ES2734143T3 - Método para diagnosticar cáncer colorrectal a partir de una muestra de heces humanas mediante PCR cuantitativa - Google Patents
Método para diagnosticar cáncer colorrectal a partir de una muestra de heces humanas mediante PCR cuantitativa Download PDFInfo
- Publication number
- ES2734143T3 ES2734143T3 ES15708187T ES15708187T ES2734143T3 ES 2734143 T3 ES2734143 T3 ES 2734143T3 ES 15708187 T ES15708187 T ES 15708187T ES 15708187 T ES15708187 T ES 15708187T ES 2734143 T3 ES2734143 T3 ES 2734143T3
- Authority
- ES
- Spain
- Prior art keywords
- seq
- sample
- quantification
- crc
- levels
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 206010009944 Colon cancer Diseases 0.000 title claims abstract description 152
- 208000001333 Colorectal Neoplasms Diseases 0.000 title claims abstract description 150
- 238000000034 method Methods 0.000 title claims abstract description 104
- 238000003753 real-time PCR Methods 0.000 title claims description 28
- 210000003608 fece Anatomy 0.000 title claims description 25
- 239000000523 sample Substances 0.000 claims abstract description 84
- 238000011002 quantification Methods 0.000 claims abstract description 75
- 230000001580 bacterial effect Effects 0.000 claims abstract description 73
- 108020004465 16S ribosomal RNA Proteins 0.000 claims abstract description 50
- 239000013068 control sample Substances 0.000 claims abstract description 22
- 238000012216 screening Methods 0.000 claims description 49
- 238000002052 colonoscopy Methods 0.000 claims description 36
- 150000007523 nucleic acids Chemical class 0.000 claims description 28
- 239000000090 biomarker Substances 0.000 claims description 19
- 108020004707 nucleic acids Proteins 0.000 claims description 15
- 102000039446 nucleic acids Human genes 0.000 claims description 15
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 7
- 108020004711 Nucleic Acid Probes Proteins 0.000 claims description 6
- 239000002853 nucleic acid probe Substances 0.000 claims description 6
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 claims description 4
- 230000004075 alteration Effects 0.000 claims description 3
- 239000003153 chemical reaction reagent Substances 0.000 claims description 3
- 239000012528 membrane Substances 0.000 claims description 2
- 239000000377 silicon dioxide Substances 0.000 claims description 2
- 238000012360 testing method Methods 0.000 description 58
- 206010028980 Neoplasm Diseases 0.000 description 41
- 208000004804 Adenomatous Polyps Diseases 0.000 description 32
- 201000011510 cancer Diseases 0.000 description 31
- 108020004414 DNA Proteins 0.000 description 30
- 208000037062 Polyps Diseases 0.000 description 26
- 230000035945 sensitivity Effects 0.000 description 25
- 208000008051 Hereditary Nonpolyposis Colorectal Neoplasms Diseases 0.000 description 24
- 206010051922 Hereditary non-polyposis colorectal cancer syndrome Diseases 0.000 description 24
- 201000005027 Lynch syndrome Diseases 0.000 description 24
- 238000004458 analytical method Methods 0.000 description 24
- 238000001514 detection method Methods 0.000 description 23
- 230000003321 amplification Effects 0.000 description 20
- 238000003199 nucleic acid amplification method Methods 0.000 description 20
- 241000894006 Bacteria Species 0.000 description 18
- 230000002550 fecal effect Effects 0.000 description 18
- 201000010099 disease Diseases 0.000 description 16
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 16
- 238000009396 hybridization Methods 0.000 description 16
- 208000022131 polyp of large intestine Diseases 0.000 description 15
- 208000006265 Renal cell carcinoma Diseases 0.000 description 13
- 208000019465 refractory cytopenia of childhood Diseases 0.000 description 13
- 108091028043 Nucleic acid sequence Proteins 0.000 description 12
- 210000001072 colon Anatomy 0.000 description 11
- 238000010494 dissociation reaction Methods 0.000 description 10
- 230000005593 dissociations Effects 0.000 description 10
- 239000002773 nucleotide Substances 0.000 description 10
- 125000003729 nucleotide group Chemical group 0.000 description 10
- 238000010200 validation analysis Methods 0.000 description 10
- 208000003200 Adenoma Diseases 0.000 description 9
- 238000012544 monitoring process Methods 0.000 description 8
- 238000007400 DNA extraction Methods 0.000 description 7
- 230000000295 complement effect Effects 0.000 description 7
- 238000003745 diagnosis Methods 0.000 description 7
- 238000007619 statistical method Methods 0.000 description 7
- 241000736262 Microbiota Species 0.000 description 6
- 238000011529 RT qPCR Methods 0.000 description 6
- 238000001574 biopsy Methods 0.000 description 6
- 238000011156 evaluation Methods 0.000 description 6
- 239000000284 extract Substances 0.000 description 6
- 238000012353 t test Methods 0.000 description 6
- 238000009534 blood test Methods 0.000 description 5
- 239000000969 carrier Substances 0.000 description 5
- 230000000875 corresponding effect Effects 0.000 description 5
- 230000002068 genetic effect Effects 0.000 description 5
- 210000004877 mucosa Anatomy 0.000 description 5
- 238000004393 prognosis Methods 0.000 description 5
- 108090000623 proteins and genes Proteins 0.000 description 5
- 210000000664 rectum Anatomy 0.000 description 5
- 238000002560 therapeutic procedure Methods 0.000 description 5
- 238000000692 Student's t-test Methods 0.000 description 4
- 238000003556 assay Methods 0.000 description 4
- 210000004027 cell Anatomy 0.000 description 4
- 230000007717 exclusion Effects 0.000 description 4
- 238000012295 fluorescence in situ hybridization assay Methods 0.000 description 4
- 230000009826 neoplastic cell growth Effects 0.000 description 4
- 206010001233 Adenoma benign Diseases 0.000 description 3
- 241000605980 Faecalibacterium prausnitzii Species 0.000 description 3
- 201000006107 Familial adenomatous polyposis Diseases 0.000 description 3
- 241000605986 Fusobacterium nucleatum Species 0.000 description 3
- 208000017095 Hereditary nonpolyposis colon cancer Diseases 0.000 description 3
- 238000012313 Kruskal-Wallis test Methods 0.000 description 3
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 3
- 208000009956 adenocarcinoma Diseases 0.000 description 3
- 230000003115 biocidal effect Effects 0.000 description 3
- 239000008280 blood Substances 0.000 description 3
- 210000004369 blood Anatomy 0.000 description 3
- 238000006243 chemical reaction Methods 0.000 description 3
- 239000003795 chemical substances by application Substances 0.000 description 3
- 208000029664 classic familial adenomatous polyposis Diseases 0.000 description 3
- 208000029742 colonic neoplasm Diseases 0.000 description 3
- 239000002299 complementary DNA Substances 0.000 description 3
- 230000034994 death Effects 0.000 description 3
- 231100000517 death Toxicity 0.000 description 3
- 230000007423 decrease Effects 0.000 description 3
- 238000003935 denaturing gradient gel electrophoresis Methods 0.000 description 3
- 238000013461 design Methods 0.000 description 3
- 238000011161 development Methods 0.000 description 3
- 230000018109 developmental process Effects 0.000 description 3
- 210000000936 intestine Anatomy 0.000 description 3
- 230000003211 malignant effect Effects 0.000 description 3
- 239000003550 marker Substances 0.000 description 3
- 230000002906 microbiologic effect Effects 0.000 description 3
- 239000002689 soil Substances 0.000 description 3
- 241000894007 species Species 0.000 description 3
- 239000000126 substance Substances 0.000 description 3
- 241000606125 Bacteroides Species 0.000 description 2
- 206010009900 Colitis ulcerative Diseases 0.000 description 2
- 208000011231 Crohn disease Diseases 0.000 description 2
- 101710113436 GTPase KRas Proteins 0.000 description 2
- 206010051066 Gastrointestinal stromal tumour Diseases 0.000 description 2
- 208000032843 Hemorrhage Diseases 0.000 description 2
- 208000022559 Inflammatory bowel disease Diseases 0.000 description 2
- 238000001276 Kolmogorov–Smirnov test Methods 0.000 description 2
- 238000000585 Mann–Whitney U test Methods 0.000 description 2
- 201000006704 Ulcerative Colitis Diseases 0.000 description 2
- 230000001464 adherent effect Effects 0.000 description 2
- 238000000540 analysis of variance Methods 0.000 description 2
- 239000011324 bead Substances 0.000 description 2
- 239000012472 biological sample Substances 0.000 description 2
- 230000000740 bleeding effect Effects 0.000 description 2
- 238000004422 calculation algorithm Methods 0.000 description 2
- 230000000112 colonic effect Effects 0.000 description 2
- 230000009089 cytolysis Effects 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 238000000605 extraction Methods 0.000 description 2
- 201000011243 gastrointestinal stromal tumor Diseases 0.000 description 2
- 239000000499 gel Substances 0.000 description 2
- 239000003112 inhibitor Substances 0.000 description 2
- 230000011987 methylation Effects 0.000 description 2
- 238000007069 methylation reaction Methods 0.000 description 2
- 239000000203 mixture Substances 0.000 description 2
- 230000035772 mutation Effects 0.000 description 2
- 208000014081 polyp of colon Diseases 0.000 description 2
- 208000015768 polyposis Diseases 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 238000002271 resection Methods 0.000 description 2
- 230000004044 response Effects 0.000 description 2
- 238000012340 reverse transcriptase PCR Methods 0.000 description 2
- 238000012552 review Methods 0.000 description 2
- 238000003860 storage Methods 0.000 description 2
- -1 that is Proteins 0.000 description 2
- 210000001519 tissue Anatomy 0.000 description 2
- 241001300301 uncultured bacterium Species 0.000 description 2
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 1
- CDKIEBFIMCSCBB-UHFFFAOYSA-N 1-(6,7-dimethoxy-3,4-dihydro-1h-isoquinolin-2-yl)-3-(1-methyl-2-phenylpyrrolo[2,3-b]pyridin-3-yl)prop-2-en-1-one;hydrochloride Chemical compound Cl.C1C=2C=C(OC)C(OC)=CC=2CCN1C(=O)C=CC(C1=CC=CN=C1N1C)=C1C1=CC=CC=C1 CDKIEBFIMCSCBB-UHFFFAOYSA-N 0.000 description 1
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 1
- 241001156739 Actinobacteria <phylum> Species 0.000 description 1
- 102100021886 Activin receptor type-2A Human genes 0.000 description 1
- 206010002091 Anaesthesia Diseases 0.000 description 1
- 102100027308 Apoptosis regulator BAX Human genes 0.000 description 1
- 108050006685 Apoptosis regulator BAX Proteins 0.000 description 1
- 108020000946 Bacterial DNA Proteins 0.000 description 1
- 108700003860 Bacterial Genes Proteins 0.000 description 1
- 108010077805 Bacterial Proteins Proteins 0.000 description 1
- FERIUCNNQQJTOY-UHFFFAOYSA-M Butyrate Chemical compound CCCC([O-])=O FERIUCNNQQJTOY-UHFFFAOYSA-M 0.000 description 1
- FERIUCNNQQJTOY-UHFFFAOYSA-N Butyric acid Natural products CCCC(O)=O FERIUCNNQQJTOY-UHFFFAOYSA-N 0.000 description 1
- 102100028914 Catenin beta-1 Human genes 0.000 description 1
- 102100025064 Cellular tumor antigen p53 Human genes 0.000 description 1
- 241001262170 Collinsella aerofaciens Species 0.000 description 1
- 208000035473 Communicable disease Diseases 0.000 description 1
- 241001464948 Coprococcus Species 0.000 description 1
- 108091029523 CpG island Proteins 0.000 description 1
- 102100024456 Cyclin-dependent kinase 8 Human genes 0.000 description 1
- 101100239628 Danio rerio myca gene Proteins 0.000 description 1
- 241000605716 Desulfovibrio Species 0.000 description 1
- 238000002965 ELISA Methods 0.000 description 1
- 206010014733 Endometrial cancer Diseases 0.000 description 1
- 206010014759 Endometrial neoplasm Diseases 0.000 description 1
- 241000792859 Enema Species 0.000 description 1
- 241000194033 Enterococcus Species 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- 241000186394 Eubacterium Species 0.000 description 1
- 102100028138 F-box/WD repeat-containing protein 7 Human genes 0.000 description 1
- 101710105178 F-box/WD repeat-containing protein 7 Proteins 0.000 description 1
- 241001608234 Faecalibacterium Species 0.000 description 1
- 241000192125 Firmicutes Species 0.000 description 1
- 102100037858 G1/S-specific cyclin-E1 Human genes 0.000 description 1
- 102100039788 GTPase NRas Human genes 0.000 description 1
- 208000012671 Gastrointestinal haemorrhages Diseases 0.000 description 1
- 241000147041 Guaiacum officinale Species 0.000 description 1
- 101000970954 Homo sapiens Activin receptor type-2A Proteins 0.000 description 1
- 101000916173 Homo sapiens Catenin beta-1 Proteins 0.000 description 1
- 101000721661 Homo sapiens Cellular tumor antigen p53 Proteins 0.000 description 1
- 101000980937 Homo sapiens Cyclin-dependent kinase 8 Proteins 0.000 description 1
- 101000738568 Homo sapiens G1/S-specific cyclin-E1 Proteins 0.000 description 1
- 101000744505 Homo sapiens GTPase NRas Proteins 0.000 description 1
- 101000605639 Homo sapiens Phosphatidylinositol 4,5-bisphosphate 3-kinase catalytic subunit alpha isoform Proteins 0.000 description 1
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 1
- 101000596771 Homo sapiens Transcription factor 7-like 2 Proteins 0.000 description 1
- 101000636213 Homo sapiens Transcriptional activator Myb Proteins 0.000 description 1
- 102100034343 Integrase Human genes 0.000 description 1
- 206010025323 Lymphomas Diseases 0.000 description 1
- 102100025751 Mothers against decapentaplegic homolog 2 Human genes 0.000 description 1
- 101710143123 Mothers against decapentaplegic homolog 2 Proteins 0.000 description 1
- 102100025748 Mothers against decapentaplegic homolog 3 Human genes 0.000 description 1
- 101710143111 Mothers against decapentaplegic homolog 3 Proteins 0.000 description 1
- 102100025725 Mothers against decapentaplegic homolog 4 Human genes 0.000 description 1
- 101710143112 Mothers against decapentaplegic homolog 4 Proteins 0.000 description 1
- 241000208125 Nicotiana Species 0.000 description 1
- 235000002637 Nicotiana tabacum Nutrition 0.000 description 1
- 101710163270 Nuclease Proteins 0.000 description 1
- 108091034117 Oligonucleotide Proteins 0.000 description 1
- 108010011536 PTEN Phosphohydrolase Proteins 0.000 description 1
- 102000014160 PTEN Phosphohydrolase Human genes 0.000 description 1
- 102100038332 Phosphatidylinositol 4,5-bisphosphate 3-kinase catalytic subunit alpha isoform Human genes 0.000 description 1
- 238000001190 Q-PCR Methods 0.000 description 1
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 1
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 description 1
- 206010038074 Rectal polyp Diseases 0.000 description 1
- 241000605947 Roseburia Species 0.000 description 1
- 241000192031 Ruminococcus Species 0.000 description 1
- 206010039491 Sarcoma Diseases 0.000 description 1
- 241001136694 Subdoligranulum Species 0.000 description 1
- QAOWNCQODCNURD-UHFFFAOYSA-L Sulfate Chemical compound [O-]S([O-])(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-L 0.000 description 1
- OUUQCZGPVNCOIJ-UHFFFAOYSA-M Superoxide Chemical compound [O-][O] OUUQCZGPVNCOIJ-UHFFFAOYSA-M 0.000 description 1
- 102100035101 Transcription factor 7-like 2 Human genes 0.000 description 1
- 102100030780 Transcriptional activator Myb Human genes 0.000 description 1
- 108010065472 Vimentin Proteins 0.000 description 1
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 1
- 230000002159 abnormal effect Effects 0.000 description 1
- 230000037005 anaesthesia Effects 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 238000003149 assay kit Methods 0.000 description 1
- 229910052788 barium Inorganic materials 0.000 description 1
- DSAJWYNOEDNPEQ-UHFFFAOYSA-N barium atom Chemical compound [Ba] DSAJWYNOEDNPEQ-UHFFFAOYSA-N 0.000 description 1
- 239000003833 bile salt Substances 0.000 description 1
- 229940093761 bile salts Drugs 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 230000000711 cancerogenic effect Effects 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 231100000315 carcinogenic Toxicity 0.000 description 1
- 208000002458 carcinoid tumor Diseases 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- UHZZMRAGKVHANO-UHFFFAOYSA-M chlormequat chloride Chemical compound [Cl-].C[N+](C)(C)CCCl UHZZMRAGKVHANO-UHFFFAOYSA-M 0.000 description 1
- 230000001684 chronic effect Effects 0.000 description 1
- 230000004732 colorectal carcinogenesis Effects 0.000 description 1
- 230000000052 comparative effect Effects 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 239000003599 detergent Substances 0.000 description 1
- 235000005911 diet Nutrition 0.000 description 1
- 230000037213 diet Effects 0.000 description 1
- 230000003292 diminished effect Effects 0.000 description 1
- 238000013399 early diagnosis Methods 0.000 description 1
- 239000012149 elution buffer Substances 0.000 description 1
- 210000004696 endometrium Anatomy 0.000 description 1
- 238000007848 endpoint PCR Methods 0.000 description 1
- 239000007920 enema Substances 0.000 description 1
- 229940095399 enema Drugs 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 238000009541 flexible sigmoidoscopy Methods 0.000 description 1
- 238000000684 flow cytometry Methods 0.000 description 1
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 208000030304 gastrointestinal bleeding Diseases 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 210000004907 gland Anatomy 0.000 description 1
- 230000000762 glandular Effects 0.000 description 1
- 230000012010 growth Effects 0.000 description 1
- 229940091561 guaiac Drugs 0.000 description 1
- 244000005709 gut microbiome Species 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 208000014617 hemorrhoid Diseases 0.000 description 1
- 229910052739 hydrogen Inorganic materials 0.000 description 1
- 239000001257 hydrogen Substances 0.000 description 1
- 230000000984 immunochemical effect Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000012296 in situ hybridization assay Methods 0.000 description 1
- 208000027866 inflammatory disease Diseases 0.000 description 1
- 238000007689 inspection Methods 0.000 description 1
- 230000000968 intestinal effect Effects 0.000 description 1
- 206010022694 intestinal perforation Diseases 0.000 description 1
- 230000003902 lesion Effects 0.000 description 1
- 239000003446 ligand Substances 0.000 description 1
- 238000007477 logistic regression Methods 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 238000010339 medical test Methods 0.000 description 1
- 230000004060 metabolic process Effects 0.000 description 1
- 230000000813 microbial effect Effects 0.000 description 1
- 238000013048 microbiological method Methods 0.000 description 1
- 238000000386 microscopy Methods 0.000 description 1
- 210000003097 mucus Anatomy 0.000 description 1
- 238000000491 multivariate analysis Methods 0.000 description 1
- 239000013642 negative control Substances 0.000 description 1
- 230000001613 neoplastic effect Effects 0.000 description 1
- 238000010606 normalization Methods 0.000 description 1
- 101150115599 nusG gene Proteins 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000000399 optical microscopy Methods 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 230000002611 ovarian Effects 0.000 description 1
- 230000007170 pathology Effects 0.000 description 1
- 230000007310 pathophysiology Effects 0.000 description 1
- 238000003752 polymerase chain reaction Methods 0.000 description 1
- 108091033319 polynucleotide Proteins 0.000 description 1
- 102000040430 polynucleotide Human genes 0.000 description 1
- 239000002157 polynucleotide Substances 0.000 description 1
- 208000022075 polyp of rectum Diseases 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 230000003449 preventive effect Effects 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 230000001681 protective effect Effects 0.000 description 1
- 238000005086 pumping Methods 0.000 description 1
- 238000010926 purge Methods 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 238000012175 pyrosequencing Methods 0.000 description 1
- 238000000275 quality assurance Methods 0.000 description 1
- 238000003762 quantitative reverse transcription PCR Methods 0.000 description 1
- 239000002096 quantum dot Substances 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 239000000243 solution Substances 0.000 description 1
- 238000000528 statistical test Methods 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000005748 tumor development Effects 0.000 description 1
- 238000002609 virtual colonoscopy Methods 0.000 description 1
- 238000012800 visualization Methods 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6806—Preparing nucleic acids for analysis, e.g. for polymerase chain reaction [PCR] assay
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6888—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for detection or identification of organisms
- C12Q1/689—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for detection or identification of organisms for bacteria
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6883—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material
- C12Q1/6886—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material for cancer
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/118—Prognosis of disease development
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/158—Expression markers
Landscapes
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Health & Medical Sciences (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Analytical Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Immunology (AREA)
- Genetics & Genomics (AREA)
- Molecular Biology (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- Microbiology (AREA)
- Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biochemistry (AREA)
- Pathology (AREA)
- Oncology (AREA)
- Hospice & Palliative Care (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Investigating Or Analysing Biological Materials (AREA)
Abstract
Método para determinar el riesgo de desarrollar cáncer colorrectal (CCR) en un sujeto humano que comprende: i. cuantificar al menos una secuencia bacteriana de ADNr 16S seleccionada de la lista que consiste en SEQ ID NO: 1, SEQ ID NO: 7 y SEQ ID NO: 10, a partir de una muestra de heces de dicho sujeto; ii. comparar los niveles de cuantificación de la muestra del sujeto en (i) con los niveles de cuantificación en una muestra de control; y iii. determinar el riesgo de desarrollar CCR en dicho sujeto humano, cuando existe una desviación de los valores de muestra del sujeto a partir de los valores en dicha muestra de control.
Description
DESCRIPCIÓN
Método para diagnosticar cáncer colorrectal a partir de una muestra de heces humanas mediante PCR cuantitativa Campo de invención
La presente invención se refiere al campo de detección de cáncer colorrectal (CCR). Específicamente, se refiere a métodos para la detección temprana, cribado del riesgo y monitorización de CCR en un sujeto humano basándose en la cuantificación de una o más secuencias bacterianas de ADNr 16S en las heces. Se refiere además al uso de dichas secuencias bacterianas como biomarcadores de cáncer colorrectal.
Antecedentes de la invención
El cáncer colorrectal (CCR) es la segunda causa principal de muerte debida a cáncer en Europa y en Estados Unidos, y es el cáncer que se diagnostica más frecuentemente en Europa, con más de 400.000 nuevos casos y 200.000 muertes en 2008. Estos datos reflejan que es necesario tomar medidas preventivas.
La medida más eficaz y económica para reducir la mortalidad e incidencia de CCR son pruebas de cribado y monitorización del riesgo de CCR. Las pruebas de cribado se agrupan en aquellas que detectan principalmente cáncer temprano; y aquellas que pueden detectar cáncer temprano y también pueden detectar pólipos adenomatosos, proporcionando por tanto un mayor potencial para la prevención a través de polipectomía (es decir, extirpación de pólipos), véanse las pautas de cribado y vigilancia de la Sociedad Americana contra el Cáncer (ACS) de 2008, Levin et al. (CA Cancer J Clinicians, 2008;58(3)130-160). Se aplican diferentes pautas de cribado en personas que tienen un riesgo promedio y en personas con un riesgo aumentado o alto (http://www.cancer.org/cancer/colonandrectumcancer/moreinformation/colonandrectumcancerearlydetection/colorect al-cancer-early-detection-acs-recommendations).
Actualmente, las pruebas que detectan principalmente CCR son pruebas fecales, que incluyen: i) pruebas de sangre fecal: la prueba de sangre oculta en las heces (“FOBT”) y la prueba inmunoquímica fecal (“FIT”); y ii) la prueba de ADN en heces (“ADNh”) (véase, http://www.cancer.org/cancer/colonandrectumcancer/moreinformation/colonandrectumcancerearlydetección/colorect al-cancer-earlydetection-screening-tests-used).
i) Pruebas de sangre fecal
Tanto la FOBT como la FIT criban CCR detectando la cantidad de sangre en una muestra de heces. Las pruebas se basan en la premisa de que el tejido neoplásico, particularmente tejido maligno, sangra más que la mucosa típica, aumentando la cantidad de sangrado con el tamaño de pólipo y el estadio de cáncer. Se recomiendan múltiples pruebas debido al sangrado intermitente. Aunque las pruebas de sangre fecal pueden detectar algunos tumores de estadio temprano en la parte inferior del colon, son incapaces de detectar (i) CCR en la parte superior del colon ya que cualquier sangre se metabolizará y/o (ii) pólipos adenomatosos más pequeños, creando por tanto falsos negativos. Cualquier sangrado gastrointestinal debido a hemorroides, fisuras, trastornos inflamatorios (colitis ulcerosa, enfermedad de Crohn), enfermedades infecciosas, incluso carreras de largas distancias, crearán falsos positivos (Beg et al., J Indian AcadClin Med, 2002;3(2)153-158). Las actuales pautas de la ACS (Levin et al., CA Cancer J Clinicians, 2008;58(3)130-160) recomiendan el cribado anual de adultos con riesgo promedio con edades de 50 años y más usando la prueba de sangre oculta en las heces basada en Guaiac (gFOBT). La FOBT es la única prueba recomendada en la Unión Europea (Segnan N. et al., 2010, European guidelines for quality assurance in colorectal cancer screening and diagnosis. Luxemburgo: Oficina para Publicaciones Oficiales de las Comunidades Europeas). Ambas pautas recomiendan que cualquier prueba FOBT positiva debe continuarse con una colonoscopia.
ii) Prueba de ADN en heces (“ADNh”)
La prueba de ADNh mide una variedad de marcadores de ADN a partir de una muestra de heces. La prueba de ADNh disponible actualmente Cologuard™ de Exact Sciences Corp. (Madison, WI), mide un panel de marcadores múltiples que incluye mutaciones puntuales diferenciadas en genes K-ras, APC y P53; una sonda para BAT-26; un marcador para la integridad de ADN (DIA); y metilación del gen vimentina (Levin et al., CA Cancer J Clinicians, 2008;58(3)130-160). Aunque algunas pautas recomiendan pruebas de ADNh otras pautas son más conservadoras y no lo recomiendan. En un estudio, una versión de la prueba de ADNh fue superior a FOBT, pero sólo detectó el 15% de los adenomas avanzados (Imperiale et al., N Engl J Med, 2004;351:2704-2714).
Las pruebas indicadas en las pautas de la ACS como que son capaces de detectar pólipos adenomatosos y cáncer son pruebas estructurales que incluyen: (i) colonoscopia, (ii) sigmoidoscopia flexible (“FSIG”), (iii) enema de bario con contraste doble (“DCBE”), y (iv) colonografía CT (“CTC”, colonoscopia virtual). Todos estos métodos requieren tanto purgado de los intestinos de un paciente como bombeo de aire en el colon para ayudar a la visualización. Las pautas actuales apoyan el uso de pruebas diseñadas para detectar tanto cáncer temprano como pólipos
adenomatosos si están disponibles los recursos y los pacientes están dispuestos a someterse a una prueba invasiva.
Una colonoscopia es una técnica invasiva que permite la inspección directa de todas las biopsias de extracción de mucosa y la resección del colon y pólipos del recto en una sesión. Esto no sólo mejora el pronóstico de cáncer colorrectal sino que previene la enfermedad. Sin embargo, las principales desventajas asociadas con esta técnica son: alto coste debido a que requiere personal cualificado, el riesgo de muerte asociado con la anestesia y el riesgo de perforación intestinal (Garborg K. et al., Ann Oncol., 2013;24(8):1963-72).
La colonoscopia en manos de un profesional experimentado es 100% sensible y 100% específica, pero debido al riesgo y coste de la colonoscopia, antes de la colonoscopia se requiere llevar a cabo un cribado de población de riesgo usando pruebas no invasivas tales como las pruebas fecales mencionadas anteriormente para la detección de sangre en heces, es decir, gFOBT o FIT, que tal como se mencionó anteriormente conducen a un número importante de falsos resultados positivos, por tanto, a un número igual de colonoscopias innecesarias. Esto se refleja en la necesidad de una herramienta de cribado de CCR no invasiva eficaz. La actual carencia de una herramienta de cribado de CCR eficaz da como resultado largas listas de espera (> 6 semanas) para una colonoscopia y una gran cantidad de recursos económicos asignados a colonoscopias que fueron indicadas incorrectamente. Esta situación representa tanto para la salud pública como privada, un gasto significativo y da como resultado la saturación del sistema (Allison J. et al., Practical Gastroenterology, 2007, 3: 21-32).
Por tanto, existe la necesidad de una mejora de la sensibilidad, especificidad, invasividad y/o rentabilidad de los métodos actuales para la detección temprana y monitorización de CCR y/o pólipos adenomatosos.
La base genética e historia natural de CCR están bien definidas, considerando que menos del 5% de los CCR son hereditarios, y la mayoría son esporádicos, diagnosticados en pacientes sin antecedentes personales o familiares de neoplasia colónica. La etiología de esta enfermedad aún se desconoce, aunque se sospecha un origen multifactorial en el que factores endógenos y exógenos están implicados activamente en el desarrollo tumoral. Estos factores son: edad, tabaco, antecedentes personales de enfermedad intestinal inflamatoria, dieta, estilo de vida y microbiota. Últimamente, se ha demostrado que las comunidades bacterianas en la mucosa colónica de pacientes con CCR difieren de individuos sanos y la microbiota intestinal se ha propuesto como agente determinante en el desarrollo y la progresión de CCR a lo largo de sus estadios (Chen W et al., PLoS One, 2012;7(6):e39743; Zhu Q et al., Tumour Biol., 2013;34(3):1285-300; Ahn J et al., J Natl Cancer Inst., 2013;105(24):1907-11; Na wu et al., Microbial ecology, 2013;66(2):462-470).
El documento WO2012/170478 se refiere a métodos para detectar adenomas y cáncer colorrectal usando una firma bacteriana. Se llevó a cabo secuenciación génica de ARNr16 para caracterizar comunidades bacterianas adherentes a partir de biopsias de mucosa. Se calcularon las abundancias relativas entre sujetos con adenoma y sin adenoma, concluyendo que el desarrollo de adenomas está asociado con cambios en la abundancia relativa de diversos taxones bacterianos presentes en la mucosa del intestino. Específicamente, se determinó la abundancia de Fusobacterium nucleatum en la mucosa normal del recto de sujetos con y sin adenomas mediante cuantificación por qPCR del gen ARNr 16S (ADN 16S), concluyendo que la abundancia es mayor en casos de adenoma en comparación con los controles. Según dichos datos, se sugiere el uso de F. nucleatum como biomarcador de carcinogénesis colorrectal.
La importancia de la microbiota del intestino como agente en el desarrollo y la evolución de CCR a lo largo de sus estadios también se ha confirmado en un estudio llevado a cabo por uno de los inventores en muestras de biopsia de mucosa, lo que muestra la asociación de la abundancia de Firmicutes, Actinobacteria y Escherichia coli en pacientes con cáncer colorrectal y de Faecalibacterium prausnitzi en sujetos sanos (Mas de Xaxars T., 2012, Dipósit legal: GI. 1664-2012, http://hdl.handle. net/10803/94513).
Se conoce bien en la técnica, sin embargo, que existen diferencias entre la composición de microbiota en biopsias de mucosa y muestras de heces. Lepage et al. (Inflamm Bowel Dis., 2005;11(5):473-80) muestran que en un individuo dado las especies dominantes difieren entre microbiota fecal y asociada a la mucosa. De manera similar, Eckburg et al. (Science, 2005;308(5728): 1635-1638) notificaron diferencias estadísticamente significativas entre los linajes filogenéticos encontrados en muestras de la mucosa y heces, postulando que la microbiota fecal representa una combinación de bacterias de la mucosa desprendidas y población luminal no adherente diferenciada.
Nechvatal et al. (J Microbiol Methods., 2008;72(2):124-32) mostraron que puede usarse ADN fecal como fuente para estudios epidemiológicos de bacterias intestinales y marcadores de cáncer humano. En particular, describe la cuantificación mediante PCR cuantitativa en tiempo real de secuencias bacterianas y humanas en extractos de ADN a partir de heces humanas. Balamurugan et al. (J GastroenterolHepatol., 2008;23:1298-303) describen la cuantificación mediante PCR cuantitativa en tiempo real de bacterias específicas con productos del metabolismo que se conoce que tienen un efecto protector (es decir, Eubacterium rectale y Faecalibacterium prausnitzii, que son bacterias productoras de butirato) o que son tóxicos o carcinógenos (es decir, Desulfovibrio (bacterias reductoras de sulfato) y Enterococcus faecaelis (que produce superóxido extracelular) en las heces de pacientes con cáncer
colorrectal. Sin embargo, ambas son silenciosas ante la determinación del valor de diagnóstico o predictivo de tales secuencias bacterianas como biomarcadores para CCR.
En el documento US2014/0024036, Wang et al. describen un método para la detección de CCR que comprende la cuantificación del gen nusG de F. nucleatum (FNN) mediante qPCR a partir de heces humanas de pacientes con CCR y controles, detectando CCR con una sensibilidad del 57% y especificidad del 89,5%.
Hassan Brim et al (PLoS ONE, 8(12), e81352) se refieren a la obtención del perfil taxonómico de secuencias bacterianas en muestras de heces de individuos sanos y pacientes con pólipos en el colon usando tecnología de microalineamiento de ARNr 16S y pirosecuenciación. La presencia de pólipos en el colon se dice que está asociada con un 10% de riesgo de progresión maligna. No se comunican diferencias en la composición de la microbiota al nivel de género entre los dos grupos. Al nivel de subgénero, se encontró que las bacterias del grupo Bacteroides eran predominantes en las muestras de pacientes con pólipos. No obstante, el análisis metagenómico no reveló grandes diferencias en prevalencia/abundancia de genes bacterianos entre los dos grupos incluso cuando el análisis y las comparaciones se limitaron a los genomas de Bacteroides disponibles.
Aunque se han descrito métodos para la detección y/o cuantificación de biomarcadores de ADN para CCR en heces, aún sigue habiendo la necesidad de métodos fiables de diagnóstico temprano, cribado del riesgo o monitorización de CCR en pacientes en un sujeto humano a partir de muestras de heces. La disponibilidad de un método de este tipo permitiría prevenir eficazmente CCR mediante detección temprana y reducir el número de pruebas de examen estructural innecesarias, tales como colonoscopias, que se realizan hoy en día en individuos que se sospecha que tienen CCR más a menudo de lo necesario debido a la baja exactitud de las pruebas FOBT y FIT que son los métodos de cribado convencionales actuales para la detección de CCR.
Sumario de la invención
El primer aspecto de la invención se refiere a un método para determinar el riesgo de desarrollar cáncer colorrectal (CCR) en un sujeto humano que comprende:
i. cuantificar al menos una secuencia bacteriana de ADNr 16S seleccionada de la lista que consiste en SEQ ID NO: 1, SEQ ID NO: 7 y SEQ ID NO: 10, a partir de una muestra de heces de dicho sujeto;
ii. comparar los niveles de cuantificación de la muestra del sujeto en (i) con los niveles de cuantificación en una muestra de control; y
iii. determinar el riesgo de desarrollar CCR en dicho sujeto humano, cuando existe una desviación de los valores de muestra del sujeto a partir de los valores en dicha muestra de control.
En un segundo aspecto, la invención se refiere a un método de cribado de cáncer colorrectal (CCR) en un sujeto humano que comprende:
i. cuantificar al menos una secuencia bacteriana de ADNr 16S seleccionada de la lista que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10 a partir de una muestra de heces de dicho sujeto;
ii. comparar los niveles de cuantificación de la muestra del sujeto en (i) con los niveles de cuantificación en una muestra de control; y
iii. diagnosticar, detectar de manera temprana o determinar recaída de CCR en dicho sujeto humano, o determinar que debe realizarse una colonoscopia en dicho sujeto humano, cuando existe una desviación de los valores de muestra del sujeto a partir de los valores en dicha muestra de control.
En un tercer aspecto, la invención se refiere al uso de un kit para diagnosticar, detectar de manera temprana o determinar recaída de CCR, determinar el riesgo de desarrollar CCR o predecir CCR o determinar si debe realizarse una colonoscopia, a partir de una muestra de heces de un sujeto humano, según el método de cualquiera de las reivindicaciones 1 a 11, comprendiendo dicho kit:
a. un reactivo seleccionado del grupo que consiste en:
i. sondas de ácido nucleico capaces de hibridarse específicamente con al menos una secuencia de ADNr 16S seleccionada de la lista que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10; o
ii. un par de cebadores de ácido nucleico capaces de amplificar específicamente al menos una secuencia de ADNr 16S seleccionada de la lista que consiste en SEQ ID NO: 1, SEQ iD NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10; y
b. instrucciones para cuantificar los niveles de una o más de dichas secuencias a partir de una muestra de heces humanas.
Breve descripción de los dibujos
Los siguientes símbolos se usan en las figuras desde 1 hasta 7 con el siguiente significado:
- * significa que la significación estadística es p= 0,05
- ** significa que la significación estadística es p= 0,01
- *** significa que la significación estadística es p= 0,005
- La significación estadística de las figuras desde 8 hasta 26 está representada por * y el valor de p aparece en las tablas correspondientes.
Figura 1. Razón de valores de Ct para 2 secuencias: SEQ ID NO: 10/SEQ ID NO: 4. CCR representa los valores obtenidos a partir de muestras de heces de pacientes con cáncer colorrectal, y C representa los valores de control obtenidos de paciente sanos.
Figura 2. Razón de valores de Ct para 2 secuencias: SEQ ID NO: 7/SEQ ID NO: 4. CCR representa los valores obtenidos a partir de muestras de heces de pacientes con cáncer colorrectal, y C representa los valores de control obtenidos de paciente sanos.
Figura 3. Razón de valores de Ct para 2 secuencias: SEQ ID NO: 4/SEQ ID NO: 1. CCR representa los valores obtenidos a partir de muestras de heces de pacientes con cáncer colorrectal, y C representa los valores de control obtenidos de paciente sanos.
Figura 4. Valores de Ct absolutos para la secuencia SEQ ID NO: 4. CCR representa los valores obtenidos a partir de muestras de heces de pacientes con cáncer colorrectal, y C representa los valores de control obtenidos de pacientes sanos.
Figura 5. Valores de Ct absolutos para la secuencia SEQ ID NO: 7. CCR representa los valores obtenidos a partir de muestras de heces de pacientes con cáncer colorrectal, y C representa los valores de control obtenidos de pacientes sanos.
Figura 6. Razón de valores de Ct para 2 secuencias: SEQ ID NO: 4/ SEQ ID NO: 1. CCR representa los valores obtenidos a partir de muestras de heces de cáncer colorrectal, alto riesgo representa los valores obtenidos a partir de individuos con síndrome de Lynch que tenían pólipos en su última colonoscopia y tienen un riesgo aumentado de desarrollar cáncer colorrectal, bajo riesgo representa los valores obtenidos a partir de individuos con síndrome de Lynch que no tenían pólipos en su última colonoscopia.
Figura 7. Valores de Ct absolutos para la secuencia SEQ ID NO: 4. CCR representa los valores obtenidos a partir de muestras de heces de cáncer colorrectal, alto riesgo representa los valores obtenidos a partir de individuos con síndrome de Lynch que tenían pólipos en su última colonoscopia y tienen un riesgo aumentado de desarrollar cáncer colorrectal, bajo riesgo representa los valores obtenidos a partir de individuos con síndrome de Lynch que no tenían pólipos en su última colonoscopia.
Figura 8. Validación de cebadores para amplificación de B3: gráficos de amplificación (8a) y curva de disociación (8b).
Figura 9. Validación de cebadores para amplificación de B10: gráficos de amplificación (9a) y curva de disociación (9b).
Figura 10. Validación de cebadores para amplificación de B41: gráficos de amplificación (10a) y curva de disociación (10b).
Figura 11. Validación de cebadores para amplificación de B46: gráficos de amplificación (11a) y curva de disociación (11b).
Figura 12. Validación de cebadores para amplificación de B48: gráficos de amplificación (12a) y curva de disociación (12b).
Figura 13. Validación de cebadores para amplificación de B50: gráficos de amplificación (13a) y curva de disociación (13b).
Figura 14. Valores de Ct absolutos para B3 en grupos de CCR y C.
Figura 15. Valores de Ct absolutos para B48 en grupos de CCR y C.
Figura 16. Valores de Ct absolutos para B10 en grupos de CCR y C.
Figura 17. Valores de Ct absolutos para B46 en grupos de CCR y C.
Figura 18. Valores de Ct absolutos para B3 en grupos de CCR, L y C.
Figura 19. Valores de Ct absolutos para B48 en grupos de CCR, L y C.
Figura 20. Valores de Ct absolutos para B10 en grupos de CCR, L y C.
Figura 21. Valores de Ct absolutos para B46 en grupos de CCR, L y C.
Figura 22. Valores de Ct absolutos para B3, B10, B46 y B48 en CCR+L frente a C.
Figura 23. Razón B48/B10 de valores de Ct absolutos en grupos de CCR, alto riesgo L, bajo riesgo L y C.
Figura 24. Razón B3/B10 de valores de Ct absolutos en grupos de CCR, alto riesgo L, bajo riesgo L y C.
Figura 25. Razón B46/B10 de valores de Ct absolutos en grupos de CCR, alto riesgo L, bajo riesgo L y C.
Figura 26. Razón B3/B48 de valores de Ct absolutos  en grupos de CCR, alto riesgo L, bajo riesgo L y C. Figura 27. Curvas ROC para B3, B10, B46 y B48 en análisis de sanos frente a CCR.
en grupos de CCR, alto riesgo L, bajo riesgo L y C. Figura 27. Curvas ROC para B3, B10, B46 y B48 en análisis de sanos frente a CCR.
Figura 28. Curvas ROC para B3, B10, B46 y B48 en análisis de sanos frente a Lynch.
Figura 29. Curvas ROC para B3, B10, B46 y B48 en análisis de sanos frente a CCR Lynch. Figura 30. Curvas ROC para B3, B10, B46 y B48 en análisis de CCR frente a Lynch.
Descripción detallada
En la presente divulgación, se han identificado secuencias bacterianas específicas asociadas con diagnóstico, detección temprana, cribado del riesgo y monitorización de CCR y/o pólipos adenomatosos.
El primer aspecto de la divulgación, se refiere a un método de cribado de cáncer colorrectal (CCR) y/o pólipos adenomatosos en un sujeto humano que comprende:
i. cuantificar al menos una secuencia bacteriana de ADNr 16S seleccionada de la lista que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10 o la secuencia de ARNr complementaria de la misma, a partir de una muestra de heces de dicho sujeto; y
ii. diagnosticar, detectar de manera temprana, determinar la recaída, determinar el riesgo de desarrollar, o predecir CCR y/o pólipos en un sujeto humano; o determinar si debe realizarse una colonoscopia en dicho sujeto humano; o determinar el pronóstico en el que dicho sujeto humano es un paciente al que se le ha diagnosticado CCR y/o pólipos; o guiar una terapia en un paciente con CCR y/o pólipos a partir de los niveles de cuantificación de al menos una de dichas secuencias.
En la presente solicitud, la secuencia identificada por SEQ ID NO: 1 también se identifica como “B3”. De manera similar, SEQ ID NO: 4 también se identifica como “B10”, SEQ ID NO: 7 también se identifica como “B46” y SEQ ID NO: 10 también se identifica como “B48”, y estas designaciones se usan de manera intercambiable. B3, B10, B46 y B48 fueron los nombres usados por los inventores de la presente solicitud para identificar las secuencias durante el rendimiento de todos los experimentos llevados a cabo para llegar a la presente invención. Las secuencias identificadas por SEQ ID NO: 1, 4, 7 y 10 están disponibles en la base de datos de secuencias pública EMBL-EBI con los siguientes números de registro: GQ411111.1 (SEQ ID NO: 1), GQ411118.1 (SEQ ID NO: 4), GQ411150.1 (SEQ ID NO: 7), GQ411152.1 (SEQ ID NO: 10).
Las secuencias B3, B10, B46 y B48 se corresponden con bandas de gel de electroforesis en gel con gradiente desnaturalizante (DGGE) aisladas previamente de aislados de bacterias no cultivadas. Se llevaron a cabo análisis BLAST con el fin de identificar las especies bacterianas correspondientes:
Mejor coincidencia BLAST para ADNr 16S de B3: Collinsella aerofaciens;
Mejor coincidencia BLAST para ADNr 16S de B10: Faecalibacterium prausnitzii;
Mejor coincidencia BLAST para ADNr 16S de B46: Faecalibacterium prausnitzii, Subdoligranulum variabil;
Mejor coincidencia BLAST para ADNr 16S de B48: Ruminococcus, Roseburia, Coprococcus.
Tal como se usa en el presente documento, el término “cáncer colorrectal” o “CCR” se usa para cáncer que se inicia en el colon o el recto. Estos cánceres también pueden denominarse por separado como cáncer de colon o cáncer colorrectal, según dónde comiencen. El cáncer de colon y cáncer colorrectal tienen muchas características en común.
Según la ACS, varios tipos de cáncer pueden iniciarse en el colon o recto. Más del 95% de los cánceres colorrectales son un tipo de cáncer conocido como adenocarcinomas. Estos cánceres se inician en células que forman glándulas que elaboran moco para lubricar el interior del colon y recto. Otros tipos de tumores menos frecuentes también pueden iniciarse en el colon y recto. Estos incluyen: tumores carcinoides, tumores estromales gastrointestinales (GIST), linfomas y sarcomas.
El objetivo del cribado de cáncer es reducir la mortalidad mediante una reducción en la incidencia de enfermedad avanzada. Para este fin, el cribado de CCR moderno puede lograr este objetivo mediante la detección de adenocarcinomas de estadio temprano y la detección y extirpación de pólipos adenomatosos, el último aceptado generalmente como lesiones precursoras no obligadas.
Un “pólipo adenomatoso” es un crecimiento no canceroso de células glandulares anómalas sobre el revestimiento interno de un órgano tal como el colon. Por ejemplo, tres tipos de pólipos adenomatosos que pueden crecer en el colon son adenomas tubulares, vellosos y tubulovellosos. Los pólipos adenomatosos son comunes en adultos de más de 50 años de edad, pero la mayoría de pólipos no se convertirá en un adenocarcinoma; la histología y el tamaño determinan su importancia clínica.
Según la ACS, se prefieren pruebas que tienen la mejor posibilidad de encontrar ambos pólipos y cáncer, ya que encontrar y extirpar sus pólipos previene que algunas personas desarrollen cáncer colorrectal. Preferiblemente, el método de la divulgación es un método para el cribado de CCR y pólipos adenomatosos.
En una realización particular, el método de la divulgación es un método de cribado para el diagnóstico o la detección de CCR y/o pólipos adenomatosos, preferiblemente para la detección temprana de CCR y/o pólipos adenomatosos. La expresión “detección temprana” se refiere a detección antes de la presencia de signos clínicos. Los términos “detección” y “diagnóstico” se usan de manera intercambiable en la presente solicitud. Se encuentra que el método de la divulgación es una potente herramienta para prevenir cáncer colorrectal mediante un diagnóstico de enfermedad en estadio temprano.
En una realización particular, el método de cribado de la divulgación se lleva a cabo en sujetos con 50 años de edad y más. Se recomienda que las mujeres y hombres de 50 años y más con riesgo promedio sigan pruebas de cribado de cáncer colorrectal (véase la tabla 2 de Levin et al., CA Cancer J Clinicians, 2008;58(3)130-160).
En otra realización, el método de cribado de la divulgación se lleva a cabo en sujetos de alto riesgo y/o de riesgo aumentado. Las pautas específicas son de aplicación a pacientes de alto riesgo o riesgo aumentado.
Según la ACS (véase la tabla 3 de Levin et al., CA Cancer J Clinicians, 2008;58(3)130-160), los sujetos de alto riesgo y riesgo aumentado incluyen los siguientes:
Riesgo aumentado
- sujetos con antecedentes de pólipos en colonoscopia previa;
- sujetos con cáncer colorrectal; y
- sujetos con antecedentes familiares de cáncer colorrectal o pólipos adenomatosos.
Alto riesgo
- sujetos con poliposis adenomatosa familiar (FAP) diagnosticada mediante pruebas genéticas, o FAP sospechada sin pruebas genéticas;
- sujetos con cáncer de colon sin poliposis hereditario (HNPCC o síndrome de Lynch), o en riesgo aumentado de HNPCC basándose en los antecedentes familiares sin pruebas genéticas; y
- sujetos con enfermedad intestinal inflamatoria, tal como colitis ulcerosa crónica o enfermedad de Crohn.
Un objetivo de la presente divulgación es proporcionar una herramienta de diagnóstico previo. Específicamente, la presente invención proporciona un método para diagnosticar cáncer colorrectal antes de presentar signos clínicos identificando sujetos con predisposición o riesgo de desarrollar CCR y/o pólipos adenomatosos.
En una realización particular, el método de cribado de la presente divulgación es un método para determinar el riesgo de desarrollar CCR y/o pólipos adenomatosos en un sujeto humano que comprende:
i. cuantificar al menos una secuencia bacteriana de ADNr 16S seleccionada de la lista que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10 o la secuencia de ARNr 16S complementaria de la misma, a partir de una muestra de heces de dicho sujeto; y
ii. determinar el riesgo de desarrollar CCR y/o pólipos adenomatosos a partir de los niveles de cuantificación de al menos una de dichas secuencias.
En una realización preferida, el método de cribado de la presente divulgación es un método para determinar el riesgo de desarrollar CCR y/o pólipos adenomatosos en sujetos de alto riesgo y/o de riesgo aumentado, preferiblemente en portadores del síndrome de Lynch.
El término “síndrome de Lynch” se refiere a cáncer colorrectal sin poliposis hereditario o HNPCC, que es un estado hereditario que aumenta enormemente el riesgo de una persona de padecer cáncer colorrectal, así como cáncer del revestimiento del útero (cáncer de endometrio), cáncer de ovario, y algunos otros cánceres. Las personas con este estado tienden a desarrollar cáncer a una edad temprana, a menudo sin tener en primer lugar muchos pólipos. El método de cribado de la divulgación ha mostrado en el ejemplo 4 (tablas 3 y 4) la capacidad de discriminar de manera estadísticamente significativa entre pacientes con síndrome de Lynch con pólipos (población de alto riesgo) y sin pólipos (población de bajo riesgo). La cuantificación de SEQ ID NO: 4 (B10) y determinación de la razón de SEQ ID NO: 7 (B46)/SEQ ID NO: 4 (B10) parecen ser buenos indicadores según los resultados en el ejemplo 4. Por consiguiente, las razones de SEQ ID nO: 4 (B10) y SEQ ID NO: 7 (B46)/SEQ ID NO: 4 (B10) son biomarcadores preferidos para su uso en el método de la divulgación para cribado de la presencia de pólipos.
En sujetos con antecedentes de pólipos en la colonoscopia previa o con antecedentes de cáncer colorrectal tras resección del cáncer, se llevan a cabo pruebas de cribado con propósitos de monitorización o vigilancia, es decir, para detectar recaída de cáncer y/o pólipos adenomatosos en dichos sujetos humanos.
En una realización particular adicional, el método de cribado de la presente divulgación es un método de monitorización para la detección de cáncer colorrectal (CCR) y/o pólipos adenomatosos en un sujeto humano con antecedentes previos de pólipos y/o cáncer colorrectal que comprende:
i. cuantificar al menos una secuencia bacteriana de ADNr 16S seleccionada de la lista que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10 o la secuencia de ARNr 16S complementaria de la misma, a partir de una muestra de heces de dicho sujeto; y
ii. determinar la recaída de CCR y/o pólipos adenomatosos a partir de los niveles de cuantificación de al menos una de dichas secuencias.
El método de cribado de la divulgación ha mostrado en el ejemplo 8 (tabla 8) la capacidad de discriminar de manera estadísticamente significativa entre pacientes con síndrome de Lynch con antecedentes previos de CCR y pólipos en su última colonoscopia (población de alto riesgo) y pacientes con síndrome de Lynch sin antecedentes previos de CCR y sin pólipos en su última colonoscopia (población de bajo riesgo). Se obtienen resultados particularmente notables con la cuantificación de las razones de Se Q ID NO: 1/s Eq ID NO: 4 (B3/B10), SEQ ID NO: 4/SEQ ID NO: 7 (B10/B46), SEQ ID NO: 1/SEQ ID NO: 10 (B3/B48) y SEQ ID NO: 10/SEQ ID NO: 4 (B48/B10).
Por consiguiente, las razones de SEQ ID NO: 1/SEQ ID NO: 4 (B3/B10), SEQ ID NO: 4/SEQ ID NO: 7 (B10/B46), SEQ ID NO: 1/SEQ ID NO: 10 (B3/B48) y SEQ ID NO: 10/SEQ ID NO: 4 (B48/B10) son biomarcadores preferidos para su uso en el método de la divulgación para cribado/monitorización de la presencia de pólipos, preferiblemente en pacientes de alto riesgo o riesgo aumentado, tales como pacientes con síndrome de Lynch con antecedentes de CCR.
En una realización particular adicional, el método de cribado de la presente divulgación es un método para determinar si debe realizarse una colonoscopia en un sujeto humano que comprende:
i. cuantificar al menos una secuencia bacteriana de ADNr 16S seleccionada de la lista que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10 o la secuencia de ARNr 16S complementaria de la misma, a partir de una muestra de heces de dicho sujeto; y
ii. determinar si debe realizarse una colonoscopia en dicho sujeto humano a partir de los niveles de cuantificación de
al menos una de dichas secuencias.
Un experto habitual en la técnica conoce varios métodos y dispositivos para la cuantificación y análisis de los marcadores bacterianos de la divulgación. El término “cuantificar” se refiere a la capacidad para cuantificar la cantidad de una secuencia específica de ácido nucleico en una muestra. En la técnica se conocen bien métodos de biología molecular para medir cantidades de secuencias diana de ácido nucleico. Estos métodos incluyen pero no se limitan a PCR de punto final, PCR competitiva, PCR con transcriptasa inversa (RT-PCR), PCR cuantitativa (qPCR), qPCR con transcriptasa inversa (RT-qPCR), PCR-ELISA, microalineamientos de ADN, ensayos de hibridación in situ tales como ensayo de transferencia puntual o de hibridación in situ de fluorescencia (FISH), ADN ramificado (Nolte, Adv. Clin. Chem., 1998,33:201-235) y múltiples versiones de dichos métodos (véase por ejemplo, Andoh et al., Current Pharmaceutical Design, 2009; 15,2066-2073). Los cebadores y/o sondas preferidos reaccionan de manera predecible, normalmente ofreciendo una respuesta directa y lineal a cantidades crecientes de secuencias bacterianas de ácido nucleico. Mediante la preparación de y comparación con patrones apropiados, puede cuantificarse fácilmente la cantidad de una secuencia de ácido nucleico dada en una muestra.
Preferiblemente, dicha secuencia de ácido nucleico es una secuencia de ADNr 16S seleccionada de la lista que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10,
Un método de cuantificación particularmente preferido es FISH, que combina hibridación de sonda con microscopía óptica fluorescente, microscopía láser confocal o citometría de flujo para cuantificación directa de secuencias bacterianas individuales. Para revisiones de la metodología FISH, véase, por ejemplo, Harmsen et al., Appl Environ Microbiol, 2002;682982-2990,Kalliomaki et al., J AllergClinImmunol, 2001;107129-134; Tkachuk et al., Genet. Anal. Tech. Appl., 1991;8:67-74; Trask et al., Trends Genet., 1991;7 (5): 149-154; y Weier et al., Expert Rev. Mol. Diagn., 2002,2(2):109-119; y patente estadounidense n.° 6.174.681.
Otro método de cuantificación particularmente preferido es PCR cuantitativa (qPCR), también conocido como PCR en tiempo real. El proceso de PCR se conoce bien en la técnica y, por tanto, no se describe en detalle en el presente documento. Están disponibles un resumen y protocolos de la tecnología de Q-PCR de vendedores tales como Sigma-Aldrich en aplicaciones de qPCR SYBR Green qPCR, véase por ejemplo http://www.sigmaaldrich.com/technical-documents/protocols/biology/sybr-green-qpcr.html o http://www.sigmaaldrich.com/life-science/molecular-biology/pcr/quantitative-pcr/qpcr-technical-guide.html. Para una revisión de métodos de qPCR para cuantificar la abundancia y expresión de marcadores de genes bacterianos véase, por ejemplo, Smith CJ y Osborn AM., FEMS Microbiol Ecol., 2009;67(1):6-20.
El término “niveles de cuantificación” puede ser la concentración (cantidad de ADN por unidad de volumen), la cantidad de ADN por número de células, el valor umbral de ciclo (valor de Ct) o cualquier transformación matemática de los mismos. En una realización preferida, la cuantificación de dichas secuencias bacterianas se realiza mediante qPCR. En una realización más preferida, la cuantificación de dichas secuencias bacterianas se realiza mediante qPCR y los niveles de cuantificación son el valor de Ct. El valor de Ct (umbral de ciclo) se define como el número de ciclos de qPCR requeridos para que la señal fluorescente cruce el umbral. Los niveles de Ct son inversamente proporcionales a la cantidad de ácido nucleico diana en la muestra (es decir, cuanto menor sea el nivel de Ct mayor será la cantidad de ácido nucleico diana en la muestra).
La cuantificación de la abundancia de una secuencia de ácido nucleico diana (por ejemplo SEQ ID NO: 1) en una muestra fecal puede ser absoluta o relativa. La cuantificación relativa se basa en uno o más genes de referencia interna, es decir, genes de ARNr 16S de cepas de referencia, tales como determinación de bacterias totales (Eubacteria) usando cebadores universales y expresando la abundancia de la secuencia de ácido nucleico diana como porcentaje de Eubacteria (por ejemplo razón de SEQ ID NO: 1/Eubacteria). La cuantificación absoluta proporciona el número exacto de moléculas diana mediante comparación con patrones de ADN.
En una realización particular, el método de la divulgación comprende además después de la etapa i) comparar los niveles de muestra del sujeto con los niveles en una muestra de control, en el que cuando existe una desviación de los niveles de una o más de las secuencias seleccionadas de la lista que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10 (preferiblemente, una desviación estadísticamente significativa) de los niveles de la(s) respectiva(s) secuencia(s) en la muestra de control es indicativa de CCR y/o pólipos adenomatosos. Por ejemplo, cuando los niveles de cuantificación presentan una desviación de la mediana del valor (punto de corte) más(+)/menos(-) la desviación estándar de/de los nivel(es) respectivo(s) medido(s) en una muestra de control es indicativo de CCR y/o pólipos adenomatosos.
En una realización preferida, en la que los niveles de concentración de una o más de dichas secuencias en dicha muestra del sujeto son menores que la mediana del valor (punto de corte) menos la desviación estándar de los niveles de la(s) respectiva(s) secuencia(s) medida en una muestra de control es indicativo de CCR y/o pólipos adenomatosos. En otra realización preferida, en la que los niveles de Ct de una o más de dichas secuencias en dicho sujeto muestra son mayores que la mediana del valor (punto de corte) más la desviación estándar de los niveles de la(s) respectiva(s) secuencia(s) medida en una muestra de control es indicativa de CCR y/o pólipos adenomatosos.
El término “muestra de control” puede referirse a una colección de muestras de control de la población de referencia, por ejemplo las muestras de control pueden ser muestras de sujetos sanos, de sujetos sin pólipos adenomatosos, de sujetos sin antecedentes previos de pólipos adenomatosos y/o cáncer colorrectal y combinaciones de los mismos. La clasificación de sujetos humanos bajo una de las poblaciones de referencia mencionadas anteriormente se lleva a cabo mediante una exploración de colonoscopia. Por ejemplo, “sujetos sanos” son aquellos que en una colonoscopia previa no presentaron ni pólipos adenomatosos ni cáncer colorrectal.
Preferiblemente, el método de la divulgación comprende cuantificar 2, 3 ó 4 secuencias seleccionadas de la lista que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ iD NO: 7 y SEQ ID NO: 10, preferiblemente las 4 secuencias.
En una realización particular, el método de la divulgación comprende la cuantificación de al menos dos secuencias seleccionadas de la lista que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10 y la determinación de la relación entre al menos dos de dichas secuencias. Preferiblemente, se determina la relación entre dos, tres o cuatro de dichas secuencias (por ejemplo razón, análisis multivariante, etc.).
En una realización preferida, la razón entre estas al menos dos secuencias se obtiene dividiendo los niveles de cuantificación de una primera secuencia entre los niveles de cuantificación de una segunda secuencia. Por ejemplo, la razón de concentración de las secuencias SEQ ID NO: 10/SEQ ID NO: 4 se obtiene dividiendo la concentración de la secuencia SEQ ID NO: 10 entre la concentración de la secuencia SEQ ID NO: 4. La razón de SEQ ID NO: 10/SEQ ID NO: 4 también pudo obtenerse dividiendo el valor de Ct de la secuencia identificada por SEQ ID NO: 10 entre el valor de Ct de la secuencia identificada por SEQ ID NO: 4.
En una realización adicional del método de la divulgación, al menos dos de dichas secuencias bacterianas se cuantifican en la etapa i) y se determina al menos una de las razones de los niveles de dichas secuencias en la muestra del sujeto, comprendiendo además comparar al menos una de dichas razones en dicho sujeto con la(s) razón/razones respectiva(s) en una muestra de control, en la que una desviación de la razón en dicha muestra de control (preferiblemente, una desviación estadísticamente significativa) es indicativa de CCR y/o pólipos adenomatosos. Por ejemplo, en la que una o más de dichas razones presentan una desviación de la mediana del valor (punto de corte) más(+)/menos(-) la desviación estándar de la(s) razón/razones respectiva(s) medida en una muestra de control es indicativa de CCR y/o pólipos adenomatosos.
El término “estadísticamente significativo” cuando hace referencia a diferencias entre la muestra de prueba y la muestra de control, se refiere a la condición de que cuando se usa el análisis estadístico apropiado, la probabilidad de que los grupos sean los mismos es menor del 5%, por ejemplo p<0,05. En otras palabras, la probabilidad de obtener los mismos resultados en una base completamente aleatoria es de menos de 5 de 100 intentos. Un experto en la técnica sabrá cómo escoger el análisis estadístico apropiado. Normalmente, el análisis estadístico apropiado se determina basándose en si la variable bajo el estudio tiene una distribución normal, por ejemplo, usando la prueba de Kolmogorov-Smirnov. Preferiblemente, en aquellos casos en los que hay una distribución normal, puede usarse un modelo paramétrico tal como prueba de la t o prueba de ANOVA; y cuando no hay una distribución normal entonces puede usarse un modelo no paramétrico tal como prueba de la U de Mann-Whitney U o prueba de Kruskal-Wallis.
En una realización particular, se usan los resultados de análisis de ROC, exactitud, especificidad, sensibilidad o una combinación de los mismos para describir el método de cribado de la divulgación. En particular, se usan para cuantificar cómo de bueno y fiable es el método.
Hay varios términos que se usan comúnmente junto con la descripción de sensibilidad, especificidad y exactitud. Son verdadero positivo (TP), verdadero negativo (TN), falso negativo (FN) y falso positivo (FP). Si se demuestra que una enfermedad está presente en un paciente, la prueba de cribado dada también indica la presencia de enfermedad, el resultado de la prueba se considera un verdadero positivo. De manera similar, si se demuestra que una enfermedad está ausente en un paciente, la prueba de cribado sugiere que la enfermedad también está ausente, el resultado de la prueba es un verdadero negativo (TN). Tanto el verdadero positivo como el verdadero negativo sugieren un resultado uniforme entre la prueba de cribado y el estado demostrado (también denominado patrón de verdad). Sin embargo, ninguna prueba médica es perfecta. Si la prueba de cribado indica la presencia de enfermedad en un paciente que realmente no tiene tal enfermedad, el resultado de la prueba es un falso positivo (FP). De manera similar, si el resultado de la prueba de cribado sugiere que la enfermedad está ausente en un paciente con enfermedad, el resultado de la prueba es un falso negativo (FN). Tanto el falso positivo como el falso negativo indican que los resultados de la prueba son los contrarios al estado real.
Sensibilidad, especificidad y exactitud se describen en cuanto a TP, TN, FN y FP.
Sensibilidad = TP/(TP FN) = (Número de evaluación de verdaderos positivos)/(número de toda la evaluación de positivos)
Especificidad = TN/(TN FP) = (Número de evaluación de verdaderos negativos)/(número de toda la evaluación de negativos)
Exactitud = (TN TP)/(TN TP FN FP) = (Número de evaluaciones correctas)/número de todas las evaluaciones).
En una realización preferida, el método de cribado de la presente divulgación diagnostica, detecta de manera temprana, determina la recaída, determina el riesgo de desarrollar, o predice CCR y/o pólipos en un sujeto humano; o determina si debe realizarse una colonoscopia en dicho sujeto humano; o determina el pronóstico cuando dicho sujeto humano es un paciente al que se le ha diagnosticado CCR y/o pólipos; o guía una terapia en un paciente con CCR y/o pólipos de manera estadísticamente significativa con una sensibilidad y/o especificidad de al menos el 60%, al menos el 65%, al menos el 70%, al menos el 75%, al menos el 80%, al menos el 85%, al menos el 90%, al menos el 95% o preferiblemente el 100%.
Tal como sugieren las ecuaciones anteriores, el término “sensibilidad” tal como se usa en el presente documento se refiere a la proporción de verdaderos positivos que se identifican correctamente mediante una prueba de cribado. Muestra cómo de buena es la prueba en la detección de una enfermedad. La sensibilidad (“sens”) puede estar dentro del intervalo de 0 (0%) <sens< 1 (100%) y de manera ideal, el número de falsos negativos iguales a cero o próximos a ser iguales a cero y la sensibilidad igual a uno (100%) o próxima a ser igual a uno (100%). Preferiblemente, tiene una sensibilidad del 70% al 90%, del 75% al 95%, del 80% al 95%, del 85% al 100%, o del 90% al 100%. Más preferiblemente, el método de la divulgación tiene valores de sensibilidad de al menos el 85%, tal como aproximadamente el 86%, el 87%, el 88%, el 89%, el 90%, el 91%, el 92%, el 93%, el 94%, el 95%, el 96%, el 97%, el 98%, el 99% o el 100%.
El término “especificidad” tal como se usa en el presente documento se refiere a la proporción de los verdaderos negativos identificados correctamente mediante una prueba de cribado. Sugiere cómo de buena es la prueba en la identificación de un estado normal (negativo). La especificidad (“spec”) puede estar dentro del intervalo de 0 (0%) < spec < 1 (100%) y de manera ideal, el número de falsos positivos es igual a cero es próximo a ser igual a cero y la especificidad es igual a uno (100%) o es próxima a ser igual a uno (100%). Preferiblemente, tiene una especificidad del 70% al 90%, del 75% al 95%, del 80% al 95%, del 85% al 100%, o del 90% al 100%. Más preferiblemente, el método de la divulgación tiene valores de especificidad de al menos el 85%, tal como aproximadamente el 86%, el 87%, el 88%, el 89%, el 90%, el 91%, el 92%, el 93%, el 94%, el 95%, el 96%, el 97%, el 98%, el 99% o el 100%. El término “exactitud” tal como se hace referencia en el presente documento es la proporción de resultados verdaderos, o bien verdadero positivo o bien verdadero negativo, en una población. Mide el grado de veracidad de una prueba de cribado en un estado, es decir, cómo de correcta es la determinación y exclusión de un estado dado. La exactitud (“acc”) puede estar en el intervalo de 0 (0%) < acc < 1 (100%) y de manera ideal, el número de falsos positivos es igual a cero o próximo a ser igual a cero y la exactitud es igual a uno (100%) o es próxima a ser igual a uno (100%). Preferiblemente, la exactitud del método de la divulgación es de al menos el 60%, al menos el 65%, al menos el 70%, al menos el 75%, al menos el 80%, al menos el 85%, al menos el 90%, al menos el 95% o preferiblemente el 100%. En una realización preferida, tiene una exactitud del 70% al 90%, del 75% al 95%, del 80% al 95%, del 85% al 100%, o del 90% al 100%. Preferiblemente, el método de la divulgación tiene valores de exactitud de al menos el 85%, tal como aproximadamente el 86%, el 87%, el 88%, el 89%, el 90%, el 91%, el 92%, el 93%, el 94%, el 95%, el 96%, el 97%, el 98%, el 99% o el 100%.
La “curva ROC” es una presentación gráfica de la relación entre tanto la sensibilidad como especificidad y ayuda a decidir el modelo óptimo mediante la determinación del mejor umbral (punto de corte óptimo) para la prueba de cribado. El área bajo la curva ROC (AUC) proporciona un modo de medir la exactitud de una prueba de cribado. Preferiblemente, los valores de intervalo de AUC del método de la divulgación son desde 0,6 hasta 1, más preferiblemente de 0,7 a 1, estando los valores más preferidos en el intervalo de 0,8 a 1, más preferiblemente de 0,9 a 1. En una realización particular, AUC es desde 0,6 hasta 0,8, tal como desde 0,6 hasta 0,75 o de 0,65 a 0,75. Además, la sensibilidad, especificidad y exactitud son proporciones, por tanto pueden calcularse los intervalos de confianza conformes usando métodos convencionales para proporciones bien conocidos en la técnica. Dos tipos de intervalos de confianza del 95% se definen generalmente alrededor de la proporciones. El intervalo de confianza exacto se define usando distribución binomial para alcanzar una estimación exacta. El intervalo de confianza asintótico se calcula suponiendo una aproximación normal de la distribución de la muestra. Un experto en la técnica sabrá cómo definir el intervalo de confianza apropiado. La elección de un tipo u otro de intervalo de confianza dependerá normalmente de si la proporción de muestra es una buena aproximación a una distribución normal. En una realización particular del método de la divulgación, antes de la cuantificación de dichas secuencias bacterianas, se extrae ADN de la muestra de heces. Se conocen varios métodos de extracción de ADN a partir de muestras fecales, todos estos métodos se basan en la alteración química o mecánica, lisis usando detergentes, o una combinación de estos enfoques (Kennedy A. et al., PLoS One, 2014;9(2):e88982). Se conocen métodos para la extracción de ADN bacteriano en muestras fecales por ejemplo de M Corist et al., Journal of Microbiological Methods, 2002; 50(2):131-139, Whitney D et al., Journal of Molecular Diagnostics, American Society for Investigative
Pathology, 2004;6(4):386-395 y documento WO2003/068788.
Los métodos preferidos usan una combinación de alteración mecánica, tal como extracción de golpeo de perlas a alta velocidad, lisis química y una etapa de purificación final, preferiblemente usando una columna de membrana de sílice tal como las incluidas en los kits de extracción de ADN disponibles comercialmente “procedimiento de extracción de ADN MobioPowerSoil®” (Mo-Bio Laboratories Inc.,), kit FastDNA ® SPIN para procedimiento de suelo (MP biomedicals) y NucleoSpin® Soil (Macherey-Nagel Gmbh& Co. KG). La presencia de inhibidores de PCR en los extractos de ADN de muestras fecales tales como bilirrubinas, sales biliares e hidratos de carbono complejos es una de las dificultades a las que se enfrenta la determinación de biomarcadores de ADN en extractos de ADN de heces (Fleckna et al., Mol Cell Probes, 2007;21(4):282-7). Métodos de extracción de ADN preferidos son aquellos que proporcionan extractos fecales con una baja cantidad de inhibidores de PCR, tal como menos del 5%, preferiblemente menos del 2%, más preferiblemente menos del 1%, incluso más preferiblemente menos del 0,5%, tal como menos del 0,25%, el 0,1%, el 0,05% o el 0,01%.
En una realización particular, el método de la divulgación comprende:
(a) determinar mediante PCR cuantitativa a partir de dicha muestra de heces humanas los niveles de al menos una secuencia bacteriana de ADNr 16S seleccionada del grupo que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10, en la que los niveles de SEQ ID NO: 1 se determinan usando cebadores con al menos una identidad del 90% con respecto a SEQ ID NO: 2-13, los niveles de SEQ ID NO: 4 se determinan usando cebadores con al menos una identidad del 90% con respecto a SEQ ID NO: 5-6, los niveles de SEQ ID NO: 7 se determinan usando cebadores con al menos una identidad del 90% con respecto a SEQ ID NO: 8-9 y los niveles de SEQ ID NO: 10 se determinan usando cebadores con al menos una identidad del 90% con respecto a SEQ ID NO: 11-12; y/o (b) determinar mediante PCR cuantitativa a partir de dicha muestra de heces humanas los niveles de al menos dos secuencias bacterianas de ADNr 16S seleccionadas del grupo que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10 tal como se menciona en la etapa a), y determinar al menos una de las razones seleccionadas del grupo que consiste en SEQ ID NO: 10/SEQ iD NO: 4, SEQ ID NO: 7/SEQ ID NO: 4, SEQ ID NO: 4/SEQ ID NO: 1, SEQ ID NO: 7/SEQ ID NO: 1; SEQ ID NO: 7/SEQ ID NO: 10 y SEQ ID NO: 10/SEQ ID 1.
En una realización preferida, el método de cribado para CCR y/o pólipos adenomatosos a partir de una muestra de heces humanas de la divulgación, comprende:
(a) determinar mediante PCR cuantitativa a partir de dicha muestra de heces humanas la concentración de al menos unas secuencias bacterianas de ADNr 16S seleccionadas del grupo que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10, en la que la concentración de SEQ iD NO: 1 se determina usando cebadores con al menos una identidad del 90% con respecto a SEQ ID NO: 2-13, la concentración de SEQ ID NO: 4 se determina usando cebadores con al menos una identidad del 90% con respecto a SEQ ID NO: 5-6, la concentración de SEQ ID NO: 7 se determina usando cebadores con al menos una identidad del 90% con respecto a SEQ ID NO: 8-9 y la concentración de SEQ ID NO: 10 se determina usando cebadores con al menos una identidad del 90% con respecto a SEQ ID NO: 11-12,
(b) opcionalmente, determinar mediante PCR cuantitativa a partir de dicha muestra de heces humanas los niveles de al menos dos secuencias bacterianas de ADNr 16S seleccionadas del grupo que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10 tal como se menciona en la etapa a), y determinar al menos una de las razones de concentraciones seleccionadas del grupo que consiste en SEQ ID NO: 10/SEQ ID NO: 4, SEQ ID NO: 7/SEQ ID NO: 4, SEQ ID NO: 4/SEQ ID NO: 1, SEQ ID NO: 7/SEQ ID NO: 1; SEQ ID NO: 7/SEQ ID NO: 10 y SEQ ID NO: 10/SEQ ID 1 y
(c) diagnosticar, determinar el riesgo o determinar la recaída de CCR y/o pólipos adenomatosos a partir de la concentración de al menos una de las secuencias de la etapa (a) y/o el valor de al menos una razón obtenida en la etapa (b).
En otra realización del método de la divulgación, dichos cebadores con al menos una identidad del 90% con respecto a SEQ ID NO: 2-13 son cebadores con al menos una identidad del 95% con respecto a SEQ ID NO: 2-13, dichos cebadores con al menos una identidad del 90% con respecto a SEQ ID NO: 5-6 son cebadores con al menos una identidad del 95% con respecto a SEQ ID NO: 5-6, dichos cebadores con al menos una identidad del 90% con respecto a SEQ ID NO: 8-9 son cebadores con al menos una identidad del 95% con respecto a SEQ ID NO: 8-9 y dichos cebadores con al menos una identidad del 90% con respecto a SEQ ID NO: 11-12 son cebadores con al menos una identidad del 95% con respecto a SEQ ID NO: 11-12.
En una realización particularmente preferida, dichos cebadores con al menos una identidad del 95% con respecto a SEQ ID NO: 2-13 son cebadores identificados por SEQ ID NO: 2-13, dichos cebadores con al menos una identidad del 95% con respecto a SEQ ID NO: 5-6 son cebadores identificados por SEQ ID NO: 5-6, dichos cebadores con al menos una identidad del 95% con respecto a SEQ ID NO: 8-9 son cebadores identificados por SEQ ID NO: 8-9 y dichos cebadores con al menos una identidad del 95% con respecto a SEQ ID NO: 11-12 son cebadores
identificados por SEQ ID NO: 11-12.
En la presente solicitud, una secuencia problemática tiene una identidad del 95% con respecto a una secuencia determinada si el 95% de los residuos de la secuencia problemática son idénticos a los residuos de la secuencia determinada.
En una realización preferida, el método de la presente divulgación es un método para el diagnóstico de cáncer colorrectal y se diagnostica cáncer colorrectal en la etapa (c) si el valor de Ct de SEQ ID NO: 1 está por encima del valor de punto de corte de Ct de 37,2, o si el valor de Ct de SEQ ID NO: 4 está por encima del valor de punto de corte de Ct de 16,56, o si el valor de Ct de SEQ ID NO: 7 está por encima del valor de punto de corte de Ct de 22,97, o si el valor de Ct de SEQ ID NO: 10 está por encima del valor de punto de corte de Ct de 19,24, o si el valor de la razón SEQ ID NO: 10/SEQ ID NO: 4 está por debajo del valor de punto de corte de 1,16, o si el valor de la razón SEQ ID NO: 7/SEQ ID NO: 4 está por debajo del valor de punto de corte de 1,40, o si el valor de la razón SEQ ID NO: 4/SEQ ID NO: 1 está por encima del valor de punto de corte de 0,44, o si el valor de la razón SEQ ID NO: 7/SEQ ID NO: 1 está por encima del valor de punto de corte de 0,62, o si el valor de la razón y SEQ ID NO: 10/SEQ ID: 1 está por encima del valor de punto de corte de 0,52, o si la SEQ ID NO: 10/SEQ ID: 7 está por encima del valor de punto de corte de 1,2.
En otra realización preferida, el método de la presente divulgación es un método para diagnosticar el riesgo de desarrollar cáncer colorrectal, en el que se diagnostica un riesgo de desarrollar cáncer colorrectal en la etapa (c) si el valor de Ct de SEQ ID NO: 1 está por encima del valor de punto de corte de Ct de 36,45, o si el valor de Ct de SEQ ID NO: 4 está por encima del valor de punto de corte de Ct de 14,02, o si el valor de Ct de SEQ ID NO: 7 está por encima del valor de punto de corte de Ct de 24,76, o si el valor de Ct de SEQ ID NO: 10 está por encima del valor de punto de corte de Ct de 21,42, o si el valor de la razón SEQ ID NO: 10/SEQ ID NO: 4 está por debajo del valor de punto de corte de 1,56, o si el valor de la razón SEQ ID NO: 7/SEQ ID NO: 4 está por debajo del valor de punto de corte de 1,78, o si el valor de la razón SEQ ID NO: 4/SEQ ID NO: 1 está por encima del valor de punto de corte de 0,38, o si el valor de la razón SEQ ID NO: 7/SEQ ID NO: 1 está por encima del valor de punto de corte de 0,68, o si el valor de la razón SEQ ID NO: 10/SEQ ID 1 está por encima del valor de punto de corte de 0,59, o si la SEQ ID NO: 10/SEQ ID: 7 está por encima del valor de punto de corte de 1,16.
En otra realización, el método de la presente divulgación comprende además detectar y/o cuantificar uno o más biomarcadores moleculares que se sabe que son indicadores de CCR. Preferiblemente, se usa un panel de marcadores múltiples. Dicho panel de marcadores múltiples puede comprender la determinación de mutaciones puntuales presentes en uno o más de los siguientes genes: APC, K-ras, b Ra F, p53, NRAS, PIK3CA, CDK8, CMYC, CCNE1, CTNNB1, NEU (HER2), MYB, FBXW7, PTEN, SMAD4, SMAD2, SMAD3, TGFpIIR, TCF7L2, ACVR2 y BAX (Fearon, E. R., Annu. Rev. Pathol. Mech. Dis., 2011;6:479-507). Otros marcadores de CCR conocidos que pueden determinarse son metilación de isla de CpG, la cantidad de ADN humano por unidad de peso de las heces, y la cantidad de ADN total por unidad de peso de las heces.
En una realización adicional, el método de la presente divulgación comprende además almacenar los resultados de la determinación en un medio legible por ordenador. Tal como se usa en el presente documento, “un medio legible por ordenador” puede ser cualquier aparato que puede incluir, almacenar, comunicar, propagar o transportar los resultados de la determinación del método. El medio puede ser un sistema (o aparato o dispositivo) electrónico, magnético, óptico, electromagnético, infrarrojo o semiconductor o un medio de propagación.
Un segundo aspecto, la divulgación se refiere al uso de al menos una secuencia bacteriana de ADNr 16S seleccionada de la lista que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10 o la secuencia de ARNr complementaria de la misma como biomarcador para diagnosticar, detectar de manera temprana, determinar la recaída, determinar el riesgo de desarrollar, o predecir CCR y/o pólipos en un sujeto humano; o determinar si debe realizarse una colonoscopia en dicho sujeto humano; o determinar el pronóstico en el que dicho sujeto humano es un paciente al que se le ha diagnosticado CCR y/o pólipos; o guiar una terapia en un paciente con CCR y/o pólipos en el que dichas secuencias bacterianas se cuantifican a partir de una muestra de heces de dicho sujeto humano.
Preferiblemente, dicha secuencia de ácido nucleico es una secuencia de ADNr 16S seleccionada de la lista que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10.
El término “biomarcador” tal como se usa en el presente documento se refiere a marcadores de enfermedad que son normalmente sustancias encontradas en una muestra corporal que pueden medirse fácilmente. La cantidad medida puede correlacionarse con una fisiopatología de la enfermedad subyacente, tal como presencia o ausencia de CCR y/o pólipos, o probabilidad de CCR y/o pólipos en el futuro. En pacientes que reciben tratamiento para su estado, la cantidad medida también se correlacionará con el grado de respuesta a la terapia.
En un tercer aspecto, la divulgación se refiere a un kit que comprende:
a. un reactivo seleccionado del grupo que consiste en:
i) sondas de ácido nucleico capaces de hibridarse específicamente con al menos una secuencia de ADNr 16S seleccionada de la lista que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10 o la secuencia de ARNr complementaria de la misma; o
ii) un par de cebadores de ácido nucleico capaces de amplificar específicamente al menos una secuencia de ADNr 16S seleccionada de la lista que consiste en SEQ ID NO: 1, s Eq ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10; y
b. instrucciones para cuantificar los niveles de una o más de dichas secuencias a partir de una muestra de heces humanas según un método de la presente divulgación.
El término “sonda” tal como se usa en el presente documento se refiere a ácidos nucleicos sintéticos o producidos de manera biológica, entre 10 y 285 pares de bases de longitud que contienen secuencias de nucleótidos específicas que permiten hibridación específica y preferencial en condiciones predeterminadas con secuencias diana de ácido nucleico, y opcionalmente contienen un resto para detección o para potenciar el rendimiento de un ensayo. Generalmente es necesario un mínimo de diez nucleótidos con el fin de obtener estadísticamente especificidad y para formar productos de hibridación estables, y un máximo de 285 nucleótidos generalmente representa un límite superior para la longitud en el que los parámetros de reacción pueden ajustarse fácilmente para determinar secuencias de apareamiento erróneo e hibridación preferencial. Las sondas pueden contener opcionalmente determinados constituyentes que contribuyen a su funcionamiento adecuado u óptimo en determinadas condiciones de ensayo. Por ejemplo, las sondas pueden modificarse para mejorar su resistencia a la degradación de nucleasas (por ejemplo, mediante ocupación de los centros activos), para llevar ligandos de detección (por ejemplo, fluoresceína) o para facilitar su captura sobre un soporte sólido (por ejemplo, “colas” de polidesoxiadenosina).
El término “cebadores” tal como se usa en el presente documento se refiere a oligonucleótidos que pueden usarse en un método de amplificación, tal como una reacción en cadena de la polimerasa (“PCR”), para amplificar una secuencia de nucleótidos. Los cebadores se diseñan basándose en la secuencia de polinucleótido de una secuencia diana particular, por ejemplo, una secuencia de ADNr 16S específica.
El diseño y la validación de cebadores y sondas se conocen bien en la técnica. Para métodos de PCR en tiempo real cuantitativa, véase por ejemplo Rodriguez A et al. (Methods Mol Biol., 2015, 1275:31-56).
“Específico” tal como se usa en el presente documento significa que una secuencia de nucleótidos se hibridará con/amplificará una secuencia diana predeterminada y no se hibridará con/amplificará sustancialmente una secuencia no diana en las condiciones del ensayo, generalmente se usan condiciones rigurosas.
“Hibridación” tal como se usa en el presente documento se refiere a un proceso mediante el cual, en condiciones de reacción predeterminadas, se permite que dos hebras parcial o completamente complementarias de ácido nucleico se junten de manera antiparalela para formar un ácido nucleico bicatenario con enlaces de hidrógeno específicos y estables, siguiendo las reglas explícitas relativas a las que las bases de ácido nucleico pueden emparejarse entre sí. “Hibridación sustancial” significa que la cantidad de hibridación observada será tal que al observar los resultados se consideraría que el resultado es positivo con respecto a datos de hibridación en controles positivos y negativos. Los datos que se consideran “ruido de fondo” no son una hibridación sustancial.
“Condiciones de hibridación rigurosas” significa de aproximadamente 35°C a 65°C en una disolución salina de aproximadamente NaCl 0,9 molar. La rigurosidad también puede regirse por tales parámetros de reacción como la concentración y el tipo de especies iónicas presente en la disolución de hibridación, los tipos y concentraciones de agentes desnaturalizantes presentes, y la temperatura de hibridación. Generalmente, a medida que las condiciones de hibridación se vuelven más rigurosas, se prefieren sondas más largas si van a formarse híbridos estables. Como norma, la rigurosidad de las condiciones en las que tiene lugar la hibridación dictará determinadas características de las sondas preferidas que van a emplearse.
Preferiblemente, dicha secuencia de ácido nucleico es una secuencia de ADNr 16S seleccionada de la lista que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10.
En una realización particular, dicho kit se usa para diagnosticar, detectar de manera temprana, determinar la recaída, determinar el riesgo de desarrollar, o predecir CCR y/o pólipos en un sujeto humano; o para determinar si debe realizarse una colonoscopia en dicho sujeto humano; o para determinar el pronóstico en un paciente al que se le ha diagnosticado CCR y/o pólipos; o para guiar una terapia en un paciente con CCR y/o pólipos. En una realización preferida, el kit puede comprender además medios de extracción de ADN, medios para llevar a cabo la hibridación y/o amplificación, medios de detección, y/o uno o más recipientes para recoger y/o mantener la muestra biológica.
En una realización particular, la presente divulgación se refiere a un kit para diagnosticar cáncer colorrectal a partir
de una muestra de heces humanas que comprende al menos un par de cebadores de PCR seleccionados del grupo de pares de cebadores que consiste en SEQ ID NO: 2-13, SEQ ID NO: 5-6, SEQ ID NO: 8-9 y SEQ ID NO: 11-12. En un cuarto aspecto, la presente divulgación se refiere a una secuencia de ácido nucleico seleccionada del grupo que consiste en SEQ ID NO: 2, SEQ ID NO: 13, SEQ ID NO: 5, SEQ ID NO: 6, SEQ ID NO: 8, SEQ ID NO: 9, SEQ ID NO: 11, y SEQ ID NO: 12; o con una identidad de al menos el 90% de los mismos, preferiblemente con una identidad del 95% de los mismos, más preferiblemente con una identidad del 96%, el 97%, el 98%, el 99% o el 100%. Preferiblemente, dichas secuencias se usan como cebadores en un ensayo de amplificación (tal como qPCR) o como sondas de ácido nucleico en un ensayo de hibridación para la cuantificación de al menos una secuencia de ADNr 16S seleccionada de la lista que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10. En una realización particular, dicha secuencia de ácido nucleico es un par de cebadores de PCR seleccionados del grupo que consiste en SEQ ID NO: 2-13, SEQ ID NO: 5-6, SEQ ID NO: 8-9 y SEQ ID NO: 11-12. En otra realización particular, dicha secuencia de ácido nucleico es una sonda de ácido nucleico seleccionada del grupo que consiste en SEQ ID NO: 2, SEQ ID NO: 13, SEQ ID NO: 5, SEQ ID NO: 6, SEQ ID NO: 8, SEQ ID NO: 9, SEQ ID NO: 11, y SEQ ID NO: 12.
En un quinto aspecto, la divulgación se refiere al uso de una secuencia de ácido nucleico seleccionada del grupo que consiste en SEQ ID NO: 2, SEQ ID NO: 13, SEQ ID NO: 5, SEQ ID NO: 6, SEQ ID NO: 8, SEQ ID NO: 9, SEQ ID NO: 11, y SEQ ID NO: 12; o con una identidad de al menos el 90% de los mismos en un método de cribado de la divulgación, en el que se usan SEQ ID NO: 2 y/o SEQ ID NO: 13 para la cuantificación de SEQ ID NO: 1; se usan SEQ ID NO: 5 y/o Se Q ID NO: 6 para la cuantificación de SEQ ID NO: 4; se usan SEQ ID NO: 8 y/o SEQ ID NO: 9 para la cuantificación de SEQ ID No : 7; y se usan SEQ ID NO: 11 y/o SEQ ID NO: 12 para la cuantificación de SEQ ID NO: 10.
Se entenderá que las realizaciones particulares descritas en los ejemplos se muestran a modo de ilustración y no como limitaciones de la invención.
Todas las publicaciones y solicitudes de patente mencionadas en la memoria descriptiva son indicativas del nivel de destreza de los expertos en la técnica a la que pertenece esta invención.
El uso de la palabra “un” o “una” puede significar “un/una”, pero también es compatible con el significado de “uno o más”, “al menos uno”, y “uno o más de uno.”
En la totalidad de esta solicitud, el término “aproximadamente” significa el valor indicado ± 5% de su valor, preferiblemente el valor indicado ± 2% de su valor, lo más preferiblemente el término “aproximadamente” significa exactamente el valor indicado (± 0%).
Ejemplos
Ejemplo 1.- Material y métodos
1. Muestras biológicas
Se obtuvieron muestras fecales de 27 pacientes a los que se les diagnosticó recientemente cáncer colorrectal (CCR) (fase 0-I), 24 pacientes portadores del síndrome de Lynch (L) y 19 individuos sanos (C). Todos los pacientes tuvieron una colonoscopia al menos 15 días antes de la recogida de muestras.
Todos ellos firmaron el correspondiente consentimiento informado. Los criterios de exclusión incluyeron tratamiento con antibióticos dentro de 1 mes antes del estudio y edad < 18 años.
2. Secuencias bacterianas de ADNr 16S:
Las secuencias B3, B10, B41, B46, B48 y B50 se corresponden con bandas de gel de electroforesis en gel de gradiente desnaturalizante (DGGE) aisladas previamente de aislados de bacterias no cultivadas.
- Secuencia bacteriana de ADNr 16S SEQ ID NO: 1 (B3), publicada en la base de datos del Archivo de Nucleótidos Europeo (ENA) EMBL-EBI como GQ411111.1;
- secuencia bacteriana de ADNr 16S SEQ ID NO: 4 (B10), publicada en la base de datos del Archivo de Nucleótidos Europeo (ENA) EMBL-EBI como GQ411118.1;
- secuencia bacteriana de ADNr 16S SEQ ID NO: 7 (B46), publicada en la base de datos del Archivo de Nucleótidos Europeo (ENA) EMBL-EBI como GQ411150.1;
- secuencia bacteriana de ADNr 16S SEQ ID NO: 10 (B48), publicada en la base de datos del Archivo de
Nucleótidos Europeo (ENA) EMBL-EBI como GQ411152.1;
- secuencia bacteriana de ADNr 16S B41, publicada en la base de datos del Archivo de Nucleótidos Europeo (ENA) EMBL-EBI como GQ411145.1; y
- secuencia bacteriana de ADNr 16S B50, publicada en la base de datos del Archivo de Nucleótidos Europeo (ENA) EMBL-EBI como GQ411154.1.
3. Recogida, conservación y almacenamiento de muestras
Se recogieron muestras fecales de 24 h en un recipiente para heces y se almacenaron a -20°C durante un mes y se transportaron a un congelador a -80°C en condiciones de la norma ISO 9001.
4. Procesamiento de muestras y extracción de ADN
Para la extracción de ADN 16S fecal se usó NucleoSpin® Soil (Macherey-Nagel).
En condiciones de seguridad biológicas clase II, se colocaron 200 mg-500 mg de muestra fecal en un tubo de perlas Nucleospin. Se añadieron 700 |il de SL1 y 150 |il de potenciador SX a un tubo de perlas.
5. Después de eso, se extrajo ADN y se purificó siguiendo las instrucciones del fabricante, y se eluyó con 50 UI de tampón de elución o Tris HCl 10 mM pH = 7,4.
6. Cálculo de la concentración de ADN
Se determinó la concentración de ADN del extracto mediante análisis fluorimétricos con el n.° de catálogo de fluorímetro Qubit ® 2.0 Q32866 usando el kit de ensayo de amplio intervalo de ADNbc Quant-IT. Este método es muy selectivo para ADNbc con respecto a ARN y proporciona una cuantificación exacta en un intervalo desde 2 ng hasta 1.000 ng. Con en este intervalo, la fluorescencia está relacionada linealmente con la concentración de ADN. Se realizaron mediciones de ADN en 5 ul del extracto.
7. PCR en tiempo real cuantitativa (qPCR) de ADN extraído de muestras fecales
Se analizó el ADN de muestras fecales mediante PCR en tiempo real cuantitativa. En particular, se evaluó la cantidad de cuatro poblaciones bacterianas por muestra: B3, B10, B48 y B46. Las secuencias bacterianas se cuantificaron usando una PCR en tiempo real cuantitativa con un tinte de ADNbc fluorescente. En este trabajo, se ha usado la mezcla previa BRYT ® de Promega (Madison, EE.UU.). Se amplificaron Eubacteria siguiendo el procedimiento descrito por Furet et al. (FEMS Microbiol Ecol., 2009;68(3):351-62).
Se expresaron las abundancias bacterianas para cada muestra como Ct normalizado frente a la concentración de ADN total. El Ct (umbral de ciclo) se define como el número de ciclos de q-PCR requeridos para que la señal fluorescente cruce el umbral. Los niveles de Ct son inversamente proporcionales al logaritmo de la concentración de ácido nucleico diana en la muestra (es decir, cuanto menor sea el nivel de Ct mayor será la cantidad de ácido nucleico diana en la muestra). Los ensayos en tiempo real se someten a 40 ciclos de amplificación.
8. Métodos de análisis estadístico
Se analizó la distribución estadística normal de los datos mediante la prueba de Kolmogorov-Smirnov. Según si hubo una distribución estadística normal de los datos o no, se usó una prueba estadística adecuada para comparar los siguientes grupos. Los grupos analizados fueron: CCR frente a sano; CCR frente a Lynch frente a sano; CCR Lynch frente a sano; y CCR frente a Lynch-alto riesgo frente a Lynch-bajo riesgo frente a sano. Para estos grupos, las variables analizadas fueron:
- cuantificación de cuatro secuencias bacterianas expresadas en Ct;
- razón de la cuantificación de cuatro secuencias bacterianas;
- peso; y
- concentración de ADN.
Usando una regresión binaria y análisis de ROC, se determinaron la correlación de la cuantificación de secuencia(s) bacteriana(s) entre el estado sano y con CCR y el riesgo (en conjunto y separado en dos condiciones de riesgo) y la sensibilidad y especificidad de la prueba.
No se observó diferencia entre grupos en ADN y peso. Se encontró que la cantidad de Eubacteria (Eub) era
diferente entre Lynch y CCR Lynch y donantes sanos (C), pero se consideró normal porque el estado de la enfermedad implica un cambio del núcleo filogenético, que incluye bacterias con menor número de copias de ADN. No implica una disminución de bacterias totales (véase por ejemplo, Sobhani et al., PLoS One, 2011,27;6(1):e16393). Por este motivo, no se usó cuantificación de Eub como referencia interna con propósitos de normalización.
Ejemplo 2. Diseño y validación de cebadores
Se diseñó el cebador para la cuantificación de los marcadores bacterianos B3, B10, B46, B48, B41 y B50 en biopsia a partir de los análisis comparativos con secuencias previamente obtenidas de grupos filogenéticos usando herramientas bioinformáticas: ClustalX del European Bioinformatics Institute (www.ebi.ac.uk), Netprimer (Premier Biosoft) y PrimerExpress (Life Tecnologies-Thermo Fischer).
El sistema de detección escogido fue SybrGreen®. Se descartó un conjunto de cebadores con menos de 3 posiciones diferentes con respecto a grupos próximos. También se descartó el conjunto de cebadores con valores de Tm en curvas de disociación diferentes de los esperados. La validación de cebadores se realizó en una muestra de biopsia y muestra fecal. Se determinó la curva de disociación con el fin de analizar el rendimiento del cebador. En las figuras 8a a 13b se muestran los gráficos de amplificación y curvas de disociación para la validación de los cebadores diseñados para la amplificación de B3, B10, B46, B48, B41 y B50, respectivamente. Se seleccionaron cebadores que muestran una curva de disociación adecuada (pico único para cada conjunto de cebadores) para la cuantificación bacteriana de ADNr 16S en muestras fecales. En particular, se seleccionaron cebadores que amplifican B3, B10, B46 y B48, estos se especifican en la tabla 9 a continuación. Se descartaron B51 y B40 debido a la falta de especificidad (picos múltiples para cada conjunto de cebadores en curvas de fusión).

Tabla 9. Pares de cebadores seleccionados para la amplificación de qPCR de secuencias bacterianas B3, B10, B46 y B48 de ADNr 16S en muestras fecales.
Ejemplo 3: Análisis de biomarcadores de ADNr 16S en pacientes con cáncer colorrectal frente a sujetos sanos Se ha analizado un total de 16 muestras de heces en 7 controles y 9 pacientes con cáncer colorrectal. La cuantificación de cada uno de los marcadores de bacterias citados en el ejemplo 1 en muestras de heces analizadas se expresa en valores de Ct. El Ct (umbral de ciclo) se define como el número de ciclos de q-PCR requeridos para que la señal fluorescente cruce el umbral. Los niveles de Ct son inversamente proporcionales al logaritmo de la concentración de ácido nucleico diana en la muestra (es decir, cuanto menor sea el nivel de Ct mayor será la cantidad de ácido nucleico diana en la muestra). Los ensayos en tiempo real se someten a 40 ciclos de amplificación. Los resultados obtenidos se muestran a continuación, en las tablas 1 y 2. La tabla 1 representa valores absolutos de Ct y la tabla 2 representa razones de Ct. Se aplicó prueba de la t de dos muestras.
Tabla 1. Valores absolutos de Ct


* La exactitud se determina como (TN TP)/(TN TP FN FP) Tabla 2. Razones de Ct


* La exactitud se determina como (TN TP)/(TN TP FN FP)
La sensibilidad y especificidad del diagnóstico de cáncer colorrectal es del 75 y el 71% para la razón SEQ ID NO: 10/SEQ ID NO: 4; el 77% y el 71%, respectivamente, para la razón SEQ ID NO: 7/SEQ ID NO: 4; el 100% y el 100%, respectivamente, para la razón SEQ iD NO: 4/SEQ ID NO: 1; el 100% y el 100%, respectivamente, para la razón SEQ ID NO: 7/ SEQ ID NO: 1; y el 75% y el 75%, respectivamente, para la razón SEQ ID NO: 10/ SEQ ID NO: 1. Las figuras 1, 2 y 3 son representaciones gráficas de razones de valores de Ct (SEQ ID NO: 10/SEQ ID NO: 4, SEQ ID NO: 7/SEQ ID NO: 4 y SEQ ID NO: 4/SEQ ID NO: 1).
Las figuras 4 y 5 son representaciones gráficas de los absolutos de Ct (SEQ ID NO: 4, SEQ ID NO: 7).
Ejemplo 4. Análisis de biomarcadores de ADNr 16S en pacientes con síndrome de Lynch: CCR frente a alto riesgo (con pólipos) frente a baio riesgo (sin pólipos)
El objetivo de este análisis es determinar el valor predictivo de los biomarcadores para detectar el riesgo de cáncer colorrectal antes de los signos clínicos.
Se analizó un total de 8 individuos con síndrome de Lynch (con riesgo genético aumentado de desarrollar cáncer colorrectal). Todos los individuos tuvieron una colonoscopia, en el periodo máximo de un año, antes de la recogida de la muestra fecal. Según un examen endoscópico 4 de ellos tuvieron un pólipo maligno (denominados alto riesgo) y 4 no tuvieron ningún pólipo (denominados bajo riesgo).
La cuantificación de cada de uno de los marcadores de bacterias citados en el ejemplo 1 en muestras de heces humanas analizadas se determinó usando los cebadores descritos en el ejemplo 2 y se cuantificaron en valores de Ct.
Los resultados obtenidos se muestran a continuación, en las tablas 3 y 4. La tabla 3 representa valores absolutos de Ct y la tabla 4 representa razones de Ct. Se aplicó una prueba de la t de dos muestras.
Tabla 3. Valores absolutos de Ct
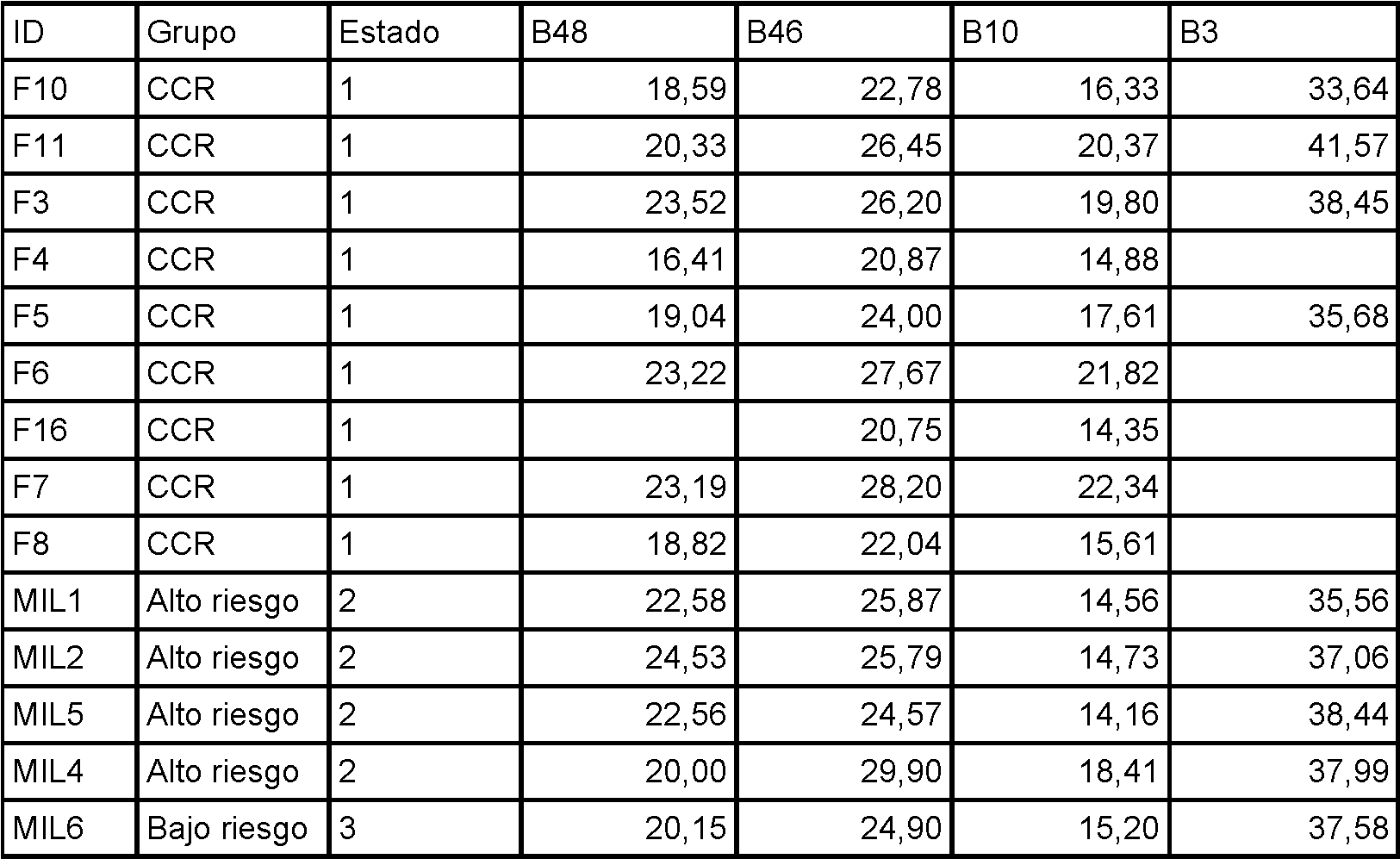

Tabla 4. Razones de Ct


Los marcadores de razones microbiológicas fueron capaces de discernir el grupo de individuos con alto riesgo de desarrollar cáncer colorrectal (pacientes con síndrome de Lynch y pólipos). La sensibilidad y especificidad en la detección de la población de alto riesgo de cáncer colorrectal fueron del 80% y el 100% para la SEQ ID NO: 4; el 75% y el 75%, respectivamente, para la razón SEQ ID NO: 4/SEQ ID NO: 1; el 80% y el 100%, respectivamente, para la razón SEQ ID NO: 7/SEQ ID NO: 4; el 75% y el 75%, respectivamente, para la razón SEQ ID No : 7/SEQ ID NO: 1; y el 75% y el 75% para la razón SEQ ID NO: 10/SEQ ID NO: 1.
La figura 6 es una representación gráfica de la razón de valores de Ct (SEQ ID NO: 4/SEQ ID NO: 1) y la figura 7 es una representación gráfica de los absolutos de Ct (SEQ ID NO: 4).
Ejemplo 5: Análisis de biomarcadores de ADNr 16S en pacientes con cáncer colorrectal frente a sujetos sanos Se obtuvieron muestras fecales de 27 pacientes a los que se les diagnosticó recientemente cáncer colorrectal (CCR) (fase 0-I), e individuos sanos (C). Todos los pacientes tuvieron una colonoscopia al menos 15 días antes de la recogida de muestras. Todos ellos firmaron el correspondiente consentimiento informado. Los criterios de exclusión incluyeron tratamiento con antibióticos dentro de 1 mes antes del estudio y edad < 18 años. En la tabla 5 (véase a continuación) se muestra que la cuantificación de las cuatro secuencias bacterianas presentó un aumento significativo en Ct en las heces de pacientes con CCR. Este hecho significa que hay una menor carga de las cuatro bacterias en este grupo.
La disminución significativa de la carga de estas cuatro bacterias podría ser una potente herramienta para cribar
pacientes con CCR. Si se analiza el rendimiento de los marcadores bacterianos por separado, se aprecia que se obtuvieron los mejores resultados con B3 que identificó pacientes con CCR con un 94% de especificidad y un 48% de sensibilidad y 0,7 de exactitud; y en segundo lugar, B46 con un 84% de especificidad y un 61,5% de sensibilidad y 0,698 de exactitud.
B48 y B10 también muestran una exactitud de 0,69 pero un 100% de especificidad y un 36% de sensibilidad, y un 57% de especificidad y un 89,5% de sensibilidad, respectivamente.
Se calculó la razón entre Ct de la cuantificación de secuencias bacterianas. Aunque no se observan diferencias estadísticas, ha de considerarse que aplicar esta razón en una muestra aumentada podría ser un algoritmo útil para completar el cribado de CCR. En esta línea, la combinación de cuatro secuencias también debe considerarse que aumenta la sensibilidad y especificidad de la prueba.
Tabla 5. Cuantificación de las 4 secuencias bacterianas en individuos sanos y pacientes con CCR (expresados en Ct), análisis estadístico a través de dos pruebas t de muestra y análisis ROC.


Las figuras 14 a 17 proporcionan la representación gráfica de valores de Ct absolutos para B3, B10, B46 y B48, respectivamente, en grupos de CCR y sanos (C).
La figura 27 proporciona las curvas ROC para B3, B10, B46 y B48 en análisis de sanos frente a CCR.
Ejemplo 6: Análisis de biomarcadores de ADNr 16S de CCR frente Lynch (sin signos clínicos) frente a individuos sanos
El objetivo de este análisis es determinar el valor predictivo de los biomarcadores para detectar el riesgo de cáncer colorrectal antes de los signos clínicos. Se obtuvieron muestras fecales de 27 pacientes a los que se les diagnosticó recientemente cáncer colorrectal (CCR) (fase 0-I), 24 pacientes portadores del síndrome de Lynch (L) y 19 individuos sanos (C). Todos los pacientes tuvieron una colonoscopia al menos 15 días antes de la recogida de muestras. Todos ellos firmaron el correspondiente consentimiento informado. Los criterios de exclusión incluyeron tratamiento con antibióticos dentro de 1 mes antes del estudio y edad < 18 años.
Se cuantificaron las cuatro secuencias bacterianas en muestras fecales de individuos sanos, pacientes a los que se les diagnosticó recientemente CCR y portadores del síndrome de Lynch. Los portadores del síndrome de Lynch están predispuestos genéticamente a desarrollar cáncer, específicamente cáncer colorrectal. Este grupo está compuesto por individuos sin neoplasia de cáncer colorrectal y sin signos clínicos, y se considera como grupo de riesgo de cáncer colorrectal.
Se observó que el grupo con síndrome de Lynch presentó un aumento significativo del valor de Ct de B3 y B48 en
comparación con grupos de pacientes sanos. Por tanto, en el grupo de Lynch hubo una carga menor de bacterias B3 y B48 en muestra de heces.
Efectivamente, el grupo de Lynch no muestra ninguna diferencia estadística de cuantificación de secuencias bacterianas en comparación con CCR excepto para B10. Lo que implica que el perfil microbiológico del grupo de Lynch es similar a CCR aunque no se observan signos clínicos y neoplasia en este grupo. Este hecho significa que la detección de uno o más de estas cuatro secuencias bacterianas puede ser una potente herramienta para cribar personas con riesgo de CCR y que pueden necesitar exploración de colonoscopia.
Tabla 6. Cuantificación de las 4 secuencias bacterianas en individuos sanos, pacientes con CCR y portadores del síndrome de Lynch (expresado en Ct), análisis estadístico mediante análisis ROC y de ANOVA de un factor.
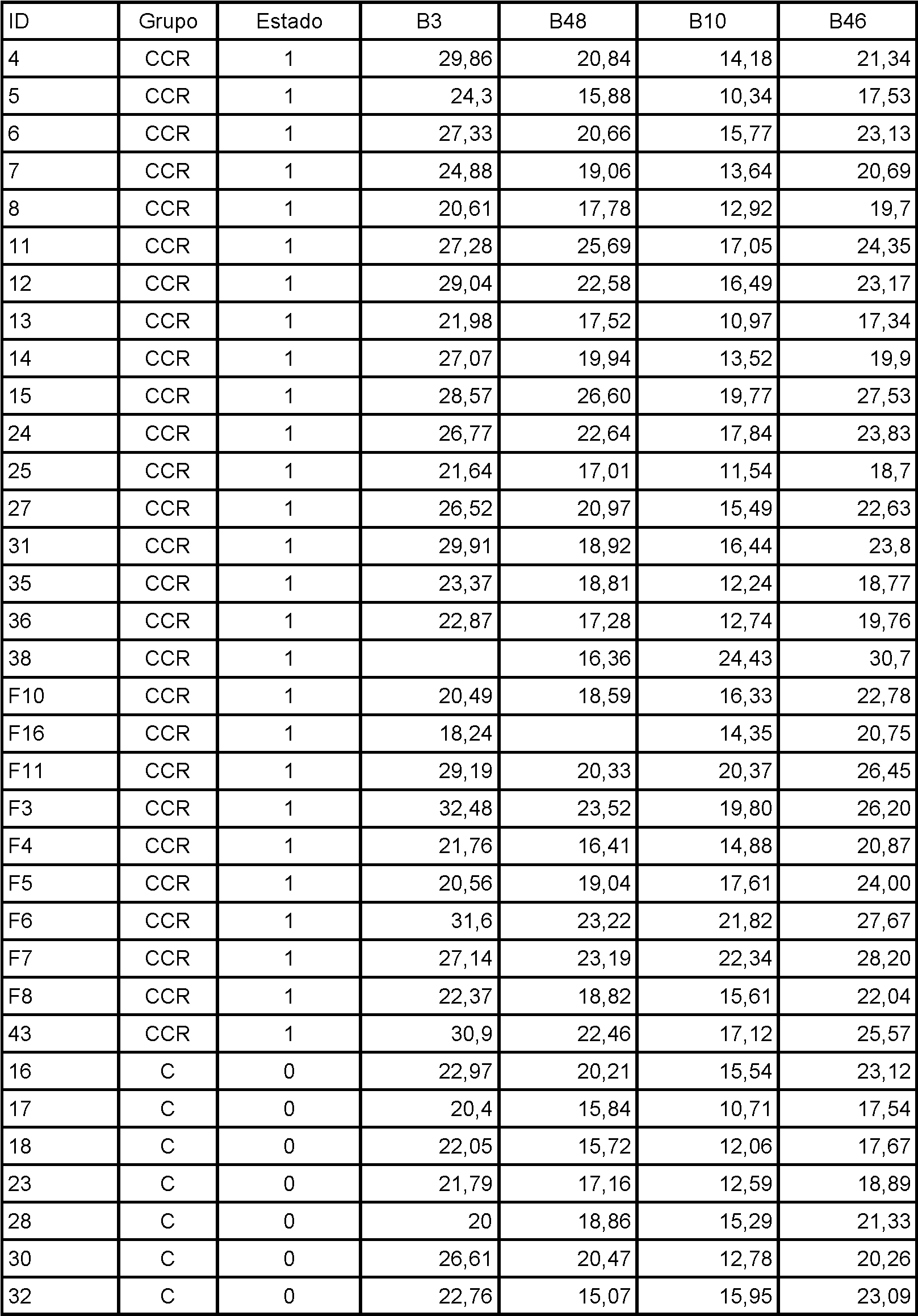


Las figuras 18 a 21 proporcionan la representación gráfica de valores de Ct absolutos en grupos de CCR, L y C de secuencias SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10, respectivamente.
La figura 28 proporciona las curvas ROC para B3, B10, B46 y B48 en análisis de sanos (C) frente a Lynch (L).
La figura 30 proporciona las curvas ROC para B3, B10, B46 y B48 en análisis de CCR frente a Lynch.
Ejemplo 7: Análisis de biomarcadores de ADNr 16S de CCR Lynch frente a individuos sanos
Según el análisis del ejemplo 6, los portadores del síndrome de Lynch tienen un perfil microbiológico en heces similar a pacientes con CCR. Por tanto, en este experimento, se pretende someter a prueba el potencial de usar detección de cuantificación de las cuatro secuencias bacterianas para cribar individuos con riesgo de cáncer colorrectal en individuos sanos e individuos con riesgo de cáncer colorrectal (CCR L), antes de la exploración de colonos
En la tabla 7, se han representado la cuantificación de secuencias bacterianas expresadas en Ct.
Se observa que B3, B48 y B46 aumentan significativamente el valor de Ct en el grupo de riesgo de cáncer colorrectal (c Cr L). Por tanto, el nivel de estas bacterias en heces disminuye.
B10 en CCR L también presenta un nivel más bajo aunque no se observan diferencias estadísticas (p=0,137). Al evaluar el rendimiento de cuantificación bacteriana en la detección de cáncer colorrectal, se muestra que B3 y B48 tienen la mejor exactitud (0,7) y, respectivamente, el 56,2% de sensibilidad-el 88,9% de especificidad y el 51% de sensibilidad-el 84% de especificidad.
En segundo lugar, B46 tienen una exactitud de 0,665 y el 94,7% de sensibilidad-el 23,12% de especificidad. Finalmente, B10 tiene una exactitud de 0,58 y el 44,9% de sensibilidad-el 89,5% de especificidad.
Se calculó la razón entre Ct de cuantificación de secuencias bacterianas. Aunque no se observan diferencias estadísticas (B3/B46 p = 0,061 con prueba de la U de Mann-Whitney; B10/B3 p = 0,132 con análisis de prueba de la t de dos muestras; B46/B10 con análisis de prueba de la t de dos muestras p = 0,127); ha de considerarse que aplicar esta razón en una muestra aumentada puede ser un algoritmo útil para completar el cribado de CCR.
En esta línea, la combinación de cuatro secuencias también debe considerarse que aumenta la sensibilidad y especificidad de la prueba.
Tabla 7. Cuantificación de las 4 secuencias bacterianas expresadas en Ct de individuos sanos (C) e individuos con riesgo de cáncer colorrectal (CCR L), análisis estadístico mediante análisis de ROC y prueba de la t de dos muestras.
ID Grupo Estado B3 B48 B10 B46


La figura 22 proporciona la representación gráfica de valores de Ct absolutos de secuencias SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID No : 7 y SEQ ID NO: 10, respectivamente, en grupos de CCR+ Lynch (L) y sanos (C).
La figura 29 proporciona las curvas ROC para B3, B10, B46 y B48 en análisis de sanos frente a CCR con síndrome de Lynch.
Ejemplo 8: Análisis de biomarcadores de ADNr 16S de CCR frente a L-alto riesgo frente a L-bajo riesgo frente a individuos sanos
En este ejemplo, se pretende definir diferentes grados de riesgo de cáncer colorrectal usando cuantificación de secuencias bacterianas en portadores del síndrome de Lynch.
Se clasificaron los portadores del síndrome de Lynch en cáncer colorrectal de alto riesgo (L-alto riesgo) y bajo riesgo (L-bajo riesgo) según sus antecedentes de neoplasia colorrectal y la presencia de adenomas en su última colonoscopia. Se tienen 6 individuos de alto riesgo y 18 de bajo.
Se realizó la cuantificación de las cuatro secuencias bacterianas y no se observaron diferencias estadísticas entre los diferentes grupos. Sólo para los niveles de B3, hubo una tendencia de un Ct disminuido en comparación con C frente a L-bajo riesgo (p = 0,088, prueba de Kruskal-Wallis) y C frente a L-alto riesgo (p = 0,143, prueba de Kruskal-Wallis).
Se calculó la razón entre Ct de cuantificación de secuencias bacterianas.
Se aplicó la prueba de Kruskal-Wallis y las razones B3/B10 y B10/B46 presentan una diferencia significativa entre C y L-bajo riesgo. La razón B3/B48 muestra una diferencia significativa al comparar C frente a L-alto riesgo. Las razones B3/B10 y B48/B10 fueron significativamente diferentes en CCR frente a L-alto riesgo.
No se realizaron los análisis de ROC debido al tamaño de la muestra, pero considerando los análisis estadísticos, se podría predecir que la mejor razón podría ser B3/B10 porque es capaz de distinguir grupo de L-bajo riesgo.
En esta línea, la combinación de cuatro secuencias también debe considerarse que aumenta la potencia de la prueba, y debe realizarse un análisis de regresión logística multivariable pero se requiere un tamaño de muestra aumentado.
Tabla 8. Cuantificación de las 4 secuencias bacterianas expresadas en Ct de individuos sanos (C), L-bajo riesgo, L-alto riesgo y CRC



Claims (11)
- REIVINDICACIONESi . Método para determinar el riesgo de desarrollar cáncer colorrectal (CCR) en un sujeto humano que comprende:i. cuantificar al menos una secuencia bacteriana de ADNr 16S seleccionada de la lista que consiste en SEQ ID NO: 1, SEQ ID NO: 7 y SEQ ID NO: 10, a partir de una muestra de heces de dicho sujeto;ii. comparar los niveles de cuantificación de la muestra del sujeto en (i) con los niveles de cuantificación en una muestra de control; yiii. determinar el riesgo de desarrollar CCR en dicho sujeto humano, cuando existe una desviación de los valores de muestra del sujeto a partir de los valores en dicha muestra de control.
- 2. Método de cribado de cáncer colorrectal (CCR) en un sujeto humano que comprende:i. cuantificar al menos una secuencia bacteriana de ADNr 16S seleccionada de la lista que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10 a partir de una muestra de heces de dicho sujeto;ii. comparar los niveles de cuantificación de la muestra del sujeto en (i) con los niveles de cuantificación en una muestra de control; yiii. diagnosticar, detectar de manera temprana o determinar recaída de CCR en dicho sujeto humano, o determinar que debe realizarse una colonoscopia en dicho sujeto humano, cuando existe una desviación de los valores de muestra del sujeto a partir de los valores en dicha muestra de control.
- 3. Método según cualquiera de las reivindicaciones 1 ó 2, en el que dicho método comprende en la etapa (i) cuantificar 2, 3 o todas de dichas secuencias bacterianas, preferiblemente todas de dichas secuencias bacterianas.
- 4. Método según cualquiera de las reivindicaciones 1 a 3, en el que al menos dos de dichas secuencias bacterianas se cuantifican en la etapa i) y al menos se determina una de las razones de los niveles de cuantificación de dichas secuencias, que comprende además comparar al menos una de dichas razones en dicho sujeto con la razón en una muestra de control, en el que una desviación de la razón de dicha muestra de control es indicadora de CCR.
- 5. Método según cualquiera de las reivindicaciones 1 a 4, en el que antes de la cuantificación de dichas secuencias bacterianas, se extrae ADN de la muestra de heces lo que implica alteración física de la muestra por cualquier medio y el ADN se purifica sobre columnas de membrana de sílice.
- 6. Método según cualquiera de las reivindicaciones 1 a 5, en el que la cuantificación de dichas secuencias bacterianas se realiza mediante PCR cuantitativa.
- 7. Método según la reivindicación 6, en el que los niveles de cuantificación de las secuencias se expresan como valor umbral de ciclo (Ct).
- 8. Método según cualquiera de las reivindicaciones 1 a 7, en el que dicho al menos un nivel de cuantificación de ADNr 16S se determina mediante PCR cuantitativa a partir de dicha muestra de heces humanas y en el que los niveles de cuantificación de SEQ ID NO: 1 se determinan usando cebadores con al menos una identidad del 90% con SEQ ID NO: 2 y 13, respectivamente; los niveles de cuantificación de SEQ ID NO: 4 se determinan usando cebadores con al menos una identidad del 90% con SEQ ID NO: 5 y 6, respectivamente; los niveles de cuantificación de SEQ ID NO: 7 se determinan usando cebadores con al menos una identidad del 90% con SEQ ID NO: 8 y 9, respectivamente; y los niveles de cuantificación de SEQ ID NO: 10 se determinan usando cebadores con al menos una identidad del 90% con SEQ ID NO: 11 y 12, respectivamente.
- 9. Método según cualquiera de las reivindicaciones 1 a 8, en el que los niveles de SEQ ID NO: 1 se determinan usando cebadores con secuencia SEQ ID NO: 2 y 13, los niveles de SEQ ID NO: 4 se determinan usando cebadores con secuencia SEQ ID NO: 5 y 6; los niveles de SEQ ID NO: 7 se determinan usando cebadores con secuencia SEQ ID NO: 8 y 9; y los niveles de SEQ ID NO: 10 se determinan usando cebadores con secuencia SEQ ID NO: 11 y 12.
- 10. Método según cualquiera de las reivindicaciones 1 a 9, en el que dicho método comprende además detectar y/o cuantificar uno o más biomarcadores moleculares que se sabe que son indicadores de CCR.
- 11. Método según cualquiera de las reivindicaciones 1 a 10, en el que dicho método comprende además almacenar los resultados del método en un medio legible por ordenador.Uso de un kit para diagnosticar, detectar de manera temprana o determinar recaída de CCR, determinar el riesgo de desarrollar CCR o determinar si debe realizarse una colonoscopia, a partir de una muestra de heces de un sujeto humano, según el método de cualquiera de las reivindicaciones 1 a 11, comprendiendo dicho kit:a. un reactivo seleccionado del grupo que consiste en:i. sondas de ácido nucleico capaces de hibridarse específicamente con al menos una secuencia de ADNr 16S seleccionada de la lista que consiste en SEQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10; oii. un par de cebadores de ácido nucleico capaces de amplificar específicamente al menos una secuencia de ADNr 16S seleccionada de la lista que consiste en SeQ ID NO: 1, SEQ ID NO: 4, SEQ ID NO: 7 y SEQ ID NO: 10; yb. instrucciones para cuantificar los niveles de una o más de dichas secuencias a partir de una muestra de heces humanas.Uso de un kit según la reivindicación 12, en el que dichas sondas de ácido nucleico en (i) o par de cebadores de ácido nucleico en (ii) se seleccionan del grupo que consiste en SEQ ID NO: 2, SEQ ID NO: 13, SEQ ID NO: 5, SEQ ID NO: 6, SEQ ID NO: 8, SEQ ID NO: 9, SEQ ID NO: 11, y SEQ ID NO: 12; o con una identidad de al menos el 90% de los mismos.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP14382074.4A EP2915884B1 (en) | 2014-03-03 | 2014-03-03 | Method for diagnosing colorectal cancer from a human feces sample by quantitive PCR |
| PCT/EP2015/054451 WO2015132273A1 (en) | 2014-03-03 | 2015-03-03 | Method for diagnosing colorectal cancer from a human feces sample by quantitive pcr, primers and kit |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2734143T3 true ES2734143T3 (es) | 2019-12-04 |
Family
ID=50241352
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES14382074.4T Active ES2661684T3 (es) | 2014-03-03 | 2014-03-03 | Método para diagnosticar cáncer colorrectal a partir de una muestra de heces humanas mediante PCR cuantitativa |
| ES15708187T Active ES2734143T3 (es) | 2014-03-03 | 2015-03-03 | Método para diagnosticar cáncer colorrectal a partir de una muestra de heces humanas mediante PCR cuantitativa |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES14382074.4T Active ES2661684T3 (es) | 2014-03-03 | 2014-03-03 | Método para diagnosticar cáncer colorrectal a partir de una muestra de heces humanas mediante PCR cuantitativa |
Country Status (17)
| Country | Link |
|---|---|
| US (1) | US10927416B2 (es) |
| EP (2) | EP2915884B1 (es) |
| JP (2) | JP7053146B2 (es) |
| KR (1) | KR102354660B1 (es) |
| CN (1) | CN106574294A (es) |
| AU (1) | AU2015226203B2 (es) |
| CA (1) | CA2941502C (es) |
| DK (1) | DK3114234T3 (es) |
| ES (2) | ES2661684T3 (es) |
| HR (1) | HRP20191108T1 (es) |
| IL (1) | IL247370B (es) |
| MX (1) | MX375586B (es) |
| PT (1) | PT3114234T (es) |
| RU (1) | RU2692555C2 (es) |
| SI (1) | SI3114234T1 (es) |
| TR (1) | TR201909533T4 (es) |
| WO (1) | WO2015132273A1 (es) |
Families Citing this family (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3130680A1 (en) | 2015-08-11 | 2017-02-15 | Universitat de Girona | Method for the detection, follow up and/or classification of intestinal diseases |
| CN105543354B (zh) | 2015-12-31 | 2019-07-26 | 广州市康立明生物科技有限责任公司 | 一种肿瘤分子检测/诊断试剂 |
| WO2017172894A2 (en) * | 2016-03-30 | 2017-10-05 | The Trustees Of Columbia University In The City Of New York | Methods of preventing, treating and detecting colorectal cancer using butyrate producing bacteria |
| CN108690864A (zh) * | 2017-10-31 | 2018-10-23 | 中山大学 | 一种粪便样本中菌群稳态评价方法及在结直肠癌筛查中的应用 |
| KR102282490B1 (ko) * | 2018-01-12 | 2021-07-28 | 주식회사 엠디헬스케어 | 패칼리박테리움 프라우스니찌 유래 나노소포 및 이의 용도 |
| WO2019226035A1 (ko) * | 2018-05-25 | 2019-11-28 | 주식회사 엠디헬스케어 | Qpcr 분석을 통한 대장암 진단방법 |
| CN110857450B (zh) * | 2018-08-22 | 2023-04-07 | 深圳华大生命科学研究院 | 结直肠癌标志物及其应用 |
| WO2020093040A1 (en) * | 2018-11-02 | 2020-05-07 | The Regents Of The University Of California | Methods to diagnose and treat cancer using non-human nucleic acids |
| FI3938542T3 (fi) | 2019-03-13 | 2025-10-03 | Goodgut S L | Parannettu menetelmä pitkälle edenneen paksu- ja peräsuolikasvaimen, pitkälle edenneen adenooman ja/tai paksu- ja peräsuolisyövän seulomiseksi, diagnosoimiseksi ja/tai seuraamiseksi |
| EP3950929A4 (en) * | 2019-03-28 | 2023-01-04 | CJ Bioscience, Inc. | FAECALIBACTERIUM SP. MICROBE AND ANTI-CANCER COMPOSITION WITH IT |
| US20220235404A1 (en) * | 2019-05-23 | 2022-07-28 | American Molecular Laboratories, Inc. | Methods for detection of rare dna sequences in fecal samples |
| KR102308931B1 (ko) * | 2019-05-24 | 2021-10-06 | 주식회사 엠디헬스케어 | qPCR 분석을 통한 대장염 진단방법 |
| CN111500732A (zh) * | 2020-05-25 | 2020-08-07 | 福建医科大学 | 微生物在作为子宫内膜癌的诊断标志物中的应用和试剂盒 |
| CN113106163B (zh) | 2020-05-27 | 2024-06-04 | 微度(苏州)生物科技有限公司 | 一种用于结直肠癌早期诊断的生物标志物组合物及应用 |
| CN112048564A (zh) * | 2020-08-11 | 2020-12-08 | 康美华大基因技术有限公司 | 一种快速检测瘤胃球菌的荧光定量pcr引物组、试剂盒及其应用 |
| CN114107527A (zh) * | 2021-12-10 | 2022-03-01 | 中国药科大学 | 用于检测丁酰辅酶a脱氢酶基因的引物对及试剂盒 |
| CN115261271B (zh) * | 2022-08-01 | 2023-12-12 | 厦门承葛生物科技有限公司 | 一种肠道菌群的高通量分离培养与筛选方法 |
| CN115963268B (zh) * | 2023-02-14 | 2023-09-19 | 浙江大学 | 一种用于结直肠癌早期诊断的血浆分泌蛋白组合及应用 |
| CN117051113B (zh) * | 2023-10-12 | 2023-12-29 | 上海爱谱蒂康生物科技有限公司 | 生物标志物组合在制备预测结直肠癌的试剂盒中的应用 |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6054278A (en) * | 1997-05-05 | 2000-04-25 | The Perkin-Elmer Corporation | Ribosomal RNA gene polymorphism based microorganism identification |
| WO2001023608A2 (en) * | 1999-09-27 | 2001-04-05 | Merck Sharp & Dohme De Espana, S.A.E. | Hybridization probes which specifically detect strains of the genera microbispora, microtetraspora, nonomuria and planobispora |
| JPWO2009057695A1 (ja) * | 2007-10-30 | 2011-03-10 | オリンパス株式会社 | 遺伝子解析による腺腫又はがんの検出方法 |
| JP2009165401A (ja) * | 2008-01-16 | 2009-07-30 | Olympus Corp | 標的物質の定量方法 |
| CN102105583A (zh) | 2008-07-23 | 2011-06-22 | 奥林巴斯株式会社 | 从粪便试样中回收核酸的方法、核酸分析方法以及粪便试样处理装置 |
| US20140171339A1 (en) * | 2011-06-06 | 2014-06-19 | The University Of North Carolina At Chapel Hill | Methods and kits for detecting adenomas, colorectal cancer, and uses thereof |
| BR112015020819A2 (pt) * | 2013-03-05 | 2017-07-18 | Academisch Ziekenhuis Groningen | uso de faecalibacterium prausnitzii htf-f (dsm 26943) para supressão de inflamação |
| ES2673276T3 (es) * | 2013-03-14 | 2018-06-21 | University Of Ottawa | Métodos para el diagnóstico y el tratamiento de la enfermedad inflamatoria intestinal |
| CN105473738B (zh) * | 2013-08-06 | 2018-09-21 | 深圳华大基因科技有限公司 | 结直肠癌生物标志物 |
-
2014
- 2014-03-03 ES ES14382074.4T patent/ES2661684T3/es active Active
- 2014-03-03 EP EP14382074.4A patent/EP2915884B1/en active Active
-
2015
- 2015-03-03 US US15/122,897 patent/US10927416B2/en active Active
- 2015-03-03 MX MX2016011377A patent/MX375586B/es active IP Right Grant
- 2015-03-03 PT PT15708187T patent/PT3114234T/pt unknown
- 2015-03-03 CN CN201580022938.6A patent/CN106574294A/zh active Pending
- 2015-03-03 CA CA2941502A patent/CA2941502C/en active Active
- 2015-03-03 TR TR2019/09533T patent/TR201909533T4/tr unknown
- 2015-03-03 EP EP15708187.8A patent/EP3114234B1/en active Active
- 2015-03-03 DK DK15708187.8T patent/DK3114234T3/da active
- 2015-03-03 KR KR1020167027370A patent/KR102354660B1/ko active Active
- 2015-03-03 RU RU2016138766A patent/RU2692555C2/ru active
- 2015-03-03 ES ES15708187T patent/ES2734143T3/es active Active
- 2015-03-03 SI SI201530802T patent/SI3114234T1/sl unknown
- 2015-03-03 WO PCT/EP2015/054451 patent/WO2015132273A1/en not_active Ceased
- 2015-03-03 JP JP2016555535A patent/JP7053146B2/ja active Active
- 2015-03-03 HR HRP20191108TT patent/HRP20191108T1/hr unknown
- 2015-03-03 AU AU2015226203A patent/AU2015226203B2/en active Active
-
2016
- 2016-08-21 IL IL247370A patent/IL247370B/en active IP Right Grant
-
2020
- 2020-05-27 JP JP2020092167A patent/JP2020146052A/ja active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| JP7053146B2 (ja) | 2022-04-12 |
| US10927416B2 (en) | 2021-02-23 |
| RU2016138766A3 (es) | 2018-04-03 |
| ES2661684T3 (es) | 2018-04-03 |
| IL247370B (en) | 2020-07-30 |
| AU2015226203A1 (en) | 2016-10-20 |
| AU2015226203B2 (en) | 2020-11-12 |
| CA2941502C (en) | 2023-09-26 |
| MX2016011377A (es) | 2017-05-04 |
| HRP20191108T1 (hr) | 2019-09-20 |
| KR102354660B1 (ko) | 2022-01-24 |
| RU2692555C2 (ru) | 2019-06-25 |
| US20170096709A1 (en) | 2017-04-06 |
| DK3114234T3 (da) | 2019-07-15 |
| WO2015132273A1 (en) | 2015-09-11 |
| EP2915884B1 (en) | 2017-12-06 |
| TR201909533T4 (tr) | 2019-07-22 |
| PT3114234T (pt) | 2019-07-12 |
| EP2915884A1 (en) | 2015-09-09 |
| KR20170028296A (ko) | 2017-03-13 |
| JP2017508464A (ja) | 2017-03-30 |
| EP3114234B1 (en) | 2019-04-24 |
| RU2016138766A (ru) | 2018-04-03 |
| IL247370A0 (en) | 2016-11-30 |
| CN106574294A (zh) | 2017-04-19 |
| EP3114234A1 (en) | 2017-01-11 |
| JP2020146052A (ja) | 2020-09-17 |
| SI3114234T1 (sl) | 2019-09-30 |
| MX375586B (es) | 2025-03-06 |
| CA2941502A1 (en) | 2015-09-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ES2734143T3 (es) | Método para diagnosticar cáncer colorrectal a partir de una muestra de heces humanas mediante PCR cuantitativa | |
| Toiyama et al. | A panel of methylated microRNA biomarkers for identifying high-risk patients with ulcerative colitis-associated colorectal cancer | |
| ES2691404T3 (es) | Diagnóstico no invasivo del cáncer | |
| Vemulapalli et al. | Failure to recognize serrated polyposis syndrome in a cohort with large sessile colorectal polyps | |
| ES2901465T3 (es) | Procedimiento para la cuantificación de los miembros del filogrupo I y/o filogrupo II de Faecalibacterium prausnitzii y uso de los mismos como biomarcadores | |
| ES2647154T3 (es) | Combinaciones de biomarcadores para tumores colorrectales | |
| Sayal et al. | Saliva‐based cell‐free DNA and cell‐free mitochondrial DNA in head and neck cancers have promising screening and early detection role | |
| ES2893469T3 (es) | Puntuaciones de riesgo basadas en la expresión de la variante 7 de la fosfodiesterasa 4D humana | |
| Vantanasiri et al. | Advances in screening for barrett esophagus and esophageal adenocarcinoma | |
| Alizadeh-Sedigh et al. | Methylation of FBN1, SPG20, ITF2, RUNX3, SNCA, MLH1, and SEPT9 genes in circulating cell-free DNA as biomarkers of colorectal cancer | |
| Kalra et al. | Discovery of methylated DNA biomarkers for potential nonendoscopic detection of barrett’s esophagus and esophageal adenocarcinoma | |
| Helm et al. | Colorectal cancer screening | |
| Tan et al. | Progress in screening for Barrett’s esophagus: beyond standard upper endoscopy | |
| Chubak et al. | Informed consent to microsatellite instability and immunohistochemistry screening for Lynch syndrome | |
| Konda et al. | Barrett’s esophagus and esophageal carcinoma: can biomarkers guide clinical practice? | |
| HK1232919B (en) | Method for diagnosing colorectal cancer from a human feces sample by quantitive pcr | |
| HK1232919A1 (en) | Method for diagnosing colorectal cancer from a human feces sample by quantitive pcr | |
| Cervilla Sosa | Faecal microrna and colorectal cancer in symptomatic patients: a case-control study | |
| RU2813653C1 (ru) | Способ ранней диагностики рецидивов рака прямой кишки при мониторинге течения заболевания | |
| Chen et al. | Prediction model based on gut microbiota as a non-invasive tool for gastric cancer diagnosis | |
| ES2972307T3 (es) | Método in vitro para el diagnóstico o pronóstico del cáncer colorrectal o un estadio precanceroso del mismo | |
| WO2019241899A1 (es) | Detección no invasiva de cáncer gástrico a través de la detección en sangre de la metilación de reprimo like | |
| Jeronimo et al. | Cell-Free DNA Methylation of Selected Genes Allows for Early Detection of the Major Cancers in Women | |
| Jacob et al. | Peritoneal Tumor Dna in a Multimodal Treatment Setting of Locally Advanced Gastric Cancer–A Novel Study Design | |
| Wang et al. | Analysis of urine cell-free DNA copy number and fragment size from healthy individuals |