JP2004199677A - キャッシュを動作させるためのシステム及び方法 - Google Patents
キャッシュを動作させるためのシステム及び方法 Download PDFInfo
- Publication number
- JP2004199677A JP2004199677A JP2003415025A JP2003415025A JP2004199677A JP 2004199677 A JP2004199677 A JP 2004199677A JP 2003415025 A JP2003415025 A JP 2003415025A JP 2003415025 A JP2003415025 A JP 2003415025A JP 2004199677 A JP2004199677 A JP 2004199677A
- Authority
- JP
- Japan
- Prior art keywords
- information
- cache
- tag
- tag memory
- memory
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images
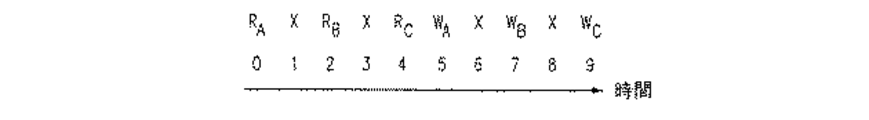



Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0844—Multiple simultaneous or quasi-simultaneous cache accessing
- G06F12/0855—Overlapped cache accessing, e.g. pipeline
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Memory System Of A Hierarchy Structure (AREA)
Abstract
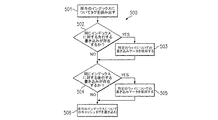
【解決手段】キャッシュの動作方法であって、少なくとも2つのキャッシュラインについてタグメモリ(104)から第1の情報を読み出し、少なくとも2つのキャッシュラインについてタグメモリ(104)から第2の情報を読み出し、タグメモリに第3の情報を書き込んで前記第1の情報を更新し、(i)前記第2の情報を読み出す前記ステップに関連するタグメモリのアドレスを(ii)前記第3の情報を書き込む前記ステップに関連する前記タグメモリのアドレスと比較し、該比較に応じて前記第2の情報を前記第3の情報に選択的に置換し、前記比較ステップの後に第4の情報を前記タグメモリに書き込んで前記第2の情報を更新する、という各ステップを含む方法。
【選択図】図1
Description
[関連特許出願の相互参照]
本特許出願は、本出願人の先の出願である、2001年5月10日出願の「FAST PRIORITY DETERMINATION CIRCUIT WITH ROTATING PRIORITY」と題する米国特許出願第09/853,738号、2001年5月10日出願の「SYSTEM OF AND METHOD FOR MEMORY ARBITRATION USING MULTIPLE QUEUES」と題する米国特許出願09/853,951号、及び2002年4月9日出願の「SYSTEM OF AND METHOD FOR FLOW CONTROL WITHIN A TAG PIPELINE」と題する米国特許出願第10/118,801号に関連するものである。
De Blasi著「Computer Architecture」 (ISBN0-201-41603-4、Addison-Wesley、1990、pp.273-291) Stone著「High Performance Computer Architecture」 (ISBN0-201-51377-3、Addison-Wesley、第2版、1990、pp.29-39) Tabak著「Advanced Microprocessors」 (ISBN0-07-062807-6、McGraw Hill、1991、pp.244-248) ダイレクトマッピングの場合、1ラインのメモリが要求された際には、キャッシュ内の1ラインのみが、一致するインデックスビットを有する。それゆえ、そのデータを直ちに取り出してデータバス上に出力した後、システムがそのアドレスの残りが一致するか否かを判定することができる。該データは、有効である場合も有効でない場合もあるが、該データが有効である通常の場合には、該データビットがデータバス上で利用可能となった後、システムが該データの妥当性を確認することができる。
1.ディレクトリベース:
1ブロックの物理的なメモリに関する情報が単一の共通の場所に維持される。該情報は通常は、どの(1つ又は2つ以上の)キャッシュが該ブロックのコピーを有しているか、及び該コピーが将来的な変更について排他的であるか否かを含む。特定のブロックへのアクセスは、最初に、ディレクトリの照会を行って、メモリデータが旧いものであり現在のデータが他の何れかのキャッシュ(もしあるなら)内に存在するかを確認する。そうである場合には、変更されたブロックを含むキャッシュが強制的にそのデータをメモリに戻す。次いで該メモリが該データを新たなリクエスタに転送し、該ブロックの新たな場所でディレクトリが更新される。このプロトコルは、バスモジュール間(又はキャッシュ間)の混乱を最小限に抑えるが、大きなディレクトリサイズを必要とすることに起因して、一般にレイテンシが長く、及び構築に要するコストが高いものとなる。
2.スヌーピング:
物理的なメモリブロックからのデータのコピーを有するあらゆるキャッシュは、そのデータブロックに関する情報のコピーも有する。各キャッシュは、通常は共有メモリバス上に配置され、全てのキャッシュコントローラが、該バスを監視し又は「スヌープ」して、それらキャッシュが共有ブロックのコピーを有するか否かを判定する。
書き込み時のプロセッサは、他のキャッシュ内の全てのコピーを無効化した後、ローカルコピーを変更する。該プロセッサは次いで、別のプロセッサがそのデータを要求する時まで、該データを自由に更新することができる。書き込み時のプロセッサは、バスを介して無効化信号を送出し、全てのキャッシュがデータのコピーを有するか否かを確認する。データのコピーを有する場合には、それらのキャッシュは該データを含むブロックを無効化しなければならない。この方式は、多数のリーダ(すなわち読み出し)を許容するが、単一のライタ(すなわち書き込み)しか許容しないものである。
共有されている全てのブロックを無効化するのではなく、書き込み時のプロセッサは、バスを介して新たなデータをブロードキャストする。次いで全てのコピーがその新たな値で更新される。この方式は、共有データに対する書き込みを連続してブロードキャストし、一方、上記の書き込み無効化方式は、後続の書き込みのために1つローカルコピーしか存在しないように全ての他のコピーを削除するものである。書き込みブロードキャストプロトコルは通常は、データを共有されたもの(ブロードキャスト)としてタグ付けすることを可能にし、又はデータを個人的なもの(ローカル)としてタグ付けすることを可能にする。コヒーレンシに関する更なる情報については、J.Hennessy,D.Patterson、Computer Architecture:A Quantitative Approach、Morgan Kaufmann Publishers,Inc(1990)を参照されたい。
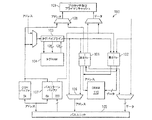
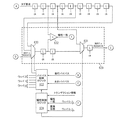
101 読み出しキュー
102 書き込みキュー
103 タグパイプライン
104 タグRAM
105 バスユニット
106 マルチプレクサ
107 バスリターンバッファ
108 マルチプレクサ
109 プロセッサ及び/又は一次キャッシュ
110 DRAM
Claims (10)
- キャッシュを動作させるための方法であって、
少なくとも2つのキャッシュラインについてタグメモリから第1の情報を読み出し、
少なくとも2つのキャッシュラインについて前記タグメモリから第2の情報を読み出し、
前記タグメモリに第3の情報を書き込んで前記第1の情報を更新し、
(i) 前記第2の情報を読み出す前記ステップに関連する前記タグメモリのアドレスを、(ii) 前記第3の情報を書き込む前記ステップに関連する前記タグメモリのアドレスと比較し、該比較に応じて前記第2の情報を前記第3の情報に選択的に置換し、
前記比較ステップの後に、第4の情報を前記タグメモリに書き込んで前記第2の情報を更新する、
という各ステップを含む、キャッシュを動作させるための方法。 - 前記比較ステップが、
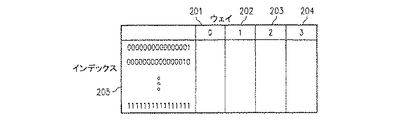
(i) 前記第2の情報を読み出す前記ステップに関連する前記タグメモリのウェイを、(ii) 前記第3の情報を書き込む前記ステップに関連する前記タグメモリのウェイと比較し、該比較に応じて前記第2の情報を前記第3の情報に選択的に置換する前記ステップを実行する、というステップを含む、請求項1に記載の方法。 - 選択的な置換を行う前記ステップが、所定の時間にわたり前記第3の情報を遅延させて遅延された情報を提供するステップを含む、請求項1に記載の方法。
- 前記遅延された情報を前記第2の情報の代わりにタグパイプラインに提供するステップを更に含む、請求項6に記載の方法。
- 前記第3の情報(WA)を書き込む前記ステップの前に、少なくとも2つのキャッシュラインについて前記タグメモリから第5の情報(RB)を読み出し、
(i)前記第2の情報を読み出す前記ステップに関連する前記タグメモリのアドレスを、(ii)前記第6の情報を書き込む前記ステップに関連する前記タグメモリのアドレスと比較し、該比較に応じて、前記第2の情報を前記第6の情報に選択的に置換する、
という各ステップを更に含む、請求項1に記載の方法。 - キャッシュを動作させるための回路であって、
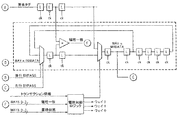
少なくとも2つのキャッシュラインの各々毎に第1及び第2の情報を格納するタグメモリ(104)と、
前記タグメモリ(104)にアドレス指定情報を供給して前記第1及び第2の情報を読み出すために前記タグメモリに接続されたタグパイプライン(103)と、
前記第1及び前記第2の情報を前記タグパイプライン(103)に送信するために前記タグメモリを前記タグパイプライン(103)に接続するデータバスとを含み、
前記タグパイプライン(103)が更に、前記タグメモリ(104)に第3の情報を書き込ませて前記第1の情報を更新させるよう構成されており、該回路が更に、
(i) 前記第2の情報に関連する前記タグメモリ(104)のアドレスを、(ii) 前記第3の情報に関連する前記タグメモリ(104)のアドレスと比較するよう構成されたコンパレータと、
該コンパレータにより出力された比較信号に応じて前記第2の情報を前記第3の情報により選択的に更新させて更新された第2の情報を形成する、第1のマルチプレクサと、
前記タグパイプラインに前記更新された第2の情報を前記第4の情報で選択的に変更させるよう動作する第2のマルチプレクサと
を含む、キャッシュを動作させるための回路。 - (i) 前記第2の情報を読み出す前記ステップに関連する前記タグメモリ(104)のウェイと、(ii) 前記第3の情報を書き込む前記ステップに関連する前記タグメモリ(104)のウェイとを受信して比較し、該比較に応じて前記第2の情報の前記第3の情報への置換を選択的に開始するよう動作する、バイパス制御ロジックを更に含む、請求項6に記載の回路。
- 前記第3の情報を所定の時間にわたり選択的に遅延させて、遅延された情報を提供するよう動作する、遅延回路を更に含む、請求項6に記載の回路。
- 前記第2の情報の代わりに前記遅延された情報を前記タグパイプライン(103)に選択的に提供するために前記タグパイプライン(103)に接続されたマルチプレクサを更に含む、請求項8に記載の回路。
- 前記第3の情報を同時に遅延させるよう互いに並列に動作する複数の前記タグパイプライン(103)を更に含む、請求項8に記載の回路。
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US10/319,205 US6950906B2 (en) | 2002-12-13 | 2002-12-13 | System for and method of operating a cache |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2004199677A true JP2004199677A (ja) | 2004-07-15 |
| JP2004199677A5 JP2004199677A5 (ja) | 2006-11-16 |
Family
ID=32506599
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2003415025A Pending JP2004199677A (ja) | 2002-12-13 | 2003-12-12 | キャッシュを動作させるためのシステム及び方法 |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US6950906B2 (ja) |
| JP (1) | JP2004199677A (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10037278B2 (en) | 2015-08-17 | 2018-07-31 | Fujitsu Limited | Operation processing device having hierarchical cache memory and method for controlling operation processing device having hierarchical cache memory |
Families Citing this family (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20040250027A1 (en) * | 2003-06-04 | 2004-12-09 | Heflinger Kenneth A. | Method and system for comparing multiple bytes of data to stored string segments |
| EP1717708B1 (en) * | 2005-04-29 | 2010-09-01 | STMicroelectronics Srl | An improved cache memory system |
| US7581068B2 (en) * | 2006-06-29 | 2009-08-25 | Intel Corporation | Exclusive ownership snoop filter |
| JP5011885B2 (ja) * | 2006-08-18 | 2012-08-29 | 富士通株式会社 | スヌープタグの制御装置 |
| US7840874B2 (en) * | 2006-12-27 | 2010-11-23 | Mips Technologies, Inc. | Speculative cache tag evaluation |
| JP4388557B2 (ja) * | 2007-01-11 | 2009-12-24 | 株式会社日立製作所 | 画像処理システム |
| US9251069B2 (en) * | 2012-12-21 | 2016-02-02 | Advanced Micro Devices, Inc. | Mechanisms to bound the presence of cache blocks with specific properties in caches |
| JP6432450B2 (ja) * | 2015-06-04 | 2018-12-05 | 富士通株式会社 | 並列計算装置、コンパイル装置、並列処理方法、コンパイル方法、並列処理プログラムおよびコンパイルプログラム |
| US11010165B2 (en) | 2019-03-12 | 2021-05-18 | Marvell Asia Pte, Ltd. | Buffer allocation with memory-based configuration |
| US11327890B1 (en) | 2019-05-29 | 2022-05-10 | Marvell Asia Pte, Ltd. | Partitioning in a processor cache |
| US11036643B1 (en) | 2019-05-29 | 2021-06-15 | Marvell Asia Pte, Ltd. | Mid-level instruction cache |
| US11093405B1 (en) | 2019-05-29 | 2021-08-17 | Marvell Asia Pte, Ltd. | Shared mid-level data cache |
| US11513958B1 (en) | 2019-05-29 | 2022-11-29 | Marvell Asia Pte, Ltd. | Shared mid-level data cache |
| US11379368B1 (en) | 2019-12-05 | 2022-07-05 | Marvell Asia Pte, Ltd. | External way allocation circuitry for processor cores |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH02224042A (ja) * | 1988-10-28 | 1990-09-06 | Apollo Computer Inc | キャッシュデータアクセス方法及び装置 |
| JPH05282203A (ja) * | 1992-01-31 | 1993-10-29 | Motorola Inc | キャッシュ・コントローラ |
| JPH06318178A (ja) * | 1992-05-18 | 1994-11-15 | Sun Microsyst Inc | キャッシュタグメモリ用キャッシュタグ制御装置及び制御方法 |
| JPH08153039A (ja) * | 1994-11-30 | 1996-06-11 | Hitachi Ltd | 半導体メモリ装置、及び、それを用いた情報処理装置 |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US118801A (en) * | 1871-09-12 | Improvement in head-blocks for saw-mills | ||
| US853738A (en) * | 1905-06-26 | 1907-05-14 | Edwin Ruud | Storage water-heater. |
| US852951A (en) * | 1906-04-25 | 1907-05-07 | August A Harnischfeger | Suspension-clamp for bacon. |
| JPH06318174A (ja) * | 1992-04-29 | 1994-11-15 | Sun Microsyst Inc | キャッシュ・メモリ・システム及び主メモリに記憶されているデータのサブセットをキャッシュする方法 |
| KR960006484B1 (ko) * | 1992-09-24 | 1996-05-16 | 마쯔시다 덴기 산교 가부시끼가이샤 | 캐쉬메모리장치 |
| US5835929A (en) * | 1996-05-20 | 1998-11-10 | Integrated Device Technology, Inc. | Method and apparatus for sub cache line access and storage allowing access to sub cache lines before completion of a line fill |
| US6289420B1 (en) * | 1999-05-06 | 2001-09-11 | Sun Microsystems, Inc. | System and method for increasing the snoop bandwidth to cache tags in a multiport cache memory subsystem |
| US6385696B1 (en) * | 1999-06-25 | 2002-05-07 | Intel Corporation | Embedded cache with way size bigger than page size |
-
2002
- 2002-12-13 US US10/319,205 patent/US6950906B2/en not_active Expired - Lifetime
-
2003
- 2003-12-12 JP JP2003415025A patent/JP2004199677A/ja active Pending
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH02224042A (ja) * | 1988-10-28 | 1990-09-06 | Apollo Computer Inc | キャッシュデータアクセス方法及び装置 |
| JPH05282203A (ja) * | 1992-01-31 | 1993-10-29 | Motorola Inc | キャッシュ・コントローラ |
| JPH06318178A (ja) * | 1992-05-18 | 1994-11-15 | Sun Microsyst Inc | キャッシュタグメモリ用キャッシュタグ制御装置及び制御方法 |
| JPH08153039A (ja) * | 1994-11-30 | 1996-06-11 | Hitachi Ltd | 半導体メモリ装置、及び、それを用いた情報処理装置 |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10037278B2 (en) | 2015-08-17 | 2018-07-31 | Fujitsu Limited | Operation processing device having hierarchical cache memory and method for controlling operation processing device having hierarchical cache memory |
Also Published As
| Publication number | Publication date |
|---|---|
| US6950906B2 (en) | 2005-09-27 |
| US20040117558A1 (en) | 2004-06-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US7032074B2 (en) | Method and mechanism to use a cache to translate from a virtual bus to a physical bus | |
| US8180981B2 (en) | Cache coherent support for flash in a memory hierarchy | |
| US6647466B2 (en) | Method and apparatus for adaptively bypassing one or more levels of a cache hierarchy | |
| US6725337B1 (en) | Method and system for speculatively invalidating lines in a cache | |
| US9792210B2 (en) | Region probe filter for distributed memory system | |
| JP3281893B2 (ja) | キャッシュ・メモリ階層内で利用するキャッシュ・コヒーレンシ機構を実施するための方法およびシステム | |
| US7266647B2 (en) | List based method and apparatus for selective and rapid cache flushes | |
| US6272602B1 (en) | Multiprocessing system employing pending tags to maintain cache coherence | |
| US20120102273A1 (en) | Memory agent to access memory blade as part of the cache coherency domain | |
| US20020169935A1 (en) | System of and method for memory arbitration using multiple queues | |
| US6915396B2 (en) | Fast priority determination circuit with rotating priority | |
| CN101088076A (zh) | 共享存储器计算机系统中自有高速缓存块的预测早写回 | |
| KR20030024895A (ko) | 캐시 코히어런트 멀티-프로세서 시스템에서 순서화된입출력 트랜잭션을 파이프라이닝하기 위한 방법 및 장치 | |
| US20050198441A1 (en) | Multiprocessor system | |
| JP4447580B2 (ja) | 分散共有メモリマルチプロセッサシステムのための分割疎ディレクトリ | |
| JP3245125B2 (ja) | 垂直キャッシュのための擬似精細i−キャッシュ包含性 | |
| US7281092B2 (en) | System and method of managing cache hierarchies with adaptive mechanisms | |
| US6973547B2 (en) | Coherence message prediction mechanism and multiprocessing computer system employing the same | |
| JP2004199677A (ja) | キャッシュを動作させるためのシステム及び方法 | |
| JP2000250884A (ja) | 不均等メモリ・アクセス・コンピュータ・システムにおいてエヴィクション・プロトコルを提供するための方法およびシステム | |
| US7117312B1 (en) | Mechanism and method employing a plurality of hash functions for cache snoop filtering | |
| US7325102B1 (en) | Mechanism and method for cache snoop filtering | |
| US7669013B2 (en) | Directory for multi-node coherent bus | |
| US6240487B1 (en) | Integrated cache buffers | |
| US7725660B2 (en) | Directory for multi-node coherent bus |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20061003 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20061003 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20091110 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20100210 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20100216 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20100727 |