ES2909841T3 - Nuevo protocolo para preparar bibliotecas de secuenciación - Google Patents
Nuevo protocolo para preparar bibliotecas de secuenciación Download PDFInfo
- Publication number
- ES2909841T3 ES2909841T3 ES18201917T ES18201917T ES2909841T3 ES 2909841 T3 ES2909841 T3 ES 2909841T3 ES 18201917 T ES18201917 T ES 18201917T ES 18201917 T ES18201917 T ES 18201917T ES 2909841 T3 ES2909841 T3 ES 2909841T3
- Authority
- ES
- Spain
- Prior art keywords
- chromosome
- sequencing
- sequence
- fetal
- sample
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Classifications
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B99/00—Subject matter not provided for in other groups of this subclass
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6806—Preparing nucleic acids for analysis, e.g. for polymerase chain reaction [PCR] assay
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6809—Methods for determination or identification of nucleic acids involving differential detection
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6813—Hybridisation assays
- C12Q1/6827—Hybridisation assays for detection of mutation or polymorphism
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6869—Methods for sequencing
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6869—Methods for sequencing
- C12Q1/6872—Methods for sequencing involving mass spectrometry
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6883—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material
-
- C—CHEMISTRY; METALLURGY
- C40—COMBINATORIAL TECHNOLOGY
- C40B—COMBINATORIAL CHEMISTRY; LIBRARIES, e.g. CHEMICAL LIBRARIES
- C40B30/00—Methods of screening libraries
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
- G16B20/10—Ploidy or copy number detection
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
- G16B30/10—Sequence alignment; Homology search
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H10/00—ICT specially adapted for the handling or processing of patient-related medical or healthcare data
- G16H10/40—ICT specially adapted for the handling or processing of patient-related medical or healthcare data for data related to laboratory analysis, e.g. patient specimen analysis
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2545/00—Reactions characterised by their quantitative nature
- C12Q2545/10—Reactions characterised by their quantitative nature the purpose being quantitative analysis
- C12Q2545/101—Reactions characterised by their quantitative nature the purpose being quantitative analysis with an internal standard/control
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/106—Pharmacogenomics, i.e. genetic variability in individual responses to drugs and drug metabolism
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/112—Disease subtyping, staging or classification
Landscapes
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Health & Medical Sciences (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Engineering & Computer Science (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Analytical Chemistry (AREA)
- Physics & Mathematics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Health & Medical Sciences (AREA)
- Biotechnology (AREA)
- Biophysics (AREA)
- Genetics & Genomics (AREA)
- Molecular Biology (AREA)
- Biochemistry (AREA)
- General Engineering & Computer Science (AREA)
- Microbiology (AREA)
- Immunology (AREA)
- Medical Informatics (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Bioinformatics & Computational Biology (AREA)
- Theoretical Computer Science (AREA)
- Evolutionary Biology (AREA)
- Pathology (AREA)
- Epidemiology (AREA)
- Primary Health Care (AREA)
- Public Health (AREA)
- General Chemical & Material Sciences (AREA)
- Medicinal Chemistry (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Investigating Or Analysing Biological Materials (AREA)
- Algebra (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Mathematical Physics (AREA)
- Pure & Applied Mathematics (AREA)
Abstract
Un método para la secuenciación de ácidos nucleicos que comprende: (a) proporcionar una muestra de ensayo que comprende moléculas de ácido nucleico, en el que dichas moléculas de ácido nucleico son moléculas de ADN genómico humano; (b) realizar la reparación de extremos de las moléculas de ácido nucleico para generar ácidos nucleicos de extremos romos; (c) realizar la adición de colas de dA a los ácidos nucleicos de extremos romos para generar ácidos nucleicos con cola de dA; (d) ligar adaptadores a los ácidos nucleicos con cola de dA para generar una biblioteca de polinucleótidos ligados a adaptadores; (e) opcionalmente amplificar la biblioteca usando cebadores de amplificación, comprendiendo dichos cebadores de amplificación una porción específica de adaptador; y (f) someter la biblioteca a una secuenciación masivamente paralela; en el que las etapas (b), (c), y (d) son etapas consecutivas.
Description
DESCRIPCIÓN
Nuevo protocolo para preparar bibliotecas de secuenciación
1. Antecedentes de la invención
La detección y el diagnóstico prenatales son una parte rutinaria de la atención prenatal. Actualmente, el diagnóstico prenatal de afecciones genéticas y cromosómicas implica pruebas invasivas, tales como la amniocentesis o el muestreo de vellosidades coriónicas (CVS), realizadas a partir de las 11 semanas de gestación y con un riesgo de aborto ~1%. La existencia de ADN libre de células en circulación en la sangre materna (Lo et al., Lancet 350: 485-487 [1997]) se está explotando para desarrollar procesos no invasivos que utilizan ácidos nucleicos fetales de una muestra de sangre periférica materna para determinar anomalías del cromosoma fetal (Fan HC y Quake SR Anal Chem 79: 7576-7579 [2007]; Fan et al., Proc Natl Acad Sci 105: 16266-16271 [2008]). Estos métodos ofrecen una fuente alternativa y más segura de material genético fetal para el diagnóstico prenatal, y podrían declarar efectivamente el final de los procedimientos invasivos.
La secuenciación de ácidos nucleicos está evolucionando rápidamente como una técnica de diagnóstico en el laboratorio clínico. Las aplicaciones que implican la secuenciación se observan en varias áreas, incluidas pruebas de cáncer que abarcan pruebas genéticas para la predisposición a padecer cáncer y la evaluación de mutaciones genéticas en el cáncer; la genética que abarca pruebas al portador y el diagnóstico de enfermedades transmitidas genéticamente; y la microbiología que abarca genotipos víricos y secuencias asociadas con resistencia a fármacos.
El advenimiento de tecnologías de secuenciación de próxima generación (NGS), que permiten la secuenciación de genomas enteros en un tiempo relativamente corto, ha proporcionado la oportunidad de comparar el material genético procedente de un cromosoma que se desea comparar con el de otro sin los riesgos asociados con métodos de muestreo invasivos. No obstante, las limitaciones de los métodos existentes, que incluyen una sensibilidad insuficiente derivada de los niveles limitados de ADNcf, y el sesgo de secuenciación de la tecnología derivada de la naturaleza inherente de la información genómica, subyacen a la necesidad continua de métodos no invasivos que proporcionen cualquiera o todas de entre especificidad, sensibilidad y aplicabilidad para diagnosticar de forma fiable aneuploidías fetales en una diversidad de entornos clínicos.
A medida que la secuenciación de ácidos nucleicos ha entrado en el ámbito clínico para pruebas de cáncer, organizaciones tales como el NCCLS (National Council Of Clinical Laboratory Services) y la Association of Clinical Cytogenetics han proporcionado directrices para la normalización de los ensayos basados en secuenciación existentes que utilizan secuenciación basada en PCR, por terminador didesoxi y por extensión de cebador realizada en secuenciadores basados en gel o en capilares (NCCLS: Nucleic Acid Sequencing Methods in Diagnostic Laboratory Medicine MM9-A, Vol. 24 N° 40), secuenciación de Sanger y QF-PCR (Association for Clinical Cytogenetics and Clinical Molecular Genetics Society, Practice Guidelines for Sanger Sequencing Analysis and Interpretation ratificadas por el CMGS Executive Committee del 7 de agosto de 2009, disponible en la dirección de Internet cmgs.org/BPGs/pdfs%20current%20bpgs/Sequencingv2.pdf QF-PCR for the diagnosis of aneuploidy best practice guidelines (2007) v2.01). Las directrices se basan en pruebas de consenso de varios protocolos y, entre otras cosas, tienen como objetivo reducir la aparición de eventos adversos en el laboratorio clínico, por ejemplo, mezclas de muestras, preservando al mismo tiempo la calidad y la fiabilidad de los ensayos. Dado que los laboratorios clínicos ya están experimentando con NIPD, se desarrollarán procedimientos de calidad para implementar las nuevas tecnologías de secuenciación con el fin de proporcionar sistemas de atención médica seguros y apropiados.
Fan et al. (PNAS 105, 16266-16271, 2008) describen el diagnóstico no invasivo de aneuploidía fetal mediante la secuenciación de escopeta de ADN procedente de sangre materna, y los autores utilizaron un protocolo de preparación de bibliotecas de Solexa/Illumina. Chu et al. (Bioinformatics, 25 (10), mayo de 2009, páginas 1244-1250) describe un "Modelo estadístico para la secuenciación de genoma completo y su aplicación a un diagnóstico mínimamente invasivo de enfermedad genética fetal".
La presente invención se refiere a métodos de secuenciación de próxima generación fiables que se pueden aplicar al menos para la práctica de diagnóstico prenatal no invasivo, y abarca procedimientos que aumentan la rapidez y la calidad de los métodos a la vez que minimizan la pérdida de material y reducen la probabilidad de errores de muestra.
2. Sumario de la invención
La invención se define en las reivindicaciones adjuntas.
La invención proporciona un método para la secuenciación de ácidos nucleicos que comprende: (a) proporcionar una muestra de ensayo que comprende moléculas de ácido nucleico, en el que dichas moléculas de ácido nucleico son moléculas de ADN genómico humano; (b) realizar la reparación de extremos de las moléculas de ácido nucleico para generar ácidos nucleicos de extremos romos; (c) realizar la adición de colas de dA a los ácidos nucleicos de extremos romos para generar ácidos nucleicos con cola de dA; (d) ligar adaptadores a los ácidos nucleicos con cola de dA para generar una biblioteca de polinucleótidos ligados a adaptadores; (e) opcionalmente amplificar la biblioteca usando
cebadores de amplificación, comprendiendo dichos cebadores de amplificación una porción específica de adaptador; y (f) someter la biblioteca a una secuenciación masivamente paralela; en el que las etapas (b), (c) y (d) son etapas consecutivas.
El método de la invención es aplicable a métodos para determinar aneuploidía y/o la fracción fetal en muestras maternas que comprenden ADNcf fetal y materno mediante secuenciación masivamente paralela. El método de la invención comprende un protocolo novedoso para preparar bibliotecas de secuenciación que mejora inesperadamente la calidad del ADN de la biblioteca a la vez que agiliza el proceso de análisis de muestras para diagnósticos prenatales.
En un caso, se divulga en el presente documento un método para determinar una aneuploidía cromosómica fetal en una muestra de sangre materna que comprende una mezcla de moléculas de ácidos nucleicos fetales y maternos, en el que el método comprende: (a) preparar una biblioteca de secuenciación a partir de la mezcla de moléculas de ácidos nucleicos fetales y maternos; en el que la preparación de dicha biblioteca comprende las etapas consecutivas de reparación de extremos, adición de colas de dA y ligación de adaptadores a dichos ácidos nucleicos; (b) secuenciar al menos una porción de las moléculas de ácido nucleico, obteniendo así información de secuencia para una pluralidad de moléculas de ácidos nucleicos fetales y maternos de una muestra de sangre materna; (c) utilizar la información de secuencia para obtener una dosis de cromosoma para un cromosoma aneuploide; y (d) comparar la dosis de cromosoma con al menos un valor umbral, e identificar así la presencia o la ausencia de aneuploidía fetal.
En otro caso, se divulga en el presente documento un método para determinar una aneuploidía cromosómica fetal en una muestra de sangre materna que comprende una mezcla de moléculas de ácidos nucleicos fetales y maternos, en el que el método comprende: (a) preparar una biblioteca de secuenciación a partir de la mezcla de moléculas de ácidos nucleicos fetales y maternos; en el que la preparación de dicha biblioteca comprende las etapas consecutivas de reparación de extremos, formación de cola dA y ligadura de adaptadores a dichos ácidos nucleicos; (b) secuenciar al menos una porción de las moléculas de ácido nucleico, obteniendo así información de secuencia para una pluralidad de moléculas de ácidos nucleicos fetales y maternos de una muestra de sangre materna; (c) utilizar la información de secuencia para obtener una dosis cromosómica para un cromosoma aneuploide; y (d) comparar la dosis cromosómica con al menos un valor umbral, e identificar así la presencia o la ausencia de aneuploidía fetal. El método comprende además utilizar la información de secuencia para identificar un número de etiquetas de secuencia mapeadas para al menos un cromosoma de normalización y para un cromosoma aneuploide; y utilizar el número de etiquetas de secuencia mapeadas identificadas para dicho cromosoma aneuploide y el número de etiquetas de secuencia mapeadas identificadas para el, al menos un, cromosoma de normalización para calcular una dosis de cromosoma para dicho cromosoma aneuploide como una relación del número de etiquetas de secuencia mapeadas identificadas para dicho cromosoma aneuploide y el número de etiquetas de secuencia mapeadas identificadas para el, al menos un, cromosoma de normalización. Opcionalmente, calcular la dosis de cromosoma comprende (i) calcular una relación de densidad de etiquetas de secuencia para el cromosoma aneuploide, relacionando el número de etiquetas de secuencia mapeadas identificadas para el cromosoma aneuploide en la etapa con la longitud de dicho cromosoma aneuploide; (ii) calcular una relación de densidad de etiquetas de secuencia para el, al menos un, cromosoma de normalización, relacionando el número de etiquetas de secuencia mapeadas identificadas para dicho, al menos un, cromosoma de normalización con la longitud del, al menos un, cromosoma de normalización; y (iii) utilizar las relaciones de densidad de etiquetas de secuencia calculadas en las etapas (i) y (ii) para calcular una dosis de cromosoma para el cromosoma aneuploide, calculándose la dosis de cromosoma como la relación entre la relación de densidad de etiquetas de secuencia para el cromosoma aneuploide y la relación de densidad de etiquetas de secuencia para el, al menos un, cromosoma de normalización.
En otro caso, se divulga en el presente documento un método para determinar una aneuploidía cromosómica fetal en una muestra de sangre materna que comprende una mezcla de moléculas de ácidos nucleicos fetales y maternos, en el que el método comprende: (a) preparar una biblioteca de secuenciación a partir de la mezcla de moléculas de ácidos nucleicos fetales y maternos; en el que la preparación de dicha biblioteca comprende las etapas consecutivas de reparación de extremos, formación de cola dA y ligadura de adaptadores a dichos ácidos nucleicos; (b) secuenciar al menos una porción de las moléculas de ácido nucleico, obteniendo así información de secuencia para una pluralidad de moléculas de ácidos nucleicos fetales y maternos de una muestra de sangre materna; (c) utilizar la información de secuencia para obtener una dosis cromosómica para un cromosoma aneuploide; y (d) comparar la dosis cromosómica con al menos un valor umbral, e identificar así la presencia o la ausencia de aneuploidía fetal. El método comprende además utilizar la información de secuencia para identificar un número de etiquetas de secuencia mapeadas para al menos un cromosoma de normalización y para un cromosoma aneuploide; y utilizar el número de etiquetas de secuencia mapeadas identificadas para dicho cromosoma aneuploide y el número de etiquetas de secuencia mapeadas identificadas para el, al menos un, cromosoma de normalización para calcular una dosis de cromosoma para dicho cromosoma aneuploide como una relación del número de etiquetas de secuencia mapeadas identificadas para dicho cromosoma aneuploide y el número de etiquetas de secuencia mapeadas identificadas para el, al menos un, cromosoma de normalización. El, al menos un, cromosoma de normalización es un cromosoma que posee la variabilidad más reducida y/o la diferenciabilidad más elevada. Opcionalmente, calcular la dosis de cromosoma comprende (i) calcular una relación de densidad de etiquetas de secuencia para el cromosoma aneuploide, relacionando el número de etiquetas de secuencia mapeadas identificadas para el cromosoma aneuploide en la etapa con la longitud de dicho cromosoma aneuploide; (ii) calcular una relación de densidad de etiquetas de secuencia para el, al menos un, cromosoma de normalización, relacionando el número de etiquetas de secuencia mapeadas
identificadas para dicho, al menos un, cromosoma de normalización con la longitud del, al menos un, cromosoma de normalización; y (iii) utilizar las relaciones de densidad de etiquetas de secuencia calculadas en las etapas (i) y (ii) para calcular una dosis de cromosoma para el cromosoma aneuploide, calculándose la dosis de cromosoma como la relación entre la relación de densidad de etiquetas de secuencia para el cromosoma aneuploide y la relación de densidad de etiquetas de secuencia para el, al menos un, cromosoma de normalización.
En otro caso, se divulga en el presente documento un método para determinar una aneuploidía cromosómica fetal en una muestra de sangre materna que comprende una mezcla de moléculas de ácidos nucleicos fetales y maternos, en el que el método comprende: (a) preparar una biblioteca de secuenciación a partir de la mezcla de moléculas de ácidos nucleicos fetales y maternos; en el que la preparación de dicha biblioteca comprende las etapas consecutivas de reparación de extremos, adición de colas de dA y ligación de adaptadores a dichos ácidos nucleicos; (b) secuenciar al menos una porción de las moléculas de ácido nucleico, obteniendo así información de secuencia para una pluralidad de moléculas de ácidos nucleicos fetales y maternos de una muestra de sangre materna; (c) utilizar la información de secuencia para obtener una dosis de cromosoma para un cromosoma aneuploide; y (d) comparar la dosis de cromosoma con al menos un valor umbral, e identificar así la presencia o la ausencia de aneuploidía fetal. El método comprende además utilizar la información de secuencia para identificar un número de etiquetas de secuencia mapeadas para al menos un cromosoma de normalización y para un cromosoma aneuploide; y utilizar el número de etiquetas de secuencia mapeadas identificadas para dicho cromosoma aneuploide y el número de etiquetas de secuencia mapeadas identificadas para el, al menos un, cromosoma de normalización para calcular una dosis de cromosoma para dicho cromosoma aneuploide como una relación del número de etiquetas de secuencia mapeadas identificadas para dicho cromosoma aneuploide y el número de etiquetas de secuencia mapeadas identificadas para el, al menos un, cromosoma de normalización. Opcionalmente, calcular la dosis de cromosoma comprende (i) calcular una relación de densidad de etiquetas de secuencia para el cromosoma aneuploide, relacionando el número de etiquetas de secuencia mapeadas identificadas para el cromosoma aneuploide en la etapa con la longitud de dicho cromosoma aneuploide; (ii) calcular una relación de densidad de etiquetas de secuencia para el, al menos un, cromosoma de normalización, relacionando el número de etiquetas de secuencia mapeadas identificadas para dicho, al menos un, cromosoma de normalización con la longitud del, al menos un, cromosoma de normalización; y (iii) utilizar las relaciones de densidad de etiquetas de secuencia calculadas en las etapas (i) y (ii) para calcular una dosis de cromosoma para el cromosoma aneuploide, calculándose la dosis de cromosoma como la relación entre la relación de densidad de etiquetas de secuencia para el cromosoma aneuploide y la relación de densidad de etiquetas de secuencia para el, al menos un, cromosoma de normalización. En los casos en los que el cromosoma aneuploide es el cromosoma 21, el, al menos un, cromosoma de normalización se selecciona de entre el cromosoma 9, el cromosoma 1, el cromosoma 2, el cromosoma 11, el cromosoma 12 y el cromosoma 14. Alternativamente, el, al menos un, cromosoma de normalización para el cromosoma 21 es un grupo de cromosomas seleccionados de entre el cromosoma 9, el cromosoma 1, el cromosoma 2, el cromosoma 11, el cromosoma 12 y el cromosoma 14. En los casos en los que el cromosoma aneuploide es el cromosoma 18, el, al menos un, cromosoma de normalización se selecciona de entre el cromosoma 8, el cromosoma 2, el cromosoma 3, el cromosoma 5, el cromosoma 6, el cromosoma 12 y el cromosoma 14. Alternativamente, el, al menos un, cromosoma de normalización para el cromosoma 18 es un grupo de cromosomas seleccionados de entre el cromosoma 8, el cromosoma 2, el cromosoma 3, el cromosoma 5, el cromosoma 6, el cromosoma 12 y el cromosoma 14. En los casos en los que el cromosoma aneuploide es el cromosoma 13, el, al menos un, cromosoma de normalización se selecciona de entre el cromosoma 2, el cromosoma 3, el cromosoma 4, el cromosoma 5, el cromosoma 6 y el cromosoma 8. Alternativamente, el, al menos un, cromosoma de normalización para el cromosoma 13 es un grupo de cromosomas seleccionados de entre el cromosoma 2, el cromosoma 3, el cromosoma 4, el cromosoma 5, el cromosoma 6 y el cromosoma 8. En los casos en los que el cromosoma aneuploide es el cromosoma X, el, al menos un, cromosoma de normalización se selecciona de entre el cromosoma 2, el cromosoma 3, el cromosoma 4, el cromosoma 5, el cromosoma 6 y el cromosoma 8. Alternativamente, el, al menos un, cromosoma de normalización para el cromosoma X es un grupo de cromosomas seleccionados de entre el cromosoma 2, el cromosoma 3, el cromosoma 4, el cromosoma 5, el cromosoma 6 y el cromosoma 8.
La muestra materna utilizada en los casos del método para determinar una aneuploidía cromosómica fetal es un fluido biológico seleccionado de entre sangre, plasma, suero, orina y saliva. Preferentemente, la muestra materna es una muestra de plasma. En algunos casos, las moléculas de ácido nucleico comprendidas en la muestra materna son moléculas de ADN libre de células. En algunos casos, las etapas consecutivas comprendidas en la preparación de la biblioteca de secuenciación se realizan en menos de una hora. Preferentemente, las etapas consecutivas se realizan en ausencia de polietilenglicol. De forma más preferida, las etapas consecutivas excluyen una purificación. La secuenciación de la biblioteca de secuenciación se realiza mediante métodos de secuenciación de próxima generación (NGS). En algunos casos, la secuenciación comprende una amplificación. En otros casos, la secuenciación es una secuenciación masivamente paralela que utiliza secuenciación por síntesis con terminadores de colorantes reversibles. En otros casos, la secuenciación es una secuenciación masivamente paralela que utiliza secuenciación por ligación. En otros casos más, la secuenciación es secuenciación de una sola molécula.
En otro caso, se divulga en el presente documento un método para determinar la presencia o la ausencia de una aneuploidía en una muestra de sangre materna que comprende una mezcla de moléculas de ácidos nucleicos fetales y maternos, comprendiendo el método: (a) preparar una biblioteca de secuenciación a partir de la mezcla; en el que la preparación de dicha biblioteca comprende las etapas consecutivas de reparación de extremos, adición de colas de dA y ligación de adaptadores a dichos ácidos nucleicos fetales y maternos; (b) secuenciar al menos una porción de la
biblioteca de secuenciación, en el que la secuenciación comprende proporcionar una pluralidad de etiquetas de secuencia; y (c) basándose en la secuenciación, determinar la presencia o la ausencia de aneuploidía en la muestra.
En otro caso, se divulga en el presente documento un método para determinar la presencia o la ausencia de una aneuploidía cromosómica o parcial en una muestra de sangre materna que comprende una mezcla de de ácidos nucleicos fetales y maternos, en el que el método comprende: (a) preparar una biblioteca de secuenciación a partir de la mezcla; en el que la preparación de dicha biblioteca comprende las etapas consecutivas de reparación de extremos, adición de colas de dA y ligación de adaptadores a dichos ácidos nucleicos fetales y maternos; (b) secuenciar al menos una porción de la biblioteca de secuenciación, en el que la secuenciación comprende proporcionar una pluralidad de etiquetas de secuencia; y (c) basándose en la secuenciación, determinar la presencia o la ausencia de la aneuploidía cromosómica o parcial en la muestra.
En otro caso, se divulga en el presente documento un método para determinar la presencia o la ausencia de una aneuploidía cromosómica en una muestra de sangre materna que comprende una mezcla de de ácidos nucleicos fetales y maternos, en el que el método comprende: (a) preparar una biblioteca de secuenciación a partir de la mezcla; en el que la preparación de dicha biblioteca comprende las etapas consecutivas de reparación de extremos, adición de colas de dA y ligación de adaptadores a dichos ácidos nucleicos fetales y maternos; (b) secuenciar al menos una porción de la biblioteca de secuenciación, en el que la secuenciación comprende proporcionar una pluralidad de etiquetas de secuencia; y (c) basándose en la secuenciación, determinar la presencia o la ausencia de la aneuploidía cromosómica en la muestra. Las aneuploidías cromosómicas que pueden determinarse según el método incluyen trisomía 8, trisomía 13, trisomía 15, trisomía 16, trisomía 18, trisomía 21, trisomía 22, monosomía X y XXX.
En otro caso, se divulga en el presente documento un método para determinar la presencia o la ausencia de una aneuploidía cromosómica o parcial en una muestra de sangre materna que comprende una mezcla de de ácidos nucleicos fetales y maternos, en el que el método comprende: (a) preparar una biblioteca de secuenciación a partir de la mezcla; en el que la preparación de dicha biblioteca comprende las etapas consecutivas de reparación de extremos, adición de colas de dA y ligación de adaptadores a dichos ácidos nucleicos fetales y maternos; (b) secuenciar al menos una porción de la biblioteca de secuenciación, en el que la secuenciación comprende proporcionar una pluralidad de etiquetas de secuencia; y (c) basándose en la secuenciación, determinar la presencia o la ausencia de la aneuploidía cromosómica o parcial en la muestra que comprende calcular una dosis de cromosoma basada en el número de dichas etiquetas de secuencia para un cromosoma de interés y para un cromosoma de normalización, y comparar dicha dosis con un valor umbral.
En otro caso, se divulga en el presente documento un método para determinar la presencia o la ausencia de una aneuploidía cromosómica en una muestra de sangre materna que comprende una mezcla de de ácidos nucleicos fetales y maternos, en el que el método comprende: (a) preparar una biblioteca de secuenciación a partir de la mezcla; en el que la preparación de dicha biblioteca comprende las etapas consecutivas de reparación de extremos, adición de colas de dA y ligación de adaptadores a dichos ácidos nucleicos fetales y maternos; (b) secuenciar al menos una porción de la biblioteca de secuenciación, en el que la secuenciación comprende proporcionar una pluralidad de etiquetas de secuencia; y (c) basándose en la secuenciación, determinar la presencia o la ausencia de la aneuploidía cromosómica en la muestra que comprende calcular una dosis de cromosoma basada en el número de dichas etiquetas de secuencia para un cromosoma de interés y para un cromosoma de normalización, y comparar dicha dosis con un valor umbral. Las aneuploidías cromosómicas que pueden determinarse según el método incluyen trisomía 8, trisomía 13, trisomía 15, trisomía 16, trisomía 18, trisomía 21, trisomía 22, monosomía X y XXX
La muestra materna utilizada en los casos del método para determinar la presencia o la ausencia de una aneuploidía es un fluido biológico seleccionado de entre sangre, plasma, suero, orina y saliva. Preferentemente, la muestra materna es una muestra de plasma. En algunos casos, las moléculas de ácidos nucleicos comprendidas en la muestra materna son moléculas de ADN desprovistas de células. En algunos casos, las etapas consecutivas comprendidas en la preparación de la biblioteca de secuenciación se realizan en menos de una hora. Preferentemente, las etapas consecutivas se realizan en ausencia de polietilenglicol. De forma más preferida, las etapas consecutivas excluyen una purificación. La secuenciación de la biblioteca de secuenciación se realiza mediante métodos de secuenciación de próxima generación (NGS). En algunos casos, la secuenciación comprende una amplificación. En otros casos, la secuenciación es una secuenciación masivamente paralela que utiliza secuenciación por síntesis con terminadores de colorantes reversibles. En otros casos, la secuenciación es una secuenciación masivamente paralela que utiliza secuenciación por ligación. En otros casos más, la secuenciación es secuenciación de una sola molécula.
En otro caso, se divulga en el presente documento un método para determinar la fracción de moléculas de ácido nucleico fetal en una muestra de sangre materna que comprende una mezcla de moléculas de ácidos nucleicos fetales y maternos, en el que el método comprende: (a) amplificar una pluralidad de ácidos nucleicos diana polimórficos en una porción de la mezcla; (b) preparar una biblioteca de secuenciación del producto amplificado obtenido en la etapa (a) en el que la preparación de la biblioteca comprende las etapas consecutivas de reparación de extremos, adición de colas de dA y ligación de adaptadores a dichas moléculas de ácidos nucleicos fetales y maternos; (c) secuenciar al menos una porción de la biblioteca de secuenciación; y (d) basándose en dicha secuenciación, determinar la fracción de las moléculas de ácido nucleico fetal. Opcionalmente, el método puede comprender también la determinación de la presencia o la ausencia de aneuploidía en una muestra materna.
En otro caso, se divulga en el presente documento un método para determinar la fracción de moléculas de ácido nucleico fetal en una muestra de sangre materna que comprende una mezcla de moléculas de ácidos nucleicos fetales y maternos, en el que el método comprende: (a) amplificar una pluralidad de ácidos nucleicos diana polimórficos en una porción de la mezcla; (b) preparar una biblioteca de secuenciación del producto amplificado obtenido en la etapa (a) en el que la preparación de la biblioteca comprende las etapas consecutivas de reparación de extremos, formación de cola dA y ligación de adaptadores a dichas moléculas de ácidos nucleicos fetales y maternos; (c) secuenciar al menos una porción de la biblioteca de secuenciación; y (d) basándose en dicha secuenciación, determinar la fracción de las moléculas de ácido nucleico fetal. Determinar la fracción comprende determinar el número de etiquetas de secuencia maternas y fetales mapeadas a un genoma diana de referencia que comprende al menos un ácido nucleico polimórfico. Opcionalmente, el método puede comprender también la determinación de la presencia o la ausencia de aneuploidía en una muestra materna.
En otro caso, se divulga en el presente documento un método para determinar la fracción de moléculas de ácido nucleico fetal en una muestra de sangre materna que comprende una mezcla de moléculas de ácidos nucleicos fetales y maternos, en el que el método comprende: (a) amplificar una pluralidad de ácidos nucleicos diana polimórficos en una porción de la mezcla, en la que cada uno de dicha pluralidad de ácidos nucleicos diana polimórficos comprende al menos un polimorfismo de un solo nucleótido (SNP); (b) preparar una biblioteca de secuenciación del producto amplificado obtenido en la etapa (a) en el que la preparación de la biblioteca comprende las etapas consecutivas de reparación de extremos, adición de colas de dA y ligación de adaptadores a dichas moléculas de ácidos nucleicos fetales y maternos; (c) secuenciar al menos una porción de la biblioteca de secuenciación; y (d) basándose en dicha secuenciación, determinar la fracción de las moléculas de ácido nucleico fetal. Opcionalmente, el método puede comprender también la determinación de la presencia o la ausencia de aneuploidía en una muestra materna.
En otro caso, se divulga en el presente documento un método para determinar la fracción de moléculas de ácido nucleico fetal en una muestra de sangre materna que comprende una mezcla de moléculas de ácidos nucleicos fetales y maternos, en el que el método comprende: (a) amplificar una pluralidad de ácidos nucleicos diana polimórficos en una porción de la mezcla, en el que cada uno de dicha pluralidad de ácidos nucleicos diana polimórficos comprende al menos un polimorfismo de un solo nucleótido (SNP); (b) preparar una biblioteca de secuenciación del producto amplificado obtenido en la etapa (a) en el que la preparación de la biblioteca comprende las etapas consecutivas de reparación de extremos, formación de cola dA y ligación de adaptadores a dichas moléculas de ácidos nucleicos fetales y maternos; (c) secuenciar al menos una porción de la biblioteca de secuenciación; y (d) basándose en dicha secuenciación, determinar la fracción de las moléculas de ácido nucleico fetal. Determinar la fracción comprende determinar el número de etiquetas de secuencia maternas y fetales mapeadas a un genoma diana de referencia que comprende al menos un ácido nucleico polimórfico. Opcionalmente, el método puede comprender también la determinación de la presencia o la ausencia de aneuploidía en una muestra materna.
En otro caso, se divulga en el presente documento un método para determinar la fracción de moléculas de ácido nucleico fetal en una muestra de sangre materna que comprende una mezcla de moléculas de ácidos nucleicos fetales y maternos, en el que el método comprende: (a) amplificar una pluralidad de ácidos nucleicos diana polimórficos en una porción de la mezcla, en la que cada uno de dicha pluralidad de ácidos nucleicos diana polimórficos comprende al menos una repetición en tándem corta (STR); (b) preparar una biblioteca de secuenciación del producto amplificado obtenido en la etapa (a) en el que la preparación de la biblioteca comprende las etapas consecutivas de reparación de extremos, adición de colas de dA y ligación de adaptadores a dichas moléculas de ácidos nucleicos fetales y maternos; (c) secuenciar al menos una porción de la biblioteca de secuenciación; y (d) basándose en dicha secuenciación, determinar la fracción de las moléculas de ácido nucleico fetal. Opcionalmente, el método puede comprender también la determinación de la presencia o la ausencia de aneuploidía en una muestra materna.
En otro caso, se divulga en el presente documento un método para determinar la fracción de moléculas de ácido nucleico fetal en una muestra de sangre materna que comprende una mezcla de moléculas de ácidos nucleicos fetales y maternos, en el que el método comprende: (a) amplificar una pluralidad de ácidos nucleicos diana polimórficos en una porción de la mezcla, en el que cada uno de dicha pluralidad de ácidos nucleicos diana polimórficos comprende al menos una repetición en tándem corta (STR); (b) preparar una biblioteca de secuenciación del producto amplificado obtenido en la etapa (a) en el que la preparación de la biblioteca comprende las etapas consecutivas de reparación de extremos, formación de cola dA y ligación de adaptadores a dichas moléculas de ácidos nucleicos fetales y maternos; (c) secuenciar al menos una porción de la biblioteca de secuenciación; y (d) basándose en dicha secuenciación, determinar la fracción de las moléculas de ácido nucleico fetal. Determinar la fracción comprende determinar el número de etiquetas de secuencia maternas y fetales mapeadas a un genoma diana de referencia que comprende al menos un ácido nucleico polimórfico. Opcionalmente, el método puede comprender también la determinación de la presencia o la ausencia de aneuploidía en una muestra materna.
En otro caso, se divulga en el presente documento un método para determinar la fracción de moléculas de ácido nucleico fetal en una muestra de sangre materna que comprende una mezcla de moléculas de ácidos nucleicos fetales y maternos, en el que el método comprende: (a) amplificar una pluralidad de ácidos nucleicos diana polimórficos en una porción de la mezcla, en la que cada uno de la pluralidad de ácidos nucleicos diana polimórficos comprende al menos un polimorfismo de un nucleótido (SNP); (b) preparar una biblioteca de secuenciación del producto amplificado
obtenido en la etapa (a) en el que la preparación de la biblioteca comprende las etapas consecutivas de reparación de extremos, adición de colas de dA y ligación de adaptadores a dichas moléculas de ácidos nucleicos fetales y maternos; (c) secuenciar al menos una porción de la biblioteca de secuenciación; y (d) basándose en dicha secuenciación, determinar la fracción de las moléculas de ácido nucleico fetal. En los métodos en los que cada uno de la pluralidad de ácidos nucleicos diana polimórficos comprende al menos un polimorfismo de un solo nucleótido (SNP), el SNP se selecciona de entre rs560681, rs1109037, rs9866013, rs13182883, rs13218440, rs7041158, rs740598, rs10773760, rs4530059, rs7205345, rs8078417, rs576261, rs2567608, rs430046, rs9951171, rs338882, rs10776839, rs9905977, rs1277284, rs258684, rs1347696, rs508485, rs9788670, rs8137254, rs3143, rs2182957, rs3739005 y rs530022. En los métodos en los que cada uno de la pluralidad de ácidos nucleicos diana polimórficos comprende al menos un polimorfismo de un nucleótido (SNP), el, al menos un, SNP es un SNP en tándem seleccionado de los pares de SNP en tándem rs7277033-rs2110153; rs2822654-rs1882882; rs368657-rs376635; rs2822731 -rs2822732; rs1475881-rs7275487; rs1735976-rs2827016; rs447340-rs2824097; rs418989-rs13047336; rs987980-rs987981; rs4143392-rs4143391; rs1691324-rs13050434; rs11909758-rs9980111; rs2826842-rs232414; rs1980969-rs1980970; rs9978999-rs9979175; rs1034346-rs12481852; rs7509629-rs2828358; rs4817013-rs7277036; rs9981121 -rs2829696; rs455921-rs2898102; rs2898102-rs458848; rs961301-rs2830208; rs2174536-rs458076; rs11088023-rs11088024; rs1011734-rs1011733; rs2831244-rs9789838; rs8132769-rs2831440; rs8134080-rs2831524; rs4817219-rs4817220; rs2250911 -rs2250997; rs2831899-rs2831900; rs2831902-rs2831903; rs11088086-rs2251447; rs2832040-rs11088088; rs2832141-rs2246777; rs2832959-rs9980934; rs2833734-rs2833735; rs933121-rs933122; rs2834140-rs12626953; rs2834485-rs3453; rs9974986-rs2834703; rs2776266-rs2835001; rs1984014-rs1984015; rs7281674-rs2835316; rs13047304-rs13047322; rs2835545-rs4816551; rs2835735-rs2835736; rs13047608-rs2835826; rs2836550-rs2212596; rs2836660-rs2836661; rs465612-rs8131220; rs9980072-rs8130031; rs418359-rs2836926; rs7278447-rs7278858; rs385787-rs367001; rs367001-rs386095; rs2837296-rs2837297 y rs2837381-rs4816672. Opcionalmente, el método puede comprender también la determinación de la presencia o la ausencia de aneuploidía en una muestra materna.
En otro caso, se divulga en el presente documento un método para determinar la fracción de moléculas de ácido nucleico fetal en una muestra de sangre materna que comprende una mezcla de moléculas de ácidos nucleicos fetales y maternos, en el que el método comprende: (a) amplificar una pluralidad de ácidos nucleicos diana polimórficos en una porción de la mezcla, en el que cada uno de dicha pluralidad de ácidos nucleicos diana polimórficos comprende al menos una repetición en tándem corta (STR); (b) preparar una biblioteca de secuenciación del producto amplificado obtenido en la etapa (a) en el que la preparación de la biblioteca comprende las etapas consecutivas de reparación de extremos, formación de cola dA y ligadura de adaptadores a dichas moléculas de ácidos nucleicos fetales y maternos; (c) secuenciar al menos una porción de la biblioteca de secuenciación; y (d) basándose en dicha secuenciación, determinar la fracción de las moléculas de ácido nucleico fetal. El, al menos un, STR se selecciona de entre CSF1PO, FGA, TH01, vWA, D3S1358, D5S818, D7S820, D8S1179, D13S317, D16S539, D18S51, D21S11, D2S1338, PentaD, PentaE, D22S1045, D20S1082, D20S482, D18S853, D17S1301, D17S974, D14S1434, D12ATA63, D11S4463, D10S1435, D10S1248, D9S2157, D9S1122, D8S1115, D6S1017, D6S474, D5S2500, D4S2408, D4S2364, D3S4529, D3S3053, D2S1776, D2S441, D1S1677, D1S1627 y D1GATA113. Opcionalmente, el método puede comprender también la determinación de la presencia o la ausencia de aneuploidía en una muestra materna.
En otro caso, se divulga en el presente documento un método para determinar la fracción de moléculas de ácido nucleico fetal en una muestra de sangre materna que comprende una mezcla de moléculas de ácidos nucleicos fetales y maternos, en el que el método comprende: (a) amplificar una pluralidad de ácidos nucleicos diana polimórficos en una porción de la mezcla, en el que cada uno de la pluralidad de ácidos nucleicos diana polimórficos comprende al menos un polimorfismo de un nucleótido (SNP); (b) preparar una biblioteca de secuenciación del producto amplificado obtenido en la etapa (a) en el que la preparación de la biblioteca comprende las etapas consecutivas de reparación de extremos, formación de cola dA y ligación de adaptadores a dichas moléculas de ácidos nucleicos fetales y maternos; (c) secuenciar al menos una porción de la biblioteca de secuenciación; y (d) basándose en dicha secuenciación, determinar la fracción de las moléculas de ácido nucleico fetal. Determinar la fracción comprende determinar el número de etiquetas de secuencia maternas y fetales mapeadas a un genoma diana de referencia que comprende al menos un ácido nucleico polimórfico. En los métodos en los que cada uno de la pluralidad de ácidos nucleicos diana polimórficos comprende al menos un polimorfismo de un solo nucleótido (SNP), el SNP se selecciona de entre rs560681, rs1109037, rs9866013, rs13182883, rs13218440, rs7041158, rs740598, rs10773760, rs4530059, rs7205345, rs8078417, rs576261, rs2567608, rs430046, rs9951171, rs338882, rs10776839, rs9905977, rs1277284, rs258684, rs1347696, rs508485, rs9788670, rs8137254, rs3143, rs2182957, rs3739005 y rs530022. En los métodos en los que cada uno de la pluralidad de ácidos nucleicos diana polimórficos comprende al menos un polimorfismo de un solo nucleótido (SNP), el, al menos un, SNP es un SNP en tándem seleccionado de los pares de SNP en tándem rs7277033-rs2110153; rs2822654-rs1882882; rs368657-rs376635; rs2822731-rs2822732; rs1475881-rs7275487; rs1735976-rs2827016; rs447340-rs2824097; rs418989-rs13047336; rs987980-rs987981; rs4143392-rs4143391; rs1691324-rs13050434; rs11909758-rs9980111; rs2826842-rs232414; rs1980969-rs1980970; rs9978999-rs9979175; rs1034346-rs12481852; rs7509629-rs2828358; rs4817013-rs7277036; rs9981121-rs2829696; rs455921-rs2898102; rs2898102-rs458848; rs961301-rs2830208; rs2174536-rs458076; rs11088023-rs11088024; rs1011734-rs1011733; rs2831244-rs9789838; rs8132769-rs2831440; rs8134080-rs2831524; rs4817219-rs4817220; rs2250911-rs2250997; rs2831899-rs2831900; rs2831902-rs2831903; rs11088086-rs2251447; rs2832040-rs11088088; rs2832141-rs2246777; rs2832959 -rs9980934; rs2833734-rs2833735; rs933121-rs933122; rs2834140-rs12626953; rs2834485-rs3453; rs9974986-rs2834703; rs2776266-rs2835001; rs1984014-rs1984015; rs7281674-rs2835316; rs13047304rs13047322; rs2835545-rs4816551; rs2835735-rs2835736; rs13047608-rs2835826; rs2836550-rs2212596; rs2836660-rs2836661; rs465612-rs8131220; rs9980072-rs8130031; rs418359-rs2836926; rs7278447-rs7278858; rs385787-rs367001; rs367001-rs386095; rs2837296-rs2837297 y rs2837381-rs4816672. Opcionalmente, el método puede comprender también la determinación de la presencia o la ausencia de aneuploidía en una muestra materna.
En otro caso, se divulga en el presente documento un método para determinar la fracción de moléculas de ácido nucleico fetal en una muestra de sangre materna que comprende una mezcla de moléculas de ácidos nucleicos fetales y maternos, en el que el método comprende: (a) amplificar una pluralidad de ácidos nucleicos diana polimórficos en una porción de la mezcla, en el que cada uno de dicha pluralidad de ácidos nucleicos diana polimórficos comprende al menos una repetición en tándem corta (STR); (b) preparar una biblioteca de secuenciación del producto amplificado obtenido en la etapa (a) en el que la preparación de la biblioteca comprende las etapas consecutivas de reparación de extremos, formación de cola dA y ligación de adaptadores a dichas moléculas de ácidos nucleicos fetales y maternos; (c) secuenciar al menos una porción de la biblioteca de secuenciación; y (d) basándose en dicha secuenciación, determinar la fracción de las moléculas de ácido nucleico fetal. Determinar la fracción comprende determinar el número de etiquetas de secuencia maternas y fetales mapeadas a un genoma diana de referencia que comprende al menos un ácido nucleico polimórfico. El, al menos un, STR se selecciona de entre CSF1PO, FGA, TH01, vWA, D3S1358, D5S818, D7S820, D8S1179, D13S317, D16S539, D18S51, D21S11, D2S1338, PentaD, PentaE, D22S1045, D20S1082, D20S482, D18S853, D17S1301, D17S974, D14S1434, D12ATA63, D11S4463, D10S1435, D10S1248, D9S2157, D9S1122, D8S1115, D6S1017, D6S474, D5S2500, D4S2408, D4S2364, D3S4529, D3S3053, D2S1776, D2S441, D1S1677, D1S1627 y D1GATA113. Opcionalmente, el método puede comprender también la determinación de la presencia o la ausencia de aneuploidía en una muestra materna.
La muestra materna utilizada en el método para determinar la fracción de moléculas de ácido nucleico fetal es un fluido biológico seleccionado de entre sangre, plasma, suero, orina y saliva. Preferentemente, la muestra materna es una muestra de plasma. En algunos casos, las moléculas de ácidos nucleicos comprendidas en la muestra materna son moléculas de ADN desprovistas de células. En algunos casos, las etapas consecutivas comprendidas en la preparación de la biblioteca de secuenciación se realizan en menos de una hora. Preferentemente, las etapas consecutivas se realizan en ausencia de polietilenglicol. De forma más preferida, las etapas consecutivas excluyen una purificación. La secuenciación de la biblioteca de secuenciación se realiza mediante métodos de secuenciación de próxima generación (NGS). En algunos casos, la secuenciación comprende una amplificación. En otros casos, la secuenciación es una secuenciación masivamente paralela que utiliza secuenciación por síntesis con terminadores de colorantes reversibles. En otros casos, la secuenciación es una secuenciación masivamente paralela que utiliza secuenciación por ligación. En otros casos más, la secuenciación es secuenciación de una sola molécula.
En otro caso, se divulga en el presente documento un medio legible por ordenador que tiene almacenadas instrucciones legibles por ordenador para llevar a cabo el método para determinar la presencia o la ausencia de una aneuploidía, por ejemplo, una aneuploidía cromosómica fetal, en una muestra de sangre materna que comprende una mezcla de moléculas de ácidos nucleicos fetales y maternos.
En un caso, el medio legible por ordenador tiene almacenadas instrucciones legibles por ordenador para llevar a cabo el método que comprende las etapas siguientes: (a) usar información de secuencia obtenida a partir de una pluralidad de moléculas de ácidos nucleicos fetales y maternos en una muestra de plasma materno para identificar un número de etiquetas de secuencia mapeadas para un cromosoma de interés; (b) usar información de secuencia obtenida a partir de una pluralidad de moléculas de ácidos nucleicos fetales y maternos en una muestra de plasma materno para identificar un número de etiquetas de secuencia mapeadas para al menos un cromosoma de normalización; (c) usar el número de etiquetas de secuencia mapeadas identificadas para un cromosoma de interés en la etapa (a) y el número de etiquetas de secuencia mapeadas identificadas para el, al menos un, cromosoma de normalización en la etapa (b) para calcular una dosis de cromosoma para dicho cromosoma de interés; y (d) comparar dicha dosis de cromosoma con al menos un valor umbral, e identificar así la presencia o la ausencia de aneuploidía fetal. Los cromosomas de interés pueden ser cualquiera de los cromosomas 21, 13, 18 y X.
En otro caso, se divulga en el presente documento un sistema de procesamiento informático que está adaptado o configurado para realizar el método para determinar la presencia o la ausencia de una aneuploidía, por ejemplo, una aneuploidía cromosómica fetal, en una muestra de sangre materna que comprende una mezcla de moléculas de ácidos nucleicos fetales y maternos.
En un caso, el sistema de procesamiento informático está adaptado o configurado para realizar las etapas siguientes: (a) usar información de secuencia obtenida a partir de una pluralidad de moléculas de ácidos nucleicos fetales y maternos en una muestra de plasma materno para identificar un número de etiquetas de secuencia mapeadas para un cromosoma de interés; (b) usar información de secuencia obtenida a partir de una pluralidad de moléculas de ácidos nucleicos fetales y maternos en una muestra de plasma materno para identificar un número de etiquetas de secuencia mapeadas para al menos un cromosoma de normalización; (c) usar el número de etiquetas de secuencia mapeadas identificadas para un cromosoma de interés en la etapa (a) y el número de etiquetas de secuencia mapeadas identificadas para el, al menos un, cromosoma de normalización en la etapa (b) para calcular una dosis de cromosoma para un cromosoma de interés; y (d) comparar dicha dosis de cromosoma con al menos un valor umbral,
e identificar así la presencia o la ausencia de aneuploidía fetal. Los cromosomas de interés pueden ser cualquiera de los cromosomas 21, 13, 18 y X.
En otro caso, se divulga en el presente documento un aparato adaptado o configurado para determinar una aneuploidía fetal en una muestra de plasma materno que comprende una mezcla de moléculas de ácidos nucleicos fetales y maternos, y en el que dicho aparato comprende: (a) un dispositivo de secuenciación adaptado o configurado para secuenciar al menos un porción de las moléculas de ácido nucleico en una muestra de plasma materno que comprende moléculas de ácidos nucleicos fetales y maternos, generando así información de secuencia; y (b) un sistema de procesamiento informático configurado para realizar las etapas siguientes: (i) usar información de secuencia generada por el dispositivo de secuenciación para identificar un número de etiquetas de secuencia mapeadas para un cromosoma de interés; (ii) usar información de secuencia generada por el dispositivo de secuenciación para identificar un número de etiquetas de secuencia mapeadas para al menos un cromosoma de normalización; (iii) usar el número de etiquetas de secuencia mapeadas identificadas para un cromosoma de interés en la etapa (i) y el número de etiquetas de secuencia mapeadas identificadas para el, al menos un, cromosoma de normalización en la etapa (ii) para calcular una dosis de cromosoma para un cromosoma de interés; y (iv) comparar dicha dosis de cromosoma con al menos un valor umbral, e identificar así la presencia o la ausencia de aneuploidía fetal. Los cromosomas de interés pueden ser cualquiera de los cromosomas 21, 13, 18 y X.
Aunque los ejemplos del presente documento se refieren a seres humanos y el lenguaje se refiere principalmente a cuestiones humanas, el concepto de la presente invención puede aplicarse a genomas de cualquier planta o animal.
3. Breve descripción de los dibujos
La figura 1 es un diagrama de flujo de un método 100 para determinar la presencia o la ausencia de una aneuploidía cromosómica en una muestra de ensayo que comprende una mezcla de ácidos nucleicos. La figura 2 es un diagrama de flujo de un método 200 para determinar simultáneamente la presencia o la ausencia de aneuploidía y la fracción fetal en una muestra de ensayo materna que comprende una mezcla de ácidos nucleicos fetales y maternos.
La figura 3 es un diagrama de flujo de un método 300 para determinar simultáneamente la presencia o la ausencia de aneuploidía fetal y la fracción fetal en una muestra de ensayo de plasma materno enriquecida en ácidos nucleicos polimórficos.
La figura 4 es un diagrama de flujo de un método 400 para determinar simultáneamente la presencia o la ausencia de aneuploidía fetal y la fracción fetal en una muestra de ensayo de ADNcf purificado materno que se ha enriquecido con ácidos nucleicos polimórficos.
La figura 5 es un diagrama de flujo de un método 500 para determinar simultáneamente la presencia o la ausencia de aneuploidía fetal y la fracción fetal en una biblioteca de secuenciación construida a partir de ácidos nucleicos fetales y maternos derivados de una muestra de ensayo materna enriquecida con ácidos nucleicos polimórficos.
La figura 6 es un diagrama de flujo de un método 600 para determinar la fracción fetal mediante secuenciación de una biblioteca de ácidos nucleicos diana polimórficos amplificados a partir de una porción de una mezcla purificada de ácidos nucleicos fetales y maternos.
L figura 7 muestra electroferogramas de una biblioteca de secuenciación de ADNcf preparada según el protocolo abreviado descrito en el ejemplo, 2a (A), y el protocolo descrito en el ejemplo, 2b (B).
La figura 8 muestra en el eje Y la relación del número de etiquetas de secuencia mapeadas a cada cromosoma (eje X) y el número total de etiquetas mapeadas a todos los cromosomas (1-22, X e Y) para la muestra M11281 cuando se preparó la biblioteca utilizando el protocolo abreviado del ejemplo, 2a ( ♦ ) y cuando se preparó según el protocolo de longitud completa del ejemplo, 2b (■). También se muestran las relaciones de etiquetas para la muestra M11297 obtenidas a partir de la secuenciación de una biblioteca preparada según el protocolo abreviado del ejemplo, 2a (▲) y según el protocolo de longitud completa del ejemplo, 2b (X).
La figura 9 muestra la distribución de la dosis de cromosoma para el cromosoma 21 determinada a partir de la secuenciación de ADNcf extraído de un conjunto de 48 muestras de sangre obtenidas de sujetos humanos, cada uno embarazado de un feto masculino o femenino. Las dosis de cromosoma 21 para muestras de ensayo calificadas, es decir, normales para el cromosoma 21 (O), y trisomía 21 (A) se muestran para los cromosomas 1-12 y X (A), y para los cromosomas 1-22 y X (B).
La figura 10 muestra la distribución de la dosis de cromosoma para el cromosoma 18 determinada a partir de la secuenciación de ADNcf extraído de un conjunto de 48 muestras de sangre obtenidas de sujetos humanos, cada uno embarazado de un feto masculino o femenino. Las dosis de cromosoma 18 para muestras de ensayo calificadas, es decir, normales para el cromosoma 18 (O), y trisomía 18 (A) se muestran para los cromosomas 1-12 y X (A), y para los cromosomas 1-22 y X (B).
La figura 11 muestra la distribución de la dosis de cromosoma para el cromosoma 13 determinada a partir de la secuenciación de ADNcf extraído de un conjunto de 48 muestras de sangre obtenidas de sujetos humanos, cada uno embarazado de un feto masculino o femenino. Las dosis de cromosoma 13 para muestras de ensayo calificadas, es decir, normales para el cromosoma 13 (O), y trisomía 13 (A) se muestran para los cromosomas 1-12 y X (A), y para los cromosomas 13-21 y X (B).
La figura 12 muestra la distribución de la dosis de cromosoma para el cromosoma X determinada a partir de la secuenciación de ADNcf extraído de un conjunto de 48 muestras de sangre de ensayo obtenidas de sujetos humanos, cada uno embarazado de un feto masculino o femenino. Las dosis de cromosoma X para muestras de sujetos masculinos (46,XY; (O)), femeninos (46,XX; (A)); monosomía X (45,X; (+)) y cariotipos complejos (Cplx (X)) se muestran para cromosomas 1-12 y X (A) y para cromosomas 1-22 y X (B).
La figura 13 muestra la distribución de la dosis de cromosoma para el cromosoma Y determinada a partir de la secuenciación de ADNcf extraído de un conjunto de 48 muestras de sangre de ensayo obtenidas de sujetos humanos, cada uno embarazado de un feto masculino o femenino. Las dosis de cromosoma Y para muestras de sujetos masculinos (46,XY; (A)), femeninos (46,XX; (O)); monosomía X (45,X; (+)) y cariotipos complejos (Cplx (X)) se muestran para cromosomas 1 -12 (A) y para cromosomas 1 -22 (B).
La figura 14 muestra el coeficiente de variación (CV) para cromosomas 21 (■), 18 (•) y 13 (▲) que se determinó a partir de las dosis mostradas en las figuras 9, 10 y 11, respectivamente.
La figura 15 muestra el coeficiente de variación (CV) para cromosomas X (■), e Y (•) que se determinó a partir de las dosis mostradas en las figuras 12 y 13, respectivamente.
La figura 16 muestra las dosis de secuencia (eje Y) para un segmento del cromosoma 11 (81000082 103000103 pb) determinadas a partir de la secuenciación de ADNcf extraído de un conjunto de 7 muestras calificadas (O) obtenidas y 1 muestra de ensayo ( ♦ ) de sujetos humanos embarazados. Se identificó una muestra de un sujeto que portaba un feto con una aneuploidía parcial del cromosoma 11 (♦ ).
La figura 17 muestra un gráfico de la relación del número de etiquetas de secuencia mapeadas a cada cromosoma y el número total de etiquetas mapeadas a todos los cromosomas (1 -22, X e Y) obtenidas a partir de la secuenciación de una biblioteca de ADNcf no enriquecida (•) y una biblioteca de ADNcf enriquecida con el 5 % (■) o el 10 % (♦ ) de una biblioteca de SNP multiplex amplificada.
La figura 18 muestra un diagrama de barras que representa la identificación de secuencias polimórficas (SNP) fetales y maternas utilizadas para determinar la fracción fetal en una muestra de ensayo. Se muestra el número total de lecturas de secuencias (eje Y) mapeadas a las secuencias SNP identificadas por números rs (eje X) y el nivel relativo de ácidos nucleicos fetales (*).
La figura 19 representa un caso de uso de la fracción fetal para determinar los umbrales de corte para la detección de aneuploidías.
La figura 20 ilustra la distribución de dosis de cromosomas normalizados para el cromosoma 21 (A), el cromosoma 18 (B), el cromosoma 13 (C), el cromosoma X (D) y el cromosoma Y (E) con respecto a la desviación estándar de la media (eje Y) para la dosis de cromosoma correspondiente en muestras no afectadas.
4. Descripción detallada de la invención
La invención proporciona un método para la secuenciación de ácidos nucleicos que comprende: (a) proporcionar una muestra de ensayo que comprende moléculas de ácido nucleico, en el que dichas moléculas de ácido nucleico son moléculas de ADN genómico humano; (b) realizar la reparación de extremos de las moléculas de ácido nucleico para generar ácidos nucleicos de extremos romos; (c) realizar la adición de colas de dA a los ácidos nucleicos de extremos romos para generar ácidos nucleicos con cola de dA; (d) ligar adaptadores a los ácidos nucleicos con cola de dA para generar una biblioteca de polinucleótidos ligados a adaptadores; (e) opcionalmente amplificar la biblioteca usando cebadores de amplificación, comprendiendo dichos cebadores de amplificación una porción específica de adaptador; y (f) someter la biblioteca a una secuenciación masivamente paralela; en el que las etapas (b), (c) y (d) son etapas consecutivas.
El método de la invención es aplicable a métodos para determinar la presencia o la ausencia de una aneuploidía, por ejemplo, una aneuploidía cromosómica o parcial, y/o la fracción fetal en muestras maternas que comprenden ácidos nucleicos fetales y maternos mediante secuenciación masivamente paralela. El método de la invención comprende un protocolo novedoso para preparar bibliotecas de secuenciación que mejora inesperadamente la calidad del ADN de la biblioteca a la vez que agiliza el proceso de análisis de muestras para diagnósticos prenatales. El método de la invención es aplicable a métodos que permiten determinar variaciones en el número de copias (CNV) de cualquier secuencia de interés en una muestra de ensayo que comprende una mezcla de ácidos nucleicos que se sabe o se sospecha que difieren en la cantidad de una o más secuencias de interés, y/o determinar la fracción de una de al menos dos poblaciones de ácidos nucleicos aportados a la muestra por diferentes genomas. Las secuencias de interés incluyen secuencias genómicas que varían desde cientos de bases a decenas de megabases a cromosomas completos que se sabe o se sospecha que están asociados con una condición genética o patológica. Los ejemplos de secuencias de interés incluyen cromosomas asociados con aneuploidías bien conocidas, por ejemplo, trisomía 21, y segmentos de cromosomas que se multiplican en enfermedades tales como el cáncer, por ejemplo, trisomía parcial 8 en leucemia mieloide aguda. Los métodos para determinar CNV divulgados en el presente documento pueden comprender un enfoque estadístico que tenga en cuenta la variabilidad acumulada derivada de la variabilidad relacionada con el proceso, intercromosómica e intersecuenciación. El método de la invención es aplicable a métodos para determinar CNV de cualquier aneuploidía fetal y CNV que se sabe o se sospecha que están asociadas con una diversidad de condiciones médicas.
A menos que se indique lo contrario, la puesta en práctica de la presente invención implica técnicas convencionales utilizadas comúnmente en biología molecular, microbiología, purificación de proteínas, ingeniería de proteínas,
secuenciación de proteínas y ADN y campos de ADN recombinante, que se encuentran dentro de la experiencia en la técnica. Dichas técnicas son conocidas por los expertos en la técnica y se describen en numerosos textos estándar y trabajos de referencia
Los intervalos numéricos incluyen los números que definen el intervalo. Se pretende que cada limitación numérica máxima dada a lo largo de la presente memoria descriptiva incluya cada limitación numérica inferior, como si dichas limitaciones numéricas inferiores estuvieran expresamente escritas en el presente documento. Cada limitación numérica mínima dada a lo largo de la presente memoria descriptiva incluirá cada limitación numérica superior, como si dichas limitaciones numéricas superiores estuvieran expresamente escritas en el presente documento. Cada intervalo numérico dado a lo largo de la presente memoria descriptiva incluirá cada intervalo numérico más estrecho que se encuentre dentro de dicho intervalo numérico más amplio, como si dichos intervalos numéricos más estrechos estuvieran todos expresamente escritos en el presente documento
5.1 Definiciones
Tal como se utilizan en el presente documento, los términos en singular "un", "un", "el" y "la" incluyen la referencia plural a menos que el contexto indique claramente lo contrario. A menos que se indique lo contrario, los ácidos nucleicos se escriben de izquierda a derecha en orientación 5' a 3' y las secuencias de aminoácidos se escriben de izquierda a derecha en orientación amino a carboxi, respectivamente.
El término "evaluar" en el presente documento se refiere a caracterizar el estado de una aneuploidía cromosómica mediante uno de los tres tipos de designaciones: "normal", "afectada" y "sin designación". Por ejemplo, en presencia de trisomía la designación "normal" se determina mediante el valor de un parámetro, por ejemplo, una dosis de cromosoma de ensayo que se encuentra por debajo de un umbral de fiabilidad definido por el usuario, la designación "afectada" se determina por un parámetro, por ejemplo, una dosis de cromosoma de ensayo, que se encuentra por encima de un umbral de fiabilidad definido por el usuario, y el resultado de "sin designación" se determina por un parámetro, por ejemplo, una dosis de cromosoma de ensayo, que se encuentra entre los umbrales de fiabilidad definidos por el usuario para realizar una designación "normal" o "afectada".
El término "variación del número de copias" en el presente documento se refiere a la variación en el número de copias de una secuencia de ácido nucleico de 1 kb o mayor presente en una muestra de ensayo en comparación con el número de copias de la secuencia de ácido nucleico presente en una muestra calificada. Una "variante del número de copias" se refiere a la secuencia de ácido nucleico de 1 kb o mayor en la que se encuentran diferencias en el número de copias mediante comparación de una secuencia de interés en la muestra de ensayo con la presente en una muestra calificada. Las variantes/variaciones del número de copias incluyen deleciones, incluidas microdeleciones, inserciones, incluidas microinserciones, duplicaciones, multiplicaciones, inversiones, translocaciones y variantes complejas de sitios múltiples. La CNV abarcan las aneuploidías cromosómicas y las aneuploidías parciales.
El término "aneuploidía" se refiere en el presente documento a un desequilibrio del material genético provocado por una pérdida o una ganancia de un cromosoma completo, o parte de un cromosoma.
El término "aneuploidía cromosómica" se refiere en el presente documento a un desequilibrio del material genético provocado por una pérdida o una ganancia de un cromosoma completo, e incluye aneuploidía de línea germinal y aneuploidía en mosaico.
El término "aneuploidía parcial" se refiere en el presente documento a un desequilibrio del material genético provocado por una pérdida o una ganancia de parte de un cromosoma, por ejemplo, monosomía parcial y trisomía parcial, y abarca los desequilibrios resultantes de translocaciones, deleciones e inserciones.
El término "pluralidad" se utiliza en el presente documento con referencia a un número de moléculas de ácido nucleico o etiquetas de secuencia que es suficiente para identificar diferencias significativas en variaciones del número de copias (por ejemplo, dosis de cromosomas) en muestras de ensayo y muestras calificadas utilizando los métodos del presente documento. En algunas formas de realización se obtienen para cada muestra de ensayo al menos aproximadamente 3 x 106 etiquetas de secuencia, al menos aproximadamente 5 x 106 etiquetas de secuencia, al menos aproximadamente 8 x 106 etiquetas de secuencia, al menos aproximadamente 10 x 106 etiquetas de secuencia, al menos aproximadamente 15 x 106 etiquetas de secuencia, al menos aproximadamente 20 x 106 etiquetas de secuencia, al menos aproximadamente 30 x 106 etiquetas de secuencia, al menos aproximadamente 40 x 106 etiquetas de secuencia, o al menos aproximadamente 50 x 106 etiquetas de secuencia que comprenden lecturas de entre 20 y 40 pb.
Los términos "polinucleótido", "ácido nucleico" y "moléculas de ácido nucleico" se utilizan indistintamente y se refieren a una secuencia de nucleótidos unida covalentemente (es decir, ribonucleótidos para ARN y desoxirribonucleótidos para ADN) en la que la posición 3' de la pentosa de un nucleótido está unida por un grupo fosfodiéster a la posición 5' de la pentosa del siguiente, e incluyen secuencias de cualquier forma de ácido nucleico, incluidas, pero sin limitación, moléculas de ARN, ADN y ADNcf. El término "polinucleótido" incluye, sin limitación, polinucleótido monocatenario y bicatenario.
El término "porción" se utiliza en el presente documento con referencia a la cantidad de información de secuencia de moléculas de ácidos nucleicos fetales y maternos en una muestra biológica que en suma asciende a menos de la información de secuencia de < 1 genoma humano.
El término "muestra de ensayo" se refiere en el presente documento a una muestra que comprende una mezcla de ácidos nucleicos que comprende al menos una secuencia de ácido nucleico cuyo número de copias se sospecha que ha sufrido una variación. Los ácidos nucleicos presentes en una muestra de ensayo se denominan "ácidos nucleicos de ensayo".
El término "muestra calificada" se refiere en el presente documento a una muestra que comprende una mezcla de ácidos nucleicos que están presentes en un número de copias conocido con los que se comparan los ácidos nucleicos de una muestra de ensayo, y es una muestra que es normal, es decir, no aneuploide, para la secuencia de interés, por ejemplo, una muestra calificada utilizada para identificar un cromosoma de normalización para el cromosoma 21 es una muestra que no es una muestra de trisomía 21.
El término "ácido nucleico calificado" se utiliza de forma intercambiable con "secuencia calificada" que es una secuencia frente a la que se compara la cantidad de una secuencia de ensayo o ácido nucleico de ensayo. Una secuencia calificada es una presente en una muestra biológica preferentemente en una representación conocida, es decir, la cantidad de una secuencia calificada es conocida. Una "secuencia calificada de interés" es una secuencia calificada para la que se conoce la cantidad en una muestra calificada, y es una secuencia que está asociada con una diferencia en la representación de la secuencia en un individuo con una condición médica.
El término "secuencia de interés" se refiere en el presente documento a una secuencia de ácido nucleico que está asociada con una diferencia en la representación de la secuencia en individuos sanos frente a enfermos. Una secuencia de interés puede ser una secuencia en un cromosoma que está tergiversada, es decir, sobrerrepresentada o subrepresentada, en una enfermedad o condición genética. Una secuencia de interés también puede ser una porción de un cromosoma, o un cromosoma. Por ejemplo, una secuencia de interés puede ser un cromosoma que está sobrerrepresentado en una condición de aneuploidía, o un gen que codifica un supresor de tumores que está subrepresentado en un cáncer. Las secuencias de interés incluyen secuencias que están sobrerrepresentadas o subrepresentadas en la población total, o una subpoblación de células de un sujeto. Una "secuencia calificada de interés" es una secuencia de interés en una muestra calificada. Una "secuencia de ensayo de interés" es una secuencia de interés en una muestra de ensayo.
El término "secuencia de normalización" se refiere en el presente documento a una secuencia que muestra una variabilidad en el número de etiquetas de secuencia que se mapean a la misma entre muestras y ejecuciones de secuenciación que mejor se aproxima a la de la secuencia de interés para la que se utiliza como parámetro de normalización, y que mejor puede diferenciar una muestra afectada de una o más muestras no afectadas. Un "cromosoma de normalización" es un ejemplo, de una "secuencia de normalización".
El término "diferenciabilidad" se refiere en el presente documento a la característica de un cromosoma de normalización que permite distinguir una o más muestras no afectadas, es decir, normales, de una o más muestras afectadas, es decir, aneuploides.
El término "dosis de secuencia" se refiere en el presente documento a un parámetro que relaciona la densidad de etiquetas de secuencia de una secuencia de interés con la densidad de etiquetas de una secuencia de normalización. Una "dosis de secuencia de ensayo" es un parámetro que relaciona la densidad de etiquetas de secuencia de una secuencia de interés, por ejemplo, el cromosoma 21, con la de una secuencia de normalización, por ejemplo, el cromosoma 9, determinada en una muestra de ensayo. De forma similar, una "dosis de secuencia calificada" es un parámetro que relaciona la densidad de etiquetas de secuencia de una secuencia de interés con la de una secuencia de normalización determinada en una muestra calificada.
El término "densidad de etiquetas de secuencia" se refiere en el presente documento al número de lecturas de secuencia que se mapean a una secuencia de genoma de referencia, por ejemplo, la densidad de etiquetas de secuencia para el cromosoma 21 es el número de lecturas de secuencia generadas por el método de secuenciación que se mapean al cromosoma 21 del genoma de referencia. El término "relación de densidad de etiquetas de secuencia" se refiere en el presente documento a la relación del número de etiquetas de secuencia que se mapean a un cromosoma del genoma de referencia, por ejemplo, el cromosoma 21, con respecto a la longitud del cromosoma 21 del genoma de referencia.
El término "parámetro" se refiere en el presente documento a un valor numérico que caracteriza un conjunto de datos cuantitativos y/o una relación numérica entre conjuntos de datos cuantitativos. Por ejemplo, una relación (o función de una relación) entre el número de etiquetas de secuencia mapeadas a un cromosoma y la longitud del cromosoma al que se mapean las etiquetas es un parámetro.
Los términos "valor umbral" y "valor umbral calificado" se refieren en el presente documento a cualquier número que se calcula utilizando un conjunto de datos calificados y que sirve como límite de diagnóstico de una variación del número de copias, por ejemplo, una aneuploidía, en un organismo. Si los resultados obtenidos en la puesta en práctica de los métodos divulgados en el presente documento superan un umbral, se puede diagnosticar a un sujeto una variación del número de copias, por ejemplo, trisomía 21.
El término "lectura" se refiere a una secuencia de ADN de longitud suficiente (por ejemplo, al menos aproximadamente 30 pb) que se puede utilizar para identificar una secuencia o región más grande, por ejemplo, que se puede alinear y asignar específicamente a un cromosoma o región genómica o gen.
El término "etiqueta de secuencia" se utiliza en el presente documento de forma intercambiable con el término "etiqueta de secuencia mapeada" para referirse a una lectura de secuencia que se ha asignado específicamente, es decir, mapeado, a una secuencia más grande, por ejemplo, un genoma de referencia, mediante alineamiento. Las etiquetas de secuencia mapeadas se mapean de forma única a un genoma de referencia, es decir, se asignan a una única ubicación en el genoma de referencia. Las etiquetas que se pueden mapear a más de una ubicación en un genoma de referencia, es decir, las etiquetas que no se mapean de forma única, no se incluyen en el análisis.
Tal como se utilizan en el presente documento, los términos "alineada", "alineamiento" o "alinear" se refieren a una o más secuencias que se identifican como una coincidencia en términos del orden de sus moléculas de ácido nucleico con una secuencia conocida de un genoma de referencia. Dicho alineamiento se puede realizar manualmente o mediante un algoritmo informático, incluyéndose entre los ejemplos el programa informático Efficient Local Alignment of Nucleotide Data (ELAND) distribuido como parte de la línea Illumina Genomics Analysis. La coincidencia de una lectura de secuencia en el alineamiento puede ser una coincidencia de secuencia del 100% o inferior al 100% (coincidencia no perfecta).
Tal como se utiliza en el presente documento, el término "genoma de referencia" se refiere a cualquier secuencia genómica conocida particular, ya sea parcial o completa, de cualquier organismo o virus que pueda utilizarse para referenciar secuencias identificadas de un sujeto. Por ejemplo, en el National Center for Biotechnology Information, en www.ncbi.nlm.nih.gov, se encuentra un genoma de referencia utilizado para sujetos humanos, así como para muchos otros organismos. Un "genoma" se refiere a la información genética completa de un organismo o un virus, expresada en secuencias de ácido nucleico.
Los términos "genoma de secuencias diana artificiales" y "genoma de referencia artificial" se refieren en el presente documento a una agrupación de secuencias conocidas que abarcan alelos de sitios polimórficos conocidos. Por ejemplo, un "genoma de referencia de SNP" es un genoma de secuencias diana artificiales que comprende una agrupación de secuencias que abarca alelos de SNP conocidos.
El término "secuencia clínicamente relevante" se refiere en el presente documento a una secuencia de ácido nucleico que se sabe o se sospecha que está asociada o implicada con una condición genética o de enfermedad. Determinar la ausencia o la presencia de una secuencia clínicamente relevante puede ser útil para determinar un diagnóstico o confirmar un diagnóstico de una condición médica, o proporcionar un pronóstico para el desarrollo de una enfermedad.
El término "derivado" cuando se utiliza en el contexto de un ácido nucleico o una mezcla de ácidos nucleicos, se refiere en el presente documentos a los medios mediante los que se obtienen los ácidos nucleicos de la fuente de la que se originan. Por ejemplo, en una forma de realización, una mezcla de ácidos nucleicos que se deriva de dos genomas diferentes significa que los ácidos nucleicos, por ejemplo, ADNcf, se liberaron de forma natural por las células a través de procesos naturales tales como la necrosis o la apoptosis. En otra forma de realización, una mezcla de ácidos nucleicos que se deriva de dos genomas diferentes significa que los ácidos nucleicos se extrajeron de dos tipos diferentes de células de un sujeto.
El término "muestra mixta" se refiere en el presente documento a una muestra que contiene una mezcla de ácidos nucleicos que se derivan de diferentes genomas.
El término "muestra materna" se refiere en el presente documento a una muestra biológica obtenida de un sujeto embarazado, por ejemplo, una mujer embarazada.
El término "muestra materna original" se refiere en el presente documento a una muestra biológica obtenida de un sujeto embarazado, por ejemplo, una mujer embarazada, que sirve como fuente de la que se extrae una porción para amplificar los ácidos nucleicos diana polimórficos. La "muestra original" puede ser cualquier muestra obtenida de un sujeto embarazado, y las fracciones procesadas de la misma, por ejemplo, una muestra de ADNcf purificado extraída de una muestra de plasma materno.
El término "fluido biológico" se refiere en el presente documento a un líquido tomado de una fuente biológica e incluye, por ejemplo, sangre, suero, plasma, esputo, líquido de lavado, líquido cefalorraquídeo, orina, semen, sudor, lágrimas, saliva y similares. Tal como se utilizan en el presente documento, los términos "sangre", "plasma" y "suero" abarcan expresamente fracciones o porciones procesadas de los mismos. De forma similar, cuando se tome una muestra de
una biopsia, hisopo, frotis, etc., la “muestra” englobará expresamente una fracción o porción procesada derivada de la biopsia, hisopo, frotis, etc.
Los términos "ácidos nucleicos maternos" y "ácidos nucleicos fetales" se refieren en el presente documento a los ácidos nucleicos de un sujeto femenino embarazado y los ácidos nucleicos del feto que porta el sujeto femenino embarazado, respectivamente.
Tal como se utiliza en el presente documento, el término "correspondiente a" se refiere a una secuencia de ácido nucleico, por ejemplo, un gen o un cromosoma, que está presente en el genoma de diferentes sujetos, y que no necesariamente tiene la misma secuencia en todos los genomas, pero que sirve para proporcionar la identidad en lugar de la información genética de una secuencia de interés, por ejemplo, un gen o un cromosoma.
Tal como se utiliza en el presente documento, el término "sustancialmente libre de células" abarca preparaciones de la muestra deseada de la que se eliminan los componentes que normalmente están asociados con la misma. Por ejemplo, una muestra de plasma se vuelve esencialmente libre de células al eliminar las células sanguíneas, por ejemplo, glóbulos rojos, que normalmente se asocian con la misma. En algunas formas de realización, las muestras sustancialmente libres de células se procesan para eliminar células que de otro modo contribuirían al material genético deseado que se va a analizar para evaluar una CNV.
Tal como se utiliza en el presente documento, el término "fracción fetal" se refiere a la fracción de ácidos nucleicos fetales presentes en una muestra que comprende ácido nucleico fetal y materno.
Tal como se utiliza en el presente documento, el término "cromosoma" se refiere al portador del gen portador de la herencia de una célula viva que se deriva de cromatina y que comprende ADN y componentes proteicos (especialmente histonas). En el presente documento se emplea el sistema de numeración de cromosomas del genoma humano individual internacionalmente reconocido convencional.
Tal como se utiliza en el presente documento, el término "longitud de polinucleótido" se refiere al número absoluto de moléculas de ácido nucleico (nucleótidos) en una secuencia o en una región de un genoma de referencia. El término "longitud del cromosoma" se refiere a la longitud conocida del cromosoma dada en pares de bases, por ejemplo, proporcionada en el ensamblaje NCBI36/hg18 del cromosoma humano que se encuentra en Internet en genome.ucsc.edu/cgi-bin/hgTracks?hgsid= 167155613&chromInfoPage=
El término "sujeto" se refiere en el presente documento a un sujeto humano, así como a un sujeto no humano tal como un mamífero, un invertebrado, un vertebrado, un hongo, una levadura, una bacteria y un virus. Aunque los ejemplos del presente documento se refieren a seres humanos y el lenguaje se refiere principalmente a cuestiones humanas, el concepto de la presente invención puede aplicarse a genomas de cualquier planta o animal, y es útil en los campos de la medicina veterinaria, ciencias animal, laboratorios de investigación y similares.
El término "condición" se refiere en el presente documento a "condición médica" como un término amplio que incluye todas las enfermedades y trastornos, pero que puede incluir lesiones y situaciones normales de salud, tales como el embarazo, que podrían afectar a la salud de una persona, beneficiarse de asistencia médica o tener implicaciones para tratamientos médicos.
El término "cromosoma aneuploide" se refiere en el presente documento a un cromosoma que está implicado en una aneuploidía.
El término "aneuploidía" se refiere en el presente documento a un desequilibrio del material genético provocado por una pérdida o una ganancia de un cromosoma completo, o parte de un cromosoma.
Los términos "biblioteca" y "biblioteca de secuenciación" se refieren en el presente documento a una colección o una pluralidad de moléculas de plantilla que comparten secuencias comunes en sus extremos 5' y secuencias comunes en sus extremos 3'.
Los términos "extremo romo" y "reparación de extremos" se utilizan en el presente documento indistintamente para referirse a un proceso enzimático que da como resultado que ambas cadenas de una molécula de ADN bicatenario terminen en un par de bases, y no incluye la purificación de los productos de extremos romos de la enzima de extremos romos.
El término "adición de colas de d-A" en el presente documento se refiere a un proceso enzimático que añade al menos una base de adenina al extremo 3' del ADN y no incluye la purificación del producto con cola de d-A de la enzima de adición de colas de d-A.
El término "ligación de adaptador" se refiere en el presente documento a un proceso enzimático que liga una secuencia de adaptador de ADN a fragmentos de ADN, y no incluye la purificación del producto ligado al adaptador de la enzima de ligación.
El término "recipiente de reacción" se refiere en el presente documento a un recipiente de cualquier forma, tamaño, capacidad o material que se puede utilizar para procesar una muestra durante un procedimiento de laboratorio, por ejemplo, de investigación o clínico.
El término "etapas consecutivas" se utiliza en el presente documento con referencia a las etapas enzimáticas sucesivas de formación de extremos romos, adición de colas de dA y ligación de adaptadores a ADN que no están interpuestos por etapas de purificación.
Tal como se utiliza en el presente documento, el término "purificado" se refiere a material (por ejemplo, un polinucleótido aislado) que se encuentra en un estado relativamente puro, por ejemplo, que es al menos aproximadamente el 80% puro, al menos aproximadamente el 85% puro, al menos aproximadamente el 90% puro, al menos aproximadamente el 95% puro, al menos aproximadamente el 98% puro, o incluso al menos aproximadamente el 99% puro.
Los términos "extraído", "recuperado", "aislado" y "separado" se refieren a un compuesto, proteína, célula, ácido nucleico o aminoácido que se retira de al menos un componente con el que está asociado naturalmente y se encuentra en la naturaleza.
El término "SNP en tándem" en el presente documento se refiere a dos o más SNP que están presentes dentro de una secuencia de ácido nucleico diana polimórfico.
Los términos "ácido nucleico diana polimórfico", "secuencia polimórfica", "secuencia de ácido nucleico diana polimórfico" y "ácido nucleico polimórfico" se utilizan indistintamente en el presente documento para referirse a una secuencia de ácido nucleico, por ejemplo, una secuencia de ADN que comprende uno o más sitios polimórficos.
El término "sitio polimórfico" se refiere en el presente documento a un polimorfismo de un solo nucleótido (SNP), una deleción o inserción de múltiples bases a pequeña escala, un polimorfismo de múltiples nucleótidos (MNP) o una repetición en tándem corta (STR).
El término "pluralidad de ácidos nucleicos diana polimórficos" se refiere en el presente documento a una serie de secuencias de ácidos nucleicos, cada una de las cuales comprende al menos un sitio polimórfico tal que al menos 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 40 o más sitios polimórficos diferentes se amplifican a partir de los ácidos nucleicos diana polimórficos para identificar y/o cuantificar los alelos fetales presentes en muestras maternas que comprenden ácidos nucleicos fetales y maternos.
El término "enriquecer" se refiere en el presente documento al proceso de amplificación de ácidos nucleicos diana polimórficos contenidos en una porción de una muestra materna y la combinación del producto amplificado con el resto de la muestra materna de la que se extrajo la porción.
El término "densidad de etiquetas de secuencia" se refiere en el presente documento al número de lecturas de secuencia que se mapean a una secuencia de genoma de referencia, por ejemplo, la densidad de etiquetas de secuencia para el cromosoma 21 es el número de lecturas de secuencia generadas por el método de secuenciación que se mapean al cromosoma 21 del genoma de referencia. El término "relación de densidad de etiquetas de secuencia" se refiere en el presente documento a la relación del número de etiquetas de secuencia que se mapean a un cromosoma del genoma de referencia, por ejemplo, el cromosoma 21, con respecto a la longitud del cromosoma 21 del genoma de referencia.
Tal como se utiliza en el presente documento, el término "amplificación en fase sólida" se refiere, tal como se utiliza en el presente documento, a cualquier reacción de amplificación de ácido nucleico llevada a cabo en un soporte sólido o en asociación con el mismo, de modo que la totalidad o una parte de los productos amplificados se inmovilicen en el soporte sólido a medida que se vayan formando. En particular, el término abarca la reacción en cadena de la polimerasa en fase sólida (PCR en fase sólida) y la amplificación isotérmica en fase sólida, que son reacciones análogas a la amplificación en fase de solución estándar, excepto que uno o ambos cebadores de amplificación directo e inverso están inmovilizados en el soporte sólido. La PCR en fase sólida abarca sistemas tales como emulsiones, en los que un cebador está anclado a una perla y el otro está en solución libre, y la formación de colonias en matrices de gel en fase sólida en las que un cebador está anclado a la superficie y el otro está en solución libre. El término fase sólida, o superficie, se utiliza para referirse a una matriz plana en la que los cebadores se unen a una superficie plana, por ejemplo, portaobjetos de microscopio de vidrio, sílice o plástico o dispositivos de celda de flujo similares; perlas, en las que uno o dos cebadores se unen a las perlas y las perlas se amplifican; o una matriz de perlas sobre una superficie después de que las perlas se hayan amplificado.
Tal como se utiliza en el presente documento, el término "grupo de cromosomas" se refiere en el presente documento a un grupo de dos o más cromosomas.
Un "polimorfismo de un solo nucleótido" (SNP) se produce en un sitio polimórfico ocupado por un solo nucleótido, que es el sitio de variación entre secuencias alélicas. El sitio suele estar precedido y seguido por secuencias altamente conservadas del alelo (por ejemplo, secuencias que varían en menos de 1/100 o 1/1000 miembros de las poblaciones). Un SNP generalmente surge debido a la sustitución de un nucleótido por otro en el sitio polimórfico. Una transición es el reemplazo de una purina por otra purina o una pirimidina por otra pirimidina. Una transversión es la sustitución de una purina por una pirimidina o viceversa. Los SNP también pueden surgir de una deleción de un nucleótido o una inserción de un nucleótido con respecto a un alelo de referencia. Los polimorfismos de un solo nucleótido (SNP) son posiciones en las que tienen lugar dos bases alternativas con una frecuencia apreciable (> 1%) en la población humana y son el tipo más común de variación genética humana.
Tal como se utiliza en el presente documento, el término "repetición en tándem corta" o "STR", tal como se utiliza en el presente documento, se refiere a una clase de polimorfismos que se producen cuando se repite un patrón de dos o más nucleótidos y las secuencias repetidas son directamente adyacentes entre sí. El patrón puede tener una longitud de 2 a 10 pares de bases (pb) (por ejemplo, (CATG)n en una región genómica) y normalmente se encuentra en la región del intrón no codificante. Examinando varios loci de STR y contando cuántas repeticiones de una secuencia de STR específica hay en un locus dado, es posible crear un perfil genético único de un individuo.
Tal como se utiliza en el presente documento, el término "miniSTR" se refiere en el presente documento a la repetición en tándem de cuatro o más pares de bases que abarca menos de aproximadamente 300 pares de bases, menos de aproximadamente 250 pares de bases, menos de aproximadamente 200 pares de bases, menos de aproximadamente 150 pares de bases, menos de aproximadamente 100 pares de bases, menos de aproximadamente 50 pares de bases o menos de aproximadamente 25 pares de bases. Los "miniSTR" son STR que se pueden amplificar a partir de plantillas de ADNcf.
El término "SNP en tándem" se refiere en el presente documento a dos o más SNP que están presentes dentro de una secuencia de ácido nucleico diana polimórfico.
Tal como se utiliza en el presente documento, el término "biblioteca enriquecida" se refiere en el presente documento a una biblioteca de secuenciación que comprende secuencias de ácidos nucleicos diana polimórficos amplificadas. Un ejemplo, de una biblioteca enriquecida es una biblioteca de secuenciación que comprende secuencias de ADNcf de origen natural y secuencias de ácido nucleico diana amplificadas. Una "biblioteca no enriquecida" se refiere en el presente documento a una biblioteca de secuenciación que no comprende, es decir, una biblioteca generada a partir de secuencias de ADNcf de origen natural. Una "biblioteca de ácidos nucleicos polimórficos diana" es una biblioteca generada a partir de ácidos nucleicos diana amplificados.
Tal como se utiliza en el presente documento, el término "secuencias de ADNcf de origen natural" se refiere en el presente documento a fragmentos de ADNcf tal como están presentes en una muestra, y en contraste con fragmentos de ADN genómico que se obtienen mediante métodos de fragmentación descritos en el presente documento.
5.2 Descripción
La invención proporciona un método para la secuenciación de ácidos nucleicos que comprende: (a) proporcionar una muestra de ensayo que comprende moléculas de ácido nucleico, en el que dichas moléculas de ácido nucleico son moléculas de ADN genómico humano; (b) realizar la reparación de extremos de las moléculas de ácido nucleico para generar ácidos nucleicos de extremos romos; (c) realizar la adición de colas de dA a los ácidos nucleicos de extremos romos para generar ácidos nucleicos con cola de dA; (d) ligar adaptadores a los ácidos nucleicos con cola de dA para generar una biblioteca de polinucleótidos ligados a adaptadores; (e) opcionalmente amplificar la biblioteca usando cebadores de amplificación, comprendiendo dichos cebadores de amplificación una porción específica de adaptador; y (f) someter la biblioteca a una secuenciación masivamente paralela; en el que las etapas (b), (c) y (d) son etapas consecutivas.
El método de la invención es aplicable a métodos para determinar la presencia o la ausencia de una aneuploidía, por ejemplo, una aneuploidía cromosómica o parcial, y/o la fracción fetal en muestras maternas que comprenden ácidos nucleicos fetales y maternos mediante secuenciación masivamente paralela. El método de la invención comprende un protocolo novedoso para preparar bibliotecas de secuenciación que mejora inesperadamente la calidad del ADN de la biblioteca a la vez que agiliza el proceso de análisis de muestras para diagnósticos prenatales. El método de la invención es aplicable a métodos que permiten determinar variaciones en el número de copias (CNV) de cualquier secuencia de interés en una muestra de ensayo que comprende una mezcla de ácidos nucleicos que se sabe o se sospecha que difieren en la cantidad de una o más secuencias de interés, y/o determinar la fracción de una de al menos dos poblaciones de ácidos nucleicos aportados a la muestra por diferentes genomas.
Métodos de secuenciación
En una forma de realización, el método descrito en el presente documento emplea tecnología de secuenciación de próxima generación (NGS) en la que se secuencian plantillas de ADN amplificadas clonalmente o moléculas de ADN individuales de forma masivamente paralela dentro de una celda de flujo (por ejemplo, tal como se describe por
Volkerding et al. Clin Chem 55:641-658 [2009]; Metzker M Nature Rev 11:31 -46 [2010]). Además de la información de secuencias de alto rendimiento, la NGS proporciona información cuantitativa digital, ya que cada lectura de secuencia es una "etiqueta de secuencia" contable que representa una plantilla de ADN clonal individual o una sola molécula de ADN. Esta cuantificación permite a la NGS expandir el concepto de PCR digital de contar moléculas de ADN libre de células (Fan et al., Proc Natl Acad Sci EE.UU. 105:16266-16271 [2008]; Chiu et al., Proc Natl Acad Sci EE.UU. 2008; 105:20458-20463 [2008]). Las tecnologías de secuenciación de NGS incluyen pirosecuenciación, secuenciación por síntesis con terminadores de colorantes reversibles, secuenciación por ligación de sonda de oligonucleótidos y secuenciación en tiempo real.
Algunas de las tecnologías de secuenciación están disponibles comercialmente, tales como la plataforma de secuenciación por hibridación de Affymetrix Inc. (Sunnyvale, CA) y las plataformas de secuenciación por síntesis de 454 Life Sciences (Bradford, CT), Illumina/Solexa (Hayward, CA) y Helicos Biosciences (Cambridge, MA), y la plataforma de secuenciación por ligación de Applied Biosystems (Foster City, CA), tal como se describe a continuación. Además de la secuenciación de una sola molécula realizada utilizando la secuenciación por síntesis de Helicos Biosciences, el método de la invención abarca otras tecnologías de secuenciación de una sola molécula e incluyen la tecnología SMRT™ de Pacific Biosciences, la tecnología Ion Torrent™ y la secuenciación por nanoporos que está desarrollando, por ejemplo, Oxford Nanopore Technologies.
Aunque el método de Sanger automatizado se considera una tecnología de "primera generación", la secuenciación de Sanger, incluida la secuenciación de Sanger automatizada, también puede emplearse por el método de la invención. También están abarcados por el método de la invención métodos de secuenciación adicionales que comprenden el uso de tecnologías de formación de imágenes de ácidos nucleicos en desarrollo, por ejemplo, la microscopía de fuerza atómica (AFM) o la microscopía electrónica de transmisión (TEM). A continuación, se describen tecnologías de secuenciación ilustrativas.
En una forma de realización, la tecnología de secuenciación de ADN que se utiliza en el método de la invención es la secuenciación de una sola molécula verdadera de Helicos (tSMS) (por ejemplo, tal como se describe por Harris T.D. et al., Science 320:106-109 [2008]). En la técnica tSMS, una muestra de ADN se escinde en cadenas de aproximadamente 100 a 200 nucleótidos y se añade una secuencia de poliA al extremo 3' de cada cadena de ADN. Cada cadena se marca mediante la adición de un nucleótido de adenosina marcado con fluorescencia. Después, las cadenas de ADN se hibridan a una celda de flujo, que contiene millones de sitios de captura de oligo-T que están inmovilizados en la superficie de la celda de flujo. Las plantillas pueden tener una densidad de aproximadamente 100 millones de plantillas/cm2. Después, la celda de flujo se carga en un instrumento, por ejemplo, un secuenciador HeliScope™, y un láser ilumina la superficie de la celda de flujo, revelando la posición de cada plantilla. Una cámara CCD puede mapear la posición de las plantillas en la superficie de la celda de flujo. Después, la etiqueta fluorescente de plantilla se corta y se elimina por lavado. La reacción de secuenciación comienza con la introducción de una ADN polimerasa y un nucleótido marcado con fluorescencia. El ácido nucleico oligo-T sirve como cebador. La polimerasa incorpora los nucleótidos marcados al cebador de una forma dirigida por plantilla. La polimerasa y los nucleótidos no incorporados se eliminan. Las plantillas que han dirigido la incorporación del nucleótido marcado con fluorescencia se distinguen mediante la obtención de imágenes de la superficie de la celda de flujo. Después de la obtención de imágenes, una etapa de escisión elimina la etiqueta fluorescente y el proceso se repite con otros nucleótidos marcados con fluorescencia hasta que se alcanza la longitud de lectura deseada. La información de la secuencia se recopila con cada etapa de adición de nucleótidos.
En una forma de realización, la tecnología de secuenciación de ADN que se utiliza en el método de la invención es la secuenciación 454 (Roche) (por ejemplo, tal como se describe por Margulies, M. et al. Nature 437:376-380 [2005]). La secuenciación 454 implica dos etapas. En la primera etapa, el ADN se corta en fragmentos de aproximadamente 300 a 800 pares de bases, y los extremos de los fragmentos se vuelven romos. Después, los adaptadores de oligonucleótidos se ligan a los extremos de los fragmentos. Los adaptadores sirven como cebadores para la amplificación y la secuenciación de los fragmentos. Los fragmentos pueden unirse a perlas de captura de ADN, por ejemplo, perlas recubiertas de estreptavidina, utilizando, por ejemplo, el adaptador B, que contiene la etiqueta 5'-biotina. Los fragmentos unidos a las perlas se amplifican por PCR dentro de las gotas de una emulsión de aceite y agua. El resultado son múltiples copias de fragmentos de ADN amplificados clonalmente en cada perla. En la segunda etapa, las perlas se capturan en pocillos (de un tamaño del orden de picolitros). Se realiza una pirosecuenciación en cada fragmento de ADN en paralelo. La adición de uno o más nucleótidos genera una señal de luz que es registrada por una cámara CCD en un instrumento de secuenciación. La intensidad de la señal es proporcional al número de nucleótidos incorporados. La pirosecuenciación utiliza pirofosfato (PPi) que se libera tras la adición de nucleótidos. El PPi se convierte en ATP mediante ATP sulfurilasa en presencia de adenosina 5' fosfosulfato. La luciferasa utiliza ATP para convertir la luciferina en oxiluciferina, y esta reacción genera luz que se discierne y se analiza.
En una forma de realización, la tecnología de secuenciación de ADN que se utiliza en el método de la invención es tecnología SOLiD™ (Applied Biosystems). En la secuenciación por ligación SOLiD™, el ADN genómico se corta en fragmentos y se unen adaptadores a los extremos 5' y 3' de los fragmentos para generar una biblioteca de fragmentos. Alternativamente, se pueden introducir adaptadores internos ligando adaptadores a los extremos 5' y 3' de los fragmentos, circularizando los fragmentos, digiriendo el fragmento circularizado para generar un adaptador interno y uniendo adaptadores a los extremos 5' y 3' de los fragmentos resultantes para generar una biblioteca de elementos
emparejados. A continuación, se preparan poblaciones de perlas clónales en microrreactores que contienen perlas, cebadores, plantilla y componentes de PCR. Después de la PCR, las plantillas se desnaturalizan y las perlas se enriquecen para separar las perlas con plantillas extendidas. Las plantillas de las perlas seleccionadas se someten a una modificación 3' que permite la unión a un portaobjetos de vidrio. La secuencia se puede determinar mediante hibridación secuencial y ligación de oligonucleótidos parcialmente aleatorios con una base determinada central (o un par de bases) que se identifica mediante un fluoróforo específico. Después de registrar un color, el oligonucleótido ligado se escinde y se elimina y después se repite el proceso.
En una forma de realización, la tecnología de secuenciación de ADN que se utiliza en el método de la invención es es la tecnología de secuenciación de una sola molécula, en tiempo real (SMRT™) de Pacific Biosciences. En la secuenciación SMRT, la incorporación continua de nucleótidos marcados con colorante se visualiza durante la síntesis de ADN. Las moléculas individuales de polimerasa de ADN se unen a la superficie inferior de los identificadores de longitud de onda de modo cero individuales (identificadores ZMW) que obtienen información de secuencia mientras los nucleótidos fosfoenlazados se incorporan a la cadena de cebador en crecimiento. Un ZMW es una estructura de confinamiento que permite la observación de la incorporación de un solo nucleótido por la ADN polimerasa contra el fondo de nucleótidos fluorescentes que se difunden rápidamente dentro y fuera del ZMW (en microsegundos). Se necesitan varios milisegundos para incorporar un nucleótido en una cadena en crecimiento. Durante este periodo de tiempo, la etiqueta fluorescente se excita y produce una señal fluorescente y la etiqueta fluorescente se escinde. La identificación de la fluorescencia correspondiente del colorante indica qué base se ha incorporado. El proceso se repite.
En una forma de realización, la tecnología de secuenciación de ADN que se utiliza en el método de la invención es la secuenciación por nanoporos (por ejemplo, tal como se describe por Soni GV y Meller A. Clin Chem 53: 1996-2001 [2007]). Varias empresas, incluida Oxford Nanopore Technologies (Oxford, Reino Unido), están desarrollando industrialmente técnicas de análisis de ADN de secuenciación por nanoporos. La secuenciación por nanoporos es una tecnología de secuenciación de una sola molécula mediante la cual una sola molécula de ADN se secuencia directamente a medida que pasa a través de un nanoporo. Un nanoporo es un agujero pequeño, del orden de 1 nanómetro de diámetro. La inmersión de un nanoporo en un fluido conductor y la aplicación de un potencial (voltaje) a través del mismo da como resultado una ligera corriente eléctrica debido a la conducción de iones a través del nanoporo. La cantidad de corriente que fluye es sensible al tamaño y la forma del nanoporo. Cuando una molécula de ADN pasa a través de un nanoporo, cada nucleótido de la molécula de ADN obstruye el nanoporo en un grado diferente, cambiando la magnitud de la corriente a través del nanoporo en diferentes grados. Así, este cambio en la corriente a medida que la molécula de ADN pasa a través del nanoporo representa una lectura de la secuencia de ADN.
En una forma de realización, la tecnología de secuenciación de ADN que se utiliza en el método de la invención es la matriz de transistores de efecto de campo sensible a productos químicos (chemFET) (por ejemplo, tal como se describe en la publicación de solicitud de patente de Estados Unidos N° 20090026082). En un ejemplo, de la técnica, las moléculas de ADN pueden disponerse en cámaras de reacción y las moléculas de plantilla pueden hibridarse con un cebador de secuenciación unido a una polimerasa. La incorporación de uno o más trifosfatos en una nueva cadena de ácido nucleico en el extremo 3' del cebador de secuenciación puede discernirse por un cambio en la corriente mediante un chemFET. Una matriz puede tener múltiples sensores chemFET. En otro ejemplo, los ácidos nucleicos individuales pueden unirse a perlas, y los ácidos nucleicos se pueden amplificar en la perla, y las perlas individuales se pueden transferir a cámaras de reacción individuales en una matriz chemFET, en la que cada cámara tiene un sensor chemFET, y los ácidos nucleicos se pueden secuenciar.
En una forma de realización, la tecnología de secuenciación de ADN que se utiliza en el método de la invención es el método de Halcyon Molecular que usa microscopía electrónica de transmisión (TEM). El método, denominado Individual Molecule Placement Rapid Nano Transfer (IMPRNT), comprende la utilización de imágenes de microscopio electrónico de transmisión de resolución de un solo átomo de ADN de alto peso molecular (150 kb o más grande) marcado selectivamente con marcadores de átomos pesados y la disposición de estas moléculas en películas ultrafinas en matrices paralelas ultradensas (3 nm de cadena a cadena) con espaciado constante de base a base. El microscopio electrónico se utiliza para obtener imágenes de las moléculas en las películas para determinar la posición de los marcadores de átomos pesados y para extraer información de la secuencia de bases del ADN. El método se describe más detalladamente en la publicación de patente PCT WO 2009/046445. El método permite secuenciar genomas humanos completos en menos de diez minutos.
En una forma de realización, la tecnología de secuenciación de ADN es la secuenciación de una sola molécula por Ion Torrent, que combina la tecnología de semiconductores con una química de secuenciación simple para traducir directamente la información codificada químicamente (A, C, G, T) en información digital (0, 1) en un chip semiconductor. En la naturaleza, cuando una polimerasa incorpora un nucleótido a una cadena de ADN, se libera un ion de hidrógeno como subproducto. Ion Torrent utiliza una matriz de alta densidad de pocillos micromecanizados para realizar este proceso bioquímico de forma masivamente paralela. Cada pocillo contiene una molécula de ADN diferente. Debajo de los pozos hay una capa sensible a los iones y debajo de la misma un sensor de iones. Cuando se añade un nucleótido, por ejemplo, una C, a una plantilla de ADN y después se incorpora a una cadena de ADN, se liberará un ion hidrógeno. La carga de ese ion cambiará el pH de la solución, que puede identificarse mediante el sensor de iones del Ion Torrent. El secuenciador, esencialmente el medidor de pH en estado sólido más pequeño del mundo, designa la base, yendo directamente de la información química a la información digital. El secuenciador Ion personal Genome Machine
(PGM™) inunda después secuencialmente el chip con un nucleótido tras otro. Si el siguiente nucleótido que inunda el chip no es una coincidencia, no se registrará ningún cambio de voltaje y no se designará ninguna base. Si hay dos bases idénticas en la cadena de ADN, el voltaje será el doble y el chip registrará dos bases idénticas designadas. La identificación directa permite registrar la incorporación de nucleótidos en segundos.
Otros métodos de secuenciación incluyen PCR digital y secuenciación por hibridación. Puede utilizarse la reacción en cadena de la polimerasa digital (PCR digital o dPCR) para identificar y cuantificar directamente los ácidos nucleicos en una muestra. La PCR digital se puede realizar en una emulsión. Los ácidos nucleicos individuales se separan, por ejemplo, en un dispositivo de cámara de microfluidos, y cada ácido nucleico se amplifica individualmente mediante PCR. Los ácidos nucleicos se pueden separar de forma que haya una media de aproximadamente 0,5 ácidos nucleicos/pocillo, o no más de un ácido nucleico/pocillo. Se pueden utilizar diferentes sondas para distinguir los alelos fetales y los alelos maternos. Los alelos se pueden enumerar para determinar el número de copias. En la secuenciación por hibridación, la hibridación comprende poner en contacto la pluralidad de secuencias de polinucleótidos con una pluralidad de sondas de polinucleótidos, pudiendo unirse cada una de la pluralidad de sondas de polinucleótidos opcionalmente a un sustrato. El sustrato podría ser una superficie plana que comprende una matriz de secuencias de nucleótidos conocidas. El patrón de hibridación con la matriz se puede utilizar para determinar las secuencias de polinucleótidos presentes en la muestra. En otras formas de realización, cada sonda está unida a una perla, por ejemplo, una perla magnética o similar. La hibridación con las perlas se puede identificar y utilizar para identificar la pluralidad de secuencias de polinucleótidos dentro de la muestra.
En una forma de realización, el método emplea la secuenciación masivamente paralela de millones de fragmentos de ADN utilizando la secuenciación por síntesis de Illumina y la química de secuenciación basada en terminadores reversibles (por ejemplo, tal como se describe por Bentley et al., Nature 6:53-59 [2009]). El ADN de plantilla puede ser ADN genómico por ejemplo, ADNcf. En algunas formas de realización, se utiliza ADN genómico de células aisladas como plantilla y se fragmenta en longitudes de varios cientos de pares de bases. En otras formas de realización, se utiliza ADNcf como la plantilla y no se requiere fragmentación ya que el ADNcf existe como fragmentos cortos. Por ejemplo, el ADNcf fetal circula en el torrente sanguíneo como fragmentos de < 300 pb, y se ha estimado que el ADNcf materno circula como fragmentos de entre aproximadamente 0,5 y 1 Kb. Li et al., Clin Chem, 50: 1002-1011 [2004]). La tecnología de secuenciación de Illumina se basa en la unión de ADN genómico fragmentado a una superficie plana ópticamente transparente en la que se unen los anclajes de oligonucleótidos. El ADN de plantilla se repara en los extremos para generar extremos romos fosforilados en 5', y la actividad de polimerasa del fragmento Klenow se utiliza para añadir una sola base A al extremo 3' de los fragmentos de ADN fosforilados romos. Esta adición prepara los fragmentos de ADN para la ligación a los adaptadores de oligonucleótidos, que tienen un saliente de una sola base T en su extremo 3' para aumentar la eficacia de la ligación. Los oligonucleótidos adaptadores son complementarios a los anclajes de la celda de flujo. En condiciones de dilución limitantes, se añade ADN de plantilla monocatenario modificado con adaptador a la celda de flujo y se inmoviliza mediante hibridación con los anclajes. Los fragmentos de ADN unidos se extienden y se amplifican en puente para crear una celda de flujo de secuenciación de densidad ultraalta con cientos de millones de clústeres, cada una con ~1000 copias de la misma plantilla. En una forma de realización, el ADN genómico fragmentado al azar, por ejemplo, ADNcf, se amplifica mediante PCR antes de someterse a la amplificación de clústeres. Como alternativa, se utiliza una preparación de biblioteca genómica sin amplificación y el ADN genómico fragmentado aleatoriamente, por ejemplo, ADNcf, se enriquece utilizando solo la amplificación de clústeres (Kozarewa et al., Nature Methods 6:291-295 [2009]). Las plantillas se secuencian utilizando una tecnología de secuenciación por síntesis de ADN de cuatro colores robusta que emplea terminadores reversibles con colorantes fluorescentes extraíbles. La identificación por fluorescencia de alta sensibilidad se realiza utilizando excitación láser y óptica de reflexión interna total. Las lecturas de secuencia corta de aproximadamente 20-40 pb, por ejemplo, de 36 pb, se alinean contra un genoma de referencia enmascarado de repetición y las diferencias genéticas se identifican utilizando un programa informático de canalización de análisis de datos especialmente desarrollado. Después de completar la primera lectura, las plantillas se pueden regenerar in situ para permitir una segunda lectura desde el extremo opuesto de los fragmentos. Así, según el método, se utiliza la secuenciación de un solo extremo o de extremos emparejados de los fragmentos de ADN. Se realiza la secuenciación parcial de los fragmentos de ADN presentes en la muestra y se cuentan etiquetas de secuencia que comprenden lecturas de longitud predeterminada, por ejemplo, 36 pb, que se mapean a un genoma de referencia conocido.
La longitud de la secuencia leída está asociada con la tecnología de secuenciación particular. Los métodos NGS proporcionan lecturas de secuencias que varían en tamaño de decenas a cientos de pares de bases. En algunas formas de realización del método descrito en el presente documento, las lecturas de secuencia son aproximadamente 20 pb, aproximadamente 25 pb, aproximadamente 30 pb, aproximadamente 35 pb, aproximadamente 40 pb, aproximadamente 45 pb, aproximadamente 50 pb, aproximadamente 55 pb, aproximadamente 60 pb, aproximadamente 65 pb, aproximadamente 70 pb, aproximadamente 75 pb, aproximadamente 80 pb, aproximadamente 85 pb, aproximadamente 90 pb, aproximadamente 95 pb, aproximadamente 100 pb, aproximadamente 110 pb, aproximadamente 120 pb, aproximadamente 130, aproximadamente 140 pb, aproximadamente 150 pb, aproximadamente 200 pb, aproximadamente 250 pb, aproximadamente 300 pb, aproximadamente 350 pb, aproximadamente 400 pb, aproximadamente 450 pb o aproximadamente 500 pb. Se espera que los avances tecnológicos permitan lecturas de un solo extremo de más de 500 pb, permitiendo lecturas de más de aproximadamente 1000 pb cuando se generen lecturas de extremos emparejados. En una forma de realización, las lecturas de secuencia son de 36 pb. Otros métodos de secuenciación que pueden emplearse por el método de la
invención incluyen los métodos de secuenciación de una sola molécula que pueden secuenciar moléculas de ácidos nucleicos > 5000 pb. La cantidad masiva de salida de secuencia se transfiere mediante una canalización de análisis que transforma la salida de imágenes primarias del secuenciador en cadenas de bases. Un paquete de algoritmos integrados realiza las etapas básicas de transformación de datos primarios: análisis de imágenes, puntuación de intensidad, designación de base y alineamiento.
En una forma de realización, se realiza la secuenciación parcial de los fragmentos de ADN presentes en la muestra y se cuentan etiquetas de secuencia que comprenden lecturas de longitud predeterminada, por ejemplo, 36 pb, que se mapean a un genoma de referencia conocido. Solo las lecturas de secuencia que se alinean de forma única con el genoma de referencia se cuentan como etiquetas de secuencia. En una forma de realización, el genoma de referencia es la secuencia NCBI36/hg18 del genoma de referencia humano, que está disponible en Internet en genoma.ucsc.edu/cgi-bin/hgGateway?org=Human&db=hg18&hgsid=166260105). Otras fuentes de información pública sobre secuencias incluyen GenBank, dbEST, dbSTS, EMBL (el Laboratorio Europeo de Biología Molecular) y DDBJ (el Banco de datos de ADN de Japón). En otra forma de realización, el genoma de referencia comprende la secuencia NCBI36/hg18 del genoma de referencia humano y un genoma de secuencias diana artificiales, que incluye secuencias diana polimórficas, por ejemplo, un genoma de SNP que comprende las SEQ ID NO: 1 -56. En otra forma de realización más, el genoma de referencia es un genoma de secuencia diana artificial que comprende secuencias diana polimórficas, por ejemplo, secuencias SNP de las SEQ ID NO: 1-56.
El mapeo de las etiquetas de secuencia se realiza comparando la secuencia de la etiqueta con la secuencia del genoma de referencia para determinar el origen cromosómico de la molécula de ácido nucleico secuenciada (por ejemplo, ADNcf), y no se necesita información de secuencia genética específica. Hay varios algoritmos informáticos disponibles para alinear secuencias, incluidos, sin limitación, BLAST (Altschul et al., 1990), BLITZ (MPsrch) (Sturrock & Collins, 1993), FASTA (Person & Lipman, 1988), BOWTIE (Langmead et al., Genome Biology 10:R25.1-R25.10 [2009]) o ELAND (Illumina, Inc., San Diego, CA, Estados Unidos). En una forma de realización, un extremo de las copias expandidas clonalmente de las moléculas de ADNcf de plasma se secuencia y se procesa mediante análisis de alineamiento bioinformático para el analizador de genoma de Illumina, que utiliza el programa informático Efficient Large-Scale Alignment of Nucleotide Databases (ELAND). El análisis de la información de secuenciación para la determinación de la aneuploidía puede permitir un pequeño grado de desajuste (0-2 desajustes por etiqueta de secuencia) para tener en cuenta los polimorfismos secundarios que pueden existir entre el genoma de referencia y los genomas de la muestra mixta. El análisis de la información de secuenciación para la determinación de la fracción fetal puede permitir un pequeño grado de desajuste dependiendo de la secuencia polimórfica. Por ejemplo, se puede permitir un pequeño grado de desajuste si la secuencia polimórfica es una STR. En los casos en los que la secuencia polimórfica es un SNP, todas las secuencias que coinciden exactamente con cualquiera de los dos alelos en el sitio del SNP se cuentan en primer lugar y se filtran de las lecturas restantes, para lo cual se puede permitir un pequeño grado de desajuste.
Preparación de bibliotecas de secuenciación
Los secuenciadores de ADN de próxima generación, tales como el 454-FLX (Roche; en la dirección de Internet 454.com), el SOLiD™3 (Applied Biosystems; en la dirección de Internet solid.appliedbiosystems.com), y Genome Analyzer (Illumina; http://www.illumina.com/pages.ilmn?ID=204) han transformado el panorama de la genética por medio de su capacidad para producir cientos de megabases de información de secuencias en una sola ejecución.
Los métodos de secuenciación requieren la preparación de bibliotecas de secuenciación. La preparación de la biblioteca de secuenciación implica la producción de una colección aleatoria de fragmentos de ADN modificados con adaptador, que están listos para ser secuenciados. Las bibliotecas de secuenciación de polinucleótidos se pueden preparar a partir de ADN o ARN, incluidos equivalentes, análogos de ADN o ADNc, que es ADN complementario o copia producido a partir de una plantilla de ARN, por ejemplo, mediante la acción de la transcriptasa inversa. Los polinucleótidos pueden originarse en forma de ADN bicatenario (ADNbc) (por ejemplo, fragmentos de ADN genómico, productos de PCR y de amplificación) o polinucleótidos que pueden haberse originado en forma monocatenaria, tales como ADN o ARN, y convertirse en forma de ADNbc. A modo de ejemplo, las moléculas de ARNm se pueden copiar en ADNc bicatenarios adecuados para su uso en la preparación de una biblioteca de secuenciación. La secuencia precisa de las moléculas de polinucleótidos primarios generalmente no es importante para el método de preparación de bibliotecas y puede ser conocida o desconocida. En una forma de realización, las moléculas de polinucleótidos son moléculas de ADN. Más particularmente, las moléculas de polinucleótidos representan el complemento genético completo de un organismo y son moléculas de ADN genómico, por ejemplo, moléculas de ADNcf, que incluyen secuencias tanto de intrones como de exones (secuencia codificante), así como secuencias reguladoras no codificantes, tales como secuencias promotoras y potenciadoras. Aún más particularmente, las moléculas de polinucleótidos primarios son moléculas de ADN genómico humano, por ejemplo, moléculas de ADNcf presentes en la sangre periférica de un sujeto embarazado. La preparación de bibliotecas de secuenciación para algunas plataformas de secuenciación NGS requiere que los polinucleótidos se encuentren en un intervalo específico de tamaños de fragmentos, por ejemplo, 0-1200 pb. Por lo tanto, es posible que se requiera la fragmentación de polinucleótidos, por ejemplo, ADN genómico. El ADNcf existe como fragmentos de < 300 pares de bases. Por lo tanto, la fragmentación de ADNcf no es necesaria para generar una biblioteca de secuenciación utilizando muestras de ADNcf. La fragmentación de moléculas de polinucleótidos por medios mecánicos, por ejemplo, nebulización,
sonicación e hidro-cizallamiento, da como resultado fragmentos con una mezcla heterogénea de extremos romos y salientes en 3' y 5'. Los polinucleótidos, tanto si se fragmentan a la fuerza o existen de forma natural en forma de fragmentos, se convierten en ADN de extremos romos que tienen 5-fosfatos y 3'-hidroxilo.
Por lo general, los extremos de los fragmentos se reparan en los extremos, es decir, los extremos se vuelven romos utilizando métodos o kits conocidos en la técnica. Los fragmentos de extremos romos se pueden fosforilar mediante tratamiento enzimático, por ejemplo, utilizando polinucleótido quinasa. En algunas formas de realización, un solo desoxinucleótido, por ejemplo, la desoxiadenosina (A), se añade a los extremos 3' de los polinucleótidos, por ejemplo, mediante la actividad de determinados tipos de ADN polimerasa, tales como la polimerasa Taq o la polimerasa Klenow exo minus. Los productos con cola de dA son compatibles con el saliente T presente en el extremo 3' de cada región dúplex de adaptadores a los que se unen en una etapa posterior. La adición de colas de dA evita la autoligación de ambos polinucleótidos de extremos romos, de modo que existe un desplazamiento hacia la formación de las secuencias ligadas al adaptador. Los polinucleótidos con cola de dA se ligan a secuencias de polinucleótidos adaptadores bicatenarios. Se puede utilizar el mismo adaptador para ambos extremos del polinucleótido, o se pueden utilizar dos conjuntos de adaptadores. Los métodos de ligación son conocidos en la técnica y utilizan enzimas ligasa tales como ADN ligasa para unir covalentemente el adaptador al polinucleótido con cola de d-A. El adaptador puede contener un resto 5'-fosfato para facilitar la unión al 3'-OH diana. El polinucleótido con cola de dA contiene un resto fosfato en 5', ya sea residual del proceso de cizallamiento o añadido mediante una etapa de tratamiento enzimático, y se ha reparado en los extremos y opcionalmente se ha extendido por una base o bases salientes, para dar un 3'-OH adecuado para la ligación. Los productos de la reacción de ligación se purifican para eliminar los adaptadores no ligados, los adaptadores que pueden haberse ligado entre sí, y para seleccionar un intervalo de tamaños de plantillas para la generación de clústeres, lo que puede venir precedido por una amplificación, por ejemplo, una amplificación por PCR. La purificación de los productos de ligación se puede obtener mediante métodos que incluyen electroforesis en gel e inmovilización reversible en fase sólida (SPRI).
Los protocolos estándar, por ejemplo, los protocolos para la secuenciación que utilizan, por ejemplo, la plataforma Illumina, instruyen a los usuarios en la purificación de los productos reparados antes de la adición de colas de dA y en la purificación de los productos de adición de colas de dA antes de las etapas de ligación del adaptador de la preparación de la biblioteca. La purificación de los productos reparados en los extremos y los productos con cola de dA elimina enzimas, tampones, sales y similares para proporcionar condiciones de reacción favorables para la etapa enzimática posterior. En la invención reivindicada, las etapas de reparación de extremos, adición de colas de dA y ligación de adaptadores excluyen las etapas de purificación. Así, el método de la invención abarca la preparación de una biblioteca de secuenciación que comprende las etapas consecutivas de reparación de extremos, adición de colas de dA y ligación de adaptador. En casos de preparación de bibliotecas de secuenciación que no requieren la etapa de adición de colas de dA, por ejemplo, protocolos para secuenciación que utilizan las plataformas Roche 454 y SOLID™ 3, las etapas de reparación de extremos y de ligación de adaptadores excluyen la etapa de purificación de los productos de reparación de extremos antes de la ligación de adaptadores.
En la etapa siguiente de una forma de realización del método, se prepara una reacción de amplificación. La etapa de amplificación introduce en las moléculas de plantilla ligadas al adaptador las secuencias de oligonucleótidos requeridas para la hibridación con la celda de flujo. El contenido de una reacción de amplificación es conocido por los expertos en la técnica e incluye sustratos apropiados (tales como dNTP), enzimas (por ejemplo, una ADN polimerasa) y componentes de tampón que se requieren para una reacción de amplificación. Opcionalmente, se puede omitir la amplificación de polinucleótidos ligados a adaptadores. Generalmente, las reacciones de amplificación requieren al menos dos cebadores de amplificación, es decir, oligonucleótidos cebadores, que pueden ser idénticos, e incluyen una 'porción específica de adaptador', capaz de hibridarse con una secuencia de unión al cebador en la molécula polinucleotídica que se va a amplificar (o el complemento de la misma si la plantilla se ve como una sola cadena) durante la etapa de hibridación. Una vez formada, la biblioteca de plantillas preparada según los métodos descritos anteriormente se puede utilizar para la amplificación de ácidos nucleicos en fase sólida. El término "amplificación en fase sólida" se refiere, tal como se utiliza en el presente documento, a cualquier reacción de amplificación de ácido nucleico llevada a cabo en un soporte sólido o en asociación con el mismo, de modo que la totalidad o una parte de los productos amplificados se inmovilicen en el soporte sólido a medida que se vayan formando. En particular, el término abarca la reacción en cadena de la polimerasa en fase sólida (PCR en fase sólida) y la amplificación isotérmica en fase sólida, que son reacciones análogas a la amplificación en fase de solución estándar, excepto que uno o ambos cebadores de amplificación directo e inverso están inmovilizados en el soporte sólido. La PCR en fase sólida abarca sistemas tales como emulsiones, en los que un cebador está anclado a una perla y el otro en solución libre, y la formación de colonias en matrices de gel en fase sólida en las que un cebador está anclado a la superficie y el otro en solución libre. Después de la amplificación, las bibliotecas de secuenciación se pueden analizar mediante electroforesis capilar microfluídica para garantizar que la biblioteca esté exenta de dímeros adaptadores o ADN monocatenario. La biblioteca de moléculas de polinucleótido de plantilla es particularmente adecuada para su uso en métodos de secuenciación en fase sólida. Además de proporcionar plantillas para la secuenciación en fase sólida y la PCR en fase sólida, las plantillas de la biblioteca proporcionan plantillas para la amplificación del genoma completo.
En una forma de realización, la biblioteca de polinucleótidos ligados a adaptadores se somete a una secuenciación masivamente paralela, que incluye técnicas para secuenciar millones de fragmentos de ácidos nucleicos, por ejemplo, utilizando la unión de a Dn genómico fragmentado aleatoriamente a una superficie plana, ópticamente transparente y
la amplificación en fase sólida para crear una celda de flujo de secuenciación de alta densidad con millones de clústeres. Las matrices agrupadas se pueden preparar o bien utilizando un proceso de termociclado, tal como se describe en la patente WO9844151, o bien un proceso mediante el cual la temperatura se mantiene constante y los ciclos de extensión y desnaturalización se realizan mediante cambios de reactivos. El método Solexa/Illumina al que se hace referencia en el presente documento se basa en la unión de ADN genómico fragmentado aleatoriamente a una superficie plana ópticamente transparente. Los fragmentos de ADN unidos se extienden y se amplifican en puente para crear una celda de flujo de secuenciación de densidad ultraalta con millones de clústeres que contienen cada una, miles de copias de la misma plantilla (documentos WO 00/18957 y WO 98/44151). Las plantillas de clústeres se secuencian utilizando una sólida tecnología de secuenciación por síntesis de ADN de cuatro colores que emplea terminadores reversibles con colorantes fluorescentes extraíbles. Alternativamente, la biblioteca se puede amplificar en perlas en las que cada perla contiene un cebador de amplificación directo e inverso.
La secuenciación de las bibliotecas amplificadas se puede llevar a cabo utilizando cualquier técnica de secuenciación adecuada tal como se describe en el presente documento. En una forma de realización, la secuenciación es una secuenciación masivamente paralela que utiliza secuenciación por síntesis con terminadores de colorantes reversibles. En otras formas de realización, la secuenciación es una secuenciación masivamente paralela que utiliza secuenciación por ligación. En otras formas de realización, la secuenciación es secuenciación de una sola molécula.
Determinación de aneuploidía
La precisión requerida para determinar correctamente si una aneuploidía está presente o ausente en una muestra se basa en parte en la variación del número de etiquetas de secuencia que se mapean al genoma de referencia entre muestras dentro de una ejecución de secuenciación (variabilidad intercromosómica), y la variación del número de etiquetas de secuencia que se mapean al genoma de referencia en diferentes ejecuciones de secuenciación (variabilidad intersecuenciación). Por ejemplo, las variaciones pueden ser particularmente pronunciadas para las etiquetas que se mapean a secuencias de referencia ricas en GC o pobres en GC. En un caso, el método utiliza información de secuenciación para calcular la dosis de cromosoma, que intrínsecamente explica la variabilidad acumulada derivada de la variabilidad intercromosómica, intersecuenciación y dependiente de la plataforma. Las dosis de cromosomas se determinan a partir de la información de secuenciación, es decir, el número de etiquetas de secuencia, para la secuencia de interés, por ejemplo, el cromosoma 21, y el número de etiquetas de secuencia para una secuencia de normalización. La identificación de una secuencia de normalización se realiza en un conjunto de muestras calificadas que se sabe que no contienen una aneuploidía de la secuencia de interés. El diagrama de flujo proporcionado en la figura 1 muestra un caso del método 100 con el que se identifican secuencias de normalización, por ejemplo, cromosomas de normalización, y se determina la presencia o la ausencia de una aneuploidía.
En la etapa 110 se obtiene un conjunto de muestras maternas calificadas para identificar secuencias de normalización calificadas, por ejemplo, cromosomas de normalización, y proporcionar valores de varianza para su uso en la determinación de la identificación estadísticamente significativa de una aneuploidía en muestras de ensayo. En la etapa 110 se obtiene una pluralidad de muestras calificadas biológicas de una pluralidad de sujetos que se sabe que comprenden células que tienen un número de copias normal para cualquier secuencia de interés, por ejemplo, un cromosoma de interés, tal como un cromosoma asociado con una aneuploidía. En un caso, las muestras calificadas se obtienen de madres embarazadas con un feto que se ha confirmado mediante medios citogenéticos que tiene un número normal de copias de cromosomas con respecto al cromosoma de interés. Las muestras biológicas maternas calificadas pueden ser muestras de fluidos biológicos, por ejemplo, muestras de plasma, o cualquier muestra adecuada tal como se ha descrito anteriormente que contiene una mezcla de moléculas de ADNcf fetal y materno. La muestra es una muestra materna que se obtiene de un sujeto femenino embarazado, por ejemplo, una mujer embarazada. Cualquier muestra biológica materna puede usarse como fuente de ácidos nucleicos fetales y maternos que están contenidos en células o que están "libres de células". En algunos casos, es ventajoso obtener una muestra materna que comprenda ácidos nucleicos libres de células, por ejemplo, ADNcf. Preferentemente, la muestra biológica materna es una muestra de fluido biológico. Un fluido biológico incluye, como ejemplos no limitantes, sangre, plasma, suero, sudor, lágrimas, esputo, orina, flujo de oído, linfa, saliva, líquido cefalorraquídeo, estragos, suspensión de médula ósea, flujo vaginal, lavado transcervical, líquido cerebral, ascitis, leche, secreciones del tracto respiratorio, intestinal y genitourinario, líquido amniótico y muestras de leucoforesis. En algunos casos, la muestra de fluido biológico es una muestra que se puede obtener fácilmente mediante procedimientos no invasivos, por ejemplo, sangre, plasma, suero, sudor, lágrimas, esputo, orina, esputo, flujo del oído y saliva. En algunos casos, la muestra biológica es una muestra de sangre periférica, o el plasma y/o las fracciones de suero del mismo. En otros casos, la muestra es una mezcla de dos o más muestras biológicas, por ejemplo, una muestra biológica puede comprender dos o más muestras de fluido biológico. Tal como se utilizan en el presente documento, los términos "sangre", "plasma" y "suero" abarcan expresamente fracciones o porciones procesadas de los mismos. En algunos casos, la muestra biológica se procesa para obtener una fracción de muestra, por ejemplo, plasma, que contiene la mezcla de ácidos nucleicos fetales y maternos. En algunos casos, la mezcla de ácidos nucleicos fetales y maternos se procesa adicionalmente a partir de la fracción de muestra, por ejemplo, plasma, para obtener una muestra que comprende una mezcla purificada de ácidos nucleicos fetales y maternos, por ejemplo, ADNcf. Los ácidos nucleicos libres de células, incluido el ADN libre de células, pueden obtenerse mediante varios métodos conocidos en la técnica a partir de muestras biológicas, incluidas, pero sin limitación, plasma, suero y orina (Fan et al., Proc Natl Acad Sci 105:16266-16271 [2008]; Koide et al., Prenatal Diagnosis 25:604-607 [2005]; Chen et al., Nature Med. 2: 1033-1035 [1996]; Lo et al., Lancet 350: 485487 [1997). Para separar el ADNcf de las células, se pueden utilizar métodos de fraccionamiento, centrifugación (por ejemplo, centrifugación por gradiente de densidad), precipitación específica de ADN o clasificación y/o separación de células de alto rendimiento. Están disponibles kits comercialmente disponibles para la separación manual y automatizada de ADNcf (Roche Diagnostics, Indianapolis, IN, Qiagen, Valencia, CA, Macherey-Nagel, Duren, DE). En algunos casos, puede resultar ventajoso fragmentar las moléculas de ácido nucleico en la muestra de ácido nucleico. La fragmentación puede ser aleatoria o puede ser específica, tal como se logra, por ejemplo, usando digestión con endonucleasas de restricción. Los métodos para la fragmentación aleatoria son bien conocidos en la técnica e incluyen, por ejemplo, digestión limitada con ADNasa, tratamiento con álcali y cizallamiento físico. En un caso, los ácidos nucleicos de muestra se obtienen como ADNcf, que no se somete a fragmentación. En otros casos, los ácidos nucleicos de muestra se obtienen como ADN genómico, que se somete a fragmentación en fragmentos de aproximadamente 500 pares de bases o más, y a los que se pueden aplicar fácilmente los métodos NGS. Se prepara una biblioteca de secuenciación a partir de ADN fragmentado de forma natural o fragmentado a la fuerza. En un caso, la preparación de la biblioteca de secuenciación comprende las etapas consecutivas de reparación de extremos, adición de colas de dA y ligación de adaptador a los fragmentos de ADN. En un caso, la preparación de la biblioteca de secuenciación comprende las etapas consecutivas de reparación de extremos y ligación de adaptador a los fragmentos de ADN.
En el paso 120, se secuencia al menos una porción de cada uno de todos los ácidos nucleicos calificados contenidos en las muestras maternas calificadas. Antes de la secuenciación, la mezcla de ácidos nucleicos fetales y maternos, por ejemplo, ADNcf purificado, se modifica para preparar una biblioteca de secuenciación para generar lecturas de secuencias de entre 20 y 40 pb por ejemplo, 36 bp, que están alineadas con un genoma de referencia, por ejemplo, hg 18. En algunos casos, las lecturas de secuencias comprenden aproximadamente 20 pb, aproximadamente 25 pb, aproximadamente 30 pb, aproximadamente 35 pb, aproximadamente 40 pb, aproximadamente 45 pb, aproximadamente 50 pb, aproximadamente 55 pb, aproximadamente 60 pb, aproximadamente 65 pb, aproximadamente 70 pb, aproximadamente 75 pb, aproximadamente 80 pb, aproximadamente 85 pb, aproximadamente 90 pb, aproximadamente 95 pb, aproximadamente 100 pb, aproximadamente 110 pb, aproximadamente 120 pb, aproximadamente 130, aproximadamente 140 pb, aproximadamente 150 pb, aproximadamente 200 pb, aproximadamente 250 pb, aproximadamente 300 pb, aproximadamente 350 pb, aproximadamente 400 pb, aproximadamente 450 pb o aproximadamente 500 pb. Se espera que los avances tecnológicos permitan lecturas de un solo extremo de más de 500 pb, permitiendo lecturas de más de aproximadamente 1000 pb cuando se generen lecturas de extremos emparejados. En un caso, las lecturas de secuencia comprenden 36 pb. Las lecturas de secuencia se alinean con un genoma de referencia humano, y las lecturas que se mapean de forma única al genoma de referencia humano se cuentan como etiquetas de secuencia. En un caso se obtienen al menos aproximadamente 3 x 106 etiquetas de secuencia calificadas, al menos aproximadamente 5 x 106 etiquetas de secuencia calificadas, al menos aproximadamente 8 x 106 etiquetas de secuencia calificadas, al menos aproximadamente 10 x 106 etiquetas de secuencia calificadas, al menos aproximadamente 15 x 106 etiquetas de secuencia calificadas, al menos aproximadamente 20 x 106 etiquetas de secuencia calificadas, al menos aproximadamente 30 x 106 etiquetas de secuencia calificadas, al menos aproximadamente 40 x 106 etiquetas de secuencia calificadas, o al menos aproximadamente 50 x 106 etiquetas de secuencia calificadas que comprenden lecturas de entre 20 y 40 pb a partir de lecturas que se mapean únicamente a un genoma de referencia.
En la etapa 130, todas las etiquetas obtenidas de la secuenciación de los ácidos nucleicos en las muestras maternas calificadas se cuentan para determinar una densidad de etiqueta de secuencia calificada. En un caso, la densidad de etiquetas de secuencia se determina como el número de etiquetas de secuencia calificadas mapeadas a la secuencia de interés en el genoma de referencia. En otro caso, la densidad de etiquetas de secuencias calificadas se determina como el número de etiquetas de secuencias calificadas mapeadas a una secuencia de interés normalizada a la longitud de la secuencia de interés calificada a la que están mapeadas. Las densidades de etiquetas de secuencia que se determinan como una relación de la densidad de etiquetas con respecto a la longitud de la secuencia de interés se denominan en el presente documento relaciones de densidad de etiquetas. No se requiere la normalización a la longitud de la secuencia de interés y se puede incluir como una etapa para reducir el número de dígitos en un número para simplificarlo para la interpretación humana. Como todas las etiquetas de secuencia calificadas se mapean y se cuentan en cada una de las muestras calificadas, la densidad de etiquetas de secuencia para una secuencia de interés, por ejemplo, un cromosoma de interés, se determina en las muestras calificadas, al igual que las densidades de etiquetas de secuencias para secuencias adicionales a partir de las cuales se identifican secuencias de normalización, por ejemplo, cromosomas, posteriormente. En un caso, la secuencia de interés es un cromosoma asociado con una aneuploidía cromosómica, por ejemplo, cromosoma 21, y la secuencia de normalización calificada es un cromosoma que no está asociado con una aneuploidía cromosómica y cuya variación en la densidad de etiquetas de secuencia se aproxima mejor a la del cromosoma 21. Por ejemplo, una secuencia de normalización calificada es una secuencia que tiene la menor variabilidad. En algunos casos, la secuencia de normalización es una secuencia que distingue mejor una o más muestras calificadas de una o más muestras afectadas, es decir, la secuencia de normalización es una secuencia que tiene la mayor diferenciabilidad. El nivel de diferenciabilidad se puede determinar como una diferencia estadística entre las dosis de cromosomas en una población de muestras calificadas y la(s) dosis de cromosoma(s) en una o más muestras de ensayo. En otro caso, la secuencia de interés es un segmento de un cromosoma asociado con una aneuploidía parcial, por ejemplo, una deleción o una inserción cromosómica, o una translocación cromosómica desequilibrada, y la secuencia de normalización es un segmento cromosómico que no
está asociado con la aneuploidía parcial y cuya variación en la densidad de etiquetas de secuencia se aproxima mejor a la del segmento cromosómico asociado con la aneuploidía parcial.
En la etapa 140, en base a las densidades de etiquetas calificadas calculadas, se determina una dosis de secuencia calificada para una secuencia de interés como la relación entre la densidad de etiquetas de secuencia para la secuencia de interés y la densidad de etiquetas de secuencia calificada para secuencias adicionales a partir de las cuales se identifican posteriormente las secuencias de normalización. En un caso, las dosis para el cromosoma de interés, por ejemplo, el cromosoma 21, se determina como una relación de la densidad de etiquetas de secuencia del cromosoma 21 y la densidad de etiquetas de secuencia para cada uno de los cromosomas restantes, es decir, los cromosomas 1 -20, el cromosoma 22, el cromosoma X y el cromosoma Y (véanse los ejemplos 3-5 y las figuras 9-15).
En la etapa 145, una secuencia de normalización, por ejemplo, un cromosoma de normalización, se identifica para una secuencia de interés, por ejemplo, el cromosoma 21, en una muestra calificada basada en las dosis de secuencia calculadas. El método identifica secuencias que inherentemente tienen características similares y que son propensas a variaciones similares entre muestras y ejecuciones de secuenciación, y que son útiles para determinar dosis de secuencia en muestras de ensayo. En algunos casos, la secuencia de normalización es la que mejor diferencia una muestra afectada, es decir, una muestra aneuploide, de una o más muestras calificadas. En otros casos, una secuencia de normalización es una secuencia que muestra una variabilidad en el número de etiquetas de secuencia que se mapean a la misma entre muestras y ejecuciones de secuenciación que mejor se aproxima a la secuencia de interés para la que se utiliza como parámetro de normalización y/o que mejor puede diferenciar una muestra afectada de una o más muestras no afectadas.
En algunos casos, se identifica más de una secuencia de normalización. Por ejemplo, la variación, por ejemplo, el coeficiente de variación, en la dosis de cromosoma para el cromosoma de interés 21 es menor cuando se utiliza la densidad de etiqueta de secuencia del cromosoma 14. En otros casos, se identifican dos, tres, cuatro, cinco, seis, siete, ocho o más secuencias de normalización para su uso en la determinación de una dosis de secuencia para una secuencia de interés en una muestra de ensayo.
En un caso, la secuencia de normalización para el cromosoma 21 se selecciona de entre el cromosoma 9, el cromosoma 1, el cromosoma 2, el cromosoma 3, el cromosoma 4, el cromosoma 5, el cromosoma 6, el cromosoma 7, el cromosoma 8, el cromosoma 10, el cromosoma 11, el cromosoma 12, el cromosoma 13, el cromosoma 14, el cromosoma 15, el cromosoma 16 y el cromosoma 17. Preferentemente, la secuencia de normalización para el cromosoma 21 se selecciona de entre el cromosoma 9, el cromosoma 1, el cromosoma 2, el cromosoma 11, el cromosoma 12 y el cromosoma 14. En un caso, la secuencia de normalización para el cromosoma 21 es un grupo de cromosomas seleccionados de entre el cromosoma 9, el cromosoma 1, el cromosoma 2, el cromosoma 3, el cromosoma 4, el cromosoma 5, el cromosoma 6, el cromosoma 7, el cromosoma 8, el cromosoma 10, el cromosoma 11, el cromosoma 12, el cromosoma 13, el cromosoma 14, el cromosoma 15, el cromosoma 16 y el cromosoma 17. En otros casos, la secuencia de normalización para el cromosoma 21 es un grupo de cromosomas seleccionados de entre el cromosoma 9, el cromosoma 1, el cromosoma 2, el cromosoma 11, el cromosoma 12 y el cromosoma 14.
En un caso, la secuencia de normalización para el cromosoma 18 se selecciona de entre el cromosoma 8, el cromosoma 2, el cromosoma 3, el cromosoma 4, el cromosoma 5, el cromosoma 6, el cromosoma 7, el cromosoma 9, el cromosoma 10, el cromosoma 11, el cromosoma 12, el cromosoma 13 y el cromosoma 14. Preferentemente, la secuencia de normalización para el cromosoma 18 se selecciona de entre el cromosoma 8, el cromosoma 2, el cromosoma 3, el cromosoma 5, el cromosoma 6, el cromosoma 12 y el cromosoma 14. Alternativamente, la secuencia de normalización para el cromosoma 18 es un grupo de cromosomas seleccionados de entre el cromosoma 8, el cromosoma 2, el cromosoma 3, el cromosoma 4, el cromosoma 5, el cromosoma 6, el cromosoma 7, el cromosoma 9, el cromosoma 10, el cromosoma 11, el cromosoma 12, el cromosoma 13 y el cromosoma 14. En otros casos, la secuencia de normalización para el cromosoma 18 es un grupo de cromosomas seleccionados de entre el cromosoma 8, el cromosoma 2, el cromosoma 3, el cromosoma 5, el cromosoma 6, el cromosoma 12 y el cromosoma 14.
En un caso, la secuencia de normalización para el cromosoma X se selecciona de entre el cromosoma 1, el cromosoma 2, el cromosoma 3, el cromosoma 4, el cromosoma 5, el cromosoma 6, el cromosoma 7, el cromosoma 8, el cromosoma 9, el cromosoma 10, el cromosoma 11, el cromosoma 12, el cromosoma 13, el cromosoma 14, el cromosoma 15 y el cromosoma 16. Preferentemente, la secuencia de normalización para el cromosoma X se selecciona de entre el cromosoma 2, el cromosoma 3, el cromosoma 4, el cromosoma 5, el cromosoma 6 y el cromosoma 8. Alternativamente, la secuencia de normalización para el cromosoma X es un grupo de cromosomas seleccionados de entre el cromosoma 1, el cromosoma 2, el cromosoma 3, el cromosoma 4, el cromosoma 5, el cromosoma 6, el cromosoma 7, el cromosoma 8, el cromosoma 9, el cromosoma 10, el cromosoma 11, el cromosoma 12, el cromosoma 13, el cromosoma 14, el cromosoma 15 y el cromosoma 16. En otros casos, la secuencia de normalización para el cromosoma X es un grupo de cromosomas seleccionados de entre el cromosoma 2, el cromosoma 3, el cromosoma 4, el cromosoma 5, el cromosoma 6 y el cromosoma 8.
En un caso, la secuencia de normalización para el cromosoma 13 se selecciona de entre el cromosoma 2, el cromosoma 3, el cromosoma 4, el cromosoma 5, el cromosoma 6, el cromosoma 7, el cromosoma 8, el cromosoma 9, el cromosoma 10, el cromosoma 11, el cromosoma 12, el cromosoma 14, el cromosoma 18 y el cromosoma 21.
Preferentemente, la secuencia de normalización para el cromosoma 13 se selecciona de entre el cromosoma 2, el cromosoma 3, el cromosoma 4, el cromosoma 5, el cromosoma 6 y el cromosoma 8. En otro caso, la secuencia de normalización para el cromosoma 13 es un grupo de cromosomas seleccionados de entre el cromosoma 2, el cromosoma 3, el cromosoma 4, el cromosoma 5, el cromosoma 6, el cromosoma 7, el cromosoma 8, el cromosoma 9, el cromosoma 10, el cromosoma 11, el cromosoma 12, el cromosoma 14, el cromosoma 18 y el cromosoma 21. En otros casos, la secuencia de normalización para el cromosoma 13 es un grupo de cromosomas seleccionados de entre el cromosoma 2, el cromosoma 3, el cromosoma 4, el cromosoma 5, el cromosoma 6 y el cromosoma 8.
La variación en la dosis de cromosoma para el cromosoma Y es superior a 30, independientemente de qué cromosoma de normalización se utilice para determinar la dosis del cromosoma Y. Por lo tanto, cualquier cromosoma, o un grupo de dos o más cromosomas seleccionados de entre los cromosomas 1-22 y el cromosoma X, puede usarse como la secuencia de normalización para el cromosoma Y. En un caso, el, al menos un, cromosoma de normalización es un grupo de cromosomas que consiste en los cromosomas 1-22 y el cromosoma X. En otro caso, el, al menos un, cromosoma de normalización es un grupo de cromosomas seleccionados de entre el cromosoma 2, el cromosoma 3, el cromosoma 4, el cromosoma 5 y el cromosoma 6.
Basándose en la identificación de la(s) secuencia(s) de normalización en muestras calificadas, se determina una dosis de secuencia para una secuencia de interés en una muestra de ensayo que comprende una mezcla de ácidos nucleicos derivados de genomas que difieren en una o más secuencias de interés.
En la etapa 115, una muestra de ensayo, por ejemplo, muestra de plasma, que comprende ácidos nucleicos fetales y maternos, por ejemplo, ADNcf, se obtiene de un sujeto embarazado, por ejemplo, una mujer embarazada, para la que se necesita determinar la presencia o la ausencia de una aneuploidía fetal.
Una biblioteca de secuenciación se prepara tal como se describe para la etapa 120, y en la etapa 125, al menos una parte de los ácidos nucleicos de ensayo en la muestra de ensayo se secuencia para generar millones de lecturas de secuencias que comprenden entre 20 y 500 pb, por ejemplo, 36pb. Como en la etapa 120, las lecturas generadas a partir de la secuenciación de los ácidos nucleicos en la muestra de ensayo se mapean de forma única a un genoma humano de referencia y se cuentan. Tal como se describe en la etapa 120, se obtienen al menos aproximadamente 3 x 106 etiquetas de secuencia calificadas, al menos aproximadamente 5 x 106 etiquetas de secuencia calificadas, al menos aproximadamente 8 x 106 etiquetas de secuencia calificadas, al menos aproximadamente 10 x 106 etiquetas de secuencia calificadas, al menos aproximadamente 15 x 106 etiquetas de secuencia calificadas, al menos aproximadamente 20 x 106 etiquetas de secuencia calificadas, al menos aproximadamente 30 x 106 etiquetas de secuencia calificadas, al menos aproximadamente 40 x 106 etiquetas de secuencia calificadas, o al menos aproximadamente 50 x 106 etiquetas de secuencia calificadas que comprenden lecturas de entre 20 y 40 pb a partir de lecturas que se mapean únicamente a un genoma de referencia humano.
En la etapa 135, todas las etiquetas obtenidas a partir de la secuenciación de los ácidos nucleicos en las muestras de ensayo se cuentan para determinar una densidad de etiqueta de secuencia de ensayo. En un caso, el número de etiquetas de secuencia de ensayo mapeadas a una secuencia de interés se normaliza a la longitud conocida de una secuencia de interés a la que están mapeadas para proporcionar una densidad de etiqueta de secuencia de ensayo. Tal como se ha descrito para las muestras calificadas, no se requiere la normalización a la longitud conocida de una secuencia de interés y se puede incluir como una etapa para reducir el número de dígitos en un número para simplificarlo para la interpretación humana. A medida que todas las etiquetas de secuencia de ensayo mapeadas se cuentan en la muestra de ensayo, la densidad de etiquetas de secuencia para una secuencia de interés, por ejemplo, una secuencia clínicamente relevante, tal como el cromosoma 21, se determina en las muestras de ensayo, al igual que las densidades de etiquetas de secuencia para secuencias adicionales que corresponden a al menos una secuencia de normalización identificada en las muestras calificadas.
En la etapa 150, basándose en la identidad de al menos una secuencia de normalización en las muestras calificadas, se determina una dosis de secuencia de ensayo para una secuencia de interés en la muestra de ensayo. La dosis de secuencia, por ejemplo, la dosis de cromosoma, para una secuencia de interés en una muestra de ensayo es una relación entre la densidad de etiquetas de secuencia determinada para la secuencia de interés en la muestra de ensayo y la densidad de etiquetas de secuencia de al menos una secuencia de normalización determinada en la muestra de ensayo, en la que la secuencia de normalización en la muestra de ensayo corresponde a la secuencia de normalización identificada en las muestras calificadas para la secuencia particular de interés. Por ejemplo, si se determina que la secuencia de normalización identificada para el cromosoma 21 en las muestras calificadas es el cromosoma 14, entonces la dosis de la secuencia de ensayo para el cromosoma 21 (secuencia de interés) se determina como la relación de la densidad de etiquetas de secuencia para el cromosoma 21 y la densidad de etiqueta de secuencia para el cromosoma 14 determinada en la muestra de ensayo. De forma similar, se determinan las dosis de cromosomas para los cromosomas 13, 18, X, Y y otros cromosomas asociados con aneuploidías cromosómicas. Tal como se ha descrito anteriormente, una secuencia de interés puede ser parte de un cromosoma, por ejemplo, un segmento cromosómico. En consecuencia, la dosis para un segmento cromosómico se puede determinar como la relación entre la densidad de etiquetas de secuencia determinada para el segmento en la muestra de ensayo y la densidad de etiquetas de secuencia para el segmento cromosómico de normalización en la muestra de ensayo,
correspondiendo el segmento de normalización en la muestra de ensayo al segmento de normalización identificado en las muestras calificadas para el segmento particular de interés.
En la etapa 155, los valores umbrales se derivan de los valores de desviación estándar establecidos para una pluralidad de dosis de secuencia calificadas. La clasificación precisa depende de las diferencias entre las distribuciones de probabilidad para las diferentes clases, es decir, el tipo de aneuploidía. Preferentemente, los umbrales se eligen a partir de la distribución empírica para cada tipo de aneuploidía, por ejemplo, trisomía 21. Los posibles valores umbrales que se establecieron para clasificar las aneuploidías de trisomía 13, trisomía 18, trisomía 21 y monosomía X son tal como se describen en los ejemplos, que describen el uso del método para determinar las aneuploidías cromosómicas mediante la secuenciación de ADNcf extraído de una muestra materna que comprende una mezcla de ácidos nucleicos fetales y maternos.
En la etapa 160, la variación del número de copias de la secuencia de interés, por ejemplo, la aneuploidía cromosómica o parcial se determina en la muestra de ensayo comparando la dosis de la secuencia de ensayo para la secuencia de interés con al menos un valor umbral establecido a partir de las dosis de la secuencia calificada.
En la etapa 160, la dosis calculada para una secuencia de ensayo de interés se compara con la establecida como los valores umbrales que se eligen según un umbral de fiabilidad definido por el usuario para clasificar la muestra como "normal", "afectada" o "sin designación" en la etapa 165. Las muestras "sin designación" son muestras para las que no se puede realizar un diagnóstico definitivo con fiabilidad.
Otro caso divulgado en el presente documento es un método para proporcionar un diagnóstico prenatal de una aneuploidía cromosómica fetal en una muestra biológica que comprende moléculas de ácidos nucleicos fetales y maternos. El diagnóstico se realiza basándose en la recepción de los datos de secuenciación de al menos una porción de la mezcla de moléculas de ácidos nucleicos fetales y maternos derivadas de una muestra de ensayo biológica, por ejemplo, una muestra de plasma materno, calculando a partir de los datos de secuenciación una dosis de cromosoma de normalización para uno o más cromosomas de interés, determinando una diferencia estadísticamente significativa entre la dosis de cromosoma de normalización para el cromosoma de interés en la muestra de ensayo y un valor umbral establecido en una pluralidad de muestras calificadas (normales), y proporcionando el diagnóstico prenatal basado en la diferencia estadística. Tal como se describe en la etapa 165 del método, se realiza un diagnóstico de normal o afectada. Se proporciona una "sin designación" en caso de que el diagnóstico de normal o afectada no se pueda realizar con seguridad.
Determinación de CNV para diagnósticos prenatales
El ADN y el ARN fetales libres de células que circulan en la sangre materna se pueden utilizar para el diagnóstico prenatal temprano no invasivo (NIPD) de un número cada vez mayor de afecciones genéticas, tanto para la gestión del embarazo como para ayudar en la toma de decisiones reproductivas. La presencia de ADN libre de células que circula en el torrente sanguíneo se conoce desde hace más de 50 años. Más recientemente se ha descubierto la presencia de pequeñas cantidades de ADN fetal circulante en el torrente sanguíneo materno durante el embarazo. Lo et al., Lancet 350:485-487 [1997]). Se cree que se origina a partir de células placentarias muertas, y se ha demostrado que el ADN fetal libre de células (ADNcf) consiste en fragmentos cortos, por lo general de menos de 200 pb de longitud Chan et al., Clin Chem 50:88-92 [2004]), que se puede distinguir ya desde las 4 semanas de gestación (Illanes et al., Early Human Dev 83:563-566 [2007]), y se sabe que se elimina de la circulación materna a las pocas horas del parto (Lo et al., Am J Hum Genet 64:218-224 [1999]). Además del ADNcf, también se pueden distinguir fragmentos de ARN fetal libre de células (ARNcf) en el torrente sanguíneo materno, que se originan a partir de genes que se transcriben en el feto o la placenta. La extracción y posterior análisis de estos elementos genéticos fetales a partir de una muestra de sangre materna ofrece nuevas oportunidades para el NIPD.
El presente método es un método independiente de polimorfismos que se usa en NIPD y que no requiere que el ADNcf fetal se distinga del ADNcf materno para permitir la determinación de una aneuploidía fetal. En algunos casos, la aneuploidía es una trisomía o monosomía cromosómica completa, o una trisomía o monosomía parcial. Las aneuploidías parciales están provocadas por la pérdida o la ganancia de parte de un cromosoma y abarcan los desequilibrios cromosómicos resultantes de translocaciones desequilibradas, inversiones desequilibradas, deleciones e inserciones. Con mucho, la aneuploidía conocida más común compatible con la vida es la trisomía 21, es decir, el síndrome de Down (DS), que está provocado por la presencia de parte o la totalidad del cromosoma 21. En raras ocasiones, el síndrome de Down puede estar provocado por un defecto hereditario o esporádico por el cual una copia adicional de la totalidad o de parte del cromosoma 21 se une a otro cromosoma (generalmente el cromosoma 14) para formar un solo cromosoma aberrante. El DS está asociado con deterioro intelectual, graves dificultades de aprendizaje y un exceso de mortalidad provocado por problemas de salud a largo plazo, tales como enfermedades cardiacas. Otras aneuploidías con significado clínico conocido incluyen el síndrome de Edward (trisomía 18) y el síndrome de Patau (trisomía 13), que frecuentemente son mortales en los primeros meses de vida. También se conocen anomalías asociadas con el número de cromosomas sexuales e incluyen la monosomía X, por ejemplo, el síndrome de Turner (XO) y el síndrome triple X (XXX) en los nacimientos femeninos y el síndrome de Kleinefelter (XXY) y el síndrome XYY en los nacimientos masculinos, todos ellos asociados con varios fenotipos que incluyen esterilidad y reducción de las
habilidades intelectuales. El método de la divulgación se puede usar para diagnosticar estas y otras anomalías cromosómicas prenatalmente.
Según los casos de la presente divulgación, la trisomía determinada por los métodos divulgados en el presente documento se selecciona de entre trisomía 21 (T21; síndrome de Down), trisomía 18 (T18; síndrome de Edward), trisomía 16 (T16), trisomía 22 (T22; síndrome de ojo de gato), trisomía 15 (T15; síndrome de Prader Willi), trisomía 13 (T13; síndrome de Patau), trisomía 8 (T8; síndrome de Warkany) y las trisomías XXY (síndrome de Kleinefelter), XYY o XXX. Se apreciará que se pueden determinar otras diversas trisomías y trisomías parciales en ADNcf fetal según las enseñanzas del presente documento. Estas incluyen, pero sin limitación, trisomía parcial 1q32-44, trisomía 9p con trisomía, trisomía 4 mosaicismo, trisomía 17p, trisomía parcial 4q26-qter, trisomía 9, trisomía parcial 2p, trisomía parcial 1q y/o trisomía parcial 6p/monosomía 6q.
El método de la presente divulgación también se puede utilizar para determinar monosomía cromosómica X y monosomías parciales tales como la monosomía 13, la monosomía 15, la monosomía 16, la monosomía 21 y la monosomía 22, que se sabe que están involucradas en el aborto espontáneo. La monosomía parcial de los cromosomas típicamente implicados en la aneuploidía completa también puede determinarse mediante el método de la divulgación. La monosomía 18p es un trastorno cromosómico raro en el que se elimina la totalidad o parte del brazo corto (p) del cromosoma 18 (monosómico). El trastorno se caracteriza típicamente por baja estatura, grados variables de retraso mental, retrasos en el habla, malformaciones del cráneo y la región facial (craneofacial) y/o anomalías físicas adicionales. Los defectos craneofaciales asociados pueden variar mucho en rango y gravedad de un caso a otro. Las condiciones provocadas por cambios en la estructura o el número de copias del cromosoma 15 incluyen el síndrome de Angelman y el síndrome de Prader-Willi, que implican una pérdida de actividad génica en la misma parte del cromosoma 15, la región 15q11-q13. Se apreciará que varias translocaciones y microdeleciones pueden ser asintomáticas en el progenitor portador, pero pueden causar una enfermedad genética importante en la descendencia. Por ejemplo, una madre sana que porta la microdeleción 15q11-q13 puede dar a luz a un niño con síndrome de Angelman, un trastorno neurodegenerativo grave. Así la presente divulgación se puede utilizar para identificar dicha deleción en el feto. La monosomía parcial 13q es un trastorno cromosómico raro que se produce cuando falta una parte del brazo largo (q) del cromosoma 13 (monosómico). Los neonatos que nacen con monosomía parcial 13q pueden presentar bajo peso al nacer, malformaciones de la cabeza y la cara (región craneofacial), anomalías esqueléticas (especialmente de las manos y los pies) y otras anomalías físicas. El retraso mental es característico de esta condición. La tasa de mortalidad durante la infancia es alta entre las personas que nacen con este trastorno. Casi todos los casos de monosomía parcial 13q se producen aleatoriamente sin razón aparente (esporádicos). El síndrome de deleción 22q11.2, también conocido como síndrome de DiGeorge, es un síndrome provocado por la deleción de una pequeña porción del cromosoma 22. La deleción (22 q11.2) se produce cerca de la mitad del cromosoma en el brazo largo de un cromosoma del par de cromosomas. Las características de este síndrome varían ampliamente, incluso entre miembros de la misma familia, y afectan a muchas partes del cuerpo. Los signos y síntomas característicos pueden incluir defectos de nacimiento tales como cardiopatías congénitas, defectos en el paladar, más comúnmente relacionados con problemas neuromusculares con cierre (insuficiencia velofaríngea), problemas de aprendizaje, diferencias leves en los rasgos faciales e infecciones recurrentes. Las microdeleciones en la región cromosómica 22q112 se asocian con un riesgo de esquizofrenia de 20 a 30 veces superior. En un caso, el método descrito en el presente documento se utiliza para determinar monosomías parciales que incluyen, pero sin limitación, la monosomía 18p, la monosomía parcial del cromosoma 15 (15q 11 -q 13), la monosomía parcial 13q, y la monosomía parcial del cromosoma 22 también se puede determinar usando el método. El ejemplo, 6 y la figura 16 ilustran el uso del método de la divulgación para determinar la presencia de una deleción parcial del cromosoma 11.
El método de divulgación también se puede utilizar para determinar cualquier aneuploidía si uno de los padres es un portador conocido de dicha anomalía. Estas incluyen, pero sin limitación, mosaico para un pequeño cromosoma marcador supernumerario (SMC); translocación t(11 ;14)(p15;p13); translocación desequilibrada t(8;11)(p23.2;p15.5); microdeleción 11q23; síndrome de Smith-Magenis; deleción 17p11.2; deleción 22q13.3; microdeleción Xp22.3; deleción 10p14; microdeleción 20p, síndrome de DiGeorge [del(22)(q112q1123)], síndrome de Williams (deleciones 7q1123 y 7q36); deleción 1p36; microdeleción 2p; neurofibromatosis tipo 1 (microdeleción 17q 112), deleción Yq; síndrome de Wolf-Hirschhorn (WHS, microdeleción 4p16.3); microdeleción 1p36.2; deleción 11q14; microdeleción 19q132; Rubinstein-Taybi (microdeleción 16 p13.3); microdeleción 7p21; síndrome de Miller-Dieker (17p13.3), deleción 17p11.2; y microdeleción 2q37.
Determinación de CNV de trastornos clínicos
Además de la determinación temprana de defectos de nacimiento, los métodos descritos en el presente documento pueden aplicarse a la determinación de cualquier anomalía en la representación de secuencias genéticas dentro del genoma. Se ha demostrado que el plasma sanguíneo y el ADN sérico de pacientes con cáncer contienen cantidades medibles de ADN tumoral, que pueden recuperarse y usarse como fuente sustituta de ADN tumoral. Los tumores se caracterizan por aneuploidía, o números inadecuados de secuencias de genes o incluso cromosomas completos. La determinación de una diferencia en la cantidad de una secuencia dada,es decir, una secuencia de interés, en una muestra de un individuo, por lo tanto, puede usarse en el diagnóstico de una condición médica, por ejemplo, cáncer.
Los casos de la divulgación se relacionan con un método para evaluar la variación del número de copias de una secuencia de interés, por ejemplo, una secuencia clínicamente relevante, en una muestra de ensayo que comprende una mezcla de ácidos nucleicos derivados de dos genomas diferentes, y que se sabe o se sospecha que difieren en la cantidad de una o más secuencias de interés. La mezcla de ácidos nucleicos se deriva de dos o más tipos de células. En un caso, la mezcla de ácidos nucleicos se deriva de células normales y cancerosas derivadas de un sujeto que padece una condición médica, por ejemplo, cáncer.
Se cree que muchos tumores sólidos, tales como el cáncer de mama, progresan desde su inicio hasta la metástasis a través de la acumulación de varias aberraciones genéticas. [Sato et al., Cancer Res., 50: 7184-7189 [1990]; Jongsma et al., J Clin PAthol: Mol Path 55:305-309 [2002])]. Dichas aberraciones genéticas, a medida que se acumulan, pueden conferir ventajas proliferativas, inestabilidad genética y la capacidad concomitante de desarrollar resistencia a fármacos rápidamente, y angiogénesis, proteolisis y metástasis potenciadas. Las aberraciones genéticas pueden afectar tanto a los "genes supresores de tumores" recesivos como a los oncogenes de acción dominante. Se cree que las deleciones y la recombinación que conducen a la pérdida de heterocigosidad (LOH) desempeñan un papel importante en la progresión del tumor al descubrir alelos supresores de tumores mutados.
Se ha encontrado ADNcf en la circulación de pacientes diagnosticados con neoplasias malignas que incluyen, pero sin limitación, cáncer de pulmón (Pathak et al. Clin Chem 52:1833-1842 [2006]), cáncer de prostata (Schwartzenbach et al. Clin Cancer Res 15:1032-8 [2009]) y cáncer de mama (Schwartzenbach et al. disponible en línea en breastcancer-research.com/content/11/5/R71 [2009]). La identificación de inestabilidades genómicas asociadas con cánceres que se pueden determinar en el ADNcf en circulación en pacientes con cáncer es una herramienta potencial de diagnóstico y pronóstico. En un caso, el método de la divulgación evalúa la CNV de una secuencia de interés en una muestra que comprende una mezcla de ácidos nucleicos derivados de un sujeto del que se sospecha o se sabe que tiene cáncer, por ejemplo, carcinoma, sarcoma, linfoma, leucemia, tumores de células germinales y blastoma. En un caso, la muestra es una muestra de plasma derivada (procesos) de sangre periférica y que comprende una mezcla de ADNcf derivado de células normales y cancerosas. En otro caso, la muestra biológica que se necesita para determinar si una CNV está presente se deriva de una mezcla de células cancerosas y no cancerosas de otros fluidos biológicos que incluyen, pero sin limitación, suero, sudor, lágrimas, esputo, orina, esputo, flujo del oído, linfa, saliva, líquido cefalorraquídeo, estragos, suspensión de médula ósea, flujo vaginal, lavado transcervical, líquido cerebral, ascitis, leche, secreciones de las vías respiratorias, intestinales y genitourinarias y muestras de leucoforesis, o en biopsias de tejido, hisopos o frotis.
La secuencia de interés es una secuencia de ácido nucleico que se sabe o se sospecha que desempeña un papel en el desarrollo y/o la progresión del cáncer. Los ejemplos de una secuencia de interés incluyen secuencias de ácidos nucleicos que se amplifican o se eliminan en células cancerosas tal como se describe a continuación.
Los genes de acción dominante asociados con tumores sólidos humanos ejercen típicamente su efecto por sobreexpresión o expresión alterada. La amplificación génica es un mecanismo común que conduce a la regulación al alza de la expresión génica. La evidencia de los estudios citogenéticos indica que se produce una amplificación significativa en más del 50% de los cánceres de mama humanos. En particular, la amplificación del protooncogén receptor 2 del factor de crecimiento epidérmico humano (HER2) ubicado en el cromosoma 17 (17(17q21-q22)) da como resultado una sobreexpresión de los receptores HER2 en la superficie celular, lo que da lugar a una señalización excesiva y desregulada en el cáncer de mama y otras neoplasias malignas (Park et al., Clinical Breast Cancer 8:392-401 [2008]). Se ha encontrado que una diversidad de oncogenes se amplifica en otras neoplasias malignas humanas. Los ejemplos de amplificación de oncogenes celulares en tumores humanos incluyen amplificaciones de: c-myc en la línea celular de leucemia promielocítica HL60 y en líneas celulares de carcinoma de pulmón de células pequeñas, N-myc en neuroblastomas primarios (estadios III y IV), líneas celulares de neuroblastoma, línea celular de retinoblastoma y tumores primarios, y líneas y tumores de carcinoma de pulmón de células pequeñas, L-myc en líneas celulares y tumores de carcinoma de pulmón de células pequeñas, c-myb en leucemia mieloide aguda y en líneas celulares de carcinoma de colon, c-erbb en células de carcinoma epidermoide y gliomas primarios, cK-ras-2 en carcinomas primarios de pulmón, colon, vejiga y recto, N-ras en la línea celular de carcinoma mamario (Varmus H., Ann Rev Genética 18: 553-612 (1984) [citado por Watson et al., Molecular Biology of the Gene (4a ed.; Benjamin/Cummings Publishing Co. 1987)].
Las deleciones cromosómicas que involucran genes supresores de tumores pueden desempeñar un papel importante en el desarrollo y la progresión de tumores sólidos. El gen supresor de tumores de retinoblastoma (Rb-1), ubicado en el cromosoma 13q14, es el gen supresor de tumores caracterizado más ampliamente. El producto del gen Rb-1, una fosfoproteína nuclear de 105 kDa, aparentemente desempeña un papel importante en la regulación del ciclo celular. (Howe et al., Proc Natl Acad Sci ( e E . U U . ) 87:5883-5887 [1990]). La expresión alterada o perdida de la proteína Rb está provocada por la inactivación de los alelos de ambos genes ya sea a través de una mutación puntual o una deleción cromosómica. Se ha descubierto que las alteraciones del gen Rb-i están presentes no solo en los retinoblastomas, sino también en otras neoplasias malignas tales como osteosarcomas, cáncer de pulmón de células pequeñas (Rygaard et al., Cancer Res 50: 5312-5317 [1990)]) y cáncer de mama. Los estudios de polimorfismo de longitud de fragmentos de restricción (RFLP) han indicado que dichos tipos de tumores con frecuencia han perdido heterocigosidad en 13q, lo que sugiere que uno de los alelos del gen Rb-1 se ha perdido debido a una deleción cromosómica macroscópica.(Bowcock et al., Am J Hum Genet, 46: 12 [1990]). Las anomalías del cromosoma 1 que
incluyen duplicaciones, deleciones y translocaciones desequilibradas que involucran al cromosoma 6 y otros cromosomas asociados indican que las regiones del cromosoma 1, en particular 1q21-1q32 y 1p11-13, podrían albergar oncogenes o genes supresores de tumores que son patogenéticamente relevantes para fases de neoplasias mieloproliferativas tanto crónicas como avanzadas (Caramazza et al., Eur J Hematol 84:191-200 [2010]). Las neoplasias mieloproliferativas también se asocian con deleciones del cromosoma 5. La pérdida completa o las deleciones intersticiales del cromosoma 5 son la anomalía cariotípica más común en síndromes mielodisplásicos (SMD). Los pacientes con SMD del(5q)/5q- aislados tienen un pronóstico más favorable que aquellos con defectos cariotípicos adicionales, que tienden a desarrollar neoplasias mieloproliferativas (NMP) y leucemia mieloide aguda. La frecuencia de deleciones desequilibradas del cromosoma 5 ha llevado a la idea de que 5q alberga uno o más genes supresores de tumores que tienen funciones fundamentales en el control del crecimiento de las células madre/progenitoras hematopoyéticas (HSC/HPC). El mapeo citogenético de regiones comúnmente eliminadas (CDR) centrado en 5q31 y 5q32 identificó genes candidatos a supresores de tumores, incluida la subunidad ribosómica RPS14, el factor de transcripción Egr1 / Krox20 y la proteína de remodelación del citoesqueleto, alfa-catenina (Eisenmann et al., Oncogen 28:3429-3441 [2009]). Los estudios citogenéticos y de alelotipado de tumores recientes y líneas de células tumorales han demostrado que la pérdida alélica de varias regiones distintas en el cromosoma 3p, incluidas 3p25, 3p21-22, 3p21.3, 3p12-13 y 3p14, son las anomalías genómicas más tempranas y frecuentes involucradas en un amplio espectro de los principales cánceres epiteliales de pulmón, mama, riñón, cabeza y cuello, ovario, cuello uterino, colon, páncreas, esófago, vejiga y otros órganos. Se han mapeado varios genes supresores de tumores en la región del cromosoma 3p y se cree que las deleciones intersticiales o la hipermetilación del promotor preceden a la pérdida del 3p o de la totalidad del cromosoma 3 en el desarrollo de carcinomas. (Angeloni D., Briefings Functional Genomics 6:19-39 [2007]).
Los recién nacidos y los niños con síndrome de Down (SD) a menudo presentan leucemia congénita transitoria y tienen un mayor riesgo de leucemia mieloide aguda y leucemia linfoblástica aguda. El cromosoma 21, que alberga alrededor de 300 genes, puede estar involucrado en numerosas aberraciones estructurales, por ejemplo, translocaciones, deleciones y amplificaciones, en leucemias, linfomas y tumores sólidos. Además, se han identificado genes localizados en el cromosoma 21 que desempeñan un papel importante en la tumorigénesis. Las aberraciones numéricas somáticas, así como estructurales del cromosoma 21 están asociadas con leucemias, y genes específicos, incluidos RUNX1, TMPRSS2 y TFF, que se encuentran en 21 q, y desempeñan un papel en la tumorigénesis. (Fonatsch C Gene Chromosomes Cancer 49: 497-508 [2010]).
En un caso, el método se refiere a un medio para evaluar la asociación entre la amplificación génica y el grado de evolución del tumor. La correlación entre la amplificación y/o deleción y el estadio o grado de un cáncer puede ser importante desde el punto de vista del pronóstico porque dicha información puede contribuir a la definición de un grado tumoral con base genética que podría predecir mejor el curso futuro de la enfermedad, teniendo los tumores más avanzados el peor pronóstico. Además, la información sobre eventos tempranos de amplificación y/o de deleción puede ser útil para asociar esos eventos como factores de pronóstico de la progresión posterior de la enfermedad. La amplificación y las deleciones de genes identificadas por el método se pueden asociar con otros parámetros conocidos, tales como el grado del tumor, la histología, el índice de marcado Brd/Urd, el estado hormonal, la afectación de los ganglios, el tamaño del tumor, la duración de la supervivencia y otras propiedades del tumor disponibles a partir de estudios epidemiológicos y bioestadísticos. Por ejemplo, el ADN tumoral que se va a analizar mediante el método podría incluir hiperplasia atípica, carcinoma ductal in situ, cáncer en estadio I-III y ganglios linfáticos metastásicos para permitir la identificación de asociaciones entre amplificaciones y deleciones y estadio. Las asociaciones realizadas pueden posibilitar una intervención terapéutica eficaz. Por ejemplo, las regiones amplificadas sistemáticamente pueden contener un gen sobreexpresado, cuyo producto puede ser atacado terapéuticamente (por ejemplo, la tirosina quinasa del receptor del factor de crecimiento, p185HER2).
El método se puede utilizar para identificar eventos de amplificación y/o deleción que están asociados con la resistencia a medicamentos mediante la determinación de la variación del número de copias de ácidos nucleicos de cánceres primarios con respecto a los de células que se han metastatizado en otros sitios. Si la amplificación y/o la deleción de genes es una manifestación de inestabilidad cariotípica que permite el desarrollo rápido de resistencia a medicamentos, se esperaría una mayor amplificación y/o deleción en tumores primarios de pacientes quimiorresistentes que en tumores de pacientes quimiosensibles. Por ejemplo, si la amplificación de genes específicos es responsable del desarrollo de la resistencia a medicamentos, se esperaría que las regiones que rodean esos genes se amplifiquen sistemáticamente en las células tumorales de derrames pleurales de pacientes quimiorresistentes, pero no en los tumores primarios. El descubrimiento de asociaciones entre la amplificación y/o la deleción de genes y el desarrollo de resistencia a medicamentos puede permitir la identificación de pacientes que se beneficiarán o no de un tratamiento adyuvante.
Determinación simultánea de aneuploidía y fracción fetal
En otro caso, el método permite la determinación simultánea de la fracción del componente secundario de ácido nucleico fetal, es decir, la fracción fetal, en una muestra que comprende una mezcla de ácidos nucleicos fetales y maternos. En particular, el método permite la determinación de la fracción de ADNcf aportada por un feto a la mezcla de ADNcf fetal y materno en una muestra materna, por ejemplo, una muestra de plasma. La diferencia entre la fracción materna y la fracción fetal se determina mediante la contribución relativa de un alelo polimórfico derivado del genoma
fetal a la contribución del alelo polimórfico correspondiente derivado del genoma materno. Se pueden utilizar secuencias polimórficas junto con ensayos de diagnóstico clínicamente relevantes como control positivo de la presencia de ADNcf con el fin de resaltar resultados falsos negativos o falsos positivos derivados de niveles bajos de ADNcf por debajo del límite de identificación. El método descrito es útil en una diversidad de edades gestacionales.
En las figuras 2-5 se representan casos ilustrativos del método para determinar simultáneamente la fracción fetal y la presencia o ausencia de una aneuploidía de la forma siguiente.
La figura 2 proporciona un diagrama de flujo de un caso del método de la divulgación 200 para determinar simultáneamente una aneuploidía fetal y la fracción de ácidos nucleicos fetales en una muestra biológica materna. En la etapa 210 se obtiene de un sujeto una muestra de ensayo que comprende una mezcla de ácidos nucleicos fetales y maternos. Las muestras de ensayo incluyen las muestras descritas en la etapa 110 del caso del método 100. En algunos casos, la muestra de ensayo es una muestra de sangre periférica obtenida de un sujeto femenino embarazado, por ejemplo, una mujer embarazada. En la etapa 220 la mezcla de ácidos nucleicos presente en la muestra se enriquece en ácidos nucleicos diana polimórficos, cada uno de los cuales comprende un sitio polimórfico. En algunos casos, los ácidos nucleicos que se enriquecen son ADNcf. Los ácidos nucleicos diana son segmentos de material genético que se sabe que comprenden al menos un sitio polimórfico. En algunos casos, los ácidos nucleicos diana comprenden un SNP. En otros casos, el ácido nucleico diana comprende un STR. En otros casos más, los ácidos nucleicos diana comprenden un STR en tándem. El enriquecimiento de una mezcla de ácidos nucleicos fetales y maternos comprende amplificar secuencias diana de una porción de ácidos nucleicos contenidos en la muestra materna original y combinar parte o la totalidad del producto amplificado con el resto de la muestra materna original. En la etapa 230, se secuencia al menos una parte de la mezcla enriquecida, se identifican las diferencias de secuencia derivadas de la naturaleza polimórfica de las secuencias diana y se determina la contribución relativa de las secuencias polimórficas derivadas del genoma fetal, es decir, la fracción fetal, en la etapa 240. En algunos casos, la muestra de ensayo materna original es una muestra de fluido biológico, por ejemplo, plasma. En otros casos, la muestra materna original es una fracción procesada de plasma que comprende ADNcf fetal y materno purificado.
Secuencias polimórficas
Los sitios polimórficos que están contenidos en los ácidos nucleicos diana incluyen, sin limitación, polimorfismos de un solo nucleótido (SNP), SNP en tándem, deleciones o inserciones de múltiples bases a pequeña escala, denominadas IN-DELS (también denominadas polimorfismos de deleción-inserción o DIP), polimorfismos de múltiples nucleótidos (MNP) y repeticiones en tándem cortas (STR). Los sitios polimórficos que abarca el método de la divulgación están ubicados en cromosomas autosómicos, lo que permite la determinación de la fracción fetal independientemente del sexo del feto. Cualquier sitio polimórfico que pueda estar abarcado por las lecturas generadas por los métodos de secuenciación descritos en el presente documento puede utilizarse para determinar simultáneamente la fracción fetal y la presencia o la ausencia de una aneuploidía en una muestra materna.
En un caso, la mezcla de ácidos nucleicos fetales y maternos en la muestra se enriquece en ácidos nucleicos diana que comprenden al menos un SNP. En algunos casos, los ácidos nucleicos diana comprenden un único SNP, es decir, uno. Las secuencias de ácido nucleico diana que comprenden SNP están disponibles en bases de datos de acceso público, incluidas, pero sin limitación, la base de datos de SNP humanos en la dirección de Internet wi.mit.edu, la página de inicio de NCBI dbSNP en la dirección de Internet ncbi.nlm.nih.gov, la dirección de Internet lifesciences.perkinelmer.com, la base de datos Celera Human SNP en la dirección de Internet celera.com, la base de datos SNP del Genome Analysis Group (GAN) en la dirección de Internet gan.iarc.fr. En un caso, los SNP elegidos para enriquecer el ADNcf fetal y materno se seleccionan del grupo de 92 SNP de identificación individual (IISNP) descrito por Pakstis et al. (Pakstis et al. Hum Genet 127:315-324 [2010]), que se ha demostrado que tiene una variación muy pequeña en la frecuencia entre las poblaciones (Fst < 0,06), y que es altamente informativo en todo el mundo con una heterocigosidad promedio > 0,4. Los SNP que están abarcados por el método de la divulgación incluyen SNP vinculados y no vinculados. Cada ácido nucleico diana comprende al menos un sitio polimórfico, por ejemplo, un único SNP, que difiere del presente en otro ácido nucleico diana para generar un panel de sitios polimórficos, por ejemplo, SNP, que contienen un número suficiente de sitios polimórficos de los cuales al menos 1, al menos 2, al menos 3, al menos 4, al menos 5, al menos 6, al menos 7, al menos 8, al menos 9, al menos 10, al menos 11, al menos 12, al menos 13, al menos 14, al menos 15, al menos 16, al menos 17, al menos 18, al menos 19, al menos 20, al menos 25, al menos 30, al menos 35, al menos 40 o más son informativos. Por ejemplo, se puede configurar un panel de SNP para que comprenda al menos un SNP informativo.
En un caso, los SNP que son el objetivo de la amplificación se seleccionan de entre rs560681, rs1109037, rs9866013, rs13182883, rs13218440, rs7041158, rs740598, rs10773760, rs4530059, rs7205345, rs8078417, rs576261, rs2567608, rs430046, rs9951171, rs338882, rs10776839, rs9905977, rs1277284, rs258684, rs1347696, rs508485, rs9788670, rs8137254, rs3143, rs2182957, rs3739005 y rs530022.
En otros casos, cada ácido nucleico diana comprende dos o más SNP, es decir, cada ácido nucleico diana comprende SNP en tándem. Preferentemente, cada ácido nucleico diana comprende dos SNP en tándem. Los SNP en tándem se analizan como una sola unidad como haplotipos cortos y se proporcionan en el presente documento como conjuntos de dos SNP. Para identificar secuencias de SNP en tándem adecuadas, se puede buscar en la base de datos del
International HapMap Consortium (The International HapMap Project, Nature 426:789-796 [2003]). La base de datos está disponible en Internet en hapmap.org. En un caso, los SNP en tándem que son el objetivo de la amplificación se seleccionan de entre los siguientes conjuntos de pares en tándem de SNP rs7277033-rs2110153; rs2822654-rs1882882; rs368657-rs376635; rs2822731-rs2822732; rs1475881-rs7275487; rs1735976-rs2827016; rs447340-rs2824097; rs418989-rs13047336; rs987980-rs987981; rs4143392-rs4143391; rs1691324-rs13050434; rs11909758-rs9980111; rs2826842-rs232414; rs1980969-rs1980970; rs9978999-rs9979175; rs1034346-rs12481852; rs7509629-rs2828358; rs4817013-rs7277036; rs9981121-rs2829696; rs455921-rs2898102; rs2898102-rs458848; rs961301-rs2830208; rs2174536-rs458076; rs11088023-rs11088024; rs1011734-rs1011733; rs2831244-rs9789838; rs8132769-rs2831440; rs8134080-rs2831524; rs4817219-rs4817220; rs2250911-rs2250997; rs2831899-rs2831900; rs2831902-rs2831903; rs11088086-rs2251447; rs2832040-rs11088088; rs2832141-rs2246777; rs2832959-rs9980934; rs2833734-rs2833735; rs933121-rs933122; rs2834140-rs12626953; rs2834485-rs3453; rs9974986-rs2834703; rs2776266-rs2835001; rs1984014-rs1984015; rs7281674-rs2835316; rs13047304-rs13047322; rs2835545-rs4816551; rs2835735-rs2835736; rs13047608-rs2835826; rs2836550-rs2212596; rs2836660-rs2836661; rs465612-rs8131220; rs9980072-rs8130031; rs418359-rs2836926; rs7278447-rs7278858; rs385787-rs367001; rs367001-rs386095; rs2837296-rs2837297; y rs2837381-rs4816672.
En otro caso, la mezcla de ácidos nucleicos fetales y maternos en la muestra se enriquece en ácidos nucleicos diana que comprenden al menos un STR. Los loci STR se encuentran en casi todos los cromosomas del genoma y se pueden amplificar utilizando una diversidad de cebadores de reacción en cadena de la polimerasa (PCR). Los científicos forenses han preferido las repeticiones de tetranucleótidos debido a su fidelidad en la amplificación por PCR, aunque también se utilizan algunas repeticiones de trinucleótidos y pentanucleótidos. En STRBase se compila una lista completa de referencias, hechos e información de secuencias sobre STR, cebadores de PCR publicados, sistemas multiplex comunes y datos de población relacionados, a la que se puede acceder a través de Internet en ibm4.carb.nist.gov:8800/ adn/home.htm. La información de secuencia de GenBank® (http://www2.ncbi.nlm.nih.gov/cgi-bin/genbank) para loci STR de uso común también está disponible a través de STRBase. La naturaleza polimórfica de las secuencias de ADN repetidas en tándem que están muy extendidas en todo el genoma humano las ha convertido en marcadores genéticos importantes para estudios de mapeo de genes, análisis de unión y pruebas de identidad humana. Debido al alto polimorfismo de los STR, la mayor parte de los individuos serán heterocigóticos, es decir, la mayor parte de las personas poseerá dos alelos (versiones) de cada uno heredado de cada padre, con un número diferente de repeticiones. Por lo tanto, la secuencia STR fetal no heredada de la madre diferirá en el número de repeticiones de la secuencia materna. La amplificación de estas secuencias STR dará como resultado dos productos de amplificación principales correspondientes a los alelos maternos (y el alelo fetal heredado de la madre) y un producto secundario correspondiente al alelo fetal no heredado de la madre. Esta técnica se notificó por primera vez en 2000 (Pertl et al., Human Genetics 106:45-49 [2002]) y posteriormente se ha desarrollado utilizando la identificación simultánea de múltiples regiones STR diferentes mediante PCR en tiempo real (Liu et al., Acta Obset Gyn Scand 86:535-541 [2007]). Así, la fracción de ácido nucleico fetal en una muestra materna también puede determinarse mediante la secuenciación de ácidos nucleicos diana polimórficos que comprenden STR, que varían entre individuos en el número de unidades repetidas en tándem entre alelos. En un caso, la determinación simultánea de aneuploidía y fracción fetal comprende la secuenciación de al menos una parte de los ácidos nucleicos fetales y maternos presentes en una muestra materna que se ha enriquecido en secuencias polimórficas que comprenden STR. Dado que el tamaño del ADNcf fetal es < 300 pb, las secuencias polimórficas comprenden miniSTR, que se pueden amplificar para generar amplicones cuya longitud es aproximadamente del tamaño de los fragmentos de ADN fetal circulante. El método puede utilizar uno o una combinación de cualquier número de miniSTR informativos para determinar la fracción de ácido nucleico fetal. Por ejemplo, puede utilizarse cualquiera o una combinación de cualquier número de miniSTR, por ejemplo, los miniSTR divulgados en la tabla 22. En un caso, la fracción de ácido nucleico fetal en una muestra materna se realiza mediante un método que incluye la determinación del número de copias del ácido nucleico materno y fetal presentes en la muestra materna mediante la amplificación de al menos un miniSTR autosómico elegido de entre CSF1PO, FGA, TH01, TPOX, vWA, D3S1358,D5S818, D7S820, D8S1179, D13S317, D16S539, D18S51, D21S11, PentaD, Penta E, D2S1338, D1S1677, D2S441, D4S2364, D10S1248, D14S1434, D22S1045, D22S1045, D20S1082, D20S482, D18S853, D17S1301, D17S974, D14S1434, D12ATA63, D11S4463, D10S1435, D10S1248, D9S2157, D9S1122, D8S1115, D6S1017, D6S474, D5S2500, D5S2500, D4S2408, D4S2364, D3S4529, D3S3053, D2S1776, D2S441, D1S1677, D1S1627 y D1GATA113. En otro caso, el, al menos un, miniSTR autosómico es el grupo de miniSTR CSF1PO, FGA, D13S317, D16S539, D18S51, D2S1338, D21S11 y D7S820.
El enriquecimiento de la muestra en los ácidos nucleicos diana se realiza mediante métodos que comprenden amplificar específicamente las secuencias de ácido nucleico diana que comprenden el sitio polimórfico. La amplificación de las secuencias diana se puede realizar mediante cualquier método que utilice PCR o variaciones del método, incluidas, pero sin limitación, PCR asimétrica, amplificación dependiente de helicasa, PCR de inicio en caliente, qPCR, PCR en fase sólida y PCR de contacto. Alternativamente, la replicación de las secuencias de ácidos nucleicos diana se puede obtener mediante métodos independientes de enzimas, por ejemplo, síntesis química en fase sólida utilizando las fosforamiditas. La amplificación de las secuencias diana se realiza utilizando pares de cebadores, cada uno de los cuales es capaz de amplificar una secuencia de ácido nucleico diana que comprende el sitio polimórfico, por ejemplo, SNP, en una reacción de PCR multiplex. Las reacciones de PCR multiplex incluyen combinar al menos 2, al menos tres, al menos 3, al menos 5, al menos 10, al menos 15, al menos 20, al menos 25, al menos 30 al menos 30, al menos 35, al menos 40 o más conjuntos de cebadores en la misma reacción para cuantificar
los ácidos nucleicos diana amplificados que comprenden al menos dos, al menos tres, al menos 5, al menos 10, al menos 15, al menos 20, al menos 25, al menos 30, al menos 30, al menos 35, al menos 40 o más sitios polimórficos en la misma reacción de secuenciación. Cualquier panel de conjuntos de cebadores se puede configurar para amplificar al menos una secuencia polimórfica informativa.
Amplificación de secuencias polimórficas
Una serie de cebadores de ácidos nucleicos que están ya disponibles para amplificar fragmentos de ADN que contienen los polimorfismos de SNP y sus secuencias se pueden obtener, por ejemplo, de las bases de datos identificadas anteriormente. También se pueden diseñar cebadores adicionales, por ejemplo, utilizando un método similar al publicado por Vieux, E. F., Kwok, P-Y y Miller, R. D. en BioTechniques (junio de 2002) vol. 32. Suplemento: "SNPs: Discovery of Marker Disease, páginas 28-32. En un caso, al menos 1, al menos 2, al menos 3, al menos 4, al menos 5, al menos 6, al menos 7, al menos 8, al menos 9, al menos 10, al menos 11, al menos 12, al menos 13, al menos 14, al menos 15, al menos 16, al menos 17, al menos 18, al menos 19, al menos 20, al menos 25, al menos 30, al menos 35, al menos 40 o más conjuntos de cebadores se eligen para amplificar un ácido nucleico diana que comprende al menos un SNP informativo en una porción de una mezcla de ADNcf fetal y materno. En un caso, los conjuntos de cebadores comprenden cebadores directos e inversos que abarcan al menos un SNP informativo seleccionado de entre rs560681, rs1109037, rs9866013, rs13182883, rs13218440, rs7041158, rs740598, rs10773760, rs4530059, rs7205345, rs8078417, rs576261, rs2567608, rs430046, rs9951171, rs338882, rs10776839, rs9905977, rs1277284, rs258684, rs1347696, rs508485, rs9788670, rs8137254, rs3143, rs2182957, rs3739005 y rs530022. En el ejemplo, 7 y en las tablas 10 y 11 se proporcionan ejemplos de conjuntos de cebadores que se utilizan para amplificar los SNP descritos en el presente documento, y se divulgan como SEQ ID NO: 57-112. En otro caso, el grupo de 13 conjuntos de cebadores SEQ ID NO: 57-82 se utiliza para amplificar un ácido nucleico objetivo, cada uno de los cuales comprende al menos un SNP, por ejemplo, un solo SNP, en una porción de una mezcla de ADNcf fetal y materno.
En otro caso, se utiliza al menos un conjunto de cebadores para amplificar un ácido nucleico diana, cada uno de los cuales comprende al menos un SNP en tándem, por ejemplo, un conjunto de dos SNP en tándem, en una porción de una mezcla de ADNcf fetal y materno. En un caso, los conjuntos de cebadores comprenden cebadores directos e inversos que abarcan al menos un SNP en tándem informativo seleccionado de entre SNP rs7277033-rs2110153; rs2822654-rs1882882; rs368657-rs376635; rs2822731-rs2822732; rs1475881-rs7275487; rs1735976-rs2827016; rs447340-rs2824097; rs418989-rs13047336; rs987980-rs987981; rs4143392-rs4143391; rs1691324-rs13050434; rs11909758-rs9980111; rs2826842-rs232414; rs1980969-rs1980970; rs9978999-rs9979175; rs1034346-rs12481852; rs7509629-rs2828358; rs4817013-rs7277036; rs9981121-rs2829696; rs455921-rs2898102; rs2898102-rs458848; rs961301-rs2830208; rs2174536-rs458076; rs11088023-rs11088024; rs1011734-rs1011733; rs2831244-rs9789838; rs8132769-rs2831440; rs8134080-rs2831524; rs4817219-rs4817220; rs2250911-rs2250997; rs2831899-rs2831900; rs2831902-rs2831903; rs11088086-rs2251447; rs2832040-rs11088088; rs2832141-rs2246777; rs2832959 -rs9980934; rs2833734-rs2833735; rs933121-rs933122; rs2834140-rs12626953; rs2834485-rs3453; rs9974986-rs2834703; rs2776266-rs2835001; rs1984014-rs1984015; rs7281674-rs2835316; rs13047304-rs13047322; rs2835545-rs4816551; rs2835735-rs2835736; rs13047608-rs2835826; rs2836550-rs2212596; rs2836660-rs2836661; rs465612-rs8131220; rs9980072-rs8130031; rs418359-rs2836926; rs7278447-rs7278858; rs385787-rs367001; rs367001-rs386095; rs2837296-rs2837297; y rs2837381-rs4816672. Los cebadores utilizados para amplificar las secuencias diana que comprenden los SNP en tándem están diseñados para abarcar ambos sitios SNP. En el ejemplo, 12 se proporcionan conjuntos de cebadores ilustrativos que se utilizan para amplificar los SNP divulgados en el presente documento y se divulgan como SEQ ID NO: 197-310.
La amplificación de los ácidos nucleicos diana se realiza utilizando cebadores específicos de secuencia que permiten la amplificación específica de secuencia. Por ejemplo, los cebadores de PCR están diseñados para discriminar la amplificación de genes similares o parálogos que se encuentran en otros cromosomas aprovechando las diferencias de secuencia entre el ácido nucleico diana y cualquier parálogo de otros cromosomas. Los cebadores de PCR directos o inversos están diseñados para hibridarse cerca del sitio SNP y amplificar una secuencia de ácido nucleico de longitud suficiente para incluirla en las lecturas generadas por métodos de secuenciación masivamente paralelos. Algunos métodos de secuenciación masivamente paralelos requieren que la secuencia de ácido nucleico tenga una longitud mínima (pb) para permitir la amplificación en puente que puede utilizarse opcionalmente antes de la secuenciación. Así, los cebadores de PCR utilizados para amplificar los ácidos nucleicos diana están diseñados para amplificar secuencias que tienen una longitud suficiente para ser amplificadas en puente e identificar los SNP que están abarcados por las lecturas de secuencias. En algunos casos, el primero de dos cebadores del conjunto de cebadores que comprende el cebador directo y el cebador inverso para amplificar el ácido nucleico diana está diseñado para identificar un solo SNP presente dentro de una lectura de secuencia de aproximadamente 20 pb, aproximadamente 25 pb, aproximadamente 30 pb, aproximadamente 35 pb, aproximadamente 40 pb, aproximadamente 45 pb, aproximadamente 50 pb, aproximadamente 55 pb, aproximadamente 60 pb, aproximadamente 65 pb, aproximadamente 70 pb, aproximadamente 75 pb, aproximadamente 80 pb, aproximadamente 85 pb, aproximadamente 90 pb, aproximadamente 95 pb, aproximadamente 100 pb, aproximadamente 110 pb, aproximadamente 120 pb, aproximadamente 130, aproximadamente 140 pb, aproximadamente 150 pb, aproximadamente 200 pb, aproximadamente 250 pb, aproximadamente 300 pb, aproximadamente 350 pb, aproximadamente 400 pb, aproximadamente 450 pb o aproximadamente 500 pb. Se espera que los avances tecnológicos en las tecnologías de secuenciación masivamente paralela permitan lecturas de un solo extremo de más
de 500 pb. En un caso, uno de los cebadores de PCR está diseñado para amplificar SNP que están incluidos en lecturas de secuencia de 36 pb. El segundo cebador está diseñado para amplificar el ácido nucleico diana como un amplicón de longitud suficiente para permitir la amplificación en puente. En un caso, los cebadores de PCR ilustrativos están diseñados para amplificar los ácidos nucleicos diana que contienen un solo SNP seleccionado de entre SNP rs560681, rs1109037, rs9866013, rs13182883, rs13218440, rs7041158, rs740598, rs10773760, rs 4530059, rs7205345, rs8078417, rs576261, rs2567608, rs430046, rs9951171, rs338882, rs10776839, rs9905977, rs1277284, rs258684, rs1347696, rs508485, rs9788670, rs8137254, rs3143, rs2182957, rs3739005 y rs530022. En otros casos, los cebadores directo e inverso están diseñados para amplificar los ácidos nucleicos diana, cada uno de los cuales comprende un conjunto de dos SNP en tándem, estando presente cada uno de los mismos en una lectura de secuencia de aproximadamente 20 pb, aproximadamente 25 pb, aproximadamente 30 pb, aproximadamente 35 pb, aproximadamente 40 pb, aproximadamente 45 pb, aproximadamente 50 pb, aproximadamente 55 pb, aproximadamente 60 pb, aproximadamente 65 pb, aproximadamente 70 pb, aproximadamente 75 pb, aproximadamente 80 pb, aproximadamente 85 pb, aproximadamente 90 pb, aproximadamente 95 pb, aproximadamente 100 pb, aproximadamente 110 pb, aproximadamente 120 pb, aproximadamente 130, aproximadamente 140 pb, aproximadamente 150 pb, aproximadamente 200 pb, aproximadamente 250 pb, aproximadamente 300 pb, aproximadamente 350 pb, aproximadamente 400 pb, aproximadamente 450 pb o aproximadamente 500 pb. En un caso, al menos uno de los cebadores está diseñado para amplificar el ácido nucleico diana que comprende un conjunto de dos SNP en tándem como un amplicón de longitud suficiente para permitir la amplificación en puente.
Los SNP, SNP individuales o en tándem, están contenidos en amplicones de ácido nucleico diana amplificados de al menos 100 pb, al menos 150 pb, al menos 200 pb, al menos 250 pb, al menos 300 pb, al menos 350 pb o al menos 400 pb. En un caso, los ácidos nucleicos diana que comprenden un sitio polimórfico, por ejemplo, un SNP, se amplifican como amplicones de al menos aproximadamente 110 pb, y que comprenden un SNP dentro de los 36 pb desde el extremo 3' o 5' del amplicón. En otro caso, los ácidos nucleicos diana que comprenden dos o más sitios polimórficos, por ejemplo, dos SNP en tándem, se amplifican como amplicones de al menos aproximadamente 110 pb, y que comprenden el primer SNP dentro de los 36 pb desde el extremo 3’ del amplicón, y/o el segundo SNP dentro de los 36 pb desde el extremo 5' del amplicón.
En un caso, al menos 1, al menos 2, al menos 3, al menos 4, al menos 5, al menos 6, al menos 7, al menos 8, al menos 9, al menos 10, al menos 11, al menos 12, al menos 13, al menos 14, al menos 15, al menos 16, al menos 17, al menos 18, al menos 19, al menos 20, al menos 25, al menos 30, al menos 35, al menos 40 o más conjuntos de cebadores se eligen para amplificar un ácido nucleico diana que comprende al menos un SNP en tándem informativo en una porción de una mezcla de ADNcf fetal y materno.
Amplificación de STR
Una serie de cebadores de ácidos nucleicos que están ya disponibles para amplificar fragmentos de ADN que contienen los STR y sus secuencias se pueden obtener, por ejemplo, de las bases de datos identificadas anteriormente. Se han utilizado amplicones de PCR de varios tamaños para discernir las respectivas distribuciones de tamaño de las especies de ADN fetal y materno circulantes, y se ha demostrado que las moléculas de ADN fetal en el plasma de las mujeres embarazadas son generalmente más cortas que las moléculas de ADN materno. Chan et al., Clin Chem 50:8892 [2004]). El fraccionamiento del tamaño del ADN fetal circulante ha confirmado que la longitud promedio de los fragmentos de ADN fetal circulante es < 300 pb, mientras que el ADN materno se ha estimado entre aproximadamente 0,5 y 1 Kb. Li et al., Clin Chem, 50: 1002-1011 [2004]). Estos hallazgos son coherentes con los de Fan et al., quien determinó utilizando NGS que el ADNcf fetal rara vez es > 340bp (Fan et al., Clin Chem 56:1279-1286 [2010]). El método de la divulgación abarca la determinación de la fracción de ácido nucleico fetal en una muestra materna que se ha enriquecido con ácidos nucleicos diana, cada uno de los cuales comprende un miniSTR que comprende la cuantificación de al menos un alelo fetal y uno materno en un miniSTR polimórfico, que se puede amplificar para generar amplicones cuya longitud es aproximadamente del tamaño de los fragmentos de ADN fetal circulante.
En un caso, el método comprende determinar el número de copias de al menos un alelo fetal y al menos un alelo materno en al menos un miniSTR polimórfico que se amplifica para generar amplicones que tienen menos de aproximadamente 300 pb, menos de aproximadamente 250 pb, menos de aproximadamente 200 pb, menos de aproximadamente 150 pb, menos de aproximadamente 100 pb o menos de aproximadamente 50 pb. En otro caso, los amplicones que se generan al amplificar los miniSTR tienen menos de aproximadamente 300 pb. En otro caso, los amplicones que se generan al amplificar los miniSTR tienen menos de aproximadamente 250 pb. En otro caso, los amplicones que se generan al amplificar los miniSTR tienen menos de aproximadamente 200 pb. La amplificación del alelo informativo incluye el uso de cebadores miniSTR, que permiten la amplificación de amplicones de tamaño reducido para discernir alelos STR que tienen menos de aproximadamente 500 pb, menos de aproximadamente 450 pb, menos de aproximadamente 400 pb, menos de aproximadamente 350 pb, menos de aproximadamente 300 pares de bases (pb), menos de aproximadamente 250 pb, menos de aproximadamente 200 pb, menos de aproximadamente 150 pb, menos de aproximadamente 100 pb o menos de aproximadamente 50 pb. Los amplicones de tamaño reducido generados por medio de los cebadores miniSTR se conocen como miniSTR y se identifican según el nombre del marcador correspondiente al locus al que se han mapeado. En un caso, los cebadores miniSTR incluyen cebadores
miniSTR que han permitido la reducción máxima del tamaño del amplicón para los 13 loci CODIS STR además del D2S1338, pentaD y pentaE que se encuentran en los kits STR disponibles comercialmente (Butler et al, J Forensic
Sci 48:1054-1064 [2003]), loci miniSTR que no están vinculados a los marcadores CODIS tal como se describe por Coble y Butler (Coble y Butler, J Forensic Sci 50:43-53 [2005]) y otros minSTR que se han caracterizado en el NIST.
Se puede acceder a la información sobre los miniSTR caracterizados en el NIST a través de Internet en cstl.nist.gov/biotech/strbase/newSTRs.htm. Puede usarse cualquier par o una combinación de dos o más pares de cebadores miniSTR para amplificar al menos un miniSTR. Por ejemplo, se selecciona al menos un conjunto de cebadores de los conjuntos de cebadores proporcionados en la tabla 22 (ejemplo, 11) y divulgados como SEQ ID NO:
113-196 que se puede usar para amplificar secuencias diana polimórficas que comprenden un STR.
El enriquecimiento de la muestra se obtiene amplificando ácidos nucleicos diana contenidos en una porción de la mezcla de ácidos nucleicos fetales y maternos en la muestra original, y combinando al menos una porción o la totalidad del producto amplificado con el resto de la muestra original no amplificada. El enriquecimiento comprende la amplificación de los ácidos nucleicos diana que están contenidos en una porción de la muestra de fluido biológico. En un caso, la muestra que se enriquece es la fracción de plasma de una muestra de sangre (véase la figura 3). Por ejemplo, se usa una porción de una muestra de plasma materno original para amplificar las secuencias de ácido nucleico diana. Posteriormente, parte o la totalidad del producto amplificado se combina con la muestra de plasma original sin amplificar restante, enriqueciéndola así (véase el ejemplo, 10). En otro caso, la muestra que se enriquece es la muestra de ADNcf purificado que se extrae del plasma (véase la figura 4). Por ejemplo, el enriquecimiento comprende amplificar los ácidos nucleicos diana que están contenidos en una porción de una muestra original de una mezcla purificada de ácidos nucleicos fetales y maternos, por ejemplo, ADNcf que se ha purificado a partir de una muestra de plasma materno, y posteriormente combinar parte o la totalidad del producto amplificado con la muestra purificada original no amplificada restante (véase el ejemplo, 9). En otro caso más, la muestra que se enriquece es una muestra de biblioteca de secuenciación preparada a partir de una mezcla purificada de ácidos nucleicos fetales y maternos (véase la figura 5). Por ejemplo, el enriquecimiento comprende amplificar los ácidos nucleicos diana que están contenidos en una porción de una muestra original de una mezcla purificada de ácidos nucleicos fetales y maternos, por ejemplo, ADNcf que se ha purificado a partir de una muestra de plasma materno, preparar una primera biblioteca de secuenciación de secuencias de ácidos nucleicos no amplificados, preparar una segunda biblioteca de secuenciación de ácidos nucleicos diana polimórficos amplificados y, posteriormente, combinar parte o la totalidad de la segunda biblioteca de secuenciación con parte o la totalidad de la primera biblioteca de secuenciación (véase el ejemplo, 8). La cantidad de producto amplificado que se usa para enriquecer la muestra original se selecciona para obtener suficiente información de secuenciación para determinar tanto la presencia o la ausencia de aneuploidía como la fracción fetal del mismo ciclo de secuenciación. Al menos aproximadamente el 3%, al menos aproximadamente el
5%, al menos aproximadamente el 7%, al menos aproximadamente el 10%, al menos aproximadamente el 15%, al menos aproximadamente el 20%, al menos aproximadamente el 25%, al menos aproximadamente el 30% o más del número total de etiquetas de secuencia obtenidas de la secuenciación se mapean para determinar la fracción fetal.
En un caso, la etapa de enriquecer la mezcla de ácidos nucleicos fetales y maternos en ácidos nucleicos diana polimórficos comprende amplificar los ácidos nucleicos diana en una porción de una muestra de ensayo, por ejemplo, una muestra de ensayo de plasma, y combinar la totalidad o una porción del producto amplificado con la muestra de ensayo de plasma restante. El caso del método 300 se representa en el diagrama de flujo proporcionado en la figura
3. En la etapa 310, una muestra de ensayo, por ejemplo, una muestra de fluido biológico tal como una muestra de sangre, se obtiene de una mujer embarazada, y en la etapa 320 una porción del ADNcf contenido en la fracción de plasma de la muestra de sangre se utiliza para amplificar los ácidos nucleicos diana que comprenden sitios polimórficos, por ejemplo, SNP. En un caso, se usó al menos aproximadamente el 1%, al menos aproximadamente el 1,5%, al menos aproximadamente el 2% y al menos aproximadamente el 10% del plasma materno para amplificar los ácidos nucleicos diana. En la etapa 330, una porción o la totalidad de los ácidos nucleicos diana amplificados se combinan con la mezcla de ADNcf fetal y materno presente en la muestra materna, y el ADNcf combinado y los ácidos nucleicos amplificados se purifican en la etapa 340, y se usan para preparar una biblioteca que se secuenció en la etapa 350.
La biblioteca se preparó a partir de ADNcf purificado y comprendía al menos aproximadamente el 10%, al menos aproximadamente el 15%, al menos aproximadamente el 20%, al menos aproximadamente el 25%, al menos aproximadamente el 30%, al menos aproximadamente el 35%, al menos aproximadamente el 40% al menos aproximadamente el 45%, o al menos aproximadamente el 50% de producto amplificado. En la etapa 360, se analizan los datos de las ejecuciones de secuenciación y se realiza la determinación simultánea de la fracción fetal y la presencia o la ausencia de aneuploidía.
En un caso, la etapa de enriquecer la mezcla de ácidos nucleicos fetales y maternos en ácidos nucleicos diana polimórficos comprende una pluralidad de ácidos nucleicos diana polimórficos en una porción de una mezcla de ácidos nucleicos fetales y maternos purificados a partir de una muestra de ensayo materna. En un caso, una porción de una mezcla de ácidos nucleicos fetales y maternos, por ejemplo, ADNcf, purificados a partir de una muestra de plasma materno, se utiliza para amplificar secuencias de ácidos nucleicos polimórficos, y una parte del producto amplificado se combina con la mezcla no amplificada de ácidos nucleicos fetales y maternos purificados, por ejemplo, ADNcf (véase la figura 4). El caso del método 400 se representa en el diagrama de flujo proporcionado en la figura 4. E etapa 410, una muestra de ensayo, por ejemplo, una muestra de fluido biológico tal como una muestra de sangre, que comprende una mezcla de ácidos nucleicos fetales y maternos, se obtiene de una mujer embarazada, y la mezcla de ácidos nucleicos fetales y maternos se purifica a partir de la fracción de plasma en la etapa 420. Tal como se ha
descrito anteriormente, los métodos para la separación del ADN libre de células del plasma son bien conocidos. En la etapa 430, una porción del ADNcf contenido en la muestra purificada se utiliza para amplificar los ácidos nucleicos diana que comprenden sitios polimórficos, por ejemplo, SNP. Al menos aproximadamente el 5%, al menos aproximadamente el 10%, al menos aproximadamente el 15%, al menos aproximadamente el 20%, al menos aproximadamente el 25%, al menos aproximadamente el 30%, al menos aproximadamente el 35% al menos aproximadamente el 40%, o al menos aproximadamente el 45% o al menos aproximadamente el 50% del ADNcf purificado se usa para amplificar los ácidos nucleicos diana. Preferentemente, la amplificación de las secuencias diana se puede realizar mediante cualquier método que utilice PCR o variaciones del método, incluidas, pero sin limitación, PCR asimétrica, amplificación dependiente de la helicasa, PCR de inicio en caliente, qPCR, PCR en fase sólida y PCR de contacto. En la etapa 440, una porción, por ejemplo, al menos aproximadamente el 0,01%, del producto amplificado se combina con la muestra de ADNcf purificado sin amplificar, y la mezcla de ácidos nucleicos fetales y maternos amplificados y sin amplificar se secuencia en la etapa 450. En un caso, la secuenciación se realiza utilizando una cualquiera de las tecnologías NGS. En la etapa 460, se analizan los datos de los ejecuciones de secuenciación y se realiza la determinación simultánea de la fracción fetal y la presencia o la ausencia de aneuploidía tal como se ha descrito en la etapa 140 del caso representado en la figura 1.
En otro caso, la etapa 220 de enriquecimiento de la mezcla de ácidos nucleicos fetales y maternos en ácidos nucleicos diana polimórficos (figura 2) comprende combinar al menos una porción de una primera biblioteca de secuenciación de moléculas de ácidos nucleicos fetales y maternos no amplificados con al menos una porción de una segunda biblioteca de secuenciación de ácidos nucleicos diana polimórficos amplificados. Así, la muestra que se enriquece es la muestra de la biblioteca que se prepara para la secuenciación (figura 5). El enriquecimiento de la muestra de la biblioteca en los ácidos nucleicos diana se realiza mediante métodos que comprenden amplificar específicamente las secuencias de ácido nucleico diana que comprenden el sitio polimórfico. En la etapa 510, una muestra de ensayo, por ejemplo, una muestra de fluido biológico tal como una muestra de sangre, que comprende una mezcla de ácidos nucleicos fetales y maternos, se obtiene de una mujer embarazada, y la mezcla de ácidos nucleicos fetales y maternos se purifica a partir de la fracción de plasma en la etapa 520. En la etapa 530, una porción del ADNcf contenido en la muestra purificada se utiliza para amplificar los ácidos nucleicos diana que comprenden sitios polimórficos, por ejemplo, SNP. Al menos aproximadamente el 5%, al menos aproximadamente el 10%, al menos aproximadamente el 15%, al menos aproximadamente el 20%, al menos aproximadamente el 25% o al menos aproximadamente el 30% del ADNcf purificado se usa para amplificar las secuencias de ácido nucleico diana. Preferentemente, la amplificación de las secuencias diana se puede realizar mediante cualquier método que utilice PCR o variaciones del método, incluidas, pero sin limitación, PCR asimétrica, amplificación dependiente de la helicasa, PCR de inicio en caliente, qPCR, PCR en fase sólida y PCR de contacto. En la etapa 540, los ácidos nucleicos diana amplificados que comprenden los sitios polimórficos, por ejemplo, SNP, se utilizan para preparar una biblioteca de secuenciación de ácidos nucleicos diana. De forma similar, la porción de ADNcf no amplificado purificado se usa para preparar una biblioteca de secuenciación primaria en la etapa 550. En la etapa 560, una porción de la biblioteca diana se combina con la biblioteca primaria generada a partir de la mezcla de ácidos nucleicos sin amplificar, y la mezcla de ácidos nucleicos fetales y maternos comprendida en las dos bibliotecas se secuencia en la etapa 570. La biblioteca enriquecida comprende al menos aproximadamente el 5%, al menos aproximadamente el 10%, al menos aproximadamente el 15%, al menos aproximadamente el 20% o al menos aproximadamente el 25% de la biblioteca diana. En la etapa 580, se analizan los datos de las ejecuciones de secuenciación y se realiza la determinación simultánea de la fracción fetal y la presencia o la ausencia de aneuploidía tal como se ha descrito en la etapa 140 del caso representado en la figura 1.
Determinación de aneuploidía a partir de bibliotecas enriquecidas de secuenciación
La presencia o la ausencia de aneuploidía se determina a partir de la secuenciación de la biblioteca enriquecida en secuencias diana polimórficas tal como se describe para la biblioteca no enriquecida descrita en el método 100.
Determinación de la fracción fetal a partir de bibliotecas enriquecidas de secuenciación
La determinación de la fracción fetal en las etapas 240 (figura 2), 360 (figura 3), 480 (figura 4) y 580 (figura 5) se basa en el número total de etiquetas que se mapean al primer alelo y el número total de etiquetas que se mapean al segundo alelo en un sitio polimórfico informativo, por ejemplo, un SNP, contenido en un genoma de referencia. Por ejemplo, el genoma de referencia es la secuencia NCBI36/hg18 del genoma de referencia humano, o el genoma de referencia comprende la secuencia NCBI36/hg18 del genoma de referencia humano y un genoma de secuencias diana artificiales, que incluye las secuencias polimórficas diana. En un caso, el genoma diana artificial abarca secuencias polimórficas que comprenden SNP rs560681, rs1109037, rs9866013, rs13182883, rs13218440, rs7041158, rs740598, rs10773760, rs4530059, rs7205345, rs8078417, rs576261, rs2567608, rs430046, rs9951171, rs338882, rs10776839, rs9905977, rs1277284, rs258684, rs1347696, rs508485, rs9788670, rs8137254, rs3143, rs2182957, rs3739005 y rs530022. En un caso, el genoma artificial incluye las secuencias diana polimórficas de las SEQ ID NO: 1 -56. En otro caso, el genoma artificial incluye las secuencias diana polimórficas de las SEQ ID NO: 1-26 (véase el ejemplo, 7). En otro caso, el genoma diana artificial abarca secuencias polimórficas que comprenden STR seleccionados de entre CSF1PO, FGA, TH01, TPOX, vWA, D3S1358,D5S818, D7S820, D8S1179, D13S317, D16S539, D18S51, D21S11, PentaD, Penta E, D2S1338, D1S1677, D2S441, D4S2364, D10S1248, D14S1434, D22S1045, D22S1045, D20S1082, D20S482, D18S853, D17S1301, D17S974, D14S1434, D12ATA63, D11S4463, D10S1435, D10S1248, D9S2157, D9S1122, D8S1115, D6S1017, D6S474, D5S2500, D5S2500, D4S2408, D4S2364, D3S4529, D3S3053, D2S1776, D2S441,
D1S1677, D1S1627 y D1GATA113. En otro caso más, el genoma diana artificial abarca secuencias polimórficas que comprenden uno o más SNP en tándem (SEQ ID NO: 1-56). La composición del genoma de las secuencias diana artificiales variará dependiendo de las secuencias polimórficas que se utilicen para determinar la fracción fetal. En consecuencia, un genoma de secuencias diana artificiales no se limita a las secuencias SNP o STR ejemplificadas en el presente documento.
El sitio polimórfico informativo, por ejemplo, SNP, se identifica por la diferencia en las secuencias alélicas y la cantidad de cada uno de los posibles alelos. El ADNcf fetal está presente en una concentración < 10% del ADNcf materno. Así, la presencia de una contribución secundaria de un alelo a la mezcla de ácidos nucleicos fetales y maternos con respecto a la contribución principal del alelo materno se puede asignar al feto. Los alelos que se derivan del genoma materno se denominan en el presente documento alelos principales, y los alelos que se derivan del genoma fetal se denominan en el presente documento alelos secundarios. Los alelos que están representados por niveles similares de etiquetas de secuencia mapeadas representan alelos maternos. Los resultados de una amplificación multiplex ilustrativa de ácidos nucleicos diana que comprenden SNP y derivados de una muestra de plasma materno se muestran en la figura 18. Los SNP informativos se distinguen por el cambio de un solo nucleótido en un sitio polimórfico predeterminado, y los alelos fetales se distinguen por su contribución relativamente secundaria a la mezcla de ácidos nucleicos fetales y maternos en la muestra en comparación con la contribución principal a la mezcla por parte de los ácidos nucleicos maternos, es decir, las secuencias SNP son informativas cuando la madre es heterocigótica y está presente un tercer alelo paterno, lo que permite una comparación cuantitativa entre el alelo heredado de la madre y el alelo heredado del padre para calcular la fracción fetal. En consecuencia, la abundancia relativa de ADNcf fetal en la muestra materna se determina como un parámetro del número total de etiquetas de secuencia única mapeadas a la secuencia de ácido nucleico diana en un genoma de referencia para cada uno de los dos alelos del sitio polimórfico predeterminado. En un caso, la fracción de ácidos nucleicos fetales en la mezcla de ácidos nucleicos fetales y maternos se calcula para cada uno de los alelos informativos (alelox) de la forma siguiente:
% de fracción fetal alelo* = ((^Etiquetas de secuencia fetal para alelo*) / (^Etiquetas de secuencia materna para alelo*)) x 100
la fracción fetal para la muestra se calcula como el promedio de la fracción fetal de todos los alelos informativos.
Opcionalmente, la fracción de ácidos nucleicos fetales en la mezcla de ácidos nucleicos fetales y maternos se calcula para cada uno de los alelos informativos (alelox) de la forma siguiente:
% de fracción fetal alelo* = (( 2 X lEtlquetas de secuencia fetal para alelo*) / (^Etiquetas de secuencia materna para alelo*)) * 100,
para compensar la presencia de 2 alelos fetales, estando uno enmascarado por el fondo materno.
El porcentaje de fracción fetal se calcula para al menos 1, al menos 2, al menos 3, al menos 4, al menos 5, al menos 6, al menos 7, al menos 8, al menos 9, al menos 10, al menos 11, al menos 12, al menos 13, al menos 14, al menos 15, al menos 16, al menos 17, al menos 18, al menos 19, al menos 20 o más alelos informativos. En un caso, la fracción fetal es la fracción fetal promedio determinada para al menos 3 alelos informativos.
De forma similar, la fracción fetal se puede calcular a partir del número de etiquetas mapeadas a alelos de SNP en tándem tal como se realiza para los SNP individuales, pero teniendo en cuenta las etiquetas mapeadas a los dos alelos x e y de SNP en tándem presentes en cada una de las secuencias polimórficas de ácido nucleico diana amplificadas que se amplifican para enriquecer las muestras, es decir, % de fracción fetal alelox+y = ((¿Etiquetas de secuencia fetal para alelox+y) / (¿Etiquetas de secuencia materna para alelox+y)) x 100
Opcionalmente, la fracción de ácidos nucleicos fetales en la mezcla de ácidos nucleicos fetales y maternos se calcula para cada uno de los alelos informativos (alelox+y) de la forma siguiente:
% de fracción fetal alelo*+y = (( 2 X ¿Etiquetas de secuencia fetal para alelo*+y) / (¿Etiquetas de secuencia materna para alelo*ty)) x 100,
para compensar la presencia de 2 conjuntos de alelos fetales en tándem, estando uno enmascarado por el fondo materno. Las secuencias de SNP en tándem son informativas cuando la madre es heterocigótica y está presente un tercer haplotipo paterno, lo que permite una comparación cuantitativa entre el haplotipo heredado de la madre y el haplotipo heredado del padre para calcular la fracción fetal.
La fracción fetal se puede determinar a partir de bibliotecas de secuenciación que comprenden secuencias diana polimórficas amplificadas que comprenden STR contando el número de etiquetas mapeadas a un alelo principal (materno) y uno secundario (fetal). Las etiquetas comprenden secuencias de longitud suficiente para abarcar los alelos STR. Los alelos STR informativos pueden dar como resultado una o dos secuencias de etiquetas principales correspondientes a los alelos maternos (y el alelo fetal heredado de la madre) y una secuencia de etiqueta secundaria correspondiente al alelo fetal no heredado de la madre. La fracción fetal se calcula como una relación del número de etiquetas mapeadas a los alelos fetales y maternos.
Determinación de la fracción fetal por secuenciación masivamente paralela
Además de utilizar el presente método para determinar simultáneamente la fracción fetal y la aneuploidía, la fracción fetal puede determinarse independientemente de la determinación de la aneuploidía tal como se describe en el presente documento, pero puede determinarse de forma independiente y/o junto con otros métodos utilizados para la determinación de la aneuploidía tales como los métodos descritos en las publicaciones de solicitud de patente de Estados Unidos N2 US 2007/0202525A1; US2010/0112575A1, US 2009/0087847A1; US2009/0029377A1; US 2008/0220422A1; US2008/0138809A1, US2008/0153090A1 y la patente de Estados Unidos N27.645.576. El método para determinar la fracción fetal también se puede combinar con ensayos para determinar otras condiciones prenatales asociadas con la madre y/o el feto. Por ejemplo, el método se puede utilizar junto con análisis prenatales, por ejemplo, tal como se describe en las publicaciones de solicitud de patente de Estados Unidos N° US2010/0112590A1, US2009/0162842A1, US2007/0207466A1 y US2001/0051341A1.
La figura 6 proporciona un diagrama de flujo de un caso del método de la divulgación para determinar la fracción de ácidos nucleicos fetales en una muestra biológica materna mediante secuenciación masivamente paralela de ácidos nucleicos diana polimórficos amplificados por PCR independientemente de la determinación simultánea de aneuploidía. El método comprende la secuenciación de una biblioteca de secuenciación de ácidos nucleicos diana polimórficos de la forma siguiente. En la etapa 610 se obtiene de un sujeto una muestra de ensayo materna que comprende una mezcla de ácidos nucleicos fetales y maternos. La muestra es una muestra materna que se obtiene de un sujeto femenino embarazado, por ejemplo, una mujer embarazada. Otras muestras maternas pueden ser de mamíferos, por ejemplo, vaca, yegua, perra o gata. Si el sujeto es un ser humano, la muestra se puede tomar en el primer o segundo trimestre de embarazo. Los ejemplos de muestras biológicas maternas son los descritos anteriormente. En la etapa 620, la mezcla de ácidos nucleicos fetales y maternos se procesa adicionalmente a partir de la fracción de muestra, por ejemplo, plasma, para obtener una muestra que comprende una mezcla purificada de ácidos nucleicos fetales y maternos, por ejemplo, ADNcf, tal como se ha descrito para el caso 100. En la etapa 630, una porción de la mezcla purificada de ADNcf fetal y materno se utiliza para amplificar una pluralidad de ácidos nucleicos diana polimórficos, cada uno de los cuales comprende un sitio polimórfico. Los sitios polimórficos que están contenidos en los ácidos nucleicos diana incluyen, sin limitación, polimorfismos de un solo nucleótido (SNP), SNP en tándem, deleciones o inserciones de múltiples bases a pequeña escala, denominadas IN-DELS (también denominadas polimorfismos de deleción-inserción o DIP), polimorfismos de múltiples nucleótidos (MNP), repeticiones en tándem cortas (STR), polimorfismo de longitud de fragmentos de restricción (RFLP) o un polimorfismo que comprende cualquier otro cambio de secuencia en un cromosoma. Las secuencias polimórficas ilustrativas y los métodos para amplificarlas son tal como se describen para los casos que se muestran en las figuras 2-5. En algunos casos, los sitios polimórficos están ubicados en cromosomas autosómicos, lo que permite la determinación de la fracción fetal independientemente del sexo del feto. Los polimorfismos asociados con cromosomas distintos de los cromosomas 13, 18, 21 e Y también pueden utilizarse en los métodos descritos en el presente documento.
En la etapa 640, una porción o la totalidad de las secuencias polimórficas amplificadas se utilizan para preparar una biblioteca de secuenciación para la secuenciación en una forma paralela tal como se describe. En un caso, la biblioteca se prepara para la secuenciación por síntesis utilizando la química de secuenciación basada en terminadores reversibles de Illumina, tal como se describe en el ejemplo, 13. En la etapa 640, la información de secuencia que se necesita para determinar la fracción fetal se obtiene utilizando un método NGS. En la etapa 650, la fracción fetal se determina en base al número total de etiquetas que se mapean al primer alelo y el número total de etiquetas que se mapean al segundo alelo en un sitio polimórfico informativo, por ejemplo, un SNP, contenido en un genoma de referencia artificial, por ejemplo, un genoma de referencia SNP. Los genomas diana artificiales son tal como se describen en el presente documento. Se identifican los sitios polimórficos informativos y se calcula la fracción fetal tal como se describe.
La determinación de la fracción fetal según el presente documento puede utilizarse junto con ensayos de diagnóstico clínicamente relevantes como control positivo de la presencia de ADNcf con el fin de resaltar resultados falsos negativos o falsos positivos derivados de niveles bajos de ADNcf por debajo del límite de identificación. En un caso, la información de la fracción fetal se puede utilizar para establecer umbrales y estimar el tamaño mínimo de la muestra en la detección de aneuploidía. Dicho uso se describe en el ejemplo, 16, más adelante. La información de la fracción fetal se puede utilizar junto con la información de secuenciación. Por ejemplo, los ácidos nucleicos de una muestra libre de células, por ejemplo, una muestra de plasma o suero materno, pueden utilizarse para enumerar secuencias en una muestra. Las secuencias pueden enumerarse utilizando cualquiera de las técnicas de secuenciación descritas anteriormente. El conocimiento de la fracción fetal se puede utilizar para establecer umbrales de "corte" para designar a los estados "aneuploidía", "normal" o "marginal/sin designación" (incierto). Después se pueden realizar cálculos para estimar el número mínimo de secuencias necesarias para lograr la sensibilidad adecuada (es decir, la probabilidad de identificar correctamente un estado de aneuploidía).
Los presentes métodos pueden aplicarse para determinar la fracción de cualquier población de ácidos nucleicos en una mezcla de ácidos nucleicos aportados por diferentes genomas. Además de determinar la fracción aportada a una muestra por dos individuos, por ejemplo, los diferentes genomas son aportados por el feto y la madre que porta al feto, los métodos pueden utilizarse para determinar la fracción de un genoma en una mezcla derivada de dos células
diferentes de un individuo, por ejemplo, los genomas son aportados a la muestra por células cancerosas aneuploides y células euploides normales del mismo sujeto.
Composiciones y kits
También se divulgan en el presente documento composiciones y kits o sistemas de reactivos útiles para poner en práctica los métodos descritos en el presente documento.
Las composiciones divulgadas en el presente documento se pueden incluir en kits para mezclas de secuenciación masivamente paralela de moléculas de ácidos nucleicos fetales y maternos, por ejemplo, ADNcf, presentes en una muestra materna, por ejemplo, una muestra de plasma. Los kits comprenden una composición que comprende al menos un conjunto de cebadores para amplificar al menos un ácido nucleico diana polimórfico en dichas moléculas de ácidos nucleicos fetales y maternos. Los ácidos nucleicos polimórficos pueden comprender, sin limitación, polimorfismos de un solo nucleótido (SNP), SNP en tándem, deleciones o inserciones de múltiples bases a pequeña escala, denominadas IN-DELS (también denominadas polimorfismos de deleción-inserción o DIP), polimorfismos de múltiples nucleótidos (MNP), repeticiones en tándem cortas (STR), polimorfismo de longitud de fragmentos de restricción (RFLP) o un polimorfismo que comprende cualquier otro cambio de secuencia en un cromosoma. Los métodos de secuenciación son métodos NGS de moléculas de ácido nucleico individuales o moléculas de ácido nucleico amplificadas clonalmente tal como se describe en el presente documento. Los métodos NGS son métodos de secuenciación masivamente paralelos que incluyen pirosecuenciación, secuenciación por síntesis con terminadores de colorantes reversibles, secuenciación en tiempo real, secuenciación por ligación de sonda de oligonucleótidos o secuenciación de una sola molécula.
En un caso, la composición incluye cebadores para amplificar ácidos nucleicos diana polimórficos que comprenden cada uno al menos un SNP. El,al menos un, SNP se selecciona de los SNP rs560681, rs1109037, rs9866013, rs13182883, rs13218440, rs7041158, rs740598, rs10773760, rs 4530059, rs7205345, rs8078417, rs576261, rs2567608, rs430046, rs9951171, rs338882, rs10776839, rs9905977, rs1277284, rs258684, rs1347696, rs508485, rs9788670, rs8137254, rs3143, rs2182957, rs3739005 y rs530022. Los conjuntos correspondientes de cebadores para amplificar los SNP se proporcionan como las SEQ ID NO: 57-112.
En otro caso, la composición comprende cebadores para amplificar ácidos nucleicos diana polimórficos que comprenden cada uno al menos un SNP en tándem. Los SNP en tándem ilustrativos incluyen rs7277033-rs2110153; rs2822654-rs1882882; rs368657-rs376635; rs2822731-rs2822732; rs1475881-rs7275487; rs1735976-rs2827016; rs447340-rs2824097; rs418989-rs13047336; rs987980-rs987981; rs4143392-rs4143391; rs1691324-rs13050434; rs11909758-rs9980111; rs2826842-rs232414; rs1980969-rs1980970; rs9978999-rs9979175; rs1034346-rs12481852; rs7509629-rs2828358; rs4817013-rs7277036; rs9981121-rs2829696; rs455921-rs2898102; rs2898102-rs458848; rs961301-rs2830208; rs2174536-rs458076; rs11088023-rs11088024; rs1011734-rs1011733; rs2831244-rs9789838; rs8132769-rs2831440; rs8134080-rs2831524; rs4817219-rs4817220; rs2250911-rs2250997; rs2831899-rs2831900; rs2831902-rs2831903; rs11088086-rs2251447; rs2832040-rs11088088; rs2832141-rs2246777; rs2832959 -rs9980934; rs2833734-rs2833735; rs933121-rs933122; rs2834140-rs12626953; rs2834485-rs3453; rs9974986-rs2834703; rs2776266-rs2835001; rs1984014-rs1984015; rs7281674-rs2835316; rs13047304-rs13047322; rs2835545-rs4816551; rs2835735-rs2835736; rs13047608-rs2835826; rs2836550-rs2212596; rs2836660-rs2836661; rs465612-rs8131220; rs9980072-rs8130031; rs418359-rs2836926; rs7278447-rs7278858; rs385787-rs367001; rs367001-rs386095; rs2837296-rs2837297; y rs2837381-rs4816672. En un caso, la composición incluye cebadores para amplificar los SNP en tándem ilustrativos divulgados en el presente documento, y la composición comprende los cebadores ilustrativos correspondientes de SEQ ID NO: 197-310.
En otro caso, la composición comprende cebadores para amplificar ácidos nucleicos diana polimórficos que comprenden cada uno al menos un STR. Los STR ilustrativos incluyen CSF1PO, FGA, TH01, TPOX, vWA, D3S1358, D5S818, D7S820, D8S1179, D13S317, D16S539, D18S51, D21S11, D2S1338, PentaD, PentaE, D22S1045, D20S1082, D20S482, D18S853, D17S1301, D17S974, D14S1434, D12ATA63, D11S4463, D10S1435, D10S1248, D9S2157, D9S1122, D8S1115, D6S1017, D6S474, D5S2500, D4S2408, D4S2364, D3S4529, D3S3053, D2S1776, D2S441, D1S1677, D1S1627 y D1GATA113. En un caso, la composición incluye cebadores para amplificar los STR en tándem ilustrativos divulgados en el presente documento, y la composición comprende los cebadores ilustrativos correspondientes de SEQ ID NO: 113-196.
Los kits pueden contener una combinación de reactivos que incluye los elementos necesarios para realizar un ensayo según los métodos divulgados en el presente documento. El sistema de reactivos se presenta en forma de paquete comercial, como una composición o mezcla cuando la compatibilidad de los reactivos lo permita, en una configuración de dispositivo de ensayo, o más típicamente como un kit de ensayo, es decir, una combinación envasada de uno o más recipientes, dispositivos o similares que contenga los reactivos necesarios, y que preferentemente incluya instrucciones escritas para la realización de los ensayos. El kit divulgado en el presente documento puede adaptarse a cualquier configuración de ensayo y puede incluir composiciones para realizar cualquiera de los diversos formatos de ensayo descritos en el presente documento. Los kits para determinar la fracción fetal comprenden composiciones que incluyen conjuntos de cebadores para amplificar ácidos nucleicos polimórficos presentes en una muestra materna tal como se describe y, cuando corresponda, reactivos para purificar ADNcf, que están dentro del alcance de la
divulgación. En un caso, un kit diseñado para permitir la cuantificación de secuencias polimórficas fetales y maternas, por ejemplo, STR y/o SNP y/o SNP en tándem, en una muestra de plasma de ADNcf, incluyen al menos un conjunto de oligonucleótidos específicos de alelo específicos para un SNP seleccionado y/o una región de repeticiones en tándem. Preferentemente, el kit incluye una pluralidad de conjuntos de cebadores para amplificar un panel de secuencias polimórficas. Un kit puede comprender otros reactivos y/o información para genotipar o cuantificar alelos en una muestra (por ejemplo, tampones, nucleótidos, instrucciones). Los kits también incluyen una pluralidad de recipientes de tampones y reactivos apropiados.
Productos informáticos
La determinación de aneuploidía y/o la determinación de la fracción fetal se deriva informáticamente de la gran cantidad de información de secuenciación que se obtiene según los métodos descritos en el presente documento. En un caso, se divulga en el presente documento un medio legible informáticamente que tiene almacenadas instrucciones legibles informáticamente para determinar la presencia o la ausencia de aneuploidía a partir de la información obtenida de la secuenciación de ácidos nucleicos fetales y maternos en una muestra materna. En un caso, el medio legible informáticamente utiliza información de secuencia obtenida de una pluralidad de moléculas de ácidos nucleicos fetales y maternos en una muestra de plasma materno para identificar un número de etiquetas de secuencia mapeadas para un cromosoma de interés y para un cromosoma de normalización. Utilizando el número de etiquetas de secuencia mapeadas identificadas para un cromosoma de interés y el número de etiquetas de secuencia mapeadas identificadas para al menos un cromosoma de normalización, el medio legible informáticamente calcula una dosis de cromosoma para un cromosoma de interés; y compara la dosis de cromosoma con al menos un valor umbral, y de ese modo identifica la presencia o la ausencia de aneuploidía fetal. Los ejemplos de cromosomas de interés incluyen, sin limitación, los cromosomas 21, 13, 18 y X.
En otro caso, se divulga en el presente documento un sistema de procesamiento que está adaptado o configurado para determinar la presencia o la ausencia de aneuploidía a partir de la información obtenida de la secuenciación de ácidos nucleicos fetales y maternos en una muestra materna. El sistema de procesamiento informático está adaptado o configurado para (a) usar información de secuencia obtenida a partir de una pluralidad de moléculas de ácidos nucleicos fetales y maternos en una muestra de plasma materno para identificar un número de etiquetas de secuencia mapeadas para un cromosoma de interés; (b) usar información de secuencia obtenida a partir de una pluralidad de moléculas de ácidos nucleicos fetales y maternos en una muestra de plasma materno para identificar un número de etiquetas de secuencia mapeadas para al menos un cromosoma de normalización; (c) usar el número de etiquetas de secuencia mapeadas identificadas para un cromosoma de interés en la etapa (a) y el número de etiquetas de secuencia mapeadas identificadas para el, al menos un, cromosoma de normalización en la etapa (b) para calcular una dosis de cromosoma para un cromosoma de interés; y (d) comparar dicha dosis de cromosoma con al menos un valor umbral, e identificar así la presencia o la ausencia de aneuploidía fetal. Los ejemplos de cromosomas de interés incluyen, sin limitación, los cromosomas 21, 13, 18 y X.
En otro caso, se divulga en el presente documento un aparato adaptado o configurado para determinar la presencia o la ausencia de aneuploidía a partir de la información obtenida de la secuenciación de ácidos nucleicos fetales y maternos en una muestra materna. El aparato está adaptado o configurado para comprender (a) un dispositivo de secuenciación adaptado o configurado para secuenciar al menos un porción de las moléculas de ácido nucleico en una muestra de plasma materno que comprende moléculas de ácidos nucleicos fetales y maternos, generando así información de secuencia; y (b) un sistema de procesamiento informático configurado para realizar las etapas siguientes: (i) usar información de secuencia generada por el dispositivo de secuenciación para identificar un número de etiquetas de secuencia mapeadas para un cromosoma de interés; (ii) usar información de secuencia generada por el dispositivo de secuenciación para identificar un número de etiquetas de secuencia mapeadas para al menos un cromosoma de normalización; (iii) usar el número de etiquetas de secuencia mapeadas identificadas para un cromosoma de interés en la etapa (i) y el número de etiquetas de secuencia mapeadas identificadas para el, al menos un, cromosoma de normalización en la etapa (ii) para calcular una dosis de cromosoma para un cromosoma de interés; y (iv) comparar dicha dosis de cromosoma con al menos un valor umbral, e identificar así la presencia o la ausencia de aneuploidía fetal. Los ejemplos de cromosomas de interés incluyen, sin limitación, los cromosomas 21, 13, 18 y X.
Ejemplo 1
Procesamiento de muestras y extracción de ADNcf
Se recogieron muestras de sangre periférica de mujeres embarazadas en su primer o segundo trimestre de embarazo y que se consideraron en riesgo de aneuploidía fetal. Se obtuvo el consentimiento informado de cada participante antes de la extracción de sangre. La sangre se recogió antes de la amniocentesis o del muestreo de vellosidades coriónicas. El análisis de cariotipos se realizó utilizando muestras de vellosidades coriónicas o de amniocentesis para confirmar el cariotipo fetal.
La sangre periférica extraída de cada sujeto se recogió en tubos ACD. Se transfirió un tubo de muestra de sangre (aproximadamente 6-9 ml/tubo) a un tubo de centrifugadora de baja velocidad de 15 ml. La sangre se centrifugó a 2640 rpm, 4°C durante 10 min utilizando una centrifugadora Beckman Allegra 6 R y un rotor modelo GA 3.8.
Para la extracción de plasma libre de células, la capa de plasma superior se transfirió a un tubo de centrifugadora de alta velocidad de 15 ml y se centrifugó a 16.000 x g, 4°C durante 10 min utilizando una centrifugadora Beckman Coulter Avanti J-E y un rotor JA-14. Las dos etapas de centrifugación se realizaron dentro de las 72 h posteriores a la extracción de sangre. El plasma libre de células que comprende ADNcf se almacenó a -80°C y se descongeló solo una vez antes de la amplificación del plasma ADNcf o para la purificación de ADNcf.
El ADN libre de células purificado (ADNcf) se extrajo del plasma libre de células usando el kit QlAamp Blood DNA Mini (Qiagen) esencialmente según las instrucciones del fabricante. Se añadió un mililitro de tampón AL y 100 gl de solución de proteasa a 1 ml de plasma. La mezcla se incubó durante 15 minutos a 56°C. Se añadió un mililitro de etanol al 100% a la digestión de plasma. La mezcla resultante se transfirió a minicolumnas QlAamp que se ensamblaron con VacValves y VacConnectors proporcionados en el ensamblaje de columna QIAvac 24 Plus (Qiagen) Se aplicó vacío a las muestras y el ADNcf retenido en los filtros de la columna se lavó al vacío con 750 gl de tampón AW1, seguido de un segundo lavado con 750 gl de tampón AW24. La columna se centrifugó a 14.000 rpm durante 5 minutos para eliminar cualquier tampón residual del filtro. El ADNcf se eluyó con tampón AE mediante centrifugación a 14.000 rpm y la concentración se determinó utilizando la plataforma de cuantificación Qubit™ (Invitrogen)
Ejemplo 2
Preparación y secuenciación de bibliotecas de secuenciación primarias y enriquecidas
a. Preparación de bibliotecas de secuenciación - protocolo abreviado
Todas las bibliotecas de secuenciación, es decir, bibliotecas primarias y enriquecidas, se prepararon a partir de aproximadamente 2 ng de ADNcf purificado que se extrajo de plasma materno. La preparación de la biblioteca se realizó utilizando reactivos del conjunto 1 de reactivos de ADN para la preparación de muestras de ADN NEBNext™ (N° de parte E6000L; New England Biolabs, Ipswich, MA), para Illumina® de la forma siguiente. Debido a que el ADN plasmático libre de células está fragmentado en la naturaleza, no se realizó ninguna fragmentación adicional por nebulización o sonicación en las muestras de ADN plasmático. Los salientes de aproximadamente 2 ng de fragmentos de ADNcf purificados contenidos en 40 gl se convirtieron en extremos romos fosforilados según el módulo de reparación de extremos NEBNext® mediante incubación en un tubo de microcentrifugadora de 1,5 ml del ADNcf con 5 gl de tampón de fosforilación 10X, 2 gl de mezcla de solución de desoxinucleótidos (10 mM cada dNTP), 1 gl de una dilución 1:5 de ADN polimerasa I, 1 gl de ADN polimerasa T4 y 1 gl de polinucleótido quinasa T4 proporcionada en el conjunto 1 de reactivos de ADN para la preparación de muestras de ADN NEBNext™ durante 15 minutos a 20°C. Después, las enzimas se inactivaron con calor incubando la mezcla de reacción a 75°C durante 5 minutos. La mezcla se enfrió a 4°C y la adición de colas de dA al ADN de extremos romos se realizó usando 10 gl de la mezcla maestra de adición de colas de dA que contenía el fragmento Klenow (3' a 5' exo minus) (conjunto 1 de reactivos de ADN para preparación de muestras de ADN NEBNext™) e incubando durante 15 minutos a 37°C. Posteriormente, el fragmento de Klenow se inactivó con calor incubando la mezcla de reacción a 75°C durante 5 minutos. Después de la inactivación del fragmento Klenow, se usó 1 gl de una dilución 1:5 de mezcla Illumina Genomic Adapter Oligo Mix (N° de parte 1000521; Illumina Inc., Hayward, CA) para ligar los adaptadores de Illumina (adaptadores Y sin índice) al ADN con cola de dA utilizando 4 gl de la ADN ligasa T4 proporcionada en el conjunto 1 de reactivos de ADN para preparación de muestras de ADN NEBNext™, incubando la mezcla de reacción durante 15 minutos a 25°C. La mezcla se enfrió a 4°C y el ADNcf ligado al adaptador se purificó de adaptadores no ligados, dímeros de adaptadores y otros reactivos utilizando perlas magnéticas provistas en el sistema de purificación de PCR Agencourt AMPure Xp (N.° de parte A63881; Beckman Coulter Genomics, Danvers, MA). Se realizaron dieciocho ciclos de PCR para enriquecer selectivamente el ADNcf ligado con adaptador (25 gl) usando la mezcla maestra Phusion® High-Fidelity Master Mix (25 gl; Finnzymes, Woburn, MA) y cebadores de PCR de Illumina (0,5 gM cada uno) complementarios a los adaptadores (N° de parte 1000537 y 1000537). El ADN ligado al adaptador se sometió a Pc R (98°C durante 30 segundos; 18 ciclos de 98°C durante 10 segundos, 65°C durante 30 segundos y 72°C durante 30; extensión final a 72°C durante 5 minutos) y se mantuvo a 4°C) usando cebadores de PCR genomicos de Illumina (N° de parte 100537 y 1000538) y la mezcla maestra Phusion HF PCR Master Mix proporcionada en el conjunto 1 de reactivos de ADN para preparación de muestras de ADN NEBNext™, según las instrucciones del fabricante. El producto amplificado se purificó utilizando el sistema de purificación por PCR Agencourt AMPure XP (Agencourt Bioscience Corporation, Beverly, MA) según las instrucciones del fabricante disponibles en www.beckmangenomics.eom/products/AMPureXPProtocol_000387v001.pdf. El producto amplificado purificado se eluyó en 40 gl de tampón EB de Qiagen, y la concentración y la distribución de tamaño de las bibliotecas amplificadas se analizó utilizando el kit Agilent DNA 1000 para el bioanalizador 2100 (Agilent technologies Inc., Santa Clara, CA).
b. Preparación de bibliotecas de secuenciación -- protocolo de duración completa
El protocolo de duración completa descrito es esencialmente el protocolo estándar proporcionado por Illumina, y solo difiere del protocolo de Illumina en la purificación de la biblioteca amplificada: el protocolo de Illumina indica que la biblioteca amplificada se purificará mediante electroforesis en gel, mientras que el protocolo descrito en el presente documento utiliza perlas magnéticas para la misma etapa de purificación. Se usaron aproximadamente 2 ng de ADNcf purificado que se había extraído de plasma materno para preparar una biblioteca de secuenciación primaria usando
el conjunto 1 de reactivos de ADN para la preparación de muestras de ADN NEBNext™ (N° de parte E6000L; New England Biolabs, Ipswich, MA) para Illumina® esencialmente según las instrucciones del fabricante. Todas las etapas, excepto la purificación final de los productos ligados con adaptador, que se realizó con perlas magnéticas y reactivos de Agencourt en lugar de la columna de purificación, se realizaron según el protocolo que acompaña a los reactivos para la preparación de muestras NEBNext™ para una biblioteca de ADN genómico que se secuencia utilizando Illumina® GAII. El protocolo NEBNext™ sigue esencialmente el proporcionado por Illumina, que está disponible en grcf.jhml.edu/hts/protocols/11257047_ChIP_SamplePrep.pdf.
Los salientes de aproximadamente 2 ng de fragmentos de ADNcf purificados contenidos en 40 pl se convirtieron en extremos romos fosforilados según el módulo de reparación de extremos NEBNext® mediante incubación en 40pl de ADNcf con 5 pl de tampón de fosforilación 10X, 2 pl de mezcla de solución de desoxinucleótidos (10 mM cada dNTP), 1 pl de una dilución 1:5 de ADN polimerasa I, 1 pl de ADN polimerasa T4 y 1 pl de polinucleótido quinasa T4 proporcionados en el conjunto 1 de reactivos de ADN para la preparación de muestras de ADN NEBNext™ en un tubo de microcentrifugadora de 200 pl en un ciclador térmico durante 30 minutos a 20°C. La muestra se enfrió a 4°C y se purificó usando una columna QIAQuick proporcionada en el kit de purificación QIAQuick PCR (QIAGEN Inc., Valencia, CA) de la forma siguiente. La reacción de 50 pl se transfirió a un tubo de microcentrifugadora de 1,5 ml y se añadieron 250 pl de tampón PB de Qiagen. Los 300 pl resultantes se transfirieron a una columna QIAquick, que se centrifugó a 13.000 rpm durante 1 minuto en una microcentrifugadora. La columna se lavó con 750 pl de tampón PE de Qiagen y se volvió a centrifugar. El etanol residual se eliminó mediante una centrifugación adicional durante 5 minutos a 13.000 rpm. El ADN se eluyó en 39 pl de tampón EB de Qiagen mediante centrifugación. La adición de colas de dA a 34 pl del ADN de extremos romos se realizó usando 16 pl de la mezcla maestra de adición de colas de dA que contenía el fragmento Klenow (3' a 5' exo minus) (conjunto 1 de reactivos de ADN para la preparación de muestras de ADN NEBNext™) e incubando durante 30 minutos a 37°C según el módulo de adición de colas de dA NEBNext® del fabricante. La muestra se enfrió a 4°C y se purificó usando una columna proporcionada en el kit de purificación por PCR MinElute (QIAGEN Inc., Valencia, CA) de la forma siguiente. La reacción de 50 pl se transfirió a un tubo de microcentrifugadora de 1,5 ml y se añadieron 250 pl de tampón PB de Qiagen. Los 300 pl se transfirieron a una columna MinElute, que se centrifugó a 13.000 rpm durante 1 minuto en una microcentrifugadora. La columna se lavó con 750 pl de tampón PE de Qiagen y se volvió a centrifugar. El etanol residual se eliminó mediante una centrifugación adicional durante 5 minutos a 13.000 rpm. El ADN se eluyó con 15 pl de tampón EB de Qiagen y se volvió a centrifugar. Diez microlitros del eluido de ADN se incubaron con 1 pl de una dilución 1:5 de mezcla Illumina Genomic Adapter Oligo Mix (N° de parte 1000521), 15 pl de 2X de tampón de reacción de ligación rápida y 4 pl de ADN ligasa T4 rápida, durante 15 minutos a 25°C según el módulo de ligación rápida NEBNext®. La muestra se enfrió a 4°C y se purificó usando una columna MinElute de la forma siguiente. Se añadieron ciento cincuenta microlitros de tampón PE de Qiagen a los 30 pl de reacción, y el volumen completo se transfirió a una columna MinElute, que se centrifugó a 13 000 rpm durante 1 minuto en una microcentrifugadora. La columna se lavó con 750 pl de tampón PE de Qiagen y se volvió a centrifugar. El etanol residual se eliminó mediante una centrifugación adicional durante 5 minutos a 13.000 rpm. El ADN se eluyó con 28 pl de tampón EB de Qiagen y se volvió a centrifugar. Veintitrés microlitros del eluido de ADN ligado al adaptador se sometieron a 18 ciclos de PCR (98°C durante 30 segundos; 18 ciclos de 98°C durante 10 segundos, 65°C durante 30 segundos y 72°C durante 30; extensión final a 72°C durante 5 minutos, y se mantuvo a 4°C) con cebadores de PCR genómicos de Illumina (N° de parte 100537 y 1000538) y la mezcla maestra Phusion HF PCR Master Mix proporcionada en el conjunto 1 de reactivos de ADN para preparación de muestras de ADN NEBNext™, según las instrucciones del fabricante. El producto amplificado se purificó utilizando el sistema de purificación por PCR Agencourt AMPure XP (Agencourt Bioscience Corporation, Beverly, MA) según las instrucciones del fabricante disponibles en www.beckmangenomics.com/products/AMPureXPProtocol_000387v001.pdf. El sistema de purificación por PCR AMPure XP de Agencourt elimina los dNTP, los cebadores, los dímeros de cebadores, las sales y otros contaminantes no incorporados, y recupera los amplicones de más de 100 pb. El producto amplificado purificado se eluyó a partir de perlas Agencourt en 40 pl de tampón EB de Qiagen, y la distribución de tamaño de las bibliotecas amplificadas se analizó utilizando el kit Agilent DNA 1000 para el bioanalizador 2100 (Agilent technologies Inc., Santa Clara, CA).
c. Análisis de bibliotecas de secuenciación preparadas según los protocolos abreviado (a) y de longitud completa (b)
Los electroferogramas generados por el bionanalizador se muestran en la figura 7. La figura 7 (A) muestra el electroferograma del ADN de la biblioteca preparado a partir de ADNcf purificado a partir de la muestra de plasma M24228 utilizando el protocolo de longitud completa descrito en (a), y la figura 7 (B) muestra el electroferograma del ADN de la biblioteca preparado a partir de ADNcf purificado a partir de la muestra de plasma M24228 utilizando el protocolo de longitud completa descrito en (b). En ambas figuras, los picos 1 y 4 representan el marcador inferior de 15 pb y el marcador superior de 1500, respectivamente; los números sobre los picos indican los tiempos de migración para los fragmentos de la biblioteca; y las líneas horizontales indican el umbral establecido para la integración. El electroferograma de la figura 7 (A) muestra un pico secundario de fragmentos de 187 pb y un pico principal de fragmentos de 263 pb, mientras que el electroferograma de la figura 7 (B) muestra solo un pico a 265 pb. La integración de las áreas de los picos dio como resultado una concentración calculada de 0,40 ng/pl para el ADN del pico de 187 pb de la figura 7 (A), una concentración de 7,34 ng/pl para el ADN del pico de 263 pb de la figura 7 (A), y una concentración de 14,72 ng/pl para el ADN del pico de 265 pb de la figura 7 (B). Se sabe que los adaptadores de Illumina que se ligaron al ADNcf tienen 92 pb, que cuando se restan de los 265 pb, indican que el tamaño máximo del
ADNcf es de 173 pb. Es posible que el pico secundario de 187 pb represente fragmentos de dos cebadores que se ligaron extremo a extremo. Los fragmentos de dos cebadores lineales se eliminan del producto final de la biblioteca cuando se utiliza el protocolo abreviado. El protocolo abreviado también elimina otros fragmentos más pequeños de menos de 187 pb. En este ejemplo, la concentración de ADNcf ligado a adaptador purificado es el doble que la del ADNcf ligado a adaptador producido utilizando el protocolo de longitud completa. Se ha observado que la concentración de los fragmentos de ADNcf ligados al adaptador es siempre mayor que la obtenida utilizando el protocolo de longitud completa (datos no mostrados).
Así, una ventaja de preparar la biblioteca de secuenciación utilizando el protocolo abreviado es que la biblioteca obtenida comprende de forma coherente un solo pico principal en el intervalo de 262 a 267 pb, mientras que la calidad de la biblioteca preparada usando el protocolo de longitud completa varía según se refleja por el número y la movilidad de picos distintos de los que representan el ADNcf. Los productos que no son ADNcf ocuparían espacio en la celda de flujo y disminuirían la calidad de la amplificación de clústeres y la obtención de imágenes posterior de las reacciones de secuenciación, lo que es la base de la asignación general del estado de aneuploidía. Se ha demostrado que el protocolo abreviado no afecta a la secuenciación de la biblioteca (véase la figura 8).
Otra ventaja de preparar la biblioteca de secuenciación con el protocolo abreviado es que las tres etapas enzimáticas de formación de extremos romos, adición de colas de d-A y ligación de adaptador tardan menos de una hora en completarse para respaldar la validación e implementación de un servicio de diagnóstico de aneuploides rápida.
Otra ventaja es que las tres etapas enzimáticas de formación de extremos romos, adición de colas de d-A y ligación de adaptador se realizan en el mismo tubo de reacción, lo que evita múltiples transferencias de muestras que podrían conducir a la pérdida de material y, lo que es más importante, a una posible mezcla de muestras y contaminación de la muestra.
Ejemplo 3
Secuenciación masivamente paralela y determinación de aneuploidía
Se obtuvieron muestras de sangre periférica de sujetos embarazados y se purificó ADNcf de la fracción de plasma tal como se describe en el ejemplo, 1. Todas las bibliotecas de secuenciación se prepararon utilizando el protocolo abreviado de preparación de bibliotecas descrito en el ejemplo, 2. El ADN amplificado se secuenció utilizando el analizador de genoma II de Illumina para obtener lecturas de un solo extremo de 36 pb. Solo se necesitan aproximadamente 30 pb de información de secuencia aleatoria para identificar una secuencia como perteneciente a un cromosoma humano específico. Las secuencias más largas pueden identificar de forma única dianas más particulares. En el presente caso se obtuvo un gran número de lecturas de 36 pb, cubriendo aproximadamente el 10% del genoma. La secuenciación del ADN de la biblioteca se realizó con el analizador de genoma II (Illumina Inc., San Diego, CA, Estados Unidos) según los protocolos estándar del fabricante. Se pueden encontrar copias del protocolo para la secuenciación del genoma completo utilizando la tecnología Illumina/Solexa en BioTechniques.RTM. Protocol Guide 2007 Publicada en diciembre de 2006: p 29, y en Internet en biotechniques.com/default.asp? página=protocolo&subsection=article_display&id=112378. La biblioteca de ADN se diluyó a 1 nM y se desnaturalizó. El ADN de la biblioteca (5 pM) se sometió a la amplificación de clústeres según el procedimiento descrito en la Cluster Station User Guide and Cluster Station Operations Guide de Illumina, disponible en Internet en illumina.com/systems/genome_analyzer/cluster_station.ilmn. Una vez completada la secuenciación de la muestra, el programa informático "Sequencer Control Software" de Illumina transfirió los archivos de imagen y de designación de bases a un servidor Unix que ejecutaba la versión 1.51 del programa informático "Genome Analyzer Pipeline" de Illumina. Se ejecutó el programa "Gerald" de Illumina para alinear secuencias con el genoma humano de referencia que se deriva del genoma hg 18 proporcionado por el National Center for Biotechnology Information (NCBI36/hg18, disponible en Internet en http://genome.ucsc. edu/cgi-bin/hgGateway?org=Human&db=hg18&hgsid=166260105). Los datos de secuencia generados a partir del procedimiento anterior que se alinearon de forma única con el genoma se leyeron desde la salida de Gerald (archivos export.txt) mediante un programa (c2c.pl) que se ejecutaba en un ordenador que ejecutaba el sistema operativo Linnux. Se permitieron alineamientos de secuencias con desajustes de bases y se incluyeron en los recuentos de alineamientos solo si se alineaban únicamente con el genoma. Se excluyeron los alineamientos de secuencias con coordenadas de inicio y final idénticas (duplicados).
Entre aproximadamente 5 y 15 millones de etiquetas de 36 pb con 2 o menos desajustes se mapearon de forma única al genoma humano. Todas las etiquetas mapeadas se contaron y se incluyeron en el cálculo de las dosis de cromosomas tanto en las muestras de ensayo como en las de calificación. Las regiones que se extienden desde la base 0 hasta la base 2 x 106, desde la base 10 x 106 hasta la base 13 x 106 y desde la base 23 x 106 hasta el final del cromosoma Y, se excluyeron específicamente del análisis porque las etiquetas derivadas de fetos tanto masculinos como femeninos se mapean a estas regiones del cromosoma Y.
Se observó que hubo cierta variación en el número total de etiquetas de secuencia mapeadas a cromosomas individuales entre muestras secuenciadas en la misma ejecución (variación intercromosómica), pero se observó una variación sustancialmente mayor entre diferentes ejecuciones de secuenciación (variación de ejecución intersecuenciación).
Ejemplo 4
Dosis y varianza para los cromosomas 13, 18, 21, X e Y
Para examinar el alcance de la variación intercromosómica e intersecuenciación en el número de etiquetas de secuencia mapeadas para todos los cromosomas, se extrajo y se secuenció ADNcf de plasma obtenido de sangre periférica de 48 sujetos embarazados voluntarios tal como se describe en el ejemplo, 1, y se analizó de la forma siguiente.
Se determinó el número total de etiquetas de secuencia que se mapearon a cada cromosoma (densidad de etiquetas de secuencia). Alternativamente, el número de etiquetas de secuencia mapeadas puede normalizarse a la longitud del cromosoma para generar una relación de densidad de etiquetas de secuencia. La normalización de la longitud del cromosoma no es una etapa necesaria y se puede realizar únicamente para reducir el número de dígitos en un número para simplificarlo para la interpretación humana. Las longitudes de los cromosomas que se pueden usar para normalizar los recuentos de etiquetas de secuencia pueden ser las longitudes proporcionadas en Internet en genoma.ucsc.edu/goldenPath/stats.html#hg18.
La densidad de etiquetas de secuencia resultante para cada cromosoma se relacionó con la densidad de etiquetas de secuencia de cada uno de los cromosomas restantes para derivar una dosis de cromosoma calificado, que se calculó como la relación de la densidad de etiquetas de secuencia para el cromosoma de interés, por ejemplo, el cromosoma 21 y la densidad de etiquetas de secuencia de cada uno de los cromosomas restantes, es decir, los cromosomas 1 20, 22 y X. La tabla 1 proporciona un ejemplo, de la dosis de cromosoma calificado calculada para los cromosomas de interés 13, 18, 21, X e Y, determinada en una de las muestras calificadas. Las dosis de cromosomas se determinaron para todos los cromosomas en todas las muestras, y las dosis promedio para los cromosomas de interés 13, 18, 21, X e Y en las muestras calificadas se proporcionan en las tablas 2 y 3, y se muestran en las figuras 9-13. Las figuras 9-13 también representan las dosis de cromosomas para las muestras de ensayo. Las dosis de cromosomas para cada uno de los cromosomas de interés en las muestras calificadas proporcionan una medida de la variación en el número total de etiquetas de secuencia mapeadas para cada cromosoma de interés con respecto a la de cada uno de los cromosomas restantes. Así, las dosis de cromosomas calificados pueden identificar el cromosoma o un grupo de cromosomas, es decir, el cromosoma de normalización, que tiene una variación entre las muestras que es más cercana a la variación del cromosoma de interés, y que serviría como secuencias ideales para normalizar los valores para una evaluación estadística adicional. Las figuras 14 y 15 representan las dosis de cromosomas promedio calculadas determinadas en una población de muestras calificadas para los cromosomas 13, 18 y 21, y los cromosomas X e Y.
En algunos casos, el mejor cromosoma de normalización puede no tener la menor variación, pero puede tener una distribución de dosis calificadas que distingue mejor una muestra o muestras de ensayo de las muestras calificadas, es decir, el mejor cromosoma de normalización puede no tener la variación más baja, pero puede tener la mayor diferenciabilidad. Así, la diferenciabilidad cuenta para la variación en la dosis de cromosoma y la distribución de las dosis en las muestras calificadas.
Las tablas 2 y 3 proporcionan el coeficiente de variación como medida de variabilidad y los valores de la prueba t de Student como medida de diferenciabilidad para los cromosomas 18, 21, X e Y, en los que cuanto menor es el valor de la prueba T, mayor es la diferenciabilidad. La diferenciabilidad para el cromosoma 13 se determinó como el cociente de la diferencia entre la dosis de cromosoma media en las muestras calificadas y la dosis para el cromosoma 13 en la única muestra de ensayo T13, y la desviación estándar de la media de la dosis calificada.
Las dosis calificadas de cromosomas también sirven como base para determinar los valores umbrales al identificar aneuploidías en las muestras de ensayo, tal como se describe a continuación.
Tabla 1


Tabla 2



Tabla 3


En el ejemplo, 3 se describen ejemplos de diagnósticos de T21, T13, T18 y un caso de síndrome de Turner obtenidos utilizando los cromosomas de normalización, las dosis de cromosomas y la diferenciabilidad para cada uno de los cromosomas de interés.
Ejemplo 5
Diagnóstico de aneuploidía fetal utilizando cromosomas de normalización
Para aplicar el uso de dosis de cromosomas para evaluar la aneuploidía en una muestra de ensayo biológica, se obtuvieron muestras de análisis de sangre materna de voluntarias embarazadas y se preparó ADNcf, y se secuenció y se analizó una biblioteca de secuenciación preparada según el protocolo abreviado descrito en el ejemplo, 2.
Trisomía 21
La tabla 4 proporciona la dosis calculada para el cromosoma 21 en una muestra de ensayo ilustrativa (#11403). El umbral calculado para el diagnóstico positivo de aneuploidía T21 se estableció en > 2 desviaciones estándar de la media de las muestras calificadas (normales). Se dio un diagnóstico para T21 basado en que la dosis de cromosoma en la muestra de ensayo era superior al umbral establecido. Los cromosomas 14 y 15 se usaron como cromosomas de normalización en cálculos separados para mostrar que se puede utilizar para identificar la aneuploidía o bien un cromosoma que tiene la variabilidad más baja, por ejemplo, el cromosoma 14, o bien un cromosoma que tiene la mayor diferenciabilidad, por ejemplo, el cromosoma 15. Se identificaron trece muestras T21 usando las dosis de cromosomas calculadas, y se confirmó que las muestras con aneuploidía eran T21 por cariotipo.
Tabla 4

Trisomía 18
La tabla 5 proporciona la dosis calculada para el cromosoma 18 en una muestra de ensayo (#11390). El umbral calculado para el diagnóstico positivo de aneuploidía T18 se estableció en 2 desviaciones estándar de la media de las muestras calificadas (normales). Se dio un diagnóstico para T18 basado en que la dosis de cromosoma en la muestra de ensayo era superior al umbral establecido. El cromosoma 8 se usó como el cromosoma de normalización. En este caso, el cromosoma 8 tenía la menor variabilidad y la mayor diferenciabilidad. Se identificaron ocho muestras T18 usando dosis de cromosomas y se confirmó que eran T18 por cariotipo.
Estos datos muestran que un cromosoma de normalización puede tener tanto la menor variabilidad como la mayor diferenciabilidad.
Tabla 5

Trisomía 13
La tabla 6 proporciona la dosis calculada para el cromosoma 13 en una muestra de ensayo (#51236). El umbral calculado para el diagnóstico positivo de aneuploidía T13 se estableció en 2 desviaciones estándar de la media de las muestras calificadas. Se dio un diagnóstico para T13 basado en que la dosis de cromosoma en la muestra de ensayo era superior al umbral establecido. La dosis de cromosoma para el cromosoma 13 se calculó utilizando o bien el cromosoma 5 o bien el grupo de cromosomas 3, 4, 5 y 6 como cromosoma de normalización. Se identificó una muestra T13.
Tabla 6

La densidad de etiquetas de secuencia para los cromosomas 3-6 es el recuento promedio de etiquetas para los cromosomas 3-6.
Los datos muestran que la combinación de los cromosomas 3, 4, 5 y 6 proporciona una variabilidad menor que la del cromosoma 5 y la mayor diferenciabilidad que cualquiera de los otros cromosomas.
Así, se puede utilizar un grupo de cromosomas como cromosoma de normalización para determinar las dosis de cromosomas e identificar las aneuploidías.
Síndrome de Turner (monosomía X)
La tabla 7 proporciona la dosis calculada para el cromosoma X e Y en una muestra de ensayo (#51238). El umbral calculado para el diagnóstico positivo del síndrome de Turner (monosomía X) se estableció para el cromosoma X en < -2 desviaciones estándar de la media, y para la ausencia del cromosoma Y en < -2 desviaciones estándar de la media para muestras calificadas (normales).
Tabla 7

Una muestra que tenía una dosis de cromosoma X menor que la del umbral establecido se identificó como que tenía menos de un cromosoma X. Se determinó que la misma muestra tenía una dosis de cromosoma Y inferior al umbral establecido, lo que indica que la muestra no tenía un cromosoma Y. Así, la combinación de dosis de cromosomas para X e Y se utilizó para identificar las muestras con síndrome de Turner (monosomía X).
Así, el método descrito en el presente documento permite la determinación de la CNV de los cromosomas. En particular, el método permite la determinación de aneuploidías cromosómicas con sobrerrepresentación y subrepresentación mediante la secuenciación masivamente paralela de ADNcf de plasma materno y la identificación de cromosomas de normalización para el análisis estadístico de los datos de secuenciación. La sensibilidad y la fiabilidad del método permiten pruebas precisas de aneuploidía en el primer y segundo trimestre.
Ejemplo 6
Determinación de aneuploidía parcial
El uso de dosis de secuencia se aplicó para evaluar la aneuploidía parcial en una muestra de ensayo biológica de ADNcf que se preparó a partir de plasma sanguíneo y se secuenció tal como se describe en el ejemplo, 1. Se confirmó mediante cariotipado que la muestra procedía de un sujeto con una deleción parcial del cromosoma 11.
El análisis de los datos de secuenciación para la aneuploidía parcial (deleción parcial del cromosoma 11, es decir, q21-q23) se realizó tal como se describe para las aneuploidías cromosómicas en los ejemplos anteriores. El mapeo de las etiquetas de secuencia en el cromosoma 11 en una muestra de ensayo reveló una pérdida significativa de recuentos de etiquetas entre los pares de bases 81000082-103000103 en el brazo q del cromosoma con respecto a los recuentos de etiquetas obtenidos para la secuencia correspondiente en el cromosoma 11 en las muestras calificadas (datos no mostrados). Se utilizaron etiquetas de secuencia mapeadas a la secuencia de interés en el cromosoma 11 (810000082-103000103 pb) en cada una de las muestras calificadas, y etiquetas de secuencia mapeadas a los 20 segmentos de megabase en el genoma completo en las muestras calificadas, es decir, densidades de etiquetas de secuencias calificadas, para determinar las dosis de secuencias calificadas como relaciones de densidades de etiquetas en todas las muestras calificadas. Se calcularon la dosis de secuencia promedio, la desviación estándar y el coeficiente de variación para todos los 20 segmentos de megabase en el genoma completo, y la secuencia de megabase de 20 que tenía la menor variabilidad fue la secuencia de normalización identificada en el cromosoma 5 (13000014-33000033 pb) (véase la tabla 8), que se utilizó para calcular la dosis para la secuencia de interés en la muestra de ensayo (véase la tabla 9). La tabla 8 proporciona la dosis de secuencia para la secuencia de interés en el cromosoma 11 (810000082-103000103 pb) en la muestra de ensayo que se calculó como la relación de etiquetas de secuencia mapeadas a la secuencia de interés y las etiquetas de secuencia mapeadas a la secuencia de normalización identificada. La figura 16 muestra las dosis de secuencia para la secuencia de interés en las 7 muestras calificadas (O) y la dosis de secuencia para la secuencia correspondiente en la muestra de ensayo (◊). La línea continua muestra la media, y la línea discontinua muestra el umbral calculado para el diagnóstico positivo de aneuploidía parcial que se estableció en 5 desviaciones estándar de la media. El diagnóstico de aneuploidía parcial se basó en que la dosis de secuencia en la muestra de ensayo era inferior al umbral establecido. Se verificó mediante cariotipado que la muestra de ensayo tenía la deleción q21 -q23 en el cromosoma 11.
Por lo tanto, además de identificar aneuploidías cromosómicas, el método de la divulgación puede usarse para identificar aneuploidías parciales.
Tabla 8

Tabla 9

Ejemplo 7
Determinación simultánea de aneuploidía y fracción fetal mediante secuenciación masivamente paralela: selección de SNP autosómicos para la determinación de la fracción fetal
Se seleccionó un conjunto de 28 SNP autosómicos de una lista de 92 SNP (Pakstis et al., Hum Genet 127:315-324 [2010]), y de secuencias SNP disponibles en Applied Biosystems en la dirección de Internet applybiosystems.com, y se validaron para su uso en la amplificación por PCR multiplexada y para secuenciación masivamente paralela para determinar la fracción fetal con o sin la determinación simultánea de la presencia o la ausencia de aneuploidía. Se diseñaron cebadores para hibridarlos con una secuencia cercana al sitio SNP en el ADNcf para garantizar que se incluyera en la lectura de 36 pb generada a partir de la secuenciación masivamente paralela en el analizador GII de Illumina, y para generar amplicones de longitud suficiente para someterlos a amplificación en puente durante la formación de clústeres. Así, se diseñaron cebadores para generar amplicones de al menos 110 pb, que cuando se combinaron con los adaptadores universales (Illumina Inc., San Diego, CA) utilizados para la amplificación de clústeres, dieron como resultado moléculas de ADNcf de al menos 200 pb. Se identificaron secuencias de cebadores y se sintetizaron conjuntos de cebadores, es decir, cebadores directo e inverso, por Integrated DNA Technologies (San Diego, CA), y se almacenaron como una solución 1 pM para su uso para amplificar secuencias diana polimórficas tal como se describe en los ejemplos 5-8. La tabla 10 proporciona los números de ID de acceso de RefSNP (rs), los cebadores utilizados para amplificar la secuencia de ADNcf diana y las secuencias de los amplicones que comprenden los posibles alelos de SNP que se generarían utilizando los cebadores. Los SNP proporcionados en la tabla 10 se utilizaron para la amplificación simultánea de 13 secuencias diana en un ensayo multiplexado para determinar simultáneamente la fracción fetal y la presencia o la ausencia de una aneuploidía en muestras de ADNcf derivadas de mujeres embarazadas. El panel proporcionado en la tabla 10 es un panel SNP ilustrativo. Se pueden emplear menos o más SNP para enriquecer el ADN fetal y materno en ácidos nucleicos diana polimórficos. Los SNP adicionales que se pueden usar incluyen los SNP que se proporcionan en la tabla 11. Los SNP de la tabla 11 se validaron en amplificaciones de PCR multiplex y se secuenciaron con el analizador GenomeII A como se ha descrito anteriormente. Los alelos SNP de las tablas 10 y 11 se muestran en negrita y subrayados.











Ejemplo 8
Determinación simultánea de aneuploidía y fracción fetal: enriquecimiento de ácidos nucleicos fetales y maternos en una muestra de biblioteca de secuenciación de ADNcf
Para determinar simultáneamente la fracción fetal y la presencia o la ausencia de una aneuploidía en una muestra materna, se enriqueció una biblioteca de secuenciación primaria de ácidos nucleicos fetales y maternos en secuencias polimórficas de ácidos nucleicos diana y se secuenció de la forma siguiente.
Se preparó ADNcf purificado a partir de una muestra de plasma materno tal como se describe en el ejemplo, 1. Se usó una primera porción de la muestra de ADNcf purificado para preparar una biblioteca de secuenciación primaria usando el protocolo abreviado descrito en el ejemplo, 2. Se usó una segunda porción de la muestra de ADNcf purificado para amplificar secuencias polimórficas de ácidos nucleicos diana, es decir, SNP y preparar una biblioteca de secuenciación diana de la forma siguiente. Se amplificó ADNcf contenido en 5 pl de ADNcf purificado en un volumen de reacción de 50 pl que contenía 7,5 pl de una mezcla de cebadores 1 pM (tabla 5), 10 pl de mezcla maestra NEB 5X y 27 pl de agua. Se realizó un termociclado con el Gene Amp9700 (Applied Biosystems). Se utilizaron las condiciones de ciclado siguientes: incubación a 95°C durante 1 minuto, seguida de 30 ciclos a 95°C durante 20 segundos, 68°C durante 1 minuto y 68°C durante 30 s, seguidos de una incubación final a 68 °C durante 5 minutos. Se añadió un mantenimiento final a 4°C hasta que se retiraron las muestras para combinarlas con la porción no amplificada de la muestra de ADNcf purificado. El producto amplificado se purificó utilizando el sistema de purificación por PCR Agencourt AMPure XP (N° de parte A63881; Beckman Coulter Genomics, Danvers, MA). Se añadió un mantenimiento final a 4°C hasta que se retiraron las muestras para preparar la biblioteca diana. El producto amplificado se analizó con un bioanalizador 2100 (Agilent Technologies, Sunnyvale, CA) y se determinó la concentración del producto amplificado. Una quinta parte del producto amplificado purificado se usó para preparar una biblioteca de secuenciación diana de ácidos nucleicos polimórficos amplificados tal como se describe en el ejemplo, 2. Las bibliotecas de secuenciación primaria y diana se diluyeron cada una a 10 nM, y la biblioteca diana se combinó en una proporción de 1:9 con la biblioteca de secuenciación para proporcionar una biblioteca de secuenciación enriquecida. La secuenciación de la biblioteca enriquecida se realizó tal como se describe en el ejemplo. El análisis de los datos de secuenciación para determinar aneuploidía se realizó tal como se describe en el ejemplo, 3 usando el genoma humano hg 18 como genoma de referencia. El análisis de los datos de secuenciación para determinar la fracción fetal se realizó de la forma siguiente. De forma concomitante al análisis para determinar la aneuploidía, se analizaron los datos de secuenciación para determinar la fracción fetal. Después de la transferencia de la imagen y los archivos de designación de bases al servidor Unix que ejecuta el programa informático de Illumina "Genome Analyzer Pipeline" versión 1.51 tal como se describe en el ejemplo, 2c, las lecturas de 36 pb se alinearon con un "genoma SNP" utilizando el programa BOWTIE. El genoma SNP se identificó como la agrupación de las secuencias de ADN polimórfico, es decir, SEQ ID NO: 1-56, que abarcan los alelos de los 13 SNP divulgados en la tabla 10 en el ejemplo, 7. Para el análisis de la fracción fetal, solo se usaron las lecturas que se mapearon únicamente al genoma del SNP. Las lecturas que coincidían perfectamente con el genoma SNP se contaron como etiquetas y se filtraron. De las lecturas restantes, solo las lecturas que tenían uno o dos desajustes se contaron como etiquetas y se incluyeron en el análisis. Se contaron las etiquetas mapeadas a cada uno de los alelos SNP y se determinó la fracción fetal. Aproximadamente un millón del número total de etiquetas de secuencia obtenidas a partir de la secuenciación de la biblioteca enriquecida correspondía a etiquetas mapeadas al genoma de referencia SNP. La figura 17 muestra un gráfico de la relación del número de etiquetas de secuencia mapeadas a cada cromosoma y el número total de etiquetas mapeadas a todos los cromosomas (1 -22, X e Y) obtenidas a partir de la secuenciación de una biblioteca de ADNcf no enriquecida (•) y una biblioteca de ADNcf enriquecida con el 5% (■) o el 10% (♦ ) de biblioteca de SNP multiplex amplificada. El gráfico indica que la combinación de una biblioteca de secuencias polimórficas amplificadas con una biblioteca de secuencias no amplificadas de la muestra materna no afecta a la información de secuenciación utilizada para determinar aneuploidía. En las tablas 12, 13 y 14 siguientes se proporcionan ejemplos de determinación de la fracción fetal para muestras obtenidas de sujetos portadores de un feto con aneuploidía cromosómica.
a. Determinación de la fracción fetal
La fracción fetal se calculó como:
% de fracción fetal alelo* = ((^Etiquetas de secuencia fetal para alelo*) / (^Etiquetas de secuencia materna para alelo*)) x 100
en la que alelox es un alelo informativo.
Tabla 12



Fración fetal (Media±S.D.) = 2,7± 1,7

Fración fetal (Media±S.D.) = 3,9± 1,2
b. Determinación de aneuploidía
La determinación de aneuploidía de los cromosomas 21, 13, 18 y X se realizó utilizando dosis de cromosomas tal como se describe en el ejemplo, 4. La dosis de cromosoma calificado, la varianza y la diferenciabilidad para los cromosomas 21, 18, 13, X e Y se proporcionan en las tablas X e Y. La clasificación de los cromosomas de normalización identificados por las dosis de cromosomas determinadas a partir de la secuenciación de la biblioteca enriquecida fue la misma que la determinada a partir de la secuenciación de una biblioteca primaria (no enriquecida) del ejemplo, 4. La figura 17 muestra que la secuenciación de una biblioteca que se ha enriquecido en secuencias diana polimórficas, por ejemplo, SNP, no se ve afectada por la inclusión de los productos SNP amplificados.
Tabla 13


Tabla 14


La dosis del cromosoma 21 se determinó utilizando el cromosoma 14 como cromosoma de normalización; la dosis del cromosoma 13 se determinó usando el grupo de los cromosomas 3, 4, 5 y 6 como el cromosoma de normalización; la dosis del cromosoma 18 se determinó usando el cromosoma 8 como el cromosoma de normalización; y la dosis del cromosoma X se determinó usando el cromosoma 4 como el cromosoma de normalización. Los umbrales se calcularon en 2 desviaciones estándar por encima y por debajo de la media determinada en las muestras calificadas.
La tabla 12 muestra los datos para la determinación de la fracción fetal en muestras ilustrativas. Los valores de dosis de cromosoma calculados para los cromosomas 21,18, 13, X e Y en muestras de ensayo ilustrativas correspondientes se proporcionan en las tablas 15, 16, 17 y 18, respectivamente.
Trisomía 21
La tabla 8 proporciona la dosis calculada para el cromosoma 21 en la muestra de ensayo (11409). Se utilizó el cromosoma 14 como cromosoma de normalización. El umbral calculado para el diagnóstico positivo de aneuploidía T21 se estableció en 2 desviaciones estándar de la media de las muestras calificadas (normales). Se dio un diagnóstico para T21 basado en que la dosis de cromosoma en la muestra de ensayo era superior al umbral establecido. Las doce muestras de T21 que se confirmó que eran T21 por cariotipo se identificaron en una población de 48 muestras de sangre.
Tabla 15
Dosis de cromosoma para una aneuploidía T21

Trisomía 18
La tabla 9 proporciona la dosis calculada para el cromosoma 18 en una muestra de ensayo (95133). El cromosoma 8 se usó como el cromosoma de normalización. En este caso, el cromosoma 8 tenía la menor variabilidad y la mayor diferenciabilidad. El umbral calculado para el diagnóstico positivo de aneuploidía T18 se estableció en > 2 desviaciones estándar de la media de las muestras calificadas (no T18). Se dio un diagnóstico para T18 basado en que la dosis de cromosoma en la muestra de ensayo era superior al umbral establecido. Se identificaron ocho muestras T18 usando dosis de cromosomas y se confirmó que eran T18 por cariotipado.
Tabla 16

Trisomía 13
Las tablas 10 y 11 proporcionan la dosis calculada para el cromosoma 13 en una muestra de ensayo (51236). El umbral calculado para el diagnóstico positivo de aneuploidía T13 se estableció en 2 desviaciones estándar de la media de las muestras calificadas (no T13). La dosis de cromosoma para el cromosoma 13 proporcionada en la tabla 10 se calculó utilizando la densidad de etiquetas de secuencia para el cromosoma 4 como el cromosoma de normalización, mientras que la dosis proporcionada en la tabla 11 se determinó utilizando el promedio de las relaciones de densidades de etiquetas de secuencia para el grupo de cromosomas 3, 4, 5 y 6 como el cromosoma de normalización. Se dio un diagnóstico para T13 basado en que la dosis de cromosoma en la muestra de ensayo era superior al umbral establecido. Se identificó una muestra T13 usando dosis de cromosomas y se confirmó que eran T13 por cariotipado.
Los datos muestran que la combinación de los cromosomas 3, 4, 5 y 6 proporciona una variabilidad (1,06) similar a la del cromosoma 4 (1,01), lo que demuestra que un grupo de cromosomas se puede utilizar como cromosoma de normalización para determinar dosis e identificar aneuploidías.
Tabla 17

Tabla 18

Síndrome de Turner (monosomía X)
Tres muestras que tenían una dosis de cromosoma inferior a la del umbral establecido se identificaron como que tenían menos de un cromosoma X. Se determinó que las mismas muestras tenían una dosis de cromosoma Y inferior al umbral establecido, lo que indica que las muestras no tenían cromosoma Y.
Las dosis calculadas para los cromosomas X e Y en la muestra de ensayo de monosomía X ilustrativa (54430) se proporcionan en la tabla 12. Se seleccionó el cromosoma 4 como el cromosoma de normalización para calcular la dosis para el cromosoma X; y todos los cromosomas, es decir, 1-22 e Y se usaron como cromosomas de normalización. El umbral calculado para el diagnóstico positivo del síndrome de Turner (monosomía X) se estableció para el cromosoma X en < -2 desviaciones estándar de la media, y para la ausencia del cromosoma Y en < -2 desviaciones estándar de la media para muestras calificadas (sin monosomía X).
Tabla 19

Así, el método permite la determinación simultánea de aneuploidías cromosómicas y la fracción fetal mediante la secuenciación masivamente paralela de una muestra materna que comprende una mezcla de ADNcf fetal y materno que se ha enriquecido en una pluralidad de secuencias polimórficas, cada una de las cuales comprende un SNP. En este ejemplo, la mezcla de ácidos nucleicos fetales y maternos se enriqueció mediante la combinación de una porción de una biblioteca de secuenciación que se construyó a partir de secuencias polimórficas fetales y maternas amplificadas con una biblioteca de secuenciación que se construyó a partir de la mezcla de ADNcf fetal y materna original no amplificada restante.
Ejemplo 9
Determinación simultánea de aneuploidía y fracción fetal:
enriquecimiento de ácidos nucleicos fetales y maternos en una muestra de ADNcf purificado
Para enriquecer el ADNcf fetal y materno contenido en una muestra purificada de ADNcf extraído de una muestra de plasma materno, se usó una porción del ADNcf purificado para amplificar secuencias polimórficas de ácido nucleico diana, comprendiendo cada una de las mismas un SNP elegido del panel de SNP que se proporciona en la tabla 6.
Se obtuvo plasma libre de células a partir de una muestra de sangre materna y se purificó ADNcf a partir de la muestra de plasma tal como se describe en el ejemplo, 1. Se determinó que la concentración final era 92,8 pg/pl.
El ADNcf contenido en 5 pl de ADNcf purificado se amplificó en un volumen de reacción de 50 pl que contenía 7,5 pl de una mezcla de cebadores 1 uM (tabla 5), 10 pl de mezcla maestra NEB 5X y 27 pl de agua. Se realizó un termociclado con el Gene Amp9700 (Applied Biosystems). Se utilizaron las condiciones de ciclado siguientes: incubación a 95°C durante 1 minuto, seguida de 30 ciclos a 95°C durante 20 segundos, 68°C durante 1 minuto y 68°C durante 30 s, seguidos de una incubación final a 68 °C durante 5 minutos. Se añadió un mantenimiento final a 4°C hasta que se retiraron las muestras para combinarlas con la porción no amplificada de la muestra de ADNcf purificado. El producto amplificado se purificó con el sistema de purificación por PCR Agencourt AMPure XP (N° de parte A63881; Beckman Coulter Genomics, Danvers, MA) y la concentración se cuantificó usando Nanodrop 2000 (Thermo Scientific, Wilmington, DE). El producto de amplificación purificado se diluyó 1:10 en agua y se añadieron 0,9 pl (371 pg) a 40 pl de muestra de ADNcf purificado para obtener un pico del 10%. El ADNcf fetal y materno enriquecido presente en la muestra de ADNcf purificado se usó para preparar una biblioteca de secuenciación y se secuenció tal como se describe en el ejemplo, 2.
La tabla 13 proporciona los recuentos de etiquetas obtenidos para cada uno de los cromosomas 21, 18, 13, X e Y, es decir, densidad de etiquetas de secuencia y recuentos de etiquetas obtenidos para las secuencias polimórficas informativas contenidas en el genoma de referencia de SNP, es decir, la densidad de etiqueta de SNP. Los datos muestran que la información de secuenciación se puede obtener mediante la secuenciación de una sola biblioteca construida a partir de una muestra de ADNcf materno purificado que se ha enriquecido en secuencias que comprenden SNP para determinar simultáneamente la presencia o la ausencia de aneuploidía y la fracción fetal. En el ejemplo, dado, los datos muestran que la fracción de ADN fetal en la muestra de plasma AFR105 era cuantificable a partir de los resultados de secuenciación de cinco SNP informativos y se determinó que era del 3,84%. Las densidades de etiquetas de secuencia se proporcionan para los cromosomas 21, 13, 18, X e Y. La muestra AFR105 fue la única muestra que se sometió al protocolo de enriquecimiento de ADNcf purificado para secuencias polimórficas amplificadas. Así, no se proporcionaron coeficientes de variación ni ensayos de diferenciabilidad. Sin embargo, el ejemplo, muestra que el protocolo de enriquecimiento proporciona los recuentos de etiquetas necesarios para determinar la aneuploidía y la fracción fetal a partir de un único proceso de secuenciación.
Tabla 20



Ejemplo 10
Determinación simultánea de aneuploidía y fracción fetal: enriquecimiento de ácidos nucleicos fetales y maternos en una muestra de plasma
Para enriquecer el ADNcf fetal y materno contenido en una muestra de plasma original derivada de una mujer embarazada, se usó una porción de la muestra de plasma original para amplificar secuencias polimórficas de ácido nucleico diana, comprendiendo cada una de las mismas un SNP elegido del panel de SNP que se proporciona en la tabla 14, y una porción del producto amplificado se combinó con la muestra de plasma original restante.
Se amplificó ADNcf contenido en 15 gl de plasma libre de células en un volumen de reacción de 50 gl que contenía 9 ul de una mezcla de cebadores 1 gM (15 plex tabla 5), 1 gl de ADN polimerasa de sangre Phusion, 25 ul del tampón de PCR en sangre 2X Phusion que contenía trifosfatos de desoxinucleótidos (dNTP: dATP, dCTP, dGTP y dTTP). Se realizó un termociclado con Gene Amp9700 (Applied Biosystems) utilizando las condiciones de ciclado siguientes: incubación a 95°C durante 3 minutos, seguida de 35 ciclos a 95°C durante 20 segundos, 55°C durante 30 s y 70°C durante 1 minuto, seguidos de una incubación final a 68°C durante 5 minutos. Se añadió un mantenimiento final a 4°C hasta que se retiraron las muestras para combinarlas con la porción no amplificada de la muestra libre de células. El producto amplificado se diluyó 1:2 con agua y se analizó con el bioanalizador. Se diluyeron 3 gl adicionales de producto amplificado con 11,85 gl de agua para obtener una concentración final de 2 ng/gl. Se combinaron 2,2 gl del producto amplificado diluido con la muestra de plasma restante. El ADNcf fetal y materno enriquecido presente en la muestra de plasma se purificó tal como se describe en el ejemplo, 1 y se usó para preparar una biblioteca de secuenciación. La secuenciación y el análisis de los datos de secuenciación se realizaron tal como se describe en los ejemplos 2 y 3.
Los resultados se proporcionan en la tabla 21. En el ejemplo, dado, los datos muestran que la fracción de ADN fetal en la muestra de plasma SAC2517 era cuantificable a partir de los resultados de secuenciación de un SNP informativo y se determinó que era del 9,5%. En el ejemplo, dado, el cariotipado demostró que la muestra SAC2517 no se vio afectada por las aneuploidías de los cromosomas 21, 13, 18, X e Y. Se proporcionan densidades de etiquetas de secuencia para los cromosomas 21, 13, 18, X e Y. La muestra SAC2517 fue la única muestra que se sometió al protocolo de enriquecimiento de ADNcf en plasma para secuencias polimórficas amplificadas. Así, no se pudieron determinar coeficientes de variación ni ensayos de diferenciabilidad. El ejemplo, demuestra que el enriquecimiento de la mezcla de ADNcf fetal y materno presente en una muestra de plasma para secuencias de ácido nucleico que comprenden al menos un SNP informativo se puede usar para proporcionar la secuencia requerida y los recuentos de etiquetas de SNP para determinar la aneuploidía y la fracción fetal a partir de un único proceso de secuenciación.
Tabla 21
Determinación simultánea de aenuploidía y fracción fetal:
Enriquecimiento de ácidos nucleicos fetales y maternos en una muestra de plasma

Ejemplo 11
Determinación simultánea de aneuploidía y fracción fetal en muestras maternas enriquecidas en secuencias polimórficas que comprenden STR
Para determinar simultáneamente la presencia o la ausencia de una aneuploidía y la fracción fetal en una mezcla de ADNcf fetal y materno obtenido de una muestra materna, la mezcla se enriquece en secuencias polimórficas que comprenden STR, se secuencian y se analizan los datos. El enriquecimiento puede ser de una biblioteca de secuenciación tal como se describe en el ejemplo, 8, de una muestra de ADNcf purificada tal como se describe en el ejemplo, 9, o de una muestra de plasma tal como se describe en el ejemplo, 10. En cada caso, la información de secuenciación se obtiene secuenciando una sola biblioteca, lo que permite determinar simultáneamente la presencia o la ausencia de una aneuploidía y la fracción fetal. Preferentemente, la biblioteca de secuenciación se prepara utilizando el protocolo abreviado proporcionado en el ejemplo, 2.
Los STR que se amplifican se eligen de los STR codis y no codis divulgados en la tabla 22, y la amplificación de las secuencias polimórficas de STR se obtiene utilizando los correspondientes conjuntos de cebadores proporcionados. Algunos de los STR que se han divulgado y/o analizado previamente para determinar la fracción fetal se enumeran en la tabla 22 y se divulgan en las solicitudes provisionales de Estados Unidos 61/296.358 y 61/360.837.
Tabla 22















Los miniSTR proporcionados en la tabla 22 se han utilizado con éxito para determinar la fracción fetal en muestras de ADN en plasma obtenidas de mujeres embarazadas con fetos o masculinos o femeninos, mediante electroforesis capilar (véase
la tabla 24 en el ejemplo, 15) para identificar y cuantificar los alelos fetales y maternos. Por lo tanto, se espera que las secuencias polimórficas que comprenden otros STR, por ejemplo, los STR restantes de la tabla 22, puedan usarse para determinar la fracción fetal mediante métodos de secuenciación masivamente paralelos.
La secuenciación de la biblioteca enriquecida en secuencias STR polimórficas se realiza mediante tecnología NGS, por ejemplo, secuenciación masivamente paralela por síntesis. Las lecturas de secuencias de longitudes de al menos 100 pb se alinean con un genoma de referencia, por ejemplo, la secuencia NCBI36/hg18 del genoma de referencia humano, y con un genoma STR, y el número de etiquetas de secuencia mapeadas al genoma humano de referencia y el genoma de referencia STR obtenido para los alelos informativos se utiliza para determinar la presencia o la ausencia de aneuploidía y la fracción fetal, respectivamente. El genoma de referencia de STR incluye las secuencias de amplicones amplificados a partir de los cebadores proporcionados.
Ejemplo 12
Determinación simultánea de aneuploidía y fracción fetal mediante secuenciación masivamente paralela de muestras maternas enriquecidas en secuencias polimórficas que comprenden SNP en tándem
Para determinar simultáneamente la aneuploidía y la fracción fetal en muestras maternas que comprenden ácidos nucleicos fetales y maternos, las muestras de plasma, las muestras de ADNcf purificado y las muestras de la biblioteca de secuenciación se enriquecen en secuencias polimórficas de ácido nucleico diana, cada una de las cuales comprende un par de SNP en tándem seleccionado de entre rs7277033-rs2110153; rs2822654-rs1882882; rs368657-rs376635; rs2822731-rs2822732; rs1475881-rs7275487; rs1735976-rs2827016; rs447340-rs2824097; rs418989-rs13047336; rs987980-rs987981; rs4143392-rs4143391; rs1691324-rs13050434; rs11909758-rs9980111; rs2826842-rs232414; rs1980969-rs1980970; rs9978999-rs9979175; rs1034346-rs12481852; rs7509629-rs2828358; rs4817013-rs7277036; rs9981121-rs2829696; rs455921-rs2898102; rs2898102-rs458848; rs961301-rs2830208; rs2174536-rs458076; rs11088023-rs11088024; rs1011734-rs1011733; rs2831244-rs9789838; rs8132769-rs2831440; rs8134080-rs2831524; rs4817219-rs4817220; rs2250911 -rs2250997; rs2831899-rs2831900; rs2831902-rs2831903; rs11088086-rs2251447; rs2832040-rs11088088; rs2832141-rs2246777; rs2832959-rs9980934; rs2833734-rs2833735; rs933121-rs933122; rs2834140-rs12626953; rs2834485-rs3453; rs9974986-rs2834703; rs2776266-rs2835001; rs1984014-rs1984015; rs7281674-rs2835316; rs13047304-rs13047322; rs2835545-rs4816551; rs2835735-rs2835736; rs13047608-rs2835826; rs2836550-rs2212596; rs2836660-rs2836661; rs465612-rs8131220; rs9980072-rs8130031; rs418359-rs2836926; rs7278447-rs7278858; rs385787-rs367001; rs367001-rs386095; rs2837296-rs2837297; y rs2837381-rs4816672. Los cebadores utilizados para amplificar las secuencias diana que comprenden los SNP en tándem están diseñados para abarcar ambos sitios SNP. Por ejemplo, el cebador directo está diseñado para abarcar el primer SNP y el cebador inverso está diseñado para abarcar el segundo del par de SNP en tándem, es decir, cada uno de los sitios SNP en el par en tándem está abarcado dentro de los 36 pb generados por el método de secuenciación. La secuenciación de extremos emparejados se puede utilizar para identificar todas las secuencias que abarcan los sitios SNP en tándem. Conjuntos ilustrativos de cebadores que se utilizan para amplificar SNP en tándem divulgados en el presente documento son rs7277033-rs2110153_F: TCCTGGAAACAAAAGTATT (SEQ ID NO:197) y rs7277033-rs2110153_R: AACCTTACAACAAAGCTAGAA (SEQ ID NO:198), conjunto rs2822654-rs1882882_F: ACTAAGCCTTGGGGATCCAG (SEQ ID NO:199) y rs2822654-rs1882882_R: TGCTGTGGAAATACTAAAAGG (SEQ ID NO:200), conjunto rs368657-rs376635_F:CTCCAGAGGTAATCCTGTGA (SEQ ID NO:201) y rs368657-rs376635_R:TGGTGTGAGATGGTATCTAGG (SEQ ID NO:202), rs2822731-rs2822732_F:GTATAATCCATGAATCTTGTTT (SEQ ID NO:203) y rs2822731-rs2822732_R:TTCAAATTGTATATAAGAGAGT (SEQ ID NO:204), rs1475881-rs7275487_F:GCAGGAAAGTTATTTTTAAT (SEQ ID NO:205) y rs1475881-rs7275487_R:TGCTTGAGAAAGCTAACACTT (SEQ ID NO:206), rs1735976-rs2827016F:CAGTGTTTGGAAATTGTCTG (SEQ ID NO:207) y rs1735976-rs2827016 R:GGCACTGGGAGATTATTGTA (SEQ ID NO:208), rs447349-rs2824097_F:TCCTGTTGTTAAGTACACAT (SEQ ID NO:209) y rs447349-rs2824097_R:GGGCCGTAATTACTTTTG (SEQ ID NO:210), rs418989-rs13047336_F:ACTCAGTAGGCACTTTGTGTC (SEQ ID NO:211) y rs418989-rs13047336_R:TCTTCCACCACACCAATC (SEQ ID NO:212), rs987980-rs987981_F:TGGCTTTTCAAAGGTAAAA (SEQ ID NO:213) y rs987980-rs987981_R: GCAACGTTAACATCTGAATTT (SEQ ID NO:214), rs4143392-rs4143391_F: rs4143392-rs4143391 (SEQ ID NO:215) y rs4143392-rs4143391_R:ATTTTATATGTCATGATCTAAG (SEQ ID NO:216), rs1691324-rs13050434_F: AGAGATTACAGGTGTGAGC (SEQ ID NO:217) y rs1691324-rs13050434_R: ATGATCCTCAACTGCCTCT (SEQ ID NO:218), rs11909758-rs9980111_F: TGAAACTCAAAAGAGAAAAG (SEQ ID NO:219) y rs11909758-rs9980111_R: ACAGATTTCTACTTAAAATT (SEQ ID NO:220), rs2826842-rs232414_F: TGAAACTCAAAAGAGAAAAG (SEQ ID NO:221) y rs2826842-rs232414_R: ACAGATTTCTACTTAAAATT (SEQ ID NO:22), rs2826842-rs232414_F: GCAAAGGGGTACTCTATGTA (SEQ ID NO:223) y rs2826842-rs232414_R: TATCGGGTCATCTTGTTAAA (SEQ ID NO:224), rs1980969-rs1980970_F: TCTAACAAAGCTCTGTCCAAAA (SEQ ID NO:225) y rs1980969-rs1980970_R: CCACACTGAATAACTGGAACA (SEQ ID NO:226), rs9978999-rs9979175_F: GCAAGCAAGCTCTCTACCTTC (SEQ ID NO:227) y rs9978999-rs9979175_R: TGTTCTTCCAAAATTCACATGC (SEQ ID NO:228), rs1034346-rs12481852_F: ATTTCACTATTCCTTCATTTT (SEQ ID NO:229) y rs1034346-rs12481852_R: TAATTGTTGCACACTAAATTAC (SEQ ID NO:230), rs4817013-rs7277036_F: AAAAAGCCACAGAAATCAGTC (SEQ ID NO:231) y rs4817013-rs7277036_R: TTCTTATATCTCACTGGGCATT (SEQ ID NO:232), rs9981121-rs2829696_F: GGATGGTAGAAGAGAAGAAAGG (SEQ ID NO:233) y rs9981121-rs2829696_R: GGATGGTAGAAGAGAAGAAAGG (SEQ ID NO:234), rs455921-rs2898102_F: TGCAAAGATGCAGAACCAAC (SEQ ID NO:235) y rs455921-rs2898102_R: TTTTGTTCCTTGTCCTGGCTGA (SEQ ID NO:236), rs2898102-rs458848_F: TGCAAAGATGCAGAACCAAC (SEQ ID NO:237) y rs2898102-rs458848_R: GCCTCCAGCTCTATCCAAGTT (SEQ ID NO:238), rs961301-rs2830208_F: CCTTAATATCTTCCCATGTCCA (SEQ ID NO:239) y rs961301 -rs2830208_R: ATTGTTAGTGCCTCTTCTGCTT (SEQ ID NO:240), rs2174536-rs458076_F: GAGAAGTGAGGTCAGCAGCT (SEQ ID NO:241) y rs2174536-rs458076_R: TTTCTAAATTTCCATTGAACAG (SEQ ID NO:242), rs11088023-rs11088024_F: GAAATTGGCAATCTGATTCT (SEQ ID NO:243) y rs11088023-rs11088024_R: CAACTTGTCCTTTATTGATGT (SEQ ID NO:244), rs1011734-rs1011733_F: CTATGTTGATAAAACATTGAAA (SEQ ID NO:245) y rs1011734-rs1011733_R: GCCTGTCTGGAATATAGTTT (SEQ ID NO:246), rs2831244-rs9789838_F: CAGGGCATATAATCTAAGCTGT (SEQ ID NO:247) y rs2831244-rs9789838_R: CAATGACTCTGAGTTGAGCAC (SEQ ID NO:248), rs8132769-rs2831440_F: ACTCTCTCCCTCCCCTCT (SEQ ID NO:249) y rs8132769-rs2831440_R: TATGGCCCCAAAACTATTCT (SEQ ID NO:250), rs8134080-rs2831524_F:
ACAAGTACTGGGCAGATTGA (SEQ ID NO:251) y rs8134080-rs2831524_R: GCCAGGTTTAGCTTTCAAGT (SEQ ID NO:252), rs4817219-rs4817220_F: TTTTATATCAGGAGAAACACTG (SEQ ID NO:253) y rs4817219-rs4817220_R: CCAGAATTTTGGAGGTTTAAT (SEQ ID NO:254), rs2250911-rs2250997_F: TGTCATTCCTCCTTTATCTCCA (SEQ ID NO:255) y rs2250911-rs2250997_R: TTCTTTTGCCTCTCCCAAAG (SEQ ID NO:256), rs2831899-rs2831900_F: ACCCTGGCACAGTGTTGACT (SEQ ID NO:257) y rs2831899-rs2831900_R: TGGGCCTGAGTTGAGAAGAT (SEQ ID NO:258), rs2831902-rs2831903_F: AATTTGTAAGTATGTGCAACG (SEQ ID NO:259) y rs2831902-rs2831903_R: TTTTTCCCATTTCCAACTCT (SEQ ID NO:260), rs11088086-rs2251447_F: AAAAGATGAGACAGGCAGGT (SEQ ID NO:261) y rs11088086-rs2251447 _R: ACCCCTGTGAATCTCAAAAT (SEQ ID NO:262), rs2832040-rs11088088_F: GCACTTGCTTCTATTGTTTGT (SEQ ID NO:263) y rs2832040-rs11088088_R: CCCTTCCTCTCTTCCATTCT (SEQ ID NO:264), rs2832141-rs2246777_F: AGCACTGCAGGTA (SEQ ID NO:265) y rs2832141-rs2246777_R: ACAGATACCAAAGAACTGCAA (SEQ ID NO:266), rs2832959 -rs9980934_F: TGGACACCTTTCAACTTAGA (SEQ ID NO:267) y rs2832959 -rs9980934_R: GAACAGT AAT GTT GAACTTTTT (SEQ ID NO:268), rs2833734-rs2833735_F: TCTTGCAAAAAGCTTAGCACA (SEQ ID NO:269) y rs2833734-rs2833735_R: AAAAAGATCTCAAAGGGTCCA (SEQ ID NO:270), rs933121-rs933122_F: GCTTTTGCTGAACATCAAGT (SEQ ID NO:271) y rs933121-rs933122_R: CCTTCCAGCAGCATAGTCT (SEQ ID NO:272), rs2834140-rs12626953_F: AAATCCAGGATGTGCAGT (SEQ ID NO:273) y rs2834140-rs12626953_R: ATGATGAGGTCAGTGGTGT (SEQ ID NO:274), rs2834485-rs3453_F: CATCACAGATCATAGTAAATGG (SEQ ID NO:275) y rs2834485-rs3453_R: AATTATTATTTTGCAGGCAAT (SEQ ID NO:276), rs9974986-rs2834703_F: CATGAGGCAAACACCTTTCC (SEQ ID NO:277) y rs9974986-rs2834703_R: GCTGGACTCAGGATAAAGAACA (SEQ ID NO:278), rs2776266-rs2835001_F: TGGAAGCCTGAGCTGACTAA (SEQ ID NO:279) y rs2776266-rs2835001_R:CCTTCTTTTCCCCCAGAATC (SEQ ID NO:280), rs1984014-rs1984015_F:TAGGAGAACAGAAGATCAGAG (SEQ ID NO:281) y rs1984014-rs1984015_R :AAAGACT ATTGCT AAATGCTT G (SEQ ID NO:282), rs7281674-rs2835316_F: TAAGCGTAGGGCTGTGTGTG (SEQ ID NO:283) y rs7281674-rs2835316_R: GGACGGATAGACTCCAGAAGG (SEQ ID NO:284), rs13047304-rs13047322_F: GAATGACCTTGGCACTTTTATCA (SEQ ID NO:285) y rs13047304-rs13047322_R: AAGGAT AGAGAT ATACAGAT GAATGGA (SEQ ID NO:286), rs2835735-rs2835736_F: CATGCACCGCGCAAATAC (SEQ ID NO:287) y rs2835735-rs2835736_R: ATGCCTCACCCACAAACAC (SEQ ID NO:288), rs13047608-rs2835826_F: TCCAAGCCCTTCTCACTCAC (SEQ ID NO:289) y rs13047608-rs2835826_R: CTGGGACGGTGACATTTTCT (SEQ ID NO:290), rs2836550-rs2212596_F: CCCAGGAAGAGTGGAAAGATT (SEQ ID NO:291) y rs2836550-rs2212596_R: TTAGCTTGCATGTACCTGTGT (SEQ ID NO:292), rs2836660-rs2836661_F: AGCTAGATGGGGTGAATTTT (SEQ ID NO:293) y_R: TGGGCTGAGGGGAGATTC (SEQ ID NO:294), rs465612-rs8131220_F: ATCAAGCTAATT AAT GTTATCT (SEQ ID NO:295) y rs465612-rs8131220_R: AATGAATAAGGTCCTCAGAG (SEQ ID NO:296), rs9980072-rs8130031_F :TTT AAT CT GAT CATTGCCCT A (SEQ ID NO:297) y rs9980072-rs8130031_R: AGCTGTGGGTGACCTTGA (SEQ ID NO:298), rs418359-rs2836926_F: TGTCCCACCATTGTGTATTA (SEQ ID NO:299) y rs418359-rs2836926_R: TCAGACTTGAAGTCCAGGAT (SEQ ID NO:300), rs7278447-rs7278858_F: GCTTCAGGGGTGTTAGTTTT (SEQ ID NO:301) y rs7278447-rs7278858_R: CTTTGTGAAAAGTCGTCCAG (SEQ ID NO:302), rs385787-rs367001_F:CCATCATGGAAAGCATGG (SEQ ID NO:303) y rs385787-rs367001_R: TCATCTCCATGACTGCACTA (SEQ ID NO:304), rs367001-rs386095_F: GAGATGACGGAGTAGCTCAT (SEQ ID NO:305) y rs367001-rs386095_R: CCCAGCTGCACTGTCTAC (SEQ ID NO:306), rs2837296-rs2837297_F: TCTTGTTCCAATCACAGGAC (SEQ ID NO:307) y rs2837296-rs2837297_R: ATGCTGTTAGCTGAAGCTCT (SEQ ID NO:308), y rs2837381-rs4816672_F: TGAAAGCTCCTAAAGCAGAG (SEQ ID NO:309) y rs2837381 -rs4816672_R:TTGAAGAGATGTGCTATCAT (SEQ ID N0:310). Se pueden incluir secuencias de polinucleótidos, por ejemplo, secuencias de fijación de GC para garantizar la hibridación específica de cebadores ricos en AT (Ghanta et al., p Lo S ONE 5(10): doi10.1371/journal.pone.0013184 [2010], disponible en Internet en plosone.org). Un ejemplo, de una secuencia de fijación de GC que se puede incluir en 5' del cebador directo o en 3' del cebador inverso es GCCGCCTGCAGCCCGCGCCCCCCGTGCCCCCGCCCCGCCGCCGGCCCGGGCGCC (SEQ ID NO:311).
La preparación de muestras y el enriquecimiento de la biblioteca de secuenciación de ADNcf, una muestra de ADNcf purificada y una muestra de plasma se realizan según el método descrito en los ejemplos 8, 9 y 10, respectivamente. Todas las bibliotecas de secuenciación se preparan tal como se describe en el ejemplo, 2a y la secuenciación se realiza tal como se describe en el ejemplo, 2b e incluye la secuenciación de extremos emparejados. El análisis de los datos de secuenciación para la determinación de la aneuploidía fetal se realiza tal como se describe en los ejemplos 4 y 5. De forma concomitante al análisis para determinar la aneuploidía, se analizaron los datos de secuenciación para determinar la fracción fetal de la forma siguiente. Después de la transferencia de los archivos de imagen y de designación de bases al servidor Unix que ejecuta el programa informático de Illumina "Genome Analyzer Pipeline" versión 1.51 tal como se describe, las lecturas de 36 pb se alinearon con un "genoma SNP en tándem" utilizando el programa BOWTIE. El genoma de SNP en tándem se identifica como la agrupación de las secuencias de ADN que abarcan los alelos de los 58 pares de SNP en tándem divulgados anteriormente. Para el análisis de la fracción fetal, solo se usaron las lecturas que se mapean únicamente al genoma del SNP en tándem. Las lecturas que coinciden perfectamente con el genoma SNP se cuentan como etiquetas y se filtran. De las lecturas restantes, solo las lecturas que tenían uno o dos desajustes se cuentan como etiquetas y se incluyen en el análisis. Se cuentan las etiquetas mapeadas a cada uno de los alelos de SNP en tándem, y la fracción fetal se determina esencialmente tal como se ha descrito en el ejemplo, 6 anterior, pero teniendo en cuenta las etiquetas mapeadas a los dos alelos x e y de SNP en tándem presentes en cada una de las secuencias polimórficas de ácido nucleico diana amplificadas, que se amplifican para enriquecer las muestras, es decir,
% de fracción fetal alelox+y = ((^Etiquetas de secuencia fetal para alelox+y) / (^Etiquetas de secuencia materna para aleloxty)) x 100
Opcionalmente, la fracción de ácidos nucleicos fetales en la mezcla de ácidos nucleicos fetales y maternos se calcula para cada uno de los alelos informativos (alelox+y) de la forma siguiente:
% de fracción fetal alelox+y = (( 2 X ^Etiquetas de secuencia fetal para alelox+y) / (^Etiquetas de secuencia materna para aleloxty» « 100,
para compensar la presencia de 2 conjuntos de alelos fetales en tándem, estando uno enmascarado por el fondo materno. Las secuencias de SNP en tándem son informativas cuando la madre es heterocigótica y está presente un tercer haplotipo paterno, lo que permite una comparación cuantitativa entre el haplotipo heredado de la madre y el haplotipo heredado del padre para calcular la fracción fetal mediante cálculo de una relación de haplotipo (HR). El porcentaje de fracción fetal se calcula para al menos 1, al menos 2, al menos 3, al menos 4, al menos 5, al menos 6, al menos 7, al menos 8, al menos 9, al menos 10, al menos 11, al menos 12, al menos 13, al menos 14, al menos 15, al menos 16, al menos 17, al menos 18, al menos 19, al menos 20, al menos 25, al menos 30, al menos 40 o más conjuntos de alelos en tándem. En un caso, la fracción fetal es la fracción fetal promedio determinada para al menos 3 conjuntos de alelos en tándem informativos.
Ejemplo 13
Determinación de la fracción fetal mediante secuenciación masivamente paralela de una biblioteca diana que comprende ácidos nucleicos polimórficos que comprenden SNP
Para determinar la fracción de ADNcf fetal en una muestra materna, se amplificaron las secuencias de ácido nucleico polimórfico diana, cada una de las cuales comprende un SNP, y se usaron para preparar una biblioteca diana para la secuenciación de forma masivamente paralela.
Se extrajo ADNcf tal como se describe en el ejemplo, 1. Se preparó una biblioteca de secuenciación diana de la forma siguiente: se amplificó ADNcf contenido en 5 pl de ADNcf purificado en un volumen de reacción de 50 pl que contenía 7,5 pl de una mezcla de cebadores 1 pM (tabla 10), 10 pl de mezcla maestra NEB 5X y 27 pl de agua. Se realizó un termociclado con Gene Amp9700 (Applied Biosystems) utilizando las condiciones de ciclado siguientes: incubación a 95°C durante 1 minuto, seguida de 20-30 ciclos a 95°C durante 20 segundos, 68°C durante 1 minuto y 68°C durante 30 s, seguidos de una incubación final a 68°C durante 5 minutos. Se añadió un mantenimiento final a 4°C hasta que se retiraron las muestras para combinarlas con la porción no amplificada de la muestra de ADNcf purificado. El producto amplificado se purificó con el sistema de purificación por PCR Agencourt AMPure XP (N° de parte A63881; Beckman Coulter Genomics, Danvers, MA) y la concentración se cuantificó usando Nanodrop 2000 (Thermo Scientific, Wilmington, DE). Se añadió un mantenimiento final a 4°C hasta que se retiraron las muestras para preparar la biblioteca diana. El producto amplificado se analizó con un bioanalizador 2100 (Agilent Technologies, Sunnyvale, CA) y se determinó la concentración del producto amplificado. Se preparó una biblioteca de secuenciación de ácidos nucleicos diana amplificados usando el protocolo abreviado descrito en el ejemplo, 2, y se secuenció de forma masivamente paralela usando secuenciación por síntesis con terminadores de colorantes reversibles y según el protocolo de Illumina. El análisis y el recuento de etiquetas mapeadas a un genoma de referencia que consiste en 26 secuencias (13 pares, cada una de las cuales representa dos alelos) que comprenden un SNP, es decir, SEQ ID NO: 1-56 se realizó tal como se describe.
La tabla 23 proporciona los recuentos de etiquetas obtenidos de la secuenciación de la biblioteca diana y la fracción fetal calculada derivada de los datos de secuenciación.
Tabla 23



Los resultados muestran que las secuencias de ácidos nucleicos polimórficos, cada una de las cuales comprende al menos un SNP, se pueden amplificar a partir de ADNcf derivado de una muestra de plasma materno para construir una biblioteca que se puede secuenciar de forma masivamente paralela para determinar la fracción de ácidos nucleicos fetales en la muestra materna. Los métodos de secuenciación masivamente paralela para determinar la fracción fetal pueden usarse en combinación con otros métodos para proporcionar diagnóstico de aneuploidía fetal y otros ensayos prenatales.
Ejemplo 14
Determinación de la fracción fetal mediante secuenciación masivamente paralela de una biblioteca diana que comprende ácidos nucleicos polimórficos que comprenden STR o SNP en tándem
La fracción fetal se puede determinar independientemente de la determinación de la aneuploidía utilizando una biblioteca diana que comprende SNP en tándem o STR tal como se describe para la biblioteca diana de SNP del ejemplo, 13. Para preparar una biblioteca diana de SNP en tándem, se utiliza una porción de una biblioteca de ADNcf purificado que comprende ácidos nucleicos fetales y maternos para amplificar secuencias diana utilizando una mezcla de cebadores, por ejemplo, las tablas 10 y 11. Para preparar una biblioteca diana de STR, se utiliza una porción de una biblioteca de ADNcf purificado que comprende ácidos nucleicos fetales y maternos para amplificar secuencias diana utilizando una mezcla de cebadores, por ejemplo, la tabla 22. La biblioteca diana de SNP en tándem se secuencia tal como se describe en el ejemplo, 12.
Las bibliotecas diana se secuencian tal como se describe, y la fracción fetal se determina a partir del número de etiquetas de secuencia mapeadas al genoma de referencia de STR o SNP en tándem, respectivamente, que comprende todos los alelos posibles de STR o SNP en tándem abarcados por los cebadores. Se identifican los alelos informativos y se determina la fracción fetal utilizando el número de etiquetas mapeadas a los alelos de las secuencias polimórficas.
Ejemplo 15
Determinación de la fracción fetal por electroforesis capilar de secuencias polimórficas que comprenden STR
Para determinar la fracción fetal en muestras maternas que comprendían ADNcf fetal y materno, se recolectaron muestras de sangre periférica de mujeres embarazadas voluntarias que portaban fetos o masculinos o femeninos. Se obtuvieron muestras de sangre periférica y se procesaron para proporcionar ADNcf purificado tal como se describe en el ejemplo, 1.
Se analizaron diez microlitros de muestras de ADNcf usando el kit de amplificación por PCR AmpFlSTR® MiniFiler™ (Applied Biosystems, Foster City, CA) según las instrucciones del fabricante. Brevemente, el ADNcf contenido en 10 pl se amplificó en un volumen de reacción de 25 pl que contenía 5 pl de cebadores marcados con fluorescencia (conjunto de cebadores AmpF/STR® MiniFiler™), y la mezcla maestra AmpF/STR® MiniFiler™, que incluye ADN polimerasa AmpliTaq Gold® y tampón asociado, sal (MgC121,5 mM) y trifosfatos de desoxinucleótidos 200 pM (dNTP: dATP, dCTP, dGTP y dTTP). Los cebadores marcados con fluorescencia son cebadores directos que están marcados con colorantes 6Fa Mtm, VlC™, NED™y PET™. Se realizó un termociclado con Gene Amp9700 (Applied Biosystems) utilizando las condiciones de ciclado siguientes: incubación a 95°C durante 10 minutos, seguida de 30 ciclos a 94°C durante 20 segundos, 59°C durante 2 minutos y 72°C durante 1 minuto, seguidos de una incubación final a 60°C durante 45 minutos. Se añadió un mantenimiento final a 4°C hasta que se retiraron las muestras para el análisis. El producto amplificado se preparó diluyendo 1 ul de producto amplificado en 8,7 ul de formamida Hi-DiTM (Applied Biosystems) y 0,3 pl de patrón de tamaño interno GeneScanTM-500 LIZ_ (Applied Biosystems), y se analizó con un analizador genético ABI PRISM3130xl (Applied Biosystems) utilizando recopilación de datos HID_G5_POP4 (Applied Biosystems) y matriz de capilares de 36 cm. Todo el genotipado se realizó con el programa informático GeneMapper_ID v3.2 (Applied Biosystems) utilizando escaleras alélicas e intervalos y paneles proporcionados por el fabricante.
Todas las mediciones de genotipado se realizaron en el analizador genético Applied Biosystems 3130xl, usando una "ventana" de ±0,5 nt alrededor del tamaño obtenido para cada alelo para permitir la detección y la asignación correcta
de alelos. Se determinó que cualquier alelo de la muestra cuyo tamaño estuviera fuera de la ventana de ±0,5 nt era OL, es decir, "Off Ladder". Los alelos OL son alelos de un tamaño que no está representada en la escalera alélica AmpF/STR® MiniFiler™ o un alelo que no corresponde a una escalera alélica, pero cuyo tamaño está justo fuera de una ventana debido a un error de medición. El umbral mínimo de altura del pico de > 50 RFU se estableció en base a los experimentos de validación realizados para evitar el tipado cuando es probable que los efectos estocásticos interfieran con la interpretación precisa de las mezclas. El cálculo de la fracción fetal se basa en promediar todos los marcadores informativos. Los marcadores informativos se identifican por la presencia de picos en el electroferograma que se encuentran dentro de los parámetros de intervalos preestablecidos para los STR que se analizan.
Los cálculos de la fracción fetal se realizaron utilizando la altura máxima promedio para los alelos principales y secundarios en cada locus STR determinado a partir de inyecciones por triplicado. Las reglas que se aplican al cálculo son:
1. los datos de alelos fuera de escalera (OL) para alelos no se incluyen en el cálculo; y
2. solo se incluyen en el cálculo las alturas de los picos derivadas de > 50 RFU (unidades relativas de fluorescencia)
3. si solo hay un intervalo, el marcador se considera no informativo; y
4. si se designa un segundo intervalo, pero los picos del primer y segundo intervalo están dentro del 50-70% de sus unidades relativas de fluorescencia (RFU) en la altura del pico, la fracción minoritaria no se mide y el marcador no se considera informativo.
La fracción del alelo secundario para cualquier marcador informativo dado se calcula dividiendo la altura del pico del componente secundario por la suma de la altura del pico del componente principal, y se expresa como un porcentaje que fue calculado primero para cada locus informativo como
fracción fetal = Qaltura de pico de alelo secundario/ ^altura de pico de alelo(s) principal(es)) X 100 ,
La fracción fetal para una muestra que comprende dos o más STR informativos se calcularía como el promedio de las fracciones fetales calculadas para los dos o más marcadores informativos.
La tabla 8 proporciona los datos obtenidos del análisis de ADNcf de una mujer embarazada de un feto masculino.
Tabla 24



Los resultados muestran que se puede utilizar ADNcf para determinar la presencia o la ausencia de ADN fetal según se indica por la detección de un componente secundario en uno o más alelos STR, para determinar el porcentaje de fracción fetal y para determinar el sexo del feto tal como se indica por la presencia o la ausencia del alelo amelogenina.
Ejemplo 16
Uso de la fracción fetal para establecer umbrales y estimar el tamaño mínimo de la muestra en la detección de aneuploidías
Los recuentos de secuencias coincidentes con diferentes cromosomas se manipulan para generar una puntuación que variará con el número de copias cromosómicas que puede interpretarse para identificar la amplificación o la deleción cromosómica. Por ejemplo, dicha puntuación podría generarse comparando la cantidad relativa de etiquetas de secuencia en un cromosoma que sufre cambios en el número de copias con un cromosoma que se sabe que es un euploide. Los ejemplos de puntuaciones que se pueden usar para identificar la amplificación o la deleción incluyen, pero sin limitación: recuentos del cromosoma de interés divididos por los recuentos de otro cromosoma de la misma ejecución experimental, recuentos del cromosoma de interés divididos por el número total de recuentos de la serie experimental, comparación de recuentos de la muestra de interés frente a una muestra de control separada. Sin pérdida de generalidad, se puede suponer que las puntuaciones aumentarán a medida que aumente el número de copias. El conocimiento de la fracción fetal se puede utilizar para establecer umbrales de "corte" para deignar los estados "aneuploidía", "normal" o "marginal" (incierto). Después se realizan cálculos para estimar el número mínimo de secuencias necesarias para lograr la sensibilidad adecuada (es decir, la probabilidad de identificar correctamente un estado de aneuploidía).
La figura 19 es un gráfico de dos poblaciones diferentes de puntuaciones. El eje x es la puntuación y el eje y es la frecuencia. Las puntuaciones en muestras de cromosomas sin aneuploidía pueden tener una distribución que se muestra en la figura 19A. La figura 19B ilustra una distribución hipotética de una población de puntuaciones en muestras con un cromosoma amplificado. Sin pérdida de generalidad, los gráficos y las ecuaciones muestran el caso de una puntuación univariante donde la condición de aneuploidía representa una amplificación del número de copias. Los casos multivariante y/o las anomalías de reducción/deleción son simples extensiones o reordenamientos de las descripciones dadas y se pretende que se encuentren dentro del alcance de esta técnica.
La cantidad de "superposición" entre las poblaciones puede determinar cómo de bien se pueden discriminar los casos normales y los de aneuploidía. En general, el aumento de la fracción fetal, ff, aumenta la potencia de discriminación al separar los dos centros de población (moviendo "C2", el "Centro de puntuaciones de aneuploidía" y aumentando "d", lo que hace que las poblaciones se superpongan menos. Además, un aumento en el valor absoluto de la magnitud, m, (por ejemplo, teniendo cuatro copias del cromosoma en lugar de una trisomía) de la amplificación también aumentará la separación de los centros de población, lo que conducirá a una mayor potencia (es decir, una mayor probabilidad de identificar correctamente los estados de aneuploidía).
El aumento del número de secuencias generadas, N, reduce las desviaciones estándar "sdevA" y/o "sdevB", la extensión de las dos poblaciones de puntuaciones, lo que también hace que las poblaciones se superpongan menos.
Establecimiento de umbrales y estimación del tamaño de la muestra
El siguiente procedimiento se puede utilizar para establecer "c", el valor crítico para designar los estados "aneuploidía", "normal" o "marginal" (incierto). Sin pérdida de generalidad, a continuación, se utilizan pruebas estadísticas unilaterales.
En primer lugar, se decide una tasa aceptable de falsos positivos, FP (a veces también denominada "error de tipo I" o "especificidad"), que es la probabilidad de un falso positivo o falsa designación de aneuploidía. Por ejemplo, FP puede ser al menos o aproximadamente 0,001,0,002, 0,003, 0,004, 0,005, 0,006, 0,007, 0,008, 0,009, 0,01,0,02, 0,03, 0,04, 0,05, 0,06, 0,07, 0,08, 0,09 o 0,1.
En segundo lugar, el valor de "c" se puede determinar resolviendo la ecuación: FP = integral de c a infinito de (f1 (x)dx).

Una vez que se ha determinado un valor crítico, c, se puede estimar el número mínimo de secuencias requeridas para lograr una determinado TP = tasa de verdaderos positivos. La tasa de verdaderos positivos puede ser, por ejemplo, de aproximadamente 0,5, 0,6, 0,7, 0,8 o 0,9. En un caso, la tasa de verdaderos positivos puede ser 0,8. En otras palabras, N es el número mínimo de secuencias necesarias para identificar la aneuploidía 100*TP por ciento del tiempo. N = número mínimo tal que TP = integral de c a infinito de f2(x,ff)dx > 0,8. N se determina resolviendo
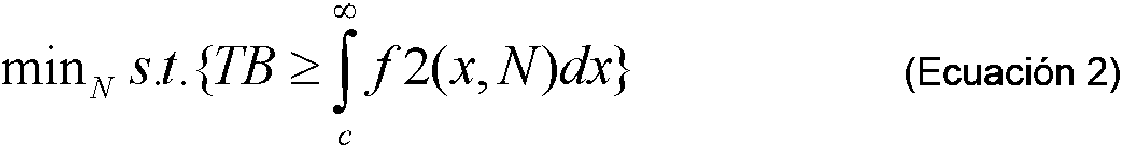
En las pruebas estadísticas clásicas, f1 y f2 son a menudo F, distribuciones F no centrales (un caso especial de distribuciones t y t no centrales) aunque esa no es una condición necesaria para esta solicitud.
Establecimiento de "niveles" de umbrales para proporcionar más control de errores
Los umbrales también se pueden establecer en etapas utilizando los métodos anteriores. Por ejemplo, se puede establecer un umbral para la designación de alta confianza de "aneuploidía", digamos ca, usando FP 0,001 y un umbral "marginal", digamos cb, usando FP 0,05. En este caso si la puntuación, S:
(S > ca) entonces designar "Trisomía"
(cb > S <= ca) entonces designar "Marginal"
(S < cb) entonces designar "Normal"
Algunas generalizaciones triviales que se encuentran dentro del alcance de esta técnica
Se pueden utilizar diferentes valores para umbrales tales como TP, FP, etc. Los procedimientos se pueden ejecutar en cualquier orden. Por ejemplo, se puede comenzar con N y resolver c, etc. Las distribuciones pueden depender de ff de modo que f1(x,N,ff), f2(x,N,ff) y/u otras variables. Las ecuaciones integrales anteriores se pueden resolver con referencia a tablas o mediante métodos informáticos iterativos. Se puede estimar un parámetro de no centralidad y se puede leer la potencia a partir de tablas estadísticas estándar. La potencia estadística y los tamaños de muestra pueden derivarse del cálculo o la estimación de las medias cuadráticas esperadas. Se pueden utilizar distribuciones teóricas de forma cerrada tales como f, t, no central, normal, etc. o estimaciones (kernel u otras) para modelar las distribuciones f1, f2. El establecimiento de un umbral empírico y la selección de parámetros mediante curvas características del operador del receptor (ROC) se pueden utilizar y cotejar con la fracción fetal. Se pueden utilizar varias estimaciones de la dispersión de la distribución (varianza, desviación absoluta media, rango intercuartílico, etc.). Se pueden utilizar varias estimaciones del centro de distribución (media, mediana, etc.). Se pueden utilizar pruebas estadísticas bilaterales en lugar de unilaterales. La prueba de hipótesis simple se puede reformular como regresión
Claims (13)
1. Un método para la secuenciación de ácidos nucleicos que comprende:
(a) proporcionar una muestra de ensayo que comprende moléculas de ácido nucleico, en el que dichas moléculas de ácido nucleico son moléculas de ADN genómico humano;
(b) realizar la reparación de extremos de las moléculas de ácido nucleico para generar ácidos nucleicos de extremos romos;
(c) realizar la adición de colas de dA a los ácidos nucleicos de extremos romos para generar ácidos nucleicos con cola de dA;
(d) ligar adaptadores a los ácidos nucleicos con cola de dA para generar una biblioteca de polinucleótidos ligados a adaptadores;
(e) opcionalmente amplificar la biblioteca usando cebadores de amplificación, comprendiendo dichos cebadores de amplificación una porción específica de adaptador; y
(f) someter la biblioteca a una secuenciación masivamente paralela;
en el que las etapas (b), (c), y (d) son etapas consecutivas.
2. El método de la reivindicación 1, en el que dichas etapas consecutivas se realizan en ausencia de polietilenglicol.
3. El método de la reivindicación 1 o la reivindicación 2, en el que dichas etapas consecutivas se realizan en menos de 1 hora.
4. El método de cualquier reivindicación anterior, en el que dichas etapas consecutivas se realizan en el mismo tubo de reacción.
5. El método de cualquier reivindicación anterior, en el que dichos ácidos nucleicos son moléculas de ADN libre de células (ADNcf).
6. El método de la reivindicación 1, en el que dicho ADN genómico se somete a fragmentación antes de las etapas consecutivas de reparación de extremos, adición de colas de dA y ligación de adaptador a dichos ácidos nucleicos.
7. El método de cualquiera de las reivindicaciones 1 -5, en el que dichos ácidos nucleicos son moléculas de ADN libre de células (ADNcf) y no se somete a fragmentación antes de las etapas consecutivas de reparación de extremos, adición de colas de dA y ligación de adaptador a dichos ácidos nucleicos.
8. El método de la reivindicación 1, en el que dicha secuenciación masivamente paralela comprende la amplificación en fase sólida para crear una celda de flujo de secuenciación de alta densidad con millones de clústeres.
9. El método de la reivindicación 1, en el que la biblioteca se amplifica en perlas y en el que cada perla comprende un cebador de amplificación directo e inverso.
10. El método de la reivindicación 1, en el que:
(i) dicha secuenciación es una secuenciación masivamente paralela que utiliza secuenciación por síntesis con terminadores de colorantes reversibles; o
(ii) dicha secuenciación es una secuenciación masivamente paralela que utiliza secuenciación por ligación.
11. El método de la reivindicación 1, en el que dicha secuenciación comprende una amplificación.
12. El método de la reivindicación 1, en el que dicha secuenciación es secuenciación de una sola molécula.
13. El método de cualquiera de las reivindicaciones 1-12, en el que la muestra:
(a) es una muestra de sangre periférica, o el plasma y/o las fracciones de suero del mismo;
(b) es una muestra de plasma derivada de sangre periférica;
(c) es una muestra de plasma derivada de sangre periférica que comprende una mezcla de ADNcf derivado de células normales y cancerosas;
(d) se deriva de una mezcla de células cancerosas y no cancerosas de un fluido biológico seleccionado de entre suero, sudor, lágrimas, esputo, orina, flujo del oído, linfa, saliva, líquido cefalorraquídeo, lavados, suspensión de médula ósea, flujo vaginal, lavado transcervical, fluido cerebral, ascitis, leche, secreciones de las vías respiratorias, intestinales y genitourinarias, y muestras de leucoforesis; o
(e) se selecciona de entre biopsias de tejido, hisopos o frotis.
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US29635810P | 2010-01-19 | 2010-01-19 | |
| US36083710P | 2010-07-01 | 2010-07-01 | |
| US45584910P | 2010-10-26 | 2010-10-26 | |
| US40701710P | 2010-10-26 | 2010-10-26 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2909841T3 true ES2909841T3 (es) | 2022-05-10 |
Family
ID=44307118
Family Applications (6)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES18160303T Active ES2870533T3 (es) | 2010-01-19 | 2010-12-01 | Métodos de determinación de la fracción de ácidos nucleicos fetales en muestras maternas |
| ES10830939.4T Active ES2534986T3 (es) | 2010-01-19 | 2010-12-01 | Determinación simultánea de aneuploidía y fracción fetal |
| ES10844163.5T Active ES2560929T3 (es) | 2010-01-19 | 2010-12-01 | Métodos de determinación de la fracción de ácido nucleico fetal en muestras maternas |
| ES17180803T Active ES2704701T3 (es) | 2010-01-19 | 2010-12-01 | Nuevo protocolo de preparación de bibliotecas de secuenciación |
| ES18201917T Active ES2909841T3 (es) | 2010-01-19 | 2010-12-01 | Nuevo protocolo para preparar bibliotecas de secuenciación |
| ES10830938.6T Active ES2534758T3 (es) | 2010-01-19 | 2010-12-01 | Métodos de secuenciación en diagnósticos prenatales |
Family Applications Before (4)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES18160303T Active ES2870533T3 (es) | 2010-01-19 | 2010-12-01 | Métodos de determinación de la fracción de ácidos nucleicos fetales en muestras maternas |
| ES10830939.4T Active ES2534986T3 (es) | 2010-01-19 | 2010-12-01 | Determinación simultánea de aneuploidía y fracción fetal |
| ES10844163.5T Active ES2560929T3 (es) | 2010-01-19 | 2010-12-01 | Métodos de determinación de la fracción de ácido nucleico fetal en muestras maternas |
| ES17180803T Active ES2704701T3 (es) | 2010-01-19 | 2010-12-01 | Nuevo protocolo de preparación de bibliotecas de secuenciación |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES10830938.6T Active ES2534758T3 (es) | 2010-01-19 | 2010-12-01 | Métodos de secuenciación en diagnósticos prenatales |
Country Status (11)
| Country | Link |
|---|---|
| US (13) | US9657342B2 (es) |
| EP (14) | EP2370599B1 (es) |
| AU (4) | AU2010343278B2 (es) |
| CA (4) | CA2786357C (es) |
| CY (1) | CY1124494T1 (es) |
| DK (6) | DK3382037T3 (es) |
| ES (6) | ES2870533T3 (es) |
| GB (5) | GB2479080B (es) |
| PL (4) | PL3260555T3 (es) |
| TR (1) | TR201807917T4 (es) |
| WO (3) | WO2011090559A1 (es) |
Families Citing this family (262)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1712639B1 (en) | 2005-04-06 | 2008-08-27 | Maurice Stroun | Method for the diagnosis of cancer by detecting circulating DNA and RNA |
| US11111543B2 (en) | 2005-07-29 | 2021-09-07 | Natera, Inc. | System and method for cleaning noisy genetic data and determining chromosome copy number |
| US11111544B2 (en) | 2005-07-29 | 2021-09-07 | Natera, Inc. | System and method for cleaning noisy genetic data and determining chromosome copy number |
| US10083273B2 (en) | 2005-07-29 | 2018-09-25 | Natera, Inc. | System and method for cleaning noisy genetic data and determining chromosome copy number |
| US8532930B2 (en) | 2005-11-26 | 2013-09-10 | Natera, Inc. | Method for determining the number of copies of a chromosome in the genome of a target individual using genetic data from genetically related individuals |
| US10081839B2 (en) | 2005-07-29 | 2018-09-25 | Natera, Inc | System and method for cleaning noisy genetic data and determining chromosome copy number |
| US9424392B2 (en) | 2005-11-26 | 2016-08-23 | Natera, Inc. | System and method for cleaning noisy genetic data from target individuals using genetic data from genetically related individuals |
| EP2351858B1 (en) * | 2006-02-28 | 2014-12-31 | University of Louisville Research Foundation | Detecting fetal chromosomal abnormalities using tandem single nucleotide polymorphisms |
| WO2009105531A1 (en) * | 2008-02-19 | 2009-08-27 | Gene Security Network, Inc. | Methods for cell genotyping |
| EP2271772B1 (en) | 2008-03-11 | 2014-07-16 | Sequenom, Inc. | Nucleic acid-based tests for prenatal gender determination |
| WO2009146335A1 (en) * | 2008-05-27 | 2009-12-03 | Gene Security Network, Inc. | Methods for embryo characterization and comparison |
| EP2321642B1 (en) * | 2008-08-04 | 2017-01-11 | Natera, Inc. | Methods for allele calling and ploidy calling |
| US8476013B2 (en) | 2008-09-16 | 2013-07-02 | Sequenom, Inc. | Processes and compositions for methylation-based acid enrichment of fetal nucleic acid from a maternal sample useful for non-invasive prenatal diagnoses |
| US8962247B2 (en) | 2008-09-16 | 2015-02-24 | Sequenom, Inc. | Processes and compositions for methylation-based enrichment of fetal nucleic acid from a maternal sample useful for non invasive prenatal diagnoses |
| WO2011041485A1 (en) | 2009-09-30 | 2011-04-07 | Gene Security Network, Inc. | Methods for non-invasive prenatal ploidy calling |
| CA2780016C (en) | 2009-11-06 | 2017-09-19 | The Chinese University Of Hong Kong | Size-based genomic analysis |
| US8835358B2 (en) | 2009-12-15 | 2014-09-16 | Cellular Research, Inc. | Digital counting of individual molecules by stochastic attachment of diverse labels |
| US9315857B2 (en) | 2009-12-15 | 2016-04-19 | Cellular Research, Inc. | Digital counting of individual molecules by stochastic attachment of diverse label-tags |
| ES2577017T3 (es) | 2009-12-22 | 2016-07-12 | Sequenom, Inc. | Procedimientos y kits para identificar la aneuploidia |
| US9323888B2 (en) | 2010-01-19 | 2016-04-26 | Verinata Health, Inc. | Detecting and classifying copy number variation |
| EP2370599B1 (en) | 2010-01-19 | 2015-01-21 | Verinata Health, Inc | Method for determining copy number variations |
| US20120010085A1 (en) | 2010-01-19 | 2012-01-12 | Rava Richard P | Methods for determining fraction of fetal nucleic acids in maternal samples |
| WO2011091063A1 (en) | 2010-01-19 | 2011-07-28 | Verinata Health, Inc. | Partition defined detection methods |
| US20120100548A1 (en) | 2010-10-26 | 2012-04-26 | Verinata Health, Inc. | Method for determining copy number variations |
| EP2513341B1 (en) | 2010-01-19 | 2017-04-12 | Verinata Health, Inc | Identification of polymorphic sequences in mixtures of genomic dna by whole genome sequencing |
| US9260745B2 (en) | 2010-01-19 | 2016-02-16 | Verinata Health, Inc. | Detecting and classifying copy number variation |
| US10388403B2 (en) | 2010-01-19 | 2019-08-20 | Verinata Health, Inc. | Analyzing copy number variation in the detection of cancer |
| US20110312503A1 (en) | 2010-01-23 | 2011-12-22 | Artemis Health, Inc. | Methods of fetal abnormality detection |
| CA2799746C (en) * | 2010-05-17 | 2020-11-24 | Sai Reddy | Rapid isolation of monoclonal antibodies from animals |
| US12152275B2 (en) | 2010-05-18 | 2024-11-26 | Natera, Inc. | Methods for non-invasive prenatal ploidy calling |
| US11408031B2 (en) | 2010-05-18 | 2022-08-09 | Natera, Inc. | Methods for non-invasive prenatal paternity testing |
| US11339429B2 (en) | 2010-05-18 | 2022-05-24 | Natera, Inc. | Methods for non-invasive prenatal ploidy calling |
| US11332785B2 (en) | 2010-05-18 | 2022-05-17 | Natera, Inc. | Methods for non-invasive prenatal ploidy calling |
| WO2013052557A2 (en) * | 2011-10-03 | 2013-04-11 | Natera, Inc. | Methods for preimplantation genetic diagnosis by sequencing |
| US11322224B2 (en) | 2010-05-18 | 2022-05-03 | Natera, Inc. | Methods for non-invasive prenatal ploidy calling |
| US11939634B2 (en) | 2010-05-18 | 2024-03-26 | Natera, Inc. | Methods for simultaneous amplification of target loci |
| US9677118B2 (en) | 2014-04-21 | 2017-06-13 | Natera, Inc. | Methods for simultaneous amplification of target loci |
| WO2011146632A1 (en) | 2010-05-18 | 2011-11-24 | Gene Security Network Inc. | Methods for non-invasive prenatal ploidy calling |
| US12545960B2 (en) | 2010-05-18 | 2026-02-10 | Natera, Inc. | Methods for simultaneous amplification of target loci |
| US11332793B2 (en) | 2010-05-18 | 2022-05-17 | Natera, Inc. | Methods for simultaneous amplification of target loci |
| US11326208B2 (en) | 2010-05-18 | 2022-05-10 | Natera, Inc. | Methods for nested PCR amplification of cell-free DNA |
| US12221653B2 (en) | 2010-05-18 | 2025-02-11 | Natera, Inc. | Methods for simultaneous amplification of target loci |
| US10316362B2 (en) | 2010-05-18 | 2019-06-11 | Natera, Inc. | Methods for simultaneous amplification of target loci |
| US20190010543A1 (en) | 2010-05-18 | 2019-01-10 | Natera, Inc. | Methods for simultaneous amplification of target loci |
| US8700338B2 (en) | 2011-01-25 | 2014-04-15 | Ariosa Diagnosis, Inc. | Risk calculation for evaluation of fetal aneuploidy |
| US11203786B2 (en) | 2010-08-06 | 2021-12-21 | Ariosa Diagnostics, Inc. | Detection of target nucleic acids using hybridization |
| US20130040375A1 (en) | 2011-08-08 | 2013-02-14 | Tandem Diagnotics, Inc. | Assay systems for genetic analysis |
| US10167508B2 (en) | 2010-08-06 | 2019-01-01 | Ariosa Diagnostics, Inc. | Detection of genetic abnormalities |
| US11031095B2 (en) | 2010-08-06 | 2021-06-08 | Ariosa Diagnostics, Inc. | Assay systems for determination of fetal copy number variation |
| US10533223B2 (en) | 2010-08-06 | 2020-01-14 | Ariosa Diagnostics, Inc. | Detection of target nucleic acids using hybridization |
| US20120034603A1 (en) | 2010-08-06 | 2012-02-09 | Tandem Diagnostics, Inc. | Ligation-based detection of genetic variants |
| US20130261003A1 (en) | 2010-08-06 | 2013-10-03 | Ariosa Diagnostics, In. | Ligation-based detection of genetic variants |
| US20140342940A1 (en) | 2011-01-25 | 2014-11-20 | Ariosa Diagnostics, Inc. | Detection of Target Nucleic Acids using Hybridization |
| ES2523140T3 (es) | 2010-09-21 | 2014-11-21 | Population Genetics Technologies Ltd. | Aumento de la confianza en las identificaciones de alelos con el recuento molecular |
| CN105243295B (zh) | 2010-11-30 | 2018-08-17 | 香港中文大学 | 与癌症相关的遗传或分子畸变的检测 |
| CN103608466B (zh) | 2010-12-22 | 2020-09-18 | 纳特拉公司 | 非侵入性产前亲子鉴定方法 |
| US11270781B2 (en) | 2011-01-25 | 2022-03-08 | Ariosa Diagnostics, Inc. | Statistical analysis for non-invasive sex chromosome aneuploidy determination |
| US20230101627A1 (en) * | 2011-01-25 | 2023-03-30 | Ariosa Diagnostics, Inc. | Noninvasive detection of fetal aneuploidy in egg donor pregnancies |
| US10131947B2 (en) | 2011-01-25 | 2018-11-20 | Ariosa Diagnostics, Inc. | Noninvasive detection of fetal aneuploidy in egg donor pregnancies |
| US8756020B2 (en) | 2011-01-25 | 2014-06-17 | Ariosa Diagnostics, Inc. | Enhanced risk probabilities using biomolecule estimations |
| US9994897B2 (en) | 2013-03-08 | 2018-06-12 | Ariosa Diagnostics, Inc. | Non-invasive fetal sex determination |
| RU2671980C2 (ru) | 2011-02-09 | 2018-11-08 | Натера, Инк. | Способы неинвазивного пренатального установления плоидности |
| WO2012129363A2 (en) | 2011-03-24 | 2012-09-27 | President And Fellows Of Harvard College | Single cell nucleic acid detection and analysis |
| AU2012236200B2 (en) | 2011-03-30 | 2015-05-14 | Verinata Health, Inc. | Method for verifying bioassay samples |
| RS57837B1 (sr) | 2011-04-12 | 2018-12-31 | Verinata Health Inc | Razrešavanje genomskih frakcija upotrebom broja kopija polimorfizama |
| AU2011365507A1 (en) * | 2011-04-14 | 2013-05-02 | Verinata Health, Inc. | Normalizing chromosomes for the determination and verification of common and rare chromosomal aneuploidies |
| GB2484764B (en) | 2011-04-14 | 2012-09-05 | Verinata Health Inc | Normalizing chromosomes for the determination and verification of common and rare chromosomal aneuploidies |
| US9411937B2 (en) | 2011-04-15 | 2016-08-09 | Verinata Health, Inc. | Detecting and classifying copy number variation |
| WO2014014498A1 (en) | 2012-07-20 | 2014-01-23 | Verinata Health, Inc. | Detecting and classifying copy number variation in a fetal genome |
| EP3495497B1 (en) | 2011-04-28 | 2021-03-24 | Life Technologies Corporation | Methods and compositions for multiplex pcr |
| US20130059762A1 (en) | 2011-04-28 | 2013-03-07 | Life Technologies Corporation | Methods and compositions for multiplex pcr |
| US20130059738A1 (en) * | 2011-04-28 | 2013-03-07 | Life Technologies Corporation | Methods and compositions for multiplex pcr |
| AU2012249531B2 (en) | 2011-04-29 | 2017-06-29 | Sequenom, Inc. | Quantification of a minority nucleic acid species |
| US20140235474A1 (en) | 2011-06-24 | 2014-08-21 | Sequenom, Inc. | Methods and processes for non invasive assessment of a genetic variation |
| AU2011373694A1 (en) * | 2011-07-26 | 2013-05-02 | Verinata Health, Inc. | Method for determining the presence or absence of different aneuploidies in a sample |
| US8712697B2 (en) | 2011-09-07 | 2014-04-29 | Ariosa Diagnostics, Inc. | Determination of copy number variations using binomial probability calculations |
| AU2012304328B2 (en) * | 2011-09-09 | 2017-07-20 | The Board Of Trustees Of The Leland Stanford Junior University | Methods for obtaining a sequence |
| WO2013040583A2 (en) * | 2011-09-16 | 2013-03-21 | Complete Genomics, Inc | Determining variants in a genome of a heterogeneous sample |
| US9984198B2 (en) | 2011-10-06 | 2018-05-29 | Sequenom, Inc. | Reducing sequence read count error in assessment of complex genetic variations |
| US10196681B2 (en) | 2011-10-06 | 2019-02-05 | Sequenom, Inc. | Methods and processes for non-invasive assessment of genetic variations |
| WO2013052907A2 (en) | 2011-10-06 | 2013-04-11 | Sequenom, Inc. | Methods and processes for non-invasive assessment of genetic variations |
| US9367663B2 (en) | 2011-10-06 | 2016-06-14 | Sequenom, Inc. | Methods and processes for non-invasive assessment of genetic variations |
| JP6073902B2 (ja) | 2011-10-06 | 2017-02-01 | セクエノム, インコーポレイテッド | 遺伝的変異の非侵襲的評価のための方法およびプロセス |
| US10424394B2 (en) | 2011-10-06 | 2019-09-24 | Sequenom, Inc. | Methods and processes for non-invasive assessment of genetic variations |
| ES2624686T3 (es) | 2011-10-11 | 2017-07-17 | Sequenom, Inc. | Métodos y procesos para la evaluación no invasiva de variaciones genéticas |
| US8688388B2 (en) | 2011-10-11 | 2014-04-01 | Sequenom, Inc. | Methods and processes for non-invasive assessment of genetic variations |
| US9845552B2 (en) | 2011-10-27 | 2017-12-19 | Verinata Health, Inc. | Set membership testers for aligning nucleic acid samples |
| CA2861856C (en) * | 2012-01-20 | 2020-06-02 | Sequenom, Inc. | Diagnostic processes that factor experimental conditions |
| EP2820174B1 (en) | 2012-02-27 | 2019-12-25 | The University of North Carolina at Chapel Hill | Methods and uses for molecular tags |
| CA2865575C (en) | 2012-02-27 | 2024-01-16 | Cellular Research, Inc. | Compositions and kits for molecular counting |
| WO2013128281A1 (en) | 2012-02-28 | 2013-09-06 | Population Genetics Technologies Ltd | Method for attaching a counter sequence to a nucleic acid sample |
| EP2820129A1 (en) | 2012-03-02 | 2015-01-07 | Sequenom, Inc. | Methods and processes for non-invasive assessment of genetic variations |
| US9892230B2 (en) | 2012-03-08 | 2018-02-13 | The Chinese University Of Hong Kong | Size-based analysis of fetal or tumor DNA fraction in plasma |
| CA2868836C (en) * | 2012-03-26 | 2019-08-06 | The Johns Hopkins University | Rapid aneuploidy detection |
| CN204440396U (zh) * | 2012-04-12 | 2015-07-01 | 维里纳塔健康公司 | 用于确定胎儿分数的试剂盒 |
| US9920361B2 (en) | 2012-05-21 | 2018-03-20 | Sequenom, Inc. | Methods and compositions for analyzing nucleic acid |
| US10504613B2 (en) | 2012-12-20 | 2019-12-10 | Sequenom, Inc. | Methods and processes for non-invasive assessment of genetic variations |
| EP3978621B1 (en) | 2012-05-21 | 2023-08-30 | Sequenom, Inc. | Methods and processes for non-invasive assessment of genetic variations |
| US10289800B2 (en) | 2012-05-21 | 2019-05-14 | Ariosa Diagnostics, Inc. | Processes for calculating phased fetal genomic sequences |
| CN104053787A (zh) * | 2012-05-23 | 2014-09-17 | 深圳华大基因医学有限公司 | 鉴定双胞胎类型的方法和系统 |
| US11261494B2 (en) * | 2012-06-21 | 2022-03-01 | The Chinese University Of Hong Kong | Method of measuring a fractional concentration of tumor DNA |
| US10497461B2 (en) | 2012-06-22 | 2019-12-03 | Sequenom, Inc. | Methods and processes for non-invasive assessment of genetic variations |
| US20140093873A1 (en) | 2012-07-13 | 2014-04-03 | Sequenom, Inc. | Processes and compositions for methylation-based enrichment of fetal nucleic acid from a maternal sample useful for non-invasive prenatal diagnoses |
| EP2875156A4 (en) | 2012-07-19 | 2016-02-24 | Ariosa Diagnostics Inc | SEQUENTIAL LIGATION-BASED MULTIPLEX DETECTION OF GENETIC VARIANTS |
| US20140100126A1 (en) | 2012-08-17 | 2014-04-10 | Natera, Inc. | Method for Non-Invasive Prenatal Testing Using Parental Mosaicism Data |
| US11913065B2 (en) | 2012-09-04 | 2024-02-27 | Guardent Health, Inc. | Systems and methods to detect rare mutations and copy number variation |
| US10876152B2 (en) | 2012-09-04 | 2020-12-29 | Guardant Health, Inc. | Systems and methods to detect rare mutations and copy number variation |
| CN104781421B (zh) | 2012-09-04 | 2020-06-05 | 夸登特健康公司 | 检测稀有突变和拷贝数变异的系统和方法 |
| US20160040229A1 (en) | 2013-08-16 | 2016-02-11 | Guardant Health, Inc. | Systems and methods to detect rare mutations and copy number variation |
| US20220411875A1 (en) * | 2012-10-03 | 2022-12-29 | Natera, Inc. | Methods for simultaneous amplification of target loci |
| CA3120521A1 (en) | 2012-10-04 | 2014-04-10 | Sequenom, Inc. | Methods and processes for non-invasive assessment of genetic variations |
| US10482994B2 (en) | 2012-10-04 | 2019-11-19 | Sequenom, Inc. | Methods and processes for non-invasive assessment of genetic variations |
| US10347361B2 (en) | 2012-10-24 | 2019-07-09 | Nantomics, Llc | Genome explorer system to process and present nucleotide variations in genome sequence data |
| US10643738B2 (en) * | 2013-01-10 | 2020-05-05 | The Chinese University Of Hong Kong | Noninvasive prenatal molecular karyotyping from maternal plasma |
| US20130309666A1 (en) | 2013-01-25 | 2013-11-21 | Sequenom, Inc. | Methods and processes for non-invasive assessment of genetic variations |
| WO2014132244A1 (en) | 2013-02-28 | 2014-09-04 | The Chinese University Of Hong Kong | Maternal plasma transcriptome analysis by massively parallel rna sequencing |
| US11060145B2 (en) | 2013-03-13 | 2021-07-13 | Sequenom, Inc. | Methods and compositions for identifying presence or absence of hypermethylation or hypomethylation locus |
| WO2014145078A1 (en) * | 2013-03-15 | 2014-09-18 | Verinata Health, Inc. | Generating cell-free dna libraries directly from blood |
| WO2014151511A2 (en) | 2013-03-15 | 2014-09-25 | Abbott Molecular Inc. | Systems and methods for detection of genomic copy number changes |
| US20140278127A1 (en) * | 2013-03-15 | 2014-09-18 | Battelle Memorial Institute | Computer Files and Methods Supporting Forensic Analysis of Nucleotide Sequence Data |
| US10930368B2 (en) | 2013-04-03 | 2021-02-23 | Sequenom, Inc. | Methods and processes for non-invasive assessment of genetic variations |
| KR102665592B1 (ko) | 2013-05-24 | 2024-05-21 | 시쿼넘, 인코포레이티드 | 유전적 변이의 비침습 평가를 위한 방법 및 프로세스 |
| WO2014204991A1 (en) | 2013-06-17 | 2014-12-24 | Verinata Health, Inc. | Method for determining copy number variations in sex chromosomes |
| ES3037160T3 (en) | 2013-06-21 | 2025-09-29 | Sequenom Inc | Methods and processes for non-invasive assessment of genetic variations |
| GB201318369D0 (en) * | 2013-10-17 | 2013-12-04 | Univ Leuven Kath | Methods using BAF |
| KR102758333B1 (ko) | 2013-08-28 | 2025-01-23 | 벡톤 디킨슨 앤드 컴퍼니 | 대량의 동시 단일 세포 분석 |
| US10577655B2 (en) | 2013-09-27 | 2020-03-03 | Natera, Inc. | Cell free DNA diagnostic testing standards |
| US9499870B2 (en) | 2013-09-27 | 2016-11-22 | Natera, Inc. | Cell free DNA diagnostic testing standards |
| US10262755B2 (en) | 2014-04-21 | 2019-04-16 | Natera, Inc. | Detecting cancer mutations and aneuploidy in chromosomal segments |
| KR102384620B1 (ko) | 2013-10-04 | 2022-04-11 | 시쿼넘, 인코포레이티드 | 유전적 변이의 비침습 평가를 위한 방법 및 프로세스 |
| US9582877B2 (en) | 2013-10-07 | 2017-02-28 | Cellular Research, Inc. | Methods and systems for digitally counting features on arrays |
| CN105874082B (zh) | 2013-10-07 | 2020-06-02 | 塞昆纳姆股份有限公司 | 用于非侵入性评估染色体改变的方法和过程 |
| ES2660989T3 (es) | 2013-12-28 | 2018-03-27 | Guardant Health, Inc. | Métodos y sistemas para detectar variantes genéticas |
| EP3736344A1 (en) | 2014-03-13 | 2020-11-11 | Sequenom, Inc. | Methods and processes for non-invasive assessment of genetic variations |
| CA2945962C (en) | 2014-04-21 | 2023-08-29 | Natera, Inc. | Detecting mutations and ploidy in chromosomal segments |
| US12492429B2 (en) | 2014-04-21 | 2025-12-09 | Natera, Inc. | Detecting mutations and ploidy in chromosomal segments |
| US20180173846A1 (en) | 2014-06-05 | 2018-06-21 | Natera, Inc. | Systems and Methods for Detection of Aneuploidy |
| US11783911B2 (en) | 2014-07-30 | 2023-10-10 | Sequenom, Inc | Methods and processes for non-invasive assessment of genetic variations |
| EP3730629A1 (en) | 2014-10-10 | 2020-10-28 | Sequenom, Inc. | Methods and processes for non-invasive assessment of genetic variations |
| US9859394B2 (en) | 2014-12-18 | 2018-01-02 | Agilome, Inc. | Graphene FET devices, systems, and methods of using the same for sequencing nucleic acids |
| US10020300B2 (en) | 2014-12-18 | 2018-07-10 | Agilome, Inc. | Graphene FET devices, systems, and methods of using the same for sequencing nucleic acids |
| US10006910B2 (en) | 2014-12-18 | 2018-06-26 | Agilome, Inc. | Chemically-sensitive field effect transistors, systems, and methods for manufacturing and using the same |
| CA2971589C (en) | 2014-12-18 | 2021-09-28 | Edico Genome Corporation | Chemically-sensitive field effect transistor |
| US9618474B2 (en) | 2014-12-18 | 2017-04-11 | Edico Genome, Inc. | Graphene FET devices, systems, and methods of using the same for sequencing nucleic acids |
| US9857328B2 (en) | 2014-12-18 | 2018-01-02 | Agilome, Inc. | Chemically-sensitive field effect transistors, systems and methods for manufacturing and using the same |
| HUE058263T2 (hu) | 2015-02-10 | 2022-07-28 | Univ Hong Kong Chinese | Mutációk detektálása rákszûrési és magzatelemzési célból |
| EP3259371B1 (en) | 2015-02-19 | 2020-09-02 | Becton, Dickinson and Company | High-throughput single-cell analysis combining proteomic and genomic information |
| KR101533792B1 (ko) * | 2015-02-24 | 2015-07-06 | 대한민국 | Ngs 기반 인간 객체의 상염색체 분석방법 |
| WO2016138496A1 (en) | 2015-02-27 | 2016-09-01 | Cellular Research, Inc. | Spatially addressable molecular barcoding |
| WO2016160844A2 (en) | 2015-03-30 | 2016-10-06 | Cellular Research, Inc. | Methods and compositions for combinatorial barcoding |
| EP4582556A3 (en) | 2015-04-23 | 2025-10-08 | Becton, Dickinson and Company | Methods and compositions for whole transcriptome amplification |
| US10844428B2 (en) * | 2015-04-28 | 2020-11-24 | Illumina, Inc. | Error suppression in sequenced DNA fragments using redundant reads with unique molecular indices (UMIS) |
| US11479812B2 (en) | 2015-05-11 | 2022-10-25 | Natera, Inc. | Methods and compositions for determining ploidy |
| EP3666902B1 (en) | 2015-05-22 | 2024-07-03 | Medicover Public Co Ltd | Multiplexed parallel analysis of targeted genomic regions for non-invasive prenatal testing |
| WO2016196229A1 (en) | 2015-06-01 | 2016-12-08 | Cellular Research, Inc. | Methods for rna quantification |
| EP3135770A1 (en) * | 2015-08-28 | 2017-03-01 | Latvian Biomedical Research and Study Centre | Set of oligonucleotides and method for detection of fetal dna fraction in maternal plasma |
| US12540351B2 (en) | 2015-09-02 | 2026-02-03 | Guardant Health, Inc. | Identification of somatic mutations versus germline variants for cell-free DNA variant calling applications |
| US11302416B2 (en) | 2015-09-02 | 2022-04-12 | Guardant Health | Machine learning for somatic single nucleotide variant detection in cell-free tumor nucleic acid sequencing applications |
| JP6940484B2 (ja) | 2015-09-11 | 2021-09-29 | セルラー リサーチ, インコーポレイテッド | ライブラリー正規化のための方法および組成物 |
| CA3002449A1 (en) * | 2015-11-16 | 2017-05-26 | Sequenom, Inc. | Methods and processes for non-invasive assessment of genetic variations |
| SG11201805119QA (en) | 2015-12-17 | 2018-07-30 | Guardant Health Inc | Methods to determine tumor gene copy number by analysis of cell-free dna |
| US10982286B2 (en) | 2016-01-22 | 2021-04-20 | Mayo Foundation For Medical Education And Research | Algorithmic approach for determining the plasma genome abnormality PGA and the urine genome abnormality UGA scores based on cell free cfDNA copy number variations in plasma and urine |
| US11753682B2 (en) | 2016-03-07 | 2023-09-12 | Father Flanagan's Boys'Home | Noninvasive molecular controls |
| RU2760913C2 (ru) | 2016-04-15 | 2021-12-01 | Натера, Инк. | Способы выявления рака легкого |
| JP7129343B2 (ja) | 2016-05-02 | 2022-09-01 | ベクトン・ディキンソン・アンド・カンパニー | 正確な分子バーコーディング |
| WO2017201081A1 (en) | 2016-05-16 | 2017-11-23 | Agilome, Inc. | Graphene fet devices, systems, and methods of using the same for sequencing nucleic acids |
| US10301677B2 (en) | 2016-05-25 | 2019-05-28 | Cellular Research, Inc. | Normalization of nucleic acid libraries |
| ES2979395T3 (es) | 2016-05-26 | 2024-09-25 | Becton Dickinson Co | Métodos de ajuste del recuento de etiquetas moleculares |
| EP4043581A1 (en) | 2016-05-27 | 2022-08-17 | Sequenom, Inc. | Method for generating a paralog assay system |
| US10640763B2 (en) | 2016-05-31 | 2020-05-05 | Cellular Research, Inc. | Molecular indexing of internal sequences |
| US10202641B2 (en) | 2016-05-31 | 2019-02-12 | Cellular Research, Inc. | Error correction in amplification of samples |
| CA3030894A1 (en) | 2016-07-27 | 2018-02-01 | Sequenom, Inc. | Methods for non-invasive assessment of genomic instability |
| CA3030890A1 (en) | 2016-07-27 | 2018-02-01 | Sequenom, Inc. | Genetic copy number alteration classifications |
| WO2018053365A1 (en) | 2016-09-15 | 2018-03-22 | ArcherDX, Inc. | Methods of nucleic acid sample preparation for analysis of cell-free dna |
| US10704082B2 (en) | 2016-09-15 | 2020-07-07 | ArcherDX, Inc. | Methods of nucleic acid sample preparation |
| US20220282305A1 (en) * | 2016-09-15 | 2022-09-08 | Archerdx, Llc | Methods of nucleic acid sample preparation |
| CN109791157B (zh) | 2016-09-26 | 2022-06-07 | 贝克顿迪金森公司 | 使用具有条形码化的寡核苷酸序列的试剂测量蛋白质表达 |
| WO2018064486A1 (en) * | 2016-09-29 | 2018-04-05 | Counsyl, Inc. | Noninvasive prenatal screening using dynamic iterative depth optimization |
| US9850523B1 (en) | 2016-09-30 | 2017-12-26 | Guardant Health, Inc. | Methods for multi-resolution analysis of cell-free nucleic acids |
| EP3461274B1 (en) | 2016-09-30 | 2020-11-04 | Guardant Health, Inc. | Methods for multi-resolution analysis of cell-free nucleic acids |
| WO2018067517A1 (en) | 2016-10-04 | 2018-04-12 | Natera, Inc. | Methods for characterizing copy number variation using proximity-litigation sequencing |
| ES2940620T3 (es) * | 2016-11-02 | 2023-05-09 | Archerdx Llc | Métodos de preparación de muestras de ácido nucleico para la secuenciación del repertorio inmunitario |
| GB201618485D0 (en) | 2016-11-02 | 2016-12-14 | Ucl Business Plc | Method of detecting tumour recurrence |
| JP7228510B2 (ja) | 2016-11-08 | 2023-02-24 | ベクトン・ディキンソン・アンド・カンパニー | 細胞標識分類の方法 |
| US11164659B2 (en) | 2016-11-08 | 2021-11-02 | Becton, Dickinson And Company | Methods for expression profile classification |
| US10011870B2 (en) | 2016-12-07 | 2018-07-03 | Natera, Inc. | Compositions and methods for identifying nucleic acid molecules |
| ES2961580T3 (es) | 2017-01-13 | 2024-03-12 | Cellular Res Inc | Revestimiento hidrófilo de canales de fluidos |
| SG11201906428SA (en) | 2017-01-18 | 2019-08-27 | Illumina Inc | Methods and systems for generation and error-correction of unique molecular index sets with heterogeneous molecular lengths |
| CA3049682C (en) | 2017-01-20 | 2023-06-27 | Sequenom, Inc. | Methods for non-invasive assessment of genetic alterations |
| CA3049457C (en) | 2017-01-20 | 2023-05-16 | Sequenom, Inc. | Methods for non-invasive assessment of copy number alterations |
| CA3049455C (en) | 2017-01-20 | 2023-06-13 | Sequenom, Inc. | Sequencing adapter manufacture and use |
| CA3207879A1 (en) | 2017-01-24 | 2018-08-02 | Sequenom, Inc. | Methods and processes for assessment of genetic variations |
| SG11201906397UA (en) | 2017-01-25 | 2019-08-27 | Univ Hong Kong Chinese | Diagnostic applications using nucleic acid fragments |
| CN110382708A (zh) | 2017-02-01 | 2019-10-25 | 赛卢拉研究公司 | 使用阻断性寡核苷酸进行选择性扩增 |
| WO2018156418A1 (en) | 2017-02-21 | 2018-08-30 | Natera, Inc. | Compositions, methods, and kits for isolating nucleic acids |
| JP7370862B2 (ja) | 2017-03-17 | 2023-10-30 | セクエノム, インコーポレイテッド | 遺伝子モザイク症のための方法およびプロセス |
| JP7170711B2 (ja) * | 2017-04-18 | 2022-11-14 | アジレント・テクノロジーズ・ベルジャム・ナムローゼ・フェンノートシャップ | Dna分析のためのオフターゲット配列の使用 |
| CN110719959B (zh) | 2017-06-05 | 2021-08-06 | 贝克顿迪金森公司 | 针对单细胞的样品索引 |
| ES2920280T3 (es) | 2017-07-07 | 2022-08-02 | Nipd Genetics Public Company Ltd | Enriquecimiento de regiones genómicas blanco para análisis paralelo multiplexado |
| WO2019008172A1 (en) | 2017-07-07 | 2019-01-10 | Nipd Genetics Public Company Limited | ENRICHED MULTIPLEXED PARALLEL ANALYSIS IN TARGET FOR TUMOR BIOMARKER EVALUATION |
| PT3649258T (pt) | 2017-07-07 | 2022-05-25 | Nipd Genetics Public Company Ltd | Análise paralela multiplexada enriquecida com alvo para avaliação de amostras de adn fetal |
| ES2925394T3 (es) | 2017-07-07 | 2022-10-17 | Nipd Genetics Public Company Ltd | Análisis paralelo multiplexado con enriquecimiento de blancos para la evaluación del riesgo de portar alteraciones genéticas |
| CN111051536A (zh) | 2017-07-26 | 2020-04-21 | 香港中文大学 | 利用不含细胞的病毒核酸改善癌症筛选 |
| EP3658689B1 (en) | 2017-07-26 | 2021-03-24 | Trisomytest, s.r.o. | A method for non-invasive prenatal detection of fetal chromosome aneuploidy from maternal blood based on bayesian network |
| WO2019025004A1 (en) | 2017-08-04 | 2019-02-07 | Trisomytest, S.R.O. | METHOD FOR NON-INVASIVE PRENATAL DETECTION OF FETUS SEX CHROMOSOMAL ABNORMALITY AND FETUS SEX DETERMINATION FOR SINGLE PREGNANCY AND GEEMELLAR PREGNANCY |
| CN111094583A (zh) | 2017-08-04 | 2020-05-01 | 十亿至一公司 | 与生物靶相关的定量中利用靶相关分子的测序输出确定和分析 |
| US11519024B2 (en) | 2017-08-04 | 2022-12-06 | Billiontoone, Inc. | Homologous genomic regions for characterization associated with biological targets |
| WO2019028462A1 (en) | 2017-08-04 | 2019-02-07 | Billiontoone, Inc. | TARGET-ASSOCIATED MOLECULES FOR CHARACTERIZATION ASSOCIATED WITH BIOLOGICAL TARGETS |
| US11447818B2 (en) | 2017-09-15 | 2022-09-20 | Illumina, Inc. | Universal short adapters with variable length non-random unique molecular identifiers |
| CN108733982B (zh) * | 2017-09-26 | 2021-02-19 | 上海凡迪基因科技有限公司 | 孕妇nipt结果校正方法、装置及计算机可读存储介质、设备 |
| CN111526793A (zh) | 2017-10-27 | 2020-08-11 | 朱诺诊断学公司 | 用于超低体积液体活检的设备、系统和方法 |
| US12084720B2 (en) | 2017-12-14 | 2024-09-10 | Natera, Inc. | Assessing graft suitability for transplantation |
| EP3728636B1 (en) | 2017-12-19 | 2024-09-11 | Becton, Dickinson and Company | Particles associated with oligonucleotides |
| KR102031841B1 (ko) * | 2017-12-22 | 2019-10-15 | 테라젠지놈케어 주식회사 | 모체 시료 중 태아 분획을 결정하는 방법 |
| EP4650456A3 (en) | 2018-01-05 | 2026-01-21 | BillionToOne, Inc. | Quality control templates for ensuring validity of sequencing-based assays |
| US12398389B2 (en) | 2018-02-15 | 2025-08-26 | Natera, Inc. | Methods for isolating nucleic acids with size selection |
| US12462935B2 (en) | 2018-03-30 | 2025-11-04 | Nucleix Ltd. | Deep learning-based methods, devices, and systems for prenatal testing |
| CN110832086A (zh) | 2018-04-02 | 2020-02-21 | 伊鲁米那股份有限公司 | 用于制造用于基于序列的遗传检验的对照的组合物和方法 |
| US12024738B2 (en) | 2018-04-14 | 2024-07-02 | Natera, Inc. | Methods for cancer detection and monitoring |
| JP7358388B2 (ja) | 2018-05-03 | 2023-10-10 | ベクトン・ディキンソン・アンド・カンパニー | 反対側の転写物末端における分子バーコーディング |
| CN112272710A (zh) | 2018-05-03 | 2021-01-26 | 贝克顿迪金森公司 | 高通量多组学样品分析 |
| IL271454B2 (en) | 2018-05-17 | 2025-04-01 | Illumina Inc | Rapid single-cell genetic sequencing with low Aggregation bias |
| WO2019227015A1 (en) | 2018-05-25 | 2019-11-28 | Illumina, Inc. | Circulating rna signatures specific to preeclampsia |
| US12234509B2 (en) | 2018-07-03 | 2025-02-25 | Natera, Inc. | Methods for detection of donor-derived cell-free DNA |
| EP3833776A4 (en) | 2018-08-06 | 2022-04-27 | Billiontoone, Inc. | DILUTION MARKER FOR QUANTIFICATION OF BIOLOGICAL TARGETS |
| JP7535998B2 (ja) | 2018-08-31 | 2024-08-19 | ガーダント ヘルス, インコーポレイテッド | マージされたリードおよびマージされないリードに基づいた遺伝的変異体の検出 |
| ES2992135T3 (es) | 2018-10-01 | 2024-12-09 | Becton Dickinson Co | Determinar secuencias de transcripción 5 |
| US11932849B2 (en) | 2018-11-08 | 2024-03-19 | Becton, Dickinson And Company | Whole transcriptome analysis of single cells using random priming |
| WO2020113577A1 (zh) * | 2018-12-07 | 2020-06-11 | 深圳华大生命科学研究院 | 一种靶基因文库的构建方法、检测装置及其应用 |
| US11492660B2 (en) | 2018-12-13 | 2022-11-08 | Becton, Dickinson And Company | Selective extension in single cell whole transcriptome analysis |
| US11371076B2 (en) | 2019-01-16 | 2022-06-28 | Becton, Dickinson And Company | Polymerase chain reaction normalization through primer titration |
| ES2945227T3 (es) | 2019-01-23 | 2023-06-29 | Becton Dickinson Co | Oligonucleótidos asociados con anticuerpos |
| WO2020160414A1 (en) | 2019-01-31 | 2020-08-06 | Guardant Health, Inc. | Compositions and methods for isolating cell-free dna |
| WO2020167920A1 (en) | 2019-02-14 | 2020-08-20 | Cellular Research, Inc. | Hybrid targeted and whole transcriptome amplification |
| US11965208B2 (en) | 2019-04-19 | 2024-04-23 | Becton, Dickinson And Company | Methods of associating phenotypical data and single cell sequencing data |
| WO2020226528A1 (ru) * | 2019-05-08 | 2020-11-12 | Общество с ограниченной ответственностью "ГЕНОТЕК ИТ" | Способ определения кариотипа плода беременной женщины |
| US12305235B2 (en) | 2019-06-06 | 2025-05-20 | Natera, Inc. | Methods for detecting immune cell DNA and monitoring immune system |
| CN120099137A (zh) | 2019-07-22 | 2025-06-06 | 贝克顿迪金森公司 | 单细胞染色质免疫沉淀测序测定 |
| WO2021037016A1 (en) * | 2019-08-30 | 2021-03-04 | The Chinese University Of Hong Kong | Methods for detecting absence of heterozygosity by low-pass genome sequencing |
| CA3159786A1 (en) | 2019-10-31 | 2021-05-06 | Sequenom, Inc. | Application of mosaicism ratio in multifetal gestations and personalized risk assessment |
| JP7522189B2 (ja) | 2019-11-08 | 2024-07-24 | ベクトン・ディキンソン・アンド・カンパニー | 免疫レパートリーシーケンシングのための完全長v(d)j情報を得るためのランダムプライミングの使用 |
| US11753685B2 (en) | 2019-11-22 | 2023-09-12 | Illumina, Inc. | Circulating RNA signatures specific to preeclampsia |
| US11649497B2 (en) | 2020-01-13 | 2023-05-16 | Becton, Dickinson And Company | Methods and compositions for quantitation of proteins and RNA |
| WO2021146219A1 (en) | 2020-01-13 | 2021-07-22 | Becton, Dickinson And Company | Cell capture using du-containing oligonucleotides |
| WO2021155057A1 (en) | 2020-01-29 | 2021-08-05 | Becton, Dickinson And Company | Barcoded wells for spatial mapping of single cells through sequencing |
| WO2021173719A1 (en) | 2020-02-25 | 2021-09-02 | Becton, Dickinson And Company | Bi-specific probes to enable the use of single-cell samples as single color compensation control |
| US12305242B2 (en) | 2020-04-24 | 2025-05-20 | The Johns Hopkins University | Methods and related aspects for quantitative polymerase chain reaction to determine fractional abundance |
| US11661625B2 (en) | 2020-05-14 | 2023-05-30 | Becton, Dickinson And Company | Primers for immune repertoire profiling |
| CN111534604B (zh) * | 2020-05-27 | 2024-01-23 | 广东华美众源生物科技有限公司 | 一种检测人常染色体dip-str遗传标记的荧光复合扩增试剂盒 |
| US12157913B2 (en) | 2020-06-02 | 2024-12-03 | Becton, Dickinson And Company | Oligonucleotides and beads for 5 prime gene expression assay |
| US11932901B2 (en) | 2020-07-13 | 2024-03-19 | Becton, Dickinson And Company | Target enrichment using nucleic acid probes for scRNAseq |
| US12391940B2 (en) | 2020-07-31 | 2025-08-19 | Becton, Dickinson And Company | Single cell assay for transposase-accessible chromatin |
| LT4211260T (lt) | 2020-09-11 | 2025-06-25 | New England Biolabs, Inc. | Imobilizuotų fermentų taikymas nanoporų bibliotekos konstravimui |
| EP4247967A1 (en) | 2020-11-20 | 2023-09-27 | Becton, Dickinson and Company | Profiling of highly expressed and lowly expressed proteins |
| JP2023552015A (ja) | 2020-12-02 | 2023-12-14 | イルミナ ソフトウェア, インコーポレイテッド | 遺伝子変異を検出するためのシステム及び方法 |
| CN116685850A (zh) | 2020-12-15 | 2023-09-01 | 贝克顿迪金森公司 | 单细胞分泌组分析 |
| EP4409039A4 (en) * | 2021-09-29 | 2025-09-03 | Pillar Biosciences Inc | CUSTOMIZED LIQUID BIOPSIES FOR CANCER USING PRIMERS FROM A PRIMER BANK |
| KR20250019610A (ko) | 2022-03-21 | 2025-02-10 | 빌리언투원, 인크. | 치료 모니터링을 위한 메틸화된 세포 유리 dna의 분자 계수 |
| WO2024186778A1 (en) | 2023-03-03 | 2024-09-12 | Laboratory Corporation Of America Holdings | Methods and systems for positive cfdna screening on genetic variations using mosaicism ratio |
| EP4713926A1 (en) | 2023-05-15 | 2026-03-25 | Laboratory Corporation of America Holdings | Machine-learning approaches to pan-cancer screening in whole genome sequencing |
| CN117965744B (zh) * | 2023-12-12 | 2024-10-11 | 东莞博奥木华基因科技有限公司 | 一种基于多重pcr捕获技术检测胎儿样本倍性和母源细胞污染的试剂盒、引物和方法 |
| IL310301B2 (en) * | 2024-01-21 | 2026-02-01 | Identifai Genetics Ltd | Methods for non-invasive prenatal diagnosis of repeat mutations |
Family Cites Families (108)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6270961B1 (en) | 1987-04-01 | 2001-08-07 | Hyseq, Inc. | Methods and apparatus for DNA sequencing and DNA identification |
| US5976790A (en) | 1992-03-04 | 1999-11-02 | The Regents Of The University Of California | Comparative Genomic Hybridization (CGH) |
| WO1994003638A1 (en) * | 1992-07-30 | 1994-02-17 | Applied Biosystems, Inc. | Method of detecting aneuploidy by amplified short tandem repeats |
| US5776737A (en) | 1994-12-22 | 1998-07-07 | Visible Genetics Inc. | Method and composition for internal identification of samples |
| US6057103A (en) | 1995-07-18 | 2000-05-02 | Diversa Corporation | Screening for novel bioactivities |
| AU735272B2 (en) | 1996-10-04 | 2001-07-05 | Intronn Llc | Sample collection devices and methods using markers and the use of such markers as controls in sample validation, laboratory evaluation and/or accreditation |
| US20010051341A1 (en) | 1997-03-04 | 2001-12-13 | Isis Innovation Limited | Non-invasive prenatal diagnosis |
| GB9704444D0 (en) | 1997-03-04 | 1997-04-23 | Isis Innovation | Non-invasive prenatal diagnosis |
| JP2002503954A (ja) | 1997-04-01 | 2002-02-05 | グラクソ、グループ、リミテッド | 核酸増幅法 |
| US5888740A (en) | 1997-09-19 | 1999-03-30 | Genaco Biomedical Products, Inc. | Detection of aneuploidy and gene deletion by PCR-based gene- dose co-amplification of chromosome specific sequences with synthetic sequences with synthetic internal controls |
| AR021833A1 (es) | 1998-09-30 | 2002-08-07 | Applied Research Systems | Metodos de amplificacion y secuenciacion de acido nucleico |
| US6440706B1 (en) | 1999-08-02 | 2002-08-27 | Johns Hopkins University | Digital amplification |
| EP1290225A4 (en) | 2000-05-20 | 2004-09-15 | Univ Michigan | METHOD FOR PRODUCING A DNA BANK BY POSITIONAL REPRODUCTION |
| US7062418B2 (en) | 2000-06-27 | 2006-06-13 | Fluidigm Corporation | Computer aided design method and system for developing a microfluidic system |
| JP2004516813A (ja) | 2000-06-30 | 2004-06-10 | インサイト・ゲノミックス・インコーポレイテッド | 関連腫瘍マーカー |
| US20020142324A1 (en) * | 2000-09-22 | 2002-10-03 | Xun Wang | Fungal target genes and methods to identify those genes |
| AU2002248149A1 (en) | 2000-11-16 | 2002-08-12 | Fluidigm Corporation | Microfluidic devices for introducing and dispensing fluids from microfluidic systems |
| US6691042B2 (en) | 2001-07-02 | 2004-02-10 | Rosetta Inpharmatics Llc | Methods for generating differential profiles by combining data obtained in separate measurements |
| US7226732B2 (en) | 2001-07-16 | 2007-06-05 | Cepheid | Methods, apparatus, and computer programs for verifying the integrity of a probe |
| US6927028B2 (en) | 2001-08-31 | 2005-08-09 | Chinese University Of Hong Kong | Non-invasive methods for detecting non-host DNA in a host using epigenetic differences between the host and non-host DNA |
| US7893248B2 (en) | 2002-02-20 | 2011-02-22 | Sirna Therapeutics, Inc. | RNA interference mediated inhibition of Myc and/or Myb gene expression using short interfering nucleic acid (siNA) |
| US6977162B2 (en) * | 2002-03-01 | 2005-12-20 | Ravgen, Inc. | Rapid analysis of variations in a genome |
| IL163600A0 (en) | 2002-03-01 | 2005-12-18 | Ravgen Inc | Methods for detection of genetic disorders |
| US20030194704A1 (en) * | 2002-04-03 | 2003-10-16 | Penn Sharron Gaynor | Human genome-derived single exon nucleic acid probes useful for gene expression analysis two |
| US7727720B2 (en) | 2002-05-08 | 2010-06-01 | Ravgen, Inc. | Methods for detection of genetic disorders |
| EP2359689B1 (en) | 2002-09-27 | 2015-08-26 | The General Hospital Corporation | Microfluidic device for cell separation and use thereof |
| US10229244B2 (en) | 2002-11-11 | 2019-03-12 | Affymetrix, Inc. | Methods for identifying DNA copy number changes using hidden markov model based estimations |
| US20040224331A1 (en) | 2003-01-17 | 2004-11-11 | The Trustees Of Boston University | Haplotype analysis |
| WO2004065629A1 (en) | 2003-01-17 | 2004-08-05 | The Chinese University Of Hong Kong | Circulating mrna as diagnostic markers for pregnancy-related disorders |
| CA2513899C (en) | 2003-01-29 | 2013-03-26 | 454 Corporation | Methods of amplifying and sequencing nucleic acids |
| EP1599608A4 (en) | 2003-03-05 | 2007-07-18 | Genetic Technologies Ltd | Identification of fetal DNA and fetal cell marker in maternal plasma or serum |
| US20040209299A1 (en) | 2003-03-07 | 2004-10-21 | Rubicon Genomics, Inc. | In vitro DNA immortalization and whole genome amplification using libraries generated from randomly fragmented DNA |
| WO2005007869A2 (en) | 2003-07-10 | 2005-01-27 | Third Wave Technologies, Inc. | Assays for the direct measurement of gene dosage |
| WO2005023091A2 (en) | 2003-09-05 | 2005-03-17 | The Trustees Of Boston University | Method for non-invasive prenatal diagnosis |
| US20050221341A1 (en) * | 2003-10-22 | 2005-10-06 | Shimkets Richard A | Sequence-based karyotyping |
| WO2005072133A2 (en) * | 2004-01-27 | 2005-08-11 | Zoragen, Inc. | Nucleic acid detection |
| US20060046258A1 (en) | 2004-02-27 | 2006-03-02 | Lapidus Stanley N | Applications of single molecule sequencing |
| US20100216153A1 (en) | 2004-02-27 | 2010-08-26 | Helicos Biosciences Corporation | Methods for detecting fetal nucleic acids and diagnosing fetal abnormalities |
| US20100216151A1 (en) | 2004-02-27 | 2010-08-26 | Helicos Biosciences Corporation | Methods for detecting fetal nucleic acids and diagnosing fetal abnormalities |
| US20050282293A1 (en) | 2004-03-03 | 2005-12-22 | Cosman Maury D | System for delivering a diluted solution |
| WO2005116257A2 (en) | 2004-05-17 | 2005-12-08 | The Ohio State University Research Foundation | Unique short tandem repeats and methods of their use |
| DE102004036285A1 (de) | 2004-07-27 | 2006-02-16 | Advalytix Ag | Verfahren zum Bestimmen der Häufigkeit von Sequenzen einer Probe |
| TW200624106A (en) | 2004-09-07 | 2006-07-16 | Uni Charm Corp | Warming article |
| JP2007327743A (ja) | 2004-09-07 | 2007-12-20 | Univ Of Tokyo | 遺伝子コピーの解析方法及び装置 |
| US20060178835A1 (en) | 2005-02-10 | 2006-08-10 | Applera Corporation | Normalization methods for genotyping analysis |
| US7645576B2 (en) | 2005-03-18 | 2010-01-12 | The Chinese University Of Hong Kong | Method for the detection of chromosomal aneuploidies |
| AU2006256374A1 (en) | 2005-06-08 | 2006-12-14 | Compugen Ltd. | Novel nucleotide and amino acid sequences, and assays and methods of use thereof for diagnosis |
| US20060286558A1 (en) | 2005-06-15 | 2006-12-21 | Natalia Novoradovskaya | Normalization of samples for amplification reactions |
| US8532930B2 (en) | 2005-11-26 | 2013-09-10 | Natera, Inc. | Method for determining the number of copies of a chromosome in the genome of a target individual using genetic data from genetically related individuals |
| DE102005057988A1 (de) | 2005-08-04 | 2007-02-08 | Bosch Rexroth Ag | Axialkolbenmaschine |
| EP3591068A1 (en) | 2006-02-02 | 2020-01-08 | The Board of Trustees of the Leland Stanford Junior University | Non-invasive fetal genetic screening by digital analysis |
| US20100184043A1 (en) | 2006-02-28 | 2010-07-22 | University Of Louisville Research Foundation | Detecting Genetic Abnormalities |
| EP2351858B1 (en) * | 2006-02-28 | 2014-12-31 | University of Louisville Research Foundation | Detecting fetal chromosomal abnormalities using tandem single nucleotide polymorphisms |
| US20080064098A1 (en) * | 2006-06-05 | 2008-03-13 | Cryo-Cell International, Inc. | Procurement, isolation and cryopreservation of maternal placental cells |
| WO2007147079A2 (en) | 2006-06-14 | 2007-12-21 | Living Microsystems, Inc. | Rare cell analysis using sample splitting and dna tags |
| EP2029779A4 (en) | 2006-06-14 | 2010-01-20 | Living Microsystems Inc | HIGHLY PARALLEL SNP GENOTYPING UTILIZATION FOR FETAL DIAGNOSIS |
| WO2009035447A1 (en) | 2006-06-14 | 2009-03-19 | Living Microsystems, Inc. | Diagnosis of fetal abnormalities by comparative genomic hybridization analysis |
| US20080050739A1 (en) * | 2006-06-14 | 2008-02-28 | Roland Stoughton | Diagnosis of fetal abnormalities using polymorphisms including short tandem repeats |
| US8137912B2 (en) | 2006-06-14 | 2012-03-20 | The General Hospital Corporation | Methods for the diagnosis of fetal abnormalities |
| DK2029778T3 (en) | 2006-06-14 | 2018-08-20 | Verinata Health Inc | DIAGNOSIS OF Fetal ABNORMITIES |
| EP2589668A1 (en) | 2006-06-14 | 2013-05-08 | Verinata Health, Inc | Rare cell analysis using sample splitting and DNA tags |
| US20080113358A1 (en) | 2006-07-28 | 2008-05-15 | Ravi Kapur | Selection of cells using biomarkers |
| US9328378B2 (en) * | 2006-07-31 | 2016-05-03 | Illumina Cambridge Limited | Method of library preparation avoiding the formation of adaptor dimers |
| US8262900B2 (en) | 2006-12-14 | 2012-09-11 | Life Technologies Corporation | Methods and apparatus for measuring analytes using large scale FET arrays |
| AU2008213634B2 (en) | 2007-02-08 | 2013-09-05 | Sequenom, Inc. | Nucleic acid-based tests for RhD typing, gender determination and nucleic acid quantification |
| PL2557520T3 (pl) | 2007-07-23 | 2021-10-11 | The Chinese University Of Hong Kong | Określanie zaburzenia równowagi sekwencji kwasu nukleinowego |
| US12180549B2 (en) * | 2007-07-23 | 2024-12-31 | The Chinese University Of Hong Kong | Diagnosing fetal chromosomal aneuploidy using genomic sequencing |
| CN101889074A (zh) | 2007-10-04 | 2010-11-17 | 哈尔西恩莫尔丘勒公司 | 采用电子显微镜对核酸聚合物测序 |
| KR101810799B1 (ko) * | 2008-02-01 | 2017-12-19 | 더 제너럴 하스피탈 코포레이션 | 의학적 질환 및 병태의 진단, 예후, 및 치료에 있어서 미세소포체의 용도 |
| EP2271772B1 (en) | 2008-03-11 | 2014-07-16 | Sequenom, Inc. | Nucleic acid-based tests for prenatal gender determination |
| US20090307180A1 (en) | 2008-03-19 | 2009-12-10 | Brandon Colby | Genetic analysis |
| WO2009120808A2 (en) | 2008-03-26 | 2009-10-01 | Sequenom, Inc. | Restriction endonuclease enhanced polymorphic sequence detection |
| US20090270601A1 (en) * | 2008-04-21 | 2009-10-29 | Steven Albert Benner | Differential detection of single nucleotide polymorphisms |
| EP2853601B1 (en) * | 2008-07-18 | 2016-09-21 | TrovaGene, Inc. | Methods for PCR-based detection of "ultra short" nucleic acid sequences |
| CA3069082C (en) | 2008-09-20 | 2022-03-22 | The Board Of Trustees Of The Leland Stanford Junior University | Noninvasive diagnosis of fetal aneuploidy by sequencing |
| US20100285537A1 (en) | 2009-04-02 | 2010-11-11 | Fluidigm Corporation | Selective tagging of short nucleic acid fragments and selective protection of target sequences from degradation |
| WO2011056094A2 (ru) * | 2009-10-26 | 2011-05-12 | Общество С Ограниченной Ответственностью "Апoгeй" | Пожарный вентиль |
| AU2010311535B2 (en) * | 2009-10-26 | 2015-05-21 | Lifecodexx Ag | Means and methods for non-invasive diagnosis of chromosomal aneuploidy |
| EP3783110B1 (en) | 2009-11-05 | 2022-11-23 | The Chinese University Of Hong Kong | Fetal genomic analysis from a maternal biological sample |
| CN102597272A (zh) | 2009-11-12 | 2012-07-18 | 艾索特里克斯遗传实验室有限责任公司 | 基因座的拷贝数分析 |
| US9260745B2 (en) | 2010-01-19 | 2016-02-16 | Verinata Health, Inc. | Detecting and classifying copy number variation |
| US20120100548A1 (en) | 2010-10-26 | 2012-04-26 | Verinata Health, Inc. | Method for determining copy number variations |
| EP2513341B1 (en) | 2010-01-19 | 2017-04-12 | Verinata Health, Inc | Identification of polymorphic sequences in mixtures of genomic dna by whole genome sequencing |
| US20120270739A1 (en) | 2010-01-19 | 2012-10-25 | Verinata Health, Inc. | Method for sample analysis of aneuploidies in maternal samples |
| WO2011091063A1 (en) | 2010-01-19 | 2011-07-28 | Verinata Health, Inc. | Partition defined detection methods |
| US9323888B2 (en) | 2010-01-19 | 2016-04-26 | Verinata Health, Inc. | Detecting and classifying copy number variation |
| US20120010085A1 (en) | 2010-01-19 | 2012-01-12 | Rava Richard P | Methods for determining fraction of fetal nucleic acids in maternal samples |
| US20120237928A1 (en) | 2010-10-26 | 2012-09-20 | Verinata Health, Inc. | Method for determining copy number variations |
| US10388403B2 (en) | 2010-01-19 | 2019-08-20 | Verinata Health, Inc. | Analyzing copy number variation in the detection of cancer |
| EP2370599B1 (en) * | 2010-01-19 | 2015-01-21 | Verinata Health, Inc | Method for determining copy number variations |
| US20110312503A1 (en) | 2010-01-23 | 2011-12-22 | Artemis Health, Inc. | Methods of fetal abnormality detection |
| DK2539450T3 (da) | 2010-02-25 | 2016-05-30 | Advanced Liquid Logic Inc | Fremgangsmåde til fremstilling af nukleinsyrebiblioteker |
| WO2012012037A1 (en) * | 2010-07-19 | 2012-01-26 | New England Biolabs, Inc. | Oligonucleotide adaptors: compositions and methods of use |
| US20120034603A1 (en) | 2010-08-06 | 2012-02-09 | Tandem Diagnostics, Inc. | Ligation-based detection of genetic variants |
| CN102409043B (zh) | 2010-09-21 | 2013-12-04 | 深圳华大基因科技服务有限公司 | 高通量低成本Fosmid文库构建的方法及其所使用标签和标签接头 |
| CN105243295B (zh) | 2010-11-30 | 2018-08-17 | 香港中文大学 | 与癌症相关的遗传或分子畸变的检测 |
| CN103620055A (zh) | 2010-12-07 | 2014-03-05 | 利兰·斯坦福青年大学托管委员会 | 在全基因组规模非侵入性确定亲本单倍型的胎儿遗传 |
| CN102127818A (zh) | 2010-12-15 | 2011-07-20 | 张康 | 利用孕妇外周血建立胎儿dna文库的方法 |
| WO2012088348A2 (en) | 2010-12-23 | 2012-06-28 | Sequenom, Inc. | Fetal genetic variation detection |
| US20120190020A1 (en) | 2011-01-25 | 2012-07-26 | Aria Diagnostics, Inc. | Detection of genetic abnormalities |
| RU2671980C2 (ru) | 2011-02-09 | 2018-11-08 | Натера, Инк. | Способы неинвазивного пренатального установления плоидности |
| RS57837B1 (sr) | 2011-04-12 | 2018-12-31 | Verinata Health Inc | Razrešavanje genomskih frakcija upotrebom broja kopija polimorfizama |
| GB2484764B (en) | 2011-04-14 | 2012-09-05 | Verinata Health Inc | Normalizing chromosomes for the determination and verification of common and rare chromosomal aneuploidies |
| US9411937B2 (en) | 2011-04-15 | 2016-08-09 | Verinata Health, Inc. | Detecting and classifying copy number variation |
| WO2014014498A1 (en) | 2012-07-20 | 2014-01-23 | Verinata Health, Inc. | Detecting and classifying copy number variation in a fetal genome |
| AU2011373694A1 (en) | 2011-07-26 | 2013-05-02 | Verinata Health, Inc. | Method for determining the presence or absence of different aneuploidies in a sample |
| WO2014081243A1 (en) | 2012-11-23 | 2014-05-30 | Seoul Viosys Co., Ltd. | Light emitting diode having a plurality of light emitting units |
| US10114015B2 (en) | 2013-03-13 | 2018-10-30 | Meso Scale Technologies, Llc. | Assay methods |
-
2010
- 2010-12-01 EP EP10825822.9A patent/EP2370599B1/en not_active Not-in-force
- 2010-12-01 AU AU2010343278A patent/AU2010343278B2/en not_active Ceased
- 2010-12-01 AU AU2010343276A patent/AU2010343276B2/en active Active
- 2010-12-01 EP EP10830938.6A patent/EP2366031B1/en active Active
- 2010-12-01 EP EP10830939.4A patent/EP2376661B1/en active Active
- 2010-12-01 PL PL17180803T patent/PL3260555T3/pl unknown
- 2010-12-01 US US12/958,353 patent/US9657342B2/en active Active
- 2010-12-01 GB GB1108794.7A patent/GB2479080B/en active Active
- 2010-12-01 DK DK18160303.6T patent/DK3382037T3/da active
- 2010-12-01 EP EP17180803.3A patent/EP3260555B1/en not_active Revoked
- 2010-12-01 WO PCT/US2010/058614 patent/WO2011090559A1/en not_active Ceased
- 2010-12-01 DK DK10844163.5T patent/DK2513339T3/en active
- 2010-12-01 CA CA2786357A patent/CA2786357C/en active Active
- 2010-12-01 EP EP15181244.3A patent/EP3006573B1/en active Active
- 2010-12-01 EP EP14192160.1A patent/EP2848703A1/en not_active Withdrawn
- 2010-12-01 GB GB1118398.5A patent/GB2485645B/en not_active Expired - Fee Related
- 2010-12-01 ES ES18160303T patent/ES2870533T3/es active Active
- 2010-12-01 EP EP14192156.9A patent/EP2883965B8/en not_active Not-in-force
- 2010-12-01 EP EP24186817.3A patent/EP4450645A3/en active Pending
- 2010-12-01 EP EP21157398.5A patent/EP3878973B1/en active Active
- 2010-12-01 AU AU2010343277A patent/AU2010343277B2/en not_active Ceased
- 2010-12-01 ES ES10830939.4T patent/ES2534986T3/es active Active
- 2010-12-01 PL PL10830939T patent/PL2376661T3/pl unknown
- 2010-12-01 ES ES10844163.5T patent/ES2560929T3/es active Active
- 2010-12-01 PL PL18201917T patent/PL3492601T3/pl unknown
- 2010-12-01 WO PCT/US2010/058612 patent/WO2011090558A1/en not_active Ceased
- 2010-12-01 GB GB1118396.9A patent/GB2485644B/en not_active Expired - Fee Related
- 2010-12-01 US US12/958,356 patent/US20110224087A1/en not_active Abandoned
- 2010-12-01 GB GB1107268.3A patent/GB2479471B/en not_active Expired - Fee Related
- 2010-12-01 DK DK17180803.3T patent/DK3260555T3/en active
- 2010-12-01 EP EP18201917.4A patent/EP3492601B1/en not_active Revoked
- 2010-12-01 EP EP21213836.6A patent/EP4074838A1/en active Pending
- 2010-12-01 ES ES17180803T patent/ES2704701T3/es active Active
- 2010-12-01 CA CA2785718A patent/CA2785718C/en active Active
- 2010-12-01 TR TR2018/07917T patent/TR201807917T4/tr unknown
- 2010-12-01 PL PL10830938T patent/PL2366031T3/pl unknown
- 2010-12-01 GB GB1108795.4A patent/GB2479476B/en not_active Expired - Fee Related
- 2010-12-01 AU AU2010343279A patent/AU2010343279B2/en active Active
- 2010-12-01 WO PCT/US2010/058609 patent/WO2011090557A1/en not_active Ceased
- 2010-12-01 ES ES18201917T patent/ES2909841T3/es active Active
- 2010-12-01 EP EP18160303.6A patent/EP3382037B1/en active Active
- 2010-12-01 EP EP10844163.5A patent/EP2513339B1/en active Active
- 2010-12-01 DK DK10830939.4T patent/DK2376661T3/en active
- 2010-12-01 DK DK18201917.4T patent/DK3492601T3/da active
- 2010-12-01 US US12/958,352 patent/US20110245085A1/en not_active Abandoned
- 2010-12-01 CA CA2786544A patent/CA2786544C/en active Active
- 2010-12-01 ES ES10830938.6T patent/ES2534758T3/es active Active
- 2010-12-01 EP EP14192165.0A patent/EP2848704B1/en active Active
- 2010-12-01 DK DK10830938.6T patent/DK2366031T3/en active
- 2010-12-01 CA CA2786351A patent/CA2786351C/en active Active
-
2011
- 2011-12-21 US US13/333,832 patent/US20120094849A1/en not_active Abandoned
-
2012
- 2012-02-02 US US13/365,240 patent/US20120165203A1/en not_active Abandoned
-
2017
- 2017-05-22 US US15/601,951 patent/US10941442B2/en active Active
- 2017-07-31 US US15/664,008 patent/US11130995B2/en not_active Expired - Fee Related
- 2017-07-31 US US15/664,043 patent/US11286520B2/en active Active
-
2021
- 2021-03-05 US US17/193,279 patent/US11884975B2/en active Active
- 2021-05-17 CY CY20211100424T patent/CY1124494T1/el unknown
- 2021-09-02 US US17/465,163 patent/US11952623B2/en active Active
- 2021-12-17 US US17/554,195 patent/US12553084B2/en active Active
-
2023
- 2023-12-11 US US18/534,929 patent/US12522869B2/en active Active
-
2025
- 2025-12-10 US US19/414,578 patent/US20260098295A1/en active Pending
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12522869B2 (en) | Sequencing methods and compositions for prenatal diagnoses | |
| US20120270739A1 (en) | Method for sample analysis of aneuploidies in maternal samples | |
| AU2022283736A1 (en) | Sequencing methods and compositions for prenatal diagnoses | |
| HK40073897A (en) | Novel protocol for preparing sequencing libraries | |
| HK1248282A1 (en) | Novel protocol for preparing sequencing libraries | |
| HK40008115A (en) | Novel protocol for preparing sequencing libraries | |
| HK40008115B (en) | Novel protocol for preparing sequencing libraries | |
| HK1248282B (en) | Novel protocol for preparing sequencing libraries |