JP4243376B2 - 任意のコーパスサブセットをほぼ一定時間でクラスタ化するための方法および装置 - Google Patents
任意のコーパスサブセットをほぼ一定時間でクラスタ化するための方法および装置 Download PDFInfo
- Publication number
- JP4243376B2 JP4243376B2 JP01764499A JP1764499A JP4243376B2 JP 4243376 B2 JP4243376 B2 JP 4243376B2 JP 01764499 A JP01764499 A JP 01764499A JP 1764499 A JP1764499 A JP 1764499A JP 4243376 B2 JP4243376 B2 JP 4243376B2
- Authority
- JP
- Japan
- Prior art keywords
- metadocument
- document
- documents
- metadocuments
- node
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
- G06F16/355—Creation or modification of classes or clusters
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99931—Database or file accessing
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99931—Database or file accessing
- Y10S707/99933—Query processing, i.e. searching
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99931—Database or file accessing
- Y10S707/99933—Query processing, i.e. searching
- Y10S707/99935—Query augmenting and refining, e.g. inexact access
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
【発明の属する技術分野】
本発明は、電子ドキュメントをほぼ一定時間でクラスタ化するための方法および装置に関する。特に、本発明は、電子ドキュメントの大きなコーパス(記録されたテキストの集合)をほとんど一定時間で、それに比べて非常に小さなクラスタのセットに分割することを目的とする。
【0002】
【従来の技術】
ドキュメントブラウジングは、大きなテキストコレクションにアクセスするために使用される有力なツールである。ブラウジングは、クエリー(質問)がないため検索と識別され、余りにも一般的であるかまたは余りにも漠然としているためのいずれかによって、幾つかの検索言語によって有効に表現できない情報ニーズに対して、都合よく作動する。たとえば、ユーザが、関心のある話題を適切な言語で記述することに不慣れである場合、またはワードの特定の選択にコミットする(明言する)ことを希望しない場合がある。実際、ユーザは、特定のものは何も要求しないが、コレクションの一般的な(全般的な)情報コンテンツ(内容)を探求したい場合がある。
【0003】
この状況において、情報アクセスシステムは有用である。情報アクセスシステムは、コレクションのコンテンツを提示すること、および、ユーザがコンテンツの幾つかの話題に固有のサブセットに関心を集中することの両者をナビゲーションできるコレクションのアウトラインを含む。このようなブラウジングシステムは、Pedersenらによる米国特許第5,442,778号(分散/集合:Scatter/Gather)および米国特許第5,483,650号に開示されており、これらの各特許は引用により本願に援用する。
【0004】
分散/集合においては、注意は、常に、ドキュメントのフォーカスセット、特にユーザの関心を引く可能性のあるサブセットに向けられる。最初に、フォーカスセットは、ドキュメントコレクション全体であるかもしれない。フォーカスセット内のドキュメントは、ドキュメントの少数の話題固有の(トピックに密着したtopic-coherent)サブセット、またはドキュメントのクラスタにクラスタ化される。用語「クラスタ化(clustering)」および「分散(scattering)」は、同義語として使用される。したがって、フォーカスセット内のドキュメントは、クラスタに分散される、ということができる。
【0005】
分散/集合においては、クラスタ要約(サマリー)が作成(develop)され、ユーザに提示される。クラスタ要約は、通常、フォーカスセットのドキュメントの輪郭(アウトライン)を示すコンテンツの表(テーブル)である。クラスタ要約は、各クラスタ内のドキュメントから自動的に決定される示唆に富むテキストを含む。各クラスタ要約は、2種類の情報を含む。すなわち、クラスタのドキュメントに最も頻繁に出現する話題の(topical)ワード、およびクラスタ内の数個の典型的なドキュメントの名称である。要約は、クラスタプロファイルに基づく。このクラスタプロファイルはクラスタのドキュメントに出現するワードを反映する。
【0006】
そこで、ユーザは、最も関心を持たせるように見える複数のクラスタを識別し、選択する。選択されたクラスタは、一緒に集合され、新しい小さいフォーカスセットを形成する。すなわち、新しいフォーカスセットは、選択されたクラスタ内のドキュメントの合併(ユニオン:union)である。ユーザがドキュメントに個別にアクセスすること、またはクエリーに基づく探索方法を使用することを求めるまで、この処理が所望の回数反復される。
【0007】
分散/集合は、必ずしも独立型情報アクセスツールである必要はない。むしろ、分散/集合は、論理探索または類似性探索などの探索方法と連携して使用することができる。類似する例は、リファレンスブック(reference book)であり、リファレンスブックは二つのアクセス方法を提供する。一つは、ブラウジングのための前にある目次(a table of contents)であり、他は、さらに直接的な探索のための最後にある索引(index)である。分類/集合は、必ずしも特定のドキュメントを探索するために使用されるとは限らない。むしろ、クラスタ要約に存在する用語(ボキャブラリー)を公開することによって、分散/集合は、相補的な探索方法を補助する。たとえば、クラスタプロファイルを、類似性探索においてコレクション全体に対するクエリーとして使用することができる。逆に言えば、分散/集合を使用し、過剰の多数のドキュメントを検索するワードを基礎とするクエリーの結果を編成することができる。
【0008】
図9は、1990年8月のNew York Times News Serviceに掲載された約5,000記事のテキストコレクションに適用される分散/集合方法を示す図である。図9においては、分散/集合方法を一層簡単に提示するために、実際のクラスタ要約の代わりに単独のワード文字(ラベル)が示されている。
【0009】
図9に示す例においては、ユーザの情報ニーズは、1990年に発生したことを一般的に決定することである。特定の話題記述は全く存在しないため、この情報ニーズを効果的に表現するワードに基づくクエリーを構成することは困難である。ユーザは、一般的な話題、たとえば、「国際的事件」を考えるが、この話題記述は、国際事件に関する記事は、通常、これらのワードを使用しないため、有効ではない。
【0010】
分散/集合によって、ある用語を提供することが強制されるのではなく、ユーザは、クラスタ要約のセット、すなわちコレクションの輪郭を提供される。ユーザニーズは、関心のある話題に関連する可能性があると考えられるクラスタを選択する。図9に示す分散/集合処理においては、その月の主要な新聞記事は、最初の分散からすぐに明らかになり、イラクのクエート侵入およびドイツ再統合問題である。これによって、ユーザは、国際問題に焦点を絞るようになり、「イラク」、「ドイツ」、および「石油」クラスタを選択する。これらの3クラスタは一緒に集合され、より小さなフォーカスセットを形成する。
【0011】
次に、この比較的小さなフォーカスセットは、クラスタ化、すなわち分散され、減少されたコレクションを包含する8個の新しいクラスタを形成する。減少されたコレクションは、記事のサブセットのみを含むので、これらの新クラスタによって、元の8個のクラスタより細かいレベルの詳細が明らかになる。イラク侵入に関する記事および石油記事の一部は、米国軍展開、石油市場に対するイラク侵入の影響、およびクエートにおける人質についてのクラスタに分離される。
【0012】
ユーザが、これらの主要な新聞記事を適切に理解するが、世界の他の部分で何が発生したかを見つけたいと思う場合、ユーザは、たとえば、「パキスタン」クラスタを選択、−このクラスタも他の外国政治新聞記事を含む−およびアフリカに関する記事を含むクラスタを選択することができる。これらのクラスタを分散することによって、多数の特定の国際状況ならびに多方面にわたる国際記事の小さなコレクションが明らかになる。このようにして、ユーザは、パキスタンにおける政変およびトリニダードで発生した人質について知る。これらの記事は、別の状態では、その月の一層重要な記事の中に埋没してしまうものである。
【0013】
図10は、分散/集合の操作を示す図である。図10に示す例においては、テキストコレクション(またはフォーカスセット)20は、グロリエ(Grolier)の百科事典のオンライン版である。フォーカスセット内の2,700,000記事は、それぞれ、独立のドキュメントとして処理される。図10に示す例においては、ユーザは、宇宙開発における女性の役割を調査することに関心がある。この情報ニーズを正式の(formal)クーリエによって表現しようとするのでなく、ユーザは、代わりに、クラスタの記述から、関心のある話題に関連すると考えられる多数のトップレベルのクラスタ22A〜22Iを提供される。次に、ユーザは、軍事経過(ヒストリー)クラスタ22A、科学および産業検出子22Cおよびアメリカ社会クラスタ22Hを選択し、グロリエの事典から得られる記事の指示されたサブセットの減少されたコーパス(またはフォーカスセット)24を形成する。
【0014】
次に、減少されたコーパスは、浮動によって(on the fly)もう一度クラスタ化され、減少されたコーパス24を対象にする新しいクラスタのセット26A〜26Jを生成する。減少されたコーパスはグロリエの事典の記事のサブセットを含むため、これらの新クラスタは、トップレベルクラスタ22A〜22Iより細かいレベルの詳細である。ユーザは、再度、関心のあるクラスタを選択する。この場合、選択されたクラスタは、軍用機クラスタ26E、工業技術クラスタ26G、および物理クラスタ26Hである。再度、さらに減少されたコーパス28が形成され、再クラスタ化される。最終セットのクラスタ30A〜30Fは、軍用機クラスタ30A、アポロ計画クラスタ30B、航空宇宙産業クラスタ30C、天候クラスタ30D、天文学クラスタ30E、および民間航空機クラスタ30Fを含む。この段階において、クラスタは、十分に小さく、記事名称の網羅的なリストを通じて直接に精読することができる。関心のある少なくとも一つの記事が見出されると仮定すると、ユーザは、同じくラスタ内に類似の特性の記事をさらに見出すこと、またはことによると探し当てた記事またはクラスタ記述の用語集(ボキャブラリー)に基づいて方向を持った(directed)探索方法を使用して追加記事を見出すことができる。
【0015】
【発明が解決しようとする課題】
ドキュメントクラスタ化に関する以前の成果は、線形時間(linear-time)法、たとえば、分散/集合および米国特許第5,483,650号に記載の線形時間法を含み、この方法によれば、クラスタ化のために要する時間は僅か数分に減少される。これは、広範囲のワードに基づくクエリーを使用し、中程度の大きさのコレクションを探索するのに十分な速さである。たとえば、毎秒およそ3000ドキュメントの速度を、分散/集合を使用し、サンマイクロシステムズ(SunMicrosysytems)のSPARCSTATION2上において、実現できる。しかし、線形時間クラスタ化でさえも、非常に大きなドキュメントコレクションの対話型ブラウジングを支援するためには遅すぎる。このことは、約750,000のドキュメントを含むテキスト検索評価のために、分散/集合をTIPSTERコレクション、DARPA標準に適用する場合を考慮すれば、特に、明らかである。毎秒3000ドキュメントの速度において、これは、分散するために4時間以上を必要とし、対話型にとっては長すぎると考えられる。したがって、ドキュメントをクラスタ化するために、一層迅速なさらに効率的な方法を見出すことが必要とされる。
【0016】
本発明は、顧客対応可能な時間/精度トレードオフを持つコーパスサブセットをほぼ一定時間でクラスタ化するための方法および装置を提供するものである。
【0017】
本発明は、基礎的なブラウジング方法、たとえば、分散/集合に使用することが可能であり、大きなドキュメントコレクションを関連のあるドキュメントのクラスタに効率的に分割するほぼ一定時間でクラスタ化するための方法も提供するものである。
【0018】
【課題を解決するための手段】
本発明による再クラスタ化方法および装置においては、入力は、全体のドキュメントの複数のメタドキュメントへのクラスタ化であり、複数のメタドキュメントから「最悪」メタドキュメントが選択される。「最悪」メタドキュメントは、その子のメタドキュメントによって置換され、関心のあるドキュメントを含まないこれらの子は除去される(pruned)。次に、残りのメタドキュメントは一緒に集合され再クラスタ化される。ユーザが所望の程度の特定性を得るまで、この処理が反復される。
【0019】
このクラスタ化方法は従来の方法より速く、この方法においては、クラスタは本来の資質(in their own right)でドキュメントとして処理され、既存の階層(hierarchy)を使用しクラスタの新しいセットを生成する。すなわち、本発明による再クラスタ化方法および装置においては、クラスタは、大きな個別ドキュメントであるかのように、クラスタ化する必要があるメタドキュメントして処理され、クラスタ化される。したがって、ファンアウトkを有するクラスタ階層の場合、本発明による再クラスタ化方法および装置は、最小のクラスタから開始し、各クラスタをそのk個の子によって置換する。親クラスタは検査され、最悪クラスタが除去される。すなわち、「最悪」親クラスタは、そのk個の子によって置換される。
【0020】
本発明のこれらおよび他の特徴および利益は、以下の好適な実施形態に関する詳細記述に記載され、明らかとなる。
【0021】
以下、本発明を添付図面を参照して詳細に述べる。図面において、同じ符号は、同じ構成要素を示す。
【0022】
【発明の実施の形態】
図1は、本発明による再クラスタ化システム10の一実施形態を示すブロック図である。システム10は、プロセッサ11、ROM12、RAM13、不揮発性メモリ14、コーパス入力15、ユーザ入力装置16、ディスプレイ装置17、および出力装置18を備える。
【0023】
ブラウジング手順を実行する前に、ドキュメントコーパスがコーパス入力15から入力される。次に、ドキュメントコーパスは、プロセッサ11によって分割される。分割手順の結果は、ディスプレイ装置17に表示される。操作者は、ユーザ入力装置16、たとえば、マウス、キーボード、タッチスクリーン、スタイラス、またはこれらの要素の組合せなどを使用し、コマンドおよびデータを入力することができる。ユーザは、ドキュメントのハードコピーのみでなくクラスタダイジェスト要約(サマリー)のプリント出力も出力装置18、たとえばプリンタに出力することができる。
【0024】
従来は、プロセッサ11によって、ドキュメントの初期順序付け(initial ordering)が準備される。初期順序付けは、たとえば、分散/集合に記載の分別法を使用して準備される。プロセッサ11によって、コーパスの最初の順序付けの要約も決定され、この要約はディスプレイ装置17に表示、または出力装置18によってユーザに出力することができる。この要約は、たとえば、分散/集合に記載されているクラスタダイジェスト法を使用し、決定することができる。
【0025】
ユーザからユーザ入力装置16を経由して適切な命令を受領後、プロセッサ11は、コーパスのさらに進んだ順序付けを実行することができる。このさらに進んだ順序付けは、たとえば、分散/集合に記載されているバックショット(buckshot:大きめの散弾)法を使用し、形成される。次に、このステップの所望の数の反復が実行され、コーパスがさらに狭くされる。結局、個別のドキュメントが検査され、または幾つかの有向探索ツールが限定コーパスに適用される場合がある。
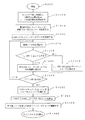
【0026】
図2は、本発明による再クラスタ化の一実施形態の輪郭(アウトライン)を示す図である。処理は、ステップS100において開始され、ステップS200に続く。ステップS200において、ユーザは、全ドキュメントコレクションの一部またはコーパスの一部を表現するドキュメントセットを選択する。後のステップにおける反復のために、フォーカスセットはメタドキュメントを含み、メタドキュメントは、それぞれ、コレクションの一部のみを表現する(代表する)。メタドキュメントセット中のメタドキュメントの数は、ほぼ所定の最大数に等しく、最大数は、たとえば、500または1000とすることができる。次に、ステップS300において、最初のメタドキュメントセットは、プロセッサ11によって選択され、クラスタ化される。好適には、メタドキュメントクラスタの所定数は、10である。一般に、必要とされることは、新メタドキュメントの所定数は、その後のメタドキュメントの所定最大数より小さいことが必要であるということのみである。メタドキュメントを選択し、クラスタ化する処理は、図3および図4に関連して、以下に述べる。次に、制御はステップS400に続く。
【0027】
ステップS400において、新メタドキュメントは、要約されて利用できる形式になる。次に、ステップS500において、たとえば、ディスプレイ装置17または出力装置18を使用し、ユーザに提示される。次に、処理は、ステップS600に続き、ステップS600において、処理は停止する。
【0028】
メタドキュメントセットはクラスタ階層Hを有し、クラスタ階層Hは、k個の子のファンアウト(fan-out)およびルートノードrを有する。階層は、クラスタのツリー構造であり、クラスタはノードと呼ばれ、ノード1のk個の子の合併はノード1自体と同じドキュメントを有するように、ノードはメタドキュメントを表現する。ドキュメントのセットSは、クラスタ化ルーチンに入力される。この処理の結果、k個のクラスタのセットとなり、このクラスタはS中のドキュメントを正確に含む。
【0029】
図3は、図2のメタドキュメント選択およびクラスタ化ステップS300の第1実施形態のさらに詳細な輪郭を示す図である。ステップS300から始まり、制御はステップS320に進む。ステップS320において、収集する必要があるノードの最大数Mが設定される。次に、ステップS330において、初期フォーカスセットTが、階層Hのルートノードrとして設定される。次に、ルートノードは、そのk個の子によって直ちに置換される。次に、制御はステップS340に進む。
【0030】
ステップS340〜S360において、ある方法において「良好」である関心のあるノードがクラスタ階層中に見出される。ノードの良好度を決定する方法について、以下に詳細に述べる。
【0031】
ステップS340において、フォーカスセットTのk個のノードは検査され、「最悪」ノードがピックされる。「最悪」ノードは、以下の述べる「良好度」検査によって決定される。次に、ステップS350において、「最悪」ノードは除去され、そのk個の子のノードによって置換され、子は関心のあるドキュメントを含む。関心のあるドキュメントを含まない子は含まれず、効果的に除去される(pruned)。
【0032】
次に、ステップS360において、制御ルーチンは、フォーカスセットTが収集する必要があるノードの最大数Mに等しいノード数またはそれより大きいノード数を有するかを決定する。フォーカスセットTのノード数が収集する必要がある最大ノード数M未満である場合、制御はステップS340に跳び戻る。そうではなく、フォーカスセットのノード数が少なくともMに等しい場合、制御は、ステップS370に続く。
【0033】
ステップS370において、フォーカスセットTはクラスタ化され、クラスタPのセットが得られる。次に、ステップS380において、クラスタPのこのセットの各ノードは、クラスタ内の、Sにおいては存在しなかったドキュメントを削除するために、関心のあるドキュメントIS(n)によって置換される。次に、制御はステップS390に続き、ここで制御はステップS400に戻る。
【0034】
前述したクラスタ化ステップにおいて、見出されたM個のノードは、線形時間クラスタ化方法を使用し、クラスタ化される。選択されるノード数が限定される限り、これによって、一定時間(constant-time)のクラスタ化が与えられる。
【0035】
クラスタ階層のノードの数は大きい場合があるため、すべてのノードを検査して「良好」ノードを見出すことはできない。その代わり、クラスタ階層は、トップからファンアウトする。階層Hのルートノードから始まり、ルートノードは、直ちにその子によって置換される。得られるセットのk個のノードは検査され、「最悪」ノードがピックされる。「最悪」ノードは除去され、そのk個の子によって置換される。この処理は、今、検討中の2k−1のノードについて反復される。実際は、すべてのk個の子ノードは、必ずしも含まれない。むしろ、子ノードのサブセットのみが、検討される。M個のノードが収集されると、処理は停止される。
【0036】
この時点において、共通集合(積集合)テーブルISが生成される。任意のノードnに対して、そのノードの共通集合IS(n)は、S∩nにおけるドキュメントのセットである。すなわち、IS(n)は、ドキュメントセットSとノードnに含まれるドキュメント間の共通集合である。したがって、共通集合テーブルISによって、ドキュメントセットSおよびノードnの両者に含まれる関心のあるドキュメントのみが、提供される。ISは、|S|log(n)時間内に作成される。共通集合テーブルISを使用し、結果として得られる各ノードが、共通集合IS(n)によって置換され、ドキュメントセットSに存在しない、クラスタ中のドキュメントが削除される。得られるノードは、クラスタ化され、k個のクラスタとなり、各ノードはなお単独の実体(エンティティ:entity)として処理される。
【0037】
任意のノードnに対するSおよびnの共通集合を求めるために、ドキュメントを処理し、ドキュメントを含む階層Hのすべてのノードを戻す関数が使用される。この関数は、ドキュメントセットSに従属せず、階層Hが決定されると同時に決定されることができる。階層Hは、一定のkのファンアウトを有するので、階層Hは深度lognを有し、したがって、各ドキュメントは、lognノードにある。
【0038】
ISを求めるために、テーブルが構成され、ノードによって索引される。テーブルの各項目は、原始状態においては、空である。ドキュメントセットSの各ドキュメントに対して、事前に計算された前述した関数を使用し、どのノードがドキュメントを包含するかを見出す。次に、ドキュメントセットをこのような各ノードに対するテーブル項目に追加する。理論上は、一定時間内に任意のサイズの空テーブルを構成することが可能であるが、実際には、明白な線形時間(リニアー・タイム)アルゴリズムは極めて迅速である。テーブル更新は、ドキュメント当たり時間logn、または全体で時間|S|lognを要する。得られるテーブルは、IS、すなわち必要とされる共通集合計算ツールである。
【0039】
図4は、図2のメタドキュメント選択およびクラスタ化ステップS300の第2実施形態のさらに詳細な輪郭を示す図であり、如何にして、追加されるカットオフ値を有する任意のデータセットに対するノードが決定されるかを示す。ステップS300において開始され、制御はステップS1305に続く。次に、ステップS1305において、カットオフ値が、cに設定され、その結果、c未満のドキュメントを含むノードは単独のドキュメントノードによって置換されることができる。再度、収集する必要があるノードの最大数Mも、設定される。次に、ステップS1315において、初期フォーカスセットTが、階層Hのルートノードとして設定される。次に、制御はステップS1320に続く。
【0040】
ステップS1320において、小さいドキュメントセットEは、ゼロに設定される。次に、ステップ1325において、フォーカスセットのkノードが検査され、「最悪」ノードがピックされる。次に、ステップS1330において、「最悪」ノードは、照合され、そのノードが、カットオフ値c未満の数のドキュメントを含むかまたはそれに等しい数のドキュメントを含むかが、決定される。ノードのドキュメントの数がカットオフ値c未満である場合、制御は、ステップS1335に続く。そうではなく、選択されるノードがカットオフ値c未満の数のドキュメントを含まない場合、制御は、ステップS1340に跳ぶ。
【0041】
ステップ1335において、ノード内のその数のドキュメントが、小さなドキュメントセットEに加えられる。次に、制御は、ステップS1345に跳ぶ。ステップS1340において、関心のあるドキュメントを含むノードの子がフォーカスセットTに加えられる。関心のあるドキュメントを含まない子は包含されず、効果的に、「除去される:pruned」。次に、制御は、ステップS1345に続く。
【0042】
ステップS1345において、フォーカスセットは、照合され、フォーカスセットが収集する必要がある最大数Mに達しているかが決定される。収集する必要があるノードの最大数Mに達している場合、制御は、ステップA1350に続く。その他の場合は、制御は、ステップS1325に跳び戻り、次の最悪ノードを見出す。
【0043】
次に、ステップS1350において、小さいドキュメントセットEがフォーカスセットTに加えられる。次に、ステップS1355において、フォーカスセットTは、クラスタ化され、クラスタPのセットが得られる。次に、ステップS1360において、各ノードPは、関心のあるドキュメントIS(n)によって、置換される。次に、制御は、ステップS1365に続く。ステップS1365において、制御は、図2のステップS400に戻る。
【0044】
このように、追加されるカットオフ値を有する任意のデータセットに対して、ノードがドキュメントセットSから得られる数個のドキュメントのみを含む場合、これらのドキュメントは、ノードを拡張する時間を消費する代わりに別のセットEに追加される。
【0045】
ノードをその子によって置換する場合、「空」の子、すなわちドキュメントセットSにいかなるドキュメントも含まない子は、明白に回避することができる。「単集合(シングルトン:Singleton)」子、すなわち、ドキュメントSから得られる一つのドキュメントのみしか包含しない子も、特別に取り扱うことができる。ノード内に一つのドキュメントしか存在しない場合は、ノード全体が包含されない。ドキュメントが簡単に取り出され、それ自体がノードとして処理される。これは、適切な終端子孫(リーフディセンデント:leaf descendent)によって子ノードを置換することと等価である。一般に、カットオフ値c未満のドキュメントを包含するノードは、c個の単独ドキュメントノードによって置換することができる。一定の数のノードのみが検査されるため、この方法によって生成される新しいノードの数も一定である。
【0046】
如何にして多数のノードが拡張されるかにcの値が影響を及ぼすようにすることは望ましくないので、単独のドキュメントノードは、通常のノードと別に数えられる。すなわち、単独のドキュメントノードをフォーカスセットT内に保持するのではなく、単独のドキュメントノードは、別のセットEに移動される。この処理は、フォーカスセットTが所定のサイズに達するまで続く。|E|は、定数によって限定されるので、この値は実行時間の解析に影響を及ぼさない。
【0047】
たとえば、図3のステップS340および図4のステップS1325において、「最悪」ノードを決定するために使用される幾つかの「良好度」検査がある。使用することができる一つの「良好度」検査は、適合度検査または割合(RATIO)検査である。ノードが包含する大部分のドキュメントもドキュメントセットSから得られる関心のあるドキュメントである場合、ノードは、「良好」である。
【0048】
たとえば、nは、dドキュメントを有する場合、nの良好度は、下式によって表される。
【0049】
【数1】
g=|IS(n)|/d
関数f(S,T)によって、フォーカスセットT内の最低の良好度を有するノードは返される。この関数は、僅かしか一致しないノード、すなわち一致しない子を有する可能性のあるノードに有利であるので、この良好度検査は、結果として、広い範囲の除去(pruned)となり、結果が改善される。他方、かなり良好な割合を有する大きなノードは、絶対値の項に多数の非一致ドキュメントを含む場合でも、フォーカスセットT内にそのままで留まる。
【0050】
一つの大きなノードが、ドキュメントセットS内に多数のドキュメントを包含する場合、割合検査は、このノードに有利である。このことはクラスタ化の場合に問題となる場合があり、その理由は、クラスタ化方法は、ノード内のドキュメントすべてを単独の実体として処理し、不均衡なクラスタサイズとなる可能性があるためである。このような大きなノードの拡張は、良好度値に重みを付けることによって促進される。たとえば、ノードnは、dドキュメントを有する場合、ノードnの加重良好度g′は、下式によって表される。
【0051】
【数2】
g’=√|IS(n)|/d
この場合、ドキュメントセットS内に多数のドキュメントを有することは、良好な割合の保証にはならない。実際に、比較的少数のドキュメントdを有することが、一層有利である。このことによって、出力ノードは、すべて、ドキュメントセットSから得られるほぼ等しい数のドキュメントを有することを保証することが容易になる。
【0052】
良好度を決定する他の手法は、情報理論による測定を使用する。ノードの子がノード自体より多くのドキュメントセットSに関する情報をコード化する場合、そのノードは、その子によって置換される良い候補である。このことは、親における一致は、子の間に不均一に分散され、その結果、劣悪な子は除去され、良好な子が維持されることを暗に示す。
【0053】
たとえば、ノードnが、サイズdを有する場合、ノードniは、ノードnの子であり、サイズdiを有する。ノードn内の情報I(n)は、下式で表される。
【0054】
【数3】
I(n)=−(|Is(n)|/d)・log2(|Is(n)|/d)
ノードnに対する情報ゲインG(n)は、下式で表される。
【0055】
【数4】
G(n)=I(n)−Σ{(|di|/|d|)・I(ni)}
ここで、Σは、iについてのサメンションである。
【0056】
ノードnに対する適切な良好度測定は、G(n)によって与えられる。関数f(S,T)によって、フォーカスセットT内の最高の情報ゲインを有するノードは返される。このことは、その子によって置換されることにより最も利益が得られるノードがピックされるという利点を有する。不都合なことに、これらの一致が子の間に均一に分散される場合、このことは、僅かな一致しか有しない大きなノードを無視することになる。
【0057】
本発明においては、非所定数の個別ドキュメントの代わりに、所定数のメタドキュメントが、クラスタ化または分散のための手順において使用される。メタドキュメントは、ツリー、たとえば、図5から図8までのツリーなどのメタドキュメントから得られる降順の複数の個別ドキュメントを表現する。
【0058】
図5から図8までの以下の討議の場合、本発明に従って、たとえば前述した割合検査などの幾つかの「良好度」検査の一つを使用し、「最悪」メタドキュメントを選択することができる。しかし、討議を容易にするために、図5から図8までにおいて、「最悪」メタドキュメントは、最低数の関心のあるドキュメントを有するメタドキュメントを選択することによって簡単に選択されるものとする。
【0059】
図5において、ツリー81のノード82〜86は、個別ドキュメント、たとえば、ドキュメント88などのコレクションを表現するメタドキュメントである。たとえば、図5において、ノード89は3個の子、ドキュメント88a、88b、88cを有する内部ノードである。内部ノード89も、内部ノード84の子であり、内部ノード84自体はルートノード82の子である。ルートノード82は、ドキュメントコレクション全体を表現するメタドキュメントである。メタドキュメント83〜86はメタドキュメント82から直接に得られる子である。さらに、メタドキュメント89のレベル87は、メタドキュメント83〜86から直接に得られる子である。最後に、個別ドキュメント88、すなわちツリーの葉は、メタドキュメント87から直接に得られる子である。ツリー81は、説明上、非常に簡単にしてある。実際には、大きなコーパスは非常に多数の個別ドキュメントおよび便利に示す必要があるメタドキュメントのレベルを有する。
【0060】
一例として、10,000のドキュメントをクラスタ化し、10の話題に関連するグループ、すなわちクラスタとする場合を考える。この例の場合、同じ10,000ドキュメントの、たとえば500クラスタへの原型のクラスタ化は、既に利用可能である。互いに極端に類似しているドキュメントは、通常、同じクラスタに現れるので、500のクラスタの内の所定のクラスタのすべてのドキュメントは、所望の10のクラスタの内の同じクラスタに同様に出現するものとする。言い換えれば、細粒度クラスタ化において一緒にクラスタ化されるほど十分に類似しているドキュメントは、粗粒度クラスタ化において、一緒にクラスタ化されることになる。これは、米国特許第5,483,650号に開示されているクラスタリファインメント(refinement)仮説である。
【0061】
本発明は、既存のクラスタをメタドキュメントとして処理し、このメタドキュメントは全体としてコーパス全体の圧縮表現を形成する。すべての個別ドキュメントを直接にクラスタ化する代わりに、本発明は、すべての個別ドキュメントを表現するメタドキュメントをクラスタ化する。前述した例において、10,000の個別ドキュメントをクラスタ化する代わりに、本発明によれば、500のメタドキュメントをクラスタ化することができる。クラスタ洗練仮説によれば、メタドキュメントクラスタ化および個別ドキュメントクラスタ化は、同様な結果を生成する。
【0062】
たとえば、ステップS340からS360までの第1反復の場合、図5のフォーカスセット100は、ドキュメントコレクション全体を表現するルートノードすなわちメタドキュメント82のみを含む。当然、第1反復中は、このメタドキュメント82は、フォーカスセットTの唯一のメタドキュメントであるので、ステップS340において選択される。ステップS350において、メタドキュメント82は、その直接の子孫、すなわち子であるメタドキュメント83〜86に拡張される。次に、これらの子メタドキュメント83〜86を使用し、図6に示すように、フォーカスセット100において、メタドキュメント82を置換する。このようにして、フォーカスセット100は、子孫のメタドキュメント83〜86を含む。
【0063】
次に、ステップS340が、図6のフォーカスセット100に関して反復される。フォーカスセット100内のメタドキュメントの数がステップS360における所定の最大数未満である限り、クラスタ化処理はステップS340〜S360を経由して循環を継続する。メタドキュメント83〜86の内、メタドキュメント84は、最低数の個別ドキュメント88を表現する。すなわち、メタドキュメント84は、6個の個別ドキュメントを表現し、一方、メタドキュメント83、85、および86は、それぞれ、7、8、および9個の個別ドキュメントを表現する。したがって、メタドキュメント84は、図7に示すように、選択され、その子孫、すなわち孫、メタドキュメント89〜92に拡張される。しかし、孫メタドキュメント90および91は、関心のあるドキュメントを含まないので除去される。したがって、フォーカスセット100は、今度は、メタドキュメント83、85〜86、89、および92を含む。
【0064】
所定の最大数のメタドキュメントが、ステップS360において、まだ実現されない場合、ステップS340が、図7に示すフォーカスセット100に関して反復される。最低数の個別ドキュメントを表現する子メタドキュメント83が、ステップS350において選択され、図8に示すように、その子孫、すなわち孫、メタドキュメント87、および93〜95に拡張される。しかし、メタドキュメント95は、関心のあるドキュメントを包含しないので、メタドキュメント95は除去される。したがって、フォーカスセット100は、ここで、子孫メタドキュメント85〜87、89、および92〜94を包含する。
【0065】
図2、図3または図4、および図5に輪郭を示す処理は、フォーカスセット内のメタドキュメントの数が所定の最大数未満である限り継続される。所定の最大数が充分に高い場合、フォーカスセットは、実質上、個別ドキュメントを含む。その場合、ステップS360によって、メタドキュメントおよび個別ドキュメントの全数が所定の最大数未満であるかが決定される。しかし、この状況は、通常発生せず、特に、処理の僅かしかない第1反復中には発生しない。
【0066】
図1に示すように、再クラスタ化システム10は、好適には、プログラム式汎用コンピュータ上において実現される。しかし、再クラスタ化システム10は、専用コンピュータ、プログラム式マイクロプロセッサまたはマイクロコントローラおよび周辺一体型回路構成要素、ASICまたは他の一体型回路、ディジタル信号プロセッサ、有線(ハードワイヤード:hardwired)電子または論理回路たとえば個別要素(ディスクリートエレメント:discrete element)回路、PLD、PLA、FPGA、PALなどのプログラマブル論理装置、などによっても実現することができる。一般に、図2から図5に示す流れ図を実行することができる有限状態機械(finite state machine)を実現できるいかなる装置を使用しても、再クラスタ化システム10を実現することができる。
【0067】
以上、特定の実施形態について述べたが、多数の代替方法、変形、および異形は当業者には明らかであることは、明白である。したがって、前述した本発明の好適な実施形態は、説明を目的とするものであり、これに限定されるものではない。特許請求の範囲によって規定される本発明の思想および範囲を離脱することなく、種々の変化を実施し得る。
[付記]
[付記1] 電子的に記憶されるドキュメントのコーパスを処理し、一つ以上の事前に識別された関心のあるドキュメントをクラスタ化する方法であって、
複数のドキュメントを代表する少なくとも一つの初期メタドキュメントを含むフォーカスセットを拡張し、複数の次のメタドキュメントとするステップであって、それぞれの次のメタドキュメントは前記初期メタドキュメントのサブセットであるステップと、
前記フォーカスセット内のメタドキュメントを選択するステップと、
前記選択されたメタドキュメントを子孫のメタドキュメントに拡張するステップと、
少なくとも一つの関心のあるドキュメントを含まない子孫のメタドキュメントを除去するステップと、
前記次のメタドキュメントの数が少なくとも所定の最大数に等しくなるまで、前記選択および拡張ステップを反復するステップと、
を含む拡張ステップと、
前記次のメタドキュメントをクラスタ化し、所定数のクラスタとするステップと、
を含むことを特徴とする方法。
[付記2] 付記1に記載の方法において、クラスタの前記所定数は、前記所定最大数未満であることを特徴とする方法。
[付記3] 付記1に記載の方法において、前記少なくとも一つの初期メタドキュメントは、ドキュメントのコーパス全体を代表する単独のメタドキュメントであることを特徴とする方法。
[付記4] 付記1に記載の方法において、前記所定最大数は、前記拡張および選択ステップが、共に、時間制約内に完了するように決定されることを特徴とする方法。
[付記5] 付記1に記載の方法において、さらに、
前記新メタドキュメントの要約を確定するステップと、
前記要約をユーザに提示するステップと、
を含むことを特徴とする方法。
[付記6] 付記5に記載の方法において、前記要約は、
各新メタドキュメントにおいて最も頻繁に現れる固定数の話題のワードと、
各新メタドキュメント内の少なくとも一つの典型的なドキュメントの名称と、
を含むことを特徴とする方法。
[付記7] 付記1に記載の方法において、前記クラスタ化ステップは、各メタドキュメントによって表現されるドキュメントの数に関係なく、多くても、所定量の時間を要することを特徴とする方法。
[付記8] 付記1に記載の方法において、前記拡張ステップは、さらに、選択されたメタドキュメント内の関心のあるドキュメントの数がカットオフ値を超えるかを決定するステップを含むことを特徴とする方法。
[付記9] 付記8に記載の方法において、前記選択されたメタドキュメント内の関心のあるドキュメントの数がカットオフ値未満である場合、前記ドキュメントは別のドキュメントセットに加えられることを特徴とする方法。
[付記10] 付記9に記載の方法において、前記拡張ステップは、さらに、前記クラスタ化ステップにおいてクラスタ化するために、前記別のドキュメントセットを前記次のメタドキュメントに加えるステップを含むことを特徴とする方法。
[付記11] 電子的に記憶されるドキュメントのコーパスを処理し、少なくとも一つの事前に識別された関心のあるドキュメントをクラスタ化する装置であって、
複数のドキュメントを代表する少なくとも一つの初期メタドキュメントを含むフォーカスセットを拡張し、複数の次のメタドキュメントとする拡張手段であって、それぞれの次のメタドキュメントは前記少なくとも一つの初期メタドキュメントのサブセットである拡張手段と、
前記フォーカスセット内のメタドキュメントを選択するための選択手段であって、選択されたメタドキュメントは拡張手段によってその子孫のメタドキュメントに拡張される選択手段と、
少なくとも一つの関心のあるドキュメントを含まない子孫のメタドキュメントを除去するための除去手段と、
を含む拡張手段と、
前記次のメタドキュメントをクラスタ化し、所定数のクラスタとするためのクラスタ化手段と、
を備え、
前記拡張手段は、前記次のメタドキュメントの数が所定の最大数に少なくとも等しくなるまで、前記フォーカスセットを拡張することを特徴とする装置。
[付記12] 付記11に記載の装置において、新メタドキュメントの前記所定数は、前記所定最大数未満であることを特徴とする装置。
[付記13] 付記11に記載の装置において、前記少なくとも一つの初期メタドキュメントは、ドキュメントのコーパス全体を代表する単独のメタドキュメントであることを特徴とする装置。
[付記14] 付記11に記載の装置において、前記所定最大数は、前記クラスタ化手段が前記次のメタドキュメントのクラスタ化を時間制約内に完了するように決定されることを特徴とする装置。
[付記15] 付記11に記載の装置において、さらに、
新メタドキュメントの要約を確定し、前記要約をユーザに提示する要約手段を備えることを特徴とする装置。
[付記16] 付記15に記載の装置において、前記要約は、
各新メタドキュメントにおいて最も頻繁に現れる固定数の話題のワードと、
各新メタドキュメント内の少なくとも一つの典型的なドキュメントの名称と、
を含むことを特徴とする装置。
[付記17] 付記11に記載の装置において、前記クラスタ化手段は、各メタドキュメントによって表現されるドキュメントの数に関係なく、多くても、所定量の時間を要することを特徴とする方法。
[付記18] 付記11に記載の装置において、前記拡張手段は、前記メタドキュメント内の関心のあるドキュメントの数がカットオフ値を超えるかを決定することを特徴とする装置。
[付記19] 付記18に記載の装置において、前記メタドキュメント内の関心のあるドキュメントの数がカットオフ値未満である場合、前記ドキュメントは別のドキュメントセットに加えられることを特徴とする装置。
[付記20] 付記19に記載の装置において、前記拡張手段は、クラスタ化手段によってクラスタ化するために、前記別のドキュメントセットを前記次のメタドキュメントに加えることを特徴とする装置。
【図面の簡単な説明】
【図1】 本発明による装置の一実施形態を示すブロック図である。
【図2】 本発明による再クラスタ化方法の一実施形態の輪郭を示す流れ図である。
【図3】 図2のメタドキュメント拡張ステップの第1実施形態の輪郭をより詳細に示す流れ図である。
【図4】 図2のメタドキュメント拡張ステップの第2実施形態の輪郭をより詳細に示す流れ図である。
【図5】 本発明の好適な実施形態によるフォーカスセットのツリーおよび変化するコンテンツを示す図である。
【図6】 本発明の好適な実施形態によるフォーカスセットのツリーおよび変化するコンテンツを示す図である。
【図7】 本発明の好適な実施形態によるフォーカスセットのツリーおよび変化するコンテンツを示す図である。
【図8】 本発明の好適な実施形態によるフォーカスセットのツリーおよび変化するコンテンツを示す図である。
【図9】 分散/集合手順を広く示す図である。
【図10】 従来の分散/集合ドキュメントブラウジング法を、ドキュメントの特定のコーパスに適用する場合を示す図である。
【符号の説明】
10 再クラスタ化システム、11 プロセッサ、12 ROM、13 RAM、14 不揮発性メモリ、15 コーパス入力、16 ユーザ入力装置、17ディスプレイ装置、18 出力装置、81 ツリー、82 ルートノード(メタドキュメント)、83〜87,89〜95 ノード(メタドキュメント)、88 ドキュメント、100 フォーカスセット。
Claims (7)
- 関連する複数のドキュメントがメタドキュメントにまとめられ、このメタドキュメントが階層的に関連づけられて電子的に記憶されるコーパスを処理して、事前に識別された関心に関連するドキュメントをクラスタ化する方法であって、
プロセッサが、
ユーザの入力に応じて、少なくとも一つの初期メタドキュメントであって下位のメタドキュメントを含む初期メタドキュメントを選択する初期選択ステップと、
選択された初期メタドキュメントを階層的関連に基づいて下層側に拡張し、次の階層の複数メタドキュメントからなるフォーカスセットを選択する拡張ステップと、
前記フォーカスセット内のメタドキュメントの良好度を検査して最悪メタドキュメントを選択する最悪選択ステップと、
前記選択された最悪メタドキュメントをその下層側の子孫のメタドキュメントに置き換える置き換えステップと、
関心のあるドキュメントを含まない子孫のメタドキュメントを除去する除去ステップと、
前記フォーカスセットのメタドキュメントの数が所定数になるまで、前記最悪選択ステップと、置き換えステップと、除去ステップを繰り返すステップと、
を実行し、
得られたフォーカスセット内のメタドキュメントをクラスタとして、所定数にクラスタ化された電子的に記憶されたドキュメントのコーパスを得ることを特徴とする方法。 - 請求項1に記載の方法において、さらに、
前記メタドキュメントの要約を確定するステップと、
前記要約をユーザに提示するステップと、
を含むことを特徴とする方法。 - 請求項2に記載の方法において、前記要約は、
各メタドキュメントにおいて最も頻繁に現れる固定数の話題のワードと、
各メタドキュメント内の少なくとも一つの典型的なドキュメントの名称と、
を含むことを特徴とする方法。 - 請求項1に記載の方法において、前記拡張ステップは、さらに、選択されたメタドキュメント内の関心のあるドキュメントの数がカットオフ値を超えるかを決定するステップを含むことを特徴とする方法。
- 請求項4に記載の方法において、前記選択されたメタドキュメント内の関心のあるドキュメントの数がカットオフ値未満である場合、前記ドキュメントは別のドキュメントセットに加えられることを特徴とする方法。
- 請求項5に記載の方法において、前記拡張ステップは、さらに、前記別のドキュメントセットを前記次のメタドキュメントに加えるステップを含むことを特徴とする方法。
- 関連する複数のドキュメントがメタドキュメントにまとめられ、このメタドキュメントが階層的に関連づけられて電子的に記憶されるコーパスを処理して、事前に識別された関心に関連するドキュメントをクラスタ化する装置であって、
ユーザの入力に応じて、少なくとも一つの初期メタドキュメントであって下位のメタドキュメントを含む初期メタドキュメントを選択する初期選択手段と、
選択された初期メタドキュメントを階層的関連に基づいて下層側に拡張し、次の階層の複数メタドキュメントからなるフォーカスセットを選択する拡張手段と、
前記フォーカスセット内のメタドキュメントの良好度を検査して最悪メタドキュメントを選択する最悪選択手段、
前記選択された最悪メタドキュメントをその下層側の子孫のメタドキュメントに置き換える置き換え手段と、
関心のあるドキュメントを含まない子孫のメタドキュメントを除去する除去手段と、
前記フォーカスセットのメタドキュメントの数が所定数になるまで、前記最悪選択手段 と、置き換え手段と、除去手段の処理を繰り返させる繰り返し手段と、
を含み、
得られたフォーカスセット内のメタドキュメントをクラスタとして、所定数にクラスタ化された電子的に記憶されたドキュメントのコーパスを得ることを特徴とする装置。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US09/013,668 US6038557A (en) | 1998-01-26 | 1998-01-26 | Method and apparatus for almost-constant-time clustering of arbitrary corpus subsets |
| US09/013,668 | 1998-01-26 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JPH11316768A JPH11316768A (ja) | 1999-11-16 |
| JPH11316768A5 JPH11316768A5 (ja) | 2006-04-06 |
| JP4243376B2 true JP4243376B2 (ja) | 2009-03-25 |
Family
ID=21761098
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP01764499A Expired - Lifetime JP4243376B2 (ja) | 1998-01-26 | 1999-01-26 | 任意のコーパスサブセットをほぼ一定時間でクラスタ化するための方法および装置 |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US6038557A (ja) |
| JP (1) | JP4243376B2 (ja) |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2004025490A1 (en) * | 2002-09-16 | 2004-03-25 | The Trustees Of Columbia University In The City Of New York | System and method for document collection, grouping and summarization |
| US7523117B2 (en) * | 2005-05-04 | 2009-04-21 | West Virginia University Research Corporation | Method for data clustering and classification by a graph theory model—network partition into high density subgraphs |
| CN1940915B (zh) * | 2005-09-29 | 2010-05-05 | 国际商业机器公司 | 训练语料扩充系统和方法 |
| US10289802B2 (en) | 2010-12-27 | 2019-05-14 | The Board Of Trustees Of The Leland Stanford Junior University | Spanning-tree progression analysis of density-normalized events (SPADE) |
| JP5389130B2 (ja) | 2011-09-15 | 2014-01-15 | 株式会社東芝 | 文書分類装置、方法およびプログラム |
| US20150006528A1 (en) * | 2013-06-28 | 2015-01-01 | Iac Search & Media, Inc. | Hierarchical data structure of documents |
| US11036764B1 (en) * | 2017-01-12 | 2021-06-15 | Parallels International Gmbh | Document classification filter for search queries |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5317507A (en) * | 1990-11-07 | 1994-05-31 | Gallant Stephen I | Method for document retrieval and for word sense disambiguation using neural networks |
| US5483650A (en) * | 1991-11-12 | 1996-01-09 | Xerox Corporation | Method of constant interaction-time clustering applied to document browsing |
| US5442778A (en) * | 1991-11-12 | 1995-08-15 | Xerox Corporation | Scatter-gather: a cluster-based method and apparatus for browsing large document collections |
| US5619709A (en) * | 1993-09-20 | 1997-04-08 | Hnc, Inc. | System and method of context vector generation and retrieval |
-
1998
- 1998-01-26 US US09/013,668 patent/US6038557A/en not_active Expired - Lifetime
-
1999
- 1999-01-26 JP JP01764499A patent/JP4243376B2/ja not_active Expired - Lifetime
Also Published As
| Publication number | Publication date |
|---|---|
| JPH11316768A (ja) | 1999-11-16 |
| US6038557A (en) | 2000-03-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12511316B2 (en) | Systems and methods for generating and using aggregated search indices and non-aggregated value storage | |
| EP0631245B1 (en) | Method of processing a corpus of electronically stored documents | |
| JP3883810B2 (ja) | 情報管理、検索及び表示システム及び関連方法 | |
| CN100590617C (zh) | 信息检索系统中基于短语的索引编制方法和系统 | |
| CN1728141B (zh) | 信息检索系统中基于短语的搜索 | |
| US20060161545A1 (en) | Method and apparatus for ordering items within datasets | |
| JP3577819B2 (ja) | 情報探索装置及び情報探索方法 | |
| CN102456071A (zh) | 文件管理装置以及文件管理方法 | |
| JP2005526317A (ja) | ドキュメントコーパスからコンセプト階層構造を自動に捜索する方法及びシステム | |
| US20070192305A1 (en) | Search term suggestion method based on analysis of correlated data in three dimensions | |
| CN106489142A (zh) | 出版物范围可视化及分析 | |
| JP4243376B2 (ja) | 任意のコーパスサブセットをほぼ一定時間でクラスタ化するための方法および装置 | |
| JPH07192020A (ja) | 文書情報検索装置 | |
| Reddy et al. | Text document clustering: the application of cluster analysis to textual document | |
| JPH0981582A (ja) | 値を基本としたデータ管理装置及びデータ管理方法 | |
| Bruggemann-Klein et al. | BibRelEx: Exploring bibliographic databases by visualization of annotated content-based relations | |
| KR20200014979A (ko) | 역 색인 구성 방법, 역 색인을 이용한 유사 데이터 검색 방법 및 장치 | |
| JP7059707B2 (ja) | データ検索方法、データ検索プログラム、及び情報処理装置 | |
| US9940345B2 (en) | Software method for data storage and retrieval | |
| EP1076305A1 (en) | A phonetic method of retrieving and presenting electronic information from large information sources, an apparatus for performing the method, a computer-readable medium, and a computer program element | |
| US12608407B2 (en) | System and method for searching tree based organizational hierarchies, including topic hierarchies, and generating and presenting search interfaces for same | |
| JP5505207B2 (ja) | 情報検索装置、情報検索方法及び情報検索プログラム | |
| JP2006501545A (ja) | オブジェクト分類のための顕著な特徴を自動的に判定する方法および装置 | |
| JP2009129373A (ja) | 同姓同名文書分別装置及びプログラム | |
| Supriyanto et al. | Indonesian articles recommender system using n-gram and Tanimoto coefficient |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20060123 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20060123 |
|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20060123 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20080805 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20081104 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20081202 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20090105 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120109 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130109 Year of fee payment: 4 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| EXPY | Cancellation because of completion of term |