ES2874149T3 - Composiciones y métodos para inhibir la expresión del gen PCSK9 - Google Patents
Composiciones y métodos para inhibir la expresión del gen PCSK9 Download PDFInfo
- Publication number
- ES2874149T3 ES2874149T3 ES19168142T ES19168142T ES2874149T3 ES 2874149 T3 ES2874149 T3 ES 2874149T3 ES 19168142 T ES19168142 T ES 19168142T ES 19168142 T ES19168142 T ES 19168142T ES 2874149 T3 ES2874149 T3 ES 2874149T3
- Authority
- ES
- Spain
- Prior art keywords
- dsrna
- pcsk9
- expression
- sequence
- nucleotide
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 101150094724 PCSK9 gene Proteins 0.000 title claims abstract description 91
- 230000014509 gene expression Effects 0.000 title claims abstract description 80
- 238000000034 method Methods 0.000 title claims description 67
- 239000000203 mixture Substances 0.000 title description 48
- 125000003729 nucleotide group Chemical group 0.000 claims abstract description 107
- 239000002773 nucleotide Substances 0.000 claims abstract description 99
- 108020004999 messenger RNA Proteins 0.000 claims abstract description 55
- 230000000295 complement effect Effects 0.000 claims abstract description 44
- 230000000692 anti-sense effect Effects 0.000 claims abstract description 33
- 230000002401 inhibitory effect Effects 0.000 claims abstract description 21
- 101001098868 Homo sapiens Proprotein convertase subtilisin/kexin type 9 Proteins 0.000 claims abstract description 16
- 229920002477 rna polymer Polymers 0.000 claims abstract description 14
- 102100038955 Proprotein convertase subtilisin/kexin type 9 Human genes 0.000 claims abstract description 12
- 108091081021 Sense strand Proteins 0.000 claims abstract description 9
- 101100135844 Homo sapiens PCSK9 gene Proteins 0.000 claims abstract description 4
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol group Chemical group [C@@H]1(CC[C@H]2[C@@H]3CC=C4C[C@@H](O)CC[C@]4(C)[C@H]3CC[C@]12C)[C@H](C)CCCC(C)C HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 claims description 45
- 239000013598 vector Substances 0.000 claims description 34
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 31
- 238000011282 treatment Methods 0.000 claims description 25
- 230000003828 downregulation Effects 0.000 claims description 22
- 238000000338 in vitro Methods 0.000 claims description 17
- 230000001404 mediated effect Effects 0.000 claims description 17
- 239000003937 drug carrier Substances 0.000 claims description 13
- 239000008194 pharmaceutical composition Substances 0.000 claims description 13
- 208000031226 Hyperlipidaemia Diseases 0.000 claims description 12
- 230000001105 regulatory effect Effects 0.000 claims description 11
- 208000037273 Pathologic Processes Diseases 0.000 claims description 9
- 230000009054 pathological process Effects 0.000 claims description 9
- 208000035475 disorder Diseases 0.000 claims description 8
- 230000015556 catabolic process Effects 0.000 claims description 6
- 238000006731 degradation reaction Methods 0.000 claims description 6
- 125000004573 morpholin-4-yl group Chemical group N1(CCOCC1)* 0.000 claims description 4
- PTMHPRAIXMAOOB-UHFFFAOYSA-L phosphoramidate Chemical compound NP([O-])([O-])=O PTMHPRAIXMAOOB-UHFFFAOYSA-L 0.000 claims description 3
- 230000002265 prevention Effects 0.000 claims description 3
- 208000035657 Abasia Diseases 0.000 claims description 2
- POULHZVOKOAJMA-UHFFFAOYSA-N dodecanoic acid Chemical compound CCCCCCCCCCCC(O)=O POULHZVOKOAJMA-UHFFFAOYSA-N 0.000 claims 2
- 210000004027 cell Anatomy 0.000 description 82
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 69
- 108091034117 Oligonucleotide Proteins 0.000 description 61
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 44
- 239000003446 ligand Substances 0.000 description 33
- 238000001727 in vivo Methods 0.000 description 27
- 239000003795 chemical substances by application Substances 0.000 description 26
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 25
- YMWUJEATGCHHMB-UHFFFAOYSA-N Dichloromethane Chemical compound ClCCl YMWUJEATGCHHMB-UHFFFAOYSA-N 0.000 description 24
- 108090000623 proteins and genes Proteins 0.000 description 24
- 239000000243 solution Substances 0.000 description 24
- 201000010099 disease Diseases 0.000 description 23
- 239000002777 nucleoside Substances 0.000 description 23
- 241000282414 Homo sapiens Species 0.000 description 21
- 108020004459 Small interfering RNA Proteins 0.000 description 19
- 239000013603 viral vector Substances 0.000 description 19
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 18
- XEKOWRVHYACXOJ-UHFFFAOYSA-N Ethyl acetate Chemical compound CCOC(C)=O XEKOWRVHYACXOJ-UHFFFAOYSA-N 0.000 description 17
- 235000012000 cholesterol Nutrition 0.000 description 17
- 150000007523 nucleic acids Chemical class 0.000 description 17
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 15
- 230000000694 effects Effects 0.000 description 15
- 150000002632 lipids Chemical class 0.000 description 15
- 238000012986 modification Methods 0.000 description 15
- 230000004048 modification Effects 0.000 description 15
- -1 nucleoside thiophosphate Chemical class 0.000 description 15
- 238000003786 synthesis reaction Methods 0.000 description 14
- 230000015572 biosynthetic process Effects 0.000 description 13
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 12
- 241000124008 Mammalia Species 0.000 description 12
- 241000699666 Mus <mouse, genus> Species 0.000 description 12
- 239000002502 liposome Substances 0.000 description 12
- 102000039446 nucleic acids Human genes 0.000 description 12
- 108020004707 nucleic acids Proteins 0.000 description 12
- 241000699670 Mus sp. Species 0.000 description 11
- 238000009472 formulation Methods 0.000 description 11
- 210000004185 liver Anatomy 0.000 description 11
- 230000027455 binding Effects 0.000 description 10
- 150000002148 esters Chemical class 0.000 description 10
- 125000003835 nucleoside group Chemical group 0.000 description 10
- 108020004414 DNA Proteins 0.000 description 9
- 108010001831 LDL receptors Proteins 0.000 description 9
- 102000000853 LDL receptors Human genes 0.000 description 9
- YXFVVABEGXRONW-UHFFFAOYSA-N Toluene Chemical compound CC1=CC=CC=C1 YXFVVABEGXRONW-UHFFFAOYSA-N 0.000 description 9
- 239000003153 chemical reaction reagent Substances 0.000 description 9
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 9
- 239000002953 phosphate buffered saline Substances 0.000 description 9
- 230000008569 process Effects 0.000 description 9
- 239000007787 solid Substances 0.000 description 9
- 241000701161 unidentified adenovirus Species 0.000 description 9
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 9
- JUJWROOIHBZHMG-UHFFFAOYSA-N Pyridine Chemical compound C1=CC=NC=C1 JUJWROOIHBZHMG-UHFFFAOYSA-N 0.000 description 8
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 8
- 239000002253 acid Substances 0.000 description 8
- OVBPIULPVIDEAO-LBPRGKRZSA-N folic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-LBPRGKRZSA-N 0.000 description 8
- 230000030279 gene silencing Effects 0.000 description 8
- 150000003833 nucleoside derivatives Chemical class 0.000 description 8
- 102000040430 polynucleotide Human genes 0.000 description 8
- 108091033319 polynucleotide Proteins 0.000 description 8
- 239000002157 polynucleotide Substances 0.000 description 8
- 238000001890 transfection Methods 0.000 description 8
- 102100031181 Glyceraldehyde-3-phosphate dehydrogenase Human genes 0.000 description 7
- 241001465754 Metazoa Species 0.000 description 7
- 241000700159 Rattus Species 0.000 description 7
- 108700019146 Transgenes Proteins 0.000 description 7
- 125000002091 cationic group Chemical group 0.000 description 7
- 238000006243 chemical reaction Methods 0.000 description 7
- 108020004445 glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 7
- 239000000047 product Substances 0.000 description 7
- 230000009467 reduction Effects 0.000 description 7
- 238000006722 reduction reaction Methods 0.000 description 7
- 239000000126 substance Substances 0.000 description 7
- 102000007330 LDL Lipoproteins Human genes 0.000 description 6
- 108010007622 LDL Lipoproteins Proteins 0.000 description 6
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 6
- RYYWUUFWQRZTIU-UHFFFAOYSA-N Thiophosphoric acid Chemical class OP(O)(S)=O RYYWUUFWQRZTIU-UHFFFAOYSA-N 0.000 description 6
- 239000000872 buffer Substances 0.000 description 6
- 238000003776 cleavage reaction Methods 0.000 description 6
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 6
- 239000003814 drug Substances 0.000 description 6
- 235000019439 ethyl acetate Nutrition 0.000 description 6
- 238000001415 gene therapy Methods 0.000 description 6
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 6
- 125000005647 linker group Chemical group 0.000 description 6
- 239000000463 material Substances 0.000 description 6
- 238000002360 preparation method Methods 0.000 description 6
- 239000011541 reaction mixture Substances 0.000 description 6
- 230000007017 scission Effects 0.000 description 6
- 238000010532 solid phase synthesis reaction Methods 0.000 description 6
- 238000012360 testing method Methods 0.000 description 6
- 239000013607 AAV vector Substances 0.000 description 5
- 241000282693 Cercopithecidae Species 0.000 description 5
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 5
- PMZURENOXWZQFD-UHFFFAOYSA-L Sodium Sulfate Chemical compound [Na+].[Na+].[O-]S([O-])(=O)=O PMZURENOXWZQFD-UHFFFAOYSA-L 0.000 description 5
- QTBSBXVTEAMEQO-UHFFFAOYSA-N acetic acid Substances CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 5
- 125000003277 amino group Chemical group 0.000 description 5
- 238000003556 assay Methods 0.000 description 5
- 239000003114 blood coagulation factor Substances 0.000 description 5
- 230000037396 body weight Effects 0.000 description 5
- 150000001875 compounds Chemical class 0.000 description 5
- 230000021615 conjugation Effects 0.000 description 5
- 230000000875 corresponding effect Effects 0.000 description 5
- 229940012413 factor vii Drugs 0.000 description 5
- 230000005764 inhibitory process Effects 0.000 description 5
- 238000002347 injection Methods 0.000 description 5
- 239000007924 injection Substances 0.000 description 5
- 230000003993 interaction Effects 0.000 description 5
- 239000002609 medium Substances 0.000 description 5
- 230000035772 mutation Effects 0.000 description 5
- VLKZOEOYAKHREP-UHFFFAOYSA-N n-Hexane Chemical class CCCCCC VLKZOEOYAKHREP-UHFFFAOYSA-N 0.000 description 5
- 239000012074 organic phase Substances 0.000 description 5
- 239000002245 particle Substances 0.000 description 5
- 239000013612 plasmid Substances 0.000 description 5
- 210000002966 serum Anatomy 0.000 description 5
- 210000001519 tissue Anatomy 0.000 description 5
- VHYFNPMBLIVWCW-UHFFFAOYSA-N 4-Dimethylaminopyridine Chemical compound CN(C)C1=CC=NC=C1 VHYFNPMBLIVWCW-UHFFFAOYSA-N 0.000 description 4
- 229930024421 Adenine Natural products 0.000 description 4
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 4
- HEDRZPFGACZZDS-UHFFFAOYSA-N Chloroform Chemical compound ClC(Cl)Cl HEDRZPFGACZZDS-UHFFFAOYSA-N 0.000 description 4
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 4
- 208000000563 Hyperlipoproteinemia Type II Diseases 0.000 description 4
- 102100034389 Low density lipoprotein receptor adapter protein 1 Human genes 0.000 description 4
- OVBPIULPVIDEAO-UHFFFAOYSA-N N-Pteroyl-L-glutaminsaeure Natural products C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)NC(CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-UHFFFAOYSA-N 0.000 description 4
- 238000012228 RNA interference-mediated gene silencing Methods 0.000 description 4
- 102000009822 Sterol Regulatory Element Binding Proteins Human genes 0.000 description 4
- 108010020396 Sterol Regulatory Element Binding Proteins Proteins 0.000 description 4
- 229960000643 adenine Drugs 0.000 description 4
- 230000001413 cellular effect Effects 0.000 description 4
- 238000004440 column chromatography Methods 0.000 description 4
- 230000009260 cross reactivity Effects 0.000 description 4
- 239000003085 diluting agent Substances 0.000 description 4
- 238000009826 distribution Methods 0.000 description 4
- 238000005516 engineering process Methods 0.000 description 4
- 235000019152 folic acid Nutrition 0.000 description 4
- 239000011724 folic acid Substances 0.000 description 4
- 229960000304 folic acid Drugs 0.000 description 4
- 230000009368 gene silencing by RNA Effects 0.000 description 4
- 210000003494 hepatocyte Anatomy 0.000 description 4
- 238000009396 hybridization Methods 0.000 description 4
- 230000001939 inductive effect Effects 0.000 description 4
- 238000001990 intravenous administration Methods 0.000 description 4
- 210000005229 liver cell Anatomy 0.000 description 4
- 239000006166 lysate Substances 0.000 description 4
- 239000000178 monomer Substances 0.000 description 4
- 239000002105 nanoparticle Substances 0.000 description 4
- 150000008300 phosphoramidites Chemical class 0.000 description 4
- 239000002243 precursor Substances 0.000 description 4
- UMJSCPRVCHMLSP-UHFFFAOYSA-N pyridine Natural products COC1=CC=CN=C1 UMJSCPRVCHMLSP-UHFFFAOYSA-N 0.000 description 4
- 230000010837 receptor-mediated endocytosis Effects 0.000 description 4
- 239000000523 sample Substances 0.000 description 4
- 238000003756 stirring Methods 0.000 description 4
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 4
- 235000000346 sugar Nutrition 0.000 description 4
- 239000000725 suspension Substances 0.000 description 4
- 238000013518 transcription Methods 0.000 description 4
- 230000035897 transcription Effects 0.000 description 4
- 229940035893 uracil Drugs 0.000 description 4
- WFDIJRYMOXRFFG-UHFFFAOYSA-N Acetic anhydride Chemical compound CC(=O)OC(C)=O WFDIJRYMOXRFFG-UHFFFAOYSA-N 0.000 description 3
- 108020000948 Antisense Oligonucleotides Proteins 0.000 description 3
- 101100168093 Caenorhabditis elegans cogc-2 gene Proteins 0.000 description 3
- 108090000565 Capsid Proteins Proteins 0.000 description 3
- 102100023321 Ceruloplasmin Human genes 0.000 description 3
- 102000004190 Enzymes Human genes 0.000 description 3
- 108090000790 Enzymes Proteins 0.000 description 3
- 208000030673 Homozygous familial hypercholesterolemia Diseases 0.000 description 3
- 101710172072 Kexin Proteins 0.000 description 3
- 239000012097 Lipofectamine 2000 Substances 0.000 description 3
- 241000282553 Macaca Species 0.000 description 3
- 101100221487 Mus musculus Cog2 gene Proteins 0.000 description 3
- 101100135848 Mus musculus Pcsk9 gene Proteins 0.000 description 3
- ZMXDDKWLCZADIW-UHFFFAOYSA-N N,N-Dimethylformamide Chemical compound CN(C)C=O ZMXDDKWLCZADIW-UHFFFAOYSA-N 0.000 description 3
- 101710163270 Nuclease Proteins 0.000 description 3
- 108091028043 Nucleic acid sequence Proteins 0.000 description 3
- 102100040283 Peptidyl-prolyl cis-trans isomerase B Human genes 0.000 description 3
- 108091028664 Ribonucleotide Proteins 0.000 description 3
- VMHLLURERBWHNL-UHFFFAOYSA-M Sodium acetate Chemical compound [Na+].CC([O-])=O VMHLLURERBWHNL-UHFFFAOYSA-M 0.000 description 3
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 3
- ZMANZCXQSJIPKH-UHFFFAOYSA-N Triethylamine Chemical compound CCN(CC)CC ZMANZCXQSJIPKH-UHFFFAOYSA-N 0.000 description 3
- 238000010521 absorption reaction Methods 0.000 description 3
- 239000000074 antisense oligonucleotide Substances 0.000 description 3
- 238000012230 antisense oligonucleotides Methods 0.000 description 3
- 239000007864 aqueous solution Substances 0.000 description 3
- 239000012298 atmosphere Substances 0.000 description 3
- 208000006112 autosomal recessive hypercholesterolemia Diseases 0.000 description 3
- 230000033228 biological regulation Effects 0.000 description 3
- 210000000234 capsid Anatomy 0.000 description 3
- 239000000969 carrier Substances 0.000 description 3
- 230000004700 cellular uptake Effects 0.000 description 3
- 229940106189 ceramide Drugs 0.000 description 3
- 238000007385 chemical modification Methods 0.000 description 3
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 3
- 239000012043 crude product Substances 0.000 description 3
- 108010048032 cyclophilin B Proteins 0.000 description 3
- 229940104302 cytosine Drugs 0.000 description 3
- BGRWYRAHAFMIBJ-UHFFFAOYSA-N diisopropylcarbodiimide Natural products CC(C)NC(=O)NC(C)C BGRWYRAHAFMIBJ-UHFFFAOYSA-N 0.000 description 3
- 239000013604 expression vector Substances 0.000 description 3
- 208000032655 familial 4 hypercholesterolemia Diseases 0.000 description 3
- 102000053786 human PCSK9 Human genes 0.000 description 3
- 230000001976 improved effect Effects 0.000 description 3
- 208000015181 infectious disease Diseases 0.000 description 3
- 238000001802 infusion Methods 0.000 description 3
- 238000003780 insertion Methods 0.000 description 3
- 230000037431 insertion Effects 0.000 description 3
- 238000007918 intramuscular administration Methods 0.000 description 3
- 239000007788 liquid Substances 0.000 description 3
- 238000010172 mouse model Methods 0.000 description 3
- 230000002018 overexpression Effects 0.000 description 3
- 229920001223 polyethylene glycol Polymers 0.000 description 3
- 102000004169 proteins and genes Human genes 0.000 description 3
- 150000003212 purines Chemical class 0.000 description 3
- 230000001177 retroviral effect Effects 0.000 description 3
- 239000002336 ribonucleotide Substances 0.000 description 3
- 125000002652 ribonucleotide group Chemical group 0.000 description 3
- 150000003839 salts Chemical class 0.000 description 3
- 239000001632 sodium acetate Substances 0.000 description 3
- 235000017281 sodium acetate Nutrition 0.000 description 3
- 239000011780 sodium chloride Substances 0.000 description 3
- 239000004094 surface-active agent Substances 0.000 description 3
- 238000013268 sustained release Methods 0.000 description 3
- 239000012730 sustained-release form Substances 0.000 description 3
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 description 3
- 239000003981 vehicle Substances 0.000 description 3
- SCYULBFZEHDVBN-UHFFFAOYSA-N 1,1-Dichloroethane Chemical compound CC(Cl)Cl SCYULBFZEHDVBN-UHFFFAOYSA-N 0.000 description 2
- JUDOLRSMWHVKGX-UHFFFAOYSA-N 1,1-dioxo-1$l^{6},2-benzodithiol-3-one Chemical compound C1=CC=C2C(=O)SS(=O)(=O)C2=C1 JUDOLRSMWHVKGX-UHFFFAOYSA-N 0.000 description 2
- KSXTUUUQYQYKCR-LQDDAWAPSA-M 2,3-bis[[(z)-octadec-9-enoyl]oxy]propyl-trimethylazanium;chloride Chemical compound [Cl-].CCCCCCCC\C=C/CCCCCCCC(=O)OCC(C[N+](C)(C)C)OC(=O)CCCCCCC\C=C/CCCCCCCC KSXTUUUQYQYKCR-LQDDAWAPSA-M 0.000 description 2
- 229960000549 4-dimethylaminophenol Drugs 0.000 description 2
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 2
- 108010039209 Blood Coagulation Factors Proteins 0.000 description 2
- 102000015081 Blood Coagulation Factors Human genes 0.000 description 2
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 2
- 241000701022 Cytomegalovirus Species 0.000 description 2
- HMFHBZSHGGEWLO-SOOFDHNKSA-N D-ribofuranose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-SOOFDHNKSA-N 0.000 description 2
- 241000702421 Dependoparvovirus Species 0.000 description 2
- RTZKZFJDLAIYFH-UHFFFAOYSA-N Diethyl ether Chemical compound CCOCC RTZKZFJDLAIYFH-UHFFFAOYSA-N 0.000 description 2
- 239000004606 Fillers/Extenders Substances 0.000 description 2
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 2
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 2
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 2
- 229940121710 HMGCoA reductase inhibitor Drugs 0.000 description 2
- 208000035150 Hypercholesterolemia Diseases 0.000 description 2
- 229930010555 Inosine Natural products 0.000 description 2
- UGQMRVRMYYASKQ-KQYNXXCUSA-N Inosine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C2=NC=NC(O)=C2N=C1 UGQMRVRMYYASKQ-KQYNXXCUSA-N 0.000 description 2
- 238000008214 LDL Cholesterol Methods 0.000 description 2
- 241000713666 Lentivirus Species 0.000 description 2
- JGFZNNIVVJXRND-UHFFFAOYSA-N N,N-Diisopropylethylamine (DIPEA) Chemical compound CCN(C(C)C)C(C)C JGFZNNIVVJXRND-UHFFFAOYSA-N 0.000 description 2
- 229930182555 Penicillin Natural products 0.000 description 2
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-N Phosphoric acid Chemical compound OP(O)(O)=O NBIIXXVUZAFLBC-UHFFFAOYSA-N 0.000 description 2
- NQRYJNQNLNOLGT-UHFFFAOYSA-N Piperidine Chemical compound C1CCNCC1 NQRYJNQNLNOLGT-UHFFFAOYSA-N 0.000 description 2
- 239000002202 Polyethylene glycol Substances 0.000 description 2
- RJKFOVLPORLFTN-LEKSSAKUSA-N Progesterone Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H](C(=O)C)[C@@]1(C)CC2 RJKFOVLPORLFTN-LEKSSAKUSA-N 0.000 description 2
- 101100135853 Rattus norvegicus Pcsk9 gene Proteins 0.000 description 2
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 description 2
- 108091027568 Single-stranded nucleotide Proteins 0.000 description 2
- 108091027967 Small hairpin RNA Proteins 0.000 description 2
- UIIMBOGNXHQVGW-UHFFFAOYSA-M Sodium bicarbonate Chemical compound [Na+].OC([O-])=O UIIMBOGNXHQVGW-UHFFFAOYSA-M 0.000 description 2
- 229920002472 Starch Polymers 0.000 description 2
- 108090000787 Subtilisin Proteins 0.000 description 2
- WYURNTSHIVDZCO-UHFFFAOYSA-N Tetrahydrofuran Chemical compound C1CCOC1 WYURNTSHIVDZCO-UHFFFAOYSA-N 0.000 description 2
- 241000906446 Theraps Species 0.000 description 2
- 241000711975 Vesicular stomatitis virus Species 0.000 description 2
- HMNZFMSWFCAGGW-XPWSMXQVSA-N [3-[hydroxy(2-hydroxyethoxy)phosphoryl]oxy-2-[(e)-octadec-9-enoyl]oxypropyl] (e)-octadec-9-enoate Chemical compound CCCCCCCC\C=C\CCCCCCCC(=O)OCC(COP(O)(=O)OCCO)OC(=O)CCCCCCC\C=C\CCCCCCCC HMNZFMSWFCAGGW-XPWSMXQVSA-N 0.000 description 2
- 150000007513 acids Chemical class 0.000 description 2
- ORILYTVJVMAKLC-UHFFFAOYSA-N adamantane Chemical compound C1C(C2)CC3CC1CC2C3 ORILYTVJVMAKLC-UHFFFAOYSA-N 0.000 description 2
- 239000000654 additive Substances 0.000 description 2
- 125000000217 alkyl group Chemical group 0.000 description 2
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 description 2
- 150000001413 amino acids Chemical class 0.000 description 2
- 125000004103 aminoalkyl group Chemical group 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 2
- 230000000903 blocking effect Effects 0.000 description 2
- 239000008280 blood Substances 0.000 description 2
- 210000004369 blood Anatomy 0.000 description 2
- OSGAYBCDTDRGGQ-UHFFFAOYSA-L calcium sulfate Chemical compound [Ca+2].[O-]S([O-])(=O)=O OSGAYBCDTDRGGQ-UHFFFAOYSA-L 0.000 description 2
- 239000006143 cell culture medium Substances 0.000 description 2
- 125000003636 chemical group Chemical group 0.000 description 2
- 238000007796 conventional method Methods 0.000 description 2
- 239000013256 coordination polymer Substances 0.000 description 2
- 125000000753 cycloalkyl group Chemical group 0.000 description 2
- 230000009089 cytolysis Effects 0.000 description 2
- 230000007423 decrease Effects 0.000 description 2
- NAGJZTKCGNOGPW-UHFFFAOYSA-N dithiophosphoric acid Chemical group OP(O)(S)=S NAGJZTKCGNOGPW-UHFFFAOYSA-N 0.000 description 2
- 229940079593 drug Drugs 0.000 description 2
- 238000009509 drug development Methods 0.000 description 2
- GEIQNJBWHDTVAY-UHFFFAOYSA-N ethyl 3-[(2-ethoxy-2-oxoethyl)-[6-(9h-fluoren-9-ylmethoxycarbonylamino)hexanoyl]amino]propanoate Chemical compound C1=CC=C2C(COC(=O)NCCCCCC(=O)N(CC(=O)OCC)CCC(=O)OCC)C3=CC=CC=C3C2=C1 GEIQNJBWHDTVAY-UHFFFAOYSA-N 0.000 description 2
- 238000001704 evaporation Methods 0.000 description 2
- 230000008020 evaporation Effects 0.000 description 2
- 239000013613 expression plasmid Substances 0.000 description 2
- 238000001125 extrusion Methods 0.000 description 2
- 239000012091 fetal bovine serum Substances 0.000 description 2
- 108020005243 folate receptor Proteins 0.000 description 2
- 102000006815 folate receptor Human genes 0.000 description 2
- 239000011521 glass Substances 0.000 description 2
- 239000005090 green fluorescent protein Substances 0.000 description 2
- 230000002209 hydrophobic effect Effects 0.000 description 2
- 239000002471 hydroxymethylglutaryl coenzyme A reductase inhibitor Substances 0.000 description 2
- 229960003786 inosine Drugs 0.000 description 2
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 2
- 238000007914 intraventricular administration Methods 0.000 description 2
- 238000011068 loading method Methods 0.000 description 2
- 238000007726 management method Methods 0.000 description 2
- 239000003550 marker Substances 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 2
- 238000002156 mixing Methods 0.000 description 2
- 230000007935 neutral effect Effects 0.000 description 2
- QJGQUHMNIGDVPM-UHFFFAOYSA-N nitrogen group Chemical group [N] QJGQUHMNIGDVPM-UHFFFAOYSA-N 0.000 description 2
- 229910052760 oxygen Inorganic materials 0.000 description 2
- 210000000496 pancreas Anatomy 0.000 description 2
- 238000007911 parenteral administration Methods 0.000 description 2
- 230000036961 partial effect Effects 0.000 description 2
- 229940049954 penicillin Drugs 0.000 description 2
- 108010044156 peptidyl-prolyl cis-trans isomerase b Proteins 0.000 description 2
- 239000000825 pharmaceutical preparation Substances 0.000 description 2
- 239000012071 phase Substances 0.000 description 2
- 125000004437 phosphorous atom Chemical group 0.000 description 2
- 229910052698 phosphorus Inorganic materials 0.000 description 2
- 239000011574 phosphorus Substances 0.000 description 2
- 229920000768 polyamine Polymers 0.000 description 2
- 239000011148 porous material Substances 0.000 description 2
- 239000000843 powder Substances 0.000 description 2
- ZCCUUQDIBDJBTK-UHFFFAOYSA-N psoralen Chemical compound C1=C2OC(=O)C=CC2=CC2=C1OC=C2 ZCCUUQDIBDJBTK-UHFFFAOYSA-N 0.000 description 2
- 238000000746 purification Methods 0.000 description 2
- 238000010992 reflux Methods 0.000 description 2
- 239000004055 small Interfering RNA Substances 0.000 description 2
- DAEPDZWVDSPTHF-UHFFFAOYSA-M sodium pyruvate Chemical compound [Na+].CC(=O)C([O-])=O DAEPDZWVDSPTHF-UHFFFAOYSA-M 0.000 description 2
- 239000002904 solvent Substances 0.000 description 2
- 239000008107 starch Substances 0.000 description 2
- 235000019698 starch Nutrition 0.000 description 2
- 239000011550 stock solution Substances 0.000 description 2
- 229960005322 streptomycin Drugs 0.000 description 2
- 238000007920 subcutaneous administration Methods 0.000 description 2
- 208000024891 symptom Diseases 0.000 description 2
- 230000008685 targeting Effects 0.000 description 2
- 229940124597 therapeutic agent Drugs 0.000 description 2
- 230000001225 therapeutic effect Effects 0.000 description 2
- 230000032258 transport Effects 0.000 description 2
- RIOQSEWOXXDEQQ-UHFFFAOYSA-N triphenylphosphine Chemical compound C1=CC=CC=C1P(C=1C=CC=CC=1)C1=CC=CC=C1 RIOQSEWOXXDEQQ-UHFFFAOYSA-N 0.000 description 2
- 241001529453 unidentified herpesvirus Species 0.000 description 2
- 241001430294 unidentified retrovirus Species 0.000 description 2
- NOOLISFMXDJSKH-UTLUCORTSA-N (+)-Neomenthol Chemical compound CC(C)[C@@H]1CC[C@@H](C)C[C@@H]1O NOOLISFMXDJSKH-UTLUCORTSA-N 0.000 description 1
- COAABSMONFNYQH-TTWCUHKNSA-N (2r,3s,4s,5r,6s)-2-(hydroxymethyl)-6-(oxiran-2-ylmethylsulfanyl)oxane-3,4,5-triol Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@H]1SCC1OC1 COAABSMONFNYQH-TTWCUHKNSA-N 0.000 description 1
- BHQCQFFYRZLCQQ-UHFFFAOYSA-N (3alpha,5alpha,7alpha,12alpha)-3,7,12-trihydroxy-cholan-24-oic acid Natural products OC1CC2CC(O)CCC2(C)C2C1C1CCC(C(CCC(O)=O)C)C1(C)C(O)C2 BHQCQFFYRZLCQQ-UHFFFAOYSA-N 0.000 description 1
- QGVQZRDQPDLHHV-DPAQBDIFSA-N (3s,8s,9s,10r,13r,14s,17r)-10,13-dimethyl-17-[(2r)-6-methylheptan-2-yl]-2,3,4,7,8,9,11,12,14,15,16,17-dodecahydro-1h-cyclopenta[a]phenanthrene-3-thiol Chemical compound C1C=C2C[C@@H](S)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 QGVQZRDQPDLHHV-DPAQBDIFSA-N 0.000 description 1
- CITHEXJVPOWHKC-UUWRZZSWSA-N 1,2-di-O-myristoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCCCCCCC CITHEXJVPOWHKC-UUWRZZSWSA-N 0.000 description 1
- KILNVBDSWZSGLL-KXQOOQHDSA-N 1,2-dihexadecanoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCCCCCCCCC KILNVBDSWZSGLL-KXQOOQHDSA-N 0.000 description 1
- CSTYETQXRJUWCP-UHFFFAOYSA-N 1,3-dihexadecoxypropan-2-ol Chemical compound CCCCCCCCCCCCCCCCOCC(O)COCCCCCCCCCCCCCCCC CSTYETQXRJUWCP-UHFFFAOYSA-N 0.000 description 1
- BDNKZNFMNDZQMI-UHFFFAOYSA-N 1,3-diisopropylcarbodiimide Chemical compound CC(C)N=C=NC(C)C BDNKZNFMNDZQMI-UHFFFAOYSA-N 0.000 description 1
- JBWYRBLDOOOJEU-UHFFFAOYSA-N 1-[chloro-(4-methoxyphenyl)-phenylmethyl]-4-methoxybenzene Chemical compound C1=CC(OC)=CC=C1C(Cl)(C=1C=CC(OC)=CC=1)C1=CC=CC=C1 JBWYRBLDOOOJEU-UHFFFAOYSA-N 0.000 description 1
- MZMNEDXVUJLQAF-UHFFFAOYSA-N 1-o-tert-butyl 2-o-methyl 4-hydroxypyrrolidine-1,2-dicarboxylate Chemical compound COC(=O)C1CC(O)CN1C(=O)OC(C)(C)C MZMNEDXVUJLQAF-UHFFFAOYSA-N 0.000 description 1
- IHPYMWDTONKSCO-UHFFFAOYSA-N 2,2'-piperazine-1,4-diylbisethanesulfonic acid Chemical compound OS(=O)(=O)CCN1CCN(CCS(O)(=O)=O)CC1 IHPYMWDTONKSCO-UHFFFAOYSA-N 0.000 description 1
- FALRKNHUBBKYCC-UHFFFAOYSA-N 2-(chloromethyl)pyridine-3-carbonitrile Chemical compound ClCC1=NC=CC=C1C#N FALRKNHUBBKYCC-UHFFFAOYSA-N 0.000 description 1
- GIUTUZDGHNZVIA-UHFFFAOYSA-N 2-(ethylamino)acetic acid;hydrochloride Chemical compound Cl.CCNCC(O)=O GIUTUZDGHNZVIA-UHFFFAOYSA-N 0.000 description 1
- VXGRJERITKFWPL-UHFFFAOYSA-N 4',5'-Dihydropsoralen Natural products C1=C2OC(=O)C=CC2=CC2=C1OCC2 VXGRJERITKFWPL-UHFFFAOYSA-N 0.000 description 1
- QCQCHGYLTSGIGX-GHXANHINSA-N 4-[[(3ar,5ar,5br,7ar,9s,11ar,11br,13as)-5a,5b,8,8,11a-pentamethyl-3a-[(5-methylpyridine-3-carbonyl)amino]-2-oxo-1-propan-2-yl-4,5,6,7,7a,9,10,11,11b,12,13,13a-dodecahydro-3h-cyclopenta[a]chrysen-9-yl]oxy]-2,2-dimethyl-4-oxobutanoic acid Chemical compound N([C@@]12CC[C@@]3(C)[C@]4(C)CC[C@H]5C(C)(C)[C@@H](OC(=O)CC(C)(C)C(O)=O)CC[C@]5(C)[C@H]4CC[C@@H]3C1=C(C(C2)=O)C(C)C)C(=O)C1=CN=CC(C)=C1 QCQCHGYLTSGIGX-GHXANHINSA-N 0.000 description 1
- 125000004172 4-methoxyphenyl group Chemical group [H]C1=C([H])C(OC([H])([H])[H])=C([H])C([H])=C1* 0.000 description 1
- OVONXEQGWXGFJD-UHFFFAOYSA-N 4-sulfanylidene-1h-pyrimidin-2-one Chemical compound SC=1C=CNC(=O)N=1 OVONXEQGWXGFJD-UHFFFAOYSA-N 0.000 description 1
- ROUFCTKIILEETD-UHFFFAOYSA-N 5-nitro-2-[(5-nitropyridin-2-yl)disulfanyl]pyridine Chemical compound N1=CC([N+](=O)[O-])=CC=C1SSC1=CC=C([N+]([O-])=O)C=N1 ROUFCTKIILEETD-UHFFFAOYSA-N 0.000 description 1
- 108091027075 5S-rRNA precursor Proteins 0.000 description 1
- FPCPONSZWYDXRD-UHFFFAOYSA-N 6-(9h-fluoren-9-ylmethoxycarbonylamino)hexanoic acid Chemical compound C1=CC=C2C(COC(=O)NCCCCCC(=O)O)C3=CC=CC=C3C2=C1 FPCPONSZWYDXRD-UHFFFAOYSA-N 0.000 description 1
- ZCYVEMRRCGMTRW-UHFFFAOYSA-N 7553-56-2 Chemical compound [I] ZCYVEMRRCGMTRW-UHFFFAOYSA-N 0.000 description 1
- 108091034151 7SK RNA Proteins 0.000 description 1
- MSSXOMSJDRHRMC-UHFFFAOYSA-N 9H-purine-2,6-diamine Chemical class NC1=NC(N)=C2NC=NC2=N1 MSSXOMSJDRHRMC-UHFFFAOYSA-N 0.000 description 1
- 102000007469 Actins Human genes 0.000 description 1
- 108010085238 Actins Proteins 0.000 description 1
- 241000710929 Alphavirus Species 0.000 description 1
- 101710095342 Apolipoprotein B Proteins 0.000 description 1
- 102100040202 Apolipoprotein B-100 Human genes 0.000 description 1
- 206010003497 Asphyxia Diseases 0.000 description 1
- 201000001320 Atherosclerosis Diseases 0.000 description 1
- FVMSZHDUAXLUFL-UHFFFAOYSA-N CCCCCCCCCCCCCCCCC(C)(CCCCCCCCCCCCCCCC)N(CC)CC.OCC(CO)O Chemical compound CCCCCCCCCCCCCCCCC(C)(CCCCCCCCCCCCCCCC)N(CC)CC.OCC(CO)O FVMSZHDUAXLUFL-UHFFFAOYSA-N 0.000 description 1
- HXVVOLDXHIMZJZ-UHFFFAOYSA-N CCCCCCCCCCCCNC(CCN(CCC(NCCCCCCCCCCCC)=O)CCNCCN(CCC(NCCCCCCCCCCCC)=O)CCN(CCC(NCCCCCCCCCCCC)=O)CCC(NCCCCCCCCCCCC)=O)=O Chemical compound CCCCCCCCCCCCNC(CCN(CCC(NCCCCCCCCCCCC)=O)CCNCCN(CCC(NCCCCCCCCCCCC)=O)CCN(CCC(NCCCCCCCCCCCC)=O)CCC(NCCCCCCCCCCCC)=O)=O HXVVOLDXHIMZJZ-UHFFFAOYSA-N 0.000 description 1
- BEJYOUOIWCGKSJ-UHFFFAOYSA-N CCOC(=O)CCN(CC(=O)OCC)C(=O)CCCCCN.Cl Chemical compound CCOC(=O)CCN(CC(=O)OCC)C(=O)CCCCCN.Cl BEJYOUOIWCGKSJ-UHFFFAOYSA-N 0.000 description 1
- BVKZGUZCCUSVTD-UHFFFAOYSA-L Carbonate Chemical compound [O-]C([O-])=O BVKZGUZCCUSVTD-UHFFFAOYSA-L 0.000 description 1
- 239000004380 Cholic acid Substances 0.000 description 1
- 101150065749 Churc1 gene Proteins 0.000 description 1
- 102000005853 Clathrin Human genes 0.000 description 1
- 108010019874 Clathrin Proteins 0.000 description 1
- 102000008186 Collagen Human genes 0.000 description 1
- 108010035532 Collagen Proteins 0.000 description 1
- 208000035473 Communicable disease Diseases 0.000 description 1
- 108020004394 Complementary RNA Proteins 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- NOOLISFMXDJSKH-UHFFFAOYSA-N DL-menthol Natural products CC(C)C1CCC(C)CC1O NOOLISFMXDJSKH-UHFFFAOYSA-N 0.000 description 1
- 241000255581 Drosophila <fruit fly, genus> Species 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 201000011001 Ebola Hemorrhagic Fever Diseases 0.000 description 1
- UPEZCKBFRMILAV-JNEQICEOSA-N Ecdysone Natural products O=C1[C@H]2[C@@](C)([C@@H]3C([C@@]4(O)[C@@](C)([C@H]([C@H]([C@@H](O)CCC(O)(C)C)C)CC4)CC3)=C1)C[C@H](O)[C@H](O)C2 UPEZCKBFRMILAV-JNEQICEOSA-N 0.000 description 1
- 241000196324 Embryophyta Species 0.000 description 1
- 102100038132 Endogenous retrovirus group K member 6 Pro protein Human genes 0.000 description 1
- 108010067770 Endopeptidase K Proteins 0.000 description 1
- 101710091045 Envelope protein Proteins 0.000 description 1
- JIGUQPWFLRLWPJ-UHFFFAOYSA-N Ethyl acrylate Chemical compound CCOC(=O)C=C JIGUQPWFLRLWPJ-UHFFFAOYSA-N 0.000 description 1
- 108090001126 Furin Proteins 0.000 description 1
- 102000004961 Furin Human genes 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- 101001098833 Homo sapiens Proprotein convertase subtilisin/kexin type 6 Proteins 0.000 description 1
- GRRNUXAQVGOGFE-UHFFFAOYSA-N Hygromycin-B Natural products OC1C(NC)CC(N)C(O)C1OC1C2OC3(C(C(O)C(O)C(C(N)CO)O3)O)OC2C(O)C(CO)O1 GRRNUXAQVGOGFE-UHFFFAOYSA-N 0.000 description 1
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 1
- 102000004877 Insulin Human genes 0.000 description 1
- 108090001061 Insulin Proteins 0.000 description 1
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 1
- 229930182816 L-glutamine Natural products 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- 102000018697 Membrane Proteins Human genes 0.000 description 1
- 108010052285 Membrane Proteins Proteins 0.000 description 1
- 102100034028 Membrane-bound transcription factor site-1 protease Human genes 0.000 description 1
- 101710193467 Membrane-bound transcription factor site-1 protease Proteins 0.000 description 1
- 208000024556 Mendelian disease Diseases 0.000 description 1
- 241000714177 Murine leukemia virus Species 0.000 description 1
- 241000699660 Mus musculus Species 0.000 description 1
- 101000819572 Mus musculus Glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 1
- REYJJPSVUYRZGE-UHFFFAOYSA-N Octadecylamine Chemical compound CCCCCCCCCCCCCCCCCCN REYJJPSVUYRZGE-UHFFFAOYSA-N 0.000 description 1
- 239000007990 PIPES buffer Substances 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 241000282577 Pan troglodytes Species 0.000 description 1
- 108091093037 Peptide nucleic acid Proteins 0.000 description 1
- 241000009328 Perro Species 0.000 description 1
- ABLZXFCXXLZCGV-UHFFFAOYSA-N Phosphorous acid Chemical class OP(O)=O ABLZXFCXXLZCGV-UHFFFAOYSA-N 0.000 description 1
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 description 1
- 229920002873 Polyethylenimine Polymers 0.000 description 1
- 108010022249 Proprotein Convertase 9 Proteins 0.000 description 1
- 108010044159 Proprotein Convertases Proteins 0.000 description 1
- 102000006437 Proprotein Convertases Human genes 0.000 description 1
- 102100038946 Proprotein convertase subtilisin/kexin type 6 Human genes 0.000 description 1
- 101710188315 Protein X Proteins 0.000 description 1
- 102000017143 RNA Polymerase I Human genes 0.000 description 1
- 108010013845 RNA Polymerase I Proteins 0.000 description 1
- 102000009572 RNA Polymerase II Human genes 0.000 description 1
- 108010009460 RNA Polymerase II Proteins 0.000 description 1
- 102000014450 RNA Polymerase III Human genes 0.000 description 1
- 108010078067 RNA Polymerase III Proteins 0.000 description 1
- 230000006819 RNA synthesis Effects 0.000 description 1
- 230000004570 RNA-binding Effects 0.000 description 1
- 206010037742 Rabies Diseases 0.000 description 1
- UIIMBOGNXHQVGW-DEQYMQKBSA-M Sodium bicarbonate-14C Chemical compound [Na+].O[14C]([O-])=O UIIMBOGNXHQVGW-DEQYMQKBSA-M 0.000 description 1
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 1
- DMWVGXGXHPOEPT-UHFFFAOYSA-N Src Inhibitor-1 Chemical compound C=12C=C(OC)C(OC)=CC2=NC=NC=1NC(C=C1)=CC=C1OC1=CC=CC=C1 DMWVGXGXHPOEPT-UHFFFAOYSA-N 0.000 description 1
- UCKMPCXJQFINFW-UHFFFAOYSA-N Sulphide Chemical compound [S-2] UCKMPCXJQFINFW-UHFFFAOYSA-N 0.000 description 1
- 101710137500 T7 RNA polymerase Proteins 0.000 description 1
- 239000004098 Tetracycline Substances 0.000 description 1
- 229920004890 Triton X-100 Polymers 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- 206010048214 Xanthoma Diseases 0.000 description 1
- RLXCFCYWFYXTON-JTTSDREOSA-N [(3S,8S,9S,10R,13S,14S,17R)-3-hydroxy-10,13-dimethyl-17-[(2R)-6-methylheptan-2-yl]-2,3,4,7,8,9,11,12,14,15,16,17-dodecahydro-1H-cyclopenta[a]phenanthren-16-yl] N-hexylcarbamate Chemical group C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC(OC(=O)NCCCCCC)[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 RLXCFCYWFYXTON-JTTSDREOSA-N 0.000 description 1
- QNEPTKZEXBPDLF-JDTILAPWSA-N [(3s,8s,9s,10r,13r,14s,17r)-10,13-dimethyl-17-[(2r)-6-methylheptan-2-yl]-2,3,4,7,8,9,11,12,14,15,16,17-dodecahydro-1h-cyclopenta[a]phenanthren-3-yl] carbonochloridate Chemical compound C1C=C2C[C@@H](OC(Cl)=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 QNEPTKZEXBPDLF-JDTILAPWSA-N 0.000 description 1
- KBMUPXLPCMFFOM-UHFFFAOYSA-N [6-[3-hydroxy-4-(hydroxymethyl)pyrrolidin-1-yl]-6-oxohexyl]carbamic acid Chemical compound OCC1CN(C(=O)CCCCCNC(O)=O)CC1O KBMUPXLPCMFFOM-UHFFFAOYSA-N 0.000 description 1
- 230000001594 aberrant effect Effects 0.000 description 1
- 206010000210 abortion Diseases 0.000 description 1
- 231100000176 abortion Toxicity 0.000 description 1
- 229960000583 acetic acid Drugs 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 230000003213 activating effect Effects 0.000 description 1
- 239000000443 aerosol Substances 0.000 description 1
- 150000001298 alcohols Chemical class 0.000 description 1
- 125000001931 aliphatic group Chemical group 0.000 description 1
- 150000001336 alkenes Chemical class 0.000 description 1
- 125000004414 alkyl thio group Chemical group 0.000 description 1
- UPEZCKBFRMILAV-UHFFFAOYSA-N alpha-Ecdysone Natural products C1C(O)C(O)CC2(C)C(CCC3(C(C(C(O)CCC(C)(C)O)C)CCC33O)C)C3=CC(=O)C21 UPEZCKBFRMILAV-UHFFFAOYSA-N 0.000 description 1
- 229910000147 aluminium phosphate Inorganic materials 0.000 description 1
- 150000001408 amides Chemical group 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 238000005571 anion exchange chromatography Methods 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 239000000427 antigen Substances 0.000 description 1
- 102000036639 antigens Human genes 0.000 description 1
- 108091007433 antigens Proteins 0.000 description 1
- 239000003524 antilipemic agent Substances 0.000 description 1
- 230000006907 apoptotic process Effects 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 239000006286 aqueous extract Substances 0.000 description 1
- 239000012300 argon atmosphere Substances 0.000 description 1
- 125000003710 aryl alkyl group Chemical group 0.000 description 1
- 239000012752 auxiliary agent Substances 0.000 description 1
- 230000001588 bifunctional effect Effects 0.000 description 1
- 239000011230 binding agent Substances 0.000 description 1
- 230000003115 biocidal effect Effects 0.000 description 1
- 230000031018 biological processes and functions Effects 0.000 description 1
- 230000001851 biosynthetic effect Effects 0.000 description 1
- TXFLGZOGNOOEFZ-UHFFFAOYSA-N bis(2-chloroethyl)amine Chemical compound ClCCNCCCl TXFLGZOGNOOEFZ-UHFFFAOYSA-N 0.000 description 1
- 230000023555 blood coagulation Effects 0.000 description 1
- 210000004556 brain Anatomy 0.000 description 1
- 239000007975 buffered saline Substances 0.000 description 1
- 235000011132 calcium sulphate Nutrition 0.000 description 1
- 238000011088 calibration curve Methods 0.000 description 1
- 125000000837 carbohydrate group Chemical group 0.000 description 1
- 229910052799 carbon Inorganic materials 0.000 description 1
- 230000006037 cell lysis Effects 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 230000033077 cellular process Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- BHQCQFFYRZLCQQ-OELDTZBJSA-N cholic acid Chemical compound C([C@H]1C[C@H]2O)[C@H](O)CC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H]([C@@H](CCC(O)=O)C)[C@@]2(C)[C@@H](O)C1 BHQCQFFYRZLCQQ-OELDTZBJSA-N 0.000 description 1
- 235000019416 cholic acid Nutrition 0.000 description 1
- 229960002471 cholic acid Drugs 0.000 description 1
- 229930193282 clathrin Natural products 0.000 description 1
- 229920001436 collagen Polymers 0.000 description 1
- 239000003184 complementary RNA Substances 0.000 description 1
- 238000013270 controlled release Methods 0.000 description 1
- 238000001816 cooling Methods 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 239000003431 cross linking reagent Substances 0.000 description 1
- 238000009295 crossflow filtration Methods 0.000 description 1
- 125000004122 cyclic group Chemical group 0.000 description 1
- OOTFVKOQINZBBF-UHFFFAOYSA-N cystamine Chemical compound CCSSCCN OOTFVKOQINZBBF-UHFFFAOYSA-N 0.000 description 1
- 229940099500 cystamine Drugs 0.000 description 1
- 230000001086 cytosolic effect Effects 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- KXGVEGMKQFWNSR-UHFFFAOYSA-N deoxycholic acid Natural products C1CC2CC(O)CCC2(C)C2C1C1CCC(C(CCC(O)=O)C)C1(C)C(O)C2 KXGVEGMKQFWNSR-UHFFFAOYSA-N 0.000 description 1
- 238000010511 deprotection reaction Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 238000000502 dialysis Methods 0.000 description 1
- UMGXUWVIJIQANV-UHFFFAOYSA-M didecyl(dimethyl)azanium;bromide Chemical compound [Br-].CCCCCCCCCC[N+](C)(C)CCCCCCCCCC UMGXUWVIJIQANV-UHFFFAOYSA-M 0.000 description 1
- 150000005690 diesters Chemical class 0.000 description 1
- 238000010790 dilution Methods 0.000 description 1
- 239000012895 dilution Substances 0.000 description 1
- 238000006471 dimerization reaction Methods 0.000 description 1
- 229960003724 dimyristoylphosphatidylcholine Drugs 0.000 description 1
- 229960005160 dimyristoylphosphatidylglycerol Drugs 0.000 description 1
- MWRBNPKJOOWZPW-CLFAGFIQSA-N dioleoyl phosphatidylethanolamine Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OCC(COP(O)(=O)OCCN)OC(=O)CCCCCCC\C=C/CCCCCCCC MWRBNPKJOOWZPW-CLFAGFIQSA-N 0.000 description 1
- 150000002009 diols Chemical class 0.000 description 1
- 239000007884 disintegrant Substances 0.000 description 1
- 238000006073 displacement reaction Methods 0.000 description 1
- BPHQZTVXXXJVHI-AJQTZOPKSA-N ditetradecanoyl phosphatidylglycerol Chemical compound CCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(=O)OC[C@@H](O)CO)OC(=O)CCCCCCCCCCCCC BPHQZTVXXXJVHI-AJQTZOPKSA-N 0.000 description 1
- GTZOYNFRVVHLDZ-UHFFFAOYSA-N dodecane-1,1-diol Chemical group CCCCCCCCCCCC(O)O GTZOYNFRVVHLDZ-UHFFFAOYSA-N 0.000 description 1
- 238000002296 dynamic light scattering Methods 0.000 description 1
- UPEZCKBFRMILAV-JMZLNJERSA-N ecdysone Chemical compound C1[C@@H](O)[C@@H](O)C[C@]2(C)[C@@H](CC[C@@]3([C@@H]([C@@H]([C@H](O)CCC(C)(C)O)C)CC[C@]33O)C)C3=CC(=O)[C@@H]21 UPEZCKBFRMILAV-JMZLNJERSA-N 0.000 description 1
- 230000002526 effect on cardiovascular system Effects 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 230000012202 endocytosis Effects 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 210000002919 epithelial cell Anatomy 0.000 description 1
- 239000000262 estrogen Substances 0.000 description 1
- 229940011871 estrogen Drugs 0.000 description 1
- JHFQLFGNGSHVGQ-UHFFFAOYSA-N ethyl 3-[(2-ethoxy-2-oxoethyl)amino]propanoate Chemical compound CCOC(=O)CCNCC(=O)OCC JHFQLFGNGSHVGQ-UHFFFAOYSA-N 0.000 description 1
- JRFPHUDKKRHKHX-UHFFFAOYSA-N ethyl 4-(ethoxycarbonylamino)butanoate Chemical compound CCOC(=O)CCCNC(=O)OCC JRFPHUDKKRHKHX-UHFFFAOYSA-N 0.000 description 1
- 125000004494 ethyl ester group Chemical group 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 239000000945 filler Substances 0.000 description 1
- 239000000706 filtrate Substances 0.000 description 1
- 238000003818 flash chromatography Methods 0.000 description 1
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 239000012362 glacial acetic acid Substances 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 125000003827 glycol group Chemical group 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 208000019622 heart disease Diseases 0.000 description 1
- 125000005842 heteroatom Chemical group 0.000 description 1
- 125000000623 heterocyclic group Chemical group 0.000 description 1
- 238000004128 high performance liquid chromatography Methods 0.000 description 1
- 229940088597 hormone Drugs 0.000 description 1
- 239000005556 hormone Substances 0.000 description 1
- 210000005260 human cell Anatomy 0.000 description 1
- IVVMYMCCLPZNRL-UHFFFAOYSA-N hydrazinylphosphonic acid Chemical compound NNP(O)(O)=O IVVMYMCCLPZNRL-UHFFFAOYSA-N 0.000 description 1
- 239000001257 hydrogen Substances 0.000 description 1
- 229910052739 hydrogen Inorganic materials 0.000 description 1
- 239000001866 hydroxypropyl methyl cellulose Substances 0.000 description 1
- UFVKGYZPFZQRLF-UHFFFAOYSA-N hydroxypropyl methyl cellulose Chemical compound OC1C(O)C(OC)OC(CO)C1OC1C(O)C(O)C(OC2C(C(O)C(OC3C(C(O)C(O)C(CO)O3)O)C(CO)O2)O)C(CO)O1 UFVKGYZPFZQRLF-UHFFFAOYSA-N 0.000 description 1
- 235000010979 hydroxypropyl methyl cellulose Nutrition 0.000 description 1
- 229920003088 hydroxypropyl methyl cellulose Polymers 0.000 description 1
- GRRNUXAQVGOGFE-NZSRVPFOSA-N hygromycin B Chemical compound O[C@@H]1[C@@H](NC)C[C@@H](N)[C@H](O)[C@H]1O[C@H]1[C@H]2O[C@@]3([C@@H]([C@@H](O)[C@@H](O)[C@@H](C(N)CO)O3)O)O[C@H]2[C@@H](O)[C@@H](CO)O1 GRRNUXAQVGOGFE-NZSRVPFOSA-N 0.000 description 1
- 229940097277 hygromycin b Drugs 0.000 description 1
- 208000006575 hypertriglyceridemia Diseases 0.000 description 1
- 238000000099 in vitro assay Methods 0.000 description 1
- 230000000415 inactivating effect Effects 0.000 description 1
- 230000002779 inactivation Effects 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 239000000411 inducer Substances 0.000 description 1
- 229940125396 insulin Drugs 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 239000007927 intramuscular injection Substances 0.000 description 1
- 239000007928 intraperitoneal injection Substances 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- 238000010253 intravenous injection Methods 0.000 description 1
- 229910052740 iodine Inorganic materials 0.000 description 1
- 239000011630 iodine Substances 0.000 description 1
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 238000001638 lipofection Methods 0.000 description 1
- 150000002634 lipophilic molecules Chemical class 0.000 description 1
- 230000004777 loss-of-function mutation Effects 0.000 description 1
- 239000000314 lubricant Substances 0.000 description 1
- 210000004962 mammalian cell Anatomy 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 238000002844 melting Methods 0.000 description 1
- 230000008018 melting Effects 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 229940041616 menthol Drugs 0.000 description 1
- 230000004060 metabolic process Effects 0.000 description 1
- 229910021645 metal ion Inorganic materials 0.000 description 1
- CXKWCBBOMKCUKX-UHFFFAOYSA-M methylene blue Chemical compound [Cl-].C1=CC(N(C)C)=CC2=[S+]C3=CC(N(C)C)=CC=C3N=C21 CXKWCBBOMKCUKX-UHFFFAOYSA-M 0.000 description 1
- 229960000907 methylthioninium chloride Drugs 0.000 description 1
- 230000000116 mitigating effect Effects 0.000 description 1
- 239000003607 modifier Substances 0.000 description 1
- 238000001823 molecular biology technique Methods 0.000 description 1
- 239000003068 molecular probe Substances 0.000 description 1
- ZUHZZVMEUAUWHY-UHFFFAOYSA-N n,n-dimethylpropan-1-amine Chemical compound CCCN(C)C ZUHZZVMEUAUWHY-UHFFFAOYSA-N 0.000 description 1
- PSHKMPUSSFXUIA-UHFFFAOYSA-N n,n-dimethylpyridin-2-amine Chemical compound CN(C)C1=CC=CC=N1 PSHKMPUSSFXUIA-UHFFFAOYSA-N 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 239000012457 nonaqueous media Substances 0.000 description 1
- 230000009437 off-target effect Effects 0.000 description 1
- 238000002515 oligonucleotide synthesis Methods 0.000 description 1
- 150000002894 organic compounds Chemical class 0.000 description 1
- 239000007800 oxidant agent Substances 0.000 description 1
- 230000003647 oxidation Effects 0.000 description 1
- 238000007254 oxidation reaction Methods 0.000 description 1
- 230000001590 oxidative effect Effects 0.000 description 1
- 239000001301 oxygen Substances 0.000 description 1
- 238000004806 packaging method and process Methods 0.000 description 1
- 125000000913 palmityl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 230000008506 pathogenesis Effects 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 230000035515 penetration Effects 0.000 description 1
- PNJWIWWMYCMZRO-UHFFFAOYSA-N pent‐4‐en‐2‐one Natural products CC(=O)CC=C PNJWIWWMYCMZRO-UHFFFAOYSA-N 0.000 description 1
- 239000008177 pharmaceutical agent Substances 0.000 description 1
- 239000000546 pharmaceutical excipient Substances 0.000 description 1
- 230000000144 pharmacologic effect Effects 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 239000008363 phosphate buffer Substances 0.000 description 1
- WTJKGGKOPKCXLL-RRHRGVEJSA-N phosphatidylcholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCC=CCCCCCCCC WTJKGGKOPKCXLL-RRHRGVEJSA-N 0.000 description 1
- 150000003904 phospholipids Chemical class 0.000 description 1
- 150000008298 phosphoramidates Chemical class 0.000 description 1
- 239000004417 polycarbonate Substances 0.000 description 1
- 229920000515 polycarbonate Polymers 0.000 description 1
- 102000054765 polymorphisms of proteins Human genes 0.000 description 1
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 1
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 1
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 1
- 150000004032 porphyrins Chemical class 0.000 description 1
- 230000001124 posttranscriptional effect Effects 0.000 description 1
- LPNYRYFBWFDTMA-UHFFFAOYSA-N potassium tert-butoxide Chemical compound [K+].CC(C)(C)[O-] LPNYRYFBWFDTMA-UHFFFAOYSA-N 0.000 description 1
- 230000002028 premature Effects 0.000 description 1
- 230000003449 preventive effect Effects 0.000 description 1
- 102000004196 processed proteins & peptides Human genes 0.000 description 1
- 108090000765 processed proteins & peptides Proteins 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 239000000186 progesterone Substances 0.000 description 1
- 229960003387 progesterone Drugs 0.000 description 1
- WGYKZJWCGVVSQN-UHFFFAOYSA-O propan-1-aminium Chemical compound CCC[NH3+] WGYKZJWCGVVSQN-UHFFFAOYSA-O 0.000 description 1
- 125000006239 protecting group Chemical group 0.000 description 1
- 102000005962 receptors Human genes 0.000 description 1
- 108020003175 receptors Proteins 0.000 description 1
- 238000006578 reductive coupling reaction Methods 0.000 description 1
- 230000008844 regulatory mechanism Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 238000010242 retro-orbital bleeding Methods 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 108020004418 ribosomal RNA Proteins 0.000 description 1
- 230000003248 secreting effect Effects 0.000 description 1
- 239000013049 sediment Substances 0.000 description 1
- 238000010187 selection method Methods 0.000 description 1
- 230000001743 silencing effect Effects 0.000 description 1
- RYMZZMVNJRMUDD-HGQWONQESA-N simvastatin Chemical compound C([C@H]1[C@@H](C)C=CC2=C[C@H](C)C[C@@H]([C@H]12)OC(=O)C(C)(C)CC)C[C@@H]1C[C@@H](O)CC(=O)O1 RYMZZMVNJRMUDD-HGQWONQESA-N 0.000 description 1
- 229910052708 sodium Inorganic materials 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- 235000017557 sodium bicarbonate Nutrition 0.000 description 1
- 229910000030 sodium bicarbonate Inorganic materials 0.000 description 1
- 229910000033 sodium borohydride Inorganic materials 0.000 description 1
- 239000012279 sodium borohydride Substances 0.000 description 1
- 235000019333 sodium laurylsulphate Nutrition 0.000 description 1
- 239000001488 sodium phosphate Substances 0.000 description 1
- 229910000162 sodium phosphate Inorganic materials 0.000 description 1
- 229940054269 sodium pyruvate Drugs 0.000 description 1
- 229940079832 sodium starch glycolate Drugs 0.000 description 1
- 239000008109 sodium starch glycolate Substances 0.000 description 1
- 229920003109 sodium starch glycolate Polymers 0.000 description 1
- 229910052938 sodium sulfate Inorganic materials 0.000 description 1
- 235000011152 sodium sulphate Nutrition 0.000 description 1
- 230000003595 spectral effect Effects 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 229940032147 starch Drugs 0.000 description 1
- 229940071117 starch glycolate Drugs 0.000 description 1
- 150000003431 steroids Chemical class 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- KDYFGRWQOYBRFD-UHFFFAOYSA-L succinate(2-) Chemical compound [O-]C(=O)CCC([O-])=O KDYFGRWQOYBRFD-UHFFFAOYSA-L 0.000 description 1
- 229940014800 succinic anhydride Drugs 0.000 description 1
- 150000008163 sugars Chemical class 0.000 description 1
- IIACRCGMVDHOTQ-UHFFFAOYSA-N sulfamic acid Chemical group NS(O)(=O)=O IIACRCGMVDHOTQ-UHFFFAOYSA-N 0.000 description 1
- 150000003456 sulfonamides Chemical group 0.000 description 1
- BDHFUVZGWQCTTF-UHFFFAOYSA-M sulfonate Chemical compound [O-]S(=O)=O BDHFUVZGWQCTTF-UHFFFAOYSA-M 0.000 description 1
- 150000003457 sulfones Chemical group 0.000 description 1
- 150000003462 sulfoxides Chemical class 0.000 description 1
- 229910052717 sulfur Inorganic materials 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 239000000375 suspending agent Substances 0.000 description 1
- 238000007910 systemic administration Methods 0.000 description 1
- 230000009885 systemic effect Effects 0.000 description 1
- 229930101283 tetracycline Natural products 0.000 description 1
- 229960002180 tetracycline Drugs 0.000 description 1
- 235000019364 tetracycline Nutrition 0.000 description 1
- 150000003522 tetracyclines Chemical class 0.000 description 1
- YLQBMQCUIZJEEH-UHFFFAOYSA-N tetrahydrofuran Natural products C=1C=COC=1 YLQBMQCUIZJEEH-UHFFFAOYSA-N 0.000 description 1
- 150000003568 thioethers Chemical class 0.000 description 1
- 238000011830 transgenic mouse model Methods 0.000 description 1
- 230000010474 transient expression Effects 0.000 description 1
- 238000003146 transient transfection Methods 0.000 description 1
- RYFMWSXOAZQYPI-UHFFFAOYSA-K trisodium phosphate Chemical compound [Na+].[Na+].[Na+].[O-]P([O-])([O-])=O RYFMWSXOAZQYPI-UHFFFAOYSA-K 0.000 description 1
- 230000010415 tropism Effects 0.000 description 1
- 125000002948 undecyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 210000003462 vein Anatomy 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 238000011179 visual inspection Methods 0.000 description 1
- 239000011782 vitamin Substances 0.000 description 1
- 229940088594 vitamin Drugs 0.000 description 1
- 235000013343 vitamin Nutrition 0.000 description 1
- 229930003231 vitamin Natural products 0.000 description 1
- 238000005406 washing Methods 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
- 210000000707 wrist Anatomy 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
- C12N15/1137—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing against enzymes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/70—Carbohydrates; Sugars; Derivatives thereof
- A61K31/7088—Compounds having three or more nucleosides or nucleotides
- A61K31/713—Double-stranded nucleic acids or oligonucleotides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/06—Antihyperlipidemics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/11—Antisense
- C12N2310/111—Antisense spanning the whole gene, or a large part of it
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/14—Type of nucleic acid interfering nucleic acids [NA]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/31—Chemical structure of the backbone
- C12N2310/315—Phosphorothioates
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/32—Chemical structure of the sugar
- C12N2310/321—2'-O-R Modification
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/32—Chemical structure of the sugar
- C12N2310/322—2'-R Modification
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/33—Chemical structure of the base
- C12N2310/332—Abasic residue
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/35—Nature of the modification
- C12N2310/351—Conjugate
- C12N2310/3515—Lipophilic moiety, e.g. cholesterol
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Chemical & Material Sciences (AREA)
- Genetics & Genomics (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Organic Chemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Health & Medical Sciences (AREA)
- Biotechnology (AREA)
- Wood Science & Technology (AREA)
- General Engineering & Computer Science (AREA)
- Zoology (AREA)
- Medicinal Chemistry (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Biochemistry (AREA)
- Physics & Mathematics (AREA)
- Microbiology (AREA)
- Plant Pathology (AREA)
- Biophysics (AREA)
- Epidemiology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Virology (AREA)
- Diabetes (AREA)
- Hematology (AREA)
- Obesity (AREA)
- Heart & Thoracic Surgery (AREA)
- Cardiology (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicines Containing Material From Animals Or Micro-Organisms (AREA)
- Cosmetics (AREA)
Abstract
Ácido ribonucleico bicatenario (ARNbc) para inhibir la expresión de un gen PCSK9 humano en una célula, en el que dicho ARNbc comprende al menos dos secuencias que son complementarias entre sí y en el que una cadena sentido comprende una primera secuencia y una cadena antisentido comprende una segunda secuencia que comprende una región de complementariedad que es totalmente complementaria a al menos una parte de un ARNm que codifica para PCSK9, en el que dicha región de complementariedad tiene menos de 30 nucleótidos de longitud y en el que dicho ARNbc, al entrar en contacto con una célula que expresa dicho PCSK9, inhibe la expresión de dicho gen PCSK9 en el que dicha parte del ARNm que codifica para PCSK9 consiste en la secuencia de las posiciones 408-426 del número de registro NM_174936.
Description
DESCRIPCIÓN
Composiciones y métodos para inhibir la expresión del gen PCSK9
Referencias cruzadas a solicitudes relacionadas
Esta solicitud reivindica prioridad sobre la solicitud provisional estadounidense n.° 60/799.458, presentada el 11 de mayo de 2006; la solicitud provisional estadounidense n.° 60/817.203, presentada el 27 de junio de 2006; la solicitud provisional estadounidense n.° 60/840.089, presentada el 25 de agosto de 2006; la solicitud provisional estadounidense n.° 60/829.914, presentada el 18 de octubre de 2006; y la solicitud provisional estadounidense n.° 60/901.134, presentada el 13 de febrero de 2007.
Campo de la invención
Esta invención se refiere a ácido ribonucleico bicatenario (ARNbc) y a su uso en la mediación de la interferencia por ARN para inhibir la expresión del gen PCSK9 y al uso del ARNbc para tratar procesos patológicos que pueden mediarse mediante regulación por disminución de PCSK9, tales como hiperlipidemia.
Antecedentes de la invención
La proproteína convertasa subtilisina kexina 9 (PCSK9) es un miembro de la familia de la subtilisina serina proteasa. Las otras ocho subtilisina proteasas de mamífero, PCSK1-PCSK8 (también denominadas PC1/3, PC2, furina, PC4, PC5/6, PACE4, PC7 y S1P/SKI-1) son proproteína convertasas que procesan una amplia variedad de proteínas en la ruta secretora y desempeñan funciones en diversos procesos biológicos (Bergeron, F. (2000) J. Mol. Endocrinol.
24, 1-22, Gensberg, K., (1998) Semin. Cell Dev. Biol. 9, 11-17, Seidah, N. G. (1999) Brain Res. 848, 45-62, Taylor, N. A., (2003) FASEB J. 17, 1215-1227 y Zhou, A., (1999) J. Biol. Chem. 274, 20745-20748). Se ha propuesto que PCSK9 desempeña un papel en el metabolismo del colesterol. La expresión del ARNm de PCSK9 está regulada por disminución por la alimentación con colesterol en ratones (Maxwell, K. N., (2003) J. Lipid Res. 44, 2109-2119), regulada por incremento por estatinas en células HepG2 (Dubuc, G., (2004) Arterioscler. Thromb. Vasc. Biol. 24, 1454-1459) y regulada por incremento en ratones transgénicos de la proteína de unión a elementos reguladores de esterol (SREBP) (Horton, J. D., (2003) Proc. Acad. Sci. USA 100, 12027-12032), similar a las enzimas biosintéticas de colesterol y al receptor de lipoproteínas de baja densidad (LDLR). Además, se ha descubierto que las mutaciones de aminoácido de PCSK9 están asociadas a una forma de hipercolesterolemia autosómica dominante (Hchola3) (Abifadel, M., et al. (2003) Nat. Genet. 34, 154-156, Timms, K. M., (2004) Hum. Genet. 114, 349-353, Leren, T. P. (2004) Clin. Genet. 65, 419-422). PCSK9 también puede desempeñar un papel en la determinación de los niveles de colesterol LDL en la población general, ya que los polimorfismos de un solo nucleótido (SNP) se han asociado con los niveles de colesterol en una población japonesa (Shioji, K., (2004) J. Hum. Genet. 49, 109-114).
Las hipercolesterolemias autosómicas dominantes (ADH) son enfermedades monogénicas en las que los pacientes presentan niveles elevados de colesterol total y LDL, xantomas tendinosos y aterosclerosis prematura (Rader, D. J., (2003) J. Clin. Invest. 111, 1795-1803). La patogénesis de las ADH y de una forma recesiva, la hipercolesterolemia autosómica recesiva (ARH) (Cohen, J. C., (2003) Curr. Opin. Lipidol. 14, 121-127), se debe a defectos en la captación de LDL por parte del hígado. La ADH puede estar provocada por mutaciones de LDLR, que impiden la captación de LDL, o por mutaciones en la proteína de LDL, apolipoproteína B, que se une a LDLR. La ARH está provocada por mutaciones en la proteína ARH que son necesarias para la endocitosis del complejo LDLR-LDL a través de su interacción con clatrina. Por tanto, si las mutaciones de PCSK9 son causantes en las familias de Hchola3, parece probable que PCSK9 desempeñe un papel en la captación de LDL mediada por el receptor.
Los estudios de sobreexpresión apuntan a un papel de PCSK9 en el control de los niveles de LDLR y, por tanto, de la captación de LDL por parte del hígado (Maxwell, K. N. (2004) Proc. Acad. Sci. USA 101, 7100-7105, Benjannet, S., et al. (2004) J. Biol. Chem. 279, 48865-48875, Park, S. W., (2004) J. Biol. Chem. 279, 50630-50638). La sobreexpresión mediada por adenovirus de PCSK9 humano o de ratón durante 3 ó 4 días en ratones da lugar a niveles elevados de colesterol total y LDL; este efecto no se observa en animales con inactivación de LDLR (Maxwell, K. N. (2004) Proc. Acad. Sci. USA 101, 7100-7105, Benjannet, S., et al. (2004) J. Biol. Chem. 279, 48865 48875, Park, S. W., (2004) J. Biol. Chem. 279, 50630-50638). Además, la sobreexpresión de PCSK9 da lugar a una fuerte reducción de la proteína LDLR hepática, sin afectar a los niveles de ARNm de LDLR, a los niveles de la proteína SREBP o a la razón entre núcleo y citoplasma de la proteína SREBP. Estos resultados indican que PCSK9, o bien directa o bien indirectamente, reduce los niveles de proteína LDLR mediante un mecanismo postranscripcional.
Se han diseñado mutaciones de pérdida de función en PCSK9 en modelos de ratón (Rashid et al., (2005) PNAS, 102, 5374-5379., y se han identificado en individuos humanos Cohen et al., (2005), Nature Genetics., 37, 161-165. En ambos casos, la pérdida de la función de PCSK9 conduce a la reducción del colesterol total y del colesterol LDLc. En un estudio retrospectivo de resultados a lo largo de 15 años, se demostró que la pérdida de una copia de PCSK9 reduce el LDLc y conduce a una mayor protección riesgo-beneficio de desarrollar cardiopatías cardiovasculares (Cohen et. al., 2006 N. Engl. J. Med., 354., 1264-1272). Evidentemente, las evidencias obtenidas hasta la fecha indican que la reducción de los niveles de PCSK9 reducirá el LDLc.
Recientemente, se ha demostrado que las moléculas de ARN bicatenario (ARNbc) bloquean la expresión génica en un mecanismo regulador altamente conservado conocido como interferencia por ARN (iARN). El documento WO 99/32619 (Fire et al.) da a conocer el uso de un ARNbc de al menos 25 nucleótidos de longitud para inhibir la expresión génica en C. elegans. También se ha demostrado que el ARNbc degrada el ARN diana en otros organismos, incluyendo plantas (véase, por ejemplo, el documento WO 99/53050, Waterhouse et al.; y el documento WO 99/61631, Heifetz et al.), Drosophila (véase, por ejemplo, Yang, D., et al., Curr. Biol. (2000) 10:1191-1200) y mamíferos (véase el documento WO 00/44895, Limmer; y el documento DE 101 00 586.5, Kreutzer et al.). Este mecanismo natural se ha convertido ahora en el centro de atención para el desarrollo de una nueva clase de agentes farmacéuticos para el tratamiento de trastornos provocados por la regulación aberrante o no deseada de un gen.
A pesar de los importantes avances en el campo de iARN y de los avances en el tratamiento de procesos patológicos que pueden mediarse mediante regulación por disminución de la expresión del gen PCSK9, sigue siendo necesario contar con agentes que puedan inhibir la expresión del gen PCSK9 y que puedan tratar enfermedades asociadas a la expresión del gen PCSK9, tales como hiperlipidemia.
Sumario de la invención
La invención proporciona una solución al problema del tratamiento de enfermedades que pueden modularse mediante regulación por disminución de la proproteína convertasa subtilisina kexina 9 (PCSK9) usando ácido ribonucleico bicatenario (ARNbc) para silenciar la expresión de PCSK9.
La invención proporciona ácido ribonucleico bicatenario (ARNbc), así como composiciones y métodos para inhibir la expresión del gen PCSK9 en una célula o un mamífero usando tal ARNbc. La invención también proporciona composiciones y métodos para tratar estados patológicos que pueden modularse mediante regulación por disminución de la expresión del gen PCSK9, tales como hiperlipidemia. El ARNbc de la invención comprende una cadena de ARN (la cadena antisentido) que tiene una región de menos de 30 nucleótidos de longitud, generalmente de 19-24 nucleótidos de longitud, y que es sustancialmente complementaria a al menos parte de un transcrito de ARNm del gen PCSK9.
En una realización, la invención proporciona moléculas de ácido ribonucleico bicatenario (ARNbc) para inhibir la expresión del gen PCSK9. El ARNbc comprende al menos dos secuencias complementarias entre sí. El ARNbc comprende una cadena sentido que comprende una primera secuencia y una cadena antisentido que comprende una segunda secuencia. La cadena antisentido comprende una secuencia de nucleótidos que es sustancialmente complementaria a al menos una parte de un ARNm que codifica para PCSK9 y la región de complementariedad tiene menos de 30 nucleótidos de longitud, generalmente de 19-24 nucleótidos de longitud. El ARNbc, al entrar en contacto con una célula que expresa PCSK9, inhibe la expresión del gen PCSK9 en al menos un 40%.
Por ejemplo, las moléculas de ARNbc de la invención pueden estar compuestas por una primera secuencia del ARNbc que se selecciona del grupo que consiste en las secuencias sentido de la tabla 1 y la tabla 2 la segunda secuencia se selecciona del grupo que consiste en las secuencias antisentido de las tablas 1 y la tabla 2. Las moléculas de ARNbc de la invención pueden estar compuestas por nucleótidos que se producen de manera natural o pueden estar compuestas por al menos un nucleótido modificado, tal como un nucleótido modificado con 2'-O-metilo, un nucleótido que comprende un grupo 5'-fosforotioato y un nucleótido terminal unido a un derivado de colesterilo. Alternativamente, el nucleótido modificado puede elegirse del grupo de: un nucleótido modificado con 2'-desoxi-2'-fluoro, un nucleótido modificado con 2'-desoxilo, un nucleótido bloqueado, un nucleótido abásico, un nucleótido modificado con 2'-amino, un nucleótido modificado con 2'-alquilo, un nucleótido de morfolino, un fosforamidato y un nucleótido que comprende una base no natural. Generalmente, tal secuencia modificada se basará en una primera secuencia de dicho ARNbc seleccionada del grupo que consiste en las secuencias sentido de las tablas 1 y la tabla 2 y una segunda secuencia seleccionada del grupo que consiste en las secuencias antisentido de las tablas 1 y la tabla 2.
En otra realización, la invención proporciona una célula que comprende uno de los ARNbc de la invención. La célula es generalmente una célula de mamífero, tal como una célula humana.
En otra realización, la invención proporciona una composición farmacéutica para inhibir la expresión del gen PCSK9 en un organismo, generalmente un sujeto humano, que comprende uno o más de los ARNbc de la invención y un portador o vehículo de administración farmacéuticamente aceptable.
En otra realización, la invención proporciona un método para inhibir la expresión del gen PCSK9 en una célula, que comprende las siguientes etapas:
(a) introducir en la célula un ácido ribonucleico bicatenario (ARNbc), en el que el ARNbc comprende al menos dos secuencias complementarias entre sí. El ARNbc comprende una cadena sentido que comprende una primera secuencia y una cadena antisentido que comprende una segunda secuencia. La cadena antisentido comprende una región de complementariedad que es sustancialmente complementaria a al menos una parte de un ARNm que codifica para PCSK9 y en la que la región de complementariedad tiene menos de 30 nucleótidos de longitud, generalmente de 19-24 nucleótidos de longitud, y en la que el ARNbc, al entrar en contacto con una célula que
expresa PCSK9, inhibe la expresión del gen PCSK9 en al menos un 40%; y
(b) mantener la célula producida en la etapa (a) durante un tiempo suficiente para obtener la degradación del transcrito de ARNm del gen PCSK9, inhibiendo así la expresión del gen PCSK9 en la célula.
En otra realización, la invención proporciona métodos de tratamiento, prevención o gestión de procesos patológicos que pueden mediarse mediante regulación por disminución de la expresión del gen PCSK9, por ejemplo, hiperlipidemia, que comprenden administrar a un paciente que necesita tal tratamiento, prevención o gestión una cantidad terapéutica o profilácticamente eficaz de uno o más de los ARNbc de la invención.
En otra realización, la invención proporciona vectores para inhibir la expresión del gen PCSK9 en una célula, que comprenden una secuencia reguladora operativamente unida a una secuencia de nucleótidos que codifica para al menos una cadena de uno de los ARNbc de la invención.
En otra realización, la invención proporciona una célula que comprende un vector para inhibir la expresión del gen PCSK9 en una célula. El vector comprende una secuencia reguladora operativamente unida a una secuencia de nucleótidos que codifica para al menos una cadena de uno de los ARNbc de la invención.
Breve descripción de las figuras
La figura 1 muestra la estructura del lípido ND-98.
La figura 2 muestra los resultados del examen in vivo de 16 ARNip de PCSK9 específicos para ratones (AL-DP-9327 hasta AL-DP-9342) dirigidos contra diferentes regiones de ORF del ARNm de PCSK9 (con el primer nucleótido correspondiente a la posición de ORF indicada en el gráfico) en ratones C57/BL6 (5 animales/grupo). La razón de ARNm de PCSK9 con respecto a ARNm de GAPDH en los lisados hepáticos se promedió en cada grupo de tratamiento y se comparó con un grupo de control tratado con PBS o con un grupo de control tratado con un ARNip no relacionado (factor de coagulación sanguínea VII).
La figura 3 muestra los resultados del examen in vivo de 16 ARNip de PCSK9 de reacción cruzada de ser humano/ratón/rata (AL-DP-9311 hasta AL-DP-9326) dirigidos contra diferentes regiones de ORF del ARNm de PCSK9 (con el primer nucleótido correspondiente a la posición de ORF indicada en el gráfico) en ratones C57/BL6 (5 animales/grupo). La razón de ARNm de PCSK9 con respecto a ARNm de GAPDH en los lisados hepáticos se promedió en cada grupo de tratamiento y se comparó con un grupo de control tratado con PBS o con un grupo de control tratado con un ARNip no relacionado (factor de coagulación sanguínea VII).
El silenciamiento del ARNm de PCSK9 dio lugar a la reducción de los niveles de colesterol sérico total.
Los ARNip más eficaces en cuanto a inactivación del mensaje de PSCK9 mostraron el efecto de reducción de colesterol más pronunciado (aproximadamente el 20-30%).
La figura 4 muestra los resultados del examen in vivo de 16 ARNip de PCSK9 específicos para ratones (AL-DP-9327 hasta AL-DP-9342) en ratones C57/BL6 (5 animales/grupo). Los niveles de colesterol sérico total se promediaron en cada grupo de tratamiento y se compararon con un grupo de control tratado con PBS o un grupo de control tratado con un ARNip no relacionado (factor de coagulación sanguínea VII).
La figura 5 muestra los resultados del examen in vivo de 16 ARNip de PCSK9 de reacción cruzada de ser humano/ratón/rata (AL-DP-9311 hasta AL-DP-9326) en ratones C57/BL6 (5 animales/grupo). Los niveles de colesterol sérico total se promediaron en cada grupo de tratamiento y se compararon con un grupo de control tratado con PBS o un grupo de control tratado con un ARNip no relacionado (factor de coagulación sanguínea VII).
La figura 6 muestra una comparación de los resultados in vitro e in vivo del silenciamiento de PCSK9.
La figura 7A y la figura 7B muestran los resultados in vitro del silenciamiento de PCSK9 usando hepatocitos primarios de mono.
La figura 8 muestra la actividad in vivo de los ARNip formulados con LNP-01 frente a pcsk-9.
La figura 9 muestra la actividad in vivo de las moléculas parentales 9314 y 10792 químicamente modificadas formuladas con LNP-01 en diferentes momentos. Las versiones claramente modificadas de 10792 muestran una actividad de silenciamiento in vivo.
Descripción detallada de la invención
La invención proporciona una solución al problema del tratamiento de enfermedades que pueden modularse mediante regulación por disminución del gen PCSK9, usando ácido ribonucleico bicatenario (ARNbc) para silenciar el gen PCSK9, proporcionando así un tratamiento para enfermedades tales como hiperlipidemia.
La invención proporciona ácido ribonucleico bicatenario (ARNbc), así como composiciones y métodos para inhibir la
expresión del gen PCSK9 en una célula o un mamífero usando el ARNbc. La invención también proporciona composiciones y métodos para el tratamiento de estados patológicos y enfermedades que pueden modularse mediante regulación por disminución de la expresión del gen PCSK9. El ARNbc dirige la degradación específica de la secuencia del ARNm a través de un proceso conocido como interferencia por ARN (iARN).
El ARNbc de la invención comprende una cadena de ARN (la cadena antisentido) que tiene una región de menos de 30 nucleótidos de longitud, generalmente de 19-24 nucleótidos de longitud, y que es sustancialmente complementaria a al menos parte de un transcrito de ARNm del gen PCSK9. El uso de estos ARNbc permite la degradación dirigida de un ARNm que está involucrado en el transporte de sodio. Usando ensayos celulares y animales, los presentes inventores han demostrado que dosificaciones muy bajas de estos ARNbc pueden mediar específica y eficientemente la iARN, dando como resultado una inhibición significativa de la expresión del gen PCSK9. Por tanto, los métodos y las composiciones de la invención que comprenden estos ARNbc son útiles para tratar procesos patológicos que pueden mediarse mediante regulación por disminución de PCSK9, tales como en el tratamiento de la hiperlipidemia.
La siguiente descripción detallada revela cómo elaborar y usar el ARNbc y las composiciones que contienen ARNbc para inhibir la expresión del gen PCSK9 diana, así como composiciones y métodos para tratar enfermedades que pueden modularse mediante regulación por disminución de la expresión de PCSK9, tales como hiperlipidemia. Las composiciones farmacéuticas de la invención comprenden un ARNbc que tiene una cadena antisentido que comprende una región de complementariedad de menos de 30 nucleótidos de longitud, generalmente de 19-24 nucleótidos de longitud, y que es sustancialmente complementaria a al menos parte de un transcrito de ARN del gen PCSK9, junto con un portador farmacéuticamente aceptable.
Por consiguiente, determinados aspectos de la invención proporcionan composiciones farmacéuticas que comprenden el ARNbc de la invención junto con un portador farmacéuticamente aceptable, métodos de uso de las composiciones para inhibir la expresión del gen PCSK9 y métodos de uso de las composiciones farmacéuticas para tratar enfermedades que pueden modularse mediante regulación por disminución de la expresión de PCSK9.
I. Definiciones
Por comodidad, a continuación se indica el significado de determinados términos y expresiones usados en la memoria descriptiva, los ejemplos y las reivindicaciones adjuntas. Si hay una discrepancia aparente entre el uso de un término en otras partes de esta memoria descriptiva y su definición proporcionada en esta sección, prevalecerá la definición en esta sección.
“G”, “C”, “A” y “U” representan generalmente un nucleótido que contiene guanina, citosina, adenina y uracilo como base, respectivamente. Sin embargo, se entenderá que el término “ribonucleótido” o “nucleótido” también puede referirse a un nucleótido modificado, tal como se detalla más adelante, o a un resto de reemplazo sustituto. El experto es consciente de que la guanina, la citosina, la adenina y el uracilo pueden reemplazarse por otras moléculas sin alterar sustancialmente las propiedades de apareamiento de bases de un oligonucleótido que comprende un nucleótido que porta tal molécula de reemplazo. Por ejemplo, sin limitación, un nucleótido que contenga inosina como base puede experimentar apareamiento de bases con nucleótidos que contengan adenina, citosina o uracilo. Por tanto, los nucleótidos que contienen uracilo, guanina o adenina pueden reemplazarse en las secuencias de nucleótidos de la invención por un nucleótido que contenga, por ejemplo, inosina. Las secuencias que comprenden tales restos de reemplazo son realizaciones de la invención.
Tal como se usa en el presente documento, “PCSK9” se refiere a la proteína o al gen de la proproteína convertasa subtilisina kexina 9 (también conocida como FH3, HCHOLA3, NARC-1, NARC1). Las secuencias de ARNm de PCSK9 se proporcionan como humana: NM_174936; de ratón: NM_153565 y de rata: NM_199253.
Tal como se usa en el presente documento, “secuencia diana” se refiere a una porción contigua de la secuencia de nucleótidos de una molécula de ARNm formada durante la transcripción del gen PCSK9, incluyendo ARNm que es un producto del procesamiento del ARN de un producto de la transcripción primaria.
Tal como se usa en el presente documento, el término “cadena que comprende una secuencia” se refiere a un oligonucleótido que comprende una cadena de nucleótidos que se describe por la secuencia referida usando la nomenclatura convencional de nucleótidos.
Tal como se usa en el presente documento, y a menos que se indique lo contrario, el término “complementario”, cuando se usa para describir una primera secuencia de nucleótidos en relación con una segunda secuencia de nucleótidos, se refiere a la capacidad de un oligonucleótido o polinucleótido que comprende la primera secuencia de nucleótidos para hibridarse y formar una estructura dúplex en determinadas condiciones con un oligonucleótido o polinucleótido que comprende la segunda secuencia de nucleótidos, tal como entenderá el experto. Tales condiciones pueden ser, por ejemplo, condiciones rigurosas, en las que las condiciones rigurosas pueden incluir: NaCl 400 mM, PIPES 40 mM pH 6,4, EDTA 1 mM, 50°C o 70°C durante 12-16 horas, seguido de lavado. Pueden aplicarse otras condiciones, tales como condiciones fisiológicamente relevantes que pueden encontrarse dentro de un organismo. El experto podrá determinar el conjunto de condiciones más apropiado para una prueba de complementariedad de dos secuencias según la aplicación final de los nucleótidos hibridados.
Esto incluye el apareamiento de bases del oligonucleótido o polinucleótido que comprende la primera secuencia de nucleótidos con el oligonucleótido o polinucleótido que comprende la segunda secuencia de nucleótidos en toda la longitud de la primera y la segunda secuencia de nucleótidos. Tales secuencias pueden denominarse en el presente documento “totalmente complementarias” entre sí. Sin embargo, cuando una primera secuencia se denomina en el presente documento “sustancialmente complementaria” con una segunda secuencia, las dos secuencias pueden ser totalmente complementarias o pueden formar uno o más, pero generalmente no más de 4, 3 ó 2 pares de bases de apareamiento erróneo tras la hibridación, conservando la capacidad para hibridarse en las condiciones más relevantes para su aplicación final. Sin embargo, cuando dos oligonucleótidos están diseñados para formar, tras la hibridación, una o más proyecciones monocatenarias, tales proyecciones no se considerarán como apareamientos erróneos con la determinación de la complementariedad. Por ejemplo, un ARNbc que comprende un oligonucleótido de 21 nucleótidos de longitud y otro oligonucleótido de 23 nucleótidos de longitud, en el que el oligonucleótido más largo comprende una secuencia de 21 nucleótidos que es totalmente complementaria al oligonucleótido más corto, puede seguir denominándose “totalmente complementaria” a los efectos de la invención.
Las secuencias “complementarias”, tal como se usan en el presente documento, también pueden incluir, o estar formadas en su totalidad por, pares de bases que no sean de Watson-Crick y/o pares de bases formados por nucleótidos no naturales y modificados, en la medida en que se cumplan los requisitos anteriores con respecto a su capacidad para hibridarse.
Los términos “complementario”, “totalmente complementario” y “sustancialmente complementario” pueden usarse en el presente documento con respecto al apareamiento de bases entre la cadena sentido y la cadena antisentido de un ARNbc, o entre la cadena antisentido de un ARNbc y una secuencia diana, tal como se entenderá a partir del contexto de su uso.
Tal como se usa en el presente documento, un polinucleótido que es “sustancialmente complementario a al menos una parte de” un ARN mensajero (ARNm) se refiere a un polinucleótido que es sustancialmente complementario a una porción contigua del ARNm de interés (por ejemplo, que codifica para PCSK9). Por ejemplo, un polinucleótido es complementario a al menos una parte de un ARNm de PCSK9 si la secuencia es sustancialmente complementaria a una porción no interrumpida de un ARNm que codifica para PCSK9.
El término “ARN bicatenario” o “ARNbc”, tal como se usa en el presente documento, se refiere a un complejo de moléculas de ácido ribonucleico, que tiene una estructura dúplex que comprende dos cadenas de ácido nucleico antiparalelas y sustancialmente complementarias, tal como se definió anteriormente. Las dos cadenas que forman la estructura dúplex pueden ser diferentes porciones de una molécula de ARN más grande, o pueden ser moléculas de ARN independientes. Cuando se trata de moléculas de ARN independientes, tales ARNbc se denominan a menudo en la bibliografía ARNip (“ARN de interferencia corto”). Cuando las dos cadenas forman parte de una molécula más grande y, por tanto, están conectadas por una cadena ininterrumpida de nucleótidos entre el extremo 3' de una cadena y el extremo 5' de la otra cadena respectiva formando la estructura dúplex, la cadena de ARN de conexión se denomina “bucle de horquilla”, “ARN de horquilla corta” o “ARNhc”. Cuando las dos cadenas están conectadas covalentemente por medios distintos a una cadena ininterrumpida de nucleótidos entre el extremo 3' de una cadena y el extremo 5' de la otra cadena respectiva formando la estructura dúplex, la estructura de conexión se denomina “ligador”. Las cadenas de ARN pueden tener el mismo o diferente número de nucleótidos. El número máximo de pares de bases es el número de nucleótidos de la cadena más corta del ARNbc menos las proyecciones presentes en el dúplex. Además de la estructura dúplex, un ARNbc puede incluir una o más proyecciones de nucleótidos. Además, tal como se usa en esta memoria descriptiva, el “ARNbc” puede incluir modificaciones químicas para ribonucleótidos, incluyendo modificaciones sustanciales en múltiples nucleótidos e incluyendo todos los tipos de modificaciones dadas a conocer en el presente documento o conocidas en la técnica. Cualquiera de tales modificaciones, tal como se usa en una molécula de tipo ARNip, se engloba en el “ARNbc” para los fines de esta memoria descriptiva y de las reivindicaciones.
Tal como se usa en el presente documento, una “proyección de nucleótidos” se refiere al nucleótido o a los nucleótidos no apareado(s) que sobresale(n) de la estructura dúplex de un ARNbc cuando el extremo 3' de una cadena del ARNbc se extiende más allá del extremo 5' de la otra cadena, o viceversa. “Romo” o “extremo romo” significa que no hay nucleótidos desapareados en ese extremo del ARNbc, es decir, que no hay proyección de nucleótidos. Un ARNbc con “extremos romos” es un ARNbc de bicatenario en toda su longitud, es decir, no hay ninguna proyección de nucleótidos que sobresalga en ningún extremo de la molécula. Para mayor claridad, las caperuzas químicas o los elementos químicos no nucleotídicos conjugados con el extremo 3' o 5' de un ARNip no se tienen en cuenta a la hora de determinar si un ARNip tiene una proyección o tiene extremos romos.
El término “cadena antisentido” se refiere a la cadena de un ARNbc que incluye una región que es sustancialmente complementaria a una secuencia diana. Tal como se usa en el presente documento, el término “región de complementariedad” se refiere a la región de la cadena antisentido que es sustancialmente complementaria a una secuencia, por ejemplo, una secuencia diana, tal como se define en el presente documento. Cuando la región de complementariedad no es totalmente complementaria a la secuencia diana, los apareamientos erróneos son más tolerados en las regiones terminales y, si están presentes, se encuentran generalmente en una región o regiones terminal(es), por ejemplo, dentro de los 6, 5, 4, 3 ó 2 nucleótidos del extremo 5' y/o 3'.
El término “cadena sentido”, tal como se usa en el presente documento, se refiere a la cadena de un ARNbc que incluye una región que es sustancialmente complementaria a una región de la cadena antisentido.
“Introducir en una célula”, cuando se refiere a un ARNbc, significa facilitar la captación o absorción en la célula, tal como lo entienden los expertos en la técnica. La absorción o captación de ARNbc puede producirse mediante procesos celulares activos o difusivos sin ayuda, o mediante agentes o dispositivos auxiliares. El significado de este término no se limita a las células in vitro; un ARNbc también puede “introducirse en una célula”, en el que la célula forma parte de un organismo vivo. En tal caso, la introducción en la célula incluirá la administración al organismo. Por ejemplo, para la administración in vivo, el ARNbc puede inyectarse en un sitio tisular o administrarse sistémicamente. La introducción in vitro en una célula incluye métodos conocidos en la técnica, tales como electroporación y lipofección.
Los términos “silenciar” e “inhibir la expresión de”, en la medida en que se refieren al gen PCSK9, se refieren en el presente documento a la supresión, al menos parcial, de la expresión del gen PCSK9 tal como se manifiesta mediante una reducción de la cantidad de ARNm transcrito a partir del gen PCSK9 que puede aislarse de una primera célula o un primer grupo de células en la(s) que se transcribe el gen PCSK9 y se ha(n) tratado de manera que se inhibe la expresión del gen PCSK9, en comparación con una segunda célula o un segundo grupo de células sustancialmente idéntica(s) a la primera célula o el primer grupo de células pero que no se ha(n) tratado de esta manera (células de control). El grado de inhibición suele expresarse en cuanto a
{[(ARNm en las células de control) -(ARNm en las células tratadas)]/(ARNm en las células de control)}x100%
Alternativamente, el grado de inhibición puede darse en cuanto a una reducción de un parámetro que esté funcionalmente unido a la transcripción del gen PCSK9, por ejemplo, la cantidad de proteína codificada por el gen PCSK9 que es secretada por una célula, o el número de células que muestran un determinado fenotipo, por ejemplo, apoptosis. En principio, el silenciamiento del gen PCSK9 puede determinarse en cualquier célula que exprese la diana, o bien de manera constitutiva o bien mediante ingeniería genómica, y mediante cualquier ensayo apropiado. Sin embargo, cuando se necesita una referencia para determinar si un ARNbc dado inhibe la expresión del gen PCSK9 en un grado determinado y, por tanto, se engloba por la presente invención, el ensayo proporcionado en los ejemplos siguientes servirá como tal referencia.
Por ejemplo, en determinados casos, la expresión del gen PCSK9 se suprime en al menos un 20%, un 25%, un 35% o un 50% mediante la administración del oligonucleótido bicatenario de la invención. En algunas realizaciones, el gen PCSK9 se suprime en al menos un 60%, un 70% o un 80% mediante la administración del oligonucleótido bicatenario de la invención. En algunas realizaciones, el gen PCSK9 se suprime en al menos un 85%, un 90% o un 95% mediante la administración del oligonucleótido bicatenario de la invención. Las tablas 1 y 2 proporcionan una amplia gama de valores de inhibición de la expresión obtenidos en un ensayo in vitro usando diversas moléculas de ARNbc de PCSK9 a diversas concentraciones.
Tal como se usa en el presente documento en el contexto de la expresión de PCSK9, los términos “tratar”, “tratamiento” y similares se refieren al alivio o a la mitigación de procesos patológicos que pueden mediarse mediante regulación por disminución del gen PCSK9. En el contexto de la presente invención, en la medida en que se refiere a cualquiera de los otros estados que se mencionan a continuación en el presente documento (distintos de los procesos patológicos que pueden mediarse mediante regulación por disminución del gen PCSK9), los términos “tratar”, “tratamiento” y similares se refieren al alivio o a la mitigación de al menos un síntoma asociado a tal estado, o a la ralentización o inversión de la progresión de tal estado. Por ejemplo, en el contexto de la hiperlipidemia, el tratamiento implicará una disminución de los niveles séricos de lípidos.
Tal como se usan en el presente documento, las expresiones “cantidad terapéuticamente eficaz” y “cantidad profilácticamente eficaz” se refieren a una cantidad que proporciona un beneficio terapéutico en el tratamiento, la prevención o la gestión de procesos patológicos que pueden mediarse mediante regulación por disminución del gen PCSK9 o un síntoma manifiesto de procesos patológicos que pueden mediarse mediante regulación por disminución del gen PCSK9. La cantidad específica que es terapéuticamente eficaz puede determinarla fácilmente el médico habitual, y puede variar dependiendo de factores conocidos en la técnica, tales como, por ejemplo, el tipo de procesos patológicos que pueden mediarse mediante regulación por disminución del gen PCSK9, los antecedentes y la edad del paciente, la etapa de los procesos patológicos que pueden mediarse mediante regulación por disminución de la expresión del gen PCSK9 y la administración de otros procesos antipatológicos que pueden mediarse mediante regulación por disminución de la expresión del gen PCSK9.
Tal como se usa en el presente documento, una “composición farmacéutica” comprende una cantidad farmacológicamente eficaz de un ARNbc y un portador farmacéuticamente aceptable. Tal como se usa en el presente documento, “cantidad farmacológicamente eficaz”, “cantidad terapéuticamente eficaz” o simplemente “cantidad eficaz” se refiere a la cantidad de un ARN eficaz para producir el resultado farmacológico, terapéutico o preventivo previsto. Por ejemplo, si un tratamiento clínico dado se considera eficaz cuando hay al menos una reducción del 25% en un parámetro medible asociado a una enfermedad o un trastorno, una cantidad terapéuticamente eficaz de un fármaco para el tratamiento de esa enfermedad o ese trastorno es la cantidad necesaria para efectuar al menos una reducción del 25% en ese parámetro.
El término “portador farmacéuticamente aceptable” se refiere a un portador para la administración de un agente terapéutico. Tales portadores incluyen, pero no se limitan a, solución salina, solución salina tamponada, dextrosa, agua, glicerol, etanol y combinaciones de los mismos, y se describen con más detalle a continuación. El término excluye específicamente un medio de cultivo celular.
Tal como se usa en el presente documento, una “célula transformada” es una célula en la que se ha introducido un vector a partir del cual puede expresarse una molécula de ARNbc.
II. Ácido ribonucleico bicatenario (ARNbc)
En una realización, la invención proporciona moléculas de ácido ribonucleico bicatenario (ARNbc) para inhibir la expresión del gen PCSK9 en una célula o un mamífero, en las que el ARNbc comprende una cadena antisentido que comprende una región de complementariedad que es complementaria a al menos una parte de un ARNm formado en la expresión del gen PCSK9 y en las que la región de complementariedad tiene menos de 30 nucleótidos de longitud, generalmente de 19-24 nucleótidos de longitud, y en las que dicho ARNbc, al entrar en contacto con una célula que expresa dicho gen PCSK9, inhibe la expresión de dicho gen PCSK9 en al menos un 40%. El ARNbc comprende dos cadenas de ARN que son lo suficientemente complementarias como para hibridarse y formar una estructura dúplex. Una cadena del ARNbc (la cadena antisentido) comprende una región de complementariedad que es sustancialmente complementaria y, en general, totalmente complementaria, a una secuencia diana, derivada de la secuencia de un ARNm formado durante la expresión del gen PCSK9, la otra cadena (la cadena sentido) comprende una región que es complementaria a la cadena antisentido, de tal manera que las dos cadenas se hibridan y forman una estructura dúplex cuando se combinan en condiciones adecuadas. Generalmente, la estructura dúplex tiene entre 15 y 30, más generalmente entre 18 y 25, aún más generalmente entre 19 y 24 y lo más generalmente entre 19 y 21 pares de bases de longitud. Del mismo modo, la región de complementariedad con la secuencia diana tiene entre 15 y 30, más generalmente entre 18 y 25, aún más generalmente entre 19 y 24 y lo más generalmente entre 19 y 21 nucleótidos de longitud. El ARNbc de la invención puede comprender además una o más proyecciones de nucleótidos monocatenarias. El ARNbc puede sintetizarse mediante métodos convencionales conocidos en la técnica, tal como se comenta más adelante, por ejemplo, mediante el uso de un sintetizador de ADN automatizado, tales como los disponibles comercialmente de, por ejemplo, Biosearch, Applied Biosystems, Inc. En una realización preferida, el gen PCSK9 es el gen PCSK9 humano. En realizaciones específicas, la cadena antisentido del ARNbc comprende una cadena seleccionada de las secuencias sentido de las tablas 1 y 2 y una segunda secuencia seleccionada del grupo que consiste en las secuencias antisentido de las tablas 1 y 2. Los agentes antisentido alternativos que se dirigen a otra parte de la secuencia diana proporcionada en las tablas 1 y 2 pueden determinarse fácilmente usando la secuencia diana y la secuencia de PCSK9 flanqueante.
En realizaciones adicionales, el ARNbc comprende al menos una secuencia de nucleótidos seleccionada de los grupos de secuencias proporcionados en las tablas 1 y 2. En otras realizaciones, el ARNbc comprende al menos dos secuencias seleccionadas de este grupo, en el que una de las al menos dos secuencias es complementaria a otra de las al menos dos secuencias, y una de las al menos dos secuencias es sustancialmente complementaria a una secuencia de un ARNm generado en la expresión del gen PCSK9. Generalmente, el ARNbc comprende dos oligonucleótidos, en el que un oligonucleótido se describe como la cadena sentido en las tablas 1 y 2 y el segundo oligonucleótido se describe como la cadena antisentido en las tablas 1 y 2.
El experto sabe que los ARNbc que comprenden una estructura dúplex de entre 20 y 23, pero específicamente 21, pares de bases han sido aclamados como particularmente eficaces para inducir interferencia por ARN (Elbashir et al., EMBO 2001, 20:6877-6888). Sin embargo, otros han encontrado que ARNbc más cortos o más largos también pueden ser eficaces. En las realizaciones descritas anteriormente, en virtud de la naturaleza de las secuencias de oligonucleótidos proporcionadas en las tablas 1 y 2, los ARNbc de la invención pueden comprender al menos una cadena de una longitud mínima de 21 nt. Puede esperarse razonablemente que los ARNbc más cortos que comprenden una de las secuencias de las tablas 1 y 2 menos sólo unos pocos nucleótidos en uno o ambos extremos puedan ser igualmente eficaces en comparación con los ARNbc descritos anteriormente. Por tanto, la invención contempla los ARNbc que comprenden una secuencia parcial de al menos 15, 16, 17, 18, 19, 20 o más nucleótidos contiguos de una de las secuencias de las tablas 1 y 2 y que difieren en su capacidad para inhibir la expresión del gen PCSK9 en un ensayo FACS tal como se describe en el presente documento en no más del 5, el 10, el 15, el 20, el 25 o el 30% de inhibición con respecto a un ARNbc que comprende la secuencia completa. Otros ARNbc que se escinden dentro de la secuencia diana proporcionada en las tablas 1 y 2 pueden elaborarse fácilmente usando la secuencia de PCSK9 y la secuencia diana proporcionada.
Además, los agentes de iARN proporcionados en las tablas 1 y 2 identifican un sitio en el ARNm de PCSK9 que es susceptible a la escisión basada en iARN. Como tal, la presente invención incluye además agentes de iARN que se dirigen dentro de la secuencia seleccionada como diana por uno de los agentes de la presente invención. Tal como se usa en el presente documento, se dice que un segundo agente de iARN se dirige dentro de la secuencia de un primer agente de iARN si el segundo agente de iARN escinde el mensaje en cualquier lugar dentro del ARNm que es complementario a la cadena antisentido del primer agente de iARN. Un segundo agente de este tipo consistirá generalmente en al menos 15 nucleótidos contiguos de una de las secuencias proporcionadas en las tablas 1 y 2 acopladas a secuencias de nucleótidos adicionales tomadas de la región contigua a la secuencia seleccionada en el gen PCSK9. Por ejemplo, los últimos 15 nucleótidos de la SEQ ID NO: 1 (menos las secuencias de AA añadidas)
combinados con los siguientes 6 nucleótidos del gen PCSK9 diana producen un agente monocatenario de 21 nucleótidos que se basa en una de las secuencias proporcionadas en las tablas 1 y 2.
El ARNbc de la invención puede contener uno o más apareamientos erróneos con la secuencia diana. En una realización preferida, el ARNbc de la invención no contiene más de 3 apareamientos erróneos. Si la cadena antisentido del ARNbc contiene apareamientos erróneos con una secuencia diana, es preferible que el área de apareamiento erróneo no esté situada en el centro de la región de complementariedad. Si la cadena antisentido del ARNbc contiene apareamientos erróneos con la secuencia diana, es preferible que el apareamiento erróneo se restrinja a 5 nucleótidos de cualquier extremo, por ejemplo, 5, 4, 3, 2 ó 1 nucleótido del extremo 5' o 3' de la región de complementariedad. Por ejemplo, para una cadena de ARNbc de 23 nucleótidos que es complementaria a una región del gen PCSK9, el ARNbc generalmente no contiene ningún apareamiento erróneo dentro de los 13 nucleótidos centrales. Los métodos descritos en la invención pueden usarse para determinar si un ARNbc que contiene un apareamiento erróneo con una secuencia diana es eficaz para inhibir la expresión del gen PCSK9. La consideración de la eficacia de los ARNbc con apareamientos erróneos en la inhibición de la expresión del gen PCSK9 es importante, especialmente si se sabe que la región de complementariedad particular en el gen PCSK9 tiene una variación de secuencia polimórfica dentro de la población.
En una realización, al menos un extremo del ARNbc tiene una proyección de nucleótidos monocatenaria de 1 a 4, generalmente de 1 ó 2 nucleótidos. Los ARNbc que tienen al menos una proyección de nucleótidos tienen propiedades inhibidoras inesperadamente superiores a las de sus homólogos con extremos romos. Además, los presentes inventores han descubierto que la presencia de una sola proyección de nucleótidos refuerza la actividad de interferencia del ARNbc, sin afectar a su estabilidad general. El ARNbc que tiene una sola proyección ha demostrado ser particularmente estable y eficaz in vivo, así como en una variedad de células, medios de cultivo celular, sangre y suero. Generalmente, la proyección monocatenaria se sitúa en el extremo 3'-terminal de la cadena antisentido o, alternativamente, en el extremo 3'-terminal de la cadena sentido. El ARNbc también puede tener un extremo romo, generalmente situado en el extremo 5' de la cadena antisentido. Tales ARNbc tienen estabilidad y actividad inhibidora mejoradas, permitiendo así la administración a dosificaciones bajas, es decir, menos de 5 mg/kg de peso corporal del receptor al día. Generalmente, la cadena antisentido del ARNbc tiene una proyección de nucleótidos en el extremo 3', y el extremo 5' es romo. En otra realización, uno o más de los nucleótidos de la proyección se reemplazan por un tiofosfato nucleosídico.
En aún otra realización, el ARNbc se modifica químicamente para potenciar la estabilidad. Los ácidos nucleicos de la invención pueden sintetizarse y/o modificarse mediante métodos bien establecidos en la técnica, tales como los descritos en “Current protocols in nucleic acid chemistry”, Beaucage, S.L. et al. (Edrs.), John Wiley & Sons, Inc., Nueva York, NY, EE.Uu . Las modificaciones químicas pueden incluir, pero no se limitan a, modificaciones en 2', modificaciones en otros sitios del azúcar o de la base de un oligonucleótido, introducción de bases no naturales en la cadena del oligonucleótido, unión covalente a un ligando o a un resto químico y reemplazo de los enlaces fosfato internucleotídicos por enlaces alternativos tales como tiofosfatos. Puede emplearse más de una de estas modificaciones.
La unión química de las dos cadenas independientes de ARNbc puede lograrse mediante una variedad de técnicas bien conocidas, por ejemplo, introduciendo enlaces covalentes, iónicos o de hidrógeno; interacciones hidrófobas, interacciones de Van der Waals o de apilamiento; mediante la coordinación de iones metálicos o mediante el uso de análogos de purina. Generalmente, los grupos químicos que pueden usarse para modificar el ARNbc incluyen, sin limitación, azul de metileno; grupos bifuncionales, generalmente bis-(2-cloroetil)amina; N-acetil-N'-(pglioxilbenzoil)cistamina; 4-tiouracilo; y psoraleno. En una realización, el ligador es un ligador de hexa-etilenglicol. En este caso, los ARNbc se producen mediante síntesis en fase sólida y el ligador de hexa-etilenglicol se incorpora según métodos convencionales (por ejemplo, Williams, D.J., y K.B. Hall, Biochem. (1996) 35:14665-14670). En una realización particular, el extremo 5' de la cadena antisentido y el extremo 3' de la cadena sentido están unidos químicamente mediante un ligador de hexaetilenglicol. En otra realización, al menos un nucleótido del ARNbc comprende un grupo fosforotioato o fosforoditioato. El enlace químico en los extremos del ARNbc se forma generalmente mediante enlaces de triple hélice. Las tablas 1 y 2 proporcionan ejemplos de agentes de iARN modificados de la invención.
En aún otra realización, los nucleótidos en una o ambas cadenas sencillas pueden modificarse para evitar o inhibir las actividades de degradación de las enzimas celulares, tales como, por ejemplo, sin limitación, determinadas nucleasas. Las técnicas para inhibir la actividad de degradación de las enzimas celulares contra los ácidos nucleicos se conocen en la técnica, incluyendo, pero sin limitarse a, modificaciones de 2'-amino, modificaciones de azúcar 2'-amino, modificaciones de azúcar 2'-F, modificaciones de azúcar 2'-alquilo, modificaciones de la estructura principal sin carga, modificaciones de morfolino, modificaciones de 2'-O-metilo y fosforamidato (véase, por ejemplo, Wagner, Nat. Med. (1995) 1:1116-8). Por tanto, al menos un grupo 2'-hidroxilo de los nucleótidos de un ARNbc se reemplaza por un grupo químico, generalmente por un grupo 2'-amino o 2'-metilo. Además, al menos un nucleótido puede modificarse para formar un nucleótido bloqueado. Tal nucleótido bloqueado contiene un puente de metileno que conecta el 2'-oxígeno de la ribosa con el 4'-carbono de la ribosa. Los oligonucleótidos que contienen el nucleótido bloqueado se describen en Koshkin, A.A., et al., Tetrahedron (1998), 54: 3607-3630) y Obika, S. et al., Tetrahedron Lett. (1998), 39: 5401-5404). La introducción de un nucleótido bloqueado en un oligonucleótido mejora la afinidad por las secuencias complementarias y aumenta la temperatura de fusión en varios grados (Braasch, D.A. y D.R.
Corey, Chem. Biol. (2001), 8:1-7).
La conjugación de un ligando con un ARNbc puede potenciar su absorción celular, así como su direccionamiento a un tejido particular o su captación por tipos específicos de células, tales como células hepáticas. En determinados casos, se conjuga un ligando hidrófobo con el ARNbc para facilitar la permeación directa de la membrana celular y/o la captación a través de las células hepáticas. Alternativamente, el ligando conjugado con el ARNbc es un sustrato para la endocitosis mediada por el receptor. Estos enfoques se han usado para facilitar la permeación celular de oligonucleótidos antisentido, así como de agentes de ARNbc. Por ejemplo, se ha conjugado el colesterol con diversos oligonucleótidos antisentido, dando lugar a compuestos que son sustancialmente más activos en comparación con sus análogos no conjugados. Véase M. Manoharan Antisense & Nucleic Acid Drug Development 2002, 12, 103. Otros compuestos lipófilos que se han conjugado con oligonucleótidos incluyen ácido 1-pirenobutírico, 1,3-bis-O-(hexadecil)glicerol y mentol. Un ejemplo de ligando para la endocitosis mediada por el receptor es el ácido fólico. El ácido fólico entra en la célula mediante endocitosis mediada por receptores de folato. Los compuestos de ARNbc que portan ácido fólico se transportarían eficientemente a la célula a través de la endocitosis mediada por receptores de folato. Li y colaboradores informan de que la unión de ácido fólico al extremo 3' de un oligonucleótido dio lugar a un aumento de 8 veces de la captación celular del oligonucleótido. Li, S.; Deshmukh, H. M.; Huang, L. Pharm. Res. 1998, 15, 1540. Otros ligandos que se han conjugado con oligonucleótidos incluyen polietilenglicoles, grupos de hidratos de carbono, agentes de reticulación, conjugados de porfirina, péptidos de administración y lípidos tales como colesterol.
En determinados casos, la conjugación de un ligando catiónico con los oligonucleótidos da como resultado una resistencia mejorada a las nucleasas. Ejemplos representativos de ligandos catiónicos son propilamonio y dimetilpropilamonio. Curiosamente, se ha informado de que los oligonucleótidos antisentido conservan su alta afinidad de unión al ARNm cuando el ligando catiónico se dispersa por todo el oligonucleótido. Véase M. Manoharan Antisense & Nucleic Acid Drug Development 2002, 12, 103 y sus referencias.
El ARNbc conjugado con ligando de la invención puede sintetizarse mediante el uso de un ARNbc que porta una funcionalidad reactiva colgante, tal como la derivada de la unión de una molécula de unión al ARNbc. Este oligonucleótido reactivo puede reaccionar directamente con ligandos comercialmente disponibles, con ligandos sintetizados que portan una variedad de grupos protectores o con ligandos que tienen una molécula de unión unida a los mismos. Los métodos de la invención facilitan la síntesis de ARNbc conjugados con ligandos mediante el uso, en algunas realizaciones preferidas, de monómeros de nucleósidos que se han conjugado adecuadamente con ligandos y que, además, pueden estar unidos a un material de soporte sólido. Tales conjugados ligando-nucleósido, opcionalmente unidos a un material de soporte sólido, se preparan según algunas realizaciones preferidas de los métodos de la invención mediante la reacción de un ligando de unión al suero seleccionado con un resto de unión situado en la posición 5' de un nucleósido u oligonucleótido. En determinados casos, un ARNbc que porta un ligando aralquilo unido al extremo 3' del ARNbc se prepara, en primer lugar, uniendo covalentemente un bloque de construcción monomérico a un soporte de vidrio de tamaño de poro controlado mediante un grupo aminoalquilo de cadena larga. A continuación, los nucleótidos se unen mediante técnicas de síntesis en fase sólida convencionales al bloque de construcción monomérico unido al soporte sólido. El bloque de construcción monomérico puede ser un nucleósido u otro compuesto orgánico compatible con la síntesis en fase sólida.
El ARNbc usado en los conjugados de la invención puede elaborarse de manera conveniente y rutinaria mediante la bien conocida técnica de síntesis en fase sólida. El equipo para tales síntesis lo comercializan varios proveedores, incluyendo, por ejemplo, Applied Biosystems (Foster City, CA). Adicional o alternativamente, puede emplearse cualquier otro medio para tal síntesis conocido en la técnica . También es conocido el uso de técnicas similares para preparar otros oligonucleótidos, tales como fosforotioatos y derivados alquilados.
Las enseñanzas relativas a la síntesis de oligonucleótidos modificados particulares pueden encontrarse en las siguientes patentes estadounidenses: patentes estadounidenses n.os 5.138.045 y 5.218.105, que se refieren a oligonucleótidos conjugados con poliaminas; patente estadounidense n.° 5.212.295, que se refiere a monómeros para la preparación de oligonucleótidos que tienen enlaces de fósforo quirales; patentes estadounidenses n.os 5.378.825 y 5.541.307, que se refieren a oligonucleótidos que tienen estructuras principales modificadas; patente estadounidense n.° 5.386.023, que se refiere a oligonucleótidos con la estructura principal modificada y a la preparación de los mismos mediante acoplamiento reductor; patente estadounidense n.° 5.457.191, que se refiere a bases nitrogenadas modificadas basadas en el sistema de anillo de 3-desazapurina y a métodos de síntesis de las mismas; patente estadounidense n.° 5.459.255, que se refiere a bases nitrogenadas modificadas basadas en purinas sustituidas en N-2; patente estadounidense n.° 5.521.302, que se refiere a procedimientos para preparar oligonucleótidos que tienen enlaces de fósforo quirales; patente estadounidense n.° 5.539.082, que se refiere a ácidos nucleicos peptídicos; patente estadounidense n.° 5.554.746, que se refiere a oligonucleótidos que tienen estructuras principales de p-lactama; patente estadounidense n.° 5.571.902, que se refiere a métodos y a materiales para la síntesis de oligonucleótidos; patente estadounidense n.° 5.578.718, que se refiere a nucleósidos que tienen grupos alquiltio, en los que tales grupos pueden usarse como ligadores de otros restos unidos en cualquiera de las diversas posiciones del nucleósido; patentes estadounidenses n.os 5.587.361 y 5.599.797, que se refieren a oligonucleótidos que tienen enlaces fosforotioato de alta pureza quiral; patente estadounidense n.° 5.506.351, que se refiere a procedimientos para la preparación de 2'-O-alquilguanosina y compuestos relacionados, incluyendo compuestos de 2,6-diaminopurina; patente estadounidense n.° 5.587.469, que se refiere a oligonucleótidos que
tienen purinas sustituidas en N-2; patente estadounidense n.° 5.587.470, que se refiere a oligonucleótidos que tienen 3-desazapurinas; patente estadounidense n.° 5.223.168 y patente estadounidense n.° 5.608.046, que se refieren ambas a análogos de 4'-desmetil-nucleósidos conjugados; patentes estadounidenses n.os 5.602.240 y 5.610.289, que se refieren a análogos de oligonucleótidos con la estructura principal modificada; patentes estadounidenses n.os 6.262.241 y 5.459.255, que se refieren, entre otras cosas, a métodos de síntesis de 2'-fluoro-oligonucleótidos.
En los nucleósidos unidos específicos de secuencia que portan moléculas de ligando y ARNbc conjugado con ligando de la invención, los oligonucleótidos y oligonucleósidos pueden ensamblarse en un sintetizador de ADN adecuado usando precursores de nucleótidos o nucleósidos convencionales, o precursores de conjugados de nucleótidos o nucleósidos que ya portan el resto de unión, precursores de nucleótidos o nucleósidos conjugados con ligandos que ya portan la molécula de ligando, o bloques de construcción que portan ligandos no nucleosídicos. Cuando se usan precursores de conjugados de nucleótidos que ya portan un resto de unión, normalmente se completa la síntesis de los nucleósidos unidos específicos de secuencia y, a continuación, se hace reaccionar la molécula de ligando con el resto de unión para formar el oligonucleótido conjugado con ligando. Los conjugados de oligonucleotídicos que portan una variedad de moléculas, tales como esteroides, vitaminas, lípidos y moléculas indicadoras, se han descrito previamente (véase Manoharan et al., solicitud PCT WO 93/07883). En una realización preferida, los oligonucleótidos o nucleósidos unidos de la invención se sintetizan mediante un sintetizador automatizado usando fosforamiditas derivadas de conjugados ligando-nucleósido además de las fosforamiditas convencionales y las fosforamiditas no convencionales que están disponibles comercialmente y se usan de manera rutinaria en la síntesis de oligonucleótidos.
La incorporación de un grupo 2'-O-metilo, 2'-O-etilo, 2'-O-propilo, 2'-O-alilo, 2'-O-aminoalquilo o 2'-desoxi-2'-fluoro en los nucleósidos de un oligonucleótido confiere propiedades de hibridación potenciadas al oligonucleótido. Además, los oligonucleótidos que contienen estructuras principales de fosforotioato tienen estabilidad de nucleasa potenciada. Por tanto, los nucleósidos unidos funcionalizados de la invención pueden aumentarse para incluir uno o ambos de una estructura principal de fosforotioato o un grupo 2'-O-metilo, 2'-O-etilo, 2'-O-propilo, 2'-O-aminoalquilo, 2'-O-alilo o 2'-desoxi-2'-fluoro. Una lista resumida de algunas de las modificaciones de oligonucleótidos conocidas en la técnica se encuentra, por ejemplo, en la publicación PCT WO 200370918.
En algunas realizaciones, las secuencias de nucleósidos funcionalizados de la invención que poseen un grupo amino en el extremo 5' se preparan usando un sintetizador de ADN y, a continuación, se hacen reaccionar con un derivado de éster activo de un ligando seleccionado. Los derivados de éster activo los conocen bien los expertos en la técnica. Los ésteres activos representativos incluyen ésteres de N-hidrosuccinimida, ésteres tetrafluorofenólicos, ésteres pentafluorofenólicos y ésteres pentaclorofenólicos. La reacción del grupo amino y el éster activo produce un oligonucleótido en el que el ligando seleccionado se une en la posición 5' a través de un grupo de unión. El grupo amino en el extremo 5' puede prepararse usando un reactivo 5'-amino-modificador de C6. En una realización, las moléculas de ligando pueden conjugarse con oligonucleótidos en la posición 5' mediante el uso de una fosforamidita de ligando-nucleósido en la que el ligando está unido al grupo 5'-hidroxilo directa o indirectamente a través de un ligador. Tales fosforamiditas de ligando-nucleósido se usan normalmente al final de un procedimiento de síntesis automatizado para proporcionar un oligonucleótido conjugado con ligando que porta el ligando en el extremo 5'. Los ejemplos de estructuras principales o enlaces internucleósidos modificados incluyen, por ejemplo, fosforotioatos, fosforotioatos quirales, fosforoditioatos, fosfotriésteres, aminoalquilfosfotriésteres, fosfonatos de metilo y otros alquilos, incluyendo fosfonatos de 3'-alquileno y fosfonatos quirales, fosfinatos fosforamidatos, incluyendo 3'-aminofosforamidato y aminoalquilfosforamidatos, tionofosforamidatos, tionoalquilfosfonatos, tionoalquilfosfotriésteres y boranofosfatos que tienen enlaces normales 3'-5', análogos de los mismos unidos en 2'-5' y aquellos que tienen polaridad invertida en los que los pares adyacentes de unidades de nucleósidos están unidos en 3'-5' a 5'-3' o 2'-5' a 5'-2'. También se incluyen diversas sales, sales mixtas y formas de ácido libre.
Las patentes estadounidenses representativas relacionadas con la preparación de los enlaces que contienen átomos de fósforo anteriores incluyen, pero no se limitan a, las patentes estadounidenses n.os 3.687.808; 4.469.863; 4.476.301; 5.023.243; 5.177.196; 5.188.897; 5.264.423; 5.276.019; 5.278.302; 5.286.717; 5.321.131; 5.399.676; 5.405.939; 5.453.496; 5.455.233; 5.466.677; 5.476.925; 5.519.126; 5.536.821; 5.541.306; 5.550.111; 5.563.253; 5.571.799; 5.587.361; 5.625.050; y 5.697.248.
Los ejemplos de estructuras principales o enlaces internucleósidos modificados que no incluyen un átomo de fósforo en los mismos (es decir, oligonucleósidos) tienen estructuras principales que están formadas por enlaces interazúcares de alquilo o cicloalquilo de cadena corta, enlaces interazúcares mixtos de heteroátomo y alquilo o cicloalquilo, o uno o más enlaces interazúcares heteroatómicos o heterocíclicos de cadena corta. Estos incluyen aquellos que tienen enlaces morfolino (formados en parte a partir de la porción de azúcar de un nucleósido); estructuras principales de siloxano; estructuras principales de sulfuro, sulfóxido y sulfona; estructuras principales de formacetilo y tioformacetilo; estructuras principales de metilenformacetilo y tioformacetilo; estructuras principales que contienen alqueno; estructuras principales de sulfamato; estructuras principales de metilenimino y metilenhidrazino; estructuras principales de sulfonato y sulfonamida; estructuras principales de amida; y otras que tienen componentes mixtos de N, O, S y CH2.
Las patentes estadounidenses representativas relacionadas con la preparación de los oligonucleósidos anteriores incluyen, pero no se limitan a, las patentes estadounidenses n.os 5.034.506; 5.166.315; 5.185.444; 5.214.134; 5.216.141; 5.235.033; 5.264.562; 5.264.564; 5.405.938; 5.434.257; 5.466.677; 5.470.967; 5.489.677; 5.541.307; 5.561.225; 5.596.086; 5.602.240; 5.610.289; 5.602.240; 5.608.046; 5.610.289; 5.618.704; 5.623.070; 5.663.312; 5.633.360; 5.677.437; y 5.677.439.
En determinados casos, el oligonucleótido puede modificarse mediante un grupo distinto de ligando. Se han conjugado varias moléculas distintas de ligando con oligonucleótidos para potenciar la actividad, la distribución celular o la captación celular del oligonucleótido, y los procedimientos para realizar tales conjugaciones están disponibles en la bibliografía científica. Tales restos distintos de ligando han incluido restos lipídicos, tales como colesterol (Letsinger et al., Proc. Natl. Acad. Sci. USA, 1989, 86:6553), ácido cólico (Manoharan et al., Bioorg. Med. Chem. Lett., 1994, 4:1053), un tioéter, por ejemplo, hexil-S-tritiltiol (Manoharan et al., Ann. N.Y. Acad. Sci., 1992, 660:306; Manoharan et al., Bioorg. Med. Chem. Let., 1993, 3:2765), un tiocolesterol (Oberhauser et al., Nucl. Acids Res., 1992, 20:533), una cadena alifática, por ejemplo, dodecanodiol o residuos de undecilo (Saison-Behmoaras et al., EMBO J., 1991, 10:111; Kabanov et al., FEBS Lett, 1990, 259:327; Svinarchuk et al., Biochimie, 1993, 75:49), un fosfolípido, por ejemplo, di-hexadecil-rac-glicerol o 1,2-di-O-hexadecil-rac-glicero-3-H-fosfonato de trietilamonio (Manoharan et al., Tetrahedron Lett., 1995, 36:3651; Shea et al., Nucl. Acids Res., 1990, 18:3777), una poliamina o una cadena de polietilenglicol (Manoharan et al., Nucleosides & Nucleotides, 1995, 14:969), o ácido adamantanacético (Manoharan et al., Tetrahedron Lett, 1995, 36:3651), un resto palmitilo (Mishra et al., Biochim. Biophys. Acta, 1995, 1264:229), o un resto octadecilamina o hexilamino-carbonil-oxicolesterol (Crooke et al., J. Pharmacol. Exp. Ther., 1996, 277:923). Las patentes estadounidenses representativas que enseñan la preparación de tales conjugados oligonucleotídicos se han enumerado anteriormente. Los protocolos de conjugación típicos implican la síntesis de oligonucleótidos que portan un ligador amino en una o más posiciones de la secuencia. A continuación, el grupo amino se hace reaccionar con la molécula que va a conjugarse usando reactivos de acoplamiento o activación adecuados. La reacción de conjugación puede llevarse a cabo con el oligonucleótido todavía unido al soporte sólido o tras la escisión del oligonucleótido en fase de disolución. La purificación del conjugado oligonucleotídico mediante HPLC suele proporcionar el conjugado puro. El uso de un conjugado de colesterol es particularmente preferido, ya que un resto de este tipo puede aumentar la selección como diana de células células hepáticas, un sitio de expresión de PCSK9.
Agentes de iARN codificados por vectores
El ARNbc de la invención también puede expresarse a partir de vectores virales recombinantes de manera intracelular in vivo. Los vectores virales recombinantes de la invención comprenden secuencias que codifican para el ARNbc de la invención y cualquier promotor adecuado para expresar las secuencias de ARNbc. Los promotores adecuados incluyen, por ejemplo, las secuencias promotoras de la ARN pol III U6 o H1 y el promotor de citomegalovirus. La selección de otros promotores adecuados está dentro de la habilidad en la técnica. Los vectores virales recombinantes de la invención también pueden comprender promotores inducibles o regulables para la expresión del ARNbc en un tejido particular o en un entorno intracelular particular. El uso de vectores virales recombinantes para administrar el ARNbc de la invención a las células in vivo se comenta con más detalle a continuación.
El ARNbc de la invención puede expresarse a partir de un vector viral recombinante, o bien como dos moléculas de ARN independientes y complementarias, o bien como una única molécula de ARN con dos regiones complementarias.
Puede usarse cualquier vector viral que pueda aceptar las secuencias de codificación para la(s) molécula(s) de ARNbc que va(n) a expresarse, por ejemplo, vectores derivados de adenovirus (AV); virus adenoasociados (AAV); retrovirus (por ejemplo, lentivirus (LV), rabdovirus, virus de la leucemia murina); virus del herpes, y similares. El tropismo de los vectores virales puede modificarse mediante el pseudotipado de los vectores con proteínas de la envoltura u otros antígenos de superficie de otros virus, o mediante la sustitución de diferentes proteínas de la cápside viral, según sea apropiado.
Por ejemplo, los vectores lentivirales de la invención pueden pseudotiparse con proteínas de superficie del virus de la estomatitis vesicular (VSV), la rabia, el Ébola, el Mokola y similares. Los vectores de AAV de la invención pueden elaborarse para dirigirse a diferentes células mediante modificación por ingeniería de los vectores para expresar diferentes serotipos de proteínas de la cápside. Por ejemplo, un vector de AAV que expresa una cápside del serotipo 2 en un genoma del serotipo 2 se denomina AAV 2/2. Este gen de la cápside del serotipo 2 en el vector de AAV 2/2 puede reemplazarse por un gen de la cápside del serotipo 5 para producir un vector de AAV 2/5. Las técnicas para construir vectores de AAV que expresan diferentes serotipos de proteínas de la cápside están dentro de la habilidad en la técnica; véase, por ejemplo, Rabinowitz J E et al. (2002), J Virol 76:791-801.
La selección de vectores virales recombinantes adecuados para su uso en la invención, métodos para insertar secuencias de ácido nucleico para expresar el ARNbc en el vector y métodos de administración del vector viral a las células de interés están dentro de la habilidad en la técnica. Véase, por ejemplo, Dornburg R (1995), Gene Therap.
2: 301-310; Eglitis M A (1988), Biotechniques 6: 608-614; Miller A D (1990), Hum Gene Therap. 1: 5-14; Anderson W F (1998), Nature 392: 25-30; y Rubinson D A et al., Nat. Genet. 33: 401-406.
Los vectores virales preferidos son aquellos derivados de AV y AAV. En una realización particularmente preferida, el ARNbc de la invención se expresa como dos moléculas de ARN monocatenario independientes y complementarias a partir de un vector de AAV recombinante que comprende, por ejemplo, los promotores de ARN U6 o H1, o el promotor de citomegalovirus (CMV).
Un vector de AV adecuado para expresar el ARNbc de la invención, un método para construir el vector de AV recombinante y un método para administrar el vector a las células diana se describen en Xia H et al. (2002), Nat. Biotech. 20: 1006-1010.
Los vectores de AAV adecuados para expresar el ARNbc de la invención, los métodos para construir el vector de AV recombinante y los métodos para administrar los vectores a las células diana se describen en Samulski R et al. (1987), J. Virol. 61: 3096-3101; Fisher K J et al. (1996), J. Virol, 70: 520-532; Samulski R et al. (1989), J. Virol. 63: 3822-3826; patente estadounidense n.° 5.252.479; patente estadounidense n.° 5.139.941; solicitud de patente internacional n.° WO 94/13788; y solicitud de patente internacional n.° WO 93/24641.
III. Composiciones farmacéuticas que comprenden ARNbc
En una realización, la invención proporciona composiciones farmacéuticas que comprenden un ARNbc, tal como se describe en el presente documento, y un portador farmacéuticamente aceptable. La composición farmacéutica que comprende el ARNbc es útil para tratar una enfermedad o un trastorno asociado con la expresión o actividad del gen PCSK9, tal como procesos patológicos que pueden mediarse mediante regulación por disminución de la expresión del gen PCSK9, tales como hiperlipidemia. Tales composiciones farmacéuticas se formulan basándose en el modo de administración. Un ejemplo son las composiciones formuladas para su administración al hígado por vía parenteral.
Las composiciones farmacéuticas de la invención se administran en dosificaciones suficientes para inhibir la expresión del gen PCSK9. Los presentes inventores han descubierto que, debido a su eficacia mejorada, las composiciones que comprenden el ARNbc de la invención pueden administrarse a dosificaciones sorprendentemente bajas. Una dosificación de 5 mg de ARNbc por kilogramo de peso corporal del receptor al día es suficiente para inhibir o suprimir la expresión del gen PCSK9 y puede administrarse sistémicamente al paciente. En general, una dosis adecuada de ARNbc estará en el intervalo de 0,01 a 5,0 miligramos por kilogramo de peso corporal del receptor al día, generalmente en el intervalo de 1 microgramo a 1 mg por kilogramo de peso corporal al día. La composición farmacéutica puede administrarse una vez al día, o el ARNbc puede administrarse en dos, tres o más subdosis a intervalos apropiados a lo largo del día o incluso mediante infusión continua o administración a través de una formulación de liberación controlada. En ese caso, el ARNbc contenido en cada subdosis debe ser correspondientemente menor para lograr la dosificación diaria total. La unidad de dosificación también puede componerse para su administración durante varios días, por ejemplo, usando una formulación de liberación sostenida convencional que proporcione una liberación sostenida del ARNbc durante un periodo de varios días. Las formulaciones de liberación sostenida se conocen bien en la técnica.
El experto apreciará que determinados factores pueden influir en la dosificación y el tiempo necesarios para tratar eficazmente a un sujeto, incluyendo, pero sin limitarse a, la gravedad de la enfermedad o el trastorno, los tratamientos anteriores, la salud general y/o la edad del sujeto y otras enfermedades presentes. Además, el tratamiento de un sujeto con una cantidad terapéuticamente eficaz de una composición puede incluir un único tratamiento o una serie de tratamientos. Las estimaciones de las dosificaciones eficaces y las semividas in vivo de los ARNbc individuales englobados por la invención pueden realizarse usando metodologías convencionales o basándose en pruebas in vivo usando un modelo animal apropiado, tal como se describe en otra parte en el presente documento.
Los avances en genética de ratones han generado varios modelos de ratón para el estudio de diversas enfermedades humanas, tales como los procesos patológicos que pueden mediarse mediante regulación por disminución de la expresión del gen PCSK9. Tales modelos se usan para las pruebas in vivo del ARNbc, así como para determinar una dosis terapéuticamente eficaz.
Puede usarse cualquier método para administrar un ARNbc de la presente invención a un mamífero. Por ejemplo, la administración puede ser directa; oral; o parenteral (por ejemplo, mediante inyección subcutánea, intraventricular, intramuscular o intraperitoneal, o por goteo intravenoso). La administración puede ser rápida (por ejemplo, mediante inyección) o puede producirse durante un periodo de tiempo (por ejemplo, mediante infusión lenta o administración de formulaciones de liberación lenta).
Normalmente, cuando se trata a un mamífero con hiperlipidemia, las moléculas de ARNbc se administran sistémicamente por vía parenteral. Por ejemplo, los ARNbc, conjugados o no conjugados o formulados con o sin liposomas, pueden administrarse por vía intravenosa a un paciente. Para ello, una molécula de ARNbc puede formularse en composiciones tales como disoluciones acuosas estériles y no estériles, disoluciones no acuosas en disolventes habituales tales como alcoholes o disoluciones en bases oleosas líquidas o sólidas. Tales disoluciones también pueden contener tampones, diluyentes y otros aditivos adecuados. Para la administración parenteral, intratecal o intraventricular, una molécula de ARNbc puede formularse en composiciones tales como disoluciones
acuosas estériles, que también pueden contener tampones, diluyentes y otros aditivos adecuados (por ejemplo, potenciadores de la penetración, compuestos portadores y otros portadores farmacéuticamente aceptables).
Además, las moléculas de ARNbc pueden administrarse a un mamífero como medio biológico o abiológico, tal como se describe, por ejemplo, en la patente estadounidense n.° 6.271.359. La administración abiológica puede llevarse a cabo mediante una variedad de métodos, incluyendo, sin limitación, (1) cargar liposomas con una molécula de ácido ARNbc proporcionada en el presente documento y (2) formar un complejo entre una molécula de ARNbc y lípidos o liposomas para formar complejos de ácido nucleico-lípido o ácido nucleico-liposoma. El liposoma puede estar compuesto por lípidos catiónicos y neutros habitualmente usados para transfectar células in vitro. Los lípidos catiónicos pueden formar complejos (por ejemplo, asociarse a la carga) con ácidos nucleicos cargados negativamente para formar liposomas. Los ejemplos de liposomas catiónicos incluyen, sin limitación, lipofectina, lipofectamina, Lipofectace y DOTAP. Los procedimientos para formar liposomas se conocen bien en la técnica. Las composiciones de liposomas pueden formarse, por ejemplo, a partir de fosfatidilcolina, dimiristoilfosfatidilcolina, dipalmitoilfosfatidilcolina, dimiristoilfosfatidilglicerol o dioleoilfosfatidiletanolamina. Hay numerosos agentes lipófilos comercialmente disponibles, tales como Lipofectin.RTM. (Invitrogen/Life Technologies, Carlsbad, California) y Effectene.TM. (Qiagen, Valencia, California). Además, los métodos de administración sistémica pueden optimizarse usando lípidos catiónicos comercialmente disponibles, tales como DDAB o DOTAP, que pueden mezclarse cada uno de los cuales con un lípido neutro tal como DOPE o colesterol. En algunos casos, pueden usarse liposomas tales como los descritos por Templeton et al. (Nature Biotechnology, 15: 647-652 (1997)). En otras realizaciones, pueden usarse policationes tales como polietilenimina para lograr la administración in vivo y ex vivo (Boletta et al., J. Am Soc. Nephrol. 7: 1728 (1996)). Puede encontrarse información adicional sobre el uso de liposomas para la administración de ácidos nucleicos en la patente estadounidense n.° 6.271.359, la publicación PCT WO 96/40964 y Morrissey, D. et al. 2005. Nat Biotechnol. 23(8):1002-7.
La administración biológica puede llevarse a cabo mediante una variedad de métodos, incluyendo, sin limitación, el uso de vectores virales. Por ejemplo, pueden usarse vectores virales (por ejemplo, vectores de adenovirus y virus del herpes) para administrar moléculas de ARNbc a las células hepáticas. Pueden usarse técnicas convencionales de biología molecular para introducir uno o más de los ARNbc proporcionados en el presente documento en uno de los muchos vectores virales diferentes desarrollados previamente para administrar ácido nucleico a las células. Estos vectores virales resultantes pueden usarse para administrar el uno o más ARNbc a las células mediante, por ejemplo, una infección.
Los ARNbc de la presente invención pueden formularse en un portador o diluyente farmacéuticamente aceptable. Un “portador farmacéuticamente aceptable” (también denominado en el presente documento “excipiente”) es un disolvente farmacéuticamente aceptable, un agente de suspensión o cualquier otro vehículo farmacológicamente inerte. Los portadores farmacéuticamente aceptables pueden ser líquidos o sólidos, y pueden seleccionarse teniendo en cuenta la forma de administración prevista, a fin de proporcionar el volumen, la consistencia y otras propiedades químicas y de transporte pertinentes. Los portadores farmacéuticamente aceptables típicos incluyen, a modo de ejemplo y sin limitación: agua; solución salina; aglutinantes (por ejemplo, polivinilpirrolidona o hidroxipropilmetilcelulosa); cargas (por ejemplo, lactosa y otros azúcares, gelatina o sulfato de calcio); lubricantes (por ejemplo, almidón, polietilenglicol o acetato de sodio); disgregantes (por ejemplo, almidón o glicolato sódico de almidón); y agentes humectantes (por ejemplo, laurilsulfato de sodio).
Además, el ARNbc que selecciona como diana el gen PCSK9 puede formularse en composiciones que contienen el ARNbc mezclado, encapsulado, conjugado o asociado de otro modo con otras moléculas, estructuras moleculares o mezclas de ácidos nucleicos. Por ejemplo, una composición que contiene uno o más agentes de ARNbc que seleccionan como diana el gen PCSK9 puede contener otros agentes terapéuticos tales como otros agentes reductores del contenido de lípidos (por ejemplo, estatinas).
Métodos para el tratamiento de enfermedades que pueden modularse mediante regulación por disminución de la expresión de PCSK9
Los métodos y las composiciones descritos en el presente documento pueden usarse para tratar enfermedades y estados que pueden modularse mediante regulación por disminución de la expresión del gen PCSK9. Por ejemplo, las composiciones descritas en el presente documento pueden usarse para tratar la hiperlipidemia y otras formas de desequilibrio lipídico, tales como hipercolesterolemia, hipertrigliceridemia y los estados patológicos asociados con estos trastornos, tales como enfermedades cardíacas y circulatorias.
Métodos para inhibir la expresión del gen PCSK9
En aún otro aspecto, la invención proporciona un método para inhibir la expresión del gen PCSK9 en un mamífero. El método comprende administrar una composición de la invención al mamífero de manera que se silencie la expresión del gen PCSK9 diana. Debido a su alta especificidad, los ARNbc de la invención seleccionan como diana específicamente los ARN (primarios o procesados) del gen PCSK9 diana. Las composiciones y los métodos para inhibir la expresión de estos genes PCSK9 usando ARNbc pueden realizarse tal como se describe en otras partes en el presente documento.
En una realización, el método comprende administrar una composición que comprende un ARNbc, en la que el ARNbc comprende una secuencia de nucleótidos que es complementaria a al menos una parte de un transcrito de ARN del gen PCSK9 del mamífero que va a tratarse. Cuando el organismo que va a tratarse es un mamífero, tal como, por ejemplo, un ser humano, la composición puede administrarse por cualquier medio conocido en la técnica, incluyendo, pero sin limitarse a, las vías oral o parenteral, incluyendo la administración intravenosa, intramuscular, subcutánea, transdérmica o aérea (aerosol). En las realizaciones preferidas, las composiciones se administran mediante infusión o inyección intravenosa.
A menos que se defina lo contrario, todos los términos técnicos y científicos usados en el presente documento tienen el mismo significado que comúnmente entiende un experto en la técnica a la que pertenece esta invención. Aunque pueden usarse métodos y materiales similares o equivalentes a los descritos en el presente documento en la práctica o en las pruebas de la invención, a continuación se describen métodos y materiales adecuados. En caso de conflicto, prevalecerá la presente memoria descriptiva, incluyendo las definiciones. Además, los materiales, métodos y ejemplos son sólo ilustrativos y no pretenden ser limitativos.
Ejemplos
Desplazamiento génico del gen PCSK9
El diseño del ARNip se llevó a cabo para identificar en dos selecciones separadas
a) ARNip que seleccionan como diana PCSK9 humano y ARNm o bien de ratón o bien de rata, y
b) todos los ARNip reactivos humanos con especificidad prevista para el gen PCSK9 diana.
Se usaron las secuencias de ARNm de PCSK9 humano, de ratón y de rata: se usó la secuencia humana NM_174936.2 como secuencia de referencia durante todo el procedimiento de selección del ARNip.
En la primera etapa, se identificaron tramos nonadecaméricos conservados en ser humano y ratón y secuencias de ARNm de PCSK9 humano y de rata, lo que dio lugar a la selección de ARNip con reactividad cruzada para ser humano y ratón y ARNip con reactividad cruzada para dianas humanas y de rata.
En una segunda selección, se identificaron ARNip que seleccionan como diana específicamente PCSK9 humano. Se extrajeron todas las posibles secuencias nonadecaméricas de PCSK9 humano y se definieron como secuencias diana candidatas. Las secuencias con reactividad cruzada para ser humano y mono y aquellas con reactividad cruzada para ratón, rata, ser humano y mono se enumeran todas ellas en las tablas 1 y 2. Las versiones químicamente modificadas de esas secuencias y su actividad en ensayos in vitro e in vivo también se enumeran en las tablas 1 y 2 y se proporcionan ejemplos en las figuras 2-8.
Para clasificar las secuencias diana candidatas y sus correspondientes ARNip y seleccionar los adecuados, se tomó como parámetro de clasificación su potencial de interacción previsto con dianas irrelevantes (potencial fuera de la diana). Los ARNip con bajo potencial fuera de la diana se definieron como preferibles y se supuso que eran más específicos in vivo.
Para predecir el potencial fuera de la diana específico del ARNip, se hicieron las siguientes suposiciones:
1) las posiciones 2 a 9 (contando de 5' a 3') de una cadena (región semilla) pueden contribuir más al potencial fuera de la diana que la parte restante de la secuencia (región no semilla y región del sitio de escisión)
2) las posiciones 10 y 11 (contando de 5' a 3') de una cadena (región del sitio de escisión) pueden contribuir más al potencial fuera de la diana que la región no semilla
3) las posiciones 1 y 19 de cada cadena no son relevantes para las interacciones fuera de la diana
4) puede calcularse una puntuación fuera de la diana para cada gen y cada cadena, basándose en la complementariedad de la secuencia de la cadena de ARNip con la secuencia del gen y la posición de los apareamientos erróneos
5) el número de regiones fuera de la diana previstas, así como la puntuación más alta de regiones fuera de la diana, deben considerarse para el potencial fuera de la diana
6) las puntuaciones fuera de la diana deben considerarse más relevantes para el potencial fuera de la diana que el número de regiones fuera de la diana
7) suponiendo el posible aborto de la actividad de la cadena sentido por las modificaciones internas introducidas, sólo será relevante el potencial fuera de la diana de la cadena antisentido
Para identificar posibles genes fuera de la diana, las secuencias candidatas nonadecaméricas se sometieron a una búsqueda de homología con respecto a las secuencias de ARNm humano disponibles públicamente.
Se extrajeron las siguientes propiedades fuera de la diana para cada secuencia de entrada nonadecamérica para cada gen fuera de la diana para calcular la puntuación fuera de la diana:
Número de apareamientos erróneos en la región no semilla
Número de apareamientos erróneos en la región semilla
Número de apareamientos erróneos en la región del sitio de escisión
La puntuación fuera de la diana se calculó considerando los siguientes supuestos 1 a 3:
Puntuación fuera de la diana = número de apareamientos erróneos de semillas * 10
+ número de apareamientos erróneos del sitio de escisión * 1,2
+ número de apareamientos erróneos no de semillas * 1
El gen fuera de la diana más relevante para cada ARNip correspondiente a la secuencia de entrada nonadecamérica se definió como el gen con la menor puntuación fuera de la diana. Por consiguiente, la puntuación fuera de la diana más baja se definió como la puntuación fuera de la diana relevante para cada ARNip.
Síntesis de ARNbc
Fuente de reactivos
Cuando la fuente de un reactivo no se indique específicamente en el presente documento, tal reactivo podrá obtenerse de cualquier proveedor de reactivos para biología molecular con un criterio de calidad/pureza para su aplicación en biología molecular.
Síntesis de ARNip
Los ARN monocatenarios se produjeron mediante síntesis en fase sólida a escala 1 amolar usando un sintetizador Expedite 8909 (Applied Biosystems, Applera Deutschland GmbH, Darmstadt, Alemania) y vidrio de tamaño de poro controlado (CPG, 500Á, Proligo Biochemie GmbH, Hamburgo, Alemania) como soporte sólido. El ARN y el ARN que contiene 2'-O-metilnucleótidos se generaron mediante síntesis en fase sólida empleando las correspondientes fosforamiditas y 2-O-metilfosforamiditas, respectivamente (Proligo Biochemie GmbH, Hamburgo, Alemania). Estos bloques de construcción se incorporaron en sitios seleccionados dentro de la secuencia de la cadena de oligorribonucleótidos usando química convencional de fosforamiditas nucleosídicas, tal como se describe en Current protocols in nucleic acid chemistry, Beaucage, S.L. et al. (Edrs.), John Wiley & Sons, Inc., Nueva York, NY, EE.UU. Los enlaces fosforotioato se introdujeron reemplazando la disolución de oxidante de yodo por una disolución del reactivo de Beaucage (Chruachem Ltd, Glasgow, Reino Unido) en acetonitrilo (1%). Otros reactivos auxiliares se obtuvieron de Mallinckrodt Baker (Griesheim, Alemania).
La desprotección y la purificación de los oligorribonucleótidos brutos mediante HPLC de intercambio aniónico se llevaron a cabo según los procedimientos establecidos. Los rendimientos y las concentraciones se determinaron mediante absorción UV de una disolución del respectivo ARN a una longitud de onda de 260 nm usando un fotómetro espectral (DU 640B, Beckman Coulter GmbH, UnterschleilJheim, Alemania). El ARN bicatenario se generó mezclando una disolución equimolar de cadenas complementarias en tampón de hibridación (fosfato de sodio 20 mM, pH 6,8; cloruro de sodio 100 mM), se calentó en un baño de agua a 85 - 90°C durante 3 minutos y se enfrió hasta temperatura ambiente durante un periodo de 3 - 4 horas. La disolución de ARN hibridado se almacenó a -20°C hasta su uso.
Para la síntesis de ARNip conjugados con 3'-colesterol (denominado a continuación en el presente documento -Chol-3'), se usó un soporte sólido adecuadamente modificado para la síntesis de ARN. El soporte sólido modificado se preparó de la siguiente manera:
Dietil-2-azabutano-1,4-dicarboxilato, AA

Se añadió una disolución acuosa 4,7 M de hidróxido de sodio (50 ml) a una disolución con agitación y helada de clorhidrato de glicinato de etilo (32,19 g, 0,23 moles) en agua (50 ml). A continuación, se añadió acrilato de etilo (23,1 g, 0,23 moles) y se agitó la mezcla a temperatura ambiente hasta que se comprobó la finalización de la reacción mediante CCF. Después de 19 h, se sometió a reparto la disolución con diclorometano (3 x 100 ml). Se
secó la fase orgánica con sulfato de sodio anhidro, se filtró y se evaporó. Se destiló el residuo para obtener AA (28,8 g, 61%).
Ester etílico del ácido 3-{etoxicarbonilmetil-[6-(9H-fluoren-9-ilmetoxicarbonil-amino)-hexanoil]-amino}-propiónico, AB

Se disolvió ácido Fmoc-6-amino-hexanoico (9,12 g, 25,83 mmol) en diclorometano (50 ml) y se enfrió con hielo. Se añadió diisopropilcarbodiimida (3,25 g, 3,99 ml, 25,83 mmol) a la disolución a 0°C. A continuación, se añadió dietilazabutano-1,4-dicarboxilato (5 g, 24,6 mmol) y dimetilaminopiridina (0,305 g, 2,5 mmol). Se llevó la disolución hasta temperatura ambiente y se agitó adicionalmente durante 6 h. Se comprobó la finalización de la reacción mediante CCF. Se concentró la mezcla de reacción a vacío y se añadió acetato de etilo para precipitar la diisopropilurea. Se filtró la suspensión. Se lavó el filtrado con ácido clorhídrico acuoso al 5%, bicarbonato de sodio al 5% y agua. Se secó la fase orgánica combinada sobre sulfato de sodio y se concentró para dar el producto bruto, que se purificó mediante cromatografía en columna (EtOAc al 50%/hexanos) para dar 11,87 g (88%) de AB.
Ester etílico del ácido 3-[(6-amino-hexanoil)-etoxicarbonilmetil]-propiónico, AC

Se disolvió éster etílico del ácido 3-{etoxicarbonilmetil-[6-(9H-fluoren-9-ilmetoxicarbonilamino)-hexanoil]-amino}-propiónico, AB (11,5 g, 21,3 mmol) en piperidina al 20% en dimetilformamida a 0°C. Se continuó agitando la disolución durante 1 h. Se concentró la mezcla de reacción a vacío, se añadió agua al residuo y se extrajo el producto con acetato de etilo. Se purificó el producto bruto por conversión en su sal de clorhidrato.
Ester etílico del ácido 3-({6-[17-(1,5-dimetil-hexil)-10,13-dimetil-2,3,4,7,8,9,10,11,12,13,14,15,16,17-tetradecahidro-1H-ciclopenta[a]fenantren-3-iloxicarbonilamino]-hexanoil}etoxicarbonilmetil-amino)-propiónico, AD

Se llevó la sal de clorhidrato de éster etílico del ácido 3-[(6-amino-hexanoil)-etoxicarbonilmetil-amino]-propiónico, AC (4,7 g, 14,8 mmol) a diclorometano. Se enfrió la suspensión hasta 0°C en hielo. A la suspensión se le añadió diisopropiletilamina (3,87 g, 5,2 ml, 30 mmol). A la disolución resultante se le añadió cloroformiato de colesterilo (6,675 g, 14,8 mmol). Se agitó la mezcla de reacción durante la noche. Se diluyó la mezcla de reacción con diclorometano y se lavó con ácido clorhídrico al 10%. Se purificó el producto mediante cromatografía ultrarrápida (10,3 g, 92%).
Éster etílico del ácido 1-{6-[17-(1,5-dimetil-hexil)-10,13-dimetil-2,3,4,7,8,9,10,11,12,13,14,15,16,17-tetradecahidro-1H-cidopenta[a]fenantren-3-iloxicarbonilamino]-hexanoil}-4-oxo-pirrolidin-3-carboxílico, AE

Se suspendió t-butóxido de potasio (1,1 g, 9,8 mmol) en 30 ml de tolueno seco. Se enfrió la mezcla hasta 0°C en hielo y se añadieron lentamente 5 g (6,6 mmol) de diéster AD con agitación en el plazo de 20 minutos. Se mantuvo la temperatura por debajo de 5°C durante la adición. Se continuó la agitación durante 30 minutos a 0°C y se añadió 1 ml de ácido acético glacial, seguido inmediatamente por 4 g de NaH2 PO4 ^ 2O en 40 ml de agua. Se extrajo la mezcla resultante dos veces con 100 ml de diclorometano cada una y se lavaron los extractos orgánicos combinados dos veces con 10 ml de tampón fosfato cada una, se secaron y se evaporaron hasta sequedad. Se disolvió el residuo en 60 ml de tolueno, se enfrió hasta 0°C y se extrajo con tres porciones de 50 ml de tampón carbonato de pH 9,5 frío. Se ajustaron los extractos acuosos a pH 3 con ácido fosfórico y se extrajeron con cinco porciones de 40 ml de cloroformo que se combinaron, se secaron y se evaporaron hasta sequedad. Se purificó el residuo mediante cromatografía en columna usando acetato de etilo al 25%/hexano para obtener 1,9 g de bcetoéster (39%).
Éster 17-(1,5-dimetil-hexil)-10,13-dimetil-2,3,4,7,8,9,10,11,12,13,14,15,16,17-tetradecahidro-1H-ciclopenta[a]fenantren-3-ilíco del ácido [6-(3-hidroxi-4-hidroximetil-pirrolidin-1-il)-6-oxo-hexil]-carbámico, AF

Se añadió metanol (2 ml) gota a gota durante un periodo de 1 h a una mezcla a reflujo de b-cetoéster AE (1,5 g, 2,2 mmol) y borohidruro de sodio (0,226 g, 6 mmol) en tetrahidrofurano (10 ml). Se continuó agitando a temperatura de reflujo durante 1 h. Después de enfriar hasta temperatura ambiente, se añadió HCl 1 N (12,5 ml), se extrajo la mezcla con acetato de etilo (3 x 40 ml). Se secó la fase de acetato de etilo combinada sobre sulfato de sodio anhidro y se concentró a vacío para obtener el producto que se purificó mediante cromatografía en columna (MeOH al 10%/CHCls) (89%).
Éster 17-(1,5-dimetil-hexil)-10,13-dimetil-2,3,4,7,8,9,10,11,12,13,14,15,16,17-tetradecahidi^-1 H-cidopenta[a]fenantren-3-ílico del ácido (6-{3-[bis-(4-metoxi-fenN)-fenN-metoximetil]-4-hidroxi-pirrolidin-1-N}-6-oxohexil)-carbámico, AG

Se secó diol AF (1,25 g, 1,994 mmol) mediante evaporación con piridina (2 x 5 ml) a vacío. Se añadieron piridina anhidra (10 ml) y cloruro de 4,4’-dimetoxitritilo (0,724 g, 2,13 mmol) con agitación. Se llevó a cabo la reacción a temperatura ambiente durante la noche. Se extinguió la reacción mediante la adición de metanol. Se concentró la mezcla de reacción a vacío y al residuo se le añadió diclorometano (50 ml). Se lavó la fase orgánica con bicarbonato de sodio acuoso 1 M. Se secó la fase orgánica sobre sulfato de sodio anhidro, se filtró y se concentró. Se retiró la piridina residual mediante evaporación con tolueno. Se purificó el producto bruto mediante cromatografía en columna (MeOH al 2%/cloroformo, Rf = 0,5 en MeOH al 5%/CHCh) (1,75 g, 95%).
Éster mono-(4-[bis-(4-metoxi-fenil)-fenil-metoximetil]-1-{6-[17-(1,5-dimetil-hexil)-10,13-dimetil-2,3,4,7,8,9,10,11,12,13,14,15,16,17-tetradecahidro-1H-ciclopenta[a]fenantren-3-iloxicarbonilamino]-hexanoil}-pirrolidin-3-ílico) del ácido succínico, AH

Se mezcló el compuesto AG (1,0 g, 1,05 mmol) con anhídrido succínico (0,150 g, 1,5 mmol) y DMAP (0,073 g, 0,6 mmol) y se secó a vacío a 40°C durante la noche. Se disolvió la mezcla en dicloroetano anhidro (3 ml), se añadió trietilamina (0,318 g, 0,440 ml, 3,15 mmol) y se agitó la disolución a temperatura ambiente bajo una atmósfera de argón durante 16 h. A continuación, se diluyó con diclorometano (40 ml) y se lavó con ácido cítrico acuoso frío (5% en peso, 30 ml) y agua (2 x 20 ml). Se secó la fase orgánica sobre sulfato de sodio anhidro y se concentró hasta sequedad. Se usó el residuo como tal para la siguiente etapa.
CPG derivatizado con colesterol, AI

Se disolvió succinato AH (0,254 g, 0,242 mmol) en una mezcla de didorometano/acetonitrilo (3:2, 3 ml). A esa disolución se le añadieron sucesivamente DMAP (0,0296 g, 0,242 mmol) en acetonitrilo (1,25 ml), 2,2’-ditio-bis(5-nitropiridina) (0,075 g, 0,242 mmol) en acetonitrilo/dicloroetano (3:1, 1,25 ml). A la disolución resultante se le añadió trifenilfosfina (0,064 g, 0,242 mmol) en acetonitrilo (0,6 ml). La mezcla de reacción adquirió un color naranja brillante. Se agitó la disolución brevemente usando un agitador de acción de muñeca (5 minutos). Se añadió alquilamina de cadena larga-CPG (LCAA-CPG) (1,5 g, 61 mM). Se agitó la suspensión durante 2 h. Se filtró el CPG a través de un embudo sinterizado y se lavó sucesivamente con acetonitrilo, diclorometano y éter. Los grupos aminos que no reaccionaron se enmascararon con anhídrido acético/piridina. La carga alcanzada del CPG se midió tomando una medición UV (37 mM/g).
La síntesis de ARNip que portan un grupo bisdecilamida del ácido 5’-12-dodecanoico (denominado a continuación en el presente documento “5’-C32-”) o un grupo derivado de 5’-colesterilo (denominado a continuación en el presente documento “5’-Chol-”) se realizó tal como se describe en el documento WO 2004/065601, excepto que, en el caso del derivado de colesterilo, la etapa de oxidación se realizó usando el reactivo de Beaucage para introducir un enlace fosforotioato en el extremo 5’ del oligómero de ácido nucleico.
Las secuencias de ácido nucleico se representan a continuación usando la nomenclatura convencional y, específicamente, las abreviaturas de la tabla 1-2.
Tabla 1-2: Abreviaturas de los monómeros de nucleótidos usados en la representación de secuencias de ácido nucleico. Se entenderá que estos monómeros, cuando están presentes en un oligonucleótido, están mutuamente unidos por enlaces 5’-3’-fosfodiéster.


aLas letras mayúsculas representan los 2’-desox¡rr¡bonucleót¡dos (ADN), las letras minúsculas representan los ribonucleótidos (ARN)
El examen de ARNip de PCSK9 en HuH7, HepG2, Hela y hepatocitos primarios de mono descubre secuencias altamente activas
Se obtuvieron células HuH-7 del banco de células JCRB (Japanese Collection of Research Bioresources) (Shinjuku, Japón, n.° de cat.: JCRB0403). Se cultivaron las células en MEM de Dulbecco (Biochrom AG, Berlín, Alemania, n.° de cat. F0435) complementado para contener suero bovino fetal (FCS) al 10% (Biochrom AG, Berlín, Alemania, n.° de cat. S0115), penicilina 100 U/ml, estreptomicina 100 pg/ml (Biochrom AG, Berlín, Alemania, n.° cat. A2213) y L-glutamina 2 mM (Biochrom AG, Berlín, Alemania, n.° de cat. K0282) a 37°C en una atmósfera con el 5% de CO2 en una incubadora humidificada (Heraeus HERAcell, Kendro Laboratory Products, Langenselbold, Alemania). Las células HepG2 y Hela se obtuvieron de la Colección Americana de Cultivos Tipo (Rockville, MD, n.° de cat. HB-8065) y se cultivaron en MEM (Gibco Invitrogen, Karlsruhe, Alemania, n.° de cat. 21090-022) complementado para contener suero bovino fetal (FCS) al 10% (Biochrom AG, Berlín, Alemania, n.° de cat. S0115), penicilina 100 U/ml, estreptomicina 100 pg/ml (Biochrom AG, Berlín, Alemania, n.° de cat. A2213), 1x aminoácidos no esenciales (Biochrom AG, Berlín, Alemania, n.° cat. K-0293) y piruvato de sodio 1 mM (Biochrom AG, Berlín, Alemania, n.° cat. L-0473) a 37°C en una atmósfera con el 5% de CO2 en una incubadora humidificada (Heraeus HERAcell, Kendro Laboratory Products, Langenselbold, Alemania).
Para la transfección con ARNip, se sembraron células HuH7, HepG2 o Hela a una densidad de 2,0 x 104 células/pocillo en placas de 96 pocillos y se transfectaron directamente. La transfección de ARNip (30 nM para el examen de dosis única) se llevó a cabo con Lipofectamine 2000 (Invitrogen GmbH, Karlsruhe, Alemania, n.° de cat. 11668-019) tal como describe el fabricante.
24 horas después de la transfección, se lisaron las células HuH7 y HepG2 y se cuantificaron los niveles de ARNm de PCSK9 con el kit Quantigene Explore (Genosprectra, Dumbarton Circle Fremont, EE.UU., n.° de cat. QG-000-02) según el protocolo. Los niveles de ARNm de PCSK9 se normalizaron con respecto al ARNm de GAP-DH. Para cada ARNip se recogieron ocho puntos de datos individuales. Como control se usaron dúplex de ARNip no relacionados con el gen PCSK9. La actividad de un dúplex de ARNip específico de PCSK9 se expresó como porcentaje de concentración de ARNm de PCSK9 en las células tratadas en relación con la concentración de ARNm de PCSK9 en las células tratadas con el dúplex de ARNip de control.
Se obtuvieron hepatocitos primarios de macaco cangrejero (crioconservados) de In vitro Technologies, Inc. (Baltimore, Maryland, EE.UU., n.° de cat. M00305) y se cultivaron en medio InVitroGRO CP (n.° de cat. Z99029) a 37°C en una atmósfera con el 5% de CO2 en una incubadora humidificada.
Para la transfección con ARNip, se sembraron células primarias de macaco cangrejero en placas recubiertas de colágeno (Fisher Scientific, n.° de cat. 08-774-5) a una densidad de 3,5 x 104 células/pocillo en placas de 96 pocillos y se transfectaron directamente. La transfección de ARNip (ocho series de dilución doble a partir de 30nM) por duplicado se llevó a cabo con Lipofectamine 2000 (Invitrogen GmbH, Karlsruhe, Alemania, n.° de cat. 11668-019) tal como describe el fabricante.
16 horas después de la transfección, el medio se cambió por un medio InVitroGRO CP nuevo al que se le añadió la mezcla de antibióticos Torpedo (In vitro Technologies, Inc, n.° de cat. Z99000).
24 horas después del cambio de medio, se lisaron las células primarias de macaco cangrejero y se cuantificaron los niveles de ARNm de PCSK9 con el kit Quantigene Explore (Genosprectra, Dumbarton Circle Fremont, EE.UU., n.°
de cat. QG-000-02) según el protocolo. Los niveles de ARNm de PCSK9 se normalizaron con respecto al ARNm de GAPDH. A continuación, se compararon las razones de PCSK9/GAPDH normalizadas con la razón de PCSK9/GAPDH del control con sólo Lipofectamine 2000.
En las tablas 1-2 (y en la figura 6) se resumen los resultados y se proporcionan ejemplos de exámenes in vitro en diferentes líneas celulares a distintas dosis. El silenciamiento del transcrito de PCSK9 se expresó como porcentaje del transcrito restante a una dosis determinada. Las secuencias altamente activas son las que tienen menos del 70% de transcrito restante tras el tratamiento con un ARNip proporcionado a una dosis menor o igual a 100 nm. Las secuencias muy activas son aquellas que tienen menos del 60% de transcrito restante tras el tratamiento con una dosis menor o igual a 100 nM. Las secuencias activas son aquellas que tienen menos del 85% de transcrito restante después del tratamiento con una dosis alta (100 nM). Los ejemplos de ARNip activos también se examinaron in vivo en ratones en formulaciones lipoides tal como se describe a continuación. Las secuencias activas in vitro también fueron generalmente activas in vivo (véase el ejemplo de la figura 6).
Examen de eficacia in vivo de ARNip de PCSK9
Procedimiento de formulación
Se usaron LNP-014HCl (PM de 1487) (figura 1), colesterol (Sigma-Aldrich) y PEG-Ceramida C16 (Avanti Polar Lipids) para preparar las nanopartículas de lípido-ARNip. Se prepararon disoluciones madre de cada uno en etanol: lNp-01, 133 mg/ml; colesterol, 25 mg/ml, PEG-Ceramida C16, 100 mg/ml. A continuación, se combinaron las disoluciones madre de LNP-01, colesterol y PEG-Ceramida C16 en una razón molar de 42:48:10. Se mezcló la disolución lipídica combinada rápidamente con el ARNip acuoso (en acetato de sodio de pH 5) de manera que la concentración final de etanol era del 35-45% y la de acetato de sodio de 100-300 mM. Las nanopartículas de lípido-ARNip se formaron espontáneamente tras el mezclado. Dependiendo de la distribución de tamaño de partícula deseada, en algunos casos, la mezcla de nanopartículas resultante se extruyó a través de una membrana de policarbonato (punto de corte de 100 nm) usando una prensa extrusora de termobarril (Lipex Extruder, Northern Lipids, Inc). En otros casos, se omitió la etapa de extrusión. La retirada de etanol y el intercambio simultáneo del tampón se llevaron a cabo mediante diálisis o filtración de flujo tangencial. El tampón se cambió por solución salina tamponada con fosfato (PBS) de pH 7,2.
Caracterización de las formulaciones
Las formulaciones preparadas mediante el método convencional o sin extrusión se caracterizan de manera similar. Las formulaciones se caracterizan en primer lugar mediante inspección visual. Deben ser disoluciones blanquecinas translúcidas, sin agregados ni sedimentos. El tamaño de partícula y la distribución del tamaño de partícula de las nanopartículas lipídicas se miden mediante dispersión dinámica de luz usando un aparato Malvern Zetasizer Nano ZS (Malvern, e E.UU.). Las partículas deben tener un tamaño de 20-300 nm e, idealmente, de 40-100 nm. La distribución del tamaño de partícula debe ser unimodal. La concentración total de ARNip en la formulación, así como la fracción atrapada, se estima mediante un ensayo de exclusión de colorante. Una muestra del ARNip formulado se incuba con el colorante de unión al ARN Ribogreen (Molecular Probes) en presencia o ausencia de un tensioactivo que altera la formulación, Triton-X100 al 0,5%. El ARNip total en la formulación se determina mediante la señal de la muestra que contiene el tensioactivo, en relación con una curva de calibración. La fracción atrapada se determina restando el contenido de ARNip “libre” (tal como se mide mediante la señal en ausencia de tensioactivo) del contenido total de ARNip. El porcentaje de ARNip atrapado suele ser superior al 85%.
Administración de dosis en bolo
La administración de dosis en bolo de los ARNip formulados en ratones C57/BL6 (5/grupo, 8-10 semanas de edad, Charles River Laboratories, MA) se realizó mediante inyección en la vena de la cola usando una aguja 27G. Los ARNip se formularon en LNP-01 (y luego se dializaron con PBS) a una concentración de 0,5 mg/ml que permitía la administración de la dosis de 5 mg/kg en 10 |il/g de peso corporal. Los ratones se mantuvieron bajo una lámpara de infrarrojos durante aproximadamente 3 minutos antes de la administración de dosis para facilitar la inyección.
48 horas tras la administración de dosis, se sacrificaron los ratones mediante asfixia con CO2. Se recogieron 0,2 ml de sangre por sangrado retroorbital y se extrajo el hígado y se congeló en nitrógeno líquido. El suero y el hígado se almacenaron a -80°C.
Los hígados congelados se trituraron usando la trituradora criogénica 6850 Freezer/Mill (SPEX CentriPrep, Inc) y los polvos se almacenaron a -80°C hasta su análisis.
Los niveles de ARNm de PCSK9 se detectaron usando el kit basado en la tecnología de ADN ramificado del sistema de reactivos QuantiGene (Genospectra) según el protocolo. Se lisaron 10-20 mg de polvo de hígado congelado en 600 ul de proteinasa K 0,16 ug/ml (Epicentre, #MPRK092) en disolución de lisis de tejidos y células (Epicentre, #MTC096H) a 65°C durante 3 horas. A continuación, se añadieron 10 ul de los lisados a 90 ul de reactivo de trabajo de lisis (1 volumen de mezcla de lisis madre en dos volúmenes de agua) y se incubaron a 52°C durante la noche en placas de captura de Genospectra con conjuntos de sondas específicas para PCSK9 de ratón y GAPDH o ciclofilina B de ratón. Las secuencias de ácido nucleico para las sondas de extensor de captura (CE), extensor de marcador
(LE) y bloqueo (BL) se seleccionaron a partir de las secuencias de ácido nucleico de PCSK9, la GAPDH y la ciclofilina B con la ayuda del software QuantiGene ProbeDesigner 2.0 (Genospectra, Fremont, CA, EE.UU., n.° de cat. QG-002-02). La quimioluminiscencia se leyó en un aparato Victor2-Light (Perkin Elmer) como unidades relativas de luz. La razón de ARNm de PCSK9 con respecto a ARNm de GAPDH o ciclofilina B en los lisados hepáticos se promedió en cada grupo de tratamiento y se comparó con un grupo de control tratado con PBS o un grupo de control tratado con un ARNip no relacionado (factor de coagulación sanguínea VII).
El colesterol sérico total en el suero de ratón se midió usando el kit StanBio Cholesterol LiquiColor (StanBio Laboratory, Boerne, Texas, EE.UU.) según las instrucciones del fabricante. Las mediciones se realizaron en un contador multimarcador Victor21420 (Perkin Elmer) a 495 nm.
Ejemplos
Se sometieron a prueba 32 ARNip de PCSK9 formulados en liposomas LNP-01 in vivo en un modelo de ratón. El experimento se realizó a una dosis de ARNip de 5 mg/kg y al menos 10 ARNip de PCSK9 mostraron una atenuación del ARNm de PCSK9 de más del 40% en comparación con un grupo de control tratado con PBS, mientras que el grupo de control tratado con un ARNip no relacionado (factor de coagulación sanguínea VII) no tuvo ningún efecto (figuras 2-5). El silenciamiento del transcrito de PCSK9 también se correlacionó con una disminución del colesterol en estos animales (figuras 4-5). Además, hubo una fuerte correlación entre las moléculas que eran activas in vitro y las que lo eran in vivo (figura 6). También se analizaron las secuencias que contenían diferentes modificaciones químicas in vitro (tablas 1 y 2) e in vivo. Por ejemplo, las secuencias menos modificadas 9314 y 9318, y las versiones más modificadas de esa secuencia 9314-(10792, 10793 y 10796); 9318-(10794, 10795 y 10797) se sometieron a prueba tanto in vitro (en hepatocitos primarios de mono) como in vivo (9314 y 10792) formuladas en LNP-01. La figura 7 (véanse también las tablas 1 y 2) muestra que las moléculas parentales 9314 y 9318 y las versiones modificadas son todas activas in vitro. La figura 8, como ejemplo, muestra que tanto la molécula parental 9314 como las secuencias más modificadas 10792 son activas in vivo, mostrando un silenciamiento del 50-60% de PCSK9 endógeno en ratones. La figura 9 ejemplifica además la actividad de otras versiones químicamente modificadas de las parentales 9314 y 10792.
Vectores de expresión de ARNbc
En otro aspecto de la invención, las moléculas de ARNbc específicas de PCSK9 que modulan la actividad de expresión del gen PCSK9 se expresan a partir de unidades de transcripción insertadas en vectores de ADN o ARN (véase, por ejemplo, Couture, A, et al. (1996), 12:5-10; Skillern, A., et al., publicación internacional PCT n.° WO 00/22113, Conrad, publicación internacional PCT n.° WO 00/22114 y Conrad, patente estadounidense n.° 6.054.299). Estos transgenes pueden introducirse como un constructo lineal, un plásmido circular o un vector viral, que puede incorporarse y heredarse como un transgén integrado en el genoma del huésped. El transgén también puede construirse para permitir que se herede como un plásmido extracromosómico (Gassmann, et al., Proc. Natl. Acad. Sci. USA (1995) 92:1292).
Las cadenas individuales de un ARNbc pueden transcribirse mediante promotores en dos vectores de expresión independientes y transfectados conjuntamente en una célula diana. Alternativamente, cada cadena individual del ARNbc puede transcribirse mediante promotores situados ambos en el mismo plásmido de expresión. En una realización preferida, un ARNbc se expresa como una repetición invertida unida por una secuencia polinucleotídica ligadora de manera que el ARNbc tenga una estructura de tallo y bucle.
Los vectores de expresión de ARNbc recombinante son generalmente plásmidos de ADN o vectores virales. Los vectores virales que expresan ARNbc pueden construirse basándose en, pero sin limitarse a, virus adenoasociado (para una revisión, véase Muzyczka, et al., Curr. Topics Micro. Immunol. (1992) 158:97-129)); adenovirus (véase, por ejemplo, Berkner, et al., BioTechniques (1998) 6:616), Rosenfeld et al. (1991, Science 252:431-434) y Rosenfeld et al. (1992), Cell 68:143-155)); o alfavirus, así como otros conocidos en la técnica. Los retrovirus se han usado para introducir una variedad de genes en muchos tipos de células diferentes, incluyendo células epiteliales, in vitro y/o in vivo (véase, por ejemplo, Eglitis, et al., Science (1985) 230:1395-1398; Danos y Mulligan, Proc. NatI. Acad. Sci. USA (1998) 85:6460-6464; Wilson et al., 1988, Proc. NatI. Acad. Sci. USA 85:3014-3018; Armentano et al., 1990, Proc. NatI. Acad. Sci. USA 87:61416145; Huber et al., 1991, Proc. NatI. Acad. Sci. USA 88:8039-8043; Ferry et al., 1991, Proc. Natl. Acad. Sci. USA 88:8377-8381; Chowdhury et al., 1991, Science 254:1802-1805; van Beusechem. et al., 1992, Proc. Nad. Acad. Sci. USA 89:7640-19; Kay et al., 1992, Human Gene Therapy 3:641-647; Dai et al., 1992, Proc. Natl.Acad. Sci. USA 89:10892-10895; Hwu et al., 1993, J. Immunol. 150:4104-4115; patente estadounidense n.° 4.868.116; patente estadounidense n.° 4.980.286; solicitud PCT WO 89/07136; solicitud PCT WO 89/02468; solicitud PCT Wo 89/05345; y solicitud PCT WO 92/07573). Los vectores retrovirales recombinantes que pueden transducir y expresar genes insertados en el genoma de una célula pueden producirse transfectando el genoma retroviral recombinante en líneas celulares de empaquetamiento adecuadas, tales como PA317 y Psi-CRIP (Comette et al., 1991, Human Gene Therapy 2:5-10; Cone et al., 1984, Proc. Natl. Acad. Sci. USA 81:6349). Los vectores adenovirales recombinantes pueden usarse para infectar una amplia variedad de células y tejidos en huéspedes susceptibles (por ejemplo, rata, hámster, perro y chimpancé) (Hsu et al., 1992, J. Infectious Disease, 166:769), y también tienen la ventaja de no requerir células mitóticamente activas para la infección.
El promotor que impulsa la expresión del ARNbc o bien en un plásmido de ADN o bien en un vector viral de la invención puede ser un promotor de la ARN polimerasa I eucariota (por ejemplo, el promotor de ARN ribosómico), de la ARN polimerasa II (por ejemplo, el promotor temprano de CMV o el promotor de actina o el promotor de ARNnp U1) o generalmente el promotor de la ARN polimerasa III (por ejemplo, el promotor de ARNnp U6 o el promotor de ARN 7SK) o un promotor procariota, por ejemplo, el promotor T7, siempre que el plásmido de expresión también codifique para la ARN polimerasa T7 necesaria para la transcripción de un promotor T7. El promotor también puede dirigir la expresión del transgén al páncreas (véase, por ejemplo, la secuencia reguladora de la insulina para el páncreas (Bucchini et al., 1986, Proc. Natl. Acad. Sci. USA 83:2511-2515)).
Además, la expresión del transgén puede regularse con precisión, por ejemplo, usando una secuencia reguladora inducible y sistemas de expresión tales como una secuencia reguladora que sea sensible a determinados reguladores fisiológicos, por ejemplo, los niveles de glucosa circulante, u hormonas (Docherty et al., 1994, FASEB J.
8:20-24). Tales sistemas de expresión inducible, adecuados para el control de la expresión del transgén en células o en mamíferos, incluyen la regulación por ecdisona, por estrógeno, progesterona, tetraciclina, inductores químicos de la dimerización e isopropil-beta-D1-tiogalactopiranósido (EPTG). Un experto en la técnica podría elegir la secuencia reguladora/promotora adecuada en función del uso previsto del transgén de ARNbc.
Generalmente, los vectores recombinantes que pueden expresar moléculas de ARNbc se administran tal como se describe a continuación y persisten en las células diana. Alternativamente, pueden usarse vectores virales que permiten la expresión transitoria de moléculas de ARNbc. Tales vectores pueden administrarse repetidamente según sea necesario. Una vez expresados, los ARNbc se unen al ARN diana y modulan su función o expresión. La administración de los vectores que expresan ARNbc puede ser sistémica, tal como, por ejemplo, mediante administración intravenosa o intramuscular, mediante la administración a células diana explantadas del paciente seguida de la reintroducción al paciente, o mediante cualquier otro medio que permita la introducción en una célula diana deseada.
Los plásmidos de ADN de expresión de ARNbc se transfectan normalmente en las células diana como un complejo con portadores lipídicos catiónicos (por ejemplo, Oligofectamine) o portadores basados en lípidos no catiónicos (por ejemplo, Transit-TKO™). La invención también contempla transfecciones múltiples de lípidos para atenuaciones génicas mediadas por ARNbc que seleccionan como diana diferentes regiones de un único gen PCSK9 o de múltiples genes PCSK9 durante un periodo de una semana o más. La introducción satisfactoria de los vectores de la invención en las células huésped puede monitorizarse mediante diversos métodos conocidos. Por ejemplo, la transfección transitoria puede señalizarse con un indicador, tal como un marcador fluorescente, tal como la proteína verde fluorescente (GFP). La transfección estable de células ex vivo puede garantizarse usando marcadores que proporcionen a la célula transfectada resistencia a factores ambientales específicos (por ejemplo, antibióticos y fármacos), tales como resistencia a la higromicina B.
Las moléculas de ARNbc específicas de PCSK9 también pueden insertarse en vectores y usarse como vectores de terapia génica para pacientes humanos. Los vectores de terapia génica pueden administrarse a un sujeto, por ejemplo, mediante inyección intravenosa, administración local (véase la patente estadounidense 5.328.470) o mediante inyección estereotáctica (véase, por ejemplo, Chen et al. (1994) Proc. Acad. Sci. USA 91:3054-3057). La preparación farmacéutica del vector de terapia génica puede incluir el vector de terapia génica en un diluyente aceptable, o puede comprender una matriz de liberación lenta en la que se incrusta el vehículo de inserción génica. Alternativamente, cuando el vector de inserción génica completo puede producirse intacto a partir de células recombinantes, por ejemplo, vectores retrovirales, la preparación farmacéutica puede incluir una o más células que producen el sistema de inserción génica.
Los expertos en la técnica están familiarizados con otros métodos y composiciones además de los expuestos específicamente en la presente divulgación, que les permitirán poner en práctica esta invención en todo el alcance de las reivindicaciones que se adjuntan a continuación en el presente documento.

_











_



_







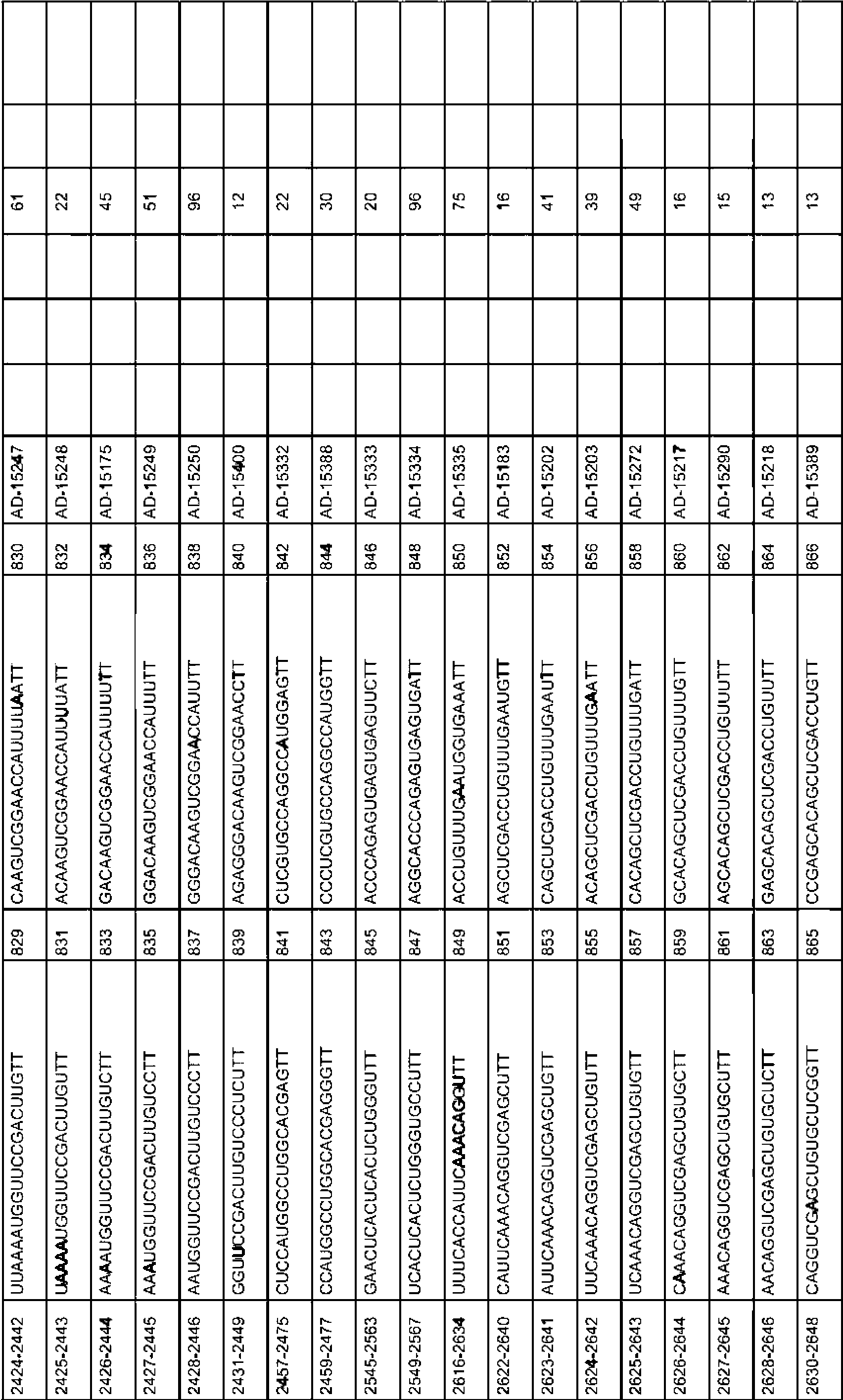

















-8 sí ® c •»O ( 0O ) c O ( pO ® T5 u 0) g ,2 c p Fk e On ® 3 .[ <0n _o " - o - c - t «
O o -CL — cD c - °o ! & * ? S a l ! X « (fl -O 05 ^ ° O C P f-p .2 p § ? ° -Z c m c cu c E
n , x o
s > r 9 f s o i 5 -cg ” m « o = > p o 5 S • - R 2 -o p 8 -o p C c/> O O - c o c ? ® 8 O S s S ® 8 - S 5 o 2br 5 (/) c Oo — g O <D Q. CO ° O C ®/í E O ) > o< w ^ - 2S o o -8 5 Q-ío ü ‘O W (D
^ § E ó S 1 i g c p sE - oo « c - sro O 5 i S £
D O p CO  u r -o o .ro
u r -o o .ro
Claims (15)
- REIVINDICACIONESi. Ácido ribonucleico bicatenario (ARNbc) para inhibir la expresión de un gen PCSK9 humano en una célula, en el que dicho ARNbc comprende al menos dos secuencias que son complementarias entre sí y en el que una cadena sentido comprende una primera secuencia y una cadena antisentido comprende una segunda secuencia que comprende una región de complementariedad que es totalmente complementaria a al menos una parte de un ARNm que codifica para PCSK9, en el que dicha región de complementariedad tiene menos de 30 nucleótidos de longitud y en el que dicho ARNbc, al entrar en contacto con una célula que expresa dicho PCSK9, inhibe la expresión de dicho gen PCSK9 en el que dicha parte del ARNm que codifica para PCSK9 consiste en la secuencia de las posiciones 408-426 del número de registro NM_174936.
- 2. El ARNbc según la reivindicación 1, en el que dicho ARNbc comprende al menos un nucleótido modificado.
- 3. El ARNbc según la reivindicación 2, en el que dicho nucleótido modificado se elige del grupo de un nucleótido modificado con 2'-O-metilo, un nucleótido que comprende un grupo 5'-fosforotioato, un nucleótido terminal unido a un derivado de colesterilo o un grupo bisdecilamida de ácido dodecanoico, un nucleótido modificado con 2'-desoxi-2'-fluoro, un nucleótido modificado con 2'-desoxilo, un nucleótido bloqueado, un nucleótido abásico, un nucleótido modificado con 2'-amino, un nucleótido modificado con 2'-alquilo, un nucleótido de morfolino, un fosforamidato y un nucleótido que comprende una base no natural.
- 4. El ARNbc según la reivindicación 2 ó 3, en el que dicha primera secuencia es una secuencia seleccionada del grupo que consiste en las SEQ ID NO: 87 y 89 y dicha segunda secuencia es una secuencia seleccionada del grupo que consiste en la secuencia de las SEQ ID NO: 88 y 90.
- 5. Composición farmacéutica para inhibir la expresión del gen PCSK9 en un organismo, que comprende un ARNbc y un portador farmacéuticamente aceptable, en la que el ARNbc es tal como se definió en una cualquiera de las reivindicaciones 1 a 4.
- 6. Método in vitro para inhibir la expresión del gen PCSK9 en una célula, comprendiendo el método:(a) introducir en la célula un ácido ribonucleico bicatenario (ARNbc), en el que el ARNbc es tal como se definió en una cualquiera de las reivindicaciones 1 a 4; y(b) mantener la célula producida en la etapa (a) durante un tiempo suficiente para obtener la degradación del transcrito de ARNm del gen PCSK9, inhibiendo así la expresión del gen PCSK9 en la célula.
- 7. ARNbc para su uso en un método de tratamiento, prevención o gestión de procesos patológicos que pueden mediarse mediante regulación por disminución de la expresión del gen PCSK9, en el que el ARNbc es tal como se definió en una cualquiera de las reivindicaciones 1 a 4.
- 8. Vector para inhibir la expresión del gen PCSK9 en una célula, comprendiendo dicho vector una secuencia reguladora operativamente unida a una secuencia de nucleótidos que codifica para al menos una cadena de un ARNbc, en el que dicho ARNbc es tal como se definió en la reivindicación 1.
- 9. Célula aislada que comprende el ARNbc según una cualquiera de las reivindicaciones 1 a 4 o el vector según la reivindicación 8.
- 10. Ácido ribonucleico bicatenario (ARNbc) para reducir el nivel de expresión de un gen PCSK9 humano en una célula, en el que dicho ARNbc es tal como se definió en una cualquiera de las reivindicaciones 1 a 4.
- 11. El ARNbc según la reivindicación 10, en el que dicho contacto reduce el nivel de expresión de dicho gen PCSK9.
- 12. El ARNbc según la reivindicación 10, en el que dicho contacto se realiza in vitro a 30 nM o menos.
- 13. Composición farmacéutica para reducir el nivel de expresión del gen PCSK9 en un organismo, que comprende el ARNbc según la reivindicación 10 y un portador farmacéuticamente aceptable.
- 14. El ARNbc según la reivindicación 10, para su uso en un método de tratamiento de un trastorno asociado a PCSK9.
- 15. El ARNbc para uso según la reivindicación 14, en el que dicho trastorno asociado a PCSK9 es hiperlipidemia.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US79945806P | 2006-05-11 | 2006-05-11 | |
| US81720306P | 2006-06-27 | 2006-06-27 | |
| US84008906P | 2006-08-25 | 2006-08-25 | |
| US82991406P | 2006-10-18 | 2006-10-18 | |
| US90113407P | 2007-02-13 | 2007-02-13 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2874149T3 true ES2874149T3 (es) | 2021-11-04 |
Family
ID=38694697
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES19168142T Active ES2874149T3 (es) | 2006-05-11 | 2007-05-10 | Composiciones y métodos para inhibir la expresión del gen PCSK9 |
| ES09015323T Active ES2392478T3 (es) | 2006-05-11 | 2007-05-10 | Composiciones y métodos para inhibir la expresión del gen PCSK9 |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES09015323T Active ES2392478T3 (es) | 2006-05-11 | 2007-05-10 | Composiciones y métodos para inhibir la expresión del gen PCSK9 |
Country Status (14)
| Country | Link |
|---|---|
| US (10) | US7605251B2 (es) |
| EP (8) | EP2584048B1 (es) |
| JP (4) | JP5570806B2 (es) |
| KR (2) | KR101320916B1 (es) |
| CN (2) | CN103614375A (es) |
| AU (2) | AU2007249329C1 (es) |
| CA (2) | CA2915441A1 (es) |
| EA (2) | EA015676B1 (es) |
| ES (2) | ES2874149T3 (es) |
| IL (3) | IL195181A (es) |
| NZ (2) | NZ572666A (es) |
| PL (2) | PL3578656T3 (es) |
| SG (1) | SG171676A1 (es) |
| WO (1) | WO2007134161A2 (es) |
Families Citing this family (180)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20070173473A1 (en) * | 2001-05-18 | 2007-07-26 | Sirna Therapeutics, Inc. | RNA interference mediated inhibition of proprotein convertase subtilisin Kexin 9 (PCSK9) gene expression using short interfering nucleic acid (siNA) |
| CN102558352A (zh) * | 2003-06-27 | 2012-07-11 | 艾默根佛蒙特有限公司 | 针对表皮生长因子受体的缺失突变体的抗体及其使用 |
| US8288354B2 (en) | 2005-12-28 | 2012-10-16 | The Scripps Research Institute | Natural antisense and non-coding RNA transcripts as drug targets |
| ES2874149T3 (es) | 2006-05-11 | 2021-11-04 | Alnylam Pharmaceuticals Inc | Composiciones y métodos para inhibir la expresión del gen PCSK9 |
| CA2667894A1 (en) | 2006-11-07 | 2008-05-15 | Merck & Co., Inc. | Antagonists of pcsk9 |
| EP2799547B1 (en) * | 2006-11-08 | 2016-12-21 | Veritas Bio, LLC | In Vivo Delivery of RNA to a Target Cell |
| JP2010510807A (ja) * | 2006-11-27 | 2010-04-08 | アイシス ファーマシューティカルズ, インコーポレーテッド | 高コレステロール血症を治療するための方法 |
| US8093222B2 (en) | 2006-11-27 | 2012-01-10 | Isis Pharmaceuticals, Inc. | Methods for treating hypercholesterolemia |
| US7910722B2 (en) * | 2007-07-05 | 2011-03-22 | Florida State University Research Foundation | RNAi therapeutic for treatment of hepatitis C infection |
| JOP20080381B1 (ar) | 2007-08-23 | 2023-03-28 | Amgen Inc | بروتينات مرتبطة بمولدات مضادات تتفاعل مع بروبروتين كونفيرتاز سيتيليزين ككسين من النوع 9 (pcsk9) |
| MX2010008394A (es) * | 2008-01-31 | 2010-11-12 | Alnylam Pharmaceuticals Inc | Metodos optimizados para administracion de arndc focalizando el gen pcsk9. |
| AR070316A1 (es) | 2008-02-07 | 2010-03-31 | Merck & Co Inc | Antagonistas de pcsk9 (proproteina subtilisina-kexina tipo 9) |
| AR070315A1 (es) | 2008-02-07 | 2010-03-31 | Merck & Co Inc | Anticuerpos 1b20 antagonistas de pcsk9 |
| US10131904B2 (en) | 2008-02-11 | 2018-11-20 | Rxi Pharmaceuticals Corporation | Modified RNAi polynucleotides and uses thereof |
| US20110028531A1 (en) * | 2008-03-20 | 2011-02-03 | Elena Feinstein | Novel sirna compounds for inhibiting rtp801 |
| CA2746527A1 (en) | 2008-09-22 | 2010-03-25 | Rxi Pharmaceuticals Corporation | Rna interference in skin indications |
| WO2010040112A2 (en) | 2008-10-03 | 2010-04-08 | Curna, Inc. | Treatment of apolipoprotein-a1 related diseases by inhibition of natural antisense transcript to apolipoprotein-a1 |
| ES2600781T3 (es) | 2008-12-04 | 2017-02-10 | Curna, Inc. | Tratamiento para enfermedades relacionadas con el factor de crecimiento del endotelio vascular (vegf) mediante la inhibición de transcritos antisentido naturales de vegf |
| RU2620970C2 (ru) | 2008-12-04 | 2017-05-30 | КьюРНА,Инк., | Лечение связанных с эритропоэтином (еро) заболеваний путем ингибирования природного антисмыслового транскрипта к еро |
| CN102361985B (zh) | 2008-12-04 | 2017-06-20 | 库尔纳公司 | 通过抑制肿瘤抑制基因的天然反义转录物治疗肿瘤抑制基因相关性疾病 |
| JO3672B1 (ar) | 2008-12-15 | 2020-08-27 | Regeneron Pharma | أجسام مضادة بشرية عالية التفاعل الكيماوي بالنسبة لإنزيم سبتيليسين كنفرتيز بروبروتين / كيكسين نوع 9 (pcsk9). |
| US9493774B2 (en) | 2009-01-05 | 2016-11-15 | Rxi Pharmaceuticals Corporation | Inhibition of PCSK9 through RNAi |
| US9745574B2 (en) | 2009-02-04 | 2017-08-29 | Rxi Pharmaceuticals Corporation | RNA duplexes with single stranded phosphorothioate nucleotide regions for additional functionality |
| WO2010093904A2 (en) | 2009-02-12 | 2010-08-19 | Curna, Inc. | Treatment of brain derived neurotrophic factor (bdnf) related diseases by inhibition of natural antisense transcript to bdnf |
| EP2408919B1 (en) | 2009-03-16 | 2017-10-18 | CuRNA, Inc. | Treatment of nuclear factor (erythroid-derived 2)-like 2 (nrf2) related diseases by inhibition of natural antisense transcript to nrf2 |
| CA2755404C (en) | 2009-03-17 | 2020-03-24 | Curna, Inc. | Treatment of delta-like 1 homolog (dlk1) related diseases by inhibition of natural antisense transcript to dlk1 |
| KR101722541B1 (ko) | 2009-05-06 | 2017-04-04 | 큐알엔에이, 인크. | Ttp에 대한 천연 안티센스 전사체의 억제에 의한 트리스테트라프롤린 관련된 질환의 치료 |
| CN102459596B (zh) | 2009-05-06 | 2016-09-07 | 库尔纳公司 | 通过针对脂质转运和代谢基因的天然反义转录物的抑制治疗脂质转运和代谢基因相关疾病 |
| ES2618572T3 (es) | 2009-05-08 | 2017-06-21 | Curna, Inc. | Tratamiento de enfermedades relacionadas con la familia de la distrofina mediante inhibición de un transcrito antisentido natural para la familia de dmd |
| WO2010135329A2 (en) | 2009-05-18 | 2010-11-25 | Curna, Inc. | Treatment of reprogramming factor related diseases by inhibition of natural antisense transcript to a reprogramming factor |
| CA2762987A1 (en) | 2009-05-22 | 2010-11-25 | Joseph Collard | Treatment of transcription factor e3 (tfe3) and insulin receptor substrate 2 (irs2) related diseases by inhibition of natural antisense transcript to tfe3 |
| KR101704988B1 (ko) | 2009-05-28 | 2017-02-08 | 큐알엔에이, 인크. | 항바이러스 유전자에 대한 천연 안티센스 전사체의 억제에 의한 항바이러스 유전자 관련된 질환의 치료 |
| ES2804764T3 (es) | 2009-06-01 | 2021-02-09 | Halo Bio Rnai Therapeutics Inc | Polinucleótidos para la interferencia de ARN multivalente, composiciones y métodos de uso de los mismos |
| WO2010147992A1 (en) * | 2009-06-15 | 2010-12-23 | Alnylam Pharmaceuticals, Inc. | Methods for increasing efficacy of lipid formulated sirna |
| NZ597504A (en) | 2009-06-15 | 2013-10-25 | Alnylam Pharmaceuticals Inc | Lipid formulated dsrna targeting the pcsk9 gene |
| ES2629339T3 (es) | 2009-06-16 | 2017-08-08 | Curna, Inc. | Tratamiento de enfermedades relacionadas con la paraoxonasa 1 (pon1) por inhibición de transcrito antisentido natural a pon1 |
| CA2765700C (en) | 2009-06-16 | 2021-01-05 | Opko Curna, Llc | Treatment of collagen gene related diseases by inhibition of natural antisense transcript to a collagen gene |
| ES2618894T3 (es) | 2009-06-24 | 2017-06-22 | Curna, Inc. | Tratamiento de enfermedades relacionadas con el receptor del factor de necrosis tumoral 2 (tnfr2) por inhibición del transcrito natural antisentido para tnfr2 |
| CN102482672B (zh) | 2009-06-26 | 2016-11-09 | 库尔纳公司 | 通过抑制唐氏综合征基因的天然反义转录物治疗唐氏综合征基因相关疾病 |
| ES2613498T3 (es) | 2009-07-01 | 2017-05-24 | Protiva Biotherapeutics Inc. | Nuevas formulaciones de lípidos para el suministro de agentes terapéuticos a tumores sólidos |
| US8563528B2 (en) | 2009-07-21 | 2013-10-22 | Santaris Pharma A/S | Antisense oligomers targeting PCSK9 |
| US20120252869A1 (en) | 2009-07-24 | 2012-10-04 | Opko Curna, Llc | Treatment of sirtuin (sirt) related diseases by inhibition of natural antisense transcript to a sirtuin (sirt) |
| ES2585360T3 (es) | 2009-08-05 | 2016-10-05 | Curna, Inc. | Tratamiento de enfermedades relacionadas con un gen de la insulina (INS) por inhibición de la transcripción antisentido natural en un gen de la insulina (INS) |
| ES2599986T3 (es) | 2009-08-11 | 2017-02-06 | Curna, Inc. | Tratamiento de enfermedades relacionadas con adiponectina (ADIPOQ) mediante la inhibición de un transcrito antisentido natural de una adiponectina (ADIPOQ) |
| CN102482670B (zh) | 2009-08-21 | 2018-06-15 | 库尔纳公司 | 通过抑制‘hsp70-相互作用蛋白的c末端’(chip)的天然反义转录物而治疗chip相关疾病 |
| EP2470657B1 (en) | 2009-08-25 | 2019-10-23 | CuRNA, Inc. | Treatment of 'iq motif containing gtpase activating protein' (iqgap) related diseases by inhibition of natural antisense transcript to iqgap |
| WO2011028938A1 (en) * | 2009-09-02 | 2011-03-10 | Alnylam Pharmaceuticals, Inc. | Methods for lowering serum cholestrol in a subject using inhibition of pcsk9 |
| US9187746B2 (en) | 2009-09-22 | 2015-11-17 | Alnylam Pharmaceuticals, Inc. | Dual targeting siRNA agents |
| DK2480669T3 (en) | 2009-09-25 | 2018-02-12 | Curna Inc | TREATMENT OF FILAGGRIN- (FLG) RELATED DISEASES BY MODULATING FLG EXPRESSION AND ACTIVITY |
| US20130079382A1 (en) | 2009-10-12 | 2013-03-28 | Larry J. Smith | Methods and Compositions for Modulating Gene Expression Using Oligonucleotide Based Drugs Administered in vivo or in vitro |
| AR079336A1 (es) * | 2009-12-11 | 2012-01-18 | Irm Llc | Antagonistas de la pro-proteina convertasa-subtilisina/quexina tipo 9 (pcsk9) |
| CA2782366A1 (en) | 2009-12-16 | 2011-07-14 | Opko Curna, Llc | Treatment of membrane bound transcription factor peptidase, site 1 (mbtps1) related diseases by inhibition of natural antisense transcript to mbtps1 |
| US20110152343A1 (en) * | 2009-12-22 | 2011-06-23 | Functional Genetics, Inc. | Protease inhibitors and broad-spectrum antiviral |
| NO2516648T3 (es) | 2009-12-23 | 2018-04-07 | ||
| RU2619185C2 (ru) | 2009-12-23 | 2017-05-12 | Курна, Инк. | Лечение заболеваний, связанных с разобщающим белком 2 (ucp2), путем ингибирования природного антисмыслового транскрипта к ucp2 |
| US8962585B2 (en) | 2009-12-29 | 2015-02-24 | Curna, Inc. | Treatment of tumor protein 63 (p63) related diseases by inhibition of natural antisense transcript to p63 |
| US8921334B2 (en) | 2009-12-29 | 2014-12-30 | Curna, Inc. | Treatment of nuclear respiratory factor 1 (NRF1) related diseases by inhibition of natural antisense transcript to NRF1 |
| DK2519632T3 (en) | 2009-12-31 | 2018-07-23 | Curna Inc | TREATMENT OF INSULIN RECEPTOR SUBSTRATE 2- (IRS2) RELATED DISEASES BY INHIBITION OF NATURAL ANTISENSE TRANSCRIPTION TO IRS2 AND TRANSCRIPTION FACTOR E3 (TFE3) |
| DK2521784T3 (en) | 2010-01-04 | 2018-03-12 | Curna Inc | TREATMENT OF INTERFERON REGULATORY FACTOR 8- (IRF8) RELATED DISEASES BY INHIBITION OF NATURAL ANTISENCE TRANSCRIPT TO IRF8 |
| KR101853509B1 (ko) | 2010-01-06 | 2018-04-30 | 큐알엔에이, 인크. | 췌장 발달 유전자에 대한 천연 안티센스 전사체의 억제에 의한 췌장 발달 유전자와 관련된 질환의 치료 |
| KR101854926B1 (ko) | 2010-01-11 | 2018-05-04 | 큐알엔에이, 인크. | 성 호르몬 결합 글로불린 (shbg)에 대한 자연 안티센스 전사체의 저해에 의한 성 호르몬 결합 글로불린 (shbg) 관련된 질환의 치료 |
| DK2529015T3 (en) | 2010-01-25 | 2018-02-26 | Curna Inc | TREATMENT OF RNASE H1-RELATED DISEASES BY INHIBITION OF NATURAL ANTISENSE TRANSCRIPT TO RNASE H1 |
| RU2608496C2 (ru) | 2010-02-22 | 2017-01-18 | Курна, Инк. | Лечение заболеваний, связанных с пирролин-5 карбоксилатредуктазой 1(pycr1), путем ингибирования природного антисмыслового транскрипта к pycr1 |
| US8980856B2 (en) | 2010-04-02 | 2015-03-17 | Curna, Inc. | Treatment of colony-stimulating factor 3 (CSF3) related diseases by inhibition of natural antisense transcript to CSF3 |
| KR101900962B1 (ko) | 2010-04-09 | 2018-09-20 | 큐알엔에이, 인크. | 섬유아세포 성장 인자 21 (fgf21)에 대한 자연 안티센스 전사체의 저해에 의한 섬유아세포 성장 인자 21 (fgf21) 관련된 질환의 치료 |
| RU2018110642A (ru) | 2010-05-03 | 2019-02-27 | Курна, Инк. | Лечение заболеваний, связанных с сиртуином (sirt), путем ингибирования природного антисмыслового транскрипта к сиртуину (sirt) |
| TWI586356B (zh) | 2010-05-14 | 2017-06-11 | 可娜公司 | 藉由抑制par4天然反股轉錄本治療par4相關疾病 |
| CA2799207C (en) | 2010-05-26 | 2019-03-26 | Curna, Inc. | Treatment of atonal homolog 1 (atoh1) related diseases by inhibition of natural antisense transcript to atoh1 |
| JP5917497B2 (ja) | 2010-05-26 | 2016-05-18 | カッパーアールエヌエー,インコーポレイテッド | メチオニンスルホキシドレダクターゼa(msra)に対する天然アンチセンス転写物の阻害によるmsra関連疾患の治療 |
| WO2011163499A2 (en) | 2010-06-23 | 2011-12-29 | Opko Curna, Llc | Treatment of sodium channel, voltage-gated, alpha subunit (scna) related diseases by inhibition of natural antisense transcript to scna |
| CN103068982B (zh) | 2010-07-14 | 2017-06-09 | 库尔纳公司 | 通过抑制盘状大同系物(dlg)的天然反义转录物而治疗dlg相关疾病 |
| ES2640755T3 (es) | 2010-10-06 | 2017-11-06 | Curna, Inc. | Tratamiento de enfermedades relacionadas con la Sialidasa 4 (neu4) mediante inhibición del transcrito antisentido natural al gen neu4 |
| US9222088B2 (en) | 2010-10-22 | 2015-12-29 | Curna, Inc. | Treatment of alpha-L-iduronidase (IDUA) related diseases by inhibition of natural antisense transcript to IDUA |
| WO2012058693A2 (en) * | 2010-10-29 | 2012-05-03 | Alnylam Pharmaceuticals, Inc. | Compositions and methods for inhibition of pcsk9 genes |
| US10000752B2 (en) | 2010-11-18 | 2018-06-19 | Curna, Inc. | Antagonat compositions and methods of use |
| ES2657590T3 (es) | 2010-11-23 | 2018-03-06 | Curna, Inc. | Tratamiento de enfermedades relacionadas con nanog mediante inhibición del transcrito antisentido natural a nanog |
| PL3395836T3 (pl) | 2011-01-28 | 2021-12-13 | Sanofi Biotechnology | Ludzkie przeciwciała przeciwko pcsk9 do zastosowania w sposobach leczenia konkretnych grup osobników |
| RU2013151301A (ru) | 2011-04-20 | 2015-05-27 | Ларри Дж. СМИТ | Способы и композиции для модулирования экспрессии генов с использованием компонентов, которые обладают способностью к самосборке в клетках и обусловливают рнкi-активность |
| JOP20200043A1 (ar) | 2011-05-10 | 2017-06-16 | Amgen Inc | طرق معالجة أو منع الاضطرابات المختصة بالكوليسترول |
| EP2718439B1 (en) | 2011-06-09 | 2017-08-09 | CuRNA, Inc. | Treatment of frataxin (fxn) related diseases by inhibition of natural antisense transcript to fxn |
| AR087305A1 (es) | 2011-07-28 | 2014-03-12 | Regeneron Pharma | Formulaciones estabilizadas que contienen anticuerpos anti-pcsk9, metodo de preparacion y kit |
| KR101991980B1 (ko) | 2011-09-06 | 2019-06-21 | 큐알엔에이, 인크. | 소형 분자로 전압-개폐된 나트륨 채널 (SCNxA)의 알파 아단위에 관련된 질환의 치료 |
| RS54639B1 (sr) * | 2011-09-13 | 2016-08-31 | Affiris Ag | Pcsk9 vakcina |
| SG11201405157PA (en) | 2012-02-24 | 2014-10-30 | Protiva Biotherapeutics Inc | Trialkyl cationic lipids and methods of use thereof |
| US20150031750A1 (en) | 2012-03-15 | 2015-01-29 | The Scripps Research Institute | Treatment of brain derived neurotrophic factor (bdnf) related diseases by inhibition of natural antisense transcript to bdnf |
| US9255154B2 (en) | 2012-05-08 | 2016-02-09 | Alderbio Holdings, Llc | Anti-PCSK9 antibodies and use thereof |
| US10125369B2 (en) * | 2012-12-05 | 2018-11-13 | Alnylam Pharmaceuticals, Inc. | PCSK9 iRNA compositions and methods of use thereof |
| DK2931897T3 (en) | 2012-12-12 | 2018-02-05 | Broad Inst Inc | CONSTRUCTION, MODIFICATION AND OPTIMIZATION OF SYSTEMS, PROCEDURES AND COMPOSITIONS FOR SEQUENCE MANIPULATION AND THERAPEUTICAL APPLICATIONS |
| WO2014093709A1 (en) | 2012-12-12 | 2014-06-19 | The Broad Institute, Inc. | Methods, models, systems, and apparatus for identifying target sequences for cas enzymes or crispr-cas systems for target sequences and conveying results thereof |
| EP2931899A1 (en) | 2012-12-12 | 2015-10-21 | The Broad Institute, Inc. | Functional genomics using crispr-cas systems, compositions, methods, knock out libraries and applications thereof |
| WO2014182661A2 (en) | 2013-05-06 | 2014-11-13 | Alnylam Pharmaceuticals, Inc | Dosages and methods for delivering lipid formulated nucleic acid molecules |
| EP2810955A1 (en) | 2013-06-07 | 2014-12-10 | Sanofi | Methods for inhibiting atherosclerosis by administering an inhibitor of PCSK9 |
| EP2862877A1 (en) | 2013-10-18 | 2015-04-22 | Sanofi | Methods for inhibiting atherosclerosis by administering an inhibitor of PCSK9 |
| TW202021614A (zh) | 2013-06-07 | 2020-06-16 | 法商賽諾菲生物技術公司 | 藉由投與pcsk9抑制劑抑制動脈粥狀硬化的方法 |
| MX2015017312A (es) * | 2013-06-17 | 2017-04-10 | Broad Inst Inc | Suministro y uso de composiciones, vectores y sistemas crispr-cas para la modificación dirigida y terapia hepáticas. |
| EP3011030B1 (en) | 2013-06-17 | 2023-11-08 | The Broad Institute, Inc. | Optimized crispr-cas double nickase systems, methods and compositions for sequence manipulation |
| KR20160019553A (ko) * | 2013-06-17 | 2016-02-19 | 더 브로드 인스티튜트, 인코퍼레이티드 | 유사분열 후 세포의 질병 및 장애를 표적화하고 모델링하기 위한 시스템, 방법 및 조성물의 전달, 유전자 조작 및 최적화 |
| WO2014204724A1 (en) | 2013-06-17 | 2014-12-24 | The Broad Institute Inc. | Delivery, engineering and optimization of tandem guide systems, methods and compositions for sequence manipulation |
| KR20250012194A (ko) | 2013-06-17 | 2025-01-23 | 더 브로드 인스티튜트, 인코퍼레이티드 | 바이러스 구성성분을 사용하여 장애 및 질환을 표적화하기 위한 crispr-cas 시스템 및 조성물의 전달, 용도 및 치료 적용 |
| EP3725885A1 (en) | 2013-06-17 | 2020-10-21 | The Broad Institute, Inc. | Functional genomics using crispr-cas systems, compositions methods, screens and applications thereof |
| ES2770667T3 (es) | 2013-06-27 | 2020-07-02 | Roche Innovation Ct Copenhagen As | Oligómeros antisentido y conjugados que se dirigen a PCSK9 |
| MX2016006226A (es) | 2013-11-12 | 2016-09-07 | Sanofi Biotechnology | Regimenes de dosificacion para uso con inhibidores de pcsk9. |
| BR112016013207A2 (pt) * | 2013-12-12 | 2017-09-26 | Massachusetts Inst Technology | administração, uso e aplicações terapêuticas dos sistemas crispr-cas e composições para o hbv e distúrbios e doenças virais |
| JP6793547B2 (ja) | 2013-12-12 | 2020-12-02 | ザ・ブロード・インスティテュート・インコーポレイテッド | 最適化機能CRISPR−Cas系による配列操作のための系、方法および組成物 |
| EP3080259B1 (en) | 2013-12-12 | 2023-02-01 | The Broad Institute, Inc. | Engineering of systems, methods and optimized guide compositions with new architectures for sequence manipulation |
| MX2016007325A (es) | 2013-12-12 | 2017-07-19 | Broad Inst Inc | Composiciones y metodos de uso de sistemas crispr-cas en desordenes debidos a repeticion de nucleotidos. |
| WO2015089364A1 (en) | 2013-12-12 | 2015-06-18 | The Broad Institute Inc. | Crystal structure of a crispr-cas system, and uses thereof |
| AU2014361781B2 (en) | 2013-12-12 | 2021-04-01 | Massachusetts Institute Of Technology | Delivery, use and therapeutic applications of the CRISPR -Cas systems and compositions for genome editing |
| US9067998B1 (en) | 2014-07-15 | 2015-06-30 | Kymab Limited | Targeting PD-1 variants for treatment of cancer |
| US9045545B1 (en) | 2014-07-15 | 2015-06-02 | Kymab Limited | Precision medicine by targeting PD-L1 variants for treatment of cancer |
| US8986694B1 (en) | 2014-07-15 | 2015-03-24 | Kymab Limited | Targeting human nav1.7 variants for treatment of pain |
| US9017678B1 (en) | 2014-07-15 | 2015-04-28 | Kymab Limited | Method of treating rheumatoid arthritis using antibody to IL6R |
| US8883157B1 (en) | 2013-12-17 | 2014-11-11 | Kymab Limited | Targeting rare human PCSK9 variants for cholesterol treatment |
| US9914769B2 (en) | 2014-07-15 | 2018-03-13 | Kymab Limited | Precision medicine for cholesterol treatment |
| US8945560B1 (en) | 2014-07-15 | 2015-02-03 | Kymab Limited | Method of treating rheumatoid arthritis using antibody to IL6R |
| US9045548B1 (en) | 2014-07-15 | 2015-06-02 | Kymab Limited | Precision Medicine by targeting rare human PCSK9 variants for cholesterol treatment |
| US8980273B1 (en) | 2014-07-15 | 2015-03-17 | Kymab Limited | Method of treating atopic dermatitis or asthma using antibody to IL4RA |
| US9034332B1 (en) | 2014-07-15 | 2015-05-19 | Kymab Limited | Precision medicine by targeting rare human PCSK9 variants for cholesterol treatment |
| US8986691B1 (en) | 2014-07-15 | 2015-03-24 | Kymab Limited | Method of treating atopic dermatitis or asthma using antibody to IL4RA |
| US9051378B1 (en) | 2014-07-15 | 2015-06-09 | Kymab Limited | Targeting rare human PCSK9 variants for cholesterol treatment |
| US8992927B1 (en) | 2014-07-15 | 2015-03-31 | Kymab Limited | Targeting human NAV1.7 variants for treatment of pain |
| US9023359B1 (en) | 2014-07-15 | 2015-05-05 | Kymab Limited | Targeting rare human PCSK9 variants for cholesterol treatment |
| SG10201913570XA (en) * | 2013-12-27 | 2020-03-30 | Bonac Corp | Artificial match-type mirna for controlling gene expression and use therefor |
| GB201403775D0 (en) | 2014-03-04 | 2014-04-16 | Kymab Ltd | Antibodies, uses & methods |
| US9139648B1 (en) | 2014-07-15 | 2015-09-22 | Kymab Limited | Precision medicine by targeting human NAV1.9 variants for treatment of pain |
| US9150660B1 (en) | 2014-07-15 | 2015-10-06 | Kymab Limited | Precision Medicine by targeting human NAV1.8 variants for treatment of pain |
| PL3169353T3 (pl) | 2014-07-16 | 2020-06-01 | Sanofi Biotechnology | SPOSOBY LECZENIA PACJENTÓW Z HETEROZYGOTYCZNĄ HIPERCHOLESTEROLEMIĄ RODZINNĄ (heFH) |
| TWI864340B (zh) * | 2014-10-10 | 2024-12-01 | 美商艾爾妮蘭製藥公司 | 用於抑制hao1(羥酸氧化酶1(乙醇酸鹽氧化酶))基因表現的組合物及方法 |
| EP3889260A1 (en) | 2014-12-12 | 2021-10-06 | The Broad Institute, Inc. | Protected guide rnas (pgrnas) |
| WO2016106244A1 (en) | 2014-12-24 | 2016-06-30 | The Broad Institute Inc. | Crispr having or associated with destabilization domains |
| ES2789049T3 (es) * | 2014-12-26 | 2020-10-23 | Nitto Denko Corp | Agentes de interferencia de ARN para modulación génica de GST-pi |
| US10792299B2 (en) | 2014-12-26 | 2020-10-06 | Nitto Denko Corporation | Methods and compositions for treating malignant tumors associated with kras mutation |
| US10264976B2 (en) | 2014-12-26 | 2019-04-23 | The University Of Akron | Biocompatible flavonoid compounds for organelle and cell imaging |
| US20180002702A1 (en) | 2014-12-26 | 2018-01-04 | Nitto Denko Corporation | Methods and compositions for treating malignant tumors associated with kras mutation |
| US11045488B2 (en) | 2014-12-26 | 2021-06-29 | Nitto Denko Corporation | RNA interference agents for GST-π gene modulation |
| WO2016205759A1 (en) | 2015-06-18 | 2016-12-22 | The Broad Institute Inc. | Engineering and optimization of systems, methods, enzymes and guide scaffolds of cas9 orthologs and variants for sequence manipulation |
| TWI813532B (zh) | 2015-06-18 | 2023-09-01 | 美商博得學院股份有限公司 | 降低脱靶效應的crispr酶突變 |
| JP2018523684A (ja) | 2015-08-18 | 2018-08-23 | リジェネロン・ファーマシューティカルズ・インコーポレイテッドRegeneron Pharmaceuticals, Inc. | リポタンパク質アフェレーシスを受けている高脂血症の患者を治療するための抗pcsk9阻害抗体 |
| JP2018525037A (ja) | 2015-08-24 | 2018-09-06 | ハロー−バイオ・アールエヌエーアイ・セラピューティックス、インコーポレイテッド | 遺伝子発現の調節のためのポリヌクレオチドナノ粒子及びその使用 |
| CN118697894A (zh) | 2015-08-25 | 2024-09-27 | 阿尔尼拉姆医药品有限公司 | 用于治疗前蛋白转化酶枯草杆菌蛋白酶kexin(pcsk9)基因相关障碍的方法和组合物 |
| WO2017070151A1 (en) | 2015-10-19 | 2017-04-27 | Rxi Pharmaceuticals Corporation | Reduced size self-delivering nucleic acid compounds targeting long non-coding rna |
| KR102379464B1 (ko) | 2016-06-20 | 2022-03-29 | 키맵 리미티드 | 항-pd-l1 항체 |
| LT3529360T (lt) * | 2016-10-18 | 2024-07-25 | Novartis Ag | Metodai, skirti širdies ir kraujagyslių ligų prevencijai mažinant proproteinų konvertazės subtilizino keksino 9 (pcsk9) baltymo kiekį |
| EP3534947A1 (en) | 2016-11-03 | 2019-09-11 | Kymab Limited | Antibodies, combinations comprising antibodies, biomarkers, uses & methods |
| JOP20190112A1 (ar) | 2016-11-14 | 2019-05-14 | Amgen Inc | علاجات مدمجة لتصلب الشرايين، شاملة مرض قلبي وعائي تصلبي |
| EP4035659A1 (en) | 2016-11-29 | 2022-08-03 | PureTech LYT, Inc. | Exosomes for delivery of therapeutic agents |
| CN108265052B (zh) * | 2016-12-30 | 2021-05-28 | 苏州瑞博生物技术股份有限公司 | 一种小干扰核酸和药物组合物及其用途 |
| JP2019508379A (ja) * | 2017-02-16 | 2019-03-28 | 日東電工株式会社 | 悪性腫瘍に対する治療方法及び治療用組成物 |
| JOP20190215A1 (ar) * | 2017-03-24 | 2019-09-19 | Ionis Pharmaceuticals Inc | مُعدّلات التعبير الوراثي عن pcsk9 |
| WO2019006455A1 (en) | 2017-06-30 | 2019-01-03 | Solstice Biologics, Ltd. | AUXILIARIES OF CHIRAL PHOSPHORAMIDITIS AND METHODS OF USE THEREOF |
| WO2019105437A1 (zh) | 2017-12-01 | 2019-06-06 | 苏州瑞博生物技术有限公司 | 一种核酸、含有该核酸的组合物与缀合物及制备方法和用途 |
| CN110945130B (zh) | 2017-12-01 | 2024-04-09 | 苏州瑞博生物技术股份有限公司 | 一种核酸、含有该核酸的组合物与缀合物及制备方法和用途 |
| CA3083968C (en) | 2017-12-01 | 2024-04-23 | Suzhou Ribo Life Science Co., Ltd. | Double-stranded oligonucleotide, composition and conjugate comprising double-stranded oligonucleotide, preparation method thereof and use thereof |
| WO2019105435A1 (zh) | 2017-12-01 | 2019-06-06 | 苏州瑞博生物技术有限公司 | 一种核酸、含有该核酸的组合物与缀合物及制备方法和用途 |
| JP7365052B2 (ja) | 2017-12-01 | 2023-10-19 | スーチョウ リボ ライフ サイエンス カンパニー、リミテッド | 核酸、当該核酸を含む組成物及び複合体ならびに調製方法と使用 |
| US20230139322A1 (en) * | 2017-12-26 | 2023-05-04 | Guangzhou Ribobio Co., Ltd. | SiRNA molecule inhibiting the expression of the PCSK9 gene and use thereof |
| CN109957565B (zh) * | 2017-12-26 | 2023-04-07 | 广州市锐博生物科技有限公司 | 一种修饰的siRNA分子及其应用 |
| CN109957567B (zh) * | 2017-12-26 | 2022-09-23 | 阿格纳生物制药有限公司 | 一种抑制PCSK9基因表达的siRNA分子及其应用 |
| EP3732185B1 (en) | 2017-12-29 | 2025-02-26 | Suzhou Ribo Life Science Co., Ltd. | Conjugates and preparation and use thereof |
| US11566248B2 (en) * | 2018-04-18 | 2023-01-31 | Dicerna Pharmaceuticals, Inc. | PCSK9 targeting oligonucleotides for treating hypercholesterolemia and related conditions |
| US11918600B2 (en) | 2018-08-21 | 2024-03-05 | Suzhou Ribo Life Science Co., Ltd. | Nucleic acid, pharmaceutical composition and conjugate containing nucleic acid, and use thereof |
| EP3862024A4 (en) | 2018-09-30 | 2022-08-17 | Suzhou Ribo Life Science Co., Ltd. | SIRNA CONJUGATE, METHOD FOR ITS PRODUCTION AND ITS USE |
| US12496347B2 (en) | 2018-12-28 | 2025-12-16 | Suzhou Ribo Life Science Co., Ltd. | Nucleic acid, composition and conjugate containing nucleic acid, preparation method therefor and use thereof |
| CN111378656B (zh) * | 2018-12-28 | 2022-07-26 | 苏州瑞博生物技术股份有限公司 | 一种抑制埃博拉病毒的核酸、含有该核酸的药物组合物及其用途 |
| AU2020280438B2 (en) | 2019-05-22 | 2025-03-06 | Suzhou Ribo Life Science Co., Ltd. | Nucleic acid, pharmaceutical composition, conjugate, preparation method, and use |
| JP7610268B2 (ja) | 2019-05-22 | 2025-01-08 | スーチョウ リボ ライフ サイエンス カンパニー、リミテッド | 核酸、薬物組成物及び複合体ならびに調製方法と使用 |
| WO2020233680A1 (zh) | 2019-05-22 | 2020-11-26 | 苏州瑞博生物技术股份有限公司 | 核酸、药物组合物与缀合物及制备方法和用途 |
| EP3978609A4 (en) | 2019-05-24 | 2024-02-07 | Suzhou Ribo Life Science Co., Ltd. | Nucleic acid, pharmaceutical composition, conjugate, preparation method, and use |
| KR20220017466A (ko) * | 2019-06-04 | 2022-02-11 | 트러스티즈 오브 터프츠 칼리지 | Mrna 전달을 위한 합성 지질 |
| US20220290156A1 (en) * | 2019-08-27 | 2022-09-15 | Sanofi | Compositions and methods for inhibiting pcsk9 |
| US12378560B2 (en) | 2019-10-29 | 2025-08-05 | Northwestern University | Sequence multiplicity within spherical nucleic acids |
| US20230183694A1 (en) * | 2020-03-16 | 2023-06-15 | Argonaute RNA Limited | Antagonist of pcsk9 |
| WO2022089486A1 (zh) * | 2020-10-28 | 2022-05-05 | 江苏柯菲平医药股份有限公司 | 抑制PCSK9基因表达的siRNA及其修饰物与应用 |
| WO2023017004A1 (en) * | 2021-08-09 | 2023-02-16 | Cargene Therapeutics Pte. Ltd. | Inhibitory nucleic acids for pcsk9 |
| CN113980966B (zh) * | 2021-09-29 | 2024-09-20 | 阿格纳生物制药有限公司 | 一种抑制pcsk9靶基因表达的核酸序列及其应用 |
| CN120272480A (zh) * | 2021-09-30 | 2025-07-08 | 北京安龙生物医药有限公司 | 用于治疗与pcsk9相关疾病的靶向寡核苷酸 |
| WO2024222898A1 (zh) * | 2023-04-28 | 2024-10-31 | 北京福元医药股份有限公司 | 用于抑制marc1基因表达的双链核糖核酸及其修饰物、缀合物和用途 |
| WO2025006782A2 (en) * | 2023-06-30 | 2025-01-02 | Chroma Medicine, Inc. | Guide rna compositions |
| CN117210468B (zh) * | 2023-11-06 | 2024-02-20 | 北京悦康科创医药科技股份有限公司 | 靶向调控PCSK9基因表达的siRNA及其应用 |
| CN117384907B (zh) * | 2023-12-11 | 2024-03-29 | 上海鼎新基因科技有限公司 | 抑制PCSK9表达的siRNA分子及其应用 |
Family Cites Families (133)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3687808A (en) | 1969-08-14 | 1972-08-29 | Univ Leland Stanford Junior | Synthetic polynucleotides |
| US4469863A (en) | 1980-11-12 | 1984-09-04 | Ts O Paul O P | Nonionic nucleic acid alkyl and aryl phosphonates and processes for manufacture and use thereof |
| US5023243A (en) | 1981-10-23 | 1991-06-11 | Molecular Biosystems, Inc. | Oligonucleotide therapeutic agent and method of making same |
| US4476301A (en) | 1982-04-29 | 1984-10-09 | Centre National De La Recherche Scientifique | Oligonucleotides, a process for preparing the same and their application as mediators of the action of interferon |
| US5550111A (en) | 1984-07-11 | 1996-08-27 | Temple University-Of The Commonwealth System Of Higher Education | Dual action 2',5'-oligoadenylate antiviral derivatives and uses thereof |
| US5185444A (en) | 1985-03-15 | 1993-02-09 | Anti-Gene Deveopment Group | Uncharged morpolino-based polymers having phosphorous containing chiral intersubunit linkages |
| US5405938A (en) | 1989-12-20 | 1995-04-11 | Anti-Gene Development Group | Sequence-specific binding polymers for duplex nucleic acids |
| US5235033A (en) | 1985-03-15 | 1993-08-10 | Anti-Gene Development Group | Alpha-morpholino ribonucleoside derivatives and polymers thereof |
| US5166315A (en) | 1989-12-20 | 1992-11-24 | Anti-Gene Development Group | Sequence-specific binding polymers for duplex nucleic acids |
| US5034506A (en) | 1985-03-15 | 1991-07-23 | Anti-Gene Development Group | Uncharged morpholino-based polymers having achiral intersubunit linkages |
| US4980286A (en) | 1985-07-05 | 1990-12-25 | Whitehead Institute For Biomedical Research | In vivo introduction and expression of foreign genetic material in epithelial cells |
| WO1987000201A1 (en) | 1985-07-05 | 1987-01-15 | Whitehead Institute For Biomedical Research | Epithelial cells expressing foreign genetic material |
| US5139941A (en) | 1985-10-31 | 1992-08-18 | University Of Florida Research Foundation, Inc. | AAV transduction vectors |
| US5276019A (en) | 1987-03-25 | 1994-01-04 | The United States Of America As Represented By The Department Of Health And Human Services | Inhibitors for replication of retroviruses and for the expression of oncogene products |
| US5264423A (en) | 1987-03-25 | 1993-11-23 | The United States Of America As Represented By The Department Of Health And Human Services | Inhibitors for replication of retroviruses and for the expression of oncogene products |
| EP0378576B1 (en) | 1987-09-11 | 1995-01-18 | Whitehead Institute For Biomedical Research | Transduced fibroblasts and uses therefor |
| US5188897A (en) | 1987-10-22 | 1993-02-23 | Temple University Of The Commonwealth System Of Higher Education | Encapsulated 2',5'-phosphorothioate oligoadenylates |
| US4924624A (en) | 1987-10-22 | 1990-05-15 | Temple University-Of The Commonwealth System Of Higher Education | 2,',5'-phosphorothioate oligoadenylates and plant antiviral uses thereof |
| WO1989005345A1 (en) | 1987-12-11 | 1989-06-15 | Whitehead Institute For Biomedical Research | Genetic modification of endothelial cells |
| JP2917998B2 (ja) | 1988-02-05 | 1999-07-12 | ホワイトヘッド・インスティチュート・フォー・バイオメディカル・リサーチ | 修飾された肝細胞およびその用途 |
| WO1989009221A1 (en) | 1988-03-25 | 1989-10-05 | University Of Virginia Alumni Patents Foundation | Oligonucleotide n-alkylphosphoramidates |
| US5278302A (en) | 1988-05-26 | 1994-01-11 | University Patents, Inc. | Polynucleotide phosphorodithioates |
| US5216141A (en) | 1988-06-06 | 1993-06-01 | Benner Steven A | Oligonucleotide analogs containing sulfur linkages |
| US5328470A (en) | 1989-03-31 | 1994-07-12 | The Regents Of The University Of Michigan | Treatment of diseases by site-specific instillation of cells or site-specific transformation of cells and kits therefor |
| US5399676A (en) | 1989-10-23 | 1995-03-21 | Gilead Sciences | Oligonucleotides with inverted polarity |
| US5264562A (en) | 1989-10-24 | 1993-11-23 | Gilead Sciences, Inc. | Oligonucleotide analogs with novel linkages |
| US5264564A (en) | 1989-10-24 | 1993-11-23 | Gilead Sciences | Oligonucleotide analogs with novel linkages |
| US5177198A (en) | 1989-11-30 | 1993-01-05 | University Of N.C. At Chapel Hill | Process for preparing oligoribonucleoside and oligodeoxyribonucleoside boranophosphates |
| US5223168A (en) | 1989-12-12 | 1993-06-29 | Gary Holt | Surface cleaner and treatment |
| US5506351A (en) | 1992-07-23 | 1996-04-09 | Isis Pharmaceuticals | Process for the preparation of 2'-O-alkyl guanosine and related compounds |
| US5587361A (en) | 1991-10-15 | 1996-12-24 | Isis Pharmaceuticals, Inc. | Oligonucleotides having phosphorothioate linkages of high chiral purity |
| WO1993007883A1 (en) | 1991-10-24 | 1993-04-29 | Isis Pharmaceuticals, Inc. | Derivatized oligonucleotides having improved uptake and other properties |
| US5587470A (en) | 1990-01-11 | 1996-12-24 | Isis Pharmaceuticals, Inc. | 3-deazapurines |
| US5212295A (en) | 1990-01-11 | 1993-05-18 | Isis Pharmaceuticals | Monomers for preparation of oligonucleotides having chiral phosphorus linkages |
| US5457191A (en) | 1990-01-11 | 1995-10-10 | Isis Pharmaceuticals, Inc. | 3-deazapurines |
| US5459255A (en) | 1990-01-11 | 1995-10-17 | Isis Pharmaceuticals, Inc. | N-2 substituted purines |
| US5578718A (en) | 1990-01-11 | 1996-11-26 | Isis Pharmaceuticals, Inc. | Thiol-derivatized nucleosides |
| US5321131A (en) | 1990-03-08 | 1994-06-14 | Hybridon, Inc. | Site-specific functionalization of oligodeoxynucleotides for non-radioactive labelling |
| US5470967A (en) | 1990-04-10 | 1995-11-28 | The Dupont Merck Pharmaceutical Company | Oligonucleotide analogs with sulfamate linkages |
| US5541307A (en) | 1990-07-27 | 1996-07-30 | Isis Pharmaceuticals, Inc. | Backbone modified oligonucleotide analogs and solid phase synthesis thereof |
| US5378825A (en) | 1990-07-27 | 1995-01-03 | Isis Pharmaceuticals, Inc. | Backbone modified oligonucleotide analogs |
| US5618704A (en) | 1990-07-27 | 1997-04-08 | Isis Pharmacueticals, Inc. | Backbone-modified oligonucleotide analogs and preparation thereof through radical coupling |
| US5489677A (en) | 1990-07-27 | 1996-02-06 | Isis Pharmaceuticals, Inc. | Oligonucleoside linkages containing adjacent oxygen and nitrogen atoms |
| US5623070A (en) | 1990-07-27 | 1997-04-22 | Isis Pharmaceuticals, Inc. | Heteroatomic oligonucleoside linkages |
| US5138045A (en) | 1990-07-27 | 1992-08-11 | Isis Pharmaceuticals | Polyamine conjugated oligonucleotides |
| US5602240A (en) | 1990-07-27 | 1997-02-11 | Ciba Geigy Ag. | Backbone modified oligonucleotide analogs |
| US5610289A (en) | 1990-07-27 | 1997-03-11 | Isis Pharmaceuticals, Inc. | Backbone modified oligonucleotide analogues |
| US5677437A (en) | 1990-07-27 | 1997-10-14 | Isis Pharmaceuticals, Inc. | Heteroatomic oligonucleoside linkages |
| US5608046A (en) | 1990-07-27 | 1997-03-04 | Isis Pharmaceuticals, Inc. | Conjugated 4'-desmethyl nucleoside analog compounds |
| US5218105A (en) | 1990-07-27 | 1993-06-08 | Isis Pharmaceuticals | Polyamine conjugated oligonucleotides |
| US5386023A (en) | 1990-07-27 | 1995-01-31 | Isis Pharmaceuticals | Backbone modified oligonucleotide analogs and preparation thereof through reductive coupling |
| ES2083593T3 (es) | 1990-08-03 | 1996-04-16 | Sterling Winthrop Inc | Compuestos y metodos para inhibir la expresion de genes. |
| US6262241B1 (en) | 1990-08-13 | 2001-07-17 | Isis Pharmaceuticals, Inc. | Compound for detecting and modulating RNA activity and gene expression |
| US5177196A (en) | 1990-08-16 | 1993-01-05 | Microprobe Corporation | Oligo (α-arabinofuranosyl nucleotides) and α-arabinofuranosyl precursors thereof |
| US5214134A (en) | 1990-09-12 | 1993-05-25 | Sterling Winthrop Inc. | Process of linking nucleosides with a siloxane bridge |
| US5561225A (en) | 1990-09-19 | 1996-10-01 | Southern Research Institute | Polynucleotide analogs containing sulfonate and sulfonamide internucleoside linkages |
| CA2092002A1 (en) | 1990-09-20 | 1992-03-21 | Mark Matteucci | Modified internucleoside linkages |
| JP3249516B2 (ja) | 1990-10-31 | 2002-01-21 | ソマティクス セラピー コーポレイション | 遺伝子治療のためのレトロウイルスのベクター |
| US5539082A (en) | 1993-04-26 | 1996-07-23 | Nielsen; Peter E. | Peptide nucleic acids |
| WO1993002340A1 (en) | 1991-07-25 | 1993-02-04 | The Whitaker Corporation | Liquid level sensor |
| US5571799A (en) | 1991-08-12 | 1996-11-05 | Basco, Ltd. | (2'-5') oligoadenylate analogues useful as inhibitors of host-v5.-graft response |
| US5599797A (en) | 1991-10-15 | 1997-02-04 | Isis Pharmaceuticals, Inc. | Oligonucleotides having phosphorothioate linkages of high chiral purity |
| US5252479A (en) | 1991-11-08 | 1993-10-12 | Research Corporation Technologies, Inc. | Safe vector for gene therapy |
| US5633360A (en) | 1992-04-14 | 1997-05-27 | Gilead Sciences, Inc. | Oligonucleotide analogs capable of passive cell membrane permeation |
| US5434257A (en) | 1992-06-01 | 1995-07-18 | Gilead Sciences, Inc. | Binding compentent oligomers containing unsaturated 3',5' and 2',5' linkages |
| US5587308A (en) | 1992-06-02 | 1996-12-24 | The United States Of America As Represented By The Department Of Health & Human Services | Modified adeno-associated virus vector capable of expression from a novel promoter |
| US5478745A (en) | 1992-12-04 | 1995-12-26 | University Of Pittsburgh | Recombinant viral vector system |
| US5476925A (en) | 1993-02-01 | 1995-12-19 | Northwestern University | Oligodeoxyribonucleotides including 3'-aminonucleoside-phosphoramidate linkages and terminal 3'-amino groups |
| GB9304618D0 (en) | 1993-03-06 | 1993-04-21 | Ciba Geigy Ag | Chemical compounds |
| CA2159629A1 (en) | 1993-03-31 | 1994-10-13 | Sanofi | Oligonucleotides with amide linkages replacing phosphodiester linkages |
| US5571902A (en) | 1993-07-29 | 1996-11-05 | Isis Pharmaceuticals, Inc. | Synthesis of oligonucleotides |
| US5625050A (en) | 1994-03-31 | 1997-04-29 | Amgen Inc. | Modified oligonucleotides and intermediates useful in nucleic acid therapeutics |
| US6054299A (en) | 1994-04-29 | 2000-04-25 | Conrad; Charles A. | Stem-loop cloning vector and method |
| US5554746A (en) | 1994-05-16 | 1996-09-10 | Isis Pharmaceuticals, Inc. | Lactam nucleic acids |
| ATE285477T1 (de) | 1995-06-07 | 2005-01-15 | Inex Pharmaceutical Corp | Herstellung von lipid-nukleinsäure partikeln duch ein hydrophobische lipid-nukleinsäuree komplexe zwischenprodukt und zur verwendung in der gentransfer |
| US6506559B1 (en) | 1997-12-23 | 2003-01-14 | Carnegie Institute Of Washington | Genetic inhibition by double-stranded RNA |
| NZ507093A (en) | 1998-04-08 | 2003-08-29 | Commw Scient Ind Res Org | Methods and means for reducing the phenotypic expression of a nucleic acid of interest in a plant |
| AR020078A1 (es) | 1998-05-26 | 2002-04-10 | Syngenta Participations Ag | Metodo para alterar la expresion de un gen objetivo en una celula de planta |
| BR9914773A (pt) | 1998-10-09 | 2002-02-05 | Ingene Inc | Conjunto de elementos genéricos, método para a produção de dna de cordão único, transcrição de mrna, construção de ácido nucléico, transcrição de ssdna, vetor, sistema vetor, célula hospedeira, conjunto para a produção de uma sequência de ácido nucléico de cordão único, método para a produção in vivo ou in vitro de uma sequência de ácido nucléico de cordão único, transcrição de cdna de cordão único, ácido nucléico inibidor, molécula heteroduplex, e composição farmacêutica |
| MXPA01003642A (es) | 1998-10-09 | 2003-07-21 | Ingene Inc | Sintesis enzimatica de adnss. |
| DE19956568A1 (de) | 1999-01-30 | 2000-08-17 | Roland Kreutzer | Verfahren und Medikament zur Hemmung der Expression eines vorgegebenen Gens |
| US6271359B1 (en) | 1999-04-14 | 2001-08-07 | Musc Foundation For Research Development | Tissue-specific and pathogen-specific toxic agents and ribozymes |
| DE10100586C1 (de) | 2001-01-09 | 2002-04-11 | Ribopharma Ag | Verfahren zur Hemmung der Expression eines Ziegens |
| WO2001057064A2 (en) | 2000-02-07 | 2001-08-09 | Roche Diagnostics Corporation | Cationic amphiphiles for use in nucleic acid transfection |
| WO2003070918A2 (en) | 2002-02-20 | 2003-08-28 | Ribozyme Pharmaceuticals, Incorporated | Rna interference by modified short interfering nucleic acid |
| WO2002081628A2 (en) | 2001-04-05 | 2002-10-17 | Ribozyme Pharmaceuticals, Incorporated | Modulation of gene expression associated with inflammation proliferation and neurite outgrowth, using nucleic acid based technologies |
| US20040259247A1 (en) | 2000-12-01 | 2004-12-23 | Thomas Tuschl | Rna interference mediating small rna molecules |
| US20030170891A1 (en) | 2001-06-06 | 2003-09-11 | Mcswiggen James A. | RNA interference mediated inhibition of epidermal growth factor receptor gene expression using short interfering nucleic acid (siNA) |
| US20070173473A1 (en) | 2001-05-18 | 2007-07-26 | Sirna Therapeutics, Inc. | RNA interference mediated inhibition of proprotein convertase subtilisin Kexin 9 (PCSK9) gene expression using short interfering nucleic acid (siNA) |
| US20080249040A1 (en) | 2001-05-18 | 2008-10-09 | Sirna Therapeutics, Inc. | RNA interference mediated inhibition of sterol regulatory element binding protein 1 (SREBP1) gene expression using short interfering nucleic acid (siNA) |
| US20040009216A1 (en) | 2002-04-05 | 2004-01-15 | Rodrigueza Wendi V. | Compositions and methods for dosing liposomes of certain sizes to treat or prevent disease |
| US7956176B2 (en) | 2002-09-05 | 2011-06-07 | Sirna Therapeutics, Inc. | RNA interference mediated inhibition of gene expression using chemically modified short interfering nucleic acid (siNA) |
| EP2305812A3 (en) * | 2002-11-14 | 2012-06-06 | Dharmacon, Inc. | Fuctional and hyperfunctional sirna |
| DE10302421A1 (de) | 2003-01-21 | 2004-07-29 | Ribopharma Ag | Doppelsträngige Ribonukleinsäure mit verbesserter Wirksamkeit |
| WO2004080406A2 (en) | 2003-03-07 | 2004-09-23 | Alnylam Pharmaceuticals | Therapeutic compositions |
| AU2004227414A1 (en) | 2003-04-03 | 2004-10-21 | Alnylam Pharmaceuticals | iRNA conjugates |
| EP1471152A1 (en) * | 2003-04-25 | 2004-10-27 | Institut National De La Sante Et De La Recherche Medicale (Inserm) | Mutations in the human PCSK9 gene associated to hypercholesterolemia |
| AU2004263830B2 (en) * | 2003-06-13 | 2008-12-18 | Alnylam Pharmaceuticals, Inc. | Double-stranded ribonucleic acid with increased effectiveness in an organism |
| ES2559828T3 (es) | 2003-07-16 | 2016-02-16 | Protiva Biotherapeutics Inc. | ARN de interferencia encapsulado en lípidos |
| WO2005045035A2 (en) * | 2003-10-23 | 2005-05-19 | Sirna Therapeutics, Inc. | RNA INTERFERENCE MEDIATED INHIBITION OF NOGO AND NOGO RECEPTOR GENE EXPRESSION USING SHORT INTERFERING NUCLEIC ACID (siNA) |
| US20080253960A1 (en) | 2004-04-01 | 2008-10-16 | The Trustees Of The University Of Pennsylvania Center For Technology Transfer | Lipoprotein-Based Nanoplatforms |
| US7745651B2 (en) | 2004-06-07 | 2010-06-29 | Protiva Biotherapeutics, Inc. | Cationic lipids and methods of use |
| US7799565B2 (en) | 2004-06-07 | 2010-09-21 | Protiva Biotherapeutics, Inc. | Lipid encapsulated interfering RNA |
| JP5042863B2 (ja) | 2005-02-14 | 2012-10-03 | サーナ・セラピューティクス・インコーポレイテッド | 生物学的に活性な分子をデリバリーするための脂質ナノ粒子系組成物および方法 |
| EP1866414B9 (en) | 2005-03-31 | 2012-10-03 | Calando Pharmaceuticals, Inc. | Inhibitors of ribonucleotide reductase subunit 2 and uses thereof |
| US7915230B2 (en) | 2005-05-17 | 2011-03-29 | Molecular Transfer, Inc. | Reagents for transfection of eukaryotic cells |
| US9005654B2 (en) | 2005-07-27 | 2015-04-14 | Protiva Biotherapeutics, Inc. | Systems and methods for manufacturing liposomes |
| US8101741B2 (en) | 2005-11-02 | 2012-01-24 | Protiva Biotherapeutics, Inc. | Modified siRNA molecules and uses thereof |
| WO2007056861A1 (en) | 2005-11-18 | 2007-05-24 | Protiva Biotherapeutics, Inc. | Sirna silencing of influenza virus gene expression |
| US7718629B2 (en) | 2006-03-31 | 2010-05-18 | Alnylam Pharmaceuticals, Inc. | Compositions and methods for inhibiting expression of Eg5 gene |
| ES2874149T3 (es) * | 2006-05-11 | 2021-11-04 | Alnylam Pharmaceuticals Inc | Composiciones y métodos para inhibir la expresión del gen PCSK9 |
| US8598333B2 (en) | 2006-05-26 | 2013-12-03 | Alnylam Pharmaceuticals, Inc. | SiRNA silencing of genes expressed in cancer |
| AU2007275365A1 (en) * | 2006-07-17 | 2008-01-24 | Sirna Therapeutics Inc. | RNA interference mediated inhibition of Proprotein Convertase Subtilisin Kexin 9 (PCSK9) gene expression using short interfering nucleic acid (siNA) |
| EP3192788A1 (en) | 2006-10-03 | 2017-07-19 | Arbutus Biopharma Corporation | Lipid containing formulations |
| JP2010510807A (ja) | 2006-11-27 | 2010-04-08 | アイシス ファーマシューティカルズ, インコーポレーテッド | 高コレステロール血症を治療するための方法 |
| WO2008109369A2 (en) | 2007-03-02 | 2008-09-12 | Mdrna, Inc. | Nucleic acid compounds for inhibiting tnf gene expression and uses thereof |
| JOP20080381B1 (ar) | 2007-08-23 | 2023-03-28 | Amgen Inc | بروتينات مرتبطة بمولدات مضادات تتفاعل مع بروبروتين كونفيرتاز سيتيليزين ككسين من النوع 9 (pcsk9) |
| WO2009082817A1 (en) | 2007-12-27 | 2009-07-09 | Protiva Biotherapeutics, Inc. | Silencing of polo-like kinase expression using interfering rna |
| WO2009086558A1 (en) | 2008-01-02 | 2009-07-09 | Tekmira Pharmaceuticals Corporation | Improved compositions and methods for the delivery of nucleic acids |
| MX2010008394A (es) | 2008-01-31 | 2010-11-12 | Alnylam Pharmaceuticals Inc | Metodos optimizados para administracion de arndc focalizando el gen pcsk9. |
| SG188121A1 (en) | 2008-03-05 | 2013-03-28 | Alnylam Pharmaceuticals Inc | Compositions and methods for inhibiting expression of eg5 and vegf genes |
| WO2009114475A2 (en) | 2008-03-09 | 2009-09-17 | Intradigm Corporation | Compositions comprising human pcsk9 and apolipoprotein b sirna and methods of use |
| AU2009238175C1 (en) | 2008-04-15 | 2023-11-30 | Arbutus Biopharma Corporation | Novel lipid formulations for nucleic acid delivery |
| EA036772B1 (ru) | 2008-10-20 | 2020-12-18 | Элнилэм Фармасьютикалз, Инк. | Композиции и способы для ингибирования экспрессии транстиретина |
| HUE037082T2 (hu) | 2008-11-10 | 2018-08-28 | Arbutus Biopharma Corp | Új lipidek és készítmények terápiás hatóanyagok szállítására |
| EP2373382B1 (en) | 2008-12-10 | 2017-02-15 | Alnylam Pharmaceuticals, Inc. | Gnaq targeted dsrna compositions and methods for inhibiting expression |
| US8311190B2 (en) * | 2008-12-23 | 2012-11-13 | International Business Machines Corporation | Performing human client verification over a voice interface |
| EP3243504A1 (en) | 2009-01-29 | 2017-11-15 | Arbutus Biopharma Corporation | Improved lipid formulation |
| KR20180094137A (ko) | 2009-05-05 | 2018-08-22 | 알닐람 파마슈티칼스 인코포레이티드 | 지질 조성물 |
| MX342785B (es) | 2009-06-10 | 2016-10-12 | Alnylam Pharmaceuticals Inc | Formulacion mejorada de lipido. |
| NZ597504A (en) | 2009-06-15 | 2013-10-25 | Alnylam Pharmaceuticals Inc | Lipid formulated dsrna targeting the pcsk9 gene |
| WO2010147992A1 (en) | 2009-06-15 | 2010-12-23 | Alnylam Pharmaceuticals, Inc. | Methods for increasing efficacy of lipid formulated sirna |
| US8563528B2 (en) | 2009-07-21 | 2013-10-22 | Santaris Pharma A/S | Antisense oligomers targeting PCSK9 |
-
2007
- 2007-05-10 ES ES19168142T patent/ES2874149T3/es active Active
- 2007-05-10 WO PCT/US2007/068655 patent/WO2007134161A2/en not_active Ceased
- 2007-05-10 CN CN201310491236.5A patent/CN103614375A/zh active Pending
- 2007-05-10 EP EP12178667.7A patent/EP2584048B1/en active Active
- 2007-05-10 AU AU2007249329A patent/AU2007249329C1/en not_active Ceased
- 2007-05-10 EP EP07762085A patent/EP2021507A4/en not_active Withdrawn
- 2007-05-10 NZ NZ572666A patent/NZ572666A/en not_active IP Right Cessation
- 2007-05-10 KR KR1020107013424A patent/KR101320916B1/ko not_active Expired - Fee Related
- 2007-05-10 EP EP14173646.2A patent/EP2835429B1/en active Active
- 2007-05-10 JP JP2009510173A patent/JP5570806B2/ja not_active Expired - Fee Related
- 2007-05-10 EP EP17162101.4A patent/EP3249052B1/en active Active
- 2007-05-10 EP EP19168142.8A patent/EP3578656B1/en active Active
- 2007-05-10 CA CA2915441A patent/CA2915441A1/en not_active Abandoned
- 2007-05-10 KR KR1020087030164A patent/KR101036126B1/ko not_active Expired - Fee Related
- 2007-05-10 EP EP21150171.3A patent/EP3872179A1/en active Pending
- 2007-05-10 US US11/746,864 patent/US7605251B2/en active Active
- 2007-05-10 PL PL19168142T patent/PL3578656T3/pl unknown
- 2007-05-10 EA EA200870528A patent/EA015676B1/ru not_active IP Right Cessation
- 2007-05-10 NZ NZ587616A patent/NZ587616A/en not_active IP Right Cessation
- 2007-05-10 CN CN2007800248541A patent/CN101484588B/zh not_active Expired - Fee Related
- 2007-05-10 EP EP09015323A patent/EP2194128B1/en active Active
- 2007-05-10 PL PL09015323T patent/PL2194128T3/pl unknown
- 2007-05-10 ES ES09015323T patent/ES2392478T3/es active Active
- 2007-05-10 SG SG201103340-4A patent/SG171676A1/en unknown
- 2007-05-10 EP EP12178664.4A patent/EP2584047B1/en active Active
- 2007-05-10 CA CA2651839A patent/CA2651839C/en not_active Expired - Fee Related
- 2007-05-14 EA EA201100907A patent/EA020840B1/ru not_active IP Right Cessation
-
2008
- 2008-11-09 IL IL195181A patent/IL195181A/en active IP Right Grant
-
2009
- 2009-09-04 US US12/554,231 patent/US8222222B2/en active Active
-
2010
- 2010-05-10 JP JP2010108836A patent/JP2010246544A/ja active Pending
- 2010-11-09 AU AU2010241357A patent/AU2010241357B2/en not_active Ceased
-
2012
- 2012-05-15 US US13/472,438 patent/US8809292B2/en active Active
- 2012-05-31 IL IL220102A patent/IL220102A/en not_active IP Right Cessation
-
2014
- 2014-02-03 JP JP2014018817A patent/JP6034316B2/ja not_active Expired - Fee Related
- 2014-07-14 US US14/330,923 patent/US9260718B2/en active Active
-
2015
- 2015-11-19 JP JP2015226712A patent/JP2016027830A/ja active Pending
-
2016
- 2016-01-25 US US15/005,933 patent/US9822365B2/en active Active
-
2017
- 2017-02-20 IL IL250678A patent/IL250678A0/en unknown
- 2017-11-08 US US15/807,275 patent/US10501742B2/en active Active
-
2019
- 2019-11-05 US US16/675,035 patent/US20200318119A1/en not_active Abandoned
-
2021
- 2021-02-26 US US17/186,078 patent/US20210403917A1/en not_active Abandoned
-
2023
- 2023-03-03 US US18/116,903 patent/US20240093199A1/en not_active Abandoned
-
2024
- 2024-11-01 US US18/934,287 patent/US20250171785A1/en active Pending
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ES2874149T3 (es) | Composiciones y métodos para inhibir la expresión del gen PCSK9 | |
| HK40058088A (en) | Compositions and methods for inhibiting expression of the pcsk9 gene | |
| AU2012261570B2 (en) | Compositions and methods for inhibiting expression of the PCSK9 gene | |
| HK40018886B (en) | Compositions and methods for inhibiting expression of the pcsk9 gene | |
| HK40018886A (en) | Compositions and methods for inhibiting expression of the pcsk9 gene | |
| AU2016203687A1 (en) | Compositions and methods for inhibiting expression of the pcsk9 gene | |
| HK1142628B (en) | Compositions and methods for inhibiting expression of the pcsk9 gene | |
| HK1142628A1 (en) | Compositions and methods for inhibiting expression of the pcsk9 gene | |
| HK1183910B (en) | Compositions and methods for inhibiting expression of the pcsk9 gene |