JP4507563B2 - マルチプロセッサシステム - Google Patents
マルチプロセッサシステム Download PDFInfo
- Publication number
- JP4507563B2 JP4507563B2 JP2003379294A JP2003379294A JP4507563B2 JP 4507563 B2 JP4507563 B2 JP 4507563B2 JP 2003379294 A JP2003379294 A JP 2003379294A JP 2003379294 A JP2003379294 A JP 2003379294A JP 4507563 B2 JP4507563 B2 JP 4507563B2
- Authority
- JP
- Japan
- Prior art keywords
- bus
- cache coherence
- directory
- cache
- processors
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images












Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0806—Multiuser, multiprocessor or multiprocessing cache systems
- G06F12/0815—Cache consistency protocols
- G06F12/0817—Cache consistency protocols using directory methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0806—Multiuser, multiprocessor or multiprocessing cache systems
- G06F12/0815—Cache consistency protocols
- G06F12/0831—Cache consistency protocols using a bus scheme, e.g. with bus monitoring or watching means
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0806—Multiuser, multiprocessor or multiprocessing cache systems
- G06F12/0813—Multiuser, multiprocessor or multiprocessing cache systems with a network or matrix configuration
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Memory System Of A Hierarchy Structure (AREA)
- Multi Processors (AREA)
Description
(1)バスを通したコヒーレンス制御
(2)NUMAネットワークを通したコヒーレンス制御
(3)バス結合の変更時の処理
を順に説明する。
[動作の概要]
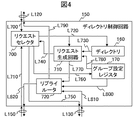
本節では、図1を用いて、本発明のマルチプロセッサシステムの動作の概要を示す。なお、説明における初期設定として、バス分割結合回路500、510、520は、500と520とが結合状態、510は分割状態だとする。つまり、CPU100とCPU200とはバスで結合されており、またCPU300とCPU400ともバスで結合されているが、CPU100&200とCPU300&400の間は分離されているとする。
(A)バスで結合されたCPU同士で、かつキャッシュコヒーレンス制御対象のデータのアドレスがバスで結合された範囲の部分主記憶に対するものである場合には、バスでのみキャッシュコヒーレンス制御を行う。
(B)(A)以外のケースについては、NUMAネットワークを使ってキャッシュコヒーレンス制御を行う。
[動作の詳細]
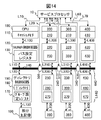
動作の詳細に入る前に、本発明で前提としているキャッシュコヒーレンスプロトコルを説明する。本発明では、各CPUのキャッシュコヒーレンス制御はMESIプロトコルに従うとする。MESIプロトコルでは、Cleanなデータ(=キャッシュメモリと主記憶との中身が一致しているデータ)は1CPU(Eステータス:Exclusive)もしくは複数CPU(Sステータス:Shared)が所有できるが、Modifiedデータ(=キャッシュメモリに更新された最新値があり主記憶には更新前の古い値が入っていることから中身が不一致を起こしているデータ)を所有できるのは1CPUのみ(Mステータス:Modified)というルールがある。故に、Sステータスの状態であるCPUがデータ更新を行うと、更新するCPU以外の各CPUへキャッシュ無効化要求が発生し、更新するCPUのみが更新後にMステータスでデータをキャッシュメモリに持つようになる。また、Mステータスにあるデータを他のCPUがアクセスした場合には、当該データはキャッシュメモリから主記憶に書き戻され、複数のCPUがCleanなデータをキャッシュメモリにSステータスで所有するようになる。
・フェッチ要求(キャッシュへの新規登録)
・キャッシュ無効化要求(キャッシュデータの更新)
・キャストアウト要求(キャッシュからメモリへの書戻し)
の3つであり、本発明でも上記3つの要求がCPUから発生するとしている。
バスを通したコヒーレンス制御は、動作概要で説明したとおり、バスで結合されたCPU同士で、かつキャッシュコヒーレンス制御対象のデータのアドレスがバスで結合された範囲の部分主記憶に対するものである場合に行う。以下、バスを通したフェッチ要求の処理、キャッシュ無効化要求の処理、キャストアウト要求の処理を順次説明する。
本節では、バス分離結合回路500、510、520がそれぞれ結合、分離、結合という設定だったということを前提に、CPU100からの部分主記憶180及び部分主記憶280へのフェッチ要求がCPU200との間でどう制御されるかを説明する。
CPU200からはキャストアウトパケットが出力される。キャストアウトパケットを図10に示す。コマンド5100は0001であり、その他に要求元プロセッサID5110(=書き込み元プロセッサIDであり今回の場合で言えばCPU200)、書き戻すべきアドレス5120、キャッシュブロック分のデータ5130から成る。
なお、本節では部分主記憶180に対するアクセスについて説明したが、同様にバスで結合される部分主記憶280へのアクセスの場合も、ディレクトリ制御回路150の代わりにディレクトリ制御回路250が主体となるだけで、その動作は基本的に同一となる。
本節では、CPU100が既にキャッシュメモリ110に登録しているデータ(他のCPUとの共有があり、キャッシュステータスは図7のSステータス2030である)に対してストアを実行する場合、他のCPUのキャッシュメモリをキャンセルする必要が発生する。本節では、この動作について説明する。なお、本節ではキャッシュ登録データの共有はCPU100とCPU200とで行われているとし、対象となるデータは部分主記憶180中に存在するものとする。つまり、ディレクトリ160の、当該データに対するエントリの値(図5相当)は1100であるとする。
Mステータス2020で登録していた情報を、他の新しいデータをキャッシュメモリ110に登録するために主記憶に書き戻す必要が発生した場合の動作を説明する(ここでは前節までと同様に部分主記憶180に対する書き戻し要求であるとする)。なお、Mステータス2020でデータを所有しているということは、同一キャッシュブロックを登録している可能性のあるCPUは他に無いことを表しているので、ディレクトリ160の当該エントリの値は1000となる。
前述の通り、バスで結合されたCPU同士でない場合、もしくはバスで結合されたCPU同士でも、キャッシュコヒーレンス制御対象のデータのアドレスがバスで結合された範囲の部分主記憶に対するものでない場合は、NUMAネットワーク1000を通したキャッシュコヒーレンス制御となる。
ここでは、まずバスで結合されていない部分主記憶に対してNUMAネットワークを経由してフェッチ要求を発行する場合を説明する。この動作はNUMA制御回路120、220、320、420にて、フェッチ要求リクエストのアドレスとバス設定レジスタ130、230、330、430の値との関係で、バスが結合されていないことをNUMA制御回路内のリクエストルータ600で判定した場合、従来バスに信号線L610、L110を経由して出力していたフェッチ要求パケットを信号線L620、L140を経由してNUMAネットワーク1000へ出力する。NUMAネットワークはパケットの要求先アドレス5020を用いて行き先を例えば部分主記憶380と判定するとその部分主記憶に対応するディレクトリ制御回路350へとパケットを伝達する。 ディレクトリ制御回路内のリクエストセレクタ700に伝達された先は、基本的にディレクトリ160の情報を用いてコヒーレンス制御を行う基本概念は(1)−1節と同一だが、フェッチ要求パケットはバス経由で入ってきたのではないことから、ディレクトリを検索した結果、全てのコヒーレンス制御パケットをディレクトリ生成回路710で生成し、リプライルータ720、信号線L820、L150を経由して、コヒーレンス制御パケットもまたNUMAネットワーク1000を用いて対象プロセッサに分配しなければならない。分配したパケットはNUMA制御回路120、220、320、420に入り、セレクタ610を経由して各CPU100、200、300、400に通達される。この結果例えばMステータスのデータを持ったCPUが存在し、キャッシュメモリ上のデータを部分主記憶に書き戻す必要が出た場合にも、NUMA制御回路120、220、320、420を経由してNUMAネットワーク1000を通って書き戻す。
NUMAネットワーク1000経由のキャッシュ無効化要求には、(2)−1と同様に、バスで結合されていない部分主記憶のデータに対するキャッシュ無効化要求の場合と、バスで結合されている部分主記憶のデータに対するキャッシュ無効化要求がバスで結合されていないCPUに対して発生するケースとがある。それぞれ基本的には(2)−1と同様であるが、但しフェッチリプライの代わりに、図13で示されるキャッシュ無効化完了パケットが返答されてくることになる。
NUMAネットワーク1000経由のキャストアウトは、バスが分離されてる部分主記憶180、280、380、480への書き戻しの際に発生するが、これもCPU100、200、300、400から書き戻し要求がNUMA制御回路120、220、320、420に伝達されると、バス設定レジスタ130、230、330、430の値に応じてリクエストルータ600によりNUMAネットワーク1000への出力が選択され、このキャストアウト要求パケットはNUMAネットワーク1000からディレクトリ制御回路150、250、350、450を経由して部分主記憶180、280、380、480に書き戻される。本実施例ではキャストアウトによる書き戻しの際にディレクトリの設定値を変更しないとしたが((1)−3参照)、NUMAネットワーク1000経由のキャストアウトでもこれは同じである。
(1)(2)の動作により、ディレクトリ制御回路150、250、350、450内のディレクトリ160、260、360、460には、バス分離・結合に関わらず、当該データブロックをキャッシュメモリに登録してうる全てのCPUが登録されている。これにより、バス結合の状態が変更されても、変更後のバスの結合・分離に従ってディレクトリ160、260、360、460に従ったキャッシュコヒーレンス制御(バスで接続されるCPUの組についてはバスでの制御期待でNUMAネットワーク経由の制御なし)が実現できる。
210、310、410…キャッシュメモリ
220、320、420…NUMA制御回路
230、330、430…バス設定レジスタ
140、240、340、440…部分バス
250、350、450…ディレクトリ制御回路
260、360、460…ディレクトリ
270、370、470…グループ設定レジスタ
280、380、480…部分主記憶
132、134、136、138…バス設定ビット
162、164、166、168…ディレクトリビット
172、174、176、178…グループ設定ビット
500、510、520…バス分割結合回路
505、515、525…バスフィルター回路
5000、5100、5200、5300、5400…コマンド
L10〜L800…信号線。
Claims (8)
- それぞれキャッシュメモリを備えた複数のプロセッサと、該複数のプロセッサに共有の主記憶とを有するマルチプロセッサシステムであって、
キャッシュコヒーレンス要求をバス経由で各プロセッサにブロードキャストすることでキャッシュコヒーレンス制御を実現する手段と、
前記バスでのブロードキャストの範囲をシステム全体ではなくシステムの一部になるように該バスを分割設定する手段とを有し、
前記主記憶に対応して該主記憶の各データブロック毎にそのデータブロックをキャッシュメモリに登録したプロセッサのIDを記録するディレクトリを有し、
前記ディレクトリに記録されたIDの情報を用いて各プロセッサの間でキャッシュコヒーレンス制御を行う手段を有し、
前記バスで結合されるプロセッサ間は前記バスを介したキャッシュコヒーレンス要求の伝達によるキャッシュコヒーレンス制御を行い、
該バスの分割設定により互いに分断されたプロセッサ間では前記ディレクトリを用いたキャッシュコヒーレンス制御を行うことを特徴とするマルチプロセッサシステム。 - 前記ディレクトリには前記バスの分割設定により分断されたプロセッサのID情報とともに、バスで結合されているプロセッサのID情報も記録されることを特徴とする請求項1に記載のマルチプロセッサシステム。
- 前記バスで結合されているプロセッサのID情報について、該ID情報に従ったキャッシュコヒーレンス要求の生成は行わないにもかかわらず、該ID情報については該バスを介したキャッシュコヒーレンス要求の伝達によるキャッシュコヒーレンス制御が実施されたと見なし、前記ディレクトリに記録された該ID情報を変更することを特徴とする請求項2に記載のマルチプロセッサシステム。
- 前記バスの分割設定が動作途中で変更になったことにより該バスで元々結合されていたプロセッサ同士の結合が分断された場合に、該バスを介したキャッシュコヒーレンス要求の伝達によるキャッシュコヒーレンス制御から前記ディレクトリに記録されていたプロセッサID情報を使用したキャッシュコヒーレンス制御に切り替えることを特徴とする請求項3に記載のマルチプロセッサシステム。
- それぞれキャッシュメモリを備えた複数のプロセッサと、該複数のプロセッサに共有であってかつ該複数のプロセッサの各々もしくはプロセッサ群の各々に対応してそれぞれ設けられた複数の部分主記憶で構成される主記憶とを有するマルチプロセッサシステムであって、
キャッシュコヒーレンス要求をバス経由で各プロセッサにブロードキャストすることでキャッシュコヒーレンス制御を実現する手段と、
前記バスでのブロードキャストの範囲をシステム全体ではなくシステムの一部になるように該バスを分割設定する手段とを有し、
前記部分主記憶の各々に対応して設けれら、各部分主記憶のデータブロック毎にそのデータブロックをキャッシュメモリに登録したプロセッサのIDを記録するディレクトリを有し、
前記ディレクトリに記録されたIDの情報を用いて各プロセッサの間でキャッシュコヒーレンス制御を行う手段を有し、
分割設定された前記バスで相互に結合されたプロセッサに対応する範囲の部分主記憶に含まれるデータに対するキャッシュコヒーレンス制御で、かつ該相互に結合されたプロセッサ間のキャッシュコヒーレンス制御の場合に、前記バスを用いたキャッシュコヒーレンス制御を行い、
前記バスの分割設定で分断されたプロセッサ間、もしくは前記バスで結合されたプロセッサ間であってもキャッシュコヒーレンス制御対象のデータが前記結合されたプロセッサに対応する範囲の部分主記憶ではなく、該範囲から外れる部分主記憶に含まれる場合には該ディレクトリを用いたキャッシュコヒーレンス制御を行うことを特徴とするマルチプロセッサシステム。 - 前記ディレクトリには前記バスの分割設定により分断されたプロセッサのID情報とともに、該バスで結合されているプロセッサのID情報も記録することを特徴とする請求項5に記載のマルチプロセッサシステム。
- 前記バスを介したキャッシュコヒーレンス要求の伝達によるキャッシュコヒーレンス制御を行う場合についても、前記ID情報については該バスによるキャッシュコヒーレンス制御が実施されたと見なし、前記ディレクトリに記録された該ID情報を変更することを特徴とする請求項6に記載のマルチプロセッサシステム。
- 前記バスの分割設定が動作途中で変更になったことにより該バスで元々結合されていたプロセッサ同士のバスが分割された場合に、該バスを介したキャッシュコヒーレンス要求の伝達によるキャッシュコヒーレンス制御から前記ディレクトリに記録されていたプロセッサID情報を使用したキャッシュコヒーレンス制御に切り替えることを特徴とする請求項6に記載のマルチプロセッサシステム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003379294A JP4507563B2 (ja) | 2003-11-10 | 2003-11-10 | マルチプロセッサシステム |
| US10/886,036 US7159079B2 (en) | 2003-11-10 | 2004-07-08 | Multiprocessor system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003379294A JP4507563B2 (ja) | 2003-11-10 | 2003-11-10 | マルチプロセッサシステム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2005141606A JP2005141606A (ja) | 2005-06-02 |
| JP4507563B2 true JP4507563B2 (ja) | 2010-07-21 |
Family
ID=34544517
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2003379294A Expired - Fee Related JP4507563B2 (ja) | 2003-11-10 | 2003-11-10 | マルチプロセッサシステム |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US7159079B2 (ja) |
| JP (1) | JP4507563B2 (ja) |
Families Citing this family (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7437618B2 (en) * | 2005-02-11 | 2008-10-14 | International Business Machines Corporation | Method in a processor for dynamically during runtime allocating memory for in-memory hardware tracing |
| US7418629B2 (en) * | 2005-02-11 | 2008-08-26 | International Business Machines Corporation | Synchronizing triggering of multiple hardware trace facilities using an existing system bus |
| US7437617B2 (en) * | 2005-02-11 | 2008-10-14 | International Business Machines Corporation | Method, apparatus, and computer program product in a processor for concurrently sharing a memory controller among a tracing process and non-tracing processes using a programmable variable number of shared memory write buffers |
| JP4945200B2 (ja) * | 2006-08-29 | 2012-06-06 | 株式会社日立製作所 | 計算機システム及びプロセッサの制御方法 |
| US8140817B2 (en) * | 2009-02-24 | 2012-03-20 | International Business Machines Corporation | Dynamic logical partition management for NUMA machines and clusters |
| JP5568939B2 (ja) * | 2009-10-08 | 2014-08-13 | 富士通株式会社 | 演算処理装置及び制御方法 |
| WO2011111215A1 (ja) | 2010-03-11 | 2011-09-15 | 富士通株式会社 | ソフトウェア制御装置、ソフトウェア制御方法、およびソフトウェア制御プログラム |
| JP5623259B2 (ja) | 2010-12-08 | 2014-11-12 | ピーエスフォー ルクスコ エスエイアールエルPS4 Luxco S.a.r.l. | 半導体装置 |
| US9478502B2 (en) * | 2012-07-26 | 2016-10-25 | Micron Technology, Inc. | Device identification assignment and total device number detection |
| US9237093B2 (en) * | 2013-03-14 | 2016-01-12 | Silicon Graphics International Corp. | Bandwidth on-demand adaptive routing |
| CN105453056B (zh) * | 2013-09-19 | 2019-05-17 | 英特尔公司 | 用于在多高速缓存环境中管理高速缓冲存储器的方法和装置 |
| US10721185B2 (en) | 2016-12-06 | 2020-07-21 | Hewlett Packard Enterprise Development Lp | Age-based arbitration circuit |
| US10452573B2 (en) | 2016-12-06 | 2019-10-22 | Hewlett Packard Enterprise Development Lp | Scripted arbitration circuit |
| US10237198B2 (en) | 2016-12-06 | 2019-03-19 | Hewlett Packard Enterprise Development Lp | Shared-credit arbitration circuit |
| US10944694B2 (en) | 2016-12-06 | 2021-03-09 | Hewlett Packard Enterprise Development Lp | Predictive arbitration circuit |
| US10693811B2 (en) | 2018-09-28 | 2020-06-23 | Hewlett Packard Enterprise Development Lp | Age class based arbitration |
| CN119248528B (zh) * | 2022-12-27 | 2025-10-03 | 华为技术有限公司 | Cc-numa服务器、锁请求的处理方法及相关装置 |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH05108578A (ja) * | 1991-10-19 | 1993-04-30 | Fuji Xerox Co Ltd | 情報処理システム |
| JPH0816474A (ja) * | 1994-06-29 | 1996-01-19 | Hitachi Ltd | マルチプロセッサシステム |
| JP3872118B2 (ja) * | 1995-03-20 | 2007-01-24 | 富士通株式会社 | キャッシュコヒーレンス装置 |
| US5673413A (en) * | 1995-12-15 | 1997-09-30 | International Business Machines Corporation | Method and apparatus for coherency reporting in a multiprocessing system |
| JPH09198309A (ja) * | 1996-01-17 | 1997-07-31 | Canon Inc | 情報処理システム及びシステム制御方法及び情報処理装置 |
| JP3849951B2 (ja) | 1997-02-27 | 2006-11-22 | 株式会社日立製作所 | 主記憶共有型マルチプロセッサ |
| US6269428B1 (en) * | 1999-02-26 | 2001-07-31 | International Business Machines Corporation | Method and system for avoiding livelocks due to colliding invalidating transactions within a non-uniform memory access system |
| FR2820850B1 (fr) * | 2001-02-15 | 2003-05-09 | Bull Sa | Controleur de coherence pour ensemble multiprocesseur, module et ensemble multiprocesseur a architecture multimodule integrant un tel controleur |
-
2003
- 2003-11-10 JP JP2003379294A patent/JP4507563B2/ja not_active Expired - Fee Related
-
2004
- 2004-07-08 US US10/886,036 patent/US7159079B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| US7159079B2 (en) | 2007-01-02 |
| US20050102477A1 (en) | 2005-05-12 |
| JP2005141606A (ja) | 2005-06-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP3722415B2 (ja) | 効率的なバス機構及びコヒーレンス制御を有する繰り返しチップ構造を有するスケーラブル共用メモリ・マルチプロセッサ・コンピュータ・システム | |
| JP3661761B2 (ja) | 共用介入サポートを有する不均等メモリ・アクセス(numa)データ処理システム | |
| JP4507563B2 (ja) | マルチプロセッサシステム | |
| US7363462B2 (en) | Performing virtual to global address translation in processing subsystem | |
| JP3644587B2 (ja) | 共用介入サポートを有する不均等メモリ・アクセス(numa)・データ処理システム | |
| US7765381B2 (en) | Multi-node system in which home memory subsystem stores global to local address translation information for replicating nodes | |
| US7577794B2 (en) | Low latency coherency protocol for a multi-chip multiprocessor system | |
| JP4848771B2 (ja) | キャッシュ一貫性制御方法およびチップセットおよびマルチプロセッサシステム | |
| KR100465583B1 (ko) | 판독 요청을 원격 처리 노드에 추론적으로 전송하는 비정형 메모리 액세스 데이터 처리 시스템 및 이 시스템에서의 통신 방법 | |
| US20040093455A1 (en) | System and method for providing forward progress and avoiding starvation and livelock in a multiprocessor computer system | |
| US20030149844A1 (en) | Block data mover adapted to contain faults in a partitioned multiprocessor system | |
| US6266743B1 (en) | Method and system for providing an eviction protocol within a non-uniform memory access system | |
| US6279085B1 (en) | Method and system for avoiding livelocks due to colliding writebacks within a non-uniform memory access system | |
| JP2000010860A (ja) | キャッシュメモリ制御回路及びプロセッサ及びプロセッサシステム及び並列プロセッサシステム | |
| CN103294612A (zh) | 一种在多级缓存一致性域系统局部域构造Share-F状态的方法 | |
| CN104615576A (zh) | 面向cpu+gpu处理器的混合粒度一致性维护方法 | |
| WO2014146424A1 (zh) | 一种基于有限数据一致性状态的服务器节点数据缓存方法 | |
| EP1611513B1 (en) | Multi-node system in which global address generated by processing subsystem includes global to local translation information | |
| US8332592B2 (en) | Graphics processor with snoop filter | |
| WO2010038301A1 (ja) | メモリアクセス方法及び情報処理装置 | |
| JP2001282764A (ja) | マルチプロセッサシステム | |
| JP3626609B2 (ja) | マルチプロセッサシステム | |
| US20110138101A1 (en) | Maintaining data coherence by using data domains | |
| JPH09311820A (ja) | マルチプロセッサシステム | |
| JP6631317B2 (ja) | 演算処理装置、情報処理装置および情報処理装置の制御方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20060424 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20061006 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20100203 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100216 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100315 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20100413 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20100426 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130514 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130514 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130514 Year of fee payment: 3 |
|
| LAPS | Cancellation because of no payment of annual fees |