JP2017107587A - 複数のビットを左にシフトし、複数の1を複数の下位ビットにプルインするための命令 - Google Patents
複数のビットを左にシフトし、複数の1を複数の下位ビットにプルインするための命令 Download PDFInfo
- Publication number
- JP2017107587A JP2017107587A JP2017021703A JP2017021703A JP2017107587A JP 2017107587 A JP2017107587 A JP 2017107587A JP 2017021703 A JP2017021703 A JP 2017021703A JP 2017021703 A JP2017021703 A JP 2017021703A JP 2017107587 A JP2017107587 A JP 2017107587A
- Authority
- JP
- Japan
- Prior art keywords
- operand
- vector
- processor
- register
- bits
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images
















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30032—Movement instructions, e.g. MOVE, SHIFT, ROTATE, SHUFFLE
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30018—Bit or string instructions
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30036—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30036—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations
- G06F9/30038—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations using a mask
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/3005—Arrangements for executing specific machine instructions to perform operations for flow control
- G06F9/30065—Loop control instructions; iterative instructions, e.g. LOOP, REPEAT
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30072—Arrangements for executing specific machine instructions to perform conditional operations, e.g. using predicates or guards
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/32—Address formation of the next instruction, e.g. by incrementing the instruction counter
- G06F9/322—Address formation of the next instruction, e.g. by incrementing the instruction counter for non-sequential address
- G06F9/325—Address formation of the next instruction, e.g. by incrementing the instruction counter for non-sequential address for loops, e.g. loop detection or loop counter
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Complex Calculations (AREA)
- Executing Machine-Instructions (AREA)
- Advance Control (AREA)
Abstract
Description
SUB rbx, rcx //calculate number of remaining iterations
KXOR k1, k1, k1 //zeroing mask
KSHLONES k1, rbx //generate mask for remainder loop
[インオーダ及びアウトオブオーダコアのブロック図]
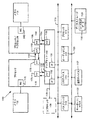
図7Aは、本発明の複数の実施形態に係る例示的なインオーダパイプライン及び例示的なレジスタリネーミング、アウトオブオーダ発行/実行パイプラインの両方を示すブロック図である。図7Bは、本発明の複数の実施形態に係るプロセッサに含まれるべきインオーダアーキテクチャコアの例示的な実施形態及び例示的なレジスタリネーミング、アウトオブオーダ発行/実行アーキテクチャコアの両方を示すブロック図である。図7A及び7Bの複数の実線のボックスは、インオーダパイプライン及びインオーダコアを示し、選択的に追加された複数の破線のボックスは、レジスタリネーミング、アウトオブオーダ発行/実行パイプライン及びコアを示す。インオーダ態様がアウトオブオーダ態様のサブセットであるとして、アウトオブオーダ態様について説明する。
図9は、本発明の複数の実施形態に係るプロセッサ900のブロック図であり、プロセッサ900は、1つより多くのコアを有してもよく、集積メモリコントローラを有してもよく、集中画像表示を有してもよい。図9の複数の実線のボックスは、単一のコア902A、システムエージェント910、1つまたは複数のバスコントローラユニット916のセットを有するプロセッサ900を示し、選択的に追加された複数の破線のボックスは、複数のコア902A−Nを有する代替的なプロセッサ900、システムエージェントユニット910内の1つまたは複数の集積メモリコントローラユニット914のセット及び特別用途ロジック908を示す。
図10−13は、例示的な複数のコンピュータアーキテクチャのブロック図である。ラップトップ、デスクトップ、ハンドヘルド型PC、携帯情報端末、エンジニアリングワークステーション、サーバ、ネットワークデバイス、ネットワークハブ、スイッチ、組み込みプロセッサ、デジタルシグナルプロセッサ(DSP)、グラフィクスデバイス、ビデオゲームデバイス、セットトップボックス、マイクロコントローラ、携帯電話、ポータブルメディアプレイヤ、ハンドヘルドデバイス及び様々な他の電子デバイス用の当技術分野で公知の他の複数のシステム設計及び複数の構成も、適切である。概して、本明細書で開示されるように、プロセッサ及び/または他の実行ロジックを組み込み可能な多様なシステムまたは電子デバイスが、概して適切である。
Claims (17)
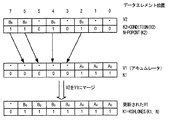
- 複数のベクトルレジスタと、前記複数のベクトルレジスタに連結される実行回路とを備え、前記複数のベクトルレジスタの1つは、アレイの複数のデータエレメントを格納し、前記実行回路は、
少なくとも第1のオペランド及び第2のオペランドを指定するマスク生成命令を受信し、
前記マスク生成命令に応答して、前記第2のオペランドにおいて規定された回数だけ、前記第1のオペランドの複数のビットを左シフトし、前記第1のオペランドの最上位ビットがシフトアウトするたびに、1である最下位ビットをプルインすることにより、複数のビットを含む結果を生成し、前記結果の各ビットは、前記アレイの前記複数のデータエレメントの1つに対応し、
前記第2のオペランドは、ベクトルオペレーションの残りのループにおける残りのイタレーションの数を指定する、装置。 - 前記第2のオペランドは、前記ベクトルオペレーションに対して、ループ制限から現在のイタレーションカウントを減じた減算結果を指定する、請求項1に記載の装置。
- 前記第1のオペランド及び前記第2のオペランドの両方は、汎用レジスタである、請求項1または2に記載の装置。
- 前記第1のオペランドは、マスクレジスタであり、前記第2のオペランドは、汎用レジスタである、請求項1または2に記載の装置。
- 1つまたは複数の状態レジスタは、前記結果に基づいて設定される、請求項1から3のいずれか1項に記載の装置。
- 複数のベクトルレジスタと、前記複数のベクトルレジスタに連結される実行回路とを備え、前記複数のベクトルレジスタの1つは、アレイの複数のデータエレメントを格納し、前記実行回路は、
少なくとも第1のオペランド及び第2のオペランドを指定するマスク生成命令を受信し、
前記マスク生成命令に応答して、前記第2のオペランドにおいて規定された回数だけ、前記第1のオペランドの複数のビットを左シフトし、前記第1のオペランドの最上位ビットがシフトアウトするたびに、1である最下位ビットをプルインすることにより、複数のビットを含む結果を生成し、前記結果の各ビットは、前記アレイの前記複数のデータエレメントの1つに対応し、
前記複数のベクトルレジスタは、第1のベクトルレジスタ及び第2のベクトルレジスタを含み、前記第2のオペランドは、ベクトル計算に対して、前記第1のベクトルレジスタ内の既存の複数のデータエレメントにマージされるべき前記第2のベクトルレジスタ内のデータエレメントの数を指定する、装置。 - プロセッサによって、少なくとも第1のオペランド及び第2のオペランドを指定するマスク生成命令を受信する段階と、
前記マスク生成命令に応答して、前記第2のオペランドにおいて規定された回数だけ、前記第1のオペランドの複数のビットを左シフトし、前記第1のオペランドの最上位ビットがシフトアウトするたびに、1である最下位ビットをプルインすることにより、複数のビットを含む結果を生成するオペレーションを実行する段階とを備え、前記結果の各ビットは、アレイのデータエレメントに対応し、
前記第2のオペランドは、ベクトルオペレーションの残りのループにおける残りのイタレーションの数を指定する、方法。 - 前記第2のオペランドは、前記ベクトルオペレーションに対して、ループ制限から現在のイタレーションカウントを減じた減算結果を指定する、請求項7に記載の方法。
- 前記第1のオペランド及び前記第2のオペランドの両方は、汎用レジスタである、請求項7または8に記載の方法。
- 前記第1のオペランドは、マスクレジスタであり、前記第2のオペランドは、汎用レジスタである、請求項7または8に記載の方法。
- 前記結果に基づいて、1つまたは複数の状態レジスタを修正する段階をさらに備える、請求項7から10のいずれか1項に記載の方法。
- プロセッサによって、少なくとも第1のオペランド及び第2のオペランドを指定するマスク生成命令を受信する段階と、
前記マスク生成命令に応答して、前記第2のオペランドにおいて規定された回数だけ、前記第1のオペランドの複数のビットを左シフトし、前記第1のオペランドの最上位ビットがシフトアウトするたびに、1である最下位ビットをプルインすることにより、複数のビットを含む結果を生成するオペレーションを実行する段階とを備え、前記結果の各ビットは、アレイのデータエレメントに対応し、
前記第2のオペランドは、ベクトル計算に対して、第1のベクトルレジスタ内の既存の複数のデータエレメントにマージされるべき、第2のベクトルレジスタ内のデータエレメントの数を指定する、方法。 - ランダムアクセスメモリと、
前記ランダムアクセスメモリに連結されるプロセッサとを備え、前記プロセッサは、
複数のベクトルレジスタと、前記複数のベクトルレジスタに連結される実行回路とを備え、前記複数のベクトルレジスタの1つは、アレイの複数のデータエレメントを格納し、前記実行回路は、
少なくとも第1のオペランド及び第2のオペランドを指定するマスク生成命令を受信し、
前記マスク生成命令に応答して、前記第2のオペランドにおいて規定された回数だけ、前記第1のオペランドの複数のビットを左シフトし、前記第1のオペランドの最上位ビットがシフトアウトするたびに、1である最下位ビットをプルインすることにより、複数のビットを含む結果を生成し、前記結果の各ビットは、前記アレイの前記複数のデータエレメントの1つに対応し、
前記第2のオペランドは、ベクトルオペレーションの残りのループにおける残りのイタレーションの数を指定する、システム。 - 前記第1のオペランド及び前記第2のオペランドの両方は、汎用レジスタである、請求項13に記載のシステム。
- 前記第1のオペランドは、マスクレジスタであり、前記第2のオペランドは、汎用レジスタである、請求項13に記載のシステム。
- 1つまたは複数の状態レジスタは、前記結果に基づいて設定される、請求項13から15のいずれか1項に記載のシステム。
- ランダムアクセスメモリと、
前記ランダムアクセスメモリに連結されるプロセッサとを備え、前記プロセッサは、
複数のベクトルレジスタと、前記複数のベクトルレジスタに連結される実行回路とを備え、前記複数のベクトルレジスタの1つは、アレイの複数のデータエレメントを格納し、前記実行回路は、
少なくとも第1のオペランド及び第2のオペランドを指定するマスク生成命令を受信し、
前記マスク生成命令に応答して、前記第2のオペランドにおいて規定された回数だけ、前記第1のオペランドの複数のビットを左シフトし、前記第1のオペランドの最上位ビットがシフトアウトするたびに、1である最下位ビットをプルインすることにより、複数のビットを含む結果を生成し、前記結果の各ビットは、前記アレイの前記複数のデータエレメントの1つに対応し、
前記複数のベクトルレジスタは、第1のベクトルレジスタ及び第2のベクトルレジスタを含み、前記第2のオペランドは、ベクトル計算に対して、前記第1のベクトルレジスタ内の既存の複数のデータエレメントにマージされるべき、前記第2のベクトルレジスタ内のデータエレメントの数を指定する、システム。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US13/630,131 | 2012-09-28 | ||
| US13/630,131 US9122475B2 (en) | 2012-09-28 | 2012-09-28 | Instruction for shifting bits left with pulling ones into less significant bits |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015534475A Division JP6092400B2 (ja) | 2012-09-28 | 2013-06-25 | 複数のビットを左にシフトし、複数の1を複数の下位ビットにプルインするための命令 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2017107587A true JP2017107587A (ja) | 2017-06-15 |
| JP2017107587A5 JP2017107587A5 (ja) | 2018-06-21 |
| JP6373425B2 JP6373425B2 (ja) | 2018-08-15 |
Family
ID=50386382
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015534475A Expired - Fee Related JP6092400B2 (ja) | 2012-09-28 | 2013-06-25 | 複数のビットを左にシフトし、複数の1を複数の下位ビットにプルインするための命令 |
| JP2017021703A Active JP6373425B2 (ja) | 2012-09-28 | 2017-02-08 | 複数のビットを左にシフトし、複数の1を複数の下位ビットにプルインするための命令 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015534475A Expired - Fee Related JP6092400B2 (ja) | 2012-09-28 | 2013-06-25 | 複数のビットを左にシフトし、複数の1を複数の下位ビットにプルインするための命令 |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US9122475B2 (ja) |
| JP (2) | JP6092400B2 (ja) |
| KR (2) | KR101817459B1 (ja) |
| CN (1) | CN104919432B (ja) |
| DE (1) | DE112013004800T5 (ja) |
| GB (1) | GB2518104B (ja) |
| WO (1) | WO2014051782A1 (ja) |
Families Citing this family (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2013089709A1 (en) * | 2011-12-14 | 2013-06-20 | Intel Corporation | System, apparatus and method for generating a loop alignment count or a loop alignment mask |
| US20140189296A1 (en) * | 2011-12-14 | 2014-07-03 | Elmoustapha Ould-Ahmed-Vall | System, apparatus and method for loop remainder mask instruction |
| US9606803B2 (en) | 2013-07-15 | 2017-03-28 | Texas Instruments Incorporated | Highly integrated scalable, flexible DSP megamodule architecture |
| US20160179548A1 (en) * | 2014-12-22 | 2016-06-23 | Intel Corporation | Instruction and logic to perform an inverse centrifuge operation |
| GB2540941B (en) * | 2015-07-31 | 2017-11-15 | Advanced Risc Mach Ltd | Data processing |
| EP3125108A1 (en) * | 2015-07-31 | 2017-02-01 | ARM Limited | Vector processing using loops of dynamic vector length |
| US20180329708A1 (en) * | 2015-09-19 | 2018-11-15 | Microsoft Technology Licensing, Llc | Multi-nullification |
| JP2018124877A (ja) * | 2017-02-02 | 2018-08-09 | 富士通株式会社 | コード生成装置、コード生成方法、およびコード生成プログラム |
| US10481910B2 (en) * | 2017-09-29 | 2019-11-19 | Intel Corporation | Apparatus and method for shifting quadwords and extracting packed words |
| US20190196822A1 (en) * | 2017-12-21 | 2019-06-27 | Intel Corporation | Apparatus and method for shifting packed quadwords and extracting packed words |
| US10963253B2 (en) * | 2018-07-10 | 2021-03-30 | Arm Limited | Varying micro-operation composition based on estimated value of predicate value for predicated vector instruction |
| CN113015958A (zh) * | 2018-09-18 | 2021-06-22 | 优创半导体科技有限公司 | 实现掩蔽向量指令的系统和方法 |
| US11074214B2 (en) * | 2019-08-05 | 2021-07-27 | Arm Limited | Data processing |
| US11275562B2 (en) | 2020-02-19 | 2022-03-15 | Micron Technology, Inc. | Bit string accumulation |
| CN112492473B (zh) * | 2020-11-04 | 2022-09-09 | 杭州士兰微电子股份有限公司 | Mems麦克风的信号处理电路及信号处理方法 |
| US11934327B2 (en) * | 2021-12-22 | 2024-03-19 | Microsoft Technology Licensing, Llc | Systems and methods for hardware acceleration of data masking using a field programmable gate array |
Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0744532A (ja) * | 1991-12-25 | 1995-02-14 | Nec Corp | ベクトル処理装置 |
| US5781457A (en) * | 1994-03-08 | 1998-07-14 | Exponential Technology, Inc. | Merge/mask, rotate/shift, and boolean operations from two instruction sets executed in a vectored mux on a dual-ALU |
| JPH11511575A (ja) * | 1995-08-31 | 1999-10-05 | インテル・コーポレーション | パック・データを処理する1組の命令 |
| JP2008083795A (ja) * | 2006-09-26 | 2008-04-10 | Oki Electric Ind Co Ltd | ビットフィールド操作回路 |
| WO2012137428A1 (ja) * | 2011-04-08 | 2012-10-11 | パナソニック株式会社 | データ処理装置、及びデータ処理方法 |
| JP2015524978A (ja) * | 2012-09-28 | 2015-08-27 | インテル・コーポレーション | 独立したデータに対する再帰演算のベクトル化のための読み出し及び書き込みマスク更新命令 |
| JP2015528610A (ja) * | 2012-09-28 | 2015-09-28 | インテル・コーポレーション | リードマスク及びライトマスクにより制御されるベクトル移動命令 |
| JP2015532477A (ja) * | 2012-09-28 | 2015-11-09 | インテル・コーポレーション | 128ビットプロセッサ上のskein256sha3アルゴリズム用命令セット |
| JP2015535982A (ja) * | 2012-09-28 | 2015-12-17 | インテル・コーポレーション | 単一の命令に応じて回転及びxorを実行するためのシステム、装置及び方法 |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6006315A (en) * | 1996-10-18 | 1999-12-21 | Samsung Electronics Co., Ltd. | Computer methods for writing a scalar value to a vector |
| US5832288A (en) * | 1996-10-18 | 1998-11-03 | Samsung Electronics Co., Ltd. | Element-select mechanism for a vector processor |
| US6446198B1 (en) * | 1999-09-30 | 2002-09-03 | Apple Computer, Inc. | Vectorized table lookup |
| JP2010204913A (ja) * | 2009-03-03 | 2010-09-16 | Nec Computertechno Ltd | ベクトル処理装置 |
| US8009682B2 (en) * | 2009-05-05 | 2011-08-30 | Citrix Systems, Inc. | Systems and methods for packet steering in a multi-core architecture |
| US8667042B2 (en) * | 2010-09-24 | 2014-03-04 | Intel Corporation | Functional unit for vector integer multiply add instruction |
-
2012
- 2012-09-28 US US13/630,131 patent/US9122475B2/en active Active
-
2013
- 2013-06-25 KR KR1020167030379A patent/KR101817459B1/ko active Active
- 2013-06-25 JP JP2015534475A patent/JP6092400B2/ja not_active Expired - Fee Related
- 2013-06-25 KR KR1020157004840A patent/KR20150038328A/ko not_active Abandoned
- 2013-06-25 WO PCT/US2013/047669 patent/WO2014051782A1/en not_active Ceased
- 2013-06-25 CN CN201380045387.6A patent/CN104919432B/zh active Active
- 2013-06-25 DE DE112013004800.0T patent/DE112013004800T5/de active Pending
- 2013-06-25 GB GB1500433.6A patent/GB2518104B/en not_active Expired - Fee Related
-
2017
- 2017-02-08 JP JP2017021703A patent/JP6373425B2/ja active Active
Patent Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0744532A (ja) * | 1991-12-25 | 1995-02-14 | Nec Corp | ベクトル処理装置 |
| US5781457A (en) * | 1994-03-08 | 1998-07-14 | Exponential Technology, Inc. | Merge/mask, rotate/shift, and boolean operations from two instruction sets executed in a vectored mux on a dual-ALU |
| JPH11511575A (ja) * | 1995-08-31 | 1999-10-05 | インテル・コーポレーション | パック・データを処理する1組の命令 |
| JP2008083795A (ja) * | 2006-09-26 | 2008-04-10 | Oki Electric Ind Co Ltd | ビットフィールド操作回路 |
| WO2012137428A1 (ja) * | 2011-04-08 | 2012-10-11 | パナソニック株式会社 | データ処理装置、及びデータ処理方法 |
| JP2015524978A (ja) * | 2012-09-28 | 2015-08-27 | インテル・コーポレーション | 独立したデータに対する再帰演算のベクトル化のための読み出し及び書き込みマスク更新命令 |
| JP2015528610A (ja) * | 2012-09-28 | 2015-09-28 | インテル・コーポレーション | リードマスク及びライトマスクにより制御されるベクトル移動命令 |
| JP2015532477A (ja) * | 2012-09-28 | 2015-11-09 | インテル・コーポレーション | 128ビットプロセッサ上のskein256sha3アルゴリズム用命令セット |
| JP2015535982A (ja) * | 2012-09-28 | 2015-12-17 | インテル・コーポレーション | 単一の命令に応じて回転及びxorを実行するためのシステム、装置及び方法 |
Non-Patent Citations (1)
| Title |
|---|
| 大貫広幸: "x86CPUだけでもマスタしたい開発技術者のためのアセンブラ入門 第17回 論理,シフト,ローテート命令", INTERFACE, vol. 第29巻,第4号, JPN6016022704, 1 April 2003 (2003-04-01), JP, pages 167 - 174, ISSN: 0003797476 * |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2015534189A (ja) | 2015-11-26 |
| JP6092400B2 (ja) | 2017-03-08 |
| CN104919432A (zh) | 2015-09-16 |
| JP6373425B2 (ja) | 2018-08-15 |
| GB2518104B (en) | 2020-07-01 |
| WO2014051782A1 (en) | 2014-04-03 |
| US20140095830A1 (en) | 2014-04-03 |
| CN104919432B (zh) | 2017-12-22 |
| KR20160130324A (ko) | 2016-11-10 |
| DE112013004800T5 (de) | 2015-06-03 |
| GB201500433D0 (en) | 2015-02-25 |
| GB2518104A (en) | 2015-03-11 |
| KR20150038328A (ko) | 2015-04-08 |
| KR101817459B1 (ko) | 2018-01-11 |
| US9122475B2 (en) | 2015-09-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6373425B2 (ja) | 複数のビットを左にシフトし、複数の1を複数の下位ビットにプルインするための命令 | |
| JP5987233B2 (ja) | 装置、方法、およびシステム | |
| JP6351682B2 (ja) | 装置および方法 | |
| JP6340097B2 (ja) | リードマスク及びライトマスクにより制御されるベクトル移動命令 | |
| CN104077107B (zh) | 利用经掩码的全寄存器访问实现部分寄存器访问的处理器、方法和系统 | |
| US9921832B2 (en) | Instruction to reduce elements in a vector register with strided access pattern | |
| JP5985526B2 (ja) | システムコールのためのロバスト且つ高性能な命令 | |
| KR20170027883A (ko) | 마스크 레지스터에서의 비트들을 반전 및 치환하기 위한 장치 및 방법 | |
| JP2018500659A (ja) | 高速ベクトルによる動的なメモリ競合検出 | |
| JP2014182800A (ja) | データ要素内のビットをゼロ化するためのシステム、装置、および方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170310 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20170310 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20180510 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20180522 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20180620 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20180717 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6373425 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |