[0021]サラウンドサウンドの発展は、現今では娯楽のための多くの出力フォーマットを利用可能にしている。そのような消費者向けのサラウンドサウンドフォーマットの例は、ある幾何学的な座標にあるラウドスピーカーへのフィードを暗黙的に指定するという点で、大半が「チャネル」ベースである。消費者向けのサラウンドサウンドフォーマットは、普及している5.1フォーマット(これは、次の6つのチャネル、すなわち、フロントレフト(FL)と、フロントライト(FR)と、センターまたはフロントセンターと、バックレフトまたはサラウンドレフトと、バックライトまたはサラウンドライトと、低周波効果(LFE)とを含む)、発展中の7.1フォーマット、7.1.4フォーマットおよび22.2フォーマット(たとえば、超高精細度テレビジョン規格とともに使用するための)などのハイトスピーカーを含む様々なフォーマットを含む。消費者向けではないフォーマットは、「サラウンドアレイ」と呼ばれることが多い(対称な、および非対称な幾何学的配置の)任意の数のスピーカーに及び得る。そのようなアレイの一例は、切頂二十面体の角の座標に配置される32個のラウドスピーカーを含む。
[0022]将来のMPEGエンコーダへの入力は、任意選択で、次の3つの可能なフォーマット、すなわち、(i)あらかじめ指定された位置でラウドスピーカーを通じて再生されることが意図される、(上で論じられたような)従来のチャネルベースオーディオ、(ii)(情報の中でも)位置座標を含む関連付けられたメタデータを有する単一オーディオオブジェクトのための離散的なパルス符号変調(PCM)データを伴うオブジェクトベースオーディオ、および(iii)球面調和基底関数の係数(「球面調和係数」すなわちSHC、「高次アンビソニックス」すなわちHOA、および「HOA係数」とも呼ばれる)を使用して音場を表すことを伴うシーンベースオーディオのうちの1つである。将来のMPEGエンコーダは、2013年1月にスイスのジュネーブで発表された、http://mpeg.chiariglione.org/sites/default/files/files/standards/parts/docs/w13411.zipにおいて入手可能な、International Organization for Standardization/International Electrotechnical Commission (ISO)/(IEC) JTC1/SC29/WG11/N13411による「Call for Proposals for 3D Audio」と題される文書においてより詳細に説明され得る。
[0023]市場には様々な「サラウンドサウンド」チャネルベースフォーマットがある。これらのフォーマットは、たとえば、5.1ホームシアターシステム(リビングルームに進出するという点でステレオ以上に最も成功した)からNHK(Nippon Hoso Kyokaiすなわち日本放送協会)によって開発された22.2システムに及ぶ。コンテンツ作成者(たとえば、ハリウッドスタジオ)は、一度に映画のサウンドトラックを作成することを望み、各々のスピーカー構成のためにサウンドトラックをリミックスする努力を行うことを望まない。最近では、規格開発組織が、規格化されたビットストリームへの符号化と、スピーカーの幾何学的配置(と数)および(レンダラを伴う)再生のロケーションにおける音響条件に適応可能でありそれらに依存しない後続の復号とを提供するための方法を考えている。
[0024]コンテンツ作成者にそのような柔軟性を提供するために、要素の階層セットが音場を表すために使用され得る。要素の階層セットは、モデル化された音場の完全な表現をより低次の要素の基本セットが提供するように要素が順序付けられる、要素のセットを指し得る。セットがより高次の要素を含むように拡張されると、表現はより詳細なものになり、分解能は向上する。
[0025]要素の階層セットの一例は、球面調和係数(SHC)のセットである。次の式は、SHCを使用する音場の記述または表現を示す。
[0026]この式は、時間tにおける音場の任意の点{r
r,θ
r,φ
r}における圧力p
iが、SHC、A
m n(k)によって一意に表され得ることを示す。ここで、
であり、cは音速(約343m/s)であり、{r
r,θ
r,φ
r}は基準点(または観測点)であり、j
n(・)は次数nの球ベッセル関数であり、Y
m n(θ
r,φ
r)は次数nおよび副次数mの球面調和基底関数である。角括弧内の項は、離散フーリエ変換(DFT)、離散コサイン変換(DCT)、またはウェーブレット変換などの様々な時間周波数変換によって近似され得る信号の周波数領域表現(すなわち、S(ω,r
r,θ
r,φ
r))であることが認識できよう。階層セットの他の例は、ウェーブレット変換係数のセット、および多分解能基底関数の係数の他のセットを含む。
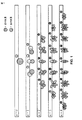
[0027]図1は、0次(n=0)から4次(n=4)までの球面調和基底関数を示す図である。理解できるように、各次数に対して、説明を簡単にするために図示されているが図1の例では明示的に示されていない副次数mの拡張が存在する。
[0028]SHC Am n(k)は、様々なマイクロフォンアレイ構成によって物理的に獲得(たとえば、録音)されることができ、または代替的に、それらは音場のチャネルベースまたはオブジェクトベースの記述から導出されることができる。SHCはシーンベースのオーディオを表し、ここで、SHCは、より効率的な送信または記憶を促し得る符号化されたSHCを取得するために、オーディオエンコーダに入力され得る。たとえば、(1+4)2個の(25個の、したがって4次の)係数を伴う4次表現が使用され得る。
[0029]上述されたように、SHCは、マイクロフォンアレイを使用したマイクロフォン録音から導出され得る。SHCがマイクロフォンアレイからどのように導出され得るかの様々な例は、Poletti,M、「Three−Dimensional Surround Sound Systems Based on Spherical Harmonics」、J.Audio Eng. Soc.、Vol. 53、No. 11、2005年11月、1004〜1025ページにおいて説明されている。
[0030]SHCがどのようにオブジェクトベースの記述から導出され得るかを例示するために、次の式を考える。個々のオーディオオブジェクトに対応する音場についての係数A
m n(k)は、
と表され得、ただし、iは、
であり、h
(2) n(・)は次数nの(第2種)球ハンケル関数であり、{r
s,θ
s、φ
s}はオブジェクトのロケーションである。周波数の関数として(たとえば、PCMストリームに対して高速フーリエ変換を実行するなど、時間周波数分析技法を使用して)オブジェクトソースエネルギーg(ω)を知ることで、各PCMオブジェクトと対応するロケーションとをSHC A
m n(k)に変換することが可能となる。さらに、各オブジェクトについてのA
m n(k)係数は、(上式は線形および直交の分解であるので)加法的であることが示され得る。このようにして、多数のPCMオブジェクトがA
m n(k)係数によって(たとえば、個々のオブジェクトについての係数ベクトルの和として)表され得る。本質的に、これらの係数は、音場についての情報(3D座標の関数としての圧力)を含んでおり、上記は、観測点{r
r,θ
r,φ
r}の近傍における、音場全体の表現への個々のオブジェクトからの変換を表す。残りの数字は、以下でオブジェクトベースのオーディオコーディングおよびSHCベースのオーディオコーディングの文脈で説明される。
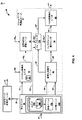
[0031]図2は、本開示で説明される技法の様々な態様を実行し得るシステム10を示す図である。図2の例に示されるように、システム10は、コンテンツ作成者デバイス12と、コンテンツ消費者デバイス14とを含む。コンテンツ作成者デバイス12およびコンテンツ消費者デバイス14の文脈で説明されているが、本技法は、オーディオデータを表すビットストリームを形成するために、SHC(HOA係数とも呼ばれ得る)または音場の任意の他の階層的表現が符号化される任意の文脈で実施され得る。その上、コンテンツ作成者デバイス12は、いくつか例を挙げると、ハンドセット(またはセルラーフォン)、タブレットコンピュータ、スマートフォン、またはデスクトップコンピュータを含む、本開示で説明される技法を実施することが可能な任意の形態のコンピューティングデバイスを表し得る。同様に、コンテンツ消費者デバイス14は、いくつか例を挙げると、ハンドセット(またはセルラーフォン)、タブレットコンピュータ、スマートフォン、セットトップボックス、またはデスクトップコンピュータを含む、本開示で説明される技法を実施することが可能な任意の形態のコンピューティングデバイスを表し得る。
[0032]コンテンツ作成者デバイス12は、コンテンツ消費者デバイス14などのコンテンツ消費者デバイスのオペレータによる消費のためのマルチチャネルオーディオコンテンツを生成し得る、映画スタジオまたは他のエンティティによって操作され得る。いくつかの例では、コンテンツ作成者デバイス12は、HOA係数11を圧縮することを望む個人ユーザによって操作され得る。多くの場合、コンテンツ作成者は、ビデオコンテンツとともに、オーディオコンテンツを生成する。コンテンツ消費者デバイス14は、個人によって操作され得る。コンテンツ消費者デバイス14は、マルチチャネルオーディオコンテンツとしての再生のためにSHCをレンダリングすることが可能な任意の形態のオーディオ再生システムを指し得る、オーディオ再生システム16を含み得る。
[0033]コンテンツ作成者デバイス12は、オーディオ編集システム18を含む。コンテンツ作成者デバイス12は、様々なフォーマットのライブ録音7(HOA係数として直接含む)とオーディオオブジェクト9とを取得し、コンテンツ作成者デバイス12は、オーディオ編集システム18を使用してこれらを編集し得る。マイクロフォン5はライブ録音7をキャプチャし得る。コンテンツ作成者は、編集プロセスの間に、オーディオオブジェクト9からのHOA係数11をレンダリングし、さらなる編集を必要とする音場の様々な態様を特定しようとして、レンダリングされたスピーカーフィードを聞き得る。コンテンツ作成者デバイス12は次いで、(潜在的に、上記で説明された方法でソースHOA係数がそれから導出され得るオーディオオブジェクト9のうちの様々なオブジェクトの操作を通じて間接的に)HOA係数11を編集し得る。コンテンツ作成者デバイス12は、HOA係数11を生成するためにオーディオ編集システム18を採用し得る。オーディオ編集システム18は、オーディオデータを編集し、このオーディオデータを1つまたは複数のソース球面調和係数として出力することが可能な任意のシステムを表す。
[0034]編集プロセスが完了すると、コンテンツ作成者デバイス12は、HOA係数11に基づいてビットストリーム21を生成し得る。すなわち、コンテンツ作成者デバイス12は、ビットストリーム21を生成するために、本開示で説明される技法の様々な態様に従って、HOA係数11を符号化またはさもなければ圧縮するように構成されたデバイスを表す、オーディオ符号化デバイス20を含む。オーディオ符号化デバイス20は、一例として、有線チャネルまたはワイヤレスチャネル、データ記憶デバイスなどであり得る送信チャネルを介した送信のために、ビットストリーム21を生成し得る。ビットストリーム21は、HOA係数11の符号化されたバージョンを表し得、主要ビットストリームと、サイドチャネル情報とも呼ばれ得る別のサイドビットストリームとを含み得る。
[0035]図2では、コンテンツ消費者デバイス14に直接的に送信されるものとして示されているが、コンテンツ作成者デバイス12は、コンテンツ作成者デバイス12とコンテンツ消費者デバイス14との間に配置された中間デバイスにビットストリーム21を出力し得る。中間デバイスは、ビットストリームを要求し得るコンテンツ消費者デバイス14に後で配信するために、ビットストリーム21を記憶し得る。中間デバイスは、ファイルサーバ、ウェブサーバ、デスクトップコンピュータ、ラップトップコンピュータ、タブレットコンピュータ、モバイルフォン、スマートフォン、または後でのオーディオデコーダによる取出しのためにビットストリーム21を記憶することが可能な任意の他のデバイスを備え得る。中間デバイスは、ビットストリーム21を要求するコンテンツ消費者デバイス14などの加入者にビットストリーム21を(場合によっては対応するビデオデータビットストリームを送信するとともに)ストリーミングすることが可能なコンテンツ配信ネットワーク内に存在し得る。
[0036]代替的に、コンテンツ作成者デバイス12は、コンパクトディスク、デジタルビデオディスク、高精細度ビデオディスク、または他の記憶媒体などの記憶媒体にビットストリーム21を記憶し得、記憶媒体の大部分はコンピュータによって読み取り可能であり、したがって、コンピュータ可読記憶媒体または非一時的コンピュータ可読記憶媒体と呼ば得る。この文脈において、送信チャネルは、これらの媒体に記憶されたコンテンツが送信されるチャネルを指し得る(および、小売店と他の店舗ベースの配信機構とを含み得る)。したがって、いずれにしても、本開示の技法は、この点に関して図2の例に限定されるべきではない。
[0037]図2の例にさらに示されるように、コンテンツ消費者デバイス14は、オーディオ再生システム16を含む。オーディオ再生システム16は、マルチチャネルオーディオデータを再生することが可能な任意のオーディオ再生システムを表し得る。オーディオ再生システム16は、いくつかの異なるレンダラ22を含み得る。レンダラ22は各々、異なる形態のレンダリングを提供し得、異なる形態のレンダリングは、ベクトルベース振幅パンニング(VBAP:vector-base amplitude panning)を実行する様々な方法の1つもしくは複数、および/または音場合成を実行する様々な方法の1つもしくは複数を含み得る。本明細書で使用される場合、「Aおよび/またはB」は、「AまたはB」、または「AとB」の両方を意味する。
[0038]オーディオ再生システム16は、オーディオ復号デバイス24をさらに含み得る。オーディオ復号デバイス24は、ビットストリーム21からHOA係数11’を復号するように構成されたデバイスを表し得、HOA係数11’は、HOA係数11と類似し得るが、損失のある演算(たとえば、量子化)および/または送信チャネルを介した送信が原因で異なり得る。オーディオ再生システム16は、HOA係数11’を取得するためにビットストリーム21を復号した後、ラウドスピーカーフィード25を出力するためにHOA係数11’をレンダリングし得る。ラウドスピーカーフィード25は、1つまたは複数のラウドスピーカー(説明を簡単にするために図2の例には示されていない)を駆動し得る。
[0039]適切なレンダラを選択するために、またはいくつかの場合には、適切なレンダラを生成するために、オーディオ再生システム16は、ラウドスピーカーの数および/またはラウドスピーカーの空間的な幾何学的配置を示すラウドスピーカー情報13を取得し得る。いくつかの場合には、オーディオ再生システム16は、基準マイクロフォンを使用してラウドスピーカー情報13を取得し、ラウドスピーカー情報13を動的に決定するような方法でラウドスピーカーを駆動し得る。他の場合には、またはラウドスピーカー情報13の動的な決定とともに、オーディオ再生システム16は、オーディオ再生システム16とインターフェースをとりラウドスピーカー情報13を入力するようにユーザに促し得る。
[0040]オーディオ再生システム16は次いで、ラウドスピーカー情報13に基づいて、オーディオレンダラ22のうちの1つを選択し得る。いくつかの場合には、オーディオ再生システム16は、ラウドスピーカー情報13において指定された幾何学的配置に対する何らかの閾値に類似した尺度(ラウドスピーカーの幾何学的配置に関する)内にいずれのオーディオレンダラ22もないとき、ラウドスピーカー情報13に基づいて、オーディオレンダラ22のうちの1つを生成し得る。オーディオ再生システム16は、いくつかの場合には、オーディオレンダラ22のうちの既存の1つを選択することを最初に試みることなく、ラウドスピーカー情報13に基づいて、オーディオレンダラ22のうちの1つを生成し得る。その際、1つまたは複数のスピーカー3は、レンダリングされたラウドスピーカーフィード25を再生し得る。
[0041]図3は、本開示で説明される技法の様々な態様を実行し得る、図2の例に示されるオーディオ符号化デバイス20の一例をより詳細に示すブロック図である。オーディオ符号化デバイス20は、コンテンツ分析ユニット26と、ベクトルベース分解ユニット27と、指向性ベース分解ユニット28とを含む。以下で手短に説明されるが、オーディオ符号化デバイス20に関するより多くの情報、およびHOA係数を圧縮またはさもなければ符号化する様々な態様は、2014年5月29に出願された「INTERPOLATION FOR DECOMPOSED REPRESENTATIONS OF A SOUND FIELD」という名称の国際特許出願公開第WO2014/194099号において入手可能である。
[0042]コンテンツ分析ユニット26は、HOA係数11がライブ録音から生成されたコンテンツを表すか、オーディオオブジェクトから生成されたコンテンツを表すかを特定するために、HOA係数11のコンテンツを分析するように構成されたユニットを表す。コンテンツ分析ユニット26は、HOA係数11が実際の音場の録音から生成されたか人工的なオーディオオブジェクトから生成されたかを決定し得る。いくつかの場合には、フレーム化されたHOA係数11が録音から生成されたとき、コンテンツ分析ユニット26は、HOA係数11をベクトルベース分解ユニット27に渡す。いくつかの場合には、フレーム化されたHOA係数11が合成オーディオオブジェクトから生成されたとき、コンテンツ分析ユニット26は、HOA係数11を指向性ベース分解ユニット28に渡す。指向性ベース分解ユニット28は、指向性ベースビットストリーム21を生成するためにHOA係数11の指向性ベース合成を実行するように構成されたユニットを表し得る。
[0043]図3の例に示されるように、ベクトルベース分解ユニット27は、線形可逆変換(LIT)ユニット30と、パラメータ計算ユニット32と、並べ替えユニット34と、フォアグラウンド選択ユニット36と、エネルギー補償ユニット38と、聴覚心理オーディオコーダユニット40と、ビットストリーム生成ユニット42と、音場分析ユニット44と、係数低減ユニット46と、バックグラウンド(BG)選択ユニット48と、空間時間的補間ユニット50と、量子化ユニット52とを含み得る。
[0044]線形可逆変換(LIT)ユニット30は、HOAチャネルの形態でHOA係数11を受信し、各チャネルは、球面基底関数の所与の次数、副次数に関連付けられた係数のブロックまたはフレーム(HOA[k]と示され得、ただし、kはサンプルの現在のフレームまたはブロックを示し得る)を表す。HOA係数11の行列は、次元D:M×(N+1)2を有し得る。
[0045]LITユニット30は、特異値分解と呼ばれるある形態の分析を実行するように構成されたユニットを表し得る。SVDに関して説明されているが、本開示で説明される技法は、線形的に無相関な、エネルギーが圧縮された出力のセットを提供する任意の類似の変換または分解に対して実行されてよい。また、本開示における「セット」への言及は、一般的に、それとは反対に特に明記されていない限り、非0のセットを指すことが意図され、いわゆる「空集合」を含む集合の古典的な数学的定義を指すことは意図されない。代替的な変換は、「PCA」と呼ばれることが多い、主成分分析を備え得る。文脈に応じて、PCAは、いくつかの例を挙げれば、離散カルーネン−レーベ変換、ホテリング変換、固有直交分解(POD)、および固有値分解(EVD)などのいくつかの異なる名前によって呼ばれ得る。オーディオデータを圧縮するという背後にある目標につながるそのような演算の特性は、マルチチャネルオーディオデータの「エネルギー圧縮」および「無相関化」である。
[0046]いずれにしても、LITユニット30が、例として、特異値分解(やはり「SVD」と呼ばれ得る)を実行すると仮定すると、LITユニット30は、HOA係数11を、変換されたHOA係数の2つ以上のセットに変換し得る。変換されたHOA係数の「セット」は、変換されたHOA係数のベクトルを含み得る。図3の例では、LITユニット30は、いわゆるV行列と、S行列と、U行列とを生成するために、HOA係数11に関してSVDを実行し得る。SVDは、線形代数学では、y×zの実行列または複素行列X(ここで、Xは、HOA係数11などのマルチチャネルオーディオデータを表し得る)の因数分解を以下の形で表し得る。
X=USV*
Uはy×yの実ユニタリー行列または複素ユニタリー行列を表し得、ここで、Uのy個の列は、マルチチャネルオーディオデータの左特異ベクトルとして知られる。Sは、対角線上に非負実数をもつy×zの矩形対角行列を表し得、ここで、Sの対角要素の値は、マルチチャネルオーディオデータの特異値として知られる。V*(Vの共役転置を示し得る)はz×zの実ユニタリー行列または複素ユニタリー行列を表し得、ここで、V*のz個の列は、マルチチャネルオーディオデータの右特異ベクトルとして知られる。
[0047]いくつかの例では、上で参照されたSVD数式中のV*行列は、複素数を備える行列にSVDが適用され得ることを反映するために、V行列の共役転置として示される。実数のみを備える行列に適用されるとき、V行列の複素共役(すなわち、言い換えれば、V*行列)は、V行列の転置であると見なされ得る。以下では、説明を簡単にするために、HOA係数11が実数を備え、その結果、V*行列ではなくV行列がSVDによって出力されると仮定される。その上、本開示ではV行列として示されるが、V行列への言及は、適切な場合にはV行列の転置を指すものとして理解されるべきである。V行列であると仮定されているが、本技法は、同様の方式で、複素係数を有するHOA係数11に適用され得、ここで、SVDの出力はV*行列である。したがって、本技法は、この点について、V行列を生成するためにSVDの適用を提供することのみに限定されるべきではなく、V*行列を生成するために複素成分を有するHOA係数11へのSVDの適用を含み得る。
[0048]このようにして、LITユニット30は、次元D:M×(N+1)2を有するUS[k]ベクトル33(SベクトルとUベクトルとの組み合わされたバージョンを表し得る)と、次元D:(N+1)2×(N+1)2を有するV[k]ベクトル35とを出力するために、HOA係数11に関してSVDを実行し得る。US[k]行列中の個々のベクトル要素はXps(k)とも呼ばれ得、一方、V[k]行列の個々のベクトルはv(k)とも呼ばれ得る。
[0049]U行列、S行列、およびV行列の分析は、それらの行列がXによって上で表される背後の音場の空間的および時間的な特性を伝え、または表すということを明らかにし得る。(M個のサンプルの長さの)Uの中のN個のベクトルの各々は、(M個のサンプルによって表される時間期間の間は)時間の関数として、互いに直交しておりあらゆる空間特性(指向性情報とも呼ばれ得る)とは切り離されている、正規化された分離されたオーディオ信号を表し得る。空間的な形状と位置(r、θ、φ)とを表す空間特性は代わりに、(各々が(N+1)2の長さの)V行列の中の個々のi番目のベクトル、v(i)(k)によって表され得る。v(i)(k)ベクトルの各々の個々の要素は、関連付けられたオーディオオブジェクトのための音場の形状(幅を含む)と位置とを記述するHOA係数を表し得る。U行列中のベクトルとV行列中のベクトルの両方が、それらの2乗平均エネルギーが1に等しくなるように正規化される。したがって、Uの中のオーディオ信号のエネルギーは、Sの中の対角線要素によって表される。したがって、US[k](個々のベクトル要素XPS(k)を有する)を形成するために、UとSとを乗算することは、エネルギーを有するオーディオ信号を表す。(Uにおける)オーディオ時間信号と、(Sにおける)それらのエネルギーと、(Vにおける)それらの空間特性とを切り離すSVD分解の能力は、本開示で説明される技法の様々な態様を支援し得る。さらに、背後のHOA[k]係数XをUS[k]とV[k]とのベクトル乗算によって合成するモデルは、「ベクトルベース分解」という用語を生じさせ、それは本文書全体で使用される。さらに、本明細書全体を通して、エネルギーを伴うオーディオ信号を表すUS[k]は、「オーディオオブジェクト」または「フォアグラウンドオーディオ信号」という用語で呼ばれ得、V[k]は、「オーディオオブジェクトに関連付けられる指向性情報」または「フォアグラウンド信号に関連付けられる指向性情報」と呼ばれ得る。HOA[k]係数は、HOA係数と呼ばれ得、HOA係数=US[k]*V[k]であるか、または言い換えると、HOA係数は、オーディオオブジェクト(US[k])とオーディオオブジェクトに関連付けられる指向性情報(V[k])との積である。
[0050]HOA係数11に関して直接実行されるものとして説明されるが、LITユニット30は、線形可逆変換をHOA係数11の派生物に適用し得る。たとえば、LITユニット30は、HOA係数11から導出された電力スペクトル密度行列に関してSVDを適用し得る。HOA係数自体ではなくHOA係数の電力スペクトル密度(PSD)に関してSVDを実行することによって、LITユニット30は潜在的に、プロセッササイクルおよび記憶空間のうちの1つまたは複数に関してSVDを実行することの計算的な複雑さを低減しつつ、SVDがHOA係数に直接適用されたかのように同じソースオーディオ符号化効率を達成し得る。
[0051]パラメータ計算ユニット32は、相関パラメータ(R)、指向性特性パラメータ(θ、φ、r)、およびエネルギー特性(e)などの様々なパラメータを計算するように構成されたユニットを表す。現在のフレームのためのパラメータの各々は、R[k]、θ[k]、φ[k]、r[k]、およびe[k]として示され得る。パラメータ計算ユニット32は、パラメータを特定するために、US[k]ベクトル33に関してエネルギー分析および/または相関(もしくはいわゆる相互相関)を実行し得る。パラメータ計算ユニット32はまた、以前のフレームのためのパラメータを決定することができ、ここで、以前のフレームパラメータは、US[k−1]ベクトルおよびV[k−1]ベクトルの以前のフレームに基づいて、R[k−1]、θ[k−1]、φ[k−1]、r[k−1]、およびe[k−1]と示され得る。パラメータ計算ユニット32は、現在のパラメータ37と以前のパラメータ39とを並べ替えユニット34に出力し得る。
[0052]パラメータ計算ユニット32によって計算されるパラメータは、オーディオオブジェクトの自然な評価または時間的な継続性を表すようにオーディオオブジェクトを並べ替えるために、並べ替えユニット34によって使用され得る。並べ替えユニット34は、第1のUS[k]ベクトル33からのパラメータ37の各々を、第2のUS[k−1]ベクトル33のためのパラメータ39の各々に対して順番ごとに比較し得る。並べ替えユニット34は、並べ替えられたUS[k]行列33’(数学的には
として示され得る)と、並べ替えられたV[k]行列35’(数学的には
として示され得る)とをフォアグラウンドサウンド(または支配的サウンド−PS(predominant sound))選択ユニット36(「フォアグラウンド選択ユニット36」)およびエネルギー補償ユニット38に出力するために、現在のパラメータ37および以前のパラメータ39に基づいて、US[k]行列33およびV[k]行列35内の様々なベクトルを(一例として、ハンガリー法を使用して)並べ替え得る。
[0053]音場分析ユニット44は、目標ビットレート41を潜在的に達成するために、HOA係数11に関して音場分析を実行するように構成されたユニットを表し得る。音場分析ユニット44は、その分析および/または受信された目標ビットレート41に基づいて、聴覚心理コーダのインスタンス化の総数(環境またはバックグラウンドチャネルの総数(BGTOT)とフォアグラウンドチャネル、または言い換えれば支配的なチャネルの数との関数であり得る)を決定し得る。聴覚心理コーダのインスタンス化の総数は、numHOATransportChannelsとして示されることができる。
[0054]音場分析ユニット44はまた、やはり目標ビットレート41を潜在的に達成するために、フォアグラウンドチャネルの総数(nFG)45と、バックグラウンド(または言い換えれば環境的な)音場の最小次数(NBG、または代替的にはMinAmbHOAorder)と、バックグラウンド音場の最小次数を表す実際のチャネルの対応する数(nBGa=(MinAmbHOAorder+1)2)と、送るべき追加のBG HOAチャネルのインデックス(i)(図3の例ではバックグラウンドチャネル情報43として総称的に示され得る)とを決定し得る。バックグラウンドチャネル情報43は、環境チャネル情報43とも呼ばれ得る。numHOATransportChannels−nBGaで残るチャネルの各々は、「追加のバックグラウンド/環境チャネル」、「アクティブなベクトルベースの支配的なチャネル」、「アクティブな指向性ベースの支配的な信号」、または「完全に非アクティブ」のいずれかであり得る。一態様では、チャネルタイプは、2ビットによって(「ChannelType」として)示されたシンタックス要素であり得る(たとえば、00:指向性ベースの信号、01:ベクトルベースの支配的な信号、10:追加の環境信号、11:非アクティブな信号)。バックグラウンド信号または環境信号の総数、nBGaは、(MinAmbHOAorder+1)2+(上記の例における)インデックス10がそのフレームのためのビットストリームにおいてチャネルタイプとして現れる回数によって与えられ得る。
[0055]音場分析ユニット44は、目標ビットレート41に基づいて、バックグラウンド(または言い換えれば環境)チャネルの数とフォアグラウンド(または言い換えれば支配的な)チャネルの数とを選択し、目標ビットレート41が比較的高いとき(たとえば、目標ビットレート41が512Kbps以上であるとき)はより多くのバックグラウンドチャネルおよび/またはフォアグラウンドチャネルを選択し得る。一態様では、ビットストリームのヘッダセクションにおいて、numHOATransportChannelsは8に設定され得るが、一方で、MinAmbHOAorderは1に設定され得る。このシナリオでは、各フレームにおいて、音場のバックグラウンド部分または環境部分を表すために4つのチャネルが確保され得るが、一方で、他の4つのチャネルは、フレームごとに、チャネルのタイプに応じて変化してよく、たとえば、追加のバックグラウンド/環境チャネルまたはフォアグラウンド/支配的なチャネルのいずれかとして使用され得る。フォアグラウンド/支配的な信号は、上記で説明されたように、ベクトルベースの信号または指向性ベースの信号のいずれかの1つであり得る。
[0056]いくつかの場合には、フレームのためのベクトルベースの支配的な信号の総数は、そのフレームのビットストリームにおいてChannelTypeインデックスが01である回数によって与えられ得る。上記の態様では、各々の追加のバックグラウンド/環境チャネル(たとえば、10というChannelTypeに対応する)に対して、(最初の4つ以外の)あり得るHOA係数のいずれがそのチャネルにおいて表され得るかの対応する情報。その情報は、4次のHOAコンテンツについては、HOA係数5〜25を示すためのインデックスであり得る。最初の4つの環境HOA係数1〜4は、minAmbHOAorderが1に設定されるときは常に送られ得、したがって、オーディオ符号化デバイスは、5〜25のインデックスを有する追加の環境HOA係数のうちの1つを示すことのみが必要であり得る。その情報はしたがって、「CodedAmbCoeffIdx」として示され得る、(4次のコンテンツのための)5ビットのシンタックス要素を使用して送られ得る。いずれにしても、音場分析ユニット44は、バックグラウンドチャネル情報43とHOA係数11とをバックグラウンド(BG)選択ユニット36に、バックグラウンドチャネル情報43を係数低減ユニット46およびビットストリーム生成ユニット42に、nFG45をフォアグラウンド選択ユニット36に出力する。
[0057]バックグラウンド選択ユニット48は、バックグラウンドチャネル情報(たとえば、バックグラウンド音場(NBG)と、送るべき追加のBG HOAチャネルの数(nBGa)およびインデックス(i)と)に基づいて、バックグラウンドまたは環境HOA係数47を決定するように構成されたユニットを表し得る。たとえば、NBGが1に等しいとき、バックグラウンド選択ユニット48は、1以下の次数を有するオーディオフレームの各サンプルのHOA係数11を選択し得る。バックグラウンド選択ユニット48は次いで、この例では、インデックス(i)のうちの1つによって特定されるインデックスを有するHOA係数11を、追加のBG HOA係数として選択することができ、ここで、nBGaは、図2および図4の例に示されるオーディオ復号デバイス24などのオーディオ復号デバイスがビットストリーム21からバックグラウンドHOA係数47を解析することを可能にするために、ビットストリーム21において指定されるために、ビットストリーム生成ユニット42に提供される。バックグラウンド選択ユニット48は次いで、環境HOA係数47をエネルギー補償ユニット38に出力し得る。環境HOA係数47は、次元D:M×[(NBG+1)2+nBGa]を有し得る。環境HOA係数47はまた、「環境HOA係数47」と呼ばれ得、ここで、環境HOA係数47の各々は、聴覚心理オーディオコーダユニット40によって符号化されるべき別個の環境HOAチャネルに対応する。
[0058]フォアグラウンド選択ユニット36は、(フォアグラウンドベクトルを特定する1つまたは複数のインデックスを表し得る)nFG45に基づいて、音場のフォアグラウンド成分または明瞭な成分を表す、並べ替えられたUS[k]行列33’と並べ替えられたV[k]行列35’とを選択するように構成されたユニットを表し得る。フォアグラウンド選択ユニット36は、(並べ替えられたUS[k]
1,...,nFG49、FG
1,...,nfG[k]49、またはX
(1..nFG) PS(k)49として示され得る)nFG信号49を、量子化補償ユニット70に出力することができ、ここで、nFG信号49は次元D:M×nFGを有し、モノラルオーディオオブジェクトを各々表し得る。フォアグラウンド選択ユニット36はまた、音場のフォアグラウンド成分に対応する並べ替えられたV[k]行列35’(またはv
(1..nFG)(k)35’)を空間時間的補間ユニット50に出力することができ、ここで、フォアグラウンド成分に対応する並べ替えられたV[k]行列35’のサブセットは、次元D:(N+1)
2×nFGを有するフォアグラウンドV[k]行列51
kとして示され得る(これは、
として数学的に示され得る)。
[0059]エネルギー補償ユニット38は、バックグラウンド選択ユニット48によるHOAチャネルのうちの様々なチャネルの除去によるエネルギー損失を補償するために、環境HOA係数47に関してエネルギー補償を実行するように構成されたユニットを表し得る。エネルギー補償ユニット38は、並べ替えられたUS[k]行列33’、並べ替えられたV[k]行列35’、nFG信号49、フォアグラウンドV[k]ベクトル51k、および環境HOA係数47のうちの1つまたは複数に関してエネルギー分析を実行し、次いで、エネルギー補償された環境HOA係数47’を生成するために、そのエネルギー分析に基づいてエネルギー補償を実行し得る。エネルギー補償ユニット38は、エネルギー補償された環境HOA係数47’を聴覚心理オーディオコーダユニット40に出力し得る。
[0060]空間時間的補間ユニット50は、k番目のフレームのためのフォアグラウンドV[k]ベクトル51kと以前のフレームに関する(したがってk−1という表記である)フォアグラウンドV[k−1]ベクトル51k-1とを受信し、補間されたフォアグラウンドV[k]ベクトルを生成するために空間時間的補間を実行するように構成されたユニットを表し得る。空間時間的補間ユニット50は、並べ替えられたフォアグラウンドHOA係数を復元するために、nFG信号49をフォアグラウンドV[k]ベクトル51kと再び組み合わせ得る。空間時間的補間ユニット50は次いで、補間されたnFG信号49’を生成するために、補間されたV[k]ベクトルによって、並べ替えられたフォアグラウンドHOA係数を分割し得る。空間時間的補間ユニット50はまた、オーディオ復号デバイス24などのオーディオ復号デバイスが補間されたフォアグラウンドV[k]ベクトルを生成しそれによってフォアグラウンドV[k]ベクトル51kを復元できるように、補間されたフォアグラウンドV[k]ベクトルを生成するために使用されたフォアグラウンドV[k]ベクトル51kを出力し得る。補間されたフォアグラウンドV[k]ベクトルを生成するために使用されたフォアグラウンドV[k]ベクトル51kは、残りのフォアグラウンドV[k]ベクトル53として示される。同じV[k]およびV[k−1]がエンコーダおよびデコーダにおいて(補間されたベクトルV[k]を作成するために)使用されることを保証するために、ベクトルの量子化された/逆量子化されたバージョンがエンコーダおよびデコーダにおいて使用され得る。空間時間的補間ユニット50は、補間されたnFG信号49’を聴覚心理オーディオコーダユニット40に出力し、補間されたフォアグラウンドV[k]ベクトル51kを係数低減ユニット46に出力し得る。
[0061]係数低減ユニット46は、低減されたフォアグラウンドV[k]ベクトル55を量子化ユニット52に出力するために、バックグラウンドチャネル情報43に基づいて残りのフォアグラウンドV[k]ベクトル53に関して係数低減を実行するように構成されたユニットを表し得る。低減されたフォアグラウンドV[k]ベクトル55は、次元D:[(N+1)2−(NBG+1)2−BGTOT]×nFGを有し得る。係数低減ユニット46は、この点において、残りのフォアグラウンドV[k]ベクトル53における係数の数を低減するように構成されたユニットを表し得る。言い換えれば、係数低減ユニット46は、指向性情報をほとんどまたはまったく有しない(残りのフォアグラウンドV[k]ベクトル53を形成する)フォアグラウンドV[k]ベクトルにおける係数を除去するように構成されたユニットを表し得る。いくつかの例では、(NBGと示され得る)1次および0次の基底関数に対応する、明瞭な、または言い換えればフォアグラウンドV[k]ベクトルの係数は、指向性情報をほとんど提供せず、したがって、(「係数低減」と呼ばれ得るプロセスを通じて)フォアグラウンドVベクトルから除去され得る。この例では、対応する係数NBGを特定するだけではなく、追加のHOAチャネル(変数TotalOfAddAmbHOAChanによって示され得る)を[(NBG+1)2+1,(N+1)2]のセットから特定するために、より大きい柔軟性が与えられ得る。
[0062]量子化ユニット52は、コーディングされたフォアグラウンドV[k]ベクトル57を生成するために低減されたフォアグラウンドV[k]ベクトル55を圧縮するための任意の形態の量子化を実行し、コーディングされたフォアグラウンドV[k]ベクトル57をビットストリーム生成ユニット42に出力するように構成されたユニットを表し得る。動作において、量子化ユニット52は、音場の空間成分、すなわちこの例では低減されたフォアグラウンドV[k]ベクトル55の1つまたは複数を圧縮するように構成されたユニットを表し得る。量子化ユニット52は、「NbitQ」で表される量子化モードシンタックス要素によって示されるような、以下の12の量子化モードのうちのいずれか1つを実行し得る。
NbitQ値 量子化モードのタイプ
0〜3: 予約済み
4: ベクトル量子化
5: ハフマンコーディングなしのスカラー量子化
6: ハフマンコーディングありの6ビットスカラー量子化
7: ハフマンコーディングありの7ビットスカラー量子化
8: ハフマンコーディングありの8ビットスカラー量子化
16: ハフマンコーディングありの16ビットスカラー量子化
量子化ユニット52は、また、前述のタイプの量子化モードのいずれかの量子化モードの予測されたバージョンを実行し得、ここで、以前のフレームのVベクトルの要素(またはベクトル量子化が実行されるときの重み)と、現在のフレームのVベクトルの要素(またはベクトル量子化が実行されるときの重み)との間の差が決定される。量子化ユニット52は、その際、現在のフレーム自体のVベクトルの要素の値ではなく、現在のフレームの要素または重みと、以前のフレームの要素または重みとの間の差を量子化し得る。
[0063]量子化ユニット52は、低減されたフォアグラウンドV[k]ベクトル55の複数の符号化されたバージョンを取得するために、低減されたフォアグラウンドV[k]ベクトル55のそれぞれに対して複数の形の量子化を実行し得る。量子化ユニット52は、符号化されたフォアグラウンドV[k]ベクトル57として、低減されたフォアグラウンドV[k]ベクトル55の符号化されたバージョンのうちの1つまたは複数を選択し得る。量子化ユニット52は、言い換えれば、本開示で説明される基準の任意の組合せに基づいて、出力切替えされ量子化されたVベクトルとして使用するために、予測されないベクトル量子化されたVベクトル、予測されベクトル量子化されたVベクトル、ハフマンコーディングされないスカラー量子化されたVベクトル、およびハフマンコーディングされスカラー量子化されたVベクトルのうちの1つを選択し得る。いくつかの例では、量子化ユニット52は、ベクトル量子化モードと1つまたは複数のスカラー量子化モードとを含む、量子化モードのセットから量子化モードを選択し、選択されたモードに基づいて(または従って)、入力Vベクトルを量子化し得る。量子化ユニット52は次いで、(たとえば、重み値またはそれを示すビットに関して)予測されないベクトル量子化されたVベクトル、(たとえば、誤差値またはそれを示すビットに関して)予測されベクトル量子化されたVベクトル、ハフマンコーディングされないスカラー量子化されたVベクトル、およびハフマンコーディングされスカラー量子化されたVベクトルのうちの選択されたものを、コーディングされたフォアグラウンドV[k]ベクトル57としてビットストリーム生成ユニット42に与え得る。量子化ユニット52はまた、量子化モードを示すシンタックス要素(たとえば、NbitsQシンタックス要素)と、Vベクトルを逆量子化またはさもなければ再構成するために使用される任意の他のシンタックス要素とを与え得る。
[0064]オーディオ符号化デバイス20に含まれる量子化補償ユニット70は、補間されたフォアグラウンドV[k]ベクトル53を量子化することから生じる量子化誤差を補償するために、空間時間的補間ユニット50から補間されたnFG信号49’および補間されたフォアグラウンドV[k]ベクトル53を、そして、量子化ユニット52からコーディングされたフォアグラウンドV[k]ベクトル57を受信し、nFG信号49’に関する量子化補償を実行するように構成されるユニットを表し得る。量子化補償ユニット70は、量子化補償されたnFG信号60を生成し、聴覚心理オーディオコーダユニット40に出力し得る。
[0065]量子化補償されたnFG信号60を決定するために、量子化補償ユニット70は、コーディングされたフォアグラウンドV[k]ベクトル57は行列であるので、コーディングされたフォアグラウンドV[k]ベクトル57の擬似逆行列を得るために、コーディングされたフォアグラウンドV[k]ベクトル57に関する擬似逆行列関数を実行し得る。擬似逆行列関数は、いくつかの例において、一般化逆行列関数、またはムーア−ペンローズの擬似逆行列関数とし得る。量子化補償ユニット70は、中間的な量子化補償されたnFG信号を決定するために、コーディングされたフォアグラウンドV[k]ベクトル57の擬似逆行列と、フォアグラウンドHOA係数との積を計算し得る。たとえば、量子化補償ユニット70は、補間されたnFG信号49’と補間されたフォアグラウンドV[k]ベクトル53との積として、フォアグラウンドHOA係数を決定し得る。中間的な量子化補償されたnFG信号は、補間されたフォアグラウンドV[k]ベクトル53の代わりに、コーディングされたフォアグラウンドV[k]ベクトル57に少なくとも部分的に基づいて計算されるので、コーディングされたフォアグラウンドV[k]ベクトル57の擬似逆行列とフォアグラウンドHOA係数との積の結果として生成されることによって、量子化補償ユニット70によって生成される中間的な量子化補償されたnFG信号は、コーディングされたフォアグラウンドV[k]ベクトル57によって導入される量子化誤差を補償し得る。したがって、オーディオ符号化デバイス20は、それにより、量子化補償されたnFG信号60を量子化する際に、補間されたフォアグラウンドV[k]ベクトル53を量子化する際に導入される任意の誤差を補償し得る。
[0066]量子化補償ユニット70はさらに、量子化補償されたnFG信号60を生成するために、現在のフレームkの中間的な量子化補償されたnFG信号の一部を、以前のフレームk−1の中間的な量子化補償されたnFG信号の一部とクロスフェードさせ得る。たとえば、量子化補償ユニット70は、1024×2のサイズの量子化補償されたnFG信号60を生成するために、現在のフレームkの中間的な量子化補償されたnFG信号の最初の256サンプルと、以前のフレームk−1の中間的な量子化補償されたnFG信号の最後の256サンプルとクロスフェードさせ得る。いくつかの例では、量子化補償ユニット70は、現在のフレームkの中間的な量子化補償されたnFG信号を、以前のフレームk−1の中間的な量子化補償されたnFG信号とクロスフェードさせない場合がある。この場合、量子化補償されたnFG信号60は、中間的な量子化補償されたnFG信号と同じであり得る。
[0067]オーディオ符号化デバイス20内に含まれる聴覚心理オーディオコーダユニット40は、聴覚心理オーディオコーダの複数のインスタンスを表し得、これらの各々は、符号化された環境HOA係数59と符号化されたnFG信号61とを生成するために、エネルギー補償された環境HOA係数47’および量子化補償されたnFG信号60の各々の異なるオーディオオブジェクトまたはHOAチャネルを符号化するために使用される。符号化された環境HOA係数59を生成することは、エネルギー補償された環境HOA係数47’の量子化を実行することを含み得、符号化されたnFG信号61を生成することは、量子化補償されたnFG信号60の量子化を実行することを含み得る。聴覚心理オーディオコーダユニット40は、符号化された環境HOA係数59と符号化されたnFG信号61とをビットストリーム生成ユニット42に出力し得る。
[0068]オーディオ符号化デバイス20内に含まれるビットストリーム生成ユニット42は、既知のフォーマット(復号デバイスによって知られているフォーマットを指し得る)に適合するようにデータをフォーマットし、それによってベクトルベースのビットストリーム21を生成するユニットを表す。ビットストリーム21は、言い換えれば、上記で説明された方法で符号化されている、符号化されたオーディオデータを表し得る。ビットストリーム生成ユニット42は、いくつかの例ではマルチプレクサを表し得、マルチプレクサは、コーディングされたフォアグラウンドV[k]ベクトル57と、符号化された環境HOA係数59と、符号化されたnFG信号61と、バックグラウンドチャネル情報43とを受信し得る。ビットストリーム生成ユニット42は次いで、コーディングされたフォアグラウンドV[k]ベクトル57と、符号化された環境HOA係数59と、符号化されたnFG信号61と、バックグラウンドチャネル情報43とに基づいて、ビットストリーム21を生成し得る。このようにして、ビットストリーム生成ユニット42は、それにより、図7の例に関して以下により詳細に説明されるように、ビットストリーム21を取得するために、ビットストリーム21内のベクトル57を指定し得る。ビットストリーム21は、主要またはメインビットストリームと、1つまたは複数のサイドチャネルビットストリームとを含み得る。
[0069]図3の例には示されないが、オーディオ符号化デバイス20はまた、現在のフレームが指向性ベース合成を使用して符号化されるべきであるかベクトルベース合成を使用して符号化されるべきであるかに基づいて、オーディオ符号化デバイス20から出力されるビットストリームを(たとえば、指向性ベースのビットストリーム21とベクトルベースのビットストリーム21との間で)切り替える、ビットストリーム出力ユニットを含み得る。ビットストリーム出力ユニットは、(HOA係数11が合成オーディオオブジェクトから生成されたことを検出した結果として)指向性ベース合成が実行されたか、または(HOA係数が録音されたことを検出した結果として)ベクトルベース合成が実行されたかを示す、コンテンツ分析ユニット26によって出力されるシンタックス要素に基づいて、切替えを実行し得る。ビットストリーム出力ユニットは、ビットストリーム21の各々とともに現在のフレームのために使用される切替えまたは現在の符号化を示すために、正しいヘッダシンタックスを指定し得る。
[0070]その上、上述されたように、音場分析ユニット44は、BGTOT環境HOA係数47を特定し得、それは、フレームごとに変化し得る(が、時々、BGTOTは、2つ以上の(時間的に)隣接するフレームにわたって一定または同じままであり得る)。BGTOTにおける変化は、低減されたフォアグラウンドV[k]ベクトル55において表された係数への変化となり得る。BGTOTにおける変化は、フレームごとに変化する(「環境HOA係数」と呼ばれることもある)バックグラウンドHOA係数となり得る(が、この場合も時々、BGTOTは、2つ以上の(時間的に)隣接するフレームにわたって一定または同じままであり得る)。この変化は、しばしば、追加の環境HOA係数の追加または除去と、対応する、低減されたフォアグラウンドV[k]ベクトル55からの係数の除去またはそれに対する係数の追加とによって表される、音場の態様のためのエネルギーの変化となる。
[0071]結果として、音場分析ユニット44は、いつ環境HOA係数がフレームごとに変化するかをさらに決定し、音場の環境成分を表すために使用されることに関して、環境HOA係数への変化を示すフラグまたは他のシンタックス要素を生成し得る(ここで、この変化はまた、環境HOA係数の「遷移」または環境HOA係数の「遷移」と呼ばれ得る)。具体的には、係数低減ユニット46は、(AmbCoeffTransitionフラグまたはAmbCoeffIdxTransitionフラグとして示され得る)フラグを生成し、そのフラグが(場合によってはサイドチャネル情報の一部として)ビットストリーム21中に含まれ得るように、そのフラグをビットストリーム生成ユニット42に与え得る。
[0072]係数低減ユニット46は、環境係数の遷移のフラグを指定することに加えて、低減されたフォアグラウンドV[k]ベクトル55が生成される方法を修正し得る。一例では、環境HOA環境係数のうちの1つが現在のフレームの間に遷移中であると決定すると、係数低減ユニット46は、遷移中の環境HOA係数に対応する低減されたフォアグラウンドV[k]ベクトル55のVベクトルの各々について、(「ベクトル要素」または「要素」とも呼ばれ得る)ベクトル係数を指定し得る。この場合も、遷移中の環境HOA係数は、BGTOTからバックグラウンド係数の総数を追加または除去し得る。したがって、バックグラウンド係数の総数において生じた変化は、環境HOA係数がビットストリーム中に含まれるか含まれないか、および、Vベクトルの対応する要素が、上記で説明された第2の構成モードおよび第3の構成モードにおいてビットストリーム中で指定されたVベクトルのために含まれるか否かに影響を及ぼす。係数低減ユニット46が、エネルギーにおける変化を克服するために、低減されたフォアグラウンドV[k]ベクトル55を指定することができる方法に関するより多くの情報は、2015年1月12日に出願された「TRANSITIONING OF AMBIENT HIGHER_ORDER AMBISONIC COEFFICIENTS」という名称の米国特許出願第14/594,533号において提供されている。
[0073]図4は、図2のオーディオ復号デバイス24をより詳細に示すブロック図である。図4の例に示されているように、オーディオ復号デバイス24は、抽出ユニット72と、指向性ベース再構成ユニット90と、ベクトルベース再構成ユニット92とを含み得る。以下で説明されるが、オーディオ復号デバイス24に関するより多くの情報、およびHOA係数を解凍またはさもなければ復号する様々な態様は、2014年5月29日に出願された「INTERPOLATION FOR DECOMPOSED REPRESENTATIONS OF A SOUND FIELD」という名称の国際特許出願公開第WO2014/194099号において入手可能である。
[0074]抽出ユニット72は、ビットストリーム21を受信し、HOA係数11の様々な符号化されたバージョン(たとえば、指向性ベースの符号化されたバージョンまたはベクトルベースの符号化されたバージョン)を抽出するように構成されたユニットを表し得る。抽出ユニット72は、HOA係数11が様々な方向ベースのバージョンを介して符号化されたか、ベクトルベースのバージョンを介して符号化されたかを示す、上述されたシンタックス要素から決定し得る。指向性ベース符号化が実行されたとき、抽出ユニット72は、HOA係数11の指向性ベースのバージョンと、符号化されたバージョンに関連付けられたシンタックス要素(図4の例では指向性ベース情報91として示される)とを抽出し、指向性ベース情報91を指向性ベース再構成ユニット90に渡し得る。指向性ベース再構成ユニット90は、指向性ベース情報91に基づいてHOA係数11’の形態でHOA係数を再構成するように構成されたユニットを表し得る。ビットストリームおよびビットストリーム内のシンタックス要素の構成が、以下で図7A〜図7Jの例に関してより詳細に説明される。
[0075]HOA係数11がベクトルベース合成を使用して符号化されたことをシンタックス要素が示すとき、抽出ユニット72は、コーディングされたフォアグラウンドV[k]ベクトル57(コーディングされた重みおよび/もしくはインデックス63またはスカラー量子化されたVベクトルを含み得る)と、符号化された環境HOA係数59と、対応するオーディオオブジェクト61(符号化されたnFG信号61と呼ばれる場合もある)とを抽出し得る。オーディオオブジェクト61はそれぞれベクトル57のうちの1つに対応する。抽出ユニット72は、コーディングされたフォアグラウンドV[k]ベクトル57をVベクトル再構成ユニット74に渡し、符号化された環境HOA係数59を符号化されたnFG信号61とともに聴覚心理オーディオ復号ユニット80に渡し得る。
[0076]Vベクトル再構成ユニット74(逆量子化ユニットとしても知られる)は、符号化されたフォアグラウンドV[k]ベクトル57から、Vベクトル(たとえば、低減されたフォアグラウンドV[k]ベクトル55k)を再構成するように構成されるユニットを表し得る。Vベクトル再構成ユニット74は、符号化されたフォアグラウンドV[k]ベクトル57を逆量子化し、低減されたフォアグラウンドV[k]ベクトル55kを生成するために、量子化ユニット52の動作と逆の方法で動作し得る。
[0077]いくつかの例では、Vベクトル再構成ユニット74は、クロスフェードされ、量子化されたV[k]ベクトルを生成するために、現在のフレームのコーディングされたフォアグラウンドV[k]ベクトル57の一部を、以前のフレームのコーディングされたフォアグラウンドV[k−1]ベクトルの一部とクロスフェードさせ得る。たとえば、抽出ユニット72は、低減されたフォアグラウンドV[k]ベクトル55kを生成するために、現在のフレームkのコーディングされたフォアグラウンドV[k]ベクトル57の最初の256サンプルを、以前のフレームk−1の量子化されたフォアグラウンドV[k]ベクトルの最後の256サンプルとクロスフェードさせ、クロスフェードし、量子化されたフォアグラウンドV[k]ベクトルを逆量子化し得る。
[0078]聴覚心理オーディオ復号ユニット80は、符号化された環境HOA係数59と符号化されたnFG信号61とを復号し、それによってエネルギー補償された環境HOA係数47’と補間されたnFG信号49’(補間されたnFGオーディオオブジェクト49’とも呼ばれ得る)とを生成するために、図3の例に示される聴覚心理オーディオコーダユニット40とは逆の方法で動作し得る。聴覚心理オーディオ復号ユニット80は、エネルギー補償された環境HOA係数47’をフェードユニット770に渡し、nFG信号49’をフォアグラウンド編成ユニット78に渡すことができる。
[0079]空間時間的補間ユニット76は、空間時間的補間ユニット50に関して上記で説明されたものと同様の方法で動作し得る。空間時間的補間ユニット76は、低減されたフォアグラウンドV[k]ベクトル55kを受信し、また、補間されたフォアグラウンドV[k]ベクトル55k’’を生成するために、フォアグラウンドV[k]ベクトル55kおよび低減されたフォアグラウンドV[k−1]ベクトル55k-1に関して空間時間的補間を実行し得る。空間時間的補間ユニット76は、補間されたフォアグラウンドV[k]ベクトル55k’’をフェードユニット770に転送し得る。
[0080]抽出ユニット72はまた、いつ環境HOA係数のうちの1つが遷移中であるかを示す信号757を、フェードユニット770に出力し得、フェードユニット770は次いで、SCHBG47’(ここで、SCHBG47’は、「環境HOAチャネル47’」または「環境HOA係数47’」とも呼ばれ得る)および補間されたフォアグラウンドV[k]ベクトル55k’’の要素のうちのいずれがフェードインまたはフェードアウトのいずれかを行われるべきであるかを決定し得る。いくつかの例では、フェードユニット770は、環境HOA係数47’および補間されたフォアグラウンドV[k]ベクトル55k’’の要素の各々に関して、反対に動作し得る。すなわち、フェードユニット770は、環境HOA係数47’のうちの対応する1つに関して、フェードインもしくはフェードアウト、またはフェードインもしくはフェードアウトの両方を実行し得、一方で、補間されたフォアグラウンドV[k]ベクトル55k’’の要素のうちの対応する1つに関して、フェードインもしくはフェードアウト、またはフェードインとフェードアウトの両方を実行し得る。フェードユニット770は、調整された環境HOA係数47’’をHOA係数編成ユニット82に出力し、調整されたフォアグラウンドV[k]ベクトル55k’’’をフォアグラウンド編成ユニット78に出力し得る。この点において、フェードユニット770は、HOA係数またはその派生物の様々な態様に関して、たとえば、環境HOA係数47’および補間されたフォアグラウンドV[k]ベクトル55k’’の要素の形態で、フェード動作を実行するように構成されたユニットを表す。
[0081]フォアグラウンド編成ユニット78は、フォアグラウンドHOA係数65を生成するために、調整されたフォアグラウンドV[k]ベクトル55k’’’および補間されたnFG信号49’に関して行列乗算を実行するように構成されたユニットを表し得る。この点において、フォアグラウンド編成ユニット78は、フォアグラウンド、または言い換えると、HOA係数11’の支配的態様を再構成するために、オーディオオブジェクト49’(それは、補間されたnFG49’を表す別の方法である)をベクトル55k’’’と組み合わせ得る。フォアグラウンド編成ユニット78は、調整されたフォアグラウンドV[k]ベクトル55k’’’による補間されたnFG信号49’の行列乗算を実行し得る。
[0082]HOA係数編成ユニット82は、HOA係数11’を取得するために、フォアグラウンドHOA係数65を調整された環境HOA係数47’’に組み合わせるように構成されたユニットを表し得る。プライム表記法は、HOA係数11’がHOA係数11と同様であるが同じではないことがあることを反映している。HOA係数11とHOA係数11’との間の差分は、損失のある送信媒体を介した送信、量子化、または他の損失のある演算が原因の損失に起因し得る。
[0083]図5Aは、本開示で説明されるベクトルベース合成技法の様々な態様を実行する際の、図3の例に示されるオーディオ符号化デバイス20などのオーディオ符号化デバイスの例示的な動作を示すフローチャートである。最初に、オーディオ符号化デバイス20は、HOA係数11を受信する(106)。オーディオ符号化デバイス20はLITユニット30を呼び出すことができ、LITユニット30は、変換されたHOA係数(たとえば、SVDの場合、変換されたHOA係数はUS[k]ベクトル33とV[k]ベクトル35とを備え得る)を出力するためにHOA係数に関してLITを適用し得る(107)。
[0084]オーディオ符号化デバイス20は次に、上記で説明された方法で様々なパラメータを特定するために、US[k]ベクトル33、US[k−1]ベクトル33、V[k]ベクトルおよび/またはV[k−1]ベクトル35の任意の組合せに関して上記で説明された分析を実行するために、パラメータ計算ユニット32を呼び出し得る。すなわち、パラメータ計算ユニット32は、変換されたHOA係数33/35の分析に基づいて少なくとも1つのパラメータを決定し得る(108)。
[0085]オーディオ符号化デバイス20は次いで、並べ替えユニット34を呼び出し得、並べ替えユニット34は、上記で説明されたように、並べ替えられた変換されたHOA係数33’/35’(または言い換えれば、US[k]ベクトル33’およびV[k]ベクトル35’)を生成するために、パラメータに基づいて、変換されたHOA係数(この場合も、SVDの文脈では、US[k]ベクトル33とV[k]ベクトル35とを指し得る)を並べ替え得る(109)。オーディオ符号化デバイス20は、前述の演算または後続の演算のいずれかの間に、音場分析ユニット44を呼び出し得る。音場分析ユニット44は、上記で説明されたように、フォアグラウンドチャネルの総数(nFG)45と、バックグラウンド音場の次数(NBG)と、送るべき追加のBG HOAチャネルの数(nBGa)およびインデックス(i)(図3の例ではバックグラウンドチャネル情報43としてまとめて示され得る)とを決定するために、HOA係数11および/または変換されたHOA係数33/35に関して音場分析を実行し得る(109)。
[0086]オーディオ符号化デバイス20はまた、バックグラウンド選択ユニット48を呼び出し得る。バックグラウンド選択ユニット48は、バックグラウンドチャネル情報43に基づいて、バックグラウンドまたは環境HOA係数47を決定し得る(110)。オーディオ符号化デバイス20はさらに、フォアグラウンド選択ユニット36を呼び出し得、フォアグラウンド選択ユニット36は、nFG45(フォアグラウンドベクトルを特定する1つまたは複数のインデックスを表し得る)に基づいて、音場のフォアグラウンド成分または明瞭な成分を表す、並べ替えられたUS[k]ベクトル33’と並べ替えられたV[k]ベクトル35’とを選択し得る(112)。
[0087]オーディオ符号化デバイス20は、エネルギー補償ユニット38を呼び出し得る。エネルギー補償ユニット38は、バックグラウンド選択ユニット48によるHOA係数のうちの様々なものの除去によるエネルギー損失を補償するために、環境HOA係数47に関してエネルギー補償を実行し(114)、それによって、エネルギー補償された環境HOA係数47’を生成し得る。
[0088]オーディオ符号化デバイス20はまた、空間時間的補間ユニット50を呼び出し得る。空間時間的補間ユニット50は、補間されたフォアグラウンド信号49’(「補間されたnFG信号49’」とも呼ばれ得る)と残りのフォアグラウンド指向性情報53(「V[k]ベクトル53」とも呼ばれ得る)とを取得するために、並べ替えられた変換されたHOA係数33’/35’に関して空間時間的補間を実行し得る(116)。オーディオ符号化デバイス20は次いで、係数低減ユニット46を呼び出し得る。係数低減ユニット46は、低減されたフォアグラウンド指向性情報55(低減されたフォアグラウンドV[k]ベクトル55とも呼ばれ得る)を取得するために、バックグラウンドチャネル情報43に基づいて残りのフォアグラウンドV[k]ベクトル53に関して係数低減を実行し得る(118)。
[0089]オーディオ符号化デバイス20は次いで、上記で説明された方法で、低減されたフォアグラウンドV[k]ベクトル55を圧縮し、コーディングされたフォアグラウンドV[k]ベクトル57を生成するために、量子化ユニット52を呼び出し得る(120)。
[0090]オーディオ符号化デバイス20は、量子化補償ユニット70を呼び出し得る。量子化補償ユニット70は、量子化補償されたnFG信号60を生成するために、コーディングされたフォアグラウンドV[k]ベクトル57の量子化誤差を補償し得る(121)。
[0091]オーディオ符号化デバイス20はまた、聴覚心理オーディオコーダユニット40を呼び出し得る。聴覚心理オーディオコーダユニット40は、符号化された環境HOA係数59と符号化されたnFG信号61とを生成するために、エネルギー補償された環境HOA係数47’および補間されたnFG信号49’の各ベクトルを聴覚心理コーディングし得る。オーディオ符号化デバイスは次いで、ビットストリーム生成ユニット42を呼び出し得る。ビットストリーム生成ユニット42は、コーディングされたフォアグラウンド指向性情報57と、コーディングされた環境HOA係数59と、コーディングされたnFG信号61と、バックグラウンドチャネル情報43とに基づいて、ビットストリーム21を生成し得る。
[0092]図5Bは、本開示で説明されるコーディング技法を実行する際のオーディオ符号化デバイスの例示的な動作を示すフローチャートである。図5Bに示されるように、オーディオ符号化デバイス20のLITユニット30は、HOA係数を、オーディオオブジェクトと、オーディオオブジェクトに関連付けられる指向性情報とに分解し得る(150)。オーディオオブジェクトは、複数の球面調和係数の左特異ベクトルを表すU行列と、複数の球面調和係数の特異値を表すS行列との積を備え得る。オーディオオブジェクトに関連付けられる指向性情報は、複数の球面調和係数の右特異ベクトルを表すV行列を備え得る。
[0093]オーディオ符号化デバイス20の聴覚心理オーディオコーダユニット40は、オーディオオブジェクトに関連付けられる指向性情報の量子化を実行した結果に少なくとも部分的に基づいて、オーディオオブジェクトの閉ループ量子化を実行し得る(152)。オーディオ符号化デバイス20は、オーディオオブジェクトに関連付けられる指向性情報の量子化を実行し、オーディオオブジェクトに関連付けられる指向性情報の量子化を実行した結果に少なくとも部分的に基づいて、オーディオオブジェクトの量子化を実行することによって、オーディオオブジェクトの閉ループ量子化を実行し得る。オーディオ符号化デバイス20は、オーディオオブジェクトに関連付けられる指向性情報の量子化を実行する(すなわち、指向性情報を量子化する)ことから生じる量子化誤差に少なくとも部分的に基づいて、オーディオオブジェクトの量子化を実行する(すなわち、オーディオオブジェクトを量子化する)ことによって、オーディオオブジェクトの量子化を実行(すなわち、オーディオオブジェクトを量子化する)し得る。
[0094]オーディオ符号化デバイス20は、オーディオオブジェクトに関連付けられる指向性情報の量子化を実行することから生じる量子化誤差を補償することによって、オーディオオブジェクトに関連付けられる指向性情報の量子化を実行することから生じる量子化誤差に少なくとも部分的に基づいて、オーディオオブジェクトの量子化を実行し得る。オーディオ符号化デバイス20は、オーディオオブジェクトに関連付けられる指向性情報の量子化を実行した結果の擬似逆行列に少なくとも部分的に基づいて、量子化補償されたオーディオオブジェクトを決定し、量子化補償されたオーディオオブジェクトの量子化を実行することによって、オーディオオブジェクトに関連付けられる指向性情報の量子化を実行することから生じる量子化誤差を補償し得る。
[0095]オーディオ符号化デバイス20は、高次アンビソニック(HOA)係数と、オーディオオブジェクトに関連付けられる指向性情報の量子化を実行した結果の擬似逆行列との積として量子化補償されたオーディオオブジェクトを決定することによって、オーディオオブジェクトに関連付けられる指向性情報の量子化を実行した結果の擬似逆行列に少なくとも部分的に基づいて、量子化補償されたオーディオオブジェクトを決定し得る。
[0096]図6Aは、本開示で説明される技法の様々な態様を実行する際の、図4に示されるオーディオ復号デバイス24などのオーディオ復号デバイスの例示的な動作を示すフローチャートである。最初に、オーディオ復号デバイス24は、ビットストリーム21を受信し得る(130)。ビットストリームを受信すると、オーディオ復号デバイス24は抽出ユニット72を呼び出し得る。説明の目的で、ベクトルベース再構成が実行されるべきであることをビットストリーム21が示すと仮定すると、抽出デバイス72は、上述された情報を取り出すためにビットストリームを解析し、その情報をベクトルベース再構成ユニット92に渡し得る。
[0097]言い換えれば、抽出ユニット72は、コーディングされたフォアグラウンド指向性情報57(この場合も、コーディングされたフォアグラウンドV[k]ベクトル57とも呼ばれ得る)と、コーディングされた環境HOA係数59と、コーディングされたフォアグラウンド信号(コーディングされたフォアグラウンドnFG信号61またはコーディングされたフォアグラウンドオーディオオブジェクト59とも呼ばれ得る)とを、上記で説明された方法でビットストリーム21から抽出し得る(132)。
[0098]オーディオ復号デバイス24はさらに、Vベクトル再構成ユニット74を呼び出し得る。Vベクトル再構成ユニット74は、低減されたフォアグラウンド指向性情報55kを取得するために、コーディングされたフォアグラウンド指向性情報57をエントロピー復号および逆量子化し得る(136)。オーディオ復号デバイス24はまた、聴覚心理オーディオ復号ユニット80を呼び出し得る。聴覚心理オーディオ復号ユニット80は、エネルギー補償された環境HOA係数47’と補間されたフォアグラウンド信号49’とを取得するために、符号化された環境HOA係数59と符号化されたフォアグラウンド信号61とを復号/逆量子化し得る(138)。聴覚心理オーディオ復号ユニット80は、エネルギー補償された環境HOA係数47’をフェードユニット770に渡し、nFG信号49’をフォアグラウンド編成ユニット78に渡し得る。
[0099]オーディオ復号デバイス24は次に、空間時間的補間ユニット76を呼び出し得る。空間時間的補間ユニット76は、並べ替えられたフォアグラウンド指向性情報55k’を受信し、また、補間されたフォアグラウンド指向性情報55k’’を生成するために、低減されたフォアグラウンド指向性情報55k/55k-1に関して空間時間的補間を実行し得る(140)。空間時間的補間ユニット76は、補間されたフォアグラウンドV[k]ベクトル55k’’をフェードユニット770に転送し得る。
[0100]オーディオ復号デバイス24は、フェードユニット770を呼び出し得る。フェードユニット770は、エネルギー補償された環境HOA係数47’がいつ遷移中であるかを示すシンタックス要素(たとえば、AmbCoeffTransitionシンタックス要素)を(たとえば、抽出ユニット72から)受信またはさもなければ取得し得る。フェードユニット770は、遷移シンタックス要素と維持された遷移状態情報とに基づいて、エネルギー補償された環境HOA係数47’をフェードインまたはフェードアウトし、調整された環境HOA係数47’’をHOA係数編成ユニット82に出力し得る。フェードユニット770はまた、シンタックス要素と維持された遷移状態情報とに基づいて、および、補間されたフォアグラウンドV[k]ベクトル55k’’の対応する1つまたは複数の要素をフェードアウトまたはフェードインし、フォアグラウンド編成ユニット78に調整されたフォアグラウンドV[k]ベクトル55k’’’を出力し得る(142)。
[0101]オーディオ復号デバイス24は、フォアグラウンド編成ユニット78を呼び出し得る。フォアグラウンド編成ユニット78は、フォアグラウンドHOA係数65を取得するために、調整されたフォアグラウンド指向性情報55k’’’による行列乗算nFG信号49’を実行し得る(144)。オーディオ復号デバイス24はまた、HOA係数編成ユニット82を呼び出し得る。HOA係数編成ユニット82は、HOA係数11’を取得するために、フォアグラウンドHOA係数65を調整された環境HOA係数47’’に加算し得る(146)。
[0102]図6Bは、本開示で説明されるコーディング技法を実行する際のオーディオ復号デバイスの例示的な動作を示すフローチャートである。図6Bに示されるように、オーディオ復号デバイス24の抽出ユニット72が、ビットストリームを受信し得る(160)。オーディオ復号デバイス24は、オーディオオブジェクトに関連付けられる指向性情報の量子化を実行した結果に少なくとも部分的に基づいて、閉ループ量子化されたオーディオオブジェクトを取得し得る(162)。たとえば、オーディオ復号デバイス24の抽出ユニット72は、閉ループ量子化されたオーディオオブジェクトと、量子化された指向性情報とを取得するように、ビットストリームを復号し得る。オーディオオブジェクトを取得するのに応答して、オーディオ復号デバイス24は、オーディオオブジェクトを逆量子化し得る(164)。
[0103]いくつかの例では、オーディオオブジェクトは、オーディオオブジェクトに関連付けられる指向性情報を量子化し、オーディオオブジェクトに関連付けられる指向性情報を量子化した結果に少なくとも部分的に基づいてオーディオオブジェクトを量子化することによって、閉ループ量子化される。いくつかの例では、オーディオオブジェクトは、オーディオオブジェクトに関連付けられる指向性情報を量子化し、オーディオオブジェクトに関連付けられる指向性情報を量子化することから生じる量子化誤差に少なくとも部分的に基づいてオーディオオブジェクトを量子化することによって、閉ループ量子化される。
[0104]いくつかの例では、オーディオオブジェクトは、オーディオオブジェクトに関連付けられる指向性情報を量子化し、オーディオオブジェクトに関連付けられる指向性情報の量子化を実行することから生じる量子化誤差を補償することを含む、オーディオオブジェクトに関連付けられる指向性情報を量子化することから生じる量子化誤差に少なくとも部分的に基づいてオーディオオブジェクトを量子化することによって、閉ループ量子化される。いくつかの例では、オーディオオブジェクトは、オーディオオブジェクトに関連付けられる指向性情報を量子化し、オーディオオブジェクトに関連付けられる指向性情報を量子化した結果の逆擬似行列に少なくとも部分的に基づいて、量子化補償されたオーディオオブジェクトを決定し、量子化補償されたオーディオオブジェクトを量子化することによって、閉ループ量子化される。
[0105]いくつかの例では、オーディオオブジェクトは、高次アンビソニック(HOA)係数と、オーディオオブジェクトに関連付けられる指向性情報の量子化を実行した結果の擬似逆行列との積として、オーディオオブジェクトを決定することによって、閉ループ量子化される。いくつかの例では、オーディオオブジェクトおよび指向性情報は高次アンビソニック係数から分解され、オーディオオブジェクトは、複数の球面調和係数の左特異ベクトルを表すU行列と、複数の球面調和係数の特異値を表すS行列との積を備え、オーディオオブジェクトに関連付けられる指向性情報は、複数の球面調和係数の右特異ベクトルを表すV行列を備える。
[0106]図7Aは、HOA信号圧縮のためのVベクトルおよびフォアグラウンド信号の閉ループ量子化を示すブロック図である。そのような閉ループ量子化は、図3の例に示されるオーディオ符号化デバイス20と、図4の例に示されるオーディオ復号デバイス24とによって実行され得る。量子化誤差を低減するために、Vベクトルが量子化され得、そのVベクトルの量子化誤差を補償することによって、USベクトルが量子化され得る。オーディオ符号化デバイス20は、Vベクトルを量子化してQ(V)にし得、Hとpinv(Q(V))との積として新たなターゲット信号T(US)を生成し得、ただし、pinv(A)は、Aの擬似逆行列である。オーディオ符号化デバイス20は、T(US)をQ(T(US))に量子化し得る。オーディオ復号デバイス24は、Q(T(US))*Q(V)’によって生成される量子化されたHOA係数Q(H)に基づいて、HOA係数11’を再構成し得る。このようにして、USベクトルは、Vベクトルの量子化誤差に基づいて量子化され得る。
[0107]図7Aに示されるように、HFGは、図7Aの例では、1280×21のサイズを有するフォアグラウンドHOA係数400を表し得る。フォアグラウンドHOA係数400は、UFGと、SFGと、VFGとの積に等しくし得、ただし、UFGは1280×2のサイズを有し得、SFGは2×2のサイズを有し得、VFGは21×2のサイズを有し得る。VベクトルVFG402は、図7Aの例では、21×2のサイズを有する、図3の低減されたフォアグラウンドV[k]ベクトル55とし得る。元のターゲットWFG=UFG *SFG404は、図7Aの例では、1280×2のサイズを有する、図3の補間されたnFG信号49’とし得る。
[0108]オーディオ符号化デバイス20は、後にさらに詳細に論じられるように、以前のフレーム
408の量子化されたVベクトルに少なくとも部分的に基づいて、VベクトルV
FG402に関する符号変更406を実行するか否かを決定し得る。このようにして、オーディオ符号化デバイス20は、以前のフレームの遅延した量子化されたVベクトル
408に少なくとも部分的に基づいて、現在のフレームのVベクトルV
FG402の符号を変更するか否かを決定し得る。オーディオ符号化デバイス20は、符号変更されないVベクトルV
FG402または符号変更されたVベクトル
410のいずれかが結果として生じるように、VベクトルV
FG402を符号変更406するか否かを決定し得る。オーディオ符号化デバイス20は、図3のコーディングされたフォアグラウンドV[k]ベクトル57であり得る、量子化されたフォアグラウンドVベクトル
414を生成するために、オーディオ符号化デバイス20の量子化ユニット52を使用することなどによって、符号変更されないVベクトルV
FG402または符号変更されたVベクトル
410のいずれかを量子化412し得る。オーディオ符号化デバイス20が、次のフレームに関するVベクトルV
FGで符号変更を実行するか否かを決定するように、次のフレームにおいて、量子化されたVベクトル
を利用し得るために、オーディオ符号化デバイスは、遅延された量子化Vベクトル
408を生成するように1フレームだけ量子化されたフォアグラウンドVベクトル
414を遅延させ得る。
[0109]オーディオ符号化デバイス20は、遅延した量子化されたVベクトル
408に基づいて、
418を決定し、それはフォアグラウンドHOA係数400と、遅延した量子化されたVベクトル
408の擬似逆行列である
との積である。また、オーディオ符号化デバイス200は、
420も決定し得、それは、W
FG=U
FG *S
FG404と、
418との積である。
420を決定することに少なくとも部分的に基づいて、オーディオ符号化デバイス20は、VベクトルV
FG402に関する符号変更406を実行し得る。たとえば、オーディオ符号化デバイス20は、
420の符号が負である場合には、VベクトルV
FG402に関する符号変更406を実行し得る。
[0110]オーディオ符号化デバイス20は、量子化されたVベクトル
408に少なくとも部分的に基づいて、
の積である新たなターゲット422
を生成し得、それは、量子化されたVベクトル
408の擬似逆行列と、フォアグラウンドHOA係数400を表し得るH
FGとの積であり、それにより、新たなターゲット422
になる。オーディオ符号化デバイス20は、先行するターゲット426
を生成するように、1フレームだけ新たなターゲット422
を遅延させ、図3の量子化補償されたnFG信号60に類似の、量子化補償されたターゲット信号を生成するように、新たなターゲット422
の、最初の256サンプルのような第1の部分を、先行するターゲット426
の、最後の256サンプルのような最後の部分と、クロスフェード428させ得る。オーディオ符号化デバイス20は、オーディオ復号デバイス24に出力される量子化されたフォアグラウンド信号432
を生成するように、図3の聴覚心理オーディオコーダユニット40を用いることなどによって、量子化補償されたターゲット信号を量子化430し得る。
[0111]オーディオ復号デバイス24は、たとえば、オーディオ符号化デバイス20から、量子化されたフォアグラウンドVベクトル
414を受信し得、遅延した量子化されたVベクトル
408を生成するように、1フレームだけ量子化されたフォアグラウンドVベクトル
414を遅延416させ得る。オーディオ復号デバイス24は、現在のフレームの量子化されたフォアグラウンドVベクトル
414の第1の数のサンプルを、遅延した量子化されたVベクトル
408の最後の数のサンプルとクロスフェードさせることができ、量子化されたフォアグラウンドHOA係数438
を生成するように、クロスフェードした量子化されたフォアグラウンドV[k]ベクトル436
と、量子化されたフォアグラウンド信号432
との積を決定し得る。たとえば、オーディオ復号デバイス24は、現在のフレームの量子化されたフォアグラウンドVベクトル
414の最初の256サンプルを、遅延した量子化されたVベクトル
408の最後の256サンプルとクロスフェードさせることができ、量子化されたフォアグラウンドHOA係数438
を生成するように、クロスフェードした量子化されたフォアグラウンドV[k]ベクトル436
と、量子化されたフォアグラウンド信号432
との積を決定し得る。スピーカーが、量子化されたフォアグラウンドHOA係数438から分解された逆量子化されたオーディオオブジェクトからレンダリングされたラウドスピーカーフィードを再生し得るように、オーディオ復号デバイス24は、フォアグラウンドHOA係数438を分解および逆量子化し得る。
[0112]図7Bは、HOA信号圧縮のためのVベクトルおよびフォアグラウンド信号の閉ループ量子化を示すブロック図である。図7Bに示されるようなオーディオ復号デバイス24は、現在のフレームの量子化されたフォアグラウンドVベクトル
414の第1の数のサンプルを、遅延した量子化されたVベクトル
408の最後の数のサンプルとクロスフェードさせないという点で、図7Bは図7Aとは異なる。また、図7Bに示されるようなオーディオ符号化デバイス20は、先行するターゲットを生成するために新たなターゲット422
を1フレームだけ遅延させず、それゆえ、量子化補償されたターゲット信号を生成するために、新たなターゲット422
の第1の部分を、先行するターゲット4の最後の部分とクロスフェードさせないという点で、図7Bは図7Aとは異なる。
[0113]フォアグラウンドHOA係数400は、UFGと、SFGと、VFGとの積に等しくあり得、ここで、UFGは1280×2のサイズを有し得、SFGは2×2のサイズを有し得、VFGは21×2のサイズを有し得る。VベクトルVFG402は、図7Aの例では、21×2のサイズを有する、図3の低減されたフォアグラウンドV[k]ベクトル55であり得る。元のターゲットWFG=UFG *SFG404は、図7Aの例では、1280×2のサイズを有する、図3の補間されたnFG信号49’であり得る。
[0114]オーディオ符号化デバイス20は、後にさらに詳細に論じられるように、以前のフレーム
408の量子化されたVベクトルに少なくとも部分的に基づいて、VベクトルV
FG402に関する符号変更406を実行するか否かを決定し得る。このようにして、オーディオ符号化デバイス20は、以前のフレームの遅延した量子化されたVベクトル
408に少なくとも部分的に基づいて、現在のフレームのVベクトルV
FG402の符号を変更するか否かを決定し得る。オーディオ符号化デバイス20は、符号変更されないVベクトルV
FG402または符号変更されたVベクトル
410のいずれかが結果として生じるように、VベクトルV
FG402を符号変更406するか否かを決定し得る。オーディオ符号化デバイス20は、図3のコーディングされたフォアグラウンドV[k]ベクトル57であり得る、量子化されたフォアグラウンドVベクトル
414を生成するように、オーディオ符号化デバイス20の量子化ユニット52を使用することなどによって、符号変更されないVベクトルV
FG402または符号変更されたVベクトル
410のいずれかを量子化412し得る。オーディオ符号化デバイス20は、次のフレームに関するVベクトルV
FGに関する符号変更を実行するか否かを決定するために、次のフレームにおいて、量子化されたVベクトル
を用い得るように、オーディオ符号化デバイスは、遅延した量子化されたVベクトル
408を生成するために、1フレームだけ量子化されたフォアグラウンドVベクトル
414を遅延させ得る。
[0115]オーディオ符号化デバイス20は、遅延した量子化されたVベクトル
408に基づいて、
418を決定し、それはフォアグラウンドHOA係数400と、遅延した量子化されたVベクトル
408の擬似逆行列である、
との積である。また、オーディオ符号化デバイス200は、
420も決定し得、それは、W
FG=U
FG *S
FG404と、
418との積である。
420を決定することに少なくとも部分的に基づいて、オーディオ符号化デバイス20は、VベクトルV
FG402で符号変更406を実行し得る。たとえば、オーディオ符号化デバイス20は、
420の符号が負である場合には、VベクトルV
FG402に関する符号変更406を実行し得る。
[0116]オーディオ符号化デバイス20は、量子化されたVベクトル
408に少なくとも部分的に基づいて、新たなターゲット422
のような、量子化されたVベクトル
408の擬似逆行列である、
と、フォアグラウンドHOA係数400を表し得る、H
FGとの積である新たなターゲット422
を生成し得る。オーディオ符号化デバイス20は、量子化されたフォアグラウンド信号432
を生成するように、新たなターゲット422
を量子化430し得る。オーディオ復号デバイス24は、たとえば、オーディオ符号化デバイス20から、量子化されたフォアグラウンドVベクトル
414を受信し得、量子化されたフォアグラウンドHOA係数438
を生成するように、量子化されたフォアグラウンドVベクトル
414と、量子化されたフォアグラウンド信号432
との積を決定し得る。スピーカーが、逆量子化されたフォアグラウンドHOA係数438から分解された逆量子化されたオーディオオブジェクトからレンダリングされたラウドスピーカーフィードを再生できるようにするように、オーディオ復号デバイス24は、フォアグラウンドHOA係数438を分解および逆量子化することができる。
[0117]図8は、図3の例に示されるオーディオ符号化デバイス20の量子化ユニット52をより詳細に示すブロック図である。図8の例では、量子化ユニット52は、一様量子化ユニット230と、nbitsユニット232と、予測ユニット234と、予測モードユニット236(「Pred Mode Unit 236」)と、カテゴリおよび残差コーディングユニット238と、ハフマンテーブル選択ユニット240と、遅延ユニット300と、符号変更ユニット302とを含む。一様量子化ユニット230は、空間成分の1つ(低減されたフォアグラウンドV[k]ベクトル55の任意の1つを表し得る)に関して上で説明された一様量子化を実行するように構成されるユニットを表す。nbitsユニット232は、nbitsパラメータまたはnbits値を決定するように構成されるユニットを表す。
[0118]遅延ユニット300は、一様量子化ユニット230の結果を1フレームだけ遅延させ得、それにより、一様量子化ユニット230が低減されたフォアグラウンドV[k]ベクトル55に作用する前に、符号変更ユニット302が、量子化されたフォアグラウンドV[k]ベクトルに少なくとも部分的に基づいて、低減されたフォアグラウンドV[k]ベクトル55に関する符号変更を実行するか否かを決定し得るようにする。符号変更ユニット302は、言い換えると、低減されたフォアグラウンドV[k]ベクトル55のうちの1つまたは複数のための符号を(正から負に、または負から正に)反転させるように構成されるユニットを表し得る。線形可逆変換の性質を考えると、V[k]ベクトル55は、以前のフレーム(または第(k−1)のフレーム)のV[k−1]ベクトル55のうちの対応する1つまたは複数が符号に関して反転するように、第kのフレームのためのHOA係数11から分解され得る。この点において、フレーム境界を越えて符号を変更する必要があり得る。したがって、現在のフレームの低減されたフォアグラウンドV[k]ベクトル55の符号を変更することが必要であるか否かは、以前のフレームの量子化されたVベクトルに依存し得る。具体的には、量子化ユニット54は、遅延したフォアグラウンド信号を生成するように、第kのフレームのためのHOA係数11と、以前のフレーム(k−1フレーム)の量子化されたVベクトルとを乗算し得る。。量子化ユニット54は、遅延したフォアグラウンド信号を、補間されたnFG信号49’と乗算し得る。遅延したフォアグラウンド信号を、補間されたnFG信号49’と乗算した結果が負である場合には、符号変更ユニット302が、低減されたフォアグラウンドV[k]ベクトル55に関する符号変更を実行し得る。
[0119]図9は、図3の例に示されるオーディオ符号化デバイス20の量子化補償ユニット70をより詳細に示すブロック図である。量子化補償ユニット70は、中間補償ユニット304と、遅延ユニット306と、クロスフェードユニット308とを含み得る。中間補償ユニット304は、コーディングされたフォアグラウンドV[k]ベクトル57の擬似逆行列を取得するように、コーディングされたフォアグラウンドV[k]ベクトル57に関する擬似逆行列関数を実行し得る。中間補償ユニット304はさらに、中間的な量子化補償されたnFG信号を決定するように、コーディングされたフォアグラウンドV[k]ベクトル57の擬似逆行列と、フォアグラウンドHOA係数との積を計算し得る。一例では、中間補償ユニット304は、補間されたnFG信号49’と、補間されたフォアグラウンドV[k]ベクトル53との積として、フォアグラウンドHOA係数を決定し得る。
[0120]遅延ユニット306は、中間補償ユニット304によって生成された中間的な量子化補償されたnFG信号を、1フレームだけ遅延させ得る。クロスフェードユニット308は、量子化補償されたnFG信号60を生成するように、中間補償ユニット304によって出力された現在のフレームkの中間的な量子化補償されたnFG信号の一部を、遅延ユニット306によって出力された以前のフレームk−1の中間的な量子化補償されたnFG信号の一部とクロスフェードさせ得る。たとえば、クロスフェードユニット308は、1024×2のサイズの量子化補償されたnFG信号60を生成するように、現在のフレームkの中間的な量子化補償されたnFG信号の最初の256サンプルと、以前のフレームk−1の中間的な量子化補償されたnFG信号の最後の256サンプルとクロスフェードさせ得る。
[0121]上記の技法は、任意の数の異なる状況およびオーディオエコシステムに関して実行され得る。いくつかの例示的な状況が以下で説明されるが、本技法はそれらの例示的な状況に限定されるべきではない。1つの例示的なオーディオエコシステムは、オーディオコンテンツと、映画スタジオと、音楽スタジオと、ゲーミングオーディオスタジオと、チャネルベースオーディオコンテンツと、コーディングエンジンと、ゲームオーディオステムと、ゲームオーディオコーディング/レンダリングエンジンと、配信システムとを含み得る。
[0122]映画スタジオ、音楽スタジオ、およびゲーミングオーディオスタジオは、オーディオコンテンツを受信することができる。いくつかの例では、オーディオコンテンツは、獲得物の出力を表し得る。映画スタジオは、デジタルオーディオワークステーション(DAW)を使用することなどによって、(たとえば、2.0、5.1、および7.1の)チャネルベースオーディオコンテンツを出力することができる。音楽スタジオは、DAWを使用することなどによって、(たとえば、2.0、および5.1の)チャネルベースオーディオコンテンツを出力し得る。いずれの場合も、コーディングエンジンは、配信システムによる出力のために、チャネルベースオーディオコンテンツベースの1つまたは複数のコーデック(たとえば、AAC、AC3、Dolby True HD、Dolby Digital Plus、およびDTS Master Audio)を受信し符号化し得る。ゲーミングオーディオスタジオは、DAWを使用することなどによって、1つまたは複数のゲームオーディオステムを出力し得る。ゲームオーディオコーディング/レンダリングエンジンは、配信システムによる出力のために、オーディオステムをチャネルベースオーディオコンテンツへとコーディングおよびまたはレンダリングし得る。本技法が実行され得る別の例示的な状況は、放送録音オーディオオブジェクトと、プロフェッショナルオーディオシステムと、消費者向けオンデバイスキャプチャと、HOAオーディオフォーマットと、オンデバイスレンダリングと、消費者向けオーディオと、TV、およびアクセサリと、カーオーディオシステムとを含み得る、オーディオエコシステムを備える。
[0123]放送録音オーディオオブジェクト、プロフェッショナルオーディオシステム、および消費者向けオンデバイスキャプチャはすべて、HOAオーディオフォーマットを使用して、それらの出力をコーディングし得る。このようにして、オーディオコンテンツは、オンデバイスレンダリング、消費者向けオーディオ、TV、およびアクセサリ、ならびにカーオーディオシステムを使用して再生され得る単一の表現へと、HOAオーディオフォーマットを使用してコーディングされ得る。言い換えれば、オーディオコンテンツの単一の表現は、オーディオ再生システム16など、汎用的なオーディオ再生システムにおいて(すなわち、5.1、7.1などの特定の構成を必要とすることとは対照的に)再生され得る。
[0124]本技法が実行され得る状況の他の例には、獲得要素と再生要素とを含み得るオーディオエコシステムがある。獲得要素は、有線および/またはワイヤレス獲得デバイス(たとえば、Eigenマイクロフォン)、オンデバイスサラウンドサウンドキャプチャ、ならびにモバイルデバイス(たとえば、スマートフォンおよびタブレット)を含み得る。いくつかの例では、有線および/またはワイヤレス獲得デバイスは、有線および/またはワイヤレス通信チャネルを介してモバイルデバイスに結合され得る。
[0125]本開示の1つまたは複数の技法によれば、モバイルデバイスが音場を獲得するために使用され得る。たとえば、モバイルデバイスは、有線および/もしくはワイヤレス獲得デバイス、ならびに/またはオンデバイスサラウンドサウンドキャプチャ(たとえば、モバイルデバイスに統合された複数のマイクロフォン)を介して、音場を獲得し得る。モバイルデバイスは次いで、再生要素のうちの1つまたは複数による再生のために、獲得された音場をHOA係数へとコーディングし得る。たとえば、モバイルデバイスのユーザは、ライブイベント(たとえば、会合、会議、劇、コンサートなど)を録音し(その音場を獲得し)、録音をHOA係数へとコーディングし得る。
[0126]モバイルデバイスはまた、HOAコーディングされた音場を再生するために、再生要素のうちの1つまたは複数を利用し得る。たとえば、モバイルデバイスは、HOAコーディングされた音場を復号し、再生要素のうちの1つまたは複数に信号を出力することができ、このことは再生要素のうちの1つまたは複数に音場を再作成させる。一例として、モバイルデバイスは、1つまたは複数のスピーカー(たとえば、スピーカーアレイ、サウンドバーなど)に信号を出力するために、ワイヤレスおよび/またはワイヤレス通信チャネルを利用し得る。別の例として、モバイルデバイスは、1つもしくは複数のドッキングステーションおよび/または1つもしくは複数のドッキングされたスピーカー(たとえば、スマート自動車および/またはスマート住宅の中のサウンドシステム)に信号を出力するために、ドッキング解決手段を利用し得る。別の例として、モバイルデバイスは、ヘッドフォンのセットに信号を出力するために、たとえばリアルなバイノーラルサウンドを作成するために、ヘッドフォンレンダリングを利用し得る。
[0127]いくつかの例では、特定のモバイルデバイスは、3D音場を獲得することと、より後の時間に同じ3D音場を再生することの両方を行い得る。いくつかの例では、モバイルデバイスは、3D音場を獲得し、3D音場をHOAへと符号化し、符号化された3D音場を再生のために1つまたは複数の他のデバイス(たとえば、他のモバイルデバイスおよび/または他の非モバイルデバイス)に送信し得る。
[0128]本技法が実行され得るまた別の状況は、オーディオコンテンツと、ゲームスタジオと、コーディングされたオーディオコンテンツと、レンダリングエンジンと、配信システムとを含み得る、オーディオエコシステムを含む。いくつかの例では、ゲームスタジオは、HOA信号の編集をサポートし得る1つまたは複数のDAWを含み得る。たとえば、1つまたは複数のDAWは、1つまたは複数のゲームオーディオシステムとともに動作する(たとえば、機能する)ように構成され得る、HOAプラグインおよび/またはツールを含み得る。いくつかの例では、ゲームスタジオは、HOAをサポートする新しいステムフォーマットを出力し得る。いずれの場合も、ゲームスタジオは、配信システムによる再生のために音場をレンダリングし得るレンダリングエンジンに、コーディングされたオーディオコンテンツを出力し得る。
[0129]本技法はまた、例示的なオーディオ獲得デバイスに関して実行され得る。たとえば、本技法は、3D音場を録音するようにまとめて構成される複数のマイクロフォンを含み得る、Eigenマイクロフォンに関して実行され得る。いくつかの例では、Eigenマイクロフォンの複数のマイクロフォンは、約4cmの半径を伴う実質的に球状の球体の表面に配置され得る。いくつかの例では、オーディオ符号化デバイス20は、マイクロフォンから直接ビットストリーム21を出力するために、Eigenマイクロフォンに統合され得る。
[0130]別の例示的なオーディオ獲得状況は、1つまたは複数のEigenマイクロフォンなど、1つまたは複数のマイクロフォンから信号を受信するように構成され得る、製作トラックを含み得る。製作トラックはまた、図3のオーディオ符号化デバイス20などのオーディオエンコーダを含み得る。
[0131]モバイルデバイスはまた、いくつかの場合には、3D音場を録音するようにまとめて構成される複数のマイクロフォンを含み得る。言い換えれば、複数のマイクロフォンは、X、Y、Zのダイバーシティを有し得る。いくつかの例では、モバイルデバイスは、モバイルデバイスの1つまたは複数の他のマイクロフォンに関してX、Y、Zのダイバーシティを提供するように回転され得るマイクロフォンを含み得る。モバイルデバイスはまた、図3のオーディオ符号化デバイス20などのオーディオエンコーダを含み得る。
[0132]耐衝撃性のビデオキャプチャデバイスは、3D音場を録音するようにさらに構成され得る。いくつかの例では、耐衝撃性のビデオキャプチャデバイスは、ある活動に関与するユーザのヘルメットに取り付けられ得る。たとえば、耐衝撃性のビデオキャプチャデバイスは、急流下りをしているユーザのヘルメットに取り付けられ得る。このようにして、耐衝撃性のビデオキャプチャデバイスは、ユーザの周りのすべての活動(たとえば、ユーザの後ろでくだける水、ユーザの前で話している別の乗員など)を表す3D音場をキャプチャし得る。
[0133]本技法はまた、アクセサリで増強されたモバイルデバイスに関して実行され得、それは、3D音場を録音するように構成され得る。いくつかの例では、モバイルデバイスは、上記で説明されたモバイルデバイスと同様であり得るが、1つまたは複数のアクセサリが追加されている。たとえば、Eigenマイクロフォンが、アクセサリで増強されたモバイルデバイスを形成するために、上述されたモバイルデバイスに取り付けられ得る。このようにして、アクセサリで増強されたモバイルデバイスは、アクセサリで増強されたモバイルデバイスと一体のサウンドキャプチャ構成要素をただ使用するよりも高品質なバージョンの3D音場をキャプチャすることができる。
[0134]本開示で説明される本技法の様々な態様を実行し得る例示的なオーディオ再生デバイスが、以下でさらに説明される。本開示の1つまたは複数の技法によれば、スピーカーおよび/またはサウンドバーは、あらゆる任意の構成で配置され得るが、一方で、依然として3D音場を再生する。その上、いくつかの例では、ヘッドフォン再生デバイスが、有線接続またはワイヤレス接続のいずれかを介してオーディオ復号デバイス24に結合され得る。本開示の1つまたは複数の技法によれば、音場の単一の汎用的な表現が、スピーカー、サウンドバー、およびヘッドフォン再生デバイスの任意の組合せで音場をレンダリングするために利用され得る。
[0135]いくつかの異なる例示的なオーディオ再生環境はまた、本開示で説明される技法の様々な態様を実行するために好適であり得る。たとえば、5.1スピーカー再生環境、2.0(たとえば、ステレオ)スピーカー再生環境、フルハイトフロントラウドスピーカーを伴う9.1スピーカー再生環境、22.2スピーカー再生環境、16.0スピーカー再生環境、自動車スピーカー再生環境、およびイヤバッド再生環境を伴うモバイルデバイスは、本開示で説明される技法の様々な態様を実行するために好適な環境であり得る。
[0136]本開示の1つまたは複数の技法によれば、音場の単一の汎用的な表現が、上記の再生環境のいずれかにおいて音場をレンダリングするために利用され得る。加えて、本開示の技法は、レンダードが、上記で説明されたもの以外の再生環境での再生のために、汎用的な表現から音場をレンダリングすることを可能にする。たとえば、設計上の考慮事項が、7.1スピーカー再生環境に従ったスピーカーの適切な配置を妨げる場合(たとえば、右側のサラウンドスピーカーを配置することが可能ではない場合)、本開示の技法は、再生が6.1スピーカー再生環境で達成され得るように、レンダーが他の6つのスピーカーとともに補償することを可能にする。
[0137]その上、ユーザは、ヘッドフォンを装着しながらスポーツの試合を見得る。本開示の1つまたは複数の技法によれば、スポーツの試合の3D音場が獲得され得(たとえば、1つまたは複数のEigenマイクロフォンが野球場の中および/または周りに配置され得)、3D音場に対応するHOA係数が取得されデコーダに送信され得、デコーダがHOA係数に基づいて3D音場を再構成して、再構成された3D音場をレンダラに出力することができ、レンダラが再生環境のタイプ(たとえば、ヘッドフォン)についての指示を取得し、再構成された3D音場を、ヘッドフォンにスポーツの試合の3D音場の表現を出力させる信号へとレンダリングし得る。
[0138]上記で説明された様々な場合の各々において、オーディオ符号化デバイス20は、ある方法を実行し、またはさもなければ、オーディオ符号化デバイス20が実行するように構成される方法の各ステップを実行するための手段を備え得ることを理解されたい。いくつかの場合には、これらの手段は1つまたは複数のプロセッサを備え得る。いくつかの場合には、1つまたは複数のプロセッサは、非一時的コンピュータ可読記憶媒体に記憶される命令によって構成される、専用のプロセッサを表し得る。言い換えれば、符号化の例のセットの各々における本技法の様々な態様は、実行されると、1つまたは複数のプロセッサに、オーディオ符号化デバイス20が実行するように構成されている方法を実行させる命令を記憶した、非一時的コンピュータ可読記憶媒体を提供し得る。
[0139]1つまたは複数の例において、前述の機能は、ハードウェア、ソフトウェア、ファームウェア、またはそれらの任意の組合せで実装され得る。ソフトウェアで実装される場合、機能は、コンピュータ可読媒体上の1つまたは複数の命令またはコード上に記憶され、またはこれを介して送信され、ハードウェアベースの処理ユニットによって実行され得る。コンピュータ可読媒体は、データ記憶媒体などの有形媒体に対応するコンピュータ可読記憶媒体を含み得る。データ記憶媒体は、本開示で説明される技法の実装のために命令、コードおよび/またはデータ構造を取り出すために、1つまたは複数のコンピュータあるいは1つまたは複数のプロセッサによってアクセスされ得る任意の利用可能な媒体であり得る。コンピュータプログラム製品は、コンピュータ可読媒体を含み得る。
[0140]同様に、上記で説明された様々な場合の各々において、オーディオ復号デバイス24は、ある方法を実行し、またはさもなければ、オーディオ復号デバイス24が実行するように構成される方法の各ステップを実行するための手段を備え得ることを理解されたい。いくつかの場合には、これらの手段は1つまたは複数のプロセッサを備え得る。いくつかの場合には、1つまたは複数のプロセッサは、非一時的コンピュータ可読記憶媒体に記憶される命令によって構成される、専用のプロセッサを表し得る。言い換えれば、符号化の例のセットの各々における本技法の様々な態様は、実行されると、1つまたは複数のプロセッサに、オーディオ復号デバイス24が実行するように構成されている方法を実行させる命令を記憶した、非一時的コンピュータ可読記憶媒体を提供し得る。
[0141]限定ではなく例として、そのようなコンピュータ可読記憶媒体は、RAM、ROM、EEPROM(登録商標)、CD−ROMもしくは他の光ディスクストレージ、磁気ディスクストレージ、もしくは他の磁気記憶デバイス、フラッシュメモリ、または命令もしくはデータ構造の形態の所望のプログラムコードを記憶するために使用され得、コンピュータによってアクセスされ得る任意の他の媒体を備えることができる。しかしながら、コンピュータ可読記憶媒体およびデータ記憶媒体は、接続、搬送波、信号、または他の一時的媒体を含むのではなく、非一時的な有形の記憶媒体を対象とすることを理解されたい。本明細書で使用するディスク(disk)およびディスク(disc)は、コンパクトディスク(disc)(CD)、レーザーディスク(登録商標)(disc)、光ディスク(disc)、デジタル多用途ディスク(disc)(DVD)、フロッピー(登録商標)ディスク(disk)およびBlu−ray(登録商標)ディスク(disc)を含み、ここで、ディスク(disk)は、通常、データを磁気的に再生し、一方、ディスク(disc)は、データをレーザーで光学的に再生する。上記の組合せも、コンピュータ可読媒体の範囲の中に含まれるべきである。
[0142]命令は、1つもしくは複数のデジタル信号プロセッサ(DSP)、汎用マイクロプロセッサ、特定用途向け集積回路(ASIC)、フィールドプログラマブルゲートアレイ(FPGA)、あるいは他の同等の集積回路またはディスクリート論理回路などの1つもしくは複数のプロセッサによって実行され得る。したがって、本明細書で使用される「プロセッサ」という用語は、前述の構造、または、本明細書で説明された技法の実装に好適な任意の他の構造のいずれかを指し得る。加えて、いくつかの態様では、本明細書で説明された機能は、符号化および復号のために構成されるか、または複合コーデックに組み込まれる、専用のハードウェアモジュールおよび/またはソフトウェアモジュール内で提供され得る。また、本技法は、1つもしくは複数の回路または論理要素で十分に実装され得る。
[0143]本開示の技法は、ワイヤレスハンドセット、集積回路(IC)もしくはICのセット(たとえば、チップセット)を含む、多種多様なデバイスまたは装置で実装され得る。本開示では、開示される技法を実行するように構成されたデバイスの機能的態様を強調するために様々な構成要素、モジュール、またはユニットが説明されるが、それらの構成要素、モジュール、またはユニットを、必ずしも異なるハードウェアユニットによって実現する必要があるとは限らない。むしろ、上で説明されたように、様々なユニットが、好適なソフトウェアおよび/またはファームウェアとともに、上記の1つまたは複数のプロセッサを含めて、コーデックハードウェアユニットにおいて組み合わせられるか、または相互動作ハードウェアユニットの集合によって与えられ得る。
[0144]本開示の様々な態様が説明された。本技法のこれらおよび他の態様は、以下の特許請求の範囲内に入る。