Recording Frames
- 496
Aufzeichnungsrahmen
- 16
Physical Sectors
- 16
Physische Sektoren
- Physical
Cluster (155 columns * 496 rows)
- Physischer
Cluster (155 Spalten * 496 Zeilen)