JP2006155703A - 半導体集積回路 - Google Patents
半導体集積回路 Download PDFInfo
- Publication number
- JP2006155703A JP2006155703A JP2004341612A JP2004341612A JP2006155703A JP 2006155703 A JP2006155703 A JP 2006155703A JP 2004341612 A JP2004341612 A JP 2004341612A JP 2004341612 A JP2004341612 A JP 2004341612A JP 2006155703 A JP2006155703 A JP 2006155703A
- Authority
- JP
- Japan
- Prior art keywords
- dummy
- semiconductor integrated
- integrated circuit
- word line
- memory
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images







Landscapes
- Static Random-Access Memory (AREA)
- Logic Circuits (AREA)
Abstract
【解決手段】 メモリ部2における複数のデータ伝送線11、13の間で生じる遅延に係わる情報をモニタするモニタ回路12と、その遅延に合わせて位相が異なる複数の内部同期クロックを生成する生成回路21と、を備える。そして、生成回路21で生成した内部同期クロックを、メモリ部2とロジック部3とのタイミングを調整する信号として用いる。
【選択図】 図1
Description
ところが、大量のデータを一度に同時処理するためには、メモリコアのデータ入出力線の本数を多くする必要がある。しかし、そのような場合には、ワードライン方向の負荷が増加するとともに、ワードラインの配線抵抗によってドライバの近傍と最遠端とのワードライン選択時間に大きな時間差(遅延)が生じてしまう。これにより、メモリ部からの読出しタイミングや書込みタイミングが、複数のデータ入出力線間で異なってしまう。
また、特許文献2〜特許文献4等には、SRAMのセルフタイミング回路において、消費電流を軽減すること等を目的として、メモリ単体で構成される回路にダミーセルを用いる技術が開示されている。
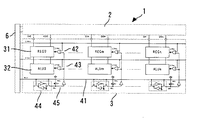
図1〜図3にて、この発明の実施の形態1について詳細に説明する。なお、本実施の形態1の説明にあたり、従来の半導体集積回路に係わる図7及び図8を適宜に参照する。
図1は、実施の形態1におけるSIMD方式の半導体集積回路を示す回路図である。これに対して、図7は、従来のSIMD方式の半導体集積回路を示す回路図である。本実施の形態1の半導体集積回路1は、複数のダミーメモリセル21が接続されたダミーワードライン12が設けられている点が、従来のものに対して構成上大きく相違する。
また、図2は実施の形態1の半導体集集積回路における動作タイミングを示すタイミングチャートであり、図3は特にロジック部のみが動作する際の動作タイミングを示すタイミングチャートである。これに対して、図8は従来の半導体集集積回路における動作タイミングを示すタイミングチャートである。
SIMD方式の半導体集積回路1は、大容量のデータを同時に並列処理するために、1本のデータ伝送線(制御信号線)で複数の回路を駆動することになる。具体的に、メモリ部2のワードライン11上には、複数のメモリセル20が接続されている。
半導体集積回路1を画像プロセッサとして用いる場合に、例えば、8ビットのデータを512PE(プロセッサエレメント)分処理することとする。このような場合には、一度に4096個のメモリセルを選択する必要がある。すなわち、1つのワードライン11で4096個ものメモリセルを駆動しなければならない。そのため、ワードライン11に対する配線負荷は非常に重く、配線長もかなり長くなる。
したがって、図7に示す従来の半導体集積回路1では、ワードライン11の近傍と最遠端とでは配線遅延による時間差が生じて、それにともないメモリ部2とロジック部3との転送をおこなうデータにも場所によってデータのあらわれるタイミングが異なってしまうという問題が生じていた。
このようにワードライン11の配線負荷を軽減させるためには、チップサイズの小面積化が達成できないという問題が生じる。小面積かつ高性能を実現するためには、メモリ部2における入出力データの場所による遅延成分はそのままにして、ロジック部3でのデータ入出力タイミングを合わせ込むことが必要になる。
詳しくは、メモリ部2におけるワードライン11(WL0(0)、WL0(m)、WL0(n))の場所的な遅延によって、ビットライン13(BL(0)、BL(m)、BL(n))を介した後のメモリ部2からの出力信号(DO(0)、DO(m)、DO(n))が異なったタイミングで出力される。この出力信号をロジック部3のレジスタ回路31で受信する場合、レジスタ回路31側でメモリ部2からの出力タイミングに合わせて取り込まなければならない。すなわち、レジスタ回路31においてCTREG信号が立ち上がるまでにメモリ部2の出力を確定させる必要がある。しかし、ロジック部3での制御信号(CTREG)の立ち上がりが速すぎると、場所によってデータの取り込みができなくなってしまう。
このように、メモリ部2とロジック部3との制御信号によるタイミングが合わずに、ロジック部2の信号が速くなってしまった場合等には、データのセットアップが不足してロジック部3が誤動作を起こしてしまう。また、ロジック部3の制御信号が遅くなってしまった場合には、メモリ部2からのデータがホールドできずにロジック部3への誤書き込みとなる。
具体的に、図1を参照して、本実施の形態1の半導体集積回路1は、メモリ部2にワードライン11の動作を模擬するためのダミーワードライン12を設けている。このダミーワードライン12には、複数のダミーメモリセル21が接続されている。ダミーメモリセル21は、1対のビットライン13における一方(DBL)に「L(ロー)」が出力されるようにデータが予め固定されている。また、このDBLの出力ノードには、その出力が予め「H(ハイ)」に固定されるようにプリチャージ回路22が接続されている。
ワードライン11(WL0(0)、WL0(m)、WL0(n))は、従来のものと同様に、デコーダ6に近い側は速く、遠い側は遅れて選択される。また、ダミーワードライン12(WLd)も、ワードライン11の動作を模擬してワードライン11と同様の動作をおこなう。
その後、ロジック部3へ同期信号が伝えられると、その同期タイミングに合わせてロジック部3でメモリ部2からのデータが取り込まれる。
また、ロジック部3へ供給される同期信号は、レジスタ回路(REG)とのタイミング調整だけではなくて,演算回路32(ALU)とのタイミング調整にも用いられるために、メモリ部2とのアクセス中に演算回路32等を動作させることが可能になる。
これはメモリセル20に特有のレイアウト形状を利用して、内部同期クロックを生成することで実現させたものである。この半導体集積回路1を用いることで、メモリ部2とロジック部3とのタイミング調整が容易になって、動作周波数を向上させることができる。また、動作タイミングを安定させることで、不要な消費電流を軽減させることができる。さらに、メモリ部2を分割せずに1つの塊として扱うために、チップサイズを比較的縮小することができる。
ロジック部3のみを動作させる場合には、ワードライン11で生じる遅延に合わせて、プロセッサエレメント(PE)方向に回路の動作タイミングをずらす必要がない。そのため、メモリ部2から供給される内部同期信号(CKI)は使用されない。ロジック部3は、その内部に予めデータベース化された論理回路が設置されているために、レジスタ回路31(REG)や演算回路32(ALU)の同期をとることは容易である。図3に示すように、ロジック部3のみを動作させる場合には、ロジック部3内でその動作タイミングが調整される。すなわち、制御信号(CTREG、CTALU)の負荷を軽くして、ロジック部3内の遅延を軽減している。これにより、ロジック部3だけの動作時において、メモリ部2を含めて動作する場合に比べて、高速動作を可能としている。
図4にて、この発明の実施の形態2について詳細に説明する。
図4は、実施の形態2における半導体集積回路1を示す回路図である。本実施の形態2の半導体集積回路1は、ロジック部3に第2のモニタ回路としてのダミーワードライン41が設けられている点が、前記実施の形態1のものとは相違する。
そして、ダミーワードライン41により出力された信号は、内部同期信号として、レジスタ回路31に接続された選択回路42と、演算回路32に接続された選択回路43と、に供給される。選択回路42、43では、それぞれ、制御信号(CTREG、CTALU)を用いるか、ダミーメモリセル44で生成された内部同期信号を用いるかが選択される。
図5にて、この発明の実施の形態3について詳細に説明する。
図5は、実施の形態3における半導体集積回路1を示す回路図である。本実施の形態3の半導体集積回路1は、ダミーワードライン12の替わりにダミービットライン23が形成されている点が、前記実施の形態1のものとは相違する。
そして、ビットライン13のデータは、センスアンプ14で増幅されて出力される。これに同期して、ダミーセンスアンプ18から出力信号の検出信号が生成される。これを内部同期信号とすることで、ワードライン11で生じる遅延成分だけではなく、ビットライン13で生じる遅延成分もモニタできることになる。したがって、メモリ部2からの出力信号に一層近いタイミングで、内部同期信号を生成することができる。
ここで、mの数が小さくなれば精度が高まることになるが、ダミー回路の挿入数が増えるためにその分だけチップサイズが大きくなってしまう。これに対して、mの数が大きくなれば、ロジック部3とのタイミングが調整しにくくなってしまう。分割数(m)は容易に変更できるために、上述の関係を理解した上で、半導体集積回路1の用途に応じて分割数(m)を適宜に変更することが好ましい。
図6にて、この発明の実施の形態3について詳細に説明する。
図6は、実施の形態4における半導体集積回路1を示す回路図である。本実施の形態4の半導体集積回路1は、ダミーワードライン12に加えて第2のダミーワードライン51が形成されている点が、前記実施の形態1のものとは相違する。
ワードライン11が立ち上がると、それと同時に逆相ワードライン51が立ち下がって、プリチャージが終了するのに合わせて内部同期信号(CKI)が立ち上がる。これに対して、ワードライン11が立ち下がると、ダミーワードライン12に接続されたダミーメモリセル21が非選択になって、それに合わせて逆相ワードライン51が選択されて、プリチャージ信号が生成される。そして、内部同期信号は、「H」から「L」へと変化する。このように,本実施の形態4の半導体集積回路1では、ワードライン11の立ち上がりや立ち下りに同期して、内部クロックを生成することができる。
2 メモリ部(メモリコア)、
3 ロジック部、 6 デコーダ、
11 ワードライン、
12、41、51 ダミーワードライン、
13 ビットライン、 14 センスアンプ、
15 ライトバッファ、 18 ダミーセンスアンプ、
20 メモリセル、
21、28、44、54 ダミーメモリセル、
23 ダミービットライン、
22、45、52 プリチャージ回路、
31 レジスタ回路、 32 演算回路、
35、36、42、43 選択回路。
Claims (12)
- 複数のデータ伝送線を有するメモリ部とロジック部とが単一の半導体チップ上に形成されて複数のデータ処理を同時におこなう半導体集積回路であって、
前記メモリ部における前記複数のデータ伝送線の間で生じる遅延に係わる情報をモニタするモニタ回路と、
前記遅延に合わせて位相が異なる複数の内部同期クロックを生成する生成回路と、を備え、
前記内部同期クロックを前記メモリ部と前記ロジック部とのタイミングを調整する信号として用いることを特徴とする半導体集積回路。 - 前記生成回路は、前記メモリ部と前記ロジック部とを接続する複数のデータ伝送線に対して所定間隔ごとに前記内部同期クロックを生成することを特徴とする請求項1に記載の半導体集積回路。
- 前記複数のデータ伝送線は、複数のワードライン及びビットラインであって、
前記モニタ回路は、前記ワードラインの動作を模擬するように形成されたダミーワードラインであることを特徴とする請求項1又は請求項2に記載の半導体集積回路。 - 前記ワードラインは、複数のメモリセルが接続され、
前記ダミーワードラインは、予め固定されたデータを保持するとともに前記メモリセルの動作を模擬するように形成されたダミーメモリセルが接続されたことを特徴とする請求項3に記載の半導体集積回路。 - 前記生成回路は、前記ダミーメモリセルであることを特徴とする請求項4に記載の半導体集積回路。
- 前記ワードラインは、複数のメモリセルが接続され、
前記ダミーワードラインは、予め固定されたデータを保持するとともに前記メモリセルの動作を模擬するように形成されたダミーメモリセルが接続され、
前記ダミーワードラインに対して逆相で動作するように形成された第2のダミーワードラインと、
前記第2のダミーワードラインに接続された第2のダミーメモリセルと、
前記ダミーメモリセルの出力ノードに接続されるとともに、前記第2のダミーメモリセルからの出力信号が入力されるプリチャージ回路と、
前記第2のダミーメモリセルの出力ノードに接続されるとともに、前記ダミーメモリセルからの出力信号が入力される第2のプリチャージ回路と、を備えたことを特徴とする請求項3〜請求項5のいずれかに記載の半導体集積回路。 - 前記生成回路は、前記ワードラインの立ち上がり又は立ち下がりの変化に合わせて前記内部同期クロックを生成することを特徴とする請求項6に記載の半導体集積回路。
- 前記複数のデータ伝送線は、複数のメモリセルが接続された複数のワードライン及びビットラインであって、
前記ビットラインの動作を模擬するように形成されたダミービットラインを備え、
前記ダミービットラインは、予め固定されたデータを保持するとともに前記メモリセルの動作を模擬するように形成されたダミーメモリセルが接続されるとともに、当該ダミービットラインの信号を増幅するダミーのセンスアンプが接続され、
前記モニタ回路は、前記ダミービットラインであることを特徴とする請求項1〜請求項7のいずれかに記載の半導体集積回路。 - 前記ダミービットラインで生成される内部同期クロックを前記メモリ部のセンスアンプ又は/及びライトバッファを制御する同期クロックとして用いることを特徴とする請求項8に記載の半導体集積回路。
- 前記ロジック部は、当該ロジック部におけるワードライン方向の遅延に係わる情報をモニタする第2のモニタ回路を備えたことを特徴とする請求項1〜請求項9のいずれかに記載の半導体集積回路。
- 前記内部同期クロックは、前記メモリ部へのアクセスがおこなわれているときに前記メモリ部と前記ロジック部とのタイミングを調整する信号として用いられることを特徴とする請求項1〜請求項10のいずれかに記載の半導体集積回路。
- 前記メモリ部へのアクセスがおこなわれていないときに、前記ロジック部における遅延に係わる情報のみで生成される内部同期信号を用いて当該ロジック部におけるタイミングの調整をおこなうことを特徴とする請求項11に記載の半導体集積回路。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004341612A JP4836162B2 (ja) | 2004-11-26 | 2004-11-26 | 半導体集積回路 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004341612A JP4836162B2 (ja) | 2004-11-26 | 2004-11-26 | 半導体集積回路 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2006155703A true JP2006155703A (ja) | 2006-06-15 |
| JP4836162B2 JP4836162B2 (ja) | 2011-12-14 |
Family
ID=36633829
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004341612A Expired - Fee Related JP4836162B2 (ja) | 2004-11-26 | 2004-11-26 | 半導体集積回路 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4836162B2 (ja) |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0214490A (ja) * | 1988-06-30 | 1990-01-18 | Ricoh Co Ltd | 半導体メモリ装置 |
| JPH0359884A (ja) * | 1989-07-27 | 1991-03-14 | Nec Corp | 半導体記憶装置 |
| JPH09128958A (ja) * | 1995-11-01 | 1997-05-16 | Sony Corp | 半導体メモリ装置 |
| JPH10302479A (ja) * | 1997-04-03 | 1998-11-13 | St Microelectron Srl | メモリデバイス |
| JPH11203873A (ja) * | 1998-01-16 | 1999-07-30 | Hitachi Ltd | 半導体集積回路及びデータ処理システム |
| JP2000516008A (ja) * | 1995-12-28 | 2000-11-28 | エルエスアイ ロジック コーポレーション | 低電力セルフタイミングメモリ装置およびその制御方法ならびに装置 |
-
2004
- 2004-11-26 JP JP2004341612A patent/JP4836162B2/ja not_active Expired - Fee Related
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0214490A (ja) * | 1988-06-30 | 1990-01-18 | Ricoh Co Ltd | 半導体メモリ装置 |
| JPH0359884A (ja) * | 1989-07-27 | 1991-03-14 | Nec Corp | 半導体記憶装置 |
| JPH09128958A (ja) * | 1995-11-01 | 1997-05-16 | Sony Corp | 半導体メモリ装置 |
| JP2000516008A (ja) * | 1995-12-28 | 2000-11-28 | エルエスアイ ロジック コーポレーション | 低電力セルフタイミングメモリ装置およびその制御方法ならびに装置 |
| JPH10302479A (ja) * | 1997-04-03 | 1998-11-13 | St Microelectron Srl | メモリデバイス |
| JPH11203873A (ja) * | 1998-01-16 | 1999-07-30 | Hitachi Ltd | 半導体集積回路及びデータ処理システム |
Also Published As
| Publication number | Publication date |
|---|---|
| JP4836162B2 (ja) | 2011-12-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2011040041A (ja) | 書き込みレベリング動作を行うためのメモリ装置の制御方法、メモリ装置の書き込みレベリング方法、及び書き込みレベリング動作を行うメモリコントローラ、メモリ装置、並びにメモリシステム | |
| US8897083B1 (en) | Memory interface circuitry with data strobe signal sharing capabilities | |
| US8169851B2 (en) | Memory device with pseudo double clock signals and the method using the same | |
| JP4515566B2 (ja) | 半導体集積回路 | |
| TW200923966A (en) | Access collision within a multiport memory | |
| WO2020131528A1 (en) | Signal skew in source-synchronous system | |
| JP2004171609A (ja) | 半導体記憶装置 | |
| US7944733B2 (en) | Static random access memory (SRAM) of self-tracking data in a read operation, and method thereof | |
| EP1878021B1 (en) | An integrated circuit memory device, system and method having interleaved row and column control | |
| KR102424896B1 (ko) | 데이터 트레이닝 장치 및 이를 포함하는 반도체 장치 | |
| JP4957719B2 (ja) | Ramマクロ、そのタイミング生成回路 | |
| KR100301046B1 (ko) | 그래픽처리속도를향상시킬수있는듀얼포트를갖는고속싱크로너스메모리장치 | |
| US7227812B2 (en) | Write address synchronization useful for a DDR prefetch SDRAM | |
| JP2005196935A (ja) | 高速にデータアクセスをするための半導体メモリ装置 | |
| JP5038657B2 (ja) | 半導体集積回路装置 | |
| JP4836162B2 (ja) | 半導体集積回路 | |
| JP5231190B2 (ja) | 半導体装置とメモリマクロ | |
| CN120452517A (zh) | 用于多周期操作的关闭周期的上升沿检测 | |
| KR20060021439A (ko) | 반도체 메모리 장치 및 반도체 메모리 장치의 센스 앰프제어 방법 | |
| JP2003187574A (ja) | 同期式半導体メモリ装置 | |
| US20070177449A1 (en) | Semiconductor memory, memory controller and control method for semiconductor memory | |
| US7457913B2 (en) | Finding a data pattern in a memory | |
| US6788615B2 (en) | System and method for low area self-timing in memory devices | |
| US7415569B2 (en) | Memory including a write training block | |
| US6804166B2 (en) | Method and apparatus for operating a semiconductor memory at double data transfer rate |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20071114 |
|
| RD03 | Notification of appointment of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7423 Effective date: 20071116 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20100127 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100204 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100402 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20101215 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110213 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20110922 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20110922 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20141007 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |