JP2007102709A - 遺伝子診断用のマーカー選定プログラム、該プログラムを実行する装置及びシステム、並びに遺伝子診断システム - Google Patents
遺伝子診断用のマーカー選定プログラム、該プログラムを実行する装置及びシステム、並びに遺伝子診断システム Download PDFInfo
- Publication number
- JP2007102709A JP2007102709A JP2005295333A JP2005295333A JP2007102709A JP 2007102709 A JP2007102709 A JP 2007102709A JP 2005295333 A JP2005295333 A JP 2005295333A JP 2005295333 A JP2005295333 A JP 2005295333A JP 2007102709 A JP2007102709 A JP 2007102709A
- Authority
- JP
- Japan
- Prior art keywords
- combination
- group
- list
- gene
- diagnostic
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images




















Classifications
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
- G16B20/20—Allele or variant detection, e.g. single nucleotide polymorphism [SNP] detection
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
- G16B20/40—Population genetics; Linkage disequilibrium
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B50/00—ICT programming tools or database systems specially adapted for bioinformatics
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B50/00—ICT programming tools or database systems specially adapted for bioinformatics
- G16B50/30—Data warehousing; Computing architectures
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Theoretical Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Medical Informatics (AREA)
- Biophysics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Biotechnology (AREA)
- Evolutionary Biology (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Genetics & Genomics (AREA)
- Molecular Biology (AREA)
- Bioethics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Databases & Information Systems (AREA)
- Chemical & Material Sciences (AREA)
- Analytical Chemistry (AREA)
- Physiology (AREA)
- Ecology (AREA)
- Apparatus Associated With Microorganisms And Enzymes (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Medical Treatment And Welfare Office Work (AREA)
- Investigating Or Analysing Biological Materials (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
【解決手段】遺伝子診断に用いるためのマーカーを選定するマーカー選定プログラムを提供する。該プログラムでは、複数の検体が属する二以上の集団がそれぞれに保有する検体データベースを用いて解析を行う。全検体データを統合せずに解析することによって、少数集団の情報であっても遺伝子探索に確実に反映させることができる。各集団の特徴を反映させることが可能であるため、精度の高い診断式を得ることができ、実用的な診断システムを提供することが可能である。
【選択図】図1
Description
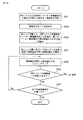
予め既知の遺伝子多型の同定情報を記録しておく遺伝子多型データ記録手段、
予め前記遺伝子多型データ中の任意の二以上の遺伝子多型を組合せた、遺伝子多型組合せリストを記録しておく遺伝子多型組合せリスト記録手段、
予め前記遺伝子多型組合せリストに記載された各遺伝子多型組合せに関する対立遺伝子型組合せリストを記録しておく、対立遺伝子型組合せリスト記録手段、
複数の検体が属する二以上の集団について、前記既知の遺伝子多型における各検体の遺伝子型、並びに診断事項に対する傾向を記録しておく、集団毎の検体データ記録手段、
前記遺伝子多型組合せリストに記載された各遺伝子多型組合せについて、該各組合せに関する対立遺伝子型組合せリストを読み出し、該リストに記載された対立遺伝子型組合せが、前記診断事項との間に相関を有するかどうかを、前記検体データベースに保存されたデータに基づいて判定する関連性演算手段、
前記関連性演算手段によって相関を有すると判定された遺伝子多型組合せ及びその対立遺伝子型組合せを、前記集団毎に関連性一覧表に記録しておく関連性一覧表記録手段、
前記集団毎の関連性一覧表を比較し、全ての関連性一覧表に共通して存在する遺伝子多型組合せ及びその対立遺伝子型組合せを、第2の関連性一覧表に記録する集団比較手段、
前記第2の関連性一覧表の中から、全ての集団において診断事項に対する傾向が同じである遺伝子多型組合せ及びその対立遺伝子型組合せを選択し、マーカー候補として第3の関連性一覧表に記載する傾向判定手段、
前記手段によって得られたマーカー候補を出力する出力手段、
として機能させるためのマーカー選定プログラムが提供される。
前記遺伝子多型組合せリスト中の遺伝子多型組合せ毎に、前記対立遺伝子型組合せリストを読み出し、
該リスト中の各対立遺伝子型組合せについて、前記検体データベースに基づき、該組合せを有する検体をA群に分類し、それ以外の検体をB群に分類し、
該A群及びB群のそれぞれにおいて、診断事項に対する傾向によって、検体を有効群と無効群とに分類し、
該A群及びB群における、有効群と無効群との割合に差があるかどうかを検定し、
該検定において有意の差があった遺伝子多型及び対立遺伝子型を、関連性ありと判定する手段であることが好ましい。
各集団の相関係数を平均し、該平均値が最大である遺伝子多型組合せ及びその対立遺伝子型組合せを選択する手段であることが好ましい。
遺伝子診断式を作成するために、コンピュータを、
請求項1又は2における前記第3の関連性一覧表のマーカー候補について、集団毎に、前記A群に属する検体をX=−1とし、前記B群に属する検体をX=+1とするか、A群に属する検体をX=+1、B群に属する検体をX=−1とするか、或いはA群に属する検体をX=α、B群に属する検体をX=βとし(ただし、αとβは互いに異なる任意の数である)、また、前記治療の有効性及び/又は病気のかかり易さによって、各検体をy=1、又はy=0とし、
各集団に対する診断式 Y=aX+t (ここで、a及びtは定数である)を作成する診断式作成手段、
作成された診断式を出力する出力手段、
として機能させるための診断式作成プログラムが提供される。
前記各マーカー候補の各集団に対する診断式の、それぞれの集団に対する寄与率Kを演算する手段、
該寄与率Kの平均値が最大であるマーカー候補の診断式を選択する選択手段、
選択された診断式を出力する出力手段、
として機能させるための診断式作成プログラムであることが好ましい。
上記のように選定されたマーカーを読み込む手段、
予め測定された診断対象検体の遺伝子配列を入力する手段、
前記選定されたマーカーと同様の遺伝子多型組合せ及びその対立遺伝子型組合せが、該検体中に存在するか否かを判定する手段、
該判定に基づき、該検体を診断する手段、
該診断結果を出力する手段、
とを具備してなることを特徴とする。
上記のように作成された診断式を読み込む手段、
予め測定された診断対象検体の遺伝子配列を入力する手段、
前記診断式に、該検体のデータを適用し、予想率を得る手段、
得られた予想率を出力する手段、
とを具備してなることを特徴とする。
(第1実施形態)
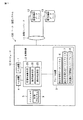
第1の実施形態として、マーカーを選定するためのプログラム、並びに該プログラムを実行するための装置及びシステムが提供される。図1は、本発明のマーカー選定プログラムを実現するための装置及びシステムの全体像を示す図である。

図12は、C型肝炎のインターフェロン治療に関するT病院の検体データベースの内容である。該データベースには、T病院で過去に行った治験結果が記録されている。図12のデータベースの内容を説明する。治験を行った患者に識別番号を振り、検体番号欄に記入する。なお、個人情報保護のため、検体番号とカルテ番号は相違する。カルテ番号と検体番号の対応表は、本発明によるシステムとは別のシステムで管理されている。
次に、集団が3つ存在する場合を例に説明する。本実施例でも、C型関連ウイルスに感染した検体に対する、インターフェロンによる治療の有効性を診断するために用いるマーカーを選定した。しかしながら、第一の実施例と異なり、最近開発された新しいタイプのインターフェロンと抗ウイルス剤の併用療法による治験結果を利用した。本新手法は、当初日本では導入されていなかったため、米国での治験結果を用いて解析を行った。
本発明の第3の実施形態に係る実施例を説明する。具体的には、第1の実施例においてインターフェロン有効性に関わるマーカー候補を選定した後(第3の関連性一覧表)、生物学的な知識に基づいて更なる絞込みを行う方法を説明する。
さらに、本発明の第4の実施形態に係る実施例を説明する。具体的には、第1の実施例においてインターフェロン有効性に関わるマーカー候補を選定した後(第3の関連性一覧表)、生物学的な知識に基づいて更なる絞込みを行う方法を説明する。
Claims (15)
- 遺伝子診断に用いるためのマーカーを選定するためにコンピュータを、
予め既知の遺伝子多型の同定情報を記録しておく遺伝子多型データ記録手段、
予め前記遺伝子多型データ中の任意の二以上の遺伝子多型を組合せた、遺伝子多型組合せリストを記録しておく遺伝子多型組合せリスト記録手段、
予め前記遺伝子多型組合せリストに記載された各遺伝子多型組合せに関する対立遺伝子型組合せリストを記録しておく、対立遺伝子型組合せリスト記録手段、
複数の検体が属する二以上の集団について、前記既知の遺伝子多型における各検体の遺伝子型、並びに診断事項に対する傾向を記録しておく、集団毎の検体データ記録手段、
前記遺伝子多型組合せリストに記載された各遺伝子多型組合せについて、該各組合せに関する対立遺伝子型組合せリストを読み出し、該リストに記載された対立遺伝子型組合せが、前記診断事項との間に相関を有するかどうかを、前記検体データベースに保存されたデータに基づいて判定する関連性演算手段、
前記関連性演算手段によって相関を有すると判定された遺伝子多型組合せ及びその対立遺伝子型組合せを、前記集団毎に関連性一覧表に記録しておく関連性一覧表記録手段、
前記集団毎の関連性一覧表を比較し、少なくとも二以上の関連性一覧表に共通して存在する遺伝子多型組合せ及びその対立遺伝子型組合せを、第2の関連性一覧表に記録する集団比較手段、
前記第2の関連性一覧表の中から、少なくとも二以上の集団において診断事項に対する傾向が同じである遺伝子多型組合せ及びその対立遺伝子型組合せを選択し、マーカー候補として第3の関連性一覧表に記載する傾向判定手段、
前記手段によって得られたマーカー候補を出力する出力手段、
として機能させるためのマーカー選定プログラム。 - 前記関連性演算手段は、
前記遺伝子多型組合せリスト中の遺伝子多型組合せ毎に、前記対立遺伝子型組合せリストを読み出し、
該リスト中の各対立遺伝子型組合せについて、前記検体データベースに基づき、該組合せを有する検体をA群に分類し、それ以外の検体をB群に分類し、
該A群及びB群のそれぞれにおいて、診断事項に対する傾向によって、検体を有効群と無効群とに分類し、
該A群及びB群における、有効群と無効群との割合に差があるかどうかを検定し、
該検定において有意の差があった遺伝子多型及び対立遺伝子型を、関連性ありと判定する、請求項1に記載のマーカー選定プログラム。 - コンピュータを、前記傾向判定手段に続いて、前記第3の関連性一覧表に記載されたマーカー候補から、遺伝子診断用に最適なマーカー候補を選択する候補選択手段として機能させることをさらに含む、請求項1又は2に記載のマーカー選定プログラム。
- 前記第3の関連性一覧表から最適なマーカー候補を選択する手段は、
各集団の相関係数を平均し、該平均値が最大である遺伝子多型組合せ及びその対立遺伝子型組合せを選択する手段である、請求項3に記載のマーカー選定プログラム。 - 遺伝子診断式を作成するために、コンピュータを、
請求項1又は2における前記第3の関連性一覧表のマーカー候補について、集団毎に、前記A群に属する検体をX=−1とし、前記B群に属する検体をX=+1とするか、A群に属する検体をX=+1、B群に属する検体をX=−1とするか、或いはA群に属する検体をX=α、B群に属する検体をX=βとし(ただし、αとβは互いに異なる任意の数である)、また、前記治療の有効性及び/又は病気のかかり易さによって、各検体をy=1、又はy=0とし、
各集団に対する診断式 Y=aX+t (ここで、a及びtは定数である)を作成する診断式作成手段、
作成された診断式を出力する出力手段、
として機能させるための診断式作成プログラム。 - 前記診断式作成手段に続いて、前記作成された診断式から、最適な診断式を選択するために、コンピュータを、
前記各マーカー候補の各集団に対する診断式の、それぞれの集団に対する寄与率Kを演算する手段、
該寄与率Kの平均値が最大であるマーカー候補の診断式を選択する選択手段、
選択された診断式を出力する出力手段、
として機能させるための、請求項5に記載の診断式作成プログラム;
ここにおいて、
寄与率Kは診断式の精度を評価するパラメータであり、
ただし、
- 請求項1〜4の何れかにおいて選定されたマーカーを用いて、診断対象検体を遺伝子診断するためのシステムであって、
請求項1〜4の何れかにおいて選定されたマーカーを読み込む手段、
予め測定された診断対象検体の遺伝子配列を入力する手段、
前記選定されたマーカーと同様の遺伝子多型組合せ及びその対立遺伝子型組合せが、該検体中に存在するか否かを判定する手段、
該判定に基づき、該検体を診断する手段、
該診断結果を出力する手段、
とを具備してなることを特徴とする遺伝子診断システム。 - 請求項5又は6において作成された診断式を用いて、診断対象検体を遺伝子診断するためのシステムであって、
請求項5又は6の何れかにおいて作成された診断式を読み込む手段、
予め測定された診断対象検体の遺伝子配列を入力する手段、
前記診断式に、該検体のデータを適用し、予想率を得る手段、
得られた予想率を出力する手段、
とを具備してなることを特徴とする遺伝子診断システム。 - 遺伝子診断に用いるためのマーカーを選定するための装置であって、
予め既知の遺伝子多型の同定情報を記録しておく遺伝子多型データ記録手段、
予め前記遺伝子多型データ中の任意の二以上の遺伝子多型を組合せた、遺伝子多型組合せリストを記録しておく遺伝子多型組合せリスト記録手段、
予め前記遺伝子多型組合せリストに記載された各遺伝子多型組合せに関する対立遺伝子型組合せリストを記録しておく、対立遺伝子型組合せリスト記録手段、
複数の検体が属する二以上の集団について、前記既知の遺伝子多型における各検体の遺伝子型、並びに診断事項に対する傾向を記録しておく、集団毎の検体データ記録手段、
前記遺伝子多型組合せリストに記載された各遺伝子多型組合せについて、該各組合せに関する対立遺伝子型組合せリストを読み出し、該リストに記載された対立遺伝子型組合せが、前記診断事項との間に相関を有するかどうかを、前記検体データベースに保存されたデータに基づいて判定する関連性演算手段、
前記関連性演算手段によって相関を有すると判定された遺伝子多型組合せ及びその対立遺伝子型組合せを、前記集団毎に関連性一覧表に記録しておく関連性一覧表記録手段、
前記集団毎の関連性一覧表を比較し、全ての関連性一覧表に共通して存在する遺伝子多型組合せ及びその対立遺伝子型組合せを、第2の関連性一覧表に記録する集団比較手段、
前記第2の関連性一覧表の中から、全ての集団において診断事項に対する傾向が同じである遺伝子多型組合せ及びその対立遺伝子型組合せを選択し、マーカー候補として第3の関連性一覧表に記載する傾向判定手段、
前記手段によって得られたマーカー候補を出力する出力手段、
を具備する、遺伝子診断用のマーカー選定装置。 - 前記関連性演算手段は、
前記遺伝子多型組合せリスト中の遺伝子多型組合せ毎に、前記対立遺伝子型組合せリストを読み出し、
該リスト中の各対立遺伝子型組合せについて、前記検体データベースに基づき、該組合せを有する検体をA群に分類し、それ以外の検体をB群に分類し、
該A群及びB群のそれぞれにおいて、診断事項に対する傾向によって、検体を有効群と無効群とに分類し、
該A群及びB群における、有効群と無効群との割合に差があるかどうかを検定し、
該検定において有意の差があった遺伝子多型及び対立遺伝子型を、関連性ありと判定する、請求項9に記載のマーカー選定装置。 - 前記第3の関連性一覧表に記載されたマーカー候補から、遺伝子診断用に最適なマーカー候補を選択する候補選択手段をさらに含む、請求項9又は10に記載のマーカー選定装置。
- 前記第3の関連性一覧表から最適なマーカー候補を選択する手段は、
各集団の相関係数を平均し、該平均値が最大である遺伝子多型組合せ及びその対立遺伝子型組合せを選択する手段である、請求項11に記載のマーカー選定装置。 - 遺伝子診断式を作成するための装置であって
請求項9又は10における前記第3の関連性一覧表のマーカー候補について、集団毎に、前記A群に属する検体をX=−1とし、前記B群に属する検体をX=+1とするか、A群に属する検体をX=+1、B群に属する検体をX=−1とするか、或いはA群に属する検体をX=α、B群に属する検体をX=βとし(ただし、αとβは互いに異なる任意の数である)、また、前記治療の有効性及び/又は病気のかかり易さによって、各検体をy=1、又はy=0とし、
各集団に対する診断式 Y=aX+t (ここで、a及びtは定数である)を作成する診断式作成手段、
作成された診断式を出力する出力手段、
を具備する、遺伝子診断式作成装置。 - 前記各マーカー候補の各集団に対する診断式の、それぞれの集団に対する寄与率Kを演算する手段、
該寄与率Kの平均値が最大であるマーカー候補の診断式を選択する選択手段、
選択された診断式を出力する出力手段、
を具備する、請求項13に記載の遺伝子診断式作成装置:
ここにおいて、
寄与率Kは診断式の精度を評価するパラメータであり、
ただし、
- 請求項5又は6において作成された遺伝子診断のための診断式が記録されたコンピュータ読み取り可能な記録媒体。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005295333A JP2007102709A (ja) | 2005-10-07 | 2005-10-07 | 遺伝子診断用のマーカー選定プログラム、該プログラムを実行する装置及びシステム、並びに遺伝子診断システム |
| US11/533,134 US20070082353A1 (en) | 2005-10-07 | 2006-09-19 | Genetic marker selection program for genetic diagnosis, apparatus and system for executing the same, and genetic diagnosis system |
| KR1020060097973A KR100806436B1 (ko) | 2005-10-07 | 2006-10-09 | 유전자 진단을 위한 마커 선택 프로그램을 포함하는 컴퓨터판독가능 매체, 마커 선택 장치 및 시스템, 및 유전자진단 함수 생성 장치 및 시스템 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005295333A JP2007102709A (ja) | 2005-10-07 | 2005-10-07 | 遺伝子診断用のマーカー選定プログラム、該プログラムを実行する装置及びシステム、並びに遺伝子診断システム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2007102709A true JP2007102709A (ja) | 2007-04-19 |
Family
ID=37911422
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2005295333A Pending JP2007102709A (ja) | 2005-10-07 | 2005-10-07 | 遺伝子診断用のマーカー選定プログラム、該プログラムを実行する装置及びシステム、並びに遺伝子診断システム |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20070082353A1 (ja) |
| JP (1) | JP2007102709A (ja) |
| KR (1) | KR100806436B1 (ja) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR100806436B1 (ko) | 2005-10-07 | 2008-02-21 | 가부시끼가이샤 도시바 | 유전자 진단을 위한 마커 선택 프로그램을 포함하는 컴퓨터판독가능 매체, 마커 선택 장치 및 시스템, 및 유전자진단 함수 생성 장치 및 시스템 |
| WO2010064413A1 (ja) * | 2008-12-01 | 2010-06-10 | 国立大学法人山口大学 | 薬剤の作用・副作用予測システムとそのプログラム |
| JP2013220226A (ja) * | 2012-04-17 | 2013-10-28 | Kddi Corp | データ解析装置、プログラムおよびデータ解析方法 |
| JP2016504667A (ja) * | 2012-11-26 | 2016-02-12 | コーニンクレッカ フィリップス エヌ ヴェKoninklijke Philips N.V. | 患患者固有の関連性評価を用いた変異と疾患の関連付けを使用する診断的遺伝子分析 |
Families Citing this family (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7844609B2 (en) | 2007-03-16 | 2010-11-30 | Expanse Networks, Inc. | Attribute combination discovery |
| US8108406B2 (en) | 2008-12-30 | 2012-01-31 | Expanse Networks, Inc. | Pangenetic web user behavior prediction system |
| EP2370929A4 (en) | 2008-12-31 | 2016-11-23 | 23Andme Inc | SEARCH FOR RELATED IN A DATABASE |
| EP2207119A1 (en) * | 2009-01-06 | 2010-07-14 | Koninklijke Philips Electronics N.V. | Evolutionary clustering algorithm |
| KR101670967B1 (ko) * | 2009-10-29 | 2016-11-09 | 삼성전자주식회사 | 유전체 마커의 선택 방법 및 장치 |
| KR101243063B1 (ko) * | 2012-08-03 | 2013-03-13 | 한국과학기술정보연구원 | 패스웨이 구축 시스템 및 방법 |
| KR101599922B1 (ko) * | 2014-10-20 | 2016-03-04 | 동아대학교 산학협력단 | 이종 간에 작용하는 유전자 마커 디자인을 위한 csgm 디자이너 플랫폼 |
| US10395759B2 (en) | 2015-05-18 | 2019-08-27 | Regeneron Pharmaceuticals, Inc. | Methods and systems for copy number variant detection |
| US12071669B2 (en) | 2016-02-12 | 2024-08-27 | Regeneron Pharmaceuticals, Inc. | Methods and systems for detection of abnormal karyotypes |
| CN107577907B (zh) * | 2017-09-08 | 2021-04-02 | 成都奇恩生物科技有限公司 | 一种基于互联网的罕见病辅助诊断系统及使用方法 |
| CN113470776B (zh) * | 2021-05-28 | 2024-07-16 | 南方医科大学皮肤病医院(广东省皮肤病医院、广东省皮肤性病防治中心、中国麻风防治研究中心) | 数据采集、分析及报告生成一体化的遗传诊断系统 |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001357130A (ja) * | 2000-06-13 | 2001-12-26 | Hitachi Ltd | 診療情報管理システム |
| JP2002312361A (ja) * | 2001-10-16 | 2002-10-25 | Mitsui Knowledge Industry Kk | 匿名化臨床研究支援方法およびそのシステム |
| WO2003048999A2 (en) * | 2001-12-03 | 2003-06-12 | Dnaprint Genomics, Inc. | Methods and apparatus for genetic classification |
| JP2003519829A (ja) * | 1999-10-13 | 2003-06-24 | シークエノム・インコーポレーテツド | データベースを作成する方法および多型遺伝的マーカーを同定するためのデータベース |
| JP2004113661A (ja) * | 2002-09-27 | 2004-04-15 | Toshiba Corp | 治療法の有効性を予測するためのプログラム、データベース、システム及び方法 |
| JP2004173505A (ja) * | 2002-11-22 | 2004-06-24 | Mitsuo Itakura | 疾患感受性遺伝子の同定方法並びにそれに用いるプログラムおよびシステム |
| JP2005259132A (ja) * | 2004-02-28 | 2005-09-22 | Samsung Electronics Co Ltd | 複合疾患と関連した多重snpマーカーから最適のマーカーセットを選択する方法 |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005085063A (ja) | 2003-09-10 | 2005-03-31 | Nec Corp | 代表snpの選択方法、選択システム、プログラム |
| JP2007102709A (ja) | 2005-10-07 | 2007-04-19 | Toshiba Corp | 遺伝子診断用のマーカー選定プログラム、該プログラムを実行する装置及びシステム、並びに遺伝子診断システム |
-
2005
- 2005-10-07 JP JP2005295333A patent/JP2007102709A/ja active Pending
-
2006
- 2006-09-19 US US11/533,134 patent/US20070082353A1/en not_active Abandoned
- 2006-10-09 KR KR1020060097973A patent/KR100806436B1/ko not_active Expired - Fee Related
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003519829A (ja) * | 1999-10-13 | 2003-06-24 | シークエノム・インコーポレーテツド | データベースを作成する方法および多型遺伝的マーカーを同定するためのデータベース |
| JP2001357130A (ja) * | 2000-06-13 | 2001-12-26 | Hitachi Ltd | 診療情報管理システム |
| JP2002312361A (ja) * | 2001-10-16 | 2002-10-25 | Mitsui Knowledge Industry Kk | 匿名化臨床研究支援方法およびそのシステム |
| WO2003048999A2 (en) * | 2001-12-03 | 2003-06-12 | Dnaprint Genomics, Inc. | Methods and apparatus for genetic classification |
| JP2006503346A (ja) * | 2001-12-03 | 2006-01-26 | ディーエヌエー・プリント・ジェノミックス・インコーポレイテッド | 分類ツリー分析を含む遺伝子学的分類における使用のための方法および装置 |
| JP2004113661A (ja) * | 2002-09-27 | 2004-04-15 | Toshiba Corp | 治療法の有効性を予測するためのプログラム、データベース、システム及び方法 |
| JP2004173505A (ja) * | 2002-11-22 | 2004-06-24 | Mitsuo Itakura | 疾患感受性遺伝子の同定方法並びにそれに用いるプログラムおよびシステム |
| JP2005259132A (ja) * | 2004-02-28 | 2005-09-22 | Samsung Electronics Co Ltd | 複合疾患と関連した多重snpマーカーから最適のマーカーセットを選択する方法 |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR100806436B1 (ko) | 2005-10-07 | 2008-02-21 | 가부시끼가이샤 도시바 | 유전자 진단을 위한 마커 선택 프로그램을 포함하는 컴퓨터판독가능 매체, 마커 선택 장치 및 시스템, 및 유전자진단 함수 생성 장치 및 시스템 |
| WO2010064413A1 (ja) * | 2008-12-01 | 2010-06-10 | 国立大学法人山口大学 | 薬剤の作用・副作用予測システムとそのプログラム |
| JP2013220226A (ja) * | 2012-04-17 | 2013-10-28 | Kddi Corp | データ解析装置、プログラムおよびデータ解析方法 |
| JP2016504667A (ja) * | 2012-11-26 | 2016-02-12 | コーニンクレッカ フィリップス エヌ ヴェKoninklijke Philips N.V. | 患患者固有の関連性評価を用いた変異と疾患の関連付けを使用する診断的遺伝子分析 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20070082353A1 (en) | 2007-04-12 |
| KR100806436B1 (ko) | 2008-02-21 |
| KR20070038925A (ko) | 2007-04-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Uffelmann et al. | Genome-wide association studies | |
| Uddin et al. | Artificial intelligence for precision medicine in neurodevelopmental disorders | |
| Liang et al. | Polygenic transcriptome risk scores (PTRS) can improve portability of polygenic risk scores across ancestries | |
| AU784645B2 (en) | Method for providing clinical diagnostic services | |
| Maron et al. | Genetics of hypertrophic cardiomyopathy after 20 years: clinical perspectives | |
| JP5464503B2 (ja) | 医療分析システム | |
| WO2019169049A1 (en) | Multimodal modeling systems and methods for predicting and managing dementia risk for individuals | |
| Ireland et al. | Genetic testing in hypertrophic cardiomyopathy | |
| Ahmed et al. | Early detection of Alzheimer's disease using single nucleotide polymorphisms analysis based on gradient boosting tree | |
| JP2007102709A (ja) | 遺伝子診断用のマーカー選定プログラム、該プログラムを実行する装置及びシステム、並びに遺伝子診断システム | |
| JP2003508853A (ja) | 遺伝子分析用人工知能システム | |
| Stafford et al. | The role of genetic testing in diagnosis and care of inherited cardiac conditions in a specialised multidisciplinary clinic | |
| US20210343414A1 (en) | Methods and apparatus for phenotype-driven clinical genomics using a likelihood ratio paradigm | |
| WO2022212337A1 (en) | Graph database techniques for machine learning | |
| Rugna et al. | Distinct Leishmania infantum Strains Circulate in Humans and Dogs in the Emilia–Romagna Region, Northeastern Italy | |
| Vinciguerra | The potential for artificial intelligence applied to epigenetics | |
| Zieliński et al. | Evaluating the risk of endometriosis based on patients’ self-assessment questionnaires | |
| Mandape et al. | Dense SNP-based analyses complement forensic anthropology biogeographical ancestry assessments | |
| US20200024663A1 (en) | Method for detecting mood disorders | |
| Tanguay-Sabourin et al. | A data-driven biopsychosocial framework determining the spreading of chronic pain | |
| JP2002107366A (ja) | 診断支援システム | |
| Liang et al. | Predicting ExWAS findings from GWAS data: a shorter path to causal genes | |
| Zentner et al. | A rapid scoring tool to assess mutation probability in patients with inherited cardiac disorders | |
| US20230289569A1 (en) | Non-Transitory Computer Readable Medium, Information Processing Device, Information Processing Method, and Method for Generating Learning Model | |
| Gangula et al. | Machine Learning in Predicting Alzheimer’s Disease: Exploring Applications and Advancements |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20070205 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20091201 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100127 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100824 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20101221 |