ES2716890T3 - Derivados de ácidos grasos de inhibidores diméricos de la PSD-95 - Google Patents
Derivados de ácidos grasos de inhibidores diméricos de la PSD-95 Download PDFInfo
- Publication number
- ES2716890T3 ES2716890T3 ES14821058T ES14821058T ES2716890T3 ES 2716890 T3 ES2716890 T3 ES 2716890T3 ES 14821058 T ES14821058 T ES 14821058T ES 14821058 T ES14821058 T ES 14821058T ES 2716890 T3 ES2716890 T3 ES 2716890T3
- Authority
- ES
- Spain
- Prior art keywords
- acid
- derivative
- amino acid
- dimeric ligand
- linker
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 150000004665 fatty acids Chemical class 0.000 title claims description 100
- 235000014113 dietary fatty acids Nutrition 0.000 title claims description 98
- 229930195729 fatty acid Natural products 0.000 title claims description 98
- 239000000194 fatty acid Substances 0.000 title claims description 98
- 108700019745 Disks Large Homolog 4 Proteins 0.000 title claims description 60
- 102000047174 Disks Large Homolog 4 Human genes 0.000 title claims 2
- 239000003112 inhibitor Substances 0.000 title description 6
- 239000003446 ligand Substances 0.000 claims description 79
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 69
- 125000000539 amino acid group Chemical group 0.000 claims description 57
- 229910052757 nitrogen Inorganic materials 0.000 claims description 47
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 28
- 239000003814 drug Substances 0.000 claims description 21
- 229910052717 sulfur Inorganic materials 0.000 claims description 21
- 150000001413 amino acids Chemical class 0.000 claims description 20
- 239000002202 Polyethylene glycol Substances 0.000 claims description 19
- 229920001223 polyethylene glycol Polymers 0.000 claims description 19
- 230000008878 coupling Effects 0.000 claims description 14
- 238000010168 coupling process Methods 0.000 claims description 14
- 238000005859 coupling reaction Methods 0.000 claims description 14
- 125000004433 nitrogen atom Chemical group N* 0.000 claims description 14
- 230000015572 biosynthetic process Effects 0.000 claims description 13
- 238000000034 method Methods 0.000 claims description 13
- 238000003786 synthesis reaction Methods 0.000 claims description 12
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 claims description 11
- 125000003088 (fluoren-9-ylmethoxy)carbonyl group Chemical group 0.000 claims description 10
- 102000009027 Albumins Human genes 0.000 claims description 9
- 108010088751 Albumins Proteins 0.000 claims description 9
- 238000011282 treatment Methods 0.000 claims description 9
- 239000002253 acid Substances 0.000 claims description 8
- 239000007790 solid phase Substances 0.000 claims description 8
- 229930182852 proteinogenic amino acid Natural products 0.000 claims description 7
- 229910052720 vanadium Inorganic materials 0.000 claims description 7
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 6
- 201000010099 disease Diseases 0.000 claims description 6
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 6
- 230000003492 excitotoxic effect Effects 0.000 claims description 6
- ZQPPMHVWECSIRJ-UHFFFAOYSA-N Oleic acid Natural products CCCCCCCCC=CCCCCCCCC(O)=O ZQPPMHVWECSIRJ-UHFFFAOYSA-N 0.000 claims description 5
- 208000002193 Pain Diseases 0.000 claims description 5
- 125000004429 atom Chemical group 0.000 claims description 5
- ZQPPMHVWECSIRJ-MDZDMXLPSA-N elaidic acid Chemical compound CCCCCCCC\C=C\CCCCCCCC(O)=O ZQPPMHVWECSIRJ-MDZDMXLPSA-N 0.000 claims description 5
- 229910052739 hydrogen Inorganic materials 0.000 claims description 5
- QXJSBBXBKPUZAA-UHFFFAOYSA-N isooleic acid Natural products CCCCCCCC=CCCCCCCCCC(O)=O QXJSBBXBKPUZAA-UHFFFAOYSA-N 0.000 claims description 5
- 125000004430 oxygen atom Chemical group O* 0.000 claims description 5
- 238000011321 prophylaxis Methods 0.000 claims description 5
- 150000003839 salts Chemical class 0.000 claims description 5
- YWWVWXASSLXJHU-AATRIKPKSA-N (9E)-tetradecenoic acid Chemical compound CCCC\C=C\CCCCCCCC(O)=O YWWVWXASSLXJHU-AATRIKPKSA-N 0.000 claims description 4
- MBMBGCFOFBJSGT-KUBAVDMBSA-N all-cis-docosa-4,7,10,13,16,19-hexaenoic acid Chemical compound CC\C=C/C\C=C/C\C=C/C\C=C/C\C=C/C\C=C/CCC(O)=O MBMBGCFOFBJSGT-KUBAVDMBSA-N 0.000 claims description 4
- DTOSIQBPPRVQHS-PDBXOOCHSA-N alpha-linolenic acid Chemical compound CC\C=C/C\C=C/C\C=C/CCCCCCCC(O)=O DTOSIQBPPRVQHS-PDBXOOCHSA-N 0.000 claims description 4
- YZXBAPSDXZZRGB-DOFZRALJSA-N arachidonic acid Chemical compound CCCCC\C=C/C\C=C/C\C=C/C\C=C/CCCC(O)=O YZXBAPSDXZZRGB-DOFZRALJSA-N 0.000 claims description 4
- GHVNFZFCNZKVNT-UHFFFAOYSA-N decanoic acid Chemical compound CCCCCCCCCC(O)=O GHVNFZFCNZKVNT-UHFFFAOYSA-N 0.000 claims description 4
- POULHZVOKOAJMA-UHFFFAOYSA-N dodecanoic acid Chemical compound CCCCCCCCCCCC(O)=O POULHZVOKOAJMA-UHFFFAOYSA-N 0.000 claims description 4
- IPCSVZSSVZVIGE-UHFFFAOYSA-N hexadecanoic acid Chemical compound CCCCCCCCCCCCCCCC(O)=O IPCSVZSSVZVIGE-UHFFFAOYSA-N 0.000 claims description 4
- VKOBVWXKNCXXDE-UHFFFAOYSA-N icosanoic acid Chemical compound CCCCCCCCCCCCCCCCCCCC(O)=O VKOBVWXKNCXXDE-UHFFFAOYSA-N 0.000 claims description 4
- WWZKQHOCKIZLMA-UHFFFAOYSA-N octanoic acid Chemical compound CCCCCCCC(O)=O WWZKQHOCKIZLMA-UHFFFAOYSA-N 0.000 claims description 4
- SECPZKHBENQXJG-FPLPWBNLSA-N palmitoleic acid Chemical compound CCCCCC\C=C/CCCCCCCC(O)=O SECPZKHBENQXJG-FPLPWBNLSA-N 0.000 claims description 4
- 229920001184 polypeptide Polymers 0.000 claims description 4
- OYHQOLUKZRVURQ-NTGFUMLPSA-N (9Z,12Z)-9,10,12,13-tetratritiooctadeca-9,12-dienoic acid Chemical compound C(CCCCCCC\C(=C(/C\C(=C(/CCCCC)\[3H])\[3H])\[3H])\[3H])(=O)O OYHQOLUKZRVURQ-NTGFUMLPSA-N 0.000 claims description 3
- WRIDQFICGBMAFQ-UHFFFAOYSA-N (E)-8-Octadecenoic acid Natural products CCCCCCCCCC=CCCCCCCC(O)=O WRIDQFICGBMAFQ-UHFFFAOYSA-N 0.000 claims description 3
- LQJBNNIYVWPHFW-UHFFFAOYSA-N 20:1omega9c fatty acid Natural products CCCCCCCCCCC=CCCCCCCCC(O)=O LQJBNNIYVWPHFW-UHFFFAOYSA-N 0.000 claims description 3
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 3
- QSBYPNXLFMSGKH-UHFFFAOYSA-N 9-Heptadecensaeure Natural products CCCCCCCC=CCCCCCCCC(O)=O QSBYPNXLFMSGKH-UHFFFAOYSA-N 0.000 claims description 3
- 239000005642 Oleic acid Substances 0.000 claims description 3
- 230000000447 dimerizing effect Effects 0.000 claims description 3
- UKMSUNONTOPOIO-UHFFFAOYSA-N docosanoic acid Chemical compound CCCCCCCCCCCCCCCCCCCCCC(O)=O UKMSUNONTOPOIO-UHFFFAOYSA-N 0.000 claims description 3
- 231100000318 excitotoxic Toxicity 0.000 claims description 3
- 230000000302 ischemic effect Effects 0.000 claims description 3
- 238000004519 manufacturing process Methods 0.000 claims description 3
- YWWVWXASSLXJHU-UHFFFAOYSA-N 9E-tetradecenoic acid Natural products CCCCC=CCCCCCCCC(O)=O YWWVWXASSLXJHU-UHFFFAOYSA-N 0.000 claims description 2
- DPUOLQHDNGRHBS-UHFFFAOYSA-N Brassidinsaeure Natural products CCCCCCCCC=CCCCCCCCCCCCC(O)=O DPUOLQHDNGRHBS-UHFFFAOYSA-N 0.000 claims description 2
- 125000001433 C-terminal amino-acid group Chemical group 0.000 claims description 2
- 239000005632 Capric acid (CAS 334-48-5) Substances 0.000 claims description 2
- 239000005635 Caprylic acid (CAS 124-07-2) Substances 0.000 claims description 2
- URXZXNYJPAJJOQ-UHFFFAOYSA-N Erucic acid Natural products CCCCCCC=CCCCCCCCCCCCC(O)=O URXZXNYJPAJJOQ-UHFFFAOYSA-N 0.000 claims description 2
- 239000005639 Lauric acid Substances 0.000 claims description 2
- 235000021353 Lignoceric acid Nutrition 0.000 claims description 2
- CQXMAMUUWHYSIY-UHFFFAOYSA-N Lignoceric acid Natural products CCCCCCCCCCCCCCCCCCCCCCCC(=O)OCCC1=CC=C(O)C=C1 CQXMAMUUWHYSIY-UHFFFAOYSA-N 0.000 claims description 2
- 235000021314 Palmitic acid Nutrition 0.000 claims description 2
- 235000021319 Palmitoleic acid Nutrition 0.000 claims description 2
- 235000021355 Stearic acid Nutrition 0.000 claims description 2
- UWHZIFQPPBDJPM-FPLPWBNLSA-M Vaccenic acid Natural products CCCCCC\C=C/CCCCCCCCCC([O-])=O UWHZIFQPPBDJPM-FPLPWBNLSA-M 0.000 claims description 2
- 235000021322 Vaccenic acid Nutrition 0.000 claims description 2
- JAZBEHYOTPTENJ-JLNKQSITSA-N all-cis-5,8,11,14,17-icosapentaenoic acid Chemical compound CC\C=C/C\C=C/C\C=C/C\C=C/C\C=C/CCCC(O)=O JAZBEHYOTPTENJ-JLNKQSITSA-N 0.000 claims description 2
- 235000020661 alpha-linolenic acid Nutrition 0.000 claims description 2
- 229940114079 arachidonic acid Drugs 0.000 claims description 2
- 235000021342 arachidonic acid Nutrition 0.000 claims description 2
- 150000001735 carboxylic acids Chemical class 0.000 claims description 2
- SECPZKHBENQXJG-UHFFFAOYSA-N cis-palmitoleic acid Natural products CCCCCCC=CCCCCCCCC(O)=O SECPZKHBENQXJG-UHFFFAOYSA-N 0.000 claims description 2
- 235000020669 docosahexaenoic acid Nutrition 0.000 claims description 2
- 229940090949 docosahexaenoic acid Drugs 0.000 claims description 2
- JAZBEHYOTPTENJ-UHFFFAOYSA-N eicosapentaenoic acid Natural products CCC=CCC=CCC=CCC=CCC=CCCCC(O)=O JAZBEHYOTPTENJ-UHFFFAOYSA-N 0.000 claims description 2
- 235000020673 eicosapentaenoic acid Nutrition 0.000 claims description 2
- 229960005135 eicosapentaenoic acid Drugs 0.000 claims description 2
- DPUOLQHDNGRHBS-KTKRTIGZSA-N erucic acid Chemical compound CCCCCCCC\C=C/CCCCCCCCCCCC(O)=O DPUOLQHDNGRHBS-KTKRTIGZSA-N 0.000 claims description 2
- FARYTWBWLZAXNK-WAYWQWQTSA-N ethyl (z)-3-(methylamino)but-2-enoate Chemical compound CCOC(=O)\C=C(\C)NC FARYTWBWLZAXNK-WAYWQWQTSA-N 0.000 claims description 2
- XMHIUKTWLZUKEX-UHFFFAOYSA-N hexacosanoic acid Chemical compound CCCCCCCCCCCCCCCCCCCCCCCCCC(O)=O XMHIUKTWLZUKEX-UHFFFAOYSA-N 0.000 claims description 2
- 208000014674 injury Diseases 0.000 claims description 2
- OYHQOLUKZRVURQ-AVQMFFATSA-N linoelaidic acid Chemical compound CCCCC\C=C\C\C=C\CCCCCCCC(O)=O OYHQOLUKZRVURQ-AVQMFFATSA-N 0.000 claims description 2
- OYHQOLUKZRVURQ-IXWMQOLASA-N linoleic acid Natural products CCCCC\C=C/C\C=C\CCCCCCCC(O)=O OYHQOLUKZRVURQ-IXWMQOLASA-N 0.000 claims description 2
- 229960004488 linolenic acid Drugs 0.000 claims description 2
- WQEPLUUGTLDZJY-UHFFFAOYSA-N n-Pentadecanoic acid Natural products CCCCCCCCCCCCCCC(O)=O WQEPLUUGTLDZJY-UHFFFAOYSA-N 0.000 claims description 2
- QIQXTHQIDYTFRH-UHFFFAOYSA-N octadecanoic acid Chemical compound CCCCCCCCCCCCCCCCCC(O)=O QIQXTHQIDYTFRH-UHFFFAOYSA-N 0.000 claims description 2
- OQCDKBAXFALNLD-UHFFFAOYSA-N octadecanoic acid Natural products CCCCCCCC(C)CCCCCCCCC(O)=O OQCDKBAXFALNLD-UHFFFAOYSA-N 0.000 claims description 2
- 229960002446 octanoic acid Drugs 0.000 claims description 2
- 229940002612 prodrug Drugs 0.000 claims description 2
- 239000000651 prodrug Substances 0.000 claims description 2
- NNNVXFKZMRGJPM-KHPPLWFESA-N sapienic acid Chemical compound CCCCCCCCC\C=C/CCCCC(O)=O NNNVXFKZMRGJPM-KHPPLWFESA-N 0.000 claims description 2
- 239000008117 stearic acid Substances 0.000 claims description 2
- TUNFSRHWOTWDNC-HKGQFRNVSA-N tetradecanoic acid Chemical compound CCCCCCCCCCCCC[14C](O)=O TUNFSRHWOTWDNC-HKGQFRNVSA-N 0.000 claims description 2
- UWHZIFQPPBDJPM-BQYQJAHWSA-N trans-vaccenic acid Chemical compound CCCCCC\C=C\CCCCCCCCCC(O)=O UWHZIFQPPBDJPM-BQYQJAHWSA-N 0.000 claims description 2
- 125000000896 monocarboxylic acid group Chemical group 0.000 claims 2
- 239000011230 binding agent Substances 0.000 claims 1
- 208000037906 ischaemic injury Diseases 0.000 claims 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 claims 1
- 230000008736 traumatic injury Effects 0.000 claims 1
- 150000001875 compounds Chemical class 0.000 description 84
- 125000005647 linker group Chemical group 0.000 description 71
- 102000008100 Human Serum Albumin Human genes 0.000 description 63
- 108091006905 Human Serum Albumin Proteins 0.000 description 63
- 102100022264 Disks large homolog 4 Human genes 0.000 description 58
- MWUXSHHQAYIFBG-UHFFFAOYSA-N Nitric oxide Chemical compound O=[N] MWUXSHHQAYIFBG-UHFFFAOYSA-N 0.000 description 30
- 229940024606 amino acid Drugs 0.000 description 24
- 235000001014 amino acid Nutrition 0.000 description 24
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical group OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 22
- 235000018102 proteins Nutrition 0.000 description 22
- 102000004169 proteins and genes Human genes 0.000 description 21
- 108090000623 proteins and genes Proteins 0.000 description 21
- DTQVDTLACAAQTR-UHFFFAOYSA-N Trifluoroacetic acid Chemical compound OC(=O)C(F)(F)F DTQVDTLACAAQTR-UHFFFAOYSA-N 0.000 description 18
- 229940079593 drug Drugs 0.000 description 17
- 108010052335 UCCB01-125 Proteins 0.000 description 15
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 14
- 210000002381 plasma Anatomy 0.000 description 14
- 102000000470 PDZ domains Human genes 0.000 description 13
- 108050008994 PDZ domains Proteins 0.000 description 13
- 239000000539 dimer Substances 0.000 description 13
- 238000002875 fluorescence polarization Methods 0.000 description 13
- 239000011347 resin Substances 0.000 description 13
- 229920005989 resin Polymers 0.000 description 13
- 239000003153 chemical reaction reagent Substances 0.000 description 11
- -1 HBTU Chemical compound 0.000 description 10
- 102000004868 N-Methyl-D-Aspartate Receptors Human genes 0.000 description 9
- 108090001041 N-Methyl-D-Aspartate Receptors Proteins 0.000 description 9
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 9
- 238000003556 assay Methods 0.000 description 9
- GQHTUMJGOHRCHB-UHFFFAOYSA-N 2,3,4,6,7,8,9,10-octahydropyrimido[1,2-a]azepine Chemical compound C1CCCCN2CCCN=C21 GQHTUMJGOHRCHB-UHFFFAOYSA-N 0.000 description 8
- JGFZNNIVVJXRND-UHFFFAOYSA-N N,N-Diisopropylethylamine (DIPEA) Chemical compound CCN(C(C)C)C(C)C JGFZNNIVVJXRND-UHFFFAOYSA-N 0.000 description 8
- 102000006538 Nitric Oxide Synthase Type I Human genes 0.000 description 8
- 108010008858 Nitric Oxide Synthase Type I Proteins 0.000 description 8
- NQRYJNQNLNOLGT-UHFFFAOYSA-N Piperidine Chemical compound C1CCNCC1 NQRYJNQNLNOLGT-UHFFFAOYSA-N 0.000 description 8
- 210000004369 blood Anatomy 0.000 description 8
- 239000008280 blood Substances 0.000 description 8
- 238000004007 reversed phase HPLC Methods 0.000 description 8
- 239000002904 solvent Substances 0.000 description 8
- 150000002148 esters Chemical class 0.000 description 7
- 238000000338 in vitro Methods 0.000 description 7
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 6
- WMFOQBRAJBCJND-UHFFFAOYSA-M Lithium hydroxide Chemical compound [Li+].[OH-] WMFOQBRAJBCJND-UHFFFAOYSA-M 0.000 description 6
- 101100240646 Scheffersomyces stipitis (strain ATCC 58785 / CBS 6054 / NBRC 10063 / NRRL Y-11545) NMA111 gene Proteins 0.000 description 6
- 125000001931 aliphatic group Chemical group 0.000 description 6
- 238000006243 chemical reaction Methods 0.000 description 6
- 238000002347 injection Methods 0.000 description 6
- 239000007924 injection Substances 0.000 description 6
- 230000003993 interaction Effects 0.000 description 6
- 230000008569 process Effects 0.000 description 6
- 239000000523 sample Substances 0.000 description 6
- 239000000126 substance Substances 0.000 description 6
- 0 CC(CCOC(C)CCC(P)=O)N(C(C)COC(C)CCC(*)=O)C(CCCNC(CCCCCCCCCCC(O)=O)=O)=O Chemical compound CC(CCOC(C)CCC(P)=O)N(C(C)COC(C)CCC(*)=O)C(CCCNC(CCCCCCCCCCC(O)=O)=O)=O 0.000 description 5
- 230000001404 mediated effect Effects 0.000 description 5
- 239000000243 solution Substances 0.000 description 5
- 238000007920 subcutaneous administration Methods 0.000 description 5
- 235000021122 unsaturated fatty acids Nutrition 0.000 description 5
- 150000004670 unsaturated fatty acids Chemical class 0.000 description 5
- ACUIFAAXWDLLTR-UHFFFAOYSA-N 4-(9h-fluoren-9-ylmethoxycarbonylamino)butanoic acid Chemical compound C1=CC=C2C(COC(=O)NCCCC(=O)O)C3=CC=CC=C3C2=C1 ACUIFAAXWDLLTR-UHFFFAOYSA-N 0.000 description 4
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 4
- 229940123119 PSD-95 Inhibitor Drugs 0.000 description 4
- 108091005804 Peptidases Proteins 0.000 description 4
- 239000004365 Protease Substances 0.000 description 4
- 230000004913 activation Effects 0.000 description 4
- 229960003767 alanine Drugs 0.000 description 4
- HOPRXXXSABQWAV-UHFFFAOYSA-N anhydrous collidine Natural products CC1=CC=NC(C)=C1C HOPRXXXSABQWAV-UHFFFAOYSA-N 0.000 description 4
- 210000004899 c-terminal region Anatomy 0.000 description 4
- 150000001732 carboxylic acid derivatives Chemical class 0.000 description 4
- UTBIMNXEDGNJFE-UHFFFAOYSA-N collidine Natural products CC1=CC=C(C)C(C)=N1 UTBIMNXEDGNJFE-UHFFFAOYSA-N 0.000 description 4
- 230000021615 conjugation Effects 0.000 description 4
- 238000010511 deprotection reaction Methods 0.000 description 4
- 238000006471 dimerization reaction Methods 0.000 description 4
- 230000008030 elimination Effects 0.000 description 4
- 238000003379 elimination reaction Methods 0.000 description 4
- BTCSSZJGUNDROE-UHFFFAOYSA-N gamma-aminobutyric acid Chemical compound NCCCC(O)=O BTCSSZJGUNDROE-UHFFFAOYSA-N 0.000 description 4
- 238000001727 in vivo Methods 0.000 description 4
- 230000005764 inhibitory process Effects 0.000 description 4
- 150000004668 long chain fatty acids Chemical class 0.000 description 4
- 150000004667 medium chain fatty acids Chemical class 0.000 description 4
- 125000000250 methylamino group Chemical group [H]N(*)C([H])([H])[H] 0.000 description 4
- 229920006395 saturated elastomer Polymers 0.000 description 4
- KZNICNPSHKQLFF-UHFFFAOYSA-N succinimide Chemical compound O=C1CCC(=O)N1 KZNICNPSHKQLFF-UHFFFAOYSA-N 0.000 description 4
- GFYHSKONPJXCDE-UHFFFAOYSA-N sym-collidine Natural products CC1=CN=C(C)C(C)=C1 GFYHSKONPJXCDE-UHFFFAOYSA-N 0.000 description 4
- 230000001225 therapeutic effect Effects 0.000 description 4
- YNJBWRMUSHSURL-UHFFFAOYSA-N trichloroacetic acid Chemical compound OC(=O)C(Cl)(Cl)Cl YNJBWRMUSHSURL-UHFFFAOYSA-N 0.000 description 4
- RIOQSEWOXXDEQQ-UHFFFAOYSA-N triphenylphosphine Chemical compound C1=CC=CC=C1P(C=1C=CC=CC=1)C1=CC=CC=C1 RIOQSEWOXXDEQQ-UHFFFAOYSA-N 0.000 description 4
- 150000004669 very long chain fatty acids Chemical class 0.000 description 4
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 3
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 3
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 3
- HOKKHZGPKSLGJE-GSVOUGTGSA-N N-Methyl-D-aspartic acid Chemical compound CN[C@@H](C(O)=O)CC(O)=O HOKKHZGPKSLGJE-GSVOUGTGSA-N 0.000 description 3
- 102000035195 Peptidases Human genes 0.000 description 3
- 150000001412 amines Chemical class 0.000 description 3
- 244000309464 bull Species 0.000 description 3
- 230000015556 catabolic process Effects 0.000 description 3
- 238000006731 degradation reaction Methods 0.000 description 3
- FAMRKDQNMBBFBR-BQYQJAHWSA-N diethyl azodicarboxylate Substances CCOC(=O)\N=N\C(=O)OCC FAMRKDQNMBBFBR-BQYQJAHWSA-N 0.000 description 3
- 231100000063 excitotoxicity Toxicity 0.000 description 3
- 229960003692 gamma aminobutyric acid Drugs 0.000 description 3
- 229940049906 glutamate Drugs 0.000 description 3
- 229930195712 glutamate Natural products 0.000 description 3
- 210000002569 neuron Anatomy 0.000 description 3
- 210000003538 post-synaptic density Anatomy 0.000 description 3
- 108010092804 postsynaptic density proteins Proteins 0.000 description 3
- 238000001556 precipitation Methods 0.000 description 3
- 239000000047 product Substances 0.000 description 3
- 150000004666 short chain fatty acids Chemical class 0.000 description 3
- 235000021391 short chain fatty acids Nutrition 0.000 description 3
- 239000007787 solid Substances 0.000 description 3
- 125000000999 tert-butyl group Chemical group [H]C([H])([H])C(*)(C([H])([H])[H])C([H])([H])[H] 0.000 description 3
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 2
- FPIRBHDGWMWJEP-UHFFFAOYSA-N 1-hydroxy-7-azabenzotriazole Chemical compound C1=CN=C2N(O)N=NC2=C1 FPIRBHDGWMWJEP-UHFFFAOYSA-N 0.000 description 2
- VHYFNPMBLIVWCW-UHFFFAOYSA-N 4-Dimethylaminopyridine Chemical compound CN(C)C1=CC=NC=C1 VHYFNPMBLIVWCW-UHFFFAOYSA-N 0.000 description 2
- JJMDCOVWQOJGCB-UHFFFAOYSA-N 5-aminopentanoic acid Chemical compound [NH3+]CCCCC([O-])=O JJMDCOVWQOJGCB-UHFFFAOYSA-N 0.000 description 2
- BPYKTIZUTYGOLE-IFADSCNNSA-N Bilirubin Chemical compound N1C(=O)C(C)=C(C=C)\C1=C\C1=C(C)C(CCC(O)=O)=C(CC2=C(C(C)=C(\C=C/3C(=C(C=C)C(=O)N\3)C)N2)CCC(O)=O)N1 BPYKTIZUTYGOLE-IFADSCNNSA-N 0.000 description 2
- 102000004506 Blood Proteins Human genes 0.000 description 2
- 108010017384 Blood Proteins Proteins 0.000 description 2
- 101800001415 Bri23 peptide Proteins 0.000 description 2
- FERIUCNNQQJTOY-UHFFFAOYSA-N Butyric acid Chemical compound CCCC(O)=O FERIUCNNQQJTOY-UHFFFAOYSA-N 0.000 description 2
- 102400000107 C-terminal peptide Human genes 0.000 description 2
- 101800000655 C-terminal peptide Proteins 0.000 description 2
- BHPQYMZQTOCNFJ-UHFFFAOYSA-N Calcium cation Chemical compound [Ca+2] BHPQYMZQTOCNFJ-UHFFFAOYSA-N 0.000 description 2
- 208000000094 Chronic Pain Diseases 0.000 description 2
- ROSDSFDQCJNGOL-UHFFFAOYSA-N Dimethylamine Chemical compound CNC ROSDSFDQCJNGOL-UHFFFAOYSA-N 0.000 description 2
- 108010016626 Dipeptides Proteins 0.000 description 2
- 241000255581 Drosophila <fruit fly, genus> Species 0.000 description 2
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 2
- 241000282412 Homo Species 0.000 description 2
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 2
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 2
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 2
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 2
- 102000042189 MAGUK family Human genes 0.000 description 2
- 108091077533 MAGUK family Proteins 0.000 description 2
- YNAVUWVOSKDBBP-UHFFFAOYSA-N Morpholine Chemical compound C1COCCN1 YNAVUWVOSKDBBP-UHFFFAOYSA-N 0.000 description 2
- 229940127523 NMDA Receptor Antagonists Drugs 0.000 description 2
- 206010029350 Neurotoxicity Diseases 0.000 description 2
- GLUUGHFHXGJENI-UHFFFAOYSA-N Piperazine Chemical compound C1CNCCN1 GLUUGHFHXGJENI-UHFFFAOYSA-N 0.000 description 2
- 102000004257 Potassium Channel Human genes 0.000 description 2
- 241000700159 Rattus Species 0.000 description 2
- 208000006011 Stroke Diseases 0.000 description 2
- 102100034686 Tight junction protein ZO-1 Human genes 0.000 description 2
- 108050001370 Tight junction protein ZO-1 Proteins 0.000 description 2
- 206010044221 Toxic encephalopathy Diseases 0.000 description 2
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 2
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Chemical compound CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 2
- 238000010521 absorption reaction Methods 0.000 description 2
- 150000007513 acids Chemical class 0.000 description 2
- 230000008499 blood brain barrier function Effects 0.000 description 2
- 210000001218 blood-brain barrier Anatomy 0.000 description 2
- 229910001424 calcium ion Inorganic materials 0.000 description 2
- 125000004432 carbon atom Chemical group C* 0.000 description 2
- 150000007942 carboxylates Chemical group 0.000 description 2
- 210000004027 cell Anatomy 0.000 description 2
- 229940125904 compound 1 Drugs 0.000 description 2
- AAOVKJBEBIDNHE-UHFFFAOYSA-N diazepam Chemical compound N=1CC(=O)N(C)C2=CC=C(Cl)C=C2C=1C1=CC=CC=C1 AAOVKJBEBIDNHE-UHFFFAOYSA-N 0.000 description 2
- 229960003529 diazepam Drugs 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 238000004108 freeze drying Methods 0.000 description 2
- 229960000789 guanidine hydrochloride Drugs 0.000 description 2
- PJJJBBJSCAKJQF-UHFFFAOYSA-N guanidinium chloride Chemical compound [Cl-].NC(N)=[NH2+] PJJJBBJSCAKJQF-UHFFFAOYSA-N 0.000 description 2
- 230000010224 hepatic metabolism Effects 0.000 description 2
- 238000004128 high performance liquid chromatography Methods 0.000 description 2
- 125000004435 hydrogen atom Chemical group [H]* 0.000 description 2
- 230000002209 hydrophobic effect Effects 0.000 description 2
- 229960000310 isoleucine Drugs 0.000 description 2
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 2
- 230000014759 maintenance of location Effects 0.000 description 2
- 239000012528 membrane Substances 0.000 description 2
- OJURWUUOVGOHJZ-UHFFFAOYSA-N methyl 2-[(2-acetyloxyphenyl)methyl-[2-[(2-acetyloxyphenyl)methyl-(2-methoxy-2-oxoethyl)amino]ethyl]amino]acetate Chemical compound C=1C=CC=C(OC(C)=O)C=1CN(CC(=O)OC)CCN(CC(=O)OC)CC1=CC=CC=C1OC(C)=O OJURWUUOVGOHJZ-UHFFFAOYSA-N 0.000 description 2
- 239000000203 mixture Substances 0.000 description 2
- 230000007135 neurotoxicity Effects 0.000 description 2
- 231100000228 neurotoxicity Toxicity 0.000 description 2
- 229910052760 oxygen Inorganic materials 0.000 description 2
- 230000020477 pH reduction Effects 0.000 description 2
- 125000000538 pentafluorophenyl group Chemical group FC1=C(F)C(F)=C(*)C(F)=C1F 0.000 description 2
- 150000003904 phospholipids Chemical class 0.000 description 2
- 230000035790 physiological processes and functions Effects 0.000 description 2
- 229920000642 polymer Polymers 0.000 description 2
- 108020001213 potassium channel Proteins 0.000 description 2
- 230000002035 prolonged effect Effects 0.000 description 2
- VVWRJUBEIPHGQF-MDZDMXLPSA-N propan-2-yl (ne)-n-propan-2-yloxycarbonyliminocarbamate Chemical compound CC(C)OC(=O)\N=N\C(=O)OC(C)C VVWRJUBEIPHGQF-MDZDMXLPSA-N 0.000 description 2
- 125000006239 protecting group Chemical group 0.000 description 2
- 238000000159 protein binding assay Methods 0.000 description 2
- 230000004850 protein–protein interaction Effects 0.000 description 2
- 230000009467 reduction Effects 0.000 description 2
- 230000013878 renal filtration Effects 0.000 description 2
- 230000003252 repetitive effect Effects 0.000 description 2
- 238000007127 saponification reaction Methods 0.000 description 2
- FSYKKLYZXJSNPZ-UHFFFAOYSA-N sarcosine Chemical compound C[NH2+]CC([O-])=O FSYKKLYZXJSNPZ-UHFFFAOYSA-N 0.000 description 2
- 150000004671 saturated fatty acids Chemical class 0.000 description 2
- 210000002966 serum Anatomy 0.000 description 2
- 229960002317 succinimide Drugs 0.000 description 2
- 230000009897 systematic effect Effects 0.000 description 2
- 150000003626 triacylglycerols Chemical class 0.000 description 2
- PJVWKTKQMONHTI-UHFFFAOYSA-N warfarin Chemical compound OC=1C2=CC=CC=C2OC(=O)C=1C(CC(=O)C)C1=CC=CC=C1 PJVWKTKQMONHTI-UHFFFAOYSA-N 0.000 description 2
- 229960005080 warfarin Drugs 0.000 description 2
- FDKWRPBBCBCIGA-REOHCLBHSA-N (2r)-2-azaniumyl-3-$l^{1}-selanylpropanoate Chemical compound [Se]C[C@H](N)C(O)=O FDKWRPBBCBCIGA-REOHCLBHSA-N 0.000 description 1
- PPDNGMUGVMESGE-JTQLQIEISA-N (2s)-2-amino-3-(4-ethynylphenyl)propanoic acid Chemical compound OC(=O)[C@@H](N)CC1=CC=C(C#C)C=C1 PPDNGMUGVMESGE-JTQLQIEISA-N 0.000 description 1
- GOPWHXPXSPIIQZ-FQEVSTJZSA-N (4s)-4-(9h-fluoren-9-ylmethoxycarbonylamino)-5-[(2-methylpropan-2-yl)oxy]-5-oxopentanoic acid Chemical compound C1=CC=C2C(COC(=O)N[C@@H](CCC(O)=O)C(=O)OC(C)(C)C)C3=CC=CC=C3C2=C1 GOPWHXPXSPIIQZ-FQEVSTJZSA-N 0.000 description 1
- ASOKPJOREAFHNY-UHFFFAOYSA-N 1-Hydroxybenzotriazole Chemical compound C1=CC=C2N(O)N=NC2=C1 ASOKPJOREAFHNY-UHFFFAOYSA-N 0.000 description 1
- JFLSOKIMYBSASW-UHFFFAOYSA-N 1-chloro-2-[chloro(diphenyl)methyl]benzene Chemical compound ClC1=CC=CC=C1C(Cl)(C=1C=CC=CC=1)C1=CC=CC=C1 JFLSOKIMYBSASW-UHFFFAOYSA-N 0.000 description 1
- REGGDLIBDASKGE-UHFFFAOYSA-N 12-methoxy-12-oxododecanoic acid Chemical compound COC(=O)CCCCCCCCCCC(O)=O REGGDLIBDASKGE-UHFFFAOYSA-N 0.000 description 1
- RHRXFESGFLYUHB-UHFFFAOYSA-N 18-methoxy-18-oxooctadecanoic acid Chemical compound COC(=O)CCCCCCCCCCCCCCCCC(O)=O RHRXFESGFLYUHB-UHFFFAOYSA-N 0.000 description 1
- HEPOIJKOXBKKNJ-UHFFFAOYSA-N 2-(propan-2-ylazaniumyl)acetate Chemical compound CC(C)NCC(O)=O HEPOIJKOXBKKNJ-UHFFFAOYSA-N 0.000 description 1
- BHUGZIJOVAVBOQ-UHFFFAOYSA-N 2-(propylazaniumyl)acetate Chemical compound CCCNCC(O)=O BHUGZIJOVAVBOQ-UHFFFAOYSA-N 0.000 description 1
- FUOOLUPWFVMBKG-UHFFFAOYSA-N 2-Aminoisobutyric acid Chemical compound CC(C)(N)C(O)=O FUOOLUPWFVMBKG-UHFFFAOYSA-N 0.000 description 1
- UPMGJEMWPQOACJ-UHFFFAOYSA-N 2-[4-[(2,4-dimethoxyphenyl)-(9h-fluoren-9-ylmethoxycarbonylamino)methyl]phenoxy]acetic acid Chemical compound COC1=CC(OC)=CC=C1C(C=1C=CC(OCC(O)=O)=CC=1)NC(=O)OCC1C2=CC=CC=C2C2=CC=CC=C21 UPMGJEMWPQOACJ-UHFFFAOYSA-N 0.000 description 1
- WPHUUIODWRNJLO-UHFFFAOYSA-N 2-nitrobenzenesulfonyl chloride Chemical compound [O-][N+](=O)C1=CC=CC=C1S(Cl)(=O)=O WPHUUIODWRNJLO-UHFFFAOYSA-N 0.000 description 1
- JMTMSDXUXJISAY-UHFFFAOYSA-N 2H-benzotriazol-4-ol Chemical compound OC1=CC=CC2=C1N=NN2 JMTMSDXUXJISAY-UHFFFAOYSA-N 0.000 description 1
- BMYNFMYTOJXKLE-UHFFFAOYSA-N 3-azaniumyl-2-hydroxypropanoate Chemical compound NCC(O)C(O)=O BMYNFMYTOJXKLE-UHFFFAOYSA-N 0.000 description 1
- 229960000549 4-dimethylaminophenol Drugs 0.000 description 1
- ULLSWWGYZWBPHK-UHFFFAOYSA-N 5-(9h-fluoren-9-ylmethoxycarbonylamino)pentanoic acid Chemical compound C1=CC=C2C(COC(=O)NCCCCC(=O)O)C3=CC=CC=C3C2=C1 ULLSWWGYZWBPHK-UHFFFAOYSA-N 0.000 description 1
- 102000003678 AMPA Receptors Human genes 0.000 description 1
- 108090000078 AMPA Receptors Proteins 0.000 description 1
- 102000052866 Amino Acyl-tRNA Synthetases Human genes 0.000 description 1
- 108700028939 Amino Acyl-tRNA Synthetases Proteins 0.000 description 1
- 241000203069 Archaea Species 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 235000021357 Behenic acid Nutrition 0.000 description 1
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical group [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- 206010051290 Central nervous system lesion Diseases 0.000 description 1
- VEXZGXHMUGYJMC-UHFFFAOYSA-M Chloride anion Chemical compound [Cl-] VEXZGXHMUGYJMC-UHFFFAOYSA-M 0.000 description 1
- 241001112695 Clostridiales Species 0.000 description 1
- 108091035707 Consensus sequence Proteins 0.000 description 1
- RYGMFSIKBFXOCR-UHFFFAOYSA-N Copper Chemical compound [Cu] RYGMFSIKBFXOCR-UHFFFAOYSA-N 0.000 description 1
- 102100027371 Cysteine-rich PDZ-binding protein Human genes 0.000 description 1
- FDKWRPBBCBCIGA-UWTATZPHSA-N D-Selenocysteine Natural products [Se]C[C@@H](N)C(O)=O FDKWRPBBCBCIGA-UWTATZPHSA-N 0.000 description 1
- XBPCUCUWBYBCDP-UHFFFAOYSA-N Dicyclohexylamine Chemical compound C1CCCCC1NC1CCCCC1 XBPCUCUWBYBCDP-UHFFFAOYSA-N 0.000 description 1
- 102100024117 Disks large homolog 2 Human genes 0.000 description 1
- 101710185758 Disks large homolog 2 Proteins 0.000 description 1
- 102100029458 Glutamate receptor ionotropic, NMDA 2A Human genes 0.000 description 1
- 101710195153 Glutamate receptor ionotropic, NMDA 2A Proteins 0.000 description 1
- 102100022630 Glutamate receptor ionotropic, NMDA 2B Human genes 0.000 description 1
- 101710195187 Glutamate receptor ionotropic, NMDA 2B Proteins 0.000 description 1
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 108020004202 Guanylate Kinase Proteins 0.000 description 1
- 101000726276 Homo sapiens Cysteine-rich PDZ-binding protein Proteins 0.000 description 1
- 101000902096 Homo sapiens Disks large homolog 4 Proteins 0.000 description 1
- 101001047515 Homo sapiens Lethal(2) giant larvae protein homolog 1 Proteins 0.000 description 1
- 102000006541 Ionotropic Glutamate Receptors Human genes 0.000 description 1
- 108010008812 Ionotropic Glutamate Receptors Proteins 0.000 description 1
- 208000032382 Ischaemic stroke Diseases 0.000 description 1
- SNDPXSYFESPGGJ-BYPYZUCNSA-N L-2-aminopentanoic acid Chemical compound CCC[C@H](N)C(O)=O SNDPXSYFESPGGJ-BYPYZUCNSA-N 0.000 description 1
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 1
- AHLPHDHHMVZTML-BYPYZUCNSA-N L-Ornithine Chemical compound NCCC[C@H](N)C(O)=O AHLPHDHHMVZTML-BYPYZUCNSA-N 0.000 description 1
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- AGPKZVBTJJNPAG-UHNVWZDZSA-N L-allo-Isoleucine Chemical compound CC[C@@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-UHNVWZDZSA-N 0.000 description 1
- 150000008575 L-amino acids Chemical class 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 1
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 1
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 1
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 1
- FFFHZYDWPBMWHY-VKHMYHEASA-N L-homocysteine Chemical compound OC(=O)[C@@H](N)CCS FFFHZYDWPBMWHY-VKHMYHEASA-N 0.000 description 1
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- SNDPXSYFESPGGJ-UHFFFAOYSA-N L-norVal-OH Natural products CCCC(N)C(O)=O SNDPXSYFESPGGJ-UHFFFAOYSA-N 0.000 description 1
- LRQKBLKVPFOOQJ-YFKPBYRVSA-N L-norleucine Chemical compound CCCC[C@H]([NH3+])C([O-])=O LRQKBLKVPFOOQJ-YFKPBYRVSA-N 0.000 description 1
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 1
- HXEACLLIILLPRG-YFKPBYRVSA-N L-pipecolic acid Chemical compound [O-]C(=O)[C@@H]1CCCC[NH2+]1 HXEACLLIILLPRG-YFKPBYRVSA-N 0.000 description 1
- ZFOMKMMPBOQKMC-KXUCPTDWSA-N L-pyrrolysine Chemical compound C[C@@H]1CC=N[C@H]1C(=O)NCCCC[C@H]([NH3+])C([O-])=O ZFOMKMMPBOQKMC-KXUCPTDWSA-N 0.000 description 1
- 125000002842 L-seryl group Chemical group O=C([*])[C@](N([H])[H])([H])C([H])([H])O[H] 0.000 description 1
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 1
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 239000000232 Lipid Bilayer Substances 0.000 description 1
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- 241000699670 Mus sp. Species 0.000 description 1
- YPIGGYHFMKJNKV-UHFFFAOYSA-N N-ethylglycine Chemical compound CC[NH2+]CC([O-])=O YPIGGYHFMKJNKV-UHFFFAOYSA-N 0.000 description 1
- 108010065338 N-ethylglycine Proteins 0.000 description 1
- 206010028980 Neoplasm Diseases 0.000 description 1
- 102000010196 Neuroligin Human genes 0.000 description 1
- 108050001755 Neuroligin Proteins 0.000 description 1
- AHLPHDHHMVZTML-UHFFFAOYSA-N Orn-delta-NH2 Natural products NCCCC(N)C(O)=O AHLPHDHHMVZTML-UHFFFAOYSA-N 0.000 description 1
- UTJLXEIPEHZYQJ-UHFFFAOYSA-N Ornithine Natural products OC(=O)C(C)CCCN UTJLXEIPEHZYQJ-UHFFFAOYSA-N 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- 241000700157 Rattus norvegicus Species 0.000 description 1
- 230000010799 Receptor Interactions Effects 0.000 description 1
- 102100037486 Reverse transcriptase/ribonuclease H Human genes 0.000 description 1
- 102000000395 SH3 domains Human genes 0.000 description 1
- 108050008861 SH3 domains Proteins 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 108010077895 Sarcosine Proteins 0.000 description 1
- 101710184528 Scaffolding protein Proteins 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 1
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 1
- 239000004473 Threonine Substances 0.000 description 1
- 102000001742 Tumor Suppressor Proteins Human genes 0.000 description 1
- 108010040002 Tumor Suppressor Proteins Proteins 0.000 description 1
- 239000003875 Wang resin Substances 0.000 description 1
- 208000027418 Wounds and injury Diseases 0.000 description 1
- NERFNHBZJXXFGY-UHFFFAOYSA-N [4-[(4-methylphenyl)methoxy]phenyl]methanol Chemical compound C1=CC(C)=CC=C1COC1=CC=C(CO)C=C1 NERFNHBZJXXFGY-UHFFFAOYSA-N 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 230000001154 acute effect Effects 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 125000003342 alkenyl group Chemical group 0.000 description 1
- 150000001345 alkine derivatives Chemical class 0.000 description 1
- 125000000217 alkyl group Chemical group 0.000 description 1
- 150000001408 amides Chemical class 0.000 description 1
- 125000003277 amino group Chemical group 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 238000004873 anchoring Methods 0.000 description 1
- 229940053200 antiepileptics fatty acid derivative Drugs 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 229960005261 aspartic acid Drugs 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 239000012131 assay buffer Substances 0.000 description 1
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 1
- 150000001540 azides Chemical class 0.000 description 1
- 239000002585 base Substances 0.000 description 1
- 229940116226 behenic acid Drugs 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 230000006931 brain damage Effects 0.000 description 1
- 231100000874 brain damage Toxicity 0.000 description 1
- 208000029028 brain injury Diseases 0.000 description 1
- 239000000872 buffer Substances 0.000 description 1
- 239000007975 buffered saline Substances 0.000 description 1
- 229910052799 carbon Inorganic materials 0.000 description 1
- 239000011203 carbon fibre reinforced carbon Substances 0.000 description 1
- 210000003169 central nervous system Anatomy 0.000 description 1
- 150000005829 chemical entities Chemical class 0.000 description 1
- 125000003636 chemical group Chemical group 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 230000001684 chronic effect Effects 0.000 description 1
- 230000001010 compromised effect Effects 0.000 description 1
- 239000013068 control sample Substances 0.000 description 1
- 238000013270 controlled release Methods 0.000 description 1
- 229910052802 copper Inorganic materials 0.000 description 1
- 239000010949 copper Substances 0.000 description 1
- 239000012043 crude product Substances 0.000 description 1
- 238000006352 cycloaddition reaction Methods 0.000 description 1
- 229960002433 cysteine Drugs 0.000 description 1
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 1
- 235000018417 cysteine Nutrition 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000001212 derivatisation Methods 0.000 description 1
- 230000001627 detrimental effect Effects 0.000 description 1
- 238000004090 dissolution Methods 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 101150003630 dlg1 gene Proteins 0.000 description 1
- 101150069842 dlg4 gene Proteins 0.000 description 1
- 239000006274 endogenous ligand Substances 0.000 description 1
- 230000006862 enzymatic digestion Effects 0.000 description 1
- DNJIEGIFACGWOD-UHFFFAOYSA-N ethyl mercaptane Natural products CCS DNJIEGIFACGWOD-UHFFFAOYSA-N 0.000 description 1
- FAMRKDQNMBBFBR-UHFFFAOYSA-N ethyl n-ethoxycarbonyliminocarbamate Chemical compound CCOC(=O)N=NC(=O)OCC FAMRKDQNMBBFBR-UHFFFAOYSA-N 0.000 description 1
- 230000005284 excitation Effects 0.000 description 1
- 230000029142 excretion Effects 0.000 description 1
- 238000001506 fluorescence spectroscopy Methods 0.000 description 1
- 239000007850 fluorescent dye Substances 0.000 description 1
- 230000004907 flux Effects 0.000 description 1
- 235000021588 free fatty acids Nutrition 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 235000013922 glutamic acid Nutrition 0.000 description 1
- 229960002989 glutamic acid Drugs 0.000 description 1
- 239000004220 glutamic acid Substances 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 229960002449 glycine Drugs 0.000 description 1
- 239000004519 grease Substances 0.000 description 1
- RQFCJASXJCIDSX-UUOKFMHZSA-N guanosine 5'-monophosphate Chemical compound C1=2NC(N)=NC(=O)C=2N=CN1[C@@H]1O[C@H](COP(O)(O)=O)[C@@H](O)[C@H]1O RQFCJASXJCIDSX-UUOKFMHZSA-N 0.000 description 1
- 102000006638 guanylate kinase Human genes 0.000 description 1
- 229940025294 hemin Drugs 0.000 description 1
- BTIJJDXEELBZFS-QDUVMHSLSA-K hemin Chemical compound CC1=C(CCC(O)=O)C(C=C2C(CCC(O)=O)=C(C)\C(N2[Fe](Cl)N23)=C\4)=N\C1=C/C2=C(C)C(C=C)=C3\C=C/1C(C)=C(C=C)C/4=N\1 BTIJJDXEELBZFS-QDUVMHSLSA-K 0.000 description 1
- 239000000833 heterodimer Substances 0.000 description 1
- 229960002885 histidine Drugs 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 239000000710 homodimer Substances 0.000 description 1
- UKAUYVFTDYCKQA-UHFFFAOYSA-N homoserine Chemical compound OC(=O)C(N)CCO UKAUYVFTDYCKQA-UHFFFAOYSA-N 0.000 description 1
- 239000001257 hydrogen Substances 0.000 description 1
- OUUQCZGPVNCOIJ-UHFFFAOYSA-N hydroperoxyl Chemical compound O[O] OUUQCZGPVNCOIJ-UHFFFAOYSA-N 0.000 description 1
- NPZTUJOABDZTLV-UHFFFAOYSA-N hydroxybenzotriazole Substances O=C1C=CC=C2NNN=C12 NPZTUJOABDZTLV-UHFFFAOYSA-N 0.000 description 1
- 125000002883 imidazolyl group Chemical group 0.000 description 1
- 230000004941 influx Effects 0.000 description 1
- 239000013067 intermediate product Substances 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 150000002500 ions Chemical class 0.000 description 1
- GCHPUFAZSONQIV-UHFFFAOYSA-N isovaline Chemical compound CCC(C)(N)C(O)=O GCHPUFAZSONQIV-UHFFFAOYSA-N 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- HXEACLLIILLPRG-RXMQYKEDSA-N l-pipecolic acid Natural products OC(=O)[C@H]1CCCCN1 HXEACLLIILLPRG-RXMQYKEDSA-N 0.000 description 1
- 229960003136 leucine Drugs 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 238000004895 liquid chromatography mass spectrometry Methods 0.000 description 1
- 229960003646 lysine Drugs 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 229940057917 medium chain triglycerides Drugs 0.000 description 1
- 238000002844 melting Methods 0.000 description 1
- 230000008018 melting Effects 0.000 description 1
- 229910021645 metal ion Inorganic materials 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 229960004452 methionine Drugs 0.000 description 1
- 150000004702 methyl esters Chemical class 0.000 description 1
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 1
- 210000003205 muscle Anatomy 0.000 description 1
- 208000004296 neuralgia Diseases 0.000 description 1
- 230000004770 neurodegeneration Effects 0.000 description 1
- 208000015122 neurodegenerative disease Diseases 0.000 description 1
- 208000021722 neuropathic pain Diseases 0.000 description 1
- 230000031787 nutrient reservoir activity Effects 0.000 description 1
- 239000003960 organic solvent Substances 0.000 description 1
- 229960003104 ornithine Drugs 0.000 description 1
- 125000006353 oxyethylene group Chemical group 0.000 description 1
- 239000001301 oxygen Substances 0.000 description 1
- 238000010647 peptide synthesis reaction Methods 0.000 description 1
- 238000002823 phage display Methods 0.000 description 1
- 239000012071 phase Substances 0.000 description 1
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 1
- 229960005190 phenylalanine Drugs 0.000 description 1
- 235000008729 phenylalanine Nutrition 0.000 description 1
- 230000010399 physical interaction Effects 0.000 description 1
- 230000001766 physiological effect Effects 0.000 description 1
- 230000010287 polarization Effects 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- 230000001686 pro-survival effect Effects 0.000 description 1
- 229960002429 proline Drugs 0.000 description 1
- VVWRJUBEIPHGQF-UHFFFAOYSA-N propan-2-yl n-propan-2-yloxycarbonyliminocarbamate Chemical compound CC(C)OC(=O)N=NC(=O)OC(C)C VVWRJUBEIPHGQF-UHFFFAOYSA-N 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 239000000376 reactant Substances 0.000 description 1
- 102000005962 receptors Human genes 0.000 description 1
- 108020003175 receptors Proteins 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 229940043230 sarcosine Drugs 0.000 description 1
- 235000003441 saturated fatty acids Nutrition 0.000 description 1
- ZKZBPNGNEQAJSX-UHFFFAOYSA-N selenocysteine Natural products [SeH]CC(N)C(O)=O ZKZBPNGNEQAJSX-UHFFFAOYSA-N 0.000 description 1
- 229940055619 selenocysteine Drugs 0.000 description 1
- 235000016491 selenocysteine Nutrition 0.000 description 1
- 230000019491 signal transduction Effects 0.000 description 1
- 229940126586 small molecule drug Drugs 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- RZWQDAUIUBVCDD-UHFFFAOYSA-M sodium;benzenethiolate Chemical compound [Na+].[S-]C1=CC=CC=C1 RZWQDAUIUBVCDD-UHFFFAOYSA-M 0.000 description 1
- 238000003756 stirring Methods 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 230000000946 synaptic effect Effects 0.000 description 1
- NPDBDJFLKKQMCM-UHFFFAOYSA-N tert-butylglycine Chemical compound CC(C)(C)C(N)C(O)=O NPDBDJFLKKQMCM-UHFFFAOYSA-N 0.000 description 1
- 210000001578 tight junction Anatomy 0.000 description 1
- 210000001519 tissue Anatomy 0.000 description 1
- 230000000472 traumatic effect Effects 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- PSVXZQVXSXSQRO-UHFFFAOYSA-N undecaethylene glycol Chemical compound OCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCO PSVXZQVXSXSQRO-UHFFFAOYSA-N 0.000 description 1
- 125000005500 uronium group Chemical group 0.000 description 1
- 239000004474 valine Substances 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
- DTOSIQBPPRVQHS-UHFFFAOYSA-N α-Linolenic acid Chemical compound CCC=CCC=CCC=CCCCCCCCC(O)=O DTOSIQBPPRVQHS-UHFFFAOYSA-N 0.000 description 1
- DGVVWUTYPXICAM-UHFFFAOYSA-N β‐Mercaptoethanol Chemical compound OCCS DGVVWUTYPXICAM-UHFFFAOYSA-N 0.000 description 1
Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/54—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an organic compound
- A61K47/542—Carboxylic acids, e.g. a fatty acid or an amino acid
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/1703—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- A61K38/1709—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/56—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an organic macromolecular compound, e.g. an oligomeric, polymeric or dendrimeric molecule
- A61K47/59—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an organic macromolecular compound, e.g. an oligomeric, polymeric or dendrimeric molecule obtained otherwise than by reactions only involving carbon-to-carbon unsaturated bonds, e.g. polyureas or polyurethanes
- A61K47/60—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an organic macromolecular compound, e.g. an oligomeric, polymeric or dendrimeric molecule obtained otherwise than by reactions only involving carbon-to-carbon unsaturated bonds, e.g. polyureas or polyurethanes the organic macromolecular compound being a polyoxyalkylene oligomer, polymer or dendrimer, e.g. PEG, PPG, PEO or polyglycerol
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/62—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being a protein, peptide or polyamino acid
- A61K47/65—Peptidic linkers, binders or spacers, e.g. peptidic enzyme-labile linkers
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/04—Centrally acting analgesics, e.g. opioids
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Animal Behavior & Ethology (AREA)
- General Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Medicinal Chemistry (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Pharmacology & Pharmacy (AREA)
- Epidemiology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Immunology (AREA)
- General Chemical & Material Sciences (AREA)
- Neurology (AREA)
- Neurosurgery (AREA)
- Organic Chemistry (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Biomedical Technology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Marine Sciences & Fisheries (AREA)
- Zoology (AREA)
- Gastroenterology & Hepatology (AREA)
- Pain & Pain Management (AREA)
- Peptides Or Proteins (AREA)
- Medicinal Preparation (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Acyclic And Carbocyclic Compounds In Medicinal Compositions (AREA)
- Organic Low-Molecular-Weight Compounds And Preparation Thereof (AREA)
Description
DESCRIPCIÓN
Derivados de ácidos grasos de inhibidores diméricos de la PSD-95
Campo técnico
La presente divulgación se refiere a compuestos capaces de unirse a los dominios PDZ de PSD-95 y su uso médico como inhibidores de la interacción proteína-proteína mediada por PSD-95.
Antecedentes
La proteína 95 de densidad postsináptica (PSD-95) es una proteína codificada en los seres humanos por el gen DLG4 (homólogo 4 de discos grandes).PSD-95 es un miembro de la familia de la guanilato quinasa asociada a la membrana (MAGUK) y junto con PSD-93 reclutada en los mismos receptores de NMDA y grupos de canales de potasio.
PSD-95 es el miembro mejor estudiado de la familia MAGUK de las proteínas que contienen el dominio PDZ. Como todas las proteínas de la familia MAGUK, incluye tres dominios PDZ, un dominio SH3 y un dominio similar a guanilato quinasa (GK) conectados por regiones enlazadoras. Se encuentra casi exclusivamente en la densidad postsináptica de las neuronas y participa en el anclaje de las proteínas sinápticas. Sus parejas de unión directa e indirecta incluyen los receptores de neuroligina, óxido nítrico sintasa neuronal (nNOS), N-metil-D-aspartato (NMDA), receptores de AMPA y los canales de potasio.
El dominio PDZ es un dominio estructural común de 80-90 aminoácidos que se encuentra predominantemente en proteínas de andamiaje de diversos organismos, incluidos los seres humanos. PDZ es un acrónimo de las tres primeras letras de proteínas: PSD-95, supresor de tumores de disco grande de Drosophila (Dlg1) y proteína 1 de Zonula occludens (ZO-1), que fueron las primeras proteínas descubiertas que comprenden el dominio.
En general, los dominios PDZ interactúan con otras proteínas mediante la unión a su extremo C-terminal. Esto se logra mediante el aumento de la película p, lo que significa que la película p en el dominio PDZ se extiende mediante la adición de la cola C-terminal de la proteína de pareja de unión y, formando así, una estructura similar a la película p extendida.
Los dominios PDZ se encuentran en un amplio intervalo de proteínas tanto en los reinos eucarióticos como en los eubacterianos, mientras que hay muy pocos ejemplos de la proteína en arqueas. Los tres dominios de PDZ de PSD-95, PDZ1-3, unen los ligandos peptídicos con una secuencia consenso similar, tales como Ser/Thr-X-Val/Ile/Leu-COOH.
La base estructural para la interacción de los dominios PDZ con péptidos C-terminales se aclaró primero mediante una estructura cristalográfica de rayos X de PDZ3 de PSD-95 complejada con un ligando peptídico nativo, CRIPT (secuencia:YKQTSV). PDZ3 contiene seis cadenas p antiparalelas (pA-pF) y dos hélices a (aA y aB), y el ligando peptídico C-terminal se une a una ranura entre la cadena pB y la hélice aB. Dos residuos en el ligando peptídico se consideran particularmente importantes para la afinidad y especificidad, el primer (P0) y el tercer (P‘2) aminoácidos se cuentan desde el extremo C-terminal. La cadena lateral del aminoácido en la posición P0 se proyecta en un bolsillo hidrófobo y se requiere un aminoácido con cadenas laterales alifáticas (Val, Ile y Leu). En la estructura cristalina de rayos X PDZ3-CRIPT, el oxígeno de hidróxilo de Ser o Thr (P‘2) forma un enlace de hidrógeno con el nitrógeno de una cadena lateral de imidazol de His372, y se ha demostrado que esta interacción es un determinante importante para la afinidad de la interacción de dominio/ligando de PDZ. Un motivo Gly-Leu-Gly-Phe conservado (posición 322-325 en PDZ3) y un residuo cargado positivamente (Arg318 en PSD-95 PDZ3) de dominios PDZ median la unión al grupo carboxilato C-terminal.
Los dominios PDZ1 y PDZ2 de PSD-95 interactúan con varias proteínas, incluida la unión simultánea del tipo NMDA de receptores de glutamato ionotrópicos y el óxido nítrico (NO) que produce la enzima nNOS. Los receptores de NMDA son los principales mediadores de la excitotoxicidad, es decir, la neurotoxicidad mediada por glutamato, que está implicada en enfermedades neurodegenerativas y lesiones cerebrales agudas, y aunque los antagonistas del receptor de NMDA reducen eficazmente la excitotoxicidad al prevenir el flujo de iones mediado por glutamato, también impiden procesos fisiológicos importantes. Por ende, los antagonistas del receptor de NMDA han fracasado en los ensayos clínicos para, por ejemplo, un accidente cerebrovascular debido a la baja tolerancia y la falta de eficacia. En su lugar, se puede obtener una inhibición específica de la excitotoxicidad al perturbar el complejo receptor nNOS/PSD-95/NMDA intracelular usando inhibidores de PSD-95.
La PSD-95 se une simultáneamente al receptor de NMDA, principalmente a las subunidades GluN2A y GluN2B, y
nNOS a través de PDZ1 y PDZ2, respectivamente. La activación del receptor de NMDA causa el influjo de iones de calcio, que activa nNOS, lo que conduce a la generación de NO. Por lo tanto, PSD-95 media una asociación específica entre la activación del receptor de NMDA y la producción de NO, que puede ser perjudicial para las células si se prolonga durante un período más largo, y es un facilitador clave de la neurotoxicidad mediada por glutamato. La inhibición del complejo ternario de la interacción del receptor nNOS/PSD-95/NMDA dirigiendo PSD-95 es conocida por prevenir el daño cerebral isquémico en ratones, al alterar el enlace funcional entre la entrada de iones de calcio y la producción de NO, mientras que la función fisiológica, tal como las vías de señalización de flujo iónico y pro supervivencia del receptor de NMDA permanecen intactas. El documento WO 2010/004003 divulga un concepto de la inhibición de PSD-95 por ligandos peptídicos diméricos unidos por un enlazador de polietilenglicol (PEG). Estos dímeros se unen simultáneamente a los dominios PDZ1 y PDZ2 de PSD-95.
Lim y col. (Journal of Controlled Release, 2013, 170, 2, 219-225) se refieren a la conjugación de ácidos grasos con pequeños péptidos terapéuticos para prolongar la semivida en suero, y divulgan la conjugación de ácidos grasos específica del sitio a un sitio permisivo de una proteína, usando cicloadición de azidas a alquinos catalizada por cobre, mediante la unión de un derivado de ácidos grasos a p-etinilfenilalanina incorporada en una proteína que utiliza un par genomanipulado de ARNt de levadura/aminoacil-ARNt sintetasa.
Los ligandos diméricos que se dirigen a la PSD-95 están bajo evaluación preclínica como tratamiento para el dolor crónico (Andreasen y col., Neuropharmacol, 2013, 67, 193-200; Bach y col., PNAS USA, 2012, 109, 3317-3322). Sin embargo, los péptidos terapéuticos son generalmente susceptibles a la eliminación de la sangre y la degradación por el aclaramiento renal y el metabolismo hepático. Por lo tanto, existe la necesidad de mejorar las propiedades farmacocinéticas y, de este modo, aumentar la estabilidad y la semivida de los ligandos peptídicos diméricos.
Resumen de la divulgación
Con el fin de abordar el problema establecido de proporcionar propiedades farmacocinéticas mejoradas y un aumento en la estabilidad in vivo de ligandos peptídicos diméricos de PSD-95, la presente divulgación describe una nueva clase de compuestos donde dos ligandos peptídicos están enlazados por un enlazador, tal como enlazador NPEG, donde uno o más ácidos grasos o derivados de ácidos grasos se han conjugado directamente con el enlazador NPEG o mediante un enlazador adicional.
Por lo tanto, los presentes inventores han desarrollado derivados de ligandos de PSD-95 diméricos que tienen semividas en plasma in vitro mejoradas en comparación con compuestos sin ácidos grasos unidos, por ejemplo, los compuestos divulgados en el documento WO2010/004003.Además, los compuestos muestran un mayor tiempo de residencia en un depósito subcutáneo tras la administración subcutánea.
En un aspecto, la presente divulgación se refiere a un compuesto que comprende un primer péptido (P1) y un segundo péptido (P2), donde P1 y P2 comprenden individualmente al menos dos residuos de aminoácidos proteinogénicos o no proteinogénicos, y donde P1 y P2 se conjugan a un primer enlazador L1 a través de sus extremos N-terminales respectivos, y donde L1 comprende polietilenglicol (PEG), donde al menos un átomo de oxígeno de dicho PEG está sustituido con un átomo de nitrógeno para dar NPEG, y donde un resto de unión a albúmina está enlazado al átomo de nitrógeno de NPEG mediante un enlace amida, o a través de un enlazador opcional L2.
Se ha demostrado que los compuestos de la presente divulgación se unen a PDZ1-2 de PSD-95 cuando se eligen P1 y P2 como se define en la presente memoria. Como PSD-95 es un objetivo importante para la terapéutica, la presente divulgación, en un aspecto, se refiere al compuesto como se define en la presente memoria para su uso como un medicamento.
Más específicamente, los compuestos de la divulgación, se pueden usar, en un aspecto, para el tratamiento o la profilaxis de una enfermedad relacionada excitotóxica, o para la profilaxis y/o el tratamiento del dolor.
Los compuestos de la presente divulgación se pueden sintetizar esquemáticamente mediante un procedimiento que comprende las etapas que consisten en:
a) preparar un enlazador diácido de Ns-NPEG,
b) preparar un péptido utilizando la síntesis de péptidos en fase sólida a base de Fmoc,
c) dimerizar el péptido Fmoc desprotegido con el enlazador diácido de Ns-NPEG,
d) acoplar un ácido graso al conjugado de enlazador-dímero, opcionalmente a través de un enlazador intermedio, tal como un enlazador de aminoácidos (L2).
Descripción de los dibujos
Figura 1: Estructura de los ligandos de referencia, UCCB01-125 y UCCB01-144.Las letras mayúsculas indican L-aminoácidos, a excepción de "N" (nitrógeno), "O" (oxígeno).
Figura 2: Afinidad por HSA de ligandos diméricos enlazados a FA (1-12), UCCB01-125 y UCCB01-144. Los datos se muestran como la media ± SEM, n = 3.
Figura 3: Afinidad a PSD-95 PDZ1-2 de ligandos diméricos enlazados a FA (1-12), UCCB01-125 y UCCB01-144 según lo determinado por FP. A) Medido en TBS; B) Medido en TBS HSA; C) Medido en TBS HSA corregido para fu. Los datos se muestran como la media ± SEM, n = 3.
Figura 4: Estabilidad plasmática in vitro de compuestos (UCCB01-125, 1, 4, 7, 13). Las semividas calculadas son: UCCB01-125:1,7 h; 1:23,6 h; 4, 7 y 13: > 24 h.
Figura 5: Perfiles de plasma de ligandos diméricos UCCB01-125 (dos dosis) y el compuesto 1, 4, 7 y 13 después de la administración s.c. en ratas.
Figura 6: Síntesis de ligandos diméricos enlazados a FA (1-12). Las condiciones de reacción de la síntesis ilustradas en el esquema 1 de esta figura fueron como se indica: (a) Fmoc-GABA-OH/Fmoc-(L)-Glu-OtBu/Fmoc-5-Ava, HATU, colidina, DMF (1 h x 2), después piperidina al 20 % en DMF; (b) FA1/FA2/FA3/FA4, HBTU, DIPEA, DMF/DCM, 45 min, después TFA/TIPS/H2O (90/5/5); (c) LiOH 0,5 M, H2O/ACN (75/25), 30 min, después TFA a pH < 2. El triángulo indica que E y T son cadenas laterales protegidas (terc-butilo).
Figura 7: Mono saponificación de éster dimetílico de octadecandioato. Condiciones de reacción: (a) NaOH (1 eq.),MeOH, 45 °C, O/N.
Descripción detallada de la divulgación
La invención se define mediante las reivindicaciones adjuntas. Cualquier realización que no se encuentre dentro del alcance de las reivindicaciones adjuntas no forma parte de la invención.
I. Definiciones
Enlace amida: El término "enlace amida", como se usa en la presente memoria, es un enlace químico formado por una reacción entre un ácido carboxílico y una amina (y la eliminación concomitante de agua). Cuando la reacción se produce entre dos residuos de aminoácidos, el enlace formado como resultado de la reacción se conoce como un enlace peptídico (enlace de péptidos).
Que comprende: El término "que comprende", como se usa en la presente memoria debe entenderse de manera inclusiva. Por lo tanto, a modo de ejemplo, una composición que comprende el compuesto X, puede comprender el compuesto X y opcionalmente compuestos adicionales.
Dímero: El término dímero, como se usa en la presente memoria, se refiere a dos restos químicos idénticos o no idénticos asociados por interacción química o física. A modo de ejemplo, el dímero puede ser un homodímero, tal como dos péptidos idénticos enlazados por un enlazador. El dímero también puede ser un heterodímero, tal como dos péptidos diferentes enlazados por un enlazador. Un ejemplo de un dímero es el inhibidor de PSD-95 de la presente divulgación, que es un compuesto que comprende dos péptidos o análogos de péptidos, que están enlazados covalentemente por medio de un enlazador, donde los péptidos o análogos de péptidos son capaces de unirse a, o interactuar con, PDZ1 y PDZ2 de PSD-95 simultáneamente.
Dipéptido: El término "dipéptido", como se usa en la presente memoria, se refiere a dos aminoácidos naturales o no naturales enlazados por un enlace peptídico.
Resto de etilenglicol: El término "resto de etilenglicol", como se usa en la presente memoria, se refiere a la unidad estructural que constituye un enlazador PEG o NPEG. Otro nombre de un "resto etilenglicol" es "oxietileno", y la fórmula química de la unidad monomérica es:
Ácido graso: El término ácido graso (abreviado FA), como se usa en la presente memoria se refiere normalmente a un ácido carboxílico con una cadena de carbono alifática larga, que puede ser saturado o insaturado. El ácido graso puede seleccionarse de entre ácidos grasos de cadena corta (SCFa ), ácidos grasos de cadena media (MCFA), ácidos grasos de cadena larga (LCFA) y ácidos grasos de cadena muy larga (VLCFA). Los ácidos grasos de cadena corta (SCFA) son ácidos grasos con colas alifáticas de menos de seis carbonos (es decir, ácido butírico). Los ácidos grasos de cadena media (AGCM) son ácidos grasos con colas alifáticas de 6-12 carbonos, que pueden formar triglicéridos de cadena media. Los ácidos grasos de cadena larga (LCFA) son ácidos grasos con colas alifáticas de 13 a 21 carbonos. Los ácidos grasos de cadena muy larga (VLCFA) son ácidos grasos con colas alifáticas de más de 22 carbonos. El ácido graso de la presente divulgación puede ser cualquier ácido graso o derivado de ácido graso adecuado conocido por los expertos en la técnica.
Enlazador: El término "enlazador", como se usa en la presente memoria, se refiere a uno o más átomos que forman una conexión de una entidad química a otra. A modo de ejemplo, el "primer enlazador" referido en la presente memoria, es un PEG o NPEG, que une los dos péptidos de unión al dominio PDZ formando un enlace a cada uno de sus extremos N-terminales.
Aminoácidos no proteinogénicos: Los aminoácidos no proteinogénicos también conocidos como aminoácidos no codificados, no estándares o no naturales, son los aminoácidos que no están codificados por el código genético. Una lista no exhaustiva de aminoácidos no proteinogénicos incluye ácido a-amino-n-butírico, norvalina, norleucina, isoleucina,aloisoleucina, terc-leucina, ácido a-amino-n-heptanoico, ácido pipecólico, ácido a, p-diaminopropiónico, ácido a, Y-diaminobutírico, ornitina, alotreonina, homocisteína, homoserina, p-alanina, p-amino-n- Ácido butírico, ácido p-aminoisobutírico, ácido Y-aminobutírico, ácido a-aminoisobutírico, isovalina, sarcosina, N-etilglicina, N-propilglicina, N-isopropilglicina, N-metillanina, N-etillanina, N-etil-metil p-alanina, N-etil p-alanina, isoserina y ácido a-hidroxi-Y-aminobutírico.
NPEG: El término NPEG, como se usa en la presente memoria, es un derivado de enlazador de un enlazador PEG, pero cuando uno o más de los átomos de oxígeno de la cadena principal se reemplaza con un átomo de nitrógeno. Enlazador diácido Ns-NPEG: El "enlazador diácido Ns-NPEG" es la estructura donde un enlazador NPEG está protegido en el nitrógeno con un grupo de protección orto-nitrobencenosulfonilo (Ns) en el nitrógeno del enlazador, y donde los extremos del enlazador NPEG comprenden ácidos carboxílicos. Este reactivo químico o bloque de construcción se utiliza para dimerizar los dos restos peptídicos, P1 y P2.
PDZ: El término "PDZ", como se usa en la presente memoria, se refiere a la proteína 95 de densidad postsináptica (PSD-95), supresor de tumores de discos grandes de homólogo de Drosophila (DIgA), proteína 1 de Zonula occludens (zo-1).
PEG: El término "PEG", como se usa en la presente memoria, se refiere a un polímero del resto de etilenglicol discutido en la presente memoria anteriormente. PEG tiene la fórmula química C2n+2H4n+6Ün+2, y la estructura de repetición es:

donde, por ejemplo, 12 restos de PEG, o PEG12, corresponden a un polímero de 12 restos de etilenglicol.
Perfil farmacocinético: El término "perfil farmacocinético", como se usa en la presente memoria, se refiere a las características in vivo de la absorción en el torrente sanguíneo, la distribución en tejidos, la metabolización y la excreción de los compuestos descritos en la presente memoria. Un ejemplo de un parámetro que se incluye en el perfil farmacocinético es la semivida en plasma medio in vitro, que modela la metabolización de los compuestos por las proteasas plasmáticas.
Aminoácidos proteinogénicos: Los aminoácidos proteinogénicos, también conocidos como aminoácidos naturales, incluyen alanina, cisteína, selenocisteína, ácido aspártico, ácido glutámico, fenilalanina, glicina, histidina, isoleucina, lisina, leucina, metionina, asparagina, prolina, pirrolisina, glutamina, arginina, serina, treonina, valina, triptófano y tirosina.
PSD-95: El término "PSD-95", como se usa en la presente memoria, se refiere a la proteína 95 de densidad postsináptica.
Inhibidor de PSD-95: El término "inhibidor de PSD-95", como se usa en la presente memoria, se refiere a un compuesto que se une a PDZ1, PDZ2, o tanto a PDZ1 como a PDZ2 de PSD-95 e inhibe las interacciones proteína-proteína facilitadas por estos dominios de PDZ en una célula. Un ejemplo de una interacción que es inhibida por un inhibidor de PSD-95 es la formación de un complejo ternario entre nNOS, PSD-95 y el receptor de NMDA.
II. Compuestos diméricos con una semivida plasmática mejorada
Los ligandos diméricos que se dirigen a la PSD-95 están bajo evaluación preclínica como tratamiento para el dolor crónico y accidente cerebrovascular isquémico (Andreasen y col., Neuropharmacol, 2013, 67, 193-200; Bach y col., PNAS USA, 2012, 109, 3317-3322).Sin embargo, los péptidos terapéuticos en general son susceptibles a la degradación por proteasas y la eliminación por filtración renal y/o metabolismo hepático (Tang y col., J Pharm Sci, 2004, 93, 2184-204).Debido al tamaño limitado de los ligandos diméricos, es probable que se depuren de la sangre por filtración renal, ya que los riñones generalmente filtran compuestos con un peso molecular inferior a 60 kDa (Dennis y col., J Biol Chem 2002, 277, 35035-43). Para hacer que los ligandos peptídicos diméricos sean más adecuados para la utilidad clínica en un entorno crónico, tal como dolor neuropático, el régimen de dosificación debe ser lo más simple posible, preferentemente una vez al día, para aumentar el cumplimiento (Claxton y col., Clin Ther 2001, 23, 1296-310). Además, la auto-administración por parte del paciente a través de vías apropiadas, tales como la administración subcutánea (s.c.), se prefiere a la inyección i.v. (intravenosa). La principal limitación de la administración s.c. es el requisito de un bajo volumen de inyección (Dychter y col., J Infus Nurs 2012, 35, 154-60) que requiere que el fármaco sea altamente potente, altamente concentrado, soluble y sea degradado y excretado lentamente de la circulación. Además, el fármaco debe ser estable en el depósito de inyección y ser absorbido lentamente en la circulación para prolongar la acción del fármaco (Havelund y col., Pharm Res 2004, 21, 1498-504). Por lo tanto, el perfil farmacocinético y la semivida in vivo de los ligandos peptídicos diméricos deben optimizarse aún más para tener en cuenta estos problemas.
Unión de albúmina
La albúmina de suero humano (HSA), que es la proteína más abundante en el suero humano con el 55 % de la proteína sérica total (Elsadek y col, J Control Release 2012, 157, 4-28), ofrece una oportunidad para resolver estos problemas. La concentración promedio en sangre de HSA es 520-830 pm, y el peso molecular es de aproximadamente 66,5 kDa (Kragh-Hansen y col. Biol Pharm Bull 2002, 25, 695-704). La HSA es abundante en sangre, tejido muscular y piel (Sleep y col., Biochim Biophys Acta 2013, 1830, 5526-34), pero no está presente dentro de las neuronas en condiciones normales. Sin embargo, puede entrar en las neuronas en estados de enfermedad donde la barrera hematoencefálica (BBB) está comprometida, tal como un accidente cerebrovascular (Loberg, APMIS 1993, 101, 777-83).HSA sirve como una proteína de transporte y depósito para numerosos ligandos endógenos, tales como ácidos grasos (FA), hemina, bilirrubina y triptófano (Simard y col., PNAS USA, 2005, 102, 17958-63; Kragh-Hansen y col., Biol Pharm Bull 2002, 25, 695-704) y fármacos, tales como la warfarina y el diazepam, así como los iones metálicos (Yamasaki y col., Biochim Biophys Acta 2013, 1830, 5435-43).
La estructura de la HSA se ha estudiado ampliamente, y más de 90 estructuras de rayos X diferentes de la HSA se depositan en el Banco de Datos de Proteínas (PDB, fecha de acceso 26/09/2013) con 71 ligandos diferentes. HSA es una molécula en forma de corazón con dimensiones aproximadas de 80 x 80 x 30 A; y consiste en tres dominios similares (I, II y III), que se dividen adicionalmente en dos subdominios (a y b) (Sugio y col., Protein Eng 1999, 12, 439 46).La mayoría de los fármacos se unen en el Sitio I de Sudlow (también llamado el sitio de warfarina) y II (también llamado el sitio de diazepam) (Elsadek y col., J Control Release 2012, 157, 4-28; Yamasaki y col., Biochim Biophys Acta 2013, 1830, 5435-43), llamado así por el trabajo pionero de Sudlow y colegas que en 1975 identificaron los sitios mediante espectroscopia de fluorescencia (Sudlow y col., Mol Pharmacol 1975, 11, 824-32). Desde entonces, los dos sitios de unión al fármaco se han mapeado y se encuentran dentro del subdominio IIa (con la contribución de los residuos en los subdominios IIIa y IIb) y IIIa, respectivamente (Yamasaki y col., Biochim Biophys Acta 2013, 1830, 5435-43). Una excepción importante a la unión general de los ligandos en el sitio I y II de Sudlow son los ácidos grasos (FAs).
El concepto de que la alta unión a HSA de un fármaco aumenta la semivida del fármaco se conoce desde la década de 1970.Sin embargo, el concepto específico de utilizar HSA para aumentar la semivida de los péptidos y proteínas terapéuticas ha evolucionado más lentamente, al duplicarse el número de publicaciones anuales desde 2002 (~250 publicaciones/año) a 2010 (~500 publicaciones/año) (Elsadek y col., J Control Release 2012, 157, 4-28).Se han descrito varios restos de unión a HSA a base de péptidos, incluidas las secuencias de unión a HSA identificadas por la expresión en fagos (Dennis y col., J Biol Chem 2002, 277, 35035-43), aislados de fuentes naturales (Jonsson y col., Protein Eng Des Sel 2008, 21, 515-27 y las llamadas adnectinas (Lipovsek y col., Protein Eng Des Sel 2011, 24, 3-9). Sin embargo, estos pueden ser susceptibles a la degradación de la proteasa, lo que puede ser particularmente un
problema en el caso actual de administración s.c., donde se supone que los compuestos desarrollados residen en el depósito s.c. durante varias horas.
Estructura general
Con el fin de mejorar el perfil farmacocinético, los presentes inventores investigan la influencia de los ácidos grasos y los tipos de enlazadores en la afinidad de HSA, la afinidad por PSD-95 y la hidrofobicidad de los compuestos generados. Al hacerlo, se han identificado nuevos compuestos que proporcionan el perfil de unión a HSA deseado y una estabilidad mejorada en plasma humano.
Por ende, en un aspecto, la presente divulgación se refiere a un compuesto que comprende un primer péptido (P1) y un segundo péptido (P2), donde Pi y P2 comprenden individualmente al menos dos residuos de aminoácidos proteinogénicos o no proteinogénicos, y donde Pi y P2 se conjugan a un primer enlazador Li a través de sus extremos N-terminales respectivos, y donde Li comprende polietilenglicol (PEG), donde al menos un átomo de oxígeno de dicho PEG está sustituido con un átomo de nitrógeno para dar NPEG, y donde un resto de unión a albúmina está enlazado al átomo de nitrógeno de NPEG mediante un enlace amida, o a través de un enlazador opcional L2.
En ciertas realizaciones de la presente divulgación, dicho compuesto tiene la fórmula general (I):

Si bien el resto de unión a albúmina puede ser cualquier albúmina de unión a un grupo químico adecuado, se prefiere que el resto de unión a albúmina sea un ácido graso (FA). En una realización de la presente divulgación, el compuesto tiene así la fórmula general (II):

El ácido graso puede ser cualquier ácido graso adecuado, tal como un ácido graso saturado o insaturado. Como se ilustra en las fórmulas (I) y (II) anteriores, el resto de unión a albúmina, tal como el ácido graso, puede enlazarse opcionalmente al átomo de nitrógeno de un enlazador NPEG (Li) a través de un segundo enlazador L2. En realizaciones de la presente divulgación donde se incluye el segundo enlazador L2, ese enlazador comprende un átomo de nitrógeno.
En una realización, el compuesto de acuerdo con la presente divulgación tiene la estructura genérica de fórmula (III) o (IV):

donde
Ri y R2 se seleccionan individualmente de entre el grupo que consiste en H y COOH,
n es un número entero de 0 a 48,
m es un número entero de 1 a 48,
p es un número entero de 0 a 28,
q es un número entero de 0 a 28,
i es un entero de 0 a 12,
j es un entero de 0 a 12
y donde P1 y P2 se seleccionan individualmente de entre péptidos que comprenden al menos dos residuos de aminoácidos proteinogénicos o no proteinogénicos.
El primer enlazador (Li)
Las propiedades exhibidas por el ácido graso en los péptidos activos P1 y P2 dependen de la manera en que estos restos están enlazados. La unión se logra a través del primer enlazador L1 y el segundo enlazador L2. El primer enlazador L1, que hasta cierto punto se ha descrito en el documento WO 2012/156308, consiste en una cantidad de restos de etilenglicol que forman un polietilenglicol, donde uno de los átomos de oxígeno ha sido reemplazado con un átomo de nitrógeno para formar un enlazador de NPEG. El enlazador NPEG puede ilustrarse como un átomo de nitrógeno flanqueado en cada lado por un número (p, q) de restos de etilenglicol.
El número de restos de etilenglicol que flanquean el átomo de nitrógeno se puede variar en diferentes realizaciones de la presente divulgación. En una realización de la presente divulgación, el número de restos de etilenglicol (p) en un lado es igual al número de restos de etilenglicol en el lado opuesto, es decir, p = q. En otras realizaciones de la presente divulgación, p > q o p < q.
En una realización de la presente divulgación, la suma de p y q es un número entero entre 0 y 28, tal como donde el número de restos de etilenglicol, p se selecciona de entre 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27 o 28.
En una realización de la presente divulgación, el número de restos de etilenglicol, p es de 1 a 4, ya que ese intervalo de p proporciona la mayor afinidad hacia PSD-95.
En una realización de la presente divulgación, el número de restos de etilenglicol, q se selecciona de entre 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27 o 28 restos de etilenglicol.
En una realización de la presente divulgación, el número de restos de etilenglicol q es de 1 a 4, ya que ese intervalo de q proporciona la mayor afinidad hacia PSD-95.
En una realización de la presente divulgación, el número total de restos de etilenglicol p q está entre 2 y 12, ya que la longitud del enlazador dentro de ese intervalo proporciona la mayor afinidad hacia PSD-95.
En una realización de la presente divulgación, el número de restos de etilenglicol, p q es 4, ya que la longitud del enlazador de ese intervalo proporciona la mayor afinidad hacia PSD-95.
En otra realización de la presente divulgación, el número de restos de etilenglicol, p q es 6, ya que la longitud del enlazador de ese intervalo proporciona una afinidad muy alta hacia PSD-95.
El segundo enlazador (L2)
El segundo enlazador L2 es opcional y puede incluirse o excluirse dependiendo de las propiedades físicas o químicas requeridas para un fin particular. Cuando está presente, el segundo enlazador L2 comprende un átomo de nitrógeno. El segundo enlazador L2 puede seleccionarse, por ejemplo, de entre el grupo que consiste en y-GIu, ácido Y-butírico (GABA), ácido 5-amino valérico (5-Ava), aminoácidos proteinogénicos, aminoácidos no proteinogénicos y cualquier compuesto que tenga la fórmula general H2N-[Q]-COOH, donde Q es cualquier átomo o átomos o molécula adecuados. Como se mencionó anteriormente en la presente memoria, el segundo enlazador puede comprender un resto de carbono repetitivo, formando así, por ejemplo, una cadena de alquilo o alquenilo. El número de unidades repetitivas (i) y/o (m) se puede variar según las propiedades deseadas. Así, i y/o m son números enteros que pueden seleccionarse individualmente de entre el grupo que consiste en 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47 y 48.
En una realización de la presente divulgación, n es un número entero entre 1 y 3, tal como en una realización de la presente divulgación donde n = 1 o n = 2 o n = 3.
En ciertas realizaciones de la presente divulgación, i y/o j es un número entero entre 0 y 12, por ejemplo, un número entero seleccionado de entre el grupo que consiste en 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 y 12.
En ciertas realizaciones de la presente divulgación, los enlazadores L1 y L2 se han elegido de modo que el compuesto de acuerdo con la divulgación se seleccione de entre el grupo que consiste en:
a) Derivado KBN41
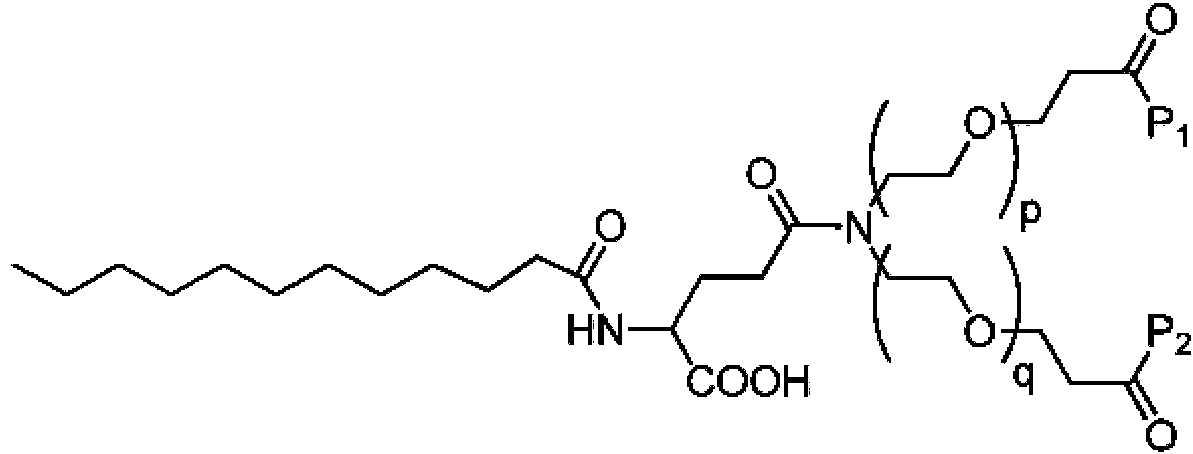
b) Derivado KBN42

c) Derivado KBN43

d) Derivado KBN44

e) Derivado KBN45

f) Derivado KBN46

g) Derivado KBN47

h) Derivado KBN48

i) Derivado KBN52

j) Derivado KBN53

k) Derivado KBN54

l) Derivado KBN55

En una realización adicional de la presente divulgación, los enlazadores se han elegido de modo que el compuesto de la divulgación se seleccione de entre el grupo que consiste en:
a) Derivado KBN41

b) Derivado KBN42

c) Derivado KBN43

d) Derivado KBN44

e) Derivado KBN45

f) Derivado KBN46

g) Derivado KBN47

h) Derivado KBN48

i) Derivado KBN52

j) Derivado KBN53

k) Derivado KBN54

l) Derivado KBN55

Ácidos grasos (FA)
Un ácido graso es un ácido carboxílico con una cola alifática (cadena), que es saturado o insaturado. Los ácidos grasos de origen más natural tienen una cadena de un número par de átomos de carbono, de 4 a 28. Los ácidos grasos se derivan generalmente de triglicéridos o fosfolípidos. Cuando no están unidos a otras moléculas, se conocen como ácidos grasos libres.
Los ácidos grasos que tienen dobles enlaces carbono-carbono se conocen como ácidos grasos insaturados, mientras que los ácidos grasos sin dobles enlaces se conocen como saturados. Los ácidos grasos insaturados tienen uno o más dobles enlaces entre los átomos de carbono. En ciertas realizaciones de la presente divulgación, el compuesto de la presente divulgación comprende un ácido graso insaturado. En tales realizaciones, el indicador (i) y/o (j) de fórmulas genéricas (III), (IV), (V) o (VI) es un número entero seleccionado individualmente de entre un número entero entre 0 y 12, tal como un número entero seleccionado de entre el grupo que consiste en 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 y 12.
Los ácidos grasos insaturados están disponibles en cualquier configuración cis o trans, o en una mezcla de ambas. Una configuración cis significa que los átomos de hidrógeno adyacentes están en el mismo lado del doble enlace. La rigidez del doble enlace congela su conformación y, en el caso del isómero cis, hace que la cadena se doble y restrinja la libertad conformacional del ácido graso. Cuantos más dobles enlaces tenga la cadena en la configuración cis, menos flexibilidad tendrá. Cuando una cadena tiene muchos dobles enlaces con configuración cis, se vuelve bastante curva en sus conformaciones más accesibles. Por ejemplo, el ácido oleico, con un doble enlace, tiene una "torcedura" en el mismo, mientras que el ácido linoleico, con dos dobles enlaces, tiene una curva más pronunciada. El ácido a-linolénico, con tres dobles enlaces, favorece una forma de gancho. El efecto de esto es que, en ambientes restringidos, como cuando los ácidos grasos son parte de un fosfolípido en una bicapa lipídica, o triglicéridos en gotitas de lípidos, los dobles enlaces cis limitan la capacidad de los ácidos grasos a ser muy compactos, y por lo tanto podrían afectar la temperatura de fusión de la membrana o de la grasa.
Una configuración trans, por el contrario, significa que los dos átomos de hidrógeno siguientes están unidos a lados opuestos del doble enlace. Como resultado, no provocan que la cadena se doble mucho, y su forma es similar a los ácidos grasos saturados lineales.
Está dentro del alcance de la presente divulgación elegir cualquier ácido graso adecuado para el fin previsto, incluyendo ácidos grasos cis, trans o mixtos.
El compuesto de acuerdo con la presente divulgación puede comprender cualquier ácido graso o derivado de ácido graso adecuado. En una realización de la presente divulgación, el ácido graso es un ácido graso como se define en las fórmulas genéricas (III) o (IV) donde m es un número entero seleccionado de entre el grupo que consiste en 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47 y 48, tal como donde m es un número entero entre 10 y 16, por ejemplo, donde m = 10 o donde m = 16, que sin duda, determinan un alto grado de interacción HSA (Tabla 1).
El ácido graso de la divulgación puede ser un ácido graso C4-C22 o un ácido graso seleccionado de entre el grupo que consiste en ácido caprílico, ácido cáprico, ácido láurico, ácido mirístico, ácido palmítico, ácido esteárico, ácido araquídico, ácido behénico, ácido lignocérico, ácido cerótico, ácido miristoleico, ácido palmitoleico, ácido sapiénico,
ácido oleico, ácido elaídico, ácido vaccénico, ácido linoleico, ácido linoelaídico, ácido a-linolénico, ácido araquidónico, ácido eicosapentaenoico, ácido erúcico y ácido docosahexaenoico.
Péptidos (Pi y P2)
El compuesto de la presente divulgación comprende dos péptidos P1 y P2.
P1 y P2 pueden ser individualmente cualquier péptido, comprendiendo cada uno de los cuales al menos dos residuos de aminoácidos y, por lo tanto, el compuesto dimérico de la presente divulgación puede adaptarse para el fin pretendido.
En una realización preferida de la presente divulgación, el compuesto de la presente divulgación es un inhibidor de PSD-95 donde dos péptidos se unen a PDZ1-2 de PSD-95. Por lo tanto, en ciertas realizaciones, el compuesto es un compuesto como se define en una cualquiera de las fórmulas genéricas (I), (II), (III) o (IV), donde:
P1 comprende la secuencia de aminoácidos X4X3X2X1 (SEQ ID NO:1), y
P2 comprende la secuencia de aminoácidos Z4Z3Z2Z1 (SEQ ID NO:2),
donde
a) X1 y/o es un residuo de aminoácido seleccionado de entre I, L y V,
b) X2 y/o Z2 es un residuo de aminoácido seleccionado de entre A, D, E, Q, N, S, V, N-Me-A, N-Me-D, N-Me-E, N-Me-Q, N-Me-N, N-Me-S y N-Me-V,
c) X3 y/o Z3 es un residuo de aminoácido seleccionado de entre S y T,
d) X4 y/o Z4 es un residuo de aminoácido seleccionado de entre E, Q, A, N y S,
donde X1 y Z1 representan individualmente el último residuo de aminoácido C-terminal que comprende un ácido carboxílico libre.
Por lo tanto, en ciertas realizaciones, el compuesto de acuerdo con la presente divulgación tiene la estructura genérica de fórmula (V) o (VI):

donde
Ri y R2 se seleccionan individualmente de entre el grupo que consiste en H y COOH,
n es un número entero de 0 a 48,
m es un número entero de 1 a 48, y
p es un número entero de 0 a 28,
q es un número entero de 0 a 28,
i es un número entero 0 a 12,
j es un número entero 0 a 12 X5 y/o Z5 son/es un residuo de aminoácido opcional, un péptidoo un polipéptido, X4 y/o Z4 es un residuo de aminoácido seleccionado de entre E, Q, A, N y S,
X3 y/o Z3 es un residuo de aminoácido seleccionado de entre S y T,
X2 y/o Z2 es un residuo de aminoácido seleccionado de entre A, D, E, Q, N, S, V, N-Me-A, N-Me-D, N-Me-E, N-Me-Q, N-Me-N, N-Me-S y N-Me-V
X1 y/o Z1 es un residuo de aminoácido seleccionado de entre I, L y V.
Si X5 es un residuo de aminoácido único, se selecciona de entre residuos de aminoácidos proteinogénicos y no proteinogénicos.
En una realización de la presente divulgación, X5 es un residuo de aminoácido seleccionado de entre el grupo que consiste en I, A, L y V.
X5 también puede ser un péptido o polipéptido que tiene una secuencia de aminoácidos que consiste en 2 a 100 residuos de aminoácidos, donde el extremo C-terminal de dicho péptido o polipéptido es un residuo de aminoácido seleccionado de entre el grupo que consiste en I, A, L y V.
En ciertas realizaciones de la presente divulgación, X5 es un péptido que comprende de 2 a 100 residuos, tal como 2 a 90 residuos de aminoácidos, tal como 2 a 80 residuos de aminoácidos, tal como 2 a 70 residuos de aminoácidos, tal
como 2 a 60 residuos de aminoácidos, tal como 2 a 50 residuos de aminoácidos, tal como 2 a 40 residuos de aminoácidos, tal como 2 a 30 residuos de aminoácidos, tal como 2 a 20 residuos de aminoácidos, tal como 2 a 10 residuos de aminoácidos, tal como 2 a 9 residuos de aminoácidos, tal como 2 a 8 residuos de aminoácidos, tal como 2 a 7 residuos de aminoácidos, tal como 2 a 6 residuos de aminoácidos, tal como 2 a 5 residuos de aminoácidos, tal como 2 a 4 residuos de aminoácidos, tal como 2 a 3 residuos de aminoácidos, donde el extremo C-terminal es un aminoácido seleccionado de entre el grupo que consiste en I, A, L y V.
Si bien el concepto de la presente divulgación es generalmente aplicable como se ilustra en las fórmulas genéricas (I), (II), (III), (IV), (V) y (V), los presentes inventores han preparado una serie de compuestos dentro de la presente divulgación, que comprende un motivo peptídico de P1 y P2, siendo adecuados para unirse a PDZ1-2 de PSD-95. De este modo, en una realización, el compuesto de acuerdo con la presente divulgación se selecciona de entre el grupo que consiste en:
a) KBN41 (5)

b) KBN42 (7)

c) KBN43 (6)

d) KBN44 (8)

e) KBN45 (9)

f) KBN46 (11)

g) KBN47 (10)

h) KBN48 (12)

j) KBN52 (1)

k) KBN53 (3)

l) KBN54 (2)

m) KBN55 (4)

n) KBN63 (15)

o) KBN64 (13)

p) KBN65 (14)

Formas de sal
El compuesto, como se define en la presente memoria puede estar en forma de una sal o profármaco farmacéuticamente aceptable de dicho compuesto. En una realización de la presente divulgación, el compuesto como se define en una cualquiera de las fórmulas generales (I), (II), (III), (IV), (V) y (VI) puede formularse como una sal de adición farmacéuticamente aceptable o hidrato de dicho compuesto, tal como pero no limitado a K+, Na+, así como no sal, por ejemplo, H+.
III. Uso médico
En un aspecto, el compuesto de la presente divulgación, como se define en la presente memoria, es para uso como medicamento.
En una realización de la presente divulgación, el compuesto, como se define en la presente memoria, es para su uso en el tratamiento o profilaxis del dolor.
En otra realización de la presente divulgación, el compuesto, como se define en la presente memoria, es para su uso en el tratamiento o profilaxis de una enfermedad relacionada excitotóxica.
En una realización adicional de la presente divulgación, la enfermedad tratable por el compuesto de la presente divulgación es una lesión isquémica o traumática del SNC.
IV. Síntesis
Los inhibidores de PSD-95 derivados de ácidos grasos de la presente divulgación, como se define en la presente memoria, pueden fabricarse mediante un procedimiento que comprende las etapas generales que consisten en: a) preparar un enlazador diácido de Ns-NPEG,
b) preparar un péptido utilizando la síntesis de péptidos en fase sólida a base de Fmoc,
c) dimerizar el péptido Fmoc desprotegido con el enlazador diácido de Ns-NPEG,
d) acoplar un ácido graso al conjugado de enlazador-dímero, opcionalmente a través de un enlazador intermedio, tal como un enlazador de aminoácidos (L2).
Los compuestos de la presente divulgación se pueden sintetizar en una realización como se define a continuación. Enlazador diácido Ns-NPEG: El enlazador NPEG (Ns) protegido con orto-nitrobencenosulfonilo se produce en fase sólida o en solución.
El procedimiento en fase sólida comienza normalmente cargando un soporte sólido útil para la síntesis de péptidos en fase sólida, tal como la resina de cloruro de 2-clorotritilo, con Fmoc-NH-PEG-CH2CH2COOH, usando un disolvente orgánico apropiado para la resina específica (por ejemplo, DCM, DMF, ACN, THF) y una base (por ejemplo, DIPEA, DBU, colidina, NMM).
El grupo Fmoc puede eliminarse mediante una base (por ejemplo, piperidina, dimetilamina, morfolina, piperazina, diciclohexilamina, DMAP) en un disolvente apropiado (por ejemplo, d MF, DCM, ACN, THF).
El cloruro de orto-nitrobencenosulfonilo se puede acoplar a la amina libre usando una base (por ejemplo, DIPEA, DBU,
colidina, NMM) y un disolvente apropiado (por ejemplo, THF, DCM) para obtener Ns-NH-PEG-CI-teCI-teCOO-resina. La segunda parte del producto enlazador puede conectarse a la parte enlazador unida a la resina mediante el uso de química de Mitsunobu. La resina se trata con trifenilfosfina, HO-PEG-CH2CH2COOtBu, disolvente y reactivos de éster o amida del ácido azodicarboxílico (por ejemplo, azodicarboxilato de diisopropilo, DIAD; azodicarboxilato de dietilo, DEAD; 1,1'-(azodicarbonil)-dipiperina, Ad Dp ).
El enlazador diácido Ns-NPEG final se obtiene tratando la resina con un ácido, tal como ácido trifluoroacético (TFA). El procedimiento en fase de solución se puede realizar mediante la protección del grupo amina de NH2-PEG-CH2CH2COOtBu con Ns, seguido de la química de Mitsunobu en solución usando trifenilfosfina y DIAD, DEAD o ADDP, o reactivos similares, HO-PEG-CH2CH2COOtBu, y disolvente apropiado (THF, DCM). El enlazador de NPEG Ns protegido final se obtiene luego por tratamiento con ácidos, tales como TFA.
Síntesis de péptidos: La secuencia peptídica se sintetiza mediante la síntesis de péptidos en fase sólida a base de Fmoc usando un soporte sólido, tal como la resina de cloruro de 2-clorotritilo o la resina de Wang, aminoácidos Fmoc protegidos, base, reactivos de acoplamiento (por ejemplo, HBTU [hexafluorofosfato de N,N,N',N'-tetrametil-O-(1H-benzotriazol-1-il)uronio], hexafluorofosfato de O-(7-azabenzotriazol-1-il)-N,N,N',N'-tetrametiluronio [HATU], PyBOB, DIC/HOBt) y disolventes. Como alternativa al acoplamiento de reactivos, se puede usar un éster activado de aminoácidos protegidos con Fmoc (por ejemplo, pentafluorofenilo, succinimida).
Dimerización: El péptido unido a resina Fmoc desprotegido se dimeriza con el enlazador diácido Ns-NPEG mediante un procedimiento de dimerización en resina mediante tratamientos repetitivos de la resina con el enlazador diácido Ns-NPEG en cantidades subestequiométricas (por ejemplo, 1/6), base, reactivo de acoplamiento y disolventes apropiados (por ejemplo, DMF, DCM, THF). Como alternativa al acoplamiento de reactivos, se puede usar el éster activado del enlazador Ns-NPEG.
El procedimiento de dimerización también puede formarse en solución utilizando el éster activado (por ejemplo, pentafluorofenilo, succinimida) del enlazador Ns-NPEG junto con 1-hidroxi-7-azabenzotriazol (HOAt) o hidroxibenzotriazol (HOBt) y péptido protegido de cadena lateral apropiada (por ejemplo, terc-butilo) en el disolvente (por ejemplo, ACN, DMF, DCM, THF).Además, la dimerización en solución se puede realizar utilizando el enlazador diácido Ns-NPEG, los reactivos de acoplamiento (por ejemplo, HBTU, HATU, etc.), la base y los disolventes.
El grupo Ns se elimina por mercaptoetanol y 1,8-diazabiciclo [5.4.0] undec-7-eno (DBU) o por tiofenolato de sodio. Enlazador y conjugación de ácidos grasos: El enlazador de aminoácidos se puede acoplar al nitrógeno libre del péptido unido a resina y NPEG dimerizado mediante acoplamientos consecutivos del enlazador Fmoc protegido (por ejemplo, Fmoc-Glu-OtBu, Fmoc-GABA, Fmoc-5-Ava-OH) utilizando el reactivo de acoplamiento y la base para la activación. Como alternativa al acoplamiento de reactivos, se puede usar éster activado de enlazadores de aminoácidos Fmoc protegidos. Los grupos Fmoc se eliminan posteriormente por procedimientos de desprotección.
El ácido graso se acopla al conjugado enlazador-dímero utilizando un reactivo de acoplamiento y una base para la activación. Alternativamente, se acopla como ésteres activados. Si el ácido graso contiene grupos carboxílicos, además del grupo carboxílico que reacciona con la amina del conjugado enlazador-dímero, estos pueden protegerse como ésteres, por ejemplo, como éster metílico.
Los ligandos diméricos enlazados a ácidos grasos pueden escindirse de la resina con desprotección de cadena lateral concomitante usando ácidos, tales como TFA o HCl.
Los grupos de protección del éster se pueden eliminar agitando los productos escindidos en una base acuosa (por ejemplo, NaOH, LiOH) y acetonitrilo seguido de acidificación con TFA o HCl.
El compuesto final de la presente divulgación se obtiene mediante liofilización y purificación por HPLC o procedimientos cromatográficos similares.
En una realización adicional de la presente divulgación, la síntesis de los compuestos de la presente divulgación se realiza como se define en el ejemplo 1.
EJEMPLOS
Ejemplo 1: Síntesis
El ligando dimérico WPEG4 IETAV unido a la resina (SEQ ID NO:3) (I1) se sintetizó como se describió anteriormente (Bach y col., PNAS USA, 2012, 109, 3317-3322).A partir de esto, los enlazadores adecuadamente protegidos (Fmoc-GABA-OH, Fmoc-(L) -Glu-OtBu y Fmoc-5-Ava, respectivamente) se unieron al nitrógeno en el enlazador WPEG4 mediante dos acoplamientos subsiguientes utilizando HATU como el reactivo de acoplamiento seguido de desprotección con piperidina/DMF para obtener los productos intermedios I2-4 (Figura 6).Los ácidos grasos (FA1-4, Figura 6) se unieron fácilmente al nitrógeno liberado en los enlazadores utilizando condiciones de síntesis de péptidos en fase sólida y se escindieron de la resina con desprotección concomitante de los grupos protectores de la cadena lateral. El grupo protector de metilo terminal de los bloques de construcción de FA mono-protegidos (éster metílico del ácido dodecanodioico y éster metílico del ácido octadecanodioico, FA2 y FA4) se eliminaron mediante saponificación del producto escindido seguido de acidificación (Figura 6). Después de la liofilización, los productos brutos se disolvieron en DMSO al 100 % y se purificaron mediante C18 RP-HPLC a gran escala. Las fracciones semipuras (50 90 % de pureza) se liofilizaron, se volvieron a disolver en DMSO/ACN/H2O y se purificaron mediante C4 RP-HPLC preparativa (> 95 % de pureza).
La Figura 6 ilustra la síntesis de ligandos diméricos enlazados a FA (1-12).Las condiciones de reacción del esquema 1 fueron las siguientes:(a) Fmoc-GABA-OH/Fmoc-(L)-Glu-OtBu/Fmoc-5-Ava, HATU, colidina, DMF (1 h x 2), después piperidina al 20 % en DMF; (b) FA1/FA2/FA3/FA4, HBTU, DIPEA, DMF/DCM, 45 min, después TFA/TIPS/H2O (90/5/5); (c) LiOH 0,5 M, H2O/ACN (75/25), 30 min, después TFA a pH < 2. El triángulo indica que E y T son cadenas laterales protegidas (terc-butilo).
El éster monometílico de octadecandioato (FA4) no estaba disponible comercialmente y se sintetizó mediante monosaponificación del éster dimetílico correspondiente con un eq. de NaOH como se describió anteriormente (Jonassen y col., Pharm Res, 2012, 29, 2104-2114) (Figura 7).
En conclusión, el ejemplo 1 demuestra que los compuestos de la presente divulgación se pueden sintetizar y obtener en forma pura.
Ejemplo 2: Método para determinar la afinidad a HSA
Los ligandos diméricos enlazados a FA sintetizados (1-12) se evaluaron para determinar su afinidad a HSA utilizando un kit de ensayo de unión a HSA TransilXL (Sovicell GMBH, Leipzig, Alemania). Los ligandos diméricos, UCCB01-125 (Bach y col., Angew.Chem, Int. Ed. 2009, 48, 9685-9689) y UCCB01-144 (Bach y col., PNAS USA, 2012, 109, 3317 3322) también se probaron para comparación (Tabla 1, Figura 1).
El kit de ensayo consistía en pocillos prellenados con concentraciones crecientes de HSA inmovilizado, así como dos pocillos de control sin HSA. La HSA se había inmovilizado de forma aleatoria para garantizar que todos los sitios de unión en la HSA estuvieran disponibles. Para llevar a cabo el ensayo, los pocillos se incubaron con una concentración conocida de los compuestos analizados, y la cantidad no unida del compuesto se cuantificó utilizando RP-HPLC analítica (columna C8). La fracción de fármaco no unido (fu) para cada punto de datos se calculó a partir de los datos de RP-HPLC en comparación con una muestra de control sin HSA. La relación de HSA-fármaco unidos (fb = 1-fu) al fármaco no unido para cada punto de datos se representó luego contra la concentración total de HSA (Ch s a ) en el pocillo y se ajustó a un modelo lineal dado por la ecuación 1, para obtener 1/Kd como la pendiente de la curva ajustada.

En la ec.1, se asume que la concentración de HSA unida a fármaco ([HSA-D]) es mucho menor que la concentración total de HSA en el pocillo ([HSA-D] << Ch s a ). El kit de ensayo ha sido diseñado de tal manera que el supuesto es válido para compuestos donde fu > 1 %. Los valores de Kd calculados se utilizaron para calcular fb a la concentración fisiológica de hSa (588 pM) utilizando la ecuación 2.

Ecuación 2:
En conclusión, el ejemplo 3 demuestra que, y cómo, se puede determinar la unión de los compuestos de la presente divulgación a la albúmina sérica humana (HSA).
Ejemplo 3: Afinidad a HSA
Los ligandos diméricos UCCB01-125 y UCCB01-144, que no contienen FAs, mostraron afinidades a HSA de154,3 pM y 317,5 pM; respectivamente, correspondientes a fracciones unidas a HSA (fb) de 75 % y 65 % respectivamente (Tabla 1). Sin embargo, todos los ligandos diméricos enlazados a FA (1-12) mostraron una afinidad mucho mayor hacia HSA en comparación con los ligandos sin FA y, por consiguiente, valores de fb más altos (Tabla 1). Por lo tanto, esto demuestra claramente que la unión a HSA se mejora considerablemente como resultado de la conjugación de FA con los ligandos diméricos.
Los compuestos que contienen el enlazador 5-Ava más largo generalmente tienen una afinidad ligeramente menor para HSA que los compuestos con los enlazadores más cortos (GABA, yGIu) (Tabla 1, Figura 2). El resto ácido adicional en el enlazador yGIu (R1) no parece tener ninguna influencia sobre la afinidad por HSA de los ligandos diméricos enlazados a FA sintetizados aquí (Tabla 1, Figura 2).Esto contrasta con lo que se ha observado en otros sistemas de proteína-ligando (Hackett y col, Adv Drug Deliv Rev, 2013, 65, 1331-1339) e indica que el carboxilato libre del enlazador yGIu no es una característica esencial para la unión a HSA para los presentes compuestos.
Los ligandos diméricos enlazados a FAs largos (m = 16) muestran una afinidad de HSA superior en comparación con los ligandos diméricos enlazados a FAs más cortos (m = 10) (Tabla 1); y un grupo carboxilo terminal (R2) tiene una influencia negativa en la afinidad de HSA (Tabla 1 y Figura 2).
Tabla 1: Unión a HSA y fracción calculada del compuesto unido a ligandos diméricos enlazados a FA (1-12) y ligandos diméricos UCCB01-125 y UCCB01-144a

En conclusión, el ejemplo 3 demuestra que los compuestos de la presente divulgación tienen una afinidad incrementada por HSA en comparación con los péptidos de referencia diméricos no derivados de FA.
Ejemplo 4: Método para determinar la afinidad a PDZ1-2 de PSD-95:
La afinidad a PSD-95 se midió usando un ensayo de polarización de fluorescencia (FP) in vitro según lo descrito por Bach y col., (PNAS USA, 2012, 109, 3317-3322). Primero, se obtuvo una curva de unión de saturación para determinar los valores de Kd para la interacción entre una sonda fluorescente dimérica y PSD-95 PDZ1-2. Se agregaron concentraciones crecientes de PDZ1-2 a una concentración constante (0,5 nM) de la sonda. La polarización de la fluorescencia de las muestras se midió a longitudes de onda de excitación/emisión de 635/670 nm y los valores de FP se ajustaron a un modelo de unión de un sitio utilizando el programa GraphPad Prism. Luego, la afinidad entre los ligandos diméricos no fluorescentes y PDZ1-2 se determinó en un ensayo de unión de competición heteróloga, donde se agregó una concentración creciente de ligando a una concentración fija de sonda dimérica (0,5 nM) y PDZ1-2 (4 nM). Los valores de FP se ajustaron a un modelo de competencia de un sitio (pendiente variable) en GraphPad Prism. La IC50 resultante se convirtió a constantes de inhibición de competición, valores de Ki, como se describe (Nikolovska-Coleska y col., Anal Biochem, 2004, 332, 261-273). El ensayo de FP modificado se realizó como se describió anteriormente con HSA al 1 % en el ensayo.
En conclusión, el ejemplo 4 demuestra cómo probar la unión de los compuestos de la presente divulgación, a PDZ1-2 de PSD-95.
Ejemplo 5: Afinidad a PDZ1-2 de PSD-95:
Los ligandos diméricos enlazados a FA sintetizados se evaluaron para determinar su afinidad a PDZ1-2 de PSD-95 en el ensayo de FP.UCCB01-125 y UCCB01-144 se usaron como compuestos de referencia (Bach y col., PNAS USA, 2012, 109, 3317-3322) (Tabla 2, Figura 3). Primero se midieron las afinidades utilizando un simple tampón de solución salina tamponada con tris (TBS) (Tabla 2, Figura 3A); pero, además, se investigó si HSA influyó en la capacidad de los dímeros enlazados a FA para unirse a PDZ1-2 de PSD95 mediante la realización del ensayo de FP con HSA presente en el tampón de ensayo (Tabla 2, Figura 3B). Debido a la unión de la sonda a HSA en concentraciones más altas, la concentración de HSA se estableció aquí en 1 % (~150 pM), aproximadamente 4 veces más baja que la concentración en sangre fisiológica estimada (520-830 pM) (Kragh-Hansen y col., Biol Pharm Bull 2002, 25, 695-704). Para un fármaco tradicional de molécula pequeña, se acepta comúnmente que la fracción no unida del fármaco es libre de difundirse a través de las membranas y ejerce el efecto fisiológico al interactuar con su diana (Berezhkovskiy y col., J Pharm Sci 2007, 96, 249-257). Es decir, si el fármaco está unido a otra molécula, entonces no puede interactuar con la diana al mismo tiempo. Para tener en cuenta esto, la fracción del fármaco no unido (fu) se calculó a partir de la ecuación 2 (fu = 1-fb) a una concentración de HSA de 150 pM, y los datos del ensayo de FP (TBS HSA) se corrigieron para el fu calculado (Tabla 2, Figura 3C).
Tabla 2: Afinidad por PDZ1-2 de PSD-95 de ligandos diméricos enlazados a FA (1-12) y ligandos diméricos (UCCB01-125 y UCCB01-144) según lo determinado por FPa, fracción calculada de fármaco no unido (fu)b, datos3 de FP de fu corregida y tiempo de retención (Rt) de los compuestos determinados por RP-HPLC (columna C8)c.


______________________________________________ ______________________________( )__________

La afinidad por PSD-95 PDZ1-2 en TBS fue comparable para todos los ligandos diméricos enlazados a FA a las afinidades de UCCB01-125 (Tabla 2, Figura 3A), mostrando que la afinidad para PSD-95 PDZ1- 2 no fue influenciada por la derivatización de FA.
La afinidad por PSD-95 PDZ1-2 en TBS con HSA al 1 % varió significativa y sistemáticamente entre los compuestos (Tabla 2, Figura 3B). Los ligandos diméricos que se enlazaron a los Fa más largas (C18:0 o C17:0-COOH) generalmente tenían una afinidad aparente > 50 veces menor para PSD-95 PDZ1-2 que los ligandos diméricos enlazados a los FA más cortos (C12:0 o C11:0-COOH).
Cuando los datos de FP se corrigieron para fu (Tabla 2, Figura 3C), se reveló una clasificación sistemática de las afinidades para PSD-95 PDZ1-2 dentro de cada serie de enlazadores. Los ligandos diméricos unidos a C12: 0 (1, 5, 9) tuvieron la afinidad más alta, seguido de C11:0-COOH (2, 6, 10), C18:0 (3, 7, 11) y C17:0-COOH (4, 8, 12).
Los datos de FP de Fu corregida también revelaron que la pérdida de afinidad observada en 50 veces de los ligandos diméricos 3, 7 y 11 enlazados a C18:0 cuando la medición de FP se realizó en TBS HSA fue causada principalmente por una unión alta de los compuestos a HSA, aunque se observó una disminución de 4 a 5 veces en la afinidad por PSD-95 para 3 y 7, en comparación con los datos de FP registrados en TBS (3:Ki = 57,2 nM vs 11,1 nM; 7:Ki = 59,1 nM vs 17,0 nM, Tabla 2) en el caso actual, la reducción en la afinidad fue dependiente de HSA, ya que no se observó una disminución en la afinidad en TBS.
Los dos ligandos diméricos 11 y 12 enlazados a 5-Ava estaban menos afectados por HSA que los ligandos diméricos correspondientes a GABA y yGIu (3, 4, 7 y 8).
En conclusión, el ejemplo 5 demuestra que los compuestos de la presente divulgación se unen a PDZ1-2 de PSD-95.
Ejemplo 6: Hidrofobicidad de ligandos diméricos enlazados a FA
Los compuestos con la mayor afinidad para HSA (3, 7, 11) también fueron los más hidrófobos de los compuestos sintetizados, según lo determinado por el tiempo de retención (Rt) determinado por RP-HPLC analítica (Tabla 2). En un intento por aumentar la hidrofilicidad y, por lo tanto, la solubilidad de estos compuestos, se crearon los análogos de 3 y 7, donde la secuencia peptídica se reemplazó con IETDV (SEQ ID NO:4) en lugar de IETAV (SEQ ID NO:3) (13, 15; Tabla 3), ya que la carga adicional introducida por el resto Asp (D) podría aumentar la hidrofilicidad de los dímeros. También se sintetizó y analizó un análogo de IETDV del compuesto de afinidad de HSA más alta que contiene un resto ácido terminal (4) para su comparación (14). Estos dímeros enlazados a FA se sintetizaron de manera análoga a 1-12 (Figura 6) utilizando la secuencia peptídica apropiada (IETDV) como punto de partida.
El análisis por HPLC reveló una disminución menor o nula en los valores de Rt, y por lo tanto la hidrofobicidad, para compuestos basados en IETDV (13-15) en relación con compuestos basados en IETAV (3, 4, 7); pero se observó una reducción sistemática en las afinidades de HSA (Tabla 3).Por ejemplo, 13 se eluyó 3 minutos antes en la RP-HPLC analítica que en el análogo de IETAV (13: 58 min, 3: 61 min, Tabla 3), pero la afinidad HSA se redujo (13: Kd = 83,0 pM, 3: Kd = 4,8 pM, tabla 3).
Tabla 3: Comparación de análogos diméricos enlazados a FA con diferentes secuencias peptídicas. Secuencia peptídica 3, 4 y 7 IETAV (SEQ ID NO:3); secuencia peptídica 13, 14 y 15 IETDV (SEQ ID NO:4).
C ( S ) ( S ) ( S ) ( S )

En conclusión, el ejemplo 6 demuestra que la afinidad por HSA depende no solo del ácido graso de elección, sino también de la secuencia peptídica elegida.
Ejemplo 7: Estabilidad plasmática del compuesto 1, 4, 7 y 13)
La estabilidad en plasma de 1, 4, 7 y 13 se evaluó en una versión modificada de un ensayo de estabilidad en plasma in vitro (Bach y col., Angew.Chem, Int. Ed, 2009, 48, 9685-9689). En el procedimiento original, el compuesto investigado se incubó en plasma humano. Las muestras se extrajeron en puntos de tiempo apropiados y las proteínas séricas se eliminaron por precipitación con ácido tricloroacético (TCA), seguido de un análisis de los sobrenadantes por RP-HPLC. Las áreas de los picos obtenidos se normalizaron a la cantidad en To y se ajustaron a un modelo de decaimiento de primer orden para calcular la semivida. Cuando este procedimiento se aplicó a los ligandos diméricos enlazados a FA, las recuperaciones de la muestra fueron bajas (< 5 %). Esto se debió a la eliminación de los ligandos diméricos enlazados a FA como complejos unidos a HSA durante la precipitación de TCA. Por lo tanto, la disolución de la muestra en clorhidrato de guanidina sólido (GnHCl) a una concentración final de 6 M se realizó antes de la precipitación del TCA. El fin de esto fue desplegar la HSA en la muestra, liberando el ligando dimérico enlazado a FA. Todos los ligandos diméricos enlazados a FA fueron más estables en el ensayo de estabilidad en plasma in vitro que UCCB01-125 (Figura 4). Sin pretender quedar ligado a teoría alguna, se espera que esto se deba a la mayor unión de HSA a los compuestos, lo que reduce la concentración libre de compuestos disponibles para la digestión enzimática. El compuesto que contiene el C12:0 FA más corto (1) se degradó más rápido que los compuestos que contienen el FA C18:0 más largo o C17:0-COOH (4, 7, 13), que eran altamente estables. La estabilidad prolongada se explica por el aumento de la afinidad a HSA, que evita que las proteasas escindan los compuestos a base de péptidos diméricos, y el impedimento estérico mediado por FA.
En conclusión, el ejemplo 7 demuestra un procedimiento de evaluación de la estabilidad del plasma sanguíneo in vitro, y que los compuestos diméricos enlazados a FA de la presente divulgación tienen una mayor estabilidad y semivida en plasma en comparación con los compuestos de referencia no enlazados a FA.
Ejemplo 8: Estudios farmacocinéticos in vivo
Para determinar las propiedades farmacocinéticas de los compuestos enlazados a FA, se midió la concentración de compuestos seleccionados en sangre mediante LC-MS/MS después de una inyección de un bolo subcutánea (s.c.) en ratas Wistar macho (Figura 5). A partir de esto, fue evidente que todos los ligandos diméricos enlazados a FA tienen Ty2; y mayor Tmax que el ligando dimérico sin FA (UCCB01-125) (Tabla 4 y Figura 5). El efecto fue más pequeño para 1, pero muy notable para 4, 7 y 13, que mostró Ty2 más de 8 horas, lo que corresponde a un aumento de > 16 veces en relación con UCCB01-125.El aumento de Tmax se explica por una absorción prolongada del sitio de inyección. En general, estas propiedades permiten la administración mediante inyecciones de depósito s.c. y, por lo tanto, la liberación lenta y constante de compuesto en la sangre, por lo que se necesitan menos administraciones para mantener las concentraciones de sangre relevantes farmacéuticas.
Tabla 4: Parámetros farmacocinéticos de ligandos diméricos enlazados a FA después de la inyección s.c. en ratas

aLos datos se dan como media ± SEM, n = 3.
Ejemplo 9: Secuencias
SEQ ID NO:1
X4X3X2X1
donde
X4 es un residuo de aminoácido seleccionado de entre E, Q, A, N y S,
X3 es un residuo de aminoácido seleccionado de entre S y T,
X2 es un residuo de aminoácido seleccionado de entre A, D, E, Q, N, S, V, N-Me-A, N-Me-D, N-Me-E, N-Me-Q, N-Me-N, N-Me-S y N-Me-V
X1 es un residuo de aminoácido seleccionado de entre I, L y V
SEQ ID NO:2
Z4Z3Z2Z1
donde
Z4 es un residuo de aminoácido seleccionado de entre E, Q, A, N y S,
Z3 es un residuo de aminoácido seleccionado de entre S y T,
Z2 es un residuo de aminoácido seleccionado de entre A, D, E, Q, N, S, V, N-Me-A, N-Me-D, N-Me-E, N-Me-Q, N-Me-N, N-Me-S y N-Me-V
Z1 es un residuo de aminoácido seleccionado de entre I, L y V
SEQ ID NO:3
IETAV SEQ ID NO:4
IETDV SEQ ID NO:5
X5X4X3X2X1
donde
X5 es cualquier residuo de aminoácido,
X4 es un aminoácido seleccionado de entre E, Q, A, N y S,
X3 es un residuo de aminoácido seleccionado de entre S y T,
X2 es un residuo de aminoácido seleccionado de entre A, D, E, Q, N, S, V, N-Me-A, N-Me-D, N-Me-E, N-Me-Q, N-Me-N, N-Me-S y N-Me-V
Claims (15)
1. Un ligando dimérico de PSD-95 que comprende un primer péptido (Pi) y un segundo péptido (P2), donde Pi y P2 comprenden individualmente al menos dos residuos de aminoácidos proteinogénicos o no proteinogénicos, tanto P1 como P2 están conjugados a un primer enlazador L1 a través de sus extremos N-terminales,
L1 comprende polietilenglicol (PEG) donde al menos un átomo de oxígeno de dicho PEG está sustituido con un átomo de nitrógeno para dar NPEG,
un resto de unión a albúmina está enlazado al átomo de nitrógeno del NPEG mediante un enlace amida, o mediante un enlazador opcional L2 , donde L2 comprende un átomo de nitrógeno,
el resto aglutinante de albúmina es un ácido graso (FA),
y donde dicho ligando dimérico tiene la estructura genérica de fórmula (II), donde L2 es opcional:

o un profármaco o una sal farmacéuticamente aceptables de estos.
2. El ligando dimérico de acuerdo con una cualquiera de las reivindicaciones precedentes, en el que el segundo enlazador L2 comprende uno o más restos seleccionados de entre el grupo que consiste en y-GIu, ácido y-butírico (GABA), ácido 5-amino valérico (5-Ava), aminoácidos proteinogénicos, aminoácidos no proteinogénicos y cualquier ligando dimérico que tenga la fórmula general H2N-[Q]-COOH, donde Q es cualquier átomo o átomos adecuados.
3. El ligando dimérico de acuerdo con una cualquiera de las reivindicaciones precedentes, donde dicho ligando dimérico tiene la estructura genérica de fórmula (III) o (IV):

donde
R1 y R2 se seleccionan individualmente de entre el grupo que consiste en H y COOH,
n es un entero de 0 a 48,
m es un entero de 1 a 48,
p es un entero de 0 a 28,
q es un entero de 0 a 28,
i es un entero de 0 a 12,
j es un número entero de 0 a 12
P1 y P2 se seleccionan individualmente de entre péptidos que comprenden al menos dos residuos de aminoácidos proteinogénicos o no proteinogénicos.
4. El ligando dimérico de acuerdo con una cualquiera de las reivindicaciones precedentes, donde el ácido graso es un ácido graso C4-C22.
5. El ligando dimérico de acuerdo con una cualquiera de las reivindicaciones precedentes, donde el ácido graso se selecciona de entre el grupo que consiste en ácido caprílico, ácido cáprico, ácido láurico, ácido mirístico, ácido palmítico, ácido esteárico, ácido araquídico, ácido behénico, ácido lignocérico, ácido cerótico, ácido miristoleico, ácido palmitoleico, ácido sapiénico, ácido oleico, ácido elaídico, ácido vaccénico, ácido linoleico, ácido linoelaídico, ácido a-linolénico, ácido araquidónico, ácido eicosapentaenoico, ácido erúcico y ácido docosahexaenoico.
6. El ligando dimérico de acuerdo con una cualquiera de las reivindicaciones precedentes, donde P1 comprende la secuencia de aminoácidos X4X3X2X1 (SEQ ID NO:1), y
P2 comprende la secuencia de aminoácidos Z4Z3Z2Z1 (SEQ ID NO:2),
donde
Xi y/o Zi es un residuo de aminoácido seleccionado de entre I, L y V,
X2 y/o Z2 es un residuo de aminoácido seleccionado de entre A, D, E, Q, N, S, V, N-Me-A, N-Me-D, N-Me-E, N-Me-Q, N-Me-N, N-Me-S y N-Me-V,
X3 y/o Z3 es un residuo de aminoácido seleccionado de entre S y T,
X4 y/o Z4 es un residuo de aminoácido seleccionado de entre E, Q, A, N y S,
donde X1 y Z1 representan individualmente el último residuo de aminoácido C-terminal que comprende un ácido carboxílico libre.
7. El ligando dimérico de acuerdo con una cualquiera de las reivindicaciones precedentes, donde dicho ligando dimérico tiene la estructura genérica de fórmula (V) o (VI):

donde
R1 y R2 se seleccionan individualmente de entre el grupo que consiste en H y COOH,
n es un entero de 0 a 48,
m es un entero de 1 a 48,
p es un entero de 0 a 28,
q es un entero de 0 a 28,
i es un entero de 0 a 12,
j es un número entero de 0 a 12
X5 y/o Z5 son/es un residuo de aminoácido proteinogénico o no proteinogénico opcional, un péptido o un polipéptido, X4 y/o Z4 es un residuo de aminoácido seleccionado de entre E, Q, A, N y S,
X3 y/o Z3 es un residuo de aminoácido seleccionado de entre S y T,
X2 y/o Z2 es un residuo de aminoácido seleccionado de entre A, D, E, Q, N, S, V, N-Me-A, N-Me-D, N-Me-E, N-Me-Q, N-Me-N, N-Me-S y N-Me-V
X1 y/o Z1 es un residuo de aminoácido seleccionado de entre I, L y V.
8. El ligando dimérico de acuerdo con una cualquiera de las reivindicaciones precedentes, donde X5 es un residuo de aminoácido seleccionado de entre el grupo que consiste en I, A, L y V.
9. El ligando dimérico de acuerdo con una cualquiera de las reivindicaciones precedentes, donde el ligando dimérico se selecciona de entre el grupo que consiste en:
a) Derivado KBN41 (5)

b) Derivado KBN42 (7)

c) Derivado KBN43 (6)


e) Derivado KBN45 (9)

f) Derivado KBN46 (11)

g) Derivado KBN47 (10)

h) Derivado KBN48 (12)

i) Derivado KBN52 (1)

j) Derivado KBN53 (3)

k) Derivado KBN54 (2)

l) Derivado KBN55 (4)

10. El ligando dimérico de acuerdo con una cualquiera de las reivindicaciones precedentes, donde el ligando dimérico se selecciona de entre el grupo que consiste en:
a) Derivado KBN41 (5)
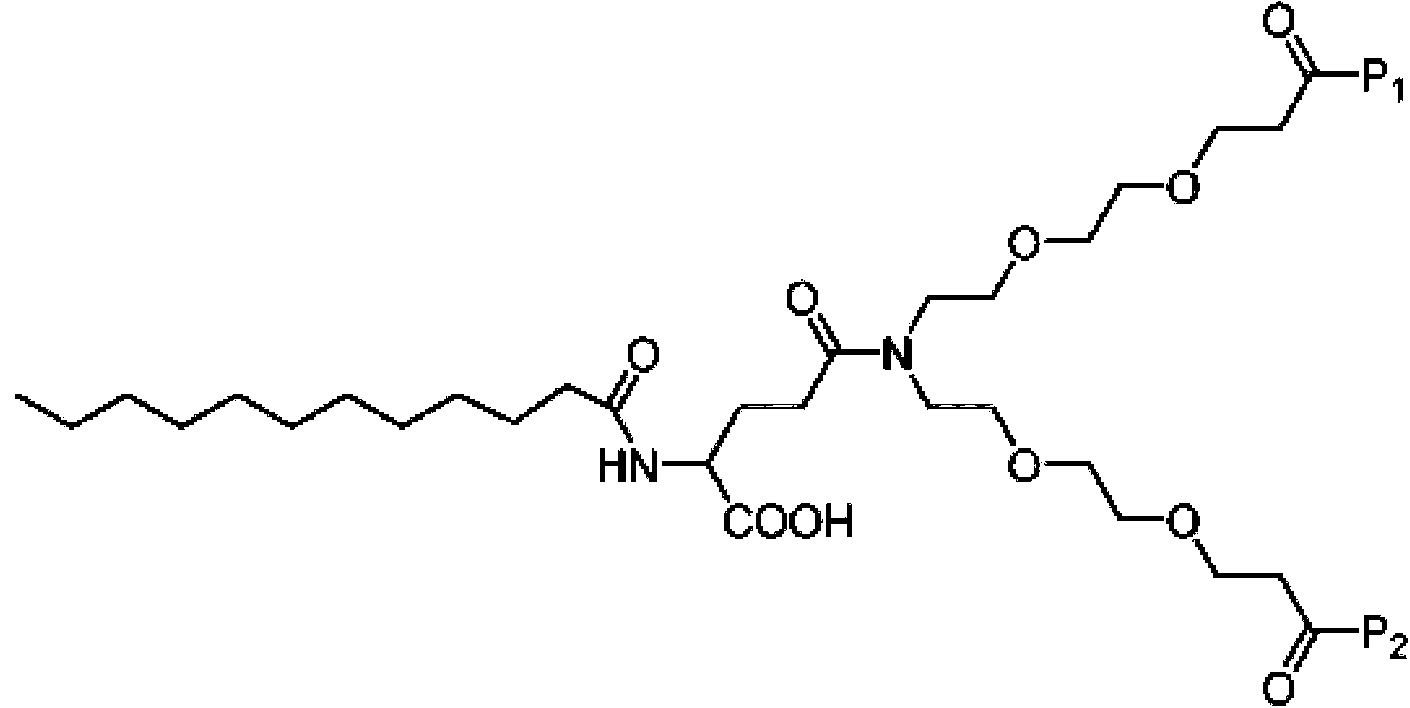
b) Derivado KBN42 (7)

c) Derivado KBN43 (6)

d) Derivado KBN44 (8)

e) Derivado KBN45 (9)

f) Derivado KBN46 (11)

g) Derivado KBN47 (10)

h) Derivado KBN48 (12)

i) Derivado KBN52 (1)

j) Derivado KBN53 (3)

k) Derivado KBN54 (2)

l) Derivado KBN55 (4)

11. El ligando dimérico de acuerdo con una cualquiera de las reivindicaciones precedentes, donde el ligando dimérico se selecciona de entre el grupo que consiste en:
a) KBN41 (5)

b) KBN42 (7)

c) KBN43 (6)

d) KBN44 (8)

e) KBN45 (9)

f) KBN46 (11)

g) KBN47 (10)
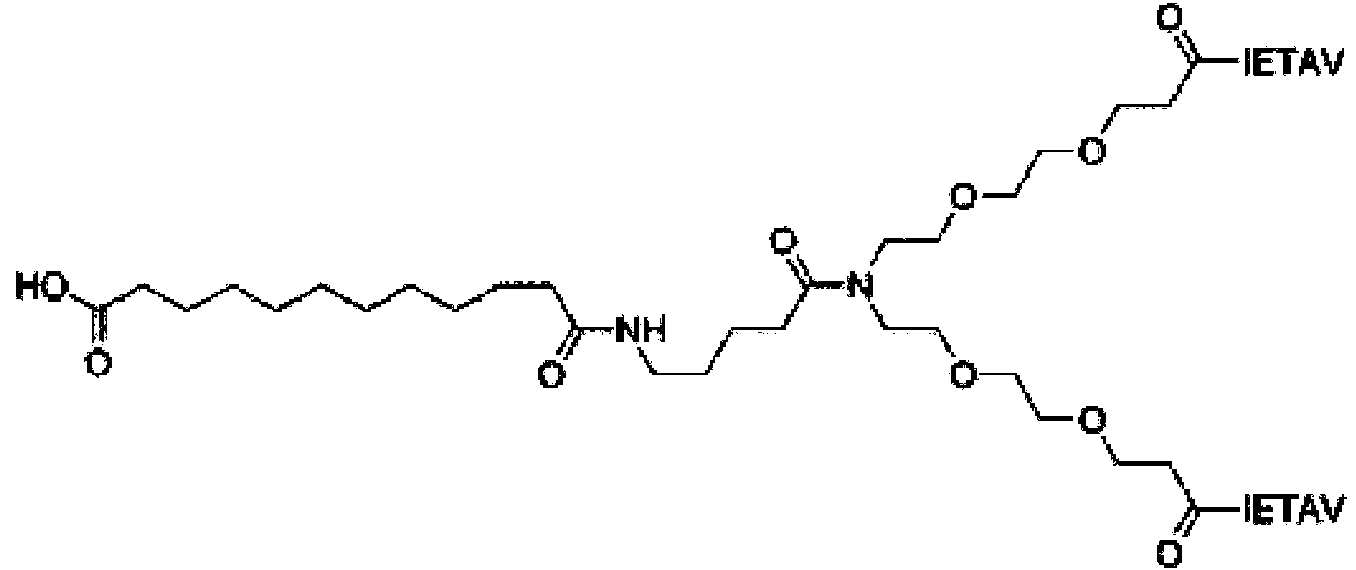
h) KBN48 (12)

j) KBN52 (1)

k) KBN53 (3)

l) KBN54 (2)

m) KBN55 (4)

n) KBN63 (15)

o) KBN64 (13 )

p) KBN65 (14)

12. Un ligando dimérico de acuerdo con una cualquiera de las reivindicaciones precedentes para su uso como medicamento.
13. Un ligando dimérico de acuerdo con una cualquiera de las reivindicaciones 1 a 13 para su uso en el tratamiento o profilaxis del dolor y/o una enfermedad relacionada excitotóxica.
14. El ligando dimérico de acuerdo con la reivindicación 13, donde la enfermedad es una lesión isquémica o traumática al/en/del SNC.
15. Un procedimiento de fabricación del ligando dimérico de acuerdo con una cualquiera de las reivindicaciones 1 a 14, comprendiendo dicho procedimiento las etapas que consisten en:
a) preparar un enlazador diácido de Ns-NPEG,
b) preparar un péptido utilizando la síntesis de péptidos en fase sólida a base de Fmoc,
c) dimerizar dicho péptido con dicho enlazador diácido de Ns-NPEG, y
d) acoplar un ácido graso al enlazador.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| DKPA201370735 | 2013-12-01 | ||
| PCT/DK2014/050402 WO2015078477A1 (en) | 2013-12-01 | 2014-11-26 | Fatty acid derivatives of dimeric inhibitors of psd-95 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2716890T3 true ES2716890T3 (es) | 2019-06-17 |
Family
ID=52272794
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES14821058T Active ES2716890T3 (es) | 2013-12-01 | 2014-11-26 | Derivados de ácidos grasos de inhibidores diméricos de la PSD-95 |
Country Status (14)
| Country | Link |
|---|---|
| US (1) | US20160303245A1 (es) |
| EP (1) | EP3074032B1 (es) |
| JP (1) | JP6633523B2 (es) |
| KR (1) | KR20160091980A (es) |
| CN (1) | CN105828832A (es) |
| AU (1) | AU2014356912B2 (es) |
| BR (1) | BR112016012391A2 (es) |
| CA (1) | CA2931694C (es) |
| DK (1) | DK3074032T3 (es) |
| ES (1) | ES2716890T3 (es) |
| IL (1) | IL245904A (es) |
| MX (1) | MX2016006966A (es) |
| PL (1) | PL3074032T3 (es) |
| WO (1) | WO2015078477A1 (es) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105189465B (zh) | 2013-03-21 | 2019-02-26 | 赛诺菲-安万特德国有限公司 | 合成含有乙内酰脲的肽产物 |
| WO2014147129A1 (en) | 2013-03-21 | 2014-09-25 | Sanofi-Aventis Deutschland Gmbh | Synthesis of cyclic imide containing peptide products |
| CN107226840A (zh) * | 2017-05-04 | 2017-10-03 | 西安交通大学 | 一种细胞穿膜肽透皮吸收促进剂及其制备方法和应用 |
| CN109030662B (zh) * | 2018-09-14 | 2021-04-13 | 广西医科大学第一附属医院 | 检测致痫大鼠海马组织谷氨酸及r-氨基丁酸含量的方法 |
| WO2021176094A1 (en) | 2020-03-06 | 2021-09-10 | University Of Copenhagen | Lipid conjugated peptide inhibitors of pick1 |
| US20240301003A1 (en) | 2021-01-08 | 2024-09-12 | Nono Inc. | Plasmin-resistant peptides for improved therapeutic index |
| KR20250134625A (ko) * | 2023-01-09 | 2025-09-11 | 베이징 투오 지에 바이오파마수티컬 컴퍼니 리미티드 | 신경 보호적 psd-95 폴리펩티드 억제제 및 이의 응용 |
| CN119569824A (zh) * | 2023-09-07 | 2025-03-07 | 湖南中晟全肽生物科技股份有限公司 | 作为神经保护剂的药用化合物及其应用 |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB9215780D0 (en) * | 1992-07-24 | 1992-09-09 | Univ London Pharmacy | Peptide compounds |
| DK2320927T3 (en) * | 2008-07-09 | 2015-09-14 | Univ Copenhagen | Modified peptides as potent inhibitors of the PSD-95 / NMDA receptor interaction |
| MX339993B (es) * | 2011-05-13 | 2016-06-21 | Københavns Univ (University Of Copenhagen) | Inhibidores dimericos de alta afinidad de psd-95 como neuroprotectores eficientes contra daño isquemico cerebral y para el tratamiento de dolor. |
| JP6084207B2 (ja) | 2011-05-13 | 2017-02-22 | ケベンハウンス ウニヴェルジテート(ユニバーシティ オブ コペンハーゲン)Koebenhavns Universitet(University Of Copenhagen) | 虚血性脳損傷及び疼痛治療用の効率的な神経保護剤としてのpsd−95の高親和性二量体阻害剤 |
| MX364562B (es) * | 2011-12-13 | 2019-04-30 | Nono Inc | Terapia para hemorragia subaracnoidea e isquemia. |
| WO2013151538A1 (en) * | 2012-04-03 | 2013-10-10 | Empire Technology Development Llc | Fluorescent labeling of living cells |
-
2014
- 2014-11-26 AU AU2014356912A patent/AU2014356912B2/en not_active Ceased
- 2014-11-26 MX MX2016006966A patent/MX2016006966A/es unknown
- 2014-11-26 CN CN201480065303.XA patent/CN105828832A/zh active Pending
- 2014-11-26 JP JP2016534121A patent/JP6633523B2/ja not_active Expired - Fee Related
- 2014-11-26 WO PCT/DK2014/050402 patent/WO2015078477A1/en not_active Ceased
- 2014-11-26 CA CA2931694A patent/CA2931694C/en not_active Expired - Fee Related
- 2014-11-26 EP EP14821058.6A patent/EP3074032B1/en not_active Not-in-force
- 2014-11-26 BR BR112016012391A patent/BR112016012391A2/pt not_active IP Right Cessation
- 2014-11-26 ES ES14821058T patent/ES2716890T3/es active Active
- 2014-11-26 KR KR1020167017206A patent/KR20160091980A/ko not_active Ceased
- 2014-11-26 DK DK14821058.6T patent/DK3074032T3/en active
- 2014-11-26 US US15/100,687 patent/US20160303245A1/en not_active Abandoned
- 2014-11-26 PL PL14821058T patent/PL3074032T3/pl unknown
-
2016
- 2016-05-29 IL IL245904A patent/IL245904A/en not_active IP Right Cessation
Also Published As
| Publication number | Publication date |
|---|---|
| EP3074032B1 (en) | 2018-12-26 |
| KR20160091980A (ko) | 2016-08-03 |
| US20160303245A1 (en) | 2016-10-20 |
| JP2017501132A (ja) | 2017-01-12 |
| JP6633523B2 (ja) | 2020-01-22 |
| IL245904A (en) | 2017-10-31 |
| AU2014356912A1 (en) | 2016-06-09 |
| EP3074032A1 (en) | 2016-10-05 |
| PL3074032T3 (pl) | 2019-06-28 |
| CN105828832A (zh) | 2016-08-03 |
| CA2931694A1 (en) | 2015-06-04 |
| IL245904A0 (en) | 2016-07-31 |
| MX2016006966A (es) | 2017-01-19 |
| WO2015078477A1 (en) | 2015-06-04 |
| CA2931694C (en) | 2020-12-01 |
| AU2014356912B2 (en) | 2019-08-01 |
| BR112016012391A2 (pt) | 2017-09-26 |
| DK3074032T3 (en) | 2019-04-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ES2716890T3 (es) | Derivados de ácidos grasos de inhibidores diméricos de la PSD-95 | |
| JP6525471B2 (ja) | ヘプシジン類似体及びその使用 | |
| US12371464B2 (en) | Polypeptides and uses thereof | |
| ES2542522T3 (es) | Péptidos modificados como inhibidores potentes de la interacción entre receptor de NMDA/PSD-95 | |
| US12600749B2 (en) | Compstatin analogues and their medical uses | |
| JP2023536463A (ja) | コンジュゲート型ヘプシジン模倣体 | |
| JP2020502051A5 (es) | ||
| ES3049784T3 (en) | Compstatin analogues and their medical uses | |
| ES2913233T3 (es) | Péptido de unión a trombospondina 1 | |
| TW202317604A (zh) | 用於治療遺傳性血鐵沉積症之鐵調素模擬物 | |
| ES2932772T3 (es) | Nuevos péptidos grapados y utilizaciones de los mismos | |
| ES3040762T3 (en) | Psd-95 inhibitors and uses thereof | |
| US20230287051A1 (en) | Inhibitors of complement factor c3 and their medical uses | |
| ES2607986T3 (es) | Agentes terapéuticos para regular el fósforo en suero | |
| WO2023027125A1 (ja) | ヒトトランスフェリンレセプター結合抗体-ペプチドコンジュゲート | |
| HK1229227B (en) | Fatty acid derivatives of dimeric inhibitors of psd-95 | |
| JP2024523280A (ja) | Ghr結合ペプチドおよびそれを含む組成物 | |
| US20140155331A1 (en) | Novel high affinity bivalent helically constrained peptide against cancer | |
| ES2772223T3 (es) | Polipeptidos | |
| CN117480176A (zh) | 用于治疗遗传性血色病的铁调素模拟物 | |
| EA053112B1 (ru) | Конъюгированные миметики гепсидина | |
| CN117730089A (zh) | 结合型铁调素模拟物 |