ES2944938T3 - Dispositivo de simulación, método de simulación y soporte de memoria - Google Patents
Dispositivo de simulación, método de simulación y soporte de memoria Download PDFInfo
- Publication number
- ES2944938T3 ES2944938T3 ES15835871T ES15835871T ES2944938T3 ES 2944938 T3 ES2944938 T3 ES 2944938T3 ES 15835871 T ES15835871 T ES 15835871T ES 15835871 T ES15835871 T ES 15835871T ES 2944938 T3 ES2944938 T3 ES 2944938T3
- Authority
- ES
- Spain
- Prior art keywords
- posterior distribution
- observation
- observation data
- posterior
- distribution
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F30/00—Computer-aided design [CAD]
- G06F30/20—Design optimisation, verification or simulation
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01W—METEOROLOGY
- G01W1/00—Meteorology
- G01W1/10—Devices for predicting weather conditions
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/16—Matrix or vector computation, e.g. matrix-matrix or matrix-vector multiplication, matrix factorization
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/17—Function evaluation by approximation methods, e.g. inter- or extrapolation, smoothing, least mean square method
- G06F17/175—Function evaluation by approximation methods, e.g. inter- or extrapolation, smoothing, least mean square method of multidimensional data
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/18—Complex mathematical operations for evaluating statistical data, e.g. average values, frequency distributions, probability functions, regression analysis
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Theoretical Computer Science (AREA)
- Mathematical Physics (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Databases & Information Systems (AREA)
- Algebra (AREA)
- Software Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- Environmental & Geological Engineering (AREA)
- Probability & Statistics with Applications (AREA)
- Evolutionary Biology (AREA)
- Operations Research (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Biodiversity & Conservation Biology (AREA)
- Computing Systems (AREA)
- Atmospheric Sciences (AREA)
- Ecology (AREA)
- Environmental Sciences (AREA)
- Evolutionary Computation (AREA)
- Geometry (AREA)
- Computer Hardware Design (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Debugging And Monitoring (AREA)
Abstract
La presente invención realiza una simulación de alta resolución y alta precisión en un amplio rango considerando datos de observación que no son ideales, discontinuos o peculiares. Un dispositivo de simulación 100 incluye un modelo de sistema 21, una unidad de procesamiento de selección de datos 30, una pluralidad de modelos de observación 31, una unidad de creación de posdistribución 40, una unidad de unificación de posdistribución 50 y una unidad de determinación 51. El modelo de sistema 21 calcula una evolución temporal de un vector de estado. La unidad de procesamiento de selección de datos 30 selecciona múltiples elementos de datos de observación. El modelo de observación 31 convierte el vector de estado del modelo de sistema 21 sobre la base de la relación con los datos de observación. La unidad de creación de distribución posterior 40 crea, sobre la base del vector de estado del modelo de observación 31 y los datos de observación seleccionados, una primera distribución posterior basada en todas las partes de los datos de observación o una segunda distribución posterior basada en datos de observación ausentes. La unidad unificadora de posdistribución 50 unifica la primera y la segunda posdistribuciones. La unidad de determinación 51 determina cuál de la segunda distribución posterior o la distribución posterior unificada se va a utilizar. (Traducción automática con Google Translate, sin valor legal)
Description
DESCRIPCIÓN
Dispositivo de simulación, método de simulación y soporte de memoria
Campo técnico
La presente invención se refiere a una tecnología de simulación de modelado matemático y cálculo numérico en un ordenador de un fenómeno que tiene lugar en el mundo real y en una situación hipotética.
Técnica anterior
La simulación modela matemáticamente y calcula numéricamente en un ordenador un fenómeno que tiene lugar en el mundo real y una situación hipotética. El modelado matemático permite realizar el cálculo con el tiempo y el espacio establecidos según se desee. Dicha simulación permite una situación en la que es difícil obtener resultados reales (por ejemplo, una situación en un lugar donde es difícil realizar una observación) y predecir un evento que puede ocurrir en el futuro. La variación de las condiciones para el cálculo permite intencionadamente que se estudien las características y el comportamiento en una situación que es difícil de observar realmente. Dicho resultado de simulación puede utilizarse como indicador en la clarificación teórica de una relación de causa y efecto, diseño, planificación o similar.
En particular, la simulación es eficaz en el caso en el que se desea captar y comprender un estado continuamente en un amplio intervalo en una situación en la que los datos de observación realmente obtenidos tienen un pequeño número de piezas de datos y una distribución sesgada no solo espacial sino también temporalmente. Sin embargo, la simulación es solo imitar una realidad matemáticamente, y la precisión de la misma depende, por lo tanto, de cómo de profundamente se entienda la realidad y de cómo se la imite fielmente. Por lo tanto, en el caso de enfocarse en un fenómeno cuyos datos de observación reales son de poca cantidad, como se describió anteriormente, y que se haya comprendido de manera incompleta, un modelo llega a incluir el carácter incompleto. Además, dado que el cálculo se realiza de forma discreta, se requieren el fraccionamiento de un dominio objetivo y una gran cantidad de cálculos para captarlo continuamente sobre un amplio intervalo. En la práctica, sin embargo, no hay otra opción que establecer una condición de cálculo que incluya el carácter incompleto de acuerdo con el tiempo de cálculo y los recursos de cálculo permisibles. Tal carácter incompleto reduce la precisión de la simulación.
Así, como un esquema para mejorar la precisión de la simulación bajo la condición de estar incompleto, se conoce la asimilación de datos. La asimilación de datos es un método de incorporar datos de observación obtenidos a partir de la realidad en una simulación numérica. Incluso realizar una simulación basada en el mismo modelo matemático produce varios resultados dependiendo del carácter incompleto interno descrito anteriormente, una condición inicial dada, una condición límite y similares. La asimilación de datos busca un resultado que explique mejor los datos de observación obtenidos en la realidad a partir de los diversos resultados de simulación y, al mismo tiempo, actualiza el modelo y las condiciones.
La asimilación de datos, que se utiliza a menudo en ciencias de la tierra y oceanografía, no solo se ha desarrollado especialmente en meteorología y ha ido contribuyendo a mejorar la precisión de las predicciones meteorológicas diarias, sino que también se han propuesto nuevos métodos de la misma sucesivamente. Esto se debe en parte a que las mejoras en las tecnologías de observación relacionadas con el clima han hecho que los datos de observación obtenibles resulten diversos y la cantidad de datos ha aumentado no solo espacial sino también temporalmente.
En el pronóstico meteorológico, mejorar la precisión espacial y temporal de la simulación para predecir con precisión una nube de tormenta y lluvia que se desarrolla rápidamente también es un problema. Como tecnología relacionada para hacer frente a tal problema, se conoce un dispositivo de predicción meteorológica descrito en PTL 1. El dispositivo de predicción meteorológica utiliza datos de agua de precipitación recopilados por receptores GPS, que se colocan en muchos lugares y que permiten la observación frecuente, datos de dirección y velocidad del viento recopilados por radares Doppler, y datos de intensidad de lluvia recopilados por Radar-AMeDAS. El dispositivo de predicción meteorológica toma los datos descritos anteriormente medidos en tiempo real o en tiempo casi real y realiza la asimilación de datos utilizando el método variacional tridimensional. Como otra tecnología relacionada para hacer frente al problema descrito anteriormente, se conoce un dispositivo de sincronización y un dispositivo de mallado descrito en PTL 2. Cuando los fragmentos de datos de una pluralidad de dispositivos de observación son asíncronos, el dispositivo de sincronización reorganiza los fragmentos de datos de observación en el eje del tiempo por medio del procesamiento de interpolación para sincronizar los fragmentos de datos de observación de manera que los fragmentos de datos de observación indiquen fragmentos de datos de observación del mismo tiempo. El dispositivo de mallado reorganiza, en un dominio objetivo, fragmentos de datos de observación sincronizados recopilados en una pluralidad de lugares para que los fragmentos de datos de observación sean posicionados en puntos de la malla (puntos de la cuadrícula) con un intervalo de distancia fijo en un espacio horizontal.
Después de un desastre natural, un accidente artificial y similar, causado por un cambio repentino en el clima o en un entorno marino, se requiere captar con precisión el estado del suelo en un amplio ámbito. Para lograr el requisito, observar y estimar un estado del suelo mediante el uso de medios de observación de amplio alcance y con alta precisión resulta un problema. Como tecnología relacionada para hacer frente a tal problema, se conoce un método descrito en PTL 3. Aunque no es un método que utilice simulación, el método, utilizando imágenes satelitales recopiladas en tres o más instantes, estima cantidades de características que representan los estados
correspondientes del suelo. Para más detalles, cuando no hay suficiente tiempo y coste para llevar a cabo la observación y la investigación en el campo o es peligroso acercarse al campo, el método utiliza datos de imagen recopilados por un radar de apertura sintética (SAR) o similar montado en un dispositivo de satélite artificial. El método, que utiliza imágenes satelitales SAR, permite conocer el estado del suelo rápidamente, sobre una amplia escala y de manera segura. Como ejemplo específico, un ejemplo en el que la salinidad del suelo y la capacidad de drenaje en una zona costera después de la ocurrencia de un tsunami se estiman sobre la base de los cambios en los valores de índice del contenido de humedad del suelo registrados en imágenes satelitales recopiladas en tres momentos: antes de la ocurrencia del tsunami; inmediatamente después; y varios meses después se describe en PTL 3.
Un ejemplo de un método, mediante el uso de imágenes satelitales SAR y un modelo de predicción del rendimiento de un cultivo, realizando la predicción del rendimiento de los arrozales en áreas amplias en la primera mitad de un período de crecimiento con poca mano de obra y con alta precisión está descrito en PTL 4. En general, un sensor óptico montado en un satélite que observa la intensidad de la luz reflejada de la luz solar en las regiones visible e infrarroja cercana está sustancialmente influenciado por el clima, como en el caso en que, cuando hay una nube, no se puede realizar la observación. Por lo tanto, en el método, se utilizan datos de imágenes SAR recopilados utilizando microondas (banda X: longitud de onda de 3,1 cm), que no se ven influenciadas por una nube. En el método, se calcula una expresión de predicción de rendimiento, mediante análisis de regresión, basada en una correlación entre los datos de imágenes SAR obtenidos y una cantidad que representa el estado de crecimiento de un cultivo, tal como la altura de la planta y el número de tallos, para realizar una predicción de cosecha.
Aunque es diferente de la simulación del mundo real, hay un caso en el que se utiliza un modelo matemático para el análisis de los datos de observación. Por ejemplo, en un uso para determinar si un objeto existe o no en un área predeterminada usando un radar de ondas milimétricas o similar, era difícil una determinación precisa basada únicamente en datos de observación. Esto se debe a que, en particular, cuando un objeto es un caminante, la intensidad de la reflexión del radar es sustancialmente pequeña (una relación SN, es decir, una relación señal a ruido, es pequeña) y, debido a varios cambios posturales del caminante, la intensidad de la reflexión cambia de un momento a otro. Como tecnología relacionada para hacer frente a tal problema, se conoce un método descrito en PTL 5. En el método, a partir de una distribución de la intensidad de la reflexión con respecto a las posiciones de detección de un objeto, se crean de antemano modelos de cantidad de características de una señal de caminante y una señal de ruido. Al comparar los datos de observación reales con los modelos, en el método, los estados que incluyen "existente", "inexistente" y "poco claro" se estiman probabilísticamente en función de los datos de observación no ideales. Además, en PTL 5, también se describe un método para, con respecto a los estados de "existencia", "inexistencia" y "poco claro", unificar probabilidades de una pluralidad de estados obtenidos a partir de una pluralidad de sensores.
Lista de citas
Bibliografía de patentes
[PTL 1] Publicación de Solicitud de Patente de Japón Sin Examinar (“Japanese Unexamined Patent Application Publication”) No. 2010-60443
[PTL 2] Publicación de Solicitud de Patente de Japón Sin Examinar (“Japanese Unexamined Patent Application Publication”) No. 2010-60444
[PTL 3] Publicación de Solicitud de Patente de Japón Sin Examinar (“Japanese Unexamined Patent Application Publication”) No. 2013-84072
[PTl 4] Solicitud de Patente Internacional PCT (“PCT International Patent Application”) No. WO2011/102520 [PTL 5] Publicación de Solicitud de Patente de Japón Sin Examinar (“Japanese Unexamined Patent Application Publication”) No. 2007-93461
Compendio de la Invención
Problema técnico
En cada una de las tecnologías relacionadas descritas anteriormente, aumentar los tipos y el número de fragmentos de datos de observación que se han de obtener es el punto de partida de los medios para resolver los problemas de mejorar la precisión de la simulación que tiene carácter de incompleta y estimar un estado basado en datos de observación no ideales. Sin embargo, dado que los datos de observación que se han de aumentar no siempre son ideales, es indispensable un método de procesamiento que tenga en consideración los datos de observación no ideales. Por ejemplo, en PTL 1, se describe un dispositivo de eliminación de valores anormales que elimina valores anormales después de haber obtenido datos de observación. El dispositivo de eliminación de valores anormales determina, como valores anormales, datos de observación que tienen una diferencia no menor que un valor predeterminado a partir de valores calculados basados en un modelo meteorológico en un tiempo idéntico. Sin embargo, en dicha determinación de valor anómalo basada en una única pieza de información que es local y un valor calculado basado en un modelo, los estados y entornos que cambian rápidamente o los fenómenos que tienen peculiaridades no pueden tenerse en consideración. La tecnología relacionada descrita en PTL 5 es capaz de estimar varios estados, incluida la posibilidad de una peculiaridad y similares, sobre la base de una mayor variedad de información debido a la realización de la unificación probabilística después de comparar los datos de observación con los modelos. Sin embargo, la tecnología relacionada utiliza principalmente un promedio ponderado general como método de unificación de probabilidades y tiene el problema de que solo los datos de observación del mismo tipo y con
el mismo número de dimensiones están sujetos a unificación. La técnica relacionada también tiene el problema de que no se tiene en consideración ningún esquema que permita la determinación o revisión de los resultados de la unificación.
Como una medida para aumentar la precisión de la simulación que tiene carácter de incompleta y realizar una estimación de estado basada en datos de observación no ideales, es concebible procesar los datos de observación obtenidos por adelantado además de aumentar los tipos y el número de fragmentos de datos de observación que se han de recopilar. Aunque el dispositivo de sincronización y el dispositivo de mallado descritos en PTL 2 realizan una interpolación temporal y espacial estadísticamente basada solo en datos de observación obtenidos, obtener datos de observación que sean continuos y que tengan una alta correlación es un requisito previo. PTL 3 incluye una descripción de un método para estimar el estado del suelo mediante la unificación de imágenes satelitales recopiladas en tres momentos diferentes. Sin embargo, PTL 3 no se refiere a ninguna medida contra un caso en el que los datos satelitales no se hayan obtenido en un momento óptimo y un caso en el que los datos muestren un valor peculiar influenciado por el agua que permanece sobre la superficie del suelo y similares. Como se describió anteriormente, las tecnologías relacionadas descritas en PTL 2 y 3 no tienen en consideración los datos de observación que tienen discontinuidad y peculiaridad. La tecnología relacionada descrita en PTL 4 utiliza datos de sensores de microondas dando prioridad a la certeza de la obtención de datos en lugar de datos de sensores ópticos caracterizados por la inestabilidad del intervalo de tiempo para la recopilación de datos de observación ideales debido a la influencia del clima. Dado que la tecnología relacionada crea un modelo de predicción de rendimiento repetidamente (inductivamente) basado en los datos obtenidos de esa manera, existe la preocupación de que la tecnología relacionada pueda crear un modelo inapropiado en el caso de que los datos tengan una discontinuidad o peculiaridad.
A continuación, se describirá con referencia al dibujo un problema de simulación que utiliza la asimilación típica de datos, descrito en PTL 1 y 2. En la Figura 15, se presenta un diagrama esquemático que ilustra la simulación utilizando la asimilación típica de datos. En la Figura 15, el eje horizontal y el eje vertical representan los valores de tiempo y observación, respectivamente. Los valores de observación son valores medidos realmente por sensores y similares. Una variable de estado es una variable para calcular las evoluciones temporales de la misma en un modelo de simulación. Los valores de observación no siempre son valores verdaderos de una cantidad objetivo debido a la influencia de la frecuencia de observación, la precisión del sensor y similares. Así, en la Figura 15, los valores verdaderos desconocidos se ilustran virtualmente con una línea discontinua. Dado que los valores de observación están relacionados con una variable de estado mediante un modelo de observación, el cálculo de una variación temporal de la variable de estado permite realizar la simulación de los valores de observación. Sin embargo, como se describió anteriormente, en el caso de que exista un carácter de incompleto en el modelo o una incertidumbre en una condición límite, o que dependa de una condición inicial dada, es difícil que la simulación reproduzca los valores reales. Por lo tanto, en la asimilación de datos, se añade intencionadamente una perturbación para realizar una simulación estocástica y, a partir de varios resultados de simulación obtenidos, se busca un resultado que explique mejor los datos de observación obtenidos de la realidad. En la Figura 15, este proceso se ilustra esquemáticamente mediante líneas continuas que expresan una pluralidad de valores calculados (simulaciones). Cada simulación se continúa usando, como valor inicial de la siguiente etapa, un valor que se revisa en base a un valor de observación. Como es obvio en la Figura 15, si el tiempo hasta obtener un valor de observación siguiente es largo, los valores de simulación durante el período no se pueden revisar, lo que hace que los errores procedentes de los valores verdaderos se sumen y crezcan. En el caso de que los valores de observación obtenidos sean inapropiados o incluyan muchos errores, dado que un valor revisado en base a los datos se utilizará como valor inicial de la siguiente etapa, los valores de simulación durante un período hasta que se obtiene un próximo valor fiable llegan a tener grandes errores.
La presente invención se realiza teniendo en consideración los problemas descritos anteriormente. Es decir, un objeto de la presente invención es proporcionar una tecnología para realizar una simulación de alta resolución y alta precisión en una amplia escala teniendo en consideración datos de observación no ideales y datos de observación que tienen una discontinuidad o peculiaridad.
Solución al problema
La invención está definida por las reivindicaciones adjuntas.
Efectos ventajosos de la Invención
La presente invención proporciona una tecnología para realizar una simulación de alta resolución y alta precisión en una amplia escala teniendo en consideración datos de observación no ideales y datos de observación que tienen una discontinuidad o peculiaridad.
Breve descripción de los dibujos
[Figura 1] La Figura 1 es un diagrama de bloques que ilustra una configuración de un dispositivo de simulación como una primera realización ejemplar de la presente invención;
[Figura 2] La Figura 2 es un diagrama de bloques que ilustra un ejemplo de una configuración de hardware del dispositivo de simulación como la primera realización ejemplar de la presente invención;
[Figura 3] La Figura 3 es un diagrama que ilustra esquemáticamente una relación entre un vector de estado y conjuntos de datos de observación en el dispositivo de simulación como la primera realización ejemplar de la presente invención;
[Figura 4] La Figura 4 es un diagrama de flujo que explica una operación al comienzo de una simulación del dispositivo de simulación como la primera realización ejemplar de la presente invención;
[Figura 5] La Figura 5 es un diagrama de flujo que explica una operación de simulación del dispositivo de simulación como el primera realización ejemplar de la presente invención;
[Figura 6] La Figura 6 es un diagrama que explica esquemáticamente un efecto ventajoso de la primera realización ejemplar de la presente invención;
[Figura 7] La Figura 7 es un diagrama de bloques que ilustra una configuración de un dispositivo de simulación como una segunda realización ejemplar de la presente invención;
[Figura 8] La Figura 8 es un diagrama que ilustra esquemáticamente una relación entre las variaciones de series temporales de conjuntos de datos de observación y un espacio de cuadrícula de cálculo en la segunda realización ejemplar de la presente invención;
[Figura 9] La Figura 9 es un diagrama que ilustra un ejemplo de un resultado de estimación de variograma en la unificación de distribución posterior realizada por el dispositivo de simulación como el segunda realización ejemplar de la presente invención;
[Figura 10] La Figura 10 es un diagrama de flujo que describe una operación de unificación de distribución posterior realizada por el dispositivo de simulación como la segunda realización ejemplar de la presente invención;
[Figura 11] La Figura 11 es un diagrama de bloques que ilustra una configuración de un dispositivo de simulación como una tercera realización ejemplar de la presente invención;
[Figura 12] La Figura 12 es un diagrama que ilustra esquemáticamente una relación entre las variaciones de series temporales de conjuntos de datos de observación y un espacio de cuadrícula de cálculo en la tercera realización ejemplar de la presente invención;
[Figura 13] La Figura 13 es un diagrama de bloques que ilustra una configuración de un dispositivo de simulación como una cuarta realización ejemplar de la presente invención;
[Figura 14] La Figura 14 es un diagrama que ilustra esquemáticamente una relación entre conjuntos de datos de observación y un espacio de cuadrícula de cálculo en la cuarta realización ejemplar de la presente invención; y [Figura 15] La Figura 15 es un diagrama que ilustra esquemáticamente la simulación utilizando la asimilación de datos de una técnica relacionada.
Descripción de realizaciones
A continuación, se describirán realizaciones ejemplares de la presente invención con referencia a los dibujos.
(Primera Realización Ejemplar)
Se describirá un dispositivo 100 de simulación como una primera realización ejemplar de la presente invención. El dispositivo 100 de simulación es aplicable a la simulación que resuelve una ecuación diferencial parcial continua en el espacio-tiempo, formulada de acuerdo con las leyes físicas y sigue una evolución en el tiempo. Estas ecuaciones diferenciales parciales incluyen, por ejemplo, una ecuación de movimiento que describe el movimiento, ecuaciones de Navier-Stokes que describen fluidos, una ecuación termodinámica que describe cambios térmicos y una ecuación de ondas en aguas poco profundas que describe tsunamis. El dispositivo 100 de simulación también es aplicable a la simulación utilizando un método de elementos finitos. En la presente realización ejemplar, se supone que un sistema sujeto a simulación es un sistema en el que un vector de estado cuyo cambio temporal se sigue se vincula con datos de observación reales mediante cualquier expresión relacional, es decir, un sistema que permite comparación entre los resultados de la simulación y los datos de observación.
En primer lugar, en la Figura 1 se ilustra una configuración del dispositivo 100 de simulación. En la Figura 1, el dispositivo 100 de simulación incluye un modelo 21 de sistema, una unidad 30 de procesamiento de selección de datos, m modelos 31 de observación (un primer modelo 31-1 de observación a un m-ésimo modelo 31-m de observación), una unidad 40 de creación de distribución posterior, una unidad unificadora 50 de distribución posterior y una unidad 51 de determinación. El dispositivo 100 de simulación también incluye una unidad 10 de entrada y una unidad 60 de salida. En la descripción anterior, m es un número entero no menor que 2 y no mayor que M, donde M es un número entero no menor que 2. En la Figura 1, el dispositivo 100 de simulación también incluye una unidad 22 de almacenamiento de distribución anterior, una primera unidad 41a de almacenamiento de distribución posterior, una segunda unidad 41b de almacenamiento de distribución posterior, y una unidad 52 de almacenamiento de distribución posterior unificada, como áreas de almacenamiento que almacenan datos que son introducidos y sacados de entre los bloques funcionales. La unidad 22 de almacenamiento de distribución anterior se incluye en una realización ejemplar de una parte de un modelo de sistema de la presente invención. Además, la primera unidad 41a de almacenamiento de distribución posterior y la segunda unidad 41b de almacenamiento de distribución posterior están incluidas en una realización ejemplar de una parte de una unidad de creación de distribución posterior de la presente invención. Además, la unidad 52 de almacenamiento de distribución posterior unificada está incluida en una realización ejemplar de una parte de una unidad unificadora de distribución posterior de la presente invención.
Un ejemplo de una configuración de hardware del dispositivo 100 de simulación se ilustra en la Figura 2. En la Figura 2, el dispositivo 100 de simulación es configurado utilizando una CPU (Unidad Central de Procesamiento) 1001, una RAM (Memoria de Acceso Aleatorio) 1002, una ROM (Memoria de Solo Lectura) 1003, un dispositivo 1004 de almacenamiento, tal como un disco duro, un dispositivo 1005 de entrada y un dispositivo 1006 de salida. En este caso, la unidad 10 de entrada es configurada utilizando el dispositivo 1005 de entrada y la CPU 1001 que carga y ejecuta, en
la RAM 1002, un programa informático almacenado en la ROM 1003 o el dispositivo 1004 de almacenamiento. El modelo 21 de sistema, la unidad 30 de procesamiento de selección de datos, los modelos 31 de observación, la unidad 40 de creación de distribución posterior, la unidad unificadora 50 de distribución posterior y la unidad 51 de determinación están configuradas como sigue. Es decir, estos bloques funcionales están configurados utilizando la CPU 1001 que carga y ejecuta, en la RAM 1002, un programa informático almacenado en la ROM 1003 o el dispositivo 1004 de almacenamiento. La unidad 60 de salida es configurada utilizando el dispositivo 1006 de salida y la CPU 1001 que carga y ejecuta, en la RAM 1002, un programa informático almacenado en la ROM 1003 o el dispositivo 1004 de almacenamiento. Sin embargo, las configuraciones de hardware del dispositivo 100 de simulación y los respectivos bloques funcionales del mismo no se limitan a las configuraciones descritas anteriormente.
A continuación, se describirán los detalles de cada uno de los bloques funcionales del dispositivo 100 de simulación.
En primer lugar, se describirá la unidad 10 de entrada. La unidad 10 de entrada obtiene un estado inicial de un vector de estado y parámetros en un dominio de observación sobre el que se ha de realizar la simulación y M tipos de datos de observación (de un primero a M-ésimo conjuntos de datos de observación). Cada uno de los M tipos de datos de observación son valores de observación procedentes de un sensor y similares. Cada uno de los M tipos de datos de observación puede tener un número diferente de dimensiones o el mismo número de dimensiones que la/las de una parte o la totalidad de los demás datos de observación. La unidad 10 de entrada puede, por ejemplo, obtener la información descrita anteriormente almacenada en el dispositivo de almacenamiento 1004. La unidad de entrada 10 también puede obtener la información descrita anteriormente al obtener su información de posición de almacenamiento en el dispositivo 1004 de almacenamiento a través del dispositivo 1005 de entrada.
A continuación, se describirá el modelo 21 de sistema. El modelo 21 de sistema simula las evoluciones en el tiempo del vector de estado sobre la base del estado inicial y los parámetros obtenidos por la unidad 10 de entrada. Mientras la evolución en el tiempo de un fenómeno real sujeto a simulación se expresa mediante una ecuación diferencial parcial tiempo-espacio continua, para realizar la simulación, un dominio sobre el que se realiza la simulación debe discretizarse en el tiempo y el espacio. El dispositivo 100 de simulación utiliza un vector de estado, que se genera a partir de una combinación de variables de estado, para seguir la evolución en el tiempo de un fenómeno real en un dominio de observación. El número de variables de estado puede definirse de acuerdo con el propósito de la simulación y establecerse en cualquier número. En la presente realización ejemplar, se hará una descripción principalmente de un ejemplo en el que el número de variables de estado es dos. En este caso, también se denotan dos variables de estado U y V, usando un vector ,^ mediante ^=(U,V).
La discretización en el tiempo se logra avanzando un paso desde una variable de estado ^t en un instante t y calculando una variable de estado t^+1 en un instante t+1. En la siguiente descripción, un tiempo indica un paso en una simulación y, por ejemplo, un instante t-1 significa el paso a paso antes de un instante t. De ahora en adelante, un paso en una simulación también se denomina paso de tiempo.
La discretización en el espacio se logra suponiendo que un espacio bidimensional está dividido en una forma de cuadrícula y denotando una variable de estado que se define en un k-ésimo punto de cuadrícula contando desde un punto de referencia y en un instante t por (^k)t. En la denotación, ^k se denota como ^k=(Uk, Vk). En otras palabras, se genera un vector de estado a partir de variables de estado en puntos de cuadrícula respectivos discretizados dentro de un dominio sobre el que se realiza una simulación. Cuando se supone que el último número de punto de cuadrícula entre los números de punto de cuadrícula que representan un dominio sobre el cual se realiza una simulación se denota por L, una combinación de variables de estado en un instante t se denota por un vector de estado Xt, que se expresa mediante la expresión (1) siguiente:

El signo T en la expresión denota transposición. El número de dimensiones del vector de estado se calcula como el producto del número de variables de estado por punto de cuadrícula y el número L de puntos de cuadrícula. En el caso de la expresión (1), el vector de estado es un vector dimensional 2L.
El modelo 21 de sistema realiza una operación de actualización de un vector de estado Xt-1 en un instante t-1 a un vector de estado Xt en un instante t en el tiempo y espacio discretizados. Cuando se supone que una correspondencia que representa la operación de actualización se denota por f, el modelo 21 de sistema se describe mediante una expresión relacional expresada por la expresión (2) siguiente:

Aquí, 0 denota un vector de parámetros que incluye varios parámetros necesarios para el cálculo en el modelo. Además, Vt denota un ruido del sistema en el instante t. El ruido Vt del sistema se introduce, con el fin de expresar numéricamente un efecto de carácter incompleto en el modelo, como un término impulsor estocástico que tiene un efecto sobre el vector de estado. El mapeo f puede ser lineal o no lineal dependiendo del fenómeno objetivo. Como es obvio de la expresión (2), el vector Xt de estado en el instante t no tiene que definirse explícitamente con el vector Xt-1 de estado en el instante t-1. Es decir, el modelo 21 de sistema de la presente realización ejemplar puede calcular el vector Xt de estado en el instante t utilizando el vector Xt-1de estado en el instante t-1 como entrada.
La operación de actualización, por el modelo 21 de sistema, de un vector de estado en un instante t-1 a un vector de estado en un instante t se describirá en detalle a continuación. En primer lugar, se describirá la aproximación de conjunto para hacer frente a una simulación que tiene carácter de incompleto. De ahora en adelante, como reflejo del carácter de incompleto del mapeo f y del carácter de incompleto en el parámetro 0 que ha de ser introducido, el vector Xt de estado y el ruido Vt del sistema en el modelo 21 de sistema se tratan como, en lugar de valores Xt y Vt definidos, distribuciones p(Xt) y p(Vt) de probabilidad, respectivamente. Aproximar las distribuciones p(Xt) y p(Vt) de probabilidad por grupos de N conjuntos i:

respectivamente, se denomina aproximación de conjunto. Por lo tanto, el modelo 21 de sistema en una simulación real calcula una evolución temporal de cada conjunto i:

para todos los conjuntos. A partir de este cálculo, la distribución p(Xt) de probabilidad del vector Xt de estado en el instante t se aproxima mediante N conjuntos:

El cálculo de conjunto expresado mediante la expresión (4) se caracteriza por ser independiente con respecto a cada conjunto. Por lo tanto, el modelo 21 de sistema no solo puede repetir el cálculo N veces, sino que también puede realizar el cálculo una vez utilizando N procesadores paralelos, y puede cambiar los métodos de cálculo de forma flexible dependiendo de los recursos de cálculo. De aquí en adelante, la distribución de probabilidad del vector Xt de estado se denota por p(Xt) y también se denomina como distribución anterior.
Como se describió anteriormente, utilizar el modelo 21 de sistema de forma independiente para cada conjunto permite la distribución p(Xt) de probabilidad del vector de estado en el instante t a calcular a partir de la distribución p(Xt-1) de probabilidad del vector de estado en el instante t-1. El modelo 21 de sistema genera la distribución p(Xt) de probabilidad calculada, como una distribución anterior, a los m modelos 31 de observación, que se describirán más adelante. El modelo 21 de sistema puede, por ejemplo, almacenar la distribución anterior calculada p(Xt) en la unidad 22 de almacenamiento de distribución anterior o similar, que es legible por los m modelos 31 de observación.
A continuación, se describirán la unidad 30 de procesamiento de selección de datos y los modelos 31 de observación. La unidad 30 de procesamiento de selección de datos selecciona m tipos de varios fragmentos de datos de observación a utilizar del primero al M-ésimo conjunto de datos de observación sobre la base de la información relativa al vector de estado. La unidad 30 de procesamiento de selección de datos envía los m tipos de datos de observación seleccionados a la unidad 40 de creación de distribución posterior, que se describirá más adelante.
En la presente realización ejemplar, se supone que la información relacionada con el vector de estado se introduce desde el modelo 21 de sistema a la unidad 30 de procesamiento de selección de datos como una señal CTL0 de control. La señal CTL0 de control puede incluir, por ejemplo, el número de dimensiones del vector Xt de estado y otra información relativa a las variables de estado. Sobre la base de la información incluida en la señal CTL0 de control, la unidad 30 de procesamiento de selección de datos selecciona m tipos de datos OBS1 a OBSm de observación en un
instante t, que se han de utilizar. La unidad 30 de procesamiento de selección de datos genera los conjuntos seleccionados de datos OBS1 a OBSm de observación a la unidad 40 de creación de distribución posterior.
La unidad 30 de procesamiento de selección de datos puede crear m modelos 31 de observación, cada uno de los cuales corresponde a uno de los m tipos de datos de observación seleccionados comparando información sobre el vector de estado establecido por el modelo 21 de sistema con los tipos respectivos de datos de observación (por ejemplo, cantidades físicas y dimensiones). La unidad 30 de procesamiento de selección de datos 30 puede, por ejemplo, crear los m modelos 31 de observación utilizando m señales CTL1 a CTLm de control para relacionar el vector Xt de estado con los conjuntos de datos OBS1 a OBSm de observación.
La creación de los modelos 31 de observación descritos anteriormente es para crear una ecuación de modelo de observación que relacione el vector Xt de estado con los conjuntos de datos OBS1 a OBSm de observación. Tales relaciones entre el vector de estado y los conjuntos de datos de observación se ilustran esquemáticamente en la Figura 3. Una ecuación del modelo de observación que expresa tales relaciones se expresa, por ejemplo, mediante la expresión (6) siguiente:

En este caso, la unidad 30 de procesamiento de selección de datos puede generar información sobre mapeos h1 a hm y cantidades de ruido w1 a wm, que deben tenerse en cuenta en los respectivos conjuntos de datos de observación, en la expresión (6) a los modelos 31-1 a 31-m de observación como las señales CTL1 a CTLm de control, respectivamente. A partir de este procesamiento, se crean los m modelos 31 de observación.
Si se supone que los conjuntos de datos de observación se obtienen idealmente en todos los puntos 1 a L de la cuadrícula, cada una de las cantidades w1 a wm de ruido y los conjuntos de datos OBS1 a OBSm de observación en la expresión (6) es un vector columna de L dimensiones. Sobre la base de un valor de varianza y la cantidad de ruido de cada conjunto de datos de observación, la unidad 30 de procesamiento de selección de datos puede establecer la cantidad de ruido en los modelos 31 de observación relacionados con el conjunto de datos de observación.
En la expresión (6), E1 a Em son matrices que asocian los puntos 1 a L de la cuadrícula del modelo 21 de sistema con resoluciones de puntos de observación en los que se obtienen realmente los conjuntos de datos de observación. Por ejemplo, cuando se supone que el número de variables en una variable de estado fy=(Uk, Vk) en cada punto k de la cuadrícula en el vector Xt de estado es dos, cada una de las matrices E1 a Em, es una matriz dimensional como mucho de 2Lx2L.
En general, en una variable ^k=(Uk, Vk) de estado en un punto k de la cuadrícula, Uk y Vk son cantidades físicas que difieren entre sí. Así, las relaciones entre Uk y los datos de observación y entre Vk y los datos de observación no pueden ser definidas por correspondencias hn a hm de una ecuación de modelo de observación idéntico. La siguiente descripción se hará así utilizando una configuración para Uk (k=1 a L) en las variables de estado como ejemplo. En este caso, cada una de las matrices E1 a Em descritas anteriormente es una matriz dimensional de 2LxL. Por ejemplo, se supone que el conjunto de datos OBS1 de observación se obtiene con respecto a todos los puntos 1 a L de la cuadrícula del modelo 21 de sistema. En este caso, E1 es una matriz dimensional 2LxL y toma la forma de una matriz expresada por la expresión (7) siguiente:

En la matriz, solo el elemento en la j-ésima (j es un número entero no menor que 1 y no mayor que L) fila y en la {1+2(j-1 )}ésima columna tiene un valor de 1.
Se considera un caso en el que no se observan datos en algunos puntos de la cuadrícula en los puntos 1 a L de la cuadrícula, como el conjunto de datos OBS2 de observación ilustrado en la Figura 3. Un signo "*" indica un punto de cuadrícula en el que se observa un fragmento de datos (punto de observación). En este caso, la matriz E2 está representada por una matriz que se obtiene cambiando los valores de los elementos de la fila, en la expresión (7), correspondiente a un punto de la cuadrícula en el que no se observan datos a un valor de 0. En este caso, en el lado izquierdo de la expresión (6), el número de dimensiones en las que h2 actúa resulta menor que L, y resulta el mismo número de dimensiones que el conjunto de datos OBS2 de observación. En el caso en que, por ejemplo, se definan J variables de estado, como (Uk, Vk, ...Zk), en un punto k de la cuadrícula, solo el elemento en la j-ésima fila y de la {1+J(j-1)}-ésima columna en la expresión (7) tiene un valor de 1. Por lo tanto, las matrices E1 a Em, se puede expresar independientemente del número de variables de estado. Las correspondencias hn a hm en la expresión (6) pueden ser lineales o no lineales dependiendo de las relaciones entre las variables de estado y los conjuntos de datos de observación. Por lo tanto, una operación aritmética expresada por la expresión (6) puede expresarse de tal manera que, en el caso de, por ejemplo, el j-ésimo modelo 31 -j de observación, cuando se introduce el vector Xt de estado en un instante t, calculado por la expresión (4),, el modelo genera:

Así, todos los m tipos de modelos 31 de observación realizan individualmente la operación aritmética expresada por la expresión (8) sobre el vector Xt de estado, y genera todos los m tipos de vectores Xt de estado transformados a la unidad 40 de creación de distribución posterior. Una combinación de la expresión (2) o la expresión (4) y la expresión (8) se denomina modelo de espacio de estado.
Aunque, en el ejemplo antes descrito de E1 a Em, se supone un caso en el que los puntos de cuadrícula (L dimensiones) del modelo 21 de sistema y los puntos de cuadrícula (L dimensiones) del modelo de observación coinciden entre sí, también es concebible en la práctica un caso de no coincidencia. En tal caso, los valores de los respectivos elementos de las matrices E1 a Em pueden cambiarse de tal manera que cada punto de observación en el que se obtiene realmente un dato de observación tenga, por ejemplo, un promedio ponderado de los valores en los puntos de cuadrícula vecinos. Como se describió anteriormente, las E1 a Em descritas anteriormente expresan operaciones de relacionar los puntos de la cuadrícula de las variables de estado con los grados de resolución de los puntos de observación para una pluralidad de fragmentos de datos de observación en forma de uno a uno, promedio ponderado, suma ponderada o similar con respecto a cada fragmento de datos de observación.
Como se describió anteriormente, cada uno de los m modelos 31 de observación está relacionado con uno de los m conjuntos de datos de observación seleccionados por la unidad 30 de procesamiento de selección de datos. Cada uno de los modelos 31 de observación transforma una salida de vector de estado del modelo 21 de sistema a un vector de estado predeterminado sobre la base de la expresión (8), que expresa una relación entre un conjunto de datos de observación y un vector de estado. Cada uno de los modelos 31 de observación genera el vector de estado transformado a la unidad 40 de creación de distribución posterior. Los vectores de estado transformados tienen distribuciones anteriores de m tipos de vectores Xt de estado transformados en un instante t.
Sobre la base de vectores de estado generados a partir de los m modelos 31 de observación y conjuntos de datos de observación seleccionados por la unidad 30 de procesamiento de selección de datos, la unidad 40 de creación de distribución posterior crea distribuciones posteriores del vector de estado. La unidad 40 de creación de distribución posterior categoriza, en las distribuciones posteriores creadas, una distribución posterior basada en todos los m tipos de datos de observación, seleccionados por la unidad 30 de procesamiento de selección de datos, como una primera distribución posterior. La unidad 40 de creación de distribución posterior también categoriza una distribución posterior basada en datos de observación que carecen de uno o más tipos de datos de observación de los m tipos de datos de observación, seleccionados por la unidad 30 de procesamiento de selección de datos, como una segunda distribución posterior. La unidad 40 de creación de distribución posterior envía la primera distribución posterior y la segunda distribución posterior creadas a la unidad unificadora 50 de distribución posterior, y similares. Por ejemplo, la unidad 40 de creación de distribución posterior puede almacenar la primera distribución posterior creada en la primera unidad 41a de almacenamiento de distribución posterior que es legible por la unidad unificadora 50 de distribución posterior, y similares. La unidad 40 de creación de distribución posterior también puede almacenar la segunda distribución posterior creada en la segunda unidad 41b de almacenamiento de distribución posterior que es legible por la unidad unificadora 50 de distribución posterior, y similares. La unidad 40 de creación de distribución posterior también envía la primera distribución posterior creada al modelo 21 de sistema y a la unidad 60 de salida. En este caso, por ejemplo, la unidad 40 de creación de distribución posterior puede almacenar la primera distribución posterior creada en la unidad 52 de almacenamiento de distribución posterior unificada, que es legible por el modelo 21 de sistema y la unidad 60 de salida.
Aquí, se describirá en detalle el procesamiento de creación de distribuciones posteriores por parte de la unidad 40 de creación de distribuciones posteriores. A la unidad 40 de creación de distribución posterior, se introducen las distribuciones anteriores de m tipos de Xt transformada en un instante t y los conjuntos de datos OBS1 a OBSm de observación. En general, una distribución posterior p(x|y) cuando se introducen una distribución anterior p(x) y una distribución p(y) de datos de observación, se expresa, según el teorema de Bayes, mediante la expresión:

En la expresión (9), p(y|x) en el numerador se refiere a una probabilidad, que es un indicador de la bondad de ajuste de una variable x de estado a un valor y de observación. En el caso en que un modelo 31 de observación se pueda separar en una correspondencia h y una cantidad w de ruido, como expresada por la expresión (8), para la probabilidad p(y|x), puede utilizarse una cantidad calculada por la expresión:

En la expresión (10), r es la función de densidad de la cantidad w de ruido. En la expresión (10), el lado derecho se redefine como una función LH de y, y de h(x). Además, al ser obtenida una probabilidad p(y1 :m|x) en el caso de m tipos de valores y={y1, y2, ...ym} de observación, se expresa utilizando un teorema de multiplicación recursivamente, en forma de producto como:

En la expresión (11), el primer término p(y1 |y1:0, x) es la probabilidad de y1 cuando no hay datos de observación, es decir, la probabilidad p(y1 |x) de x cuando se obtiene y1. El segundo término p(y2|y1:1, x) es la probabilidad de y2 cuando se obtiene y1. Sin embargo, los datos de observación respectivos se recopilan utilizando sensores separados o similares, y no existe distribución conjunta de y1 e y2. Así, el segundo término, como resultado, se convierte en la probabilidad p(y2|x) de x cuando se obtiene y2. Por tanto, la distribución posterior expresada por la expresión (9) en este caso viene expresada por la expresión:

En la expresión (12), se supone que Z en el denominador es una constante de normalización. Si se utiliza esta relación, debido a que m tipos de datos de observación y se han obtenido como OBS1 a OBSm, la distribución posterior de la variable de estado Uk en un punto k de la cuadrícula es, asumiendo que la distribución anterior de Uk es denotada por p(Uk), expresada por la expresión:

El numerador es, como lo expresa la expresión (12), el producto del producto de las probabilidades basadas en los respectivos conjuntos de datos de observación y la distribución anterior p(Uk). Además, dado que cada probabilidad se expresa mediante la expresión (10), la distribución posterior de la expresión (13) se expresa mediante la expresión:

Como se describió anteriormente, la unidad 40 de creación de distribución posterior calcula la distribución posterior de la variable Uk de estado en un punto k de cuadrícula sobre la base de m tipos de probabilidades LH, que se calculan sobre la base de m conjuntos de datos OBS1 a OBSm de observación y las correspondencias hn a hm, y la distribución anterior p(Uk). De manera similar, la unidad 40 de creación de distribución posterior calcula distribuciones posteriores con respecto a todos los puntos 1 a L de la cuadrícula utilizando la expresión (13), es decir, la expresión (14).
Sin embargo, la unidad 40 de creación de distribución posterior utiliza la expresión (15) siguiente en lugar de la expresión (13) con respecto a un punto de cuadrícula en el que faltan uno o más tipos de datos de observación en los m tipos de datos de observación. Por ejemplo, como OBS2 ilustrado en la Figura 3, hay un caso en el que los datos de observación se han obtenido solo en una parte de los puntos de la cuadrícula. En este caso, la unidad 40 de creación de distribución posterior no puede calcular el producto de las probabilidades con respecto a todos los datos de observación, tal como se expresa en el numerador de la expresión (13). Por ejemplo, si se supone un caso en el que, en un punto k' de la cuadrícula, solo se pueden obtener m-1 tipos de datos de observación, la distribución posterior se expresa mediante la expresión:

Es decir,

y el número de probabilidades incluidas en el numerador disminuye a m-1. En la expresión (15) y la expresión (16), la expresión "m-1" indica que al menos un tipo de datos de observación en los m tipos de datos de observación no se ha obtenido y no limita el número de tipos de datos de observación que no se han obtenido (faltan) a uno.
Como se ha descrito anteriormente, la unidad 40 de creación de distribución posterior crea una distribución posterior para cada una de las variables de estado en cada uno de los puntos de la cuadrícula. De ahora en adelante, la distribución posterior para cada una de las variables de estado en cada uno de los puntos de la cuadrícula también se denomina una distribución posterior con respecto a cada combinación de una variable de estado y un punto de la cuadrícula. La unidad 40 de creación de distribución posterior genera una distribución posterior calculada sobre la base de todos los datos de observación usando la expresión (13) como una primera distribución posterior. La unidad 40 de creación de distribución posterior también genera una distribución posterior calculada sobre la base de datos de observación que carecen de al menos un tipo de datos de observación en los m tipos de datos de observación usando la expresión (15) como una segunda distribución posterior.
Ahora se supone que una distribución anterior p(x) sigue una distribución normal con una media p0 y una varianza Vprio, y n valores y1, y2, ...yn de observación también siguen una distribución normal con una media p y una varianza V. En este caso, la distribución posterior p(x|y), que se calcula según el teorema de Bayes expresado por la expresión (9), también resulta una distribución normal, y la varianza Vpost del mismo se expresa por la expresión:

Esto indica que, a medida que aumenta el número de valores de observación utilizados para el cálculo de la distribución posterior, la varianza disminuye, es decir, mejora la precisión de la distribución posterior.
Si bien una primera y una segunda distribución posterior no siempre son distribuciones normales individualmente, los datos de observación más pequeños se toman en una segunda distribución posterior que los de una primera distribución posterior. Así, la varianza de la primera distribución posterior p(Uk|OBS1m) de la expresión (13) y la varianza de la segunda distribución posterior p(Uk'|OBS1:m-1) de la expresión (15) se denotan respectivamente por Var(p(Uk |OBS1:m)) y Var(p(Uk'|OBS1:m-1)). Entonces, se cumple una desigualdad expresada por la expresión (18) siguiente:

A continuación, se describirá la unidad unificadora 50 de distribución posterior. La unidad unificadora 50 de distribución posterior unifica una primera distribución posterior y una segunda distribución posterior. Más específicamente, la unidad unificadora 50 de distribución posterior calcula una nueva distribución posterior para cada combinación de una variable de estado y un punto de cuadrícula para el cual se ha calculado la segunda distribución posterior unificando la primera distribución posterior y la segunda distribución posterior en la nueva distribución posterior. La unidad unificadora 50 de distribución posterior genera la nueva distribución posterior después de la unificación a la unidad 51 de determinación. Dado que, en la presente realización ejemplar, una distribución posterior se aproxima mediante un grupo de conjuntos, la unidad unificadora 50 de distribución posterior puede realizar la unificación por medio de conjuntos superpuestos que se aproximan a una primera distribución posterior y conjuntos que se aproximan a una segunda distribución posterior en una relación predeterminada.
Específicamente, la unidad unificadora 50 de distribución posterior obtiene las primeras distribuciones posteriores y las segundas distribuciones posteriores descritas anteriormente como entrada de la primera unidad 41a de almacenamiento de distribución posterior y de la segunda unidad 41b de almacenamiento de distribución posterior. Debido a la relación expresada por la expresión (18), p(Uk'|OBS1m-1), que es una de las segundas distribuciones posteriores, tiene una varianza mayor (es decir, menor precisión) que al menos p(Uk|OBS1:m), que es una de las primeras distribuciones posteriores. Así, la unidad unificadora 50 de distribución posterior calcula una nueva distribución posterior para cada combinación de una variable de estado y un punto de cuadrícula para el que se ha calculado la segunda distribución posterior unificando la primera distribución posterior y otra segunda distribución posterior en una nueva distribución posterior. Por ejemplo, se supone que, con respecto a un punto j de cuadrícula, se ha calculado una segunda distribución posterior p(Uj|OBS1m-1). En este caso, con respecto al punto j de cuadrícula, la unidad unificadora 50 de distribución posterior, suponiendo que g es una función, calcula una nueva distribución posterior p'(Uj|OBS1m) mediante la expresión (19) siguiente:

Aquí, n denota un conjunto de parámetros que determina la función g. Además, k indica un punto de cuadrícula en el que se ha creado la primera distribución posterior. Además, i denota otro punto de cuadrícula en el que se ha creado la segunda distribución posterior. En la expresión, se cumple i^j. De ahora en adelante, la tilde (') de la distribución p' de probabilidad en la expresión (19) indica que la distribución p’ de probabilidad es una distribución de probabilidad después de la unificación realizada por la unidad unificadora 50 de distribución posterior. La unidad unificadora 50 de distribución posterior genera la distribución posterior p'(Uj|OBS1m ) recién calculada de tal manera y la segunda distribución posterior original p(Uj|OBS1:m-1) a la unidad 51 de determinación.
A continuación, se describirá la unidad 51 de determinación. La unidad 51 de determinación determina cuál de una segunda distribución posterior o de una distribución posterior unificada se ha de utilizar. Más específicamente, para cada combinación de una variable de estado y un punto de cuadrícula para la que se ha creado una segunda distribución posterior, la unidad 51 de determinación determina cuál de la segunda distribución posterior original y de la
distribución posterior unificada se ha de utilizar como distribución posterior. Específicamente, la unidad 51 de determinación puede almacenar la distribución posterior determinada en la unidad 52 de almacenamiento de distribución posterior unificada. En la unidad 52 de almacenamiento de distribución posterior unificada, como se ha descrito anteriormente, se ha almacenado una primera distribución posterior. La operación de almacenamiento hace que la primera distribución posterior o la distribución posterior determinada se almacene en la unidad 52 de almacenamiento de distribución posterior unificada para cada combinación de una variable de estado y un punto de cuadrícula.
Por ejemplo, la unidad 51 de determinación puede determinar, sobre la base de los respectivos valores de varianza de una segunda distribución posterior y una distribución posterior unificada, cuál se ha de utilizar. En concreto, a la unidad 51 de determinación, la distribución posterior unificada p'(Uj|OBS1:m), que es nuevamente calculada por la unidad unificadora 50 de distribución posterior, y la segunda distribución posterior original p(Uj|OBS1:m-1) son introducidas. Ambas distribuciones posteriores son distribuciones posteriores en un punto j de cuadrícula. Por ejemplo, la unidad 51 de determinación puede, como con la expresión (18), calcular y comparar las varianzas de estas distribuciones posteriores. En este caso, si la varianza de la distribución posterior unificada p'(Uj|OBS1:m) es menor, la unidad 51 de determinación selecciona y genera la distribución posterior unificada. La unidad 51 de determinación también almacena la distribución posterior seleccionada en la unidad 52 de almacenamiento de distribución posterior unificada.
Por otro lado, si la varianza de la distribución posterior unificada p'(Uj|OBS1m ) es mayor, la unidad 51 de determinación puede repetir el cálculo variando el parámetro n de la función g en la expresión (19) hasta que la varianza de la distribución posterior unificada sea menor que la varianza de la segunda distribución posterior original. Por ejemplo, en el caso en que la función g sea una función de promedio ponderado, la unidad 51 de determinación puede variar los factores de ponderación de la misma. La unidad 51 de determinación puede asumir una distribución anterior p(nprio) para el parámetro n, y calcular una distribución posterior p(npost) del parámetro n que minimiza la varianza de la misma utilizando el teorema de Bayes, expresado por la expresión (9), con los valores de varianza de la expresión (4) tratados como valores de observación. Cuando varía el parámetro n da como resultado que la varianza de la distribución posterior unificada resulta más pequeña que la varianza de la segunda distribución posterior original, la unidad 51 de determinación selecciona y almacena la distribución posterior unificada en la unidad 52 de almacenamiento de la distribución posterior unificada. En el caso de que variar el parámetro n no hace que la varianza sea menor, la unidad 51 de determinación selecciona y almacena la segunda distribución posterior original en la unidad 52 de almacenamiento de distribución posterior unificada.
De esta forma, en la unidad 52 de almacenamiento de distribución posterior unificada, todo el conjunto de distribuciones posteriores de la variable Uk de estado en un instante t en todos los puntos k de la cuadrícula (k=1 a L) se completa con la primera distribución posterior y la distribución posterior unificada o la segunda distribución posterior, que ha sido seleccionada por la unidad 51 de determinación.
A continuación, se describirá la unidad 60 de salida. En el caso de continuar la simulación, la unidad 60 de salida introduce el vector de estado en un instante t, el cual que se ha generado a partir de una distribución posterior seleccionada por la unidad 51 de determinación y una primera distribución posterior, al modelo 21 de sistema. El modelo 21 de sistema, utilizando las distribuciones posteriores en el instante t, calcula las distribuciones anteriores en el instante t+1, que es el siguiente paso de tiempo. La unidad 60 de salida genera, como resultado de la simulación, una serie temporal del vector de estado, que se genera a partir de la distribución posterior seleccionada por la unidad 51 de determinación y la primera distribución posterior, al dispositivo 1006 de salida y similares.
Como se describió anteriormente, en la unidad 52 de almacenamiento de distribución posterior unificada, el conjunto completo de distribuciones posteriores de la variable Uk de estado en un instante t en todos los puntos k de la cuadrícula (k=1 a L) se completa con la primera distribución posterior y la distribución posterior unificada o la segunda distribución posterior, que ha sido seleccionada por la unidad 51 de determinación. La unidad 60 de salida puede introducir distribuciones posteriores para las combinaciones respectivas de una variable de estado y un punto de cuadrícula, que se almacenan en la unidad 52 de almacenamiento de distribución posterior unificada, al modelo 21 de sistema y emitir una serie temporal de las mismas.
Aunque, como se ha descrito hasta ahora, las configuraciones de los respectivos bloques funcionales se describen utilizando las variables Uk de estado (k=1 a L) como ejemplo, los respectivos bloques funcionales se configuran de la misma manera con respecto a otras variables de estado (por ejemplo, Vk (k=1 a L)).
Una operación del dispositivo 100 de simulación configurado como se describe anteriormente se describirá con referencia a los dibujos.
En primer lugar, se describirá una operación que realiza el dispositivo 100 de simulación al comienzo de una simulación utilizando la Figura 4. En la Figura 4, se supone que el instante en el que comienza la simulación es la base para las siguientes etapas, es decir, un instante t=1.
En la Figura 4, para realizar una simulación discretizada en el tiempo y el espacio, el modelo 21 del sistema determina primero un paso de tiempo, puntos de cuadrícula y variables de estado para simular las evoluciones en el tiempo de los
mismos (etapa S101). Por ejemplo, para el paso de tiempo y los puntos de la cuadrícula, se pueden elegir valores apropiados sobre la base de la precisión requerida o para que el cálculo converja.
A continuación, la unidad 10 de entrada obtiene primero M-ésimos conjuntos de datos de observación (etapa S102).
A continuación, con referencia a la información sobre las variables de estado establecidas por el modelo 21 de sistema, la unidad 30 de procesamiento de selección de datos selecciona m tipos de datos de observación que se han de utilizar desde el primero hasta el M-ésimo conjunto de datos de observación (etapa S103).
A continuación, la unidad 30 de procesamiento de selección de datos establece una expresión relacional que relaciona las variables de estado y los m tipos de datos de observación entre sí y las cantidades de ruido incluidas en ellos, y crea los modelos 31-1 a 31-m de observación (etapa S104). Por ejemplo, la unidad 30 de procesamiento de selección de datos puede establecer la expresión relacional y las cantidades de ruido sobre la base de tipos, propiedades y cantidades físicas de los conjuntos de datos de observación, el número de dimensiones de los conjuntos de datos de observación y variables de estado, y similares. Esto hace que se creen los m modelos 31 de observación.
Con este procesamiento, el dispositivo 100 de simulación completa la operación realizada al comienzo de una simulación.
A continuación, se describirá una operación mediante la cual el dispositivo 100 de simulación realiza una simulación utilizando la Figura 5.
En la Figura 5, la unidad 10 de entrada obtiene primero conjuntos que representan un estado inicial del vector de estado y parámetros, y genera los conjuntos y parámetros obtenidos al modelo 21 de sistema (etapa S201).
A continuación, el modelo 21 de sistema calcula conjuntos en un paso de tiempo siguiente, es decir, distribuciones anteriores, y almacena las distribuciones anteriores calculadas en la unidad 22 de almacenamiento de distribución anterior (etapa S202).
La unidad 10 de entrada determina ahora si se obtiene o no al menos alguno de los conjuntos primero a m-ésimo de datos de observación en el instante de este paso de tiempo (etapa S203).
En el caso de que no se obtengan datos de observación (No en la etapa S203), el modelo 21 de sistema, utilizando las distribuciones anteriores en el siguiente paso de tiempo, que se almacena en la unidad 22 de almacenamiento de distribución anterior, realiza la etapa S202 nuevamente y realiza el cálculo de avanzar un paso más en el tiempo.
Se supone que también se determina No en la etapa S203 en el caso de que se especifique no revisar los datos en este paso de tiempo incluso cuando se obtiene cualquier conjunto de datos de observación.
Por otro lado, en el caso de que se obtenga al menos cualquiera de los conjuntos de datos de observación del primero al m-ésimo y los datos deban revisarse (Sí en la etapa S203), cada uno de los modelos 31-1 a 31-m de observación transforma las distribuciones anteriores almacenadas en la unidad 22 de almacenamiento de distribución anterior (etapa S204).
En este instante, en una simulación idéntica, los modelos de observación creados en la etapa S104 al comienzo de la simulación se utilizan básicamente como modelos 31-1 a 31-m de observación. Sin embargo, incluso en una simulación idéntica, en un caso excepcional, tal como un caso en el que el comportamiento de los datos de observación cambia sustancialmente y un caso en el que el cálculo de la simulación no funciona bien, la etapa S104 descrito anteriormente se puede realizar de nuevo. En este caso, en esta etapa S204, la transformación se puede realizar utilizando m modelos 31 de observación recién creados.
A continuación, la unidad 40 de creación de distribución posterior crea una distribución posterior para cada combinación de una variable de estado y un punto de cuadrícula sobre la base de los m tipos creados de distribuciones anteriores transformadas y los m tipos de datos de observación en el momento de este paso de tiempo (etapa S205). Esta operación hace que se revisen las distribuciones anteriores originales.
A continuación, la unidad 40 de creación de distribución posterior determina si la distribución posterior, creada en la etapa S205, para cada combinación de una variable de estado y un punto de cuadrícula es una distribución posterior basada en todos los m tipos de datos de observación seleccionados en la etapa S103 o una distribución posterior basada en datos de observación que carecen de una parte de los m tipos de datos de observación (etapa S206).
Cuando se determina que la distribución posterior es una distribución posterior en base a todos los m tipos de datos de observación, la unidad 40 de creación de distribución posterior almacena la distribución posterior, como una primera distribución posterior, en la primera unidad 41a de almacenamiento de distribución posterior (etapa S207).
En este caso, la unidad 40 de creación de distribución posterior también almacena la primera distribución posterior, como una distribución posterior para la combinación de una variable de estado y un punto de cuadrícula, en la unidad 52 de almacenamiento de distribución posterior unificada (etapa S208).
Por otro lado, en la etapa S206, cuando se determina que la distribución posterior es una distribución posterior basada en datos de observación que carecen de una porción de los m tipos de datos de observación, la unidad 40 de creación de distribución posterior categoriza la distribución posterior como una segunda distribución posterior y calcula un valor V0 de varianza de la misma (etapa S209). La unidad 40 de creación de distribución posterior almacena la segunda distribución posterior y el valor V0 de varianza de la misma en la segunda unidad 41b de almacenamiento de distribución posterior.
A continuación, la unidad unificadora 50 de distribución posterior calcula una nueva distribución posterior (distribución posterior unificada) cuyo valor V de varianza es mínimo, para cada combinación de una variable de estado y un punto de cuadrícula para el que se crea la segunda distribución posterior, unificando la primera distribución posterior y la segunda distribución posterior (etapa S300).
Específicamente, la unidad unificadora 50 de distribución posterior puede, para cada combinación objetivo de una variable de estado y un punto de cuadrícula, calcular una distribución posterior unificada repetidamente usando la expresión (19) y buscar el n que minimiza el valor V de varianza mientras varía un conjunto de parámetros n. Por ejemplo, la unidad unificadora 50 de distribución posterior puede realizar la búsqueda utilizando el método de los mínimos cuadrados o el teorema de Bayes. Un valor mínimo de la varianza, obtenido de la búsqueda, se denota por Vmin.
A continuación, la unidad 51 de determinación compara el valor mínimo Vmin de la varianza con el valor V0 de varianza antes de la unificación (etapa S301).
Si el valor mínimo Vmin de la varianza después de la unificación es menor, la unidad 51 de determinación establece la distribución posterior unificada como una nueva distribución posterior para la combinación de una variable de estado y un punto de cuadrícula (etapa S302), y almacena la distribución posterior unificada en la unidad 52 de almacenamiento de distribución posterior unificada (etapa S208).
Por otro lado, si el valor mínimo Vmin de la varianza después de la unificación no resulta más pequeño, la unidad 51 de determinación interrumpe la unificación, establece la segunda distribución posterior como una distribución posterior para la combinación de una variable de estado y un punto de cuadrícula (etapa S303), y almacena la segunda distribución posterior en la unidad 52 de almacenamiento de distribución posterior unificada (etapa S208).
A continuación, si la simulación no alcanza un tiempo predefinido o un paso predefinido (No en la etapa S304), el dispositivo 100 de simulación repite las operaciones después de la etapa S202. Es decir, el modelo 21 de sistema realiza la etapa S202 usando, como entrada, distribuciones posteriores para las combinaciones respectivas de una variable de estado y un punto de cuadrícula, almacenadas en la unidad 52 de almacenamiento de distribución posterior unificada, y comienza el cálculo de la siguiente etapa.
Por otro lado, cuando la simulación alcanza el tiempo predefinido o la etapa predefinida (Sí en la etapa S304), la unidad 60 de salida genera una serie de tiempo de distribuciones posteriores para las respectivas combinaciones de una variable de estado y un punto de cuadrícula, almacenada en la unidad 52 de almacenamiento de distribución posterior unificada, y finaliza la operación de simulación.
A continuación, se describirá un efecto ventajoso de la primera realización ejemplar de la presente invención.
El dispositivo de simulación como primera realización ejemplar de la presente invención puede realizar una simulación de alta resolución y alta precisión en una amplia escala teniendo en consideración datos de observación no ideales y datos de observación que tienen una discontinuidad o peculiaridad.
Se describirán las razones del efecto ventajoso anterior. En la presente realización ejemplar, el modelo del sistema simula las evoluciones en el tiempo del vector de estado. La unidad de procesamiento de selección de datos selecciona m tipos de datos de observación a partir de M tipos de datos de observación. Los m modelos de observación, cada uno de los cuales corresponde a uno de los m tipos de datos de observación, transforman las distribuciones anteriores del vector de estado en una etapa siguiente, que es calculada por el modelo del sistema, sobre la base de las relaciones entre los m tipos de datos de observación y el vector de estado En función de los m tipos transformados de distribuciones anteriores y de los m tipos seleccionados de datos de observación, la unidad de creación de distribución posterior crea una distribución posterior para cada combinación de una variable de estado y un punto de cuadrícula. La unidad de creación de distribución posterior categoriza, en las distribuciones posteriores creadas, una distribución posterior basada en todos los m tipos de datos de observación como una primera distribución posterior y una distribución posterior basada en datos de observación que carecen de una porción de los m tipos de datos de observación como una segunda distribución posterior. La unidad unificadora de distribución posterior, para cada combinación de una variable de estado y un punto de cuadrícula para la que se crea la segunda distribución posterior,
unifica la primera distribución posterior y la segunda distribución posterior, y crea una nueva distribución posterior. La unidad de determinación determina cuál de la segunda distribución posterior o de la nueva distribución posterior debe seleccionarse, y establece la distribución posterior determinada como una distribución posterior después de la unificación para la combinación de una variable de estado y un punto de cuadrícula. El modelo del sistema calcula el vector de estado en la etapa siguiente utilizando, como entrada, distribuciones posteriores del vector de estado, que se generan a partir de la primera distribución posterior y la distribución posterior unificada.
Por las razones descritas anteriormente, incluso en el caso de que una parte de los datos de observación sean inapropiados o incluyan muchos errores, la presente realización ejemplar puede, mediante la unificación de distribuciones posteriores, realizar una revisión teniendo en consideración otros datos de observación. Alternativamente, dado que dichos datos de observación no se utilizan para la revisión, la presente realización ejemplar puede evitar que aumente un error. Dado que, incluso para los datos de observación que tienen una frecuencia de medición baja, la presente realización ejemplar puede realizar una revisión teniendo en consideración los datos de observación que tienen una frecuencia de medición alta, la presente realización ejemplar permite la simulación con mayor precisión.
El efecto ventajoso descrito anteriormente se describirá utilizando la Figura 6, que ilustra esquemáticamente el efecto ventajoso. En la Figura 6, el eje horizontal representa el tiempo. Como variables de estado se establecen las variables para las que se van a calcular las evoluciones temporales en un modelo de simulación y como valores de observación los valores realmente medidos por medio de sensores y similares. Estos ajustes son los mismos que en la Figura 15, que ilustra esquemáticamente la simulación por medio de la asimilación de datos de la tecnología relacionada. Sin embargo, en la Figura 6, se ilustra un caso en el que una unidad de procesamiento de datos selecciona dos tipos de valores de observación (conjunto 1 de valores de observación y conjunto 2 de valores de observación). Mediante el uso de m tipos diferentes de modelos de observación, cada uno de los cuales está relacionado con uno de los m tipos de datos de observación, la presente realización ejemplar puede relacionar diferentes tipos de datos de observación con el mismo tipo de variables de estado. En la Figura 6, un modelo de observación relacionado con el conjunto 1 de valores de observación se ilustra como un modelo 1 de observación, y un modelo de observación relacionado con el conjunto 2 de valores de observación se ilustra como un modelo 2 de observación. Con respecto al conjunto 1 de valores de observación, se supone que se han obtenido valores de observación del mismo tipo y los mismos valores que los valores de observación en la simulación de la Figura 15, según la tecnología relacionada.
La comparación entre la Figura 6 y la Figura 15 indica que, en la simulación por la tecnología relacionada ilustrada en la Figura 15, los errores se acumulan en las simulaciones que utilizan el conjunto 1 de valores de observación debido a la influencia de la frecuencia de medición del conjunto 1 de valores de observación. Por el contrario, en la Figura 6, el conjunto 2 de valores de observación se observa en un ciclo más corto en comparación con el conjunto 1 de valores de observación. Por lo tanto, el efecto de la revisión basada en los valores de observación aparece en los valores de simulación del conjunto 1 de valores de observación. Eso se debe a que tanto los valores de simulación del conjunto 1 de valores de observación como el conjunto 2 de valores de observación se crean a partir del mismo tipo de variables de estado, aunque existe una diferencia entre los modelos de observación. Por lo tanto, la presente realización ejemplar permite una simulación con mayor precisión en comparación con la tecnología relacionada no solo para el conjunto 2 de valores de observación, cuya frecuencia de observación es alta, sino también para el conjunto 1 de valores de observación, cuya frecuencia de observación es baja. Se describirá un caso en el que se obtienen valores de observación que incluyen más valores inapropiados o errores (conjunto 1 de valores de observación indicado por un triángulo en la Figura 6) que en el caso de la técnica relacionada ilustrada en la Figura 15. Incluso en tal caso, la presente realización ejemplar puede, por medio de la unificación de distribuciones posteriores, revisar valores de simulación basados en el conjunto 1 de valores de observación con los otros valores de observación, es decir, el conjunto 2 de valores de observación, tomado en consideración, y, además, dicho conjunto 1 de valores de observación no se utilizará para la revisión. Por lo tanto, la presente realización ejemplar puede evitar que aumenten los errores.
Como se describió anteriormente, incluso cuando se proporcionan datos de observación que, cuando se usan solos, incluyen solo una cantidad insuficiente de fragmentos de datos o tienen una distribución sesgada espacial y temporalmente, la presente realización ejemplar puede, mediante el uso de una variedad de tipos de tales datos de observación, permitir realizar una simulación de alta resolución y alta precisión en un intervalo más amplio. En el futuro, debido al progreso en las tecnologías de observación y recopilación de información de una gran cantidad de sensores, como, por ejemplo, en M2M (Machine-to-Machine (“Máquina a Máquina”)), se espera que se recopile una mayor variedad y una mayor cantidad de datos de observación. En tal situación en la que se recopila una mayor variedad y una mayor cantidad de datos, la presente realización ejemplar puede, mediante el uso de información de una pluralidad de conjuntos de datos de observación de manera unificadora, realizar una simulación más eficaz en comparación con la tecnología relacionada en la que la precisión de la simulación está restringida por las características de los datos de observación.
(Segunda Realización Ejemplar)
A continuación, se describirá una segunda realización ejemplar de la presente invención con referencia a los dibujos. La presente realización ejemplar es aplicable a la simulación usando datos de observación que son espacialmente discretos pero cuyos valores son de alta precisión y datos de observación que son espacialmente continuos pero cuyos valores son de precisión insuficiente. En la siguiente descripción, se describirá un ejemplo específico en el que,
utilizando un dispositivo de simulación de la presente invención, se realiza la simulación del contenido de humedad del suelo. En los respectivos dibujos a los que se hace referencia en la segunda realización ejemplar de la presente invención, se asignan los mismos signos a los mismos componentes y etapas que en la primera realización ejemplar de la presente invención y se omitirá una descripción detallada de los mismos en la presente realización ejemplar.
En primer lugar, en la Figura 7 se ilustra una configuración de un dispositivo 200 de simulación como segunda realización ejemplar de la presente invención. En la Figura 7, el dispositivo 200 de simulación tiene una configuración en la que se aplica un modelo 221 de suelo como modelo 21 de sistema en el dispositivo 100 de simulación como la primera realización ejemplar de la presente invención. El dispositivo 200 de simulación también tiene una configuración en la que dos modelos 231-1 y 231-2 de observación, que están relacionados con dos tipos de datos de observación, se aplican como los m modelos 31 de observación en el dispositivo 100 de simulación como la primera realización ejemplar de la presente invención. El dispositivo 200 de simulación difiere del dispositivo 100 de simulación como la primera realización ejemplar de la presente invención en que el dispositivo 200 de simulación incluye una unidad unificadora 250 de distribución posterior en lugar de la unidad unificadora 50 de distribución posterior.
En la presente realización ejemplar, se aplica un estado inicial del suelo como estado inicial en la presente invención, y los parámetros meteorológicos/del terreno se aplican como parámetros en la presente invención. Como dos (M=2) conjuntos de datos de observación, se aplican dos tipos de datos de observación, datos OBS1 de humedad del suelo y datos satelitales OBS2.
Aquí, se describirán los dos tipos de datos de observación que se han de utilizar en la presente realización ejemplar, los datos OBS1 de humedad del suelo y los datos satelitales OBS2. En la Figura 8, con respecto a los datos OBS1 de humedad del suelo y los datos satelitales OBS2, se ilustran esquemáticamente variaciones de series de tiempo (en cuatro pasos t-3 a t) de los mismos en un espacio de cuadrícula de cálculo (que incluye nueve cuadrículas 1 a 9) que es un objetivo del mismo. En la Figura 8, las partes sombreadas indican los puntos de la cuadrícula en los que se recopilan los datos de observación. En la presente realización ejemplar, se supone que el ámbito espacial y el intervalo de recopilación de los dos tipos de datos de observación son los mismos que los del espacio de cuadrícula de cálculo. Incluso si un punto de recopilación de datos está ubicado localmente dentro de cada cuadrícula, un valor dentro de la cuadrícula se considera uniforme.
Los datos OBS1 de humedad del suelo pueden ser, por ejemplo, valores de observación obtenidos de sensores de humedad del suelo con constante dieléctrica, que están enterrados bajo el suelo y calculan los valores de humedad del suelo sobre la base de las constantes dieléctricas. Además, los datos OBS1 de humedad del suelo pueden ser valores de observación recopilados por otros tipos de sensores. Una característica de los datos OBS1 de humedad del suelo es que, aunque los valores de observación son discretos en el espacio porque solo se pueden medir los valores en los puntos donde se colocan los sensores, los valores de observación son de alta precisión porque se miden directamente cantidades físicas equivalentes a la humedad del suelo. En la Figura 8, se supone que los sensores se colocan en solo tres puntos con los números 1,3 y 8 de punto de cuadrícula.
Los datos satelitales OBS2 pueden ser, por ejemplo, datos de teledetección obtenidos del sensor ASTER montado en el satélite Terra (Terra/ASTER). Más específicamente, los datos recopilados por Terra/ASTER, que representan la intensidad de la luz reflejada de la luz solar en el infrarrojo cercano (Banda 3, 0.78-0.86 μm) e infrarrojos de longitud de onda corta (Banda 4, 1.600-1.700 μm) las longitudes de onda son aplicables como los datos satelitales OBS2. Además, como los datos satelitales OBS2, pueden ser aplicables los datos recopilados por otros métodos o en otras longitudes de onda. Una característica de los datos satelitales OBS2 es que, dado que la intensidad de la luz reflejada en la superficie del suelo por la luz solar en los intervalos de longitud de onda del infrarrojo cercano y del infrarrojo de longitud de onda corta se pueden recopilar como datos de imágenes bidimensionales, los valores de observación son continuos en el espacio. Sin embargo, dado que los datos satelitales OBS2 se estiman sobre la base de los datos obtenidos utilizando una correlación estadísticamente significativa entre la intensidad de la luz reflejada, la reflectividad o similar en las longitudes de onda anteriores y el contenido de humedad del suelo de la capa superficial del terreno, los valores de observación son valores indirectos y, por lo tanto, existe una posibilidad de que la exactitud de los mismos resulte insuficiente.
A continuación, se describirá el modelo 221 de suelo. El modelo 221 de suelo es un ejemplo del modelo 21 de sistema en la primera realización ejemplar de la presente invención. El modelo 221 de suelo calcula la variación espacial y temporal del contenido de humedad del suelo y similares usando, como parámetros, las propiedades físicas del suelo a observar, tales como los grados de pendiente y drenaje, y las condiciones meteorológicas, tales como la precipitación. Al modelo 221 de suelo, por ejemplo, se le puede aplicar un LSM (LAND-SURFACE MODEL (“Mo d ElO DE SUPERFICIE TERRESTRE”)). Al modelo 221 de suelo, también se le puede aplicar un módulo de suelo de un sistema de soporte de decisiones para agricultura DSSAT (Decision Support System for Agrotechnology Transfer (“Sistema de Soporte de Decisiones para Transferencia de Agrotecnología”)) y similares.
La unidad unificadora 250 de distribución posterior, como con la primera realización ejemplar de la presente invención, calcula una nueva distribución posterior unificando una primera distribución posterior y una segunda distribución posterior en la nueva distribución posterior para cada combinación de una variable de estado y un punto de cuadrícula. para lo cual se crea la segunda distribución posterior. Además, al realizar el procesamiento de unificación, la unidad
unificadora 250 de distribución posterior puede usar un modelo que se crea sobre la base de las correlaciones espaciales entre las respectivas distribuciones posteriores que ya han sido calculadas. Como modelo, por ejemplo, son aplicables una función de covarianza y una función de variograma. Sin embargo, la unidad unificadora de distribución posterior de la presente invención puede utilizar otro modelo basado en correlaciones espaciales entre distribuciones posteriores respectivas. En este caso, la unidad unificadora 250 de distribuciones posteriores puede aplicar la actualización Bayesiana a los parámetros, que caracterizan las operaciones aritméticas en el modelo utilizado para la unificación, sobre la base de las correlaciones espaciales entre distribuciones posteriores respectivas que ya han sido calculadas. El procesamiento utilizando un modelo basado en correlaciones espaciales y el procesamiento de aplicar la actualización Bayesiana al parámetro del mismo se describirán en la siguiente descripción de una operación en combinación con un ejemplo específico.
Se describirá un ejemplo específico de una operación del dispositivo 200 de simulación configurado como se ha descrito anteriormente.
Primero, el modelo 221 de suelo obtiene un estado inicial del suelo y parámetros del terreno/clima a través de la unidad 10 de entrada y establece el contenido SMk de humedad del suelo en un punto k de la cuadrícula a una variable de estado (etapa S101 en la Figura 4 y etapa S201 en la Figura 5).
Cuando se supone que las variables de estado en un punto k de cuadrícula (k=1 a 9) ilustrado en la Figura 8 incluyen solo el contenido SMk de humedad del suelo, un vector de estado en un instante t en la simulación del contenido de humedad del suelo se expresa mediante la expresión:

Aquí, se hará una descripción principalmente de un ejemplo en el que solo el contenido de humedad del suelo se establece como una variable de estado en un punto de cuadrícula. Sin embargo, además de una variable dinámica que varía en el tiempo y una cantidad cuyo valor se ha de estimar, una variable estática es aplicable como una variable de estado. Las variables de estado pueden elegirse dependiendo de un fenómeno sujeto a simulación, un modelo de sistema, un propósito y similares. Las variables de estado pueden elegirse de modo que, como lo expresa la expresión (2), se pueda crear un vector de estado en un instante sobre la base de un vector de estado en la etapa anterior y el modelo 221 de suelo. Dado que, como el número de las variables de estado aumentan, la cantidad de cálculo aumenta, las variables de estado se establecen preferiblemente de manera apropiada de acuerdo con los recursos computacionales permitidos.
A continuación, una unidad 30 de procesamiento de selección de datos obtiene dos tipos de datos de observación (etapa S102 en la Figura 4) y, como m tipos de datos de observación a utilizar, selecciona los datos OBS1 de humedad del suelo y los datos satelitales OBS2 (etapa S103).
A continuación, la unidad 30 de procesamiento de selección de datos crea dos modelos de observación que incluyen un primer modelo 231-1 de observación relacionado con los datos OBS1 de humedad del suelo y un segundo modelo 231-2 de observación relacionado con los datos satelitales OBS2 (etapa S104).
Se supone aquí un caso en el que los datos OBS1 de humedad del suelo tienen el mismo número de dimensiones que las variables SM de estado y los ruidos en los valores de observación siguen distribuciones Gaussianas (normales). También se supone que, como se ilustra en la Figura 8, los puntos de la cuadrícula de cálculo y los puntos de la cuadrícula de observación coinciden entre sí. En este caso, la matriz expresada por la expresión (7) resulta una matriz identidad. Por lo tanto, los datos OBS1 de observación y las variables de estado son, según la ecuación del modelo de observación expresada por la expresión (8), expresados por una expresión relacional lineal expresada por la expresión:

Aquí, el ruido w1 de observación puede establecerse para que sea, por ejemplo, una distribución Gaussiana con una media de 0 y una varianza o1. De esta forma, la unidad 30 de procesamiento de selección de datos crea el primer modelo 231 -1 de observación expresado por la expresión (21).
Se supone que, con respecto a los datos satelitales OBS2, la intensidad de la luz reflejada o la reflectividad observada en las longitudes de onda del infrarrojo cercano e infrarrojo de longitud de onda corta y el contenido de humedad del suelo están relacionados entre sí por medio de una función h2 no lineal. Sin embargo, se supone que los puntos de la
cuadrícula de observación coinciden con los puntos de la cuadrícula de cálculo, al igual que con los datos OBSi de humedad del suelo. En este caso, los datos OBS2 de observación y las variables de estado son, según la ecuación del modelo de observación expresada por la expresión (8), expresados por una expresión relacional no lineal expresada por la expresión:
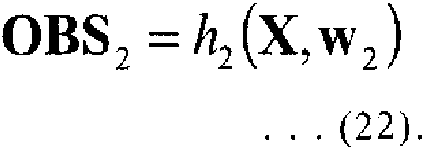
Aquí, el ruido w2 de observación también se puede establecer para que sea, por ejemplo, una distribución Gaussiana con una media de 0 y una varianza o2. De esta manera, la unidad 30 de procesamiento de selección de datos crea el segundo modelo 231-2 de observación expresado por la expresión (22).
A continuación, el modelo 221 de suelo, en el punto de inicio de una simulación, obtiene conjuntos basados en el estado inicial del suelo (t=0 en la expresión (20)), los parámetros del terreno/clima y conjuntos que representan un sistema de ruido. El modelo 221 de suelo calcula distribuciones previas del vector de estado en t=1 usando la ecuación de evolución temporal de cada conjunto, expresada por la expresión (4), y almacena las distribuciones anteriores calculadas en una unidad 22 de almacenamiento de distribución anterior (etapa S202 en la Figura 5).
A continuación, se supone que, en el instante t=1, se obtienen los datos OBS1 y OBS2 de observación (Sí en la etapa 5203) . Así, los modelos 231 -1 y 231 -2 de observación transforman los conjuntos del vector de estado en el instante t=1, almacenados en la unidad 22 de almacenamiento de distribución anterior, utilizando las expresiones (21) y (22) (etapa 5204) .
A continuación, la unidad 40 de creación de distribución posterior, para cada punto de la cuadrícula, calcula una distribución posterior usando el teorema de Bayes expresada por la expresión (9) (etapa S205). Sin embargo, como se ilustra en la Figura 8, mientras se obtienen dos valores OBS1 y OBS2 de observación para cada uno de los puntos 1,3 y 8 de la cuadrícula, solo se obtiene un valor OBS2 de observación para cada uno de los puntos 2, 4, 5, 6, 7 y 9 de la cuadrícula. Por lo tanto, para cada uno de los puntos 1, 3, y 8 de la cuadrícula anteriores, la unidad 40 de creación de distribución posterior calcula una primera distribución posterior utilizando todos los datos de observación seleccionados por la unidad 30 de procesamiento de selección de datos y la expresión (23) siguiente, que se basa en la expresión (13):
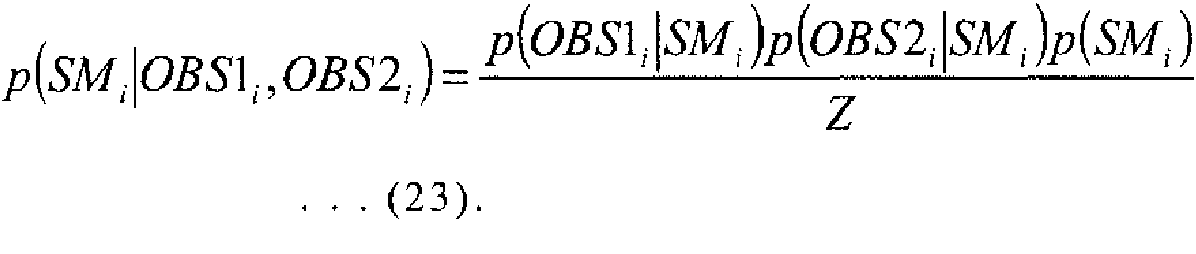
Aquí, la expresión (23) es válida para i=1, 3 y 8. Se supone que OBS1 y OBS2i denotan partes de los datos OBS1 y OBS2 de observación obtenidos en el punto i de la cuadrícula, respectivamente. Las primeras distribuciones posteriores en los puntos 1, 3 y 8 de la cuadrícula, que se calculan usando la expresión (23), se almacenan en una primera unidad 41a de almacenamiento de distribución posterior (Y en la etapa S206 y en la etapa S207). Las primeras distribuciones posteriores en los puntos 1, 3 y 8 de la cuadrícula también se almacenan en una unidad 52 de almacenamiento de distribución posterior unificada (etapa S208).
Dado que, en cada uno de los últimos puntos 2, 4, 5, 6, 7 y 9 de la cuadrícula, falta uno de los tipos de datos de observación seleccionados por la unidad 30 de procesamiento de selección de datos, la unidad 40 de creación de distribución posterior calcula una segunda distribución posterior utilizando la expresión (24) siguiente, que se basa en la expresión (15):

Aquí, la expresión (24) es válida para j=2, 4, 5, 6, 7 y 9. Las segundas distribuciones posteriores en los puntos 2, 4, 5, 6, 7 y 9 de la cuadrícula, que se han calculado usando la expresión (24), se almacenan en una segunda unidad 41b de almacenamiento de distribución posterior (N en la etapa S206 y en la etapa S209).
A continuación, la unidad unificadora 250 de distribución posterior unifica la primera y la segunda distribuciones posteriores, que se calculan utilizando las expresiones (23) y (24) (etapa S300).
En la presente realización ejemplar, como función g para unificar distribuciones posteriores, que se expresa mediante la expresión (19), por ejemplo, se considera una combinación lineal de distribuciones posteriores en puntos de cuadrícula circundantes. Por ejemplo, con respecto al punto 2 de la cuadrícula ilustrado en la Figura 8, dado que los datos de observación incluyen solo los datos satelitales OBS2, una segunda distribución posterior expresada por la expresión (24) se almacena en la segunda unidad 41b de almacenamiento de distribución posterior. Cuando una distribución posterior en el punto 2 de la cuadrícula se expresa mediante una combinación lineal de distribuciones posteriores en los puntos de la cuadrícula que no sean el punto 2 de la cuadrícula, la distribución posterior se expresa como:

Aquí, a1 a a9 son factores de ponderación que son equivalentes a un conjunto de parámetros n en la expresión (19). En adelante, la tilde (') de la distribución p’ de probabilidad en la expresión (25) indica que la distribución de probabilidad es una distribución de probabilidad después de la unificación por la unidad unificadora 250 de distribución posterior. Entonces, la expresión (25) puede considerarse equivalente al denominado método Kriging, en el que se determina un valor desconocido en el punto 2 de la cuadrícula sobre la base de una interrelación probabilística con valores en los puntos de cuadrícula circundantes, es decir, una correlación espacial. Sin embargo, los valores en los puntos de la cuadrícula no son valores definidos sino distribuciones posteriores calculadas utilizando las expresiones (23) y (24). Es decir, cuando se obtiene una función de covarianza que expresa una correlación espacial entre distribuciones posteriores p(SM|OBS) del contenido de humedad del suelo en una posición rk de un punto k de la cuadrícula y una posición rk+Y de un punto de la cuadrícula separado del punto k de la cuadrícula por una distancia y.

también se obtienen los factores a1 a a9 de ponderación en la expresión (25), es decir, el conjunto de parámetros n. En la expresión (26), SM(x) denota una variable SM de estado en un punto de la cuadrícula ubicado en una posición x. Además, OBS denota m tipos de datos de observación. El conjunto de parámetros se puede obtener resolviendo un sistema de ecuaciones Kriging simple como se expresa, por ejemplo, en la expresión (27) siguiente. En la presente invención, el método para obtener los parámetros n en la función g, que utiliza la unidad unificadora de distribución posterior para unificar distribuciones posteriores, no se limita al método descrito anteriormente, y puede ser otro método.

A continuación, se describirá una operación de obtención de una función de covarianza expresada por la expresión (26). Dado que, entre una función C(y ) de covarianza y una función V(y ) de variograma, existe una relación simple:

puede ser buena para obtener cualquiera de las funciones. En la siguiente descripción se describirá en primer lugar un caso de, en la unidad unificadora 250 de distribución posterior, obtener una función V(y ) de variograma. Un variograma, como una función de covarianza, representa una interacción probabilística, es decir, una correlación espacial entre una posición rk de un punto k de la cuadrícula y una posición rk+Y de un punto de rejilla separado del punto k de la
cuadrícula por una distancia y. En el lado izquierdo de la Figura 9, se ilustra un ejemplo de un resultado de estimación de variograma. En el ejemplo, para los resultados del cálculo de variogramas en puntos de cuadrícula que no sean un punto de cuadrícula en el que se realizará el cálculo de unificación, se establece un modelo de variograma exponencial:

y sus parámetros Z son estimados. En la expresión (29), Z denota un conjunto de tres tipos de parámetros que caracterizan un variograma, que generalmente se denominan como una pepita t2, un rango 9, y un surco o2. En el ejemplo, se ilustra un resultado a partir de una estimación realizada, según el teorema de Bayes expresado por la expresión (9), con respecto a un rango 9 y una pepita t2, entre los parámetros. Específicamente, asumiendo una distribución anterior uniforme para el rango 9 y una distribución anterior exponencial para la pepita t2 debido a que se esperan valores cercanos a 0 para la pepita t2, las distribuciones posteriores de los respectivos parámetros se obtuvieron sobre la base de variogramas realmente calculados de acuerdo con el teorema de Bayes. Los ejemplos de los resultados obtenidos se ilustran en el lado derecho de la Figura 9. Como es evidente en el dibujo, las distribuciones posteriores tienen valores máximos, que pueden considerarse valores de los parámetros que mejor reproducen los variogramas calculados, es decir, valores de máxima probabilidad. La curva (valores estimados) en el lado izquierdo de la Figura 9 se dibuja de acuerdo con la expresión (29) debajo de los parámetros. Como una función que representa el variograma V(y ) se puede calcular como se describe anteriormente, la función de covarianza también se puede calcular utilizando la expresión (28). Aunque en el ejemplo se describe un método de estimación de parámetros según el teorema de Bayes, el método es solo un ejemplo y puede usarse otro método. La Figura 9 ilustra solo un ejemplo de los resultados de la estimación y no ilustra los resultados de la estimación relacionados con el espacio de cuadrícula (cuadrículas 1 a 9) ilustrados en la Figura 8.
Por lo tanto, dado que se calcula la función C(y) de covarianza expresada por la expresión (26), se puede resolver el sistema de ecuaciones Kriging simple expresado por la expresión (27), por ejemplo. Dado que, por eso, los coeficientes en la expresión (25) que expresan unificación de distribuciones posteriores, es decir, se calcula el conjunto de parámetros n, la unidad unificadora 250 de distribución posterior es capaz de obtener la distribución posterior unificada p'(SM2| OBS1, OBS2) en el punto 2 de la cuadrícula. La unidad unificadora 250 de distribución posterior también obtiene una distribución posterior unificada p'(SMk| OBS1, OBS2) con respecto a otro punto k de la cuadrícula en el que se crea una segunda distribución posterior de la misma manera.
Aquí, los detalles de la operación de unificación realizada por la unidad unificadora 250 de distribución posterior en la etapa S300 se ilustran en la Figura 10. En la Figura 10, se ha ilustrado una operación de unificación para un punto de la cuadrícula, como objetivo, en el que se calcula una segunda distribución posterior.
En la Figura 10, la unidad unificadora 250 de distribución posterior calcula en primer lugar variogramas o covarianzas con respecto a puntos de cuadrícula distintos de un punto de cuadrícula objetivo (etapa S401).
A continuación, la unidad unificadora 250 de distribución posterior define una función que puede ajustarse a los variogramas o covarianzas calculados en la etapa S401 (etapa S402).
A continuación, la unidad unificadora 250 de distribución posterior asume distribuciones anteriores para parámetros de la función definida en la etapa S402 (etapa S403).
A continuación, la unidad unificadora 250 de distribución posterior obtiene distribuciones posteriores de los parámetros actualizando las distribuciones anteriores, asumidas en la etapa S403, de los parámetros sobre la base de los variogramas o covarianzas calculados mediante el uso del teorema de Bayes (etapa S404).
A continuación, la unidad unificadora 250 de distribución posterior deriva una función de covarianza usando las distribuciones posteriores de los parámetros obtenidos en la etapa S404 (etapa S405).
A continuación, la unidad unificadora 250 de distribución posterior, utilizando una ecuación Kriging, obtiene factores de ponderación (conjunto de parámetros n) utilizados para unificar distribuciones posteriores en puntos de cuadrícula distintos del punto de cuadrícula objetivo (etapa S406).
A continuación, la unidad unificadora 250 de distribución posterior, utilizando el conjunto de parámetros n obtenido en la etapa S406, unifica las distribuciones posteriores en puntos de cuadrícula distintos del punto de cuadrícula objetivo (etapa S407).
De esta forma, en la etapa S300 de la Figura 5, se calcula una distribución posterior unificada.
Posteriormente, el dispositivo 200 de simulación realiza las etapas S301 a S304 y S208 de la misma manera que en la primera realización ejemplar de la presente invención. Por esto, con respecto a cada punto de la cuadrícula en el que se crea una segunda distribución posterior, se almacena una distribución posterior unificada o la segunda distribución posterior en la unidad 52 de almacenamiento de distribución posterior unificada. El modelo 221 de suelo, utilizando el vector de estado generado a partir de posterior distribuciones en el paso de tiempo, que se almacenan en la unidad 52 de almacenamiento de distribución posterior unificada, continúa el cálculo para el siguiente paso de tiempo.
A continuación, se describirá un efecto ventajoso de la segunda realización ejemplar de la presente invención.
El dispositivo de simulación como la segunda realización ejemplar de la presente invención puede realizar una simulación de alta resolución y alta precisión en un amplio intervalo teniendo en consideración datos de observación no ideales y datos de observación que tienen una discontinuidad o peculiaridad.
Se describirán las razones para el efecto ventajoso anterior. Esto se debe a que la presente realización ejemplar incluye la siguiente configuración además de la misma configuración que la de la primera realización ejemplar de la presente invención. Es decir, eso se debe a que la unidad unificadora de distribución posterior, al unificar una primera distribución posterior y una segunda distribución posterior con respecto a cada punto de la cuadrícula en el que se crea la segunda distribución posterior, utiliza un modelo que se crea sobre la base de correlaciones espaciales. entre distribuciones posteriores calculadas. Esto también se debe a que la unidad unificadora de la distribución posterior aplica la actualización Bayesiana a los parámetros que caracterizan las operaciones aritméticas en el modelo utilizado en la unificación sobre la base de las correlaciones espaciales entre las distribuciones posteriores calculadas.
En consecuencia, incluso cuando se proporcionan datos de observación que, cuando se usan solos, incluyen solo un número insuficiente de fragmentos de datos o tienen una distribución que está sesgada espacialmente, al usar tales datos de observación en múltiples variedades, la presente realización ejemplar puede unificar distribuciones posteriores en puntos de la cuadrícula con mayor precisión. Como resultado, la presente realización ejemplar permite realizar una simulación de alta resolución y alta precisión sobre un intervalo más amplio.
En la segunda realización ejemplar de la presente invención, se describe un ejemplo en el que se aplica un modelo de suelo como modelo de sistema, se aplican datos de sensores de suelo y datos de satélite como una pluralidad de conjuntos de datos de observación, y se realiza una simulación del contenido de humedad del suelo. Además de eso, la presente realización ejemplar se puede realizar para otro objeto usando otro modelo de sistema y datos de observación. Por ejemplo, la presente realización ejemplar se puede realizar aplicando un modelo meteorológico como modelo de sistema y datos de sensores meteorológicos y datos de satélite como una pluralidad de conjuntos de datos de observación.
(Tercera Realización Ejemplar)
A continuación, se describirá una tercera realización ejemplar de la presente invención con referencia a los dibujos. La presente realización ejemplar puede aplicarse a la simulación en el caso en que los intervalos de cuadrícula de observación de una pluralidad de conjuntos de datos de observación difieran entre sí y la simulación en el caso en que los intervalos de tiempo de recopilación de los mismos difieran entre sí. En la siguiente descripción, se describirá un ejemplo específico en el que se realiza la simulación del crecimiento de un cultivo utilizando un dispositivo de simulación de la presente invención. En los dibujos a los que se hace referencia en la tercera realización ejemplar de la presente invención, se asignan los mismos signos a los mismos componentes y etapas que en la primera realización ejemplar de la presente invención y se omitirá una descripción detallada de los mismos en la presente realización ejemplar.
En primer lugar, en la Figura 11 se ilustra una configuración de un dispositivo 300 de simulación como tercera realización ejemplar de la presente invención. En la Figura 11, el dispositivo 300 de simulación tiene una configuración en la que se aplica un modelo 321 de cultivo como el modelo 21 de sistema en el dispositivo 100 de simulación como la primera realización ejemplar de la presente invención. El dispositivo 300 de simulación también tiene una configuración en la que dos modelos 331-1 y 331-2 de observación, que se relacionan con dos tipos de datos de observación, se aplican como los m modelos 31 de observación en el dispositivo 100 de simulación como la primera realización ejemplar de la presente invención. El dispositivo 300 de simulación difiere del dispositivo 100 de simulación como la primera realización ejemplar de la presente invención en que el dispositivo 300 de simulación incluye una unidad unificadora 350 de distribución posterior en lugar de la unidad unificadora 50 de distribución posterior.
En la presente realización ejemplar, se aplica un estado inicial del suelo como estado inicial en la presente invención, y se aplican los parámetros del terreno/clima/cultivo como parámetros en la presente invención. Como dos (M=2) conjuntos de datos de observación, se aplican dos tipos de datos satelitales (datos de teledetección).
A continuación se describirán dos tipos de datos de observación que se han de utilizar en la presente realización ejemplar, datos satelitales OBS1 y datos satelitales OBS2.
Como se ilustra en la Figura 12, en la presente realización ejemplar, los primeros datos satelitales se recopilan a alta frecuencia y tienen una resolución espacial baja, y los segundos datos satelitales se recopilan a una frecuencia baja y tienen una resolución espacial alta. En la Figura 12, con respecto a los primeros datos satelitales OBS1 y a los segundos datos satelitales OBS2, se ilustran esquemáticamente variaciones de series temporales (en cuatro etapas t-3 a t) de los mismos en un espacio de cuadrícula de cálculo (que incluye dieciséis cuadrículas 1 a 16) como objetivo. En la Figura 12, las partes sombreadas indican los puntos de la cuadrícula en los que se recopilan los datos de observación.
Los primeros datos satelitales, que se recopilan a alta frecuencia y tienen una baja resolución espacial, pueden ser datos obtenidos, por ejemplo, a partir de un sensor MODIS montado en el satélite Terra o en el satélite AQUA (Terra-AQUNMODIS). Más específicamente, los datos recopilados por Terra-AQUNMODIS, que representan la intensidad de la luz reflejada de la luz solar en la banda roja visible (longitud de onda de 0,58-0.86 gm) y la banda del infrarrojo cercano (longitud de onda de 0,725-1,100 gm) son aplicables como los primeros datos satelitales. Los primeros datos satelitales descritos anteriormente pueden, aunque dependiendo de la latitud de la región donde se recopilan los datos, recopilarse básicamente todos los días. Sin embargo, los primeros datos satelitales descritos anteriormente tienen una resolución espacial a nivel del suelo tan baja como de aproximadamente 250 m.
Los datos de observación que se pueden utilizar como segundos datos satelitales, que se recopilan a baja frecuencia y tienen una alta resolución espacial, incluyen datos de observación obtenidos, por ejemplo, de un satélite LANDSAT, un satélite PLEIADES, el satélite ASNARO o similares. El intervalo de longitudes de onda de los datos de satélite recopilados por los satélites descritos anteriormente es aproximadamente la misma que la longitud de onda de los datos recopilados como los primeros datos satelitales. La frecuencia de recopilación y la resolución a nivel del suelo de los segundos datos satelitales como se describe anteriormente son, en el caso de un satélite LANDSAT, cada 8 a 16 días y aproximadamente 30 m, y, en el caso de un satélite PLEIADES y del satélite ASNARO, cada 2 a 3 días y aproximadamente 2 m.
El Índice de Vegetación de Diferencia Normalizada (NDVI), que generalmente se utiliza como un índice de vegetación que indica el estado de crecimiento de un cultivo, se puede calcular a partir de los valores de reflectividad en las dos bandas descritas anteriormente (la banda roja visible y la banda del infrarrojo cercano). Sin embargo, el intervalo de longitud de onda de los datos recopilados como datos de observación no está necesariamente limitado a las bandas anteriores. En la presente realización ejemplar, el modelo 321 de cultivo calcula el Índice de Área Foliar (LAI) como una cantidad que representa el estado de crecimiento de un cultivo. Se sabe que el LAI tiene una correlación con el índice de vegetación NDVI. El LAI como se describe anteriormente se calcula tras introducir datos de un estado inicial del suelo y parámetros de terreno/clima/cultivo establecidos en el modelo 321 de cultivo.
Una de las diferencias entre la presente realización ejemplar y las otras realizaciones ejemplares descritas anteriormente de la presente invención es que los intervalos de cuadrícula de los dos tipos de datos OBS1 y OBS2 de observación difieren entre sí. Así, las cuadrículas de cálculo del modelo 321 de cultivo se configuran de manera que coincidan con las cuadrículas de al menos uno cualquiera de los datos OBS1 y OBS2 de observación. Con respecto a los otros datos de observación, un vector en una ecuación de modelo de observación expresada por la expresión (7) puede cambiarse para tener, por ejemplo, promedios ponderados de valores en puntos de cuadrícula vecinos como elementos del mismo. Otra diferencia entre la presente realización ejemplar y las otras realizaciones ejemplares descritas anteriormente de la presente invención es que los intervalos de tiempo de recopilación de los dos tipos de datos OBS1 y OBS2 de observación difieren entre sí. Así, la unidad unificadora 350 de distribución posterior, al estimar las distribuciones posteriores obtenidas de los datos OBS2 de observación, que se recopilan a baja frecuencia, sobre la base de correlaciones temporales, unifica las distribuciones posteriores obtenidas a partir de los datos OBS2 de observación con distribuciones posteriores obtenidas a partir de los datos OBS1 de observación, que se recopilan a alta frecuencia, en sincronización con los tiempos de recopilación de las distribuciones posteriores obtenidas a partir de los datos OBS1 de observación.
Usando un ejemplo de dos tipos de datos OBS1 y OBS2 de observación ilustrado en la Figura 12, a continuación se describirá específicamente una operación del dispositivo 300 de simulación.
Primero, el modelo 321 de cultivo establece índices de área foliar LAIk como variables de estado en los puntos k de la cuadrícula (k=1 a 16) ilustrados en la Figura 12 (etapa S101 en la Figura 4). Se puede elegir una variable de estado que se ha de establecer en un punto de la cuadrícula de acuerdo con la dependencia de la variable en el tiempo y el número de cantidades desconocidas que se han de estimar.
A continuación, una unidad 30 de procesamiento de selección de datos obtiene los dos tipos de datos de observación (etapa S102) y selecciona los primeros datos satelitales OBS1 y los segundos datos satelitales OBS2 como m tipos de datos de observación a utilizar (etapa S103).
A continuación, la unidad 30 de procesamiento de selección de datos crea dos modelos de observación, un primer modelo 331-1 de observación relacionado con los primeros datos satelitales OBS1 y un segundo modelo 331-2 de observación relacionado con los segundos datos satelitales OBS2 (etapa S104).
Con referencia a la Figura 12, con respecto a los primeros datos OBSi de observación, un valor en un punto de cuadrícula de recopilación de datos de observación (una parte sombreada en el dibujo) se puede asociar con el promedio de valores en cuatro puntos de cuadrícula de cálculo superpuestos por el punto de cuadrícula de recopilación de datos de observación. Por lo tanto, el modelo 331-1 de observación es, usando relaciones entre los primeros datos OBS1 de observación en cuatro puntos de la cuadrícula de observación y las variables LAIk (k=1 a 16) de estado, expresado por la expresión:

Dado que los puntos de la cuadrícula en los que se recopilan los segundos datos OBS2 de observación corresponden a los puntos de la cuadrícula de cálculo de forma biunívoca, el modelo 331-2 de observación, utilizando una matriz identidad, se expresa mediante la expresión:

Aquí, H1 y H2 son correspondencias que incluyen una correspondencia h que asocia sus respectivos conjuntos de datos de observación con las variables LAI de estado y matrices que asocian conjuntos de puntos de cuadrícula entre sí. Además, w1 y w2 son ruidos de observación y pueden establecerse, por ejemplo, en una distribución Gaussiana con una media de 0 y una varianza o y similares. Los modelos 331-1 y 331-2 de observación expresados por las expresiones (30) y (31) son ejemplos específicos de la ecuación del modelo de observación expresado por la expresión (8).
A continuación, el modelo 321 de cultivo obtiene un estado inicial del suelo y parámetros de terreno/clima/cultivo y calcula distribuciones anteriores del vector de estado en la siguiente etapa de la simulación (etapas S201 y S202 en la Figura 5). Los modelos 331-1 y 331-2 de observación, utilizando las expresiones (30) y (31), transforman las distribuciones anteriores (etapa S203). Aquí, se supone que, en la etapa S203 después de que la operación ilustrada en la Figura 5 se haya repetido apropiadamente, las distribuciones anteriores transformadas p(LAIk) en un instante t-1 en la Figura 12 han sido calculadas.
A continuación, una unidad 40 de creación de distribución posterior crea una distribución posterior de la variable LAIk de estado en cada punto k (k=1 a 16) de la cuadrícula en el instante t-1 en la Figura 12. Dado que, en el instante t-1, se obtienen ambos datos OBS1 y OBS2 de observación, la unidad 40 de creación de distribución posterior calcula, como una primera distribución posterior:

y almacena la primera distribución posterior calculada en una primera unidad 41a de almacenamiento de distribución posterior (etapa S205, Sí en la etapa S206 y etapa S207). En la expresión (32), LH es una función que calcula una probabilidad expresada por la expresión (13), y Z en el denominador es una constante de normalización.
También se describirá un caso en el que las distribuciones anteriores transformadas p(LAIk) en el instante t en la Figura 12 se calculan en la etapa S203. En este caso, dado que, en el instante t, los segundos datos OBS2 de observación faltan, la unidad 40 de creación de distribución posterior calcula, como una segunda distribución posterior:

y almacena la segunda distribución posterior calculada en una segunda unidad 41b de almacenamiento de distribución posterior (etapa S205, No en la etapa S206 y etapa S209).
A continuación, la unidad unificadora 350 de distribución posterior unifica la primera distribución posterior expresada por la expresión (32) y la segunda distribución posterior expresada por la expresión (33). En concreto, en la presente realización ejemplar, como función g para unificar distribuciones posteriores, que se expresa mediante la expresión (19), se aplica una combinación lineal de una segunda distribución posterior en un instante actual y una distribución posterior estimada a partir de una primera distribución posterior en un instante diferente sobre la base de una correlación temporal. Por ejemplo, con respecto a una distribución posterior en el instante en la Figura 12, dado que, como se describió anteriormente, los datos de observación incluyen solo los primeros datos satelitales OBS1, una segunda distribución posterior expresada por la expresión (33) se almacena en la segunda unidad 41b de almacenamiento de distribución posterior. Así, la unidad unificadora 350 de distribución posterior estima y crea una primera distribución posterior en el instante t para ser unificada con la segunda distribución posterior en el instante t a partir de una distribución posterior que se ha creado en un instante pasado antes del instante t en base a una correlación temporal. Una primera distribución posterior en el instante t estimada a partir de distribuciones posteriores en los instantes t=1 a t-1 se denota por p(LAIk|OBS1, OBS2)1:t-1. La unidad unificadora 350 de distribución posterior unifica una segunda distribución posterior p(LAIk| OBS1)t en el instante t y la primera distribución posterior p(LAIk)OBS1, OBS2)1 :t-1 en el instante t, que se estima sobre la base de una correlación temporal, mediante la expresión (34) siguiente:

En la expresión (34), a0 y p0 son factores de ponderación que son equivalentes al conjunto de parámetros n en la expresión (19). En la expresión (34), la tilde (') de la distribución p’ de probabilidad indica que la distribución de probabilidad es una distribución de probabilidad después de la unificación por la unidad unificadora 350 de distribución posterior.
Se describirá a continuación un ejemplo específico del procesamiento de estimación de una distribución posterior p(LAIk|OBS1, OBS2)1:t-1 en un instante t a partir de distribuciones posteriores en instantes (t-1, t-2, t-3,...) antes del instante t en base a correlaciones temporales. En general, como método para estimar un valor en un instante t a partir de valores en instantes (t-1, t-2, t-3, ...) antes del instante t, es aplicable el llamado modelo auto-regresivo (AR):
Aquí, un caso en el que un modelo fAR de AR se expresa en forma lineal se considera como un ejemplo. Se supone que un instante en el que tanto los primeros datos satelitales OBS1 y los segundos datos satelitales OBS2 se han observado y se ha creado una primera distribución posterior y ese es un instante antes de un instante t se denota por t-i (i=1 y 3 en la Figura 12). La expresión (35) en el caso de realizar una estimación basada únicamente en una primera distribución posterior en un instante t-i se expresa específicamente mediante la expresión:

Se considera un caso en el que una distribución posterior en un instante en el que no se han obtenido segundos datos OBS2 de observación y se crea una segunda distribución posterior (en la Figura 12, t-2, t-4,...) también se tiene en consideración. En este caso, utilizando una distribución posterior unificada almacenada en una unidad 52 de almacenamiento de distribución posterior unificada con respecto a un instante anterior al instante t, la expresión (35) se expresa específicamente mediante la expresión:

En la expresión (37), el instante t-i indica un instante en el que se calcula una primera distribución posterior, y el instante t-j indica un instante en el que se calcula una segunda distribución posterior. En el caso de la Figura 12, i=1 y 3 y j=2, y se cumple i^j. En la presente realización ejemplar, se supone un caso en el que se utiliza una distribución posterior unificada almacenada en la unidad 52 de almacenamiento de distribución posterior unificada en la expresión (37). Por lo tanto, en la Figura 11, los trayectos de datos a través de los cuales se transmite información sobre una distribución posterior unificada desde la unidad 52 de almacenamiento de distribución posterior unificada a la unidad unificadora 350 de distribución posterior se indican mediante flechas.
Utilizando la distribución posterior p(LAIk|OBS1, OBS2)1:t-1 en el instante t así estimada, la unidad unificadora 350 de distribución posterior realiza la unificación utilizando la expresión (34) (etapa S300).
Posteriormente, el dispositivo 300 de simulación ejecuta las etapas S301 a S304 y S208 como con la primera realización ejemplar de la presente invención. Por esto, la distribución posterior unificada o la segunda distribución posterior se almacena en la unidad 52 de almacenamiento de distribución posterior unificada con respecto a cada punto de cuadrícula en un instante t en el que se crea la segunda distribución posterior en el punto de cuadrícula. Usando el vector de estado, que se genera a partir de distribuciones posteriores en un instante t almacenado en la unidad 52 de almacenamiento de distribución posterior unificada, el modelo 321 de cultivo continúa el cálculo para el siguiente paso de tiempo.
Cuando se alcanza un tiempo predefinido, el dispositivo de simulación 300 finaliza la operación.
A continuación, se describirá un efecto ventajoso de la tercera realización ejemplar de la presente invención.
El dispositivo de simulación como tercera realización ejemplar de la presente invención puede realizar una simulación de alta resolución y alta precisión sobre un amplio intervalo tomando en consideración datos de observación no ideales y datos de observación que tienen una discontinuidad o peculiaridad.
Se describirán las razones del efecto ventajoso anterior. Esto se debe a que la presente realización ejemplar incluye la siguiente configuración además de la misma configuración que la de la primera realización ejemplar de la presente invención. En otras palabras, eso se debe a que la unidad unificadora de distribución posterior, al unificar una distribución posterior con respecto a cada punto de la cuadrícula en el que se crea una segunda distribución posterior, utiliza un modelo que se crea sobre la base de correlaciones temporales entre distribuciones posteriores que han sido ya calculadas en el pasado.
Como se describió anteriormente, la presente realización ejemplar estima, a partir de distribuciones posteriores que ya se calcularon en el pasado antes de un instante t en el que se crean las segundas distribuciones posteriores, distribuciones posteriores en el instante t sobre la base de correlaciones temporales y, utilizando las distribuciones posteriores estimadas, calcula distribuciones posteriores unificadas en el instante t. Con este procesamiento, la presente realización ejemplar permite unificar una pluralidad de conjuntos de datos de observación que se recopilan a diferentes frecuencias en sincronización con tiempos de recopilación de datos de observación que se observan a una frecuencia más alta. Es decir, en la presente realización ejemplar, las distribuciones anteriores en un instante t (resultados de la simulación) se revisan a distribuciones posteriores unificadas más probables en un intervalo más corto. Como resultado, la presente realización ejemplar puede reducir errores en la estimación de valores después de un próximo paso de tiempo.
Aunque, en la presente realización ejemplar, se describe un ejemplo en el que se aplica un modelo de cultivo como modelo de sistema y se aplican datos de satélite como una pluralidad de conjuntos de datos de observación, la presente realización ejemplar no limita el modelo de sistema y los tipos y contenidos de los datos de observación. Por ejemplo, en la presente realización ejemplar, se puede aplicar un modelo de fluidos y dinámica del agua como modelo de sistema, y los datos del sensor de nivel de agua y los datos de satélite de un río se pueden aplicar como datos de observación. Como se describió anteriormente, la presente realización ejemplar se puede aplicar a una combinación de datos de observación que se recopilan a alta frecuencia pero son localmente discretos y datos de observación que se recopilan a baja frecuencia pero tienen una alta resolución y están generalizados, usando un modelo de sistema correspondiente al mismo de forma adecuada.
(Cuarta Realización Ejemplar)
A continuación, se describirá una cuarta realización ejemplar de la presente invención con referencia a los dibujos. En la presente realización ejemplar, se describirá un ejemplo concreto en el que, utilizando un dispositivo de simulación de la presente invención, se realiza una simulación de precipitación. La cuarta realización ejemplar de la presente invención es una realización ejemplar en el que el espacio de cuadrícula de cálculo en la segunda realización ejemplar de la presente invención se expande a un espacio tridimensional. En los dibujos a los que se hace referencia en la cuarta realización ejemplar de la presente invención, se asignan los mismos signos a los mismos componentes y etapas que en la segunda realización ejemplar de la presente invención y se omitirá una descripción detallada de los mismos en la presente realización ejemplar.
En primer lugar, en la Figura 13 se ilustra una configuración de un dispositivo 400 de simulación como cuarta realización ejemplar de la presente invención. En la Figura 13, el dispositivo 400 de simulación tiene una configuración en la que se aplica un modelo meteorológico 421 en lugar del modelo 221 de suelo en el dispositivo 200 de simulación como segunda realización ejemplar de la presente invención. El dispositivo 400 de simulación también tiene una configuración en la que se aplican dos modelos 431-1 y 431 -2 de observación en lugar de los dos modelos 231 -1 y 231 -2 de observación en el dispositivo 200 de simulación como segunda realización ejemplar de la presente invención. En la presente realización ejemplar, se aplica un estado inicial de valor meteorológico como estado inicial en la presente invención, y los parámetros del terreno se aplican como parámetros en la presente invención. Como dos (M=2) conjuntos de datos de observación, se aplican datos OBS1 de agua de precipitación GPS y datos OBS2 de radar acústico.
Aquí, dos tipos de datos de observación, los datos OBS1 de agua de precipitación GPS y datos OBS2 de radar acústico, que se supone que se han de utilizar en la presente realización ejemplar. El agua de precipitación GPS son datos obtenidos mediante la estimación de un contenido de vapor de agua integrado verticalmente en la atmósfera, sobre la base de una característica de que, como el vapor de agua en la atmósfera en un trayecto hasta que una onda de radio radiada desde un satélite GPS (Sistema de Posicionamiento Global) alcanza un receptor de GPS aumenta, el tiempo de llegada se retrasa más. El agua de precipitación GPS ha contribuido a una mejora en la precisión de la estimación del momento en el que se produce una fuerte lluvia local y la estimación de la cantidad total de lluvia en una secuencia de lluvia. El agua de precipitación GPS tiene la característica de que, dado que, en el lado del suelo, solo se requiere disponer receptores de GPS, la densificación se logra con relativa facilidad en la superficie terrestre. Por el contrario, con respecto a la dirección vertical, dado que el agua de precipitación GPS es solo una cantidad integrada en la dirección vertical, es difícil expresar correctamente la distribución espacial por medio del agua de precipitación GPS. Por otro lado, el uso de un radar acústico permite medir la dependencia en altitud del contenido de vapor de agua. Por ejemplo, cuando se emite una onda de sonido hacia arriba en dirección vertical y se recibe un eco de dispersión debido a la turbulencia en la atmósfera, el eco depende del gradiente en altitud de la refracción atmosférica. Además, el gradiente en altitud de la refracción atmosférica depende en gran medida del gradiente en altitud del contenido de vapor de agua. Por lo tanto, la observación del eco permite medir la dependencia en altitud del contenido de vapor de agua.
Los modelos 431 de observación que representan las relaciones entre tales dos tipos de datos de observación y variables de estado se describirán utilizando la Figura 14. En la Figura 14, los puntos 1 a 8 de cuadrícula de cálculo están dispuestos en un espacio tridimensional. En la presente realización ejemplar, a un vector de estado, solo se establecen precipitaciones LLUVIAk como variables de estado en los puntos k (k=1 a 8) de la cuadrícula ilustrados en la Figura 14.
En la presente realización ejemplar, con respecto a los datos OBS1 de agua de precipitación, un valor en un punto de cuadrícula de observación se puede asociar con un valor integrado de valores en dos puntos de cuadrícula de cálculo que tienen los mismos valores de coordenadas en el plano xy y diferentes valores de coordenadas z (verticales). En la Figura 14, OBS1 son datos recopilados en los puntos de cuadrícula de observación donde los valores en los puntos de cuadrícula respectivos se pueden asociar con los valores integrados de los valores en los puntos 1 y 5, 2 y 6, y 4 y 8 de cuadrícula de cálculo, cada uno de los cuales tiene los mismos valores de coordenadas xy, respectivamente. Por lo tanto, el modelo 431 -1 de observación que representa una relación entre los primeros datos OBS1 de observación y las variables LLUVIAk (k=1 a 8) de estado se expresa mediante la expresión (38) siguiente. La expresión (38) es un ejemplo específico de un modelo de observación expresado por la expresión (8).

A continuación, con respecto a los datos OBS2 del radar acústico, un valor en un punto de cuadrícula de recopilación de datos de observación se puede asociar con el promedio de valores en cuatro puntos de cuadrícula de cálculo que tienen el mismo valor de coordenada z (vertical), es decir, que están incluidos en un plano idéntico. En la Figura 14, OBS2 son datos recopilados en puntos de observación donde los valores en los puntos de observación se pueden asociar con los promedios de los valores en los puntos 1 a 4 y 5 a 8 de la cuadrícula de cálculo, cada uno de los cuales tiene el mismo valor de coordenada z, respectivamente. Por lo tanto, el modelo 431-2 de observación que representa una relación entre los segundos datos OBS2 de observación y las variables LLUVIAk (k=1 a 8) de estado se expresa mediante la expresión (39) siguiente. La expresión (39) es un ejemplo específico de un modelo de observación expresado por la expresión (8).

El dispositivo 400 de simulación configurado como se ha descrito anteriormente funciona sustancialmente de la misma manera que el dispositivo 200 de simulación como la segunda realización ejemplar de la presente invención.
En otras palabras, el modelo meteorológico 241 calcula distribuciones anteriores del vector de estado en el siguiente paso de tiempo, que se calcula sobre la base de un estado inicial del valor meteorológico y parámetros del terreno (etapas S201 y S202 en la Figura 5). Los dos modelos 431-1 y 431-2 de observación descritos anteriormente transforman individualmente las distribuciones anteriores (etapas S203 y S204). Una unidad 40 de creación de distribución posterior0 crea una primera distribución posterior o una segunda distribución posterior en cada punto de la cuadrícula (etapas S205 a S207 y S209). En este instante, ya que no hay primeros datos OBS1 de observación se observa en los puntos 3 y 7 de cuadrícula, se crean segundas distribuciones posteriores. En los otros puntos de la cuadrícula, se crean las primeras distribuciones posteriores.
Una unidad unificadora 250 de distribución posterior y una unidad 51 de determinación, con respecto a los puntos 3 y 7 de cuadrícula en los que se crea la segunda distribución posterior, crean una distribución posterior unificada y determinan cuál de la distribución posterior unificada creada y la segunda distribución posterior original se ha de utilizar (etapas S300 a S303). El modelo meteorológico 421, utilizando el vector de estado generado a partir de distribuciones posteriores, cada una de las cuales es una primera distribución posterior o una distribución posterior determinada, con respecto a los puntos de cuadrícula respectivos, continúa la simulación. Cuando se alcanza un instante predefinido (Sí en la etapa S304), una unidad 60 de salida emite una serie de tiempo del vector de estado y finaliza la operación.
Como se describió anteriormente, el dispositivo de simulación como cuarta realización ejemplar de la presente invención es aplicable incluso a un caso en el que los datos de observación no pueden asociarse con puntos de cuadrícula simplemente de una manera unívoca y una simulación en un espacio tridimensional. Incluso en tal caso, la presente realización ejemplar puede, mediante el uso de modelos de observación apropiados, realizar una simulación de alta resolución y alta precisión en un amplio intervalo teniendo en consideración datos de observación no ideales y datos de observación que tienen una discontinuidad o peculiaridad.
En cada uno de los ejemplos de realización de la presente invención descritos anteriormente, la descripción se realiza principalmente sobre un ejemplo en el que los respectivos bloques funcionales de un dispositivo de simulación se logran mediante una CPU que ejecuta un programa informático almacenado en un dispositivo de almacenamiento o una ROM. Sin limitarse al ejemplo anterior, una parte o la totalidad de los bloques funcionales o una combinación de los mismos puede lograrse mediante hardware dedicado.
En cada una de las realizaciones ejemplares descritas anteriormente de la presente invención, los bloques funcionales de un dispositivo de simulación pueden lograrse de manera distribuida en una pluralidad de dispositivos.
En cada una de las realizaciones ejemplares descritas anteriormente de la presente invención, una operación de un dispositivo de simulación que se describe con referencia a un diagrama de flujo puede almacenarse en un dispositivo de almacenamiento (medio de almacenamiento) como un programa informático de la presente invención. Dicho programa informático puede configurarse para ser leído y ejecutado por la CPU del dispositivo de simulación. En tal caso, la presente invención se configura como un código de dicho programa informático o un medio de almacenamiento que almacena el programa informático.
Las realizaciones ejemplares descritas anteriormente se pueden realizar combinadas apropiadamente entre sí.
La presente invención se describe usando las realizaciones ejemplares anteriores de la misma como ejemplos típicos. Sin embargo, la presente invención no se limita a los ejemplos de realización anteriores. Es decir, varios modos que pueden ser comprendidos por un experto en la técnica pueden aplicarse a la presente invención dentro del alcance de la presente invención.
Esta solicitud reivindica prioridad basada en la Solicitud de Patente de Japón (“Japanese Patent Application”) No. 2014 172371, presentada el 27 de agosto de 2014.
Lista de signos de referencia
100, 200, 300, 400 Dispositivo de simulación
10 Unidad de entrada
21 Modelo de sistema
221 Modelo de suelo
321 Modelo de cultivo
421 Modelo meteorológico
22 Unidad de almacenamiento de distribución anterior
30 Unidad de procesamiento de selección de datos
31,231,331,431 Modelo de observación
40 Unidad de creación de distribución posterior
418 Primera unidad de almacenamiento de distribución posterior
41b Segunda unidad de almacenamiento de distribución posterior
50, 250, 350 Unidad unificadora de distribución posterior
51 Unidad de determinación
52 Unidad de almacenamiento de distribución posterior unificada
60 Unidad de salida
1001 UPC
1002 RAM
1003 ROM
1004 Dispositivo de almacenamiento
1005 Dispositivo de entrada
1006 Dispositivo de salida
Claims (10)
1. Un dispositivo de simulación, que comprende:
medios de entrada para obtener un estado inicial de un vector de estado que representa un sujeto y un parámetro en una simulación y una pluralidad de fragmentos de datos de observación como entrada, en donde la pluralidad de fragmentos de datos de observación se obtiene mediante diferentes sensores que miden el sujeto;
un modelo de sistema que, basado en el estado inicial y el parámetro, simula una evolución temporal del vector de estado, en donde el vector de estado se genera a partir de variables de estado en puntos de la cuadrícula respectivos;
medios de procesamiento de selección de datos para, basándose en la información relacionada con el vector de estado en el modelo del sistema, seleccionar, a partir de la pluralidad de fragmentos de datos de observación, una pluralidad de fragmentos de datos de observación que se han de utilizar;
una pluralidad de modelos de observación, cada uno de los cuales está asociado con uno de la pluralidad seleccionada de fragmentos de datos de observación, cada uno de los cuales transforma y genera una salida de vector de estado a partir del modelo del sistema basado en una relación entre la pluralidad seleccionada de fragmentos de datos de observación y el vector de estado;
medios de creación de distribución posterior para, en base a los vectores de estado resultantes de la pluralidad de modelos de observación y fragmentos de datos de observación seleccionados por los medios de procesamiento de selección de datos,
crear distribuciones posteriores, en donde
las distribuciones posteriores se generan usando probabilidades de la pluralidad seleccionada de fragmentos de datos de observación y distribuciones anteriores de variables de estado, en donde se crea una distribución posterior para cada una de las variables de estado en cada uno de los puntos de la cuadrícula,
para cada combinación de una variable de estado y un punto de cuadrícula y si todos los fragmentos de la pluralidad seleccionada de datos de observación se obtienen en el punto de la cuadrícula, generar una distribución posterior basada en todos los fragmentos de datos de observación seleccionados por los medios de procesamiento de selección de datos como una primera distribución posterior, y para cada combinación de una variable de estado y un punto de la cuadrícula y si al menos uno de la pluralidad seleccionada de fragmentos de datos de observación no se obtiene en el punto de cuadrícula, generar una distribución posterior basada en un conjunto de datos de observación que carecen de uno o más fragmentos de datos de observación en la pluralidad seleccionada de fragmentos de datos de observación como una segunda distribución posterior;
medios unificadores de distribución posterior para realizar, para cada combinación de una variable de estado y un punto de la cuadrícula para la que se ha calculado la segunda distribución posterior, la unificación de una primera distribución posterior y otra segunda distribución posterior en base a valores de varianza de la primera y otra segunda distribuciones posteriores y generar una distribución posterior unificada;
medios de determinación para determinar, para cada combinación de una variable de estado y un punto de la cuadrícula para la que se ha calculado la segunda distribución posterior, cuál de la segunda distribución posterior y una distribución posterior unificada después de la unificación se ha de utilizar, en donde si la varianza de la distribución posterior unificada es menor que la de la segunda distribución posterior, los medios de determinación seleccionan y emiten la distribución posterior unificada; y medios de salida para, además de introducir un vector de estado generado a partir de una distribución posterior determinada por los medios de determinación y una primera distribución posterior al modelo del sistema, generar una serie temporal del vector de estado,
en donde el sujeto es un cultivo y el vector de estado indica el estado de crecimiento del cultivo.
2. El dispositivo de simulación según la reivindicación 1, en donde
los medios de procesamiento de selección de datos, comparando fragmentos de información que se relacionan con un conjunto de vectores de estado en el modelo de sistema con los fragmentos de datos de observación, crean los modelos de observación relacionados con los fragmentos de datos de observación.
3. El dispositivo de simulación según la reivindicación 1 o 2, en donde
los medios de procesamiento de selección de datos establecen cantidades de ruido de los modelos de observación relacionados con los fragmentos de datos de observación.
4. El dispositivo de simulación según cualquiera de las reivindicaciones 1 a 3, en donde
los medios unificadores de distribución posterior, en el procesamiento de unificación de la primera distribución posterior y la segunda distribución posterior, utilizan un modelo creado en base a una correlación entre distribuciones posteriores que ya están calculadas.
5. El dispositivo de simulación según la reivindicación 4, en donde
los medios unificadores de distribuciones posteriores aplican la actualización Bayesiana a un parámetro que caracteriza una operación aritmética del modelo que se ha de utilizar en la unificación en base a una correlación entre distribuciones posteriores ya calculadas.
6. El dispositivo de simulación según cualquiera de las reivindicaciones 1 a 5, en donde
los medios de determinación, basado en los valores de varianza de la segunda distribución posterior y de la distribución posterior unificada después de la unificación, determinan cuál de la segunda distribución posterior y de la distribución posterior después de la unificación se ha de utilizar.
7. El dispositivo de simulación según cualquiera de las reivindicaciones 1 a 6, en donde
el vector de estado incluye variables de estado, cada una de las cuales está relacionada con uno de los puntos de la cuadrícula discretizados en un dominio sobre el cual se realiza la simulación, y
los modelos de observación relacionan los puntos de la cuadrícula relacionados con las variables de estado con un grado de resolución de un punto de observación de uno de la pluralidad de fragmentos de datos de observación para cada uno de los fragmentos de datos de observación.
8. El dispositivo de simulación según cualquiera de las reivindicaciones 1 a 7, en donde
una distribución de probabilidad de cada una de las variables de estado se aproxima mediante un grupo de conjuntos que se discretizan y calculan independientemente uno de otro, y
los medios unificadores de distribuciones posteriores realizan la unificación mediante la superposición de distribuciones de probabilidad de las variables de estado en una relación predeterminada, siendo aproximadas las distribuciones de probabilidad por los grupos de conjuntos.
9. Un método de simulación implementado por ordenador, comprendiendo el método
cuando se introducen un estado inicial de un vector de estado que representa un sujeto y un parámetro en una simulación y una pluralidad de fragmentos de datos de observación, en donde la pluralidad de fragmentos de datos de observación se obtiene mediante diferentes sensores que miden el sujeto,
simular una evolución en el tiempo del vector de estado utilizando un modelo de sistema basado en el estado inicial y el parámetro, en donde el vector de estado se genera a partir de variables de estado en puntos de la cuadrícula respectivos;
seleccionar, de la pluralidad de fragmentos de datos de observación, una pluralidad de fragmentos de datos de observación para usar en base a la información relacionada con el vector de estado en el modelo de sistema; transformar, mediante el uso de una pluralidad de modelos de observación, cada uno de los cuales está asociado con una de la pluralidad seleccionada de fragmentos de datos de observación, el vector de estado generado procedente del modelo del sistema basado en una relación entre la pluralidad seleccionada de fragmentos de datos de observación y el vector de estado;
crear distribuciones posteriores basadas en vectores de estado resultantes de la pluralidad de modelos de observación y los fragmentos seleccionados de datos de observación, en donde las distribuciones posteriores se generan usando probabilidades de la pluralidad seleccionada de fragmentos de datos de observación y distribuciones anteriores de variables de estado, en donde se crea una distribución posterior para cada una de las variables de estado en cada uno de los puntos de la cuadrícula,
para cada combinación de una variable de estado y un punto de cuadrícula y si todos los fragmentos de la pluralidad seleccionada de fragmentos de datos de observación se obtienen en el punto de la cuadrícula, generar una distribución posterior basada en todos los fragmentos de datos de observación seleccionados como una primera distribución posterior, y
para cada combinación de una variable de estado y un punto de la cuadrícula y si al menos uno de la pluralidad seleccionada de fragmentos de datos de observación no se obtiene en el punto de cuadrícula generar una distribución posterior basada en un conjunto de datos de observación que carecen de uno o más fragmentos de datos de observación en la pluralidad seleccionada de fragmentos de datos de observación como una segunda distribución posterior;
para cada combinación de una variable de estado y un punto de la cuadrícula para el que se ha calculado la segunda distribución posterior, realizar la unificación de una primera distribución posterior y otra segunda distribución posterior en función de los valores de varianza de la primera y otra segunda distribución posteriores y generar una distribución posterior unificada;
para cada combinación de una variable de estado y un punto de la cuadrícula para la que se ha calculado la segunda distribución posterior, determinar cuál de la segunda distribución posterior y de una distribución posterior unificada después de la unificación se ha de utilizar, en donde si la varianza de la distribución posterior unificada es menor que la de la segunda distribución posterior, seleccionar y generar la distribución posterior unificada;
introducir un vector de estado generado a partir de una distribución posterior determinada y una primera distribución posterior al modelo del sistema; y generar una serie temporal del vector de estado generado a partir de la distribución posterior determinada y la primera distribución posterior,
en donde el sujeto es un cultivo y el vector de estado indica el estado de crecimiento del cultivo.
10. Un medio de almacenamiento legible por ordenador que comprende instrucciones que, cuando son ejecutadas por un ordenador, hacen que el ordenador lleve a cabo el método de la reivindicación 9.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2014172371 | 2014-08-27 | ||
| PCT/JP2015/004081 WO2016031174A1 (ja) | 2014-08-27 | 2015-08-18 | シミュレーション装置、シミュレーション方法、および、記憶媒体 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2944938T3 true ES2944938T3 (es) | 2023-06-27 |
Family
ID=55399091
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES15835871T Active ES2944938T3 (es) | 2014-08-27 | 2015-08-18 | Dispositivo de simulación, método de simulación y soporte de memoria |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US10474770B2 (es) |
| EP (1) | EP3188060B1 (es) |
| JP (1) | JP6635038B2 (es) |
| CN (1) | CN106605225A (es) |
| ES (1) | ES2944938T3 (es) |
| PT (1) | PT3188060T (es) |
| WO (1) | WO2016031174A1 (es) |
Families Citing this family (31)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10613252B1 (en) * | 2015-10-02 | 2020-04-07 | Board Of Trustees Of The University Of Alabama, For And On Behalf Of The University Of Alabama In Huntsville | Weather forecasting systems and methods |
| WO2017170086A1 (ja) * | 2016-03-31 | 2017-10-05 | 日本電気株式会社 | 情報処理システム、情報処理装置、シミュレーション方法およびシミュレーションプログラムが記録された記録媒体 |
| JP6626430B2 (ja) * | 2016-12-13 | 2019-12-25 | 日本電信電話株式会社 | 土壌含水率推定方法および土壌含水率推定装置 |
| KR101881784B1 (ko) * | 2017-01-12 | 2018-07-25 | 경북대학교 산학협력단 | 예측장 생성방법, 이를 수행하기 위한 기록매체 및 장치 |
| EP3575991A4 (en) | 2017-01-24 | 2020-02-19 | Nec Corporation | INFORMATION PROCESSING DEVICE, INFORMATION PROCESSING METHOD, AND RECORDING MEDIUM ON WHICH AN INFORMATION PROCESSING PROGRAM IS RECORDED |
| WO2018139300A1 (ja) | 2017-01-24 | 2018-08-02 | 日本電気株式会社 | 情報処理装置、情報処理方法、及び、情報処理プログラムが記録された記録媒体 |
| FR3064774B1 (fr) * | 2017-03-29 | 2020-03-13 | Elichens | Procede d'etablissement d'une cartographie de la concentration d'un analyte dans un environnement |
| JP6966716B2 (ja) * | 2017-03-30 | 2021-11-17 | 日本電気株式会社 | レーダ画像解析システム |
| JP2018170971A (ja) * | 2017-03-31 | 2018-11-08 | 沖電気工業株式会社 | 温度予測装置、温度予測方法、温度予測プログラム及び温度予測システム |
| WO2019003441A1 (ja) * | 2017-06-30 | 2019-01-03 | 日本電気株式会社 | 予測装置、予測方法、予測プログラムが記録された記録媒体、及び、遺伝子推定装置 |
| US10998984B2 (en) * | 2018-05-04 | 2021-05-04 | Massachuusetts Institute of Technology | Methods and apparatus for cross-medium communication |
| JP7017712B2 (ja) | 2018-06-07 | 2022-02-09 | 日本電気株式会社 | 関係性分析装置、関係性分析方法およびプログラム |
| JP2019217510A (ja) * | 2018-06-15 | 2019-12-26 | 日本製鉄株式会社 | 連続鋳造鋳型内可視化装置、方法、およびプログラム |
| CN112154464B (zh) * | 2018-06-19 | 2024-01-02 | 株式会社岛津制作所 | 参数搜索方法、参数搜索装置以及参数搜索用程序 |
| KR102033762B1 (ko) * | 2018-10-24 | 2019-10-17 | 김춘지 | 주변격자 최댓값 앙상블 확률 및 검정지수를 이용한 앙상블 예측 시스템의 성능 진단 방법 및 시스템 |
| CN109444232B (zh) * | 2018-12-26 | 2024-03-12 | 苏州同阳科技发展有限公司 | 一种多通道智能化污染气体监测装置与扩散溯源方法 |
| JP7107246B2 (ja) * | 2019-02-21 | 2022-07-27 | 日本電信電話株式会社 | 推定装置、推定方法、及びプログラム |
| CN110163426A (zh) * | 2019-05-09 | 2019-08-23 | 中国科学院深圳先进技术研究院 | 一种多模式集成降水预报方法及装置 |
| JP7335499B2 (ja) * | 2019-09-13 | 2023-08-30 | 日本製鉄株式会社 | 連続鋳造鋳型内可視化装置、方法、およびプログラム |
| JP7332875B2 (ja) * | 2019-09-13 | 2023-08-24 | 日本製鉄株式会社 | 連続鋳造鋳型内可視化装置、方法、およびプログラム |
| JP2021102221A (ja) * | 2019-12-25 | 2021-07-15 | 日本製鉄株式会社 | 連続鋳造鋳型内可視化装置、方法、およびプログラム |
| US11901204B2 (en) | 2020-05-22 | 2024-02-13 | Applied Materials, Inc. | Predictive wafer scheduling for multi-chamber semiconductor equipment |
| WO2022059189A1 (ja) * | 2020-09-18 | 2022-03-24 | 日本電気株式会社 | データ算出装置、データ算出方法および記録媒体 |
| CN112612995B (zh) * | 2021-03-08 | 2021-07-09 | 武汉理工大学 | 一种基于贝叶斯回归的多来源降雨数据融合算法及装置 |
| US20240160809A1 (en) * | 2021-03-09 | 2024-05-16 | University Public Corporation Osaka | Method of acquiring estimated value of physical constant |
| JP2022175081A (ja) * | 2021-05-12 | 2022-11-25 | 株式会社日立製作所 | 解析装置およびプログラム |
| WO2022259295A1 (ja) * | 2021-06-07 | 2022-12-15 | 日本電信電話株式会社 | 処理装置、処理方法およびプログラム |
| CN113378476B (zh) * | 2021-06-28 | 2022-07-19 | 武汉大学 | 一种全球250米分辨率时空连续的叶面积指数卫星产品生成方法 |
| CN113420459B (zh) * | 2021-07-16 | 2022-09-02 | 利晟(杭州)科技有限公司 | 一种基于大延时算法的污水处理系统 |
| CN115169252B (zh) * | 2022-09-07 | 2022-12-13 | 哈尔滨工业大学(深圳)(哈尔滨工业大学深圳科技创新研究院) | 一种结构化仿真数据生成系统及生成方法 |
| CN115630937B (zh) * | 2022-12-21 | 2023-05-30 | 北京京东振世信息技术有限公司 | 物流网络仿真的时间同步方法、装置和存储介质 |
Family Cites Families (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6480814B1 (en) * | 1998-10-26 | 2002-11-12 | Bennett Simeon Levitan | Method for creating a network model of a dynamic system of interdependent variables from system observations |
| JP3854111B2 (ja) * | 2001-09-18 | 2006-12-06 | 株式会社東芝 | 気象予測システム、気象予測方法及び気象予測プログラム |
| US7454336B2 (en) * | 2003-06-20 | 2008-11-18 | Microsoft Corporation | Variational inference and learning for segmental switching state space models of hidden speech dynamics |
| US7480615B2 (en) * | 2004-01-20 | 2009-01-20 | Microsoft Corporation | Method of speech recognition using multimodal variational inference with switching state space models |
| JP4882329B2 (ja) | 2005-09-29 | 2012-02-22 | 株式会社豊田中央研究所 | 信頼度算出装置 |
| JP5203104B2 (ja) * | 2008-09-04 | 2013-06-05 | 一般財団法人日本気象協会 | 降水予測システム、方法及びプログラム |
| JP2010060443A (ja) * | 2008-09-04 | 2010-03-18 | Japan Weather Association | 気象予測装置、方法及びプログラム |
| US20100274102A1 (en) * | 2009-04-22 | 2010-10-28 | Streamline Automation, Llc | Processing Physiological Sensor Data Using a Physiological Model Combined with a Probabilistic Processor |
| US8560283B2 (en) * | 2009-07-10 | 2013-10-15 | Emerson Process Management Power And Water Solutions, Inc. | Methods and apparatus to compensate first principle-based simulation models |
| JP2011167163A (ja) | 2010-02-22 | 2011-09-01 | Pasuko:Kk | 水稲収量予測モデル生成方法、及び水稲収量予測方法 |
| CN101794115B (zh) | 2010-03-08 | 2011-09-14 | 清华大学 | 一种基于规则参数全局协调优化的调度规则智能挖掘方法 |
| US8645304B2 (en) * | 2011-08-19 | 2014-02-04 | International Business Machines Corporation | Change point detection in causal modeling |
| JP5795932B2 (ja) | 2011-10-07 | 2015-10-14 | 株式会社日立製作所 | 土地状態推定方法 |
-
2015
- 2015-08-18 PT PT158358713T patent/PT3188060T/pt unknown
- 2015-08-18 CN CN201580045955.1A patent/CN106605225A/zh active Pending
- 2015-08-18 US US15/506,505 patent/US10474770B2/en active Active
- 2015-08-18 EP EP15835871.3A patent/EP3188060B1/en active Active
- 2015-08-18 WO PCT/JP2015/004081 patent/WO2016031174A1/ja not_active Ceased
- 2015-08-18 JP JP2016544935A patent/JP6635038B2/ja active Active
- 2015-08-18 ES ES15835871T patent/ES2944938T3/es active Active
Also Published As
| Publication number | Publication date |
|---|---|
| EP3188060B1 (en) | 2023-04-26 |
| US20170255720A1 (en) | 2017-09-07 |
| US10474770B2 (en) | 2019-11-12 |
| WO2016031174A1 (ja) | 2016-03-03 |
| JP6635038B2 (ja) | 2020-01-22 |
| PT3188060T (pt) | 2023-06-27 |
| EP3188060A1 (en) | 2017-07-05 |
| CN106605225A (zh) | 2017-04-26 |
| JPWO2016031174A1 (ja) | 2017-06-29 |
| EP3188060A4 (en) | 2018-05-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ES2944938T3 (es) | Dispositivo de simulación, método de simulación y soporte de memoria | |
| Jones et al. | The Rossby Centre regional atmospheric climate model part I: model climatology and performance for the present climate over Europe | |
| Romagnoli et al. | Assessment of the SWAT model to simulate a watershed with limited available data in the Pampas region, Argentina | |
| Sellars et al. | Computational Earth science: Big data transformed into insight | |
| Fan et al. | A comparative study of four merging approaches for regional precipitation estimation | |
| EP3857269A1 (en) | Method and system of real-time simulation and forecasting in a fully-integrated hydrologic environment | |
| CN109522516A (zh) | 基于随机森林回归算法的土壤湿度检测方法、装置及电子设备 | |
| US20210208307A1 (en) | Training a machine learning algorithm and predicting a value for a weather data variable, especially at a field or sub-field level | |
| Walker et al. | Hydrologic data assimilation | |
| Tiwari et al. | Predictive skill comparative assessment of WRF 4DVar and 3DVar data assimilation: An Indian Ocean tropical cyclone case study | |
| Bhutia et al. | Exploring shifting patterns of land use and land cover dynamics in the Khangchendzonga biosphere reserve (1992–2032): a Geospatial forecasting approach | |
| CN114611699A (zh) | 土壤水分降尺度方法、装置、电子设备及存储介质 | |
| Le Toumelin et al. | A two-fold deep-learning strategy to correct and downscale winds over mountains | |
| Doherty et al. | Fine-grained topographic diversity data improve site prioritization outcomes for bees | |
| Martel et al. | Exploring the ability of LSTM-based hydrological models to simulate streamflow time series for flood frequency analysis | |
| CN117871472A (zh) | 一种卫星土壤水分产品降尺度方法以及装置 | |
| Zus et al. | Development and optimization of the IPM MM5 GPS slant path 4DVAR system | |
| CN119442890B (zh) | 一种基于气象的推演方法及系统 | |
| Jafari et al. | Comprehensive introduction to Digital Elevation Models, as a key dataset in soil erosion mapping | |
| Shukla et al. | Implementation of random forest algorithm for crop mapping across an aridic to ustic area of Indian states | |
| Muñoz-Sabater et al. | Soil moisture retrievals based on active and passive microwave data: State-of-the-art and operational applications | |
| Schumann et al. | Assessment of soil moisture fields from imperfect climate models with uncertain satellite observations | |
| Ramadhani | Mapping the vegetative stage of rice cultivation using deep learning | |
| Ezeomedo et al. | Accessing Agulu Lake through the Application of Remote Sensing and Geospatial Information Technology | |
| Lussana et al. | Evaluation of seNorge2, a conventional climatological datasets for snow-and hydrological modeling in Norway |