JP3676237B2 - データ処理装置及び演算器 - Google Patents
データ処理装置及び演算器 Download PDFInfo
- Publication number
- JP3676237B2 JP3676237B2 JP2000595228A JP2000595228A JP3676237B2 JP 3676237 B2 JP3676237 B2 JP 3676237B2 JP 2000595228 A JP2000595228 A JP 2000595228A JP 2000595228 A JP2000595228 A JP 2000595228A JP 3676237 B2 JP3676237 B2 JP 3676237B2
- Authority
- JP
- Japan
- Prior art keywords
- data
- arithmetic unit
- register
- cpu
- bus
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images












Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/76—Architectures of general purpose stored program computers
- G06F15/80—Architectures of general purpose stored program computers comprising an array of processing units with common control, e.g. single instruction multiple data processors
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/42—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by implementation details or hardware specially adapted for video compression or decompression, e.g. dedicated software implementation
- H04N19/43—Hardware specially adapted for motion estimation or compensation
Landscapes
- Engineering & Computer Science (AREA)
- Computer Hardware Design (AREA)
- Theoretical Computer Science (AREA)
- Computing Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Image Processing (AREA)
- Advance Control (AREA)
Description
本発明はデータ処理装置、更に詳しく言えば、映像信号圧縮、伸長処理で用いる動き検出、動き補償の処理等のように、大量のデータをプロセッサを使用して高速かつ効率的に行うデータ処理装置に関するものである。
背景技術
画像や音声の伸張、圧縮処理等では大量のデータに対し、同一の演算処理を繰り返し高速度で行う必要がある。そのため、上記同一の演算処理を行う部分は専用の演算装置を儲け、その演算装置を高速動作させるため、並列に配置された複数のプロセッサエレメント(演算ユニット)を持ち、それらを同一のプログラムによって動作させるSIMD(Single Instruction Multiple Data)演算装置で構成するデータ処理装置が知られている。なお、SIMD演算装置については、文献「インターフェイス」の1998年3月号の111頁から113頁に記載がある。具体的には、米国インテル社のペンティアムのMMXテクノロジが知られている。
SIMD方式の演算装置では、メモリからデータを絶え間なく供給し、演算器の稼働率を上げることが、パフォーマンスを決める重要な要素となる。しかし、従来知られているセントラルプロセッサユニット(CPUと略称)とSIMD方式の演算器を組み合わせたデータ処理装置は、装置構成上、CPUとSIMD演算装置が共通のデータバス及びアドレスバスを介して接続されている。そのため、メモリーからSIMD演算装置内のレジスタへのデータ転送を行い、次に演算を行い、次にレジスタ内の演算結果をメモリーに転送して、次のデータ処理が開始できるという動作であった。この場合、隣接したプロセッサエレメントで使用したデータを使用して、演算効率を上げることができないという問題があった。
この問題を解決するため考えられる方式は、システムLSIの考え方に従ってSIMD演算装置と内蔵メモリとの間をシステムバスと独立の大きなバス幅のローカルバスで接続することが考えられる。しかしこの方法ではSIMD演算装置とメモリのデータ転送性能は向上するが、CPUからSIMD演算装置に受け渡す演算命令を限定しないシステムバスのトラヒックが問題となり、CPUとSIMD演算装置の両方にアドレス発生器を必要とし、CPUはメモリのデータ読み出しとSIMD演算装置のデータ格納との両者を一元的に管理できない。そのため、SIMD演算装置の高速性能を有効に利用することができないという問題がある。
発明の開示
本発明の主な目的は、データの高速処理ができるデータ処理装置を実現することである。
本発明の他の目的は、中央処理装置によって制御されかつメモリとローカルバスで接続された演算ユニットを持つデータ処理装置において、中央処理装置がメモリのデータ読み出しと演算ユニットのデータ格納との両者を一元的に管理できるデータ処理装置を実現することである。
本発明の更に他の目的は、演算ユニットを構成するプロセッサエレメントに対するデータの供給を絶え間なくできるようにして、できるだけ毎クロック演算が可能になり、データの高速処理ができるデータ処理装置を実現することである。
上記目的を達成するため、本発明のデータ処理装置は、CPU装置により制御される演算ユニットと、第一の記憶手段と、上記CPU、演算ユニット及び第一の記憶手段に共通に接続されたアドレスバスと、上記CPUのもつデータバスのバス幅より広いバス幅を持ち上記算ユニットとを結合するローカルデータバスとを設けて構成した。
本発明では、第一の記憶手段と演算ユニットとの間にローカルデータバスを設けることにより、データ転送性能を向上し、CPUから演算ユニットへ制御線を接続することにより、演算ユニットへ供給される演算命令をシステムバスのトラフィックから独立している。更に、アドレスバスは、CPU装置、演算ユニット及び第一の記憶手段に共通に接続されたているため、アドレス発生器は、CPU装置のみに設ければよく、演算ユニットに設ける必要がない。第一の記憶手段も演算ユニットのレジスタと共にCPU装置のアドレス空間にあり、CPU装置は第一の記憶手段のデータ読み出しと、演算ユニットのレジスタのデータ格納との両者のアドレス指定を一元的に管理できる。
本発明の好ましい実施形態によれば、上記演算ユニットは複数のプロセッサエレメントを持つSIMD制御型の演算器で構成され、上記各プロセッサエレメントは第一の入力端子と第二の入力端子と出力端子を持ち、全てのプロセッサエレメントの第一の入力端子のビット幅を合計したビット幅の第一のレジスタと、全てのプロセッサエレメントの第二の入力端子のビット幅を合計したビット幅の第二のレジスタと、プロセッサエレメントの第二の入力端子のビット幅以上のビット幅を持ち第二のレジスタに第二の入力端子のビット幅単位でデータのシフトができるように構成された第三のレジスタをもつ構成とする。
本発明のデータ処理装置は特に以下の実施形態で説明するように、画像の符号化処理に置ける動き検出処理などに有効であるが、高速の演算処理をCPUの処理と平行して行う必要がある処理装置に適用できる。
【図面の簡単な説明】
第1図は本発明によるデータ処理装置の第1実施例の構成を示すブロック図
第2図は第1図のSIMD型演算器4の内部構成を示す回路図
第3図は第1図のCPU2の内部構成図
第4図は第2図のプロセッサエレメント38の内部構成図
第5図は第2図のSIMD型演算器4の動作説明図
第6図は第2図のSIMD型演算器4の動作説明図
第7図は第1実施形態で用いる参照画像データの説明図
第8図は第1実施形態で用いる符号化画像データの説明図
第9図は第1図のDRAM16上のアドレスマップ
第10図は第1図のワークRAM12上のアドレスマップ
第11図は第1実施形態の動作フローチャート
第12図は第1実施形態のSIMD型演算器4のレジスタのデータ転送の様子を説明する図
第13図は第1実施形態におけるベクトル(0,0)の演算範囲の説明図
第14図は第1実施形態におけるベクトル(1,0)の演算範囲の説明図
第15図は本発明によるデータ処理装置の第2実施形態の構成を示すブロック図
第16図は第2実施形態のCPUの内部構成図
第17図は第2実施形態の動作フローチャート
第18図は本発明によるデータ処理装置の第3実施形態の構成を示すブロック図
第19図は本発明によるデータ処理装置の第4実施形態の構成を示すブロック図
第20図は第4実施形態におけるVPU160の内部構成図
発明を実施するための最良の形態
<実形態1>
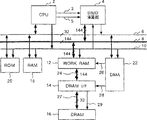
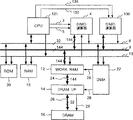
第1図は本発明によるデータ処理装置の第1の実施形態の構成を示すブロック図である。本実施形態のデータ処理装置は、画像符号化処理において、ブロックマッチング法による動き検出の処理を演算ユニットで行うものである。先に装置の構成を説明し、後で動き検出の処理の動作を説明する。
図示のように本データ処理装置は、中央処理装置(以下CPUと略称)2により制御線3及び5を介して直接制御されるSIMD演算器で構成された演算ユニット4と、記憶手段であるワークRAM12と、CPU2、演算ユニット4及びワークRAM12に共通に接続されたアドレスバス10と、CPU2のもつデータバス6のバス幅より広いバス幅を持ち演算ユニット4とワークRAM12を結合するローカルデータバス8とをもつ。
CPU2は、命令をデコードし全体を制御する。本実形態では、RISC型マイクロプロセッサを用いている。20はCPU装置2のプログラムなどを格納するROM、18はCPU装置2のデータあるいはプログラムなどを格納するRAMである。12はSIMD型演算器4の演算データを一時的に保持するためのワークRAM、16は画像データが格納されるDRAM、14はDRAM16とワークRAM12とのDRAMインターフェイス回路、22はDRAM16とワークRAM12とのDMA(Direct Memory Access)転送を制御するDMA回路である。
本実施例は、3種のバスを有し、CPU2のデータバス6のバス幅は32ビット、アドレスバス10のバス幅は32ビット、データバス8及び24のバス幅は144ビットである。図中バス線に斜線とを付し数はバス幅(ビット数)を示す。
以下各部の構成動作を詳しく説明する。
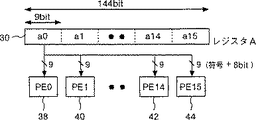
第2図は、第1図のSIMD型演算器4の内部構成を示す回路図である。演算ユニット4は16個の並列に配置されたプロセッサエレメント38、40…42、44を持つSIMD制御型の演算器で構成され、各プロセッサエレメントは、セレクタ32を介してレジスタ30に接続された第一の入力端子とレジスタ34に接続された第二の入力端子とデータバス6及び8に接続された出力端子を持つ。レジスタ30は全てのプロセッサエレメント38、40…42、44の第一入力端子のビット幅を合計したビット幅を持つ。レジスタ34は全てのプロセッサエレメントの第二入力端子のビット幅を合計したビット幅を持つ。更にプロセッサエレメントの第二入力端子のビット幅以上のビット幅を持ち、レジスタ34に第二の入力端子のビット幅単位でデータのシフトができる第三のレジスタ36をもつ。
各プロセッサエレメント38、40…42、44は、制御線3と5を介してCPU2によって制御される。レジスタ30からプロセッサエレメント38,40…42、44へのデータ供給は、セレクタ32により変えることができる。また、レジスタ30、34及び36は、それそれアドレスバス10によって制御される書き込み回路50、46及び48からローカルバス8を介してデータが書き込まれる。
第3図は、第1図のRISC型マイクロプロセッサ2の構成を示すブロック図である。この構成は、従来知られているマイクロプロセッサの構成と全く同様で、命令フェッチ回路60からフェッチした命令を線路72を介して入力しデコードする命令デコード回路58、命令デコード回路58からの命令68を実行する演算回路64、プログラムカウンタ54、汎用レジスタ56から構成されている。
更に命令デコード回路58では、例えば、SIMD型演算器4に対する演算命令の場合は信号線3を、SIMD型演算器4に対する結果の読み出し命令の場合は信号線5をアクティブにする。66、68、62、73及び74は命令及びデータ伝送線である。
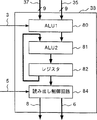
第4図は、上記プロセッサエレメントの構成を示すブロック図である。SIMD型演算器4の16個のプロセッサエレメント38、40、…42、44の構成は全て同じである。ここでは、代表してプロセッサエレメント38を例に説明する。プロセッサエレメント38は、演算回路80、81の演算結果を保持するためのレジスタ82、ローカルデータバス8又はデータバス6への読み出しを制御するための読み出し制御回路84から構成されている。演算回路80には、レジスタ30の144ビットのビット幅の一部の9ビットがバス37を介して、また、レジスタ34の144ビットのビット幅の一部の9ビットがバス35を介して入力される。入力された2つのデータは、演算回路80で演算(減算)され、演算回路80の出力は演算回路81でレジスタ82の値と加算される。演算回路81の演算結果はレジスタ82に格納される。
第5図及び第6図は、セレクタ32の接続形態を説明する図である。第1の接続形態では、第5図で示されるように、レジスタ30の144ビットの最上位ビットから9ビットa0が各プロセッサエレメント38、40…44,42に共通に供給される。また、第2の接続形態では、第6図に示されるように、レジスタ30の全内容144ビットが、上位から9ビットづつのa0、a2、…a14、a15がそれぞれプロセッサエレメント38、40…44、42に供給される。従って、図に示されるa0の9ビットのデータは0番のプロセッサエレメント38に、a1の9ビットのデータは1番のプロセッサエレメント40に、という様にデータが分配供給される。
次に、上記データ処理装置を使用してMPEG2の規格による画像信号の符号化処理の中で行われる画像の動き検出を行う場合を説明する。
規格MPEG2による画像の動き検出は、水平16画素、垂直16画素のマクロブロック単位で、符号化されるマクロブロックが、比較対照となる参照画面に対し、探索範囲の中で一番似ているマクロブロックの場所を求め、その2つのマクロブロック間の画像フレームにおける距離を求める処理を行う。通常、動き検出は、ブロックマッチング法で行われる。ブロックマッチング法とは、符号化される画像の画素と対応する参照画像の画素の差分絶対値をマクロブロック内の全ての画素に対し累積加算を行って、累積加算値の最も値の小さいマクロブロックの場所を見つける処理を行う。
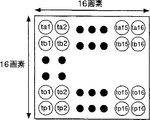
第7図及び第8図は、それぞれ上記画像を符号化する際の参照画像データ及び符号化画像のマクロブロックである符号化画像の画素を示す。ここでは、参照画像データは水平方向352画素、垂直方向240画素を想定している。図中丸で囲む記号ra1、ra2…rb1…rp17…等は画素を識別する記号である。また、マクロブロックは、水平方向16画素、垂直方向16画素で、図中丸で囲む記号ta1、ta2…tp16等は画素を識別する記号である。
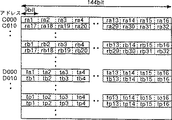
第9図は、第1図のDRAM16に格納されているデータの様子を示す。図中の記号ra1,ra2,…ta1…tb8…等は、第7図、第8図に示した記号に対応した画素を表す。アドレスA000からが参照画像データの領域に割り当てられており、DRAM16のビット幅である32ビットで水平方向の4画素が格納されている。アドレスB000からがマクロブロック即ち符号化画像データの領域に割り当てられている。
第10図は、ワークRAM12に格納された符号化画像データと参照画像データを示す。ここでは、アドレスC000からが参照画像データの領域に割り当てられている。各画素のデータは9ビットのデータとなり、アドレスC000からの144ビットには、画素ra1から画素ra16までの水平16画素のデータが格納される。また、アドレスD000からが符号化画像データの領域に割り当てられている。参照画像データの場合と同様に、アドレスD000の144ビットに画素ta1から画素ta16までの水平16画素が格納される。
第11図は、上記データ処理装置における動き検出の処理フローチャートである。
まず、DRAM16のデータ(第9図)をDRAMインターフェイス14を介して、ワークRAM12に転送する(ステップ90)。この時、1画素あたり8ビットのデータに符号ビットを付加して、1画素あたり9ビットのデータとする符号拡張を行う。DRAM16上で4ロングワードのデータを並べて144ビットのデータを作り出す。このような転送を繰り返して、バス24を介してワークRAM12にデータを格納する。
次に、ローカルデータバス8を介してワークRAM12からSIMD演算器4のレジスタ34に参照画像データを転送する(ステップ92)。
第12図はステップ92の詳細な動作を説明するための図で、16個のプロセッサエレメント38,40、…42、44と、144ビットのレジスタA30、レジスタB34、レジスタC36の信号の流れを時間との関係で示している。すなわち、縦方向に示す時刻tとその時のレジスタ30、34、36の内容の変化も示している。
前述のように、レジスタA30は、符号化すべき画像の複数の画素データが格納され、一連のビット列の上位9ビットが全てのプロセッサエレメント38、40…42、44に共通に供給され、レジスタB34には参照画像の複数の画素データ画格納され、上位9ビットがプロセッサエレメント38に、次の9ビットがプロセッサエレメント40とゆうように、9ビット毎に別のプロセッサエレメントに供給され。レジスタC36は、レジスタB34にデータをシフトして供給する。9ビットのシフト命令の場合、レジスタB34の下位9ビットにレジスタC36の上位9ビットが供給される。
ここで、時刻t=0(ステップ92)では、レジスタB34の参照画像データの画素ra1から画素ra16までが、144ビットの幅で一度に転送されていることが分かる。
時刻t=1(ステップ94)では、ワークRAM12からレジスタC36にデータを転送する。この結果、新たに参照画像データの画素ra17から画素ra32までが、144ビットの幅でレジスタC36に一度に転送される。その結果、水平32画素の1ラインの参照画像データがレジスタB34とレジスタC36に亘って格納される。
時刻t=2(ステップ96)では、ワークRAM12からレジスタA30に符号化画像データのマクロブロック画素ta1から画素ta16までの144ビットの幅のデータを一度に転送する。ここで、レジスタ30、34、36演算に必要な全てのデータが格納される。
時刻t=3(ステップ98)では、プロセッサエレメント38、40…42、44による同時並列演算とレジスタ34とレジスタ36の9ビットのシフトを行う。その結果、プロセッサエレメント38は、参照画像データra1と符号化画像データta1との差分絶対値を求める演算を行う。そして、結果を第4図で示したプロセッサエレメント内部のレジスタ82に格納する。また、プロセッサエレメント40では、同様に、参照画像データra2と符号化画像データta1との差分絶対値を求める演算を行い、プロセッサエレメント40内部のレジスタ82に結果を格納する。他のプロセッサエレメント42、44等も同様である。
時刻t=4(ステップ100)では、再度、複数のプロセッサエレメントの並列演算とレジスタ34とレジスタ36の9ビットのシフトを行う。その結果、プロセッサエレメント38では、参照画像データra2と符号化画像データta2との差分絶対値を求める演算を行う。そして、レジスタ82のデータと加算して、レジスタ82に書き込む。また、プロセッサエレメント40では、同様にして、参照画像データra3と符号化画像データta1との差分絶対値を求める演算を行い、プロセッサエレメント内部のレジスタ82の値と加算する。
上述の動作を繰り返し、16回目の演算とレジスタ34とレジスタ36の9ビットのシフトを行った時(ステップ102)の、レジスタの状態は、第12図の時刻t=18で示される。ブロックマッチングを行う範囲が水平16画素の場合は、この時点で1水平ラインの演算が終了する。
ここで、1ライン下のデータを演算するために、ワークRAM12から3つレジスタ30、34、36へのデータ転送を行う。まず、時刻t=19(ステップ104)では、ワークRAM12からレジスタBにデータを転送する。
時刻t=20(ステップ106)では、ワークRAM12からレジスタ36にデータを転送する。この結果、第12図の時刻t=20の状態なり、先に演算したライン下の1ラインの参照画像のデータ、画素rb1からrb32がレジスタ34とレジスタ36にまたがって格納される。
時刻t=21(ステップ108)では、ワークRAM12からレジスタAにデータを転送する。この結果、先に演算した下の1ラインの符号化画像の画素ta1からta16までがレジスタAに格納され、3つのレジスタ30、34、36の全てにデータが格納される。そして、前述と同様にして、演算を行う。さらに、この動作を16ライン分、繰り返す。
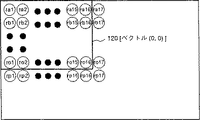
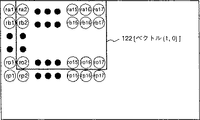
その結果、プロセッサエレメント38の内部レジスタ82には、全ての画素に対する差分絶対値の累積加算値が格納される。この値は、第13図におけるベクトル(0,0)のブロックマッチング演算の結果即ちベクトル(0,0)に対応する近似度を表す。
一方、プロセッサエレメント40の内部レジスタ82には、第14図におけるベクトル(1,0)のブロックマッチング演算の結果が格納され、同様にして16個のプロセッサエレメント38…44で同時に16個の動きベクトルのブロックマッチング演算の結果を得ることができる。
本実形態では、ワークRAM12からSIMD演算器4に、データ処理装置のシステムデータ8を介することなく、多量のデータが一度に転送できると共に、SIMD演算器4にアドレス発生器を設けることなく、CPU4のアドレス管理によってワークRAM12とSIMD演算器4との間のデータ転送が一元的に管理できる。従って、画像処理の動き検出をブロックマッチング法によって行うような、1つの命令によって同種の多数の演算を必要とするデータ処理に有効である。
<実施形態2>
第15図は本発明によるデータ処理装置の第2の実施形態の構成を示すブロック図である。本実施形態は第1図のデータ処理装置に第二のSIMD演算器130が追加されている。これに伴い、CPU131からの制御線134と132が追加されている。ここで、第二のSIMD演算器130の内部構成は、第2図で示したものと同じで、同一対応構成要素については同じ番号を付して説明を省く。また他の構成要素で第1図に示したものと実質的に同じ部分に関しては、同じ番号を付して説明を省く。
第16図は、第2の実施形態(第15図)におけるCPU131の構成を示すブロック図である。CPU131の構成は、第3図で示した実施形態1におけるCPU2に、命令デコード回路133から出る制御線132及び134が付加された点を除いては、CPU2に実質的に同じである。制御線132及び134は、第二のSIMD演算器130を制御するためのものである。
第17図は、実施形態2のデータ処理装置の動作を説明する処理フローチャートを示す。実施形態2において、SIMD演算器4の3つのレジスタにデータを格納する動作、つまり、DRAM16らワークRAM12にデータ転送する動作(ステップ90)から、ワークRAM12からレジスタAに符号化画像データを転送する動作(ステップ96)までは、第11図に示した同じステップ番号を付した部分と同じである。
ステップ96の次に、本実施形態の場合、SIMD演算器130のレジスタにデータを格納する。最初に、ワークRAM12からレジスタBに参照画像データを転送する(ステップ140)。次に、ワークRAM12からレジスタCに参照画像データを転送する(ステップ142)。最後に、ワークRAM12からレジスタAに符号化画像データを転送する(ステップ144)。そして、実施例1の場合と同様に、プロセッサエレメント(PE)による演算を行う。その結果、同時に32個のプロセッサエレメントを用いて、異なるベクトルのブロックマッチングを行うことができ、より高速の処理ができる。
<実施形態3>
第18図は本発明によるデータ処理装置の第3の実施形態の構成を示すブロック図である。本実施形態では、2つのワークRAM144及び146を持ち、DRAM16側とSIMD演算器4側とを切り替えて使用する。
ワークRAM144にデータが格納され、このデータを用いてSIMD演算器4が信号処理を行っているとき、ワークRAM144は、セレクタ142と152によってSIMD演算器4側に接続されている。一方、ワークRAM146は、セレクタ148と150によってDMAC122側に接続されている。そして、ワークRAM146には、DMAC122がDRAM16から、SIMD演算器4が次に使用する画像データを転送している。ここで、SIMD演算器4が、ワークRAM144内の信号処理を終了すると、ワークRAM144とワークRAM146を切り替える。つまり、ワークRAM144をDMAC122側に接続し、ワークRAM146をSIMD演算器4側に接続する。この構成によって、ワークRAM146には、既に使うデータがDRAM16から転送されているため、SIMD演算器4は、すぐに演算動作を開始することができる。従って、演算効率を高めることができる。
<実施形態4>
第19図は、本発明によるデータ処理装置の第4の実施形態を示す図である。本実施形態は、発明のデータ処理装置を画像信号圧縮LSIの中に構成したものである。
マイクロプロセッサユニット166のバス184に、各構成要素ブロックが接続されている。構成要素ブロックは、外部のモデムとのインタフェイス機能を持つ通信インターフェイス168、外部のオーディオ信号と入出力機能を有するオーディオインターフェイス170、外部のビデオ信号との入出力機能を有するビデオインターフェイスブロック172、可変長符号の符号化と復号化を担当する可変長符号化復号化ブロック164、量子化、逆量子化、DCT、逆DCT処理を担当するQ-DCT/IQ-IDCTブロック162、DRAM176の制御を担当するDRAM制御ブロック174、動き検出ブロック160を含む。動き検出ブロック160は第1の実施形態で説明したものと同じである。
本実施形態では、第1図に示した装置と比較して、DRAMインターフェイス14とDRAM16に対応するDRAM176がLSIの外に出ている点、また、MPU166が動き検出ブロック160を制御するためのコントロールレジスタ185を持っているところが異なっている。このコントロールレジスタ185により、動き検出ブロック160のCPU180の制御が行われる。
本構成による画像圧縮時の動作を説明する。ビデオインターフェイスブロック172により入力された符号化画像データは、一度、DRAM176に格納される。そして、マクロブロック単位で動き検出ブロック160のワークRAMに読み込まれる。この時、対応する探索範囲の参照画像データも同時に、動き検出ブロック160のワークRAMに読み込まれる。第1の実施形態で説明したように、各動きベクトルの差分絶対値演算の累積加算を行う。全ベクトルの演算を終了した後、最も差分絶対値演算値の小さいベクトルをこのマクロブロックに対する動きベクトルとする。そして、この時の符号化画像と参照画像の対応する各画素の差分値をとり、その結果をQ-DCT/IQ-IDCTブロック164に送る。Q-DCT/IQ-IDCTブロック164では、動き検出ブロック160から送られてきた結果に対し、DCT処理と量子化処理を行い、可変長符号化復号化ブロック164に送る。ここでは、可変長符号化処理を行い、画像データの圧縮処理が完了する。
上述のように、本発明を画像信号圧縮LSIに適用することにより、プログラマビリティの高く、高性能な画像信号圧縮LSIを構成することができる。
産業上の利用可能性
上述の実施形態で説明したように、本発明は、SIMD型演算器を構成するプロセッサエレメントに対するデータの供給を絶え間なくできるようになり、特に、画像信号を圧縮、伸長する多大の演算処理を繰り返り行う信号処理における演算効率を上げることができる。
Claims (13)
- CPUと、
上記CPUにより制御される演算ユニットと、記憶手段と、
上記CPUのデータバス幅よりも広いバス幅を持ち、上記演算ユニットと上記記憶手段とを接続するローカルデータバスと、
上記CPU、上記演算ユニット及び上記記憶手段に共通に接続されたアドレスバスを持ち、
上記演算ユニットは、
第一の入力端子、第二の入力端子及び出力端子をもち、上記CPUからの制御信号によって動作する複数のプロセッサエレメントと、
上記複数のプロセッサエレメントの全ての第一の入力端子のビット幅を合計したビット幅の第一のレジスタと、
上記複数のプロセッサエレメントの全ての第二の入力端子のビット幅を合計したビット幅を持ち全てのビット幅を重なりがないように全てのプロセッサエレメントの第二の入力端子に加える第二のレジスタと、
上記プロセッサエレメントの第二の入力端子のビット幅以上のビット幅を持ち第二のレジスタに第二の入力端子のビット幅単位でデータのシフトができる第三のレジスタと、
上記第一のレジスタとのデータを選択して最上位ビットから上記プロセッサエレメントの第一の入力端子のビット幅を全ての上記プロセッサエレメントの第一の入力端子に共通に供給するセレクタと、
上記アドレスバスによって制御され、上記ローカルデータバスを介してそれぞれ上記第一、第二及び第三レジスタにデータを書き込む書き込み制御回路と、
上記出力端子のデータを上記ローカルデータバスに出力する回路とを持つSIMD制御型の演算器で構成されたデータ処理装置。 - 上記演算ユニットはSIMD型の演算器である第1項記載のデータ処理装置。
- 上記演算ユニットが複数個並列に上記ローカルデータバスに接続された第1項記載のデータ処理装置。
- 上記記憶手段は第1メモリと、第2メモリとを有し、
上記アドレスバス及び上記ローカルデータバスに接続されかつ第1メモリと第2メモリ間のデータの転送を制御するDMA回路とを持つ第1項記載のデータ処理装置。 - 上記記憶手段は上記第2メモリから上記第1メモリにDMA回路で転送する際に符号拡張を行う手段を持つ第4項記載のデータ処理装置。
- 上記第1メモリは、第1及び第2ワークメモリを持ち、上記記憶手段は上記第1及び第2のワークメモリと上記演算ユニットの接続及び上記第2メモリとの接続を交互に切り替える手段を更に持つ第4項記載のデータ処理装置。
- 上記演算ユニットは、上記CPUからの単一命令で複数のデータを並列に演算処理するSIMD制御型の演算器であることを特徴とする請求項第1項に記載のデータ処理装置。
- 上記プロセッサエレメントは、上記第一及び第二の入力端子のデータの減算値を一定の範囲に亘り積算し出力する演算回路であり、上記第一のレジスタに符号化すべき画像の複数の画素のデータが格納され、上記第二のレジスタに参照すべき参照画像の複数の画素のデータが格納され、上記複数のプロセッサエレメントの出力を画像の複数の動きベクトルに対応する近似度として取り出す請求項1に記載の画像処理用データ処理装置。
- CPUと、
演算ユニットと、
記憶手段と、
上記CPUと上記記憶手段とを接続するアドレスバスと、
上記演算ユニットと上記記憶手段とを接続するローカルデータバスとを有するデータ処理装置であって、
上記CPUは、命令をデコードする命令デコード回路を有し、上記命令デコード回路の処理結果によって上記の演算ユニットを制御し、
上記ローカルデータバスは上記CPUよりも広いバス幅を有し、
上記演算ユニットは、
上記CPUからの制御信号によって複数の入力データを用いて演算処理動作を行う複数のプロセッサエレメントと、
上記複数のプロセッサエレメントに接続され演算処理データを供給可能な第一のレジスタと及び第二のレジスタと、
上記第二のレジスタに接続され、所定のビット幅単位でデータのシフトを行い、シフトしたデータを上記第二のレジスタに供給することができる第三のレジスタと、
上記第一のレジスタ及びプロセッサエレメントに接続され、データの供給制御を行うセレクタと、
上記CPUから供給されたアドレスを用いてアクセス可能とされ、上記ローカルデータバスを介して供給されたデータをそれぞれ上記第一、第二及び第三レジスタにデータを書き込むことが可能な書き込み制御回路と、
上記複数のプロセッサエレメントの演算処理データを上記ローカルデータバスに出力する回路とを持つSIMD制御型の演算器で構成されることを特徴とするデータ処理装置。 - 上記第一の演算ユニットがSIMD型の演算器である請求項9
記載のデータ処理装置。 - バスを介して接続可能されたメモリに格納された命令をフェッチし、実行することが可能なCPUと、
上記CPUに接続されたアドレスバスと第一のデータバスと、
上記CPUに上記アドレスバスを介して接続されたメモリと、
上記メモリに第二のデータバスを介して接続された演算ユニットを有し、
上記第二のデータバスは上記第一のデータバスよりも広いバス幅であり、
上記CPUは、上記フェッチされた所定の命令を実行することにより、上記演算ユニットを制御可能で、
上記演算ユニットは上記第二のデータバスを介して接続される上記メモリに格納されたデータを用いて演算処理を実行可能で、
上記演算ユニットは、
第一の入力端子、第二の入力端子及び出力端子をもち、上記CPUからの制御信号によって動作する複数のプロセッサエレメントと、
上記複数のプロセッサエレメントの全ての第一の入力端子のビット幅を合計したビット幅の第一のレジスタと、
上記複数のプロセッサエレメントの全ての第二の入力端子のビット幅を合計したビット幅を持ち全てのビット幅を重なりがないように全てのプロセッサエレメントの第二の入力端子に加える第二のレジスタと、
上記プロセッサエレメントの第二の入力端子のビット幅以上のビット幅を持ち第二のレジスタに第二の入力端子のビット幅単位でデータのシフトができる第三のレジスタと、
上記第一のレジスタとのデータを選択して最上位ビットから上記プロセッサエレメントの第一の入力端子のビット幅を全ての上記プロセッサエレメントの第一の入力端子に共通に供給するセレクタと、
上記アドレスバスによって制御され、上記ローカルデータバスを介してそれぞれ上記第一、第二及び第三レジスタにデータを書き込む書き込み制御回路と、
上記出力端子のデータを上記ローカルデータバスに出力する回路とを持つSIMD制御型の演算器で構成されることを特徴とするデータ処理装置。 - 上記演算ユニットがSIMD型の演算器であることを特徴とする請求項11記載のデータ処理装置。
- 上記アドレスバスと上記第一のデータバスと上記メモリとに接続されたDMA回路を有することを特徴とする請求項11又は12記載のデータ処理装置。
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP1999/000181 WO2000043868A1 (fr) | 1999-01-20 | 1999-01-20 | Processeur de donnees et dispositif d'operation arithmetique |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPWO2000043868A1 JPWO2000043868A1 (ja) | 2002-05-21 |
| JP3676237B2 true JP3676237B2 (ja) | 2005-07-27 |
Family
ID=14234742
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2000595228A Expired - Fee Related JP3676237B2 (ja) | 1999-01-20 | 1999-01-20 | データ処理装置及び演算器 |
Country Status (3)
| Country | Link |
|---|---|
| JP (1) | JP3676237B2 (ja) |
| TW (1) | TW535107B (ja) |
| WO (1) | WO2000043868A1 (ja) |
Families Citing this family (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003280982A (ja) | 2002-03-20 | 2003-10-03 | Seiko Epson Corp | 多次元メモリのデータ転送装置及び多次元メモリのデータ転送プログラム、並びに多次元メモリのデータ転送方法 |
| US7392368B2 (en) | 2002-08-09 | 2008-06-24 | Marvell International Ltd. | Cross multiply and add instruction and multiply and subtract instruction SIMD execution on real and imaginary components of a plurality of complex data elements |
| WO2004015563A1 (en) | 2002-08-09 | 2004-02-19 | Intel Corporation | Multimedia coprocessor control mechanism including alignment or broadcast instructions |
| US6986023B2 (en) * | 2002-08-09 | 2006-01-10 | Intel Corporation | Conditional execution of coprocessor instruction based on main processor arithmetic flags |
| US7496114B2 (en) | 2003-04-16 | 2009-02-24 | Fujitsu Limited | IP image transmission apparatus |
| JP4037411B2 (ja) * | 2003-04-16 | 2008-01-23 | 富士通株式会社 | Ip画像伝送装置 |
| JP4699685B2 (ja) | 2003-08-21 | 2011-06-15 | パナソニック株式会社 | 信号処理装置及びそれを用いた電子機器 |
| JP4516020B2 (ja) * | 2003-08-28 | 2010-08-04 | 株式会社日立超エル・エス・アイ・システムズ | 画像処理装置 |
| WO2006057182A1 (ja) * | 2004-11-26 | 2006-06-01 | Matsushita Electric Industrial Co., Ltd. | 復号化回路、復号化装置、及び復号化システム |
| JP5404294B2 (ja) * | 2009-10-09 | 2014-01-29 | 三菱電機株式会社 | データ演算装置の制御回路及びデータ演算装置 |
| JP2010055629A (ja) * | 2009-11-30 | 2010-03-11 | Panasonic Corp | 画像音声信号処理装置及びそれを用いた電子機器 |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2754825B2 (ja) * | 1989-02-03 | 1998-05-20 | 日本電気株式会社 | マイクロプロセッサ |
| JPH05268593A (ja) * | 1992-03-23 | 1993-10-15 | Nippon Telegr & Teleph Corp <Ntt> | 差分絶対値和・差分自乗和並列演算装置 |
| JP2549256B2 (ja) * | 1992-12-01 | 1996-10-30 | インターナショナル・ビジネス・マシーンズ・コーポレイション | 浮動小数点プロセッサへデータを転送する方法及び装置 |
| JPH06324868A (ja) * | 1993-05-18 | 1994-11-25 | Hitachi Ltd | 専用演算器付きディジタル信号処理プロセッサ |
| JPH0969047A (ja) * | 1995-09-01 | 1997-03-11 | Sony Corp | Risc型マイクロプロセッサおよび情報処理装置 |
-
1999
- 1999-01-20 JP JP2000595228A patent/JP3676237B2/ja not_active Expired - Fee Related
- 1999-01-20 WO PCT/JP1999/000181 patent/WO2000043868A1/ja not_active Ceased
- 1999-11-03 TW TW88119144A patent/TW535107B/zh not_active IP Right Cessation
Also Published As
| Publication number | Publication date |
|---|---|
| TW535107B (en) | 2003-06-01 |
| WO2000043868A1 (fr) | 2000-07-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8369419B2 (en) | Systems and methods of video compression deblocking | |
| US8213511B2 (en) | Video encoder software architecture for VLIW cores incorporating inter prediction and intra prediction | |
| US20050190976A1 (en) | Moving image encoding apparatus and moving image processing apparatus | |
| US8233537B2 (en) | Efficient implementation of H.264 4 by 4 intra prediction on a VLIW processor | |
| JP3676237B2 (ja) | データ処理装置及び演算器 | |
| JPH06292178A (ja) | 適応形ビデオ信号演算処理装置 | |
| US20100321579A1 (en) | Front End Processor with Extendable Data Path | |
| CN101729893B (zh) | 基于软硬件协同处理的mpeg多格式兼容解码方法及其装置 | |
| JPWO2000043868A1 (ja) | データ処理装置及び演算器 | |
| Hartenstein et al. | Reconfigurable machine for applications in image and video compression | |
| US20210383504A1 (en) | Apparatus and method for efficient motion estimation | |
| Lee et al. | Multi-pass and frame parallel algorithms of motion estimation in H. 264/AVC for generic GPU | |
| Park et al. | Programmable multimedia platform based on reconfigurable processor for 8K UHD TV | |
| US7330595B2 (en) | System and method for video data compression | |
| Stolberg et al. | HiBRID-SoC: A multi-core SoC architecture for multimedia signal processing | |
| JP4625903B2 (ja) | 画像処理プロセッサ | |
| US7350035B2 (en) | Information-processing apparatus and electronic equipment using thereof | |
| Schmidt et al. | A parallel accelerator architecture for multimedia video compression | |
| Dias et al. | Reconfigurable architectures and processors for real-time video motion estimation | |
| JP2004234407A (ja) | データ処理装置 | |
| Chang et al. | An efficient design of H. 264 inter interpolator with bandwidth optimization | |
| JPH07121687A (ja) | 画像コーデック用プロセッサおよびアクセスパターン変換方法 | |
| US20040257374A1 (en) | Method and apparatus for the efficient representation of block-based images | |
| US20090006665A1 (en) | Modified Memory Architecture for CODECS With Multiple CPUs | |
| JP2005244845A (ja) | 動画像処理装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20041207 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20050204 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20050308 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20050323 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20050419 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20050427 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20080513 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20090513 Year of fee payment: 4 |
|
| LAPS | Cancellation because of no payment of annual fees |